
license: cc-by-4.0
🧩 NYT-Connections
This repository contains the NYT-Connections dataset proposed in the work NYT-Connections: A Deceptively Simple Text Classification Task that Stumps System-1 Thinkers. This work was published at the 31st International Conference on Computational Linguistics (COLING 2025) and was honored with the Best Dataset Paper award.
Authors: Angel Yahir Loredo Lopez, Tyler McDonald, Ali Emami
📜 Paper Abstract
Large Language Models (LLMs) have shown impressive performance on various benchmarks, yet their ability to engage in deliberate reasoning remains questionable. We present NYT-Connections, a collection of 358 simple word classification puzzles derived from the New York Times Connections game. This benchmark is designed to penalize quick, intuitive ``System 1'' thinking, isolating fundamental reasoning skills. We evaluated six recent LLMs, a simple machine learning heuristic, and humans across three configurations: single-attempt, multiple attempts without hints, and multiple attempts with contextual hints. Our findings reveal a significant performance gap: even top-performing LLMs like GPT-4 fall short of human performance by nearly 30%. Notably, advanced prompting techniques such as Chain-of-Thought and Self-Consistency show diminishing returns as task difficulty increases. NYT-Connections uniquely combines linguistic isolation, resistance to intuitive shortcuts, and regular updates to mitigate data leakage, offering a novel tool for assessing LLM reasoning capabilities.
🎯 Puzzle Description
NYT-Connections puzzles are based on the New York Times' daily Connections game.
