
Attribute-to-Delete: Machine Unlearning via Datamodel Matching
Paper • 2410.23232 • Published
The dataset viewer is not available because its heuristics could not detect any supported data files. You can try uploading some data files, or configuring the data files location manually.
Dataset for the evaluation of data-unlearning techniques using KLOM (KL-divergence of Margins).
KLOM works by:
Originally proposed in the work Attribute-to-Delete: Machine Unlearning via Datamodel Matching (https://arxiv.org/abs/2410.23232), described in detail in E.1.
Outline of how KLOM works:
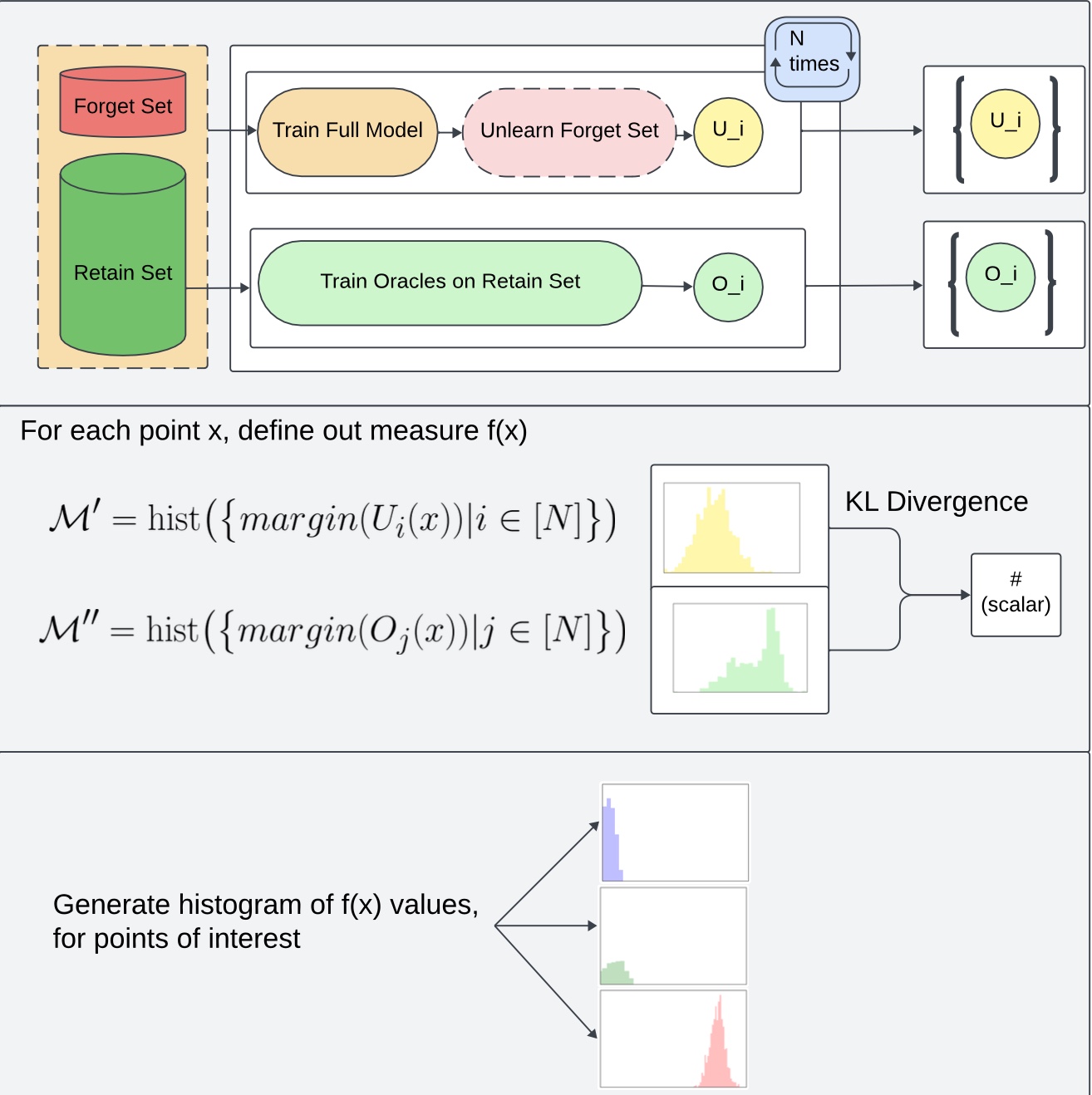
Algorithm Description:

The overal structure is as follows:
full_models
├── CIFAR10
├── CIFAR10_augmented
└── LIVING17
oracles
└── CIFAR10
├── forget_set_1
├── forget_set_2
├── forget_set_3
├── forget_set_4
├── forget_set_5
├── forget_set_6
├── forget_set_7
├── forget_set_8
├── forget_set_9
└── forget_set_10
Each folder has
## for validation points## for train points##__val_margins_#.npy - margins of model ## at epoch # (this is derived from logits)sd_##____epoch_#.pt - model ## checkpoint at epoch #Create script download_folder.sh
#!/bin/bash
REPO_URL=https://huggingface.co/datasets/royrin/KLOM-models
TARGET_DIR=KLOM-models # name it what you wish
FOLDER=$1 # e.g., "oracles/CIFAR10/forget_set_3"
mkdir -p $TARGET_DIR
git clone --filter=blob:none --no-checkout $REPO_URL $TARGET_DIR
cd $TARGET_DIR
git sparse-checkout init --cone
git sparse-checkout set $FOLDER
git checkout main
Example how to run script:
bash download_folder.sh oracles/CIFAR10/forget_set_3
We have 10 different forget sets: sets 1,2,3 are random forget sets of sizes 10,100,1000 respectively; sets 4-9 correspond to semantically coherent subpopulations of examples (e.g., all dogs facing a similar direction) identified using clustering methods.
Specifically, we take a $n \times n$ datamodel matrix constructed by concatenating train x train datamodels ($n=50,000$). Next, we compute the top principal components (PCs) of the influence matrix and construct the following forget sets:
\paragraph{ImageNet Living-17.} We use three different forget sets: