|
|
--- |
|
|
license: cc-by-nc-nd-4.0 |
|
|
task_categories: |
|
|
- audio-classification |
|
|
- image-classification |
|
|
language: |
|
|
- zh |
|
|
- en |
|
|
tags: |
|
|
- music |
|
|
- art |
|
|
pretty_name: Music Genre Dataset |
|
|
size_categories: |
|
|
- 10K<n<100K |
|
|
dataset_info: |
|
|
- config_name: eval |
|
|
features: |
|
|
- name: mel |
|
|
dtype: image |
|
|
- name: cqt |
|
|
dtype: image |
|
|
- name: chroma |
|
|
dtype: image |
|
|
- name: fst_level_label |
|
|
dtype: |
|
|
class_label: |
|
|
names: |
|
|
'0': Classic |
|
|
'1': Non_classic |
|
|
- name: sec_level_label |
|
|
dtype: |
|
|
class_label: |
|
|
names: |
|
|
'0': Symphony |
|
|
'1': Opera |
|
|
'2': Solo |
|
|
'3': Chamber |
|
|
'4': Pop |
|
|
'5': Dance_and_house |
|
|
'6': Indie |
|
|
'7': Soul_or_RnB |
|
|
'8': Rock |
|
|
- name: thr_level_label |
|
|
dtype: |
|
|
class_label: |
|
|
names: |
|
|
'0': Symphony |
|
|
'1': Opera |
|
|
'2': Solo |
|
|
'3': Chamber |
|
|
'4': Pop_vocal_ballad |
|
|
'5': Adult_contemporary |
|
|
'6': Teen_pop |
|
|
'7': Contemporary_dance_pop |
|
|
'8': Dance_pop |
|
|
'9': Classic_indie_pop |
|
|
'10': Chamber_cabaret_and_art_pop |
|
|
'11': Soul_or_RnB |
|
|
'12': Adult_alternative_rock |
|
|
'13': Uplifting_anthemic_rock |
|
|
'14': Soft_rock |
|
|
'15': Acoustic_pop |
|
|
splits: |
|
|
- name: train |
|
|
num_bytes: 19661943 |
|
|
num_examples: 29100 |
|
|
- name: validation |
|
|
num_bytes: 2453757 |
|
|
num_examples: 3637 |
|
|
- name: test |
|
|
num_bytes: 2456508 |
|
|
num_examples: 3638 |
|
|
download_size: 4436653005 |
|
|
dataset_size: 24572208 |
|
|
configs: |
|
|
- config_name: eval |
|
|
data_files: |
|
|
- split: train |
|
|
path: eval/train/data-*.arrow |
|
|
- split: validation |
|
|
path: eval/validation/data-*.arrow |
|
|
- split: test |
|
|
path: eval/test/data-*.arrow |
|
|
--- |
|
|
|
|
|
# Dataset Card for Music Genre |
|
|
The Default dataset comprises approximately 1,700 musical pieces in .mp3 format, sourced from the NetEase music. The lengths of these pieces range from 270 to 300 seconds. All are sampled at the rate of 22,050 Hz. As the website providing the audio music includes style labels for the downloaded music, there are no specific annotators involved. Validation is achieved concurrently with the downloading process. They are categorized into a total of 16 genres. |
