
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
unknown | revision_date
unknown | committer_date
unknown | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
unknown | gha_updated_at
unknown | gha_pushed_at
unknown | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
itsnitigya/HtmlGenerator | https://github.com/itsnitigya/HtmlGenerator | 12e7c4d24e804bce00633813f166f6239285677b | 8b1a63b4d0379db1531ddbed8b0c84c289b2b26d | 4d9dce7368a19798d14d6eb4a7e02951aa041796 | refs/heads/master | "2022-04-11T12:56:40.699905" | "2020-01-30T17:03:22" | "2020-01-30T17:03:22" | 237,060,893 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.578255295753479,
"alphanum_fraction": 0.5946119427680969,
"avg_line_length": 36.54216766357422,
"blob_id": "30704432c3b9388097ad329fe4c2e40f1e702487",
"content_id": "28c273d90952eb79a42810250a0c39c466abc960",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3118,
"license_type": "no_license",
"max_line_length": 287,
"num_lines": 83,
"path": "/app.py",
"repo_name": "itsnitigya/HtmlGenerator",
"src_encoding": "UTF-8",
"text": "from flask import Flask, jsonify, abort, request, redirect\nfrom bs4 import BeautifulSoup\nimport requests\nimport json\nimport subprocess\n\napp = Flask(__name__)\n\n\ndef html_maker(URL):\n #get url link here\n response = requests.get(URL)\n source = response.text\n soup = BeautifulSoup(source, 'html.parser')\n qname = soup.find('div',{'class':'title'}).text[3:]\n problem = soup.find('div',{'class':'problem-statement'})\n statement = problem.find_all('div')[10].text\n inputformat = soup.find('div',{'class':'input-specification'}).text[5:]\n outputformat = soup.find('div',{'class':'output-specification'}).text[6:]\n sample = soup.find('div',{'class':'sample-test'})\n inputsample = sample.find('div',{'class':'input'}).text\n outputsample = sample.find('div',{'class':'output'}).text\n html = \"<h2>\" + qname + \"</h2>\" + \"<h3>Problem Statement</h3>\" + \"<p>\" + statement + \"</p>\" + \"<h3>Input Format</h3>\" + inputformat + \"<h3>Output Format</h3>\" + outputformat + \"<h3>Sample Input</h3><pre>\" + inputsample + \"</pre><h3>Sample Output</h3><pre>\" + outputsample + \"</pre>\"\n html = html.replace(\"\\le\",\"<=\")\n html = html.replace(\"$$$\",\"\")\n html = html.replace(\"\\cdot\",\"*\")\n html = html.replace(\"\\dots\",\"...\")\n html = html.replace(\"\\sum\",\"Summation\")\n html = html.replace(u'\\u2014',\"-\")\n html = html.replace(\"\\,\",\",\")\n return html\n\ndef html_makerV2(URL):\n #get url link here\n html = {}\n response = requests.get(URL)\n source = response.text\n soup = BeautifulSoup(source, 'html.parser')\n qname = soup.find('title').text\n qname, sep, tail = qname.partition('|')\n body = soup.find('body')\n problem = body.find('div',{'class':'primary-colum-width-left'}).text\n n = len(problem)\n x = slice(515,n)\n problem = problem[x]\n problem, sep, tail = problem.partition('Author')\n html = \"<h2>\" + qname + \"</h2>\" + \"<pre>\" + problem + \"</pre>\"\n html = html.replace(\"### Input\",\"<h2>Input</h2>\")\n html = html.replace(\"### Output\",\"<h2>Input</h2>\")\n html = html.replace(\"### Constraints\",\"<h2>Constraints</h2>\")\n html = html.replace(\"### Subtasks\",\"<h2>Subtasks</h2>\")\n html = html.replace(\"### Explanation\",\"<h2>Explanation</h2>\")\n html = html.replace(\"### Example Input\",\"<h2>Example Input</h2>\")\n html = html.replace(\"### Example Output\",\"<h2>Example Output</h2>\")\n html = html.replace(\"\\le\",\"<=\")\n html = html.replace(\"\\ldots\",\"...\")\n html = html.replace(\"*\",\"\")\n html = html.replace(\"\\cdot\",\"*\")\n html = html.replace(\"\\sum\",\"Summation\")\n html = html.replace(\"$\",\"\")\n return html\n\ndef output_maker():\n #get solution file here\n subprocess.call(\"g++ solution.cpp\",shell = True)\n subprocess.call(\"./test.sh\",shell = True)\n\[email protected]('/', methods=['POST','GET'])\ndef main():\n url = request.json['url']\n if \"codeforces\" in url:\n response = html_maker(url)\n elif \"codechef\" in url:\n response = html_makerV2(url)\n else:\n response = {\"html\":{}}\n #output_maker()\n return response\n\n\n\nif __name__ == '__main__':\n app.run(host='0.0.0.0', port=8000, debug=True)\n\n\n"
},
{
"alpha_fraction": 0.509471595287323,
"alphanum_fraction": 0.7078763842582703,
"avg_line_length": 16.910715103149414,
"blob_id": "ea37324014e91666c0a0e9eca0fd53c67a0b7104",
"content_id": "ab8de0dff2e1fb25e5ed1449e84e1c82d1a907f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1003,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 56,
"path": "/requirements.txt",
"repo_name": "itsnitigya/HtmlGenerator",
"src_encoding": "UTF-8",
"text": "asn1crypto==0.24.0\nasyncio==3.4.3\nbackports.functools-lru-cache==1.5\nbeautifulsoup4==4.8.0\nbs4==0.0.1\ncertifi==2019.11.28\ncffi==1.12.2\nchardet==3.0.4\nClick==7.0\ncryptography==2.6.1\ncssselect==1.1.0\ndecorator==4.4.0\nenum34==1.1.6\nFlask==1.0.2\nFlask-HTTPAuth==3.3.0\nflask-profiler==1.8.1\ngunicorn==19.9.0\nhtml5lib==1.0.1\nidna==2.8\nipaddress==1.0.22\nitsdangerous==1.1.0\nJinja2==2.10.1\nlogging==0.4.9.6\nlxml==4.4.2\nMarkupSafe==1.1.1\nMechanicalSoup==0.12.0\nmechanize==0.4.3\nmysql-connector-python==8.0.16\nmysql-connector-python-rf==2.2.2\nnumpy==1.16.5\nopencv-python==4.1.2.30\nparse==1.12.1\npbr==5.4.3\nPillow==6.2.1\nprotobuf==3.7.1\npycparser==2.19\npycurl==7.43.0.4\npymongo==3.5.1\npytesseract==0.3.0\npython-crontab==2.4.0\npython-dateutil==2.8.1\npython-firebase==1.2\nredis==3.3.11\nrequests==2.22.0\nsimplejson==3.16.0\nsix==1.12.0\nsoupsieve==1.9.3\nSQLAlchemy==1.3.8\nsqlalchemy-migrate==0.12.0\nsqlparse==0.3.0\nTempita==0.5.2\ntesseract==0.1.3\nurllib3==1.25.7\nvirtualenv==16.5.0\nwebencodings==0.5.1\nWerkzeug==0.15.2\n"
}
] | 2 |
shsarv/ContactBookAPI | https://github.com/shsarv/ContactBookAPI | 8952418ccb84774a6236a84e8e876a4c46b0c6b4 | 197a8ee697eff06637c70dca9c43430a24766127 | 52497b605949e73ab96e050e01cec583eb2dda86 | refs/heads/master | "2023-02-19T20:56:08.531081" | "2021-01-24T04:11:19" | "2021-01-24T04:11:19" | 332,364,584 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7022900581359863,
"alphanum_fraction": 0.7022900581359863,
"avg_line_length": 10.909090995788574,
"blob_id": "17f7e186349f886f0cc66aa653e78af0fc05cb50",
"content_id": "73826d75d3f4723e7915a7beb62a56f921948af4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 11,
"path": "/README.md",
"repo_name": "shsarv/ContactBookAPI",
"src_encoding": "UTF-8",
"text": "# ContactBook\n\nA CRUD API for a contact book APP.\n\n### tools and technologies used:\n\n* python\n* flask\n* MongoDB\n* VSCode\n* Postman\n"
},
{
"alpha_fraction": 0.4554455578327179,
"alphanum_fraction": 0.6831682920455933,
"avg_line_length": 14.947368621826172,
"blob_id": "c289f3de35044620d907bae0a47d25e0ae2cc7fc",
"content_id": "00de8e82b0e88c021d53dc621c43945638aa0300",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 19,
"path": "/requirements.txt",
"repo_name": "shsarv/ContactBookAPI",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.4\nbson==0.5.10\nclick==7.1.2\ndistlib==0.3.1\nfilelock==3.0.12\nFlask==1.1.2\nFlask-PyMongo==2.3.0\nitsdangerous==1.1.0\nJinja2==2.11.2\nMarkupSafe==1.1.1\nnumpy==1.19.2\npandas==1.1.3\npygame==2.0.0\npymongo==3.11.2\npython-dateutil==2.8.1\npytz==2020.1\nsix==1.15.0\nvirtualenv==20.0.30\nWerkzeug==0.15.5\n"
},
{
"alpha_fraction": 0.6672413945198059,
"alphanum_fraction": 0.6753694415092468,
"avg_line_length": 32.54545593261719,
"blob_id": "2097fbda5d9777114ff492607614f457ed3323cb",
"content_id": "2afbf0bd2d4c33c3551751e71f26f8f1d2376358",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4060,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 121,
"path": "/app.py",
"repo_name": "shsarv/ContactBookAPI",
"src_encoding": "UTF-8",
"text": "'''\nAn Api for a ContactBook with features like adding, deleting and updating contacts.\nthat also suports searching of a contact using name or emailID.\n\n'''\n# importing flask and its modules\nfrom flask import Flask,redirect,url_for,render_template,request,jsonify\n\n# importing pymongo to work with MongoDB.\nfrom flask_pymongo import PyMongo\n\n# importing bson dumps to convert bson files.\nfrom bson.json_util import dumps\nfrom bson.objectid import ObjectId\n\n#creating app\napp = Flask(__name__)\napp.config['MONGO_URI'] = \"mongodb://localhost:27017/ContactBook\"\nmongo = PyMongo(app)\n\n\[email protected]('/')\ndef operation():\n Operations = {\n 1: '/add (enter name, emailID and mobile number you want to add to your contact book)',\n 2: '/delete (enter emailID of contact person you need to Delete)', \n 3: '/update (enter new name, emailID and mobile number, you need to update)', \n 4: '/searchByEmail (enter emailID of person you want to search)', \n 5: '/searchByName (enter Contact-person name you want to search)',\n 0 :'enter details of every path in Json format only.'\n }\n return jsonify(data=Operations)\n\n# route and function to add new Contact.\n\[email protected]('/add', methods=['POST'])\ndef add_contact():\n my_json = request.json\n contact_name = my_json['name']\n contact_email = my_json['email']\n contact_mobile = my_json['mobile']\n condtion = dumps(mongo.db.contact.find({\"_id\": contact_email}))\n print(condition)\n if condition != \"[]\":\n return jsonify(\"Ooops !!!!, This emailID already exists,check EmailID or use a different EmailID !\")\n\n elif contact_name and contact_email and contact_mobile and request.method == 'POST':\n mongo.db.contact.insert({'_id': contact_email, 'name': contact_name, 'mobile': contact_mobile})\n result = jsonify(\"User Added Successfully\")\n result.status_code = 200\n return result\n else:\n return error_handle()\n\n# Route & function to delete a Contact.\n\[email protected]('/delete', methods=['DELETE'])\ndef delete_contact():\n my_json = request.json\n email_todelete = my_json[\"email\"]\n mongo.db.contact.delete_one({\"_id\": email_todelete})\n result = jsonify(\"Contact with given emailID deated SuccessFully\")\n result.status_code = 200\n return result\n\n# Route & function to update a Contact.\n\[email protected]('/update', methods=['PUT'])\ndef updateContact():\n my_json = request.json\n email_toupdate = my_json[\"email\"]\n name_toupdate = my_json[\"name\"]\n mobile_toupdate = my_json[\"mobile\"]\n\n if name_toupdate and email_toupdate and mobile_toupdate and request.method == 'PUT':\n mongo.db.contact.update_one({\"_id\": email_toupdate}, {'$set': {'name': name_toupdate, 'mobile': name_toupdate}})\n result = jsonify(\"Contact updation Successful.\")\n result.status_code = 200\n return result\n else:\n return error_handle()\n\n# Route & function to searching a Contact using contact name.\n\[email protected]('/searchByName', methods=['GET'])\ndef searchByName():\n my_json = request.json\n name_tosearch = my_json[\"name\"]\n user_check = mongo.db.contact.find({\"name\": name_tosearch})\n result = dumps(user_check)\n if result == \"[]\":\n return jsonify(\"User with this Name is not found\")\n return result\n\n\n# Route & function to search a Contact using EmailID.\n\[email protected]('/searchByEmail', methods=['GET'])\ndef searchByEmail():\n myn_json = request.json\n email_tosearch = myn_json[\"email\"]\n user_check = mongo.db.contact.find({\"_id\": email_tosearch})\n result = dumps(user_check)\n if result == \"[]\":\n return jsonify(\"No Contact person found with given emailID\")\n return result\n\n# To Handle 404 ERROR\n\[email protected](404)\ndef error_handle(error=None):\n message = {'message': 'Oooops !!, Can not reach your proposed request. kindly check the details & fill correctly !!!'}\n result = jsonify(message)\n result.status_code = 404\n return result\n\n# main Function\n\nif __name__ == '__main__':\n #DEBUG is SET to TRUE. CHANGE FOR PROD\n app.run(port=5000,debug=True)\n\n"
}
] | 3 |
chuan0418-com/Quintuple-Stimulus-Voucher-TVBS-survey-voter | https://github.com/chuan0418-com/Quintuple-Stimulus-Voucher-TVBS-survey-voter | 3d9a56b20879bfdbf30f4775a507653791b2ab44 | fd58a6f18ba34854d32cf71422c9c89e088b8c4c | c33155e841f9c48a20288721f01fbc07324858e2 | refs/heads/main | "2023-06-29T01:53:27.979654" | "2021-08-04T13:53:23" | "2021-08-04T13:53:23" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6756320595741272,
"alphanum_fraction": 0.7310382127761841,
"avg_line_length": 34.769229888916016,
"blob_id": "25f0c88c9d3309b0e894d14b6b4b754b4997e2d9",
"content_id": "ddf5138328506e7537f2a18bc072b564a191a81d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1899,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 52,
"path": "/main.py",
"repo_name": "chuan0418-com/Quintuple-Stimulus-Voucher-TVBS-survey-voter",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport time\nimport sys\ndriver = webdriver.Chrome()\ndriver.get(\"https://www.surveycake.com/s/2xOyK\")\ntime.sleep(3)\n\n#現金\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[1]/div[2]/div[2]/div[2]/div/div[1]/div/span/span[2]\")\nbutton.click()\n\n#實領 6,000元或以上\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[2]/div[2]/div[2]/div[2]/div/div[7]/div/span/span[2]\")\nbutton.click()\n\n#新北市\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[3]/div[2]/div[2]/div[2]/div/div[1]/div/span/span[2]\")\nbutton.click()\n\n#40-49歲\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[4]/div[2]/div[2]/div[2]/div/div[4]/div/span/span[2]\")\nbutton.click()\n\n#男性\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[1]/div[5]/div[2]/div[2]/div[2]/div/div[1]/div/span/span[2]\")\nbutton.click()\n\n#送出\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div/div/div/div[2]/div/div/div[1]/div/div[2]/button/span\")\nbutton.click()\n\n#確定送出\njs=\"var q=document.documentElement.scrollTop=100000\"\ndriver.execute_script(js)\nbutton = driver.find_element_by_xpath(\"/html/body/div[2]/div/footer/button[2]/span\")\nbutton.click()\n\ntime.sleep(2)\n# driver.close()\ndriver.quit()"
},
{
"alpha_fraction": 0.7279999852180481,
"alphanum_fraction": 0.7799999713897705,
"avg_line_length": 19.83333396911621,
"blob_id": "df314220d0c837ec24013fe0883204676d4ba974",
"content_id": "3f58d5de1751a2a704455689c8bf5c0507519ef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 12,
"path": "/README.md",
"repo_name": "chuan0418-com/Quintuple-Stimulus-Voucher-TVBS-survey-voter",
"src_encoding": "UTF-8",
"text": "# TVBS振興五倍券的自動投票工具\n自動填寫表單for: https://www.surveycake.com/s/2xOyK\n\n# 目前問卷調查已結束\n\n## 注意!!!\n本投票工具將自動選取選項依序為:\n現金、實領 6,000元或以上、新北市、40-49歲、男性\n可自行更換Xpath以符合您的需求。\n\n### 本投票工具僅適用於Chrome 92版本之電腦\n若您的版本非92,可以到 https://chromedriver.chromium.org/downloads 下載對應您的版本。\n"
}
] | 2 |
Amenoimi/tessdata_chi_tra.traineddata_test | https://github.com/Amenoimi/tessdata_chi_tra.traineddata_test | 6fe111c848223ae5c1e1e31a913723e6dd697a8f | 8af3323639ac9d3ffd53f808ecdf585823aafd9f | f2f56cf51716a2c8389638c77e91277bc7f30d0d | refs/heads/master | "2020-03-25T01:25:43.906730" | "2018-08-29T01:44:53" | "2018-08-29T01:44:53" | 143,237,113 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5357686281204224,
"alphanum_fraction": 0.5509893298149109,
"avg_line_length": 15.02439022064209,
"blob_id": "dbb680bc47ea07310915b24b3fc7ec0b2ed70d7f",
"content_id": "43a9112a069cd910251f20599a518f9f7ad3d942",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 41,
"path": "/tool/get_chr.py",
"repo_name": "Amenoimi/tessdata_chi_tra.traineddata_test",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*- \n\nimport sys\nimport os\n\nmin_chr=19968\n\n\n\ngo_chr= input('請輸入你的訓練集:')\ngo_chr=list(go_chr)\nn=6\nout=[]\n\n\ndef write_file(path, data):\n\twith open(path, \"w\", encoding='UTF-8') as f:\n\t\tf.writelines(data)\n\n\n#for a in go_chr:\n\n# if ord(a)-int(n/2) <= min_chr:\n# for x in range(n):\n# out+=chr(ord(a)+x)\n# else:\n# for x in range(n):\n# out+=chr(ord(a)+x-int(n/2))\nout=go_chr\ntmp=[]\n[tmp.append(i) for i in out if not i in tmp]\nout=tmp\ntmp=[]\nfor a in range(len(out)):\n tmp.append(ord(out[a]))\ntmp=sorted(tmp)\n\nfor a in range(len(tmp)):\n out[a]=chr(tmp[a])\n\nwrite_file(\"out.txt\", out)\n"
},
{
"alpha_fraction": 0.39919623732566833,
"alphanum_fraction": 0.4795713424682617,
"avg_line_length": 21.26865577697754,
"blob_id": "59d253176d0163128f06173094f8a97e0150f233",
"content_id": "e3dc8ac2416e6542e046b1228af103bfb6abcb01",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1577,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 67,
"path": "/tool/box_tool.py",
"repo_name": "Amenoimi/tessdata_chi_tra.traineddata_test",
"src_encoding": "UTF-8",
"text": "def read_file(path):\n\ttmp = None\n\twith open(path,'r', encoding='UTF-8') as f:\n\t\ttmp = f.readlines()\n\n\tout = []\n\tfor r in tmp:\n\t\tout.append(r.split(' '))\n\n\treturn out\n\ndef write_file(path, data):\n\twith open(path, \"w\", encoding='UTF-8') as f:\n\t\tf.writelines(data)\n\ndef approach(data, offset):\n\tout = []\n\n\tfor index in range(len(data)):\n\t\ttmp = [ int(r) for r in data[index][1:] ]\n\t\tconf_type = len(offset[tmp[-1]])\n\n\t\tif conf_type == 4:\n\t\t\tfor index2 in range(4):\n\t\t\t\tdata[index][index2+1] = tmp[index2] + offset[tmp[-1]][index2]\n\t\telif conf_type == 2:\n\t\t\tfor index2 in range(2):\n\t\t\t\tdata[index][index2+1] = tmp[index2] + offset[tmp[-1]][index2]\n\t\t\t\tdata[index][index2+3] = tmp[index2+2] + offset[tmp[-1]][index2]\n\t\t\n\t\tout.append( ' '.join(str(e) for e in data[index]) )\n\n\treturn out\n\nif __name__ == '__main__':\n\t# 可以把自動產生出來的 *.box 數值進行偏移\n\t# 陣列代表第幾頁\n\t# 偏移的設定檔寫法有兩種\n\t# [10, 10, 0, 0] 左 上 右 下\n\t# [10, 10] 左右 上下\n\toffset_conf = [\n\t\t[0, 0, 0, 0],\n\t\t[0, 37, 0, 0],\n\t\t[0, 37, 0, 0],\n\t\t[0, 0, 0, 0],\n\t\t[0, 37, 0, 0],\n\t\t[0, 37, 0, 0],\n\t\t[0, 0, 0, 0],\n\t\t[0, 37, 0, 0],\n [0, 37, 0, 0],\n [0, 37, 0, 0],\n [0, 0, 0, 0],\n [0, 37, 0, 0],\n [0, 37, 0, 0],\n [0, 0, 0, 0],\n [0, 37, 0, 0],\n [0, 37, 0, 0],\n [0, 0, 0, 0],\n [0, 0, 0, 0],\n\t]\n\n\tpath = \"chi_tra.dfkai-sb.exp0.box\"\n\tdata = read_file(path)\n\n\tout = approach(data, offset_conf)\n\n\twrite_file(\"out.box\", out)\n\n"
},
{
"alpha_fraction": 0.7593985199928284,
"alphanum_fraction": 0.7593985199928284,
"avg_line_length": 25.200000762939453,
"blob_id": "cafbcb319b925422cc22c4210c24608c0769d8eb",
"content_id": "038c1630bf0a0863b588a063ca7ba022d46e9e8b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 133,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 5,
"path": "/README.md",
"repo_name": "Amenoimi/tessdata_chi_tra.traineddata_test",
"src_encoding": "UTF-8",
"text": "# tessdata_chi_tra.traineddata_test\n\n#This is tesseract-ocr chi_tra mod \n\n#This is my experiment to train and download to Android.\n\n\n"
},
{
"alpha_fraction": 0.6625000238418579,
"alphanum_fraction": 0.75,
"avg_line_length": 40.904762268066406,
"blob_id": "f3908a405e15640ff25eb9ac5828dd078951e593",
"content_id": "660dc4044ff29678fda4a660af01c12cb2ce21d7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 882,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 21,
"path": "/tool/bool_bitmap_tool.py",
"repo_name": "Amenoimi/tessdata_chi_tra.traineddata_test",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*- \n\nimport cv2\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimg=cv2.imread('img.dfkai-sb.exp0.tif')\nGrayImage=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\nret1,thresh1=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY)\nret2,thresh2=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY_INV)\nret3,thresh3=cv2.threshold(GrayImage,127,255,cv2.THRESH_TRUNC)\nret4,thresh4=cv2.threshold(GrayImage,127,255,cv2.THRESH_TOZERO)\nret5,thresh5=cv2.threshold(GrayImage,127,255,cv2.THRESH_TOZERO_INV)\nthresh6=cv2.GaussianBlur(img,(5,5),127,255)\ntitles = ['Gray Image','BINARY','BINARY_INV','TRUNC','TOZERO','GaussianBlur']\nimages = [GrayImage, thresh1, thresh2, thresh3, thresh4,thresh6]\nfor i in range(len(images)):\n plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')\n plt.title(titles[i])\n plt.xticks([]),plt.yticks([])\n#cv2.imwrite('output.tiff', thresh2)\nplt.show()\n"
}
] | 4 |
shawntan/predict-forum-pgm | https://github.com/shawntan/predict-forum-pgm | 39b92e20b3ab22b4f9e8cec744e7068fefc0c26e | bf8cadc8f6fae417635a2d5255aebd0f1ccc8626 | e887ade1ecbff1506d2de7f4cf6f561e79a4285d | refs/heads/master | "2016-09-03T07:15:40.057569" | "2012-10-21T08:18:22" | "2012-10-21T08:18:22" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6542782783508301,
"alphanum_fraction": 0.6629213690757751,
"avg_line_length": 22.139999389648438,
"blob_id": "b5a2b20b28384404bc3f81c4a8b4b1b6664e2393",
"content_id": "a24fbb54329a3e72131b495a08ed1dd20a2955ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1157,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 50,
"path": "/lib/io/writer.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 24, 2012\n\n@author: shawn\n'''\nfrom lib.options.config import configuration as config\nimport __builtin__\n\nclass FileWrapper(object):\n\tdef __init__(self,obj):\n\t\tself._obj = obj\n\n\tdef close(self,*args,**kwargs):\n\t\tprint \"Closing file...\"\n\t\tself._obj.close(*args,**kwargs)\n\n\tdef __getattr__(self, attr):\n\t\t# see if this object has attr\n\t\t# NOTE do not use hasattr, it goes into\n\t\t# infinite recurrsion\n\t\tif attr in self.__dict__:\n\t\t\t# this object has it\n\t\t\treturn getattr(self, attr)\n\t\t# proxy to the wrapped object\n\t\treturn getattr(self._obj, attr)\n\ndef marked_open(*params):\n\tglobal _open\n\t#print params\n\tif len(params) > 1 and (params[1] == 'w' or params[1] == 'wb' or params[1] == 'w+'):\n\t\tprint \"Opening file...\"\n\t\treturn FileWrapper(_open(*params))\n\telse:\n\t\treturn _open(*params)\n\n_open = __builtin__.open\n__builtin__.open = marked_open\n\"\"\"\ndef __defattr__(self,attr):\n\tif hasattr(self.obj, attr):\n\t\tattr_value = getattr(self.obj,attr)\n\t\tif isinstance(attr_value,types.MethodType):\n\t\t\tdef callable(*args, **kwargs):\n\t\t\t\treturn attr_value(*args, **kwargs)\n\t\t\treturn callable\n\t\telse:\n\t\t\treturn attr_value\n\telse:\n\t\traise AttributeError\n\"\"\"\n"
},
{
"alpha_fraction": 0.6121794581413269,
"alphanum_fraction": 0.6429487466812134,
"avg_line_length": 23.375,
"blob_id": "efe88ce5abcdc459b1292618eb111e202daf1c16",
"content_id": "834adba29ecacca300e97c435ca92e83ec8e2629",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1560,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 64,
"path": "/lib/training/test.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import lda\nfrom utils.reader import windowed,filter_tokenise\nimport sys\nimport matplotlib.pyplot as plt\nfrom collections import defaultdict\ndef plot_hist(bin_size,bin_list, upper =None):\n\tfor bins in bin_list:\n\t\tfig = plt.figure()\n\t\tax = fig.add_subplot(1,1,1)\n\t\tup_bound = upper or max(bins)\n\t\tx = [i for i in range(up_bound+1)]\n\t\ty = [bins[i] for i in range(up_bound+1)]\n#\t\tprint x\n#\t\tprint y\n\t\tax.bar(x,y,width=1)\n\t\tplt.show()\n\n\ndocs = [' '.join(w[2]) for w,_ in windowed(sys.argv[2:],int(sys.argv[1]))]\ntokenised_docs = [filter_tokenise(i) for i in docs]\nnum_topics = 3\nlda = lda.LDASampler(\n\tdocs=tokenised_docs,\n\tnum_topics=num_topics, \n\talpha=0.25,\n\tbeta=0.25)\n\nprint 'Sampling...'\nfor _ in range(100):\n\tzs = lda.assignments\n\t#print zs\n\t#print '[%i %i] [%i %i]' % (zs[0][3], zs[1][3], zs[2][3], zs[3][3])\n\tlda.next()\nprint\n\nprint 'words ordered by probability for each topic:'\ntks = lda.topic_keys()\nfor i, tk in enumerate(tks):\n\tprint '%3d'%i , tk[:10]\n#\tprint '%3s'%'', tk[10:20]\n#\tprint '%3s'%'', tk[20:30]\nprint\n\nprint 'document keys:'\ndks = lda.doc_keys()\nsize = 20\ntime_differences = [dt for _,dt in windowed(sys.argv[2:],int(sys.argv[1]))]\n\nbin_list = []\nfor i in range(num_topics):\n\tbins = defaultdict(float)\n\tbin_list.append(bins)\n\nfor dt, doc, dk in zip(time_differences, docs, dks):\n\tprint '%5d'%dt + '\\t'+\\\n\t\t doc[:40] +\"...\" + '\\t' +\\\n\t\t str(dk)\n\tfor p,i in dk:\n\t\tbin = int(float(dt)/size)\n\t\tbin_list[i][bin] += p\n\nplot_hist(size,bin_list)\n#print 'topic assigned to each word of first document in the final iteration:'\n#lda.doc_detail(0)\n"
},
{
"alpha_fraction": 0.6588541865348816,
"alphanum_fraction": 0.6588541865348816,
"avg_line_length": 26.428571701049805,
"blob_id": "72a88b9b4ecb3621f5a859e2e68cd6a3eb9d38fa",
"content_id": "6a2d5d3dac3601fba8cb0d957f8095ad4a609b68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 14,
"path": "/lib/io/pickled_globals.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import cPickle as pickle\nclass pickled_globals(object):\n\tdef __init__(self,pg_dir):\n\t\tself.pg_dir = pg_dir \n\tdef __getattr__(self, attr_name):\n\t\t\"\"\"\n\t\tLoads the file from pg_dir into an object,\n\t\tthen caches the object in memory.\n\t\t\"\"\"\n\t\tobj = pickle.load(open('%s/%s'%(self.pg_dir,attr_name),'rb'))\n\t\tself.__setattr__(attr_name,obj)\n\t\treturn obj\n\npg = pickled_globals('global_objs')\n"
},
{
"alpha_fraction": 0.7219153046607971,
"alphanum_fraction": 0.7228360772132874,
"avg_line_length": 28.351350784301758,
"blob_id": "475cefe5a960bb52c68180d7d9d851d3d5a5d311",
"content_id": "4c331885fba65756718170bd21a3d421b7e06130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1086,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 37,
"path": "/lib/training/trainer.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "from utils.reader import windowed\nfrom utils.reporting import *\nfrom utils.util import *\nfrom regression_performance import performance\nimport pickle,math,getopt\n\ndef train(model,extractor,filenames,window_size,iterations = 1):\n\tfor _ in range(iterations):\n\t\tfor f in filenames:\n\t\t\ttry:\n\t\t\t\tmodel.train(extracted_vecs(extractor,f,window_size))\n\t\t\texcept ValueError as e:\n\t\t\t\traise e\n\t\t\t\t\n\tmodel.finalise()\n\treturn model.save()\n\t\"\"\"\n\tf = timestamp_model('model')\n\tpickle.dump(model,f)\n\tf.close()\n\t\"\"\"\n\ndef train_extractor(extractor,filenames,window_size):\n\textractor.train(windowed(filenames,window_size))\n\textractor.finalise()\n\treturn extractor.save()\n\nif __name__ == \"__main__\":\n\to,args = read_options()\n\treporting_init(o,\"pickled_models\")\n\textractor = load_from_file(o.extractor_name, \"Extractor\")\n\tmodel = load_from_file(o.model_name,\"Model\",o)\n\t\n\tif hasattr(extractor,'train'):\n\t\ttrain_extractor( extractor,args,o.window_size)\n\tfilename = train(model,extractor,args,o.window_size)\n\tprint performance(model,extractor,[o.test_file],o.window_size,o.verbose,filename)\n"
},
{
"alpha_fraction": 0.6005726456642151,
"alphanum_fraction": 0.6130995154380798,
"avg_line_length": 22.274999618530273,
"blob_id": "6dd95ea82d411c0996df100b627b4c15bae9109f",
"content_id": "67eac4fa31343dde48d4805ddc85eef44c1c757c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2794,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 120,
"path": "/lib/evaluation/evaluate_window.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "\t#!/usr/bin/python2\nfrom lib.io.reader\t\t\t\timport windowed\nfrom lib.io.reporting\t\t\timport reporting_init,timestamp_log\nfrom lib.io.util\t\t\t\timport *\nfrom lib.options\t\t\t\timport *\nfrom lib.interfaces.model_utils import unpickle_model\n\n\ndef evaluate(threadfile, model, extractor, window_size = 1, bandwidth = 1000000, LAG_TIME = 10, offset=0):\n\tposts_log, visit_log, result_log = timestamp_log(\n\t\t\t'posts',\n\t\t\t'visit',\n\t\t\t'sliding_window')\n\ttry:\n\t\ttime = 0\n\t\td_visit = LAG_TIME\n\t\ttime_visit = time\n\t\ttime_visit += d_visit\n\t\tpost_buffer = []\n\t\tvisits = 0\n\t\t\n\t\tvisit_times = []\n\t\tposts_times = []\n\t\tfor window,d_t in windowed([threadfile],window_size,offset):\n\n\t\t\t#post being made\n\t\t\tprint \"%d\\t-->\"%time\n\t\t\tposts_log.write(\"%d\\n\"%time)\n\t\t\tposts_times.append(time)\n\n\t\t\tassert(time_visit - time > 0)\n\n\t\t\ttime_post = time + d_t\n\t\t\tpost_buffer.append(window)\n\n\t\t\tlast_post_time = time\n\t\t\twhile time_visit <= time_post:\n\t\t\t\t#visit being made\n\t\t\t\ttime = time_visit\n\t\t\t\tprint \"%d\\t<--\"%time\n\t\t\t\tvisits += 1\n\t\t\t\tvisit_log.write(\"%d\\n\"%time)\n\t\t\t\tvisit_times.append(time)\n\t\t\t\t\n\t\t\t\tif post_buffer:\n\t\t\t\t\tfeature_vec = extractor.extract(post_buffer[-1])\n\t\t\t\t\td_visit = model.predict(feature_vec,d_t)\n\t\t\t\t\tpost_buffer = []\n\t\t\t\telse:\n\t\t\t\t\td_visit = model.repredict()\n\n\t\t\t\tp_from_last_post = last_post_time + d_visit\n\n\t\t\t\tif time < p_from_last_post:\n\t\t\t\t\ttime_visit = p_from_last_post\n\t\t\t\telse:\n\t\t\t\t\td_visit = model.repredict()\n\t\t\t\t\ttime_visit = time + d_visit\n\n\t\t\ttime = time_post\n\n\t\tk = 120\n\t\tN = int(max(visit_times[-1],posts_times[-1]))\n\t\t\n\t\tsum_Phi = 0\n\t\tsum_Psi = 0\n\t\tsum_ref = 0\n\t\tfor i in range(N-k):\n\t\t\tr = len([j for j in posts_times if j >= i and j < i + k ])\n\t\t\th = len([j for j in visit_times if j >= i and j < i + k ])\n\t\t\tif r > 0: sum_ref += 1\n\t\t\tif r > h: sum_Phi += 1\n\t\t\telif r < h: sum_Psi += 1\n\t\t\t\n\t\tPr_miss = float(sum_Phi)/sum_ref\n\t\tPr_fa = float(sum_Psi)/float(N-k)\n\t\t\n\t\t\n\t\tPr_error = 0.5*Pr_miss + 0.5*Pr_fa\n\t\tresult_log.write(str(Pr_miss) + ' , ' + str(Pr_fa) + '\\n')\n\t\tmodel.add_experiment('prerror_test',threadfile,Pr_error)\n\t\tmodel.save()\n\n\t\treturn Pr_error,visits\n\texcept Exception:\n\t\traise\n\tfinally:\n\t\tposts_log.close()\n\t\tvisit_log.close()\n\t\tresult_log.close()\n\n\neval_file = None\nmodel_name = None\nextr_name = None\n\nclass Extractor:\n\tdef extract(self,window):\n\t\treturn window[0]\n\n\nif __name__ == \"__main__\":\n\to,args = read_options()\n\treporting_init(o,\"reports\")\n\textractor = load_from_file(o['extractor_name'], \"Extractor\")\n\tmodel = load_from_file(o['model_name'],\"Model\",o)\n\t\n\tif o.has_key('pickled_model'):\n\t\tpickle_file = o['pickled_model']\n\t\tmodel = unpickle_model(open(pickle_file,'rb'))\n\n\tresult = evaluate(\n\t\t\t\t\to['test_file'],\n\t\t\t\t\tmodel,\n\t\t\t\t\textractor,\n\t\t\t\t\tpickle_file,\n\t\t\t\t\to['window_size']\n\t\t\t)\n\tprint result\n\t#for i,j in windowed([\"thread\"],1):print j\n"
},
{
"alpha_fraction": 0.6385542154312134,
"alphanum_fraction": 0.6621872186660767,
"avg_line_length": 25.629629135131836,
"blob_id": "b8300f081e269e403af92ab232d9f12966288126",
"content_id": "0920f63a20b5feb0058427e5ad7fc003aca0ff16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2158,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 81,
"path": "/learn_topics",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom algo.lda import LDASampler\nfrom lib.io.reader import windowed,filter_tokenise\nimport pickle\nimport sys\nfrom collections import defaultdict\n\n\nwindow_size_max\t= int(sys.argv[1])\nnum_topics_max\t= int(sys.argv[2])\ndocuments\t= [\"data/%s\"%i.strip() for i in open(sys.argv[3])]\noutput \t\t= sys.argv[-1]\nwindow_size\t= 15\n\nprint \"Loading file\"\ndocs = [' '.join(w[2]) for w,_ in windowed(documents,window_size)]\nprint \"Tokenising documents.\"\ntokenised_docs = [filter_tokenise(i) for i in docs]\nfor num_topics in range(num_topics_max,num_topics_max+1):\n\tprint \"Window size = %d, Topics = %d\"%(window_size,num_topics)\n\tlda = LDASampler(\n\t\tdocs=tokenised_docs,\n\t\tnum_topics=num_topics, \n\t\talpha=0.25,\n\t\tbeta=0.25)\n\n\tprint 'Sampling...'\n\tfor _ in range(100):\n\t#\tzs = lda.assignments\n\t#\tprint zs\n\t#\tprint '[%i %i] [%i %i]' % (zs[0][3], zs[1][3], zs[2][3], zs[3][3])\n\t\tlda.next()\n\tprint\n\n\tprint 'words ordered by probability for each topic:'\n\ttks = lda.topic_keys()\n\tfor i, tk in enumerate(tks):\n\t\tprint '%3d'%i , tk[:10]\n\t\tprint '%3s'%'', tk[10:20]\n\t\tprint '%3s'%'', tk[20:30]\n\tprint\n\n\tprint 'document keys:'\n\tdks = lda.doc_keys()\n\t#print 'topic assigned to each word of first document in the final iteration:'\n\n\tsize = 20\n\ttime_differences = [dt for _,dt in windowed(documents,window_size)]\n\tbin_list = []\n\tfor i in range(num_topics):\n\t\tbins = defaultdict(float)\n\t\tbin_list.append(bins)\n\n\tfor dt, doc, dk in zip(time_differences, docs, dks):\n\t\tprint '%5d'%dt + '\\t'+\\\n\t\t\t doc[:40] +\"...\" + '\\t' +\\\n\t\t\t str(dk)\n\t\tfor p,i in dk:\n\t\t\tbin = int(float(dt)/size)\n\t\t\tbin_list[i][bin] += p\n\n\n\tprint lda.doc_distribution(lda.docs[0])\n\tprint lda.doc_distribution(lda.docs[1])\n\tprint lda.doc_distribution(lda.docs[2])\n\tprint lda.doc_distribution(lda.docs[3])\n\tprint lda.doc_distribution(lda.docs[-4])\n\tprint lda.doc_distribution(lda.docs[-3])\n\tprint lda.doc_distribution(lda.docs[-2])\n\tprint lda.doc_distribution(lda.docs[-1])\n\tFILE = open(\"w%d_t%d_%s\"%(window_size,num_topics,output),'wb')\n\tpickle.dump(lda,FILE)\n\tFILE.close()\n\t#graphing.\n\t\"\"\"\n\n\tfor i in range(num_topics):\n\t\tbins = defaultdict(float)\n\t\tbin_list.append(bins)\n\t#plot_hist(size,bin_list)\n\t\"\"\"\n\n"
},
{
"alpha_fraction": 0.6816479563713074,
"alphanum_fraction": 0.7191011309623718,
"avg_line_length": 28.66666603088379,
"blob_id": "a785b2e2e35d29107dfb7200a6af4b8dd25358cb",
"content_id": "369a069df1eb3b6b8430535ad7ce33648293a146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/generate_plots",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/bin/python2\n\nimport cPickle as pickle\nimport lib.io.pickled_globals\nimport lib.graphs as graphs\n\nfor i in range(1,10):\n\thist = pickle.load(open('graphs/histograms/w%d_histograms'%(i+1),'rb'))\n\tgraphs.plot_hist(20,hist, upper = 50,directory='hist_%d_topics'%(i+1))\n"
},
{
"alpha_fraction": 0.6361829042434692,
"alphanum_fraction": 0.6660040020942688,
"avg_line_length": 26.94444465637207,
"blob_id": "a23d00c82f2ec21540856ea9170e828021d61162",
"content_id": "9e1af7e4e19df316a5580a25f2288460b7e5f0b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 18,
"path": "/print_topics",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/bin/python2\n\nimport cPickle as pickle\nimport lib.io.pickled_globals\nimport lib.graphs as graphs\n\n\n\nfor i in range(1,10):\n\tprint \"Loading pickled topic model with %d topics ...\"%(i+1)\n\tlda\t\t= pickle.load(open('global_objs/w15_t%d_learnt_topics'%(i+1),'rb'))\n\tprint \"Retrieving topics...\"\n\ttop_tok = lda.topic_keys(num_displayed=100)\n\tprint \"Writing to files...\"\n\tfor j, tk in enumerate(top_tok):\n\t\tout = open('graphs/hist_%d_topics/%03d'%(i+1,j+1),'w')\n\t\tout.write('\\t'.join(tk) + '\\n')\n\t\tout.close()\n"
},
{
"alpha_fraction": 0.8648648858070374,
"alphanum_fraction": 0.8648648858070374,
"avg_line_length": 17.5,
"blob_id": "2a3a639d85e9c59663c01a32b700bb53a3e01959",
"content_id": "84dd8aeb6adf1e09c0b77e7cdca4f7285bd3f271",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/lib/io/__init__.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import pickled_globals\nimport writer\n"
},
{
"alpha_fraction": 0.7049413323402405,
"alphanum_fraction": 0.7102737426757812,
"avg_line_length": 27.704082489013672,
"blob_id": "6a704c4be1095c03284dbca825bcd86016c27583",
"content_id": "ea5cfe0300f96f40817206f2312fe9e3a47e6f60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2813,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 98,
"path": "/lib/training/trainer_test.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "from utils.reader import windowed\nfrom utils.reporting import *\nfrom utils.util import *\nimport pickle,math,getopt\nfrom evaluate_window import evaluate as evaluate_window\nfrom utils.options import read_options, read_model_extractor_options\ndef train(model,extractor,iterator,window_size,iterations = 1):\n\tfor _ in range(iterations):\n\t\tmodel.train(iterator)\n\tmodel.finalise()\n\treturn model.save()\n\t\"\"\"\n\tf = timestamp_model('model')\n\tpickle.dump(model,f)\n\tf.close()\n\t\"\"\"\n\n\ndef performance(model,extractor,rest_instances,window_size,verbose,model_file):\n\tprint \"Calculating MAPE\"\n\tprint \"=====================\"\n\ttotal_percent_error = 0\n\tcount = 0\n\tfor fv,d_t in rest_instances:\n\t\tp = model.predict(fv)\n\t\tif d_t > 0:\n\t\t\tpercent_error = math.fabs(float(p - d_t)/d_t)\n\t\t\tif verbose: print \"delta_t: %d\\tpredicted: %d\\tAPE: %0.2f\"%(\n\t\t\t\t\td_t,\n\t\t\t\t\tp,\n\t\t\t\t\tpercent_error\n\t\t\t\t)\n\t\t\ttotal_percent_error += percent_error\n\t\t\tcount += 1\n\n\tave_percentage_error = total_percent_error/count\n\t\n\treturn ave_percentage_error\n\n\n\ndef train_extractor(extractor,filenames,window_size):\n\textractor.train(windowed(filenames,window_size))\n\textractor.finalise()\n\treturn extractor.save()\n\ndef file_len(fname):\n\twith open(fname) as f:\n\t\tfor i, l in enumerate(f):\n\t\t\tpass\n\treturn i + 1\n\nfrom evaluate import evaluate\nif __name__ == \"__main__\"\n'Visit/Post':\n\to,args = read_options()\n\treporting_init(o,\"pickled_models\")\n\textractor = load_from_file(o.extractor_name, \"Extractor\")\n\tmodel = load_from_file(o.model_name,\"Model\",o)\n\targs = read_model_extractor_options(args,extractor,model)\n\n\t\n\tprint \"Training extractor...\"\n\tif hasattr(extractor,'train'):\n\t\ttrain_extractor( extractor,args,o.window_size)\n\n\tinstances = [i for i in extracted_vecs(extractor,args[0],o.window_size)]\n\tinstance_count = len(instances)\n\tif instance_count < 2:\n\t\tprint \"Insufficient instances\"\n\t\tsys.exit()\n\treporting_init(o,\"pickled_models\")\n\ttrain_count = int(instance_count*0.75)\n\ttrainset,testset = instances[:train_count],instances[train_count:]\n\t#trainset,testset = instances,instances\n\t#print trainset\n\tprint \"Instance split:\",len(trainset),len(testset)\n\t\n\tprint \"Training model...\"\n\tfilename = train(\n\t\t\t\tmodel,\n\t\t\t\textractor,\n\t\t\t\ttrainset,\n\t\t\t\to.window_size)\n\t\n\tprint \"Evaluating...\"\n\tave_percentage_error = performance(model,extractor,testset,o.window_size,o.verbose,filename)\n\tprint ave_percentage_error\n\tmodel.add_experiment('regression_test(partial thread)',filename,ave_percentage_error)\n\tresult = evaluate(args[0], model, extractor, o.window_size, o.bandwidth,\n\t\t\t\t\toffset = train_count,\n\t\t\t\t\tsliding_window_size=sum(i for _,i in trainset)/len(trainset),\n\t\t\t\t\tverbose = o.verbose)\n\tresult['filename'] = args[0]\n\tresult['offset'] = train_count\n\tprint model.experiments\n\tmodel.add_experiment('visit_evaluation',filename,result)\n\tmodel.save()\n"
},
{
"alpha_fraction": 0.6324110627174377,
"alphanum_fraction": 0.6521739363670349,
"avg_line_length": 25.578947067260742,
"blob_id": "e5c2f0616c77a7ea34499bebb0c35d162c5a4df1",
"content_id": "285a98f0cd2bfb73699162262ddcfe6c98af1997",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/lib/graphs.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import os\ndef plot_hist(bin_size, bin_list, directory=None, upper=None):\n\tif not os.path.exists(directory): os.makedirs(directory)\n\timport matplotlib.pyplot as plt\n\tcount = 1\n\tfor bins in bin_list:\n\t\tfig = plt.figure()\n\t\tax = fig.add_subplot(1,1,1)\n\t\tup_bound = upper or max(bins)\n\t\tx = [i for i in range(up_bound+1)]\n\t\ty = [bins[i] for i in range(up_bound+1)]\n#\t\tprint x\n#\t\tprint y\n\t\tax.bar(x,y,width=1)\n\t\tif not directory:\n\t\t\tplt.show()\n\t\telse:\n\t\t\tplt.savefig('%s/%03d'%(directory, count))\n\t\tcount += 1\n\n"
},
{
"alpha_fraction": 0.6296064853668213,
"alphanum_fraction": 0.6392879486083984,
"avg_line_length": 24.015625,
"blob_id": "d3b99d6f3a6ef44c8f3bf06d6256d139ed6cc85b",
"content_id": "74064107cf8f2eb7e7b19f38673dc0a17551955c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3202,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 128,
"path": "/lib/evaluation/evaluate.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\n\nfrom lib.io.reader\t\t\t\timport windowed\nfrom lib.io.reporting\t\t\timport reporting_init,timestamp_log\nfrom lib.io.util\t\t\t\timport *\nfrom lib.options\t\t\t\timport *\nfrom lib.interfaces.model_utils import unpickle_model\n\nfrom lib.evaluation.sliding_window\timport SlidingWindow\nfrom lib.evaluation.pairwise\t\timport PairwiseScoring\n\ndef evaluate(threadfile, model, extractor,\n\t\t\twindow_size = 1,\n\t\t\tbandwidth = 1000000,\n\t\t\tLAG_TIME = 10,\n\t\t\toffset = 0,\n\t\t\tsliding_window_size = 120,\n\t\t\tverbose = False\n\t\t\t):\n\tposts_log, visit_log, result_log_tscore,result_log_window = timestamp_log(\n\t\t\t'posts',\n\t\t\t'visit',\n\t\t\t't_score',\n\t\t\t'sliding_window')\n\ttry:\n\t\ttime = 0\n\t\td_visit = LAG_TIME\n\t\ttime_visit = time\n\t\ttime_visit += d_visit\n\t\tpost_buffer = []\n\t\t\n\t\tt_score_cum = 0\n\t\tcount = 0\n\t\tvisits = 0\n\t\t\n\n\t\tcorrect_count,wrong_count = 0,0\n\t\tw = SlidingWindow(K = 20, alpha = 0.5)\n\t\tps = PairwiseScoring()\n\t\tfor window,d_t in windowed([threadfile],window_size, offset):\n\t\t\t#post being made\n\t\t\tif verbose: print \"%d\\t-->\"%time\n\t\t\tposts_log.write(\"%d\\n\"%time)\n\t\t\tw.event('post',time)\n\t\t\tps.event('post',time)\n\n\t\t\tassert(time_visit - time > 0)\n\t\t\tt_score_cum += time_visit-time\n\t\t\tcount += 1\n\t\t\ttime_post = time + d_t\n\t\t\tpost_buffer.append((extractor.extract(window),d_t))\n\n\t\t\tlast_post_time = time\n\t\t\t\n\t\t\t\n\t\t\twhile time_visit <= time_post:\n\t\t\t\t#visit being made\n\t\t\t\ttime = time_visit\n\t\t\t\tif verbose: print \"%d\\t<--\"%time\n\t\t\t\tvisits += 1\n\t\t\t\tvisit_log.write(\"%d\\n\"%time)\n\t\t\t\tw.event('visit',time)\n\t\t\t\tps.event('visit',time)\n\t\t\t\t#start correction\n\t\t\t\td_visit = None\n\t\t\t\tif post_buffer: feature_vec,_ = post_buffer[-1]\n\t\t\t\td_visit = model.predict(\n\t\t\t\t\t\tfeature_vec,d_t,\n\t\t\t\t\t\tcurrent_d_t = time - last_post_time,\n\t\t\t\t\t\tunseen = post_buffer[:-1]\n\t\t\t\t)\n\n\t\t\t\tif post_buffer: post_buffer = []\n\t\t\t\ttime_visit = last_post_time + d_visit\n\t\t\t\t\n\t\t\t\tassert(time < time_visit)\n\t\t\t\t\n\t\t\t\t#end correction\n\t\t\ttime = time_post\n\n\t\tPr_miss, Pr_fa, Pr_error = w.pr_error()\n\t\tresult_log_window.write(str(Pr_miss) + ' , ' + str(Pr_fa) + '\\n')\n\t\tmodel.add_experiment('prerror_test',threadfile,Pr_error)\n\t\tmodel.add_experiment('pairwise_scoring',threadfile,ps.score())\n\n\t\tt_score = t_score_cum/float(count)\n\t\tresult_log_tscore.write(str(t_score)+'\\n')\n\t\tmodel.add_experiment('t-score_test',threadfile,t_score)\n\t\t#save_model(pickle_file,model)\n\t\tmodel.save()\n\n\t\treturn {\n\t\t\t'T-score': t_score,\n\t\t\t'Pr_error': (Pr_miss,Pr_fa,Pr_error),\n\t\t\t'Visits': visits,\n\t\t\t'Posts': count,\n\t\t\t'Pairwise': ps.score()\n\t\t\t#'Invalid Predictions': (correct_count+wrong_count,\n\t\t\t\t\t\t\t#\twrong_count/float(correct_count+wrong_count))\n\t\t\t}\n\texcept Exception:\n\t\traise\n\tfinally:\n\t\tposts_log.close()\n\t\tvisit_log.close()\n\t\tresult_log_tscore.close()\n\t\tresult_log_window.close()\n\n\nif __name__ == \"__main__\":\n\to,args = read_options()\n\treporting_init(o,\"reports\")\n\textractor = load_from_file(o.extractor_name, \"Extractor\")\n\tmodel = load_from_file(o.model_name,\"Model\",o)\n\t\n\tif o.pickled_model:\n\t\tpickle_file = o.pickled_model\n\t\tmodel = unpickle_model(open(pickle_file,'rb'))\n\n\tresult = evaluate(\n\t\t\t\t\to.test_file,\n\t\t\t\t\tmodel,\n\t\t\t\t\textractor,\n\t\t\t\t\to.window_size,\n\t\t\t\t\tverbose = o.verbose\n\t\t\t)\n\t#print result\n\t#for i,j in windowed([\"thread\"],1):print j\n"
},
{
"alpha_fraction": 0.6189111471176147,
"alphanum_fraction": 0.6250511407852173,
"avg_line_length": 29.13580322265625,
"blob_id": "ec9deaa565982072a9af97c74b660ee75441f43f",
"content_id": "03afd00f64519a5e695b87b3291a343ea939c4d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2443,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 81,
"path": "/lib/options/options.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "from optparse import OptionParser\nfrom random import random\n\nopts,args = None,None\np_opts = None\n\ndef read_options():\n\tglobal opts,args\n\t\n\tp = OptionParser()\n\tp.add_option(\"-M\",\"--model\",metavar = \"MODEL_PATH.py\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"model_name\",\n\t\t\t\thelp = \"Model to be used for current experiment\")\n\t\n\tp.add_option(\"-E\",\"--extractor\",metavar = \"EXTRACTOR_PATH.py\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"extractor_name\",\n\t\t\t\thelp = \"Extractor to be used for current experiment\")\n\t\n\tp.add_option(\"-t\",\"--test-file\", metavar = \"FILE\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"test_file\",\n\t\t\t\thelp = \"file model will be evaluated on\")\n\tp.add_option(\"-n\",\"--name\",metavar = \"NAME\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"experiment_name\",\n\t\t\t\thelp = \"Name given to experiment\")\n\tp.add_option(\"-S\",\"--pickled-extractor\",metavar = \"PICKLED_EXTRACTOR\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"pickled_extractor\",\n\t\t\t\thelp = \"Pickled extractor to be used for current experiment\\n\\\n\t\t\t\t\t\t\t--extractor must be specified\")\n\n\tp.add_option(\"-P\",\"--pickled-model\",metavar = \"PICKLED_MODEL\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"pickled_model\",\n\t\t\t\thelp = \"Pickled model to be used for current experiment\\n\\\n\t\t\t\t\t\t\t--model must be specified\")\n\tp.add_option(\"-N\",\"--window-size\",metavar = \"N\",\n\t\t\t\ttype = \"int\",\n\t\t\t\tdefault = 1,\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"window_size\",\n\t\t\t\thelp = \"Window size to segment thread stream into\")\n\tp.add_option(\"-B\",\"--bandwidth\",metavar = \"BW\",\n\t\t\t\taction = \"store\",\n\t\t\t\tdest = \"bandwidth\",type = \"int\",default = 1000,\n\t\t\t\thelp = \"Bandwidth limit. Default is 1000\")\n\tp.add_option(\"-v\",\"--verbose\",\n\t\t\t\taction = \"store_true\",\n\t\t\t\tdest = \"verbose\",\n\t\t\t\thelp = \"print extra debug information\")\n\t\n\n\t\n\t(opts,args) = p.parse_args()\n\tprint opts,args\n\tif not opts.extractor_name:\n\t\topts.extractor_name = opts.model_name\n\t\n\tif opts.experiment_name and opts.experiment_name.endswith('RANDOM'):\n\t\topts.experiment_name = opts.experiment_name.replace(\n\t\t\t\t\t\t\t\t\t\t'RANDOM',\n\t\t\t\t\t\t\t\t\t\tstr(random.randint(100,999)))\n\treturn opts,args\nimport sys\ndef read_model_extractor_options(args,extractor=None,model=None):\n\tglobal p_opts\n\tp = OptionParser()\n\ttry: extractor.opt_cfg(p)\n\texcept: print \"Extractor has no options\"\n\ttry: model.opt_cfg(p)\n\texcept: print \"Model has no options\"\n\n\tp_opts,args = p.parse_args(args)\n\tprint p_opts\n\treturn args\n\t\nif __name__==\"__main__\":\n\tread_options()\n\n\n"
},
{
"alpha_fraction": 0.6702970266342163,
"alphanum_fraction": 0.6861386299133301,
"avg_line_length": 32.400001525878906,
"blob_id": "3dd6f21be5ab609f6db68ae9b50eafc308abb7bb",
"content_id": "98597a99a6ada952a6dc23b4fc26b57b6893f282",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 30,
"path": "/predictor.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import cPickle as pickle\nimport sys\nimport lib.io.pickled_globals\nimport lib.graphs as graphs\nfrom hist_to_probdist import time_dist\nfrom lib.io.reader import windowed,filter_tokenise\n\nwindow_size = 15\ntime_bin \t= 20\ndef load_model(topics):\n\ttimdist = pickle.load(open('graphs/prob_dist/dist_t%03d'%topics,'rb'))\n\tlda\t\t= pickle.load(\n\t\t\topen('global_objs/w%d_t%d_learnt_topics'%(window_size,topics),'rb')\n\t\t\t)\n\tprior = pickle.load(open('graphs/prob_dist/dist_t%03d_prior'%topics,'rb'))\n\treturn lda,timdist,prior\ndef main():\n\tprint \"loading documents...\"\n\tdocuments\t= ['data/'+i.strip() for i in open(sys.argv[1],'r')]\n\tprint documents\n\tlda, time_model,prior = load_model(9)\n\tdocs = ((' '.join(w[2]),dt) for w,dt in windowed(documents,window_size))\n\t\n\tfor doc,dt in docs:\n\t\ttopic_dist = lda.doc_distribution(filter_tokenise(doc))\n\t\tdt_dist = time_dist(topic_dist,time_model,prior,limit=24*3*7)\n\t\tprint sum((i*(time_bin/2)) * p for i,p in enumerate(dt_dist)), dt\n\nif __name__ == \"__main__\":\n\tmain()\n\n\t\t\n\n\n\n\n"
},
{
"alpha_fraction": 0.6811468005180359,
"alphanum_fraction": 0.683753252029419,
"avg_line_length": 25.65116310119629,
"blob_id": "f95f7fa7d292f9b97f7c34bb9d1088de8148c137",
"content_id": "fc7cc31c8f1e80eddb5635711c512ff2221677eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 43,
"path": "/lib/io/util.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "from reader import windowed\nimport sys, imp, traceback, md5, pickle\n\ndef load_from_file(filepath,class_name,*params):\n\tclass_inst = None\n\n\t\"\"\"\n\tmod_name,file_ext = os.path.splitext(os.path.split(filepath)[-1])\n\tif file_ext.lower() == '.py':\n\t\tpy_mod = imp.load_source(mod_name, filepath)\n\telif file_ext.lower() == '.pyc':\n\t\tpy_mod = imp.load_compiled(mod_name, filepath)\n\t\"\"\"\n\n\ttry:\n\t\ttry:\n\t\t\t#code_dir = os.path.dirname(filepath)\n\t\t\t#code_file = os.path.basename(filepath)\n\t\t\tfin = open(filepath, 'rb')\n\t\t\tmodule_name = md5.new(filepath).hexdigest()\n\t\t\tpy_mod = imp.load_source(module_name, filepath, fin)\n\t\t\tprint \"%s loaded as %s\"%(filepath,module_name)\n\t\tfinally:\n\t\t\ttry: fin.close()\n\t\t\texcept: pass\n\texcept ImportError:\n\t\ttraceback.print_exc(file = sys.stderr)\n\t\traise\n\texcept:\n\t\ttraceback.print_exc(file = sys.stderr)\n\t\traise\n\n\tif hasattr(py_mod, class_name):\n\t\tclass_ = getattr(py_mod,class_name)\n\t\tclass_inst = class_(*params)\n\t\n\treturn class_inst\n\n\ndef extracted_vecs(extractor, filename, window_size, first = None):\n\tfor window,d_t in windowed([filename],window_size):\n\t\tfeature_vec = extractor.extract(window)\n\t\tyield feature_vec,d_t\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5674916505813599,
"alphanum_fraction": 0.5813586115837097,
"avg_line_length": 27.202970504760742,
"blob_id": "3e13493a2e35a4d19bb62bdd360e95b31f672c79",
"content_id": "c14df3b4ec4413c50f141acade7129628e3933d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5697,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 202,
"path": "/lib/evaluation/play.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "from lib.io.reporting import set_directory\nfrom lib.io.util import load_from_file\nfrom lib.options import *\nfrom lib.interfaces.model_utils import unpickle_model\nimport os\nimport glob\nimport matplotlib as mpl\nmpl.use('Agg')\nfrom matplotlib import pyplot\nimport numpy as np\n\ndef plot(values,output,\n\t\tx_axis = 'Values',\n\t\ty_axis = 'Frequency',\n\t\ttitle = 'Histogram',\n\t\trange_min = None,\n\t\trange_max = None):\n\tif range_min != None: values = [v for v in values if v >= range_min]\n\tif range_max != None: values = [v for v in values if v <= range_max]\n\tfig = pyplot.figure()\n\tn, bins, patches = pyplot.hist(\n\t\t\tvalues,\n\t\t\t60,\n\t\t\tfacecolor = 'green',\n\t\t\talpha=0.75\n\t\t)\n\tprint n, bins, patches\n\tpyplot.xlabel(x_axis)\n\tpyplot.ylabel(y_axis)\n\tpyplot.title(title)\n\tpyplot.axis([min(values),max(values),0,max(n)])\n\tpyplot.grid(True)\n\n\tfig.savefig('collated/%s'%output)\n\ndef scatter_plot(x_vals,y_vals,c_vals,output,\n\t\tx_axis = 'Values',\n\t\ty_axis = 'Frequency',\n\t\ttitle = 'Scatterplot'):\n\n\tfig = pyplot.figure()\n\tax = fig.add_subplot(1,1,1)\n\tax.set_yscale('log')\n\t#ax.set_xscale('log')\n\tpyplot.ylim((0.1,1000))\n\tpyplot.xlim((0,7500))\n\tpyplot.scatter(x_vals,y_vals,c=c_vals, cmap=mpl.cm.Greens)\n\tpyplot.xlabel(x_axis)\n\tpyplot.ylabel(y_axis)\n\tpyplot.title(title)\n\tfig.savefig('collated/%s'%output)\n\n\n\n\nws_ex = [\n\t\t#('Average $w = %d$',\t \t\t\t'*w%d_winavg*',\t\t'w%d_dt_average.result'),\n\t\t#('$w=%d,\\\\dtvec$',\t\t \t\t\t'*w%d_dt-*',\t\t'w%d_rbf_dt'),\n\t\t#('$w=%d,\\\\dtvec,\\\\ctxvec$',\t\t\t'*w%d_dt_ctx*',\t\t'w%d_rbf_dt_ctx'),\n\t\t#('$w=%d,\\\\vocab$',\t \t'*w%d_lang-*',\t\t\t'w%d_rbf_lang_fs'),\n\t\t#('$\\\\alpha=%0.1f,\\\\vocab$',\t \t'*w%0.1f_lang_decay-*',\t'w%0.1f_rbf_lang_fs_decay'),\n\t\t#('$w=%d,\\\\vocab$,p', \t'*w%d_lang_punc-*',\t\t'w%d_rbf_lang_p_fs')\n\t\t#('$w=%d,\\\\vocab,\\\\dtvec$',\t\t\t'*w%d_lang_dt-*',\t'w%d_rbf_lang_dt_fs'),\n\t\t#('$w=%d,\\\\vocab,\\\\dtvec$',\t\t\t'*w%d_lang_dt_decay-*',\t'w%d_rbf_lang_dt_fs')\n\t\t#('cluster',\t'*cluster_time-*','cluster_time')\n\t\t]\n\nvocab_size_ex = [\n\t\t('$\\\\vocab,|\\\\vocab|=%d',\t \t\t\t\t'*w15_lang_top%d-*',\t\t'vocab-size%d'),\n\t\t]\n\n\npatterns = []\nalpha_sizes = [5,10,15,20,25,30,35,40,45,50]\nfor i,j,k in vocab_size_ex:\n\tpatterns += [(i%w,j%w,k%w) for w in alpha_sizes]\n\n\n\n\nif __name__ == '__main__':\n\to,args = read_options()\n\t#extractor = load_from_file(o['extractor_name'], \"Extractor\")\n\tfor n in glob.glob('models/*.py'):\n\t\tload_from_file(n,\"Model\",o)\n\t\n\tsummary = open('collated/summary','w')\n\n\n\theader_tuple = [\n\t\t\t\t'MAPE',\n\t\t\t\t'$Pr_{miss}$',\n\t\t\t\t'$Pr_{fa}$',\n\t\t\t\t'$Pr_{error}$',\n\t\t\t\t'$T$-score',\n\t\t\t\t#'Inv. pred',\n\t\t\t\t#'Posts',\n\t\t\t\t#'Visits',\n\t\t\t\t'Pairwise',\n\t\t\t\t'Visit/Post'\n\t\t\t\t]\n\tsummary.write('%20s &\\t'%'')\n\tsummary.write(' &\\t'.join(\"%10s\"%i for i in header_tuple) + ' \\\\\\\\\\n\\\\hline\\n')\n\n\tfor l_col,p,outfile in patterns:\n\t\tprint 'pickled_models/'+p+'/model'\n\t\tfiles = glob.glob('pickled_models/'+p+'/model')\n\t\tlog_file = open('collated/'+outfile,'w')\n\t\tlog_file_coeffs = open('collated/'+outfile+'_coeffs','w')\n\t\tprint len(files)\n\t\t\n\t\tcount = 0\n\t\tsum_tup = [0]*len(header_tuple)\n\t\tlog_file.write('\\t'.join(\"%10s\"%i for i in header_tuple) + '\\n')\n\n\n\t\tregression_perfs = []\n\t\tt_scores = []\n\t\tpv_ratios = []\n\n\t\ttscore_pv_plot = []\n\t\tposts_vals = []\n\t\tfor pickle_file in files:\n\t\t\tset_directory(os.path.dirname(pickle_file))\n\t\t\tmodel = unpickle_model(open(pickle_file,'rb'))\n\t\t\tprint model.experiments\n\t\t\tfor k in model.experiments:\n\t\t\t\texps = model.experiments[k]\n\t\t\t\tvalues = dict((e_name,result) for e_name,_,result in exps)\n\t\t\t\tif values.has_key('visit_evaluation'):\n\t\t\t\t\ttry:\n\t\t\t\t\t\t#print values\n\t\t\t\t\t\tregression_perf = values['regression_test(partial thread)']\n\t\t\t\t\t\tpr_miss,pr_fa,pr_error = values['visit_evaluation']['Pr_error']\n\t\t\t\t\t\tt_score = values['visit_evaluation']['T-score']\n\t\t\t\t\t\tposts = values['visit_evaluation']['Posts']\n\t\t\t\t\t\tvisits = values['visit_evaluation']['Visits']\n\t\t\t\t\t\tfilename = values['visit_evaluation']['filename']\n\t\t\t\t\t\tpairwise = values['visit_evaluation']['Pairwise']\n\t\t\t\t\t\tpv_ratio = visits/float(posts)\n\t\t\t\t\t\t#inv_preds = values['visit_evaluation']['Invalid Predictions'][1]\n\t\t\t\t\t\ttuple = [\n\t\t\t\t\t\t\t\tregression_perf,\n\t\t\t\t\t\t\t\tpr_miss,\n\t\t\t\t\t\t\t\tpr_fa,\n\t\t\t\t\t\t\t\tpr_error,\n\t\t\t\t\t\t\t\tt_score,\n\t\t\t\t\t\t\t\tpairwise,\n\t\t\t\t\t\t\t\t#inv_preds,\n\t\t\t\t\t\t\t\tpv_ratio\n\t\t\t\t\t\t\t\t]\n\n\t\t\t\t\t\tregression_perfs.append(regression_perf)\n\t\t\t\t\t\tt_scores.append(t_score)\n\t\t\t\t\t\tpv_ratios.append(pv_ratio)\n\t\t\t\t\t\tposts_vals.append(posts)\n\n\t\t\t\t\t\tsum_tup = [s + i for s,i in zip(sum_tup,tuple)]\n\t\t\t\t\t\tcount += 1\n\t\t\t\t\t\tlog_file.write('\\t'.join(\"%10.3f\"%i for i in tuple) +\\\n\t\t\t\t\t\t\t\t\t\t'\\t' + filename + '\\n')\n\t\t\t\t\texcept KeyError as ke:\n\t\t\t\t\t\tprint ke\n\t\t\t\tif values.has_key('token_score'):\n\t\t\t\t\tcoeffs = values['token_score']\n\t\t\t\t\tlog_file_coeffs.write('\\t'.join(\"%10s\"%i for _,i in coeffs[:-1]) + '\\n')\n\t\t\t\t\tlog_file_coeffs.write('\\t'.join(\"%10.3f\"%i for i,_ in coeffs[:-1]) + '\\t' +\\\n\t\t\t\t\t\t\t\t\t\t\"%10.3f\"%coeffs[-1] + '\\n')\n\n\t\t\"\"\"\n\t\tplot(\toutput = 'mape_dist_%s.png'%outfile,\n\t\t\t\tvalues = regression_perfs,\n\t\t\t\tx_axis = 'MAPE',\n\t\t\t)\n\t\tplot(\toutput = 't_score_dist_%s.png'%outfile,\n\t\t\t\tvalues = t_scores,\n\t\t\t\tx_axis = '$T$-score',\n\t\t\t)\n\t\tplot(\toutput = 'pv_ratio_dist_%s.png'%outfile,\n\t\t\t\tvalues = pv_ratios,\n\t\t\t\tx_axis = 'Post/Visit ratio'\n\t\t\t)\n\t\t\"\"\"\n\t\tscatter_plot(\n\t\t\t\tx_vals = t_scores,\n\t\t\t\ty_vals = pv_ratios,\n\t\t\t\tc_vals = posts_vals,\n\t\t\t\tx_axis = '$T$-scores',\n\t\t\t\ty_axis = 'Post/Visit ratio',\n\t\t\t\toutput = 'tscore_pv_plot%s.png'%outfile,\n\t\t\t\ttitle = '$T$-score vs. Post/Visit ratio'\n\t\t)\n\n\t\tavg_tup = [float(s)/count for s in sum_tup]\n\t\tlog_file.write('\\n')\n\t\tlog_file.write('\\t'.join(\"%10.3f\"%i for i in avg_tup) + '\\n')\n\t\tsummary.write('%20s &\\t'%l_col)\n\t\tsummary.write(' &\\t'.join(\"%10.3f\"%i for i in avg_tup) + ' \\\\\\\\\\n')\n\n\tlog_file.close()\n\tlog_file_coeffs.close()\n\tsummary.close()\n"
},
{
"alpha_fraction": 0.8313252925872803,
"alphanum_fraction": 0.8313252925872803,
"avg_line_length": 26.66666603088379,
"blob_id": "f9396904a6ad9946a9a825eef8c9f72df8654a09",
"content_id": "20be6ad6cd1ad49f01e59a1686e42a1e82e74841",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/preamble.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import cPickle as pickle\nimport lib.io.pickled_globals\nimport lib.graphs as graphs\n"
},
{
"alpha_fraction": 0.6165191531181335,
"alphanum_fraction": 0.6289085745811462,
"avg_line_length": 21.600000381469727,
"blob_id": "0d737604aaa0902ff44fa9ca903c97a38d4a3120",
"content_id": "bf11c7d48ffdb24830306c03037ae335d98bb58e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1695,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 75,
"path": "/lib/io/reader.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\nimport nltk,re\nfrom nltk.stem.porter import PorterStemmer\nimport time\n\nbin_size = 10\nusers = set()\n\ndef text_tdelta(input_file):\n\tprev_tup = None\n\tfor line in open(input_file):\n\t\ttup = line.split('\\t')\n\t\tif prev_tup: yield (\n\t\t\t\t(float(tup[0])-float(prev_tup[0]))/60,\n\t\t\t\ttup[1].strip(),\n\t\t\t\ttup[2].strip(),\n\t\t\t\ttime.localtime(float(tup[0]))\n\t\t\t\t)\n\t\tprev_tup = tup\n\n\ndef class_text(threadfiles):\n\tfor threadfile in threadfiles:\n\t\tfor line in open(threadfile):\n\t\t\ttup = line.split('\\t')\n\t\t\tusers.add(tup[1])\n\n\tfor threadfile in threadfiles:\n\t\tfor td,text,t in text_tdelta(threadfile):\n\t\t\tyield (td,text,t)\n\n\ndef windowed(threadfiles,N, offset = -1):\n\tcount = 0\n\tfor threadfile in threadfiles:\n\t\twindow = [None]\n\t\tprev_window = None\n\t\tfor tup in text_tdelta(threadfile):\n\t\t\twindow.append(tup)\n\t\t\tif prev_window: \n\t\t\t\tif count <= offset:\n\t\t\t\t\tcount += 1\n\t\t\t\telse:yield prev_window,tup[0]\n\t\t\tif len(window) > N:\n\t\t\t\twindow.pop(0)\n\t\t\t\tresult = [None]*len(tup)\n\t\t\t\tfor i in range(len(tup)): result[i] = [t[i] for t in window]\n\t\t\t\tprev_window = tuple(result)\n\ndef filter_tokenise(text):\n\ttext = text.lower()\n\tr = []\n\tfor w in re.split('[^0-9a-z\\.\\$]+',text):\n\t\tw = preprocess(w)\n\t\tif w: r.append(w)\n\treturn r\n\n\nnon_alphanum = re.compile('\\W') \nnumber = re.compile('[0-9]')\nsplitter = re.compile('[\\s\\.\\-\\/]+')\nmodel = re.compile('([.\\#]+\\w+|\\w+[.\\#]+)')\nstemmer = PorterStemmer()\nstop_words = set(nltk.corpus.stopwords.words('english'))\ndef preprocess(word):\n\tglobal users\n\tw = word\n\tw = w.lower()\n\tif w in stop_words: return\n\tw = number.sub(\"#\",w)\n\tif model.match(w): return #w = \"#MODEL#\"\n\tif w in users: return \"#USER#\"\n\tw = stemmer.stem_word(w)\n\tif len(w) < 3 : return\n\treturn w\n"
},
{
"alpha_fraction": 0.7374429106712341,
"alphanum_fraction": 0.7374429106712341,
"avg_line_length": 35.41666793823242,
"blob_id": "fe9626bc9a914d4268418594280a07065f144c42",
"content_id": "25a75dc1601a5bc64f68527fcf46585cafbd5783",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 12,
"path": "/lib/options/config.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import ConfigParser\nfrom collections import namedtuple\nsections = ['dirs','filename_formats']\ndef subconf(section):\n\tConf = namedtuple(section,(k for k,_ in c.items(section)))\n\tconf = Conf(**dict(c.items(section)))\n\treturn conf\nc = ConfigParser.RawConfigParser()#allow_no_value=True)\nc.readfp(open('config','r'))\nPConf = namedtuple('Configuration',sections)\nd = dict((sect,subconf(sect)) for sect in sections)\nconfiguration = PConf(**d)\n\n"
},
{
"alpha_fraction": 0.5462962985038757,
"alphanum_fraction": 0.5740740895271301,
"avg_line_length": 22.700000762939453,
"blob_id": "a1f26b5a5955e9457ce1f9162e258e8ec1559729",
"content_id": "ff78a40c4751de75690fb34b0145215c98b50abf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2376,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 100,
"path": "/lib/evaluation/sliding_window.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "class SlidingWindow():\n\tdef __init__(self,K = 60, alpha = 0.5):\n\t\tself.window = []\n\t\tself.low = 0\n\t\tself.window_size = K\n\t\tself.alpha = alpha\n\t\tself.phi_count = 0\n\t\tself.psi_count = 0\n\t\tself.ref_count = 0\n\t\tself.all_count = 0\n\n\tdef event(self,event_type,time):\n\t\ttime = int(time)\n\t\tif time >= self.low + self.window_size :\n\t\t\tlow = self.low\n\t\t\tfor t in range(low, time - self.window_size + 1):\n\t\t\t\t#print t\n\t\t\t\tself.low = t\n\t\t\t\t#Add appropriate counts\n\t\t\t\tif self.window:\n\t\t\t\t\twhile self.window[0][0] < self.low:\n\t\t\t\t\t\tself.window.pop(0)\n\t\t\t\t\t\tif not self.window: break\n\t\t\t\tself.count()\n\t\t\tself.low = t + 1\n\t\t\tself.window.append((time,event_type))\n\t\t\t#print self.low, self.window[0]\n\t\t\twhile self.window[0][0] < self.low:\n\t\t\t\tself.window.pop(0)\n\t\t\t\tif not self.window: break\n\t\telse:\n\t\t\tself.window.append((time,event_type))\n\t\t#print self.window\n\t\t\n\tdef count(self):\n\t\tR = [j for j,et in self.window if et == 'post']\n\t\tH = [j for j,et in self.window if et == 'visit']\n\t\t\n\t\t#print H, self.low + self.window_size -1\n\t\tr = len(R)\n\t\th = len(H)\n\t\tif r > 0: self.ref_count += 1\n\t\tif r > h: self.phi_count += 1\n\t\telif r < h: self.psi_count += 1\n\t\tself.all_count += 1\n\n\tdef pr_error(self):\n\t\tpr_miss = float(self.phi_count)/self.ref_count\n\t\tpr_fa = float(self.psi_count)/(self.all_count)\n\t\tpr_error = self.alpha*pr_miss + (1-self.alpha)*pr_fa\n\n\t\treturn pr_miss, pr_fa, pr_error\n\n\n\nif __name__ == \"__main__\":\n\tk = 10\n\t\n\t\n\tposts = [(t*2 ,'post') for t in range(10)] +\\\n\t\t\t[(t*2 ,'post') for t in range(30,40)]\n\t\n\tvisit = [(t*8+1\t,'visit') for t in range(10)]\n\t\n\tsum = 0\n\tfor i in range(len(posts)-1):\n\t\ta,b = posts[i:i+2]\n\t\tsum += b[0]-a[0]\n\t\t\n\tw = SlidingWindow(K =int(float(sum)*0.5/(len(posts) -1)) )\n\tevents = posts + visit\n\tevents.sort()\n\tprint events[-1]\n\tposts_times = [i for i,_ in posts]\n\tvisit_times = [i for i,_ in visit]\n\t\"\"\"\n\tsum_Phi = 0\n\tsum_Psi = 0\n\tsum_ref = 0\n\tfor i in range(events[-1][0]-k + 1):\n\t\tR = [j for j in posts_times if j >= i and j < i + k ]\n\t\tH = [j for j in visit_times if j >= i and j < i + k ]\n\t\tprint H, i + k - 1\n\t\tr = len(R)\n\t\th = len(H)\n\t\tif r > 0: sum_ref += 1\n\t\tif r > h: sum_Phi += 1\n\t\telif r < h: sum_Psi += 1\n\t\t\n\tPr_miss = float(sum_Phi)/sum_ref\n\tPr_fa = float(sum_Psi)/float(events[-1][0]-k + 1)\n\n\t\n\tPr_error = 0.5*Pr_miss + 0.5*Pr_fa\n\n\tprint Pr_miss,Pr_fa,Pr_error\n\t\"\"\"\n\n\tfor t,e in events: w.event(e,t)\n\tprint w.pr_error()\n\t\n\n\t\n\n"
},
{
"alpha_fraction": 0.6690712571144104,
"alphanum_fraction": 0.678088366985321,
"avg_line_length": 20.269229888916016,
"blob_id": "3cd565656daf755e4e2d5f7bb652c00c20966691",
"content_id": "29dd0efca867dfcec9b5253eb6d6e4bc37726b20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1109,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 52,
"path": "/lib/io/dataset.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom sklearn import linear_model\nfrom itertools import permutations\nfrom lang_model import Extractor\nfrom utils.reader import *\nimport csv,sys\n\ncount = 0\n\nclf = linear_model.LinearRegression()\nfilenames = [sys.argv[1]]\nfilename_x = \"X\"\nfilename_y = \"Y\"\nwindow_size = 15\n\ne = Extractor()\ncount = sum(1 for _ in windowed(filenames,window_size))\n\nclass RewinderWindow():\n\tdef __init__(self,filenames,window_size):\n\t\tself.filenames = filenames\n\t\tself.window_size = window_size\n\tdef reset(self):\n\t\treturn windowed(self.filenames,self.window_size)\ne.train(RewinderWindow(filenames,window_size))\ne.finalise()\n\n\ndef first(vec_size,vec_count):\n\tX = np.memmap(\n\t\t\tfilename_x,\n\t\t\tmode = 'w+',\n\t\t\tshape = (vec_count,vec_size),\n\t\t\tdtype=\"float64\"\n\t\t)\n\tY = np.memmap(\n\t\t\tfilename_y,\n\t\t\tmode = \"w+\",\n\t\t\tshape = (vec_count,),\n\t\t\tdtype = \"float64\"\n\t\t)\n\treturn X,Y\nX,Y = None,None\nfor i,instance in enumerate(windowed(filenames,window_size)):\n\twindow, d_t = instance\n\tx_vec = e.extract(window)\n\tif i == 0: X,Y = first(len(x_vec),count)\n\tX[i][:] = x_vec[:]\n\tY[i] = d_t\n\nprint X, X.shape\nprint Y, Y.shape\n\n\n\n"
},
{
"alpha_fraction": 0.6987577676773071,
"alphanum_fraction": 0.717391312122345,
"avg_line_length": 17.882352828979492,
"blob_id": "e2ac82f22f52a10aedb05d84f41a7fcaba37f156",
"content_id": "da81f686f9959134a1e72d672b691a00b46eb652",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 17,
"path": "/lib/interfaces/model_utils.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Jul 19, 2012\n\n@author: shawn\n'''\nfrom lib.io.reporting import get_directory\n\nimport pickle\ndef save_model(filename,model):\n\tfullpath = \"%s/%s\"%(get_directory(),filename)\n\tf = open(fullpath,'wb')\n\tpickle.dump(model,f)\n\tf.close()\n\treturn fullpath\n\ndef unpickle_model(filepath):\n\treturn pickle.load(filepath)\n\n"
},
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 21,
"blob_id": "a3cddedb961ca71513990d58d2bd525bba6560e4",
"content_id": "40a01025ffb202a49dadde8cc6cfa8c3ad6cf487",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 1,
"path": "/lib/options/__init__.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import options,config\n\n"
},
{
"alpha_fraction": 0.6654135584831238,
"alphanum_fraction": 0.6766917109489441,
"avg_line_length": 22.64444351196289,
"blob_id": "de303932be880fde4d8851685f84a5c598e644d2",
"content_id": "6a95e9c7360bde60ef3b541fafbb2357f4734001",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 45,
"path": "/lib/interfaces/generic_model.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Jul 17, 2012\n\n@author: shawn\n'''\n\nimport md5\nfrom model_utils import save_model\nfrom collections import defaultdict\n\nclass GenericModel(object):\n\tepsilon = 0.1\n\tdef __init__(self,o):\n\t\tself.options = o\n\t\tself.experiments = defaultdict(list)\n\n\tdef predict(self,feature_vec = None, d_t = None, current_d_t = None):\n\t\tpred = self.avg\n\t\tif current_d_t:\n\t\t\tk = 0\n\t\t\twhile k*self.avg + pred <= current_d_t + self.epsilon: k += 1\n\t\t\treturn k*self.avg + pred\n\t\telse:\n\t\t\treturn pred\n\t\n\tdef ensure_prediction_conditions(self,pred,feature_vec,d_t,current_d_t):\n\t\tif current_d_t:\n\t\t\tif pred > current_d_t + self.epsilon:\n\t\t\t\treturn pred\n\t\t\telse:\n\t\t\t\treturn GenericModel.predict(self,feature_vec,d_t,current_d_t)\n\t\telse:\n\t\t\treturn pred\n\n\tdef add_experiment(self,test_type,test_files,result):\n\t\tif hasattr(test_files,'sort'):\n\t\t\ttest_files.sort()\n\t\t\tnames = '\\n'.join(test_files)\n\t\telse:\n\t\t\tnames = test_files\n\t\t\tkey = md5.new(names).hexdigest()\n\t\t\tself.experiments[key].append((test_type,test_files,result))\n\t\n\tdef save(self):\n\t\treturn save_model('model', self)\n"
},
{
"alpha_fraction": 0.5284227132797241,
"alphanum_fraction": 0.586068868637085,
"avg_line_length": 23.372549057006836,
"blob_id": "934dc9128ba9b12538ee3a727237cd989249fa10",
"content_id": "03f71256e5e8e65ec13e5ee44a4bf82450ace9bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1249,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/lib/evaluation/pairwise.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import math\n\nclass PairwiseScoring():\n\tdef __init__(self,scoring = {\n\t\t('visit','visit') : lambda e1,e2: math.exp(0.01*(e1-e2)),\n\t\t('post', 'visit') : lambda e1,e2: 1-math.exp(0.01*(e1-e2)),\n\t\t('post', 'post' ) : lambda e1,e2: 0\t\t\t\t\t\t,\n\t\t('visit','post' ) : lambda e1,e2: 0}):\n\t\tself.total_score = 0\n\t\tself.count = 0\n\t\tself.prev_event = (None,0)\n\t\tself.scoring = scoring\n\n\tdef event(self,event_type,time):\n\t\tif self.prev_event[0]:\n\t\t\tet1,et2 = self.prev_event[0],event_type\n\t\t\tt1,t2 = self.prev_event[1],time\n\t\t\tscore = self.scoring[et1,et2](float(t1),float(t2))\n\t\t\t#print \"%10s\\t%10s\\t%10d\\t%10d\\t%10.10f\"%(et1,et2,t1,t2,score)\n\t\t\tif score > 0 : self.count += 1\n\t\t\tself.total_score += score\n\t\tself.prev_event = (event_type,time)\n\t\t\n\tdef score(self):\n\t\treturn self.total_score/self.count\n\n\n\n\nif __name__ == \"__main__\":\n\tk = 10\n\t\n\tposts = [(t*10 ,'post') for t in range(10)] +\\\n\t\t\t[(t*10 ,'post') for t in range(30,40)]\n\t\n\tvisit = [(t+13 ,'visit') for t,_ in posts]\n\t\n\tsum = 0\n\tfor i in range(len(posts)-1):\n\t\ta,b = posts[i:i+2]\n\t\tsum += b[0]-a[0]\n\t\t\n\tevents = posts + visit\n\tevents.sort()\n\tposts_times = [i for i,_ in posts]\n\tvisit_times = [i for i,_ in visit]\n\t\n\tw = PairwiseScoring()\n\n\tfor t,e in events: w.event(e,t)\n\tprint w.score()\n\t\n\n\t\n\n"
},
{
"alpha_fraction": 0.6610845327377319,
"alphanum_fraction": 0.6762360334396362,
"avg_line_length": 29.585365295410156,
"blob_id": "764ac6d8ae2914eb7f45b70c72b597efe4be95fa",
"content_id": "96d39afd52b4b487296fad2045089433977a1617",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1254,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 41,
"path": "/hist_to_probdist.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\nimport os\nimport numpy as np\nimport cPickle as pickle\nfrom collections import defaultdict\nimport lib.io.pickled_globals\nimport lib.graphs as graphs\n\ndef main():\n\tdirectory = 'graphs/prob_dist'\n\tif not os.path.exists(directory): os.makedirs(directory)\n\tfor i in range(1,10):\n\t\thist = pickle.load(open('graphs/histograms/w%d_histograms'%(i+1),'rb'))\n\t\tmodel = [] \n\t\ttopic_dist = []\n\t\tfor topic_hist in hist:\n\t\t\ttotal = sum(topic_hist[i] for i in topic_hist)\n\t\t\tprob_dist = defaultdict(float,((i,topic_hist[i]/float(total)) for i in topic_hist))\n\t\t\tmodel.append(prob_dist)\n\t\t\ttopic_dist.append(total)\n\t\t\tprint prob_dist\n\t\t\n\t\ttopic_dist = np.array(topic_dist)/float(sum(topic_dist))\n\t\tpickle.dump(topic_dist,open('graphs/prob_dist/dist_t%03d_prior'%i,'wb'))\n\n\t\tpickle.dump(model,open('graphs/prob_dist/dist_t%03d'%i,'wb'))\n\n\ndef time_dist(topic_dist,prior,model,limit = 24*3*2):\n\tt_dist = np.zeros(limit)\n\tfor i in range(limit):\n\t\tt_dist[i] = sum(\n\t\t\t\tmodel[t][i] * topic_dist[t] * prior[t]\n\t\t\t\tfor t in range(len(topic_dist)))\n\tt_dist = t_dist/sum(t_dist)\n\treturn t_dist\nif __name__ == '__main__':\n\tmain()\n\tmodel = pickle.load(open('graphs/prob_dist/dist_t%03d'%9,'rb'))\n\t#print model\n\tprint time_dist([0.1 for i in range(9)],model)\n"
},
{
"alpha_fraction": 0.6924290060997009,
"alphanum_fraction": 0.7018927335739136,
"avg_line_length": 24.399999618530273,
"blob_id": "b199319a94bf23ab67ea256c5a6df2adcd350629",
"content_id": "dd8357c2a1dd980a291be083ae378840d6f7ddee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 634,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/lib/interfaces/extractor_utils.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Jul 19, 2012\n\n@author: shawn\n'''\nfrom lib.io.reporting\timport get_directory\nfrom lib.options\t\timport read_options\nfrom lib.io.reader\t\timport windowed\nfrom lib.io.util\t\timport load_from_file\n\nimport pickle\ndef save_model(filename,model):\n\tf = open(\"%s/%s\"%(get_directory(),filename),'wb')\n\tpickle.dump(model,f)\n\tf.close()\n\ndef unpickle_model(filepath):\n\treturn pickle.load(filepath)\n\nif __name__ == '__main__':\n\to,args = read_options()\n\textractor = load_from_file(o['extractor_name'], \"Extractor\")\n\tfor window,d_t in windowed([o['test_file']],o['window_size']):\n\t\tprint extractor.extract(window),d_t\n\textractor.save()"
},
{
"alpha_fraction": 0.7291960716247559,
"alphanum_fraction": 0.741890013217926,
"avg_line_length": 32.761905670166016,
"blob_id": "d0ac4c5133e48630685919bfc3254dffe2006cfd",
"content_id": "4fa77e0afb4c8b589780a6f45ebe20068dba90e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 21,
"path": "/README.md",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "Predicting Forum Thread Posts\n=============================\n\nUse of probabilistic graphical Models to predict forum posts in avsforum.com. Project for CS5340\n\n##Directory structure\n1. `working`: Stores working files for use later. e.g.\n\t* pickled models to be used for evaluation\n\n2. `obj_globals`: global objects to be used for accessing data quickly\n\t* pickled LDA model. Topics, tokens etc.\n\n3. `reports`: Generated files showing performance of models\n\t* TSVs\n\t* CSVs\n\t* partial .tex files of tables\n\n##Preprocessing\n1. `learn_topics` topics learnt from data.\n2. `topic_time_dist` generates arrays of time histograms of topics.\n\tWe're looking for time distributions significantly different between topics.\n"
},
{
"alpha_fraction": 0.6340166926383972,
"alphanum_fraction": 0.6594533324241638,
"avg_line_length": 28.584270477294922,
"blob_id": "2b475d5b772009002a103642f503979b36ef6a80",
"content_id": "e58a93d8c4b478ffeab82907e22aef9545acdce5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2634,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 89,
"path": "/lib/evaluation/analyse_bins.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "import sys,operator\nimport shelve\nimport matplotlib.pyplot as plt\nimport matplotlib.cm as cm\nimport numpy as np\nimport bsddb3\n\nfrom collections import defaultdict\n\nK = int(sys.argv[1])\noutput_file = sys.argv[2]\ntransit_file = sys.argv[3]\nbins = shelve.BsdDbShelf(bsddb3.hashopen('bins.data', 'r'))\n#bins = shelve.open('bins.data','r')\n\n\nout = open(output_file,'w')\nkeys = [int(key) for key in bins]\nkeys.sort()\n\nfor key in keys:\n\tkey = str(key)\n\tprint \"Evaluating \",key, \" ...\"\n\tsorted_top = sorted(\n\t\t\tbins[key].iteritems(),\n\t\t\tkey=operator.itemgetter(1),\n\t\t\treverse = True)[:K]\n\ttotal = sum(v for _,v in sorted_top)\n\tsorted_top = map(lambda tup: (tup[0],float(tup[1])/total), sorted_top)\n\tout.write('%10d\\t'%(20*int(key)))\n\tout.write('\\t'.join('%10s' %i \tfor i,_ in sorted_top) + '\\n')\n\tout.write('%10s\\t'%\"\")\n\tout.write('\\t'.join('%10.5f'%i\tfor _,i in sorted_top) + '\\n')\nout.close()\nbins.close()\n\nstates = set()\n#time_trans = shelve.open('trans_bins.data','r')\ntime_trans = shelve.BsdDbShelf(bsddb3.hashopen('trans_bins.data', 'r'))\nstate_total = defaultdict(int)\ntransited_to = set()\ntransited_from = set()\nfor key in time_trans:\n\tp,n = [int(i) for i in key.split('-')]\n\ttransited_to.add(n)\n\ttransited_from.add(p)\n\ntransited_to = sorted(list(transited_to))\ntransited_from = sorted(list(transited_from))\n\nfor i in transited_from: state_total[i] = sum(time_trans.get(\"%d-%d\"%(i,j),0) for j in transited_to)\n\n\"\"\"\nout=open(transit_file,'w')\nout.write('\\t'.join(\"%5s\"%j for j in transited_to)+ '\\n')\nfor i in transited_from:\n\tout.write('\\t'.join(\"%5.4f\"%(time_trans.get(\"%d-%d\"%(i,j),0)/float(state_total[i]))for j in transited_to)+ '\\n')\nout.close()\n\"\"\"\n\ndef pdensity(dimI,dimJ):\n\tprint \"Creating sparse matrix %d,%d\"%(dimI,dimJ)\n\t#pd = lil_matrix((dimI,dimJ),dtype=np.float32)\n\tpd = np.zeros((dimI,dimJ),dtype=np.float32)\n\tfor key in time_trans:\n\t\ti,j = [int(i) for i in key.split('-')]\n\t\tif i > dimI or j > dimJ: continue\n\t\tpd[i-1,j-1] = time_trans[key]/float(state_total[i])\n\treturn pd\n# make these smaller to increase the resolution\n\n#x = arange(0, transited_from[-1], 1)\n#y = arange(0, transited_to[-1], 1)\nprint \"Constructing density matrix...\"\n#Z = pdensity(transited_from[-1], transited_to[-1])\nZ = pdensity(100, 100)\nfig = plt.figure()\n#plt.imshow(Z.toarray(),cmap=cm.Greys)\nim = plt.imshow(Z,cmap=cm.Greys,interpolation='nearest')\n\n#im.set_interpolation('bicubic')\n#ax.set_image_extent(-3, 3, -3, 3)\n#plt.axis([0,200*20, 0, 200*20])\n#fig.savefig('collated/%s'%output)\nplt.title(\"Density matrix plot of $p(q_{t+1}|q_t)$\")\n\nplt.xlabel(\"$q_{t+1}$ (20 minute blocks)\")\nplt.ylabel(\"$q_{t}$ (20 minute blocks)\")\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6151232123374939,
"alphanum_fraction": 0.6210705041885376,
"avg_line_length": 22.440000534057617,
"blob_id": "57fb0e0402e38ed1bfdd8a1012b0287f93f22b4d",
"content_id": "6e5b0db00b9f1377a24845820ac30e182cbbe9a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1177,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 50,
"path": "/lib/io/reporting.py",
"repo_name": "shawntan/predict-forum-pgm",
"src_encoding": "UTF-8",
"text": "REPORTS = None\nSUBDIR = None\nimport sys,os\nfrom datetime import datetime\ndef set_directory(directory):\n\tglobal SUBDIR\n\tSUBDIR = directory\n\t\ndef get_directory():\n\tglobal SUBDIR\n\treturn SUBDIR\ndef reporting_init(options,directory):\n\tglobal SUBDIR,REPORTS\n\tREPORTS = directory\n\tSUBDIR = '%s/%s'%(directory,datetime.now().strftime('%Y%m%d%H%M') +\\\n\t\t\t\t\t\t\t\t(' - %s'%options.experiment_name\\\n\t\t\t\t\t\t\t\t if options.experiment_name else ''))\n\tensure_dir(SUBDIR)\n\twith open(\"%s/%s\"%(SUBDIR,'command'),'w') as f:\n\t\tf.write(sys.executable)\n\t\tf.write(' ')\n\t\tf.write(sys.argv[0])\n\t\tfor i in sys.argv[1:]:\n\t\t\tif i[0] == '-':\n\t\t\t\tf.write(' \\\\\\n\\t')\n\t\t\t\tf.write(i)\n\t\t\telse:\n\t\t\t\tf.write(' ')\n\t\t\t\tf.write('\"%s\"'%i)\t\n\t\tf.write('\\n')\n\ndef ensure_dir(f):\n\tif not os.path.exists('./%s'%f):\n\t\tos.makedirs(f)\n\n\ndef timestamp_log(*filenames):\n\ttest = [open(\"%s/%s\"%(SUBDIR,f),'w') for f in filenames]\n\tif len(test) == 1: return test[0]\n\telse: return test\n\t\n\n\ndef timestamp_model(*filenames):\n\ttest = [open(\"%s/%s\"%(SUBDIR,f),'wb') for f in filenames]\n\tif len(test) == 1: return test[0]\n\telse: return test\n\t\ndef write_value(key,value):\n\twith open(\"%s/%s\"%(SUBDIR,key),'w') as f:f.write('%s\\n'%value)\n\t\t\n\t\n"
}
] | 30 |
socawarrior/TicTacToe | https://github.com/socawarrior/TicTacToe | 6dd6a88f56f35bde800331ee0aa1f98e821597f4 | 12e789addebbc637cf40046d20e1e0d3d601f5be | 6a99b9ce3682e6c207813c72ef6ab673ea497c9c | refs/heads/main | "2023-03-11T23:03:03.329408" | "2021-03-01T17:17:13" | "2021-03-01T17:17:13" | 343,432,865 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4857931435108185,
"alphanum_fraction": 0.5177788734436035,
"avg_line_length": 31.66666603088379,
"blob_id": "0495bc569fdff9b285ed0ec5db47264b421c586c",
"content_id": "b9cca95b7a4f7e276e73710ef34d30c0df3b777f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6159,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 183,
"path": "/TicTacToe.py",
"repo_name": "socawarrior/TicTacToe",
"src_encoding": "UTF-8",
"text": "import os\r\n\r\ndef clear_output():\r\n os.system('cls')\r\n\r\n\r\ndef display_game(gamelist):\r\n # print out board\r\n print('')\r\n print('')\r\n print(gamelist[0][0] + ' | ' + gamelist[0][1] + ' | ' + gamelist[0][2])\r\n print('---------')\r\n print(gamelist[1][0] + ' | ' + gamelist[1][1] + ' | ' + gamelist[1][2])\r\n print('---------')\r\n print(gamelist[2][0] + ' | ' + gamelist[2][1] + ' | ' + gamelist[2][2])\r\n\r\n\r\ndef player1_move():\r\n # get input from a user to choose location\r\n board_options = ['1', '2', '3', '4', '5', '6', '7', '8', '9']\r\n player1choice = 'wrong'\r\n while player1choice not in board_options:\r\n player1choice = input(\"Player 1, please choose your position (1-9):\")\r\n clear_output()\r\n display_game(gamelist)\r\n\r\n # dictionary containing the board # (1-9) and its coordinates\r\n board_library = {1: [2, 0], 2: [2, 1], 3: [2, 2], 4: [1, 0], 5: [1, 1], 6: [1, 2], 7: [0, 0], 8: [0, 1], 9: [0, 2]}\r\n\r\n # assigning coordinates based on user input\r\n y = board_library[int(player1choice)][0]\r\n x = board_library[int(player1choice)][1]\r\n\r\n # assinging the user's location a mark\r\n if gamelist[y][x] == ' ':\r\n gamelist[y][x] = 'X'\r\n clear_output()\r\n display_game(gamelist)\r\n return True\r\n else:\r\n clear_output()\r\n display_game(gamelist)\r\n print(\"sorry that's taken, try again!\")\r\n return False\r\n\r\n\r\n\r\ndef player2_move():\r\n # get input from a user to choose location\r\n board_options = ['1', '2', '3', '4', '5', '6', '7', '8', '9']\r\n player2choice = 'wrong'\r\n while player2choice not in board_options:\r\n player2choice = input(\"Player 2, please choose your position (1-9):\")\r\n clear_output()\r\n display_game(gamelist)\r\n\r\n # dictionary containing the board # (1-9) and its coordinates\r\n board_library = {1: [2, 0], 2: [2, 1], 3: [2, 2], 4: [1, 0], 5: [1, 1], 6: [1, 2], 7: [0, 0], 8: [0, 1], 9: [0, 2]}\r\n\r\n # assigning coordinates based on user input\r\n y = board_library[int(player2choice)][0]\r\n x = board_library[int(player2choice)][1]\r\n\r\n # trurning true and assinging the user's location a mark if the space is empty,\r\n # otherwise return false and display a message\r\n if gamelist[y][x] == ' ':\r\n gamelist[y][x] = 'O'\r\n clear_output()\r\n display_game(gamelist)\r\n return True\r\n else:\r\n clear_output()\r\n display_game(gamelist)\r\n print(\"sorry that's taken, try again!\")\r\n return False\r\n\r\n\r\n\r\ndef play_game():\r\n # set won equal to false and create a list of 9 turns\r\n won = False\r\n turns = [1, 2, 3, 4, 5, 6, 7, 8, 9]\r\n\r\n # for loop through the turns, with a condition that if won is false, then check if the turn is even or odd\r\n # there is another condition depending on if the move function returns true or false, if false play again\r\n # a player will move accordingly, otherwise break out of the loop if someone wins\r\n for turn in turns:\r\n while won == False:\r\n if turn % 2 == 0:\r\n valid = player2_move()\r\n if valid == True:\r\n won = game_check()\r\n break\r\n else:\r\n player2_move()\r\n continue\r\n else:\r\n valid = player1_move()\r\n if valid == True:\r\n won = game_check()\r\n break\r\n else:\r\n player1_move()\r\n continue\r\n else:\r\n break\r\n\r\n\r\ndef game_check():\r\n # this function checks if across, vertically, and diagonal for 3 consecutive values (X or O). It is a while loop\r\n # and prints \"you win!\" if this condition is true, returns true for the playgame() function, and breaks out of the loop.\r\n\r\n acceptable_values = ['X', 'O']\r\n win = False\r\n # across check\r\n while win == False:\r\n if gamelist[0][0] == gamelist[0][1] == gamelist[0][2] and gamelist[0][0] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n elif gamelist[1][0] == gamelist[1][1] == gamelist[1][2] and gamelist[1][0] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n elif gamelist[2][0] == gamelist[2][1] == gamelist[2][2] and gamelist[2][0] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n # vertical check\r\n elif gamelist[0][0] == gamelist[1][0] == gamelist[2][0] and gamelist[0][0] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n elif gamelist[0][1] == gamelist[1][1] == gamelist[2][1] and gamelist[0][1] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n elif gamelist[0][2] == gamelist[1][2] == gamelist[2][2] and gamelist[0][2] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n # diagnal check\r\n elif gamelist[0][0] == gamelist[1][1] == gamelist[2][2] and gamelist[0][0] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n elif gamelist[0][2] == gamelist[1][1] == gamelist[2][0] and gamelist[0][2] in acceptable_values:\r\n win = True\r\n print('You win!')\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef continuegame():\r\n letsgo = 'wrong'\r\n values =['Y','y','N','n']\r\n while letsgo not in values:\r\n letsgo = input('would you like to keep playing? (Y/N)')\r\n clear_output()\r\n display_game(gamelist)\r\n\r\n if letsgo.lower() == 'y':\r\n return True\r\n else:\r\n return False\r\n\r\n\r\n\r\n\r\nplayagain = True\r\n\r\nwhile playagain == True:\r\n # display board\r\n gamelist = [[' ', ' ', ' '], [' ', ' ', ' '], [' ', ' ', ' ']]\r\n display_game(gamelist)\r\n\r\n # play game\r\n play_game()\r\n\r\n # ask if use wants to continue and clear screen\r\n playagain = continuegame()\r\n clear_output()"
},
{
"alpha_fraction": 0.7651098966598511,
"alphanum_fraction": 0.776098906993866,
"avg_line_length": 90,
"blob_id": "1f9d0d8f4f28486083995ef429353db63d12edc9",
"content_id": "607002dcfb6cfd9464052c54841c060a14dce2bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 8,
"path": "/README.md",
"repo_name": "socawarrior/TicTacToe",
"src_encoding": "UTF-8",
"text": "# TicTacToe\nMy first python program using functions. \n\nIts a simple Tic Tac Toe game that allows two people to play together on the same computer using the num pad as the board and can be run through the command prompt.\nThe program will accept player 1 and player 2 input (1-9 on the numpad) and will display and update the Tic Tac Toe board. It will only accept 1-9 for the input, and will\nrun for 9 round unless one player gets three in a row (vertical, across, or diagna). There is a (Y/N) option to continue playing at the end of the 9 rounds or if someone wins.\n\nI hope to build on this and create a desktop application with a nice user interface. I appreciate any advice or suggestions on how to improve the code. Thanks!\n"
}
] | 2 |
Nkaruna00/GANs-MINST | https://github.com/Nkaruna00/GANs-MINST | e89fb6f380ba100307a5f289945aff1ba9821b67 | b9092732e267d15a525140820627db16e1f4fa2b | 18e5f3db9f0a197e84a2db83a80085ba9bf3968b | refs/heads/master | "2022-07-02T08:43:51.901340" | "2020-05-16T22:04:42" | "2020-05-16T22:04:42" | 264,535,437 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5583677887916565,
"alphanum_fraction": 0.6136363744735718,
"avg_line_length": 29.234375,
"blob_id": "68753e282713d623d8a3449b1cd0f63c37cf23ba",
"content_id": "db84fa3b3cf87fbd0c89362fe0fdc08bed36aa01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1936,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 64,
"path": "/GANs.py",
"repo_name": "Nkaruna00/GANs-MINST",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/e-'nv python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Feb 18 13:03:30 2020\n\n@author: nithushan\n\"\"\"\n\nfrom __future__ import print_function\nimport torch\nimport torch.nn as nn\nimport torch.nn.parallel\nimport torch.utils.data\nimport torch.optim as optim\nimport torchvision.datasets as dset\nimport torchvision.transforms as transforms\nimport torchvision.utils as vutils\nfrom torch.autograd import Variable\n\nbatchSize = 64\nimageSize = 64\n\ntransform = transforms.Compose([transforms.Scale(imageSize), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])\n\ndataset = dset.CIFAR10(root = './data', download = True, transform = transform)\ndataloader = torch.utils.data.DataLoader(dataset, batch_size = batchSize, shuffle = True, num_workers = 2) # We use dataLoader to get the images of the training set batch by batch.\n\n\ndef weights_init(m):\n classname = m.__class__.__name__\n if classname.find('Conv') != -1:\n m.weight.data.normal_(0.0, 0.02)\n elif classname.find('BatchNorm') != -1:\n m.weight.data.normal_(1.0, 0.02)\n m.bias.data.fill_(0)\n\n\nclass G(nn.Module):\n\n def __init__(self):\n super(G, self).__init__()\n self.main = nn.Sequential(\n nn.ConvTranspose2d(100, 512, 4, 1, 0, bias = False),\n nn.BatchNorm2d(512),\n nn.ReLU(True),\n nn.ConvTranspose2d(512, 256, 4, 2, 1, bias = False),\n nn.BatchNorm2d(256),\n nn.ReLU(True),\n nn.ConvTranspose2d(256, 128, 4, 2, 1, bias = False),\n nn.BatchNorm2d(128),\n nn.ReLU(True),\n nn.ConvTranspose2d(128, 64, 4, 2, 1, bias = False),\n nn.BatchNorm2d(64),\n nn.ReLU(True),\n nn.ConvTranspose2d(64, 3, 4, 2, 1, bias = False),\n nn.Tanh()\n )\n\n def forward(self, input):\n output = self.main(input)\n return output\n\nnetG = G()\nnetG.apply(weights_init)\n\n"
}
] | 1 |
art1415926535/intel_edison_oled | https://github.com/art1415926535/intel_edison_oled | a418072d0304af526ec870ea9abd5a1c9f8ce70c | 224836b44d5307bc8fe10e64bc7dee5fb2828805 | f7b815fefd8ed274dd4d21dbcbfd679f97db4acb | refs/heads/master | "2021-01-13T02:11:53.054979" | "2015-08-22T07:12:04" | "2015-08-22T07:12:04" | 41,175,442 | 2 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.608540952205658,
"alphanum_fraction": 0.6334519386291504,
"avg_line_length": 24.545454025268555,
"blob_id": "3686508341af968795d3d87cad70b34e9e286e74",
"content_id": "19963e270749c3edb102649dd4d0ebce71287bbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 11,
"path": "/locale_RU.sh",
"repo_name": "art1415926535/intel_edison_oled",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"en_US.UTF-8 UTF-8\" > /etc/locale.gen\necho \"ru_RU.UTF-8 UTF-8\" >> /etc/locale.gen\n\nlocale-gen\n\necho \"LC_CTYPE=ru_RU.UTF-8\" >> ~/.bashrc\necho \"LC_COLLATE=ru_RU.UTF-8\" >> ~/.bashrc\necho \"LANG=ru_RU.UTF-8\" >> ~/.bashrc\necho \"export LC_CTYPE LC_COLLATE\" >> ~/.bashrc\n"
},
{
"alpha_fraction": 0.6539179086685181,
"alphanum_fraction": 0.6940298676490784,
"avg_line_length": 30.841583251953125,
"blob_id": "ab82764f0c9cb7f42dc49aa9f1cff0598beeaf69",
"content_id": "8ed7ea358c20cc4522f11b978cd51cf6a94ca7ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3216,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 101,
"path": "/example2-oled96-edison.py",
"repo_name": "art1415926535/intel_edison_oled",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# INTEL EDISON VERSION\n\n# NOTE: You need to have PIL installed for your python at the Edison\n\nfrom lib_oled96 import ssd1306\nfrom time import sleep\nfrom PIL import ImageFont, ImageDraw, Image\nfont = ImageFont.load_default()\n\n\nfrom smbus import SMBus\ni2cbus = SMBus(6)\n\noled = ssd1306(i2cbus)\ndraw = oled.canvas # \"draw\" onto this canvas, then call display() to send the canvas contents to the hardware.\n\n\n# Draw some shapes.\n# First define some constants to allow easy resizing of shapes.\npadding = 2\nshape_width = 20\ntop = padding\nbottom = oled.height - padding - 1\n# Draw a rectangle of the same size of screen\ndraw.rectangle((0, 0, oled.width-1, oled.height-1), outline=1, fill=0)\n# Move left to right keeping track of the current x position for drawing shapes.\nx = padding\n\n# Draw an ellipse.\ndraw.ellipse((x, top, x+shape_width, bottom), outline=1, fill=0)\nx += shape_width + padding\n# Draw a filled rectangle.\ndraw.rectangle((x, top, x+shape_width, bottom), outline=1, fill=1)\nx += shape_width + padding\n# Draw a triangle.\ndraw.polygon([(x, bottom), (x+shape_width/2, top), (x+shape_width, bottom)], outline=1, fill=0)\nx += shape_width+padding\n# Draw an X.\ndraw.line((x, bottom, x+shape_width, top), fill=1)\ndraw.line((x, top, x+shape_width, bottom), fill=1)\n#x += shape_width+padding\n\n# Load default font.\nfont = ImageFont.load_default()\n\n# Nah, second thoughts ... Alternatively load another TTF font.\n\nfont = ImageFont.truetype('FreeSerif.ttf', 15)\n\n\noled.display()\nsleep(3)\n\n# Write two lines of text.\ndraw.text((x, top), 'Hello', font=font, fill=1)\ndraw.text((x, top+40), 'World!', font=font, fill=1)\noled.display()\nsleep(3)\ndraw.rectangle((0, 0, oled.width-1, oled.height-1), outline=255, fill=1)\noled.display()\nsleep(3)\nlogo = Image.open('intel_logo.png')\ndraw.bitmap((32, 0), logo, fill=0)\n\noled.display()\nsleep(3)\ndraw.rectangle((0, 0, oled.width-1, oled.height-1), outline=1, fill=0)\nfont = ImageFont.truetype('FreeSerifItalic.ttf', 57)\ndraw.text((18, 0), 'A5y', font=font, fill=1)\noled.display()\n\nsleep(3)\ndraw.rectangle((0, 0, oled.width-1, oled.height-1), outline=1, fill=0)\nfont = ImageFont.truetype('FreeSans.ttf', 10)\ndraw.text((0, 0), 'Hello me very good mateys ...', font=font, fill=1)\ndraw.text((0, 10), 'Well now, what would you like', font=font, fill=1)\ndraw.text((0, 20), 'to be told this sunny Sunday?', font=font, fill=1)\ndraw.text((0, 30), 'Would a wild story amuse you?', font=font, fill=1)\ndraw.text((0, 40), 'This is a very long statement,', font=font, fill=1)\ndraw.text((0, 50), 'so believe it if you like.', font=font, fill=1)\noled.display()\n\n\nsleep(3)\ndraw.rectangle((0, 0, oled.width-1, oled.height-1), outline=20, fill=0)\nfont = ImageFont.truetype('FreeSans.ttf', 14)\ndraw.text((0, 0), 'Hello me good mateys', font=font, fill=1)\ndraw.text((0, 15), 'What would you like', font=font, fill=1)\ndraw.text((0, 30), 'to be told this day?', font=font, fill=1)\ndraw.text((0, 45), 'This is a long story,', font=font, fill=1)\noled.display()\n\nsleep(3)\noled.onoff(0) # kill the oled. RAM contents still there.\nsleep(3)\noled.onoff(1) # Wake it up again. Display contents intact\n\nsleep(3)\noled.cls() # Oled still on, but screen contents now blacked out\n"
},
{
"alpha_fraction": 0.7429824471473694,
"alphanum_fraction": 0.769298255443573,
"avg_line_length": 48.565216064453125,
"blob_id": "5cc429acf7921b8f068c175ce81a7b50d14e4a4e",
"content_id": "4644784c0fd8bf1936b5e4bee3383e15116eaf06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1140,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 23,
"path": "/README.md",
"repo_name": "art1415926535/intel_edison_oled",
"src_encoding": "UTF-8",
"text": "A python library for I2C 0.96\" 128x64 OLED display using SSD1306 chip.\nWith this library you can easilly manipulate oled on Inte Edison board.\n\nVersion 0.1 (August 2015) supports python3.\n \nThis oled display is the monochrome 4-pin type (I2C), not the SPI ones (identify by more pins).\n\nThere are some \"two-colour\" ones, but these are simply a different (fixed) colour for the top 16 pixel lines.\n\nInterfacing is trivial, and they seem to work fine on 3.3V and 5V.\nOn arduino (V-GPIO) the arduino's high-value pullups seem to work OK without anything added.\n\nThe text, font, image and graphic work is handled by the Python Imaging Library,\nand ttf or other font files from anywhere work fine, at any scaling. 1-bit BMP or PNG images can be displayed.\n\n\"PIL\" is wonderfully versatile and competent for \"writing/drawing\" to a display like this.\nHowever, original PIL is now becoming obsolete. Instead use the clone \"\"Pillow\"\", now available for Python (2) and Python3.\n\nAnd, oh yes, some eBay versions might look very similar, but they don't necessarily have same pin order.\nI have two with swapped VCC and GND. Oops!\n\n\nlib by @maxim-smirnov\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.7681159377098083,
"avg_line_length": 17,
"blob_id": "988f8b4459fa34a20ff78c900de46583bc2da97f",
"content_id": "ef7380b6e3f2f9643ab6e3d264b09ac8ca49adc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 23,
"path": "/install.sh",
"repo_name": "art1415926535/intel_edison_oled",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd\n\napt-get install unzip gcc python3-pip i2c-tools libi2c-dev python3-dev libjpeg-dev libtiff5 libtiff5-dev libfreetype6 libfreetype6-dev i2c-tools\npip-3.2 install pillow\n\ngit clone https://github.com/madler/zlib.git\ncd zlib\n./configure\nmake\nmake install\ncd\nrm -r zlib\n\ncd intel_edison_oled/py-smbus\npython3 setup.py install\ncd ..\nrm -r py-smbus\n\nchmod +x locale_RU.sh\n./locale_RU.sh\nrm locale_RU.sh\n"
}
] | 4 |
meganelloso/python-guide | https://github.com/meganelloso/python-guide | d582176f4601c0ac78f1b3eeb304f678c6b3cfcb | 2a3665f7455066c7ebcd610d6fdbca4e659d65d7 | 9c0c7ebb4c798fed8dee92914c36d55ea813cf97 | refs/heads/main | "2023-08-16T10:32:57.868449" | "2021-08-22T13:00:01" | "2021-08-22T13:00:01" | 382,371,557 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7760000228881836,
"alphanum_fraction": 0.7760000228881836,
"avg_line_length": 41,
"blob_id": "cb122ccf3c01d44dcf6b6dbfff29f7908a8c69e7",
"content_id": "5c6b4a34b5d428554ef586ea906b86f0d94da891",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 3,
"path": "/README.md",
"repo_name": "meganelloso/python-guide",
"src_encoding": "UTF-8",
"text": "# python-guide\nThis repo serves as my practice as I try to code using Python.\nSummary of all the basic things I need to know."
},
{
"alpha_fraction": 0.5072928071022034,
"alphanum_fraction": 0.536108136177063,
"avg_line_length": 18.80281639099121,
"blob_id": "41f2d5df3e707e44951d9b1c0f6446bb02367a15",
"content_id": "5f0bdbb2687b93b4d53b3e84f46a92ca83df8b82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2811,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 142,
"path": "/func_prac.py",
"repo_name": "meganelloso/python-guide",
"src_encoding": "UTF-8",
"text": "#UDEMY COURSE PRAC\n\n#Function Prac Exercise\n#Warm-up\ndef lesser_of_two_evens(a, b):\n \n if a < b:\n bigger_num = b\n lesser_num = a\n modulo = b % a\n else:\n bigger_num = a\n lesser_num = b\n modulo = a % b\n\n if modulo == 0:\n return lesser_num\n else: return bigger_num\n\n#Warm-up\ndef animal_crackers(text):\n text_split = text.split(\" \")\n if text_split[0] == text_split[1]:\n return True\n else: \n return False\n\n#Warm-up\ndef makes_twenty(a, b):\n sum = a + b\n if sum == 20 or a == 20 or b == 20:\n return True\n else: return False\n\n#Level 1 Prob\n\n#1\ndef old_macdonald(name):\n new_name = ''\n for i in range(len(name)):\n if i == 3 or i == 0:\n new_name += name[i].capitalize()\n else:\n new_name += name[i].lower()\n return print(new_name)\n\nold_macdonald('macdonald')\n\n#2\ndef master_yoda(text):\n name_split = text.split()\n name_split.reverse()\n\n new_name = ' '.join(name_split)\n return print(new_name)\n\nmaster_yoda(\"Hello World\")\n\n#3\ndef almost_there(n):\n num = [100, 200]\n check = 0\n for i in range(len(num)):\n less = num[i] - 10\n more = num[i] + 10\n\n if n > less and n < more:\n check += 1\n\n if check >= 1:\n return print(True)\n else:\n return print(False)\n\nalmost_there(209)\n\n#Level 2\n\n#1\ndef has_33(nums):\n for i in range(len(nums)):\n check_num = 0\n check_num = f'{nums[i]}' + f'{nums[i + 1]}'\n\n if check_num == '33':\n return print(True)\n return print(False)\n\nhas_33([1,3,3,1,1])\n\n#2\ndef paper_doll(text):\n new_text = ''\n for i in range(len(text)):\n new_text += text[i] * 3\n return print(new_text)\n\npaper_doll(\"Hello\")\n\n#3\ndef blackjack(a, b, c):\n my_list = []\n sum = 0\n final_sum = 0\n is_11 = False\n my_list.append(a, b, c)\n \n for i in len(my_list):\n num = int(my_list[i])\n if num <= 11 and num >= 1:\n sum += num\n \n if num == 11:\n is_11 = True\n \n if sum > 21 and is_11 == True:\n final_sum = sum - 10\n \n if final_sum > 21:\n return 'BUST'\n else: return sum\n \n#4\ndef spy_game(nums):\n check = ''\n for i in range(len(nums)):\n if str(nums[i]) == '0' or str(nums[i]) == '7':\n check += str(nums[i])\n \n if check == '007':\n return print(True)\n else: return print(False)\n\n\nspy_game([1,7,2,0,4,5,0])\n\n#Lambda expressions + Map & filter functions \n#lambda create what are known as anonymous functions; one time use functions\n#map func = dinadaanan niya lahat ng nasa list\n#filter func = dapat returns true or false sa function na iccall\n\n#legb rule format = local, enclosing function locals, global (module) and built-in"
},
{
"alpha_fraction": 0.6366374492645264,
"alphanum_fraction": 0.6693592667579651,
"avg_line_length": 20.23546600341797,
"blob_id": "e3942eb741c3239e12befbd14d02b2367276c3b5",
"content_id": "b1c2ef1a95e70c0330dc0c1cb2472636c198f977",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7304,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 344,
"path": "/index.py",
"repo_name": "meganelloso/python-guide",
"src_encoding": "UTF-8",
"text": "#1\n#Data Types = string, int, float, complex(?)\n\n\n#2 - String Slicing[start:stop:step] stop not included in the string\nfreeCodeCamp = \"freeCodeCamp\"\n\nfreeCodeCamp[2:8]\n#eeCode\nfreeCodeCamp[0:3]\n#fre\nfreeCodeCamp[4:7]\n#Cod\nfreeCodeCamp[8:11]\n#Cam\nfreeCodeCamp[8:13]\n#Camp\nfreeCodeCamp[2:10:3]\n#eoC\nfreeCodeCamp[1:12:4]\n#roa\nfreeCodeCamp[3:9:2]\n#eoe\nfreeCodeCamp[10:2:-1]\n#maCedoCe\nfreeCodeCamp[11:4:-2]\n#paeo\nfreeCodeCamp[5:2:-4]\n#o\n\n\n#3 - f-Strings (only in Python 3.6)\nfirst_name = \"Megan\"\nfavorite_language = \"Python\"\nprint(f\"Hi I'm {first_name} and I'm currently studying {favorite_language}.\")\n\nvalue = 5\nprint(f\"The value is {value}. If you multiply it by 2, product will be {value * 2}\")\n\ncodeCamp = \"CODECAMP\"\nprint(f\"{codeCamp.lower()}\")\n\n#4 - String Methods\nfreeCodeCamp = \"freeCodeCamp\"\n\nfreeCodeCamp.capitalize()\n#Freecodecamp\nfreeCodeCamp.count(\"C\")\n#2\nfreeCodeCamp.find(\"e\")\n#2 - first e he can find\nfreeCodeCamp.index(\"p\")\n#11\nfreeCodeCamp.isalnum()\n#True (?)\nfreeCodeCamp.isalpha()\n#True (?)\nfreeCodeCamp.isdecimal()\n#False\nfreeCodeCamp.isdigit()\n#False\nfreeCodeCamp.isidentifier()\n#True (?)\nfreeCodeCamp.islower()\n#False\nfreeCodeCamp.isnumeric()\n#False\nfreeCodeCamp.isprintable()\n#True\nfreeCodeCamp.istitle()\n#False(?)\nfreeCodeCamp.isupper()\n#False\nfreeCodeCamp.lower()\n#freecodecamp\nfreeCodeCamp.lstrip(\"f\")\n#reeCodeCamp\nfreeCodeCamp.rstrip(\"p\")\n#freeCodeCam\nfreeCodeCamp.replace(\"e\",\"a\")\n#fraaCodaCamp\nfreeCodeCamp.split(\"C\")\n#['free','ode','amp']\nfreeCodeCamp.swapcase()\n#FREEcODEcAMP\nfreeCodeCamp.title()\n#Freecodecamp\nfreeCodeCamp.upper()\n#FREECODECAMP\n\n#5 Boolean value - should always be upper to recognize as boolean\ntype(False)\n#returns boolean\n#type(false)\n#returns error\n\n#6 - len() function to return length of the list\n\n#7 - List Slicing; same structure with string slicing\n\n#8 - Tuple like list but immutable; cant be inserted/updated\n# diff tuple vs list?? ok with/without parentheses\n# can also have nested tuples\n# can slice\nmy_tuple = (1, 2, 3, 4, 5)\nmy_tuple = ([1, 2, 3, 4], (5, 6, 7, 8))\n\n#9 Tuple assignment - exclusive for Python only\na, b = 1, 2\n#a = 1; b = 2\n\n#10 Dictionary\nmy_dict = {\"a\": 1, \"b\": 2, \"c\": 3}\n#dictionary key can be anything except list but dict values can be any data type.\n# can add, update, call a key in dict. to add, must be a new key name\n# to delete, use del statement\n#del my_dict[\"c\"]\n\nmy_dict.get(\"a\") #1\nmy_dict.items() #shows all\nmy_dict.keys() #shows keys only\n\nTrue + False #1 bec 1 + 0 = 1\n\n#11 Operators (Unique)\n#Exponentiation **: 5 ** 2 = 25; 6 ** 8 = 1679616 (6*6*6*6*6*6*6*6)\n#16 ** (1/2) = 4.0?\n#125 ** (1/3) 4.999999?\n\"Hello\" * 4\n#HelloHelloHelloHello\n\"Hello\" * 0 #''\n\"Hello\" * -1 #''\n#/ Operator - returns float even operands = integer\n#// Operator - returns integer if operands = integer, returns float if operands = float\n\"Hello\" > \"World\" #False; this is based on alphabetical order\n\n#If else statements\nx = 5\nif x < 9:\n print(\"Hello!\")\nelif x < 15:\n print(\"WIts gr8 to see you\")\nelse:\n print(\"Bye!\")\n\nprint(\"End\")\n\n#For Loop statements\nfor num in range(8):\n print(\"Hello\" * num)\n#Hello\n#HelloHello\n#HelloHelloHello etc\n\nmy_list = [\"a\", \"b\", \"c\", \"d\"]\n\nfor i in range(len(my_list)):\n print(my_list[i])\n\nfor i in range(2,10):\n print(i)\n#prints 2 - 9\n\nfor key in my_dict:\n print(key)\n#prints a b c\n\n#for value in my_dict.values:\n# print(value)\n#prints 1 2 3\n\nfor key, value in my_dict.items():\n print(key, value)\n#prints a 1, b 2, c 3\n\nfor key in my_dict.items():\n print(key)\n#prints ('a', 1) ('b', 2) ('c', 3) a tuple\n\n#Break and Continue in Python\n#break - ends the loop\n#continue - skips but loop continues\n\ntodays_list = [1, 2, 3, 4, 5]\n\nfor num in todays_list:\n if num % 2 == 0:\n print(\"Even:\", num)\n print(\"break\")\n break\n else:\n print(\"Odd:\", num)\n\n#prints Odd: 1, Even: 2 break\n\nfor num in todays_list:\n if num % 2 == 0:\n print(\"continue\")\n continue\n else:\n print(\"Odd\", num)\n\n#prints Odd: 1, continue, Odd: 3, continue etc\n\n#zip() function - iterate multiple sequences at once in a for loop\nmy_list1 = [1, 2, 3, 4]\nmy_list2 = [5, 6, 7, 8]\n\nfor elem1, elem2 in zip(my_list1, my_list2):\n print(elem1,elem2)\n#prints 1 5, 2 6, 3 7, 4 8\n\n#enumerate() function - keep track of the index on loop\n\nfor i, elem in enumerate(my_list):\n print(i, elem)\n\nfor i, elem in enumerate(my_list, 2):\n print(i, elem)\n#magsstart sa 2 instead of 0\n\n#else clause in for loop\n#if you want a block of code after the loop completes\n#else does not run if \"break\" was executed vice versa\n\nfor elem in my_list1:\n if elem > 6:\n print(\"Found\")\n break\nelse:\n print(\"Not Found\")\n\n#prints not found\n#we can also do this in while loop\n\n#Nested loops - the inner loop runs for each iteration of the other loop\nfor i in range(3):\n for j in range(2):\n print(i,j)\n# 0 0\n# 0 1\n# 1 0\n# 1 1\n# 2 0\n# 2 1\n\nfor i in range(3):\n print(\"==> Outer Loop\")\n print(f\"i = {i}\")\n for j in range(2):\n print(\"Inner loop\")\n print(f\"j = {j}\")\n \n\ndef print_product(a, b=5):\n print(a * b)\n\n#kapag walang binigay na value for b, 5 yung default value.\n#pwede maoverride ung 5 kapag binigyan ng value\n#note na kailangan magkadikit yan pag arguement\n\n#Exception Handling\n#ZeroDivisionError when divisor is 0\n#IndexError sobra index na namention\n#KeyError key is not in the dictionary\n#NameError variable that does not even defined\n\nindex = int(input(\"Enter the index here: \"))\n\ntry:\n sample_list = [1, 2, 3, 4]\n print(sample_list[index])\nexcept IndexError as e:\n print(\"Error raised: \", e)\n\na = int(input(\"Enter value of a variable: \"))\nb = int(input(\"Enter value of b variable: \"))\n\ntry:\n division = a / b\n print(division)\nexcept ZeroDivisionError as e:\n print(\"Error raised: \", e)\nelse:\n print(\"both variables are valid.\")\n#prints try and else block if no 0 on the variables\n#you can add \"finally:\" if u want to run it with or without error\n#finally can be used if you want to close a file even when it throws an exception\n\n#OOP in Python\n#__int__ - to store attributes\n\n#Set = only accepts unique value\nmyset = set()\nmyset.add(1)\nmyset.add(2)\nmyset.add(2)\nset(myset)\n\n#from python lib\nfrom random import shuffle\n\nexample_shuffle = [1,2,3,4,5,6,7,8,9]\n\ndef shuffle_dict(sample_list):\n shuffle(sample_list)\n return sample_list\n\nshuffle_dict(example_shuffle)\n\n#*args **kwargs\n#*args - to have multiple arguements in a function; will pass as a tuple\n#pwede iba pangalan for args and kwargs\n\ndef myfunc(*args):\n for item in args:\n print(item)\n\nmyfunc(1,2,3,4,5,6,7,8,9,0)\n\n#**kwargs - same as args pero dictionary yung \n\ndef myfunc_kwargs(**kwargs):\n print(kwargs)\n if 'fruit' in kwargs:\n print('my fruit of choice is {}'.format(kwargs['fruit']))\n else:\n print('i dont see any fruit here')\n\nmyfunc_kwargs(fruit='apple', veggie = 'lettuce')\n\n#pwede *args and **kwargs in one function\n#pero kung nauna ung args, args dapat unang ipapasok\n\ndef myfunc_both(*args, **kwargs):\n print(args, kwargs)\n print('I would like {} {}'.format(args[0],kwargs['food']))\n\nmyfunc_both(10, 20, 30, food='eggs', animal='dog')\n\n#SUMMARY\n# Lists: Ordered sequence of objs (mutable)\n# Tuples;: Ordered seq of obj (immutable)\n# Dictionary: Key-value pairing that is unordered"
}
] | 3 |
mauricecyril/OnionDustSensor | https://github.com/mauricecyril/OnionDustSensor | 13c0079fbb8084080c6dcbdc09835b5a9ab416a2 | c0211014e38bcbd3fa4772a23b49e672174b0b37 | d9de1c9c16015c3472660161e29997fbf0b60fd6 | refs/heads/master | "2020-03-19T19:44:09.434510" | "2018-06-11T14:00:05" | "2018-06-11T14:00:05" | 136,871,810 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.64462810754776,
"alphanum_fraction": 0.6721763014793396,
"avg_line_length": 18.052631378173828,
"blob_id": "a6a1e3fb55c5a99115b6523f3174785e95e5d4e6",
"content_id": "de9fd9179f56cc62dd7ab891fb2ea0ab9cad0ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 19,
"path": "/python/oniongpioinputtest.py",
"repo_name": "mauricecyril/OnionDustSensor",
"src_encoding": "UTF-8",
"text": "# Using Python 2 to test\n\nimport time \nimport onionGpio \n\ngpioNum = 18\n\ngpioObj\t= onionGpio.OnionGpio(gpioNum) \n\n# set to input \nstatus \t= gpioObj.setInputDirection() \n\n# read and print the value once every 30 second \nloop = 1 \nwhile loop == 1: \t\n value = gpioObj.getValue() \n print 'GPIO%d input value: %d'%(gpioNum, int(value)) \t \t\n\n time.sleep(0.01)\n\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 33,
"blob_id": "f998a9e9dab31b7d19bf793ab86d740c4b9de69c",
"content_id": "30ec2573d64fb09a71d0b91f0aed3776d0d5ef03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 1,
"path": "/python/readme.md",
"repo_name": "mauricecyril/OnionDustSensor",
"src_encoding": "UTF-8",
"text": "Various Work in Progress Scripts.\n\n"
},
{
"alpha_fraction": 0.6328125,
"alphanum_fraction": 0.6953125,
"avg_line_length": 31,
"blob_id": "351e7dba3837e33af5417809b0eba335011f7741",
"content_id": "f4c2cff78cc242081a9768a110bd8d8eaa969c92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 4,
"path": "/python/webcamtest.py",
"repo_name": "mauricecyril/OnionDustSensor",
"src_encoding": "UTF-8",
"text": "import os\nfrom time import sleep\n\nos.system('fswebcam --no-banner -r 1280x720 /tmp/mounts/SD-P1/capture-\"%Y-%m-%d_%H%M%S\".jpg')\n"
},
{
"alpha_fraction": 0.7602837085723877,
"alphanum_fraction": 0.7978723645210266,
"avg_line_length": 47.55172348022461,
"blob_id": "6bd3461f05a3ae1d325ea7089ef260595cf1e097",
"content_id": "7266b9e23c2f0fb00653bed84b8df2af3d75529f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1410,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 29,
"path": "/README.md",
"repo_name": "mauricecyril/OnionDustSensor",
"src_encoding": "UTF-8",
"text": "# OnionDustSensor\nAttempts to get the GROVE / Shinyei PPD42NS dust sensor running on the Onion Omega Platform\n\nOnion Omega GPIO\nhttps://docs.onion.io/omega2-docs/using-gpios.html\nhttps://docs.onion.io/omega2-docs/gpio-python-module.html\n\nReferences:\nhttp://wiki.seeedstudio.com/Grove-Dust_Sensor/\nhttps://github.com/Seeed-Studio/Grove_Dust_Sensor\n\nhttps://indiaairquality.com/2014/12/14/building-pickle-jr-the-low-cost-networked-pm2-5-monitor-part-2/\nhttps://indiaairquality.com/2014/12/14/measuring-the-pickle-jr-a-modified-ppd42-with-an-attached-fan/\nhttp://irq5.io/2013/07/24/testing-the-shinyei-ppd42ns/\nhttp://www.howmuchsnow.com/arduino/airquality/grovedust/\n\n\nSome direction on how to get the sensor running on a Raspberry Pi\nhttps://github.com/DexterInd/GrovePi\nhttps://www.raspberrypi.org/forums/viewtopic.php?t=122298\nhttps://github.com/DexterInd/GrovePi/blob/master/Software/Python/grove_dust_sensor.py\n\nhttps://github.com/otonchev/grove_dust\nhttps://andypi.co.uk/2016/08/19/weather-monitoring-part-2-air-quality-sensing-with-shinyei-ppd42ns/\n\nSome good reference on how to calculate readings using the pi and the primary source of where we'll be attempting to use the onion omega platform instead of the raspberry pi.\nhttp://abyz.co.uk/rpi/pigpio/examples.html\nhttps://github.com/andy-pi/weather-monitor/blob/master/air_quality.py\nhttps://github.com/andy-pi/weather-monitor/blob/master/pigpio.py\n\n\n"
},
{
"alpha_fraction": 0.49936822056770325,
"alphanum_fraction": 0.5696234703063965,
"avg_line_length": 28.296297073364258,
"blob_id": "e7d4052d8da03afa9f0fb7af463359ca94d27945",
"content_id": "ceca3a0d71febf2fdeefa22866e59ebeb76c9ba9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3963,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 135,
"path": "/python/dustsenor2.py",
"repo_name": "mauricecyril/OnionDustSensor",
"src_encoding": "UTF-8",
"text": "import time\nimport os\nimport onionGpio\nimport math\n\ngpioNum = 18\n\ngpioObj\t= onionGpio.OnionGpio(gpioNum) \n\n# set to input \nstatus \t= gpioObj.setInputDirection() \n\n# read and print the value once every 30 second \nloop = 1 \nwhile loop == 1: \t\n value = gpioObj.getValue() \n# print 'GPIO%d input value: %d'%(gpioNum, int(value)) \t \t\n\n interval = low_ticks + high_ticks\n\n if interval > 0:\n ratio = float(low_ticks)/float(interval)*100.0\n conc = 1.1*pow(ratio,3)-3.8*pow(ratio,2)+520*ratio+0.62;\n else:\n ratio = 0\n conc = 0.0\n\n start_tick = None\n last_tick = None\n low_ticks = 0\n high_ticks = 0\n\n\n if start_tick is not None:\n ticks = tickDiff(last_tick, tick)\n last_tick = tick\n\n if level == 0: # Falling edge.\n high_ticks = high_ticks + ticks\n\n elif level == 1: # Rising edge.\n low_ticks = low_ticks + ticks\n \n# else: # timeout level, not used\n# pass\n \n else:\n start_tick = tick\n last_tick = tick\n \n '''\n Convert concentration of PM2.5 particles per 0.01 cubic feet to µg/ metre cubed\n this method outlined by Drexel University students (2009) and is an approximation\n does not contain correction factors for humidity and rain\n '''\n # Assume all particles are spherical, with a density of 1.65E12 µg/m3\n densitypm25 = 1.65 * math.pow(10, 12)\n \n # Assume the radius of a particle in the PM2.5 channel is .44 µm\n rpm25 = 0.44 * math.pow(10, -6)\n \n # Volume of a sphere = 4/3 * pi * radius^3\n volpm25 = (4/3) * math.pi * (rpm25**3)\n \n # mass = density * volume\n masspm25 = densitypm25 * volpm25\n \n # parts/m3 = parts/foot3 * 3531.5\n # µg/m3 = parts/m3 * mass in µg\n concentration_ugm3 = concentration_pcf * 3531.5 * masspm25\n \n return concentration_ugm3\n\n '''\n Convert concentration of PM2.5 particles in µg/ metre cubed to the USA \n Environment Agency Air Quality Index - AQI\n https://en.wikipedia.org/wiki/Air_quality_index\n Computing_the_AQI\n https://github.com/intel-iot-devkit/upm/pull/409/commits/ad31559281bb5522511b26309a1ee73cd1fe208a?diff=split\n '''\n \n cbreakpointspm25 = [ [0.0, 12, 0, 50],\\\n [12.1, 35.4, 51, 100],\\\n [35.5, 55.4, 101, 150],\\\n [55.5, 150.4, 151, 200],\\\n [150.5, 250.4, 201, 300],\\\n [250.5, 350.4, 301, 400],\\\n [350.5, 500.4, 401, 500], ]\n \n C=ugm3\n \n if C > 500.4:\n aqi=500\n\n else:\n for breakpoint in cbreakpointspm25:\n if breakpoint[0] <= C <= breakpoint[1]:\n Clow = breakpoint[0]\n Chigh = breakpoint[1]\n Ilow = breakpoint[2]\n Ihigh = breakpoint[3]\n aqi=(((Ihigh-Ilow)/(Chigh-Clow))*(C-Clow))+Ilow\n \n return aqi\n\n\n # Use 30s for a properly calibrated reading.\n time.sleep(30)\n \n # get the gpio, ratio and concentration in particles / 0.01 ft3\n g, r, c = value.read()\n \n if (c==1114000.62):\n print \"Error\\n\"\n continue\n\n print \"Air Quality Measurements for PM2.5:\"\n print \" \" + str(int(c)) + \" particles/0.01ft^3\"\n\n # convert to SI units\n concentration_ugm3=s.pcs_to_ugm3(c)\n print \" \" + str(int(concentration_ugm3)) + \" ugm^3\"\n \n # convert SI units to US AQI\n # input should be 24 hour average of ugm3, not instantaneous reading\n aqi=s.ugm3_to_aqi(concentration_ugm3)\n \n print \" Current AQI (not 24 hour avg): \" + str(int(aqi))\n print \"\"\n\n \n# Follow guide on how to install fswebcam https://onion.io/taking-photos-with-a-usb-webcam-on-the-omega/\n# SD Card Path /tmp/mounts/SD-P1/\n# Trigger FSWebcam to take photo\n# os.system('fswebcam --no-banner -r 1280x720 /tmp/mounts/SD-P1/capture-\"%Y-%m-%d_%H%M%S\".jpg')\n\n\n"
}
] | 5 |
SatyamRajawat/File-base-record-system | https://github.com/SatyamRajawat/File-base-record-system | a0fda5f6e4c4bc25d4a5e3549ada63858da805f0 | 66ba8eaca407de9f9292b8dc6803e4f620d943d7 | 37dc0ae927e3b42d863f7b408f14f90518b4da8a | refs/heads/main | "2023-02-15T00:25:16.342789" | "2021-01-08T03:59:20" | "2021-01-08T03:59:20" | 327,793,830 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5621798038482666,
"alphanum_fraction": 0.6120167970657349,
"avg_line_length": 38.54716873168945,
"blob_id": "09b5b8c5ee7dee195e996ec25962c597fd25144c",
"content_id": "1aec4c6d8e6607514f89966f9c9534dd8af6c1e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2147,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 53,
"path": "/login.py",
"repo_name": "SatyamRajawat/File-base-record-system",
"src_encoding": "UTF-8",
"text": "from tkinter import*\r\nfrom tkinter import messagebox\r\nclass Login:\r\n def __init__(self,root):\r\n self.root=root\r\n self.root.title(\"File Based Record System\")\r\n self.root.geometry(\"1350x700+0+0\")\r\n\r\n self.uname=StringVar()\r\n self.password=StringVar()\r\n\r\n F1=Frame(self.root,bd=10,relief=GROOVE)\r\n F1.place(x=450,y=150,height=350)\r\n\r\n title=Label(F1,text=\"Login System\",font=(\"times\",30,\"bold\")).grid(row=0,columnspan=2,pady=20)\r\n\r\n lbluser=Label(F1,text=\"Username\",font=(\"times\",25,\"bold\")).grid(row=1,column=0,padx=10,pady=10)\r\n txtuser=Entry(F1,bd=7,textvariable=self.uname,relief=GROOVE,width=25,font=\"arial 15 bold\").grid(row=1,column=1,padx=10,pady=10)\r\n\r\n lblpass=Label(F1,text=\"Password\",font=(\"times\",25,\"bold\")).grid(row=2,column=0,padx=10,pady=10)\r\n txtpass=Entry(F1,bd=7,show=\"*\",textvariable=self.password,relief=GROOVE,width=25,font=\"arial 15 bold\").grid(row=2,column=1,padx=10,pady=10)\r\n\r\n btnlog=Button(F1,text=\"Login\",font=\"arial 15 bold\",bd=7,width=10,command=self.login).place(x=10,y=250)\r\n btnreset=Button(F1,text=\"Reset\",font=\"arial 15 bold\",bd=7,width=10,command=self.reset).place(x=170,y=250)\r\n btnexit=Button(F1,text=\"Exit\",font=\"arial 15 bold\",bd=7,width=10,command=self.exit).place(x=330,y=250)\r\n\r\n def login(self):\r\n if self.uname.get()==\"\" or self.password.get()==\"\": \r\n messagebox.showerror(\"Error\",\"All fields ar required!!\")\r\n\r\n elif self.uname.get()==\"admin\" and self.password.get()==\"admin\":\r\n # messagebox.showin fo(\"Successfull\",f\"Welcome {self.uname.get()}\")\r\n self.root.destroy()\r\n import software\r\n software.File_App()\r\n\r\n else:\r\n messagebox.showerror(\"Error\",\"Invalid Useranme or Password!!\")\r\n\r\n def reset(self):\r\n self.uname.set(\"\")\r\n self.password.set(\"\")\r\n\r\n def exit(self):\r\n option=messagebox.askyesno(\"Exit\",\"Do you realy want to exit\")\r\n if option > 0:\r\n self.root.destroy()\r\n else:\r\n return\r\n\r\nroot=Tk()\r\nob=Login(root)\r\nroot.mainloop()"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 25,
"blob_id": "e08206b8dd6773f13e68a96e2ed832e82040a44a",
"content_id": "1a0422682facc4ec9da5cddd3a6a80dfc0627aba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 1,
"path": "/README.md",
"repo_name": "SatyamRajawat/File-base-record-system",
"src_encoding": "UTF-8",
"text": "# File-base-record-system"
}
] | 2 |
xrustalik/leetcode-tasks | https://github.com/xrustalik/leetcode-tasks | e27109f5b392dc560ff4f177c1a3c68fd431a80e | 5de5c90e9b6e5b3bfbf9f6cdbfd64991eca67ead | 8257ce89f6cafe2128b38aab3fe7c3e4933e8feb | refs/heads/master | "2022-11-07T13:52:12.204800" | "2020-06-20T16:43:40" | "2020-06-20T16:43:40" | 239,786,284 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6890130639076233,
"alphanum_fraction": 0.7020484209060669,
"avg_line_length": 30.58823585510254,
"blob_id": "84fe3a155ff5ee50e917c9d608aacdf1a560b380",
"content_id": "e1a9d143174d5ab4e4c765efc194dd105015d0f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/roman_to_int/test_roman_to_int.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "\nimport pytest\nfrom roman_to_int.roman_to_int import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\ndef test_roman_to_int(init_solution):\n assert init_solution.romanToInt('IX')==9\n assert init_solution.romanToInt('III')==3\n assert init_solution.romanToInt('IV')==4\n assert init_solution.romanToInt('V')==5\n # assert init_solution.romanToInt(3)=='III'\n # assert init_solution.romanToInt(4)=='IV'\n # assert init_solution.romanToInt(5)=='V'"
},
{
"alpha_fraction": 0.6539924144744873,
"alphanum_fraction": 0.6882129311561584,
"avg_line_length": 19.230770111083984,
"blob_id": "4fda3662cad4607327be687524be1595b79cf8ba",
"content_id": "97330ebf68556011d0203d2c72aa613d46a34681",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 13,
"path": "/two_sum/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom two_sum.two_sum import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\n\ndef test_twoSum(init_solution):\n assert init_solution.twoSum([2, 7, 11, 15], 9) == (0, 1)\n"
},
{
"alpha_fraction": 0.33191490173339844,
"alphanum_fraction": 0.346808522939682,
"avg_line_length": 25.11111068725586,
"blob_id": "9e617a76c0acbb5ca36177ce3303ac517ceb4112",
"content_id": "182165e3e1bc36c92d25c3fac5196e90d2f74ba1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 18,
"path": "/longest_substring_without_repeating_characted/longest_substr.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def lengthOfLongestSubstring(self, s):\n b = []\n a = []\n k = 0\n if len(s) == 0:\n return 0\n for i in range(len(s)):\n if s[i] not in a:\n k += 1\n a.append(s[i])\n else:\n a = list(s[s.index(s[i], i - k) + 1:i + 1])\n b.append(k)\n k = len(a)\n if k != 0:\n b.append(k)\n return max(b)\n"
},
{
"alpha_fraction": 0.5773353576660156,
"alphanum_fraction": 0.6753445863723755,
"avg_line_length": 30.095237731933594,
"blob_id": "dda6b59eed59a31a06a24ff8d571790bfe5c977e",
"content_id": "238ccee7fbd38f98846fbec73acf3a7a0e98e156",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 653,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 21,
"path": "/atoi/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom atoi.atoi import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\n\ndef test_myAtoi(init_solution):\n assert init_solution.myAtoi(\"42\") == 42\n assert init_solution.myAtoi(\" -42\") == -42\n assert init_solution.myAtoi(\"4193 with words\") == 4193\n assert init_solution.myAtoi(\"words and 987\") == 0\n assert init_solution.myAtoi(\"-91283472332\") == -2147483648\n assert init_solution.myAtoi(\"\") == 0\n assert init_solution.myAtoi(\"+\") == 0\n assert init_solution.myAtoi(\"++++++\") ==0\n assert init_solution.myAtoi(\"2147483648\") ==2147483647\n"
},
{
"alpha_fraction": 0.7269737124443054,
"alphanum_fraction": 0.7335526347160339,
"avg_line_length": 26.727272033691406,
"blob_id": "b7d8e4c3d74596a01fc303b3562aaa8bf913a910",
"content_id": "f82ea23707e78b2d85f49e607c467b88cae1a1bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 11,
"path": "/zigzag/test_zigzag.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom zigzag import ZigZag\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution=ZigZag()\n return solution\ndef test_convert(init_solution):\n assert init_solution.convert(\"AB\", 1)==\"AB\"\n assert init_solution.convert(\"PAYPALISHIRING\", 3)==\"PAHNAPLSIIGYIR\""
},
{
"alpha_fraction": 0.6423357725143433,
"alphanum_fraction": 0.6824817657470703,
"avg_line_length": 20.076923370361328,
"blob_id": "6f3ba36dd59dc7ceacbce483e3b0d22c8e58de3b",
"content_id": "9a89839b402d897af9e9ccd2ba2fb17b7659514e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 13,
"path": "/max_area/test_max_area.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom max_area.max_area import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\n\ndef test_max_area(init_solution):\n assert init_solution.maxArea([1, 8, 6, 2, 5, 4, 8, 3, 7]) == 49\n"
},
{
"alpha_fraction": 0.3908984959125519,
"alphanum_fraction": 0.4259043037891388,
"avg_line_length": 27.566667556762695,
"blob_id": "6f5b35756dc3536b26883a172e57e177e4d22bb6",
"content_id": "ae007b39eecec5632c9cd594694438418d265b04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 857,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 30,
"path": "/atoi/atoi.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def myAtoi(self, str):\n \"\"\"\n :type str: str\n :rtype: int\n \"\"\"\n\n char_ord_array = [x for x in range(48, 58)]\n plus_minus = [43, 45]\n str = str.strip()\n if len(str) == 0:\n return 0\n result_str = \"\"\n if ord(str[0]) not in char_ord_array and ord(str[0]) not in plus_minus:\n return 0\n else:\n result_str += str[0]\n str = str[1:]\n for char in str:\n if ord(char) in char_ord_array:\n result_str += char\n else:\n break\n # Check for int32\n try:\n if abs(int(result_str)) > (1 << 31) - 1:\n return -(1 << 31) if result_str[0] == \"-\" else (1 << 31) - 1\n return int(result_str)\n except:\n return 0\n"
},
{
"alpha_fraction": 0.4074941575527191,
"alphanum_fraction": 0.43325525522232056,
"avg_line_length": 25.6875,
"blob_id": "bbc486804e6e95c9c9ab2aede4b8db37f8f7cedf",
"content_id": "2823c07695783c922bcc4ce0f100fa6522fc5c93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 16,
"path": "/reverse_integer/reverse_integer.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def reverse(self, x):\n\n \"\"\"\n :type x: int\n :rtype: int\n \"\"\"\n\n if abs(x) > (1 << 31) - 1:\n return 0\n else:\n revers_str = \"\".join(list(reversed(list(str(abs(x))))))\n revers_int = int(revers_str) if int(revers_str) < ((1 << 31) - 1) else 0\n if x < 0:\n return -revers_int\n return revers_int\n"
},
{
"alpha_fraction": 0.4307115972042084,
"alphanum_fraction": 0.4344569146633148,
"avg_line_length": 23.272727966308594,
"blob_id": "23b5f43c0fb8780e4c6aee5f57f19c51039666b3",
"content_id": "e1e9db223ce87bed1c714da33db2205e497b0b40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 11,
"path": "/palindrome_number/palindrome_number.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def isPalindrome(self, x):\n \"\"\"\n :type x: int\n :rtype: bool\n \"\"\"\n arr = list(str(x))\n for i in range(len(arr)):\n if arr[i] != arr[-i-1]:\n return False\n return True\n"
},
{
"alpha_fraction": 0.37769079208374023,
"alphanum_fraction": 0.43248531222343445,
"avg_line_length": 33.06666564941406,
"blob_id": "cb6a851e41b9731092e60b85d26a955fc065ce0e",
"content_id": "a141366de891efe9e7876cb30ab4eafceaadcd04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 511,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 15,
"path": "/int_to_roman/int_to_roman.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def intToRoman(self, num):\n \"\"\"\n :type num: int\n :rtype: str\n \"\"\"\n enum = {1: 'I', 4:'IV',5: 'V', 9:'IX',10: 'X', 40:'XL',50: 'L', 90:'XC' ,100: 'C', 400: 'CD', 500: 'D', 900:'CM', 1000: 'M'}\n res = ''\n enum_keys = sorted(enum.keys(), reverse=True)\n for i in range(len(enum_keys)):\n key=enum_keys[i]\n while num>=key:\n num-=key\n res+=''.join(enum.get(key))\n return res\n"
},
{
"alpha_fraction": 0.712195098400116,
"alphanum_fraction": 0.7219512462615967,
"avg_line_length": 24.6875,
"blob_id": "b9861c5806c7facc24c8196ab9d672ed68f2c804",
"content_id": "38adaeb5c6b4c6944d3a4f83233b7267f2c88fd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 16,
"path": "/int_to_roman/test_int_to_roman.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import random\n\nimport pytest\nfrom int_to_roman.int_to_roman import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\ndef test_int_to_roman(init_solution):\n assert init_solution.intToRoman(9)=='IX'\n assert init_solution.intToRoman(3)=='III'\n assert init_solution.intToRoman(4)=='IV'\n assert init_solution.intToRoman(5)=='V'"
},
{
"alpha_fraction": 0.4725685715675354,
"alphanum_fraction": 0.5012468695640564,
"avg_line_length": 26.65517234802246,
"blob_id": "099998110a402195e0f139676fadcb93c03d4c22",
"content_id": "2cc2c68b7f5c9763ee32f8b9009f9e83905aabbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 29,
"path": "/median_of_two_sorted_arrays/median.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def findMedianSortedArrays(self, nums1, nums2):\n \"\"\"\n :type nums1: List[int]\n :type nums2: List[int]\n :rtype: float\n \"\"\"\n n = len(nums1)\n m = len(nums2)\n for i in nums1:\n nums2.insert(bsearch(nums2, i), i)\n return nums2[(m + n) // 2] if (m + n) % 2 == 1 else (nums2[(m + n) // 2] + nums2[(m + n) // 2 - 1]) / 2\n\n\n# log(higher-lower)\ndef bsearch(array, x, lower=None, higher=None):\n if lower is None:\n lower = 0\n if lower < 0:\n raise ValueError\n if higher is None:\n higher = len(array)\n while lower < higher:\n middle = (lower + higher) // 2\n if array[middle] < x:\n lower = middle + 1\n else:\n higher = middle\n return lower\n"
},
{
"alpha_fraction": 0.7690631747245789,
"alphanum_fraction": 0.7755991220474243,
"avg_line_length": 31.714284896850586,
"blob_id": "b046a24a39de6fe5201150163b82191b9b08ecb0",
"content_id": "c8a0f184c923f756fa6142dd5bc9960b4f188e2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 14,
"path": "/longest_substring_without_repeating_characted/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom longest_substring_without_repeating_characted.longest_substr import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution=Solution()\n return solution\n\ndef test_lengthOfLongestSubstring(init_solution):\n assert init_solution.lengthOfLongestSubstring(\"abcabcbb\") == 3\n assert init_solution.lengthOfLongestSubstring(\"bbbbb\") == 1\n assert init_solution.lengthOfLongestSubstring(\"pwwkew\") == 3\n\n"
},
{
"alpha_fraction": 0.707317054271698,
"alphanum_fraction": 0.7371273636817932,
"avg_line_length": 27.384614944458008,
"blob_id": "9168cd6524bacdc175ce09f5a8fffa03352c026f",
"content_id": "7b9d0843b2b35e7edd1644f3e3504c97fd21e07f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 13,
"path": "/median_of_two_sorted_arrays/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom median_of_two_sorted_arrays.median import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\ndef test_findMedianSortedArrays(init_solution):\n assert init_solution.findMedianSortedArrays([1, 3], [2])==2.0\n assert init_solution.findMedianSortedArrays([1,2], [3,4])==2.5\n"
},
{
"alpha_fraction": 0.7359550595283508,
"alphanum_fraction": 0.7584269642829895,
"avg_line_length": 24.428571701049805,
"blob_id": "8a1c5b0d3b0c72619b8a77558415376a51034648",
"content_id": "8ea335a2ab0da5c4f98b242cf50e3588a346f558",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 356,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/palindrome_number/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "\nimport pytest\n\nfrom palindrome_number import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution=Solution()\n return solution\n\ndef test_isPalindrome(init_solution):\n assert init_solution.isPalindrome(121)==True\n assert init_solution.isPalindrome(-121)==False\n assert init_solution.isPalindrome(10)==False"
},
{
"alpha_fraction": 0.6263498663902283,
"alphanum_fraction": 0.7365010976791382,
"avg_line_length": 26.235294342041016,
"blob_id": "3a77aa2aff638d8593fec63798304d1284ecd47b",
"content_id": "43e65efb3738239c1132b3b47eda1731dafb5929",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 17,
"path": "/reverse_integer/test_solution.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom reverse_integer.reverse_integer import Solution\n\n\[email protected](scope='session', autouse=True)\ndef init_solution():\n solution = Solution()\n return solution\n\n\ndef test_reverse(init_solution):\n assert init_solution.reverse(123) == 321\n assert init_solution.reverse(-123) == -321\n assert init_solution.reverse(120) == 21\n assert init_solution.reverse(1111111123819283791823)==0\n assert init_solution.reverse(1534236469)==0\n"
},
{
"alpha_fraction": 0.29860228300094604,
"alphanum_fraction": 0.3430749773979187,
"avg_line_length": 30.399999618530273,
"blob_id": "9fc0b1f316c35515e5c541b39c3d419ae0d4d3a6",
"content_id": "14ee48a5ac242d5e34d49f9e0e1c107ba746890d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 25,
"path": "/roman_to_int/roman_to_int.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class Solution(object):\n def romanToInt(self, s):\n \"\"\"\n :type s: str\n :rtype: int\n \"\"\"\n enum = {'I':1, 'IV':4,'V':5, 'IX':9,'X':10, 'XL':40, 'L':50, 'XC':90 , 'C':100, 'CD':400, 'D':500, 'CM':900, 'M':1000}\n res = 0\n enum_keys = sorted(enum.keys(), reverse=True)\n i=0\n while i < len(s):\n if s[i] in ('I', 'X', 'C') and i<len(s)-1:\n tmp = s[i]+s[i+1]\n if tmp in enum_keys:\n res+=enum.get(tmp)\n i+=2\n continue\n else:\n res+=enum.get(s[i])\n i+=1\n continue\n else:\n res+=enum.get(s[i])\n i+=1\n return res\n\n\n"
},
{
"alpha_fraction": 0.7430894374847412,
"alphanum_fraction": 0.7430894374847412,
"avg_line_length": 31.36842155456543,
"blob_id": "5be660254d81c3113226c088ee7a69e8b8b5cf98",
"content_id": "fd056f643bf5a357dca9d496e8fcbfc0de17828c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 19,
"path": "/README.md",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "# Leetcode Tasks\n\nLeetcode Tasks is a python playground to solve leetcode tasks.\n\n- [x] Longest substring without repeating character\n- [x] Palindrome Number\n- [x] Reverse Integer\n- [x] Two sums\n- [x] Zig Zag\n- [x] Atoi\n- [x] Container With Most Water\n- [x] Median of two sorted arrays\n\n## Installation\n\nTo run this you will need to install python. Also, it supports tests using pytest.\n\n## Contributing\nPull requests are welcome. You can add whatever changes you would like too. Also new test cases are welcome, for every task there is a ` test_<name>.py ` file where you can add some new assertions. Thanks a lot\n"
},
{
"alpha_fraction": 0.4791666567325592,
"alphanum_fraction": 0.4854166805744171,
"avg_line_length": 33.28571319580078,
"blob_id": "a4c16c04d915ee75c7684d1e4bc055c9f07dba90",
"content_id": "0161e0026f937d9fa76ed528de3dcaf1392c154c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 480,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 14,
"path": "/zigzag/zigzag.py",
"repo_name": "xrustalik/leetcode-tasks",
"src_encoding": "UTF-8",
"text": "class ZigZag(object):\n def convert(self, s, numRows):\n s = str(s)\n res = [[] for i in range(numRows)]\n res_str = \"\"\n zig = numRows * 2 - 2\n if numRows >= len(s) or numRows == 1:\n return s\n for i in range(len(s)):\n numberOfRow = i % zig if i % zig < numRows else zig - i % zig\n res[numberOfRow].append(s[i])\n for i in range(numRows):\n res_str += ''.join(res[i])\n return res_str\n"
}
] | 19 |
bharat1015/demobygit | https://github.com/bharat1015/demobygit | d8f4b87f2394c0e5720f13c61d8c566c30a94117 | 03b1a080ea564abf71de70d2c3580080c2e2b3d6 | d1538eba68595d8faf7f4869e5c1f223469ceeec | refs/heads/master | "2022-12-23T00:42:57.346738" | "2020-09-21T12:10:53" | "2020-09-21T12:10:53" | 297,324,442 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.65625,
"alphanum_fraction": 0.65625,
"avg_line_length": 15.5,
"blob_id": "cca97ce28743f19a035be520c2de3448990f2bd7",
"content_id": "63c0868072cec3f8add947f5b14384947ca5f198",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 2,
"path": "/demo.py",
"repo_name": "bharat1015/demobygit",
"src_encoding": "UTF-8",
"text": "print(\"Hello\")\nprint(\"Welome bharat\")"
}
] | 1 |
supasate/FBPCS | https://github.com/supasate/FBPCS | 2c4c3adc744b0181cc74f4a6807432b92f1a6451 | b381e01416dfd52068d1f57d3cea0f1bc6a77de9 | f1e24e156a8c6304a3c248af2f1399f482c3a72b | refs/heads/main | "2023-05-14T12:22:01.971334" | "2021-06-02T03:02:05" | "2021-06-02T03:03:11" | 373,349,778 | 1 | 0 | MIT | "2021-06-03T01:41:38" | "2021-06-02T03:03:18" | "2021-06-02T03:03:15" | null | [
{
"alpha_fraction": 0.7957879900932312,
"alphanum_fraction": 0.7998107075691223,
"avg_line_length": 110.21052551269531,
"blob_id": "72c85cc670a72383c137c3fba32257a780dcabe0",
"content_id": "4bf10adda548e89f6d8f5b7c401f9290d0efde44",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4226,
"license_type": "permissive",
"max_line_length": 1032,
"num_lines": 38,
"path": "/docs/PrivateScaling.md",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "# Introduction\nHandling large volumes of data is crucial for products like Private Lift that leverage privacy enhancing technologies including multiparty computation games. Unfortunately, EMP-toolkit and similar MPC platforms cannot handle large enough data sets at the required scale and speed imposed by our product. In this document we go over the design of our solution on how to do sharding on the inputs, without revealing the output of each shard and aggregate the output in a privacy-preserving way such that only the final output will be revealed. As an additional option, we also explain how we can have only one party learn the output and the other party will only participate in the computation without learning any information as the result of the participation.\n\n# Product Requirements\n1. Ability to scale horizontally\n 1. Our current product requirements require up to 500M rows\n 2. EMP-toolkit is limited to 2M row input when we run on the AWS Fargate best option available. (Note: It could be higher when we run on a better machine such as on EC2, however, the scale is limited when using only one machine.)\n2. Maintain input privacy and prevent privacy leakage while scaling horizontally, i.e. not revealing the intermediary data.\n 1. Product is required to maintain the privacy of the inputs, except that revealed by the lift statistics.\n 2. Revealing the lift statistics of each shard would cause privacy leakage, thus we must aggregate sharded results privately.\n 3. We require this option to hide the output of the computation from one party.\n\n# Our Protocol\nWe propose to implement a privacy-preserving sharding mechanism such that the intermediary output of each shard remains private, i.e. the garbled values will not be open to the parties. Instead, each party will learn an XOR share of the value. Consequently, the aggregation step will happen after the data is reconstructed from the XOR-shares in the garbled circuit and only the final result of the computation will be revealed.\n\n## Sharding Design\nThe following figures show the high-level design of the solution. Both parties have a PL-Coordinator and multiple PL-Workers. The PL-Coordinator partitions the input database into shards in a round robin method, and assigns each shard to a PL-worker.\n\n<img src=\"ShardingDesignFB.jpg\" alt=\"Figure 1: FB side sharding design\">\n\n<img src=\"ShardingDesignClient.jpg\" alt=\"Figure 2: Client side sharding design\">\n\n## Private Partitioning and Aggregation with EMP-toolkit\nTo ensure that PL-workers will not learn the output of the computation on one shard, we do not reveal the intermediary output at the end of their game. Instead, The server will choose a random number as a new input and XOR the result of the computation with that random number in the garbled circuit (The process also called one-time pad). At the end of the game, the evaluator knows the result of the computation xored with that random number and garbler knows the random number. Jointly, they can reconstruct the result but individually, they do not have any information about it due to the security of one time pads. The following example shows how to implement games for a simple worker and aggregator in EMP (using the reveal function) while preserving privacy. The first game shows how to implement worker without revealing the intermediary result. The second game is the aggregator that accepts the Xored inputs. The third game is the same aggregator with an additional option that reveals the final output to only one party.\n\n#### The worker game outputs XOR results\nPut the XOR argument in the reveal function of the game\n\n<img src=\"XORoutput.jpg\" alt=\"Figure 3: The worker game outputs XOR results\">\n\n#### The aggregator game accepts XORed inputs and reveals the output to both parties\nThe game should xor the inputs before aggregating them.\n\n<img src=\"AggregateTwoParties.jpg\" alt=\"Figure 4: The aggregator game accepts XORed inputs and reveals the output to both parties\">\n\n#### Optional. The aggregator game accepts XORed inputs and reveals the output to only one party\n\n<img src=\"AggregateOneParty.jpg\" alt=\"Figure 5: The aggregator game accepts XORed inputs and reveals the output to only one party\">\n"
},
{
"alpha_fraction": 0.6586177945137024,
"alphanum_fraction": 0.6627810001373291,
"avg_line_length": 29.794872283935547,
"blob_id": "ce41d04a02355e39fc1f9d35ac0f3df61ee5cc1c",
"content_id": "bc09be3d8e5386bf7d86d1752b7747905eca7ac8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1201,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 39,
"path": "/tests/util/test_yaml.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport json\nimport unittest\nfrom unittest.mock import patch, mock_open\n\nfrom fbpcs.util.yaml import load, dump\n\nTEST_FILENAME = \"TEST_FILE\"\nTEST_DICT = {\n \"test_dict\": [\n {\"test_key_1\": \"test_value_1\"},\n {\"test_key_1\": \"test_value_2\"},\n ]\n}\n\n\nclass TestYaml(unittest.TestCase):\n data = json.dumps(TEST_DICT)\n\n @patch(\"builtins.open\", new_callable=mock_open, read_data=data)\n def test_load(self, mock_file):\n self.assertEqual(open(TEST_FILENAME).read(), self.data)\n load_data = load(TEST_FILENAME)\n self.assertEqual(load_data, TEST_DICT)\n mock_file.assert_called_with(TEST_FILENAME)\n\n @patch(\"builtins.open\")\n @patch(\"yaml.dump\")\n def test_dump(self, mock_dump, mock_open):\n mock_dump.return_value = None\n stream = mock_open().__enter__.return_value\n self.assertIsNone(dump(TEST_DICT, TEST_FILENAME))\n mock_open.assert_called_with(TEST_FILENAME, \"w\")\n mock_dump.assert_called_with(TEST_DICT, stream)\n"
},
{
"alpha_fraction": 0.709876537322998,
"alphanum_fraction": 0.7181069850921631,
"avg_line_length": 26,
"blob_id": "29ac50f2cf5b126770a60b43f2f5ff2ec6af756f",
"content_id": "b255348667375363c5a5d793507af9357edaea85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 18,
"path": "/onedocker/tests/test_util.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport subprocess\nimport unittest\n\nfrom util import run_cmd\n\n\nclass TestUtil(unittest.TestCase):\n def test_run_cmd(self):\n self.assertEqual(0, run_cmd(\"cat\", 1))\n\n def test_run_cmd_with_timeout(self):\n self.assertRaises(subprocess.TimeoutExpired, run_cmd, \"vi\", 1)\n"
},
{
"alpha_fraction": 0.4897959232330322,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 15.333333015441895,
"blob_id": "aeb5e4b07a54ae4d30b6754f727e3674a8cd4ec6",
"content_id": "2669b99743da22314ac893478b6b6150f1d864d8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 98,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 6,
"path": "/onedocker/pip_requirements.txt",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "docopt ~= 0.6\nschema ~= 0.7\njmespath ~= 0.10\ns3transfer ~= 0.3\nparameterized ~= 0.7\npsutil ~= 5.8\n"
},
{
"alpha_fraction": 0.545945942401886,
"alphanum_fraction": 0.546846866607666,
"avg_line_length": 25.428571701049805,
"blob_id": "33d9449b3c3dcfb2ee08022ca1caa4a14dd1de5b",
"content_id": "8fda4e5b6a7591a53004a39401b3953d0cdc6776",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 42,
"path": "/tests/error/mapper/test_aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom botocore.exceptions import ClientError\nfrom fbpcs.error.mapper.aws import map_aws_error\nfrom fbpcs.error.pcs import PcsError\nfrom fbpcs.error.throttling import ThrottlingError\n\n\nclass TestMapAwsError(unittest.TestCase):\n def test_pcs_error(self):\n err = ClientError(\n {\n \"Error\": {\n \"Code\": \"Exception\",\n \"Message\": \"test\",\n },\n },\n \"test\",\n )\n err = map_aws_error(err)\n\n self.assertIsInstance(err, PcsError)\n\n def test_throttling_error(self):\n err = ClientError(\n {\n \"Error\": {\n \"Code\": \"ThrottlingException\",\n \"Message\": \"test\",\n },\n },\n \"test\",\n )\n err = map_aws_error(err)\n\n self.assertIsInstance(err, ThrottlingError)\n"
},
{
"alpha_fraction": 0.6366065740585327,
"alphanum_fraction": 0.6419505476951599,
"avg_line_length": 29.5510196685791,
"blob_id": "6cdb10c863ecd1d50cf6da49c43e703676e96f44",
"content_id": "cb7e1861ce8bfdef533466b793898337aeadef94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1497,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 49,
"path": "/fbpcs/gateway/ec2.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import Any, Dict, List, Optional\n\nimport boto3\nfrom fbpcs.decorator.error_handler import error_handler\nfrom fbpcs.entity.vpc_instance import Vpc\nfrom fbpcs.mapper.aws import map_ec2vpc_to_vpcinstance\n\n\nclass EC2Gateway:\n def __init__(\n self,\n region: str,\n access_key_id: Optional[str],\n access_key_data: Optional[str],\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.region = region\n config = config or {}\n\n if access_key_id is not None:\n config[\"aws_access_key_id\"] = access_key_id\n\n if access_key_data is not None:\n config[\"aws_secret_access_key\"] = access_key_data\n\n # pyre-ignore\n self.client = boto3.client(\"ec2\", region_name=self.region, **config)\n\n @error_handler\n def describe_vpcs(self, vpc_ids: List[str]) -> List[Vpc]:\n response = self.client.describe_vpcs(VpcIds=vpc_ids)\n return [map_ec2vpc_to_vpcinstance(vpc) for vpc in response[\"Vpcs\"]]\n\n @error_handler\n def describe_vpc(self, vpc_id: str) -> Vpc:\n return self.describe_vpcs([vpc_id])[0]\n\n @error_handler\n def list_vpcs(self) -> List[str]:\n all_vpcs = self.client.describe_vpcs()\n return [vpc[\"VpcId\"] for vpc in all_vpcs[\"Vpcs\"]]\n"
},
{
"alpha_fraction": 0.6848484873771667,
"alphanum_fraction": 0.6857143044471741,
"avg_line_length": 34,
"blob_id": "ba83ef7a043a30a35cf3b9bc8ef7381c0186d3df",
"content_id": "85b56d035fa1413c2b9e6878375504101333e55f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1155,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 33,
"path": "/onedocker/util.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport os\nimport signal\nimport subprocess\nfrom typing import Optional\n\n\ndef run_cmd(cmd: str, timeout: Optional[int]) -> int:\n # The handler dealing signal SIGINT, which could be Ctrl + C from user's terminal\n def _handler(signum, frame):\n raise InterruptedError\n\n signal.signal(signal.SIGINT, _handler)\n \"\"\"\n If start_new_session is true the setsid() system call will be made in the\n child process prior to the execution of the subprocess, which makes sure\n every process in the same process group can be killed by OS if timeout occurs.\n note: setsid() will set the pgid to its pid.\n \"\"\"\n with subprocess.Popen(cmd, shell=True, start_new_session=True) as proc:\n try:\n proc.communicate(timeout=timeout)\n except (subprocess.TimeoutExpired, InterruptedError) as e:\n proc.terminate()\n os.killpg(proc.pid, signal.SIGTERM)\n raise e\n\n return proc.wait()\n"
},
{
"alpha_fraction": 0.6052854061126709,
"alphanum_fraction": 0.6109936833381653,
"avg_line_length": 32.78571319580078,
"blob_id": "45a5833f950461e7cb0ed7e29800c0bf021e9264",
"content_id": "eb4aecf18b198b84447e3de1563bb5bf1a9efe0f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4730,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 140,
"path": "/tests/service/test_container_aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.service.container_aws import (\n ContainerInstance,\n ContainerInstanceStatus,\n AWSContainerService,\n)\n\nTEST_INSTANCE_ID_1 = \"test-instance-id-1\"\nTEST_INSTANCE_ID_2 = \"test-instance-id-2\"\nTEST_REGION = \"us-west-2\"\nTEST_KEY_ID = \"test-key-id\"\nTEST_KEY_DATA = \"test-key-data\"\nTEST_CLUSTER = \"test-cluster\"\nTEST_SUBNET = \"test-subnet\"\nTEST_IP_ADDRESS = \"127.0.0.1\"\nTEST_CONTAINER_DEFNITION = \"test-task-definition#test-container-definition\"\n\n\nclass TestAWSContainerService(unittest.TestCase):\n @patch(\"fbpcs.gateway.ecs.ECSGateway\")\n def setUp(self, MockECSGateway):\n self.container_svc = AWSContainerService(\n TEST_REGION, TEST_CLUSTER, TEST_SUBNET, TEST_KEY_ID, TEST_KEY_DATA\n )\n self.container_svc.ecs_gateway = MockECSGateway()\n\n def test_create_instances(self):\n created_instances = [\n ContainerInstance(\n TEST_INSTANCE_ID_1,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ContainerInstance(\n TEST_INSTANCE_ID_2,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ]\n\n self.container_svc.ecs_gateway.run_task = MagicMock(\n side_effect=created_instances\n )\n\n cmd_list = [\"test_cmd\", \"test_cmd-1\"]\n container_instances = self.container_svc.create_instances(\n TEST_CONTAINER_DEFNITION, cmd_list\n )\n self.assertEqual(container_instances, created_instances)\n self.assertEqual(\n self.container_svc.ecs_gateway.run_task.call_count, len(created_instances)\n )\n\n async def test_create_instances_async(self):\n created_instances = [\n ContainerInstance(\n TEST_INSTANCE_ID_1,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ContainerInstance(\n TEST_INSTANCE_ID_2,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ]\n\n self.container_svc.ecs_gateway.run_task = MagicMock(\n side_effect=created_instances\n )\n\n cmd_list = [\"test_cmd\", \"test_cmd-1\"]\n container_instances = await self.container_svc.create_instances_async(\n TEST_CONTAINER_DEFNITION, cmd_list\n )\n self.assertEqual(container_instances, created_instances)\n self.assertEqual(\n self.container_svc.ecs_gateway.run_task.call_count, len(created_instances)\n )\n\n def test_create_instance(self):\n created_instance = ContainerInstance(\n TEST_INSTANCE_ID_1,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n )\n\n self.container_svc.ecs_gateway.run_task = MagicMock(\n return_value=created_instance\n )\n container_instance = self.container_svc.create_instance(\n TEST_CONTAINER_DEFNITION, \"test-cmd\"\n )\n self.assertEqual(container_instance, created_instance)\n\n def test_get_instance(self):\n container_instance = ContainerInstance(\n TEST_INSTANCE_ID_1,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n )\n self.container_svc.ecs_gateway.describe_task = MagicMock(\n return_value=container_instance\n )\n instance = self.container_svc.get_instance(TEST_INSTANCE_ID_1)\n self.assertEqual(instance, container_instance)\n\n def test_get_instances(self):\n container_instances = [\n ContainerInstance(\n TEST_INSTANCE_ID_1,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ContainerInstance(\n TEST_INSTANCE_ID_2,\n TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ]\n self.container_svc.ecs_gateway.describe_tasks = MagicMock(\n return_value=container_instances\n )\n instances = self.container_svc.get_instances(\n [TEST_INSTANCE_ID_1, TEST_INSTANCE_ID_2]\n )\n self.assertEqual(instances, container_instances)\n\n def test_list_tasks(self):\n instance_ids = [TEST_INSTANCE_ID_1, TEST_INSTANCE_ID_2]\n self.container_svc.ecs_gateway.list_tasks = MagicMock(return_value=instance_ids)\n self.assertEqual(instance_ids, self.container_svc.list_tasks())\n"
},
{
"alpha_fraction": 0.6524008512496948,
"alphanum_fraction": 0.6544885039329529,
"avg_line_length": 29.90322494506836,
"blob_id": "d2763b615f7c541f5ed13a1e61f1efffc093b5e4",
"content_id": "65f5e23e40572fb5819c1e2c26f0a33e7dac1c99",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 958,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 31,
"path": "/fbpcs/service/log_cloudwatch.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import Any, Dict, Optional\n\nfrom fbpcs.gateway.cloudwatch import CloudWatchGateway\nfrom fbpcs.service.log import LogService\n\n\nclass CloudWatchLogService(LogService):\n def __init__(\n self,\n log_group: str,\n region: str = \"us-west-1\",\n access_key_id: Optional[str] = None,\n access_key_data: Optional[str] = None,\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.cloudwatch_gateway = CloudWatchGateway(\n region, access_key_id, access_key_data, config\n )\n self.log_group = log_group\n\n def fetch(self, log_path: str) -> Dict[str, Any]:\n \"\"\"Fetch logs\"\"\"\n return self.cloudwatch_gateway.get_log_events(self.log_group, log_path)\n"
},
{
"alpha_fraction": 0.6978723406791687,
"alphanum_fraction": 0.7010638117790222,
"avg_line_length": 35.153846740722656,
"blob_id": "e8149bde243e9baf341d3185b195f59f7131bff4",
"content_id": "d4097b419e3ef682dd66480181f9f0406daf7275",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 940,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 26,
"path": "/tests/gateway/test_cloudwatch.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.gateway.cloudwatch import CloudWatchGateway\n\n\nclass TestCloudWatchGateway(unittest.TestCase):\n REGION = \"us-west-1\"\n GROUP_NAME = \"test-group-name\"\n STREAM_NAME = \"test-stream-name\"\n\n @patch(\"boto3.client\")\n def test_get_log_events(self, BotoClient):\n gw = CloudWatchGateway(self.REGION)\n mocked_log = {\"test-events\": [{\"test-event-name\": \"test-event-data\"}]}\n gw.client = BotoClient()\n gw.client.get_log_events = MagicMock(return_value=mocked_log)\n returned_log = gw.get_log_events(self.GROUP_NAME, self.STREAM_NAME)\n gw.client.get_log_events.assert_called()\n self.assertEqual(mocked_log, returned_log)\n"
},
{
"alpha_fraction": 0.5477099418640137,
"alphanum_fraction": 0.5510495901107788,
"avg_line_length": 31.24615478515625,
"blob_id": "331b7703f7cad7da51854bd3cd5eecabcc0a3787",
"content_id": "67b3994fbb816f269db625616c4d730c580b837a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2096,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 65,
"path": "/tests/gateway/test_ec2.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.entity.vpc_instance import Vpc, VpcState\nfrom fbpcs.gateway.ec2 import EC2Gateway\n\nTEST_VPC_ID = \"test-vpc-id\"\nTEST_ACCESS_KEY_ID = \"test-access-key-id\"\nTEST_ACCESS_KEY_DATA = \"test-access-key-data\"\nTEST_VPC_TAG_KEY = \"test-vpc-tag-key\"\nTEST_VPC_TAG_VALUE = \"test-vpc-tag-value\"\nREGION = \"us-west-2\"\n\n\nclass TestEC2Gateway(unittest.TestCase):\n @patch(\"boto3.client\")\n def setUp(self, BotoClient):\n self.gw = EC2Gateway(REGION, TEST_ACCESS_KEY_ID, TEST_ACCESS_KEY_DATA)\n self.gw.client = BotoClient()\n\n def test_describe_vpcs(self):\n client_return_response = {\n \"Vpcs\": [\n {\n \"State\": \"UNKNOWN\",\n \"VpcId\": TEST_VPC_ID,\n \"Tags\": [\n {\n \"Key\": TEST_VPC_TAG_KEY,\n \"Value\": TEST_VPC_TAG_VALUE,\n },\n ],\n }\n ]\n }\n tags = {TEST_VPC_TAG_KEY: TEST_VPC_TAG_VALUE}\n self.gw.client.describe_vpcs = MagicMock(return_value=client_return_response)\n vpcs = self.gw.describe_vpcs([TEST_VPC_ID])\n expected_vpcs = [\n Vpc(\n TEST_VPC_ID,\n VpcState.UNKNOWN,\n tags,\n ),\n ]\n self.assertEqual(vpcs, expected_vpcs)\n self.gw.client.describe_vpcs.assert_called()\n\n def test_list_vpcs(self):\n client_return_response = {\n \"Vpcs\": [\n {\"VpcId\": TEST_VPC_ID},\n ]\n }\n self.gw.client.describe_vpcs = MagicMock(return_value=client_return_response)\n vpcs = self.gw.list_vpcs()\n expected_vpcs = [TEST_VPC_ID]\n self.assertEqual(vpcs, expected_vpcs)\n self.gw.client.describe_vpcs.assert_called()\n"
},
{
"alpha_fraction": 0.4324324429035187,
"alphanum_fraction": 0.6756756901741028,
"avg_line_length": 13.800000190734863,
"blob_id": "32f9abeacf4c229591cc55fad29b2b14fd5ce477",
"content_id": "a9ef9e83f4e6cc0cbd78a486f4954e5419294066",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 74,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 5,
"path": "/lint_requirements.txt",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "black==21.4b2\nufmt==1.2\nusort==0.6.4\nflake8==3.9.0\nflake8-bugbear==21.3.2\n"
},
{
"alpha_fraction": 0.7251655459403992,
"alphanum_fraction": 0.7268211841583252,
"avg_line_length": 21.370370864868164,
"blob_id": "18aba0d9391b15b8fc8d82bcdd2bb878fd0cf467",
"content_id": "44afa86b4ac025a33c7a281349a971071682c01b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 27,
"path": "/fbpcs/entity/vpc_instance.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom dataclasses import dataclass, field\nfrom enum import Enum\nfrom typing import Dict\n\nfrom dataclasses_json import dataclass_json\n\n\nclass VpcState(Enum):\n UNKNOWN = \"UNKNOWN\"\n PENDING = \"PENDING\"\n AVAILABLE = \"AVAILABLE\"\n\n\n@dataclass_json\n@dataclass\nclass Vpc:\n vpc_id: str\n state: VpcState = VpcState.UNKNOWN\n tags: Dict[str, str] = field(default_factory=lambda: {})\n"
},
{
"alpha_fraction": 0.5863893628120422,
"alphanum_fraction": 0.6065714955329895,
"avg_line_length": 37.15023422241211,
"blob_id": "097fff06a7492ed63aac15f383c50ad8a6ec1114",
"content_id": "07a82a08f8acdccbd195ca646b5729e6a357adb4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8150,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 213,
"path": "/tests/service/test_storage_s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport os\nimport unittest\nfrom unittest.mock import call, MagicMock, patch\n\nfrom fbpcs.service.storage_s3 import S3StorageService\n\n\nclass TestS3StorageService(unittest.TestCase):\n LOCAL_FILE = \"/usr/test_file\"\n LOCAL_FOLDER = \"/foo\"\n S3_FILE = \"https://bucket.s3.Region.amazonaws.com/test_file\"\n S3_FILE_COPY = \"https://bucket.s3.Region.amazonaws.com/test_file_copy\"\n S3_FOLDER = \"https://bucket.s3.Region.amazonaws.com/test_folder/\"\n S3_FOLDER_COPY = \"https://bucket.s3.Region.amazonaws.com/test_folder_copy/\"\n S3_FILE_WITH_SUBFOLDER = (\n \"https://bucket.s3.Region.amazonaws.com/test_folder/test_file\"\n )\n \"\"\"\n The layout of LOCAL_DIR:\n /foo/\n ├── bar/\n └── baz/\n ├── a\n └── b\n \"\"\"\n LOCAL_DIR = [\n (\"/foo\", (\"bar\",), (\"baz\",)),\n (\"/foo/baz\", (), (\"a\", \"b\")),\n ]\n\n S3_DIR = [\n \"test_folder/bar/\",\n \"test_folder/baz/\",\n \"test_folder/baz/a\",\n \"test_folder/baz/b\",\n ]\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_local_to_s3(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.upload_file = MagicMock(return_value=None)\n service.copy(self.LOCAL_FILE, self.S3_FILE)\n service.s3_gateway.upload_file.assert_called_with(\n str(self.LOCAL_FILE), \"bucket\", \"test_file\"\n )\n\n def test_copy_local_dir_to_s3_recursive_false(self):\n service = S3StorageService(\"us-west-1\")\n with patch(\"os.path.isdir\", return_value=True):\n self.assertRaises(\n ValueError, service.copy, self.LOCAL_FOLDER, self.S3_FOLDER, False\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_local_dir_to_s3_recursive_true(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.put_object = MagicMock(return_value=None)\n service.s3_gateway.upload_file = MagicMock(return_value=None)\n\n with patch(\"os.path.isdir\", return_value=True):\n with patch(\"os.walk\", return_value=self.LOCAL_DIR):\n service.copy(self.LOCAL_FOLDER, self.S3_FOLDER, True)\n\n service.s3_gateway.put_object.assert_called_with(\n \"bucket\", \"test_folder/bar/\", \"\"\n )\n\n service.s3_gateway.upload_file.assert_has_calls(\n [\n call(\"/foo/baz/a\", \"bucket\", \"test_folder/baz/a\"),\n call(\"/foo/baz/b\", \"bucket\", \"test_folder/baz/b\"),\n ],\n any_order=True,\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_to_local(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.download_file = MagicMock(return_value=None)\n service.copy(self.S3_FILE, self.LOCAL_FILE)\n service.s3_gateway.download_file.assert_called_with(\n \"bucket\", \"test_file\", str(self.LOCAL_FILE)\n )\n\n def test_copy_s3_dir_to_local_recursive_false(self):\n service = S3StorageService(\"us-west-1\")\n self.assertRaises(\n ValueError, service.copy, self.S3_FOLDER, self.LOCAL_FOLDER, False\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_dir_to_local_source_does_not_exist(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.object_exists = MagicMock(return_value=False)\n self.assertRaises(\n ValueError, service.copy, self.S3_FOLDER, self.LOCAL_FOLDER, False\n )\n\n @patch(\"os.makedirs\")\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_dir_to_local_ok(self, MockS3Gateway, os_makedirs):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.object_exists = MagicMock(return_value=True)\n service.s3_gateway.list_object2 = MagicMock(return_value=self.S3_DIR)\n service.s3_gateway.download_file = MagicMock(return_value=None)\n\n service.copy(self.S3_FOLDER, self.LOCAL_FOLDER, True)\n\n os.makedirs.assert_has_calls(\n [\n call(\"/foo/bar\"),\n call(\"/foo/baz\"),\n ],\n any_order=True,\n )\n\n service.s3_gateway.download_file.assert_has_calls(\n [\n call(\"bucket\", \"test_folder/baz/a\", \"/foo/baz/a\"),\n call(\"bucket\", \"test_folder/baz/b\", \"/foo/baz/b\"),\n ],\n any_order=True,\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_local_to_local(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n self.assertRaises(ValueError, service.copy, self.LOCAL_FILE, self.LOCAL_FILE)\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_to_s3(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.copy(self.S3_FILE, self.S3_FILE_COPY)\n service.s3_gateway.copy.assert_called_with(\n \"bucket\", \"test_file\", \"bucket\", \"test_file_copy\"\n )\n\n def test_copy_s3_dir_to_s3_recursive_false(self):\n service = S3StorageService(\"us-west-1\")\n self.assertRaises(\n ValueError, service.copy, self.S3_FOLDER, self.S3_FOLDER_COPY, False\n )\n\n def test_copy_s3_dir_to_s3_source_and_dest_are_the_same(self):\n service = S3StorageService(\"us-west-1\")\n self.assertRaises(\n ValueError, service.copy, self.S3_FOLDER, self.S3_FOLDER, True\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_dir_to_s3_source_does_not_exist(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.object_exists = MagicMock(return_value=False)\n self.assertRaises(\n ValueError, service.copy, self.S3_FOLDER, self.S3_FOLDER_COPY, False\n )\n\n @patch(\"os.makedirs\")\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_copy_s3_dir_to_s3_ok(self, MockS3Gateway, os_makedirs):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.s3_gateway.object_exists = MagicMock(return_value=True)\n service.s3_gateway.list_object2 = MagicMock(return_value=self.S3_DIR)\n service.s3_gateway.put_object = MagicMock(return_value=None)\n service.s3_gateway.copy = MagicMock(return_value=None)\n\n service.copy(self.S3_FOLDER, self.S3_FOLDER_COPY, True)\n\n service.s3_gateway.put_object.assert_has_calls(\n [\n call(\"bucket\", \"test_folder_copy/bar/\", \"\"),\n call(\"bucket\", \"test_folder_copy/baz/\", \"\"),\n ],\n any_order=True,\n )\n\n service.s3_gateway.copy.assert_has_calls(\n [\n call(\"bucket\", \"test_folder/baz/a\", \"bucket\", \"test_folder_copy/baz/a\"),\n call(\"bucket\", \"test_folder/baz/b\", \"bucket\", \"test_folder_copy/baz/b\"),\n ],\n any_order=True,\n )\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_delete_s3(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n service.s3_gateway = MockS3Gateway()\n service.delete(self.S3_FILE)\n service.s3_gateway.delete_object.assert_called_with(\"bucket\", \"test_file\")\n\n @patch(\"fbpcs.gateway.s3.S3Gateway\")\n def test_file_exists(self, MockS3Gateway):\n service = S3StorageService(\"us-west-1\")\n\n service.s3_gateway = MockS3Gateway()\n service.file_exists(self.S3_FILE)\n service.s3_gateway.object_exists.assert_called_with(\"bucket\", \"test_file\")\n"
},
{
"alpha_fraction": 0.6944172382354736,
"alphanum_fraction": 0.6953966617584229,
"avg_line_length": 25.86842155456543,
"blob_id": "b424c5942cc9c6bec55a3d207d8445444a000c82",
"content_id": "bd8bd1b1db4108e09c5c8b397d34f8a761bda13c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1021,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 38,
"path": "/fbpcs/service/container.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport abc\nfrom typing import List\n\nfrom fbpcs.entity.container_instance import ContainerInstance\n\n\nclass ContainerService(abc.ABC):\n @abc.abstractmethod\n def create_instance(self, container_definition: str, cmd: str) -> ContainerInstance:\n pass\n\n @abc.abstractmethod\n def create_instances(\n self, container_definition: str, cmds: List[str]\n ) -> List[ContainerInstance]:\n pass\n\n @abc.abstractmethod\n async def create_instances_async(\n self, container_definition: str, cmds: List[str]\n ) -> List[ContainerInstance]:\n pass\n\n @abc.abstractmethod\n def get_instance(self, instance_id: str) -> ContainerInstance:\n pass\n\n @abc.abstractmethod\n def get_instances(self, instance_ids: List[str]) -> List[ContainerInstance]:\n pass\n"
},
{
"alpha_fraction": 0.6930860280990601,
"alphanum_fraction": 0.6998313665390015,
"avg_line_length": 27.238094329833984,
"blob_id": "89954330a6a60861ff7be6171c1f677385fd97a7",
"content_id": "757f55a8728e59d2a64cb7762e22d021408a8b2a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 593,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 21,
"path": "/tests/util/test_typing.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom fbpcs.util.typing import checked_cast\n\nTEST_STR = \"test\"\nTEST_NUM = 123\n\n\nclass TestTyping(unittest.TestCase):\n def test_checked_cast(self):\n error = f\"Value was not of type {type!r}:\\n{TEST_STR!r}\"\n with self.assertRaisesRegex(ValueError, error):\n checked_cast(int, TEST_STR)\n\n self.assertEqual(checked_cast(int, TEST_NUM), TEST_NUM)\n"
},
{
"alpha_fraction": 0.6633093357086182,
"alphanum_fraction": 0.6714628338813782,
"avg_line_length": 39.096153259277344,
"blob_id": "22a6fd18ab73759ac5a7b7fd5e991a0de56fc0be",
"content_id": "9dcf044168ea5e0b9c020b61ac40eb0c533c6a0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2085,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 52,
"path": "/fbpcs/repository/instance_s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport pickle\n\nfrom fbpcs.entity.instance_base import InstanceBase\nfrom fbpcs.service.storage_s3 import S3StorageService\n\n\nclass S3InstanceRepository:\n def __init__(self, s3_storage_svc: S3StorageService, base_dir: str) -> None:\n self.s3_storage_svc = s3_storage_svc\n self.base_dir = base_dir\n\n def create(self, instance: InstanceBase) -> None:\n if self._exist(instance.get_instance_id()):\n raise RuntimeError(f\"{instance.get_instance_id()} already exists\")\n\n filename = f\"{self.base_dir}{instance.get_instance_id()}\"\n # Use pickle protocol 0 to make ASCII only bytes that can be safely decoded into a string\n self.s3_storage_svc.write(filename, pickle.dumps(instance, 0).decode())\n\n def read(self, instance_id: str) -> InstanceBase:\n if not self._exist(instance_id):\n raise RuntimeError(f\"{instance_id} does not exist\")\n\n filename = f\"{self.base_dir}{instance_id}\"\n instance = pickle.loads(self.s3_storage_svc.read(filename).encode())\n return instance\n\n def update(self, instance: InstanceBase) -> None:\n if not self._exist(instance.get_instance_id()):\n raise RuntimeError(f\"{instance.get_instance_id()} does not exist\")\n\n filename = f\"{self.base_dir}{instance.get_instance_id()}\"\n # Use pickle protocol 0 to make ASCII only bytes that can be safely decoded into a string\n self.s3_storage_svc.write(filename, pickle.dumps(instance, 0).decode())\n\n def delete(self, instance_id: str) -> None:\n if not self._exist(instance_id):\n raise RuntimeError(f\"{instance_id} does not exist\")\n\n filename = f\"{self.base_dir}{instance_id}\"\n self.s3_storage_svc.delete(filename)\n\n def _exist(self, instance_id: str) -> bool:\n return self.s3_storage_svc.file_exists(f\"{self.base_dir}{instance_id}\")\n"
},
{
"alpha_fraction": 0.7399576902389526,
"alphanum_fraction": 0.7526426911354065,
"avg_line_length": 26.823530197143555,
"blob_id": "9f5c5855eb56e7c05824c5d920c3a240afb6f9b9",
"content_id": "38cc60380200a4c5b4c1ba71be756f4f655919e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 17,
"path": "/tests/util/test_reflect.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom fbpcs.util.reflect import get_class\nfrom fbpcs.util.s3path import S3Path\n\nTEST_CLASS_PATH = \"fbpcs.util.s3path.S3Path\"\n\n\nclass TestReflect(unittest.TestCase):\n def test_get_class(self):\n self.assertEqual(S3Path, get_class(TEST_CLASS_PATH))\n"
},
{
"alpha_fraction": 0.6480380296707153,
"alphanum_fraction": 0.6753864288330078,
"avg_line_length": 25.28125,
"blob_id": "5a5c4d917c741f06b6795318fdf6bccd9fd86656",
"content_id": "d46071734ebb4d4eff382671601e4c652d7a65b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 841,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\nfrom setuptools import setup, find_packages\n\ninstall_requires = [\n \"boto3==1.11.11\",\n \"dataclasses-json==0.5.2\",\n \"pyyaml==5.4.1\",\n \"tqdm==4.55.1\",\n]\n\nwith open(\"README.md\", encoding=\"utf-8\") as f:\n long_description = f.read()\n\nsetup(\n name=\"fbpcs\",\n version=\"0.1.0\",\n description=\"Facebook Private Computation Service\",\n author=\"Facebook\",\n author_email=\"[email protected]\",\n url=\"https://github.com/facebookresearch/FBPCS\",\n install_requires=install_requires,\n packages=find_packages(),\n long_description_content_type=\"text/markdown\",\n long_description=long_description,\n python_requires=\">=3.8\",\n)\n"
},
{
"alpha_fraction": 0.7702564001083374,
"alphanum_fraction": 0.7801709175109863,
"avg_line_length": 55.25,
"blob_id": "e6415f362a5d04a58778c27e65b3b746af9f6e74",
"content_id": "8c1a887f641765078f5f775ebc12ca4ea72f75c1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2925,
"license_type": "permissive",
"max_line_length": 691,
"num_lines": 52,
"path": "/README.md",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "# FBPCS (Facebook Private Computation Service)\n[Secure multi-party computation](https://en.wikipedia.org/wiki/Secure_multi-party_computation) (also known as secure computation, multi-party computation (MPC), or privacy-preserving computation) is a subfield of cryptography with the goal of creating methods for parties to jointly compute a function over their inputs while keeping those inputs private.\n\nFBPCS (Facebook Private Computation Service) is a secure, privacy safe and scalable architecture to deploy MPC (Multi Party Computation) applications in a distributed way on virtual private clouds. [FBPCF](https://github.com/facebookresearch/fbpcf) (Facebook Private Computation Framework) is for scaling MPC computation up via threading, while FBPCS is for scaling MPC computation out via [Private Scaling](https://github.com/facebookresearch/FBPCS/blob/main/docs/PrivateScaling.md) architecture. FBPCS consists of various services, interfaces that enalbe various private measurement solutions, e.g. [Private Lift](https://github.com/facebookresearch/fbpcf/blob/master/docs/PrivateLift.md).\n\n[Private Scaling](https://github.com/facebookresearch/FBPCS/blob/main/docs/PrivateScaling.md) resembles the map/reduce architecture and is secure against a semi-honest adversary who tries to learn the inputs of the computation. The goal is to secure the intermediate output of each shard to prevent potential privacy leak.\n\n## Installation Requirements:\n### Prerequisites for working on Ubuntu 18.04:\n* An AWS account (Access Key ID, Secret Access Key) to use AWS SDK (boto3 API) in FBPCS\n* python >= 3.8\n* python3-pip\n\n## Installing prerequisites on Ubuntu 18.04:\n* python3.8\n```sh\nsudo apt-get install -y python3.8\n```\n* python3-pip\n```sh\nsudo apt-get install -y python3-pip\n```\n## Installing fbpcs\n```sh\npython3.8 -m pip install 'git+https://github.com/facebookresearch/FBPCS.git'\n# (add --user if you don't have permission)\n\n# Or, to install it from a local clone:\ngit clone https://github.com/facebookresearch/FBPCS.git\npython3.8 -m pip install -e FBPCS\n# (add --user if you don't have permission)\n\n# Or, to install it from Pypi\npython3.8 -m pip install fbpcs\n```\n\n## Architecture\n<img src=\"https://github.com/facebookresearch/FBPCS/blob/main/docs/PCSArch.jpg?raw=true\" alt=\"Figure 1: Architecture of FBPCS\" width=\"50%\" height=\"50%\">\n\n### Services:\n\n* MPCService is the public interface that provides APIs to distribute a MPC application with large dataset to multiple MPC workers on cloud.\n\n\n### [Other components](https://github.com/facebookresearch/FBPCS/blob/main/docs/FBPCSComponents.md)\n\n## Join the FBPCS community\n* Website: https://github.com/facebookresearch/fbpcs\n* See the [CONTRIBUTING](https://github.com/facebookresearch/FBPCS/blob/main/CONTRIBUTING.md) file for how to help out.\n\n## License\nFBPCS is [MIT](https://github.com/facebookresearch/FBPCS/blob/main/LICENSE) licensed, as found in the LICENSE file.\n"
},
{
"alpha_fraction": 0.687017023563385,
"alphanum_fraction": 0.770479142665863,
"avg_line_length": 25.95833396911621,
"blob_id": "36655610d0112ca45c4589d4f669ab12eac81b1a",
"content_id": "97939345d532b7ed559c31b2b0d6f42c577c611c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1294,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 48,
"path": "/onedocker/install_emp.sh",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# get emp readme scripts\ncd /root || exit\ngit clone https://github.com/emp-toolkit/emp-readme.git\ncd emp-readme || exit\ngit checkout d31ffad00ee86f470dcb12ff50b3d88567577d1f\n\n# install emp dependencies\ncd /root || exit\nbash ./emp-readme/scripts/install_packages.sh\nbash ./emp-readme/scripts/install_relic.sh\n#EC STRING SIZE\nsed -i \"s/FB_POLYN:STRING=283/FB_POLYN:STRING=251/\" ~/relic/CMakeCache.txt\n\n# get and install emp-tool\ngit clone https://github.com/emp-toolkit/emp-tool.git\ncd emp-tool || exit\ngit checkout 508db1726c3c040fd12ad1f4d870169b29dbda13\ncd /root/emp-tool || exit\ncmake . -DTHREADING=ON\nmake\nmake install\n\n# get and install emp-ot\ncd /root || exit\ngit clone https://github.com/emp-toolkit/emp-ot.git\ncd emp-ot || exit\ngit checkout 7a3ff4b567631ef441ba6a85aadd395bfe925839\ncmake . -DTHREADING=ON\nmake\nmake install\n\n# get and install emp-sh2pc\ncd /root || exit\ngit clone https://github.com/emp-toolkit/emp-sh2pc.git\ncd emp-sh2pc || exit\ngit checkout 07271059d99312cfc0c6589f43fc2d9ddfe6788b\ncd /root/emp-sh2pc || exit\nmkdir build\ncd build || exit\ncmake .. -DTHREADING=ON\nmake\nmake install\n"
},
{
"alpha_fraction": 0.5761986374855042,
"alphanum_fraction": 0.5839040875434875,
"avg_line_length": 28.94871711730957,
"blob_id": "133db6185fd9dd529d686df2e1ef6ca192af9063",
"content_id": "b755f493d8a64e79c917468e67bd8b2292e7e349",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1168,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 39,
"path": "/fbpcs/util/s3path.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport re\nfrom typing import Tuple\n\n\nclass S3Path:\n region: str\n bucket: str\n key: str\n\n def __init__(self, fileURL: str) -> None:\n self.region, self.bucket, self.key = self._get_region_bucket_key(fileURL)\n\n def __eq__(self, other: \"S3Path\") -> bool:\n return (\n self.region == other.region\n and self.bucket == other.bucket\n and self.key == other.key\n )\n\n # virtual host style url\n # https://bucket-name.s3.Region.amazonaws.com/key-name\n def _get_region_bucket_key(self, fileURL: str) -> Tuple[str, str, str]:\n match = re.search(\"^https?:/([^.]+).s3.([^.]+).amazonaws.com/(.*)$\", fileURL)\n if not match:\n raise ValueError(f\"Could not parse {fileURL} as an S3Path\")\n bucket, region, key = (\n match.group(1).strip(\"/\"),\n match.group(2),\n match.group(3).strip(\"/\"),\n )\n return (region, bucket, key)\n"
},
{
"alpha_fraction": 0.6353065371513367,
"alphanum_fraction": 0.6405919790267944,
"avg_line_length": 20.5,
"blob_id": "41e065a202afe60cf88f9651c09db70877033065",
"content_id": "67f61914c6f0959856076898c73f0ffbedf7fdff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 946,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 44,
"path": "/fbpcs/service/storage.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport abc\nfrom enum import Enum\n\n\nclass PathType(Enum):\n Local = 1\n S3 = 2\n\n\nclass StorageService(abc.ABC):\n @abc.abstractmethod\n def read(self, filename: str) -> str:\n pass\n\n @abc.abstractmethod\n def write(self, filename: str, data: str) -> None:\n pass\n\n @abc.abstractmethod\n def copy(self, source: str, destination: str) -> None:\n pass\n\n @abc.abstractmethod\n def file_exists(self, filename: str) -> bool:\n pass\n\n @staticmethod\n def path_type(filename: str) -> PathType:\n if filename.startswith(\"https:\"):\n return PathType.S3\n\n return PathType.Local\n\n @abc.abstractmethod\n def get_file_size(self, filename: str) -> int:\n pass\n"
},
{
"alpha_fraction": 0.6838006377220154,
"alphanum_fraction": 0.6853582262992859,
"avg_line_length": 26.913043975830078,
"blob_id": "b3cc1e600728a58c28edd09fb27db5448c6b12b8",
"content_id": "8bc0473a20f46e93957cbd1ca9f93fcb7859e18a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 23,
"path": "/fbpcs/decorator/error_handler.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom typing import Callable\n\nfrom botocore.exceptions import ClientError\nfrom fbpcs.error.mapper.aws import map_aws_error\nfrom fbpcs.error.pcs import PcsError\n\n\ndef error_handler(f: Callable) -> Callable:\n def wrap(*args, **kwargs):\n try:\n return f(*args, **kwargs)\n except ClientError as err:\n raise map_aws_error(err)\n except Exception as err:\n raise PcsError(err)\n\n return wrap\n"
},
{
"alpha_fraction": 0.601080060005188,
"alphanum_fraction": 0.6192768216133118,
"avg_line_length": 36.69026565551758,
"blob_id": "2b5c1b734de65adb058f0e2e373831d271035bfb",
"content_id": "db10871fb0fe1f2c6684d42bfe55e6e7d7825f39",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8518,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 226,
"path": "/tests/service/test_mpc.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import AsyncMock, MagicMock, patch\n\nfrom fbpcs.entity.container_instance import ContainerInstance, ContainerInstanceStatus\nfrom fbpcs.entity.mpc_instance import MPCInstance, MPCInstanceStatus, MPCRole\nfrom fbpcs.service.mpc import MPCService\n\n\nTEST_INSTANCE_ID = \"123\"\nTEST_GAME_NAME = \"lift\"\nTEST_MPC_ROLE = MPCRole.SERVER\nTEST_NUM_WORKERS = 1\nTEST_SERVER_IPS = [\"192.0.2.0\", \"192.0.2.1\"]\nTEST_INPUT_ARGS = \"test_input_file\"\nTEST_OUTPUT_ARGS = \"test_output_file\"\nTEST_CONCURRENCY_ARGS = 1\nTEST_INPUT_DIRECTORY = \"TEST_INPUT_DIRECTORY/\"\nTEST_OUTPUT_DIRECTORY = \"TEST_OUTPUT_DIRECTORY/\"\nTEST_TASK_DEFINITION = \"test_task_definition\"\nINPUT_DIRECTORY = \"input_directory\"\nOUTPUT_DIRECTORY = \"output_directory\"\nGAME_ARGS = [\n {\n \"input_filenames\": TEST_INPUT_ARGS,\n \"input_directory\": TEST_INPUT_DIRECTORY,\n \"output_filenames\": TEST_OUTPUT_ARGS,\n \"output_directory\": TEST_OUTPUT_DIRECTORY,\n \"concurrency\": TEST_CONCURRENCY_ARGS,\n }\n]\n\n\nclass TestMPCService(unittest.TestCase):\n def setUp(self):\n cspatcher = patch(\"fbpcs.service.container_aws.AWSContainerService\")\n sspatcher = patch(\"fbpcs.service.storage_s3.S3StorageService\")\n irpatcher = patch(\n \"fbpcs.repository.mpc_instance_local.LocalMPCInstanceRepository\"\n )\n gspatcher = patch(\"fbpcs.service.mpc_game.MPCGameService\")\n container_svc = cspatcher.start()\n storage_svc = sspatcher.start()\n instance_repository = irpatcher.start()\n mpc_game_svc = gspatcher.start()\n for patcher in (cspatcher, sspatcher, irpatcher, gspatcher):\n self.addCleanup(patcher.stop)\n self.mpc_service = MPCService(\n container_svc,\n storage_svc,\n instance_repository,\n \"test_task_definition\",\n mpc_game_svc,\n )\n\n @staticmethod\n def _get_sample_mpcinstance():\n return MPCInstance(\n instance_id=TEST_INSTANCE_ID,\n game_name=TEST_GAME_NAME,\n mpc_role=TEST_MPC_ROLE,\n num_workers=TEST_NUM_WORKERS,\n server_ips=TEST_SERVER_IPS,\n status=MPCInstanceStatus.CREATED,\n game_args=GAME_ARGS,\n )\n\n @staticmethod\n def _get_sample_mpcinstance_with_game_args():\n return MPCInstance(\n instance_id=TEST_INSTANCE_ID,\n game_name=TEST_GAME_NAME,\n mpc_role=TEST_MPC_ROLE,\n num_workers=TEST_NUM_WORKERS,\n status=MPCInstanceStatus.CREATED,\n server_ips=TEST_SERVER_IPS,\n game_args=GAME_ARGS,\n )\n\n @staticmethod\n def _get_sample_mpcinstance_client():\n return MPCInstance(\n instance_id=TEST_INSTANCE_ID,\n game_name=TEST_GAME_NAME,\n mpc_role=MPCRole.CLIENT,\n num_workers=TEST_NUM_WORKERS,\n server_ips=TEST_SERVER_IPS,\n status=MPCInstanceStatus.CREATED,\n game_args=GAME_ARGS,\n )\n\n async def test_spin_up_containers_one_docker_inconsistent_arguments(self):\n with self.assertRaisesRegex(\n ValueError,\n \"The number of containers is not consistent with the number of game argument dictionary.\",\n ):\n await self.mpc_service._spin_up_containers_onedocker(\n game_name=TEST_GAME_NAME,\n mpc_role=MPCRole.SERVER,\n num_containers=TEST_NUM_WORKERS,\n game_args=[],\n )\n\n with self.assertRaisesRegex(\n ValueError,\n \"The number of containers is not consistent with number of ip addresses.\",\n ):\n await self.mpc_service._spin_up_containers_onedocker(\n game_name=TEST_GAME_NAME,\n mpc_role=MPCRole.CLIENT,\n num_containers=TEST_NUM_WORKERS,\n ip_addresses=TEST_SERVER_IPS,\n )\n\n def test_create_instance_with_game_args(self):\n self.mpc_service.create_instance(\n instance_id=TEST_INSTANCE_ID,\n game_name=TEST_GAME_NAME,\n mpc_role=TEST_MPC_ROLE,\n num_workers=TEST_NUM_WORKERS,\n server_ips=TEST_SERVER_IPS,\n game_args=GAME_ARGS,\n )\n self.mpc_service.instance_repository.create.assert_called()\n self.assertEqual(\n self._get_sample_mpcinstance_with_game_args(),\n self.mpc_service.instance_repository.create.call_args[0][0],\n )\n\n def test_create_instance(self):\n self.mpc_service.create_instance(\n instance_id=TEST_INSTANCE_ID,\n game_name=TEST_GAME_NAME,\n mpc_role=TEST_MPC_ROLE,\n num_workers=TEST_NUM_WORKERS,\n server_ips=TEST_SERVER_IPS,\n game_args=GAME_ARGS,\n )\n # check that instance with correct instance_id was created\n self.mpc_service.instance_repository.create.assert_called()\n self.assertEquals(\n self._get_sample_mpcinstance(),\n self.mpc_service.instance_repository.create.call_args[0][0],\n )\n\n def _read_side_effect_start(self, instance_id: str):\n \"\"\"mock MPCInstanceRepository.read for test_start\"\"\"\n if instance_id == TEST_INSTANCE_ID:\n return self._get_sample_mpcinstance()\n else:\n raise RuntimeError(f\"{instance_id} does not exist\")\n\n def test_start_instance(self):\n self.mpc_service.instance_repository.read = MagicMock(\n side_effect=self._read_side_effect_start\n )\n created_instances = [\n ContainerInstance(\n \"arn:aws:ecs:us-west-1:592513842793:task/57850450-7a81-43cc-8c73-2071c52e4a68\", # noqa\n \"10.0.1.130\",\n ContainerInstanceStatus.STARTED,\n )\n ]\n self.mpc_service.container_svc.create_instances_async = AsyncMock(\n return_value=created_instances\n )\n built_one_docker_args = (\"private_lift/lift\", \"test one docker arguments\")\n self.mpc_service.mpc_game_svc.build_one_docker_args = MagicMock(\n return_value=built_one_docker_args\n )\n # check that update is called with correct status\n self.mpc_service.start_instance(TEST_INSTANCE_ID)\n self.mpc_service.instance_repository.update.assert_called()\n latest_update = self.mpc_service.instance_repository.update.call_args_list[-1]\n updated_status = latest_update[0][0].status\n self.assertEqual(updated_status, MPCInstanceStatus.STARTED)\n\n def test_start_instance_missing_ips(self):\n self.mpc_service.instance_repository.read = MagicMock(\n return_value=self._get_sample_mpcinstance_client()\n )\n # Exception because role is client but server ips are not given\n with self.assertRaises(ValueError):\n self.mpc_service.start_instance(TEST_INSTANCE_ID)\n\n def _read_side_effect_update(self, instance_id):\n \"\"\"\n mock MPCInstanceRepository.read for test_update,\n with instance.containers is not None\n \"\"\"\n if instance_id == TEST_INSTANCE_ID:\n mpc_instance = self._get_sample_mpcinstance()\n else:\n raise RuntimeError(f\"{instance_id} does not exist\")\n\n mpc_instance.status = MPCInstanceStatus.STARTED\n mpc_instance.containers = [\n ContainerInstance(\n \"arn:aws:ecs:us-west-1:592513842793:task/57850450-7a81-43cc-8c73-2071c52e4a68\", # noqa\n \"10.0.1.130\",\n ContainerInstanceStatus.STARTED,\n )\n ]\n return mpc_instance\n\n def test_update_instance(self):\n self.mpc_service.instance_repository.read = MagicMock(\n side_effect=self._read_side_effect_update\n )\n container_instances = [\n ContainerInstance(\n \"arn:aws:ecs:us-west-1:592513842793:task/cd34aed2-321f-49d1-8641-c54baff8b77b\", # noqa\n \"10.0.1.130\",\n ContainerInstanceStatus.STARTED,\n )\n ]\n self.mpc_service.container_svc.get_instances = MagicMock(\n return_value=container_instances\n )\n self.mpc_service.update_instance(TEST_INSTANCE_ID)\n self.mpc_service.instance_repository.update.assert_called()\n"
},
{
"alpha_fraction": 0.6531620621681213,
"alphanum_fraction": 0.6536561250686646,
"avg_line_length": 26.72602653503418,
"blob_id": "baf551721ad72fa915f80dca36f433e1aaff2f53",
"content_id": "b35985c11f200e93df173342d4b67a4727eb9c24",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2024,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 73,
"path": "/fbpcs/entity/mpc_instance.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Any, Dict, List, Mapping, Optional\n\nfrom dataclasses_json import dataclass_json\nfrom fbpcs.entity.container_instance import ContainerInstance\nfrom fbpcs.entity.instance_base import InstanceBase\n\n\nclass MPCRole(Enum):\n SERVER = \"SERVER\"\n CLIENT = \"CLIENT\"\n\n\nclass MPCInstanceStatus(Enum):\n UNKNOWN = \"UNKNOWN\"\n CREATED = \"CREATED\"\n STARTED = \"STARTED\"\n COMPLETED = \"COMPLETED\"\n FAILED = \"FAILED\"\n\n\n@dataclass_json\n@dataclass\nclass MPCInstance(InstanceBase):\n instance_id: str\n game_name: str\n mpc_role: MPCRole\n num_workers: int\n server_ips: Optional[List[str]]\n containers: List[ContainerInstance]\n status: MPCInstanceStatus\n game_args: Optional[List[Dict[str, Any]]]\n arguments: Mapping[str, Any]\n\n def __init__(\n self,\n instance_id: str,\n game_name: str,\n mpc_role: MPCRole,\n num_workers: int,\n ip_config_file: Optional[str] = None,\n server_ips: Optional[List[str]] = None,\n containers: Optional[List[ContainerInstance]] = None,\n status: MPCInstanceStatus = MPCInstanceStatus.UNKNOWN,\n game_args: Optional[List[Dict[str, Any]]] = None,\n **arguments # pyre-ignore\n ) -> None:\n self.instance_id = instance_id\n self.game_name = game_name\n self.mpc_role = mpc_role\n self.num_workers = num_workers\n self.ip_config_file = ip_config_file\n self.server_ips = server_ips\n self.containers = containers or []\n self.status = status\n self.game_args = game_args\n self.arguments = arguments\n\n def get_instance_id(self) -> str:\n return self.instance_id\n\n def __str__(self) -> str:\n # pyre-ignore\n return self.to_json()\n"
},
{
"alpha_fraction": 0.6360989809036255,
"alphanum_fraction": 0.6517467498779297,
"avg_line_length": 41.9375,
"blob_id": "4c93ed66e34da83c5afe329979c4407809f6c50f",
"content_id": "22429ef0e294786007dff298b73612259058ae0d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2748,
"license_type": "permissive",
"max_line_length": 161,
"num_lines": 64,
"path": "/tests/service/test_onedocker.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import AsyncMock, patch\n\nfrom fbpcs.entity.container_instance import ContainerInstance, ContainerInstanceStatus\nfrom fbpcs.service.onedocker import OneDockerService\n\n\nclass TestOneDockerService(unittest.TestCase):\n @patch(\"fbpcs.service.container.ContainerService\")\n def setUp(self, MockContainerService):\n container_svc = MockContainerService()\n self.onedocker_svc = OneDockerService(container_svc)\n\n def test_start_container(self):\n mocked_container_info = ContainerInstance(\n \"arn:aws:ecs:region:account_id:task/container_id\",\n \"192.0.2.0\",\n ContainerInstanceStatus.STARTED,\n )\n self.onedocker_svc.container_svc.create_instances_async = AsyncMock(\n return_value=[mocked_container_info]\n )\n returned_container_info = self.onedocker_svc.start_container(\n \"task_def\", \"project/exe_name\", \"cmd_args\"\n )\n self.assertEqual(returned_container_info, mocked_container_info)\n\n def test_start_containers(self):\n mocked_container_info = [\n ContainerInstance(\n \"arn:aws:ecs:region:account_id:task/container_id_1\",\n \"192.0.2.0\",\n ContainerInstanceStatus.STARTED,\n ),\n ContainerInstance(\n \"arn:aws:ecs:region:account_id:task/container_id_2\",\n \"192.0.2.1\",\n ContainerInstanceStatus.STARTED,\n ),\n ]\n self.onedocker_svc.container_svc.create_instances_async = AsyncMock(\n return_value=mocked_container_info\n )\n returned_container_info = self.onedocker_svc.start_containers(\n \"task_def\", \"project/exe_name\", [\"--k1=v1\", \"--k2=v2\"]\n )\n self.assertEqual(returned_container_info, mocked_container_info)\n\n def test_get_cmd(self):\n package_name = \"project/exe_name\"\n cmd_args = \"--k1=v1 --k2=v2\"\n timeout = 3600\n expected_cmd_without_timeout = \"python3.8 -m one_docker_runner --package_name=project/exe_name --cmd='/root/one_docker/package/exe_name --k1=v1 --k2=v2'\"\n expected_cmd_with_timeout = expected_cmd_without_timeout + \" --timeout=3600\"\n cmd_without_timeout = self.onedocker_svc._get_cmd(package_name, cmd_args)\n cmd_with_timeout = self.onedocker_svc._get_cmd(package_name, cmd_args, timeout)\n self.assertEqual(expected_cmd_without_timeout, cmd_without_timeout)\n self.assertEqual(expected_cmd_with_timeout, cmd_with_timeout)\n"
},
{
"alpha_fraction": 0.664298415184021,
"alphanum_fraction": 0.671403169631958,
"avg_line_length": 25.809524536132812,
"blob_id": "ffdc337bc494a7d8123526ca234098d400848620",
"content_id": "95d544302d688b977f73cb22d8bc98f5c634d0a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 563,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 21,
"path": "/fbpcs/util/typing.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import Type, TypeVar\n\n\nT = TypeVar(\"T\")\nV = TypeVar(\"V\")\n\n\n# pyre-fixme[34]: `T` isn't present in the function's parameters.\ndef checked_cast(typ: Type[V], val: V) -> T:\n if not isinstance(val, typ):\n raise ValueError(f\"Value was not of type {type!r}:\\n{val!r}\")\n # pyre-fixme[7]: Expected `T` but got `V`.\n return val\n"
},
{
"alpha_fraction": 0.650994598865509,
"alphanum_fraction": 0.6564195156097412,
"avg_line_length": 25.33333396911621,
"blob_id": "d05371ec706b70ac42e8dbd39056a752ccb263ac",
"content_id": "901eaa97a259fd9670132f596872f7eef4c5da11",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 553,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 21,
"path": "/scripts/run-python-tests.sh",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nset -e\n\nSCRIPTS_DIRECTORY=\"$( cd \"$( dirname \"${BASH_SOURCE[0]}\" )\" && pwd )\"\necho \"${SCRIPTS_DIRECTORY}\"\ncd \"${SCRIPTS_DIRECTORY}/..\"\n\nfiles=$(find tests \"${SCRIPTS_DIRECTORY}\" -name '*.py')\necho \"${files}\"\nif [[ -z \"${files}\" ]]; then\n echo 'No test files found, exiting.'\n exit 1\nfi\n\necho \" Running all tests:\"\necho \"${files}\" | xargs python3 -m unittest -v\n"
},
{
"alpha_fraction": 0.6635600924491882,
"alphanum_fraction": 0.6821994185447693,
"avg_line_length": 34.766666412353516,
"blob_id": "97933d9d24cc752e41b3f5a37e95c6848f8b9398",
"content_id": "8df1d4842922f58d6aeabf602663a541ff5d18cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1073,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 30,
"path": "/tests/util/test_s3path.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom fbpcs.util.s3path import S3Path\n\n\nclass TestS3Path(unittest.TestCase):\n def test_s3path_no_subfolder(self):\n test_s3path = S3Path(\"https://bucket-name.s3.Region.amazonaws.com/key-name\")\n self.assertEqual(test_s3path.region, \"Region\")\n self.assertEqual(test_s3path.bucket, \"bucket-name\")\n self.assertEqual(test_s3path.key, \"key-name\")\n\n def test_s3path_with_subfoler(self):\n test_s3path = S3Path(\n \"https://bucket-name.s3.Region.amazonaws.com/subfolder/key\"\n )\n self.assertEqual(test_s3path.region, \"Region\")\n self.assertEqual(test_s3path.bucket, \"bucket-name\")\n self.assertEqual(test_s3path.key, \"subfolder/key\")\n\n def test_s3path_invalid_fileURL(self):\n test_url = \"an invalid fileURL\"\n with self.assertRaises(ValueError):\n S3Path(test_url)\n"
},
{
"alpha_fraction": 0.7303921580314636,
"alphanum_fraction": 0.7328431606292725,
"avg_line_length": 23,
"blob_id": "fe1a00fdca3664b1b3db1a1acbaad838e710cde0",
"content_id": "4c76a22f377eeb69c94f3c69e80f9948aaff89de",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 17,
"path": "/fbpcs/repository/mpc_game_repository.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport abc\n\nfrom fbpcs.entity.mpc_game_config import MPCGameConfig\n\n\nclass MPCGameRepository(abc.ABC):\n @abc.abstractmethod\n def get_game(self, name: str) -> MPCGameConfig:\n pass\n"
},
{
"alpha_fraction": 0.7047872543334961,
"alphanum_fraction": 0.707446813583374,
"avg_line_length": 22.5,
"blob_id": "28adfc57af4323d496a1ad1acd82e7b71c827e16",
"content_id": "6c005bd3a1ec44f3fb5802e9649197b0fc144c51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 16,
"path": "/fbpcs/service/log.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport abc\nfrom typing import Any, Dict\n\n\nclass LogService(abc.ABC):\n @abc.abstractmethod\n def fetch(self, log_path: str) -> Dict[str, Any]:\n pass\n"
},
{
"alpha_fraction": 0.7292531132698059,
"alphanum_fraction": 0.7302904725074768,
"avg_line_length": 31.133333206176758,
"blob_id": "0177474819975857a22e95a0cccdbef96101f7bd",
"content_id": "ca994dcb9d31b1dde442027705119210c22f9776",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 964,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 30,
"path": "/fbpcs/repository/mpc_instance_local.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import cast\n\nfrom fbpcs.entity.mpc_instance import MPCInstance\nfrom fbpcs.repository.instance_local import LocalInstanceRepository\nfrom fbpcs.repository.mpc_instance import MPCInstanceRepository\n\n\nclass LocalMPCInstanceRepository(MPCInstanceRepository):\n def __init__(self, base_dir: str) -> None:\n self.repo = LocalInstanceRepository(base_dir)\n\n def create(self, instance: MPCInstance) -> None:\n self.repo.create(instance)\n\n def read(self, instance_id: str) -> MPCInstance:\n return cast(MPCInstance, self.repo.read(instance_id))\n\n def update(self, instance: MPCInstance) -> None:\n self.repo.update(instance)\n\n def delete(self, instance_id: str) -> None:\n self.repo.delete(instance_id)\n"
},
{
"alpha_fraction": 0.7973901033401489,
"alphanum_fraction": 0.7980769276618958,
"avg_line_length": 103,
"blob_id": "1d446f20ce80e5aef8e2b8b8490b5fe7152a391e",
"content_id": "c4b31103a9524019f0e3c8567c8108d92af0e168",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1458,
"license_type": "permissive",
"max_line_length": 544,
"num_lines": 14,
"path": "/docs/MVCS.md",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "# Why MVCS\nMVC was designed for single web application. In this type of app, backend usually exposes only one kind of endpoint which is web/http. In modern SOA or micro service architecture, it becomes more complex. One service may have to support different kinds of endpoints, such as web, mobile, and api (rest/thrift). For each set of endpoints, we need to implement a set of controllers. Code could be duplicated and difficult to manage and maintain. That’s why a new abstraction layer named Service was introduced and MVCS design pattern was defined.\n\n# What is MVCS\nMVCS defines the following components.\n\n<img src=\"MVCS.jpeg\" alt=\"Figure 1: MVCS\">\n\n* Handler: Exposes external endpoints, e.g. XController, GraphAPI, thrift etc. Handlers will address request related issues, like parameter validation, response generation, authentication, authorization, rate limiting, etc. It should not handle any business logic. (e.g. [GraphAPI design principles](https://developers.facebook.com/docs/graph-api/)).\n* Repository: Encapsulates database operations.\n* Gateway: Encapsulates interface of dependent services.\n* Mapper: Deals with data transformation between components, such as thrift object to entity and vice versa.\n* Entity: Represents business objects.\n* Service: Holds all business logic and exposes internal APIs to handlers or internal components within the same code base. There could be multiple services defined and implemented in this layer.\n"
},
{
"alpha_fraction": 0.623935341835022,
"alphanum_fraction": 0.6333260536193848,
"avg_line_length": 36.53278732299805,
"blob_id": "20b5bd7d882815607a1c60143b4c36a910cfa6a6",
"content_id": "bde90520ba3e9c5bef50d26c89631ef1e6203dde",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4579,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 122,
"path": "/tests/gateway/test_s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.gateway.s3 import S3Gateway\n\n\nclass TestS3Gateway(unittest.TestCase):\n TEST_LOCAL_FILE = \"test-local-file\"\n TEST_BUCKET = \"test-bucket\"\n TEST_FILE = \"test-file\"\n TEST_ACCESS_KEY_ID = \"test-access-key-id\"\n TEST_ACCESS_KEY_DATA = \"test-access-key-data\"\n REGION = \"us-west-1\"\n\n @patch(\"boto3.client\")\n def test_create_bucket(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.create_bucket = MagicMock(return_value=None)\n gw.create_bucket(self.TEST_BUCKET)\n gw.client.create_bucket.assert_called()\n\n @patch(\"boto3.client\")\n def test_delete_bucket(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.delete_bucket = MagicMock(return_value=None)\n gw.delete_bucket(self.TEST_BUCKET)\n gw.client.delete_bucket.assert_called()\n\n @patch(\"boto3.client\")\n def test_put_object(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.put_object = MagicMock(return_value=None)\n gw.put_object(\n self.TEST_BUCKET, self.TEST_ACCESS_KEY_ID, self.TEST_ACCESS_KEY_DATA\n )\n gw.client.put_object.assert_called()\n\n @patch(\"os.path.getsize\", return_value=100)\n @patch(\"boto3.client\")\n def test_upload_file(self, BotoClient, mock_getsize):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.upload_file = MagicMock(return_value=None)\n gw.upload_file(self.TEST_LOCAL_FILE, self.TEST_BUCKET, self.TEST_FILE)\n gw.client.upload_file.assert_called()\n\n @patch(\"boto3.client\")\n def test_download_file(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.head_object.return_value = {\"ContentLength\": 100}\n gw.client.download_file = MagicMock(return_value=None)\n gw.download_file(self.TEST_BUCKET, self.TEST_FILE, self.TEST_LOCAL_FILE)\n gw.client.download_file.assert_called()\n\n @patch(\"boto3.client\")\n def test_delete_object(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.delete_object = MagicMock(return_value=None)\n gw.delete_object(self.TEST_BUCKET, self.TEST_FILE)\n gw.client.delete_object.assert_called()\n\n @patch(\"boto3.client\")\n def test_copy(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.copy = MagicMock(return_value=None)\n gw.copy(\n self.TEST_BUCKET, self.TEST_FILE, self.TEST_BUCKET, f\"{self.TEST_FILE}_COPY\"\n )\n gw.client.copy.assert_called()\n\n @patch(\"boto3.client\")\n def test_object_exists(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.head_object = MagicMock(return_value=None)\n self.assertTrue(gw.object_exists(self.TEST_BUCKET, self.TEST_ACCESS_KEY_ID))\n gw.client.head_object.assert_called()\n\n @patch(\"boto3.client\")\n def test_object_not_exists(self, BotoClient):\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.head_object = MagicMock(side_effect=Exception)\n self.assertFalse(gw.object_exists(self.TEST_BUCKET, self.TEST_ACCESS_KEY_ID))\n gw.client.head_object.assert_called()\n\n @patch(\"boto3.client\")\n def test_list_object2(self, BotoClient):\n test_page_content_key1 = \"test-page-content-key1\"\n test_page_content_key2 = \"test-page-content-key2\"\n client_return_response = [\n {\n \"Contents\": [\n {\"Key\": test_page_content_key1},\n {\"Key\": test_page_content_key2},\n ],\n }\n ]\n gw = S3Gateway(self.REGION)\n gw.client = BotoClient()\n gw.client.get_paginator(\"list_objects_v2\").paginate = MagicMock(\n return_value=client_return_response\n )\n key_list = gw.list_object2(self.TEST_BUCKET, self.TEST_ACCESS_KEY_ID)\n expected_key_list = [\n test_page_content_key1,\n test_page_content_key2,\n ]\n self.assertEqual(key_list, expected_key_list)\n gw.client.get_paginator(\"list_object_v2\").paginate.assert_called()\n"
},
{
"alpha_fraction": 0.6135532855987549,
"alphanum_fraction": 0.6144930720329285,
"avg_line_length": 35.41444778442383,
"blob_id": "969a6754d072bfbf5dee8f5d15361530bef93407",
"content_id": "03048118cdc59018c99d0fc1422a546b5de11bff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9577,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 263,
"path": "/fbpcs/service/mpc.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport asyncio\nimport logging\nfrom typing import Any, Dict, List, Optional\n\nfrom fbpcs.entity.container_instance import ContainerInstance, ContainerInstanceStatus\nfrom fbpcs.entity.mpc_instance import MPCInstance, MPCInstanceStatus, MPCRole\nfrom fbpcs.repository.mpc_instance import MPCInstanceRepository\nfrom fbpcs.service.container import ContainerService\nfrom fbpcs.service.mpc_game import MPCGameService\nfrom fbpcs.service.onedocker import OneDockerService\nfrom fbpcs.service.storage import StorageService\nfrom fbpcs.util.typing import checked_cast\n\n\nclass MPCService:\n \"\"\"MPCService is responsible for distributing a larger MPC game to multiple\n MPC workers\n \"\"\"\n\n def __init__(\n self,\n container_svc: ContainerService,\n storage_svc: StorageService,\n instance_repository: MPCInstanceRepository,\n task_definition: str,\n mpc_game_svc: MPCGameService,\n ) -> None:\n \"\"\"Constructor of MPCService\n Keyword arguments:\n container_svc -- service to spawn container instances\n storage_svc -- service to read/write input/output files\n instance_repository -- repository to CRUD MPCInstance\n task_definition -- containers task definition\n mpc_game_svc -- service to generate package name and game arguments.\n \"\"\"\n if (\n container_svc is None\n or storage_svc is None\n or instance_repository is None\n or mpc_game_svc is None\n ):\n raise ValueError(\n f\"Dependency is missing. container_svc={container_svc}, mpc_game_svc={mpc_game_svc}, \"\n f\"storage_svc={storage_svc}, instance_repository={instance_repository}\"\n )\n\n self.container_svc = container_svc\n self.storage_svc = storage_svc\n self.instance_repository = instance_repository\n self.task_definition = task_definition\n self.mpc_game_svc: MPCGameService = mpc_game_svc\n self.logger: logging.Logger = logging.getLogger(__name__)\n\n self.onedocker_svc = OneDockerService(self.container_svc)\n\n \"\"\"\n The game_args should be consistent with the game_config, which should be\n defined in caller's game repository.\n\n For example,\n If the game config looks like this:\n\n game_config = {\n \"game\": {\n \"one_docker_package_name\": \"package_name\",\n \"arguments\": [\n {\"name\": \"input_filenames\", \"required\": True},\n {\"name\": \"input_directory\", \"required\": True},\n {\"name\": \"output_filenames\", \"required\": True},\n {\"name\": \"output_directory\", \"required\": True},\n {\"name\": \"concurrency\", \"required\": True},\n ],\n },\n\n The game args should look like this:\n [\n # 1st container\n {\n \"input_filenames\": input_path_1,\n \"input_directory\": input_directory,\n \"output_filenames\": output_path_1,\n \"output_directory\": output_directory,\n \"concurrency\": cocurrency,\n },\n # 2nd container\n {\n \"input_filenames\": input_path_2,\n \"input_directory\": input_directory,\n \"output_filenames\": output_path_2,\n \"output_directory\": output_directory,\n \"concurrency\": cocurrency,\n },\n ]\n \"\"\"\n\n def create_instance(\n self,\n instance_id: str,\n game_name: str,\n mpc_role: MPCRole,\n num_workers: int,\n server_ips: Optional[List[str]] = None,\n game_args: Optional[List[Dict[str, Any]]] = None,\n ) -> MPCInstance:\n self.logger.info(f\"Creating MPC instance: {instance_id}\")\n\n instance = MPCInstance(\n instance_id=instance_id,\n game_name=game_name,\n mpc_role=mpc_role,\n num_workers=num_workers,\n server_ips=server_ips,\n status=MPCInstanceStatus.CREATED,\n game_args=game_args,\n )\n\n self.instance_repository.create(instance)\n return instance\n\n def start_instance(\n self,\n instance_id: str,\n output_files: Optional[List[str]] = None,\n server_ips: Optional[List[str]] = None,\n timeout: Optional[int] = None,\n ) -> MPCInstance:\n return asyncio.run(\n self.start_instance_async(instance_id, output_files, server_ips, timeout)\n )\n\n async def start_instance_async(\n self,\n instance_id: str,\n output_files: Optional[List[str]] = None,\n server_ips: Optional[List[str]] = None,\n timeout: Optional[int] = None,\n ) -> MPCInstance:\n \"\"\"To run a distributed MPC game\n Keyword arguments:\n instance_id -- unique id to identify the MPC instance\n \"\"\"\n instance = self.instance_repository.read(instance_id)\n self.logger.info(f\"Starting MPC instance: {instance_id}\")\n\n if instance.mpc_role is MPCRole.CLIENT and not server_ips:\n raise ValueError(\"Missing server_ips\")\n\n # spin up containers\n self.logger.info(\"Spinning up container instances\")\n game_args = instance.game_args\n instance.containers = await self._spin_up_containers_onedocker(\n instance.game_name,\n instance.mpc_role,\n instance.num_workers,\n game_args,\n server_ips,\n timeout,\n )\n\n if len(instance.containers) != instance.num_workers:\n self.logger.warning(\n f\"Instance {instance_id} has {len(instance.containers)} containers spun up, but expecting {instance.num_workers} containers!\"\n )\n\n if instance.mpc_role is MPCRole.SERVER:\n ip_addresses = [\n checked_cast(str, instance.ip_address)\n for instance in instance.containers\n ]\n instance.server_ips = ip_addresses\n\n instance.status = MPCInstanceStatus.STARTED\n self.instance_repository.update(instance)\n\n return instance\n\n def get_instance(self, instance_id: str) -> MPCInstance:\n self.logger.info(f\"Getting MPC instance: {instance_id}\")\n return self.instance_repository.read(instance_id)\n\n def update_instance(self, instance_id: str) -> MPCInstance:\n instance = self.instance_repository.read(instance_id)\n\n self.logger.info(f\"Updating MPC instance: {instance_id}\")\n\n if instance.status in [MPCInstanceStatus.COMPLETED, MPCInstanceStatus.FAILED]:\n return instance\n\n # skip if no containers registered under instance yet\n if instance.containers:\n instance.containers = self._update_container_instances(instance.containers)\n\n if len(instance.containers) != instance.num_workers:\n self.logger.warning(\n f\"Instance {instance_id} has {len(instance.containers)} containers after update, but expecting {instance.num_workers} containers!\"\n )\n\n instance.status = self._get_instance_status(instance)\n self.instance_repository.update(instance)\n\n return instance\n\n async def _spin_up_containers_onedocker(\n self,\n game_name: str,\n mpc_role: MPCRole,\n num_containers: int,\n game_args: Optional[List[Dict[str, Any]]] = None,\n ip_addresses: Optional[List[str]] = None,\n timeout: Optional[int] = None,\n ) -> List[ContainerInstance]:\n if game_args is not None and len(game_args) != num_containers:\n raise ValueError(\n \"The number of containers is not consistent with the number of game argument dictionary.\"\n )\n if ip_addresses is not None and len(ip_addresses) != num_containers:\n raise ValueError(\n \"The number of containers is not consistent with number of ip addresses.\"\n )\n cmd_tuple_list = []\n for i in range(num_containers):\n game_arg = game_args[i] if game_args is not None else {}\n server_ip = ip_addresses[i] if ip_addresses is not None else None\n cmd_tuple_list.append(\n self.mpc_game_svc.build_one_docker_args(\n game_name=game_name,\n mpc_role=mpc_role,\n server_ip=server_ip,\n **game_arg,\n )\n )\n cmd_args_list = [cmd_args for (package_name, cmd_args) in cmd_tuple_list]\n\n return await self.onedocker_svc.start_containers_async(\n self.task_definition, cmd_tuple_list[0][0], cmd_args_list, timeout\n )\n\n def _update_container_instances(\n self, containers: List[ContainerInstance]\n ) -> List[ContainerInstance]:\n ids = [container.instance_id for container in containers]\n return self.container_svc.get_instances(ids)\n\n def _get_instance_status(self, instance: MPCInstance) -> MPCInstanceStatus:\n status = MPCInstanceStatus.COMPLETED\n\n for container in instance.containers:\n if container.status == ContainerInstanceStatus.FAILED:\n return MPCInstanceStatus.FAILED\n if container.status == ContainerInstanceStatus.UNKNOWN:\n return MPCInstanceStatus.UNKNOWN\n if container.status == ContainerInstanceStatus.STARTED:\n status = MPCInstanceStatus.STARTED\n\n return status\n"
