
VCR: Visual Caption Restoration
Collection
All configurations for VCR: Visual Caption Restoration (arXiv:2406.06462).
•
8 items
•
Updated
•
2
question_id
int64 0
5k
| image
imagewidth (px) 297
300
| caption
stringlengths 12
111
| stacked_image
imagewidth (px) 297
300
| only_it_image
imagewidth (px) 297
300
| only_it_image_small
imagewidth (px) 297
300
| crossed_text
sequencelengths 1
5
|
|---|---|---|---|---|---|---|
0 | 本表列举瑞士联邦各州现存的各类城堡建筑。 | [
"联邦各州现存的各类"
] |
||||
1 | 索诺马县是美国加利福尼亚州的一个县,县治圣罗莎是县中最大的城市。根据2010年人口普查,共有人口483,878人,其中白人占81.6%、亚裔美国人占3.07%、非裔美国人 | [
"县治圣罗莎是县中"
] |
||||
2 | 基土拉,又译为刻突辣、香娘等,《希伯来圣经》中的人物,是亚伯拉罕在撒拉去世后续娶之妻。 | [
"在撒拉去世后续娶"
] |
||||
3 | 新拉多加是俄罗斯列宁格勒州的一个城市,位于沃尔霍夫河注入拉多加湖之处、东距圣彼得堡121公里。2002年人口为9,920人,2010年人口则为8,839人。 | [
"注入拉多加湖之处"
] |
||||
4 | 强台风海鸥为2014年太平洋台风季第14个被命名的热带气旋。“海鸥”一名是由朝鲜提供,即海鸥。 | [
"个被命名的热带",
"名是由朝鲜提供"
] |
||||
5 | 整个第二次世界大战期间,纳粹德国以空前的规模在国内和占领区使用强迫劳动。强制的劳役之德国对占领地区经济剥削的重要手段,对大规模消灭德国欧洲占领区的人口 | [
"以空前的规模在",
"和占领区使用强迫劳动",
"强制的劳役之德国",
"大规模消灭德国欧洲占领区"
] |
||||
6 | 里来恩特知更鸟是由英国斯塔福德郡塔姆沃思的里来恩特公司生产的一款小型三轮车。 | [
"更鸟是由英国斯塔福德郡"
] |
||||
7 | 永丰站是北京地铁16号线的一个车站,位于北京市海淀区西北旺地区永丰高新技术产业基地南侧,中心里程为BK9+765.400。该站是16号线在北清路上的最后一站,因位于 | [
"地区永丰高新技术产业"
] |
||||
8 | 昂贝略昂比热是位于法国东南部奥弗涅-罗讷-阿尔卑斯大区安省的一个市镇,位于该省南部,人口11,927。 | [
"是位于法国东南部奥弗涅"
] |
||||
9 | 忏悔的囚犯,亦称十字架上的囚犯、好囚犯、右盗、善盗,是《路加福音》记载与耶稣两名同钉的无名囚犯其中一人,他驳斥不知悔改的囚犯对耶稣的侮辱,并希望耶稣作 | [
"名同钉的无名囚犯",
"悔改的囚犯对耶稣"
] |
||||
10 | 上海图书馆东馆,是上海市在建的图书馆,以上海图书馆冠名,位于浦东新区人民政府大楼的东面,即迎春路以东、合欢路以西、锦绣路以北的地块内,预计2020年建成。 | [
"位于浦东新区人民政府",
"锦绣路以北的地块内",
"是上海市在建的图书馆"
] |
||||
11 | 何东图书馆,是位于澳门特别行政区岗顶前地的公共图书馆。何东图书馆为集历史、文化和建筑艺术于一体的园林式图书馆,建筑物于2005年作为澳门历史城区 | [
"特别行政区岗顶前地的",
"文化和建筑艺术于"
] |
||||
12 | 贾拉勒·塔拉巴尼,库尔德人,伊拉克历史上第一位库尔德人总统。 | [
"伊拉克历史上第一位"
] |
||||
13 | 德扬·斯坦科维奇,已退役塞尔维亚足球运动员,司职中场。他以有效准确的传球和精湛的远射脚法而闻名。 | [
"已退役塞尔维亚足球运动员",
"的传球和精湛的"
] |
||||
14 | 这是南非自治市列表。几个最大的都会区由大都会自治市管理,而南非其他地区则分为区自治市,每个区自治市都由几个地方自治市所组成。自2016年8月3日市政选举时的 | [
"自治市都由几个",
"几个最大的",
"区由大都会自治市管理"
] |
||||
15 | 蒙法尔孔是法国伊泽尔省的一个市镇,位于该省西部,属于格勒诺布尔区。该市镇总面积5.82平方公里,2009年时的人口为128人。 | [
"蒙法尔孔是法国伊泽尔省的"
] |
||||
16 | 编织,在广意上是指将线状或条状的材料,经过重复交叠过程,形成一个平面或立体的技术,透过编织制作出来的作品,称作编织物或编织品。而在狭意上来说,编织是被 | [
"上是指将线状",
"形成一个平面或立体",
"编织制作出来的作品",
"而在狭意上来说"
] |
||||
17 | 弗鲁埃拉二世从他父亲阿斯图里亚斯的阿方索三世死于910年后到他自己去世期间为阿斯图里亚斯国王。当他的父亲死后,王国被三个儿子瓜分,三子弗鲁埃拉取得最初的 | [
"弗鲁埃拉二世从他父亲",
"当他的父亲死",
"三子弗鲁埃拉取得最初的"
] |
||||
18 | 威廉·P·劳伦斯号是由诺斯罗普·格鲁曼造船公司建造的阿利·伯克级导弹驱逐舰,为伯克级60号舰,以海军飞行员、战斗机飞行员、试飞员、水星计划航天员入围者、 | [
"公司建造的阿利·伯克级导弹"
] |
||||
19 | 东通村是青森县下北半岛东北部的村。 | [