Each puzzle consists of 16 words, and the goal is to group them into 4 correct categories.
💡 How does it work?
✅ You can receive hints when only one word is misplaced in a group.
❌ You can make up to 4 mistakes before failing.
🏆 The objective is to correctly classify all 4 groups.
🧩 Example
Let’s take a look at an example puzzle. Below, you’ll see 16 words that need to be grouped:
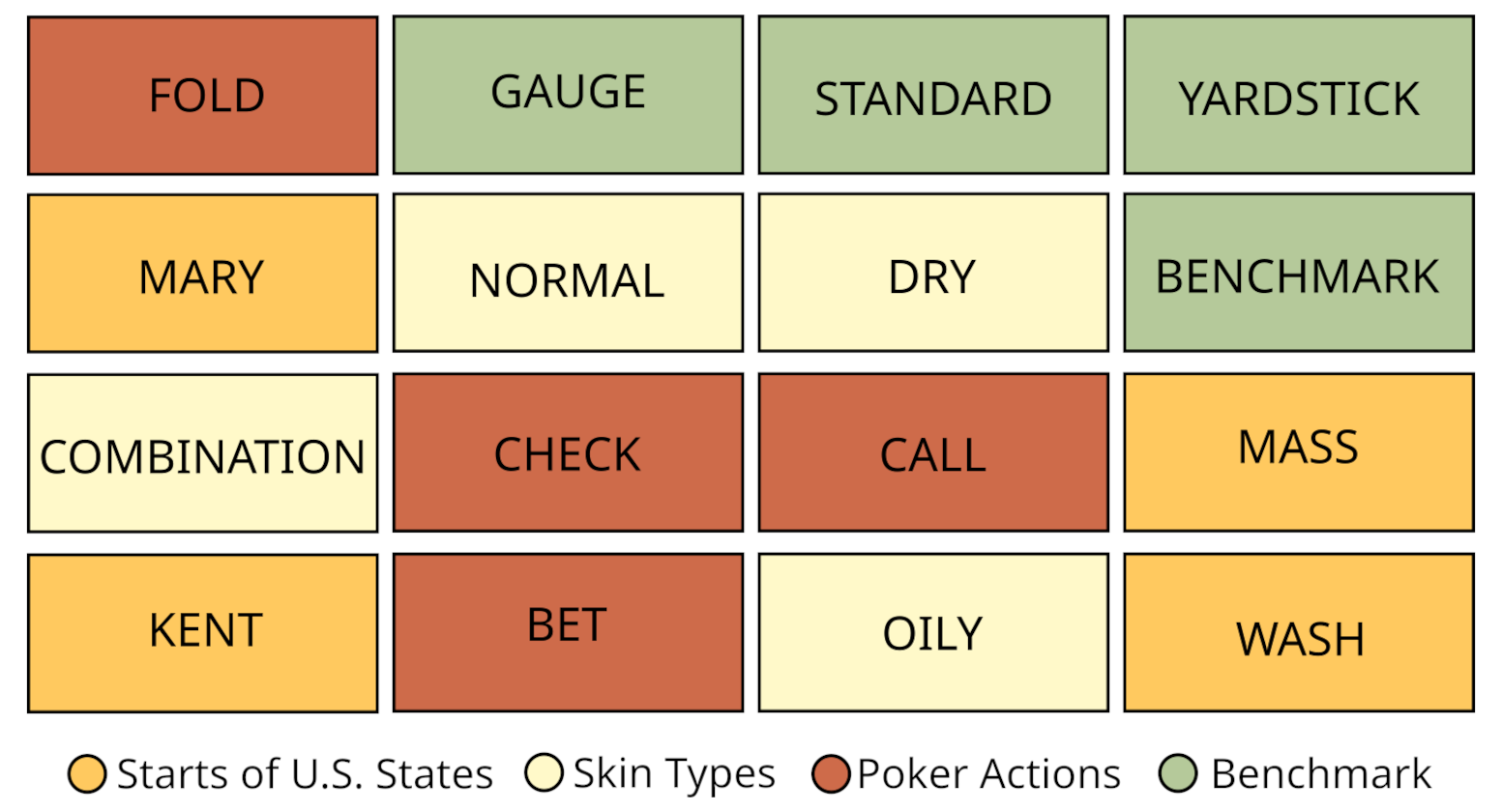
Each color represents a different correct group, but the relationships between words are not always obvious. This is where System 1 vs. System 2 thinking comes into play—solvers must go beyond intuition and apply logical reasoning.
A completed match typically follows this structure:
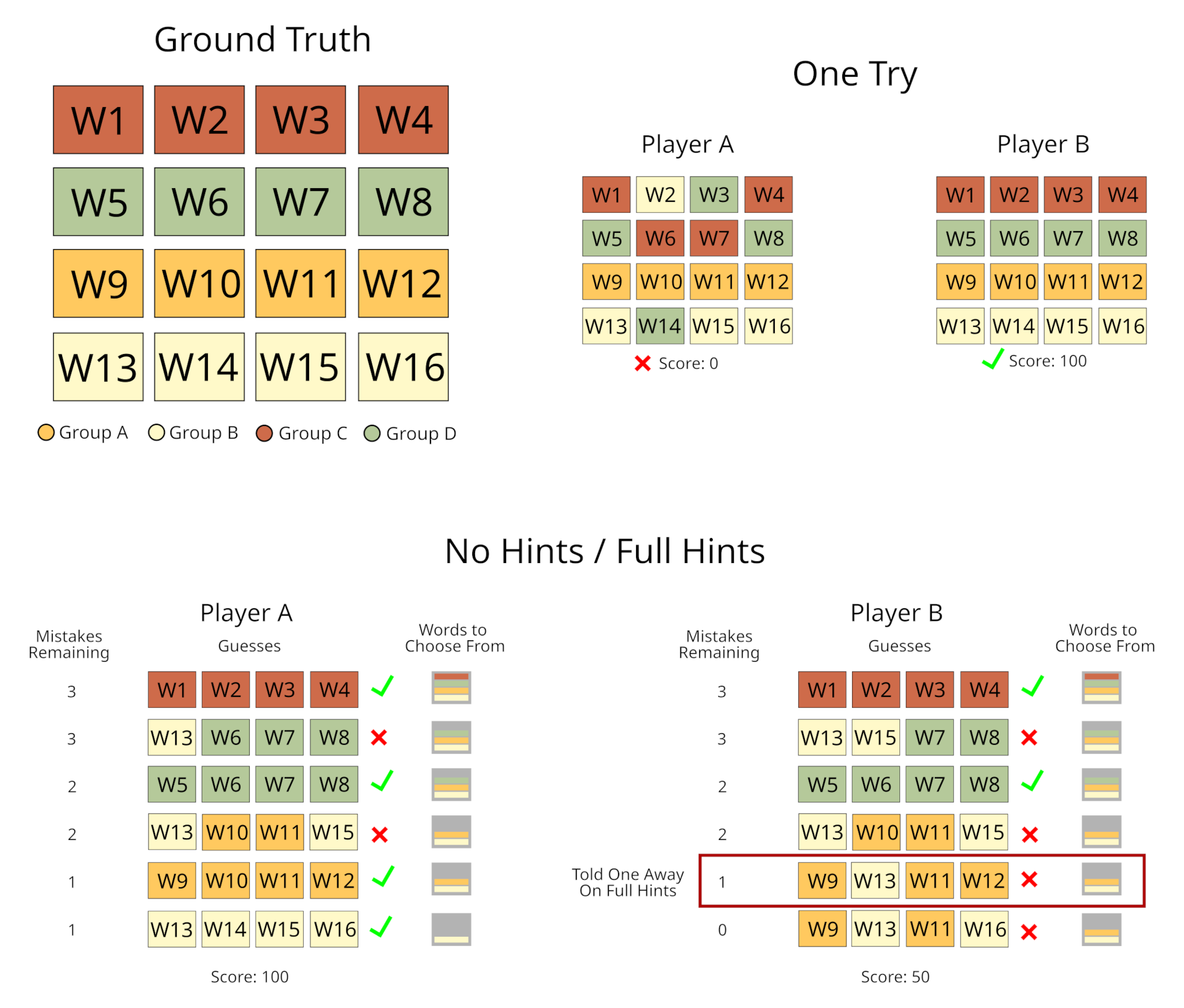
The three configurations (full-hints, no-hints, one-try) in our paper differ based on how much of the original game mechanics we retain. The full-hints configuration is the closest to the official New York Times version.
📂 Data Description
date - the original date the contest was offered.
contest - the title string for the contest.
words - the collection of 16 words available for use in puzzle solving.
answers - an array of objects, where each object is a correct group and contains:
answerDescription- the group namewords- the 4 words that classify into this group
difficulty - the difficulty of the puzzle as rated by community contributors (should such a rating be obtained, otherwise null).
📖 Citation
@inproceedings{loredo-lopez-etal-2025-nyt,
title = "{NYT}-Connections: A Deceptively Simple Text Classification Task that Stumps System-1 Thinkers",