},
{
"alpha_fraction": 0.7188841104507446,
"alphanum_fraction": 0.7231759428977966,
"avg_line_length": 24.88888931274414,
"blob_id": "58c743fee4c7faee59a70e3a4e9efbfdfe846723",
"content_id": "ad1435cfc841d941f2eda7a64d594b3bba3a65a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 18,
"path": "/fbpcs/util/reflect.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom importlib import import_module\nfrom typing import Any\n\n\n# pyre-ignore\ndef get_class(class_path: str) -> Any:\n module_name, class_name = class_path.rsplit(\".\", 1)\n module = import_module(module_name)\n\n return getattr(module, class_name)\n"
},
{
"alpha_fraction": 0.6924242377281189,
"alphanum_fraction": 0.6984848380088806,
"avg_line_length": 30.428571701049805,
"blob_id": "74e33b1703d22d94591f65f95d1b683741c0c6ad",
"content_id": "969db4a8ce0bde87d6eda763936e4363b2a82496",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 660,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 21,
"path": "/tests/service/test_storage.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom fbpcs.service.storage import PathType, StorageService\n\n\nclass TestStorageService(unittest.TestCase):\n def test_path_type_s3(self):\n type_ = StorageService.path_type(\n \"https://bucket-name.s3.Region.amazonaws.com/key-name\"\n )\n self.assertEqual(type_, PathType.S3)\n\n def test_path_type_local(self):\n type_ = StorageService.path_type(\"/usr/file\")\n self.assertEqual(type_, PathType.Local)\n"
},
{
"alpha_fraction": 0.6322025060653687,
"alphanum_fraction": 0.6357924938201904,
"avg_line_length": 29.950000762939453,
"blob_id": "dd13880a6cf3eccf7921373f64fdc87da6f1e12b",
"content_id": "52389c072eac7f968e24e27981438184533caad8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5571,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 180,
"path": "/onedocker/onedocker_runner.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\n\"\"\"\nCLI for running an executable in one docker\n\n\nUsage:\n onedocker-runner <package_name> --cmd=<cmd> [options]\n\nOptions:\n -h --help Show this help\n --repository_path=<repository_path> The folder repository that the executables are to downloaded from\n --exe_path=<exe_path> The folder that the executables are located at\n --timeout=<timeout> Set timeout (in sec) to task to avoid endless running\n --log_path=<path> Override the default path where logs are saved\n --verbose Set logging level to DEBUG\n\"\"\"\n\nimport logging\nimport os\nimport subprocess\nimport sys\nfrom pathlib import Path\nfrom typing import Tuple, Any, Optional\n\nimport psutil\nimport schema\nfrom docopt import docopt\nfrom env import ONEDOCKER_EXE_PATH, ONEDOCKER_REPOSITORY_PATH\nfrom fbpcs.service.storage_s3 import S3StorageService\nfrom fbpcs.util.s3path import S3Path\nfrom util import run_cmd\n\n\n# the folder on s3 that the executables are to downloaded from\nDEFAULT_REPOSITORY_PATH = \"https://one-docker-repository.s3.us-west-1.amazonaws.com/\"\n\n# the folder in the docker image that is going to host the executables\nDEFAULT_EXE_FOLDER = \"/root/one_docker/package/\"\n\n\ndef run(\n repository_path: str,\n exe_path: str,\n package_name: str,\n cmd: str,\n logger: logging.Logger,\n timeout: int,\n) -> None:\n # download executable from s3\n if repository_path.upper() != \"LOCAL\":\n logger.info(\"Downloading executables ...\")\n _download_executables(repository_path, package_name)\n else:\n logger.info(\"Local repository, skip download ...\")\n\n # grant execute permission to the downloaded executable file\n team, exe_name = _parse_package_name(package_name)\n subprocess.run(f\"chmod +x {exe_path}/{exe_name}\", shell=True)\n\n # TODO update this line after proper change in fbcode/measurement/private_measurement/pcs/oss/fbpcs/service/onedocker.py to take\n # out the hard coded exe_path in cmd string\n if repository_path.upper() == \"LOCAL\":\n cmd = exe_path + cmd\n\n # run execution cmd\n logger.info(f\"Running cmd: {cmd} ...\")\n net_start: Any = psutil.net_io_counters()\n\n return_code = run_cmd(cmd, timeout)\n if return_code != 0:\n logger.info(f\"Subprocess returned non-zero return code: {return_code}\")\n\n net_end: Any = psutil.net_io_counters()\n logger.info(\n f\"Net usage: {net_end.bytes_sent - net_start.bytes_sent} bytes sent, {net_end.bytes_recv - net_start.bytes_recv} bytes received\"\n )\n\n sys.exit(return_code)\n\n\ndef _download_executables(\n repository_path: str,\n package_name: str,\n) -> None:\n s3_region = S3Path(repository_path).region\n team, exe_name = _parse_package_name(package_name)\n exe_local_path = DEFAULT_EXE_FOLDER + exe_name\n exe_s3_path = repository_path + package_name\n storage_svc = S3StorageService(s3_region)\n storage_svc.copy(exe_s3_path, exe_local_path)\n\n\ndef _parse_package_name(package_name: str) -> Tuple[str, str]:\n return package_name.split(\"/\")[0], package_name.split(\"/\")[1]\n\n\ndef _read_config(\n logger: logging.Logger,\n config_name: str,\n argument: Optional[str],\n env_var: str,\n default_val: str,\n):\n if argument:\n logger.info(f\"Read {config_name} from program arguments...\")\n return argument\n\n if os.getenv(env_var):\n logger.info(f\"Read {config_name} from environment variables...\")\n return os.getenv(env_var)\n\n logger.info(f\"Read {config_name} from default value...\")\n return default_val\n\n\ndef main():\n s = schema.Schema(\n {\n \"<package_name>\": str,\n \"--cmd\": schema.Or(None, str),\n \"--repository_path\": schema.Or(None, schema.And(str, len)),\n \"--exe_path\": schema.Or(None, schema.And(str, len)),\n \"--timeout\": schema.Or(None, schema.Use(int)),\n \"--log_path\": schema.Or(None, schema.Use(Path)),\n \"--verbose\": bool,\n \"--help\": bool,\n }\n )\n\n arguments = s.validate(docopt(__doc__))\n\n log_path = arguments[\"--log_path\"]\n log_level = logging.DEBUG if arguments[\"--verbose\"] else logging.INFO\n logging.basicConfig(filename=log_path, level=log_level)\n logger = logging.getLogger(__name__)\n\n # timeout could be None if the caller did not provide the value\n timeout = arguments[\"--timeout\"]\n\n repository_path = _read_config(\n logger,\n \"repository_path\",\n arguments[\"--repository_path\"],\n ONEDOCKER_REPOSITORY_PATH,\n DEFAULT_REPOSITORY_PATH,\n )\n exe_path = _read_config(\n logger,\n \"exe_path\",\n arguments[\"--exe_path\"],\n ONEDOCKER_EXE_PATH,\n DEFAULT_EXE_FOLDER,\n )\n\n logger.info(\"Starting program....\")\n try:\n run(\n repository_path=repository_path,\n exe_path=exe_path,\n package_name=arguments[\"<package_name>\"],\n cmd=arguments[\"--cmd\"],\n logger=logger,\n timeout=timeout,\n )\n except subprocess.TimeoutExpired:\n logger.error(f\"{timeout} seconds have passed. Now exiting the program....\")\n sys.exit(1)\n except InterruptedError:\n logger.error(\"Receive abort command from user, Now exiting the program....\")\n sys.exit(1)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6049901247024536,
"alphanum_fraction": 0.6069663763046265,
"avg_line_length": 31.384000778198242,
"blob_id": "114d892d9c9ae4c7b835e867dc291aafa47b788d",
"content_id": "4efd1a3aa0ad95388e4df3bdef2e69a7011ecc5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4048,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 125,
"path": "/fbpcs/gateway/s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport os\nfrom typing import Any, Dict, List, Optional\n\nimport boto3\nfrom fbpcs.decorator.error_handler import error_handler\nfrom tqdm.auto import tqdm\n\n\nclass S3Gateway:\n def __init__(\n self,\n region: str = \"us-west-1\",\n access_key_id: Optional[str] = None,\n access_key_data: Optional[str] = None,\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.region = region\n config = config or {}\n\n if access_key_id:\n config[\"aws_access_key_id\"] = access_key_id\n\n if access_key_data:\n config[\"aws_secret_access_key\"] = access_key_data\n\n # pyre-ignore\n self.client = boto3.client(\"s3\", region_name=self.region, **config)\n\n @error_handler\n def create_bucket(self, bucket: str, region: Optional[str] = None) -> None:\n region = region if region is not None else self.region\n self.client.create_bucket(\n Bucket=bucket, CreateBucketConfiguration={\"LocationConstraint\": region}\n )\n\n @error_handler\n def delete_bucket(self, bucket: str) -> None:\n self.client.delete_bucket(Bucket=bucket)\n\n @error_handler\n def upload_file(self, file_name: str, bucket: str, key: str) -> None:\n file_size = os.path.getsize(file_name)\n self.client.upload_file(\n file_name,\n bucket,\n key,\n Callback=self.ProgressPercentage(file_name, file_size),\n )\n\n @error_handler\n def download_file(self, bucket: str, key: str, file_name: str) -> None:\n file_size = self.get_object_size(bucket, key)\n self.client.download_file(\n bucket,\n key,\n file_name,\n Callback=self.ProgressPercentage(file_name, file_size),\n )\n\n @error_handler\n def put_object(self, bucket: str, key: str, data: str) -> None:\n self.client.put_object(Bucket=bucket, Key=key, Body=data.encode())\n\n @error_handler\n def get_object(self, bucket: str, key: str) -> str:\n res = self.client.get_object(Bucket=bucket, Key=key)\n return res[\"Body\"].read().decode()\n\n @error_handler\n def get_object_size(self, bucket: str, key: str) -> int:\n return self.client.head_object(Bucket=bucket, Key=key)[\"ContentLength\"]\n\n @error_handler\n def get_object_info(self, bucket: str, key: str) -> Dict[str, Any]:\n return self.client.get_object(Bucket=bucket, Key=key)\n\n @error_handler\n def list_object2(self, bucket: str, key: str) -> List[str]:\n paginator = self.client.get_paginator(\"list_objects_v2\")\n pages = paginator.paginate(Bucket=bucket, Prefix=key)\n\n key_list = []\n for page in pages:\n for content in page[\"Contents\"]:\n key_list.append(content[\"Key\"])\n\n return key_list\n\n @error_handler\n def delete_object(self, bucket: str, key: str) -> None:\n self.client.delete_object(Bucket=bucket, Key=key)\n\n @error_handler\n def object_exists(self, bucket: str, key: str) -> bool:\n try:\n # Result intentionally discarded\n _ = self.client.head_object(Bucket=bucket, Key=key)\n return True\n except Exception:\n return False\n\n @error_handler\n def copy(\n self, source_bucket: str, source_key: str, dest_bucket: str, dest_key: str\n ) -> None:\n source = {\"Bucket\": source_bucket, \"Key\": source_key}\n self.client.copy(source, dest_bucket, dest_key)\n\n class ProgressPercentage(object):\n def __init__(self, file_name: str, file_size: int) -> None:\n self._progressbar = tqdm(total=file_size, desc=file_name)\n\n def __call__(self, bytes_amount: int) -> None:\n self._progressbar.update(bytes_amount)\n\n def __del__(self) -> None:\n self._progressbar.close()\n"
},
{
"alpha_fraction": 0.7515060305595398,
"alphanum_fraction": 0.7530120611190796,
"avg_line_length": 22.714284896850586,
"blob_id": "5064be4c74bea41deea635e294014626e207523d",
"content_id": "b7a112306181fede7e16344e4c5c2fd226fea83f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 664,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 28,
"path": "/fbpcs/entity/container_instance.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Optional\n\nfrom dataclasses_json import dataclass_json\n\n\nclass ContainerInstanceStatus(Enum):\n UNKNOWN = \"UNKNOWN\"\n STARTED = \"STARTED\"\n COMPLETED = \"COMPLETED\"\n FAILED = \"FAILED\"\n\n\n@dataclass_json\n@dataclass\nclass ContainerInstance:\n instance_id: str\n ip_address: Optional[str] = None\n status: ContainerInstanceStatus = ContainerInstanceStatus.UNKNOWN\n"
},
{
"alpha_fraction": 0.6884328126907349,
"alphanum_fraction": 0.6902984976768494,
"avg_line_length": 22.30434799194336,
"blob_id": "12ad99a15ac1bc703121ff5743c326af9c8abf63",
"content_id": "d61950a2058d5b41098dbb40dec4f95b36b4416e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 536,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 23,
"path": "/fbpcs/util/yaml.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom pathlib import Path\nfrom typing import Any, Dict\n\nimport yaml\n\n\ndef load(file_path: Path) -> Dict[str, Any]:\n with open(file_path) as stream:\n return yaml.safe_load(stream)\n\n\n# pyre-ignore\ndef dump(data: Any, file_path: Path) -> None:\n with open(file_path, \"w\") as f:\n return yaml.dump(data, f)\n"
},
{
"alpha_fraction": 0.6264651417732239,
"alphanum_fraction": 0.6283158659934998,
"avg_line_length": 33.12631607055664,
"blob_id": "2f8e5386dca58dc7bc2183f5ae3f6743e00c87c0",
"content_id": "aff0ac97669ba2ef61ec57782cef950536073baa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3242,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 95,
"path": "/fbpcs/service/onedocker.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport asyncio\nimport logging\nfrom typing import List, Optional\n\nfrom fbpcs.entity.container_instance import ContainerInstance\nfrom fbpcs.service.container import ContainerService\n\n\nONE_DOCKER_CMD_PREFIX = (\n # patternlint-disable-next-line f-string-may-be-missing-leading-f\n \"python3.8 -m one_docker_runner --package_name={0} --cmd='/root/one_docker/package/\"\n)\n\n\nclass OneDockerService:\n \"\"\"OneDockerService is responsible for executing executable(s) in a Fargate container\"\"\"\n\n def __init__(self, container_svc: ContainerService) -> None:\n \"\"\"Constructor of OneDockerService\n container_svc -- service to spawn container instances\n TODO: log_svc -- service to read cloudwatch logs\n \"\"\"\n if container_svc is None:\n raise ValueError(f\"Dependency is missing. container_svc={container_svc}, \")\n\n self.container_svc = container_svc\n self.logger: logging.Logger = logging.getLogger(__name__)\n\n def start_container(\n self,\n container_definition: str,\n package_name: str,\n cmd_args: str,\n timeout: Optional[int] = None,\n ) -> ContainerInstance:\n # TODO: ContainerInstance mapper\n return asyncio.run(\n self.start_containers_async(\n container_definition, package_name, [cmd_args], timeout\n )\n )[0]\n\n def start_containers(\n self,\n container_definition: str,\n package_name: str,\n cmd_args_list: List[str],\n timeout: Optional[int] = None,\n ) -> List[ContainerInstance]:\n return asyncio.run(\n self.start_containers_async(\n container_definition, package_name, cmd_args_list, timeout\n )\n )\n\n async def start_containers_async(\n self,\n container_definition: str,\n package_name: str,\n cmd_args_list: List[str],\n timeout: Optional[int] = None,\n ) -> List[ContainerInstance]:\n \"\"\"Asynchronously spin up one container per element in input command list.\"\"\"\n cmds = [\n self._get_cmd(package_name, cmd_args, timeout) for cmd_args in cmd_args_list\n ]\n self.logger.info(\"Spinning up container instances\")\n container_ids = await self.container_svc.create_instances_async(\n container_definition, cmds\n )\n return container_ids\n\n def _get_exe_name(self, package_name: str) -> str:\n return package_name.split(\"/\")[1]\n\n def _get_cmd(\n self, package_name: str, cmd_args: str, timeout: Optional[int] = None\n ) -> str:\n cmd_timeout = \"\"\n \"\"\"\n If we passed --timeout=None, the schema module will raise error,\n since f-string converts None to \"None\" and schema treats None\n in --timeout=None as a string\n \"\"\"\n if timeout is not None:\n cmd_timeout = f\" --timeout={timeout}\"\n return f\"{ONE_DOCKER_CMD_PREFIX.format(package_name, timeout)}{self._get_exe_name(package_name)} {cmd_args}'{cmd_timeout}\"\n"
},
{
"alpha_fraction": 0.5685245990753174,
"alphanum_fraction": 0.5731147527694702,
"avg_line_length": 26.23214340209961,
"blob_id": "797e2eb8cdda15ed11a198f2582d18a10473b872",
"content_id": "a761d1519d14ded0352aea599158ddbf0300def4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1525,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 56,
"path": "/tests/decorator/test_error_handler.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom botocore.exceptions import ClientError\nfrom fbpcs.decorator.error_handler import error_handler\nfrom fbpcs.error.pcs import PcsError\nfrom fbpcs.error.throttling import ThrottlingError\n\n\nclass TestErrorHandler(unittest.TestCase):\n def test_pcs_error(self):\n @error_handler\n def foo():\n raise ValueError(\"just a test\")\n\n self.assertRaises(PcsError, foo)\n\n def test_throttling_error(self):\n @error_handler\n def foo():\n err = ClientError(\n {\n \"Error\": {\n \"Code\": \"ThrottlingException\",\n \"Message\": \"test\",\n },\n },\n \"test\",\n )\n\n raise err\n\n self.assertRaises(ThrottlingError, foo)\n\n def test_wrapped_function_args(self):\n @error_handler\n def foo(**kwargs):\n raise ValueError(\"just a test f\")\n\n error_msgs = {\n \"error_type1\": \"error_msg1\",\n \"error_type2\": \"error_msg2\",\n }\n self.assertRaises(PcsError, foo, error_msgs)\n\n def test_wrapped_function_kwargs(self):\n @error_handler\n def foo(*args):\n raise ValueError(\"just a test\")\n\n self.assertRaises(PcsError, foo, \"error1\", \"error2\")\n"
},
{
"alpha_fraction": 0.6265060305595398,
"alphanum_fraction": 0.6284598112106323,
"avg_line_length": 32.021507263183594,
"blob_id": "23380b42bda2d5cb28457c221b609c10f7f6bb6b",
"content_id": "6b632ddc435a71130678f37993d4998ff3fd22c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3071,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 93,
"path": "/fbpcs/gateway/ecs.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import Any, Dict, List, Optional\n\nimport boto3\nfrom fbpcs.decorator.error_handler import error_handler\nfrom fbpcs.entity.cluster_instance import Cluster\nfrom fbpcs.entity.container_instance import ContainerInstance\nfrom fbpcs.mapper.aws import (\n map_ecstask_to_containerinstance,\n map_esccluster_to_clusterinstance,\n)\n\n\nclass ECSGateway:\n def __init__(\n self,\n region: str,\n access_key_id: Optional[str],\n access_key_data: Optional[str],\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.region = region\n config = config or {}\n\n if access_key_id is not None:\n config[\"aws_access_key_id\"] = access_key_id\n\n if access_key_data is not None:\n config[\"aws_secret_access_key\"] = access_key_data\n\n # pyre-ignore\n self.client = boto3.client(\"ecs\", region_name=self.region, **config)\n\n @error_handler\n def run_task(\n self, task_definition: str, container: str, cmd: str, cluster: str, subnet: str\n ) -> ContainerInstance:\n response = self.client.run_task(\n taskDefinition=task_definition,\n cluster=cluster,\n networkConfiguration={\n \"awsvpcConfiguration\": {\n \"subnets\": [subnet],\n \"assignPublicIp\": \"ENABLED\",\n }\n },\n overrides={\"containerOverrides\": [{\"name\": container, \"command\": [cmd]}]},\n )\n\n return map_ecstask_to_containerinstance(response[\"tasks\"][0])\n\n @error_handler\n def describe_tasks(self, cluster: str, tasks: List[str]) -> List[ContainerInstance]:\n response = self.client.describe_tasks(cluster=cluster, tasks=tasks)\n return [map_ecstask_to_containerinstance(task) for task in response[\"tasks\"]]\n\n @error_handler\n def describe_task(self, cluster: str, task: str) -> ContainerInstance:\n return self.describe_tasks(cluster, [task])[0]\n\n @error_handler\n def list_tasks(self, cluster: str) -> List[str]:\n return self.client.list_tasks(cluster=cluster)[\"taskArns\"]\n\n @error_handler\n def stop_task(self, cluster: str, task_id: str) -> Dict[str, Any]:\n return self.client.stop_task(\n cluster=cluster,\n task=task_id,\n )\n\n @error_handler\n def describe_clusters(self, clusters: List[str]) -> List[Cluster]:\n response = self.client.describe_clusters(clusters=clusters, include=[\"TAGS\"])\n return [\n map_esccluster_to_clusterinstance(cluster)\n for cluster in response[\"clusters\"]\n ]\n\n @error_handler\n def describe_cluster(self, cluster: str) -> Cluster:\n return self.describe_clusters([cluster])[0]\n\n @error_handler\n def list_clusters(self) -> List[str]:\n return self.client.list_clusters()[\"clusterArns\"]\n"
},
{
"alpha_fraction": 0.7708830833435059,
"alphanum_fraction": 0.7732697129249573,
"avg_line_length": 37.09090805053711,
"blob_id": "471c89153b9790374e0344e6b90e4229f7350c2d",
"content_id": "8f17928d37628c1fa91cedb3ff68e33372705c47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 11,
"path": "/onedocker/env.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# This is the repository path that OneDocker downloads binaries from\nONEDOCKER_REPOSITORY_PATH = \"ONEDOCKER_REPOSITORY_PATH\"\n\n# This is the local path that the binaries reside\nONEDOCKER_EXE_PATH = \"ONEDOCKER_EXE_PATH\"\n"
},
{
"alpha_fraction": 0.6708229184150696,
"alphanum_fraction": 0.6733167171478271,
"avg_line_length": 20.105262756347656,
"blob_id": "2e0d7e7f96e201f0b0f70ca62e9f9f071995b81b",
"content_id": "efb9eb3e2093ffd7f456797e60a32b44c6179f00",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 401,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 19,
"path": "/fbpcs/entity/instance_base.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport abc\n\n\nclass InstanceBase(abc.ABC):\n @abc.abstractmethod\n def get_instance_id(self) -> str:\n pass\n\n @abc.abstractmethod\n def __str__(self) -> str:\n pass\n"
},
{
"alpha_fraction": 0.6571056246757507,
"alphanum_fraction": 0.6610169410705566,
"avg_line_length": 30.52054786682129,
"blob_id": "42ebf4eec2ffc64ec4bf166592abed0600e8d003",
"content_id": "0d1c72ae9b8fb88c159e7db6f08fee2aa284cd38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2301,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 73,
"path": "/fbpcs/mapper/aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom functools import reduce\nfrom typing import Any, Dict, List\n\nfrom fbpcs.entity.cluster_instance import Cluster, ClusterStatus\nfrom fbpcs.entity.container_instance import ContainerInstance, ContainerInstanceStatus\nfrom fbpcs.entity.vpc_instance import Vpc, VpcState\n\n\ndef map_ecstask_to_containerinstance(task: Dict[str, Any]) -> ContainerInstance:\n container = task[\"containers\"][0]\n ip_v4 = (\n container[\"networkInterfaces\"][0][\"privateIpv4Address\"]\n if len(container[\"networkInterfaces\"]) > 0\n else None\n )\n\n status = container[\"lastStatus\"]\n if status == \"RUNNING\":\n status = ContainerInstanceStatus.STARTED\n elif status == \"STOPPED\":\n if container[\"exitCode\"] == 0:\n status = ContainerInstanceStatus.COMPLETED\n else:\n status = ContainerInstanceStatus.FAILED\n else:\n status = ContainerInstanceStatus.UNKNOWN\n\n return ContainerInstance(task[\"taskArn\"], ip_v4, status)\n\n\ndef map_esccluster_to_clusterinstance(cluster: Dict[str, Any]) -> Cluster:\n status = cluster[\"status\"]\n if status == \"ACTIVE\":\n status = ClusterStatus.ACTIVE\n elif status == \"INACTIVE\":\n status = ClusterStatus.INACTIVE\n else:\n status = ClusterStatus.UNKNOWN\n\n tags = _convert_aws_tags_to_dict(cluster[\"tags\"], \"key\", \"value\")\n return Cluster(cluster[\"clusterArn\"], cluster[\"clusterName\"], status, tags)\n\n\ndef map_ec2vpc_to_vpcinstance(vpc: Dict[str, Any]) -> Vpc:\n state = vpc[\"State\"]\n if state == \"pending\":\n state = VpcState.PENDING\n elif state == \"available\":\n state = VpcState.AVAILABLE\n else:\n state = VpcState.UNKNOWN\n\n vpc_id = vpc[\"VpcId\"]\n # some vpc instances don't have any tags\n tags = (\n _convert_aws_tags_to_dict(vpc[\"Tags\"], \"Key\", \"Value\") if \"Tags\" in vpc else {}\n )\n\n return Vpc(vpc_id, state, tags)\n\n\ndef _convert_aws_tags_to_dict(\n tag_list: List[Dict[str, str]], tag_key: str, tag_value: str\n) -> Dict[str, str]:\n return reduce(lambda x, y: {**x, **{y[tag_key]: y[tag_value]}}, tag_list, {})\n"
},
{
"alpha_fraction": 0.47589239478111267,
"alphanum_fraction": 0.4796142876148224,
"avg_line_length": 34.39521026611328,
"blob_id": "05a910d2cd833d7341b5f36171be91c75ae467b5",
"content_id": "86792c6a2dfd25385fb5900da35a5229a4602a93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5911,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 167,
"path": "/tests/gateway/test_ecs.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.entity.cluster_instance import ClusterStatus, Cluster\nfrom fbpcs.entity.container_instance import ContainerInstanceStatus, ContainerInstance\nfrom fbpcs.gateway.ecs import ECSGateway\n\n\nclass TestECSGateway(unittest.TestCase):\n TEST_TASK_ARN = \"test-task-arn\"\n TEST_TASK_DEFINITION = \"test-task-definition\"\n TEST_CONTAINER = \"test-container\"\n TEST_CLUSTER = \"test-cluster\"\n TEST_CMD = \"test-cmd\"\n TEST_SUBNET = \"test-subnet\"\n TEST_ACCESS_KEY_ID = \"test-access-key-id\"\n TEST_ACCESS_KEY_DATA = \"test-access-key-data\"\n TEST_IP_ADDRESS = \"127.0.0.1\"\n TEST_FILE = \"test-file\"\n TEST_CLUSTER_TAG_KEY = \"test-tag-key\"\n TEST_CLUSTER_TAG_VALUE = \"test-tag-value\"\n REGION = \"us-west-2\"\n\n @patch(\"boto3.client\")\n def setUp(self, BotoClient):\n self.gw = ECSGateway(\n self.REGION, self.TEST_ACCESS_KEY_ID, self.TEST_ACCESS_KEY_DATA\n )\n self.gw.client = BotoClient()\n\n def test_run_task(self):\n client_return_response = {\n \"tasks\": [\n {\n \"containers\": [\n {\n \"name\": \"container_1\",\n \"exitcode\": 123,\n \"lastStatus\": \"RUNNING\",\n \"networkInterfaces\": [\n {\n \"privateIpv4Address\": self.TEST_IP_ADDRESS,\n },\n ],\n }\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n }\n ]\n }\n self.gw.client.run_task = MagicMock(return_value=client_return_response)\n task = self.gw.run_task(\n self.TEST_TASK_DEFINITION,\n self.TEST_CONTAINER,\n self.TEST_CMD,\n self.TEST_CLUSTER,\n self.TEST_SUBNET,\n )\n expected_task = ContainerInstance(\n self.TEST_TASK_ARN,\n self.TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n )\n self.assertEqual(task, expected_task)\n self.gw.client.run_task.assert_called()\n\n def test_describe_tasks(self):\n client_return_response = {\n \"tasks\": [\n {\n \"containers\": [\n {\n \"name\": self.TEST_CONTAINER,\n \"exitcode\": 123,\n \"lastStatus\": \"RUNNING\",\n \"networkInterfaces\": [\n {\n \"privateIpv4Address\": self.TEST_IP_ADDRESS,\n },\n ],\n }\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n }\n ]\n }\n self.gw.client.describe_tasks = MagicMock(return_value=client_return_response)\n tasks = [\n self.TEST_TASK_DEFINITION,\n ]\n tasks = self.gw.describe_tasks(self.TEST_CLUSTER, tasks)\n expected_tasks = [\n ContainerInstance(\n self.TEST_TASK_ARN,\n self.TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ]\n self.assertEqual(tasks, expected_tasks)\n self.gw.client.describe_tasks.assert_called()\n\n def test_stop_task(self):\n client_return_response = {\n \"task\": {\n \"containers\": [\n {\n \"name\": self.TEST_CONTAINER,\n \"exitcode\": 1,\n \"lastStatus\": \"STOPPED\",\n \"networkInterfaces\": [\n {\n \"privateIpv4Address\": self.TEST_IP_ADDRESS,\n },\n ],\n }\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n }\n }\n self.gw.client.stop_task = MagicMock(return_value=client_return_response)\n self.gw.stop_task(self.TEST_CLUSTER, self.TEST_TASK_ARN)\n self.gw.client.stop_task.assert_called()\n\n def test_list_tasks(self):\n client_return_response = {\"taskArns\": [self.TEST_TASK_ARN]}\n self.gw.client.list_tasks = MagicMock(return_value=client_return_response)\n tasks = self.gw.list_tasks(self.TEST_CLUSTER)\n expected_tasks = [self.TEST_TASK_ARN]\n self.assertEqual(tasks, expected_tasks)\n self.gw.client.list_tasks.assert_called()\n\n def test_describe_clusers(self):\n client_return_response = {\n \"clusters\": [\n {\n \"clusterArn\": self.TEST_CLUSTER,\n \"clusterName\": \"cluster_1\",\n \"tags\": [\n {\n \"key\": self.TEST_CLUSTER_TAG_KEY,\n \"value\": self.TEST_CLUSTER_TAG_VALUE,\n },\n ],\n \"status\": \"ACTIVE\",\n }\n ]\n }\n self.gw.client.describe_clusters = MagicMock(\n return_value=client_return_response\n )\n clusters = self.gw.describe_clusters(\n [\n self.TEST_CLUSTER,\n ]\n )\n tags = {self.TEST_CLUSTER_TAG_KEY: self.TEST_CLUSTER_TAG_VALUE}\n expected_clusters = [\n Cluster(self.TEST_CLUSTER, \"cluster_1\", ClusterStatus.ACTIVE, tags)\n ]\n self.assertEqual(expected_clusters, clusters)\n self.gw.client.describe_clusters.assert_called()\n"
},
{
"alpha_fraction": 0.6245551705360413,
"alphanum_fraction": 0.628113865852356,
"avg_line_length": 27.820512771606445,
"blob_id": "2db81762cddf4df8bd83e6c3d5f9a34c7dadf4d0",
"content_id": "f0fba58a7faaa5f82233a6659dc2f5b5c2f0a0ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1124,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 39,
"path": "/fbpcs/gateway/cloudwatch.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom typing import Any, Dict, Optional\n\nimport boto3\nfrom fbpcs.decorator.error_handler import error_handler\n\n\nclass CloudWatchGateway:\n def __init__(\n self,\n region: str = \"us-west-1\",\n access_key_id: Optional[str] = None,\n access_key_data: Optional[str] = None,\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.region = region\n config = config or {}\n\n if access_key_id:\n config[\"aws_access_key_id\"] = access_key_id\n\n if access_key_data:\n config[\"aws_secret_access_key\"] = access_key_data\n\n # pyre-ignore\n self.client = boto3.client(\"logs\", region_name=self.region, **config)\n\n @error_handler\n def get_log_events(self, log_group: str, log_stream: str) -> Dict[str, Any]:\n return self.client.get_log_events(\n logGroupName=log_group, logStreamName=log_stream\n )\n"
},
{
"alpha_fraction": 0.6690337657928467,
"alphanum_fraction": 0.6817301511764526,
"avg_line_length": 43.25714111328125,
"blob_id": "114428920fead29cacb3817d206f18a542e62b70",
"content_id": "1d923ac3e5f2153dbb12cde0ebd0480cb777c06f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4647,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 105,
"path": "/tests/repository/test_instance_s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport pickle\nimport unittest\nimport uuid\nfrom unittest.mock import MagicMock\n\nfrom fbpcs.entity.mpc_instance import MPCInstance, MPCInstanceStatus, MPCRole\nfrom fbpcs.repository.instance_s3 import S3InstanceRepository\nfrom fbpcs.service.storage_s3 import S3StorageService\n\n\nclass TestS3InstanceRepository(unittest.TestCase):\n TEST_BASE_DIR = \"./\"\n TEST_INSTANCE_ID = str(uuid.uuid4())\n TEST_GAME_NAME = \"lift\"\n TEST_MPC_ROLE = MPCRole.SERVER\n TEST_NUM_WORKERS = 1\n TEST_SERVER_IPS = [\"192.0.2.0\", \"192.0.2.1\"]\n TEST_INPUT_ARGS = [{\"input_filenames\": \"test_input_file\"}]\n TEST_OUTPUT_ARGS = [{\"output_filenames\": \"test_output_file\"}]\n TEST_CONCURRENCY_ARGS = {\"concurrency\": 2}\n TEST_INPUT_DIRECTORY = \"TEST_INPUT_DIRECTORY/\"\n TEST_OUTPUT_DIRECTROY = \"TEST_OUTPUT_DIRECTORY/\"\n ERROR_MSG_ALREADY_EXISTS = f\"{TEST_INSTANCE_ID} already exists\"\n ERROR_MSG_NOT_EXISTS = f\"{TEST_INSTANCE_ID} does not exist\"\n\n def setUp(self):\n storage_svc = S3StorageService(\"us-west-1\")\n self.s3_storage_repo = S3InstanceRepository(storage_svc, self.TEST_BASE_DIR)\n self.mpc_instance = MPCInstance(\n instance_id=self.TEST_INSTANCE_ID,\n game_name=self.TEST_GAME_NAME,\n mpc_role=self.TEST_MPC_ROLE,\n num_workers=self.TEST_NUM_WORKERS,\n server_ips=self.TEST_SERVER_IPS,\n status=MPCInstanceStatus.CREATED,\n input_args=self.TEST_INPUT_ARGS,\n output_args=self.TEST_OUTPUT_ARGS,\n concurrency_args=self.TEST_CONCURRENCY_ARGS,\n input_directory=self.TEST_INPUT_DIRECTORY,\n output_directory=self.TEST_OUTPUT_DIRECTROY,\n )\n\n def test_create_non_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(return_value=False)\n self.s3_storage_repo.s3_storage_svc.write = MagicMock(return_value=None)\n self.s3_storage_repo.create(self.mpc_instance)\n self.s3_storage_repo.s3_storage_svc.write.assert_called()\n\n def test_create_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(\n side_effect=RuntimeError(self.ERROR_MSG_ALREADY_EXISTS)\n )\n with self.assertRaisesRegex(RuntimeError, self.ERROR_MSG_ALREADY_EXISTS):\n self.s3_storage_repo.create(self.mpc_instance)\n\n def test_read_non_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(\n side_effect=RuntimeError(self.ERROR_MSG_NOT_EXISTS)\n )\n with self.assertRaisesRegex(RuntimeError, self.ERROR_MSG_NOT_EXISTS):\n self.s3_storage_repo.read(self.TEST_INSTANCE_ID)\n\n def test_read_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(return_value=True)\n self.s3_storage_repo.s3_storage_svc.read = MagicMock(\n return_value=pickle.dumps(self.mpc_instance, 0).decode()\n )\n instance = self.s3_storage_repo.read(self.mpc_instance)\n self.assertEqual(self.mpc_instance, instance)\n\n def test_update_non_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(\n side_effect=RuntimeError(self.ERROR_MSG_NOT_EXISTS)\n )\n with self.assertRaisesRegex(RuntimeError, self.ERROR_MSG_NOT_EXISTS):\n self.s3_storage_repo.update(self.mpc_instance)\n\n def test_update_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(return_value=True)\n self.s3_storage_repo.s3_storage_svc.write = MagicMock(return_value=None)\n self.s3_storage_repo.update(self.mpc_instance)\n self.s3_storage_repo.s3_storage_svc.write.assert_called()\n\n def test_delete_non_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(\n side_effect=RuntimeError(self.ERROR_MSG_NOT_EXISTS)\n )\n with self.assertRaisesRegex(RuntimeError, self.ERROR_MSG_NOT_EXISTS):\n self.s3_storage_repo.delete(self.TEST_INSTANCE_ID)\n\n def test_delete_existing_instance(self):\n self.s3_storage_repo._exist = MagicMock(return_value=True)\n self.s3_storage_repo.s3_storage_svc.delete = MagicMock(return_value=None)\n self.s3_storage_repo.delete(self.TEST_INSTANCE_ID)\n self.s3_storage_repo.s3_storage_svc.delete.assert_called()\n\n def test_exists(self):\n self.s3_storage_repo.s3_storage_svc.file_exists = MagicMock(return_value=True)\n self.assertTrue(self.s3_storage_repo._exist(self.TEST_INSTANCE_ID))\n"
},
{
"alpha_fraction": 0.7366197109222412,
"alphanum_fraction": 0.7408450841903687,
"avg_line_length": 31.272727966308594,
"blob_id": "e471c4c96ce396a0c47227ba348a4b2ecfb3e21e",
"content_id": "0ba395a3c6cff4d29f6f4941f433dfecbf4f65c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 710,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 22,
"path": "/fbpcs/error/mapper/aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nfrom botocore.exceptions import ClientError\nfrom fbpcs.error.pcs import PcsError\nfrom fbpcs.error.throttling import ThrottlingError\n\n\n# reference: https://boto3.amazonaws.com/v1/documentation/api/latest/guide/error-handling.html\ndef map_aws_error(error: ClientError) -> PcsError:\n code = error.response[\"Error\"][\"Code\"]\n message = error.response[\"Error\"][\"Message\"]\n\n if code == \"ThrottlingException\":\n return ThrottlingError(message)\n else:\n return PcsError(message)\n"
},
{
"alpha_fraction": 0.37717205286026,
"alphanum_fraction": 0.3827938735485077,
"avg_line_length": 31.793296813964844,
"blob_id": "5df54e4a09dcddb9a22494d3fe181c6e63122bd6",
"content_id": "a4bfb67392f1a33a0a4ef1c132b79e8b440de61d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5870,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 179,
"path": "/tests/mapper/test_aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\n\nfrom fbpcs.entity.cluster_instance import ClusterStatus, Cluster\nfrom fbpcs.entity.container_instance import ContainerInstanceStatus, ContainerInstance\nfrom fbpcs.mapper.aws import (\n map_ecstask_to_containerinstance,\n map_esccluster_to_clusterinstance,\n)\n\n\nclass TestAWSMapper(unittest.TestCase):\n TEST_IP_ADDRESS = \"127.0.0.1\"\n TEST_TASK_ARN = \"test-task-arn\"\n TEST_CLUSTER_ARN = \"test-cluster-arn\"\n TEST_CLUSTER_NAME = \"test-cluster-name\"\n\n def test_map_ecstask_to_containerinstance(self):\n ecs_task_response = {\n \"tasks\": [\n {\n \"containers\": [\n {\n \"exitCode\": None,\n \"lastStatus\": \"RUNNING\",\n \"networkInterfaces\": [\n {\n \"privateIpv4Address\": self.TEST_IP_ADDRESS,\n },\n ],\n },\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n },\n {\n \"containers\": [\n {\n \"exitCode\": 0,\n \"lastStatus\": \"STOPPED\",\n \"networkInterfaces\": [],\n },\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n },\n {\n \"containers\": [\n {\n \"exitCode\": 1,\n \"lastStatus\": \"STOPPED\",\n \"networkInterfaces\": [],\n },\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n },\n {\n \"containers\": [\n {\n \"exitCode\": -1,\n \"lastStatus\": \"UNKNOWN\",\n \"networkInterfaces\": [],\n },\n ],\n \"taskArn\": self.TEST_TASK_ARN,\n },\n ]\n }\n\n expected_task_list = [\n ContainerInstance(\n self.TEST_TASK_ARN,\n self.TEST_IP_ADDRESS,\n ContainerInstanceStatus.STARTED,\n ),\n ContainerInstance(\n self.TEST_TASK_ARN,\n None,\n ContainerInstanceStatus.COMPLETED,\n ),\n ContainerInstance(\n self.TEST_TASK_ARN,\n None,\n ContainerInstanceStatus.FAILED,\n ),\n ContainerInstance(\n self.TEST_TASK_ARN,\n None,\n ContainerInstanceStatus.UNKNOWN,\n ),\n ]\n tasks_list = [\n map_ecstask_to_containerinstance(task)\n for task in ecs_task_response[\"tasks\"]\n ]\n\n self.assertEqual(tasks_list, expected_task_list)\n\n def test_map_esccluster_to_clusterinstance(self):\n tag_key_1 = \"tag-key-1\"\n tag_key_2 = \"tag-key-2\"\n tag_value_1 = \"tag-value-1\"\n tag_value_2 = \"tag-value-2\"\n ecs_cluster_response = {\n \"clusters\": [\n {\n \"clusterName\": self.TEST_CLUSTER_NAME,\n \"clusterArn\": self.TEST_CLUSTER_ARN,\n \"status\": \"ACTIVE\",\n \"tags\": [\n {\n \"key\": tag_key_1,\n \"value\": tag_value_1,\n },\n {\n \"key\": tag_key_2,\n \"value\": tag_value_2,\n },\n ],\n },\n {\n \"clusterName\": self.TEST_CLUSTER_NAME,\n \"clusterArn\": self.TEST_CLUSTER_ARN,\n \"status\": \"INACTIVE\",\n \"tags\": [\n {\n \"key\": tag_key_1,\n \"value\": tag_value_1,\n },\n ],\n },\n {\n \"clusterName\": self.TEST_CLUSTER_NAME,\n \"clusterArn\": self.TEST_CLUSTER_ARN,\n \"status\": \"UNKNOWN\",\n \"tags\": [\n {\n \"key\": tag_key_1,\n \"value\": tag_value_1,\n },\n ],\n },\n ]\n }\n multi_tag_value_pair = {\n tag_key_1: tag_value_1,\n tag_key_2: tag_value_2,\n }\n single_tag_value_pair = {tag_key_1: tag_value_1}\n\n expected_cluster_list = [\n Cluster(\n self.TEST_CLUSTER_ARN,\n self.TEST_CLUSTER_NAME,\n ClusterStatus.ACTIVE,\n multi_tag_value_pair,\n ),\n Cluster(\n self.TEST_CLUSTER_ARN,\n self.TEST_CLUSTER_NAME,\n ClusterStatus.INACTIVE,\n single_tag_value_pair,\n ),\n Cluster(\n self.TEST_CLUSTER_ARN,\n self.TEST_CLUSTER_NAME,\n ClusterStatus.UNKNOWN,\n single_tag_value_pair,\n ),\n ]\n cluster_list = [\n map_esccluster_to_clusterinstance(cluster)\n for cluster in ecs_cluster_response[\"clusters\"]\n ]\n\n self.assertEqual(cluster_list, expected_cluster_list)\n"
},
{
"alpha_fraction": 0.506039559841156,
"alphanum_fraction": 0.5201747417449951,
"avg_line_length": 37.52475357055664,
"blob_id": "118fc5565f3cc784071ca12d49dfef43db294d1b",
"content_id": "67fb3a860c9f3caea2a7e18859cbd515c13e1fd9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7782,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 202,
"path": "/fbpcs/service/storage_s3.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport os\nfrom os import path\nfrom os.path import join, normpath, relpath\nfrom typing import Any, Dict, Optional\n\nfrom fbpcs.gateway.s3 import S3Gateway\nfrom fbpcs.service.storage import PathType, StorageService\nfrom fbpcs.util.s3path import S3Path\n\n\nclass S3StorageService(StorageService):\n def __init__(\n self,\n region: str = \"us-west-1\",\n access_key_id: Optional[str] = None,\n access_key_data: Optional[str] = None,\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.s3_gateway = S3Gateway(region, access_key_id, access_key_data, config)\n\n def read(self, filename: str) -> str:\n \"\"\"Read a file data\n Keyword arguments:\n filename -- \"https://bucket-name.s3.Region.amazonaws.com/key-name\"\n \"\"\"\n s3_path = S3Path(filename)\n return self.s3_gateway.get_object(s3_path.bucket, s3_path.key)\n\n def write(self, filename: str, data: str) -> None:\n \"\"\"Write data into a file\n Keyword arguments:\n filename -- \"https://bucket-name.s3.Region.amazonaws.com/key-name\"`\n \"\"\"\n s3_path = S3Path(filename)\n self.s3_gateway.put_object(s3_path.bucket, s3_path.key, data)\n\n def copy(self, source: str, destination: str, recursive: bool = False) -> None:\n \"\"\"Move a file or folder between local storage and S3, as well as, S3 and S3\n Keyword arguments:\n source -- source file\n destination -- destination file\n recursive -- whether to recursively copy a folder\n \"\"\"\n if StorageService.path_type(source) == PathType.Local:\n # from local to S3\n if StorageService.path_type(destination) == PathType.Local:\n raise ValueError(\"Both source and destination are local files\")\n s3_path = S3Path(destination)\n if path.isdir(source):\n if not recursive:\n raise ValueError(f\"Source {source} is a folder. Use --recursive\")\n self.upload_dir(source, s3_path.bucket, s3_path.key)\n else:\n self.s3_gateway.upload_file(source, s3_path.bucket, s3_path.key)\n else:\n source_s3_path = S3Path(source)\n if StorageService.path_type(destination) == PathType.S3:\n # from S3 to S3\n dest_s3_path = S3Path(destination)\n if source_s3_path == dest_s3_path:\n raise ValueError(\n f\"Source {source} and destination {destination} are the same\"\n )\n\n if source.endswith(\"/\"):\n if not recursive:\n raise ValueError(\n f\"Source {source} is a folder. Use --recursive\"\n )\n\n self.copy_dir(\n source_s3_path.bucket,\n source_s3_path.key + \"/\",\n dest_s3_path.bucket,\n dest_s3_path.key,\n )\n else:\n self.s3_gateway.copy(\n source_s3_path.bucket,\n source_s3_path.key,\n dest_s3_path.bucket,\n dest_s3_path.key,\n )\n else:\n # from S3 to local\n if source.endswith(\"/\"):\n if not recursive:\n raise ValueError(\n f\"Source {source} is a folder. Use --recursive\"\n )\n self.download_dir(\n source_s3_path.bucket,\n source_s3_path.key + \"/\",\n destination,\n )\n else:\n self.s3_gateway.download_file(\n source_s3_path.bucket, source_s3_path.key, destination\n )\n\n def upload_dir(self, source: str, s3_path_bucket: str, s3_path_key: str) -> None:\n for root, dirs, files in os.walk(source):\n for file in files:\n local_path = join(root, file)\n destination_path = s3_path_key + \"/\" + relpath(local_path, source)\n\n self.s3_gateway.upload_file(\n local_path,\n s3_path_bucket,\n destination_path,\n )\n for dir in dirs:\n local_path = join(root, dir)\n destination_path = s3_path_key + \"/\" + relpath(local_path, source)\n\n self.s3_gateway.put_object(\n s3_path_bucket,\n destination_path + \"/\",\n \"\",\n )\n\n def download_dir(\n self, s3_path_bucket: str, s3_path_key: str, destination: str\n ) -> None:\n if not self.s3_gateway.object_exists(s3_path_bucket, s3_path_key):\n raise ValueError(\n f\"Key {s3_path_key} does not exist in bucket {s3_path_bucket}\"\n )\n keys = self.s3_gateway.list_object2(s3_path_bucket, s3_path_key)\n for key in keys:\n local_path = normpath(destination + \"/\" + key[len(s3_path_key) :])\n if key.endswith(\"/\"):\n if not path.exists(local_path):\n os.makedirs(local_path)\n else:\n self.s3_gateway.download_file(s3_path_bucket, key, local_path)\n\n def copy_dir(\n self,\n source_bucket: str,\n source_key: str,\n destination_bucket: str,\n destination_key: str,\n ) -> None:\n if not self.s3_gateway.object_exists(source_bucket, source_key):\n raise ValueError(\n f\"Key {source_key} does not exist in bucket {source_bucket}\"\n )\n keys = self.s3_gateway.list_object2(source_bucket, source_key)\n for key in keys:\n destination_path = destination_key + \"/\" + key[len(source_key) :]\n if key.endswith(\"/\"):\n self.s3_gateway.put_object(\n source_bucket,\n destination_path,\n \"\",\n )\n else:\n self.s3_gateway.copy(\n source_bucket,\n key,\n destination_bucket,\n destination_path,\n )\n\n def delete(self, filename: str) -> None:\n \"\"\"Delete an s3 file\n Keyword arguments:\n filename -- the s3 file to be deleted\n \"\"\"\n if StorageService.path_type(filename) == PathType.S3:\n s3_path = S3Path(filename)\n self.s3_gateway.delete_object(s3_path.bucket, s3_path.key)\n else:\n raise ValueError(\"The file is not an s3 file\")\n\n def file_exists(self, filename: str) -> bool:\n if StorageService.path_type(filename) == PathType.S3:\n s3_path = S3Path(filename)\n return self.s3_gateway.object_exists(s3_path.bucket, s3_path.key)\n else:\n raise ValueError(f\"File {filename} is not an S3 filepath\")\n\n def ls_file(self, filename: str) -> Dict[str, Any]:\n \"\"\"Show file information (last modified time, type and size)\n Keyword arguments:\n filename -- the s3 file to be shown\n \"\"\"\n s3_path = S3Path(filename)\n return self.s3_gateway.get_object_info(s3_path.bucket, s3_path.key)\n\n def get_file_size(self, filename: str) -> int:\n s3_path = S3Path(filename)\n return self.s3_gateway.get_object_size(s3_path.bucket, s3_path.key)\n"
},
{
"alpha_fraction": 0.668158769607544,
"alphanum_fraction": 0.6693524122238159,
"avg_line_length": 36.233333587646484,
"blob_id": "892995c4d70dda7b1a5ff319f657c20a6ef80e89",
"content_id": "93cfad90553e17c99bc58b529c5fec0fd86535ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3351,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 90,
"path": "/fbpcs/service/container_aws.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n# pyre-strict\n\nimport asyncio\nfrom typing import Any, Dict, List, Optional, Tuple\n\nfrom fbpcs.entity.container_instance import ContainerInstance, ContainerInstanceStatus\nfrom fbpcs.gateway.ecs import ECSGateway\nfrom fbpcs.service.container import ContainerService\nfrom fbpcs.util.typing import checked_cast\n\n\nclass AWSContainerService(ContainerService):\n def __init__(\n self,\n region: str,\n cluster: str,\n subnet: str,\n access_key_id: Optional[str] = None,\n access_key_data: Optional[str] = None,\n config: Optional[Dict[str, Any]] = None,\n ) -> None:\n self.region = region\n self.cluster = cluster\n self.subnet = subnet\n self.ecs_gateway = ECSGateway(region, access_key_id, access_key_data, config)\n\n def create_instance(self, container_definition: str, cmd: str) -> ContainerInstance:\n return asyncio.run(self._create_instance_async(container_definition, cmd))\n\n def create_instances(\n self, container_definition: str, cmds: List[str]\n ) -> List[ContainerInstance]:\n return asyncio.run(self._create_instances_async(container_definition, cmds))\n\n async def create_instances_async(\n self, container_definition: str, cmds: List[str]\n ) -> List[ContainerInstance]:\n return await self._create_instances_async(container_definition, cmds)\n\n def get_instance(self, instance_id: str) -> ContainerInstance:\n return self.ecs_gateway.describe_task(self.cluster, instance_id)\n\n def get_instances(self, instance_ids: List[str]) -> List[ContainerInstance]:\n return self.ecs_gateway.describe_tasks(self.cluster, instance_ids)\n\n def list_tasks(self) -> List[str]:\n return self.ecs_gateway.list_tasks(cluster=self.cluster)\n\n def stop_task(self, task_id: str) -> Dict[str, Any]:\n return self.ecs_gateway.stop_task(cluster=self.cluster, task_id=task_id)\n\n def _split_container_definition(self, container_definition: str) -> Tuple[str, str]:\n \"\"\"\n container_definition = task_definition#container\n \"\"\"\n s = container_definition.split(\"#\")\n return (s[0], s[1])\n\n async def _create_instance_async(\n self, container_definition: str, cmd: str\n ) -> ContainerInstance:\n task_definition, container = self._split_container_definition(\n container_definition\n )\n instance = self.ecs_gateway.run_task(\n task_definition, container, cmd, self.cluster, self.subnet\n )\n\n # wait until the container is in running state\n while instance.status is ContainerInstanceStatus.UNKNOWN:\n await asyncio.sleep(1)\n instance = self.get_instance(instance.instance_id)\n\n return instance\n\n async def _create_instances_async(\n self, container_definition: str, cmds: List[str]\n ) -> List[ContainerInstance]:\n tasks = [\n asyncio.create_task(self._create_instance_async(container_definition, cmd))\n for cmd in cmds\n ]\n res = await asyncio.gather(*tasks)\n return [checked_cast(ContainerInstance, instance) for instance in res]\n"
},
{
"alpha_fraction": 0.8022727370262146,
"alphanum_fraction": 0.8040909171104431,
"avg_line_length": 69.96774291992188,
"blob_id": "3faeaac0543a957aa4e92d66b7a252afe4215a5c",
"content_id": "d66faeadc1477335f050ecd246ac37f8a1f219f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2200,
"license_type": "permissive",
"max_line_length": 393,
"num_lines": 31,
"path": "/docs/FBPCSComponents.md",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "### Components:\nFacebook Private Computation Service follows [MVCS(Model View Controller Service)](MVCS.md) design pattern.\n\n### Repository\nRepository is responsible for encapsulating database-like operations. In our design, we have MPC instance repositories for both Amazon S3 and local storage. The end point service will call MPC service to create an MPC instance and all the files and information related to this instance will be stored on Amazon S3 or local storage, depending on which repository the end point service is using.\n\n### Gateway:\nGateway is responsible for encapsulating the interface of dependent services, which is AWS API in our design. Since we need to run tasks on ECS and store files on S3, it is required to call AWS API to do the operations and these api calls reside in the gateways.\n\n### Mapper:\nMapper deals with data transformation between components. Any response from AWS API calls should be mapped to the data we self defined.\n\n### Entity:\nEntity represents business objects, in our case, the MPC Instance, Container Instance and Cluster Instance, etc. In our design:\n\nMPC Instance contains information about a MPC game. For example, MPC game name, ECS fargate containers running the tasks, etc.\n\nContainer Instance contains information about a container on an ECS cluster. For example, the instance id, ip address and container status.\n\n### Service:\nMPCService is the public interface that FBPCS provides. All other services are internal only so subject to changes.\n\nService holds all business logic and exposes internal APIs to controllers or other services within the same code base. Besides MPC Sevice, MPC Game Service and OneDocker Service:\n\n* OneDockerService is a cloud agnostic, serverless container management service. Currently, it supports AWS ECS.\n\n* MPCGameService bridges MPCService and OneDockerService together. Given a MPC game and it's arguments, MPCGameService transforms them to OneDocker arguments.\n\n* ContainerService is a generic interface that each cloud may extend to implement a concrete container service. Currently, we support AWS ECS.\n\n* Storage Service provides APIs to do CRUD operations on a particular storage, such as local and S3.\n"
},
{
"alpha_fraction": 0.7352085113525391,
"alphanum_fraction": 0.7371484041213989,
"avg_line_length": 38.653846740722656,
"blob_id": "a3d8f4a3019e7df47a0a70b09e41ac1cb518f71b",
"content_id": "2cfe6a6691ee44f3aa077c5ff3abfea13c8da13d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1031,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 26,
"path": "/tests/service/test_log_cloudwatch.py",
"repo_name": "supasate/FBPCS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport unittest\nfrom unittest.mock import MagicMock, patch\n\nfrom fbpcs.service.log_cloudwatch import CloudWatchLogService\n\nREGION = \"us-west-1\"\nLOG_GROUP = \"test-group-name\"\nLOG_PATH = \"test-log-path\"\n\n\nclass TestCloudWatchLogService(unittest.TestCase):\n @patch(\"fbpcs.gateway.cloudwatch.CloudWatchGateway\")\n def test_fetch(self, MockCloudWatchGateway):\n log_service = CloudWatchLogService(LOG_GROUP, REGION)\n mocked_log = {\"test-events\": [{\"test-event-name\": \"test-event-data\"}]}\n log_service.cloudwatch_gateway = MockCloudWatchGateway()\n log_service.cloudwatch_gateway.fetch = MagicMock(return_value=mocked_log)\n returned_log = log_service.cloudwatch_gateway.fetch(LOG_PATH)\n log_service.cloudwatch_gateway.fetch.assert_called()\n self.assertEqual(mocked_log, returned_log)\n"
}
] | 57 |
prachi285/autocorrect-transliteration | https://github.com/prachi285/autocorrect-transliteration | 8edf58c2d3061951add83b957eba505f9d61a0a9 | 5d269788f81aba7b5d6842b1c8a2886af29934b9 | 2bd9ea868cd4e37ec9bf0860e87f0afbcd79188f | refs/heads/master | "2021-01-23T00:33:53.627268" | "2017-03-23T18:47:33" | "2017-03-23T18:47:33" | 85,738,716 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7406806945800781,
"alphanum_fraction": 0.743922233581543,
"avg_line_length": 23.68000030517578,
"blob_id": "730b539ab01bc49d6b97082abc65f920eae55e3f",
"content_id": "c82b42816e6909f3665a4818c8b4bc28a89b09e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/run.py",
"repo_name": "prachi285/autocorrect-transliteration",
"src_encoding": "UTF-8",
"text": "import auto_correct as auto\nimport sys\nimport StringIO\n\n# queries to train the model\nqueries = ['how to handle a 1.5 year old when hitting',\n 'how can i avoid getting sick in china',\n 'how do male penguins survive without eating for four months',\n 'how do i remove candle wax from a polar fleece',\n 'how do i find an out of print book',\n 'yeh query hai']\n\n# train the model\n\n# supressing the output of training model\nstdout = sys.stdout\nsys.stdout = StringIO.StringIO()\n\nmodel = auto.auto_correct(re_train=True,data=queries)\n\n# enabling the output standard output\nsys.stdout = stdout\n\n# running the model\nmodel.run()\n"
}
] | 1 |
UshshaqueBarira/Data-Analysis | https://github.com/UshshaqueBarira/Data-Analysis | d7018663164d6c76de6452f20bb1099d25a5de55 | d870426adc37f451d55601becfa2046f90cb38c9 | a0f6262a8ab76ae790ba8ad62f538db2baf1dc79 | refs/heads/main | "2023-07-13T18:38:02.052836" | "2021-08-26T09:38:39" | "2021-08-26T09:38:39" | 380,935,218 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6312893033027649,
"alphanum_fraction": 0.6713836193084717,
"avg_line_length": 12.347368240356445,
"blob_id": "f08c8f6c41656514d6ec178d34837cbbb9ba3630",
"content_id": "6467f7b45bacdd0cb5df877c8b2e42aa60d98127",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 95,
"path": "/DecisionTree_heartattack.py",
"repo_name": "UshshaqueBarira/Data-Analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[7]:\n\n\nimport pandas as pd\nimport seaborn as sns\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import metrics\nfrom sklearn.tree import DecisionTreeClassifier\n\n\n# In[49]:\n\n\nheart=pd.read_csv(\"./heart.csv\")\nheart.head()\n\n\n# In[50]:\n\n\nsns.set_style('white')\n\n\n# In[52]:\n\n\nsns.relplot(x='age',y='chol',data=heart,color='green',hue='sex')\n\n\n# In[54]:\n\n\nsns.relplot(x='age',y='cp',data=heart,hue='sex')\n\n\n# In[68]:\n\n\nfeature_cols=['age','cp','trtbps','chol','fbs','restecg','thalachh','exng','oldpeak','slp','caa','thall','output']\nfeature_cols\n\n\n# In[115]:\n\n\nX=heart[feature_cols]\ny=heart.sex\ny1=heart.chol\n\n\n# In[116]:\n\n\nx_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=1)\n\n\n# In[117]:\n\n\nclf=DecisionTreeClassifier()\nclf=clf.fit(x_train,y_train)\ny_pred=clf.predict(x_test)\n\n\n# In[118]:\n\n\nprint(\"Accuracy:(Gender)\",(metrics.accuracy_score(y_test,y_pred))*100)\n\n\n# In[122]:\n\n\nx_train,x_test,y_train,y_test=train_test_split(X,y1,test_size=0.4,random_state=1)\n\n\n# In[123]:\n\n\nclf1=DecisionTreeClassifier()\nclf1=clf1.fit(x_train,y_train)\ny_pred=clf1.predict(x_test)\n\n\n# In[124]:\n\n\nprint(\"Accuracy:(Cholestrol)\",(metrics.accuracy_score(y_test,y_pred)*100))\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.6692056655883789,
"alphanum_fraction": 0.7007616758346558,
"avg_line_length": 13.296875,
"blob_id": "c3b43a2058a91d71bfd235c02b3991f2871b4b45",
"content_id": "ec9572c60ccc2f3f58cb5e032b00790002e22d6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 919,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 64,
"path": "/Decision Tree_Titanic.py",
"repo_name": "UshshaqueBarira/Data-Analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[3]:\n\n\n#titanic data set is all manipulated thus we have an accuracy level of 1.0 that is 100 matching as trained and test data\n\nimport pandas as pd\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import metrics\nimport seaborn as sns\n\n\n# In[4]:\n\n\nsns.set_style('dark')\n\n\n# In[51]:\n\n\ntitanic=sns.load_dataset('titanic')\ntitanic.head()\n\n\n# In[66]:\n\n\nfeature_cols=['survived','pclass','sibsp','parch','fare']\n\n\n# In[78]:\n\n\nX=titanic[feature_cols]\n#y=titanic.pclass\ny1=titanic.survived\n#print(X.isnull())\n\n\n# In[79]:\n\n\nx_train,x_test,y_train,y_test=train_test_split(X,y1,test_size=0.4,random_state=1)#test 30% and 70% train data\n\n\n# In[80]:\n\n\nclf=DecisionTreeClassifier()\nclf=clf.fit(x_train,y_train)\ny_pred=clf.predict(x_test)\n\n\n# In[81]:\n\n\nprint(\"Accuracy:\",metrics.accuracy_score(y_test,y_pred))\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.643827497959137,
"alphanum_fraction": 0.674542248249054,
"avg_line_length": 11.699248313903809,
"blob_id": "38390e13fee75a219c16e2bfb5575487842835a4",
"content_id": "04ff3fd54742c03be7bce96c7ff43eafe40741c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1693,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 133,
"path": "/seaborn.py",
"repo_name": "UshshaqueBarira/Data-Analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[10]:\n\n\nimport pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nget_ipython().run_line_magic('matplotlib.pyplot', '% inline')\n\n\n# In[11]:\n\n\nsns.get_dataset_names()\n\n\n# In[12]:\n\n\nattention=sns.load_dataset('attention')\nattention.head()\n\n\n# In[13]:\n\n\nsns.relplot(x='subject',y='score',data=attention,hue='attention',size='subject')\n\n\n# In[14]:\n\n\ntips=sns.load_dataset('tips')\ntips.head()\n\n\n# In[15]:\n\n\nsns.scatterplot(x='total_bill',y='tip',data=tips)\n\n\n# In[16]:\n\n\n# using linear regression technique----one independent variable and one dependent variable(total_bill, tip)\nimport sklearn.linear_model\ntips.head()\n\n\n# In[17]:\n\n\nx=tips['total_bill']\ny=tips['tip']\n\n\n# In[29]:\n\n\nx.train=x[:100]\nx.test=x[-100:]\ny.train=y[:100]\ny.test=y[-100:]\n\n\n# In[18]:\n\n\nplt.scatter(x.test,y.test,color='blue')\n\n\n# In[19]:\n\n\nregr=linear_model.LinearRegression()\nregr.fit(x.train,y.train)\nplt.plot(x.test,regr.predict(x.test),color='green',linewidth=2)\n\n\n# In[20]:\n\n\nsns.set_style('dark')\nsns.regplot(x,y,data=tips,color='green')\n\n\n# In[24]:\n\n\n#using the different dataset as car_crashes\ncar_crashes=sns.load_dataset('car_crashes')\ncar_crashes.head()\n\n\n# In[25]:\n\n\npenguins=sns.load_dataset('penguins')\npenguins.head()\n\n\n# In[29]:\n\n\n#cross dimensional features correlation graph\nsns.pairplot(penguins,hue='species',height=2.5);\n\n\n# In[31]:\n\n\nsns.relplot(x='bill_length_mm',y='bill_depth_mm',data=penguins,hue='sex')\n\n\n# In[35]:\n\n\nsns.set_style('white')\nsns.scatterplot(x='bill_length_mm',y='species',data=penguins,color='green')\n\n\n# In[37]:\n\n\n\nsns.scatterplot(x='bill_length_mm',y='sex',data=penguins,color='orange')\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 3 |
DrPyser/dependency-management | https://github.com/DrPyser/dependency-management | d20918149a712a750af61d35481757343e3f3126 | fcaeef58f7158bb990e27a410b086f8793e79414 | 44e1092610bfdb477d1342233b6bc648b3ca7c3e | refs/heads/master | "2020-07-22T13:54:39.042529" | "2019-09-09T04:33:05" | "2019-09-09T04:38:15" | 207,224,964 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5524364113807678,
"alphanum_fraction": 0.555349588394165,
"avg_line_length": 24.006622314453125,
"blob_id": "c320d490afeafa1506715f5f02aa4566ee3653ab",
"content_id": "9446726b9cd8a536bc90f56899ae4fea3e2419c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3776,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 151,
"path": "/path.py",
"repo_name": "DrPyser/dependency-management",
"src_encoding": "UTF-8",
"text": "import operator as op\nimport typing\nimport itertools\nimport collections\n\n\ndef first(it, default=None, pred=None):\n return next((x for x in it if pred is None or pred(x)), default)\n\n\ndef last(it, default=None, pred=None): \n return next(iter(collections.deque((x for x in it if pred is None or pred(x)), maxlen=1)), default)\n\n\nclass InvalidPath(ValueError):\n def __init__(self, path, obj):\n super().__init__(f\"Invalid path {path} for object {obj}\")\n self.path = path\n self.obj = obj\n\nT = typing.TypeVar(\"T\")\n \nclass Path(tuple):\n def __new__(cls, *components):\n return tuple.__new__(cls, components)\n\n def __repr__(self):\n components = \", \".join(map(repr, self))\n return f\"{type(self).__name__}({components})\"\n\n @classmethod\n def _getter(cls, cwd: T, c: str) -> T:\n raise NotImplementedError\n\n def follow(self, obj):\n cwd = obj\n for c in self:\n cwd = self._getter(cwd, c)\n yield cwd\n\n def follow_or(self, obj, default):\n cwd = obj\n try:\n yield from self.follow(obj)\n except InvalidPath:\n yield default\n\n def __add__(self, other):\n return PathChain(self, other)\n\n def prepend(self, c: str):\n return type(self)(c, *self)\n\n def append(self, c: str):\n return type(self)(*self, c)\n\n def __truediv__(self, c: str):\n return self.append(c)\n\n def __rtruediv__(self, c: str):\n return self.prepend(c)\n \n\nclass PathChain(Path):\n def __new__(cls, *paths: Path):\n return tuple.__new__(cls, (t(*itertools.chain.from_iterable(g)) for t, g in itertools.groupby(paths, type)))\n\n def follow(self, obj):\n cwd = obj\n for subpath in self:\n for cwd in subpath.follow(cwd):\n yield cwd\n\n \nclass AttrPath(Path):\n def __str__(self):\n return \"$.\" + \".\".join(self)\n\n @classmethod\n def from_str(cls, path: str):\n return cls(*path.lstrip(\"$.\").split(\".\"))\n\n def _getter(self, obj, at):\n try:\n return getattr(obj, at)\n except AttributeError as ex:\n raise InvalidPath(self, obj) from ex\n\n\nclass KeyPath(Path):\n def __str__(self):\n return \"$:\" + \":\".join(map(repr, self))\n\n @classmethod\n def from_str(cls, path: str):\n return cls(*path.lstrip(\"$:\").split(\":\"))\n\n def _getter(self, obj, at):\n try:\n return obj[at]\n except KeyError as ex:\n raise InvalidPath(self, obj) from ex\n \n \ndef identity(x):\n return x\n \n\ndef cd(obj: typing.Any, path: Path) -> typing.Any:\n return last(path.follow(obj))\n\n\nclass Attribute(typing.NamedTuple):\n name: str\n value: typing.Any\n \n\nclass Key(typing.NamedTuple):\n name: str\n value: typing.Any\n\n\nclass Cursor(typing.NamedTuple):\n track: typing.Sequence[typing.Tuple[str, typing.Any]]\n destination: Path\n \n def back(self):\n if self.track:\n return Cursor(\n track=self.track[:-2],\n destination=self.destination.prepend(self.track[-1][0])\n )\n else:\n # TODO: raise appropriate custom error\n raise ValueError\n\n def forward(self):\n if self.track and self.destination:\n return Cursor(\n track=(*self.track, (self.destination[0], next(self.destination.follow(self.track[-1][1])))),\n destination=self.destination.prepend(self.track[-1][0])\n )\n else:\n # TODO: raise appropriate custom error\n raise ValueError\n\n def get(self):\n return self.track[-1][1]\n\n def __str__(self):\n return f\"{type(self).__name__}(focus={self.track})\"\n"
},
{
"alpha_fraction": 0.6277899742126465,
"alphanum_fraction": 0.6281043887138367,
"avg_line_length": 31.459182739257812,
"blob_id": "4807207aa1429be0f12e16dff47aa265c268c4f9",
"content_id": "1b1ce9ba40d40bd05dfcf505c52a4578dece77a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6362,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 196,
"path": "/deps.py",
"repo_name": "DrPyser/dependency-management",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDependency management implementation.\n* Dependency graph to model dependency relationships between entities and code components\n* Automatic extraction of dependency relationships through signature inspection(type annotations, default values)\n\nGoals/Todos:\n* easily declare dependencies between code components with minimal boilerplate, maximum flexibility\n* inspectable dependency graph\n* runtime provider: interface to provide a component(instance), automatically resolving and instantiating dependencies\n (provide A -> resolve A deps -> provide A deps -> ...)\n* namespaces: dependency relationships are namespaced, such that EntityA.dep1 != EntityB.dep1, \n even if both dependencies are specified identically. \n* provider scope, shared dependencies, ability to provide dependency objects with different scoping: global (shared) singleton, per-type, per-thread, ... \n\n\"\"\"\nimport typing\nimport inspect\nimport collections\nimport types\n\n\nT = typing.TypeVar(\"T\")\n\n# move to utils\ndef first(it, default=None, pred=None):\n return next((x for x in it if pred is None or pred(x)), default)\n\n\n# move to utils\ndef record_init(self, *args, **kwargs):\n slots = getattr(type(self), \"__slots__\")\n for a, k in zip(args, slots):\n setattr(self, k, a)\n \n for k, v in kwargs.items():\n setattr(self, k, v)\n\n# move to utils\ndef record_repr(self):\n type_name = type(self).__name__\n slots = getattr(type(self), \"__slots__\")\n field_string = \", \".join(\n k+\"=\"+str(getattr(self, k))\n for k in slots\n )\n return f\"{type_name}({field_string})\"\n \n# move to utils\ndef record_type(name, bases, nmspc, **kwargs):\n annotations = nmspc.get(\"__annotations__\", {})\n slots = list(annotations.keys())\n nmspc.update(__slots__=slots, __init__=record_init, __repr__=record_repr)\n return types.new_class(name, bases, exec_body=lambda ns: ns.update(nmspc), kwds=kwargs)\n\n\n# move to utils\nclass RecordType(type):\n def __new__(cls, name, bases, nmspc, **kwargs):\n print(cls, name, bases, nmspc, kwargs)\n annotations = nmspc.get(\"__annotations__\", {})\n slots = list(annotations.keys())\n nmspc.update(__slots__=slots, __init__=record_init, __repr__=record_repr)\n return type.__new__(cls, name, bases, nmspc, **kwargs)\n\n\n# move to utils\nclass RecordBase(metaclass=RecordType):\n __init__ = record_init\n __repr__ = record_repr\n \n\n\n# move to utils\ndef subclass(parent: typing.Type[T], name: str, exec_body=None, mixins: tuple=(), **kwargs) -> typing.Type[T]:\n return types.new_class(name, bases=(*mixins, parent), kwds=kwargs, exec_body=exec_body)\n\n\n# move to utils\nclass delegate:\n def __init__(self, source, name=None):\n self.source = source\n self.name = name\n self.target = name and getattr(source, name)\n\n def __set_name__(self, name):\n if self.name is None:\n self.name = name\n self.target = getattr(self.source, self.name)\n\n def __get__(self, instance, owner):\n return self.target.__get__(instance, owner)\n\n \n\nclass Dependency(typing.Generic[T], RecordBase):\n factory: typing.Callable[..., T]\n type: typing.Type[T]\n\n def provide(self, *args, **kwargs) -> T:\n return self.factory(*args, **kwargs)\n \n \nclass Node(typing.Generic[T], metaclass=RecordType):\n name: str\n dependency_type: Dependency[T]\n\n\n# TODO: look into using algebraic graph impl.: dep = connect (vertex Dependency) (overlay [Dependency ...])\nclass DepGraph:\n def __init__(self):\n self.type_index: typing.Dict[type, typing.Set[Node]] = collections.defaultdict(set)\n self.name_index: typing.Dict[str, Node] = {}\n # Invariant: set.union(*self.type_index.values()) == set(self.name_index.values())\n\n self.relationships: typing.Set[typing.Tuple[Node, Node]] = set()\n # Invariant: set().union(*self.relationships.values()) == set(self.name_index.values())\n\n def add_node(self, dep: Node, dependencies=None):\n if dep.name not in self.name_index:\n self.type_index[dep.dependency_type.type].add(dep)\n self.name_index[dep.name] = dep\n else:\n # Probably should log something, or return some special value\n ...\n\n if dependencies:\n for d in dependencies:\n self.add_node(d)\n self.relationships.add(\n (dep, d)\n )\n\n def add_dependencies(self, name: str, dependencies: typing.Set[Node]):\n node = self.name_index[name]\n for d in dependencies:\n self.relationships.add(\n (node, d)\n )\n\n def add_relationship(self, dependent: str, dependence: str):\n assert dependent in self.name_index\n assert dependence in self.name_index\n self.relationships.add((self.name_index[dependent], self.name_index[dependence]))\n\n def get_by_name(self, name: str):\n return self.name_index[name]\n\n def get_dependents(self, name: str):\n node = self.name_index[name]\n dependents = set(\n dt\n for dt, dc in self.relationships\n if dc is node\n )\n return dependents\n\n def get_dependencies(self, name: str):\n node = self.name_index[name]\n dependencies = set(\n dc\n for dt, dc in self.relationships\n if dt is node\n )\n return dependencies\n \n\ndef extract_dependencies(dependent: typing.Callable) -> typing.Dict[str, Dependency]:\n \"\"\"\n Given a callable(usually class or function), identify dependencies\n by looking at attributes or signature\n \"\"\"\n if hasattr(dependent, \"__dependencies__\"):\n return dependent.__dependencies__\n else:\n dependent_sig = inspect.signature(dependent)\n deps: typing.Dict[str, Dependency] = {\n p_name: Dependency(type=p.annotation, factory=p.default.factory if isinstance(p.default, Dependency) else p.annotation)\n for p_name, p in dependent_sig.parameters.items()\n }\n return deps\n\n\n \n \n# class Balh:\n# def __init__(self, a: A, b: B):\n# ...\n\n# class DependencyManager:\n# def register(self, dependency: DependencyProfile):\n# ...\n\n# def provide_type(self, klass: typing.Type[T]) -> T:\n# ...\n\n# def provide_dependency()\n"
}
] | 2 |
maxoelerking/python_hiring_test | https://github.com/maxoelerking/python_hiring_test | 8fdf2a28ed5c7e4ce86e9b33e4703c76170353fd | 33ca6fa3e2c918e20dcc69e73402a750f1d93f2f | d7230f5c971e58228f2c6daffbe893af97e52613 | refs/heads/master | "2021-09-10T04:08:55.930261" | "2018-03-20T23:43:12" | "2018-03-20T23:43:12" | 126,096,858 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6733333468437195,
"alphanum_fraction": 0.6733333468437195,
"avg_line_length": 25.272727966308594,
"blob_id": "a948b24d7ec2c7314866b0b42144836ca00d1581",
"content_id": "d2f200182a325ee6c15c4b940df130dbe7095b6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 11,
"path": "/python_hiring_test/__init__.py",
"repo_name": "maxoelerking/python_hiring_test",
"src_encoding": "UTF-8",
"text": "\"\"\"Import python_hiring_test.\"\"\"\r\nimport os\r\n\r\n# set up some basic path names for easier compatibility\r\nROOT = os.path.dirname(__file__)\r\n\r\nDATA = os.path.join(ROOT, 'data')\r\n\r\nRAW = os.path.join(DATA, 'raw')\r\nREFERENCE = os.path.join(DATA, 'reference')\r\nPROCESSED = os.path.join(DATA, 'processed')\r\n"
},
{
"alpha_fraction": 0.795918345451355,
"alphanum_fraction": 0.795918345451355,
"avg_line_length": 23.5,
"blob_id": "e7efa15cdd47b1e0b47c779d9d7a874f0c3b02e7",
"content_id": "effaff08bf704ec476665d20a6d55bec68c9abac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 2,
"path": "/README.md",
"repo_name": "maxoelerking/python_hiring_test",
"src_encoding": "UTF-8",
"text": "# python_hiring_test\nPython test for Inside Edge\n"
},
{
"alpha_fraction": 0.551094114780426,
"alphanum_fraction": 0.5822199583053589,
"avg_line_length": 41.1370735168457,
"blob_id": "6342286a767085afab8bca3df8c3d3dd16ac53af",
"content_id": "418c65108c515bd9c5b35a89ecef6675fad32eb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13847,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 321,
"path": "/python_hiring_test/run.py",
"repo_name": "maxoelerking/python_hiring_test",
"src_encoding": "UTF-8",
"text": "\"\"\"Main script for generating output.csv.\"\"\"\r\nimport csv\r\nimport pandas as pd\r\n\r\n# Max Oelerking/March 20,2018\r\n\r\ndef main():\r\n #INPUT DATA FRAME\r\n PitchingData = pd.read_csv('./data/raw/pitchdata.csv')\r\n#SUB DATA FRAMES FOR PLAYER STATS\r\n#Grouping and Aggregating\r\n #RIGHT HANDED HITTER\r\n vsRHH = PitchingData.loc[PitchingData['HitterSide'] == 'R']\r\n vsRHH = vsRHH.groupby(['PitcherId']).sum()\r\n vsRHH = vsRHH[vsRHH['PA'] > 24]\r\n vsRHH['PitcherId'] = vsRHH.index\r\n vsRHH['AVG'] = round(vsRHH['H']/vsRHH['AB'],3)\r\n vsRHH['OBP'] = round((vsRHH['H']+vsRHH['BB']+vsRHH['HBP'])/(vsRHH['AB']+vsRHH['BB']+vsRHH['HBP']+vsRHH['SF']),3)\r\n vsRHH['SLG'] = round(vsRHH['TB']/vsRHH['AB'],3)\r\n vsRHH['OPS'] = round(vsRHH['OBP']+vsRHH['SLG'],3)\r\n #LEFT HANDED HITTERS\r\n vsLHH = PitchingData.loc[PitchingData['HitterSide'] == 'L']\r\n vsLHH = vsLHH.groupby(['PitcherId']).sum()\r\n vsLHH = vsLHH[vsLHH['PA'] > 24]\r\n vsLHH['PitcherId'] = vsLHH.index\r\n vsLHH['AVG'] = round(vsLHH['H']/vsLHH['AB'],3)\r\n vsLHH['OBP'] = round((vsLHH['H']+vsLHH['BB']+vsLHH['HBP'])/(vsLHH['AB']+vsLHH['BB']+vsLHH['HBP']+vsLHH['SF']),3)\r\n vsLHH['SLG'] = round(vsLHH['TB']/vsLHH['AB'],3)\r\n vsLHH['OPS'] = round(vsLHH['OBP']+vsLHH['SLG'],3)\r\n #RIGHT HANDED PITCHERS\r\n vsRHP = PitchingData.loc[PitchingData['PitcherSide'] == 'R']\r\n vsRHP = vsRHP.groupby(['HitterId']).sum()\r\n vsRHP = vsRHP[vsRHP['PA'] > 24]\r\n vsRHP['HitterId'] = vsRHP.index\r\n vsRHP['AVG'] = round(vsRHP['H']/vsRHP['AB'],3)\r\n vsRHP['OBP'] = round((vsRHP['H']+vsRHP['BB']+vsRHP['HBP'])/(vsRHP['AB']+vsRHP['BB']+vsRHP['HBP']+vsRHP['SF']),3)\r\n vsRHP['SLG'] = round(vsRHP['TB']/vsRHP['AB'],3)\r\n vsRHP['OPS'] = round(vsRHP['OBP']+vsRHP['SLG'],3)\r\n #LEFT HANDED PITCHERS\r\n vsLHP = PitchingData.loc[PitchingData['PitcherSide'] == 'L']\r\n vsLHP = vsLHP.groupby(['HitterId']).sum()\r\n vsLHP = vsLHP[vsLHP['PA'] > 24]\r\n vsLHP['HitterId'] = vsLHP.index\r\n vsLHP['AVG'] = round(vsLHP['H']/vsLHP['AB'],3)\r\n vsLHP['OBP'] = round((vsLHP['H']+vsLHP['BB']+vsLHP['HBP'])/(vsLHP['AB']+vsLHP['BB']+vsLHP['HBP']+vsLHP['SF']),3)\r\n vsLHP['SLG'] = round(vsLHP['TB']/vsLHP['AB'],3)\r\n vsLHP['OPS'] = round(vsLHP['OBP']+vsLHP['SLG'],3)\r\n#SUB DATA FRAMES FOR TEAM STATS\r\n#Grouping and Aggregating\r\n #RIGHT HANDED HITTERS\r\n vsRHHt = PitchingData.loc[PitchingData['HitterSide'] == 'R']\r\n vsRHHt = vsRHHt.groupby(['PitcherTeamId']).sum()\r\n vsRHHt['PitcherTeamId'] = vsRHHt.index\r\n vsRHHt['AVG'] = round(vsRHHt['H']/vsRHHt['AB'],3)\r\n vsRHHt['OBP'] = round((vsRHHt['H']+vsRHHt['BB']+vsRHHt['HBP'])/(vsRHHt['AB']+vsRHHt['BB']+vsRHHt['HBP']+vsRHHt['SF']),3)\r\n vsRHHt['SLG'] = round(vsRHHt['TB']/vsRHHt['AB'],3)\r\n vsRHHt['OPS'] = round(vsRHHt['OBP']+vsRHHt['SLG'],3)\r\n #LEFT HANDED HITTERS\r\n vsLHHt = PitchingData.loc[PitchingData['HitterSide'] == 'L']\r\n vsLHHt = vsLHHt.groupby(['PitcherTeamId']).sum()\r\n vsLHHt['PitcherTeamId'] = vsLHHt.index\r\n vsLHHt['AVG'] = round(vsLHHt['H']/vsLHHt['AB'],3)\r\n vsLHHt['OBP'] = round((vsLHHt['H']+vsLHHt['BB']+vsLHHt['HBP'])/(vsLHHt['AB']+vsLHHt['BB']+vsLHHt['HBP']+vsLHHt['SF']),3)\r\n vsLHHt['SLG'] = round(vsLHHt['TB']/vsLHHt['AB'],3)\r\n vsLHHt['OPS'] = round(vsLHHt['OBP']+vsLHHt['SLG'],3)\r\n #RIGHT HANDED PITCHERS\r\n vsRHPt = PitchingData.loc[PitchingData['PitcherSide'] == 'R']\r\n vsRHPt = vsRHPt.groupby(['HitterTeamId']).sum()\r\n vsRHPt['HitterTeamId'] = vsRHPt.index\r\n vsRHPt['AVG'] = round(vsRHPt['H']/vsRHPt['AB'],3)\r\n vsRHPt['OBP'] = round((vsRHPt['H']+vsRHPt['BB']+vsRHPt['HBP'])/(vsRHPt['AB']+vsRHPt['BB']+vsRHPt['HBP']+vsRHPt['SF']),3)\r\n vsRHPt['SLG'] = round(vsRHPt['TB']/vsRHPt['AB'],3)\r\n vsRHPt['OPS'] = round(vsRHPt['OBP']+vsRHPt['SLG'],3)\r\n #LEFT HANDED PITCHERS\r\n vsLHPt = PitchingData.loc[PitchingData['PitcherSide'] == 'L']\r\n vsLHPt = vsLHPt.groupby(['HitterTeamId']).sum()\r\n vsLHPt['HitterTeamId'] = vsLHPt.index\r\n vsLHPt['AVG'] = round(vsLHPt['H']/vsLHPt['AB'],3)\r\n vsLHPt['OBP'] = round((vsLHPt['H']+vsLHPt['BB']+vsLHPt['HBP'])/(vsLHPt['AB']+vsLHPt['BB']+vsLHPt['HBP']+vsLHPt['SF']),3)\r\n vsLHPt['SLG'] = round(vsLHPt['TB']/vsLHPt['AB'],3)\r\n vsLHPt['OPS'] = round(vsLHPt['OBP']+vsLHPt['SLG'],3)\r\n#SUB DATA FRAMES FOR SPLIT COMBINATIONS\r\n #AVG,HitterId,vs RHP\r\n o1 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o1['SubjectId'] = vsRHP['HitterId']\r\n o1['Stat'] = \"AVG\"\r\n o1['Split'] = \"vs RHP\"\r\n o1['Subject'] = \"HitterId\"\r\n o1['Value'] = vsRHP['AVG']\r\n #OBP,HitterId,vs RHP\r\n o2 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o2['SubjectId'] = vsRHP['HitterId']\r\n o2['Stat'] = \"OBP\"\r\n o2['Split'] = \"vs RHP\"\r\n o2['Subject'] = \"HitterId\"\r\n o2['Value'] = vsRHP['OBP']\r\n #SLG,HitterId,vs RHP\r\n o3 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o3['SubjectId'] = vsRHP['HitterId']\r\n o3['Stat'] = \"SLG\"\r\n o3['Split'] = \"vs RHP\"\r\n o3['Subject'] = \"HitterId\"\r\n o3['Value'] = vsRHP['SLG']\r\n #OPS,HitterId,vs RHP\r\n o4 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o4['SubjectId'] = vsRHP['HitterId']\r\n o4['Stat'] = \"OPS\"\r\n o4['Split'] = \"vs RHP\"\r\n o4['Subject'] = \"HitterId\"\r\n o4['Value'] = vsRHP['OPS']\r\n #AVG,HitterId,vs LHP\r\n o5 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o5['SubjectId'] = vsLHP['HitterId']\r\n o5['Stat'] = \"AVG\"\r\n o5['Split'] = \"vs LHP\"\r\n o5['Subject'] = \"HitterId\"\r\n o5['Value'] = vsLHP['AVG']\r\n #OBP,HitterId,vs LHP\r\n o6 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o6['SubjectId'] = vsLHP['HitterId']\r\n o6['Stat'] = \"OBP\"\r\n o6['Split'] = \"vs LHP\"\r\n o6['Subject'] = \"HitterId\"\r\n o6['Value'] = vsLHP['OBP']\r\n #SLG,HitterId,vs LHP\r\n o7 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o7['SubjectId'] = vsLHP['HitterId']\r\n o7['Stat'] = \"SLG\"\r\n o7['Split'] = \"vs LHP\"\r\n o7['Subject'] = \"HitterId\"\r\n o7['Value'] = vsLHP['SLG']\r\n #OPS,HitterId,vs LHP\r\n o8 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o8['SubjectId'] = vsLHP['HitterId']\r\n o8['Stat'] = \"OPS\"\r\n o8['Split'] = \"vs LHP\"\r\n o8['Subject'] = \"HitterId\"\r\n o8['Value'] = vsLHP['OPS']\r\n #AVG,HitterTeamId,vs RHP\r\n o9 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o9['SubjectId'] = vsRHPt['HitterTeamId']\r\n o9['Stat'] = \"AVG\"\r\n o9['Split'] = \"vs RHP\"\r\n o9['Subject'] = \"HitterTeamId\"\r\n o9['Value'] = vsRHPt['AVG']\r\n #OBP,HitterTeamId,vs RHP\r\n o10 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o10['SubjectId'] = vsRHPt['HitterTeamId']\r\n o10['Stat'] = \"OBP\"\r\n o10['Split'] = \"vs RHP\"\r\n o10['Subject'] = \"HitterTeamId\"\r\n o10['Value'] = vsRHPt['OBP']\r\n #SLG,HitterTeamId,vs RHP\r\n o11 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o11['SubjectId'] = vsRHPt['HitterTeamId']\r\n o11['Stat'] = \"SLG\"\r\n o11['Split'] = \"vs RHP\"\r\n o11['Subject'] = \"HitterTeamId\"\r\n o11['Value'] = vsRHPt['SLG']\r\n #OPS,HitterTeamId,vs RHP\r\n o12 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o12['SubjectId'] = vsRHPt['HitterTeamId']\r\n o12['Stat'] = \"OPS\"\r\n o12['Split'] = \"vs RHP\"\r\n o12['Subject'] = \"HitterTeamId\"\r\n o12['Value'] = vsRHPt['OPS']\r\n #AVG,HitterTeamId,vs LHP\r\n o13 = pd.DataFrame(columns=['SubjectID','Stat','Split','Subject','Value'])\r\n o13['SubjectId'] = vsLHPt['HitterTeamId']\r\n o13['Stat'] = \"AVG\"\r\n o13['Split'] = \"vs LHP\"\r\n o13['Subject'] = \"HitterTeamId\"\r\n o13['Value'] = vsLHPt['AVG']\r\n #OBP,HitterTeamId,vs LHP\r\n o14 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o14['SubjectId'] = vsLHPt['HitterTeamId']\r\n o14['Stat'] = \"OBP\"\r\n o14['Split'] = \"vs LHP\"\r\n o14['Subject'] = \"HitterTeamId\"\r\n o14['Value'] = vsRHPt['OBP']\r\n #SLG,HitterTeamId,vs LHP\r\n o15 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o15['SubjectId'] = vsLHPt['HitterTeamId']\r\n o15['Stat'] = \"SLG\"\r\n o15['Split'] = \"vs LHP\"\r\n o15['Subject'] = \"HitterTeamId\"\r\n o15['Value'] = vsLHPt['SLG']\r\n #OPS,HitterTeamId,vs LHP\r\n o16 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o16['SubjectId'] = vsLHPt['HitterTeamId']\r\n o16['Stat'] = \"OPS\"\r\n o16['Split'] = \"vs LHP\"\r\n o16['Subject'] = \"HitterTeamId\"\r\n o16['Value'] = vsLHPt['OPS']\r\n #AVG,PitcherId,vs RHH\r\n o17 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o17['SubjectId'] = vsRHH['PitcherId']\r\n o17['Stat'] = \"AVG\"\r\n o17['Split'] = \"vs RHH\"\r\n o17['Subject'] = \"PitcherId\"\r\n o17['Value'] = vsRHH['AVG']\r\n #OBP,PitcherId,vs RHH\r\n o18 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o18['SubjectId'] = vsRHH['PitcherId']\r\n o18['Stat'] = \"OBP\"\r\n o18['Split'] = \"vs RHH\"\r\n o18['Subject'] = \"PitcherId\"\r\n o18['Value'] = vsRHH['OBP']\r\n #SLG,PitcherId,vs RHH\r\n o19 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o19['SubjectId'] = vsRHH['PitcherId']\r\n o19['Stat'] = \"SLG\"\r\n o19['Split'] = \"vs RHH\"\r\n o19['Subject'] = \"PitcherId\"\r\n o19['Value'] = vsRHH['SLG']\r\n #OPS,PitcherId,vs RHH\r\n o20 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o20['SubjectId'] = vsRHH['PitcherId']\r\n o20['Stat'] = \"OPS\"\r\n o20['Split'] = \"vs RHH\"\r\n o20['Subject'] = \"PitcherId\"\r\n o20['Value'] = vsRHH['OPS']\r\n #AVG,PitcherId,vs LHH\r\n o21 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o21['SubjectId'] = vsLHH['PitcherId']\r\n o21['Stat'] = \"AVG\"\r\n o21['Split'] = \"vs LHH\"\r\n o21['Subject'] = \"PitcherId\"\r\n o21['Value'] = vsLHH['AVG']\r\n #OBP,PitcherId,vs LHH\r\n o22 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o22['SubjectId'] = vsLHH['PitcherId']\r\n o22['Stat'] = \"OBP\"\r\n o22['Split'] = \"vs LHH\"\r\n o22['Subject'] = \"PitcherId\"\r\n o22['Value'] = vsLHH['OBP']\r\n #SLG,PitcherId,vs LHH\r\n o23 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o23['SubjectId'] = vsLHH['PitcherId']\r\n o23['Stat'] = \"SLG\"\r\n o23['Split'] = \"vs LHH\"\r\n o23['Subject'] = \"PitcherId\"\r\n o23['Value'] = vsLHH['SLG']\r\n #OPS,PitcherId,vs LHH\r\n o24 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o24['SubjectId'] = vsLHH['PitcherId']\r\n o24['Stat'] = \"OPS\"\r\n o24['Split'] = \"vs LHH\"\r\n o24['Subject'] = \"PitcherId\"\r\n o24['Value'] = vsLHH['OPS']\r\n #AVG,PitcherTeamId,vs RHH\r\n o25 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o25['SubjectId'] = vsRHHt['PitcherTeamId']\r\n o25['Stat'] = \"AVG\"\r\n o25['Split'] = \"vs RHH\"\r\n o25['Subject'] = \"PitcherTeamId\"\r\n o25['Value'] = vsRHHt['AVG']\r\n #OBP,PitcherTeamId,vs RHH\r\n o26 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o26['SubjectId'] = vsRHHt['PitcherTeamId']\r\n o26['Stat'] = \"OBP\"\r\n o26['Split'] = \"vs RHH\"\r\n o26['Subject'] = \"PitcherTeamId\"\r\n o26['Value'] = vsRHHt['OBP']\r\n #SLG,PitcherTeamId,vs RHH\r\n o27 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o27['SubjectId'] = vsRHHt['PitcherTeamId']\r\n o27['Stat'] = \"SLG\"\r\n o27['Split'] = \"vs RHH\"\r\n o27['Subject'] = \"PitcherTeamId\"\r\n o27['Value'] = vsRHHt['SLG']\r\n #OPS,PitcherTeamId,vs RHH\r\n o28 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o28['SubjectId'] = vsRHHt['PitcherTeamId']\r\n o28['Stat'] = \"OPS\"\r\n o28['Split'] = \"vs RHH\"\r\n o28['Subject'] = \"PitcherTeamId\"\r\n o28['Value'] = vsRHHt['OPS']\r\n #AVG,PitcherTeamId,vs LHH\r\n o29 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o29['SubjectId'] = vsLHHt['PitcherTeamId']\r\n o29['Stat'] = \"AVG\"\r\n o29['Split'] = \"vs LHH\"\r\n o29['Subject'] = \"PitcherTeamId\"\r\n o29['Value'] = vsLHHt['AVG']\r\n #OBP,PitcherTeamId,vs LHH\r\n o30 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o30['SubjectId'] = vsLHHt['PitcherTeamId']\r\n o30['Stat'] = \"OBP\"\r\n o30['Split'] = \"vs LHH\"\r\n o30['Subject'] = \"PitcherTeamId\"\r\n o30['Value'] = vsLHHt['OBP']\r\n #SLG,PitcherTeamId,vs LHH\r\n o31 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o31['SubjectId'] = vsLHHt['PitcherTeamId']\r\n o31['Stat'] = \"SLG\"\r\n o31['Split'] = \"vs LHH\"\r\n o31['Subject'] = \"PitcherTeamId\"\r\n o31['Value'] = vsLHHt['SLG']\r\n #OPS,PitcherTeamId,vs LHH\r\n o32 = pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n o32['SubjectId'] = vsLHHt['PitcherTeamId']\r\n o32['Stat'] = \"OPS\"\r\n o32['Split'] = \"vs LHH\"\r\n o32['Subject'] = \"PitcherTeamId\"\r\n o32['Value'] = vsLHHt['OPS']\r\n#CREATE DATA FRAME FOR OUTPUT\r\n #DATA FRAME HEADERS {ID NUMBER STAT TYPE SPLIT TYPE ID TYPE NUMBER}\r\n OutPutData=pd.DataFrame(columns=['SubjectId','Stat','Split','Subject','Value'])\r\n #APPEND ALL CATEGORICAL DATA FRAMES\r\n OutPutData = o1.append([o2,o3,o4,o5,o6,o7,o8,o9,o10,o11,o12,o13,o14,o15,o16,o17,o18,o19,o20,o21,o22,o23,o24,o25,o26,o27,o28,o29,o30,o31,o32])\r\n #SORT FINAL DATA FRAME\r\n OutPutData.sort_values([\"SubjectId\",\"Stat\",\"Split\",\"Subject\",\"Value\"],inplace=True,ascending=True)\r\n #HEADERS FOR CSV FILE\r\n header = [\"SubjectId\",\"Stat\",\"Split\",\"Subject\",\"Value\"]\r\n #MOVE DATA FRAME TO CSV FILE WITH HEADER\r\n OutPutData.to_csv('./data/reference/output.csv',columns=header,index=False)\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
}
] | 3 |
mtosca/dictionary-app | https://github.com/mtosca/dictionary-app | 7e360c367b8f05b2a3597da6d7b5947aaea62777 | 521d73d515e61ad8a3c1f6dd2bd6c819a00c4dcd | ab3b887299a9dfa4a1c99226e8e3d0328c0c9767 | refs/heads/master | "2022-10-26T16:58:21.466144" | "2020-06-09T18:52:40" | "2020-06-09T18:52:40" | 260,766,744 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6369248032569885,
"alphanum_fraction": 0.642536461353302,
"avg_line_length": 26.84375,
"blob_id": "903d8d7fc86e700b4ce3a895f5b02b894acba1b0",
"content_id": "0ee9b6208f59b345597ca4377c3829c5f2028c23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1782,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 64,
"path": "/app.py",
"repo_name": "mtosca/dictionary-app",
"src_encoding": "UTF-8",
"text": "import difflib\nfrom difflib import get_close_matches\nimport psycopg2\n\nbr = \"\\n\"\n\n\ndef fetch_word_definition(cursor, word):\n # handle different situations as Paris, paris or PARIS\n word_list = (word.lower(), word.title(), word.upper())\n fetch_sql = \"\"\"select definition from definitions where word in %s\"\"\"\n cursor.execute(fetch_sql, (word_list,))\n defs = cursor.fetchall()\n return [d[0] for d in defs]\n\n\ndef fetch_all_words(cursor):\n all_words_sql = \"SELECT DISTINCT word FROM definitions;\"\n cursor.execute(all_words_sql)\n words = cursor.fetchall()\n return [w[0] for w in words]\n\n\ndef handle_type_error(cursor, word):\n # handle close matches as 'rainn' to 'rain'\n matches = get_close_matches(word, fetch_all_words(cur), 3, 0.8)\n\n if matches:\n confirm = input(f\"Did you mean '{matches[0]}' instead? Enter 'Yes' or 'No' \")\n if confirm.lower() == \"yes\":\n return define(cursor, matches[0])\n elif confirm.lower() == \"no\":\n return \"The word does not exist. Please double check it.\"\n else:\n return \"Invalid entry.\"\n else:\n return \"The word does not exist. Please double check it.\"\n\n\ndef define(cur, word):\n definitions = fetch_word_definition(cur, word)\n if definitions:\n return br.join(definitions)\n\n return handle_type_error(cur, word)\n\n\ninput_word = input(\"Enter word: \")\n\ntry:\n # connect to DB\n conn = psycopg2.connect(\n \"dbname='english_dictionary' user='postgres' host='localhost' password='postgres'\"\n )\n cur = conn.cursor()\n\n result = define(cur, input_word)\n print(result)\n\nexcept (Exception, psycopg2.DatabaseError) as error:\n print(f\"Failed for word '{input_word}'. Exit with error: '{error}'\")\n\nfinally:\n conn.close()\n"
},
{
"alpha_fraction": 0.644444465637207,
"alphanum_fraction": 0.6476190686225891,
"avg_line_length": 23.256410598754883,
"blob_id": "4d0076cb2be2166695a26ca3f423dc2616a9a474",
"content_id": "25bc1bb85a1b5f07331b198532063111c95304ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 945,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 39,
"path": "/json-to-db.py",
"repo_name": "mtosca/dictionary-app",
"src_encoding": "UTF-8",
"text": "import json\nimport psycopg2\n\ninsert_definition_sql = \"\"\"INSERT INTO definitions(word, definition)\n VALUES(%s, %s);\"\"\"\n\nclear_definitions_sql = \"TRUNCATE definitions\"\n\ntry:\n # read data form json file\n jsonfile = open('data.json')\n data = json.load(jsonfile)\n jsonfile.close()\n\n # connect to DB\n conn = psycopg2.connect(\"dbname='english_dictionary' user='postgres' host='localhost' password='postgres'\")\n cur = conn.cursor()\n\n # clear DB first\n cur.execute(clear_definitions_sql)\n \n # insert every definition as a row\n for entry in data:\n for definition in data[entry]:\n cur.execute(insert_definition_sql, (entry, definition))\n \n # commit changes and close comm with DB\n conn.commit()\n cur.close()\n \nexcept (Exception, psycopg2.DatabaseError) as error:\n print(\"Exit error: %s\", error)\n\nfinally:\n if conn is not None:\n conn.close()\n\n\nprint(\"Success!\")"
}
] | 2 |
Sunburst0909/JupyterLearningCodes | https://github.com/Sunburst0909/JupyterLearningCodes | 01f1800ef1ad4be471be89fd18c1720f4e605113 | 69c35651c101a3ff7b868369a48982e79235bafd | c694e04c10d21c4cfad0bb3b7c194c63b1c0f5f7 | refs/heads/master | "2023-06-19T00:02:16.016112" | "2021-07-19T15:19:36" | "2021-07-19T15:19:36" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.5659824013710022,
"avg_line_length": 16.100000381469727,
"blob_id": "76d39d7cdd8a11c94efceac83701e92250ce9c57",
"content_id": "a4dd13b762e0a91584ee7729f56876040a126b09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 20,
"path": "/guess.py",
"repo_name": "Sunburst0909/JupyterLearningCodes",
"src_encoding": "UTF-8",
"text": "import random\n\nanswer=random.randint(1,100)\ncounter=0\n\nwhile True:\n counter+=1\n n=int(input('Guess:'))\n if n>answer:\n print('Too Big.')\n elif n<answer:\n print('Too Small.')\n else:\n print('Yes!')\n break\n \nprint('You Guessed %d Times'% counter)\n\nif counter>7:\n print('Eeee! So many times!')"
},
{
"alpha_fraction": 0.7137255072593689,
"alphanum_fraction": 0.8117647171020508,
"avg_line_length": 41.5,
"blob_id": "30d5c4777544ab268b6946d10f10ae0da6641493",
"content_id": "ac4ee190409d8b7c069bbd62d9455218e1585b34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Sunburst0909/JupyterLearningCodes",
"src_encoding": "UTF-8",
"text": "# Jupyter Learning Codes\nThis is the demo codes for HiFrank's Jupyter Learning Book.\n\n此处提供《Jupyter 入门与实战》一书的示例代码。\n《Jupyter 入门与实战》于 2021.5.1 由人民邮电出版社出版发行。\n具体信息可参见人民邮电出版社官网:https://www.ptpress.com.cn/shopping/buy?bookId=19ebbcdd-44d9-49d4-99ba-09a8c351f784\n"
}
] | 2 |
estebanfloresf/testcases | https://github.com/estebanfloresf/testcases | 1d3b6bf8a3b7e9885ba9e79509a651bc7809575a | 1be1951864cc45e8664c947051a7a9cb1ee5ed03 | cca99342cba8b3991bcccdb8f024880a5ea68f4c | refs/heads/master | "2018-10-20T23:13:31.230564" | "2018-07-23T23:43:08" | "2018-07-23T23:43:08" | 116,885,293 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5371713638305664,
"alphanum_fraction": 0.5403445363044739,
"avg_line_length": 45.9361686706543,
"blob_id": "bd9504bfb67bbbcef1d3f604f5704a7cde8332fa",
"content_id": "1318cf2588b39fe6c5af972c45f00348267df888",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2206,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 47,
"path": "/testcases/spiders/createTestCase.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom scrapy.utils.project import get_project_settings\nfrom ..items import TestCasesItem\nfrom scrapy.loader import ItemLoader\n\n\nclass createTestCaseSpider(scrapy.Spider):\n name = \"createTestCase\"\n settings = get_project_settings()\n http_user = settings.get('HTTP_USER')\n http_pass = settings.get('HTTP_PASS')\n allowed_domains = [\"confluence.verndale.com\"]\n start_urls = ['https://confluence.verndale.com/display/GEHC/My+Profile+Page+-+DOC']\n\n def parse(self, response):\n item = TestCasesItem()\n title = response.xpath('//*[@id=\"title-text\"]/a/text()').extract_first()\n print('Documentation: '+title)\n table_xpath = '//*[@id=\"main-content\"]/div/div[4]/div/div/div[1]/table/tbody/tr'\n table = response.xpath(table_xpath)\n\n for index, row in enumerate(table):\n if (index > 0):\n components = row.select('.//td[2]/text() | .//td[2]/p/text()').extract()\n for compName in components:\n item['component'] = str(compName)\n print('Verify ' + compName + ' Component')\n # This path is usually the one to be used\n component_xpath = \".//td[3][contains(@class,'confluenceTd')]\"\n\n description = \"\"\n if (row.select(component_xpath + \"/a/text()\").extract()):\n requirements = row.select(component_xpath + \"/a//text()\").extract()\n description = \"|\".join(requirements)\n else:\n if (row.select(component_xpath + \"/ul//*/text()\").extract()):\n requirements = row.select(component_xpath + \"/ul//li//text()\").extract()\n print(requirements)\n description = \"|\".join(requirements)\n else:\n if (row.select(component_xpath +\"/div\"+ \"/ul//*/text()\").extract()):\n requirements = row.select(component_xpath +\"/div\"+ \"/ul//li//text()\").extract()\n description = \"|\".join(requirements)\n\n item['requirements'] = str(description)\n yield item\n"
},
{
"alpha_fraction": 0.5606981515884399,
"alphanum_fraction": 0.5630515813827515,
"avg_line_length": 36.21897888183594,
"blob_id": "59aa98bb2ed29ab2819a7909c5318bf0a168ec11",
"content_id": "0c076c5b0888858cb2d520ca12423900eee1aa47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5099,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 137,
"path": "/testcases/spiders/testSpider.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom scrapy import Request\nfrom scrapy.utils.project import get_project_settings\nfrom ..items import TestCasesItem, Responsive, Requirements\nfrom scrapy.spidermiddlewares.httperror import HttpError\nfrom twisted.internet.error import DNSLookupError\nfrom twisted.internet.error import TimeoutError, TCPTimedOutError\n\n\nclass TestspiderSpider(scrapy.Spider):\n name = \"testspider\"\n\n settings = get_project_settings()\n http_user = settings.get('HTTP_USER')\n http_pass = settings.get('HTTP_PASS')\n allowed_domains = [\"confluence.verndale.com\"]\n\n def __init__(self, url):\n super(TestspiderSpider, self).__init__()\n self.start_urls = [url]\n\n def parse(self, response):\n\n table = response.xpath('//*[@id=\"main-content\"]/div/div[4]/div/div/div[1]/table/tbody/tr')\n for index, row in enumerate(table):\n testcase = TestCasesItem()\n if index > 0:\n testcase['component'] = str(row.select('.//td[2]/text() | .//td[2]/p/text()').extract_first()).strip()\n request = Request(\n self.start_urls[0],\n callback=self.responsive_req,\n errback=self.errback_httpbin,\n dont_filter=True,\n meta={'testcase': testcase, 'row': row}\n )\n\n yield request\n\n def responsive_req(self, response):\n\n row = response.meta['row']\n testcase = response.meta['testcase']\n list_responsive = []\n\n # Section Responsive Notes\n responsive_path = row.xpath(\".//td[3]/div[contains(@class,'content-wrapper')]\")\n path = \".//div[contains(@class,'confluence-information-macro confluence-information-macro-information conf-macro output-block')]\"\n\n # If to see if the component has responsive requirements\n if responsive_path.xpath(path):\n\n for req in responsive_path.xpath(path):\n\n # If to see if the responsive requirements has devices\n if req.xpath(\".//div/p/span/text()\").extract():\n\n for device in req.xpath(\".//div/p/span/text()\").extract():\n\n # Save Devices\n responsive = Responsive()\n responsive['device'] = str(device).strip(':')\n request = Request(\n self.start_urls[0],\n callback=self.requirements,\n errback=self.errback_httpbin,\n dont_filter=True,\n meta={'responsive': responsive, 'row': row, 'testcase': testcase}\n )\n yield request\n\n else:\n responsive = Responsive()\n requirement = Requirements()\n requirement_list = []\n for index,req in enumerate(req.xpath(\".//div/p/text()\").extract()):\n requirement['description'] = req\n requirement_list.append(requirement)\n\n responsive['requirements']=requirement_list\n testcase['responsive'] = responsive\n yield testcase\n\n\n else:\n\n yield testcase\n\n # testcase['responsive'] = list_responsive\n\n def requirements(self, response):\n\n responsive = response.meta['responsive']\n testcase = response.meta['testcase']\n responsive['requirements'] = \"sample\"\n testcase['responsive'] = responsive\n\n\n\n #\n # requirements = []\n # path = \".//div[contains(@class,'confluence-information-macro-body')]//*/text()\"\n #\n # for elem in response.xpath(path).extract():\n # if (str(elem).strip(':') not in responsive['device']):\n # requirements.append(str(elem).strip())\n #\n # responsive['requirements'] = requirements\n # # Final testcase is added the devices and requirements for each\n #\n # # After creating the item appended to the devices list\n # devices.append(responsive)\n # testcase['responsive'] = devices\n # yield testcase\n\n # Function for handling Errors\n def errback_httpbin(self, failure):\n # log all failures\n self.logger.error(repr(failure))\n\n # in case you want to do something special for some errors,\n # you may need the failure's type:\n\n if failure.check(HttpError):\n # these exceptions come from HttpError spider middleware\n # you can get the non-200 response\n response = failure.value.response\n self.logger.error('HttpError on %s', response.url)\n\n elif failure.check(DNSLookupError):\n # this is the original request\n request = failure.request\n self.logger.error('DNSLookupError on %s', request.url)\n\n elif failure.check(TimeoutError, TCPTimedOutError):\n request = failure.request\n self.logger.error('TimeoutError on %s', request.url)\n"
},
{
"alpha_fraction": 0.49674054980278015,
"alphanum_fraction": 0.5001303553581238,
"avg_line_length": 34.37963104248047,
"blob_id": "890e4ee8607aae0c484619c3c6c09428457c3708",
"content_id": "038673eb873fd80bb73e3f74967561d06b153053",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3835,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 108,
"path": "/utils/generateTC.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "from openpyxl import load_workbook\n#import the pandas library and aliasing as pd and numpy as np\nimport pandas as pd\nimport numpy as np\nimport os \n\n\nclass createTestCase():\n def __init__(self):\n self.dir_path = os.path.dirname(os.path.realpath(__file__))\n \n self.wb = load_workbook(self.dir_path+'\\\\files\\\\inputTC.xlsx')\n self.ws = self.wb['Sheet1']\n \n self.commonWords = [\"note:\",\"notes:\",\"important note:\",\"onclick/ontap\",\"consists of:\"]\n self.changeWords = [\n {\"from\": \"will be\", \"to\": \"is\"},\n {\"from\": \"will wrap\", \"to\": \"wraps\"},\n {\"from\": \"will not be\", \"to\": \"is not\"},\n {\"from\": \"will dissapear\", \"to\": \"dissapears\"},\n {\"from\": \"will have\", \"to\": \"has\"},\n {\"from\": \"will move up\", \"to\": \"moves up\"},\n {\"from\": \"will fall back\", \"to\": \"fallbacks\"},\n {\"from\": \"will never be\", \"to\": \"is never\"},\n {\"from\": \"if\", \"to\": \"when\"}\n\n ]\n self.verifyLst= []\n self.expectedLst= []\n # # Transform the ws into a panda dataframe\n self.df = pd.DataFrame(self.ws.values)\n # # replace None values with NA and drop them\n self.df = self.df.replace(to_replace='None', value=np.nan).dropna()\n \n \n header = self.df.iloc[0]\n self.df = self.df[1:]\n self.df = self.df.rename(columns = header)\n self.df = self.df.reset_index(drop=True)\n self.dfList = self.df[header].values\n \n\n def __main__(self):\n self.createVfyLst(self.dfList)\n self.createExpLst(self.dfList)\n self.df.to_csv(self.dir_path+'\\\\resultsTC.csv',encoding='utf-8', index=False)\n \n \n\n def createVfyLst(self,dfList):\n try: \n for req in dfList:\n band =0 \n req = str(req[0]).lower() \n reqToLst = req.split(' ')\n for word in reqToLst:\n if(word in self.commonWords):\n band =1\n break\n if(band==0):\n self.verifyLst.append(\"Verify \"+req)\n else:\n self.verifyLst.append(req.capitalize())\n \n # Find the name of the column by index\n replaceClmn = self.df.columns[0] \n # Drop that column\n self.df.drop(replaceClmn, axis = 1, inplace = True)\n # Put whatever series you want in its place\n self.df[replaceClmn] = self.verifyLst\n except ValueError:\n print(\"There was a problem\")\n\n\n def createExpLst(self,dfList):\n \n try:\n for req in dfList: \n req = str(req[0]).lower()\n for wordrplc in self.changeWords:\n if(wordrplc['from'] in req):\n req = req.replace(wordrplc['from'],wordrplc['to'] )\n break\n\n self.expectedLst.append(str(req).capitalize()) \n \n self.df['Expected'] = self.expectedLst\n # Adding columns wth -1 value for the excel testcase format\n browserList = [-1] * len(self.expectedLst)\n browserListNoApply = ['---'] * len(self.expectedLst)\n self.df['windowsIE'] = browserList\n self.df['windowsCH'] = browserList\n self.df['windowsFF'] = browserList\n self.df['macSF'] = browserListNoApply\n self.df['macCH'] = browserListNoApply\n self.df['macFF'] = browserListNoApply\n \n print(\"CSV file generated with success\")\n except ValueError:\n print(\"There was a problem\")\n \n \n \n\n\nif __name__ == \"__main__\":\n app = createTestCase()\n app.__main__()\n\n\n\n\n\n \n"
},
{
"alpha_fraction": 0.4622741639614105,
"alphanum_fraction": 0.46794191002845764,
"avg_line_length": 34.73417663574219,
"blob_id": "67d8843537bbdbb8b66e2e07f6a33c2c8565f9b4",
"content_id": "8dc50e0a9c89aa2131dff6f77e7ec30ad58ab86b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2823,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 79,
"path": "/utils/readTestCases.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "from openpyxl import load_workbook\nimport re\nimport json\n\nclass readFile():\n def __init__(self):\n path = 'C:\\\\Users\\\\Esteban.Flores\\\\Documents\\\\1 Verndale\\\\2 Projects\\\\GE-GeneralElectric\\\\GE TestCases\\\\0942-(QA) Course Registration Module.xlsx'\n self.wb = load_workbook(path, data_only=True)\n self.cleanWords = [\n {\"from\": \"Verify\", \"to\": \"\"},\n {\"from\": \":\", \"to\": \"\"},\n {\"from\": \"On click\", \"to\": \"cta\"},\n {\"from\": \"On hover\", \"to\": \"cta\"},\n {\"from\": \"Component\", \"to\": \"\"},\n {\"from\": \"page displays accordingly in mobile\", \"to\": \"mobile/tablet\"},\n {\"from\": \"rtf (rich text format)\", \"to\": \"verify optional content managed rtf (rich text format)\"},\n ]\n self.tagWords = [\n {\"has\": \"text\", \"tag\": \"text\"},\n {\"has\": \"hover\", \"tag\": \"cta\"},\n {\"has\": \"click\", \"tag\": \"cta\"},\n {\"has\": \"rtf\", \"tag\": \"text\"},\n {\"has\": \"link\", \"tag\": \"link\"},\n {\"has\": \"image\", \"tag\": \"image\"},\n \n ]\n self.final =[]\n\n def __main__(self):\n\n for a in self.wb.sheetnames:\n validSheet = re.compile('TC|Mobile')\n # validate expression to see if sheetname is an actual testcase\n if(bool(re.search(validSheet, a))):\n self.readCells(a)\n\n def readCells(self, sheet):\n item = {\n \"component\":\"\",\n \"testcases\":[]\n }\n # Get Component Name of the sheet\n item['component'] = self.cleanCell(self.wb[str(sheet)].cell(row=1,column=2).value)\n\n # Make a list of all the description columns\n data = [self.wb[str(sheet)].cell(\n row=i, column=2).value for i in range(13, 150)]\n counter = 0\n for cell in data:\n test = {}\n if(cell != None):\n if('Verify' in cell):\n # Get testcase of sheet\n test[str(counter)] = cell.lower()\n counter+=1\n # Get tag for each testcase\n for tag in self.tagWords:\n if(tag['has'] in cell):\n test[\"tag\"] = tag['tag']\n if(item['component']=='mobile/tablet'):\n test[\"tag\"] = 'mobile'\n if(test != {}):\n item[\"testcases\"].append(test)\n \n self.final.append(item)\n \n with open('data.json', 'w') as outfile:\n json.dump(self.final, outfile)\n\n def cleanCell(self,cell):\n for word in self.cleanWords:\n cell = cell.replace(word['from'],word['to'])\n cell = cell.lower()\n \n return cell.strip()\n\nif(__name__ == \"__main__\"):\n app=readFile()\n app.__main__()\n"
},
{
"alpha_fraction": 0.5317796468734741,
"alphanum_fraction": 0.5476694703102112,
"avg_line_length": 34,
"blob_id": "28d47d0014a4cbba2fb28de3ff2c58c110689744",
"content_id": "9f63978e18f8f3386ba5baed1e3e9b613b485d2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 944,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 27,
"path": "/utils/readFiles.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "import os\nimport re\n\npath = os.chdir('C://Users//503025052//Documents//GE//GE TestCases')\nfilenames = os.listdir(path)\n\n\nfor index,filename in enumerate(filenames):\n try:\n extension = os.path.splitext(filename)[1][1:]\n if(extension=='xlsx'):\n number =re.findall(r'\\d+', str(filename))\n if(number[0]):\n taskName = filename.replace(number[0],'')\n taskName = taskName.replace(extension,'')\n taskName = taskName.replace('-','')\n taskName = taskName.replace('.','')\n taskName = taskName.replace('(QA)','')\n taskName = taskName.strip()\n \n numberJira = int(number[0])-3\n print(str(index)+'|'+str(taskName)+'|https://jira.verndale.com/browse/GEHC-'+str(numberJira))\n \n except IOError:\n print('Cant change %s' % (filename))\n\nprint(\"All Files have been updated\")"
},
{
"alpha_fraction": 0.8484848737716675,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 15.5,
"blob_id": "aba88c53777bba16295620dcee5c0a2d885f8904",
"content_id": "bb6c958e1f789dee25f43b1562ef5527f8a767f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/README.md",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "# TestCases\nTestcases Automation\n"
},
{
"alpha_fraction": 0.6816326379776001,
"alphanum_fraction": 0.6836734414100647,
"avg_line_length": 17.148147583007812,
"blob_id": "b5802d9004bd9f62e9032cdd4fa80030f24d4785",
"content_id": "a0b4e358ce879e9d72721475350d2b0a5861597c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 27,
"path": "/testcases/items.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# http://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass TestCasesItem(scrapy.Item):\n component = scrapy.Field()\n requirements = scrapy.Field()\n responsive = scrapy.Field()\n pass\n\n\nclass Requirements(scrapy.Item):\n\n description = scrapy.Field()\n pass\n\n\nclass Responsive(scrapy.Item):\n device = scrapy.Field()\n requirements = scrapy.Field()\n pass\n"
},
{
"alpha_fraction": 0.7435897588729858,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 19,
"blob_id": "50718e2eacdc7d4f48376d037a1d42e562aa3076",
"content_id": "0d441c94f06da15836f57d3fb1afade45f6d306e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/testcases/variables.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "USER='Esteban.Flores'\nPASS='estebanFS10'"
},
{
"alpha_fraction": 0.7243697643280029,
"alphanum_fraction": 0.7243697643280029,
"avg_line_length": 30.3157901763916,
"blob_id": "44f659df3075f1cb72f5dd6245b46460f2fb8e81",
"content_id": "dff74db77237d47e1f5475755f0fe5938af08c78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 595,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 19,
"path": "/testcases/main.py",
"repo_name": "estebanfloresf/testcases",
"src_encoding": "UTF-8",
"text": "from scrapy import cmdline\nimport os\nimport inspect\nimport logging\n\npath = os.path.abspath(os.path.join(os.path.dirname(\n os.path.realpath(__file__)), os.pardir)) # script directory\n\n\n# To generate the verified labels from the input excel (uncomment line below)\n# os.system('python '+path+'\\\\utils\\\\generateTC.py')\n\n# To Make a scrape of the confluence page (uncomment line below)\n# var = input(\"Please enter something: \")\n# print(\"You entered \" + str(var))\ncmdline.execute(\"scrapy crawl createTestCase\".split())\n\n# To read excel file\n# os.system('python '+path+'\\\\utils\\\\readTestCases.py')\n"
}
] | 9 |
yjfighting/testgit | https://github.com/yjfighting/testgit | a8d68a059d3d5fdf88114ebf7218a82d24fbf72d | 80a243b7aef729d4b579413d539c74e7d8d8c038 | 254e822bb06666c78a2229964f3bb6456fb21154 | refs/heads/master | "2020-04-09T04:28:14.956956" | "2018-12-02T08:02:27" | "2018-12-02T08:02:27" | 160,024,478 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7064846158027649,
"alphanum_fraction": 0.7201365232467651,
"avg_line_length": 18.511110305786133,
"blob_id": "1d5023e621871d42f965c9fc6ed9b46867a3db22",
"content_id": "b3a9b91782d3b98593d63774047a81bb23c3dae3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 935,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 45,
"path": "/hello_word.py",
"repo_name": "yjfighting/testgit",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2.7\n#-*- coding: utf-8 -*-\n\nmessage = \"hello python\"\nprint(message)\nprint(\"hello everyone.\")\n#将首字母大写\nprint(message.title())\n#将字符串全部大写\n\nfavorite_language=' python '\nfavorite_language.rstrip()\nprint(favorite_language)\nprint(favorite_language.strip())\nprint(favorite_language.lstrip()+favorite_language.strip()+ '\\n'+favorite_language)\n\n#对数列的增删改查\nalist=['apple','pear','egg','bear']\nprint alist\nprint(alist[0],alist[1],alist[2],alist[3])\nprint(\"so sorry for \"+alist[2]+\" that can't come here!\")\ndel alist[2]\nalist.insert(2,'star')\nprint alist\nalist[2]='car'\nprint alist\nalist.append('moon')\nprint alist\nalist.pop()\nprint alist\nalist.pop()\nalist.pop()\nalist.pop()\nprint alist\ndel alist[0]\nprint alist\n\n#对数列的排序\nblist=['pear','egg','bear','orange','moon']\nsorted(blist)\nprint blist\nprint(sorted(blist))\nprint(sorted(blist,reverse=True))\nprint blist\nprint(len(blist))\n\n"
}
] | 1 |
HarveyGW/Angrams.py | https://github.com/HarveyGW/Angrams.py | 2fa94fe5aa54de5c50ed490b62245f5672d813c5 | cef2c872f5a9d6f8ef05382b6b4c441ff792c096 | 5a114af70a151d81eb54bc81e9c3fe27488e378c | refs/heads/master | "2020-04-22T12:08:19.655990" | "2019-02-12T17:56:39" | "2019-02-12T17:56:39" | 170,362,862 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7906976938247681,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 20.5,
"blob_id": "aeec3e325f95f9d1c12682e2c25e3cd5ebff428c",
"content_id": "8db10e04b159d9deff3631d0b5a8aa76f6885b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/README.md",
"repo_name": "HarveyGW/Angrams.py",
"src_encoding": "UTF-8",
"text": "# Angrams.py\nAnagram Solver Made In Python\n"
},
{
"alpha_fraction": 0.6222222447395325,
"alphanum_fraction": 0.6333333253860474,
"avg_line_length": 17.842105865478516,
"blob_id": "c626ccbef40677710a409a74c091e2580cf183b2",
"content_id": "b5a10a7d7a71090c41aec8d137d3d89f24f6908b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 19,
"path": "/Main.py",
"repo_name": "HarveyGW/Angrams.py",
"src_encoding": "UTF-8",
"text": "#Made By HarveyGW\n\ndef anagramchk(word,chkword):\n for letter in word:\n if letter in chkword:\n chkword = chkword.replace(letter,'',1)\n else:\n return 0\n return 1\n\nwordin = input(\"Enter Anagram: \")\n\nf=open('Dictionary.txt', 'r')\nfor line in f:\n line=line.strip()\n if len(line)>=3:\n if anagramchk(line,wordin):\n print(line)\nf.close()\n\n\n"
}
] | 2 |
chixigua-kivi/Reinforcement-Learning-Practice | https://github.com/chixigua-kivi/Reinforcement-Learning-Practice | 8e156300e3ead1e165fb69d341f0c7b8e145785b | 57b937f506a6a475de46f243b206ba17c0540cab | 82c6754fb4142a96810ff73e165fb25423e4e7f2 | refs/heads/master | "2021-04-02T13:24:07.170447" | "2020-03-23T12:56:56" | "2020-03-23T12:56:56" | 248,280,297 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8070739507675171,
"alphanum_fraction": 0.8135048151016235,
"avg_line_length": 22.884614944458008,
"blob_id": "35b057409888d75f27fac532dad9b903e466057b",
"content_id": "b689a48898684c3c6bf9656a577c3546f62cf844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 26,
"path": "/README.md",
"repo_name": "chixigua-kivi/Reinforcement-Learning-Practice",
"src_encoding": "UTF-8",
"text": "# Reinforcement-Learning-Practice\n机器人大创项目强化学习部分编程代码\n\n主要包括:\n\nnatural-DQN\n\ndouble-DQN\n\ndueling-DQN\n\nprioritized-DQN\n\ndueling-DDQN\n\nprioritized-DDQN\n\n伪rainbow-DQN\n\n待改进的points:\n\n* e-greedy可以改为e不断衰减\n* PDDQN中$w_{i}=\\left(\\frac{1}{N \\cdot P_{\\mathrm{PRB}}(i)}\\right)^{\\beta}$重要性采样系数可以让β 在训练开始时赋值为一个小于1 的数,然后随着训练迭代数的增加,让β数不断变大,并最终到达 1(变回replay buffer) 。这样我们既可以确保训练速度能够增加,又可以让模型的收敛性得到保证。\n* 在硬件支持的情况下:a.加大记忆库的容量 b.减小learning rate但是不要太小 c.增大神经网络的规模:层数,神经元数目\n* reward-engineering:修改为连续变化的reward:随着离目标点的距离的变化也可以获得reward,而不是仅仅在到达目标点才获得+1的reward(sparse reward)\n* feature-engineering:创建能够反应state更多信息的feature;一般输入整个图像反应的信息较多,但是需要GPU加速支持\n\n"
},
{
"alpha_fraction": 0.4991539716720581,
"alphanum_fraction": 0.5173434615135193,
"avg_line_length": 27.299999237060547,
"blob_id": "dca4a1f8dd984cbbf5086a83093747f71c7312bc",
"content_id": "03086003e2a014abe0553b2e24a7262dc52d5ea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2778,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 80,
"path": "/prioritized-DQN/run_this.py",
"repo_name": "chixigua-kivi/Reinforcement-Learning-Practice",
"src_encoding": "UTF-8",
"text": "from maze_env1 import Maze\r\nfrom RL_brain import DeepQNetwork\r\nimport numpy as np\r\nimport tensorflow.compat.v1 as tf\r\ntf.disable_v2_behavior()\r\nimport matplotlib.pyplot as plt\r\nimport pickle\r\n\r\nepisodes = []\r\nsteps = []\r\n\r\ndef run_maze():\r\n step = 0 # 用来控制什么时候学习\r\n for episode in range(600):\r\n # 初始化环境\r\n observation = env.reset()\r\n\r\n while True:\r\n # 刷新环境\r\n env.render()\r\n\r\n # DQN 根据观测值选择行为 epison_greedy策略\r\n action = RL.choose_action(observation)\r\n\r\n # 环境根据行为给出下一个 state, reward, 是否终止\r\n observation_, reward, done = env.step(action)\r\n\r\n # DQN 存储记忆\r\n RL.store_transition(observation, action, reward, observation_)\r\n\r\n # 控制学习起始时间和频率 (先累积一些记忆再开始学习)\r\n #首先在200步之后才开始学习,之后每5步学习一次\r\n if (step > 500) and (step % 5 == 0):\r\n RL.learn()\r\n\r\n # 将下一个 state_ 变为 下次循环的 state\r\n observation = observation_\r\n\r\n # 如果终止, 就跳出循环\r\n if done:\r\n steps.append(step)\r\n episodes.append(episode)\r\n break\r\n step += 1 # 总步数\r\n\r\n # end of game\r\n print('game over')\r\n env.destroy()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n env = Maze()\r\n RL = DeepQNetwork(env.n_actions,\r\n env.n_features,#observation/state 的属性,如长宽高\r\n learning_rate=0.01,\r\n reward_decay=0.9,\r\n e_greedy=0.9,\r\n prioritized=True,\r\n replace_target_iter=200, # 每 200 步替换一次 target_net 的参数\r\n memory_size=2000, # 记忆上限\r\n # output_graph=True # 是否输出 tensorboard 文件\r\n )\r\n env.after(100, run_maze)#进行强化学习训练\r\n env.mainloop()\r\n\r\n #观看训练时间曲线\r\n his_prioritize = np.vstack((episodes, steps))\r\n\r\n file = open('his_prioritize.pickle', 'wb')\r\n pickle.dump(his_prioritize, file)\r\n file.close()\r\n\r\n plt.plot(his_prioritize[0, :], his_prioritize[1, :] - his_prioritize[1, 0], c='b', label='Prioritize DQN')\r\n plt.legend(loc='best') # legend图例,其中’loc’参数有多种,’best’表示自动分配最佳位置\r\n plt.ylabel('total training time')\r\n plt.xlabel('episode')\r\n plt.grid() # 显示网格线 1=True=默认显示;0=False=不显示\r\n plt.show()\r\n\r\n RL.plot_cost() # 观看神经网络的误差曲线\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
peturparkur/PythonA_star | https://github.com/peturparkur/PythonA_star | d6667fddb02ab2d54b9838f2efd2409a1ab5aca9 | fa01e173cf4e1cf2303aa19fda1b1ca745a0b610 | 447a14f1a20859145029af33c0e17d515e89a857 | refs/heads/master | "2022-12-19T05:10:38.519917" | "2020-10-05T18:22:46" | "2020-10-05T18:22:46" | 296,318,053 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7707006335258484,
"alphanum_fraction": 0.7834395170211792,
"avg_line_length": 25.16666603088379,
"blob_id": "1c51ee4e090d4b805c1a19a0959fc3455dede1aa",
"content_id": "f3994511ce82c6eb8dece9ba274af96fb0df162f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 6,
"path": "/README.md",
"repo_name": "peturparkur/PythonA_star",
"src_encoding": "UTF-8",
"text": "# PythonA_star\nA* Algorithm made in Python\n\nAStar2.py is the 2D grid A* pathfinding algorithm\n\nAStarN.py is the N-dimensional grid A* pathfinding algorithm.\n"
},
{
"alpha_fraction": 0.5936242938041687,
"alphanum_fraction": 0.6029093265533447,
"avg_line_length": 33.82222366333008,
"blob_id": "4793b5beebbb335974719bd45f5c05a1c71c232f",
"content_id": "2995b8367d8e850c580da07b2eebd8b3c21d1b82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6462,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 180,
"path": "/AStar2.py",
"repo_name": "peturparkur/PythonA_star",
"src_encoding": "UTF-8",
"text": "import time\r\nimport threading\r\nimport numpy as np\r\n\r\nclass point:\r\n x=0\r\n y=0\r\n g=0\r\n h=0\r\n parentX=0\r\n parentY=0\r\n #parent = point(x,y) #the previous points\r\n\r\n def __init__(self, x, y): #we create a gridpoint\r\n self.x = x\r\n self.y = y\r\n\r\n def f(self):\r\n return self.g+self.h\r\n\r\n def strPos(self):\r\n return str(self.x) + \", \" + str(self.y)\r\n\r\n def __lt__(self, other): #comparison between 2 points\r\n return self.f() < other.f()\r\n def __gt__(self, other):\r\n return self.f() > other.f()\r\n def __le__(self, other):\r\n return self.f() <= other.f()\r\n def __ge__(self, other):\r\n return self.f() >= other.f()\r\n\r\n\r\n\r\n#required each point has weight f\r\n#this is broken down as f = g+h where g is move cost from starting point, h is estimated cost to target\r\n#Note that Dijkstra pathfinding is the same as A* with h=0 for all nodes\r\n\r\n#create a closed list which we have visited already\r\n#create an open list which we have yet to visit\r\n#put the starting point in the open list\r\n\r\n# while the open list in non-empty take the smallest value from it and find its successors/neighbours\r\n\r\n# for each successor calculate the distance from start and estimated distance from end\r\n# set the values in the successor\r\n\r\n#if the there exists the same point in the open list as the successor with lower value skip\r\n# if there exists a point in closed list as the successor which has lower value skip, if it has higher value add the successor to the open list\r\n#end for each\r\n\r\n#put original point in the closed list\r\n\r\ndef InsertAt(list, val): #we want to insert val to the appropriate place\r\n for i in range(len(list)):\r\n if val < list[i]: \r\n list.insert(i,val)\r\n return i\r\n list.append(val)\r\n return len(list)-1\r\n #print(\"list at \" + str(i) + \" = \" + str(list[i].f()))\r\n for i in range(len(list)):\r\n print(\"list at \" + str(i) + \" = \" + str(list[i].f()))\r\n\r\ndef FindInList(list, val): #find a point in the list by coordinate\r\n for i in range(len(list)):\r\n if val.x != list[i].x: continue\r\n if val.y != list[i].y: continue\r\n return i #if both coordinates are the same return index\r\n return -1 #it never matched indecies return -1\r\n\r\n\r\ndef OneNorm(p1, p2):\r\n return abs(p1.x - p2.x) + abs(p1.y - p2.y)\r\n\r\ndef Is_Valid(p):\r\n if p.x<0 or p.x>gridSize[0]-1: return False\r\n if p.y<0 or p.y>gridSize[1]-1: return False\r\n return True\r\n\r\ndef Is_Blocked(p):\r\n for a in blockedList:\r\n if p.x != a.x: continue\r\n if p.y != a.y: continue\r\n return True #both coordinates are the same => blocked\r\n return False #None of the blocked coordinates are the same => not blocked\r\n\r\ngridSize = [10,10]\r\nblockedList = []\r\nfor i in range(4):\r\n x= 2*i + 1\r\n r = i % 2\r\n for j in range(9):\r\n blockedList.append(point(x,j+r))\r\n\r\nfor b in blockedList:\r\n print(\"blocked list Coordinates = \" + b.strPos())\r\n\r\nopenList = []\r\nclosedList = []\r\nstart = point(0,0) #starting point\r\nend = point(gridSize[0]-1, gridSize[1]-1) #target end point\r\nstart.g = 0\r\nstart.h = OneNorm(start,end) #manhattan distance or more mathematically known as one-norm\r\nopenList.append(start) #we add the initial starting point\r\n\r\nprint(\"target is at \" + end.strPos())\r\nt=0\r\nmoveList = []\r\nwhile len(openList) > 0: #as long as we have atleast one open element\r\n t +=1\r\n parent = openList.pop(0)#remove at get item at index 0\r\n successors = []\r\n successors.append(point(parent.x-1, parent.y))\r\n successors.append(point(parent.x+1, parent.y))\r\n successors.append(point(parent.x, parent.y-1))\r\n successors.append(point(parent.x, parent.y+1))\r\n #these are the potential successive points\r\n for a in successors:\r\n if not Is_Valid(a): continue #if a is not a valid point go for next successor\r\n if Is_Blocked(a): continue\r\n \r\n a.parentX=parent.x\r\n a.parentY=parent.y\r\n\r\n #for graphs should should be the edge length\r\n a.g = parent.g+1 #we took one more step than the previous point\r\n a.h = OneNorm(a,end)\r\n f = a.f()\r\n print(\"a.h = \" + str(a.h))\r\n\r\n if a.h <= 0.001: #we check if the estimated stiance is less than some small delta\r\n #this is the target\r\n print(\"found path\")\r\n moveList.append(a) #add the target\r\n pX = parent.parentX\r\n pY = parent.parentY\r\n moveList.append(parent)\r\n while pX != start.x or pY != start.y:\r\n #print(\"pX = \" + str(pX) + \", pY = \" + str(pY))\r\n pi = FindInList(closedList, point(pX, pY)) # try to find parent in closed list\r\n par = closedList[pi] #parent\r\n moveList.append(par)\r\n pX = par.parentX\r\n pY = par.parentY\r\n successors.clear()\r\n openList.clear()\r\n break #break from outer while loop as we have found the path to target\r\n\r\n #now we check if this successor is already in the open list\r\n index = FindInList(openList, a)\r\n #if the successor is not in the list we get -1 if it is in we get the index\r\n cindex = FindInList(closedList, a)\r\n #print(\"went past indecies\")\r\n\r\n\r\n #we note that a point can't be in both open and closed lists at once\r\n if index >= 0:\r\n #the point is already in the openList\r\n if f >= openList[index].f(): continue\r\n if cindex >=0:\r\n if f >= closedList[cindex].f(): continue\r\n closedList.remove(a) #since it is in the closed list and it has lower f remove from the closed list\r\n\r\n at = InsertAt(openList, a)\r\n #print(\"inserted at \" + str(at))\r\n continue\r\n\r\n closedList.append(parent) #once we have went through all the successors add the paprent to the closed / already visited points\r\n print(\"t=\"+str(t))\r\n #if t>5: break #for debugging we quit out of the while loop after 5 iterations\r\n\r\nfor a in moveList: # movelist has the target first and the first move in last index\r\n print(a.strPos()) # we print the positions\r\n\r\nif len(openList)>0:\r\n p = openList[0] #the closest estimated point to target\r\n print(\"closest point position = \" + str(p.x) + \", \" + str(p.y))\r\n print(\"closest point estimated distance h = \" + str(p.h))\r\n print(\"closest point distance from start g = \" + str(p.g))\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
austin1howard/snorkel-training-lib | https://github.com/austin1howard/snorkel-training-lib | 15e8bf14b5e582d4526456cc154872f85b8eb102 | 899ad00c4f1c767f706fd5858ecaba0cb222aa9c | 73a3701ef101537d1a5040dd740e141fda5bdc8e | refs/heads/master | "2020-05-01T18:19:51.065374" | "2019-03-25T21:09:51" | "2019-03-25T21:09:51" | 177,622,120 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7175572514533997,
"alphanum_fraction": 0.7251908183097839,
"avg_line_length": 27.478260040283203,
"blob_id": "4064b1d3bfd6b4959a80658730d48cfaff4403d7",
"content_id": "3ba84421988b8d93662ed1bcb8aa39d35af86e5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 655,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 23,
"path": "/setup.py",
"repo_name": "austin1howard/snorkel-training-lib",
"src_encoding": "UTF-8",
"text": "import os\nimport re\n\nimport setuptools\n\ndirectory = os.path.dirname(os.path.abspath(__file__))\n\n# Extract long_description\npath = os.path.join(directory, 'README.md')\nwith open(path) as read_file:\n long_description = read_file.read()\n\nsetuptools.setup(\n name='snorkel-training-lib',\n version='v0.7.0-beta',\n url='https://github.com/HazyResearch/snorkel/tree/master/tutorials/workshop/lib',\n description='Training libs from snorkel examples',\n long_description_content_type='text/markdown',\n long_description=long_description,\n license='Apache License 2.0',\n packages=setuptools.find_packages(),\n include_package_data=True,\n)\n"
},
{
"alpha_fraction": 0.8224852085113525,
"alphanum_fraction": 0.8224852085113525,
"avg_line_length": 169,
"blob_id": "68df123a650e88afc986b400053d5e23eff9b094",
"content_id": "c2bce74d1a8916e5adbbe5103d968e2143eff1de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 169,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 1,
"path": "/README.md",
"repo_name": "austin1howard/snorkel-training-lib",
"src_encoding": "UTF-8",
"text": "Extracted lib directory from snorkel project (found [here](https://github.com/HazyResearch/snorkel/tree/master/tutorials/workshop/lib)) into a standalone python library."
}
] | 2 |
tanmesh/cat-and-dog | https://github.com/tanmesh/cat-and-dog | 244271dc361fe71f8f3b1bcdd82274a38d6c721e | 1fa52036a796668dfbf2cc3d01ef80c2c4089cea | 95708dcf473af30348af8aba46f5bec2b5d337fd | refs/heads/master | "2020-04-16T05:34:28.128153" | "2019-01-16T21:38:52" | "2019-01-16T21:38:52" | 165,177,126 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 13,
"blob_id": "ecc58d09547b36f5d4d865610272911174e93e88",
"content_id": "1bd1deca38f207d4ce433acd70fcd3013ffc6a04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 1,
"path": "/README.md",
"repo_name": "tanmesh/cat-and-dog",
"src_encoding": "UTF-8",
"text": "# cat-and-dog\n"
},
{
"alpha_fraction": 0.652294397354126,
"alphanum_fraction": 0.6732368469238281,
"avg_line_length": 35.07777786254883,
"blob_id": "5b344fe64345d6b508989bee7c9245a22fdc4b2e",
"content_id": "33175235c6d135463dcb82cf68cbc6fa889c99e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3247,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 90,
"path": "/img_cla.py",
"repo_name": "tanmesh/cat-and-dog",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom keras.layers import Activation\nfrom keras.layers import Conv2D\nfrom keras.layers import Dense\nfrom keras.layers import Flatten\nfrom keras.layers import MaxPooling2D\nfrom keras.models import Sequential\nfrom keras_preprocessing.image import ImageDataGenerator\nfrom sklearn.model_selection import train_test_split\n\nfrom prepare_data import prepare_data, split_data\n\n\ndef img_classi():\n print(\"Splitting data into train and test...\")\n train_images_dogs_cats, test_images_dogs_cats = split_data()\n img_width = 150\n img_height = 150\n\n print(\"Preparing the train data...\")\n x, y = prepare_data(train_images_dogs_cats, img_width, img_height)\n print(\"Splitting the train data into training and validation set...\")\n x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=1)\n n_train = len(x_train)\n n_val = len(x_val)\n\n batch_size = 16\n\n print(\"Building the model..\")\n model = Sequential()\n\n print(\"Running the first layer...\")\n model.add(Conv2D(32, (3, 3), input_shape=(img_width, img_height, 3)))\n model.add(Activation('relu'))\n model.add(MaxPooling2D(pool_size=(2, 2)))\n\n print(\"Running the second layer...\")\n model.add(Conv2D(32, (3, 3)))\n model.add(Activation('relu'))\n model.add(MaxPooling2D(pool_size=(2, 2)))\n\n print(\"Running the third layer...\")\n model.add(Conv2D(64, (3, 3)))\n model.add(Activation('relu'))\n model.add(MaxPooling2D(pool_size=(2, 2)))\n\n print(\"Running the last layer...\")\n model.add(Flatten())\n model.add(Dense(64))\n model.add(Activation('relu'))\n # try:\n # model.add(Dropout(0.5))\n # except Exception as e:\n # print(\"There is error.........\"+str(e))\n model.add(Dense(1))\n model.add(Activation('sigmoid'))\n\n print(\"Compiling the model...\")\n model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])\n\n print(\"Model build.\")\n\n print('Data augmentation...')\n train_data_gen = ImageDataGenerator(rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)\n val_data_gen = ImageDataGenerator(rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)\n\n print('Preparing generators for training and validation sets...')\n train_generator = train_data_gen.flow(np.array(x_train), y_train, batch_size=batch_size)\n validation_generator = val_data_gen.flow(np.array(x_val), y_val, batch_size=batch_size)\n\n print('Fitting the model...')\n model.fit_generator(train_generator, steps_per_epoch=n_train // batch_size, epochs=30,\n validation_data=validation_generator, validation_steps=n_val // batch_size)\n\n print('Saving the model...')\n model.save_weights('model_wieghts.h5')\n model.save('model_keras.h5')\n print(\"Model saved...\")\n\n print('Generating test data...')\n x_test, y_test = prepare_data(test_images_dogs_cats, img_width, img_height)\n test_data_gen = ImageDataGenerator(rescale=1. / 255)\n test_generator = test_data_gen.flow(np.array(x_test), batch_size=batch_size)\n\n print(\"Predicting...\")\n pred = model.predict_generator(test_generator, verbose=1, steps=len(test_generator))\n print(\"Prediction is \" + str(pred))\n\n\nimg_classi()\n"
},
{
"alpha_fraction": 0.6247960925102234,
"alphanum_fraction": 0.6419249773025513,
"avg_line_length": 29.625,
"blob_id": "6accf7562d2e5704ced60925f2cfb5c3840003ba",
"content_id": "71d7f0b925e4117ae85c905ffcecb541637b3954",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1226,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 40,
"path": "/prepare_data.py",
"repo_name": "tanmesh/cat-and-dog",
"src_encoding": "UTF-8",
"text": "import os\nimport re\nimport cv2\n\n\ndef atoi(text):\n return int(text) if text.isdigit() else text\n\n\ndef natural_keys(text):\n return [atoi(c) for c in re.split('(\\d+)', text)]\n\n\ndef prepare_data(list_of_images_path, img_width, img_height):\n x = [] # images as arrays\n y = [] # labels\n for image_path in list_of_images_path:\n read_image = cv2.imread(image_path)\n tmp = cv2.resize(read_image, (img_width, img_height), interpolation=cv2.INTER_CUBIC)\n x.append(tmp)\n\n for i in list_of_images_path:\n if 'dog' in i:\n y.append(1)\n elif 'cat' in i:\n y.append(0)\n\n return x, y\n\n\ndef split_data():\n train_dir = '/Users/tanmesh/dev/cat_and_dog/dataset/train/'\n test_dir = '/Users/tanmesh/dev/cat_and_dog/dataset/test/'\n train_images_dogs_cats = [train_dir + i for i in os.listdir(train_dir)] # use this for full dataset\n test_images_dogs_cats = [test_dir + i for i in os.listdir(test_dir)]\n train_images_dogs_cats.sort(key=natural_keys)\n # train_images_dogs_cats = train_images_dogs_cats[0:1300] + train_images_dogs_cats[12500:13800]\n test_images_dogs_cats.sort(key=natural_keys)\n\n return train_images_dogs_cats, test_images_dogs_cats\n\n"
}
] | 3 |
RobMurray98/BribeNet | https://github.com/RobMurray98/BribeNet | 25fe1e448495e83ba4f393787e79b1f3118a6a4c | 09ddd8f15d9ab5fac44ae516ed92c6ba5e5119bc | 11e7407b390dac33f54b0025fd24fc212a002467 | refs/heads/master | "2022-11-25T11:24:48.851071" | "2020-05-09T11:37:43" | "2020-05-09T11:37:43" | 220,001,977 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7180511355400085,
"alphanum_fraction": 0.7228434681892395,
"avg_line_length": 36.93939208984375,
"blob_id": "077e65176c3a65b1c797af7144a91545067ef882",
"content_id": "0177c9a24b19cee247bde259c7f7cafe7bb8e6de",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 33,
"path": "/test/BribeNet/bribery/temporal/action/test_briberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\nfrom unittest.mock import MagicMock\n\nfrom BribeNet.bribery.temporal.action.briberyAction import BriberyActionTimeNotCorrectException, \\\n BriberyActionExecutedMultipleTimesException\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\n\n\nclass TestBriberyAction(TestCase):\n\n def setUp(self) -> None:\n self.briber = NonBriber(1)\n self.graph = NoCustomerActionGraph(self.briber)\n self.action = SingleBriberyAction(self.briber)\n\n def test_perform_action_fails_if_at_different_times(self):\n try:\n self.graph.get_time_step = MagicMock(return_value=self.action.get_time_step()+1)\n self.action.perform_action()\n except BriberyActionTimeNotCorrectException:\n return\n self.fail()\n\n def test_perform_action_fails_if_already_executed(self):\n try:\n self.action.add_bribe(0, 0.01)\n self.action.perform_action()\n self.action.perform_action()\n except BriberyActionExecutedMultipleTimesException:\n return\n self.fail()\n"
},
{
"alpha_fraction": 0.6101086735725403,
"alphanum_fraction": 0.6144126057624817,
"avg_line_length": 40.56651306152344,
"blob_id": "53ff6743d07d5eef8754341e30aefe41d127add2",
"content_id": "8d88ce61ac2a2ded8f0019bccfa26e462f3adb84",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18123,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 436,
"path": "/src/BribeNet/graph/ratingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\nfrom abc import ABC\nfrom copy import deepcopy\nfrom typing import Tuple, Optional, List, Any, Set\n\nimport networkit as nk\nimport numpy as np\nfrom weightedstats import weighted_mean, weighted_median, mean, median\n\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.flatWeightGenerator import FlatWeightedGraphGenerator\nfrom BribeNet.graph.generation.generator import GraphGenerator\nfrom BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\nDEFAULT_GEN = FlatWeightedGraphGenerator(GraphGeneratorAlgo.WATTS_STROGATZ, 30, 5, 0.3)\nMAX_RATING = 1.0\nMAX_DIFF = 0.6\n\n\nclass BribersAreNotTupleException(BribeNetException):\n pass\n\n\nclass NoBriberGivenException(BribeNetException):\n pass\n\n\nclass BriberNotSubclassOfBriberException(BribeNetException):\n pass\n\n\nclass VotesNotInstantiatedBySpecificsException(BribeNetException):\n pass\n\n\nclass TruthsNotInstantiatedBySpecificsException(BribeNetException):\n pass\n\n\nclass GammaNotSetException(BribeNetException):\n pass\n\n\nclass RatingGraph(ABC):\n \"\"\"\n Representation of network graph which bribers interact with\n \"\"\"\n\n def __init__(self, bribers: Tuple[Any], generator: GraphGenerator = DEFAULT_GEN, specifics=None,\n **kwargs):\n \"\"\"\n Abstract class for rating graphs\n :param bribers: the bribing actors on the graph\n :param generator: the graph generator used to instantiate the graph\n :param specifics: function in implementing class to call after the superclass initialisation,\n but prior to _finalise_init (template design pattern)\n :param **kwargs: additional keyword arguments to the graph, such as max_rating\n \"\"\"\n # Generate random ratings network\n self._g = generator.generate()\n from BribeNet.bribery.briber import Briber\n if issubclass(bribers.__class__, Briber):\n bribers = tuple([bribers])\n if not isinstance(bribers, tuple):\n raise BribersAreNotTupleException()\n if not bribers:\n raise NoBriberGivenException()\n for b in bribers:\n if not issubclass(b.__class__, Briber):\n raise BriberNotSubclassOfBriberException(f\"{b.__class__.__name__} is not a subclass of Briber\")\n self._bribers = bribers\n self._max_rating: float = MAX_RATING\n self._votes: np.ndarray[Optional[float]] = None\n self._truths: np.ndarray[float] = None\n self._rating_method: RatingMethod = RatingMethod.P_RATING\n self._gamma: Optional[float] = None\n if specifics is not None:\n specifics()\n self._finalise_init()\n\n def _finalise_init(self):\n \"\"\"\n Perform assertions that ensure everything is initialised\n \"\"\"\n if not isinstance(self._bribers, tuple):\n raise BribersAreNotTupleException(\"specifics of implementing class did not instantiate self._bribers \"\n \"as a tuple\")\n from BribeNet.bribery.briber import Briber\n for briber in self._bribers:\n if not issubclass(briber.__class__, Briber):\n raise BriberNotSubclassOfBriberException(f\"{briber.__class__.__name__} is not a subclass of Briber\")\n # noinspection PyProtectedMember\n briber._set_graph(self)\n if not isinstance(self._votes, np.ndarray):\n raise VotesNotInstantiatedBySpecificsException()\n if not isinstance(self._truths, np.ndarray):\n raise TruthsNotInstantiatedBySpecificsException()\n\n def get_bribers(self) -> Tuple[Any]:\n \"\"\"\n Get the bribers active on the graph\n :return: the bribers\n \"\"\"\n return self._bribers\n\n def get_max_rating(self) -> float:\n \"\"\"\n Get the maximum rating\n :return: the maximum rating\n \"\"\"\n return self._max_rating\n\n def set_rating_method(self, rating_method: RatingMethod):\n \"\"\"\n Set the rating method being used\n :param rating_method: the rating method to use\n \"\"\"\n self._rating_method = rating_method\n\n def set_gamma(self, gamma: float):\n \"\"\"\n Set gamma which is used as the dampening factor in P-gamma-rating\n :param gamma: the dampening factor in P-gamma-rating\n \"\"\"\n self._gamma = gamma\n\n def get_rating(self, node_id: int = 0, briber_id: int = 0, rating_method: Optional[RatingMethod] = None,\n nan_default: Optional[int] = None):\n \"\"\"\n Get the rating for a certain node and briber, according to the set rating method\n :param node_id: the node to find the rating of (can be omitted for O-rating)\n :param briber_id: the briber to find the rating of (can be omitted in single-briber rating graphs)\n :param rating_method: a rating method to override the current set rating method if not None\n :param nan_default: optional default integer value to replace np.nan as default return\n :return: the rating\n \"\"\"\n rating_method_used = rating_method or self._rating_method\n rating = np.nan\n if rating_method_used == RatingMethod.O_RATING:\n rating = self._o_rating(briber_id)\n elif rating_method_used == RatingMethod.P_RATING:\n rating = self._p_rating(node_id, briber_id)\n elif rating_method_used == RatingMethod.MEDIAN_P_RATING:\n rating = self._median_p_rating(node_id, briber_id)\n elif rating_method_used == RatingMethod.SAMPLE_P_RATING:\n rating = self._sample_p_rating(node_id, briber_id)\n elif rating_method_used == RatingMethod.WEIGHTED_P_RATING:\n rating = self._p_rating_weighted(node_id, briber_id)\n elif rating_method_used == RatingMethod.WEIGHTED_MEDIAN_P_RATING:\n rating = self._median_p_rating_weighted(node_id, briber_id)\n elif rating_method_used == RatingMethod.P_GAMMA_RATING:\n if self._gamma is None:\n raise GammaNotSetException()\n rating = self._p_gamma_rating(node_id, briber_id, self._gamma)\n if np.isnan(rating) and nan_default is not None:\n rating = nan_default\n return rating\n\n def get_graph(self):\n \"\"\"\n Return the NetworKit graph of the network\n Ensure this information isn't used by a briber to \"cheat\"\n :return: the graph\n \"\"\"\n return self._g\n\n def _neighbours(self, node_id: int, briber_id: int = 0) -> List[int]:\n \"\"\"\n Get the voting neighbours of a node\n :param node_id: the node to get neighbours of\n :param briber_id: the briber on which voting has been done\n :return: the voting neighbours of the node for the briber\n \"\"\"\n return [n for n in self.get_graph().neighbors(node_id) if not np.isnan(self._votes[n][briber_id])]\n\n def get_customers(self) -> List[int]:\n \"\"\"\n Get the customer ids without knowledge of edges or ratings\n :return: the customer ids in the graph\n \"\"\"\n return list(self.get_graph().iterNodes())\n\n def customer_count(self) -> int:\n \"\"\"\n Get the number of customers\n :return: the number of nodes in the graph\n \"\"\"\n return self.get_graph().numberOfNodes()\n\n def get_random_customer(self, excluding: Optional[Set[int]] = None) -> int:\n \"\"\"\n Gets the id of a random customer\n :param excluding: set of customer ids not to be returned\n :return: random node id in the graph\n \"\"\"\n if excluding is None:\n excluding = set()\n return random.choice(tuple(set(self.get_graph().iterNodes()) - excluding))\n\n def get_vote(self, idx: int):\n \"\"\"\n Returns the vote of a voter in the current network state\n :param idx: the id of the voter\n :return: np.nan if non-voter, otherwise float if single briber, np.ndarray of floats if multiple bribers\n \"\"\"\n return self._votes[idx]\n\n def _p_rating(self, node_id: int, briber_id: int = 0):\n \"\"\"\n Get the P-rating for the node\n :param node_id: the id of the node\n :param briber_id: the id number of the briber\n :return: mean of actual rating of neighbouring voters\n \"\"\"\n ns = self._neighbours(node_id, briber_id)\n if len(ns) == 0:\n return np.nan\n return mean([self.get_vote(n)[briber_id] for n in ns])\n\n def _p_rating_weighted(self, node_id: int, briber_id: int = 0):\n \"\"\"\n Get the P-rating for the node, weighted based on trust\n :param node_id: the id of the node\n :param briber_id: the id number of the briber\n :return: mean of actual rating of neighbouring voters\n \"\"\"\n ns = self._neighbours(node_id, briber_id)\n if len(ns) == 0:\n return np.nan\n weights = [self.get_weight(n, node_id) for n in ns]\n votes = [self.get_vote(n)[briber_id] for n in ns]\n return weighted_mean(votes, weights)\n\n def _median_p_rating(self, node_id: int, briber_id: int = 0):\n \"\"\"\n Get the median-based P-rating for the node\n :param node_id: the id of the node\n :param briber_id: the id number of the briber\n :return: median of actual rating of neighbouring voters\n \"\"\"\n ns = self._neighbours(node_id, briber_id)\n if len(ns) == 0:\n return np.nan\n return median([self.get_vote(n)[briber_id] for n in ns])\n\n def _median_p_rating_weighted(self, node_id: int, briber_id: int = 0):\n \"\"\"\n Get the median-based P-rating for the node, weighted based on trust\n :param node_id: the id of the node\n :param briber_id: the id number of the briber\n :return: median of actual rating of neighbouring voters\n \"\"\"\n ns = self._neighbours(node_id, briber_id)\n if len(ns) == 0:\n return np.nan\n weights = [self.get_weight(n, node_id) for n in ns]\n votes = [self.get_vote(n)[briber_id] for n in ns]\n return weighted_median(votes, weights)\n\n def _sample_p_rating(self, node_id: int, briber_id: int = 0):\n \"\"\"\n Get the sample-based P-rating for the node\n :param node_id: the id of the node\n :param briber_id: the id number of the briber\n :return: mean of a sample of actual rating of neighbouring voters\n \"\"\"\n ns = self._neighbours(node_id, briber_id)\n if len(ns) == 0:\n return np.nan\n sub = random.sample(ns, random.randint(1, len(ns)))\n return mean([self.get_vote(n)[briber_id] for n in sub])\n\n def _o_rating(self, briber_id: int = 0):\n \"\"\"\n Get the O-rating for the node\n :param briber_id: the id number of the briber\n :return: mean of all actual ratings\n \"\"\"\n ns = [n for n in self.get_graph().iterNodes() if not np.isnan(self._votes[n][briber_id])]\n if len(ns) == 0:\n return np.nan\n return mean([self.get_vote(n)[briber_id] for n in ns])\n\n def _p_gamma_rating(self, node_id: int, briber_id: int = 0, gamma: float = 0.05):\n \"\"\"\n Get the P-gamma-rating for the node, which weights nodes based on the gamma factor:\n The gamma factor is defined as gamma^(D(n,c) - 1), where n is our starting node, c\n is the node we are considering and D(n,c) is the shortest distance.\n :param briber_id: the id number of the briber\n :return: weighted mean of all actual ratings based on the gamma factor\n \"\"\"\n ns = [n for n in self._g.iterNodes() if (not np.isnan(self._votes[n][briber_id])) and n != node_id]\n # noinspection PyUnresolvedReferences\n unweighted_g = nk.graphtools.toUnweighted(self.get_graph())\n # noinspection PyUnresolvedReferences\n bfs_run = nk.distance.BFS(unweighted_g, node_id).run()\n distances = bfs_run.getDistances()\n weights = [gamma ** (distances[n] - 1) for n in ns]\n votes = [self.get_vote(n)[briber_id] for n in ns]\n return weighted_mean(votes, weights)\n\n def is_influential(self, node_id: int, k: float = 0.1, briber_id: int = 0,\n rating_method: Optional[RatingMethod] = None, charge_briber: bool = True) -> float:\n \"\"\"\n Determines if a node is influential using a small bribe\n :param node_id: the id of the node\n :param k: the cost of information\n :param briber_id: the briber for which the node may be influential\n :param rating_method: a rating method to override the current set rating method if not None\n :param charge_briber: whether this query is being made by a briber who must be charged and the ratings adjusted\n :return: float > 0 if influential, 0 otherwise\n \"\"\"\n prev_p = self.eval_graph(briber_id, rating_method)\n vote = self.get_vote(node_id)[briber_id]\n if (not np.isnan(vote)) and (vote < 1 - k):\n if charge_briber:\n # bribe via the briber in order to charge their utility\n self._bribers[briber_id].bribe(node_id, k)\n reward = self.eval_graph(briber_id, rating_method) - prev_p - k\n else:\n # \"bribe\" directly on the graph, not charging the briber and not affecting ratings\n g_ = deepcopy(self)\n g_.bribe(node_id, k, briber_id)\n reward = g_.eval_graph(briber_id, rating_method) - prev_p - k\n if reward > 0:\n return reward\n return 0.0\n\n def _get_influence_weight(self, node_id: int, briber_id: Optional[int] = 0):\n \"\"\"\n Get the influence weight of a node in the graph, as defined by Grandi\n and Turrini.\n :param node_id: the node to fetch the influence weight of\n :param briber_id: the briber (determines which neighbours have voted)\n :return: the influence weight of the node\n \"\"\"\n neighbourhood_sizes = [len(self._neighbours(n, briber_id)) for n in self._neighbours(node_id, briber_id)]\n neighbour_weights = [1.0 / n for n in neighbourhood_sizes if n > 0] # discard size 0 neighbourhoods\n return sum(neighbour_weights)\n\n def bribe(self, node_id, b, briber_id=0):\n \"\"\"\n Increase the rating of a node by an amount, capped at the max rating\n :param node_id: the node to bribe\n :param b: the amount to bribe the node\n :param briber_id: the briber who's performing the briber\n \"\"\"\n if not np.isnan(self._votes[node_id][briber_id]):\n self._votes[node_id][briber_id] = min(self._max_rating, self._votes[node_id][briber_id] + b)\n else:\n self._votes[node_id][briber_id] = min(self._max_rating, b)\n\n def eval_graph(self, briber_id=0, rating_method=None):\n \"\"\"\n Metric to determine overall rating of the graph\n :param rating_method: a rating method to override the current set rating method if not None\n :param briber_id: the briber being considered in the evaluation\n :return: the sum of the rating across the network\n \"\"\"\n return sum(self.get_rating(node_id=n, briber_id=briber_id, rating_method=rating_method, nan_default=0)\n for n in self.get_graph().iterNodes())\n\n def average_rating(self, briber_id=0, rating_method=None):\n voting_customers = [c for c in self.get_graph().iterNodes() if not np.isnan(self.get_vote(c))[briber_id]]\n return self.eval_graph(briber_id, rating_method) / len(voting_customers)\n\n def set_weight(self, node1_id: int, node2_id: int, weight: float):\n \"\"\"\n Sets a weight for a given edge, thus allowing for trust metrics to affect graph structure.\n :param node1_id: the first node of the edge\n :param node2_id: the second node of the edge\n :param weight: the weight of the edge to set\n \"\"\"\n self.get_graph().setWeight(node1_id, node2_id, weight)\n\n def get_weight(self, node1_id: int, node2_id: int) -> float:\n \"\"\"\n Gets the weight of a given edge.\n :param node1_id: the first node of the edge\n :param node2_id: the second node of the edge\n \"\"\"\n return self.get_graph().weight(node1_id, node2_id)\n\n def get_edges(self) -> [(int, int)]:\n return list(self.get_graph().iterEdges())\n\n def trust(self, node1_id: int, node2_id: int) -> float:\n \"\"\"\n Determines the trust of a given edge, which is a value from 0 to 1.\n This uses the average of the difference in vote between each pair of places.\n :param node1_id: the first node of the edge\n :param node2_id: the second node of the edge\n \"\"\"\n votes1 = self.get_vote(node1_id)\n votes2 = self.get_vote(node2_id)\n differences = votes1 - votes2\n nans = np.isnan(differences)\n differences[nans] = 0\n differences = np.square(differences)\n trust = 1 - (np.sum(differences) / (len(differences) * MAX_DIFF ** 2))\n return max(0, min(1, trust))\n\n def average_trust(self):\n \"\"\"\n Average trust value for all pairs of nodes\n \"\"\"\n trusts = [self.get_weight(a, b)\n for (a, b) in self.get_graph().iterEdges()]\n return np.mean(trusts)\n\n def __copy__(self):\n \"\"\"\n copy operation.\n :return: A shallow copy of the instance\n \"\"\"\n cls = self.__class__\n result = cls.__new__(cls)\n result.__dict__.update(self.__dict__)\n return result\n\n def __deepcopy__(self, memo=None):\n \"\"\"\n deepcopy operation.\n :param memo: the memo dictionary\n :return: A deep copy of the instance\n \"\"\"\n if memo is None:\n memo = {}\n cls = self.__class__\n result = cls.__new__(cls)\n memo[id(self)] = result\n for k, v in self.__dict__.items():\n # noinspection PyArgumentList\n setattr(result, k, deepcopy(v, memo))\n return result\n"
},
{
"alpha_fraction": 0.7368420958518982,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 18,
"blob_id": "4d11d84247e408bf3092f9cb9306d256c94fe806",
"content_id": "37c180cde10942d0d598ac3bb9fd5729d9026169",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 8,
"path": "/src/BribeNet/bribery/static/nonBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.static.briber import StaticBriber\n\n\n# performs no bribery\nclass NonBriber(StaticBriber):\n\n def _next_bribe(self):\n pass\n"
},
{
"alpha_fraction": 0.8168498277664185,
"alphanum_fraction": 0.8168498277664185,
"avg_line_length": 33.125,
"blob_id": "cfc1a4eaec0afc44846d6e41731a9083a286fa8e",
"content_id": "daf0781e06ba3ae93154b1ee6fef2551d65232e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 8,
"path": "/src/BribeNet/bribery/temporal/nonBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import TemporalBriber\n\n\nclass NonBriber(TemporalBriber):\n\n def _next_action(self) -> SingleBriberyAction:\n return SingleBriberyAction(self)\n"
},
{
"alpha_fraction": 0.7371202111244202,
"alphanum_fraction": 0.7397622466087341,
"avg_line_length": 38.78947448730469,
"blob_id": "018000a2ae440d7de8d1a5e6de5830b458011ed1",
"content_id": "1fc293a9702563bf2d2ca9fa4581e036040c5ebd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 757,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 19,
"path": "/test/BribeNet/bribery/temporal/test_oneMoveRandomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.temporal.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom test.BribeNet.bribery.temporal.briberTestCase import BriberTestCase\n\n\nclass TestOneMoveRandomBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = OneMoveRandomBriber(10)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def test_next_action_increases_p_rating(self):\n graph = self.briber._g\n action = self.briber.next_action()\n briber_id = self.briber.get_briber_id()\n prev_eval = graph.eval_graph(briber_id=briber_id)\n\n action.perform_action()\n self.assertGreaterEqual(graph.eval_graph(briber_id=briber_id), prev_eval)\n\n"
},
{
"alpha_fraction": 0.7455357313156128,
"alphanum_fraction": 0.7477678656578064,
"avg_line_length": 27,
"blob_id": "ac1e70efeab8e4bbfcded0ac33822a306a26619d",
"content_id": "3c288366a80c6c169b802751fe448c130d1b638a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 448,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 16,
"path": "/test/BribeNet/bribery/temporal/briberTestCase.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nfrom unittest import TestCase\n\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\n\n\nclass BriberTestCase(TestCase, ABC):\n\n @abstractmethod\n def setUp(self) -> None:\n self.briber = NonBriber(0)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def tearDown(self) -> None:\n del self.briber, self.rg\n"
},
{
"alpha_fraction": 0.5415365099906921,
"alphanum_fraction": 0.552779495716095,
"avg_line_length": 35.1127815246582,
"blob_id": "b5a1def4a05aa17bb3fd94a80ff9cf53942aaa5f",
"content_id": "52a01deff3d47e71c2287356e3578f4889ab5d10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4803,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 133,
"path": "/src/BribeNet/gui/apps/static/graph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\nfrom matplotlib.colors import rgb2hex\nfrom networkit.nxadapter import nk2nx\nfrom networkit.viztasks import drawGraph\nfrom networkx import spring_layout\n\n\nclass GraphFrame(tk.Frame):\n \"\"\"\n Frame for showing the current state and actions that can be taken for the static model being run\n \"\"\"\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.controller = controller\n self.fig = plt.figure(figsize=(8, 8))\n self.ax = self.fig.add_subplot(111)\n self.canvas = FigureCanvasTkAgg(self.fig, master=self)\n self.canvas.get_tk_widget().pack(side=tk.BOTTOM, fill=tk.BOTH, expand=True)\n self.results = []\n self.graph = None\n self.pos = None\n self.briber = None\n\n button1 = tk.Button(self, text=\"Exit\", command=lambda: self.master.show_frame(\"WizardFrame\"))\n button1.pack()\n\n button2 = tk.Button(self, text=\"Show Influential Nodes\", command=self.show_influential)\n button2.pack()\n\n button3 = tk.Button(self, text=\"Bribe\", command=self.next_bribe)\n button3.pack()\n\n button4 = tk.Button(self, text=\"Results\", command=self.to_results)\n button4.pack()\n\n self.txt = tk.StringVar()\n lbl = tk.Label(self, textvariable=self.txt)\n lbl.pack()\n self.txt.set(\"Average P-Rating: -- \\nLast Briber: --\")\n\n def set_graph(self, graph, briber):\n self.graph = graph\n self.pos = spring_layout(nk2nx(self.graph.get_graph()))\n self.briber = briber\n self.results.append(self.graph.eval_graph())\n self.display_graph()\n\n def to_results(self):\n self.master.plot_results(self.results)\n self.results = []\n self.master.show_frame(\"ResultsFrame\")\n\n def display_graph(self, last=None):\n\n cmap = plt.get_cmap(\"Purples\")\n colors = []\n for c in self.graph.get_customers():\n if np.isnan(self.graph.get_vote(c)):\n colors.append(\"gray\")\n else:\n colors.append(rgb2hex(cmap(self.graph.get_vote(c)[0])[:3]))\n # labels = {c: round(self.graph.p_rating(c), 2) for c in self.graph.get_customers()}\n\n self.ax.clear()\n\n drawGraph(self.graph.get_graph(), node_size=400, node_color=colors, ax=self.ax, pos=self.pos)\n for c in self.graph.get_customers():\n if np.isnan(self.graph.get_vote(c)):\n rating = \"None\"\n else:\n rating = round(self.graph.get_vote(c)[0], 2)\n\n self.ax.annotate(\n str(c) + \":\\n\" +\n \"Rating: \" + str(rating) + \"\\n\" +\n \"PRating: \" + str(round(self.graph.get_rating(c), 2)),\n xy=(self.pos[c][0], self.pos[c][1]),\n bbox=dict(boxstyle=\"round\", fc=\"w\", ec=\"0.5\", alpha=0.9)\n )\n if last is not None:\n self.ax.add_artist(plt.Circle(\n (self.pos[last][0], self.pos[last][1]), 0.1,\n color=\"r\",\n fill=False,\n linewidth=3.0\n ))\n self.canvas.draw()\n avp = str(round(self.graph.eval_graph(), 2))\n if last is not None:\n self.txt.set(\"Average P-Rating: \" + avp + \" \\nLast Bribed: --\")\n else:\n self.txt.set(\"Average P-Rating: \" + avp + \" \\nLast Bribed: \" + str(last))\n\n def next_bribe(self):\n c = self.briber.next_bribe()\n self.display_graph(last=c)\n avp = self.graph.eval_graph()\n self.results.append(avp)\n self.canvas.draw()\n\n def show_influential(self):\n cmap = plt.get_cmap(\"Purples\")\n colors = []\n\n for c in self.graph.get_customers():\n if self.graph.is_influential(c, charge_briber=False):\n colors.append(\"yellow\")\n elif np.isnan(self.graph.get_vote(c)):\n colors.append(\"gray\")\n else:\n colors.append(rgb2hex(cmap(self.graph.get_vote(c)[0])[:3]))\n self.ax.clear()\n\n for c in self.graph.get_customers():\n if np.isnan(self.graph.get_vote(c)):\n rating = \"None\"\n else:\n rating = round(self.graph.get_vote(c)[0], 2)\n\n self.ax.annotate(\n str(c) + \":\\n\" +\n \"Rating: \" + str(rating) + \"\\n\" +\n \"PRating: \" + str(round(self.graph.get_rating(c), 2)),\n xy=(self.pos[c][0], self.pos[c][1]),\n bbox=dict(boxstyle=\"round\", fc=\"w\", ec=\"0.5\", alpha=0.9)\n )\n drawGraph(self.graph.get_graph(), node_size=500, node_color=colors, ax=self.ax, pos=self.pos)\n self.canvas.draw()\n"
},
{
"alpha_fraction": 0.8072289228439331,
"alphanum_fraction": 0.8072289228439331,
"avg_line_length": 34.57143020629883,
"blob_id": "8d75707360f661c6d0199bbf2a0719c44eb97f09",
"content_id": "fe65502dc8c97c626f78a5da72aed4e70602651c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 7,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/o_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass ORating(RatingMethodFrame):\n enum_value = RatingMethod.O_RATING\n name = 'o_rating'\n"
},
{
"alpha_fraction": 0.7090908885002136,
"alphanum_fraction": 0.7227272987365723,
"avg_line_length": 49.769229888916016,
"blob_id": "bdbe218e7fe56457535eea17543007e85ce0f69e",
"content_id": "632330aab327e7b77e33ace5588e17e80810b1c1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 660,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 13,
"path": "/run.sh",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nSCRIPTPATH=\"$( cd \"$(dirname \"$0\")\" >/dev/null 2>&1 || exit ; pwd -P )\"\ncd \"$SCRIPTPATH\" || exit\nif ! [[ $PYTHONPATH =~ $SCRIPTPATH ]]\nthen\n export PYTHONPATH=$PYTHONPATH:$SCRIPTPATH/src\nfi\napt-get install -y docker.io x11-xserver-utils # ensure docker and xhost commands are available\nsystemctl start docker # ensure docker daemon is running\nservice docker start # ensure docker service is running\ndocker build -t temporal_model_gui . # build the docker container\nxhost + # let the docker container use the host display\ndocker run -it --rm -e DISPLAY=$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix temporal_model_gui # run the docker container\n"
},
{
"alpha_fraction": 0.6380141973495483,
"alphanum_fraction": 0.6487943530082703,
"avg_line_length": 44.19230651855469,
"blob_id": "9972eceacde4e67d3a4bf6406d00f24c679b7d84",
"content_id": "04a907f773b6a7a72c5ed22c1a4597afbd268b7c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3525,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 78,
"path": "/src/BribeNet/gui/apps/temporal/wizard/wizard.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nimport numpy as np\n\nfrom BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.bribers import TemporalBribers\nfrom BribeNet.gui.apps.temporal.wizard.generation import TemporalGeneration\nfrom BribeNet.gui.apps.temporal.wizard.rating_method import TemporalRatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.settings import TemporalSettings\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\nSUBFRAME_CLASSES = (TemporalSettings, TemporalBribers, TemporalGeneration, TemporalRatingMethod)\nSUBFRAME_DICT = {i: c.__class__.__name__ for (i, c) in enumerate(SUBFRAME_CLASSES)}\n\n\nclass WizardFrame(tk.Frame):\n \"\"\"\n Frame for the wizard to construct a temporal model run\n \"\"\"\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.parent = parent\n self.controller = controller\n\n self.subframes = {}\n\n for c in SUBFRAME_CLASSES:\n page_name = c.__name__\n frame = c(self)\n self.subframes[page_name] = frame\n\n self.subframes[TemporalSettings.__name__].grid(row=0, column=0, padx=10, pady=10, sticky=\"nsew\")\n self.subframes[TemporalBribers.__name__].grid(row=0, column=1, rowspan=2, padx=10, pady=10, sticky=\"nsew\")\n self.subframes[TemporalGeneration.__name__].grid(row=1, column=0, rowspan=2, padx=10, pady=10, sticky=\"nsew\")\n self.subframes[TemporalRatingMethod.__name__].grid(row=1, column=1, padx=10, pady=10, sticky=\"nsew\")\n\n run_button = tk.Button(self, text=\"Run\", command=self.on_button)\n run_button.grid(row=2, column=1, pady=20, sticky='nesw')\n\n def add_briber(self, b_type, u0):\n self.controller.add_briber(b_type, u0)\n\n def on_button(self):\n graph_type = self.subframes[TemporalGeneration.__name__].get_graph_type()\n graph_args = self.subframes[TemporalGeneration.__name__].get_args()\n bribers = self.subframes[TemporalBribers.__name__].get_all_bribers()\n rating_method = self.subframes[TemporalRatingMethod.__name__].get_rating_method()\n rating_method_args = self.subframes[TemporalRatingMethod.__name__].get_args()\n\n if not bribers:\n # noinspection PyUnresolvedReferences\n tk.messagebox.showerror(message=\"Graph needs one or more bribers\")\n return\n\n try:\n for briber in bribers:\n strat_type = briber[0]\n briber_args = briber[1:]\n self.controller.add_briber(strat_type, *(briber_args[:-2]))\n true_averages = np.asarray([args[-2] for args in bribers])\n true_std_devs = np.asarray([args[-1] for args in bribers])\n params = self.subframes[TemporalSettings.__name__].get_args() + (true_averages, true_std_devs)\n self.controller.add_graph(graph_type, graph_args, params)\n self.controller.g.set_rating_method(rating_method)\n if rating_method == RatingMethod.P_GAMMA_RATING:\n self.controller.g.set_gamma(rating_method_args[0])\n self.controller.update_results()\n except Exception as e:\n if issubclass(e.__class__, BribeNetException):\n # noinspection PyUnresolvedReferences\n tk.messagebox.showerror(message=f\"{e.__class__.__name__}: {str(e)}\")\n self.controller.clear_graph()\n return\n self.controller.clear_graph()\n raise e\n\n self.controller.show_frame(\"GraphFrame\")\n"
},
{
"alpha_fraction": 0.8237287998199463,
"alphanum_fraction": 0.8237287998199463,
"avg_line_length": 41.14285659790039,
"blob_id": "67d7ff20301c86f7726810186374ab3527bcab2e",
"content_id": "8097ac9829bd56b53a65887ce6aabfea8ad1d5f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 295,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 7,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/weighted_median_p_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass WeightedMedianPRating(RatingMethodFrame):\n enum_value = RatingMethod.WEIGHTED_MEDIAN_P_RATING\n name = 'weighted_median_p_rating'\n"
},
{
"alpha_fraction": 0.7250134944915771,
"alphanum_fraction": 0.7298757433891296,
"avg_line_length": 43.07143020629883,
"blob_id": "cf9073225770e1c0a24538849dc4ec2f4dd6f470",
"content_id": "830704377516a37dd1cdc22724956df52954aa3b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1851,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 42,
"path": "/test/BribeNet/graph/static/test_ratingGraphBuilder.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom BribeNet.bribery.static.influentialNodeBriber import InfluentialNodeBriber\nfrom BribeNet.bribery.static.mostInfluentialNodeBriber import MostInfluentialNodeBriber\nfrom BribeNet.bribery.static.nonBriber import NonBriber\nfrom BribeNet.bribery.static.oneMoveInfluentialNodeBriber import OneMoveInfluentialNodeBriber\nfrom BribeNet.bribery.static.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.bribery.static.randomBriber import RandomBriber\nfrom BribeNet.graph.static.ratingGraphBuilder import RatingGraphBuilder, BriberType\n\n\nclass TestRatingGraphBuilder(TestCase):\n\n def setUp(self) -> None:\n self.builder = RatingGraphBuilder()\n\n def tearDown(self) -> None:\n del self.builder\n\n def test_add_briber(self):\n classes = zip(BriberType._member_names_, [NonBriber, RandomBriber, OneMoveRandomBriber, InfluentialNodeBriber,\n MostInfluentialNodeBriber, OneMoveInfluentialNodeBriber])\n for b, c in classes:\n self.builder.add_briber(getattr(BriberType, b), u0=10)\n self.assertIsInstance(self.builder.bribers[-1], c)\n\n def test_build_no_bribers(self):\n rg = self.builder.build()\n self.assertIsInstance(rg.get_bribers()[0], NonBriber)\n\n def test_build_one_briber(self):\n self.builder.add_briber(BriberType.Random)\n rg = self.builder.build()\n self.assertIsInstance(rg.get_bribers()[0], RandomBriber)\n\n def test_build_multiple_bribers(self):\n self.builder.add_briber(BriberType.Random).add_briber(BriberType.InfluentialNode)\n rg = self.builder.build()\n bribers = rg.get_bribers()\n self.assertEqual(len(bribers), 2)\n self.assertIsInstance(bribers[0], RandomBriber)\n self.assertIsInstance(bribers[1], InfluentialNodeBriber)\n"
},
{
"alpha_fraction": 0.6744681000709534,
"alphanum_fraction": 0.6787233948707581,
"avg_line_length": 23.736841201782227,
"blob_id": "c36cd542f3272c0aca21016df8af1d01952ee575",
"content_id": "3df061d647fdd05be8a7641b92337434d7fc3e66",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 19,
"path": "/src/docker_main.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from sys import exit\n\nfrom BribeNet.gui.main import GUI\n\n\"\"\"\nDue to a bug where app.mainloop() will not exit on closing of the root Tk instance if a Toplevel was at any stage\ninstantiated, we use sys.exit(0) to 'hard exit' such that the Docker container does not hang after closing.\n\"\"\"\n\n\ndef hard_exit(tk_app):\n tk_app.destroy()\n exit(0)\n\n\nif __name__ == \"__main__\":\n app = GUI()\n app.protocol(\"WM_DELETE_WINDOW\", lambda: hard_exit(app))\n app.mainloop()\n"
},
{
"alpha_fraction": 0.5959596037864685,
"alphanum_fraction": 0.6262626051902771,
"avg_line_length": 11.375,
"blob_id": "09e1e4433c5f16bf0452c2adac162bdbd784b72f",
"content_id": "09b28d1441544ea78bea7a7c0f543e853d8d2b17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 8,
"path": "/src/BribeNet/graph/temporal/action/actionType.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import enum\n\n\[email protected]\nclass ActionType(enum.Enum):\n NONE = 0\n BRIBED = 1\n SELECT = 2\n"
},
{
"alpha_fraction": 0.6695765852928162,
"alphanum_fraction": 0.6769969463348389,
"avg_line_length": 37.830509185791016,
"blob_id": "c39055dc4814d2178b79a81f7bb1e661270cb0bd",
"content_id": "fe95aa4abe2f9cef84e0551846e17d61331e753d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2291,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 59,
"path": "/src/BribeNet/graph/temporal/weighting/communityWeighting.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\n# noinspection PyUnresolvedReferences\nfrom networkit import Graph\n# noinspection PyUnresolvedReferences\nfrom networkit.community import PLM\n\n\ndef get_communities(graph: Graph) -> [[int]]:\n \"\"\"\n Gets the underlying communities of the graph, as sets of nodes.\n \"\"\"\n communities = PLM(graph, refine=False).run().getPartition()\n return [communities.getMembers(i) for i in communities.getSubsetIds()]\n\n\ndef gauss_constrained(mean: float, std: float) -> float:\n return max(0, min(1, random.gauss(mean, std)))\n\n\ndef get_std_dev(total_size: int, comm_size: int) -> float:\n \"\"\"\n In community generation, larger communities should have a smaller standard\n deviation (representing tighter-knit communities). This generates a std dev\n based on the ratio of the number of nodes in this community to the number\n of nodes in the total graph.\n\n Since we want a larger standard deviation for a smaller ratio, we take\n 1/ratio, which goes from total_size (for comm_size=1) to 1 (for ratio = 1).\n We divide this by total_size to get a normalised value, and then by 3 so\n that we can easily go three standard deviations without leaving the range.\n \"\"\"\n ratio = comm_size / total_size # range 0 to 1.\n return (1 / ratio) / (total_size * 3)\n\n\ndef assign_community_weights(graph: Graph, mean: float, std_dev: float = 0.05) -> [float]:\n \"\"\"\n For each community, assign it a mean and then give values within it a\n normally distributed random value with that mean and standard deviation\n proportional to community size.\n \"\"\"\n weights = [0 for _ in graph.iterNodes()]\n communities = get_communities(graph)\n print(communities)\n total_size = len(weights)\n for community in communities:\n comm_size = len(community)\n comm_mean = gauss_constrained(mean, std_dev)\n if comm_size == 1:\n # noinspection PyTypeChecker\n # manually verified to be correct typing (rob)\n weights[community[0]] = comm_mean\n else:\n for node in community:\n # noinspection PyTypeChecker\n # manually verified to be correct typing (rob)\n weights[node] = gauss_constrained(comm_mean, get_std_dev(total_size, comm_size))\n return weights\n"
},
{
"alpha_fraction": 0.6388422846794128,
"alphanum_fraction": 0.6522650718688965,
"avg_line_length": 43.14814758300781,
"blob_id": "45c4838cc7aa6ddc3a20d723317048fd0eca6e08",
"content_id": "f5effbb06de36eea074b5042fbd6504598d56f96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2384,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 54,
"path": "/src/BribeNet/graph/temporal/weighting/traverseWeighting.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from random import gauss\n\n# noinspection PyUnresolvedReferences\nfrom networkit import Graph\nfrom numpy import mean as average\n\n\ndef assign_traverse_averaged(graph: Graph, mean: float, std_dev: float = 0.2) -> [float]:\n \"\"\"\n Assign node 0 with the mean. Then assign all of its neighbours with a value\n close to that mean (weight + N(0, std_dev)), then their neighbours and so on.\n By properties of normals, every node has weight ~ N(mean, x * (std_dev**2))\n where x is the shortest distance from node 0, but nodes that are linked\n share very similar weights. Locally similar, globally variable.\n This version allows nodes with already assigned weights to be affected, by\n tracking each weight as a set and using its average.\n \"\"\"\n weight_sets = [[] for _ in graph.iterNodes()]\n weight_sets[0] = [mean]\n nodeset = [0]\n\n while len(nodeset) > 0:\n node = nodeset[0]\n nodeset = nodeset[1:]\n for neighbour in graph.neighbors(node):\n if len(weight_sets[neighbour]) == 0:\n nodeset.append(neighbour)\n weight_sets[neighbour].append(average(weight_sets[node]) + gauss(0, std_dev))\n weights = [average(weight_sets[i]) for i in range(len(weight_sets))]\n avg_weight = average(weights)\n return [min(1, max(0, weights[i] * mean / avg_weight)) for i in range(len(weights))]\n\n\ndef assign_traverse_weights(graph: Graph, mean: float, std_dev: float = 0.05) -> [float]:\n \"\"\"\n Assign node 0 with the mean. Then assign all of its neighbours with a value\n close to that mean (weight + N(0, std_dev)), then their neighbours and so on.\n By properties of normals, every node has weight ~ N(mean, x * (std_dev**2))\n where x is the shortest distance from node 0, but nodes that are linked\n share very similar weights. Locally similar, globally variable.\n \"\"\"\n weights = [-1 for _ in graph.iterNodes()]\n # noinspection PyTypeChecker\n weights[0] = mean\n nodeset = [0]\n while len(nodeset) > 0:\n node = nodeset[0]\n nodeset = nodeset[1:]\n for neighbour in graph.neighbors(node):\n if weights[neighbour] == -1:\n weights[neighbour] = weights[node] + gauss(0, std_dev)\n nodeset.append(neighbour)\n avg_weight = average(weights)\n return [min(1, max(0, weights[i] * mean / avg_weight)) for i in range(len(weights))]\n"
},
{
"alpha_fraction": 0.524193525314331,
"alphanum_fraction": 0.5501791834831238,
"avg_line_length": 30.885713577270508,
"blob_id": "65f78e42dbacfbb06dd641cc62f58777e63a8d43",
"content_id": "1c23ed065e2159e63bd66eac34f96910384ff7a5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1116,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 35,
"path": "/src/BribeNet/gui/classes/tooltip.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\n# noinspection PyUnusedLocal\nclass ToolTip(object):\n \"\"\"\n Show a tooltip\n from https://stackoverflow.com/a/56749167/5539184\n \"\"\"\n\n def __init__(self, widget, text):\n self.widget = widget\n self.tip_window = None\n self.id = None\n self.x = self.y = 0\n self.text = text\n\n def show_tip(self, *args):\n if self.tip_window is not None or not self.text:\n return\n x, y, cx, cy = self.widget.bbox(\"insert\")\n x = x + self.widget.winfo_rootx() + 57\n y = y + cy + self.widget.winfo_rooty() + 27\n self.tip_window = tw = tk.Toplevel(self.widget)\n tw.wm_overrideredirect(1)\n tw.wm_geometry(\"+%d+%d\" % (x, y))\n label = tk.Label(tw, text=self.text, wraplength=400, justify=tk.LEFT,\n background=\"#ffffe0\", relief=tk.SOLID, borderwidth=1,\n font=(\"tahoma\", \"10\", \"normal\"))\n label.pack(ipadx=1)\n\n def hide_tip(self, *args):\n if self.tip_window is not None:\n self.tip_window.destroy()\n self.tip_window = None\n"
},
{
"alpha_fraction": 0.5804474353790283,
"alphanum_fraction": 0.5884155631065369,
"avg_line_length": 37.845237731933594,
"blob_id": "85e9d3c336433f52d7cd7111efb886e8e5147569",
"content_id": "c2f735f42da308c67997ded7ed9e11d644863c67",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3263,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 84,
"path": "/test/BribeNet/graph/static/test_multiBriberRatingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nfrom unittest import TestCase\n\nfrom BribeNet.bribery.static.nonBriber import NonBriber\nfrom BribeNet.bribery.static.randomBriber import RandomBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\n\n\nclass TestMultiBriberRatingGraph(TestCase):\n\n def setUp(self) -> None:\n # noinspection PyTypeChecker\n self.rg = StaticRatingGraph((RandomBriber(10), NonBriber(10)))\n\n def tearDown(self) -> None:\n del self.rg\n\n def test_neighbours(self):\n for i in range(len(self.rg.get_bribers())):\n for node in self.rg.get_customers():\n self.assertIsInstance(self.rg._neighbours(node, i), list)\n\n def test_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_rating(i, b) >= 0)\n\n def test_median_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._median_p_rating(i, b) >= 0)\n\n def test_sample_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._sample_p_rating(i, b) >= 0)\n\n def test_p_gamma_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n self.assertAlmostEqual(self.rg._p_gamma_rating(i, gamma=0), self.rg._p_rating(i))\n\n def test_weighted_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_weighted_median_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_o_rating(self):\n for b in range(len(self.rg.get_bribers())):\n rating = self.rg._o_rating(b)\n self.assertTrue(rating >= 0)\n\n def test_is_influential(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertGreaterEqual(self.rg.is_influential(i, 0.2, b, charge_briber=False), 0)\n\n def test_bribe(self):\n for i in range(len(self.rg.get_bribers())):\n initial_value = self.rg.eval_graph(i)\n for j in self.rg.get_customers():\n g_copy = deepcopy(self.rg)\n g_copy.bribe(j, 0.1, i)\n bribed_value = g_copy.eval_graph(i)\n self.assertTrue(initial_value != bribed_value)\n\n def test_eval_graph(self):\n for b in range(len(self.rg.get_bribers())):\n self.assertGreaterEqual(self.rg.eval_graph(b), 0)\n \n def test_trust(self):\n for u in self.rg.get_customers():\n for v in self.rg.get_customers():\n trust1 = self.rg.trust(u, v)\n trust2 = self.rg.trust(v, u)\n self.assertEqual(trust1, trust2)\n self.assertGreaterEqual(trust1, 0)\n self.assertLessEqual(trust1, 1)\n"
},
{
"alpha_fraction": 0.6629244089126587,
"alphanum_fraction": 0.667305588722229,
"avg_line_length": 39.35359191894531,
"blob_id": "a0d750abab2013fc19b38b736256f30c361e800f",
"content_id": "de74e39683dda032028a381201dc9b0085a54891",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7304,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 181,
"path": "/src/BribeNet/gui/apps/temporal/main.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nimport os\n\nfrom networkit.nxadapter import nk2nx\nfrom networkx import spring_layout\n\nfrom BribeNet.bribery.temporal.budgetNodeBriber import BudgetNodeBriber\nfrom BribeNet.bribery.temporal.influentialNodeBriber import InfluentialNodeBriber\nfrom BribeNet.bribery.temporal.mostInfluentialNodeBriber import MostInfluentialNodeBriber\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.bribery.temporal.oneMoveEvenBriber import OneMoveEvenBriber\nfrom BribeNet.bribery.temporal.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.bribery.temporal.pGreedyBriber import PGreedyBriber\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.flatWeightGenerator import FlatWeightedGraphGenerator\nfrom BribeNet.graph.temporal.action.actionType import ActionType\nfrom BribeNet.graph.temporal.thresholdGraph import ThresholdGraph\nfrom BribeNet.gui.apps.static.wizard.algos.barabasi_albert import BarabasiAlbert\nfrom BribeNet.gui.apps.static.wizard.algos.composite import Composite\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.budget import BudgetFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.even import EvenFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.influential import InfluentialFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.most_influential import MostInfluentialFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.non import NonFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.p_greedy import PGreedyFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.random import RandomFrame\nfrom BribeNet.gui.apps.temporal.graph import GraphFrame\nfrom BribeNet.gui.apps.temporal.result import ResultsFrame\nfrom BribeNet.gui.apps.temporal.results_wizard.results import ResultsStore\nfrom BribeNet.gui.apps.temporal.wizard.wizard import WizardFrame\nfrom BribeNet.helpers.override import override\n\nFRAMES_CLASSES = (WizardFrame, GraphFrame, ResultsFrame)\n\nFRAMES_DICT = {i: c.__class__.__name__ for (i, c) in enumerate(FRAMES_CLASSES)}\n\nX_AXIS_OPTIONS = (\"Time\", \"Utility Spent\")\nY_AXIS_OPTIONS = (\"Average Rating\", \"Total Utility\", \"Average Trust\")\n\n\ndef switch_briber(strategy_type, *args):\n switcher = {\n RandomFrame.name: OneMoveRandomBriber,\n InfluentialFrame.name: InfluentialNodeBriber,\n MostInfluentialFrame.name: MostInfluentialNodeBriber,\n NonFrame.name: NonBriber,\n EvenFrame.name: OneMoveEvenBriber,\n BudgetFrame.name: BudgetNodeBriber,\n PGreedyFrame.name: PGreedyBriber\n }\n return switcher.get(strategy_type)(*args)\n\n\nclass TemporalGUI(tk.Toplevel):\n \"\"\"\n Window for the temporal wizard and running environment\n \"\"\"\n\n def __init__(self, controller, *args, **kwargs):\n super().__init__(controller, *args, **kwargs)\n self.title(\"Temporal Model\")\n self.controller = controller\n\n # application window\n container = tk.Frame(self)\n container.grid(row=0, column=0, sticky='nsew')\n container.grid_rowconfigure(0, weight=1)\n container.grid_columnconfigure(0, weight=1)\n\n # frame for each displayed page\n self.frames = {}\n for F in FRAMES_CLASSES:\n page_name = F.__name__\n frame = F(parent=container, controller=self)\n self.frames[page_name] = frame\n\n frame.grid(row=0, column=0, sticky=\"nsew\")\n\n self.show_frame(WizardFrame.__name__)\n self.bribers = []\n self.bribers_spent = []\n self.results = ResultsStore(X_AXIS_OPTIONS, Y_AXIS_OPTIONS)\n self.briber_names = []\n self.g = None\n\n def clear_graph(self):\n self.bribers = []\n self.bribers_spent = []\n self.results = ResultsStore(X_AXIS_OPTIONS, Y_AXIS_OPTIONS)\n self.briber_names = []\n self.g = None\n\n def show_frame(self, page):\n self.frames[page].tkraise()\n\n def add_briber(self, b, *args):\n self.bribers.append(switch_briber(b, *args))\n self.bribers_spent.append(0)\n self.briber_names.append(f\"Briber{len(self.bribers)}: {b}: u0={args[0]}\")\n\n def add_graph(self, gtype, args, params):\n if not self.bribers:\n raise RuntimeError(\"No Bribers added to graph\")\n\n if gtype == BarabasiAlbert.name:\n gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.BARABASI_ALBERT, *args)\n elif gtype == Composite.name:\n gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.COMPOSITE, *args)\n else:\n gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.WATTS_STROGATZ, *args)\n\n self.g = ThresholdGraph(\n tuple(self.bribers),\n generator=gen,\n non_voter_proportion=params[0],\n threshold=params[1],\n d=params[2],\n q=params[3],\n pay=params[4],\n apathy=params[5],\n learning_rate=params[6],\n true_averages=params[7],\n true_std_devs=params[8]\n )\n\n self.frames[GraphFrame.__name__].set_pos(spring_layout(nk2nx(self.g.get_graph())))\n\n self.frames[GraphFrame.__name__].add_briber_dropdown()\n self.frames[GraphFrame.__name__].draw_basic_graph(self.g)\n\n def update_results(self):\n\n self.results.add(\"Average Rating\", [self.g.average_rating(briber_id=b) for b in range(0, len(self.bribers))])\n self.results.add(\"Total Utility\", [b.get_resources() for b in self.bribers])\n self.results.add(\"Average Trust\", self.g.average_trust())\n self.results.add(\"Utility Spent\", [self.bribers_spent[b] for b in range(0, len(self.bribers))])\n self.results.add(\"Time\", self.g.get_time_step())\n\n def plot_results(self, x_label, y_label):\n self.frames[ResultsFrame.__name__].plot_results(self.results, x_label, y_label)\n self.show_frame(ResultsFrame.__name__)\n\n def next_step(self):\n\n last_round_was_bribery = self.g.is_bribery_round()\n self.g.step()\n\n if last_round_was_bribery:\n for bribers, bribe in self.g.get_last_bribery_actions()[-1].get_bribes().items():\n self.bribers_spent[bribers] += sum(bribe.values())\n\n self.update_results()\n\n if last_round_was_bribery:\n info = \"BRIBES\\n\"\n for bribers, bribe in self.g.get_last_bribery_actions()[-1].get_bribes().items():\n for c, n in bribe.items():\n info += f\"Briber {bribers + 1}: {c} --> {n}\\n\"\n else:\n info = \"CUSTOMERS\\n\"\n for c, a in self.g.get_last_customer_action().actions.items():\n if a[0] == ActionType.NONE:\n info += f\"Customer {c}: No Action\\n\"\n elif a[0] == ActionType.BRIBED:\n info += f\"Customer {c}: Bribed to {a[1]}\\n\"\n elif a[0] == ActionType.SELECT:\n info += f\"Customer {c}: Going to {a[1]}\\n\"\n\n self.frames[GraphFrame.__name__].draw_basic_graph(self.g)\n self.frames[GraphFrame.__name__].set_info(info)\n\n @override\n def destroy(self):\n if self.controller is not None:\n self.controller.show_main()\n super().destroy()\n\n\nif __name__ == '__main__':\n app = TemporalGUI(None)\n app.mainloop()\n"
},
{
"alpha_fraction": 0.6747283339500427,
"alphanum_fraction": 0.6831405758857727,
"avg_line_length": 48.18965530395508,
"blob_id": "3a77d3ddbed0d371a7ce7cdd7cab2c4f4b734cc0",
"content_id": "395c23c212df55c34ad2d4aac015549484960897",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2853,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 58,
"path": "/test/BribeNet/graph/temporal/action/test_customerAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.graph.temporal.action.customerAction import CustomerAction, CustomerActionExecutedMultipleTimesException,\\\n CustomerActionTimeNotCorrectException\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom BribeNet.graph.temporal.action.actionType import ActionType\nfrom random import sample, randint, shuffle\nfrom unittest.mock import MagicMock\n\n\nclass TestCustomerAction(TestCase):\n\n def setUp(self) -> None:\n self.briber = NonBriber(0)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def test_set_bribed_from_bribery_action(self):\n nodes = self.rg.get_customers()\n for _ in range(10):\n customer_action = CustomerAction(self.rg)\n bribery_action = SingleBriberyAction(self.briber)\n bribed_nodes = sample(nodes, randint(1, len(nodes)))\n for bribed_node in bribed_nodes:\n bribery_action.add_bribe(bribed_node, 1.0)\n customer_action.set_bribed_from_bribery_action(bribery_action)\n bribed_in_customer_action = [c[0] for c in customer_action.actions.items() if c[1][0] == ActionType.BRIBED]\n self.assertEqual(set(bribed_in_customer_action), set(bribed_nodes))\n not_bribed_in_customer_action = [c[0] for c in customer_action.actions.items()\n if c[1][0] != ActionType.BRIBED]\n self.assertEqual(set(not_bribed_in_customer_action) & set(bribed_nodes), set())\n\n @staticmethod\n def __partition(list_in, n):\n shuffle(list_in)\n return [list_in[i::n] for i in range(n)]\n\n def test_perform_action_runs_normally(self):\n nodes = self.rg.get_customers()\n for _ in range(10):\n customer_action = CustomerAction(self.rg)\n partition = TestCustomerAction.__partition(nodes, 3)\n for n in partition[0]:\n customer_action.set_bribed(n, [0])\n for n in partition[1]:\n customer_action.set_select(n, 0)\n customer_action.perform_action(0)\n self.assertTrue(customer_action.get_performed())\n\n def test_perform_action_fails_when_time_incorrect(self):\n customer_action = CustomerAction(self.rg)\n self.rg.get_time_step = MagicMock(return_value=self.rg.get_time_step()+1)\n self.assertRaises(CustomerActionTimeNotCorrectException, customer_action.perform_action, 0)\n\n def test_perform_action_fails_when_executed_twice(self):\n customer_action = CustomerAction(self.rg)\n customer_action.perform_action(0)\n self.assertRaises(CustomerActionExecutedMultipleTimesException, customer_action.perform_action, 0)\n"
},
{
"alpha_fraction": 0.6934523582458496,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 38.52941131591797,
"blob_id": "252109009962909262e171eb8c03ea37fdf99b66",
"content_id": "28a03960c354c16ee29b81fb8fe7c88bf476d213",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 17,
"path": "/src/BribeNet/bribery/temporal/randomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import TemporalBriber\n\nDELTA = 0.001 # ensures total bribes do not exceed budget\n\n\nclass RandomBriber(TemporalBriber):\n\n def _next_action(self) -> SingleBriberyAction:\n customers = self.get_graph().get_customers()\n # array of random bribes\n bribes = [random.uniform(0.0, 1.0) for _ in customers]\n bribes = [b * (max(0.0, self.get_resources() - DELTA)) / sum(bribes) for b in bribes]\n bribery_dict = {i: bribes[i] for i in customers}\n return SingleBriberyAction(self, bribes=bribery_dict)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 20.77777862548828,
"blob_id": "96cb65de655f0d2bedab6555003e284068df921d",
"content_id": "aa0494c1b2a21a6f6ed3d1fe0452475f18d4e0fb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 9,
"path": "/test/BribeNet/graph/test_ratingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\n\nclass TestRatingGraph(TestCase):\n \"\"\"\n See test/graph/static/test_singleBriberRatingGraph and test/graph/static/test_multiBriberRatingGraph\n \"\"\"\n\n pass\n"
},
{
"alpha_fraction": 0.7705696225166321,
"alphanum_fraction": 0.7729430198669434,
"avg_line_length": 33.16216278076172,
"blob_id": "872fca2aec485c8647d84a018c5524bbf9c20f03",
"content_id": "7e21edd837ec43dadedd4a1562da8989659c3a19",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1264,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 37,
"path": "/src/BribeNet/graph/generation/__init__.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import enum\n\nfrom networkit.generators import WattsStrogatzGenerator, BarabasiAlbertGenerator\n\nfrom BribeNet.graph.generation.algo.compositeGenerator import CompositeGenerator\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass GraphGenerationAlgoNotDefinedException(BribeNetException):\n pass\n\n\[email protected]\nclass GraphGeneratorAlgo(enum.Enum):\n \"\"\"\n Enum of usable NetworKit graph generation algorithms\n \"\"\"\n WATTS_STROGATZ = 0\n BARABASI_ALBERT = 1\n COMPOSITE = 2\n\n\ndef algo_to_constructor(g: GraphGeneratorAlgo):\n \"\"\"\n Conversion method from an instance of the GraphGeneratorAlgo enum to a instantiable NetworKit generator class\n :param g: the algorithm\n :return: the relevant NetworKit generator class\n :raises GraphGenerationAlgoNotDefinedException: if g is not a member of the GraphGeneratorAlgo enum\n \"\"\"\n if g == GraphGeneratorAlgo.WATTS_STROGATZ:\n return WattsStrogatzGenerator\n if g == GraphGeneratorAlgo.BARABASI_ALBERT:\n return BarabasiAlbertGenerator\n if g == GraphGeneratorAlgo.COMPOSITE:\n return CompositeGenerator\n # Add more algorithms here if needed\n raise GraphGenerationAlgoNotDefinedException(f\"{g} is not a member of the GraphGeneratorAlgo enum\")\n"
},
{
"alpha_fraction": 0.6652078628540039,
"alphanum_fraction": 0.6652078628540039,
"avg_line_length": 30.517240524291992,
"blob_id": "8174f82a3861d9be87c0e3df1a0699fc8aa88e61",
"content_id": "1212d54f356201c152a9eafe16f310fa6d61e1f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 914,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 29,
"path": "/src/BribeNet/graph/generation/generator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import abc\n\n# noinspection PyUnresolvedReferences\nfrom networkit import Graph\n\nfrom BribeNet.graph.generation import GraphGeneratorAlgo, algo_to_constructor\n\n\nclass GraphGenerator(abc.ABC):\n\n def __init__(self, a: GraphGeneratorAlgo, *args, **kwargs):\n \"\"\"\n Thin wrapper class for NetworKit graph generation algorithms\n :param a: the GraphGenerationAlgo to use\n :param args: any arguments to this generator\n :param kwargs: any keyword arguments to this generator\n \"\"\"\n self._algo = a\n self._args = args\n self._kwargs = kwargs\n self._generator = algo_to_constructor(self._algo)(*args, **kwargs)\n\n @abc.abstractmethod\n def generate(self) -> Graph:\n \"\"\"\n Call generate on the generator defined by this class and perform any additional actions\n :return: a NetworKit Graph\n \"\"\"\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.5777137875556946,
"alphanum_fraction": 0.5884045958518982,
"avg_line_length": 44.457942962646484,
"blob_id": "6ac5999725ae385ce5b8142fa0eed365686eccd2",
"content_id": "5729bb8441d9dd97515d7d5ab00dfcea56d94c8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4864,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 107,
"path": "/src/BribeNet/graph/generation/algo/compositeGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from math import floor, log, ceil\nfrom random import gauss, sample, random\n\nimport networkit as nk\n# noinspection PyUnresolvedReferences\nfrom networkit import Graph\nfrom networkit.generators import BarabasiAlbertGenerator, WattsStrogatzGenerator\n\n\ndef _make_complete(n: int):\n g_ = Graph(n)\n for i in g_.iterNodes():\n for j in g_.iterNodes():\n if i < j:\n g_.addEdge(i, j)\n return g_\n\n\nclass CompositeGenerator(object):\n \"\"\"\n Pretend to extend inaccessible networkit._NetworKit.StaticGraphGenerator\n \"\"\"\n\n def __init__(self, n: int, community_count: int, small_world_neighbours: int, rewiring: float,\n scale_free_k: int, probability_reduce: float = 0.05):\n self._n = n\n self._community_count = community_count\n self._small_world_neighbours = small_world_neighbours\n self._rewiring = rewiring\n self._scale_free_k = scale_free_k\n self._probability_reduce = probability_reduce\n\n def generate(self):\n # First, generate a scale free network, which acts as our community network.\n communities = BarabasiAlbertGenerator(self._scale_free_k, self._community_count, 4, True).generate()\n small_world_graphs = {}\n node_count = communities.numberOfNodes()\n community_size = self._n / self._community_count\n # Then generate a small world graph for each node with size decided\n # by a Gaussian distribution around the average node size.\n i = node_count - 1\n for node in communities.iterNodes():\n local_size = gauss(community_size, community_size / 3)\n # Choose local_n such that all communities have size at least two.\n local_n = max(min(round(local_size), self._n - (2 * i)), 2)\n # If it's the last iteration, we much \"use up\" the rest of the nodes.\n if i == 0:\n local_n = self._n\n # For a random graph to be connected, we require that 2k >> ln(n).\n # (2k because of how NetworKit defines k.)\n # => k < (n-1)/2\n connectivity = max(self._small_world_neighbours, floor(log(local_n)))\n # However, we also require that 2k < n-1, since otherwise you end\n # up with double links.\n connectivity = max(0, min(ceil((local_n - 1) / 2) - 1, connectivity))\n if local_n > 3:\n # Sometimes WattsStrogatzGenerators return unconnected graphs.\n # This is due to the fact that 2k >> ln(n) is vague, and also\n # bounded above by 2k < n-1.\n # Therefore, we repeat the process until a connected graph is\n # created. This shouldn't loop too many times.\n is_connected = False\n while not is_connected:\n small_world_graphs[node] = WattsStrogatzGenerator(local_n, connectivity, self._rewiring).generate()\n # noinspection PyUnresolvedReferences\n connected_components = nk.components.ConnectedComponents(small_world_graphs[node]).run()\n is_connected = connected_components.numberOfComponents() == 1\n else:\n small_world_graphs[node] = _make_complete(local_n)\n self._n -= local_n\n i -= 1\n # Build a merged graph.\n big_graph = Graph(0, False, False)\n ranges = [0]\n partition = []\n neighbours = [list(communities.neighbors(node)) for node in communities.iterNodes()]\n # To avoid neighbour sets having edges going both ways, delete references to nodes larger than themselves.\n for n in range(len(neighbours)):\n neighbours[n] = list(filter(lambda x: x < n, neighbours[n]))\n for graph in small_world_graphs.values():\n # noinspection PyUnresolvedReferences\n nk.graphtools.append(big_graph, graph)\n ranges.append(big_graph.numberOfNodes())\n partition.append(list(range(ranges[-2], ranges[-1])))\n # Finally, connect these small world graphs where their parent nodes are connected.\n for i in range(len(neighbours)):\n for j in neighbours[i]:\n # Connect partitions i and j\n n1 = partition[i]\n n2 = partition[j]\n p = 1.0\n for nc1 in sample(n1, len(n1)):\n for nc2 in sample(n2, len(n2)):\n # Connect with probability p\n if random() <= p:\n big_graph.addEdge(nc1, nc2)\n p = p * self._probability_reduce\n return big_graph\n\n\nif __name__ == '__main__':\n import matplotlib.pyplot as plt\n from networkit.viztasks import drawGraph\n\n g = CompositeGenerator(4000, 15, 50, 0.1, 2).generate()\n drawGraph(g)\n plt.show()\n"
},
{
"alpha_fraction": 0.6736111044883728,
"alphanum_fraction": 0.6736111044883728,
"avg_line_length": 17,
"blob_id": "844e28790e592a03957c50cdfd41000af479df39",
"content_id": "b638dd90feb724adb452937f30867011e5fe6f8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 8,
"path": "/src/BribeNet/gui/apps/static/briber_wizard/frame.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\nclass StaticBriberWizardFrame(tk.Frame):\n \"\"\"\n Frame for pop-up wizard for adding a static briber\n \"\"\"\n pass\n"
},
{
"alpha_fraction": 0.6605431437492371,
"alphanum_fraction": 0.6629393100738525,
"avg_line_length": 32.83783721923828,
"blob_id": "f6df7615e4f33e5868770ac450102182eef57266",
"content_id": "01a5935cdab19820018a53cefa0b0cfabf7d3a41",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 37,
"path": "/src/BribeNet/bribery/static/briber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nfrom BribeNet.bribery.briber import Briber, BriberyGraphNotSetException\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass GraphNotSubclassOfStaticRatingGraphException(BribeNetException):\n pass\n\n\nclass StaticBriber(Briber, ABC):\n \"\"\"\n Static bribers perform static bribery actions instantaneously on StaticRatingGraphs\n The abstract method next_bribe must be implemented to define the bribery action of the briber\n \"\"\"\n\n def __init__(self, u0: float):\n super().__init__(u0=u0)\n\n def _set_graph(self, g):\n from BribeNet.graph.static.ratingGraph import StaticRatingGraph\n if not issubclass(g.__class__, StaticRatingGraph):\n raise GraphNotSubclassOfStaticRatingGraphException(f\"{g.__class__.__name__} is not a subclass of \"\n \"StaticRatingGraph\")\n super()._set_graph(g)\n\n @abstractmethod\n def _next_bribe(self):\n \"\"\"\n Statically perform some bribery action on the graph\n \"\"\"\n raise NotImplementedError\n\n def next_bribe(self):\n if self.get_graph() is None:\n raise BriberyGraphNotSetException()\n self._next_bribe()\n"
},
{
"alpha_fraction": 0.5814506411552429,
"alphanum_fraction": 0.5921521782875061,
"avg_line_length": 34.787235260009766,
"blob_id": "4c19ddcf3b5cb658eb1d5f6a3dd3e2bd2104c877",
"content_id": "64b9089ad9b9876fad0adf70d6cb96c955e1644a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1682,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 47,
"path": "/src/BribeNet/gui/classes/param_list_frame.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import abc\nimport os\nimport tkinter as tk\n\nfrom PIL import ImageTk, Image\n\nfrom BribeNet.gui.classes.tooltip import ToolTip\n\n\nclass ParamListFrame(tk.Frame, abc.ABC):\n name = \"ABC\"\n\n def __init__(self, parent):\n super().__init__(parent)\n self.parent = parent\n self.params = {}\n self.descriptions = {}\n img_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'info.png')\n self.info_img = ImageTk.PhotoImage(Image.open(img_path))\n self.tooltips = []\n self.images = []\n\n def get_args(self):\n return tuple(p.get() for p in self.params.values())\n\n def get_name(self):\n return self.name\n\n def grid_params(self, show_name=True):\n offset = 0\n if show_name:\n name_label = tk.Label(self, text=self.name)\n name_label.grid(row=0, column=0, columnspan=3, pady=10)\n offset = 1\n for i, (name, var) in enumerate(self.params.items()):\n label = tk.Label(self, text=name)\n label.grid(row=i + offset, column=0)\n canvas_frame = tk.Frame(self)\n canvas = tk.Canvas(master=canvas_frame, width=16, height=16)\n self.tooltips.append(ToolTip(canvas_frame, self.descriptions[name]))\n canvas_frame.bind('<Enter>', self.tooltips[i].show_tip)\n canvas_frame.bind('<Leave>', self.tooltips[i].hide_tip)\n self.images.append(canvas.create_image(0, 0, anchor=tk.NW, image=self.info_img))\n entry = tk.Entry(self, textvariable=var)\n canvas.pack()\n canvas_frame.grid(row=i + offset, column=1, padx=30)\n entry.grid(row=i + offset, column=2)\n"
},
{
"alpha_fraction": 0.5752480626106262,
"alphanum_fraction": 0.5829658508300781,
"avg_line_length": 38.868133544921875,
"blob_id": "e2071583c24690056d0a75775ec4436dc8c71760",
"content_id": "e8b357922af1d572d28393e9079f9ba6080ea3af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3628,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 91,
"path": "/test/BribeNet/graph/temporal/test_multiBriberRatingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nfrom unittest import TestCase\n\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.bribery.temporal.randomBriber import RandomBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\n\n\nclass TestMultiBriberRatingGraph(TestCase):\n\n def setUp(self) -> None:\n self.rg = NoCustomerActionGraph((RandomBriber(10), NonBriber(10)))\n\n def tearDown(self) -> None:\n del self.rg\n\n def test_neighbours(self):\n for i in range(len(self.rg.get_bribers())):\n for node in self.rg.get_customers():\n self.assertIsInstance(self.rg._neighbours(node, i), list)\n\n def test_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_rating(i, b) >= 0)\n\n def test_median_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._median_p_rating(i, b) >= 0)\n\n def test_sample_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._sample_p_rating(i, b) >= 0)\n\n def test_o_rating(self):\n for b in range(len(self.rg.get_bribers())):\n self.assertTrue(self.rg._o_rating(b) >= 0)\n\n def test_p_gamma_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n self.assertAlmostEqual(self.rg._p_gamma_rating(i, gamma=0), self.rg._p_rating(i))\n\n def test_weighted_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_weighted_median_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_is_influential(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertGreaterEqual(self.rg.is_influential(i, 0.2, b, charge_briber=False), 0)\n\n def test_bribe(self):\n for i in range(len(self.rg.get_bribers())):\n initial_value = self.rg.eval_graph(i)\n for j in self.rg.get_customers():\n g_copy = deepcopy(self.rg)\n g_copy.bribe(j, 0.1, i)\n bribed_value = g_copy.eval_graph(i)\n self.assertTrue(initial_value != bribed_value)\n\n def test_eval_graph(self):\n for b in range(len(self.rg.get_bribers())):\n self.assertGreaterEqual(self.rg.eval_graph(b), 0)\n\n def test_trust_update(self):\n # Set all votes to 0.\n g_copy = deepcopy(self.rg)\n for u in g_copy.get_customers():\n g_copy._votes[u][0] = 0\n for c in g_copy.get_customers():\n g_copy_2 = deepcopy(g_copy)\n # Then bribe one individual.\n g_copy_2.bribe(0, 1, 0)\n # Update the trust.\n g_copy_2._update_trust()\n # Make sure that the trust goes down for each connected node.\n for n in g_copy.get_customers():\n if self.rg._g.hasEdge(c, n):\n initial_trust = g_copy.get_weight(c, n)\n updated_trust = g_copy_2.get_weight(c, n)\n self.assertGreaterEqual(initial_trust, updated_trust)\n"
},
{
"alpha_fraction": 0.7455268502235413,
"alphanum_fraction": 0.7514910697937012,
"avg_line_length": 34.92856979370117,
"blob_id": "269e3834778da245ec55f51c21956510269711a2",
"content_id": "19101f93540670d4e5c37d279c4f558c1d155aae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 14,
"path": "/test/BribeNet/bribery/static/test_randomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.static.randomBriber import RandomBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\nfrom test.BribeNet.bribery.static.briberTestCase import BriberTestCase\n\n\nclass TestRandomBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = RandomBriber(10)\n self.rg = StaticRatingGraph(self.briber)\n\n def test_next_bribe_does_not_exceed_budget(self):\n self.briber.next_bribe()\n self.assertTrue(self.briber.get_resources() >= 0)\n"
},
{
"alpha_fraction": 0.6252252459526062,
"alphanum_fraction": 0.6252252459526062,
"avg_line_length": 26.75,
"blob_id": "c7fa4d7997f4fd9664861f974fb82e143fd05c4a",
"content_id": "4578c2fffe93acbf5479518a81034e39a72d7f00",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 20,
"path": "/src/BribeNet/bribery/static/oneMoveRandomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\nimport numpy as np\n\nfrom BribeNet.bribery.static.briber import StaticBriber\n\n\nclass OneMoveRandomBriber(StaticBriber):\n\n def _next_bribe(self):\n customers = self.get_graph().get_customers()\n # pick random customer from list\n c = random.choice(customers)\n max_rating = self.get_graph().get_max_rating()\n vote = self.get_graph().get_vote(c)[self.get_briber_id()]\n if np.isnan(vote):\n self.bribe(c, max_rating)\n else:\n self.bribe(c, max_rating - vote)\n return c\n"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8181818127632141,
"avg_line_length": 38.28571319580078,
"blob_id": "19d188566f05e4e85b303af5b4d5f79df3f9376b",
"content_id": "d93e58c4ac18e7d73e99811ff6dad0d0a7828441",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 275,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 7,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/weighted_p_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass WeightedPRating(RatingMethodFrame):\n enum_value = RatingMethod.WEIGHTED_P_RATING\n name = 'weighted_p_rating'\n"
},
{
"alpha_fraction": 0.619788408279419,
"alphanum_fraction": 0.6253889203071594,
"avg_line_length": 38.19512176513672,
"blob_id": "4e18150fa83451f16ee9893ff97d4fab1aaf83dd",
"content_id": "b81addad3ddc554dcabd71c88b3e14e3beea1688",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1607,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 41,
"path": "/src/BribeNet/bribery/static/oneMoveInfluentialNodeBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.briber import BriberyGraphNotSetException\n\nfrom BribeNet.bribery.static.briber import StaticBriber\nfrom BribeNet.helpers.override import override\n\n\nclass OneMoveInfluentialNodeBriber(StaticBriber):\n def __init__(self, u0, k=0.1):\n super().__init__(u0)\n self.influencers = []\n self._k = k # will be reassigned when graph set\n\n @override\n def _set_graph(self, g):\n super()._set_graph(g)\n # Make sure that k is set such that there are enough resources left to actually bribe people.\n self._k = min(self._k, 0.5 * (self.get_resources() / self.get_graph().customer_count()))\n\n # sets influencers to ordered list of most influential nodes\n def _get_influencers(self):\n if self.get_graph() is None:\n raise BriberyGraphNotSetException()\n self.influencers = []\n for c in self.get_graph().get_customers():\n reward = self.get_graph().is_influential(c, k=self._k, briber_id=self.get_briber_id())\n if reward > 0:\n self.influencers.append((reward, c))\n # Sort based on highest reward\n self.influencers = sorted(self.influencers, reverse=True)\n\n # returns node bribed number\n def _next_bribe(self):\n if self.get_graph() is None:\n raise BriberyGraphNotSetException()\n self.influencers = self._get_influencers()\n if self.influencers:\n (r, c) = self.influencers[0]\n self.bribe(c, self.get_graph().get_max_rating() - self.get_graph().get_vote(c))\n return c\n else:\n return 0\n"