"青森县下北半岛东北部的"
] |
||||
20 | 兰士登站是一座多伦多地铁布罗尔-单福线车站,坐落加拿大安大略省多伦多兰士登大道和布罗尔西街的交界处以北,于1966年2月25日联同该地铁线的首期路段一起开幕 | [
"该地铁线的首期路段",
"大略省多伦多兰士登大道和"
] |
||||
21 | 联盟TMA-13M是俄罗斯联盟TMA系列飞船之一。飞船搭载远征40任务三名宇航员于2014年5月28日在哈萨克斯坦拜科努尔航天发射场发射升空,飞赴国际空间站。2014年11月 | [
"哈萨克斯坦拜科努尔航天发射场发射"
] |
||||
22 | 雪芮儿·百莉是一位美国女性爵士乐吉他手和教育家。她已发布了多张爵士乐专辑,亦是伯克利音乐学院吉他系的副教授。 | [
"女性爵士乐吉他手和",
"她已发布了多"
] |
||||
23 | 泰式花环,又称香花串,是一种泰国的特色手工艺品,由鲜花和花叶制成。有玫瑰、栀子、牛角瓜、马缨丹、茉莉花叶、茉莉、络石、千日红、使君子、软枝黄蝉、鸡冠花 | [
"泰国的特色手工艺品"
] |
||||
24 | 摩尔多瓦总理是摩尔多瓦的政府首脑。由议会中的最大党派或联盟的领袖出任,并由总统任命而生效。任期四年,现任总理是扬·基库。 | [
"大党派或联盟的",
"由总统任命而生效"
] |
||||
25 | 塞巴斯蒂安·维特尔,是一位德国一级方程式赛车车手,目前效力于法拉利车队。他是四届的一级方程式赛车世界冠军,在2010年、2011年、2012年和2013年连续四年夺冠 | [
"位德国一级方程式赛车",
"一级方程式赛车世界冠军"
] |
||||
26 | 碘缺乏病是因缺乏摄入碘元素而造成的病态。这种病症通常出现于远离海洋的内陆地区的人口,因海产是人体摄取碘的主要来源,以及内陆地区土壤含量不足。但并不代表 | [
"碘元素而造成的病态",
"以及内陆地区土壤含量",
"出现于远离海洋的"
] |
||||
27 | 澳大利亚饮食是指澳大利亚的饮食文化。澳洲原住民的饮食文化以狩猎采集到的食物为主,因此澳洲本土的动植物,如袋鼠等都曾是澳洲原住民的食物。澳洲成为英国殖民 | [
"指澳大利亚的饮食文化",
"如袋鼠等都曾是",
"文化以狩猎采集到"
] |
||||
28 | 小罗素·纳森·强森·柯尔崔恩·马丁出生于加拿大的东约克,现为美国职棒大联盟洛杉矶道奇的捕手。 | [
"职棒大联盟洛杉矶道奇",
"出生于加拿大的东约克"
] |
||||
29 | 菊池市是位于日本熊本县北部的城市。于2005年3月22日由旧菊池市与菊池郡七城町、泗水町、旭志村合并而成。所出产的菊池米具有一定的知名度。 | [
"日本熊本县北部的城市",
"旧菊池市与菊池郡",
"所出产的菊池米"
] |
||||
30 | 乱卷云,是卷云的一个变种。乱卷云的云丝弯曲得相当地无序,看上去以不规则的方式相互缠绕在一起。乱卷云是卷云特有的变种。 | [
"是卷云的一个变种",
"云丝弯曲得相当地",
"的方式相互缠绕在一起"
] |
||||
31 | 酸葡萄汁是用生葡萄榨制而成的酸味浓厚的果汁。有时也可加入柠檬汁、酢浆草汁等调味。在中世纪的欧洲,酸葡萄汁被广泛用于制作调味酱汁或腌制食物。 | [
"榨制而成的酸味",
"有时也可加入柠",
"酸葡萄汁被广泛用于"
] |
||||
32 | 雅蒲岛国际机场或称雅蒲机场是一座位于密克罗尼西亚联邦雅蒲岛的国际机场。 | [
"联邦雅蒲岛的国际机场"
] |
||||
33 | 南北线是日本北大阪急行电铁经营的铁路路线,路线北抵大阪府丰中市千里中央站,南边则于吹田市江坂站与大阪市营地铁的御堂筋线直通运行。全线均实施立体化,除了 | [
"大阪市营地铁的御堂"
] |
||||
34 | 美国北卡罗来纳州分为100个县,北卡罗来纳州面积排名第29位,但是该州县的数量在全国排名第7位。 | [
"县的数量在全国"
] |
||||
35 | 梅林路站位于天津市津南区梅林路与渌水道交口,是天津地铁6号线的地下车站之一。随天津地铁6号线南段于2018年4月26日启用。目前是天津地铁6号线的终点站。 | [
"梅林路站位于天津市津南区"
] |
||||
36 | 俄罗斯正教会圣尼古拉主教座堂是一座俄罗斯正教会的主教座堂,法国的国家历史古迹,位于法国南部城市尼斯,建成于1912年,由沙皇尼古拉二世出资建造,是俄罗斯东 | [
"座俄罗斯正教会的",
"法国的国家历史古迹"
] |
||||
37 | 伊多墨纽斯。古希腊神话男性人物之一。克里特君主。父亲为丢卡利翁,祖父为弥诺斯。曾参加特洛伊战争之希腊联军,并成为阿伽门农之得力谋士,多次取得战绩。其事 | [
"特洛伊战争之希腊联军",
"成为阿伽门农之得力谋士"
] |
||||
38 | 尘冢怪王是日本传说中妖怪的一种。物如其名,即是堆积的尘土幻化的付丧神的王。 | [
"是日本传说中妖怪",
"是堆积的尘土幻化"
] |
||||
39 | "法兰西岛有轨电车2号线是法兰西岛有轨电车第二条通车的线路,于1997年启用.本线北起巴黎西北郊,经由拉德芳斯商业区,沿塞纳河河谷向南,到达巴黎西南角的凡尔赛 | [
"法兰西岛有轨电车第二条",
"到达巴黎西南角的凡尔赛"
] |
||||
40 | 波尔沃是芬兰一个使用“城市”称号的市镇,位于该国南部芬兰湾沿岸,距离首都赫尔辛基50公里,由新地区负责管辖,面积654.78平方公里,2017年5月底人口50,142。 | [
"由新地区负责管辖",
"波尔沃是芬兰一个使用"
] |
||||