|
|
|
|
|
## Dataset Structure |
|
|
<style> |
|
|
.genres td { |
|
|
vertical-align: middle !important; |
|
|
text-align: center; |
|
|
} |
|
|
.genres th { |
|
|
text-align: center; |
|
|
} |
|
|
</style> |
|
|
|
|
|
### Eval Subset |
|
|
<table class="genres"> |
|
|
<tr> |
|
|
<th>mel</th> |
|
|
<th>cqt</th> |
|
|
<th>chroma</th> |
|
|
<th>fst_level_label (2-class)</th> |
|
|
<th>sec_level_label (9-class)</th> |
|
|
<th>thr_level_label (16-class)</th> |
|
|
</tr> |
|
|
<tr> |
|
|
<td>.jpg, 11.4s, 48000Hz</td> |
|
|
<td>.jpg, 11.4s, 48000Hz</td> |
|
|
<td>.jpg, 11.4s, 48000Hz</td> |
|
|
<td>1_Classic / 2_Non_classic</td> |
|
|
<td>3_Symphony / 4_Opera / 5_Solo / 6_Chamber / 7_Pop / 8_Dance_and_house / 9_Indie / 10_Soul_or_r_and_b / 11_Rock</td> |
|
|
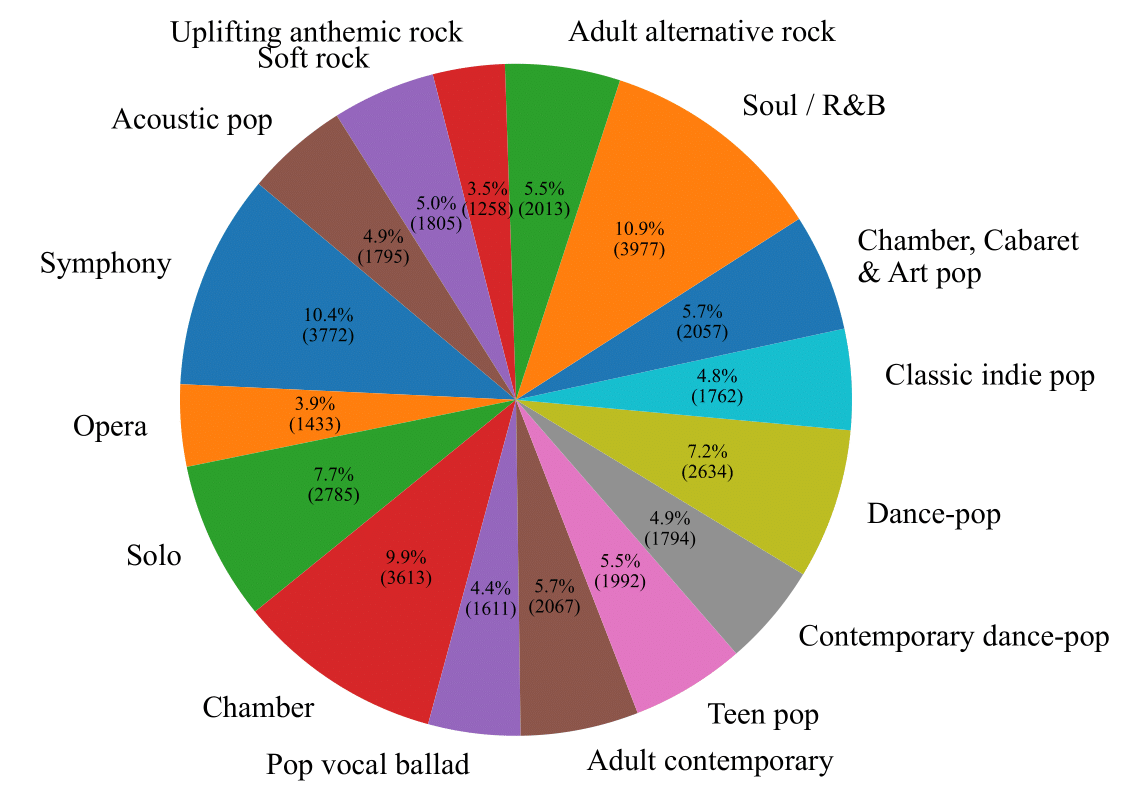
<td>3_Symphony / 4_Opera / 5_Solo / 6_Chamber / 12_Pop_vocal_ballad / 13_Adult_contemporary / 14_Teen_pop / 15_Contemporary_dance_pop / 16_Dance_pop / 17_Classic_indie_pop / 18_Chamber_cabaret_and_art_pop / 10_Soul_or_r_and_b / 19_Adult_alternative_rock / 20_Uplifting_anthemic_rock / 21_Soft_rock / 22_Acoustic_pop</td> |
|
|
</tr> |
|
|
</table> |
|
|
|
|
|
### Data Instances |
|
|
.zip(.jpg) |
|
|
|
|
|
### Data Fields |
|
|
```txt |
|
|
1_Classic |
|
|
3_Symphony |
|
|
4_Opera |
|
|
5_Solo |
|
|
6_Chamber |
|
|
|
|
|
2_Non_classic |
|
|
7_Pop |
|
|
12_Pop_vocal_ballad |
|
|
13_Adult_contemporary |
|
|
14_Teen_pop |
|
|
|
|
|
8_Dance_and_house |
|
|
15_Contemporary_dance_pop |
|
|
16_Dance_pop |
|
|
|
|
|
9_Indie |
|
|
17_Classic_indie_pop |
|
|
18_Chamber_cabaret_and_art_pop |
|
|
|
|
|
10_Soul_or_RnB |
|
|
|
|
|
11_Rock |
|
|
19_Adult_alternative_rock |
|
|
20_Uplifting_anthemic_rock |
|
|
21_Soft_rock |
|
|
22_Acoustic_pop |
|
|
``` |
|
|
|
|
|
 |
|
|
|
|
|
### Data Splits |
|
|
| Splits | Eval | |
|
|
| :-------------: | :---: | |
|
|
| train(80%) | 29100 | |
|
|
| validation(10%) | 3637 | |
|
|
| test(10%) | 3638 | |
|
|
| total | 36375 | |
|
|
|
|
|
## Dataset Description |
|
|
### Dataset Summary |
|
|
This database contains about 1700 musical pieces (.mp3 format) with lengths of 270-300s that are divided into 17 genres in total. |
|
|
|
|
|
### Supported Tasks and Leaderboards |
|
|
Audio classification |
|
|
|
|
|
### Languages |
|
|
Multilingual |