},
{
"alpha_fraction": 0.539301335811615,
"alphanum_fraction": 0.539301335811615,
"avg_line_length": 20.809524536132812,
"blob_id": "92943549caaae0a68fc05561f51a7ab8af6a9fc9",
"content_id": "6b7ff97e924abade3d0a1c1a4210247a24b682c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 21,
"path": "/src/BribeNet/gui/apps/temporal/results_wizard/results.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "class ResultsStore:\n \"\"\"\n Class for storing results during runs, identified by keys, seperated to xs and ys\n \"\"\"\n\n def __init__(self, xs, ys):\n self.xs = xs\n self.ys = ys\n self.data = {k: [] for k in (xs + ys)}\n\n def add(self, k, v):\n self.data[k].append(v)\n\n def get(self, k):\n return self.data[k]\n\n def get_x_options(self):\n return self.xs\n\n def get_y_options(self):\n return self.ys\n"
},
{
"alpha_fraction": 0.6386001110076904,
"alphanum_fraction": 0.6472626328468323,
"avg_line_length": 44.09375,
"blob_id": "3b706b2937a1ffece12dfbbf41ef032fdfb50e34",
"content_id": "15623e8c0725a73f82507ab16d1684602a34740d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2886,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 64,
"path": "/test/BribeNet/bribery/temporal/test_budgetBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.temporal.budgetNodeBriber import BudgetNodeBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom test.BribeNet.bribery.temporal.briberTestCase import BriberTestCase\nfrom unittest.mock import MagicMock\n\n\nclass TestBudgetBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = BudgetNodeBriber(10, b=0.5)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def test_next_action_increases_p_rating(self):\n graph = self.briber._g\n action = self.briber.next_action()\n briber_id = self.briber.get_briber_id()\n prev_eval = graph.eval_graph(briber_id=briber_id)\n action.perform_action()\n self.assertGreaterEqual(graph.eval_graph(briber_id=briber_id), prev_eval)\n\n def test_next_action_bribes_if_suitable(self):\n graph = self.briber._g\n self.briber._previous_rating = 0\n graph.eval_graph = MagicMock(return_value=1)\n graph.get_vote = MagicMock(return_value=[0.5])\n self.briber._next_node = 0\n action = self.briber.next_action()\n self.assertDictEqual(action._bribes, {0: 0.5})\n\n def test_next_action_moves_on_if_not_influential(self):\n graph = self.briber._g\n self.briber._previous_rating = 1\n graph.eval_graph = MagicMock(return_value=1) # will never be influential\n graph.get_vote = MagicMock(return_value=[1.0]) # will always be affordable\n prev_nodes = []\n for i in range(graph.customer_count()):\n action = self.briber.next_action()\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n\n def test_next_action_moves_on_if_not_in_budget(self):\n graph = self.briber._g\n graph.eval_graph = MagicMock(return_value=1)\n graph.get_vote = MagicMock(return_value=[0.0]) # will always be not in budget\n prev_nodes = []\n for i in range(graph.customer_count()):\n self.briber._previous_rating = 0 # will always be influential\n action = self.briber.next_action()\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n\n def test_next_action_does_not_fail_if_no_nodes_influential(self):\n graph = self.briber._g\n self.briber._previous_rating = 1\n graph.eval_graph = MagicMock(return_value=1) # will never be influential\n graph.get_vote = MagicMock(return_value=[1.0]) # will always be affordable\n prev_nodes = []\n for i in range(graph.customer_count() + 1):\n action = self.briber.next_action()\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n"
},
{
"alpha_fraction": 0.834645688533783,
"alphanum_fraction": 0.834645688533783,
"avg_line_length": 24.399999618530273,
"blob_id": "fc1169008e719db236af26895377cde168fb2dd5",
"content_id": "de8b063459c6ea30362d2d7e42196bead2702a39",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 127,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 5,
"path": "/src/BribeNet/gui/apps/temporal/wizard/generation.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.gui.apps.static.wizard.generation import StaticGeneration\n\n\nclass TemporalGeneration(StaticGeneration):\n pass\n"
},
{
"alpha_fraction": 0.42105263471603394,
"alphanum_fraction": 0.6105263233184814,
"avg_line_length": 16.363636016845703,
"blob_id": "b07a2451b30b147a1d21deca84ff98dc34849446",
"content_id": "a73f2c2430fc863cbfff8807772a2a75517ad6ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 190,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 11,
"path": "/requirements.txt",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "matplotlib == 3.1.2\nnetworkit == 6.1.0\nnetworkx == 2.4\nsnap == 0.5\ncython == 0.29.14\nnumpy == 1.17.4\npandas == 0.25.3\npytest == 5.3.0\nipython == 7.13.0\npillow == 7.0.0\nweightedstats == 0.4.1"
},
{
"alpha_fraction": 0.6706730723381042,
"alphanum_fraction": 0.6730769276618958,
"avg_line_length": 36.818180084228516,
"blob_id": "f21c01cc2255674f8126cef992b2ea583b93f65e",
"content_id": "2148efe9a8b8e850432309ec2c820eeb0b12d858",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 832,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 22,
"path": "/src/BribeNet/bribery/temporal/oneMoveEvenBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\nimport numpy as np\n\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import TemporalBriber\n\n\nclass OneMoveEvenBriber(TemporalBriber):\n\n def _next_action(self) -> SingleBriberyAction:\n customers = self.get_graph().get_customers()\n # pick random customer from list\n c = random.choice(list(filter(lambda x: x % 2 == 0, customers)))\n max_rating = self.get_graph().get_max_rating()\n vote = self.get_graph().get_vote(c)[self.get_briber_id()]\n resources = self.get_resources()\n if np.isnan(vote):\n bribery_dict = {c: min(resources, max_rating)}\n else:\n bribery_dict = {c: min(resources, max_rating - vote)}\n return SingleBriberyAction(self, bribes=bribery_dict)\n"
},
{
"alpha_fraction": 0.7546584010124207,
"alphanum_fraction": 0.7546584010124207,
"avg_line_length": 25.83333396911621,
"blob_id": "02767365c212fec29601abfd372fdd06976e6427",
"content_id": "b310ebe3b31adad5e76379a16125ae28cae32ac7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 12,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/rating_method_frame.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import abc\nfrom typing import Optional\n\nfrom BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass RatingMethodFrame(ParamListFrame, abc.ABC):\n enum_value: Optional[RatingMethod] = None\n\n def __init__(self, parent):\n super().__init__(parent)\n"
},
{
"alpha_fraction": 0.7350746393203735,
"alphanum_fraction": 0.746268630027771,
"avg_line_length": 18.214284896850586,
"blob_id": "cbeb607bb5e4d0a29ecd289780418b97104e758b",
"content_id": "b31edd4211dc54c268a58d671df1400fd22cd258",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 268,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 14,
"path": "/Dockerfile",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "FROM python:3.7.7-slim-buster\nMAINTAINER [email protected]\n\nCOPY requirements.txt /\n\nRUN apt update\nRUN apt-get install -y wget gcc g++ make cmake tk\nRUN pip install -r /requirements.txt\n\nRUN mkdir src\nCOPY src/ src/\nWORKDIR src\n\nENTRYPOINT [\"python\", \"docker_main.py\"]"
},
{
"alpha_fraction": 0.6408888697624207,
"alphanum_fraction": 0.641777753829956,
"avg_line_length": 41.45283126831055,
"blob_id": "f9170a2bc640df84231c49a9c106d399ae9926fc",
"content_id": "44f2da4a3f49a3564e80b935ddabe53262b9d357",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2250,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 53,
"path": "/src/BribeNet/bribery/temporal/action/singleBriberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import sys\nfrom typing import Dict, Optional\n\nfrom BribeNet.bribery.temporal.action import BribeMustBeGreaterThanZeroException, NodeDoesNotExistException, \\\n BriberyActionExceedsAvailableUtilityException\nfrom BribeNet.bribery.temporal.action.briberyAction import BriberyAction\n\n\nclass SingleBriberyAction(BriberyAction):\n\n def __init__(self, briber, bribes: Optional[Dict[int, float]] = None):\n from BribeNet.bribery.temporal.briber import TemporalBriber\n from BribeNet.graph.temporal.ratingGraph import BriberNotSubclassOfTemporalBriberException\n if not issubclass(briber.__class__, TemporalBriber):\n raise BriberNotSubclassOfTemporalBriberException(f\"{briber.__class__.__name__} is not a subclass of \"\n \"TemporalBriber\")\n super().__init__(graph=briber.get_graph())\n if bribes is not None:\n for _, bribe in bribes.items():\n if bribe < 0:\n raise BribeMustBeGreaterThanZeroException()\n self.briber = briber\n self._bribes: Dict[int, float] = bribes or {}\n self.__time = self.briber.get_graph().get_time_step()\n\n @classmethod\n def empty_action(cls, briber):\n return cls(briber, None)\n\n def add_bribe(self, node_id: int, bribe: float):\n if bribe < 0:\n raise BribeMustBeGreaterThanZeroException()\n if node_id not in self.briber.get_graph().get_customers():\n raise NodeDoesNotExistException()\n if node_id in self._bribes:\n print(f\"WARNING: node {node_id} bribed twice in single time step, combining...\", file=sys.stderr)\n self._bribes[node_id] += bribe\n else:\n self._bribes[node_id] = bribe\n\n def _perform_action(self):\n if sum(self._bribes.values()) > self.briber.get_resources():\n raise BriberyActionExceedsAvailableUtilityException()\n for customer, bribe in self._bribes.items():\n self.briber.bribe(node_id=customer, amount=bribe)\n\n def is_bribed(self, node_id):\n if node_id in self._bribes:\n return True, [self.briber.get_briber_id()]\n return False, []\n\n def get_bribes(self):\n return self._bribes\n"
},
{
"alpha_fraction": 0.5990990996360779,
"alphanum_fraction": 0.630630612373352,
"avg_line_length": 17.5,
"blob_id": "08113dd4fc40f513fe0cb9b683fc95468347f2cb",
"content_id": "45066932b6eba58c554121e0df5b737b5d87d596",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 12,
"path": "/src/BribeNet/graph/ratingMethod.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import enum\n\n\[email protected]\nclass RatingMethod(enum.Enum):\n O_RATING = 0\n P_RATING = 1\n MEDIAN_P_RATING = 2\n SAMPLE_P_RATING = 3\n P_GAMMA_RATING = 4\n WEIGHTED_P_RATING = 5\n WEIGHTED_MEDIAN_P_RATING = 6\n"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.6299840807914734,
"avg_line_length": 38.1875,
"blob_id": "1b630c1500d39849084f67c5142c6be1d1b5ea89",
"content_id": "915ab2e895d4d42b23dccef7f16bb427f6bbabc4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 16,
"path": "/src/BribeNet/gui/apps/main.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\nclass Main(tk.Frame):\n \"\"\"\n Frame for the main menu of the GUI\n \"\"\"\n\n def __init__(self, master, *args, **kwargs):\n tk.Frame.__init__(self, master=master, *args, **kwargs)\n title_text = tk.Label(self, text=\"Bribery Networks\", font=(\"Calibri\", 16, \"bold\"), pady=20)\n title_text.pack()\n static_button = tk.Button(self, text=\"Static Model\", command=self.master.show_static_gui, pady=10)\n static_button.pack(pady=10)\n temporal_button = tk.Button(self, text=\"Temporal Model\", command=self.master.show_temporal_gui, pady=10)\n temporal_button.pack()\n"
},
{
"alpha_fraction": 0.6160072088241577,
"alphanum_fraction": 0.6204036474227905,
"avg_line_length": 44.28506851196289,
"blob_id": "60024854719a012ccf623f29a75121ab6aaefd20",
"content_id": "cf3df0051052ae87fe7a8b003676e90a52b381c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10008,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 221,
"path": "/src/BribeNet/graph/temporal/ratingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import abc\nimport random\nfrom sys import maxsize\nfrom typing import Tuple, Union, Any, Optional, List\n\nimport numpy as np\n\nfrom BribeNet.bribery.temporal.action.briberyAction import BriberyAction\nfrom BribeNet.bribery.temporal.action.multiBriberyAction import MultiBriberyAction\nfrom BribeNet.graph.ratingGraph import DEFAULT_GEN, RatingGraph, BribersAreNotTupleException, NoBriberGivenException\nfrom BribeNet.graph.static.ratingGraph import DEFAULT_NON_VOTER_PROPORTION # (0.2)\nfrom BribeNet.graph.temporal.action.customerAction import CustomerAction\nfrom BribeNet.graph.temporal.weighting.traverseWeighting import assign_traverse_averaged\nfrom BribeNet.helpers.bribeNetException import BribeNetException\nfrom BribeNet.helpers.override import override\n\nDEFAULT_REMOVE_NO_VOTE = False\nDEFAULT_Q = 0.5\nDEFAULT_PAY = 1.0\nDEFAULT_APATHY = 0.0\nDEFAULT_D = 2 # number of rounds in a cycle (D-1 bribes and then one customer round)\nDEFAULT_TRUE_AVERAGE = 0.5\nDEFAULT_TRUE_STD_DEV = 0.2\nDEFAULT_LEARNING_RATE = 0.1\n\nKWARG_NAMES = (\"non_voter_proportion\", \"remove_no_vote\", \"q\", \"pay\", \"apathy\", \"d\", \"learning_rate\")\nKWARG_LOWER_BOUNDS = dict(zip(KWARG_NAMES, (0, False, 0, 0, 0, 2, 0)))\nKWARG_UPPER_BOUNDS = dict(zip(KWARG_NAMES, (1, True, 1, float('inf'), 1, maxsize, 1)))\n\nMIN_TRUE_AVERAGE = 0.0\nMAX_TRUE_AVERAGE = 1.0\nMIN_TRUE_STD_DEV = 0.0\nMAX_TRUE_STD_DEV = float('inf')\n\n\nclass BriberNotSubclassOfTemporalBriberException(BribeNetException):\n pass\n\n\nclass BriberKeywordArgumentOutOfBoundsException(BribeNetException):\n pass\n\n\nclass TrueAverageIncorrectShapeException(BribeNetException):\n pass\n\n\nclass TrueStdDevIncorrectShapeException(BribeNetException):\n pass\n\n\nclass TemporalRatingGraph(RatingGraph, abc.ABC):\n\n def __init__(self, bribers: Union[Tuple[Any], Any], generator=DEFAULT_GEN, **kwargs):\n from BribeNet.bribery.temporal.briber import TemporalBriber\n if issubclass(bribers.__class__, TemporalBriber):\n bribers = tuple([bribers])\n if not isinstance(bribers, tuple):\n raise BribersAreNotTupleException(\"bribers must be a tuple of instances of subclasses of TemporalBriber\")\n if not bribers:\n raise NoBriberGivenException(\"must be at least one briber\")\n for b in bribers:\n if not issubclass(b.__class__, TemporalBriber):\n raise BriberNotSubclassOfTemporalBriberException(f\"{b.__class__.__name__} is not a subclass of \"\n \"TemporalBriber\")\n self.__tmp_bribers = bribers\n self.__tmp_kwargs = kwargs\n self._time_step: int = 0\n super().__init__(bribers, generator, specifics=self.__specifics, **kwargs)\n # must come after super().__init__() such that bribers[0] has graph set\n if len(bribers) == 1:\n self._last_bribery_actions: List[BriberyAction] = []\n self._last_customer_action: Optional[CustomerAction] = CustomerAction.empty_action(self)\n else:\n self._last_bribery_actions: List[BriberyAction] = []\n self._last_customer_action: Optional[CustomerAction] = CustomerAction.empty_action(self)\n\n @staticmethod\n def kwarg_in_bounds(k, v):\n return KWARG_LOWER_BOUNDS[k] <= v <= KWARG_UPPER_BOUNDS[k]\n\n def __specifics(self):\n self._votes = np.zeros((self.get_graph().numberOfNodes(), len(self._bribers)))\n self._truths = np.zeros((self.get_graph().numberOfNodes(), len(self._bribers)))\n for kwarg in KWARG_NAMES:\n if kwarg in self.__tmp_kwargs:\n if not self.kwarg_in_bounds(kwarg, self.__tmp_kwargs[kwarg]):\n raise BriberKeywordArgumentOutOfBoundsException(\n f\"{kwarg}={self.__tmp_kwargs[kwarg]} out of bounds ({KWARG_LOWER_BOUNDS[kwarg]}, \"\n f\"{KWARG_UPPER_BOUNDS[kwarg]})\")\n # Generate random ratings network\n if \"non_voter_proportion\" in self.__tmp_kwargs:\n non_voter_proportion = self.__tmp_kwargs[\"non_voter_proportion\"]\n else:\n non_voter_proportion = DEFAULT_NON_VOTER_PROPORTION\n if \"q\" in self.__tmp_kwargs:\n self._q: float = self.__tmp_kwargs[\"q\"] * self._max_rating\n else:\n self._q: float = DEFAULT_Q * self._max_rating\n if \"pay\" in self.__tmp_kwargs:\n self._pay: float = self.__tmp_kwargs[\"pay\"]\n else:\n self._pay: float = DEFAULT_PAY\n if \"apathy\" in self.__tmp_kwargs:\n self._apathy: float = self.__tmp_kwargs[\"apathy\"]\n else:\n self._apathy: float = DEFAULT_APATHY\n if \"d\" in self.__tmp_kwargs:\n self._d: int = self.__tmp_kwargs[\"d\"]\n else:\n self._d: int = DEFAULT_D\n if \"true_averages\" in self.__tmp_kwargs:\n true_averages = self.__tmp_kwargs[\"true_averages\"]\n if true_averages.shape[0] != len(self._bribers):\n raise TrueAverageIncorrectShapeException(f\"{true_averages.shape[0]} != {len(self._bribers)}\")\n if not np.all(true_averages >= MIN_TRUE_AVERAGE):\n raise BriberKeywordArgumentOutOfBoundsException(f\"All true averages must be >= {MIN_TRUE_AVERAGE}\")\n if not np.all(true_averages <= MAX_TRUE_AVERAGE):\n raise BriberKeywordArgumentOutOfBoundsException(f\"All true averages must be <= {MAX_TRUE_AVERAGE}\")\n self._true_averages: np.ndarray[float] = true_averages\n else:\n self._true_averages: np.ndarray[float] = np.repeat(DEFAULT_TRUE_AVERAGE, len(self._bribers))\n if \"true_std_devs\" in self.__tmp_kwargs:\n true_std_devs = self.__tmp_kwargs[\"true_std_devs\"]\n if true_std_devs.shape[0] != len(self._bribers):\n raise TrueStdDevIncorrectShapeException(f\"{true_std_devs.shape[0]} != {len(self._bribers)}\")\n if not np.all(true_std_devs >= MIN_TRUE_STD_DEV):\n raise BriberKeywordArgumentOutOfBoundsException(f\"All true std devs must be >= {MIN_TRUE_STD_DEV}\")\n if not np.all(true_std_devs <= MAX_TRUE_STD_DEV):\n raise BriberKeywordArgumentOutOfBoundsException(f\"All true std devs must be <= {MAX_TRUE_STD_DEV}\")\n self._true_std_devs: np.ndarray[float] = true_std_devs\n else:\n self._true_std_devs: np.ndarray[float] = np.repeat(DEFAULT_TRUE_STD_DEV, len(self._bribers))\n if \"learning_rate\" in self.__tmp_kwargs:\n self._learning_rate: float = self.__tmp_kwargs[\"learning_rate\"]\n else:\n self._learning_rate: float = DEFAULT_LEARNING_RATE\n community_weights = {}\n for b, _ in enumerate(self._bribers):\n community_weights[b] = assign_traverse_averaged(self.get_graph(), self._true_averages[b],\n self._true_std_devs[b])\n for n in self.get_graph().iterNodes():\n for b, _ in enumerate(self._bribers):\n rating = community_weights[b][n]\n self._truths[n][b] = rating\n if random.random() > non_voter_proportion:\n self._votes[n][b] = rating\n else:\n self._votes[n][b] = np.nan\n self._time_step = 0\n del self.__tmp_bribers, self.__tmp_kwargs\n\n @override\n def _finalise_init(self):\n \"\"\"\n Perform assertions that ensure everything is initialised\n \"\"\"\n from BribeNet.bribery.temporal.briber import TemporalBriber\n for briber in self._bribers:\n if not issubclass(briber.__class__, TemporalBriber):\n raise BriberNotSubclassOfTemporalBriberException(\"member of graph bribers not an instance of a \"\n \"subclass of TemporalBriber\")\n super()._finalise_init()\n\n def get_time_step(self):\n return self._time_step\n\n def get_d(self):\n return self._d\n\n def get_last_bribery_actions(self):\n return self._last_bribery_actions\n\n def get_last_customer_action(self):\n return self._last_customer_action\n\n @abc.abstractmethod\n def _customer_action(self) -> CustomerAction:\n \"\"\"\n Perform the action of each customer in the graph\n \"\"\"\n raise NotImplementedError\n\n def _bribery_action(self) -> MultiBriberyAction:\n actions = [b.next_action() for b in self._bribers]\n return MultiBriberyAction.make_multi_action_from_single_actions(actions)\n\n def _update_trust(self):\n \"\"\"\n Update the weights of the graph based on the trust between nodes.\n \"\"\"\n # Get the weights and calculate the new weights first.\n new_weights = {}\n for (u, v) in self.get_edges():\n prev_weight = self.get_weight(u, v)\n new_weight = prev_weight + self._learning_rate * (self.trust(u, v) - prev_weight)\n new_weights[(u, v)] = new_weight\n # Then set them, as some ratings systems could give different values\n # if the weights are modified during the calculations.\n for (u, v) in self.get_edges():\n self.set_weight(u, v, new_weights[(u, v)])\n\n def is_bribery_round(self):\n return not (self._time_step % self._d == self._d - 1)\n\n def step(self):\n \"\"\"\n Perform the next step, either bribery action or customer action and increment the time step\n We do d-1 bribery steps (self._time_step starts at 0) and then a customer step.\n \"\"\"\n if self.is_bribery_round():\n bribery_action = self._bribery_action()\n bribery_action.perform_action()\n self._last_bribery_actions.append(bribery_action)\n else:\n customer_action = self._customer_action()\n customer_action.perform_action(pay=self._pay)\n self._last_customer_action = customer_action\n self._last_bribery_actions = []\n self._update_trust()\n self._time_step += 1\n"
},
{
"alpha_fraction": 0.5225027203559875,
"alphanum_fraction": 0.5729967355728149,
"avg_line_length": 26.606060028076172,
"blob_id": "c9c5f2b271341112e3629d4ea8d5d7aededa8132",
"content_id": "cfd9b846cf0b714b23251cdeb77ea245fa907ffa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 33,
"path": "/setup.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\nsetuptools.setup(\n name=\"BribeNet\",\n version=\"1.0.0\",\n author=\"Robert Murray\",\n author_email=\"[email protected]\",\n description=\"Simulation of networks of bribers and consumers\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/RobMurray98/CS407Implementation\",\n install_requires=[\n 'matplotlib==3.1.2',\n 'networkit==6.1.0',\n 'networkx==2.4',\n 'snap==0.5',\n 'cython==0.29.14',\n 'numpy==1.17.4',\n 'pandas==0.25.3',\n 'pytest==5.3.0',\n 'ipython==7.13.0',\n 'pillow==7.0.0',\n 'weightedstats==0.4.1'\n ],\n package_data={'': ['*.png']},\n include_package_data=True,\n package_dir={'': 'src'},\n packages=setuptools.find_packages(where='src'),\n python_requires='>=3.7'\n)\n"
},
{
"alpha_fraction": 0.6467908620834351,
"alphanum_fraction": 0.6559005975723267,
"avg_line_length": 35.044776916503906,
"blob_id": "6e4818c98b961eb597f0ec2fd684ee95f822701b",
"content_id": "c7c458e2323f318e8734ecaa44b166f1a227dcc0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2415,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 67,
"path": "/src/BribeNet/gui/apps/temporal/wizard/bribers.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.temporal.briber_wizard.window import TemporalBriberWizardWindow\nfrom BribeNet.helpers.override import override\n\n\nclass TemporalBribers(tk.Frame):\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.briber_wizard = None\n self.bribers_list = []\n\n bribers_title_label = tk.Label(self, text=\"Bribers\")\n bribers_title_label.grid(row=1, column=1, columnspan=2, pady=10)\n\n self.bribers_listbox = tk.Listbox(self)\n self.bribers_listbox.grid(row=2, column=1, rowspan=3)\n\n scrollbar = tk.Scrollbar(self, orient=\"vertical\")\n scrollbar.config(command=self.bribers_listbox.yview)\n scrollbar.grid(row=2, column=2, rowspan=3, sticky=\"ns\")\n\n self.bribers_listbox.config(yscrollcommand=scrollbar.set)\n\n self.add_briber_button = tk.Button(self, text=\"Add\", command=self.open_briber_wizard)\n self.add_briber_button.grid(row=2, column=3, sticky='nsew')\n\n self.duplicate_briber_button = tk.Button(self, text=\"Duplicate\", command=self.duplicate_selected_briber)\n self.duplicate_briber_button.grid(row=3, column=3, sticky='nsew')\n\n self.delete_briber_button = tk.Button(self, text=\"Delete\", command=self.delete_selected_briber)\n self.delete_briber_button.grid(row=4, column=3, sticky='nsew')\n\n def open_briber_wizard(self):\n if self.briber_wizard is None:\n self.briber_wizard = TemporalBriberWizardWindow(self)\n else:\n self.briber_wizard.lift()\n\n def duplicate_selected_briber(self):\n cur_sel = self.bribers_listbox.curselection()\n if not cur_sel:\n return\n self.bribers_list.append(self.bribers_list[cur_sel[0]])\n self.bribers_listbox.insert(tk.END, self.bribers_list[cur_sel[0]][0])\n\n def delete_selected_briber(self):\n cur_sel = self.bribers_listbox.curselection()\n if not cur_sel:\n return\n self.bribers_listbox.delete(cur_sel[0])\n del self.bribers_list[cur_sel[0]]\n\n def add_briber(self, strat_type, *args):\n self.bribers_list.append((strat_type, *args))\n self.bribers_listbox.insert(tk.END, strat_type)\n\n def get_all_bribers(self):\n return self.bribers_list\n\n @override\n def destroy(self):\n if self.briber_wizard is not None:\n self.briber_wizard.destroy()\n super().destroy()\n"
},
{
"alpha_fraction": 0.792682945728302,
"alphanum_fraction": 0.792682945728302,
"avg_line_length": 12.666666984558105,
"blob_id": "2141cefff8800956e028cba24d05259d3410ca6c",
"content_id": "a233e5f6d2dbc2626e2408a26983881fe8dcfd94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 6,
"path": "/test/BribeNet/graph/temporal/test_ratingGraphBuilder.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\n\nclass TestRatingGraphBuilder(TestCase):\n\n pass\n"
},
{
"alpha_fraction": 0.6787479519844055,
"alphanum_fraction": 0.6935749650001526,
"avg_line_length": 26.590909957885742,
"blob_id": "ee7873e5b2cfc49381c69032b314e71d148ce01c",
"content_id": "06a67f42499946e2b0fb4ec764f75a5f53d565e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 607,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 22,
"path": "/test/BribeNet/bribery/static/briberTestCase.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nfrom unittest import TestCase\n\nfrom BribeNet.bribery.static.nonBriber import NonBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\n\n\nclass BriberTestCase(TestCase, ABC):\n\n @abstractmethod\n def setUp(self) -> None:\n self.briber = NonBriber(1)\n self.rg = StaticRatingGraph(self.briber)\n\n def tearDown(self) -> None:\n del self.briber, self.rg\n\n def _p_rating_increase(self, g1, g2):\n rating2 = g2.eval_graph()\n rating1 = g1.eval_graph()\n self.assertGreaterEqual(rating2, rating1)\n return None\n"
},
{
"alpha_fraction": 0.7131242752075195,
"alphanum_fraction": 0.7340301871299744,
"avg_line_length": 40,
"blob_id": "5126439cd623df62829d7f8cc3cadc333a579d00",
"content_id": "795d0f5533d4ed9c570bbbea8458d86e5cc040ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 861,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 21,
"path": "/test/BribeNet/graph/generation/test_weightedGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\nfrom BribeNet.graph.generation.flatWeightGenerator import FlatWeightedGraphGenerator\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\n\n\nclass TestFlatWeightedGraphGenerator(TestCase):\n\n def test_generate_ws(self):\n graph_gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.WATTS_STROGATZ, 30, 5, 0.3)\n graph = graph_gen.generate()\n self.assertTrue(graph.isWeighted())\n\n def test_generate_ba(self):\n graph_gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.BARABASI_ALBERT, 5, 30, 0, True)\n graph = graph_gen.generate()\n self.assertTrue(graph.isWeighted())\n\n def test_generate_composite(self):\n graph_gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.COMPOSITE, 30, 15, 50, 0.1, 2)\n graph = graph_gen.generate()\n self.assertTrue(graph.isWeighted())\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5787923336029053,
"avg_line_length": 27.29166603088379,
"blob_id": "22221607a28a66250c87b7332bf72707b6019c01",
"content_id": "439d32067f7698b3ff9bb38b6e3ee9660feaf80d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 679,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 24,
"path": "/src/BribeNet/gui/apps/static/wizard/algos/watts_strogatz.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass WattsStrogatz(ParamListFrame):\n name = \"Watts-Strogatz\"\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.params = {\n 'n_nodes': tk.IntVar(self, value=30),\n 'n_neighbours': tk.IntVar(self, value=5),\n 'p': tk.DoubleVar(self, value=0.3)\n }\n\n self.descriptions = {\n 'n_nodes': 'number of nodes in the graph',\n 'n_neighbours': 'number of neighbors on each side of a node',\n 'p': 'the probability of rewiring a given edge'\n }\n\n self.grid_params(show_name=False)\n"
},
{
"alpha_fraction": 0.6021180152893066,
"alphanum_fraction": 0.6076651811599731,
"avg_line_length": 33.78947448730469,
"blob_id": "054b67178b11924d5bc8535bc83da0c60b0f430a",
"content_id": "d67651f095ee726cca519c19e31a3ed1b2205484",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1983,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 57,
"path": "/test/BribeNet/graph/static/test_singleBriberRatingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nfrom unittest import TestCase\n\nfrom BribeNet.bribery.static.nonBriber import NonBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\n\n\nclass TestSingleBriberRatingGraph(TestCase):\n\n def setUp(self) -> None:\n self.rg = StaticRatingGraph(NonBriber(0))\n\n def tearDown(self) -> None:\n del self.rg\n\n def test_neighbors(self):\n for i in self.rg.get_customers():\n self.assertIsInstance(self.rg._neighbours(i), list)\n\n def test_p_rating(self):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_rating(i) >= 0)\n\n def test_median_p_rating(self):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._median_p_rating(i) >= 0)\n\n def test_sample_p_rating(self):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._sample_p_rating(i) >= 0)\n\n def test_weighted_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_weighted_median_p_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n\n def test_p_gamma_rating(self):\n for b in range(len(self.rg.get_bribers())):\n for i in self.rg.get_customers():\n self.assertTrue(self.rg._p_gamma_rating(i) >= 0)\n self.assertAlmostEqual(self.rg._p_gamma_rating(i, gamma=0), self.rg._p_rating(i))\n\n def test_o_rating(self):\n self.assertTrue(self.rg._o_rating() >= 0)\n\n def test_bribe(self):\n initial_value = self.rg.eval_graph()\n for i in self.rg.get_customers():\n g_copy = deepcopy(self.rg)\n g_copy.bribe(i, 0.1)\n bribed_value = g_copy.eval_graph()\n self.assertTrue(initial_value != bribed_value)\n"
},
{
"alpha_fraction": 0.6920821070671082,
"alphanum_fraction": 0.7101286053657532,
"avg_line_length": 48.808990478515625,
"blob_id": "5bf604428f939bf302dae81ccec1a949590831c9",
"content_id": "a5d28c1e6b292d546306e1517782df7d8ed9cd5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4433,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 89,
"path": "/test/BribeNet/bribery/temporal/action/test_multiBriberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom BribeNet.bribery.temporal.action.multiBriberyAction import MultiBriberyAction, \\\n BriberyActionsAtDifferentTimesException, BriberyActionsOnDifferentGraphsException, \\\n NoActionsToFormMultiActionException\nfrom BribeNet.bribery.temporal.action import *\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom unittest.mock import MagicMock\n\n\n# noinspection PyBroadException\nclass TestMultiBriberyAction(TestCase):\n\n def setUp(self) -> None:\n self.bribers = (NonBriber(1), NonBriber(1), NonBriber(1), NonBriber(1))\n self.valid_action_dict = {0: {0: 0.5}, 2: {0: 0.5}, 3: {0: 0.5}}\n self.graph = NoCustomerActionGraph(self.bribers)\n\n def tearDown(self) -> None:\n del self.bribers, self.graph\n\n def test_add_bribe_fails_if_bribe_not_greater_than_zero(self):\n action = MultiBriberyAction(self.graph)\n self.assertRaises(BribeMustBeGreaterThanZeroException, action.add_bribe, 0, 0, -1.0)\n\n def test_add_bribe_fails_if_node_id_not_present(self):\n action = MultiBriberyAction(self.graph)\n self.assertRaises(NodeDoesNotExistException, action.add_bribe, 0, -1, 1.0)\n\n def test_add_bribe_fails_if_briber_id_not_present_1(self):\n action = MultiBriberyAction(self.graph)\n self.assertRaises(BriberDoesNotExistException, action.add_bribe, -1, 0, 1.0)\n\n def test_add_bribe_fails_if_briber_id_not_present_2(self):\n action = MultiBriberyAction(self.graph)\n self.assertRaises(BriberDoesNotExistException, action.add_bribe, 4, 0, 1.0)\n\n def test_add_bribe_passes_1(self):\n action = MultiBriberyAction(self.graph)\n action.add_bribe(0, 0, 1.0)\n self.assertEqual(action._bribes[0][0], 1.0)\n\n def test_add_bribe_passes_2(self):\n action = MultiBriberyAction(self.graph, bribes={0: {0: 1.0}})\n action.add_bribe(0, 0, 1.0)\n self.assertEqual(action._bribes[0][0], 2.0)\n\n def test_perform_action_fails_when_bribes_exceed_budget(self):\n action = MultiBriberyAction(self.graph, bribes={0: {0: 10.0}})\n self.assertRaises(BriberyActionExceedsAvailableUtilityException, action.perform_action)\n\n def test_perform_action(self):\n action = MultiBriberyAction(self.graph, bribes=self.valid_action_dict)\n action.perform_action()\n self.assertTrue(action.get_performed())\n\n def test_make_multi_action_from_single_actions_fails_if_on_different_graphs(self):\n other_briber = NonBriber(1)\n # noinspection PyUnusedLocal\n other_graph = NoCustomerActionGraph(other_briber)\n action0 = SingleBriberyAction(other_briber)\n action1 = SingleBriberyAction(self.bribers[0])\n self.assertRaises(BriberyActionsOnDifferentGraphsException,\n MultiBriberyAction.make_multi_action_from_single_actions, [action0, action1])\n\n def test_make_multi_action_from_single_actions_fails_if_no_actions(self):\n self.assertRaises(NoActionsToFormMultiActionException,\n MultiBriberyAction.make_multi_action_from_single_actions, [])\n\n def test_make_multi_action_from_single_actions_fails_if_bribe_not_greater_than_zero(self):\n action = SingleBriberyAction(self.bribers[0])\n action._bribes[0] = -1.0\n self.assertRaises(BribeMustBeGreaterThanZeroException,\n MultiBriberyAction.make_multi_action_from_single_actions, [action])\n\n def test_make_multi_action_from_single_actions_fails_if_at_different_times(self):\n action0 = SingleBriberyAction(self.bribers[0])\n action1 = SingleBriberyAction(self.bribers[1])\n action0.get_time_step = MagicMock(return_value=action0.get_time_step()+1)\n self.assertRaises(BriberyActionsAtDifferentTimesException,\n MultiBriberyAction.make_multi_action_from_single_actions, [action0, action1])\n\n def test_make_multi_action_from_single_actions(self):\n single_actions = [SingleBriberyAction(self.bribers[i], self.valid_action_dict[i])\n for i in self.valid_action_dict.keys()]\n multi_action = MultiBriberyAction.make_multi_action_from_single_actions(single_actions)\n self.assertEqual(multi_action._bribes, self.valid_action_dict)\n"
},
{
"alpha_fraction": 0.6220930218696594,
"alphanum_fraction": 0.6233170032501221,
"avg_line_length": 39.849998474121094,
"blob_id": "76df5272392a8ffcfab0f89b900f3bc5b219be73",
"content_id": "e4c2b3319d5f2cd8b27cd848dccdac42ebb1d4fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3268,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 80,
"path": "/src/BribeNet/graph/temporal/action/customerAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from typing import Dict, Any, Tuple, List\n\nimport numpy as np\n\nfrom BribeNet.bribery.temporal.action.briberyAction import BriberyAction\nfrom BribeNet.bribery.temporal.briber import GraphNotSubclassOfTemporalRatingGraphException\nfrom BribeNet.graph.temporal.action.actionType import ActionType\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass CustomerActionExecutedMultipleTimesException(BribeNetException):\n pass\n\n\nclass CustomerActionTimeNotCorrectException(BribeNetException):\n pass\n\n\nclass CustomerAction(object):\n\n def __init__(self, graph):\n from BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph # local import to remove cyclic dependency\n if not issubclass(graph.__class__, TemporalRatingGraph):\n raise GraphNotSubclassOfTemporalRatingGraphException(f\"{graph.__class__.__name__} is not a subclass of \"\n \"TemporalRatingGraph\")\n self.graph = graph\n self.actions: Dict[int, Tuple[ActionType, Any]] = {c: (ActionType.NONE, None)\n for c in self.graph.get_customers()}\n self.__time_step = self.graph.get_time_step()\n self.__performed = False\n\n @classmethod\n def empty_action(cls, graph):\n return cls(graph)\n\n def get_time_step(self):\n return self.__time_step\n\n def get_performed(self):\n return self.__performed\n\n def get_action_type(self, node_id: int):\n return self.actions[node_id][0]\n\n def set_bribed(self, node_id: int, briber_ids: List[int]):\n self.actions[node_id] = (ActionType.BRIBED, briber_ids)\n\n def set_none(self, node_id: int):\n self.actions[node_id] = (ActionType.NONE, 0)\n\n def set_select(self, node_id: int, briber_id):\n self.actions[node_id] = (ActionType.SELECT, briber_id)\n\n def set_bribed_from_bribery_action(self, bribery_action: BriberyAction):\n for c in self.actions:\n bribed, bribers = bribery_action.is_bribed(c)\n if bribed:\n self.set_bribed(c, bribers)\n\n # noinspection PyProtectedMember\n def perform_action(self, pay: float):\n \"\"\"\n Perform the described action on the graph\n :param pay: the amount to increase a selected briber's utility\n \"\"\"\n if not self.__performed:\n if self.__time_step == self.graph.get_time_step():\n for c in self.actions:\n if self.actions[c][0] == ActionType.SELECT:\n selected = self.actions[c][1]\n if np.isnan(self.graph._votes[c][selected]): # no previous vote or bribe\n self.graph._votes[c][selected] = self.graph._truths[c][selected]\n self.graph._bribers[selected].add_resources(pay)\n self.__performed = True\n else:\n message = f\"The time step of the TemporalRatingGraph ({self.graph.get_time_step()}) is not equal to \" \\\n f\"the intended execution time ({self.__time_step})\"\n raise CustomerActionTimeNotCorrectException(message)\n else:\n raise CustomerActionExecutedMultipleTimesException()\n"
},
{
"alpha_fraction": 0.6986429691314697,
"alphanum_fraction": 0.7051941752433777,
"avg_line_length": 38.574073791503906,
"blob_id": "2983bb91007dcc5299357e01afceca032196fbd5",
"content_id": "9da51035c9a27951e0dd1293aff405d943f1a3b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2137,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 54,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_method.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.median_p_rating import MedianPRating\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.o_rating import ORating\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.p_gamma_rating import PGammaRating\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.p_rating import PRating\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.weighted_median_p_rating import WeightedMedianPRating\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.weighted_p_rating import WeightedPRating\n\nMETHOD_SUBFRAMES = (ORating, PRating, MedianPRating, PGammaRating, WeightedPRating, WeightedMedianPRating)\nMETHOD_DICT = {v: k for k, v in enumerate([a.name for a in METHOD_SUBFRAMES])}\n\n\nclass TemporalRatingMethod(tk.Frame):\n \"\"\"\n Frame for pop-up wizard for adding a temporal briber\n \"\"\"\n\n def __init__(self, parent):\n super().__init__(parent)\n self.parent = parent\n self.method_type = tk.StringVar(self)\n\n self.subframes = tuple(c(self) for c in METHOD_SUBFRAMES)\n self.options = tuple(f.get_name() for f in self.subframes)\n\n name_label = tk.Label(self, text=\"Rating Method\")\n name_label.grid(row=0, column=0, pady=10)\n\n self.dropdown = tk.OptionMenu(self, self.method_type, *self.options)\n self.dropdown.grid(row=1, column=0, pady=10)\n\n self.method_type.set(self.options[0])\n for f in self.subframes:\n f.grid(row=2, column=0, sticky=\"nsew\", pady=20)\n\n self.method_type.trace('w', self.switch_frame)\n\n self.show_subframe(1) # (p-rating)\n\n def show_subframe(self, page_no):\n frame = self.subframes[page_no]\n frame.tkraise()\n\n # noinspection PyUnusedLocal\n def switch_frame(self, *args):\n self.show_subframe(METHOD_DICT[self.method_type.get()])\n\n def get_rating_method(self) -> RatingMethod:\n return self.subframes[METHOD_DICT[self.method_type.get()]].enum_value\n\n def get_args(self):\n return self.subframes[METHOD_DICT[self.method_type.get()]].get_args()\n"
},
{
"alpha_fraction": 0.5866770148277283,
"alphanum_fraction": 0.5981409549713135,
"avg_line_length": 35.88571548461914,
"blob_id": "c54921df2bfb7dafaf55c1aad19d3db1733d0eeb",
"content_id": "ced3cfc6a507a18d22dd8347bf0761fe46a4e559",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6455,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 175,
"path": "/src/BribeNet/gui/apps/temporal/graph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\nfrom matplotlib.colors import rgb2hex\nfrom networkit.viztasks import drawGraph\n\nfrom BribeNet.gui.apps.temporal.results_wizard.window import TemporalResultsWizardWindow\n\n\nclass GraphFrame(tk.Frame):\n \"\"\"\n Frame for showing the current state and actions that can be taken for the temporal model being run\n \"\"\"\n\n def __init__(self, parent, controller):\n\n tk.Frame.__init__(self, parent)\n self.controller = controller\n self.parent = parent\n self.fig = plt.figure(figsize=(8, 8))\n self.ax = self.fig.add_subplot(111)\n self.canvas = FigureCanvasTkAgg(self.fig, master=self)\n self.grid_rowconfigure(1, weight=1)\n self.canvas.get_tk_widget().grid(row=1, column=0, rowspan=10)\n self.results = []\n self.pos = None\n self.gamma = None\n self.briber_buttons = None\n self.briber_name_to_index = None\n self.rating_string_var = None\n\n step_button = tk.Button(self, text=\"Next Step\", command=self.controller.next_step)\n step_button.grid(row=3, column=2, sticky='nsew')\n\n results_button = tk.Button(self, text=\"Results\", command=self.show_results_wizard)\n results_button.grid(row=4, column=2, sticky='nsew')\n\n exit_button = tk.Button(self, text=\"Exit\", command=self.return_to_wizard)\n exit_button.grid(row=7, column=2, sticky='nsew')\n\n steps_slide = tk.Scale(self, from_=1, to=100, orient=tk.HORIZONTAL)\n steps_slide.grid(row=6, column=2, sticky='nsew')\n n_steps_button = tk.Button(self, text=\"Perform n steps\", command=lambda: self.n_steps(steps_slide.get()))\n n_steps_button.grid(row=5, column=2, sticky='nsew')\n\n self.info = tk.StringVar(parent)\n round_desc_canvas = tk.Canvas(self)\n round_desc_scroll = tk.Scrollbar(self, orient='vertical', command=round_desc_canvas.yview)\n round_desc_frame = tk.Frame(self)\n round_desc_frame.bind(\n \"<Configure>\",\n lambda e: round_desc_canvas.configure(\n scrollregion=round_desc_canvas.bbox(\"all\")\n )\n )\n round_desc_canvas.create_window((0, 0), window=round_desc_frame, anchor=\"n\")\n round_desc_canvas.config(yscrollcommand=round_desc_scroll.set)\n round_desc_label = tk.Label(round_desc_frame, textvariable=self.info)\n round_desc_label.pack(fill=tk.BOTH, expand=1)\n\n round_desc_canvas.grid(row=1, column=1, columnspan=2, pady=10, padx=10, sticky='nsew')\n round_desc_scroll.grid(row=1, column=2, pady=10, sticky='nse')\n self.info.set(\"--\")\n\n def return_to_wizard(self):\n self.results = []\n self.info.set(\"--\")\n self.controller.clear_graph()\n self.controller.show_frame(\"WizardFrame\")\n\n def set_info(self, s):\n self.info.set(s)\n\n def set_pos(self, pos):\n self.pos = pos\n\n def n_steps(self, n):\n for i in range(0, n):\n self.controller.next_step()\n\n def add_briber_dropdown(self):\n\n view_title_label = tk.Label(self, text=\"View rating for briber\")\n view_title_label.grid(row=3, column=1)\n\n rating_choices = ['None'] + self.controller.briber_names\n\n self.briber_name_to_index = {v: k for k, v in enumerate(self.controller.briber_names)}\n self.rating_string_var = tk.StringVar(self)\n self.rating_string_var.set('None')\n\n rating_dropdown = tk.OptionMenu(self, self.rating_string_var, *rating_choices)\n\n # noinspection PyUnusedLocal\n def change_dropdown(*args):\n var_val = self.rating_string_var.get()\n if var_val == 'None':\n self.draw_basic_graph(self.controller.g)\n else:\n self.draw_briber_graph(self.briber_name_to_index[var_val])\n\n self.rating_string_var.trace('w', change_dropdown)\n\n rating_dropdown.grid(row=4, column=1, sticky='nsew')\n\n trust_button = tk.Button(self, text=\"Show Trust\", command=lambda: self.show_trust(self.controller.g))\n trust_button.grid(row=6, column=1, sticky='nsew')\n\n def show_results_wizard(self):\n results_wizard = TemporalResultsWizardWindow(self.controller, self.controller.results)\n results_wizard.lift()\n\n def draw_basic_graph(self, graph):\n colours = [\"gray\" for _ in graph.get_customers()] # nodes\n edge_colours = [\"#000000\" for _ in graph.get_edges()] # edges\n self._update_graph(graph, colours, edge_colours)\n self.canvas.draw()\n\n def draw_briber_graph(self, b):\n\n # node colours\n graph = self.controller.g\n\n colour_map = plt.get_cmap(\"Purples\")\n colours = []\n for c in graph.get_customers():\n if np.isnan(graph.get_vote(c)[b]):\n colours.append(\"gray\")\n else:\n colours.append(rgb2hex(colour_map(graph.get_vote(c)[b])[:3]))\n edge_colours = [\"#000000\" for _ in graph.get_edges()] # edges\n\n self._update_graph(graph, colours, edge_colours)\n self._add_annotations(b)\n self.canvas.draw()\n\n def _update_graph(self, graph, colours, edge_colours):\n\n self.ax.clear()\n drawGraph(\n graph.get_graph(),\n node_size=400,\n node_color=colours,\n edge_color=edge_colours,\n ax=self.ax, pos=self.pos,\n with_labels=True\n )\n\n def _add_annotations(self, b):\n graph = self.controller.g\n for c in graph.get_customers():\n if np.isnan(graph.get_vote(c)[b]):\n rating = \"None\"\n else:\n rating = round(graph.get_vote(c)[b], 2)\n\n self.ax.annotate(\n str(c) + \":\\n\"\n + \"Vote: \" + str(rating) + \"\\n\"\n + \"Rating: \" + str(round(graph.get_rating(c), 2)),\n xy=(self.pos[c][0], self.pos[c][1]),\n bbox=dict(boxstyle=\"round\", fc=\"w\", ec=\"0.5\", alpha=0.9)\n )\n\n def show_trust(self, graph):\n\n colours = [\"gray\" for _ in graph.get_customers()] # nodes\n colour_map = plt.get_cmap(\"Greys\")\n edge_colours = []\n for (u, v) in graph.get_edges():\n edge_colours.append(rgb2hex(colour_map(graph.get_weight(u, v))[:3]))\n self._update_graph(graph, colours, edge_colours)\n self.canvas.draw()\n"
},
{
"alpha_fraction": 0.6328327059745789,
"alphanum_fraction": 0.6349042057991028,
"avg_line_length": 26.98550796508789,
"blob_id": "816f6b64dd29dacdabb21ec58a4f1f9afeccf99d",
"content_id": "fd95fc9620a7d93cdd6b9c1a893cff267f43ba3b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1931,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 69,
"path": "/src/BribeNet/bribery/briber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC\nfrom typing import Optional\n\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass BriberyGraphNotSetException(BribeNetException):\n pass\n\n\nclass BriberyGraphAlreadySetException(BribeNetException):\n pass\n\n\nclass BriberNotRegisteredOnGraphException(BribeNetException):\n pass\n\n\nclass GraphNotSubclassOfRatingGraphException(BribeNetException):\n pass\n\n\nclass Briber(ABC):\n def __init__(self, u0: float):\n \"\"\"\n Abstract class for bribing actors\n :param u0: the initial utility available to the briber\n \"\"\"\n self._u = u0\n from BribeNet.graph.ratingGraph import RatingGraph\n self._g: Optional[RatingGraph] = None\n\n def _set_graph(self, g):\n from BribeNet.graph.ratingGraph import RatingGraph\n if not issubclass(g.__class__, RatingGraph):\n raise GraphNotSubclassOfRatingGraphException(f\"{g.__class__.__name__} is not a subclass of RatingGraph\")\n if self._g is not None:\n raise BriberyGraphAlreadySetException()\n self._g = g\n\n def get_graph(self):\n return self._g\n\n def get_briber_id(self):\n if self._g is None:\n raise BriberyGraphNotSetException()\n g_bribers = self._g.get_bribers()\n if issubclass(g_bribers.__class__, Briber):\n return 0\n for i, briber in enumerate(g_bribers):\n if briber is self:\n return i\n raise BriberNotRegisteredOnGraphException()\n\n def set_resources(self, u: float):\n self._u = u\n\n def add_resources(self, u: float):\n self._u += u\n\n def get_resources(self) -> float:\n return self._u\n\n def bribe(self, node_id: int, amount: float):\n if self._g is None:\n raise BriberyGraphNotSetException()\n if amount <= self._u:\n self._g.bribe(node_id, amount, self.get_briber_id())\n self._u -= amount\n"
},
{
"alpha_fraction": 0.655500590801239,
"alphanum_fraction": 0.664636492729187,
"avg_line_length": 32.25316619873047,
"blob_id": "d73163c514f43f107bb3b7dbcb2ae26a73d03ad6",
"content_id": "70f6e91e157a61a2ccbabc5534e3bee8cf61f7b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2627,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 79,
"path": "/src/BribeNet/gui/apps/static/static.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.bribery.static.oneMoveInfluentialNodeBriber import OneMoveInfluentialNodeBriber\nfrom BribeNet.bribery.static.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.flatWeightGenerator import FlatWeightedGraphGenerator\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\nfrom BribeNet.gui.apps.static.graph import GraphFrame\nfrom BribeNet.gui.apps.static.result import ResultsFrame\nfrom BribeNet.gui.apps.static.wizard.wizard import WizardFrame\nfrom BribeNet.helpers.override import override\n\nFRAMES_CLASSES = [WizardFrame,\n GraphFrame,\n ResultsFrame]\nFRAMES_DICT = {i: c.__class__.__name__ for (i, c) in enumerate(FRAMES_CLASSES)}\n\n\ndef switch_briber(argument):\n switcher = {\n \"r\": lambda: OneMoveRandomBriber(10),\n \"i\": lambda: OneMoveInfluentialNodeBriber(10)\n }\n return switcher.get(argument)\n\n\nclass StaticGUI(tk.Toplevel):\n \"\"\"\n Window for the static wizard and running environment\n \"\"\"\n\n def __init__(self, controller, *args, **kwargs):\n super().__init__(controller, *args, **kwargs)\n self.title(\"Static Model\")\n self.controller = controller\n self.grid_rowconfigure(0, weight=1)\n self.grid_columnconfigure(0, weight=1)\n\n self.frames = {}\n for F in FRAMES_CLASSES:\n page_name = F.__name__\n frame = F(parent=self, controller=controller)\n self.frames[page_name] = frame\n\n frame.grid(row=0, column=0, sticky=\"nsew\")\n\n self.show_frame(\"WizardFrame\")\n\n def show_frame(self, page):\n frame = self.frames[page]\n frame.tkraise()\n\n def generate_graph(self, gtype, btype):\n briber = switch_briber(btype)()\n\n ba_gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.BARABASI_ALBERT, 5, 30, 0, True)\n comp_gen = FlatWeightedGraphGenerator(GraphGeneratorAlgo.COMPOSITE, 50, 5, 2, 0.1, 3, 0.05)\n\n if gtype == \"ba\":\n rg = StaticRatingGraph(briber, generator=ba_gen)\n elif gtype == \"cg\":\n rg = StaticRatingGraph(briber, generator=comp_gen)\n else:\n rg = StaticRatingGraph(briber)\n self.frames[\"GraphFrame\"].set_graph(rg, briber)\n\n def plot_results(self, results):\n self.frames[\"ResultsFrame\"].plot_results(results)\n\n @override\n def destroy(self):\n if self.controller is not None:\n self.controller.show_main()\n super().destroy()\n\n\nif __name__ == '__main__':\n app = StaticGUI(None)\n app.mainloop()\n"
},
{
"alpha_fraction": 0.6383763551712036,
"alphanum_fraction": 0.6531365513801575,
"avg_line_length": 32.875,
"blob_id": "60b148ee5db56c3f09a995c2948c07d2a4f874cc",
"content_id": "7618473e310cdf53b27336f28e940165321f8459",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 271,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 8,
"path": "/test.sh",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nSCRIPTPATH=\"$( cd \"$(dirname \"$0\")\" >/dev/null 2>&1 || exit ; pwd -P )\"\ncd \"$SCRIPTPATH\" || exit\nif ! [[ $PYTHONPATH =~ $SCRIPTPATH ]]\nthen\n export PYTHONPATH=$PYTHONPATH:$SCRIPTPATH/src\nfi\npython3 -m unittest discover -s \"$SCRIPTPATH\"/test -t \"$SCRIPTPATH\"\n"
},
{
"alpha_fraction": 0.6259689927101135,
"alphanum_fraction": 0.6414728760719299,
"avg_line_length": 29.352941513061523,
"blob_id": "95b641b1adba41f12083e24c307de42c4a8ae874",
"content_id": "4935b957ddd6415f87a7f8329a25438706866d75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 516,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 17,
"path": "/src/BribeNet/bribery/static/randomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\nfrom BribeNet.bribery.static.briber import StaticBriber\n\nDELTA = 0.001 # ensures total bribes do not exceed budget\n\n\nclass RandomBriber(StaticBriber):\n\n def _next_bribe(self):\n customers = self.get_graph().get_customers()\n # array of random bribes\n bribes = [random.uniform(0.0, 1.0) for _ in customers]\n bribes = [b * (self.get_resources() - DELTA) / sum(bribes) for b in bribes]\n # enact bribes\n for i in customers:\n self.bribe(i, bribes[i])\n"
},
{
"alpha_fraction": 0.7324106097221375,
"alphanum_fraction": 0.7358708381652832,
"avg_line_length": 35.125,
"blob_id": "4df97d958d878fe651d29616ef5316595ffeedd7",
"content_id": "1c152bcf47de4d22404452c472e12f9e8a57ca61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 867,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 24,
"path": "/test/BribeNet/bribery/test_briber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\n\nfrom test.BribeNet.bribery.static.briberTestCase import BriberTestCase\nfrom BribeNet.bribery.briber import BriberyGraphAlreadySetException, BriberyGraphNotSetException\nfrom BribeNet.bribery.static.nonBriber import NonBriber\n\n\nclass TestBriber(BriberTestCase):\n\n def setUp(self) -> None:\n super().setUp()\n\n def test_bribe(self):\n initial_u = self.briber.get_resources()\n bribe = random.randrange(0, initial_u)\n self.briber.bribe(0, bribe)\n self.assertEqual(self.briber.get_resources(), initial_u-bribe)\n\n def test_next_bribe_fails_if_graph_not_set(self):\n briber = NonBriber(0)\n self.assertRaises(BriberyGraphNotSetException, briber.next_bribe)\n\n def test_set_graph_fails_if_graph_already_set(self):\n self.assertRaises(BriberyGraphAlreadySetException, self.briber._set_graph, self.rg)\n"
},
{
"alpha_fraction": 0.6907630562782288,
"alphanum_fraction": 0.6987951993942261,
"avg_line_length": 30.125,
"blob_id": "2abf158bb5e3544a790a337437f7667460cd70f8",
"content_id": "7d23edabaa43d1300e606ddb1f24445976a8e2f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 498,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 16,
"path": "/src/BribeNet/gui/apps/temporal/results_wizard/window.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.temporal.results_wizard.frame import TemporalResultsWizardFrame\n\n\nclass TemporalResultsWizardWindow(tk.Toplevel):\n \"\"\"\n Window for pop-up wizard for selecting results displayed\n \"\"\"\n\n def __init__(self, controller, results):\n super().__init__(controller)\n self.title(\"Results Wizard\")\n self.controller = controller\n self.frame = TemporalResultsWizardFrame(self, results)\n self.frame.pack(pady=10, padx=10)\n"
},
{
"alpha_fraction": 0.6845637559890747,
"alphanum_fraction": 0.6845637559890747,
"avg_line_length": 17.625,
"blob_id": "8755fba60dc0fe5d27768845137e9da2498eea4b",
"content_id": "9fa745417c2b9e6c57ef4fec87ab58697ac2e4d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 8,
"path": "/src/BribeNet/gui/apps/static/briber_wizard/window.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\nclass StaticBriberWizardWindow(tk.Toplevel):\n \"\"\"\n Window for pop-up wizard for adding a static briber\n \"\"\"\n pass\n"
},
{
"alpha_fraction": 0.7262247800827026,
"alphanum_fraction": 0.7262247800827026,
"avg_line_length": 30.545454025268555,
"blob_id": "26e457ca7d9c4fd352a9ae4a384bbb177832a625",
"content_id": "ea8882868b3c6d269f16facd8e1c56e641486bb3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 11,
"path": "/src/BribeNet/graph/generation/unweightedGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.generator import GraphGenerator\n\n\nclass UnweightedGraphGenerator(GraphGenerator):\n\n def __init__(self, a: GraphGeneratorAlgo, *args, **kwargs):\n super().__init__(a, *args, **kwargs)\n\n def generate(self):\n return self._generator.generate()\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7044642567634583,
"avg_line_length": 37.620689392089844,
"blob_id": "c9e8a275ddee5d415c3e762859705a083cb16660",
"content_id": "d628512add52b6408648555b247db42bfa6c27d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2240,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 58,
"path": "/src/BribeNet/gui/apps/temporal/briber_wizard/frame.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.budget import BudgetFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.even import EvenFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.influential import InfluentialFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.most_influential import MostInfluentialFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.non import NonFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.p_greedy import PGreedyFrame\nfrom BribeNet.gui.apps.temporal.briber_wizard.strategies.random import RandomFrame\n\nSTRAT_SUBFRAMES = (NonFrame, RandomFrame, InfluentialFrame, MostInfluentialFrame, EvenFrame, BudgetFrame, PGreedyFrame)\nSTRAT_DICT = {v: k for k, v in enumerate([a.name for a in STRAT_SUBFRAMES])}\n\n\nclass TemporalBriberWizardFrame(tk.Frame):\n \"\"\"\n Frame for pop-up wizard for adding a temporal briber\n \"\"\"\n\n def __init__(self, parent):\n super().__init__(parent)\n self.parent = parent\n self.strat_type = tk.StringVar(self)\n\n self.subframes = tuple(c(self) for c in STRAT_SUBFRAMES)\n self.options = tuple(f.get_name() for f in self.subframes)\n\n self.dropdown = tk.OptionMenu(self, self.strat_type, *self.options)\n self.dropdown.grid(row=0, column=0)\n\n self.strat_type.set(self.options[0])\n for f in self.subframes:\n f.grid(row=1, column=0, sticky=\"nsew\", pady=20)\n\n self.strat_type.trace('w', self.switch_frame)\n\n self.show_subframe(0)\n\n self.submit_button = tk.Button(self, text=\"Submit\", command=self.add_briber)\n self.submit_button.grid(row=2, column=0)\n\n def show_subframe(self, page_no):\n frame = self.subframes[page_no]\n frame.tkraise()\n\n # noinspection PyUnusedLocal\n def switch_frame(self, *args):\n self.show_subframe(STRAT_DICT[self.strat_type.get()])\n\n def get_args(self):\n return self.subframes[STRAT_DICT[self.strat_type.get()]].get_args()\n\n def get_graph_type(self):\n return self.strat_type.get()\n\n def add_briber(self):\n self.parent.controller.add_briber(self.get_graph_type(), *(self.get_args()))\n self.parent.destroy()\n"
},
{
"alpha_fraction": 0.7471042275428772,
"alphanum_fraction": 0.7471042275428772,
"avg_line_length": 33.53333282470703,
"blob_id": "00b5f17ee4a50a48c5b3da0d479fe26905a742f1",
"content_id": "c5ae7321a4aeab8be1b2a98c2106f177bc06c264",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 518,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 15,
"path": "/src/BribeNet/graph/temporal/noCustomerActionGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingGraph import DEFAULT_GEN\nfrom BribeNet.graph.temporal.action.customerAction import CustomerAction\nfrom BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph\n\n\nclass NoCustomerActionGraph(TemporalRatingGraph):\n \"\"\"\n A temporal rating graph solely for testing purposes.\n \"\"\"\n\n def __init__(self, bribers, generator=DEFAULT_GEN, **kwargs):\n super().__init__(bribers, generator=generator, **kwargs)\n\n def _customer_action(self):\n return CustomerAction(self)\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6202020049095154,
"avg_line_length": 36.125,
"blob_id": "5c18ac16e74b84ad8747359d123e353d2398cb97",
"content_id": "4e0dbafe0b7013b10213c7ec4570e87adb037a79",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1485,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 40,
"path": "/src/BribeNet/gui/apps/temporal/results_wizard/frame.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\nclass TemporalResultsWizardFrame(tk.Frame):\n \"\"\"\n Frame for pop-up wizard for selecting results displayed\n \"\"\"\n\n def __init__(self, parent, results):\n super().__init__(parent)\n self.parent = parent\n\n self.x_string_var = tk.StringVar(self)\n self.y_string_var = tk.StringVar(self)\n\n self.title_text = tk.Label(self, text=\"Select Values\", font=(\"Calibri\", 16, \"bold\"), pady=20)\n self.title_text.grid(row=0, column=0, columnspan=2)\n\n self.x_text = tk.Label(self, text=\"X-axis\", padx=20, pady=10)\n self.x_text.grid(row=1, column=0)\n\n self.y_text = tk.Label(self, text=\"Y-axis\", padx=20, pady=10)\n self.y_text.grid(row=2, column=0)\n\n x_options = results.get_x_options()\n self.x_string_var.set(x_options[0])\n self.drop_xs = tk.OptionMenu(self, self.x_string_var, *x_options)\n self.drop_xs.grid(row=1, column=1, sticky='ew')\n\n y_options = results.get_y_options()\n self.y_string_var.set(y_options[0])\n self.drop_ys = tk.OptionMenu(self, self.y_string_var, *y_options)\n self.drop_ys.grid(row=2, column=1, sticky='ew')\n\n self.submit_button = tk.Button(self, text=\"Submit\", command=self.submit)\n self.submit_button.grid(row=3, column=0, columnspan=2, pady=20, sticky='nsew')\n\n def submit(self):\n self.parent.controller.plot_results(self.x_string_var.get(), self.y_string_var.get())\n self.parent.destroy()\n"
},
{
"alpha_fraction": 0.554347813129425,
"alphanum_fraction": 0.5636646151542664,
"avg_line_length": 25.83333396911621,
"blob_id": "f171b95045142a05896d6399ab9f8c6350d26233",
"content_id": "978e3a7a926944971fd887ece3f858a3ca41dc61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 645,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 24,
"path": "/src/BribeNet/gui/apps/static/wizard/algos/barabasi_albert.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass BarabasiAlbert(ParamListFrame):\n name = \"Barabási-Albert\"\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.params = {\n 'k': tk.DoubleVar(self, value=5),\n 'n_max': tk.IntVar(self, value=30),\n 'n_0': tk.IntVar(self, value=0)\n }\n\n self.descriptions = {\n 'k': 'number of attachments per node',\n 'n_max': 'number of nodes in the graph',\n 'n_0': 'number of connected nodes to begin with'\n }\n\n self.grid_params(show_name=False)\n"
},
{
"alpha_fraction": 0.6668818593025208,
"alphanum_fraction": 0.6746287941932678,
"avg_line_length": 35.02325439453125,
"blob_id": "fe127745ebf9abc028d53af3c127b8e36775c2eb",
"content_id": "7d2257bdf736770a08e4cb9c5497d6a66c1f59e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1549,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 43,
"path": "/test/BribeNet/graph/temporal/test_thresholdGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.graph.temporal.action.actionType import ActionType\nfrom BribeNet.graph.temporal.thresholdGraph import ThresholdGraph\nfrom unittest.mock import MagicMock\n\n\nclass TestThresholdGraph(TestCase):\n\n def setUp(self) -> None:\n self.rg = ThresholdGraph((NonBriber(10), NonBriber(10)), threshold=0.4, q=0.5)\n\n def tearDown(self) -> None:\n del self.rg\n\n def test_customer_action_runs_successfully(self):\n self.rg.step()\n self.rg.step()\n action = self.rg.get_last_customer_action()\n self.assertIsNotNone(action)\n self.assertTrue(action.get_performed())\n\n def test_customer_action_no_votes_runs_successfully(self):\n self.rg.get_rating = MagicMock(return_value=0)\n self.rg.step()\n self.rg.step()\n action = self.rg.get_last_customer_action()\n self.assertIsNotNone(action)\n for k in action.actions:\n self.assertNotEqual(action.actions[k], ActionType.SELECT)\n self.assertTrue(action.get_performed())\n\n def test_customer_action_disconnected_graph_runs_successfully(self):\n self.rg._neighbours = MagicMock(return_value=[])\n self.rg._q = 0.5\n self.rg.step()\n self.rg.step()\n action = self.rg.get_last_customer_action()\n self.assertIsNotNone(action)\n for k in action.actions:\n self.assertEqual(action.actions[k][0], ActionType.SELECT)\n self.assertTrue(action.get_performed())\n"
},
{
"alpha_fraction": 0.7657232880592346,
"alphanum_fraction": 0.7688679099082947,
"avg_line_length": 36.411766052246094,
"blob_id": "c473977fcac4656384626c9b2fac6c7349674ff9",
"content_id": "47d3f76a65aab03d9b1fc20358e041fbda3508b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 17,
"path": "/test/BribeNet/bribery/static/test_oneMoveInfluentialNodeBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\n\nfrom BribeNet.bribery.static.oneMoveInfluentialNodeBriber import OneMoveInfluentialNodeBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\nfrom test.BribeNet.bribery.static.briberTestCase import BriberTestCase\n\n\nclass TestOneMoveInfluentialNodeBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = OneMoveInfluentialNodeBriber(10)\n self.rg = StaticRatingGraph(self.briber)\n\n def test_next_bribe_increases_p_rating(self):\n initial_g = deepcopy(self.briber._g)\n self.briber.next_bribe()\n self._p_rating_increase(initial_g, self.briber._g)\n"
},
{
"alpha_fraction": 0.6099210977554321,
"alphanum_fraction": 0.6178128719329834,
"avg_line_length": 39.318180084228516,
"blob_id": "7fa8cabf3c91cba244c68164f40bb2b799b5b2bd",
"content_id": "927640f3bf3100c9a3349b30463c813ba97a396e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 887,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 22,
"path": "/src/BribeNet/bribery/static/influentialNodeBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.static.briber import StaticBriber\nfrom BribeNet.helpers.override import override\n\n\nclass InfluentialNodeBriber(StaticBriber):\n\n def __init__(self, u0, k=0.1):\n super().__init__(u0)\n self._k = k # will be reassigned when graph set\n\n @override\n def _set_graph(self, g):\n super()._set_graph(g)\n # Make sure that k is set such that there are enough resources left to actually bribe people.\n self._k = min(self._k, 0.5 * (self.get_resources() / self.get_graph().customer_count()))\n\n def _next_bribe(self):\n for c in self.get_graph().get_customers():\n reward = self.get_graph().is_influential(c, k=self._k, briber_id=self.get_briber_id())\n if reward > 0:\n # max out customers rating\n self.bribe(c, self.get_graph().get_max_rating() - self.get_graph().get_vote(c))\n"
},
{
"alpha_fraction": 0.6079703569412231,
"alphanum_fraction": 0.6121408939361572,
"avg_line_length": 37.53571319580078,
"blob_id": "d88c17429c5971e53c4370290143260d3ebb28ba",
"content_id": "a01d320c7f48d589a0275e070831e812392b4f97",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2158,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 56,
"path": "/src/BribeNet/bribery/temporal/pGreedyBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import sys\nimport numpy as np\n\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import TemporalBriber\n\n\"\"\"\nIMPORTANT!\nThis briber cheats and uses the direct influential node information.\nThis is for testing whether trust is powerful enough to beat P-greedy bribery\neven when the briber has perfect information.\n\"\"\"\n\n\nclass PGreedyBriber(TemporalBriber):\n\n def __init__(self, u0: float):\n \"\"\"\n Constructor\n :param u0: initial utility\n \"\"\"\n super().__init__(u0)\n self._targets = []\n self._index = 0\n self._bribed = set()\n\n def _set_graph(self, g):\n super()._set_graph(g)\n \n def _get_influential_nodes(self, g):\n # noinspection PyProtectedMember\n influence_weights = [(n, g._get_influence_weight(n, self.get_briber_id())) for n in self._g.get_customers()]\n influence_weights = sorted(influence_weights, key=lambda x: x[1], reverse=True)\n self._targets = [n for (n, w) in influence_weights if w >= 1 and not n in self._bribed]\n\n def _next_action(self) -> SingleBriberyAction:\n \"\"\"\n Next action of briber, just bribe the next node as fully as you can.\n :return: SingleBriberyAction for the briber to take in the next temporal time step\n \"\"\"\n next_act = SingleBriberyAction(self)\n if self._index >= len(self._targets):\n self._get_influential_nodes(self._g)\n self._index = 0\n if self._index < len(self._targets):\n # Bribe the next target as fully as you can.\n target = self._targets[self._index]\n target_vote = self._g.get_vote(target)[self.get_briber_id()]\n if np.isnan(target_vote): target_vote = 0\n next_act.add_bribe(target, min(self.get_resources(),\n self._g.get_max_rating() - target_vote))\n self._index += 1\n self._bribed.add(target)\n else:\n print(f\"WARNING: {self.__class__.__name__} found no influential nodes, not acting...\", file=sys.stderr)\n return next_act\n"
},
{
"alpha_fraction": 0.5830039381980896,
"alphanum_fraction": 0.5895915627479553,
"avg_line_length": 43.64706039428711,
"blob_id": "aaf2ef1b8f693751021ce93383a96e064aa85ae2",
"content_id": "a7c7607003eb1be3852c03474bb30a4d3ab84a37",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1518,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 34,
"path": "/src/BribeNet/gui/apps/static/wizard/algos/composite.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass Composite(ParamListFrame):\n name = \"Composite\"\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.params = {\n 'n_nodes': tk.IntVar(self, value=50),\n 'n_communities': tk.IntVar(self, value=5),\n 'n_neighbours': tk.IntVar(self, value=2),\n 'p_rewiring': tk.DoubleVar(self, value=0.3),\n 'k': tk.DoubleVar(self, value=3),\n 'p_reduce': tk.DoubleVar(self, value=0.05)\n }\n\n self.descriptions = {\n 'n_nodes': 'number of nodes in the graph',\n 'n_communities': 'how many small world networks the composite network should consist of',\n 'n_neighbours': 'how many neighbours each node should have at the start of small world generation (k from '\n 'Watts-Strogatz)',\n 'p_rewiring': 'the probability of rewiring a given edge during small world network generation (p from '\n 'Watts-Strogatz)',\n 'k': 'number of attachments per community (k for Barabasi-Albert for our parent graph)',\n 'p_reduce': \"how much the probability of joining two nodes in two different communities is reduced by - \"\n \"once a successful connection is made, the probability of connecting two edges p' becomes p' \"\n \"* probability_reduce \"\n }\n\n self.grid_params(show_name=False)\n"
},
{
"alpha_fraction": 0.6474645137786865,
"alphanum_fraction": 0.6474645137786865,
"avg_line_length": 34.21428680419922,
"blob_id": "142dde8b3f9217cbe562daf93dccb560d40e06f3",
"content_id": "2fefb9f1bc9de1b69287eaed8f707942f874fa69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2465,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 70,
"path": "/src/BribeNet/bribery/temporal/action/briberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nfrom typing import List\n\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass BriberyActionExecutedMultipleTimesException(BribeNetException):\n pass\n\n\nclass BriberyActionTimeNotCorrectException(BribeNetException):\n pass\n\n\nclass BriberyAction(ABC):\n\n def __init__(self, graph):\n\n from BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph # local import to remove cyclic dependency\n from BribeNet.bribery.temporal.briber import GraphNotSubclassOfTemporalRatingGraphException\n if not issubclass(graph.__class__, TemporalRatingGraph):\n raise GraphNotSubclassOfTemporalRatingGraphException(f\"{graph.__class__.__name__} is not a subclass of \"\n \"TemporalRatingGraph\")\n self.graph = graph\n self.__time_step = self.graph.get_time_step()\n self.__performed = False\n\n @classmethod\n @abstractmethod\n def empty_action(cls, graph):\n raise NotImplementedError\n\n def perform_action(self):\n \"\"\"\n Perform the action safely\n :raises BriberyActionTimeNotCorrectException: if action not at same time step as graph\n :raises BriberyActionExecutedMultipleTimesException: if action already executed\n \"\"\"\n if not self.__performed:\n if self.__time_step == self.graph.get_time_step():\n self._perform_action()\n self.__performed = True\n else:\n message = f\"The time step of the TemporalRatingGraph ({self.graph.get_time_step()}) is not equal to \" \\\n f\"the intended execution time ({self.__time_step})\"\n raise BriberyActionTimeNotCorrectException(message)\n else:\n raise BriberyActionExecutedMultipleTimesException()\n\n def get_time_step(self):\n return self.__time_step\n\n def get_performed(self):\n return self.__performed\n\n @abstractmethod\n def _perform_action(self):\n \"\"\"\n Perform the stored bribery actions simultaneously\n \"\"\"\n raise NotImplementedError\n\n @abstractmethod\n def is_bribed(self, node_id) -> (bool, List[int]):\n \"\"\"\n Determine if the bribery action results in a node being bribed this time step\n :param node_id: the node\n :return: whether the node is bribed this time step\n \"\"\"\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.7107728123664856,
"alphanum_fraction": 0.7318500876426697,
"avg_line_length": 39.66666793823242,
"blob_id": "fc3385a17fcc6a4d683aff2db6acfeaaf3f7248d",
"content_id": "744c04672b1deb585ec20bb03dbcba316d6fd1a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 854,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 21,
"path": "/test/BribeNet/graph/generation/test_unweightedGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\nfrom BribeNet.graph.generation.unweightedGenerator import UnweightedGraphGenerator\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\n\n\nclass TestUnweightedGraphGenerator(TestCase):\n\n def test_generate_ws(self):\n graph_gen = UnweightedGraphGenerator(GraphGeneratorAlgo.WATTS_STROGATZ, 30, 5, 0.3)\n graph = graph_gen.generate()\n self.assertFalse(graph.isWeighted())\n\n def test_generate_ba(self):\n graph_gen = UnweightedGraphGenerator(GraphGeneratorAlgo.BARABASI_ALBERT, 5, 30, 0, True)\n graph = graph_gen.generate()\n self.assertFalse(graph.isWeighted())\n\n def test_generate_composite(self):\n graph_gen = UnweightedGraphGenerator(GraphGeneratorAlgo.COMPOSITE, 30, 15, 50, 0.1, 2)\n graph = graph_gen.generate()\n self.assertFalse(graph.isWeighted())\n"
},
{
"alpha_fraction": 0.6164812445640564,
"alphanum_fraction": 0.6175243258476257,
"avg_line_length": 42.57575607299805,
"blob_id": "14e74c62338bf1d8d695ee1a2a4dc2633662f20f",
"content_id": "c709f4c811ba9279682fac3a86908bf9255313cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2876,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 66,
"path": "/src/BribeNet/graph/static/ratingGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\nfrom typing import Tuple, Union, Any\n\nimport numpy as np\n\nfrom BribeNet.graph.ratingGraph import RatingGraph, DEFAULT_GEN, BribersAreNotTupleException, NoBriberGivenException\nfrom BribeNet.helpers.bribeNetException import BribeNetException\nfrom BribeNet.helpers.override import override\n\nDEFAULT_NON_VOTER_PROPORTION = 0.2\n\n\nclass BriberNotSubclassOfStaticBriberException(BribeNetException):\n pass\n\n\nclass StaticRatingGraph(RatingGraph):\n\n def __init__(self, bribers: Union[Tuple[Any], Any], generator=DEFAULT_GEN, **kwargs):\n from BribeNet.bribery.static.briber import StaticBriber\n if issubclass(bribers.__class__, StaticBriber):\n bribers = tuple([bribers])\n if not isinstance(bribers, tuple):\n raise BribersAreNotTupleException()\n if not bribers:\n raise NoBriberGivenException()\n for b in bribers:\n if not issubclass(b.__class__, StaticBriber):\n raise BriberNotSubclassOfStaticBriberException(f\"{b.__class__.__name__} is not a subclass of \"\n \"StaticBriber\")\n self.__tmp_bribers = bribers\n self.__tmp_kwargs = kwargs\n super().__init__(bribers, generator=generator, specifics=self.__specifics, **kwargs)\n\n @override\n def _finalise_init(self):\n \"\"\"\n Perform assertions that ensure everything is initialised\n \"\"\"\n from BribeNet.bribery.static.briber import StaticBriber\n for briber in self._bribers:\n if not issubclass(briber.__class__, StaticBriber):\n raise BriberNotSubclassOfStaticBriberException(f\"{briber.__class__.__name__} is not a subclass of \"\n \"StaticBriber\")\n super()._finalise_init()\n\n def __specifics(self):\n from BribeNet.bribery.static.briber import StaticBriber\n self._bribers: Tuple[StaticBriber] = self.__tmp_bribers\n # noinspection PyTypeChecker\n self._votes = np.zeros((self.get_graph().numberOfNodes(), len(self._bribers)))\n self._truths = np.zeros((self.get_graph().numberOfNodes(), len(self._bribers)))\n # Generate random ratings network\n if \"non_voter_proportion\" in self.__tmp_kwargs:\n non_voter_proportion = self.__tmp_kwargs[\"non_voter_proportion\"]\n else:\n non_voter_proportion = DEFAULT_NON_VOTER_PROPORTION\n for n in self.get_graph().iterNodes():\n for b, _ in enumerate(self._bribers):\n rating = random.uniform(0, self._max_rating)\n self._truths[n][b] = rating\n if random.random() > non_voter_proportion:\n self._votes[n][b] = rating\n else:\n self._votes[n][b] = np.nan\n del self.__tmp_bribers, self.__tmp_kwargs\n"
},
{
"alpha_fraction": 0.5826330780982971,
"alphanum_fraction": 0.593837559223175,
"avg_line_length": 28.75,
"blob_id": "b6ceabb908d1b087ebea1a89ea871b5b648c3a3b",
"content_id": "93973b8b3ac60726bbe19f03a64deec607a309cd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 714,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 24,
"path": "/src/BribeNet/gui/apps/temporal/briber_wizard/strategies/p_greedy.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass PGreedyFrame(ParamListFrame):\n name = \"P-Greedy\"\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.params = {\n 'u_0': tk.DoubleVar(self, value=10),\n 'true_average': tk.DoubleVar(self, value=0.5),\n 'true_std_dev': tk.DoubleVar(self, value=0.2)\n }\n\n self.descriptions = {\n 'u_0': 'starting budget',\n 'true_average': 'the average of customer ground truth for this briber',\n 'true_std_dev': 'the standard deviation of customer ground truth for this briber'\n }\n\n self.grid_params(show_name=False)\n"
},
{
"alpha_fraction": 0.7566189169883728,
"alphanum_fraction": 0.7638752460479736,
"avg_line_length": 62.75,
"blob_id": "9a5673e9bc896e3f72370ecd12347056c4ba7259",
"content_id": "71582a1ffd10327368a92f929f93aa8a25ef8cd5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5099,
"license_type": "permissive",
"max_line_length": 616,
"num_lines": 80,
"path": "/README.md",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "# BribeNet\n\nBribeNet implements various models and bribing strategies for graphs of customers being influenced by bribing actors under a certain rating method. Please see the Final Report for a full discussion of the project.\n\n4th year group project by:\n\n* Robert Murray ([[email protected]](mailto:[email protected]))\n* Finnbar Keating ([[email protected]](mailto:[email protected]))\n* Callum Marvell ([[email protected]](mailto:[email protected]))\n* Nathan Cox ([[email protected]](mailto:[email protected]))\n\n\n\n## Prerequisites\n\n### Operating System\nIt is strongly recommended to run BribeNet on a Debian-based Linux distribution such as Ubuntu. The implementation has been tested on Ubuntu 16.04 LTS through to Ubuntu 20.04 LTS. NetworKit, a core dependency of our implementation, is not supported for Windows, and is supported for MacOS but this is untested for our implementation. It may be possible to run the BribeNet GUI on Windows 10 using Windows Subsystem for Linux, Docker for Windows (using a host Docker server from within the Windows Subsystem for Linux environment) and an X server for Windows such as Xming, but this is again untested and unsupported.\n\n### Hardware Requirements\n\nThe implementation is not especially computationally demanding and is expected to run smoothly on most modern systems. During implementation the implementation was run on a Ubuntu 16.04 LTS virtual machine given 8GB RAM and 4 virtual processing cores, but is anticipated to function well with lower specifications than this.\n\n## Run GUI using Docker\nFirst download the latest release of the `.tar.gz` archive of BribeNet and extract it using:\n```bash\ntar -xzf BribeNet-x.x.x.tar.gz\n```\nAt the top level of the implementation directory there is the bash script `run.sh`. This script will install Docker and `x11-xserver-utils` (required for the GUI to display on the host machine). It will then enable and start the Docker daemon and service, then build and run the `Dockerfile` defined at the top level of the implementation directory. The Docker image is based off of the `python:3.7.7-slim-buster` image. In case this script does not work, we will describe the steps needed to run the GUI in a Docker container.\n* `sudo apt-get install docker.io x11-xserver-utils` - installs Docker and the `xhost` command if not already installed.\n* `systemctl start docker' - ensure the Docker daemon is running.\n* `service docker start` - ensure the Docker service is running.\n* `xhost +` - disable access control for the X window system such that the Docker container can display the GUI on the host machine.\n* `docker build -t model\\_gui .` - build the Docker container. Ensure you are in the same directory as the `Dockerfile` before running. The container will then be named `model\\_gui:latest`.\n* `docker run -it --rm -e DISPLAY=\\$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix model\\_gui` - run the Docker container. We talk through what each option does below.\n * `-it` - run in interactive mode and attach to the container.\n * `--rm` - automatically remove the container when it exits.\n * `-e DISPLAY=\\$DISPLAY` - set the `DISPLAY` environment variable inside the container to be the value of the `DISPLAY` environment variable on the host machine.\n * `-v /tmp/.X11-unix/:/tmp/.X11-unix` - mount the host machine's X11 server Unix-domain socket in to the same location in the container, allowing the container to access the host's display.\n\n\n## Run GUI locally\nFirst download the latest release of the `.tar.gz` archive of BribeNet and extract it using:\n```bash\ntar -xzf BribeNet-x.x.x.tar.gz\n```\nPrior to installing the dependencies of BribeNet, make sure that the required packages are installed for the dependencies. First run `sudo apt-get update` and then install the required packages:\n```bash\nsudo apt-get install wget gcc g++ make cmake tk\n```\nAs an optional step, in order to work in a clean Python environment, [install Conda](https://docs.continuum.io/anaconda/install/linux/) and create a new environment for BribeNet and activate it:\n```bash\nconda create -n bribe_net python=3.7\nconda activate bribe_net\n```\nThen to install the dependencies, at the top level of the implementation directory use `pip} to install the dependencies defined in the `requirements.txt} file:\n```bash\npip install -r requirements.txt\n```\nWe can then run the GUI by running:\n```bash\npython src/main.py\n```\nIf you are having issues where the application does not exit after closing all windows, you can use an alternative runner which is guaranteed to exit:\n```bash\npython src/docker_main.py\n```\n\n## Install as package\nPrior to installing BribeNet as a package, make sure that the required packages are installed for the dependencies. First run `sudo apt-get update} and then install the required packages:\n```bash\nsudo apt-get install wget gcc g++ make cmake tk\n```\nFirst download the wheel of the latest release (`.whl` file) archive of BribeNet and install it using:\n```bash\npip install BribeNet-x.x.x-py3-none-any.whl\n```\nThis will automatically install the requirements as well as BribeNet. You can now import and use the entire codebase, or you can still run the GUI using:\n```bash\npython -m BribeNet.gui.main\n```"
},
{
"alpha_fraction": 0.619258463382721,
"alphanum_fraction": 0.6236856579780579,
"avg_line_length": 44.17499923706055,
"blob_id": "e4d08fe32c602f6ad7954cbc04417bd121c41b5c",
"content_id": "71bb0f26b42361f406be086404b75f08c03e1950",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3614,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 80,
"path": "/src/BribeNet/graph/temporal/thresholdGraph.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import random\nfrom typing import List\n\nimport numpy as np\n\nfrom BribeNet.graph.ratingGraph import DEFAULT_GEN\nfrom BribeNet.graph.temporal.action.actionType import ActionType\nfrom BribeNet.graph.temporal.action.customerAction import CustomerAction\nfrom BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph, BriberKeywordArgumentOutOfBoundsException\n\nDEFAULT_THRESHOLD = 0.5\nMIN_THRESHOLD = 0.0\nMAX_THRESHOLD = 1.0\n\n\nclass ThresholdGraph(TemporalRatingGraph):\n\n def __init__(self, bribers, generator=DEFAULT_GEN, **kwargs):\n \"\"\"\n Threshold model for temporal rating graph\n :param bribers: the bribers active on the network\n :param generator: the generator to be used to generate the customer graph\n :param kwargs: additional parameters to the threshold temporal rating graph\n :keyword threshold: float - threshold for being considered\n :keyword remove_no_vote: bool - whether to allow non voted restaurants\n :keyword q: float - percentage of max rating given to non voted restaurants\n :keyword pay: float - the amount of utility gained by a restaurant when a customer visits\n :keyword apathy: float - the probability a customer does not visit any restaurant\n \"\"\"\n super().__init__(bribers, generator=generator, **kwargs)\n if \"threshold\" in kwargs:\n threshold = kwargs[\"threshold\"]\n if not MIN_THRESHOLD <= threshold <= MAX_THRESHOLD:\n raise BriberKeywordArgumentOutOfBoundsException(\n f\"threshold={threshold} out of bounds ({MIN_THRESHOLD}, {MAX_THRESHOLD})\")\n self._threshold: float = threshold\n else:\n self._threshold: float = DEFAULT_THRESHOLD\n\n def _customer_action(self):\n\n # obtain customers ratings before any actions at this step, assumes all customers act simultaneously\n curr_ratings: List[List[float]] = [[self.get_rating(n, b.get_briber_id(), nan_default=0) for b in self._bribers]\n for n in self.get_customers()]\n voted: List[List[bool]] = [[len(self._neighbours(n, b.get_briber_id())) > 0 for b in self._bribers]\n for n in self.get_customers()]\n\n action = CustomerAction(self)\n for bribery_action in self._last_bribery_actions:\n action.set_bribed_from_bribery_action(bribery_action)\n\n # for each customer\n for n in self.get_graph().iterNodes():\n # get weightings for restaurants\n # 0 if below_threshold, q if no votes\n weights = np.zeros(len(self._bribers))\n\n for b in range(0, len(self._bribers)):\n # Check for no votes\n if not voted[n][b]:\n weights[b] = self._q\n # P-rating below threshold\n elif curr_ratings[n][b] < self._threshold:\n weights[b] = 0\n # Else probability proportional to P-rating\n else:\n weights[b] = curr_ratings[n][b]\n\n # no restaurants above threshold so no action for this customer\n if np.count_nonzero(weights) == 0:\n continue\n\n # select at random\n selected = random.choices(range(0, len(self._bribers)), weights=weights)[0]\n\n if random.random() >= self._apathy: # has no effect by default (DEFAULT_APATHY = 0.0)\n if action.get_action_type(n) == ActionType.NONE: # if not already selected or bribed\n action.set_select(n, selected)\n\n return action\n"
},
{
"alpha_fraction": 0.7032297253608704,
"alphanum_fraction": 0.7221206426620483,
"avg_line_length": 40.025001525878906,
"blob_id": "0871d361b61233a3b5f9858087ccdddfe9be6b66",
"content_id": "50b0d34ffb1e766ca35bafe4d969eaa98e6f1166",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1641,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 40,
"path": "/test/BribeNet/bribery/temporal/action/test_singleBriberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.nonBriber import NonBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom BribeNet.bribery.temporal.action import *\n\n\nclass TestSingleBriberyAction(TestCase):\n\n def setUp(self) -> None:\n self.briber = NonBriber(1)\n self.graph = NoCustomerActionGraph(self.briber)\n\n def test_add_bribe_fails_if_bribe_not_greater_than_zero(self):\n action = SingleBriberyAction(self.briber)\n self.assertRaises(BribeMustBeGreaterThanZeroException, action.add_bribe, 0, -1.0)\n\n def test_add_bribe_fails_if_node_id_not_present(self):\n action = SingleBriberyAction(self.briber)\n self.assertRaises(NodeDoesNotExistException, action.add_bribe, -1, 1.0)\n\n def test_add_bribe_passes_1(self):\n action = SingleBriberyAction(self.briber)\n action.add_bribe(0, 1.0)\n self.assertEqual(action._bribes[0], 1.0)\n\n def test_add_bribe_passes_2(self):\n action = SingleBriberyAction(self.briber, bribes={0: 1.0})\n action.add_bribe(0, 1.0)\n self.assertEqual(action._bribes[0], 2.0)\n\n def test__perform_action_fails_when_bribes_exceed_budget(self):\n action = SingleBriberyAction(self.briber, bribes={1: 10.0})\n self.assertRaises(BriberyActionExceedsAvailableUtilityException, action._perform_action)\n\n def test_perform_action(self):\n action = SingleBriberyAction(self.briber, bribes={0: 0.5})\n action.perform_action()\n self.assertTrue(action.get_performed())\n"
},
{
"alpha_fraction": 0.6783439517021179,
"alphanum_fraction": 0.6847133636474609,
"avg_line_length": 27.545454025268555,
"blob_id": "5a0d3b0ad5b8d7b1978d9695d3f084d8fc47fd39",
"content_id": "92f11c5e05d4baa61704aa72011cfc20ce2f7c6e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 628,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 22,
"path": "/src/BribeNet/gui/apps/temporal/briber_wizard/window.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.temporal.briber_wizard.frame import TemporalBriberWizardFrame\nfrom BribeNet.helpers.override import override\n\n\nclass TemporalBriberWizardWindow(tk.Toplevel):\n \"\"\"\n Window for pop-up wizard for adding a temporal briber\n \"\"\"\n\n def __init__(self, controller):\n super().__init__(controller)\n self.title(\"Briber Wizard\")\n self.controller = controller\n self.frame = TemporalBriberWizardFrame(self)\n self.frame.pack(pady=10, padx=10)\n\n @override\n def destroy(self):\n self.controller.briber_wizard = None\n super().destroy()\n"
},
{
"alpha_fraction": 0.5974131226539612,
"alphanum_fraction": 0.6119644045829773,
"avg_line_length": 34.342857360839844,
"blob_id": "725b59ee41c3b42e3ec9434234ceea1102ea3f93",
"content_id": "0b09378a858698872228f717580ff347b221e700",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1240,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 35,
"path": "/src/BribeNet/gui/apps/static/wizard/wizard.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\n\nclass WizardFrame(tk.Frame):\n \"\"\"\n Frame for the wizard to construct a static model run\n \"\"\"\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.controller = controller\n\n gtype = tk.StringVar(parent)\n gtype.set(\"L\")\n btype = tk.StringVar(parent)\n btype.set(\"L\")\n\n rb1 = tk.Radiobutton(self, variable=gtype, value=\"ws\", text=\"Watts-Strogatz\")\n rb2 = tk.Radiobutton(self, variable=gtype, value=\"ba\", text=\"Barabási–Albert\")\n rb3 = tk.Radiobutton(self, variable=gtype, value=\"cg\", text=\"Composite Generator\")\n rb1.grid(row=0, column=0)\n rb2.grid(row=1, column=0)\n rb3.grid(row=2, column=0)\n\n rba = tk.Radiobutton(self, variable=btype, value=\"r\", text=\"Random\")\n rbb = tk.Radiobutton(self, variable=btype, value=\"i\", text=\"Influential\")\n rba.grid(row=0, column=1)\n rbb.grid(row=1, column=1)\n\n b = tk.Button(self, text=\"Graph + Test\", command=lambda: self.on_button(gtype.get(), btype.get()))\n b.grid(row=1, column=2)\n\n def on_button(self, gtype, btype):\n self.master.generate_graph(gtype, btype)\n self.master.show_frame(\"GraphFrame\")\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 21.5,
"blob_id": "13c9abc2439c888d1ced6edfd50c1fb2ead09e9e",
"content_id": "86db575c61cf864ea5cc9bcb607bb8918eaf7ebd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 2,
"path": "/src/BribeNet/helpers/bribeNetException.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "class BribeNetException(Exception):\n pass\n"
},
{
"alpha_fraction": 0.5935828685760498,
"alphanum_fraction": 0.6042780876159668,
"avg_line_length": 39.90625,
"blob_id": "442027c03091cdba55f143a8a5919203aa730e94",
"content_id": "a37c2c7bff7e9b3a6881a7b503eae318ccd92f35",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1309,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 32,
"path": "/src/BribeNet/gui/apps/temporal/wizard/settings.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.classes.param_list_frame import ParamListFrame\n\n\nclass TemporalSettings(ParamListFrame):\n name = 'Model Parameters'\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.descriptions = {\n 'non_voter_proportion': 'the proportion of customers which start with no vote',\n 'threshold': 'the minimum rating for a customer to consider visiting a bribing actor',\n 'd': 'the period of non-bribery rounds (minimum 2)',\n 'q': 'the vote value to use in place of non-votes in rating calculations',\n 'pay': 'the amount of utility given to a bribing actor each time a customer chooses them',\n 'apathy': 'the probability that a customer performs no action',\n 'learning_rate': 'how quickly the edge weights are updated by trust'\n }\n\n self.params = {\n 'non_voter_proportion': tk.DoubleVar(self, value=0.2),\n 'threshold': tk.DoubleVar(self, value=0.5),\n 'd': tk.IntVar(self, value=2),\n 'q': tk.DoubleVar(self, value=0.5),\n 'pay': tk.DoubleVar(self, value=1.0),\n 'apathy': tk.DoubleVar(self, value=0.0),\n 'learning_rate': tk.DoubleVar(self, value=0.1),\n }\n\n self.grid_params()\n"
},
{
"alpha_fraction": 0.6426475644111633,
"alphanum_fraction": 0.6501467227935791,
"avg_line_length": 41.01369857788086,
"blob_id": "45fd39d1bc34cde187d64087bd32a6002d262922",
"content_id": "4b39d656ddfe90846372c55cf1739d80cf99abf7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3067,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 73,
"path": "/test/BribeNet/bribery/temporal/test_mostInfluentialBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.temporal.mostInfluentialNodeBriber import MostInfluentialNodeBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom test.BribeNet.bribery.temporal.briberTestCase import BriberTestCase\nfrom unittest.mock import MagicMock\n\nTEST_I = 7\n\n\nclass TestMostInfluentialBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = MostInfluentialNodeBriber(10, i=TEST_I)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def test_next_action_increases_p_rating(self):\n graph = self.briber._g\n action = self.briber.next_action()\n briber_id = self.briber.get_briber_id()\n prev_eval = graph.eval_graph(briber_id=briber_id)\n\n action.perform_action()\n self.assertGreaterEqual(graph.eval_graph(briber_id=briber_id), prev_eval)\n\n def test_next_action_gains_information_for_suitable_time(self):\n prev_nodes = []\n for i in range(TEST_I - 1):\n action = self.briber.next_action()\n self.assertEqual(len(action._bribes), 1)\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n\n def test_next_action_performs_bribe_on_best_node(self):\n self.briber._c = self.briber._i\n self.briber._best_node = 1\n graph = self.briber._g\n graph.eval_graph = MagicMock(return_value=0)\n action = self.briber.next_action()\n self.assertIn(1, action._bribes)\n self.assertEqual(self.briber._c, 0)\n self.assertEqual(self.briber._max_rating_increase, 0)\n\n def test_next_action_finds_best_node(self):\n graph = self.briber._g\n graph.eval_graph = MagicMock(return_value=10)\n graph.get_random_customer = MagicMock(return_value=3)\n self.briber._previous_rating = 1\n self.briber._max_rating_increase = 0\n action = self.briber.next_action()\n self.assertIn(3, action._bribes)\n self.assertEqual(self.briber._max_rating_increase, 9)\n\n def test_next_action_does_not_fail_if_no_nodes_influential_within_i_step(self):\n graph = self.briber._g\n self.briber._previous_rating = 1\n graph.eval_graph = MagicMock(return_value=1) # will never be influential\n prev_nodes = []\n for i in range(TEST_I + 1):\n action = self.briber.next_action()\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n\n def test_next_action_does_not_fail_if_no_nodes_influential_at_all(self):\n graph = self.briber._g\n self.briber._previous_rating = 1\n graph.eval_graph = MagicMock(return_value=1) # will never be influential\n prev_nodes = []\n for i in range(graph.customer_count() + 1):\n action = self.briber.next_action()\n for prev_node in prev_nodes:\n self.assertNotIn(prev_node, action._bribes)\n prev_nodes.append(self.briber._next_node)\n"
},
{
"alpha_fraction": 0.5858974456787109,
"alphanum_fraction": 0.5982051491737366,
"avg_line_length": 31.773109436035156,
"blob_id": "0762003c9c48334c77bb0e73131d493fa084be88",
"content_id": "65a475e0a0419db8b1ea5ee50b1ac913f5ccd433",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3900,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 119,
"path": "/src/BribeNet/prediction/parameterPrediction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "# noinspection PyUnresolvedReferences\nfrom networkit.centrality import LocalClusteringCoefficient\n# noinspection PyUnresolvedReferences\nfrom networkit.distance import APSP\nfrom networkit.generators import WattsStrogatzGenerator\nfrom numpy import logspace\nfrom numpy import sum as np_sum\n\nTRIALS = 5\nINFINITY = float(\"inf\")\n\n'''\nFinds the clustering coefficient of a given graph.\n'''\n\n\nclass ParameterPrediction(object):\n\n def __init__(self, graph):\n self.__g = graph\n\n def average_clustering(self, turbo=True):\n # If graphs get too large, turn off Turbo mode (which requires more memory)\n lcc = LocalClusteringCoefficient(self.__g, turbo)\n lcc.run()\n scores = lcc.scores()\n return sum(scores) / len(scores)\n\n '''\n Finds the average shortest path length of a given graph.\n '''\n\n def average_shortest_path_length(self):\n apsp = APSP(self.__g)\n apsp.run()\n n = self.__g.numberOfNodes()\n # npsum needed as we are summing values in a matrix\n # Note! The matrix returned by getDistances is n*n, but we divide by n*n-1\n # since the central diagonal represents distances from a node to itself.\n distances = apsp.getDistances()\n return np_sum(distances) / (n * (n - 1))\n\n '''\n Given an existing graph (from networkx), predict the parameters that should be used given.\n Returns (n,k,p), where:\n n: the number of nodes\n k: the degree of nodes of the starting regular graph (that we rewire)\n p: the probability of rewiring\n '''\n\n def predict_small_world(self):\n n = self.__g.numberOfNodes()\n k = sum([len(self.__g.neighbors(i)) for i in self.__g.iterNodes()]) // (2 * n)\n probs = logspace(-5, 0, 64, False, 10)\n (lvs, cvs, l0, c0) = self.generate_example_graphs(n, k, probs)\n lp = self.average_shortest_path_length()\n l_ratio = lp / l0\n cp = self.average_clustering()\n c_ratio = cp / c0\n\n # Find the p according to l and c ratios\n index_l = self.closest_index(lvs, l_ratio)\n index_c = self.closest_index(cvs, c_ratio)\n prob_l = probs[index_l]\n prob_c = probs[index_c]\n\n p = (prob_l + prob_c) / 2\n return n, k, p\n\n @staticmethod\n def closest_index(values, target):\n min_diff = INFINITY\n best = 0\n for i in range(len(values)):\n lv = values[i]\n diff = abs(lv - target)\n if diff < min_diff:\n best = i\n min_diff = diff\n return best\n\n '''\n For a set of p-values, generate existing WS graphs and get the values of L(p)/L(0) and C(p)/C(0).\n Returns (l_values, c_values, l0, c0)\n '''\n\n @staticmethod\n def generate_example_graphs(n, k, ps):\n generator0 = WattsStrogatzGenerator(n, k, 0)\n graph0 = generator0.generate()\n pred0 = ParameterPrediction(graph0)\n l0 = pred0.average_shortest_path_length()\n c0 = pred0.average_clustering()\n result = ([], [], l0, c0)\n for p in ps:\n l_tot = 0\n c_tot = 0\n generator = WattsStrogatzGenerator(n, k, p)\n for i in range(TRIALS):\n graph = generator.generate()\n pred_i = ParameterPrediction(graph)\n l_tot += pred_i.average_shortest_path_length()\n c_tot += pred_i.average_clustering()\n lp = l_tot / TRIALS\n cp = c_tot / TRIALS\n result[0].append(lp / l0)\n result[1].append(cp / c0)\n return result\n\n\ndef test_parameter_prediction():\n print(\"Testing small world prediction with obviously Watts-Strogatz Graph (50,6,0.1)\")\n generator = WattsStrogatzGenerator(50, 6, 0.1)\n pred = ParameterPrediction(generator.generate())\n print(pred.predict_small_world())\n\n\nif __name__ == '__main__':\n test_parameter_prediction()\n"
},
{
"alpha_fraction": 0.6711409687995911,
"alphanum_fraction": 0.6736577153205872,
"avg_line_length": 34.05882263183594,
"blob_id": "c42e4ff6afd3da3db94a290af7f5276b4f2bb875",
"content_id": "d25ccd865be97976286cff189daca39fa57c467a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 34,
"path": "/src/BribeNet/bribery/temporal/briber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nfrom BribeNet.bribery.briber import Briber, BriberyGraphNotSetException\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass GraphNotSubclassOfTemporalRatingGraphException(BribeNetException):\n pass\n\n\nclass TemporalBriber(Briber, ABC):\n\n def __init__(self, u0: float):\n super().__init__(u0=u0)\n\n def _set_graph(self, g):\n from BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph\n if not issubclass(g.__class__, TemporalRatingGraph):\n raise GraphNotSubclassOfTemporalRatingGraphException(f\"{g.__class__.__name__} is not a subclass of \"\n \"TemporalRatingGraph\")\n super()._set_graph(g)\n\n def next_action(self) -> SingleBriberyAction:\n if self.get_graph() is None:\n raise BriberyGraphNotSetException()\n return self._next_action()\n\n @abstractmethod\n def _next_action(self) -> SingleBriberyAction:\n \"\"\"\n Defines the temporal model behaviour\n \"\"\"\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.6648351550102234,
"alphanum_fraction": 0.6877289414405823,
"avg_line_length": 31.117647171020508,
"blob_id": "e2cdd8fa15f0afb5d5e5dcd6348ba95259e77984",
"content_id": "86be2d7ae4157acfb25e7d8319f6a5566593abf2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1092,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 34,
"path": "/test/BribeNet/prediction/test_parameterPrediction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\n\nfrom networkit.generators import WattsStrogatzGenerator\nfrom numpy import logspace\n\nfrom BribeNet.prediction.parameterPrediction import ParameterPrediction\n\n\nclass TestParameterPrediction(TestCase):\n\n def setUp(self) -> None:\n self.generator = WattsStrogatzGenerator(50, 6, 0.1)\n self.pred = ParameterPrediction(self.generator.generate())\n\n def tearDown(self) -> None:\n del self.pred, self.generator\n\n def test_average_clustering(self):\n self.assertTrue(self.pred.average_clustering() > 0)\n\n def test_average_shortest_path_length(self):\n self.assertTrue(self.pred.average_shortest_path_length() > 0)\n\n def test_predict_small_world(self):\n n, k, p = self.pred.predict_small_world()\n self.assertTrue(n > 0)\n self.assertTrue(k > 0)\n self.assertTrue(p > 0)\n\n def test_generate_example_graphs(self):\n l_values, c_values, l0, c0 = ParameterPrediction.generate_example_graphs(50, 6, logspace(-5, 0, 64, False, 10))\n self.assertTrue(l0 > 0)\n self.assertTrue(c0 > 0)\n"
},
{
"alpha_fraction": 0.6592920422554016,
"alphanum_fraction": 0.6668773889541626,
"avg_line_length": 32.65957260131836,
"blob_id": "7fff1d2dfb90f9ec216abe8241288f1b3149fe85",
"content_id": "84cf9a0c02f1c265e4000e9be2af21f49ee2429e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1582,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 47,
"path": "/src/BribeNet/gui/apps/static/wizard/generation.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.static.wizard.algos.barabasi_albert import BarabasiAlbert\nfrom BribeNet.gui.apps.static.wizard.algos.composite import Composite\nfrom BribeNet.gui.apps.static.wizard.algos.watts_strogatz import WattsStrogatz\n\nALGO_SUBFRAMES = (BarabasiAlbert, Composite, WattsStrogatz)\nALGO_DICT = {v: k for k, v in enumerate([a.name for a in ALGO_SUBFRAMES])}\n\n\nclass StaticGeneration(tk.Frame):\n\n def __init__(self, parent):\n super().__init__(parent)\n self.parent = parent\n self.graph_type = tk.StringVar(self)\n\n title_label = tk.Label(self, text='Graph Generation Algorithm')\n title_label.grid(row=0, column=0, pady=10)\n\n self.subframes = tuple(c(self) for c in ALGO_SUBFRAMES)\n self.options = tuple(f.get_name() for f in self.subframes)\n\n self.dropdown = tk.OptionMenu(self, self.graph_type, *self.options)\n self.dropdown.grid(row=1, column=0, pady=10, sticky='nsew')\n\n self.graph_type.set(self.options[0])\n for f in self.subframes:\n f.grid(row=2, column=0, sticky=\"nsew\")\n\n self.graph_type.trace('w', self.switch_frame)\n\n self.show_subframe(0)\n\n def show_subframe(self, page_no):\n frame = self.subframes[page_no]\n frame.tkraise()\n\n # noinspection PyUnusedLocal\n def switch_frame(self, *args):\n self.show_subframe(ALGO_DICT[self.graph_type.get()])\n\n def get_args(self):\n return self.subframes[ALGO_DICT[self.graph_type.get()]].get_args()\n\n def get_graph_type(self):\n return self.graph_type.get()\n"
},
{
"alpha_fraction": 0.6517316699028015,
"alphanum_fraction": 0.6527004241943359,
"avg_line_length": 43.397850036621094,
"blob_id": "e99c248de840868b7641646ea38b8cdbe138de83",
"content_id": "17294f4b3cb114788a882318c03f423777898748",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4129,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 93,
"path": "/src/BribeNet/bribery/temporal/action/multiBriberyAction.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import sys\nfrom typing import Dict, Optional, List\n\nfrom BribeNet.bribery.temporal.action import BribeMustBeGreaterThanZeroException, NodeDoesNotExistException, \\\n BriberDoesNotExistException, BriberyActionExceedsAvailableUtilityException\nfrom BribeNet.bribery.temporal.action.briberyAction import BriberyAction\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import GraphNotSubclassOfTemporalRatingGraphException\nfrom BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass NoActionsToFormMultiActionException(BribeNetException):\n pass\n\n\nclass BriberyActionsOnDifferentGraphsException(BribeNetException):\n pass\n\n\nclass BriberyActionsAtDifferentTimesException(BribeNetException):\n pass\n\n\nclass MultiBriberyAction(BriberyAction):\n\n def __init__(self, graph, bribes: Optional[Dict[int, Dict[int, float]]] = None):\n from BribeNet.graph.temporal.ratingGraph import TemporalRatingGraph\n if not issubclass(graph.__class__, TemporalRatingGraph):\n raise GraphNotSubclassOfTemporalRatingGraphException(f\"{graph.__class__.__name__} is not a subclass of \"\n \"TemporalRatingGraph\")\n super().__init__(graph=graph)\n if bribes is not None:\n for _, bribe in bribes.items():\n for _, value in bribe.items():\n if value < 0:\n raise BribeMustBeGreaterThanZeroException()\n self._bribes: Dict[int, Dict[int, float]] = bribes or {}\n\n @classmethod\n def empty_action(cls, graph):\n return cls(graph, None)\n\n @classmethod\n def make_multi_action_from_single_actions(cls, actions: List[SingleBriberyAction]):\n if not actions:\n raise NoActionsToFormMultiActionException()\n graph = actions[0].briber.get_graph()\n if not all(b.briber.get_graph() is graph for b in actions):\n raise BriberyActionsOnDifferentGraphsException()\n time_step = actions[0].get_time_step()\n if not all(b.get_time_step() == time_step for b in actions):\n raise BriberyActionsAtDifferentTimesException()\n return cls(graph=graph, bribes={b.briber.get_briber_id(): b.get_bribes() for b in actions})\n\n def add_bribe(self, briber_id: int, node_id: int, bribe: float):\n if bribe <= 0:\n raise BribeMustBeGreaterThanZeroException()\n if node_id not in self.graph.get_customers():\n raise NodeDoesNotExistException()\n if briber_id not in range(len(self.graph.get_bribers())):\n raise BriberDoesNotExistException()\n if briber_id in self._bribes:\n if node_id in self._bribes[briber_id]:\n print(\"WARNING: node bribed twice in single time step, combining...\", file=sys.stderr)\n self._bribes[briber_id][node_id] += bribe\n else:\n self._bribes[briber_id][node_id] = bribe\n else:\n self._bribes[briber_id] = {node_id: bribe}\n\n def _perform_action(self):\n bribers = self.graph.get_bribers()\n for briber_id, bribe in self._bribes.items():\n total_bribe_quantity = sum(bribe.values())\n if total_bribe_quantity > bribers[briber_id].get_resources():\n message = f\"MultiBriberyAction exceeded resources available to briber {briber_id}: \" \\\n f\"{str(bribers[briber_id])} - {total_bribe_quantity} > {bribers[briber_id].get_resources()}\"\n raise BriberyActionExceedsAvailableUtilityException(message)\n for briber_id, bribe in self._bribes.items():\n for customer, value in bribe.items():\n bribers[briber_id].bribe(node_id=customer, amount=value)\n\n def is_bribed(self, node_id):\n bribers = []\n for briber_id in self._bribes:\n if node_id in self._bribes[briber_id]:\n bribers.append(briber_id)\n if not bribers:\n return False, bribers\n return True, bribers\n\n def get_bribes(self):\n return self._bribes\n"
},
{
"alpha_fraction": 0.5955273509025574,
"alphanum_fraction": 0.60077303647995,
"avg_line_length": 45.43589782714844,
"blob_id": "61f09692f2e56e57df3059870e0e188834221720",
"content_id": "affca422ad79112b8d9bfae637e0d91def6a4333",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3622,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 78,
"path": "/src/BribeNet/bribery/temporal/mostInfluentialNodeBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import sys\nimport numpy as np\n\nfrom BribeNet.bribery.temporal.action.singleBriberyAction import SingleBriberyAction\nfrom BribeNet.bribery.temporal.briber import TemporalBriber\n\n\nclass MostInfluentialNodeBriber(TemporalBriber):\n\n def __init__(self, u0: float, k: float = 0.1, i: int = 7):\n \"\"\"\n Constructor\n :param u0: initial utility\n :param k: cost of information\n :param i: maximum loop iterations for finding most influential node\n \"\"\"\n super().__init__(u0)\n self._k = k\n self._c = 0 # current loop iteration\n self._i = i # maximum loop iterations for finding most influential node\n self._current_rating = None\n self._previous_rating = None\n self._max_rating_increase = 0\n self._best_node = None\n self._next_node = 0\n self._last_node = 0\n self._info_gained = set()\n self._bribed = set()\n\n def _set_graph(self, g):\n super()._set_graph(g)\n # Make sure that k is set such that there are enough resources left to actually bribe people.\n self._k = min(self._k, 0.5 * (self.get_resources() / self.get_graph().customer_count()))\n\n def _bribe_to_max(self):\n bribe_to_max = self.get_graph().get_max_rating() - self.get_graph().get_vote(self._next_node)[self.get_briber_id()]\n if np.isnan(bribe_to_max): bribe_to_max = 1.0\n return bribe_to_max\n\n def _next_action(self) -> SingleBriberyAction:\n \"\"\"\n Next action of briber, either to gain information or to fully bribe the most influential node\n :return: SingleBriberyAction for the briber to take in the next temporal time step\n \"\"\"\n self._current_rating = self.get_graph().eval_graph(self.get_briber_id())\n if self._previous_rating is None:\n self._previous_rating = self._current_rating\n next_act = SingleBriberyAction(self)\n try:\n self._next_node = self.get_graph().get_random_customer(excluding=self._info_gained | self._bribed)\n except IndexError:\n print(f\"WARNING: {self.__class__.__name__} found no influential nodes, not acting...\", file=sys.stderr)\n return next_act\n if self._current_rating - self._previous_rating > self._max_rating_increase:\n self._best_node = self._last_node\n self._max_rating_increase = self._current_rating - self._previous_rating\n maximum_bribe = min(self.get_resources(), self._bribe_to_max())\n if self._c >= self._i and self._best_node is not None and maximum_bribe > 0:\n next_act.add_bribe(self._best_node, maximum_bribe)\n self._bribed.add(self._best_node)\n self._info_gained = set()\n self._c = 0\n self._max_rating_increase = 0\n self._best_node = 0\n else:\n if self._c >= self._i:\n print(f\"WARNING: {self.__class__.__name__} has not found an influential node in {self._c} tries \"\n f\"(intended maximum tries {self._i}), continuing search...\",\n file=sys.stderr)\n # Bid an information gaining bribe, which is at most k, but is\n # smaller if you need to bribe less to get to the full bribe\n # or don't have enough money to bid k.\n next_act.add_bribe(self._next_node, min(self._bribe_to_max(), min(self.get_resources(), self._k)))\n self._info_gained.add(self._next_node)\n self._c = self._c + 1\n self._last_node = self._next_node\n self._previous_rating = self._current_rating\n return next_act\n"
},
{
"alpha_fraction": 0.6924138069152832,
"alphanum_fraction": 0.6979310512542725,
"avg_line_length": 33.52381134033203,
"blob_id": "bb39d59e2827cff439c6a1c5cc5c537f5537da94",
"content_id": "4a36bf9d5c6ab1766ec66860dc256c1d5a41b1b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 725,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 21,
"path": "/src/BribeNet/graph/generation/flatWeightGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import networkit as nk\nimport networkit.nxadapter as adap\n\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.weightedGenerator import WeightedGraphGenerator\n\n\nclass FlatWeightedGraphGenerator(WeightedGraphGenerator):\n\n def __init__(self, a: GraphGeneratorAlgo, *args, **kwargs):\n super().__init__(a, *args, **kwargs)\n\n # Networkit does not let you add weights to a previously unweighted graph.\n # Thus we convert it to a Networkx graph, add weights and then revert.\n def generate(self) -> nk.graph:\n nxg = adap.nk2nx(self._generator.generate())\n\n for (u, v) in nxg.edges():\n nxg[u][v]['weight'] = 1.0\n\n return adap.nx2nk(nxg, 'weight')\n"
},
{
"alpha_fraction": 0.8141263723373413,
"alphanum_fraction": 0.8141263723373413,
"avg_line_length": 37.42856979370117,
"blob_id": "bacd3aaacc789e1b7021b736215dbdbf48926686",
"content_id": "5b668f7b304d85b5a94356978070de6a52b910f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 7,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/median_p_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass MedianPRating(RatingMethodFrame):\n enum_value = RatingMethod.MEDIAN_P_RATING\n name = 'median_p_rating'\n"
},
{
"alpha_fraction": 0.6591640114784241,
"alphanum_fraction": 0.6639871597290039,
"avg_line_length": 27.272727966308594,
"blob_id": "d3e4839aa34795c98c81a21e517b1883068ecbe3",
"content_id": "33201892f4fb3a369b9c2f656334f9faa1eb89ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 22,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/p_gamma_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass PGammaRating(RatingMethodFrame):\n enum_value = RatingMethod.P_GAMMA_RATING\n name = 'p_gamma_rating'\n\n def __init__(self, parent):\n super().__init__(parent)\n\n self.params = {\n 'gamma': tk.DoubleVar(self, value=0.05)\n }\n\n self.descriptions = {\n 'gamma': 'dampening factor that defines the effect of nodes based on their distance'\n }\n\n self.grid_params(show_name=False)\n"
},
{
"alpha_fraction": 0.7280219793319702,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 37.31578826904297,
"blob_id": "7f84bb0c0d8276709c5a00ed4099e8934fd6488d",
"content_id": "efae7a1e3d7e328cff38be0b5aa801310e00777c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 728,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 19,
"path": "/test/BribeNet/bribery/temporal/test_randomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.bribery.temporal.randomBriber import RandomBriber\nfrom BribeNet.graph.temporal.noCustomerActionGraph import NoCustomerActionGraph\nfrom test.BribeNet.bribery.temporal.briberTestCase import BriberTestCase\n\n\nclass TestRandomBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = RandomBriber(10)\n self.rg = NoCustomerActionGraph(self.briber)\n\n def test_next_action_increases_p_rating(self):\n graph = self.briber._g\n action = self.briber.next_action()\n briber_id = self.briber.get_briber_id()\n prev_eval = graph.eval_graph(briber_id=briber_id)\n\n action.perform_action()\n self.assertGreaterEqual(graph.eval_graph(briber_id=briber_id), prev_eval)\n"
},
{
"alpha_fraction": 0.8452721834182739,
"alphanum_fraction": 0.8452721834182739,
"avg_line_length": 19.52941131591797,
"blob_id": "81a11a790182db73fb6391350fd2eda9d7437731",
"content_id": "c8fe745c94334437090a62f855d5f4bbf15c9074",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 17,
"path": "/src/BribeNet/bribery/temporal/action/__init__.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.helpers.bribeNetException import BribeNetException\n\n\nclass BribeMustBeGreaterThanZeroException(BribeNetException):\n pass\n\n\nclass NodeDoesNotExistException(BribeNetException):\n pass\n\n\nclass BriberDoesNotExistException(BribeNetException):\n pass\n\n\nclass BriberyActionExceedsAvailableUtilityException(BribeNetException):\n pass\n"
},
{
"alpha_fraction": 0.6135995388031006,
"alphanum_fraction": 0.6189962029457092,
"avg_line_length": 33.314815521240234,
"blob_id": "92e8b500b6564b9125d37526fd28dd22990ee1df",
"content_id": "f0e86bbe41ca3340f1a0a1674859ea2b6175fff8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1853,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 54,
"path": "/src/BribeNet/gui/apps/temporal/result.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\n\nfrom BribeNet.gui.apps.temporal.results_wizard.window import TemporalResultsWizardWindow\n\n\nclass ResultsFrame(tk.Frame):\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.controller = controller\n self.parent = parent\n self.fig = plt.figure(figsize=(8, 8))\n self.ax = self.fig.add_subplot(111)\n self.canvas = FigureCanvasTkAgg(self.fig, master=self)\n self.canvas.get_tk_widget().pack(side=tk.BOTTOM, fill=tk.BOTH, expand=True)\n\n replot_button = tk.Button(self, text=\"Change Variables\", command=self.replot)\n replot_button.pack()\n\n exit_button = tk.Button(self, text=\"Exit\", command=self.exit)\n exit_button.pack()\n\n def plot_results(self, results, x_label, y_label):\n self.ax.clear()\n # for each briber\n xs = results.get(x_label)\n ys = results.get(y_label)\n\n if not isinstance(xs[0], list) and not isinstance(ys[0], list):\n self.ax.plot(xs, ys)\n else:\n for b in range(0, len(self.controller.briber_names)):\n x_plot = [r[b] for r in xs] if isinstance(xs[0], list) else xs\n y_plot = [r[b] for r in ys] if isinstance(ys[0], list) else ys\n\n print(x_plot)\n print(y_plot)\n\n self.ax.plot(x_plot, y_plot, label=self.controller.briber_names[b])\n\n self.ax.legend()\n\n self.ax.set_xlabel(x_label)\n self.ax.set_ylabel(y_label)\n self.canvas.draw()\n\n def replot(self):\n results_wizard = TemporalResultsWizardWindow(self.controller, self.controller.results)\n results_wizard.lift()\n\n def exit(self):\n self.controller.show_frame(\"GraphFrame\")\n"
},
{
"alpha_fraction": 0.6091803312301636,
"alphanum_fraction": 0.6170491576194763,
"avg_line_length": 28.326923370361328,
"blob_id": "0a9d11e72109babe3b96b6648a5764733888cc59",
"content_id": "9ad4da32947c49f790af67974175fd71e9949c38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1525,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 52,
"path": "/src/BribeNet/gui/main.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nfrom BribeNet.gui.apps.main import Main\nfrom BribeNet.gui.apps.static.static import StaticGUI\nfrom BribeNet.gui.apps.temporal.main import TemporalGUI\nfrom BribeNet.helpers.override import override\n\n\nclass GUI(tk.Tk):\n \"\"\"\n Main menu window for the GUI\n Self-withdraws when model wizard opened, and deiconifies when wizard closed\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n tk.Tk.__init__(self, *args, **kwargs)\n self.title(\"Bribery Networks\")\n self.main_frame = Main(self)\n self.main_frame.grid(row=1, column=1)\n self.grid_rowconfigure(1, weight=1)\n self.grid_columnconfigure(1, weight=1)\n self.minsize(400, 400)\n self.static_gui = None\n self.temporal_gui = None\n\n def show_static_gui(self):\n if (self.static_gui is None) and (self.temporal_gui is None):\n self.static_gui = StaticGUI(self)\n self.withdraw()\n\n def show_temporal_gui(self):\n if (self.static_gui is None) and (self.temporal_gui is None):\n self.temporal_gui = TemporalGUI(self)\n self.withdraw()\n\n def show_main(self):\n self.static_gui = None\n self.temporal_gui = None\n self.deiconify()\n\n @override\n def destroy(self):\n if self.static_gui is not None:\n self.static_gui.destroy()\n if self.temporal_gui is not None:\n self.temporal_gui.destroy()\n super().destroy()\n\n\nif __name__ == \"__main__\":\n app = GUI()\n app.mainloop()\n"
},
{
"alpha_fraction": 0.7054794430732727,
"alphanum_fraction": 0.7054794430732727,
"avg_line_length": 35.5,
"blob_id": "ee57f0effceb1a9102b00f0c54274e34d6929851",
"content_id": "2682ab5e7efe7861b685c8ed72f159f3b694736a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 16,
"path": "/src/BribeNet/graph/generation/weightedGenerator.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import abc\n\nfrom BribeNet.graph.generation import GraphGeneratorAlgo\nfrom BribeNet.graph.generation.generator import GraphGenerator\n\n\nclass WeightedGraphGenerator(GraphGenerator, abc.ABC):\n\n def __init__(self, a: GraphGeneratorAlgo, *args, **kwargs):\n \"\"\"\n Thin wrapper class for NetworKit graph generation algorithms which add weights to edges\n :param a: the GraphGenerationAlgo to use\n :param args: any arguments to this generator\n :param kwargs: any keyword arguments to this generator\n \"\"\"\n super().__init__(a, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.7553366422653198,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 34.82352828979492,
"blob_id": "544312342b6b3a08a8294ad235fda8e7d6229277",
"content_id": "c3b8870943e57b0c7e45e1e4fe0514cabec4c7f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 609,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 17,
"path": "/test/BribeNet/bribery/static/test_oneMoveRandomBriber.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\n\nfrom BribeNet.bribery.static.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\nfrom test.BribeNet.bribery.static.briberTestCase import BriberTestCase\n\n\nclass TestOneMoveInfluentialNodeBriber(BriberTestCase):\n\n def setUp(self) -> None:\n self.briber = OneMoveRandomBriber(10)\n self.rg = StaticRatingGraph(self.briber)\n\n def test_next_bribe_increases_p_rating(self):\n initial_g = deepcopy(self.briber._g)\n self.briber.next_bribe()\n self._p_rating_increase(initial_g, self.briber._g)\n"
},
{
"alpha_fraction": 0.6205607652664185,
"alphanum_fraction": 0.6280373930931091,
"avg_line_length": 31.42424201965332,
"blob_id": "2ecc3feb7b07bf05d4687b895122a7a57d2abaef",
"content_id": "34cb1582340a038c37636abc95ea15921e5d0a7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1070,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 33,
"path": "/src/BribeNet/gui/apps/static/result.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\n\n\nclass ResultsFrame(tk.Frame):\n \"\"\"\n Frame for showing the current results of the static model being run\n \"\"\"\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self.controller = controller\n self.fig = plt.figure(figsize=(8, 8))\n self.ax = self.fig.add_subplot(111)\n self.canvas = FigureCanvasTkAgg(self.fig, master=self)\n self.canvas.get_tk_widget().pack(side=tk.BOTTOM, fill=tk.BOTH, expand=True)\n button1 = tk.Button(self, text=\"Exit\", command=self.exit)\n button1.pack()\n self.results = []\n\n def plot_results(self, results):\n xs = [i for i in range(0, len(results))]\n self.ax.clear()\n self.ax.plot(xs, results)\n self.ax.set_xlabel(\"Moves over time\")\n self.ax.set_ylabel(\"Average P-rating\")\n self.canvas.draw()\n\n def exit(self):\n self.results = []\n self.master.show_frame(\"WizardFrame\")\n"
},
{
"alpha_fraction": 0.8072289228439331,
"alphanum_fraction": 0.8072289228439331,
"avg_line_length": 34.57143020629883,
"blob_id": "530ec4c72feffe6da6dcdedf98332dde3150bfb6",
"content_id": "8dc30f85a2a353bde6bb4a3fb1aed52918943166",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 7,
"path": "/src/BribeNet/gui/apps/temporal/wizard/rating_methods/p_rating.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "from BribeNet.graph.ratingMethod import RatingMethod\nfrom BribeNet.gui.apps.temporal.wizard.rating_methods.rating_method_frame import RatingMethodFrame\n\n\nclass PRating(RatingMethodFrame):\n enum_value = RatingMethod.P_RATING\n name = 'p_rating'\n"
},
{
"alpha_fraction": 0.6964871287345886,
"alphanum_fraction": 0.7021077275276184,
"avg_line_length": 34,
"blob_id": "79a29bb9292baf28736e24d29e032259df195224",
"content_id": "eff9759cb2d31775573df7b511372d33b1dbe278",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2135,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 61,
"path": "/src/BribeNet/graph/static/ratingGraphBuilder.py",
"repo_name": "RobMurray98/BribeNet",
"src_encoding": "UTF-8",
"text": "import enum\nimport sys\nfrom typing import List\n\nfrom BribeNet.bribery.briber import Briber\nfrom BribeNet.bribery.static.influentialNodeBriber import InfluentialNodeBriber\nfrom BribeNet.bribery.static.mostInfluentialNodeBriber import MostInfluentialNodeBriber\nfrom BribeNet.bribery.static.nonBriber import NonBriber\nfrom BribeNet.bribery.static.oneMoveInfluentialNodeBriber import OneMoveInfluentialNodeBriber\nfrom BribeNet.bribery.static.oneMoveRandomBriber import OneMoveRandomBriber\nfrom BribeNet.bribery.static.randomBriber import RandomBriber\nfrom BribeNet.graph.ratingGraph import DEFAULT_GEN\nfrom BribeNet.graph.static.ratingGraph import StaticRatingGraph\n\n\[email protected]\nclass BriberType(enum.Enum):\n Non = 0\n Random = 1\n OneMoveRandom = 2\n InfluentialNode = 3\n MostInfluentialNode = 4\n OneMoveInfluentialNode = 5\n\n @classmethod\n def get_briber_constructor(cls, idx, *args, **kwargs):\n c = None\n if idx == cls.Non:\n c = NonBriber\n if idx == cls.Random:\n c = RandomBriber\n if idx == cls.OneMoveRandom:\n c = OneMoveRandomBriber\n if idx == cls.InfluentialNode:\n c = InfluentialNodeBriber\n if idx == cls.MostInfluentialNode:\n c = MostInfluentialNodeBriber\n if idx == cls.OneMoveInfluentialNode:\n c = OneMoveInfluentialNodeBriber\n return lambda u0: c(u0, *args, **kwargs)\n\n\nclass RatingGraphBuilder(object):\n\n def __init__(self):\n self.bribers: List[Briber] = []\n self.generator = DEFAULT_GEN\n\n def add_briber(self, briber: BriberType, u0: int = 0, *args, **kwargs):\n self.bribers.append(BriberType.get_briber_constructor(briber, *args, **kwargs)(u0))\n return self\n\n def set_generator(self, generator):\n self.generator = generator\n return self\n\n def build(self) -> StaticRatingGraph:\n if not self.bribers:\n print(\"WARNING: StaticRatingGraph built with no bribers. Using NonBriber...\", file=sys.stderr)\n return StaticRatingGraph(tuple([NonBriber(0)]))\n return StaticRatingGraph(tuple(self.bribers))\n"
}
] | 102 |
dorwell/TwStcok | https://github.com/dorwell/TwStcok | f10ba9bfa772a4a5d445d486fed4ead0be39eae4 | b91ae74b24598a3779ae1f11c6f9481ef6d61ba6 | 11c0ec62d67c86a01bf77d12079a6242969df52c | refs/heads/master | "2020-06-19T08:57:35.697865" | "2019-11-28T06:48:19" | "2019-11-28T06:48:19" | 196,651,584 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.547335147857666,
"alphanum_fraction": 0.569448709487915,
"avg_line_length": 32.7250862121582,
"blob_id": "cfb4c8754ddcd4017ba05cf158b7120fc3704b71",
"content_id": "119db323f2feb4db7cadd195c4d7954913249217",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9813,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 291,
"path": "/bt_test.py",
"repo_name": "dorwell/TwStcok",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jul 8 16:04:40 2019\n\n@author: wade.lin\n\"\"\"\nimport pandas as pd\nimport backtrader as bt\nfrom datetime import datetime\nimport locale\nfrom locale import atof\nimport time\n\nimport backtrader.indicators as btind\n\nclass Hodl(bt.Strategy):\n def __init__(self):\n pass\n\n def next(self):\n stake = 1 / len(self.datas)\n #for d in self.datas:\n self.order_target_percent(target=stake, data=self.datas[0])\n\nclass SMA_CrossOver(bt.Strategy):\n params = (\n ('fast', 10),\n ('slow', 30),\n ('_movav', btind.MovAv.SMA)\n )\n\n def __init__(self):\n sma_fast = self.p._movav(period=self.p.fast)\n sma_slow = self.p._movav(period=self.p.slow)\n self.buysig = btind.CrossOver(sma_fast, sma_slow)\n\n def next(self):\n stake = 1 / len(self.datas)\n if self.buysig > 0:\n self.order_target_percent(target=stake, data=self.datas[0])\n\n elif self.buysig < 0:\n self.order_target_percent(target=0.0, data=self.datas[0])\n\n# Create a Stratey\nclass MyStrategy(bt.Strategy):\n params = (\n ('ssa_window', 15),\n ('maperiod', 15),\n )\n \n def log(self, txt, dt=None):\n ''' Logging function fot this strategy'''\n dt = dt or self.datas[0].datetime.date(0)\n print('%s, %s' % (dt.isoformat(), txt))\n \n def __init__(self):\n # Keep a reference to the \"close\" line in the data[0] dataseries\n self.dataclose = self.datas[0].close\n \n # To keep track of pending orders and buy price/commission\n self.order = None\n self.buyprice = None\n self.buycomm = None\n \n # Add a MovingAverageSimple indicator\n # self.ssa = ssa_index_ind(\n # self.datas[0], ssa_window=self.params.ssa_window)\n self.sma = bt.indicators.SimpleMovingAverage(\n self.datas[0], period=self.params.maperiod)\n \n \n def next(self):\n if self.order:\n return\n if not self.position:\n if self.dataclose[0] > self.sma[0]:\n self.order = self.buy()\n \n else:\n \n if self.dataclose[0] < self.sma[0]:\n # Keep track of the created order to avoid a 2nd order\n self.order = self.sell()\n \n def stop(self):\n self.log('(MA Period %2d) Ending Value %.2f' %\n (self.params.maperiod, self.broker.getvalue()))\n\n\nclass firstStrategy(bt.Strategy):\n params = (\n ('maxlevel', 70),\n ('minlevel', 20),\n )\n \n def __init__(self):\n self.lastbuy = 0\n self.revenue = 0\n self.totalrevenue = 0\n self.tradetime = 0\n self.rsi = bt.indicators.RSI_SMA(self.data.close, period=21)\n self.dataclose = self.datas[0].close\n self.kd = bt.indicators.StochasticSlow(self.datas[0], period = 9, period_dfast= 3, period_dslow = 3)\n def log(self, txt, dt=None):\n ''' Logging function fot this strategy'''\n dt = dt or self.datas[0].datetime.date(0)\n print('%s, %s' % (dt.isoformat(), txt))\n def next(self):\n if not self.position:\n if self.kd[-1] > self.params.minlevel and self.kd[0] < self.params.minlevel:\n self.lastbuy = self.dataclose[0]\n# print('Buy, %.2f' % self.dataclose[0])\n self.buy(size=100)\n else:\n if self.kd[-1] < self.params.maxlevel and self.kd[0] > self.params.maxlevel:\n self.tradetime = self.tradetime + 1\n self.revenue = self.dataclose[0] - self.lastbuy\n self.totalrevenue = self.totalrevenue + self.revenue\n# print('Sell, %.2f' % self.dataclose[0])\n# print('Trade times ${}'.format(self.tradetime), 'Revenue ${}'.format(self.revenue), 'Total revenue ${}'.format(self.totalrevenue))\n self.revenue = 0\n self.lastbuy = 0\n self.sell(size=100)\n \n# if not self.position:\n# if self.rsi < 30:\n# print('Buy, %.2f' % self.dataclose[0])\n# self.buy(size=100)\n# else:\n# if self.rsi > 50:\n# print('Sell, %.2f' % self.dataclose[0])\n# self.sell(size=100) \n\n# def notify_order(self, order):\n# if order.status in [order.Submitted, order.Accepted]:\n# # Buy/Sell order submitted/accepted to/by broker - Nothing to do\n# return\n#\n# # Check if an order has been completed\n# # Attention: broker could reject order if not enough cash\n# if order.status in [order.Completed]:\n# if order.isbuy():\n# self.log(\n# 'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %\n# (order.executed.price,\n# order.executed.value,\n# order.executed.comm))\n#\n# self.buyprice = order.executed.price\n# self.buycomm = order.executed.comm\n# else: # Sell\n# self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %\n# (order.executed.price,\n# order.executed.value,\n# order.executed.comm))\n#\n# self.bar_executed = len(self)\n#\n# elif order.status in [order.Canceled, order.Margin, order.Rejected]:\n# self.log('Order Canceled/Margin/Rejected')\n#\n# # Write down: no pending order\n# self.order = None\n# def notify_trade(self, trade):\n# if not trade.isclosed:\n# return\n# self.log('OPERATION PROFIT, GROSS %.2f, NET %.2f' %\n# (trade.pnl, trade.pnlcomm))\n def stop(self):\n self.log('(minlevel %2d) (maxlevel %2d) Ending Value %.2f' %\n (self.params.minlevel, self.params.maxlevel, self.broker.getvalue()))\ndef tw2bt():\n res_df = pd.read_pickle('res_df.pkl')\n# print(res_df)\n bt_df = res_df.loc[:, ['date', 'begin', 'highest', 'lowest', 'end', 'volume']]\n bt_df['openinterest'] = '0'\n bt_df.columns = [\"date\",\"open\", \"high\",\"low\", \"close\", \"volume\", \"openinterest\"]\n# locale.setlocale(locale.LC_NUMERIC, '')\n# bt_df[[\"open\", \"high\",\"low\", \"close\", \"volume\"]] = bt_df[[\"open\", \"high\",\"low\", \"close\", \"volume\"]].applymap(atof)\n bt_df['volume'].replace(regex=[','], value='', inplace=True)\n bt_df['date'].replace(regex=['/'], value='-', inplace=True)\n bt_df['date'].replace(regex=['100'], value='2011', inplace=True)\n bt_df['date'].replace(regex=['101'], value='2012', inplace=True)\n bt_df['date'].replace(regex=['102'], value='2013', inplace=True)\n bt_df['date'].replace(regex=['103'], value='2014', inplace=True)\n bt_df['date'].replace(regex=['104'], value='2015', inplace=True)\n bt_df['date'].replace(regex=['105'], value='2016', inplace=True)\n bt_df['date'].replace(regex=['106'], value='2017', inplace=True)\n bt_df['date'].replace(regex=['107'], value='2018', inplace=True)\n bt_df[[\"open\", \"high\",\"low\", \"close\", \"volume\"]] = bt_df[[\"open\", \"high\",\"low\", \"close\", \"volume\"]].apply(pd.to_numeric)\n bt_df[\"date\"] = bt_df[\"date\"].apply(pd.to_datetime)\n print(bt_df)\n bt_df.to_csv('example.txt', index=False)\n\n# print(bt_df)\n\ndef main():\n \n# tw2bt()\n\n #Variable for our starting cash\n startcash = 10000\n \n #Create an instance of cerebro\n cerebro = bt.Cerebro()\n \n #Add our strategy\n# cerebro.addstrategy(firstStrategy)\n cerebro.broker.setcommission(commission=0.001)\n cerebro.addstrategy(SMA_CrossOver)\n cerebro.addstrategy(Hodl)\n# cerebro.optstrategy(\n# MyStrategy,\n# maperiod=range(10, 31))\n\n# cerebro.optstrategy(\n# firstStrategy,\n# minlevel=range(5, 40),\n# maxlevel=range(60, 100),\n# )\n \n #Get Apple data from Yahoo Finance.\n #data = bt.feeds.Quandl(\n # dataname='AAPL',\n # fromdate = datetime(2016,1,1),\n # todate = datetime(2017,1,1),\n # buffered= True\n # )\n #print(data)\n #\n #print(type(data))\n #data = bt.feeds.PandasData(dataname=bt_df)\n \n datapath = ('example.txt')\n \n # Simulate the header row isn't there if noheaders requested\n #skiprows = 1 if args.noheaders else 0\n #header = None if args.noheaders else 0\n \n dataframe = pd.read_csv(\n datapath,\n # skiprows=skiprows,\n # header=header,\n # parse_dates=[0],\n parse_dates=True,\n index_col=0,\n )\n# dataframe = dataframe.head(200)\n print(dataframe)\n \n # Pass it to the backtrader datafeed and add it to the cerebro\n data = bt.feeds.PandasData(dataname=dataframe,\n # datetime='Date',\n nocase=True,\n )\n \n #data0 = bt.feeds.PandasData(dataname=bt_df, fromdate = datetime.datetime(100, 1, 4), todate = datetime.datetime(100, 4, 7))\n cerebro.adddata(data)\n \n #Add the data to Cerebro\n #cerebro.adddata(data)\n \n # Set our desired cash start\n cerebro.broker.setcash(startcash)\n \n# print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())\n# cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name = 'SharpeRatio')\n# cerebro.addanalyzer(bt.analyzers.DrawDown, _name='DW')\n\n # Run over everything\n results = cerebro.run()\n \n# start = results[0]\n# print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())\n# print('SR:', start.analyzers.SharpeRatio.get_analysis())\n# print('DW:', start.analyzers.DW.get_analysis())\n\n #Get final portfolio Value\n portvalue = cerebro.broker.getvalue()\n pnl = portvalue - startcash\n \n #Print out the final result\n print('Final Portfolio Value: ${}'.format(portvalue))\n print('P/L: ${}'.format(pnl))\n \n #Finally plot the end results\n cerebro.plot(style='candlestick')\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5208186507225037,
"alphanum_fraction": 0.5462244153022766,
"avg_line_length": 28.994709014892578,
"blob_id": "f0d59cab14973a9c98e8529b1e1fda482c85d78c",
"content_id": "53fedc7224133c3912ebf02a28cf04d6a5104414",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5668,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 189,
"path": "/stock_crawler.py",
"repo_name": "dorwell/TwStcok",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jun 5 18:27:56 2019\n\n@author: wade.lin\n\"\"\"\n\nimport pandas as pd\nfrom bs4 import BeautifulSoup\nimport requests as rq\nimport matplotlib.pyplot as plt\nimport time\nimport talib as ta\nfrom talib import abstract\n\n\n# Get a dataframe from twse\n# date: 20110401\n# date: 0050\n\n#class Order():\n# def __init__(self):\n# self.\n\ndef backtesting_v1(dataframe):\n buy_price = 0 \n earning = 0\n trade_count = 0\n for index, row in dataframe.iterrows():\n # if(row['end_5day'].isnull()):\n # continue\n if(float(row['end_2day'])>float(row['end_5day'])):\n if(buy_price == 0):\n print(\"Buy\", index, row['date'], row['end'],row['end_5day'])\n buy_price = float(row['end'])\n if(float(row['end_2day'])<float(row['end_5day'])):\n if(buy_price > 0):\n print(\"Sell\", index, row['date'], row['end'],row['end_5day'])\n diff =(buy_price - float(row['end']))\n earning = earning + diff\n print(\"\\t Earning:\"+str(diff))\n buy_price = 0\n trade_count += 1\n print(\"Trade count:\"+str(trade_count)) \n print(\"Total earning:\"+str(earning)) \n\ndef twstock_mon(date,stocknum):\n # Check parameters\n url = \"http://www.twse.com.tw/exchangeReport/STOCK_DAY?response=html&date=\"+date+\"&stockNo=\"+stocknum\n rows_list = list()\n response = rq.get(url)\n soup = BeautifulSoup(response.text, 'html.parser')\n# print(soup)\n trs = soup.find_all('tr')\n idx = 0\n for tr in trs:\n# print(tr)\n# print('##################')\n if(idx >= 2):\n cols = tr.find_all('td')\n# print(cols)\n cols = [ele.text.strip() for ele in cols]\n rows_list.append(cols)\n \n idx+=1\n # rows_list.append([td.text.replace('\\n', '').replace('\\xa0', '') for td in tr.find_all('td')])\n# print(rows_list)\n labels =['date', 'trans', 'exchange', 'begin', 'highest', 'lowest', 'end', 'difference', 'volume']\n df = pd.DataFrame.from_records(rows_list, columns = labels)\n return df\n \ndef parse_stock():\n stocknum = \"0050\"\n dfs = []\n for year in range(2011, 2019, 1):\n for month in range(1, 13, 1):\n # df = twstock_mon(,stocknutwm)\n # print(str(year).zfill(2), str(month).zfill(2))\n str_date = \"{:04d}\".format(year)+\"{:02d}\".format(month)+\"01\"\n print(\"Parse \"+str_date)\n dfs.append(twstock_mon(str_date, stocknum))\n time.sleep(8)\n # df1 = twstock_mon(date,stocknum)\n # df2 = twstock_mon(\"20110501\",stocknum)\n # dfs = [df1, df2]\n# print(type(dfs))\n# print(dfs)\n res_df = pd.concat(dfs,axis=0, ignore_index=True)\n res_df.to_pickle('res_df.pkl') \n\ndef main():\n\n\n# parse_stock()\n\n # return \n win_2 = 5\n win_3 = 20\n res_df = pd.read_pickle('res_df.pkl')\n #res_df = pd.DataFrame(res_df)\n print(res_df)\n \n #print(res_df.iloc[:,1:2])\n col_end = res_df.iloc[:,6:7]\n #print(col_end)\n col_end_avg_1day = col_end.rolling(window=1).mean()\n col_end_avg_2day = col_end.rolling(window=win_2).mean()\n col_end_avg_5day = col_end.rolling(window=win_3).mean()\n #col_end_avg_5day.columns = ['end_5day']\n col_end_avg_2day.rename(columns={'end':'end_2day'}, inplace=True)\n col_end_avg_5day.rename(columns={'end':'end_5day'}, inplace=True)\n print(col_end_avg_2day)\n print(col_end_avg_5day)\n #print(type(col_end))\n #print(type(col_end_avg_2day))\n ## Append by column\n df_append_col = pd.concat([res_df,col_end_avg_2day], axis=1)\n df_append_col = pd.concat([df_append_col,col_end_avg_5day], axis=1)\n print(df_append_col)\n # for index, row in df_append_col.iterrows():\n # row['end_5day'] = 0\n # print(index, row['date'], row['end'])\n #assign a value to a specific cell\n #df_append_col['end_5day'][1] = 0\n df_append_col.drop([0,win_3])\n print(df_append_col)\n backtesting_v1(df_append_col)\n #result = pd.DataFrame({'end':col_end, 'AVG 2 Day':col_end_avg_2day, 'AVG 5 Day': col_end_avg_5day})\n #result.plot()\n col_end_MA = ta.MA(res_df.end)\n col_end_RSI = ta.MA(res_df.end)\n ax = col_end_avg_2day.plot(kind='line')\n ax = col_end_MA.plot(ax = ax)\n# ax = col_end_avg_5day.plot(ax = ax)\n# ax = col_end_avg_1day.plot(ax = ax)\n #col_end_avg_5day.plot(kind='line',x='name',y='num_children')\n \n# ax = abstract.MACD(col_end).plot(ax = ax)\n plt.show()\n \n# close = pd.DataFrame({k:d['end'] for k,d in res_df.items()}).transpose()\n# close.index = pd.to_datetime(close.index)\n# print(close)\n \n# print(res_df['end'])\n# print(type(res_df))\n# print(type(res_df['end'].value))\n# print(res_df['end'].value)\n# print(ta.MA(res_df.end))\n# print(ta.MACD(res_df.end))\n# print(abstract.MA(res_df.end))\n #for tr in trs:\n # print(tr)\n # print('#################')\n # tds = soup.find_all('td')\n # for td in tds:\n # print(td.string) \n \n \n #\n #dfs = pd.read_html(url)[0]\n #dfs2 = pd.read_html(url2)[0]\n ##print(dfs)\n #\n #for index, row in dfs:\n # print(dfs[index])\n # print(str(index)+\",\"+str(row))\n ## print(dfs[row])\n ##print(dfs[b''])\n #\n ##print(dfs.loc[:,:])\n # \n #\n #df1 = dfs.ix[:,0:2]\n ##print(df1)\n #print(\"#############################\")\n # \n #df2 = dfs2.ix[:,0:2]\n ##print(df2)\n #print(\"#############################\")\n #res = pd.concat([df1, df2], axis=0)\n ##print(res)\n #print(type(dfs))\n #print(type(df1))\n #print(type(url))\n #print(type(dfs[index]))\n\nif __name__ == '__main__':\n main()"
}
] | 2 |
tchaguitos/loterias-caixa | https://github.com/tchaguitos/loterias-caixa | f8a78009c1ed1eedbb66b079b3404e17f7f3c89c | d3c4618cd7c4fe09a3c9f0079912fb18f39ad232 | eb0e2e1bc8cdb26a8e79103d75118d9ccff26c3e | refs/heads/master | "2021-06-04T12:35:34.056289" | "2018-10-22T21:13:35" | "2018-10-22T21:13:35" | 153,676,468 | 2 | 0 | null | "2018-10-18T19:25:39" | "2020-12-01T17:18:25" | "2021-06-01T22:50:18" | Python | [
{
"alpha_fraction": 0.6269574761390686,
"alphanum_fraction": 0.6294742822647095,
"avg_line_length": 22.682119369506836,
"blob_id": "6dfb64958f3de0b0e6003adfbe72dfd32a1fd2dd",
"content_id": "44d31a4aac02530ff05bd3c487b7ae1016a64d30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3579,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 151,
"path": "/mega.py",
"repo_name": "tchaguitos/loterias-caixa",
"src_encoding": "UTF-8",
"text": "import urllib\nimport random\nimport json\n\nfrom collections import Counter\nfrom urllib import request\nfrom datetime import date\n\ndef get_full_url(url, game, number=None):\n\n if number:\n full_url = f'{ url }/{ game }/{ number }'\n\n else:\n full_url = f'{ url }/{ game }'\n\n return full_url\n\n\ndef get_and_read_response(url):\n req = request.Request(url)\n opener = request.build_opener()\n res = opener.open(req)\n\n results = json.loads(res.read())\n\n return results\n\n\ndef parse_resonse(response):\n \n if response:\n parsed = json.loads(response)\n return parsed\n\n else:\n pass\n\n\ndef get_last_game_results(url):\n\n results = get_and_read_response(url)\n\n if not isinstance(results, bool):\n\n response = {\n 'numbers': results['sorteio'],\n 'last_game_number': results['numero'],\n 'date': results['data']\n }\n\n return json.dumps(response)\n\n\ndef get_last_to_first_game_results(url, game, number):\n\n all_results = []\n\n while number > 0:\n\n print(f'buscando informações do concurso de número { number } da { game }')\n\n full_url = get_full_url(url, game, number)\n\n response_result = get_last_game_results(full_url)\n parsed = parse_resonse(response_result)\n\n if parsed:\n all_results += parsed['numbers']\n\n number = number - 1\n\n return all_results\n\n\ndef get_results(game):\n\n try:\n file = open(f'{ game }-all-results.txt', 'r')\n\n last_to_first_games = file.read()\n last_to_first_games = last_to_first_games.split(', ')\n \n except Exception:\n url = 'https://www.lotodicas.com.br/api'\n\n full_url = get_full_url(url, game)\n response_result = get_last_game_results(full_url)\n parsed = parse_resonse(response_result)\n\n last_game_number = parsed['last_game_number']\n last_to_first_games = get_last_to_first_game_results(url, game, last_game_number)\n\n open_or_create_file_and_write_results(game, last_to_first_games, 'all-results')\n\n return last_to_first_games\n\n\ndef get_most_common(game, result_list, quantity_of_numbers):\n\n cnt = Counter(result_list)\n\n most_numbers_frequency = cnt.most_common(quantity_of_numbers)\n numbers_most_sorted = [pair[0] for pair in most_numbers_frequency]\n\n shuffle_numbers = sorted(numbers_most_sorted, key=lambda k: random.random())\n numbers = sorted(shuffle_numbers, key=lambda k: random.random())\n\n open_or_create_file_and_write_results(game, numbers, f'{ quantity_of_numbers }-most-common')\n\n return numbers\n\n\ndef get_games(game, most_common, total_of_games, total_of_numbers_by_game):\n\n games = []\n\n init = 0\n last = total_of_numbers_by_game\n\n limit = (total_of_games*total_of_numbers_by_game+1)\n\n while(last < limit):\n\n list_game = list(most_common[init:last])\n\n list_game.sort()\n\n games.append(list_game)\n \n init += total_of_numbers_by_game\n last += total_of_numbers_by_game\n \n open_or_create_file_and_write_results(game, games, f'{ total_of_games }-games-{ date.today() }')\n\n return games\n\ndef open_or_create_file_and_write_results(game, result_list, description):\n file = open(f'{ game }-{ description }.txt', 'w')\n\n file.write(str(result_list))\n\n file.close()\n\n return file\n\nresult_list = get_results('mega-sena') # lotofacil, mega-sena, quina, dupla-sena, lotomania, dia-de-sorte\nmost_common = get_most_common('mega-sena', result_list, 24)\ngames = get_games('mega-sena', most_common, 2, 6)\n\nprint(games)\n"
}
] | 1 |
willemml/python-testing | https://github.com/willemml/python-testing | e7e1aa90566de3dfcfdc7906db60cc5bda2dc22a | 3e6106658ca14676fe022b5a0c46521d1ed14b00 | fa2e452d0266816bb4b8285b7bfa5a18eb368020 | refs/heads/master | "2022-04-04T02:28:06.458823" | "2019-12-06T21:18:25" | "2019-12-06T21:18:25" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5983379483222961,
"alphanum_fraction": 0.6371191143989563,
"avg_line_length": 29.08333396911621,
"blob_id": "9912f8ab45fb09fd9b34387be50762717dc5f906",
"content_id": "c5d3619e4a07438ad43afcd06637b8c19a707637",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 12,
"path": "/getlineinf-numworks.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from calcline import *\nfrom drawline import *\n\ndef line():\n print(\"Welcome to line info!\")\n xa=float(input(\"enter Xa: \")\n ya=float(input(\"enter Ya: \")\n xb=float(input(\"enter Xb: \")\n yb=float(input(\"enter Yb: \")\n print(\"y at x0 (p): \",str(getlinep(xa,ya,xb,yb))\n print(\"y-p at x1 (m): \",str(getlinem(xa,ya,xb,yb))\n draw_line(160+xa,111-ya,160+xb,111-yb)\n"
},
{
"alpha_fraction": 0.5069444179534912,
"alphanum_fraction": 0.5399305820465088,
"avg_line_length": 25.18181800842285,
"blob_id": "0e7a8b285a1150dcc43d97b4e3383d41ba8fe575",
"content_id": "1274a72aa65f78b09388b48b0237f81253b7754a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 576,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 22,
"path": "/primes.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "import sys\n\ny = [2] # this array will contain the prime numbers that are found\nx = 1000000 # will check for primes up to this number\np = 1 # number of primes found\n\nprint(\"Looking for primes from 0 to \" + str(x) + \".\")\nprint(\"2 is a prime.\")\n\nfor i in range(3, x):\n isaprime = 1\n for u in range(0, len(y)):\n if (i % y[u]) == 0:\n isaprime = 0\n break\n if isaprime == 1:\n print(str(i) + \" is a prime.\")\n y.append(i)\n p = p + 1\n\nprint(\"Found \" + str(p) + \" prime(s) from 0 to \" + str(x) + \".\")\nprint(sys.getsizeof(y))\n"
},
{
"alpha_fraction": 0.41442716121673584,
"alphanum_fraction": 0.4356435537338257,
"avg_line_length": 21.09375,
"blob_id": "32cdcfecd420e7fea4672efd0b8b53084177beb9",
"content_id": "72acec55088f46ccab49b7b3e5f9e8cb88742222",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 32,
"path": "/drawline-v2-numworks.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from math import *\nfrom kandinsky import *\n\ndef dpl(a,b,max,bas,col,ros):\n if bas==0:\n while a<max:\n set_pixel(round(a),round(b),col)\n a=a+1\n b=b+ros\n elif baas==1:\n while b<max:\n set_pixel(round(a),round(b),col)\n a=a+ros\n b=b+1\n\ndef drawline(a,b,c,d,col):\n if d-b==0:\n s=[c,d,a,b]\n a=s[0]\n b=s[1]\n c=s[2]\n d=s[3]\n if type(col)==type(0):\n col=color(col,col,col)\n if (d-b>c-a or c-a==0) and d-b!=0:\n ros=(c-a)/(d-b)\n dpl(a,b,c,0,col,ros)\n elif c-a>d-b and c-a!=0:\n ros=(d-b)/(c-a)\n dpl(a,b,d,1,col,ros)\n else:\n print(\"incorrect\")\n"
},
{
"alpha_fraction": 0.5212504267692566,
"alphanum_fraction": 0.5518088936805725,
"avg_line_length": 24.881818771362305,
"blob_id": "6ac66fdb540afd01c6df98364ed6774dbd1f4955",
"content_id": "6cd2e30d34a82f3159adbf85b9ccc08d92ec52e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2847,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 110,
"path": "/vector_draw.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from math import *\nfrom turtle import *\nfrom kandinsky import *\n\nspeed(10)\nhideturtle()\nsetheading(0)\npoints = []\nlines = []\nexitprg = 0\n\ndef drawline(line):\n xa=-160+line[0]\n ya=-110+line[1]\n xb=-160+line[2]\n yb=-110+line[3]\n penup()\n goto(xa,ya)\n pendown()\n goto(xb,yb)\n penup()\n\ndef drawpoint(point):\n x=-160+point[1]\n y=-110+point[2]\n penup()\n goto(x-5,y)\n pendown()\n forward(9)\n penup()\n goto(x,y-5)\n pendown()\n left(90)\n forward(9)\n right(90)\n draw_string(point[0],point[1]+6,223-point[2]-18)\n\ndef cmd():\n command = input(\"> \")\n if command == \"h\":\n print(\"Help menu:\")\n print(\"h - get to this menu\")\n print(\"np - create a new point\")\n print(\"nl - new line between points\")\n print(\"rp - remove a point\")\n print(\"lp - list existing points\")\n print(\"ll - list existing lines\")\n print(\"dp - draw all points\")\n print(\"dl - draw all lines\")\n print(\"da - draw everything\")\n if command == \"np\":\n print(\"Create a new point:\")\n npointname = \"\"\n isnotdupe = 0\n while isnotdupe == 0:\n isnotdupe = 1\n npointname = input(\"NAME: \")\n for i in points:\n if npointname == i[0]:\n isnotdupe = 0\n npointx = int(input(\"XPOS: \"))\n npointy = int(input(\"YPOS: \"))\n points.append([npointname,npointx,npointy])\n if command == \"nl\":\n name = \"\"\n isnotdupe = 0\n while isnotdupe == 0:\n isnotdupe = 1\n name = input(\"NAME: \")\n for i in lines:\n if name == i[3]:\n isnotdupe = 0\n a = int(input(\"start point(0-\" + str(len(points)-1) + \"): \"))\n b = int(input(\"end point(0-\" + str(len(points)-1) + \"): \"))\n c = [points[b][1] - points[a][1], points[b][2] - points[a][2]]\n ab = sqrt((points[b][1]-points[a][1])^2+(points[b][2]-points[a][2])^2)\n lines.append([points[a][1], points[a][2], points[b][1], points[b][2], length, name])\n if command == \"dp\":\n for i in points:\n drawpoint(i)\n keyhasbeenpressed = 0\n while keyhasbeenpressed == 0:\n if len(get_keys()) > 0:\n keyhasbeenpressed = 1\n if command == \"ll\":\n print(\"command not yet created\")\n if command == \"da\":\n print(\"command not yet created\")\n if command == \"dl\":\n print(\"command not yet created\")\n if command == \"rp\":\n print(\"Remove a point:\")\n point = int(input(\"point number (0-\" + str(len(points)-1) + \"): \"))\n print(\"Is this right?\")\n print(str(point) + \". point '\" + str(points[point][0]) + \"' x=\" + str(points[point][1]) + \" y=\" + str(points[point][2]))\n yesno = input(\"[y/n] > \")\n if yesno == \"y\":\n points.pop(point)\n if yesno == \"n\":\n cmd()\n if command == \"lp\":\n print(\"List of existing points:\")\n pnum = 0\n for i in points:\n print(str(pnum) + \". point '\" + i[0] + \"' x=\" + str(i[1]) + \" y=\" + str(i[2]))\n\ndef main():\n print(\"Draw tool:\")\n while exitprg == 0:\n cmd()\n"
},
{
"alpha_fraction": 0.47643980383872986,
"alphanum_fraction": 0.49040138721466064,
"avg_line_length": 16.363636016845703,
"blob_id": "5feea018d720747d810b16bd45fe4e56e825ea3a",
"content_id": "b54e3fb8a9665f084c42cc47af2c4b461fce4500",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 33,
"path": "/drawline-numworks.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from math import *\nfrom kandinsky import *\n\ndef draw_line(a,b,c,d,colore):\n if type(colore)==type(0):\n colore=color(colore,colore,colore)\n if a>c:\n tmp=a\n a=c\n c=tmp\n tmp=b\n b=d\n d=tmp\n if a-c==0:\n print(1)\n while b<d:\n set_pixel(a,b,colore)\n b=b+1\n else:\n ros=(b-d)/(a-c)\n if b<d:\n print(2)\n while b<d:\n set_pixel(round(a),round(b),colore)\n b=b+ros\n a=a+1\n else:\n print(3)\n ros=(a-c)/(b-d)\n while a<c:\n set_pixel(round(a),round(b),colore)\n b=b+1\n a=a+ros\n"
},
{
"alpha_fraction": 0.5023255944252014,
"alphanum_fraction": 0.5906976461410522,
"avg_line_length": 16.91666603088379,
"blob_id": "246cde63fd4201320dc46bd61136163c5dbad111",
"content_id": "25b75773449556440a5e1cbdb053664698f468c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/keyspressed-numworks.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from kandinsky import *\nfrom math import *\nwhile True:\n x=get_keys()\n y=\"\"\n if len(x)>0:\n from i in x:\n y=y+i+\" \"\n fill_rect(0,0,320,50,color(255,255,255)\n draw_string(y,5,5)\n wait_vblank()\n print(x)\n"
},
{
"alpha_fraction": 0.6482758522033691,
"alphanum_fraction": 0.6482758522033691,
"avg_line_length": 17.125,
"blob_id": "b0555e46fcdb434963fefc5d9e968292fe5a7dac",
"content_id": "28b81c53d4fff623842bb7fd0057cf98f4c389ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 8,
"path": "/calcline-numworks.py",
"repo_name": "willemml/python-testing",
"src_encoding": "UTF-8",
"text": "from math import *\n\ndef getlinem(xa,ya,xb,yb):\n return (yb-ya)/xb-xa)\n\ndef getlinep(xa,ya,xb,yb):\n m=getlinem(xa,ya,xb,yb):\n return ya-(xa*m)\n"
}
] | 7 |
BrianKTran/djangularDataScientist | https://github.com/BrianKTran/djangularDataScientist | cbbc8cb59ae29ed58c869fea5cd1a6a44dabd835 | 0e69cd671bac8fd999d0fd9d263f7a62bbceb634 | a9e5d2f7af4ecd4d554a26ba674d67f84f30e395 | refs/heads/master | "2020-06-07T12:15:13.102863" | "2019-12-06T17:18:13" | "2019-12-06T17:18:13" | 192,996,493 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.527999997138977,
"alphanum_fraction": 0.581333339214325,
"avg_line_length": 19.83333396911621,
"blob_id": "6be44a4c4d9d1911161435887755cf4c3a263d0c",
"content_id": "21099366958c35de42cf1c1a0af1c04218246d8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/Django-RestApi-server-MySQL-Angular/gkzRestApi/customers/migrations/0002_auto_20190620_1449.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-06-20 18:49\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('customers', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='customer',\n name='age',\n field=models.IntegerField(default=1),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6960061192512512,
"alphanum_fraction": 0.701093852519989,
"avg_line_length": 35.738319396972656,
"blob_id": "06171e5f8b0f67e13b79d12bb16d61ceff9cb87b",
"content_id": "60cbacd1bed84df785c6fff2d96b9c5a8b49cbf1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3931,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 107,
"path": "/Django-RestApi-server-MySQL-Angular/gkzRestApi/customers/views.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.http import HttpResponse, HttpResponseRedirect\n# from django.http import HttpResponse\nfrom django.http.response import JsonResponse\nfrom django.views.decorators.csrf import csrf_exempt\nfrom rest_framework.parsers import JSONParser\nfrom rest_framework import status\nfrom django.urls import reverse\nfrom customers.models import Customer\nfrom customers.serializers import CustomerSerializer\n\n\n@csrf_exempt\ndef customer_list(request):\n if request.method == 'GET':\n customers = Customer.objects.all()\n customers_serializer = CustomerSerializer(customers, many=True)\n return JsonResponse(customers_serializer.data, safe=False)\n # In order to serialize objects, we must set 'safe=False'\n\n elif request.method == 'POST':\n customer_data = JSONParser().parse(request)\n customer_serializer = CustomerSerializer(data=customer_data)\n if customer_serializer.is_valid():\n customer_serializer.save()\n return JsonResponse(customer_serializer.data, status=status.HTTP_201_CREATED)\n return JsonResponse(customer_serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n Customer.objects.all().delete()\n return HttpResponse(status=status.HTTP_204_NO_CONTENT)\n\n\n@csrf_exempt\ndef customer_detail(request, pk):\n try:\n customer = Customer.objects.get(pk=pk)\n except Customer.DoesNotExist:\n return HttpResponse(status=status.HTTP_404_NOT_FOUND)\n\n if request.method == 'GET':\n customer_serializer = CustomerSerializer(customer)\n return JsonResponse(customer_serializer.data)\n\n elif request.method == 'PUT':\n customer_data = JSONParser().parse(request)\n customer_serializer = CustomerSerializer(customer, data=customer_data)\n if customer_serializer.is_valid():\n customer_serializer.save()\n return JsonResponse(customer_serializer.data)\n return JsonResponse(customer_serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n elif request.method == 'DELETE':\n customer.delete()\n return HttpResponse(status=status.HTTP_204_NO_CONTENT)\n\n\n@csrf_exempt\ndef customer_list_age(request, age):\n customers = Customer.objects.filter(age=age)\n\n if request.method == 'GET':\n customers_serializer = CustomerSerializer(customers, many=True)\n return JsonResponse(customers_serializer.data, safe=False)\n # In order to serialize objects, we must set 'safe=False'\n\ndef get(self, request, file_name):\n\n bicloudreposervice = BiCloudRepoService()\n\n file_obj = bicloudreposervice.get_user_file(request.user.email, file_name)\n file_path = file_obj.name\n\n with open(file_path, 'rb') as tmp:\n\n if 'xls' in file_name:\n resp = HttpResponse(tmp, content_type='application/vnd.ms-excel;charset=UTF-8')\n else:\n resp = HttpResponse(tmp, content_type='application/text;charset=UTF-8')\n\n resp['Content-Disposition'] = \"attachment; filename=%s\" % file_name\n\n self.logger.debug('Downloading file')\n\n return resp\ndef index(request):\n if not request.user.is_authenticated:\n return render(request, \"users/login.html\", {\"message\": None})\n context = {\n \"user\": request.user\n }\n return render(request, \"users/user.html\", context)\n\ndef login_view(request):\n username = request.POST[\"username\"]\n password = request.POST[\"password\"]\n user = authenticate(request, username=username, password=password)\n if user is not None:\n login(request, user)\n return HttpResponseRedirect(reverse(\"index\"))\n else:\n return render(request, \"users/login.html\", {\"message\": \"Invalid credentials.\"})\n\ndef logout_view(request):\n logout(request)\n return render(request, \"users/login.html\", {\"message\": \"Logged out.\"})\n"
},
{
"alpha_fraction": 0.48543688654899597,
"alphanum_fraction": 0.6990291476249695,
"avg_line_length": 16.16666603088379,
"blob_id": "1fbcb15bfec4cfe1466ab2c8e5b38648745d0a46",
"content_id": "02c3f931478c36ccd9fe44ea57de6bde4f3cc0b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 6,
"path": "/Angular-Django-example-Angular-Rest-Client/AngularDjango/src/app/requirements.txt",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "dj-database-url==0.5.0\ngunicorn==19.9.0\npostgres==2.2.2\npsycopg2==2.8.3\npytz==2019.1\nwhitenoise==4.1.2\n"
},
{
"alpha_fraction": 0.6699029207229614,
"alphanum_fraction": 0.6699029207229614,
"avg_line_length": 27.090909957885742,
"blob_id": "ee6ad3baa0eab94aa9e5a7e5abcab8f5eea32830",
"content_id": "3727d4d31d2e4795358de385879ca1dc83bb4d08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 11,
"path": "/Django-RestApi-server-MySQL-Angular/gkzRestApi/gkzRestApi/urls.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom django.urls import path\nfrom customers import views\n\nurlpatterns = [\n url(r'^', include('customers.urls')),\n # path(\"\", views.index, name=\"index\"),\n path(\"login\", views.login_view, name=\"login\"),\n path(\"logout\", views.logout_view, name=\"logout\"),\n\n]\n"
},
{
"alpha_fraction": 0.656862735748291,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 33,
"blob_id": "77f351134ae66e2a07b69f923f3e6a1ff6c88e8d",
"content_id": "ee7295ffc84f36f0c5343a245085726149dabee3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 12,
"path": "/Django-RestApi-server-MySQL-Angular/gkzRestApi/customers/urls.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom customers import views\nfrom django.contrib import admin\nfrom django.urls import include, path\n\nurlpatterns = [\n url(r'^customers/$', views.customer_list),\n url(r'^customers/(?P<pk>[0-9]+)$', views.customer_detail),\n url(r'^customers/age/(?P<age>[0-9]+)/$', views.customer_list_age),\n # path('', include('users.urls')),\n path('admin/', admin.site.urls),\n]\n"
},
{
"alpha_fraction": 0.6564245820045471,
"alphanum_fraction": 0.673184335231781,
"avg_line_length": 15.318181991577148,
"blob_id": "9612021c3adec454f1ea5d8c6c4af05a4aca09b8",
"content_id": "b0c8732faef56387ecd1af5956592e463df10873",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 22,
"path": "/customerStats/customerMeanAge.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\n\n# %matplotlib inline\nimport matplotlib.pyplot as plt\nplt.style.use('ggplot')\n\n# Read in data into a dataframe\ndf = pd.read_csv('customer.csv')\n\n# Show the first 5 (or 10) rows of the table\n# df.tail(10)\n\ndf = df.iloc[:,:4]\n# df = df.iloc[:,:]\n# df.head()\n\nhead = df.head()\ndesc = df.describe()\n\nprint(head)\nprint(desc)"
},
{
"alpha_fraction": 0.6218181848526001,
"alphanum_fraction": 0.6218181848526001,
"avg_line_length": 21.91666603088379,
"blob_id": "f2cf78e8a558a5575de2d5869d21e5d237b3d1fb",
"content_id": "c3b569f7601baf624bc25ee0d21de33804ed34ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 36,
"path": "/Angular-Django-example-Angular-Rest-Client/AngularDjango/src/app/app.component.ts",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "import { Component } from '@angular/core';\n\n\n\n@Component({\n selector: 'app-root',\n templateUrl: './app.component.html',\n styleUrls: ['./app.component.css']\n})\nexport class AppComponent {\n title = 'DjAngular Analytical Solution';\n description = 'Postgres Database - Angular Client - Django Server - Pandas, MatPlotLib';\n csvoutput = 'Download List in CSV';\n\n\n\n // downloadFile(name){\n // this.connectorsService.downloadFile(name).subscribe(\n // res => {this.successDownloadFile(res, name);},\n // error => this.errorMessage = <any>error,\n // ()=> {});\n // }\n //\n // successDownloadFile(res: any, name: String){\n //\n // this.showLoader = false;\n // let blob;\n //\n // blob = new Blob([res._body], {type: 'application/vnd.ms-excel'});\n //\n // FileSaver.saveAs(blob, name.toString());\n // }\n\n\n\n}\n"
},
{
"alpha_fraction": 0.6078231334686279,
"alphanum_fraction": 0.6088435649871826,
"avg_line_length": 24.34482765197754,
"blob_id": "dc224361f62fb009de7f16cba24319f27acec4a0",
"content_id": "25b582a7403f89f8ecb2a1919b0e230da8b86b5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2940,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 116,
"path": "/Angular-Django-example-Angular-Rest-Client/AngularDjango/src/app/customers-list/customers-list.component.ts",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "import { Component, OnInit } from '@angular/core';\nimport { Observable } from 'rxjs';\nimport { CustomerService } from '../customer.service';\nimport { Customer } from '../customer';\nimport * as saveAs from 'file-saver';\nimport { take } from 'rxjs/operators';\n\n@Component({\n selector: 'customers-list',\n templateUrl: './customers-list.component.html',\n styleUrls: ['./customers-list.component.css']\n})\n\nexport class CustomersListComponent implements OnInit {\n\n customers: Observable<Customer[]>;\n\n constructor(private customerService: CustomerService) { }\n\n\n ngOnInit() {\n this.reloadData();\n }\n\n deleteCustomers() {\n this.customerService.deleteAll()\n .subscribe(\n data => {\n console.log(data);\n this.reloadData();\n },\n error => console.log('ERROR: ' + error));\n }\n\n reloadData() {\n this.customers = this.customerService.getCustomersList();\n }\n\n\n\n convertToCSV(data: any, columns: string, header: string, delimiter: string |\nundefined) {\n\n let row = '';\n const del = delimiter ? delimiter : ';';\n const col = columns.split(del);\n const head = header.split(del);\n\n\n // creating the header\n for (const headerTxt of head) {\n row += headerTxt + del;\n }\n row += '\\r\\n';\n // start with the rows\n for (const dataset of data) {\n let line = '';\n for (let i = 0; i < col.length; i++) {\n let dataToAdd = dataset[col[i]];\n if (dataset[col[i]] == null || dataset[col[i]] === undefined) {\n dataToAdd = '';\n }\n line += '\"' + dataToAdd + '\"' + del;\n }\n row += line + '\\r\\n';\n }\n return row;\n}\n\ndownload(data: any, filename: string, columns: string, header: string, delimiter: string | undefined) {\n const csvData = this.convertToCSV(data, columns, header, delimiter);\n const link: any = document.createElement('a');\n link.setAttribute('style', 'display:none;');\n document.body.appendChild(link);\n const blob = new Blob([csvData], {type: 'text/csv'});\n link.href = window.URL.createObjectURL(blob);\n\n const isIE = !!(<any> document).documentMode;\n\n if (isIE) {\n navigator.msSaveBlob(blob, filename + '.csv');\n } else {\n link.download = filename + '.csv';\n }\n link.click();\n link.remove();\n}\n\n\ngetcsvFile() {\n\n this.customerService.getCustomersList()\n .pipe(take(1)) // <-- HERE\n .subscribe(customers=>{ // <-- AND HERE\n if (customers) {\n this.download(customers, 'customer','id,name,age,active','ID,Name,Age,Active', ',');\n }\n });\n\n}\n\n}\n\n// getcsvFile() {\n//\n//\n// this.customers = this.customerService.getCustomersList();\n// let file = new Blob([JSON.stringify(this.customers)], { type: 'data:application/csv;charset=utf-8,content_encoded_as_url' });\n// this.convertToCSV(file, 'customer',\n// ['id', 'name', 'age', 'active'],\n// ['ID', 'Name', 'Age', 'Active'], ',')\n// download(file, 'customer',\n// ['id', 'name', 'age', 'active'],\n// ['ID', 'Name', 'Age', 'Active'], ',')\n//\n// }\n"
},
{
"alpha_fraction": 0.6745049357414246,
"alphanum_fraction": 0.6831682920455933,
"avg_line_length": 26.89655113220215,
"blob_id": "a6c6811ae587896e97d73729cd4c94f7e33e3264",
"content_id": "19bf7de0801c99966e08bb5be3892d4a0b451589",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 808,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 29,
"path": "/customerStats/csvToPostgres.py",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "import psycopg2\nimport csv\n# import mssql\nimport pyodbc\n\ndriver = 'ODBC Driver 17 for SQL Server'\nserver = 'DESKTOP-NSHCQFO'\ndb1 = 'mvcDB'\ntcon = 'yes'\n# uname = 'DESKTOP-NSHCQFO/Brian Tran'\n# pword = '**my-password**'\n# conn = psycopg2.connect(host=\"localhost\", database=\"postgres\", user=\"postgres\", password=\"Phili467\")\n\nconn = pyodbc.connect(DRIVER=driver, \n\t\t\t\t\t SERVER=server,\n\t\t\t\t\t DATABASE=db1)\n\t\t\t\t\t # Trusted_Connection=tcon)\ncur = conn.cursor()\ntargetCsv = 'C:/Users/Admin/Downloads/djangularDataScientist-master/customerStats/customer.csv'\n# targetCsv\nwith open('customerGender1.csv', 'r') as f:\n# Notice that we don't need the `csv` module.\n\tnext(f) # Skip the header row.\n\tcur.copy_from(\n\t\tf, \n\t\t'public.customers_customer', sep=',', \n\t\tcolumns=['ID', 'Name', 'Age', 'Active']\n\t\t)\n\tconn.commit()"
},
{
"alpha_fraction": 0.7596899271011353,
"alphanum_fraction": 0.7674418687820435,
"avg_line_length": 17.428571701049805,
"blob_id": "584d9a87491bbe3c8c5318273b75e432b54f7fd2",
"content_id": "ae41cf47546dfd4d9cd51970d4e5b64f9d9ecd6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 7,
"path": "/Django-RestApi-server-MySQL-Angular/gkzRestApi/requirements1.txt",
"repo_name": "BrianKTran/djangularDataScientist",
"src_encoding": "UTF-8",
"text": "dj-database-url==@latest\nDjango==@latest\ngunicorn==@latest\npostgres==@latest\npsycopg2==@latest\npytz==@latest\nwhitenoise==@latest\n"
}
] | 10 |
constable-ldp/gym_management_app | https://github.com/constable-ldp/gym_management_app | d54e87b35a403888f76048e3237f05b7839054f7 | 25beff0458a69ede5296e7d2e54f6dce5f63fcb3 | 9fc9ae72f5ee7a4a9096301c577d31b857b10da8 | refs/heads/main | "2023-04-22T03:16:15.007767" | "2021-05-10T07:17:11" | "2021-05-10T07:17:11" | 350,312,348 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6979320645332336,
"alphanum_fraction": 0.6979320645332336,
"avg_line_length": 30.511627197265625,
"blob_id": "896485d3f8be593601bec60a6df7810940055845",
"content_id": "acd5f79356ac1ff3a841ca05afaaefef1dc20fd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1354,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 43,
"path": "/controllers/room_controller.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, Flask, redirect, render_template, request\nfrom models.room import Room\nimport repositories.room_repository as room_repository\n\nrooms_blueprint = Blueprint('rooms', __name__)\n\n@rooms_blueprint.route('/rooms')\ndef rooms():\n rooms = room_repository.select_all()\n return render_template('rooms/index.html', rooms=rooms)\n\n@rooms_blueprint.route('/rooms/new')\ndef new_room():\n return render_template('rooms/new.html')\n\n@rooms_blueprint.route('/rooms/new', methods=['POST'])\ndef add_room():\n name = request.form['name']\n capacity = request.form['capacity']\n description = request.form['description']\n room = Room(name, capacity, description, id)\n room_repository.save(room)\n return redirect('/rooms')\n\n@rooms_blueprint.route('/rooms/<id>')\ndef see_room(id):\n room = room_repository.select(id)\n return render_template('rooms/edit.html', room=room)\n\n\n@rooms_blueprint.route('/rooms/<id>', methods=['POST'])\ndef edit_room(id):\n name = request.form['name']\n capacity = request.form['capacity']\n description = request.form['description']\n room = Room(name, capacity, description, id)\n room_repository.update(room)\n return redirect('/rooms')\n\n@rooms_blueprint.route('/rooms/<id>/delete', methods=['POST'])\ndef delete_room(id):\n room_repository.delete(id)\n return redirect('/rooms')"
},
{
"alpha_fraction": 0.6871035695075989,
"alphanum_fraction": 0.7103593945503235,
"avg_line_length": 15.310344696044922,
"blob_id": "70b727e024692c8dca6634f3b9afb2371e8f94a3",
"content_id": "f8445c3af524515cd3e257d6039059aeeccceaff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 29,
"path": "/README.md",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "# Gym Managment App\n\n### Overview\n\nA responsive CRUD application made using Flask, HTML, CSS and postgreSQL, built over 5 days. \n\n### Demo\n\nTo run the app locally: \n\n1. Clone the repo and navigate to that directory. \n\n2. Create the database: \n\n> psql -d gym_management -f database/gym_management.sql\n\n3. Populate the database:\n\n> python3 console.py\n\n4. Start the App:\n\n> flask run\n\n5. View the app at http://localhost:5000/\n\n### Features\n\n### Challenges & Things I Learnt\n"
},
{
"alpha_fraction": 0.7227652072906494,
"alphanum_fraction": 0.7239571213722229,
"avg_line_length": 42.70833206176758,
"blob_id": "e091c6b0adb869953c9a05642209a5bfc20e7356",
"content_id": "7c3a311b9d0d06428e0fba27035fee1f62620f2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4195,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 96,
"path": "/controllers/schedule_controller.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, Flask, redirect, render_template, request\nfrom models.schedule import Schedule\nfrom models.schedule_member import ScheduleMember\nimport repositories.schedule_repository as schedule_repository\nimport repositories.instructor_details_repository as details_repository\nimport repositories.gym_class_repository as gym_class_repository\nimport repositories.room_repository as room_repository\nimport repositories.member_repository as member_repository\nfrom datetime import date\nfrom datetime import timedelta\nimport calendar\n\nschedule_blueprint = Blueprint('schedule', __name__)\n\n@schedule_blueprint.route('/schedule')\ndef schedules():\n rooms = room_repository.select_all()\n schedules = schedule_repository.select_dates()\n schedules_dict = {}\n dates = [date.today()+timedelta(days=i) for i in range(7)]\n days = [calendar.day_name[dates[i].weekday()] for i in range(7)]\n for i in range(7):\n if schedules[i] is not None: \n schedules_dict['today_schedules_' + str(i)] = schedules[i] \n else:\n schedules_dict['today_schedules_' + str(i)] = None\n return render_template('schedule/index.html', schedules=schedules, dates=dates, \n days=days, schedules_dict=schedules_dict, rooms=rooms)\n\n@schedule_blueprint.route('/schedule/new')\ndef new_schedule():\n instructors = details_repository.select_all()\n classes = gym_class_repository.select_all()\n rooms = room_repository.select_all()\n return render_template('schedule/new.html', instructors=instructors, classes=classes, rooms=rooms)\n\n@schedule_blueprint.route('/schedule/new', methods=['POST'])\ndef add_schedule():\n class_date = request.form['class_date']\n start_time = request.form['start_time']\n length_mins = request.form['length_mins']\n instructor_id = request.form['instructor_id']\n class_id = request.form['class_id']\n room_id = request.form['room_id']\n instructor = details_repository.select(instructor_id)\n gym_class = gym_class_repository.select(class_id)\n room = room_repository.select(room_id)\n schedule = Schedule(class_date, start_time, length_mins, instructor, gym_class, room, id)\n schedule_repository.save(schedule)\n return redirect('/schedule')\n\n@schedule_blueprint.route('/schedule/<id>')\ndef show_schedule(id):\n current_cap = schedule_repository.count_member(id)\n schedule = schedule_repository.select(id)\n selected_members = member_repository.selected_members(id)\n return render_template('schedule/show.html', schedule=schedule, members=selected_members, current_cap=current_cap[0][0])\n\n@schedule_blueprint.route('/schedule/<id>/new')\ndef new_member(id):\n schedule = schedule_repository.select(id)\n members = member_repository.non_selected_members(id)\n return render_template('schedule/new_member.html', schedule=schedule, members=members)\n\n@schedule_blueprint.route('/schedule/<id>/new', methods=['POST'])\ndef add_member(id):\n member_id = request.form['member_id']\n member = member_repository.select(member_id)\n schedule = schedule_repository.select(id)\n schedule_member = ScheduleMember(member, schedule)\n schedule_repository.save_member(schedule_member)\n return redirect('/schedule')\n\n@schedule_blueprint.route('/schedule/all')\ndef show_all():\n upcoming_classes = []\n previous_classes = []\n schedules = schedule_repository.select_all()\n for schedule in schedules:\n if schedule.class_date < date.today():\n previous_classes.append(schedule)\n else:\n upcoming_classes.append(schedule)\n return render_template('schedule/all.html', previous_classes=previous_classes, upcoming_classes=upcoming_classes)\n\n@schedule_blueprint.route('/schedule/<id>/remove')\ndef remove_select_member(id):\n schedule = schedule_repository.select(id)\n members = member_repository.selected_members(id)\n return render_template('schedule/remove_member.html', schedule=schedule, members=members)\n\n@schedule_blueprint.route('/schedule/<id>/remove', methods=['POST'])\ndef remove_member(id):\n member_id = request.form['member_id']\n schedule_repository.remove_member(id, member_id)\n return redirect('/schedule')"
},
{
"alpha_fraction": 0.6539468765258789,
"alphanum_fraction": 0.6539468765258789,
"avg_line_length": 34.18421173095703,
"blob_id": "34070845d6613a177756ac174f7fda5c1c24af5d",
"content_id": "eeae2507f3a67ef23912d89b4e6c066c7d925110",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2673,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 76,
"path": "/controllers/member_controller.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, Flask, redirect, render_template, request\nfrom models.member import Member\nimport repositories.member_repository as member_repository\nimport datetime\n\nmembers_blueprint = Blueprint('members', __name__)\n\n@members_blueprint.route('/members')\ndef members():\n members = member_repository.select_all()\n return render_template('members/index.html', members=members)\n\n@members_blueprint.route('/members/<id>')\ndef member(id):\n member = member_repository.select(id)\n classes = member_repository.select_classes(id)\n return render_template('members/edit.html', member=member, classes=classes)\n\n@members_blueprint.route('/members/<id>', methods=['POST'])\ndef edit_member(id):\n first_name = request.form['first_name']\n last_name = request.form['last_name']\n date_of_birth = request.form['date_of_birth']\n email = request.form['email']\n phone = request.form['phone']\n if request.form.get('membership'):\n membership = True\n member_since = request.form['member_since']\n member_until = request.form['member_until']\n if request.form.get('premium'):\n premium = True\n else:\n premium = False\n else:\n membership = False\n premium = False\n member_since = None\n member_until = None\n member = Member(first_name, last_name, email, phone, date_of_birth, membership,\n premium, member_since, member_until, id)\n member_repository.update(member)\n return redirect('/members')\n\n@members_blueprint.route('/members/new')\ndef new_member():\n return render_template('members/new.html')\n\n@members_blueprint.route('/members/new', methods=['POST'])\ndef add_member():\n first_name = request.form['first_name']\n last_name = request.form['last_name']\n date_of_birth = request.form['date_of_birth']\n email = request.form['email']\n phone = request.form['phone']\n if request.form.get('membership'):\n membership = True\n member_since = request.form['member_since']\n member_until = request.form['member_until']\n if request.form.get('premium'):\n premium = True\n else:\n premium = False\n else:\n membership = False\n premium = False\n member_since = None\n member_until = None\n member = Member(first_name, last_name, email, phone, date_of_birth, membership,\n premium, member_since, member_until, id)\n member_repository.save(member)\n return redirect('/members')\n\n@members_blueprint.route('/members/<id>/delete', methods=['POST'])\ndef delete_member(id):\n member_repository.delete(id)\n return redirect('/members')"
},
{
"alpha_fraction": 0.6307554244995117,
"alphanum_fraction": 0.7263050079345703,
"avg_line_length": 56.762962341308594,
"blob_id": "ce419bbb6ba9885e576ce93809633ab5799ea23e",
"content_id": "766e8a06bb11c5e1cab03957ff72e3410052f85f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7797,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 135,
"path": "/console.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from models.gym_class import GymClass\nfrom models.member import Member\nfrom models.room import Room\nfrom models.instructor import InstructorDetails, InstructorSchedule, InstructorTimetable\nfrom models.schedule import Schedule\nimport repositories.gym_class_repository as class_repository\nimport repositories.member_repository as member_repository\nimport repositories.room_repository as room_repository\nimport repositories.instructor_timetable_repository as timetable_repository\nimport repositories.instructor_details_repository as details_repository\nimport repositories.instructor_schedule_repository as i_schedule_repository\nimport repositories.schedule_repository as schedule_repository\nimport datetime\n\nclass_1 = GymClass('Hot Yoga', 'Yoga in a very warm studio', 60, 16)\nclass_2 = GymClass('CrossFit', 'Bodyweight workout', 90, 24)\nclass_3 = GymClass('Spinning', 'Stationary indoor cycling', 60, 20)\nclass_4 = GymClass('Adult Swimming Lessons', 'Adult Swimming Lessons', 60, 20)\nclass_5 = GymClass('Water Aerobics', 'Water Exercises', 60, 25)\n\nclass_repository.save(class_1)\nclass_repository.save(class_2)\nclass_repository.save(class_3)\nclass_repository.save(class_4)\nclass_repository.save(class_5)\n\nmember_1 = Member('John', 'Smith', '[email protected]', '07595964019', \n datetime.date(1997, 5, 17), True, False, datetime.date(2021, 3, 21),\n datetime.date(2022, 3, 21))\nmember_2 = Member('Luke', 'Jones', '[email protected]', '07595964018', \n datetime.date(1992, 1, 15), False, False, None, None)\nmember_3 = Member('Mary', 'Taylor', '[email protected]', '07595964048', \n datetime.date(1988, 12, 1), True, True, datetime.date(2021, 4, 15),\n datetime.date(2022, 7, 15))\nmember_4 = Member('Susan', 'Wilson', '[email protected]', '07595964013', \n datetime.date(1968, 12, 1), False, False, None, None)\n\nmember_repository.save(member_1)\nmember_repository.save(member_2)\nmember_repository.save(member_3)\nmember_repository.save(member_4)\n\nroom_1 = Room('Studio 1', 24, 'Large Room')\nroom_2 = Room('Studio 2', 4, 'Small Room')\nroom_3 = Room('Swimming Pool', 50, 'Pool')\n\nroom_repository.save(room_1)\nroom_repository.save(room_2)\nroom_repository.save(room_3)\n\n\ninstructor_dets_1 = InstructorDetails('Mary', 'Johnson', datetime.date(1992, 3, 12))\ninstructor_dets_2 = InstructorDetails('Zach', 'Smith', datetime.date(1990, 8, 14))\ninstructor_dets_3 = InstructorDetails('John', 'Wilson', datetime.date(1990, 8, 14))\n\n\n# instructor_sch = InstructorSchedule('9-5', True, True, True, \n# True, True, False, False, datetime.time(9, 0), \n# datetime.time(17, 0))\n# instructor_tim = InstructorTimetable(datetime.date(2021, 3, 21), instructor_dets, instructor_sch)\n\n\ndetails_repository.save(instructor_dets_1)\ndetails_repository.save(instructor_dets_2)\ndetails_repository.save(instructor_dets_3)\n# i_schedule_repository.save(instructor_sch)\n# timetable_repository.save(instructor_tim)\n\nschedule_1 = Schedule(datetime.date(2021, 5, 3), datetime.time(10, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_2 = Schedule(datetime.date(2021, 5, 3), datetime.time(13, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_3 = Schedule(datetime.date(2021, 5, 3), datetime.time(16, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_4 = Schedule(datetime.date(2021, 5, 5), datetime.time(10, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_5 = Schedule(datetime.date(2021, 5, 5), datetime.time(13, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_6 = Schedule(datetime.date(2021, 5, 5), datetime.time(16, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_7 = Schedule(datetime.date(2021, 5, 7), datetime.time(10, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_8 = Schedule(datetime.date(2021, 5, 7), datetime.time(13, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_9 = Schedule(datetime.date(2021, 5, 7), datetime.time(16, 0), 60, instructor_dets_1, class_1, room_1)\nschedule_10 = Schedule(datetime.date(2021, 5, 4), datetime.time(11, 0), 60, instructor_dets_1, class_3, room_2)\nschedule_11 = Schedule(datetime.date(2021, 5, 4), datetime.time(14, 0), 60, instructor_dets_1, class_3, room_2)\nschedule_12 = Schedule(datetime.date(2021, 5, 6), datetime.time(11, 0), 60, instructor_dets_1, class_3, room_2)\nschedule_13 = Schedule(datetime.date(2021, 5, 6), datetime.time(14, 0), 60, instructor_dets_1, class_3, room_2)\n\nschedule_14 = Schedule(datetime.date(2021, 5, 3), datetime.time(9, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_15 = Schedule(datetime.date(2021, 5, 3), datetime.time(12, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_16 = Schedule(datetime.date(2021, 5, 3), datetime.time(15, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_17 = Schedule(datetime.date(2021, 5, 5), datetime.time(9, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_18 = Schedule(datetime.date(2021, 5, 5), datetime.time(12, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_19 = Schedule(datetime.date(2021, 5, 5), datetime.time(15, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_20 = Schedule(datetime.date(2021, 5, 7), datetime.time(9, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_21 = Schedule(datetime.date(2021, 5, 7), datetime.time(12, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_22 = Schedule(datetime.date(2021, 5, 7), datetime.time(15, 0), 60, instructor_dets_2, class_2, room_2)\nschedule_23 = Schedule(datetime.date(2021, 5, 4), datetime.time(8, 0), 60, instructor_dets_2, class_4, room_3)\nschedule_24 = Schedule(datetime.date(2021, 5, 4), datetime.time(12, 0), 60, instructor_dets_2, class_4, room_3)\nschedule_25 = Schedule(datetime.date(2021, 5, 6), datetime.time(8, 0), 60, instructor_dets_2, class_4, room_3)\nschedule_26 = Schedule(datetime.date(2021, 5, 6), datetime.time(12, 0), 60, instructor_dets_2, class_4, room_3)\n\nschedule_27 = Schedule(datetime.date(2021, 5, 3), datetime.time(15, 0), 60, instructor_dets_3, class_5, room_3)\nschedule_28 = Schedule(datetime.date(2021, 5, 3), datetime.time(18, 0), 60, instructor_dets_3, class_5, room_3)\nschedule_29 = Schedule(datetime.date(2021, 5, 5), datetime.time(15, 0), 60, instructor_dets_3, class_5, room_3)\nschedule_30 = Schedule(datetime.date(2021, 5, 5), datetime.time(18, 0), 60, instructor_dets_3, class_5, room_3)\nschedule_31 = Schedule(datetime.date(2021, 5, 7), datetime.time(15, 0), 60, instructor_dets_3, class_5, room_3)\nschedule_32 = Schedule(datetime.date(2021, 5, 7), datetime.time(18, 0), 60, instructor_dets_3, class_5, room_3)\n\nschedule_repository.save(schedule_1)\nschedule_repository.save(schedule_2)\nschedule_repository.save(schedule_3)\nschedule_repository.save(schedule_4)\nschedule_repository.save(schedule_5)\nschedule_repository.save(schedule_6)\nschedule_repository.save(schedule_7)\nschedule_repository.save(schedule_8)\nschedule_repository.save(schedule_9)\nschedule_repository.save(schedule_10)\nschedule_repository.save(schedule_11)\nschedule_repository.save(schedule_12)\nschedule_repository.save(schedule_13)\nschedule_repository.save(schedule_14)\nschedule_repository.save(schedule_15)\nschedule_repository.save(schedule_16)\nschedule_repository.save(schedule_17)\nschedule_repository.save(schedule_18)\nschedule_repository.save(schedule_19)\nschedule_repository.save(schedule_20)\nschedule_repository.save(schedule_21)\nschedule_repository.save(schedule_22)\nschedule_repository.save(schedule_23)\nschedule_repository.save(schedule_24)\nschedule_repository.save(schedule_25)\nschedule_repository.save(schedule_26)\nschedule_repository.save(schedule_27)\nschedule_repository.save(schedule_28)\nschedule_repository.save(schedule_29)\nschedule_repository.save(schedule_30)\nschedule_repository.save(schedule_31)\nschedule_repository.save(schedule_32)"
},
{
"alpha_fraction": 0.5662976503372192,
"alphanum_fraction": 0.5685116648674011,
"avg_line_length": 35.28571319580078,
"blob_id": "aad4c9a08187987d250d32c9697d857b2e46bd2b",
"content_id": "106307f75462a2898f7152d0516be014ed0a4daa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4065,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 112,
"path": "/repositories/member_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.member import Member\nimport repositories.schedule_repository as schedule_repository\nfrom datetime import date\n\ndef save(member):\n sql = \"\"\"INSERT INTO members\n (first_name, last_name, email, phone, date_of_birth, \n membership, premium, member_since, member_until) \n VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s) \n RETURNING id\"\"\"\n values = [member.first_name, member.last_name, member.email, member.phone, member.date_of_birth,\n member.membership, member.premium, member.member_since, member.member_until]\n results = run_sql(sql, values)\n member.id = results[0]['id']\n return member\n\ndef select_all():\n members = []\n sql = \"SELECT * FROM members\"\n results = run_sql(sql)\n for row in results:\n member = Member(row['first_name'], row['last_name'], row['email'], row['phone'],\n row['date_of_birth'], row['membership'], row['premium'], \n row['member_since'], row['member_until'], row['id'])\n members.append(member)\n return members\n\ndef select(id):\n member = None\n sql = \"SELECT * FROM members WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n member = Member(result['first_name'], result['last_name'], result['email'], \n result['phone'], result['date_of_birth'], result['membership'], \n result['premium'], result['member_since'], result['member_until'], \n result['id'])\n return member\n\ndef update(member):\n sql = \"\"\"UPDATE members\n SET first_name = %s,\n last_name = %s,\n email = %s,\n phone = %s,\n date_of_birth = %s,\n membership = %s,\n premium = %s,\n member_since = %s,\n member_until = %s\n WHERE id = %s\"\"\"\n values = [member.first_name, member.last_name, member.email, member.phone, member.date_of_birth,\n member.membership, member.premium, member.member_since, member.member_until,\n member.id]\n run_sql(sql, values)\n\ndef delete_all():\n sql = \"DELETE FROM members\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM members WHERE id = %s\"\n values = [id]\n run_sql(sql, values)\n\ndef selected_members(id):\n sql = \"\"\"SELECT members.* FROM members\n INNER JOIN schedules_members ON schedules_members.member_id = members.id\n WHERE schedules_members.schedule_id = %s\"\"\"\n values = [id]\n members = run_sql(sql, values)\n return members\n\ndef non_selected_members(id):\n sql = \"\"\"SELECT members.id FROM members\n FULL OUTER JOIN schedules_members ON schedules_members.member_id = members.id\n WHERE schedule_id = %s\"\"\"\n values = [id]\n rows = run_sql(sql, values)\n member_ids = tuple([row[0] for row in rows])\n if member_ids == ():\n sql2 = \"SELECT * FROM members\"\n members = run_sql(sql2)\n else:\n sql2 = \"\"\"SELECT * FROM members WHERE id NOT IN %s\"\"\"\n values2 = [member_ids]\n members = run_sql(sql2, values2)\n return members\n\ndef sort(type):\n members = []\n sql = \"SELECT * FROM members ORDER BY %s\"\n values = [type]\n results = run_sql(sql, values)\n for row in results:\n member = Member(row['first_name'], row['last_name'], row['email'], row['phone'],\n row['date_of_birth'], row['membership'], row['premium'], \n row['member_since'], row['member_until'], row['id'])\n members.append(member)\n return members\n\ndef select_classes(id):\n classes = []\n sql = \"SELECT * FROM schedules_members WHERE member_id = %s\"\n values = [id]\n results = run_sql(sql, values)\n for row in results:\n schedule = schedule_repository.select(row['schedule_id'])\n if schedule.class_date >= date.today():\n classes.append(schedule)\n return classes\n\n"
},
{
"alpha_fraction": 0.6474783420562744,
"alphanum_fraction": 0.674987256526947,
"avg_line_length": 41.543479919433594,
"blob_id": "9fab40deccbd02029a876de4e2fde370e9153e81",
"content_id": "f952b88f47294913ba60f23c1265e1c654d2f573",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1963,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 46,
"path": "/tests/instructor_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom models.instructor import InstructorDetails, InstructorSchedule\nimport datetime\n\nclass TestInstructorDetails(unittest.TestCase):\n\n def setUp(self):\n self.instructor = InstructorDetails('Mary', 'Jones', datetime.date(1992, 3, 12))\n\n def test_instructor_has_first_name(self):\n self.assertEqual('Mary', self.instructor.first_name)\n\n def test_instructor_has_last_name(self):\n self.assertEqual('Jones', self.instructor.last_name)\n\n def test_instructor_has_date_of_birth(self):\n self.assertEqual('1992-03-12', str(self.instructor.date_of_birth))\n\nclass TestInstructorSchedule(unittest.TestCase):\n\n def setUp(self):\n self.instructor_dets = InstructorDetails('Mary', 'Jones', datetime.date(1992, 3, 12))\n self.instructor = InstructorSchedule(datetime.date(2021, 3, 22), True, True, True, \n True, True, False, False, datetime.time(9, 0), \n datetime.time(17, 0), self.instructor_dets)\n \n def test_instructor_has_week_start_date(self):\n self.assertEqual('2021-03-22', str(self.instructor.week_start_date))\n\n def test_instructor_has_instructor(self):\n self.assertEqual('Mary', self.instructor.instructor.first_name)\n\n def test_instructor_has_day(self):\n self.assertEqual(True, self.instructor.monday)\n self.assertEqual(True, self.instructor.tuesday)\n self.assertEqual(True, self.instructor.wednesday)\n self.assertEqual(True, self.instructor.thursday)\n self.assertEqual(True, self.instructor.friday)\n self.assertEqual(False, self.instructor.saturday)\n self.assertEqual(False, self.instructor.sunday)\n\n def test_instructor_has_start_time(self):\n self.assertEqual('09:00:00', str(self.instructor.start_time))\n\n def test_instructor_has_end_time(self):\n self.assertEqual('17:00:00', str(self.instructor.end_time))\n\n \n"
},
{
"alpha_fraction": 0.6079545617103577,
"alphanum_fraction": 0.6079545617103577,
"avg_line_length": 36.71428680419922,
"blob_id": "be47586a542da9fb723b40ecf20ab6aa9b0ad551",
"content_id": "0be9f81652116cff0da747b79d73ce71cbcfebcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 14,
"path": "/models/member.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class Member:\n\n def __init__(self, first_name, last_name, email, phone, date_of_birth, membership=False,\n premium=False, member_since=None, member_until=None, id=None):\n self.first_name = first_name\n self.last_name = last_name\n self.email = email\n self.phone = phone\n self.date_of_birth = date_of_birth\n self.membership = membership\n self.premium = premium\n self.member_since = member_since\n self.member_until = member_until\n self.id = id\n"
},
{
"alpha_fraction": 0.8059490323066711,
"alphanum_fraction": 0.8059490323066711,
"avg_line_length": 31.136363983154297,
"blob_id": "8ddb9b57ef209b830940ecc7486c5abdf13953a6",
"content_id": "659473020986e68c51c5dd9dff71173829825832",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 22,
"path": "/app.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template\n\nfrom controllers.class_controller import classes_blueprint\nfrom controllers.member_controller import members_blueprint\nfrom controllers.room_controller import rooms_blueprint\nfrom controllers.instructor_controller import instructors_blueprint\nfrom controllers.schedule_controller import schedule_blueprint\n\napp = Flask(__name__)\n\napp.register_blueprint(classes_blueprint)\napp.register_blueprint(members_blueprint)\napp.register_blueprint(rooms_blueprint)\napp.register_blueprint(instructors_blueprint)\napp.register_blueprint(schedule_blueprint)\n\[email protected]('/')\ndef home():\n return render_template('index.html')\n\nif __name__ == '__main__':\n app.run(debug=True)"
},
{
"alpha_fraction": 0.618677020072937,
"alphanum_fraction": 0.618677020072937,
"avg_line_length": 31.25,
"blob_id": "8446a7aa801652a9ce749e3c68e76d7df0005427",
"content_id": "cc432d6b642ed0e13c1bf44bf2aa73322b7cd775",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 257,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 8,
"path": "/models/gym_class.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class GymClass:\n\n def __init__(self, class_name, description, max_time, capacity, id=None):\n self.class_name = class_name\n self.description = description\n self.max_time = max_time\n self.capacity = capacity\n self.id = id"
},
{
"alpha_fraction": 0.7108280062675476,
"alphanum_fraction": 0.7108280062675476,
"avg_line_length": 33.911109924316406,
"blob_id": "7bc80da7c42f6f1aaaa865fbc22ff9d8accd33ca",
"content_id": "c0bdc29d915ce3580dfb23eaad14884085e5d9c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1570,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 45,
"path": "/controllers/class_controller.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, Flask, redirect, render_template, request\nfrom models.gym_class import GymClass\nimport repositories.gym_class_repository as class_repository\n\nclasses_blueprint = Blueprint('classes', __name__)\n\n@classes_blueprint.route('/classes')\ndef classes():\n classes = class_repository.select_all()\n return render_template('classes/index.html', classes=classes)\n\n@classes_blueprint.route('/classes/new')\ndef new_class():\n return render_template('classes/new.html')\n\n@classes_blueprint.route('/classes/new', methods=['POST'])\ndef add_class():\n name = request.form['name']\n description = request.form['description']\n max_time = request.form['max_time']\n capacity = request.form['capacity']\n gym_class = GymClass(name, description, max_time, capacity, id)\n class_repository.save(gym_class)\n return redirect('/classes')\n\n@classes_blueprint.route('/classes/<id>')\ndef see_class(id):\n gym_class = class_repository.select(id)\n return render_template('classes/edit.html', gym_class=gym_class)\n\n\n@classes_blueprint.route('/classes/<id>', methods=['POST'])\ndef edit_class(id):\n name = request.form['name']\n description = request.form['description']\n max_time = request.form['max_time']\n capacity = request.form['capacity']\n gym_class = GymClass(name, description, max_time, capacity, id)\n class_repository.update(gym_class)\n return redirect('/classes')\n\n@classes_blueprint.route('/classes/<id>/delete', methods=['POST'])\ndef delete_class(id):\n class_repository.delete(id)\n return redirect('/classes')"
},
{
"alpha_fraction": 0.805111825466156,
"alphanum_fraction": 0.805111825466156,
"avg_line_length": 30.399999618530273,
"blob_id": "5e53f3794c88b121ec6bfce83ef6e3624f56ecbc",
"content_id": "bc577ccf0db2aa16ab7651656343ac16656e33bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 10,
"path": "/run_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom tests.member_test import TestMember\nfrom tests.gym_class_test import TestGymClass\nfrom tests.instructor_test import TestInstructorDetails, TestInstructorSchedule\nfrom tests.room_test import TestRoom\nfrom tests.schedule_test import TestSchedule\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.6083844304084778,
"alphanum_fraction": 0.6083844304084778,
"avg_line_length": 30.580644607543945,
"blob_id": "c5a24c9aeefb48a707dad449b41e4f3131dd78f0",
"content_id": "89649ca99cacf2962522e881cfbcebe46f631e51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 978,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 31,
"path": "/models/instructor.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class InstructorDetails:\n\n def __init__(self, first_name, last_name, date_of_birth, id=None) :\n self.first_name = first_name\n self.last_name = last_name\n self.date_of_birth = date_of_birth\n self.id = id\n\nclass InstructorSchedule:\n\n def __init__(self, nickname, monday, tuesday, wednesday, thursday, friday, \n saturday, sunday, start_time, end_time, id=None):\n self.nickname = nickname\n self.monday = monday\n self.tuesday = tuesday\n self.wednesday = wednesday\n self.thursday = thursday\n self.friday = friday\n self.saturday = saturday\n self.sunday = sunday\n self.start_time = start_time\n self.end_time = end_time\n self.id = id\n\nclass InstructorTimetable:\n\n def __init__(self, week_start_date, detail, schedule, id=None):\n self.week_start_date = week_start_date\n self.detail = detail\n self.schedule = schedule\n self.id = id"
},
{
"alpha_fraction": 0.5441709160804749,
"alphanum_fraction": 0.5448949933052063,
"avg_line_length": 42.171875,
"blob_id": "e095e2fe85b05e9b5881979d702970e50f6a1d12",
"content_id": "7dce90db77c220ceb3175b640eda69f5cafe847e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2762,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 64,
"path": "/repositories/instructor_schedule_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.instructor import InstructorSchedule\n\ndef save(instructor):\n sql = \"\"\"INSERT INTO instructor_schedules\n (nickname, monday, tuesday, wednesday, thursday, friday,\n saturday, sunday, start_time, end_time) \n VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s ) \n RETURNING id\"\"\"\n values = [instructor.nickname, instructor.monday, instructor.tuesday,\n instructor.wednesday, instructor.thursday, instructor.friday, \n instructor.saturday, instructor.sunday, instructor.start_time,\n instructor.end_time]\n results = run_sql( sql, values )\n instructor.id = results[0]['id']\n return instructor\n\ndef select_all():\n instructors = []\n sql = \"SELECT * FROM instructor_schedules\"\n results = run_sql(sql)\n for row in results:\n instructor = InstructorSchedule(row['nickname'], row['monday'], \n row['tuesday'], row['wednesday'], \n row['thursday'], row['friday'], \n row['saturday'], row['sunday'],\n row['start_time'], row['end_time'], row['id'])\n instructors.append(instructor)\n return instructors\n\ndef select(id):\n instructor = None\n sql = \"SELECT * FROM instructor_schedules WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n instructor = InstructorSchedule(result['nickname'], result['monday'], \n result['tuesday'], result['wednesday'], \n result['thursday'], result['friday'], \n result['saturday'], result['sunday'],\n result['start_time'], result['end_time'],\n result['id'])\n return instructor\n\ndef update(instructor):\n sql = \"\"\"UPDATE instructor_schedules\n SET nickname = %s, monday = %s, tuesday = %s,\n wednesday = %s, thursday = %s, friday = %s, saturday = %s,\n sunday = %s, start_time = %s, end_time = %s\n WHERE id = %s\"\"\"\n values = [instructor.nickname, instructor.monday, instructor.tuesday, \n instructor.wednesday, instructor.thursday, instructor.friday,\n instructor.saturday, instructor.sunday, instructor.start_time,\n instructor.end_time, instructor.id]\n run_sql(sql, values)\n\ndef delete_all():\n sql = \"DELETE FROM instructor_schedules\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM instructor_scheudles WHERE id = %s\"\n values = [id]\n run_sql(sql, values)"
},
{
"alpha_fraction": 0.5957943797111511,
"alphanum_fraction": 0.6479750871658325,
"avg_line_length": 33.72972869873047,
"blob_id": "7563e86f3b73db0736296c13207be38c873c8a35",
"content_id": "a4a7a2d32c5725ef7f67a181d577cdd55261105c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1284,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 37,
"path": "/tests/member_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\nimport datetime\nfrom models.member import Member \n\nclass TestMember(unittest.TestCase):\n\n def setUp(self):\n self.member = Member('John', 'Smith', '[email protected]', '07595964019', \n datetime.date(1997, 5, 17), True, False, datetime.date(2021, 3, 21),\n datetime.date(2021, 4, 21))\n\n def test_member_has_first_name(self):\n self.assertEqual('John', self.member.first_name)\n\n def test_member_has_last_name(self):\n self.assertEqual('Smith', self.member.last_name)\n\n def test_member_has_email(self):\n self.assertEqual('[email protected]', self.member.email)\n \n def test_member_has_phone(self):\n self.assertEqual('07595964019', self.member.phone)\n\n def test_member_has_date_of_birth(self):\n self.assertEqual('1997-05-17', str(self.member.date_of_birth))\n\n def test_member_has_membership(self):\n self.assertEqual(True, self.member.membership)\n\n def test_member_has_premium(self):\n self.assertEqual(False, self.member.premium)\n\n def test_member_has_member_since(self):\n self.assertEqual('2021-03-21', str(self.member.member_since))\n\n def test_member_has_member_until(self):\n self.assertEqual('2021-04-21', str(self.member.member_until))"
},
{
"alpha_fraction": 0.6621004343032837,
"alphanum_fraction": 0.6757990717887878,
"avg_line_length": 28.200000762939453,
"blob_id": "00debf495e24f73e29b050cdabb73b9107fe3765",
"content_id": "c5849a6a65c911c94e3ab88c3d1b3f136e62aa0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 15,
"path": "/tests/room_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom models.room import Room\n\nclass TestRoom(unittest.TestCase):\n def setUp(self):\n self.room = Room('Room 1', 24, 'Large Room')\n\n def test_room_has_name(self):\n self.assertEqual('Room 1', self.room.room_name)\n\n def test_room_has_capacity(self):\n self.assertEqual(24, self.room.capacity)\n\n def test_room_has_description(self):\n self.assertEqual('Large Room', self.room.description)\n"
},
{
"alpha_fraction": 0.7032520174980164,
"alphanum_fraction": 0.7040650248527527,
"avg_line_length": 35.17647171020508,
"blob_id": "82cb8d6d5a978430afa3a072723827250d322075",
"content_id": "e98099dd4b63505b31b3a03e4879a2f36716b232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 34,
"path": "/repositories/instructor_timetable_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\n\nfrom models.instructor import InstructorDetails, InstructorSchedule, InstructorTimetable\nimport repositories.instructor_details_repository as details_repository\nimport repositories.instructor_schedule_repository as schedule_repository\n\ndef save(timetable):\n sql = \"\"\"INSERT INTO instructor_timetables ( week_start, i_details_id, i_schedules_id ) \n VALUES ( %s, %s, %s ) RETURNING id\"\"\"\n values = [timetable.week_start_date, timetable.detail.id, timetable.schedule.id]\n results = run_sql( sql, values )\n timetable.id = results[0]['id']\n return timetable\n\n\ndef select_all():\n timetables = []\n sql = \"SELECT * FROM instructor_timetables\"\n results = run_sql(sql)\n for row in results:\n detail = details_repository.select(row['i_details_id'])\n schedule = schedule_repository.select(row['i_schedules_id'])\n timetable = InstructorTimetable(row['week_start'], detail, schedule, row['id'])\n timetables.append(timetable)\n return timetables\n\ndef delete_all():\n sql = \"DELETE FROM instructor_timetables\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM instructor_timetables WHERE id = %s\"\n values = [id]\n run_sql(sql, values)\n"