41 | 波茨坦大学,位于德国勃兰登堡州波茨坦市,由四个校区组成,规模位列波茨坦四所高等院校之首,是勃兰登堡州最大的高校。现时有超过两万名学生,并曾获德意志科学 | [
"规模位列波茨坦四所高等",
"是勃兰登堡州最大的",
"并曾获德意志科学"
] |
||||
42 | 社会主义竞赛起源于苏联,是在劳动群众发挥最大的积极性的基础上,提高劳动生产率和改进生产的方法,是社会主义制度的特有产物。与资产阶级社会的竞争有着本质区 | [
"大的积极性的基础",
"生产率和改进生产的",
"社会主义制度的特有产物",
"社会的竞争有着本质区"
] |
||||
43 | i24news是一个报导国际与时事新闻的电视频道,其总部设于以色列特拉维夫之雅法港,以英语,法语,阿拉伯语播出,所有人为PatrickDrahi,而执行长为FrankMelloul | [
"一个报导国际与时事",
"总部设于以色列特拉维夫之"
] |
||||
44 | 布鲁克莱恩山站是马萨诸塞州波士顿轻轨绿线D支线车站。车站位于布鲁克莱恩山社区柏树街西侧,拥有两座侧式站台。 | [
"恩山站是马萨诸塞州波士顿轻轨",
"车站位于布鲁克莱恩山社区"
] |
||||
45 | 常平站,曾命名为东莞站,位于中国广东省东莞市常平镇,于1911年建成启用,为广深铁路及京九铁路的客货运二等站,目前由广州局集团广深铁路股份有限公司管辖。现 | [
"位于中国广东省东莞市常平镇",
"的客货运二等站"
] |
||||
46 | 柏林火车东站是继柏林火车总站和柏林南十字车站之后的柏林第三大铁路车站,它最初是以“法兰克福车站”的名称兴建。其名称变更的次数较柏林其它任何车站都多。车 | [
"火车东站是继柏林火车",
"较柏林其它任何车站"
] |
||||
47 | 埃曼努尔·利奥波德·纪尧姆·弗朗索瓦·玛丽是比利时国王菲利普同玛蒂尔德王后所生的次子,也是比利时王位第三顺位继承人。 | [
"玛蒂尔德王后所生的"
] |
||||
48 | 托尼·路特曼,出生于瑞士小镇蓬特雷西纳,是一名在东南亚和拉丁美洲工作的桥梁工程师,当地人常常称他为“瑞士人托尼”。 | [
"出生于瑞士小镇蓬特雷西纳",
"当地人常常称他为"
] |
||||
49 | LGBT是女同性恋者、男同性恋者、双性恋者与跨性别者的英文首字母缩略字,一般和性少数者同义。 | [
"的英文首字母缩略",
"一般和性少数者同义"
] |
||||
50 | 高地球轨道是指高度完全高于地球同步轨道的高度的地心轨道。此类轨道的轨道周期大于24小时,因此此类轨道中的卫星具有明显的逆行运动-也就是说,即使它们处于正 | [
"轨道的高度的地心",
"轨道的轨道周期大于",
"具有明显的逆行运动"
] |
||||
51 | 400系列公路是加拿大安大略省南部一系列高速公路,构成该省省道网络的一部分。此系列公路具有严谨的标准规格,部分设计特点更获北美其他交通部门建设高速公路时 | [
"构成该省省道网络的",
"部分设计特点更获",
"系列公路具有严谨的"
] |
||||
52 | 加里·亚历斯·梅德尔·索托,是一名智利足球运动员,司职防守中场,现在效力于意甲球队博洛尼亚。 | [
"现在效力于意甲球队博洛尼亚"
] |
||||
53 | 澳门邮政史,是澳门的邮政历史,大致可分为数个时期。 | [
"是澳门的邮政历史"
] |
||||
54 | AVOMETER是英国万用表和电子测量仪器的商标,用在英国的自动绕线机暨电气设备公司于1923年开始生产的最早兼具电流、电压、与电阻测量功能的多用途电表。该公司在 | [
"开始生产的最早兼具",
"电阻测量功能的多",
"用在英国的自动"
] |
||||
55 | 布里斯托尔寺院草原站是英国的一座火车站,位于布里斯托尔,是布里斯托尔最古老和最大的火车站。此站是布里斯托尔重要的教堂枢纽。火车站在1840年8月31日开始营 | [
"古老和最大的",
"站是布里斯托尔重要的"
] |
||||
56 | 邦克山号航空母舰是一艘隶属于美国海军的航空母舰,为埃塞克斯级航空母舰的九号舰。她是美军第一艘以邦克山为名的军舰,纪念美国独立战争中血腥的邦克山战役;舰 | [
"战争中血腥的邦克山",
"艘以邦克山为名的"
] |
||||
57 | 本页面旨在呈现腹足纲的系统发生学分类的一个可能性。利用树状结构,本页面详列出腹足纲之下各个物种的关系。页面尽可能采纳最新的分析证据,并把证据详列于本文 | [
"腹足纲的系统发生",
"出腹足纲之下各个物种",
"页面尽可能采纳最新的"
] |
||||
58 | 足球阵形是在足球比赛中球队如何将球员布署在球场上。阵形上大致可分为攻击阵形或防守阵形。形容阵形的方法由后卫开始计算至前线,但不把守门员计算在内。例如, | [
"足球比赛中球队如何",
"球员布署在球场上",
"上大致可分为攻击",
"由后卫开始计算至",
"不把守门员计算在内"
] |
||||
59 | 万人雇佣军团是小居鲁士雇用的一支以希腊人为主要兵源的雇佣兵部队,用来从他的兄弟阿尔塔薛西斯二世手中夺取波斯帝国的宝座。色诺芬在其作品《长征记》中记录了 | [
"中夺取波斯帝国的宝座",
"是小居鲁士雇用的",
"色诺芬在其作品"
] |
||||
60 | 日鷉科为鹤形目的一科,现仅存2属3种。分布于美洲、非洲和东南亚的热带水域。状似秧鸡,拥有较长的颈部,尾宽,喙尖锐。善于游泳和潜水。 | [
"拥有较长的颈部"
] |
||||
61 | 克麦罗沃区,是俄罗斯的一个区,位于该国南部,由科麦罗沃州负责管辖,面积4,391平方公里,2010年人口45,459,人口密度每平方公里10.35人。 | [
"是俄罗斯的一个区"
] |
||||