|
|
|
|
|
## Usage |
|
|
### Eval Subset |
|
|
```python |
|
|
from datasets import load_dataset |
|
|
|
|
|
ds = load_dataset("ccmusic-database/music_genre", name="eval") |
|
|
for item in ds["train"]: |
|
|
print(item) |
|
|
|
|
|
for item in ds["validation"]: |
|
|
print(item) |
|
|
|
|
|
for item in ds["test"]: |
|
|
print(item) |
|
|
``` |
|
|
|
|
|
## Maintenance |
|
|
```bash |
|
|
GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:datasets/ccmusic-database/music_genre |
|
|
cd music_genre |
|
|
``` |
|
|
|
|
|
## Mirror |
|
|
<https://www.modelscope.cn/datasets/ccmusic-database/music_genre> |
|
|
|
|
|
## Dataset Creation |
|
|
### Curation Rationale |
|
|
Promoting the development of AI in the music industry |
|
|
|
|
|
### Source Data |
|
|
#### Initial Data Collection and Normalization |
|
|
Zhaorui Liu, Monan Zhou |
|
|
|
|
|
#### Who are the source language producers? |
|
|
Composers of the songs in the dataset |
|
|
|
|
|
### Annotations |
|
|
#### Annotation process |
|
|
Students collected about 1700 musical pieces (.mp3 format) with lengths of 270-300s divided into 17 genres in total. |
|
|
|
|
|
#### Who are the annotators? |
|
|
Students from CCMUSIC |
|
|
|
|
|
### Personal and Sensitive Information |
|
|
Due to copyright issues with the original music, only spectrograms are provided in the dataset. |
|
|
|
|
|
## Considerations for Using the Data |
|
|
### Social Impact of Dataset |
|
|
Promoting the development of AI in the music industry |
|
|
|
|
|
### Discussion of Biases |
|
|
Most are English songs |
|
|
|
|
|
### Other Known Limitations |
|
|
Samples are not balanced enough |
|
|
|
|
|
## Additional Information |
|
|
### Dataset Curators |
|
|
Zijin Li |
|
|
|
|
|
### Evaluation |
|
|
<https://huggingface.co/ccmusic-database/music_genre> |
|
|
|
|
|
### Citation Information |
|
|
```bibtex |
|
|
@dataset{zhaorui_liu_2021_5676893, |
|
|
author = {Zhaorui Liu and Zijin Li}, |
|
|
title = {Music Data Sharing Platform for Computational Musicology Research (CCMUSIC DATASET)}, |
|
|
month = nov, |
|
|
year = 2021, |
|
|
publisher = {Zenodo}, |
|
|
version = {1.1}, |
|
|
doi = {10.5281/zenodo.5676893}, |
|
|
url = {https://doi.org/10.5281/zenodo.5676893} |
|
|
} |
|
|
``` |
|
|
|
|
|
### Contributions |
|
|
Provide a dataset for music genre classification |