},
{
"alpha_fraction": 0.6055995225906372,
"alphanum_fraction": 0.606816828250885,
"avg_line_length": 33.25,
"blob_id": "403ce34b801911c5241b7b3c20ab98429be20973",
"content_id": "ab37a04355e3e5cfdcae16532412e0965ce48245",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1643,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 48,
"path": "/repositories/instructor_details_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.instructor import InstructorDetails\n\ndef save(instructor):\n sql = \"\"\"INSERT INTO instructor_details\n (first_name, last_name, date_of_birth) \n VALUES ( %s, %s, %s ) \n RETURNING id\"\"\"\n values = [instructor.first_name, instructor.last_name, instructor.date_of_birth]\n results = run_sql( sql, values )\n instructor.id = results[0]['id']\n return instructor\n\ndef select(id):\n instructor = None\n sql = \"SELECT * FROM instructor_details WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n instructor = InstructorDetails(result['first_name'], result['last_name'], \n result['date_of_birth'], result['id'])\n return instructor\n\ndef select_all():\n instructors = []\n sql = \"SELECT * FROM instructor_details\"\n results = run_sql(sql)\n for row in results:\n instructor = InstructorDetails(row['first_name'], row['last_name'], \n row['date_of_birth'], row['id'])\n instructors.append(instructor)\n return instructors\n\ndef update(instructor):\n sql = \"\"\"UPDATE instructor_details\n SET first_name = %s, last_name = %s, date_of_birth = %s\n WHERE id = %s\"\"\"\n values = [instructor.first_name, instructor.last_name, instructor.date_of_birth, instructor.id]\n run_sql(sql, values)\n\ndef delete_all():\n sql = \"DELETE FROM instructor_details\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM instructor_details WHERE id = %s\"\n values = [id]\n run_sql(sql, values)"
},
{
"alpha_fraction": 0.5662291049957275,
"alphanum_fraction": 0.5674224495887756,
"avg_line_length": 31.25,
"blob_id": "d53bfd127f4b71f70021916e9fa253d7c5f44ef4",
"content_id": "f68ffa6ae7c3a81a679b0030f24953cb7e9ebf8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1676,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 52,
"path": "/repositories/gym_class_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.gym_class import GymClass\n\ndef save(gym_class):\n sql = \"\"\"INSERT INTO classes\n (class_name, description, max_time, capacity) \n VALUES ( %s, %s, %s, %s ) \n RETURNING id\"\"\"\n values = [gym_class.class_name, gym_class.description, gym_class.max_time, gym_class.capacity]\n results = run_sql(sql, values)\n gym_class.id = results[0]['id']\n return gym_class\n\ndef select_all():\n gym_classes = []\n sql = \"SELECT * FROM classes ORDER BY id\"\n results = run_sql(sql)\n for row in results:\n gym_class = GymClass(row['class_name'], row['description'], row['max_time'], \n row['capacity'], row['id'])\n gym_classes.append(gym_class)\n return gym_classes\n\ndef select(id):\n gym_class = None\n sql = \"SELECT * FROM classes WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n gym_class = GymClass(result['class_name'], result['description'], result['max_time'],\n result['capacity'], result['id'])\n return gym_class\n\ndef update(gym_class):\n sql = \"\"\"UPDATE classes\n SET class_name = %s,\n description = %s,\n max_time = %s,\n capacity = %s\n WHERE id = %s\"\"\"\n values = [gym_class.class_name, gym_class.description, gym_class.max_time,\n gym_class.capacity, gym_class.id]\n run_sql(sql, values)\n\ndef delete_all():\n sql = \"DELETE FROM classes\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM classes WHERE id = %s\"\n values = [id]\n run_sql(sql, values)"
},
{
"alpha_fraction": 0.6142857074737549,
"alphanum_fraction": 0.6142857074737549,
"avg_line_length": 29.14285659790039,
"blob_id": "319949ed78c9bb3bef075025d00653079d29a952",
"content_id": "b8922329a7c8d1625bfc0410bffe2239874a6de1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 7,
"path": "/models/room.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class Room:\n\n def __init__(self, room_name, capacity, descripton=None, id=None):\n self.room_name = room_name\n self.capacity = capacity\n self.description = descripton\n self.id = id"
},
{
"alpha_fraction": 0.6303160190582275,
"alphanum_fraction": 0.6312663555145264,
"avg_line_length": 37.97222137451172,
"blob_id": "af4e98a9a970f3eca5c49b18690d4a4a846c0e38",
"content_id": "f3729e7fdce4fc8904cc8be547b7f48579737d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4209,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 108,
"path": "/repositories/schedule_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.schedule import Schedule\nfrom models.instructor import InstructorDetails\nfrom models.gym_class import GymClass\nfrom models.room import Room\nfrom models.schedule_member import ScheduleMember\nimport repositories.instructor_details_repository as instructor_repository\nimport repositories.gym_class_repository as gym_class_repository\nimport repositories.room_repository as room_repository\nimport repositories.member_repository as member_repository\nfrom datetime import timedelta\nfrom datetime import date\n\ndef save(schedule):\n sql = \"\"\"INSERT INTO schedules \n (class_date, start_time, length_mins, instructor_id, class_id, room_id)\n VALUES ( %s, %s, %s, %s, %s, %s ) RETURNING id\"\"\"\n values = [schedule.class_date, schedule.start_time, schedule.length_mins, schedule.instructor.id,\n schedule.gym_class.id, schedule.room.id]\n results = run_sql(sql, values)\n id = results[0]['id']\n schedule.id = id\n\ndef select_all():\n schedules = []\n sql = \"SELECT * FROM schedules ORDER BY class_date\"\n results = run_sql(sql)\n for row in results:\n instructor = instructor_repository.select(row['instructor_id'])\n gym_class = gym_class_repository.select(row['class_id'])\n room = room_repository.select(row['room_id'])\n schedule = Schedule(row['class_date'], row['start_time'], row['length_mins'], instructor,\n gym_class, room, row['id'])\n schedules.append(schedule)\n return schedules\n\n\ndef select_dates():\n schedules_list = []\n sql = \"SELECT * FROM schedules WHERE class_date = %s ORDER BY start_time\"\n for index in range(7):\n schedules = []\n values = [date.today() + timedelta(days=index)]\n results = run_sql(sql, values)\n if results is not None:\n for row in results:\n instructor = instructor_repository.select(row['instructor_id'])\n gym_class = gym_class_repository.select(row['class_id'])\n room = room_repository.select(row['room_id'])\n schedule = Schedule(row['class_date'], row['start_time'], row['length_mins'], instructor,\n gym_class, room, row['id'])\n schedules.append(schedule)\n else:\n schedule = None\n schedules.append(schedule)\n schedules_list.append(schedules)\n return schedules_list\n\ndef update(schedule):\n sql = \"\"\"UPDATE schedules \n SET (class_date, length_mins, start_time, instructor_id, class_id, room_id) = \n (%s, %s, %s, %s, %s, %s) \n WHERE id = %s\"\"\"\n values = [schedule.class_date, schedule.length_mins, schedule.start_time, schedule.instructor.id,\n schedule.gym_class.id, schedule.room.id]\n run_sql(sql, values)\n\ndef select(id):\n schedule = None\n sql = \"SELECT * FROM schedules WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n instructor = instructor_repository.select(result['instructor_id'])\n gym_class = gym_class_repository.select(result['class_id'])\n room = room_repository.select(result['room_id'])\n schedule = Schedule(result['class_date'], result['start_time'], result['length_mins'], instructor,\n gym_class, room, result['id'])\n return schedule\n\ndef delete_all():\n sql = \"DELETE FROM schedules\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM schedules WHERE id = %s\"\n values = [id]\n run_sql(sql, values)\n\ndef save_member(member):\n sql = \"\"\"INSERT INTO schedules_members (member_id, schedule_id)\n VALUES (%s, %s)\n RETURNING id\"\"\"\n values = [member.member.id, member.schedule.id]\n results = run_sql(sql, values)\n id = results[0]['id']\n member.id = id\n\ndef count_member(id):\n sql = \"\"\"SELECT COUNT(member_id) FROM schedules_members WHERE schedule_id = %s\"\"\"\n values = [id]\n count = run_sql(sql, values)\n return count\n\ndef remove_member(id, member_id):\n sql = \"DELETE FROM schedules_members WHERE schedule_id = %s AND member_id = %s\"\n values = [id, member_id]\n run_sql(sql, values)\n"
},
{
"alpha_fraction": 0.6064516305923462,
"alphanum_fraction": 0.6064516305923462,
"avg_line_length": 30.200000762939453,
"blob_id": "f8f737e7bacd39334a875ff36e61aaf68907fc01",
"content_id": "6dfe7a9dbde60a01c836237bb9b365ff5bbd8240",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 5,
"path": "/models/schedule_member.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class ScheduleMember:\n def __init__(self, member, schedule, id=None):\n self.member = member\n self.schedule = schedule\n self.id = id"
},
{
"alpha_fraction": 0.6967418789863586,
"alphanum_fraction": 0.7127819657325745,
"avg_line_length": 23.950000762939453,
"blob_id": "d2b687ff4a22f41c9521afb2fc7968b9adb6a0aa",
"content_id": "1223d0bdd7542049a7c38bf6712ebc3ca9cbeaf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1995,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 80,
"path": "/database/gym_management.sql",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "DROP TABLE IF EXISTS instructor_timetables;\nDROP TABLE IF EXISTS schedules_members;\nDROP TABLE IF EXISTS schedules;\nDROP TABLE IF EXISTS instructor_schedules;\nDROP TABLE IF EXISTS instructor_details;\nDROP TABLE IF EXISTS classes;\nDROP TABLE IF EXISTS rooms;\nDROP TABLE IF EXISTS members;\n\nCREATE TABLE members (\n id SERIAL PRIMARY KEY,\n first_name VARCHAR(255),\n last_name VARCHAR(255),\n email VARCHAR(255),\n phone VARCHAR(30),\n date_of_birth DATE,\n membership BOOLEAN,\n premium BOOLEAN,\n member_since DATE,\n member_until DATE\n);\n\nCREATE TABLE rooms (\n id SERIAL PRIMARY KEY,\n room_name VARCHAR(255),\n capacity INT,\n description VARCHAR(255)\n);\n\nCREATE TABLE classes (\n id SERIAL PRIMARY KEY,\n class_name VARCHAR(255),\n description VARCHAR(255),\n capacity INT,\n max_time INT\n);\n\nCREATE TABLE instructor_details (\n id SERIAL PRIMARY KEY,\n first_name VARCHAR(255),\n last_name VARCHAR(255),\n date_of_birth DATE\n);\n\nCREATE TABLE instructor_schedules (\n id SERIAL PRIMARY KEY,\n nickname VARCHAR(255),\n monday BOOLEAN,\n tuesday BOOLEAN,\n wednesday BOOLEAN,\n thursday BOOLEAN,\n friday BOOLEAN,\n saturday BOOLEAN,\n sunday BOOLEAN,\n start_time TIME,\n end_time TIME\n);\n\nCREATE TABLE instructor_timetables (\n id SERIAL PRIMARY KEY,\n week_start DATE,\n i_details_id INT REFERENCES instructor_details(id) ON DELETE CASCADE,\n i_schedules_id INT REFERENCES instructor_schedules(id) ON DELETE CASCADE\n);\n\nCREATE TABLE schedules (\n id SERIAL PRIMARY KEY,\n class_date DATE,\n start_time TIME,\n length_mins INT,\n instructor_id INT REFERENCES instructor_details(id) ON DELETE CASCADE,\n class_id INT REFERENCES classes(id) ON DELETE CASCADE,\n room_id INT REFERENCES rooms(id) ON DELETE CASCADE\n);\n\nCREATE TABLE schedules_members (\n id SERIAL PRIMARY KEY,\n member_id INT REFERENCES members(id) ON DELETE CASCADE,\n schedule_id INT REFERENCES schedules(id) ON DELETE CASCADE\n);"
},
{
"alpha_fraction": 0.5666666626930237,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 25.72222137451172,
"blob_id": "8e3b14f54575a90b42a27226824b32583fc8e00f",
"content_id": "30a719b4de207330f156a873eac5255066c6b3b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 480,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 18,
"path": "/templates/schedule/remove_member.html",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n\n{% block content %}\n\n<form action=\"/schedule/{{schedule.id}}/remove\"\" method=\"post\">\n <label for=\"member\">Select an member:</label>\n <select name=\"member_id\" id=\"member\">\n {% for member in members %}\n <option value=\"{{ member.id }}\">{{ member.first_name }} {{ member.last_name }}</option>\n {% endfor %}\n </select>\n\n\n <section>\n <input type=\"submit\" value=\"Remove Member\">\n </section>\n</form>\n{% endblock %}"
},
{
"alpha_fraction": 0.6127167344093323,
"alphanum_fraction": 0.6127167344093323,
"avg_line_length": 33.70000076293945,
"blob_id": "6a8a4326ee63ade39ac7cc02eef8a0bb8a83f289",
"content_id": "ad5054903222972d5036474d168a317f92b059d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 10,
"path": "/models/schedule.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "class Schedule:\n\n def __init__(self, class_date, start_time, length_mins, instructor, gym_class, room, id=None):\n self.class_date = class_date\n self.start_time = start_time\n self.length_mins = length_mins\n self.instructor = instructor\n self.gym_class = gym_class\n self.room = room\n self.id = id"
},
{
"alpha_fraction": 0.5846036672592163,
"alphanum_fraction": 0.5861280560493469,
"avg_line_length": 27.5,
"blob_id": "7116a86d5be4018947ec7f0d453f860410626d7b",
"content_id": "9d336466c2c7478fae118f8127088204fc0a4066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1312,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 46,
"path": "/repositories/room_repository.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from database.run_sql import run_sql\nfrom models.room import Room\n\ndef save(room):\n sql = \"\"\"INSERT INTO rooms\n (room_name, capacity, description)\n VALUES (%s, %s, %s) \n RETURNING id\"\"\"\n values = [room.room_name, room.capacity, room.description]\n results = run_sql(sql, values)\n room.id = results[0]['id']\n return room\n\ndef select_all():\n rooms = []\n sql = \"SELECT * FROM rooms ORDER BY id\"\n results = run_sql(sql)\n for row in results:\n room = Room(row['room_name'], row['capacity'], row['description'], row['id'])\n rooms.append(room)\n return rooms\n\ndef select(id):\n room = None\n sql = \"SELECT * FROM rooms WHERE id = %s\"\n values = [id]\n result = run_sql(sql, values)[0]\n if result is not None:\n room = Room(result['room_name'], result['capacity'], result['description'], result['id'])\n return room\n\ndef update(room):\n sql = \"\"\"UPDATE rooms\n SET room_name = %s, capacity = %s, description = %s\n WHERE id = %s\"\"\"\n values = [room.room_name, room.capacity, room.description, room.id]\n run_sql(sql, values)\n\ndef delete_all():\n sql = \"DELETE FROM rooms\"\n run_sql(sql)\n\ndef delete(id):\n sql = \"DELETE FROM rooms WHERE id = %s\"\n values = [id]\n run_sql(sql, values)\n\n"
},
{
"alpha_fraction": 0.713658332824707,
"alphanum_fraction": 0.7171717286109924,
"avg_line_length": 43.656864166259766,
"blob_id": "4da29d766d84c8a39ec6dd9f6aba107fce8f5e2a",
"content_id": "7a60dbed652e28e48c5ecf5f55c642dc80195190",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4554,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 102,
"path": "/controllers/instructor_controller.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, Flask, redirect, render_template, request\nfrom models.instructor import InstructorTimetable, InstructorDetails, InstructorSchedule\nimport repositories.instructor_timetable_repository as timetable_repository\nimport repositories.instructor_details_repository as details_repository\nimport repositories.instructor_schedule_repository as schedule_repository\n\ninstructors_blueprint = Blueprint('instructors', __name__)\n\n@instructors_blueprint.route('/instructors')\ndef instructors():\n instructors = details_repository.select_all()\n return render_template('instructor/index.html', instructors=instructors)\n\n@instructors_blueprint.route('/instructors/new_instructor')\ndef show_instructor():\n return render_template('instructor/new_dets.html')\n\n\n@instructors_blueprint.route('/instructors/new_instructor', methods=['POST'])\ndef new_instructor():\n first_name = request.form['first_name']\n last_name = request.form['last_name']\n date_of_birth = request.form['date_of_birth']\n instructor = InstructorDetails(first_name, last_name, date_of_birth, id) \n details_repository.save(instructor)\n return redirect('/instructors')\n\n@instructors_blueprint.route('/instructors/new_schedule')\ndef show_schedule():\n return render_template('instructor/new_sch.html')\n\n\n@instructors_blueprint.route('/instructors/new_schedule', methods=['POST'])\ndef new_scheudle():\n nickname = request.form['nickname']\n variables = [False] * 7\n strings = ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']\n for index in range(len(variables)):\n if request.form.get(strings[index]):\n variables[index] = True\n start_time = request.form['start_time']\n end_time = request.form['end_time']\n instructor = InstructorSchedule(nickname, variables[0], variables[1], variables[2], variables[3],\n variables[4], variables[5], variables[6], start_time, end_time, id) \n schedule_repository.save(instructor)\n return redirect('/instructors')\n\n@instructors_blueprint.route('/instructors/new_timetable')\ndef show_timetable():\n instructors = details_repository.select_all()\n schedules = schedule_repository.select_all()\n return render_template('instructor/new_tim.html', instructors=instructors, schedules=schedules)\n\n@instructors_blueprint.route('/instructors/new_timetable', methods=['POST'])\ndef add_timetable():\n instructor_id = request.form['instructor_id']\n schedule_id = request.form['schedule_id']\n start_date = request.form['start_date']\n instructor = details_repository.select(instructor_id)\n schedule = schedule_repository.select(schedule_id)\n timetable = InstructorTimetable(start_date, instructor, schedule, id)\n timetable_repository.save(timetable)\n return redirect('/instructors')\n\n@instructors_blueprint.route('/instructors/schedule/<id>')\ndef e_schedule(id):\n schedule = schedule_repository.select(id)\n return render_template('instructor/edit_sch.html', schedule=schedule)\n\n@instructors_blueprint.route('/instructors/schedule/<id>', methods=['POST'])\ndef edit_schedule(id):\n nickname = request.form['name']\n variables = [False] * 7\n strings = ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday']\n for index in range(len(variables)):\n if request.form.get(strings[index]):\n variables[index] = True\n start_time = request.form['start_time']\n end_time = request.form['end_time']\n instructor = InstructorSchedule(nickname, variables[0], variables[1], variables[2], variables[3],\n variables[4], variables[5], variables[6], start_time, end_time, id) \n schedule_repository.update(instructor)\n return redirect('/instructors')\n\n@instructors_blueprint.route('/instructors/details/<id>')\ndef e_details(id):\n details = details_repository.select(id)\n return render_template('instructor/edit_dets.html', details=details)\n\n@instructors_blueprint.route('/instructors/details/<id>', methods=['POST'])\ndef edit_details(id):\n first_name = request.form['first_name']\n last_name = request.form['last_name']\n date_of_birth = request.form['date_of_birth']\n instructor = InstructorDetails(first_name, last_name, date_of_birth, id) \n details_repository.update(instructor)\n return redirect('/instructors')\n\n@instructors_blueprint.route('/instructors/details/<id>/delete', methods=['POST'])\ndef delete_instructor(id):\n details_repository.delete(id)\n return redirect('/instructors')"
},
{
"alpha_fraction": 0.6715328693389893,
"alphanum_fraction": 0.7177615761756897,
"avg_line_length": 30.69230842590332,
"blob_id": "a64a53755dfc539d4b5e80a9fa735f6637e6bb9f",
"content_id": "c2ee09d7aaef437be6082aa08f6508ab667756da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/tests/schedule_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom models.schedule import Schedule\nimport datetime\n\nclass TestSchedule(unittest.TestCase):\n def setUp(self):\n self.schedule = Schedule(datetime.date(2021, 3, 21), 45)\n\n def test_schedule_has_class_date(self):\n self.assertEqual('2021-03-21', str(self.schedule.class_date))\n\n def test_schedule_has_length_mins(self):\n self.assertEqual(45, self.schedule.length_mins)"
},
{
"alpha_fraction": 0.6813187003135681,
"alphanum_fraction": 0.6938775777816772,
"avg_line_length": 32.578948974609375,
"blob_id": "1d10bd6d0453f8c6a5409934f6fe8c3fa9e31106",
"content_id": "e0755001daddfaaf6c5fd2a83ef1446e42d4622f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 19,
"path": "/tests/gym_class_test.py",
"repo_name": "constable-ldp/gym_management_app",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom models.gym_class import GymClass\n\nclass TestGymClass(unittest.TestCase):\n\n def setUp(self):\n self.gym_class = GymClass('Hot Yoga', 'Yoga performed in a very warm studio', 60, 16)\n\n def test_class_has_name(self):\n self.assertEqual('Hot Yoga', self.gym_class.class_name)\n\n def test_class_has_description(self):\n self.assertEqual('Yoga performed in a very warm studio', self.gym_class.description)\n \n def test_class_has_max_time(self):\n self.assertEqual(60, self.gym_class.max_time)\n\n def test_class_has_capacity(self):\n self.assertEqual(16, self.gym_class.capacity)"
}
] | 29 |
Redent0r/Libra | https://github.com/Redent0r/Libra | 9a7f2bae1a2a01be5d8685be7078f56657cee318 | 075bb9d19bcc81750cae100898429487e3024aee | 4444247c0635a760e626d449ed891583160a51a3 | refs/heads/master | "2020-03-20T11:44:52.371307" | "2018-07-31T23:27:03" | "2018-07-31T23:27:03" | 137,410,854 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5536695122718811,
"alphanum_fraction": 0.5602204203605652,
"avg_line_length": 39.287986755371094,
"blob_id": "575c02f078bd3e561a1dccce4dedee3548546f25",
"content_id": "f8d658baa08755e7598b98d116c4f25897799557",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 51901,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 1257,
"path": "/master_admin.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "\r\n### std lib ###\r\nimport sys\r\nimport sqlite3\r\nimport time\r\nimport os\r\n\r\n### PyQt4 ###\r\nfrom PyQt4 import QtCore, QtGui, QtSql\r\n\r\n### GUIs ###\r\nfrom gui_inventory import Ui_MainWindow as InventoryGui\r\nfrom gui_purchase import Ui_Dialog as PurchaseGui\r\nfrom gui_sale import Ui_Dialog as SaleGui\r\nfrom gui_client import Ui_Dialog as ClientGui\r\nfrom gui_modify import Ui_Dialog as ModifyGui\r\nfrom gui_move import Ui_Dialog as MoveGui\r\nfrom gui_client_modify import Ui_Dialog as ClientModifyGui\r\n\r\nimport mec_inventory#, stresstest\r\n\r\n\r\nclass Inventory (QtGui.QMainWindow, InventoryGui):\r\n ### constants ###\r\n useNas = False ### change this to use nas\r\n DB_LOCATION = \".libra.db\" # database\r\n\r\n def __init__ (self, parent=None):\r\n\r\n start = time.time()\r\n\r\n ### sets up visual gui ###\r\n QtGui.QMainWindow.__init__(self, parent) # parent shit for exit bug; object hierarchy\r\n self.setupUi(self)\r\n self.setAttribute(QtCore.Qt.WA_DeleteOnClose) # maybe takes care of closing bug\r\n\r\n ### Database Connection, for qsqlquerymodel ###\r\n self.db = QtSql.QSqlDatabase.addDatabase('QSQLITE')\r\n self.db.setDatabaseName(self.DB_LOCATION)\r\n self.db.open()\r\n\r\n ### Table Models ###\r\n self.mdlClients = QtSql.QSqlQueryModel()\r\n self.mdlPurchases = QtSql.QSqlQueryModel()\r\n self.mdlSales = QtSql.QSqlQueryModel()\r\n self.mdlInventory = QtSql.QSqlQueryModel()\r\n # bal\r\n self.mdlPurchasesBal = QtSql.QSqlQueryModel()\r\n self.mdlSalesBal = QtSql.QSqlQueryModel()\r\n \r\n ### sort filter proxy model ###\r\n self.proxyInventory = QtGui.QSortFilterProxyModel()\r\n self.proxyInventory.setSourceModel(self.mdlInventory)\r\n self.proxyPurchases = QtGui.QSortFilterProxyModel()\r\n self.proxyPurchases.setSourceModel(self.mdlPurchases)\r\n self.proxySales = QtGui.QSortFilterProxyModel()\r\n self.proxySales.setSourceModel(self.mdlSales)\r\n self.proxyClients = QtGui.QSortFilterProxyModel()\r\n self.proxyClients.setSourceModel(self.mdlClients)\r\n # bal\r\n self.proxyPurchasesBal = QtGui.QSortFilterProxyModel()\r\n self.proxyPurchasesBal.setSourceModel(self.mdlPurchasesBal)\r\n self.proxySalesBal = QtGui.QSortFilterProxyModel()\r\n self.proxySalesBal.setSourceModel(self.mdlSalesBal)\r\n\r\n ### proxy filter parameters\r\n self.proxyInventory.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive) # case insennsitive\r\n self.proxyPurchases.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive)\r\n self.proxySales.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive)\r\n self.proxyClients.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive)\r\n # bal\r\n self.proxyPurchasesBal.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive)\r\n self.proxySalesBal.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive)\r\n\r\n #### setting models to tables ###\r\n self.tblInventory.setModel(self.proxyInventory)\r\n self.tblPurchases.setModel(self.proxyPurchases)\r\n self.tblSales.setModel(self.proxySales)\r\n self.tblClients.setModel(self.proxyClients)\r\n # bal\r\n self.tblPurchasesBal.setModel(self.proxyPurchasesBal)\r\n self.tblSalesBal.setModel(self.proxySalesBal)\r\n\r\n ### Actions functionality ###\r\n self.actionRefresh.triggered.connect(self.refreshTables)\r\n self.actionPurchase.triggered.connect(self.action_purchase)\r\n self.actionSale.triggered.connect(self.action_sale)\r\n self.actionClient.triggered.connect(self.action_client)\r\n\r\n self.btnModifyInventory.clicked.connect(self.modify_inventory)\r\n self.btnMove.clicked.connect(self.move_item)\r\n self.btnRemovePurchase.clicked.connect(self.remove_purchase)\r\n self.btnRemoveSale.clicked.connect(self.reverse_sale)\r\n self.btnSettle.clicked.connect(self.settle_debt)\r\n self.btnRemoveClient.clicked.connect(self.remove_client)\r\n self.btnModifyClient.clicked.connect(self.modify_client)\r\n self.leditInventory.textEdited.connect(lambda: self.search(self.leditInventory.text(), self.proxyInventory))\r\n self.leditPurchases.textEdited.connect(lambda: self.search(self.leditPurchases.text(), self.proxyPurchases))\r\n self.leditSales.textEdited.connect(lambda: self.search(self.leditSales.text(), self.proxySales))\r\n self.leditClients.textEdited.connect(lambda: self.search(self.leditClients.text(), self.proxyClients))\r\n\r\n self.cmboxInventory.activated.connect(lambda: self.combo_box_changed(self.cmboxInventory, self.proxyInventory))\r\n self.cmboxPurchases.activated.connect(lambda: self.combo_box_changed(self.cmboxPurchases, self.proxyPurchases))\r\n self.cmboxSales.activated.connect(lambda: self.combo_box_changed(self.cmboxSales, self.proxySales))\r\n self.cmboxClients.activated.connect(lambda: self.combo_box_changed(self.cmboxClients, self.proxyClients))\r\n\r\n self.radioHistoric.toggled.connect(lambda: self.set_balance(self.radioHistoric))\r\n self.radioAnnual.toggled.connect(lambda: self.set_balance(self.radioAnnual))\r\n self.radioMonthly.toggled.connect(lambda: self.set_balance(self.radioMonthly))\r\n self.dateAnnual.dateChanged.connect(lambda: self.set_balance(self.radioAnnual))\r\n self.dateMonthly.dateChanged.connect(lambda: self.set_balance(self.radioMonthly))\r\n\r\n self.calBalance.selectionChanged.connect(self.calendar_changed)\r\n self.calBalance.showToday()\r\n\r\n ### Creates tables if not exists, for mec_inventario ###\r\n self.conn = sqlite3.connect(self.DB_LOCATION)\r\n self.c = self.conn.cursor()\r\n mec_inventory.create_tables(self.conn, self.c)\r\n\r\n ########################## STRESSS TESTTTTTT ################################\r\n #stresstest.test_entries(self.conn, self.c, 10)\r\n #stresstest.test_entries(self.conn, self.c, 100)\r\n #stresstest.test_entries(self.conn, self.c, 250)\r\n #stresstest.test_entries(self.conn, self.c, 500)\r\n #stresstest.test_entries(self.conn, self.c, 1000)\r\n ################################################################################\r\n\r\n self.set_balance(self.radioHistoric)\r\n self.refreshTables()\r\n\r\n headers = [\"Code\", \"Name\", \"Group\", \"Available Quantity\", \"Unit Cost\",\r\n \"Suggested Price\", \"Minimum Quantity\", \"Maximum Quantity\", \"Category\"]\r\n for i in range(len(headers)):\r\n self.mdlInventory.setHeaderData(i, QtCore.Qt.Horizontal, headers[i]) # +1 for id col\r\n self.cmboxInventory.addItems(headers) # add headers to combo box\r\n\r\n headers = [\"Date\", \"Transaction\", \"Code\", \"Name\", \"Group\", \"Quantity\", \"Vendor\",\r\n \"Unit Cost\", \"Total Cost\", \"Category\"]\r\n for i in range(len(headers)):\r\n self.mdlPurchases.setHeaderData(i, QtCore.Qt.Horizontal, headers[i])\r\n self.cmboxPurchases.addItems(headers)\r\n\r\n headers = [\"Date\", \"Transaction\", \"Code\", \"Name\", \"Group\", \"Quantity\", \"Unit Price\",\r\n \"Total Price\", \"Client\", \"Pay\"]\r\n for i in range(len(headers)):\r\n self.mdlSales.setHeaderData(i, QtCore.Qt.Horizontal, headers[i])\r\n self.cmboxSales.addItems(headers)\r\n\r\n headers = [\"ID\", \"Name\", \"Invested\", \"Debt\",\r\n \"E-mail\", \"Phone\", \"Cellphone\"]\r\n for i in range(len(headers)):\r\n self.mdlClients.setHeaderData(i, QtCore.Qt.Horizontal, headers[i])\r\n self.cmboxClients.addItems(headers)\r\n\r\n # headers bal\r\n headers = [\"Date\", \"Transaction\", \"Code\", \"Quantity\", \"Total Cost\"]\r\n for i in range(len(headers)):\r\n self.mdlPurchasesBal.setHeaderData(i, QtCore.Qt.Horizontal, headers[i])\r\n\r\n headers = [\"Date\", \"Transaction\", \"Code\", \"Quantity\", \"Total Price\"]\r\n for i in range(len(headers)):\r\n self.mdlSalesBal.setHeaderData(i, QtCore.Qt.Horizontal, headers[i])\r\n\r\n ### table uniform stretch ###\r\n self.tblInventory.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n self.tblPurchases.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n self.tblSales.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n self.tblClients.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n\r\n # bal stretch\r\n self.tblBalance.horizontalHeader().setResizeMode(QtGui.QHeaderView.Stretch)\r\n self.tblBalance.verticalHeader().setResizeMode(QtGui.QHeaderView.Stretch)\r\n self.tblPurchasesBal.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n self.tblSalesBal.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n\r\n end = time.time()\r\n print(\"constructor time: \" + str(end - start))\r\n\r\n def refreshTables(self):\r\n\r\n start = time.time()\r\n\r\n self.mdlInventory.setQuery(\"\"\"SELECT code, name, groupx, avail, costUni, priceUniSug,\r\n stockmin, stockmax, category FROM Inventory\"\"\", self.db)\r\n\r\n self.mdlPurchases.setQuery(\"\"\"SELECT dat, trans, code, name, groupx, quantity, \r\n provider, costUni, costItems, category FROM Entries\"\"\", self.db)\r\n\r\n self.mdlSales.setQuery(\"\"\"SELECT dat, trans, code, name, groupx, quantity, priceUni, \r\n priceItems, client, payment FROM Outs\"\"\", self.db)\r\n\r\n self.mdlClients.setQuery(\"\"\"SELECT identification, name, money_invested, debt,\r\n mail, num, cel FROM Clients\"\"\", self.db)\r\n\r\n # bal tables\r\n self.mdlPurchasesBal.setQuery(\"\"\" SELECT dat, trans, code, quantity, costItems \r\n FROM Entries \"\"\", self.db)\r\n\r\n self.mdlSalesBal.setQuery(\"\"\"SELECT dat, trans, code, quantity,\r\n priceItems FROM Outs\"\"\", self.db)\r\n\r\n\r\n end = time.time()\r\n print(\"refresh time: \" + str(end - start))\r\n \r\n def settle_debt(self):\r\n\r\n index = self.tblSales.selectionModel().selectedRows()\r\n if index:\r\n row = int(index[0].row()) # selected row\r\n code = self.proxySales.data(self.proxySales.index(row, 1)) # 0 = fecha, 1 = codigo\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Settle\",\r\n \"Are you sure you wish to settle\\n\"\r\n \"the debt generated by sale number: \" + code + \"?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n \r\n mec_inventory.paid(self.conn, self.c, code)\r\n QtGui.QMessageBox.information(self, 'Message', \"The debt generated by sale number: \" + code +\r\n \"\\nhas been settled successfully\")\r\n self.refreshTables()\r\n\r\n else:\r\n\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the sale by\\n\" +\r\n \"credit you wish to settle\")\r\n def calendar_changed(self):\r\n\r\n start = time.time()\r\n\r\n self.radioDaily.setChecked(True)\r\n\r\n date = str(self.calBalance.selectedDate().toPyDate())\r\n self.search(date, self.proxyPurchasesBal)\r\n self.search(date, self.proxySalesBal)\r\n items = mec_inventory.calc_bal_day(self.c, date[0:4], date[5:7], date[8:10])\r\n self.tblBalance.setItem(0, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[2]))) # ventas contado\r\n self.tblBalance.setItem(1, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[3]))) # ventas credito \r\n self.tblBalance.setItem(2, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[1]))) # ingreso tot\r\n self.tblBalance.setItem(3, 1, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[0]))) # costo\r\n self.tblBalance.setItem(4, 1, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[5]))) # impuesto\r\n self.tblBalance.setItem(5, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[6]))) # ganancia\r\n if items[0] != 0:\r\n self.tblBalance.setItem(6, 2, QtGui.QTableWidgetItem('% {0:.2f}'.format(items[6]/items[0] * 100))) \r\n else:\r\n self.tblBalance.setItem(6, 2, QtGui.QTableWidgetItem('% 0.00'))\r\n\r\n end = time.time()\r\n\r\n print(\"cal: \" + str(end - start))\r\n\r\n def set_balance(self, radioButton):\r\n\r\n start = time.time()\r\n\r\n if radioButton.isChecked():\r\n items = []\r\n if radioButton == self.radioHistoric:\r\n\r\n self.search(\"\", self.proxyPurchasesBal)\r\n self.search(\"\", self.proxySalesBal)\r\n items = mec_inventory.calc_bal_his(self.c)\r\n # [costoTot,precioTot,cd,cc,ingresoTot,impuestoTot,gananciaTot]\r\n\r\n elif radioButton == self.radioAnnual:\r\n \r\n date = str(self.dateAnnual.date().toPyDate())\r\n self.search(date[0:4], self.proxyPurchasesBal)\r\n self.search(date[0:4], self.proxySalesBal)\r\n items = mec_inventory.calc_bal_year(self.c, date[0:4])\r\n # [costoTot,precioTot,cd,cc,ingresoTot,impuestoTot,gananciaTot]\r\n \r\n else: # radio mensual\r\n \r\n date = str(self.dateMonthly.date().toPyDate())\r\n self.search((date[0:4] + \"-\" + date[5:7]), self.proxyPurchasesBal)\r\n self.search((date[0:4] + \"-\" + date[5:7]), self.proxySalesBal)\r\n items = mec_inventory.calc_bal_mes(self.c, date[0:4], date[5:7])\r\n # [costoTot,precioTot,cd,cc,ingresoTot,impuestoTot,gananciaTot]\r\n\r\n self.tblBalance.setItem(0, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[2])))\r\n self.tblBalance.setItem(1, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[3])))\r\n self.tblBalance.setItem(2, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[1])))\r\n self.tblBalance.setItem(3, 1, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[0])))\r\n self.tblBalance.setItem(4, 1, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[5])))\r\n self.tblBalance.setItem(5, 2, QtGui.QTableWidgetItem('$ {0:.2f}'.format(items[6])))\r\n if items[0] != 0:\r\n self.tblBalance.setItem(6, 2, QtGui.QTableWidgetItem('% {0:.2f}'.format(items[6]/items[0] * 100)))\r\n else:\r\n self.tblBalance.setItem(6, 2, QtGui.QTableWidgetItem('% 0.00'))\r\n\r\n end = time.time()\r\n\r\n print(\"bal: \" + str(end - start))\r\n\r\n def combo_box_changed(self, comboBox, proxy):\r\n\r\n proxy.setFilterKeyColumn(comboBox.currentIndex())\r\n\r\n def search(self, text, proxy):\r\n\r\n proxy.setFilterRegExp(\"^\" + text)\r\n\r\n def move_item(self):\r\n\r\n index = self.tblInventory.selectionModel().selectedRows() ### list of indexes\r\n if index:\r\n \r\n row = int(index[0].row()) # selected row\r\n code = self.proxyInventory.data(self.proxyInventory.index(row, 0))\r\n group = self.proxyInventory.data(self.proxyInventory.index(row, 2))\r\n available = self.proxyInventory.data(self.proxyInventory.index(row, 3))\r\n move = Move(code, available, group, self)\r\n move.show()\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the \\n\" +\r\n \"item you wish to move\")\r\n\r\n def modify_inventory(self):\r\n\r\n index = self.tblInventory.selectionModel().selectedRows() ### list of indexes\r\n if index:\r\n \r\n row = int(index[0].row()) # selected row\r\n code = self.proxyInventory.data(self.proxyInventory.index(row, 0))\r\n group = self.proxyInventory.data(self.proxyInventory.index(row, 2))\r\n modifyInventory = ModifyInventory(code, group, self)\r\n modifyInventory.show()\r\n self.tblInventory.clearSelection() # clear choice\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the \\n\" +\r\n \"item you wish to modify\")\r\n\r\n def remove_client(self):\r\n\r\n index = self.tblClients.selectionModel().selectedRows()\r\n\r\n if index:\r\n\r\n row = int(index[0].row()) # selected row\r\n name = self.proxyClients.data(self.proxyClients.index(row, 1)) # 0 = fecha, 1 = codigo\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Delete\",\r\n \"Are you sure you want to delete: \" + name + \"?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n if mec_inventory.del_client_name(self.conn, self.c, name):\r\n self.refreshTables() # refresh\r\n QtGui.QMessageBox.information(self, 'Message', \"The client: \" + name +\r\n \"\\nhas been deleted sucessfully\")\r\n else:\r\n\r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error has occurred.\\n'+\r\n 'Please try again.')\r\n\r\n self.tblClients.clearSelection() # clear choice\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the \\n\" +\r\n \"client you wish to delete\")\r\n\r\n def modify_client(self):\r\n\r\n index = self.tblClients.selectionModel().selectedRows()\r\n\r\n if index:\r\n\r\n row = int(index[0].row()) # selected row\r\n name = self.proxyClients.data(self.proxyClients.index(row, 1)) # 0 = fecha, 1 = codigo\r\n modifyClient = ModifyClient(name, self)\r\n modifyClient.show()\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the \\n\" +\r\n \"client you wish to modify\")\r\n\r\n def remove_purchase(self):\r\n\r\n index = self.tblPurchases.selectionModel().selectedRows()\r\n if index:\r\n row = int(index[0].row()) # selected row\r\n code = self.proxyPurchases.data(self.proxyPurchases.index(row, 1)) # 0 = fecha, 1 = codigo\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Delete\",\r\n \"Are you sure you want to delete purchase\\n\"\r\n \" number: \" + code + \"?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n if mec_inventory.del_general(self.conn, self.c, code):\r\n self.refreshTables() # refresh\r\n QtGui.QMessageBox.information(self, 'Message', \"Purchase number: \" + code +\r\n \"\\nhas been deleted successfully.\\n\" +\r\n \"Inventory must be reduced manually\")\r\n else:\r\n\r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error has occurred.\\n'+\r\n 'Please try again.')\r\n\r\n self.tblPurchases.clearSelection() # clear choice\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', \"Please select the\\n\" +\r\n \"purchase that you want to delete\")\r\n\r\n def reverse_sale(self):\r\n\r\n index = self.tblSales.selectionModel().selectedRows()\r\n if index:\r\n row = int(index[0].row()) # selected row\r\n code = self.proxySales.data(self.proxySales.index(row, 1)) # 0 = fecha, 1 = codigo\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Reverse\",\r\n \"Are you sure you want to reverse\\n\"\r\n \"purchase number: \" + code + \"?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n if mec_inventory.del_general(self.conn, self.c, code):\r\n self.refreshTables() # refresh\r\n QtGui.QMessageBox.information(self, 'Message', \"Purchase number: \" + code +\r\n \"\\nhas been reversed successfully\")\r\n else:\r\n\r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error has occurred.\\n'+\r\n 'Please try again.')\r\n\r\n self.tblSales.clearSelection() # clear choice\r\n\r\n else:\r\n QtGui.QMessageBox.warning(self, 'Message', \"Please select the\\n\" +\r\n \"purchase you want to reverse\")\r\n\r\n def action_client(self):\r\n\r\n client = Client(self)\r\n client.show()\r\n\r\n def action_sale(self):\r\n\r\n sale = Sale(self)\r\n sale.show()\r\n\r\n def action_purchase(self):\r\n\r\n purchase = Purchase(self)\r\n purchase.show()\r\n\r\n def closeEvent(self,event):\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Warning\",\r\n \"Are you sure you want to exit?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n self.db.close()\r\n self.c.close()\r\n self.conn.close()\r\n event.accept()\r\n\r\n else:\r\n event.ignore()\r\n\r\nclass Purchase(QtGui.QDialog, PurchaseGui):\r\n\r\n def __init__ (self, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n\r\n ### functionality ###\r\n self.btnAdd.clicked.connect(self.add)\r\n self.btnUndo.clicked.connect(self.undo)\r\n \r\n self.spnboxMargin.valueChanged.connect(self.margin_changed)\r\n self.spnboxPrice.valueChanged.connect(self.price_changed)\r\n self.spnboxCost.valueChanged.connect(self.cost_changed)\r\n\r\n\r\n ### connection, from parent #######\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n ### combo box categoria config\r\n self.cmboxCategory.addItems(mec_inventory.unique(self.c, \"category\", \"Inventory\"))\r\n self.cmboxCategory.completer().setCompletionMode(QtGui.QCompleter.PopupCompletion)\r\n\r\n ### code combo box ###\r\n self.cmBoxCode.addItems(mec_inventory.unique(self.c, \"code\", \"Inventory\"))\r\n self.cmBoxCode.completer().setCompletionMode(QtGui.QCompleter.PopupCompletion)\r\n self.cmBoxCode.setEditText(\"\")\r\n\r\n self.cmBoxCode.activated.connect(self.code_return)\r\n self.cmboxGroup.activated.connect(self.group_return)\r\n\r\n self.code = \"\" # controlling multiple code input\r\n\r\n def cost_changed(self):\r\n\r\n self.spnboxMargin.setValue(0)\r\n self.spnboxPrice.setValue(0)\r\n\r\n def price_changed(self):\r\n\r\n cost = self.spnboxCost.value()\r\n if cost > 0:\r\n price = self.spnboxPrice.value()\r\n margin = (price/cost - 1) * 100\r\n\r\n self.spnboxMargin.setValue(margin)\r\n\r\n def margin_changed(self):\r\n\r\n margin = self.spnboxMargin.value()\r\n cost = self.spnboxCost.value()\r\n price = cost * (1 + margin/100)\r\n\r\n self.spnboxPrice.setValue(price)\r\n\r\n def code_return(self):\r\n\r\n code = self.cmBoxCode.currentText()\r\n if self.code != code:\r\n self.cmboxGroup.clear()\r\n self.cmboxGroup.addItems(mec_inventory.unique(self.c, \"group\", \"inventory\", \"code\", code))\r\n self.code = code\r\n self.group_return()\r\n\r\n def group_return(self):\r\n\r\n code = self.cmBoxCode.currentText()\r\n\r\n group = self.cmboxGroup.currentText()\r\n\r\n query = mec_inventory.query_add(self.c, code, group) ### temp error\r\n\r\n if query:\r\n self.leditName.setText(query[0]) # nombre\r\n self.spnboxCost.setValue(query[1]) # costo\r\n self.spnboxPrice.setValue(query[2]) # precio sugerido\r\n self.cmboxCategory.setEditText(query[3]) # categoria\r\n self.spnBoxMin.setValue(query[4]) # min\r\n self.spnBoxMax.setValue(query[5]) # max\r\n\r\n self.price_changed()\r\n \r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', ' No previous records of this code have\\n'+\r\n 'been found. New records will be created.')\r\n \r\n def undo(self):\r\n \r\n self.leditName.clear()\r\n self.spnboxCost.setValue(0)\r\n self.spnBoxQuantity.setValue(1)\r\n self.spnboxMargin.setValue(0)\r\n self.spnboxPrice.setValue(0)\r\n self.cmboxCategory.clearEditText()\r\n self.cmboxGroup.clearEditText()\r\n self.leditVendor.clear()\r\n self.spnBoxMin.setValue(1)\r\n self.spnBoxMax.setValue(100)\r\n self.cmBoxCode.clearEditText()\r\n\r\n def add(self):\r\n\r\n code = self.cmBoxCode.currentText()\r\n name = self.leditName.text().capitalize()\r\n\r\n if code != \"\" and name != \"\":\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Purchase\",\r\n \"Are you sure you want to\\n\"\r\n \"store this purchase?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n start = time.time()\r\n\r\n cost = self.spnboxCost.value()\r\n margin = self.spnboxMargin.value()\r\n price = self.spnboxPrice.value()\r\n quantity = self.spnBoxQuantity.value()\r\n group = self.cmboxGroup.currentText()\r\n cat = self.cmboxCategory.currentText().capitalize()\r\n vendor = self.leditVendor.text().capitalize()\r\n stockMin = self.spnBoxMin.value() \r\n stockMax = self.spnBoxMax.value() \r\n \r\n\r\n ### anadiendo ###\r\n succesful = mec_inventory.add_item_entry(self.conn, self.c, code, name,\r\n quantity, vendor, cost, price, group, cat, stockMin, stockMax)\r\n\r\n if succesful:\r\n\r\n self.parent().refreshTables()\r\n self.undo() # this has to go after refresh\r\n QtGui.QMessageBox.information(self, 'Message', 'This purchase has been\\n'+\r\n 'regstered successfully')\r\n\r\n self.close()\r\n \r\n else:\r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error occurred.\\n'+\r\n 'Please try again')\r\n\r\n end = time.time()\r\n print(\"compra time: \" + str(end-start))\r\n\r\n elif code == \"\":\r\n QtGui.QMessageBox.warning(self, 'Warning', 'Please enter a code')\r\n\r\n else: # nombre == \"\"\r\n QtGui.QMessageBox.warning(self, 'Warning', 'Please enter a name')\r\n \r\n\r\nclass Sale(QtGui.QDialog, SaleGui):\r\n\r\n def __init__(self, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n \r\n ### functionality ###\r\n self.btnInsert.clicked.connect(self.add)\r\n self.btnUndo.clicked.connect(self.undo)\r\n self.btnConfirm.clicked.connect(self.confirm)\r\n self.btnDelete.clicked.connect(self.delete_entry)\r\n self.spnboxPrice.valueChanged.connect(self.price_changed)\r\n self.spnBoxMargin.valueChanged.connect(self.margin_changed)\r\n self.spnBoxQuantity.valueChanged.connect(self.quantity_changed)\r\n self.tblInventory.clicked.connect(self.table_clicked)\r\n\r\n ### combo box nombre config ###\r\n self.cmboxClient.setModel(self.parent().mdlClients)\r\n self.cmboxClient.setModelColumn(1)\r\n self.cmboxClient.completer().setCompletionMode(QtGui.QCompleter.PopupCompletion)\r\n self.cmboxClient.setEditText(\"\")\r\n\r\n ### table ###\r\n self.model = QtGui.QStandardItemModel()\r\n self.model.setColumnCount(5)\r\n header = [\"Code\", \"Name\", \"Item Price\", \"Quantity\", \"Total Price\"]\r\n self.model.setHorizontalHeaderLabels(header)\r\n self.tblItems.setModel(self.model)\r\n\r\n ### abstract table / list of lists ###\r\n self.abstractTable = []\r\n\r\n ### mini innventario ###\r\n self.mdlInventory = QtSql.QSqlQueryModel()\r\n self.proxyInventory = QtGui.QSortFilterProxyModel()\r\n self.proxyInventory.setSourceModel(self.mdlInventory)\r\n self.tblInventory.setModel(self.proxyInventory)\r\n\r\n self.refresh_inventory()\r\n header = [\"Code\", \"Name\", \"Available\", \"Group\"]\r\n for i in range(len(header)):\r\n self.mdlInventory.setHeaderData(i, QtCore.Qt.Horizontal, header[i])\r\n self.cmboxInventory.addItems(header) # add headers to combo box\r\n\r\n self.tblInventory.horizontalHeader().setResizeMode(QtGui.QHeaderView.Interactive)\r\n\r\n # search funnctionality\r\n self.cmboxInventory.activated.connect(self.combo_box_changed)\r\n self.leditInventory.textChanged.connect(lambda: self.search(self.leditInventory.text()))\r\n self.proxyInventory.setFilterCaseSensitivity(QtCore.Qt.CaseInsensitive) # case insennsitive\r\n\r\n ### sqlite 3 connection from parent ###\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n def combo_box_changed(self):\r\n\r\n self.proxyInventory.setFilterKeyColumn(self.cmboxInventory.currentIndex())\r\n\r\n def search(self, text):\r\n\r\n self.proxyInventory.setFilterRegExp(\"^\" + text)\r\n\r\n def refresh_inventory(self):\r\n\r\n self.mdlInventory.setQuery(\"\"\"SELECT code, name, avail, groupx\r\n FROM Inventory\"\"\", self.parent().db) # uses parent connection\r\n\r\n def table_clicked(self):\r\n\r\n self.spnBoxQuantity.setValue(1) # reset cantidad\r\n index = self.tblInventory.selectionModel().selectedRows() ### list of indexes\r\n row = int(index[0].row()) # selected row\r\n code = self.proxyInventory.data(self.proxyInventory.index(row, 0))\r\n group = self.proxyInventory.data(self.proxyInventory.index(row, 3))\r\n\r\n query = mec_inventory.query_sale(self.c, code, group)\r\n \r\n if query:\r\n\r\n self.leditCode.setText(code) # arg\r\n self.leditName.setText(query[0])\r\n self.leditGroup.setText(group)\r\n self.spnboxPrice.setValue(query[1])\r\n self.spnboxCost.setValue(query[2])\r\n self.price_changed()\r\n\r\n else:\r\n QtGui.QMessageBox.critical(self, 'Error', \"An unexpected error has occurred.\\n\" +\r\n \"Please try again\")\r\n self.refresh_inventory()\r\n\r\n def margin_changed(self):\r\n\r\n price = (1 + (self.spnBoxMargin.value() / 100)) * self.spnboxCost.value()\r\n self.spnboxPrice.setValue(price)\r\n\r\n self.quantity_changed()\r\n\r\n def quantity_changed(self):\r\n\r\n priceTotalItem = self.spnboxPrice.value() * self.spnBoxQuantity.value()\r\n self.spnBoxTotalItemPrice.setValue(priceTotalItem)\r\n\r\n def refreshTotals(self):\r\n\r\n if self.abstractTable:\r\n taxes = 0.0\r\n discounts = 0.0\r\n subtotal = 0.0\r\n\r\n for line in self.abstractTable:\r\n taxes += line[2] * line[3] * line[1] # impuesto * precio * cantidad\r\n discounts += (1 + line[2]) * line [3] * line[4] * line[1] # (1 + impuesto) * precio * desc * cant\r\n subtotal += line[3] * line[1] # precio * cantidad\r\n\r\n self.spnBoxSubtotal.setValue(subtotal)\r\n self.spnBoxTaxT.setValue(taxes)\r\n self.spnBoxDiscountT.setValue(discounts)\r\n self.spnBoxGrandTotal.setValue(subtotal + taxes - discounts)\r\n\r\n else:\r\n self.spnBoxSubtotal.setValue(0)\r\n self.spnBoxTaxT.setValue(0)\r\n self.spnBoxDiscountT.setValue(0)\r\n self.spnBoxGrandTotal.setValue(0)\r\n \r\n def delete_entry(self):\r\n \r\n index = self.tblItems.selectionModel().selectedRows() ### list of indexes\r\n if (index):\r\n row = int(index[0].row()) # selected row\r\n\r\n self.model.removeRow(row)\r\n\r\n if row == 0:\r\n self.cmboxClient.setEnabled(True)\r\n\r\n del self.abstractTable[row] # deletes from abstract table\r\n\r\n self.refreshTotals()\r\n\r\n self.tblItems.clearSelection()\r\n\r\n else:\r\n QtGui.QMessageBox.information(self, 'Message', 'Please select the line\\n' +\r\n 'you wish to remove')\r\n\r\n def price_changed(self):\r\n\r\n if self.spnboxCost.value() > 0:\r\n margin = (self.spnboxPrice.value() / self.spnboxCost.value()) * 100 - 100\r\n self.spnBoxMargin.setValue(margin) # sets margin\r\n\r\n self.quantity_changed()\r\n\r\n def undo (self):\r\n \r\n self.leditCode.clear()\r\n self.leditName.clear()\r\n self.leditGroup.clear()\r\n self.spnboxCost.setValue(0)\r\n self.spnboxPrice.setValue(0)\r\n self.spnBoxQuantity.setValue(1)\r\n self.spnBoxMargin.setValue(0)\r\n self.spnboxDiscount.setValue(0)\r\n self.chkBoxItbms.setChecked(True)\r\n self.chkBoxCredit.setChecked(False)\r\n self.spnBoxTotalItemPrice.setValue(0.00)\r\n \r\n def add(self):\r\n\r\n ### table view ###\r\n code = self.leditCode.text()\r\n \r\n if code != \"\":\r\n \r\n client = self.cmboxClient.currentText()\r\n quantity = self.spnBoxQuantity.value()\r\n group = self.leditGroup.text()\r\n error = mec_inventory.sale_valid(self.c, code, client, quantity, group) # returns list of errors\r\n\r\n if not error:\r\n ### shopping cart table ###\r\n line = []\r\n line.append(QtGui.QStandardItem(self.leditCode.text()))\r\n line.append(QtGui.QStandardItem(self.leditName.text()))\r\n line.append(QtGui.QStandardItem(self.spnboxPrice.text()))\r\n line.append(QtGui.QStandardItem(self.spnBoxQuantity.text()))\r\n line.append(QtGui.QStandardItem(self.spnBoxTotalItemPrice.text()))\r\n \r\n self.model.appendRow(line)\r\n\r\n ### abstract table ###\r\n line = []\r\n line.append(self.leditCode.text()) # 0\r\n line.append(quantity) # 1\r\n line.append(float(0.07 if self.chkBoxItbms.isChecked() else 0.0)) # 2\r\n line.append(self.spnboxPrice.value()) # 3\r\n line.append(self.spnboxDiscount.value() / 100) # 4 # percentage\r\n line.append(\"CRE\" if self.chkBoxCredit.isChecked() else \"DEB\") # 5\r\n line.append(self.cmboxClient.currentText()) # 6\r\n line.append(self.leditGroup.text()) # 7\r\n \r\n self.abstractTable.append(line)\r\n self.refreshTotals()\r\n self.undo()\r\n self.cmboxClient.setEnabled(False) # disable edit client\r\n\r\n elif 3 in error: # error code for missinng client\r\n QtGui.QMessageBox.information(self, 'Message', 'No previous records of this client\\n' +\r\n 'have been found. Please create it')\r\n newClient = Client(self.parent())\r\n newClient.leditName.setText(client)\r\n newClient.show()\r\n\r\n elif 2 in error:\r\n QtGui.QMessageBox.warning(self, 'Warning', 'The item quantity you wish to sell\\n' +\r\n 'is not available in your inventory')\r\n else:\r\n\r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error has occurred.\\n' +\r\n 'Please try again')\r\n self.refresh_inventory()\r\n else: # code == \"\"\r\n QtGui.QMessageBox.warning(self, 'Error', 'Please select\\n' +\r\n 'an inventory item')\r\n\r\n def confirm(self):\r\n\r\n if self.abstractTable:\r\n\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Sell\",\r\n \"Are you sure you\\n\"\r\n \"want to make this sale?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n start = time.time()\r\n\r\n if mec_inventory.shopping_cart(self.conn, self.c, self.abstractTable):\r\n\r\n self.parent().refreshTables()\r\n del self.abstractTable [:]\r\n for i in range(self.model.rowCount()):\r\n self.model.removeRow(0)\r\n self.refreshTotals()\r\n self.cmboxClient.clearEditText()\r\n self.undo()\r\n self.cmboxClient.setEnabled(True)\r\n\r\n end = time.time()\r\n print(\"time venta: \" + str(end - start))\r\n\r\n QtGui.QMessageBox.information(self, 'Message', 'The transaction has been\\n'+\r\n 'registered successfully')\r\n else:\r\n \r\n QtGui.QMessageBox.critical(self, 'Error', 'An unexpected error has occurred.\\n' +\r\n 'Please try again')\r\n self.refresh_inventory() # regardless succesful or not\r\n else:\r\n QtGui.QMessageBox.warning(self, 'Warning', 'Please insert an item\\n' +\r\n 'to be sold')\r\n\r\nclass Client(QtGui.QDialog, ClientGui):\r\n\r\n def __init__(self, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n\r\n ### functionality ###\r\n self.btnUndo.clicked.connect(self.undo)\r\n self.btnAdd.clicked.connect(self.anadir)\r\n\r\n ### validators ###\r\n regexpPhone = QtCore.QRegExp(\"^[0-9-()]*$\") # 0-9 or - or ()\r\n phoneVal = QtGui.QRegExpValidator(regexpPhone)\r\n self.leditPhone.setValidator(phoneVal)\r\n self.leditCellphone.setValidator(phoneVal)\r\n self.leditFax.setValidator(phoneVal)\r\n\r\n ### connection, from parent ###\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n def anadir(self):\r\n\r\n name = self.leditName.text().title()\r\n if name != \"\":\r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Add Client\",\r\n \"Are you sure you want to\\n\"\r\n \"add this client?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n start = time.time()\r\n\r\n id = self.leditID.text()\r\n phone = self.leditPhone.text()\r\n cellphone = self.leditCellphone.text()\r\n address = self.leditAddress.text().capitalize()\r\n email = self.leditEmail.text()\r\n fax = self.leditFax.text()\r\n\r\n if mec_inventory.add_client(self.conn, self.c, id, name, email, phone, cellphone, fax, address):\r\n \r\n self.parent().refreshTables()\r\n self.undo()\r\n QtGui.QMessageBox.information(self, 'Message', 'The client has been\\n'+\r\n 'added successfully')\r\n \r\n else:\r\n QtGui.QMessageBox.warning(self, 'Error', 'The client that you are trying\\n' +\r\n 'to add already exists')\r\n\r\n end = time.time()\r\n print(\"time cliente: \" + str(end - start))\r\n\r\n else: # nombre == \"\"\r\n QtGui.QMessageBox.warning(self, 'Warning', 'Please insert a name')\r\n\r\n def undo(self):\r\n\r\n self.leditName.clear()\r\n self.leditID.clear()\r\n self.leditPhone.clear()\r\n self.leditCellphone.clear()\r\n self.leditAddress.clear()\r\n self.leditFax.clear()\r\n self.leditEmail.clear()\r\n\r\nclass ModifyInventory(QtGui.QDialog, ModifyGui):\r\n \r\n def __init__(self, code, group, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n \r\n self.setupUi(self)\r\n\r\n # parent connection\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n self.leditCode.setText(code)\r\n self.cmboxGroup.addItem(group)\r\n self.cmboxGroup.addItem(\"Global\")\r\n\r\n items = mec_inventory.query_modify(self.c, code, group)\r\n # Returns [disponible,precioUniSug,costoUni,categoria,stockmin,stockmax]\r\n\r\n if items:\r\n\r\n self.available = items[0]\r\n self.price = items[1]\r\n self.cost = items[2]\r\n self.category = items[3]\r\n self.min = items[4]\r\n self.max = items[5] \r\n self.name = items[6]\r\n\r\n self.spnboxAvailable.setValue(self.available)\r\n self.spnboxPrice.setValue(self.price)\r\n self.spnboxCost.setValue(self.cost)\r\n self.cmboxCategory.setEditText(self.category)\r\n self.spnboxMin.setValue(self.min)\r\n self.spnboxMax.setValue(self.max)\r\n self.leditName.setText(self.name)\r\n self.spnboxMargin.setValue(((self.price / self.cost) - 1) * 100)\r\n\r\n ### functionality ###\r\n self.btnModify.clicked.connect(self.modify_inventory)\r\n self.btnUndo.clicked.connect(self.undo)\r\n \r\n self.spnboxMargin.valueChanged.connect(self.margin_changed)\r\n self.spnboxPrice.valueChanged.connect(self.price_changed)\r\n self.spnboxCost.valueChanged.connect(self.cost_changed)\r\n\r\n def modify_inventory(self):\r\n \r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Modify\",\r\n \"Are you sure you want\\n\"\r\n \"to modify this item?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n start = time.time()\r\n\r\n code = self.leditCode.text()\r\n name = self.leditName.text()\r\n cost = self.spnboxCost.value()\r\n margin = self.spnboxMargin.value()\r\n price = self.spnboxPrice.value()\r\n available = self.spnboxAvailable.value()\r\n group = self.cmboxGroup.currentText()\r\n cat = self.cmboxCategory.currentText().capitalize()\r\n stockMin = self.spnboxMin.value() \r\n stockMax = self.spnboxMax.value() \r\n \r\n ### modificando ###\r\n mec_inventory.modify(self.conn, self.c, code, group,\r\n available, price, cat, stockMin, stockMax, cost, name)\r\n\r\n self.parent().refreshTables()\r\n QtGui.QMessageBox.information(self, 'Message', 'The modification has been\\n'+\r\n 'registered successfully')\r\n self.close()\r\n \r\n end = time.time()\r\n print(\"modificar time: \" + str(end-start))\r\n\r\n def cost_changed(self):\r\n\r\n self.spnboxMargin.setValue(0)\r\n self.spnboxPrice.setValue(0)\r\n\r\n def price_changed(self):\r\n\r\n cost = self.spnboxCost.value()\r\n if cost > 0:\r\n price = self.spnboxPrice.value()\r\n margin = (price/cost - 1) * 100\r\n\r\n self.spnboxMargin.setValue(margin)\r\n\r\n def margin_changed(self):\r\n\r\n margin = self.spnboxMargin.value()\r\n cost = self.spnboxCost.value()\r\n price = cost * (1 + margin/100)\r\n\r\n self.spnboxPrice.setValue(price)\r\n\r\n def undo(self):\r\n \r\n self.leditName.setText(self.name)\r\n self.spnboxCost.setValue(self.cost)\r\n self.spnboxAvailable.setValue(self.available)\r\n self.spnboxMargin.setValue((self.price / self.cost - 1) * 100)\r\n self.spnboxPrice.setValue(self.price)\r\n self.cmboxCategory.setEditText(self.category)\r\n self.cmboxGroup.setCurrentIndex(0)\r\n self.spnboxMin.setValue(self.min)\r\n self.spnboxMax.setValue(self.max)\r\n\r\nclass ModifyClient(QtGui.QDialog, ClientModifyGui):\r\n\r\n def __init__(self, name, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n\r\n self.leditName.setText(name)\r\n\r\n # functionality\r\n self.btnUndo.clicked.connect(self.undo)\r\n self.btnModify.clicked.connect(self.modify)\r\n\r\n ### validators ###\r\n regexpPhone = QtCore.QRegExp(\"^[0-9-()]*$\") # 0-9 or - or ()\r\n phoneVal = QtGui.QRegExpValidator(regexpPhone)\r\n self.leditPhone.setValidator(phoneVal)\r\n self.leditCellphone.setValidator(phoneVal)\r\n self.leditFax.setValidator(phoneVal)\r\n\r\n ### connection, from parent ###\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n info = mec_inventory.query_client(self.c, name)\r\n if info:\r\n\r\n self.id = info[0]\r\n self.email = info[1]\r\n self.phone = info[2]\r\n self.cel = info[3]\r\n self.fax = info[4]\r\n self.address = info[5]\r\n\r\n self.leditName.setText(name)\r\n self.leditID.setText(info[0])\r\n self.leditEmail.setText(info[1])\r\n self.leditPhone.setText(info[2])\r\n self.leditCellphone.setText(info[3])\r\n self.leditFax.setText(info[4])\r\n self.leditAddress.setText(info[5])\r\n\r\n else:\r\n\r\n QtGui.QMessageBox.warning(self, 'Error','An unexpected error has occurred.\\n'+\r\n 'Please try again')\r\n self.close()\r\n\r\n\r\n def modify(self):\r\n \r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Add Client\",\r\n \"Are you sure you want\\n\"\r\n \"to modify this client?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n start = time.time()\r\n\r\n name = self.leditName.text()\r\n id = self.leditID.text()\r\n phone = self.leditPhone.text()\r\n cell = self.leditCellphone.text()\r\n address = self.leditAddress.text().capitalize()\r\n email = self.leditEmail.text()\r\n fax = self.leditFax.text()\r\n\r\n mec_inventory.modify_client(self.conn, self.c, name, id,\r\n email, phone, cell, fax, address)\r\n \r\n self.parent().refreshTables()\r\n QtGui.QMessageBox.information(self, 'Message', 'The client has been\\n'+\r\n 'modified successfully')\r\n self.close()\r\n \r\n end = time.time()\r\n print(\"time mod cliente: \" + str(end - start))\r\n\r\n def undo(self):\r\n\r\n self.leditID.setText(self.id)\r\n self.leditPhone.setText(self.phone)\r\n self.leditCellphone.setText(self.cel)\r\n self.leditAddress.setText(self.address)\r\n self.leditFax.setText(self.fax)\r\n self.leditEmail.setText(self.email)\r\n\r\nclass Move(QtGui.QDialog, MoveGui):\r\n\r\n def __init__(self, code, available, group, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n\r\n self.conn = self.parent().conn\r\n self.c = self.parent().c\r\n\r\n self.leditCode.setText(code)\r\n self.spnboxQuantity.setMaximum(available)\r\n self.leditFromGroup.setText(str(group))\r\n\r\n self.cmboxToGroup.addItems(mec_inventory.unique(self.c, \"groupx\", \"inventory\", \"code\", code))\r\n self.cmboxToGroup.removeItem(self.cmboxToGroup.findText(group))\r\n\r\n self.btnConfirm.clicked.connect(self.confirm)\r\n\r\n def confirm(self):\r\n \r\n msgbox = QtGui.QMessageBox(QtGui.QMessageBox.Icon(4), \"Sell\",\r\n \"Are you sure you want to\\n\"\r\n \"move this item?\", parent=self)\r\n btnYes = msgbox.addButton(\"Yes\", QtGui.QMessageBox.ButtonRole(0)) # yes\r\n btnNo = msgbox.addButton(\"No\", QtGui.QMessageBox.ButtonRole(1)) # no\r\n\r\n msgbox.exec_()\r\n\r\n if msgbox.clickedButton() == btnYes:\r\n\r\n code = self.leditCode.text()\r\n quantity = self.spnboxQuantity.value()\r\n fromGroup = self.leditFromGroup.text()\r\n toGroup = self.cmboxToGroup.currentText()\r\n\r\n print(str(code) + str(quantity) + str(fromGroup) + str(toGroup))\r\n\r\n mec_inventory.move(self.conn, self.c, code, fromGroup, toGroup, quantity)\r\n self.parent().refreshTables()\r\n\r\n QtGui.QMessageBox.information(self, 'Message', 'The operation has been \\n'+\r\n 'made successfully')\r\n\r\n self.close()\r\n##################### starts everything #############################################\r\nif __name__ == \"__main__\":\r\n\r\n app = QtGui.QApplication(sys.argv)\r\n\r\n inventory = Inventory() # borrar esto\r\n inventory.show() # si se va a condicionar al nas location\r\n\r\n # if os.path.isdir(\"\\\\\\\\NASPAREDES\\\\db\"):\r\n # inventario = Inventario()\r\n # inventario.show()\r\n # else:\r\n # widget = QtGui.QWidget()\r\n # QtGui.QMessageBox.warning( widget, 'Error de conexin', 'Necesitamos que este conectado a\\n' +\r\n # 'la red wifi')\r\n\r\n sys.exit(app.exec_())\r\n"
},
{
"alpha_fraction": 0.6834490895271301,
"alphanum_fraction": 0.6999421119689941,
"avg_line_length": 42.20000076293945,
"blob_id": "98d4dbe013e89b9b975d8c161a0416a563e5de46",
"content_id": "9317adec12c3288fe2e0b5fe7b85b5c05238e843",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3456,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 80,
"path": "/gui_login.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_login.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.resize(172, 150)\n Dialog.setMinimumSize(QtCore.QSize(172, 150))\n Dialog.setMaximumSize(QtCore.QSize(172, 150))\n font = QtGui.QFont()\n font.setFamily(_fromUtf8(\"Arial\"))\n font.setPointSize(10)\n font.setStyleStrategy(QtGui.QFont.NoAntialias)\n Dialog.setFont(font)\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/access-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Dialog.setWindowIcon(icon)\n self.verticalLayout = QtGui.QVBoxLayout(Dialog)\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.label = QtGui.QLabel(Dialog)\n font = QtGui.QFont()\n font.setPointSize(17)\n font.setBold(True)\n font.setWeight(75)\n self.label.setFont(font)\n self.label.setAlignment(QtCore.Qt.AlignCenter)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.verticalLayout.addWidget(self.label)\n self.leditUser = QtGui.QLineEdit(Dialog)\n self.leditUser.setAlignment(QtCore.Qt.AlignCenter)\n self.leditUser.setObjectName(_fromUtf8(\"leditUser\"))\n self.verticalLayout.addWidget(self.leditUser)\n self.leditPassword = QtGui.QLineEdit(Dialog)\n self.leditPassword.setEchoMode(QtGui.QLineEdit.Password)\n self.leditPassword.setAlignment(QtCore.Qt.AlignCenter)\n self.leditPassword.setObjectName(_fromUtf8(\"leditPassword\"))\n self.verticalLayout.addWidget(self.leditPassword)\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem)\n self.btnLogin = QtGui.QPushButton(Dialog)\n self.btnLogin.setObjectName(_fromUtf8(\"btnLogin\"))\n self.horizontalLayout.addWidget(self.btnLogin)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem1)\n self.verticalLayout.addLayout(self.horizontalLayout)\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"Inventory\", None))\n self.label.setText(_translate(\"Dialog\", \"Member Login\", None))\n self.leditUser.setPlaceholderText(_translate(\"Dialog\", \"Username\", None))\n self.leditPassword.setPlaceholderText(_translate(\"Dialog\", \"Password\", None))\n self.btnLogin.setText(_translate(\"Dialog\", \"Login\", None))\n\nimport res_rc\n"
},
{
"alpha_fraction": 0.686763346195221,
"alphanum_fraction": 0.7059836983680725,
"avg_line_length": 53.60396194458008,
"blob_id": "f81082f2503edef6886ae918e4388114ab5a6631",
"content_id": "3036d5bc546c5384c3a9b3e3ef3538a70d17849f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11030,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 202,
"path": "/gui_purchase.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_compra.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.setWindowModality(QtCore.Qt.NonModal)\n Dialog.resize(220, 366)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Preferred, QtGui.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(Dialog.sizePolicy().hasHeightForWidth())\n Dialog.setSizePolicy(sizePolicy)\n Dialog.setMinimumSize(QtCore.QSize(220, 366))\n Dialog.setMaximumSize(QtCore.QSize(400, 366))\n font = QtGui.QFont()\n font.setPointSize(10)\n Dialog.setFont(font)\n Dialog.setContextMenuPolicy(QtCore.Qt.DefaultContextMenu)\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/plus-icon-0.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Dialog.setWindowIcon(icon)\n Dialog.setSizeGripEnabled(False)\n Dialog.setModal(True)\n self.verticalLayout = QtGui.QVBoxLayout(Dialog)\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.formLayout = QtGui.QFormLayout()\n self.formLayout.setObjectName(_fromUtf8(\"formLayout\"))\n self.label = QtGui.QLabel(Dialog)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.LabelRole, self.label)\n self.label_2 = QtGui.QLabel(Dialog)\n self.label_2.setObjectName(_fromUtf8(\"label_2\"))\n self.formLayout.setWidget(2, QtGui.QFormLayout.LabelRole, self.label_2)\n self.leditName = QtGui.QLineEdit(Dialog)\n self.leditName.setPlaceholderText(_fromUtf8(\"\"))\n self.leditName.setObjectName(_fromUtf8(\"leditName\"))\n self.formLayout.setWidget(2, QtGui.QFormLayout.FieldRole, self.leditName)\n self.label_5 = QtGui.QLabel(Dialog)\n self.label_5.setObjectName(_fromUtf8(\"label_5\"))\n self.formLayout.setWidget(4, QtGui.QFormLayout.LabelRole, self.label_5)\n self.label_3 = QtGui.QLabel(Dialog)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.LabelRole, self.label_3)\n self.spnBoxQuantity = QtGui.QSpinBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.spnBoxQuantity.sizePolicy().hasHeightForWidth())\n self.spnBoxQuantity.setSizePolicy(sizePolicy)\n self.spnBoxQuantity.setMinimumSize(QtCore.QSize(0, 0))\n self.spnBoxQuantity.setWrapping(False)\n self.spnBoxQuantity.setFrame(True)\n self.spnBoxQuantity.setButtonSymbols(QtGui.QAbstractSpinBox.UpDownArrows)\n self.spnBoxQuantity.setAccelerated(False)\n self.spnBoxQuantity.setMaximum(999999)\n self.spnBoxQuantity.setProperty(\"value\", 1)\n self.spnBoxQuantity.setObjectName(_fromUtf8(\"spnBoxQuantity\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.FieldRole, self.spnBoxQuantity)\n self.label_4 = QtGui.QLabel(Dialog)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.formLayout.setWidget(9, QtGui.QFormLayout.LabelRole, self.label_4)\n self.label_6 = QtGui.QLabel(Dialog)\n self.label_6.setObjectName(_fromUtf8(\"label_6\"))\n self.formLayout.setWidget(10, QtGui.QFormLayout.LabelRole, self.label_6)\n self.leditVendor = QtGui.QLineEdit(Dialog)\n self.leditVendor.setPlaceholderText(_fromUtf8(\"\"))\n self.leditVendor.setObjectName(_fromUtf8(\"leditVendor\"))\n self.formLayout.setWidget(10, QtGui.QFormLayout.FieldRole, self.leditVendor)\n self.label_7 = QtGui.QLabel(Dialog)\n self.label_7.setObjectName(_fromUtf8(\"label_7\"))\n self.formLayout.setWidget(11, QtGui.QFormLayout.LabelRole, self.label_7)\n self.spnBoxMin = QtGui.QSpinBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.spnBoxMin.sizePolicy().hasHeightForWidth())\n self.spnBoxMin.setSizePolicy(sizePolicy)\n self.spnBoxMin.setAccelerated(False)\n self.spnBoxMin.setMaximum(999999)\n self.spnBoxMin.setProperty(\"value\", 1)\n self.spnBoxMin.setObjectName(_fromUtf8(\"spnBoxMin\"))\n self.formLayout.setWidget(11, QtGui.QFormLayout.FieldRole, self.spnBoxMin)\n self.spnBoxMax = QtGui.QSpinBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.spnBoxMax.sizePolicy().hasHeightForWidth())\n self.spnBoxMax.setSizePolicy(sizePolicy)\n self.spnBoxMax.setAccelerated(True)\n self.spnBoxMax.setMaximum(999999)\n self.spnBoxMax.setProperty(\"value\", 100)\n self.spnBoxMax.setObjectName(_fromUtf8(\"spnBoxMax\"))\n self.formLayout.setWidget(12, QtGui.QFormLayout.FieldRole, self.spnBoxMax)\n self.label_9 = QtGui.QLabel(Dialog)\n self.label_9.setObjectName(_fromUtf8(\"label_9\"))\n self.formLayout.setWidget(7, QtGui.QFormLayout.LabelRole, self.label_9)\n self.label_10 = QtGui.QLabel(Dialog)\n self.label_10.setObjectName(_fromUtf8(\"label_10\"))\n self.formLayout.setWidget(6, QtGui.QFormLayout.LabelRole, self.label_10)\n self.label_8 = QtGui.QLabel(Dialog)\n self.label_8.setObjectName(_fromUtf8(\"label_8\"))\n self.formLayout.setWidget(12, QtGui.QFormLayout.LabelRole, self.label_8)\n self.cmBoxCode = QtGui.QComboBox(Dialog)\n self.cmBoxCode.setEditable(True)\n self.cmBoxCode.setObjectName(_fromUtf8(\"cmBoxCode\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.FieldRole, self.cmBoxCode)\n self.spnboxCost = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxCost.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxCost.setKeyboardTracking(False)\n self.spnboxCost.setSuffix(_fromUtf8(\"\"))\n self.spnboxCost.setDecimals(2)\n self.spnboxCost.setMaximum(9999.0)\n self.spnboxCost.setObjectName(_fromUtf8(\"spnboxCost\"))\n self.formLayout.setWidget(4, QtGui.QFormLayout.FieldRole, self.spnboxCost)\n self.spnboxMargin = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxMargin.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxMargin.setKeyboardTracking(False)\n self.spnboxMargin.setMaximum(9999.0)\n self.spnboxMargin.setObjectName(_fromUtf8(\"spnboxMargin\"))\n self.formLayout.setWidget(6, QtGui.QFormLayout.FieldRole, self.spnboxMargin)\n self.spnboxPrice = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxPrice.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxPrice.setKeyboardTracking(False)\n self.spnboxPrice.setMaximum(99999.0)\n self.spnboxPrice.setObjectName(_fromUtf8(\"spnboxPrice\"))\n self.formLayout.setWidget(7, QtGui.QFormLayout.FieldRole, self.spnboxPrice)\n self.cmboxCategory = QtGui.QComboBox(Dialog)\n self.cmboxCategory.setEditable(True)\n self.cmboxCategory.setObjectName(_fromUtf8(\"cmboxCategory\"))\n self.formLayout.setWidget(9, QtGui.QFormLayout.FieldRole, self.cmboxCategory)\n self.label_11 = QtGui.QLabel(Dialog)\n self.label_11.setObjectName(_fromUtf8(\"label_11\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.LabelRole, self.label_11)\n self.cmboxGroup = QtGui.QComboBox(Dialog)\n self.cmboxGroup.setEditable(True)\n self.cmboxGroup.setObjectName(_fromUtf8(\"cmboxGroup\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.FieldRole, self.cmboxGroup)\n self.verticalLayout.addLayout(self.formLayout)\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem)\n self.btnAdd = QtGui.QPushButton(Dialog)\n self.btnAdd.setAutoDefault(False)\n self.btnAdd.setDefault(False)\n self.btnAdd.setObjectName(_fromUtf8(\"btnAdd\"))\n self.horizontalLayout.addWidget(self.btnAdd)\n self.btnUndo = QtGui.QPushButton(Dialog)\n self.btnUndo.setAutoDefault(False)\n self.btnUndo.setObjectName(_fromUtf8(\"btnUndo\"))\n self.horizontalLayout.addWidget(self.btnUndo)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem1)\n self.verticalLayout.addLayout(self.horizontalLayout)\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"Purchase\", None))\n Dialog.setWhatsThis(_translate(\"Dialog\", \"Write a code and press ENTER.\\n\"\n\"the fields will fill out automatically if this code was recorded previously\", None))\n self.label.setText(_translate(\"Dialog\", \"Code:\", None))\n self.label_2.setText(_translate(\"Dialog\", \"Name:\", None))\n self.label_5.setText(_translate(\"Dialog\", \"Unit Cost:\", None))\n self.label_3.setText(_translate(\"Dialog\", \"Quantity:\", None))\n self.label_4.setText(_translate(\"Dialog\", \"Category:\", None))\n self.label_6.setText(_translate(\"Dialog\", \"Vendor:\", None))\n self.label_7.setText(_translate(\"Dialog\", \"Minimum Quantity:\", None))\n self.label_9.setText(_translate(\"Dialog\", \"Suggested Price:\", None))\n self.label_10.setText(_translate(\"Dialog\", \"Profit Margin:\", None))\n self.label_8.setText(_translate(\"Dialog\", \"Maximum Quantity:\", None))\n self.spnboxCost.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.spnboxMargin.setPrefix(_translate(\"Dialog\", \"% \", None))\n self.spnboxPrice.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.label_11.setText(_translate(\"Dialog\", \"Group:\", None))\n self.btnAdd.setText(_translate(\"Dialog\", \"Add\", None))\n self.btnUndo.setText(_translate(\"Dialog\", \"Undo\", None))\n\nimport res_rc\n"
},
{
"alpha_fraction": 0.6721991896629333,
"alphanum_fraction": 0.6926002502441406,
"avg_line_length": 50.18584060668945,
"blob_id": "c3bfd8b1f0ca9d09858d0e4817262ab0e11c4c1e",
"content_id": "88dcd5903cb84fb82502897d5a77be87ca9d95fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5784,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 113,
"path": "/gui_client.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_cliente.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.resize(188, 227)\n Dialog.setMinimumSize(QtCore.QSize(188, 227))\n Dialog.setMaximumSize(QtCore.QSize(350, 227))\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/manager-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Dialog.setWindowIcon(icon)\n Dialog.setModal(True)\n self.gridLayout = QtGui.QGridLayout(Dialog)\n self.gridLayout.setObjectName(_fromUtf8(\"gridLayout\"))\n self.formLayout = QtGui.QFormLayout()\n self.formLayout.setObjectName(_fromUtf8(\"formLayout\"))\n self.label = QtGui.QLabel(Dialog)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.LabelRole, self.label)\n self.label_2 = QtGui.QLabel(Dialog)\n self.label_2.setObjectName(_fromUtf8(\"label_2\"))\n self.formLayout.setWidget(2, QtGui.QFormLayout.LabelRole, self.label_2)\n self.leditName = QtGui.QLineEdit(Dialog)\n self.leditName.setObjectName(_fromUtf8(\"leditName\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.FieldRole, self.leditName)\n self.leditPhone = QtGui.QLineEdit(Dialog)\n self.leditPhone.setObjectName(_fromUtf8(\"leditPhone\"))\n self.formLayout.setWidget(2, QtGui.QFormLayout.FieldRole, self.leditPhone)\n self.label_3 = QtGui.QLabel(Dialog)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.formLayout.setWidget(4, QtGui.QFormLayout.LabelRole, self.label_3)\n self.label_4 = QtGui.QLabel(Dialog)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.formLayout.setWidget(6, QtGui.QFormLayout.LabelRole, self.label_4)\n self.leditAddress = QtGui.QLineEdit(Dialog)\n self.leditAddress.setObjectName(_fromUtf8(\"leditAddress\"))\n self.formLayout.setWidget(4, QtGui.QFormLayout.FieldRole, self.leditAddress)\n self.leditEmail = QtGui.QLineEdit(Dialog)\n self.leditEmail.setObjectName(_fromUtf8(\"leditEmail\"))\n self.formLayout.setWidget(6, QtGui.QFormLayout.FieldRole, self.leditEmail)\n self.label_5 = QtGui.QLabel(Dialog)\n self.label_5.setObjectName(_fromUtf8(\"label_5\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.LabelRole, self.label_5)\n self.leditCellphone = QtGui.QLineEdit(Dialog)\n self.leditCellphone.setObjectName(_fromUtf8(\"leditCellphone\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.FieldRole, self.leditCellphone)\n self.label_6 = QtGui.QLabel(Dialog)\n self.label_6.setObjectName(_fromUtf8(\"label_6\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.LabelRole, self.label_6)\n self.leditFax = QtGui.QLineEdit(Dialog)\n self.leditFax.setObjectName(_fromUtf8(\"leditFax\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.FieldRole, self.leditFax)\n self.label_7 = QtGui.QLabel(Dialog)\n self.label_7.setObjectName(_fromUtf8(\"label_7\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.LabelRole, self.label_7)\n self.leditID = QtGui.QLineEdit(Dialog)\n self.leditID.setMinimumSize(QtCore.QSize(0, 0))\n self.leditID.setPlaceholderText(_fromUtf8(\"\"))\n self.leditID.setObjectName(_fromUtf8(\"leditID\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.FieldRole, self.leditID)\n self.gridLayout.addLayout(self.formLayout, 0, 0, 1, 1)\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem)\n self.btnAdd = QtGui.QPushButton(Dialog)\n self.btnAdd.setObjectName(_fromUtf8(\"btnAdd\"))\n self.horizontalLayout.addWidget(self.btnAdd)\n self.btnUndo = QtGui.QPushButton(Dialog)\n self.btnUndo.setObjectName(_fromUtf8(\"btnUndo\"))\n self.horizontalLayout.addWidget(self.btnUndo)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout.addItem(spacerItem1)\n self.gridLayout.addLayout(self.horizontalLayout, 1, 0, 1, 1)\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"Add Client\", None))\n self.label.setText(_translate(\"Dialog\", \"Name: \", None))\n self.label_2.setText(_translate(\"Dialog\", \"Phone: \", None))\n self.label_3.setText(_translate(\"Dialog\", \"Address: \", None))\n self.label_4.setText(_translate(\"Dialog\", \"E-mail: \", None))\n self.label_5.setText(_translate(\"Dialog\", \"Cellphone: \", None))\n self.label_6.setText(_translate(\"Dialog\", \"Fax:\", None))\n self.label_7.setText(_translate(\"Dialog\", \"ID:\", None))\n self.btnAdd.setText(_translate(\"Dialog\", \"Add\", None))\n self.btnUndo.setText(_translate(\"Dialog\", \"Undo\", None))\n\nimport res_rc\n"
},
{
"alpha_fraction": 0.6149040460586548,
"alphanum_fraction": 0.6175814270973206,
"avg_line_length": 30.94285774230957,
"blob_id": "1f2a63aaac3e55e03e2bbf60b9515dbd56f7ba04",
"content_id": "30f299490821452d07ef9314352955df864dd4ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2241,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 70,
"path": "/mec_login.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "\"\"\"\n Author:Christopher Holder\n Project : Version 1.0(Login)\n\"\"\"\nimport sqlite3\nimport sys\n\ndef create_login_table(cursor,connection):#Creates login table.\n cursor.execute(\"CREATE TABLE IF NOT EXISTS login(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, User TEXT NOT NULL, Pass TEXT NOT NULL,class TEXT NOT NULL,dat TEXT);\")\n cursor.execute(\"SELECT User FROM login WHERE User = 'Administrator'\")\n data = cursor.fetchone()\n \n if data == None:\n print(\"...............Adding admin account\")\n cursor.execute(\"INSERT INTO login (User, Pass,class,dat)\"\"VALUES ('Administrator','nimda','admin',date('now'))\")\n print(\"...............Account added\")\n connection.commit()\n return True\n\ndef check_login(cursor,username,password):# Logs in ,returns current user.\n a = (username,password,)\n cursor.execute(\"SELECT User,Pass FROM login WHERE User = ? AND Pass = ?\",a)\n data = cursor.fetchone()#Returns a single tuple.\n if data == None:#f returns type None.\n print(\"Not registered\")\n return False\n return True \n\ndef add_user(cursor,username,password):\n a = (username,)\n b = (username,password,)\n cursor.execute(\"SELECT User FROM login WHERE User =?\", a)\n data = cursor.fetchone()\n if data == None:\n print(\"Username not valid\")\n if len(password) < 8:\n print(\"Must be at least 8 characters.\")\n return False\n cursor.execute(\"INSERT INTO login (User, Pass,class,dat) VALUES (?,?,'regular',date('now'))\", b)\n print(\"Succesful registration.\")\n return True\n else:\n print(\"Already registered\")\n return False\n\n\ndef print_login_table(cursor):\n elems = cursor.execute(\"SELECT * FROM login\")\n data = cursor.fetchall()\n for row in data:\n print(row)\ndef check_if_admin(cursor,username):\n a =(username,)\n cursor.execute(\"SELECT class FROM login WHERE User = ?\",a)\n data = cursor.fetchone()\n if data == None:\n return False\n elif data[0] == 'admin':\n return True\n else:\n return False\ndef remove_user():\n pass\n\ndef log_out(cursor,connection):\n print('')\n print('.................Closing')\n connection.commit()\n cursor.close()\n sys.exit()\n \n"
},
{
"alpha_fraction": 0.6869980692863464,
"alphanum_fraction": 0.7076188325881958,
"avg_line_length": 46.98958206176758,
"blob_id": "d52b6c618d1a7855c4c81abccbc8270f6dbe47d5",
"content_id": "d785092b3e8e70139c53bf37e523f03a446fa3b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4607,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 96,
"path": "/gui_move.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_mover.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.resize(313, 99)\n Dialog.setMinimumSize(QtCore.QSize(227, 99))\n Dialog.setMaximumSize(QtCore.QSize(500, 99))\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/swap-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Dialog.setWindowIcon(icon)\n self.verticalLayout = QtGui.QVBoxLayout(Dialog)\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.horizontalLayout_2 = QtGui.QHBoxLayout()\n self.horizontalLayout_2.setContentsMargins(-1, -1, 0, -1)\n self.horizontalLayout_2.setObjectName(_fromUtf8(\"horizontalLayout_2\"))\n self.label = QtGui.QLabel(Dialog)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.horizontalLayout_2.addWidget(self.label)\n self.spnboxQuantity = QtGui.QSpinBox(Dialog)\n self.spnboxQuantity.setMinimum(1)\n self.spnboxQuantity.setMaximum(99999)\n self.spnboxQuantity.setObjectName(_fromUtf8(\"spnboxQuantity\"))\n self.horizontalLayout_2.addWidget(self.spnboxQuantity)\n self.leditCode = QtGui.QLineEdit(Dialog)\n self.leditCode.setReadOnly(True)\n self.leditCode.setObjectName(_fromUtf8(\"leditCode\"))\n self.horizontalLayout_2.addWidget(self.leditCode)\n self.verticalLayout.addLayout(self.horizontalLayout_2)\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.label_3 = QtGui.QLabel(Dialog)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.horizontalLayout.addWidget(self.label_3)\n self.leditFromGroup = QtGui.QLineEdit(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Fixed, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.leditFromGroup.sizePolicy().hasHeightForWidth())\n self.leditFromGroup.setSizePolicy(sizePolicy)\n self.leditFromGroup.setReadOnly(True)\n self.leditFromGroup.setObjectName(_fromUtf8(\"leditFromGroup\"))\n self.horizontalLayout.addWidget(self.leditFromGroup)\n self.label_4 = QtGui.QLabel(Dialog)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.horizontalLayout.addWidget(self.label_4)\n self.cmboxToGroup = QtGui.QComboBox(Dialog)\n self.cmboxToGroup.setEditable(True)\n self.cmboxToGroup.setObjectName(_fromUtf8(\"cmboxToGroup\"))\n self.horizontalLayout.addWidget(self.cmboxToGroup)\n self.verticalLayout.addLayout(self.horizontalLayout)\n self.horizontalLayout_3 = QtGui.QHBoxLayout()\n self.horizontalLayout_3.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_3.setObjectName(_fromUtf8(\"horizontalLayout_3\"))\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_3.addItem(spacerItem)\n self.btnConfirm = QtGui.QPushButton(Dialog)\n self.btnConfirm.setObjectName(_fromUtf8(\"btnConfirm\"))\n self.horizontalLayout_3.addWidget(self.btnConfirm)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_3.addItem(spacerItem1)\n self.verticalLayout.addLayout(self.horizontalLayout_3)\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"Move\", None))\n self.label.setText(_translate(\"Dialog\", \"Move:\", None))\n self.label_3.setText(_translate(\"Dialog\", \"From group:\", None))\n self.label_4.setText(_translate(\"Dialog\", \"To group:\", None))\n self.btnConfirm.setText(_translate(\"Dialog\", \"Confirm\", None))\n\nimport res_rc\n"
},
{
"alpha_fraction": 0.6949670314788818,
"alphanum_fraction": 0.7144398093223572,
"avg_line_length": 59.91240692138672,
"blob_id": "a5e48517b0a9052dc0c303d31292a30bb60a9ac1",
"content_id": "338b191490348461d61b807867b603b98b93df51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33380,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 548,
"path": "/gui_inventory.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_inventory.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(_fromUtf8(\"MainWindow\"))\n MainWindow.resize(1269, 712)\n font = QtGui.QFont()\n font.setPointSize(10)\n MainWindow.setFont(font)\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/dbIcon.ico\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n MainWindow.setWindowIcon(icon)\n MainWindow.setLocale(QtCore.QLocale(QtCore.QLocale.Spanish, QtCore.QLocale.Panama))\n MainWindow.setIconSize(QtCore.QSize(60, 60))\n MainWindow.setToolButtonStyle(QtCore.Qt.ToolButtonIconOnly)\n MainWindow.setDocumentMode(False)\n MainWindow.setTabShape(QtGui.QTabWidget.Rounded)\n MainWindow.setUnifiedTitleAndToolBarOnMac(False)\n self.centralwidget = QtGui.QWidget(MainWindow)\n self.centralwidget.setObjectName(_fromUtf8(\"centralwidget\"))\n self.gridLayout = QtGui.QGridLayout(self.centralwidget)\n self.gridLayout.setObjectName(_fromUtf8(\"gridLayout\"))\n self.tabWidget = QtGui.QTabWidget(self.centralwidget)\n font = QtGui.QFont()\n font.setPointSize(10)\n self.tabWidget.setFont(font)\n self.tabWidget.setLocale(QtCore.QLocale(QtCore.QLocale.English, QtCore.QLocale.UnitedStates))\n self.tabWidget.setTabPosition(QtGui.QTabWidget.North)\n self.tabWidget.setTabShape(QtGui.QTabWidget.Rounded)\n self.tabWidget.setIconSize(QtCore.QSize(25, 25))\n self.tabWidget.setElideMode(QtCore.Qt.ElideNone)\n self.tabWidget.setObjectName(_fromUtf8(\"tabWidget\"))\n self.tab_balance = QtGui.QWidget()\n self.tab_balance.setObjectName(_fromUtf8(\"tab_balance\"))\n self.verticalLayout_3 = QtGui.QVBoxLayout(self.tab_balance)\n self.verticalLayout_3.setMargin(0)\n self.verticalLayout_3.setObjectName(_fromUtf8(\"verticalLayout_3\"))\n self.verticalLayout_2 = QtGui.QVBoxLayout()\n self.verticalLayout_2.setSizeConstraint(QtGui.QLayout.SetDefaultConstraint)\n self.verticalLayout_2.setContentsMargins(0, 0, -1, -1)\n self.verticalLayout_2.setObjectName(_fromUtf8(\"verticalLayout_2\"))\n self.horizontalLayout_5 = QtGui.QHBoxLayout()\n self.horizontalLayout_5.setObjectName(_fromUtf8(\"horizontalLayout_5\"))\n self.horizontalLayout_7 = QtGui.QHBoxLayout()\n self.horizontalLayout_7.setObjectName(_fromUtf8(\"horizontalLayout_7\"))\n self.verticalLayout_7 = QtGui.QVBoxLayout()\n self.verticalLayout_7.setContentsMargins(0, -1, -1, -1)\n self.verticalLayout_7.setObjectName(_fromUtf8(\"verticalLayout_7\"))\n self.groupBox = QtGui.QGroupBox(self.tab_balance)\n self.groupBox.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignVCenter)\n self.groupBox.setObjectName(_fromUtf8(\"groupBox\"))\n self.horizontalLayout = QtGui.QHBoxLayout(self.groupBox)\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.formLayout = QtGui.QFormLayout()\n self.formLayout.setSizeConstraint(QtGui.QLayout.SetDefaultConstraint)\n self.formLayout.setFormAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignTop)\n self.formLayout.setContentsMargins(0, -1, -1, -1)\n self.formLayout.setVerticalSpacing(6)\n self.formLayout.setObjectName(_fromUtf8(\"formLayout\"))\n self.dateAnnual = QtGui.QDateEdit(self.groupBox)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Fixed, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.dateAnnual.sizePolicy().hasHeightForWidth())\n self.dateAnnual.setSizePolicy(sizePolicy)\n self.dateAnnual.setDateTime(QtCore.QDateTime(QtCore.QDate(2017, 1, 2), QtCore.QTime(0, 0, 0)))\n self.dateAnnual.setDate(QtCore.QDate(2017, 1, 2))\n self.dateAnnual.setMinimumDateTime(QtCore.QDateTime(QtCore.QDate(2017, 1, 2), QtCore.QTime(0, 0, 0)))\n self.dateAnnual.setMinimumDate(QtCore.QDate(2017, 1, 2))\n self.dateAnnual.setObjectName(_fromUtf8(\"dateAnnual\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.FieldRole, self.dateAnnual)\n self.radioMonthly = QtGui.QRadioButton(self.groupBox)\n self.radioMonthly.setObjectName(_fromUtf8(\"radioMonthly\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.LabelRole, self.radioMonthly)\n self.dateMonthly = QtGui.QDateEdit(self.groupBox)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Fixed, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.dateMonthly.sizePolicy().hasHeightForWidth())\n self.dateMonthly.setSizePolicy(sizePolicy)\n self.dateMonthly.setDateTime(QtCore.QDateTime(QtCore.QDate(2017, 5, 1), QtCore.QTime(0, 0, 0)))\n self.dateMonthly.setDate(QtCore.QDate(2017, 5, 1))\n self.dateMonthly.setMinimumDateTime(QtCore.QDateTime(QtCore.QDate(2017, 5, 1), QtCore.QTime(0, 0, 0)))\n self.dateMonthly.setMinimumDate(QtCore.QDate(2017, 5, 1))\n self.dateMonthly.setCurrentSection(QtGui.QDateTimeEdit.MonthSection)\n self.dateMonthly.setObjectName(_fromUtf8(\"dateMonthly\"))\n self.formLayout.setWidget(5, QtGui.QFormLayout.FieldRole, self.dateMonthly)\n self.radioAnnual = QtGui.QRadioButton(self.groupBox)\n self.radioAnnual.setObjectName(_fromUtf8(\"radioAnnual\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.LabelRole, self.radioAnnual)\n self.radioHistoric = QtGui.QRadioButton(self.groupBox)\n self.radioHistoric.setChecked(True)\n self.radioHistoric.setObjectName(_fromUtf8(\"radioHistoric\"))\n self.formLayout.setWidget(2, QtGui.QFormLayout.LabelRole, self.radioHistoric)\n self.radioDaily = QtGui.QRadioButton(self.groupBox)\n self.radioDaily.setObjectName(_fromUtf8(\"radioDaily\"))\n self.formLayout.setWidget(6, QtGui.QFormLayout.LabelRole, self.radioDaily)\n self.horizontalLayout.addLayout(self.formLayout)\n self.calBalance = QtGui.QCalendarWidget(self.groupBox)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.MinimumExpanding, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.calBalance.sizePolicy().hasHeightForWidth())\n self.calBalance.setSizePolicy(sizePolicy)\n self.calBalance.setMinimumSize(QtCore.QSize(300, 0))\n self.calBalance.setMaximumSize(QtCore.QSize(16777215, 100))\n self.calBalance.setLocale(QtCore.QLocale(QtCore.QLocale.English, QtCore.QLocale.UnitedStates))\n self.calBalance.setSelectedDate(QtCore.QDate(2017, 3, 1))\n self.calBalance.setMinimumDate(QtCore.QDate(2017, 3, 1))\n self.calBalance.setMaximumDate(QtCore.QDate(2100, 12, 31))\n self.calBalance.setFirstDayOfWeek(QtCore.Qt.Monday)\n self.calBalance.setGridVisible(True)\n self.calBalance.setHorizontalHeaderFormat(QtGui.QCalendarWidget.NoHorizontalHeader)\n self.calBalance.setVerticalHeaderFormat(QtGui.QCalendarWidget.NoVerticalHeader)\n self.calBalance.setNavigationBarVisible(True)\n self.calBalance.setObjectName(_fromUtf8(\"calBalance\"))\n self.horizontalLayout.addWidget(self.calBalance)\n self.verticalLayout_7.addWidget(self.groupBox)\n self.groupBox_2 = QtGui.QGroupBox(self.tab_balance)\n self.groupBox_2.setObjectName(_fromUtf8(\"groupBox_2\"))\n self.gridLayout_2 = QtGui.QGridLayout(self.groupBox_2)\n self.gridLayout_2.setObjectName(_fromUtf8(\"gridLayout_2\"))\n self.tblPurchasesBal = QtGui.QTableView(self.groupBox_2)\n self.tblPurchasesBal.setAlternatingRowColors(True)\n self.tblPurchasesBal.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblPurchasesBal.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblPurchasesBal.setSortingEnabled(True)\n self.tblPurchasesBal.setObjectName(_fromUtf8(\"tblPurchasesBal\"))\n self.tblPurchasesBal.horizontalHeader().setStretchLastSection(True)\n self.tblPurchasesBal.verticalHeader().setVisible(False)\n self.gridLayout_2.addWidget(self.tblPurchasesBal, 0, 0, 1, 1)\n self.verticalLayout_7.addWidget(self.groupBox_2)\n self.groupBox_3 = QtGui.QGroupBox(self.tab_balance)\n self.groupBox_3.setObjectName(_fromUtf8(\"groupBox_3\"))\n self.gridLayout_3 = QtGui.QGridLayout(self.groupBox_3)\n self.gridLayout_3.setObjectName(_fromUtf8(\"gridLayout_3\"))\n self.tblSalesBal = QtGui.QTableView(self.groupBox_3)\n self.tblSalesBal.setAlternatingRowColors(True)\n self.tblSalesBal.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblSalesBal.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblSalesBal.setSortingEnabled(True)\n self.tblSalesBal.setObjectName(_fromUtf8(\"tblSalesBal\"))\n self.tblSalesBal.horizontalHeader().setStretchLastSection(True)\n self.tblSalesBal.verticalHeader().setVisible(False)\n self.gridLayout_3.addWidget(self.tblSalesBal, 0, 0, 1, 1)\n self.verticalLayout_7.addWidget(self.groupBox_3)\n self.horizontalLayout_7.addLayout(self.verticalLayout_7)\n self.tblBalance = QtGui.QTableWidget(self.tab_balance)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Ignored)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.tblBalance.sizePolicy().hasHeightForWidth())\n self.tblBalance.setSizePolicy(sizePolicy)\n self.tblBalance.setMinimumSize(QtCore.QSize(350, 0))\n font = QtGui.QFont()\n font.setPointSize(14)\n self.tblBalance.setFont(font)\n self.tblBalance.setFrameShape(QtGui.QFrame.Box)\n self.tblBalance.setFrameShadow(QtGui.QFrame.Raised)\n self.tblBalance.setEditTriggers(QtGui.QAbstractItemView.NoEditTriggers)\n self.tblBalance.setTabKeyNavigation(False)\n self.tblBalance.setProperty(\"showDropIndicator\", False)\n self.tblBalance.setDragDropOverwriteMode(False)\n self.tblBalance.setAlternatingRowColors(False)\n self.tblBalance.setSelectionMode(QtGui.QAbstractItemView.NoSelection)\n self.tblBalance.setTextElideMode(QtCore.Qt.ElideLeft)\n self.tblBalance.setShowGrid(True)\n self.tblBalance.setGridStyle(QtCore.Qt.SolidLine)\n self.tblBalance.setWordWrap(True)\n self.tblBalance.setCornerButtonEnabled(False)\n self.tblBalance.setRowCount(7)\n self.tblBalance.setColumnCount(3)\n self.tblBalance.setObjectName(_fromUtf8(\"tblBalance\"))\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(0, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(0, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(1, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(1, 1, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(1, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(2, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(2, 1, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(2, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(3, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(3, 1, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(3, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(4, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(4, 1, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(4, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(5, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(5, 1, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(5, 2, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(6, 0, item)\n item = QtGui.QTableWidgetItem()\n self.tblBalance.setItem(6, 2, item)\n self.tblBalance.horizontalHeader().setVisible(False)\n self.tblBalance.verticalHeader().setVisible(False)\n self.horizontalLayout_7.addWidget(self.tblBalance)\n self.horizontalLayout_5.addLayout(self.horizontalLayout_7)\n self.verticalLayout_2.addLayout(self.horizontalLayout_5)\n self.verticalLayout_3.addLayout(self.verticalLayout_2)\n icon1 = QtGui.QIcon()\n icon1.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/calculator.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.tabWidget.addTab(self.tab_balance, icon1, _fromUtf8(\"\"))\n self.tab_inventory = QtGui.QWidget()\n self.tab_inventory.setObjectName(_fromUtf8(\"tab_inventory\"))\n self.verticalLayout_6 = QtGui.QVBoxLayout(self.tab_inventory)\n self.verticalLayout_6.setMargin(0)\n self.verticalLayout_6.setObjectName(_fromUtf8(\"verticalLayout_6\"))\n self.horizontalLayout_6 = QtGui.QHBoxLayout()\n self.horizontalLayout_6.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_6.setObjectName(_fromUtf8(\"horizontalLayout_6\"))\n self.btnModifyInventory = QtGui.QPushButton(self.tab_inventory)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Maximum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.btnModifyInventory.sizePolicy().hasHeightForWidth())\n self.btnModifyInventory.setSizePolicy(sizePolicy)\n self.btnModifyInventory.setText(_fromUtf8(\"\"))\n icon2 = QtGui.QIcon()\n icon2.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/edit_write_pencil_pen_page-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnModifyInventory.setIcon(icon2)\n self.btnModifyInventory.setIconSize(QtCore.QSize(20, 20))\n self.btnModifyInventory.setObjectName(_fromUtf8(\"btnModifyInventory\"))\n self.horizontalLayout_6.addWidget(self.btnModifyInventory)\n self.btnMove = QtGui.QPushButton(self.tab_inventory)\n self.btnMove.setText(_fromUtf8(\"\"))\n icon3 = QtGui.QIcon()\n icon3.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/swap-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnMove.setIcon(icon3)\n self.btnMove.setObjectName(_fromUtf8(\"btnMove\"))\n self.horizontalLayout_6.addWidget(self.btnMove)\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_6.addItem(spacerItem)\n self.cmboxInventory = QtGui.QComboBox(self.tab_inventory)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Fixed, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.cmboxInventory.sizePolicy().hasHeightForWidth())\n self.cmboxInventory.setSizePolicy(sizePolicy)\n self.cmboxInventory.setMinimumSize(QtCore.QSize(20, 0))\n self.cmboxInventory.setSizeIncrement(QtCore.QSize(0, 0))\n self.cmboxInventory.setEditable(False)\n self.cmboxInventory.setInsertPolicy(QtGui.QComboBox.InsertAtBottom)\n self.cmboxInventory.setModelColumn(0)\n self.cmboxInventory.setObjectName(_fromUtf8(\"cmboxInventory\"))\n self.horizontalLayout_6.addWidget(self.cmboxInventory)\n self.leditInventory = QtGui.QLineEdit(self.tab_inventory)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.leditInventory.sizePolicy().hasHeightForWidth())\n self.leditInventory.setSizePolicy(sizePolicy)\n self.leditInventory.setMinimumSize(QtCore.QSize(40, 0))\n self.leditInventory.setObjectName(_fromUtf8(\"leditInventory\"))\n self.horizontalLayout_6.addWidget(self.leditInventory)\n self.verticalLayout_6.addLayout(self.horizontalLayout_6)\n self.tblInventory = QtGui.QTableView(self.tab_inventory)\n self.tblInventory.setEditTriggers(QtGui.QAbstractItemView.NoEditTriggers)\n self.tblInventory.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblInventory.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblInventory.setSortingEnabled(True)\n self.tblInventory.setCornerButtonEnabled(False)\n self.tblInventory.setObjectName(_fromUtf8(\"tblInventory\"))\n self.tblInventory.horizontalHeader().setStretchLastSection(True)\n self.verticalLayout_6.addWidget(self.tblInventory)\n icon4 = QtGui.QIcon()\n icon4.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/paper-box-icon-63457.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.tabWidget.addTab(self.tab_inventory, icon4, _fromUtf8(\"\"))\n self.tab_purchases = QtGui.QWidget()\n self.tab_purchases.setObjectName(_fromUtf8(\"tab_purchases\"))\n self.verticalLayout = QtGui.QVBoxLayout(self.tab_purchases)\n self.verticalLayout.setMargin(0)\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.horizontalLayout_2 = QtGui.QHBoxLayout()\n self.horizontalLayout_2.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_2.setObjectName(_fromUtf8(\"horizontalLayout_2\"))\n self.btnRemovePurchase = QtGui.QPushButton(self.tab_purchases)\n self.btnRemovePurchase.setText(_fromUtf8(\"\"))\n icon5 = QtGui.QIcon()\n icon5.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/Remove.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnRemovePurchase.setIcon(icon5)\n self.btnRemovePurchase.setIconSize(QtCore.QSize(20, 20))\n self.btnRemovePurchase.setObjectName(_fromUtf8(\"btnRemovePurchase\"))\n self.horizontalLayout_2.addWidget(self.btnRemovePurchase)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_2.addItem(spacerItem1)\n self.cmboxPurchases = QtGui.QComboBox(self.tab_purchases)\n self.cmboxPurchases.setObjectName(_fromUtf8(\"cmboxPurchases\"))\n self.horizontalLayout_2.addWidget(self.cmboxPurchases)\n self.leditPurchases = QtGui.QLineEdit(self.tab_purchases)\n self.leditPurchases.setObjectName(_fromUtf8(\"leditPurchases\"))\n self.horizontalLayout_2.addWidget(self.leditPurchases)\n self.verticalLayout.addLayout(self.horizontalLayout_2)\n self.tblPurchases = QtGui.QTableView(self.tab_purchases)\n self.tblPurchases.setAlternatingRowColors(True)\n self.tblPurchases.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblPurchases.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblPurchases.setVerticalScrollMode(QtGui.QAbstractItemView.ScrollPerPixel)\n self.tblPurchases.setSortingEnabled(True)\n self.tblPurchases.setWordWrap(True)\n self.tblPurchases.setCornerButtonEnabled(False)\n self.tblPurchases.setObjectName(_fromUtf8(\"tblPurchases\"))\n self.tblPurchases.horizontalHeader().setStretchLastSection(True)\n self.tblPurchases.verticalHeader().setVisible(False)\n self.tblPurchases.verticalHeader().setSortIndicatorShown(False)\n self.verticalLayout.addWidget(self.tblPurchases)\n icon6 = QtGui.QIcon()\n icon6.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/cart-arrow-down-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.tabWidget.addTab(self.tab_purchases, icon6, _fromUtf8(\"\"))\n self.tab_sales = QtGui.QWidget()\n self.tab_sales.setObjectName(_fromUtf8(\"tab_sales\"))\n self.verticalLayout_4 = QtGui.QVBoxLayout(self.tab_sales)\n self.verticalLayout_4.setMargin(0)\n self.verticalLayout_4.setObjectName(_fromUtf8(\"verticalLayout_4\"))\n self.horizontalLayout_3 = QtGui.QHBoxLayout()\n self.horizontalLayout_3.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_3.setObjectName(_fromUtf8(\"horizontalLayout_3\"))\n self.btnRemoveSale = QtGui.QPushButton(self.tab_sales)\n self.btnRemoveSale.setText(_fromUtf8(\"\"))\n icon7 = QtGui.QIcon()\n icon7.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/undo-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnRemoveSale.setIcon(icon7)\n self.btnRemoveSale.setIconSize(QtCore.QSize(20, 20))\n self.btnRemoveSale.setObjectName(_fromUtf8(\"btnRemoveSale\"))\n self.horizontalLayout_3.addWidget(self.btnRemoveSale)\n self.btnSettle = QtGui.QPushButton(self.tab_sales)\n self.btnSettle.setText(_fromUtf8(\"\"))\n icon8 = QtGui.QIcon()\n icon8.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/payment-256.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnSettle.setIcon(icon8)\n self.btnSettle.setIconSize(QtCore.QSize(20, 20))\n self.btnSettle.setObjectName(_fromUtf8(\"btnSettle\"))\n self.horizontalLayout_3.addWidget(self.btnSettle)\n spacerItem2 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_3.addItem(spacerItem2)\n self.cmboxSales = QtGui.QComboBox(self.tab_sales)\n self.cmboxSales.setObjectName(_fromUtf8(\"cmboxSales\"))\n self.horizontalLayout_3.addWidget(self.cmboxSales)\n self.leditSales = QtGui.QLineEdit(self.tab_sales)\n self.leditSales.setObjectName(_fromUtf8(\"leditSales\"))\n self.horizontalLayout_3.addWidget(self.leditSales)\n self.verticalLayout_4.addLayout(self.horizontalLayout_3)\n self.tblSales = QtGui.QTableView(self.tab_sales)\n self.tblSales.setEditTriggers(QtGui.QAbstractItemView.NoEditTriggers)\n self.tblSales.setAlternatingRowColors(True)\n self.tblSales.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblSales.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblSales.setSortingEnabled(True)\n self.tblSales.setCornerButtonEnabled(False)\n self.tblSales.setObjectName(_fromUtf8(\"tblSales\"))\n self.tblSales.horizontalHeader().setStretchLastSection(True)\n self.tblSales.verticalHeader().setVisible(False)\n self.verticalLayout_4.addWidget(self.tblSales)\n icon9 = QtGui.QIcon()\n icon9.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/cashier-icon-png-8.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.tabWidget.addTab(self.tab_sales, icon9, _fromUtf8(\"\"))\n self.tab_clients = QtGui.QWidget()\n self.tab_clients.setObjectName(_fromUtf8(\"tab_clients\"))\n self.verticalLayout_5 = QtGui.QVBoxLayout(self.tab_clients)\n self.verticalLayout_5.setMargin(0)\n self.verticalLayout_5.setObjectName(_fromUtf8(\"verticalLayout_5\"))\n self.horizontalLayout_4 = QtGui.QHBoxLayout()\n self.horizontalLayout_4.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_4.setObjectName(_fromUtf8(\"horizontalLayout_4\"))\n self.btnRemoveClient = QtGui.QPushButton(self.tab_clients)\n self.btnRemoveClient.setText(_fromUtf8(\"\"))\n self.btnRemoveClient.setIcon(icon5)\n self.btnRemoveClient.setIconSize(QtCore.QSize(20, 20))\n self.btnRemoveClient.setObjectName(_fromUtf8(\"btnRemoveClient\"))\n self.horizontalLayout_4.addWidget(self.btnRemoveClient)\n self.btnModifyClient = QtGui.QPushButton(self.tab_clients)\n self.btnModifyClient.setText(_fromUtf8(\"\"))\n icon10 = QtGui.QIcon()\n icon10.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/edit_user_male_write_pencil_man-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.btnModifyClient.setIcon(icon10)\n self.btnModifyClient.setIconSize(QtCore.QSize(20, 20))\n self.btnModifyClient.setObjectName(_fromUtf8(\"btnModifyClient\"))\n self.horizontalLayout_4.addWidget(self.btnModifyClient)\n spacerItem3 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_4.addItem(spacerItem3)\n self.cmboxClients = QtGui.QComboBox(self.tab_clients)\n self.cmboxClients.setObjectName(_fromUtf8(\"cmboxClients\"))\n self.horizontalLayout_4.addWidget(self.cmboxClients)\n self.leditClients = QtGui.QLineEdit(self.tab_clients)\n self.leditClients.setObjectName(_fromUtf8(\"leditClients\"))\n self.horizontalLayout_4.addWidget(self.leditClients)\n self.verticalLayout_5.addLayout(self.horizontalLayout_4)\n self.tblClients = QtGui.QTableView(self.tab_clients)\n self.tblClients.setAlternatingRowColors(True)\n self.tblClients.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblClients.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblClients.setSortingEnabled(True)\n self.tblClients.setCornerButtonEnabled(False)\n self.tblClients.setObjectName(_fromUtf8(\"tblClients\"))\n self.tblClients.horizontalHeader().setStretchLastSection(True)\n self.tblClients.verticalHeader().setVisible(False)\n self.verticalLayout_5.addWidget(self.tblClients)\n icon11 = QtGui.QIcon()\n icon11.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/15656.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.tabWidget.addTab(self.tab_clients, icon11, _fromUtf8(\"\"))\n self.gridLayout.addWidget(self.tabWidget, 0, 1, 1, 1)\n MainWindow.setCentralWidget(self.centralwidget)\n self.toolBar = QtGui.QToolBar(MainWindow)\n self.toolBar.setLayoutDirection(QtCore.Qt.LeftToRight)\n self.toolBar.setLocale(QtCore.QLocale(QtCore.QLocale.English, QtCore.QLocale.UnitedStates))\n self.toolBar.setMovable(True)\n self.toolBar.setIconSize(QtCore.QSize(30, 30))\n self.toolBar.setToolButtonStyle(QtCore.Qt.ToolButtonTextUnderIcon)\n self.toolBar.setFloatable(False)\n self.toolBar.setObjectName(_fromUtf8(\"toolBar\"))\n MainWindow.addToolBar(QtCore.Qt.LeftToolBarArea, self.toolBar)\n self.actionPurchase = QtGui.QAction(MainWindow)\n icon12 = QtGui.QIcon()\n icon12.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/plus-icon-0.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionPurchase.setIcon(icon12)\n self.actionPurchase.setObjectName(_fromUtf8(\"actionPurchase\"))\n self.actionSale = QtGui.QAction(MainWindow)\n icon13 = QtGui.QIcon()\n icon13.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/product_basket-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionSale.setIcon(icon13)\n self.actionSale.setObjectName(_fromUtf8(\"actionSale\"))\n self.actionClient = QtGui.QAction(MainWindow)\n icon14 = QtGui.QIcon()\n icon14.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/manager-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionClient.setIcon(icon14)\n self.actionClient.setObjectName(_fromUtf8(\"actionClient\"))\n self.actionRefresh = QtGui.QAction(MainWindow)\n icon15 = QtGui.QIcon()\n icon15.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/Oxygen-Icons.org-Oxygen-Actions-view-refresh.ico\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n self.actionRefresh.setIcon(icon15)\n self.actionRefresh.setObjectName(_fromUtf8(\"actionRefresh\"))\n self.toolBar.addAction(self.actionRefresh)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionSale)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionPurchase)\n self.toolBar.addSeparator()\n self.toolBar.addAction(self.actionClient)\n self.toolBar.addSeparator()\n\n self.retranslateUi(MainWindow)\n self.tabWidget.setCurrentIndex(0)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"Libra v1.0.0\", None))\n self.groupBox.setTitle(_translate(\"MainWindow\", \"Period\", None))\n self.dateAnnual.setDisplayFormat(_translate(\"MainWindow\", \"yyyy\", None))\n self.radioMonthly.setText(_translate(\"MainWindow\", \"Monthly\", None))\n self.dateMonthly.setDisplayFormat(_translate(\"MainWindow\", \"MMM/yyyy\", None))\n self.radioAnnual.setText(_translate(\"MainWindow\", \"Annual\", None))\n self.radioHistoric.setText(_translate(\"MainWindow\", \"Historic\", None))\n self.radioDaily.setText(_translate(\"MainWindow\", \"Daily\", None))\n self.groupBox_2.setTitle(_translate(\"MainWindow\", \"Purchases\", None))\n self.groupBox_3.setTitle(_translate(\"MainWindow\", \"Sales\", None))\n __sortingEnabled = self.tblBalance.isSortingEnabled()\n self.tblBalance.setSortingEnabled(False)\n item = self.tblBalance.item(0, 0)\n item.setText(_translate(\"MainWindow\", \"Sales (paid)\", None))\n item = self.tblBalance.item(0, 2)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(1, 0)\n item.setText(_translate(\"MainWindow\", \"Sales (credit)\", None))\n item = self.tblBalance.item(1, 2)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(2, 0)\n item.setText(_translate(\"MainWindow\", \"Total revenue\", None))\n item = self.tblBalance.item(2, 2)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(3, 0)\n item.setText(_translate(\"MainWindow\", \"Costs\", None))\n item = self.tblBalance.item(3, 1)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(4, 0)\n item.setText(_translate(\"MainWindow\", \"Taxes\", None))\n item = self.tblBalance.item(4, 1)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(5, 0)\n item.setText(_translate(\"MainWindow\", \"Profit\", None))\n item = self.tblBalance.item(5, 2)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n item = self.tblBalance.item(6, 0)\n item.setText(_translate(\"MainWindow\", \"Profit (margin)\", None))\n item = self.tblBalance.item(6, 2)\n item.setText(_translate(\"MainWindow\", \"0.00\", None))\n self.tblBalance.setSortingEnabled(__sortingEnabled)\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_balance), _translate(\"MainWindow\", \"Balance\", None))\n self.btnModifyInventory.setToolTip(_translate(\"MainWindow\", \"Modify inventory\", None))\n self.btnMove.setToolTip(_translate(\"MainWindow\", \"Move Item\", None))\n self.leditInventory.setPlaceholderText(_translate(\"MainWindow\", \"Search...\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_inventory), _translate(\"MainWindow\", \"Inventory\", None))\n self.btnRemovePurchase.setToolTip(_translate(\"MainWindow\", \"Remove purchase\", None))\n self.leditPurchases.setPlaceholderText(_translate(\"MainWindow\", \"Search...\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_purchases), _translate(\"MainWindow\", \"Purchases\", None))\n self.btnRemoveSale.setToolTip(_translate(\"MainWindow\", \"Reverse sale\", None))\n self.btnSettle.setToolTip(_translate(\"MainWindow\", \"Settle debt\", None))\n self.leditSales.setPlaceholderText(_translate(\"MainWindow\", \"Search...\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_sales), _translate(\"MainWindow\", \"Sales\", None))\n self.btnRemoveClient.setToolTip(_translate(\"MainWindow\", \"Remove client\", None))\n self.btnModifyClient.setToolTip(_translate(\"MainWindow\", \"Modify Client\", None))\n self.leditClients.setPlaceholderText(_translate(\"MainWindow\", \"Search...\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_clients), _translate(\"MainWindow\", \"Clients\", None))\n self.toolBar.setWindowTitle(_translate(\"MainWindow\", \"toolBar\", None))\n self.actionPurchase.setText(_translate(\"MainWindow\", \"Purchase\", None))\n self.actionSale.setText(_translate(\"MainWindow\", \"Sale\", None))\n self.actionClient.setText(_translate(\"MainWindow\", \"Client\", None))\n self.actionRefresh.setText(_translate(\"MainWindow\", \"Refresh\", None))\n\nimport res_rc\n"
},
{
"alpha_fraction": 0.5665265917778015,
"alphanum_fraction": 0.5686274766921997,
"avg_line_length": 22.620689392089844,
"blob_id": "c79744cfc5731bb02f966c8714c52eaaac316d5b",
"content_id": "d31ffb31ea365693e2ecc2b33a63520f3bf93f8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1428,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 58,
"path": "/main_login.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "\r\nimport sys\r\nimport sqlite3\r\n\r\nfrom PyQt4 import QtCore, QtGui, QtSql\r\n\r\nfrom gui_login import Ui_Dialog as LoginGui\r\nimport master_admin\r\n\r\nimport mec_login\r\nfrom mec_login import check_login # tengo que importarlo\r\n\r\n\r\nclass Login(QtGui.QDialog, LoginGui):\r\n\r\n def __init__(self, parent=None):\r\n\r\n QtGui.QDialog.__init__(self, parent)\r\n self.setupUi(self)\r\n \r\n\r\n ### functionality ###\r\n self.btnLogin.clicked.connect(self.start)\r\n\r\n ### database ###\r\n self.conn = sqlite3.connect(\".libra.db\")\r\n self.c = self.conn.cursor()\r\n mec_login.create_login_table(self.c, self.conn)\r\n self.show()\r\n\r\n def start(self):\r\n\r\n usuario = self.leditUser.text()\r\n password = self.leditPassword.text()\r\n\r\n if check_login(self.c, usuario, password):\r\n print(\"success\")\r\n self.accept()\r\n\r\n else:\r\n self.leditUser.clear()\r\n self.leditPassword.clear()\r\n QtGui.QMessageBox.warning(self, 'Error', 'Incorrect username or password')\r\n\r\n\r\n def closeEvent(self, e):\r\n print(\"closing\")\r\n self.c.close()\r\n self.conn.close()\r\n e.accept()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n app = QtGui.QApplication(sys.argv)\r\n login = Login()\r\n if login.exec_() == QtGui.QDialog.Accepted:\r\n mainwindow = master_admin.Inventory()\r\n mainwindow.show()\r\n sys.exit(app.exec_())"
},
{
"alpha_fraction": 0.5277260541915894,
"alphanum_fraction": 0.5384952425956726,
"avg_line_length": 36.990291595458984,
"blob_id": "1d1aa49e257478df730a045f3b46116c3a79c5d2",
"content_id": "2079ec4f5040fbf0314ac2c5fdaa994f7ec6d765",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27393,
"license_type": "no_license",
"max_line_length": 300,
"num_lines": 721,
"path": "/mec_inventory.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\n Author:Christopher Holder\n\"\"\"\ndef create_tables(connection,cursor):\n \"\"\"\n This function creates the neccessary tables in the database.\n \"\"\"\n \n cursor.execute(\"CREATE TABLE IF NOT EXISTS OrdinalNumber(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,num TEXT NOT NULL)\")\n \n cursor.execute('CREATE TABLE IF NOT EXISTS OrdinalNumberS(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, num TEXT NOT NULL)')\n \n cursor.execute(\"\"\"CREATE TABLE IF NOT EXISTS Inventory(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,code TEXT NOT NULL,name TEXT NOT NULL,avail INTEGER NOT NULL,costUni REAL NOT NULL,priceUniSug REAL NOT NULL,groupx TEXT NOT NULL,category TEXT,stockmin INTEGER,stockmax INTEGER)\"\"\")\n \n cursor.execute(\"\"\"CREATE TABLE IF NOT EXISTS Entries(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,dat TEXT,trans TEXT,code TEXT NOT NULL,name TEXT NOT NULL,quantity INTEGER NOT NULL,provider TEXT ,costUni REAL NOT NULL,costItems REAL NOT NULL,groupx TEXT NOT NULL, category TEXT)\"\"\") \n \n cursor.execute(\"\"\"CREATE TABLE IF NOT EXISTS Outs(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,dat TEXT,trans TEXT,code TEXT NOT NULL,name TEXT NOT NULL,quantity INTEGER NOT NULL,groupx TEXT NOT NULL,priceUni REAL,priceItems REAL,tax REAL,revenue REAL,winnings REAL,payment TEXT,client TEXT)\"\"\")\n \n cursor.execute('CREATE TABLE IF NOT EXISTS Clients(ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,identification TEXT,name TEXT,mail TEXT,num TEXT,cel TEXT,fax TEXT ,direction TEXT,bought INTEGER,money_invested REAL,paid REAL,debt REAL)')\n\n add_client(connection,cursor,'Misc','','','','','','')\n connection.commit()\n return True\n \ndef add_item_entry(connection,cursor,code = '#',name = \"\",quantity = 0,provider = \"\",costUni = 0.00,priceUniSug = 100 ,groupx = '',category = \"\",stockmin = \"\",stockmax = \"\"):\n \"\"\"\n This function adds entries to the table Inventory and Entries.\n \"\"\"\n cursor.execute('SELECT code,groupx FROM Inventory WHERE code=? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n if data == None:\n transnum = ordinal_generator(connection,cursor)\n avail = quantity\n costItems = costUni * quantity\n costItems = round(costItems,2)\n priceUniSug = round(priceUniSug,2)\n costUni = round(costUni,2)\n b = (code,name,avail,costUni,priceUniSug,groupx,category,stockmin,stockmax)\n c = (transnum,code,name,quantity,provider,costUni,costItems,groupx,category)\n cursor.execute(\"INSERT INTO Inventory (code,name,avail,costUni,priceUniSug,groupx,category,stockmin,stockmax) VALUES(?,?,?,?,?,?,?,?,?)\",b)\n cursor.execute(\"INSERT INTO Entries (dat,trans,code,name,quantity,provider,costUni,costItems,groupx,category) VALUES(date('now'),?,?,?,?,?,?,?,?,?)\",c)\n connection.commit()\n else: \n transnum = ordinal_generator(connection,cursor)\n avail = quantity\n costItems = costUni * quantity\n costItems = round(costItems,2)\n c = (transnum,code,name,quantity,provider,round(costUni,2),costItems,groupx,category)\n #-------------------------------------------------------------------------------------------------------\n increase_stock(cursor,code,groupx,quantity)\n update_all(cursor,code,groupx,costUni,priceUniSug,name,category) \n #-------------------------------------------------------------------------------------------------------\n cursor.execute(\"INSERT INTO Entries (dat,trans,code,name,quantity,provider,costUni,costItems,groupx,category) VALUES(date('now'),?,?,?,?,?,?,?,?,?)\",c)\n connection.commit()\n return True\n\ndef add_item_exit_fixed(connection,cursor,code = \"#\",quantity = 1,tax = 0.07,pricef = 10.00,discount = 0,payment = 'CRE',client = '',trans='',groupx = ''):\n \n a =(code,groupx)\n cursor.execute('SELECT name FROM Inventory WHERE code = ? AND groupx = ?',a)\n data0 = cursor.fetchone()\n name = str(data0[0])\n decrease_stock(cursor,code,groupx,quantity)\n priceUni = pricef\n taxTot = tax * priceUni * quantity\n taxTot = round(taxTot,2)\n priceItems = priceUni * (tax + 1) * quantity\n if (discount == 0):\n priceItems = round(priceItems,2)\n else:\n discount = priceItems * discount\n priceItems = priceItems - discount\n priceItems = round(priceItems,2)\n cursor.execute('SELECT costUni FROM Inventory WHERE code = ? AND groupx = ?',a)\n data2 = cursor.fetchone()\n costItems = (float(data2[0]))* quantity\n costItems = round(costItems,2)\n revenue = priceItems - costItems \n revenue = round(revenue,2)\n winnings = revenue - taxTot\n winnings = round(winnings,2)\n\n auto_del_0(connection,cursor)\n \n b = (trans,code,name,quantity,groupx,priceUni,priceItems,taxTot,revenue,winnings,payment,client)\n cursor.execute(\"INSERT INTO Outs (dat,trans,code,name,quantity,groupx,priceUni,priceItems,tax,revenue,winnings,payment,client) VALUES(date('now'),?,?,?,?,?,?,?,?,?,?,?,?)\",b)\n update_client_info(connection,cursor,client)\n connection.commit()\n #-------------------------------------------------------------------------------------------------------\n return True\n#-------------------------------------------------------------------------------------------------------\ndef modify(connection,cursor,code,groupx,avail,priceUni,category,smin,smax,costUni, name):\n if (groupx == 'Global'):\n cursor.execute('UPDATE Inventory SET name = ?,priceUniSug = ?,category = ?, stockmin = ?,stockmax = ? ,costUni = ? WHERE code = ?',(name,priceUni,category,smin,smax,costUni,code))\n else:\n cursor.execute('UPDATE Inventory SET name = ?,avail = ?,priceUniSug = ?,category = ?, stockmin = ?,stockmax = ? ,costUni = ? WHERE code = ? AND groupx = ?',(name,avail,priceUni,category,smin,smax,costUni,code,groupx))\n connection.commit()\n\ndef modify_client(connection,cursor,name,identification,mail,num,cel,fax,direction):\n sel = (identification,mail,num,cel,fax,direction,name)\n cursor.execute('UPDATE Clients SET identification = ?,mail = ?,num = ?,cel = ?,fax = ?,direction = ? WHERE name = ?',sel)\n connection.commit()\n \n \ndef move(connection,cursor,code,groupx1,groupx2,quantity):\n cursor.execute('SELECT code,name,avail,costUni,priceUniSug,groupx,category,stockmin,stockmax FROM Inventory WHERE code = ? and groupx = ?',(code,groupx1))\n data = cursor.fetchone()\n decrease_stock(cursor,code,groupx1,quantity)\n auto_del_0(connection,cursor)\n cursor.execute('SELECT name FROM Inventory WHERE code = ? AND groupx = ?' , (code,groupx2))\n data2 = cursor.fetchone()\n if (data2 == None):\n c = (data[0],data[1],quantity,data[3],data[4],groupx2,data[6],data[7],data[8])\n cursor.execute('INSERT INTO Inventory (code,name,avail,costUni,priceUniSug,groupx,category,stockmin,stockmax) VALUES(?,?,?,?,?,?,?,?,?)',c)\n else:\n increase_stock(cursor,code,groupx2,quantity)\n connection.commit()\n\ndef shopping_cart(connection,cursor,lista):\n \"\"\"\n This function does multiple sales.lista is a list of lists.\n The elements should contain the following arguments. : [code,quantity,tax,pricef,discount,payment,client,groupx]\n \"\"\"\n counter = 0\n results =[]\n failed = {}\n for e in lista:\n a = sale_valid2(cursor,e[0],e[1],e[7])\n results.append(a)\n for el in range(len(results)):\n if (results[el] != 0):\n failed.setdefault((el+1),results[el])\n \n if (len(failed) > 0):\n print(failed)\n return failed\n t = ordinal_generator2(connection,cursor) \n for e in lista:\n counter += 1\n transa = t + (str(counter).zfill(3))\n add_item_exit_fixed(connection,cursor,e[0],e[1],e[2],e[3],e[4],e[5],e[6],transa,e[7])\n \n return True\n \n \ndef sale_valid(cursor,code,client_name,quantity,groupx):\n \"\"\"\n Checks If client ,quantity, or code exists.\n 0 = Sucessful\n 1 = does not exists. 2 = reduces below existing units ,\n 3 = client does not exist\n \n \"\"\" \n l = []\n a = (code,groupx)\n b = (client_name,)\n cursor.execute('SELECT code,avail FROM Inventory WHERE code = ? AND groupx = ?',a)\n data0 = cursor.fetchone()\n if (data0 == None):\n l.append(1)\n if (data0 != None):\n if (data0[1] < quantity):\n l.append(2)\n \n \n cursor.execute('SELECT name FROM Clients WHERE name = ?',b)\n data2 = cursor.fetchone()\n if (data2 == None):\n l.append(3)\n \n if (len(l) == 0):\n l = 0\n \n return l\n\ndef sale_valid2(cursor,code,quantity,groupx):\n \"\"\"\n Checks If client ,quantity, or code exists.\n 0 = Sucessful\n 1 = does not exists. 2 = reduces below existing units ,\n \n \"\"\" \n l = []\n a = (code,groupx)\n cursor.execute('SELECT code,avail FROM Inventory WHERE code = ? AND groupx = ?',a)\n data0 = cursor.fetchone()\n if (data0 == None):\n l.append(1)\n if (data0 != None):\n if (data0[1] < quantity):\n l.append(2)\n \n if (len(l) == 0):\n l = 0\n \n return l\n\ndef query_add(cursor,code,groupx):\n cursor.execute('SELECT name,costUni,priceUniSug,category,stockmin,stockmax FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n if (data == None):\n return False\n return data\n\ndef query_sale(cursor,code,groupx):\n \"\"\"\n Returns list with [name,priceUniSug,costUni]\n \"\"\"\n cursor.execute('SELECT name,priceUniSug,costUni FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n if (data == None):\n print('No name with that code')\n return False\n\n return data \n\ndef query_modify(cursor,code,groupx):\n \"\"\"\n Returns [avail,priceUniSug,costUni,category,stockmin,stockmax,name]\n \"\"\"\n cursor.execute('SELECT avail,priceUniSug,costUni,category,stockmin,stockmax, name FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n return data\n\ndef query_client(cursor,name):\n \"\"\"\n Returns [identification,mail,num,cel,fax,direction,bought,money_invested,paid,debt]\n \"\"\"\n cursor.execute('SELECT identification,mail,num,cel,fax,direction FROM Clients WHERE name = ?',(name,))\n data = cursor.fetchone()\n return data\n\n#-------------------------------------------------------------------------------------------------------\n \ndef add_client(connection,cursor,identification,name,mail,num,cel,fax,direction):\n \"\"\"\n Adds client to client table.\n Returns False if the name has been used before.\n \"\"\"\n bought = 0\n money_invested = 0.0\n paid = 0.0\n debt = 0.0\n i = (name,)\n cursor.execute('SELECT name FROM Clients WHERE name = ?',i)\n data = cursor.fetchone()\n if (data != None):\n print('Name already used.')\n return False\n t = (identification,name,mail,num,cel,fax,direction,bought,money_invested,paid,debt)\n cursor.execute(\"INSERT INTO Clients (identification,name,mail,num,cel,fax,direction,bought,money_invested,paid,debt) VALUES (?,?,?,?,?,?,?,?,?,?,?)\",t)\n connection.commit()\n return True\n \n \ndef update_client_info(connection,cursor,user):\n\n a = (user,)\n money = []\n articles = []\n cursor.execute('SELECT priceItems,quantity FROM Outs WHERE client = ? ',a)\n data2 = cursor.fetchall()\n if (data2 == None):\n return False\n for row2 in data2:\n money.append(row2[0])\n for row2 in data2:\n articles.append(row2[1])\n debit = []\n credit = []\n cursor.execute(\"SELECT priceItems FROM Outs WHERE client = ? AND payment = 'DEB'\",a)\n data4 = cursor.fetchall()\n for row4 in data4:\n debit.append(row4[0])\n \n cursor.execute(\"SELECT priceItems FROM Outs WHERE client = ? AND payment = 'CRE'\",a)\n data5 = cursor.fetchall()\n for row5 in data5:\n credit.append(row5[0])\n \n money = sum(money)\n articles = sum(articles)\n debit = sum(debit)\n credit =sum(credit)\n \n cursor.execute('UPDATE Clients SET bought = ?,money_invested = ?,paid = ?,debt = ? WHERE name = ?',(articles,money,debit,credit,user))\n\n connection.commit()\n \n\ndef del_client_id(connection,cursor,identification):\n cursor.execute('DELETE FROM Clients WHERE identification = ?',(identification,))\n connection.commit()\n return True\n\n\ndef del_client_name(connection,cursor,name):\n cursor.execute('DELETE FROM Clients WHERE name = ?',(name,))\n connection.commit()\n return True\n \n#-------------------------------------------------------------------------------------------------------\ndef calc_bal_his(cursor):\n \"\"\"\n CalcuLates balances of all exits and entries ever and adds them to the historic balance db.\n \"\"\"\n t = []\n cursor.execute('SELECT costItems FROM Entries')\n data = cursor.fetchall()\n for row0 in data:\n t.append(row0[0])\n costTot = sum(t)\n\n cursor.execute('SELECT priceItems,revenue,tax,winnings FROM Outs')\n query = cursor.fetchall()\n \n #-------------------------------------------------------------------------------------------------------\n\n p = []\n for row2 in query:\n p.append(row2[0])\n priceTot = sum(p)\n #-------------------------------------------------------------------------------------------------------\n g = []\n for row3 in query:\n g.append(row3[1])\n revenueTot = sum(g)\n #-------------------------------------------------------------------------------------------------------\n i = []\n for row4 in query:\n i.append(row4[2])\n taxTot = sum(i)\n #-------------------------------------------------------------------------------------------------------\n x = []\n for row5 in query:\n x.append(row5[3])\n winningsTot = sum(x)\n #-------------------------------------------------------------------------------------------------------\n cd = calc_deb(cursor)\n cc = calc_cre(cursor) \n\n return [costTot,priceTot,cd,cc,round((priceTot - costTot),2),taxTot,round((priceTot - costTot - taxTot),2)]\n \ndef calc_bal_mes(cursor,year,month):\n\n if (len(year) != 4) or (int(year) < 2016) or (int(year)> 3000) or (isinstance(year,float)) or (len(month) != 2) or (isinstance(month,float)) or (int(month)< 0) or (int(month)>12) :\n print('Bad date')\n return False\n date = year+'-'+ month\n entries = []\n\n #-------------------------------------------------------------------------------------------------------\n cursor.execute('SELECT dat,costItems FROM Entries')\n data = cursor.fetchall()\n for row in data:\n if (date in row[0]):\n entries.append(row[1])\n costTot = sum(entries)\n\n cursor.execute('SELECT dat,priceItems,revenue,tax,winnings FROM Outs ')\n query = cursor.fetchall()\n #-------------------------------------------------------------------------------------------------------\n p = []\n for e in query:\n if (date in e[0]):\n p.append(e[1])\n priceTot = sum(p)\n #-------------------------------------------------------------------------------------------------------\n g = []\n for d in query:\n if (date in d[0]):\n g.append(d[2])\n revenueTot = sum(g)\n #-------------------------------------------------------------------------------------------------------\n i = []\n for elem in query:\n if (date in elem[0]):\n i.append(elem[3])\n taxTot = sum(i)\n #-------------------------------------------------------------------------------------------------------\n x = []\n for al in query:\n if(date in al[0]):\n x.append(al[4])\n winningsTot = sum(x)\n #-------------------------------------------------------------------------------------------------------\n cd = calc_deb(cursor,date)\n cc = calc_cre(cursor,date)\n \n return [costTot,priceTot,cd,cc,round((priceTot - costTot),2),taxTot,round((priceTot - costTot - taxTot),2)]\n \ndef calc_bal_year(cursor,year):\n\n if (len(year) != 4) or (int(year) < 2016) or (int(year)> 3000) or (isinstance(year,float)) :\n print('Not proper date.')\n return False\n date = year \n entries = []\n #-------------------------------------------------------------------------------------------------------\n cursor.execute('SELECT dat,costItems FROM Entries')\n data = cursor.fetchall()\n for row in data:\n if (date in row[0]):\n entries.append(row[1])\n costTot = sum(entries)\n\n cursor.execute('SELECT dat,priceItems,revenue,tax,winnings FROM Outs ')\n query = cursor.fetchall()\n #-------------------------------------------------------------------------------------------------------\n p = []\n for e in query:\n if (date in e[0]):\n p.append(e[1])\n priceTot = sum(p)\n #-------------------------------------------------------------------------------------------------------\n g = []\n for d in query:\n if (date in d[0]):\n g.append(d[2])\n revenueTot = sum(g)\n #-------------------------------------------------------------------------------------------------------\n i = []\n for elem in query:\n if (date in elem[0]):\n i.append(elem[3])\n taxTot = sum(i)\n #-------------------------------------------------------------------------------------------------------\n x = []\n for al in query:\n if(date in al[0]):\n x.append(al[4])\n winningsTot = sum(x)\n #-------------------------------------------------------------------------------------------------------\n cd = calc_deb(cursor,date)\n cc = calc_cre(cursor,date)\n \n return [costTot,priceTot,cd,cc,round((priceTot - costTot),2),taxTot,round((priceTot - costTot - taxTot),2)]\n \n\n\ndef calc_bal_day(cursor,year,month,day):\n\n if (len(year) != 4) or (int(year) < 2016) or (int(year)> 3000) or (isinstance(year,float)) or (len(month) != 2) or (isinstance(month,float)) or (int(month)< 0) or (int(month)>12) or (int(day) > 31) or (len(day) != 2):\n print('Bad date')\n return False\n date = year+'-'+ month + '-' + day\n \n entries = []\n cursor.execute('SELECT dat,costItems FROM Entries')\n data = cursor.fetchall()\n for row in data:\n if (date in row[0]):\n entries.append(row[1])\n costTot = sum(entries)\n\n cursor.execute('SELECT dat,priceItems,revenue,tax,winnings FROM Outs ')\n query = cursor.fetchall()\n #-------------------------------------------------------------------------------------------------------\n p = []\n for e in query:\n if (date in e[0]):\n p.append(e[1])\n priceTot = sum(p)\n #-------------------------------------------------------------------------------------------------------\n g = []\n for d in query:\n if (date in d[0]):\n g.append(d[2])\n revenueTot = sum(g)\n #-------------------------------------------------------------------------------------------------------\n i = []\n for elem in query:\n if (date in elem[0]):\n i.append(elem[3])\n taxTot = sum(i)\n #-------------------------------------------------------------------------------------------------------\n x = []\n for al in query:\n if(date in al[0]):\n x.append(al[4])\n winningsTot = sum(x)\n #-------------------------------------------------------------------------------------------------------\n cd = calc_deb(cursor,date)\n cc = calc_cre(cursor,date)\n\n \n return [costTot,priceTot,cd,cc,round((priceTot - costTot),2),taxTot,round((priceTot - costTot - taxTot),2)]\n#-------------------------------------------------------------------------------------------------------\ndef gen_query(cursor,table,column,stri,num):\n \"\"\"\n Returns a list with elements that contain the string.\n Returns empty list if it does find one.\n \"\"\"\n list1 = []\n list2 = []\n \n query = 'SELECT '+ str(column) +' FROM '+ str(table) \n cursor.execute(query)\n data = cursor.fetchall()\n if (data == None):\n return list1\n \n for row in data:\n list1.append(row[0])\n for e in list1:\n if (stri in e ):\n list2.append(e)\n \n while (len(list2) > num):\n list2.pop()\n \n print(list2)\n return list2\n \ndef paid(connection,cursor,trans):\n \"\"\"\n Marks an item as paid.\n \"\"\"\n t = (trans,)\n cursor.execute(\"UPDATE Outs SET payment = 'DEB' WHERE trans = ?\",(trans,))\n cursor.execute(\"SELECT client FROM Outs WHERE trans = ?\",(trans,))\n data = cursor.fetchone()\n update_client_info(connection,cursor,data[0])\n connection.commit()\n \ndef move_to_credit(connection,cursor,trans):\n \"\"\"\n Marks an item as not paid.\n \"\"\"\n cursor.execute(\"UPDATE Outs SET payment = 'CRE' WHERE trans = ?\",(trans,))\n cursor.execute(\"SELECT client FROM Outs WHERE trans = ?\",(trans,))\n data = cursor.fetchone()\n update_client_info(connection,cursor,data[0])\n connection.commit()\n \ndef calc_deb(cursor, date = None):\n \"\"\"\n Calculates liquidity.\n \"\"\"\n deb = []\n if (date == None):\n cursor.execute(\"SELECT priceItems FROM Outs WHERE payment = 'DEB'\")\n data = cursor.fetchall()\n for e in data:\n deb.append(e[0])\n else: \n cursor.execute(\"SELECT priceItems,dat FROM Outs WHERE payment = 'DEB'\")\n data = cursor.fetchall()\n for e in data:\n if (date in e[1]):\n deb.append(e[0])\n deb = round(sum(deb),2)\n return deb\n\ndef calc_cre(cursor,date = None):\n \"\"\"\n Calculates money customers currently owe.\n \"\"\"\n cre = []\n if (date == None):\n cursor.execute(\"SELECT priceItems FROM Outs WHERE payment = 'CRE'\")\n data = cursor.fetchall()\n for e in data:\n cre.append(e[0])\n else: \n cursor.execute(\"SELECT priceItems,dat FROM Outs WHERE payment = 'CRE'\")\n data = cursor.fetchall()\n for e in data:\n if (date in e[1]):\n cre.append(e[0])\n cre = round(sum(cre),2)\n return cre\n \n#-------------------------------------------------------------------------------------------------------\n \ndef del_general(connection,cursor,trans):\n \"\"\"\n Generalizes use of delete function.\n Clients table delete not included.\n \"\"\"\n try:\n if(trans[0] == '1'):\n return del_item_entries(connection,cursor,trans)\n elif(trans[0] == '2'):\n return del_item_salidas(connection,cursor,trans)\n else:\n print('Unknown transaction number')\n return False\n \n except TypeError:\n print('Error in cell')\n return False\n\ndef del_item_entries(connection,cursor,trans):\n \"\"\"\n Deletes items from entries by transaction number.\n \"\"\"\n cursor.execute('DELETE FROM Entries WHERE trans = ?',(trans,))\n connection.commit()\n return True\ndef del_item_inventory(connection,cursor,code,groupx):\n \"\"\"\n Deletes items from inventory by code.\n \"\"\"\n cursor.execute('DELETE FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n connection.commit()\n return True\ndef del_item_salidas(connection,cursor,trans):\n \"\"\"\n Deletes items by transaction number.\n \"\"\"\n cursor.execute('SELECT quantity FROM Outs WHERE trans = ?',(trans,))\n data = cursor.fetchone()\n if (data == None):\n print('Transaction number not from an Out')\n return False\n cursor.execute('SELECT priceItems,client FROM Outs WHERE trans = ?',(trans,))\n p = cursor.fetchone()\n cursor.execute('SELECT money_invested FROM Clients WHERE name = ? ',(p[1],))\n d = cursor.fetchone()\n f = d[0]- p[0]\n cursor.execute('UPDATE Clients SET money_invested = ? WHERE name = ?',(f,p[1]))\n\n cursor.execute('SELECT code,groupx FROM Outs WHERE trans = ?',(trans,))\n data2 = cursor.fetchone()\n #-------------------------------------------------------------------------------------------------------\n g = (data2[0],data2[1])\n cursor.execute('SELECT avail FROM Inventory WHERE code = ? AND groupx = ?',g)\n data3 = cursor.fetchone()\n avail = data3[0] + data[0]\n b =(avail,data2[0],data2[1])\n cursor.execute('UPDATE Inventory SET avail = ? WHERE code = ? AND groupx = ?',b)\n #-------------------------------------------------------------------------------------------------------\n cursor.execute('DELETE FROM Outs WHERE trans = ?',(trans,))\n\n\n connection.commit()\n return True\n\ndef auto_del_0(connection,cursor):\n cursor.execute('SELECT avail FROM Inventory WHERE avail = 0')\n data4 = cursor.fetchone()\n if data4 != None:\n cursor.execute('DELETE FROM Inventory WHERE avail = 0')\n \ndef unique(cursor,column,table,key_column = \"\",key = \"\"):\n if key_column == \"\":\n cursor.execute(\"SELECT DISTINCT \"+ column + \" FROM \" + table)\n else:\n cursor.execute(\"SELECT DISTINCT \" + column + \" FROM \" + table + \" WHERE \" + key_column + \" = ?\",(key,))\n unique_values = []\n data = cursor.fetchall()\n if data != None:\n for line in data:\n unique_values.append(line[0])\n return unique_values\n#-------------------------------------------------------------------------------------------------------\n \ndef ordinal_generator(connection,cursor):\n \"\"\"\n Generates string numbers starting with 1 and makes sure to never\n have used them before.It also adds them complementary 0's until it \n has a minimum length of 8 characters.\n \"\"\"\n exists = False\n trans = \"\"\n\n cursor.execute('SELECT MAX(ID) FROM OrdinalNumber')\n index = cursor.fetchone()\n if (index[0] == None):\n trans = '00000000'\n else:\n index = str(index[0])\n trans = index.zfill(8)\n d = ('a',)\n cursor.execute('INSERT INTO OrdinalNumber(num) VALUES (?)',d)\n connection.commit()\n return ('1' + trans)\n\ndef ordinal_generator2(connection,cursor):\n exists = False\n trans = \"\"\n\n cursor.execute('SELECT MAX(ID) FROM OrdinalNumberS')\n index = cursor.fetchone()\n if (index[0] == None):\n trans = '000000'\n else:\n index = str(index[0])\n trans = index.zfill(6)\n d = ('a',)\n cursor.execute('INSERT INTO OrdinalNumberS(num) VALUES (?)',d)\n connection.commit()\n return ('2' + trans)\n \n \ndef update_all(cursor,code,groupx,cost,price,name,category):\n t = (name,price,cost,category,code,groupx)\n cursor.execute('UPDATE Inventory SET name = ?,priceUniSug = ?,costUni = ?,category = ? WHERE code = ? AND groupx = ?',t)\n \ndef increase_stock(cursor,code,groupx,quantity):\n cursor.execute('SELECT avail FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n avail = int(data[0]) + quantity\n cursor.execute('UPDATE Inventory SET avail = ? WHERE code = ? AND groupx = ?',(avail,code,groupx))\n return True\n\ndef decrease_stock(cursor,code,groupx,quant):\n #Reduce stock\n cursor.execute('SELECT avail FROM Inventory WHERE code = ? AND groupx = ?',(code,groupx))\n data = cursor.fetchone()\n avail = int(data[0]) - quant\n cursor.execute('UPDATE Inventory SET avail = ? WHERE code = ? AND groupx = ?',(avail,code,groupx))\n return True\n\ndef print_(cursor,table):#Print any table.\n cursor.execute('SELECT * FROM '+ table)\n data = cursor.fetchall()\n for row in data:\n print(row)\n return True\n\n"
},
{
"alpha_fraction": 0.7751572132110596,
"alphanum_fraction": 0.7767295837402344,
"avg_line_length": 43.42856979370117,
"blob_id": "6f029a31c263ae5bfb2a0e6c211de1bd8c82f32a",
"content_id": "272cf1fc5a0a5644455b4351349f459e4efb65db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1276,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 28,
"path": "/readme.txt",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# Libra\r\n\r\n## Project Description:\r\n\r\nThis project is an asset management system that allows a company \r\nto keep track of their current stock. This involves a number \r\nof different type of transactions all surrounding the retail of \r\nmerchandise and products. It is also able to calculate price based \r\non profit margins, revenue, costs, and taxes on the main window \r\ntab. Several interfaces were designed to deal with sales, purchases \r\nand clients. On the main window, other tabs were created to register \r\nmovements within the inventory and transaction to clients. The client \r\nwindow serves as an interface to access client information. One \r\ncan also classify items based on specifc properties with the ‘group’ \r\nfunctions. The program also supports a search bar to access items \r\nquickly. Additionally every table window supports sorting. Midway \r\nthrough the development of our project, we realized our goals were \r\ntoo ambitious given the time we had to develop it. \r\n\r\n## How to Run Libra:\r\n\r\nIn order to make the user experience more convenient, \r\nwe decided to add an executable called Libra.exe which \r\nonly needs to be run eithr through the terminal or clicked on.\r\n\r\n## Dependencies:\r\n\r\nLibraries used are SqLite3, PyQt4 and built-ins to measure runtime.\r\n"
},
{
"alpha_fraction": 0.6880698800086975,
"alphanum_fraction": 0.7086207866668701,
"avg_line_length": 55.79178237915039,
"blob_id": "bc02c05dbdd767b41d298634560543271c7880ab",
"content_id": "9296d294fffe57eb9599ff23d848b1efce2af8a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20729,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 365,
"path": "/gui_sale.py",
"repo_name": "Redent0r/Libra",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'gui_venta.ui'\n#\n# Created by: PyQt4 UI code generator 4.12.1\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.setWindowModality(QtCore.Qt.WindowModal)\n Dialog.resize(1311, 488)\n Dialog.setMinimumSize(QtCore.QSize(750, 488))\n Dialog.setMaximumSize(QtCore.QSize(16777215, 488))\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(_fromUtf8(\":/icons/resources/product_basket-512.png\")), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n Dialog.setWindowIcon(icon)\n Dialog.setModal(True)\n self.horizontalLayout = QtGui.QHBoxLayout(Dialog)\n self.horizontalLayout.setContentsMargins(9, -1, -1, -1)\n self.horizontalLayout.setSpacing(8)\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.groupBox_2 = QtGui.QGroupBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Preferred, QtGui.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.groupBox_2.sizePolicy().hasHeightForWidth())\n self.groupBox_2.setSizePolicy(sizePolicy)\n self.groupBox_2.setObjectName(_fromUtf8(\"groupBox_2\"))\n self.verticalLayout_2 = QtGui.QVBoxLayout(self.groupBox_2)\n self.verticalLayout_2.setObjectName(_fromUtf8(\"verticalLayout_2\"))\n self.horizontalLayout_4 = QtGui.QHBoxLayout()\n self.horizontalLayout_4.setContentsMargins(-1, 0, -1, -1)\n self.horizontalLayout_4.setObjectName(_fromUtf8(\"horizontalLayout_4\"))\n self.cmboxInventory = QtGui.QComboBox(self.groupBox_2)\n self.cmboxInventory.setObjectName(_fromUtf8(\"cmboxInventory\"))\n self.horizontalLayout_4.addWidget(self.cmboxInventory)\n self.leditInventory = QtGui.QLineEdit(self.groupBox_2)\n self.leditInventory.setObjectName(_fromUtf8(\"leditInventory\"))\n self.horizontalLayout_4.addWidget(self.leditInventory)\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_4.addItem(spacerItem)\n self.verticalLayout_2.addLayout(self.horizontalLayout_4)\n self.tblInventory = QtGui.QTableView(self.groupBox_2)\n self.tblInventory.setMinimumSize(QtCore.QSize(280, 0))\n self.tblInventory.setAlternatingRowColors(True)\n self.tblInventory.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblInventory.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblInventory.setSortingEnabled(True)\n self.tblInventory.setObjectName(_fromUtf8(\"tblInventory\"))\n self.tblInventory.horizontalHeader().setStretchLastSection(True)\n self.tblInventory.verticalHeader().setVisible(False)\n self.verticalLayout_2.addWidget(self.tblInventory)\n self.horizontalLayout.addWidget(self.groupBox_2)\n self.verticalLayout = QtGui.QVBoxLayout()\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.formLayout_2 = QtGui.QFormLayout()\n self.formLayout_2.setFieldGrowthPolicy(QtGui.QFormLayout.AllNonFixedFieldsGrow)\n self.formLayout_2.setObjectName(_fromUtf8(\"formLayout_2\"))\n self.label_11 = QtGui.QLabel(Dialog)\n font = QtGui.QFont()\n font.setBold(True)\n font.setWeight(75)\n self.label_11.setFont(font)\n self.label_11.setObjectName(_fromUtf8(\"label_11\"))\n self.formLayout_2.setWidget(0, QtGui.QFormLayout.LabelRole, self.label_11)\n self.label = QtGui.QLabel(Dialog)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.formLayout_2.setWidget(1, QtGui.QFormLayout.LabelRole, self.label)\n self.leditCode = QtGui.QLineEdit(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.leditCode.sizePolicy().hasHeightForWidth())\n self.leditCode.setSizePolicy(sizePolicy)\n self.leditCode.setReadOnly(True)\n self.leditCode.setPlaceholderText(_fromUtf8(\"\"))\n self.leditCode.setObjectName(_fromUtf8(\"leditCode\"))\n self.formLayout_2.setWidget(1, QtGui.QFormLayout.FieldRole, self.leditCode)\n self.label_10 = QtGui.QLabel(Dialog)\n self.label_10.setObjectName(_fromUtf8(\"label_10\"))\n self.formLayout_2.setWidget(2, QtGui.QFormLayout.LabelRole, self.label_10)\n self.leditName = QtGui.QLineEdit(Dialog)\n self.leditName.setReadOnly(True)\n self.leditName.setObjectName(_fromUtf8(\"leditName\"))\n self.formLayout_2.setWidget(2, QtGui.QFormLayout.FieldRole, self.leditName)\n self.label_6 = QtGui.QLabel(Dialog)\n font = QtGui.QFont()\n font.setBold(True)\n font.setWeight(75)\n self.label_6.setFont(font)\n self.label_6.setObjectName(_fromUtf8(\"label_6\"))\n self.formLayout_2.setWidget(5, QtGui.QFormLayout.LabelRole, self.label_6)\n self.label_2 = QtGui.QLabel(Dialog)\n self.label_2.setObjectName(_fromUtf8(\"label_2\"))\n self.formLayout_2.setWidget(6, QtGui.QFormLayout.LabelRole, self.label_2)\n self.spnBoxQuantity = QtGui.QSpinBox(Dialog)\n self.spnBoxQuantity.setAccelerated(True)\n self.spnBoxQuantity.setKeyboardTracking(False)\n self.spnBoxQuantity.setMinimum(1)\n self.spnBoxQuantity.setMaximum(999999)\n self.spnBoxQuantity.setProperty(\"value\", 1)\n self.spnBoxQuantity.setObjectName(_fromUtf8(\"spnBoxQuantity\"))\n self.formLayout_2.setWidget(6, QtGui.QFormLayout.FieldRole, self.spnBoxQuantity)\n self.label_3 = QtGui.QLabel(Dialog)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.formLayout_2.setWidget(7, QtGui.QFormLayout.LabelRole, self.label_3)\n self.label_8 = QtGui.QLabel(Dialog)\n self.label_8.setObjectName(_fromUtf8(\"label_8\"))\n self.formLayout_2.setWidget(8, QtGui.QFormLayout.LabelRole, self.label_8)\n self.chkBoxItbms = QtGui.QCheckBox(Dialog)\n self.chkBoxItbms.setChecked(True)\n self.chkBoxItbms.setTristate(False)\n self.chkBoxItbms.setObjectName(_fromUtf8(\"chkBoxItbms\"))\n self.formLayout_2.setWidget(9, QtGui.QFormLayout.LabelRole, self.chkBoxItbms)\n self.label_9 = QtGui.QLabel(Dialog)\n font = QtGui.QFont()\n font.setBold(True)\n font.setWeight(75)\n self.label_9.setFont(font)\n self.label_9.setObjectName(_fromUtf8(\"label_9\"))\n self.formLayout_2.setWidget(10, QtGui.QFormLayout.LabelRole, self.label_9)\n self.spnBoxTotalItemPrice = QtGui.QDoubleSpinBox(Dialog)\n self.spnBoxTotalItemPrice.setReadOnly(True)\n self.spnBoxTotalItemPrice.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxTotalItemPrice.setSuffix(_fromUtf8(\"\"))\n self.spnBoxTotalItemPrice.setMaximum(999999.0)\n self.spnBoxTotalItemPrice.setObjectName(_fromUtf8(\"spnBoxTotalItemPrice\"))\n self.formLayout_2.setWidget(10, QtGui.QFormLayout.FieldRole, self.spnBoxTotalItemPrice)\n self.label_13 = QtGui.QLabel(Dialog)\n self.label_13.setObjectName(_fromUtf8(\"label_13\"))\n self.formLayout_2.setWidget(4, QtGui.QFormLayout.LabelRole, self.label_13)\n self.cmboxClient = QtGui.QComboBox(Dialog)\n self.cmboxClient.setEditable(True)\n self.cmboxClient.setObjectName(_fromUtf8(\"cmboxClient\"))\n self.formLayout_2.setWidget(0, QtGui.QFormLayout.FieldRole, self.cmboxClient)\n self.chkBoxCredit = QtGui.QCheckBox(Dialog)\n self.chkBoxCredit.setObjectName(_fromUtf8(\"chkBoxCredit\"))\n self.formLayout_2.setWidget(9, QtGui.QFormLayout.FieldRole, self.chkBoxCredit)\n self.spnboxCost = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxCost.setAlignment(QtCore.Qt.AlignLeading|QtCore.Qt.AlignLeft|QtCore.Qt.AlignVCenter)\n self.spnboxCost.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxCost.setDecimals(2)\n self.spnboxCost.setMaximum(99999.0)\n self.spnboxCost.setObjectName(_fromUtf8(\"spnboxCost\"))\n self.formLayout_2.setWidget(4, QtGui.QFormLayout.FieldRole, self.spnboxCost)\n self.spnboxPrice = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxPrice.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxPrice.setMaximum(9999999.0)\n self.spnboxPrice.setObjectName(_fromUtf8(\"spnboxPrice\"))\n self.formLayout_2.setWidget(5, QtGui.QFormLayout.FieldRole, self.spnboxPrice)\n self.spnBoxMargin = QtGui.QDoubleSpinBox(Dialog)\n self.spnBoxMargin.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxMargin.setMaximum(999999.0)\n self.spnBoxMargin.setObjectName(_fromUtf8(\"spnBoxMargin\"))\n self.formLayout_2.setWidget(7, QtGui.QFormLayout.FieldRole, self.spnBoxMargin)\n self.spnboxDiscount = QtGui.QDoubleSpinBox(Dialog)\n self.spnboxDiscount.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnboxDiscount.setMaximum(99999.0)\n self.spnboxDiscount.setObjectName(_fromUtf8(\"spnboxDiscount\"))\n self.formLayout_2.setWidget(8, QtGui.QFormLayout.FieldRole, self.spnboxDiscount)\n self.label_14 = QtGui.QLabel(Dialog)\n self.label_14.setObjectName(_fromUtf8(\"label_14\"))\n self.formLayout_2.setWidget(3, QtGui.QFormLayout.LabelRole, self.label_14)\n self.leditGroup = QtGui.QLineEdit(Dialog)\n self.leditGroup.setReadOnly(True)\n self.leditGroup.setObjectName(_fromUtf8(\"leditGroup\"))\n self.formLayout_2.setWidget(3, QtGui.QFormLayout.FieldRole, self.leditGroup)\n self.verticalLayout.addLayout(self.formLayout_2)\n self.horizontalLayout_3 = QtGui.QHBoxLayout()\n self.horizontalLayout_3.setObjectName(_fromUtf8(\"horizontalLayout_3\"))\n self.btnInsert = QtGui.QPushButton(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.btnInsert.sizePolicy().hasHeightForWidth())\n self.btnInsert.setSizePolicy(sizePolicy)\n self.btnInsert.setAutoDefault(False)\n self.btnInsert.setDefault(False)\n self.btnInsert.setObjectName(_fromUtf8(\"btnInsert\"))\n self.horizontalLayout_3.addWidget(self.btnInsert)\n self.btnUndo = QtGui.QPushButton(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.btnUndo.sizePolicy().hasHeightForWidth())\n self.btnUndo.setSizePolicy(sizePolicy)\n self.btnUndo.setAutoDefault(False)\n self.btnUndo.setObjectName(_fromUtf8(\"btnUndo\"))\n self.horizontalLayout_3.addWidget(self.btnUndo)\n self.verticalLayout.addLayout(self.horizontalLayout_3)\n self.formLayout = QtGui.QFormLayout()\n self.formLayout.setObjectName(_fromUtf8(\"formLayout\"))\n self.label_4 = QtGui.QLabel(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Fixed, QtGui.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())\n self.label_4.setSizePolicy(sizePolicy)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.LabelRole, self.label_4)\n self.spnBoxSubtotal = QtGui.QDoubleSpinBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.spnBoxSubtotal.sizePolicy().hasHeightForWidth())\n self.spnBoxSubtotal.setSizePolicy(sizePolicy)\n self.spnBoxSubtotal.setStyleSheet(_fromUtf8(\"\"))\n self.spnBoxSubtotal.setWrapping(False)\n self.spnBoxSubtotal.setReadOnly(True)\n self.spnBoxSubtotal.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxSubtotal.setMaximum(99999.99)\n self.spnBoxSubtotal.setObjectName(_fromUtf8(\"spnBoxSubtotal\"))\n self.formLayout.setWidget(0, QtGui.QFormLayout.FieldRole, self.spnBoxSubtotal)\n self.label_7 = QtGui.QLabel(Dialog)\n self.label_7.setObjectName(_fromUtf8(\"label_7\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.LabelRole, self.label_7)\n self.spnBoxTaxT = QtGui.QDoubleSpinBox(Dialog)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Fixed)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.spnBoxTaxT.sizePolicy().hasHeightForWidth())\n self.spnBoxTaxT.setSizePolicy(sizePolicy)\n self.spnBoxTaxT.setReadOnly(True)\n self.spnBoxTaxT.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxTaxT.setMaximum(999999.0)\n self.spnBoxTaxT.setObjectName(_fromUtf8(\"spnBoxTaxT\"))\n self.formLayout.setWidget(1, QtGui.QFormLayout.FieldRole, self.spnBoxTaxT)\n self.label_12 = QtGui.QLabel(Dialog)\n self.label_12.setObjectName(_fromUtf8(\"label_12\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.LabelRole, self.label_12)\n self.spnBoxDiscountT = QtGui.QDoubleSpinBox(Dialog)\n self.spnBoxDiscountT.setReadOnly(True)\n self.spnBoxDiscountT.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxDiscountT.setMaximum(99999.0)\n self.spnBoxDiscountT.setObjectName(_fromUtf8(\"spnBoxDiscountT\"))\n self.formLayout.setWidget(3, QtGui.QFormLayout.FieldRole, self.spnBoxDiscountT)\n self.verticalLayout.addLayout(self.formLayout)\n self.line = QtGui.QFrame(Dialog)\n self.line.setFrameShape(QtGui.QFrame.HLine)\n self.line.setFrameShadow(QtGui.QFrame.Sunken)\n self.line.setObjectName(_fromUtf8(\"line\"))\n self.verticalLayout.addWidget(self.line)\n self.formLayout_3 = QtGui.QFormLayout()\n self.formLayout_3.setObjectName(_fromUtf8(\"formLayout_3\"))\n self.label_5 = QtGui.QLabel(Dialog)\n font = QtGui.QFont()\n font.setPointSize(11)\n font.setBold(True)\n font.setWeight(75)\n self.label_5.setFont(font)\n self.label_5.setFrameShape(QtGui.QFrame.NoFrame)\n self.label_5.setFrameShadow(QtGui.QFrame.Plain)\n self.label_5.setScaledContents(False)\n self.label_5.setWordWrap(False)\n self.label_5.setObjectName(_fromUtf8(\"label_5\"))\n self.formLayout_3.setWidget(0, QtGui.QFormLayout.LabelRole, self.label_5)\n self.spnBoxGrandTotal = QtGui.QDoubleSpinBox(Dialog)\n font = QtGui.QFont()\n font.setPointSize(11)\n font.setBold(True)\n font.setWeight(75)\n font.setStrikeOut(False)\n self.spnBoxGrandTotal.setFont(font)\n self.spnBoxGrandTotal.setAutoFillBackground(False)\n self.spnBoxGrandTotal.setStyleSheet(_fromUtf8(\"\"))\n self.spnBoxGrandTotal.setFrame(True)\n self.spnBoxGrandTotal.setReadOnly(True)\n self.spnBoxGrandTotal.setButtonSymbols(QtGui.QAbstractSpinBox.NoButtons)\n self.spnBoxGrandTotal.setMaximum(999999.0)\n self.spnBoxGrandTotal.setObjectName(_fromUtf8(\"spnBoxGrandTotal\"))\n self.formLayout_3.setWidget(0, QtGui.QFormLayout.FieldRole, self.spnBoxGrandTotal)\n self.verticalLayout.addLayout(self.formLayout_3)\n self.horizontalLayout_2 = QtGui.QHBoxLayout()\n self.horizontalLayout_2.setObjectName(_fromUtf8(\"horizontalLayout_2\"))\n self.btnConfirm = QtGui.QPushButton(Dialog)\n self.btnConfirm.setAutoDefault(False)\n self.btnConfirm.setObjectName(_fromUtf8(\"btnConfirm\"))\n self.horizontalLayout_2.addWidget(self.btnConfirm)\n self.btnDelete = QtGui.QPushButton(Dialog)\n self.btnDelete.setAutoDefault(False)\n self.btnDelete.setObjectName(_fromUtf8(\"btnDelete\"))\n self.horizontalLayout_2.addWidget(self.btnDelete)\n self.verticalLayout.addLayout(self.horizontalLayout_2)\n self.horizontalLayout.addLayout(self.verticalLayout)\n self.groupBox = QtGui.QGroupBox(Dialog)\n self.groupBox.setObjectName(_fromUtf8(\"groupBox\"))\n self.gridLayout = QtGui.QGridLayout(self.groupBox)\n self.gridLayout.setObjectName(_fromUtf8(\"gridLayout\"))\n self.tblItems = QtGui.QTableView(self.groupBox)\n self.tblItems.setAlternatingRowColors(True)\n self.tblItems.setSelectionMode(QtGui.QAbstractItemView.SingleSelection)\n self.tblItems.setSelectionBehavior(QtGui.QAbstractItemView.SelectRows)\n self.tblItems.setSortingEnabled(False)\n self.tblItems.setCornerButtonEnabled(False)\n self.tblItems.setObjectName(_fromUtf8(\"tblItems\"))\n self.tblItems.horizontalHeader().setStretchLastSection(True)\n self.gridLayout.addWidget(self.tblItems, 0, 1, 1, 1)\n self.horizontalLayout.addWidget(self.groupBox)\n self.horizontalLayout.setStretch(0, 1)\n self.horizontalLayout.setStretch(2, 1)\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"Sale\", None))\n self.groupBox_2.setTitle(_translate(\"Dialog\", \"Inventory\", None))\n self.leditInventory.setPlaceholderText(_translate(\"Dialog\", \"Search...\", None))\n self.label_11.setText(_translate(\"Dialog\", \"Client:\", None))\n self.label.setText(_translate(\"Dialog\", \"Code:\", None))\n self.leditCode.setToolTip(_translate(\"Dialog\", \"Press Enter to \\n\"\n\"search item by code\", None))\n self.leditCode.setWhatsThis(_translate(\"Dialog\", \"Insert the code item here\\n\"\n\"\", None))\n self.label_10.setText(_translate(\"Dialog\", \"Name:\", None))\n self.label_6.setText(_translate(\"Dialog\", \"Item Price:\", None))\n self.label_2.setText(_translate(\"Dialog\", \"Quantity:\", None))\n self.label_3.setText(_translate(\"Dialog\", \"Margin:\", None))\n self.label_8.setText(_translate(\"Dialog\", \"Discount:\", None))\n self.chkBoxItbms.setText(_translate(\"Dialog\", \"Include Tax\", None))\n self.label_9.setText(_translate(\"Dialog\", \"Total Item Price:\", None))\n self.spnBoxTotalItemPrice.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.label_13.setText(_translate(\"Dialog\", \"Cost:\", None))\n self.chkBoxCredit.setText(_translate(\"Dialog\", \"Credit\", None))\n self.spnboxCost.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.spnboxPrice.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.spnBoxMargin.setPrefix(_translate(\"Dialog\", \"% \", None))\n self.spnboxDiscount.setPrefix(_translate(\"Dialog\", \"% \", None))\n self.label_14.setText(_translate(\"Dialog\", \"Group:\", None))\n self.btnInsert.setText(_translate(\"Dialog\", \"Insert\", None))\n self.btnUndo.setText(_translate(\"Dialog\", \"Undo\", None))\n self.label_4.setText(_translate(\"Dialog\", \"Subtotal:\", None))\n self.spnBoxSubtotal.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.label_7.setText(_translate(\"Dialog\", \"Sales Tax:\", None))\n self.spnBoxTaxT.setToolTip(_translate(\"Dialog\", \"7.00%\", None))\n self.spnBoxTaxT.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.label_12.setText(_translate(\"Dialog\", \"Discount:\", None))\n self.spnBoxDiscountT.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.label_5.setText(_translate(\"Dialog\", \"Grand Total:\", None))\n self.spnBoxGrandTotal.setToolTip(_translate(\"Dialog\", \"SubTotal + \\n\"\n\"ITBMS (7.00%)\", None))\n self.spnBoxGrandTotal.setPrefix(_translate(\"Dialog\", \"$ \", None))\n self.btnConfirm.setText(_translate(\"Dialog\", \"Confirm\", None))\n self.btnDelete.setText(_translate(\"Dialog\", \"Delete Entry\", None))\n self.groupBox.setTitle(_translate(\"Dialog\", \"Items\", None))\n\nimport res_rc\n"
}
] | 11 |
hyjy/smart-meter | https://github.com/hyjy/smart-meter | ce0ea70dfdfd32290cce046eb17052fd496b9a92 | 209a03e31d68dd3ca02aeb8b974efdfee68c009e | 7bfbc1bef9a32030c2fe1f1490da1fc66086b7a9 | refs/heads/master | "2021-01-11T18:22:12.698950" | "2016-12-23T21:32:31" | "2016-12-23T21:32:31" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7468085289001465,
"alphanum_fraction": 0.7510638236999512,
"avg_line_length": 36.599998474121094,
"blob_id": "706327dbf3b4feb205177429daa5d07f5afe9c3d",
"content_id": "35d0f9ae80e6a5ffe1a95ac96000cdbd64f761ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 941,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 25,
"path": "/README.md",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "# smart-meter\nTo demonstrate a Smart Meter Big Data Application.\n\n\n\n## Excel\n\n### Install the ODBC Driver\n\n* Get the Driver from http://www.simba.com/drivers/cassandra-odbc-jdbc/\n* Follow the Installation Instructions (on MacOS, don't forget first to install [iODBC](http://www.iodbc.org/))\n* Save the Licence file you received by Mail (`SimbaApacheCassandraODBCDriver.lic`) into the right location\n\n### Create a SDN File\n\n* Define a SDN file, such as [excel/cassandra.dsn](excel/cassandra.dsn)\n* You could load & test it directly through the iODBC Administrator App:\n\n\n### Connect to the External Data from Excel using the `iODBC Data Source Chooser` (File DSN)\n\n* You might use the SQL syntax, such as `select * from raw_voltage_data limit 10;`\n* Et Voilà!\n\n\n"
},
{
"alpha_fraction": 0.8258528113365173,
"alphanum_fraction": 0.8258528113365173,
"avg_line_length": 14.914285659790039,
"blob_id": "3f18ab7e3a57348791f6ced955aa44d77edb7421",
"content_id": "392a08fc82029e903cb1586eaf622d819c496474",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 557,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 35,
"path": "/build-local.sh",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "pushd dockerfile-inject\nsbt update\nsbt docker\nsbt eclipse\npopd\n\npushd dockerfile-app-streaming\nsbt update\nsbt docker\nsbt eclipse\npopd\n\npushd dockerfile-app-batch\nsbt update\nsbt docker\nsbt eclipse\npopd\n\npushd dockerfile-monitor\nsbt update\nsbt docker\nsbt eclipse\npopd\n\npushd dockerfile-cassandra\ndocker build -t logimethods/smart-meter:cassandra-local .\npopd\n\npushd dockerfile-cassandra-inject\ndocker build -t logimethods/smart-meter:cassandra-inject-local .\npopd\n\npushd dockerfile-nats-server\ndocker build -t logimethods/smart-meter:nats-server-local .\npopd\n"
},
{
"alpha_fraction": 0.5964371562004089,
"alphanum_fraction": 0.6320657730102539,
"avg_line_length": 27.627450942993164,
"blob_id": "3784cc40672989c0a4f348ba45c57321591963d2",
"content_id": "0f0a1b7fcf625a6811fb6eb5914ab22d7e18f3ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 2919,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 102,
"path": "/dockerfile-cassandra-inject/go/src/app/main.go",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "package main\n\nimport (\n\t\"os\"\n\t\"log\"\n\t\"fmt\"\n\t\"time\"\n\t\"strings\"\n\n//\t\"bytes\"\n \"encoding/binary\"\n \"math\"\n \"strconv\"\n// \"unsafe\"\n\t\n\t\"github.com/nats-io/nats\"\n\t\"github.com/gocql/gocql\"\n)\n\nfunc main() {\n\tfmt.Println(\"Welcome to the NATS to Cassandra Bridge\")\n\n\tfmt.Println(\"The time is\", time.Now())\n\t\n\tnats_uri := os.Getenv(\"NATS_URI\")\n\tnc, _ := nats.Connect(nats_uri)\n\t\n\tfmt.Println(\"Subscribed to NATS: \", nats_uri)\n\n\tnats_subject := os.Getenv(\"NATS_SUBJECT\")\n\tfmt.Println(\"NATS Subject: \", nats_subject)\n\t\n\t// CASSANDRA\n\n\tcassandra_url := os.Getenv(\"CASSANDRA_URL\")\n\tfmt.Printf(\"Cassandra URL: \", cassandra_url)\n\t\n // connect to the cluster\n cluster := gocql.NewCluster(cassandra_url)\n cluster.Keyspace = \"smartmeter\"\n cluster.Consistency = gocql.Quorum\n session, _ := cluster.CreateSession()\n defer session.Close()\n\t\n\tfmt.Println(\"Connected to Cassandra\")\n\n // insert a message into Cassandra\n// if err := session.Query(`INSERT INTO messages (subject, message) VALUES (?, ?)`,\n// \"subject1\", \"First message\").Exec(); err != nil {\n// log.Print(err)\n// }\n\t\n\t// Simple Async Subscriber\n\tnc.Subscribe(nats_subject, func(m *nats.Msg) {\t\t\n\t\t/*** Point ***/\n\t\t\n\t\t// https://www.dotnetperls.com/split-go\n\t\tsubjects := strings.Split(m.Subject, \".\")\n\t\t// smartmeter.voltage.data.3.3.2\t | (2016-11-16T20:05:04,116.366646)\n\t\tlen := len(subjects)\t\t\n\t\t\n\t\t// http://stackoverflow.com/questions/30299649/golang-converting-string-to-specific-type-of-int-int8-int16-int32-int64\n\t\tline, _ := strconv.ParseInt(subjects[len -3], 10, 8) // tinyint, // 8-bit signed int \n\t\ttransformer, _ := strconv.ParseInt(subjects[len -2], 10, 32)\t// int, // 32-bit signed int\n\t\tusagePoint, _ := strconv.ParseInt(subjects[len -1], 10, 32)\t// int,\n\n\t\t/*** Date ***/\n\t\t\n\t\tlongBytes := m.Data[:8]\n\t\t// http://stackoverflow.com/questions/22491876/convert-byte-array-uint8-to-float64-in-golang\n\t\tepoch := int64(binary.BigEndian.Uint64(longBytes))\n\t\tdate := time.Unix(epoch, 0)\n\n\t\t// https://golang.org/pkg/time/#Time\n\t\tyear, month, day := date.Date()\t\t\t\n\t\thour, minute, _ := date.Clock() \n\t\tday_of_week := date.Weekday()\n\n\t\t/*** Voltage ***/\n\t\t\n\t\tfloatBytes := m.Data[8:]\n\t\t// http://stackoverflow.com/questions/22491876/convert-byte-array-uint8-to-float64-in-golang\n\t\tvoltage := math.Float32frombits(binary.BigEndian.Uint32(floatBytes))\n\t \n\t /** insert the Data into Cassandra **/\n\t \n\t\tquery := \"INSERT INTO raw_voltage_data (\" +\n\t\t\t\t\"line, transformer, usagePoint, year, month, day, hour, minute, day_of_week, voltage)\" +\n\t\t\t\t\" VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\"\n\t\t\n\t if err := session.Query(query,\n\t int8(line), int32(transformer), int32(usagePoint), int16(year), int8(month), int8(day), \n\t\t int8(hour), int8(minute), int8(day_of_week), voltage).Exec(); err != nil {\n\t log.Print(err)\n\t }\n\t})\n\t\n\tfmt.Println(\"Ready to store NATS messages into CASSANDRA\")\n\n\tfor {\n\t}\n}"
},
{
"alpha_fraction": 0.8613138794898987,
"alphanum_fraction": 0.8613138794898987,
"avg_line_length": 44.66666793823242,
"blob_id": "44c13fd853d65c6a40e98415c5157160a27690c0",
"content_id": "e29ab636852686d342530243e539fefc258cb8ac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 137,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 3,
"path": "/pull.sh",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "docker pull logimethods/smart-meter:inject\ndocker pull logimethods/smart-meter:monitor\ndocker pull logimethods/smart-meter:app-streaming\n"
},
{
"alpha_fraction": 0.6834203600883484,
"alphanum_fraction": 0.6927763223648071,
"avg_line_length": 31.821428298950195,
"blob_id": "f95f86f7ee7ace11614952564e0c78b860c7a70c",
"content_id": "01d35b27b2fb41983d886a79dbc48cbadd3f3539",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4596,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 140,
"path": "/start-services.py",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport subprocess\nimport docker\nclient = docker.from_env()\n\nif (len(sys.argv) > 1):\n\tpostfix = sys.argv[0]\n\tprint(\"Images will be postfixed by \" + postfix)\nelse:\n\tpostfix = \"\"\n\ndef update_replicas(service, replicas):\n\tparam = service.name + \"=\" + str(replicas)\n\tsubprocess.run([\"docker\", \"service\", \"scale\", param])\n\ndef create_service(name, replicas, postfix):\n\tif replicas > 0:\n\t\tsubprocess.run([\"bash\", \"docker_service.sh\", \"-r\", str(replicas), \"-p\", postfix, \"create_service_\" + name])\n\ndef call(type, name, parameters):\n\tsubprocess.run([\"bash\", \"docker_service.sh\", \"-p\", postfix, type + \"_\" + name] + parameters)\n\ndef get_service(name):\n\tservices = client.services.list()\n\tfor service in services:\n\t\tif service.name == name:\n\t\t\treturn service\n\treturn None\n\ndef create_or_update_service(name, replicas, postfix):\n\tservice = get_service(name)\n\tif service is not None:\n\t\tupdate_replicas(service, replicas)\n\telse:\n\t\tcreate_service(name, replicas, postfix)\n\ndef create_network():\n\tclient.networks.create(\"smart-meter-net\", driver=\"overlay\")\n\ncreate_network = [\"create\", \"network\"]\ncreate_service_cassandra = [\"create_service\", \"cassandra\", 1]\ncreate_service_spark_master = [\"create_service\", \"spark-master\", 1]\ncreate_service_spark_slave = [\"create_service\", \"spark-slave\", 2]\ncreate_service_nats = [\"create_service\", \"nats\", 1]\ncreate_service_app_streaming = [\"create_service\", \"app-streaming\", 1]\ncreate_service_monitor = [\"create_service\", \"monitor\", 1]\ncreate_service_reporter = [\"create_service\", \"reporter\", 1]\ncreate_cassandra_tables = [\"call\", \"cassandra_cql\", \"/cql/create-timeseries.cql\"]\ncreate_service_cassandra_populate = [\"create_service\", \"cassandra-populate\", 1]\ncreate_service_inject = [\"create_service\", \"inject\", 1]\ncreate_service_app_batch = [\"create_service\", \"app-batch\", 1]\n\nstop_service_cassandra = [\"create_service\", \"cassandra\", 0]\nstop_service_spark_master = [\"create_service\", \"spark-master\", 0]\nstop_service_spark_slave = [\"create_service\", \"spark-slave\", 0]\nstop_service_nats = [\"create_service\", \"nats\", 0]\nstop_service_app_streaming = [\"create_service\", \"app-streaming\", 0]\nstop_service_monitor = [\"create_service\", \"monitor\", 0]\nstop_service_reporter = [\"create_service\", \"reporter\", 0]\nstop_service_cassandra_populate = [\"create_service\", \"cassandra-populate\", 0]\nstop_service_inject = [\"create_service\", \"inject\", 0]\nstop_service_app_batch = [\"create_service\", \"app-batch\", 0]\n\nall_steps = [\n\tcreate_network,\n\tcreate_service_cassandra,\n\tcreate_service_spark_master,\n\tcreate_service_spark_slave,\n\tcreate_service_nats,\n\tcreate_service_app_streaming,\n\tcreate_service_monitor,\n\tcreate_service_reporter,\n\tcreate_cassandra_tables,\n\tcreate_service_cassandra_populate,\n\tcreate_service_inject,\n\tcreate_service_app_batch\n\t]\n\ndef run_scenario(steps):\n\tif not isinstance(steps[0], list):\n\t\tsteps = [steps]\n\tfor step in steps:\n\t\tif step[0] == \"create_service\" :\n\t\t\tcreate_or_update_service(step[1], step[2], postfix)\n\t\telse:\n\t\t\tcall(step[0], step[1], step[2:])\n\ndef run_or_kill_scenario(steps):\n\tif not isinstance(steps[0], list):\n\t\tsteps = [steps]\n\t# Collect all existing services names\n\tall_remaining_services = []\n\tfor step in all_steps:\n\t\tif step[0] == \"create_service\" :\n\t\t\tall_remaining_services.append(step[1])\n\t# Remove all requested services\n\tfor step in steps:\n\t\tif (step[0] == \"create_service\") and (step[2] > 0):\n\t\t\tall_remaining_services.remove(step[1])\n\t#\n\tprint(\"All of those services will be desactivated: \" + str(all_remaining_services))\n\tfor name in all_remaining_services:\n\t\tcreate_or_update_service(name, 0, postfix)\n\t# Finaly, run the requested scenario\n\trun_scenario(steps)\n\ndef run_all_steps():\n\trun_scenario(all_steps)\n\ndef run_inject_raw_data_into_cassandra():\n\trun_or_kill_scenario([\n\t\tcreate_network,\n\t\tcreate_service_cassandra,\n\t\tcreate_service_nats,\n\t\tcreate_cassandra_tables,\n\t\tcreate_service_cassandra_populate,\n\t\tcreate_service_inject,\n\t\t[\"wait\", \"service\", \"inject\"],\n\t\t[\"logs\", \"service\", \"inject\"]\n\t\t])\n\ndef run_app_batch():\n\trun_or_kill_scenario([\n\t\tcreate_network,\n\t\tstop_service_app_batch,\n\t\t[\"build\", \"app-batch\"],\n\t\tcreate_service_cassandra,\n\t\tcreate_service_spark_master,\n\t\t[\"wait\", \"service\", \"spark-master\"],\n\t\tcreate_service_spark_slave,\n\t\t[\"wait\", \"service\", \"cassandra\"],\n\t\t[\"run\", \"image\", \n\t\t\t\"-e\", \"SPARK_MASTER_URL=spark://spark-master:7077\", \n#\t\t\t\"-e\", \"CASSANDRA_URL=\\\"$(docker ps | grep \\'cassandra\\' | rev | cut -d' ' -f1 | rev)\\\"\", \n\t\t\t\"-e\", \"CASSANDRA_URL=cassandra\", \n\t\t\t\"logimethods/smart-meter:app-batch-\"+postfix],\n#\t\t[\"wait\", \"service\", \"app-batch\"],\n#\t\t[\"logs\", \"service\", \"app-batch\"]\n\t\t])\n\n"
},
{
"alpha_fraction": 0.7276595830917358,
"alphanum_fraction": 0.7382978796958923,
"avg_line_length": 30.399999618530273,
"blob_id": "87ef9eead1b4526fb48af71ee18a8b704c080c57",
"content_id": "1b849632bd3c70c34903236e025de6833d759ad8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 470,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 15,
"path": "/dockerfile-cassandra/cql/create-messages.cql",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright 2016 Logimethods - Laurent Magnin\n */\n\n//DROP KEYSPACE IF EXISTS power_data;\n//\"Attempting to create an already existing keyspace will return an error unless the IF NOT EXISTS option is used.\" -> We don't want to erase existing data\nCREATE KEYSPACE IF NOT EXISTS smartmeter WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };\n\nUSE smartmeter;\n\nCREATE TABLE IF NOT EXISTS messages (\n\tsubject text,\n\tmessage text,\n\tPRIMARY KEY (subject)\n);"
},
{
"alpha_fraction": 0.6543868184089661,
"alphanum_fraction": 0.6734529137611389,
"avg_line_length": 22.44318199157715,
"blob_id": "fca1c1339fae3816220fa781d42da391566b0b81",
"content_id": "86e32ff6cc4573c4e6d49989b0ba309af7b4b1aa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6189,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 264,
"path": "/docker_service.sh",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nreplicas=1\npostfix=\"\"\nshift_nb=0\n\nwhile getopts \":r:p:\" opt; do\n case $opt in\n r) replicas=\"$OPTARG\"\n ((shift_nb+=2))\n ;;\n p) postfix=\"-$OPTARG\"\n ((shift_nb+=2))\n ;;\n \\?) echo \"Invalid option -$OPTARG\"\n ((shift_nb+=1))\n ;;\n esac\ndone\n\nshift $shift_nb\n\n# ./start-services.sh \"-local\"\n\nNATS_USERNAME=\"smartmeter\"\nNATS_PASSWORD=\"xyz1234\"\n\ncreate_network() {\n\tdocker network create --driver overlay --attachable smart-meter-net\n#docker service rm $(docker service ls -q)\n}\n\n### Create Service ###\n\ncreate_service_cassandra() {\n# https://hub.docker.com/_/cassandra/\n# http://serverfault.com/questions/806649/docker-swarm-and-volumes\n# https://clusterhq.com/2016/03/09/fun-with-swarm-part1/\ndocker service create \\\n\t--name cassandra \\\n\t--replicas=${replicas} \\\n\t--network smart-meter-net \\\n\t--mount type=volume,source=cassandra-volume,destination=/var/lib/cassandra \\\n\t-e CASSANDRA_BROADCAST_ADDRESS=\"cassandra\" \\\n\t-e CASSANDRA_CLUSTER_NAME=\"Smartmeter Cluster\" \\\n\t-p 9042:9042 \\\n\t-p 9160:9160 \\\n\tlogimethods/smart-meter:cassandra${postfix}\n}\n\ncreate_service_spark-master() {\ndocker service create \\\n\t--name spark-master \\\n\t-e SERVICE_NAME=spark-master \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\t--constraint 'node.role == manager' \\\n\t--log-driver=json-file \\\n\tgettyimages/spark:2.0.2-hadoop-2.7\n}\n\ncreate_service_spark-slave() {\ndocker service create \\\n\t--name spark-slave \\\n\t-e SERVICE_NAME=spark-slave \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\tgettyimages/spark:2.0.2-hadoop-2.7 \\\n\t\tbin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077\n}\n\ncreate_service_nats() {\ndocker service create \\\n\t--name nats \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\t-e NATS_USERNAME=${NATS_USERNAME} \\\n\t-e NATS_PASSWORD=${NATS_PASSWORD} \\\n\tlogimethods/smart-meter:nats-server${postfix}\n}\n\ncreate_service_app-streaming() {\n#docker pull logimethods/smart-meter:app-streaming\ndocker service create \\\n\t--name app-streaming \\\n\t-e NATS_URI=nats://${NATS_USERNAME}:${NATS_PASSWORD}@nats:4222 \\\n\t-e SPARK_MASTER_URL=spark://spark-master:7077 \\\n\t-e LOG_LEVEL=INFO \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\tlogimethods/smart-meter:app-streaming${postfix} \\\n\t\t\"smartmeter.voltage.data.>\" \"smartmeter.voltage.data. => smartmeter.voltage.extract.max.\"\n}\n\ncreate_service_app-batch() {\n#docker pull logimethods/smart-meter:app-batch\ndocker service create \\\n\t--name app-batch \\\n\t-e SPARK_MASTER_URL=spark://spark-master:7077 \\\n\t-e LOG_LEVEL=INFO \\\n\t-e CASSANDRA_URL=$(docker ps | grep \"cassandra\" | rev | cut -d' ' -f1 | rev) \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\tlogimethods/smart-meter:app-batch${postfix} \n}\n\ncreate_service_monitor() {\n#docker pull logimethods/smart-meter:monitor\ndocker service create \\\n\t--name monitor \\\n\t-e NATS_URI=nats://${NATS_USERNAME}:${NATS_PASSWORD}@nats:4222 \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\tlogimethods/smart-meter:monitor${postfix} \\\n\t\t\"smartmeter.voltage.extract.>\"\n}\n\ncreate_service_reporter() {\n#docker pull logimethods/nats-reporter\ndocker service create \\\n\t--name reporter \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\t-p 8888:8080 \\\n\tlogimethods/nats-reporter\n}\n\ncreate_service_cassandra-populate() {\ndocker service create \\\n\t--name cassandra-inject \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\t-e NATS_URI=nats://${NATS_USERNAME}:${NATS_PASSWORD}@nats:4222 \\\n\t-e NATS_SUBJECT=\"smartmeter.voltage.data.>\" \\\n\t-e CASSANDRA_URL=$(docker ps | grep \"cassandra\" | rev | cut -d' ' -f1 | rev) \\\n\tlogimethods/smart-meter:cassandra-populate${postfix}\n}\n\ncreate_service_inject() {\n#docker pull logimethods/smart-meter:inject\ndocker service create \\\n\t--name inject \\\n\t-e GATLING_TO_NATS_SUBJECT=smartmeter.voltage.data \\\n\t-e NATS_URI=nats://${NATS_USERNAME}:${NATS_PASSWORD}@nats:4222 \\\n\t--network smart-meter-net \\\n\t--replicas=${replicas} \\\n\tlogimethods/smart-meter:inject${postfix} \\\n\t\t--no-reports -s com.logimethods.smartmeter.inject.NatsInjection\n}\n\n\ncall_cassandra_cql() {\n\tuntil docker exec -it $(docker ps | grep \"cassandra\" | rev | cut -d' ' -f1 | rev) cqlsh -f \"$1\"; do echo \"Try again to execute $1\"; sleep 4; done\n}\n\nupdate_service_scale() {\n\tdocker service scale SERVICE=REPLICAS\n}\n\n### RUN DOCKER ###\n\nrun_image() {\n#\tname=${1}\n#\tshift\n\techo \"docker run --network smart-meter-net $@\"\n\tdocker run --network smart-meter-net $@\n}\n\n### BUILDS ###\n\nbuild_inject() {\n\tpushd dockerfile-inject\n\tsbt --warn update docker\n\tpopd\n}\n\nbuild_app-streaming() {\n\tpushd dockerfile-app-streaming\n\tsbt --warn update docker\n\tpopd\n}\n\nbuild_app-batch() {\n\tpushd dockerfile-app-batch\n\tsbt --warn update docker\n\tpopd\n}\n\nbuild_monitor() {\n\tpushd dockerfile-monitor\n\tsbt --warn update docker\n\tpopd\n}\n\nbuild_cassandra() {\n\tpushd dockerfile-cassandra\n\tdocker build -t logimethods/smart-meter:cassandra-local .\n\tpopd\n}\n\nbuild_cassandra-inject() {\n\tpushd dockerfile-cassandra-inject\n\tdocker build -t logimethods/smart-meter:cassandra-inject-local .\n\tpopd\n}\n\nbuild_nats-server() {\n\tpushd dockerfile-nats-server\n\tdocker build -t logimethods/smart-meter:nats-server-local .\n\tpopd\n}\n\n### WAIT ###\n\nwait_service() {\n\t# http://unix.stackexchange.com/questions/213110/exiting-a-shell-script-with-nested-loops\n\techo \"Waiting for the $1 Service to Start\"\n\twhile : \n\tdo\n\t\techo \"--------- $1 ----------\"\n\t\tdocker ps | while read -r line\n\t\tdo\n\t\t\ttokens=( $line )\n\t\t\tfull_name=${tokens[1]}\n\t\t\tname=${full_name##*:}\n\t\t\tif [ \"$name\" == \"$1\" ] ; then\n\t\t\t\texit 1\n\t\t\tfi\n\t\tdone\n\t\t[[ $? != 0 ]] && exit 0\n\t\n\t\tdocker service ls | while read -r line\n\t\tdo\n\t\t\ttokens=( $line )\n\t\t\tname=${tokens[1]}\n\t\t\tif [ \"$name\" == \"$1\" ] ; then\n\t\t\t\treplicas=${tokens[3]}\n\t\t\t\tactual=${replicas%%/*}\n\t\t\t\texpected=${replicas##*/}\n\t\t\t\t#echo \"$actual : $expected\"\n\t\t\t\tif [ \"$actual\" == \"$expected\" ] ; then\n\t\t\t\t\texit 1\n\t\t\t\telse\n\t\t\t\t\tbreak\n\t\t\t\tfi\n\t\t\tfi\n\t\tdone\n\t\t[[ $? != 0 ]] && exit 0\n\t\t\n\t\tsleep 2\n\tdone\n}\n\n### LOGS ###\n\nlogs_service() {\n\tdocker logs $(docker ps | grep \"$1\" | rev | cut -d' ' -f1 | rev)\n}\n\n### Actual CMD ###\n\n# See http://stackoverflow.com/questions/8818119/linux-how-can-i-run-a-function-from-a-script-in-command-line\necho \"!!! $@ !!!\"\n\"$@\"\n"
},
{
"alpha_fraction": 0.6438848972320557,
"alphanum_fraction": 0.6978417038917542,
"avg_line_length": 54.400001525878906,
"blob_id": "e36702e75f47284aa44f4215a646a44d86f73291",
"content_id": "2890c28c41bf701cf24a8487195168d236648050",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 278,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 5,
"path": "/stop.sh",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "docker service rm $(docker service ls -q)\ndocker stop $(docker ps -a -q)\ndocker rm $(docker ps -a -q)\n#https://gist.github.com/brianclements/f72b2de8e307c7b56689\ndocker rmi $(docker images | grep \"<none>\" | awk '{print $3}') 2>/dev/null || echo \"No untagged images to delete.\"\n\n"
},
{
"alpha_fraction": 0.5527950525283813,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 79.5,
"blob_id": "c1d6bc81653cc33647b226b37ce3bd4d11a23e0d",
"content_id": "e0be2fe023eb2bc4aeb52e2f93b40410a24bd5b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 161,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 2,
"path": "/cqlsh.sh",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "docker exec -it $(docker ps | grep \"cassandra-root\" | rev | cut -d' ' -f1 | rev) cqlsh \n\t\t\t\t\t\t# $(docker ps | grep \"cassandra-root\" | rev | cut -d' ' -f1 | rev)\n"
},
{
"alpha_fraction": 0.6712328791618347,
"alphanum_fraction": 0.698630154132843,
"avg_line_length": 17.25,
"blob_id": "84e0354ea9b2f064cc6fb5916c4af11011aceb2e",
"content_id": "12f0859c607784f5b0d196c932662e19d3212014",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 73,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 4,
"path": "/dockerfile-cassandra/Dockerfile",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "# https://hub.docker.com/_/cassandra/\nFROM cassandra:3.5\n\nCOPY /cql /cql\n"
},
{
"alpha_fraction": 0.6678004264831543,
"alphanum_fraction": 0.6791383028030396,
"avg_line_length": 37.34782791137695,
"blob_id": "64d1d28ded7a15c5b821ef162e843bcb3df74bc4",
"content_id": "f88795d1894baddcb314bc2a9c81707eea5c8806",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 882,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 23,
"path": "/dockerfile-cassandra/cql/create-timeseries.cql",
"repo_name": "hyjy/smart-meter",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright 2016 Logimethods - Laurent Magnin\n */\n\n//DROP KEYSPACE IF EXISTS power_data;\n//\"Attempting to create an already existing keyspace will return an error unless the IF NOT EXISTS option is used.\" -> We don't want to erase existing data\nCREATE KEYSPACE IF NOT EXISTS smartmeter WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };\n\nUSE smartmeter;\n\nCREATE TABLE IF NOT EXISTS raw_voltage_data (\n line tinyint, // 8-bit signed int \n transformer int, // 32-bit signed int\n usagePoint int,\n year smallint, // 16-bit signed int\n month tinyint, \n day tinyint, \n hour tinyint, \n minute tinyint, \n day_of_week tinyint,\n voltage float,\n PRIMARY KEY ((line, transformer, usagePoint), year, month, day, hour, minute)\n) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC, minute DESC);\n"
}
] | 11 |
AshishSingha/PythonPracticeFromLinkedinLearning | https://github.com/AshishSingha/PythonPracticeFromLinkedinLearning | 80aa5d3a990bfe63e9152de5f04e4b439d9f53b5 | 0f42a74f4878e8fe935a3c10e8e086927ed2bb9d | c10e1637344ecb631f8368c0cdd5eb446aee9c2d | refs/heads/master | "2018-04-11T12:36:29.342589" | "2017-05-08T12:00:44" | "2017-05-08T12:00:44" | 90,031,039 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6190476417541504,
"alphanum_fraction": 0.6190476417541504,
"avg_line_length": 27,
"blob_id": "ad3beb650297487260dda62419591cf14f44afa8",
"content_id": "1c6b13b15ee4055142a521cd1548ca97e3a3a4e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 3,
"path": "/arbitary.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "def concat(*args,sep=\"/\"):\n print(sep.join(args))\nconcat(\"earth\",\"mars\",\"venus\")\n"
},
{
"alpha_fraction": 0.6489361524581909,
"alphanum_fraction": 0.6702127456665039,
"avg_line_length": 14.833333015441895,
"blob_id": "18bd63426296719f285ede3bbf6a9ffcec5c9b9c",
"content_id": "ce3335925fdca326c198510f81cc296c83443c7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 6,
"path": "/tuple.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "work={}\nwork[\"doctor\"]=1\nwork[\"engineer\"]=2\n\nprint(work[\"doctor\"])\nprint(work.get(\"engineer\"))"
},
{
"alpha_fraction": 0.49275362491607666,
"alphanum_fraction": 0.510869562625885,
"avg_line_length": 22,
"blob_id": "4e9ce436846980c43eadd0682e3d12e80c10c291",
"content_id": "f28710f6bf799571f6ad13674d3975ef9d5ab237",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 12,
"path": "/classoop.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "class Fibonacci():\n def __init__(self,a,b):\n self.a=a\n self.b=b\n def series(self):\n while(True):\n yield(self.b)\n self.a,self.b=self.b,self.a+self.b\nf=Fibonacci(0,1)\nfor r in f.series():\n if r>100: break\n print(r,end=\" \")\n"
},
{
"alpha_fraction": 0.5890411138534546,
"alphanum_fraction": 0.5890411138534546,
"avg_line_length": 23.33333396911621,
"blob_id": "c8a312f6a1eaa8dbebf726a6b162128a14b9dd0f",
"content_id": "ffbe8e470aed54a0ec55e7a6abe5e0b7b90b7681",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 3,
"path": "/forloop.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "fh=open(\"d://q.txt\")\nfor line in fh.readlines():\n print(line,end=\" \")\n"
},
{
"alpha_fraction": 0.5137614607810974,
"alphanum_fraction": 0.5412843823432922,
"avg_line_length": 14.714285850524902,
"blob_id": "bf36736b346a4791313a1f39b668678cd86eedd2",
"content_id": "70e1c4fe94ed272526507bfcb5ecb00a343749d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 7,
"path": "/keywordsargs.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "def add_number(*args):\n total=0\n for a in args:\n total+=a\n print(total)\n \nadd_number(3,2)"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.5428571701049805,
"avg_line_length": 18.18181800842285,
"blob_id": "ef72efdae10bc2d03dcea816d406e1d3a433fd43",
"content_id": "4b455364f0ef7c10b24f5e6000b5f5dd98ec2d16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 11,
"path": "/forstatements.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "words=['cat','jack','windowsd']\nfor w in words:\n print(w,len(w))\n\nfor a in words[:]:\n if len(a)>6:\n words.insert(0,a)\n\na=['mary','had','a','little','lamb']\nfor i in range(len(a)):\n print(i,a[i])"
},
{
"alpha_fraction": 0.522292971611023,
"alphanum_fraction": 0.5350318551063538,
"avg_line_length": 25.16666603088379,
"blob_id": "afbf1f8128461a7ce37a70efbe4b7f1e226be86c",
"content_id": "a1f90f75fef5f1d024991d70fa4cd6aca3a1ed99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 6,
"path": "/loop.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "a,b=0,1\nif a>b:\n print('a {} is not less than b ({})'.format(a,b))\nelse:\n print('a {} is less than b ({})'.format(a,b))\nprint(\"foo\" if a<b else \"bar\")\n"
},
{
"alpha_fraction": 0.5769230723381042,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 17.714284896850586,
"blob_id": "dddf1d98ccf99277b861ead83abfb3e6e5e47d42",
"content_id": "03aa379b7b8c638568572a1a35ad4ab0e219d432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 7,
"path": "/ifstatements.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "x=int(input('please enter an integer: '))\nif x<0:\n print('invalid')\nelif x==0:\n print('zero')\nelif x>0:\n print('awesome')"
},
{
"alpha_fraction": 0.45390069484710693,
"alphanum_fraction": 0.4822694957256317,
"avg_line_length": 14.666666984558105,
"blob_id": "42000deda69d173e3cb09952843cbfe96a3ce574",
"content_id": "1a66f1d86a8be3586e7888b908201aa5e9278838",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 18,
"path": "/generatorfunctions.py",
"repo_name": "AshishSingha/PythonPracticeFromLinkedinLearning",
"src_encoding": "UTF-8",
"text": "def isprime(n):\n if n==1:\n return False\n for x in range(2,n):\n if n%x==0:\n return False\n else:\n return True\ndef primes(n=1):\n while(True):\n if isprime(n): yield n\n n +=1\n\n\n\nfor n in primes():\n if n>100:break\n print(n)\n"
}
] | 9 |
dominguezjavier/CIS_104 | https://github.com/dominguezjavier/CIS_104 | 3761294ba5d014328f68ba4c0a66507da29e988a | ac7da199812eaf9becb387d1eac9f87f94d97322 | dcedfc1b2fca6d2b2c3874d30627e4fdc44029e6 | refs/heads/master | "2020-04-19T08:29:07.073332" | "2019-01-29T02:57:18" | "2019-01-29T02:57:18" | 168,078,508 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 14.666666984558105,
"blob_id": "48263e9b926ca1cb7faffa68e8f7d9458e77380a",
"content_id": "d81f90b893130327ea9887c3254f6ea877f85739",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 3,
"path": "/Python_Home_Work1/Hello.py",
"repo_name": "dominguezjavier/CIS_104",
"src_encoding": "UTF-8",
"text": "x = \"Good Bye \"\r\ny = \"Cruel World\"\r\nprint(x + y)"
},
{
"alpha_fraction": 0.6717724204063416,
"alphanum_fraction": 0.6827133297920227,
"avg_line_length": 55.125,
"blob_id": "f7835655830de0540e5998e40bc9bd4ebd23aceb",
"content_id": "03ecbf020df4f8857d909a9e1db447d8b246f48a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 8,
"path": "/Python_Home_Work1/H1P1.PY",
"repo_name": "dominguezjavier/CIS_104",
"src_encoding": "UTF-8",
"text": "first_name = input(\"please input your first name: \")\r\nlast_name = input(\"please input your last name: \")\r\nage = int(input(\"please input your age: \"))\r\nconfidence = input(\"please express your confidence in programmers 0 - 100%: \")\r\nage_dog_years = int(age *7)\r\nprint(\"Hello\", first_name, last_name, \"nice to meet you!\")\r\nprint(\"You are\", age_dog_years, \"in dog years\")\r\nprint(\"you might be \", age, \"in human years, but in dog years you are\", age_dog_years)\r\n"
},
{
"alpha_fraction": 0.5727699398994446,
"alphanum_fraction": 0.6291079521179199,
"avg_line_length": 33.83333206176758,
"blob_id": "a8e6a58507c5d9f02f254d397cbe745331a387ed",
"content_id": "de427963ad17159f4f9245b9cf765fd769ff0145",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 6,
"path": "/Python_Home_Work1/List_Excercise_In_Class_01_28_2019.py",
"repo_name": "dominguezjavier/CIS_104",
"src_encoding": "UTF-8",
"text": "coin value = [1, 5, 10, 25, 50 100]\r\nlist = [pennies, nickels, dimes, quarters, half dollars, dollars]\r\nfor coin in list:\r\ncoin - int(input(how many \" + coin + \" ya got?: \"))\r\nvalue_in_dollars = 0\r\nvalue list = []"
}
] | 3 |
FWFWUU/wikidea | https://github.com/FWFWUU/wikidea | 4544c81f002029b1081db39c63ac39cdd54426d0 | 2f27f7e484355f24812db586c2999f0f2581f96d | c28fc14ec6af39e05f943b91c457a1ecd87dc314 | refs/heads/main | "2023-07-26T18:41:08.445381" | "2021-09-17T14:26:59" | "2021-09-17T14:26:59" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6182608604431152,
"alphanum_fraction": 0.6265217661857605,
"avg_line_length": 27.139240264892578,
"blob_id": "9cec288e4ad08f709bdd56177b62e51400608985",
"content_id": "db7bedac71d214d50da202962eb8244e7f5978df",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2300,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 79,
"path": "/wikidea.py",
"repo_name": "FWFWUU/wikidea",
"src_encoding": "UTF-8",
"text": "'''\r\nCreated by https://github.com/asciidea/wikidea\r\nV. 1.0.0\r\nAuthor: Alisson\r\n'''\r\n\r\nfrom bs4 import BeautifulSoup as bs\r\nimport requests\r\nimport argparse\r\nimport json\r\n\r\nparser = argparse.ArgumentParser()\r\n\r\nhelps = [\r\n\t\"--wiki <article name> return wikipedia article text.\",\r\n\t\"--index <paragraph index> set wikipedia article page paragraph.\",\r\n\t\"--lang <wikipedia language en | pt | es | ...> set wikipedia server region.\",\r\n\t\"--find <article keyword> search article names\"\r\n]\r\n\r\ndef create_parse(_parser):\r\n\t_parser.add_argument(\"--wiki\", dest = 'wiki_l', required=False, default='', help=helps[0])\r\n\t_parser.add_argument(\"--index\", dest = 'wiki_p', required=False, type = int, default = -1, help=helps[1])\r\n\t_parser.add_argument(\"--lang\", dest = 'wiki_e', required=False, type=str, default='en', help=helps[2])\r\n\t_parser.add_argument(\"--find\", dest = 'wiki_f', required=False, type=str, help=helps[3])\r\n\tpass\r\ncreate_parse(parser)\r\nargs = parser.parse_args()\r\n\r\ndef make_search(r, index, l):\r\n\tu = requests.get(\"https://{}.wikipedia.org/wiki/{}\".format(l, r)).text\r\n\tv = bs(u, \"html.parser\")\r\n\tw = v.find(\"div\", {\r\n\t\t\"class\": \"mw-parser-output\"\r\n\t\t})\r\n\r\n\tif w:\r\n\t\tx = bs(w.decode(), \"html.parser\").find_all(\"p\")\r\n\t\r\n\t\tif not index < 0:\r\n\t\t\tif index < len(x):\r\n\t\t\t\tx = x[index]\r\n\t\t\telse:\r\n\t\t\t\tprint(\"$ index > page paragraphs! changed index to 0\")\r\n\t\t\t\tx = x[0]\r\n\t\t\tprint(x.text)\r\n\t\telse:\r\n\t\t\tfor i in range(len(x)):\r\n\t\t\t\tprint(x[i].text)\r\n\telse:\r\n\t\tprint(\"this article not exists\")\r\n\t\r\ndef search_article(lang, keyword):\r\n\tr = requests.get(\"https://{}.wikipedia.org/w/api.php?action=opensearch&search={}\".format(lang, keyword)).text\r\n\tsearch_values = json.loads(r)[1]\r\n\t\r\n\tfor i in range(len(search_values)):\r\n\t\tprint(i, \" {}\".format(search_values[i]))\r\n\t\r\n\t_max = len(search_values)\r\n\r\n\tif len(search_values) > 0:\r\n\t\twhile True:\r\n\t\t\tx = input(\"Type search index number: \")\r\n\t\t\tif x.isnumeric():\r\n\t\t\t\tif int(x) < _max and int(x) > -1:\r\n\t\t\t\t\tprint(\"++in your marks...\")\r\n\t\t\t\t\tmake_search(search_values[int(x)], args.wiki_p, args.wiki_e)\r\n\t\t\t\t\tbreak\r\n\telse:\r\n\t\tprint(\"error 404! ooooohhh, sorry!\")\r\n\tpass\r\n\r\nif len(args.wiki_l) > 0:\r\n\tmake_search(args.wiki_l, args.wiki_p, args.wiki_e)\r\nelif args.wiki_f:\r\n\tsearch_article(args.wiki_e, args.wiki_f)\r\nelse:\r\n\tprint(\"$ --wiki needs a article name\")"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.725806474685669,
"avg_line_length": 24.83333396911621,
"blob_id": "96a974c6dc4a46adc5fe68f302b95c687346d28d",
"content_id": "77f609ddaedb9d2f9ab323e652fce1d27d89f268",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 310,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 12,
"path": "/README.md",
"repo_name": "FWFWUU/wikidea",
"src_encoding": "UTF-8",
"text": "# wikidea\nCLI for wikipedia article searches\n\nwikidea.py\n--\n--wiki < article name > return wikipedia article text.\n\n--index < paragraph index > set wikipedia article page paragraph.\n\n--lang < wikipedia language en | pt | es | ... > set wikipedia server region.\n\n--find < article keyword > search article names\n"
}
] | 2 |
f1ed/ML-HW2 | https://github.com/f1ed/ML-HW2 | 6f63719000ae8f4df9b05374316be7500ca5bfa5 | d53f9b0106f9d91264e74942ef3503bb0d9bfc33 | 8be7f3ae3d97f8ce375d7e8ac59fb0a9a5d13bc9 | refs/heads/master | "2021-05-27T09:36:29.930923" | "2020-04-15T10:06:49" | "2020-04-15T10:06:49" | 254,251,157 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5678889751434326,
"alphanum_fraction": 0.5793572068214417,
"avg_line_length": 29.824323654174805,
"blob_id": "06c04c9b614bceb013fe51aea92a60960e822357",
"content_id": "073eb1463a1298d15ad38b0bede9be907b1a3f2b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7063,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 222,
"path": "/logistic.py",
"repo_name": "f1ed/ML-HW2",
"src_encoding": "UTF-8",
"text": "#################\r\n# Data:2020-04-05\r\n# Author: Fred Lau\r\n# ML-Lee: HW2 : Binary Classification\r\n###########################################################\r\nimport numpy as np\r\nimport csv\r\nimport sys\r\nimport matplotlib.pyplot as plt\r\n\r\n##########################################################\r\n# prepare data\r\nX_train_fpath = './data/X_train'\r\nY_train_fpath = './data/Y_Train'\r\nX_test_fpath = './data/X_test'\r\noutput_fpath = './logistic_output/output_logistic.csv'\r\nfpath = './logistic_output/logistic'\r\n\r\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\r\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\r\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\r\n\r\nX_train = X_train[1:, 1:]\r\nY_train = Y_train[1:, 1:]\r\nX_test = X_test[1:, 1:]\r\n\r\n\r\ndef _normalization(X, train=True, X_mean=None, X_std=None):\r\n # This function normalize columns of X.\r\n # Output:\r\n # X: normalized data\r\n # X_mean, X_std\r\n if train:\r\n X_mean = np.mean(X, axis=0)\r\n X_std = np.std(X, axis=0)\r\n for j in range(X.shape[1]):\r\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\r\n return X, X_mean, X_std\r\n\r\n\r\ndef _train_dev_split(X, Y, dev_ratio=0.25):\r\n # This function splits data into training set and development set.\r\n train_size = int(X.shape[0] * (1 - dev_ratio))\r\n return X[:train_size], Y[:train_size], X[train_size:], Y[train_size:]\r\n\r\n\r\n# Normalize train_data and test_data\r\nX_train, X_mean, X_std = _normalization(X_train, train=True)\r\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\r\n\r\n# Split data into train data and development data\r\ndev_ratio = 0.1\r\nX_train, Y_train, X_dev, Y_dev = _train_dev_split(X_train, Y_train, dev_ratio=dev_ratio)\r\n\r\ntrain_size = X_train.shape[0]\r\ndev_size = X_dev.shape[0]\r\ntest_size = X_test.shape[0]\r\ndata_dim = X_train.shape[1]\r\n\r\nwith open(fpath, 'w') as f:\r\n f.write('In logistic model:\\n')\r\n f.write('Size of Training set: {}\\n'.format(train_size))\r\n f.write('Size of development set: {}\\n'.format(dev_size))\r\n f.write('Size of test set: {}\\n'.format(test_size))\r\n f.write('Dimension of data: {}\\n'.format(data_dim))\r\n\r\n\r\nnp.random.seed(0)\r\n\r\n###############################################################\r\n# useful function\r\n\r\ndef _shuffle(X, Y):\r\n # This function shuffles two two list/array, X and Y, together.\r\n randomize = np.arange(len(X))\r\n np.random.shuffle(randomize)\r\n return X[randomize], Y[randomize]\r\n\r\ndef _sigmod(z):\r\n # Sigmod function can be used to calculate probability\r\n # To avoid overflow\r\n return np.clip(1 / (1.0 + np.exp(-z)), 1e-8, 1 - (1e-8))\r\n\r\n\r\ndef _f(X, w, b):\r\n # This is the logistic function, parameterized by w and b\r\n #\r\n # Arguments:\r\n # X: input data, shape = [batch_size, data_dimension]\r\n # w: weight vector, shape = [data_dimension, 1]\r\n # b: bias, scalar\r\n # Output:\r\n # predict probability of each row of X being positively labeled, shape = [batch_size, 1]\r\n return _sigmod(np.dot(X, w) + b)\r\n\r\n\r\ndef _predict(X, w, b):\r\n # This fucntion returns a truth value prediction for each row of X by logistic regression\r\n return np.around(_f(X, w, b)).astype(np.int)\r\n\r\n\r\ndef _accuracy(Y_pred, Y_label):\r\n # This function calculates prediction accuracy\r\n # Y_pred: 0 or 1\r\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\r\n return acc\r\n\r\n\r\ndef _cross_entropy_loss(y_pred, Y_label):\r\n # This function calculates the cross entropy of Y_pred and Y_label\r\n #\r\n # Argument:\r\n # y_pred: predictions, float vector\r\n # Y_label: truth labels, bool vector\r\n cross_entropy = - np.dot(Y_label.T, np.log(y_pred)) - np.dot((1 - Y_label).T, np.log(1 - y_pred))\r\n return cross_entropy[0][0]\r\n\r\n\r\ndef _gradient(X, Y_label, w, b):\r\n # This function calculates the gradient of cross entropy\r\n # X, Y_label, shape = [batch_size, ]\r\n y_pred = _f(X, w, b)\r\n pred_error = Y_label - y_pred\r\n w_grad = - np.dot(X.T, pred_error)\r\n b_grad = - np.sum(pred_error)\r\n return w_grad, float(b_grad)\r\n\r\n\r\n#######################################\r\n# training by logistic model\r\n\r\n# Initial weights and bias\r\nw = np.zeros((data_dim, 1))\r\nb = np.float(0.)\r\nw_grad_sum = np.full((data_dim, 1), 1e-8) # avoid divided by zeros\r\nb_grad_sum = np.float(1e-8)\r\n\r\n# Some parameters for training\r\nepoch = 20\r\nbatch_size = 2**3\r\nlearning_rate = 0.2\r\n\r\n# Keep the loss and accuracy history at every epoch for plotting\r\ntrain_loss = []\r\ndev_loss = []\r\ntrain_acc = []\r\ndev_acc = []\r\n\r\n# Iterative training\r\nfor it in range(epoch):\r\n # Random shuffle at every epoch\r\n X_train, Y_train = _shuffle(X_train, Y_train)\r\n\r\n # Mini-batch training\r\n for id in range(int(np.floor(train_size / batch_size))):\r\n X = X_train[id*batch_size: (id+1)*batch_size]\r\n Y = Y_train[id*batch_size: (id+1)*batch_size]\r\n\r\n # calculate gradient\r\n w_grad, b_grad = _gradient(X, Y, w, b)\r\n\r\n # adagrad gradient update\r\n w_grad_sum = w_grad_sum + w_grad**2\r\n b_grad_sum = b_grad_sum + b_grad**2\r\n w_ada = np.sqrt(w_grad_sum)\r\n b_ada = np.sqrt(b_grad_sum)\r\n w = w - learning_rate * w_grad / np.sqrt(w_grad_sum)\r\n b = b - learning_rate * b_grad / np.sqrt(b_grad_sum)\r\n\r\n # compute loss and accuracy of training set and development set at every epoch\r\n y_train_pred = _f(X_train, w, b)\r\n Y_train_pred = np.around(y_train_pred)\r\n train_loss.append(_cross_entropy_loss(y_train_pred, Y_train)/train_size)\r\n train_acc.append(_accuracy(Y_train_pred, Y_train))\r\n\r\n y_dev_pred = _f(X_dev, w, b)\r\n Y_dev_pred = np.around(y_dev_pred)\r\n dev_loss.append(_cross_entropy_loss(y_dev_pred, Y_dev)/dev_size)\r\n dev_acc.append(_accuracy(y_dev_pred, Y_dev))\r\n\r\nwith open(fpath, 'a') as f:\r\n f.write('Training loss: {}\\n'.format(train_loss[-1]))\r\n f.write('Training accuracy: {}\\n'.format(train_acc[-1]))\r\n f.write('Development loss: {}\\n'.format(dev_loss[-1]))\r\n f.write('Development accuracy: {}\\n'.format(dev_acc[-1]))\r\n\r\n###################\r\n# Plotting Loss and accuracy curve\r\n# Loss curve\r\nplt.plot(train_loss, label='train')\r\nplt.plot(dev_loss, label='dev')\r\nplt.title('Loss')\r\nplt.legend()\r\nplt.savefig('./logistic_output/loss.png')\r\nplt.show()\r\n\r\nplt.plot(train_acc, label='train')\r\nplt.plot(dev_acc, label='dev')\r\nplt.title('Accuracy')\r\nplt.legend()\r\nplt.savefig('./logistic_output/acc.png')\r\nplt.show()\r\n\r\n#################################\r\n# Predict\r\npredictions = _predict(X_test, w, b)\r\nwith open(output_fpath, 'w') as f:\r\n f.write('id, label\\n')\r\n for id, label in enumerate(predictions):\r\n f.write('{}, {}\\n'.format(id, label[0]))\r\n\r\n###############################\r\n# Output the weights and bias\r\nind = (np.argsort(np.abs(w), axis=0)[::-1]).reshape(1, -1)\r\n\r\nwith open(X_test_fpath) as f:\r\n content = f.readline().strip('\\n').split(',')\r\ncontent = content[1:]\r\n\r\nwith open(fpath, 'a') as f:\r\n for i in ind[0, 0: 10]:\r\n f.write('{}: {}\\n'.format(content[i], w[i]))"
},
{
"alpha_fraction": 0.5887850522994995,
"alphanum_fraction": 0.6090342402458191,
"avg_line_length": 33.037879943847656,
"blob_id": "3b777c99280d98ad8e66aefd66210e32390a7239",
"content_id": "e2d4198df4bcb3bf5bc6c6311f510843fe929dea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4494,
"license_type": "permissive",
"max_line_length": 169,
"num_lines": 132,
"path": "/generative.py",
"repo_name": "f1ed/ML-HW2",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\n\nnp.random.seed(0)\n##############################################\n# Prepare data\nX_train_fpath = './data/X_train'\nY_train_fpath = './data/Y_train'\nX_test_fpath = './data/X_test'\noutput_fpath = './generative_output/output_{}.csv'\nfpath = './generative_output/generative'\n\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\n\nX_train = X_train[1:, 1:]\nY_train = Y_train[1:, 1:]\nX_test = X_test[1:, 1:]\n\ndef _normalization(X, train=True, X_mean=None, X_std=None):\n # This function normalize columns of X\n # Output:\n # X: normalized data\n # X_mean, X_std\n if train:\n X_mean = np.mean(X, axis=0)\n X_std = np.std(X, axis=0)\n for j in range(X.shape[1]):\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\n return X, X_mean, X_std\n\n# Normalize train_data and test_data\nX_train, X_mean, X_std = _normalization(X_train, train=True)\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\n\ntrain_size = X_train.shape[0]\ntest_size = X_test.shape[0]\ndata_dim = X_train.shape[1]\n\nwith open(fpath, 'w') as f:\n f.write('In generative model:\\n')\n f.write('Size of training data: {}\\n'.format(train_size))\n f.write('Size of test set: {}\\n'.format(test_size))\n f.write('Dimension of data: {}\\n\\n'.format(data_dim))\n\n########################\n# Useful functions\ndef _sigmod(z):\n # Sigmod function can be used to compute probability\n # To avoid overflow\n return np.clip(1/(1.0 + np.exp(-z)), 1e-8, 1-(1e-8))\n\ndef _f(X, w, b):\n # This function is the linear part of sigmod function\n # Arguments:\n # X: input data, shape = [size, data_dimension]\n # w: weight vector, shape = [data_dimension, 1]\n # b: bias, scalar\n # Output:\n # predict probabilities\n return _sigmod(np.dot(X, w) + b)\n\ndef _predict(X, w, b):\n # This function returns a truth value prediction for each row of X belonging to class1(label=0)\n return np.around(_f(X, w, b)).astype(np.int)\n\ndef _accuracy(Y_pred, Y_label):\n # This function computes prediction accuracy\n # Y_pred: 0 or 1\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\n return acc\n\n#######################\n# Generative Model: closed-form solution, can be computed directly\n\n# compute in-class mean\nX_train_0 = np.array([x for x, y in zip(X_train, Y_train) if y == 0])\nX_train_1 = np.array([x for x, y in zip(X_train, Y_train) if y == 1])\n\nmean_0 = np.mean(X_train_0, axis=0)\nmean_1 = np.mean(X_train_1, axis=0)\n\n# compute in-class covariance\ncov_0 = np.zeros(shape=(data_dim, data_dim))\ncov_1 = np.zeros(shape=(data_dim, data_dim))\n\nfor x in X_train_0:\n # (D,1)@(1,D) np.matmul(np.transpose([x]), x)\n cov_0 += np.matmul(np.transpose([x - mean_0]), [x - mean_0]) / X_train_0.shape[0]\nfor x in X_train_1:\n cov_1 += np.dot(np.transpose([x - mean_1]), [x - mean_1]) / X_train_1.shape[0]\n\n# shared covariance\ncov = (cov_0 * X_train_0.shape[0] + cov_1 * X_train_1.shape[0]) / (X_train.shape[0])\n\n# compute weights and bias\n# Since covariance matrix may be nearly singular, np.linalg.in() may give a large numerical error.\n# Via SVD decomposition, one can get matrix inverse efficiently and accurately.\n# cov = u@s@vh\n# cov_inv = dot(vh.T * 1 / s, u.T)\nu, s, vh = np.linalg.svd(cov, full_matrices=False)\ns_inv = s # s_inv avoid <1e-8\nfor i in range(s.shape[0]):\n if s[i] < (1e-8):\n break\n s_inv[i] = 1./s[i]\ncov_inv = np.matmul(vh.T * s_inv, u.T)\n\nw = np.matmul(cov_inv, np.transpose([mean_0 - mean_1]))\nb = (-0.5) * np.dot(mean_0, np.matmul(cov_inv, mean_0.T)) + (0.5) * np.dot(mean_1, np.matmul(cov_inv, mean_1.T)) + np.log(float(X_train_0.shape[0]) / X_train_1.shape[0])\n\n# compute accuracy on training set\nY_train_pred = 1 - _predict(X_train, w, b)\nwith open(fpath, 'a') as f:\n f.write('\\nTraining accuracy: {}\\n'.format(_accuracy(Y_train_pred, Y_train)))\n\n# Predict\npredictions = 1 - _predict(X_test, w, b)\nwith open(output_fpath.format('generative'), 'w') as f:\n f.write('id, label\\n')\n for i, label in enumerate(predictions):\n f.write('{}, {}\\n'.format(i, label))\n\n# Output the most significant weight\nwith open(X_test_fpath) as f:\n content = f.readline().strip('\\n').split(',')\ncontent = content[1:]\n\nind = np.argsort(np.abs(np.concatenate(w)))[::-1]\nwith open(fpath, 'a')as f:\n for i in ind[0:10]:\n f.write('{}: {}\\n'.format(content[i], w[i]))\n"
},
{
"alpha_fraction": 0.5874502062797546,
"alphanum_fraction": 0.6181250810623169,
"avg_line_length": 27.298477172851562,
"blob_id": "83ded2bdfac14718b429ea01bc6b41254e186d7e",
"content_id": "63afa3ee3efd3225215736e9a2a179b734327a17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 30005,
"license_type": "permissive",
"max_line_length": 477,
"num_lines": 985,
"path": "/readme.md",
"repo_name": "f1ed/ML-HW2",
"src_encoding": "UTF-8",
"text": "这篇文章中,手刻实现了「机器学习-李宏毅」的HW2-Binary Income Prediction的作业。分别用Logistic Regression和Generative Model实现。\n包括对数据集的处理,训练模型,可视化,预测等。\n有关HW2的相关数据、源代码、预测结果等,欢迎光临小透明的[博客](https://github.com/f1ed/ML-HW2)\n主要吧,博客公式显示没问题,GitHub的公式显示还没修QAQ。\n<!--more-->\n# Task introduction and Dataset\n\n Kaggle competition: [link](https://www.kaggle.com/c/ml2020spring-hw2) \n\n**Task: Binary Classification**\n\nPredict whether the income of an individual exceeds $50000 or not ?\n\n**Dataset: ** Census-Income (KDD) Dataset\n\n(Remove unnecessary attributes and balance the ratio between positively and negatively labeled data)\n\n\n\n# Feature Format\n\n- train.csv, test_no_label.csv【都是没有处理过的数据,可作为数据参考和优化参考】\n\n - text-based raw data\n\n - unnecessary attributes removed, positive/negative ratio balanced.\n\n- X_train, Y_train, X_test【已经处理过的数据,可以直接使用】\n\n - discrete features in train.csv => one-hot encoding in X_train (education, martial state...)\n\n - continuous features in train.csv => remain the same in X_train (age, capital losses...).\n\n - X_train, X_test : each row contains one 510-dim feature represents a sample.\n\n - Y_train: label = 0 means “<= 50K” 、 label = 1 means “ >50K ”\n\n注:数据集超大,用notepad查看比较舒服;调试时,也可以先调试小一点的数据集。\n\n# Logistic Regression\n\nLogistic Regression 原理部分见[这篇博客](https://f1ed.github.io/2020/04/01/Classification2/)。\n\n## Prepare data\n\n本文直接使用X_train Y_train X_test 已经处理好的数据集。\n\n``` py\n# prepare data\nX_train_fpath = './data/X_train'\nY_train_fpath = './data/Y_Train'\nX_test_fpath = './data/X_test'\noutput_fpath = './logistic_output/output_logistic.csv'\nfpath = './logistic_output/logistic'\n\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\n\nX_train = X_train[1:, 1:]\nY_train = Y_train[1:, 1:]\nX_test = X_test[1:, 1:]\n\n\n```\n\n统计一下数据集:\n\n```py\ntrain_size = X_train.shape[0]\ndev_size = X_dev.shape[0]\ntest_size = X_test.shape[0]\ndata_dim = X_train.shape[1]\n\nwith open(fpath, 'w') as f:\n f.write('In logistic model:\\n')\n f.write('Size of Training set: {}\\n'.format(train_size))\n f.write('Size of development set: {}\\n'.format(dev_size))\n f.write('Size of test set: {}\\n'.format(test_size))\n f.write('Dimension of data: {}\\n'.format(data_dim))\n\n```\n\n结果如下:\n\n```ps\nIn logistic model:\nSize of Training set: 48830\nSize of development set: 5426\nSize of test set: 27622\nDimension of data: 510\n```\n\n### normalize\n\nnormalize data.\n\n对于train data,计算出每个feature的mean和std,保存下来用来normalize test data。\n\n代码如下:\n\n``` py\ndef _normalization(X, train=True, X_mean=None, X_std=None):\n # This function normalize columns of X.\n # Output:\n # X: normalized data\n # X_mean, X_std\n if train:\n X_mean = np.mean(X, axis=0)\n X_std = np.std(X, axis=0)\n for j in range(X.shape[1]):\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\n return X, X_mean, X_std\n \n# Normalize train_data and test_data\nX_train, X_mean, X_std = _normalization(X_train, train=True)\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\n\n```\n\n### Development set split\n\n在logistic regression中使用的gradient,没有closed-form解,所以在train set中划出一部分作为development set 优化参数。\n\n``` py\ndef _train_dev_split(X, Y, dev_ratio=0.25):\n # This function splits data into training set and development set.\n train_size = int(X.shape[0] * (1 - dev_ratio))\n return X[:train_size], Y[:train_size], X[train_size:], Y[train_size:]\n\n# Split data into train data and development data\ndev_ratio = 0.1\nX_train, Y_train, X_dev, Y_dev = _train_dev_split(X_train, Y_train, dev_ratio=dev_ratio)\n```\n\n\n\n## Useful function\n\n### _shuffle(X, Y)\n\n本文使用mini-batch gradient。\n\n所以在每次epoch时,以相同顺序同时打乱X_train,Y_train数组,再mini-batch。\n\n```py\nnp.random.seed(0)\n\ndef _shuffle(X, Y):\n # This function shuffles two two list/array, X and Y, together.\n randomize = np.arange(len(X))\n np.random.shuffle(randomize)\n return X[randomize], Y[randomize]\n\n```\n\n\n\n### _sigmod(z)\n\n计算 $\\frac{1}{1+e^{-z}}$ ,注意:防止溢出,给函数返回值规定上界和下界。\n\n```py\ndef _sigmod(z):\n # Sigmod function can be used to compute probability\n # To avoid overflow\n return np.clip(1/(1.0 + np.exp(-z)), 1e-8, 1-(1e-8))\n\n```\n\n### _f(X, w, b)\n\n是sigmod函数的输入,linear part。\n\n- 输入:\n - X:shape = [size, data_dimension]\n - w:weight vector, shape = [data_dimension, 1]\n - b: bias, scalar\n- 输出:\n - 属于Class 1的概率(Label=0,即收入小于$50k的概率)\n\n``` py\ndef _f(X, w, b):\n # This function is the linear part of sigmod function\n # Arguments:\n # X: input data, shape = [size, data_dimension]\n # w: weight vector, shape = [data_dimension, 1]\n # b: bias, scalar\n # Output:\n # predict probabilities\n return _sigmod(np.dot(X, w) + b)\n \n```\n\n### _predict(X, w, b)\n\n预测Label=0?(0或者1,不是概率)\n\n```py\ndef _predict(X, w, b):\n # This function returns a truth value prediction for each row of X belonging to class1(label=0)\n return np.around(_f(X, w, b)).astype(np.int)\n\n```\n\n### _accuracy(Y_pred, Y_label)\n\n计算预测出的结果(0或者1)和真实结果的正确率。\n\n这里使用 $1-\\overline{error}$ 来表示正确率。\n\n```py\ndef _accuracy(Y_pred, Y_label):\n # This function calculates prediction accuracy\n # Y_pred: 0 or 1\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\n return acc\n\n```\n\n### _cross_entropy_loss(y_pred, Y_label)\n\n计算预测出的概率(是sigmod的函数输出)和真实结果的交叉熵。\n\n计算公式为: $\\sum_n {C(y_{pred},Y_{label})}=-\\sum[Y_{label}\\ln{y_{pred}}+(1-Y_{label})\\ln(1-{y_{pred}})]$ \n\n```py\ndef _cross_entropy_loss(y_pred, Y_label):\n # This function calculates the cross entropy of Y_pred and Y_label\n #\n # Argument:\n # y_pred: predictions, float vector\n # Y_label: truth labels, bool vector\n cross_entropy = - np.dot(Y_label.T, np.log(y_pred)) - np.dot((1 - Y_label).T, np.log(1 - y_pred))\n return cross_entropy[0][0]\n\n```\n\n### _gradient(X, Y_label, w, b)\n\n和Regression的最小二乘一样。(严谨的说,最多一个系数不同)\n\n```\ndef _gradient(X, Y_label, w, b):\n # This function calculates the gradient of cross entropy\n # X, Y_label, shape = [batch_size, ]\n y_pred = _f(X, w, b)\n pred_error = Y_label - y_pred\n w_grad = - np.dot(X.T, pred_error)\n b_grad = - np.sum(pred_error)\n return w_grad, float(b_grad)\n```\n\n## Training (Adagrad)\n\n初始化一些参数。\n\n**这里特别注意** :\n\n由于adagrad的参数更新是 $w \\longleftarrow w-\\eta \\frac{gradient}{ \\sqrt{gradsum}}$ .\n\n**防止除0**,初始化gradsum的值为一个较小值。\n\n```py\n# training by logistic model\n\n# Initial weights and bias\nw = np.zeros((data_dim, 1))\nb = np.float(0.)\nw_grad_sum = np.full((data_dim, 1), 1e-8) # avoid divided by zeros\nb_grad_sum = np.float(1e-8)\n\n# Some parameters for training\nepoch = 20\nbatch_size = 2**3\nlearning_rate = 0.2\n\n```\n\n### Adagrad\n\nAagrad具体原理见[这篇博客](https://f1ed.github.io/2020/03/01/Gradient/)的1.2节。\n\n迭代更新时,每次epoch计算一次loss和accuracy,以便可视化更新过程,调整参数。\n\n``` py\n# Keep the loss and accuracy history at every epoch for plotting\ntrain_loss = []\ndev_loss = []\ntrain_acc = []\ndev_acc = []\n\n# Iterative training\nfor it in range(epoch):\n # Random shuffle at every epoch\n X_train, Y_train = _shuffle(X_train, Y_train)\n\n # Mini-batch training\n for id in range(int(np.floor(train_size / batch_size))):\n X = X_train[id*batch_size: (id+1)*batch_size]\n Y = Y_train[id*batch_size: (id+1)*batch_size]\n\n # calculate gradient\n w_grad, b_grad = _gradient(X, Y, w, b)\n\n # adagrad gradient update\n w_grad_sum = w_grad_sum + w_grad**2\n b_grad_sum = b_grad_sum + b_grad**2\n w_ada = np.sqrt(w_grad_sum)\n b_ada = np.sqrt(b_grad_sum)\n w = w - learning_rate * w_grad / np.sqrt(w_grad_sum)\n b = b - learning_rate * b_grad / np.sqrt(b_grad_sum)\n\n # compute loss and accuracy of training set and development set at every epoch\n y_train_pred = _f(X_train, w, b)\n Y_train_pred = np.around(y_train_pred)\n train_loss.append(_cross_entropy_loss(y_train_pred, Y_train)/train_size)\n train_acc.append(_accuracy(Y_train_pred, Y_train))\n\n y_dev_pred = _f(X_dev, w, b)\n Y_dev_pred = np.around(y_dev_pred)\n dev_loss.append(_cross_entropy_loss(y_dev_pred, Y_dev)/dev_size)\n dev_acc.append(_accuracy(y_dev_pred, Y_dev))\n\n```\n\n### Loss & accuracy\n\n输出最后一次迭代的loss和accuracy。\n\n结果如下:\n\n```ps\nTraining loss: 0.2933570286596322\nTraining accuracy: 0.8839238173254147\nDevelopment loss: 0.31029505347634456\nDevelopment accuracy: 0.8336166253549906\n```\n\n画出loss 和 accuracy的更新过程:\n\nloss:\n\n[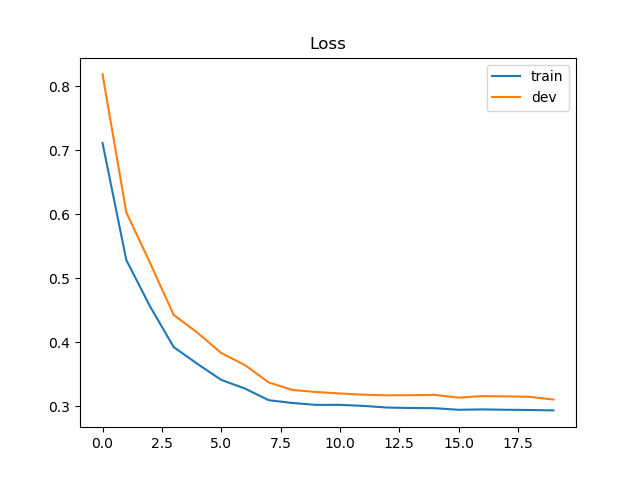](https://imgchr.com/i/JPCjx0) \n\naccuracy:\n\n[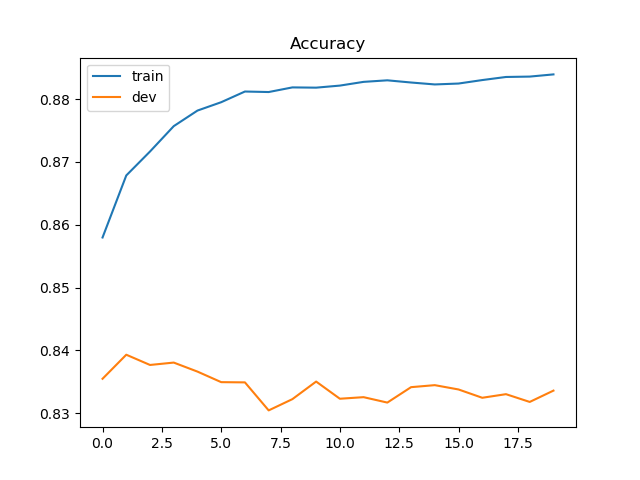](https://imgchr.com/i/JPCxMV) \n\n\n\n由于Feature数量较大,将权重影响最大的feature输出看看:\n\n```ps\nOther Rel <18 spouse of subfamily RP: [7.11323764]\n Grandchild <18 ever marr not in subfamily: [6.8321061]\n Child <18 ever marr RP of subfamily: [6.77322397]\n Other Rel <18 ever marr RP of subfamily: [6.76688406]\n Other Rel <18 never married RP of subfamily: [6.37488958]\n Child <18 spouse of subfamily RP: [5.97717831]\n United-States: [5.53932651]\n Grandchild 18+ spouse of subfamily RP: [5.42948497]\n United-States: [5.41543809]\n Mexico: [4.79920763]\n```\n\n## Code\n\n完整数据集、代码等,欢迎光临小透明[GitHub](https://github.com/f1ed/ML-HW2) \n\n```py\n#################\n# Data:2020-04-05\n# Author: Fred Lau\n# ML-Lee: HW2 : Binary Classification\n###########################################################\nimport numpy as np\nimport csv\nimport sys\nimport matplotlib.pyplot as plt\n\n##########################################################\n# prepare data\nX_train_fpath = './data/X_train'\nY_train_fpath = './data/Y_Train'\nX_test_fpath = './data/X_test'\noutput_fpath = './logistic_output/output_logistic.csv'\nfpath = './logistic_output/logistic'\n\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\n\nX_train = X_train[1:, 1:]\nY_train = Y_train[1:, 1:]\nX_test = X_test[1:, 1:]\n\n\ndef _normalization(X, train=True, X_mean=None, X_std=None):\n # This function normalize columns of X.\n # Output:\n # X: normalized data\n # X_mean, X_std\n if train:\n X_mean = np.mean(X, axis=0)\n X_std = np.std(X, axis=0)\n for j in range(X.shape[1]):\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\n return X, X_mean, X_std\n\n\ndef _train_dev_split(X, Y, dev_ratio=0.25):\n # This function splits data into training set and development set.\n train_size = int(X.shape[0] * (1 - dev_ratio))\n return X[:train_size], Y[:train_size], X[train_size:], Y[train_size:]\n\n\n# Normalize train_data and test_data\nX_train, X_mean, X_std = _normalization(X_train, train=True)\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\n\n# Split data into train data and development data\ndev_ratio = 0.1\nX_train, Y_train, X_dev, Y_dev = _train_dev_split(X_train, Y_train, dev_ratio=dev_ratio)\n\ntrain_size = X_train.shape[0]\ndev_size = X_dev.shape[0]\ntest_size = X_test.shape[0]\ndata_dim = X_train.shape[1]\n\nwith open(fpath, 'w') as f:\n f.write('In logistic model:\\n')\n f.write('Size of Training set: {}\\n'.format(train_size))\n f.write('Size of development set: {}\\n'.format(dev_size))\n f.write('Size of test set: {}\\n'.format(test_size))\n f.write('Dimension of data: {}\\n'.format(data_dim))\n\n\nnp.random.seed(0)\n\n###############################################################\n# useful function\n\ndef _shuffle(X, Y):\n # This function shuffles two two list/array, X and Y, together.\n randomize = np.arange(len(X))\n np.random.shuffle(randomize)\n return X[randomize], Y[randomize]\n\ndef _sigmod(z):\n # Sigmod function can be used to calculate probability\n # To avoid overflow\n return np.clip(1 / (1.0 + np.exp(-z)), 1e-8, 1 - (1e-8))\n\n\ndef _f(X, w, b):\n # This is the logistic function, parameterized by w and b\n #\n # Arguments:\n # X: input data, shape = [batch_size, data_dimension]\n # w: weight vector, shape = [data_dimension, 1]\n # b: bias, scalar\n # Output:\n # predict probability of each row of X being positively labeled, shape = [batch_size, 1]\n return _sigmod(np.dot(X, w) + b)\n\n\ndef _predict(X, w, b):\n # This fucntion returns a truth value prediction for each row of X by logistic regression\n return np.around(_f(X, w, b)).astype(np.int)\n\n\ndef _accuracy(Y_pred, Y_label):\n # This function calculates prediction accuracy\n # Y_pred: 0 or 1\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\n return acc\n\n\ndef _cross_entropy_loss(y_pred, Y_label):\n # This function calculates the cross entropy of Y_pred and Y_label\n #\n # Argument:\n # y_pred: predictions, float vector\n # Y_label: truth labels, bool vector\n cross_entropy = - np.dot(Y_label.T, np.log(y_pred)) - np.dot((1 - Y_label).T, np.log(1 - y_pred))\n return cross_entropy[0][0]\n\n\ndef _gradient(X, Y_label, w, b):\n # This function calculates the gradient of cross entropy\n # X, Y_label, shape = [batch_size, ]\n y_pred = _f(X, w, b)\n pred_error = Y_label - y_pred\n w_grad = - np.dot(X.T, pred_error)\n b_grad = - np.sum(pred_error)\n return w_grad, float(b_grad)\n\n\n#######################################\n# training by logistic model\n\n# Initial weights and bias\nw = np.zeros((data_dim, 1))\nb = np.float(0.)\nw_grad_sum = np.full((data_dim, 1), 1e-8) # avoid divided by zeros\nb_grad_sum = np.float(1e-8)\n\n# Some parameters for training\nepoch = 20\nbatch_size = 2**3\nlearning_rate = 0.2\n\n# Keep the loss and accuracy history at every epoch for plotting\ntrain_loss = []\ndev_loss = []\ntrain_acc = []\ndev_acc = []\n\n# Iterative training\nfor it in range(epoch):\n # Random shuffle at every epoch\n X_train, Y_train = _shuffle(X_train, Y_train)\n\n # Mini-batch training\n for id in range(int(np.floor(train_size / batch_size))):\n X = X_train[id*batch_size: (id+1)*batch_size]\n Y = Y_train[id*batch_size: (id+1)*batch_size]\n\n # calculate gradient\n w_grad, b_grad = _gradient(X, Y, w, b)\n\n # adagrad gradient update\n w_grad_sum = w_grad_sum + w_grad**2\n b_grad_sum = b_grad_sum + b_grad**2\n w_ada = np.sqrt(w_grad_sum)\n b_ada = np.sqrt(b_grad_sum)\n w = w - learning_rate * w_grad / np.sqrt(w_grad_sum)\n b = b - learning_rate * b_grad / np.sqrt(b_grad_sum)\n\n # compute loss and accuracy of training set and development set at every epoch\n y_train_pred = _f(X_train, w, b)\n Y_train_pred = np.around(y_train_pred)\n train_loss.append(_cross_entropy_loss(y_train_pred, Y_train)/train_size)\n train_acc.append(_accuracy(Y_train_pred, Y_train))\n\n y_dev_pred = _f(X_dev, w, b)\n Y_dev_pred = np.around(y_dev_pred)\n dev_loss.append(_cross_entropy_loss(y_dev_pred, Y_dev)/dev_size)\n dev_acc.append(_accuracy(y_dev_pred, Y_dev))\n\nwith open(fpath, 'a') as f:\n f.write('Training loss: {}\\n'.format(train_loss[-1]))\n f.write('Training accuracy: {}\\n'.format(train_acc[-1]))\n f.write('Development loss: {}\\n'.format(dev_loss[-1]))\n f.write('Development accuracy: {}\\n'.format(dev_acc[-1]))\n\n###################\n# Plotting Loss and accuracy curve\n# Loss curve\nplt.plot(train_loss, label='train')\nplt.plot(dev_loss, label='dev')\nplt.title('Loss')\nplt.legend()\nplt.savefig('./logistic_output/loss.png')\nplt.show()\n\nplt.plot(train_acc, label='train')\nplt.plot(dev_acc, label='dev')\nplt.title('Accuracy')\nplt.legend()\nplt.savefig('./logistic_output/acc.png')\nplt.show()\n\n#################################\n# Predict\npredictions = _predict(X_test, w, b)\nwith open(output_fpath, 'w') as f:\n f.write('id, label\\n')\n for id, label in enumerate(predictions):\n f.write('{}, {}\\n'.format(id, label[0]))\n\n###############################\n# Output the weights and bias\nind = (np.argsort(np.abs(w), axis=0)[::-1]).reshape(1, -1)\n\nwith open(X_test_fpath) as f:\n content = f.readline().strip('\\n').split(',')\ncontent = content[1:]\n\nwith open(fpath, 'a') as f:\n for i in ind[0, 0: 10]:\n f.write('{}: {}\\n'.format(content[i], w[i]))\n```\n\n# Generative Model\n\nGenerative Model 原理部分见[这篇博客](https://f1ed.github.io/2020/03/21/Classification1/)\n\n## Prepare data\n\n这部分和Logistic regression一样。\n\n只是,因为generative model有closed-form solution,不需要划分development set。\n\n``` py\n# Prepare data\nX_train_fpath = './data/X_train'\nY_train_fpath = './data/Y_train'\nX_test_fpath = './data/X_test'\noutput_fpath = './generative_output/output_{}.csv'\nfpath = './generative_output/generative'\n\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\n\nX_train = X_train[1:, 1:]\nY_train = Y_train[1:, 1:]\nX_test = X_test[1:, 1:]\n\ndef _normalization(X, train=True, X_mean=None, X_std=None):\n # This function normalize columns of X\n # Output:\n # X: normalized data\n # X_mean, X_std\n if train:\n X_mean = np.mean(X, axis=0)\n X_std = np.std(X, axis=0)\n for j in range(X.shape[1]):\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\n return X, X_mean, X_std\n\n# Normalize train_data and test_data\nX_train, X_mean, X_std = _normalization(X_train, train=True)\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\n\ntrain_size = X_train.shape[0]\ntest_size = X_test.shape[0]\ndata_dim = X_train.shape[1]\n\nwith open(fpath, 'w') as f:\n f.write('In generative model:\\n')\n f.write('Size of training data: {}\\n'.format(train_size))\n f.write('Size of test set: {}\\n'.format(test_size))\n f.write('Dimension of data: {}\\n\\n'.format(data_dim))\n\n```\n\n## Useful functions\n\n``` py\n# Useful functions\ndef _sigmod(z):\n # Sigmod function can be used to compute probability\n # To avoid overflow\n return np.clip(1/(1.0 + np.exp(-z)), 1e-8, 1-(1e-8))\n\ndef _f(X, w, b):\n # This function is the linear part of sigmod function\n # Arguments:\n # X: input data, shape = [size, data_dimension]\n # w: weight vector, shape = [data_dimension, 1]\n # b: bias, scalar\n # Output:\n # predict probabilities\n return _sigmod(np.dot(X, w) + b)\n\ndef _predict(X, w, b):\n # This function returns a truth value prediction for each row of X belonging to class1(label=0)\n return np.around(_f(X, w, b)).astype(np.int)\n\ndef _accuracy(Y_pred, Y_label):\n # This function computes prediction accuracy\n # Y_pred: 0 or 1\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\n return acc\n\n```\n\n## Training\n\n### 公式再推导\n\n计算公式: \n\n{% raw %}\n$$\n\\begin{equation}\\begin{aligned}P\\left(C_{1} | x\\right)&=\\frac{P\\left(x | C_{1}\\right) P\\left(C_{1}\\right)}{P\\left(x | C_{1}\\right) P\\left(C_{1}\\right)+P\\left(x | C_{2}\\right) P\\left(C_{2}\\right)}\\\\&=\\frac{1}{1+\\frac{P\\left(x | C_{2}\\right) P\\left(C_{2}\\right)}{P\\left(x | C_{1}\\right) P\\left(C_{1}\\right)}}\\\\&=\\frac{1}{1+\\exp (-z)} =\\sigma(z)\\qquad(z=\\ln \\frac{P\\left(x | C_{1}\\right) P\\left(C_{1}\\right)}{P\\left(x | C_{2}\\right) P\\left(C_{2}\\right)}\\end{aligned}\\end{equation}\n$$\n{% endraw %}\n\n计算z的过程:\n\n1. 首先计算Prior Probability。\n2. 假设模型是Gaussian的,算出 $\\mu_1,\\mu_2 ,\\Sigma$ 的closed-form solution 。\n3. 根据 $\\mu_1,\\mu_2,\\Sigma$ 计算出 $w,b$ 。\n\n---\n\n1. **计算Prior Probability。** \n\n 程序中用list comprehension处理较简单。\n\n ```py\n # compute in-class mean\n X_train_0 = np.array([x for x, y in zip(X_train, Y_train) if y == 0])\n X_train_1 = np.array([x for x, y in zip(X_train, Y_train) if y == 1])\n \n ```\n\n2. 计算 $\\mu_1,\\mu_2 ,\\Sigma$ (Gaussian)\n\n $\\mu_0=\\frac{1}{C0} \\sum_{n=1}^{C0} x^{n} $ (Label=0)\n\n $\\mu_1=\\frac{1}{C1} \\sum_{n=1}^{C1} x^{n} $ (Label=0)\n\n $\\Sigma_0=\\frac{1}{C0} \\sum_{n=1}^{C0}\\left(x^{n}-\\mu^{*}\\right)^{T}\\left(x^{n}-\\mu^{*}\\right)$ (**注意** :这里的 $x^n,\\mu$ 都是行向量,注意转置的位置)\n\n $\\Sigma_1=\\frac{1}{C1} \\sum_{n=1}^{C1}\\left(x^{n}-\\mu^{*}\\right)^{T}\\left(x^{n}-\\mu^{*}\\right)$ \n\n $\\Sigma=(C0 \\times\\Sigma_0+C1\\times\\Sigma_1)/(C0+C1)$ (shared covariance) \n\n ```py\n mean_0 = np.mean(X_train_0, axis=0)\n mean_1 = np.mean(X_train_1, axis=0)\n \n # compute in-class covariance\n cov_0 = np.zeros(shape=(data_dim, data_dim))\n cov_1 = np.zeros(shape=(data_dim, data_dim))\n \n for x in X_train_0:\n # (D,1)@(1,D) np.matmul(np.transpose([x]), x)\n cov_0 += np.matmul(np.transpose([x - mean_0]), [x - mean_0]) / X_train_0.shape[0]\n for x in X_train_1:\n cov_1 += np.dot(np.transpose([x - mean_1]), [x - mean_1]) / X_train_1.shape[0]\n \n # shared covariance\n cov = (cov_0 * X_train_0.shape[0] + cov_1 * X_train_1.shape[0]) / (X_train.shape[0])\n \n ```\n\n \n\n3. 计算 $w,b$ \n\n 在 [这篇博客](https://f1ed.github.io/2020/03/21/Classification1/)中的第2小节中的公式推导中, $x^n,\\mu$ 都是列向量,公式如下:\n\n {% raw %}\n $$\n z=\\left(\\mu^{1}-\\mu^{2}\\right)^{T} \\Sigma^{-1} x-\\frac{1}{2}\\left(\\mu^{1}\\right)^{T} \\Sigma^{-1} \\mu^{1}+\\frac{1}{2}\\left(\\mu^{2}\\right)^{T} \\Sigma^{-1} \\mu^{2}+\\ln \\frac{N_{1}}{N_{2}}\n $$\n {% endraw %}\n {% raw %} $w^T=\\left(\\mu^{1}-\\mu^{2}\\right)^{T} \\Sigma^{-1} \\qquad b=-\\frac{1}{2}\\left(\\mu^{1}\\right)^{T} \\Sigma^{-1} \\mu^{1}+\\frac{1}{2}\\left(\\mu^{2}\\right)^{T} \\Sigma^{-1} \\mu^{2}+\\ln \\frac{N_{1}}{N_{2}}$ {% endraw %}\n\n ---\n\n **但是** ,一般我们在处理的数据集,$x^n,\\mu$ 都是行向量。推导过程相同,公式如下:\n\n <font color=#f00> **(主要注意转置和矩阵乘积顺序)** </font>\n\n {% raw %}\n $$\n z=x\\cdot \\Sigma^{-1}\\left(\\mu^{1}-\\mu^{2}\\right)^{T} -\\frac{1}{2} \\mu^{1}\\Sigma^{-1}\\left(\\mu^{1}\\right)^{T}+\\frac{1}{2}\\mu^{2}\\Sigma^{-1} \\left(\\mu^{2}\\right)^{T} +\\ln \\frac{N_{1}}{N_{2}}\n $$\n {% endraw %}\n {% raw %} $w=\\Sigma^{-1}\\left(\\mu^{1}-\\mu^{2}\\right)^{T} \\qquad b=-\\frac{1}{2} \\mu^{1}\\Sigma^{-1}\\left(\\mu^{1}\\right)^{T}+\\frac{1}{2}\\mu^{2}\\Sigma^{-1} \\left(\\mu^{2}\\right)^{T} +\\ln \\frac{N_{1}}{N_{2}}$ {% endraw %}\n\n---\n\n\n\n<font color=#f00>但是,协方差矩阵的逆怎么求呢? </font> \n\nnumpy中有直接求逆矩阵的方法(np.linalg.inv),但当该矩阵是nearly singular,是奇异矩阵时,就会报错。\n\n而我们的协方差矩阵(510*510)很大,很难保证他不是奇异矩阵。\n\n于是,有一个 ~~牛逼~~ 强大的数学方法,叫SVD(singular value decomposition, 奇异值分解) 。\n\n原理步骤我……还没有完全搞清楚QAQ(先挖个坑)[1]\n\n利用SVD,可以将任何一个矩阵(即使是奇异矩阵),分界成 $A=u s v^T$ 的形式:其中u,v都是标准正交矩阵,s是对角矩阵。(numpy.linalg.svd方法实现了SVD)\n\n<font color=#f00>可以利用SVD求矩阵的伪逆 </font> \n\n- $A=u s v^T$\n - u,v是标准正交矩阵,其逆矩阵等于其转置矩阵\n - s是对角矩阵,其”逆矩阵“**(注意s矩阵的对角也可能有0元素)** 将非0元素取倒数即可。\n- $A^{-1}=v s^{-1} u$\n\n计算 $w,b$ 的代码如下:\n\n```py\n# compute weights and bias\n# Since covariance matrix may be nearly singular, np.linalg.in() may give a large numerical error.\n# Via SVD decomposition, one can get matrix inverse efficiently and accurately.\n# cov = u@s@vh\n# cov_inv = dot(vh.T * 1 / s, u.T)\nu, s, vh = np.linalg.svd(cov, full_matrices=False)\ns_inv = s # s_inv avoid <1e-8\nfor i in range(s.shape[0]):\n if s[i] < (1e-8):\n break\n s_inv[i] = 1./s[i]\ncov_inv = np.matmul(vh.T * s_inv, u.T)\n\nw = np.matmul(cov_inv, np.transpose([mean_0 - mean_1]))\nb = (-0.5) * np.dot(mean_0, np.matmul(cov_inv, mean_0.T)) + (0.5) * np.dot(mean_1, np.matmul(cov_inv, mean_1.T)) + np.log(float(X_train_0.shape[0]) / X_train_1.shape[0])\n\n```\n\n\n\n## Accuracy\n\n accuracy结果:\n\n```ps\nTraining accuracy: 0.8756450899439694\n```\n\n也将权重较大的feature输出看看:\n\n```ps\nage: [-0.51867291]\n Masters degree(MA MS MEng MEd MSW MBA): [-0.49912643]\n Spouse of householder: [0.49786805]\nweeks worked in year: [-0.44710924]\n Spouse of householder: [-0.43305697]\ncapital gains: [-0.42608727]\ndividends from stocks: [-0.41994666]\n Doctorate degree(PhD EdD): [-0.39310961]\nnum persons worked for employer: [-0.37345994]\n Prof school degree (MD DDS DVM LLB JD): [-0.35594107]\n```\n\n\n\n## Code\n\n具体数据集和代码,欢迎光临小透明[GitHub](https://github.com/f1ed/ML-HW2) \n\n```py\n\nimport numpy as np\n\nnp.random.seed(0)\n##############################################\n# Prepare data\nX_train_fpath = './data/X_train'\nY_train_fpath = './data/Y_train'\nX_test_fpath = './data/X_test'\noutput_fpath = './generative_output/output_{}.csv'\nfpath = './generative_output/generative'\n\nX_train = np.genfromtxt(X_train_fpath, delimiter=',')\nY_train = np.genfromtxt(Y_train_fpath, delimiter=',')\nX_test = np.genfromtxt(X_test_fpath, delimiter=',')\n\nX_train = X_train[1:, 1:]\nY_train = Y_train[1:, 1:]\nX_test = X_test[1:, 1:]\n\ndef _normalization(X, train=True, X_mean=None, X_std=None):\n # This function normalize columns of X\n # Output:\n # X: normalized data\n # X_mean, X_std\n if train:\n X_mean = np.mean(X, axis=0)\n X_std = np.std(X, axis=0)\n for j in range(X.shape[1]):\n X[:, j] = (X[:, j] - X_mean[j]) / (X_std[j] + 1e-8) # avoid X_std==0\n return X, X_mean, X_std\n\n# Normalize train_data and test_data\nX_train, X_mean, X_std = _normalization(X_train, train=True)\nX_test, _, _ = _normalization(X_test, train=False, X_mean=X_mean, X_std=X_std)\n\ntrain_size = X_train.shape[0]\ntest_size = X_test.shape[0]\ndata_dim = X_train.shape[1]\n\nwith open(fpath, 'w') as f:\n f.write('In generative model:\\n')\n f.write('Size of training data: {}\\n'.format(train_size))\n f.write('Size of test set: {}\\n'.format(test_size))\n f.write('Dimension of data: {}\\n\\n'.format(data_dim))\n\n########################\n# Useful functions\ndef _sigmod(z):\n # Sigmod function can be used to compute probability\n # To avoid overflow\n return np.clip(1/(1.0 + np.exp(-z)), 1e-8, 1-(1e-8))\n\ndef _f(X, w, b):\n # This function is the linear part of sigmod function\n # Arguments:\n # X: input data, shape = [size, data_dimension]\n # w: weight vector, shape = [data_dimension, 1]\n # b: bias, scalar\n # Output:\n # predict probabilities\n return _sigmod(np.dot(X, w) + b)\n\ndef _predict(X, w, b):\n # This function returns a truth value prediction for each row of X belonging to class1(label=0)\n return np.around(_f(X, w, b)).astype(np.int)\n\ndef _accuracy(Y_pred, Y_label):\n # This function computes prediction accuracy\n # Y_pred: 0 or 1\n acc = 1 - np.mean(np.abs(Y_pred - Y_label))\n return acc\n\n#######################\n# Generative Model: closed-form solution, can be computed directly\n\n# compute in-class mean\nX_train_0 = np.array([x for x, y in zip(X_train, Y_train) if y == 0])\nX_train_1 = np.array([x for x, y in zip(X_train, Y_train) if y == 1])\n\nmean_0 = np.mean(X_train_0, axis=0)\nmean_1 = np.mean(X_train_1, axis=0)\n\n# compute in-class covariance\ncov_0 = np.zeros(shape=(data_dim, data_dim))\ncov_1 = np.zeros(shape=(data_dim, data_dim))\n\nfor x in X_train_0:\n # (D,1)@(1,D) np.matmul(np.transpose([x]), x)\n cov_0 += np.matmul(np.transpose([x - mean_0]), [x - mean_0]) / X_train_0.shape[0]\nfor x in X_train_1:\n cov_1 += np.dot(np.transpose([x - mean_1]), [x - mean_1]) / X_train_1.shape[0]\n\n# shared covariance\ncov = (cov_0 * X_train_0.shape[0] + cov_1 * X_train_1.shape[0]) / (X_train.shape[0])\n\n# compute weights and bias\n# Since covariance matrix may be nearly singular, np.linalg.in() may give a large numerical error.\n# Via SVD decomposition, one can get matrix inverse efficiently and accurately.\n# cov = u@s@vh\n# cov_inv = dot(vh.T * 1 / s, u.T)\nu, s, vh = np.linalg.svd(cov, full_matrices=False)\ns_inv = s # s_inv avoid <1e-8\nfor i in range(s.shape[0]):\n if s[i] < (1e-8):\n break\n s_inv[i] = 1./s[i]\ncov_inv = np.matmul(vh.T * s_inv, u.T)\n\nw = np.matmul(cov_inv, np.transpose([mean_0 - mean_1]))\nb = (-0.5) * np.dot(mean_0, np.matmul(cov_inv, mean_0.T)) + (0.5) * np.dot(mean_1, np.matmul(cov_inv, mean_1.T)) + np.log(float(X_train_0.shape[0]) / X_train_1.shape[0])\n\n# compute accuracy on training set\nY_train_pred = 1 - _predict(X_train, w, b)\nwith open(fpath, 'a') as f:\n f.write('\\nTraining accuracy: {}\\n'.format(_accuracy(Y_train_pred, Y_train)))\n\n# Predict\npredictions = 1 - _predict(X_test, w, b)\nwith open(output_fpath.format('generative'), 'w') as f:\n f.write('id, label\\n')\n for i, label in enumerate(predictions):\n f.write('{}, {}\\n'.format(i, label))\n\n# Output the most significant weight\nwith open(X_test_fpath) as f:\n content = f.readline().strip('\\n').split(',')\ncontent = content[1:]\n\nind = np.argsort(np.abs(np.concatenate(w)))[::-1]\nwith open(fpath, 'a')as f:\n for i in ind[0:10]:\n f.write('{}: {}\\n'.format(content[i], w[i]))\n\n```\n\n\n\n# Reference\n\n1. SVD原理,待补充"
}
] | 3 |
Abhisus2112/Time-Series-Analysis | https://github.com/Abhisus2112/Time-Series-Analysis | 57807e3a00706179fac22c75978c420633241e84 | 5ba7a091a602d2c55a8912b32c3e8a98faa0036f | 30b4f5e358334862c0ac859126f34f6df0ff7b41 | refs/heads/main | "2023-05-03T08:59:18.724241" | "2021-05-21T16:58:49" | "2021-05-21T16:58:49" | 369,601,052 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5555194020271301,
"alphanum_fraction": 0.5958970785140991,
"avg_line_length": 8.861736297607422,
"blob_id": "7e11ccaedabb6ec60d5057c61e6e36a5dfbf4595",
"content_id": "c55510752810a7686d519769b61191f2242b8ac0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3071,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 311,
"path": "/TimeSeriesAnalysis.py",
"repo_name": "Abhisus2112/Time-Series-Analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nget_ipython().run_line_magic('matplotlib', 'inline')\n\n\n# In[2]:\n\n\nshampoo = pd.read_csv('F:/Python/Sampoo/shampoo_with_exog.csv')\n\n\n# In[3]:\n\n\nshampoo.head()\n\n\n# In[4]:\n\n\ntype(shampoo)\n\n\n# In[11]:\n\n\n#converting the type from Dataframe to Series\nshampoo = pd.read_csv('F:/Python/Sampoo/shampoo_with_exog.csv', index_col= [0], parse_dates = True, squeeze = True)\n\n\n# In[12]:\n\n\ntype(shampoo)\n\n\n# In[4]:\n\n\nshampoo.drop('Inflation', inplace=True, axis=1)\n\n\n# In[5]:\n\n\nshampoo.head()\n\n\n# In[6]:\n\n\nshampoo.columns\n\n\n# In[21]:\n\n\nshampoo.plot()\n\n\n# In[29]:\n\n\nshampoo.columns\n\n\n# In[30]:\n\n\nshampoo.plot(style = 'k.')\n\n\n# In[8]:\n\n\nshampoo.size\n\n\n# In[9]:\n\n\nshampoo.describe()\n\n\n# In[25]:\n\n\n#smoothing the time Series that is Moving Average\n\nshampoo_ma = shampoo.rolling(window = 10).mean()\n\n\n# In[26]:\n\n\nshampoo_ma.plot()\n\n\n# In[13]:\n\n\nshampoo_base = pd.concat([shampoo,shampoo.shift(1)], axis=1)\n\n\n# In[14]:\n\n\nshampoo_base\n\n\n# In[30]:\n\n\nshampoo\n\n\n# In[23]:\n\n\nshampoo_base.columns = ['Actual_Sales', 'Forecast_Sales']\n\n\n# In[24]:\n\n\nshampoo_base\n\n\n# In[25]:\n\n\nshampoo_base.dropna(inplace=True)\n\n\n# In[26]:\n\n\nshampoo_base\n\n\n# In[18]:\n\n\nfrom sklearn.metrics import mean_squared_error\nimport numpy as np\n\n\n# In[27]:\n\n\nshampoo_error = mean_squared_error(shampoo_base.Actual_Sales, shampoo_base.Forecast_Sales)\n\n\n# In[28]:\n\n\nshampoo_error\n\n\n# In[38]:\n\n\nnp.sqrt(shampoo_error)\n\n\n# In[16]:\n\n\nfrom statsmodels.graphics.tsaplots import plot_acf,plot_pacf\n\n\n# In[63]:\n\n\nplot_acf(shampoo)\n\n\n# In[40]:\n\n\nplot_pacf(shampoo)\n\n\n# In[41]:\n\n\nfrom statsmodels.tsa.arima_model import ARIMA\n\n\n# In[42]:\n\n\nshampoo.size\n\n\n# In[30]:\n\n\nshampoo_train = shampoo[0:25]\nshampoo_test = shampoo[25:36]\n\n\n# In[31]:\n\n\nlen(shampoo_train)\n\n\n# In[32]:\n\n\nlen(shampoo_test)\n\n\n# In[46]:\n\n\nshampoo_model = ARIMA(shampoo_train, order = (3,1,2))\n\n\n# In[47]:\n\n\nshampoo_model\n\n\n# In[48]:\n\n\nshampoo_model_fit = shampoo_model.fit()\n\n\n# In[49]:\n\n\nshampoo_model_fit\n\n\n# In[50]:\n\n\nshampoo_model_fit.aic\n\n\n# In[51]:\n\n\nshampoo_forecast = shampoo_model_fit.forecast(steps=11)[0]\n\n\n# In[52]:\n\n\nshampoo_model_fit.plot_predict(1,47)\n\n\n# In[53]:\n\n\nshampoo_forecast\n\n\n# In[54]:\n\n\nnp.sqrt(mean_squared_error(shampoo_test, shampoo_forecast))\n\n\n# In[55]:\n\n\np_values = range(0,5)\nd_values = range(0,3)\nq_values = range(0,5)\n\n\n# In[56]:\n\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n\n\n# In[57]:\n\n\nfor p in p_values:\n for d in d_values:\n for q in q_values:\n order = (p,d,q)\n train,test = shampoo[0:25], shampoo[25:36]\n predictions = list()\n for i in range(len(test)):\n try:\n model = ARIMA(train,order)\n model_fit = model.fit(disp=0)\n pred_y = model_fit.forecast()[0]\n predictions.append(pred_y)\n error = mean_squared_error(test,predictions)\n print('ARIMA%s RMSE = %.2f'% (order,error))\n except:\n continue\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 1 |
gouravsaini021/maruti | https://github.com/gouravsaini021/maruti | 2a4aaca29748b058dd8a0196406d5f88d762d008 | fd51161b13f70b30a522d8a740fe9817f94d3a20 | 6e9dd3408ac0dd31a8456121bc3a412c4e2b2c63 | refs/heads/master | "2023-08-21T19:28:58.539113" | "2020-03-28T08:43:04" | "2020-03-28T08:43:04" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7435897588729858,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 18.5,
"blob_id": "62a4d5f6622b9ddaff0980b2ad490a7fc217f939",
"content_id": "518233b9c2fb1a17558d95a641bd2ec22b3a6832",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 2,
"path": "/maruti/imports/__init__.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from . import general\nfrom . import ml\n"
},
{
"alpha_fraction": 0.559548020362854,
"alphanum_fraction": 0.5687342286109924,
"avg_line_length": 34.96783447265625,
"blob_id": "56d9457b5bdcacc3ec746de4331f84ed016c7d20",
"content_id": "b21930daf4e929decae6c54931dd519905098e52",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12301,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 342,
"path": "/maruti/deepfake/dataset.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import pathlib\nfrom warnings import warn\nimport subprocess\nimport maruti\nimport os\nfrom os.path import join\nfrom PIL import Image\nimport torch\nimport shlex\nimport time\nfrom collections import defaultdict\nfrom ..vision.video import get_frames_from_path, get_frames\nimport random\nfrom ..utils import unzip, read_json\nfrom ..sizes import file_size\nimport numpy as np\nimport cv2\nfrom tqdm.auto import tqdm\nfrom torchvision import transforms as torch_transforms\nfrom torch.utils.data import Dataset\nfrom ..torch.utils import def_norm as normalize\nDATA_PATH = join(os.path.dirname(__file__), 'data/')\n__all__ = ['split_videos', 'VideoDataset', 'transform', 'group_transform']\n\ntransform = {\n 'train': torch_transforms.Compose(\n [\n torch_transforms.ToPILImage(),\n torch_transforms.ColorJitter(0.3, 0.3, 0.3, 0.1),\n torch_transforms.RandomHorizontalFlip(),\n torch_transforms.RandomResizedCrop((224, 224), scale=(0.65, 1.0)),\n torch_transforms.ToTensor(),\n normalize,\n ]\n ),\n 'val': torch_transforms.Compose([\n torch_transforms.ToTensor(),\n normalize, ]\n )\n}\ngroup_transform = {\n 'train': lambda x: torch.stack(list(map(transform['train'], x))),\n 'val': lambda x: torch.stack(list(map(transform['val'], x)))\n}\n\n\nclass ImageReader:\n\n def __init__(self, path, metadata, is_path_cache=False, vb=True, ignore_frame_errors=False):\n self.vid2part = {}\n self.meta = metadata\n self.ignore_frame_errors = ignore_frame_errors\n\n if not is_path_cache:\n parts = os.listdir(path)\n assert len(parts) > 0, 'no files found'\n start = time.perf_counter()\n\n for part in parts:\n path_to_part = os.path.join(path, part)\n imgs = os.listdir(path_to_part)\n\n for img in imgs:\n self.vid2part[self.vid_name(img)] = path_to_part\n\n end = time.perf_counter()\n if vb:\n print('Total time taken:', (end - start) / 60, 'mins')\n\n else:\n self.vid2part = maruti.read_json(path)\n\n def is_real(self, vid):\n return self.meta[vid]['label'] == 'REAL'\n\n def is_fake(self, vid):\n return not self.is_real(vid)\n\n def is_error(self, vid):\n return 'error' in self.meta[vid]\n\n def vid_name(self, img_name):\n name = img_name.split('_')[0]\n return name + '.mp4'\n\n def create_name(self, vid, frame, person):\n return f'{vid[:-4]}_{frame}_{person}.jpg'\n\n def total_persons(self, vid):\n if self.is_real(vid):\n return self.meta[vid]['pc']\n\n orig_vid = self.meta[vid]['original']\n return self.meta[orig_vid]['pc']\n\n def random_person(self, vid, frame):\n person = random.choice(range(self.total_persons(vid)))\n return self.get_image(vid, frame, person)\n\n def random_img(self, vid):\n frame = random.choice(range(self.total_frames(vid)))\n person = random.choice(range(self.total_persons(vid)))\n return self.get_image(vid, frame, person)\n\n def sample(self):\n vid = random.choice(list(self.vid2part))\n while self.is_error(vid):\n vid = random.choice(list(self.vid2part))\n frame = random.choice(range(self.total_frames(vid)))\n person = random.choice(range(self.total_persons(vid)))\n return self.get_image(vid, frame, person)\n\n def total_frames(self, vid):\n return self.meta[vid]['fc'] - 1\n\n def create_absolute(self, name):\n path = os.path.join(self.vid2part[self.vid_name(name)], name)\n return path\n\n def get_image(self, vid, frame, person):\n if self.total_persons(vid) <= person:\n raise Exception('Not Enough Persons')\n\n if self.total_frames(vid) <= frame:\n if self.ignore_frame_errors:\n frame = self.total_frames(vid) - 1\n else:\n raise Exception('Not Enough Frames')\n\n img = self.create_name(vid, frame, person)\n path = self.create_absolute(img)\n return Image.open(path)\n\n\ndef split_videos(meta_file):\n '''\n Groups real-fake videos in dictionary\n '''\n split = defaultdict(lambda: set())\n for vid in meta_file:\n if meta_file[vid]['label'] == 'FAKE':\n split[meta_file[vid]['original']].add(vid)\n return split\n\n\nclass VideoDataset:\n '''\n create dataset from videos and metadata.\n @params:\n\n To download and create use VideoDataset.from_part method\n '''\n\n def __init__(self, path, metadata_path=None):\n self.path = pathlib.Path(path)\n self.video_paths = list(self.path.glob('*.mp4'))\n\n metadata_path = metadata_path if metadata_path else self.path / 'metadata.json'\n try:\n self.metadata = read_json(metadata_path)\n except FileNotFoundError:\n del metadata_path\n print('metadata file not found.\\n Some functionalities may not work.')\n\n if hasattr(self, 'metadata'):\n self.video_groups = split_videos(self.metadata)\n\n @staticmethod\n def download_part(part='00', download_path='.', cookies_path=join(DATA_PATH, 'kaggle', 'cookies.txt')):\n dataset_path = f'https://www.kaggle.com/c/16880/datadownload/dfdc_train_part_{part}.zip'\n # folder = f'dfdc_train_part_{int(part)}'\n command = f'wget -c --load-cookies {cookies_path} {dataset_path} -P {download_path}'\n command_args = shlex.split(command)\n fp = open(os.devnull, 'w')\n download = subprocess.Popen(command_args, stdout=fp, stderr=fp)\n bar = tqdm(total=10240, desc='Downloading ')\n zip_size = 0\n while download.poll() is None:\n time.sleep(0.1)\n try:\n new_size = int(\n file_size(download_path + f'/dfdc_train_part_{part}.zip'))\n bar.update(new_size - zip_size)\n zip_size = new_size\n except FileNotFoundError:\n continue\n if download.poll() != 0:\n print('some error')\n print('download', download.poll())\n download.terminate()\n fp.close()\n bar.close()\n return download_path + f'/dfdc_train_part_{part}.zip'\n\n @classmethod\n def from_part(cls, part='00',\n cookies_path=join(DATA_PATH, 'kaggle', 'cookies.txt'),\n download_path='.'):\n folder = f'dfdc_train_part_{int(part)}'\n\n if os.path.exists(pathlib.Path(download_path) / folder):\n return cls(pathlib.Path(download_path) / folder)\n downloaded_zip = cls.download_part(\n part=part, download_path=download_path, cookies_path=cookies_path)\n unzip(downloaded_zip, path=download_path)\n os.remove(download_path + f'/dfdc_train_part_{part}.zip')\n path = pathlib.Path(download_path) / folder\n return cls(path)\n\n def __len__(self):\n return len(self.video_paths)\n\n def n_groups(self, n, k=-1):\n '''\n returns random n real-fake pairs by default.\n else starting from k.\n '''\n if k != -1:\n if n + k >= len(self.video_groups):\n warn(RuntimeWarning(\n 'n+k is greater then video length. Returning available'))\n n = len(self.video_groups) - k - 1\n return self.video_groups[k:n + k]\n if n >= len(self.video_groups):\n warn(RuntimeWarning('n is greater then total groups. Returning available'))\n n = len(self.video_groups) - 1\n return choices(self.video_groups, k=n)\n\n\nclass VidFromPathLoader:\n \"\"\" Loader to use with DeepfakeDataset class\"\"\"\n\n def __init__(self, paths, img_reader=None):\n \"\"\"paths as {'00':/part/00,'01'..}\"\"\"\n self.path = paths\n self.img_reader = self.img_reader if img_reader is None else img_reader\n\n @staticmethod\n def img_reader(path, split='val', max_limit=40):\n frame_no = 0 if split == 'val' else random.randint(0, max_limit)\n frame = list(get_frames_from_path(\n path, [frame_no]))[0]\n return frame\n\n @staticmethod\n def img_group_reader(path, split='val', mode='distributed', num_frames=4, mode_info=[None]):\n \"\"\"use with partial to set mode\n mode info: distributed -> No Use\n forward -> {jumps, index:0, readjust_jumps: True}\n backward -> {jumps, index:-1, readjust_jumps: True} -1 refers to end\"\"\"\n cap = cv2.VideoCapture(path)\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n if mode == 'distributed':\n frames = np.linspace(0, frame_count - 1, num_frames, dtype=int)\n elif mode == 'forward':\n start = mode_info.get('index', 0)\n adjust = mode_info.get('readjust_jumps', True)\n jumps = mode_info['jumps']\n if adjust:\n frames = np.linspace(start, min(\n frame_count - 1, start + (num_frames - 1) * jumps), num_frames, dtype=int)\n else:\n frames = np.linspace(\n start, start + (num_frames - 1) * jumps, num_frames, dtype=int)\n elif mode == 'backward':\n end = mode_info.get('index', frame_count)\n adjust = mode_info.get('readjust_jumps', True)\n jumps = mode_info['jumps']\n if adjust:\n frames = np.linspace(\n max(0, start - (num_frames - 1) * jumps), end, num_frames, dtype=int)\n else:\n frames = np.linspace(\n start + (num_frames - 1) * jumps, num_frames, end, dtype=int)\n return get_frames(cap, frames, 'rgb')\n\n def __call__(self, metadata, video, split='val'):\n vid_meta = metadata[video]\n video_path = join(self.path[vid_meta['part']], video)\n\n return self.img_reader(video_path, split)\n\n\nclass DeepfakeDataset(Dataset):\n \"\"\"Methods 'f12' r1-f1, r1-f2..,(default)\n 'f..' r1-f1/f2/f3..\n 'f1' r1-f1,\n 'ff' r f1 f2 f3..\n\n Metadata 'split'(train-val),'label'(FAKE-REAL),'fakes'([video,video])\n loader func(metadata,video,split)->input\n error_handler func(self, index, error)->(input, label)\"\"\"\n iteration = 0\n\n def __init__(self, metadata, loader, transform=None, split='train', method='f12', error_handler=None):\n self.transform = transform\n self.split = split\n self.loader = loader\n self.method = method\n self.error_handler = error_handler\n self.metadata = metadata\n self.dataset = []\n real_videos = filter(\n lambda x: metadata[x]['split'] == split, list(split_videos(metadata)))\n for real_video in real_videos:\n fake_videos = list(metadata[real_video]['fakes'])\n self.dataset.append(real_video)\n if method == 'f12':\n self.dataset.append(\n fake_videos[self.iteration % len(fake_videos)])\n elif method == 'f..':\n self.dataset.append(random.choice(fake_videos))\n elif method == 'f1':\n self.dataset.append(fake_videos[0])\n elif method == 'ff':\n for fake_video in fake_videos:\n self.dataset.append(fake_video)\n else:\n raise ValueError(\n 'Not a valid method. Choose from f12, f.., f1, ff')\n\n def __getitem__(self, i):\n if i == 0:\n self.iteration += 1\n\n try:\n img = self.loader(self.metadata, self.dataset[i], split=self.split)\n label = torch.tensor(\n [float(self.metadata[self.dataset[i]]['label'] == 'FAKE')])\n if self.transform is not None:\n img = self.transform(img)\n return img, label\n except Exception as e:\n if self.error_handler is None:\n def default_error_handler(obj, x, e):\n print(f'on video {self.dataset[x]} error: {e}')\n return self[random.randint(1, len(self) - 1)]\n self.error_handler = default_error_handler\n return self.error_handler(self, i, e)\n\n def __len__(self):\n return len(self.dataset)\n"
},
{
"alpha_fraction": 0.5526427030563354,
"alphanum_fraction": 0.5729547142982483,
"avg_line_length": 32.556602478027344,
"blob_id": "422badb00d7ee68b5c561ea03b91540b3f4dd5d2",
"content_id": "b7155827342ebc7417e3de9e5c521d7d717e5e44",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14228,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 424,
"path": "/maruti/vision/video.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nfrom .. import vision as mvis\nfrom facenet_pytorch import MTCNN\nimport torch\nfrom PIL import Image\nfrom collections import defaultdict\ndevice = 'cuda:0' if torch.cuda.is_available() else 'cpu'\n\n\nclass Video(cv2.VideoCapture):\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.release()\n\n\ndef vid_info(path):\n \"return frame_count, (h, w)\"\n cap = cv2.VideoCapture(path)\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))\n w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))\n return frame_count, (h, w)\n\n\ndef get_frames(cap: 'cv2.VideoCapture object', frames: 'iterable<int>', code='rgb', start_frame=0):\n \"\"\"Frame numbers out of the scope will be ignored\"\"\"\n curr_index = int(cap.get(cv2.CAP_PROP_POS_FRAMES))\n if curr_index != start_frame:\n cap.set(cv2.CAP_PROP_POS_FRAMES, curr_index)\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n frames = set(frames)\n last_frame = max(frames)\n if frame_count == 0:\n raise Exception('The video is corrupt. Closing')\n for i in range(curr_index, frame_count):\n _ = cap.grab()\n if i in frames:\n _, frame = cap.retrieve()\n if code == 'rgb':\n yield cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n else:\n yield frame\n if i == last_frame:\n cap.release()\n break\n cap.release()\n\n\ndef get_frames_from_path(path: 'str or posix', frames: 'iterable<int>', code='rgb'):\n cap = cv2.VideoCapture(str(path))\n return get_frames(cap, frames, code)\n\n\ndef crop_face(img, points, size: \"(h,w)\" = None):\n if size:\n size = size[1], size[0] # cv2 resize needs (w,h)\n face = img[points[1]:points[3],\n points[0]:points[2]]\n if size is not None:\n face = cv2.resize(face, size,)\n return face\n\n\ndef bbox_from_det(det_list):\n working_det = np.array([[0, 0,\n 224, 224]])\n bbox = []\n for detection in det_list:\n if detection is None:\n bbox.append(working_det.astype(int) * 2)\n else:\n bbox.append(detection.astype(int) * 2)\n working_det = detection.copy()\n return bbox\n\n\ndef _face_from_det(frame_idx, detect_idx, frames, det_list, f_h, f_w, margin=30, size=(224, 224), mtcnn=None):\n start = frame_idx[0]\n n_h, n_w = f_h // 2, f_w // 2\n full_det_list = [None] * len(frame_idx)\n\n # first frame should be correct so it can compunsate upcomings\n if det_list[0] is None:\n _detection = mtcnn.detect(frames[0])[0]\n if _detection is not None:\n det_list[0] = _detection / 2\n #\n\n for i, box in zip(detect_idx, det_list):\n full_det_list[i - start] = box\n bbox = bbox_from_det(full_det_list)\n working_pred = np.array([(f_h // 2) - 112, (f_w // 2) - 112,\n (f_h // 2) + 112, (f_w // 2) + 112])\n faces = []\n for frame, box in zip(frames, bbox):\n best_pred = box[0]\n best_pred[[0, 1]] -= margin // 2\n best_pred[[2, 3]] += (margin + 1) // 2\n try:\n cropped_faces = crop_face(frame, best_pred, size=size)\n working_pred = best_pred\n except:\n cropped_faces = crop_face(frame, working_pred, size=size)\n faces.append(cropped_faces)\n\n return faces\n\n\ndef non_overlapping_ranges(rngs):\n all_idx = set()\n for rng in rngs:\n for i in range(rng[0], rng[1]):\n all_idx.add(i)\n min_i = min(all_idx)\n max_i = max(all_idx)\n non_overlapping_rngs = []\n last = min_i\n start = min_i\n i = min_i + 1\n while i < max_i + 1:\n if i in all_idx:\n last = i\n i += 1\n continue\n else:\n non_overlapping_rngs.append([start, last + 1])\n while i not in all_idx:\n i += 1\n start = i\n last = i\n non_overlapping_rngs.append([start, last + 1])\n return non_overlapping_rngs\n\n\ndef get_face_frames2(path, frame_rngs, jumps=4, margin=30, mtcnn=None, size: \"(h,w)\" = (224, 224)):\n # for height and width\n cap = cv2.VideoCapture(path)\n f_h, f_w = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(\n cap.get(cv2.CAP_PROP_FRAME_WIDTH))\n n_h, n_w = f_h // 2, f_w // 2\n cap.release()\n #\n non_overlapping_rngs = non_overlapping_ranges(frame_rngs)\n idx2face = defaultdict(lambda: None)\n idx2frame = defaultdict(lambda: None)\n if mtcnn is None:\n mtcnn = MTCNN(select_largest=False, device=device,)\n\n # getting video frames in one shot\n all_frames_idx = []\n for rng in non_overlapping_rngs:\n all_frames_idx.extend(range(rng[0], rng[1]))\n vid_frames = list(get_frames_from_path(path, all_frames_idx))\n for i, frame in zip(all_frames_idx, vid_frames):\n idx2frame[i] = frame\n\n # getting detection in one shot\n all_detect_idx = []\n for frame_rng in non_overlapping_rngs:\n all_detect_idx.extend(range(frame_rng[0], frame_rng[1], jumps))\n all_detect_small_frames = [cv2.resize(frame, (n_w, n_h)) for i, frame in zip(\n all_frames_idx, vid_frames) if i in all_detect_idx]\n det, conf = mtcnn.detect(all_detect_small_frames)\n idx2det = defaultdict(lambda: None)\n for i, det in zip(all_detect_idx, det):\n idx2det[i] = det\n\n # face crop for each non-overlapping range\n for frame_rng in non_overlapping_rngs:\n start, end = frame_rng\n frame_idx = list(range(start, end))\n detect_idx = list(range(start, end, jumps))\n frames = [idx2frame[i] for i in frame_idx]\n det_list = [idx2det[i] for i in detect_idx]\n faces = _face_from_det(\n frame_idx, detect_idx, frames, det_list, f_h, f_w, margin=margin, size=size, mtcnn=mtcnn)\n for i, face in zip(frame_idx, faces):\n idx2face[i] = face\n\n # distribution to each range\n rng_faces = []\n for rng in frame_rngs:\n curr_rng_faces = []\n for i in range(rng[0], rng[1]):\n curr_rng_faces.append(idx2face[i])\n rng_faces.append(curr_rng_faces)\n return rng_faces\n\n\ndef crop(frame, bb):\n return frame[bb[1]:bb[3], bb[0]:bb[2]]\n\n\ndef toint(bb):\n return [int(i) for i in bb]\n\n\ndef apply_margin(bb, margin, size):\n bb = [max(0,bb[0]-margin),max(0, bb[1] - margin),min(size[0] -1, bb[2]+margin),min(size[1]-1, bb[3]+margin)]\n return bb\n\n\ndef expand_detection(detections, idx, length):\n assert (len(detections) == len(\n idx)), f'length of detection ({len(detections)}) and indices ({len(idx)}) must be same'\n\n j = 0\n last = detections[j] if detections[j] is not None else []\n final_detections = []\n\n for i in range(length):\n if i in idx:\n last = detections[idx.index(i)]\n if last is None:\n last = []\n final_detections.append(last)\n return final_detections\n\n\ndef get_all_faces(path: 'str', detections=32, mtcnn=None, margin=20):\n if mtcnn is None:\n mtcnn = MTCNN(select_largest=False, device=device,)\n\n cap = cv2.VideoCapture(path)\n frames = []\n next_frame = True\n while next_frame:\n next_frame, fr = cap.read()\n if next_frame:\n frames.append(cv2.cvtColor(fr, cv2.COLOR_BGR2RGB))\n np_det_idx = np.linspace(0, len(frames), detections,\n endpoint=False, dtype=int)\n detection_idx = list(map(int, np_det_idx))\n detection_frames = [frame for i, frame in enumerate(\n frames) if i in detection_idx]\n detection = mtcnn.detect(detection_frames)\n\n detection = detection[0]\n del detection_frames\n detection = expand_detection(detection, detection_idx, len(frames))\n\n faces = []\n\n for i, bboxes in enumerate(detection):\n faces.append([])\n for bbox in bboxes:\n bbox = apply_margin(bbox, margin, frames[0].shape[:2])\n faces[-1].append(crop(frames[i], toint(bbox)))\n\n return faces\n\n\n\ndef get_face_frames(path, frame_idx, margin=30, mtcnn=None, size: \"(h,w)\" = (224, 224),):\n \"\"\"\n Consumes more RAM as it stores all the frames in full resolution.\n Try to detect in small batches if needed.\n \"\"\"\n # for height and width\n cap = cv2.VideoCapture(path)\n f_h, f_w = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(\n cap.get(cv2.CAP_PROP_FRAME_WIDTH))\n cap.release()\n #\n\n n_h, n_w = f_h // 2, f_w // 2\n if mtcnn is None:\n mtcnn = MTCNN(select_largest=False, device=device,)\n\n frames = list(get_frames_from_path(path, frame_idx))\n small_faces = [cv2.resize(frame, (n_w, n_h)) for frame in frames]\n det, conf = mtcnn.detect(small_faces)\n det_list = list(map(lambda x: x, det))\n bbox = bbox_from_det(det_list)\n working_pred = np.array([(f_h // 2) - 112, (f_w // 2) - 112,\n (f_h // 2) + 112, (f_w // 2) + 112])\n faces = []\n for frame, box in zip(frames, bbox):\n best_pred = box[0]\n best_pred[[0, 1]] -= margin // 2\n best_pred[[2, 3]] += (margin + 1) // 2\n try:\n cropped_faces = crop_face(frame, best_pred, size=size)\n working_pred = best_pred\n except:\n cropped_faces = crop_face(frame, working_pred, size=size)\n faces.append(cropped_faces)\n\n return faces\n\n\ndef get_faces_frames(path, frame_idx, margin=30, mtcnn=None, size: \"(h,w)\" = (224, 224),):\n \"\"\"\n Consumes more RAM as it stores all the frames in full resolution.\n Try to detect in small batches if needed.\n \"\"\"\n # for height and width\n _, (f_h, f_w) = vid_info(path)\n #\n\n n_h, n_w = f_h // 2, f_w // 2\n if mtcnn is None:\n mtcnn = MTCNN(select_largest=False, device=device,)\n\n frames = list(get_frames_from_path(path, frame_idx))\n small_faces = [cv2.resize(frame, (n_w, n_h)) for frame in frames]\n det, conf = mtcnn.detect(small_faces)\n det_list = list(map(lambda x: x, det))\n if det_list[0] is None:\n _detection = mtcnn.detect(frames[0])[0]\n if _detection is not None:\n det_list[0] = _detection / 2\n bbox = bbox_from_det(det_list)\n working_pred = np.array([(f_h // 2) - 112, (f_w // 2) - 112,\n (f_h // 2) + 112, (f_w // 2) + 112])\n faces = []\n for frame, box in zip(frames, bbox):\n all_faces = []\n for face_det in box:\n best_pred = face_det\n best_pred[[0, 1]] -= margin // 2\n best_pred[[2, 3]] += (margin + 1) // 2\n try:\n cropped_faces = crop_face(frame, best_pred, size=size)\n working_pred = best_pred\n except:\n cropped_faces = crop_face(frame, working_pred, size=size)\n all_faces.append(cropped_faces)\n faces.append(all_faces)\n\n return faces\n\n\ndef _face_from_det(frame_idx, detect_idx, frames, det_list, f_h, f_w, margin=30, size=(224, 224), mtcnn=None):\n start = frame_idx[0]\n n_h, n_w = f_h // 2, f_w // 2\n full_det_list = [None] * len(frame_idx)\n\n # first frame should be correct so it can compunsate upcomings\n if det_list[0] is None:\n _detection = mtcnn.detect(frames[0])[0]\n if _detection is not None:\n det_list[0] = _detection / 2\n #\n\n for i, box in zip(detect_idx, det_list):\n full_det_list[i - start] = box\n bbox = bbox_from_det(full_det_list)\n working_pred = np.array([(f_h // 2) - 112, (f_w // 2) - 112,\n (f_h // 2) + 112, (f_w // 2) + 112])\n faces = []\n for frame, box in zip(frames, bbox):\n all_faces = []\n for face_det in box:\n best_pred = face_det\n best_pred[[0, 1]] -= margin // 2\n best_pred[[2, 3]] += (margin + 1) // 2\n try:\n cropped_faces = crop_face(frame, best_pred, size=size)\n working_pred = best_pred\n except:\n cropped_faces = crop_face(frame, working_pred, size=size)\n all_faces.append(cropped_faces)\n faces.append(all_faces)\n\n return faces\n\n\ndef get_faces_frames2(path, frame_rngs, jumps=4, margin=30, mtcnn=None, size: \"(h,w)\" = (224, 224)):\n # for height and width\n cap = cv2.VideoCapture(path)\n f_h, f_w = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(\n cap.get(cv2.CAP_PROP_FRAME_WIDTH))\n n_h, n_w = f_h // 2, f_w // 2\n cap.release()\n #\n non_overlapping_rngs = non_overlapping_ranges(frame_rngs)\n idx2face = defaultdict(lambda: None)\n idx2frame = defaultdict(lambda: None)\n if mtcnn is None:\n mtcnn = MTCNN(select_largest=False, device=device,)\n\n # getting video frames in one shot\n all_frames_idx = []\n for rng in non_overlapping_rngs:\n all_frames_idx.extend(range(rng[0], rng[1]))\n vid_frames = list(get_frames_from_path(path, all_frames_idx))\n for i, frame in zip(all_frames_idx, vid_frames):\n idx2frame[i] = frame\n\n # getting detection in one shot\n all_detect_idx = []\n for frame_rng in non_overlapping_rngs:\n all_detect_idx.extend(range(frame_rng[0], frame_rng[1], jumps))\n all_detect_small_frames = [cv2.resize(frame, (n_w, n_h)) for i, frame in zip(\n all_frames_idx, vid_frames) if i in all_detect_idx]\n det, conf = mtcnn.detect(all_detect_small_frames)\n idx2det = defaultdict(lambda: None)\n for i, det in zip(all_detect_idx, det):\n idx2det[i] = det\n\n # face crop for each non-overlapping range\n for frame_rng in non_overlapping_rngs:\n start, end = frame_rng\n frame_idx = list(range(start, end))\n detect_idx = list(range(start, end, jumps))\n frames = [idx2frame[i] for i in frame_idx]\n det_list = [idx2det[i] for i in detect_idx]\n faces = _faces_from_det(\n frame_idx, detect_idx, frames, det_list, f_h, f_w, margin=margin, size=size, mtcnn=mtcnn)\n for i, face in zip(frame_idx, faces):\n idx2face[i] = face\n\n # distribution to each range\n rng_faces = []\n for rng in frame_rngs:\n curr_rng_faces = []\n for i in range(rng[0], rng[1]):\n curr_rng_faces.append(idx2face[i])\n rng_faces.append(curr_rng_faces)\n return rng_faces\n"
},
{
"alpha_fraction": 0.8258064389228821,
"alphanum_fraction": 0.8258064389228821,
"avg_line_length": 37.75,
"blob_id": "8a2fc4fd2d8346807249da4e8e5e33c0ce63f86f",
"content_id": "48dc71b78e7b7a77fde906a18e462743b8260df7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 4,
"path": "/maruti/deepfake/__init__.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from . import dataset\nfrom . import models\nfrom .dataset import VideoDataset, DeepfakeDataset, ImageReader\nfrom .dataset import transform, group_transform\n"
},
{
"alpha_fraction": 0.5661442875862122,
"alphanum_fraction": 0.5674149394035339,
"avg_line_length": 32.410377502441406,
"blob_id": "94cc2aedf0d1fa2315adb9768e8c18034ffdd380",
"content_id": "b5de41d35e0a975429d078e7eb36b6837d7a6ba9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7083,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 212,
"path": "/maruti/torch/callback.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import os\nfrom datetime import datetime, timezone, timedelta\nfrom torch.utils.tensorboard import SummaryWriter\nfrom copy import deepcopy\n\n\nclass Callback:\n def on_epoch_end(self, losses, metrics, extras, epoch):\n \"\"\"\n extras-> dict ['time']['model']\n \"\"\"\n pass\n\n def on_epoch_start(self, epoch):\n pass\n\n def on_batch_start(self, epoch, batch):\n pass\n\n def on_batch_end(self, loss, metrics, extras, epoch, batch):\n pass\n\n def on_validation_start(self, epoch):\n pass\n\n def on_validation_end(self, loss, metrics, epoch):\n pass\n\n def on_min_val_start(self, epoch, batch):\n pass\n\n def on_min_val_end(self, loss, metrics, extras, epoch, batch):\n \"\"\"extras['model']\"\"\"\n pass\n\n def on_train_start(self, epoch):\n pass\n\n\ndef Compose(callbacks):\n class NewCallback(Callback):\n def on_epoch_end(self, losses, metrics, extras, epoch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_epoch_end(\n losses, metrics, extras, epoch)\n return isEnd\n\n def on_epoch_start(self, epoch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_epoch_start(epoch)\n return isEnd\n\n def on_batch_start(self, epoch, batch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_batch_start(epoch, batch)\n return isEnd\n\n def on_batch_end(self, loss, metrics, extras, epoch, batch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_batch_end(loss, metrics, extras,\n epoch, batch)\n return isEnd\n\n def on_validation_start(self, epoch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_validation_start(epoch)\n return isEnd\n\n def on_validation_end(self, loss, metrics, epoch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_validation_end(\n loss, metrics, epoch)\n return isEnd\n\n def on_min_val_start(self, epoch, batch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_min_val_start(\n epoch, batch)\n return isEnd\n\n def on_min_val_end(self, loss, metrics, extras, epoch, batch):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_min_val_end(\n loss, metrics, extras, epoch, batch)\n return isEnd\n\n def on_train_start(self, epochs):\n isEnd = False\n for callback in callbacks:\n isEnd = isEnd or callback.on_train_start(epochs)\n return isEnd\n return NewCallback()\n\n\nclass Recorder(Callback):\n\n def __init__(self):\n self.best_model = None\n self.best_score = float('inf')\n self.summaries = []\n self.others = []\n self.prevs = []\n # to monitor if the learner was stopped in between of an epoch\n self.epoch_started = False\n\n def on_train_start(self, epochs):\n self.new_state()\n\n def new_state(self):\n sd = self.state_dict()\n del sd['prevs']\n self.prevs.append(self.state_dict())\n self.summaries = []\n self.others = []\n\n def on_epoch_start(self, epoch):\n if self.epoch_started:\n self.new_state()\n self.summaries.append({})\n self.others.append({'train_losses': [], 'train_metrics': []})\n self.epoch_started = True\n\n def on_batch_end(self, train_loss, train_metrics, extras, epoch, batch):\n self.others[epoch]['train_losses'].append(train_loss)\n self.others[epoch]['train_metrics'].append(train_metrics)\n\n @property\n def last_summary(self):\n if self.summaries:\n return self.summaries[-1]\n raise Exception('no summaries exists')\n\n def on_min_val_end(self, loss, metrics, extras, epoch, batch):\n if loss < self.best_score:\n self.best_score = loss\n self.best_model = deepcopy(extras['model'].state_dict())\n\n def on_epoch_end(self, losses, metrics, extras, epoch):\n self.summaries[epoch]['train_loss'] = losses['train']\n self.summaries[epoch]['train_metrics'] = metrics['train']\n self.summaries[epoch]['time'] = extras['time']\n representative_loss = 'train' # for best model udpate\n\n if 'val' in losses:\n representative_loss = 'val'\n self.summaries[epoch]['val_loss'] = losses['val']\n\n if 'val' in metrics:\n self.summaries[epoch]['val_metrics'] = metrics['val']\n\n if losses[representative_loss] < self.best_score:\n self.best_score = losses[representative_loss]\n self.best_model = deepcopy(extras['model'])\n self.epoch_started = False\n\n def state_dict(self):\n state = {}\n state['best_score'] = self.best_score\n state['best_model'] = self.best_model\n state['summaries'] = self.summaries\n state['others'] = self.others\n state['prevs'] = self.prevs\n return deepcopy(state)\n\n def load_state_dict(self, state):\n self.best_score = state['best_score']\n self.best_model = state['best_model']\n self.summaries = state['summaries']\n self.others = state['others']\n self.prevs = state['prevs']\n\n\nclass BoardLog(Callback):\n def __init__(self, comment='learn', path='runs'):\n self.path = path\n self.run = 0\n self.comment = comment\n self.batch_count = 0\n\n def on_train_start(self, epochs):\n india_timezone = timezone(timedelta(hours=5.5))\n time_str = datetime.now(tz=india_timezone).strftime('%d_%b_%H:%M:%S')\n path = os.path.join(self.path, self.comment, time_str)\n\n self.writer = SummaryWriter(log_dir=path, flush_secs=30)\n self.run += 1\n\n def on_batch_end(self, loss, metrics, extras, epoch, batch):\n lr_vals = {}\n for i, param in enumerate(extras['optimizer'].param_groups):\n lr_vals['lr_' + str(i)] = param['lr']\n self.writer.add_scalars(\n 'batch', {'loss': loss, **metrics, **lr_vals}, global_step=self.batch_count)\n self.batch_count += 1\n\n def on_min_val_end(self, loss, metrics, extras, epoch, batch):\n self.writer.add_scalars(\n 'min_val', {'loss': loss, **metrics}, global_step=self.batch_count)\n\n def on_epoch_end(self, losses, metrics, extras, epoch):\n self.writer.add_scalars('losses', losses, global_step=epoch)\n for metric in metrics['train']:\n self.writer.add_scalars(metric, {'val': metrics['val'][metric],\n 'train': metrics['train'][metric]}, global_step=epoch)\n"
},
{
"alpha_fraction": 0.5672568678855896,
"alphanum_fraction": 0.5856518745422363,
"avg_line_length": 32.4538459777832,
"blob_id": "084ee1513f5ed0b5eb9ffac088b4a45cb92bb1e0",
"content_id": "cd11e24e932e040818b74f016f084ddb13066f3a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4349,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 130,
"path": "/maruti/deepfake/models.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import torch.nn as nn\nimport torchvision\nfrom ..torch.utils import freeze\nfrom torch.nn.utils.rnn import PackedSequence, pack_sequence\nimport itertools\nfrom .dataset import group_transform\n\n\ndef resnext50(feature=False, pretrained=False):\n model = torchvision.models.resnext50_32x4d(pretrained)\n if feature:\n model.fc = nn.Identity()\n else:\n model.fc = nn.Linear(2048, 1)\n return model\n\n\ndef binaryClassifier(input_features):\n return nn.Sequential(\n nn.Linear(input_features, input_features // 2),\n nn.ReLU(),\n nn.BatchNorm1d(input_features // 2),\n\n nn.Linear(input_features // 2, input_features // 2),\n nn.ReLU(),\n nn.BatchNorm1d(input_features // 2),\n\n nn.Linear(input_features // 2, 128),\n nn.ReLU(),\n nn.Dropout(),\n\n nn.Linear(128, 1),\n nn.Flatten())\n\n\nclass ResLSTM(nn.Module):\n\n def __init__(self, pretrained=False, hidden_size=512, num_layers=1, bidirectional=True, dropout=0.5):\n super().__init__()\n # resnext\n self.feature_model = resnext50(True, pretrained)\n\n # lstm\n self.hidden_size = hidden_size\n self.lstm = nn.LSTM(2048, hidden_size=hidden_size, num_layers=num_layers,\n bidirectional=bidirectional, dropout=dropout)\n classifier_features = hidden_size * num_layers\n if bidirectional:\n classifier_features *= 2\n self.classifier = binaryClassifier(classifier_features)\n\n def forward(self, x):\n # indices\n unsorted_indices = x.unsorted_indices\n\n # prediction on all images from each batch\n x_data = self.feature_model(x.data)\n\n # converting again to PackedSequence\n x = PackedSequence(x_data, x.batch_sizes)\n\n # lstm\n out, (h, c) = self.lstm(x)\n batch_size = h.shape[1]\n\n # treat each batch differently instaed of lstm layer\n split_on_batch = h.permute(1, 0, 2)\n\n # reshape to make each bach flat\n combining_passes = split_on_batch.reshape(batch_size, -1)\n\n # classify\n val = self.classifier(combining_passes).squeeze(1)\n return val[unsorted_indices]\n\n def param(self, i=-1):\n # all\n if i == -1:\n return self.parameters()\n\n # grouped\n if i == 0:\n return itertools.chain(self.feature_model.conv1.parameters(),\n self.feature_model.bn1.parameters(),\n self.feature_model.layer1.parameters(),)\n if i == 1:\n return itertools.chain(self.feature_model.layer2.parameters(),\n self.feature_model.layer3.parameters())\n if i == 2:\n return itertools.chain(self.feature_model.layer4.parameters(),\n self.feature_model.fc.parameters())\n if i == 3:\n return itertools.chain(self.lstm.parameters(),\n self.classifier.parameters())\n else:\n print('there are only 4 param groups -> 0,1,2,3')\n\n\nclass ReslstmNN(nn.Module):\n def __init__(self, num_sets=6, pretrained=False, hidden_size=512, num_layers=1, bidirectional=True, dropout=0.5):\n super().__init__()\n self.feature = ResLSTM(pretrained=pretrained, hidden_size=hidden_size,\n num_layers=num_layers, bidirectional=bidirectional, dropout=dropout)\n self.feature.classifier[9] = nn.Identity()\n self.feature.classifier[10] = nn.Identity()\n self.classifier = binaryClassifier(128 * num_sets)\n\n def forward(x):\n preds = []\n for vid_set in x:\n preds.append(self.feature(vid_set))\n preds = torch.cat(preds, dim=1)\n preds = self.classifier(preds)\n return preds.squeeze(dim=1)\n\n @staticmethod\n def transform(vid_sets):\n transformed = []\n for vid in vid_sets:\n transformed.append(group_transform(vid))\n return transformed\n\n @staticmethod\n def collate(batches):\n ps_list = []\n for set_idx in range(len(batches[0][0])):\n vids = [batch[set_idx] for batch, target in batches]\n ps = pack_sequence(vids, False)\n ps_list.append(ps)\n return ps, torch.tensor([target for _, target in batches])\n"
},
{
"alpha_fraction": 0.5922509431838989,
"alphanum_fraction": 0.5959409475326538,
"avg_line_length": 24.809524536132812,
"blob_id": "459b0f554b2a973e30fbd71d0aa12a4568ef0f96",
"content_id": "1ed66cf8ed145740d8170682d2ae08d2dc1b3a8f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 21,
"path": "/tests/test_utils.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import maruti\nimport unittest\nimport tempfile\nfrom maruti import utils\nimport os\n\n\nclass UtilsTests(unittest.TestCase):\n\n def test_read_write_json(self):\n with tempfile.TemporaryDirectory() as dir:\n # creating dictionary\n sample = {'h': 3, 'd': {'j': 4}}\n path = os.path.join(dir, 'test.json')\n\n # writing to file\n utils.write_json(sample, path)\n\n # reading same file\n sample_read = utils.read_json(path)\n self.assertEqual(sample, sample_read)\n"
},
{
"alpha_fraction": 0.6010262966156006,
"alphanum_fraction": 0.6100063920021057,
"avg_line_length": 33.64444351196289,
"blob_id": "e6209aab67e3fc8a98b36fd314957082cb67b52a",
"content_id": "e14bb7450c7db50c939391464529ed43ff2ecd5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1559,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 45,
"path": "/tests/torch/test_utils.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import unittest\nimport tempfile\nimport os\nimport torchvision\nimport torch\nfrom maruti.torch import utils\n\n\nclass TorchUtilsTest(unittest.TestCase):\n def setUp(self):\n self.model = torchvision.models.resnet18(False)\n\n def tearDown(self):\n self.model = None\n\n def test_freeze_unfreeze(self):\n utils.freeze(self.model)\n for param in self.model.parameters():\n self.assertFalse(param.requires_grad)\n utils.unfreeze(self.model)\n for param in self.model.parameters():\n self.assertTrue(param.requires_grad)\n\n def test_layer_freeze_unfreeze(self):\n layers = ['fc.weight', 'layer1.0', 'layer2', 'layer1', 'layer3.0']\n utils.freeze_layers(self.model, layers)\n for name, layer in self.model.named_parameters():\n tested = False\n for to_freeze in layers:\n if name.startswith(to_freeze):\n tested = True\n self.assertFalse(layer.requires_grad)\n if not tested:\n self.assertTrue(layer.requires_grad)\n utils.unfreeze_layers(self.model, layers)\n for param in self.model.parameters():\n self.assertTrue(param.requires_grad)\n\n def test_children_names(self):\n names = utils.children_names(self.model)\n layers = {'fc', 'layer1', 'layer2', 'layer3',\n 'layer4', 'conv1', 'bn1', 'relu', 'maxpool', 'avgpool'}\n self.assertEquals(len(names), len(layers))\n for name in names:\n self.assertTrue(name in layers)\n"
},
{
"alpha_fraction": 0.6180482506752014,
"alphanum_fraction": 0.6306400895118713,
"avg_line_length": 33.03571319580078,
"blob_id": "2bba6c13d679c151011bece134239b2215f9d171",
"content_id": "113eb21cc6f08c1c0fe2d93497093ba566f1df03",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 953,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 28,
"path": "/setup.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\nsetuptools.setup(\n name=\"maruti\",\n version=\"1.3.4\",\n author=\"Ankit Saini\",\n author_email=\"[email protected]\",\n description=\"Maruti Library\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/ankitsainidev/maruti\",\n download_url='https://github.com/ankitsainidev/maruti/archive/v1.3.tar.gz',\n packages=['maruti', 'maruti.vision', 'maruti.deepfake',\n 'maruti.torch', 'maruti.imports'],\n package_dir={'maruti': 'maruti'},\n package_data={'maruti': ['deepfake/data/*/*']},\n include_package_data=True,\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n ],\n python_requires='>=3.5',\n install_requires=['tqdm==4.40.2', 'opencv-python', 'facenet_pytorch']\n)\n"
},
{
"alpha_fraction": 0.7179487347602844,
"alphanum_fraction": 0.7219973206520081,
"avg_line_length": 34.28571319580078,
"blob_id": "8779057e970747fd0be461ee2f9c4142574291ef",
"content_id": "5a876612245ed4559c68e67969d6cf7c4d126397",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 21,
"path": "/maruti/imports/ml.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from .general import *\nfrom .general import __all__ as gen_all\nimport torch\nimport torch.nn as nn\nimport torchvision.transforms as torch_transforms\nimport torchvision\nimport maruti.torch as mtorch\nimport maruti.deepfake.dataset as mdata\nimport maruti\nimport maruti.deepfake as mfake\nimport numpy as np\nimport cv2\nimport maruti.vision as mvis\nimport pandas as pd\nimport torch.utils.data as tdata\nimport matplotlib.pyplot as plt\nfrom torch.utils import data\nimport torch.optim as optim\ndevice = 'cuda:0' if torch.cuda.is_available() else 'cpu'\n__all__ = gen_all + ['mfake','mvis', 'cv2', 'mdata', 'tdata', 'pd', 'device', 'plt', 'np', 'torch', 'nn', 'torch_transforms',\n 'torchvision', 'mtorch', 'maruti', 'data', 'optim']\n"
},
{
"alpha_fraction": 0.7336244583129883,
"alphanum_fraction": 0.7336244583129883,
"avg_line_length": 24.44444465637207,
"blob_id": "36e1cfd722e4c4c8f7f725b341c7a4c82d13b3d7",
"content_id": "f36cb36f55b52bb7916bf58f1076ad2c706d8615",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 229,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 9,
"path": "/maruti/imports/general.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\nfrom glob import glob\nfrom tqdm.auto import tqdm\nimport itertools\nimport random\nimport time\nfrom functools import partial\n__all__ = ['time','random','os', 'shutil', 'glob', 'tqdm', 'itertools', 'partial']\n"
},
{
"alpha_fraction": 0.569460391998291,
"alphanum_fraction": 0.5740528106689453,
"avg_line_length": 21.33333396911621,
"blob_id": "9efb07bb91e4fd98e9f533fab41636c55db3d5a6",
"content_id": "01b8baa725e9dd7fdb51b8899ad22f0630d70c1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 39,
"path": "/maruti/utils.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import json\nimport zipfile\nimport time\nfrom tqdm.auto import tqdm\n\n__all__ = ['rep_time', 'read_json', 'write_json', 'unzip']\n\n\ndef rep_time(seconds):\n if seconds >= 3600:\n return time.strftime('%H:%M:%S', time.gmtime(seconds))\n else:\n return time.strftime('%M:%S', time.gmtime(seconds))\n\n\ndef read_json(path):\n '''\n Read Json file as dict.\n '''\n with open(path, 'rb') as file:\n json_dict = json.load(file)\n return json_dict\n\n\ndef write_json(dictionary, path):\n \"\"\"\n Write dict as a json file\n \"\"\"\n with open(path, 'w') as fp:\n json.dump(dictionary, fp)\n\n\ndef unzip(zip_path, path='.'):\n with zipfile.ZipFile(zip_path) as zf:\n for member in tqdm(zf.infolist(), desc='Extracting '):\n try:\n zf.extract(member, path)\n except zipfile.error as e:\n pass\n"
},
{
"alpha_fraction": 0.8214285969734192,
"alphanum_fraction": 0.8214285969734192,
"avg_line_length": 13.5,
"blob_id": "1d2d63ef10a2d88850a81a09209070e67913487e",
"content_id": "373acfd9e1e0c93fea1b680fe817ccc7084f23d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 28,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 2,
"path": "/README.md",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "# HELPING LIBRARY\nFor myself"
},
{
"alpha_fraction": 0.5448108911514282,
"alphanum_fraction": 0.5496460199356079,
"avg_line_length": 34.52760696411133,
"blob_id": "3abc814f51f5995651c2ea1c1a701c9823aa061e",
"content_id": "5fc0837036ea13708bb403c8ff83da8880da739c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11582,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 326,
"path": "/maruti/torch/utils.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "# from torch_lr_finder import LRFinder\nfrom tqdm.auto import tqdm\nfrom functools import partial\nimport torch\nimport time\nimport numpy as np\nfrom collections import Counter\nfrom torchvision import transforms as torch_transforms\nfrom . import callback as mcallback\ntqdm_nl = partial(tqdm, leave=False)\n\n__all__ = ['unfreeze', 'freeze', 'unfreeze_layers', 'freeze_layers', 'Learner']\n\ndef_norm = torch_transforms.Normalize(mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225])\n\n\ndef children_names(model):\n return set([child[0] for child in model.named_children()])\n\n\ndef apply_method(model, method):\n for param in model.parameters():\n param.requires_grad = True if method == 'unfreeze' else False\n\n\ndef unfreeze(model):\n apply_method(model, 'unfreeze')\n\n\ndef freeze(model):\n apply_method(model, 'freeze')\n\n\ndef apply_recursively(model, layer_dict, method):\n if layer_dict is None:\n apply_method(model, method)\n else:\n memo = set()\n for name, child in model.named_children():\n if name in layer_dict:\n memo.add(name)\n apply_recursively(child, layer_dict[name], method)\n for name, parameter in model.named_parameters():\n if name in layer_dict and name not in memo:\n parameter.requires_grad = True if method == 'unfreeze' else False\n\n\ndef _dict_from_layers(layers):\n if layers is None:\n return {None}\n\n splitted = [layer.split('.') for layer in layers]\n childs = [split[0] for split in splitted]\n child_count = Counter(childs)\n layer_dict = {child: {} for child in child_count}\n none_layers = set()\n for split in splitted:\n if len(split) == 1:\n none_layers.add(split[0])\n else:\n layer_dict[split[0]] = {**layer_dict[split[0]],\n **_dict_from_layers(split[1:]), }\n for none_layer in none_layers:\n layer_dict[none_layer] = None\n return layer_dict\n\n\ndef freeze_layers(model: 'torch.nn Module', layers: 'generator of layer names'):\n apply_recursively(model, _dict_from_layers(layers), 'freeze')\n\n\ndef unfreeze_layers(model: 'torch.nn Module', layers: 'generator of layer names'):\n apply_recursively(model, _dict_from_layers(layers), 'unfreeze')\n\n\ndef _limit_string(string, length):\n string = str(string)\n if length > len(string):\n return string\n else:\n return string[:length - 2] + '..'\n\n\ndef _time_rep(seconds):\n if seconds >= 3600:\n return time.strftime('%H:%M:%S', time.gmtime(seconds))\n else:\n return time.strftime('%M:%S', time.gmtime(seconds))\n\n\nclass Learner:\n def __init__(self, model):\n self.model = model\n self.call_count = 0\n self.record = mcallback.Recorder()\n\n def compile(self, optimizer, loss, lr_scheduler=None,\n device='cpu', metrics=None, callback=mcallback.Callback(), max_metric_prints=3):\n self.optimizer = optimizer\n self.loss = loss\n self.metrics_plimit = max_metric_prints\n self.device = device\n self.cb = mcallback.Compose([callback, self.record])\n if lr_scheduler is not None:\n self.lr_scheduler = lr_scheduler\n if metrics is not None:\n self.metrics = metrics\n else:\n self.metrics = []\n\n def state_dict(self):\n if not hasattr(self, 'optimizer'):\n print('You first need to compile the learner')\n return\n\n state = {\n 'record': self.record.state_dict(),\n 'model': self.model.state_dict(),\n 'optimizer': self.optimizer.state_dict(),\n }\n\n if hasattr(self, 'lr_scheduler'):\n state['lr_scheduler'] = self.lr_scheduler.state_dict()\n\n return state\n\n def load_state_dict(self, state):\n \"\"\"Return True if everything wents write. Else raises error or returns False.\"\"\"\n if not hasattr(self, 'optimizer'):\n print('Compile with earlier settings.')\n return False\n self.optimizer.load_state_dict(state['optimizer'])\n self.model.load_state_dict(state['model'])\n self.record.load_state_dict(state['record'])\n if hasattr(self, 'lr_scheduler'):\n self.lr_scheduler.load_state_dict(state['lr_scheduler'])\n else:\n if 'lr_scheduler' in state:\n print(\n 'lr_scheduler is missing. Recommended to compile with same settings.')\n return False\n return True\n\n @property\n def header_str(self):\n header_string = ''\n # loss\n headings = ['Train Loss', 'Val Loss']\n\n # metrics\n for i in range(len(self.metrics)):\n headings.append(self.metrics[i].__name__)\n if i == self.metrics_plimit:\n break\n\n # time\n headings.append('Time')\n\n # getting together\n for heading in headings:\n header_string += _limit_string(heading, 12).center(12) + '|'\n\n return header_string\n\n @property\n def epoch_str(self):\n info = self.record.last_summary\n info_string = ''\n info_vals = [info['train_loss'], info['val_loss']\n if 'val_loss' in info else None]\n for i in range(len(self.metrics)):\n info_vals.append(info['val_metrics'][self.metrics[i].__name__])\n if i == self.metrics_plimit:\n break\n info_vals.append(_time_rep(info['time']))\n for info_val in info_vals:\n if isinstance(info_val, int):\n info_val = round(info_val, 5)\n info_string += _limit_string(info_val, 12).center(12) + '|'\n\n return info_string\n\n @property\n def summary_str(self):\n total_time = sum(\n map(lambda x: x['time'], self.record.summaries))\n best_score = self.record.best_score\n return f'Total Time: {_time_rep(total_time)}, Best Score: {best_score}'\n\n def execute_metrics(self, ypred, y):\n metric_vals = {}\n for metric in self.metrics:\n # TODO: make better handling of non_scalar metrics\n metric_vals[metric.__name__] = metric(ypred, y).item()\n return metric_vals\n\n def fit(self, epochs, train_loader, val_loader=None, accumulation_steps=1, save_on_epoch='learn.pth', min_validations=0):\n # TODO: test for model on same device\n # Save_on_epoch = None or False to stop save, else path to save\n min_validation_idx = set(np.linspace(\n 0, len(train_loader), min_validations + 1, dtype=int)[1:])\n\n self.call_count += 1\n\n print(self.header_str)\n\n # train\n self.optimizer.zero_grad()\n if self.cb.on_train_start(epochs):\n return\n for epoch in tqdm_nl(range(epochs)):\n epoch_predictions = []\n epoch_targets = []\n if self.cb.on_epoch_start(epoch):\n return\n\n self.model.train()\n\n start_time = time.perf_counter()\n train_length = len(train_loader)\n\n for i, (inputs, targets) in tqdm_nl(enumerate(train_loader), total=train_length, desc='Training: '):\n if self.cb.on_batch_start(epoch, i):\n return\n inputs, targets = inputs.to(\n self.device), targets.to(self.device)\n pred = self.model(inputs)\n loss = self.loss(pred, targets)\n\n # logging\n epoch_predictions.append(pred.clone().detach())\n epoch_targets.append(targets.clone().detach())\n batch_metrics = self.execute_metrics(pred, targets)\n\n #\n\n loss.backward()\n if (i + 1) % accumulation_steps == 0:\n self.optimizer.step()\n if hasattr(self, 'lr_scheduler'):\n self.lr_scheduler.step()\n self.optimizer.zero_grad()\n\n batch_extras = {'optimizer': self.optimizer, }\n if hasattr(self, 'lr_scheduler'):\n batch_extras['lr_scheduler'] = self.lr_scheduler\n\n if self.cb.on_batch_end(loss.item(), batch_metrics, batch_extras, epoch, i):\n return\n if val_loader is not None:\n\n if i in min_validation_idx:\n del inputs\n del targets\n if self.cb.on_min_val_start(epoch, i):\n return\n min_val_loss, min_val_metrics = self._validate(\n val_loader)\n min_val_extras = {'model': self.model}\n if self.cb.on_min_val_end(min_val_loss, min_val_metrics, min_val_extras, epoch, i):\n return\n self.model.train()\n\n epoch_predictions = torch.cat(epoch_predictions)\n epoch_targets = torch.cat(epoch_targets)\n train_loss = self.loss(\n epoch_predictions, epoch_targets).clone().detach().item()\n train_metrics = self.execute_metrics(\n epoch_predictions, epoch_targets)\n losses = {'train': train_loss}\n metrics = {'train': train_metrics}\n if val_loader is not None:\n if self.cb.on_validation_start(epoch):\n return\n val_loss, val_metrics = self._validate(val_loader)\n losses['val'] = val_loss\n metrics['val'] = val_metrics\n if self.cb.on_validation_end(val_loss, val_metrics, epoch):\n return\n\n if save_on_epoch:\n torch.save(self.state_dict(), save_on_epoch)\n\n epoch_extra_dict = {'time': time.perf_counter() - start_time,\n 'model': self.model.state_dict(),\n 'optimizer': self.optimizer,\n }\n if hasattr(self, 'lr_scheduler'):\n epoch_extra_dict['lr_scheduler'] = self.lr_scheduler\n if self.cb.on_epoch_end(losses, metrics, epoch_extra_dict, epoch):\n return\n # this should after the epoch_end callback to be ready\n tqdm.write(self.epoch_str)\n print(self.summary_str)\n\n def predict(self, data_loader, with_targets=True):\n self.model.eval()\n prediction_ar = []\n target_ar = []\n\n with torch.no_grad():\n if with_targets:\n for inputs, targets in tqdm_nl(data_loader, desc='Predicting: '):\n inputs, targets = inputs.to(\n self.device), targets.to(self.device)\n pred = self.model(inputs)\n prediction_ar.append(pred)\n target_ar.append(targets)\n return torch.cat(prediction_ar), torch.cat(target_ar)\n\n for inputs in tqdm_nl(data_loader, desc='Predicting: '):\n inputs = inputs.to(self.device)\n pred = self.model(inputs)\n prediction_ar.append(pred)\n return torch.cat(prediction_ar)\n\n def validate(self, val_loader):\n self.call_count += 1\n return self._validate(val_loader)\n\n def _validate(self, val_loader):\n pred, target = self.predict(val_loader)\n loss = self.loss(pred, target).clone().detach().item()\n metrics = self.execute_metrics(pred, target)\n return loss, metrics\n"
},
{
"alpha_fraction": 0.5225856900215149,
"alphanum_fraction": 0.5288162231445312,
"avg_line_length": 33.702701568603516,
"blob_id": "280c05559466ec3deaf676712d6e3e9063b275f4",
"content_id": "9a38df896ea740d5d705fd92cf9845ef5b013920",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5136,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 148,
"path": "/maruti/deepfake/utils.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "# from torch_lr_finder import LRFinder\nfrom tqdm.auto import tqdm\nfrom functools import partial\nimport torch\nimport time\n\ntqdm_nl = partial(tqdm, leave=False)\n\n\nclass Callback:\n pass\n\n\ndef _limit_string(string, length):\n string = str(string)\n if length > len(string):\n return string\n else:\n return string[:length - 2] + '..'\n\n\ndef _time_rep(seconds):\n if seconds >= 3600:\n return time.strftime('%H:%M:%S', time.gmtime(seconds))\n else:\n return time.strftime('%M:%S', time.gmtime(seconds))\n\n\nclass Learner:\n def __init__(self, model):\n self.model = model\n\n def compile(self, optimizer, loss, lr_scheduler=None, device='cpu', metrics=None):\n self.optimizer = optimizer\n self.loss = loss\n self.device = device\n if lr_scheduler is not None:\n self.lr_scheduler = lr_scheduler\n if metrics is not None:\n self.metrics = metrics\n else:\n self.metrics = []\n\n def fit(self, epochs, train_loader, val_loader=None, accumulation_steps=1):\n # TODO: test for model on same device\n best_loss = float('inf')\n each_train_info = []\n each_val_info = []\n complete_info = {}\n header_string = ''\n headings = ['Train Loss', 'Val Loss']\n for i in range(len(self.metrics)):\n headings.append(self.metrics[i].__name__)\n if i == 2:\n break\n\n for heading in headings:\n header_string += _limit_string(heading, 12).center(12) + '|'\n header_string += 'Time'.center(12) + '|'\n print(header_string)\n\n # train\n self.optimizer.zero_grad()\n\n for epoch in tqdm_nl(range(epochs)):\n\n self.model.train()\n train_info = {}\n val_info = {}\n train_info['losses'] = []\n\n start_time = time.perf_counter()\n train_length = len(train_loader)\n\n for i, (inputs, targets) in tqdm_nl(enumerate(train_loader), total=train_length, desc='Training: '):\n inputs, targets = inputs.to(\n self.device), targets.to(self.device)\n pred = self.model(inputs)\n loss = self.loss(pred, targets)\n train_info['losses'].append(loss)\n loss.backward()\n\n if (i + 1) % accumulation_steps == 0:\n self.optimizer.step()\n if hasattr(self, 'lr_scheduler'):\n self.lr_scheduler.step()\n self.optimizer.zero_grad()\n train_info['time'] = time.perf_counter() - start_time\n\n if val_loader is not None:\n val_info = self.validate(val_loader)\n info_string = ''\n\n def format_infos(x, length):\n return _limit_string(round(torch.stack(x).mean().item(), 2), 12).center(12)\n info_values = [format_infos(train_info['losses'], 12)]\n\n if 'losses' in val_info:\n info_values.append(format_infos(val_info['losses'], 12))\n if torch.stack(val_info['losses']).mean().item() < best_loss:\n complete_info['best_state_dict'] = self.model.state_dict()\n else:\n if torch.stack(train_info['losses']).mean().item() < best_loss:\n complete_info['best_state_dict'] = self.model.state_dict()\n info_values.append(str(None).center(12))\n\n for i, metric in enumerate(self.metrics):\n info_values.append(format_infos(\n val_info['metrics'][metric.__name__], 12))\n if i == 2:\n break\n total_time = train_info['time']\n if 'time' in val_info:\n total_time += val_info['time']\n info_values.append(_time_rep(total_time).center(12))\n\n tqdm.write('|'.join(info_values) + '|')\n\n each_train_info.append(train_info)\n each_val_info.append(val_info)\n complete_info = {**complete_info,\n 'train': each_train_info, 'val': each_val_info}\n return complete_info\n\n def validate(self, val_loader):\n information = {}\n information['losses'] = []\n information['metrics'] = {}\n for metric in self.metrics:\n information['metrics'][metric.__name__] = []\n\n self.model.eval()\n val_loss = torch.zeros(1)\n start_time = time.perf_counter()\n with torch.set_grad_enabled(False):\n for inputs, targets in tqdm_nl(val_loader, desc='Validating: '):\n inputs, targets = inputs.to(\n self.device), targets.to(self.device)\n pred = self.model(inputs)\n loss = self.loss(pred, targets)\n information['losses'].append(loss)\n for metric in self.metrics:\n information['metrics'][metric.__name__].append(\n metric(pred, targets))\n\n total_time = time.perf_counter() - start_time\n information['time'] = total_time\n return information\n"
},
{
"alpha_fraction": 0.7555555701255798,
"alphanum_fraction": 0.7555555701255798,
"avg_line_length": 21.5,
"blob_id": "502fc3f8643d535aeb735178134906aaf96e9df7",
"content_id": "051f5fe3f74a26a5bdd767ea3b0a8d3a1063d464",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 4,
"path": "/maruti/vision/__init__.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from . import image\nfrom . import video\nfrom .image import make_grid\nfrom .video import *\n"
},
{
"alpha_fraction": 0.5884184241294861,
"alphanum_fraction": 0.6264010071754456,
"avg_line_length": 34.71111297607422,
"blob_id": "d9c92d1b41c85afbbb62e8106f5da8bb6ad93400",
"content_id": "cc7e2301c5b9dcc8e633ee8aa7c06ab3b79fd615",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1606,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 45,
"path": "/tests/vision/test_image.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import unittest\nimport cv2\nfrom cv2 import dnn_Net\nfrom maruti.vision import image\nimport os\nTEST_DATA_PATH = 'test_data'\n\n\nclass ImageTests(unittest.TestCase):\n\n def setUp(self):\n self.img_path = os.path.join(TEST_DATA_PATH, 'img1.jpeg')\n self.img = cv2.imread(self.img_path)\n\n def test_create_net(self):\n self.assertIsInstance(image.create_net(), dnn_Net)\n\n def test_brightness_score(self):\n self.assertAlmostEqual(\n image.brightness_score(self.img), 1.76, delta=1e-2)\n\n def test_adjust_brightness(self):\n brightness = image.brightness_score(self.img)\n new_img = image.adjust_brightness(self.img, 2*brightness)\n self.assertGreaterEqual(image.brightness_score(new_img), brightness)\n\n def test_crop_around_point(self):\n h, w = self.img.shape[:2]\n points = [(0, 0), (h-1, w-1), (h//2, w//2)]\n sizes = [(224, 224), (160, 160), (3000, 4000)]\n for point in points:\n for size in sizes:\n cropped = image.crop_around_point(self.img, point, size)\n self.assertEqual(size, cropped.shape[:2])\n\n def test_get_face_center(self):\n old_brightness = image.brightness_score(self.img)\n (x, y), brightness = image.get_face_center(self.img)\n self.assertEqual(old_brightness, brightness)\n\n def test_detect_sized_rescaled_face(self):\n sizes = [(224, 224), (160, 160), (3000, 4000)]\n for size in sizes[::-1]:\n face = image.detect_sized_rescaled_face(self.img, size,rescale_factor=2)\n self.assertEqual(size, face.shape[:2])"
},
{
"alpha_fraction": 0.7719298005104065,
"alphanum_fraction": 0.7719298005104065,
"avg_line_length": 21.799999237060547,
"blob_id": "d03cbf26955cb9a8b2b66999fea8fcb8063d9e20",
"content_id": "7e5d9f28d66f1dd45274820898d0c1c162e00c56",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 228,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 10,
"path": "/maruti/__init__.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from . import utils\nfrom . import sizes\nfrom . import vision\nfrom . import deepfake\nfrom . import kaggle\nfrom . import torch\nfrom .utils import *\nfrom .sizes import *\nfrom .deepfake import ImageReader\nfrom .torch import Learner\n"
},
{
"alpha_fraction": 0.7460317611694336,
"alphanum_fraction": 0.7460317611694336,
"avg_line_length": 20,
"blob_id": "a28456f6bab0a47dbc8922150be0a7951809b494",
"content_id": "c993026b6f7699bbf13d373fae1a6f97eac0688e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 3,
"path": "/maruti/torch/__init__.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from . import utils\nfrom . import metrics\nfrom .utils import *\n"
},
{
"alpha_fraction": 0.6106408834457397,
"alphanum_fraction": 0.6130592226982117,
"avg_line_length": 33.45833206176758,
"blob_id": "6b8cbeeeee6744d21c30c252e9bb7c2761468dc4",
"content_id": "204c884681e765d26a7b417c662c6f83aa9daea8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 827,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 24,
"path": "/maruti/kaggle.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import os\nimport subprocess\nfrom pathlib import Path\nimport zipfile\n\n\ndef set_variables(credentials: 'lists[str,str]=[username, token]'):\n os.environ['KAGGLE_USERNAME'] = credentials[0]\n os.environ['KAGGLE_KEY'] = credentials[1]\n\n\ndef update_dataset(path, slug, message='new version', clean=False):\n folder = os.path.basename(path)\n path = os.path.dirname(path)\n path = Path(path)\n os.mkdir(path / folder / folder)\n subprocess.call(['kaggle', 'datasets', 'download', '-p',\n str(path / folder / folder), 'ankitsainiankit/' + slug, '--unzip'])\n\n subprocess.call(['kaggle', 'datasets', 'metadata', '-p',\n str(path / folder), 'ankitsainiankit/' + slug])\n\n subprocess.call(['kaggle', 'datasets', 'version',\n '-m', message, '-p', path / folder])\n"
},
{
"alpha_fraction": 0.5214545726776123,
"alphanum_fraction": 0.5458182096481323,
"avg_line_length": 25.69902992248535,
"blob_id": "ed68cd6601e5401602e3257f83a016dd2bd3a790",
"content_id": "891c7ace3db57b0fb590986c30ad228641870d7a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2750,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 103,
"path": "/maruti/vision/image.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nfrom functools import lru_cache\nfrom functools import partial\nfrom os.path import join\nimport os\nfrom PIL import Image\nimport torch\n\n\n__all__ = ['brightness_score', 'adjust_brightness',\n 'crop_around_point', 'make_grid']\n\nDATA_PATH = join(os.path.dirname(__file__), 'data')\n\n\ndef brightness_score(img):\n '''\n @params:\n img - an array with shape (w/h, w/h, 3)\n '''\n cols, rows = img.shape[:2]\n return np.sum(img) / (255 * cols * rows)\n\n\ndef adjust_brightness(img, min_brightness):\n '''\n Increase of decrease brightness\n @params:\n img - an array with shape (w,h,3)\n '''\n brightness = brightness_score(img)\n ratio = brightness / min_brightness\n return cv2.convertScaleAbs(img, alpha=1 / ratio, beta=0)\n\n\ndef crop_around_point(img, point, size):\n '''\n crop a rectangle with size centered at point\n @params: size (h,w)\n @params: point (x,y)\n '''\n h, w = img.shape[:2]\n n_h, n_w = size\n r_h, r_w = h, w\n\n if h < n_h:\n r_h = n_h\n if w < n_w:\n r_w = n_w\n\n h_ratio = r_h / h\n w_ratio = r_w / w\n if h_ratio > w_ratio:\n r_w = int(r_w * h_ratio / w_ratio)\n elif w_ratio > h_ratio:\n r_h = int(r_h * w_ratio / h_ratio)\n\n pre_w, post_w = n_w // 2, n_w - (n_w // 2)\n pre_h, post_h = n_h // 2, n_h - (n_h // 2)\n img = cv2.resize(img, (r_w, r_h))\n midx, midy = point\n startX, startY, endX, endY = 0, 0, 0, 0\n if midx - pre_w < 0:\n startX, endX = 0, n_w\n elif midx + post_w - 1 >= r_w:\n startX, endX = r_w - n_w, r_w\n else:\n startX, endX = midx - pre_w, midx + post_w\n\n if midy - pre_h < 0:\n startY, endY = 0, n_h\n elif midy + post_h - 1 >= r_h:\n startY, endY = r_h - n_h, r_h\n else:\n startY, endY = midy - pre_h, midy + post_h\n\n return img[startY:endY, startX:endX]\n\n\ndef _unNormalize(img, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):\n mt = torch.FloatTensor(mean).view(1, 1, 3)\n st = torch.FloatTensor(std).view(1, 1, 3)\n return (((img * st) + mt) * 255).int().numpy().astype(np.uint8)\n\n\ndef make_grid(imgs: '(n,h,w,c) tensor or list of (h,w,c) tensor', cols=8):\n \"return numpy array of size (h,w,c) easy for plotting\"\n count = len(imgs)\n rows = (count + cols - 1) // cols\n if not (imgs[0] > 5).any():\n imgs = [_unNormalize(img) for img in imgs]\n h, w = imgs[0].shape[:-1]\n new_img_w = h * cols\n new_img_h = w * rows\n new_img = Image.new('RGB', (new_img_w, new_img_h))\n\n for i in range(len(imgs)):\n img = Image.fromarray(np.array(imgs[i]).astype(np.uint8))\n x = h * (i % cols)\n y = h * (i // cols)\n new_img.paste(img, (x, y))\n return np.array(new_img)\n"
},
{
"alpha_fraction": 0.5234806537628174,
"alphanum_fraction": 0.5593922734260559,
"avg_line_length": 26.846153259277344,
"blob_id": "d9d3ab6cd8693d982e5df8ffdd9231ba0f399af8",
"content_id": "63283120e7ba278fa1d1ae9cce2cbeeb979905f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 724,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 26,
"path": "/tests/test_sizes.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "import unittest\nimport tempfile\nimport os\nfrom maruti import sizes\n\n\nclass DeepfakeTest(unittest.TestCase):\n\n def test_byte_to_mb(self):\n self.assertEqual(sizes.byte_to_mb(1024*1024), 1)\n self.assertAlmostEqual(sizes.byte_to_mb(1024),\n 0.0009765624, delta=1e-8)\n\n def test_sizes(self):\n with tempfile.TemporaryDirectory() as dir:\n # dir test\n sizes.dir_size(dir)\n sizes.dir_size()\n\n # file test\n with open(os.path.join(dir, 'test_file.txt'), 'w') as f:\n f.write(\"It's a test\")\n sizes.file_size(os.path.join(dir, 'test_file.txt'))\n\n # var test\n sizes.var_size(dir)\n"
},
{
"alpha_fraction": 0.5903083682060242,
"alphanum_fraction": 0.5991189479827881,
"avg_line_length": 21.733333587646484,
"blob_id": "5d504d8047ca49b9ad9aa805a93885e8e7acb604",
"content_id": "c102a80cf94e975d61284bdfe9de64b049c6e7c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 681,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 30,
"path": "/maruti/sizes.py",
"repo_name": "gouravsaini021/maruti",
"src_encoding": "UTF-8",
"text": "from sys import getsizeof\nimport os\n\n__all__ = ['dir_size','file_size','var_size']\n\ndef byte_to_mb(size):\n return size/(1024**2)\n\n\ndef dir_size(start_path='.'):\n total_size = 0\n for dirpath, dirnames, filenames in os.walk(start_path):\n for f in filenames:\n fp = os.path.join(dirpath, f)\n # skip if it is symbolic link\n if not os.path.islink(fp):\n total_size += os.path.getsize(fp)\n\n return byte_to_mb(total_size)\n\n\ndef file_size(path):\n file_stats = os.stat(path)\n return byte_to_mb(file_stats.st_size)\n\n\ndef var_size(var):\n return byte_to_mb(getsizeof(var))\n\n__all__ = ['var_size','file_size','dir_size']"
}
] | 23 |
KimGyuri875/TIL | https://github.com/KimGyuri875/TIL | 9b9a107daf5170afc0dc5caa9bde6d9304096985 | 5c8ad8f9950e682a4924efea84fdc6f7a2953015 | 62da55b8ad93fcf53ff5b585a0fe70fff9b506d9 | refs/heads/master | "2023-03-08T16:41:41.203947" | "2021-02-26T10:59:05" | "2021-02-26T10:59:05" | 325,204,921 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6060606241226196,
"alphanum_fraction": 0.6060606241226196,
"avg_line_length": 10,
"blob_id": "754bb94f6c6c1b25dff360c588e4efc70a0ef812",
"content_id": "2dac5f0aa46f830fccf43f40a0bf3b570b90b688",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 3,
"path": "/README.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "# TIL\n\n- 매일 매일 배운 것을 기록하는 레포입니다.\n"
},
{
"alpha_fraction": 0.6869391798973083,
"alphanum_fraction": 0.7020604610443115,
"avg_line_length": 37.05194854736328,
"blob_id": "947c8231169e54f28b3f5ace3f73c3687af37a47",
"content_id": "137e238d45bdecb3cb5f21be9fc748fb8d852ccb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 7822,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 154,
"path": "/SQL/practice/oracle3_practice.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--1. 학생이름과 주소지를 표시하시오. 단, 출력 헤더는 \"학생 이름\", \"주소지\"로 하고, 정렬은 이름으로 오름차순 표시\r\n\r\nSELECT STUDENT_NAME AS \"학생 이름\", STUDENT_ADDRESS AS 주소지\r\nFROM TB_STUDENT\r\nORDER BY \"학생 이름\";\r\n\r\n--2. 휴학중인 학생들의 이름과 주민번호를 나이가 적은 순서로 화면에 출력하시오.\r\nSELECT STUDENT_NAME AS \"학생 이름\", STUDENT_SSN\r\nFROM TB_STUDENT\r\nWHERE ABSENCE_YN = 'Y'\r\nORDER BY STUDENT_SSN DESC;\r\n\r\n-- 3.주소지가 강원도나 경기도인 학생들 중 1900 년대 학번을 가진 학생들의 이름과 학번, 주소를 이름의 오름차순으로 화면에 출력하시오. \r\nSELECT STUDENT_NAME AS \"학생이름\", STUDENT_NO AS 학번, STUDENT_ADDRESS AS \"거주지 주소\"\r\nFROM TB_STUDENT\r\nWHERE (STUDENT_ADDRESS LIKE '경기도%' OR STUDENT_ADDRESS LIKE '강원도%') AND STUDENT_NO LIKE '9%'\r\nORDER BY 학생이름;\r\n\r\n--4. 현재 법학과 교수 중 가장 나이가 맋은 사람부터 이름을 확인핛 수 있는 SQL 문장, (법학과의 '학과코드'는 학과 테이블(TB_DEPARTMENT)을 조회)\r\nSELECT PROFESSOR_NAME, PROFESSOR_SSN\r\nFROM TB_PROFESSOR\r\nJOIN TB_DEPARTMENT USING (DEPARTMENT_NO)\r\nWHERE DEPARTMENT_NAME ='법학과'\r\nORDER BY 2;\r\n\r\n--5. 2004 년 2 학기에 'C3118100' 과목을 수강핚 학생들의 학점을 조회하려고 핚다. \r\n--학점이 높은 학생부터 표시하고, 학점이 같으면 학번이 낮은 학생부터 표시\r\nSELECT STUDENT_NO, ROUND(POINT, 2)\r\nFROM TB_GRADE\r\nWHERE CLASS_NO = 'C3118100' AND TERM_NO = '200402'\r\nORDER BY POINT DESC, STUDENT_NO;\r\n\r\n--6. 학생 번호, 학생 이름, 학과 이름을 학생 이름으로 오름차순 정렬하여 출력하는 SQL\r\n\r\nSELECT STUDENT_NO,STUDENT_NAME, DEPARTMENT_NAME\r\nFROM TB_STUDENT,TB_DEPARTMENT\r\nWHERE TB_DEPARTMENT.DEPARTMENT_NO = TB_STUDENT.DEPARTMENT_NO\r\nORDER BY STUDENT_NAME;\r\n\r\n--7.과목 이름과 과목의 학과 이름을 출력하는 SQL 문장을 작성하시오.\r\nSELECT CLASS_NAME, DEPARTMENT_NAME\r\nFROM TB_CLASS,TB_DEPARTMENT\r\nWHERE TB_DEPARTMENT.DEPARTMENT_NO = TB_CLASS.DEPARTMENT_NO;\r\n\r\n--8. 과목별 교수 이름을 찾으려고 핚다. 과목 이름과 교수 이름을 출력하는 SQL 문\r\nSELECT CLASS_NAME, PROFESSOR_NAME\r\nFROM TB_CLASS,TB_CLASS_PROFESSOR,TB_PROFESSOR\r\nWHERE TB_CLASS.CLASS_NO = TB_CLASS_PROFESSOR.CLASS_NO AND TB_PROFESSOR.PROFESSOR_NO = TB_CLASS_PROFESSOR.PROFESSOR_NO;\r\n\r\n--9. 8 번의 결과 중 ‘인문사회’ 계열에 속핚 과목의 교수 이름을 찾으려고 핚다. 이에 해당하는 과목 이름과 교수 이름을 출력하는 SQL \r\nSELECT CLASS_NAME, PROFESSOR_NAME\r\nFROM TB_CLASS,TB_CLASS_PROFESSOR,TB_PROFESSOR,TB_DEPARTMENT\r\nWHERE TB_CLASS.CLASS_NO = TB_CLASS_PROFESSOR.CLASS_NO AND TB_PROFESSOR.PROFESSOR_NO = TB_CLASS_PROFESSOR.PROFESSOR_NO \r\nAND TB_PROFESSOR.DEPARTMENT_NO = TB_DEPARTMENT.DEPARTMENT_NO AND CATEGORY='인문사회';\r\n\r\n--10.‘음악학과’ 학생들의 평점을 구하려고 핚다. 음악학과 학생들의 \"학번\", \"학생 이름\",\r\n--\"전 평점\"을 출력하는 SQL 문장을 작성하시오. (단, 평점은 소수점 1 자리까지만 반올림하여 표시핚다.)\r\n\r\nSELECT TB_STUDENT.STUDENT_NO AS 학번, TB_STUDENT.STUDENT_NAME AS \"학생 이름\", ROUND(AVG(POINT),1) AS \"전체 평점\"\r\nFROM TB_GRADE,TB_STUDENT,TB_DEPARTMENT\r\nWHERE TB_DEPARTMENT.DEPARTMENT_NO = TB_STUDENT.DEPARTMENT_NO AND DEPARTMENT_NAME='음악학과' AND TB_STUDENT.STUDENT_NO = TB_GRADE.STUDENT_NO\r\nGROUP BY TB_STUDENT.STUDENT_NO,TB_STUDENT.STUDENT_NAME\r\nORDER BY TB_STUDENT.STUDENT_NO;\r\n\r\n--11. 학번이 A313047의 학과 이름, 학생 이름과 지도 교수 이름이 필요하다.\r\n\r\nSELECT DEPARTMENT_NAME AS 학과이름, STUDENT_NAME AS 학생이름, PROFESSOR_NAME AS 지도교수이름 \r\nFROM TB_STUDENT, TB_DEPARTMENT,TB_PROFESSOR\r\nWHERE TB_STUDENT.DEPARTMENT_NO = TB_DEPARTMENT.DEPARTMENT_NO AND TB_STUDENT.COACH_PROFESSOR_NO=TB_PROFESSOR.PROFESSOR_NO\r\nAND TB_STUDENT.STUDENT_NO = 'A313047';\r\n\r\n--12. 2007 년도에 '인간관계론' 과목을 수강한 학생을 찾아 학생이름과 수강학기를 표시하는 SQL\r\nSELECT STUDENT_NAME, TERM_NO\r\nFROM TB_STUDENT,TB_GRADE,TB_CLASS\r\nWHERE TB_STUDENT.STUDENT_NO = TB_GRADE.STUDENT_NO AND TB_CLASS.CLASS_NO=TB_GRADE.CLASS_NO\r\nAND TERM_NO LIKE '2007%' AND CLASS_NAME = '인간관계론';\r\n\r\n--13. 예체능 계열 과목 중 과목 담당교수를 핚 명도 배정받지 못핚 과목을 찾아 그 과목이름과 학과 이름을 출력하는 SQL 문장을 작성하시오.\r\nSELECT CLASS_NAME, DEPARTMENT_NAME\r\nFROM TB_CLASS LEFT OUTER JOIN TB_CLASS_PROFESSOR ON TB_CLASS_PROFESSOR.CLASS_NO = TB_CLASS.CLASS_NO\r\nLEFT OUTER JOIN TB_DEPARTMENT ON TB_DEPARTMENT.DEPARTMENT_NO = TB_CLASS.DEPARTMENT_NO\r\nWHERE CATEGORY = '예체능' AND PROFESSOR_NO IS NULL ;\r\n\r\n-- 14. 서반아어학과 학생들의 지도교수를 게시하고자 핚다. 학생이름과 지도교수 이름을 찾고, 지도 교수가 없는 학생일 경우 \"지도교수 미지정‛으로\r\nSELECT STUDENT_NAME AS \"학생이름\", NVL(PROFESSOR_NAME, '지도교수 미지정') AS \"지도교수\" \r\nFROM TB_STUDENT A\r\nJOIN TB_DEPARTMENT USING(DEPARTMENT_NO)\r\nLEFT JOIN TB_PROFESSOR ON(A.COACH_PROFESSOR_NO = TB_PROFESSOR.PROFESSOR_NO )\r\nWHERE DEPARTMENT_NAME = '서반아어학과'\r\nORDER BY STUDENT_NO;\r\n\r\n--15. 휴학생이 아닌 학생 중 평점이 4.0 이상인 학생을 찾아 그 학생의 학번, 이름, 학과이름, 평점을 출력하는 SQL 문을 작성하시오.\r\nSELECT STUDENT_NO, DEPARTMENT_NAME, STUDENT_NAME, AVG(POINT)\r\nFROM TB_STUDENT A\r\nJOIN TB_DEPARTMENT USING(DEPARTMENT_NO)\r\nJOIN TB_GRADE USING(STUDENT_NO)\r\nWHERE ABSENCE_YN = 'N'\r\nGROUP BY STUDENT_NO, STUDENT_NAME, DEPARTMENT_NAME\r\nHAVING AVG(POINT) >=4.0;\r\n\r\n--16. 환경조경학과 전공과목들의 과목 별 평점을 파악핛 수 있는 SQL 문을 작성하시오.\r\nSELECT CLASS_NO, CLASS_NAME, AVG(POINT)\r\nFROM TB_CLASS\r\nJOIN TB_GRADE USING (CLASS_NO)\r\nJOIN TB_DEPARTMENT USING (DEPARTMENT_NO)\r\nWHERE DEPARTMENT_NAME = '환경조경학과' AND CLASS_TYPE LIKE '%전공%'\r\nGROUP BY CLASS_NO, CLASS_NAME\r\n\r\n-- 17. 최경희 학생과 같은 과 학생들의 이름과 주소를 출력하는 SQL 문을 작성하시오.\r\nSELECT STUDENT_NAME, STUDENT_ADDRESS\r\nFROM TB_STUDENT\r\nWHERE DEPARTMENT_NO = ( SELECT DEPARTMENT_NO \r\n FROM TB_STUDENT\r\n WHERE STUDENT_NAME = '최경희')\r\n\r\n-- 18. 국어국문학과에서 총 평점이 가장 높은 학생의 이름과 학번을 표시하는 SQL 문\r\nSELECT STUDENT_NO,\r\n STUDENT_NAME\r\nFROM (\r\n\tSELECT STUDENT_NAME,\r\n STUDENT_NO,\r\n AVG(POINT),\r\n RANK () OVER (ORDER BY AVG(POINT) DESC) AS RANK\r\n FROM TB_DEPARTMENT\r\n JOIN TB_CLASS USING (DEPARTMENT_NO)\r\n JOIN TB_GRADE USING (CLASS_NO)\r\n JOIN TB_STUDENT USING (STUDENT_NO)\r\n WHERE DEPARTMENT_NAME = '국어국문학과'\r\n GROUP BY STUDENT_NAME, STUDENT_NO \r\n)\r\nWHERE RANK = '1';\r\n\r\n\r\nSELECT STUDENT_NAME,\r\n\tSTUDENT_NO,\r\n\tAVG(POINT),\r\n\tRANK () OVER (ORDER BY AVG(POINT) DESC) AS RANK\r\nFROM TB_DEPARTMENT\r\nJOIN TB_CLASS USING (DEPARTMENT_NO)\r\nJOIN TB_GRADE USING (CLASS_NO)\r\nJOIN TB_STUDENT USING (STUDENT_NO)\r\nWHERE DEPARTMENT_NAME = '국어국문학과' \r\nGROUP BY STUDENT_NAME, STUDENT_NO \r\n\r\n--19. \"환경조경학과\"가 속한 같은 계열 학과들의 학과 별 전공과목 평점을 SQL .\r\nSELECT DEPARTMENT_NAME AS \"계열 학과명\", ROUND(AVG(POINT),1) AS \"전공평점\"\r\nFROM TB_CLASS\r\nJOIN TB_DEPARTMENT USING (DEPARTMENT_NO)\r\nJOIN TB_GRADE USING (CLASS_NO)\r\nWHERE CATEGORY = ( SELECT CATEGORY\r\n FROM TB_DEPARTMENT\r\n WHERE DEPARTMENT_NAME = '환경조경학과')\r\nGROUP BY DEPARTMENT_NAME\r\nORDER BY 1;\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.654321014881134,
"alphanum_fraction": 0.6913580298423767,
"avg_line_length": 31.399999618530273,
"blob_id": "24107e22e64bba4adacb0a995287c76e64219283",
"content_id": "a23b070013ec85c1db4005700ff3eda7f1847163",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 5,
"path": "/Python/코테 회고.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### 21.1.16 코딩마스터즈\n1. 완전탐색 순열 조합 itertools, product을 사용해서 시간초과가 발생 => 완전탐색으로 하기 어려우면 BFS으로 하는 방법이 있다. \n> 참고 문제 : \n- 프로그래머스/깊이우선탐색/타켓넘버\n- 프로그래머스/완전탐색/소수찾기_BFS.ver\n"
},
{
"alpha_fraction": 0.5303605198860168,
"alphanum_fraction": 0.5453510284423828,
"avg_line_length": 22.285715103149414,
"blob_id": "d0a93f6882a495f6709e3e8e73a4f82681b4316c",
"content_id": "16d4f7f6df73d8674ff6964851df8e8af7d6f7aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6318,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 217,
"path": "/Python/pandas.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "# pandas lib\r\n\r\n### 1. pandas lib 사용\r\n\r\n- csv, excel, json에서 사용되는 lib\r\n\r\n- `pip install pandas` or `conda install pandas`\r\n\r\n- `pandas`는 `DataFrame`이라는 테이블 형식의 타입을 제공한다\r\n\r\n- `pandas`는 `series` 이라는 벡터 형식의 타입을 제공한다\r\n\r\n ```python\r\n import pandas as pd\r\n \r\n bmiDataset = pd.read_csv('./word/service_bmi.csv', encoding ='utf-8')\t\t\t\t\t# DataFrame type.\r\n print(bmiDataset.info())\r\n print(bmiDataset.head()) # 최상위 데이터 5개를 보여준다.\r\n print(bmiDataset.tail()) # 최하위 데이터 5개를 보여준다.\r\n ```\r\n\r\n - data type - `Series`\r\n\r\n ```python\r\n print(bmiDataset.height) # series라는 데이터 타입. 벡터 형태와 유사하다\r\n print(bmiDataset['weight']) # 이런 형식으로도 접근이 가능하다\r\n print(bmiDataset['label'])\r\n ```\r\n\r\n- 연산 가능\r\n\r\n ```python\r\n # EX) 키와 몸무게의 평균\r\n print('키 avg {} , 몸무게 avg {}'.format( sum(bmiDataset.height) / len(bmiDataset.height), sum(bmiDataset['weight']) / len(bmiDataset['weight'])))\r\n \r\n # EX) 키와 몸무게의 최대값\r\n print('키 최대값', max(bmiDataset.height))\r\n print('몸무게 최대값', max(bmiDataset.weight))\r\n \r\n # EX) label 의 빈도수\r\n count = [0,0,0]\r\n for i in bmiDataset.label:\r\n if i == 'thin':\r\n count[0] +=1\r\n elif i == 'normal':\r\n count[1] +=1\r\n elif i == 'fat':\r\n count[2] +=1\r\n \r\n print('thin count : ', count[0])\r\n print('normal count : ', count[1])\r\n print('fat count : ', count[2])\r\n \r\n labelCnt = {}\r\n for label in bmiDataset.label:\r\n labelCnt[label] = labelCnt.get(label, 0) + 1\r\n print(labelCnt)\r\n ```\r\n\r\n- `DataFrame`\r\n\r\n ```python\r\n import pandas as pd\r\n spamDataset = pd.read_csv('./word/spam_data.csv', header = None,encoding ='ms949')\r\n print(spamDataset.info())\r\n print(type(spamDataset)) # type : DataFrame\r\n print(spamDataset.head())\r\n \r\n target = spamDataset[0]\r\n print('target - ', target, type(target))\r\n text = spamDataset[1]\r\n print('text - ', text, type(text))\r\n \r\n # spam = 1, ham = 0 새로운 타켓을 만들고 싶다면?\r\n target = [1 if t == 'spam' else 0 for t in target]\r\n print(target)\r\n ```\r\n\r\n\r\n\r\n### 2. `import re` , regular expression \r\n\r\n- 코드클린 - 문자열에 대한 정규표현식을 이용해서 문자를 제거하는 작업\r\n\r\n- 크롤링 등등 할 때 정규 표현식을 사용\r\n\r\n- 메타 문자 : . ^ $ * + {} [] \\ | ()\r\n\r\n - . 는 무엇이든 한 글자를 의미\r\n\r\n - ^ 는 시작문자 지정\r\n\r\n - `*` 는 0 or more\r\n\r\n - `+` 는 1 or more\r\n\r\n - ? 는 0 or 1\r\n\r\n - 괄호를 통해서 조합 \r\n\r\n ```\r\n [abc] 는 a, b, c 중 한문자와 매치\r\n [^0-5] 는 not 의미\r\n ^[0-5] 는 시작문자 의미\r\n \\d 는 숫자의 자릿수\r\n \\D 는 숫자가 아닌 문자매칭의 자릿수\r\n \\w 는 문자 + 숫자를 의미\r\n \\W 는 문자 + 숫자 아닌 문자와 매치\r\n \\s 는 공백\r\n 010-0000-0000 ----> ^\\d{3}-\\d{4}-\\d{4}, 반드시 숫자로 시작하는 3자리 4자리 4자리\r\n ```\r\n\r\n \r\n\r\n- 대표 함수\r\n - sub()\r\n - match()\r\n - findall()\r\n - finditer()\r\n \r\n```python\r\nimport re\r\np = re.compile('[a-z]]+') # 하나이상\r\nmatch = p.match('PYTHON')\r\nprint(match) #None\r\n text = spamDataset[1]\r\n def cleanText(str):\r\n # re.sub 대체\r\n # re.sub(pattern= , replace to = , str)\r\n str = re.sub('[,.?!:;]', ' ', str)\r\n str = re.sub('[0-9]', ' ', str)\r\n str = re.sub('[0-9a-zA-Z]', ' ', str)\r\n str = ' '.join(str.split()) #split() 모든 공백을 하나의 공백으로 join\r\n \tprint(str)\r\n cleanText('5000 amdmDDDf 어어!')\r\n \r\n ex) \r\n import re\r\n import pandas as pd\r\n\r\n def cleanText(str):\r\n # re.sub 대체\r\n # re.sub(pattern= , replace to = , str)\r\n answer = []\r\n str = re.sub('[,.?!:;]', ' ', str)\r\n str = re.sub('[0-9]', ' ', str)\r\n str = re.sub('[0-9a-zA-Z]', ' ', str)\r\n str = ' '.join(str.split()) #split() 모든 공백을 하나의 공백으로 join\r\n return str\r\n\r\n spamDataset = pd.read_csv('./word/spam_data.csv', header = None,encoding ='ms949')\r\n text = spamDataset[1]\r\n print(text)\r\n cleanText = [cleanText(t) for t in text]\r\n print(cleanText)\r\n\r\n Excel File 읽기 \r\n kospiDataset = pd.ExcelFile('./word/sam_kospi.xlsx')\r\n kospi = kospiDataset.parse('sam_kospi')\r\n print(kospi.info())\r\n\r\n from statistics import *\r\n 통계를 계산할 때 사용하는 함수\r\n print('high mean - ', mean(kospi.High))\r\n```\r\n\r\n\r\n### 3. json 파일 입출력\r\n- json file: 네트워크 상에서 표준으로 사용되는 파일 형식 \r\n\r\n- 웹에선 AJAX, 비동기 통신 데이터 타입이 다 json이다.\r\n\r\n- 구성 : {key : value , key : value}\r\n\r\n- encoding : python(dict, list) => json 문자열(즉, json file 로 변환)\r\n\r\n- decoding : json 문자열 => python 객체(dict 나 list)로\r\n \r\n- import json\r\n \r\n```python\r\n import json\r\n # python -> json\r\nuser = {'id' : 1234, 'name' : '홍길동'}\r\nprint(type(user)) # dict\r\n \r\n # dict 처럼 보이지만 문자열이다. 그래서 어떻게 토큰화해서 정보에 접근 할거냐.\r\n # 파이썬 객체에서 json, encoding\r\n \r\n jsonStr = json.dumps(user) # object -> json str\r\n print(jsonStr, type(jsonStr)) # str\r\n \r\n # decoding\r\n \r\n pyObj = json.loads(jsonStr)\r\n print(pyObj, type(pyObj)) # 문자열 -> python, dict으로 바뀐거라서 key,value로 접근 가능\r\n print(pyObj['name'])\r\n \r\n # 홍길동이라는 한글 값을 check 해줘야해\r\n with open(file = './word/usagov_bitly.txt', mode='r', encoding='utf-8') as file:\r\n lines = file.readlines()\r\n # # 줄단위로 list type\r\n # print(type(lines), len(lines))\r\n # # 5개, 문자열의 형식\r\n # print(lines[:5])\r\n rows = [json.loads(line) for line in lines] # rows 안에는 list 안에 딕셔너리이다.\r\n print(type(rows)) # list\r\n print(type(rows[0])) # dict\r\n\r\n for row in rows:\r\n for key, value in row.items():\r\n print('key - {}, value - {}'.format(key, value))\r\n\r\n # list[dict] => 행렬, 데이터 분석에 용이한 pd.DataFrame(행렬)\r\n rowsDF = pd.DataFrame(rows)\r\n print(rowsDF.head) # 정형화된 형식이 된다.\r\n```\r\n"
},
{
"alpha_fraction": 0.6247590780258179,
"alphanum_fraction": 0.6286142468452454,
"avg_line_length": 23.3641300201416,
"blob_id": "d4e80246b77c502c03963f73b428a9dfa028b89b",
"content_id": "822e2c8f12301bdcdbd12cc3417da51dcd39547d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 5627,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 184,
"path": "/SQL/oracle4_subq.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UHC",
"text": "--SET operator : UNION, UNION ALL, INTERSECT, MINUS\r\n-- 두개 이상의 쿼리 결과를 하나로 결합시키는 연산자 \r\n-- SELECT 절에 기술하는 컬럼 개수와 데이터 타입은 모든 쿼리에서 동일해야함\r\n\r\n--UNION : 중복결과는 한번\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM EMPLOYEE_ROLE\r\nUNION\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM ROLE_HISTORY;\r\n\r\n--UNION ALL: 중복결과도 다 표시\r\n\r\n--INTERSECT : 교집합\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM EMPLOYEE_ROLE\r\nINTERSECT\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM ROLE_HISTORY;\r\n\r\n--MINUS: 차집합\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM EMPLOYEE_ROLE\r\nMINUS\r\nSELECT EMP_ID, ROLE_NAME\r\nFROM ROLE_HISTORY;\r\n\r\n-- 데이터개수가 같게하기 위해서 NULL, DUMMY 를 넣어준다\r\nSELECT EMP_NAME, JOB_ID, HIRE_DATE\r\nFROM EMPLOYEE\r\nWHERE DEPT_ID = '20'\r\nUNION\r\nSELECT DEPT_NAME, DEPT_ID, NULL\r\nFROM DEPARTMENT\r\nWHERE DEPT_ID = '20';\r\n\r\n--UNION 50번 부서원을 관리자 직원으로 구분하여 표시하고 싶다면?\r\nSELECT EMP_ID, EMP_NAME, '관리자' AS 구분\r\nFROM EMPLOYEE\r\nWHERE MGR_ID IS NULL AND DEPT_ID='50'\r\nUNION\r\nSELECT EMP_ID, EMP_NAME, '직원' AS 구분\r\nFROM EMPLOYEE\r\nWHERE MGR_ID IS NOT NULL AND DEPT_ID='50'\r\nORDER BY 3;\r\n\r\n-- 직급(JOB_TITLE)이 대리 또는 사월 정보를 조회(이름, 직급)\r\n--UNION\r\nSELECT EMP_NAME, JOB_TITLE\r\nFROM EMPLOYEE\r\nJOIN JOB USING(JOB_ID)\r\nWHERE JOB_TITLE = '대리'\r\nUNION\r\nSELECT EMP_NAME, JOB_TITLE\r\nFROM EMPLOYEE\r\nJOIN JOB USING(JOB_ID)\r\nWHERE JOB_TITLE = '사원';\r\n\r\nSELECT EMP_NAME, JOB_TITLE\r\nFROM EMPLOYEE\r\nJOIN JOB USING(JOB_ID)\r\nWHERE JOB_TITLE IN ('사원', '대리');\r\n\r\n--SUBQUERY\r\n--()로 묶어서 표현, \r\n-- SELECT ,FROM, WHERE, HAVING 절 등에서 사용가능\r\n-- 단일 행 서브쿼리, 다중 행 서브쿼리 인지를 CHECK 해야한다. \r\n-- 단일이면 비교연산자도 사용가능, 다중행은 IN, ANY, ALL을 주로 사용한다. \r\n\r\n\r\n-- 나승원과 직급(JOB_ID)이 동일하고 나승원보다 급여가 많은 사원의 이름, 직급, 급여를 조회하라\r\nSELECT EMP_NAME, JOB_ID, SALARY\r\nFROM EMPLOYEE\r\nWHERE JOB_ID = (SELECT JOB_ID\r\nFROM EMPLOYEE\r\nWHERE EMP_NAME='나승원')\r\nAND SALARY > (SELECT SALARY\r\n FROM EMPLOYEE\r\n WHERE EMP_NAME='나승원');\r\n\r\n-- 최소급여를 받는 사월의 이름, 직급, 급여를 조회\r\n\r\nSELECT EMP_NAME, JOB_ID, SALARY\r\nFROM EMPLOYEE\r\nWHERE SALARY = (SELECT MIN(SALARY)\r\n FROM EMPLOYEE )\r\n \r\n-- 부서별 급여 총합이 가장 큰 부서의 이름, 급여총합을 조회\r\n\r\nSELECT DEPT_NAME, SUM(SALARY)\r\nFROM EMPLOYEE\r\nJOIN DEPARTMENT USING(DEPT_ID)\r\nGROUP BY DEPT_NAME\r\nHAVING SUM(SALARY) = (SELECT MAX(SUM(SALARY))\r\n FROM EMPLOYEE\r\n GROUP BY DEPT_ID)\r\n \r\n-- IN, NOT IN ,ANY, ALL 연산자들 다중행 서브쿼리에서 사용할 수 있다.\r\n-- NOT IN 의 결과에는 NULL이 포함되어서 안된다. 안그러면 전체를 NULL로 출력한다. \r\nSELECT EMP_ID, EMP_NAME, '관리자' AS 구분\r\nFROM EMPLOYEE\r\nWHERE EMP_ID IN (SELECT MGR_ID FROM EMPLOYEE)\r\nUNION\r\nSELECT EMP_ID, EMP_NAME, '직원' AS 구분\r\nFROM EMPLOYEE\r\nWHERE EMP_ID NOT IN (SELECT MGR_ID FROM EMPLOYEE WHERE MGR_ID IS NOT NULL)\r\n\r\n--위 구현 코드를 다른 방식으로 구현한다면?\r\nSELECT EMP_ID, EMP_NAME, \r\n CASE \r\n WHEN EMP_ID IN(SELECT MGR_ID FROM EMPLOYEE) THEN '관리자' \r\n ELSE '직원' \r\n END\r\nFROM EMPLOYEE\r\n\r\nSELECT EMP_ID, EMP_NAME, \r\n CASE \r\n WHEN MGR_ID IS NOT NULL THEN '직원' \r\n ELSE '관리자' \r\n END AS 구분\r\nFROM EMPLOYEE\r\n\r\n-- < ANY : 비교 대상 중 최대 값보다 작음\r\n-- > ANY : 비교 대상 중 최소 값보다 큼\r\n-- = ANY : 연산자와 동일\r\n\r\n-- < ALL : 비교 대상 중 최소값 보다 작음\r\n-- > ALL : 비교 대상 중 최대 값 보다 큼\r\n\r\nSELECT EMP_NAME, SALARY \r\nFROM EMPLOYEE\r\nJOIN JOB USING (JOB_ID)\r\nWHERE JOB_TITLE = '대리'\r\n AND SALARY > ANY ( SELECT SALARY FROM EMPLOYEE JOIN JOB USING(JOB_ID) WHERE JOB_TITLE = '과장')\r\n\r\n\r\nSELECT EMP_NAME, SALARY \r\nFROM EMPLOYEE\r\nJOIN JOB USING (JOB_ID)\r\nWHERE JOB_TITLE = '대리'\r\n AND SALARY > ALL ( SELECT SALARY FROM EMPLOYEE JOIN JOB USING(JOB_ID) WHERE JOB_TITLE = '과장')\r\n\r\n--자기 직급의 평균 급여를 받는 직원을 조회하라\r\nSELECT EMP_NAME, JOB_TITLE, SALARY\r\nFROM EMPLOYEE\r\nJOIN JOB USING(JOB_ID)\r\nWHERE (JOB_ID, SALARY) IN (SELECT JOB_ID, TRUNC(AVG(SALARY), -5)\r\n FROM EMPLOYEE\r\n GROUP BY JOB_ID)\r\n\r\nSELECT JOB_TITLE, TRUNC(AVG(SALARY), -5)\r\nFROM EMPLOYEE\r\nJOIN JOB USING(JOB_ID)\r\nGROUP BY JOB_TITLE\r\n\r\nSELECT EMP_NAME, JOB_TITLE, SALARY\r\nFROM (SELECT JOB_ID, TRUNC(AVG(SALARY), -5) AS JOB_AVG\r\n FROM EMPLOYEE\r\n GROUP BY JOB_ID) V\r\nJOIN EMPLOYEE E ON(V.JOB_ID = E.JOB_ID AND V.JOB_AVG = E.SALARY)\r\nJOIN JOB J ON(E.JOB_ID = J.JOB_ID)\r\n\r\n-- 상관관계 서브쿼리(CORRELATED SUBQUERY)\r\nSELECT EMP_NAME, JOB_TITLE, SALARY\r\nFROM EMPLOYEE E\r\nJOIN JOB J ON(E.JOB_ID = J.JOB_ID)\r\nWHERE SALARY = (SELECT TRUNC(AVG(SALARY), -5)\r\n FROM EMPLOYEE\r\n WHERE JOB_ID = E.JOB_ID)\r\n \r\n-- EXISTS, NOT EXISTS\r\n-- EXISTS : 존재하면 TRUE, NOT EXISTS : 존재하지 않으면 TRUE\r\nSELECT EMP_ID, EMP_NAME,'관리자' AS 구분\r\nFROM EMPLOYEE E\r\nWHERE EXISTS (SELECT NULL\r\n FROM EMPLOYEE\r\n WHERE E.EMP_ID = MGR_ID)\r\nUNION\r\nSELECT EMP_ID, EMP_NAME, '직원' AS 구분\r\nFROM EMPLOYEE E2\r\nWHERE NOT EXISTS (SELECT NULL\r\n FROM EMPLOYEE\r\n WHERE E2.EMP_ID = MGR_ID)\r\nORDER BY 3;\r\n\r\n"
},
{
"alpha_fraction": 0.6266611218452454,
"alphanum_fraction": 0.6266611218452454,
"avg_line_length": 31.47222137451172,
"blob_id": "c8d1624d55d011feffbffeaaba8352d8a719fc06",
"content_id": "18cdc8f96355d384436b9cacc0791138fa0472c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2432,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 72,
"path": "/Django/bbsApp_ORM practice/views.py",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\r\nfrom .models import *\r\n# Create your views here.\r\n\r\n# select * from table;\r\n# -> modelName.objects.all()\r\n\r\n# select * from table where id = xxxx;\r\n# -> modelName.objects.get(id = xxxx)\r\n# -> modelName.objects.filter(id = xxxx)\r\n\r\n# select * from table where id = xxxx and pwd = yyyy;\r\n# -> modelName.objects.get(id = xxxx, pwd = yyyy)\r\n# -> modelName.objects.filter(id = xxxx, pwd = yyyy)\r\n\r\n# select * from table where id = xxxx or pwd = yyyy;\r\n# -> modelName.objects.filter(Q(id = xxxx) | Q(pwd = yyyy))\r\n\r\n# select * from table where subject like '%공지%'\r\n# -> modelName.objects.filter(subject_icontains='공지')\r\n# select * from table where subject like '공지%'\r\n# -> modelName.objects.filter(subject_startswith='공지')\r\n# select * from table where subject like '공지%'\r\n# -> modelName.objects.filter(subject_endswith='공지')\r\n\r\n# insert into table values()\r\n# model(attr=value, attr=value)\r\n# model.save()\r\n\r\n# delete * from tableName where id = xxxx\r\n# -> modelName.objects.get(id=xxxx).delete()\r\n\r\n# update tableName set attr = value where id = xxxx\r\n# -> obj = modelName.objects.get(id=xxxx)\r\n# odj.attr = value\r\n# obj.save() --auto commit\r\n\r\n\r\ndef index(request):\r\n return render(request, 'login.html')\r\n\r\ndef loginProc(request):\r\n print('request - loginProc')\r\n if request.method == \"GET\" :\r\n return redirect('index')\r\n elif request.method == \"POST\":\r\n id = request.POST['id']\r\n pwd = request.POST['pwd']\r\n #select * from BbsUserRegister where user_id = id and user_pwd = pwd\r\n #user = BbsUserRegister.objects.filter(user_id=id, user_pwd =pwd)\r\n user = BbsUserRegister.objects.get(user_id=id, user_pwd=pwd)\r\n print('user result - ', user)\r\n if user is not None:\r\n return render(request, 'home.html')\r\n else:\r\n return redirect('index')\r\n\r\ndef registerForm(request):\r\n return render(request, 'join.html')\r\n\r\ndef register(request):\r\n print('request - register')\r\n if request.method == \"GET\":\r\n return redirect('index')\r\n elif request.method == \"POST\":\r\n id = request.POST['id']\r\n pwd = request.POST['pwd']\r\n name = request.POST['name']\r\n register = BbsUserRegister(user_id=id, user_pwd=pwd,user_name=name )\r\n # insert into table values()\r\n register.save()\r\n return render(request, 'login.html')"
},
{
"alpha_fraction": 0.6429110169410706,
"alphanum_fraction": 0.6768476366996765,
"avg_line_length": 20.552845001220703,
"blob_id": "412b231c82da786d04dcf6f5f458ea43e3c62853",
"content_id": "b88ab22772eb4ea96e4285e17ab80cbac800d17b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 3814,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 123,
"path": "/SQL/oracle1.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--COMMENT\nSELECT *\nFROM EMPLOYEE;\n\nSELECT [특정컬럼] | *(전체컬럼)| 표현식 | DISTINCT | AS 컬럼별칭\nFROM 테이블 이름:\nWHERE 조건식(행의 제한)\n\n--전체컬럼 \nSELECT *\nFROM EMPLOYEE;\n\n--특정 컬럼\nSELECT EMP_NAME, EMP_NO\nFROM EMPLOYEE;\n\n--별칭\n--주의사항 : 반드시 문자로 시작(숫자로 시작할 수 없다.), 만약 특수 부호가 들어가면 \"\"으로 감싼다\n--AS 생략가능\nSELECT EMP_NAME AS \"이 름\", EMP_NO AS 주민번호, SALARY AS \"급여(원)\", DEPT_ID 부서번호\nFROM EMPLOYEE;\n\n--DISTINCT : 값의 중복을 제거할 때 사용하는 키워드\nSELECT DISTINCT JOB_ID\nFROM EMPLOYEE;\n\n--표현식\n--컬럼 값에 대한 연산을 식으로 작성할 수 있다.\nSELECT EMP_NAME AS 사원명, SALARY AS 급여, (SALARY + (SALARY * BONUS_PCT)) * 12 AS 연봉\nFROM EMPLOYEE;\n\n--더미컬럼, 컬럼을 추가할 수 있다. \n--'' : 데이터를 의미한다.\n--\"\" : 키워드로 취급\nSELECT EMP_ID, EMP_NAME, '재직' AS 근무여부\nFROM EMPLOYEE;\n-- 실행 결과로 근무여부 칼럼이 생기고 안에 데이터는 '재직'으로 채워진다.\n\n--행에 대한 제한을 두기 \n--WHERE : 행의 제한\n--조건절에서 연산자를 사용할 수 있다\n--부서번호가 90번인 사원들의 정보만 확인하고 싶다면 \nSELECT *\nFROM EMPLOYEE\nWHERE DEPT_ID = 90;\n\n--EX\n--부서코드가 90이고 급여가 2000000보다 많이 받는 사월의 이름, 부서코드, 급여를 조회\n--AND\nSELECT EMP_NAME, DEPT_ID, SALARY\nFROM EMPLOYEE\nWHERE SALARY > 2000000 AND DEPT_ID = 90;\n\n--EX)\n--부서코드가 90이거나 20번인 사원의 이름, 부서코드 급여를 조회\n--OR\nSELECT EMP_NAME, DEPT_ID, SALARY\nFROM EMPLOYEE\nWHERE (DEPT_ID = 90 OR DEPT_ID = 20);\n\n-- || : 연결연산자\n-- [컬럼||컬럼] [컬럼||'문자열']\nSELECT EMP_ID||EMP_NAME||SALARY\nFROM EMPLOYEE\n\nSELECT EMP_ID||'의 월급은 '||SALARY||'입니다'\nFROM EMPLOYEE\n\n--Operator \n-- 비교 연산자 - BETWEEN AND : 비교하려는 값이 지정한 범위(상한 값과 하한 값의 경계포함)에 포함되면 TRUE를 반환하는 연산자\nSELECT EMP_NAME, SALARY\nFROM EMPLOYEE\nWHERE SALARY BETWEEN 3500000 AND 5500000;\n-- 또는\nSELECT EMP_NAME, SALARY\nFROM EMPLOYEE\nWHERE SALARY >= 3500000 AND SALARY <= 5500000;\n\n--비교 연산자 - LIKE : 비교하려는 값이 지정한 특정 패턴을 만족시키면 TRUE를 반환\n--패턴 지정을 위해 와일드 카드 사용\n-- % : %에 임의 문자열(0개 이상의 문자)이 있다는 의미\n-- _ : _부분에 문자 1개만 있다는 의미, '_'사이에는 공백이 없음\nSELECT EMP_NAME, SALARY\nFROM EMPLOYEE\nWHERE EMP_NAME LIKE '김%';\n\nSELECT EMP_NAME, PHONE\nFROM EMPLOYEE\nWHERE PHONE LIKE '___9_______'\n\n--EX)\n-- EMAIL ID 중 '_'앞 자리가 3자리인 직원의 이름, 이메일을 조회\n-- ESCAPE을 통해서 와일드 카드가 아님을 나타냄\nSELECT EMP_NAME, EMAIL \nFROM EMPLOYEE\nWHERE EMAIL LIKE '___#_%' ESCAPE '#';\n\n-- NOT LIKE\n--'김'씨 성이 아닌 직원의 이름과 급여를 조회\nSELECT EMP_NAME, SALARY\nFROM EMPLOYEE\nWHERE EMP_NAME NOT LIKE '김%';\n\n-- 부서가 없는데도 불구하고 보너스를 지급받는 직원의 이름, 부서, 보너스를 조회\nSELECT EMP_NAME, DEPT_ID, BONUS_PCT\nFROM EMPLOYEE\nWHERE DEPT_ID = NULL AND BONUS_PCT != NULL\n-- 하면 안된다!\n--NULL은 비교 연산자가 안된다\n-- IS NULL, IS NOT NULL\nSELECT EMP_NAME, DEPT_ID, BONUS_PCT\nFROM EMPLOYEE\nWHERE DEPT_ID IS NULL AND BONUS_PCT IS NOT NULL\n\n-- IN=OR\nSELECT EMP_NAME, DEPT_ID, SALARY\nFROM EMPLOYEE\nWHERE DEPT_ID IN('90', '20');\n\n-- 부서 번호가 20번 또는 90번인 사원 중 급여가 3000000 많이(초과)받는 직원의 이름, 급여, 부서코드를 조회\nSELECT EMP_NAME, DEPT_ID, SALARY\nFROM EMPLOYEE\nWHERE DEPT_ID IN('90', '20') AND SALARY > 3000000;\n\n"
},
{
"alpha_fraction": 0.5770862698554993,
"alphanum_fraction": 0.5785006880760193,
"avg_line_length": 10.96610164642334,
"blob_id": "eff7c81ff5365d321e068d084710450b5f7ecf0f",
"content_id": "d03fe2967bc310b7f140ed96d1958df2e97cd179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 963,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 59,
"path": "/SQL/SQL.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### front-end \n\n- 브라우저 상에서 \n\n- html(구조)\n- js(동작)-jQuery\n- css(디자인)\n\n\n\n### back-end\n\n- java(Spring)\t\t\t\t\t=>MVC\n- python(Flask, Django) => MVT\n- framework(MVC, MVT)\n- Persentation(view) - Business - Persistance(DB 관련된 작업)\n\n\n\n### DataBase\n\n- 정형DB(SQL)\t\t\t\t=> 표편적으로 table(2차원)에 넣어서 관리 => Oracle, MySQL, MariaDB,\n- 비정형DB(NO-SQL) => {key, value} , dict형태로 => MongoDB\n\n\n\njdk 에서 제공하는 jre, jvm 실행 환경이 필요하다. \n\n\n\n### SQL (struct Query language)\n\n#### crud\n\nC - INSERT 구문\n\nR - SELECT 구문\n\nU - UPDATE 구문\n\nD - DELETE 구문 \n\n\n\n데이터에 대해서만 대소문자를 구별한다. \n\n현업에서는 RDB, 관계형(Relational) 데이터베이스 업무 적응력이 좋다 \n\n주요용어 \n\n- 행(row , record)\n- 컬럼 \n\nSQL\n\n- SELECT , 데이터 검색\n- dml, 데이터 조작\n- DDL, 데이터 정의\n- TCL, 트랜젝션 \n"
},
{
"alpha_fraction": 0.6491511464118958,
"alphanum_fraction": 0.6588520407676697,
"avg_line_length": 26.76744270324707,
"blob_id": "386d8543f2273021636a0cdc7826f4bd62a534a0",
"content_id": "e232fb432db47bdf9780650cf6f49b944fae86f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 3260,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 86,
"path": "/SQL/oracle3_join.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--1. ORDER BY\r\n--2. GROUP BY\r\n--3. HAVING\r\n--4. JOIN\r\n-- (1). JOIN USING\r\n-- (2). JOIN ON\r\n-- (3). OUTER JOIN : LEFT|FIGHT JOIN, FULL OUTER JOIN\r\n-- (4). CROSS JOIN\r\n-- (5). NON EQUIJOIN\r\n-- (6). SELF JOIN\r\n-- ORDER BY 기준 1 [ASC | DESC], 기준2 [ACS | DESC] 오름차순 내림차순\r\n-- 항상 SELECT 구문의 맨 마지막에 위치\r\n\r\n-- GROUP BY\r\n-- GROUP BY 절에 기술한 컬럼/표현식을 기준으로 데이터 그룹 생성\r\n-- 각 그룹별로 SELECT 절에 기술한 그룹 함수가 적용\r\n-- WHERE 절에는 그룹 함수를 사욯할 수 없음\r\n-- GROUP BY 절에는 컬럼 이름만 사용 가능(별칭, 순서 사용 불가)\r\n-- SELECT 절에 기술한 컬럼 중, 그룹 함수에 사용되지 않은 컬럼은, GROUP BY 절에 반드시 기술되어야 함\r\n-- 즉, GROUP BY를 SELECT을 쓰면 모든 SELECT에 기술된 컬럼은 GROUP BY 컬럼이거나 그룹함수여야함.\r\nSELECT DEPT_ID, COUNT(*)\r\nFROM EMPLOYEE\r\nGROUP BY DEPT_ID \r\nORDER BY 1;\r\n\r\nSELECT EMP_NAME, DEPT_ID, COUNT(*)\r\nFROM EMPLOYEE\r\nGROUP BY EMP_NAME, DEPT_ID;\r\n \r\n -- HAVING : GROUP BY 에 의해 그룹화 된 데이터에 대한 그룹 함수 실행 결과를 제한하기 위해 사용 (WHERE는 원본 데이터 제한)\r\n \r\n-- JOIN, INNER JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN\r\n\r\n-- JOIN USING : 조인 조건으로 사용하는 컬럼 이름이 동일한 경우 사용, 별칭 사용할 수 없음\r\nSELECT EMP_NAME, LOC_ID\r\nFROM EMPLOYEE2\r\nJOIN DEPARTMENT USING (DEPT_ID, LOC_ID);\r\n\r\n-- JOIN ON : 조인 조건으로 사용하는 컬럼 이름이 서로 다른 경우 사용\r\nSELECT DEPT_NAME, LOC_DESCRIBE\r\nFROM DEPARTMENT\r\nJOIN LOCATION ON (LOC_ID = LOCATION_ID);\r\n\r\n-- OUTER JOIN : 조건을 만족시키지 못하는 행까지 RESULT SET에 포함시키는 조인 유형\r\n-- OUTER JOIN : 합집합, LEFT JOIN, RIGHT JOIN, FULL JOIN\r\n-- 이때 left와 outer를 정하는 기준은 FROM절에 적어준 테이블이 left가 되고, \r\n-- JOIN절에 적어준 테이블이 right가 됩니다. \r\n-- WHERE E.DEPT_ID = D.DEPT_ID(+); 와 같은 의미\r\n-- 정보가 없는 직원을 결과에 포함하려면 OUTER JOIN을 사용해야 함\r\nSELECT EMP_NAME, DEPT_NAME\r\nFROM EMPLOYEE\r\nLEFT JOIN DEPARTMENT USING (DEPT_ID)\r\nORDER BY 1;\r\n\r\n-- JOIN - NON EQUIJOIN\r\nSELECT EMP_NAME, SALARY, SLEVEL \r\nFROM EMPLOYEE\r\nJOIN SAL_GRADE ON (SALARY BETWEEN LOWEST AND HIGHEST)\r\nORDER BY 3;\r\n\r\n-- SELF JOIN: 테이블 별칭을 사용해야 함\r\nSELECT E.EMP_NAME AS 직원,\r\n M.EMP_NAME AS 관리자\r\nFROM EMPLOYEE E\r\nJOIN EMPLOYEE M ON (E.MGR_ID = M.EMP_ID)\r\nORDER BY 1;\r\n\r\n-- FULL OUTER JOIN : \r\n-- INNER JOIN: 교집합\r\n--조인시에 table1과 table2의 어떤 컬럼을 기준으로 할지는 ON 뒤에 작성합니다.\r\n-- JOIN table2 ON table2.col1 = table2.col2\r\n\r\nselect employee.empName, department.deptName\r\nfrom employee\r\nleft outer join department on employee.deptNo = department.deptNo;\r\n-- 일치하는 EMPLOYEE.EMPNAME이 없어도 출력되도록 \r\n\r\n-- CROSS JOIN\r\n\r\nSELECT EMP_NAME, SALARY, SLEVEL\r\nFROM EMPLOYEE, SAL_GRADE\r\nWHERE SALARY BETWEEN LOWEST AND HIGHEST;\r\n\r\nSELECT EMP_NAME, SALARY, SLEVEL\r\nFROM EMPLOYEE\r\nJOIN SAL_GRADE ON(SALARY BETWEEN LOWEST AND HIGHEST);\r\n"
},
{
"alpha_fraction": 0.5845410823822021,
"alphanum_fraction": 0.5942028760910034,
"avg_line_length": 12.733333587646484,
"blob_id": "01b805008e2a2ad034ed761a090f22dbd307de97",
"content_id": "07051d164455c7e57412af111dc0b6f9eaa2cd21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 15,
"path": "/Git/Git intro.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "# Git intro\n\n### 0. Git ? Github?\n\n- git : 기술 \n- github : 기술을 이용한 커뮤니티\n\n\n\n### 1. Git\n\n- (분산) 버전 관리 시스템\n- 코드의 history를 관리하는 도구\n- 개발된 과정과 역사를 볼 수 있으며, 프로젝트의 이전 버전을 복원하고 변경 사항을 비교 분석\n- 차이(diff)와 수정 이유 log에 기록\n\n"
},
{
"alpha_fraction": 0.5063548684120178,
"alphanum_fraction": 0.5297407507896423,
"avg_line_length": 16.25438690185547,
"blob_id": "cd620bf4b2aeb6fa80de94e3fe0df81d0960ec52",
"content_id": "aec002c82a6fced49560239470129408805364ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2335,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 114,
"path": "/Python/Module.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### collection 모듈\n\n- Counter 클래스\n\n 데이터의 개수를 셀 때 유용한 파이썬\n\n ```python\n def countLetters(word):\n counter = {}\n for letter in word:\n if letter not in counter:\n counter[letter] = 0\n counter[letter] += 1\n return counter\n \n countLetters('hello world'))\n # {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}\n ```\n\n `collections` 모듈의 `Counter` 클래스를 사용해보자\n\n ```python\n from collections import Counter\n \n Counter('hello world') # Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})\n ```\n\n 응용을 해보자.\n\n ```python\n from collections import Counter\n \n def find_max(word):\n counter = Counter(word)\n max_count = -1\n for letter in counter:\n if counter[letter] > max_count:\n max_count = counter[letter]\n max_letter = letter\n return max_letter, max_count\n \n find_max('hello world') # ('l', 3)\n ```\n\n - 출처 https://www.daleseo.com/python-collections-counter/\n \n \n### heapq 모듈 \n\n> 데이터를 정렬된 상태로 저장하기 위해서 사용\n\n- `import heapq`\n\n- 힙에 원소 추가\n\n ```python\n heap = []\n \n heapq.heapq.heappush(heap, 4)\n heapq.heappush(heap, 1) \n ```\n\n `heappush()`함수는 `O(logN)`의 시간 복잡도를 가진다\n \n- 힙에서 원소 삭제\n\n ```python\n print(heapq.heappop(heap))\n ```\n\n- 최소값 삭제하지 않고 얻기\n\n ```python\n print(heap[0])\n ```\n\n- 기존 리스트를 힙으로 변환\n\n ```python\n heap = [4, 1, 7, 3, 8, 5]\n heapq.heapify(heap)\n ```\n\n- heapq 모듈을 이용한 최대 힙\n\n ```python\n import heapq\n \n nums = [4, 1, 7, 3, 8, 5]\n heap = []\n \n for num in nums:\n heapq.heappush(heap, (-num, num)) # (우선 순위, 값)\n \n while heap:\n print(heapq.heappop(heap)[1]) # index 1, index 0 은 우선순위\n ```\n - 출처 https://www.daleseo.com/python-heapq/\n \n### map 사용\t\n\n> map은 리스트의 요소를 지정된 함수로 처리해주는 함수입니다. (map은 원본 리스트를 변경하지 않고 새 리스트를 생성합니다).\n\n- `list(map(함수, 리스트))`\n\n ```python\n a = [1.2, 2.5, 3.7, 4.6]\n for i in range(len(a)):\n a[i] = int(a[i])\n ```\n \n ```python\n a = list(map(int, a))\n ```\n"
},
{
"alpha_fraction": 0.6015346646308899,
"alphanum_fraction": 0.6505892276763916,
"avg_line_length": 32.40565872192383,
"blob_id": "d83cb44ca24c3e4187448565e8f6702568e0dc26",
"content_id": "13790b6efe84bc75bb5b967dd08611489a3892a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 5005,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 106,
"path": "/SQL/practice/oracle2_practice.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--1. 영어영문학과(학과코드 002) 학생들의 학번과 이름, 입학 년도를 입학 년도가 빠른 순으로 표시하는 SQL 문장을 작성하시오.( 단, 헤더는 \"학번\", \"이름\", \"입학년도\" 가 표시.)\r\n\r\nSELECT STUDENT_NO AS 학번, STUDENT_NAME AS 이름, TO_CHAR(ENTRANCE_DATE, 'RRRR-MM-DD') AS 입학년도\r\nFROM TB_STUDENT\r\nWHERE DEPARTMENT_NO ='002'\r\nORDER BY ENTRANCE_DATE;\r\n\r\n--2.교수 중 이름이 세 글자가 아닌 교수가 1 명 있다고 핚다. 그 교수의 이름과 주민번호를 화면에 출력하는 SQL 문장을 작성해 보자.문장의 결과 값이 예상과 다르게 나올 수 있다. 원인이 무엇일지 생각해볼 것)\r\n\r\nSELECT PROFESSOR_NAME, PROFESSOR_SSN\r\nFROM TB_PROFESSOR\r\nWHERE PROFESSOR_NAME NOT LIKE '___';\r\n\r\n--?3. 남자 교수들의 이름과 나이를 출력하는 SQL 문장을 작성하시오. 단 이때 나이가 적은 사람에서 많은 사람 순서로 화면에 출력.\r\n\r\nSELECT PROFESSOR_NAME AS 교수이름,\r\n TO_NUMBER(TO_CHAR(SYSDATE, 'YYYY')) - TO_NUMBER('19' || SUBSTR(PROFESSOR_SSN, 1, 2)) AS 나이\r\nFROM TB_PROFESSOR\r\nWHERE SUBSTR(PROFESSOR_SSN, 8, 1) = '1'\r\nORDER BY 2, 1;\r\n\r\n--SELECT PROFESSOR_NAME AS 교수이름, TO_CHAR(SUBSTR(PROFESSOR_SSN, 0,6), 'YYYY\"년\" MM\"월\" DD\"일\"') AS 나이\r\n\r\n-- 4. 교수들의 이름 중 성을 제외한이름만 출력하는 SQL 문장을 작성\r\nSELECT SUBSTR(PROFESSOR_NAME, 2) AS 이름\r\nFROM TB_PROFESSOR;\r\n\r\n-- ?5. 재수생 입학자를 구하려고 핚다. 19살에 입학하면 재수를 하지 않은 것으로 간주.\r\n-- TO_CHAR 를 할땐 DATE를 원하는 길이로 자르거나 길게 늘어뜨려서? 사용할 수 있다 \r\n-- TO_DATE 는 그대로 모양을 유지해서 CHAR에서 DATE로 만들어야한다. 글자수가 동일해야한다\r\n-- 입학 나이 \r\nSELECT STUDENT_NO,\r\n STUDENT_NAME\r\nFROM TB_STUDENT\r\nWHERE TO_NUMBER(TO_CHAR(ENTRANCE_DATE, 'YYYY')) - TO_NUMBER(TO_CHAR(TO_DATE(SUBSTR(STUDENT_SSN, 1, 2), 'RR'), 'YYYY')) > 19\r\nORDER BY 1;\r\n\r\n-- 6.2020 년 크리스마스는 무슨 요일인가?\r\nSELECT TO_CHAR(TO_DATE('20201215','YYYYMMDD'), 'day') \r\nFROM dual\r\n\r\nSELECT TO_CHAR(TO_DATE('2020/12/25'), 'YYYYMMDD DAY') FROM DUAL;\r\n-- 7. TO_DATE('99/10/11','YY/MM/DD'), TO_DATE('49/10/11','YY/MM/DD') 은 각각 몇 년 몇월 몇 일을 의미핛까? \r\n--또 TO_DATE('99/10/11','RR/MM/DD'), TO_DATE('49/10/11','RR/MM/DD') 은 각각 몇 년 몇 월 몇 일을 의미핛까\r\n\r\nSELECT TO_CHAR(TO_DATE('99/10/11','YY/MM/DD'),'YYYY\"년\" MM\"월\" DD\"일\"'), TO_CHAR(TO_DATE('49/10/11','YY/MM/DD'),'YYYY\"년\" MM\"월\" DD\"일\"')\r\nFROM dual;\r\n\r\nSELECT TO_CHAR(TO_DATE('99/10/11','RR/MM/DD'),'YYYY\"년\" MM\"월\" DD\"일\"'), TO_CHAR(TO_DATE('49/10/11','RR/MM/DD'),'YYYY\"년\" MM\"월\" DD\"일\"')\r\nFROM dual;\r\n\r\n--8. 2000 년도 이후 입학자들은 학번이 A 로 시작하게 되어있다. 2000 년도 이전 학번을 받은 학생들의 학번과 이름을 보여주는 SQL 문장을 작성하시오.\r\nSELECT STUDENT_NO, STUDENT_NAME\r\nFROM TB_STUDENT\r\nWHERE STUDENT_NO NOT LIKE 'A%';\r\n\r\n-- 9. 학번이 A517178 인 한아름 학생의 학점 총 평점을 구하는 SQL 문을 작성하시오. \r\nSELECT ROUND(AVG(POINT),1) AS 평점\r\nFROM TB_GRADE\r\nWHERE STUDENT_NO = 'A517178';\r\n\r\n-- 10.학과별 학생수를 구하여 \"학과번호\", \"학생수(명)\" 의 형태로 헤더를 맊들어 결과값이 출력\r\nSELECT DEPARTMENT_NO AS 학과번호, COUNT(DEPARTMENT_NO) AS \"학생수(명)\"\r\nFROM TB_STUDENT\r\nGROUP BY DEPARTMENT_NO\r\nORDER BY 학과번호;\r\n\r\n--11. 지도 교수를 배정받지 못한 학생의 수는 몇 명 정도 되는 알아내는 SQL 문\r\nSELECT COUNT(*)\r\nFROM TB_STUDENT\r\nWHERE COACH_PROFESSOR_NO IS NULL;\r\n\r\n--12. 학번이 A112113 인 김고운 학생의 년도 별 평점을 구하는 SQL 문을 작성하시오. \r\nSELECT SUBSTR(TERM_NO, 1, 4) AS 년도, ROUND(AVG(POINT),1) AS \"년도 별 평점\"\r\nFROM TB_GRADE\r\nWHERE STUDENT_NO = 'A112113'\r\nGROUP BY SUBSTR(TERM_NO, 1, 4)\r\n\r\n--?13. 학과 별 휴학생 수를 파악하고자 핚다. 학과 번호와 휴학생 수를 표시하는 SQL 문장을\r\n\r\nSELECT DEPARTMENT_NO, NVL(COUNT(*),0)\r\nFROM TB_STUDENT \r\nWHERE ABSENCE_YN = 'Y'\r\nGROUP BY DEPARTMENT_NO\r\nORDER BY DEPARTMENT_NO;\r\n\r\nSELECT DEPARTMENT_NO AS 학과코드명,\r\n SUM(CASE WHEN ABSENCE_YN ='Y' THEN 1 \r\n\t\t\t ELSE 0 END) AS \"휴학생 수\"\r\nFROM TB_STUDENT\r\nGROUP BY DEPARTMENT_NO\r\n--ORDER BY 1\r\n\r\n--14. 동명이인(同名異人) 학생들의 이름을 찾고자 핚다. 어떤 SQL\r\n\r\nSELECT STUDENT_NAME, COUNT(*)\r\nFROM TB_STUDENT\r\nGROUP BY STUDENT_NAME\r\nHAVING COUNT(*)>1;\r\n\r\n--15. 학번이 A112113 인 김고운 학생의 년도, 학기 별 평점과 년도 별 누적 평점 , 총평점을 구하는 SQL 문을 작성하시오. \r\nSELECT SUBSTR(TERM_NO, 1, 4) AS 년도, SUBSTR(TERM_NO, 5, 2) AS 학기, ROUND(AVG(POINT),1) AS \"평점\"\r\nFROM TB_GRADE\r\nWHERE STUDENT_NO = 'A112113'\r\nGROUP BY ROLLUP(SUBSTR(TERM_NO, 1, 4),SUBSTR(TERM_NO, 5, 2))\r\nORDER BY 년도\r\n\r\n"
},
{
"alpha_fraction": 0.5618034601211548,
"alphanum_fraction": 0.6043566465377808,
"avg_line_length": 10.84337329864502,
"blob_id": "c27428ec3420b0dcbae45a443541a671fb989354",
"content_id": "b57d5bb44e5e3f6cd9ba84fda0738e65a9b408b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3024,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 166,
"path": "/Git/Git Command.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "# Git Command\n\n> Git 명령어 정리\n\n\n\n\n\n## 초기 설정\n\n### 0. init\n\n- `git init`\n\n- `.git/` 폴더를 생성해준다.\n\n \n\n- `.git` 폴더가 생성된 경우 오른쪽에 `master` 라는 표시가 나온다\n- 최초에 한번만 하면된다.\n\n### 1. config\n\n- `git config --glovla user.email \"[email protected]\" `\n - 이메일의 경우 깃헙에 올릴경우 잔디가 심어지는 기준이므로 정확하게 입력!\n- `git config --global user.name \"myname\"`\n- 최초에 한번만 하면된다.\n\n\n\n\n\n## 커밋 기록\n\n### 1. add\n\n- `git add <추가하고 싶은 파일>`\n - `git add . `:현재 폴더의 모든 파일과 폴더를 add\n- working directory => staging area로 파일 이동\n\n### 2. commit\n\n- `git commit -m \"메세지\"`\n- 스냅샷을 찍는 동작\n- add 되어 있는 파일들을 하나의 묶음으로 저장\n- 메세지에 들어가는 내용은 기능 단위로\n\n### 3. remote \n\n- `git remote add origin <주소>`\n- 원격 저장소와 현재 로컬 저장소를 연결.\n- 한번만 진행\n\n### 4. push\n\n- `git push origin master`\n- 깃아 올려줘 origin으로, master를\n- 원격저장소에, 로컬저장소의 데이터를\n\n\n\n\n\n## 상태확인\n\n### 1. status\n\n- `git status`\n\n- 현재 git 상태를 출력\n\n- 해당 git에 수정사항이 있는지 확인\n\n### 2. log\n\n- `git log`\n\n- 커밋 기록을 전체 다 출력\n\n- 옵션\n\n - `--oneline` : author, date 같은 정보를 제외하고 한줄로 출력\n - `graph`: 커밋들을 점으로 표현하고 그 커밋을 선으로 연결해서 그래프 형태로 출력\n\n\n\n### 3. diff\n\n- `git diff`\n- 현재 변경사항을 체크(add하기전에)\n\n\n\n\n\n## 추가파일\n\n### 1. gitignore\n\n- `git ignore` 파일을 생성 후 git으로 관리하고 싶지 않은 파일들을 저장\n\n- gitignore.io\n- 이때 mac, window 둘다 넣어서 세팅 (팀원의 운영체제까지 고려)\n\n\n\n\n\n## 브랜치\n\n> branch 기능을 차곡차곡 생성 => branch를 병합 => branch 삭제\n\n### 1. 생성\n\n- `git branch <브랜치 이름>`\n- branch는 기능별로 생성\n- `git branch` : 생성된 브랜치를 확인 가능\n\n\n\n### 2. 이동\n\n- `git switch <브랜치 이름>` =>최신 문법\n- `git checkout <브랜치 이름>`\n\n\n\n### 3. 삭제\n\n- `git branch -d <브랜치 이름>`\n\n\n\n### 4. 병합\n\n- `git merge <브랜치 이름>`\n- base 가 되는 branch로 이동해서 명령어 사용\n- 충돌이 발생한 경우 => 충돌을 해결하고 다시 add, commit, push 진행\n- HEAD -> master, kim 이렇게 모두를 가리키면 병합 완료\n- github에서 병합가능\n\n\n\n\n\n## 불러오기\n\n### 1. Pull\n\n- `git pull origin master`\n\n\n\n\n\n## 다른 사람 코드 수정해보기\n\n### 1. fork\n\n- 남이 만든 코드를 수정하고 싶은데 권한이 없을 때\n\n - github에서 내 repo로 fork\n\n - 내 repo에 fork된 프로젝트를 clone\n\n - git bash에서 `git clone <clone 주소>` 입력\n\n \n\n\n"
},
{
"alpha_fraction": 0.6824958324432373,
"alphanum_fraction": 0.6824958324432373,
"avg_line_length": 24.492958068847656,
"blob_id": "3446849528ccaf1e77a2ff4f3453c60e1589ed40",
"content_id": "36284969c33845c7ff278950752ceb47982c68c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2703,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 71,
"path": "/Django/Django_session.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "## static 복습 \n\n정적 파일(static) : css .javascript (plugin 파일들)\n\n각 APP에 static 파일이 있다. 흩어진 static을 web에서 총괄하기 위해서 `collectstatic`을 한다. 예시로 header.html 와 footer.html 모든 app에서 사용되니깐 WEB에 저장을 하는데 header와 footer도 css가 공통으로 적용이 되어야하니깐 collectstatic을 해준다. \n\n반드시 templates > static 안에 존재해야한다. \n\n각 html 파일 위에 `{% load static %}`을 선언해야 static이 적용된다. \n\n화면 레이아웃 공통의 코드를 매번 쓰는게 아니라 include을 통해서 \n\n## Session \n\nhttpResponse : connectionless, stateless -> 유지를 하지 못한다.\n\n=> 쿠키, 세션으로 상태정보를 서버 side에서 유지. 웹의 tracking 메커니즘을 지원한다. \n\nex) 멤버만이 접근할 수 있는 페이지가 존재. \n\n### 사용자의 상태정보 저장을 위해서는 session, cookie \n\n##### 세션을 create하는 작업\n\n`request.session['user_name'] = user.user_name` session에 다가 데이터베이스에 있는 정보를 담았다. \n\n##### 메모리상에 write 하는 작업 \n\n```\ncontext = {}\ncontext['name'] = request.session['user_name']\ncontext['id'] = request.session['user_id']\nreturn render(request, 'home.html', context)\n```\n\nreturn render 에서 사용해서 context \n\n그냥 render에다가 직접 내용을 쓰면 이동하는 페이지까지만 사용가능하지만 session을 어디가쓰면 데이터를 공유할 수 있는 범위가 templates에 있는 모든 html파일에서 사용가능하다. \n\n#### session의 값 날리기. logout하기 \n\nsession 값을 null로 채우기.\n\n```\nrequest.session['user_name'] = {}\nrequest.session['user_id'] = {}\nrequest.session.modified =True\t# commit 허용\nreturn redirect('index')\n```\n\nlogin을 할 때 session을 심는다. 그러면 index 페이지에 들어갈 때 session이 존재하면 index창이 바로 home으로 render. 그대신 계속 session에 있는 값을 계속 render에 심어줘야한다. \n\n```\ncontext = {'id' : request.session['user_id'],\n 'name' : request.session['user_name']}\nreturn render(request, 'home.html', context)\n```\n\n이를 templates에서 사용하기 위해서는 {{}}, {% %}을 이용해서 출력할 수 있는데 print는 {{}}이니깐 변수를 print한다라는 개념으로 이해하자.\n\n#### button 이벤트는 script\n\nscript안에 는 태그를 쓰지 못하니깐 a href( get 방식) 태그 대신 location.href 를 쓰면 된다. \n\n#### 데이터베이스에 있는 내용을 url로 넘겨주기\n\n```\n<a href= \"../bbs_read?id={{board.id}}\">\n//장고 방식\n<a href=\"{% url 'bbs_read' id=board.id %}\">\n```\n\n"
},
{
"alpha_fraction": 0.6752136945724487,
"alphanum_fraction": 0.6752136945724487,
"avg_line_length": 33.099998474121094,
"blob_id": "ba4a6c436ed62304c6067926bcea16cc1444d483",
"content_id": "9920606661b1302f9e01cf4320e1b44c905b69c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 10,
"path": "/Django/bbsApp_ORM practice/urls.py",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom django.urls import path, include\r\nfrom bbsApp import views\r\n\r\nurlpatterns = [\r\n path('index/', views.index, name='index'),\r\n path('login/', views.loginProc, name='login'),\r\n path('registerForm/', views.registerForm, name='registerForm'),\r\n path('register/', views.register, name='register'),\r\n]\r\n"
},
{
"alpha_fraction": 0.5514403581619263,
"alphanum_fraction": 0.5637860298156738,
"avg_line_length": 13.235294342041016,
"blob_id": "b5903910242b5be005d4e780d712ea7536acb2d2",
"content_id": "fcb9ec12e6a4e239a1f6e3e297bdf509f2073850",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 17,
"path": "/Python/basic functions.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### split()\n\n> split함수는 문자열을 공백 혹은 어떠한 기준으로 나눌때 사용하는 함수\n>\n> 나누어진 값은 리스트에 요소로 저장된다.\n\n`a.split(\".\"), ` \n\n`a.split(\".\", 2) ` => 2개만 `.`을 기준으로 나뉘어진다. \n\n\n\n### list[A:B:C]\n\n> index A부터 index B 전까지 C의 간격으로 list을 만든다\n\n`list[::-1]` =>전체 list를 reverse\n\n"
},
{
"alpha_fraction": 0.6361111402511597,
"alphanum_fraction": 0.6527777910232544,
"avg_line_length": 30.727272033691406,
"blob_id": "361fb496daded3f64947d4cef2b1195500085c37",
"content_id": "3067f743ec21c3ba8051d772c55741ad1d29a5b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/Django/bbsApp_ORM practice/models.py",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "from django.db import models\r\n\r\n# Create your models here.\r\n#class is table\r\nclass BbsUserRegister(models.Model) :\r\n user_id = models.CharField(max_length=50)\r\n user_pwd = models.CharField(max_length=50)\r\n user_name = models.CharField(max_length=50)\r\n\r\n def __str__(self):\r\n return self.user_id +\" , \" + self.user_pwd +\" , \"+self.user_name\r\n"
},
{
"alpha_fraction": 0.6917510628700256,
"alphanum_fraction": 0.730824887752533,
"avg_line_length": 28.404254913330078,
"blob_id": "d5cee0ecc64eb8f8fc8f964556c1e0d3d5eeec86",
"content_id": "3cbef113ee4feb03b71539a081fef10bfb2d5cc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1920,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 47,
"path": "/SQL/practice/practice1.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--1. 대학교 학과명, 계열을 표시하시오. 헤더는 '학과명' '계열'으로 표시한다\n\nSELECT DEPARTMENT_NAME AS 학과명, CATEGORY AS 계열\nFROM TB_DEPARTMENT;\n\n--2. 학과의 정원을 출력\nSELECT DEPARTMENT_NAME||'의 정원은 '||CAPACITY||'명 입니다.' AS \"학과별 정원\"\nFROM TB_DEPARTMENT;\n\n--3. \"국어국문학과\"에 다니는 여학생중 휴학중인 학생\nSELECT STUDENT_NAME\nFROM TB_DEPARTMENT, TB_STUDENT\nWHERE TB_DEPARTMENT.DEPARTMENT_NAME IN ('국어국문학과') AND TB_STUDENT.ABSENCE_YN IN ('Y') AND STUDENT_SSN LIKE '%-2%' AND TB_DEPARTMENT.DEPARTMENT_NO = TB_STUDENT.DEPARTMENT_NO;\n\n--4.\nSELECT STUDENT_NAME\nFROM TB_STUDENT\nWHERE STUDENT_NO IN ('A513079', 'A513090', 'A513091', 'A513110', 'A513119');\n\n--5.입학정원이 20 명 이상 30 명 이하인 학과들의 학과 이름과 계열을 출력하시오.\nSELECT DEPARTMENT_NAME , CATEGORY \nFROM TB_DEPARTMENT\nWHERE CAPACITY BETWEEN 20 AND 30; \n\n--6. 총장을 제외하고 모든 교수들이 소속 학과를 가지고 있다. 그럼 총장의 이름을 알아낼 수 있는 SQL 문장을 작성하시오.\nSELECT PROFESSOR_NAME\nFROM TB_PROFESSOR\nWHERE DEPARTMENT_NO IS NULL ;\n\n--7.학과가 지정되어 있지 않은 학생이 있는지 확인\nSELECT *\nFROM TB_STUDENT\nWHERE DEPARTMENT_NO IS NULL;\n\n--8. 선수과목이 존재하는 과목들은 어떤 과목인지 과목번호를 조회해보시오.\nSELECT CLASS_NO\nFROM TB_CLASS\nWHERE PREATTENDING_CLASS_NO IS NOT NULL;\n\n--9. 어떤 계열(CATEGORY)들이 있는지 조회해보시오.\nSELECT DISTINCT CATEGORY\nFROM TB_DEPARTMENT;\n\n-- 10. 02학번 전주 거주자들의 모임을 휴학한 사람들 제외 재학중인 학생들의 학번, 이름, 주민번호를 출력하는 구문을 작성하시오.\nSELECT STUDENT_NO, STUDENT_NAME, STUDENT_SSN\nFROM TB_STUDENT\nWHERE ABSENCE_YN IN ('N') AND STUDENT_ADDRESS LIKE '%전주%' AND ENTRANCE_DATE LIKE '02%';\n"
},
{
"alpha_fraction": 0.6023362874984741,
"alphanum_fraction": 0.6653411388397217,
"avg_line_length": 26.748275756835938,
"blob_id": "37f63cdd410e1a962f3c3156ed50fdbe301815cb",
"content_id": "c35446dd219a09c252db5db851884e0167157cf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 10453,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 290,
"path": "/SQL/oracle2_function.sql",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "--1. 함수\n--2. ORDER BY\n--3. GROUP BY\n--4. HAVING\nSELECT [특정 컬럼 | * (전체컬럼) | 표현식 | DISTINCT | AS 컬럼별칭\nFROM 테이블 이름\nWHERE 조건식\nGROUP BY 기준 컬럼\nHAVING 조건식\nORDER BY 기준컬럼;\n--ORBER BY 는 항상 마지막\n\n--1. 함수: 문자열 함수, 숫자 함수, 날짜 함수, 타입변환 함수, 기타함수\n--(1) 문자열 함수: LENGTH, LPAD/RPAD, INSTR, LTIRM/RTIRM/TRIM, SUBSTR\n\n--LENGTH() : NUMBER이 반환타입, 문자열의 길이를 반환\nSELECT CHARTYPE, LENGTH(CHARTYPE), VARCHARTYPE, LENGTH(VARCHARTYPE)\nFROM COLUMN_LENGTH;\n-- CHAR(고정길이), VARCHAR2(가변길이), (주로 VARCHAR2를 사용한다)\n-- CHAR TYPE : 실제 데이터 길이에 상관없이 컬럼 전체 길이를 반환\n-- VARCHAR2 : 실제 데이터 길이 반환 \n\n--INSTR() : 찾는 문자(열)이 지정한 위치부터 지정한 회수만큼 나타난 시작 위치를 반환하는 함수\n-- INSTR(문자열, 찾으려는 문자, 시작 위치, 그중 몇번째로 발견되는)\nSELECT EMAIL,\nINSTR( EMAIL,'c',-1,2 ) 위치\nFROM EMPLOYEE ;\n\nSELECT EMAIL,\nINSTR( EMAIL, 'c', INSTR( EMAIL,'.' )-1 ) 위치\nFROM EMPLOYEE ;\n-- '.'의 위치를 먼저 찾고 그 위치에서 한 자리수 앞.\n\n--LPAD, RPAD(STRING, N ,[STR]) : 컬럼/문자열에 임의의 문자(열)을 왼쪽/오른쪽에 덧붙여 결과가 길이 N의 문자열을 반환\nSELECT EMAIL AS 원본데이터,\n LENGTH(EMAIL) AS 원본길이,\n LPAD(EMAIL, 20, '.') AS 적용결과,\n LENGTH(LPAD(EMAIL, 20, '.')) AS 결과길이\nFROM EMPLOYEE;\n\n--LTIRM/RTRIM/TRIM : 컬럼/문자열읭 왼쪽/오른쪽에서 지정한 STR에 포함된 모든 문자를 제거한 나머지를 반환하는 함수\n-- 패턴을 제거하는 의미가 아님\nSELECT LTRIM('...TECH') FROM DUAL;\nSELECT LTRIM('...TECH','.') FROM DUAL;\nSELECT LTRIM('6748TECH', '0123456789') FROM DUAL;\nSELECT LTRIM('1234TECH123', '1234') FROM DUAL;\n--결과 : TECH123\nSELECT TRIM(' TECH ') FROM DUAL;\n --TRIM( LEADING|TRAILING|BOTH [trim_char] FROM trim_source )\nSELECT TRIM(BOTH '1' FROM '123TECH111') FROM DUAL;\n --23TECH\nSELECT TRIM(LEADING '0' FROM '00012300') FROM DUAL; \nSELECT TRIM(TRAILING '1' FROM '11Tech11') FROM DUAL; \n\n--단일행 함수 : N개 INPUT - > FUNCTION - > N개 OUTPUT\n--그룹 함수 : N개 INPUT - > FUNCTION - > 1개의 그룹, (N개가 아닌 결과가 나오면 그룹 함수)\n--함수는 SELECT, WHERE 적용 가능하다\n\n--SUBSTR : 컬럼/문자열에서 지정한 위치부터 지정한 개수 만큼의 문자열을 잘라내어 반환하는 함수\n--STRING, POSITION, LENGTH(반환 개수)\nSELECT SUBSTR('THIS IS A TEST', 6, 2) \nFROM DUAL;\n-- 결과 : IS \n\nSELECT SUBSTR('THIS IS A TEST', 6) \nFROM DUAL;\n-- 결과 : IS A TEST\n\nSELECT SUBSTR('TECHONTHENET', -3, 3) \nFROM DUAL;\n-- 결과 : NET\n\nSELECT SUBSTR('THIS IS A TEST', -6, 3) \nFROM DUAL;\n-- 결과 :A T\n\n--(2) 숫자 함수\n\n-- ROUND 함수 : 지정한 자릿수에서 반올림 하는 함수, 소수점도 중요하기 때문에 사요을 추천하지 않는 함수\n-- ROUND(number, [deciaml_places}) -> number \nSELECT ROUND(125.315) FROM DUAL;\n--출력 결과 : 125\n\nSELECT ROUND(125.315, 0) FROM DUAL;\n--출력 결과 : 125\n\nSELECT ROUND(125.315, 1) FROM DUAL;\n--출력 결과 : 125.3\n\nSELECT ROUND(125.315, -1) FROM DUAL;\n--출력 결과 : 130\n\nSELECT ROUND(-125.315, 2) FROM DUAL;\n--출력 결과 : -125.32\n\n--TRUNC 함수 : 지정한 자릿수에서 버림을 하는 함수.\nSELECT TRUNC(125.315) FROM DUAL;\n--출력 결과 : 125\n\nSELECT TRUNC(125.315, 0) FROM DUAL;\n--출력 결과 : 125\n\nSELECT TRUNC(125.315, 1) FROM DUAL;\n--출력 결과 : 125.3\n\nSELECT TRUNC(125.315, -1) FROM DUAL;\n--출력 결과 : 120\n\nSELECT TRUNC(-125.315, 2) FROM DUAL;\n--출력 결과 : -125.31\n\n--(3) 날짜 함수\n-- SYSDATE : 반환 타입 DATE 타입이다. \nSELECT SYSDATE\nFROM DUAL;\n\n-- ADD_MONTHS : DATE TYPE, 월수 ->DATE TYPE\nSELECT EMP_NAME, HIRE_DATE, ADD_MONTHS(HIRE_DATE, 240)\nFROM EMPLOYEE;\n--결과 : 20년이 더해진 값\n\n--MONTHS_BETWEEN : 두 날짜 사이의 개월수를 반환, 뒤에있는 인자가 크면 음수로 리턴이 된다.-> NUMBER 타입 반환\nSELECT EMP_NAME, HIRE_DATE, MONTHS_BETWEEN(SYSDATE, HIRE_DATE)/12 AS 근무년수\nFROM EMPLOYEE\nWHERE MONTHS_BETWEEN(SYSDATE, HIRE_DATE) >120;\n-- MONTH 이니깐 년수로 바꾸기 위해서 12로 나눔\n\n-- (4) 타입변환 함수 : TO_DATE, TO_CHAR\n\n--데이터 타입을 변환하는 두가지 방법을 제공, 암시적 변환, 명시적 변환\n-- NUMBER -- CHARACTER -- DATE (NUMBER 에서 DATE 는 CHARACTER를 통해서 변환되어야함)\n-- TO_CHAR : NUMBER / DATE 타입을 CHARARCTER 타입으로 변환하는 함수\n-- TO_CHAR : '9'는 자리수 지정, '0':남즞 자리를 0으로 표시, '$ 또는 L' : 통화기호 표시, '. 또는 , ':지정한 위치에 . 또는 , 표시\nSELECT TO_CHAR(1234, '99999') FROM DUAL;\n-- 1234\nSELECT TO_CHAR(1234, '09999') FROM DUAL;\n--01234\nSELECT TO_CHAR(1234, 'L99999') FROM DUAL;\n--₩1234\nSELECT TO_CHAR(1234, '99,999') FROM DUAL;\n--1,234\nSELECT TO_CHAR(1234, '09,999') FROM DUAL;\n--01,234\nSELECT TO_CHAR(1000, '9.9EEEE') FROM DUAL;\n-- 1.0E+03\nSELECT TO_CHAR(1234, '999') FROM DUAL;\n--####\n\n--TO_CHAR (날짜 | 숫자, 표현 형식) -> 문자열\nSELECT SYSDATE, TO_CHAR(SYSDATE, 'PM YYYY- MM-DD HH:MI:SS')\nFROM DUAL;\n\n--분기 출력\nSELECT SYSDATE, TO_CHAR(SYSDATE, 'Q')\nFROM DUAL;\n\nSELECT EMP_NAME, HIRE_DATE, TO_CHAR(HIRE_DATE, 'YYYY\"년\" MM\"월\" DD\"일\"')\nFROM EMPLOYEE;\n\nSELECT EMP_NAME, HIRE_DATE, TO_CHAR(HIRE_DATE, 'YYYY\"년\" MM\"월\" DD\"일\"'), \nSUBSTR(HIRE_DATE,1,2)||'년'|| SUBSTR(HIRE_DATE,4,2)||'월'|| SUBSTR(HIRE_DATE,7,2)||'일' AS 입사일 \nFROM EMPLOYEE;\n\n-- TO_DATE :\n-- 입력(문자열 정수!, 문자열인데 숫자여야함 - 같은 것도 들어가면 안됨) -> 출력으로는 입력과 똑같은 출력 형식을 가져야함\nSELECT TO_DATE('20100101', 'YYYYMMDD') FROM DUAL;\n--10/01/01\n\nSELECT TO_CHAR( TO_DATE('20100101', 'YYYYMMDD'),'YYYY, MON') FROM DUAL;\n--2010, 1월 \n\nSELECT TO_DATE('041030 143000', 'YYMMDD HH24MISS') FROM DUAL;\n--04/10/30\n\nSELECT TO_CHAR(TO_DATE('041030 143000', 'YYMMDD HH24MISS'), 'DD-MON-YY HH:MI:SS PM') FROM DUAL;\n--30-10월-04 02:30:00 오후\n-- 먼저 숫자를 DATE로 바꾸고 원하는 형식으로 바꾸기 위해서 CHAR로 바꿔준다. \n\nSELECT HIRE_DATE\nFROM EMPLOYEE\nWHERE HIRE_DATE = TO_DATE('900401 133030', 'YYMMDD HH24MISS');\n-- 만약 시분초가 들어가 있는 데이터이면 HIRE_DATE = '900401'으로 비교하면 비교가 안된다. \n-- TO_CHAR(HIRE_DATE, 'YYMMDD') = '900401' 근데 성능적으로 추천하지 않음\nSELECT HIRE_DATE\nFROM EMPLOYEE\nWHERE TO_CHAR(HIRE_DATE, 'YYMMDD') = '900401';\n--YYYY-RR\n\n--TO_NUMBER : CHAR -> NUMBER TYPE으로 \nSELECT EMP_NAME, EMP_NO,\n SUBSTR(EMP_NO,1,6)AS 앞부분,\n SUBSTR(EMP_NO,8) AS 뒷부분,\n TO_NUMBER( SUBSTR(EMP_NO,1,6) ) + TO_NUMBER( SUBSTR(EMP_NO,8) ) AS 결과\nFROM EMPLOYEE\nWHERE EMP_ID = '101';\n\n--(5) 기타 함수\n-- NVL : NULL을 지정한 값으로 변환하는 함수, NVL(NULL이 없으면 이 값을 반환, NULL이면 이 값을 반환), \nSELECT EMP_NAME, SALARY , NVL(BONUS_PCT,0)\nFROM EMPLOYEE\nWHERE SALARY > 3500000;\n\nSELECT EMP_NAME, (SALARY *12)+((SALARY *12)*BONUS_PCT)\nFROM EMPLOYEE\nWHERE SALARY > 3500000;\n\nSELECT EMP_NAME, (SALARY *12)+((SALARY *12)*NVL(BONUS_PCT,0))\nFROM EMPLOYEE\nWHERE SALARY > 3500000;\n\n--DECODE : SELECT 구문에서 IF-ELSE 논리를 제한적으로 구현한 오라클 DMBS함수\n--DECODE(대상, 비교값, TRUE일 경우 RESULT값, FALSE일 경우 RESULT 값])\nSELECT EMP_NO, DECODE(SUBSTR(EMP_NO, 8, 1),'1','남자', '3', '남자', '여자' ) AS GENDER\nFROM EMPLOYEE;\n\nSELECT EMP_ID, EMP_NAME, DECODE(MGR_ID, NULL, '관리자', MGR_ID) AS MANAGER, NVL(MGR_ID, '관리자') AS OTHERSCASE\nFROM EMPLOYEE\nWHERE JOB_ID = 'J4';\n\n--직원의 직급별 인상급여를 확인하고 싶다\n-- J7 -> 20%, J6->15%, J5->10%\nSELECT JOB_ID, EMP_NAME, SALARY, DECODE(JOB_ID, 'J7', SALARY*1.2,'J6', SALARY*1.15,'J5', SALARY*1.1, SALARY) AS \"인상 급여\"\nFROM EMPLOYEE;\n\n-- CASE : DECODE 함수와 유사한 ANSI 표준 구문\n-- CASE WHEN으로 조건식도 넣을 수 있어서 효율적이다\nSELECT JOB_ID, EMP_NAME, SALARY, CASE JOB_ID WHEN 'J7' THEN SALARY*1.2 WHEN 'J6'THEN SALARY*1.15 WHEN 'J5'THEN SALARY*1.1 ELSE SALARY END AS \"인상 급여\"\nFROM EMPLOYEE;\n\n-- 그룹함수\n-- SUM, AVG, // 입력 NUMBER형, MIN, MAX, COUNT // ANY형 입력을 받을 수 있다.\n-- NULL 값에 대한 처리를 확실히 해야함. \n-- 그룹함수가 SELECT 절에 사용되면 다른 컬럼 정의는 불가\n \nSELECT SUM(SALARY), EMP_NAME\nFROM EMPLOYEE;\n \nSELECT *\nFROM EMPLOYEE;\n--ORDER BY\n-- ORDER BY [기준 컬럼] [ASC|DESC]\n-- 부서번호 50이거나 부서번호가 존재하지 앟는 사원의 이름, 급여를 조회하라\n SELECT SALARY, EMP_NAME\n FROM EMPLOYEE\n WHERE DEPT_ID ='50' OR DEPT_ID IS NULL\n ORDER BY SALARY DESC;\n\n SELECT DEPT_ID, EMP_NAME, HIRE_DATE\n FROM EMPLOYEE\n WHERE HIRE_DATE > TO_DATE('03/01/01', 'RR/MM/DD')\n ORDER BY DEPT_ID DESC NULLS LAST, HIRE_DATE ASC, EMP_NAME;\n\n--부서별 평균 급여\nSELECT DEPT_ID, ROUND( AVG(SALARY), -5) AS 급여평균\nFROM EMPLOYEE\nGROUP BY DEPT_ID\nORDER BY 급여평균 DESC;\n\n--성별에 따른 급여 평균을 구한다면\nSELECT DEPT_ID, ROUND( AVG(SALARY), -5) AS 급여평균\nFROM EMPLOYEE\nGROUP BY DEPT_ID\nORDER BY 급여평균 DESC;\n\n-- GROUP BY 는 인덱스 별칭 적용이 안된다.\n-- ORDER BY [기준 컬럼 | 컬럼인덱스 | 별칭] \nSELECT DECODE(SUBSTR(EMP_NO, 8, 1), '2', '여자','4','여자', '남자'), AVG(SALARY)\nFROM EMPLOYEE\nGROUP BY DECODE(SUBSTR(EMP_NO, 8, 1), '2', '여자','4','여자', '남자')\nORDER BY 2 DESC;\n-- 2 의 의미는 두번쨰 컬럼을 기준으로 하겠다는 의미\n\nSELECT CASE SUBSTR(EMP_NO, 8,1) WHEN '1' THEN '남자' WHEN '3' THEN 남자 ELSE '여자' END , AVG(SALARY)\nFROM EMPLOYEE\nGROUP BY CASE SUBSTR(EMP_NO, 8,1) WHEN '1' THEN '남자' WHEN '3' THEN 남자 ELSE '여자' END\nORDER BY 2 DESC;\n\n--WHERE 절에는 그룹함수를 쓸 수 없다, 전체 테이블에 대한 조건은 WHERE \n--HAVING 은 그룹에 대한 조건 \nSELECT DEPT_ID, ROUND( AVG(SALARY), -5) AS 급여평균\nFROM EMPLOYEE\nGROUP BY DEPT_ID\nHAVING AVG(SALARY) > 3000000\nORDER BY 급여평균 DESC;\n\n-- 중간 중간 소계를 확인할 수 있다.\nSELECT DEPT_ID, ROUND( AVG(SALARY), -5) AS 급여평균,JOB_ID\nFROM EMPLOYEE\nGROUP BY ROLLUP(DEPT_ID, JOB_ID)\nORDER BY 급여평균 DESC;\n"
},
{
"alpha_fraction": 0.588265061378479,
"alphanum_fraction": 0.600910484790802,
"avg_line_length": 20.94186019897461,
"blob_id": "6e9b62510e5f5f0d91c23660fa022aaa1ee1452a",
"content_id": "439c14c52886783b3ffa013498a2794195824e7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5446,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 172,
"path": "/Django/Django_backend.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "\r\n\r\n\r\n\r\n\r\n\r\n## MVT 패턴이란\r\n\r\nModel은 데이터 베이스에 저장되는 데이터를 의미하는 것이고, Template은 사용자에게 보여지는 UI부분(html)을, View는 실질적으로 프로그램 로직이 동작하여 데이터를 가져오고 적절하게 처리한 결과를 Template에 전달하는 역할을 수행한다. Url를 통해서 정보를 요청하고 view는 control 역할로 모델과 템플렛에서 할 일을 나눠준다. \r\n\r\n\r\n\r\n## Django 프로젝트 구조\r\n\r\nterminal에 명령어\r\n\r\n```\r\ndjango-admin startproject baseWEB\r\n```\r\n\r\n를 실행하면 baseWEB 이 생성된다.\r\n\r\n위 명령어 실행 결과는 다음과 같다.\r\n\r\n```\r\n프로젝트_이름/\r\n baseWEB/\r\n baseWEB/\r\n __init__.py\r\n settings.py\r\n urls.py\r\n wsgi.py\r\n manage.py \r\n venv/\r\n```\r\n\r\n`settings.py` : 환경에 관한 정보를 관리하는 root 가 생성된 것이다. 만들어준 APP은 꼭 `INSTALLED_APPS` 에 등록을 해주어야한다. `DEBUG=True` 는 배포할때 false로 바꾼다. 데이터베이스는 sqlite3로 기본설정이 되어있다. \r\n\r\n`urls.py` : 사용자의 request가 이곳으로 들어와 맞는 APP으로 연결을 시켜준다.\r\n\r\n\r\n\r\n## Django 앱 구조\r\n\r\nTerminal 에 명령어\r\n\r\n```\r\n>dir/w\r\n>cd baseWEB\r\n>python manage.py runserver\r\n```\r\n\r\n를 통해 WEB에 있는 manage.py가 있는 디렉토리로 들어온다. `runserver`를 통해서 서버를 실행시킨다. 이때 runserver를 통해서 port 번호를 지정해서 접근할 수도 있다.\r\n\r\nmanage.py 파일이 있는 디텍토리에서 앱(APP) 만들기 위해서 명령어\r\n\r\n```\r\n>python manage.py startapp HelloApp\r\n```\r\n\r\n를 수행해 `HelloApp`을 만든다. \r\n\r\n이때 만든 APP을 settings `INSTALLED_APPS =`에 등록을 시켜줘야한다.\r\n\r\n위 명령어 실행 결과, APP의 형태는 다음과 같다.\r\n\r\n```\r\n프로젝트_이름/\r\n baseWEB/\r\n \tbaseWEB/\r\n HelloApp/\r\n __init__.py\r\n admin.py\r\n apps.py\r\n models.py\r\n tests.py\r\n views.py\r\n manage.py \r\n venv/\r\n```\r\n\r\n이제 만든 app를 base urls에 연결해서 사용자의 request가 들어갔을 때 연결되도록 한다.\r\n\r\n먼저 HelloApp폴더에 `urls.py`을 만든다.\r\n\r\nbase urls.py에 include 해준다\r\n\r\n```python\r\npath('hello/', include('HelloApp.urls')),\r\n```\r\n\r\n\r\n\r\n> base.urls 로 요청이 들어오고 -> 여기 HelloApp.urls로 이동을 해서 HelloApp.urls에서 .views의 특정 함수를 찾아서 이동한다. \r\n\r\n\r\n\r\n## Views\r\n\r\nHelloApp.urls에는 연결될 views의 함수를 정의한다. \r\n\r\n```python\r\nfrom django.contrib import admin\r\nfrom django.urls import path, include\r\nfrom HelloApp import views\r\nurlpatterns = [\r\n #localhost:8000/hello/index/\r\n path('index/', views.index),\r\n path('baseball/', views.baseball),\r\n path('football/', views.football, name ='foot'),\r\n path('basketball/', views.basketball),\r\n path('login/', views.login),\r\n]\r\n```\r\n\r\n`path`의 첫번째 인자는 url에 작성되는 이름?형태이고 두번째는 실제 호출되는 views의 함수이름이다. football처럼 `name=''`이라는 별칭을 붙여줘 접근성을 높일 수 있다. 상대 경로, 절대경로 대신 `<a href={% url 'foot' %}> 축구 </a>; ` 으로 접근할 수 있게 해준다. \r\n\r\nviews의 함수는 꼭 사용자의 request 객체가 인자로 들어와야한다.\r\n\r\n```python\r\nfrom django.shortcuts import render, HttpResponse\r\n\r\n# Create your views here.\r\ndef index(request):\r\n #return HttpResponse('*** 여기는 시작 페이지 입니다 ***')\r\n context = {'ment' : '이곳은 연습장입니다.'}\r\n return render(request, 'hello/index.html', context)\r\n\r\ndef login(request):\r\n msg = request.POST['msg']\r\n print('param msg - ', msg)\r\n return HttpResponse('*** 여기는 login 페이지 입니다 ***')\r\n```\r\n\r\n이때 필요한 패키지 import하는거 잊으면 안된다.\r\n\r\n{{}} 는 프린트 역할을 해준다.\r\n\r\n\r\n\r\n## Templates\r\n\r\nHelloApp 아래 `templates`라는 디렉토리를 생성한다. 디렉토리안에 폴더를 만들어 html templates 들을 생성한다. \r\n\r\n```\r\nform method =\"post|get\" action=\"destination\">\r\n```\r\n\r\n- GET 방식 : 클라이언트의 데이터를 URL에 붙여서 보낸다. 즉 뒤에 ,querystring이 붙는다. \r\n- POST 방식 : 데이터 전송을 기반으로 한 요청 메소드이다. 즉 POST방식은 BODY에 데이터를 넣어서 보낸다. \r\n\r\nurl : xxxx.xom?key = value & key = value ->get \r\n\r\n\t\t\t\t\t\t\t<- querystring------->\r\n\r\nurl : xxxx.com -> post\r\n\r\n```python\r\n <div align = \"center\">{{ment}}</div>\r\n <hr/>\r\n <form method =\"post\" action=\"../login/\">\r\n {% csrf_token %}\r\n <input type=\"text\" name=\"msg\">\r\n <input type=\"submit\" value=\"send\">\r\n </form>\r\n <hr/>\r\n <a href=\"../baseball\"> 야구 </a> \r\n <a href={% url 'foot' %}> 축구 </a> \r\n <a href=\"http://127.0.0.1:8000/hello/basketball\"> 농구 </a>\r\n```\r\n\r\n`{% csrf_token %}`은 msg에 전달되는 text내용을 console에 print한다. 왜냐 form을 통해서 url로 login 함수를 요청한 것이다. view.login 함수가 실행되면서 print함수가 수행된다. \r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6923931241035461,
"alphanum_fraction": 0.6940588355064392,
"avg_line_length": 31.849056243896484,
"blob_id": "d00c34bd895116c2215144c4a247c4d2f19fddfb",
"content_id": "431627a5f61f9f21e627e097d9b580c9fbe076d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3559,
"license_type": "no_license",
"max_line_length": 273,
"num_lines": 53,
"path": "/Django/jquery.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### json? Ajax? jQuery? \r\n\r\n\r\n\r\njson : restful service \r\n\r\nAJAX : 비동기 통신, json 형식으로 변환해서 사용하는 추세이다.\r\n\r\n사용하는 이유 : 페이지가 정적으로 멈춰있는 상태에서 특정 영역만 render 없이 변경하도록 한다. \r\n\r\n### AJAX\r\n\r\nAjax는 웹 페이지에서 새로운 데이터를 보여주려고 할 때 웹페이지 전체를 새로고침 하지 않고, 보여주고자 하는 데이터가 포함된 페이지의 일부 만을 로드 하기 위한 기법이다.\r\n\r\nAjax는 비동기 처리 모델 (또는 non-blocking 이라고도 함)을 사용하여 데이터를 처리한다. 동기 처리 모델에서 브라우저는 자바스크립트 코드를 만나면 스크립트를 처리하기 전까지 다른 작업을 일시 중지하고, 자바스크립트 코드의 처리가 끝난 후 기존 작업을 진행한다.\r\n\r\n반면에 Ajax를 사용하면 브라우저는 서버에 데이터를 요청한 뒤 페이지의 나머지를 로드하고 페이지와 사용자의 상호작용을 처리한다. 웹서버가 사용자에게 데이터를 전달하면 이벤트가 발생하게 되며, 데이터를 처리할 함수를 호출하게 된다. 이를 다시 정리하면 아래와 같다.\r\n\r\n**Ajax 동작방식**\r\n\r\n1. 요청(request) - 브라우저가 서버에 정보를 요청한다.\r\n2. 서버의 동작 - 서버는 JSON, XML 등의 형식으로 데이터를 전달한다.\r\n3. 응답(response) - 브라우저에서 이벤트가 발생하여 콘텐츠를 처리한다.\r\n\r\n> 출처.https://tutorialpost.apptilus.com/code/posts/js/js-ajax/\r\n\r\n**Ajax 데이터 형식**\r\n\r\nXML 형식으로 데이터를 주고 받을 수 있다. 하지만 최근에는 많은 경우 JSON (JavaScript Object Notation) 형식으로 데이터를 주고 받는다.\r\n\r\n\r\n\r\n### JSON\r\n\r\nJSON (JavaScript Object Notation)은 자바스크립트의 객체 표현식과 유사한 방식으로 데이터를 주고 받는 방법이다. JSON은 객체를 정의하지는 않는다. 즉, 자바스크립트 객체가 아니라 객체 표현식으로 데이터를 표현한다. 따라서 다른 도메인에서도 요청을 보낼 수 있다.JSON은 기존에 많이 사용하던 XML 문법보다 훨씬 간결한 문법을 가지고 있습니다. 다만, 문법에 예민한 편입니다.JSON 사용 시 악의적인 콘텐츠를 통한 공격이 있을 수 있으므로 주의해야 합니다.\r\n\r\n\r\n\r\n\r\n\r\n### jQuery\r\n\r\njQuery는 클라이언트 측 HTML 스크립팅을 간소화하기 위해 고안된 크로스 플랫폼 자바스크립트 라이브러리다. jQuery는 오늘날 가장 인기 있는 자바스크립트 라이브러리입니다. \r\n\r\njquery를 쓰려면 먼저 html 파일의 상단 head에 script태그에 사용할 jQuery CDN을 넣어준다. html은 interpret 영역이기 때문에 위에서 아래로 디버깅?이 되기 때문에 jquery를 실제로 사용하는 <body> <script>보다 위에 써줘야한다. \r\n\r\n\r\n\r\n`<script>` 에서 도큐먼트에 접근해서 도큐먼트에 정의된 object를 변경한다. document는 body태그 전체를 의미한다. 이 script를 통해서 도큐먼트에 삽입 삭제, 즉 제어를 할 수 있다. \r\n\r\n\r\n\r\n`$` 기호를 이용해서 jQuery 함수에 접근을 하고 어디를 변경하고 싶은지를 써준다. 만약 특정 object, 태그를 변경하고 싶으면 `#` 와 id 를 써주면 된다. 이때 id 와 name를 헷갈리면 안된다. name은 서버와 통신하기 위한 것이고 id는 script에 접근하기 위한 속성이다. \r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6409762501716614,
"alphanum_fraction": 0.6441875696182251,
"avg_line_length": 26.803571701049805,
"blob_id": "7dedc436a1a129e7e86b927a9bf8521c928249c9",
"content_id": "2e7f0aa11ecde0cf8465a4fb2a77de38359029cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2659,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 56,
"path": "/Django/Django_AJAX.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "### script 복습\n\n```\n<form method=\"post\" id=\"removeFrm\">\n {% csrf_token %}\n <input type=\"hidden\" name=\"id\" value=\"{{board.id}}\">\n</form>\n```\n\n위에 form에 action이 존재하지 않는다. action을 script를 통해서 추가를 할거다. \nscript라는 것이 도큐먼트에 수정 삭제 추가를 할 수 있는 거니깐.\n\n```\n$('#remoBtn').click(function() {\n $('#removeFrm').attr('action', \"{% url 'bbs_remove' %}\").submit()\n})\n```\n\n이 script를 통해서 action이라는 속성을 추가하는 것이다. \n\n\n\n### AJAX 복습 \n\n```\n$.ajax({\n url :\"{% url 'bbs_search' %}\",\n type: \"post\",\n data: {\"csrfmiddlewaretoken\" : '{{csrf_token}}',\n type : type,\n keyword : keyword},\n dateType: 'json',\n success:function(ary){\n alert('success')\n }\n})\n```\n\najax 통신을 하기 위해선 딕셔너리 형태로 넘겨줘야하는데 여러개라면 list로 묶어서 딕셔너리로 묶어서 넘겨준다. \n\n#### AJAX 란\nAjax는 프레임워크가 아닌 구현하는 방식을 의미한다. 데이터를 이동하고 화면을 구성하는데 있어서 웹 화면을 갱신하지 않고 필요한 데이터를 서버로 보내고 가져오는 방법이다. 화면 갱신이 없어서 사용자 입장에서는 매우 편리하고 빠르게 작업을 처리하는 것처럼 느끼게 한다.\n\n##### 데이터 전송\nAjax는 서버와 클라이언트간에 데이터를 이동하고 화면을 구성하는 구현 방식입니다. 비동기식 데이터 전송이다. 서버로 데이터를 요청하고 응답을 기다리는 동안 웹은 자신의 다른 업무를 진행하고 응답이 오면 그 후 작업을 진행한다. 즉, 사용자 입장에서는 화면 갱신도 없고, 요청-응답 사이 시간에도 다른 일을 진행할 수 있기 때문에 편리하고 빠르게 작업을 처리하는 것처럼 느껴진다.\n\n##### 데이터 형식\nAjax 통신에서 데이터를 전송하는 형식은 크게 3가지로 CSV, JSON, XML 형식이 있다. JSON형식은 JavaScript의 객체 형태로 데이터를 전송하는 형식이다. XML과 CSV형식의 단점을 최소화한 형식이다. \n\n##### 데이터 전송 형식\nGET(열람), POST(생성), PUT(갱신), DELETE(삭제), HEAD(요청). CRUD방식으로 GET,POST방식을 주로 지원한다. GET방식은 단순히 읽어 오는 경우에 쓰이며 POST방식의 경우 데이터를 생성, 수정, 삭제하는 경우에 쓰인다. \n\n##### jQuery Ajax\njQuery 라이브러리에서의 Ajax는 보다 다양하고 단순한 방법으로 javaScript Ajax를 구현을 할 수 있게 해준다. \n\n> 출처 및 참조 https://www.nextree.co.kr/p9521/\n"
},
{
"alpha_fraction": 0.5679012537002563,
"alphanum_fraction": 0.5703703761100769,
"avg_line_length": 7.911110877990723,
"blob_id": "708bce52941d34c7b6d06cf5e58d4df99bbac0f8",
"content_id": "506bc9018e7f7fc186760ea8b35311492eb71286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 45,
"path": "/CLI/command.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "# CLI 명령어\n\n> CLI (command line interface)는 명령어를 통해 컴퓨터에게 여러가지 명령을 할 수 있다. \n\n\n\n### ls\n\n- list의 약자\n- 현재 위치의 파일과 폴더 목록을 출력\n - 기본적으로 숨김폴더, 숨김파일은 출력하지 않음\n - `ls -a` 명령어를 통해 숨겨진 목록도 같이 출력\n\n\n\n### pwd\n\n- print working directory\n- 내가 있는 현재 폴더를 출력\n\n\n\n### cd\n\n- change directory\n\n```bash\ncd <이동하고싶은 폴더 이름>\ncd .. => 상위폴더로 이동\ncd git => git 폴더로 이동\n```\n\n\n\n### touch \n\n- 파일을 생성\n- `touch <생성하고 싶은 파일이름>`\n- \n\n\n\n\n\n1. \n\n\n\n"
},
{
"alpha_fraction": 0.6144151091575623,
"alphanum_fraction": 0.6207168102264404,
"avg_line_length": 21.728971481323242,
"blob_id": "22d6c97c4602a9cfaa3463f5c4b285d083fa913e",
"content_id": "c63ab9f4510713bb05398905a51d1ea9c6952df1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3515,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 107,
"path": "/Django/bbsApp_ORM practice/README.md",
"repo_name": "KimGyuri875/TIL",
"src_encoding": "UTF-8",
"text": "## header, footer, templates (css, js) 적용하는 방법\r\n\r\ncss, js는 static 이라는 폴더에 저장을 해줘야 한다. \r\n\r\nheader.html, footer.html은 여러 app에서 사용될거니깐 WEB아래 templates 폴더 안에 넣어준다.\r\n\r\n\r\n\r\n#### settings 변경해주기\r\n\r\n```\r\nSTATICFILES_DIRS = [\r\n os.path.join(BASE_DIR, 'bbsApp', 'static'),\r\n]\r\n```\r\n\r\n settings에 다가 정적 파일이 있는 곳을 작성해주어야한다. \r\n\r\n```\r\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\r\n```\r\n\r\n```\r\nTEMPLATES = [\r\n {\r\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\r\n 'DIRS': [os.path.join(BASE_DIR), 'web/templates'],\r\n 'APP_DIRS': True,\r\n 'OPTIONS': {\r\n 'context_processors': [\r\n 'django.template.context_processors.debug',\r\n 'django.template.context_processors.request',\r\n 'django.contrib.auth.context_processors.auth',\r\n 'django.contrib.messages.context_processors.messages',\r\n ],\r\n },\r\n },\r\n```\r\n\r\n`'DIRS': [os.path.join(BASE_DIR), 'web/templates'],` 는 header, footer 처럼 공통 되는 코드를 가리키는 곳으로, html 파일에 include를 통해서 넣는다. \r\n\r\n\r\n\r\n#### html에 header, footer 적용하기\r\n\r\n`{% include 'header.html' %}`을 바디(home.html)에 다가 include 하고 \r\n\r\nblock 임을 `{% block content%}` 전체 ~~~ `{%endblock %}`으로 표시한다. \r\n\r\n\r\n\r\n#### static 폴더를 하나로 모으기\r\n\r\nstatic으로 있는 내용이 여러 디렉터리에 흩어져있는걸 하나로 모아야한다. \r\n\r\nbaseWeb에 있는 footer.html, header.html도 bbsApp안에있는 static의 resource를 사용할 수 있도록 \r\n\r\n`>python manage.py collectstatic `\r\n\r\n그결과 baseWeb 아래 static 이라는 폴더가 생기면서 모이게 된다. \r\n\r\n`{% load static %}` 을 통해서 login.html 와 같은 곳에 static을 사용해줄 것임을 작성한다. \r\n\r\n\r\n\r\n\r\n## MODEL ORM\r\n\r\nmodels.py 를 통해 테이블을 생성하고 admin.py를 통해서 orm을 등록, 관리한다. \r\n\r\nmodel 을 class을 통해서 생성 class 는 table 과 같은 의미로 컬럼을 등록하면 된다. \r\n\r\n`>python manage.py makemigrations`\r\n\r\n`>python manage.py migrate`\r\n\r\n이제 orm을 관리할 수 있는 관리자를 만들 수 있다. 관리자는 데이터베이스 관리를 위한 계정이다. \r\n\r\n`>python manage.py createsuperuser`\r\n\r\nhttp://127.0.0.1:8000/admin/login 에서 admin 로그인 하고 테이블을 관리할 수 있다. \r\n\r\nviews.py 파일에 어떤식으로 데이터베이스에 접근해야하는지 정리해놨다.\r\n\r\n\r\n\r\n## views return 방식(화면 분기 방식)\r\n\r\n- HttpResponse() - X\r\n\r\n- JsonResponse() - json\r\n\r\n- render() - templates(xxxx.html)으로 이동, url을 보면 변경이 되지 않음\r\n\r\n- redirect(path를 쓰는게 아니라 path의 별칭, alias를 넣어준다) : 요청을 재지정하는 것이다. \r\n\r\n urls---> views에서 request를 받아서 templates로 보내는게 아니라 views에서 또다른 request를 요청하는 것이다. \r\n\r\n ex) 글을 씀 -> list 페이지로 이동 -> 이럴때 render를 쓰는게 아니다. 왜냐 글을 썼으면 DB에 저장 insert(update, delete) select가 동시에 일어나기 위해서는 insert를 하고 select를 위한 또다른 요청을 보내는거다. \r\n\r\n redirect를 할 경우 url이 변경된다. (함수에 함수 부르기)\r\n\r\n \r\n\r\n{{}} --print\r\n\r\n{% %} -- code (if , for )\r\n"
}
] | 24 |
Shubham-gupta007/Pattern-using-python | https://github.com/Shubham-gupta007/Pattern-using-python | 8dac1e7bd1a24216c4767089c7799ba03ab2d838 | edf9adc3d8f01a829082b60ce1a9f1a2c8bb64ce | 7097bc5ca7d98f8d3334a05542e7752bbfc59371 | refs/heads/master | "2020-03-28T01:30:46.901072" | "2018-09-05T12:01:01" | "2018-09-05T12:01:01" | 147,510,266 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5180723071098328,
"alphanum_fraction": 0.5397590398788452,
"avg_line_length": 17.863636016845703,
"blob_id": "8eb3fa8b72b4fd25dd0a53523fe816132e720bf9",
"content_id": "9bf127b81ae60fed3f42827a0455658ab8f1d8da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 22,
"path": "/Pattern/p5.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "n = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(n,-1,-2):\n\tprint((c*i).ljust(n))\n\n\n\nn = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).rjust(n) + c + (c*i).ljust(n))\nfor i in range(n, -1,-1):\n\tprint((c*i).rjust(n) + c + (c*i).ljust(n))\n\n\n\nn = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).ljust(n))\nfor i in range(n-1,-1,-1):\n\tprint((c*i).ljust(n))\n"
},
{
"alpha_fraction": 0.5158730149269104,
"alphanum_fraction": 0.5396825671195984,
"avg_line_length": 19.83333396911621,
"blob_id": "f070963d05bb666351113ddf5d058f7638ae3118",
"content_id": "c2a0814a15a5db6763372e12056080dc55e69575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/Pattern/p12.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "n = int(input(\"Enter number: \"))\nnum = 65\nch = chr(num)\nfor i in range(n+1):\n\tprint('%s' % ((ch*i).rjust(n)))\n\tnum = num + i\n\n"
},
{
"alpha_fraction": 0.5481481552124023,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 7.900000095367432,
"blob_id": "88a39e6401e02faa1321b8af5310413230baa63f",
"content_id": "30796db41e7ae5b814d987e7d7480703b0221733",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 30,
"path": "/Pattern/p9.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "\n\n\nn = int(input(\"Enter number: \"))\nnum = 65\n\nfor i in range(n+1):\t\n\tch = chr(num-1)\n\tprint('%s' % ((ch*i).ljust(n)))\t\n\tnum = num + 1\n\n\"\"\"\no/p:\n\nA \nBB \nCCC \nDDDD \nEEEEE\n\nprblm\ni have to print below pattern using ljust\n\nA\nBC\nDEF\nGHIJ\nKLMNO\n\n\nwhat should i do?\n\n\"\"\"\n"
},
{
"alpha_fraction": 0.46621620655059814,
"alphanum_fraction": 0.5135135054588318,
"avg_line_length": 16.875,
"blob_id": "cedd03d27d8de71af8769ca24bb6dc3384422800",
"content_id": "93aec42222593615fe7d28e8a696fdc7fc2c2ef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 8,
"path": "/Pattern/p8.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "#width = 10\nn = int(input(\"Enter number: \"))\nnum = 65\n\nfor i in range(n+1):\t\n\tch = chr(num-1)\n\tprint('%s' % ((ch*i).ljust(n)))\t\n\tnum = num + 1\n\t\n\n\n\n"
},
{
"alpha_fraction": 0.521276593208313,
"alphanum_fraction": 0.5531914830207825,
"avg_line_length": 22.25,
"blob_id": "2e30ebd0bcd7e6418d36995643c8bd02cd728c8e",
"content_id": "bb5344e9063bc3582876a5e642b62d06d920bb7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 4,
"path": "/Pattern/p6.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "n = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(-1,n+1,2):\n\tprint((c*i).ljust(n))\n\n"
},
{
"alpha_fraction": 0.4779411852359772,
"alphanum_fraction": 0.5036764740943909,
"avg_line_length": 32.75,
"blob_id": "3092940d9f459bd50c769d6f5cf5da791dfdebed",
"content_id": "42c6c3d6a6479119478b548b951b106f263869bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 8,
"path": "/Pattern/p13.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "\nn = int(input(\"Enter the number: \"))\nnum = str(int(5))\nfor i in range(n,0,-1):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(i-1))\nfor i in range(1,n+1):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(1)+i)\n\n"
},
{
"alpha_fraction": 0.5403726696968079,
"alphanum_fraction": 0.5590062141418457,
"avg_line_length": 39,
"blob_id": "bc0c2fd265481ca1b85c5b00a8200e66cebac4ad",
"content_id": "10c50f48689de73e5cf67d08e08afc2a41d70006",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 4,
"path": "/Pattern/p7.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "n = int(input(\"Enter the number: \")) #This must be an odd number\nc = '*'\nfor i in range(n):\n print(((c*(n-i-1)).rjust(n)+c+(c*(n-i-1)).ljust(n)).rjust(n*6)) \n"
},
{
"alpha_fraction": 0.501118540763855,
"alphanum_fraction": 0.526472806930542,
"avg_line_length": 20.26984214782715,
"blob_id": "08db0f5912784665367733bd971a8d41c824edd5",
"content_id": "14fd5bd5fe87ffae90b574fdebd125750fe5e0b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1341,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 63,
"path": "/Pattern/p11.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "#width = 10\nn = int(input(\"Enter the number: \"))\nnum = str(int(1))\nfor i in range(n+1):\n\tprint ('%s' % ((num*i).ljust(n)))\n\tnum = str(int(1)+i)\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(9))\nfor i in range(n+1):\n\tprint ('%s' % ((num*i).rjust(n)))\n\tnum = str(int(9)-i)\n\t#num2 = str(int(1)+ i) + str(int(i))\n\t#print(num2) \n\n\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(1))\nfor i in range(n+1):\n\tprint ('%s' % ((num*i).ljust(n)))\n\tnum = str(int(1)+i)\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(5))\nfor i in range(n,-1,-1):\n\tprint ('%s' % ((num*i).ljust(n)))\n\tnum = str(int(i-1))\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(5))\nfor i in range(n,-1,-1):\n\tprint ('%s' % ((num*i).rjust(n)))\n\tnum = str(int(i-1))\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(5))\nfor i in range(n,-1,-1):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(i-1))\n\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(1))\nfor i in range(n+1):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(1)+i)\n\n\n\nn = int(input(\"Enter the number: \"))\nnum = str(int(5))\nfor i in range(n,0,-1):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(i-1))\nfor i in range(n):\n\tprint ('%s' % ((num*i).ljust(n)) + '%s' % ((num*i).rjust(n)))\n\tnum = str(int(1)+i)\n\n"
},
{
"alpha_fraction": 0.5163934230804443,
"alphanum_fraction": 0.5573770403862,
"avg_line_length": 16.428571701049805,
"blob_id": "0c106ee0bb3b52dd46096dc04a362752727d5d0c",
"content_id": "8051c6369bb9b5075b3cf0aaabf7c63161e15b6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/Pattern/p10.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "n = int(input(\"Enter number: \"))\nnum = 69\n\nfor i in range(n+1):\t\n\tch = chr(num-1)\n\tprint((ch*i).ljust(n))\t\n\tnum = num + 1\n"
},
{
"alpha_fraction": 0.5480093955993652,
"alphanum_fraction": 0.5573770403862,
"avg_line_length": 18.272727966308594,
"blob_id": "91269c1468ea9646157b8c6ca78f76e59661b4d1",
"content_id": "11e6a1ae1662f6523e55e8f8725f51408b5a9517",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 22,
"path": "/Pattern/p2.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "\n\nn = int(input(\"enter the number:\")) #This must be an odd number\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).ljust(n))\n\n\n\nn = int(input(\"Enter the number:\"))\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).rjust(n))\n\n\nn = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).ljust(n) + (c*i).rjust(n))\n\nn = int(input(\"enter the number:\"))\nc = '*'\nfor i in range(n+1):\n\tprint((c*i).rjust(n) + c + (c*i).ljust(n))\n\n"
},
{
"alpha_fraction": 0.5835543870925903,
"alphanum_fraction": 0.6021220088005066,
"avg_line_length": 21.058822631835938,
"blob_id": "c404949d1f94e087add299990e62a28f8e9e7e02",
"content_id": "a8629bcb44b7d7d2744b0c7f9663ae32e8e0c886",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/Pattern/pattern1.py",
"repo_name": "Shubham-gupta007/Pattern-using-python",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\nr = int(input(\"Enter the no. rows: \"))\nfor i in range(1,r+1):\n\tfor j in range(1, i+1):\n\t\tprint(\"*\",end=\"\")\n\tprint()\n\nthickness = int(input()) #This must be an odd number\nc = '*'\nfor i in range(thickness+1):\n print((c*i).ljust(thickness))\n\"\"\"\n\nthickness = int(input()) #This must be an odd number\nc ='*'\nfor i in range(thickness+1):\n print((c*i).ljust(thickness+1))\n\n"
}
] | 11 |
mrbcan/My-ML-Library | https://github.com/mrbcan/My-ML-Library | 3d2c011c3f8c31bae4ab610ca60b62bdaf3b6886 | fabf09c77a3ea21766e9d926bc3b8e0f7c6ec2a5 | fbca93df5aed1438afe1a57c1122c006a908c549 | refs/heads/master | "2023-04-05T07:33:02.597258" | "2021-04-24T16:59:41" | "2021-04-24T16:59:41" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7098491787910461,
"alphanum_fraction": 0.7275953888893127,
"avg_line_length": 18.678571701049805,
"blob_id": "ff61c2c3f71d44544e6a9a483a55bbfbd5e22f8b",
"content_id": "751ff8b75941d8b4d7cb208fbcdc8124a6e9e7f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1135,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 56,
"path": "/2Regression/verionislemesablonu.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jul 6 18:50:13 2020\n\n@author: sadievrenseker\n\"\"\"\n\n#1.kutuphaneler\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n\n#2.1.veri yukleme\nveriler = pd.read_csv('satislar.csv')\n\n\n\n#2.veri onisleme\naylar=veriler[['Aylar']]\nsatislar=veriler[['Satislar']]\n\n\n#verilerin egitim ve test icin bolunmesi\nfrom sklearn.model_selection import train_test_split\n\nx_train, x_test,y_train,y_test = train_test_split(aylar,satislar,test_size=0.33, random_state=0)\n\"\"\"\n#verilerin olceklenmesi\nfrom sklearn.preprocessing import StandardScaler\n\nsc=StandardScaler()\n\nX_train = sc.fit_transform(x_train)\nX_test = sc.fit_transform(x_test)\n\nY_train=sc.fit_transform(y_train)\nY_test=sc.fit_transform(y_test)\n\"\"\"\n#model inşası (linear regression)\nfrom sklearn.linear_model import LinearRegression\n\nlr=LinearRegression()\nlr.fit(x_train,y_train)\n\ntahmin=lr.predict(x_test)\n\n#sıralıyoz\nx_train=x_train.sort_index()\ny_train=y_train.sort_index()\n\nplt.plot(x_train,y_train)\nplt.plot(x_test,tahmin)\nplt.title('aylara göre satıs')\nplt.xlabel('aylar')\nplt.ylabel('satışlar')\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.746874988079071,
"alphanum_fraction": 0.7593749761581421,
"avg_line_length": 21.34883689880371,
"blob_id": "098e371842387aaa5e1f86f6783e6ecae2a2d251",
"content_id": "05d03377415aa558e8bae165e928b869f7121423",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 43,
"path": "/3Regression(Polinom)/polinomsablon.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport numpy\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n#veri yükleme\nveriler=pd.read_csv(\"maaslar.csv\")\n#data frame dilimleme(slice)\nx=veriler.iloc[:,1:2]\ny=veriler.iloc[:,2:]\n#Numpy array-dizi dönüşümü\nX=x.values\nY=y.values\n\n#linear regression-doğrusal model olusturma\nfrom sklearn.linear_model import LinearRegression\nlin_reg=LinearRegression()\nlin_reg.fit(X,Y)\n\n\n#polynomial regression-doğrusal olmayan model olusturma\nfrom sklearn.preprocessing import PolynomialFeatures\npoly_reg=PolynomialFeatures(degree=4)\nx_poly=poly_reg.fit_transform(X)\nlin_reg2=LinearRegression()\nlin_reg2.fit(x_poly,y)\n\n\n#görselleştirmeler sırasıyla(linear ve 4.dereceden)\nplt.scatter(X,Y,color='red')\nplt.plot(x,lin_reg.predict(X),color='blue')\nplt.show()\n\n\nplt.scatter(X,Y,color='red')\nplt.plot(X,lin_reg2.predict(x_poly),color='blue')\nplt.show()\n\n#tahminler\n\nprint(lin_reg.predict([[6]]))\nprint(lin_reg2.predict(poly_reg.fit_transform([[6]])))"
},
{
"alpha_fraction": 0.7661085724830627,
"alphanum_fraction": 0.7813292741775513,
"avg_line_length": 24.506492614746094,
"blob_id": "aced736c2d9580378cf7205befc8b11fe8385d3a",
"content_id": "9b19f32d39df5f27a611b8d55ea3d6bc33091220",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2016,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 77,
"path": "/14dimension reduction(pca,lda)/pca_vs_lda.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n#Kütüphaneler\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n#veri kümesi\nveriler=pd.read_csv('Wine.csv')\nX=veriler.iloc[:,0:13].values\ny=veriler.iloc[:,13].values\n\n\n#test and train (verileri bölme)\nfrom sklearn.model_selection import train_test_split\nx_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)\n\n#verilerin ölçeklendirme 0ve 1 aralığına sıkıştırmak için\nfrom sklearn.preprocessing import StandardScaler\nsc=StandardScaler()\nX_train=sc.fit_transform(x_train)\nX_test=sc.fit_transform(x_test)\n\n\n#PCA\nfrom sklearn.decomposition import PCA\npca=PCA(n_components=2) #2 boyuta (colona ) indirgendi\n\nX_train2=pca.fit_transform(X_train)\nX_test2=pca.fit_transform(X_test)\n\n\nfrom sklearn.linear_model import LogisticRegression\n#pca dönüşümünden önce gelen gelen LR\nclassifier=LogisticRegression(random_state=0)\nclassifier.fit(X_train,y_train)\n\n#pca dönüşümünden sonra gelen gelen LR\nclassifier_pca=LogisticRegression(random_state=0)\nclassifier_pca.fit(X_train2,y_train)\n\n#tahminler\ny_pred=classifier.predict(X_test)\ny_pred2=classifier_pca.predict(X_test2)\n\n#confusion matrixle karşılaştırma PCA öncesi ve sonrası\nfrom sklearn.metrics import confusion_matrix\ncm=confusion_matrix(y_test,y_pred)\nprint(\"PCA ' SIZ \")\nprint(cm)\n\ncm2=confusion_matrix(y_test,y_pred2)\nprint('PCA')\nprint(cm2)\n\ncm3=confusion_matrix(y_pred,y_pred2)\nprint('PCAsız ve PCA lı')\nprint(cm3)\n\n#LDA\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA\nlda=LDA(n_components=2)\n\nX_train_lda=lda.fit_transform(X_train, y_train)#sınıfları öğrenmesiiçin yyi de ver\nX_test_lda=lda.transform(X_test)\n\n#lda dönüşümünden sonra gelen gelen LR\nclassifier_lda=LogisticRegression(random_state=0)\nclassifier_lda.fit(X_train_lda,y_train)\n\n#LDA verisini tahmin et\ny_pred_lda=classifier_lda.predict(X_test_lda)\n#Lda sonrası / orijinal veri\n\nprint('LDA vs orjinal')\ncm3=confusion_matrix(y_pred,y_pred_lda)\nprint(cm3)\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7378378510475159,
"alphanum_fraction": 0.7522522807121277,
"avg_line_length": 21.285715103149414,
"blob_id": "6452b52e1db29eab2bd784410aecb422118b2111",
"content_id": "276a638cc46ce093a1203547e544f7c84d45eeae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 49,
"path": "/16XGBoost/xgboost_kodu.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nveriler=pd.read_csv('Churn_Modelling.csv')\n\nX=veriler.iloc[:,3:13].values\nY=veriler.iloc[:,13].values\n\n#encoder: Kategorik -> Numeric\nfrom sklearn import preprocessing\n\nle=preprocessing.LabelEncoder()\nX[:,1]=le.fit_transform(X[:,1])\n\n\nle2=preprocessing.LabelEncoder()\nX[:,2]=le.fit_transform(X[:,2])\n\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n#birden fazla heterojen yapıdaki kolonu aynı anda dönüştürür\n\nohe=ColumnTransformer([(\"ohe\",OneHotEncoder(dtype=float),[1])],\nremainder='passthrough')\n\nX=ohe.fit_transform(X)\nX=X[:,1:]\n\n#test and train (verileri bölme)\n\nfrom sklearn.model_selection import train_test_split\n\nx_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=.33,random_state=0)\n\n\n#XG BOOST ALGORİTMASI\nfrom xgboost import XGBClassifier\nclassifier=XGBClassifier()\nclassifier.fit(x_train, y_train)\n\ny_pred=classifier.predict(x_test)\n\nfrom sklearn.metrics import confusion_matrix\ncm=confusion_matrix(y_pred,y_test)\nprint(cm)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6524063944816589,
"alphanum_fraction": 0.6951871514320374,
"avg_line_length": 22.375,
"blob_id": "ece6c3d66a65d2f4e7d0846b954a0dcb3cdd93ba",
"content_id": "f9b7891c11a7629342bac35772756e388c449d8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 16,
"path": "/10apriori/apriori_my.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\nveriler=pd.read_csv('sepet.csv',header=None)\n\nt=[]\nfor i in range(0,7501):\n t.append([str(veriler.values[i,j]) for j in range (0,20)])\n \n \nfrom apyori import apriori\nkurallar=apriori(t,min_support=0.01,min_confidence=0.2,min_lift=3,min_lenght=2)\nprint(list(kurallar))\n"
},
{
"alpha_fraction": 0.749009907245636,
"alphanum_fraction": 0.7658416032791138,
"avg_line_length": 26.80555534362793,
"blob_id": "da50f94502ca57aba1f701b110422d18debb80e4",
"content_id": "2c97a90c638f3ef252baa354f761ea8e353f9592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2068,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 72,
"path": "/13Exercise(Churn Modelling with keras)/ysa_keras.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nveriler=pd.read_csv('Churn_Modelling.csv')\n\nX=veriler.iloc[:,3:13].values\nY=veriler.iloc[:,13].values\n\n#encoder: Kategorik -> Numeric\nfrom sklearn import preprocessing\n\nle=preprocessing.LabelEncoder()\nX[:,1]=le.fit_transform(X[:,1])\n\n\nle2=preprocessing.LabelEncoder()\nX[:,2]=le.fit_transform(X[:,2])\n\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.compose import ColumnTransformer\n#birden fazla heterojen yapıdaki kolonu aynı anda dönüştürür\n\nohe=ColumnTransformer([(\"ohe\",OneHotEncoder(dtype=float),[1])],\nremainder='passthrough')\n\nX=ohe.fit_transform(X)\nX=X[:,1:]\n\n#test and train (verileri bölme)\n\nfrom sklearn.model_selection import train_test_split\n\nx_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=.33,random_state=0)\n\n\n#verilerin ölçeklendirme 0ve 1 aralığına sıkıştırmak için\nfrom sklearn.preprocessing import StandardScaler\n\nsc=StandardScaler()\n\nX_train=sc.fit_transform(x_train)\nX_test=sc.fit_transform(x_test)\n\n#YAPAY SİNİR AĞI -YSA (KERAS)\n\nimport keras\nfrom keras.models import Sequential\nfrom keras.layers import Dense #katman\n\nclassifier=Sequential()\n#giriş katmanı oldu için input_dim belirtcez\nclassifier.add(Dense(6,kernel_initializer='uniform',activation='relu',input_dim=11)) \n#yeni gizli bir katman\nclassifier.add(Dense(6,kernel_initializer='uniform',activation='relu')) #(11+1)x+y/2 genelde :D ,init ilk değeri verir 0a yakın,\n#çıkış katmanı\nclassifier.add(Dense(1,kernel_initializer='uniform',activation='sigmoid')) \n#nöron ve katmanlarının synapsizlerini nasıl optimize edileceği hangi fonk,metric\nclassifier.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'],)\n\nclassifier.fit(X_train,y_train,epochs=50)#epoc hs çalışırma miktarı\n\ny_pred=classifier.predict(X_test)\n#bırakır mı bırakmaz mı 1veya 0 olarak bölücez\ny_pred=(y_pred>0.5)\n\nfrom sklearn.metrics import confusion_matrix\ncm=confusion_matrix(y_test, y_pred)\nprint(cm)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7955800890922546,
"alphanum_fraction": 0.7955800890922546,
"avg_line_length": 88.5,
"blob_id": "ccfbe502c2a17786636f67f521750c32a4c1f60e",
"content_id": "2b80c439e9535e40919926886bfc5b25406c7b02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 2,
"path": "/README.md",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# Machine-Learning-Library\nI have made this repo while im learning Machine Learning.All procces what I've done include it.Also there are lots of small-projects in it to practice. \n\n"
},
{
"alpha_fraction": 0.6952104568481445,
"alphanum_fraction": 0.7082728743553162,
"avg_line_length": 17.5,
"blob_id": "ff9d906cee262a545d64afc358443ee6cffe863c",
"content_id": "939a47433e6e1ddcbb1cdca6848c01a429aaf4de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 36,
"path": "/17Save Model(Pickle)/pickle.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# -*- coding: utf-8 -*-\n\nimport numpy\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n#veri yükleme\nveriler=pd.read_csv(\"maaslar.csv\")\n#data frame dilimleme(slice)\nx=veriler.iloc[:,1:2]\ny=veriler.iloc[:,2:]\n#Numpy array-dizi dönüşümü\nX=x.values\nY=y.values\n\nfrom sklearn.model_selection import train_test_split\nX_train,X_test,Y_train,Y_test=train_test_split(X, Y,test_size=0.33,random_state=0)\n\n\nfrom sklearn.linear_model import LinearRegression\nlr=LinearRegression()\nlr.fit(X_train,Y_train)\n\n\n\nimport pickle\n\ndosya=\"model.kayit\"\n\npickle.dump(lr,open(dosya,'wb'))\n\n\nyuklenen=pickle.load(open(dosya,'rb'))\nprint(yuklenen.predict(X_test)) "
},
{
"alpha_fraction": 0.6483851075172424,
"alphanum_fraction": 0.7007921934127808,
"avg_line_length": 24.88888931274414,
"blob_id": "26ab792db7656df1c6fab26c6dc3ceb7454e2ca0",
"content_id": "c817edd2657b26d0d56cf34f0857ac6a50a8bee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1649,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 63,
"path": "/9Clustering/kmeans_aglomerative.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Nov 11 22:29:53 2020\n\n@author: Mr Bcan\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nveriler=pd.read_csv('musteriler.csv')\n\nX=veriler.iloc[:,2:4].values\n\n#kmeans\nfrom sklearn.cluster import KMeans\n\nkmeans=KMeans(n_clusters=3, init='k-means++')\nkmeans.fit(X)\n\nprint(kmeans.cluster_centers_)\nsonuclar=[]\n\nfor i in range(1,11):\n kmeans=KMeans(n_clusters=i,init='k-means++',random_state=123)\n kmeans.fit(X)\n sonuclar.append(kmeans.inertia_) #Wcss değeri\n \nplt.plot(range(1,11),sonuclar)\nplt.show()\n\nkmeans=KMeans(n_clusters=4,init='k-means++',random_state=123)\nY_tahmin=kmeans.fit_predict(X)\nprint(Y_tahmin)\nplt.scatter(X[Y_tahmin==0,0],X[Y_tahmin==0,1],s=100,c='red')\nplt.scatter(X[Y_tahmin==1,0],X[Y_tahmin==1,1],s=100,c='blue')\nplt.scatter(X[Y_tahmin==2,0],X[Y_tahmin==2,1],s=100,c='green')\nplt.scatter(X[Y_tahmin==3,0],X[Y_tahmin==3,1],s=100,c='yellow')\n\nplt.title('KMeans')\nplt.show()\n\n\n#agglomerative hiyerarşik clustering\nfrom sklearn.cluster import AgglomerativeClustering\nac=AgglomerativeClustering(n_clusters=4,affinity='euclidean',linkage='ward')\n\nY_tahmin=ac.fit_predict(X)\nprint(Y_tahmin)\n\nplt.scatter(X[Y_tahmin==0,0],X[Y_tahmin==0,1],s=100,c='red')\nplt.scatter(X[Y_tahmin==1,0],X[Y_tahmin==1,1],s=100,c='blue')\nplt.scatter(X[Y_tahmin==2,0],X[Y_tahmin==2,1],s=100,c='green')\nplt.scatter(X[Y_tahmin==3,0],X[Y_tahmin==3,1],s=100,c='yellow')\n\nplt.title('HC')\nplt.show()\n\n#dendograma bakarak kırılma noktası k nın değerini görebiliyoz\nimport scipy.cluster.hierarchy as sch\ndendrogram=sch.dendrogram(sch.linkage(X,method='ward'))\nplt.show()\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5821759104728699,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 17.80434799194336,
"blob_id": "548766fc42a52c48c7ca1ebd2ee93ac34032f980",
"content_id": "df31aab5901fd4c42918544d72cff2e5d8c557e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 46,
"path": "/11Reinforced Learning/thompson.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Nov 14 14:52:40 2020\n\n@author: Mr Bcan\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport random\nveriler=pd.read_csv('Ads_CTR_Optimisation.csv')\n\nimport math\n#UCB\nN=10000 #10.000 tıklama\nd=10 #toplam 10 ilan var\n#Ri(n)\n#Ni(n)\n\ntoplam=0 #toplam odul\nsecilenler=[]\nbirler=[0]*d\nsifirlar=[0]*d\n\nfor n in range(1,N):\n ad=0 #secilen ilan\n max_th=0\n for i in range(0,d):\n rasbeta=random.betavariate(birler[i]+1, sifirlar[i]+1)\n if rasbeta >max_th:\n max_th=rasbeta\n ad=i\n secilenler.append(ad)\n odul=veriler.values[n,ad] #verierdeki n.satır=1 ise odul 1\n if odul==1:\n birler[ad]=birler[ad]+1\n else:\n sifirlar[ad]=sifirlar[ad]+1\n \n toplam=toplam+odul\n \nprint('Toplam odul:',toplam)\n\nplt.hist(secilenler)\nplt.show()"
},
{
"alpha_fraction": 0.7404744625091553,
"alphanum_fraction": 0.7634795308113098,
"avg_line_length": 22.593219757080078,
"blob_id": "385805d0287838f59a96eacee985493ad04ea005",
"content_id": "713cb9c81742b3306f4c51e8d8dd4334b35a7cc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1405,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 59,
"path": "/1data preprocessing/verionisleme.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "#kütüphaneler\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n#veri önişleme\n#2.1 veri yükleme\nveriler=pd.read_csv('eksikveriler.csv')\n\n\n#eksik veriler sci-kit learn\nfrom sklearn.impute import SimpleImputer\n\nimputer=SimpleImputer(missing_values=np.nan,strategy='mean')\nYas=veriler.iloc[:,1:4].values\nimputer=imputer.fit(Yas[:,1:4])\nYas[:,1:4]=imputer.transform(Yas[:,1:4])\n\n#encoder: Nominal ordinal->Numeric\nulke=veriler.iloc[:,0:1].values\n\n\nfrom sklearn import preprocessing\n\nle=preprocessing.LabelEncoder()\nulke[:,0]=le.fit_transform(veriler.iloc[:,0])\n\n\n\nohe=preprocessing.OneHotEncoder()\nulke=ohe.fit_transform(ulke).toarray()\n\n#numpy dizileri dataframe dönüşümü\n\nsonuc=pd.DataFrame(data=ulke,index=range(22),columns=['fr','tr','us'])\n\nsonuc2=pd.DataFrame(data=Yas,index=range(22),columns=[\"boy\",'kilo','yas'])\n\n\ncinsiyet=veriler.iloc[:,-1].values\nsonuc3=pd.DataFrame(data=cinsiyet,index=range(22),columns=['cinsiyet'])\n#dataframe birleştirme\ns=pd.concat([sonuc,sonuc2],axis=1)\ns2=pd.concat([s,sonuc2],axis=1)\n\n#test and train (verileri bölme)\n\nfrom sklearn.model_selection import train_test_split\n\nx_train,x_test,y_train,y_test=train_test_split(s,sonuc3,test_size=.33,random_state=0)\nprint(x_train)\n\n#verilerin ölçeklendirme\nfrom sklearn.preprocessing import StandardScaler\n\nsc=StandardScaler()\n\nX_train=sc.fit_transform(x_train)\nX_test=sc.fit_transform(x_test)"
},
{
"alpha_fraction": 0.4023529291152954,
"alphanum_fraction": 0.4650980532169342,
"avg_line_length": 12.625,
"blob_id": "23265b0e35c48a956a25e5e632111661f0fd3f31",
"content_id": "df5d917e2c44304cf41c72be3ce665f6d91c652a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1275,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 88,
"path": "/12NLP(natural lang proc)/tensorflowdeneme.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Nov 17 17:19:01 2020\n\n@author: Mr Bcan\n\"\"\"\n\n\n#import tensorflow as tf\nimport tensorflow.compat.v1 as tf\ntf.disable_v2_behavior()\n\nhello=tf.constant('HEllo , TEnsor')\nsess=tf.Session()\nprint(sess.run(hello))\n\n\n\n\"\"\"\n\ndef dels(first,second):\n a=len(first)\n b=len(second)\n \n if a >b :\n del first[:b]\n print(first)\n \n if a<b:\n c=[]\n c.append(second[0])\n c=c+first\n c=c+second[1:]\n print(c)\n \n if a==b:\n c=[]\n print(c)\n \n \ndels([3,4,2,5,6,7],[1,3,4]) \ndels([2,5],[3,4,7,8,9]) \ndels([2,3,4],[8,7,9])\n\n\n\n\n\n\n\ndef dels(a,b):\n\n if(len(a)>len(b)):\n return a[len(b):]\n\n elif(len(b)>len(a)):\n return (b[0:1]+a[:]+b[1:])\n\n else:\n return []\n\nprint(dels([3,4,2,5,6,7],[1,3,4]))\nprint(dels([2,5],[3,4,7,8,9]))\nprint(dels([2,3,4],[8,7,9]))\n\n\n\n\ndef digits(num):\n\n if(num<10):\n return [num]\n\n else:\n last = digits(int(num%10))\n return (digits(int(num/10)))+last\n\nprint(digits(532))\n\ndef multiply(num,zeros):\n\n return digits(num)+digits(zeros)[1:]\n\nprint(multiply(5,1000))\n\n\nprint(digits(3))\n \"\"\"\n\n\n "
},
{
"alpha_fraction": 0.6834123134613037,
"alphanum_fraction": 0.7085307836532593,
"avg_line_length": 25.012500762939453,
"blob_id": "4d60d2fbffcbcc6925b4eb2b7ccc1e2ae2dc5fc4",
"content_id": "77cd256b551f3d050bf51ac3955df939ad7396fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2144,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 80,
"path": "/15Model selection/grid_search.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Jul 8 10:03:40 2018\n\n@author: sadievrenseker\n\"\"\"\n\n#1. kutuphaneler\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n# veri kümesi\ndataset = pd.read_csv('Social_Network_Ads.csv')\nX = dataset.iloc[:, [2, 3]].values\ny = dataset.iloc[:, 4].values\n\n# eğitim ve test kümelerinin bölünmesi\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)\n\n# Ölçekleme\nfrom sklearn.preprocessing import StandardScaler\nsc = StandardScaler()\nX_train = sc.fit_transform(X_train)\nX_test = sc.transform(X_test)\n\n# SVM\nfrom sklearn.svm import SVC\nclassifier = SVC(kernel = 'rbf', random_state = 0)\nclassifier.fit(X_train, y_train)\n\n# Tahminler\ny_pred = classifier.predict(X_test)\n\n# Confusion Matrix\nfrom sklearn.metrics import confusion_matrix\ncm = confusion_matrix(y_test, y_pred)\n\nprint(cm)\n\n#k-fold_cross_validation \nfrom sklearn.model_selection import cross_val_score\n\"\"\"\n1.estimator: classifier (bizim durum)\n2.X\n3.Y\n5. cv:kaç katlamalı\n\"\"\"\nbasari=cross_val_score(estimator=classifier,X=X_train,y=y_train,cv=4)\nprint(basari.mean()) #accurys değeri başarılarının ortalaması\nprint(basari.std()) #standart sapması ne kadar az okadar iyi\n\n#parametre optimizasyonu ve algoritma seçimi\nfrom sklearn.model_selection import GridSearchCV\np=[\n {'C':[1,2,3,4,5],'kernel':['linear']},\n {'C':[1,10,100,1000],'kernel':['rbf'], 'gamma':[1,0.5,0.1,0.01]}\n ]\n\n\"\"\"\nGSCV parametreleri:\nestimator:sınıflandırma algoritması(neyi optimize etmek istedin)\nparam_grid=parametreler/denenecekler\nscoring:neye göre skorlanacak:örneğin 'accuracy'\ncv:kaç katlamalı olacağı\nn_jobs:aynı anda çalışacak iş\n\"\"\"\ngs=GridSearchCV( estimator=classifier,#svm algoritması\n param_grid=p,\n scoring='accuracy',\n cv=10,\n n_jobs=-1)\n\ngrid_search=gs.fit(X_train,y_train)\neniyisonuc=grid_search.best_score_\neniyiparametreler=grid_search.best_params_\nprint(eniyisonuc)\nprint(eniyiparametreler)\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.701529324054718,
"alphanum_fraction": 0.7306364178657532,
"avg_line_length": 24.80769157409668,
"blob_id": "d596bef8c38a8bc0a900d53f505eac7f17fe31f4",
"content_id": "47fb924976d38fd4a60da623e62502343626c8b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2028,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 78,
"path": "/5Exercise(Regression weather condition for play tennis)/3.2.2 - python_mlr_tahmin.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jul 6 18:50:13 2020\n\n@author: sadievrenseker\n\"\"\"\n\n#1.kutuphaneler\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n\n#1.veri yukleme\nveriler = pd.read_csv('odev_tenis.csv')\nprint(veriler)\n#2.veri onisleme\n#Toplu encoder Kategorik-> Numeric\nfrom sklearn import preprocessing\nveriler2=veriler.apply(preprocessing.LabelEncoder().fit_transform)\n\nc=veriler2.iloc[:,:1]\nfrom sklearn import preprocessing\nohe=preprocessing.OneHotEncoder()\nc=ohe.fit_transform(c).toarray()\nprint(c)\n\nhavadurumu=pd.DataFrame(data=c,index=range(14),columns=['overcast','rainny','sunny'])\nsonveriler=pd.concat([havadurumu,veriler.iloc[:,1:3]],axis=1)\nsonveriler=pd.concat([veriler2.iloc[:,-2:],sonveriler],axis=1)\n\n\n#3-verilerin egitim ve test icin bolunmesi\nfrom sklearn.model_selection import train_test_split\n\nx_train, x_test,y_train,y_test = train_test_split(sonveriler.iloc[:,:-1],sonveriler.iloc[:,-1:],test_size=0.33, random_state=0)\n\n \nfrom sklearn.linear_model import LinearRegression\nregressor = LinearRegression()\nregressor.fit(x_train,y_train)\n\ny_pred = regressor.predict(x_test)\nprint(y_pred)\n\n\n#Backward elimination\n \nimport statsmodels.api as sm\n\nX=np.append(arr=np.ones((14,1)).astype(int),values=sonveriler.iloc[:,:-1],axis=1)\n\nX_l=sonveriler.iloc[:,[0,1,2,3,4,5]].values\nX_l=np.array(X_l,dtype=float)\nmodel=sm.OLS(sonveriler.iloc[:,-1:],X_l).fit()\nprint(model.summary())\n\n#ilk (windy) at \nsonveriler=sonveriler.iloc[:,1:]\nimport statsmodels.api as sm\n\nX=np.append(arr=np.ones((14,1)).astype(int),values=sonveriler.iloc[:,:-1],axis=1)\n\nX_l=sonveriler.iloc[:,[0,1,2,3,4]].values\nX_l=np.array(X_l,dtype=float)\nmodel=sm.OLS(sonveriler.iloc[:,-1:],X_l).fit()\nprint(model.summary())\n\n#yeni predict yapma windy yi atma x_test ve train den \n\nx_train=x_train.iloc[:,1:]\nx_test=x_test.iloc[:,1:]\n#tekrar sistemi eğitme\nfrom sklearn.linear_model import LinearRegression\nregressor = LinearRegression()\nregressor.fit(x_train,y_train)\n\ny_pred = regressor.predict(x_test)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.734649121761322,
"alphanum_fraction": 0.7478070259094238,
"avg_line_length": 30.20689582824707,
"blob_id": "edb9acbac895d6816f1717d957d4643054171864",
"content_id": "9a020dce259517944f2cc3b487b18aa62cadd39a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1860,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 58,
"path": "/12NLP(natural lang proc)/nlp.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport pandas as pd\nimport numpy as np\n\n# 1-preprocessing işlemleri veri önişlemee(stopwords,case,parsers(html))\nyorumlar=pd.read_csv('Restaurant_Reviews2.csv',sep=r'\\s*,\\s*')\n\"\"\"\nnp.isnan(yorumlar)\nnp.where(np.isnan(yorumlar))\nnp.nan_to_num(yorumlar)\n\"\"\"\n\n\nimport re #regular expression ile kelimeleri temizleme\nimport nltk\nfrom nltk.stem.porter import PorterStemmer#kelimeleri kökünü alır\n\nps=PorterStemmer()\nnltk.download('stopwords')\n\nfrom nltk.corpus import stopwords\n\nderlem=[]\nfor i in range(716):\n yorum=re.sub('[^a-zA-Z]',' ',yorumlar['Column1'][i])\n yorum=yorum.lower()\n yorum=yorum.split() #♠kelimeleri böl listeye koy str->list\n yorum=[ps.stem(kelime) for kelime in yorum if not kelime in set(stopwords.words('english'))]\n yorum=' '.join(yorum) #boşluk bırakarak stringe çevirdik tekrardan\n derlem.append(yorum)\n \n# 2-Feature Extraction-->öznitelik çıkarımı(kelime sayıları,kelime grupları,n-gram,tf-ıdf)\n#Bag of Words (BOW) 1ler ve 0dan kelimelerle çanta oluşturma\nfrom sklearn.feature_extraction.text import CountVectorizer\n\ncv=CountVectorizer(max_features=2000) #max 2bin kelime al baba,ramin sikilmesin\nX=cv.fit_transform(derlem).toarray() #bağımsız değişken\ny=yorumlar.iloc[:,1].values #bağımlı değişken\n\"\"\"\nfrom sklearn.impute import SimpleImputer\nimputer = SimpleImputer(missing_values=np.nan, strategy='mean')\nimputer=imputer.fit(y)\ny=imputer.transform(y)\n\"\"\"\n# 3-Makine öğrenmesi\nfrom sklearn.model_selection import train_test_split\nx_train, x_test,y_train,y_test = train_test_split(X,y,test_size=0.20, random_state=0)\n\nfrom sklearn.naive_bayes import GaussianNB\ngnb=GaussianNB()\ngnb.fit(x_train,y_train)\n\ny_pred=gnb.predict(x_test)\n\nfrom sklearn.metrics import confusion_matrix\ncm=confusion_matrix(y_test, y_pred)\nprint(cm) #%72.5 accuracy\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.786912739276886,
"alphanum_fraction": 0.7877516746520996,
"avg_line_length": 26.83333396911621,
"blob_id": "5cf338bd73b7587ad77d1cf05c593d8992604caa",
"content_id": "cb84f6c1a14ca60dcad51413cea77260ea03dcbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 42,
"path": "/19HousePrices ( NOT COMPLETED YET)/HousePrice.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Import Dependencies\n%matplotlib inline\n\n# Start Python Imports\nimport math, time, random, datetime\n\n# Data Manipulation\nimport numpy as np\nimport pandas as pd\n\n# Visualization \nimport matplotlib.pyplot as plt\nimport seaborn as sns\nplt.style.use('seaborn-whitegrid')\n\n# Preprocessing\nfrom sklearn.preprocessing import OneHotEncoder, LabelEncoder, label_binarize\n\n# Machine learning\n\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import model_selection, tree, preprocessing, metrics, linear_model\nfrom sklearn.svm import LinearSVC\nfrom sklearn.ensemble import GradientBoostingClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.linear_model import LinearRegression, LogisticRegression, SGDClassifier\nfrom sklearn.tree import DecisionTreeClassifier\n\n\n# Let's be rebels and ignore warnings for now\nimport warnings\nwarnings.filterwarnings('ignore')\n\n# Import train & test data \ntrain = pd.read_csv('train.csv')\ntest = pd.read_csv('test.csv')\ngender_submission = pd.read_csv('sample_submission.csv') # example of what a submission should look like\n\n\ntrain.head()\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7311698794364929,
"alphanum_fraction": 0.7475961446762085,
"avg_line_length": 22.02777862548828,
"blob_id": "284cacb1742312370bf4128745ea0b2e20eac6da",
"content_id": "da533d43e6e1f48d46a73d922c35735f24017342",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2523,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 108,
"path": "/6support vector regression(svr)/svr.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport numpy\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import r2_score\n\n\n#veri yükleme\nveriler=pd.read_csv(\"maaslar.csv\")\n#data frame dilimleme(slice)\nx=veriler.iloc[:,1:2]\ny=veriler.iloc[:,2:]\n#Numpy array-dizi dönüşümü\nX=x.values\nY=y.values\n\n#linear regression-doğrusal model olusturma\nfrom sklearn.linear_model import LinearRegression\nlin_reg=LinearRegression()\nlin_reg.fit(X,Y)\n\nprint('Linear r2 değeri')\nprint(r2_score(Y,lin_reg.predict(X)))\n\n\n#polynomial regression-doğrusal olmayan model olusturma\nfrom sklearn.preprocessing import PolynomialFeatures\npoly_reg=PolynomialFeatures(degree=4)\nx_poly=poly_reg.fit_transform(X)\nlin_reg2=LinearRegression()\nlin_reg2.fit(x_poly,y) \n\n\n#görselleştirmeler sırasıyla(linear ve 4.dereceden)\nplt.scatter(X,Y,color='red')\nplt.plot(x,lin_reg.predict(X),color='blue')\nplt.show()\n\n\nplt.scatter(X,Y,color='red')\nplt.plot(X,lin_reg2.predict(x_poly),color='blue')\nplt.show()\n\n\n\n#tahminler\n\nprint(lin_reg.predict([[6]]))\nprint(lin_reg2.predict(poly_reg.fit_transform([[6]])))\n\nprint('Polynomial r2 değeri')\nprint(r2_score(Y,lin_reg2.predict(poly_reg.fit_transform(X))))\n\n#verilerin ölçeklendirme scaler\nfrom sklearn.preprocessing import StandardScaler\n\nsc1=StandardScaler()\nx_olcekli=sc1.fit_transform(X)\n\nsc2=StandardScaler()\ny_olcekli=sc2.fit_transform(Y)\n\n#svr da scaler kullanilmasi onemli\nfrom sklearn.svm import SVR\n\nsvr_reg=SVR(kernel='rbf')\nsvr_reg.fit(x_olcekli,y_olcekli)\n\nplt.scatter(x_olcekli,y_olcekli,color='red')\nplt.plot(x_olcekli,svr_reg.predict(x_olcekli),color='blue')\nplt.show()\n\nprint('svr r2 değeri')\nprint(r2_score(y_olcekli,svr_reg.predict(x_olcekli)))\n\n#Decision tree reg.\nfrom sklearn.tree import DecisionTreeRegressor\nr_dt=DecisionTreeRegressor(random_state=0)\nr_dt.fit(X,Y)\nZ=X+0.5\nK=X-0.4\n\nplt.scatter(X, Y,color='purple')\nplt.plot(x,r_dt.predict(X),color='red')\n#SONUCLAR MUHAKKAK O AĞAÇTAKİLER ÇICKAK\nplt.scatter(x,r_dt.predict(Z) ,color='yellow')\nplt.plot(x,r_dt.predict(K))\nplt.show()\nprint(r_dt.predict([[11]]))\nprint(r_dt.predict([[6.6]]))\n\nprint('decision tree r2 değeri')\nprint(r2_score(Y,r_dt.predict(X)))\n\n#Random Forest reg.\nfrom sklearn.ensemble import RandomForestRegressor\nrf_reg=RandomForestRegressor(n_estimators=10,random_state=(0))\n\nrf_reg.fit(X,Y.ravel())\n\nprint(rf_reg.predict([[6.6]]))\n\nplt.scatter(X,Y,color='red')\nplt.plot(X,rf_reg.predict(X),color='blue')\nplt.plot(x,rf_reg.predict(Z),color='green')\n\n#R2 ile yöntemleri karşılaştırabiliyoruz\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7086973190307617,
"alphanum_fraction": 0.7246487140655518,
"avg_line_length": 20.735536575317383,
"blob_id": "6db689ee0aaa1c5487036ea1017b17030088b7c0",
"content_id": "64188f38405f8014f7654ceff9a139e30f4f9cb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2668,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 121,
"path": "/8Classifications/class_sablon.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jul 6 18:50:13 2020\n\n@author: sadievrenseker\n\"\"\"\n\n#1.kutuphaneler\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom sklearn.metrics import confusion_matrix\n\n#2.1.veri yukleme\nveriler = pd.read_csv('veriler.csv')\n\n\n\n#2.veri onisleme\nx=veriler.iloc[:,1:4].values #bağımsız\ny=veriler.iloc[:,4:].values #bağımlı\n\n\n#verilerin egitim ve test icin bolunmesi\nfrom sklearn.model_selection import train_test_split\n\nx_train, x_test,y_train,y_test = train_test_split(x,y,test_size=0.33, random_state=0)\n\n#verilerin olceklenmesi\nfrom sklearn.preprocessing import StandardScaler\n\nsc=StandardScaler()\n\nX_train = sc.fit_transform(x_train)\nX_test = sc.transform(x_test)\n#Buradan itibaren sınıflandırma algoritmaları baslar\n# 1- Logistic Regression\nfrom sklearn.linear_model import LogisticRegression\n\nlogr=LogisticRegression(random_state=0)\n\nlogr.fit(X_train,y_train)\n\ny_pred=logr.predict(X_test)\nprint(y_pred)\nprint(y_test)\n\n#confusion matrix \n#nasıl sınıflandırdığını doğrumu yanlısmı derli toplu sunar 1 doğru 0 yanlış olan sayı\n\ncm=confusion_matrix(y_test,y_pred)\nprint(cm)\nprint('**********************************')\n\n# 2- KNN\nfrom sklearn.neighbors import KNeighborsClassifier\n\nknn=KNeighborsClassifier(n_neighbors=1,metric='minkowski') #kdeğeri== Karekök(eğitimboyutu) /2\nknn.fit(X_train,y_train) #train varsa 70se= 4 olur \n\ny_pred=knn.predict(X_test)\n\ncm=confusion_matrix(y_test, y_pred)\nprint(cm)\nprint('**********************************')\n# 3- SVC\nfrom sklearn.svm import SVC\nsvc=SVC(kernel='rbf') #kernelları çeşit çeşit\nsvc.fit(X_train,y_train)\n\ny_pred=svc.predict(X_test)\n\ncm=confusion_matrix(y_test, y_pred)\nprint('SVC')\nprint(cm)\n\n# 4- Naive Bayes\nfrom sklearn.naive_bayes import GaussianNB\ngnb=GaussianNB()\ngnb.fit(X_train,y_train)\n\ny_pred=gnb.predict(X_test)\n\ncm=confusion_matrix(y_test, y_pred)\nprint('GNB')\nprint(cm)\n#5- Devision Tree\nfrom sklearn.tree import DecisionTreeClassifier\ndtc=DecisionTreeClassifier(criterion='entropy')\n\ndtc.fit(X_train,y_train)\ny_pred=dtc.predict(X_test)\n\ncm=confusion_matrix(y_test, y_pred)\nprint('DTC')\nprint(cm)\n\n# 6- Random Forest\nfrom sklearn.ensemble import RandomForestClassifier\nrfc=RandomForestClassifier(n_estimators=10,criterion='entropy')\nrfc.fit(X_train,y_train)\n\n\n\ny_pred=rfc.predict(X_test)\n\ncm=confusion_matrix(y_test, y_pred)\nprint('RFC')\nprint(cm)\n\n\n\n# 7- ROC, TPR,FPR değerleriprint(y_test) (İLAVE)\n\ny_proba=rfc.predict_proba(X_test)\nprint(y_proba[:,0])\n\nfrom sklearn import metrics\nfpr,tpr,thold=metrics.roc_curve(y_test,y_proba[:,0],pos_label='e')\nprint(fpr)\nprint(tpr)\n\n\n\n"
},
{
"alpha_fraction": 0.5869894027709961,
"alphanum_fraction": 0.6278365850448608,
"avg_line_length": 18.696969985961914,
"blob_id": "84bffb6ed76ca07649345df67efec8638ef62254",
"content_id": "298001a53ddb412a19911640634d259a7d217852",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 66,
"path": "/11Reinforced Learning/ucb_random.py",
"repo_name": "mrbcan/My-ML-Library",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Nov 13 22:26:11 2020\n\n@author: Mr Bcan\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nveriler=pd.read_csv('Ads_CTR_Optimisation.csv')\n\n\"\"\"\nimport random\n\nN=10000\nd=10\ntoplam=0\nsecilenler=[]\n\nfor n in range(0,N):\n ad=random.randrange(d) \n secilenler.append(ad)\n odul=veriler.values[n,ad]#verierdeki n.satır=1 ise odul 1\n toplam=toplam+odul\n \nplt.hist(secilenler)\nplt.show()\n\n\"\"\"\n\nimport math\n#UCB\nN=10000 #10.000 tıklama\nd=10 #toplam 10 ilan var\n#Ri(n)\noduller=[0]*d #ilk basta butun ilanların odulu 0\n#Ni(n)\ntiklamalar=[0]*d #o ana kadarki tıklamalar\ntoplam=0 #toplam odul\nsecilenler=[]\n\nfor n in range(1,N):\n ad=0 #secilen ilan\n max_ucb=0\n for i in range(0,d):\n if(tiklamalar[i]>0):\n ortalama=oduller[i] / tiklamalar[i]\n delta=math.sqrt(3/2*math.log(n)/tiklamalar[i])\n ucb=ortalama+delta\n else:\n ucb=N*10\n if max_ucb<ucb: #maxtan büyük bir ucb çıktı\n max_ucb=ucb\n ad=i\n secilenler.append(ad)\n tiklamalar[ad]=tiklamalar[ad]+1\n odul=veriler.values[n,ad] #verierdeki n.satır=1 ise odul 1\n oduller[ad]=oduller[ad]+odul\n toplam=toplam+odul\n \nprint('Toplam odul:',toplam)\n\nplt.hist(secilenler)\nplt.show()\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
}
] | 19 |
lambda-linux/mock-builder | https://github.com/lambda-linux/mock-builder | 2cae0bb1116c9b5a64d2b20287639cde440028da | c885cfe0fc3bfba433070943b6b129f47c48252c | a20770a10e3708ca818c0c13721d6bd04a485976 | refs/heads/master | "2020-04-16T07:27:44.017404" | "2017-08-02T04:51:54" | "2017-08-02T04:51:54" | 62,380,795 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6248000264167786,
"alphanum_fraction": 0.656000018119812,
"avg_line_length": 30.25,
"blob_id": "a944566ac1b3adde4c83ba5237e45b2b75424c7c",
"content_id": "e6685e70ae2b0023f4b8695aa9fa5fb777de334c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 40,
"path": "/Dockerfile",
"repo_name": "lambda-linux/mock-builder",
"src_encoding": "UTF-8",
"text": "FROM lambdalinux/baseimage-amzn:2017.03-003\n\nCMD [\"/sbin/my_init\"]\n\nCOPY [ \\\n \"./extras/etc-mock-default.cfg\", \\\n \"./extras/etc-sudoers.d-docker\", \\\n \"/tmp/docker-build/\" \\\n]\n\nRUN \\\n # yum\n yum update && \\\n \\\n # install mock\n yum install git && \\\n yum install sudo && \\\n yum install tree && \\\n yum install vim && \\\n yum install which && \\\n # setup epll repository\n curl -X GET -o /tmp/docker-build/RPM-GPG-KEY-lambda-epll https://lambda-linux.io/RPM-GPG-KEY-lambda-epll && \\\n rpm --import /tmp/docker-build/RPM-GPG-KEY-lambda-epll && \\\n curl -X GET -o /tmp/docker-build/epll-release-2017.03-1.2.ll1.noarch.rpm https://lambda-linux.io/epll-release-2017.03-1.2.ll1.noarch.rpm && \\\n yum install /tmp/docker-build/epll-release-2017.03-1.2.ll1.noarch.rpm && \\\n yum -y --enablerepo=epll install mock mock-scm && \\\n \\\n # setup symbolic link\n ln -s /home/ll-user/mock-builder/git-blobs /tmp/git-blobs.lambda-linux.io && \\\n \\\n # copy mock configuration file\n cp /tmp/docker-build/etc-mock-default.cfg /etc/mock/default.cfg && \\\n \\\n # setup sudo\n usermod -a -G wheel ll-user && \\\n cp /tmp/docker-build/etc-sudoers.d-docker /etc/sudoers.d/docker && \\\n chmod 440 /etc/sudoers.d/docker && \\\n \\\n # cleanup\n rm -rf /tmp/docker-build\n"
},
{
"alpha_fraction": 0.5233100056648254,
"alphanum_fraction": 0.5337995290756226,
"avg_line_length": 28.084745407104492,
"blob_id": "7820184be5529490d7e8ef63a5f61ec1930fe0b1",
"content_id": "4321036e901a50bb714890c2667e00670486f616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1716,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 59,
"path": "/bin/copy_build",
"repo_name": "lambda-linux/mock-builder",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# Copyright 2016 Atihita Inc.\n\nimport os\nimport shutil\n\nfrom rpmUtils.miscutils import splitFilename\n\n\nclass Main(object):\n def __init__(self):\n pass\n\n def run(self):\n rpm_files = []\n\n for f in os.listdir('/var/lib/mock/amzn-latest-x86_64/result'):\n if f[-8:] == '.src.rpm':\n srpm_file = f\n continue\n\n if f[-4:] == '.rpm':\n rpm_files.append(f)\n continue\n\n print('SRPM: %s' % srpm_file)\n print('RPMs: %r' % rpm_files)\n\n (name, version, release, epoch, arch) = splitFilename(srpm_file)\n\n output_build_toppath = '/home/ll-user/mock-builder/build-artifacts/{name}/{version}/{release}'.format(\n name=name, version=version, release=release)\n\n if not os.path.exists(output_build_toppath):\n os.makedirs(output_build_toppath)\n\n srpm_pkg_path = '{toppath}/src'.format(toppath=output_build_toppath)\n if not os.path.exists(srpm_pkg_path):\n os.makedirs(srpm_pkg_path)\n shutil.copy(\n '/var/lib/mock/amzn-latest-x86_64/result/{srpm}'.format(\n srpm=srpm_file),\n srpm_pkg_path)\n\n for rpm in rpm_files:\n (n, v, r, e, a) = splitFilename(rpm)\n rpm_pkg_path = '{toppath}/{arch}'.format(\n toppath=output_build_toppath, arch=a)\n if not os.path.exists(rpm_pkg_path):\n os.makedirs(rpm_pkg_path)\n shutil.copy(\n '/var/lib/mock/amzn-latest-x86_64/result/{rpm}'.format(\n rpm=rpm),\n rpm_pkg_path)\n\n\nif __name__ == '__main__':\n main = Main()\n main.run()\n"
},
{
"alpha_fraction": 0.6863468885421753,
"alphanum_fraction": 0.6918818950653076,
"avg_line_length": 29.11111068725586,
"blob_id": "963a6d5f14a23cb5360e0ddb760f913837a0e4e5",
"content_id": "179f039cd82cdd7cc4000c89b355c23338ca2d95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1084,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 36,
"path": "/GETTING_STARTED.md",
"repo_name": "lambda-linux/mock-builder",
"src_encoding": "UTF-8",
"text": "# `mock-builder`\n\n`mock-builder` is a docker container used by Lambda Linux Project to build and maintain RPMs for Amazon Linux.\n\n## Building `mock-builder` container\n\n```\n$ cd ~/mock-builder\n\n$ docker build -t mock-builder:latest .\n```\n\n## Running `mock-builder` container\n\n```\n$ cd ~/mock-builder\n\n$ docker run --rm -h ll-builder-1.build --privileged=true -t -v `pwd`:/home/ll-user/mock-builder -i mock-builder /sbin/my_init -- /usr/bin/sudo -i -u ll-user\n```\n\nOnce inside the container, set the `mock` environment\n\n```\n[ll-user@ll-builder-1] ~ $ source ~/mock-builder/bin/setenv\n```\n\nTo build package\n\n```\n[ll-user@ll-builder-1] ~ $ mock --buildsrpm --scm-enable --scm-option package=<package_name> --scm-option branch=<branch_name>\n\n[ll-user@ll-builder-1] ~ $ cd ~/mock-builder/builddir/amzn/build/SOURCES/; git fat init; git fat pull; cd ~/mock-builder/; mock --shell \"chown -R mockbuild:mockbuild /builddir/build/SOURCES\"\n\n[ll-user@ll-builder-1] ~/mock-builder $ mock --rebuild <srpm_package>\n[ll-user@ll-builder-1] ~/mock-builder $ mock --no-clean --rebuild <srpm_package>\n```\n"
},
{
"alpha_fraction": 0.7650793790817261,
"alphanum_fraction": 0.7650793790817261,
"avg_line_length": 34,
"blob_id": "7ca313f3393a24c6eb07b1b84a2982f19d4f070b",
"content_id": "730f5bd3865c4ce6e14d56b469da4fad3e630e67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 9,
"path": "/README.md",
"repo_name": "lambda-linux/mock-builder",
"src_encoding": "UTF-8",
"text": "# Mock Builder\n\n`mock-builder` is a docker container used by Lambda Linux Project to build and maintain RPMs for Amazon Linux.\n\nPlease see [`GETTING_STARTED.md`](GETTING_STARTED.md).\n\nIf you need help, please contact us on our [support](https://lambda-linux.io/support) channels.\n\nThank you for using mock-builder.\n"
}
] | 4 |
srschnei/Cogs18Repo | https://github.com/srschnei/Cogs18Repo | d3cb3b055f3836ce0a30a7b27fa9e67a0610cd51 | b9a1cef2c0bf0b993ddd9e90c09e8bc8883482b4 | 7acac5fcfdd3dcd4db19527d2249b61d0ba98890 | refs/heads/master | "2020-06-03T21:58:40.632838" | "2019-06-13T11:35:54" | "2019-06-13T11:35:54" | 191,748,149 | 0 | 0 | null | "2019-06-13T11:14:19" | "2019-06-13T11:14:22" | "2019-06-13T11:18:31" | null | [
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.75,
"avg_line_length": 7,
"blob_id": "2c3a157b3db3430baf004058246a4102e8db432f",
"content_id": "36bdf8622ac17f24195e37d1335688e3c2c9b8b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 2,
"path": "/README.md",
"repo_name": "srschnei/Cogs18Repo",
"src_encoding": "UTF-8",
"text": "# Cogs18Repo\nhi\n"
},
{
"alpha_fraction": 0.6764705777168274,
"alphanum_fraction": 0.6955484747886658,
"avg_line_length": 49.36000061035156,
"blob_id": "e09dd8a59f30bbb517bed928a56513bd8740daa7",
"content_id": "2a166df3121785d0fb4a164ee13a106c93e81faf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1273,
"license_type": "no_license",
"max_line_length": 660,
"num_lines": 25,
"path": "/ProjectTemplate/my_module/test_functions.py",
"repo_name": "srschnei/Cogs18Repo",
"src_encoding": "UTF-8",
"text": "from my_module.functions import dogmode, what_fact, who_fact, where_fact, why_fact, when_fact, cat_bot\n\n\n\"\"\"Test for my functions.\n\"\"\"\n\ndef test_dogmode():\n assert callable(dogmode)\n input_list = ('My dog would chase you')\n assert dogmode(input_list) == True\n \n \ndef test_dogmode():\n assert callable(dogmode)\n input_list = ('My cat would chase you')\n assert dogmode(input_list) == False\n\n\ndef test_what_fact(input_string):\n whatfacts = ['A group of cats is called a clowder.', \"A cat's brain is 90% similar to a human's — more similar than to a dog's.\", \"The world's largest cat measured 48.5 inches long.\", \"A cat's cerebral cortex (the part of the brain in charge of cognitive information processing) has 300 million neurons, compared with a dog's 160 million.\", 'Cats sleep 70% of their lives.', 'Cats have over 20 muscles that control their ears.', 'Cats are the most popular pet in the United States: There are 88 million pet cats and 74 million dogs.', \"Cats can't taste sweetness.\", 'There are cats who have survived falls from over 32 stories (320 meters) onto concrete.']\n return random.choice(whatfacts)\n msg = 'what'\n if question == True:\n if 'what' in msg_list:\n assert out_msg == what_fact(msg)"
},
{
"alpha_fraction": 0.6086115837097168,
"alphanum_fraction": 0.614719033241272,
"avg_line_length": 41.167381286621094,
"blob_id": "23adb6748088620a6add0db4d356a5b8dca98a88",
"content_id": "88aec2b2c2bb9b27517db95da7f4b8e233614547",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9863,
"license_type": "no_license",
"max_line_length": 660,
"num_lines": 233,
"path": "/ProjectTemplate/my_module/functions.py",
"repo_name": "srschnei/Cogs18Repo",
"src_encoding": "UTF-8",
"text": "\"\"\"A collection of functions to utilize for my CatBot project.\"\"\"\n\nimport string\nimport random\n\n# The below variables define a collection of inputs and outputs CatBot can recognize and respond to.\n\nGREETINGS_IN = ['hello', 'hi', 'hey', 'sup', 'meow', 'mew', 'hola', 'welcome', 'bonjour', 'greetings']\nGREETINGS_OUT = [\"Merrow\", 'Butt scratches?', \"Hi I like pets\", \"Have any schnacks?\"]\n\ndistinguished_cats_in = ['Garfield', 'Felix', 'Grumpy', 'Chi', 'Cheshire', 'Stubbs', 'Shiro', 'Oskar', 'Klaus', 'Henri', 'Chococat']\ndistinguished_cats_out = ['Was a very important character.', 'Yeah, we go way back.', 'Oh goodness, nope we are not on good terms.']\n\nfun_in = ['funny', 'hilarious', 'ha', 'haha', 'hahaha', 'lol', 'joke']\nfun_out = [\"I may have 9 lives but I have no sense of hu-merw\"] \n\nnope_in = ['water', 'loud', 'bark', 'unknown', 'tummyscratch', 'enemy']\nnope_out = ['*runs away*', '*hiss*', '*swat swat*', '*flicks tail*', '*growls*']\n\nUNKNOWN = ['Mew', 'Meow', 'Merw?', 'Merrh!', '*Purrrring*', '*Nuzzles leg*', '*Chases tail*', '*yaaaawn*', '*Tisk Tisk*', '*Licks butt*', '*Swats at air*']\n\nQUESTION = \"I'm currently pondering the meaning of life. Have any other questions?\"\n\ndef is_question(input_string):\n \"\"\"\n This function checks if inputted string contains a ?\n This function was borrowed from A3 assignment. \n \"\"\"\n output = False\n for i in input_string:\n if i == '?':\n output = True\n return output\n\n\ndef remove_punctuation(input_string):\n \"\"\"\n This function removes punctuation from input string.\n This function was borrowed from A3 assignment. \n \"\"\"\n out_string = ''\n for i in input_string:\n if not i in string.punctuation:\n out_string += i\n return out_string\n\ndef prepare_text(input_string):\n \"\"\"\n This function utilizes the remove_punctuation function and creates a list of split strings.\n This function was borrowed from A3 assignment. \n \"\"\"\n out_list = []\n xstring = remove_punctuation(input_string).lower()\n out_list = xstring.split(' ')\n return out_list\n\ndef selector(input_list, check_list, return_list):\n \"\"\"\n This function randomizes a preset output for the chatbot, given the input.\n \n Parameters \n ---------\n input_list = a list of words \n check_list = a list of words that will check if they appear in the input \n return_list = a list of potential words that will output to the desired inputs \n \n This function was borrowed from A3 assignment. \n \"\"\"\n output = None\n for i in input_list:\n if i in check_list:\n output = random.choice(return_list)\n break\n\n#outputs bark\ndef dogmode(input_list):\n \"\"\"\n This function removes punctuation from input string.\n Parameters \n ---------\n out_string = string to return \n out_list = a list of words that will be added randomly to out_string \n numbarks = the number of times each word from out_list will be outputted (length of input) \n \"\"\"\n out_string = ''\n out_list = ['woof ', 'bark ', 'drool ', 'aruOoOoO? ', '*pant pant* ', 'arf ']\n numbarks = len(input_list)\n for i in range(numbarks):\n out_string += random.choice(out_list)\n return out_string\n\n\n\"\"\"\nThe 5 below functions output random cat facts within the scope of who, what, where, when, and why topics.\n\nCredit for catfacts:\nURL: https://www.buzzfeed.com/chelseamarshall/meows\nTitle: 82 Astounding Facts About Cats\nWebsite Host: Buzzfeed\nAuthor: Chelsea Marshall\n\"\"\"\n\ndef what_fact(input_string):\n whatfacts = ['A group of cats is called a clowder.', \"A cat's brain is 90% similar to a human's — more similar than to a dog's.\", \"The world's largest cat measured 48.5 inches long.\", \"A cat's cerebral cortex (the part of the brain in charge of cognitive information processing) has 300 million neurons, compared with a dog's 160 million.\", 'Cats sleep 70% of their lives.', 'Cats have over 20 muscles that control their ears.', 'Cats are the most popular pet in the United States: There are 88 million pet cats and 74 million dogs.', \"Cats can't taste sweetness.\", 'There are cats who have survived falls from over 32 stories (320 meters) onto concrete.']\n return random.choice(whatfacts)\n\ndef who_fact(input_string):\n whofacts = ['A cat has been mayor of Talkeetna, Alaska, for 15 years. His name is Stubbs.', \"The world's richest cat is worth $13 million after his human passed away and left her fortune to him.\", 'When asked if her husband had any hobbies, Mary Todd Lincoln is said to have replied \"cats.\"', 'Isaac Newton is credited with inventing the cat door.', 'In the 15th century, Pope Innocent VIII began ordering the killing of cats, pronouncing them demonic.']\n return random.choice(whofacts)\n\ndef where_fact(input_string):\n wherefacts = ['The first cat in space was French. She was named Felicette, or \"Astrocat.\" She survived the trip.', \"There are 45 Hemingway cats living at the author's former home in Key West, Fla. Polydactyl cats are also referred to as 'Hemingway cats' because the author was so fond of them.\", 'Cats were mythic symbols of divinity in ancient Egypt.']\n return random.choice(wherefacts)\n\ndef when_fact(input_string):\n whenfacts = [\"Evidence suggests domesticated cats have been around since 3600 B.C., 2,000 years before Egypt's pharaohs.\", 'The oldest cat video on YouTube dates back to 1894 (when it was made, not when it was uploaded, duh).', 'In the 1960s, the CIA tried to turn a cat into a bonafide spy by implanting a microphone into her ear and a radio transmitter at the base of her skull. She somehow survived the surgery but got hit by a taxi on her first mission.']\n return random.choice(whenfacts)\n\ndef why_fact(input_string):\n whyfacts = ['Owning a cat can reduce the risk of stroke and heart attack by a third.', 'Cat owners who are male tend to be luckier in love, as they are perceived as more sensitive.', \"The frequency of a domestic cat's purr is the same at which muscles and bones repair themselves.\", 'Cat owners are 17% more likely to have a graduate degree.']\n return random.choice(whyfacts)\n\ndef end_chat(input_list):\n \"\"\"\n This function quits the conversation with CatBot. \n \n Parameters \n ---------\n input_list = a list of words\n 'quit' is the specified word that will produce an output \n \n Response \n --------\n When presented with the word 'bye' the CatBot quits \n \n This function was borrored from A3 assignment. \n \"\"\"\n output = False\n if 'bye' in input_list:\n output = True\n return output\n\ndef cat_bot():\n \"\"\"\n This is the main function for the CatBot chatbot.\n It was borrowed/modified from A3 assignment with emphasis on relevance to the all powerful CatBot's wishes. \n \"\"\"\n print(\"Meow! I am a claw-ver cat bot! Give me your pets and your food or else!!!!!.....\\\n \\nI only answer to regular english human speech.\\\n \\nSay: 'bye' to quit, 'dog' for dogmode,\\\n \\nAsk me who/what/where/when/why questions for random cat facts!\")\n \n\n chat = True\n while chat:\n \n # Get message from user\n msg = input('ME: ')\n out_msg = None\n \n # Check if the input is a question\n question = is_question(msg)\n \n # Prepare the input message\n msg = prepare_text(msg)\n \n # Check for an end msg \n if end_chat(msg):\n out_msg = \"Goodbye! \\\n \\nIf you want to adopt a cat, you can visit your local \\\n \\nHumane Society or check out petfinder.com. \\\n \\nCat facts provided by Buzzfeed.\"\n chat = False\n\n #Prepare and inplement outputs for specific inputs and non expected inputs\n if not out_msg:\n \n \n msg_list = []\n \n# question = False\n\n msg_list = prepare_text(msg)\n\n #for loop initializing random preset responses for undelightful inputs for CatBot\n for i in nope_in:\n if i in msg:\n out_msg = random.choice(nope_out)\n\n \n #implement dogmode function\n if 'dog' in msg_list:\n out_msg = dogmode(msg)\n \n #implement is_question\n if is_question(msg):\n question = True\n\n #output what_fact function if asked 'what' (with '?')\n if question == True:\n if 'what' in msg_list:\n out_msg = what_fact(msg)\n \n #output who_fact function if asked 'who' (with '?') \n if question == True:\n if 'who' in msg_list:\n out_msg = who_fact(msg) \n \n #output where_fact function if asked 'where' (with '?') \n if question == True:\n if 'where' in msg_list:\n out_msg = where_fact(msg) \n \n #output where_fact function if asked 'when' (with '?') \n if question == True:\n if 'when' in msg_list:\n out_msg = when_fact(msg) \n \n #output where_fact function if asked 'why' (with '?') \n if question == True:\n if 'why' in msg:\n out_msg = why_fact(msg) \n \n \n # If we don't have an output yet, but the input was a question, return msg related to it being a question\n if not out_msg and question:\n out_msg = QUESTION\n\n # Catch-all to say something if msg not caught & processed so far\n if not out_msg:\n out_msg = random.choice(UNKNOWN)\n \n print('CatBot:', out_msg)"
}
] | 3 |
jeremw264/SheetsUnlockerExcel | https://github.com/jeremw264/SheetsUnlockerExcel | 7f21293709e15cfa78d9f99e45e8cd2a7a5121a5 | 4def71f5701c4b885c380d9001b38e01ad3d564c | 629b11ddbed7e57d24e38401f15f312301e420f9 | refs/heads/master | "2023-06-28T18:27:29.700677" | "2021-08-03T10:07:48" | "2021-08-03T10:07:48" | 392,267,200 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7792207598686218,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 21.14285659790039,
"blob_id": "498b211305342f7423bd13f1e18ae0da3bac69de",
"content_id": "2b1ee1f9dc00e563447e088c8b4228035ce22e23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 7,
"path": "/README.md",
"repo_name": "jeremw264/SheetsUnlockerExcel",
"src_encoding": "UTF-8",
"text": "# SheetsUnlockerExcel\n\nEverything is in the name\n\n# Quick Start\n\nDefine the path of the file in the variable filePath line 7 of main.py and launch main.py"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5042644143104553,
"avg_line_length": 29.25806427001953,
"blob_id": "b5b604fe3fa670b754a6d6c6354a33f47dcee2fc",
"content_id": "322df595f8bc9cc2ed85cf4ee9a342561191f078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1876,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 62,
"path": "/model/unlockSheet.py",
"repo_name": "jeremw264/SheetsUnlockerExcel",
"src_encoding": "UTF-8",
"text": "from model.log import Log\nimport os\nimport re\n\n\nclass UnlockSheet:\n def __init__(self, pathZip):\n self.pathZip = pathZip\n self.sheetsPath = []\n\n self.searchSheetPath()\n\n def unlock(self):\n\n for path in self.sheetsPath:\n data = \"\"\n Log().writteLog(\"Read xl/worksheets/\" + path)\n with open(\"TempExtract/xl/worksheets/\" + path, \"r\") as sheet:\n data = self.searchSheetProtection(sheet.read(), path)\n if data != 0:\n with open(\"TempExtract/xl/worksheets/\" + path, \"w\") as test:\n test.write(data)\n Log().writteLog(\"Unlock Sheet Finish\")\n\n def searchSheetPath(self):\n try:\n pathSheets = []\n for path in os.listdir(\"TempExtract/xl/worksheets\"):\n if re.search(\".xml\", path):\n pathSheets.append(path)\n pathSheets.sort()\n self.sheetsPath = pathSheets\n Log().writteLog(\"Sheet Found\")\n return len(self.sheetsPath) > 0\n except FileNotFoundError:\n Log().writteLog(\"Error Sheet Not Found\", 1)\n return False\n\n def searchSheetProtection(self, str, path):\n try:\n s = str.index(\"<sheetProtection\")\n\n cmp = 1\n\n for c in str[s:]:\n if c != \">\":\n cmp += 1\n else:\n Log().writteLog(\"Protection found\")\n return self.rewriteSheet(str, [s, s + cmp], path)\n\n except ValueError:\n Log().writteLog(\"Protection not found\")\n return False\n\n def rewriteSheet(self, str, ind, path):\n Log().writteLog(\"Rewritte Sheet File in \" + path)\n r = \"\"\n for i in range(len(str)):\n if i < ind[0] or i > ind[1] - 1:\n r += str[i]\n return r\n"
},
{
"alpha_fraction": 0.6136114001274109,
"alphanum_fraction": 0.6158068180084229,
"avg_line_length": 25.794116973876953,
"blob_id": "7f3c3be9bac8893dce6d36c8a865aaa65756b58e",
"content_id": "56a8b8214137f578b07bd9f2205d8356884c5d94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 34,
"path": "/main.py",
"repo_name": "jeremw264/SheetsUnlockerExcel",
"src_encoding": "UTF-8",
"text": "import zipfile\nimport shutil\nimport os\nfrom model.log import Log\nfrom model.unlockSheet import UnlockSheet\n\nfilePath = \"filePath\"\n\nif __name__ == \"__main__\":\n\n Log().writteLog(\"Launch Program on \" + filePath)\n\n try:\n zipPath = filePath[: len(filePath) - 4] + \"zip\"\n os.rename(filePath, zipPath)\n zf = zipfile.ZipFile(zipPath)\n nameListOrigin = zf.namelist()\n zf.extractall(\"TempExtract/\")\n\n Log().writteLog(\"Extract Finish\")\n\n UnlockSheet(zipPath).unlock()\n with zipfile.ZipFile(zipPath, \"w\") as myzip:\n for name in nameListOrigin:\n myzip.write(\"TempExtract/\" + name, name)\n\n Log().writteLog(\"Rewritte ZIP Finish\")\n\n shutil.rmtree(\"TempExtract/\")\n os.mkdir(\"TempExtract\")\n os.rename(zipPath, filePath)\n\n except FileNotFoundError:\n Log().writteLog(\"File \" + filePath + \" not Found\", 2)\n"
},
{
"alpha_fraction": 0.46900826692581177,
"alphanum_fraction": 0.4752066135406494,
"avg_line_length": 22.047618865966797,
"blob_id": "bd02628981985d8c51115ffd3743fd2bdf9743fe",
"content_id": "8ebe6c806e99b55f9add40c67f501bcdf63ec989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 21,
"path": "/model/log.py",
"repo_name": "jeremw264/SheetsUnlockerExcel",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nclass Log:\n def __init__(self) -> None:\n\n self.path = \"log/log.txt\"\n\n def writteLog(self, str, level=0):\n\n now = datetime.now()\n\n if level == 1:\n levelMsg = \"[Warning] \"\n elif level == 2:\n levelMsg = \"[Error] \"\n else:\n levelMsg = \"\"\n\n with open(self.path, \"a\") as log:\n log.write(now.strftime(\"[%d/%m/%Y|%H:%M:%S] \") + levelMsg + str + \"\\n\")\n print(str)\n"
}
] | 4 |
calderona/PlotsConfigurations | https://github.com/calderona/PlotsConfigurations | 9c7fcb3fe9433b41bdd82fb87bb12d9aad7b1be1 | 35fe2adc8739fc1f94cb92bb6537d20230d40ae6 | 3e408ce3cb72ee62600cc5635da3fa15f0d0e43e | refs/heads/master | "2022-05-01T08:16:07.734277" | "2019-05-31T15:12:29" | "2019-05-31T15:12:29" | 190,613,581 | 0 | 1 | null | "2019-06-06T16:23:45" | "2019-05-31T15:12:47" | "2019-05-31T15:12:45" | null | [
{
"alpha_fraction": 0.3328530192375183,
"alphanum_fraction": 0.41426512598991394,
"avg_line_length": 38.657142639160156,
"blob_id": "69d64874a194db247da1c053ac254098ad7912c5",
"content_id": "6b8f314ec07bdcd508f9f5a3eb6a0bf64f6fc9e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1388,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 35,
"path": "/Configurations/ControlRegions/DY/Full2016_nAOD/cuts.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# cuts\n\nsupercut = 'mll>80 && mll<100 && Lepton_pt[0]>20 && Lepton_pt[1]>10 && (nLepton>=2 && Alt$(Lepton_pt[2],0)<10) && abs(Lepton_eta[0])<2.5 && abs(Lepton_eta[1])<2.5'\n\n\ncuts['Zee'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -11*11) \\\n && Lepton_pt[0]>25 && Lepton_pt[1]>13 \\\n '\n\ncuts['Zmm'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -13*13) \\\n '\n\n#for iPer in [ ['B','1'] , ['C','2'] , ['D','3'] , ['E','4'], ['F','5'] ] :\n# cuts['Zee_Run'+iPer[0]] = cuts['Zee'] + '&& run_period=='+iPer[1]\n# cuts['Zmm_Run'+iPer[0]] = cuts['Zmm'] + '&& run_period=='+iPer[1] \n\ncuts['Zee0j'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -11*11) \\\n && Lepton_pt[0]>25 && Lepton_pt[1]>13 \\\n && Alt$(CleanJet_pt[0],0)<30 \\\n '\n\ncuts['Zmm0j'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -13*13) \\\n && Alt$(CleanJet_pt[0],0)<30 \\\n '\n\ncuts['Zee1j'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -11*11) \\\n && Lepton_pt[0]>25 && Lepton_pt[1]>13 \\\n && Alt$(CleanJet_pt[0],0)>=30 \\\n && Alt$(CleanJet_pt[1],0)<30 \\\n '\n\ncuts['Zmm1j'] = '(Lepton_pdgId[0] * Lepton_pdgId[1] == -13*13) \\\n && Alt$(CleanJet_pt[0],0)>=30 \\\n && Alt$(CleanJet_pt[1],0)<30 \\\n '\n"
},
{
"alpha_fraction": 0.5224444270133972,
"alphanum_fraction": 0.5354663133621216,
"avg_line_length": 37.20904541015625,
"blob_id": "1e76c55e501f92351e7a87b0b2e6609fad714f9c",
"content_id": "27a58bbdf151f6f1b62a923b2d18bb1d7f8ad6cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31255,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 818,
"path": "/Configurations/Differential/tools/restructure_input.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport re\nimport time\nimport math\nfrom array import array\nimport tempfile\nargv = sys.argv\nsys.argv = argv[:1]\nimport ROOT\n\nFIRENZE = False\nNOHIGGS = True\nSRONLY = True\n\nclass SourceGetter(object):\n '''Tool to get source histograms'''\n\n tag = ''\n\n def __init__(self, path, sample = ''):\n if sample:\n self.source = ROOT.TFile.Open('%s/plots_%s_ALL_%s.root' % (path, self.tag, sample))\n else:\n self.source = ROOT.TFile.Open(path)\n if not self.source:\n raise RuntimeError(path)\n\n ROOT.gROOT.GetListOfFiles().Remove(self.source)\n self.cwd = ''\n\n def cd(self, path):\n self.cwd = path\n\n def pwd(self):\n return self.source.GetName() + ':' + self.cwd\n\n def get(self, name, noraise=False):\n h = self.source.Get(self.cwd + '/' + name)\n if not h and not noraise:\n raise RuntimeError(self.pwd() + '/' + name + ' not accessible')\n\n return h\n\n def getkeys(self):\n d = self.source.GetDirectory(self.cwd)\n if not d:\n raise RuntimeError(self.pwd() + ' not accessible')\n\n return d.GetListOfKeys()\n\n def close(self):\n self.source.Close()\n\n\ndef nonnegatify(histogram):\n for iX in range(1, histogram.GetNbinsX() + 1):\n if histogram.GetBinContent(iX) < 0.:\n histogram.SetBinContent(iX, 0.)\n\n\nclass HistogramMerger(object):\n '''Tool to restructure and merge histograms'''\n\n pt2confs = ['pt2lt20', 'pt2ge20']\n flavconfs = ['em', 'me']\n chrgconfs = ['pm', 'mp']\n split = []\n\n lnNSpecific = {}\n renormalizedVariations = {}\n perBinVariations = []\n\n recoBinMap = {}\n outBins = []\n crCategories = []\n\n def __init__(self):\n self.subsamples = []\n self.sourceDirectories = []\n\n self.getter = None\n\n self.outCutDir = None\n\n def getSRSourceDirectories(self, category):\n self.sourceDirectories = []\n for recoBin in self.recoBinMap[self._recoOutBin]:\n if category is None:\n for pt2 in self.pt2confs:\n for flav in self.flavconfs:\n for chrg in self.chrgconfs:\n self.sourceDirectories.append('hww_%s_cat%s%s%s_%s' % (recoBin, pt2, flav, chrg, self.year))\n \n elif category in self.pt2confs:\n for flav in self.flavconfs:\n for chrg in self.chrgconfs:\n self.sourceDirectories.append('hww_%s_cat%s%s%s_%s' % (recoBin, category, flav, chrg, self.year))\n \n elif category in [pt2 + flav for pt2 in self.pt2confs for flav in self.flavconfs]:\n for chrg in self.chrgconfs:\n self.sourceDirectories.append('hww_%s_cat%s%s_%s' % (recoBin, category, chrg, self.year))\n \n else:\n self.sourceDirectories.append('hww_%s_cat%s_%s' % (recoBin, category, self.year))\n \n def getCRSourceDirectories(self, sel):\n self.sourceDirectories = []\n\n if self._recoOutBin not in self.recoBinMap:\n return\n\n for recoBin in self.recoBinMap[self._recoOutBin]:\n if FIRENZE:\n recoBin = recoBin.replace('NJ_', '').lower() + 'j'\n self.sourceDirectories.append('hww_CR_cat%s_%s_%s' % (sel, recoBin, self.year))\n else:\n self.sourceDirectories.append('hww_CR_cat%s_%s_%s' % (recoBin, sel, self.year))\n \n ### Functions for actual merging steps\n \n def addFromOneDirectory(self, sample, sourceSample):\n outNominal = self._outNominals[self.outCutDir.GetName()][self.templateName]\n\n # pick up the nominal input\n inNominal = self.getter.get('histo_%s' % sourceSample)\n \n # then deal with variations\n for variation, outVariation in self._outVariations[self.outCutDir.GetName()][self.templateName].iteritems():\n if variation in self.lnNSpecific:\n lnNDef = self.lnNSpecific[variation]\n \n if sample in lnNDef:\n inVariation = inNominal.Clone('histo_%s_%s' % (sourceSample, variation))\n \n if type(lnNDef[sample]) is tuple:\n # AsLnN type\n inVariationSource = self.getter.get('histo_%s_%s' % (sourceSample, variation))\n numer = inVariationSource.Integral()\n denom = inVariation.Integral()\n if numer > 0. and denom > 0.:\n inVariation.Scale(numer / denom / lnNDef[sample][1])\n else:\n # float values\n inVariation.Scale(lnNDef[sample])\n else:\n inVariation = None\n else:\n inVariation = self.getter.get('histo_%s_%s' % (sourceSample, variation), noraise=True)\n \n if inVariation:\n if (sample, variation) in self.renormalizedVariations:\n inVariation.Scale(self.renormalizedVariations[(sample, variation)])\n\n try:\n outVariation.Add(inVariation)\n except:\n print self.outCutDir.GetName(), self.templateName, outNominal.GetName(), variation\n raise\n\n inVariation.Delete()\n else:\n outVariation.Add(inNominal)\n \n # unknown variations (only need to do this once per input sample in principle)\n for key in self.getter.getkeys():\n matches = re.match('histo_%s_(.+)$' % sourceSample, key.GetName())\n if not matches or matches.group(1) in self._outVariations[self.outCutDir.GetName()][self.templateName]:\n continue\n \n variation = matches.group(1)\n \n # temporary\n if 'CMS_scale_met_DYCR' in variation or ('CMS_btag_' in variation and '_topCR_' in variation):\n continue\n\n outVariation = self.newOutVariation(variation)\n \n inVariation = key.ReadObj()\n if (sample, variation) in self.renormalizedVariations:\n inVariation.Scale(self.renormalizedVariations[(sample, variation)])\n \n outVariation.Add(inVariation)\n inVariation.Delete()\n \n for variation, lnNDef in self.lnNSpecific.iteritems():\n if sample not in lnNDef or variation in self._outVariations[self.outCutDir.GetName()][self.templateName]:\n continue\n\n outVariation = self.newOutVariation(variation)\n \n inVariation = inNominal.Clone('histo_%s_%s' % (sourceSample, variation))\n if type(lnNDef[sample]) is tuple:\n # AsLnN type\n inVariationSource = self.getter.get('histo_%s_%s' % (sourceSample, variation))\n numer = inVariationSource.Integral()\n denom = inVariation.Integral()\n if numer > 0. and denom > 0.:\n inVariation.Scale(numer / denom / lnNDef[sample][1])\n else:\n inVariation.Scale(lnNDef[sample])\n \n outVariation.Add(inVariation)\n inVariation.Delete()\n \n # finally update out nominal\n outNominal.Add(inNominal)\n inNominal.Delete()\n\n def newOutVariation(self, variation):\n outNominal = self._outNominals[self.outCutDir.GetName()][self.templateName]\n\n if variation in self.perBinVariations:\n if variation.endswith('Up'):\n variationCore = variation[:-2]\n updown = 'Up'\n else:\n variationCore = variation[:-4]\n updown = 'Down'\n\n outVariationName = '%s_%s_%s%s' % (outNominal.GetName(), variationCore, self._recoOutBin, updown)\n else:\n outVariationName = '%s_%s' % (outNominal.GetName(), variation)\n\n self.outCutDir.cd(self.templateName)\n outVariation = outNominal.Clone(outVariationName)\n outVariation.SetTitle(outVariationName)\n\n self._outVariations[self.outCutDir.GetName()][self.templateName][variation] = outVariation\n\n return outVariation\n \n def mergeSampleTemplate(self, sample):\n for sourceDirectory in self.sourceDirectories:\n self.getter.cd('%s/%s' % (sourceDirectory, self.templateName))\n for subsample in self.subsamples:\n if not subsample:\n sourceSample = sample\n else:\n sourceSample = '%s_%s' % (sample, subsample)\n \n self.addFromOneDirectory(sample, sourceSample)\n \n def mergeSample(self, templateSpecs, sample):\n for templateName, templateBins in templateSpecs:\n if not self.outCutDir.GetDirectory(templateName):\n self.outCutDir.mkdir(templateName)\n\n self.templateName = templateName\n\n try:\n outNominal = self._outNominals[self.outCutDir.GetName()][templateName]\n except KeyError:\n self.outCutDir.cd(self.templateName)\n if type(templateBins) is int:\n outNominal = ROOT.TH1D(self._outNominalName, self._outNominalName, templateBins, 0., float(templateBins))\n elif type(templateBins) is tuple:\n outNominal = ROOT.TH1D(self._outNominalName, self._outNominalName, *templateBins)\n elif type(templateBins) is list:\n outNominal = ROOT.TH1D(self._outNominalName, self._outNominalName, len(templateBins) - 1, array('d', templateBins))\n \n self._outNominals[self.outCutDir.GetName()][self.templateName] = outNominal\n self._outVariations[self.outCutDir.GetName()][self.templateName] = {}\n\n self.mergeSampleTemplate(sample)\n \n def restructureSR(self, output, sample):\n # merge sample from one sample at each output cut\n\n for dkey in output.GetListOfKeys():\n matches = re.match('hww_((?:PTH|NJ)_(?:[0-9]+|G[ET][0-9]+|[0-9]+_[0-9]+))(?:_cat(.+)|)_[0-9]+$', dkey.GetName())\n if not matches:\n continue\n\n recoOutBin = matches.group(1)\n category = matches.group(2)\n\n self._recoOutBin = recoOutBin\n \n self.getSRSourceDirectories(category)\n\n templateSpecs = [getTemplateSpec(recoOutBin, category)]\n if FIRENZE:\n templateSpecs.append(('events', (1, 0., 2.)))\n else:\n templateSpecs.append(('events', 1))\n self.outCutDir = output.GetDirectory(dkey.GetName())\n \n self.mergeSample(templateSpecs, sample)\n \n def restructureCR(self, output, sample):\n # merge sample from one sample at each output cut\n\n for dkey in output.GetListOfKeys():\n if FIRENZE:\n matches = re.match('hww_CR_cat(top|DY|WW)_((?:ge|)[0-4]j)_[0-9]+$', dkey.GetName())\n else:\n matches = re.match('hww_CR_cat((?:PTH|NJ)_(?:[0-9]+|G[ET][0-9]+|[0-9]+_[0-9]+))_(top|DY|WW)_[0-9]+$', dkey.GetName())\n\n if matches:\n if FIRENZE:\n sel = matches.group(1)\n recoOutBin = matches.group(2)\n recoOutBin = 'NJ_' + recoOutBin[:-1].upper()\n else:\n recoOutBin = matches.group(1)\n sel = matches.group(2)\n\n self._recoOutBin = recoOutBin\n\n self.getCRSourceDirectories(sel)\n elif dkey.GetName().startswith('hww_CR'):\n self._recoOutBin = None\n self.sourceDirectories = [dkey.GetName()]\n else:\n continue\n\n if FIRENZE:\n templateSpecs = [('events', (1, 0., 2.))]\n else:\n templateSpecs = [('events', 1)]\n\n self.outCutDir = output.GetDirectory(dkey.GetName())\n \n self.mergeSample(templateSpecs, sample)\n\n def writeTarget(self, output):\n \"\"\"\n Make all bin content non-negative and write to output\n \"\"\"\n\n for dname, templates in self._outNominals.iteritems():\n for tname, histogram in templates.iteritems():\n output.cd('%s/%s' % (dname, tname))\n\n nonnegatify(histogram)\n\n nominalSumW = histogram.GetSumOfWeights()\n\n for vh in self._outVariations[dname][tname].itervalues():\n nonnegatify(vh)\n\n if nominalSumW > 0. and vh.GetSumOfWeights() / nominalSumW < 1.e-4:\n vname = vh.GetName()\n vh.Delete()\n vh = histogram.Clone(vname)\n vh.Scale(1.5e-4)\n\n vh.Write()\n vh.Delete()\n\n histogram.Write()\n histogram.Delete()\n \n def createOutputAndMerge(self, outputPath, sourcePath, targets):\n ### Create the output directory structure first\n \n output = ROOT.TFile.Open(outputPath, 'recreate')\n ROOT.gROOT.GetListOfFiles().Remove(output)\n\n dnames = []\n binCategories = {}\n for outBin, nsplit in zip(self.outBins, self.split):\n binCategories[outBin] = []\n if nsplit == 8:\n for pt2 in self.pt2confs:\n for flav in self.flavconfs:\n for chrg in self.chrgconfs:\n dname = 'hww_%s_cat%s%s%s_%s' % (outBin, pt2, flav, chrg, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n \n elif nsplit == 4:\n for pt2 in self.pt2confs:\n for flav in self.flavconfs:\n dname = 'hww_%s_cat%s%s_%s' % (outBin, pt2, flav, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n \n elif nsplit == 3:\n for flav in self.flavconfs:\n dname = 'hww_%s_catpt2lt20%s_%s' % (outBin, flav, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n\n dname = 'hww_%s_catpt2ge20_%s' % (outBin, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n \n elif nsplit == 2:\n for pt2 in self.pt2confs:\n dname = 'hww_%s_cat%s_%s' % (outBin, pt2, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n \n elif nsplit == 1:\n dname = 'hww_%s_%s' % (outBin, self.year)\n dnames.append(dname)\n binCategories[outBin].append(dname)\n \n for cat in self.crCategories:\n dname = 'hww_CR_cat%s_%s' % (cat, self.year)\n dnames.append(dname)\n binCategories[cat] = [dname]\n\n for dname in dnames:\n output.mkdir(dname)\n \n ### Now merge\n \n if os.path.isfile(sourcePath):\n self.getter = SourceGetter(sourcePath)\n \n for outSample, snames in targets:\n self._outNominals = dict((dname, dict()) for dname in dnames)\n self._outVariations = dict((dname, dict()) for dname in dnames)\n\n self._outNominalName = 'histo_%s' % outSample\n\n for sample in snames:\n if type(sample) is tuple:\n self.subsamples = sample[1]\n sample = sample[0]\n print '%s/%s(%s) -> %s/%s' % (sourcePath, sample, ', '.join(self.subsamples), outputPath, outSample)\n else:\n self.subsamples = ['']\n print '%s/%s -> %s/%s' % (sourcePath, sample, outputPath, outSample)\n \n if os.path.isdir(sourcePath):\n self.getter = SourceGetter(sourcePath, sample)\n\n # Signal region directories\n self.restructureSR(output, sample)\n \n # Control region directories\n self.restructureCR(output, sample)\n\n if os.path.isdir(sourcePath):\n self.getter.close()\n \n self.writeTarget(output)\n \n output.Close()\n\n\ndef mergeOne(sourcePath, jobArg, queue):\n tmpdir = tempfile.mkdtemp()\n outputPath = '%s/out.root' % tmpdir\n merger = HistogramMerger()\n merger.createOutputAndMerge(outputPath, sourcePath, [jobArg])\n\n queue.put(outputPath)\n\n\nif __name__ == '__main__':\n sys.argv = argv\n\n import multiprocessing\n import Queue\n import subprocess\n import shutil\n from argparse import ArgumentParser\n \n argParser = ArgumentParser(description = 'Restructure the input into a ROOT file containing only the plots needed for a differential measurement.')\n argParser.add_argument('sourcePath', metavar = 'PATH', help = 'Input ROOT file / directory name.')\n argParser.add_argument('outputPath', metavar = 'PATH', help = 'Output ROOT file name.')\n argParser.add_argument('observable', metavar = 'OBS', help = 'Observable name.')\n argParser.add_argument('--tag', '-t', metavar = 'TAG', dest = 'tag', default = '', help = 'Tag name when input is a directory.')\n argParser.add_argument('--year', '-y', metavar = 'YEAR', dest = 'year', default = '', help = 'Year.')\n argParser.add_argument('--signal-fiducial-only', action = 'store_true', dest = 'signal_fiducial_only', help = 'Signal is fiducial only.')\n argParser.add_argument('--signal-ggH-separate', action = 'store_true', dest = 'signal_ggH_separate', help = 'Separate ggH and xH in signal.')\n argParser.add_argument('--signal-hww-only', action = 'store_true', dest = 'signal_hww_only', help = 'Signal is HWW only.')\n argParser.add_argument('--background-minor-merge', action = 'store_true', dest = 'background_minor_merge', help = 'Merge minor backgrounds into one sample.')\n argParser.add_argument('--input-fake-flavored', action = 'store_true', dest = 'input_fake_flavored', help = 'Input Fake sample is split into Fake_em and Fake_me.')\n argParser.add_argument('--input-major-split', metavar = '(NJ|PTH)', dest = 'input_major_split', help = 'Input sample is split in reco bins of NJ or PTH.')\n argParser.add_argument('--make-asimov-with-bias', metavar = 'SAMPLE=bias', nargs = '+', dest = 'make_asimov_with_bias', help = 'Replace histo_DATA with an Asimov dataset with biased sample scales')\n argParser.add_argument('--num-processes', '-j', metavar = 'N', dest = 'num_processes', type = int, default = 1, help = 'Number of parallel processes.')\n \n args = argParser.parse_args()\n\n if not args.year:\n if '2016' in args.tag:\n args.year = '2016'\n elif '2017' in args.tag:\n args.year = '2017'\n else:\n raise RuntimeError('Cannot determine year')\n \n ### Load the configuration\n\n _samples_noload = True\n samples = {}\n with open('samples.py') as samplesfile:\n exec(samplesfile)\n cuts = {}\n with open('cuts.py') as cutsfile:\n exec(cutsfile)\n nuisances = {}\n with open('nuisances.py') as nuisancesfile:\n exec(nuisancesfile)\n \n ### How we merge the bins & categories\n\n if args.observable == 'ptH':\n HistogramMerger.outBins = ['PTH_0_20', 'PTH_20_45', 'PTH_45_80', 'PTH_80_120', 'PTH_120_200', 'PTH_200_350', 'PTH_GT350']\n #HistogramMerger.outBins = ['PTH_0_15', 'PTH_15_30', 'PTH_30_45', 'PTH_45_80', 'PTH_80_120', 'PTH_120_200', 'PTH_200_350', 'PTH_GT350']\n \n HistogramMerger.recoBinMap = {\n 'PTH_0_20': ['PTH_0_10', 'PTH_10_15', 'PTH_15_20'],\n 'PTH_20_45': ['PTH_20_30', 'PTH_30_45'],\n 'PTH_45_80': ['PTH_45_60', 'PTH_60_80'],\n 'PTH_80_120': ['PTH_80_100', 'PTH_100_120'],\n 'PTH_120_200': ['PTH_120_155', 'PTH_155_200'],\n 'PTH_200_350': ['PTH_200_260', 'PTH_260_350'],\n 'PTH_GT350': ['PTH_GT350']\n }\n \n HistogramMerger.split = [8, 8, 4, 3, 2, 2, 1]\n \n def getTemplateSpec(recoOutBin, category):\n if category is None or category.startswith('pt2lt20'):\n return 'mllVSmth_6x6', 36\n else:\n return 'mllVSmth_8x9', 72\n\n HistogramMerger.crCategories = []\n if not SRONLY:\n for sel in ['top', 'DY', 'WW']:\n HistogramMerger.crCategories.extend('%s_%s' % (outBin, sel) for outBin in HistogramMerger.outBins)\n \n else:\n HistogramMerger.outBins = ['NJ_0', 'NJ_1', 'NJ_2', 'NJ_3', 'NJ_GE4']\n \n HistogramMerger.recoBinMap = {\n 'NJ_0': ['NJ_0'],\n 'NJ_1': ['NJ_1'],\n 'NJ_2': ['NJ_2'],\n 'NJ_3': ['NJ_3'],\n 'NJ_GE4': ['NJ_GE4']\n }\n\n if FIRENZE:\n HistogramMerger.split = [8, 8, 1, 1, 1]\n else:\n #HistogramMerger.split = [8, 8, 2, 2, 2]\n HistogramMerger.split = [8, 8, 1, 1, 1]\n \n def getTemplateSpec(recoOutBin, category):\n if FIRENZE:\n if recoOutBin in ['NJ_0', 'NJ_1']:\n if category.startswith('pt2lt20'):\n return 'mllVSmth_pt2lt20', 36\n else:\n return 'mllVSmth_pt2ge20', 72\n elif recoOutBin == 'NJ_2':\n return 'mllVSmth_2j', 36\n else:\n return 'mll_optim', [12.,30.,50.,70.,90.,110.,150.,200.]\n else:\n if category is None or category.startswith('pt2lt20'):\n return 'mllVSmth_6x6', 36\n else:\n return 'mllVSmth_8x9', 72\n\n if FIRENZE:\n crs = ['top', 'DY']\n else:\n crs = ['top', 'DY', 'WW']\n\n HistogramMerger.crCategories = []\n if not SRONLY:\n for sel in crs:\n if FIRENZE:\n HistogramMerger.crCategories.extend('%s_%sj' % (sel, nj) for nj in ['0', '1', '2', '3', 'ge4'])\n else:\n HistogramMerger.crCategories.extend('%s_%s' % (outBin, sel) for outBin in HistogramMerger.outBins)\n \n ### Sample merging configuration according to the flags at the beginning\n \n allBins = sum((HistogramMerger.recoBinMap[outBin] for outBin in HistogramMerger.outBins), [])\n\n if args.make_asimov_with_bias:\n backgrounds = {}\n else:\n backgrounds = {'DATA': ['DATA']}\n signals = {}\n \n ggH_hww = ['ggH_hww']\n xH_hww = [\n 'qqH_hww',\n 'ZH_hww',\n 'ggZH_hww',\n 'WH_hww',\n 'bbH_hww',\n 'ttH_hww'\n ]\n ggH_htt = ['ggH_htt']\n xH_htt = ['qqH_htt', 'ZH_htt', 'WH_htt']\n \n # temporary workaround - some missing samples\n if args.year == '2016':\n minors = ['ggWW', 'Vg', 'WZgS_L', 'WZgS_H', 'VZ', 'VVV']\n else:\n xH_hww.remove('bbH_hww')\n minors = ['ggWW', 'Vg', 'WZgS_H', 'VZ', 'VVV']\n\n if not NOHIGGS:\n if args.signal_hww_only:\n if args.signal_ggH_separate:\n signals['ggH_hww'] = ggH_hww\n signals['xH_hww'] = xH_hww\n else:\n signals['smH_hww'] = ggH_hww + xH_hww\n \n backgrounds['htt'] = [(sample, [f + b for f in ['fid_', 'nonfid_'] for b in allBins]) for sample in (ggH_htt + xH_htt)]\n else:\n if args.signal_ggH_separate:\n signals['ggH'] = ggH_hww + ggH_htt\n signals['xH'] = xH_hww + xH_htt\n else:\n signals['smH'] = ggH_hww + xH_hww + ggH_htt + xH_htt\n \n if args.input_fake_flavored:\n backgrounds['Fake_em'] = [('Fake', ['em'])]\n backgrounds['Fake_me'] = [('Fake', ['me'])]\n else:\n backgrounds['Fake'] = ['Fake']\n \n if args.background_minor_merge:\n backgrounds['minor'] = minors\n else:\n for name in minors:\n backgrounds[name] = [name]\n \n if args.input_major_split == 'NJ':\n for nj in ['0j', '1j', '2j', '3j', 'ge4j']:\n backgrounds['WW_%s' % nj] = [('WW', [nj])]\n backgrounds['top_%s' % nj] = [('top', [nj])]\n backgrounds['DY_%s' % nj] = [('DY', [nj])]\n elif args.input_major_split == 'PTH':\n pass\n elif args.input_major_split is None:\n backgrounds['WW'] = ['WW']\n backgrounds['top'] = ['top']\n backgrounds['DY'] = ['DY']\n \n genBinMerging = []\n if args.signal_fiducial_only:\n backgrounds['nonfid'] = [(s, ['nonfid_' + b for b in allBins]) for s in sum(signals.values(), [])]\n \n for outBin in HistogramMerger.outBins:\n genBinMerging.append((outBin, ['fid_' + s for s in HistogramMerger.recoBinMap[outBin]]))\n else:\n for outBin in HistogramMerger.outBins:\n genBinMerging.append((outBin, ['fid_' + s for s in HistogramMerger.recoBinMap[outBin]] + ['nonfid_' + s for s in HistogramMerger.recoBinMap[outBin]]))\n\n HistogramMerger.year = args.year\n SourceGetter.tag = args.tag\n\n ### Prepare nuisance editing\n \n HistogramMerger.lnNSpecific = {}\n HistogramMerger.perBinVariations = []\n for nuisance in nuisances.itervalues():\n if 'perRecoBin' in nuisance and nuisance['perRecoBin']:\n HistogramMerger.perBinVariations.append(nuisance['name'] + 'Up')\n HistogramMerger.perBinVariations.append(nuisance['name'] + 'Down')\n \n if 'type' not in nuisance or 'samples' not in nuisance:\n continue\n \n if nuisance['type'] != 'lnN' and 'AsLnN' not in nuisance:\n continue\n \n # if there is no mixing of affected and unaffected samples, we let the nuisance stay as lnN\n mixing = False\n for sname in nuisance['samples']:\n for target, snames in signals.items() + backgrounds.items():\n if sname in snames:\n if len(set(snames) - set(nuisance['samples'].keys())) != 0:\n # snames (merge list) and the sample list in nuisance only partially overlaps\n mixing = True\n break\n if mixing:\n break\n \n if not mixing:\n continue\n \n if nuisance['type'] == 'lnN':\n lnNUp = HistogramMerger.lnNSpecific[nuisance['name'] + 'Up'] = {}\n lnNDown = HistogramMerger.lnNSpecific[nuisance['name'] + 'Down'] = {}\n for sname, vdef in nuisance['samples'].iteritems():\n if '/' in vdef:\n vdef = tuple(reversed(vdef.split('/')))\n \n if type(vdef) is list or type(vdef) is tuple:\n lnNUp[sname] = float(vdef[0])\n lnNDown[sname] = float(vdef[1])\n else:\n lnNUp[sname] = float(vdef)\n lnNDown[sname] = 2. - float(vdef)\n \n elif nuisance['type'] == 'shape' and 'AsLnN' in nuisance and float(nuisance['AsLnN']) >= 1.:\n lnNUp = HistogramMerger.lnNSpecific[nuisance['name'] + 'Up'] = {}\n lnNDown = HistogramMerger.lnNSpecific[nuisance['name'] + 'Down'] = {}\n for sname, vdef in nuisance['samples'].iteritems():\n lnNUp[sname] = ('histo', float(nuisance['AsLnN']))\n lnNDown[sname] = ('histo', float(nuisance['AsLnN']))\n\n HistogramMerger.renormalizedVariations = {}\n source = ROOT.TFile.Open(os.path.dirname(__file__) + '/renormalize_theoretical_%s.root' % args.year)\n hup = source.Get('up')\n hdown = source.Get('down')\n for iX in range(1, hup.GetNbinsX() + 1):\n name = hup.GetXaxis().GetBinLabel(iX)\n\n if '/' in name:\n # TODO: we should make it all in this format\n sname, nname = name.split('/')\n else:\n sname = 'ggH_hww'\n nname = name\n\n sup = 1. / hup.GetBinContent(iX)\n sdown = 1. / hdown.GetBinContent(iX)\n \n HistogramMerger.renormalizedVariations[(sname, nname + 'Up')] = sup\n HistogramMerger.renormalizedVariations[(sname, nname + 'Down')] = sdown\n \n source.Close()\n\n binnedSignals = {}\n for target, snames in signals.iteritems():\n for genOutBin, genSourceBins in genBinMerging: # merge histograms from source truth bins\n binnedSignals['%s_%s' % (target, genOutBin)] = [(sname, genSourceBins) for sname in snames]\n\n jobArgs = binnedSignals.items() + backgrounds.items()\n\n if args.num_processes == 1:\n merger = HistogramMerger()\n merger.createOutputAndMerge(args.outputPath, args.sourcePath, jobArgs)\n\n else:\n queue = multiprocessing.Queue()\n\n processes = []\n outputs = []\n \n def checkProcess():\n for proc in list(processes):\n if not proc.is_alive():\n # clear up the queue first\n while True:\n try:\n outputs.append(queue.get(False))\n except Queue.Empty:\n break\n \n proc.join()\n processes.remove(proc)\n \n for jobArg in jobArgs:\n while len(processes) >= args.num_processes:\n time.sleep(1)\n checkProcess()\n \n proc = multiprocessing.Process(target = mergeOne, args = (args.sourcePath, jobArg, queue))\n proc.start()\n processes.append(proc)\n \n while len(processes) != 0:\n time.sleep(1)\n checkProcess()\n \n while True:\n try:\n outputs.append(queue.get(False))\n except Queue.Empty:\n break\n \n proc = subprocess.Popen(['haddfast', '-f', args.outputPath] + outputs)\n proc.communicate()\n \n for path in outputs:\n shutil.rmtree(os.path.dirname(path))\n\n if args.make_asimov_with_bias:\n scales = {}\n for expr in args.make_asimov_with_bias:\n sample, _, sval = expr.partition('=')\n scales[sample] = float(sval)\n \n output = ROOT.TFile.Open(args.outputPath, 'update')\n for ckey in output.GetListOfKeys():\n cdir = ckey.ReadObj()\n for vkey in cdir.GetListOfKeys():\n cdir.cd(vkey.GetName())\n hobs = None\n for sname, _ in jobArgs:\n hsample = ROOT.gDirectory.Get('histo_' + sname)\n if hobs is None:\n hobs = hsample.Clone('histo_DATA')\n hobs.Reset()\n\n if sname in scales:\n hsample.Scale(scales[sname])\n\n hobs.Add(hsample)\n\n for ix in range(1, hobs.GetNbinsX() + 1):\n hobs.SetBinContent(ix, max(0., round(hobs.GetBinContent(ix))))\n hobs.SetBinError(ix, math.sqrt(hobs.GetBinContent(ix)))\n\n hobs.Write()\n hobs.Delete()\n"
},
{
"alpha_fraction": 0.5374619960784912,
"alphanum_fraction": 0.5822068452835083,
"avg_line_length": 34.47583770751953,
"blob_id": "e05e849cdd1b622ecc32d71931360b1636c9ea9b",
"content_id": "62efb3d2eb4062c1f8d4910498ad2e44f03d5070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9543,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 269,
"path": "/Configurations/Differential/tools/plot_sigma.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "import sys\nimport array\nimport math\nimport ROOT\n\nROOT.gROOT.SetBatch(True)\nROOT.gStyle.SetOptStat(0)\nROOT.gStyle.SetTextFont(42)\nROOT.gStyle.SetLabelSize(0.035, 'X')\nROOT.gStyle.SetLabelSize(0.035, 'Y')\nROOT.gStyle.SetTitleSize(0.035, 'X')\nROOT.gStyle.SetTitleSize(0.035, 'Y')\nROOT.gStyle.SetTitleOffset(1.4, 'X')\nROOT.gStyle.SetTitleOffset(1.8, 'Y')\nROOT.gStyle.SetNdivisions(208, 'X')\nROOT.gStyle.SetFillStyle(0)\n\nROOT.gSystem.Load('libLatinoAnalysisMultiDraw.so')\n\nlumi = 35867. + 41530.\n#lumi = 35867.\n\nADDOBS = True\n\nif ADDOBS:\n resultsPath = {\n 'ptH': sys.argv[1],\n 'njet': sys.argv[2]\n }\n\nRECOMPUTE = False\n\nobservables = ['ptH', 'njet']\n\ndef ptHSource(low, high):\n return 'PTH_%.0f_%.0f' % (low, high) if low < 300. else 'PTH_GT350'\n\ndef njetSource(low, high):\n return 'NJ_%.0f' % round((low + high) * 0.5) if low < 3. else 'NJ_GE4'\n\ncomputeConfigs = {\n 'ptH': ([0., 20., 45., 80., 120., 200., 350., 400.], 'genPth'),\n 'njet': ([-0.5, 0.5, 1.5, 2.5, 3.5, 4.5], 'nCleanGenJet')\n}\n\nplottingConfigs = {\n 'ptH': (ptHSource, None, 'p_{T}^{H}', 'GeV', 'fb/GeV', True),\n 'njet': (njetSource, ['0', '1', '2', '3', '#geq4'], 'N_{jet}', '', 'fb', False)\n}\n\nBR2l2v = 0.215*0.108*0.108*9\nBRWW = 0.215\nnominalSignal = [\n ('ggH', [('ggH', 'GluGluHToWWTo2L2NuPowheg_M125', 48.52 * BR2l2v, 0.039, 0.032)], '1f77b4'),\n ('qqH', [('qqH', 'VBFHToWWTo2L2Nu_M125', 3.779 * BR2l2v, 0.04 / math.sqrt(3.), 0.021)], 'ff7f0e'),\n ('WH', [('WminusH', 'HWminusJ_HToWW_M125', 0.5313 * BRWW, 0.007 / math.sqrt(3.), 0.019), ('WplusH', 'HWplusJ_HToWW_M125', 0.8380 * BRWW, 0.007 / math.sqrt(3.), 0.019)], '2ca02c'),\n ('ZH', [('ggZH', 'ggZH_HToWW_M125', 0.1227 * BRWW, 0.251 / math.sqrt(3.), 0.024), ('ZH', 'HZJ_HToWW_M125', 0.7612 * BRWW, 0.006 / math.sqrt(3.), 0.019)], 'd62728'),\n ('ttH', [('ttH', 'ttHToNonbb_M125', 0.5065 * (1 - 0.577), 0.092 / math.sqrt(3.), 0.036)], '9467bd')\n]\n\nif RECOMPUTE:\n from setupfiducial import setupfiducial\n \n out = ROOT.TFile.Open('sigma.root', 'recreate')\n \n _histograms = []\n\n for _, srcSpec, _ in nominalSignal:\n for proc, filename, _, _, _ in srcSpec:\n drawer = ROOT.multidraw.MultiDraw('latino')\n drawer.setWeightBranch('GEN_weight_SM')\n drawer.setFilter('1')\n drawer.addInputPath('/eos/cms/store/cmst3/user/yiiyama/hww/latino_' + filename + '*.root')\n setupfiducial(drawer)\n \n outdir = out.mkdir(proc)\n outdir.cd()\n total = ROOT.TH1D('total', '', 1, 0., 1.)\n _histograms.append(total)\n drawer.addPlot(total, '0.5')\n\n for observable in observables:\n binning, xvar = computeConfigs[observable]\n for ibin in range(len(binning) - 1):\n binname = '%s_bin%d' % (observable, ibin)\n outdir.cd()\n counter = ROOT.TH1D(binname, '', 1, 0., 1.)\n _histograms.append(counter)\n if ibin == len(binning) - 2:\n cutExpr = 'fiducial && %s >= %f' % (xvar, binning[-2])\n else:\n cutExpr = 'fiducial && %s >= %f && %s < %f' % (xvar, binning[ibin], xvar, binning[ibin + 1])\n \n drawer.addCut(binname, cutExpr)\n drawer.addPlot(counter, '0.5', binname)\n \n drawer.execute()\n \n out.cd()\n out.Write()\n\nelse:\n out = ROOT.TFile.Open('sigma.root')\n\nfrom plotstyle import DataMCCanvas\nif ADDOBS:\n canvas = DataMCCanvas(lumi = lumi)\nelse:\n canvas = DataMCCanvas(sim = True)\ncanvas.Clear()\n\n#canvas = ROOT.TCanvas('c1', 'c1', 600, 600)\n#canvas.SetLeftMargin(0.15)\n#canvas.SetRightMargin(0.05)\n#canvas.SetBottomMargin(0.15)\n#canvas.SetTopMargin(0.05)\n\ncanvas.legend.setPosition(0.55, 0.7, 0.9, 0.9)\n#canvas.legend.add('obs', 'Asimov fit', opt = 'LP', color = ROOT.kBlack, lwidth = 2, mstyle = 8)\n#canvas.legend.add('nominal', 'Nominal', opt = 'LF', color = ROOT.kGray, lwidth = 2, fstyle = 3354)\n#colors = {}\n#for name, _, colstr in nominalSignal:\n# color = ROOT.TColor.GetColor('#' + colstr)\n# dcolor = ROOT.TColor.GetColorDark(color)\n# colors[name] = (color, dcolor)\n# canvas.legend.add(name, name, opt = 'LF', fcolor = color, lcolor = dcolor, lwidth = 2, fstyle = 1001)\n\n#legend.SetBorderSize(0)\n#legend.SetFillStyle(0)\n#legend.SetTextSize(0.035)\n#legend.AddEntry(observed, 'Asimov fit', 'LP')\n#legend.AddEntry(nominal, 'POWHEG+MINLO', 'LF')\n#legend.Draw()\n\n#cmssim = ROOT.TPaveText()\n#cmssim.SetX1NDC(0.18)\n#cmssim.SetY1NDC(0.86)\n#cmssim.SetX2NDC(0.4)\n#cmssim.SetY2NDC(0.95)\n#cmssim.SetTextAlign(11)\n#cmssim.SetTextFont(62)\n#cmssim.SetTextSize(0.035)\n#cmssim.SetFillStyle(0)\n#cmssim.SetBorderSize(0)\n#cmssim.AddText('CMS Preliminary')\n\nfor observable in observables:\n binning = computeConfigs[observable][0]\n sourcebin, binlabels, xtitle, xunit, yunit, logy = plottingConfigs[observable]\n \n ROOT.gROOT.cd()\n if xunit:\n fullxtitle = '%s (%s)' % (xtitle, xunit)\n else:\n fullxtitle = xtitle\n\n nominal = ROOT.TH1D('%s_nominal' % observable, ';%s;#Delta#sigma/#Delta%s (%s)' % (fullxtitle, xtitle, yunit), len(binning) - 1, array.array('d', binning))\n #alternative = ROOT.TH1D('%s_alternative' % observable, ';%s;#Delta#sigma/#Delta%s (%s)' % (fullxtitle, xtitle, yunit), len(binning) - 1, array.array('d', binning))\n\n permode = {}\n for name, _, _ in nominalSignal:\n hist = ROOT.TH1D('%s_%s' % (observable, name), ';%s;#Delta#sigma/#Delta%s (%s)' % (fullxtitle, xtitle, yunit), len(binning) - 1, array.array('d', binning))\n hist.Sumw2()\n #canvas.legend.apply(name, hist)\n\n permode[name] = hist\n\n if ADDOBS:\n observed = ROOT.TGraphAsymmErrors(len(binning) - 1) \n source = ROOT.TFile.Open(resultsPath[observable])\n resultsTree = source.Get('fitresults')\n cent = array.array('f', [0.])\n up = array.array('f', [0.])\n down = array.array('f', [0.])\n err = array.array('f', [0.])\n \n for ibin in range(len(binning) - 1):\n binname = '%s_bin%d' % (observable, ibin)\n\n sbinname = sourcebin(binning[ibin], binning[ibin + 1])\n\n width = binning[ibin + 1] - binning[ibin]\n\n if ADDOBS:\n resultsTree.SetBranchAddress('smH_hww_%s_mu' % sbinname, cent)\n resultsTree.SetBranchAddress('smH_hww_%s_mu_minosup' % sbinname, up)\n resultsTree.SetBranchAddress('smH_hww_%s_mu_minosdown' % sbinname, down)\n resultsTree.SetBranchAddress('smH_hww_%s_mu_err' % sbinname, err)\n resultsTree.GetEntry(0)\n \n if up[0] < -98.:\n up[0] = err[0]\n if down[0] < -98.:\n down[0] = err[0]\n\n dsigma = 0.\n dsigmaErr2 = 0.\n\n for name, srcSpec, _ in nominalSignal:\n for proc, _, sigma, qcdunc, pdfunc in srcSpec:\n norm = out.Get('%s/total' % proc).GetBinContent(1)\n contrib = out.Get('%s/%s' % (proc, binname)).GetBinContent(1)\n \n contrib /= norm\n contrib *= sigma\n\n if yunit.startswith('fb'):\n contrib *= 1.e+3\n \n hist = permode[name]\n hist.SetBinContent(ibin + 1, hist.GetBinContent(ibin + 1) + contrib)\n cerr = hist.GetBinError(ibin + 1)\n hist.SetBinError(ibin + 1, math.sqrt(cerr * cerr + contrib * contrib * (qcdunc * qcdunc + pdfunc * pdfunc)))\n \n dsigma += contrib\n dsigmaErr2 += contrib * contrib * (qcdunc * qcdunc + pdfunc * pdfunc)\n\n for hist in permode.itervalues():\n hist.SetBinContent(ibin + 1, hist.GetBinContent(ibin + 1) / width)\n hist.SetBinError(ibin + 1, hist.GetBinError(ibin + 1) / width)\n\n dsigma /= width\n dsigmaErr = math.sqrt(dsigmaErr2) / width\n\n nominal.SetBinContent(ibin + 1, dsigma)\n nominal.SetBinError(ibin + 1, dsigmaErr)\n\n if binlabels is not None:\n nominal.GetXaxis().SetBinLabel(ibin + 1, binlabels[ibin])\n\n if ADDOBS:\n observed.SetPoint(ibin, (binning[ibin] + binning[ibin + 1]) * 0.5, dsigma * cent[0])\n observed.SetPointEYhigh(ibin, dsigma * up[0])\n observed.SetPointEYlow(ibin, dsigma * down[0])\n\n for name, _, colstr in nominalSignal:\n color = ROOT.TColor.GetColor('#' + colstr)\n canvas.addStacked(permode[name], title = name, color = color)\n\n #nominalLine = nominal.Clone('line')\n #canvas.legend.apply('nominal', nominalLine)\n #nominalLine.SetFillStyle(0)\n\n #canvas.legend.apply('nominal', nominal)\n #nominal.SetMaximum(nominal.GetMaximum() * 1.2)\n\n #canvas.legend.apply('obs', observed)\n #observed.SetTitle('')\n\n if ADDOBS:\n #canvas.addHistogram(nominal, drawOpt = 'E2')\n #canvas.addHistogram(nominalLine, drawOpt = 'HIST')\n canvas.addObs(observed, drawOpt = 'EP')\n\n canvas.xtitle = nominal.GetXaxis().GetTitle()\n canvas.ytitle = nominal.GetYaxis().GetTitle()\n canvas.rtitle = 'Fit / prediction'\n\n if logy:\n canvas.ylimits = (nominal.GetBinContent(nominal.GetNbinsX()) * 0.1, nominal.GetBinContent(1) * 5.)\n else:\n canvas.ylimits = (0., -1.)\n\n #canvas.printWeb('hww/20190205', 'sigma_%s' % observable, logy = logy)\n canvas.printWeb('20190218_tmp', 'sigma_%s' % observable, logy = logy)\n canvas.Clear()\n\n #nominalLine.Delete()\n nominal.Delete()\n"
},
{
"alpha_fraction": 0.2741820812225342,
"alphanum_fraction": 0.3072546124458313,
"avg_line_length": 38,
"blob_id": "3f904b730c1c7b9116ccb1427de8affb7ba035cc",
"content_id": "ec6fa7326bb1bf10d7cd3a740a81f666f12914c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2812,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 72,
"path": "/Configurations/ZH3l/Full2016/SignalRegion/variables_zh_fit.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# variables\n\n#variables = {}\n \n#'fold' : # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n \nvariables['events'] = { 'name': '1', \n 'range' : (1,0,2), \n 'xaxis' : 'events', \n 'fold' : 3\n }\n\nvariables['pt1'] = { 'name': 'std_vector_lepton_pt[0]', # variable name \n 'range' : (10,0.,200), # variable range\n 'xaxis' : 'lept1_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n \nvariables['pt2'] = { 'name': 'std_vector_lepton_pt[1]', # variable name \n 'range' : (10,0.,200), # variable range\n 'xaxis' : 'lept2_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n\nvariables['pt3'] = { 'name': 'std_vector_lepton_pt[2]', # variable name \n 'range' : (10,0.,100), # variable range\n 'xaxis' : 'lept3_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n\n\nvariables['njet'] = { 'name' : 'njet',\n 'range' : (10,0,10),\n 'xaxis' : 'N_{jet}',\n 'fold' : 0\n }\n\nvariables['lead_jetPT'] = { 'name': 'std_vector_jet_pt[0]', # variable name\n 'range' : (10,0,200), # variable range\n 'xaxis' : 'Leading Jet PT [GeV]', # x axis name\n 'fold' : 0\n }\n\nvariables['metPfType1'] = { 'name' : 'metPfType1',\n 'range' : (40,0,200),\n 'xaxis' : 'pfmet [GeV]',\n 'fold' : 0\n }\n\nvariables['mjj'] = { 'name' : 'mjj',\n 'range' : (40,0,200),\n 'xaxis' : 'm_{jj} [GeV]',\n 'fold' : 0\n }\n\nvariables['dphilmetjj'] = { 'name' : 'dphilmetjj',\n 'range' : (16,0,3.14159),\n 'xaxis' : 'dphilmetjj',\n 'fold' : 0\n }\n\nvariables['mTlmetjj'] = { 'name' : 'mTlmetjj',\n 'range' : (20,0,400),\n 'xaxis' : 'mTlmetjj',\n 'fold' : 0\n }\n\nvariables['ptz'] = { 'name' : 'ptz',\n 'range' : (20,0,400),\n 'xaxis' : 'ptz',\n 'fold' : 0\n }\n\n\n\n\n"
},
{
"alpha_fraction": 0.5719641447067261,
"alphanum_fraction": 0.5793278813362122,
"avg_line_length": 24.233108520507812,
"blob_id": "317df7d021128b906e7e224c59e5d8cb69bf09a1",
"content_id": "31bd0fc1bb7ee40c34a42ee2e25854fd289b0387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7469,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 296,
"path": "/Configurations/Differential/tools/structure_plot.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# structure configuration for datacard\n# works with input file produced by restructure_input.py\n\n#structure = {} or plot = {}\n\n# imported from mkDatacards.py\n# opt\n\nimport collections\nimport re\nimport copy\n\nPLOT_DATA_BLINDED = True\n\ntry:\n len(structure)\nexcept NameError:\n # not invoked as a structure file\n doStructure = False\nelse:\n doStructure = True\n\ntry:\n len(plot)\n len(groupPlot)\nexcept NameError:\n # not invoked as a plot file\n doPlot = False\nelse:\n doPlot = True\n\n# redefine samples and cuts as simple lists\nsamples = set()\ncuts = []\nvariables = {} # redefine variables too\n\nsignals = set()\ncrs = []\nrecoBins = set()\n\n# open the input file and pick up all sample, cut, and variable names\nsource = ROOT.TFile.Open(opt.inputFile)\n\nfor ckey in source.GetListOfKeys():\n cname = ckey.GetName()\n\n if doStructure and '_CR_' in cname and '_WW_' in cname:\n continue\n\n cuts.append(cname)\n if '_CR_' in cname:\n crs.append(cname)\n\n cutdir = ckey.ReadObj()\n for vkey in cutdir.GetListOfKeys():\n vname = vkey.GetName()\n if vname not in variables:\n # first encounter\n\n variables[vname] = {'cuts': [], 'samples': []}\n\n vardir = vkey.ReadObj()\n for hkey in vardir.GetListOfKeys():\n hname = hkey.GetName()\n \n if hname.endswith('Up') or hname.endswith('Down'):\n continue\n \n matches = re.match('histo_(.+)$', hname)\n sname = matches.group(1)\n\n variables[vname]['samples'].append(sname)\n\n variables[vname]['cuts'].append(cname)\n\n # pick up all sample names in the cut (events should have all samples allowed for the cut)\n eventsdir = source.GetDirectory('%s/events' % cname)\n for hkey in eventsdir.GetListOfKeys():\n hname = hkey.GetName()\n \n if hname.endswith('Up') or hname.endswith('Down'):\n continue\n\n matches = re.match('histo_(.+)$', hname)\n sname = matches.group(1)\n\n if sname in signals or sname in samples:\n continue\n\n if sname.startswith('smH_hww') or sname.startswith('ggH_hww') or sname.startswith('xH_hww'):\n signals.add(matches.group(1))\n else:\n # signal procs added after sorting\n samples.add(matches.group(1))\n\n # extract reco bin name\n matches = re.match('.*((?:PTH|NJ)_(?:GE|GT|)[0-9]+(?:_[0-9]+|))_.+', cname)\n if matches:\n recoBins.add(matches.group(1))\n\nsource.Close()\n\nsignals = sorted(signals, key = lambda sname: int(re.match('(?:sm|gg|x)H_hww_[^_]+_(?:GE|GT|)([0-9]+)', sname).group(1)))\nsamples = sorted(samples)\nsamples.extend(signals)\ncuts.sort()\n\nif doPlot:\n plot['DATA'] = { \n 'nameHR': 'Data',\n 'color': 1, \n 'isSignal': 0,\n 'isData': 1,\n 'isBlind': (1 if PLOT_DATA_BLINDED else 0)\n }\n\n pdefs = [\n ('top', 'tW and t#bar{t}', ['top.*'], 0, ROOT.kYellow),\n ('WW', 'WW', ['WW.*', 'ggWW'], 0, ROOT.kAzure - 9),\n ('Fake', 'Non-prompt', ['Fake.*'], 0, ROOT.kGray + 1),\n ('DY', 'DY', ['DY.*'], 0, ROOT.kGreen + 2),\n ('VZ', 'VZ', ['VZ', 'WZ', 'ZZ', 'WZgS_H'], 0, ROOT.kViolet + 1),\n ('Vg', 'V#gamma', ['Vg', 'Wg'], 0, ROOT.kOrange + 10),\n ('VgS', 'V#gamma*', ['VgS','WZgS_L'], 0, ROOT.kGreen - 9),\n ('VVV', 'VVV', ['VVV'], 0, ROOT.kAzure - 3),\n ('htt', 'H#tau#tau', ['.*H_htt.*'], 0, ROOT.kRed + 2),\n ('hww', 'HWW', ['.*H_hww.*'], 1, ROOT.kRed)\n ]\n \n for gname, title, patterns, isSignal, color in pdefs:\n groupPlot[gname] = {\n 'nameHR': title,\n 'isSignal': isSignal,\n 'color': color,\n 'samples': []\n }\n \n for pattern in patterns:\n for sname in samples:\n if re.match(pattern, sname):\n plot[sname] = { \n 'color': color,\n 'isSignal': isSignal,\n 'isData': 0,\n 'scale': 1.\n }\n \n groupPlot[gname]['samples'].append(sname)\n\n # additional options\n \n legend['lumi'] = 'L = 35.9/fb'\n \n legend['sqrt'] = '#sqrt{s} = 13 TeV'\n\nif doStructure:\n for sname in samples:\n if sname == 'DATA':\n structure['DATA'] = {\n 'isSignal' : 0,\n 'isData' : 1\n }\n \n elif sname.startswith('smH_hww') or sname.startswith('ggH_hww') or sname.startswith('xH_hww'):\n structure[sname] = {\n 'isSignal' : 1,\n 'isData' : 0,\n #'removeFromCuts': crs\n }\n \n else:\n structure[sname] = {\n 'isSignal' : 0,\n 'isData' : 0\n }\n \n #structure['htt']['removeFromCuts'] = crs\n\n# restructure nuisances\n\nsampleMapping = {\n 'Fake_em': 'Fake_em',\n 'Fake_me': 'Fake_me',\n 'ggH_htt': 'htt',\n 'qqH_htt': 'htt',\n 'ZH_htt': 'htt',\n 'WH_htt': 'htt'\n}\n\nsignal_ggH_separate = False\nfor sname in signals:\n if sname.startswith('ggH'):\n signal_ggH_separate = True\n break\n\nif signal_ggH_separate:\n ggH = [sname for sname in signals if sname.startswith('ggH')]\n xH = [sname for sname in signals if not sname.startswith('ggH')]\n\n sampleMapping.update([\n ('ggH_hww', ggH),\n ('qqH_hww', xH),\n ('ZH_hww', xH),\n ('ggZH_hww', xH),\n ('WH_hww', xH),\n ('bbH_hww', xH),\n ('ttH_hww', xH)\n ])\n\nelse:\n sampleMapping.update([\n ('ggH_hww', signals),\n ('qqH_hww', signals),\n ('ZH_hww', signals),\n ('ggZH_hww', signals),\n ('WH_hww', signals),\n ('bbH_hww', signals),\n ('ttH_hww', signals)\n ])\n\nif 'minor' in samples:\n sampleMapping.update([\n ('ggWW', 'minor'),\n ('Vg', 'minor'),\n ('WZgS_L', 'minor'),\n ('WZgS_H', 'minor'),\n ('VZ', 'minor'),\n ('VVV', 'minor')\n ])\n\nnjs = ['0j', '1j', '2j', '3j', 'ge4j']\nif 'WW' not in samples:\n sampleMapping['WW'] = ['WW_%s' % nj for nj in njs]\nif 'top' not in samples:\n sampleMapping['top'] = ['top_%s' % nj for nj in njs]\nif 'DY' not in samples:\n sampleMapping['DY'] = ['DY_%s' % nj for nj in njs]\n\nfor nkey, nuisance in nuisances.items():\n if 'perRecoBin' in nuisance and nuisance['perRecoBin']:\n for bin in recoBins:\n nuisances[nkey + '_' + bin] = copy.copy(nuisance)\n nuisances[nkey + '_' + bin]['name'] += '_' + bin\n nuisances[nkey + '_' + bin]['cuts'] = [cut for cut in cuts if bin in cut]\n\n nuisances.pop(nkey)\n\nreverseSampleMapping = {}\nfor sname, value in sampleMapping.iteritems():\n if type(value) is list:\n key = tuple(value)\n else:\n key = value\n\n try:\n reverseSampleMapping[key].append(sname)\n except KeyError:\n reverseSampleMapping[key] = [sname]\n\nfor nuisance in nuisances.itervalues():\n if 'samples' not in nuisance:\n continue\n\n if 'samplespost' in nuisance:\n nuisance['samples'] = nuisance['samplespost'](nuisance, samples)\n\n if 'cutspost' in nuisance:\n nuisance['cuts'] = nuisance['cutspost'](nuisance, cuts)\n\n toShape = False\n for sname, value in nuisance['samples'].items():\n if sname not in sampleMapping:\n continue\n\n if nuisance['type'] == 'lnN':\n if not toShape:\n # has this nuisance been turned into shape?\n if type(sampleMapping[sname]) is list:\n key = tuple(sampleMapping[sname])\n else:\n key = sampleMapping[sname]\n \n mergedSnames = reverseSampleMapping[key]\n if len(set(mergedSnames) - set(nuisance['samples'])) != 0:\n print nuisance['name'], 'to shape because of', sname\n print mergedSnames, nuisance['samples']\n toShape = True\n\n if type(sampleMapping[sname]) is list:\n for mapped in sampleMapping[sname]:\n nuisance['samples'][mapped] = value\n else:\n nuisance['samples'][sampleMapping[sname]] = value\n\n if toShape:\n nuisance['type'] = 'shape'\n"
},
{
"alpha_fraction": 0.5112936496734619,
"alphanum_fraction": 0.552874743938446,
"avg_line_length": 73.92308044433594,
"blob_id": "d82c2d7a8034afee658e79d82e313087a4b699fa",
"content_id": "88d61f5f2693661419520f32030dba93eaf227b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1948,
"license_type": "no_license",
"max_line_length": 275,
"num_lines": 26,
"path": "/Configurations/Test/samples.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# samples\n\n\nmcW = 'baseW*puW'\n\n\nsamples['DY'] = {'name' : ['latino_DYJetsToLL_M-50_0000__part0.root'], 'weight' : mcW}\nsamples['top'] = {'name' : ['latino_TTTo2L2Nu_ext1__part0.root'], 'weight' : mcW}\nsamples['WW'] = {'name' : ['latino_WWTo2L2Nu.root'], 'weight' : mcW}\nsamples['VVV'] = {'name' : ['latino_WZZ.root'], 'weight' : mcW}\nsamples['ggWW'] = {'name' : ['latino_GluGluWWTo2L2Nu_MCFM.root'], 'weight' : mcW}\nsamples['Vg'] = {'name' : ['latino_Wg_MADGRAPHMLM.root'], 'weight' : mcW}\nsamples['VgS'] = {'name' : ['latino_WgStarLNuMuMu.root'], 'weight' : mcW}\nsamples['VZ'] = {'name' : ['latino_WZTo2L2Q__part0.root'], 'weight' : mcW}\nsamples['H_htt'] = {'name' : ['latino_GluGluHToTauTau_M125.root'], 'weight' : mcW}\nsamples['ggH_hww'] = {'name' : ['latino_GluGluHToWWTo2L2NuPowheg_M125.root'], 'weight' : mcW}\nsamples['qqH_hww'] = {'name' : ['latino_VBFHToWWTo2L2Nu_alternative_M125.root'], 'weight' : mcW}\nsamples['ggZH_hww'] = {'name' : ['latino_ggZH_HToWW_M125.root'], 'weight' : mcW}\nsamples['WH_hww'] = {'name' : ['latino_HWplusJ_HToWW_M125.root'], 'weight' : mcW}\nsamples['ZH_hww'] = {'name' : ['latino_HZJ_HToWW_M125.root'], 'weight' : mcW}\n\n\nsamples['Fake'] = {'name': ['../../../../../../../../../../eosBig/cms/store/group/phys_higgs/cmshww/amassiro/HWW6p3/21Jun2016_v2_Run2016B_PromptReco/l2loose__hadd__EpTCorr__fakeW12fb/latino_Run2016B_PromptReco_MuonEG.root'], 'weight' : 'trigger*fakeW2l0j', 'isData': ['all']}\n\n\nsamples['DATA'] = {'name': ['../../../../../../../../../../eosBig/cms/store/group/phys_higgs/cmshww/amassiro/HWW6p3/21Jun2016_v2_Run2016B_PromptReco/l2loose__hadd__EpTCorr__l2tight/latino_Run2016B_PromptReco_MuonEG.root'], 'weight' : 'trigger', 'isData': ['all']}\n"
},
{
"alpha_fraction": 0.5550903081893921,
"alphanum_fraction": 0.5875425338745117,
"avg_line_length": 25.35172462463379,
"blob_id": "d02535923a44cdc4ecb1274f22bccdb9283fa644",
"content_id": "7f6ec7cef8dfcf33bff53680b0247f6c16ccd9db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11463,
"license_type": "no_license",
"max_line_length": 387,
"num_lines": 435,
"path": "/Configurations/Differential/ggH2016/aliases.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#aliases = {}\n\n# imported from samples.py:\n# samples, signals\n\nmc = [skey for skey in samples if skey not in ('Fake', 'DATA')]\ntop = [skey for skey in samples if skey.startswith('top')]\n\n##############################\n\nbWP='L'\n#bWP='M'\n#bWP='T'\nbSF='bPogSF_CMVA'+bWP\n#bSF='bPogSF_CSV'+bWP\n#bSF='bPogSF_deepCSV'+bWP\n\n#eleWP='cut_WP_Tight80X'\n#eleWP='cut_WP_Tight80X_SS'\n#eleWP='mva_80p_Iso2015'\n#eleWP='mva_80p_Iso2016'\n#eleWP='mva_90p_Iso2015'\neleWP='mva_90p_Iso2016'\n\nmuWP='cut_Tight80x'\n\n##############################\n\n## categorization\n#aliases['leade'] = {\n# 'expr': 'abs(std_vector_lepton_flavour[0]) == 11'\n#}\n#\n#aliases['leadm'] = {\n# 'expr': 'abs(std_vector_lepton_flavour[0]) == 13'\n#}\n\n#aliases['highptTrail'] = {\n# 'expr': 'std_vector_lepton_pt[1] > 20.'\n#}\n#\n#aliases['lowptTrail'] = {\n# 'expr': 'std_vector_lepton_pt[1] < 20.'\n#}\n\n# Trailing lepton is a muon (with pt > 10 GeV implied) or an electron with pt > 13 GeV\naliases['trailingE13'] = {\n 'expr': 'abs(std_vector_lepton_flavour[1]) == 13 || std_vector_lepton_pt[1]>13'\n}\n\n# Leading two leptons have opposite sign & flavor\naliases['osof'] = {\n 'expr': 'std_vector_lepton_flavour[0] * std_vector_lepton_flavour[1] == -11*13'\n}\n\naliases['passConversionVeto'] = {\n 'expr': '(TMath::Abs(std_vector_lepton_flavour[0]) == 13 || std_vector_electron_passConversionVeto[0] == 1) && (TMath::Abs(std_vector_lepton_flavour[1]) == 13 || std_vector_electron_passConversionVeto[1] == 1)'\n}\n\n# Precompiled lepton cuts\naliases['LepWPCut'] = {\n 'expr': 'LepCut2l__ele_'+eleWP+'__mu_'+muWP,\n 'samples': mc + ['DATA']\n}\n\n# No jet with pt > 30 GeV\naliases['zeroJet'] = {\n 'expr': 'std_vector_jet_pt[0] < 30.'\n}\n\n# ==1 jet with pt > 30 GeV\naliases['oneJet'] = {\n 'expr': 'std_vector_jet_pt[0] >= 30. && std_vector_jet_pt[1] < 30.'\n}\n\n# ==2 jets with pt > 30 GeV\naliases['twoJet'] = {\n 'expr': 'std_vector_jet_pt[0] >= 30. && std_vector_jet_pt[1] >= 30. && std_vector_jet_pt[2] < 30.'\n}\n\n# ==3 jets with pt > 30 GeV\naliases['threeJet'] = {\n 'expr': 'std_vector_jet_pt[0] >= 30. && std_vector_jet_pt[1] >= 30. && std_vector_jet_pt[2] >= 30. && std_vector_jet_pt[3] < 30.'\n}\n\n# >=2 jets with pt > 30 GeV\naliases['manyJets'] = {\n 'expr': 'std_vector_jet_pt[0] >= 30. && std_vector_jet_pt[1] >= 30. && std_vector_jet_pt[2] >= 30. && std_vector_jet_pt[3] >= 30.'\n}\n\n## >=2 jets with pt > 30 GeV limiting to \"ggh\" configuration\n#aliases['manyJetGGH'] = {\n# 'expr': 'manyJet && (mjj < 65. || (mjj > 105. && mjj < 400.))'\n#}\n\n## number of jets capped at 2\n#aliases['njetCapped'] = {\n# 'expr': 'njet * (njet < 3) + 2 * (njet > 2)'\n#}\n\n## number of bjets\n#aliases['nbjet'] = {\n# 'expr': 'Sum$(std_vector_jet_pt > 30. && std_vector_jet_cmvav2 > -0.5884)'\n#}\n\n# b-jet veto\naliases['bVeto'] = {\n 'expr': 'bveto_CMVA' + bWP\n}\n\naliases['std_vector_jet_breq'] = {\n 'expr': 'std_vector_jet_cmvav2 > -0.5884'\n}\n\naliases['toprwgt'] = {\n 'expr': 'TMath::Sqrt(TMath::Exp(0.0615-0.0005*topLHEpt) * TMath::Exp(0.0615-0.0005*antitopLHEpt))',\n 'samples': top\n}\n\n# Lepton px, py\n#aliases['px0'] = {\n# 'expr': 'std_vector_lepton_pt[0] * cos(std_vector_lepton_phi[0])'\n#}\n#aliases['py0'] = {\n# 'expr': 'std_vector_lepton_pt[0] * sin(std_vector_lepton_phi[0])'\n#}\n#aliases['px1'] = {\n# 'expr': 'std_vector_lepton_pt[1] * cos(std_vector_lepton_phi[1])'\n#}\n#aliases['py1'] = {\n# 'expr': 'std_vector_lepton_pt[1] * sin(std_vector_lepton_phi[1])'\n#}\n\n# pxll, pyll\n#aliases['pxll'] = {\n# 'expr': 'px0 + px1'\n#}\n#aliases['pyll'] = {\n# 'expr': 'py0 + py1'\n#}\n\n# pxH, pyH\n#aliases['pxH'] = {\n# 'expr': 'pxll + metPfType1 * cos(metPfType1Phi)'\n#}\n#aliases['pyH'] = {\n# 'expr': 'pyll + metPfType1 * sin(metPfType1Phi)'\n#}\n\n# pTH - identical to pTWW\n#aliases['ptH'] = {\n# 'expr': 'sqrt(pxH * pxH + pyH * pyH)'\n#}\n\n# Lepton & b-jet id efficiency scale factor\naliases['sfWeight'] = {\n 'expr': ' * '.join(['SFweight2l', bSF, 'LepSF2l__ele_'+eleWP+'__mu_'+muWP, 'LepWPCut']),\n 'samples': mc\n}\n# And variations\naliases['sfWeightEleUp'] = {\n 'expr': 'LepSF2l__ele_'+eleWP+'__Up',\n 'samples': mc\n}\naliases['sfWeightEleDown'] = {\n 'expr': 'LepSF2l__ele_'+eleWP+'__Do',\n 'samples': mc\n}\naliases['sfWeightMuUp'] = {\n 'expr': 'LepSF2l__mu_'+muWP+'__Up',\n 'samples': mc\n}\naliases['sfWeightMuDown'] = {\n 'expr': 'LepSF2l__mu_'+muWP+'__Do',\n 'samples': mc\n}\naliases['sfWeightBtagBCUp'] = {\n 'expr': '('+bSF+'_bc_up)/('+bSF+')',\n 'samples': mc\n}\naliases['sfWeightBtagBCDown'] = {\n 'expr': '('+bSF+'_bc_down)/('+bSF+')',\n 'samples': mc\n}\naliases['sfWeightBtagUDSGUp'] = {\n 'expr': '('+bSF+'_udsg_up)/('+bSF+')',\n 'samples': mc\n}\naliases['sfWeightBtagUDSGDown'] = {\n 'expr': '('+bSF+'_udsg_down)/('+bSF+')',\n 'samples': mc\n}\n\n# Fake leptons transfer factor\naliases['fakeWeight'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP,\n 'samples': ['Fake']\n}\n# And variations - already divided by central values in formulas !\naliases['fakeWeightEleUp'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_EleUp',\n 'samples': ['Fake']\n}\naliases['fakeWeightEleDown'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_EleDown',\n 'samples': ['Fake']\n}\naliases['fakeWeightMuUp'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_MuUp',\n 'samples': ['Fake']\n}\naliases['fakeWeightMuDown'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_MuDown',\n 'samples': ['Fake']\n}\naliases['fakeWeightStatEleUp'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_statEleUp',\n 'samples': ['Fake']\n}\naliases['fakeWeightStatEleDown'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_statEleDown',\n 'samples': ['Fake']\n}\naliases['fakeWeightStatMuUp'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_statMuUp',\n 'samples': ['Fake']\n}\naliases['fakeWeightStatMuDown'] = {\n 'expr': 'fakeW2l_ele_'+eleWP+'_mu_'+muWP+'_statMuDown',\n 'samples': ['Fake']\n}\n\n# Gen lepton match\naliases['GenLepMatch'] = {\n 'expr': 'GenLepMatch2l',\n 'samples': mc\n}\n\n# Gen HT (includes leptons!)\naliases['genHT'] = {\n 'expr': 'Sum$(std_vector_LHEparton_pt * (std_vector_LHEparton_pt > 0))',\n 'samples': mc\n}\n\n# Gen Mll\naliases['genMll'] = {\n 'expr': 'sqrt(2*std_vector_dressedLeptonGen_pt[0] * std_vector_dressedLeptonGen_pt[1] * (cosh(std_vector_dressedLeptonGen_eta[0]-std_vector_dressedLeptonGen_eta[1])-cos(std_vector_dressedLeptonGen_phi[0]-std_vector_dressedLeptonGen_phi[1])))',\n 'samples': mc\n}\n\n# Gen px, py\naliases['genPx0'] = {\n 'expr': 'std_vector_dressedLeptonGen_pt[0] * cos(std_vector_dressedLeptonGen_phi[0])',\n 'samples': mc\n}\naliases['genPy0'] = {\n 'expr': 'std_vector_dressedLeptonGen_pt[0] * sin(std_vector_dressedLeptonGen_phi[0])',\n 'samples': mc\n}\naliases['genPx1'] = {\n 'expr': 'std_vector_dressedLeptonGen_pt[1] * cos(std_vector_dressedLeptonGen_phi[1])',\n 'samples': mc\n}\naliases['genPy1'] = {\n 'expr': 'std_vector_dressedLeptonGen_pt[1] * sin(std_vector_dressedLeptonGen_phi[1])',\n 'samples': mc\n}\n\n# Gen pxll, pyll\naliases['genPxll'] = {\n 'expr': 'genPx0 + genPx1',\n 'samples': mc\n}\naliases['genPyll'] = {\n 'expr': 'genPy0 + genPy1',\n 'samples': mc\n}\n\n# Gen met x, y\naliases['genMetx'] = {\n 'expr': 'metGenpt * cos(metGenphi)',\n 'samples': mc\n}\naliases['genMety'] = {\n 'expr': 'metGenpt * sin(metGenphi)',\n 'samples': mc\n}\n\n# Gen pxH, pyH\naliases['genPxH'] = {\n 'expr': 'genPxll + genMetx',\n 'samples': mc\n}\naliases['genPyH'] = {\n 'expr': 'genPyll + genMety',\n 'samples': mc\n}\n\naliases['genPth'] = {\n 'expr': 'sqrt(genPxH * genPxH + genPyH * genPyH)',\n 'samples': mc\n}\n\n# Gen pTll\naliases['genPtll'] = {\n 'expr': 'sqrt(genPxll * genPxll + genPyll * genPyll)',\n 'samples': mc\n}\n\n## Gen H pz\n#aliases['genPzH'] = {\n# 'expr': 'higgsGenpt * TMath::SinH(higgsGeneta)',\n# 'samples': mc\n#}\n#\n## Gen H energy\n#aliases['genEH'] = {\n# 'expr': 'TMath::Sqrt(higgsGenmass * higgsGenmass + TMath::Power(higgsGenpt * TMath::CosH(higgsGeneta), 2.))',\n# 'samples': mc\n#}\n#\n## Gen yH\n#aliases['genYH'] = {\n# 'expr': 'TMath::Log((genEH + genPzH) / (higgsGenmass * higgsGenmass + higgsGenpt * higgsGenpt))',\n# 'samples': mc\n#}\n#\n## Gen yH\n#aliases['absGenYH'] = {\n# 'expr': 'abs(genYH)',\n# 'samples': mc\n#}\n\n# Gen mth\naliases['genMth'] = {\n 'expr': 'sqrt(2 * metGenpt * (genPtll - genPxll * cos(metGenphi) - genPyll * sin(metGenphi)))',\n 'samples': mc\n}\n\n# Gen mtw2\naliases['genMtw2'] = {\n 'expr': 'sqrt(2 * std_vector_dressedLeptonGen_pt[1] * metGenpt * (1-cos(std_vector_dressedLeptonGen_phi[1]-metGenphi)))',\n 'samples': mc\n}\n\n# Overlap cleaning for gen jets\naliases['genJetClean'] = {\n 'expr': 'TMath::Power(std_vector_jetGen_eta - std_vector_dressedLeptonGen_eta[0], 2.) + TMath::Power(TVector2::Phi_mpi_pi(std_vector_jetGen_phi - std_vector_dressedLeptonGen_phi[0]), 2.) > 0.16 && TMath::Power(std_vector_jetGen_eta - std_vector_dressedLeptonGen_eta[1], 2.) + TMath::Power(TVector2::Phi_mpi_pi(std_vector_jetGen_phi - std_vector_dressedLeptonGen_phi[1]), 2.) > 0.16',\n 'samples': mc\n}\n\n# Components for the fiducial cut\naliases['genLeptonPt'] = {\n 'expr': 'std_vector_dressedLeptonGen_pt[0]>25 && std_vector_dressedLeptonGen_pt[1]>10 && std_vector_dressedLeptonGen_pt[2]<10',\n 'samples': signals\n}\naliases['genOSOF'] = {\n 'expr': 'std_vector_dressedLeptonGen_pid[0] * std_vector_dressedLeptonGen_pid[1] == -11 * 13',\n 'samples': signals\n}\naliases['genTrailingE13'] = {\n 'expr': '(abs(std_vector_dressedLeptonGen_pid[1]) == 13 || std_vector_dressedLeptonGen_pt[1]>13)',\n 'samples': signals\n}\n\n#aliases['genMjj'] = {\n# 'expr': expr,\n# 'samples': mc\n#}\n#aliases['genDetajj'] = {\n# 'expr': 'abs(std_vector_jetGen_eta[0] - std_vector_jetGen_eta[1])',\n# 'samples': mc\n#}\n\n# Number of gen jets with pt > 30 GeV\naliases['nCleanGenJet'] = {\n 'expr': 'Sum$(std_vector_jetGen_pt > 30 && genJetClean)',\n 'samples': mc\n}\n\n#aliases['nGenJetCapped'] = {\n# 'expr': 'nGenJet * (nGenJet < 3) + 2 * (nGenJet > 2)',\n# 'samples': mc\n#}\n\n#aliases['nGenJetGGH'] = {\n# 'expr': 'nGenJet * (nGenJet < 2) + nGenJet * (nGenJet >= 2 && (genMjj < 65. || (genMjj > 105. && genMjj < 400.)))',\n# 'samples': mc\n#}\n\n# Fiducial cut for differential measurements\naliases['fiducial'] = {\n #'expr': 'genLeptonPt && genOSOF && genTrailingE13 && genMll>12 && metGenpt>20 && genPtll>30 && genMth>=60 && genMtw2>30'\n 'expr': 'genLeptonPt && genOSOF && genTrailingE13 && genMll>12 && genPtll>30 && genMth>=60 && genMtw2>30',\n 'samples': signals\n}\n\n#aliases['gen_STXS_VBF'] = {\n# 'expr': 'higgsGenpt < 200. && genMjj > 400. && genDetajj > 2.8',\n# 'samples': signals\n#}\n#aliases['bin_njet_2_STXS_ggF_gg'] = {\n# 'expr': 'nGenJet >= 2 && !gen_STXS_VBF',\n# 'samples': signals\n#}\n#aliases['bin_njet_2_STXS_ggF_VBF'] = {\n# 'expr': 'nGenJet >= 2 && gen_STXS_VBF',\n# 'samples': signals\n#}\n#\n## Reco cuts for STXS\n#aliases['STXS_VBF'] = {\n# 'expr': 'pTWW < 200. && mjj > 400. && detajj > 2.8'\n#}\n#\n## Reco cuts used by HWW 2016\n#aliases['historical_gg'] = {\n# 'expr': 'mjj < 65. || (mjj > 105. && mjj < 400.)'\n#}\n#aliases['historical_VBF'] = {\n# 'expr': 'mjj > 400.'\n#}\n#aliases['historical_VBF'] = {\n# 'expr': 'mjj > 65. && mjj < 105.'\n#}\n#\n## >=2 jet with pt > 30 GeV, ggH tag\n#aliases['manyJet_STXS_ggF_gg'] = {\n# 'expr': 'manyJet && !STXS_VBF'\n#}\n#\n## >=2 jet with pt > 30 GeV, ggH tag\n#aliases['manyJet_STXS_ggF_VBF'] = {\n# 'expr': 'manyJet && STXS_VBF'\n#}\n"
},
{
"alpha_fraction": 0.47972509264945984,
"alphanum_fraction": 0.5459335446357727,
"avg_line_length": 24.526315689086914,
"blob_id": "8a76201918710cd1ce557300520d2044961535c8",
"content_id": "0f2eea3b5577e1a369abecb06da70944ef6a55b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4365,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 171,
"path": "/Configurations/Differential/ggH2017/variables.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#variables = {}\n\n# imported from cuts.py\n# cuts\n# imported from samples.py\n# samples signals\n\ntry:\n variables\nexcept NameError:\n import collections\n variables = collections.OrderedDict()\n cuts = []\n\nsr = [ckey for ckey in cuts if '_CR' not in ckey]\ncr = [ckey for ckey in cuts if '_CR' in ckey]\n\nnosignal = [skey for skey in samples if skey not in signals]\n\n#'fold' : # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n\nvariables['events'] = {\n 'name': '0.5',\n 'range': (1,0,1),\n 'xaxis': 'events'\n}\n\nmthbinning = [60,80,90,100,110,120,130,150,200]\nmllbinning = [10,25,35,40,45,50,55,70,90,210]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_8x9'] = {\n 'name': name,\n 'range': (72, 0., 72.),\n 'xaxis': 'm^{ll}:m_{T}^{H}', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': sr\n}\n\nmthbinning = [60,80,90,110,130,150,200]\nmllbinning = [10,25,40,50,70,90,210]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_6x6'] = {\n 'name': name,\n 'range': (36, 0., 36.),\n 'xaxis': 'm^{ll}:m_{T}^{H}', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': sr\n}\n\nmthbinning = [60,80,90,110,130,150,200]\nmllbinning = [10,20,30,50,70,90,150]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_6x6low'] = {\n 'name': name,\n 'range': (36, 0., 36.),\n 'xaxis': 'm^{ll}:m_{T}^{H}',\n 'doWeight': 1,\n 'cuts': sr\n}\n\nmllbinning = [12,30,50,70,90,110,150,200]\nname = ''\nmllbin = ['0.5'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\n \nvariables['mll_optim'] = {\n 'name': name,\n 'range': (len(mllbinning) - 1, 0., len(mllbinning) - 1.),\n 'xaxis': 'imll',\n 'cuts': sr\n}\n\nmllbinning = [10,25,35,40,45,50,55,70,90,210]\n\nvariables['mll'] = {\n 'name': 'mll',\n 'range': (mllbinning,),\n 'xaxis': 'm^{ll} [GeV]', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['jet1Eta'] = {\n 'name': 'CleanJet_eta[0] * (CleanJet_pt[0] > 30.) - 5. * (CleanJet_pt[0] < 30.)',\n 'range': (50, -4.7, 4.7),\n 'xaxis': '#eta^{j1}',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['jet2Eta'] = {\n 'name': 'CleanJet_eta[1] * (CleanJet_pt[1] > 30.) - 5. * (CleanJet_pt[1] < 30.)',\n 'range': (50, -4.7, 4.7),\n 'xaxis': '#eta^{j2}',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['met'] = {\n 'name': 'PuppiMET_pt',\n 'range': (50, 0., 100.),\n 'xaxis': 'E_{T}^{miss} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['metPhi'] = {\n 'name': 'PuppiMET_phi',\n 'range': (50, -math.pi, math.pi),\n 'xaxis': '#phi(E_{T}^{miss})',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['ptWW'] = {\n 'name': 'pTWW',\n 'range': (50, 0., 400.),\n 'xaxis': 'p_{T}^{WW} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['ht'] = {\n 'name': ('Sum$(CleanJet_pt * (CleanJet_pt > 30. && TMath::Abs(CleanJet_eta) < 4.7))',),\n 'range': (50, 0., 1000.),\n 'xaxis': 'H_{T} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n"
},
{
"alpha_fraction": 0.661109209060669,
"alphanum_fraction": 0.7039809226989746,
"avg_line_length": 46.40322494506836,
"blob_id": "57e2129c28b6af93cf30f872fe05cdad8a7d24ba",
"content_id": "d6d257320b82e79173141ad42413611a85d0a553",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2939,
"license_type": "no_license",
"max_line_length": 468,
"num_lines": 62,
"path": "/Configurations/Differential/tools/fiducial/skimslim.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nargv = sys.argv\nsys.argv = argv[:1]\n\nimport ROOT\nROOT.PyConfig.IgnoreCommandLineOptions = True\n\nfrom PhysicsTools.NanoAODTools.postprocessing.framework.eventloop import Module\n\nclass FiducialTreeMaker(Module):\n def __init__(self):\n if \"/hwwfiducial_cc.so\" not in ROOT.gSystem.GetLibraries():\n ROOT.gROOT.LoadMacro(os.path.dirname(os.path.realpath(__file__)) + '/hwwfiducial.cc+')\n\n self.worker = ROOT.HWWFiducial()\n self.readerversion = 0\n\n def initReaders(self, tree): # this function gets the pointers to Value and ArrayReaders and sets them in the C++ worker class\n print 'initReaders'\n self.worker.setTreeReaders(tree._ttreereader)\n self.readerversion = tree._ttreereaderversion # self._ttreereaderversion must be set AFTER all calls to tree.valueReader or tree.arrayReader\n\n def beginFile(self, inputFile, outputFile, inputTree, wrappedOutputTree):\n self.initReaders(inputTree)\n\n self.out = wrappedOutputTree\n self.out.branch('GenPtH', 'F')\n self.out.branch('nGenJetClean', 'i')\n self.out.branch('GenJetClean_eta', 'F', lenVar='nGenJetClean')\n self.out.branch('GenJetClean_phi', 'F', lenVar='nGenJetClean')\n self.out.branch('GenJetClean_pt', 'F', lenVar='nGenJetClean')\n\n def analyze(self, event):\n if event._tree._ttreereaderversion > self.readerversion:\n self.initReaders(event._tree)\n # do NOT access other branches in python between the check/call to initReaders and the call to C++ worker code\n if not self.worker.fiducial():\n return False\n\n self.out.fillBranch('GenPtH', self.worker.GenPtH())\n self.out.fillBranch('nGenJetClean', self.worker.nGenJetClean())\n self.out.fillBranch('GenJetClean_eta', self.worker.GenJetClean_eta())\n self.out.fillBranch('GenJetClean_phi', self.worker.GenJetClean_phi())\n self.out.fillBranch('GenJetClean_pt', self.worker.GenJetClean_pt())\n\n return True\n\nif __name__ == '__main__':\n\n from PhysicsTools.NanoAODTools.postprocessing.framework.postprocessor import PostProcessor\n\n proc = PostProcessor(\n outputDir='.',\n inputFiles=['root://cms-xrd-global.cern.ch//store/mc/RunIIFall17NanoAOD/GluGluHToWWTo2L2Nu_M125_13TeV_powheg2_JHUGenV714_pythia8/NANOAODSIM/PU2017_12Apr2018_94X_mc2017_realistic_v14-v1/110000/145E8413-D0B3-E811-A291-06F01C0001FD.root', 'root://cms-xrd-global.cern.ch//store/mc/RunIIFall17NanoAOD/GluGluHToWWTo2L2Nu_M125_13TeV_powheg2_JHUGenV714_pythia8/NANOAODSIM/PU2017_12Apr2018_94X_mc2017_realistic_v14-v1/110000/E8593D16-D1B3-E811-9924-008CFA0A55E8.root'],\n cut='nGenDressedLepton > 1',\n branchsel=os.path.dirname(os.path.realpath(__file__)) + '/branchselection.txt',\n modules=[FiducialTreeMaker()],\n outputbranchsel=os.path.dirname(os.path.realpath(__file__)) + '/outbranchselection.txt'\n )\n\n proc.run()\n"
},
{
"alpha_fraction": 0.41480553150177,
"alphanum_fraction": 0.4961104094982147,
"avg_line_length": 21.89655113220215,
"blob_id": "da2950b9402220003cbfa2bc22928b287be721f0",
"content_id": "690fb5436fbbbb0ba76c31d07e12ac21c340057a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3985,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 174,
"path": "/Configurations/VH2j/Full2017/cuts.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": " # cuts for VH2j analysis - G Camacho\n\n\n_tmp = [ \n 'mll>12.',\n 'Lepton_pt[0]>25.',\n 'Lepton_pt[1]>10.',\n '(abs(Lepton_pdgId[1]) == 13 || Lepton_pt[1]>13.)', #if its an electron, pt2>13\n '(nLepton>=2 && Alt$(Lepton_pt[2],0)<10.)', #at least 2 jets\n 'ptll>30',\n # 'fabs(Lepton_eta[0])<2.5 && fabs(Lepton_eta[1])<2.5',\n 'MET_pt > 20.', \n # 'Sum$(abs(CleanJet_eta)>2.5) == 0',\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13', #electron & muon with op. charge\n ]\n\nsupercut = ' && '.join(_tmp)\n\ndef addcut(name, exprs):\n cuts[name] = ' && '.join(exprs)\n\n_tmp = [\n 'Sum$(CleanJet_pt>30.)>=2', #At least 2 jets\n 'abs(CleanJet_eta[0])<2.5',\n 'abs(CleanJet_eta[1])<2.5',\n 'mth>60.',\n 'mth<125.',\n 'drll<2.', #DeltaRll<2\n '(Sum$(CleanJet_pt > 20. && Jet_btagDeepB[CleanJet_jetIdx] > 0.1522) == 0)', #no bjets with pt>20\n 'mjj>65.',\n 'mjj<105.',\n 'detajj<3.5',# delta eta entre dos jets \n ]\n\naddcut('VH_2j_emu', _tmp)\n\n\n_tmp = [\n 'Sum$(CleanJet_pt>30)>=2', #At least 2 jets\n 'abs(CleanJet_eta[0])<2.5',\n 'abs(CleanJet_eta[1])<2.5',\n # 'mth>60',\n # 'mth<125',\n # 'drll<2', #DeltaRll<2, not in the Top CR\n # '(Sum$(CleanJet_pt > 20. && Jet_btagDeepB[CleanJet_jetIdx] > 0.1522) == 0)', #no bjets with pt>20\n 'mjj>65',\n 'mjj<105',\n 'detajj<3.5', \n 'mll>50',\n '((Jet_btagDeepB[CleanJet_jetIdx[0]] > 0.1522) || (Jet_btagDeepB[CleanJet_jetIdx[1]] > 0.1522))', # At least one of the 2 lead jets is btagged\n ]\n\naddcut('VH_2j_topemu', _tmp)\n\n\n_tmp = [\n 'Sum$(CleanJet_pt>30)>=2', #At least 2 jets\n 'abs(CleanJet_eta[0])<2.5',\n 'abs(CleanJet_eta[1])<2.5',\n 'mth<60',\n 'drll<2', #DeltaRll<2\n '(Sum$(CleanJet_pt > 30. && Jet_btagDeepB[CleanJet_jetIdx] > 0.1522) == 0)', #no bjets with pt>30\n 'mjj>65',\n 'mjj<105',\n 'detajj<3.5',\n 'mll>40', #>40 in the DYTT CR\n 'mll<80',\n ]\n\naddcut('VH_2j_DYtautau', _tmp)\n\n\n################################\n# Jet_btagDeepB\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)<30',\n bVeto,\n ]\n\n#addcut('WW_0j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)<30',\n bVeto,\n ]\n\n#addcut('WW_1j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == 11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)<30',\n bVeto,\n ]\n\n#addcut('SS_0j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == 11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)<30',\n bVeto,\n ]\n\n#addcut('SS_1j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)<30',\n '!'+bVeto,\n ]\n\n#addcut('Top_0j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll > 30.',\n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)<30',\n '!'+bVeto,\n ]\n\n#addcut('Top_1j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll < 30.',\n 'mll<80.',\n 'Alt$(CleanJet_pt[0],0)<30',\n bVeto,\n ]\n\n#addcut('DY_0j_em', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'ptll < 30.',\n 'mll<80.',\n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)<30',\n bVeto,\n ]\n\n#addcut('DY_1j_em', _tmp)\n\n\n#_tmp = [\n# 'Lepton_pdgId[0]*Lepton_pdgId[1] == -13*13', #Dos muones de carga opuesta\n# 'ptll > 30.', #DY>mm\n# 'Alt$(CleanJet_pt[0],0)<30', #Condicion de que no haya ningun jet (con pt mayor que 30)\n# bVeto,\n# ]\n#\n#addcut('DY_0j_mm', _tmp)\n\n\n###Synchronisation\n_tmp = [\n 'ptll>30.',\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -13*13',\n 'fabs(mll - 91.1876) > 15.',\n 'Sum$(abs(CleanJet_eta)>2.5) == 0',\n bVeto,\n ]\n\n#addcut('Control_Synch_DY_Incl_mm_out', _tmp)\n"
},
{
"alpha_fraction": 0.6659919023513794,
"alphanum_fraction": 0.7024291753768921,
"avg_line_length": 34.21428680419922,
"blob_id": "6ff94548bf0411ebcb5531ab0dc4d183e10ea000",
"content_id": "cfc038627612de29621c6d0331f8ae8219c84115",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 220,
"num_lines": 14,
"path": "/Configurations/Test/README.md",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "Test\n====\n\nSteps to get plots and datacards.\n\n cd /tmp/$USER\n eosmount eosBig\n cd -\n\n mkShapes.py --pycfg=configuration.py --doThreads=True --inputDir=/tmp/$USER/eosBig/cms/store/group/phys_higgs/cmshww/amassiro/HWW12fb_v2/07Jun2016_spring16_mAODv2_12pXfbm1/MCl2loose__hadd__bSFL2pTEff__l2tight/\n \n mkPlot.py --pycfg=configuration.py --inputFile=rootFile/plots_Test.root\n \n mkDatacards.py --pycfg=configuration.py --inputFile=rootFile/plots_Test.root\n\n"
},
{
"alpha_fraction": 0.6406126618385315,
"alphanum_fraction": 0.6559297442436218,
"avg_line_length": 29.82986068725586,
"blob_id": "81bd2556b20ecf1ebbad3b7ec90529ab45d805f0",
"content_id": "c1f1d65daf4e81abd7668ed824dd1ef7daeb59f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8879,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 288,
"path": "/Configurations/Differential/tools/fiducial/hwwfiducial.cc",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#include \"TTreeReader.h\"\n#include \"TTreeReaderValue.h\"\n#include \"TTreeReaderArray.h\"\n#include \"TVector2.h\"\n#include \"TLorentzVector.h\"\n\n#include <cmath>\n#include <iostream>\n#include <vector>\n\nenum StatusBits {\n kIsPrompt = 0,\n kIsDecayedLeptonHadron,\n kIsTauDecayProduct,\n kIsPromptTauDecayProduct,\n kIsDirectTauDecayProduct,\n kIsDirectPromptTauDecayProduct,\n kIsDirectHadronDecayProduct,\n kIsHardProcess,\n kFromHardProcess,\n kIsHardProcessTauDecayProduct,\n kIsDirectHardProcessTauDecayProduct,\n kFromHardProcessBeforeFSR,\n kIsFirstCopy,\n kIsLastCopy,\n kIsLastCopyBeforeFSR\n};\n\nclass HWWFiducial {\npublic:\n HWWFiducial() {}\n ~HWWFiducial() { deleteTreeReaders(); }\n\n void setTreeReaders(TTreeReader*);\n void deleteTreeReaders();\n bool fiducial();\n\n Float_t GenPtH() const { return GenPtH_; }\n UInt_t nGenJetClean() const { return nGenJetClean_; }\n std::vector<Float_t> const& GenJetClean_eta() const { return GenJetClean_eta_; }\n std::vector<Float_t> const& GenJetClean_phi() const { return GenJetClean_phi_; }\n std::vector<Float_t> const& GenJetClean_pt() const { return GenJetClean_pt_; }\n\nprivate:\n TTreeReaderValue<UInt_t>* nGenPart_{nullptr};\n TTreeReaderArray<Int_t>* GenPart_genPartIdxMother_{nullptr};\n TTreeReaderArray<Int_t>* GenPart_pdgId_{nullptr};\n TTreeReaderArray<Int_t>* GenPart_status_{nullptr};\n TTreeReaderArray<Int_t>* GenPart_statusFlags_{nullptr};\n TTreeReaderArray<Float_t>* GenPart_eta_{nullptr};\n TTreeReaderArray<Float_t>* GenPart_phi_{nullptr};\n TTreeReaderArray<Float_t>* GenPart_pt_{nullptr};\n TTreeReaderValue<UInt_t>* nGenDressedLepton_{nullptr};\n TTreeReaderArray<Int_t>* GenDressedLepton_pdgId_{nullptr};\n TTreeReaderArray<Float_t>* GenDressedLepton_eta_{nullptr};\n TTreeReaderArray<Float_t>* GenDressedLepton_phi_{nullptr};\n TTreeReaderArray<Float_t>* GenDressedLepton_pt_{nullptr};\n TTreeReaderArray<Float_t>* GenDressedLepton_mass_{nullptr};\n TTreeReaderValue<Float_t>* GenMET_phi_{nullptr};\n TTreeReaderValue<Float_t>* GenMET_pt_{nullptr};\n TTreeReaderValue<UInt_t>* nGenJet_{nullptr};\n TTreeReaderArray<Float_t>* GenJet_eta_{nullptr};\n TTreeReaderArray<Float_t>* GenJet_phi_{nullptr};\n TTreeReaderArray<Float_t>* GenJet_pt_{nullptr};\n \n Float_t GenPtH_{};\n UInt_t nGenJetClean_{};\n std::vector<Float_t> GenJetClean_eta_{};\n std::vector<Float_t> GenJetClean_phi_{};\n std::vector<Float_t> GenJetClean_pt_{};\n};\n\nvoid\nHWWFiducial::setTreeReaders(TTreeReader* _reader)\n{\n deleteTreeReaders();\n\n nGenPart_ = new TTreeReaderValue<UInt_t>(*_reader, \"nGenPart\");\n GenPart_genPartIdxMother_ = new TTreeReaderArray<Int_t>(*_reader, \"GenPart_genPartIdxMother\");\n GenPart_pdgId_ = new TTreeReaderArray<Int_t>(*_reader, \"GenPart_pdgId\");\n GenPart_status_ = new TTreeReaderArray<Int_t>(*_reader, \"GenPart_status\");\n GenPart_statusFlags_ = new TTreeReaderArray<Int_t>(*_reader, \"GenPart_statusFlags\");\n GenPart_eta_ = new TTreeReaderArray<Float_t>(*_reader, \"GenPart_eta\");\n GenPart_phi_ = new TTreeReaderArray<Float_t>(*_reader, \"GenPart_phi\");\n GenPart_pt_ = new TTreeReaderArray<Float_t>(*_reader, \"GenPart_pt\");\n nGenDressedLepton_ = new TTreeReaderValue<UInt_t>(*_reader, \"nGenDressedLepton\");\n GenDressedLepton_pdgId_ = new TTreeReaderArray<Int_t>(*_reader, \"GenDressedLepton_pdgId\");\n GenDressedLepton_eta_ = new TTreeReaderArray<Float_t>(*_reader, \"GenDressedLepton_eta\");\n GenDressedLepton_phi_ = new TTreeReaderArray<Float_t>(*_reader, \"GenDressedLepton_phi\");\n GenDressedLepton_pt_ = new TTreeReaderArray<Float_t>(*_reader, \"GenDressedLepton_pt\");\n GenDressedLepton_mass_ = new TTreeReaderArray<Float_t>(*_reader, \"GenDressedLepton_mass\");\n GenMET_phi_ = new TTreeReaderValue<Float_t>(*_reader, \"GenMET_phi\");\n GenMET_pt_ = new TTreeReaderValue<Float_t>(*_reader, \"GenMET_pt\");\n nGenJet_ = new TTreeReaderValue<UInt_t>(*_reader, \"nGenJet\");\n GenJet_eta_ = new TTreeReaderArray<Float_t>(*_reader, \"GenJet_eta\");\n GenJet_phi_ = new TTreeReaderArray<Float_t>(*_reader, \"GenJet_phi\");\n GenJet_pt_ = new TTreeReaderArray<Float_t>(*_reader, \"GenJet_pt\");\n}\n\nvoid\nHWWFiducial::deleteTreeReaders()\n{\n delete nGenPart_;\n delete GenPart_genPartIdxMother_;\n delete GenPart_pdgId_;\n delete GenPart_status_;\n delete GenPart_statusFlags_;\n delete GenPart_eta_;\n delete GenPart_phi_;\n delete GenPart_pt_;\n delete nGenDressedLepton_;\n delete GenDressedLepton_pdgId_;\n delete GenDressedLepton_eta_;\n delete GenDressedLepton_phi_;\n delete GenDressedLepton_pt_;\n delete GenDressedLepton_mass_;\n delete GenMET_phi_;\n delete GenMET_pt_;\n delete nGenJet_;\n delete GenJet_eta_;\n delete GenJet_phi_;\n delete GenJet_pt_;\n}\n\nbool\nHWWFiducial::fiducial()\n{\n unsigned nL(*nGenDressedLepton_->Get());\n if (nL < 2)\n return false;\n\n unsigned nG(*nGenPart_->Get());\n int hwwLeptons[2] = {-1, -1}; // find exactly two status 1 leptons directly from W that's from H\n std::vector<unsigned> promptLeptons;\n for (unsigned iG(0); iG != nG; ++iG) {\n // needs to be prompt\n int statusFlags(GenPart_statusFlags_->At(iG));\n if ((statusFlags & (1 << kIsPrompt)) == 0)\n continue;\n\n int status(GenPart_status_->At(iG));\n unsigned absId(std::abs(GenPart_pdgId_->At(iG)));\n\n // a prompt finalstate e or mu, or a prompt last-copy tau\n if ((status == 1 && (absId == 11 || absId == 13)) || ((statusFlags & (1 << kIsLastCopy)) != 0 && absId == 15))\n promptLeptons.push_back(iG);\n\n if (absId != 11 && absId != 13)\n continue;\n\n int motherIdx(GenPart_genPartIdxMother_->At(iG));\n unsigned motherAbsId(0);\n\n while (true) {\n if (motherIdx == -1)\n break;\n\n motherAbsId = std::abs(GenPart_pdgId_->At(motherIdx));\n if (motherAbsId == absId)\n motherIdx = GenPart_genPartIdxMother_->At(motherIdx);\n else\n break;\n }\n if (motherAbsId != 24)\n continue;\n\n motherIdx = GenPart_genPartIdxMother_->At(motherIdx);\n motherAbsId = 0;\n\n while (true) {\n if (motherIdx == -1)\n break;\n\n motherAbsId = std::abs(GenPart_pdgId_->At(motherIdx));\n if (motherAbsId == 24)\n motherIdx = GenPart_genPartIdxMother_->At(motherIdx);\n else\n break;\n }\n if (motherAbsId != 25)\n continue;\n\n if (hwwLeptons[0] < 0)\n hwwLeptons[0] = iG;\n else if (hwwLeptons[1] < 0)\n hwwLeptons[1] = iG;\n else // too many leptons\n return false;\n }\n\n if (hwwLeptons[1] < 0)\n return false;\n\n if (GenPart_pdgId_->At(hwwLeptons[0]) * GenPart_pdgId_->At(hwwLeptons[1]) != -11*13)\n return false;\n\n double lEta[2];\n double lPhi[2];\n for (unsigned iX(0); iX != 2; ++iX) {\n lEta[iX] = GenPart_eta_->At(hwwLeptons[iX]);\n lPhi[iX] = GenPart_phi_->At(hwwLeptons[iX]);\n }\n\n TLorentzVector p4ltmp[2];\n\n for (unsigned iL(0); iL != nL; ++iL) {\n int dlId(GenDressedLepton_pdgId_->At(iL));\n double dlEta(GenDressedLepton_eta_->At(iL));\n double dlPhi(GenDressedLepton_phi_->At(iL));\n\n for (unsigned iX(0); iX != 2; ++iX) {\n double dEta(dlEta - lEta[iX]);\n double dPhi(TVector2::Phi_mpi_pi(dlPhi - lPhi[iX]));\n\n if (dEta * dEta + dPhi * dPhi < 0.01) {\n p4ltmp[iX].SetPtEtaPhiM(GenDressedLepton_pt_->At(iL), dlEta, dlPhi, GenDressedLepton_mass_->At(iL));\n break;\n }\n }\n }\n\n TLorentzVector* p4l[2];\n if (p4ltmp[0].Pt() > p4ltmp[1].Pt()) {\n p4l[0] = &p4ltmp[0];\n p4l[1] = &p4ltmp[1];\n }\n else {\n p4l[0] = &p4ltmp[1];\n p4l[1] = &p4ltmp[0];\n }\n\n if (p4l[0]->Pt() < 25. || p4l[1]->Pt() < 10. || std::abs(p4l[0]->Eta()) > 2.5 || std::abs(p4l[1]->Eta()) > 2.5)\n return false;\n\n TLorentzVector p4ll(p4ltmp[0] + p4ltmp[1]);\n if (p4ll.M() < 12. || p4ll.Pt() < 30.)\n return false;\n\n TVector2 ptll(p4ll.X(), p4ll.Y());\n TVector2 met;\n met.SetMagPhi(*GenMET_pt_->Get(), *GenMET_phi_->Get());\n\n if (std::sqrt(2. * met.Mod() * ptll.Mod() * (1. - std::cos(ptll.Phi() - met.Phi()))) < 60.)\n return false;\n\n if (std::sqrt(2. * met.Mod() * p4l[1]->Pt() * (1. - std::cos(p4l[1]->Phi() -met.Phi()))) < 30.)\n return false;\n\n GenPtH_ = (ptll + met).Mod();\n\n nGenJetClean_ = 0;\n GenJetClean_eta_.clear();\n GenJetClean_phi_.clear();\n GenJetClean_pt_.clear();\n\n unsigned nJ(*nGenJet_->Get());\n for (unsigned iJ(0); iJ != nJ; ++iJ) {\n double jPt(GenJet_pt_->At(iJ));\n if (jPt < 30.)\n continue;\n\n double jEta(GenJet_eta_->At(iJ));\n if (std::abs(jEta) > 4.7)\n continue;\n\n double jPhi(GenJet_phi_->At(iJ));\n\n bool matches(false);\n for (unsigned iP : promptLeptons) {\n double dEta(jEta - GenPart_eta_->At(iP));\n double dPhi(TVector2::Phi_mpi_pi(jPhi - GenPart_phi_->At(iP)));\n\n if (dEta * dEta + dPhi * dPhi < 0.16) {\n matches = true;\n break;\n }\n }\n if (matches)\n continue;\n\n GenJetClean_eta_.push_back(jEta);\n GenJetClean_phi_.push_back(jPhi);\n GenJetClean_pt_.push_back(jPt);\n ++nGenJetClean_;\n }\n\n return true;\n}\n"
},
{
"alpha_fraction": 0.3980144262313843,
"alphanum_fraction": 0.4855595529079437,
"avg_line_length": 21.59183692932129,
"blob_id": "d68c35b171ec9a19edebd51ebc0663453d7267a2",
"content_id": "0a457886ec6f905558ed3db01b2d385fa499e73b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 49,
"path": "/Configurations/ControlRegions/Top/Full2018/cuts.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# cuts\n\n # cuts\n\n_tmp = [ \n 'Lepton_pt[0]>20. && Lepton_pt[1]>13.' ,\n '(abs(Lepton_pdgId[0])==13 || Lepton_pt[0]>25)',\n '(abs(Lepton_pdgId[1])==13 || Lepton_pt[1]>13)', \n '(nLepton>=2 && Alt$(Lepton_pt[2],0)<10.)',\n 'fabs(Lepton_eta[0])<2.5 && fabs(Lepton_eta[1])<2.5',\n 'mll>12.',\n 'PuppiMET_pt > 20.',\n 'ptll > 30.',\n 'mth > 60.',\n 'Lepton_pdgId[0]*Lepton_pdgId[1] <0',\n ]\n\nsupercut = ' && '.join(_tmp)\n\ndef addcut(name, exprs):\n cuts[name] = ' && '.join(exprs)\n\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'Lepton_pt[1]>20', \n 'Alt$(CleanJet_pt[0],0)<30',\n 'btag0',\n ]\naddcut('top_0j_df', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'Lepton_pt[1]>20', \n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)<30',\n 'btag1',\n ]\naddcut('top_1j_df', _tmp)\n\n_tmp = [\n 'Lepton_pdgId[0]*Lepton_pdgId[1] == -11*13',\n 'Lepton_pt[1]>20', \n 'Alt$(CleanJet_pt[0],0)>30',\n 'Alt$(CleanJet_pt[1],0)>30',\n 'Alt$(CleanJet_pt[2],0)<30',\n 'btag2',\n ]\naddcut('top_2j_df', _tmp)\n\n"
},
{
"alpha_fraction": 0.6448276042938232,
"alphanum_fraction": 0.665517270565033,
"avg_line_length": 25.363636016845703,
"blob_id": "3f2bf71e25f09e9d4386fe48d439b7893e23a555",
"content_id": "5ac5690ca0a7360c82c31f166c70ab135fefd6be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 290,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 11,
"path": "/Configurations/Differential/tools/merge_plots.sh",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSAMPLE=$1\nTAG=$2\nINDIR=$3\nOUTDIR=$4\n\n#hadd -f -j 8 plots_${TAG}_ALL_$SAMPLE.root $INDIR/plots_${TAG}_ALL_$SAMPLE.*.root\n$CMSSW_BASE/bin/$SCRAM_ARCH/haddfast -C -j 8 plots_${TAG}_ALL_$SAMPLE.root $INDIR/plots_${TAG}_ALL_$SAMPLE.*.root\n\nmv plots_${TAG}_ALL_$SAMPLE.root $OUTDIR/\n"
},
{
"alpha_fraction": 0.6337823271751404,
"alphanum_fraction": 0.6359664797782898,
"avg_line_length": 34.675323486328125,
"blob_id": "97e583fd428a4ea85cc8d54bdda1d8f7eed40320",
"content_id": "aebf117fc430b8c0dfa40c629865d2299ff469b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2747,
"license_type": "no_license",
"max_line_length": 214,
"num_lines": 77,
"path": "/Configurations/Differential/tools/submit_merge_plots.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n####################################################################################\n### Run hadd in batch\n### We have too many cuts and samples in the differential measurement that a\n### single hadd (with or without multicore option) fails. The second-best thing\n### we can do is to merge them by sample. mkPlot and mkDatacard have been updated\n### to accept a directory with per-sample histogram files as the \"inputFile\"\n### argument.\n####################################################################################\n\nimport os\nimport sys\nimport shutil\nimport subprocess\nimport collections\nfrom argparse import ArgumentParser\n\nargParser = ArgumentParser(description = 'Run hadd in batch')\nargParser.add_argument('--pycfg', '-c', metavar = 'PATH', dest = 'pycfg', default = 'configuration.py', help = 'Configuration file name.')\nargParser.add_argument('--out-suffix', '-x', metavar = 'NAME', dest = 'out_suffix', default = 'merged', help = 'Suffix for the output directory name. Appended to the outputDir parameter of the configuration file.')\n\nargs = argParser.parse_args()\ndel sys.argv[1:]\n\nexecfile(args.pycfg)\n\nif os.path.isdir('%s_%s' % (outputDir, args.out_suffix)):\n sys.stderr.write('Directory %s_%s already exists.' % (outputDir, args.out_suffix))\n sys.exit(2)\n\nsamples = collections.OrderedDict()\nexecfile(samplesFile)\n\nos.makedirs(outputDir + '_merged')\n\ntry:\n os.mkdir('merge_log')\nexcept OSError:\n pass\n\ninFullPath = os.path.realpath(outputDir)\noutFullPath = os.path.realpath('%s_%s' % (outputDir, args.out_suffix))\n\nrootFiles = os.listdir(outputDir)\nneed_merging = []\n\nfor sname in samples:\n files = [f for f in rootFiles if f.startswith('plots_' + tag + '_ALL_' + sname + '.')]\n if len(files) > 1:\n need_merging.append(sname)\n else:\n newname = 'plots_' + tag + '_ALL_' + sname + '.root'\n shutil.copyfile('%s/%s' % (outputDir, files[0]), '%s_%s/%s' % (outputDir, args.out_suffix, newname))\n\njds = 'executable = %s/merge_plots.sh\\n' % os.path.dirname(os.path.realpath(__file__))\njds += 'universe = vanilla\\n'\njds += 'arguments = \"$(Sample) %s %s %s\"\\n' % (tag, inFullPath, outFullPath)\njds += 'getenv = True\\n'\njds += 'output = merge_log/$(Sample).out\\n'\njds += 'error = merge_log/$(Sample).err\\n'\njds += 'log = merge_log/$(Sample).log\\n'\njds += 'request_cpus = 8\\n'\njds += '+JobFlavour = \"longlunch\"\\n'\njds += 'queue Sample in (\\n'\nfor sname in need_merging:\n jds += sname + '\\n'\njds += ')\\n'\n\nproc = subprocess.Popen(['condor_submit'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, stdin=subprocess.PIPE)\nout, err = proc.communicate(jds)\n\nif proc.returncode != 0:\n sys.stderr.write(err)\n raise RuntimeError('Job submission failed.')\n\nprint out.strip()\n"
},
{
"alpha_fraction": 0.5277710556983948,
"alphanum_fraction": 0.559301495552063,
"avg_line_length": 29.316177368164062,
"blob_id": "8f94dfb4c6384dee24e5ffed7a98873ff4bdd591",
"content_id": "67878057c6417f589573afa43eb92e547ce0ac4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4123,
"license_type": "no_license",
"max_line_length": 260,
"num_lines": 136,
"path": "/Configurations/Differential/ggH2016/cuts.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# cuts\n\nimport re\n\n#cuts = {}\n\n# imported from samples.py:\n# samples, signals, pthBins, njetBinning\n\n_tmp = [\n 'mll>12',\n 'std_vector_lepton_pt[0]>25 && std_vector_lepton_pt[1]>10 && std_vector_lepton_pt[2]<10',\n 'metPfType1>20',\n 'ptll>30',\n 'osof',\n 'trailingE13'\n]\nsupercut = ' && '.join(_tmp)\n\ndef addcut(name, exprs):\n cuts[name] = {'expr': ' && '.join(exprs)}\n\n### sample lists separating signal bins\n\nslist_njsignal = [sname for sname in samples if sname not in signals]\nfor sname in signals:\n sample = samples[sname]\n for bname in sample['subsamples']:\n if re.match('.*_NJ_.*', bname):\n slist_njsignal.append('%s/%s' % (sname, bname))\n\nslist_pthsignal = [sname for sname in samples if sname not in signals]\nfor sname in signals:\n sample = samples[sname]\n for bname in sample['subsamples']:\n if re.match('.*_PTH_.*', bname):\n slist_pthsignal.append('%s/%s' % (sname, bname))\n\nnjetCuts = {\n '0': 'zeroJet',\n '1': 'oneJet',\n '2': 'twoJet',\n '3': 'threeJet',\n 'GE4': 'manyJets'\n}\n\npthCuts = {}\nfor pth in pthBins:\n if pth.startswith('GT'):\n pthCuts[pth] = 'pTWW >= %s' % pth[2:]\n else:\n pthCuts[pth] = 'pTWW >= %s && pTWW < %s' % tuple(pth.split('_'))\n\n### Control regions\n\n# top || DY || WW\ncrCut = '(mtw2>30 && mll>50 && !bVeto && ((zeroJet && Sum$(std_vector_jet_pt > 20. && std_vector_jet_breq) != 0) || Sum$(std_vector_jet_pt > 30. && std_vector_jet_breq) != 0)) || (mth<60 && mll>40 && mll<80 && bVeto) || (mth>60 && mtw2>30 && mll>100 && bVeto)'\n\n# top + DY + WW\ncategorization = '(mtw2>30 && mll>50 && !bVeto)*(%s)+(mth<60 && mll>40 && mll<80 && bVeto)*(%s)+(mth>60 && mtw2>30 && mll>100 && bVeto)*(%s)'\n\ndef addcr(name, binning, cutsMap, slist):\n addcut(name, [crCut])\n cuts[name]['categories'] = []\n cuts[name]['samples'] = slist\n\n topcat = []\n for ibin, bin in enumerate(binning):\n cuts[name]['categories'].append('%s_top_2016' % bin)\n if ibin != 0:\n topcat.append('%d*(%s)' % (ibin, cutsMap[bin]))\n \n dycat = []\n for ibin, bin in enumerate(binning):\n cuts[name]['categories'].append('%s_DY_2016' % bin)\n if ibin == 0:\n dycat.append('%d' % len(binning))\n else:\n dycat.append('%d*(%s)' % (ibin, cutsMap[bin]))\n \n wwcat = []\n for ibin, bin in enumerate(binning):\n cuts[name]['categories'].append('%s_WW_2016' % bin)\n if ibin == 0:\n wwcat.append('%d' % (2 * len(binning)))\n else:\n wwcat.append('%d*(%s)' % (ibin, cutsMap[bin]))\n \n cuts[name]['categorization'] = categorization % ('+'.join(topcat), '+'.join(dycat), '+'.join(wwcat))\n\n\naddcr('hww_CR_catNJ', njetBinning, njetCuts, slist_njsignal)\naddcr('hww_CR_catPTH', pthBins, pthCuts, slist_pthsignal)\n\n### Signal regions\n\npt2cats = [\n ('pt2lt20', 'std_vector_lepton_pt[1] < 20.'),\n ('pt2ge20', 'std_vector_lepton_pt[1] >= 20.')\n]\nflavcats = [\n ('em', 'abs(std_vector_lepton_flavour[0]) == 11'),\n ('me', 'abs(std_vector_lepton_flavour[0]) == 13')\n]\nchargecats = [\n ('pm', 'std_vector_lepton_flavour[0] > 0'),\n ('mp', 'std_vector_lepton_flavour[0] < 0')\n]\n\ndef addsr(name, binning, cutsMap, slist):\n addcut(name, ['mth>=60', 'mtw2>30', 'bVeto'])\n cuts[name]['categories'] = []\n cuts[name]['samples'] = slist\n\n cats = []\n for ibin, bin in enumerate(binning):\n for pt2cat, _ in pt2cats:\n for flavcat, _ in flavcats:\n for chargecat, _ in chargecats:\n cuts[name]['categories'].append('%s_cat%s%s%s_2016' % (bin, pt2cat, flavcat, chargecat))\n\n if ibin != 0:\n cats.append('%d*(%s)' % (8 * ibin, cutsMap[bin]))\n\n cats.append('4*(%s)' % pt2cats[1][1])\n cats.append('2*(%s)' % flavcats[1][1])\n cats.append('(%s)' % chargecats[1][1])\n\n # all bins cover the full phase space - no need for a default category\n cuts[name]['categorization'] = '+'.join(cats)\n\n\naddsr('hww_NJ', njetBinning, njetCuts, slist_njsignal)\naddsr('hww_PTH', pthBins, pthCuts, slist_pthsignal)\n\n#cuts = {'hww_NJ': cuts['hww_NJ']}\n"
},
{
"alpha_fraction": 0.5410821437835693,
"alphanum_fraction": 0.5731462836265564,
"avg_line_length": 27.927536010742188,
"blob_id": "c2fdb92703e86300c16b0c66aadec704e4dab7be",
"content_id": "52dcf6bb06a15c5759f5d0e83afc794baee69595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11976,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 414,
"path": "/Configurations/Differential/ggH2017/samples.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "import os\nimport copy\nfrom LatinoAnalysis.Tools.commonTools import getSampleFiles, getBaseW, addSampleWeight\n\ndef nanoGetSampleFiles(inputDir, Sample):\n return getSampleFiles(inputDir, Sample, False, 'nanoLatino_')\n\n# samples\n\ntry:\n len(samples)\nexcept NameError:\n import collections\n samples = collections.OrderedDict()\n\n################################################\n############### Fiducial bins ##################\n################################################\n\npthBinning = ['0', '10', '15', '20', '30', '45', '60', '80', '100', '120', '155', '200', '260', '350', 'inf']\npthBins = []\nfor ibin in range(len(pthBinning) - 1):\n low, high = pthBinning[ibin:ibin + 2]\n if high == 'inf':\n pthBins.append('GT%s' % low)\n else:\n pthBins.append('%s_%s' % (low, high))\n\n#yhBinning = [0., 0.15, 0.3, 0.6, 0.9, 1.2, 2.5, 10.]\nnjetBinning = ['0', '1', '2', '3', 'GE4']\n\n################################################\n################# SKIMS ########################\n################################################\n\nmcProduction = 'Fall2017_nAOD_v1_Full2017v2'\n\ndataReco = 'Run2017_nAOD_v1_Full2017v2'\n\nmcSteps = 'MCl1loose2017v2__MCCorr2017__btagPerEvent__l2loose__l2tightOR2017{var}__wwSel'\n#mcSteps = 'MCl1loose2017v2__MCCorr2017__btagPerEvent__l2loose__l2tightOR2017{var}'\n\ndef makeMCDirectory(var = ''):\n if var:\n return os.path.join(treeBaseDir, mcProduction, mcSteps.format(var = '__' + var))\n else:\n return os.path.join(treeBaseDir, mcProduction, mcSteps.format(var = ''))\n\nfakeSteps = 'DATAl1loose2017v2__DATACorr2017__l2loose__fakeW__hadd__wwSel'\n#fakeSteps = 'DATAl1loose2017v2__DATACorr2017__l2loose__fakeW'\n\ndataSteps = 'DATAl1loose2017v2__DATACorr2017__l2loose__l2tightOR2017__hadd__wwSel'\n#dataSteps = 'DATAl1loose2017v2__DATACorr2017__l2loose'\n\n##############################################\n###### Tree base directory for the site ######\n##############################################\n\nSITE=os.uname()[1]\nif 'iihe' in SITE:\n treeBaseDir = '/pnfs/iihe/cms/store/user/xjanssen/HWW2015'\nelif 'cern' in SITE:\n treeBaseDir = '/eos/cms/store/group/phys_higgs/cmshww/amassiro/HWWNano'\n\nmcDirectory = makeMCDirectory()\nfakeDirectory = os.path.join(treeBaseDir, dataReco, fakeSteps)\ndataDirectory = os.path.join(treeBaseDir, dataReco, dataSteps)\n\n################################################\n############ DATA DECLARATION ##################\n################################################\n\nDataRun = [\n ['B','Run2017B-31Mar2018-v1'],\n ['C','Run2017C-31Mar2018-v1'],\n ['D','Run2017D-31Mar2018-v1'],\n ['E','Run2017E-31Mar2018-v1'],\n ['F','Run2017F-31Mar2018-v1']\n]\n\nDataSets = ['MuonEG','SingleMuon','SingleElectron','DoubleMuon', 'DoubleEG']\n\nDataTrig = {\n 'MuonEG' : ' Trigger_ElMu' ,\n 'SingleMuon' : '!Trigger_ElMu && Trigger_sngMu' ,\n 'SingleElectron' : '!Trigger_ElMu && !Trigger_sngMu && Trigger_sngEl',\n 'DoubleMuon' : '!Trigger_ElMu && !Trigger_sngMu && !Trigger_sngEl && Trigger_dblMu',\n 'DoubleEG' : '!Trigger_ElMu && !Trigger_sngMu && !Trigger_sngEl && !Trigger_dblMu && Trigger_dblEl'\n}\n\n#########################################\n############ MC COMMON ##################\n#########################################\n\nmcCommonWeight = 'XSWeight*SFweight*GenLepMatch2l*METFilter_MC'\n\n###########################################\n############# BACKGROUNDS ###############\n###########################################\n\n###### DY #######\n\nuseDYtt = False\n\nif useDYtt:\n files = nanoGetSampleFiles(mcDirectory, 'DYJetsToTT_MuEle_M-50') + \\\n nanoGetSampleFiles(mcDirectory, 'DYJetsToLL_M-10to50-LO')\n\n samples['DY'] = {\n 'name': files,\n 'weight': mcCommonWeight,\n 'FilesPerJob': 16,\n }\n addSampleWeight(samples,'DY','DYJetsToTT_MuEle_M-50','ptllDYW_NLO')\n addSampleWeight(samples,'DY','DYJetsToLL_M-10to50-LO','ptllDYW_LO')\n\n ## Remove OF from inclusive sample (is it needed?)\n #cutSF = '(abs(Lepton_pdgId[0]*Lepton_pdgId[1]) == 11*11)||(Lepton_pdgId[0]*Lepton_pdgId[1]) == 13*13)'\n #addSampleWeight(samples,'DY','DYJetsToLL_M-50',cutSF)\n\nelse:\n files = nanoGetSampleFiles(mcDirectory, 'DYJetsToLL_M-50') + \\\n nanoGetSampleFiles(mcDirectory, 'DYJetsToLL_M-10to50-LO')\n\n samples['DY'] = {\n 'name': files,\n 'weight': mcCommonWeight,\n 'FilesPerJob': 16,\n }\n addSampleWeight(samples,'DY','DYJetsToLL_M-50','ptllDYW_NLO')\n addSampleWeight(samples,'DY','DYJetsToLL_M-10to50-LO','ptllDYW_LO')\n\n#samples['DY']['subsamples'] = {\n# '0j': 'zeroJet',\n# '1j': 'oneJet',\n# '2j': 'twoJet',\n# '3j': 'threeJet',\n# 'ge4j': 'manyJets'\n#}\n\n###### Top #######\n\nfiles = nanoGetSampleFiles(mcDirectory, 'TTTo2L2Nu') + \\\n nanoGetSampleFiles(mcDirectory, 'ST_s-channel') + \\\n nanoGetSampleFiles(mcDirectory, 'ST_t-channel_antitop') + \\\n nanoGetSampleFiles(mcDirectory, 'ST_t-channel_top') + \\\n nanoGetSampleFiles(mcDirectory, 'ST_tW_antitop') + \\\n nanoGetSampleFiles(mcDirectory, 'ST_tW_top')\n\nsamples['top'] = {\n 'name': files,\n 'weight': mcCommonWeight,\n 'FilesPerJob': 10,\n 'EventsPerJob': 100000\n}\n\naddSampleWeight(samples,'top','TTTo2L2Nu','Top_pTrw')\n\n#samples['top']['subsamples'] = {\n# '0j': 'zeroJet',\n# '1j': 'oneJet',\n# '2j': 'twoJet',\n# '3j': 'threeJet',\n# 'ge4j': 'manyJets'\n#}\n\n###### WW ########\n\nsamples['WW'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'WWTo2L2Nu_PrivateNano'),\n 'weight': mcCommonWeight + '*nllW',\n 'FilesPerJob': 8\n}\n\n#samples['WW']['subsamples'] = {\n# '0j': 'zeroJet',\n# '1j': 'oneJet',\n# '2j': 'twoJet',\n# '3j': 'threeJet',\n# 'ge4j': 'manyJets'\n#}\n\nsamples['WWewk'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'WpWmJJ_EWK'),\n 'weight': mcCommonWeight + '*(Sum$(abs(GenPart_pdgId)==6)==0)' #filter tops\n}\n\n#FIXME Check if k-factor is already taken into account in XSWeight\nfiles = nanoGetSampleFiles(mcDirectory, 'GluGluToWWToENEN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToENMN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToENTN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToMNEN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToMNMN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToMNTN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToTNEN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToTNMN') + \\\n nanoGetSampleFiles(mcDirectory, 'GluGluToWWToTNTN')\n\nsamples['ggWW'] = {\n 'name': files,\n 'weight': mcCommonWeight,\n 'FilesPerJob': 10\n}\n\n######## Vg ########\n\n#FIXME Add Zg when available\nsamples['Vg'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'Wg_MADGRAPHMLM'),\n #+ nanoGetSampleFiles(mcDirectory, 'Zg'),\n #'weight': XSWeight+'*'+SFweight+'*'+METFilter_MC + '* !(Gen_ZGstar_mass > 0 && Gen_ZGstar_MomId == 22 )',\n 'weight': 'XSWeight*SFweight*METFilter_MC*(Gen_ZGstar_mass<4)'\n}\n\n######## VgS ########\n\n#FIXME Use WZTo3LNu_mllmin01 sample (gstar mass > 100 MeV) when available. This one has gstar mass > 4 GeV\n#FIXME Add normalization k-factor\nsamples['WZgS_H'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'WZTo3LNu'),\n 'weight': mcCommonWeight+'*(Gen_ZGstar_mass>4)',\n 'FilesPerJob': 4\n}\n\n############ VZ ############\n\nfiles = nanoGetSampleFiles(mcDirectory, 'ZZTo2L2Nu') + \\\n nanoGetSampleFiles(mcDirectory, 'ZZTo2L2Q') + \\\n nanoGetSampleFiles(mcDirectory, 'ZZTo4L') + \\\n nanoGetSampleFiles(mcDirectory, 'WZTo2L2Q')\n\nsamples['VZ'] = {\n 'name': files,\n 'weight': mcCommonWeight + '*0.98',\n 'FilesPerJob': 15\n}\n\n########## VVV #########\n\nfiles = nanoGetSampleFiles(mcDirectory, 'ZZZ') + \\\n nanoGetSampleFiles(mcDirectory, 'WZZ') + \\\n nanoGetSampleFiles(mcDirectory, 'WWZ') + \\\n nanoGetSampleFiles(mcDirectory, 'WWW')\n#+ nanoGetSampleFiles(mcDirectory, 'WWG'), #should this be included? or is it already taken into account in the WW sample?\n\nsamples['VVV'] = {\n 'name': files,\n 'weight': mcCommonWeight\n}\n\n###########################################\n############# SIGNALS ##################\n###########################################\n\nsignals = []\n\n#### ggH -> WW\n\nsamples['ggH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'GluGluHToWWTo2L2NuPowheg_M125_PrivateNano'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 5\n}\n\nsignals.append('ggH_hww')\n\n############ VBF H->WW ############\nsamples['qqH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'VBFHToWWTo2L2NuPowheg_M125_PrivateNano'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 1\n}\n\nsignals.append('qqH_hww')\n\n############ ZH H->WW ############\n\nsamples['ZH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'HZJ_HToWWTo2L2Nu_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 4\n}\n\nsignals.append('ZH_hww')\n\nsamples['ggZH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'GluGluZH_HToWW_M125'),\n 'weight': mcCommonWeight\n}\n\nsignals.append('ggZH_hww')\n\n############ WH H->WW ############\n\nsamples['WH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'HWplusJ_HToWW_M125')\n + nanoGetSampleFiles(mcDirectory, 'HWminusJ_HToWW_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 30\n}\n\nsignals.append('WH_hww')\n\n############ ttH ############\n\nsamples['ttH_hww'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'ttHToNonbb_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 1\n}\n\nsignals.append('ttH_hww')\n\n############ bbH ############\n#FIXME Missing samples\n\n############ H->TauTau ############\n\nsamples['ggH_htt'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'GluGluHToTauTau_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 3\n}\n\nsignals.append('ggH_htt')\n\nsamples['qqH_htt'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'VBFHToTauTau_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 3\n}\n\nsignals.append('qqH_htt')\n\nsamples['ZH_htt'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'HZJ_HToTauTau_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 1\n}\n\nsignals.append('ZH_htt')\n\nsamples['WH_htt'] = {\n 'name': nanoGetSampleFiles(mcDirectory, 'HWplusJ_HToTauTau_M125')\n + nanoGetSampleFiles(mcDirectory, 'HWminusJ_HToTauTau_M125'),\n 'weight': mcCommonWeight,\n 'FilesPerJob': 1\n}\n\nsignals.append('WH_htt')\n\nfor sname in signals:\n sample = samples[sname]\n sample['subsamples'] = {}\n\n for flabel, fidcut in [('fid', 'fiducial'), ('nonfid', '!fiducial')]:\n for pth in pthBins:\n binName = '%s_PTH_%s' % (flabel, pth)\n if pth.startswith('GT'):\n cut = '%s && genPth > %s' % (fidcut, pth[2:])\n else:\n cut = '%s && genPth > %s && genPth < %s' % ((fidcut,) + tuple(pth.split('_')))\n \n sample['subsamples'][binName] = cut\n \n for nj in njetBinning:\n binName = '%s_NJ_%s' % (flabel, nj)\n if nj.startswith('GE'):\n cut = '%s && nCleanGenJet >= %s' % (fidcut, nj[2:])\n else:\n cut = '%s && nCleanGenJet == %s' % (fidcut, nj)\n \n sample['subsamples'][binName] = cut\n\n###########################################\n################## FAKE ###################\n###########################################\n\nsamples['Fake'] = {\n 'name': [],\n 'weight': 'METFilter_DATA*fakeW',\n 'weights': [],\n 'isData': ['all'],\n 'FilesPerJob': 15,\n}\n\nfor _, sd in DataRun:\n for pd in DataSets:\n files = nanoGetSampleFiles(fakeDirectory, pd + '_' + sd)\n samples['Fake']['name'].extend(files)\n samples['Fake']['weights'].extend([DataTrig[pd]] * len(files))\n\nsamples['Fake']['subsamples'] = {\n 'em': 'abs(Lepton_pdgId[0]) == 11',\n 'me': 'abs(Lepton_pdgId[0]) == 13'\n}\n\n###########################################\n################## DATA ###################\n###########################################\n\nsamples['DATA'] = {\n 'name': [],\n 'weight': 'METFilter_DATA*LepWPCut',\n 'weights': [],\n 'isData': ['all'],\n 'FilesPerJob': 30,\n}\n\nfor _, sd in DataRun:\n for pd in DataSets:\n files = nanoGetSampleFiles(dataDirectory, pd + '_' + sd)\n samples['DATA']['name'].extend(files)\n samples['DATA']['weights'].extend([DataTrig[pd]] * len(files))\n"
},
{
"alpha_fraction": 0.3983471095561981,
"alphanum_fraction": 0.49421486258506775,
"avg_line_length": 24.16666603088379,
"blob_id": "1cbd65fe995e3a5aeeb1737a0ae83f49ee6ddd39",
"content_id": "c45f4864f6f620b3440c45feb77d865e3b0b865c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 605,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 24,
"path": "/Configurations/ZH3l/Full2016/SignalRegion/cuts_test.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# cuts\n\n#cuts = {}\n#eleWP='cut_WP_Tight80X'\n# eleWP='cut_WP_Tight80X_SS' \n# eleWP='mva_80p_Iso2015'\n# eleWP='mva_80p_Iso2016'\n# eleWP='mva_90p_Iso2015'\n#eleWP='mva_90p_Iso2016'\n \nsupercut = 'mllmin3l>12 \\\n && std_vector_lepton_pt[0]>25 && std_vector_lepton_pt[1]>20 \\\n && std_vector_lepton_pt[2]>15 \\\n && std_vector_lepton_pt[3]<10 \\\n && abs(chlll) == 1 \\\n '\ncuts['preselection'] = '1'\n\ncuts['2jet_cut'] = ' ( std_vector_jet_pt[0] >= 30 ) \\\n && ( std_vector_jet_pt[1] >= 30 ) \\\n '\n #11 = e\n# 13 = mu\n# 15 = tau\n\n"
},
{
"alpha_fraction": 0.5647743940353394,
"alphanum_fraction": 0.6062591075897217,
"avg_line_length": 26.479999542236328,
"blob_id": "50738289f886add92b788267595f3fa9fac1a465",
"content_id": "7eca927d4bb94d39f9c2059716532bc6e9629ee6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1374,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 50,
"path": "/Configurations/ZH3l/Full2016/SignalRegion/quickplot.C",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "{\n TFile *f0 = TFile::Open(\"rootFiles_ZH3lSR/plots_ZH3lSR.root\");\n\n gStyle->SetHistMinimumZero();\n gStyle->SetHistLineWidth(3);\n gStyle->SetOptStat(0);\n\n\n TH1F* h_ZH = (TH1F*) f0->Get(\"dphi_cut/mjj/histo_ZH_hww\");\n TH1F* h_ggZH = (TH1F*) f0->Get(\"dphi_cut/mjj/histo_ggZH_hww\");\n TH1F* h_WZ = (TH1F*) f0->Get(\"dphi_cut/mjj/histo_WZ\");\n TH1F* h_Fake = (TH1F*) f0->Get(\"dphi_cut/mjj/histo_Fake\");\n\n h_ZH->SetLineColor(kViolet+1);\n h_ggZH->SetLineColor(kRed);\n h_WZ->SetLineColor(kGreen+2);\n h_Fake->SetLineColor(kBlue);\n\n h_ZH->Rebin(4);\n h_ggZH->Rebin(4);\n h_WZ->Rebin(4);\n h_Fake->Rebin(4);\n\n h_ZH->SetLineWidth(3);\n h_ggZH->SetLineWidth(3);\n h_WZ->SetLineWidth(3);\n h_Fake->SetLineWidth(3);\n\n h_ZH->Scale(1./h_ZH->Integral());\n h_ggZH->Scale(1./h_ggZH->Integral());\n h_WZ->Scale(1./h_WZ->Integral());\n h_Fake->Scale(1./h_Fake->Integral());\n\n h_ggZH->SetTitle(\"\");\n h_ggZH->GetXaxis()->SetTitle(\"m_{jj}\");\n h_ggZH->Draw(\"HIST\");\n h_ZH->Draw(\"HIST SAME\");\n h_WZ->Draw(\"HIST SAME\");\n h_ggZH->Draw(\"HIST SAME\");\n\n\n // TLegend* lgnd = new TLegend(0.12,0.67,0.34,0.89);\t\t// upper left\n TLegend* lgnd = new TLegend(0.65,0.67,0.89,0.89);\n lgnd->SetFillColor(0); lgnd->SetBorderSize(0);\n lgnd->AddEntry(h_WZ, \"WZ\");\n lgnd->AddEntry(h_ZH, \"qqZH\");\n lgnd->AddEntry(h_ggZH, \"ggZH\");\n lgnd->AddEntry(h_Fake, \"Fake\");\n lgnd->Draw();\n}\n"
},
{
"alpha_fraction": 0.2647804021835327,
"alphanum_fraction": 0.29645270109176636,
"avg_line_length": 38.41666793823242,
"blob_id": "3c1b2d91e125a5859fe8c1083575f0f1fc95085a",
"content_id": "82b24c149c6c08247f48e03471eae4dd2fc1e61a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4736,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 120,
"path": "/Configurations/ZH3l/Full2016/ControlRegion/variables_zh.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# variables\n\n#variables = {}\n \n#'fold' : # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n \nvariables['events'] = { 'name': '1', \n 'range' : (1,0,2), \n 'xaxis' : 'events', \n 'fold' : 3\n }\n\nvariables['pt1'] = { 'name': 'std_vector_lepton_pt[0]', # variable name \n 'range' : (10,0.,200), # variable range\n 'xaxis' : 'lept1_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n \nvariables['pt2'] = { 'name': 'std_vector_lepton_pt[1]', # variable name \n 'range' : (10,0.,200), # variable range\n 'xaxis' : 'lept2_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n\nvariables['pt3'] = { 'name': 'std_vector_lepton_pt[2]', # variable name \n 'range' : (7,0.,100), # variable range\n 'xaxis' : 'lept3_p_{T} [GeV]', # x axis name\n 'fold' : 0\n }\n\n\nvariables['mllmin3l'] = { 'name': 'mllmin3l', # variable name\n 'range' : (10,10,100), # variable range\n 'xaxis' : 'min m_{ll} [GeV]', # x axis name\n 'fold' : 0\n }\n\nvariables['mll'] = { 'name': 'mll', # variable name \n 'range' : (32,0,160), # variable range\n 'xaxis' : 'm_{ll} [GeV]', # x axis name\n 'fold' : 3\n }\n\nvariables['njet'] = { 'name' : 'njet',\n 'range' : (10,0,10),\n 'xaxis' : 'N_{jet}',\n 'fold' : 0\n }\n\nvariables['lead_jetPT'] = { 'name': 'std_vector_jet_pt[0]', # variable name\n 'range' : (10,0,200), # variable range\n 'xaxis' : 'Leading Jet PT [GeV]', # x axis name\n 'fold' : 0\n }\n\nvariables['dphilllmet'] = { 'name': 'dphilllmet', # variable name\n 'range' : (10,0.,3.5), # variable range\n 'xaxis' : 'min #Delta#Phi(lll,MET)', # x axis name\n 'fold' : 0\n }\n\nvariables['chlll'] = { 'name' : 'chlll',\n 'range' : (8,-2,6),\n 'xaxis' : 'ch_{lll}',\n 'fold' : 0\n }\n\nvariables['metPfType1'] = { 'name' : 'metPfType1',\n 'range' : (40,0,200),\n 'xaxis' : 'pfmet [GeV]',\n 'fold' : 0\n }\n\nvariables['mjj'] = { 'name' : 'mjj',\n 'range' : (40,0,200),\n 'xaxis' : 'm_{jj} [GeV]',\n 'fold' : 0\n }\n\nvariables['z4lveto'] = { 'name' : 'z4lveto',\n 'range' : (20,0,400),\n 'xaxis' : 'z4lveto',\n 'fold' : 0\n }\n\nvariables['dmjjmW'] = { 'name' : 'dmjjmW',\n 'range' : (20,0,200),\n 'xaxis' : 'dmjjmW',\n 'fold' : 0\n }\n\nvariables['mtw_notZ'] = { 'name' : 'mtw_notZ',\n 'range' : (20,0,200),\n 'xaxis' : 'mtw_notZ',\n 'fold' : 0\n }\n\nvariables['dphilmetjj'] = { 'name' : 'dphilmetjj',\n 'range' : (16,0,3.14159),\n 'xaxis' : 'dphilmetjj',\n 'fold' : 0\n }\n\nvariables['mTlmetjj'] = { 'name' : 'mTlmetjj',\n 'range' : (25,0,500),\n 'xaxis' : 'mTlmetjj',\n 'fold' : 0\n }\n\nvariables['ptz'] = { 'name' : 'ptz',\n 'range' : (20,0,400),\n 'xaxis' : 'ptz',\n 'fold' : 0\n }\n\nvariables['checkmZ'] = { 'name' : 'checkmZ',\n 'range' : (20,0,200),\n 'xaxis' : 'checkmZ',\n 'fold' : 0\n }\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.3809877038002014,
"alphanum_fraction": 0.43323442339897156,
"avg_line_length": 29.14696502685547,
"blob_id": "ba6a03306e13ce7fca56e0d07e7a38193d35b31c",
"content_id": "db19fc32e5e022d653d2233ea2a53b6abf955f10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9436,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 313,
"path": "/Configurations/Differential/ggH2016/variables.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "#variables = {}\n\n# imported from cuts.py\n# cuts\n# imported from samples.py\n# samples signals\n\ntry:\n variables\nexcept NameError:\n import collections\n variables = collections.OrderedDict()\n cuts = []\n\nsr = [ckey for ckey in cuts if '_CR' not in ckey]\ncr = [ckey for ckey in cuts if '_CR' in ckey]\n\nnosignal = [skey for skey in samples if skey not in signals]\n\n#'fold' : # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n\nvariables['events'] = {\n 'name': '0.5',\n 'range': (1,0,1),\n 'xaxis': 'events'\n}\n\nmthbinning = [60,80,90,100,110,120,130,150,200]\nmllbinning = [10,25,35,40,45,50,55,70,90,210]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_8x9'] = {\n 'name': name,\n 'range': (72, 0., 72.),\n 'xaxis': 'm^{ll}:m_{T}^{H}', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': sr\n}\n\nmthbinning = [60,80,90,110,130,150,200]\nmllbinning = [10,25,40,50,70,90,210]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_6x6'] = {\n 'name': name,\n 'range': (36, 0., 36.),\n 'xaxis': 'm^{ll}:m_{T}^{H}', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': sr\n}\n\nmthbinning = [60,80,90,110,130,150,200]\nmllbinning = [10,20,30,50,70,90,150]\nname = ''\nmllbin = ['1'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\nname += ' + %d*(' % (len(mllbinning) - 1)\nmthbin = [] # 1-1 for first bin\nfor imth in range(1, len(mthbinning) - 1):\n mthbin.append('(mth >= %d)' % mthbinning[imth])\nname += '+'.join(mthbin)\nname += ') - 0.5'\n\nvariables['mllVSmth_6x6low'] = {\n 'name': name,\n 'range': (36, 0., 36.),\n 'xaxis': 'm^{ll}:m_{T}^{H}',\n 'doWeight': 1,\n 'cuts': sr\n}\n\nmllbinning = [12,30,50,70,90,110,150,200]\nname = ''\nmllbin = ['0.5'] # folding underflow -> always 1\nfor imll in range(1, len(mllbinning) - 1):\n mllbin.append('(mll >= %d)' % mllbinning[imll])\nname += '+'.join(mllbin)\n \nvariables['mll_optim'] = {\n 'name': name,\n 'range': (len(mllbinning) - 1, 0., len(mllbinning) - 1.),\n 'xaxis': 'imll',\n 'cuts': sr\n}\n\nmllbinning = [10,25,35,40,45,50,55,70,90,210]\n\nvariables['mll'] = {\n 'name': 'mll',\n 'range': (mllbinning,),\n 'xaxis': 'm^{ll} [GeV]', # x axis name\n 'doWeight': 1, # do weighted plot too\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['jet1Eta'] = {\n 'name': 'std_vector_jet_eta[0] * (std_vector_jet_pt[0] > 30.) - 5. * (std_vector_jet_pt[0] < 30.)',\n 'range': (50, -4.7, 4.7),\n 'xaxis': '#eta^{j1}',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['jet2Eta'] = {\n 'name': 'std_vector_jet_eta[1] * (std_vector_jet_pt[1] > 30.) - 5. * (std_vector_jet_pt[1] < 30.)',\n 'range': (50, -4.7, 4.7),\n 'xaxis': '#eta^{j2}',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['met'] = {\n 'name': 'metPfType1',\n 'range': (50, 0., 100.),\n 'xaxis': 'E_{T}^{miss} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['metPhi'] = {\n 'name': 'metPfType1Phi',\n 'range': (50, -math.pi, math.pi),\n 'xaxis': '#phi(E_{T}^{miss})',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['ptWW'] = {\n 'name': 'pTWW',\n 'range': (50, 0., 400.),\n 'xaxis': 'p_{T}^{WW} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\nvariables['ht'] = {\n 'name': ('Sum$(std_vector_jet_pt * (std_vector_jet_pt > 30. && TMath::Abs(std_vector_jet_eta) < 4.7))',),\n 'range': (50, 0., 1000.),\n 'xaxis': 'H_{T} [GeV]',\n 'doWeight': 1,\n 'cuts': cr,\n 'samples': nosignal\n}\n\n#variables['njet'] = {\n# 'name': 'njet', \n# 'range': (5,0,5), \n# 'xaxis': 'Number of jets',\n# 'fold': 2,\n#}\n#\n#variables['ptllmet'] = {\n# 'name': 'ptH',\n# 'range': (100,0,300),\n# 'xaxis': 'p_{T}^{llmet} [GeV]',\n# 'fold': 3\n#}\n#\n#variables['ptllmet_reco'] = {\n# 'name': 'ptH',\n# 'range': (ptHBinning,),\n# 'xaxis': 'p_{T}^{llmet} [GeV]'\n#}\n#\n#variables['ptllmet_gen'] = {\n# 'name': 'higgsGenpt',\n# 'range': (ptHBinning,),\n# 'xaxis': 'p_{T}^{llmet} [GeV]',\n# 'samples': mc\n#}\n#\n#variables['rmat_pth'] = {\n# 'name': 'higgsGenpt:pTWW',\n# 'range': ([0.,15.,30.,45.,60.,80.,120.,200.,350.,400.],[0.,15.,30.,45.,60.,80.,120.,200.,350.,400.]),\n# 'xaxis': 'Reco p_{T}^{H} [GeV]',\n# 'yaxis': 'Gen p_{T}^{H} [GeV]',\n# 'fold': 2,\n# 'samples': ['ggH_hww']\n#}\n#\n#variables['rmat_njet'] = {\n# 'name': 'nGenJetCapped:njet',\n# 'range': ([0.,1.,2.,3.],[0.,1.,2.,3.]),\n# 'xaxis': 'Reco number of jets',\n# 'yaxis': 'Gen number of jets',\n# 'fold': 2,\n# 'samples': ['ggH_hww']\n#}\n\n# # just for fun plots:\n \n#variables['drll'] = { 'name': 'drll', # variable name \n# 'range': (100,0,2), # variable range\n# 'xaxis': 'DR_{ll}', # x axis name\n# 'fold': 3\n# }\n#\n#\n#variables['nvtx'] = { 'name': 'nvtx', \n# 'range': (40,0,40), \n# 'xaxis': 'nvtx', \n# 'fold': 3\n# }\n#\n#variables['mll'] = { 'name': 'mll', # variable name \n# 'range': (20,10,200), # variable range\n# 'xaxis': 'm_{ll} [GeV]', # x axis name\n# 'fold': 0\n# }\n# \n#variables['mth'] = { 'name': 'mth', # variable name \n# 'range': (10,60,200), # variable range\n# 'xaxis': 'm_{T}^{H} [GeV]', # x axis name\n# 'fold': 0\n# }\n#\n#variables['ptll'] = { 'name': 'ptll', # variable name \n# 'range': (20,0,200), # variable range\n# 'xaxis': 'pt_{ll} [GeV]', # x axis name\n# 'fold': 0\n# }\n#\n#variables['met'] = { 'name': 'metPfType1', # variable name \n# 'range': (20,0,200), # variable range\n# 'xaxis': 'pfmet [GeV]', # x axis name\n# 'fold': 0\n# }\n#\n#variables['dphill'] = { 'name': 'abs(dphill)', \n# 'range': (20,0,3.14), \n# 'xaxis': ' #Delta #phi_{ll}',\n# 'fold': 3\n# }\n#\n#variables['pt1'] = { 'name': 'std_vector_lepton_pt[0]', \n# 'range': (40,0,200), \n# 'xaxis': 'p_{T} 1st lep',\n# 'fold': 0 \n# }\n#\n#variables['pt2'] = { 'name': 'std_vector_lepton_pt[1]', \n# 'range': (40,0,100), \n# 'xaxis': 'p_{T} 2nd lep',\n# 'fold': 0 \n# }\n#\n#\n#\n#variables['eta1'] = { 'name': 'std_vector_lepton_eta[0]', \n# 'range': (20,-3,3), \n# 'xaxis': ' #eta 1st lep',\n# 'fold': 3 \n# }\n#\n#variables['eta2'] = { 'name': 'std_vector_lepton_eta[1]', \n# 'range': (20,-3,3), \n# 'xaxis': ' #eta 2nd lep',\n# 'fold': 3 \n# }\n#\n#variables['jetpt1'] = {\n# 'name': 'std_vector_jet_pt[0]', \n# 'range': (40,0,200), \n# 'xaxis': 'p_{T} 1st jet',\n# 'fold': 2 # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n# }\n#\n#variables['jetpt2'] = {\n# 'name': 'std_vector_jet_pt[1]', \n# 'range': (40,0,200), \n# 'xaxis': 'p_{T} 2nd jet',\n# 'fold': 2 # 0 = not fold (default), 1 = fold underflowbin, 2 = fold overflow bin, 3 = fold underflow and overflow\n# }\n#\n#variables['jeteta1'] = { 'name': 'std_vector_jet_eta[0]',\n# 'range': (80,-5.0,5.0),\n# 'xaxis': ' #eta 1st jet',\n# 'fold': 0\n# }\n#\n#variables['jeteta2'] = { 'name': 'std_vector_jet_eta[1]',\n# 'range': (80,-5.0,5.0),\n# 'xaxis': ' #eta 2nd jet',\n# 'fold': 0\n# }\n"
},
{
"alpha_fraction": 0.5648446083068848,
"alphanum_fraction": 0.5787781476974487,
"avg_line_length": 17.8383846282959,
"blob_id": "2de52e832bac1aa47e8388fd61e9d90065502724",
"content_id": "5cda0812524142ceb7c0bbcad0dcd9b2c70a7d1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1866,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 99,
"path": "/Configurations/Differential/ggH2016/structure.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# structure configuration for datacard\n\n#structure = {}\n\n# imported from samples.py:\n# samples, treeBaseDir, mcProduction, mcSteps\n# imported from cuts.py\n# cuts\n\n# first remove samples we won't use in limit setting\nsamples.pop('DY')\nsamples.pop('top')\nsamples.pop('ggH_hww')\nsamples.pop('XH_hww')\n\nmc = [skey for skey in samples if skey not in ('Fake', 'DATA')]\ndy = [skey for skey in samples if skey.startswith('DY')]\ntop = [skey for skey in samples if skey.startswith('top')]\nsignal = [skey for skey in samples if '_hww' in skey]\nggh = [skey for skey in samples if skey.startswith('ggH_hww')]\nxh = [skey for skey in samples if skey.startswith('XH_hww')]\n\ntopcr = [ckey for ckey in cuts if ckey.startswith('topcr')]\ndycr = [ckey for ckey in cuts if ckey.startswith('dycr')]\nsr = [ckey for ckey in cuts if ckey.startswith('sr')]\n\n# keys here must match keys in samples.py\n#\nfor skey in dy:\n structure[skey] = {\n 'isSignal' : 0,\n 'isData' : 0\n }\n\nfor skey in top:\n structure[skey] = {\n 'isSignal' : 0,\n 'isData' : 0\n }\n\nstructure['Fake'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['WW'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['ggWW'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['Vg'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['WZgS_L'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['WZgS_H'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['VZ'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nstructure['VVV'] = {\n 'isSignal' : 0,\n 'isData' : 0\n}\n\nfor skey in signal:\n structure[skey] = {\n 'isSignal' : 1,\n 'isData' : 0,\n 'removeFromCuts': dycr + topcr\n }\n\nstructure['H_htt'] = {\n 'isSignal' : 0,\n 'isData' : 0,\n 'removeFromCuts': dycr + topcr\n}\n\n# data\n\nstructure['DATA'] = {\n 'isSignal' : 0,\n 'isData' : 1\n}\n\n"
},
{
"alpha_fraction": 0.7029361128807068,
"alphanum_fraction": 0.7400690913200378,
"avg_line_length": 22.15999984741211,
"blob_id": "8576355794e5589a5c5001f2fa63d0e54e454c96",
"content_id": "e67fae9a37676b56ae0616cc7d38027c1acdc6b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 50,
"path": "/Configurations/ZH3l/Full2016/ControlRegion/configuration.py",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "# example of configuration file\n\n#eleWP='cut_WP_Tight80X'\n# eleWP='cut_WP_Tight80X_SS'\n#eleWP='mva_80p_Iso2015'\n#eleWP='mva_80p_Iso2016'\n#eleWP='mva_90p_Iso2015'\neleWP='mva_90p_Iso2016'\n\n#tag = 'WH3l_ControlRegion_Final_'+eleWP\n#tag = 'WH3l_ControlRegion_forPlots_'+eleWP\ntag = 'ZH3lCRs'\n\n# used by mkShape to define output directory for root files\noutputDir = 'rootFiles_'+tag\n#outputDir = 'rootFiles_forplots'+tag\n\n\n# file with list of variables\n#variablesFile = 'variables.py'\nvariablesFile = 'variables_zh.py'\n\n# file with list of cuts\n#cutsFile = 'cuts.py' \ncutsFile = 'cuts_zhCR.py'\n\n# file with list of samples\nsamplesFile = 'samples_zh.py' \n\n# file with list of samples\nplotFile = 'plot.py' \n\n# luminosity to normalize to (in 1/fb)\n#lumi = 12.2950\nlumi = 35.867\n\n# used by mkPlot to define output directory for plots\n# different from \"outputDir\" to do things more tidy\noutputDirPlots = 'plot_'+tag\n\n# used by mkDatacards to define output directory for datacards\noutputDirDatacard = 'datacards_'+tag\n\n\n# structure file for datacard\nstructureFile = 'structure.py'\n\n\n# nuisances file for mkDatacards and for mkShape\nnuisancesFile = 'nuisances_empty.py'\n"
},
{
"alpha_fraction": 0.669792890548706,
"alphanum_fraction": 0.7444314360618591,
"avg_line_length": 70.95774841308594,
"blob_id": "7bee2ede326c73ffd66722ab3028940747a7353f",
"content_id": "b91c0f513cdd98906e083fb4e38f6cbae44993fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5118,
"license_type": "no_license",
"max_line_length": 220,
"num_lines": 71,
"path": "/Configurations/VH2j/scripts/doVH2j.sh",
"repo_name": "calderona/PlotsConfigurations",
"src_encoding": "UTF-8",
"text": "\n# cd ~/Framework/CMSSW_7_1_15/src/\ncd ~/Framework/Combine/CMSSW_7_4_7/src/\n\neval `scramv1 runtime -sh`\ncd -\n\n# fix\n# \n# cat VH2j/datacards/hww2l2v_13TeV_of2j_vh2j/mll/datacard.txt.pruned.txt | grep -v \"DY_ibin_2\" | grep -v \"DY_ibin_4\" &> VH2j/datacards/hww2l2v_13TeV_of2j_vh2j/mll/datacard.test.txt.pruned.txt\n# mv VH2j/datacards/hww2l2v_13TeV_of2j_vh2j/mll/datacard.test.txt.pruned.txt VH2j/datacards/hww2l2v_13TeV_of2j_vh2j/mll/datacard.txt.pruned.txt\n#\ncat VH2j/datacards/hww2l2v_13TeV_top_of2j_vh2j/events/datacard.txt.pruned.txt | grep -v \"DY_ibin_1\" | grep -v \"Vg_ibin_1\" &> VH2j/datacards/hww2l2v_13TeV_top_of2j_vh2j/events/datacard.test.txt.pruned.txt\nmv VH2j/datacards/hww2l2v_13TeV_top_of2j_vh2j/events/datacard.test.txt.pruned.txt VH2j/datacards/hww2l2v_13TeV_top_of2j_vh2j/events/datacard.txt.pruned.txt\n\n\ncat VH2j/datacards/hww2l2v_13TeV_dytt_of2j_vh2j/events/datacard.txt.pruned.txt | grep -v \"DY_ibin_1\" | grep -v \"Vg_ibin_1\" &> VH2j/datacards/hww2l2v_13TeV_dytt_of2j_vh2j/events/datacard.test.txt.pruned.txt\nmv VH2j/datacards/hww2l2v_13TeV_dytt_of2j_vh2j/events/datacard.test.txt.pruned.txt VH2j/datacards/hww2l2v_13TeV_dytt_of2j_vh2j/events/datacard.txt.pruned.txt\n\n# \n# cat ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.txt.pruned.txt | grep -v \"_DY_ibin_1\" | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.txt.pruned.txt\n# \n# cat ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.txt.pruned.txt | grep -v \"_DY_ibin_1\" | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.txt.pruned.txt\n# \n# cat ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.txt.pruned.txt | grep -v \"_DY_ibin_1\" | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.txt.pruned.txt\n\n# \n# cat ggH/datacards/hww2l2v_13TeV_top_of0j/events/datacard.txt.pruned.txt | grep -v \"_DY_ibin_1\" | grep -v \"_Vg_ibin_1\" | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_top_of0j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_top_of0j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_top_of0j/events/datacard.txt.pruned.txt\n# \n# cat ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.txt.pruned.txt | grep -v \"_DY_ibin_1\" | grep -v \"_Vg_ibin_1\" | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_top_of1j/events/datacard.txt.pruned.txt\n# \n# cat ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.txt.pruned.txt | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_dytt_of0j/events/datacard.txt.pruned.txt\n# \n# cat ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.txt.pruned.txt | grep -v \"_VVV_ibin_1\" &> ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.test.txt.pruned.txt\n# mv ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.test.txt.pruned.txt ggH/datacards/hww2l2v_13TeV_dytt_of1j/events/datacard.txt.pruned.txt\n\n\n\n\n\n\n\n# combine\n \ncombineCards.py of2jvh2j13=VH2j/datacards/hww2l2v_13TeV_of2j_vh2j/mll/datacard.txt.pruned.txt \\\n of2jvh2j13Top=VH2j/datacards/hww2l2v_13TeV_top_of2j_vh2j/events/datacard.txt.pruned.txt \\\n of2jvh2j13DYtt=VH2j/datacards/hww2l2v_13TeV_dytt_of2j_vh2j/events/datacard.txt.pruned.txt \\\n > Data2016.vh2j.pruned.txt\n\n# results\n\ncombine -M MaxLikelihoodFit --rMin=-9 --rMax=10 -t -1 --expectSignal 1 Data2016.vh2j.pruned.txt > result.MaxLikelihoodFit.Data2016.vh2j.pruned.txt\n\ncombine -M ProfileLikelihood --significance -t -1 --expectSignal 1 Data2016.vh2j.pruned.txt > result.Significance.Data2016.vh2j.pruned.txt\n\n\ncombine -M MultiDimFit Data2016.vh2j.pruned.txt -m 125 -t -1 --expectSignal 1 --algo=grid --points 200 --setPhysicsModelParameterRanges r=-9,10 -n \"LHScanHVH2j\" > result.LikelihoodScan.Data2016.vh2j.pruned.txt\n\n\n# data\n\ncombine -M MaxLikelihoodFit --rMin=-9 --rMax=10 Data2016.vh2j.pruned.txt > result.data.MaxLikelihoodFit.Data2016.vh2j.pruned.txt\n\ncombine -M ProfileLikelihood --significance Data2016.vh2j.pruned.txt > result.data.Significance.Data2016.vh2j.pruned.txt\n\ncombine -M MultiDimFit Data2016.vh2j.pruned.txt -m 125 --algo=grid --points 200 --setPhysicsModelParameterRanges r=-9,10 -n \"LHScanHdataVH2j\" > result.data.LikelihoodScan.Data2016.vh2j.pruned.txt\n\n\n\n "
}
] | 24 |
fordft168/Connect4AI | https://github.com/fordft168/Connect4AI | 3164f07f45e27ada8cfab766380e09ef5d76320a | a62b096dae7c50bddbd894d64e13d31723343d7f | 9236a45f42b907ee607f24a61b8eab444c5db71d | refs/heads/master | "2022-04-06T01:14:21.609936" | "2019-12-22T02:49:17" | "2019-12-22T02:49:17" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6927453875541687,
"alphanum_fraction": 0.6965386271476746,
"avg_line_length": 50.43902587890625,
"blob_id": "3e71aa14dfc28db233c03fde5451c2137ed29e3b",
"content_id": "64534588293bfc7a2f9360d52ec596a34ea32102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2109,
"license_type": "no_license",
"max_line_length": 274,
"num_lines": 41,
"path": "/README.md",
"repo_name": "fordft168/Connect4AI",
"src_encoding": "UTF-8",
"text": "# Connect4AI\nA [Monte Carlo](https://en.wikipedia.org/wiki/Monte_Carlo_method) AI for [Connect4](https://en.wikipedia.org/wiki/Connect_Four) written in [Python](https://python.org). \n\nThis project was tested in Python 3.8 and should work with any Python 3 install.\n\n# Usage:\n ```python Connect4.py``` will run a simulated game AI vs AI.\n \n# Options:\n ``` --singleplayer ``` lets you play against the AI.\n \n ``` --multiplayer ``` lets you play against a friend (or yourself if you dont have any :().\n\n ``` --norush ``` will let the AI take its time, hey we aren't in a rush here!\n \n ``` --rush ``` will make the AI rush its simulations if simulations are not proving favorable. This is on by default. \n \n ``` --pretty ``` will allow you to live in the world of color TV. Makes use of [Colorama](https://pypi.org/project/colorama/)\n \n ``` --clearable ``` makes the console clear itself when the board redraws.\n \n ``` --first``` and ```--second``` lets you choose if you go first or not in singleplayer mode. This defaults to first.\n \n ``` --easy ```,``` --medium ```,``` --hard ```,``` --insane ```,``` --master ```,``` --demigod ```, ```--god``` are difficulty options, see if you can beat them all! However after insane the computer takes forever to move depending on your CPU single threaded performance.\n\n# Things to Tweak\n```BOARD_WIDTH```, ```BOARD_HEIGHT```, and ```AI_STRENGTH``` can all be easily changed, just put in any non-zero positve integer.\n\n``` BOARD_WIDTH ``` is the width of the game board.\n\n``` BOARD_HEIGHT ``` is the height of the game board.\n\n``` AI_STRENGTH ``` is how many simulations the AI runs on each of the possible moves.\n\n# Potential Improvements\nMultithreading/Multiprocessing - run all 7 possible move simulations in parallel. Might not make sense considering the GIL.\n\nNumpy - find a way to speed up calculations using numpy, or by using things other than expensive python objects.\n\n# Inspiration\nInspired by https://github.com/antirez/connect4-montecarlo. Antirez did a great job writing his version in C. C is nice, however Python is the language of the gods.\n"
},
{
"alpha_fraction": 0.4985657334327698,
"alphanum_fraction": 0.5113352537155151,
"avg_line_length": 32.610591888427734,
"blob_id": "74119fbeeb470ca11a813c5cd7d9814126c32677",
"content_id": "14f725c6fd75da5bda59ce7948dcca1fd84ca8d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10807,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 321,
"path": "/Connect4.py",
"repo_name": "fordft168/Connect4AI",
"src_encoding": "UTF-8",
"text": "import sys\nimport time\nfrom copy import deepcopy\nfrom random import randint, shuffle\n\nBOARD_WIDTH = 7\nBOARD_HEIGHT = 6\nAI_STRENGTH = 200\ncellOptions = [\" \", \"Y\", \"R\"]; # empty, Yellow symbol, Red symbol\n\nCIRCLE_INVALID = -1\nCIRCLE_EMPTY = 0\nCIRCLE_YELLOW = 1\nCIRCLE_RED = 2\nCIRCLE_DRAW = 3\nNO_WINNER = 4\nCOLORAMA = False\nCLEARABLE = False\nRUSH = True\nemptyBoard = [[0 for x in range(BOARD_WIDTH)] for y in range(BOARD_HEIGHT)]\nBX = BOARD_WIDTH - 1\nBY = BOARD_HEIGHT - 1\nttmList = []\nBANNER = ''' _/_/_/ _/ _/ _/ \n _/ _/_/ _/_/_/ _/_/_/ _/_/ _/_/_/ _/_/_/_/ _/ _/ \n _/ _/ _/ _/ _/ _/ _/ _/_/_/_/ _/ _/ _/_/_/_/ \n_/ _/ _/ _/ _/ _/ _/ _/ _/ _/ _/ \n _/_/_/ _/_/ _/ _/ _/ _/ _/_/_/ _/_/_/ _/_/ _/ '''\n\nSMALL_BANNER = ''' _ \n/ _ ._ ._ _ __|_|_|_ \n\\_(_)| || |(/_(_ |_ | '''\n\ndef Get(b, level, col):\n if col < 0 or col > BX or level < 0 or level > BY:\n return CIRCLE_INVALID\n return b[level][col]\n\n\ndef Set(b, level, col, value):\n b[level][col] = value\n\n\ndef ColIsFull(b, col):\n return (Get(b, BY, col) != CIRCLE_EMPTY)\n\n\ndef Drop(b, col, value):\n if (ColIsFull(b,col) == CIRCLE_INVALID):\n return 0\n for level in range(0,BOARD_HEIGHT):\n if Get(b, level, col) == CIRCLE_EMPTY:\n Set(b, level, col, value)\n break\n return 1\n \n \ndef printGameBoard(b):\n export = \"\"\n if CLEARABLE:\n os.system('cls||echo -e \\\\\\\\033c')\n if COLORAMA:\n export = export + colorama.Fore.YELLOW + SMALL_BANNER + colorama.Style.RESET_ALL + \"\\n\"\n else:\n export = export + SMALL_BANNER + \"\\n\"\n for level in range(BY, -1, -1):\n export = export + str(level)\n for col in range(0, BOARD_WIDTH):\n color = Get(b, level, col)\n if COLORAMA:\n if color == CIRCLE_YELLOW:\n export = export + colorama.Fore.YELLOW+\"[Y]\"+colorama.Style.RESET_ALL\n elif color == CIRCLE_RED:\n export = export + colorama.Fore.RED+\"[R]\"+colorama.Style.RESET_ALL\n else:\n export = export + \"[ ]\"\n else:\n export = export + \"[\" + str(cellOptions[color]) + \"]\"\n export = export + \"\\n\"\n export = export + \" \"\n for col in range(0, BOARD_WIDTH):\n export = export + \" \" + str(col) + \" \"\n print(export)\n\n\ndef GetWinner(b):\n empty = 0\n sp = 0\n for level in range(BY, -1, -1):\n for col in range(0, BX):\n color = Get(b, level, col)\n if (color == CIRCLE_EMPTY):\n empty = empty + 1\n continue\n directory = [[1,0],[0,1],[1,1],[-1,1]]\n \n for d in range(0, 4):\n start_col = col\n start_level = level\n while(Get(b, start_level-directory[d][1], start_col-directory[d][0]) == color):\n start_col = start_col - directory[d][0]\n start_level = start_level - directory[d][1]\n \n count = 0\n while(Get(b, start_level, start_col) == color):\n count = count + 1\n start_col = start_col + directory[d][0]\n start_level = start_level + directory[d][1]\n if (count >= 4):\n return color\n if(empty <= BOARD_HEIGHT * BOARD_WIDTH):\n return CIRCLE_EMPTY\n return CIRCLE_DRAW\n\n\ndef RandomGame(b, tomove):\n for i in range(0, BOARD_HEIGHT * BOARD_WIDTH):\n potentialMoves = [x for x in range(0,BOARD_WIDTH)]\n shuffle(potentialMoves)\n for move in potentialMoves:\n if(not ColIsFull(b, move)):\n nextMove = move\n break\n if (Drop(b, nextMove, tomove)):\n if(tomove == CIRCLE_YELLOW):\n tomove = CIRCLE_RED\n else:\n tomove = CIRCLE_YELLOW\n winner = GetWinner(b)\n if (winner != CIRCLE_EMPTY):\n return winner\n return CIRCLE_DRAW\n\n\ndef SuggestMove(b, tomove, simulations=AI_STRENGTH):\n best = -1\n best_ratio = 0\n if COLORAMA:\n if tomove == CIRCLE_YELLOW:\n print(colorama.Fore.YELLOW + \"YELLOW IS THINKING\" + colorama.Style.RESET_ALL)\n elif tomove == CIRCLE_RED:\n print(colorama.Fore.RED + \"RED IS THINKING\" + colorama.Style.RESET_ALL)\n for move in range(0,BX+1):\n ttm = time.time()\n if (ColIsFull(b,move)):\n continue\n won = 0\n lost = 0\n draw = 0\n print_neutral = 1\n for j in range(0, simulations):\n copy = deepcopy(b)\n Drop(copy, move, tomove);\n if (GetWinner(copy) == tomove):\n return move\n if (tomove == CIRCLE_YELLOW):\n nextPlayer = CIRCLE_RED\n else:\n nextPlayer = CIRCLE_YELLOW\n winner = RandomGame(copy, nextPlayer)\n if (winner == CIRCLE_YELLOW or winner == CIRCLE_RED):\n if (winner == tomove):\n won = won + 1\n else:\n lost = lost + 1\n else:\n draw = draw + 1\n if j == AI_STRENGTH/2 and RUSH == True:\n ratio = float(won)/(lost+won+1);\n if(ratio+0.05 <= best_ratio and best != -1):\n if COLORAMA:\n print(colorama.Fore.RED + \"X\" + colorama.Style.RESET_ALL, end = \" \")\n print_neutral = 0\n break\n ratio = float(won)/(lost+won+1);\n if(ratio > best_ratio or best == -1):\n best = move\n best_ratio = ratio\n if COLORAMA:\n print(colorama.Fore.GREEN + \"$\" + colorama.Style.RESET_ALL, end = \" \")\n print_neutral = 0\n if COLORAMA and print_neutral == 1:\n print(colorama.Fore.YELLOW + \"?\" + colorama.Style.RESET_ALL, end = \" \")\n ttmList.append(time.time() - ttm)\n print(\"Move\", move, \":\", round(ratio*100,1), \"draws:\", draw, \"ttm:\", round(ttmList[-1],1), \"attm:\", round(sum(ttmList)/len(ttmList),1))\n\n return best\n\n\ndef sim():\n board = deepcopy(emptyBoard)\n while(1):\n printGameBoard(board)\n if showPotentialWinner(board): return\n Drop(board,SuggestMove(board, CIRCLE_RED, AI_STRENGTH), CIRCLE_RED)\n if showPotentialWinner(board): return\n printGameBoard(board)\n Drop(board, SuggestMove(board, CIRCLE_YELLOW, AI_STRENGTH), CIRCLE_YELLOW)\n\n \ndef singlePlayer(whoStarts=1):\n board = deepcopy(emptyBoard)\n\n if whoStarts == 1:\n while(1):\n printGameBoard(board)\n if showPotentialWinner(board): return\n Drop(board, getMoveFromPlayer(board), CIRCLE_RED)\n printGameBoard(board)\n if showPotentialWinner(board): return\n computer_move = SuggestMove(board, CIRCLE_YELLOW, AI_STRENGTH)\n Drop(board, computer_move, CIRCLE_YELLOW)\n elif whoStarts == 2:\n while(1):\n printGameBoard(board)\n if showPotentialWinner(board): return\n Drop(board, SuggestMove(board, CIRCLE_YELLOW, AI_STRENGTH), CIRCLE_YELLOW) \n printGameBoard(board)\n if showPotentialWinner(board): return\n Drop(board, getMoveFromPlayer(board, CIRCLE_RED), CIRCLE_RED)\n\n\n\ndef showPotentialWinner(board):\n winner = GetWinner(board)\n if winner != CIRCLE_EMPTY and winner != CIRCLE_DRAW:\n printGameBoard(board)\n if COLORAMA:\n if winner == CIRCLE_YELLOW: \n print(colorama.Fore.YELLOW+\" winner: YELLOW\" + colorama.Style.RESET_ALL)\n else:\n print(colorama.Fore.RED+\" winner: RED\" + colorama.Style.RESET_ALL)\n return True \n else:\n print(\"winner: \", winner)\n return True\n elif winner == CIRCLE_DRAW:\n printGameBoard(board)\n print(\"DRAW!\")\n return False\n \ndef getMoveFromPlayer(b, color):\n potentialPlayerMove = -1\n while(potentialPlayerMove == -1):\n try:\n potentialPlayerMove = int(input(\"Player \"+ str(color) +\", state your move: \"))\n except ValueError:\n print(\"Invalid move, try again!\")\n potentialPlayerMove = -1\n continue\n if potentialPlayerMove == 9:\n return SuggestMove(b, color)\n if (potentialPlayerMove > (BX) or potentialPlayerMove < 0):\n print(\"Invalid move, try again!\")\n potentialPlayerMove = -1\n if (potentialPlayerMove != -1 and ColIsFull(b, potentialPlayerMove) != CIRCLE_EMPTY):\n print(\"Invalid move, try again!\")\n potentialPlayerMove = -1\n return potentialPlayerMove\n\n\ndef twoPlayer():\n board = deepcopy(emptyBoard)\n while(1):\n printGameBoard(board)\n if showPotentialWinner(board): return \n Drop(board, getMoveFromPlayer(board, CIRCLE_RED), CIRCLE_RED)\n printGameBoard(board)\n potentialPlayerMove = -1\n if showPotentialWinner(board): return\n Drop(board, getMoveFromPlayer(board, CIRCLE_YELLOW), CIRCLE_YELLOW)\n \n\nif __name__== \"__main__\":\n print(BANNER)\n print(\"By Jory Detwiler v1.0.0.0 | https://github.com/JoryD\")\n if \"--easy\" in sys.argv:\n AI_STRENGTH = 250\n elif \"--medium\" in sys.argv or \"--med\" in sys.argv:\n AI_STRENGTH = 500\n elif \"--hard\" in sys.argv:\n AI_STRENGTH = 1000\n \n elif \"--insane\" in sys.argv:\n AI_STRENGTH = 2500\n \n elif \"--master\" in sys.argv:\n AI_STRENGTH = 5000\n \n elif \"--demigod\" in sys.argv:\n AI_STRENGTH = 10000\n \n elif \"--god\" in sys.argv:\n AI_STRENGTH = 100000\n \n if \"--norush\" in sys.argv:\n RUSH = False\n \n elif \"--rush\" in sys.argv:\n RUSH = True\n \n if \"--pretty\" in sys.argv:\n try:\n import colorama\n colorama.init()\n COLORAMA = 1\n except ImportError:\n print(\"You do not have COLORAMA installed. No colors for you :(\")\n print(\"Try `pip install colorama`, `python pip install colorama`, `python3 pip install colorama`, or maybe `pip3 install colorama`\")\n if \"--clearable\" in sys.argv:\n import os\n CLEARABLE = 1\n if \"--singleplayer\" in sys.argv:\n if \"--second\" in sys.argv:\n singlePlayer(2)\n else:\n singlePlayer(1)\n elif \"--multiplayer\" in sys.argv:\n twoPlayer()\n else:\n sim()\n \n \n"
}
] | 2 |
X4D0/Task3_MOSI | https://github.com/X4D0/Task3_MOSI | ec2aaf09249f416a3bb2298664dedb8936389d3d | 7a98401b5bc076316997de70595c050601f25e0d | aef141869cfa833d0fe5d21e85463e74d0ee3702 | refs/heads/master | "2022-04-16T18:22:24.681136" | "2020-04-14T07:13:47" | "2020-04-14T07:13:47" | 255,311,517 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5940740704536438,
"alphanum_fraction": 0.6266666650772095,
"avg_line_length": 23,
"blob_id": "d7e49ada52dcb5db0d2e55ed27760a2e2a75b314",
"content_id": "d4c30919c8bedb8c72bfb3eab9dc5848fb4be747",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 27,
"path": "/Pi_MonteCarlo.py",
"repo_name": "X4D0/Task3_MOSI",
"src_encoding": "UTF-8",
"text": "import random\r\nimport math\r\nimport matplotlib.pyplot as plt\r\n\r\n# Initialization\r\ntotal = 450 # Number of Dart\r\nhit = 0 # Number of dart fall inside the circle's part\r\nndart = 0 # Number of threw dart\r\n\r\n# Throw Dart\r\nfor dart in range(0,total):\r\n Xrand = random.randint(0,1)\r\n Yrand = random.randint(0,1)\r\n ndart += 1\r\n # Check Condition\r\n if (Xrand**2)+(Yrand**2)<=1:\r\n hit += 1\r\n\r\nprint(\"Total Dart = \"+str(total))\r\nprint(\"Hits = \"+str(hit))\r\nprint(\"Throws = \"+str(ndart)+\" times\")\r\npi = (hit/total)*4\r\nprint(\"Pi = \"+str(pi))\r\nerrorDecimal = math.pi-pi\r\npercent = (pi/math.pi)*100\r\nerrorPercent = 100-percent\r\nprint(\"Error = \"+str(errorPercent)+\"%\")\r\n"
},
{
"alpha_fraction": 0.5838150382041931,
"alphanum_fraction": 0.8092485666275024,
"avg_line_length": 42.25,
"blob_id": "ff8bf8b0dfb1c7572edf4b11268afc8d0c34b0d4",
"content_id": "277520086f97bdd4854ed299c9d4d9bfbc723060",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 4,
"path": "/README.md",
"repo_name": "X4D0/Task3_MOSI",
"src_encoding": "UTF-8",
"text": "# Task3_MOSI\nEstimating value of Pi using Monte Carlo Method\n\n\n"
}
] | 2 |
kuziaa/P_10 | https://github.com/kuziaa/P_10 | 133b90aaf46223c50a45d43a823d733d614ca5b2 | 80032ca9fbfc75410c3031c5fe45889b20fe4b10 | b15c8fa78c725e29ce56327f7bcc0bfbd7cd52b6 | refs/heads/master | "2021-04-15T19:01:59.169218" | "2018-03-24T00:01:03" | "2018-03-24T00:01:03" | 126,350,259 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5684075951576233,
"alphanum_fraction": 0.59693443775177,
"avg_line_length": 41.44578170776367,
"blob_id": "fabdb726117e1ca81cb832bc3faa0bb28611debd",
"content_id": "d69dd85d3e91f71c3de1ecb18fee1481c4633f63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7046,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 166,
"path": "/P10.py",
"repo_name": "kuziaa/P_10",
"src_encoding": "UTF-8",
"text": "import random, copy\nfrom pprint import pprint as pp\n\n# The function is not used.\n# It can count how much fuel was used\n# It works up to 990000 km\ndef spent_fuel_func(rout, cons, change_after, change_on):\n if rout > change_after:\n return change_after * cons / 100 + func_1(rout - change_after, cons * (1 + change_on / 100), change_after, change_on)\n else:\n return rout * cons / 100\n\n# Assumptions:\n# 1 - We have money for fuel and repair.\n# 2 - Car is getting cheaper, but it costs nothing for us.\n\n\nclass Car(object):\n created = 0\n engine_parameters = {\n 'gasoline': {'fuel_cost': 2.4, # dolar per liter\n 'car_cost': 10000.0, # new car cost\n 'car_gettind_cheaper': [1000.0, 9.5], # every {0} km car gettind cheaper on {1} dollars\n 'repair': [100000.0, 500.0], # every {0} km car need be repaired on {1} dollars\n 'fuel_consumption_100': [8.0, 1000.0, 1.0]}, # [primary fuel consumption, change_after_{1}_km, change_on_{2}_percents]\n 'diesel': {'fuel_cost': 1.8,\n 'car_cost': 10000.0,\n 'car_gettind_cheaper': [1000.0, 10.5],\n 'repair': [150000.0, 700],\n 'fuel_consumption_100': [6.0, 1000.0, 1.0]}\n }\n \n def __init__(self):\n x = 2\n Car.created += 1\n self.num_of_car = Car.created\n self.engine_parameters = Car.engine_parameters\n self.have_money = 10000\n self.fuel_cost = self.engine_parameters[self.engine_type]['fuel_cost']\n self.car_cost = self.engine_parameters[self.engine_type]['car_cost']\n self.car_gettind_cheaper_after = self.engine_parameters[self.engine_type]['car_gettind_cheaper'][0]\n self.car_gettind_cheaper_on = self.engine_parameters[self.engine_type]['car_gettind_cheaper'][1]\n self.range_before_repair = self.engine_parameters[self.engine_type]['repair'][0]\n self.cost_repair = self.engine_parameters[self.engine_type]['repair'][1]\n self.fuel_consumption = self.engine_parameters[self.engine_type]['fuel_consumption_100'][0]\n self.change_fuel_consumption_after = self.engine_parameters[self.engine_type]['fuel_consumption_100'][1]\n self.change_fuel_consumption_on = self.engine_parameters[self.engine_type]['fuel_consumption_100'][2]\n self.amount_of_fuel = self.tank_sizes\n self.can_run_before_utilization = round((self.car_cost / self.car_gettind_cheaper_on) * self.car_gettind_cheaper_after, 2)\n\n self.engine_repair_was = 0 # times\n self.was_fueling = 0 # times\n self.spent_on_fuel = 0\n self.spent_on_repair = 0\n self.history_range = []\n\n @property\n def engine_type(self):\n all_types = ('gasoline', 'diesel')\n if self.num_of_car % 3 != 0:\n return all_types[0]\n else:\n return all_types[1]\n\n @property\n def tank_sizes(self):\n all_sizes = (60, 75)\n if self.num_of_car % 5 == 0:\n return all_sizes[1]\n else:\n return all_sizes[0]\n\n def move(self, rout):\n while rout != 0:\n# Rout is divided on segments\n fuel_remains_on = round(self.amount_of_fuel / self.fuel_consumption * 100, 2)\n range_for_stop = [rout]\n range_for_stop.append(fuel_remains_on)\n range_for_stop.append(self.change_fuel_consumption_after)\n range_for_stop.append(self.can_run_before_utilization)\n range_for_stop.append(self.range_before_repair)\n\n min_range = min(range_for_stop)\n if not min_range and not self.have_money:\n break\n\n self.history_range.append(min_range)\n self.amount_of_fuel = round(self.amount_of_fuel - min_range * self.fuel_consumption / 100)\n self.change_fuel_consumption_after = round(self.change_fuel_consumption_after - min_range, 2)\n self.can_run_before_utilization = round(self.can_run_before_utilization - min_range, 2)\n self.range_before_repair = round(self.range_before_repair - min_range, 2)\n rout = round(rout - min_range, 2)\n\n if self.amount_of_fuel == 0:\n self.fueling()\n continue\n\n if self.change_fuel_consumption_after == 0:\n self.change_fuel_consumption()\n continue\n\n if self.can_run_before_utilization == 0:\n break\n\n if self.range_before_repair == 0:\n self.maintenance()\n continue\n\n def fueling(self):\n if self.have_money > self.fuel_cost * self.tank_sizes:\n self.have_money = round(self.have_money - self.fuel_cost * self.tank_sizes, 2)\n self.amount_of_fuel = self.tank_sizes\n else:\n self.amount_of_fuel = round(self.have_money / self.fuel_cost, 2)\n self.have_money = 0\n self.was_fueling += 1\n self.spent_on_fuel += self.amount_of_fuel * self.fuel_cost\n\n def change_fuel_consumption(self):\n self.fuel_consumption = self.fuel_consumption * (1 + self.change_fuel_consumption_on / 100)\n self.change_fuel_consumption_after = self.engine_parameters[self.engine_type]['fuel_consumption_100'][1]\n\n def maintenance(self):\n self.engine_repair_was += 1\n self.spent_on_repair += self.cost_repair\n self.range_before_repair = self.engine_parameters[self.engine_type]['repair'][0]\n\n @property\n def odometr(self):\n return round(sum(self.history_range), 2)\n\n @property\n def depreciated_cost(self):\n return round(self.car_cost - (sum(self.history_range) / 1000) * self.car_gettind_cheaper_on, 2)\n\n# Able run for the remaining money\n @property\n def able_run(self):\n temp_car = copy.deepcopy(self)\n while True:\n temp_car.move(100000)\n if temp_car.have_money == 0 or temp_car.can_run_before_utilization == 0:\n return round(sum(temp_car.history_range) - sum(self.history_range))\n\n\ncar_park = []\nfor _ in range(200):\n car_park.append(Car())\n\nfor car in car_park:\n route = random.randint(5000, 286000)\n car.move(route)\n\ngasoline_cars = list(filter(lambda x: x.engine_type == 'gasoline', car_park))\ngasoline_cars.sort(key=lambda x: x.able_run)\n\ndiesel_cars = list(filter(lambda x: x.engine_type == 'diesel', car_park))\ndiesel_cars.sort(key=lambda x: x.depreciated_cost)\n\ntotal_cost = reduce(lambda a, b: a + b.depreciated_cost, [car_park[0].depreciated_cost] + car_park[1:])\n\nprint('GASOLINE_CARS')\npp(['{}; able_run = {}; have_money = {}; rout = {}'.format(_.num_of_car, _.able_run, _.have_money, sum(_.history_range)) for _ in gasoline_cars])\nprint('\\nDIESEL_CARS')\npp(['{}; depreciated_cost = {}; have_money = {}; rout = {}'.format(_.num_of_car, _.depreciated_cost, _.have_money, sum(_.history_range)) for _ in diesel_cars])\nprint('\\nTotal_cost = {}'.format(total_cost))\n"
}
] | 1 |
codecompilemagic/Test-Driven-Project | https://github.com/codecompilemagic/Test-Driven-Project | 7826abba7cbd4dd8ec02e37d4445012a1f845bd6 | d9121313c7f7a1dd9f595116a20ec9dc13639709 | 4721f8c4c5a0d706f761ee3db6afb646d6058516 | refs/heads/master | "2021-01-16T23:20:55.398591" | "2017-03-01T15:25:44" | "2017-03-01T15:25:44" | 82,908,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.700597882270813,
"alphanum_fraction": 0.7044842839241028,
"avg_line_length": 37.23428726196289,
"blob_id": "2b15155149869e68490222cd1221c3622039c21e",
"content_id": "504ef6123c2d56aa2419f960b4e7d3bb075019f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6690,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 175,
"path": "/functional_tests/tests.py",
"repo_name": "codecompilemagic/Test-Driven-Project",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\n\"\"\" Keys allow us to use input keys like ENTER, Ctrl, etc \"\"\"\nfrom selenium.webdriver.common.keys import Keys\n\nimport unittest\n\nfrom django.test import LiveServerTestCase\nimport re\n\n###### The comments inside '#' are used for USER STORY to build the test\n###### The comments inside '\"\"\"' are used to describe the function or application usage \n\n\n\"\"\" The test Class inherits from unittest \"\"\"\n# class NewVisitorTest(unittest.TestCase):\nclass NewVisitorTest(LiveServerTestCase):\n\t\"\"\" setUp() and tearDown() are special methods which get run\n\t\tbefore and after each test.\n\t\tThey are similar to try/except \"\"\"\n\n\t\"\"\" Currently using setUp() to start our browser \"\"\"\n\tdef setUp(self):\n\t\tself.browser = webdriver.Chrome('C:\\Users\\Zigmyal\\Desktop\\dir\\chromedriver_win32\\chromedriver')\n\t\t\"\"\" implicitly_wait() tells Selenium to wait for \n\t\t\tgiven seconds if needed.\n\t\t\tHowever, it is best for small apps. For more complex\n\t\t\tand larger apps, explicit wait algorithms are required \"\"\"\n\t\t# self.browser.implicitly_wait(3)\n\n\t\"\"\" Currently using tearDown() to stop our browser \"\"\"\n\tdef tearDown(self):\n\t\tself.browser.quit()\n\n\tdef check_for_row_in_list_table(self, row_text):\n\t\ttable = self.browser.find_element_by_id('id_list_table')\n\t\trows = table.find_elements_by_tag_name('tr')\n\t\tself.assertIn(row_text, [row.text for row in rows])\n\n\t\"\"\" Any method whose name starts with test is a test method\n\t\tand will be run by the test runner.\n\t\tYou can have more than one test_ method per class.\n\t\tReadable names for test methods are a good idea \"\"\"\n\tdef test_can_start_a_list_and_retrieve_it_later(self):\n\t\t# User visits to-do app\n\t\t# User goes to check the homepage\n\t\t# self.browser.get('http://localhost:8000')\n\t\tself.browser.get(self.live_server_url)\n\n\t\t# User notices the page title and header mention to-do lists\n\t\t\"\"\" Instead of ---> assert 'To-Do' in browser.title, \"Browser title was \" + browser.title\n\t\t\twe user self.assertIn to make our test assertions\n\t\t\tunittest provides lots of helper functions like this (assertEqual, assertTrue, assertFalse, etc) \n\n\t\t\tself.fail just fails no matter what, producing the error message given \"\"\"\n\t\tself.assertIn('To-Do', self.browser.title)\n\t\t\"\"\" find_element_by_tag_name() returns an element\n\t\t\tand raises an exception if it can't find it \"\"\"\n\t\theader_text = self.browser.find_element_by_tag_name('h1').text\n\t\tself.assertIn('To-Do', header_text)\n\t\t\n\n\t\t# User is invited to enter a to-do item straight away\n\t\tinputbox = self.browser.find_element_by_id('id_new_item')\n\t\tself.assertEqual(inputbox.get_attribute('placeholder'), 'Enter a to-do item')\n\n\t\t# User types \"Buy apples and milk\" into a text box\n\t\tinputbox.send_keys('Buy apples and milk')\n\n\t\t# When the user hits enter, the page updates, and now the page lists\n\t\t# \"1: Buy apples and milk\" as an item in a to-do list\n\t\tinputbox.send_keys(Keys.ENTER)\n\t\t\"\"\" Testing for a new url \"\"\"\n\t\tuser_list_url = self.browser.current_url\n\t\t# assertRegex() is a helper function from unittest\n\t\t# that checks whether a string matches a regular expression\n\t\tself.assertRegexpMatches(user_list_url, '/lists/.+')\n\n\t\t\n\n\t\t\"\"\" Using time.sleep() to pause the test during execution \"\"\"\n\t\t# import time\n\t\t# time.sleep(8)\n\n\t\t# table = self.browser.find_element_by_id('id_list_table')\n\t\t\"\"\" find_elements_by_tag_name() returns a list, which may be empty \"\"\"\n\t\t# rows = table.find_elements_by_tag_name('tr')\n\n\t\t\"\"\" any() Python function will return True when atleast \n\t\t\tone of the elements is found/exists.\n\t\t\tInside the any() function is a generator expresion\n\t\t\t<--- Note: Python also has a all() function ---> \"\"\"\n\t\t############# modifying the function below #############\t\n\t\t# self.assertTrue(\n\t\t# \tany(row.text == '1: Buy apples and milk' for row in rows),\n\t\t# \t# Error message to display if not found\n\t\t# \t'New to-do item did not appear in table -- it was: \\n%s' %table.text,\n\t\t# )\n\n\t\t# self.assertIn('1: Buy apples and milk', [row.text for row in rows])\n\t\tself.check_for_row_in_list_table('1: Buy apples and milk')\n\n\t\t# There is still a text box inviting/prompting the user to add another item\n\t\t# The user enters \"Make apple pie for dessert\"\n\t\tinputbox = self.browser.find_element_by_id('id_new_item')\n\t\tinputbox.send_keys('Make apple pie for dessert')\n\t\tinputbox.send_keys(Keys.ENTER)\n\t\t\n\t\t\n\n\t\t# The page updates again, and now shows both items on her list\n\t\t\"\"\" Code check \"\"\"\n\t\t# table = self.browser.find_element_by_id('id_list_table')\n\t\t# rows = table.find_elements_by_tag_name('tr')\n\t\t# self.assertIn('1: Buy apples and milk', [row.text for row in rows])\n\t\t# self.assertIn('2: Make apple pie for dessert', [row.text for row in rows])\n\n\t\t\"\"\" Using helper method to replace the Code check \"\"\"\n\t\tself.check_for_row_in_list_table('1: Buy apples and milk')\n\t\tself.check_for_row_in_list_table('2: Make apple pie for dessert')\n\n\t\t# self.fail('Finish the test!')\n\n\t\t# The user is not sure if the site will remember the list. Then the user sees\n\t\t# that the site has generated a unique URL for user -- there is some\n\t\t# explanatory text\n\n\t\t# The user visits the URL - and the to-do list is still there\n\n\t\t# Satisfied, the user goes to take a bath\n\t\t# browser.quit()\n\n\n\n\t\t###### Now a new user, user2, comes along to the site #######\n\t\t## We use a new browser session to make sure that no information\n\t\t## of the previous user is coming through from cookies, etc\n\t\tself.browser.quit()\n\n\t\tself.browser = webdriver.Chrome('C:\\Users\\Zigmyal\\Desktop\\dir\\chromedriver_win32\\chromedriver')\n\n\t\t# User2 visits the home page. There is no sing of previous users list\n\t\tself.browser.get(self.live_server_url)\n\t\tpage_text = self.browser.find_element_by_tag_name('body').text\n\t\t\n\t\tself.assertNotIn('Buy apples and milk', page_text)\n\t\tself.assertNotIn('Make apple pie for dessert', page_text)\n\n\n\t\t# User2 starts a new list by entering a new item\n\t\tinputbox = self.browser.find_element_by_id('id_new_item')\n\t\tinputbox.send_keys('Buy cookies')\n\t\tinputbox.send_keys(Keys.ENTER)\n\n\n\t\t# User2 gets their own unique URL\n\t\tuser2_list_url = self.browser.current_url\n\t\tself.assertRegexpMatches(user2_list_url, '/lists/.+')\n\t\tself.assertNotEqual(user2_list_url, user_list_url)\n\n\n\t\t# Again, there is no trace of previous user's lists\n\t\tpage_text = self.browser.find_element_by_tag_name('body').text\n\t\tself.assertNotIn('Buy apples and milk', page_text)\n\t\tself.assertIn('Buy cookies', page_text)\n\n\n# if __name__ == '__main__':\n\t\"\"\" unittest.main() launches the unittest test runner\n\t\twhich will automatically find test classes and methods\n\t\tin the file and run them.\n\n\t\twarning = 'ignore' surppresses a ResourceWarning. \n\t\tRemove it if no warning is issued after removal \"\"\"\n\t# unittest.main(warnings='ignore')\n\t# unittest.main()"
},
{
"alpha_fraction": 0.7032967209815979,
"alphanum_fraction": 0.7073856592178345,
"avg_line_length": 33.782222747802734,
"blob_id": "1bd5a8bdadc0837f402e1ad90abe60a35b0ed4bf",
"content_id": "1cfde82a28b898cde0c6d612e3817f34874e428c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7826,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 225,
"path": "/lists/tests.py",
"repo_name": "codecompilemagic/Test-Driven-Project",
"src_encoding": "UTF-8",
"text": "\"\"\" The TestCase imported from django.test\n\tis a modified version of unittest.TestCase\n\tand has some Django-specific features \"\"\"\n\nfrom django.test import TestCase\n\nfrom django.core.urlresolvers import resolve\nfrom lists.views import home_page\n\nfrom django.http import HttpRequest\nfrom django.template.loader import render_to_string\n\nfrom lists.models import Item, List\n\nclass ItemModelTest(TestCase):\n\n\tdef test_saving_and_retrieving_items(self):\n\t\tlist_ = List()\n\t\tlist_.save()\n\n\t\tfirst_item = Item()\n\t\tfirst_item.text = 'The first list item'\n\t\tfirst_item.list = list_\n\t\tfirst_item.save()\n\n\t\tsecond_item = Item()\n\t\tsecond_item.text = 'The second list item'\n\t\tsecond_item.list = list_\n\t\tsecond_item.save()\n\n\t\tsaved_list = List.objects.first()\n\t\t\"\"\" Behind the scenes, saved_list and list_\n\t\t\tcompare against each other using their primary key \"\"\"\n\t\tself.assertEqual(saved_list, list_)\n\n\t\tsaved_items = Item.objects.all()\n\t\tself.assertEqual(saved_items.count(), 2)\n\n\t\tfirst_saved_item = saved_items[0]\n\t\tsecond_saved_item = saved_items[1]\n\t\tself.assertEqual(first_saved_item.text, 'The first list item')\n\t\tself.assertEqual(first_saved_item.list, list_)\n\t\tself.assertEqual(second_saved_item.text, 'The second list item')\n\t\tself.assertEqual(second_saved_item.list, list_)\n\n# Create your tests here.\nclass HomePageTest(TestCase):\n\n\tdef test_root_url_resolves_to_home_page_view(self):\n\t\t\"\"\" resolve() is the function Django uses internally to\n\t\t\tresolve URLs and find what view function it should map to.\n\t\t\t'/' represents the root of the site. \"\"\"\n\t\tfound = resolve('/')\n\t\tself.assertEqual(found.func, home_page)\n\n\n\tdef test_home_page_returns_correct_html(self):\n\t\t\"\"\" Creating a HttpRequest object, which Django sees\n\t\t\twhen a user's browser asks for a page \"\"\"\n\t\trequest = HttpRequest()\n\n\t\t\"\"\" Passing the home_page() view to response.\n\t\t\tIt is an instance of HttpResponse class \"\"\"\n\t\tresponse = home_page(request)\n\n\t\t\"\"\" asserting .content of response has specific properties\n\t\t\n\t\t\twe use b'' syntax to compare because response.content \n\t\t\tis RAW BYTES, not a Python string \"\"\"\n\t\t# self.assertTrue(response.content.startswith(b'<html>'))\n\n\t\t\"\"\" render_to_string() requires a request=request argument \n\t\t\tin Django 1.9+, however it will work without the request\n\t\t\targument in Django 1.8 and prior \n\n\t\t\trender_to_string manually renders a template for \n\t\t\tcomparison in the assertEqual() statement \"\"\"\n\t\texpected_html = render_to_string('home.html', request=request)\n\n\t\t\"\"\" We want the <title> tag in somewhere in the middle\n\t\t\twith the words 'To-Do lists' in it because that's what\n\t\t\twe specified in our functional test. \"\"\"\n\t\t\n\t\t### (1) testing bytes with bytes here ###\n\t\t# self.assertIn(b'<title>To-Do lists</title>', response.content)\n\t\t# self.assertTrue(response.content.endswith(b'</html>'))\n\n\t\t\"\"\" We use .decode() to convert the response.content bytes into\n\t\t\ta Python unicode string, which allows us to compare strings\n\t\t\twith strings, instead of bytes with bytes like in (1) \"\"\"\n\t\tself.assertEqual(response.content.decode(), expected_html)\n\n\n\n\t# def test_home_page_only_saves_items_when_necessary(self):\n\t# \trequest = HttpRequest()\n\t# \thome_page(request)\n\t# \tself.assertEqual(Item.objects.count(), 0)\n\n\n\t# def test_home_page_displays_all_list_items(self):\n\t# \tItem.objects.create(text=' Item 1')\n\t# \tItem.objects.create(text=' Item 2')\n\n\t# \trequest = HttpRequest()\n\t# \tresponse = home_page(request)\n\n\t# \tself.assertIn('Item 1', response.content.decode())\n\t# \tself.assertIn('Item 2', response.content.decode())\n\n\n\nclass ListViewTest(TestCase):\n\n\t# def test_displays_all_items(self):\n\tdef test_displays_only_items_for_that_list(self):\n\t\t# list_ = List.objects.create()\n\t\tcorrect_list = List.objects.create()\n\t\tItem.objects.create(text='Item 1', list=correct_list)\n\t\tItem.objects.create(text='Item 2', list=correct_list)\n\t\tother_list = List.objects.create()\n\t\tItem.objects.create(text='Other list Item 1', list=other_list)\n\t\tItem.objects.create(text='Other list Item 2', list=other_list)\n\n\t\t# instead of calling the view function directly, we use\n\t\t# the Django test client called self.client()\n\t\t# response = self.client.get('/lists/the-only-list-in-the-world/')\n\t\tresponse = self.client.get('/lists/%d/' %(correct_list.id))\n\n\t\t# assertContains method knows how to deal with responses\n\t\t# and the bytes of their content\n\t\t# we don't have to use response.content.decode() with assertContains()\n\t\tself.assertContains(response, 'Item 1')\n\t\tself.assertContains(response, 'Item 2')\n\t\tself.assertNotContains(response, 'Other list Item 1')\n\t\tself.assertNotContains(response, 'Other list Item 2')\n\n\tdef test_uses_list_template(self):\n\t\tlist_ = List.objects.create()\n\t\tresponse = self.client.get('/lists/%d/' %(list_.id))\n\t\tself.assertTemplateUsed(response, 'list.html')\n\n\tdef test_passes_correct_list_to_template(self):\n\t\tother_list = List.objects.create()\n\t\tcorrect_list = List.objects.create()\n\t\tresponse = self.client.get('/lists/%d/' %(correct_list.id,))\n\t\tself.assertEqual(response.context['list'], correct_list)\n\n\nclass NewListTest(TestCase):\n\n\tdef test_saving_a_POST_request(self):\n\t\t# The 3 statements below represents Setup\n\t\t# request = HttpRequest()\n\t\t# request.method = 'POST'\n\t\t# request.POST['item_text'] = 'A new list item'\n\n\t\t# # The single statement below represents Exercise\n\t\t# \"\"\" Calling home_page(), to function under test \"\"\"\n\t\t# response = home_page(request)\n\n\t\tself.client.post('/lists/new', data={'item_text': 'A new list item'})\n\n\t\t# Check if a new Item has been saved to the database\n\t\tself.assertEqual(Item.objects.count(), 1)\n\t\tnew_item = Item.objects.first()\t\t# objects.first() is the same as doing objects.all()[0]\n\t\tself.assertEqual(new_item.text, 'A new list item')\t# check that the item's text is correct\n\n\t\t# The statement below represents Assert\n\t\t# self.assertIn('A new list item', response.content.decode())\n\n\t\t\"\"\" Testing if the view is passing in the correct\n\t\t\tvalue for new_item_text \"\"\"\n\t\t# expected_html = render_to_string('home.html', \n\t\t# \t{'new_item_text': 'A new list item'}, request=request)\n\t\t\n\t\t# self.assertEqual(response.content.decode(), expected_html)\n\n\t\t# no longer expect a response with a .content rendered by template\n\t# Response will represent an HTTP redirect,\n\t# so we should have status code 302, and points the browser\n\t# to a new location\n\t\"\"\" Good unit testing practice says\n\t\tthat each test should only test one thing \"\"\"\n\tdef test_redirects_after_POST(self):\n\t\t# request = HttpRequest()\n\t\t# request.method = 'POST'\n\t\t# request.POST['item_text'] = 'A new list item'\n\n\t\t# response = home_page(request)\n\t\t\"\"\" URLs with no trailing slashes are 'action' ,i.e, they modify the database \"\"\"\n\t\tresponse = self.client.post('/lists/new', data={'item_text': 'A new list item'})\n\n\t\tnew_list = List.objects.first()\n\t\t# self.assertEqual(response.status_code, 302)\n\t\t# self.assertEqual(response['location'], '/')\n\t\t# self.assertEqual(response['location'], '/lists/the-only-list-in-the-world/')\n\t\tself.assertRedirects(response, '/lists/%d/' %(new_list.id))\n\nclass NewItemTest(TestCase):\n\n\tdef test_can_save_a_POST_request_to_an_existing_list(self):\n\t\t# other_list = List.objects.create()\n\t\tcorrect_list = List.objects.create()\n\n\t\tself.client.post(\n\t\t\t'/lists/%d/add_item' %(correct_list.id,), \n\t\t\tdata={'item_text': 'A new item for an existing list'}\n\t\t)\n\n\t\tself.assertEqual(Item.objects.count(), 1)\n\t\tnew_item = Item.objects.first()\n\t\tself.assertEqual(new_item.text, 'A new item for an existing list')\n\t\tself.assertEqual(new_item.list, correct_list)\n\n\tdef test_redirects_to_list_view(self):\n\t\tother_list = List.objects.create()\n\t\tcorrect_list = List.objects.create()\n\n\t\tresponse = self.client.post(\n\t\t\t'/lists/%d/add_item' %(correct_list.id),\n\t\t\tdata={'item_text': 'A new item for an existing list'}\n\t\t)\n\n\t\tself.assertRedirects(response, '/lists/%d/' %(correct_list.id))\n"
}
] | 2 |
bertfordley/PeanutButter | https://github.com/bertfordley/PeanutButter | 01c7070f0e70cc2dd8a13f6371cd4bbf4d8d2ef0 | 553e9c56193e663a0b378be5256ca89a2bb33c0a | 63ef6055f2b42fadadc189de0572d7143af9b65e | refs/heads/master | "2021-01-15T14:53:20.277929" | "2017-08-09T19:44:50" | "2017-08-09T19:44:50" | 99,698,386 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.42514607310295105,
"alphanum_fraction": 0.43401169776916504,
"avg_line_length": 41.60085678100586,
"blob_id": "2cd0011a10d899a1813658d2e41f566576048927",
"content_id": "8986e672ab8fe44b6f36da01a3abe26953bb6340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9926,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 233,
"path": "/Parser.py",
"repo_name": "bertfordley/PeanutButter",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jun 30 12:14:19 2017\n\n@author: rob moseley\n\nParse through query html files from PeanutButter and create a master table\n\n\"\"\"\n\nimport os, re\nfrom bs4 import BeautifulSoup\nimport pandas as pd\nfrom itertools import izip\nfrom joblib import Parallel, delayed\nimport multiprocessing\n\ndef Parser(directory, inputFile, columns):\n\n cols = columns \n \n subTable = pd.DataFrame(columns = cols)\n \n # get species name\n species = directory.split(\"/\")[-1]\n \n # create beautifulsoup object of html file\n with open(os.path.join(directory, inputFile), 'r') as htmlFile:\n parsed_html = BeautifulSoup(htmlFile) \n # get query ID\n queryID = parsed_html.h3.string.split(\" \")[3][5:].encode('utf-8') \n\n dataMatrix = list()\n \n # get all hits\n ps = parsed_html.find_all('p', {'style' : 'margin-top: 1em; margin-bottom: 0em;'})\n total_ps = len(ps)\n total_hits = parsed_html.find_all('p')[1].text.split(\" \")[1]\n if total_hits == \"no\":\n print(\"No hits for %s\" % queryID)\n total_hits = 0\n total_ps = 0\n percentage = 0\n ID = \"NA\"\n Hit_Species = \"NA\"\n Desc = 'NA'\n IDP = 'NA' \n CP = 'NA'\n Func = \"NA\"\n Sub = \"NA\"\n DP = \"NA\"\n artLink = \"NA\"\n pubmedID = \"NA\"\n pubmedLink = \"NA\"\n More = \"NA\"\n articleTitle = \"NA\"\n journal = \"NA\"\n pubYear = \"NA\"\n pubmedLink = \"NA\"\n pubmedID = \"NA\"\n keyWord = \"NA\"\n data = [species, queryID.encode('utf-8'), ID.encode('utf-8'), Hit_Species.encode('utf-8'), \n IDP.encode('utf-8'), CP.encode('utf-8'), \n Desc, Func.encode('utf-8'), \n Sub, DP, articleTitle,\n journal, pubYear, artLink,\n pubmedID.encode('utf-8'), \n pubmedLink.encode('utf-8'), keyWord, More,\n total_hits, total_ps, percentage]\n dataMatrix.append(data)\n else:\n percentage = (float(total_ps)/float(total_hits))*100\n percentage = \"%.2f\" % percentage\n print(\"Parsing %s: Total Hits = %s; Total p's = %d\" % (queryID, total_hits, total_ps)) \n \n \n # keywords = stomatal, stomata, guard cell, guard cells, \n # keyword regex\n patterns = re.compile(r'\\bstomata\\b|\\bstomatal\\b|\\bguard cell\\b|\\bguard cells\\b')\n pubmed = re.compile(r'\\bPubMed\\b')\n # loop through hits and extract info \n \n for p in ps: \n \n ID = \"NA\"\n Hit_Species = \"NA\"\n Desc = 'NA'\n IDP = 'NA' \n CP = 'NA'\n Func = \"NA\"\n Sub = \"NA\"\n DP = \"NA\"\n artLink = \"NA\"\n pubmedID = \"NA\"\n pubmedLink = \"NA\"\n More = \"NA\"\n \n for a in p.find_all('a'):\n if str(a.get('title')) == \"None\":\n continue\n if a.get('title')[0].isdigit():\n [IDP, CP] = a.string.split(\",\")\n if a.get('title') in [\"SwissProt\", \"MicrobesOnline\", \"RefSeq\"]:\n ID = a.string.encode('utf-8')\n if a.get('title') == \"SwissProt\":\n Desc = p.b.text.encode('utf-8')\n if a.get('title') in [\"MicrobesOnline\", \"RefSeq\"]:\n if ID == \"NA\":\n Desc = p.text.partition(\" \")[2].encode('utf-8')\n else:\n Desc = Desc + \";\" + p.text.partition(\" \")[2].encode('utf-8')\n \n for it in p.find_all('i'):\n Hit_Species = it.text.encode('utf-8')\n break\n \n for li in p.next_sibling:\n if not isinstance(li, unicode):\n if li.text == \"More\":\n More = li.text\n\n else:\n articleTitle = \"\"\n journal = \"\"\n pubYear = \"\"\n keyWord = \"\"\n More = \"\"\n data = [species, queryID.encode('utf-8'), ID.encode('utf-8'), Hit_Species.encode('utf-8'), \n IDP.encode('utf-8'), CP.encode('utf-8'), \n Desc, Func.encode('utf-8'), \n Sub, DP, articleTitle,\n journal, pubYear, artLink,\n pubmedID.encode('utf-8'), \n pubmedLink.encode('utf-8'), keyWord, More,\n total_hits, total_ps, percentage]\n dataMatrix.append(data)\n\n for li in p.next_sibling:\n if not isinstance(li, unicode):\n if li.text != \"More\": \n if li.text.startswith(\"FUNC\") or li.text.startswith(\"SUB\") or li.text.startswith(\"DIS\"): \n subDesc = li.text.split(\"\\n\")\n for text in subDesc:\n if text.startswith(\"FUNC\"):\n Func = subDesc[0][10:]\n if text.startswith(\"SUB\"):\n Sub = text[9:]\n if text.startswith(\"DIS\"):\n DP = text[22:]\n else: \n articleTitle = \"NA\"\n journal = \"NA\"\n pubYear = \"NA\"\n pubmedLink = \"NA\"\n pubmedID = \"NA\"\n keyWord = \"NA\"\n for a,i in izip(li.find_all('a'), li.find_all('small')):\n artLink = a.get(\"href\")\n if patterns.search(str(li.li)):\n keyWord = \"Stomatal\"\n articleTitle = a.get_text()\n if i is not None:\n if pubmed.search(str(i)):\n id_link = i.a.next_sibling.next_sibling.get(\"href\")\n pubmedLink = id_link\n pubmedID = id_link[-8:]\n pubmedSplit = i.text.partition(\",\")[2]\n journal = pubmedSplit[1:-14]\n pubYear = pubmedSplit[-13:-9]\n else:\n textSplit = i.text.partition(\",\")[2]\n journal = textSplit[1:-6]\n pubYear = textSplit[-5:]\n articleTitle = articleTitle.encode('utf-8') \n data = [species, queryID.encode('utf-8'), ID.encode('utf-8'), Hit_Species.encode('utf-8'), \n IDP.encode('utf-8'), CP.encode('utf-8'), \n Desc, Func.encode('utf-8'), \n Sub, DP, articleTitle,\n journal, pubYear, artLink,\n pubmedID.encode('utf-8'), \n pubmedLink.encode('utf-8'), keyWord, More,\n total_hits, total_ps, percentage]\n dataMatrix.append(data)\n \n subTable = pd.DataFrame(dataMatrix, columns=cols)\n \n outfile = directory + \"_output.txt\"\n \n if os.stat(outfile).st_size == 0:\n subTable.to_csv(outfile, mode=\"a\", header=True, sep=\"\\t\", index=False, encoding=\"utf-8\") \n else:\n subTable.to_csv(outfile, mode=\"a\", header=False, sep=\"\\t\", index=False, encoding=\"utf-8\")\n\nif __name__ == \"__main__\":\n \n n_jobs = multiprocessing.cpu_count() \n \n cols = [\"Species\", \"Query_ID\", \"ID\", \"Hit_Species\", \"Identity_%\", \"Coverage_%\", \n \"Description\", \"Function\", \"Subunit\", \"Disruption_Phenotype\", \n \"Article_Title\", \"Journal\", \"Publication_Year\", \"Journal_Link\", \n \"PubMed_ID\", \"PubMed_Link\", \"Keyword_Match\", \"More_Link\", \"Total_Hits\",\n \"Total_Hits_Listed\", \"Percent_Covered\"]\n \n topDir = \"/Users/rkd/Desktop/PeanutButter\" \n\n# Non-parallel\n# for spDir in os.listdir(topDir):\n## if not spDir.startswith('.') and (spDir == \"Kafe\" or spDir == \"Arth\"):\n# if not spDir.startswith('.') and (spDir == \"test1\" or spDir == \"test2\"): \n# OUT = open(os.path.join(topDir, spDir + \"_output.txt\"), \"w\")\n# OUT.close()\n# head = False\n# directory = os.path.join(topDir, spDir)\n# for htmlfile in os.listdir(directory):\n# if not htmlfile.startswith(\".\"):\n# print(htmlfile)\n# species_df = Parser(directory, htmlfile, cols)\n# if not head:\n# species_df.to_csv(os.path.join(topDir, spDir + \"_output.txt\"),\n# mode=\"a\", header=True, sep=\"\\t\", index=False)\n# head = True\n# else:\n# species_df.to_csv(os.path.join(topDir, spDir + \"_output.txt\"),\n# mode=\"a\", header=False, sep=\"\\t\", index=False)\n\n for spDir in os.listdir(topDir):\n# if not spDir.startswith('.') and (spDir == \"Kafe\" or spDir == \"Arth\"):\n if not spDir.startswith('.') and (spDir == \"test1\" or spDir == \"test2\"): \n OUT = open(os.path.join(topDir, spDir + \"_output.txt\"), \"w\")\n OUT.close()\n head = False\n directory = os.path.join(topDir, spDir)\n Parallel(n_jobs=n_jobs) (delayed(Parser) (directory, htmlfile, cols) for htmlfile in os.listdir(directory))\n"
}
] | 1 |
sudo-dax/PythonScript_NmapToMacchange | https://github.com/sudo-dax/PythonScript_NmapToMacchange | 21eab9d7835052d836713117f8a7beff3063b8a9 | 82958d52fb904621a519cab0510964892d459580 | b4be9d13561c3f527659928d26b0f47e6df09c85 | refs/heads/master | "2023-02-28T21:27:59.158363" | "2021-01-31T10:31:47" | "2021-01-31T10:31:47" | 330,326,638 | 1 | 1 | null | "2021-01-17T06:09:35" | "2021-01-17T09:23:38" | "2021-01-31T10:31:47" | Python | [
{
"alpha_fraction": 0.7009021639823914,
"alphanum_fraction": 0.7064538598060608,
"avg_line_length": 23.84482765197754,
"blob_id": "fa8cb025b7b46645d90de25b92447ece98cc3e73",
"content_id": "c6bc01cd546a0174488581731f2a8f8cd6b9e763",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1441,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 58,
"path": "/macch.py",
"repo_name": "sudo-dax/PythonScript_NmapToMacchange",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n#Library\nimport os\nimport subprocess\nimport collections\nimport socket\n\nimport subnet\n\n# Clear Screen\nsubprocess.call('clear', shell=True)\n\n# Get Subnet\nadapter = subnet.get_adapter_names()[-1]\nSubnet = subnet.get_subnets(adapter)[0]\n\n# Start Network Scan\nprint(f'Scanning {adapter} Network for Devices')\nprint(' ')\nos.system(\"sudo nmap -sP \" + Subnet + \"\"\" | awk '/Nmap scan report for/{printf $5;}/MAC Address:/{print \" => \"$3;}' | sort >> ips_macs_py.txt\"\"\")\nprint('Scan complete! ~~ Output in ips_macs_py.txt')\n\n# Counting Number of connections per Device so far\ndata = open(\"ips_macs_py.txt\",\"r\")\n\nc = collections.Counter()\n\nfor line in data:\n\tif ' => ' not in line:\n\t\tcontinue\n\tline = line.strip()\n\tip, mac = line.split(' => ')\n\tc[mac] += 1\n\n\n# Changing MAC Address \nmac_ad = c.most_common()[-1][0]\n# print(mac_ad)\nprint(f\"Chainging MAC to -1 Common on Network {mac_ad}\")\n\nprint(\"Bringing down WiFi Adapter\")\nos.system(f\"sudo ip link set {adapter} down\")\n\nprint(\"Bringing down Network Manager\")\nos.system(\"sudo systemctl stop NetworkManager\")\nos.system(\"sudo systemctl disable NetworkManager\")\n\nprint(\"Changing MAC\")\nos.system(f\"sudo macchanger -m {mac_ad} {adapter}\")\n\nprint(\"Bringing up Network Manager\")\nos.system(\"sudo systemctl enable NetworkManager\")\nos.system(\"sudo systemctl start NetworkManager\")\n\nprint(\"Bringing down WiFi Adapter\")\nos.system(f\"sudo ip link set {adapter} up\")\nprint(\"Mac Change Complete!\")\n"
},
{
"alpha_fraction": 0.6757741570472717,
"alphanum_fraction": 0.6830601096153259,
"avg_line_length": 22.869565963745117,
"blob_id": "cd04cf7828150d5f660fa9913e37a16f6e6d0bd1",
"content_id": "335fa7617068a807e97c2d38ed2c5ff03aeb393b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 23,
"path": "/scan.py",
"repo_name": "sudo-dax/PythonScript_NmapToMacchange",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n#Library\nimport os\nimport subprocess\nimport socket\n\n# Clear Screen\nsubprocess.call('clear', shell=True)\n\n# Get Subnet\nadapter = subnet.get_adapter_names()[-1]\nSubnet = subnet.get_subnets(adapter)[0]\n\nprint(f'Scanning {adapter} Network for Devices')\nprint(' ')\n\n# Start Network Scan\nprint('Scannig Network for Devices')\nprint(' ')\nos.system(\"sudo nmap -sP \" + Subnet + \"\"\" | awk '/Nmap scan report for/{printf $5;}/MAC Address:/{print \" => \"$3;}' | sort >> ips_macs_py.txt\"\"\")\n\nprint('Scan complete! ~~ Output in ips_macs_py.txt')\n"
},
{
"alpha_fraction": 0.7623947858810425,
"alphanum_fraction": 0.7680074572563171,
"avg_line_length": 34.66666793823242,
"blob_id": "ff074e054d8c5e5b41350e4c1cf5371796da78b7",
"content_id": "d5ac1cc9babd5c987c38f7edea7693bdc3d5acc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 30,
"path": "/README.md",
"repo_name": "sudo-dax/PythonScript_NmapToMacchange",
"src_encoding": "UTF-8",
"text": "# Network Ninja\n\n### A script to quickly scan and hide on a wifi network as a previously connected device.\n### Aim: to avoid having to input personal data to connect to a network which uses MAC filtering.\n\n## Required\n- Nmap\n- Macchanger\n- Python\n\nThe macch.py script will work as follows:\n1. It will scan the network and output the scanned device's MAC addresses and ouput results to a text file. (.txt)\n- Note: (Can separately just scan network to get more comprehensive data without changing MAC Address using scan.py)\n\n2. It will then count the number of times each MAC appears in the text file.\n\n3. It will then bring down the WiFi Adapter & NetworkManger\n\n4. It will then select least common MAC on network and change to that MAC using Macchanger.\n\n5. It will bring up network device and manager.\n\nYou now appear to be a previously connected device other than your own. \n\n### Still Needed In Future\n- Select MACs with different adapter names automatically (Other than wlan0)\n- User input to select which mac to use \n\nI welcome any comments or suggestions. \nEnjoy."