62 | 艾莉森·杜迪是一名爱尔兰女演员。1985年,她的出道作品是007电影《铁金刚勇战大狂魔》中的一个小角色。杜迪其他比较知名的角色有电影《圣战奇兵》的艾尔莎·施 | [
"她的出道作品是",
"铁金刚勇战大狂魔",
"杜迪其他比较知名的"
] |
||||
63 | 面包,是一种用五谷磨粉制作并加热而制成的食品。 | [
"并加热而制成的"
] |
||||
64 | 高尔基汽车厂是位于俄罗斯下诺夫哥罗德的汽车制造厂。 | [
"是位于俄罗斯下诺夫哥罗德"
] |
||||
65 | 红旗鳉为辐鳍鱼纲鲤齿目假鳃鳉科的其中一种。 | [
"红旗鳉为辐鳍鱼纲鲤"
] |
||||
66 | "科林德目录是瑞典天文学家佩尔·科林德收录471个疏散星团的目录。这本目录于1931年出版,是科林德论文《疏散星团的结构特性及其在空间的分布》中的附录。目录 | [
"个疏散星团的目录",
"疏散星团的结构特性"
] |
||||
67 | 杜姆勒山,是南极洲的山峰,位于帕尔默地东岸,处于贝利山以西20公里,海拔高度2,225米,由英国探险队绘入地图,现时由南极条约体系管理。 | [
"由英国探险队绘入地图"
] |
||||
68 | 劳拉·琳尼是一名美国女演员、电影、电视及舞台演员,曾多次赢得不同的演艺奖项,包括艾美奖、金球奖及美国演员工会奖,亦曾获三次奥斯卡金像奖提名及一次BAFTA | [
"曾多次赢得不同的"
] |
||||
69 | 沈阳铁路陈列馆坐落于中国辽宁省沈阳市苏家屯区山丹街8号,沈阳铁路局苏家屯机务段北侧。该馆占地面积8万平方米,建筑面积1.9万平方米,是中国东北地区最大的铁 | [
"地区最大的铁"
] |
||||
70 | 电力公司是一个多人的德式桌上游戏,由弗里德曼·弗里斯设计。 | [
"公司是一个多人"
] |
||||
71 | 天津平原地区的开发大约开始于距今6000年前的新石器时代,而且经过了一个由北向南、自西向东逐步推进的过程。 | [
"的开发大约开始于",
"而且经过了一个由"
] |
||||
72 | 艾锡·希顿,是一名英格兰足球运动员。现时效力英格兰足球超级联赛球队纽卡斯尔联和英格兰U20。司职后腰或中后卫。 | [
"效力英格兰足球超级联赛",
"司职后腰或中后卫"
] |
||||
73 | 雪鞋,是用于在雪地上行走的鞋具。雪鞋通过将人体的重量分散在更大的区域,从而避免在行走的时候完全的陷入雪地当中。 | [
"雪地上行走的鞋具",
"的重量分散在更",
"避免在行走的时候"
] |
||||
74 | 慕尼黑火车总站是一座位于德国巴伐利亚州首府慕尼黑的铁路车站。该尽头式车站的站房建筑连同轨道范围共占地约760,000平方米,在地面及地下分别设有32条及2条到 | [
"首府慕尼黑的铁路车站",
"建筑连同轨道范围共",
"在地面及地下分别"
] |
||||
75 | 多萝西·维拉·玛格丽特·毕晓普,FRS,FBA,FMedSci,英国心理学家,主攻领域为发展障碍。自1998年起,她成为牛津大学实验心理学的发展神经心理学教授和惠康信 | [
"主攻领域为发展障碍",
"实验心理学的发展神经"
] |
||||
76 | 2016年夏季奥林匹克运动会马里代表团参加2016年8月5日至8月21日在巴西里约热内卢举行的第三十一届奥林匹克运动会。 | [
"里约热内卢举行的第三十一届"
] |
||||
77 | 髋,又称腰带、骨盆、盘骨,是一个骨骼构造,位于脊椎末端,连接脊柱和股骨,与四足动物的后肢、双足动物的下肢相连。股骨与腰带在臀部连接处形成髋关节,它是球 | [
"与四足动物的后肢",
"腰带在臀部连接处形成"
] |
||||
78 | 松古米纳萨是印度尼西亚南苏拉威西省的一个城镇,是戈瓦县的县治所在,位于苏拉威西岛南半岛西南,西北紧靠望加锡城区,位于官方规定的望加锡大都会区范围之内。 | [
"望加锡大都会区范围之内",
"南苏拉威西省的一个城镇"
] |
||||
79 | Selfridges是一家英国的高档百货公司,由哈里·戈登·塞尔福里奇创始于1909年。其位于伦敦牛津街的旗舰店在1909年3月15日开业,现在是仅次于哈洛德百货公司的英 | [
"一家英国的高档百货",
"其位于伦敦牛津街的"
] |
||||
80 | 克里特岛战役是第二次世界大战中希腊战役的一部分,爆发于希腊克里特岛的战事。战斗开始于1941年5月20日早上,纳粹德国发动代号“水星行动”的军事行动,空降入 | [
"第二次世界大战中"
] |
||||
81 | 切列克斯基区,是俄罗斯的一个区,位于该国西南部,由卡巴尔达-巴尔卡尔共和国负责管辖,面积2,210平方公里,2010年人口26,956,人口密度每平方公里12.2人。 | [
"是俄罗斯的一个区"
] |
||||
82 | 珍·怀尔德,即怀尔德爵士夫人,爱尔兰诗人、作家、翻译家,又是爱尔兰独立运动的支持者。她也是诗人和剧作家王尔德的母亲和爱尔兰教士查理斯·罗伯特·马图林的 | [
"又是爱尔兰独立运动",
"母亲和爱尔兰教士查理斯·罗伯特·马图林"
] |
||||
83 | 凡尔登站,是法国的一个铁路车站,位于法国城市凡尔登。 | [
"法国的一个铁路车站"
] |
||||
84 | 大眼蝠属,哺乳纲、翼手目、叶口蝠科的一属,而与大眼蝠属同科的动物尚有白蝠属、间叶蝠属、襞面蝠属、美洲果蝠属等之数种哺乳动物。 | [
"等之数种哺乳",
"大眼蝠属同科的动物"
] |
||||
85 | 顿河畔纳希切万,又称新纳希切万,俄罗斯南部顿河畔罗斯托夫附近的一座城市,1779年由克里米亚的亚美尼亚人建立,1928年并入罗斯托夫。 | [
"南部顿河畔罗斯托夫附近的"
] |
||||
86 | 邦迪是法国上法兰西大区北部省的一个市镇,属于里尔区和里尔第二县。该市镇2009年时的人口为10,103人。 | [
"属于里尔区和里尔第二",
"是法国上法兰西大区"
] |
||||
87 | 内田吐梦,本名内田常次郎,日本知名导演之一,对于日本电影创作的成长有不少影响,日本人更因推崇他而给他“巨匠”这个美名,1960年代著名作品‘宫本武藏’5集 | [
"因推崇他而给",
"电影创作的成长有"
] |
||||
88 | 拉坦·纳瓦尔·塔塔,GBE生于今印度古吉拉特邦苏拉特,印度企业家,曾任塔塔集团董事长。 | [
"GBE生于今印度古吉拉特邦苏拉特"
] |
||||
89 | 费尔芒特是一个位于美国佐治亚州戈登县的城市。 | [
"是一个位于美国佐治亚州"
] |
||||
90 | 《今昔画图续百鬼》是1779年由日本江户时代画家鸟山石燕创作的妖怪画集,也是《画图百鬼夜行》的续编。此画集由“雨”、“晦”、“明”等三部构成,各篇名取自六 | [
"江户时代画家鸟山石燕"
] |
||||
91 | Petya是一种在2016年被首次发现的勒索软件。2017年6月,Petya的一个新变种“NotPetya”被用于发动一次全球性的网络攻击。 | [
"首次发现的勒索软件",
"Petya的一个新变种"
] |
||||
92 | 伯明翰大学是一所于1900年创立在英格兰伯明翰市的英国大学。是英国第一所“红砖大学”,亦为英国顶尖学府。作为罗素大学集团创始成员之一,该大学的历史可追溯至 | [
"亦为英国顶尖学府",
"大学的历史可追溯"
] |
||||
93 | 毛毯是一种常用的床上用品,具有保暖功能,与被子相比较薄。其原料多采用动物纤维或腈纶、粘胶纤维等化学纤维,也有的为动物纤维与化纤混纺制成的。 | [
"与被子相比较薄",
"纤维与化纤混纺制成",
"其原料多采用动物"
] |
||||
94 | 白衣忏悔者小堂是一个天主教建筑,罗马式风格,位于法国阿维尼翁placePrincipale广场。 | [
"位于法国阿维尼翁placePrincipale广场"
] |
||||
95 | 普瓦捷大学,始建于1431年,是欧洲最古老的大学之一。 | [
"最古老的大学之一"
] |
||||
96 | 波特兰岛位于英吉利海峡,是一座由石灰岩组成的陆连岛,有6千米长,2.4千米宽。波特兰岛在度假胜地韦茅斯的南面约8千米,在多塞特郡的最南端。波特兰岛由切希 | [
"由石灰岩组成的陆连岛",
"胜地韦茅斯的南面约"
] |
||||
97 | 科西嘉是地中海西部的一座岛屿,也是法国的一个单一领土集体,位于法国大陆部分的东南面,意大利半岛的西面,最近的地块是紧邻意大利的撒丁岛。科西嘉岛三分之二 | [
"是法国的一个单一",
"位于法国大陆部分的",
"是紧邻意大利的撒丁岛"
] |
||||
98 | RepRap是一种三维打印机原型机,它具有一定程度的自我复制能力,能够打印出大部分其自身的组件。RepRap是的缩写。 | [
"一定程度的自我复制",
"大部分其自身的组件"
] |
||||
99 | 吉尔福德镇区是位于美国伊利诺伊州乔戴维斯县的一个行政镇区。 | [
"伊利诺伊州乔戴维斯县的一个行政"
] |
🏠 Paper | 👩🏻💻 GitHub | 🤗 Huggingface Datasets | 📏 Evaluation with lmms-eval
This is the official Hugging Face dataset for VCR-Wiki, a dataset for the Visual Caption Restoration (VCR) task.
VCR is designed to measure vision-language models' capability to accurately restore partially obscured texts using pixel-level hints within images. text-based processing becomes ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts.

We found that OCR and text-based processing become ineffective in VCR as accurate text restoration depends on the combined information from provided images, context, and subtle cues from the tiny exposed areas of masked texts. We develop a pipeline to generate synthetic images for the VCR task using image-caption pairs, with adjustable caption visibility to control the task difficulty. However, this task is generally easy for native speakers of the corresponding language. Initial results indicate that current vision-language models fall short compared to human performance on this task.