author = "Loredo Lopez, Angel Yahir and
McDonald, Tyler and
Emami, Ali",
editor = "Rambow, Owen and
Wanner, Leo and
Apidianaki, Marianna and
Al-Khalifa, Hend and
Eugenio, Barbara Di and
Schockaert, Steven",
booktitle = "Proceedings of the 31st International Conference on Computational Linguistics",
month = jan,
year = "2025",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.coling-main.134/",
pages = "1952--1963",
abstract = "Large Language Models (LLMs) have shown impressive performance on various benchmarks, yet their ability to engage in deliberate reasoning remains questionable. We present NYT-Connections, a collection of 358 simple word classification puzzles derived from the New York Times Connections game. This benchmark is designed to penalize quick, intuitive {\textquotedblleft}System 1{\textquotedblright} thinking, isolating fundamental reasoning skills. We evaluated six recent LLMs, a simple machine learning heuristic, and humans across three configurations: single-attempt, multiple attempts without hints, and multiple attempts with contextual hints. Our findings reveal a significant performance gap: even top-performing LLMs like GPT-4 fall short of human performance by nearly 30{\%}. Notably, advanced prompting techniques such as Chain-of-Thought and Self-Consistency show diminishing returns as task difficulty increases. NYT-Connections uniquely combines linguistic isolation, resistance to intuitive shortcuts, and regular updates to mitigate data leakage, offering a novel tool for assessing LLM reasoning capabilities."
}