},
{
"alpha_fraction": 0.6247504949569702,
"alphanum_fraction": 0.6407185792922974,
"avg_line_length": 25.36842155456543,
"blob_id": "bb8b63960d2e46e6a08f453f81b112dc048926f4",
"content_id": "7692f043363e37a0b469c16ea655fd88e1a5f984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 38,
"path": "/subnet.py",
"repo_name": "sudo-dax/PythonScript_NmapToMacchange",
"src_encoding": "UTF-8",
"text": "\"\"\"\nSome helper functions to get adapter names and ipv4 subnets on that adapter\n\"\"\"\nimport ipaddress\n\nimport ifaddr\n\n\ndef compressed_subnet(host, bits):\n \"\"\"\n Given an ip and number of bits, (e.g. 10.0.3.1, 8), returns the compressed\n subnet mask (10.0.0.0/8)\n \"\"\"\n net_string = '{host}/{bits}'.format(host=host, bits=bits)\n network = ipaddress.ip_network(net_string, strict=False)\n return network.compressed\n\n\ndef get_subnets(adapter_name='wlan0'):\n \"\"\"\n Returns a list of ipv4 subnet strings for the given adapter.\n \"\"\"\n all_adapters = {adapter.name: adapter\n for adapter in ifaddr.get_adapters()}\n adapter = all_adapters[adapter_name]\n\n subnets = {compressed_subnet(ip.ip, ip.network_prefix)\n for ip in adapter.ips\n if len(ip.ip) > 3}\n\n return list(subnets)\n\n\ndef get_adapter_names():\n \"\"\"\n Returns a list of available adapter names\n \"\"\"\n return [adapter.name for adapter in ifaddr.get_adapters()]\n"
},
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.773809552192688,
"avg_line_length": 15.800000190734863,
"blob_id": "4763b490680198cbcfdbb49514936692014c89e6",
"content_id": "3fce0b3606c4bcf512cd5e15ea50b39bf708ad9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/install.sh",
"repo_name": "sudo-dax/PythonScript_NmapToMacchange",
"src_encoding": "UTF-8",
"text": "#/bin/sh\n\n# simple script to install dependencies\n\npip3 install -r requirements.txt\n"
}
] | 5 |
vltanh/CaNet | https://github.com/vltanh/CaNet | 755084d64a08f254b2ad8b9068262b06a0addd7a | 6dcd806677c42df2958c8b1ce4244ab393e9c57c | 20f4d82161125920cbe5f01636295712f3739160 | refs/heads/master | "2022-12-01T14:35:02.956331" | "2020-08-12T07:29:50" | "2020-08-12T07:29:50" | 279,299,170 | 0 | 0 | null | "2020-07-13T12:40:35" | "2020-07-13T12:33:55" | "2020-06-06T10:55:56" | null | [
{
"alpha_fraction": 0.6044604778289795,
"alphanum_fraction": 0.6280747652053833,
"avg_line_length": 30.76041603088379,
"blob_id": "abb8f69a9d87e9207a165181938d696681ee433a",
"content_id": "19da9682aaea37f309699821fbf2bcc259e1191e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3049,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 96,
"path": "/visualize.py",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "import torchvision.transforms as tvtf\nfrom PIL import Image\nimport argparse\nimport torch\nfrom torch import nn\nfrom torch.utils.data import DataLoader\nimport torch.nn.functional as F\nimport torchvision\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom one_shot_network import Res_Deeplab\nfrom utils import load_resnet50_param, convert_image_np\nimport random\n# plt.rcParams[\"figure.figsize\"] = (15, 5)\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--gpus', default='0')\nparser.add_argument('--weight')\nparser.add_argument('--refid')\nparser.add_argument('--queid')\nparser.add_argument('--classid', type=int)\nparser.add_argument('--niters', default=5, type=int)\nparser.add_argument('--a', action='store_true')\nparser.add_argument('--root', type=str)\nargs = parser.parse_args()\n\nIMG_MEAN = [0.485, 0.456, 0.406]\nIMG_STD = [0.229, 0.224, 0.225]\n\n\ndef set_seed(seed):\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n\n\nmodel = Res_Deeplab(num_classes=2, use_attn=args.a)\nmodel = load_resnet50_param(model, stop_layer='layer4')\nmodel = nn.DataParallel(model, [0])\nmodel.load_state_dict(torch.load(args.weight))\nmodel.cuda()\nmodel.eval()\n\nCLASSES = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle',\n 'bus', 'car', 'cat', 'chair', 'cow',\n 'diningtable', 'dog', 'horse', 'motorbike', 'person',\n 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']\nroot = args.root\nref_img_path = root + '/JPEGImages/' + args.refid + '.jpg'\nref_mask_path = root + '/Annotations/' + \\\n CLASSES[args.classid - 1] + '/' + args.refid + '.png'\nque_img_path = root + '/JPEGImages/' + args.queid + '.jpg'\n\nniters = args.niters\n\nwith torch.no_grad():\n ref_img = Image.open(ref_img_path).convert('RGB')\n ref_mask = Image.open(ref_mask_path).convert('P')\n query_img = Image.open(que_img_path).convert('RGB')\n\n tf = tvtf.Compose([\n tvtf.ToTensor(),\n tvtf.Normalize(IMG_MEAN, IMG_STD),\n ])\n ref_img = tf(ref_img).unsqueeze(0).cuda()\n ref_mask = torch.FloatTensor(\n np.array(ref_mask) > 0).unsqueeze(0).unsqueeze(0).cuda()\n query_img = tf(query_img).unsqueeze(0).cuda()\n history_mask = torch.zeros(1, 2, 41, 41).cuda()\n\n fig, ax = plt.subplots(1, niters+1)\n\n ax[0].imshow(convert_image_np(ref_img[0].cpu()))\n ax[0].imshow(ref_mask[0, 0].cpu(), alpha=0.5)\n # ax[0].set_title('Reference')\n ax[0].set_xticks([])\n ax[0].set_yticks([])\n\n for i in range(niters):\n out = model(query_img, ref_img, ref_mask, history_mask)\n history_mask = torch.softmax(out, dim=1)\n pred = F.interpolate(history_mask, size=query_img.shape[-2:],\n mode='bilinear',\n align_corners=True)\n pred = torch.argmax(pred, dim=1)\n\n ax[1+i].imshow(convert_image_np(query_img[0].cpu()))\n ax[1+i].imshow(pred[0].cpu(), alpha=0.5)\n # ax[1+i].set_title(f'Query')\n ax[1+i].set_xticks([])\n ax[1+i].set_yticks([])\n\n fig.tight_layout()\n plt.show()\n plt.close()\n"
},
{
"alpha_fraction": 0.5031375885009766,
"alphanum_fraction": 0.5201930999755859,
"avg_line_length": 33.52777862548828,
"blob_id": "c3cdd89379ab4333566682b2c4995816bd0dba7c",
"content_id": "93844d8752f5d012b8d5038fdd74cd06b6decdfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6215,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 180,
"path": "/val.py",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "from torch.utils import data\nimport torch.optim as optim\nimport torch.backends.cudnn as cudnn\nimport os.path as osp\nfrom utils import *\nimport time\nimport torch.nn.functional as F\nimport tqdm\nimport random\nimport argparse\nfrom dataset_mask_train import Dataset as Dataset_train\nfrom dataset_mask_val import Dataset as Dataset_val\nimport os\nimport torch\nfrom one_shot_network import Res_Deeplab\nimport torch.nn as nn\nimport numpy as np\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument('-fold',\n type=int,\n help='fold',\n default=0)\nparser.add_argument('-gpu',\n type=str,\n help='gpu id to use',\n default='0,1')\nparser.add_argument('-iter_time',\n type=int,\n default=5)\nparser.add_argument('-w',\n type=str,\n help='path to weight file')\nparser.add_argument('-d',\n type=str,\n help='path to dataset')\nparser.add_argument('-s',\n type=int,\n help='random seed',\n default=3698)\nparser.add_argument('-a',\n action='store_true',\n help='use attention or not')\nparser.add_argument('-p',\n type=int,\n help='number of exps')\noptions = parser.parse_args()\n\n\ndef set_seed(seed):\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n\n\n# GPU-related\ngpu_list = [int(x) for x in options.gpu.split(',')]\nos.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'\nos.environ['CUDA_VISIBLE_DEVICES'] = options.gpu\ncudnn.enabled = True\n\nIMG_MEAN = [0.485, 0.456, 0.406]\nIMG_STD = [0.229, 0.224, 0.225]\nnum_class = 2\ninput_size = (321, 321)\n\n# Create network.\nmodel = Res_Deeplab(num_classes=num_class, use_attn=options.a)\nmodel = load_resnet50_param(model, stop_layer='layer4')\nmodel = nn.DataParallel(model, [0])\nmodel.load_state_dict(torch.load(options.w))\nmodel.cuda()\n\nset_seed(options.s)\nseeds = random.sample(range(10**5), options.p)\nprint(seeds)\n\nfinal_iou = []\nfor s in seeds:\n set_seed(s)\n\n valset = Dataset_val(data_dir=options.d, fold=options.fold,\n input_size=input_size,\n normalize_mean=IMG_MEAN, normalize_std=IMG_STD,\n is_train=False)\n valloader = data.DataLoader(valset, batch_size=1, shuffle=False, num_workers=4,\n drop_last=False)\n\n iou_list = []\n highest_iou = 0\n begin_time = time.time()\n with torch.no_grad():\n print('----Evaluation----')\n model = model.eval()\n\n valset.history_mask_list = [None] * 1000\n best_iou = 0\n for eva_iter in range(options.iter_time):\n save_root = f'viz{options.fold}_{options.a}'\n save_dir = f'{save_root}/{eva_iter}'\n os.makedirs(save_dir, exist_ok=True)\n #f = open(\n # f'{save_root}/score{options.fold}_{eva_iter}.csv', 'w')\n #f.write('support,query,class,score\\n')\n\n all_inter, all_union, all_predict = [0] * 5, [0] * 5, [0] * 5\n for i_iter, batch in enumerate(tqdm.tqdm(valloader)):\n # if i_iter != 55:\n # continue\n\n query_rgb, query_mask, support_rgb, support_mask, history_mask, sample_class, index, support_name, query_name = batch\n\n query_rgb = (query_rgb).cuda(0)\n support_rgb = (support_rgb).cuda(0)\n support_mask = (support_mask).cuda(0)\n # change formation for crossentropy use\n query_mask = (query_mask).cuda(0).long()\n\n # remove the second dim,change formation for crossentropy use\n query_mask = query_mask[:, 0, :, :]\n history_mask = (history_mask).cuda(0)\n\n pred = model(query_rgb, support_rgb,\n support_mask, history_mask)\n pred_softmax = F.softmax(pred, dim=1).data.cpu()\n\n # update history mask\n for j in range(support_mask.shape[0]):\n sub_index = index[j]\n valset.history_mask_list[sub_index] = pred_softmax[j]\n\n pred = nn.functional.interpolate(pred, size=query_mask.shape[-2:], mode='bilinear',\n align_corners=True) # upsample # upsample\n\n _, pred_label = torch.max(pred, 1)\n\n #plt.subplot(1, 2, 1)\n #plt.imshow(convert_image_np(support_rgb[0].cpu()))\n #plt.imshow(support_mask[0][0].cpu(), alpha=0.5)\n\n #plt.subplot(1, 2, 2)\n #plt.imshow(convert_image_np(query_rgb[0].cpu()))\n #plt.imshow(pred_label[0].cpu(), alpha=0.5)\n\n #plt.tight_layout()\n #plt.savefig(f'{save_dir}/{i_iter:03d}')\n ## plt.show()\n #plt.close()\n\n _, pred_label = torch.max(pred, 1)\n inter_list, union_list, _, num_predict_list = get_iou_v1(\n query_mask, pred_label)\n #f.write(\n # f'{support_name[0]},{query_name[0]},{sample_class[0]},{float(inter_list[0])/union_list[0]}\\n')\n for j in range(query_mask.shape[0]): # batch size\n all_inter[sample_class[j] -\n (options.fold * 5 + 1)] += inter_list[j]\n all_union[sample_class[j] -\n (options.fold * 5 + 1)] += union_list[j]\n\n IOU = [0] * 5\n\n for j in range(5):\n IOU[j] = all_inter[j] / all_union[j]\n\n mean_iou = np.mean(IOU)\n print(IOU)\n print('IOU:%.4f' % (mean_iou))\n #if mean_iou > best_iou:\n # best_iou = mean_iou\n\n #f.close()\n best_iou = mean_iou\n print('IOU for this epoch: %.4f' % (best_iou))\n final_iou.append(best_iou)\n\n epoch_time = time.time() - begin_time\n print('This epoch takes:', epoch_time, 'second')\n print(np.mean(final_iou), np.std(final_iou))\n"
},
{
"alpha_fraction": 0.5939849615097046,
"alphanum_fraction": 0.6167839169502258,
"avg_line_length": 30,
"blob_id": "d488e52f325851f2f9227f4729b9d080db0c8ba8",
"content_id": "2e1ca48317cc7005c5fd213e9d4dc0ae5dce568c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4123,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 133,
"path": "/utils.py",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "import torchvision\nimport os\nimport torch\nimport torch.nn as nn\nfrom pylab import plt\nimport numpy as np\n\n\ndef convert_image_np(inp):\n \"\"\"Convert a Tensor to numpy image.\"\"\"\n inp = inp.numpy().transpose((1, 2, 0))\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n inp = std * inp + mean\n inp = np.clip(inp, 0, 1)\n return inp\n\n\ndef load_resnet50_param(model, stop_layer='layer4'):\n resnet50 = torchvision.models.resnet50(pretrained=True)\n saved_state_dict = resnet50.state_dict()\n new_params = model.state_dict().copy()\n for i in saved_state_dict:\n i_parts = i.split('.')\n if not i_parts[0] == stop_layer:\n new_params['.'.join(i_parts)] = saved_state_dict[i]\n else:\n break\n model.load_state_dict(new_params)\n model.train()\n return model\n\n\ndef check_dir(checkpoint_dir):\n if not os.path.exists(checkpoint_dir):\n os.makedirs(os.path.join(checkpoint_dir, 'model'))\n os.makedirs(os.path.join(checkpoint_dir, 'pred_img'))\n\n\ndef optim_or_not(model, yes):\n for param in model.parameters():\n if yes:\n param.requires_grad = True\n else:\n param.requires_grad = False\n\n\ndef turn_off(model):\n optim_or_not(model.module.conv1, False)\n optim_or_not(model.module.bn1, False)\n optim_or_not(model.module.layer1, False)\n optim_or_not(model.module.layer2, False)\n optim_or_not(model.module.layer3, False)\n\n\ndef get_10x_lr_params(model):\n b = []\n if model.module.use_attn:\n b.append(model.module.layer5_K.parameters())\n b.append(model.module.layer5_V.parameters())\n else:\n b.append(model.module.layer5.parameters())\n b.append(model.module.layer55.parameters())\n b.append(model.module.layer6_0.parameters())\n b.append(model.module.layer6_1.parameters())\n b.append(model.module.layer6_2.parameters())\n b.append(model.module.layer6_3.parameters())\n b.append(model.module.layer6_4.parameters())\n b.append(model.module.layer7.parameters())\n b.append(model.module.layer9.parameters())\n b.append(model.module.residule1.parameters())\n b.append(model.module.residule2.parameters())\n b.append(model.module.residule3.parameters())\n\n for j in range(len(b)):\n for i in b[j]:\n yield i\n\n\ndef loss_calc_v1(pred, label, gpu):\n label = label.long()\n criterion = torch.nn.CrossEntropyLoss(ignore_index=255).cuda(gpu)\n return criterion(pred, label)\n\n\ndef plot_loss(checkpoint_dir, loss_list, save_pred_every):\n n = len(loss_list)\n x = range(0, n * save_pred_every, save_pred_every)\n y = loss_list\n plt.switch_backend('agg')\n plt.plot(x, y, color='blue', marker='.', label='Train loss')\n plt.xticks(\n range(0, n * save_pred_every + 3,\n (n * save_pred_every + 10) // 10)\n )\n plt.legend()\n plt.grid()\n plt.savefig(os.path.join(checkpoint_dir, 'loss_fig.pdf'))\n plt.close()\n\n\ndef plot_iou(checkpoint_dir, iou_list):\n n = len(iou_list)\n x = range(0, len(iou_list))\n y = iou_list\n plt.switch_backend('agg')\n plt.plot(x, y, color='red', marker='.', label='IOU')\n plt.xticks(range(0, n + 3, (n + 10) // 10))\n plt.legend()\n plt.grid()\n plt.savefig(os.path.join(checkpoint_dir, 'iou_fig.pdf'))\n plt.close()\n\n\ndef get_iou_v1(query_mask, pred_label, mode='foreground'):\n if mode == 'background':\n query_mask = 1 - query_mask\n pred_label = 1 - pred_label\n B = query_mask.shape[0]\n num_predict_list, inter_list, union_list, iou_list = [], [], [], []\n for i in range(B):\n num_predict = (pred_label[i] > 0).sum().float().item()\n combination = query_mask[i] + pred_label[i]\n inter = (combination == 2).sum().float().item()\n union = (combination == 1).sum().float().item() + inter\n inter_list.append(inter)\n union_list.append(union)\n num_predict_list.append(num_predict)\n if union != 0:\n iou_list.append(inter / union)\n else:\n iou_list.append(0.0)\n return inter_list, union_list, iou_list, num_predict_list\n"
},
{
"alpha_fraction": 0.48184266686439514,
"alphanum_fraction": 0.5134269595146179,
"avg_line_length": 35.839141845703125,
"blob_id": "75434c4bafee8de2b25d1eadbfb6e763d67b9b59",
"content_id": "f37dec2662453e4f4e82f17fb0481f19737550c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13741,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 373,
"path": "/one_shot_network.py",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "import torch.nn as nn\nimport torch\nimport numpy as np\nimport torch.nn.functional as F\nimport math\nfrom utils import convert_image_np\n\n# code of dilated convolution part is referenced from https://github.com/speedinghzl/Pytorch-Deeplab\n\naffine_par = True\n\n\nclass Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None):\n super(Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1,\n stride=stride, bias=False)\n self.bn1 = nn.BatchNorm2d(planes, affine=affine_par)\n for i in self.bn1.parameters():\n i.requires_grad = False\n\n padding = dilation\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,\n stride=1, padding=padding, dilation=dilation, bias=False)\n self.bn2 = nn.BatchNorm2d(planes, affine=affine_par)\n for i in self.bn2.parameters():\n i.requires_grad = False\n self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)\n self.bn3 = nn.BatchNorm2d(planes * 4, affine=affine_par)\n for i in self.bn3.parameters():\n i.requires_grad = False\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.bn3(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass Memory(nn.Module):\n def __init__(self):\n super(Memory, self).__init__()\n\n def forward(self, m_k, m_v, q_k):\n # m_k: B, Dk, Hm, Wm\n # m_v: B, Dv, Hm, Wm\n # q_k: B, Dk, Hq, Wq\n\n B, Dk, Hm, Wm = m_k.size()\n _, _, Hq, Wq = q_k.size()\n _, Dv, _, _ = m_v.size()\n\n mk = m_k.reshape(B, Dk, Hm*Wm) # mk: B, Dk, Hm*Wm\n mk = torch.transpose(mk, 1, 2) # mk: B, Hm*Wm, Dk\n\n qk = q_k.reshape(B, Dk, Hq*Wq) # qk: B, Dk, Hq*Wq\n\n p = torch.bmm(mk, qk) # p: B, Hm*Wm, Hq*Wq\n p = p / math.sqrt(Dk) # p: B, Hm*Wm, Hq*Wq\n p = F.softmax(p, dim=1) # p: B, Hm*Wm, Hq*Wq\n\n mv = m_v.reshape(B, Dv, Hm*Wm) # mv: B, Dv, Hm*Wm\n mem = torch.bmm(mv, p) # B, Dv, Hq*Wq\n mem = mem.reshape(B, Dv, Hq, Wq) # B, Dv, Hq, Wq\n\n return mem, p\n\n\nclass ResNet(nn.Module):\n def __init__(self, block, layers, num_classes, use_attn):\n self.inplanes = 64\n self.use_attn = use_attn\n super(ResNet, self).__init__()\n\n # ResNet-50 (Deeplab variant)\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7,\n stride=2, padding=3, bias=False)\n self.bn1 = nn.BatchNorm2d(64, affine=affine_par)\n self.relu = nn.ReLU(inplace=True)\n self.maxpool = nn.MaxPool2d(kernel_size=3,\n stride=2, padding=1, ceil_mode=True)\n self.layer1 = self._make_layer(block, 64, layers[0])\n self.layer2 = self._make_layer(block, 128, layers[1],\n stride=2)\n self.layer3 = self._make_layer(block, 256, layers[2],\n stride=1, dilation=2)\n #self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4)\n\n # Key-Value generator\n if not self.use_attn:\n self.layer5 = nn.Sequential(\n nn.Conv2d(in_channels=1536, out_channels=256, kernel_size=3,\n stride=1, padding=2, dilation=2, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n else:\n self.layer5_K = nn.Sequential(\n nn.Conv2d(in_channels=1536, out_channels=256, kernel_size=3,\n stride=1, padding=2, dilation=2, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer5_V = nn.Sequential(\n nn.Conv2d(in_channels=1536, out_channels=256, kernel_size=3,\n stride=1, padding=2, dilation=2, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n # Memory augmented feature map post-process\n self.layer55 = nn.Sequential(\n nn.Conv2d(in_channels=256 * 2, out_channels=256, kernel_size=3,\n stride=1, padding=2, dilation=2, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n # ASPP\n self.layer6_0 = nn.Sequential(\n nn.Conv2d(256, 256, kernel_size=1,\n stride=1, padding=0, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer6_1 = nn.Sequential(\n nn.Conv2d(256, 256, kernel_size=1,\n stride=1, padding=0, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer6_2 = nn.Sequential(\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=6, dilation=6, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer6_3 = nn.Sequential(\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=12, dilation=12, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer6_4 = nn.Sequential(\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=18, dilation=18, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n self.layer7 = nn.Sequential(\n nn.Conv2d(1280, 256, kernel_size=1,\n stride=1, padding=0, bias=True),\n nn.ReLU(),\n nn.Dropout2d(p=0.5),\n )\n\n # Decoder (Iterative Optimization Module)\n self.residule1 = nn.Sequential(\n nn.ReLU(),\n nn.Conv2d(256+2, 256, kernel_size=3,\n stride=1, padding=1, bias=True),\n nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=1, bias=True)\n )\n\n self.residule2 = nn.Sequential(\n nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=1, bias=True),\n nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=1, bias=True)\n )\n\n self.residule3 = nn.Sequential(\n nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=1, bias=True),\n nn.ReLU(),\n nn.Conv2d(256, 256, kernel_size=3,\n stride=1, padding=1, bias=True)\n )\n\n # Prediction\n self.layer9 = nn.Conv2d(\n 256, num_classes, kernel_size=1, stride=1, bias=True)\n\n # Memory\n self.memory = Memory()\n\n # Initialization\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n m.weight.data.normal_(0, 0.01)\n elif isinstance(m, nn.BatchNorm2d):\n m.weight.data.fill_(1)\n m.bias.data.zero_()\n\n def _make_layer(self, block, planes, blocks, stride=1, dilation=1, downsample=None):\n if stride != 1 or self.inplanes != planes * block.expansion or dilation == 2 or dilation == 4:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1,\n stride=stride, bias=False),\n nn.BatchNorm2d(planes * block.expansion, affine=affine_par)\n )\n for i in downsample._modules['1'].parameters():\n i.requires_grad = False\n layers = []\n layers.append(block(self.inplanes, planes,\n stride, dilation=dilation, downsample=downsample))\n self.inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.inplanes, planes, dilation=dilation))\n return nn.Sequential(*layers)\n\n def forward(self, query_rgb, support_rgb, support_mask, history_mask, vis_attn=False):\n ref_img = support_rgb.clone()\n ref_mask = support_mask.clone()\n query_img = query_rgb.clone()\n #print('Input:', query_img.shape)\n\n # === Query feature extraction\n query_rgb = self.conv1(query_rgb)\n #print('Conv 0:', query_rgb.shape)\n query_rgb = self.bn1(query_rgb)\n query_rgb = self.relu(query_rgb)\n query_rgb = self.maxpool(query_rgb)\n #print('Layer 0:', query_rgb.shape)\n query_rgb = self.layer1(query_rgb)\n #print('Layer 1:', query_rgb.shape)\n query_rgb = self.layer2(query_rgb)\n #print('Layer 2:', query_rgb.shape)\n query_feat_layer2 = query_rgb\n query_rgb = self.layer3(query_rgb)\n #print('Layer 3:', query_rgb.shape)\n # query_rgb = self.layer4(query_rgb)\n query_rgb_ = torch.cat([query_feat_layer2, query_rgb], dim=1)\n feature_size = query_rgb_.shape[-2:]\n #print('Encoder:', query_rgb_.shape)\n\n # === Query key-value generation\n if not self.use_attn:\n query_rgb = self.layer5(query_rgb_)\n else:\n query_rgb_K = self.layer5_K(query_rgb_)\n query_rgb_V = self.layer5_V(query_rgb_)\n #print('Key/Value:', query_rgb_K.shape)\n\n # === Reference feature extraction\n support_rgb = self.conv1(support_rgb)\n support_rgb = self.bn1(support_rgb)\n support_rgb = self.relu(support_rgb)\n support_rgb = self.maxpool(support_rgb)\n support_rgb = self.layer1(support_rgb)\n support_rgb = self.layer2(support_rgb)\n support_feat_layer2 = support_rgb\n support_rgb = self.layer3(support_rgb)\n #support_rgb = self.layer4(support_rgb)\n support_rgb_ = torch.cat([support_feat_layer2, support_rgb], dim=1)\n\n # === Reference key-value generation\n if not self.use_attn:\n support_rgb = self.layer5(support_rgb_)\n else:\n support_rgb_K = self.layer5_K(support_rgb_)\n support_rgb_V = self.layer5_V(support_rgb_)\n\n # === Dense comparison OR Memory read\n support_mask = F.interpolate(support_mask, support_rgb.shape[-2:],\n mode='bilinear', align_corners=True)\n if not self.use_attn:\n z = support_mask * support_rgb\n z, viz = self.memory(z, z, query_rgb)\n out = torch.cat([query_rgb, z], dim=1)\n else:\n z_K = support_mask * support_rgb_K\n z_V = support_mask * support_rgb_V\n z, viz = self.memory(z_K, z_V, query_rgb_K)\n out = torch.cat([query_rgb_V, z], dim=1)\n #print(out.shape)\n\n if vis_attn:\n import matplotlib.pyplot as plt\n for i in range(viz.size(2)):\n m = torch.zeros(query_rgb.shape[-2], query_rgb.shape[-1])\n m[i // query_rgb.shape[-1], i % query_rgb.shape[-1]] = 1\n m = F.interpolate(m.unsqueeze(0).unsqueeze(\n 0), (query_img.shape[-2], query_img.shape[-1])).squeeze(0).squeeze(0)\n # f = query_img[0].permute(1, 2, 0).detach().cpu()\n plt.figure(figsize=(16, 8), dpi=100)\n plt.subplot(1, 2, 1)\n plt.imshow(convert_image_np(query_img[0].cpu()))\n plt.imshow(m, alpha=0.5)\n plt.xticks([])\n plt.yticks([])\n plt.subplot(1, 2, 2)\n v = viz[0, :, i].reshape(\n support_rgb.shape[-2], support_rgb.shape[-1]).detach().cpu()\n v = F.interpolate(v.unsqueeze(\n 0).unsqueeze(0), (ref_img.shape[-2], ref_img.shape[-1])).squeeze(0).squeeze(0)\n f = ref_img[0].detach().cpu()\n plt.imshow(convert_image_np(f))\n plt.imshow(v, alpha=0.5)\n plt.xticks([])\n plt.yticks([])\n plt.tight_layout()\n plt.savefig(f'viz/{i:04d}')\n # plt.show()\n plt.close()\n\n # === Decoder\n # Residue blocks\n history_mask = F.interpolate(history_mask, feature_size,\n mode='bilinear', align_corners=True)\n out = self.layer55(out)\n out_plus_history = torch.cat([out, history_mask], dim=1)\n out = out + self.residule1(out_plus_history)\n out = out + self.residule2(out)\n out = out + self.residule3(out)\n #print('ResBlocks:', out.shape)\n\n # ASPP\n global_feature = F.avg_pool2d(out, kernel_size=feature_size)\n global_feature = self.layer6_0(global_feature)\n global_feature = global_feature.expand(-1, -1,\n feature_size[0], feature_size[1])\n out = torch.cat([global_feature,\n self.layer6_1(out),\n self.layer6_2(out),\n self.layer6_3(out),\n self.layer6_4(out)],\n dim=1)\n out = self.layer7(out)\n #print('ASPP:', out.shape)\n\n # === Prediction\n out = self.layer9(out)\n #print('Output:', out.shape)\n\n return out\n\n\ndef Res_Deeplab(num_classes=2, use_attn=False):\n model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes, use_attn)\n return model\n"
},
{
"alpha_fraction": 0.5273709297180176,
"alphanum_fraction": 0.5447779297828674,
"avg_line_length": 33.70833206176758,
"blob_id": "8e300ed6e88335a39318f786e0c97a35e6610c5b",
"content_id": "5e38027eb7418bf86d11583f3e36946418cd721e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8330,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 240,
"path": "/train.py",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "from torch.utils import data\nimport torch.optim as optim\nimport torch.backends.cudnn as cudnn\nimport os.path as osp\nfrom utils import *\nimport time\nimport torch.nn.functional as F\nimport tqdm\nimport random\nimport argparse\nfrom dataset_mask_train import Dataset as Dataset_train\nfrom dataset_mask_val import Dataset as Dataset_val\nimport os\nimport torch\nfrom one_shot_network import Res_Deeplab\nimport torch.nn as nn\nimport numpy as np\n\n# === Parse CMD arguments\nparser = argparse.ArgumentParser()\nparser.add_argument('-lr',\n type=float,\n help='learning rate',\n default=0.00025)\nparser.add_argument('-prob',\n type=float,\n help='dropout rate of history mask',\n default=0.7)\nparser.add_argument('-bs',\n type=int,\n help='batch size in training',\n default=4)\nparser.add_argument('-fold',\n type=int,\n help='fold',\n default=0)\nparser.add_argument('-gpu',\n type=str,\n help='gpu id to use',\n default='0,1')\nparser.add_argument('-iter_time',\n type=int,\n help='number of iterations for the IOM',\n default=5)\nparser.add_argument('-data',\n type=str,\n help='path to the dataset folder')\nparser.add_argument('-attn',\n action='store_true',\n help='whether or not to separate')\noptions = parser.parse_args()\n\n\ndef set_seed(seed):\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n\n\ndef set_determinism():\n torch.backends.cudnn.benchmark = False\n torch.backends.cudnn.deterministic = True\n\n\n# === Constants/Variables\nIMG_MEAN = [0.485, 0.456, 0.406]\nIMG_STD = [0.229, 0.224, 0.225]\nnum_class = 2\nnum_epoch = 200\nlearning_rate = options.lr # 0.000025#0.00025\ninput_size = (321, 321)\nbatch_size = options.bs\nweight_decay = 0.0005\nmomentum = 0.9\n\n# === GPU-related\ngpu_list = [int(x) for x in options.gpu.split(',')]\nos.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'\nos.environ['CUDA_VISIBLE_DEVICES'] = options.gpu\ncudnn.enabled = True\n\n# === Log directory\ncheckpoint_dir = 'checkpoint/fo=%d/' % options.fold\ncheck_dir(checkpoint_dir)\n\n# === Network architecture\nset_seed(3698)\nmodel = Res_Deeplab(num_classes=num_class, use_attn=options.attn)\nmodel = load_resnet50_param(model, stop_layer='layer4')\nmodel = nn.DataParallel(model, [0])\nturn_off(model)\n\n# === Dataset\n# Train\nset_seed(3698)\ndataset = Dataset_train(data_dir=options.data, fold=options.fold,\n input_size=input_size,\n normalize_mean=IMG_MEAN, normalize_std=IMG_STD,\n prob=options.prob)\ntrainloader = data.DataLoader(dataset,\n batch_size=batch_size,\n shuffle=True,\n num_workers=4)\n\n# Validation\nset_seed(3698)\nvalset = Dataset_val(data_dir=options.data, fold=options.fold,\n input_size=input_size,\n normalize_mean=IMG_MEAN, normalize_std=IMG_STD,\n is_train=True)\nvalloader = data.DataLoader(valset,\n batch_size=1,\n shuffle=False,\n num_workers=4)\n\nsave_pred_every = len(trainloader)\n\n# === Optimizer\noptimizer = optim.SGD([{'params': get_10x_lr_params(model),\n 'lr': 10 * learning_rate}],\n lr=learning_rate, momentum=momentum, weight_decay=weight_decay)\n\nloss_list = []\niou_list = []\nhighest_iou = 0\n\nmodel.cuda()\ntempory_loss = 0\nmodel = model.train()\nbest_epoch = 0\nfor epoch in range(0, num_epoch):\n begin_time = time.time()\n\n # === Train stage\n model.train()\n tqdm_gen = tqdm.tqdm(trainloader)\n for i_iter, batch in enumerate(tqdm_gen):\n query_rgb, query_mask, support_rgb, support_mask, history_mask, sample_class, index = batch\n\n query_rgb = (query_rgb).cuda(0)\n support_rgb = (support_rgb).cuda(0)\n support_mask = (support_mask).cuda(0)\n query_mask = (query_mask).cuda(0).long()\n query_mask = query_mask[:, 0, :, :]\n history_mask = (history_mask).cuda(0)\n\n optimizer.zero_grad()\n\n pred = model(query_rgb, support_rgb, support_mask, history_mask)\n pred_softmax = F.softmax(pred, dim=1).data.cpu()\n\n # update history mask\n for j in range(support_mask.shape[0]):\n sub_index = index[j]\n dataset.history_mask_list[sub_index] = pred_softmax[j]\n pred = nn.functional.interpolate(pred, size=input_size,\n mode='bilinear', align_corners=True)\n\n loss = loss_calc_v1(pred, query_mask, 0)\n loss.backward()\n optimizer.step()\n\n tqdm_gen.set_description(\n 'e:%d loss = %.4f-:%.4f' % (epoch, loss.item(), highest_iou)\n )\n\n # save training loss\n tempory_loss += loss.item()\n if i_iter % save_pred_every == 0 and i_iter != 0:\n loss_list.append(tempory_loss / save_pred_every)\n plot_loss(checkpoint_dir, loss_list, save_pred_every)\n np.savetxt(osp.join(checkpoint_dir, 'loss_history.txt'),\n np.array(loss_list))\n tempory_loss = 0\n\n # === Validation stage\n with torch.no_grad():\n print('----Evaluation----')\n model.eval()\n\n valset.history_mask_list = [None] * 1000\n best_iou = 0\n for eva_iter in range(options.iter_time):\n all_inter, all_union, all_predict = [0] * 5, [0] * 5, [0] * 5\n for i_iter, batch in enumerate(valloader):\n query_rgb, query_mask, support_rgb, support_mask, history_mask, sample_class, index = batch\n\n query_rgb = query_rgb.cuda(0)\n support_rgb = support_rgb.cuda(0)\n support_mask = support_mask.cuda(0)\n query_mask = query_mask.cuda(0).long()\n query_mask = query_mask[:, 0, :, :]\n history_mask = history_mask.cuda(0)\n\n pred = model(query_rgb, support_rgb,\n support_mask, history_mask)\n pred_softmax = F.softmax(pred, dim=1).data.cpu()\n\n # update history mask\n for j in range(support_mask.shape[0]):\n sub_index = index[j]\n valset.history_mask_list[sub_index] = pred_softmax[j]\n pred = nn.functional.interpolate(pred, size=query_rgb.shape[-2:],\n mode='bilinear', align_corners=True)\n _, pred_label = torch.max(pred, 1)\n inter_list, union_list, _, num_predict_list = \\\n get_iou_v1(query_mask, pred_label)\n for j in range(query_mask.shape[0]):\n mapped_cid = sample_class[j] - (options.fold * 5 + 1)\n all_inter[mapped_cid] += inter_list[j]\n all_union[mapped_cid] += union_list[j]\n\n IOU = [0] * 5\n for j in range(5):\n IOU[j] = all_inter[j] / all_union[j]\n mean_iou = np.mean(IOU)\n print('IOU:%.4f' % (mean_iou))\n if mean_iou > best_iou:\n best_iou = mean_iou\n else:\n break\n\n iou_list.append(best_iou)\n plot_iou(checkpoint_dir, iou_list)\n np.savetxt(osp.join(checkpoint_dir, 'iou_history.txt'),\n np.array(iou_list))\n if best_iou > highest_iou:\n highest_iou = best_iou\n model = model.eval()\n torch.save(model.cpu().state_dict(),\n osp.join(checkpoint_dir, 'model', 'best' '.pth'))\n model = model.train()\n best_epoch = epoch\n print('A better model is saved')\n print('IOU for this epoch: %.4f' % (best_iou))\n model.cuda()\n epoch_time = time.time() - begin_time\n print('best epoch:%d ,iout:%.4f' % (best_epoch, highest_iou))\n print('This epoch taks:', epoch_time, 'second')\n print('still need hour:%.4f' % ((num_epoch - epoch) * epoch_time / 3600))\n"
},
{
"alpha_fraction": 0.5526179075241089,
"alphanum_fraction": 0.5536547303199768,
"avg_line_length": 31.16666603088379,
"blob_id": "433fd3b9faeaff95af5dd735a0484c75e5fe6665",
"content_id": "5a6afd76814f8db572f2e19a8037b724b467518a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1929,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 60,
"path": "/README.md",
"repo_name": "vltanh/CaNet",
"src_encoding": "UTF-8",
"text": "# Train\n\nTo train, use `train.py`\n\n```\nusage: train.py [-h] [-lr LR] [-prob PROB] [-bs BS] [-fold FOLD] [-gpu GPU]\n [-iter_time ITER_TIME] [-data DATA] [-attn]\n\noptional arguments:\n -h, --help show this help message and exit\n -lr LR learning rate\n -prob PROB dropout rate of history mask\n -bs BS batch size in training\n -fold FOLD fold\n -gpu GPU gpu id to use\n -iter_time ITER_TIME number of iterations for the IOM\n -data DATA path to the dataset folder\n -attn whether or not to separate\n```\n\n# Evaluate\n\nTo evaluate a trained model, use `val.py`\n\n```\nusage: val.py [-h] [-fold FOLD] [-gpu GPU] [-iter_time ITER_TIME] [-w W]\n [-d D] [-s S] [-a] [-p P]\n\noptional arguments:\n -h, --help show this help message and exit\n -fold FOLD fold\n -gpu GPU gpu id to use\n -iter_time ITER_TIME number of iterations in IOM\n -w W path to weight file\n -d D path to dataset\n -s S random seed\n -a use attention or not\n -p P number of exps\n```\n\n# Visualize\n\nTo make inference on one sample of the PASCAL-5i and visualize, use `visualize.py`\n\n```\nusage: visualize.py [-h] [--gpus GPUS] [--weight WEIGHT] [--root ROOT]\n [--refid REFID] [--queid QUEID] [--classid CLASSID]\n [--niters NITERS] [--a]\n\noptional arguments:\n -h, --help show this help message and exit\n --gpus GPUS gpu(s) to be used\n --weight WEIGHT path to pretrained weights\n --root ROOT root folder of the PASCAL-5i\n --refid REFID id of reference image\n --queid QUEID id of the query image\n --classid CLASSID id of the semantic class\n --niters NITERS number of iterations for IOM\n --a separate attention or not\n```"
}
] | 6 |
riteshsharma29/python_based_webtable_scraping | https://github.com/riteshsharma29/python_based_webtable_scraping | 9e04f3bd24e285fe56db5a97e1cc325b54e2c818 | 7c188e33d2be1ec0efe778fa31109783129627ea | 851401c0a2f0cc5bbe0b941eecfcd7f5d3cdffc4 | refs/heads/master | "2021-09-27T01:17:44.283714" | "2018-11-05T08:07:51" | "2018-11-05T08:07:51" | 109,389,341 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6061439514160156,
"alphanum_fraction": 0.6098120212554932,
"avg_line_length": 22.20212745666504,
"blob_id": "3bad8e9ea1dfee6d42b3772caeed017d9d6bb1b9",
"content_id": "e5e6514e3f73a11c1ffc78270d532f7e775eff4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2181,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 94,
"path": "/webtable_extractor.py",
"repo_name": "riteshsharma29/python_based_webtable_scraping",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\nimport pandas as pd\nfrom pandas import ExcelWriter\nfrom openpyxl import load_workbook\nfrom openpyxl import __version__\nimport codecs,os,sys\n\n\n###########################################################################################################################################\n\ndef remove_log(logfile):\n\tif os.path.isfile(logfile):\n\t\tos.remove(logfile)\n\t\t\nremove_log('log.txt')\nremove_log('done.txt')\n\t\nfile = codecs.open('log.txt','w',encoding=\"utf-8\")\n\nif not os.path.isfile('input.txt'):\n\tprint \"\"\n\tprint \"\"\n\tprint \"input.txt Not found\"\n\tfile.write(\"input.txt Not found\" + '\\n' + '\\n')\n\tprint \"\"\n\tprint \"\"\n\tprint \"Please keep input.txt with tool\"\n\tfile.write(\"Please keep input.txt with tool\" + '\\n' + '\\n' + \"and try again ....\")\n\tprint \"\"\n\tprint \"\"\n\tsys.exit()\nelif not os.path.isfile('tables.xlsx'):\n\tprint \"\"\n\tprint \"\"\n\tprint \"tables.xlsx Not found\"\n\tfile.write(\"tables.xlsx Not found\" + '\\n' + '\\n')\n\tprint \"\"\n\tprint \"\"\n\tprint \"Please keep tables.xlsx with tool\"\n\tfile.write(\"Please keep tables.xlsx with tool\" + '\\n' + '\\n' + \"and try again ....\")\n\tprint \"\"\n\tprint \"\"\n\tsys.exit()\n\n\nXvals=[]; Yvals=[]\ni = open('input.txt','r')\n\nfor line in i:\n\t \n\t x, y = line.split('=', 1)\n\t Xvals.append(str(x)) \n\t Yvals.append(str(y))\n\n#read html link\n\nhtmllink = Yvals[0]\nhtmllink = htmllink.rstrip()\nhtmllink = htmllink.lstrip()\nhtmllink = htmllink.lstrip('\\n')\n\n\ntry:\n\tdf = pd.read_html(htmllink)\n\nexcept:\n\tfile.write(\"Tool could not open the link. Something went wrong !!!. Please check the link passed in the input.txt. Please make sure webpage has html Tables to extract !!!\" + '\\n' + '\\n')\n\tsys.exit()\n\nfile_2 = codecs.open('done.txt','w',encoding=\"utf-8\")\n\ndef pd_html_excel():\n\n\tbook = load_workbook('tables.xlsx')\n\twriter = ExcelWriter('tables.xlsx', engine='openpyxl') \t\n\twriter.book = book\n\twriter.sheets = dict((ws.title, ws) for ws in book.worksheets)\n\n\tfor x in range(0,len(df)):\n\n\t\tdf[x].to_excel(writer,sheet_name=\"table_\" + str(x))\n\t\n\twriter.save()\n\n\tfile_2.write(\"Success !!! Please check tables.xlsx for extracted tables from the webpage.\" + '\\n' + '\\n')\n\n\npd_html_excel()\n\nfile.close()\nremove_log('log.txt')\n"
},
{
"alpha_fraction": 0.7811059951782227,
"alphanum_fraction": 0.789170503616333,
"avg_line_length": 33.63999938964844,
"blob_id": "346d51f4d0599ec279fbaee21eb8b64685444f1f",
"content_id": "ae99fc2e9e4fdef644702ae2c5c19828fcf10222",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 25,
"path": "/README.md",
"repo_name": "riteshsharma29/python_based_webtable_scraping",
"src_encoding": "UTF-8",
"text": "# python_based_webtable_scraping\n\nTask : Automating task of downloading html web tables from webpages.\n\nPurpose : \nThis Python pandas based script is for extracting html table information from webpage into an xlsx file with ease. \nPlease use this tool for ethical web scraping only. \nAny possible tool error will be logged in the log.txt file.\n\nUSAGE:\n1) Please keep webtable_extractor.py and tables.xlsx in any permissible path of your Linux directory.\n2) Upadte input.txt with URL having html tables and save the file. \n3) URL updated in the input.txt should be valid.\n4) Run as python webtable_extractor.py command OR ./webtable_extractor.py\n5) Webtables will be extracted in the tables.xlsx file. Ignore the 1st sheet.\n\nPython Dependencies OR Requirement [Linux users can use pip and windows users can sue pip.exe ]:\n\npandas\nopenpyxl\nlxml\nhtml5lib\ncodecs\nsys\nos\n\n\n"
}
] | 2 |
saadwazir/DOTA-FasterRCNN | https://github.com/saadwazir/DOTA-FasterRCNN | 768a76b509661924b93e30954f45ecafbce25f87 | 8faf5b3b8f9e58224e2acb804b680945bacef58d | 409c2635fe82534c4ffaa72c50cee34bc0b69bb7 | refs/heads/master | "2021-05-17T14:27:30.638835" | "2020-03-28T15:07:46" | "2020-03-28T15:07:46" | 250,821,075 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6384839415550232,
"alphanum_fraction": 0.6574344038963318,
"avg_line_length": 24.941177368164062,
"blob_id": "76794da890d56b73a38dec6e1c1b753e6a80aa33",
"content_id": "5e6128838e05c4ff6e6a12281fceba5745549bdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 51,
"path": "/create-dataframe.py",
"repo_name": "saadwazir/DOTA-FasterRCNN",
"src_encoding": "UTF-8",
"text": "import os\r\nimport pandas as pd\r\nimport csv\r\nfrom pandas import read_csv\r\nfrom matplotlib import pyplot as plt\r\nimport matplotlib as mpl\r\nimport numpy as np\r\n\r\nentries = os.listdir('dota-dataset-split/labels-un')\r\nprint(entries)\r\n\r\nroot_path = \"dota-dataset-split/labels-un/\"\r\n\r\n\r\ndf1 = pd.DataFrame()\r\n\r\n\r\nfor i in entries:\r\n df = read_csv(root_path + i, names=['image-name', 'x1', 'y1', 'x2', 'y2', 'class'],na_values=['.'])\r\n df1 = df1.append(df,ignore_index=True)\r\n\r\nprint(df1)\r\n\r\nexport_csv = df1.to_csv(r'annotation-new.txt', index = None, header=False)\r\n\r\n#base_path = \"/content/drive/My Drive/dota-dataset/\"\r\n\r\ndf = pd.read_csv(\"annotation-new.txt\", names=['image-name', 'x1', 'y1', 'x2', 'y2', 'class'])\r\nprint(df)\r\n\r\nfirst_split = df.sample(frac=0.7)\r\nprint(first_split)\r\n\r\nsecond_split=df.drop(first_split.index)\r\nprint(second_split)\r\n\r\n#third_split = second_split.sample(frac=0.02)\r\n#print(third_split)\r\n\r\n\r\nexport_csv = first_split.to_csv(r'train_annotation.txt', index = None, header=False)\r\nexport_csv = second_split.to_csv(r'test_annotation.txt', index = None, header=False)\r\n\r\n\r\n#base_path = \"/content/drive/My Drive/dota-dataset/\"\r\n\r\ndf = pd.read_csv(\"train_annotation.txt\", names=['image-name', 'x1', 'y1', 'x2', 'y2', 'class'])\r\nprint(df)\r\n\r\ndf = pd.read_csv(\"test_annotation.txt\", names=['image-name', 'x1', 'y1', 'x2', 'y2', 'class'])\r\nprint(df)"
},
{
"alpha_fraction": 0.6701119542121887,
"alphanum_fraction": 0.6830318570137024,
"avg_line_length": 20.090909957885742,
"blob_id": "2afd1da888886f6de36536a3a2c4b917b2384501",
"content_id": "f69aeed61764063f12964e10a736255d6368a6db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1161,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 55,
"path": "/bbox_multi.py",
"repo_name": "saadwazir/DOTA-FasterRCNN",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport random\nfrom skimage import io\nimport pandas as pd\nfrom matplotlib import pyplot as plt\nfrom shutil import copyfile\n\nimport cv2\nimport tensorflow as tf\nfrom pandas import read_csv\nimport tensorflow as tf\ngpu_options = tf.compat.v1.GPUOptions(allow_growth=True)\nsession = tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(gpu_options=gpu_options))\n\nprint(gpu_options)\nprint(session)\n\n\n#%%\n\nroot_path = \"/home/saad/DOTA_devkit/\"\n\ndf = pd.DataFrame()\ndf = read_csv(root_path + 'train_annotation.txt',names=['image-name', 'x1', 'y1', 'x2', 'y2', 'class'],na_values=['.'])\n#print(df)\n\n\n#%%\n\nimg_data_single_names = pd.DataFrame()\n\ndata = df[['image-name']]\n#print(data.loc[1])\n\ntemp = \"\"\n\nfor index, row in range( data.iterrows() ):\n img_name_1 = row['image-name']\n\n if temp == img_name_1:\n continue\n else:\n #print(img_name_1)\n img_data_single_names = img_data_single_names.append({'image-name':img_name_1},ignore_index=True)\n temp = img_name_1\n\n\n\nroot_path = \"/home/saad/DOTA_devkit/dota-dataset-split/\"\n\nimg_file = img_data_single_names.iloc[2]\nimg_file = img_file['image-name']\n\nprint(img_file)\n\n"
},
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 16,
"blob_id": "c4bf25a306bb2434947306d896969b2b664a20bd",
"content_id": "f8bd9fdaf9cff831820a4cd9e03ee593341ad10f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 2,
"path": "/README.md",
"repo_name": "saadwazir/DOTA-FasterRCNN",
"src_encoding": "UTF-8",
"text": "# DOTA-FasterRCNN\nDOTA-FasterRCNN\n"
},
{
"alpha_fraction": 0.4976809024810791,
"alphanum_fraction": 0.5153061151504517,
"avg_line_length": 31.1641788482666,
"blob_id": "1edcacfa9ddc62c1dadabbb0879c1a56c01ab7e2",
"content_id": "0a8bf3923cdbe46f579888bd10e8bb2ae5c60ff7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2156,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 67,
"path": "/YOLO_Transform.py",
"repo_name": "saadwazir/DOTA-FasterRCNN",
"src_encoding": "UTF-8",
"text": "import dota_utils as util\nimport os\nimport numpy as np\nfrom PIL import Image\n\n\ndef convert(img_w, img_h,x,y,w,h):\n box = np.zeros(4)\n dw = 1./img_w\n dh = 1./img_h\n x = x/dw\n w = w/dw\n y = y/dh\n h = h/dh\n box[0] = x-(w/2.0)\n box[1] = x+(w/2.0)\n box[2] = y-(h/2.0)\n box[3] = y+(h/2.0)\n\n #box[0] = box[0] / img_w\n #box[1] = box[1] / img_w\n #box[2] = box[2] / img_h\n #box[3] = box[3] / img_h\n\n return (box)\n\n## trans dota format to format YOLO(darknet) required\ndef dota2darknet(imgpath, txtpath, dstpath, extractclassname):\n \"\"\"\n :param imgpath: the path of images\n :param txtpath: the path of txt in dota format\n :param dstpath: the path of txt in YOLO format\n :param extractclassname: the category you selected\n :return:\n \"\"\"\n filelist = util.GetFileFromThisRootDir(txtpath)\n for fullname in filelist:\n objects = util.parse_dota_poly(fullname)\n name = os.path.splitext(os.path.basename(fullname))[0]\n print (name)\n img_fullname = os.path.join(imgpath, name + '.png')\n img = Image.open(img_fullname)\n img_w, img_h = img.size\n #print (img_w,img_h)\n with open(os.path.join(dstpath, name + '.txt'), 'w') as f_out:\n for obj in objects:\n poly = obj['poly']\n bbox = np.array(util.dots4ToRecC(poly, img_w, img_h))\n if (sum(bbox <= 0) + sum(bbox >= 1)) >= 1:\n continue\n if (obj['name'] in extractclassname):\n id = obj['name']\n else:\n continue\n bbox_con = convert(img_w, img_h, bbox[0], bbox[1], bbox[2], bbox[3] )\n outline = str(name) + '.png' + ',' + ','.join(list(map(str, bbox_con))) + ',' + str(id)\n f_out.write(outline + '\\n')\n #print(bbox[0], '--', bbox_con[0])\n print (\"-- ALL Done --\")\n \n \nif __name__ == '__main__':\n ## an example\n dota2darknet('dota-dataset-split/images',\n 'dota-dataset-split/labelTxt',\n 'dota-dataset-split/labels-un',\n util.wordname_15)\n\n"
}
] | 4 |
bac2qh/Django | https://github.com/bac2qh/Django | ab1bb8de1134668fc819847e1bada0eccf9aaf5f | 4e41a64795a09e7df1ef00d7d9e340bf8c5da569 | 837cc427ec4bed5fd5e2ff7c1a138c158d6bfb41 | refs/heads/master | "2020-07-02T03:33:03.738809" | "2019-10-09T03:12:27" | "2019-10-09T03:12:27" | 201,395,499 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7852349281311035,
"alphanum_fraction": 0.7852349281311035,
"avg_line_length": 23.83333396911621,
"blob_id": "28f08fea57bdb41c1d5a10324dce2e17b1f3f4d9",
"content_id": "95f61785140f3d7d5de99d34c687932a3860afb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 6,
"path": "/first_project/blog/admin.py",
"repo_name": "bac2qh/Django",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Post\n\nadmin.site.register(Post)\n\n# Register your models here. so they show up on our admin page\n"
},
{
"alpha_fraction": 0.7148217558860779,
"alphanum_fraction": 0.7176360487937927,
"avg_line_length": 38.48147964477539,
"blob_id": "bab088ff9fec5b8b8af0a4273e638afd404fc855",
"content_id": "6adb2664286a76229aa2e0b46d0da695b46379e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 27,
"path": "/first_project/blog/models.py",
"repo_name": "bac2qh/Django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom django.urls import reverse\n# Create your models here.\n\n# each class will be a table in the DB\nclass Post(models.Model):\n # each attribute will be a different field in the DB\n title = models.CharField(max_length=100)\n content = models.TextField()\n # date_posted = models.DateTimeField(auto_now=True) for last updated field\n # auto_now_add record the time it was created and can not be changed later on\n date_posted = models.DateTimeField(default=timezone.now)\n # ForeignKey to relate to a different table\n author = models.ForeignKey(User, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.title\n\n # tell django how to find a model object, is to create a get_absolute_url\n # method in our model @ models app\n\n # redirect goes to a specific route\n # reverse will return the full url to that url as a string.\n def get_absolute_url(self):\n return reverse('post-detail', kwargs={'pk':self.pk})\n"
},
{
"alpha_fraction": 0.6459272503852844,
"alphanum_fraction": 0.6489329934120178,
"avg_line_length": 30.685714721679688,
"blob_id": "7c6966139ecdd37ae767a0b164cc3278410bc0ae",
"content_id": "73414c6f4b8f2ed63ba85d4ec1415c727ee6b3ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3327,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 105,
"path": "/first_project/blog/views.py",
"repo_name": "bac2qh/Django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, get_object_or_404\nfrom django.contrib.auth.mixins import LoginRequiredMixin, UserPassesTestMixin # decorator for a class\nfrom django.contrib.auth.models import User\nfrom django.views.generic import (\n ListView,\n DetailView,\n CreateView,\n UpdateView,\n DeleteView\n)\nfrom .models import Post\n\n# from django.http import HttpResponse\n\n# Create your views here.\n\n# # dummy post\n# posts = [\n# {\n# 'author' : 'CoreyMS',\n# 'title' : 'Blog Post 1',\n# 'content' : 'First post content',\n# 'date_posted' : 'Today'\n# },\n# {\n# 'author' : 'Paddy D',\n# 'title' : 'Blog Post 2',\n# 'content' : 'Second post content',\n# 'date_posted' : 'Tmr'\n# }\n# ]\n\n\ndef home(request):\n context = {\n 'posts' : Post.objects.all()\n }\n return render(request, 'blog/home.html', context)\n\nclass PostListView(ListView):\n model = Post\n template_name = 'blog/home.html' # <app>/<model>_<viewtype>.html\n context_object_name = 'posts'\n ordering = ['-date_posted'] # change the ordering from newest to oldest\n paginate_by = 5 # seems like there is no import needed here?\n\n# create a view that display the posts from a user\nclass UserPostListView(ListView):\n model = Post\n template_name = 'blog/user_posts.html' # <app>/<model>_<viewtype>.html\n context_object_name = 'posts'\n paginate_by = 5 # seems like there is no import needed here?\n\n # change the query set so it returns the posts linked to a username\n def get_queryset(self):\n user = get_object_or_404(User, username=self.kwargs.get('username'))\n return Post.objects.filter(author=user).order_by('-date_posted')\n\n\n# create a view for individual posts\nclass PostDetailView(DetailView):\n model = Post\n # <app>/<model>_<viewtype>.html\n # => blog/post_detail.html\n\nclass PostCreateView(LoginRequiredMixin, CreateView):\n model = Post\n # <app>/<model>_<viewtype>.html\n fields = ['title', 'content']\n # override form valid method so now the author is the logged in user\n def form_valid(self, form):\n form.instance.author = self.request.user\n return super().form_valid(form) # this runs anyways but with this\n # function, it is run after the author is assigned\n\n # tell django how to find a model object, is to create a get_absolute_url\n # method in our model @ models app\n\nclass PostUpdateView(LoginRequiredMixin, UserPassesTestMixin, UpdateView):\n model = Post\n # <app>/<model>_<viewtype>.html\n fields = ['title', 'content']\n # override form valid method so now the author is the logged in user\n def form_valid(self, form):\n form.instance.author = self.request.user\n return super().form_valid(form)\n\n def test_func(self):\n post = self.get_object()\n if self.request.user == post.author:\n return True\n return False\n\nclass PostDeleteView(LoginRequiredMixin, UserPassesTestMixin, DeleteView):\n model = Post\n success_url = '/' # so that django knows where to go after deletion\n\n def test_func(self):\n post = self.get_object()\n if self.request.user == post.author:\n return True\n return False\n\ndef about(request):\n return render(request, 'blog/about.html', {'title' : 'About'})\n"
}
] | 3 |
snigelpiss/messageboard | https://github.com/snigelpiss/messageboard | 8bfdebb8507c9d1abb5f401a48406f234a5385fb | 38a211088fe9fd3937ffd424428fe3b0f9720e9f | 47bfa4a94e22abd0aa73dc4a45faa9802c203955 | refs/heads/master | "2021-01-14T08:25:33.173248" | "2014-09-11T06:37:37" | "2014-09-11T06:37:37" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6914893388748169,
"alphanum_fraction": 0.6914893388748169,
"avg_line_length": 12.428571701049805,
"blob_id": "3605ad9fa4ac1ae028bea28dc2cbc7c375293785",
"content_id": "a779a713c6ef6c7041cf940b8bead51cd233af13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 7,
"path": "/README.md",
"repo_name": "snigelpiss/messageboard",
"src_encoding": "UTF-8",
"text": "messageboard\n============\n\nstudent project building a simple messageboard\n\n\n**API ENDPOINTS**\n"
},
{
"alpha_fraction": 0.6483145952224731,
"alphanum_fraction": 0.649438202381134,
"avg_line_length": 17.957447052001953,
"blob_id": "97d0b52591043c62153f2fd8aaa4b8d693cc4e6c",
"content_id": "22bdf38243955f52c6ab1c657a52f25780ea21c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 890,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 47,
"path": "/messageboard/views.py",
"repo_name": "snigelpiss/messageboard",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request\n\nfrom webbapp import app\n\n\n\n#satndard get\[email protected]('/', methods=[\"GET\"])\ndef hello_world():\n return render_template(\"index.html\",name = \"bosse\", title=\"Hello from flask\")\n\n\n# get parameters\[email protected]('/hejsan', methods=[\"GET\"])\ndef hejsan():\n\n name=request.args.get(\"name\",\"dude\")\n\n return \"hejsan \" + name\n\n#this is restfull route's\[email protected]('/user/<name>', methods=[\"GET\"])\ndef user_home(name):\n\n return \"Hello \" + name\n\[email protected]('/user/<name>/settings', methods=[\"GET\"])\ndef user_setting(name):\n\n return \"Hello \" + name + \" your settings\"\n\n#post\[email protected]('/user', methods=[\"GET\",\"POST\"])\ndef user5():\n\n #return str(request.form.keys)\n name=request.form['name']\n\n\n\n return \"Hello \" + name\n\n\[email protected]('/pnr', methods=[\"GET\"])\ndef checkpnr():\n\n return render_template(\"checkpnr.html\", title=\"personummerkoll\")"
}
] | 2 |
fitzw/Scheduling-using-SAT-Solver | https://github.com/fitzw/Scheduling-using-SAT-Solver | a4bff7b4e2ace5716fa8c683f24f852f002eacbe | e019e230f5e161ce8001df3282db288468a918aa | bfb546799a52b0b7d1e49a0242048ee9832f20b6 | refs/heads/master | "2021-01-18T20:09:01.741491" | "2017-04-07T16:14:01" | "2017-04-07T16:14:01" | 86,941,976 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.42269882559776306,
"alphanum_fraction": 0.48436102271080017,
"avg_line_length": 18.189655303955078,
"blob_id": "30d80c419a5ae3e2f284e06cf07bc692546e9eea",
"content_id": "73b77eb019caa9b66c855abb0bb0fc6dd81a3d48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 58,
"path": "/professor_data.py",
"repo_name": "fitzw/Scheduling-using-SAT-Solver",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[1]:\n\n# import csv\n\n\n# with open('professor_data', 'wb') as myfile:\n# wr = csv.writer(myfile, quoting=csv.QUOTE_ALL)\n# wr.writerow(mylist)\n\n\n# In[27]:\n\nimport random as rd\nimport csv\nCourse_number = 50\n\n\n# In[21]:\n\nP = {'A':[0,3,[],(1,30),'Building A','Tue'],\n 'B':[1,3,[],(2,30),'Building A','Tue'],\n 'C':[2,1,[],(1,30),'Building A','Fri'],\n 'D':[3,2,[],(1,30),'Building B','Mon'],\n 'E':[4,1,[],(1,30),'Building A','WED'],\n 'F':[5,2,[],(1,30),'Building C','Tue'],\n 'G':[6,3,[],(1,30),'Building B','Thu'],\n 'H':[7,1,[],(1,30),'Building C','Thu'],\n 'I':[8,2,[],(1,30),'Building A','Tue'],\n 'J':[9,1,[],(1,30),'Building C','Fri'],\n }\n\n\n# In[24]:\n\nfor k in P:\n iter_n = P[k][1]\n P[k][2] = []\n for i in range(iter_n):\n P[k][2].append(rd.randint(1,Course_number))\n\n\n# In[25]:\n\nP\n\n\n# In[32]:\n\n# with open('Prof_data.csv', 'w') as f: # Just use 'w' mode in 3.x\n# w = csv.DictWriter(f, P.keys())\n# w.writeheader()\n# w.writerows(P)\n \nwith open('Prof_data.csv','w') as f:\n w = csv.writer(f)\n w.writerows(P.items()) \n\n"
},
{
"alpha_fraction": 0.5117021203041077,
"alphanum_fraction": 0.51382976770401,
"avg_line_length": 24.405405044555664,
"blob_id": "9a14142c4bd816c99387e0185aa6a8f0897b91d2",
"content_id": "c50789275d8408390c2caa747957d6001d111326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 940,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 37,
"path": "/Professor.py",
"repo_name": "fitzw/Scheduling-using-SAT-Solver",
"src_encoding": "UTF-8",
"text": "class Professor:\n def __init__(self, id, name, courses_ids,n,pref,office,unava):\n self.id = id\n self.name = name\n #courses_ids = [class1, class2,...]\n self.courses_ids = courses_ids\n # n of class teaching MAX\n self.n = n\n # pref = [(date, hours)...]\n self.pref = pref\n # office => building id\n self.office = office\n # unava => days or hours unavailable [(date, hours)...]\n self.unava = unava\n def p_id(self):\n return self.id\n \n def teaching(self):\n return self.courses_ids\n \n def n_teaching(self):\n return self.n\n \n def pref(self):\n return self.pref\n \n def office(self):\n return self.office\n \n def unava(self):\n return self.unava\n \n def __str__(self):\n return self.name\n \n def __repr__(self):\n return '{\"id\":%d, \"name\":\"%s\"}'%(self.id, self.name)\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 30,
"blob_id": "5c2c387440bdd3c7276a4381aca8915a2ab9ec28",
"content_id": "6f2f8d77bbf923e4afdf95957023bbe49728c202",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 1,
"path": "/README.md",
"repo_name": "fitzw/Scheduling-using-SAT-Solver",
"src_encoding": "UTF-8",
"text": "# Scheduling-using-SAT-Solver-"
},
{
"alpha_fraction": 0.47941887378692627,
"alphanum_fraction": 0.47941887378692627,
"avg_line_length": 23.294116973876953,
"blob_id": "227fe6394a565c8be6d8ce5d547dc7585d8cc166",
"content_id": "065c1a032c616c670727daa2710cd548bf89b4c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 17,
"path": "/Room.py",
"repo_name": "fitzw/Scheduling-using-SAT-Solver",
"src_encoding": "UTF-8",
"text": "class Room:\n \n def __init__(self, id, name, size, b_id):\n #self.type = type\n self.id = id\n self.name = name\n self.size = size\n self.b_id = b_id\n \n def b_id(self):\n return self.b_id\n def size(self):\n return self.size\n def __str__(self):\n return self.name\n def __repr__(self):\n return '{\"id\":%d, \"name\":\"%s\"}'%(self.id, self.name)\n"
}
] | 4 |
jfwaldo/waldo-jfwaldo | https://github.com/jfwaldo/waldo-jfwaldo | 14b10c1b9e7bc972b43315fe1312a9c9450fc6a0 | f0b3506f86b92308accf3fdfcaf6cf9e71dbb4f5 | 4f7a7e93bc06bb21b096a8ab7f12cdc09e99b79e | refs/heads/master | "2020-03-23T15:46:48.395047" | "2018-07-21T02:26:01" | "2018-07-21T02:26:01" | 141,774,009 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7263345122337341,
"alphanum_fraction": 0.7411032319068909,
"avg_line_length": 49.17856979370117,
"blob_id": "9d5e54f1df9cd33305561f2e3be503911c84aa77",
"content_id": "2a6f4c1fdfd1d04b88de3b6f6961a59bfe1abf78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5620,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 112,
"path": "/subimage.py",
"repo_name": "jfwaldo/waldo-jfwaldo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport cv2\n\nimport sys\nfrom os import access, R_OK\nfrom os.path import isfile\n#import asyncio\n#import numpy # could be useful for more precise analysis of the template matching result, e.g. to reduce false positives\n#import time # for tracking timing results\n\n## NOTE: asynchronous image loading is unused... some quick tests showed that using async instead of serial synchronous\n## loads may be more performant once there are at least 10 or 20 images to load, so it's not applicable for our case here.\n\n## a couple other notes: if load_images is used, then the resultant list will need to be checked for `None` to ensure\n## no failures occurred. alternatively, asyncio.wait may give more granular control over aborting if it's important to\n## fail parallel loading as soon as possible\n# def load_images(*imagePaths):\n# loop = asyncio.get_event_loop()\n# images = loop.run_until_complete(asyncio.gather(*[_load_image(imagePath) for imagePath in imagePaths]))\n# return images\n\n# async def _load_image(imagePath):\n# image = cv2.imread(imagePath, cv2.IMREAD_GRAYSCALE)\n# return image\n\n\n\n#\n# Checks to see if the file at the given path exists, is not a directory, and is readable\n#\ndef can_load_file(imagePath):\n return isfile(imagePath) and access(imagePath, R_OK)\n\n#\n# Reads a given image path with color mode and returns an opencv image object (or None if the read failed)\n#\n# NOTE: for now, just using grayscale to reduce computation time. But, not sure what the exact use case would be etc.\ndef load_image(imagePath, flags=cv2.IMREAD_GRAYSCALE):\n image = cv2.imread(imagePath, flags)\n return image\n\n\n# Returns \"x,y\" if a match is found, otherwise returns -1,-1 if a match is not found.\nif __name__ == \"__main__\":\n #TODO: add `--help` and `--version` support\n if len(sys.argv) != 3:\n sys.exit('Error: Two image paths must be provided.\\n\\nExample: python3 subimage.py path/to/image1.jpg path/to/image2.jpg\\n')\n\n imagePath1 = sys.argv[1]\n imagePath2 = sys.argv[2]\n\n # I'm not sure what the environment looks like where this could be used, i.e. what kinds of failure modes are possible.\n # So I'm covering the basics for now: file exists, is not a directory, is readable, and then relying on imread\n # to determine whether or not the file is an image/is compatible with opencv.\n if can_load_file(imagePath1) is not True:\n sys.exit(f'Error: {imagePath1} does not exist, is a directory, or has insufficient read privileges.')\n if can_load_file(imagePath2) is not True:\n sys.exit(f'Error: {imagePath2} does not exist, is a directory, or has insufficient read privileges.')\n\n #TODO: maybe add file size check to make sure imagePath1 and imagePath2 can both be stored in memory--not sure about environment\n # (also check if opencv supports disk-based operations for these larger cases)\n\n image1 = load_image(imagePath1)\n if image1 is None:\n sys.exit(f'Error: {imagePath1} is not a compatible image.')\n\n image2 = load_image(imagePath2)\n if image2 is None:\n sys.exit(f'Error: {imagePath2} is not a compatible image.')\n\n # make sure not to do variable unpacking here--shape can sometimes have 3 elements instead of 2 depending on the given read flags\n width1 = image1.shape[0]\n height1 = image1.shape[1]\n width2 = image2.shape[0]\n height2 = image2.shape[1]\n\n # for now, i'm assuming rotation/resize transforms are not being taken into account, so it will simply fail if the\n # dimensions are not compatible\n if width1 <= width2 and height1 <= height2:\n fullImage = image2\n templateImage = image1\n elif width2 < width1 and height2 < height1:\n fullImage = image1\n templateImage = image2\n else: # neither image is strictly smaller than the other along both x and y, so a determination cannot be made\n sys.exit(f'Error: Bad dimensions. Neither image can be a proper subset of the other: ({width1}, {height1}), ({width2}, {height2})')\n\n # probably overkill depending on the reqs, but since we duplicated the objs above and they may be large...\n del image1, image2\n\n # adapted from: https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_template_matching/py_template_matching.html\n\n # NOTE: I'm not sure what the best approach is here for the template matching. There are six algos available, as listed here:\n # https://docs.opencv.org/2.4/doc/tutorials/imgproc/histograms/template_matching/template_matching.html#which-are-the-matching-methods-available-in-opencv\n\n # In the req writeup, it mentions being able to support lossy jpeg images. I'm not sure if that means that the template image\n # could have different artifacts/compression levels from the full image... in that case, maybe blurring both images slightly\n # before performing the template match would make sense. But I'm not an opencv/image processing expert.\n\n # For now, I'm using normalized cross-correlation, which gives an nd-array of values normalized to [-1, +1]. So I'm just looking\n # for the global max values and set a very high threshold as close to +1 as possible to eliminate false positives. Probably there\n # is a better solution here, e.g. looking at the median of the top n max values or something.\n matchTemplateResult = cv2.matchTemplate(fullImage, templateImage, cv2.TM_CCORR_NORMED)\n minValue, maxValue, minLocation, maxLocation = cv2.minMaxLoc(matchTemplateResult)\n\n if maxValue >= 0.98: # super rough threshold determined empirically--adjust as desired. This could be moved to a constant at the top of file or as an env var\n xTop = maxLocation[0] \n yTop = maxLocation[1]\n print(f\"{xTop},{yTop}\")\n else:\n print(\"-1,-1\")\n"
},
{
"alpha_fraction": 0.7522522807121277,
"alphanum_fraction": 0.7590090036392212,
"avg_line_length": 39.272727966308594,
"blob_id": "8aa2c8a7c5f9cf8c1240257f33215bef768e201e",
"content_id": "6cf83868ad9926e9eb21cd955eaefca017def979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 11,
"path": "/README.md",
"repo_name": "jfwaldo/waldo-jfwaldo",
"src_encoding": "UTF-8",
"text": "# waldo-jfwaldo\n\nTo install:\n\n* Make sure virtualenv and python3 are already installed on locally on the machine\n* `cd` into the root directory\n* Run `virtualenv -p /path/to/python3 .`\n* Run `source bin/activate`\n* Run `pip install -r requirements.txt` to install dependencies\n* Run `python3 subimage.py images/big_full.png images/big_partial.png` as desired\n* When finished, close out the terminal or run `deactivate` to exit the virtual env\n\n"
}
] | 2 |
DanielPlatan/mtrcs | https://github.com/DanielPlatan/mtrcs | a80469d1ee00cc5fd44fe67f90fd469bc2141cd2 | 6234c3b96859a6f297e79c624372baabbec62064 | b36cc5427e71a1a648bf11ec99bbccaa65d2b0a5 | refs/heads/master | "2020-06-25T11:45:49.748561" | "2019-07-31T08:31:01" | "2019-07-31T08:31:01" | 199,299,618 | 0 | 0 | null | "2019-07-28T14:47:16" | "2019-07-31T08:31:04" | "2021-04-08T19:41:00" | Python | [
{
"alpha_fraction": 0.7544910311698914,
"alphanum_fraction": 0.7544910311698914,
"avg_line_length": 22.85714340209961,
"blob_id": "799c568bcf26f9f62efb9f8406532b33068f1030",
"content_id": "eb8ed27df907d5732195821d26834e3f99a385b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 7,
"path": "/mtrcs/metrics/views.py",
"repo_name": "DanielPlatan/mtrcs",
"src_encoding": "UTF-8",
"text": "from metrics.parser import parse\n\n# Create your views here.\nfrom django.http import HttpResponse\ndef index(request):\n parse()\n return HttpResponse(\"Parsing OK\")\n"
},
{
"alpha_fraction": 0.6297376155853271,
"alphanum_fraction": 0.6297376155853271,
"avg_line_length": 35.157894134521484,
"blob_id": "f1db7b2397e0ed2870657dcf087bb58cef443bbd",
"content_id": "893c8791bbc7d436043a5e60ae0cc1b34799a937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 19,
"path": "/mtrcs/api_mtrx/serializers.py",
"repo_name": "DanielPlatan/mtrcs",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom metrics.models import Metrics\n\n\nclass MetricsPreviewSerializer(serializers.ModelSerializer):\n class Meta:\n model = Metrics\n fields = ['date','channel','country','os','impressions','clicks','installs','spend','revenue','cpi']\n\n def __init__(self, *args, **kwargs):\n super(MetricsPreviewSerializer, self).__init__(*args, **kwargs)\n\n fields = self.context['request'].query_params.get('col')\n if fields:\n fields = fields.split(',')\n allowed = set(fields)\n existing = set(self.fields.keys())\n for field_name in existing - allowed:\n self.fields.pop(field_name)"
},
{
"alpha_fraction": 0.5431034564971924,
"alphanum_fraction": 0.732758641242981,
"avg_line_length": 18.33333396911621,
"blob_id": "51c69b5d6c391b20b90368bf9a4460f1dfaa3f88",
"content_id": "2b3ad84e08741aabca010aa2470ea2a3e7b3778f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 116,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/mtrcs/requirements.txt",
"repo_name": "DanielPlatan/mtrcs",
"src_encoding": "UTF-8",
"text": "Django==2.2.3\ndjango-rest-framework==0.1.0\ndjangorestframework==3.10.1\npsycopg2==2.8.3\npytz==2019.1\nsqlparse==0.3.0\n"
},
{
"alpha_fraction": 0.7743055820465088,
"alphanum_fraction": 0.7743055820465088,
"avg_line_length": 56.599998474121094,
"blob_id": "e0eaa195dbc1f4422f3584af6ca5401c1a148413",
"content_id": "61a0bc226e0a51299f71866b25b8906e6034304d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 5,
"path": "/README.md",
"repo_name": "DanielPlatan/mtrcs",
"src_encoding": "UTF-8",
"text": "Please, read the file /mtrcs/readme(urls).txt\n\nAnd please, do not be surprised that the project pushed from one githab account, \nand then there are commits from another. I started it from work, and then at home \nI added and edited the Readme. Both of these github accounts belong to me.)\n"
},
{
"alpha_fraction": 0.7362637519836426,
"alphanum_fraction": 0.7362637519836426,
"avg_line_length": 14.166666984558105,
"blob_id": "dce9f3b8fa467aebee1a4bbcfa510de4e4e213a1",
"content_id": "f990e93965206b8ab292fbf0866c69a65e2de255",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 6,
"path": "/mtrcs/api_mtrx/apps.py",
"repo_name": "DanielPlatan/mtrcs",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\n\nclass ApiMtrxConfig(AppConfig):\n name = 'api_mtrx'\n"
}
] | 5 |
d4ngy4n/jianshuAuthorSpider | https://github.com/d4ngy4n/jianshuAuthorSpider | 1c1f3c392f5ddc36f2cbad764c48a8ecd83b0462 | 139b8bdf97884fa318a216f296fef345b50b10dd | fc63fee4b8f0a7a96ac3adb45d250994c4da1e2d | refs/heads/master | "2021-01-21T10:59:17.259345" | "2017-05-19T13:11:52" | "2017-05-19T13:11:52" | 91,715,997 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5555797219276428,
"alphanum_fraction": 0.5681966543197632,
"avg_line_length": 55.75308609008789,
"blob_id": "c5bcd0135748d05040401a8986f2829208229d6b",
"content_id": "be11e1d91bda08234e6ea2badbef45fe79688be2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4809,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 81,
"path": "/jianshu/spiders/jsMemberSpider.py",
"repo_name": "d4ngy4n/jianshuAuthorSpider",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom jianshu.items import ArticleItem\n\nclass JsmemberspiderSpider(scrapy.Spider):\n name = \"jsMemberSpider\"\n # allowed_domains = [\"jianshu\"]\n jianshu = 'http://www.jianshu.com'\n start_urls = ['http://www.jianshu.com/u/54b5900965ea?order_by=shared_at&page=1', ]\n \n article_all = []\n\n start_url = 'http://www.jianshu.com/u/54b5900965ea?order_by=shared_at&page={}'\n start_page = 1\n userID = '54b5900965ea'\n pageNumber = 1\n stop_url = 'http://www.jianshu.com/u/{USERID}?order_by=shared_at&page={pageNumber}'.format(USERID = userID, pageNumber = pageNumber)\n\n def parse(self, response):\n # 获取文章总数\n article_count = response.css(\n 'body > div.container.person > div > div.col-xs-16.main > div.main-top > div.info > ul > li:nth-child(3) > div > a > p::text').extract_first()\n # 计算共分了多少页,每页9篇文章\n countPageNumber = int(int(article_count) / 9 + 0.5)\n # 获取文章列表\n articles = response.css('ul.note-list > li')\n for article in articles:\n articleItem = ArticleItem()\n # 获取作者名称\n articleItem['author_name'] = article.css('a.blue-link::text').extract_first()\n # author_name = article.css('a.blue-link::text').extract_first()\n # 获取作者的头像连接\n articleItem['author_image'] = 'http:' + article.css('div.author > a > img::attr(src)').extract_first()\n # author_image = 'http:' + article.css('div.author > a > img::attr(src)').extract_first()\n # 获取文章发布时间\n articleItem['article_release_time'] = article.css('div.name > span.time::attr(data-shared-at)').extract_first()\n article_release_time = article.css('div.name > span.time::attr(data-shared-at)').extract_first()\n # 获取标题\n articleItem['article_title'] = article.css('a.title::text').extract_first()\n # article_title = article.css('a.title::text').extract_first()\n # 获取文章描述 \n articleItem['article_desc'] = article.css('p.abstract::text').extract_first().strip()\n # article_desc = article.css('p.abstract::text').extract_first().strip()\n # 获取文章链接\n articleItem['article_link'] = JsmemberspiderSpider.jianshu + article.css('div.content > a::attr(href)').extract_first()\n # article_link = JsmemberspiderSpider.jianshu + article.css('div.content > a::attr(href)').extract_first()\n # 获取阅读量,回复量,喜欢人数,赞赏人数\n articleItem['read_count'] = article.css('div.meta > a')[0].css('::text').extract()[-1].strip()\n articleItem['reply_count'] = article.css('div.meta > a')[1].css('::text').extract()[-1].strip()\n articleItem['likeit_count'] = article.css('div.meta > span')[0].css('::text').extract_first().strip()\n articleItem['payit_count'] = article.css('div.meta > span')[1].css('::text').extract_first().strip() if len(article.css('div.meta > span'))>=2 else 0\n # read_count = article.css('div.meta > a')[0].css('::text').extract()[-1].strip()\n # reply_count = article.css('div.meta > a')[1].css('::text').extract()[-1].strip()\n # likeit_count = article.css('div.meta > span')[0].css('::text').extract_first().strip()\n # payit_count = article.css('div.meta > span')[1].css('::text').extract_first().strip() if len(article.css('div.meta > span'))>=2 else 0\n # yield {\n # 'author_name': author_name, \n # 'author_image': author_image, \n # 'article_release_time': article_release_time, \n # 'article_title': article_title,\n # 'article_desc': article_desc,\n # 'article_link': article_link,\n # 'read_count': read_count, \n # 'reply_count': reply_count, \n # 'likeit_count': likeit_count, \n # 'payit_count': payit_count,\n # }\n JsmemberspiderSpider.article_all.append(articleItem)\n yield articleItem\n # pages = (i for i in range(2, countPageNumber + 1))\n current_page = int(response.url.split('page=')[1])\n next_page = JsmemberspiderSpider.start_url.format(current_page + 1)\n # 爬虫结束的条件,如果当前页是最后一页\n if current_page == countPageNumber:\n next_page = None\n if next_page is not None:\n next_page = response.urljoin(next_page)\n # yield {\n # '爬取中:': next_page,\n # }\n yield scrapy.Request(next_page, callback=self.parse)\n"
},
{
"alpha_fraction": 0.6735632419586182,
"alphanum_fraction": 0.7080459594726562,
"avg_line_length": 23.58823585510254,
"blob_id": "f71ba100c344eacde738233f59a0f86760bf057c",
"content_id": "96189b590743d7ffa118b5271bb77298dc99da1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 889,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 17,
"path": "/README.md",
"repo_name": "d4ngy4n/jianshuAuthorSpider",
"src_encoding": "UTF-8",
"text": "# 以[向右奔跑老师的简书](http://www.jianshu.com/u/54b5900965ea)做爬虫\r\n## 爬取@向右奔跑所有的文章\r\n爬取的信息如下:\r\n - 作者名称\r\n - 作者的头像\r\n - 文章标题\r\n - 文章链接\r\n - 文章描述 \r\n - 文章阅读量\r\n - 评论量\r\n - 喜欢的人数及赞赏的人数\r\n \r\nBug:第一次爬取完后如果再次进行爬取的话,会将同样的数据存到MongoDB数据库中 \r\n\r\n解决办法:将**文章链接**及**文章最后一次编辑的时间**存储到数据库中,加入数据库前先判断这两个添加是否一致.如果不一致,删除数据库中对应链接的信息,重新将新捕获到的数据加入到数据库当中. \r\n\r\n注意:**文章最后一次编辑的时间**与爬取的页面不在同一个页面,可参考[Scrapy抓取在不同级别Request之间传递参数](http://www.jianshu.com/p/de61ed0f961d)\r\n"
},
{
"alpha_fraction": 0.6717171669006348,
"alphanum_fraction": 0.6734007000923157,
"avg_line_length": 25.954545974731445,
"blob_id": "6328c5b6987e2ea0c07c988492b3e28cee1cecd5",
"content_id": "24ea709a710dcb76aa541c025c88ead7536dc280",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 22,
"path": "/jianshu/items.py",
"repo_name": "d4ngy4n/jianshuAuthorSpider",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# http://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass ArticleItem(scrapy.Item):\n # define the fields for your item here like:\n author_name = scrapy.Field()\n author_image = scrapy.Field()\n article_release_time = scrapy.Field()\n article_title = scrapy.Field()\n article_desc = scrapy.Field()\n article_link = scrapy.Field()\n read_count = scrapy.Field()\n reply_count = scrapy.Field()\n likeit_count = scrapy.Field()\n payit_count = scrapy.Field()\n\n"
}
] | 3 |
KozyrevIN/repo-for-Kozyrev | https://github.com/KozyrevIN/repo-for-Kozyrev | cb295710e5ecb605971538ad528b6a20d5a691b0 | c39b10cd1b02753fb89a94494135325216d21ed0 | 23e555ab0ffb330b4b662c19ff42fb07e2f999f8 | refs/heads/main | "2023-08-15T08:02:51.896188" | "2021-10-04T09:11:14" | "2021-10-04T09:11:14" | 413,307,933 | 0 | 0 | null | "2021-10-04T06:57:24" | "2021-10-04T06:56:40" | "2021-10-04T06:55:49" | null | [
{
"alpha_fraction": 0.519665002822876,
"alphanum_fraction": 0.5894731283187866,
"avg_line_length": 54.16374206542969,
"blob_id": "7c1774fb830ba7d86ea8e3e7090f2f1c8cd5de9d",
"content_id": "218f370038b9f73a1edbfc9b0223c5ce8599b6e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18866,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 342,
"path": "/exercise_2_draw.py",
"repo_name": "KozyrevIN/repo-for-Kozyrev",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom random import randint\nfrom pygame.draw import *\n\n# colours used for picture\nRED = (255, 000, 000)\nBLUE = (000, 000, 255)\nGREEN = (000, 255, 000)\nB_GREEN = (170, 222, 105)\nL_GREEN = (112, 200, 55)\nWHITE = (255, 255, 255)\nYELLOW = (255, 255, 000)\nGRAY = (128, 128, 128)\nBLACK = (000, 000, 000)\nSKY = (185, 211, 238)\nPURPLE = (229, 128, 255)\n\n\n# Array of functions drawing lama\ndef leg(pos, size, reverse=False):\n \"\"\"\n Draws lama's leg with given coordinates and size\n :param pos: coordinates tuple of the top left corner of the leg (if reversed than right corner)\n :param size: size of the leg / default size (default height is 79 px)\n :param reverse: if revers is true, draws a leg pointing left; else - pointing right\n \"\"\"\n if reverse:\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(15 * size), pos[1], int(15 * size), int(40 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(15 * size), pos[1] + int(33 * size), int(15 * size),\n int(40 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(20 * size), pos[1] + int(68 * size), int(20 * size),\n int(11 * size)))\n else:\n ellipse(screen, WHITE, pygame.Rect(pos[0], pos[1], int(15 * size), int(40 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0], pos[1] + int(33 * size), int(15 * size), int(40 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0], pos[1] + int(68 * size), int(20 * size), int(11 * size)))\n\n\ndef legs(pos, size, reverse=False):\n \"\"\"\n Draws legs of lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of lama's body (if reversed then top right corner)\n :param size: size of the lama / default size (default size is (217, 134) px)\n :param reverse: if revers is true, draws a lama pointing left; else - pointing right\n \"\"\"\n if reverse:\n leg((pos[0], pos[1] + int(20 * size)), size, reverse)\n leg((pos[0] - int(25 * size), pos[1] + int(30 * size)), size, reverse)\n leg((pos[0] - int(68 * size), pos[1] + int(20 * size)), size, reverse)\n leg((pos[0] - int(86 * size), pos[1] + int(35 * size)), size, reverse)\n else:\n leg((pos[0], pos[1] + int(20 * size)), size, reverse)\n leg((pos[0] + int(25 * size), pos[1] + int(30 * size)), size, reverse)\n leg((pos[0] + int(68 * size), pos[1] + int(20 * size)), size, reverse)\n leg((pos[0] + int(86 * size), pos[1] + int(35 * size)), size, reverse)\n\n\ndef body(pos, size, reverse=False):\n \"\"\"\n Draws body of lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of lama's body (if reversed then top right corner)\n :param size: size of the lama / default size (default size is (217, 134) px)\n :param reverse: if revers is true, draws a lama pointing left; else - pointing right\n \"\"\"\n if reverse:\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(117 * size), pos[1], int(117 * size), int(46 * size)))\n else:\n ellipse(screen, WHITE, pygame.Rect(pos[0], pos[1], int(117 * size), int(46 * size)))\n\n\ndef neck(pos, size, reverse=False):\n \"\"\"\n Draws neck of lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of the lama (if reversed than right corner)\n :param size: size of the legs / default size (default height is 114 px)\n :param reverse: if revers is true, draws a legs pointing left; else - pointing right\n \"\"\"\n if reverse:\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(87 * size) - int(34 * size), pos[1] - int(65 * size),\n int(34 * size), int(90 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(93 * size) - int(41 * size), pos[1] - int((83 * size)),\n int(41 * size), int(25 * size)))\n else:\n ellipse(screen, WHITE, pygame.Rect(pos[0] + int(87 * size), pos[1] - int(65 * size), int(34 * size),\n int(90 * size)))\n ellipse(screen, WHITE, pygame.Rect(pos[0] + int(93 * size), pos[1] - int((83 * size)), int(41 * size),\n int(25 * size)))\n\n\ndef eyes(pos, size, reverse=False):\n \"\"\"\n Draws eyes of lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of lama's body (if reversed then top right corner)\n :param size: size of the lama / default size (default size is (217, 134) px)\n :param reverse: if revers is true, draws a lama pointing left; else - pointing right\n \"\"\"\n if reverse:\n circle(screen, PURPLE, (pos[0] - int(112 * size), pos[1] - int(70 * size)), int(8 * size))\n circle(screen, BLACK, (pos[0] - int(115 * size), pos[1] - int(70 * size)), int(4 * size))\n ellipse(screen, WHITE, pygame.Rect(pos[0] - int(106 * size) - int(6 * size), pos[1] - int(75 * size),\n int(6 * size), int(4 * size)))\n else:\n circle(screen, PURPLE, (pos[0] + int(112 * size), pos[1] - int(70 * size)), int(8 * size))\n circle(screen, BLACK, (pos[0] + int(115 * size), pos[1] - int(70 * size)), int(4 * size))\n ellipse(screen, WHITE, pygame.Rect(pos[0] + int(106 * size), pos[1] - int(75 * size), int(6 * size),\n int(4 * size)))\n\n\ndef ears(pos, size, reverse=False):\n \"\"\"\n This function draws ears of lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of lama's body (if reversed then top right corner)\n :param size: size of the lama / default size (default size is (217, 134) px)\n :param reverse: if revers is true, draws a lama pointing left; else - pointing right\n \"\"\"\n if reverse:\n ear1 = [pos[0] - int(96 * size), pos[1] - int(75 * size)]\n polygon(screen, WHITE, [ear1, (ear1[0] + int(15 * size), ear1[1] - int(22 * size)),\n (ear1[0] - int(10 * size), ear1[1])])\n ear2 = [pos[0] - int(108 * size), pos[1] - int(80 * size)]\n polygon(screen, WHITE,\n [ear2, (ear2[0] + int(15 * size), ear2[1] - int(22 * size)), (ear2[0] - int(10 * size), ear2[1])])\n else:\n ear1 = [pos[0] + int(96 * size), pos[1] - int(75 * size)]\n polygon(screen, WHITE, [ear1, (ear1[0] - int(15 * size), ear1[1] - int(22 * size)),\n (ear1[0] + int(10 * size), ear1[1])])\n ear2 = [pos[0] + int(108 * size), pos[1] - int(80 * size)]\n polygon(screen, WHITE,\n [ear2, (ear2[0] - int(15 * size), ear2[1] - int(22 * size)), (ear2[0] + int(10 * size), ear2[1])])\n\n\ndef draw_lama(pos, size, reverse=False):\n \"\"\"\n This function draws lama with given coordinates and size\n :param pos: coordinates tuple of the top left corner of lama's body (if reversed then top right corner)\n :param size: size of the lama / default size (default size is (217, 134) px)\n :param reverse: if revers is true, draws a lama pointing left; else - pointing right\n \"\"\"\n # Resizing the position\n pos[0] = int(pos[0] * size)\n pos[1] = int(pos[1] * size)\n\n # Drawing the lama\n body(pos, size, reverse)\n legs(pos, size, reverse)\n neck(pos, size, reverse)\n eyes(pos, size, reverse)\n ears(pos, size, reverse)\n\n\n# Array of functions drawing flowers and bushes\ndef draw_flower(pos, size):\n \"\"\"\n Draws random flower with given coordinates and size\n :param pos: coordinates tuple of the top left corner of flower\n :param size: size of the flower / default size (default size is (42, 21) px)\n \"\"\"\n num = randint(1, 4)\n eval('flower_{}({}, {})'.format(num, pos, size))\n\n\ndef flower_1(pos, size):\n \"\"\"\n Draws 9 petals flower with given coordinates and size\n :param pos: coordinates tuple of the top left corner of flower\n :param size: size of the flower / default size (default size is (42, 21) px)\n \"\"\"\n random_color = (randint(0, 255), randint(0, 255), randint(0, 255))\n param = [15, 7]\n param[0] = int(param[0] * size)\n param[1] = int(param[1] * size)\n ellipse(screen, YELLOW,\n pygame.Rect(pos[0] + int(15 * size), pos[1] + int(6 * size), int(18 * size), int(9 * size)))\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(1 * size), pos[1] + int(6 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(1 * size), pos[1] + int(6 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(10 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(10 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(12 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(12 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(5 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(5 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(9 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(9 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(13 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(13 * size), param[0], param[1]), 1)\n\n\ndef flower_2(pos, size):\n \"\"\"\n Draws 8 petals flower with given coordinates and size\n :param pos: coordinates tuple of the top left corner of flower\n :param size: size of the flower / default size (default size is (42, 21) px)\n \"\"\"\n random_color = (randint(0, 255), randint(0, 255), randint(0, 255))\n param = [15, 7]\n param[0] = int(param[0] * size)\n param[1] = int(param[1] * size)\n ellipse(screen, YELLOW,\n pygame.Rect(pos[0] + int(15 * size), pos[1] + int(6 * size), int(18 * size), int(9 * size)))\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(1 * size), pos[1] + int(6 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(1 * size), pos[1] + int(6 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(10 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(10 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(12 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(12 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(7 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(7 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(11 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(11 * size), param[0], param[1]), 1)\n\n\ndef flower_3(pos, size):\n \"\"\"\n Draws 7 petals flower with given coordinates and size\n :param pos: coordinates tuple of the top left corner of flower\n :param size: size of the flower / default size (default size is (42, 21) px)\n \"\"\"\n random_color = (randint(0, 255), randint(0, 255), randint(0, 255))\n param = [15.5, 7.5]\n param[0] = int(param[0] * size)\n param[1] = int(param[1] * size)\n ellipse(screen, YELLOW,\n pygame.Rect(pos[0] + int(15 * size), pos[1] + int(6 * size), int(18 * size), int(9 * size)))\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(2 * size), pos[1] + int(8 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(2 * size), pos[1] + int(8 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(13 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(13 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(12 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(12 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(15 * size), pos[1] + int(0 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(23 * size), pos[1] + int(3 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(7 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(28 * size), pos[1] + int(7 * size), param[0], param[1]), 1)\n\n\ndef flower_4(pos, size):\n \"\"\"\n Draws 6 petals flower with given coordinates and size\n :param pos: coordinates tuple of the top left corner of flower\n :param size: size of the flower / default size (default size is (42, 21) px)\n \"\"\"\n random_color = (randint(0, 255), randint(0, 255), randint(0, 255))\n param = [17, 8]\n param[0] = int(param[0] * size)\n param[1] = int(param[1] * size)\n ellipse(screen, YELLOW,\n pygame.Rect(pos[0] + int(15 * size), pos[1] + int(6 * size), int(18 * size), int(9 * size)))\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(5 * size), pos[1] + int(2 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(2 * size), pos[1] + int(8 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(2 * size), pos[1] + int(8 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(13 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(10 * size), pos[1] + int(13 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(12 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(20 * size), pos[1] + int(12 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(17 * size), pos[1] + int(1 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(17 * size), pos[1] + int(1 * size), param[0], param[1]), 1)\n ellipse(screen, random_color, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(6 * size), param[0], param[1]))\n ellipse(screen, BLACK, pygame.Rect(pos[0] + int(25 * size), pos[1] + int(6 * size), param[0], param[1]), 1)\n\n\ndef bush(pos, size):\n \"\"\"\n Draws round bush with given coordinates and size\n :param pos: coordinates tuple of the top left corner of bush\n :param size: size of the flower / default size (default size is (200, 200) px)\n \"\"\"\n # Setting a bush\n radius = 100\n circle(screen, L_GREEN, pos, int(radius * size))\n # Scattering 5 flowers on the bush\n draw_flower((pos[0] - int(5 * size), pos[1] + int(35 * size)), 1.6 * size)\n draw_flower((pos[0] - int(70 * size), pos[1] - int(45 * size)), 1.4 * size)\n draw_flower((pos[0] - int(30 * size), pos[1] - int(20 * size)), 1.2 * size)\n draw_flower((pos[0] + int(10 * size), pos[1] - int(55 * size)), 1.8 * size)\n draw_flower((pos[0] - int(75 * size), pos[1] + int(25 * size)), 1.8 * size)\n\n\npygame.init()\n\n# Screen settings\nFPS = 30\nscreen = pygame.display.set_mode((900, 706))\n\n# Sky and mountains drawing\nrect(screen, SKY, (0, 0, 900, 706))\n\nmountains_contour = [(0, 216), (60, 73), (104, 172), (172, 93), (297, 282), (389, 88), (419, 122),\n (490, 130), (570, 250), (750, 140), (900, 300), (900, 706), (0, 706)]\npolygon(screen, GRAY, mountains_contour)\npolygon(screen, BLACK, mountains_contour, 1)\n\nfield_contour = [(0, 373), (38, 362), (75, 359), (114, 352), (271, 355),\n (280, 414), (294, 418), (900, 419), (900, 706), (0, 706)]\npolygon(screen, B_GREEN, field_contour)\npolygon(screen, BLACK, field_contour, 1)\n\n# Creating bushes\nbush([420, 581], 0.7)\nbush([650, 530], 0.5)\nbush([110, 625], 0.8)\nbush([110, 625], 1.4)\nbush([440, 400], 0.7)\nbush([850, 450], 0.7)\n\n# Drawing lamas\ndraw_lama([500, 800], 0.7, True)\ndraw_lama([600, 1000], 0.4, True)\ndraw_lama([600, 800], 0.5)\ndraw_lama([-80, 190], 3)\ndraw_lama([600, 350], 1.5, True)\ndraw_lama([800, 550], 0.7)\ndraw_lama([900, 850], 0.7, True)\n\n# FPS settings\npygame.display.update()\nclock = pygame.time.Clock()\nfinished = False\n\nwhile not finished:\n clock.tick(FPS)\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n finished = True\n\npygame.quit()\n"
}
] | 1 |
rpkelly/PyGames | https://github.com/rpkelly/PyGames | 6b6b93a08eb68b7da88d2fbc9abd6fa31a0200a5 | 97700575e4ab3cd88e9a1793656beaf987c9e0c1 | 5bbcffd6bfa8bd578b9b5a11ce329d54044516a0 | refs/heads/master | "2016-09-05T08:57:32.397675" | "2014-01-23T16:03:39" | "2014-01-23T16:03:39" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6388888955116272,
"alphanum_fraction": 0.6416666507720947,
"avg_line_length": 29,
"blob_id": "6f4e403736481ffbf4f33154fc2bdd4b22c95844",
"content_id": "a33a4b815453dbf2aa6b205cde71ab140bf59bbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 12,
"path": "/helloWorld.py",
"repo_name": "rpkelly/PyGames",
"src_encoding": "UTF-8",
"text": "command = 'p'\nwhile(1):\n\tif(command == 'p'):\n\t\tprint('Hello, World!\\n')\n\t\tcommand = input('Enter Command(h for help):')\n\telif(command == 'h'):\n\t\tprint('p prints statement, q quits, and h is help')\n\t\tcommand = input('Enter Command(h for help):')\n\telif(command == 'q'):\n\t\tbreak\n\telse:\n\t\tcommand = input('Unrecognized command, please enter another(h for help):')\n"
}
] | 1 |
Omrigan/essay-writer | https://github.com/Omrigan/essay-writer | bd2557549243adc6db3b90bf5a946816520b741d | 590c7bd91480871d6af9e28c0fe428a106ec4d5c | eea13f9b1dce2bf4d8a730d824a2ad6e9a8bfeb6 | refs/heads/master | "2022-01-03T01:15:25.993550" | "2021-12-26T13:59:58" | "2021-12-26T13:59:58" | 56,916,266 | 44 | 3 | null | "2016-04-23T11:39:08" | "2017-09-07T02:33:27" | "2017-03-21T20:04:31" | Python | [
{
"alpha_fraction": 0.4525691568851471,
"alphanum_fraction": 0.46640315651893616,
"avg_line_length": 23.095237731933594,
"blob_id": "e518eaf94975ae37a74ab47ec0628f386ddb9876",
"content_id": "aee11552f5cace31de5c0506a4bc7d30822b3aa8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 21,
"path": "/emotions.py",
"repo_name": "Omrigan/essay-writer",
"src_encoding": "UTF-8",
"text": "mat = [\n 'сука', \"блять\", \"пиздец\", \"нахуй\", \"твою мать\", \"епта\"]\nimport random\nimport re\n\n# strong_emotions = re.sub('[^а-я]', ' ', open('strong_emotions').read().lower()).split()\n\n\ndef process(txt, ch):\n words = txt.split(\" \")\n nxt = words[0] + ' '\n i = 1\n while i < len(words) - 1:\n\n if words[i - 1][-1] != '.' and random.random() < ch:\n nxt += random.choice(mat) + \" \"\n else:\n nxt += words[i] + \" \"\n i += 1\n nxt += words[-1]\n return nxt\n"
},
{
"alpha_fraction": 0.8004987239837646,
"alphanum_fraction": 0.811305046081543,
"avg_line_length": 47.119998931884766,
"blob_id": "efc88e7983f6b186a6937122887e24092e4be5a5",
"content_id": "c20fe2ce0f2aa8242fc32240817fcabafaeb3e7a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2052,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 25,
"path": "/Readme.md",
"repo_name": "Omrigan/essay-writer",
"src_encoding": "UTF-8",
"text": "# Генератор сочинений\nПеред вами крик отчаяния, вызванный подготовкой к написанию сочинения на ЕГЭ. \nПрограмма генерирует сочинения в формате ЕГЭ по заданному тексту.\nПримеры работы программы в папке samples.\n\n## Установка\n1. git clone https://github.com/Omrigan/essay-writer (или скачать zip-архив с кодом)\n2. pip3 install -r requirements.txt\n3. python3 essay.py --help\n\n## Использование\nПрограмма принимает в качестве аргумента текстовый файл на русском языке, в котором содержится исходный текст, а последняя строка - фамилия и инициалы автора\nТакже можно повысить \"эмоциональность\" текста, передав дополнительный аргумент -e, который принимает число от 0 до 1, обозначающее будущую эмоциональность вашего сочинения\n\n## Используемые разделы знаний\n\n1. Теория формальных языков (спасибо В. В. Мерзлякову)\n2. Методика написания сочинений (спасибо Л. В. Никитенко)\n3. Аргументы к сочинениям (спасибо русским и зарубежным писателям)\n4. Python3 и библиотеки pymorph2 и plumbum.\n\n## Лицензия\n\nКаждый, кто успешно сдаст сочинение, сгенерированное данной программой, обязуется купить автору кружку пива.\nСвободно для любого использования (включая копированние, изменение, использование в коммерческих целях)\n"
},
{
"alpha_fraction": 0.4926958978176117,
"alphanum_fraction": 0.5007967948913574,
"avg_line_length": 31.7391300201416,
"blob_id": "84ca42d1863eed23f3da488afe543ddd77f0dd24",
"content_id": "ec693539e80ee3ee979c3384454d32021a9f6840",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7807,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 230,
"path": "/essay.py",
"repo_name": "Omrigan/essay-writer",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport re\nimport random\nimport pymorphy2\nimport json\nimport emotions\nfrom plumbum import cli\n\nmorph = pymorphy2.MorphAnalyzer()\n\ncodes = {\n 'n': 'nomn',\n 'g': 'gent',\n 'd': 'datv',\n 'ac': 'accs',\n 'a': 'ablt',\n 'l': 'loct'\n}\n\nkeywords = set(open('keywords.txt').read().replace(' ', '').split('\\n'))\narguments = json.load(open('arguments.json'))\n\nshuffled = set()\n\n\ndef mychoise(lst):\n kek = lst.pop(0)\n lst.append(kek)\n return random.choice(lst)\n\n\ndef to_padez(val, padez):\n if padez in codes:\n padez = codes[padez]\n return morph.parse(val)[0].inflect({padez}).word\n\n\ndef getwordlist(s):\n clear_text = re.sub(\"[^а-яА-Я]\",\n \" \", # The pattern to replace it with\n s)\n s = s[0].lower() + s[1:]\n local_words = clear_text.split()\n return local_words\n\n\nclass EssayBuilder:\n def __init__(self, raw_text):\n self.text = raw_text.split('\\n')\n self.text = list(filter(lambda a: len(a)>5, self.text))\n self.author = self.text[-1]\n self.text = \"\".join(self.text[:-1])\n\n self.text_tokens = list(map(lambda s: s[1:] if s[0] == ' ' else s,\n filter(lambda a: len(a) > 4, re.split(\"\\.|\\?|!|;\", self.text))))\n\n words = {}\n for i, s in zip(range(10 ** 9), self.text_tokens):\n local_words = getwordlist(s)\n words_cnt = {}\n for w in local_words:\n p = morph.parse(w)\n j = 0\n while len(p) > 0 and 'NOUN' not in p[0].tag and j < 1:\n p = p[1:]\n j += 1\n if len(p) > 0 and 'NOUN' in p[0].tag:\n w = p[0].normal_form\n if w not in words_cnt:\n words_cnt[w] = 0\n words_cnt[w] += 1\n\n for w in words_cnt:\n if w not in words:\n words[w] = {\n 'total': 0,\n 'sent': []\n }\n words[w]['total'] += words_cnt[w]\n words[w]['sent'].append((i, words_cnt[w]))\n self.all_words = sorted([{'word': w,\n 'total': val['total'],\n 'sent': sorted(val['sent'], key=lambda a: a[1])} for w, val in\n words.items()], key=lambda a: -a['total'])\n\n self.good_words = list(filter(lambda a: a['word'] in keywords, self.all_words))\n\n self.samples = json.load(open('awesome_text.json'))\n self.samples['baseword'] = [self.good_words[0]['word']]\n\n for s in self.samples:\n random.shuffle(self.samples[s])\n\n def get_str(self, val):\n if val == \"author\":\n if random.randint(0, 4) == 0: return self.author\n vals = val.split('_')\n self.samples[vals[0]] = self.samples[vals[0]][1:] + [self.samples[vals[0]][0]]\n ret = self.samples[vals[0]][-1]\n if len(vals) > 1:\n if vals[1] in codes:\n vals[1] = codes[vals[1]]\n ret = morph.parse(ret)[0].inflect({vals[1]}).word\n return ret\n\n def get_problem(self):\n return ['#intro',\n \"#wholeproblem\"]\n\n def get_quatation_comment(self):\n w = mychoise(self.good_words)\n s = self.text_tokens[mychoise(w['sent'])[0]]\n comment = [\"#commentbegin, #author в словах \\\"%s\\\" #speaks о %s\" % \\\n (s, to_padez(w['word'], 'loct'))]\n return comment\n\n def get_epitet(self):\n noun = []\n w = None\n while len(noun) < 2:\n noun = []\n w = mychoise(self.good_words)\n s = self.text_tokens[mychoise(w['sent'])[0]]\n for _ in getwordlist(s):\n word = morph.parse(_)[0]\n if w['word'] != word.normal_form and 'NOUN' in word.tag:\n noun.append(word.normal_form)\n\n comment = [\"показывая важность понятия \\\"%s\\\", #author оперирует понятиями %s и %s\" % \\\n (w['word'], to_padez(noun[0], 'g'), to_padez(noun[1], 'g'))]\n return comment\n\n def get_comment(self):\n comment_sources = [self.get_quatation_comment, self.get_epitet]\n comment = []\n for i in range(3):\n comment.extend(mychoise(comment_sources)())\n return comment\n\n def get_author_position(self):\n return [\"позиция #author_g в этом фрагменте лучше всего выраженна цитатой: \\\"%s\\\"\" %\n (random.choice(self.text_tokens))]\n\n def get_my_position(self):\n return [\"#myposition\"]\n\n def get_lit_argument(self):\n curbook = mychoise(arguments)\n curarg = mychoise(curbook['args'])\n replacements = {\n 'author': curbook['author'],\n 'book': curbook['book'],\n 'hero': curarg['hero'],\n 'action': random.choice(curarg['actions'])\n }\n if curbook['native']:\n replacements['native'] = 'отечественной '\n else:\n replacements['native'] = ''\n\n return [\"в %(native)sлитературе много примеров #baseword_g\" % replacements,\n \"#example, в романе %(book)s, который написал %(author)s,\"\n \" герой по имени %(hero)s %(action)s, показывая таким образом своё отношение к #baseword_d\" % replacements]\n\n def get_left_argument(self):\n return self.get_lit_argument()\n\n def get_conclusion(self):\n return [\"#conclude0 #many в жизни зависит от #baseword_g\",\n \"Необходимо всегда помнить о важности этого понятия в нашей жизни\"]\n\n def build_essay(self):\n abzaces = [self.get_problem(), self.get_comment(), self.get_author_position(),\n self.get_my_position(), self.get_lit_argument(), self.get_left_argument(), self.get_conclusion()]\n nonterm = re.compile('#[a-z0-9_]+')\n str_out_all = ''\n for a in abzaces:\n str_out = ''\n for s in a:\n while re.search(nonterm, s) is not None:\n val = re.search(nonterm, s).group()[1:]\n if val.split('_')[0] in self.samples:\n s = s.replace('#' + val, self.get_str(val))\n else:\n s = s.replace('#' + val, '%' + val)\n\n str_out += s[0].upper() + s[1:] + '. '\n str_out += '\\n'\n str_out_all += str_out\n return str_out_all\n\n\nfrom sys import stdin, stdout\n\n\nclass MyApp(cli.Application):\n _abuse = 0\n _output = ''\n\n @cli.switch(['-e'], float, help='Change emotionality')\n def abuse_lexical(self, abuse):\n self._abuse = abuse\n\n @cli.switch(['-o'], str, help='Output')\n def output(self, output):\n self._output = output\n\n @cli.switch(['--new'], str, help='New arguments')\n def output(self, args):\n global arguments\n if args:\n arguments = json.load(open('arguments-new.json'))\n else:\n arguments = json.load(open('arguments.json'))\n random.shuffle(arguments)\n print(arguments)\n\n def main(self, filename='text.txt'):\n raw_text = open(filename, 'r').read()\n if self._output == '':\n self._output = filename + '.out'\n out = open(self._output, 'w')\n e = EssayBuilder(raw_text)\n str_out = e.build_essay()\n str_out = emotions.process(str_out, self._abuse)\n out.write(str_out)\n\n\nif __name__ == '__main__':\n MyApp.run()\n"
}
] | 3 |
oviazlo/ParticleFlowAnalysis | https://github.com/oviazlo/ParticleFlowAnalysis | 381cc23c0dec56e455b856625e49ee8bb0fa9448 | 58a3a8da7215c066314a01394c62de02752be103 | 27277ae4543afe1f37ab9c5306693b9f3e1e17c2 | refs/heads/master | "2022-02-17T19:22:57.266705" | "2019-09-25T16:05:27" | "2019-09-25T16:05:27" | 106,678,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6662604808807373,
"alphanum_fraction": 0.6936761140823364,
"avg_line_length": 40.025001525878906,
"blob_id": "82c732c482a790152615bcc94ae7ae52b7d42362",
"content_id": "d67ad9793fc342c9a5d95b4d16002b92b8d1c5e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8207,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 200,
"path": "/PhotonECAL/src/photonEffCalculator.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <photonEffCalculator.h>\n#include <IMPL/ReconstructedParticleImpl.h>\n\nint photonEffCalculator::init(){\n\n\tTH1D* tmpHist;\n\ttmpHist = new TH1D(\"dAngle\",\"(PFO,MCTruth) angle; angle [degree]; Counts\",1800,0.0,90.0);\n\thistMap[\"dAngle\"] = tmpHist;\n\ttmpHist = new TH1D(\"dE\",\"E_{PFO}-E_{MC}; Energy [GeV]; Counts\",100,-25.0,25.0);\n\thistMap[\"dE\"] = tmpHist;\n\ttmpHist = new TH1D(\"dE_matched\",\"E_{PFO}-E_{MC}^{matched}; Energy [GeV]; Counts\",1000,-25.0,25.0);\n\thistMap[\"dE_matched\"] = tmpHist;\n\ttmpHist = new TH1D(\"PFO_E\",\"E_{PFO}; Energy [GeV]; Counts\",750,0.0,150.0);\n\thistMap[\"PFO_E\"] = tmpHist;\n\ttmpHist = new TH1D(\"findableMC_vs_theta\",\"Number of findable MC particle vs theta; Theta [degree]; Counts\",180,0.0,180.0);\n\thistMap[\"findableMC_vs_theta\"] = tmpHist;\n\ttmpHist = new TH1D(\"matchedMC_vs_theta\",\"Number of matched MC particle vs theta; Theta [degree]; Counts\",180,0.0,180.0);\n\thistMap[\"matchedMC_vs_theta\"] = tmpHist;\n\ttmpHist = new TH1D(\"findableMC_vs_cosTheta\",\"Number of findable MC particle vs cos(theta); Cos(Theta); Counts\",2*180,-1.0,1.0);\n\thistMap[\"findableMC_vs_cosTheta\"] = tmpHist;\n\ttmpHist = new TH1D(\"matchedMC_vs_cosTheta\",\"Number of matched MC particle vs cos(theta); Cos(Theta); Counts\",2*180,-1.0,1.0);\n\thistMap[\"matchedMC_vs_cosTheta\"] = tmpHist;\n\ttmpHist = new TH1D(\"findableMC_vs_E\",\"Number of findable MC particle vs energy; Energy [GeV]; Counts\",19,7.5,102.5);\n\thistMap[\"findableMC_vs_E\"] = tmpHist;\n\ttmpHist = new TH1D(\"matchedMC_vs_E\",\"Number of matched MC particle vs energy; Energy [GeV]; Counts\",19,7.5,102.5);\n\thistMap[\"matchedMC_vs_E\"] = tmpHist;\n\tdebugFlag = false;\n\tdPhiMergeValue = 0;\n\tonlyOneRecoClusterPerEvent = false;\n\treturn 0;\n\n}\n\nEVENT::ReconstructedParticle* photonEffCalculator::getMatchedPFO(const EVENT::MCParticle* inMCPart, const vector<EVENT::ReconstructedParticle*> findablePFO){\n\n\tEVENT::ReconstructedParticle* matchedPFO = NULL;\n\n\t// get MC part vector\n\tTVector3 v0;\n\tconst double *partMom = inMCPart->getMomentum();\n\tv0.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble inPartTheta = 180.*v0.Theta()/TMath::Pi();\n\tdouble inPartEnergy = inMCPart->getEnergy();\n\thistMap[\"findableMC_vs_theta\"]->Fill(inPartTheta);\n\thistMap[\"findableMC_vs_cosTheta\"]->Fill(cos(inPartTheta/180.0*TMath::Pi()));\n\thistMap[\"findableMC_vs_E\"]->Fill(inPartEnergy);\n\t\n\t// check matching with each PFO\n\tfor (unsigned int i=0; i<findablePFO.size(); i++){\n\t\tauto part = findablePFO[i];\n\t\tconst double* partMom = part->getMomentum();\n\t\tTVector3 v1;\n\t\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\t\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\t\t// Direction requirement:\n\t\t// within a cone of 1 degree\n\t\thistMap[\"dAngle\"]->Fill(180.0*v0.Angle(v1)/TMath::Pi());\n\t\t// if (180.0*v0.Angle(v1)/TMath::Pi()>1.0) continue;\n\t\t// Energy requirement:\n\t\t// energy difference less than resolution\n\t\tdouble eRes = 2*TMath::Sqrt(inPartEnergy)+0.5;\n\t\tdouble dE = part->getEnergy()- inPartEnergy;\n\t\thistMap[\"PFO_E\"]->Fill(part->getEnergy());\n\t\thistMap[\"dE\"]->Fill(dE);\n\t\t// if ( abs(dE) > eRes ) continue;\n\t\thistMap[\"dE_matched\"]->Fill(dE);\n\t\thistMap[\"matchedMC_vs_theta\"]->Fill(inPartTheta);\n\t\thistMap[\"matchedMC_vs_cosTheta\"]->Fill(cos(inPartTheta/180.0*TMath::Pi()));\n\t\thistMap[\"matchedMC_vs_E\"]->Fill(inPartEnergy);\n\t\tmatchedPFO = part;\n\t\tbreak;\n\t}\n\n\treturn matchedPFO;\n}\n\nint photonEffCalculator::fillEvent(const EVENT::LCEvent* event){\n\t// read collections\n\ttry {\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|particleFill]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t}\n\ttry {\n\t\tMCTruthCollection = event->getCollection(MCTruthCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|particleFill]\\tCan't find collection: \" << MCTruthCollectionName << endl;\n\t\treturn -1;\n\t}\n\t\n\t// find primary generated MC particle which is the only findable in the event by definition [particle gun]\n\tEVENT::MCParticle* genPart = NULL;\n\tint nElements = MCTruthCollection->getNumberOfElements();\n\tfor(int j=0; j < nElements; j++) {\n\t\tauto part = dynamic_cast<EVENT::MCParticle*>(MCTruthCollection->getElementAt(j));\n\t\tif (part->getGeneratorStatus()==1){\n\t\t\tconst double *partMom = part->getMomentum();\n\t\t\tTVector3 v1;\n\t\t\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\t\t\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\t\t\tif (partTheta<8 || partTheta>172) \n\t\t\t\treturn 0;\n\t\t\tif (part->isDecayedInTracker()) \n\t\t\t\treturn 0;\n\t\t\tgenPart = part;\n\t\t\tbreak;\n\t\t}\n\t}\n\n\tif (PFOPartType==0){\n\t\tPFOPartType = genPart->getPDG();\n\t\t// WARNING FIXME according to Mathias Padora can return only these types:\n\t\tvector<int> PandoraAllowedTypes = {11,13,22,211,2112};\n\t\tif (find(PandoraAllowedTypes.begin(), PandoraAllowedTypes.end(), abs(PFOPartType))==PandoraAllowedTypes.end() )\n\t\t\tPFOPartType = 2112; // neutron\n\t\tcout << \"[INFO]\\t[photonEffCalculator] Efficiency PFO type is assigned to: \" << PFOPartType << endl;\n\t}\n\n\tvector<EVENT::ReconstructedParticle*> recoPFOs = getObjVecFromCollection<EVENT::ReconstructedParticle*>(PFOCollection);\n\t// cout << \"[DEBUG]\\trecoPFOs.size():\" << recoPFOs.size() << endl;\n\tif (recoPFOs.size()==0) \n\t\treturn 0; // no reco PFOs\n\t// FIXME hardcoded type!!!\n\t// if (PFOPartType==22 && onlyOneRecoClusterPerEvent && recoPFOs.size()!=1) return 0;\n\tint itMostEnergeticOfType = -1;\n\tfor (int i=0; i<recoPFOs.size(); i++){\n\t\t// cout << \"[DEBUG]\\tPFOPartType: \" << PFOPartType << \"\\trecoPFOs[i]->getType(): \" << recoPFOs[i]->getType() << endl;\n\t\tif (recoPFOs[i]->getType()!=PFOPartType) \n\t\t\tcontinue;\n\t\tif (itMostEnergeticOfType==-1){\n\t\t\titMostEnergeticOfType = i;\n\t\t\tbreak;\n\t\t}\n\t\tif (recoPFOs[i]->getEnergy()>recoPFOs[itMostEnergeticOfType]->getEnergy())\n\t\t\titMostEnergeticOfType = i;\n\t}\n\n\t// if (itMostEnergeticOfType == -1) return 0; // no PFO of needed type\n\t// cout << \"[DEBUG]\\titMostEnergeticOfType: \" << itMostEnergeticOfType << endl;\n\n\t// FIXME WARNING **********************************\n\t// create modifiable PFO\n\tif (itMostEnergeticOfType != -1 && dPhiMergeValue>0.0){\n\t\tIMPL::ReconstructedParticleImpl* partMod = new IMPL::ReconstructedParticleImpl();\n\t\tpartMod->setEnergy(recoPFOs[itMostEnergeticOfType]->getEnergy());\n\t\tpartMod->setMomentum(recoPFOs[itMostEnergeticOfType]->getMomentum());\n\t\tpartMod->setType(recoPFOs[itMostEnergeticOfType]->getType());\n\n\t\t// delete non-modifiable one\n\t\trecoPFOs.erase(recoPFOs.begin() + itMostEnergeticOfType);\n\n\t\t// merge allPFOs within criteria\n\t\tTVector3 vecToMerge;\n\t\tconst double *partMomMod = partMod->getMomentum();\n\t\tvecToMerge.SetXYZ(partMomMod[0],partMomMod[1],partMomMod[2]);\n\t\tfor (int i=0; i<recoPFOs.size(); i++){\n\t\t\tconst double *partMom2 = recoPFOs[i]->getMomentum();\n\t\t\tTVector3 v2;\n\t\t\tv2.SetXYZ(partMom2[0],partMom2[1],partMom2[2]);\n\t\t\tdouble dPhi = vecToMerge.DeltaPhi(v2)*180./TMath::Pi();\n\t\t\tif (abs(dPhi)<dPhiMergeValue)\n\t\t\t\tpartMod->setEnergy(partMod->getEnergy()+recoPFOs[i]->getEnergy());\n\t\t}\n\t\trecoPFOs.push_back(partMod);\n\t}\n\t// FIXME WARNING **********************************\n\n\tauto maxEnergeticRecoPFO = recoPFOs.back();\n\tfor (int j=0; j<(recoPFOs.size()-1); j++){\n\t\tauto part = recoPFOs[j];\n\t\tif (part->getEnergy()>maxEnergeticRecoPFO->getEnergy())\n\t\t\tmaxEnergeticRecoPFO = part;\n\t}\n\n\tvector<EVENT::ReconstructedParticle*> findablePFO;\n\tif (maxEnergeticRecoPFO->getType() == PFOPartType) \n\t\tfindablePFO.push_back(maxEnergeticRecoPFO);\n\n\tEVENT::ReconstructedParticle* matchedPFO = getMatchedPFO(genPart,findablePFO);\n\tif (matchedPFO==NULL)\n\t\treturn 0;\n\t// TODO continue logic...\n\t// fill some histograms for number of findable and number of matched\n\treturn 0;\n\n}\n\nint photonEffCalculator::writeToFile(TFile* outFile){\n\tvector<string> postFix = {\"E\", \"theta\", \"cosTheta\"};\n\tfor (unsigned int i=0; i<postFix.size(); i++) {\n\t\tif (histMap.find(\"findableMC_vs_\" + postFix[i])!=histMap.end() && histMap.find(\"matchedMC_vs_\" + postFix[i])!=histMap.end()){\n\t\t\tTH1D* tmpHist = dynamic_cast<TH1D*>(histMap[\"matchedMC_vs_\"+postFix[i]]->Clone((\"efficiency_vs_\"+postFix[i]).c_str()));\n\t\t\ttmpHist->Divide(histMap[\"findableMC_vs_\" + postFix[i]]);\n\t\t\ttmpHist->GetYaxis()->SetTitle(\"Efficiency\");\n\t\t\thistMap[\"efficiency_vs_\"+postFix[i]] = tmpHist;\n\t\t}\n\t}\n\treturn objectFill::writeToFile(outFile);\n}\n\n\n"
},
{
"alpha_fraction": 0.7406168580055237,
"alphanum_fraction": 0.7584540843963623,
"avg_line_length": 45.39655303955078,
"blob_id": "78e043450695f3885e7b4482f13e1af4d6d51c87",
"content_id": "11c9b2967d6f0cd25502033633e653a0d0973287",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2691,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 58,
"path": "/MuonReco/src/energyFillAllCalo.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <energyFillAllCalo.h>\nint energyFillAllCalo::init(){\n\n\tcreateTH1D(\"CALratio_EcalToHcal_BarrelAndEndcaps\",\"Ecal/Hcal Energy Ratio; Ecal/Hcal; Counts\",500,0,50);\n\tcreateTH1D(\"CALratio_HcalToEcal_BarrelAndEndcaps\",\"Hcal/Ecal Energy Ratio; Hcal/Ecal; Counts\",500,0,50);\n\tcreateTH1D(\"CALratio_EcalToHcal_BarrelOnly\",\"Ecal/Hcal Barrel Energy Ratio; Barrel Ecal/Hcal; Counts\",500,0,50);\n\tcreateTH1D(\"CALratio_HcalToEcal_BarrelOnly\",\"Hcal/Ecal Barrel Energy Ratio; Barrel Hcal/Ecal; Counts\",500,0,50);\n\tcreateTH1D(\"CALratio_EcalToHcal_EndcapOnly\",\"Ecal/Hcal Endcap Energy Ratio; Endcap Ecal/Hcal; Counts\",500,0,50);\n\tcreateTH1D(\"CALratio_HcalToEcal_EndcapOnly\",\"Hcal/Ecal Endcap Energy Ratio; Endcap Hcal/Ecal; Counts\",500,0,50);\n\n\tfor(auto const &iMapElement : histMap) {\n\t\tiMapElement.second->AddDirectory(kFALSE);\n\t}\n\n\treturn 0;\n}\n\nint energyFillAllCalo::fillEvent(const EVENT::LCEvent* event){\n\n\tvector<string> energyFillCollections = {\"ECALBarrel\",\"ECALEndcap\", \"HCALBarrel\",\"HCALEndcap\"};\n\tmap<string, double> totalEnergyMap;\n\n\tfor (auto collectionName: energyFillCollections){\n\t\ttry {\n\t\t\tcollection = event->getCollection(collectionName);\n\t\t} catch (EVENT::DataNotAvailableException &e) {\n\t\t\tcout << \"[ERROR|energyFillAllCalo]\\tCan't find collection: \" << collectionName << endl;\n\t\t\treturn -1;\n\t\t}\n\n\t\tif( collection ) {\n\t\t\tconst int nElements = collection->getNumberOfElements();\n\t\t\tdouble totalEnergyDeposited = 0.0;\n\t\t\tfor(int j=0; j < nElements; j++){\n\t\t\t\tauto calHit = dynamic_cast<EVENT::CalorimeterHit*>(collection->getElementAt(j));\n\t\t\t\ttotalEnergyDeposited += calHit->getEnergy();\n\t\t\t}\n\t\t\ttotalEnergyMap[collectionName] = totalEnergyDeposited;\n\t\t}\n\t}\n\n\tgetHistFromMap(\"CALratio_EcalToHcal_BarrelAndEndcaps\")->Fill((totalEnergyMap[\"ECALBarrel\"] + totalEnergyMap[\"ECALEndcap\"]) / (totalEnergyMap[\"HCALBarrel\"] + totalEnergyMap[\"HCALEndcap\"]));\n\tgetHistFromMap(\"CALratio_HcalToEcal_BarrelAndEndcaps\")->Fill((totalEnergyMap[\"HCALBarrel\"] + totalEnergyMap[\"HCALEndcap\"]) / (totalEnergyMap[\"ECALBarrel\"] + totalEnergyMap[\"ECALEndcap\"]));\n\n\tgetHistFromMap(\"CALratio_EcalToHcal_BarrelOnly\")->Fill(totalEnergyMap[\"ECALBarrel\"]/totalEnergyMap[\"HCALBarrel\"]);\n\tgetHistFromMap(\"CALratio_HcalToEcal_BarrelOnly\")->Fill(totalEnergyMap[\"HCALBarrel\"]/totalEnergyMap[\"ECALBarrel\"]);\n\tgetHistFromMap(\"CALratio_EcalToHcal_EndcapOnly\")->Fill(totalEnergyMap[\"ECALEndcap\"]/totalEnergyMap[\"HCALEndcap\"]);\n\tgetHistFromMap(\"CALratio_HcalToEcal_EndcapOnly\")->Fill(totalEnergyMap[\"HCALEndcap\"]/totalEnergyMap[\"ECALEndcap\"]);\n\n\treturn 0;\n}\n\nint energyFillAllCalo::writeToFile(TFile* outFile){\n\n\t// unsigned int nEvents = getHistFromMap(\"CAL_Energy\")->GetEntries();\n\n\tobjectFill::writeToFile(outFile);\n}\n"
},
{
"alpha_fraction": 0.7150874733924866,
"alphanum_fraction": 0.7222303152084351,
"avg_line_length": 40.82926940917969,
"blob_id": "6b7bcfe493cab767d7d40faed22908892cbc86ad",
"content_id": "24cff3791a2a7583058b1faea7bf147d1aeae7a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 13720,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 328,
"path": "/PhotonECAL/src/truthParticleSelector.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <truthParticleSelector.h>\n\nint truthParticleSelector::init(){\n\tTH1::SetDefaultSumw2();\n\tdiscardFSREvents = false;\n\tdPhiMergeValue = 0;\n\tonlyOneRecoClusterPerEvent = false;\n\t// for (int i; i<particleFillCollections.size(); i++){\n\t// particleFill* tmpPartFill = new particleFill(particleFillCollections[i]);\n\t// tmpPartFill->setCollectionName(particleFillCollections[i]);\n\t// tmpPartFill->setReconstructedParticleType(PFOTypes[i]);\n\t// string postfixRootDirName = \"\";\n\t// for (auto j=0; j<PFOTypes[i].size(); j++)\n\t// postfixRootDirName += \"_\" + DoubToStr(PFOTypes[i][j]);\n\t// tmpPartFill->updateRootDirName(particleFillCollections[i]+postfixRootDirName);\n\t// if (dPhiMergeValue > 0.0)\n\t// tmpPartFill->setDPhiMergeValue(dPhiMergeValue);\n\t// objFillMap[particleFillCollections[i]+postfixRootDirName] = tmpPartFill;\n\t// }\n\t// for (int i; i<energyFillCollections.size(); i++){\n\t// energyFill* tmpEnergyFill = new energyFill(energyFillCollections[i]);\n\t// tmpEnergyFill->setCollectionName(energyFillCollections[i]);\n\t// objFillMap[energyFillCollections[i]] = tmpEnergyFill;\n\t// }\n\n\teventHistFiller* eventFill = NULL;\n\tobjectFill* objFill = NULL;\n\tstring mergeTag = \"\";\n\n\tif (config::vm.count(\"debug\")){\n\t\t// mergeTag = \"photonAndNeutralRecl_looseThetaCut\";\n\t\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\t\t// objFillMap[\"eventHists_\"+mergeTag]->init();\n\n\n\t\t// mergeTag = \"photonRecl_noAngularMatching_caloE\";\n\t\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t\t// eventFill->setClusterMerging(\"photonMerge\");\n\t\t// eventFill->SetApplyAngularMatching(false);\n\t\t// eventFill->SetUseCaloInfoForEnergyMerging(true);\n\t\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\t\t// objFillMap[\"eventHists_\"+mergeTag]->init();\n\n\t\t// mergeTag = \"photonAndNeutralRecl_looseThetaCut\";\n\t\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\t\tmergeTag = \"photonRecl_useCaloForMergedCandidates\";\n\t\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t\teventFill->setClusterMerging(\"photonMerge\");\n\t\teventFill->SetUseCaloCutInsteadMomentumForMergedCandidates(true);\n\t\teventFill->SetUseCaloInfoForEnergyMerging(true);\n\t\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\t\tfor(auto const &mapElement : objFillMap){\n\t\t\tcout << \"Init mapElement: \" << mapElement.first << endl;\n\t\t\tmapElement.second->init();\n\t\t}\n\n\t\treturn 0;\n\t}\n\n\teventFill = new eventHistFiller(\"eventHists\",effCollection);\n\tobjFillMap[\"eventHists\"] = eventFill;\n \n\teventFill = new eventHistFiller(\"eventHists_noConv\",effCollection);\n\tobjFillMap[\"eventHists_noConv\"] = eventFill;\n \n\teventFill = new eventHistFiller(\"eventHists_conv\",effCollection);\n\tobjFillMap[\"eventHists_conv\"] = eventFill;\n\n\teventFill = new eventHistFiller(\"eventHists_noFSR\",effCollection);\n\tobjFillMap[\"eventHists_noFSR\"] = eventFill;\n\n\teventFill = new eventHistFiller(\"eventHists_FSR\",effCollection);\n\tobjFillMap[\"eventHists_FSR\"] = eventFill;\n\n\tmergeTag = \"photonRecl\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n //\n\t// mergeTag = \"photonReclMomDep\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonMergeMomentumDep\");\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n //\n\t// mergeTag = \"photonAndNeutralRecl\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonAndNeutralMerge\");\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonAndNeutralRecl_looseThetaCut\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\t// mergeTag = \"photonAndNeutralRecl_looseThetaCut_caloEMatching_clusterE\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t// eventFill->SetUseCaloInfoForEnergyMerging(true);\n\t// eventFill->SetUseCaloCutInsteadMomentum(true);\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n //\n // mergeTag = \"photonAndNeutralRecl_looseThetaCut_clusterE\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t// eventFill->SetUseCaloInfoForEnergyMerging(true);\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n //\n // mergeTag = \"photonAndNeutralRecl_looseThetaCut_caloEMatchin\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonAndNeutralLooseMerge\");\n\t// eventFill->SetUseCaloCutInsteadMomentum(true);\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"conv_noEnergyMatching\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->SetApplyEnergyMatching(false);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonRecl_conv_noEnergyMatching\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\teventFill->SetApplyEnergyMatching(false);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonRecl_noConv_noEnergyMatching\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\teventFill->SetApplyEnergyMatching(false);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonRecl_conv\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonRecl_noConv\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\n\tmergeTag = \"photonRecl_noAngularMatching\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\teventFill->SetApplyAngularMatching(false);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\tmergeTag = \"photonRecl_noEnergyMatching\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\teventFill->SetApplyEnergyMatching(false);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\t// mergeTag = \"photonRecl_noAngularMatching_caloE\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonMerge\");\n\t// eventFill->SetApplyAngularMatching(false);\n\t// eventFill->SetUseCaloInfoForEnergyMerging(true);\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n //\n\t// mergeTag = \"photonRecl_noEnergyMatching_caloE\";\n\t// eventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\t// eventFill->setClusterMerging(\"photonMerge\");\n\t// eventFill->SetApplyEnergyMatching(false);\n\t// eventFill->SetUseCaloInfoForEnergyMerging(true);\n\t// objFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\t\n\tmergeTag = \"photonRecl_useCaloForMergedCandidates\";\n\teventFill = new eventHistFiller(\"eventHists_\"+mergeTag,effCollection);\n\teventFill->setClusterMerging(\"photonMerge\");\n\teventFill->SetUseCaloCutInsteadMomentumForMergedCandidates(true);\n\teventFill->SetUseCaloInfoForEnergyMerging(true);\n\tobjFillMap[\"eventHists_\"+mergeTag] = eventFill;\n\n\t// ELECTRON STUDY\n\t// objFill = new electronStudy(\"electronStudy\",effCollection);\n\t// objFillMap[\"electronStudy\"] = objFill;\n //\n\t// objFill = new electronStudy(\"electronStudy_noFSR\",effCollection);\n\t// objFillMap[\"electronStudy_noFSR\"] = objFill;\n //\n\t// objFill = new electronStudy(\"electronStudy_FSR\",effCollection);\n\t// objFillMap[\"electronStudy_FSR\"] = objFill;\n\t \n\t\n\n\t// vector<int> pfoTypeVec = {11,22};\n\t// vector<int> pfoTypeVec = {11};\n\t// for (int ii=0; ii<pfoTypeVec.size(); ii++){\n\t// int pfoTypeToUse = pfoTypeVec[ii];\n\t// cout << \"pfoTypeToUse: \" << pfoTypeToUse << endl;\n\t// string histDirPrefix = config::pfoTypeIntStringMap[pfoTypeToUse]+\"_eventHist\";\n\t// cout << \"histDirPrefix: \" << histDirPrefix << endl;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// objFillMap[histDirPrefix+\"\"] = eventFill;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"_noConv\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setDiscardConvertions(true);\n\t// objFillMap[histDirPrefix+\"_noConv\"] = eventFill;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"_photonRecl\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setMergePfoType(22);\n\t// objFillMap[histDirPrefix+\"_photonRecl\"] = eventFill;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"_photonAndNeutralRecl\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setMergePfoType({22,2112});\n\t// objFillMap[histDirPrefix+\"_photonAndNeutralRecl\"] = eventFill;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"_photonAndNeutralRecl_looseThetaCut\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setMergePfoType({22,2112});\n\t// eventFill->setThetaMergingCut(2.0);\n\t// objFillMap[histDirPrefix+\"_photonAndNeutralRecl_looseThetaCut\"] = eventFill;\n\t// //\n\t// eventFill = new eventHistFiller(histDirPrefix+\"_conv\",pfoTypeToUse);\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setSelectConvertions(true);\n\t// objFillMap[histDirPrefix+\"_conv\"] = eventFill;\n\t// }\n // //\n\t// eventFill = new eventHistFiller(\"Photons_Neutral_eventHists_photonAndNeutralRecl\",{22,2112});\n\t// eventFill->setPFOCollection(effCollection);\n\t// eventFill->setMergePfoType({22,2112});\n\t// objFillMap[\"Photons_Neutral_eventHists_photonAndNeutralRecl\"] = eventFill;\n\n\t// photonEffCalculator* effCalculator = new photonEffCalculator(\"photonEfficiency\");\n\t// effCalculator->setPFOCollection(effCollection);\n\t// effCalculator->setPFOType(efficiencyPFOType);\n\t// effCalculator->setEfficiencyOneClusterRequirement(onlyOneRecoClusterPerEvent);\n\t// if (dPhiMergeValue > 0.0)\n\t// effCalculator->setDPhiMergeValue(dPhiMergeValue);\n\t// objFillMap[\"photonEfficiency\"] = effCalculator;\n\n\tfor(auto const &mapElement : objFillMap){\n\t\tcout << \"Init mapElement: \" << mapElement.first << endl;\n\t\tmapElement.second->init();\n\t}\n\n}\n\nbool truthParticleSelector::selectEvent(const EVENT::LCEvent* event){\n\t\n\tEVENT::MCParticle* part = truthCondition::instance()->getGunParticle();\n\tif (discardFSREvents && truthCondition::instance()->getnTruthParticles()!=1) \n\t\treturn 0;\n\tconst double *partMom = part->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tif (partTheta<8 || partTheta>172) \n\t\treturn false;\n\tdouble partMomMag = v1.Mag();\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tif ((partMomMag<energyRange.first) || (partMomMag>energyRange.second))\n\t\treturn false;\n\tif ((partTheta<thetaRange.first) || (partTheta>thetaRange.second))\n\t\treturn false;\n\tif ((partPhi<phiRange.first) || (partPhi>phiRange.second))\n\t\treturn false;\n\n\t\n\tfor(auto const &mapElement : objFillMap){\n\t\tif (IsInWord(mapElement.first,\"_noFSR\")){\n\t\t\tif (truthCondition::instance()->get_simFSRPresent()==false)\n\t\t\t\tmapElement.second->fillEvent(event);\n\t\t}\n\t\telse if (IsInWord(mapElement.first,\"_FSR\")){\n\t\t\tif (truthCondition::instance()->get_simFSRPresent()==true)\n\t\t\t\tmapElement.second->fillEvent(event);\n\t\t}\n\t\telse if (IsInWord(mapElement.first,\"_conv\")){\n\t\t\tif (truthCondition::instance()->get_partGun_isStablePartDecayedInTracker()==true)\n\t\t\t\tmapElement.second->fillEvent(event);\n\t\t}\n\t\telse if (IsInWord(mapElement.first,\"_noConv\")){\n\t\t\tif (truthCondition::instance()->get_partGun_isStablePartDecayedInTracker()==false)\n\t\t\t\tmapElement.second->fillEvent(event);\n\t\t}\n\t\telse{\n\t\t\tmapElement.second->fillEvent(event);\n\t\t}\n\t}\n\treturn true;\n}\n\ntruthParticleSelector::truthParticleSelector(){\n\tenergyRange = make_pair(0.0,std::numeric_limits<double>::max());\n\tthetaRange = make_pair(-180.0,180.);\n\tphiRange = make_pair(-360.0,360.);\n\n\tefficiencyPFOType = 0;\t\n\n}\n\ntruthParticleSelector::~truthParticleSelector(){\n\tfor(auto const &mapElement : objFillMap){\n\t\tmapElement.second->DeleteHists();\n\t\tdelete mapElement.second;\n\t} \n}\n\n\nvoid truthParticleSelector::writeToFile(TFile *outFile){\n\tfor(auto const &mapElement : objFillMap){\n\t\tmapElement.second->writeToFile(outFile);\n\t}\n}\n\nstring truthParticleSelector::getPostFixString(){\n\tstring postFix = \"E\"+DoubToStr((energyRange.first+energyRange.second)/2.0);\n\tif (thetaRange != make_pair(-180.0,180.))\n\t\tpostFix += \"_Theta\" + DoubToStr(thetaRange.first)+\"_\"+DoubToStr(thetaRange.second);\n\tif (phiRange != make_pair(-360.0,360.))\n\t\tpostFix += \"_Phi\"+ DoubToStr(phiRange.first)+\"_\"+DoubToStr(phiRange.second);\t\n\treturn postFix;\n}\n"
},
{
"alpha_fraction": 0.6647768616676331,
"alphanum_fraction": 0.6805504560470581,
"avg_line_length": 37.4340934753418,
"blob_id": "323fff1df7bd530b221bd789af34e9b9e552997d",
"content_id": "7b513dd1a3d3d17e0d84d3514269d9c479720908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 21872,
"license_type": "no_license",
"max_line_length": 361,
"num_lines": 569,
"path": "/PhotonECAL/src/electronStudy.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/electronStudy.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n\n#include \"electronStudy.h\"\n\n/*===========================================================================*/\n/*===============================[ function implementations ]================*/\n/*===========================================================================*/\n\nint electronStudy::init(){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\\telectronStudy::init()\" << endl;\n\n\t// TODO hardcoded\n\t// trackCollectionName = \"SiTracks_Refitted\";\n\ttrackCollectionName = \"SiTracks\";\n\tecalBarrelCollectionName = \"ECalBarrelCollection\";\n\n\tTH1* tmpHist;\n\ttmpHist = new TH1I(\"nTracks\",\"Number of Tracks; Number of tracks; Counts\",5,0,5);\n\thistMap[\"nTracks\"] = tmpHist;\n\n\tmap <string, unsigned int> tmpMap;\n\tstring tmpString = \"\";\n\n\ttmpMap.clear();\n\ttmpString = \"OneElectron\";\n\ttmpMap[\"Electron\"] = 1;\n\ttmpMap[\"Total\"] = 1;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OnePion\";\n\ttmpMap[\"Pion\"] = 1;\n\ttmpMap[\"Total\"] = 1;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OnePhoton\";\n\ttmpMap[\"Photon\"] = 1;\n\ttmpMap[\"Total\"] = 1;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OneNeutralHadron\";\n\ttmpMap[\"NeutralHadron\"] = 1;\n\ttmpMap[\"Total\"] = 1;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"TwoPhotons\";\n\ttmpMap[\"Photon\"] = 2;\n\ttmpMap[\"Total\"] = 2;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OneElectronOnePhoton\";\n\ttmpMap[\"Photon\"] = 1;\n\ttmpMap[\"Electron\"] = 1;\n\ttmpMap[\"Total\"] = 2;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OneElectronTwoPhotons\";\n\ttmpMap[\"Photon\"] = 2;\n\ttmpMap[\"Electron\"] = 1;\n\ttmpMap[\"Total\"] = 3;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"OneElectronPlusMore\";\n\ttmpMap[\"Electron\"] = 1;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"NoElectron\";\n\ttmpMap[\"Electron\"] = 0;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\ttmpMap.clear();\n\ttmpString = \"NoElectronNoPion\";\n\ttmpMap[\"Electron\"] = 0;\n\ttmpMap[\"Pion\"] = 0;\n\tcategoryMap[tmpString] = tmpMap;\n\ttmpMap.clear();\n\n\tfor (auto it = categoryMap.begin(); it != categoryMap.end(); it++){\n\t\tstring prefix = it->first;\n\n\t\t// HISTS with type + energyIndex postfix\n\t\tfor (auto iType = config::pfoTypeIntStringMap.begin(); iType != config::pfoTypeIntStringMap.end(); iType++) {\n\t\t\tfor (int ii=0; ii<20; ii++){\n\t\t\t\tstring postFix = iType->second + DoubToStr(ii);\n\n\t\t\t\ttmpString = prefix + \"_\" + \"dPhi\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"#phi_{reco}-#phi_{truth}; Phi [rad]; Counts\",400,-0.5,0.5);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\t\t\t\t\n\t\t\t\ttmpString = prefix + \"_\" + \"dTheta\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"#Theta_{reco}-#Theta_{truth}; Theta [rad]; Counts\",1000,-0.025,0.025);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"dPhiTrack\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"#phi_{pfo}-#phi_{track}; Phi [rad]; Counts\",1200,-TMath::Pi(),TMath::Pi());\n\t\t\t\thistMap[tmpString] = tmpHist;\n\t\t\t\t\n\t\t\t\ttmpString = prefix + \"_\" + \"dThetaTrack\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"#Theta_{pfo}-#Theta_{track}; Theta [rad]; Counts\",1200,-TMath::Pi(),TMath::Pi());\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"E\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"PFO energy; E [GeV]; Counts\",5000,0,125);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"nClusters\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Number of clusters per PFO; Number of clusters; Counts\",5,0,5);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"trackClusterParallelDistance\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track-Cluster Parallel Distance; Distance [mm]; Counts\",1000,0.,250);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"trackClusterPerpendicularDistance\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track-Cluster Perpendicular Distance; Distance [mm]; Counts\",1000,0.,250);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"trackClusterPerpendicularDistanceWithCut\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track-Cluster Perpendicular Distance with Cut; Distance [mm]; Counts\",1000,0.,250);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\t\t\t\t\n\t\t\t\ttmpString = prefix + \"_\" + \"trackClusterCosAngle\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track-Cluster Cosine Angle; Cos(Opening Angle); Counts\",1000,-1.,1.);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"trackZ0\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track Z0; Z0 [mm]; Counts\",800,-100,100);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\t\t\t\t\n\t\t\t\ttmpString = prefix + \"_\" + \"trackD0\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Track D0; D0 [mm]; Counts\",800,-100,100);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\n\t\t\t\ttmpString = prefix + \"_\" + \"trackR0\" + \"-\" + postFix;\n\t\t\t\ttmpHist = new TH1I(tmpString.c_str(),\"Radius of the innermost hit that has been used in the track fit; R0 [mm]; Counts\",400,0,100);\n\t\t\t\thistMap[tmpString] = tmpHist;\n\t\t\t}\n\t\t}\n\n\t\t// OTHER HISTS\n\t\ttmpString = prefix + \"_\" + \"nTracks\";\n\t\ttmpHist = new TH1I(tmpString.c_str(),\"Number of Tracks; Number of tracks; Counts\",5,0,5);\n\t\thistMap[tmpString] = tmpHist;\n\n\t\ttmpString = prefix + \"_\" + \"nTracks\";\n\t\ttmpHist = new TH1I(tmpString.c_str(),\"Number of Tracks; Number of tracks; Counts\",5,0,5);\n\t\thistMap[tmpString] = tmpHist;\n\n\t\ttmpString = prefix + \"_\" + \"truthCosTheta\";\n\t\ttmpHist = new TH1I(tmpString.c_str(),\"Truth Cos(#Theta); Cos(#Theta); Counts per Event\",180*2,-1,1);\n\t\thistMap[tmpString] = tmpHist;\n\n\t\ttmpString = prefix + \"_\" + \"truthPhi\";\n\t\ttmpHist = new TH1I(tmpString.c_str(),\"Truth #Phi; #Phi; Counts per Event\",180*2,-180,180);\n\t\thistMap[tmpString] = tmpHist;\n\t}\n\n\n\n\n\t// else if (pfoCounter[\"Electron\"]==1 && pfoCounter[\"Total\"]>1){\n\t//\n\t// }\n\t// else if (pfoCounter[\"Electron\"]==0 && pfoCounter[\"Photon\"]>2){\n\t//\n\t// }\n\n\n\treturn 0;\n}\n\nint electronStudy::fillEvent(const EVENT::LCEvent* event){\n\ttry {\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|electronStudy]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t}\n\ttry {\n\t\ttrackCollection = event->getCollection(trackCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|electronStudy]\\tCan't find collection: \" << trackCollectionName << endl;\n\t\treturn -1;\n\t}\n\ttry {\n\t\tecalBarrelCollection = event->getCollection(ecalBarrelCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|electronStudy]\\tCan't find collection: \" << ecalBarrelCollectionName << endl;\n\t\treturn -1;\n\t}\n\t_encoder = new UTIL::BitField64(ecalBarrelCollection->getParameters().getStringVal( EVENT::LCIO::CellIDEncoding ));\n\n\t// cout << \"Event \" << event->getEventNumber() << endl;\n\t// cout << \"NumberOfElements in \" << PFOCollectionName << \" collection: \" << PFOCollection->getNumberOfElements() << endl;\n\n\t// init pfoCounter\n\tpfoCounter.clear();\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++)\n\t\tpfoCounter[it->second] = 0;\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\telectronStudy::fillEvent: \" << event->getEventNumber() << endl;\n\n\tEVENT::MCParticle* genPart = truthCondition::instance()->getGunParticle();\n\tconst double *partMom = genPart->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble truthTheta = 180.*v1.Theta()/TMath::Pi();\n\tdouble truthPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble cosTruthTheta = TMath::Cos(TMath::Pi()*truthTheta/180.);\n\tdouble truthEnergy = genPart->getEnergy();\n\tdouble truthPt = v1.Pt();\n\n\trecoPFOs = getObjVecFromCollection<EVENT::ReconstructedParticle*>(PFOCollection);\n\tif (recoPFOs.size()==0){\n\t\tcout << \"[WARNING]\\t Event \" << event->getEventNumber() << \" has no PFOs!!!\" << endl;\n\t\treturn 0; // no reco PFOs\n\t}\n\n\tpfoIdSortedByEnergyAndType.clear();\n\tfor (int i=0; i<recoPFOs.size(); i++){\n\t\tunsigned int pfoType = abs(recoPFOs[i]->getType());\n\t\tdouble pfoEnergy = recoPFOs[i]->getEnergy();\n\t\tpfoIdSortedByEnergyAndType.push_back( make_pair( pfoEnergy, make_pair(i, pfoType) ) );\n\t\t// double energyRanking\n\t}\n\tsort(pfoIdSortedByEnergyAndType.begin(),pfoIdSortedByEnergyAndType.end());\n\treverse(pfoIdSortedByEnergyAndType.begin(),pfoIdSortedByEnergyAndType.end());\n\t// cout << \"nPFOs: \" << pfoIdSortedByEnergyAndType.size() << endl;\n\tperformEnergyPfoTypeRanking();\n\n\tvector<EVENT::Track*> tracks = getObjVecFromCollection<EVENT::Track*>(trackCollection);\n\tgetHistFromMap(\"nTracks\")->Fill(tracks.size());\n\tfillHistsPerCategory(\"nTracks\",tracks.size(),-1);\n\tfillHistsPerCategory(\"truthCosTheta\",cosTruthTheta,-1);\n\tfillHistsPerCategory(\"truthPhi\",truthPhi,-1);\n\n\tfor (int i=0; i<recoPFOs.size(); i++){\n\t\tint pfoType = abs(recoPFOs[i]->getType());\n\t\tconst double *partMom = recoPFOs[i]->getMomentum();\n\t\tTVector3 v1;\n\t\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\t\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\t\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\t\tdouble partPt = v1.Pt();\n\t\tdouble cosPartTheta = TMath::Cos(TMath::Pi()*partTheta/180.);\n\t\tdouble pfoE = recoPFOs[i]->getEnergy();\n\t\tdouble dPhi = TMath::Pi()*(partPhi-truthPhi)/180.0;\n\t\tdouble dTheta = TMath::Pi()*(partTheta-truthTheta)/180.0;\n\n\t\tfillHistsPerCategory(\"dPhi\",dPhi,i);\n\t\tfillHistsPerCategory(\"dTheta\",dTheta,i);\n\t\tfillHistsPerCategory(\"E\",pfoE,i);\n\t\tfillHistsPerCategory(\"nClusters\",recoPFOs[i]->getClusters().size(),i);\n\n\n\t\tif (config::vm.count(\"debug\")) cout << endl << \"access cluster\" << endl;\n\t\tauto clusterVec = recoPFOs[i]->getClusters();\n\t\tif (config::vm.count(\"debug\")) cout << \"number of clusters: \" << clusterVec.size() << \"; partType: \" << pfoType << endl;\n\t\tif (clusterVec.size()>0){\n\t\t\tauto cluster = clusterVec[0];\n\t\t\tif (config::vm.count(\"debug\")) cout << \"access caloHit vector\" << endl;\n\t\t\tauto tmpVec = cluster->getCalorimeterHits();\n\t\t\tif (config::vm.count(\"debug\")) cout << \"size of caloHit vector: \" << tmpVec.size() << endl;\n\t\t\tif (config::vm.count(\"debug\")) cout << \"continue further\" << endl;\n\t\t\tif (config::vm.count(\"debug\")) cout << endl;\n\t\t}\n\t\t// cout << \"Size of caloHits vector: \" << tmpVec.size() << endl;\n\t\t\n\t\t// cout << \"layerNumber: \" << getLayerNumber(tmpVec[0]) << endl;\n\t\t// pandora::Cluster* myCluster = new pandora::Cluster(recoPFOs[i]->getClusters()[0]);\n\t\t// for (auto it = tmpVec.begin(); it!=tmpVec.end(); it++){\n\t\t// myCluster->AddCaloHit(it);\n\t\t// }\n\t\t\n\t\tif (tracks.size()==1){\n\t\t\tauto trackStateMomentum = getTrackStateMomentum(tracks[0]);\n\t\t\tfillHistsPerCategory(\"dPhiTrack\",v1.Phi()-trackStateMomentum->Phi(),i);\n\t\t\tfillHistsPerCategory(\"dThetaTrack\",v1.Theta()-trackStateMomentum->Theta(),i);\n\n\t\t\tauto trackClusterDistanceMap = getTrackClusterDistance(recoPFOs[i],tracks[0]);\n\n\t\t\tfillHistsPerCategory(\"trackClusterPerpendicularDistance\",trackClusterDistanceMap[\"trackClusterPerpendicularDistance\"],i);\n\t\t\tfillHistsPerCategory(\"trackClusterPerpendicularDistanceWithCut\",trackClusterDistanceMap[\"trackClusterPerpendicularDistanceWithCut\"],i);\n\t\t\tfillHistsPerCategory(\"trackClusterParallelDistance\",trackClusterDistanceMap[\"trackClusterParallelDistance\"],i);\n\t\t\tfillHistsPerCategory(\"trackClusterCosAngle\",trackClusterDistanceMap[\"trackClusterCosAngle\"],i);\n\n\t\t\tfillHistsPerCategory(\"trackZ0\",tracks[0]->getZ0(),i);\n\t\t\tfillHistsPerCategory(\"trackD0\",tracks[0]->getD0(),i);\n\t\t\tfillHistsPerCategory(\"trackR0\",tracks[0]->getRadiusOfInnermostHit(),i);\n\t\t\t\n\t\t\t// for (auto it=trackClusterDistanceMap.begin(); it!=trackClusterDistanceMap.end(); it++){\n\t\t\t// cout << \"[Sasha]\\t \" << (*it).first << \": \" << (*it).second << endl;\n\t\t\t// }\n\t\t\t// cout << endl;\n\n\t\t}\n\t\t\n\n\n\t}\n\n\treturn 0;\n}\n\nvoid electronStudy::fillHistsPerCategory(string histNameCore, double fillValue, int pfoId){\n\tfor (auto it = categoryMap.begin(); it != categoryMap.end(); it++){\n\t\tbool passRequirement = true;\n\t\tfor (auto itTmp = it->second.begin(); itTmp != it->second.end(); itTmp++){\n\t\t\t// cout << \"itTmp->first = \" << itTmp->first << \"itTmp->second = \" << itTmp->second << \"; pfoCounter[itTmp->first] = \" << pfoCounter[itTmp->first] << endl;\n\t\t\tif (itTmp->second != pfoCounter[itTmp->first]){\n\t\t\t\tpassRequirement = false;\n\t\t\t\tbreak;\n\t\t\t}\n\n\t\t}\n\t\tif (passRequirement==false)\n\t\t\tcontinue;\n\t\tstring prefix = it->first;\n\t\t\n\t\tstring tmpString = prefix + \"_\" + histNameCore;\n\t\tif (pfoId>=0)\n\t\t\ttmpString = tmpString + \"-\" + pfoIdEnergyTypeMap[pfoId];\n\t\tgetHistFromMap(tmpString)->Fill(fillValue);\n\t}\n}\n\n\n\n\n\nint electronStudy::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\telectronStudy::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\t// getHistFromMap(\"totalEnergyVsTheta\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\t// getHistFromMap(\"nTruthPartsVsTheta\")->Sumw2();\n\t\n\n\tif (!outFile->IsOpen()){\n\t\tcout << \"[ERROR|writeToFile]\\tno output file is found!\" << endl;\n\t\treturn -1;\n\t}\n\toutFile->cd();\n\tTDirectory *mainDir = outFile->mkdir(outDirName.c_str());\n\tmainDir->cd();\n\n\tmap<string,unsigned int> prefixCounter;\n\tmap<string,string> namePrefixMap;\n\tmap<string,bool> isPrefixSubdirCreated;\n\tmap<string,string> nameWithoutPrefixMap;\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tvector<string> tmpStrVec = GetSplittedWords(histName,\"_\");\n\t\tif (tmpStrVec.size()<2) \n\t\t\tcontinue;\n\t\tstring prefix = \"\";\n\t\tfor (int i=0; i<tmpStrVec.size()-1; i++){\n\t\t\tif (i==tmpStrVec.size()-2)\n\t\t\t\tprefix += tmpStrVec[i];\n\t\t\telse\n\t\t\t\tprefix += tmpStrVec[i] + \"_\";\n\t\t}\n\t\tnameWithoutPrefixMap[histName] = tmpStrVec[tmpStrVec.size()-1];\n\t\tprefixCounter[prefix] += 1;\n\t\tisPrefixSubdirCreated[prefix] = false;\n\t\tnamePrefixMap[histName] = prefix;\n\t}\n\t\n\n\tfor(auto const &it : histMap) {\n\t\tif (it.second->GetEntries()==0)\n\t\t\tcontinue;\n\t\tstring histName = it.first;\n\t\tstring prefix = namePrefixMap[histName];\n\t\tif (prefixCounter[prefix]<2){\n\t\t\tmainDir->cd();\n\t\t\tit.second->Write();\n\t\t}\n\t\telse{\n\t\t\tif (isPrefixSubdirCreated[prefix]==false){\n\t\t\t\tmainDir->mkdir(prefix.c_str());\n\t\t\t\tisPrefixSubdirCreated[prefix]=true;\n\t\t\t}\n\t\t\tmainDir->cd(prefix.c_str());\n\t\t\tit.second->SetName(nameWithoutPrefixMap[histName].c_str());\n\t\t\tit.second->Write();\n\t\t\tmainDir->cd();\n\t\t}\n\t}\n\toutFile->cd();\n\treturn 0;\n\n}\n\nvoid electronStudy::performEnergyPfoTypeRanking(){\n\tfor (auto iType = config::pfoTypeIntStringMap.begin(); iType != config::pfoTypeIntStringMap.end(); iType++) {\n\t\tunsigned int pdgId = iType->first;\n\t\tstring typeString = iType->second;\n\t\tfor (int iCount=0; iCount<pfoIdSortedByEnergyAndType.size(); iCount++){\n\t\t\tpair<unsigned int, unsigned int> idTypePair = pfoIdSortedByEnergyAndType[iCount].second;\n\t\t\tunsigned int pfoId = idTypePair.first;\n\t\t\tunsigned int pfoType = idTypePair.second;\n\n\t\t\tif (pdgId == pfoType){\n\t\t\t\tpfoIdEnergyTypeMap[ pfoId ] = typeString + DoubToStr(pfoCounter[typeString]+1);\n\t\t\t\tpfoCounter[typeString]++;\n\t\t\t\tpfoCounter[\"Total\"]++;\n\t\t\t\t// cout << \"ID: \" << pfoId << \"; Type: \" << pfoType << \"; Energy: \" << pfoIdSortedByEnergyAndType[iCount].first << \"; label: \" << pfoIdEnergyTypeMap[ pfoId ] << endl;\n\t\t\t}\n\t\t}\n\t}\n}\n\nTVector3* electronStudy::getTrackStateMomentum(EVENT::Track *inTrack){\n\tdouble bField = 2.0;\n\tauto pTrackState = inTrack->getTrackState (EVENT::TrackState::AtCalorimeter);\n\tconst double pt(bField * 2.99792e-4 / std::fabs(pTrackState->getOmega()));\n\n\tconst double px(pt * std::cos(pTrackState->getPhi()));\n\tconst double py(pt * std::sin(pTrackState->getPhi()));\n\tconst double pz(pt * pTrackState->getTanLambda());\n\n\tTVector3* outVec = new TVector3(px,py,pz);\n\treturn outVec;\n}\n\n\nTVector3* electronStudy::getTrackStatePosition(EVENT::Track *inTrack){\n\tauto pTrackState = inTrack->getTrackState (EVENT::TrackState::AtCalorimeter);\n\tconst double xs(pTrackState->getReferencePoint()[0]);\n\tconst double ys(pTrackState->getReferencePoint()[1]);\n\tconst double zs(pTrackState->getReferencePoint()[2]);\n\tTVector3* outVec = new TVector3(xs,ys,zs);\n\treturn outVec;\n}\n\nint electronStudy::getLayerNumber(EVENT::CalorimeterHit* calHit){\n\tlcio::long64 cellId = long( calHit->getCellID0() & 0xffffffff ) | ( long( calHit->getCellID1() ) << 32 );\n\t_encoder->setValue(cellId);\n\treturn (*_encoder)[\"layer\"].value();\n}\n\n\npandora::TrackState* electronStudy::getPandoraTrackState(const EVENT::TrackState *const pTrackState)\n{\n\tif (!pTrackState)\n\t\tthrow pandora::StatusCodeException(pandora::STATUS_CODE_NOT_INITIALIZED);\n\n\tdouble m_bField = 2.0;\n\tconst double pt(m_bField * 2.99792e-4 / std::fabs(pTrackState->getOmega()));\n\n\tconst double px(pt * std::cos(pTrackState->getPhi()));\n\tconst double py(pt * std::sin(pTrackState->getPhi()));\n\tconst double pz(pt * pTrackState->getTanLambda());\n\n\tconst double xs(pTrackState->getReferencePoint()[0]);\n\tconst double ys(pTrackState->getReferencePoint()[1]);\n\tconst double zs(pTrackState->getReferencePoint()[2]);\n\n\t// cout << \"[DEBUG|electronStudy::CopyTrackState]\\t\" << \" xs: \" << xs << \" ys: \" << ys << \" zs: \" << zs << \" px: \" << px << \" py: \" << py << \" pz: \" << pz << endl;\n\n\treturn new pandora::TrackState(xs, ys, zs, px, py, pz);\n}\n\n\nmap <string, double> electronStudy::getTrackClusterDistance(const EVENT::ReconstructedParticle* const inPart, const EVENT::Track* const inTrack){\n\tmap<string,double> outMap;\n\tauto clusterVec = inPart->getClusters();\n\tfloat minDistanceSquared(std::numeric_limits<float>::max());\n\tfloat minDistanceSquaredWithCut(std::numeric_limits<float>::max());\n\tfloat minTrackClusterCosAngle(std::numeric_limits<float>::max());\n\tpandora::TrackState* pTrackState = getPandoraTrackState(inTrack->getTrackState (EVENT::TrackState::AtCalorimeter));\n\tif (clusterVec.size()>0){\n\t\tauto cluster = clusterVec[0];\n\t\tauto caloHitVec = cluster->getCalorimeterHits();\n\t\tpandora::CartesianVector* tmpVec = new pandora::CartesianVector(pTrackState->GetPosition());\n\t\tconst pandora::CartesianVector &trackPosition(pTrackState->GetPosition());\n\t\tconst pandora::CartesianVector trackDirection(pTrackState->GetMomentum().GetUnitVector());\n\n\t\tconst pandora::CartesianVector* clusterDirection = new pandora::CartesianVector(inPart->getMomentum()[0],inPart->getMomentum()[1],inPart->getMomentum()[2]);\n\t\tdouble trackClusterCosAngle = trackDirection.GetCosOpeningAngle(clusterDirection->GetUnitVector());\n\n\t\tdouble minParallelDistance = std::numeric_limits<double>::max();\n\n\t\tEVENT::CalorimeterHitVec::const_iterator savedHitIter;\n\n\t\tunsigned int hitCounter = 0;\n\t\tunsigned int previousHitLayer = 0;\n\t\tfor (auto hitIter=caloHitVec.begin(); hitIter!=caloHitVec.end(); hitIter++){\n\t\t\tunsigned int hitLayer = getLayerNumber(*hitIter);\n\t\t\t// if (hitLayer>maxCaloSearchLayer)\n\t\t\t// continue;\n\t\t\tauto caloHitPositionVec = (*hitIter)->getPosition();\n\t\t\t// cout << \"caloHitID: \" << hitCounter << \"\\tlayer: \" << hitLayer << endl;\n\t\t\tconst pandora::CartesianVector* caloHitPosition = new pandora::CartesianVector(caloHitPositionVec[0],caloHitPositionVec[1],caloHitPositionVec[2]);\n\t\t\t// const pandora::CartesianVector &caloHitPosition((*hitIter)->getPosition()[0],(*hitIter)->getPosition()[1],(*hitIter)->getPosition()[2]);\n\t\t\tconst pandora::CartesianVector positionDifference(*caloHitPosition - trackPosition);\n\t\t\tdouble parallelDistance = std::fabs(trackDirection.GetDotProduct(positionDifference));\n\t\t\tconst float perpendicularDistanceSquared((trackDirection.GetCrossProduct(positionDifference)).GetMagnitudeSquared());\n\n\t\t\t// cout << \"HitID: \" << hitCounter << \"\\tlayer: \" << hitLayer << \"\\tpos[x,y,z]: \" << caloHitPositionVec[0] << \"\\t\" << caloHitPositionVec[1] << \"\\t\" << caloHitPositionVec[2] << \"\\tr: \" << sqrt(caloHitPositionVec[0]*caloHitPositionVec[0]+caloHitPositionVec[1]*caloHitPositionVec[1]) << \"\\ttrackClusterDistance: \" << sqrt(perpendicularDistanceSquared) << endl;\n\t\t\thitCounter++;\n\t\t\t// TODO remove 2 lines below and uncomment the same lines above!!!\n\t\t\t// if (hitLayer>maxCaloSearchLayer)\n\t\t\t// continue;\n\n\t\t\tif (hitLayer>maxCaloSearchLayer)\n\t\t\t\tbreak;\n\t\t\tif (hitLayer<previousHitLayer)\n\t\t\t\tbreak;\n\n\t\t\tpreviousHitLayer = hitLayer;\n\t\t\tif (minParallelDistance>parallelDistance)\n\t\t\t\tminParallelDistance = parallelDistance;\n\t\t\tif (perpendicularDistanceSquared < minDistanceSquared)\n\t\t\t\tminDistanceSquared = perpendicularDistanceSquared;\n\t\t\tif (perpendicularDistanceSquared < minDistanceSquaredWithCut && parallelDistance<100.0 && trackClusterCosAngle>0.0){\n\t\t\t\tminDistanceSquaredWithCut = perpendicularDistanceSquared;\n\t\t\t\tsavedHitIter = hitIter;\n\t\t\t}\n\t\t}\n\n\t\toutMap[\"trackClusterPerpendicularDistance\"] = std::sqrt(minDistanceSquared);\n\t\toutMap[\"trackClusterPerpendicularDistanceWithCut\"] = std::sqrt(minDistanceSquaredWithCut);\n\t\toutMap[\"trackClusterParallelDistance\"] = minParallelDistance;\n\t\toutMap[\"trackClusterCosAngle\"] = trackClusterCosAngle;\n\n\t\t// cout << \"[Sasha]\\tnCaloHitsInCluster: \" << caloHitVec.size() << endl;\n\t\t// cout << \"[Sasha]\\ttrackDirection: \" << trackDirection << endl;\n\t\t// cout << \"[Sasha]\\ttrackPosition: \" << trackPosition << endl;\n\t\t// auto caloHitPositionVec = (*savedHitIter)->getPosition();\n\t\t// const pandora::CartesianVector* caloHitPosition = new pandora::CartesianVector(caloHitPositionVec[0],caloHitPositionVec[1],caloHitPositionVec[2]);\n\t\t// cout << \"[Sasha]\\tcaloHitPosition: \" << (*caloHitPosition) << endl;\n\t\t// const pandora::CartesianVector positionDifference(*caloHitPosition - trackPosition);\n\t\t// cout << \"[Sasha]\\tpositionDifference: \" << positionDifference << endl;\n\t\t// cout << \"[Sasha]\\tcaloHitLayer: \" << getLayerNumber(*savedHitIter) << endl;\n\n\n\n\t}\n\t// cout << \"1\" << endl;\n\treturn outMap;\n}\n\n \n"
},
{
"alpha_fraction": 0.7561436891555786,
"alphanum_fraction": 0.7561436891555786,
"avg_line_length": 21.04166603088379,
"blob_id": "bcdf020896f42878740d6f8a2e39e23ce7820400",
"content_id": "5719179f1bb7c2b6c883d0bcb36226a7ef8dc424",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 24,
"path": "/MuonReco/include/energyFillAllCalo.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef energyFillAllCalo_H\n#define energyFillAllCalo_H\n\n#include <objectFill.h>\n\n#include <UTIL/CellIDEncoder.h>\n\nclass energyFillAllCalo : public objectFill{\n\n\tpublic:\n\t\tenergyFillAllCalo(string _outDirName) : objectFill(_outDirName) {}\n\t\t~energyFillAllCalo(){}\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\t// void setCollectionName(const string _collectionName){collectionName = _collectionName;}\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tEVENT::LCCollection *collection;\n\t\tstring collectionName;\n};\n\n\n#endif\n"
},
{
"alpha_fraction": 0.6790837645530701,
"alphanum_fraction": 0.7020223140716553,
"avg_line_length": 41.995880126953125,
"blob_id": "5e8c63cf08151b4af40a0e949ea75cb571306af7",
"content_id": "6ae72319d0fcf5cf8aae1da778cad7bf21220475",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 31301,
"license_type": "no_license",
"max_line_length": 274,
"num_lines": 728,
"path": "/MuonReco/src/particleFill.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <particleFill.h>\n#include <IMPL/ReconstructedParticleImpl.h>\n// #include <globalConfig.h>\n\n#define nBinsPerGeV 10\n#define nExampleClusterHists 10\n#define maxEnergyRatioExampleClusterHist 2.0\n\nvoid particleFill::initHistStructs(){\n\t// all histogram NEED to have unique names!!!\n\tsingleParticleHistStructMap[\"Energy\"] = histStruct(\"Particle Energy; Energy [GeV]; Counts\",250*nBinsPerGeV,0.0,250.0);\n\tsingleParticleHistStructMap[\"Phi\"] = histStruct(\"Particle Phi; Phi; Counts\",360,-180,180);\n\tsingleParticleHistStructMap[\"Theta\"] = histStruct(\"Particle Theta; Theta; Counts\",180*2,0,180);\n\tsingleParticleHistStructMap[\"CosTheta\"] = histStruct(\"Particle Cos(#Theta); Cos(#Theta); Counts\",180*2,-1,1);\n\tsingleParticleHistStructMap[\"Type\"] = histStruct(\"Particle Type; Type; Counts\",2200,0,2200,\"TH1I\");\n\n\ttwoParticleCorrelationHistStructMap[\"dPhi\"] = histStruct(\"dPhi; Phi; Counts\",360,-180,180);\n\ttwoParticleCorrelationHistStructMap[\"dTheta\"] = histStruct(\"dTheta; Theta; Counts\",360,-18,18);\n\ttwoParticleCorrelationHistStructMap[\"dR\"] = histStruct(\"dR; #Delta R; Counts\",200,0,2);\n\ttwoParticleCorrelationHistStructMap[\"dE\"] = histStruct(\"E_{1}-E_{2}; E_{1}-E_{2}; Counts\",100*nBinsPerGeV,0.0,100.0);\n\ttwoParticleCorrelationHistStructMap[\"sumE\"] = histStruct(\"E_{1}+E_{2}; E_{1}+E_{2} [GeV] ; Counts\",250*nBinsPerGeV,0.0,250.0);\n\ttwoParticleCorrelationHistStructMap[\"TwoParticleType\"] = histStruct(\"Particle Type; Type; Counts\",2200,0,2200,\"TH1I\");\n\n\tsingleRecoParticleClustersHistStructMap[\"ECALtoHCALRatio\"] = histStruct(\"ECAL/HCAL Energy Ratio; ECAL/HCAL ratio; Counts\",250,0,100);\n\tsingleRecoParticleClustersHistStructMap[\"ECALEnergy\"] = histStruct(\"ECAL Energy; ECAL Energy [GeV]; Counts\",125*nBinsPerGeV,0.0,125.0);\n\tsingleRecoParticleClustersHistStructMap[\"HCALEnergy\"] = histStruct(\"HCAL Energy; HCAL Energy [GeV]; Counts\",125*nBinsPerGeV,0.0,125.0);\n\tsingleRecoParticleClustersHistStructMap[\"TestCorrectedEnergy\"] = histStruct(\"CAL Energy; CAL Energy [GeV]; Counts\",125*nBinsPerGeV,0.0,125.0);\n\tsingleRecoParticleClustersHistStructMap[\"clusterPositionZR\"] = histStruct(\"Cluster Position; Z [mm]; R [mm]\",800,-4000,4000,\"TH2D\",400,0,4000);\n\tsingleRecoParticleClustersHistStructMap[\"clusterPositionMoreECALEnergy\"] = histStruct(\"Cluster Position; Z [mm]; R [mm]\",800,-4000,4000,\"TH2D\",400,0,4000);\n\tsingleRecoParticleClustersHistStructMap[\"clusterPositionMoreHCALEnergy\"] = histStruct(\"Cluster Position; Z [mm]; R [mm]\",800,-4000,4000,\"TH2D\",400,0,4000);\n\tfor (unsigned int i; i<nExampleClusterHists; i++)\n\t\tsingleRecoParticleClustersHistStructMap[\"hitPositionsOneEventExample\"+DoubToStr(i)] = histStruct(\"Calo hits position; Z [mm]; R [mm]\",800,-4000,4000,\"TH2D\",400,0,4000);\n\t\n\n}\n\nint particleFill::init(){\n\n\tinitHistStructs();\n\tfor (int i=0; i<nExampleClusterHists; i++)\n\t\tboolVecDefaultFalse.push_back(false);\n\n\tif (IsInWord(\"MCParticle\",collectionName)){ \n\t\tcreateSingleParticleHists(\"truthParticle_\");\n\t\tTH1I* tmpHist = new TH1I(\"truthParticle_isDecayedInTracker\",\"Sim. Status; Sim. Status; Counts\",35,0,35);\n\t\thistMap[\"truthParticle_isDecayedInTracker\"] = tmpHist;\n\t}\n\telse if(IsInWord(\"SiTracks\",collectionName)){\n\t\t// add track-related hists. TODO rewrite it with functions\n\t\tTH1I* tmpHist = new TH1I(\"tracking_nTracks\",\"Number of tracks; # of tracks; Counts\", 5, 0, 5);\n\t\thistMap[\"tracking_nTracks\"] = tmpHist;\n\t\tTH1D* tmpHist2 = new TH1D(\"tracking_allTracksMomentum\",\"Track momentum; Momentum [GeV]; Counts\",250*nBinsPerGeV,0.0,250);\n\t\thistMap[\"tracking_allTracksMomentum\"] = tmpHist2;\n\t\ttmpHist2 = new TH1D(\"tracking_1st_trackMomentum\",\"Track momentum; Momentum [GeV]; Counts\",250*nBinsPerGeV,0.0,250);\n\t\thistMap[\"tracking_1st_trackMomentum\"] = tmpHist2;\n\t\ttmpHist2 = new TH1D(\"tracking_2nd_trackMomentum\",\"Track momentum; Momentum [GeV]; Counts\",250*nBinsPerGeV,0.0,250);\n\t\thistMap[\"tracking_2nd_trackMomentum\"] = tmpHist2;\n\t\ttmpHist2 = new TH1D(\"tracking_3rd_trackMomentum\",\"Track momentum; Momentum [GeV]; Counts\",250*nBinsPerGeV,0.0,250);\n\t\thistMap[\"tracking_3rd_trackMomentum\"] = tmpHist2;\n\t\ttmpHist2 = new TH1D(\"tracking_1st_trackPt\",\"Track Pt; Pt [GeV]; Counts\",250*nBinsPerGeV,0.0,250);\n\t\thistMap[\"tracking_1st_trackPt\"] = tmpHist2;\n\t}\n\telse{ // Reconstructed particles\n\t\tcreateSingleParticleHists(\"allPartsOfType_\");\n\t\tcreateSingleParticleHists(\"signalPFO_\");\n\t\tcreateSingleParticleHists(\"signalPFO_truthParts_\");\n\t\tcreateSingleParticleHists(\"signalPFO_noAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"signalPFO_noAdditionalPFOs_truthParts_\");\n\t\t// createSingleParticleHists(\"signalPFO_noAdditionalPFOs_truthParts_withinEnergyCut_\");\n\t\tcreateSingleParticleHists(\"signalPFO_thereAreAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"firstEnergeticPartOfWrongType_\");\n\t\tcreateSingleParticleHists(\"secondEnergeticPart_\");\n\t\tcreateSingleParticleHists(\"mostEnergeticPFO_noPFOofType_\");\n\n\t\tcreateSingleParticleHists(\"PFOofType_\");\n\t\tcreateSingleParticleHists(\"PFOofType_noAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"PFOofType_thereAreAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"PFOofType_thereAreAdditionalPFOs_withinEnergyCut_\");\n\t\tcreateSingleParticleHists(\"PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\tcreateSingleParticleHists(\"PFONOTofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\n\t\tcreateSingleParticleHists(\"noConv_PFOofType_\");\n\t\tcreateSingleParticleHists(\"noConv_PFOofType_noAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"noConv_PFOofType_thereAreAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"noConv_PFOofType_thereAreAdditionalPFOs_withinEnergyCut_\");\n\t\tcreateSingleParticleHists(\"noConv_PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\tcreateSingleParticleHists(\"noConv_PFONOTofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\n\t\tcreateSingleParticleHists(\"conv_PFOofType_\");\n\t\tcreateSingleParticleHists(\"conv_PFOofType_noAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"conv_PFOofType_thereAreAdditionalPFOs_\");\n\t\tcreateSingleParticleHists(\"conv_PFOofType_thereAreAdditionalPFOs_withinEnergyCut_\");\n\t\tcreateSingleParticleHists(\"conv_PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\tcreateSingleParticleHists(\"conv_PFONOTofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\t// truth hists:\n\t\tcreateSingleParticleHists(\"truthParticle_onlyOneRecoPFO_\");\n\t\tcreateSingleParticleHists(\"truthParticle_twoOrMoreRecoPFO_\");\n\n\t\tcreateTwoParticleCorrelationHists(\"signalPFO_secondEnergeticPFO_\");\n\t\tcreateTwoParticleCorrelationHists(\"signalPFO_secondEnergeticPhoton_\");\n\t\tcreateTwoParticleCorrelationHists(\"PFOofType_secondPFO_outsideEnergyCut_\");\n\t\tcreateTwoParticleCorrelationHists(\"PFOofType_truthPart_outsideEnergyCut_\");\n\t\tcreateTwoParticleCorrelationHists(\"secondPFO_truthPart_outsideEnergyCut_\");\n\t\tcreateTwoParticleCorrelationHists(\"firstEnergetic_truthPart_\");\n\t\tcreateTwoParticleCorrelationHists(\"secondEnergetic_truthPart_\");\n\t\tcreateTwoParticleCorrelationHists(\"notFirstEnergetic_truthPart_\");\n\t\tcreateTwoParticleCorrelationHists(\"allPFO_truthPart_\");\n\n\n\t\tcreateSingleRecoParticleClustersHists(\"signalPFO_clusterInfo_\");\n\t\tcreateSingleRecoParticleClustersHists(\"signalPFO_noAdditionalPFOs_clusterInfo_\");\n\n\t\tcreateSingleRecoParticleClustersHists(\"PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_clusterInfo_\");\n\t\tcreateSingleRecoParticleClustersHists(\"secondPFO_thereAreAdditionalPFOs_outsideEnergyCut_clusterInfo_\");\n\n\t\tTH1I* h_setPartType = new TH1I(\"setPFOPartType\",\"Set PFO particle type to use; Type; Counts\",2200,0,2200); // max part.type = 2112 (neutron)\n\t\thistMap[\"setPFOPartType\"] = h_setPartType;\n\t\tfor (auto i=0; i<partTypeToSelect.size(); i++)\n\t\t\thistMap[\"setPFOPartType\"]->Fill(partTypeToSelect[i]);\n\n\t\tif (partTypeToSelect.size()==0)\n\t\t\tcout << \"[ERROR|particleFill]\\tNo PFO type particle are set up for collection: \" << collectionName << \"\" << endl;\n\t}\n\n\n\n\tfor(auto const &iMapElement : histMap) {\n\t\tiMapElement.second->AddDirectory(kFALSE);\n\t}\n\n\tdPhiMergeValue = 0;\n\tcollection = NULL;\n\n\treturn 0;\n}\n\n\n\nint particleFill::fillParticleCorrelations (const EVENT::ReconstructedParticle* inPart1, const EVENT::ReconstructedParticle* inPart2, const string prefix){\n\t// TODO implement dE, dPhi between properly reconstructed and second energetic PFOs\n\tconst double *partMom1 = inPart1->getMomentum();\n\tTVector3 v1, v2;\n\tv1.SetXYZ(partMom1[0],partMom1[1],partMom1[2]);\n\tconst double *partMom2 = inPart2->getMomentum();\n\tv2.SetXYZ(partMom2[0],partMom2[1],partMom2[2]);\n\tdouble dPhi = v1.DeltaPhi(v2)*180./TMath::Pi();\n\tdouble dR = v1.DeltaR(v2);\n\tdouble dTheta = 180./TMath::Pi()*(v1.Theta()-v2.Theta());\n\n\tdouble dE = inPart1->getEnergy() - inPart2->getEnergy();\n\tdouble sumE = inPart1->getEnergy() + inPart2->getEnergy();\n\n\tfillHist(dPhi, \"dPhi\", prefix);\n\tfillHist(dTheta, \"dTheta\", prefix);\n\tfillHist(dR, \"dR\", prefix);\n\tfillHist(dE, \"dE\", prefix);\n\tfillHist(sumE, \"sumE\", prefix);\n\n\tfillHist(inPart1->getType(), \"TwoParticleType\", prefix);\n\tfillHist(inPart2->getType(), \"TwoParticleType\", prefix);\n\n\treturn 0;\n}\n\n\nint particleFill::fillParticleCorrelations (const EVENT::ReconstructedParticle* inPart1, const EVENT::MCParticle* inPart2, const string prefix){\n\t// TODO implement dE, dPhi between properly reconstructed and second energetic PFOs\n\tconst double *partMom1 = inPart1->getMomentum();\n\tTVector3 v1, v2;\n\tv1.SetXYZ(partMom1[0],partMom1[1],partMom1[2]);\n\tconst double *partMom2 = inPart2->getMomentum();\n\tv2.SetXYZ(partMom2[0],partMom2[1],partMom2[2]);\n\tdouble dPhi = v1.DeltaPhi(v2)*180./TMath::Pi();\n\tdouble dR = v1.DeltaR(v2);\n\tdouble dTheta = 180./TMath::Pi()*(v1.Theta()-v2.Theta());\n\n\tdouble dE = inPart1->getEnergy() - inPart2->getEnergy();\n\tdouble sumE = inPart1->getEnergy() + inPart2->getEnergy();\n\n\tfillHist(dTheta, \"dTheta\", prefix);\n\tfillHist(dPhi, \"dPhi\", prefix);\n\tfillHist(dR, \"dR\", prefix);\n\tfillHist(dE, \"dE\", prefix);\n\tfillHist(sumE, \"sumE\", prefix);\n\n\tfillHist(inPart1->getType(), \"TwoParticleType\", prefix);\n\tfillHist(inPart2->getPDG(), \"TwoParticleType\", prefix);\n\n\treturn 0;\n\n}\n\nint particleFill::fillEvent(const EVENT::LCEvent* event){\n\ttry {\n\t\tcollection = event->getCollection(collectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|particleFill]\\tCan't find collection: \" << collectionName << endl;\n\t\treturn -1;\n\t}\n\t// if (config::vm.count(\"accessCaloHitInfo\")){\n\t// string caloHitCollectionName = \"ECalBarrelCollection\";\n\t// try {\n\t// EVENT::LCCollection *caloCollection = event->getCollection(caloHitCollectionName);\n\t// } catch (EVENT::DataNotAvailableException &e) {\n\t// cout << \"[ERROR|particleFill]\\tCan't find collection: \" << caloHitCollectionName << endl;\n\t// return -1;\n\t// }\n\t// }\n\n\tif( collection ) {\n\t\tstring collectionType = collection->getTypeName();\n\t\tconst int nElements = collection->getNumberOfElements();\n\t\tif (nElements<=0)\n\t\t\treturn 0;\n\t\t// unsigned int countE_1 = 0;\n\t\t// unsigned int countE_2 = 0;\n\t\t// double E_1 = 0.0;\n\t\t// double E_2 = 0.0;\n\t\t\n\t\tdouble E_1 = 0.0;\n\t\tdouble E_2 = 0.0;\n\n\t\tif (collectionType==\"ReconstructedParticle\"){\n\t\t\tintMap[\"id_firstEnergeticPFO\"] = -1;\n\t\t\tintMap[\"id_secondEnergeticPFO\"] = -1;\n\t\t\tintMap[\"id_mostEnergeticPFOofType\"] = -1;\n\t\t\tintMap[\"id_mostEnergeticPFONOTofType\"] = -1;\n\t\t\tintMap[\"n_PFOofType\"] = 0;\n\t\t\tintMap[\"n_PFONOTofType\"] = 0;\n\t\t\tintMap[\"n_PFO\"] = nElements;\n\t\t\tPFOtypeAndEnergyVec.clear();\n\t\t}\n\n\t\t\n \t\tfor(int j=0; j < nElements; j++) {\n\t\t\tif (collectionType==\"MCParticle\"){\n\t\t\t\tauto part = dynamic_cast<EVENT::MCParticle*>(collection->getElementAt(j));\n\t\t\t\tif (config::vm.count(\"debug\")){ \n\t\t\t\t\tdumpTruthPart(part, j);\n\t\t\t\t\tcout << endl;\n\t\t\t\t}\n\t\t\t\t// dumpTruthPart(part, j);\n\t\t\t\tif (part->isCreatedInSimulation()!=0) \n\t\t\t\t\tcontinue;\n\t\t\t\tif (part->getGeneratorStatus()!=1) \n\t\t\t\t\tcontinue;\n\t\t\t\tfillPart(part);\n\t\t\t\thistMap[\"truthParticle_isDecayedInTracker\"]->Fill(part->isDecayedInTracker());\n\t\t\t}\n\t\t\telse if (collectionType==\"Track\"){\n\t\t\t\tauto track = dynamic_cast<EVENT::Track*>(collection->getElementAt(j));\n\t\t\t\tdouble omtrack = track->getOmega();\n\t\t\t\tdouble tLtrack = track->getTanLambda();\n\t\t\t\tdouble recoThetaRad = 3.141592/2.0 - atan(tLtrack);\n\t\t\t\tdouble m_magneticField = 2.0;\n\t\t\t\tdouble recoPt = 0.3*m_magneticField/(fabs(omtrack)*1000.);\n\t\t\t\tdouble momentum = recoPt/sin(recoThetaRad);\n\t\t\t\tif (j==0){\n\t\t\t\t\thistMap[\"tracking_nTracks\"]->Fill(nElements);\n\t\t\t\t\thistMap[\"tracking_1st_trackMomentum\"]->Fill(momentum);\n\t\t\t\t\thistMap[\"tracking_1st_trackPt\"]->Fill(recoPt);\n\t\t\t\t}\n\t\t\t\tif (j==1)\n\t\t\t\t\thistMap[\"tracking_2nd_trackMomentum\"]->Fill(momentum);\n\t\t\t\tif (j==2)\n\t\t\t\t\thistMap[\"tracking_3rd_trackMomentum\"]->Fill(momentum);\n\t\t\t\thistMap[\"tracking_allTracksMomentum\"]->Fill(momentum);\n\t\t\t}\n\t\t\telse if (collectionType==\"ReconstructedParticle\"){\n\t\t\t\tauto part = dynamic_cast<EVENT::ReconstructedParticle*>(collection->getElementAt(j));\n\t\t\t\tif (config::vm.count(\"debug\")) \n\t\t\t\t\tdumpReconstructedPart(part, j);\n\t\t\t\tif(find(partTypeToSelect.begin(), partTypeToSelect.end(), part->getType()) != partTypeToSelect.end()){\n\t\t\t\t\tfillPart(part,\"allPartsOfType_\");\n\t\t\t\t}\n\n\n\t\t\t\tclasiffyPFO(part);\n\n\t\t\t\t// if (j==0){\n\t\t\t\t// E_1 = part->getEnergy();\n\t\t\t\t// }\n\t\t\t\t// else{\n\t\t\t\t// double E = part->getEnergy();\n\t\t\t\t// if (E>E_1){\n\t\t\t\t// intMap[\"id_secondEnergeticPFO\"] = intMap[\"id_firstEnergeticPFO\"];\n\t\t\t\t// E_2 = E_1;\n\t\t\t\t// E_1 = E;\n\t\t\t\t// intMap[\"id_firstEnergeticPFO\"] = j;\n\t\t\t\t// }\n\t\t\t\t// if (E>E_2 && E<E_1){\n\t\t\t\t// E_2 = E;\n\t\t\t\t// intMap[\"id_secondEnergeticPFO\"] = j;\n\t\t\t\t// }\n\t\t\t\t// }\n\t\t\t\t// cout << j << \":\\tE1: \" << E_1 << \"; E2: \" << E_2 << endl;\n\t\t\t}\n\t\t\telse{\n\t\t\t\tcout << \"[ERROR|fillEvent]\\tuknown particle collection: \" << collectionType << endl;\n\t\t\t}\n\t\t}\n\n\n\t\tif (collectionType==\"ReconstructedParticle\"){\n\t\t\tif (nElements>=2) {\n\t\t\t\tauto firstEPart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_firstEnergeticPFO\"]));\n\t\t\t\tauto secondEPart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_secondEnergeticPFO\"]));\n\t\t\t\tfillParticleCorrelations(firstEPart,truthCondition::instance()->getGunParticle(),\"firstEnergetic_truthPart_\");\n\t\t\t\tfillParticleCorrelations(secondEPart,truthCondition::instance()->getGunParticle(),\"secondEnergetic_truthPart_\");\n\n\t\t\t\tfor(int kk=0; kk < nElements; kk++) {\n\t\t\t\t\tauto tmpPart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(kk));\n\t\t\t\t\tfillParticleCorrelations(tmpPart,truthCondition::instance()->getGunParticle(),\"allPFO_truthPart_\");\n\t\t\t\t\tif (kk==intMap[\"id_firstEnergeticPFO\"])\n\t\t\t\t\t\tcontinue;\n\t\t\t\t\tfillParticleCorrelations(tmpPart,truthCondition::instance()->getGunParticle(),\"notFirstEnergetic_truthPart_\");\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t// auto part = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(countE_1));\n\t\t\tauto part = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_firstEnergeticPFO\"]));\n\t\t\t\n\t\t\t// FIXME WARNING testing merging of clusters...\n\t\t\tif (dPhiMergeValue > 0.0){\n\t\t\t\tauto tmpPart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_firstEnergeticPFO\"]));\n\t\t\t\tpart = new IMPL::ReconstructedParticleImpl();\n\t\t\t\tpart->setEnergy(tmpPart->getEnergy());\n\t\t\t\tpart->setMomentum(tmpPart->getMomentum());\n\t\t\t\tpart->setType(tmpPart->getType());\n\n\t\t\t\tfor(int j=0; j < nElements; j++) {\n\t\t\t\t\tif (j==intMap[\"id_firstEnergeticPFO\"]) \n\t\t\t\t\t\tcontinue;\n\t\t\t\t\tTVector3 v1, v2;\n\t\t\t\t\tconst double *partMom1 = part->getMomentum();\n\t\t\t\t\tv1.SetXYZ(partMom1[0],partMom1[1],partMom1[2]);\n\n\t\t\t\t\tauto part2 = dynamic_cast<EVENT::ReconstructedParticle*>(collection->getElementAt(j));\n\t\t\t\t\tconst double *partMom2 = part2->getMomentum();\n\t\t\t\t\tv2.SetXYZ(partMom2[0],partMom2[1],partMom2[2]);\n\t\t\t\t\tdouble dPhi = v1.DeltaPhi(v2)*180./TMath::Pi();\n\t\t\t\t\tif (abs(dPhi)<2.0)\n\t\t\t\t\t\tpart->setEnergy(part->getEnergy()+part2->getEnergy());\n\t\t\t\t}\n\t\t\t}\n\t\t\t// FIXME\n\t\t\t\n\t\t\t// if (find(partTypeToSelect.begin(), partTypeToSelect.end(), part->getType()) != partTypeToSelect.end()){\n\t\t\tif ( intMap[\"id_firstEnergeticPFO\"] == intMap[\"id_mostEnergeticPFOofType\"] ){\n\n\t\t\t\tfillPart(part,\"signalPFO_\");\n\t\t\t\tfillPart(truthCondition::instance()->getGunParticle(),\"signalPFO_truthParts_\");\n\t\t\t\tif (config::vm.count(\"accessCaloHitInfo\"))\n\t\t\t\t\tfillClusterInfo(part,\"signalPFO_clusterInfo_\");\n\t\t\t\t// if (nElements>=2 && countE_1!=countE_2){\n\t\t\t\tif (intMap[\"id_secondEnergeticPFO\"]>=0){\n\t\t\t\t\tauto part2 = dynamic_cast<EVENT::ReconstructedParticle*>(collection->getElementAt(intMap[\"id_secondEnergeticPFO\"]));\n\t\t\t\t\tfillPart(part2,\"secondEnergeticPart_\");\n\t\t\t\t\tfillParticleCorrelations(part,part2,\"signalPFO_secondEnergeticPFO_\");\n\t\t\t\t\tif (part2->getType()==22)\n\t\t\t\t\t\tfillParticleCorrelations(part,part2,\"signalPFO_secondEnergeticPhoton_\");\n\t\t\t\t}\n\t\t\t\t// if (nElements>=2 && countE_1==countE_2){\n\t\t\t\t// cout << \"countE: \" << countE_2 << \"; E1: \" << E_1 << \"; E2: \" << E_2 << endl;\n\t\t\t\t// }\n\n\n\t\t\t\tif (intMap[\"n_PFO\"]>=2){\n\t\t\t\t\tfillPart(part,\"signalPFO_thereAreAdditionalPFOs_\");\n\t\t\t\t\tfillPart(truthCondition::instance()->getGunParticle(),\"truthParticle_twoOrMoreRecoPFO_\");\n\t\t\t\t}\n\t\t\t\telse{\n\t\t\t\t\tfillPart(part,\"signalPFO_noAdditionalPFOs_\");\n\t\t\t\t\tfillPart(truthCondition::instance()->getGunParticle(),\"signalPFO_noAdditionalPFOs_truthParts_\");\n\t\t\t\t\tfillPart(truthCondition::instance()->getGunParticle(),\"truthParticle_onlyOneRecoPFO_\");\n\t\t\t\t\tif (config::vm.count(\"accessCaloHitInfo\"))\n\t\t\t\t\t\tfillClusterInfo(part,\"signalPFO_noAdditionalPFOs_clusterInfo_\");\n\t\t\t\t\t\n\t\t\t\t}\n\n\n\t\t\t}\n\t\t\telse\n\t\t\t\tfillPart(part,\"firstEnergeticPartOfWrongType_\");\n\t\t\n\n\t\t\tif (intMap[\"n_PFOofType\"]>=1){\n\t\t\t\tpart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_mostEnergeticPFOofType\"]));\n\t\t\t\tfillRecoPhoton(part,truthCondition::instance()->getGunParticle(),\"PFOofType_\");\n\t\t\t\tif (intMap[\"n_PFO\"]==1)\n\t\t\t\t\tfillRecoPhoton(part,truthCondition::instance()->getGunParticle(),\"PFOofType_noAdditionalPFOs_\");\n\t\t\t\telse{\n\t\t\t\t\tfillRecoPhoton(part,truthCondition::instance()->getGunParticle(),\"PFOofType_thereAreAdditionalPFOs_\");\n\t\t\t\t\tdouble truthE = truthCondition::instance()->getGunParticle()->getEnergy();\n\t\t\t\t\t// if (abs(part->getEnergy()-truthE)<(2*sqrt(truthE)+0.5))\n\t\t\t\t\tif (abs(part->getEnergy()-truthE)<(0.75*sqrt(truthE)))\n\t\t\t\t\t\tfillRecoPhoton(part,truthCondition::instance()->getGunParticle(),\"PFOofType_thereAreAdditionalPFOs_withinEnergyCut_\");\n\t\t\t\t\telse{\n\t\t\t\t\t\tfillRecoPhoton(part,truthCondition::instance()->getGunParticle(),\"PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\t\t\t\t\tint tmpId = -1;\n\t\t\t\t\t\tif (intMap[\"id_mostEnergeticPFOofType\"]==intMap[\"id_firstEnergeticPFO\"])\n\t\t\t\t\t\t\ttmpId = intMap[\"id_secondEnergeticPFO\"];\n\t\t\t\t\t\telse\n\t\t\t\t\t\t\ttmpId = intMap[\"id_firstEnergeticPFO\"];\n\n\t\t\t\t\t\tauto partTemp = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(tmpId));\n\t\t\t\t\t\tfillPart(partTemp,\"PFONOTofType_thereAreAdditionalPFOs_outsideEnergyCut_\");\n\t\t\t\t\t\tfillParticleCorrelations(part,partTemp,\"PFOofType_secondPFO_outsideEnergyCut_\");\n\n\t\t\t\t\t\tfillParticleCorrelations(part,truthCondition::instance()->getGunParticle(),\"PFOofType_truthPart_outsideEnergyCut_\");\n\t\t\t\t\t\tfillParticleCorrelations(partTemp,truthCondition::instance()->getGunParticle(),\"secondPFO_truthPart_outsideEnergyCut_\");\n\n\t\t\t\t\t\t\n\t\t\t\t\t\t\n\n\t\t\t\t\t\tif (config::vm.count(\"accessCaloHitInfo\")){\n\t\t\t\t\t\t\tfillClusterInfo(part,\"PFOofType_thereAreAdditionalPFOs_outsideEnergyCut_clusterInfo_\");\n\t\t\t\t\t\t\tfillClusterInfo(partTemp,\"secondPFO_thereAreAdditionalPFOs_outsideEnergyCut_clusterInfo_\");\n\t\t\t\t\t\t}\n\n\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\telse{\n\t\t\t\tpart = dynamic_cast<IMPL::ReconstructedParticleImpl*>(collection->getElementAt(intMap[\"id_firstEnergeticPFO\"]));\n\t\t\t\t// cout << \"[DEBUG]\\tid_mostEnergeticPFOofType: \" << intMap[\"id_mostEnergeticPFOofType\"] << endl;\n\t\t\t\t// cout << \"[DEBUG]\\tpart type: \" << part->getType() << endl;\n\t\t\t\tfillPart(part,\"mostEnergeticPFO_noPFOofType_\");\n\t\t\t}\n\t\t\t\t\n\n\t\t}\n\t}\n\treturn 0;\n}\n\nvoid particleFill::fillRecoPhoton(const EVENT::ReconstructedParticle* inPart, const EVENT::MCParticle* mcPart, const string prefix){\n\tvector<string> prefixExt = {\"\",\"conv_\",\"noConv_\"};\n\tvector<bool> fillFlag = {true, mcPart->isDecayedInTracker(),!mcPart->isDecayedInTracker()};\n\tfor (unsigned int i=0;i<prefixExt.size();i++) {\n\t\tif (fillFlag[i]) \n\t\t\tfillPart(inPart,prefixExt[i]+prefix);\n\t}\n}\n\nint particleFill::fillPart (const EVENT::MCParticle* inPart, const string prefix) {\n\tconst double *partMom = inPart->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tdouble partEnergy = inPart->getEnergy();\n\tfillHist(partEnergy, \"Energy\", prefix);\n\tfillHist(partPhi, \"Phi\", prefix);\n\tfillHist(partTheta, \"Theta\", prefix);\n\tfillHist(TMath::Cos(TMath::Pi()*partTheta/180.), \"CosTheta\", prefix);\n\tfillHist(inPart->getPDG(), \"Type\", prefix);\n\treturn 0;\n}\n\nint particleFill::fillPart (const EVENT::ReconstructedParticle* inPart, const string prefix){\n\tconst double *partMom = inPart->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tdouble partEnergy = inPart->getEnergy();\n\tint partType= inPart->getType();\n\tfillHist(partEnergy, \"Energy\", prefix);\n\tfillHist(partPhi, \"Phi\", prefix);\n\tfillHist(partTheta, \"Theta\", prefix);\n\tfillHist(TMath::Cos(TMath::Pi()*partTheta/180.), \"CosTheta\", prefix);\n\tfillHist(partType, \"Type\", prefix);\n\treturn 0;\n}\n\nint particleFill::fillClusterInfo (const EVENT::ReconstructedParticle* inPart, const string prefix){\n\t\n\tint debugCounter = 0;\n\tvector<EVENT::Cluster*> clusterVec = inPart->getClusters();\n\tcout << \"[debug_0]\" << debugCounter++ << endl;\n\tcout << \"clusterVec.size(): \" << clusterVec.size() << endl;\n\tfor (int i=0; i<clusterVec.size(); i++){\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tcout << \"clusterVec[\"<<i<<\"]: \" << clusterVec[i] << endl;\n\t\tif (clusterVec[i]==NULL) continue;\n\t\tconst float *pos = clusterVec[i]->getPosition();\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tfillHist(pos[2],sqrt(pos[1]*pos[1]+pos[0]*pos[0]), \"clusterPositionZR\", prefix);\n\t\t// \"ecal\", \"hcal\", \"yoke\", \"lcal\", \"lhcal\", \"bcal\"\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tvector<float> subdetEnergies = clusterVec[i]->getSubdetectorEnergies();\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tdouble ratio = subdetEnergies[0]/subdetEnergies[1];\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tfillHist(subdetEnergies[0], \"ECALEnergy\", prefix);\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tfillHist(subdetEnergies[1], \"HCALEnergy\", prefix);\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tdouble testCorrectedEnergy = 1.1191707392*(subdetEnergies[0]/1.02425625854) + 1.18038308419*(subdetEnergies[1]/1.02425625854);\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tfillHist(testCorrectedEnergy, \"TestCorrectedEnergy\", prefix);\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tfillHist(ratio, \"ECALtoHCALRatio\", prefix);\n\t\tcout << \"[debug]\" << debugCounter++ << endl;\n\t\tif (ratio>1)\n\t\t\tfillHist(pos[2],sqrt(pos[1]*pos[1]+pos[0]*pos[0]), \"clusterPositionMoreECALEnergy\", prefix);\n\t\telse\n\t\t\tfillHist(pos[2],sqrt(pos[1]*pos[1]+pos[0]*pos[0]), \"clusterPositionMoreHCALEnergy\", prefix);\n\n\t\t// EXAMPLE CLUSTER HISTS\n\t\tfor (unsigned int iExample = 0; iExample<nExampleClusterHists; iExample++){\n\t\t\tif (ratio > (maxEnergyRatioExampleClusterHist/nExampleClusterHists*iExample) && ratio < (maxEnergyRatioExampleClusterHist/nExampleClusterHists*(iExample+1)) && boolVecDefaultFalse[iExample]==false){\n\t\t\t\tboolVecDefaultFalse[iExample]=true;\n\t\t\t\thistMap[prefix+\"hitPositionsOneEventExample\"+DoubToStr(iExample)]->SetTitle((\"E: \" + DoubToStr(clusterVec[i]->getEnergy()) + \" GeV, ECAL to HCAL ratio: \" + DoubToStr(ratio)).c_str());\n\t\t\t\tvector<EVENT::CalorimeterHit*> caloHits = clusterVec[i]->getCalorimeterHits();\n\t\t\t\tfor (int j=0; j<caloHits.size(); j++){\n\t\t\t\t\tconst float *hitPos = caloHits[j]->getPosition();\n\t\t\t\t\tfillHist(hitPos[2],sqrt(hitPos[1]*hitPos[1]+hitPos[0]*hitPos[0]), \"hitPositionsOneEventExample\"+DoubToStr(iExample), prefix);\n\t\t\t\t}\n\n\t\t\t}\n\t\t}\n\n\t}\n\n\treturn 0;\n}\n\nvoid particleFill::dumpTruthPart(const EVENT::MCParticle* part, const int counter){\n\tconst double *partMom = part->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tbool inTracker = part->isDecayedInTracker();\n\tbool inCal = part->isDecayedInCalorimeter();\n\tint genStatus = part->getGeneratorStatus();\n\tint pdgId = part->getPDG();\n\tcout << \"t\" << counter << \": pdg: \" << pdgId << \": E: \" << (round(100*part->getEnergy())/100.0) << \" GeV; theta: \" << partTheta << \"; phi: \" << partPhi << \"; inTracker: \" << inTracker << \"; inCal: \" << inCal << \"; genStatus: \" << genStatus << \"; pointer: \" << part << endl;\n\n}\n\nvoid particleFill::dumpReconstructedPart(const EVENT::ReconstructedParticle* part, const int counter){\n\tconst double *partMom = part->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tint partType= part->getType();\n\tcout << \"r\" << counter << \": E: \" << round(100*part->getEnergy())/100.0 << \" GeV; theta: \" << partTheta << \"; phi: \" << partPhi << \"; partType: \" << partType << endl;\n}\n\nint particleFill::fillHist(const double inVal, const string baseString, const string prefix){\n\ttry {\n\t\tif (histMap[prefix+baseString]==NULL){\n\t\t\tcout << \"[FATAL]\\t[particleFill] Can't find histogram with name: \" << prefix+baseString << endl;\n\t\t\tthrow 1;\n\t\t}\n\t}\n\tcatch (const std::exception& e) {\n\t\tcout << \"[ERROR]\\t[particleFill] Exception was caught, during accessing element: <\" << prefix << baseString << \"> from histMap:\"\n\t\t\t << endl << e.what() << endl;\n\t}\n\n\treturn histMap[prefix+baseString]->Fill(inVal);\n}\n\nint particleFill::fillHist(const double inVal1, const double inVal2, const string baseString, const string prefix){\n\ttry {\n\t\tif (histMap[prefix+baseString]==NULL){\n\t\t\tcout << \"[FATAL]\\t[particleFill] Can't find histogram with name: \" << prefix+baseString << endl;\n\t\t\tthrow 1;\n\t\t}\n\t}\n\tcatch (const std::exception& e) {\n\t\tcout << \"[ERROR]\\t[particleFill] Exception was caught, during accessing element: <\" << prefix << baseString << \"> from histMap:\"\n\t\t\t << endl << e.what() << endl;\n\t}\n\n\treturn histMap[prefix+baseString]->Fill(inVal1,inVal2);\n}\n\n\ndouble particleFill::getMeanEnergy(){\n\treturn histMap[\"allPartsOfType_Energy\"]->GetMean();\n}\n\ndouble particleFill::getMeanTheta(){\n\treturn histMap[\"allPartsOfType_Theta\"]->GetMean();\n}\n\n\n\n\nvoid particleFill::createSingleRecoParticleClustersHists(const string prefix){\n\tcreateHistsFromMap(singleRecoParticleClustersHistStructMap,prefix);\n}\nvoid particleFill::createSingleParticleHists(const string prefix){\n\tcreateHistsFromMap(singleParticleHistStructMap,prefix);\n}\nvoid particleFill::createTwoParticleCorrelationHists(const string prefix){\n\tcreateHistsFromMap(twoParticleCorrelationHistStructMap,prefix);\n}\n\n\nint particleFill::writeToFile(TFile* outFile){\n\tif (!outFile->IsOpen()){\n\t\tcout << \"[ERROR|writeToFile]\\tno output file is found!\" << endl;\n\t\treturn -1;\n\t}\n\toutFile->cd();\n\tTDirectory *mainDir = outFile->mkdir(outDirName.c_str());\n\tmainDir->cd();\n\n\tmap<string,unsigned int> prefixCounter;\n\tmap<string,string> namePrefixMap;\n\tmap<string,bool> isPrefixSubdirCreated;\n\tmap<string,string> nameWithoutPrefixMap;\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tvector<string> tmpStrVec = GetSplittedWords(histName,\"_\");\n\t\tif (tmpStrVec.size()<2) \n\t\t\tcontinue;\n\t\tstring prefix = \"\";\n\t\tfor (int i=0; i<tmpStrVec.size()-1; i++){\n\t\t\tif (i==tmpStrVec.size()-2)\n\t\t\t\tprefix += tmpStrVec[i];\n\t\t\telse\n\t\t\t\tprefix += tmpStrVec[i] + \"_\";\n\t\t}\n\t\tnameWithoutPrefixMap[histName] = tmpStrVec[tmpStrVec.size()-1];\n\t\tprefixCounter[prefix] += 1;\n\t\tisPrefixSubdirCreated[prefix] = false;\n\t\tnamePrefixMap[histName] = prefix;\n\t}\n\t\n\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tstring prefix = namePrefixMap[histName];\n\t\tif (prefixCounter[prefix]<2){\n\t\t\tmainDir->cd();\n\t\t\tit.second->Write();\n\t\t}\n\t\telse{\n\t\t\tif (isPrefixSubdirCreated[prefix]==false){\n\t\t\t\tmainDir->mkdir(prefix.c_str());\n\t\t\t\tisPrefixSubdirCreated[prefix]=true;\n\t\t\t}\n\t\t\tmainDir->cd(prefix.c_str());\n\t\t\tit.second->SetName(nameWithoutPrefixMap[histName].c_str());\n\t\t\tit.second->Write();\n\t\t\tmainDir->cd();\n\t\t}\n\t}\n\toutFile->cd();\n\treturn 0;\n\n}\nvoid particleFill::clasiffyPFO(EVENT::ReconstructedParticle* inPFO){\n\t\n\tconst int PFOtype = inPFO->getType();\n\tconst double PFOenergy = inPFO->getEnergy();\n\t// cout << \"[DEBUG]\\tPFOtype: \" << PFOtype << endl;\n\t// cout << \"[DEBUG]\\tpartTypeToSelect[0]: \" << partTypeToSelect[0] << endl;\n\t// cout << \"[DEBUG]\\tif statement: \" << (find(partTypeToSelect.begin(), partTypeToSelect.end(), PFOtype) != partTypeToSelect.end()) << endl;\n\n\tif (intMap[\"id_firstEnergeticPFO\"] == -1){\n\t\tintMap[\"id_firstEnergeticPFO\"] = 0;\n\t\tif(find(partTypeToSelect.begin(), partTypeToSelect.end(), PFOtype) != partTypeToSelect.end()){\n\t\t\tintMap[\"id_mostEnergeticPFOofType\"] = 0;\n\t\t\tintMap[\"n_PFOofType\"] = 1;\n\t\t}\n\t\telse{\n\t\t\tintMap[\"id_mostEnergeticPFONOTofType\"] = 0;\n\t\t\tintMap[\"n_PFONOTofType\"] = 1;\n\t\t}\n\t}\n\telse{\n\t\tif (PFOenergy>PFOtypeAndEnergyVec.at(intMap[\"id_firstEnergeticPFO\"]).second){\n\t\t\tintMap[\"id_secondEnergeticPFO\"] = intMap[\"id_firstEnergeticPFO\"];\n\t\t\tintMap[\"id_firstEnergeticPFO\"] = PFOtypeAndEnergyVec.size();\n\t\t}\n\t\telse{\n\t\t\tif (intMap[\"id_secondEnergeticPFO\"] == -1){\n\t\t\t\tintMap[\"id_secondEnergeticPFO\"] = PFOtypeAndEnergyVec.size();\n\t\t\t}\n\t\t\telse{\n\t\t\t\tif (PFOenergy>PFOtypeAndEnergyVec.at(intMap[\"id_secondEnergeticPFO\"]).second)\n\t\t\t\t\tintMap[\"id_secondEnergeticPFO\"] = PFOtypeAndEnergyVec.size();\n\t\t\t}\n\t\t}\n\t\tif(find(partTypeToSelect.begin(), partTypeToSelect.end(), PFOtype) != partTypeToSelect.end()){\n\t\t\tif (intMap[\"n_PFOofType\"] == 0){\n\t\t\t\tintMap[\"id_mostEnergeticPFOofType\"] = PFOtypeAndEnergyVec.size();\n\t\t\t\t// cout << \"[dd2]\\tid_mostEnergeticPFOofType: \" << intMap[\"id_mostEnergeticPFOofType\"] << endl;\n\t\t\t\t// cout << \"[dd2]\\tPFOtypeAndEnergyVec.size(): \" << PFOtypeAndEnergyVec.size() << endl;\n\t\t\t}\n\t\t\telse{\n\t\t\t\tif (PFOenergy>PFOtypeAndEnergyVec.at(intMap[\"id_mostEnergeticPFOofType\"]).second)\n\t\t\t\t\tintMap[\"id_mostEnergeticPFOofType\"] = PFOtypeAndEnergyVec.size();\n\t\t\t}\n\t\t\tintMap[\"n_PFOofType\"]++;\n\t\t}\n\t\telse{\n\t\t\tif (intMap[\"n_PFONOTofType\"] == 0){\n\t\t\t\tintMap[\"id_mostEnergeticPFONOTofType\"] = PFOtypeAndEnergyVec.size();\n\t\t\t}\n\t\t\telse{\n\t\t\t\tif (PFOenergy>PFOtypeAndEnergyVec.at(intMap[\"id_mostEnergeticPFONOTofType\"]).second)\n\t\t\t\t\t intMap[\"id_mostEnergeticPFONOTofType\"] = PFOtypeAndEnergyVec.size();\n\t\t\t}\n\t\t\tintMap[\"n_PFONOTofType\"]++;\n\t\t}\n\t}\n\t\n\tPFOtypeAndEnergyVec.push_back( pair<int, double>(PFOtype, PFOenergy) );\n\t// cout << \"[DEBUG]\\tintMap printout:\" << endl;\n\t// cout << \"id_firstEnergeticPFO: \" << intMap[\"id_firstEnergeticPFO\"] << endl;\n\t// cout << \"id_secondEnergeticPFO: \" << intMap[\"id_secondEnergeticPFO\"] << endl;\n\t// cout << \"id_mostEnergeticPFOofType: \" << intMap[\"id_mostEnergeticPFOofType\"] << endl;\n\t// cout << \"n_PFOofType: \" << intMap[\"n_PFOofType\"] << endl;\n\t// cout << \"n_PFO: \" << intMap[\"n_PFO\"] << endl;\n\t// cout << \"PFOtypeAndEnergyVec.size(): \" << PFOtypeAndEnergyVec.size() << endl;\n \n}\n"
},
{
"alpha_fraction": 0.6186572313308716,
"alphanum_fraction": 0.6374917030334473,
"avg_line_length": 31.702898025512695,
"blob_id": "4dd57c28161498d9ae9a7b32ddbe9d9e1b372e5d",
"content_id": "2aef3495737e402e4a773965c5a2cdf91dc99ef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4513,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 138,
"path": "/python/drawPlotsFromAllFiles.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "# Draw plots specific plots for all files in the directory.\n# One TPad can contain many plots from ONE file\n\n#!/bin/python\nimport glob, os, ROOT, math, sys\nfrom ROOT import TCanvas, TGraph, TLegend, TF1, TH1, TH1F\nfrom ROOT import gROOT, gStyle\nimport yaml # WARNING use this environment ~/env/setupPyTools27.env to enable yaml package!!!\n\n# rebinFactor = 2\n# yAxisRange = [0, 600]\n# yAxisRange = []\n# xAxisRange = [0, 110]\n# histNamePrefix = \"truthParticle_\"\n# histNamePostfix = \"_CosTheta\"\n# histNamePrefix = \"firstEnergeticPartOfType_\"\n# histNamePostfix = \"Energy\"\n\n# histInfo = [\n# [\"onlyOneRecoPFO\",1,\"one reconstructed PFO\"],\n# [\"twoOrMoreRecoPFO\",2,\"2 or more reconstructed PFOs\"]\n# [\"noAdditionalPFOs\",1,\"one reconstructed PFO\"],\n# [\"thereAreAdditionalPFOs\",2,\"2 or more reconstructed PFOs\"]\n# ]\n\n# string format: particleGun_E<>_Theta<>_Phi<>.root\ndef getPhaseSpacePoint(inStr):\n\ttmpStrArr = ('.'.join(inStr.split(\".\")[:-1])).split(\"_\")\n\tE = float( tmpStrArr[1].split(\"E\")[1] )\n\tTheta = float( tmpStrArr[2].split(\"Theta\")[1] )\n\tPhi = float( tmpStrArr[3].split(\"Phi\")[1] )\n\treturn [E, Theta, Phi]\n\nif __name__ == \"__main__\":\n\n\twith open(\"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/python/config/drawPlotsFromAllFiles/globalConfig.yml\", 'r') as ymlfile:\n\t\ttmpCfg = yaml.load(ymlfile)\n\t\tpfoTypeMap = tmpCfg[\"pfo_type_map\"]\n\n\twith open(\"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/python/config/drawPlotsFromAllFiles/plotConfigExample.yml\", 'r') as ymlfile:\n\t\tglobalCfg = yaml.load(ymlfile)\n\t\n\n\tif (len(sys.argv)==1):\n\t\tpfoType = \"Photon\"\n\telse:\n\t\tpfoType = sys.argv[1]\n\t\n\tfileCounter = 0\n\n\tgStyle.SetOptStat(0)\n\tos.chdir(\"./\")\n\tfor iFile in glob.glob(\"*.root\"):\n\t\tmyFile = ROOT.TFile.Open(iFile,\"read\")\n\t\tphaceSpacePoint = getPhaseSpacePoint(iFile)\n\t\tprint (iFile)\n\t\tprint (phaceSpacePoint)\n\t\tiE = phaceSpacePoint[0]\n\t\tiTheta = phaceSpacePoint[1]\n\t\tiPhi = phaceSpacePoint[2]\n\t\tcounter = 0\n\t\tfor cfgIterator in globalCfg:\n\t\t\tcfg = globalCfg[cfgIterator]\n\t\t\thistNamePrefix = \"\"\n\t\t\thistNamePostfix = \"\"\n\t\t\tif (\"histNamePrefix\" in cfg):\n\t\t\t\thistNamePrefix = cfg['histNamePrefix']\n\t\t\tif (\"histNamePostfix\" in cfg):\n\t\t\t\thistNamePostfix = cfg['histNamePostfix']\n\t\t\thistNameBase = cfg['histNameBase']\n\t\t\tinFileDir = \"PandoraPFOs_\" + str(pfoTypeMap[pfoType]) + \"/\"\n\t\t\tif (\"customInFileDirOrHistName\" in cfg):\n\t\t\t\tinFileDir = \"\"\n\n\t\t\thists = []\n\t\t\tnEntries = []\n\t\t\tfor histIt in range(0,len(histNameBase)):\n\t\t\t\thistName = inFileDir+histNamePrefix+histNameBase[histIt]+histNamePostfix\n\t\t\t\tprint (histName)\n\n\t\t\t\thist = myFile.Get(histName)\n\t\t\t\thist.SetTitle(pfoType+\" Gun, E=%i GeV, Theta=%i, Phi=%i\" % (iE,iTheta,iPhi))\n\t\t\t\tnEntries.append(hist.GetEntries())\n\n\t\t\t\tif (\"histColor\" in cfg):\n\t\t\t\t\thist.SetLineColor(cfg['histColor'][histIt])\n\t\t\t\telse:\n\t\t\t\t\thist.SetLineColor(histIt+1)\n\t\t\t\tif (\"rebinFactor\" in cfg):\n\t\t\t\t\thist.Rebin(cfg['rebinFactor'])\n\t\t\t\tif (\"xAxisRange\" in cfg):\n\t\t\t\t\thist.GetXaxis().SetRangeUser(cfg[\"xAxisRange\"][0],cfg[\"xAxisRange\"][1])\n\t\t\t\tif (\"yAxisRange\" in cfg):\n\t\t\t\t\thist.GetYaxis().SetRangeUser(cfg[\"yAxisRange\"][0],cfg[\"yAxisRange\"][1])\n\n\t\t\t\thists.append(hist)\n\n\t\t\ttotalEntries = sum(nEntries)\n\t\t\tcan = TCanvas( 'c1_'+cfgIterator, 'A Simple Graph Example', 0, 0, 800, 600 )\n\t\t\tif (\"legPos\" in cfg):\n\t\t\t\tleg = TLegend(cfg[\"legPos\"][0],cfg[\"legPos\"][1],cfg[\"legPos\"][2],cfg[\"legPos\"][3])\n\t\t\telse:\n\t\t\t\tleg = TLegend(0.25,0.3,0.75,0.55)\n\n\t\t\tfor i in range(0,len(hists)):\n\t\t\t\thist = hists[i]\n\t\t\t\tif (\"histLegend\" in cfg):\n\t\t\t\t\tleg.AddEntry(hist,\"%s (%i%%)\" % (cfg[\"histLegend\"][i],round(100.0*nEntries[i]/totalEntries)),\"l\")\n\t\t\t\tif (i==0):\n\t\t\t\t\thist.Draw()\n\t\t\t\telse:\n\t\t\t\t\thist.Draw(\"same\")\n\n\t\t\tif (\"histLegend\" in cfg):\n\t\t\t\tleg.Draw(\"same\")\n\t\t\t# can.SetLogy()\n\t\t\t# can.SaveAs(\"E%i_Theta%i_Phi%i\" % (iE, iTheta, iPhi) +cfgIterator+\".png\" )\n\t\t\tif (counter == 0):\n\t\t\t\tcan.Print(\"E%i_Theta%i_Phi%i\" % (iE, iTheta, iPhi) + \".pdf(\",\"pdf\")\n\t\t\telse:\n\t\t\t\tcan.Print(\"E%i_Theta%i_Phi%i\" % (iE, iTheta, iPhi) + \".pdf\",\"pdf\")\n\t\t\tcounter = counter + 1\n\n\t\t\tif (fileCounter == 0):\n\t\t\t\tcan.Print(cfgIterator + \".pdf(\",\"pdf\")\n\t\t\telif (fileCounter==(len(glob.glob(\"*.root\"))-1)):\n\t\t\t\tcan.Print(cfgIterator + \".pdf)\",\"pdf\")\n\t\t\telse:\n\t\t\t\tcan.Print(cfgIterator + \".pdf\",\"pdf\")\n\n\t\tcan = TCanvas( 'c2_'+cfgIterator, 'A Simple Graph Example', 0, 0, 800, 600 )\n\t\tcan.Print(\"E%i_Theta%i_Phi%i\" % (iE, iTheta, iPhi) + \".pdf)\",\"pdf\")\n\n\t\t\n\t\tfileCounter = fileCounter + 1\n\n\tprint (\"****************************************************************\")\n\tprint (\"[INFO]\\tRUN OVER PFO TYPE: %s\" % (pfoType))\n"
},
{
"alpha_fraction": 0.7233664989471436,
"alphanum_fraction": 0.7329545617103577,
"avg_line_length": 27.1200008392334,
"blob_id": "74e7fbf4fdefb087920109f210ebac4d70acce2e",
"content_id": "df0f72c24901433256b5632003641344eb73d874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2816,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 100,
"path": "/MuonReco/include/muonEffInJets.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/muonEffInJets.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef MUONEFFINJETS_H\n#define MUONEFFINJETS_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n#include \"truthZWCondition.h\"\n\n#include <cmath>\n#include <gsl/gsl_sf_gamma.h>\n#include <vector>\n\n#include <marlin/Global.h>\n#include <GeometryUtil.h>\n\n#include <DD4hep/DD4hepUnits.h>\n#include <DD4hep/DetType.h>\n#include <DD4hep/DetectorSelector.h>\n#include <DD4hep/Detector.h>\n#include <DDRec/DetectorData.h>\n\n#include \"EVENT/ReconstructedParticle.h\"\n#include \"EVENT/MCParticle.h\"\n#include \"EVENT/Cluster.h\"\n#include <lcio.h>\n\n#include <EVENT/CalorimeterHit.h>\n#include \"CalorimeterHitType.h\"\n\n#include <ClusterShapes.h>\n\nstruct yokeHitsStruct{\n\tunsigned int nHits;\t\n\tunsigned int clusterLayerSpan;\n\tunsigned int nLayers;\n};\n\nstruct truthPartParameters{\n\tdouble truthTheta;\n\tdouble cosTruthTheta;\n\tdouble truthPhi;\n\tdouble truthPt;\n\tdouble truthEnergy;\n\tdouble vertexR;\n\tdouble vertexZ;\n};\n\n// partParameters extractTruthParticleParameters(MCParticle* genPart){\n// truthPartParameters tmpPars;\n// TVector3 vTruthMom(genPart->getMomentum());\n// tmpPars.truthTheta = vTruthMom.Theta()*TMath::RadToDeg();\n// tmpPars.cosTruthTheta = TMath::Cos(truthTheta*TMath::DegToRad());\n// tmpPars.truthPhi = vTruthMom.Phi()*TMath::RadToDeg();\n// tmpPars.truthPt = vTruthMom.Pt();\n// tmpPars.truthEnergy = genPart->getEnergy();\n//\n// const double *vertexPos = genPart->getVertex();\n// tmpPars.vertexR = sqrt(vertexPos[0]*vertexPos[0]+vertexPos[1]*vertexPos[1]);\n// tmpPars.vertexZ = vertexPos[2];\n// return tmpPars;\n// }\n\nclass muonEffInJets : public objectFill{\n\tpublic:\n\t\tmuonEffInJets(string _outDirName, string _PFOCollectionName = \"PandoraPFO\") : objectFill(_outDirName) {PFOCollectionName = _PFOCollectionName;}\n\t\t~muonEffInJets(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tstring PFOCollectionName;\n\t\tEVENT::LCCollection *PFOCollection = nullptr;\n\n\t\tEVENT::MCParticle* genPart = nullptr;\n\n\t\tunsigned int nPFOs = 0;\n\n\t\tint fillMuonClusterInfo();\n\t\tEVENT::FloatVec getClusterShape(EVENT::Cluster* pCluster);\n\t\tyokeHitsStruct getNumberOfYokeHits(EVENT::Cluster* pCluster); \n\n\t\tvector<EVENT::ReconstructedParticle*> matchedRecoPartsOfType;\n\t\tvector<EVENT::ReconstructedParticle*> nonMatchedRecoPartsOfType;\n\t\tvector<EVENT::MCParticle*> matchedTruthPartsOfType;\n\t\tvector<EVENT::MCParticle*> nonMatchedTruthPartsOfType;\n\n\t\tvoid findMatchedRecoParts();\n\t\tvoid fillTruthInfo();\n\t\tvoid fillTruthInfoHelper(string histNamePrefix, vector<EVENT::MCParticle*> inTruthPartVec);\n\n};\n#endif \n\n\n\n"
},
{
"alpha_fraction": 0.796669602394104,
"alphanum_fraction": 0.7975460290908813,
"avg_line_length": 34.65625,
"blob_id": "08e61786c08103d4f989a1950a1add1c7937d3cc",
"content_id": "f9a33bdde49cc8eb5a9be9d185af28dba2ec3de1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1141,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 32,
"path": "/PhotonECAL/include/photonEffCalculator.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef photonEffCalculator_H\n#define photonEffCalculator_H\n\n#include <objectFill.h>\n\nclass photonEffCalculator : public objectFill{\n\n\tpublic:\n\t\tphotonEffCalculator(string _outDirName) : objectFill(_outDirName) {PFOPartType = 0;}\n\t\t~photonEffCalculator(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tvoid setPFOCollection(const string _collectionName){PFOCollectionName = _collectionName;}\n\t\tvoid setPFOType(const int pfoType){PFOPartType = pfoType;}\n\t\tvoid setMCTruthCollection(const string _collectionName){MCTruthCollectionName = _collectionName;}\n\t\tvoid setDPhiMergeValue(const double inVal){dPhiMergeValue = inVal;}\n\t\tint writeToFile(TFile* outFile);\n\t\tvoid setEfficiencyOneClusterRequirement(bool inVal){onlyOneRecoClusterPerEvent = inVal;}\n\n\n\tprivate:\n\t\tstring PFOCollectionName;\n\t\tstring MCTruthCollectionName;\n\t\tEVENT::LCCollection *PFOCollection;\n\t\tEVENT::LCCollection *MCTruthCollection;\n\t\tEVENT::ReconstructedParticle* getMatchedPFO(const EVENT::MCParticle* inMCPart, const vector<EVENT::ReconstructedParticle*> findablePFO);\n\t\tint PFOPartType;\n\t\tdouble dPhiMergeValue;\n\t\tbool onlyOneRecoClusterPerEvent;\n};\n#endif\n"
},
{
"alpha_fraction": 0.5756497979164124,
"alphanum_fraction": 0.5956224203109741,
"avg_line_length": 44.08641815185547,
"blob_id": "c72f1defd3cdeb02203561ad6d068491da917b67",
"content_id": "862cfe78d733be4473cea4d8ad7a4325498ec05f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3655,
"license_type": "no_license",
"max_line_length": 519,
"num_lines": 81,
"path": "/PhotonECAL/src/truthCondition.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/truthCondition.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t15th Dec 2017\n * \tLast Update:\t15th Dec 2017\n */\n\n#include \"truthCondition.h\"\n\ntruthCondition* truthCondition::s_instance = NULL; \n\n/*===========================================================================*/\n/*===============================[ implementation ]===============================*/\n/*===========================================================================*/\n\nvoid truthCondition::processEvent(){\n\n\tnTruthParticles = 0;\n\tnStableGenParticles = 0;\n\tsimFSRPresent = false;\n\n\ttry {\n\t\tMCTruthCollection = event->getCollection(MCTruthCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tstd::cout << \"[ERROR|truthCondition::setEvent]\\tCan't find collection: \" << MCTruthCollectionName << std::endl;\n\t}\n\n\tnTruthParticles = MCTruthCollection->getNumberOfElements();\n\tif (config::vm.count(\"debug\"))\n\t\tstd::cout << \"Truth particles:\" << std::endl;\n\tfor(int j=0; j < nTruthParticles; j++) {\n\t\tauto part = static_cast<EVENT::MCParticle*>(MCTruthCollection->getElementAt(j));\n\t\tif (config::vm.count(\"debug\"))\n\t\t\tdumpTruthPart(part,j);\n\t\tif (part->getGeneratorStatus()==1){\n\t\t\tnStableGenParticles++;\n\t\t\tpartGun_idStableGenPart = j;\n\t\t\tpartGun_stablePartType = part->getPDG();\n\t\t\tif (part->isDecayedInTracker())\n\t\t\t\tpartGun_isStablePartDecayedInTracker = true;\n\t\t\telse\n\t\t\t\tpartGun_isStablePartDecayedInTracker = false;\n\t\t}\n\t\telse{\n\t\t\tif (part->vertexIsNotEndpointOfParent()==true)\n\t\t\t\tsimFSRPresent = true;\n\t\t}\n\t}\n\t// if (config::vm.count(\"debug\"))\n\t// dumpTruthCondition();\n\t// if (simFSRPresent==false && nTruthParticles>1)\n\t// dumpTruthCondition();\n\n}\n\nvoid truthCondition::dumpTruthCondition(){\n\n\tstd::cout << \"Event\\t\" << event->getEventNumber() << \"; nTruthParticles: \" << nTruthParticles << \"; nStableGenParticles: \" << nStableGenParticles << \"; partGun_stablePartType: \" << partGun_stablePartType << \"; partGun_isStablePartDecayedInTracker: \" << partGun_isStablePartDecayedInTracker << \"; partGun_idStableGenPart: \" << partGun_idStableGenPart << \"; simFSRPresent: \" << simFSRPresent << std::endl << std::endl;\t\n\n}\n\nvoid truthCondition::dumpTruthPart(const EVENT::MCParticle* part, const int counter){\n\tconst double *partMom = part->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tbool inTracker = part->isDecayedInTracker();\n\tbool inCal = part->isDecayedInCalorimeter();\n\tint genStatus = part->getGeneratorStatus();\n\tint pdgId = part->getPDG();\n\tbool vertexIsNotEndpointOfParent = part->vertexIsNotEndpointOfParent();\n\tconst double *vertexPos = part->getVertex();\n\tdouble vertexR = sqrt(vertexPos[0]*vertexPos[0]+vertexPos[1]*vertexPos[1]);\n\tdouble vertexZ = vertexPos[2];\n\tstd::cout << \"t\" << counter << \": pdg: \" << std::setw(5) << pdgId << \": E: \" << std::setw(6) << (round(100*part->getEnergy())/100.0) << \": pT: \" << std::setw(6) << (round(100*v1.Pt())/100.0) << \"; theta: \" << std::setw(6) << round(100*partTheta)/100.0 << \"; phi: \" << std::setw(6) << round(100*partPhi)/100.0 << \"; inTracker: \" << inTracker << \"; inCal: \" << inCal << \"; genStatus: \" << genStatus << \"; isRadiation: \" << vertexIsNotEndpointOfParent << \"; vertexR: \" << vertexR << \"; vertexZ: \" << vertexZ << std::endl;\n}\n/*===========================================================================*/\n/*===============================[ implementation ]===============================*/\n/*===========================================================================*/\n\n\n\n"
},
{
"alpha_fraction": 0.6821345686912537,
"alphanum_fraction": 0.7172273993492126,
"avg_line_length": 48.956520080566406,
"blob_id": "4709efb2c0f7a1e4cdd504a13e44e1a791e361d5",
"content_id": "8171cd221661df1668dc51c8a7f56884b2ec474c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3448,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 69,
"path": "/MuonReco/src/muonEffInJets_initHists.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"muonEffInJets.h\"\n\nint muonEffInJets::init(){\n\n\tclassName = \"muonEffInJets\";\n\tif (config::vm.count(\"debug\")){\n\t\tcout << \"[INFO]\"+className+\"::init(); outDirName: \" << outDirName << endl;\n\t}\n\n\tcreateTH1D(\"cluster_xt90\",\"radius where 90\\% of the cluster energy exists; R [mm]; Counts\",5000,0,500);\n\tcreateTH1D(\"cluster_depth\",\"depth of the cluster; L [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_RhitMean\",\"mean of the radius of the hits wrt cog; <R_{hit}> [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_RhitRMS\",\"RMS of the radius of the hits wrt cog; RMS(R_{hit}) [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_nYokeHits\",\"Number of yoke hits in cluster; nHits; Counts\",100,0,100);\n\tcreateTH1D(\"cluster_nLayers\",\"Number of yoke layers in cluster; nLayers; Counts\",10,0,10);\n\tcreateTH1D(\"cluster_clusterLayerSpan\",\"Number of yoke hits in cluster; nLayers; Counts\",10,0,10);\n\n\tvector<string> truthPartDirPrefix = {\"truthPartAll\",\"truthPartMatched\",\"truthPartNotMatched\",\"eff_truthPartMatched\"};\n\tfor (auto iDir: truthPartDirPrefix){\n\t\tcreateTH1D(iDir+\"_E\",\"Truth Energy; Energy [GeV]; Counts\",50,0,500);\n\t\tcreateTH1D(iDir+\"_pt\",\"Truth Pt; pT [GeV]; Counts\",15,0,150);\n\t\tcreateTH1D(iDir+\"_theta\",\"Truth Theta; Theta [#circ]; Counts\",45,0,180);\n\t\tcreateTH1D(iDir+\"_cosTheta\",\"Truth cos(Theta); cos(Theta); Counts\",50,-1,1);\n\t\tcreateTH1D(iDir+\"_phi\",\"Truth Phi; Phi [#circ]; Counts\",45,-180,180);\n\t\tcreateTH1D(iDir+\"_vertexR\",\"Truth Vertex R; R [mm]; Counts\",100,0,50);\n\t\tcreateTH1D(iDir+\"_vertexZ\",\"Truth Vertex Z; Z [mm]; Counts\",100,0,50);\n\t}\n\n\treturn 0;\n}\n\n\nint muonEffInJets::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\"+className+\"::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\tstring histNamePrefix = \"eff_truthPartMatched\";\n\tstring histNameDenominator = \"truthPartAll\";\n\n\tgetHistFromMap(histNamePrefix + \"_E\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_pt\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_theta\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_cosTheta\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_phi\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_vertexR\")->Sumw2();\n\tgetHistFromMap(histNamePrefix + \"_vertexZ\")->Sumw2();\n\n\tcreateTEff(histNamePrefix + \"_E\",histNameDenominator + \"_E\");\n\tcreateTEff(histNamePrefix + \"_pt\",histNameDenominator + \"_pt\");\n\tcreateTEff(histNamePrefix + \"_theta\",histNameDenominator + \"_theta\");\n\tcreateTEff(histNamePrefix + \"_cosTheta\",histNameDenominator + \"_cosTheta\");\n\tcreateTEff(histNamePrefix + \"_phi\",histNameDenominator + \"_phi\");\n\tcreateTEff(histNamePrefix + \"_vertexR\",histNameDenominator + \"_vertexR\");\n\tcreateTEff(histNamePrefix + \"_vertexZ\",histNameDenominator + \"_vertexZ\");\n\n\tgetHistFromMap(histNamePrefix + \"_E\")->Divide(getHistFromMap(histNameDenominator + \"_E\"));\n\tgetHistFromMap(histNamePrefix + \"_pt\")->Divide(getHistFromMap(histNameDenominator + \"_pt\"));\n\tgetHistFromMap(histNamePrefix + \"_theta\")->Divide(getHistFromMap(histNameDenominator + \"_theta\"));\n\tgetHistFromMap(histNamePrefix + \"_cosTheta\")->Divide(getHistFromMap(histNameDenominator + \"_cosTheta\"));\n\tgetHistFromMap(histNamePrefix + \"_phi\")->Divide(getHistFromMap(histNameDenominator + \"_phi\"));\n\tgetHistFromMap(histNamePrefix + \"_vertexR\")->Divide(getHistFromMap(histNameDenominator + \"_vertexR\"));\n\tgetHistFromMap(histNamePrefix + \"_vertexZ\")->Divide(getHistFromMap(histNameDenominator + \"_vertexZ\"));\n\n\tobjectFill::writeToFile(outFile);\n\treturn 0;\n\n\n}\n\n"
},
{
"alpha_fraction": 0.38042473793029785,
"alphanum_fraction": 0.4090489447116852,
"avg_line_length": 37.57143020629883,
"blob_id": "1e9b3ab19de031c9f3d7a7af6ae869714895b482",
"content_id": "809bcefd14cae7596a1250e7445e2028f0e99a32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1083,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 28,
"path": "/PhotonECAL/src/globalConfig.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/globalConfig.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t30th Nov 2017\n * \tLast Update:\t30th Nov 2017\n */\n\n/*===========================================================================*/\n/*===============================[ globalConfig ]===============================*/\n/*===========================================================================*/\n\n#include \"globalConfig.h\"\nnamespace config\n{\n\tint some_config_int = 123;\n\tstd::string some_config_string = \"foo\";\n\tboost::program_options::variables_map vm;\n\tstd::map<unsigned int, std::string> pfoTypeIntStringMap = {{11,\"Electron\"}, {13,\"Muon\"},{22,\"Photon\"},{211,\"Pion\"},{2112,\"NeutralHadron\"}};\n}\n\nbool config::loadConfigBoostOptions(boost::program_options::variables_map &vm){\n\treturn true;\n}\n\n/*===========================================================================*/\n/*===============================[ globalConfig ]===============================*/\n/*===========================================================================*/\n\n\n\n"
},
{
"alpha_fraction": 0.6776581406593323,
"alphanum_fraction": 0.7018842697143555,
"avg_line_length": 27.55769157409668,
"blob_id": "4d22f7bb12dcc31fb580f8f30ce2651da88fa15c",
"content_id": "7d8453091b0ebc4d6636206dc2258105b59512e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1486,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 52,
"path": "/python/OLD/drawEfficiency.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport glob, os, ROOT, math, sys\nfrom ROOT import TCanvas, TGraph, TLegend, TF1\nfrom ROOT import gROOT, gStyle\nfrom array import array\nfrom math import tan\n\ndef getThetaFromFileName(fileName):\n\t# example of input file name:\n\t# ECAL_photonGun_E55_theta40.root\n\treturn int(round(float(('.'.join(fileName.split(\".\")[0:-1])).split(\"_\")[-1].split(\"theta\")[-1])))\n\ndef getFiles(dirName, regexString):\n\tos.chdir(dirName)\n\treturn glob.glob(regexString)\n\ndef styleGraph(inGr, iColor):\n\tinGr.SetMarkerStyle(34)\n\tinGr.SetMarkerSize(1.2)\n\tinGr.SetMarkerColor(iColor)\n\nif __name__ == \"__main__\":\n\n\tif (len(sys.argv)<=1):\n\t\tprint (\"Specify input file!\")\n\t\tsys.exit()\n\n\tgStyle.SetOptStat(0)\n\n\tmyFile = ROOT.TFile.Open(sys.argv[1],\"read\")\n\tnumerator = [myFile.Get(\"photonEfficiency/matchedMC_vs_E\"),myFile.Get(\"photonEfficiency/matchedMC_vs_theta\")]\n\tdenominator = [myFile.Get(\"photonEfficiency/findableMC_vs_E\"),myFile.Get(\"photonEfficiency/findableMC_vs_theta\")]\n\tratioPlots = []\n\tfor i in range(0,len(numerator)):\n\t\tnumerator[i].Sumw2()\n\t\tdenominator[i].Sumw2()\n\t\ttmpHist = numerator[i].Clone(\"ratio\")\n\t\ttmpHist.GetYaxis().SetTitle(\"Efficiency\")\n\t\tif (i==1):\n\t\t\ttmpHist.GetXaxis().SetTitle(\"Theta [degree]\")\n\t\ttmpHist.SetTitle(\"\")\n\t\ttmpHist.Divide(denominator[i])\n\t\tratioPlots.append(tmpHist)\n\n\tc1 = TCanvas( 'c1', 'A Simple Graph Example', 0, 0, 800, 600 )\n\tc1.Divide(1,len(numerator))\n\n\tfor i in range(0,len(numerator)):\n\t\tc1.cd(i+1)\n\t\tratioPlots[i].Draw()\n\n\tc1.SaveAs(\"temp.png\")\n\n"
},
{
"alpha_fraction": 0.6265486478805542,
"alphanum_fraction": 0.63640958070755,
"avg_line_length": 40.1875,
"blob_id": "ab6ac03e85c83b7ca994e143167f3abe86f7a350",
"content_id": "e0e4e740166e1f40a2a1f71e870a9e844a6e3e28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3955,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 96,
"path": "/python/testClasses-drawComparison.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nimport unittest\nfrom classesForDrawComparison import helperClass, nLegendCaptions, notUsedAttribute, noMandatoryAttribute, pythonEvalFuncError\nimport sys\nimport yaml # WARNING use this environment ~/env/setupPyTools27.env to enable yaml package!!!\nimport ROOT\n\n# Main body of the test suite starts here\nclass QueueTest(unittest.TestCase):\n\n def readConfig(self):\n with open('/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/python/config/FOR_TEST_DO_NOT_REMOVE.yml', 'r') as yamlFile:\n globalCfg = yaml.load(yamlFile)\n # print (\"[info]\\t Read yaml file: \\n\\t\\t%s\" % (yamlFile))\n\n if (globalCfg.get(\"default\") is not None):\n defaultCfg = globalCfg.get(\"default\")\n for cfgIterator in globalCfg:\n cfg = globalCfg[cfgIterator]\n if (cfg == defaultCfg):\n continue\n for cfgIt in defaultCfg:\n if (cfg.get(cfgIt) is None):\n cfg[cfgIt] = defaultCfg.get(cfgIt)\n globalCfg.pop(\"default\")\n self.globalCfg = globalCfg\n\n def setUp(self):\n self.q = helperClass()\n self.readConfig()\n\n def testConstructor(self):\n self.assertTrue(self.globalCfg.get('default') is None)\n self.assertTrue(len(self.globalCfg) == 9)\n\n def testGetProcessedHists(self):\n cfg = self.globalCfg['thetaRes_DR11_FCCee_vs_CLIC_vsCosTheta']\n hists = self.q.getProcessedHists(cfg)\n self.assertEqual(len(hists), 4)\n self.assertEqual(list(x.GetMarkerStyle() for x in hists), [4,5,6,ROOT.kOpenCircle] )\n self.assertEqual(list(x.GetMarkerColor() for x in hists), [777,888,999,ROOT.kBlack] )\n\n def testGetLegend(self):\n cfg = self.globalCfg['thetaRes_DR11_FCCee_vs_CLIC_vsCosTheta']\n # print(cfg)\n hists = self.q.getProcessedHists(cfg)\n tmpCfg = dict(cfg)\n self.assertRaises(nLegendCaptions, self.q.getLegend,hists,tmpCfg)\n cfg['legTitle'] += ['#sqrt{s} = 365 GeV, DR09']\n leg = self.q.getLegend(hists,cfg)\n # second call of the functino getLegend:\n self.assertTrue(self.q.getLegend(hists,cfg))\n # print(cfg)\n \n def testGetTextLabels(self):\n cfg = dict(self.globalCfg['testTextLabels'])\n cfg.pop('histName')\n self.assertRaises(noMandatoryAttribute,self.q.getProcessedHists,cfg)\n\n cfg = dict(self.globalCfg['testTextLabels2'])\n hists = self.q.getProcessedHists(cfg)\n self.assertRaises(notUsedAttribute,self.q.getTextLabels,hists,cfg)\n\n # attempts to use eval() with wrong input type\n cfg = dict(self.globalCfg['testLatexLabels1'])\n hists = self.q.getProcessedHists(cfg)\n self.assertRaises(pythonEvalFuncError,self.q.getLatexLabels,hists,cfg)\n\n # attempts to use eval() for set-function with multiple arguments (not implemented yet)\n cfg = dict(self.globalCfg['testLatexLabels2'])\n hists = self.q.getProcessedHists(cfg)\n self.assertRaises(pythonEvalFuncError,self.q.getLatexLabels,hists,cfg)\n\n def testTF1_nFuncs(self):\n cfg = dict(self.globalCfg['testTF1_1'])\n funcs = self.q.getTF1s(cfg)\n self.assertTrue(len(funcs)==2)\n\n def testTF1_wrongFuncName(self):\n cfg = dict(self.globalCfg['testTF1_2'])\n funcs = self.q.getTF1s(cfg)\n self.assertTrue(len(funcs)==1)\n\n# ----------------------------------------------------------------------\n\n# Unittest does not expect to find the extra parameters we pass (time\n# limit, implementation). Remove them before running unittest.\nsys.argv = sys.argv[:1]\n\ntry:\n # unittest shuts down the interpreter when it finishes the\n # tests. We want to delay the exit, in order to display some\n # timing information, so we handle the SystemExit exception.\n unittest.main()\nexcept SystemExit:\n pass\n\n"
},
{
"alpha_fraction": 0.643081784248352,
"alphanum_fraction": 0.6713836193084717,
"avg_line_length": 23.423076629638672,
"blob_id": "a13c37d51f4900fd4451116ae6fc0778efc8b672",
"content_id": "e48ad17d757b4cc832a49630e7f0eae694dc3f3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 26,
"path": "/MuonReco/src/trackerTiming_initHists.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"trackerTiming.h\"\n\nint trackerTiming::init(){\n\n\tclassName = \"trackerTiming\";\n\tif (config::vm.count(\"debug\")){\n\t\tcout << \"[INFO]\"+className+\"::init(); outDirName: \" << outDirName << endl;\n\t}\n\n\tcreateTH1D(\"lastBarrelLayerTiming\",\"Time information from the outermost OT layer; Time [ns]; Counts\",10000,0,10);\n\tcreateTH1I(\"nTracks\",\"Number of tracks per event, nPFOs==1; nTracks; Counts\",10,0,10);\n\n\treturn 0;\n}\n\n\nint trackerTiming::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\"+className+\"::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\tobjectFill::writeToFile(outFile);\n\treturn 0;\n\n\n}\n\n"
},
{
"alpha_fraction": 0.607106626033783,
"alphanum_fraction": 0.6467005014419556,
"avg_line_length": 45.761905670166016,
"blob_id": "c219003ba048f95590a7cebf278ea25a26b1852a",
"content_id": "505a3f9b56ebaefe9e69adf2a44e5c9f925a3d93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 985,
"license_type": "no_license",
"max_line_length": 318,
"num_lines": 21,
"path": "/python/makeAnalyzeCommand.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\n\n# availableParticleTypes = [\"e-\",\"mu-\",\"gamma\",\"pi-\"]\navailableParticleTypes = [\"SinglePart_gamm\"]\navailableParticleEnergies = [5,10,20,50,100]\n\nscriptPath = \"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/build_20jun2019/PhotonECAL/StudyElectronPerformance\"\ndetModel = \"FCCee_o1_v03\"\nsoftVer = \"ILCSoft-2018-04-26_gcc62\"\ndataPath = \"/eos/experiment/clicdp/grid/ilc/user/o/oviazlo/\"\nproductionTag = \"ConformalTr_run1_50mm\"\n\n\nfor particleType in availableParticleTypes:\n outDir = particleType\n f = open(outDir + '/runIt.sh', 'w')\n for iE in availableParticleEnergies:\n runCommand = 'nohup ' + scriptPath + ' -f \"' + dataPath + detModel + '_' + softVer + '_' + particleType + '_E' + str(iE) + '_' + productionTag + '_files/' + detModel + '_' + softVer + '_' + particleType + '_E' + str(iE) + '_' + productionTag + '_*\" --energy ' + str(iE-1) + ' ' + str(iE+1) + ' --theta 50 130 &'\n print (runCommand)\n f.write(runCommand+'\\n')\n f.close()\n\n\n\n"
},
{
"alpha_fraction": 0.7368203997612,
"alphanum_fraction": 0.7438220977783203,
"avg_line_length": 35.76515197753906,
"blob_id": "459276d8e17460e96a01637ddee2b4b2e487b7bb",
"content_id": "14bc5276be1949b3129dab896b458ed7fea02c05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4856,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 132,
"path": "/MuonReco/include/eventHistFiller.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/eventHistFiller.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef EVENTHISTFILLER_H\n#define EVENTHISTFILLER_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n#include \"truthCondition.h\"\n\n#include <cmath>\n// #include <gsl/gsl_sf_gamma.h>\n#include <vector>\n\n// #include <marlin/Global.h>\n// #include <GeometryUtil.h>\n\n// #include <DD4hep/DD4hepUnits.h>\n// #include <DD4hep/DetType.h>\n// #include <DD4hep/DetectorSelector.h>\n// #include <DD4hep/Detector.h>\n// #include <DDRec/DetectorData.h>\n\n#include \"EVENT/ReconstructedParticle.h\"\n#include \"EVENT/Cluster.h\"\n#include <lcio.h>\n\n// #include <EVENT/CalorimeterHit.h>\n// #include \"CalorimeterHitType.h\"\n//\n// #include <ClusterShapes.h>\n\nstruct PFOMergeSettings{\n\tunsigned int pfoTypeToMerge;\n\tdouble thetaCone;\n\tdouble phiCone;\n};\n\n// struct mergedEnergyContainer{\n// double mergedEnergy;\n// mergedEnergyContainer(): mergedEnergy(0.0){}\n// mergedEnergyContainer(double partE): mergedEnergy(partE){}\n// vector<PFOMergeSettings> > PFOmergeMap;\n// bool tryToMergeParticle(EVENT::ReconstructedParticle* inPart){\n//\n// }\n// };\n\nclass eventHistFiller : public objectFill{\n\tpublic:\n\t\teventHistFiller(string _outDirName, string _PFOCollectionName = \"PandoraPFO\") : objectFill(_outDirName) {PFOCollectionName = _PFOCollectionName; mergeTag = \"nominal\"; applyAngularMatching = true; applyEnergyMatching = true;}\n\t\t~eventHistFiller(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\n\t\tvoid setClusterMerging(string _mergeTag);\n\t\tvoid SetApplyAngularMatching(bool _applyAngularMatching){applyAngularMatching = _applyAngularMatching;}\n\t\tvoid SetApplyEnergyMatching(bool _applyEnergyMatching){applyEnergyMatching = _applyEnergyMatching;}\n\t\tvoid SetUseCaloInfoForEnergyMerging(bool _useCaloInfoDuringEnergyMerging){useCaloInfoDuringEnergyMerging = _useCaloInfoDuringEnergyMerging;}\n\t\tvoid SetUseCaloCutInsteadMomentum(bool _useCaloCutInsteadMomentum){useCaloCutInsteadMomentum = _useCaloCutInsteadMomentum;}\n\n\tprivate:\n\t\tstring PFOCollectionName;\n\t\tEVENT::LCCollection *PFOCollection = nullptr;\n\t\tint checkPfoType(vector<unsigned int> inVec);\n\t\t// map<string,histStruct> singleParticleHistStructMap;\n\t\t// vector<string> effType = {\"nominal\",\"photonMerge\",\"photonAndNeutralMerge\",\"photonAndNeutralLooseMerge\",\"bremRecovery\"};\n\t\tvector<string> effType = {\"nominal\",\"photonMerge\",\"photonAndNeutralMerge\",\"photonAndNeutralLooseMerge\",\"photonMergeMomentumDep\"};\n\t\t// vector<string> effType = {\"nominal\",\"photonMerge\"};\n\t\tmap<string,vector<PFOMergeSettings> > PFOmergeMap;\n\t\tstring mergeTag;\n\n\t\tbool applyAngularMatching = true;\n\t\tbool applyEnergyMatching = true;\n\t\tbool useCaloInfoDuringEnergyMerging = false;\n\t\tbool useCaloCutInsteadMomentum = false;\n\n\t\tEVENT::MCParticle* genPart = nullptr;\n\t\tIMPL::ReconstructedParticleImpl* partCandidate = nullptr;\n\t\tunsigned int idOfPartCandidate = std::numeric_limits<unsigned int>::max();\n\n\t\tdouble truthTheta = std::numeric_limits<double>::max();\n\t\tdouble cosTruthTheta = std::numeric_limits<double>::max();\n\t\tdouble truthPhi = std::numeric_limits<double>::max();\n\t\tdouble truthPt = std::numeric_limits<double>::max();\n\t\tdouble truthEnergy = std::numeric_limits<double>::max();\n\t\tint truthType = std::numeric_limits<int>::max();\n\n\t\tmap <string, unsigned int> pfoCounter;\n\t\tunsigned int nPFOs = 0;\n\n\t\tdouble totalRecoEnergy = 0.0;\n\n\t\tvoid fillOtherHists();\n\t\tvoid angularAndEnergyMatching();\n\t\tvoid fillEventsFailedSelection();\n\t\tvector <unsigned int> mergeClusters();\n\t\tvoid fillPfoCounterAndFillGeneralPfoInfo(unsigned int partId);\n\t\tvoid initTruthInfoAndFillIt();\n\n\n\t\tvoid createTH1I(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange){\n\t\t\t// string finalHistName = outDirName+\"-\"+histName;\n\t\t\tstring finalHistName = histName;\n\t\t\tdelete gROOT->FindObject(finalHistName.c_str());\n\t\t\tTH1I* tmpHist = new TH1I(finalHistName.c_str(),histTitle.c_str(),nBins,leftRange,rightRange);\n\t\t\ttmpHist->SetDirectory(0);\n\t\t\thistMap[finalHistName] = tmpHist;\n\t\t}\n\t\tvoid createTH1D(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange){\n\t\t\tstring finalHistName = histName;\n\t\t\tdelete gROOT->FindObject(finalHistName.c_str());\n\t\t\tTH1D* tmpHist = new TH1D(finalHistName.c_str(),histTitle.c_str(),nBins,leftRange,rightRange);\n\t\t\ttmpHist->SetDirectory(0);\n\t\t\thistMap[finalHistName] = tmpHist;\n\t\t}\n\n\t\tTH1* getHistFromMap(string _histID){\n\t\t\tstring histID = _histID;\n\t\t\tif (histMap[histID]==NULL)\n\t\t\t\tcout << \"[ERROR]\\teventHistFiller::getHistFromMap(\" << histID << \") no hist in the histMap with name <\" << histID << \">\" << endl;\n\t\t\treturn histMap[histID];\n\t\t}\n\n};\n#endif // EVENTHISTFILLER_H\n\n\n\n"
},
{
"alpha_fraction": 0.7001140117645264,
"alphanum_fraction": 0.7194982767105103,
"avg_line_length": 30.14285659790039,
"blob_id": "ba0aeb264b01621ecbc6d98d143cb5310b87b0f4",
"content_id": "631a00eca5dce723ee6e90055b21191a14cedd9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 877,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 28,
"path": "/python/getHistRatio.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport glob, os, ROOT, math, sys\nfrom ROOT import TCanvas, TGraph, TLegend, TF1, TH1, TH1F\nfrom ROOT import gROOT, gStyle\n\n# numeratorDir = \"PandoraPFOs_22_2112\"\nnumeratorDir = \"PandoraPFOs_2112\"\nnumeratorHist = [numeratorDir+\"/truthParticle_onlyOneRecoPFO_Theta\", numeratorDir+\"/truthParticle_twoOrMoreRecoPFO_Theta\"]\ndenominatorHist = \"MCParticlesSkimmed/truthParticle_Theta\"\n\nif __name__ == \"__main__\":\n\n\tgStyle.SetOptStat(0)\n\tos.chdir(\"./\")\n\n\toutRootFile = ROOT.TFile.Open(\"ratioFile.root\",\"RECREATE\")\n\n\tfor iFile in glob.glob(\"particleGun*.root\"):\n\t\tmyFile = ROOT.TFile.Open(iFile,\"read\")\n\t\tnum = myFile.Get(numeratorHist[0])\n\t\tfor i in range(1,len(numeratorHist)):\n\t\t\tnum.Add(myFile.Get(numeratorHist[i]))\n\t\tden = myFile.Get(denominatorHist)\n\t\tnum.Divide(den)\n\t\tnum.SetName(iFile.split(\".\")[0])\n\t\toutRootFile.cd()\n\t\tnum.Write()\n\toutRootFile.Close()\n\t\t\t\t\n"
},
{
"alpha_fraction": 0.6296066641807556,
"alphanum_fraction": 0.6648343205451965,
"avg_line_length": 30.118072509765625,
"blob_id": "086295e0ab932c63e4c13ba34606680f20f5b5da",
"content_id": "aec998db8176eb14c647b9efe4ea45a9d3f92a60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12916,
"license_type": "no_license",
"max_line_length": 316,
"num_lines": 415,
"path": "/python/photonGunPerfPlots_test.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport glob, os, ROOT, math, sys\nfrom ROOT import TCanvas, TGraph, TLegend, TF1, TH1, TH1F\nfrom ROOT import gROOT, gStyle\nfrom array import array\nfrom math import tan, sqrt\n\ndef getRMS90Resolution(pTH1F, resolution, resolutionError):\n\t\n\n#\tFLOAT_MAX = sys.float_info.max\n\tFLOAT_MAX = 9999.0\n\n\tsum = 0.\n\ttotal = 0.\n\tsx = 0.\n\tsxx = 0.\n\tnbins = pTH1F.GetNbinsX()\n\n\tfor i in range(0,nbins):\n\n\t\tbinx = pTH1F.GetBinLowEdge(i) + 0.5 * pTH1F.GetBinWidth(i)\n\t\tyi = pTH1F.GetBinContent(i)\n\t\tsx = sx + yi * binx\n\t\tsxx = sxx + yi * binx * binx\n\t\ttotal = total+ yi\n \n\n\trawMean = sx / total\n\trawMeanSquared = sxx / total\n\n\trawRms = sqrt(rawMeanSquared - rawMean * rawMean)\n\tprint (\"rawRms: %f\" % (rawRms))\n\n\tsum = 0.\n\tis0 = 0\n\n \n\tfor i in range(0,nbins+1):\n\t\tif (sum < total / 10.):\n\t\t\tsum += pTH1F.GetBinContent(i)\n\t\t\tis0 = i\n\t\telse:\n\t\t\tbreak\n\tprint (\"sum: %f\" % (sum))\n\tprint (\"total: %f\" % (total))\n\tprint (\"is0: %d\" % (is0))\n\n\trmsmin = FLOAT_MAX\n\tsigma = FLOAT_MAX\n\tsigmasigma = FLOAT_MAX\n\tfrac = FLOAT_MAX\n\tefrac = FLOAT_MAX\n\tmean = FLOAT_MAX\n\tlow = FLOAT_MAX\n\trms = FLOAT_MAX\n\thigh = 0.0\n\n\tfor istart in range(0,is0+1):\n\t\tsumn = 0.\n\t\tcsum = 0.\n\t\tsumx = 0.\n\t\tsumxx = 0.\n\t\tiend = 0\n\n\t\tfor istart in range(istart,nbins+1):\n\t\t\tif (csum < 0.9 * total):\n\t\t\t\tbinx = pTH1F.GetBinLowEdge(i) + (0.5 * pTH1F.GetBinWidth(i))\n\t\t\t\tyi = pTH1F.GetBinContent(i)\n\t\t\t\tcsum = csum + yi\n\n\t\t\t\tif (sumn < 0.9 * total):\n\t\t\t\t\tsumn = sumn + yi\n\t\t\t\t\tsumx = sumx + yi * binx\n\t\t\t\t\tsumxx = sumxx + yi * binx * binx\n\t\t\t\t\tiend = i\n\t\t\telse:\n\t\t\t\tbreak\n\n\t\tprint (\"iend: %d\" % (iend))\n\n\t\tlocalMean = sumx / sumn\n\t\tlocalMeanSquared = sumxx / sumn\n\t\tlocalRms = sqrt(localMeanSquared - localMean * localMean)\n\n \tif (localRms < rmsmin):\n\t\t\tmean = localMean\n\t\t\trms = localRms\n\t\t\tlow = pTH1F.GetBinLowEdge(istart)\n\t\t\thigh = pTH1F.GetBinLowEdge(iend)\n\t\t\trmsmin = localRms\n\n\t\tsigma = rms\n\t\tsigmasigma = sigma / sqrt(total)\n \n\tprint (\"mean: %f\" % (mean))\n\tprint (\"rms: %f\" % (rms))\n\tprint (\"rmsmin: %f\" % (rmsmin))\n\n\tresolution = frac\n\tresolutionError = efrac\n\n\tprint (\"resolution: %f\" % (resolution))\n\tprint (\"resolutionError: %f\" % (resolutionError))\n\ndef getFiles(dirName, regexString):\n\tos.chdir(dirName)\n\treturn glob.glob(regexString)\n\ndef addPathToFileName(path, fileList):\n\tfor i in range(0, len(fileList)):\n\t\tfileList[i] = path + \"/\" + fileList[i]\n\ndef styleGraph(inGr, iColor):\n\tinGr.SetMarkerStyle(34)\n\tinGr.SetMarkerSize(1.2)\n\tinGr.SetMarkerColor(iColor)\n\ndef getTruthInfo(inFile):\n\tscale = 0.1\n\tenergyHistName = \"MCParticlesSkimmed/truthParticle/Energy\"\n\tthetaHistName = \"MCParticlesSkimmed/truthParticle/Theta\"\n\tenergyHist = inFile.Get(energyHistName)\n\tthetaHist = inFile.Get(thetaHistName)\n\tif not energyHist:\n\t\tprint (\"[ERROR]\\tno hist found --> inFile: %s, hist: %s\" % (inFile,energyHistName))\n\t\tsys.exit()\n\tif not energyHist:\n\t\tprint (\"[ERROR]\\tno hist found --> inFile: %s, hist: %s\" % (inFile,thetaHistName))\n\t\tsys.exit()\n\tenergy = energyHist.GetMean()\n\ttheta = thetaHist.GetMean()\n\n\tenergy = math.floor( energy / scale + 0.5)*scale\n\ttheta = math.floor( theta / scale + 0.5)*scale\n\t# print (\"%f, %f\" % (energy, theta))\n\treturn [energy, theta]\n\n# def getRAWEcalEnergy(inFile):\n# return [inFile.Get(\"ECalBarrelCollection/ECAL_Energy\").GetMean(), inFile.Get(\"ECalEndcapCollection/ECAL_Energy\").GetMean()]\n#\n# def getRAWHcalEnergy(inFile):\n# return [inFile.Get(\"HCalBarrelCollection/ECAL_Energy\").GetMean(), inFile.Get(\"HCalEndcapCollection/ECAL_Energy\").GetMean()]\n#\n# def getEcalEnergy(inFile):\n# return [inFile.Get(\"ECALBarrel/ECAL_Energy\").GetMean(), inFile.Get(\"ECALEndcap/ECAL_Energy\").GetMean()]\n#\n# def getHcalEnergy(inFile):\n# return [inFile.Get(\"HCALBarrel/ECAL_Energy\").GetMean(), inFile.Get(\"HCALEndcap/ECAL_Energy\").GetMean()]\n#\ndef getRAWEcalEnergy(inFile):\n\treturn [0,0];\n\ndef getRAWHcalEnergy(inFile):\n\treturn [0,0];\n\ndef getEcalEnergy(inFile):\n\treturn [0,0];\n\ndef getHcalEnergy(inFile):\n\treturn [0,0];\n\n\ndef getEfficiency(inFile):\n\tnumerator = inFile.Get(\"photonEfficiency/matchedMC_vs_theta\").GetEntries()\n\tdenominator = inFile.Get(\"photonEfficiency/findableMC_vs_theta\").GetEntries()\n\treturn numerator/denominator\n\ndef getThetaEffPlot(inFile):\n\tnumerator = inFile.Get(\"photonEfficiency/matchedMC_vs_theta\")\n\tdenominator = inFile.Get(\"photonEfficiency/findableMC_vs_theta\")\n\tratioPlot = numerator.Clone(\"thetaEff\")\n\tratioPlot.Divide(denominator)\n\treturn ratioPlot\n\n\ndef getFitResult(inFile):\n\tdEHist = inFile.Get(\"photonEfficiency/dE_matched\")\n\tf1 = TF1(\"f1\", \"gaus\", -50, 50);\n\tdEHist.Fit(\"f1\", \"Rq\");\n\tprint (\"FIT: inFile: %s, par1: %f #pm %f, par2: %f #pm %f\" % (inFile.GetName(), f1.GetParameter(1), f1.GetParError(1), f1.GetParameter(2), f1.GetParError(2)))\n\tresolution = 0\n\tresolutionError = 0\n\tgetRMS90Resolution(inFile.Get(\"photonEfficiency/PFO_E\"), resolution, resolutionError)\n\tprint (\"RMS90: res: %f #pm %f\" % (resolution, resolutionError))\n\treturn [f1.GetParameter(1),f1.GetParameter(2)]\n\ndef createGraphs(inArr, index):\n\tuniqueEnergy = []\n\tuniqueTheta = []\n\tfor arrElement in inArr:\n\t\tenergy = arrElement[0]\n\t\ttheta = arrElement[1]\n\t\tif not energy in uniqueEnergy:\n\t\t\tuniqueEnergy.append(energy)\n\t\tif not theta in uniqueTheta:\n\t\t\tuniqueTheta.append(theta)\n\t# print (uniqueEnergy)\n\t# print (uniqueTheta)\n\n\tenergyGraph = []\n\tthetaGraph = []\n\tfor i in range(0,len(uniqueEnergy)):\n\t\ttmpGr = TGraph(len(uniqueTheta))\n\t\ttmpGr.SetTitle(\"Energy: %i\" % (int(uniqueEnergy[i])))\n\t\tstyleGraph(tmpGr,1)\n\t\tthetaGraph.append(tmpGr)\n\tfor i in range(0,len(uniqueTheta)):\n\t\ttmpGr = TGraph(len(uniqueEnergy))\n\t\ttmpGr.SetTitle(\"Theta: %i\" % (int(uniqueTheta[i])))\n\t\tstyleGraph(tmpGr,1)\n\t\tenergyGraph.append(tmpGr)\n\n\tfor kk in range(0,len(uniqueEnergy)):\n\t\ttargetEnergy = uniqueEnergy[kk]\n\t\ttargetGraph = thetaGraph[kk]\n\t\tpointCounter = 0\n\t\t\n\t\tfor arrElement in inArr:\n\t\t\tenergy = arrElement[0]\n\t\t\ttheta = arrElement[1]\n\t\t\tif (energy==targetEnergy):\n\t\t\t\ttargetGraph.SetPoint(pointCounter,theta,arrElement[index])\n\t\t\t\t# print (\"targetEnergy: %f, theta: %f, mean: %f\" % (targetEnergy,theta,arrElement[index]))\n\t\t\t\tpointCounter = pointCounter + 1\n\n\tfor kk in range(0,len(uniqueTheta)):\n\t\ttargetTheta = uniqueTheta[kk]\n\t\ttargetGraph = energyGraph[kk]\n\t\tpointCounter = 0\n\t\t\n\t\tfor arrElement in inArr:\n\t\t\tenergy = arrElement[0]\n\t\t\ttheta = arrElement[1]\n\t\t\tif (theta==targetTheta):\n\t\t\t\ttargetGraph.SetPoint(pointCounter,energy,arrElement[index])\n\t\t\t\t# print (\"targetTheta: %f, energy: %f, mean: %f\" % (targetTheta,energy,arrElement[index]))\n\t\t\t\tpointCounter = pointCounter + 1\n\treturn [energyGraph, thetaGraph]\n\n\nif __name__ == \"__main__\":\n\n\tif (len(sys.argv)!=2):\n\t\tprint (\"[ERROR]\\tSpecify input directory!\")\n\t\tsys.exit()\n\n\tfileList = getFiles(sys.argv[1],\"*.root\")\n\tif (len(fileList)==0):\n\t\tprint (\"[ERROR]\\tNo input files found... terminate!\")\n\t\tsys.exit()\n\t\n\taddPathToFileName(sys.argv[1], fileList)\n\tprint ((\"[INFO]\\t%i file found. Processing...\")%(len(fileList)))\n\tgStyle.SetOptStat(0)\n\n\n\tglobalArr = []\n\tfor iFile in fileList:\n\t\tprint (\"Read file: %s\" % (iFile))\n\t\tmyFile = ROOT.TFile.Open(iFile,\"read\")\n\t\ttruthInfo = getTruthInfo(myFile)\n\t\teff = getEfficiency(myFile)\n\t\tfitResult = getFitResult(myFile)\n\t\tEcalRAWEnergy = getRAWEcalEnergy(myFile)[0] + getRAWEcalEnergy(myFile)[1]\n\t\tHcalRAWEnergy = getRAWHcalEnergy(myFile)[0] + getRAWHcalEnergy(myFile)[1]\n\n\t\tEcalEnergy = getEcalEnergy(myFile)[0] + getEcalEnergy(myFile)[1]\n\t\tHcalEnergy = getHcalEnergy(myFile)[0] + getHcalEnergy(myFile)[1]\n\n\t\t# print (\"[INFO]\\tFile %s\" % (iFile))\n\t\t# print (\"[INFO]\\t Truth Energy: %f, theta: %f\" % (truthInfo[0],truthInfo[1]))\n\t\t# print (\"[INFO]\\t Efficiency: %f\" % (eff))\n\t\t# print (\"[INFO]\\t Fit info, mean: %f, sigma: %f\" % (fitResult[0],fitResult[1]))\n\n\t\ttmpArr = []\n\t\ttmpArr.append(round(truthInfo[0]))\n\t\ttmpArr.append(round(truthInfo[1]))\n\t\t# tmpArr.append(int(truthInfo[0]))\n\t\t# tmpArr.append(int(truthInfo[1]))\n\t\ttmpArr.append(100.0*fitResult[0]/truthInfo[0])\n\t\t# tmpArr.append(fitResult[0])\n\t\ttmpArr.append(100.0*fitResult[1]/truthInfo[0])\n\t\ttmpArr.append(eff)\n\t\ttmpArr.append(EcalRAWEnergy)\n\t\ttmpArr.append(HcalRAWEnergy)\n\t\ttmpArr.append(getRAWEcalEnergy(myFile)[0])\n\t\ttmpArr.append(getRAWHcalEnergy(myFile)[0])\n\t\ttmpArr.append(EcalEnergy)\n\t\ttmpArr.append(EcalEnergy+HcalEnergy)\n\t\ttmpArr.append(EcalRAWEnergy+HcalRAWEnergy)\n\t\ttmpArr.append((fitResult[0]+truthInfo[0]))\n\t\t# tmpArr.append(getThetaEffPlot(myFile))\n\t\t# print (tmpArr)\n\t\tglobalArr.append(tmpArr)\n\n\t\t# histToDraw.append([myFile.Get(\"ECALBarrel/ECAL_EnergyPerLayers\"),myFile.Get(\"ECALEndcap/ECAL_EnergyPerLayers\")])\n\t\t\n\n\n\toutFileNamePrefix = [\"energyScaleBias\",\"energyResolution\",\"efficiency\",\"EcalRawEnergy\",\"HcalRawEnergy\",\"BarrelEcalRawEnergy\",\"BarrelHcalRawEnergy\",\"EcalEnergy\",\"EcalHcalEnergy\",\"TotalRawEnergy\",\"PFOEnergy\",\"thetaEfficiency\"]\n\tyAxisTitle = [\"(E_{PFO}-E_{truth})/E_{truth} [%]\", \"#sigma(E_{PFO})/E_{truth} [%]\", \"Efficiency\",\"ECAL Raw Energy [GeV]\",\"HCAL Raw Energy [GeV]\",\"Barrel ECAL Raw Energy [GeV]\",\"Barrel HCAL Raw Energy [GeV]\",\"ECAL Energy [GeV]\",\"ECAL+HCAL Energy [GeV]\", \"ECAL+HCAL Raw Energy [GeV]\",\"PFO Energy [GeV]\", \"Efficiency\"]\n\txAxisTitle = [\"Energy [GeV]\",\"Theta\"]\n\tpostFix = [\"energy\",\"theta\"]\n\tyAxisScale = [ [-1.0,3.0],[0.5,6.0],[0.7,1.1],[0.28,0.3],[0,0.04], [0,0.4],[0,0.04], [9.5,10.2],[9.5,10.2], [0.27,0.29], [0.5,51.0], [0.5,1.1] ]\n\tlegendPosition = [ [0.6,0.75,0.85,0.9],[0.6,0.65,0.85,0.9],[0.6,0.15,0.85,0.4],[0.6,0.65,0.85,0.9],[0.6,0.15,0.85,0.4],[0.6,0.15,0.85,0.4],[0.6,0.15,0.85,0.4],[0.6,0.15,0.85,0.4],[0.6,0.15,0.85,0.4],[0.6,0.15,0.85,0.4], [0.6,0.15,0.85,0.4], [0.6,0.15,0.85,0.4] ]\n\n\toutRootDir = \"out/\"\n\tif not os.path.exists(outRootDir):\n\t\tos.makedirs(outRootDir)\n\toutRootFile = ROOT.TFile.Open(outRootDir+\"outFile.root\",\"RECREATE\")\n\n\t# for jj in range(1,2):\n\t# for ii in {0,3,4,5,6,7,8,9,10}:\n\tfor jj in range(0,1):\n\t\tfor ii in {0,1,2,10}:\n\t\t# for ii in range(0,9):\n\t\t\tgraphs = createGraphs(globalArr,ii+2) # +2 is needed since two first elements in the array correspond to the truth information\n\t\t\tc1 = TCanvas( 'c1', 'A Simple Graph Example', 0, 0, 800, 600 )\n\t\t\tc1.cd()\n\t\t\tleg = TLegend(legendPosition[ii][0],legendPosition[ii][1],legendPosition[ii][2],legendPosition[ii][3])\n\t\t\tleg.SetBorderSize(0)\n\t\t\tleg.SetTextSize(0.03)\n\n\t\t\tfor kk in range(0,len(graphs[jj])):\n\t\t\t\tiGr = graphs[jj][kk]\n\t\t\t\tstyleGraph(iGr,kk+1)\n\t\t\t\tleg.AddEntry(iGr,iGr.GetTitle(),\"p\")\n\t\t\t\tif kk==0:\n\t\t\t\t\tiGr.SetTitle(\"\")\n\t\t\t\t\tiGr.GetYaxis().SetTitle(yAxisTitle[ii])\n\t\t\t\t\tiGr.GetXaxis().SetTitle(xAxisTitle[jj])\n\t\t\t\t\tiGr.GetYaxis().SetTitleOffset(1.3)\n\t\t\t\t\tiGr.Draw(\"AP\")\n\t\t\t\t\tiGr.GetYaxis().SetRangeUser(yAxisScale[ii][0],yAxisScale[ii][1])\n\t\t\t\t\tiGr.Draw(\"AP\")\n\t\t\t\telse:\n\t\t\t\t\tiGr.Draw(\"P same\")\n\t\t\t\t\n\t\t\t\toutRootFile.cd()\n\t\t\t\tiGr.SetName(postFix[jj]+\"_\"+outFileNamePrefix[ii])\n\t\t\t\tiGr.Write()\n\t\t\t\t\n\t\t\t# leg.Draw(\"same\")\n\n\t\t\tc1.SaveAs(\"%s_%s.png\" % (outFileNamePrefix[ii], postFix[jj]))\n\t\t\t# c1.SaveAs(\"%s_%s.root\" % (outFileNamePrefix[ii], postFix[jj]))\n\n\tfor iFile in fileList:\n\t\tmyFile = ROOT.TFile.Open(iFile,\"read\")\n\t\ttmpPlot = getThetaEffPlot(myFile)\n\t\ttruthInfo = getTruthInfo(myFile)\n\t\ttmpPlot.SetTitle((\"Energy: %i GeV; Theta; Efficiency\" % (truthInfo[0])))\n\t\ttmpPlot.SetName((\"eff_E_%i\" % (truthInfo[0])))\n\t\tpfoEPlot = myFile.Get(\"photonEfficiency/PFO_E\")\n\t\tpfoEPlot.SetTitle((\"Energy: %i GeV; Theta; Efficiency\" % (truthInfo[0])))\n\t\tpfoEPlot.SetName((\"PFO_E_%i\" % (truthInfo[0])))\n\t\toutRootFile.cd()\n\t\ttmpPlot.Write()\n\t\tpfoEPlot.Write()\n\n\toutRootFile.Close()\n#################################################################################\n\n\tc2 = TCanvas( 'c2', 'A Simple Graph Example', 0, 0, 800, 600 )\n\tc2.cd()\n\txShift = 0\n\tyShift = 0.55\n\tleg2 = TLegend(0.65+xShift, 0.14+yShift, 0.94+xShift, 0.36+yShift)\n\tleg2.SetBorderSize(0)\n\tleg2.SetTextSize(0.03)\n\t# grList = []\n\t# thetaToDraw = [20,70]\n\t# momentumToDraw = [10,100]\n\tthetaToDraw = []\n\tmomentumToDraw = [10]\n\n\ti=0\n\tfor iFile in fileList:\n\t\tmyFile = ROOT.TFile.Open(iFile,\"read\")\n\t\tROOT.SetOwnership(myFile,False)\n\t\ttruthInfo = getTruthInfo(myFile)\n\n\t\tthetaInt = int(truthInfo[1])\n\t\tmomentumInt = int(truthInfo[0])\n\n\t\tif ((not (thetaInt in thetaToDraw)) and (not len(thetaToDraw)==0)):\n\t\t\tcontinue\n\t\tif ((not (momentumInt in momentumToDraw)) and (not len(momentumToDraw)==0) ):\n\t\t\tcontinue\n\n\t\tiGr_barrel = myFile.Get(\"ECALBarrel/ECAL_AverageEnergyPerLayers\")\n\t\tiGr_endcap = myFile.Get(\"ECALEndcap/ECAL_AverageEnergyPerLayers\")\n\t\tif truthInfo[1]<45:\n\t\t\tiGr_barrel = iGr_endcap \n\t\t\t\n\t\tiGr_barrel.SetLineColor(i+1)\n\t\tiGr_barrel.SetLineWidth(2)\n\t\tiGr_endcap.SetLineColor(i+1)\n\t\tiGr_endcap.SetLineWidth(2)\n\t\tif i==0:\n\t\t\tiGr_barrel.GetYaxis().SetRangeUser(0.0,0.07)\n\t\t\tiGr_barrel.Draw(\"H\")\n\t\telse:\n\t\t\tiGr_barrel.Draw(\"Hsame\")\n\t\t# iGr_endcap.Draw(\"Hsame\")\n\t\tleg2.AddEntry(iGr_barrel, ( \"E: %d, theta: %d\" % (truthInfo[0],truthInfo[1]) ) ,\"l\")\n\t\ti = i+1\n\n\t# print (\"OUT_OF_LOOP: %f\" % (grList[0].GetMean()))\n\n\tleg2.Draw()\n\tc2.Update()\n\t# raw_input()\n\tc2.SaveAs(\"E_vs_layerNumber.png\")\n\t\n"