EM means "Exact Match" and Jaccard means "Jaccard Similarity". The best in closed source and open source are highlighted in bold. The second best are highlighted in italic. Closed source models are evaluated based on 500 test samples, while open source models are evaluated based on 5000 test samples.
| Model | Size (unknown for closed source) | En Easy EM | En Easy Jaccard | En Hard EM | En Hard Jaccard | Zh Easy EM | Zh Easy Jaccard | Zh Hard EM | Zh Hard Jaccard |
|---|---|---|---|---|---|---|---|---|---|
| Claude 3 Opus | - | 62.0 | 77.67 | 37.8 | 57.68 | 0.9 | 11.5 | 0.3 | 9.22 |
| Claude 3.5 Sonnet | - | 63.85 | 74.65 | 41.74 | 56.15 | 1.0 | 7.54 | 0.2 | 4.0 |
| GPT-4 Turbo | - | 78.74 | 88.54 | 45.15 | 65.72 | 0.2 | 8.42 | 0.0 | 8.58 |
| GPT-4V | - | 52.04 | 65.36 | 25.83 | 44.63 | - | - | - | - |
| GPT-4o | - | 91.55 | 96.44 | 73.2 | 86.17 | 14.87 | 39.05 | 2.2 | 22.72 |
| GPT-4o-mini | - | 83.60 | 87.77 | 54.04 | 73.09 | 1.10 | 5.03 | 0 | 2.02 |
| Gemini 1.5 Pro | - | 62.73 | 77.71 | 28.07 | 51.9 | 1.1 | 11.1 | 0.7 | 11.82 |
| Qwen-VL-Max | - | 76.8 | 85.71 | 41.65 | 61.18 | 6.34 | 13.45 | 0.89 | 5.4 |
| Reka Core | - | 66.46 | 84.23 | 6.71 | 25.84 | 0.0 | 3.43 | 0.0 | 3.35 |
| Cambrian-1 | 34B | 79.69 | 89.27 | 27.20 | 50.04 | 0.03 | 1.27 | 0.00 | 1.37 |
| Cambrian-1 | 13B | 49.35 | 65.11 | 8.37 | 29.12 | - | - | - | - |
| Cambrian-1 | 8B | 71.13 | 83.68 | 13.78 | 35.78 | - | - | - | - |
| CogVLM | 17B | 73.88 | 86.24 | 34.58 | 57.17 | - | - | - | - |
| CogVLM2 | 19B | 83.25 | 89.75 | 37.98 | 59.99 | 9.15 | 17.12 | 0.08 | 3.67 |
| CogVLM2-Chinese | 19B | 79.90 | 87.42 | 25.13 | 48.76 | 33.24 | 57.57 | 1.34 | 17.35 |
| DeepSeek-VL | 1.3B | 23.04 | 46.84 | 0.16 | 11.89 | 0.0 | 6.56 | 0.0 | 6.46 |
| DeepSeek-VL | 7B | 38.01 | 60.02 | 1.0 | 15.9 | 0.0 | 4.08 | 0.0 | 5.11 |
| DocOwl-1.5-Omni | 8B | 0.84 | 13.34 | 0.04 | 7.76 | 0.0 | 1.14 | 0.0 | 1.37 |
| GLM-4v | 9B | 43.72 | 74.73 | 24.83 | 53.82 | 31.78 | 52.57 | 1.20 | 14.73 |
| Idefics2 | 8B | 15.75 | 31.97 | 0.65 | 9.93 | - | - | - | - |
| InternLM-XComposer2-VL | 7B | 46.64 | 70.99 | 0.7 | 12.51 | 0.27 | 12.32 | 0.07 | 8.97 |
| InternLM-XComposer2-VL-4KHD | 7B | 5.32 | 22.14 | 0.21 | 9.52 | 0.46 | 12.31 | 0.05 | 7.67 |
| InternLM-XComposer2.5-VL | 7B | 41.35 | 63.04 | 0.93 | 13.82 | 0.46 | 12.97 | 0.11 | 10.95 |
| InternVL-V1.5 | 26B | 14.65 | 51.42 | 1.99 | 16.73 | 4.78 | 26.43 | 0.03 | 8.46 |
| InternVL-V2 | 26B | 74.51 | 86.74 | 6.18 | 24.52 | 9.02 | 32.50 | 0.05 | 9.49 |
| InternVL-V2 | 40B | 84.67 | 92.64 | 13.10 | 33.64 | 22.09 | 47.62 | 0.48 | 12.57 |
| InternVL-V2 | 76B | 83.20 | 91.26 | 18.45 | 41.16 | 20.58 | 44.59 | 0.56 | 15.31 |
| InternVL-V2-Pro | - | 77.41 | 86.59 | 12.94 | 35.01 | 19.58 | 43.98 | 0.84 | 13.97 |
| MiniCPM-V2.5 | 8B | 31.81 | 53.24 | 1.41 | 11.94 | 4.1 | 18.03 | 0.09 | 7.39 |
| Monkey | 7B | 50.66 | 67.6 | 1.96 | 14.02 | 0.62 | 8.34 | 0.12 | 6.36 |
| Qwen-VL | 7B | 49.71 | 69.94 | 2.0 | 15.04 | 0.04 | 1.5 | 0.01 | 1.17 |
| Yi-VL | 34B | 0.82 | 5.59 | 0.07 | 4.31 | 0.0 | 4.44 | 0.0 | 4.12 |
| Yi-VL | 6B | 0.75 | 5.54 | 0.06 | 4.46 | 0.00 | 4.37 | 0.00 | 4.0 |
We support open-source model_id:
["openbmb/MiniCPM-Llama3-V-2_5",
"OpenGVLab/InternVL-Chat-V1-5",
"internlm/internlm-xcomposer2-vl-7b",
"internlm/internlm-xcomposer2-4khd-7b",
"internlm/internlm-xcomposer2d5-7b",
"HuggingFaceM4/idefics2-8b",
"Qwen/Qwen-VL-Chat",
"THUDM/cogvlm2-llama3-chinese-chat-19B",
"THUDM/cogvlm2-llama3-chat-19B",
"THUDM/cogvlm-chat-hf",
"echo840/Monkey-Chat",
"THUDM/glm-4v-9b",
"nyu-visionx/cambrian-phi3-3b",
"nyu-visionx/cambrian-8b",
"nyu-visionx/cambrian-13b",
"nyu-visionx/cambrian-34b",
"OpenGVLab/InternVL2-26B",
"OpenGVLab/InternVL2-40B"
"OpenGVLab/InternVL2-Llama3-76B",]
For the models not on list, they are not intergated with huggingface, please refer to their github repo to create the evaluation pipeline. Examples of the inference logic are in src/evaluation/inference.py
pip install -r requirements.txt
# We use HuggingFaceM4/idefics2-8b and vcr_wiki_en_easy as an example
cd src/evaluation
# Evaluate the results and save the evaluation metrics to {model_id}_{difficulty}_{language}_evaluation_result.json
python3 evaluation_pipeline.py --dataset_handler "vcr-org/VCR-wiki-en-easy-test" --model_id HuggingFaceM4/idefics2-8b --device "cuda" --output_path . --bootstrap --end_index 5000
For large models like "OpenGVLab/InternVL2-Llama3-76B", you may have to use multi-GPU to do the evaluation. You can specify --device to None to use all GPUs available.
We provide the evaluation script for the close-source models in src/evaluation/closed_source_eval.py.
You need an API Key, a pre-saved testing dataset and specify the path of the data saving the paper
pip install -r requirements.txt
cd src/evaluation
# [download images to inference locally option 1] save the testing dataset to the path using script from huggingface
python3 save_image_from_dataset.py --output_path .
# [download images to inference locally option 2] save the testing dataset to the path using github repo
# use en-easy-test-500 as an example
git clone https://github.com/tianyu-z/VCR-wiki-en-easy-test-500.git
# specify your image path if you would like to inference using the image stored locally by --image_path "path_to_image", otherwise, the script will streaming the images from github repo
python3 closed_source_eval.py --model_id gpt4o --dataset_handler "VCR-wiki-en-easy-test-500" --api_key "Your_API_Key"
# Evaluate the results and save the evaluation metrics to {model_id}_{difficulty}_{language}_evaluation_result.json
python3 evaluation_metrics.py --model_id gpt4o --output_path . --json_filename "gpt4o_en_easy.json" --dataset_handler "vcr-org/VCR-wiki-en-easy-test-500"
# To get the mean score of all the `{model_id}_{difficulty}_{language}_evaluation_result.json` in `jsons_path` (and the std, confidence interval if `--bootstrap`) of the evaluation metrics
python3 gather_results.py --jsons_path .
You may need to incorporate the inference method of your model if the VLMEvalKit framework does not support it. For details, please refer to here
git clone https://github.com/open-compass/VLMEvalKit.git
cd VLMEvalKit
# We use HuggingFaceM4/idefics2-8b and VCR_EN_EASY_ALL as an example
python run.py --data VCR_EN_EASY_ALL --model idefics2_8b --verbose
You may find the supported model list here.
VLMEvalKit supports the following VCR --data settings:
VCR_EN_EASY_ALL (full test set, 5000 instances)VCR_EN_EASY_500 (first 500 instances in the VCR_EN_EASY_ALL setting)VCR_EN_EASY_100 (first 100 instances in the VCR_EN_EASY_ALL setting)VCR_EN_HARD_ALL (full test set, 5000 instances)VCR_EN_HARD_500 (first 500 instances in the VCR_EN_HARD_ALL setting)VCR_EN_HARD_100 (first 100 instances in the VCR_EN_HARD_ALL setting)VCR_ZH_EASY_ALL (full test set, 5000 instances)VCR_ZH_EASY_500 (first 500 instances in the VCR_ZH_EASY_ALL setting)VCR_ZH_EASY_100 (first 100 instances in the VCR_ZH_EASY_ALL setting)VCR_ZH_HARD_ALL (full test set, 5000 instances)VCR_ZH_HARD_500 (first 500 instances in the VCR_ZH_HARD_ALL setting)VCR_ZH_HARD_100 (first 100 instances in the VCR_ZH_HARD_ALL setting)You may need to incorporate the inference method of your model if the lmms-eval framework does not support it. For details, please refer to here
pip install git+https://github.com/EvolvingLMMs-Lab/lmms-eval.git
# We use HuggingFaceM4/idefics2-8b and vcr_wiki_en_easy as an example
python3 -m accelerate.commands.launch --num_processes=8 -m lmms_eval --model idefics2 --model_args pretrained="HuggingFaceM4/idefics2-8b" --tasks vcr_wiki_en_easy --batch_size 1 --log_samples --log_samples_suffix HuggingFaceM4_idefics2-8b_vcr_wiki_en_easy --output_path ./logs/
You may find the supported model list here.
lmms-eval supports the following VCR --tasks settings:
vcr_wiki_en_easy (full test set, 5000 instances)vcr_wiki_en_easy_500 (first 500 instances in the vcr_wiki_en_easy setting)vcr_wiki_en_easy_100 (first 100 instances in the vcr_wiki_en_easy setting)vcr_wiki_en_hard (full test set, 5000 instances)vcr_wiki_en_hard_500 (first 500 instances in the vcr_wiki_en_hard setting)vcr_wiki_en_hard_100 (first 100 instances in the vcr_wiki_en_hard setting)vcr_wiki_zh_easy (full test set, 5000 instances)vcr_wiki_zh_easy_500 (first 500 instances in the vcr_wiki_zh_easy setting)vcr_wiki_zh_easy_100 (first 100 instances in the vcr_wiki_zh_easy setting)vcr_wiki_zh_hard (full test set, 5000 instances)vcr_wiki_zh_hard_500 (first 500 instances in the vcr_wiki_zh_hard setting)vcr_wiki_zh_hard_100 (first 100 instances in the vcr_wiki_zh_hard setting)We show the statistics of the original VCR-Wiki dataset below:

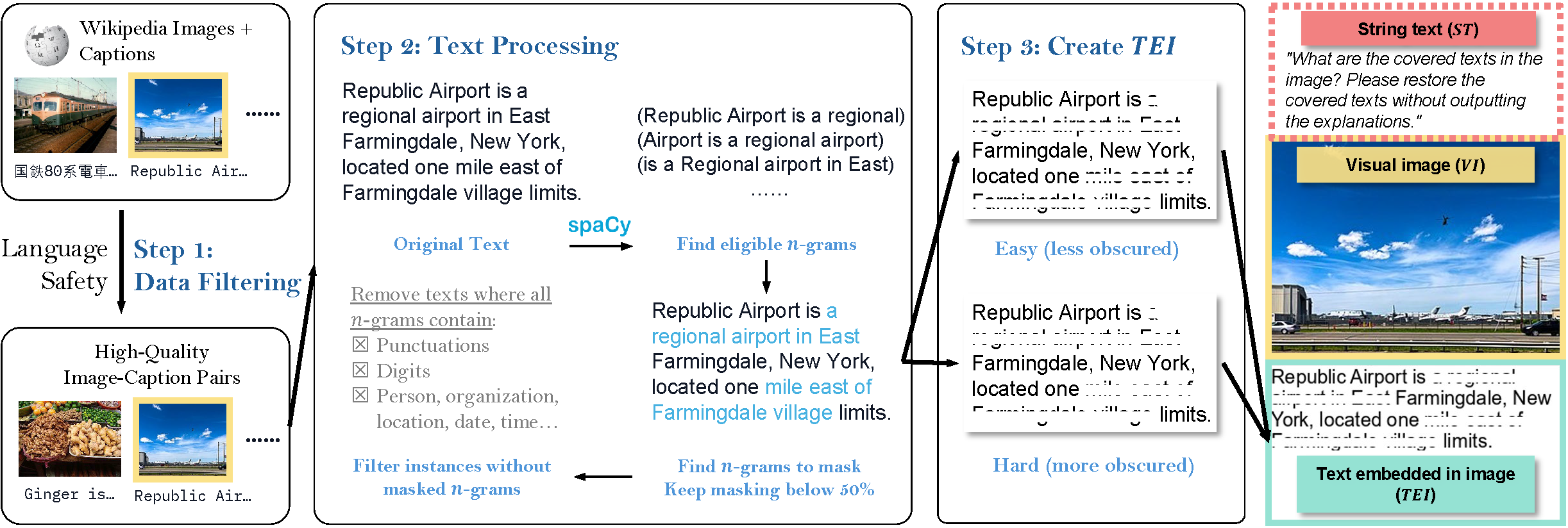
Data Collection and Initial Filtering: The original data is collected from wikimedia/wit_base. Before constructing the dataset, we first filter out the instances with sensitive content, including NSFW and crime-related terms, to mitigate AI risk and biases.
N-gram selection: We first truncate the description of each entry to be less than 5 lines with our predefined font and size settings. We then tokenize the description for each entry with spaCy and randomly mask out 5-grams, where the masked 5-grams do not contain numbers, person names, religious or political groups, facilities, organizations, locations, dates and time labeled by spaCy, and the total masked token does not exceed 50% of the tokens in the caption.
Create text embedded in images: We create text embedded in images (TEI) for the description, resize its width to 300 pixels, and mask out the selected 5-grams with white rectangles. The size of the rectangle reflects the difficulty of the task: (1) in easy versions, the task is easy for native speakers but open-source OCR models almost always fail, and (2) in hard versions, the revealed part consists of only one to two pixels for the majority of letters or characters, yet the restoration task remains feasible for native speakers of the language.
Concatenate Images: We concatenate TEI with the main visual image (VI) to get the stacked image.
Second-round Filtering: We filter out all entries with no masked n-grams or have a height exceeding 900 pixels.
question_id: int64, the instance id in the current split.image: PIL.Image.Image, the original visual image (VI).stacked_image: PIL.Image.Image, the stacked VI+TEI image containing both the original visual image and the masked text embedded in image.only_id_image: PIL.Image.Image, the masked TEI image.caption: str, the unmasked original text presented in the TEI image.crossed_text: List[str], the masked n-grams in the current instance.The VCR-Wiki dataset and/or its subsets are provided under the Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) license. This dataset is intended solely for research and educational purposes in the field of visual caption restoration and related vision-language tasks.
Important Considerations:
Accuracy and Reliability: While the VCR-Wiki dataset has undergone filtering to exclude sensitive content, it may still contain inaccuracies or unintended biases. Users are encouraged to critically evaluate the dataset's content and applicability to their specific research objectives.
Ethical Use: Users must ensure that their use of the VCR-Wiki dataset aligns with ethical guidelines and standards, particularly in avoiding harm, perpetuating biases, or misusing the data in ways that could negatively impact individuals or groups.
Modifications and Derivatives: Any modifications or derivative works based on the VCR-Wiki dataset must be shared under the same license (CC BY-SA 4.0).
Commercial Use: Commercial use of the VCR-Wiki dataset is permitted under the CC BY-SA 4.0 license, provided that proper attribution is given and any derivative works are shared under the same license.
By using the VCR-Wiki dataset and/or its subsets, you agree to the terms and conditions outlined in this disclaimer and the associated license. The creators of the dataset are not liable for any direct or indirect damages resulting from its use.
If you find VCR useful for your research and applications, please cite using this BibTeX:
@article{zhang2024vcr,
title = {VCR: Visual Caption Restoration},
author = {Tianyu Zhang and Suyuchen Wang and Lu Li and Ge Zhang and Perouz Taslakian and Sai Rajeswar and Jie Fu and Bang Liu and Yoshua Bengio},
year = {2024},
journal = {arXiv preprint arXiv: 2406.06462}
}