},
{
"alpha_fraction": 0.6167157292366028,
"alphanum_fraction": 0.6435934901237488,
"avg_line_length": 39.65151596069336,
"blob_id": "6936b93f3d298f41c8f2a69663904b5a12e90157",
"content_id": "4413cf9b2c3194550f27e1cc55c5f52913891be2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2716,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 66,
"path": "/python/getEfficiencyVsEnergy.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport glob, os, ROOT, math, sys\nfrom ROOT import TCanvas, TGraph, TGraphErrors, TLegend, TF1, TH1, TH1F\nfrom ROOT import gROOT, gStyle\n\n# numeratorDir = \"PandoraPFOs_22_2112\"\n# absPath = \"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/outData/FCCee_singleParticle_performace/gamma/FCCee_testConvertionDetection/\"\n# absPath = \"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/outData/FCCee_singleParticle_performace/gamma/FCCee_testConvertionDetection/e-/theta10_170/\"\nabsPath = \"./\"\n# rootDir = \"eventHists_photonAndNeutralRecl\"\n# rootDir = [\"eventHists\",\"eventHists_photonRecl\",\"eventHists_noConv\",\"eventHists_photonAndNeutralRecl\",\"eventHists_photonAndNeutralRecl_looseThetaCut\",\"eventHists_noFSR\"]\n# rootDir = [\"eventHists\", \"eventHists_photonRecl\", \"eventHists_photonAndNeutralRecl_looseThetaCut\"]\nrootDir = [\"eventHists\"]\n# rootDir = [\"eventHists_noFSR\"]\n# rootDir = \"eventHists\"\n# rootDir = \"eventHists_noConv\"\n# rootDir = \"eventHists_conv\"\nhistName = \"efficiencyVsEnergy_onlyType\"\n# histName = \"efficiencyVsEnergy\"\nfileNamePrefix = \"particleGun_E\"\nfileNameIndex = [\"5\",\"10\",\"20\",\"50\",\"100\"]\n# fileNameIndex = [\"10\",\"20\",\"50\",\"100\"]\n# fileNameIndex = [\"1\",\"2\",\"5\",\"10\",\"20\",\"50\"]\nfileNamePostfix = \"_Theta9_171.root\"\n# fileNamePostfix = \"_Theta60_120.root\"\n\ndef styleGraph(inGr, iColor):\n inGr.SetMarkerStyle(34)\n inGr.SetMarkerSize(1.2)\n inGr.SetMarkerColor(iColor)\n\nif __name__ == \"__main__\":\n\n for iDir in rootDir:\n gStyle.SetOptStat(0)\n os.chdir(\"./\")\n\n outRootFile = ROOT.TFile.Open(iDir+\".root\",\"RECREATE\")\n\n # tmpGr = TGraph(len(fileNameIndex))\n # tmpGr = TGraph(len(fileNameIndex)-1)\n tmpGr = TGraphErrors(len(fileNameIndex)-1)\n tmpGr.SetTitle(\"\")\n tmpGr.GetXaxis().SetTitle(\"Energy [GeV]\")\n tmpGr.GetYaxis().SetTitle(\"Efficiency\")\n styleGraph(tmpGr,1)\n for i in range(0,len(fileNameIndex)):\n fileName = absPath + fileNamePrefix + fileNameIndex[i] + fileNamePostfix\n myFile = ROOT.TFile.Open(fileName,\"read\")\n iHist = myFile.Get(iDir+\"/\"+histName)\n maxBin = iHist.GetMaximumBin()\n energy = iHist.GetBinCenter(maxBin)\n eff = iHist.GetBinContent(maxBin)\n effErr = iHist.GetBinError(maxBin)\n tmpGr.SetPoint(i,energy,eff)\n tmpGr.SetPointError(i,0,effErr)\n print(\"E:%f, eff:%f +- %f\" % (energy, eff, effErr))\n\n \n outRootFile.cd()\n tmpGr.Write()\n outRootFile.Close()\n c1 = TCanvas( 'c1', 'A Simple Graph Example', 0, 0, 800, 600 )\n c1.cd()\n # tmpGr.Draw(\"ALP\")\n # c1.SaveAs(iDir+\".png\")\n \n\n"
},
{
"alpha_fraction": 0.7351664304733276,
"alphanum_fraction": 0.7380607724189758,
"avg_line_length": 21.29032325744629,
"blob_id": "7b700f3feca8d50e0bdfe6c9d900ab3749808789",
"content_id": "a02fb58280b594c2acdf9a6a03cffc97c839b7c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 691,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 31,
"path": "/PhotonECAL/include/energyFill.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef energyFill_H\n#define energyFill_H\n\n#include <objectFill.h>\n\n#include <UTIL/CellIDEncoder.h>\n\nclass energyFill : public objectFill{\n\n\tpublic:\n\t\tenergyFill(string _outDirName) : objectFill(_outDirName) {}\n\t\t~energyFill(){}\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tvoid setCollectionName(const string _collectionName){collectionName = _collectionName;}\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tint fillEnergy(const double energy);\n\t\tint fillNHits(const int nHits);\n\t\tint fillMaxLayer(const int maxLayer);\n\t\tint createHists();\n\t\tEVENT::LCCollection *collection;\n\t\tstring collectionName;\n\t\t\n\t\t//Initialize CellID encoder\n\t\t// UTIL::BitField64 m_encoder;\n};\n\n\n#endif\n"
},
{
"alpha_fraction": 0.7214983701705933,
"alphanum_fraction": 0.7459283471107483,
"avg_line_length": 23.559999465942383,
"blob_id": "2dfc07d3047a271b9e02a7c813e1e099e3776252",
"content_id": "41cc54d2aad669940fc7bd6995721d3f97d101c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 614,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 25,
"path": "/PhotonECAL/include/globalConfig.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/globalConfig.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t30th Nov 2017\n * \tLast Update:\t30th Nov 2017\n */\n#ifndef GLOBALCONFIG_H\n#define GLOBALCONFIG_H\n\n#include <boost/program_options.hpp>\n\nnamespace config\n{\n\textern std::map<unsigned int, std::string> pfoTypeIntStringMap;\n\textern std::string some_config_string;\n\textern int some_config_int;\n\n\textern boost::program_options::variables_map vm;\n\tbool loadConfigBoostOptions(boost::program_options::variables_map &vm);\n\t// bool loadConfigFile();\n}\n\n\n#endif // GLOBALCONFIG_H\n"
},
{
"alpha_fraction": 0.7745318412780762,
"alphanum_fraction": 0.7760299444198608,
"avg_line_length": 29.689655303955078,
"blob_id": "a09d5f0b57518d1e2bd54359a0479197b2d873da",
"content_id": "b75826bade5a4f6b6d316590346f7713f1cfb8d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2670,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 87,
"path": "/PhotonECAL/include/truthParticleSelector.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef truthParticleSelector_H\n#define truthParticleSelector_H\n\n//ROOT\n#include <TH1D.h>\n#include <TH2D.h>\n#include <TCanvas.h>\n#include <TLegend.h>\n#include <TF1.h>\n#include <TFitResult.h>\n#include <TList.h>\n#include <TLegendEntry.h>\n#include <TPaveText.h>\n#include <TGaxis.h>\n#include <TMath.h>\n#include <TVector3.h>\n#include <TVectorD.h>\n\n//LCIO\n#include <IOIMPL/LCFactory.h>\n#include <EVENT/LCEvent.h>\n#include <EVENT/LCCollection.h>\n#include <EVENT/SimCalorimeterHit.h>\n#include <EVENT/MCParticle.h>\n#include <EVENT/ReconstructedParticle.h>\n#include <EVENT/Cluster.h>\n#include <Exceptions.h>\n\n//STD\n#include <string>\n#include <vector>\n#include <cstdlib>\n#include <cmath>\n#include <iostream>\n#include <sstream>\n#include <algorithm>\n#include <iterator>\n\n#include <energyFill.h>\n#include <particleFill.h>\n#include <photonEffCalculator.h>\n#include <serviceFunctions.h>\n#include <eventHistFiller.h>\n#include <electronStudy.h>\n#include \"globalConfig.h\"\n\nclass truthParticleSelector{\n\tpublic:\n\t\ttruthParticleSelector();\n\t\t~truthParticleSelector();\n\t\t\n\t\tvoid setDebugFlag(const bool inFlag){debugFlag = inFlag;}\n\t\tvoid setEfficiencyCollection(const string _effCollection){effCollection=_effCollection;}\n\t\tvoid setEfficiencyPFOType(const int pfoType){efficiencyPFOType=pfoType;}\n\t\tvoid setParticleFillCollections(const vector<string> _particleFillCollections){particleFillCollections = _particleFillCollections;}\n\t\tvoid setPFOTypes(const vector<vector<int> > inVec){PFOTypes = inVec;}\n\t\tvoid setEnergyFillCollections(const vector<string> _energyFillCollections){energyFillCollections = _energyFillCollections;}\n\t\tint init(); \n\t\n\t\tvoid setEnergyRange(const double min, const double max){energyRange = make_pair(min,max);}\n\t\tvoid setThetaRange(const double min, const double max){thetaRange = make_pair(min,max);}\n\t\tvoid setPhiRange(const double min, const double max){phiRange = make_pair(min,max);}\n\t\tstring getPostFixString();\n\t\tbool selectEvent(const EVENT::LCEvent*);\n\n\t\tvoid writeToFile(TFile *outFile); \n\t\tvoid setDiscardFSREvents(const bool inBool){discardFSREvents = inBool;}\n\t\tvoid setDPhiMergeValue(const double inVal){dPhiMergeValue = inVal;}\n\t\tvoid setEfficiencyOneClusterRequirement(bool inVal){onlyOneRecoClusterPerEvent = inVal;}\n\n\tprivate:\n\t\tstring effCollection;\n\t\tbool debugFlag;\n\t\tmap<string, objectFill*> objFillMap;\n\t\tpair<double,double> energyRange;\n\t\tpair<double,double> thetaRange;\n\t\tpair<double,double> phiRange;\n\t\tvector<string> particleFillCollections;\n\t\tvector<string> energyFillCollections;\n\t\tvector<vector<int> > PFOTypes;\n\t\tint efficiencyPFOType;\n\t\tbool discardFSREvents;\n\t\tdouble dPhiMergeValue;\n\t\tbool onlyOneRecoClusterPerEvent;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6487026214599609,
"alphanum_fraction": 0.7075848579406738,
"avg_line_length": 37.53845977783203,
"blob_id": "06580d39a0d1ff4d6222d13f958a4c4a5ed1a1ac",
"content_id": "506e404549dcf9c690a0c83c7cf3a5627062432f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 26,
"path": "/python/runPFAAnalyser.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport subprocess\n\nfileDir = '/ssd/viazlo/data/CLIC_o3_v13_ILCSoft-2017-08-23_gcc62_photons_v10_files/'\nfilePrefix = 'CLIC_o3_v13_ILCSoft-2017-08-23_gcc62_photons_v10'\n\nenergyToUse = [10]\nthetaToUse = [30,31,32,33,34,35,36,37,38,39,40]\nbashCommand = 'bash /afs/cern.ch/user/v/viazlo/SCRIPTS/executeParallelThreads.sh'\n\ncounter = 0\n\nfor iE in energyToUse:\n\tfor iTheta in thetaToUse:\n\t\tbashCommand = bashCommand + ' \"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/data/PhotonEfficiency ' + fileDir + filePrefix + '_E' + str(iE) + '_theta' + str(iTheta) + '*\"'\n\t\tcounter = counter + 1\n\t\tif (counter > 7):\n\t\t\t# process = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)\n\t\t\t# output, error = process.communicate()\n\t\t\tprint (bashCommand)\n\t\t\tbashCommand = 'bash ~/SCRIPTS/executeParallelThreads.sh'\n\t\t\tcounter = 0\nif (counter != 0):\n\t# process = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)\n # output, error = process.communicate()\n\tprint (bashCommand)\n"
},
{
"alpha_fraction": 0.7582469582557678,
"alphanum_fraction": 0.7662582397460938,
"avg_line_length": 25.860759735107422,
"blob_id": "bed7c6cd3dc66e977887620610ce4c167561a7d6",
"content_id": "af9ab1b6420edcfae92478d24401c7a3971958b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2122,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 79,
"path": "/MuonReco/include/truthCondition.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/truthCondition.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t15th Dec 2017\n * \tLast Update:\t15th Dec 2017\n */\n#ifndef TRTUTHCONDITION_H\n#define TRTUTHCONDITION_H\n\n// ROOT\n#include <TVector3.h>\n#include <TMath.h>\n\n//LCIO\n#include <EVENT/LCEvent.h>\n#include <EVENT/LCCollection.h>\n#include <EVENT/MCParticle.h>\n#include <Exceptions.h>\n#include <globalConfig.h>\n\nclass truthCondition\n{\n\npublic:\n\tstatic truthCondition *instance(){\n\t\tif (!s_instance){\n\t\t\ts_instance = new truthCondition;\n\t\t\ts_instance->initDefault();\n\t\t}\n\t\treturn s_instance;\n\t}\n\tstatic truthCondition& get(){\n\t\tstatic truthCondition instance;\n\t\treturn instance;\n\t}\n\n\t// Set functions\n\tvoid setEvent(const EVENT::LCEvent* _event){event = _event;}\n\tvoid setMCTruthCollectionName(std::string inStr){MCTruthCollectionName = inStr;}\n\tvoid setDebugFlag(bool _debugFlag){debugFlag=_debugFlag;}\n\n\t// Dump function\n\tvoid dumpTruthPart(const EVENT::MCParticle* part, const int counter = 0);\n\tvoid dumpTruthCondition();\n\t\n\tunsigned int getnTruthParticles(){return nTruthParticles;}\n\tint getpartGun_stablePartType(){return partGun_stablePartType;}\n\tint get_partGun_isStablePartDecayedInTracker(){return partGun_isStablePartDecayedInTracker;}\n\tbool get_simFSRPresent(){return simFSRPresent;}\n\n\t// Main functions\n\tvoid processEvent();\n\tEVENT::MCParticle* getGunParticle(){return static_cast<EVENT::MCParticle*>(MCTruthCollection->getElementAt(partGun_idStableGenPart));}\n\nprotected:\n\nprivate:\n\ttruthCondition(){};\n\ttruthCondition(const truthCondition&){};\n\ttruthCondition& operator=(const truthCondition&){};\n\tstatic truthCondition* s_instance;\n\n\tvoid initDefault(){debugFlag = config::vm.count(\"debug\"); simFSRPresent=false;}\n\n\tconst EVENT::LCEvent* event;\n\tunsigned int nTruthParticles;\n\tunsigned int nStableGenParticles;\n\tunsigned int partGun_idStableGenPart;\n\tbool partGun_isStablePartDecayedInTracker;\n\tbool simFSRPresent;\n\tint partGun_stablePartType;\n\tEVENT::LCCollection *MCTruthCollection;\n\tstd::string MCTruthCollectionName;\n\tbool debugFlag;\n};\n\n\n#endif // TRTUTHCONDITION_H\n"
},
{
"alpha_fraction": 0.7137704491615295,
"alphanum_fraction": 0.7521501779556274,
"avg_line_length": 54.73196029663086,
"blob_id": "1d18db0491b0ae4cd24bde6b470bd69a8953ec4d",
"content_id": "c0840866fd5b1bcc299ecb83c82b818398d3d5a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10813,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 194,
"path": "/MuonReco/src/eventHistFiller_initHists.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"eventHistFiller.h\"\n\nvector<string> typeOfCutFails = {\"FailType\",\"FailAngularMatching\",\"FailEnergyMatching\"};\n\nint eventHistFiller::init(){\n\n\tclassName = \"eventHistFiller\";\n\n\tif (config::vm.count(\"debug\")){\n\t\tcout << \"[INFO]\\teventHistFiller::init(); outDirName: \" << outDirName << endl;\n\t}\n\n\tcreateTH1I(\"nPFOs\",\"Number of PFOs in event; Number of PFOs; Counts\",5,0,5);\n\tcreateTH1I(\"PFOType\",\"PFO particle type; Type; Counts\",2200,0,2200); // max part.type = 2112 (neutron)\n\t\n\tcreateTH1D(\"nPFOsVsTheta_all\",\"nPFOs vs Theta; Theta; Counts per Event\",180*2,0,180);\n\tcreateTH1D(\"nPFOsVsCosTheta_all\",\"nPFOs vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\n\tcreateTH1D(\"totalEnergyVsTheta\",\"Sum of PFOs Energy vs Theta; Theta; Energy [GeV]\",180*2,0,180);\n\tcreateTH1D(\"matchedEnergyVsTheta\",\"Sum of matched PFOs Energy vs Theta; Theta; Energy [GeV]\",180*2,0,180);\n\n\tfor (auto const &it : typeOfCutFails)\n\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tcreateTH1D((\"nPFOsVsTheta_\"+it->second).c_str(),(\"n\"+it->second+\"s vs Theta; Theta; Counts per Event\").c_str(),180*2,0,180);\n\t\tcreateTH1D((\"nPFOsVsCosTheta_\"+it->second).c_str(),(\"n\"+it->second+\"s vs cos(#theta); cos(#theta); Counts per Event\").c_str(),180*2,-1,1);\n\t\tcreateTH1D((\"nPFOsVsCosThetaFailType_\"+it->second).c_str(),(\"n\"+it->second+\"s vs cos(#theta); cos(#theta); Counts per Event\").c_str(),180*2,-1,1);\n\n\t}\n\t\n\tcreateTH1D(\"nTruthPartsVsTheta\",\"nTruthParts vs Theta; Theta; Counts per Event\",180*2,0,180);\n\tcreateTH1D(\"nTruthPartsVsCosTheta\",\"nTruthParts vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"nTruthPartsVsEnergy\",\"nTruthParts vs Energy ;Energy [GeV]; Counts per Event\",100,0.5,100.5); \n\n\tcreateTH1D(\"efficiencyVsTheta\",\"efficiency vs Theta; Theta; Counts per Event\",180*2,0,180);\n\tcreateTH1D(\"efficiencyVsCosTheta\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsEnergy\",\"efficiency vs Energy; Energy [GeV]; Counts per Event\",100,0.5,100.5);\n\tcreateTH1D(\"efficiencyVsEnergy_onlyType\",\"efficiency vs Energy; Energy [GeV]; Counts per Event\",100,0.5,100.5);\n\n\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_all\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_onlyPion\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_onlyMuon\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_onlyElectron\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_noChargedParts\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailType_chargePartsOfTwoOrMoreTypes\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailAngularMatching\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\tcreateTH1D(\"efficiencyVsCosThetaFailEnergyMatching\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\n\tcreateTH1D(\"efficiencyVsCosThetaSum\",\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\n\tfor (int iCount=0; iCount<=9; iCount++){\n\t\tcreateTH1D((\"efficiencyVsCosThetaCat\"+DoubToStr(iCount)).c_str(),\"efficiency vs cos(#theta); cos(#theta); Counts per Event\",180*2,-1,1);\n\t}\n\n\tcreateTH1I(\"truthParticle_isDecayedInTracker\",\"isDecayedInTracker; isDecayedInTracker flag; Counts\",2,-0.5,1.5);\n\n\t// cout << \"debug1\" << endl;\n\n\tcreateTH1D(\"PFO_passed_eff_E\",\"Candidate Energy After Reclustering; E [GeV]; Counts\",1250,0,125);\n\tcreateTH1D(\"PFO_passed_eff_Pt\",\"Candidate pT After Reclustering; p_T [GeV]; Counts\",1250,0,125);\n\tcreateTH1D(\"candidateEnergyBeforeRecl\",\"Candidate Energy Before Reclustering; E [GeV]; Counts\",1250,0,125);\n\tcreateTH1D(\"totalRecoEnergy\",\"Total Reconstructed energy; E [GeV]; Counts\",1250,0,125);\n\n\tcreateTH1D(\"PFO_passed_eff_dTheta\",\"#Delta #theta; Theta [rad]; Counts\",1000,-0.025,0.025);\n\tcreateTH1D(\"PFO_passed_eff_dPhi\",\"#Delta #phi; Phi [rad]; Counts\",40000,-0.5,0.5);\n\tcreateTH1D(\"PFO_passed_eff_dPt\",\"#(Delta pt)/pt; dPt/Pt; Counts\",300,-0.15,0.15);\n\tcreateTH1D(\"PFO_passed_eff_dE\",\"#(Delta E)/E; dE/E; Counts\",200,-1.0,1.0);\n\t\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++){\n\t\tcreateTH1D((\"phiResolution_\"+it->second).c_str(),(it->second+\" Phi resolution; dPhi [rad]; Counts\").c_str(),20000,-0.2,0.2);\n\t\tcreateTH1D((\"thetaResolution_\"+it->second).c_str(),(it->second+\" Theta resolution; dTheta [rad]; Counts\").c_str(),400,-0.01,0.01);\n\t\tcreateTH1D((\"energyResolution_\"+it->second).c_str(),(it->second+\" Energy resolution; E [GeV]; Counts\").c_str(),1250,0,125);\n\t\tcreateTH1D((\"energyResolution2_\"+it->second).c_str(),(it->second+\" Energy resolution; E [GeV]; Counts\").c_str(),2500,0,125);\n\t\tcreateTH1D((\"energyResolution3_\"+it->second).c_str(),(it->second+\" Energy resolution; E [GeV]; Counts\").c_str(),5000,0,125);\n\t\tcreateTH1D((\"energyResolution4_\"+it->second).c_str(),(it->second+\" Energy resolution; E [GeV]; Counts\").c_str(),625,0,125);\n\t}\n\n\t// cout << \"debug2\" << endl;\n\n\tvector<PFOMergeSettings> tmpVec;\n\tPFOMergeSettings tmpPFOMergeSettings;\n\n\tPFOmergeMap[\"nominal\"] = tmpVec;\n\ttmpVec.clear();\n\n\ttmpPFOMergeSettings.pfoTypeToMerge = 22;\n\ttmpPFOMergeSettings.thetaCone = 0.01*TMath::RadToDeg();\n\ttmpPFOMergeSettings.phiCone = 0.2*TMath::RadToDeg();\n\ttmpVec.push_back(tmpPFOMergeSettings);\n\tPFOmergeMap[\"photonMerge\"] = tmpVec;\n\n\ttmpPFOMergeSettings.pfoTypeToMerge = 2112;\n\ttmpPFOMergeSettings.thetaCone = 0.01*TMath::RadToDeg();\n\ttmpPFOMergeSettings.phiCone = 0.2*TMath::RadToDeg();\n\ttmpVec.push_back(tmpPFOMergeSettings);\n\tPFOmergeMap[\"photonAndNeutralMerge\"] = tmpVec;\n\ttmpVec.clear();\n\n\ttmpPFOMergeSettings.pfoTypeToMerge = 22;\n\ttmpPFOMergeSettings.thetaCone = 0.01*TMath::RadToDeg();\n\ttmpPFOMergeSettings.phiCone = 0.2*TMath::RadToDeg();\n\ttmpVec.push_back(tmpPFOMergeSettings);\n\ttmpPFOMergeSettings.pfoTypeToMerge = 2112;\n\ttmpPFOMergeSettings.thetaCone = 0.035*TMath::RadToDeg();\n\ttmpPFOMergeSettings.phiCone = 0.2*TMath::RadToDeg();\n\ttmpVec.push_back(tmpPFOMergeSettings);\n\tPFOmergeMap[\"photonAndNeutralLooseMerge\"] = tmpVec;\n\ttmpVec.clear();\n\n\treturn 0;\n\n}\n\n\nint eventHistFiller::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\teventHistFiller::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\tgetHistFromMap(\"nTruthPartsVsTheta\")->Sumw2();\n\tgetHistFromMap(\"nTruthPartsVsCosTheta\")->Sumw2();\n\tgetHistFromMap(\"nTruthPartsVsEnergy\")->Sumw2();\n\n\tgetHistFromMap(\"totalEnergyVsTheta\")->Sumw2();\n\tgetHistFromMap(\"totalEnergyVsTheta\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Sumw2();\n\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Sumw2();\n\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\t}\n\n\tgetHistFromMap(\"nPFOsVsTheta_all\")->Sumw2();\n\tgetHistFromMap(\"nPFOsVsTheta_all\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Sumw2();\n\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\n\tgetHistFromMap(\"efficiencyVsTheta\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsTheta\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosTheta\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosTheta\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsEnergy\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsEnergy\")->Divide(getHistFromMap(\"nTruthPartsVsEnergy\"));\n\tgetHistFromMap(\"efficiencyVsEnergy_onlyType\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsEnergy_onlyType\")->Divide(getHistFromMap(\"nTruthPartsVsEnergy\"));\n\t\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tgetHistFromMap(\"nPFOsVsCosThetaFailType_\"+it->second)->Sumw2();\n\t}\n\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_all\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_all\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_noChargedParts\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_noChargedParts\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyPion\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyPion\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyElectron\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyElectron\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyMuon\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyMuon\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailEnergyMatching\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailEnergyMatching\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaFailAngularMatching\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaFailAngularMatching\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\t\n\tgetHistFromMap(\"efficiencyVsCosThetaSum\")->Add(getHistFromMap(\"efficiencyVsCosTheta\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaSum\")->Add(getHistFromMap(\"efficiencyVsCosThetaFailType_all\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaSum\")->Add(getHistFromMap(\"efficiencyVsCosThetaFailEnergyMatching\"));\n\tgetHistFromMap(\"efficiencyVsCosThetaSum\")->Add(getHistFromMap(\"efficiencyVsCosThetaFailAngularMatching\"));\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tgetHistFromMap(\"nPFOsVsCosThetaFailType_\"+it->second)->Sumw2();\n\t\tgetHistFromMap(\"nPFOsVsCosThetaFailType_\"+it->second)->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\t\tgetHistFromMap(\"nPFOsVsCosThetaFailType_\"+it->second)->Divide(getHistFromMap(\"efficiencyVsCosThetaFailType_all\"));\n\t}\n\n\n\tfor (int iCount=1; iCount<=4; iCount++){\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat\"+DoubToStr(iCount))->Sumw2();\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat\"+DoubToStr(iCount))->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat0\")->Add(getHistFromMap(\"efficiencyVsCosThetaCat\"+DoubToStr(iCount)));\n\t}\n\tgetHistFromMap(\"efficiencyVsCosThetaCat5\")->Sumw2();\n\tgetHistFromMap(\"efficiencyVsCosThetaCat5\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\n\tobjectFill::writeToFile(outFile);\n\treturn 0;\n\n\n}\n\n"
},
{
"alpha_fraction": 0.7373040914535522,
"alphanum_fraction": 0.7429466843605042,
"avg_line_length": 30.899999618530273,
"blob_id": "d3973b69e9aa19df1a0f8568ae619f4650d9de49",
"content_id": "4f4b454dc0d4aeff23ba89c6ab0e3d6ddf6f88b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3190,
"license_type": "no_license",
"max_line_length": 300,
"num_lines": 100,
"path": "/MuonReco/include/objectFill.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef objectFill_H\n#define objectFill_H\n \n//ROOT\n#include <TH1D.h>\n#include <TH2D.h>\n#include <TCanvas.h>\n#include <TLegend.h>\n#include <TF1.h>\n#include <TFitResult.h>\n#include <TList.h>\n#include <TLegendEntry.h>\n#include <TPaveText.h>\n#include <TGaxis.h>\n#include <TMath.h>\n#include <TVector3.h>\n#include <TVectorD.h>\n#include <TEfficiency.h>\n\n//LCIO\n#include <IOIMPL/LCFactory.h>\n#include <EVENT/LCEvent.h>\n#include <EVENT/LCCollection.h>\n#include <EVENT/SimCalorimeterHit.h>\n#include <EVENT/MCParticle.h>\n#include <EVENT/ReconstructedParticle.h>\n#include <IMPL/ReconstructedParticleImpl.h>\n#include <EVENT/Cluster.h>\n#include <Exceptions.h>\n\n//STD\n#include <string>\n#include <vector>\n#include <cstdlib>\n#include <cmath>\n#include <iostream>\n#include <sstream>\n#include <algorithm>\n#include <iterator>\n\n#include <serviceFunctions.h>\n// #include <globalConfig.h>\n\nstruct histStruct{\n\tstring title;\n\tunsigned int nBins;\n\tdouble xLow;\n\tdouble xHigh;\n\tdouble yLow;\n\tdouble yHigh;\n\tunsigned int ynBins;\n\tstring histType;\n\thistStruct(){}\n\thistStruct( string _title, unsigned int _nBins, double _xLow, double _xHigh, string _histType = \"TH1D\", unsigned int _ynBins = 0, double _yLow = 0.0, double _yHigh = 0.0 ) : title(_title), nBins(_nBins), xLow(_xLow), xHigh(_xHigh), histType(_histType), ynBins(_ynBins), yLow(_yLow), yHigh(_yHigh) {}\n};\n\n\nclass objectFill{\n\tpublic:\n\t\tobjectFill(const string _outDirName);\n\t\t~objectFill();\n\t\tvirtual int writeToFile(TFile* outFile);\n\t\tvirtual int init(){return 0;}\n\t\tvirtual int fillEvent(const EVENT::LCEvent*){return 0;}\n\t\tvoid setDebugFlag(const bool inFlag){debugFlag = inFlag;}\n\t\t// vector<EVENT::ReconstructedParticle*> getObjVecFromCollection(const EVENT::LCCollection* inCollection);\n\t\tvoid createHistsFromMap(const map<string,histStruct> inHistStructMap, const string prefix);\n\t\tTH1* getHistFromMap(string histID);\n\t\tIMPL::ReconstructedParticleImpl* CopyReconstructedParticle (const EVENT::ReconstructedParticle* const pfo_orig );\n\n\t\t// template <class T> vector<T> getObjVecFromCollection(EVENT::LCCollection* inCollection);\n\t\ttemplate <class T> vector<T> getObjVecFromCollection(EVENT::LCCollection* inCollection){\n\t\t\tint nElements = inCollection->getNumberOfElements();\n\t\t\tvector<T> outVec;\n\t\t\tfor(int j=0; j < nElements; j++) {\n\t\t\t\tauto part = dynamic_cast<T>(inCollection->getElementAt(j));\n\t\t\t\toutVec.push_back(part);\n\t\t\t}\n\t\t\treturn outVec;\n\t\t}\n\t\tvoid DeleteHists();\n\t\tvoid createTH1I(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange); \n\t\tvoid createTH1D(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange);\n\t\tvoid createTEff(string numeratorHistName, string denominatorHistName){\n\t\t\tTEfficiency* tmpTEff = new TEfficiency(*getHistFromMap(numeratorHistName),*getHistFromMap(denominatorHistName));\t\n\t\t\ttmpTEff->SetName(numeratorHistName.c_str());\n\t\t\ttmpTEff->SetDirectory(0);\n\t\t\ttEffMap[numeratorHistName] = tmpTEff;\n\t\t}\n\n\tprotected:\n\t\tstd::map<std::string, TH1*> histMap;\n\t\tstd::map<std::string, TEfficiency*> tEffMap;\n\t\tstring outDirName;\n\t\tbool debugFlag;\n\t\tdouble get_dPhi(double phi_reco, double phi_truth);\n\t\tstring className = \"objectFill\";\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6365232467651367,
"alphanum_fraction": 0.6935908794403076,
"avg_line_length": 35.709678649902344,
"blob_id": "e9cee9175f9334cf2a4553ff74473bfa50c9be76",
"content_id": "03ed3f2933e8adfb4a8f5f12d38ef99c4455c543",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1139,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 31,
"path": "/MuonReco/src/muonClusterFiller_initHists.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"muonClusterFiller.h\"\n\nint muonClusterFiller::init(){\n\n\tclassName = \"muonClusterFiller\";\n\tif (config::vm.count(\"debug\")){\n\t\tcout << \"[INFO]\"+className+\"::init(); outDirName: \" << outDirName << endl;\n\t}\n\n\tcreateTH1D(\"cluster_xt90\",\"radius where 90\\% of the cluster energy exists; R [mm]; Counts\",5000,0,500);\n\tcreateTH1D(\"cluster_depth\",\"depth of the cluster; L [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_RhitMean\",\"mean of the radius of the hits wrt cog; <R_{hit}> [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_RhitRMS\",\"RMS of the radius of the hits wrt cog; RMS(R_{hit}) [mm]; Counts\",5000,0,5000);\n\tcreateTH1D(\"cluster_nYokeHits\",\"Number of yoke hits in cluster; nHits; Counts\",100,0,100);\n\tcreateTH1D(\"cluster_nLayers\",\"Number of yoke layers in cluster; nLayers; Counts\",10,0,10);\n\tcreateTH1D(\"cluster_clusterLayerSpan\",\"Number of yoke hits in cluster; nLayers; Counts\",10,0,10);\n\n\treturn 0;\n}\n\n\nint muonClusterFiller::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\"+className+\"::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\tobjectFill::writeToFile(outFile);\n\treturn 0;\n\n\n}\n\n"
},
{
"alpha_fraction": 0.6025640964508057,
"alphanum_fraction": 0.6868131756782532,
"avg_line_length": 35.400001525878906,
"blob_id": "2dd8b875261d6fb517e16f30f9e3ecea0d151a94",
"content_id": "194d84f28ea6d68f47045d8bf50c2947ea19c8b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 15,
"path": "/python/makeRunCommands.py",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport sys\nenergy = [1,2,5,10,20,50,100]\nparticleType = \"pi-\"\ndirPrefix = \"/ssd/viazlo/data/FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_\"\ndirPostfix = \"IsoGun_all_files\"\nfilePrefix = \"FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_\"\n\nif __name__ == \"__main__\":\n\n\tif (len(sys.argv)>=2):\n\t\tparticleType = sys.argv[1]\n\n\tfor iE in energy:\n\t\tprint ( '/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/build/PhotonECAL/AnalyzeIsotropPhotonSample -f \"%s%s%s/%s*E%i_*\" --energy %f %f ' % (dirPrefix,particleType,dirPostfix,filePrefix,iE,0.99*iE,1.01*iE ) )\n"
},
{
"alpha_fraction": 0.7399741411209106,
"alphanum_fraction": 0.753557562828064,
"avg_line_length": 23.09375,
"blob_id": "166a4892e306566787ec2fbd8aa2668cd0de7eed",
"content_id": "fe092cf3ae45b1267cc469f340f809232a3a23b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1546,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 64,
"path": "/MuonReco/include/muonClusterFiller.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/muonClusterFiller.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef MUONCLUSTERFILLER_H\n#define MUONCLUSTERFILLER_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n#include \"truthCondition.h\"\n\n#include <cmath>\n#include <gsl/gsl_sf_gamma.h>\n#include <vector>\n\n#include <marlin/Global.h>\n#include <GeometryUtil.h>\n\n#include <DD4hep/DD4hepUnits.h>\n#include <DD4hep/DetType.h>\n#include <DD4hep/DetectorSelector.h>\n#include <DD4hep/Detector.h>\n#include <DDRec/DetectorData.h>\n\n#include \"EVENT/ReconstructedParticle.h\"\n#include \"EVENT/Cluster.h\"\n#include <lcio.h>\n\n#include <EVENT/CalorimeterHit.h>\n#include \"CalorimeterHitType.h\"\n\n#include <ClusterShapes.h>\n\nstruct yokeHitsStruct{\n\tunsigned int nHits;\t\n\tunsigned int clusterLayerSpan;\n\tunsigned int nLayers;\n};\n\nclass muonClusterFiller : public objectFill{\n\tpublic:\n\t\tmuonClusterFiller(string _outDirName, string _PFOCollectionName = \"PandoraPFO\") : objectFill(_outDirName) {PFOCollectionName = _PFOCollectionName;}\n\t\t~muonClusterFiller(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tstring PFOCollectionName;\n\t\tEVENT::LCCollection *PFOCollection = nullptr;\n\n\t\tEVENT::MCParticle* genPart = nullptr;\n\n\t\tunsigned int nPFOs = 0;\n\n\t\tint fillMuonClusterInfo();\n\t\tEVENT::FloatVec getClusterShape(EVENT::Cluster* pCluster);\n\t\tyokeHitsStruct getNumberOfYokeHits(EVENT::Cluster* pCluster); \n};\n#endif \n\n\n\n"
},
{
"alpha_fraction": 0.7264537215232849,
"alphanum_fraction": 0.7411957383155823,
"avg_line_length": 24.893617630004883,
"blob_id": "ab44650ba6128bcd3760c2c9bdab5c792cd7c1e0",
"content_id": "92f27c0c8147e8b62df697192ade93bd169c3428",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1221,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 47,
"path": "/MuonReco/include/trackerTiming.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/trackerTiming.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef TRACKERTIMING_H\n#define TRACKERTIMING_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n#include \"truthCondition.h\"\n\n#include <cmath>\n#include <vector>\n\n#include \"EVENT/ReconstructedParticle.h\"\n#include <lcio.h>\n\n#include <UTIL/CellIDDecoder.h>\n#include <EVENT/TrackerHit.h>\n\nclass trackerTiming : public objectFill{\n\tpublic:\n\t\ttrackerTiming(string _outDirName, string _PFOCollectionName = \"PandoraPFO\") : objectFill(_outDirName) {PFOCollectionName = _PFOCollectionName;}\n\t\t~trackerTiming(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tstring PFOCollectionName;\n\t\tEVENT::LCCollection *PFOCollection = nullptr;\n\t\tEVENT::LCCollection *trackCollection = nullptr;\n\n\t\tEVENT::MCParticle* genPart = nullptr;\n\n\t\tunsigned int nPFOs = 0;\n\n\t\tint fillTrackerTimingInfo();\n\t\tinline float getSimpleTimeOfFlight(float x, float y, float z);\n\t\tint getLayer(EVENT::TrackerHit* hit, UTIL::BitField64 &encoder);\n\t\tinline float getHitRadius(float x, float y);\n};\n#endif \n\n\n\n"
},
{
"alpha_fraction": 0.7576601505279541,
"alphanum_fraction": 0.7692001461982727,
"avg_line_length": 28.220930099487305,
"blob_id": "a5a861b7b1efad4515cd124f1eb3f64392897921",
"content_id": "5baf10a34c85be95354e9f9fad652bee1b1f7b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2513,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 86,
"path": "/MuonReco/include/truthZWCondition.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/truthZWCondition.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t15th Dec 2017\n * \tLast Update:\t15th Dec 2017\n */\n#ifndef TRUTHZWCONDITION_H\n#define TRUTHZWCONDITION_H\n\n// ROOT\n#include <TVector3.h>\n#include <TMath.h>\n\n//LCIO\n#include <EVENT/LCEvent.h>\n#include <EVENT/LCCollection.h>\n#include <EVENT/MCParticle.h>\n#include <Exceptions.h>\n#include <globalConfig.h>\n#include <vector>\n\nclass truthZWCondition\n{\n\npublic:\n\tstatic truthZWCondition *instance(){\n\t\tif (!s_instance){\n\t\t\ts_instance = new truthZWCondition;\n\t\t\ts_instance->initDefault();\n\t\t}\n\t\treturn s_instance;\n\t}\n\tstatic truthZWCondition& get(){\n\t\tstatic truthZWCondition instance;\n\t\treturn instance;\n\t}\n\n\t// Set functions\n\tvoid setMCTruthCollectionName(std::string inStr){MCTruthCollectionName = inStr;}\n\tvoid setDebugFlag(bool _debugFlag){debugFlag=_debugFlag;}\n\tvoid setPartTypeToSelect(unsigned int _partType){partTypeToSelect = _partType;}\n\tvoid setEnergySelectionCut(double _energyCut){particleEnergyCut = _energyCut;}\n\tvoid setThetaSelectionCut(double _thetaCut){particleThetaCut = _thetaCut;}\n\tvoid setMotherPDG(double _motherPDG){motherPDG = _motherPDG;}\n\n\tunsigned int getPartTypeToSelect(){return partTypeToSelect;}\n\tdouble getEnergySelectionCut(){return particleEnergyCut;}\n\tdouble getThetaSelectionCut(){return particleThetaCut;}\n\n\t// Dump function\n\tvoid dumpTruthPart(const EVENT::MCParticle* part, const int counter = 0);\n\tvoid dumpTruthCondition();\n\t\n\tunsigned int getnTruthParticles(){return nTruthParticles;}\n\tunsigned int getnStableGenParticles(){return nStableGenParticles;}\n\n\t// Main functions\n\tvoid processEvent(const EVENT::LCEvent* _event);\n\tstd::vector<EVENT::MCParticle*> getGenParticles(){return particlesOfInterest;}\n\nprotected:\n\nprivate:\n\ttruthZWCondition(){};\n\ttruthZWCondition(const truthZWCondition&){};\n\ttruthZWCondition& operator=(const truthZWCondition&){};\n\tstatic truthZWCondition* s_instance;\n\n\tvoid initDefault(){debugFlag = config::vm.count(\"debug\"); partTypeToSelect = 13; particleEnergyCut = 0.0; particleThetaCut = 0.0; }\n\n\tunsigned int partTypeToSelect = 0;\n\tconst EVENT::LCEvent* event;\n\tunsigned int nTruthParticles;\n\tunsigned int nStableGenParticles;\n\tdouble particleEnergyCut = 0.0;\n\tdouble particleThetaCut = 0.0;\n\tdouble motherPDG = 0;\n\tstd::vector<EVENT::MCParticle*> particlesOfInterest;\n\tEVENT::LCCollection *MCTruthCollection;\n\tstd::string MCTruthCollectionName;\n\tbool debugFlag;\n};\n\n\n#endif // TRUTHZWCONDITION_H\n"
},
{
"alpha_fraction": 0.6939711570739746,
"alphanum_fraction": 0.7152686715126038,
"avg_line_length": 37.150001525878906,
"blob_id": "5caf05f16c08d459460c5e917355c716a9d843ba",
"content_id": "28dfde64f7302407f0ba069b80c3ebfa88a53c41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3052,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 80,
"path": "/PhotonECAL/src/energyFill.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <energyFill.h>\n\nint energyFill::init(){\n\tTH1D *h_ECALTotalEnergy = new TH1D(\"CAL_Energy\",\"energy; Total Energy [GeV]; Counts\",250,0.0,125);\n\tTH1I *h_ECALNHits = new TH1I(\"CAL_Nhits\",\"Number of hits; Number of ECAL hits; Counts\",3000,0,3000);\n\tTH1I *h_ECALMaxLayer = new TH1I(\"CAL_maxLayer\",\"Max fired layer; max. layer; Counts\",45,0,45);\n\tTH1D *h_ECALEnergyPerLayers = new TH1D(\"CAL_EnergyPerLayers\",\"Energy per layer; Layer number; Deposited energy [MeV]\",50,0,50);\n\tTH1D *h_ECALAverageEnergyPerLayers = new TH1D(\"CAL_AverageEnergyPerLayers\",\"Average Energy per layer; Layer number; Deposited energy fraction\",50,0,50);\n\n\thistMap[\"CAL_Energy\"] = h_ECALTotalEnergy;\n\thistMap[\"CAL_Nhits\"] = h_ECALNHits;\n\thistMap[\"CAL_maxLayer\"] = h_ECALMaxLayer;\n\thistMap[\"CAL_EnergyPerLayers\"] = h_ECALEnergyPerLayers;\n\thistMap[\"CAL_AverageEnergyPerLayers\"] = h_ECALAverageEnergyPerLayers;\n\n\tfor(auto const &iMapElement : histMap) {\n\t\tiMapElement.second->AddDirectory(kFALSE);\n\t}\n\t//Initialize CellID encoder\n\t// m_encoder = new UTIL::BitField64(lcio::LCTrackerCellID::encoding_string());\n\n\treturn 0;\n}\n\n\nint energyFill::fillEvent(const EVENT::LCEvent* event){\n\n\ttry {\n\t\tcollection = event->getCollection(collectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|energyFill]\\tCan't find collection: \" << collectionName << endl;\n\t\treturn -1;\n\t}\n\n\tif( collection ) {\n\t\tstring collectionType = collection->getTypeName();\n\t\tconst int nElements = collection->getNumberOfElements();\n\t\tdouble energyCount = 0.0;\n\t\tdouble totalEnergyDeposited = 0.0;\n\t\tint maxLayer = 0;\n\t\tfor(int j=0; j < nElements; j++){\n\t\t\tauto calHit = dynamic_cast<EVENT::CalorimeterHit*>(collection->getElementAt(j));\n\t\t\ttotalEnergyDeposited += calHit->getEnergy();\n\t\t\t// int nContributions = calHit->getNMCContributions();\n\t\t\t// for (int iCont = 0; iCont < nContributions;++iCont){\n\t\t\t// energyCount = calHit->getEnergyCont(iCont);\n\t\t\t// totalEnergyDeposited += energyCount;\n\t\t\t// }\n\n\t\t\tUTIL::BitField64 _encoder(collection->getParameters().getStringVal( EVENT::LCIO::CellIDEncoding ));\n\t\t\tlcio::long64 cellId = long( calHit->getCellID0() & 0xffffffff ) | ( long( calHit->getCellID1() ) << 32 );\n\t\t\t_encoder.setValue(cellId);\n\t\t\tint layer=_encoder[\"layer\"].value();\n\t\t\tif (layer>maxLayer)\n\t\t\t\tmaxLayer = layer;\n\t\t\thistMap[\"CAL_EnergyPerLayers\"]->Fill(layer,calHit->getEnergy());\n\t\t\thistMap[\"CAL_AverageEnergyPerLayers\"]->Fill(layer,calHit->getEnergy());\n\n\t\t}\n\t\tfillMaxLayer(maxLayer);\n\t\tfillEnergy(totalEnergyDeposited);\n\t\tfillNHits(nElements);\n\t}\n\treturn 0;\n}\n\nint energyFill::fillEnergy(const double energy){\n\treturn histMap[\"CAL_Energy\"]->Fill(energy);\n}\nint energyFill::fillNHits(const int nHits){\n\treturn histMap[\"CAL_Nhits\"]->Fill(nHits);\n}\nint energyFill::fillMaxLayer(const int maxLayer){\n\treturn histMap[\"CAL_maxLayer\"]->Fill(maxLayer);\n}\n\nint energyFill::writeToFile(TFile* outFile){\n\thistMap[\"CAL_AverageEnergyPerLayers\"]->Scale(1.0/histMap[\"CAL_Energy\"]->GetEntries()/histMap[\"CAL_Energy\"]->GetMean());\n\tobjectFill::writeToFile(outFile);\n}\n"
},
{
"alpha_fraction": 0.6798861622810364,
"alphanum_fraction": 0.6920303702354431,
"avg_line_length": 31.331289291381836,
"blob_id": "b1d19db4105391c73c48b2d148bbbd9580540dc3",
"content_id": "abdb810a3406600ce5e5a27745206dd1ba50c782",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5270,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 163,
"path": "/PhotonECAL/src/objectFill.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <objectFill.h>\n#include <TGraphAsymmErrors.h>\n\nobjectFill::objectFill(string _outDirName){\n\toutDirName = _outDirName;\n}\n\nobjectFill::~objectFill(){\n\tfor(auto const &it : histMap) {\n\t\tit.second->Delete();\n\t}\n\t// for(auto const &it : tEffMap) {\n\t// it.second->~TEfficiency();\n\t// }\n}\n\nint objectFill::writeToFile(TFile* outFile){\n\tif (!outFile->IsOpen()){\n\t\tcout << \"[ERROR|writeToFile]\\tno output file is found!\" << endl;\n\t\treturn -1;\n\t}\n\toutFile->cd();\n\tTDirectory *mainDir = outFile->mkdir(outDirName.c_str());\n\tmainDir->cd();\n\n\tmainDir->mkdir(\"tEff\");\n\tmainDir->cd(\"tEff\");\n\tfor(auto const &it : tEffMap){\n\t\t// cout << \"tEff name: \" << it.second->GetName();\n\t\tTGraphAsymmErrors *tmpGr = it.second->CreateGraph();\n\t\ttmpGr->SetName(it.second->GetName());\n\t\ttmpGr->Write();\n\t}\n\tmainDir->cd();\n\n\tmap<string,unsigned int> prefixCounter;\n\tmap<string,string> namePrefixMap;\n\tmap<string,bool> isPrefixSubdirCreated;\n\tmap<string,string> nameWithoutPrefixMap;\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tvector<string> tmpStrVec = GetSplittedWords(histName,\"_\");\n\t\tif (tmpStrVec.size()<2) \n\t\t\tcontinue;\n\t\tstring prefix = \"\";\n\t\tfor (int i=0; i<tmpStrVec.size()-1; i++){\n\t\t\tif (i==tmpStrVec.size()-2)\n\t\t\t\tprefix += tmpStrVec[i];\n\t\t\telse\n\t\t\t\tprefix += tmpStrVec[i] + \"_\";\n\t\t}\n\t\tnameWithoutPrefixMap[histName] = tmpStrVec[tmpStrVec.size()-1];\n\t\tprefixCounter[prefix] += 1;\n\t\tisPrefixSubdirCreated[prefix] = false;\n\t\tnamePrefixMap[histName] = prefix;\n\t}\n\t\n\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tstring prefix = namePrefixMap[histName];\n\t\tif (prefixCounter[prefix]<2){\n\t\t\tmainDir->cd();\n\t\t\tit.second->Write();\n\t\t}\n\t\telse{\n\t\t\tif (isPrefixSubdirCreated[prefix]==false){\n\t\t\t\tmainDir->mkdir(prefix.c_str());\n\t\t\t\tisPrefixSubdirCreated[prefix]=true;\n\t\t\t}\n\t\t\tmainDir->cd(prefix.c_str());\n\t\t\tit.second->SetName(nameWithoutPrefixMap[histName].c_str());\n\t\t\tit.second->Write();\n\t\t\tmainDir->cd();\n\t\t}\n\t}\n\toutFile->cd();\n\treturn 0;\n\t// if (!outFile->IsOpen()){\n\t// cout << \"[ERROR|writeToFile]\\tno output file is found!\" << endl;\n\t// return -1;\n\t// }\n\t// outFile->cd();\n\t// TDirectory *dir = outFile->mkdir(outDirName.c_str());\n\t// dir->cd();\n\t// for(auto const &it : histMap) {\n\t// it.second->Write();\n\t// }\n\t// outFile->cd();\n\t// return 0;\n}\n\ndouble objectFill::get_dPhi(double phi_reco, double phi_truth){\n\tdouble dPhi = phi_reco - phi_truth;\n\tif (fabs(dPhi)<=180.0)\n\t\treturn dPhi;\n\tif (dPhi>0.0)\n\t\treturn dPhi - 360.0;\n\telse\n\t\treturn 360.0 + dPhi;\n}\n\nvoid objectFill::createHistsFromMap(const map<string,histStruct> inHistStructMap, const string prefix){\n\tfor(auto const &ent1 : inHistStructMap){\n\t\tTH1* tmpHist;\n\t\tif (ent1.second.histType==\"TH1D\")\n\t\t\ttmpHist = new TH1D((prefix+ent1.first).c_str(),ent1.second.title.c_str(),ent1.second.nBins,ent1.second.xLow,ent1.second.xHigh);\n\t\tif (ent1.second.histType==\"TH1I\")\n\t\t\ttmpHist = new TH1I((prefix+ent1.first).c_str(),ent1.second.title.c_str(),ent1.second.nBins,ent1.second.xLow,ent1.second.xHigh);\n\t\tif (ent1.second.histType==\"TH2D\")\n\t\t\ttmpHist = new TH2D((prefix+ent1.first).c_str(),ent1.second.title.c_str(),ent1.second.nBins,ent1.second.xLow,ent1.second.xHigh,ent1.second.ynBins,ent1.second.yLow,ent1.second.yHigh);\n\t\thistMap[prefix+ent1.first] = tmpHist;\n\t}\n\t\n}\n\nvoid objectFill::DeleteHists(){\n\tfor(auto &mapElement : histMap){\n\t\tdelete mapElement.second;\n\t\thistMap.erase(mapElement.first); \n\t}\n\tfor(auto &mapElement : tEffMap){\n\t\tdelete mapElement.second;\n\t\thistMap.erase(mapElement.first); \n\t}\n}\n\nTH1* objectFill::getHistFromMap(string histID){\n\tif (histMap[histID]==NULL)\n\t\tcout << \"[ERROR]\\t\" + className + \"::getHistFromMap(\" << histID << \") no hist in the histMap with name <\" << histID << \">\" << endl;\n\treturn histMap[histID];\n}\n\nIMPL::ReconstructedParticleImpl* objectFill::CopyReconstructedParticle (const EVENT::ReconstructedParticle* const pfo_orig ) {\n\t// copy this in an ugly fashion to be modifiable - a versatile copy constructor would be much better!\n\tIMPL::ReconstructedParticleImpl* pfo = new IMPL::ReconstructedParticleImpl();\n\tpfo->setMomentum(pfo_orig->getMomentum());\n\tpfo->setEnergy(pfo_orig->getEnergy());\n\tpfo->setType(pfo_orig->getType());\n\tpfo->setCovMatrix(pfo_orig->getCovMatrix());\n\tpfo->setMass(pfo_orig->getMass());\n\tpfo->setCharge(pfo_orig->getCharge());\n\tpfo->setParticleIDUsed(pfo_orig->getParticleIDUsed());\n\tpfo->setGoodnessOfPID(pfo_orig->getGoodnessOfPID());\n\tpfo->setStartVertex(pfo_orig->getStartVertex());\n\treturn pfo;\n}\n\nvoid objectFill::createTH1I(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange){\n\t// string finalHistName = outDirName+\"-\"+histName;\n\tstring finalHistName = histName;\n\tdelete gROOT->FindObject(finalHistName.c_str());\n\tTH1I* tmpHist = new TH1I(finalHistName.c_str(),histTitle.c_str(),nBins,leftRange,rightRange);\n\ttmpHist->SetDirectory(0);\n\thistMap[finalHistName] = tmpHist;\n}\nvoid objectFill::createTH1D(string histName, string histTitle, unsigned int nBins, double leftRange, double rightRange){\n\tstring finalHistName = histName;\n\tdelete gROOT->FindObject(finalHistName.c_str());\n\tTH1D* tmpHist = new TH1D(finalHistName.c_str(),histTitle.c_str(),nBins,leftRange,rightRange);\n\ttmpHist->SetDirectory(0);\n\thistMap[finalHistName] = tmpHist;\n}\n"
},
{
"alpha_fraction": 0.6831682920455933,
"alphanum_fraction": 0.697029709815979,
"avg_line_length": 28.275362014770508,
"blob_id": "168650fbfff1899e8b0dfdc0a23431f7b03c153c",
"content_id": "38e59217ba899a3344226247239e501bf8887f6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2020,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 69,
"path": "/MuonReco/src/trackerTiming.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"trackerTiming.h\"\n#include <UTIL/LCTrackerConf.h>\n\nint trackerTiming::fillEvent(const EVENT::LCEvent* event){\n\ttry {\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|trackerTiming]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t\n\t}\n\n\tstring trackCollectionName = \"SiTracks_Refitted\";\n\t// trackCollectionName = \"SiTracks\";\n\ttry {\n\t\ttrackCollection = event->getCollection(trackCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|electronStudy]\\tCan't find collection: \" << trackCollectionName << endl;\n\t\treturn -1;\n\t}\n\n\tnPFOs = PFOCollection->getNumberOfElements();\n\n\tfillTrackerTimingInfo();\n\treturn 0;\n\n}\n\n\nint trackerTiming::fillTrackerTimingInfo(){\n\tif (nPFOs!=1)\n\t\treturn 1;\n\n\tUTIL::BitField64 encoder( lcio::LCTrackerCellID::encoding_string() ) ;\n\tencoder.reset();\n\n\tvector<EVENT::Track*> tracks = getObjVecFromCollection<EVENT::Track*>(trackCollection);\n\tgetHistFromMap(\"nTracks\")->Fill(tracks.size());\n\n\tif (tracks.size()!=1)\n\t\treturn 1;\n\tauto track = tracks[0];\n\tauto trackHits = track->getTrackerHits();\n\t// cout << \"\\nnHits: \" << trackHits.size() << endl;\n\tfor (auto iHit: trackHits){\n\t\tconst double *hitPos = iHit->getPosition();\n\t\tdouble hitRadius = getHitRadius(hitPos[0],hitPos[1]);\n\t\tunsigned int layer = getLayer(iHit,encoder);\n\t\t// cout << \"radius: \" << hitRadius << \"; layer: \" << layer << endl;\n\t\tif (hitRadius>2100)\n\t\t\tgetHistFromMap(\"lastBarrelLayerTiming\")->Fill(iHit->getTime());\n\t}\n}\n\n\ninline float trackerTiming::getSimpleTimeOfFlight(float x, float y, float z){\n\treturn std::sqrt((x * x) + (y * y) + (z * z))/299.792458;\n}\n\ninline float trackerTiming::getHitRadius(float x, float y){\n\treturn std::sqrt((x * x) + (y * y));\n}\n\nint trackerTiming::getLayer(EVENT::TrackerHit* hit, UTIL::BitField64 &encoder){\n const int celId = hit->getCellID0() ;\n encoder.setValue(celId) ;\n int layer = encoder[lcio::LCTrackerCellID::layer()].value();\n return layer;\n}\n"
},
{
"alpha_fraction": 0.7482638955116272,
"alphanum_fraction": 0.7612847089767456,
"avg_line_length": 31,
"blob_id": "5081b04f1f2fe489a92c58e031d644cf72bc66aa",
"content_id": "906291ec2dc0a703579d22aa08f269dd9b01e0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1152,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 36,
"path": "/PhotonECAL/include/jetPfoStudy.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/jetPfoStudy.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef EVENTHISTFILLER_H\n#define EVENTHISTFILLER_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n// #include \"truthCondition.h\"\n\nclass jetPfoStudy : public objectFill{\n\tpublic:\n\t\tjetPfoStudy(string _outDirName, string _mcCollectionName = \"MCParticle\", string _PFOCollectionName = \"PandoraPFO\") : objectFill(_outDirName) {MCCollectionName = _mcCollectionName; PFOCollectionName = _PFOCollectionName;}\n\t\t~jetPfoStudy(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\t\tstring getPFOCollectionName(){return PFOCollectionName;}\n\t\tvoid setDebugFlag(bool _debugFlag){debugFlag=_debugFlag;}\n\n\tprivate:\n\t\tunsigned int nSelectecTruthParticles;\n\t\tstring PFOCollectionName;\n\t\tstring MCCollectionName;\n\t\tEVENT::LCCollection *PFOCollection;\n\t\tint checkPfoType(vector<unsigned int> inVec);\n\t\tvector<const EVENT::MCParticle*> mcQuarkVector;\n\t\tdouble jetTheta, jetCosTheta;\n\t\tbool debugFlag;\n};\n#endif // EVENTHISTFILLER_H\n"
},
{
"alpha_fraction": 0.6625054478645325,
"alphanum_fraction": 0.6778115630149841,
"avg_line_length": 35.991966247558594,
"blob_id": "3e988a08ed18d704e93b5cff083b39e4a9d31dd6",
"content_id": "a0ae009addceedaaa8ffc15d640b1bfce426b4c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9212,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 249,
"path": "/PhotonECAL/src/jetPfoStudy.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/jetPfoStudy.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n\n#include \"jetPfoStudy.h\"\n\n/*===========================================================================*/\n/*===============================[ function implementations ]================*/\n/*===========================================================================*/\n\nint jetPfoStudy::init(){\n\tdebugFlag = false;\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\\tjetPfoStudy::init()\" << endl;\n\n\tTH1* tmpHist;\n\ttmpHist = new TH1I(\"nPFOs\",\"Number of PFOs in event; Number of PFOs; Counts\",100,0,100);\n\thistMap[\"nPFOs\"] = tmpHist;\n\ttmpHist= new TH1I(\"PFOType\",\"PFO particle type; Type; Counts\",2200,0,2200); // max part.type = 2112 (neutron)\n\thistMap[\"PFOType\"] = tmpHist;\n\t\n\ttmpHist = new TH1D(\"nPFOsVsTheta_all\",\"nPFOs vs Theta; Theta; Counts per Event\",180,0,180);\n\thistMap[\"nPFOsVsTheta_all\"] = tmpHist;\n\ttmpHist = new TH1D(\"nPFOsVsCosTheta_all\",\"nPFOs vs cos(#theta); cos(#theta); Counts per Event\",180,-1,1);\n\thistMap[\"nPFOsVsCosTheta_all\"] = tmpHist;\n\n\ttmpHist = new TH1D(\"totalEnergyVsTheta\",\"Sum of PFOs Energy vs Theta; Theta; Energy [GeV]\",180,0,180);\n\thistMap[\"totalEnergyVsTheta\"] = tmpHist;\n\ttmpHist = new TH1D(\"totalEnergyVsCosTheta\",\"Sum of PFOs Energy vs CosTheta; Theta; Energy [GeV]\",180,-1,1);\n\thistMap[\"totalEnergyVsCosTheta\"] = tmpHist;\n\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\ttmpHist = new TH1D((\"nPFOsVsTheta_\"+it->second).c_str(),(\"n\"+it->second+\"s vs Theta; Theta; Counts per Event\").c_str(),180,0,180);\n\t\thistMap[\"nPFOsVsTheta_\"+it->second] = tmpHist;\n\t\ttmpHist = new TH1D((\"nPFOsVsCosTheta_\"+it->second).c_str(),(\"n\"+it->second+\"s vs cos(#theta); cos(#theta); Counts per Event\").c_str(),180,-1,1);\n\t\thistMap[\"nPFOsVsCosTheta_\"+it->second] = tmpHist;\n\n\t}\n\t\n\ttmpHist = new TH1D(\"nTruthPartsVsTheta\",\"nTruthParts vs Theta; Theta; Counts per Event\",180,0,180);\n\thistMap[\"nTruthPartsVsTheta\"] = tmpHist;\n\ttmpHist = new TH1D(\"nTruthPartsVsCosTheta\",\"nTruthParts vs cos(#theta); cos(#theta); Counts per Event\",180,-1,1);\n\thistMap[\"nTruthPartsVsCosTheta\"] = tmpHist;\n\n\ttmpHist = new TH1D(\"totalRecoEnergy\",\"Total Reconstructed energy; E [GeV]; Counts\",1250,0,125);\n\thistMap[\"totalRecoEnergy\"] = tmpHist;\n\n\treturn 0;\n}\n\nint jetPfoStudy::fillEvent(const EVENT::LCEvent* event){\n\tmcQuarkVector.clear();\n\tjetTheta = std::numeric_limits<double>::max();\n\tjetCosTheta = std::numeric_limits<double>::max();\n\n\tif (debugFlag)\n\t\tcout << \"before reading collections\\n\";\n\n\ttry {\n\t\tif (debugFlag)\n\t\t\tcout << \"Try to read <\" << MCCollectionName << \"> collection...\\n\";\n\t\tEVENT::LCCollection* mcCollection = event->getCollection(MCCollectionName);\n\t\tif (debugFlag){\n\t\t\tcout << \"Collection pointer: \" << mcCollection << endl;\n\t\t\tcout << \"Try to access it...\\n\";\n\t\t\tcout << \"nElements: \" << mcCollection->getNumberOfElements() << endl;\n\t\t}\n\t\tfor (unsigned int i = 0, nElements = mcCollection->getNumberOfElements(); i < nElements; ++i)\n\t\t{\n\t\t\tif (debugFlag)\n\t\t\t\tcout << \"Try to access element: \" << i << endl;\n\t\t\tconst EVENT::MCParticle *pMCParticle = dynamic_cast<EVENT::MCParticle*>(mcCollection->getElementAt(i));\n\n\t\t\tif (NULL == pMCParticle)\n\t\t\t\tthrow EVENT::Exception(\"Collection type mismatch\");\n\n\t\t\tconst int absPdgCode(std::abs(pMCParticle->getPDG()));\n\n\t\t\tif ((absPdgCode >= 1) && (absPdgCode <= 6) && pMCParticle->getParents().empty())\n\t\t\t\tmcQuarkVector.push_back(pMCParticle);\n\t\t}\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|jetPfoStudy]\\tCan't find collection: \" << MCCollectionName << endl;\n\t\treturn -1;\n\t}\n\n\ttry {\n\t\tif (debugFlag)\n\t\t\tcout << \"Try to read <\" << PFOCollectionName << \"> collection\\n\";\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|jetPfoStudy]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t}\n\n\tif (!mcQuarkVector.empty()){\n\t\tint m_qPdg = std::abs(mcQuarkVector[0]->getPDG());\n\t\tfloat energyTot(0.f);\n\t\tfloat costTot(0.f);\n\n\t\tfor (unsigned int i = 0; i < mcQuarkVector.size(); ++i)\n\t\t{\n\t\t const float px(mcQuarkVector[i]->getMomentum()[0]);\n\t\t const float py(mcQuarkVector[i]->getMomentum()[1]);\n\t\t const float pz(mcQuarkVector[i]->getMomentum()[2]);\n\t\t const float energy(mcQuarkVector[i]->getEnergy());\n\t\t const float p(std::sqrt(px * px + py * py + pz * pz));\n\t\t const float cost(std::fabs(pz) / p);\n\t\t energyTot += energy;\n\t\t costTot += cost * energy;\n\t\t}\n\n\t\tjetCosTheta = costTot / energyTot;\n\t\tjetTheta = acos(jetCosTheta);\n\t}\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\tjetPfoStudy::fillEvent: \" << event->getEventNumber() << endl;\n\n\tconst double truthTheta = jetTheta*TMath::RadToDeg();\n\tconst double cosTruthTheta = jetCosTheta;\n\n\tgetHistFromMap(\"nTruthPartsVsCosTheta\")->Fill(cosTruthTheta);\n\tgetHistFromMap(\"nTruthPartsVsTheta\")->Fill(truthTheta);\n\n\tvector<EVENT::ReconstructedParticle*> recoPFOs = getObjVecFromCollection<EVENT::ReconstructedParticle*>(PFOCollection);\n\tgetHistFromMap(\"nPFOs\")->Fill(recoPFOs.size());\n\n\tmap <string, unsigned int> pfoCounter;\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++)\n\t\tpfoCounter[it->second] = 0;\n\n\tdouble totalRecoEnergy = 0.0;\n\n\tfor (int i=0; i<recoPFOs.size(); i++){\n\n\t\tconst int pfoType = abs(recoPFOs[i]->getType());\n\t\tconst double *partMom = recoPFOs[i]->getMomentum();\n\t\tTVector3 vPartMom(partMom[0],partMom[1],partMom[2]);\n\t\tconst double partTheta = vPartMom.Theta()*TMath::RadToDeg();\n\t\tconst double partPhi = vPartMom.Phi()*TMath::RadToDeg();\n\t\tconst double partPt = vPartMom.Pt();\n\t\tconst double cosPartTheta = TMath::Cos(partTheta*TMath::DegToRad());\n\t\tconst double partEnergy = recoPFOs[i]->getEnergy();\n\n\t\tgetHistFromMap(\"PFOType\")->Fill(pfoType);\n\t\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Fill(cosTruthTheta);\n\t\tgetHistFromMap(\"nPFOsVsTheta_all\")->Fill(truthTheta);\n\t\tgetHistFromMap(\"totalEnergyVsTheta\")->Fill(truthTheta,recoPFOs[i]->getEnergy());\n\t\tgetHistFromMap(\"totalEnergyVsCosTheta\")->Fill(cosTruthTheta,recoPFOs[i]->getEnergy());\n\t\ttotalRecoEnergy += recoPFOs[i]->getEnergy();\n\n\t\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\t\tif (abs(pfoType)==it->first) {\n\t\t\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Fill(cosTruthTheta);\n\t\t\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Fill(truthTheta);\n\t\t\t\tpfoCounter[it->second]++;\n\t\t\t}\n\t\t}\n\t}\n\n\tgetHistFromMap(\"totalRecoEnergy\")->Fill(totalRecoEnergy);\n\n}\n\n\nint jetPfoStudy::writeToFile(TFile* outFile){\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[INFO]\tjetPfoStudy::writeToFile(\" << outFile->GetName() << \")\" << endl;\n\n\tgetHistFromMap(\"nTruthPartsVsTheta\")->Sumw2();\n\tgetHistFromMap(\"nTruthPartsVsCosTheta\")->Sumw2();\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Sumw2();\n\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Sumw2();\n\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\t}\n\n\tgetHistFromMap(\"nPFOsVsTheta_all\")->Sumw2();\n\tgetHistFromMap(\"nPFOsVsTheta_all\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Sumw2();\n\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\tgetHistFromMap(\"totalEnergyVsTheta\")->Sumw2();\n\tgetHistFromMap(\"totalEnergyVsTheta\")->Divide(getHistFromMap(\"nTruthPartsVsTheta\"));\n\tgetHistFromMap(\"totalEnergyVsCosTheta\")->Sumw2();\n\tgetHistFromMap(\"totalEnergyVsCosTheta\")->Divide(getHistFromMap(\"nTruthPartsVsCosTheta\"));\n\n\n\tif (!outFile->IsOpen()){\n\t\tcout << \"[ERROR|writeToFile]\\tno output file is found!\" << endl;\n\t\treturn -1;\n\t}\n\toutFile->cd();\n\tTDirectory *mainDir = outFile->mkdir(outDirName.c_str());\n\tmainDir->cd();\n\n\tmap<string,unsigned int> prefixCounter;\n\tmap<string,string> namePrefixMap;\n\tmap<string,bool> isPrefixSubdirCreated;\n\tmap<string,string> nameWithoutPrefixMap;\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tvector<string> tmpStrVec = GetSplittedWords(histName,\"_\");\n\t\tif (tmpStrVec.size()<2) \n\t\t\tcontinue;\n\t\tstring prefix = \"\";\n\t\tfor (int i=0; i<tmpStrVec.size()-1; i++){\n\t\t\tif (i==tmpStrVec.size()-2)\n\t\t\t\tprefix += tmpStrVec[i];\n\t\t\telse\n\t\t\t\tprefix += tmpStrVec[i] + \"_\";\n\t\t}\n\t\tnameWithoutPrefixMap[histName] = tmpStrVec[tmpStrVec.size()-1];\n\t\tprefixCounter[prefix] += 1;\n\t\tisPrefixSubdirCreated[prefix] = false;\n\t\tnamePrefixMap[histName] = prefix;\n\t}\n\t\n\n\tfor(auto const &it : histMap) {\n\t\tstring histName = it.first;\n\t\tstring prefix = namePrefixMap[histName];\n\t\tif (prefixCounter[prefix]<2){\n\t\t\tmainDir->cd();\n\t\t\tit.second->Write();\n\t\t}\n\t\telse{\n\t\t\tif (isPrefixSubdirCreated[prefix]==false){\n\t\t\t\tmainDir->mkdir(prefix.c_str());\n\t\t\t\tisPrefixSubdirCreated[prefix]=true;\n\t\t\t}\n\t\t\tmainDir->cd(prefix.c_str());\n\t\t\tit.second->SetName(nameWithoutPrefixMap[histName].c_str());\n\t\t\tit.second->Write();\n\t\t\tmainDir->cd();\n\t\t}\n\t}\n\toutFile->cd();\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.7933177947998047,
"alphanum_fraction": 0.7964258193969727,
"avg_line_length": 42.62711715698242,
"blob_id": "4d831c2971995791e14c68ffef6ed6a868e31584",
"content_id": "8881d8ed18b9bbbe7fdb871157aa86138cc3b005",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2574,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 59,
"path": "/MuonReco/include/particleFill.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#ifndef particleFill_H\n#define particleFill_H\n\n#include <objectFill.h>\n#include <globalConfig.h>\n#include \"truthCondition.h\"\n\n\n\nclass particleFill : public objectFill{\n\n\tpublic:\n\t\tparticleFill(string _outDirName) : objectFill(_outDirName) {}\n\t\t~particleFill(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tdouble getMeanEnergy();\n\t\tdouble getMeanTheta();\n\t\tvoid setCollectionName(const string _collectionName){collectionName = _collectionName;}\n\t\tvoid setReconstructedParticleType(const int _partTypeToSelect){partTypeToSelect.push_back(_partTypeToSelect);}\n\t\tvoid setReconstructedParticleType(const vector<int> _partTypeToSelect){partTypeToSelect = _partTypeToSelect;}\n\t\tvoid updateRootDirName(const string inStr){outDirName = inStr;}\n\t\tvoid setDPhiMergeValue(const double inVal){dPhiMergeValue = inVal;}\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tvoid initHistStructs();\n\t\tvoid createSingleRecoParticleClustersHists(const string prefix);\n\t\tvoid createSingleParticleHists(const string prefix);\n\t\tvoid createTwoParticleCorrelationHists(const string prefix);\n\t\tint fillHist(const double inVal, const string baseString, const string prefix);\n\t\tint fillHist(const double inVal1, const double inVal2, const string baseString, const string prefix);\n\t\tvoid dumpTruthPart(const EVENT::MCParticle* part, const int counter = 0);\n\t\tvoid dumpReconstructedPart(const EVENT::ReconstructedParticle* part, const int counter = 0);\n\t\tint fillPart (const EVENT::MCParticle* inPart, const string prefix=\"truthParticle_\");\n\t\tint fillPart (const EVENT::ReconstructedParticle* inPart, const string prefix);\n\t\tvoid fillRecoPhoton(const EVENT::ReconstructedParticle* inPart, const EVENT::MCParticle* mcPart, const string prefix);\n\t\tint fillParticleCorrelations (const EVENT::ReconstructedParticle* inPart1, const EVENT::ReconstructedParticle* inPart2, const string prefix);\n\t\tint fillParticleCorrelations (const EVENT::ReconstructedParticle* inPart1, const EVENT::MCParticle* inPart2, const string prefix);\n\t\tint fillClusterInfo (const EVENT::ReconstructedParticle* inPart, const string prefix);\n\n\t\tEVENT::LCCollection *collection;\n\t\tstring collectionName;\n\t\tvector<int> partTypeToSelect;\n\t\tmap<string,histStruct> singleParticleHistStructMap;\n\t\tmap<string,histStruct> singleRecoParticleClustersHistStructMap;\n\t\tmap<string,histStruct> twoParticleCorrelationHistStructMap;\n\t\tdouble dPhiMergeValue;\n\t\tvector<bool> boolVecDefaultFalse;\n\t\tmap<string,int> intMap;\n\t\tvector< pair<int, double> > PFOtypeAndEnergyVec;\n\t\tvoid clasiffyPFO(EVENT::ReconstructedParticle* inPFO);\n\n\n\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.7150141596794128,
"alphanum_fraction": 0.7356940507888794,
"avg_line_length": 39.102272033691406,
"blob_id": "5a6c169688dc9a513f6402321ce62fa6f2cf4aae",
"content_id": "8b098c9820ba777c5ac6b07c71d72ee02cfd3756",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 3530,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 88,
"path": "/CMakeLists.txt",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "CMAKE_MINIMUM_REQUIRED( VERSION 2.8 )\n\nPROJECT( ECalAnalysis )\n\nlist(APPEND CMAKE_MODULE_PATH \"${CMAKE_SOURCE_DIR}/CMakeModules\")\n\nSET( PROJECT_VERSION_MAJOR 0 )\nSET( PROJECT_VERSION_MINOR 1 )\n#FIXME remove line below\nSET( MarlinUtil_DIR \"/cvmfs/clicdp.cern.ch/iLCSoft/builds/2019-04-17/x86_64-slc6-gcc62-opt/MarlinUtil/HEAD/\")\n#FIXME remove line below\nSET( PandoraSDK_DIR \"/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/modStandartPackages/PandoraPFANew_modTrackClusterAssCuts\")\n\n# FIND_PACKAGE( ILCUTIL REQUIRED COMPONENTS ILCSOFT_CMAKE_MODULES )\n# INCLUDE( ilcsoft_default_settings )\n\nset(Boost_INCLUDE_DIR \"/cvmfs/clicdp.cern.ch/software/Boost/1.62.0/x86_64-slc6-gcc62-opt/include/\")\nset(Boost_LIBRARY_DIR \"/cvmfs/clicdp.cern.ch/software/Boost/1.62.0/x86_64-slc6-gcc62-opt/lib/\")\n\ninclude_directories(${Boost_INCLUDE_DIR})\nlink_directories(${Boost_LIBRARY_DIR})\n\nINCLUDE_DIRECTORIES ( ${BOOST_ROOT}/include )\nINCLUDE_DIRECTORIES ( ${PROJECT_SOURCE_DIR}/include )\nINCLUDE_DIRECTORIES ( ${PROJECT_SOURCE_DIR}/../MyServiceFunctions/include )\nINCLUDE_DIRECTORIES ( ${PROJECT_SOURCE_DIR}/../BoostServiceFunctions/include )\n\nFIND_PACKAGE( MarlinUtil 1.4 REQUIRED )\nFIND_PACKAGE( Marlin 1.0 REQUIRED )\nINCLUDE_DIRECTORIES( SYSTEM ${Marlin_INCLUDE_DIRS} )\nLINK_LIBRARIES( ${Marlin_LIBRARIES} )\nADD_DEFINITIONS( ${Marlin_DEFINITIONS} )\n\n#FIXME uncomment line below\n# FIND_PACKAGE( GSL REQUIRED )\n\nfind_package( DD4hep REQUIRED COMPONENTS DDRec )\nset(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} ${DD4hep_ROOT}/cmake )\ninclude( DD4hep )\ninclude(DD4hep_XML_setup)\nINCLUDE_DIRECTORIES( SYSTEM ${DD4hep_INCLUDE_DIRS} )\nLINK_LIBRARIES( ${DD4hep_LIBRARIES} ${DD4hep_COMPONENT_LIBRARIES} )\n\n#FIXME uncomment line below\n# FOREACH( pkg LCIO PandoraSDK DD4hep Marlin MarlinUtil GSL)\n#FIXME remove line below\nFOREACH( pkg LCIO PandoraSDK DD4hep Marlin MarlinUtil)\n FIND_PACKAGE (${pkg} REQUIRED )\n IF( ${pkg}_FOUND )\n\tINCLUDE_DIRECTORIES( SYSTEM ${${pkg}_INCLUDE_DIRS} )\n\tLINK_LIBRARIES( ${${pkg}_LIBRARIES} )\n\tADD_DEFINITIONS( ${${pkg}_DEFINITIONS} )\n\t# ADD_DEFINITIONS( -DUSE_${pkg} )\n ENDIF()\nENDFOREACH()\n\n\nLINK_DIRECTORIES(${PROJECT_SOURCE_DIR}/../MyServiceFunctions/build/)\nLINK_DIRECTORIES(${PROJECT_SOURCE_DIR}/../BoostServiceFunctions/build/)\n\nSET( CMAKE_INSTALL_PREFIX ${PROJECT_SOURCE_DIR} )\n\n# SET(GCC_COVERAGE_COMPILE_FLAGS \"-O3 -Wall -Wextra -Wshadow -ansi -Wno-long-long -Wuninitialized -fopenmp -flto -Weffc++ --std=c++11 -ggdb\" )\n# SET(GCC_COVERAGE_LINK_FLAGS \"-flto -O3 -ggdb\" )\n# SET( CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${GCC_COVERAGE_COMPILE_FLAGS}\" )\n# SET( CMAKE_EXE_LINKER_FLAGS \"${CMAKE_EXE_LINKER_FLAGS} ${GCC_COVERAGE_LINK_FLAGS}\" )\n\n# LIST ( APPEND CMAKE_CXX_FLAGS \"-O3 -Wall -Wextra -Wshadow -ansi -Wno-long-long -Wuninitialized -fopenmp -flto -Weffc++ --std=c++11 -ggdb\" )\nLIST ( APPEND CMAKE_CXX_FLAGS \"-O3 -ansi -fopenmp -flto --std=c++11 -ggdb\" )\nLIST ( APPEND CMAKE_LD_FLAGS \"-flto -O3 -ggdb\" )\n\n\nfind_package ( ROOT REQUIRED )\ninclude(${ROOT_USE_FILE})\n\nset(Boost_USE_STATIC_LIBS OFF)\nset(Boost_USE_MULTITHREADED ON)\nset(Boost_USE_STATIC_RUNTIME OFF)\n# find_package(Boost 1.45.0 COMPONENTS program_options)\nfind_package(Boost 1.62.0 COMPONENTS program_options)\ninclude_directories(${Boost_INCLUDE_DIRS})\n\nADD_SUBDIRECTORY ( ${PROJECT_SOURCE_DIR}/PhotonECAL )\nADD_SUBDIRECTORY ( ${PROJECT_SOURCE_DIR}/MuonReco )\n\nMESSAGE (STATUS \"*** Build Type ${CMAKE_BUILD_TYPE} ***\" )\nMESSAGE (STATUS \"*** Compiler Flags: ${CMAKE_CXX_FLAGS}\" )\nMESSAGE (STATUS \"*** Compiler Flags: ${CMAKE_CXX_FLAGS_DEBUG}\" )\n\n"
},
{
"alpha_fraction": 0.6371755003929138,
"alphanum_fraction": 0.6579439043998718,
"avg_line_length": 42.57013702392578,
"blob_id": "3197abec460f842b1f2a17d74436cb2678fe736a",
"content_id": "12fcb4212a5037d7afd97d247143740a049f9123",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9630,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 221,
"path": "/MuonReco/src/muonClusterFiller.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"muonClusterFiller.h\"\n\nint muonClusterFiller::fillEvent(const EVENT::LCEvent* event){\n\ttry {\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|muonClusterFiller]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t\n\t}\n\tnPFOs = PFOCollection->getNumberOfElements();\n\t// cout << \"nPFOs: \" << nPFOs << endl;\n\n\tfillMuonClusterInfo();\n\treturn 0;\n\n}\n\n\nint muonClusterFiller::fillMuonClusterInfo(){\n\t// if (PFOCollection->getNumberOfElements()!=1)\n\t// return 1;\n\tfor (int iPart=0; iPart<PFOCollection->getNumberOfElements(); iPart++){\n\t\tEVENT::ReconstructedParticle* recoPart = static_cast<IMPL::ReconstructedParticleImpl*>(PFOCollection->getElementAt(iPart));\n\t\tif (abs(recoPart->getType())!=13)\n\t\t\tcontinue;\n\t\tauto clusters = recoPart->getClusters();\n\t\t// cout << \"[MuonReco]\\tnClusters: \" << clusters.size() << endl;\n\t\t\n\t\tauto cluster = clusters[0];\n\t\t// auto clusterShape = getClusterShape(cluster);\n\t\t// if (clusterShape.size()>3){\n\t\t// cout << \"xt90: \" << clusterShape[0] << \"; depth of the cluster: \" << clusterShape[1] << \"; RhitMean: \" << clusterShape[2] << \"; RhitRMS: \" << clusterShape[3] << endl;\n\t\t// getHistFromMap(\"cluster_xt90\")->Fill(clusterShape[0]);\n\t\t// getHistFromMap(\"cluster_depth\")->Fill(clusterShape[1]);\n\t\t// getHistFromMap(\"cluster_RhitMean\")->Fill(clusterShape[2]);\n\t\t// getHistFromMap(\"cluster_RhitRMS\")->Fill(clusterShape[3]);\n\t\t// getHistFromMap(\"cluster_nYokeHits\")->Fill(clusterShape[4]);\n\t\t// }\n\t\tyokeHitsStruct yokeHitCount = getNumberOfYokeHits(cluster);\n\t\tgetHistFromMap(\"cluster_nYokeHits\")->Fill(yokeHitCount.nHits);\n\t\tgetHistFromMap(\"cluster_nLayers\")->Fill(yokeHitCount.nLayers);\n\t\tgetHistFromMap(\"cluster_clusterLayerSpan\")->Fill(yokeHitCount.clusterLayerSpan);\n\t}\n}\n\nyokeHitsStruct muonClusterFiller::getNumberOfYokeHits(EVENT::Cluster* pCluster) { \n\tunsigned int nYokeHits = 0;\n unsigned int nHitsInCluster(pCluster->getCalorimeterHits().size());\n\tstd::set<unsigned int> hitLayer;\n\tfor (unsigned int iHit = 0; iHit < nHitsInCluster; ++iHit)\n\t{\n\t\tEVENT::CalorimeterHit *pCalorimeterHit = (EVENT::CalorimeterHit*)(pCluster->getCalorimeterHits()[iHit]);\n\t\tif (CHT(pCalorimeterHit->getType()).caloID()==CHT::yoke){\n\t\t\thitLayer.insert(CHT(pCalorimeterHit->getType()).layer());\n\t\t\tnYokeHits++;\n\t\t}\n\t}\n\tyokeHitsStruct yokeHitCount;\n\tyokeHitCount.clusterLayerSpan = *hitLayer.end() - *hitLayer.begin();\n\tyokeHitCount.nLayers = hitLayer.size();\n\tyokeHitCount.nHits = nYokeHits;\n\t// cout << \"nYokeHits: \" << nYokeHits << \"; nLayers: \" << nLayers << \"; clusterLayerSpan: \" << clusterLayerSpan << endl;\n\treturn yokeHitCount;\n}\n\nEVENT::FloatVec muonClusterFiller::getClusterShape(EVENT::Cluster* pCluster) { \n \n EVENT::FloatVec shapes;\n const unsigned int ecal_Index(0) ;\n const unsigned int hcal_Index(1) ;\n const unsigned int yoke_Index(2) ;\n const unsigned int lcal_Index(3) ;\n const unsigned int lhcal_Index(4);\n const unsigned int bcal_Index(5) ;\n\n bool useOnlyYokeHits = false;\n\n // const unsigned int nHitsInCluster(pCluster->getCalorimeterHits().size());\n unsigned int nHitsInCluster(pCluster->getCalorimeterHits().size());\n // cout << \"nAllHits: \" << nHitsInCluster << \"; \";\n \n if (useOnlyYokeHits==true){\n\t vector<unsigned int> idOfYokeHits;\n\t for (unsigned int iHit = 0; iHit < nHitsInCluster; ++iHit)\n\t\t{\n\t\t EVENT::CalorimeterHit *pCalorimeterHit = (EVENT::CalorimeterHit*)(pCluster->getCalorimeterHits()[iHit]);\n\t\t if (CHT(pCalorimeterHit->getType()).caloID()==CHT::yoke){\n\t\t\tidOfYokeHits.push_back(iHit);\n\t\t }\n\t\t}\n\n\t nHitsInCluster = idOfYokeHits.size();\n\t // cout << \"; nYokeHits: \" << nHitsInCluster << endl;\n }\n if (nHitsInCluster==0)\n\t return shapes;\n\n float clusterEnergy(0.);\n float *pHitE = new float[nHitsInCluster];\n float *pHitX = new float[nHitsInCluster];\n float *pHitY = new float[nHitsInCluster];\n float *pHitZ = new float[nHitsInCluster];\n int *typ = new int[nHitsInCluster];\n\n unsigned int nYokeHits = 0;\n\n for (unsigned int iHit = 0; iHit < nHitsInCluster; ++iHit)\n // for (auto iHit: idOfYokeHits)\n\t{\n\t EVENT::CalorimeterHit *pCalorimeterHit = (EVENT::CalorimeterHit*)(pCluster->getCalorimeterHits()[iHit]);\n\n\t const float caloHitEnergy(pCalorimeterHit->getEnergy());\n\t \n\t pHitE[iHit] = caloHitEnergy;\n\t pHitX[iHit] = pCalorimeterHit->getPosition()[0];\n\t pHitY[iHit] = pCalorimeterHit->getPosition()[1];\n\t pHitZ[iHit] = pCalorimeterHit->getPosition()[2];\n\t clusterEnergy += caloHitEnergy;\n\n\t switch (CHT(pCalorimeterHit->getType()).caloID())\n\t {\n\t case CHT::ecal: typ[iHit]=ecal_Index; break;\n\t case CHT::hcal: typ[iHit]=hcal_Index; break;\n\t case CHT::yoke: typ[iHit]=yoke_Index; nYokeHits++; break;\n\t case CHT::lcal: typ[iHit]=lcal_Index; break;\n\t case CHT::lhcal: typ[iHit]=lhcal_Index; break;\n\t case CHT::bcal: typ[iHit]=bcal_Index; break;\n\t default: cout << \"[DEBUG]\\tno subdetector found for hit with type: \" << pCalorimeterHit->getType() << std::endl;\n\t }\n\t}\n \n ClusterShapes* pClusterShapes = new ClusterShapes(nHitsInCluster, pHitE, pHitX, pHitY, pHitZ);\n pClusterShapes->setHitTypes(typ); //set hit types\n\n //here is cluster shape study - cluster transverse & longitudinal information\n //define variables\n float chi2,a,b,c,d,xl0,CoG[3],xStart[3]; //for fitting parameters\n float X0[2]={0,0}; //in mm. //this is the exact value of tangsten and iron\n float Rm[2]={0,0}; //in mm. need to change to estimate correctly times 2\n float _X01 = 3.50;\n float _X02 = 17.57;\n float _Rm1 = 9.0;\n float _Rm2 = 17.19;\n X0[0]=_X01;\n X0[1]=_X02;\n Rm[0]=_Rm1;\n Rm[1]=_Rm2;\n\n //get barrel detector surfce\n //Get ECal Barrel extension by type, ignore plugs and rings\n // const dd4hep::rec::LayeredCalorimeterData * eCalBarrelExtension= MarlinUtil::getLayeredCalorimeterData( ( dd4hep::DetType::CALORIMETER | dd4hep::DetType::ELECTROMAGNETIC | dd4hep::DetType::BARREL),\n\t\t\t\t\t\t\t\t\t\t\t\t\t // ( dd4hep::DetType::AUXILIARY | dd4hep::DetType::FORWARD ) );\n // float ecalrad = eCalBarrelExtension->extent[0]/dd4hep::mm;\n\n //get endcap detector surfce\n //Get ECal Endcap extension by type, ignore plugs and rings\n // const dd4hep::rec::LayeredCalorimeterData * eCalEndcapExtension= MarlinUtil::getLayeredCalorimeterData( ( dd4hep::DetType::CALORIMETER | dd4hep::DetType::ELECTROMAGNETIC | dd4hep::DetType::ENDCAP),\n\t\t\t\t\t\t\t\t\t\t\t\t\t // ( dd4hep::DetType::AUXILIARY | dd4hep::DetType::FORWARD ) );\n // float plugz = eCalEndcapExtension->extent[2]/dd4hep::mm;\n \n //looking for the hit which corresponds to the nearest hit from IP in the direction of the center of gravity\n int index_xStart=0;\n float lCoG=0.0,tmpcos=0.0,tmpsin=0.0,detsurface=0.0;\n CoG[0]=pClusterShapes->getEigenVecInertia()[0];\n CoG[1]=pClusterShapes->getEigenVecInertia()[1];\n CoG[2]=pClusterShapes->getEigenVecInertia()[2];\n //CoG2[0]=pCluster->getPosition()[0];\n //CoG2[1]=pCluster->getPosition()[1];\n //CoG2[2]=pCluster->getPosition()[2];\n \n lCoG=sqrt(CoG[0]*CoG[0]+CoG[1]*CoG[1]+CoG[2]*CoG[2]);\n tmpcos=CoG[2]/lCoG;\n tmpsin=sqrt(CoG[0]*CoG[0]+CoG[1]*CoG[1])/lCoG;\n pClusterShapes->fit3DProfile(chi2,a,b,c,d,xl0,xStart,index_xStart,X0,Rm); //is this good??\n float lxstart=sqrt(xStart[0]*xStart[0]+xStart[1]*xStart[1]);\n //calculate detector surface\n // if(fabs(xStart[2])<plugz){ //if in the barrel\n\t// detsurface=(lxstart-ecalrad)/tmpsin;\n // }else{ //if in plug\n\t// detsurface=(fabs(xStart[2])-plugz)/fabs(tmpcos);\n // }\n \n //float maxed=a*pow(b/c,b)*exp(-b); //for simple fitting\n float maxed = a*c*gsl_sf_gammainv(b)*pow(b-1,b-1)*exp(-b+1); //for advanced multiply with fabs(d) to avoid NaN\n float maxlength_pho=(1.0*std::log(clusterEnergy/(X0[0] * 0.021/Rm[0]))-0.5); //this definition, +0.5 if gamma\n\n TVector3 clusdirection(CoG[0]-xStart[0],CoG[1]-xStart[1],CoG[2]-xStart[2]);\n\n\n //these variables are fit based variables\n // shapes.push_back(chi2);\n // shapes.push_back(maxed);\n // // shapes.push_back(((b-1.0)*X0[0]/c+xl0+detsurface)/(2.0*X0[0]));\n // shapes.push_back(1/fabs(d));\n // shapes.push_back(maxlength_pho);\n // shapes.push_back(((b-1.0)/c)/maxlength_pho);\n // shapes.push_back(Rm[0]*2.0);\n // // shapes.push_back(detsurface);\n // shapes.push_back(xl0);\n // shapes.push_back(a);\n // shapes.push_back(b);\n // shapes.push_back(c);\n // shapes.push_back(d);\n // //these variables are detector based variables\n // shapes.push_back(pClusterShapes->getEmax(xStart,index_xStart,X0,Rm));\n // shapes.push_back(pClusterShapes->getsmax(xStart,index_xStart,X0,Rm));\n shapes.push_back(pClusterShapes->getxt90(xStart,index_xStart,X0,Rm));\n // shapes.push_back(pClusterShapes->getxl20(xStart,index_xStart,X0,Rm));\n \n //20150708 add variables by Hale\n shapes.push_back(clusdirection.Mag()); // depth of the cluster\n shapes.push_back(pClusterShapes->getRhitMean(xStart,index_xStart,X0,Rm)); // mean of the radius of the hits wrt cog\n shapes.push_back(pClusterShapes->getRhitRMS(xStart,index_xStart,X0,Rm)); // RMS of the radius of the hits wrt cog\n shapes.push_back(nYokeHits);\n\n delete pClusterShapes;\n delete[] pHitE; delete[] pHitX; delete[] pHitY; delete[] pHitZ;\n\n return shapes;\n}\n\n"
},
{
"alpha_fraction": 0.6752328276634216,
"alphanum_fraction": 0.7080027461051941,
"avg_line_length": 46.917354583740234,
"blob_id": "d0a64a1f7ec52bc36ae5cff05dbaf85b1741c420",
"content_id": "53e8706f48b28b6e026e57216c30fb30aa0ecbe3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5798,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 121,
"path": "/MuonReco/src/energyFill.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include <energyFill.h>\nint energyFill::init(){\n\tTH1D *h_ECALTotalEnergy = new TH1D(\"CAL_Energy\",\"energy; Total Energy [GeV]; Counts\",250,0.0,125);\n\tTH1I *h_ECALNHits = new TH1I(\"CAL_Nhits\",\"Number of hits; Number of ECAL hits; Counts\",3000,0,3000);\n\tTH1I *h_ECALMaxLayer = new TH1I(\"CAL_maxLayer\",\"Max fired layer; max. layer; Counts\",45,0,45);\n\tTH1D *h_ECALEnergyPerLayers = new TH1D(\"CAL_EnergyPerLayers\",\"Energy per layer; Layer number; Deposited energy [???]\",50,0,50);\n\tTH1D *h_ECALAverageEnergyPerLayers = new TH1D(\"CAL_AverageEnergyPerLayers\",\"Average Energy per layer; Layer number; Deposited energy fraction\",50,0,50);\n\n\thistMap[\"CAL_Energy\"] = h_ECALTotalEnergy;\n\thistMap[\"CAL_Nhits\"] = h_ECALNHits;\n\thistMap[\"CAL_maxLayer\"] = h_ECALMaxLayer;\n\thistMap[\"CAL_EnergyPerLayers\"] = h_ECALEnergyPerLayers;\n\thistMap[\"CAL_AverageEnergyPerLayers\"] = h_ECALAverageEnergyPerLayers;\n\n\tcreateTH1D(\"CAL_hitTiming\",\"Hit Timing; Time [ns]; Counts\",5000,0,500);\n\tcreateTH1D(\"CAL_energyVsHitTiming\",\"Energy vs. Hit Timing; Time [ns]; Energy [GeV / 1 ns]\",500,0,500);\n\tcreateTH1D(\"CAL_energyVsRadius\",\"Hit Energy vs Radius; Radius [mm]; Hit Energy [GeV / 50 mm]\",80,0,4000);\n\tcreateTH1D(\"CAL_energyVsZ\",\"Hit Energy vs Z; Z [mm]; Hit Energy [GeV / 51 mm]\",160,-4088,4088);\n\tcreateTH1D(\"CAL_energyVsZ2\",\"Hit Energy vs Z; Z [mm]; Hit Energy [GeV / 51 mm]\",160,-4090.5,4085.5);\n\tcreateTH1D(\"CAL_energyVsZ3\",\"Hit Energy vs Z; Z [mm]; Hit Energy [GeV / 51 mm]\",26,-3900,3900);\n\tcreateTH1D(\"CAL_energyVsTheta\",\"Hit Energy vs Theta; Theta [deg]; Hit Energy [GeV / 5 deg]\",36,0,180);\n\tcreateTH1D(\"CAL_energyVsCosTheta\",\"Hit Energy vs cosTheta; cos(Theta); Hit Energy [GeV / 0.02]\",40,-1,1);\n\tcreateTH1D(\"CAL_energySpectrum\",\"Hit Energy Spectrum; Enegy [GeV]; Counts\",10000,0,1);\n\n\tfor(auto const &iMapElement : histMap) {\n\t\tiMapElement.second->AddDirectory(kFALSE);\n\t}\n\t//Initialize CellID encoder\n\t// m_encoder = new UTIL::BitField64(lcio::LCTrackerCellID::encoding_string());\n\n\treturn 0;\n}\n\n\nint energyFill::fillEvent(const EVENT::LCEvent* event){\n\n\ttry {\n\t\tcollection = event->getCollection(collectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|energyFill]\\tCan't find collection: \" << collectionName << endl;\n\t\treturn -1;\n\t}\n\n\tif( collection ) {\n\t\tstring collectionType = collection->getTypeName();\n\t\tconst int nElements = collection->getNumberOfElements();\n\t\tdouble energyCount = 0.0;\n\t\tdouble totalEnergyDeposited = 0.0;\n\t\tint maxLayer = 0;\n\t\tfor(int j=0; j < nElements; j++){\n\t\t\tauto calHit = dynamic_cast<EVENT::CalorimeterHit*>(collection->getElementAt(j));\n\t\t\ttotalEnergyDeposited += calHit->getEnergy();\n\t\t\t// int nContributions = calHit->getNMCContributions();\n\t\t\t// for (int iCont = 0; iCont < nContributions;++iCont){\n\t\t\t// energyCount = calHit->getEnergyCont(iCont);\n\t\t\t// totalEnergyDeposited += energyCount;\n\t\t\t// }\n\n\t\t\t// cout << endl << \"totalEnergy: \" << calHit->getEnergy() << endl;\n\n\t\t\tUTIL::BitField64 _encoder(collection->getParameters().getStringVal( EVENT::LCIO::CellIDEncoding ));\n\t\t\tlcio::long64 cellId = long( calHit->getCellID0() & 0xffffffff ) | ( long( calHit->getCellID1() ) << 32 );\n\t\t\t_encoder.setValue(cellId);\n\t\t\tint layer=_encoder[\"layer\"].value();\n\t\t\tif (layer>maxLayer)\n\t\t\t\tmaxLayer = layer;\n\t\t\thistMap[\"CAL_EnergyPerLayers\"]->Fill(layer,calHit->getEnergy());\n\t\t\thistMap[\"CAL_AverageEnergyPerLayers\"]->Fill(layer,calHit->getEnergy());\n\t\t\tauto caloRawHit = dynamic_cast<EVENT::SimCalorimeterHit*>(calHit->getRawHit());\n\t\t\tconst unsigned int n = caloRawHit->getNMCContributions(); //number of subhits of this SimHit\n\t\t\tfor (unsigned int i_t=0; i_t<n; i_t++){\n\t\t\t\tfloat timei = caloRawHit->getTimeCont(i_t); //absolute hit timing of current subhit\n\t\t\t\tgetHistFromMap(\"CAL_hitTiming\")->Fill(timei);\n\t\t\t\tgetHistFromMap(\"CAL_energyVsHitTiming\")->Fill(timei,caloRawHit->getEnergyCont(i_t));\n\t\t\t\t// cout << \"deposit_\" << i_t << \": \" << caloRawHit->getEnergyCont(i_t) << endl;\n\t\t\t}\n\t\t\tauto hitPos = calHit->getPosition();\n\t\t\tdouble hitRadius = sqrt((hitPos[0] * hitPos[0]) + (hitPos[1] * hitPos[1]));\n\t\t\tdouble hitZ = hitPos[2];\n\t\t\tdouble hitTheta = TVector3(hitPos[0],hitPos[1],hitPos[2]).Theta();\n\t\t\tdouble hitCosTheta = cos(hitTheta);\n\t\t\tgetHistFromMap(\"CAL_energyVsRadius\")->Fill(hitRadius,calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energyVsZ\")->Fill(hitZ,calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energyVsZ2\")->Fill(hitZ,calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energyVsZ3\")->Fill(hitZ,calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energyVsTheta\")->Fill(hitTheta*TMath::RadToDeg(),calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energyVsCosTheta\")->Fill(hitCosTheta,calHit->getEnergy());\n\t\t\tgetHistFromMap(\"CAL_energySpectrum\")->Fill(calHit->getEnergy());\n\n\t\t}\n\t\tfillMaxLayer(maxLayer);\n\t\tfillEnergy(totalEnergyDeposited);\n\t\tfillNHits(nElements);\n\t}\n\treturn 0;\n}\n\nint energyFill::fillEnergy(const double energy){\n\treturn histMap[\"CAL_Energy\"]->Fill(energy);\n}\nint energyFill::fillNHits(const int nHits){\n\treturn histMap[\"CAL_Nhits\"]->Fill(nHits);\n}\nint energyFill::fillMaxLayer(const int maxLayer){\n\treturn histMap[\"CAL_maxLayer\"]->Fill(maxLayer);\n}\n\nint energyFill::writeToFile(TFile* outFile){\n\thistMap[\"CAL_AverageEnergyPerLayers\"]->Scale(1.0/histMap[\"CAL_Energy\"]->GetEntries()/histMap[\"CAL_Energy\"]->GetMean());\n\n\tunsigned int nEvents = getHistFromMap(\"CAL_Energy\")->GetEntries();\n\tgetHistFromMap(\"CAL_energyVsRadius\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsZ\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsZ2\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsZ3\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsTheta\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsCosTheta\")->Scale(1.0/nEvents);\n\tgetHistFromMap(\"CAL_energyVsHitTiming\")->Scale(1.0/nEvents);\n\n\tobjectFill::writeToFile(outFile);\n}\n"
},
{
"alpha_fraction": 0.6964074373245239,
"alphanum_fraction": 0.6995657086372375,
"avg_line_length": 31.461538314819336,
"blob_id": "500bdc83897d28fefa973892d47bf3ddb7166766",
"content_id": "9518eac53a7a7b8453387c00e28590f1c59c3420",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2533,
"license_type": "no_license",
"max_line_length": 264,
"num_lines": 78,
"path": "/PhotonECAL/PhotonECAL.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "//custom libs\n#include <particleFill.h>\n#include <energyFill.h>\n\nusing namespace std;\nint main (int argn, char* argv[]) {\n\t// Read collections\n\tstd::vector<std::string> m_fileNames;\n\n\tif (argn < 2) {\n\t\tstd::cout << \"[WARNING]\\tNo input arguments. Exit!\" << std::endl;\n\t\treturn 0;\n\t}\n\telse{\n\t\tfor (int i = 1; i < argn; ++i) {\n\t\t\tvector<string> tmpStrVec = getFilesMatchingPattern(argv[i]);\n\t\t\tm_fileNames.insert(m_fileNames.end(), tmpStrVec.begin(), tmpStrVec.end());\n\t\t}\n\t}\n\tcout << \"[INFO]\\tNumber of input files to be used: \" << m_fileNames.size() << \" files\" << endl;\n\n\tbool printVerbose = false;\n\n\t// Open Files\n\tauto m_reader( IOIMPL::LCFactory::getInstance()->createLCReader());\n\n\ttry{\n\t\tm_reader->open( m_fileNames );\n\t} catch (IO::IOException &e) {\n\t\tstd::cerr << \"Error opening files: \" << e.what() << std::endl;\n\t\treturn 1;\n\t}\n\n\tmap<string, objectFill*> objFillMap;\n\tvector<string> particleFillCollections = {\"MCParticlesSkimmed\",\"LooseSelectedPandoraPFOs\",\"TightSelectedPandoraPFOs\"};\n\tvector<string> energyFillCollections = {\"ECALBarrel\",\"ECALEndcap\"/*, \"ECalBarrelCollection\", \"ECalEndcapCollection\"*/};\n\tfor (int i; i<particleFillCollections.size(); i++){\n\t\tparticleFill* tmpPartFill = new particleFill(particleFillCollections[i]);\n\t\ttmpPartFill->setCollectionName(particleFillCollections[i]);\n\t\tobjFillMap[particleFillCollections[i]] = tmpPartFill;\n\t}\n\tfor (int i; i<energyFillCollections.size(); i++){\n\t\tenergyFill* tmpEnergyFill = new energyFill(energyFillCollections[i]);\n\t\ttmpEnergyFill->setCollectionName(energyFillCollections[i]); \n\t\tobjFillMap[energyFillCollections[i]] = tmpEnergyFill;\n\t}\n\n\tfor(auto const &mapElement : objFillMap){\n\t\tmapElement.second->init();\n\t}\n\n\tobjFillMap[\"MCParticlesSkimmed\"]->setDebugFlag(true);\n\n\tEVENT::LCEvent *event = NULL;\n\tint eventCounter = 0;\n\twhile ( ( event = m_reader->readNextEvent() ) ) {\n\t\t// if (eventCounter>100) break;\n\t\tif (printVerbose) cout << endl << \"Event \" << eventCounter << \":\" << endl;\n\t\teventCounter++;\n\t\t\n\t\tfor(auto const &mapElement : objFillMap){\n\t\t\tmapElement.second->fillEvent(event);\n\t\t} \n\t}\n\n\tTFile *outFile = new TFile((\"ECAL_photonGun_E\"+DoubToStr(static_cast<particleFill*>(objFillMap[\"MCParticlesSkimmed\"])->getMeanEnergy())+\"_theta\"+DoubToStr(static_cast<particleFill*>(objFillMap[\"MCParticlesSkimmed\"])->getMeanTheta())+\".root\").c_str(), \"RECREATE\");\n\n\tfor(auto const &mapElement : objFillMap){\n\t\tmapElement.second->writeToFile(outFile);\n\t} \n\n\toutFile->Close();\n\n\tfor(auto const &mapElement : objFillMap){\n\t\tdelete mapElement.second;\n\t} \n\t\n}\n\n"
},
{
"alpha_fraction": 0.693889319896698,
"alphanum_fraction": 0.7090058922767639,
"avg_line_length": 49.03845977783203,
"blob_id": "1cdfc76d0324ab1cc517a6e2790fac0f0215de7f",
"content_id": "b0e4ecf0e0f7a1670f6fdc6ae157da898f55ea72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 15612,
"license_type": "no_license",
"max_line_length": 518,
"num_lines": 312,
"path": "/PhotonECAL/src/eventHistFiller_mainFunctions.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "#include \"eventHistFiller.h\"\n\nvoid eventHistFiller::initTruthInfoAndFillIt(){\n\tgenPart = truthCondition::instance()->getGunParticle();\n\n\ttruthType = genPart->getPDG();\n\tconst double *truthMom = genPart->getMomentum(); \n\tTVector3 vTruthMom(truthMom[0],truthMom[1],truthMom[2]);\n\ttruthTheta = vTruthMom.Theta()*TMath::RadToDeg();\n\tcosTruthTheta = TMath::Cos(truthTheta*TMath::DegToRad());\n\ttruthPhi = vTruthMom.Phi()*TMath::RadToDeg();\n\ttruthPt = vTruthMom.Pt();\n\ttruthEnergy = genPart->getEnergy();\n\n\tgetHistFromMap(\"truthParticle_isDecayedInTracker\")->Fill(genPart->isDecayedInTracker());\n\tif (genPart->isDecayedInTracker()){\n\t\tconst double *endPoint = genPart->getEndpoint();\n\t\tdouble decayRadius = sqrt(endPoint[0]*endPoint[0]+endPoint[1]*endPoint[1]);\n\t\tgetHistFromMap(\"truthParticle_convRadius\")->Fill(decayRadius);\n\t}\n\tgetHistFromMap(\"nTruthPartsVsCosTheta\")->Fill(cosTruthTheta);\n\tgetHistFromMap(\"nTruthPartsVsTheta\")->Fill(truthTheta);\n\tgetHistFromMap(\"nTruthPartsVsEnergy\")->Fill(truthEnergy);\n} \n\n\n\nvoid eventHistFiller::fillPfoCounterAndFillGeneralPfoInfo(unsigned int partId){\n\tEVENT::ReconstructedParticle* recoPart = static_cast<IMPL::ReconstructedParticleImpl*>(PFOCollection->getElementAt(partId));\n\n\tconst int pfoType = fabs(recoPart->getType());\n\tconst double *partMom = recoPart->getMomentum();\n\tTVector3 vPartMom(partMom[0],partMom[1],partMom[2]);\n\tconst double partTheta = vPartMom.Theta()*TMath::RadToDeg();\n\tconst double partPhi = vPartMom.Phi()*TMath::RadToDeg();\n\tconst double cosPartTheta = TMath::Cos(partTheta*TMath::DegToRad());\n\tconst double partEnergy = recoPart->getEnergy();\n\tconst double dPhiPartTruth = get_dPhi(partPhi,truthPhi)*TMath::DegToRad();\n\tconst double dThetaPartTruth = (partTheta-truthTheta)*TMath::DegToRad();\n\n\tgetHistFromMap(\"PFOType\")->Fill(pfoType);\n\tgetHistFromMap(\"nPFOsVsCosTheta_all\")->Fill(cosTruthTheta);\n\tgetHistFromMap(\"nPFOsVsTheta_all\")->Fill(truthTheta);\n\tgetHistFromMap(\"totalEnergyVsTheta\")->Fill(truthTheta,recoPart->getEnergy());\n\ttotalRecoEnergy += recoPart->getEnergy();\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\tif (fabs(pfoType)==it->first) {\n\t\t\tgetHistFromMap(\"nPFOsVsCosTheta_\"+it->second)->Fill(cosTruthTheta);\n\t\t\tgetHistFromMap(\"nPFOsVsTheta_\"+it->second)->Fill(truthTheta);\n\t\t\tgetHistFromMap(\"thetaResolution_\"+it->second)->Fill(dThetaPartTruth);\n\t\t\tgetHistFromMap(\"phiResolution_\"+it->second)->Fill(dPhiPartTruth);\n\t\t\tgetHistFromMap(\"energyResolution_\"+it->second)->Fill(partEnergy);\n\n\t\t\tif(PFOCollection->getNumberOfElements()==1){\n\t\t\t\tgetHistFromMap(\"energyResolution2_\"+it->second)->Fill(partEnergy);\n\t\t\t\tif (dThetaPartTruth<0.1 && dPhiPartTruth<0.1)\n\t\t\t\t\tgetHistFromMap(\"energyResolution3_\"+it->second)->Fill(partEnergy);\n\t\t\t\tif (dThetaPartTruth<0.2 && dPhiPartTruth<0.2)\n\t\t\t\t\tgetHistFromMap(\"energyResolution4_\"+it->second)->Fill(partEnergy);\n\t\t\t}\n\t\t\t// getHistFromMap(\"energyResolution3_\"+it->second)->Fill(partEnergy);\n\t\t\t// getHistFromMap(\"energyResolution4_\"+it->second)->Fill(partEnergy);\n\t\t\tpfoCounter[it->second]++;\n\t\t}\n\t}\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"r\" << partId << \": pdg: \" << setw(5) << pfoType << \"; E: \" << setw(6) << round(100*partEnergy)/100.0 << \": pT: \" << std::setw(6) << (round(100*vPartMom.Pt())/100.0) << \"; theta: \" << setw(6) << round(100*partTheta)/100.0 << \"; phi: \" << setw(6) << round(100*partPhi)/100.0 << \"; dPhi: \" << setw(6) << round(100*dPhiPartTruth*TMath::RadToDeg())/100.0 << \"; dTheta: \" << setw(6) << round(100*dThetaPartTruth*TMath::RadToDeg())/100.0 << endl;\n}\n\nvoid eventHistFiller::fillEventsFailedSelection(){\n\n\tfor (int kkk=0; kkk<nPFOs; kkk++){\n\t\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++) {\n\t\t\tif (fabs(static_cast<EVENT::ReconstructedParticle*>(PFOCollection->getElementAt(kkk))->getType())==it->first) {\n\t\t\t\tgetHistFromMap(\"nPFOsVsCosThetaFailType_\"+it->second)->Fill(cosTruthTheta);\n\t\t\t}\n\t\t}\n\t}\n\tgetHistFromMap(\"efficiencyVsCosThetaFailType_all\")->Fill(cosTruthTheta);\n\tif (pfoCounter[\"Electron\"]==0 && pfoCounter[\"Muon\"]==0 && pfoCounter[\"Pion\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailType_noChargedParts\")->Fill(cosTruthTheta);\n\telse if (pfoCounter[\"Electron\"]==0 && pfoCounter[\"Muon\"]>0 && pfoCounter[\"Pion\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyMuon\")->Fill(cosTruthTheta);\n\telse if (pfoCounter[\"Electron\"]==0 && pfoCounter[\"Muon\"]==0 && pfoCounter[\"Pion\"]>0) \n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyPion\")->Fill(cosTruthTheta);\n\telse if (pfoCounter[\"Electron\"]>0 && pfoCounter[\"Muon\"]==0 && pfoCounter[\"Pion\"]==0) \n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailType_onlyElectron\")->Fill(cosTruthTheta);\n\telse\n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailType_chargePartsOfTwoOrMoreTypes\")->Fill(cosTruthTheta);\n\n}\n\nvector <unsigned int> eventHistFiller::mergeClusters(){\n\tvector<unsigned int> idOfMergedParticles;\n\tif (config::vm.count(\"debug\")){\n\t\tcout << \"[DEBUG]\\tINFO FROM eventHistFiller::mergeClusters(): START\" << endl;\n\t\tcout << \"[DEBUG]\\tpartCandidate pointer: \" << partCandidate << endl;\n\t\tcout << \"[DEBUG]\\tpartCandidate->getClusters().size(): \" << partCandidate->getClusters().size() << endl;\n\t}\n\n\tif (partCandidate->getClusters().size()==0){\n\t\tcout << \"[ERROR]\\tin eventHistFiller::mergeClusters(): partCandidate->getClusters().size()==0\" << endl;\n\t\treturn idOfMergedParticles;\n\t}\n\n\tdouble tmpPartCandidateClusterEnergy = partCandidate->getClusters()[0]->getEnergy();\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[DEBUG]\\tpartCandEnergy: \" << partCandidate->getEnergy() << \"; partCandClusterEnergy: \" << tmpPartCandidateClusterEnergy << endl;\n\tpartCandidate = CopyReconstructedParticle(partCandidate);\n\n\tif (useCaloInfoDuringEnergyMerging){\n\t\tpartCandidate->setEnergy(tmpPartCandidateClusterEnergy);\n\t}\n\n\tconst double* candMom = partCandidate->getMomentum();\n\tTVector3 vCandMom(candMom[0],candMom[1],candMom[2]);\n\tconst double candTheta = vCandMom.Theta()*TMath::RadToDeg();\n\tconst double candPhi = vCandMom.Phi()*TMath::RadToDeg();\n\n\tdouble tmpMomentum[3];\n\ttmpMomentum[0] = partCandidate->getMomentum()[0]; \n\ttmpMomentum[1] = partCandidate->getMomentum()[1]; \n\ttmpMomentum[2] = partCandidate->getMomentum()[2]; \n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[DEBUG]\\tnPFOs: \" << nPFOs << endl;\n\tif (PFOmergeMap[mergeTag].size()>0 ) {\n\t\tfor (int j=0; j<nPFOs; j++){\n\t\t\tif (config::vm.count(\"debug\"))\n\t\t\t\tcout << \"[DEBUG]\\tj: \" << j << \"; idOfPartCandidate: \" << idOfPartCandidate << endl;\n\t\t\tif (j==idOfPartCandidate) \n\t\t\t\tcontinue;\n\t\t\tEVENT::ReconstructedParticle* recoPart = static_cast<EVENT::ReconstructedParticle*>(PFOCollection->getElementAt(j));\n\t\t\tconst unsigned int partTypeLoop = recoPart->getType();\n\t\t\tconst double* partMomLoop = recoPart->getMomentum();\n\t\t\tTVector3 vPartMomLoop(partMomLoop[0],partMomLoop[1],partMomLoop[2]);\n\t\t\tconst double partThetaLoop = vPartMomLoop.Theta()*TMath::RadToDeg();\n\t\t\tconst double partPhiLoop = vPartMomLoop.Phi()*TMath::RadToDeg();\n\t\t\tconst double partEnergyLoop = recoPart->getEnergy();\n\n\t\t\tfor (int iMerge=0; iMerge<PFOmergeMap[mergeTag].size(); iMerge++){\n\t\t\t\tPFOMergeSettings mergeSettings = PFOmergeMap[mergeTag][iMerge];\n\t\t\t\tif (fabs(partTypeLoop)!=mergeSettings.pfoTypeToMerge)\n\t\t\t\t\tcontinue;\n\n\t\t\t\tdouble dPhi = get_dPhi(partPhiLoop,candPhi);\n\t\t\t\tbool passTheta = fabs(candTheta-partThetaLoop)<mergeSettings.thetaCone;\n\t\t\t\tbool passPhi = fabs(dPhi)<mergeSettings.phiCone; \n\t\t\t\n\t\t\t\tif (config::vm.count(\"debug\"))\n\t\t\t\t\tcout << \"[INFO] passTheta: \" << passTheta << \"; passPhi: \" << passPhi << \"; E: \" << partEnergyLoop << \" GeV; thetaCone: \" << mergeSettings.thetaCone << \"; dTheta: \" << fabs(candTheta-partThetaLoop) << \"; phiCone: \" << mergeSettings.phiCone << \"; dPhi: \" << fabs(dPhi) << endl;\n\n\t\t\t\tif (passTheta && passPhi) {\n\t\t\t\t\n\t\t\t\t\ttmpMomentum[0] += recoPart->getMomentum()[0]; \n\t\t\t\t\ttmpMomentum[1] += recoPart->getMomentum()[1]; \n\t\t\t\t\ttmpMomentum[2] += recoPart->getMomentum()[2]; \n\t\t\t\t\t// TODO implement recalculation of momentum based on Cluster from charged particle not from ReconstructedParticle\n\t\t\t\t\t// if (useCaloInfoDuringEnergyMerging){\n\t\t\t\t\t// tmpMomentum[0] += partCandidate->getMomentum()[0];\n\t\t\t\t\t// tmpMomentum[1] += partCandidate->getMomentum()[1];\n\t\t\t\t\t// tmpMomentum[2] += partCandidate->getMomentum()[2];\n\t\t\t\t\t// }\n\t\t\t\t\t// else{\n\t\t\t\t\t// tmpMomentum[0] += partCandidate->getClusters()[0]->getMomentum()[0];\n\t\t\t\t\t// }\n\n\t\t\t\t\tdouble tmpEnergy = recoPart->getEnergy();\n\t\t\t\t\tif (useCaloInfoDuringEnergyMerging){\n\t\t\t\t\t\ttmpEnergy = recoPart->getClusters()[0]->getEnergy();\n\t\t\t\t\t\tif (config::vm.count(\"debug\")){\n\t\t\t\t\t\t\tauto clusterPos = recoPart->getClusters()[0]->getPosition();\n\t\t\t\t\t\t\tdouble clusterDist = sqrt(pow(clusterPos[0],2)+pow(clusterPos[1],2)+pow(clusterPos[2],2));\n\t\t\t\t\t\t\tTVector3 *clusterMom = new TVector3();\n\t\t\t\t\t\t\tclusterMom->SetX(clusterPos[0]*recoPart->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tclusterMom->SetY(clusterPos[1]*recoPart->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tclusterMom->SetZ(clusterPos[2]*recoPart->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tdouble clusterPhi = clusterMom->Phi()*TMath::RadToDeg();\n\t\t\t\t\t\t\tdouble clusterTheta = clusterMom->Theta()*TMath::RadToDeg();\n\n\t\t\t\t\t\t\tcout << \"[SASHA]\\tnClusters: \" << recoPart->getClusters().size() << endl;\n\t\t\t\t\t\t\tcout << \"[SASHA]\\tpartEnergy: \" << recoPart->getEnergy() << endl;\n\t\t\t\t\t\t\tcout << \"[SASHA]\\tclusterIPhi: \" << recoPart->getClusters()[0]->getIPhi()*TMath::RadToDeg() << \"; clusterITheta: \" << recoPart->getClusters()[0]->getITheta()*TMath::RadToDeg() << endl;\n\t\t\t\t\t\t\tcout << \"[SASHA]\\tclusterTheta: \" << clusterTheta << \"; clusterPhi: \" << clusterPhi << endl;\n\n\n\t\t\t\t\t\t\tEVENT::ReconstructedParticle* candPartTemp = static_cast<EVENT::ReconstructedParticle*>(PFOCollection->getElementAt(idOfPartCandidate));\n\t\t\t\t\t\t\tclusterPos = candPartTemp->getClusters()[0]->getPosition();\n\t\t\t\t\t\t\tclusterDist = sqrt(pow(clusterPos[0],2)+pow(clusterPos[1],2)+pow(clusterPos[2],2));\n\t\t\t\t\t\t\tclusterMom->SetX(clusterPos[0]*candPartTemp->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tclusterMom->SetY(clusterPos[1]*candPartTemp->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tclusterMom->SetZ(clusterPos[2]*candPartTemp->getClusters()[0]->getEnergy()/clusterDist);\n\t\t\t\t\t\t\tclusterPhi = clusterMom->Phi()*TMath::RadToDeg();\n\t\t\t\t\t\t\tclusterTheta = clusterMom->Theta()*TMath::RadToDeg();\n\t\t\t\t\t\t\tcout << \"[SASHA]\\tcandClusterTheta: \" << clusterTheta << \"; candClusterPhi: \" << clusterPhi << endl;\n\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t}\n\t\t\t\t\t\t// tmpEnergy = partCandidate->getEnergy();\n\t\t\t\t\t}\n\n\t\t\t\t\ttmpEnergy += partCandidate->getEnergy();\n\n\t\t\t\t\tpartCandidate->setMomentum(tmpMomentum);\n\t\t\t\t\tpartCandidate->setEnergy(tmpEnergy);\n\n\t\t\t\t\tidOfMergedParticles.push_back(j);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"[DEBUG]\\tINFO FROM eventHistFiller::mergeClusters(): END\" << endl;\n\treturn idOfMergedParticles;\n}\n\nvoid eventHistFiller::angularAndEnergyMatching(){\n\n\t// Here we already have most energetic candidate of the type\n\n\tbool passAngularMatching = false;\n\tbool passTransMomMatching = false;\n\tbool passEnergyMatching = false;\n\tdouble dPhi_angularMatchingCut = 0.02;\n\tdouble dTheta_angularMatchingCut = 0.01;\n\tdouble caloCut_energyMatching = 0.75;\n\t// double transMomCut_energyMatching = 0.05;\n\tdouble transMomCut_energyMatching = 0.1;\n\n\tconst double *partMom = partCandidate->getMomentum();\n\tTVector3 vPartMom(partMom[0],partMom[1],partMom[2]);\n\tconst double partTheta = vPartMom.Theta()*TMath::RadToDeg();\n\tconst double partPhi = vPartMom.Phi()*TMath::RadToDeg();\n\tconst double cosPartTheta = TMath::Cos(partTheta*TMath::DegToRad());\n\tconst double partEnergy = partCandidate->getEnergy();\n\tconst double partPt = vPartMom.Pt();\n\tconst double dPhiPartTruth = get_dPhi(partPhi,truthPhi)*TMath::DegToRad();\n\tconst double dThetaPartTruth = (partTheta-truthTheta)*TMath::DegToRad();\n\n\tif ( fabs(dPhiPartTruth)<dPhi_angularMatchingCut && fabs(dThetaPartTruth)<dTheta_angularMatchingCut)\n\t\tpassAngularMatching = true;\n\n\tif (fabs(partEnergy-truthEnergy)<caloCut_energyMatching*sqrt(truthEnergy))\n\t\tpassEnergyMatching = true;\n\n\tif ((fabs(truthPt-partPt))<transMomCut_energyMatching*truthPt)\n\t\tpassTransMomMatching = true;\n\n\tpassAngularMatching = passAngularMatching || (!applyAngularMatching) || (isMergedCandidate && noAngularMatchingForMergedCandidates);\n\tpassEnergyMatching = passEnergyMatching || (!applyEnergyMatching);\n\tpassTransMomMatching = passTransMomMatching || (!applyEnergyMatching);\n\n\tbool passFinalEnergyMomMatching = ((passEnergyMatching && (truthType==22 || useCaloCutInsteadMomentum || (useCaloCutInsteadMomentumForMergedCandidates && isMergedCandidate))) || (passTransMomMatching==true && truthType!=22));\n\n\tif (config::vm.count(\"debug\")){\n\t\tstd::cout << \"r: pdg: \" << std::setw(5) << partCandidate->getType() << \": E: \" << std::setw(6) << (round(100*partEnergy)/100.0) << \": pT: \" << std::setw(6) << (round(100*partPt)/100.0) << \"; theta: \" << std::setw(6) << round(100*partTheta)/100.0 << \"; phi: \" << std::setw(6) << round(100*partPhi)/100.0 << \"; AngularMatching: \" << passAngularMatching << \"; EnergyMatching: \" << passEnergyMatching << \"; TransMomMatching: \" << passTransMomMatching << \"; passFinalEnMom: \" << passFinalEnergyMomMatching << std::endl;\n\t\tstd::cout << \"fabs(dPhiPartTruth): \" << fabs(dPhiPartTruth) << \"; dPhi_angularMatchingCut: \" << dPhi_angularMatchingCut << \"; fabs(dThetaPartTruth): \" << fabs(dThetaPartTruth) << \"; dTheta_angularMatchingCut: \" << dTheta_angularMatchingCut << std::endl;\n\t}\n\t\t\n\n\tif (passFinalEnergyMomMatching == true && passAngularMatching == true){\n\t\tgetHistFromMap(\"efficiencyVsTheta\")->Fill(truthTheta);\n\t\tgetHistFromMap(\"efficiencyVsCosTheta\")->Fill(cosTruthTheta);\n\t\tgetHistFromMap(\"efficiencyVsEnergy\")->Fill(truthEnergy);\n\n\t\tgetHistFromMap(\"PFO_passed_eff_E\")->Fill(partEnergy);\n\t\tgetHistFromMap(\"PFO_passed_eff_Pt\")->Fill(partPt);\n\t\tgetHistFromMap(\"PFO_passed_eff_dE\")->Fill((partEnergy-truthEnergy)/truthEnergy);\n\t\tgetHistFromMap(\"PFO_passed_eff_dPt\")->Fill((truthPt-partPt)/truthPt);\n\t\t// WARNING TODO proper dPhi and dTheta\n\t\tgetHistFromMap(\"PFO_passed_eff_dTheta\")->Fill(dThetaPartTruth);\n\t\tgetHistFromMap(\"PFO_passed_eff_dPhi\")->Fill(dPhiPartTruth);\n\n\t}\n\telse if (passAngularMatching==false && passFinalEnergyMomMatching == true){\n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailAngularMatching\")->Fill(cosTruthTheta);\n\t}\n\telse if (passFinalEnergyMomMatching==false){\n\t\tgetHistFromMap(\"efficiencyVsCosThetaFailEnergyMatching\")->Fill(cosTruthTheta);\n\t}\n\n}\n\nvoid eventHistFiller::fillOtherHists(){\n\n\tgetHistFromMap(\"totalRecoEnergy\")->Fill(totalRecoEnergy);\n\n\t// std::map<unsigned int, std::string> pfoTypeIntStringMap = {{11,\"Electron\"}, {13,\"Muon\"},{22,\"Photon\"},{211,\"Pion\"},{2112,\"NeutralHadron\"}};\n\tif (pfoCounter[\"Electron\"]==0 && pfoCounter[\"Pion\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat1\")->Fill(cosTruthTheta);\n\telse if (pfoCounter[\"Electron\"]==1 && pfoCounter[\"Pion\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat2\")->Fill(cosTruthTheta);\n\telse if (pfoCounter[\"Pion\"]==1 && pfoCounter[\"Electron\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat3\")->Fill(cosTruthTheta);\n\telse\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat4\")->Fill(cosTruthTheta);\n\tif (pfoCounter[\"Electron\"]==1 && pfoCounter[\"Pion\"]==0)\n\t\tgetHistFromMap(\"efficiencyVsCosThetaCat5\")->Fill(cosTruthTheta);\n\n\n}\n\nvoid eventHistFiller::setClusterMerging(string _mergeTag){\n\tif (!IsInVector<string>(_mergeTag,effType))\n\t\tcout << \"[eventHistFiller::setClusterMerging]\\tERROR mergeTag <\" << _mergeTag << \"> is not supported!!!\" << endl;\n\telse\n\t\tmergeTag = _mergeTag;\n}\n"
},
{
"alpha_fraction": 0.5712077617645264,
"alphanum_fraction": 0.5895341038703918,
"avg_line_length": 40.52293395996094,
"blob_id": "b0bdf7eebf6632117bde57ab762a1c2a292783cb",
"content_id": "d5450fc0e7f76940efc44b38a081c84b34641805",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4529,
"license_type": "no_license",
"max_line_length": 583,
"num_lines": 109,
"path": "/MuonReco/src/truthZWCondition.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/truthZWCondition.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t15th Dec 2017\n * \tLast Update:\t15th Dec 2017\n */\n\n#include \"truthZWCondition.h\"\n\ntruthZWCondition* truthZWCondition::s_instance = NULL; \n\n/*===========================================================================*/\n/*===============================[ implementation ]===============================*/\n/*===========================================================================*/\n\nvoid truthZWCondition::processEvent(const EVENT::LCEvent* _event){\n\tevent = _event;\n\n\tnTruthParticles = 0;\n\tnStableGenParticles = 0;\n\tparticlesOfInterest.clear();\n\n\ttry {\n\t\tMCTruthCollection = event->getCollection(MCTruthCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tstd::cout << \"[ERROR|truthZWCondition::setEvent]\\tCan't find collection: \" << MCTruthCollectionName << std::endl;\n\t}\n\n\tnTruthParticles = MCTruthCollection->getNumberOfElements();\n\tif (config::vm.count(\"debug\"))\n\t\tstd::cout << \"Truth particles:\" << std::endl;\n\t// std::cout << \"Truth particles:\" << std::endl;\n\tfor(int j=0; j < nTruthParticles; j++) {\n\t\tauto part = static_cast<EVENT::MCParticle*>(MCTruthCollection->getElementAt(j));\n\t\tTVector3 v1(part->getMomentum());\n\t\tdouble partTheta = v1.Theta()*TMath::RadToDeg();\n\t\tauto parents = part->getParents();\n\t\tint parentPDG = 0;\n\t\tif (parents.size()==1)\n\t\t\tparentPDG = parents[0]->getPDG();\n\n\t\tif (config::vm.count(\"debug\") )\n\t\t\tdumpTruthPart(part,j);\n\t\tif (\n\t\t\t\tpart->getGeneratorStatus()>=1\n\t\t\t\t&& abs(part->getPDG())==partTypeToSelect \n\t\t\t\t&& (part->getEnergy()>particleEnergyCut)\n\t\t\t\t&& (partTheta>particleThetaCut) && (partTheta<(180.0-particleThetaCut))\n\t\t\t\t// && (abs(parentPDG)==abs(motherPDG))\n\t\t )\n\t\t{\n\t\t\t// dumpTruthPart(part,j);\n\t\t\t// auto daughters = part->getDaughters();\n\t\t\t// for (auto iPartInnerLoop: daughters){\n\t\t\t// dumpTruthPart(iPartInnerLoop,j);\n\t\t\t// }\n\n\t\t\t// EVENT::MCParticle* loopPart = nullptr;\n\t\t\t// bool noStableLeptonsOfInterest = false;\n\t\t\t// while (noStableLeptonsOfInterest == false){\n\t\t\t// for (auto iPartInnerLoop: daughters){\n\t\t\t// dumpTruthPart(iPartInnerLoop,j);\n\t\t\t// // if abs(iPartInnerLoop->getPDG())==partTypeToSelect &&\n\t\t\t// }\n\t\t\t// noStableLeptonsOfInterest = true;\n\t\t\t// }\n\t\t\tnStableGenParticles++;\n\t\t\tparticlesOfInterest.push_back(part);\n\t\t}\n\t}\n\t// if (config::vm.count(\"debug\"))\n\t// dumpTruthCondition();\n\t// if (simFSRPresent==false && nTruthParticles>1)\n\t// dumpTruthCondition();\n\n}\n\nvoid truthZWCondition::dumpTruthCondition(){\n\n\tstd::cout << \"Event\\t\" << event->getEventNumber() << \"; nTruthParticles: \" << nTruthParticles << \"; nStableGenParticles: \" << nStableGenParticles << std::endl << std::endl;\t\n\n}\n\n// bool hasParentOfType(const EVENT::MCParticle* part, unsigned int parentPDG){\n//\n// }\n\nvoid truthZWCondition::dumpTruthPart(const EVENT::MCParticle* part, const int counter){\n\tconst double *partMom = part->getMomentum();\n\tTVector3 v1;\n\tv1.SetXYZ(partMom[0],partMom[1],partMom[2]);\n\tdouble partPhi = 180.*v1.Phi()/TMath::Pi();\n\tdouble partTheta = 180.*v1.Theta()/TMath::Pi();\n\tbool inTracker = part->isDecayedInTracker();\n\tbool inCal = part->isDecayedInCalorimeter();\n\tint genStatus = part->getGeneratorStatus();\n\tint pdgId = part->getPDG();\n\tbool vertexIsNotEndpointOfParent = part->vertexIsNotEndpointOfParent();\n\tconst double *vertexPos = part->getVertex();\n\tdouble vertexR = sqrt(vertexPos[0]*vertexPos[0]+vertexPos[1]*vertexPos[1]);\n\tdouble vertexZ = vertexPos[2];\n\tunsigned int nParents = part->getParents().size();\n\tunsigned int nDaughters = part->getDaughters().size();\n\tstd::cout << \"t\" << counter << \": pdg: \" << std::setw(5) << pdgId << \": E: \" << std::setw(6) << (round(100*part->getEnergy())/100.0) << \": pT: \" << std::setw(6) << (round(100*v1.Pt())/100.0) << \"; theta: \" << std::setw(6) << round(100*partTheta)/100.0 << \"; phi: \" << std::setw(6) << round(100*partPhi)/100.0 << \"; inTracker: \" << inTracker << \"; inCal: \" << inCal << \"; genStatus: \" << genStatus << \"; isRadiation: \" << vertexIsNotEndpointOfParent << \"; vertexR: \" << vertexR << \"; vertexZ: \" << vertexZ << \"; nParents: \" << nParents << \"; nDaughters: \" << nDaughters << std::endl;\n}\n/*===========================================================================*/\n/*===============================[ implementation ]===============================*/\n/*===========================================================================*/\n\n\n\n"
},
{
"alpha_fraction": 0.6703545451164246,
"alphanum_fraction": 0.6821724772453308,
"avg_line_length": 33.877193450927734,
"blob_id": "ec6fef39392e4abe821abb8615fe5b934e72f418",
"content_id": "58dba0b8c24243c61ef7816b1efe28f5afff4a5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3977,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 114,
"path": "/PhotonECAL/JetPerformance.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "//custom libs\n#include <jetPfoStudy.h>\n#include <truthParticleSelector.h>\n#include <boostServiceFunctions.h>\n// #include \"truthCondition.h\"\n// #include <globalConfig.h>\n\n\nusing namespace std;\nusing namespace config; \n\nvector<string> collectionsToRead = {};\n// vector<string> particleFillCollections = {\"PandoraPFOs\",\"LooseSelectedPandoraPFOs\",\"SelectedPandoraPFOs\",\"TightSelectedPandoraPFOs\"};\nvector<string> particleFillCollections = {\"PandoraPFOs\"};\nvector<string> energyFillCollections = {};\nvector<string> additionalCollections = {\"MCParticle\"};\n\nint main (int argn, char* argv[]) {\n\n\tpo::options_description desc(\"Options\");\n\tdesc.add_options()\n\t\t(\"help,h\", \"Example:\\n ./JetPerformance -f \\\"/ssd/viazlo/data/FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_photons_cosTheta_v1_files/FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_photons_cosTheta_v1_E10_*\\\" -n 10\")\n\t\t(\"filesTemplate,f\", po::value<string>()->required(), \"file template\")\n\t\t(\"nFiles,n\", po::value<unsigned int>(), \"Set up limit on number of files to read\")\n\t\t(\"debug,d\", \"debug flag\")\n\t\t;\n\n\t/// get global input arguments\n\tconst size_t returnedMessage = parseOptionsWithBoost(vm,argn,argv, desc);\n\tif (returnedMessage!=SUCCESS) \n\t\tstd::exit(returnedMessage);\n\n\t// Read collections\n\tstd::vector<std::string> m_fileNames = getFilesMatchingPattern(vm[\"filesTemplate\"].as<string>());\n\tif (m_fileNames.size()==0){\n\t\tcout << \"[ERROR]\\t[StudyElectronPerformance] No input files found...\" << endl;\n\t\treturn 0;\n\t}\n\n\n\tif (vm.count(\"nFiles\"))\n\t\tif (vm[\"nFiles\"].as<unsigned int>()<m_fileNames.size())\n\t\t\tm_fileNames.resize(vm[\"nFiles\"].as<unsigned int>());\n\n\tcout << endl << \"[INFO]\\tNumber of input files to be used: \" << m_fileNames.size() << \" files\" << endl;\n\n\n\t// Open Files\n\tauto m_reader( IOIMPL::LCFactory::getInstance()->createLCReader());\n\ttry{\n\t\tm_reader->open( m_fileNames );\n\t} catch (IO::IOException &e) {\n\t\tstd::cerr << \"Error opening files: \" << e.what() << std::endl;\n\t\treturn 1;\n\t}\n\n\tif (vm.count(\"debug\")){\n\t\tcout << \"First file to be read: \" << m_fileNames[0] << endl;\n\t\tcout << \"Number of events to be read: \" << m_reader->getNumberOfEvents() << endl;\n\t}\n\n\tcollectionsToRead.insert(collectionsToRead.end(),energyFillCollections.begin(),energyFillCollections.end());\n\tcollectionsToRead.insert(collectionsToRead.end(),particleFillCollections.begin(),particleFillCollections.end());\n\tcollectionsToRead.insert(collectionsToRead.end(),additionalCollections.begin(),additionalCollections.end());\n\n\tcout << endl << \"Collections to be read:\" << endl;\n\tfor (int kk=0; kk<collectionsToRead.size(); kk++){\n\t\tcout << \"- \" << collectionsToRead[kk] << endl;\n\t}\n\tcout << endl;\n\t// m_reader->setReadCollectionNames(collectionsToRead);\n \n\tvector<jetPfoStudy*> selectors;\n\tfor (auto colIt=particleFillCollections.begin(); colIt!=particleFillCollections.end(); colIt++){\n\t\tjetPfoStudy *sel = new jetPfoStudy(\"jetStudy\",additionalCollections[0],*colIt);\n\t\t// jetPfoStudy *sel = new jetPfoStudy(\"jetStudy_\"+*colIt,additionalCollections[0],*colIt);\n\t\tsel->init();\n\t\tif (vm.count(\"debug\")) \n\t\t\tsel->setDebugFlag(true);\n\t\tselectors.push_back(sel);\n\t}\n\n\n\tTFile *outFile = new TFile(\"jetStudy.root\", \"RECREATE\");\n\toutFile->Close();\n\n\t// LOOP OVER EVENTS\n\tif (vm.count(\"debug\")) cout << \"Reading first event...\" << endl;\n\tEVENT::LCEvent *event = m_reader->readNextEvent();\n\t// EVENT::LCEvent *event = m_reader->readEvent(0,1);\n\tint eventCounter = 0;\n\tif (vm.count(\"debug\"))\n\t\tcout << \"First event pointer: \" << event << endl;\n\n\twhile ( event != NULL ) {\n\t\tif (vm.count(\"debug\")) \n\t\t\tcout << endl << \"Event \" << eventCounter << \":\" << endl;\n\t\n\t\tfor(auto i=0; i<selectors.size(); i++){\n\t\t\tselectors[i]->fillEvent(event);\n\t\t}\n\t\tevent = m_reader->readNextEvent();\n\t\teventCounter++;\n\t\tif (eventCounter%10==0)\n\t\t\tcout << \"Event processed: \" << eventCounter << \":\" << endl;\n\t}\n\n\tfor(auto i=0; i<selectors.size(); i++){\n\t\tTFile *outFile = new TFile(\"jetStudy.root\", \"UPDATE\");\n\t\tselectors[i]->writeToFile(outFile);\n\t\toutFile->Close();\n\t}\n\n}\n\n"
},
{
"alpha_fraction": 0.5998110771179199,
"alphanum_fraction": 0.6196473836898804,
"avg_line_length": 31.060606002807617,
"blob_id": "cea6ce00c070f47e5affcb1c652702badf443f6f",
"content_id": "0c6f1bcfbfe94c4056dbe0ab62d2503f307bb021",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3176,
"license_type": "no_license",
"max_line_length": 371,
"num_lines": 99,
"path": "/PhotonECAL/src/eventHistFiller.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/src/eventHistFiller.cpp\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n\n#include \"eventHistFiller.h\"\n\n/*===========================================================================*/\n/*===============================[ function implementations ]================*/\n/*===========================================================================*/\n\n// double round(double value, unsigned int prec = 1)\n// {\n// return floor( value*pow(10,prec) + 0.5 )/pow(10,prec);\n// }\n\n\nint eventHistFiller::fillEvent(const EVENT::LCEvent* event){\n\ttry {\n\t\tPFOCollection = event->getCollection(PFOCollectionName);\n\t} catch (EVENT::DataNotAvailableException &e) {\n\t\tcout << \"[ERROR|eventHistFiller]\\tCan't find collection: \" << PFOCollectionName << endl;\n\t\treturn -1;\n\t\n\t}\n\tnPFOs = PFOCollection->getNumberOfElements();\n\n\t// if (config::vm.count(\"debug\"))\n\t// cout << \"[INFO]\teventHistFiller::fillEvent: \" << event->getEventNumber() << endl;\n\n\tinitTruthInfoAndFillIt();\n\n\tvector<EVENT::ReconstructedParticle*> recoPFOs = getObjVecFromCollection<EVENT::ReconstructedParticle*>(PFOCollection);\n\tgetHistFromMap(\"nPFOs\")->Fill(recoPFOs.size());\n\tif (recoPFOs.size()==0) \n\t\treturn 0; // no reco PFOs\n\n\tfor (auto it = config::pfoTypeIntStringMap.begin(); it != config::pfoTypeIntStringMap.end(); it++)\n\t\tpfoCounter[it->second] = 0;\n\n\ttotalRecoEnergy = 0.0;\n\tbool efficiencyHistWasAlreadyFilled = false;\n\n\tbool passTypeCut = false;\n\tbool passAngularCut = false;\n\tbool passEnergyCut = false;\n\n\tdouble tmpEnergy = std::numeric_limits<double>::min();\n\n\tif (config::vm.count(\"debug\"))\n\t\tcout << \"Reconstructed particles:\" << endl;\n\tfor (int i=0; i<recoPFOs.size(); i++){\n\n\t\tfillPfoCounterAndFillGeneralPfoInfo(i);\n\n\t\tif (recoPFOs[i]->getType()==truthType){\n\t\t\tpassTypeCut = true;\n\t\t\tif (recoPFOs[i]->getEnergy()>tmpEnergy){\n\t\t\t\ttmpEnergy = recoPFOs[i]->getEnergy();\n\t\t\t\tidOfPartCandidate = i;\n\t\t\t}\n\t\t}\n\t}\n\n\n\tif (passTypeCut==false){\n\t\tfillEventsFailedSelection();\n\t\tif (config::vm.count(\"debug\"))\n\t\t\tcout << \"***Do Not Pass Type Cut***\" << endl;\n\t}\n\telse{\n\t\tpartCandidate = static_cast<IMPL::ReconstructedParticleImpl*>(PFOCollection->getElementAt(idOfPartCandidate));\n\t\tgetHistFromMap(\"efficiencyVsEnergy_onlyType\")->Fill(truthEnergy);\n\n\t\t//##### Cluster merging\n\t\tvector<unsigned int> mergedParticleIds = mergeClusters();\n\t\tisMergedCandidate = (mergedParticleIds.size()>0);\n\n\t\tif (config::vm.count(\"debug\")){\n\t\t\tstd::cout << endl << \"Main Truth and Reconstructed Candidates:\" << endl << \"t: pdg: \" << std::setw(5) << truthType << \": E: \" << std::setw(6) << (round(100*truthEnergy)/100.0) << \": pT: \" << std::setw(6) << (round(100*truthPt)/100.0) << \"; theta: \" << std::setw(6) << round(100*truthTheta)/100.0 << \"; phi: \" << std::setw(6) << round(100*truthPhi)/100.0 << std::endl;\n\t\t\tcout << endl << \"Merged particles: \"; \n\t\t\tfor(auto const& value: mergedParticleIds) \n\t\t\t std::cout << value << \" \";\n\t\t\tcout << endl << endl;\n\t\t}\n\n\t\t//##### Angular and energy matching\n\t\tangularAndEnergyMatching();\n\n\t\t//##### Histogram filling\n\t\tfillOtherHists();\n\n\n\t}\n\n}\n\n\n"
},
{
"alpha_fraction": 0.7428935170173645,
"alphanum_fraction": 0.7526516914367676,
"avg_line_length": 32.197181701660156,
"blob_id": "74d3ae08e88d0acb717defc263269383521c92b9",
"content_id": "76fc0a597bdbf8d36e499ac62aab89b320d69e0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2357,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 71,
"path": "/PhotonECAL/include/electronStudy.h",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "/**@file\t/afs/cern.ch/work/v/viazlo/analysis/PFAAnalysis/PhotonECAL/include/electronStudy.h\n * @author\tviazlo\n * @version\t800\n * @date\n * \tCreated:\t05th Dec 2017\n * \tLast Update:\t05th Dec 2017\n */\n#ifndef ELECTRONSTUDY_H\n#define ELECTRONSTUDY_H\n\n#include <objectFill.h>\n#include <energyFill.h>\n#include <globalConfig.h>\n#include \"truthCondition.h\"\n#include \"Objects/CartesianVector.h\"\n#include \"Objects/TrackState.h\"\n#include \"EVENT/TrackState.h\"\n// #include \"Objects/Cluster.h\"\n\n// struct PFOMergeSettings{\n// unsigned int pfoTypeToMerge;\n// double thetaCone;\n// double phiCone;\n// double phiConeMomentumDep = 0.0;\n// };\n\nclass electronStudy : public objectFill{\n\tpublic:\n\t\telectronStudy(string _outDirName, string _PFOCollectionName = \"PandoraPFOs\") : objectFill(_outDirName) {PFOCollectionName = _PFOCollectionName;}\n\t\t~electronStudy(){}\n\n\t\tint init();\n\t\tint fillEvent(const EVENT::LCEvent*);\n\t\tint writeToFile(TFile* outFile);\n\n\tprivate:\n\t\tunsigned int nSelectecTruthParticles;\n\t\tstring PFOCollectionName;\n\t\tstring trackCollectionName;\n\t\tstring ecalBarrelCollectionName;\n\t\tEVENT::LCCollection *PFOCollection;\n\t\tEVENT::LCCollection *trackCollection;\n\t\tEVENT::LCCollection *ecalBarrelCollection;\n\n\t\tUTIL::BitField64* _encoder;\n\n\t\tmap <string,map <string, unsigned int> > categoryMap;\n\t\t// if pfoId<0 - dont apply prefix\n\t\tvoid fillHistsPerCategory(string histNameCore, double fillValue, int pfoId);\n\t\tmap <string, unsigned int> pfoCounter;\n\t\tmap <unsigned int, unsigned int> energyRanking;\n\t\t// (energy, pfoID, pfoType)\n\t\tvector<pair<double, pair<unsigned int, unsigned int> > > pfoIdSortedByEnergyAndType; \n\t\tmap<unsigned int, string> pfoIdEnergyTypeMap;\n\t\tvector<EVENT::ReconstructedParticle*> recoPFOs;\n\n\t\tvoid performEnergyPfoTypeRanking();\n\n\t\tTVector3* getTrackStateMomentum(EVENT::Track *inTrack);\n\t\tTVector3* getTrackStatePosition(EVENT::Track *inTrack);\n\n\t\t// void CopyTrackState(const EVENT::TrackState *const pTrackState, pandora::TrackState &inputTrackState) const;\n\t\tpandora::TrackState* getPandoraTrackState(const EVENT::TrackState *const pTrackState);\n\n\t\tint getLayerNumber(EVENT::CalorimeterHit* calHit);\n\t\tunsigned int maxCaloSearchLayer = 9;\n\n\t\tmap <string, double> getTrackClusterDistance(const EVENT::ReconstructedParticle* const inPart, const EVENT::Track* const inTrack);\n\n};\n#endif // ELECTRONSTUDY_H\n"
},
{
"alpha_fraction": 0.6472841501235962,
"alphanum_fraction": 0.6735143661499023,
"avg_line_length": 41.43842315673828,
"blob_id": "02d659f9eadcd3feca3c5d31f5dd46b736178a49",
"content_id": "2327308919fba1f4e97b26d40d610eef77f2e1f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8616,
"license_type": "no_license",
"max_line_length": 264,
"num_lines": 203,
"path": "/PhotonECAL/AnalyzeIsotropPhotonSample.cpp",
"repo_name": "oviazlo/ParticleFlowAnalysis",
"src_encoding": "UTF-8",
"text": "//custom libs\n// #include <particleFill.h>\n#include <truthParticleSelector.h>\n#include <boostServiceFunctions.h>\n#include \"truthCondition.h\"\n// #include <globalConfig.h>\n\nusing namespace std;\nusing namespace config; \n\n// 11:\t\telectron\n// 13:\t\tmuon\n// 22:\t\tphoton\n// 211: \tpi+\n// 2112:\tneutron\n \n// COLLECTIONS TO USE\n// vector<string> particleFillCollections = {\"SiTracks\",\"MCParticlesSkimmed\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\",\"PandoraPFOs\"};\n// vector<string> particleFillCollections = {\"MCParticlesSkimmed\",\"PandoraPFOs\",\"PandoraPFOs\"};\n// vector<vector<int> > PFOPartTypes = {{},{},{11},{-11},{13},{-13},{22},{-211},{211},{2112},{11,22},{11,-11,13,-13,211,-211},{22,2112}};\n// vector<vector<int> > PFOPartTypes = {{},{22},{2112}};\n// vector<vector<int> > PFOPartTypes = {{},{22},{11,-11,13,-13,211,-211,22,2112}};\nvector<string> particleFillCollections = {\"MCParticlesSkimmed\",\"PandoraPFOs\",\"PandoraPFOs\"};\nvector<vector<int> > PFOPartTypes = {{},\t\t\t{11},{-211}};\n// int efficiencyPFOType = 11;\n// vector<string> energyFillCollections = {\"ECALBarrel\",\"ECALEndcap\"[>, \"ECalBarrelCollection\", \"ECalEndcapCollection\"<]};\n// vector<string> energyFillCollections = {\"ECALBarrel\",\"ECALEndcap\",\"ECalBarrelCollection\", \"ECalEndcapCollection\", \"HCALBarrel\",\"HCALEndcap\",\"HCalBarrelCollection\", \"HCalEndcapCollection\"};\n// vector<string> energyFillCollections = {\"ECALBarrel\",\"ECALEndcap\", \"HCALBarrel\",\"HCALEndcap\"};\nvector<string> energyFillCollections = {};\nvector<string> additionalCollections = {};\n// po::variables_map vm;\n\nint main (int argn, char* argv[]) {\n\n\tpo::options_description desc(\"Options\");\n\tdesc.add_options()\n\t\t(\"help,h\", \"Example:\\n ./AnalyzeIsotropPhotonSample -f \\\"/ssd/viazlo/data/FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_photons_cosTheta_v1_files/FCCee_o5_v04_ILCSoft-2017-07-27_gcc62_photons_cosTheta_v1_E10_*\\\" -n 10 --energy 9 11 --theta 50 60 70 80 90 --phi 0 10 20\")\n\t\t(\"filesTemplate,f\", po::value<string>()->required(), \"file template\")\n\t\t(\"nFiles,n\", po::value<unsigned int>(), \"Set up limit on number of files to read\")\n\t\t(\"energy\", po::value<vector<double> >()->multitoken(), \"To specify energy ranges. \\nFormat: 10 50 100\")\n\t\t(\"theta\", po::value<vector<double> >()->multitoken(), \"To specify theta ranges. \\nFormat: 0 45 90\")\n\t\t(\"phi\", po::value<vector<double> >()->multitoken(), \"To specify phi ranges. \\nFormat: 0 90 180\")\n\t\t(\"minE\", po::value<double>(), \"minimum energy\")\n\t\t(\"maxE\", po::value<double>(), \"maximum energy\")\n\t\t(\"minTh\", po::value<double>(), \"minimum theta\")\n\t\t(\"maxTh\", po::value<double>(), \"maximum theta\")\n\t\t(\"minPhi\", po::value<double>(), \"minimum phi\")\n\t\t(\"maxPhi\", po::value<double>(), \"maximum phi\")\n\t\t(\"nE\", po::value<unsigned int>(), \"number of energy bins\")\n\t\t(\"nTh\", po::value<unsigned int>(), \"number of theta bins\")\n\t\t(\"nPhi\", po::value<unsigned int>(), \"number of phi bins\")\n\t\t(\"effPfoType\", po::value<int>(), \"PFO type to use for efficiency calculation\")\n\t\t(\"noFSR\", \"discard events with FSR (only one truth particle allowed)\")\n\t\t(\"dPhiMerge\", po::value<double>(), \"dPhi value in degrees to merge clusters\")\n\t\t(\"accessCaloHitInfo\", \"fill in CaloHitInfo - 2x slower\")\n\t\t(\"debug,d\", \"debug flag\")\n\t\t;\n\n\t/// get global input arguments\n\tconst size_t returnedMessage = parseOptionsWithBoost(vm,argn,argv, desc);\n\tif (returnedMessage!=SUCCESS) \n\t\tstd::exit(returnedMessage);\n\n\t// Read collections\n\tstd::vector<std::string> m_fileNames = getFilesMatchingPattern(vm[\"filesTemplate\"].as<string>());\n\tif (m_fileNames.size()==0){\n\t\tcout << \"[ERROR]\\t[AnalyzeIsotropPhotonSample] No input files found...\" << endl;\n\t\treturn 0;\n\t}\n\n\n\tif (vm.count(\"nFiles\"))\n\t\tif (vm[\"nFiles\"].as<unsigned int>()<m_fileNames.size())\n\t\t\tm_fileNames.resize(vm[\"nFiles\"].as<unsigned int>());\n\n\tcout << \"[INFO]\\tNumber of input files to be used: \" << m_fileNames.size() << \" files\" << endl;\n\n\tbool printVerbose = false;\n\n\t// Open Files\n\tauto m_reader( IOIMPL::LCFactory::getInstance()->createLCReader());\n\ttry{\n\t\tm_reader->open( m_fileNames );\n\t} catch (IO::IOException &e) {\n\t\tstd::cerr << \"Error opening files: \" << e.what() << std::endl;\n\t\treturn 1;\n\t}\n\tvector<string> collectionsToRead = {};\n\tif (!vm.count(\"accessCaloHitInfo\")) {\n\t\tenergyFillCollections = {};\n\t}\n\telse{\n\t\tadditionalCollections = {\"ECALBarrel\",\"ECALEndcap\", \"HCALBarrel\",\"HCALEndcap\",\"ECalBarrelCollection\", \"ECalEndcapCollection\",\"HCalBarrelCollection\", \"HCalEndcapCollection\"};\n\t}\n\tcollectionsToRead.insert(collectionsToRead.end(),energyFillCollections.begin(),energyFillCollections.end());\n\tcollectionsToRead.insert(collectionsToRead.end(),particleFillCollections.begin(),particleFillCollections.end());\n\tcollectionsToRead.insert(collectionsToRead.end(),additionalCollections.begin(),additionalCollections.end());\n\tm_reader->setReadCollectionNames(collectionsToRead);\n\n\tvector<double> energyRanges = {9.9,10.1};\n\tvector<double> thetaRanges = {-180.0,180.0};\n\tvector<double> phiRanges = {-360.0,360.0};\n\n\tif (vm.count(\"energy\"))\n\t\tenergyRanges = vm[\"energy\"].as<vector<double> >();\n\tif (vm.count(\"theta\"))\n\t\tthetaRanges = vm[\"theta\"].as<vector<double> >();\n\tif (vm.count(\"phi\"))\n\t\tphiRanges = vm[\"phi\"].as<vector<double> >();\n\n\tif (vm.count(\"minE\") && vm.count(\"maxE\") && vm.count(\"nE\")){\n\t\tenergyRanges = {};\n\t\tfor (auto i=0; i<vm[\"nE\"].as<unsigned int>()+1; i++){\n\t\t\tdouble iE = vm[\"minE\"].as<double>() + i*( vm[\"maxE\"].as<double>() - vm[\"minE\"].as<double>() )/vm[\"nE\"].as<unsigned int>();\n\t\t\tenergyRanges.push_back(iE);\n\t\t}\n\t}\n\t\n\tif (vm.count(\"minTh\") && vm.count(\"maxTh\") && vm.count(\"nTh\")){\n\t\tthetaRanges = {};\n\t\tfor (auto i=0; i<vm[\"nTh\"].as<unsigned int>()+1; i++){\n\t\t\tdouble iTh = vm[\"minTh\"].as<double>() + i*( vm[\"maxTh\"].as<double>() - vm[\"minTh\"].as<double>() )/vm[\"nTh\"].as<unsigned int>();\n\t\t\tthetaRanges.push_back(iTh);\n\t\t}\n\t}\n\tif (vm.count(\"minPhi\") && vm.count(\"maxPhi\") && vm.count(\"nPhi\")){\n\t\tphiRanges = {};\n\t\tfor (auto i=0; i<vm[\"nPhi\"].as<unsigned int>()+1; i++){\n\t\t\tdouble iPhi = vm[\"minPhi\"].as<double>() + i*( vm[\"maxPhi\"].as<double>() - vm[\"minPhi\"].as<double>() )/vm[\"nPhi\"].as<unsigned int>();\n\t\t\tphiRanges.push_back(iPhi);\n\t\t}\n\t}\n\n\tvector<truthParticleSelector*> selectors;\n\tfor(auto iE=0; iE<energyRanges.size()-1;iE++){\n\tfor(auto iTheta=0; iTheta<thetaRanges.size()-1;iTheta++){\n\tfor(auto iPhi=0; iPhi<phiRanges.size()-1;iPhi++){\n\t\t\n\t\ttruthParticleSelector *sel1 = new truthParticleSelector();\n\t\tsel1->setEnergyRange(energyRanges[iE],energyRanges[iE+1]);\n\t\tsel1->setThetaRange(thetaRanges[iTheta],thetaRanges[iTheta+1]);\n\t\tsel1->setPhiRange(phiRanges[iPhi],phiRanges[iPhi+1]);\n\t\tsel1->setEfficiencyCollection(\"PandoraPFOs\");\n\t\tif (vm.count(\"effPfoType\"))\n\t\t\tsel1->setEfficiencyPFOType(vm[\"effPfoType\"].as<int>());\n\t\tif (vm.count(\"dPhiMerge\"))\n\t\t\tsel1->setDPhiMergeValue(vm[\"dPhiMerge\"].as<double>());\n\t\tsel1->setParticleFillCollections(particleFillCollections);\n\t\tsel1->setPFOTypes(PFOPartTypes);\n\t\tsel1->setEnergyFillCollections(energyFillCollections);\n\t\tsel1->init();\n\t\tif (vm.count(\"noFSR\"))\n\t\t\tsel1->setDiscardFSREvents(true);\n\t\tselectors.push_back(sel1);\n\n\t}\n\t}\n\t}\n\n\n\t// LOOP OVER EVENTS\n\tEVENT::LCEvent *event = m_reader->readNextEvent();\n\tint eventCounter = 0;\n\n\ttruthCondition::instance()->setMCTruthCollectionName(\"MCParticlesSkimmed\");\n\tif (vm.count(\"debug\"))\n\t\ttruthCondition::instance()->setDebugFlag(false);\n\n\twhile ( event != NULL ) {\n\t\ttruthCondition::instance()->setEvent(event);\n\t\ttruthCondition::instance()->processEvent();\n\t\t// cout << \"[DEBUG]\\t event:\" << eventCounter << endl;\n\t\t// if (eventCounter>1000)\n\t\t// break;\n\t\tif (printVerbose) \n\t\t\tcout << endl << \"Event \" << eventCounter << \":\" << endl;\n\t\teventCounter++;\n\t\n\t\tfor(auto i=0; i<selectors.size(); i++){\n\t\t\tselectors[i]->selectEvent(event);\n\t\t}\n\t\tevent = m_reader->readNextEvent();\n\t}\n\n\tfor(auto i=0; i<selectors.size(); i++){\n\t\tTFile *outFile = new TFile((\"particleGun_\"+ selectors[i]->getPostFixString() +\".root\").c_str(), \"RECREATE\");\n\t\tselectors[i]->writeToFile(outFile);\n\t\toutFile->Close();\n\t}\n\n\t// SAVE OUTPUT HISTOGRAMS\n\t// double scale = 0.1;\n\t// string meanEnergy = DoubToStr( floor(static_cast<particleFill*>(objFillMap[\"MCParticlesSkimmed\"])->getMeanEnergy() / scale + 0.5)*scale );\n\t// string meanTheta = DoubToStr( floor(static_cast<particleFill*>(objFillMap[\"MCParticlesSkimmed\"])->getMeanTheta() / scale + 0.5)*scale );\n\t// TFile *outFile = new TFile((\"ECAL_photonGun_E\"+meanEnergy+\"_theta\"+meanTheta+\".root\").c_str(), \"RECREATE\");\n //\n\t// for(auto const &mapElement : objFillMap){\n\t// mapElement.second->writeToFile(outFile);\n\t// }\n\n\t// outFile->Close();\n\n}\n\n"
}
] | 48 |
showandtellinar/askjarvis | https://github.com/showandtellinar/askjarvis | f7dd18c844a2dcd77be44ae2e0ca78d84d785f02 | fef6fc089990deed7904bdd8c6b6f8820855107a | 62fed162a6aabb50400485c05b722ed3cc1e4fda | refs/heads/master | "2021-01-25T07:35:13.583005" | "2014-09-22T06:10:05" | "2014-09-22T06:10:05" | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5895741581916809,
"alphanum_fraction": 0.6030347347259521,
"avg_line_length": 34.842105865478516,
"blob_id": "4916e0c5cbecf0d52ecffb2f07b60b2f8472f45d",
"content_id": "7f159ae2ac1b90ba0feb4d21ebcc40aa7d3b7128",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4086,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 114,
"path": "/modules/LocationContext/LocationContext.py",
"repo_name": "showandtellinar/askjarvis",
"src_encoding": "UTF-8",
"text": "import datetime, folium, random, numpy as np, pandas as pd\nfrom bs4 import BeautifulSoup\n\ndef parse_kml(filename):\n \"\"\"Parses a KML file into a Pandas DataFrame\"\"\"\n with open(filename) as f:\n rows = []\n soup = BeautifulSoup(f)\n for time, coords in zip(soup.findAll('when'), soup.findAll('gx:coord')):\n timestamp = time.string\n coords = coords.string.split(' ')[:2]\n latitude = float(coords[0])\n longitude = float(coords[1])\n rows.append([timestamp, latitude, longitude])\n df = pd.DataFrame(rows, columns=['Timestamp', 'Longitude', 'Latitude'])\n df['Timestamp'] = pd.to_datetime(df.Timestamp.str.slice(0,23), format='%Y-%m-%dT%H:%M:%S.%f')\n return df\n\ndef clean_data(df):\n \"\"\"Only look at data within 75 miles of the median latitude and longitude.\"\"\"\n miles = 75.0\n degrees = miles / 69.11\n for col in ('Latitude', 'Longitude'):\n median = df[col].median()\n df = df[(df[col] >= median - degrees) & (df[col] <= median + degrees)]\n return df\n\ndef get_work_df(df):\n \"\"\"Get all data between 10AM and 4PM Monday-Friday\"\"\"\n return df[(df.hour >= 10) & (df.hour <= 16) & (df.day >= 0) & (df.day <= 4)]\n\ndef get_home_df(df):\n \"\"\"Get all data between 11PM and 5AM Monday-Thursday\"\"\"\n return df[((df.hour >= 23) | (df.hour <= 5)) & (df.day >= 0) & (df.day <= 3)]\n\ndef format_for_clustering(df):\n \"\"\"Format data for the clustering algorithm\"\"\"\n lng = df.Longitude\n lat = df.Latitude\n return np.array(zip(lng, lat))\n\n\n# Clustering algorithm from the internet\n# ------------------------------------- #\ndef cluster_points(X, mu):\n clusters = {}\n for x in X:\n bestmukey = min([(i[0], np.linalg.norm(x-mu[i[0]])) for i in enumerate(mu)], key=lambda t:t[1])[0]\n try:\n clusters[bestmukey].append(x)\n except KeyError:\n clusters[bestmukey] = [x]\n return clusters\n \ndef reevaluate_centers(mu, clusters):\n newmu = []\n keys = sorted(clusters.keys())\n for k in keys:\n newmu.append(np.mean(clusters[k], axis = 0))\n return newmu\n \ndef has_converged(mu, oldmu):\n return (set([tuple(a) for a in mu]) == set([tuple(a) for a in oldmu]))\n\ndef find_centers(X, K):\n # Initialize to K random centers\n oldmu = random.sample(X, K)\n mu = random.sample(X, K)\n while not has_converged(mu, oldmu):\n oldmu = mu\n # Assign all points in X to clusters\n clusters = cluster_points(X, mu)\n # Reevaluate centers\n mu = reevaluate_centers(oldmu, clusters)\n return {'centers': mu, 'datapoints': clusters}\n# ------------------------------------- #\n\ndef setup():\n \"\"\"Set up the master DataFrame\"\"\"\n df = parse_kml('brady_location.kml')\n df = clean_data(df)\n df['hour'] = df.Timestamp.map(lambda x: x.hour)\n df['day'] = df.Timestamp.map(lambda x: x.dayofweek)\n return df\n\ndef get_location(df, location_func, n):\n \"\"\"Use clustering to get a location for a certain time period\"\"\"\n location_df = location_func(df)\n location_data = format_for_clustering(location_df)\n location_cluster = find_centers(location_data, n)\n def f(x):\n err1 = abs(x[0] - location_df.Longitude.median())\n err2 = abs(x[1] - location_df.Latitude.median())\n return err1 + err2\n location_result = min(location_cluster['centers'], key=lambda x: f(x))\n return location_result\n\ndef display(initial_lat, initial_long, locations, map_path):\n \"\"\"Use folium to display locations\"\"\"\n fmap = folium.Map(location=[initial_lat, initial_long], zoom_start=13)\n for location in locations:\n fmap.simple_marker([location[0][1], location[0][0]], popup=location[1])\n fmap.create_map(path=map_path)\n\ndef main():\n \"\"\"Main function\"\"\"\n df = setup()\n work_location = get_location(df, get_work_df, 6)\n home_location = get_location(df, get_home_df, 6)\n locations = [(work_location, 'Work'), (home_location, 'Home')]\n display(df.Latitude.irow(0), df.Longitude.irow(0), locations, \"map.html\")\n return locations\n\nmain()\n"
},
{
"alpha_fraction": 0.7678571343421936,
"alphanum_fraction": 0.7678571343421936,
"avg_line_length": 27,
"blob_id": "875dbe3a7d661eaf4b8213b1c8716148cf1fbceb",
"content_id": "36f4890330381802edcb775db6e2b8cda0d3833c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 4,
"path": "/README.md",
"repo_name": "showandtellinar/askjarvis",
"src_encoding": "UTF-8",
"text": "askjarvis\n=========\n\nA modular open-source platform for reactive and predictive data analysis and presentation.\n"
}
] | 2 |
lostleaf/smear-detection | https://github.com/lostleaf/smear-detection | 7de012b5a51a8ea8b7122c072951f08812fc38bb | 8d2a33406a5fb057ad3f63eefd3afc438493506b | 597f23355e6d4f8090f494cb7474d6ee29b933a1 | refs/heads/master | "2020-04-11T08:07:20.310718" | "2016-02-17T22:46:16" | "2016-02-17T22:46:16" | 50,702,518 | 0 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.5854145884513855,
"alphanum_fraction": 0.6053946018218994,
"avg_line_length": 26.80555534362793,
"blob_id": "61f8385dcbdfe8a92b7522bdbe73b85d02a6c509",
"content_id": "5650b3ee09cf9d2dca9074cf1d735bea4687e8f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 36,
"path": "/variance.py",
"repo_name": "lostleaf/smear-detection",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport glob\nimport sys\nimport os\n\ndef calc_variance(file_names):\n img = cv2.imread(file_names[0], cv2.IMREAD_GRAYSCALE)\n img_sum = np.zeros_like(img, dtype=np.float64)\n img_sqr_sum = np.zeros_like(img, dtype=np.float64)\n for name in file_names:\n img = cv2.imread(name, cv2.IMREAD_GRAYSCALE).astype(np.float64)\n img_sum += img\n img_sqr_sum += img ** 2\n n = len(file_names)\n variance = img_sqr_sum / n - ((img_sum / n) ** 2)\n return variance\n\ndef main(argv):\n if len(argv) != 2:\n print \"usage: python %s [folder of images]\" % argv[0]\n sys.exit(-1)\n path = argv[1]\n variance = calc_variance(glob.glob(os.path.join(path, \"*.jpg\")))\n plt.imshow(variance)\n plt.colorbar()\n plt.show()\n if path[-1] == '/':\n path = path[:-1]\n basename = os.path.basename(path)\n np.save(\"%s_variance.npy\" % basename, variance)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n"
},
{
"alpha_fraction": 0.5073028206825256,
"alphanum_fraction": 0.5355404019355774,
"avg_line_length": 26.026315689086914,
"blob_id": "379676489b16b8ddf04036689ca46aaf835cd005",
"content_id": "bc51fa4e19e27615ec8d66b16baf33248c8b2723",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 38,
"path": "/smear_det.py",
"repo_name": "lostleaf/smear-detection",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport glob\nimport matplotlib.pyplot as plt\nfrom collections import deque\n\nTHRESHOLD1 = 200\nTHRESHOLD2 = 600\n\ndef bfs(variance, pos):\n CX = [1, 0, -1, 0]\n CY = [0, 1, 0, -1]\n s = set([(x, y) for x, y in pos])\n que = deque(pos)\n mask = np.zeros_like(variance, dtype=np.uint8)\n mask[variance < THRESHOLD1] = 255\n while len(que):\n x, y = que.popleft()\n for cx, cy in zip(CX, CY):\n nx, ny = x + cx, y + cy\n if variance[nx, ny] < THRESHOLD2 and (nx, ny) not in s:\n s.add((nx, ny)) \n mask[nx, ny] = 255\n que.append((nx, ny))\n return mask\n\ndef main():\n vfile_names = glob.glob(\"*.npy\")\n for idx, name in enumerate(vfile_names):\n variance = np.load(name)\n pos = np.c_[np.where(variance < THRESHOLD1)].tolist()\n mask = bfs(variance, pos)\n plt.subplot(231 + idx)\n plt.imshow(mask, cmap=\"gray\")\n plt.title(name)\n plt.show()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.7322695255279541,
"alphanum_fraction": 0.741134762763977,
"avg_line_length": 25.85714340209961,
"blob_id": "202e5acd3835c7fda0f3aa4734322952025356d3",
"content_id": "cdcf9a3e01c1e835195d38db658bdfe863123e6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 21,
"path": "/README.md",
"repo_name": "lostleaf/smear-detection",
"src_encoding": "UTF-8",
"text": "# Geospatial assigment2: Smear Detection\n\nFirst, make sure you have `Python2`, `numpy` and the Python interface of `OpenCV` installed.\n\nThen, run `variance.py` to generate variance map for each camera.\n\n```\npython variance [path-to-cam_0-images]\npython variance [path-to-cam_1-images]\n...\npython variance [path-to-cam_5-images]\n```\n\nAnd you will get `cam_[number]_vairance.npy` stores the variance map of each camera.\n\nLast, detect smear regions by\n\n```\npython smear_det.py\n```\nIt will plot a binary image for each npy file showing the smear and non-smear region.\n"
}
] | 3 |
jmservera/S3toAZ | https://github.com/jmservera/S3toAZ | 65cc37d1321eac47050d14d4a3ba52ca3c42c6d8 | 77b7f9dfe54b3ebcae0e1fe8ab54b627f6db76de | 4981714ae09c3fbd5c7f0ca9180d535375df836e | refs/heads/master | "2023-03-04T23:30:38.749572" | "2023-02-22T22:45:52" | "2023-02-22T22:45:52" | 186,000,505 | 0 | 0 | MIT | "2019-05-10T14:17:10" | "2019-06-12T09:01:32" | "2020-02-21T23:20:11" | PowerShell | [
{
"alpha_fraction": 0.6859660148620605,
"alphanum_fraction": 0.69246906042099,
"avg_line_length": 43.56074905395508,
"blob_id": "72d5cff30d3b73c230fd6c2b435dae4aab572101",
"content_id": "1801b2339dda0621fc41a312de9a7d28f24eb353",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4767,
"license_type": "permissive",
"max_line_length": 251,
"num_lines": 107,
"path": "/main.py",
"repo_name": "jmservera/S3toAZ",
"src_encoding": "UTF-8",
"text": "import boto3\nimport argparse\nimport os\nimport logging\nfrom azure.storage.blob import BlockBlobService,BlobBlock\nimport platform\nimport datetime\nimport uuid\n\ndef __getArgs():\n \"\"\"Gets the needed values from the command line arguments\"\"\"\n parser= argparse.ArgumentParser(\"Copy S3 to Azure Storage\")\n parser.add_argument('--source_bucket', type=str,help=\"The S3 bucket as in [BucketName]: https://[region like s3-eu-west-1].amazonaws.com/[bucketname]/[foldername]/[filename], can also be set by the [AWS_SOURCE_BUCKET] environment variable\")\n parser.add_argument('--source_file', type=str,help=\"The S3 bucket as in [foldername]/[filename]: https://[region like s3-eu-west-1].amazonaws.com/[bucketname]/[foldername]/[filename], can also be set by the [AWS_SOURCE_FILE] environment variable\")\n parser.add_argument('--source_secret_id',type=str,help=\"The S3 SECRET ID, can also be set by the [AWS_SECRET_ID] environment variable\")\n parser.add_argument('--source_secret_key',type=str,help=\"The S3 SECRET ACCESS KEY, can also be set by the [AWS_SECRET_ID] environment variable\")\n parser.add_argument('--destination_account',type=str, help=\"The Azure Storage account, can also be set by the [AZ_DESTINATION] environment variable\")\n parser.add_argument('--destination_SAS',type=str, help=\"The Azure Storage SAS Token, can also be set by the [AZ_DESTINATION_SAS] environment variable\")\n parser.add_argument('--destination_container',type=str, help=\"The Azure Storage blob container, can also be set by the [AZ_DESTINATION_CONTAINER] environment variable\")\n parser.add_argument('--destination_file',type=str, help=\"The path to the destination file, can also be set by the [AZ_DESTINATION_FILE] environment variable\")\n return parser.parse_args()\n\ndef __getEnv():\n \"\"\"Gets needed values from OS Environment\"\"\"\n class Object(object):\n pass\n\n env_data=Object()\n env_data.source_bucket=os.environ.get(\"AWS_SOURCE_BUCKET\")\n env_data.source_file=os.environ.get(\"AWS_SOURCE_FILE\")\n env_data.source_secret_id=os.environ.get('AWS_SECRET_ID')\n env_data.source_secret_key=os.environ.get('AWS_SECRET_ACCESS_KEY')\n env_data.destination_account=os.environ.get(\"AZ_DESTINATION_ACCOUNT\")\n env_data.destination_SAS=os.environ.get(\"AZ_DESTINATION_SAS\")\n env_data.destination_container=os.environ.get(\"AZ_DESTINATION_CONTAINER\")\n env_data.destination_file=os.environ.get(\"AZ_DESTINATION_FILE\")\n \n return env_data\n\ndef __merge(source,dest):\n \"\"\"Merge two objects, it will update only the empty (None) attributes in [dest] from [source]\n \"\"\"\n elements=vars(source)\n for element in elements:\n value=elements[element]\n if getattr(dest,element)==None:\n setattr(dest,element,value)\n \n elements=vars(dest)\n\ndef __checkValues(obj):\n \"\"\"Checks that all the needed values are filled and creates a warning if not\"\"\"\n elements=vars(obj)\n allValues=True\n for element in elements:\n if elements[element]==None:\n allValues=False\n logging.warning(element+\" does not have a value.\")\n #if all needed values are not supplied exit\n return allValues\n\ndef __initArgs():\n args= __getArgs()\n env= __getEnv()\n __merge(env,args)\n __checkValues(args)\n return args\n\ndef __copy(args):\n s3cli = boto3.resource(\"s3\", aws_access_key_id=args.source_secret_id, aws_secret_access_key=args.source_secret_key)\n azblob= BlockBlobService(args.destination_account, args.destination_SAS)\n\n s3object=s3cli.Object(args.source_bucket, args.source_file)\n print(\"Opening S3 object {0}/{1}\".format(args.source_bucket, args.source_file))\n chunk=s3object.get(PartNumber=1)\n nchunks=chunk['PartsCount']\n blocks=[]\n\n for x in range(1,nchunks+1):\n chunk=s3object.get(PartNumber=x)\n print(\"Reading part {0}/{1}\".format(x,nchunks))\n part=chunk['Body'].read()\n print(\"Writing part {0}/{1}. Size: {2} bytes\".format(x,nchunks,len(part)))\n blockid=str(uuid.uuid4())\n azblob.put_block(args.destination_container,args.destination_file,part,blockid)\n blocks.append(BlobBlock(id=blockid))\n\n print(\"Committing file {0}/{1}\".format(args.destination_container, args.destination_file))\n azblob.put_block_list(args.destination_container,args.destination_file,blocks)\n print(\"Committed\")\n\ndef __doCopyFromCmd():\n try:\n start=datetime.datetime.now()\n print(\"Start: %s\" % start)\n print(\"Running in: %s\" % (platform.platform()))\n args=__initArgs()\n __copy(args)\n finally:\n print(\"Ellapsed: %s\" % (datetime.datetime.now()-start))\n\ndef doCopy():\n args=__getEnv()\n if __checkValues(args):\n __copy(args)\n\nif __name__ =='__main__':__doCopyFromCmd()"
},
{
"alpha_fraction": 0.5796568393707275,
"alphanum_fraction": 0.595588207244873,
"avg_line_length": 26.233333587646484,
"blob_id": "70589671751c64bceac6678dddf9311d9ab944a2",
"content_id": "1a3fa3c206aa88e7b7f8397b43d4b4d4c1153c78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 816,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 30,
"path": "/README.md",
"repo_name": "jmservera/S3toAZ",
"src_encoding": "UTF-8",
"text": "# S3toAZ\n\nA simple S3 to AZ Storage copier in Python so you can create a scheduled function in Azure to copy files.\n\nYou need an AWS S3 bucket with a Bucket Policy for an IAM user like this:\n\n``` json\n{\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\n \"Sid\": \"Minimal Permissions for getting an object\",\n \"Effect\": \"Allow\",\n \"Principal\": {\n \"AWS\": \"arn:aws:iam::[id]:user/[username]\"\n },\n \"Action\": \"s3:GetObject\",\n \"Resource\": \"arn:aws:s3:::[bucketname]/*\"\n }\n ]\n}\n```\n\nFor testing purposes you can use the command line, but it is recommended to use environment variables when you deploy it to an Azure Function.\n\n**AWS_SOURCE**\n**AWS_SECRET_ID**\n**AWS_SECRET_ACCESS_KEY**\n**AZ_DESTINATION**\n**AZ_DESTINATION_SAS**"
},
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 20.5,
"blob_id": "cbfc8fc2721e0cf62fdbf24d1b9be15bddbf1748",
"content_id": "e2d46ecdea3cedb3e94c861cec6a64210e152a42",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 2,
"path": "/requirements.txt",
"repo_name": "jmservera/S3toAZ",
"src_encoding": "UTF-8",
"text": "boto3==1.26.77\nazure-storage-blob==12.15.0"
},
{
"alpha_fraction": 0.7154695987701416,
"alphanum_fraction": 0.7209944725036621,
"avg_line_length": 19.16666603088379,
"blob_id": "0ea61ebd0d5a9fff2948ffa5cd337ea645eeb3e4",
"content_id": "36a606fd31c026c8732bf7a3a66afccc507abec9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 362,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 18,
"path": "/Dockerfile",
"repo_name": "jmservera/S3toAZ",
"src_encoding": "UTF-8",
"text": "FROM python:3.7-slim-stretch as base\n\nFROM base as builder\n\nRUN mkdir /install\nWORKDIR /install\n\nRUN apt-get update && apt-get install -y gcc libffi-dev libssl-dev \n\nADD requirements.txt /\nRUN pip install --install-option=\"--prefix=/install\" -r /requirements.txt\n\nFROM base\n\nCOPY --from=builder /install /usr/local\nADD main.py /\n\nCMD [\"python\",\"-u\", \"./main.py\"]"
}
] | 4 |
gregorynoma/c4cs-f17-rpn | https://github.com/gregorynoma/c4cs-f17-rpn | 1c345e10671d1448bb5b556cd6c1f58fbcb0b1eb | 71a902c89a605cddc9e23b65c31f4ccd09140555 | 704862983fb8449d033d53255c374ff37021f6a6 | refs/heads/master | "2021-07-20T23:11:12.612505" | "2017-10-28T19:00:03" | "2017-10-28T19:00:03" | 108,616,516 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7250000238418579,
"alphanum_fraction": 0.7718750238418579,
"avg_line_length": 105.66666412353516,
"blob_id": "8f2bfe68e1c834fb5260b9c1aa0f57215627b924",
"content_id": "303f79d5d54dccc88d9fd2d5b95634b8db9e7df6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 3,
"path": "/README.md",
"repo_name": "gregorynoma/c4cs-f17-rpn",
"src_encoding": "UTF-8",
"text": "# c4cs-f17-rpn\n[](https://travis-ci.org/gregorynoma/c4cs-f17-rpn)\n[](https://coveralls.io/github/gregorynoma/c4cs-f17-rpn?branch=master)\n"
},
{
"alpha_fraction": 0.5432098507881165,
"alphanum_fraction": 0.5476190447807312,
"avg_line_length": 22.12244987487793,
"blob_id": "7b1495169f7da759144e59bcde06fae372880893",
"content_id": "5bf7bdc15e119b8d243e4ab0c5b3fe92e7a3b67f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 49,
"path": "/rpn.py",
"repo_name": "gregorynoma/c4cs-f17-rpn",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nimport operator\nimport readline\nimport argparse\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument('--debug', help = 'print debug info for stack, oper, or all')\n args = parser.parse_args()\n\n stackDebug = args.debug == 'all' or args.debug == 'stack'\n operDebug = args.debug == 'all' or args.debug == 'oper'\nelse:\n stackDebug = False\n operDebug = False\n\nops = {\n '+': operator.add,\n '-': operator.sub,\n '^': operator.pow,\n '*': operator.mul\n}\n\ndef calculate(arg):\n stack = list()\n for token in arg.split():\n try:\n stack.append(int(token))\n except ValueError:\n arg2 = stack.pop()\n arg1 = stack.pop()\n function = ops[token]\n result = function(arg1, arg2)\n stack.append(result)\n if operDebug:\n print(token, function)\n if stackDebug:\n print(stack)\n val = stack.pop()\n print('Result:', val)\n return val\n\ndef main():\n while True:\n calculate(input(\"rpn calc> \"))\n\nif __name__ == '__main__':\n main()\n\n"
}
] | 2 |
JM0222/AWS_test | https://github.com/JM0222/AWS_test | 127a42f449e3ebe953dc562feea6b742379f7dc1 | 0b21a5b4df166d69a6d9a7ca75e7386ae2aa349b | 2ca585e595fb368fc0f52fdaa1691f2bc599fb7e | refs/heads/master | "2023-02-23T04:45:54.705394" | "2021-01-25T13:26:20" | "2021-01-25T13:26:20" | 332,755,078 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.516608476638794,
"alphanum_fraction": 0.5430507063865662,
"avg_line_length": 43.20326614379883,
"blob_id": "1567727d2850c8a0d8b5bd187319bf87cd71ec04",
"content_id": "b49c18ff2d81ae9266cddaa50f2abf0d24617a4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 24813,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 551,
"path": "/fullstact_latest2/static/js/main.js",
"repo_name": "JM0222/AWS_test",
"src_encoding": "UTF-8",
"text": "(() => {\n\n let yoffset = 0; // pageYoffset\n let preScrollHeight = 0; // 이전 스크롤 높이값의 합\n let currentScene = 0; // 현재 활성화된 씬\n enterNewScene = false; // 새로운 씬이 시작된 순간 true\n\n\n const sceneInfo = [\n { //0\n type : 'sticky',\n heightNum : 5,\n scrollHeight: 0,\n objs: {\n container: document.querySelector('#scroll-section-0'),\n msgA: document.querySelector('#scroll-section-0 .main-message.a'),\n msgB: document.querySelector('#scroll-section-0 .main-message.b'),\n msgC: document.querySelector('#scroll-section-0 .main-message.c'),\n msgD: document.querySelector('#scroll-section-0 .main-message.d'),\n // video interaction\n canvas: document.querySelector('#video-canvas-0'),\n\t\t\t\tcontext: document.querySelector('#video-canvas-0').getContext('2d'),\n\t\t\t\tvideoImages: []\n\n },\n values: {\n videoImageCount: 170,\n imageSequence: [0, 169],\n canvas_opacity: [1, 0, {start: 0.9, end: 1}],\n msgA_opacity_in: [0, 1, {start: 0.1, end: 0.2 }],\n msgA_opacity_out: [1, 0, {start: 0.25, end: 0.3 }],\n msgA_translateY_in: [20, 0, {start: 0.1, end: 0.2 }],\n msgA_translateY_out: [0, -20, {start: 0.25, end: 0.3 }],\n msgB_opactiy_in: [0, 1, {start: 0.3, end: 0.4}],\n msgB_opactiy_out: [1, 0, {start: 0.45, end: 0.5}],\n msgB_translateY_in: [20, 0, {start:0.3, end: 0.4}],\n msgB_translateY_out: [0, -20, {start:0.45, end: 0.5}],\n msgC_opacity_in: [0, 1, {start: 0.5, end: 0.6}],\n msgC_opacity_out: [1, 0, {start: 0.65, end: 0.7}],\n msgC_translateY_in: [20, 0, {start: 0.5, end: 0.6}],\n msgC_translateY_out: [0, -20, {start: 0.65, end: 0.7}],\n msgD_opacity_in: [0, 1, {start: 0.7, end: 0.8}],\n msgD_opacity_out: [1, 0, {start: 0.85, end: 0.9}],\n msgD_translate_in: [20, 0, {start: 0.7, end: 0.8}],\n msgD_translate_out: [0, -80, {start: 0.85, end: 0.9}]\n\n\n\n \n\n }\n },\n { //1\n type : 'normal',\n heightNum : 5,\n scrollHeight: 0,\n objs: {\n container: document.querySelector('#scroll-section-1'),\n descmsgA: document.getElementById('desc-msgA'),\n descmsgB: document.getElementById('desc-msgB'),\n descmsgC: document.getElementById('desc-msgC'),\n\n },\n values: {\n descmsgA_opacity_in : [0, 1, {start: 0.1, end: 0.2}],\n // descmsgA_opacity_out : [0, 1, {start: 0.2, end: 0.25}],\n descmsgB_opacity_in : [0, 1, {start: 0.35, end: 0.45}],\n // descmsgB_opacity_out : [0, 1, {start: 0, end: 0}],\n descmsgC_opacity_in : [0, 1, {start: 0.6, end: 0.7}],\n // descmsgC_opacity_out : [0, 1, {start: 0, end: 0}],\n }\n },\n { //2\n type : 'sticky',\n heightNum : 5,\n scrollHeight: 0,\n objs: {\n container: document.querySelector('#scroll-section-2'),\n msgA: document.querySelector('#scroll-section-2 .a'),\n msgB: document.querySelector('#scroll-section-2 .b'),\n msgC: document.querySelector('#scroll-section-2 .c'),\n msgD: document.querySelector('#scroll-section-2 .d'),\n pinB: document.querySelector('#scroll-section-2 .b .pin'),\n pinC: document.querySelector('#scroll-section-2 .c .pin'),\n canvas: document.querySelector('#video-canvas-1'),\n\t\t\t\tcontext: document.querySelector('#video-canvas-1').getContext('2d'),\n\t\t\t\tvideoImages: []\n\n\n\n },\n values: {\n videoImageCount: 162,\n imageSequence: [0, 161],\n canvas_opacity: [1, 0, {start: 0.9, end: 1}],\n msgA_opacity_in: [0, 1, {start: 0.1, end: 0.2 }],\n msgA_opacity_out: [1, 0, {start: 0.25, end: 0.3 }],\n msgA_translateY_in: [20, 0, {start: 0.1, end: 0.2 }],\n msgA_translateY_out: [0, -20, {start: 0.25, end: 0.3 }],\n msgB_opactiy_in: [0, 1, {start: 0.3, end: 0.4}],\n msgB_opactiy_out: [1, 0, {start: 0.45, end: 0.5}],\n msgB_translateY_in: [30, 0, {start:0.3, end: 0.4}],\n msgB_translateY_out: [0, -20, {start:0.45, end: 0.5}],\n msgC_opacity_in: [0, 1, {start: 0.5, end: 0.6}],\n msgC_opacity_out: [1, 0, {start: 0.65, end: 0.7}],\n msgC_translateY_in: [30, 0, {start: 0.5, end: 0.6}],\n msgC_translateY_out: [0, -20, {start: 0.65, end: 0.7}],\n msgD_opacity_in: [0, 1, {start: 0.7, end: 0.8}],\n msgD_opacity_out: [1, 0, {start: 0.85, end: 0.9}],\n msgD_translateY_in: [30, 0, {start: 0.7, end: 0.8}],\n msgD_translateY_out: [0, -20, {start: 0.85, end: 0.9}],\n pinB_scaleY: [0.5, 1, {start: 0.3, end: 0.4}],\n pinC_scaleY: [0.5, 1, {start: 0.5, end: 0.6}],\n // pinB_opacity_in: [0, 1, {start: 0.3, end: 0.4}],\n // pinB_opacity_out: [1, 0, {start: 0.45, end: 0.5}],\n // pinC_opacity_in: [0, 1, {start: 0.5, end: 0.6}],\n // pinC_opacity_out: [1, 0, {start: 0.65, end: 0.7}]\n\n\n }\n },\n { \n type : 'sticky',\n heightNum : 5,\n scrollHeight: 0,\n objs: {\n container: document.querySelector('#scroll-section-3'),\n canvasCaption: document.querySelector('.canvas-caption'),\n canvas: document.querySelector('.image-blend-canvas'),\n\t\t\t\tcontext: document.querySelector('.image-blend-canvas').getContext('2d'),\n\t\t\t\timagesPath: [\n\t\t\t\t\t'/static/images/blend-image-1.jpg',\n\t\t\t\t\t'/static/images/blend-image-2.jpg'\n\t\t\t\t],\n\t\t\t\timages2: []\n },\n values:{\n //좌표값 미리 세팅(whiteRect)\n rect1X: [0, 0, {start:0, end: 0}],\n rect2X: [0, 0, {start:0, end: 0}],\n //캔버스 값조정\n blendHeight: [0, 0, {start:0, end: 0}],\n canvas_scale3: [0, 0, {start:0, end: 0}],\n rectStartY: 0,\n canvasCaption_opacity : [0, 1, {start: 0, end: 0}],\n canvasCaption_translateY : [20, 0, {start: 0, end: 0}]\n\n \n }\n }\n ];\n\n function setCanvasImages() {\n let imgElem;\n\t\tfor (let i = 0; i < sceneInfo[0].values.videoImageCount; i++) {\n\t\t\timgElem = new Image();\n\t\t\timgElem.src = `/static/video4/${1 + i}.jpg`;\n\t\t\tsceneInfo[0].objs.videoImages.push(imgElem);\n }// $1+i\n let imgElem2;\n\t\tfor (let i = 0; i < sceneInfo[2].values.videoImageCount; i++) {\n\t\t\timgElem2 = new Image();\n\t\t\timgElem2.src = `/static/video5/${1 + i}.jpg`;\n\t\t\tsceneInfo[2].objs.videoImages.push(imgElem2);\n }\n let imgElem3;\n\t\tfor (let i = 0; i < sceneInfo[3].objs.imagesPath.length; i++) {\n\t\t\timgElem3 = new Image();\n\t\t\timgElem3.src = sceneInfo[3].objs.imagesPath[i];\n\t\t\tsceneInfo[3].objs.images2.push(imgElem3);\n\t\t}\n // console.log(sceneInfo[3].objs.images2);\n \n\n }\n setCanvasImages();\n\n function checkMenu() {\n if (yoffset > 44) {\n document.body.classList.add('local-nav-sticky');\n } else {\n document.body.classList.remove('local-nav-sticky');\n }\n }\n\n function setLayout() {\n for (let i = 0; i < sceneInfo.length; i++) {\n sceneInfo[i].scrollHeight = sceneInfo[i].heightNum * window.innerHeight;\n sceneInfo[i].objs.container.style.height = `${sceneInfo[i].scrollHeight}px`;\n }\n yoffset = window.pageYOffset;\n let totalScrollHeight = 0;\n for (let i = 0; i< sceneInfo.length; i++) {\n totalScrollHeight += sceneInfo[i].scrollHeight;\n if (totalScrollHeight >= yoffset) {\n currentScene = i;\n break;\n }\n }\n document.body.setAttribute('id', `show-scene-${currentScene}`);\n\n const heightRatio = window.innerHeight / 1080;\n sceneInfo[0].objs.canvas.style.transform = `translate3d(-50%, -50%, 0) scale(${heightRatio})`;\n sceneInfo[2].objs.canvas.style.transform = `translate3d(-50%, -50%, 0) scale(${heightRatio})`;\n\n\n }\n\n function calcValues(values, currentYoffset) {\n let rv;\n const scrollRatio = currentYoffset / sceneInfo[currentScene].scrollHeight;\n const scrollHeight = sceneInfo[currentScene].scrollHeight;\n if (values.length === 3) {\n // start ~end 사이의 애니메이션 실행\n const partScrollStart = values[2].start * scrollHeight;\n const partScrollEnd = values[2].end * scrollHeight;\n const partScrollHeight = partScrollEnd - partScrollStart;\n\n if (currentYoffset >= partScrollStart && currentYoffset <= partScrollEnd) {\n rv = ((currentYoffset - partScrollStart) / partScrollHeight * (values[1] - values[0]) + values[0]);\n } else if (currentYoffset < partScrollStart) {\n rv = values[0];\n } else if (currentYoffset > partScrollEnd) {\n rv = values[1];\n }\n } else {\n rv = scrollRatio * (values[1] - values[0]) + values[0];\n }\n\n return rv;\n }\n function playAnimation() {\n const objs = sceneInfo[currentScene].objs;\n const values = sceneInfo[currentScene].values;\n const currentYoffset = yoffset - preScrollHeight;\n const scrollHeight = sceneInfo[currentScene].scrollHeight;\n const scrollRatio = (yoffset-preScrollHeight) / scrollHeight;\n\n switch (currentScene) {\n case 0:\n\n let sequence = Math.round(calcValues(values.imageSequence, currentYoffset));\n objs.context.drawImage(objs.videoImages[sequence],0,0)\n objs.canvas.style.opacity = calcValues(values.canvas_opacity, currentYoffset);\n if (scrollRatio <= 0.22) {\n // in\n objs.msgA.style.opacity = calcValues(values.msgA_opacity_in, currentYoffset);\n objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_in, currentYoffset)}%)`;\n } else{\n // out\n objs.msgA.style.opacity = calcValues(values.msgA_opacity_out, currentYoffset);\n objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_out, currentYoffset)}%)`;\n }\n if (scrollRatio <= 0.42) {\n // in\n objs.msgB.style.opacity = calcValues(values.msgB_opactiy_in, currentYoffset);\n objs.msgB.style.transform = `translateY(${calcValues(values.msgB_translateY_in, currentYoffset)}%)`;\n } else{\n objs.msgB.style.opacity = calcValues(values.msgB_opactiy_out, currentYoffset);\n objs.msgB.style.transform = `translateY(${calcValues(values.msgB_translateY_out, currentYoffset)}%)`;\n }\n if (scrollRatio <= 0.625) {\n // in\n objs.msgC.style.opacity = calcValues(values.msgC_opacity_in, currentYoffset);\n objs.msgC.style.transform = `translateY(${calcValues(values.msgC_translateY_in, currentYoffset)}%)`;\n } else{\n objs.msgC.style.opacity = calcValues(values.msgC_opacity_out, currentYoffset);\n objs.msgC.style.transform = `translateY(${calcValues(values.msgC_translateY_out, currentYoffset)}%)`;\n }\n if (scrollRatio <= 0.82) {\n // in\n objs.msgD.style.opacity = calcValues(values.msgD_opacity_in, currentYoffset);\n objs.msgD.style.transform = `translateY(${calcValues(values.msgD_translateY_in, currentYoffset)}%)`;\n } else{\n // out\n objs.msgD.style.opacity = calcValues(values.msgD_opacity_out, currentYoffset);\n objs.msgD.style.transform = `translateY(${calcValues(values.msgD_translateY_out, currentYoffset)}%)`;\n }\n \n // let msgA_opacity_out = calcValues(values.msgA_opacity, currentYoffset);\n\n break;\n case 1:\n if (scrollRatio <= 0.22) {\n // in \n \n objs.descmsgA.style.opacity = calcValues(values.descmsgA_opacity_in, currentYoffset);\n // objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_in, currentYoffset)}%)`;\n }\n if (scrollRatio <= 0.46) {\n // in\n objs.descmsgB.style.opacity = calcValues(values.descmsgB_opacity_in, currentYoffset);\n // objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_in, currentYoffset)}%)`;\n }\n if (scrollRatio <= 0.72) {\n // in\n objs.descmsgC.style.opacity = calcValues(values.descmsgC_opacity_in, currentYoffset);\n // objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_in, currentYoffset)}%)`;\n }\n // console.log(scrollRatio)\n break;\n case 2:\n\n let sequence2 = Math.round(calcValues(values.imageSequence, currentYoffset));\n objs.context.drawImage(objs.videoImages[sequence2],0,0)\n \n if (scrollRatio <= 0.22) {\n // in\n objs.msgA.style.opacity = calcValues(values.msgA_opacity_in, currentYoffset);\n objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_in, currentYoffset)}%)`;\n } else{\n // out\n objs.msgA.style.opacity = calcValues(values.msgA_opacity_out, currentYoffset);\n objs.msgA.style.transform = `translateY(${calcValues(values.msgA_translateY_out, currentYoffset)}%)`;\n }\n // if (scrollRatio <= 0.42) {\n // // in\n // objs.msgB.style.opacity = calcValues(values.msgB_opactiy_in, currentYoffset);\n // objs.msgB.style.transform = `translateY(${calcValues(values.msgB_translateY_in, currentYoffset)}%)`;\n // objs.pinB.style.transform = `scaleY(${calcValues(values.pinB_scaleY, currentYoffset)})`;\n // } else{\n // objs.msgB.style.opacity = calcValues(values.msgB_opactiy_out, currentYoffset);\n // objs.msgB.style.transform = `translateY(${calcValues(values.msgB_translateY_out, currentYoffset)}%)`;\n // objs.pinB.style.transform = `scaleY(${calcValues(values.pinB_scaleY, currentYoffset)})`;\n // }\n if (scrollRatio <= 0.625) {\n // in\n objs.msgC.style.opacity = calcValues(values.msgC_opacity_in, currentYoffset);\n objs.msgC.style.transform = `translateY(${calcValues(values.msgC_translateY_in, currentYoffset)}%)`;\n objs.pinC.style.transform = `scaleY(${calcValues(values.pinC_scaleY, currentYoffset)})`;\n\n } else{\n objs.msgC.style.opacity = calcValues(values.msgC_opacity_out, currentYoffset);\n objs.msgC.style.transform = `translateY(${calcValues(values.msgC_translateY_out, currentYoffset)}%)`;\n objs.pinC.style.transform = `scaleY(${calcValues(values.pinC_scaleY, currentYoffset)})`;\n\n }\n if (scrollRatio <= 0.82) {\n // in\n objs.msgD.style.opacity = calcValues(values.msgD_opacity_in, currentYoffset);\n objs.msgD.style.transform = `translateY(${calcValues(values.msgD_translateY_in, currentYoffset)}%)`;\n } else{\n // out\n objs.msgD.style.opacity = calcValues(values.msgD_opacity_out, currentYoffset);\n objs.msgD.style.transform = `translateY(${calcValues(values.msgD_translateY_out, currentYoffset)}%)`;\n }\n //미리 캔버스 그려주기\n if (scrollRatio > 0.9) {\n\t\t\t\t\tconst objs = sceneInfo[3].objs;\n\t\t\t\t\tconst values = sceneInfo[3].values;\n\t\t\t\t\tconst widthRatio = window.innerWidth / objs.canvas.width;\n\t\t\t\t\tconst heightRatio = window.innerHeight / objs.canvas.height;\n\t\t\t\t\tlet canvasScaleRatio;\n\n\t\t\t\t\tif (widthRatio <= heightRatio) {\n\t\t\t\t\t\t// 캔버스보다 브라우저 창이 홀쭉한 경우\n\t\t\t\t\t\tcanvasScaleRatio = heightRatio;\n\t\t\t\t\t} else {\n\t\t\t\t\t\t// 캔버스보다 브라우저 창이 납작한 경우\n\t\t\t\t\t\tcanvasScaleRatio = widthRatio;\n\t\t\t\t\t}\n\n\t\t\t\t\tobjs.canvas.style.transform = `scale(${canvasScaleRatio})`;\n\t\t\t\t\tobjs.context.fillStyle = 'red';\n\t\t\t\t\tobjs.context.drawImage(objs.images2[0], 0, 0);\n\n\t\t\t\t\t// 캔버스 사이즈에 맞춰 가정한 innerWidth와 innerHeight\n\t\t\t\t\tconst recalculatedInnerWidth = document.body.offsetWidth / canvasScaleRatio;\n\t\t\t\t\tconst recalculatedInnerHeight = window.innerHeight / canvasScaleRatio;\n\n\t\t\t\t\tconst whiteRectWidth = recalculatedInnerWidth * 0.15;\n\t\t\t\t\tvalues.rect1X[0] = (objs.canvas.width - recalculatedInnerWidth) / 2;\n\t\t\t\t\tvalues.rect1X[1] = values.rect1X[0] - whiteRectWidth;\n\t\t\t\t\tvalues.rect2X[0] = values.rect1X[0] + recalculatedInnerWidth - whiteRectWidth;\n\t\t\t\t\tvalues.rect2X[1] = values.rect2X[0] + whiteRectWidth;\n\n\t\t\t\t\t// 좌우 흰색 박스 그리기\n\t\t\t\t\tobjs.context.fillRect(\n\t\t\t\t\t\tparseInt(values.rect1X[0]),\n\t\t\t\t\t\t0,\n\t\t\t\t\t\tparseInt(whiteRectWidth),\n\t\t\t\t\t\tobjs.canvas.height\n\t\t\t\t\t);\n\t\t\t\t\tobjs.context.fillRect(\n\t\t\t\t\t\tparseInt(values.rect2X[0]),\n\t\t\t\t\t\t0,\n\t\t\t\t\t\tparseInt(whiteRectWidth),\n\t\t\t\t\t\tobjs.canvas.height\n\t\t\t\t\t);\n\t\t\t\t}// currentScene 3에서 쓰는 캔버스를 미리 그려주기 시작\n\t\t\t\t\n\n\t\t\t\tbreak;\n\n\t\t\tcase 3:\n\t\t\t\t// console.log('3 play');\n\t\t\t\tlet step = 0;\n\t\t\t\t// 가로/세로 모두 꽉 차게 하기 위해 여기서 세팅(계산 필요)\n\t\t\t\tconst widthRatio = window.innerWidth / objs.canvas.width;\n\t\t\t\tconst heightRatio = window.innerHeight / objs.canvas.height;\n\t\t\t\tlet canvasScaleRatio;\n\n\t\t\t\tif (widthRatio <= heightRatio) {\n\t\t\t\t\t// 캔버스보다 브라우저 창이 홀쭉한 경우\n\t\t\t\t\tcanvasScaleRatio = heightRatio;\n\t\t\t\t} else {\n\t\t\t\t\t// 캔버스보다 브라우저 창이 납작한 경우\n\t\t\t\t\tcanvasScaleRatio = widthRatio;\n\t\t\t\t}\n\n\t\t\t\tobjs.canvas.style.transform = `scale(${canvasScaleRatio})`;\n\t\t\t\tobjs.context.fillStyle = 'white';\n\t\t\t\tobjs.context.drawImage(objs.images2[0], 0, 0);\n\n\t\t\t\t// 캔버스 사이즈에 맞춰 가정한 innerWidth와 innerHeight\n\t\t\t\tconst recalculatedInnerWidth = document.body.offsetWidth / canvasScaleRatio;\n\t\t\t\tconst recalculatedInnerHeight = window.innerHeight / canvasScaleRatio;\n\n\t\t\t\tif (!values.rectStartY) {\n\t\t\t\t\tvalues.rectStartY = objs.canvas.getBoundingClientRect().top;\n\t\t\t\t\t// values.rectStartY = objs.canvas.offsetTop + (objs.canvas.height - objs.canvas.height * canvasScaleRatio) / 2;\n\t\t\t\t\t\n\t\t\t\t\tvalues.rect1X[2].end = values.rectStartY / scrollHeight;\n values.rect2X[2].end = values.rectStartY / scrollHeight;\n // console.log(values.rect1X[2].start,values.rect1X[2].end)\n\t\t\t\t}\n\n\t\t\t\tconst whiteRectWidth = recalculatedInnerWidth * 0.15;\n\t\t\t\tvalues.rect1X[0] = (objs.canvas.width - recalculatedInnerWidth) / 2;\n\t\t\t\tvalues.rect1X[1] = values.rect1X[0] - whiteRectWidth;\n\t\t\t\tvalues.rect2X[0] = values.rect1X[0] + recalculatedInnerWidth - whiteRectWidth;\n\t\t\t\tvalues.rect2X[1] = values.rect2X[0] + whiteRectWidth;\n\n\t\t\t\t// 좌우 흰색 박스 그리기\n\t\t\t\tobjs.context.fillRect(\n\t\t\t\t\tparseInt(calcValues(values.rect1X, currentYoffset)),\n\t\t\t\t\t0,\n\t\t\t\t\tparseInt(whiteRectWidth),\n\t\t\t\t\tobjs.canvas.height\n\t\t\t\t);\n\t\t\t\tobjs.context.fillRect(\n\t\t\t\t\tparseInt(calcValues(values.rect2X, currentYoffset)),\n\t\t\t\t\t0,\n\t\t\t\t\tparseInt(whiteRectWidth),\n\t\t\t\t\tobjs.canvas.height\n\t\t\t\t);\n\n\t\t\t\tif (scrollRatio < 0.455) {\n\t\t\t\t\tstep = 1;\n\t\t\t\t\t// console.log('캔버스 닿기 전');\n\t\t\t\t\tobjs.canvas.classList.remove('sticky');\n\t\t\t\t} else {\n step = 2;\n // 캔버스 블렌딩 처리 하기\n values.blendHeight[0] = 0;\n values.blendHeight[1] = objs.canvas.height;\n values.blendHeight[2].start = 0.456;\n values.blendHeight[2].end = values.blendHeight[2].start + 0.2;\n\n const blendHeight = calcValues(values.blendHeight, currentYoffset);\n objs.context.drawImage(objs.images2[1],\n 0, objs.canvas.height-blendHeight, objs.canvas.width, blendHeight,\n 0, objs.canvas.height-blendHeight, objs.canvas.width, blendHeight\n );\n objs.canvas.classList.add('sticky');\n objs.canvas.style.top = `${-163}px`\n\n if (scrollRatio > values.blendHeight[2].end) {\n values.canvas_scale3[0] = canvasScaleRatio;\n values.canvas_scale3[1] = document.body.offsetWidth / (1.5* objs.canvas.width);\n // console.log(values.canvas_scale3[0],values.canvas_scale3[1])\n values.canvas_scale3[2].start = values.blendHeight[2].end;\n values.canvas_scale3[2].end = values.canvas_scale3[2].start + 0.2;\n\n objs.canvas.style.transform = `scale(${calcValues(values.canvas_scale3, currentYoffset)})`;\n\n objs.canvas.style.marginTop = 0;\n\n\n }\n if (scrollRatio > values.canvas_scale3[2].end && values.canvas_scale3[2].end > 0) {\n objs.canvas.classList.remove('sticky');\n objs.canvas.style.marginTop = `${scrollHeight * 0.4}px`;\n //아래 이미지 opacity ,translte 값 조정\n\n values.canvasCaption_opacity[2].start = values.canvas_scale3[2].end;\n values.canvasCaption_opacity[2].end = values.canvasCaption_opacity[2].start + 0.1;\n values.canvasCaption_translateY[2].start = values.canvas_scale3[2].end;\n values.canvasCaption_translateY[2].end = values.canvasCaption_opacity[2].start + 0.1;\n\n objs.canvasCaption.style.opacity = calcValues(values.canvasCaption_opacity, currentYoffset);\n objs.canvasCaption.style.transform = `translate3d(0, ${calcValues(values.canvasCaption_translateY, currentYoffset)}%, 0)`;\n // console.log(scrollRatio)\n\n\n }\n }\n // console.log(scrollRatio)\n break;\n }\n }\n\n function scrollLoop() {\n enterNewScene = false;\n preScrollHeight = 0;\n for (i = 0; i < currentScene; i++) {\n preScrollHeight += sceneInfo[i].scrollHeight;\n }\n\n if (yoffset > preScrollHeight + sceneInfo[currentScene].scrollHeight) {\n currentScene++;\n enterNewScene = true;\n document.body.setAttribute('id', `show-scene-${currentScene}`);\n\n }\n if (yoffset < preScrollHeight) {\n if (currentScene === 0) return;\n currentScene--;\n enterNewScene = true;\n document.body.setAttribute('id', `show-scene-${currentScene}`);\n\n }\n if (enterNewScene) return;\n playAnimation();\n\n // document.body.setAttribute('id', `show-scene-${currentScene}`);\n\n\n\n }\n \n \n window.addEventListener('resize',setLayout);\n window.addEventListener('scroll',() => {\n yoffset = window.pageYOffset;\n scrollLoop();\n checkMenu();\n });\n window.addEventListener('load', () => {\n document.body.classList.remove('before-load')\n setLayout();\n sceneInfo[0].objs.context.drawImage(sceneInfo[0].objs.videoImages[0], 0, 0);\n\n });\n window.addEventListener('resize', setLayout);\n window.addEventListener('orientationchange',setLayout);\n document.querySelector('.loading').addEventListener('transitionend', (e)=> {\n document.body.removeChild(e.currentTarget);\n });\n\n})();"
},
{
"alpha_fraction": 0.6485461592674255,
"alphanum_fraction": 0.6605562567710876,
"avg_line_length": 27.763635635375977,
"blob_id": "eaa349c6ba4c92393c2c6b5db40d7e2f0015cbd8",
"content_id": "b69b4ae6927dda23dcaee43346f473a7bfa8d92b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1582,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 55,
"path": "/fullstact_latest2/web_test.py",
"repo_name": "JM0222/AWS_test",
"src_encoding": "UTF-8",
"text": "from flask import Flask, jsonify, request, render_template, make_response, session, url_for, redirect\n# from flask_login import LoginManager, current_user, login_required, login_user, logout_user\nfrom flask_cors import CORS\n# from web_view import view\n# from web_control.user_mgmt import User\nimport datetime\napp = Flask(__name__, static_url_path='/static')\n# CORS(app)\n# app.secret_key = 'jm_server'\n\n# login_manager = LoginManager()\n# login_manager.init_app(app)\n# login_manager.session_protection = 'strong'\n# app.register_blueprint(view.web_test, url_prefix='/web')\n\n# subscribe \n# @login_manager.user_loader\n# def load_user(user_id):\n# return User.get(user_id)\n\[email protected]('/set_email', methods=['GET','POST'])\n# def set_email():\n# if request.method == 'GET':\n# print('set_email', request.args.get('user_email'))\n# return redirect(url_for('web'))\n# else:\n# print('set_email', request.form['user_email'])\n# user = User.create(request.form['user_email'])\n# login_user(user, remember=True, duration=datetime.timedelta(days=7))\n# return redirect(url_for('web'))\n\n# webpage\[email protected]('/')\ndef web():\n return render_template('index.html')\n\[email protected]('/web2')\ndef web2():\n return render_template('index2.html')\n\[email protected]('/video')\ndef video():\n return render_template('index3.html')\n\[email protected]('/web3')\ndef web3():\n return render_template('index4.html')\n\[email protected]('/web4')\ndef web4():\n return render_template('index5.html')\n\n# run \nif __name__ == '__main__':\n app.run(host='0.0.0.0', port='5000')\n"
}
] | 2 |
shikharbahl/multiworld | https://github.com/shikharbahl/multiworld | 6105627c2a57a7610d5cdcbfe2cc62a5b076ee61 | 85b3200dc9a5821754c2d8ba2b8a7b6add874828 | e7bc888a5a258fc6558f86a8656eebf6a4b54b91 | refs/heads/master | "2020-03-21T17:03:48.770960" | "2018-10-29T20:10:36" | "2018-10-29T20:10:36" | 138,811,108 | 1 | 0 | MIT | "2018-06-27T01:00:48" | "2018-10-29T21:49:53" | "2018-10-30T19:44:44" | Python | [
{
"alpha_fraction": 0.7052559852600098,
"alphanum_fraction": 0.7057090997695923,
"avg_line_length": 27.662338256835938,
"blob_id": "695e0a8e7e6dc2827a4f03f09f2a7c45a3a92924",
"content_id": "d16364bc9f95b2f4f545eac343009c5614b54c7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4414,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 154,
"path": "/README.md",
"repo_name": "shikharbahl/multiworld",
"src_encoding": "UTF-8",
"text": "# multiworld\nMultitask Environments for RL\n\n## Basic Usage\nThis library contains a variety of gym `GoalEnv`s.\n\nAs a running example, let's say we have a `CarEnv`.\nLike normal gym envs, we can do\n```\nenv = CarEnv()\nobs = env.reset()\nnext_obs, reward, done, info = env.step(action)\n```\n\nUnlike `Env`s, the observation space of `GoalEnv`s is a dictionary.\n```\nprint(obs)\n\n# Output:\n# {\n# 'observation': ...,\n# 'desired_goal': ...,\n# 'achieved_goal': ...,\n# }\n```\nThis can make it rather difficult to use these envs with existing RL code, which\nusually expects a flat vector.\nHence, we include a wrapper that converts this dictionary-observation env into a\nnormal \"flat\" environment:\n\n```\nbase_env = CarEnv()\nenv = FlatGoalEnv(base_env, obs_key='observation')\nobs = env.reset() # returns vector in 'observation' key\naction = policy_that_takes_in_vector(obs)\n```\n\nThe observation space of FlatGoalEnv will be the corresponding env of the vector\n(e.g. `gym.space.Box`).\n**However, the goal is not part of the observation!**\nNot giving the goal to the policy might make the task impossible.\n\nWe provide two possible solutions to this:\n\n(1) Use the `get_goal` function\n```\nbase_env = CarEnv()\nenv = FlatGoalEnv(base_env, obs_key='observation')\nobs = env.reset() # returns just the 'observation'\ngoal = env.get_goal()\naction = policy_that_takes_in_two_vectors(obs, goal)\n```\n(2) Set\n`append_goal_to_obs` to `True`.\n```\nbase_env = CarEnv()\nenv = FlatGoalEnv(\n base_env,\n append_goal_to_obs=True, # default value is False\n)\nobs = env.reset() # returns 'observation' concatenated to `desired_goal`\naction = policy_that_takes_in_vector(obs)\n```\n\n## Extending Obs/Goals - Debugging and Multi-Modality\nOne nice thing about using Dict spaces + FlatGoalEnv is that it makes it really\neasy to extend and debug.\n\nFor example, this repo includes an `ImageMujocoEnv` wrapper which converts\nthe observation space of a Mujoco GoalEnv into images.\nRather than completely overwriting `observation`, we simply append the\nimages to the dictionary:\n\n```\nbase_env = CarEnv()\nenv = ImageEnv(base_env)\nobs = env.reset()\n\nprint(obs)\n\n# Output:\n# {\n# 'observation': ...,\n# 'desired_goal': ...,\n# 'achieved_goal': ...,\n# 'image_observation': ...,\n# 'image_desired_goal': ...,\n# 'image_achieved_goal': ...,\n# 'state_observation': ..., # CarEnv sets these values by default\n# 'state_desired_goal': ...,\n# 'state_achieved_goal': ...,\n# }\n```\n\nThis makes it really easy to debug your environment, by e.g. using state-based\nobservation but image-based goals:\n```\nbase_env = CarEnv()\nwrapped_env = ImageEnv(base_env)\nenv = FlatGoalEnv(\n base_env,\n obs_key='state_observation',\n goal_key='image_desired_goal',\n)\n```\n\nIt also makes multi-model environments really easy to write!\n```\nbase_env = CarEnv()\nwrapped_env = ImageEnv(base_env)\nwrapped_env = LidarEnv(wrapped_env)\nwrapped_env = LanguageEnv(wrapped_env)\nenv = FlatGoalEnv(\n base_env,\n obs_key=['image_observation', 'lidar_observation'],\n goal_key=['language_desired_goal', 'image_desired_goal'],\n)\nobs = env.reset() # image + lidar observation\ngoal = env.get_goal() # language + image goal\n```\n\nNote that you don't have to use FlatGoalEnv: you can always just use the\nenvironments manually choose the keys that you care about from the\nobservation.\n\n## WARNING: `compute_reward` incompatibility\nThe `compute_reward` interface is slightly different from gym's.\nRather than `compute_reward(desired_goal, achieved_goal, info)` our interface is\n `compute_reward(action, observation)`, where the observation is a dictionary.\n\n\n## Extra features\n### `fixed_goal`\nThe environments also all taken in `fixed_goal` as a parameter, which disables\nresampling the goal each time `reset` is called. This can be useful for\ndebugging: first make sure the env can solve the single-goal case before trying\nthe multi-goal case.\n\n### `get_diagnostics`\nThe function `get_diagonstics(rollouts)` returns an `OrderedDict` of potentially\nuseful numbers to plot/log.\n`rollouts` is a list. Each element of the list should be a dictionary describing\na rollout. A dictionary should have the following keys with the corresponding\nvalues:\n```\n{\n 'observations': np array,\n 'actions': np array,\n 'next_observations': np array,\n 'rewards': np array,\n 'terminals': np array,\n 'env_infos': list of dictionaries returned by step(),\n}\n```\n"
},
{
"alpha_fraction": 0.5226860046386719,
"alphanum_fraction": 0.5426497459411621,
"avg_line_length": 22.95652198791504,
"blob_id": "d8824bd530a0287a433c159c0d2e6087350b0636",
"content_id": "588bff16ebea79a3f6ff6a44b6b0c9c6f603ef55",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1102,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 46,
"path": "/multiworld/envs/pygame/__init__.py",
"repo_name": "shikharbahl/multiworld",
"src_encoding": "UTF-8",
"text": "from gym.envs.registration import register\nimport logging\n\nLOGGER = logging.getLogger(__name__)\n\n_REGISTERED = False\n\n\ndef register_custom_envs():\n global _REGISTERED\n if _REGISTERED:\n return\n _REGISTERED = True\n\n LOGGER.info(\"Registering multiworld pygame gym environments\")\n register(\n id='Point2DLargeEnv-offscreen-v0',\n entry_point='multiworld.envs.pygame.point2d:Point2DEnv',\n tags={\n 'git-commit-hash': '166f0f3',\n 'author': 'Vitchyr'\n },\n kwargs={\n 'images_are_rgb': True,\n 'target_radius': 1,\n 'ball_radius': 1,\n 'render_onscreen': False,\n },\n )\n register(\n id='Point2DLargeEnv-onscreen-v0',\n entry_point='multiworld.envs.pygame.point2d:Point2DEnv',\n tags={\n 'git-commit-hash': '166f0f3',\n 'author': 'Vitchyr'\n },\n kwargs={\n 'images_are_rgb': True,\n 'target_radius': 1,\n 'ball_radius': 1,\n 'render_onscreen': True,\n },\n )\n\n\nregister_custom_envs()\n"
},
{
"alpha_fraction": 0.4711712896823883,
"alphanum_fraction": 0.5262460112571716,
"avg_line_length": 29.287527084350586,
"blob_id": "1c2ffad442fd6793bd4c3727e7662e61858f9a27",
"content_id": "25645fdb746775555cb51f3a39171f60678385e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14326,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 473,
"path": "/multiworld/envs/mujoco/__init__.py",
"repo_name": "shikharbahl/multiworld",
"src_encoding": "UTF-8",
"text": "import gym\nfrom gym.envs.registration import register\nimport logging\n\nLOGGER = logging.getLogger(__name__)\n\n_REGISTERED = False\n\n\ndef register_custom_envs():\n global _REGISTERED\n if _REGISTERED:\n return\n _REGISTERED = True\n\n LOGGER.info(\"Registering multiworld mujoco gym environments\")\n\n \"\"\"\n Reaching tasks\n \"\"\"\n register(\n id='SawyerReachXYEnv-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_reach:SawyerReachXYEnv',\n tags={\n 'git-commit-hash': 'c5e15f7',\n 'author': 'vitchyr'\n },\n kwargs={\n 'hide_goal_markers': False,\n },\n )\n register(\n id='Image48SawyerReachXYEnv-v0',\n entry_point=create_image_48_sawyer_reach_xy_env_v0,\n tags={\n 'git-commit-hash': 'c5e15f7',\n 'author': 'vitchyr'\n },\n )\n register(\n id='Image84SawyerReachXYEnv-v0',\n entry_point=create_image_84_sawyer_reach_xy_env_v0,\n tags={\n 'git-commit-hash': 'c5e15f7',\n 'author': 'vitchyr'\n },\n )\n\n \"\"\"\n Pushing tasks, XY, With Reset\n \"\"\"\n register(\n id='SawyerPushAndReacherXYEnv-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_push_and_reach_env:SawyerPushAndReachXYEnv',\n tags={\n 'git-commit-hash': '3503e9f',\n 'author': 'vitchyr'\n },\n kwargs=dict(\n hide_goal_markers=True,\n action_scale=.02,\n puck_low=[-0.25, .4],\n puck_high=[0.25, .8],\n mocap_low=[-0.2, 0.45, 0.],\n mocap_high=[0.2, 0.75, 0.5],\n goal_low=[-0.2, 0.45, 0.02, -0.25, 0.4],\n goal_high=[0.2, 0.75, 0.02, 0.25, 0.8],\n )\n )\n register(\n id='Image48SawyerPushAndReacherXYEnv-v0',\n entry_point=create_Image48SawyerPushAndReacherXYEnv_v0,\n tags={\n 'git-commit-hash': '3503e9f',\n 'author': 'vitchyr'\n },\n )\n register(\n id='Image48SawyerPushAndReachXYEasyEnv-v0',\n entry_point=create_image_48_sawyer_reach_and_reach_xy_easy_env_v0,\n tags={\n 'git-commit-hash': 'fec148f',\n 'author': 'vitchyr'\n },\n )\n\n register(\n id='SawyerPushXYEnv-WithResets-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_push_and_reach_env:SawyerPushAndReachXYEnv',\n tags={\n 'git-commit-hash': '1e2652f',\n 'author': 'vitchyr',\n },\n kwargs=dict(\n reward_type='puck_distance',\n hand_low=(-0.28, 0.3, 0.05),\n hand_high=(0.28, 0.9, 0.3),\n puck_low=(-.4, .2),\n puck_high=(.4, 1),\n goal_low=(-0.25, 0.3, 0.02, -.2, .4),\n goal_high=(0.25, 0.875, 0.02, .2, .8),\n num_resets_before_puck_reset=int(1e6),\n num_resets_before_hand_reset=int(1e6),\n )\n )\n register(\n id='SawyerPushAndReachXYEnv-WithResets-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_push_and_reach_env:SawyerPushAndReachXYEnv',\n tags={\n 'git-commit-hash': '1e2652f',\n 'author': 'vitchyr',\n },\n kwargs=dict(\n reward_type='state_distance',\n hand_low=(-0.28, 0.3, 0.05),\n hand_high=(0.28, 0.9, 0.3),\n puck_low=(-.4, .2),\n puck_high=(.4, 1),\n goal_low=(-0.25, 0.3, 0.02, -.2, .4),\n goal_high=(0.25, 0.875, 0.02, .2, .8),\n num_resets_before_puck_reset=int(1e6),\n num_resets_before_hand_reset=int(1e6),\n )\n )\n\n \"\"\"\n Pushing tasks, XY, Reset Free\n \"\"\"\n register(\n id='SawyerPushXYEnv-CompleteResetFree-v1',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_push_and_reach_env:SawyerPushAndReachXYEnv',\n tags={\n 'git-commit-hash': 'b9b5ce0',\n 'author': 'murtaza'\n },\n kwargs=dict(\n reward_type='puck_distance',\n hand_low=(-0.28, 0.3, 0.05),\n hand_high=(0.28, 0.9, 0.3),\n puck_low=(-.4, .2),\n puck_high=(.4, 1),\n goal_low=(-0.25, 0.3, 0.02, -.2, .4),\n goal_high=(0.25, 0.875, 0.02, .2, .8),\n num_resets_before_puck_reset=int(1e6),\n num_resets_before_hand_reset=int(1e6),\n )\n )\n register(\n id='SawyerPushAndReachXYEnv-CompleteResetFree-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz.sawyer_push_and_reach_env:SawyerPushAndReachXYEnv',\n tags={\n 'git-commit-hash': '4ba667f',\n 'author': 'vitchyr'\n },\n kwargs=dict(\n reward_type='state_distance',\n hand_low=(-0.28, 0.3, 0.05),\n hand_high=(0.28, 0.9, 0.3),\n puck_low=(-.4, .2),\n puck_high=(.4, 1),\n goal_low=(-0.25, 0.3, 0.02, -.2, .4),\n goal_high=(0.25, 0.875, 0.02, .2, .8),\n num_resets_before_puck_reset=int(1e6),\n num_resets_before_hand_reset=int(1e6),\n )\n )\n\n \"\"\"\n Push XYZ\n \"\"\"\n register(\n id='SawyerDoorPullEnv-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door:SawyerDoorEnv',\n tags={\n 'git-commit-hash': '19f2be6',\n 'author': 'vitchyr'\n },\n kwargs=dict(\n goal_low=(-.25, .3, .12, -1.5708),\n goal_high=(.25, .6, .12, 0),\n action_reward_scale=0,\n reward_type='angle_difference',\n indicator_threshold=(.02, .03),\n fix_goal=False,\n fixed_goal=(0, .45, .12, -.25),\n num_resets_before_door_and_hand_reset=1,\n fixed_hand_z=0.12,\n hand_low=(-0.25, 0.3, .12),\n hand_high=(0.25, 0.6, .12),\n target_pos_scale=1,\n target_angle_scale=1,\n min_angle=-1.5708,\n max_angle=0,\n xml_path='sawyer_xyz/sawyer_door_pull.xml',\n )\n )\n\n \"\"\"\n Door Hook Env\n \"\"\"\n register(\n id='SawyerDoorHookEnv-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'b5ac6f9',\n 'author': 'vitchyr',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.42, 0.05, 0),\n goal_high=(0.0, 0.65, .075, 1.0472),\n hand_low=(-0.1, 0.42, 0.05),\n hand_high=(0., 0.65, .075),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n )\n )\n register(\n id='Image48SawyerDoorHookEnv-v0',\n entry_point=create_Image48SawyerDoorHookEnv_v0,\n tags={\n 'git-commit-hash': 'b5ac6f9',\n 'author': 'vitchyr',\n },\n )\n register(\n id='SawyerDoorHookResetFreeEnv-v0',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'b5ac6f9',\n 'author': 'vitchyr',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.42, 0.05, 0),\n goal_high=(0.0, 0.65, .075, 1.0472),\n hand_low=(-0.1, 0.42, 0.05),\n hand_high=(0., 0.65, .075),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n register(\n id='Image48SawyerDoorHookResetFreeEnv-v0',\n entry_point=create_Image48SawyerDoorHookResetFreeEnv_v0,\n tags={\n 'git-commit-hash': 'b5ac6f9',\n 'author': 'vitchyr',\n },\n )\n\n register(\n id='SawyerDoorHookResetFreeEnv-v1',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': '333776f',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.45, 0.15, 0),\n goal_high=(0.0, 0.65, .225, 1.0472),\n hand_low=(-0.1, 0.45, 0.15),\n hand_high=(0., 0.65, .225),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n register(\n id='Image48SawyerDoorHookResetFreeEnv-v1',\n entry_point=create_Image48SawyerDoorHookResetFreeEnv_v1,\n tags={\n 'git-commit-hash': '333776f',\n 'author': 'murtaza',\n },\n )\n\n register(\n id='SawyerDoorHookResetFreeEnv-v2',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': '2879edb',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.45, 0.15, 0),\n goal_high=(0.0, 0.65, .225, 1.0472),\n hand_low=(-0.1, 0.45, 0.15),\n hand_high=(0., 0.65, .225),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n\n register(\n id='SawyerDoorHookResetFreeEnv-v3',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'ffdb56e',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.45, 0.15, 0),\n goal_high=(0.0, 0.65, .225, 1.0472),\n hand_low=(-0.1, 0.45, 0.15),\n hand_high=(0., 0.65, .225),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n\n register( #do not use!!!\n id='SawyerDoorHookResetFreeEnv-v4',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'ffdb56e',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.2, 0.45, 0.1, 0),\n goal_high=(0.2, 0.65, .25, 1.0472),\n hand_low=(-0.2, 0.45, 0.15),\n hand_high=(.2, 0.65, .25),\n max_angle=1.0472,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n register(\n id='SawyerDoorHookResetFreeEnv-v5',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'ffdb56e',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.45, 0.1, 0),\n goal_high=(0.05, 0.65, .25, .83),\n hand_low=(-0.1, 0.45, 0.1),\n hand_high=(0.05, 0.65, .25),\n max_angle=.83,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n\n register(\n id='SawyerDoorHookResetFreeEnv-v6',\n entry_point='multiworld.envs.mujoco.sawyer_xyz'\n '.sawyer_door_hook:SawyerDoorHookEnv',\n tags={\n 'git-commit-hash': 'ffdb56e',\n 'author': 'murtaza',\n },\n kwargs=dict(\n goal_low=(-0.1, 0.4, 0.1, 0),\n goal_high=(0.05, 0.65, .25, .93),\n hand_low=(-0.1, 0.4, 0.1),\n hand_high=(0.05, 0.65, .25),\n max_angle=.93,\n xml_path='sawyer_xyz/sawyer_door_pull_hook.xml',\n reset_free=True,\n )\n )\n\n\ndef create_image_48_sawyer_reach_xy_env_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_xyz_reacher_camera\n\n wrapped_env = gym.make('SawyerReachXYEnv-v0')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_xyz_reacher_camera,\n transpose=True,\n normalize=True,\n )\n\n\ndef create_image_84_sawyer_reach_xy_env_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_xyz_reacher_camera\n\n wrapped_env = gym.make('SawyerReachXYEnv-v0')\n return ImageEnv(\n wrapped_env,\n 84,\n init_camera=sawyer_xyz_reacher_camera,\n transpose=True,\n normalize=True,\n )\n\n\ndef create_image_48_sawyer_reach_and_reach_xy_easy_env_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_pusher_camera_upright_v2\n\n wrapped_env = gym.make('SawyerPushAndReachXYEasyEnv-v0')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_pusher_camera_upright_v2,\n transpose=True,\n normalize=True,\n )\n\n\ndef create_Image48SawyerPushAndReacherXYEnv_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_pusher_camera_top_down\n\n wrapped_env = gym.make('SawyerPushAndReacherXYEnv-v0')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_pusher_camera_top_down,\n transpose=True,\n normalize=True,\n )\n\n\ndef create_Image48SawyerDoorHookEnv_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_door_env_camera_v3\n\n wrapped_env = gym.make('SawyerDoorHookEnv-v0')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_door_env_camera_v3,\n transpose=True,\n normalize=True,\n )\n\n\ndef create_Image48SawyerDoorHookResetFreeEnv_v0():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_door_env_camera_v3\n\n wrapped_env = gym.make('SawyerDoorHookResetFreeEnv-v0')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_door_env_camera_v3,\n transpose=True,\n normalize=True,\n )\n\ndef create_Image48SawyerDoorHookResetFreeEnv_v1():\n from multiworld.core.image_env import ImageEnv\n from multiworld.envs.mujoco.cameras import sawyer_door_env_camera_v3\n\n wrapped_env = gym.make('SawyerDoorHookResetFreeEnv-v1')\n return ImageEnv(\n wrapped_env,\n 48,\n init_camera=sawyer_door_env_camera_v3,\n transpose=True,\n normalize=True,\n )\n\n\nregister_custom_envs()\n"
},
{
"alpha_fraction": 0.5567106008529663,
"alphanum_fraction": 0.6129571199417114,
"avg_line_length": 24.172897338867188,
"blob_id": "4eca971444f2f3faced74864ed7ca4388f4fccaa",
"content_id": "7c20a5d0a36282a85e330e3fffbdb943e39489e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5387,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 214,
"path": "/multiworld/envs/mujoco/cameras.py",
"repo_name": "shikharbahl/multiworld",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef create_sawyer_camera_init(\n lookat=(0, 0.85, 0.3),\n distance=0.3,\n elevation=-35,\n azimuth=270,\n trackbodyid=-1,\n):\n def init(camera):\n camera.lookat[0] = lookat[0]\n camera.lookat[1] = lookat[1]\n camera.lookat[2] = lookat[2]\n camera.distance = distance\n camera.elevation = elevation\n camera.azimuth = azimuth\n camera.trackbodyid = trackbodyid\n\n return init\n\n\ndef init_sawyer_camera_v1(camera):\n \"\"\"\n Do not get so close that the arm crossed the camera plane\n \"\"\"\n camera.lookat[0] = 0\n camera.lookat[1] = 1\n camera.lookat[2] = 0.3\n camera.distance = 0.35\n camera.elevation = -35\n camera.azimuth = 270\n camera.trackbodyid = -1\n\n\ndef init_sawyer_camera_v2(camera):\n \"\"\"\n Top down basically. Sees through the arm.\n \"\"\"\n camera.lookat[0] = 0\n camera.lookat[1] = 0.8\n camera.lookat[2] = 0.3\n camera.distance = 0.3\n camera.elevation = -65\n camera.azimuth = 270\n camera.trackbodyid = -1\n\n\ndef init_sawyer_camera_v3(camera):\n \"\"\"\n Top down basically. Sees through the arm.\n \"\"\"\n camera.lookat[0] = 0\n camera.lookat[1] = 0.85\n camera.lookat[2] = 0.3\n camera.distance = 0.3\n camera.elevation = -35\n camera.azimuth = 270\n camera.trackbodyid = -1\n\ndef sawyer_pick_and_place_camera(camera):\n camera.lookat[0] = 0.0\n camera.lookat[1] = .67\n camera.lookat[2] = .1\n camera.distance = .7\n camera.elevation = 0\n camera.azimuth = 180\n camera.trackbodyid = 0\n\ndef init_sawyer_camera_v4(camera):\n \"\"\"\n This is the same camera used in old experiments (circa 6/7/2018)\n \"\"\"\n camera.lookat[0] = 0\n camera.lookat[1] = 0.85\n camera.lookat[2] = 0.3\n camera.distance = 0.3\n camera.elevation = -35\n camera.azimuth = 270\n camera.trackbodyid = -1\n\ndef sawyer_pick_and_place_camera_slanted_angle(camera):\n camera.lookat[0] = 0.0\n camera.lookat[1] = .67\n camera.lookat[2] = .1\n camera.distance = .65\n camera.elevation = -37.85\n camera.azimuth = 180\n camera.trackbodyid = 0\n\n\ndef init_sawyer_camera_v5(camera):\n \"\"\"\n Purposely zoomed out to be hard.\n \"\"\"\n camera.lookat[0] = 0\n camera.lookat[1] = 0.85\n camera.lookat[2] = 0.3\n camera.distance = 1\n camera.elevation = -35\n camera.azimuth = 270\n camera.trackbodyid = -1\n\n\ndef sawyer_xyz_reacher_camera(camera):\n # TODO: reformat or delete\n camera.trackbodyid = 0\n camera.distance = 1.0\n\n # 3rd person view\n cam_dist = 0.3\n rotation_angle = 270\n cam_pos = np.array([0, 1.0, 0.5, cam_dist, -30, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n\n\ndef sawyer_torque_reacher_camera(camera):\n # TODO: reformat or delete\n camera.trackbodyid = 0\n camera.distance = 1.0\n\n # 3rd person view\n cam_dist = 0.3\n rotation_angle = 270\n cam_pos = np.array([0, 1.0, 0.65, cam_dist, -30, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n\ndef sawyer_door_env_camera(camera):\n camera.trackbodyid = 0\n camera.distance = 1.0\n cam_dist = 0.1\n rotation_angle = 0\n cam_pos = np.array([0, 0.725, .9, cam_dist, -90, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n\ndef sawyer_door_env_camera_v2(camera):\n camera.trackbodyid = 0\n camera.distance = 1.0\n cam_dist = 0.1\n rotation_angle = 0\n cam_pos = np.array([.1, 0.55, .9, cam_dist, -90, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n\ndef sawyer_door_env_camera_v3(camera):\n camera.trackbodyid = 0\n camera.distance = 1.0\n\n # 3rd person view\n cam_dist = 0.25\n rotation_angle = 360\n cam_pos = np.array([-.2, .55, 0.6, cam_dist, -60, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n\ndef sawyer_pusher_camera_upright(camera):\n camera.trackbodyid = 0\n camera.distance = .45\n camera.lookat[0] = 0\n camera.lookat[1] = 0.85\n camera.lookat[2] = 0.45\n camera.elevation = -50\n camera.azimuth = 270\n camera.trackbodyid = -1\n\ndef sawyer_pusher_camera_upright_v2(camera):\n camera.trackbodyid = 0\n camera.distance = .45\n camera.lookat[0] = 0\n camera.lookat[1] = 0.85\n camera.lookat[2] = 0.45\n camera.elevation = -60\n camera.azimuth = 270\n camera.trackbodyid = -1\n\ndef sawyer_pusher_camera_top_down(camera):\n camera.trackbodyid = 0\n cam_dist = 0.1\n rotation_angle = 0\n cam_pos = np.array([0, 0.6, .9, cam_dist, -90, rotation_angle])\n\n for i in range(3):\n camera.lookat[i] = cam_pos[i]\n camera.distance = cam_pos[3]\n camera.elevation = cam_pos[4]\n camera.azimuth = cam_pos[5]\n camera.trackbodyid = -1\n"
}
] | 4 |
alphacruncher/snowflake-connector-python | https://github.com/alphacruncher/snowflake-connector-python | 9763457417aab0d3dd72ebc44ef7a6080e989957 | 7c3b7f4530fe938a58116f83c61a929b226da955 | 3abfbe4c39b5b5cadde66d9caba19cfaf1a3a368 | refs/heads/master | "2021-01-01T19:57:45.516452" | "2018-03-20T20:24:56" | "2018-03-20T20:24:56" | 98,728,864 | 0 | 0 | null | "2017-07-29T11:42:52" | "2017-07-14T15:00:18" | "2017-07-26T20:31:47" | null | [
{
"alpha_fraction": 0.4957627058029175,
"alphanum_fraction": 0.5025423765182495,
"avg_line_length": 35.875,
"blob_id": "6db37102bdac52cc55d530397bca9177c454446e",
"content_id": "12a79002f4016f48064388a44324113a80559255",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2360,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 64,
"path": "/test/test_qmark.py",
"repo_name": "alphacruncher/snowflake-connector-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (c) 2012-2017 Snowflake Computing Inc. All right reserved.\n#\n\n\nimport pytest\n\nfrom snowflake.connector import errors\n\n\ndef test_qmark_paramstyle(conn_cnx, db_parameters):\n \"\"\"\n Binding question marks is not supported in Python\n \"\"\"\n try:\n with conn_cnx() as cnx:\n cnx.cursor().execute(\n \"CREATE OR REPLACE TABLE {name} \"\n \"(aa STRING, bb STRING)\".format(\n name=db_parameters['name']))\n cnx.cursor().execute(\n \"INSERT INTO {name} VALUES('?', '?')\".format(\n name=db_parameters['name']))\n for rec in cnx.cursor().execute(\n \"SELECT * FROM {name}\".format(name=db_parameters['name'])):\n assert rec[0] == \"?\", \"First column value\"\n with pytest.raises(errors.ProgrammingError):\n cnx.cursor().execute(\n \"INSERT INTO {name} VALUES(?,?)\".format(\n name=db_parameters['name']))\n finally:\n with conn_cnx() as cnx:\n cnx.cursor().execute(\n \"DROP TABLE IF EXISTS {name}\".format(\n name=db_parameters['name']))\n\n\ndef test_numeric_paramstyle(conn_cnx, db_parameters):\n \"\"\"\n Binding numeric positional style is not supported in Python\n \"\"\"\n try:\n with conn_cnx() as cnx:\n cnx.cursor().execute(\n \"CREATE OR REPLACE TABLE {name} \"\n \"(aa STRING, bb STRING)\".format(\n name=db_parameters['name']))\n cnx.cursor().execute(\n \"INSERT INTO {name} VALUES(':1', ':2')\".format(\n name=db_parameters['name']))\n for rec in cnx.cursor().execute(\n \"SELECT * FROM {name}\".format(name=db_parameters['name'])):\n assert rec[0] == \":1\", \"First column value\"\n with pytest.raises(errors.ProgrammingError):\n cnx.cursor().execute(\n \"INSERT INTO {name} VALUES(:1,:2)\".format(\n name=db_parameters['name']))\n finally:\n with conn_cnx() as cnx:\n cnx.cursor().execute(\n \"DROP TABLE IF EXISTS {name}\".format(\n name=db_parameters['name']))\n"
},
{
"alpha_fraction": 0.6868327260017395,
"alphanum_fraction": 0.6953736543655396,
"avg_line_length": 32.99193572998047,
"blob_id": "0e39fa45aea44831b717fef238c6f79465d9c6a9",
"content_id": "1a392e2af6db58e68fe5b2486c64daee5e73deea",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4215,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 124,
"path": "/test/test_unit_ocsp.py",
"repo_name": "alphacruncher/snowflake-connector-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (c) 2012-2017 Snowflake Computing Inc. All right reserved.\n#\nimport codecs\nimport os\nfrom logging import getLogger\n\nimport pytest\nfrom OpenSSL.crypto import (load_certificate, FILETYPE_PEM)\nfrom pyasn1.codec.der import decoder as der_decoder\nfrom pyasn1.codec.der import encoder as der_encoder\nfrom pyasn1.error import (SubstrateUnderrunError)\nfrom pyasn1.type import (univ)\n\nlogger = getLogger(__name__)\nTHIS_DIR = os.path.dirname(os.path.realpath(__file__))\n\nfrom snowflake.connector.errors import OperationalError\nfrom snowflake.connector.ocsp_pyopenssl import (\n SnowflakeOCSP,\n _extract_values_from_certificate, is_cert_id_in_cache, execute_ocsp_request,\n process_ocsp_response)\nfrom snowflake.connector.rfc6960 import (OCSPResponse)\n\nCERT_TESTS_DATA_DIR = os.path.join(THIS_DIR, 'data', 'cert_tests')\n\n\ndef _load_certificate(pem_file):\n with codecs.open(pem_file, 'r', encoding='utf-8') as f:\n c = f.read()\n return load_certificate(FILETYPE_PEM, c)\n\n\ndef _load_ocsp_uri(txt):\n with codecs.open(txt, 'r',\n encoding='utf-8') as f:\n c = f.read()\n return c.rstrip()\n\n\ndef test_ocsp_validation():\n PROD_CERT_TESTS_DATA_DIR = os.path.join(\n CERT_TESTS_DATA_DIR, 'production')\n\n subject_cert = _load_certificate(\n os.path.join(PROD_CERT_TESTS_DATA_DIR, 'snowflakecomputing.crt')\n )\n issuer_cert = _load_certificate(\n os.path.join(PROD_CERT_TESTS_DATA_DIR, 'networksolutions.crt')\n )\n\n ocsp = SnowflakeOCSP()\n ocsp_issuer = _extract_values_from_certificate(issuer_cert)\n ocsp_subject = _extract_values_from_certificate(subject_cert)\n assert ocsp.validate_by_direct_connection(\n ocsp_issuer['ocsp_uri'], ocsp_issuer, ocsp_subject), \\\n 'Failed to validate the revocation status for snowflakecomputing'\n\n # second one should be cached\n assert ocsp.validate_by_direct_connection(\n ocsp_issuer['ocsp_uri'], ocsp_issuer, ocsp_subject), \\\n 'Failed to validate the revocation status for snowflakecomputing'\n\n serial_number = ocsp_subject['serial_number']\n ocsp_subject['serial_number'] = 123\n\n # bogus serial number\n with pytest.raises(OperationalError):\n ocsp.validate_by_direct_connection(\n ocsp_issuer['ocsp_uri'], ocsp_issuer, ocsp_subject)\n\n ocsp_subject['serial_number'] = serial_number\n\n\ndef test_negative_response():\n PROD_CERT_TESTS_DATA_DIR = os.path.join(\n CERT_TESTS_DATA_DIR, 'production')\n subject_cert = _load_certificate(\n os.path.join(PROD_CERT_TESTS_DATA_DIR, 'networksolutions.crt')\n )\n issuer_cert = _load_certificate(\n os.path.join(PROD_CERT_TESTS_DATA_DIR, 'usertrust.crt')\n )\n\n ocsp_issuer = _extract_values_from_certificate(issuer_cert)\n ocsp_subject = _extract_values_from_certificate(subject_cert)\n\n # get a valid OCSPResponse\n status, cert_id, ocsp_response = is_cert_id_in_cache(\n ocsp_issuer, ocsp_subject, use_cache=False)\n logger.debug(cert_id.prettyPrint())\n\n response = execute_ocsp_request(ocsp_issuer['ocsp_uri'], cert_id)\n\n # extract\n ocsp_response, _ = der_decoder.decode(response, OCSPResponse())\n\n response_bytes = ocsp_response['responseBytes']\n backup_response_type = response_bytes['responseType']\n response_bytes['responseType'] = \\\n univ.ObjectIdentifier((1, 3, 6, 1, 5, 5, 7, 48, 1, 1000))\n response = der_encoder.encode(ocsp_response)\n\n # bogus response type\n with pytest.raises(OperationalError):\n process_ocsp_response(response, ocsp_issuer)\n\n # bogus response\n response_bytes['responseType'] = backup_response_type\n backup_response_bytes_respose = response_bytes['response']\n response_bytes['response'] = univ.OctetString(hexValue=\"ABCDEF\")\n response = der_encoder.encode(ocsp_response)\n\n with pytest.raises(SubstrateUnderrunError):\n process_ocsp_response(response, ocsp_issuer)\n\n response_bytes['response'] = backup_response_bytes_respose\n response = der_encoder.encode(ocsp_response)\n\n # invalid issuer certificate\n with pytest.raises(OperationalError):\n process_ocsp_response(response, ocsp_subject)\n"
},
{
"alpha_fraction": 0.5963655710220337,
"alphanum_fraction": 0.6214858293533325,
"avg_line_length": 34.30188751220703,
"blob_id": "9f41b452569f8a1fd5593bf423b1fa9e8d266a6d",
"content_id": "b3d3f239b264f1d00990bd82b384e0935b886a56",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9355,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 265,
"path": "/test/test_unit_s3_util.py",
"repo_name": "alphacruncher/snowflake-connector-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (c) 2012-2017 Snowflake Computing Inc. All right reserved.\n#\nimport codecs\nimport errno\nimport glob\nimport os\nimport tempfile\nfrom collections import defaultdict\nfrom os import path\n\nimport OpenSSL\n\nfrom snowflake.connector.compat import PY2\nfrom snowflake.connector.constants import (SHA256_DIGEST, UTF8)\nfrom snowflake.connector.s3_util import (\n SnowflakeS3Util,\n SnowflakeS3FileEncryptionMaterial,\n ERRORNO_WSAECONNABORTED, DEFAULT_MAX_RETRY)\n\nTHIS_DIR = path.dirname(path.realpath(__file__))\n\nif PY2:\n from mock import Mock, MagicMock\nelse:\n from unittest.mock import Mock, MagicMock\n\n\ndef test_encrypt_decrypt_file():\n \"\"\"\n Encrypt and Decrypt a file\n \"\"\"\n s3_util = SnowflakeS3Util()\n s3_metadata = {}\n\n encryption_material = SnowflakeS3FileEncryptionMaterial(\n query_stage_master_key='ztke8tIdVt1zmlQIZm0BMA==',\n query_id='123873c7-3a66-40c4-ab89-e3722fbccce1',\n smk_id=3112)\n data = 'test data'\n input_fd, input_file = tempfile.mkstemp()\n encrypted_file = None\n decrypted_file = None\n try:\n with codecs.open(input_file, 'w', encoding=UTF8) as fd:\n fd.write(data)\n\n encrypted_file = s3_util.encrypt_file(\n s3_metadata, encryption_material, input_file)\n decrypted_file = s3_util.decrypt_file(\n s3_metadata, encryption_material, encrypted_file)\n\n contents = ''\n fd = codecs.open(decrypted_file, 'r', encoding=UTF8)\n for line in fd:\n contents += line\n assert data == contents, \"encrypted and decrypted contents\"\n finally:\n os.close(input_fd)\n os.remove(input_file)\n if encrypted_file:\n os.remove(encrypted_file)\n if decrypted_file:\n os.remove(decrypted_file)\n\n\ndef test_encrypt_decrypt_large_file(tmpdir, test_files):\n \"\"\"\n Encrypt and Decrypt a large file\n \"\"\"\n s3_util = SnowflakeS3Util()\n s3_metadata = {}\n\n encryption_material = SnowflakeS3FileEncryptionMaterial(\n query_stage_master_key='ztke8tIdVt1zmlQIZm0BMA==',\n query_id='123873c7-3a66-40c4-ab89-e3722fbccce1',\n smk_id=3112)\n\n # generates N files\n number_of_files = 1\n number_of_lines = 10000\n tmp_dir = test_files(tmpdir, number_of_lines, number_of_files)\n\n files = glob.glob(os.path.join(tmp_dir, 'file*'))\n input_file = files[0]\n encrypted_file = None\n decrypted_file = None\n try:\n encrypted_file = s3_util.encrypt_file(\n s3_metadata, encryption_material, input_file)\n decrypted_file = s3_util.decrypt_file(\n s3_metadata, encryption_material, encrypted_file)\n\n contents = ''\n cnt = 0\n fd = codecs.open(decrypted_file, 'r', encoding=UTF8)\n for line in fd:\n contents += line\n cnt += 1\n assert cnt == number_of_lines, \"number of lines\"\n finally:\n os.remove(input_file)\n if encrypted_file:\n os.remove(encrypted_file)\n if decrypted_file:\n os.remove(decrypted_file)\n\n\ndef test_extract_bucket_name_and_path():\n \"\"\"\n Extract bucket name and S3 path\n \"\"\"\n s3_util = SnowflakeS3Util()\n\n s3_loc = s3_util.extract_bucket_name_and_path(\n 'sfc-dev1-regression/test_sub_dir/')\n assert s3_loc.bucket_name == 'sfc-dev1-regression'\n assert s3_loc.s3path == 'test_sub_dir/'\n\n s3_loc = s3_util.extract_bucket_name_and_path(\n 'sfc-dev1-regression/stakeda/test_stg/test_sub_dir/')\n assert s3_loc.bucket_name == 'sfc-dev1-regression'\n assert s3_loc.s3path == 'stakeda/test_stg/test_sub_dir/'\n\n s3_loc = s3_util.extract_bucket_name_and_path(\n 'sfc-dev1-regression/')\n assert s3_loc.bucket_name == 'sfc-dev1-regression'\n assert s3_loc.s3path == ''\n\n s3_loc = s3_util.extract_bucket_name_and_path(\n 'sfc-dev1-regression//')\n assert s3_loc.bucket_name == 'sfc-dev1-regression'\n assert s3_loc.s3path == '/'\n\n s3_loc = s3_util.extract_bucket_name_and_path(\n 'sfc-dev1-regression///')\n assert s3_loc.bucket_name == 'sfc-dev1-regression'\n assert s3_loc.s3path == '//'\n\n\ndef test_upload_one_file_to_s3_wsaeconnaborted():\n \"\"\"\n Tests Upload one file to S3 with retry on ERRORNO_WSAECONNABORTED.\n The last attempted max_currency should be (initial_parallel/max_retry)\n \"\"\"\n upload_file = MagicMock(\n side_effect=OpenSSL.SSL.SysCallError(\n ERRORNO_WSAECONNABORTED, 'mock err. connection aborted'))\n s3object = MagicMock(metadata=defaultdict(str), upload_file=upload_file)\n s3client = Mock()\n s3client.Object.return_value = s3object\n initial_parallel = 100\n upload_meta = {\n u'no_sleeping_time': True,\n u'parallel': initial_parallel,\n u'put_callback': None,\n u'put_callback_output_stream': None,\n u'existing_files': [],\n u's3client': s3client,\n SHA256_DIGEST: '123456789abcdef',\n u'stage_location': 'sfc-customer-stage/rwyi-testacco/users/9220/',\n u'dst_file_name': 'data1.txt.gz',\n u'src_file_name': path.join(THIS_DIR, 'data', 'put_get_1.txt'),\n }\n upload_meta[u'real_src_file_name'] = upload_meta['src_file_name']\n upload_meta[u'upload_size'] = os.stat(upload_meta['src_file_name']).st_size\n tmp_upload_meta = upload_meta.copy()\n try:\n SnowflakeS3Util.upload_one_file_to_s3(tmp_upload_meta)\n raise Exception(\"Should fail with OpenSSL.SSL.SysCallError\")\n except OpenSSL.SSL.SysCallError:\n assert upload_file.call_count == DEFAULT_MAX_RETRY\n assert 'last_max_concurrency' in tmp_upload_meta\n assert tmp_upload_meta[\n 'last_max_concurrency'\n ] == initial_parallel / DEFAULT_MAX_RETRY\n\n # min parallel == 1\n upload_file.reset_mock()\n initial_parallel = 4\n upload_meta[u'parallel'] = initial_parallel\n tmp_upload_meta = upload_meta.copy()\n try:\n SnowflakeS3Util.upload_one_file_to_s3(tmp_upload_meta)\n raise Exception(\"Should fail with OpenSSL.SSL.SysCallError\")\n except OpenSSL.SSL.SysCallError:\n assert upload_file.call_count == DEFAULT_MAX_RETRY\n assert 'last_max_concurrency' in tmp_upload_meta\n assert tmp_upload_meta['last_max_concurrency'] == 1\n\n\ndef test_upload_one_file_to_s3_econnreset():\n \"\"\"\n Tests Upload one file to S3 with retry on errno.ECONNRESET.\n The last attempted max_currency should not be changed.\n \"\"\"\n for error_code in [errno.ECONNRESET,\n errno.ETIMEDOUT,\n errno.EPIPE,\n -1]:\n upload_file = MagicMock(\n side_effect=OpenSSL.SSL.SysCallError(\n error_code, 'mock err. connection aborted'))\n s3object = MagicMock(metadata=defaultdict(str), upload_file=upload_file)\n s3client = Mock()\n s3client.Object.return_value = s3object\n initial_parallel = 100\n upload_meta = {\n u'no_sleeping_time': True,\n u'parallel': initial_parallel,\n u'put_callback': None,\n u'put_callback_output_stream': None,\n u'existing_files': [],\n SHA256_DIGEST: '123456789abcdef',\n u'stage_location': 'sfc-customer-stage/rwyi-testacco/users/9220/',\n u's3client': s3client,\n u'dst_file_name': 'data1.txt.gz',\n u'src_file_name': path.join(THIS_DIR, 'data', 'put_get_1.txt'),\n }\n upload_meta[u'real_src_file_name'] = upload_meta['src_file_name']\n upload_meta[\n u'upload_size'] = os.stat(upload_meta['src_file_name']).st_size\n try:\n SnowflakeS3Util.upload_one_file_to_s3(upload_meta)\n raise Exception(\"Should fail with OpenSSL.SSL.SysCallError\")\n except OpenSSL.SSL.SysCallError:\n assert upload_file.call_count == DEFAULT_MAX_RETRY\n assert 'last_max_concurrency' not in upload_meta\n\n\ndef test_upload_one_file_to_s3_unknown_openssl_error():\n \"\"\"\n Tests Upload one file to S3 with unknown OpenSSL error\n \"\"\"\n for error_code in [123]:\n\n upload_file = MagicMock(\n side_effect=OpenSSL.SSL.SysCallError(\n error_code, 'mock err. connection aborted'))\n s3object = MagicMock(metadata=defaultdict(str), upload_file=upload_file)\n s3client = Mock()\n s3client.Object.return_value = s3object\n initial_parallel = 100\n upload_meta = {\n u'no_sleeping_time': True,\n u'parallel': initial_parallel,\n u'put_callback': None,\n u'put_callback_output_stream': None,\n u'existing_files': [],\n SHA256_DIGEST: '123456789abcdef',\n u'stage_location': 'sfc-customer-stage/rwyi-testacco/users/9220/',\n u's3client': s3client,\n u'dst_file_name': 'data1.txt.gz',\n u'src_file_name': path.join(THIS_DIR, 'data', 'put_get_1.txt'),\n }\n upload_meta[u'real_src_file_name'] = upload_meta['src_file_name']\n upload_meta[\n u'upload_size'] = os.stat(upload_meta['src_file_name']).st_size\n try:\n SnowflakeS3Util.upload_one_file_to_s3(upload_meta)\n raise Exception(\"Should fail with OpenSSL.SSL.SysCallError\")\n except OpenSSL.SSL.SysCallError:\n assert upload_file.call_count == 1\n"
}
] | 3 |
Partisanship-Project/Partisanship-Project.github.io | https://github.com/Partisanship-Project/Partisanship-Project.github.io | abc3c184d6d71a6a406c8e8a0d04747893d96424 | 64f6cba332ac6773d9f62c9b57b0980e700f3627 | 06fa223e58d8059e4bee88089e93a52c67acd45d | refs/heads/master | "2020-04-02T04:43:02.326497" | "2020-01-19T18:59:40" | "2020-01-19T18:59:40" | 154,030,770 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5583597421646118,
"alphanum_fraction": 0.5670161843299866,
"avg_line_length": 40.06153869628906,
"blob_id": "753e0ac39d84e317f4de39075150503d85cd4a5d",
"content_id": "2a993b3d565456f32c16adbb717a0cbfded779a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24606,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 585,
"path": "/assets/replication/Scripts/Monthly_Partisan_Phrases.py",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "\r\n'''\r\nCode to detect and visualize the most partisan phrases every month.\r\n'''\r\n\r\n#cd 'C:\\Users\\Boss\\Dropbox\\Twitter_NaiveBayes'\r\n\r\nimport datetime as dt\r\nfrom dateutil import rrule\r\nimport re,os,csv,nltk,operator\r\n\r\nfrom sklearn import svm\r\nfrom sklearn.naive_bayes import MultinomialNB as mnb\r\nfrom sklearn import neighbors\r\nimport random as rn\r\nimport numpy as np\r\nfrom sklearn.feature_extraction.text import TfidfVectorizer as tfidf\r\nimport cPickle\r\nfrom sklearn.metrics import classification_report\r\n\r\n\r\ndef Twitter_Tokenize(text,stopwords='nltk'):\r\n '''this function tokenizes `text` using simple rules:\r\n tokens are defined as maximal strings of letters, digits\r\n and apostrophies.\r\n The optional argument `stopwords` is a list of words to\r\n exclude from the tokenzation'''\r\n if stopwords=='nltk':\r\n stopwords=nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www','https','amp']\r\n retweet=False\r\n if 'RT @' in text:\r\n retweet=True\r\n # make lowercase\r\n text = text.lower()\r\n # grab just the words we're interested in\r\n text = re.findall(r\"[\\d\\w'#@]+\",text)\r\n # remove stopwords\r\n res = []\r\n for w in text:\r\n if w=='http':\r\n res.append('HLINK')\r\n continue\r\n if w.startswith('@') and w!='@':\r\n res.append('MNTON')\r\n if w.startswith('#'):\r\n res.append('HSHTG')\r\n if w not in stopwords:\r\n res.append(w)\r\n if retweet:\r\n res.append('RTWT')\r\n return(res)\r\n\r\ndef Clean_Tweets(text,stopwords='nltk',onlyHashtags=False):\r\n '''this function tokenizes `tweets` using simple rules:\r\n tokens are defined as maximal strings of letters, digits\r\n and apostrophies.\r\n The optional argument `stopwords` is a list of words to\r\n exclude from the tokenzation. This code eliminates hypertext and markup features to\r\n focus on the substance of tweets'''\r\n if stopwords=='nltk':\r\n stopwords=nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n #print stopwords\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www','https','amp']\r\n retweet=False\r\n if 'RT @' in text:\r\n retweet=True\r\n # make lowercase\r\n text = text.lower()\r\n #ELEMINATE HYPERLINKS\r\n ntext=[]\r\n text=text.split(' ')\r\n for t in text:\r\n if t.startswith('http'):\r\n #ntext.append('hlink')\r\n continue\r\n else:\r\n ntext.append(t)\r\n text=' '.join(ntext)\r\n # grab just the words we're interested in\r\n text = re.findall(r\"[\\d\\w'#@]+\",text)\r\n # remove stopwords\r\n if onlyHashtags==True:\r\n htags=[]\r\n for w in text:\r\n if w.startswith('#'):\r\n htags.append(w)\r\n return htags\r\n res = []\r\n for w in text:\r\n if w=='hlink':\r\n res.append('HLINK')\r\n continue\r\n if w.startswith('@') and w!='@':\r\n res.append('MNTON'+'_'+w[1:])\r\n continue\r\n if w.startswith('#'):\r\n res.append('HSHTG'+'_'+w[1:])\r\n continue\r\n if w not in stopwords:\r\n res.append(w)\r\n if retweet:\r\n res.append('RTWT')\r\n return res\r\n\r\ndef makeMetaData():\r\n '''metadata header is DWNominate score, name, party, ICPSR, state code, State-District,\r\n data is a dictionary of data[twitterID]=[]'''\r\n data={}\r\n polKey={}\r\n missing=[]\r\n with open('..\\Data\\metadata.csv') as f:\r\n \r\n dta=csv.reader(f)\r\n for i,line in enumerate(dta):\r\n if i>0:\r\n if line[5]!='':\r\n tid=line[5].lower()\r\n party=line[3]\r\n if line[3]=='R': #recode to 1,0 fits with previous code and keeps direction of analysis the sm\r\n biparty=1\r\n elif line[3]=='D':\r\n biparty=0\r\n else:\r\n biparty=''\r\n name=line[0]\r\n state=line[1]\r\n district=line[2]\r\n incumbent=line[4]\r\n polldate=line[6]\r\n winprob=line[12]\r\n predVoteShare=line[13]\r\n if district.lower()=='senate':\r\n district=0\r\n if int(district)==0:\r\n senate='1'\r\n \r\n else:\r\n senate='0'\r\n data[tid]=[name,biparty,party,state,district,senate,incumbent,polldate,winprob,predVoteShare]\r\n polKey[tid]=biparty\r\n #else:\r\n # missing.append([tid,'House member has Twitter but not in scraped data'])\r\n \r\n \r\n #f=open('Metadata\\112Tweets3.txt','r')\r\n #for n in f.readlines():\r\n # print n\r\n # d=n.split(',')\r\n # data[d[0].lower()]+=[d[1],d[2].strip()]\r\n #f.close()\r\n header=['TwitterID','name','lib-con','party','state','district','senate','incumbent','polldate','winprob','predVoteShare']\r\n \r\n return data, header, polKey\r\n\r\n\r\ndef MakeDateEssays(months,metaData, indir=''):\r\n '''This function turns a directory (indir) composed of every individual's tweets each contained in a csv file \r\n into a directory (outdir) of .txt files of person-level aggregates of those tweets within the date window given in 'dates'\r\n dates=[beginningDate,endDate] formatted as ['1/1/1900','12/30/1900']\r\n \r\n For example, the .csv file AlFranken.csv in Raw2 contains each tweet collected with the parameters: \r\n text\\tfavorited\\treplyToSN\\tcreated\\ttruncated\\treplyToSID\\tid\\treplyToUID\\tstatusSource\\tscreenName\r\n With this code, that file is turned into a .txt file called AlFranken.txt containing of all tweets under the \"text\" field\r\n separated by \\t\r\n \r\n As a part of this data formating process, this code also produces counts of the total number of tweets and characters for each person\r\n returned as 'numTxt' and 'numWds' respectively.\r\n '''\r\n if indir=='':\r\n indir='G:\\Congress\\Twitter\\Data'\r\n text={}\r\n broken=[]\r\n for fn in os.listdir(indir):\r\n if fn.endswith('json'):\r\n continue\r\n tid=fn.split(\".\")[0].lower()\r\n if tid in metaData.keys():\r\n texts=[]\r\n count=0\r\n with open(indir+'\\\\'+fn,'rb') as f:\r\n data=csv.reader(f)\r\n for i,line in enumerate(data):\r\n if i>0:\r\n count+=1\r\n time=line[3]\r\n time=time.split(' ')[0]\r\n time=dt.datetime.strptime(time,'%m/%d/%Y')# %a %b %d %H:%M:%S +0000 %Y').strftime('%m/%d/%Y %H:%M:%S')\r\n if time>=months[0] and time<=months[1]:\r\n texts.append(line[0])\r\n #if count>3000 and lastTime>begin:\r\n # broken.append([tid,'hit twitter limit in time period - '+str(count)])\r\n # continue\r\n #if len(texts)<2:\r\n # broken.append([tid,'not enough data in time period (min of 2)'])\r\n # continue\r\n #numTxt=len(texts)\r\n texts=' '.join(Clean_Tweets(' '.join(texts),stopwords='nltk',onlyHashtags=False))#generate feature space of tweet by eliminating stops and adding metatext features\r\n text[tid]=texts\r\n #numWds=len(texts) \r\n return text, broken, metaData\r\n\r\n\r\ndef Vectorize(texts,polKey):\r\n vectorizer= tfidf(texts.values(),ngram_range=(1,2),stop_words='english',min_df=5) #the only real question I have with this is whether it ejects twitter-specific text (ie. @ or #)\r\n vec=vectorizer.fit_transform(texts.values()) \r\n labels=[]\r\n for k in texts.keys():\r\n labels.append(polKey[k])\r\n labels=np.asarray(labels) \r\n return vec,labels,vectorizer\r\n\r\ndef Sample(vec,labels,texts,clf='knn',pct=.2):\r\n '''This code creates the randomized test/train samples and the trains and tests the classifier\r\n and returns the vectors of test and train texts and labels as well as keys for linking results to TwitterIDs'''\r\n trainIds=rn.sample(xrange(np.shape(labels)[0]),int(round(np.shape(labels)[0]*pct)))\r\n testIds=[]\r\n trainKey={}\r\n testKey={}\r\n ts=0\r\n tr=0\r\n for t in xrange(np.shape(labels)[0]): \r\n if t not in trainIds:\r\n testIds.append(t)\r\n testKey[ts]=texts.keys()[t]\r\n ts+=1\r\n else:\r\n trainKey[tr]=texts.keys()[t]\r\n tr+=1\r\n trainTexts=vec[trainIds]\r\n trainLabels=labels[trainIds]\r\n testTexts=vec[testIds]\r\n testLabels=labels[testIds]\r\n \r\n return trainTexts, trainLabels, testTexts,testLabels,trainKey,testKey\r\n\r\n\r\ndef Classify(trainT,trainL,testT,testL,clf='knn'):\r\n '''Code to train and test classifiers. type can be 'knn' 'nb' or 'svm'\r\n returns the fit matrix #a dictionary of {twitterID: likelihood ratio}'''\r\n if clf=='knn':\r\n cl = neighbors.KNeighborsClassifier()\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n if clf=='svm':\r\n cl=svm.SVC(C=100,gamma=.1,probability=True)\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n if clf=='nb':\r\n cl=mnb()\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n return fit, cl\r\n\r\ndef CleanResults(fit,testKeys):\r\n '''This code takes the results of classifier.predict_proba() and cleans out extreme scores and produces z-scored likelihood ratios.\r\n It replaces any probabilites of 1 or 0 (which produce inf likelihoods) with the nearest max and min probabilites given.\r\n It then computes the likelihood ratio and z-scores them, returning res as a dictionary of {twitterID: z-scored likelihood ratio}'''\r\n #identify any possible infinite values and recode using the next maximum probability\r\n if 0 in fit:\r\n lis=sorted(fit[:,0],reverse=True)\r\n lis+=sorted(fit[:,1],reverse=True)\r\n for l in sorted(lis,reverse=True):\r\n if l!=1.0:\r\n fit[fit==1.0]=l\r\n break\r\n for l in sorted(lis):\r\n if l!=0.0:\r\n fit[fit==0.0]=l\r\n break\r\n\r\n res=dict(zip(testKeys.values(),[0 for i in xrange(len(testKeys.keys()))]))\r\n for i,line in enumerate(fit):\r\n res[testKeys[i]]=[line[0],line[1],np.log(line[0]/line[1])]\r\n vals=[i[2] for i in res.values()]\r\n m=np.mean(vals)\r\n sd=np.std(vals)\r\n for k,v in res.iteritems():\r\n res[k]=[v[0],v[1],(v[2]-m)/sd]\r\n adjust=[m,sd]\r\n return res, adjust\r\n \r\n\r\ndef NBTopWords(vec,clf,n=20):\r\n topWords={}\r\n feature_names =vec.get_feature_names()\r\n coefs_with_fns = sorted(zip(clf.coef_[0], feature_names,xrange(clf.coef_.shape[1])))\r\n top = coefs_with_fns[:-(n + 1):-1]\r\n for w in top:\r\n word=w[1]\r\n for j, f in enumerate(vec.get_feature_names()):\r\n if f==word:\r\n dem=np.exp(clf.feature_log_prob_[0][j])\r\n rep=np.exp(clf.feature_log_prob_[1][j])\r\n party=1*(rep>dem)\r\n \r\n topWords[word]=[party,rep,dem]\r\n return topWords\r\n\r\ndef TopWordsperPerson(vectorizer,vec,clf,texts,n=500):\r\n print 'getting top partisan words for members'\r\n personWords={}\r\n feature_names =vectorizer.get_feature_names()\r\n coefs_with_fns = sorted(zip(classifier.coef_[0], feature_names,xrange(classifier.coef_.shape[1])))\r\n top = coefs_with_fns[:-(n + 1):-1]\r\n for i,row in enumerate(vec): \r\n person=texts.keys()[i]\r\n personWords[person]={}\r\n for (r,w,idx) in top:\r\n personWords[person][w]=vec[i,idx]*r\r\n \r\n for person, worddict in personWords.iteritems():\r\n personWords[person] = sorted(worddict.iteritems(), key=operator.itemgetter(1))[0:20]\r\n \r\n return personWords\r\n\r\n\r\ndef ClassificationReport(testLabels, testTexts,classifier):\r\n \r\n y_pred=classifier.predict(testTexts)\r\n print(classification_report(testLabels, y_pred))\r\n #print(accuracy(testLabels, y_pred))\r\n report=classification_report(testLabels, y_pred)\r\n \r\n return report\r\n\r\n\r\ndef SaveResults(data,metaHeader,classHeader,outfile=''):\r\n #check code for writing correctness then validate format and add headers for initial data creation\r\n '''This function joins the classifier results with the classifier metadata and the person metadata to\r\n the existing data of the same structure:\r\n PersonData, classifier data, classificaiton results\r\n res is the z-scored likelihood ratio data {twitterid: scored ratio}\r\n metadata is the dictionary {twitterID: list of person data}\r\n classMeta is a list of classifier features including sample pct, type of classifier, and iteration\r\n fname is the name of the data file being dumped to.'''\r\n \r\n print 'saving data'\r\n #header=metaHeader+classHeader+['RepProb','DemProb','zLkRatio']\r\n header=['Time_Index',\"Time_Label\",'TwitterID','zLkRatio']\r\n with open(outfile,'wb') as f:\r\n writeit=csv.writer(f)\r\n writeit.writerow(header)\r\n for line in data:\r\n writeit.writerow([line[1],line[2],line[3],line[len(line)-1]]) #save \r\n return\r\n\r\n\r\ndef SaveWords(words,outfile=''):\r\n #check code for writing correctness then validate format and add headers for initial data creation\r\n '''This function saves the top words each month.'''\r\n \r\n print 'saving data'\r\n header=['month','word','party','repprob','demprob']\r\n header=['Time','Word','Log Likelihood']\r\n f=open(outfile,'wb')\r\n writeit=csv.writer(f)\r\n writeit.writerow(header)\r\n for month,worddict in words.iteritems():\r\n for word, res in worddict.iteritems():\r\n logprob=np.log(res[1]/res[2])\r\n writeit.writerow([month, word,logprob])\r\n #line=[month]\r\n #for word,dat in worddict.iteritems():\r\n # line.append(word)\r\n # #line=[month,word]+dat\r\n #writeit.writerow(line)\r\n f.close()\r\n return\r\n\r\ndef AggregateEstimate(clfs = ['nb','knn','svm'],samples=[.5],iters=200,outfile=''):\r\n ''' This code runs the classifiers across iterations and sample sizes producing the core data used in the final\r\n analysis. test data for the classifier in 'clf' for 'iters' number of iterations.\r\n It pulls in the metadata, keys, and essays, and then iterates by random sampling, classification,\r\n and data cleaning producing lists of dictionaries of {TwitterID: z-scored likelihood ratios} for each iteration'''\r\n Data={}\r\n for c in clfs:\r\n Data[c]={}\r\n dates=['1/03/2000','1/03/2019']\r\n begin=dt.datetime.strptime(dates[0],'%m/%d/%Y')\r\n end=dt.datetime.strptime(dates[1],'%m/%d/%Y')\r\n indir='G:\\Congress\\Twitter\\Data'\r\n adjust={}\r\n words={}\r\n cache=True\r\n if cache:\r\n with open('G:\\cache\\mpp.pkl','rb') as f:\r\n print 'importing from cache'\r\n metaData,metaHeader,texts,vec,labels,vectorizer=cPickle.load(f)\r\n else:\r\n print 'getting meta data'\r\n metaData, metaHeader, polKey=makeMetaData()\r\n #print len(missing), \" Number of missing congress members. Here's who and why: \"\r\n #print missing\r\n print 'importing tweets'\r\n texts, broken, metaData=MakeDateEssays([begin,end],metaData, indir) #get polkey from makeMetaData and go from there\r\n #print len(broken), \" Number of excluded congress members. Here's who and why: \"\r\n #print broken\r\n print 'vectorizing texts'\r\n vec,labels,vectorizer=Vectorize(texts,polKey)\r\n print 'caching files'\r\n f='G:\\cache\\mpp.pkl'\r\n with open(f,'wb') as fl:\r\n cPickle.dump([metaData,metaHeader,texts,vec,labels,vectorizer],fl)\r\n \r\n for clf in clfs:\r\n best=0\r\n data={}\r\n for samp in samples:\r\n #accs=[]\r\n for it in xrange(iters):\r\n print \"Doing: \", clf, ' ', samp, ' ', it\r\n classMeta=[clf,samp,it]\r\n classHeader=['Classifier','SamplePct','Iteration']\r\n trainTexts, trainLabels, testTexts,testLabels,trainKey,testKey =Sample(vec,labels,texts,pct=samp)\r\n fit,classifier=Classify(trainTexts, trainLabels, testTexts,testLabels,clf=clf)\r\n classifier.score(testTexts,testLabels) \r\n report=ClassificationReport(testLabels, testTexts,classifier)\r\n print(report)\r\n #accs.append([classifier.score(testTexts,testLabels),np.mean([int(l) for l in testLabels])])\r\n print \"Accuracy of \", clf, ' was ',classifier.score(testTexts,testLabels)\r\n res,adj=CleanResults(fit, testKey)\r\n if clf=='nb' and best < classifier.score(testTexts,testLabels):\r\n #words[it]=NBTopWords(vectorizer,classifier,n=200)\r\n personWords=TopWordsperPerson(vectorizer,vec,classifier,texts,n=500)\r\n best=classifier.score(testTexts,testLabels)\r\n #print adj\r\n adjust[clf+'-'+str(it)]=adj\r\n for k,r in res.iteritems():\r\n if k in data.keys():\r\n for j,num in enumerate(r):\r\n data[k][j].append(num)\r\n else:\r\n data[k]=[[num] for num in r]\r\n \r\n #f='G:/Research Data/2017-01-12 Backup/CongressTweets/Classifiers/'+clf+str(it)+'clf.pkl'\r\n #with open(f,'wb') as fl:\r\n # cPickle.dump(classifier,fl)\r\n \r\n #print \"Averge Accuracy of \", clf, \" for \", month, ' was ', np.mean(accs)\r\n for k, res in data.iteritems():\r\n Data[clf][k]=map(np.mean,res) #Data['nb']['barackobama'][avgprobreb,avgprobdem,avgzlkration]\r\n \r\n \r\n \r\n \r\n #print \"Accuracy of \", clf, \" classifer on \",samp,\" samples is \",np.mean([a[0] for a in accs]),' from ', np.mean([a[1] for a in accs])/2.0 , ' probability'\r\n \r\n print 'saving data'\r\n outdata={}\r\n for clf, tdata in Data.iteritems():\r\n outdata[clf]={}\r\n for tid,res in tdata.iteritems():\r\n #line=[tid]+res\r\n outdata[clf][tid]=res[2]\r\n \r\n print 'saving data'\r\n #header=metaHeader+classHeader+['RepProb','DemProb','zLkRatio']\r\n for clf, data in outdata.iteritems():\r\n output_file='..\\Results\\Aggregate_Metadata_'+clf+'.csv'\r\n output_header=metaHeader+['TwitterID','zLkRatio']\r\n with open(outfile,'wb') as f:\r\n writeit=csv.writer(f)\r\n writeit.writerow(output_header)\r\n for k,v in metaData.iteritems():\r\n if k in outdata[clf].keys():\r\n writeit.writerow([k]+v+[outdata[clf][k]]) #save\r\n else:\r\n writeit.writerow([k]+v+['']) #save\r\n \r\n header=['Time Index',\"Time Label\",'TwitterID','zLkRatio']\r\n \r\n #header=metaHeader+classHeader+['RepProb','DemProb','zLkRatio']\r\n header=['CLF','TwitterID','zLkRatio']\r\n with open(outfile,'wb') as f:\r\n writeit=csv.writer(f)\r\n writeit.writerow(header)\r\n for line in data:\r\n writeit.writerow([line[1],line[2],line[3],line[len(line)-1]]) #save \r\n #SaveResults(data,metaHeader,classHeader,outfile=outfile)\r\n with open('..\\Results\\Essay_StandardizeValues.txt','w') as f:\r\n f.write('Classifier,Iteration,Mean,Std\\n')\r\n for fn,val in adjust.iteritems():\r\n f.write(fn.replace('-',',')+','+','.join(map(str,val))+'\\n')\r\n \r\n with open('..\\Results\\AggregatePartisanWords.csv','w') as f:\r\n writeit=csv.writer(f) \r\n writeit.writerow(['Iteration','Word','IsRepub','RepScore','DemScore'])\r\n for it, ws in words.iteritems():\r\n for w,scores in ws.iteritems():\r\n writeit.writerow([it,w]+[scores])\r\n\r\n with open('..\\Results\\PartisanWordsPerMember.csv','w') as f:\r\n writeit=csv.writer(f)\r\n for person, wordset in personWords.iteritems():\r\n #for (w,scores) in wordset:\r\n writeit.writerow([person]+[w[0] for w in wordset]) \r\n \r\n \r\n return data,adjust,words\r\n\r\ndef MonthlyEstimate(clfs = ['nb','knn','svm'],samples=[.5],iters=200,outfile=''):\r\n ''' This code runs the classifiers across iterations and sample sizes producing the core data used in the final\r\n analysis. test data for the classifier in 'clf' for 'iters' number of iterations.\r\n It pulls in the metadata, keys, and essays, and then iterates by random sampling, classification,\r\n and data cleaning producing lists of dictionaries of {TwitterID: z-scored likelihood ratios} for each iteration'''\r\n Data={}\r\n for c in clfs:\r\n Data[c]={}\r\n indir='G:\\Congress\\Twitter\\Data'\r\n dates=['1/01/2018','10/19/2018']\r\n begin=dt.datetime.strptime(dates[0],'%m/%d/%Y')\r\n end=dt.datetime.strptime(dates[1],'%m/%d/%Y')\r\n monthKey={}\r\n words={}\r\n metaData, metaHeader, polKey=makeMetaData()\r\n for i,d in enumerate(rrule.rrule(rrule.MONTHLY, dtstart=begin, until=end)):\r\n if i==0:\r\n oldDate=d\r\n if i>0:\r\n months=[oldDate,d]\r\n month=oldDate.strftime('%b')+' '+d.strftime('%Y')\r\n texts, broken, metaData=MakeDateEssays(months,metaData, indir) #get polkey from makeMetaData and go from there\r\n vec,labels,vectorizer=Vectorize(texts,polKey)\r\n monthKey[i]=month\r\n for clf in clfs:\r\n Data[clf][i]={}\r\n data={}\r\n for samp in samples:\r\n print \"Doing: \", clf, ' on ',month,\r\n accs=[]\r\n for it in xrange(iters):\r\n trainTexts, trainLabels, testTexts,testLabels,trainKey,testKey =Sample(vec,labels,texts,pct=samp)\r\n fit,classifier=Classify(trainTexts, trainLabels, testTexts,testLabels,clf=clf)\r\n words[month]=NBTopWords(vectorizer,classifier,n=20)\r\n \r\n \r\n \r\n accs.append(classifier.score(testTexts,testLabels))\r\n res,adjust=CleanResults(fit, testKey)\r\n for k,r in res.iteritems():\r\n if k in data.keys():\r\n for j,num in enumerate(r):\r\n data[k][j].append(num)\r\n else:\r\n data[k]=[[num] for num in r]\r\n print \"Averge Accuracy of \", clf, \" for \", month, ' was ', np.mean(accs)\r\n report=ClassificationReport(testLabels, testTexts,classifier)\r\n print(report)\r\n for k, res in data.iteritems():\r\n Data[clf][i][k]=map(np.mean,res)\r\n# print clf, samp, accs\r\n# \r\n# print \"Accuracy of \", clf, \" classifer on \",samp,\" samples is \",np.mean([a[0] for a in accs]),' from ', np.mean([a[1] for a in accs])/2.0 , ' probability'\r\n oldDate=d\r\n outdata={}\r\n for clf, mons in Data.iteritems():\r\n outdata[clf]=[]\r\n for mon,tdata in mons.iteritems():\r\n for tid,res in tdata.iteritems():\r\n line=[clf]+[mon]+[monthKey[mon]]+[tid]+res\r\n outdata[clf].append(line)\r\n for clf, data in outdata.iteritems():\r\n metaHeader=['Classifier','Month','StrMonth','TwitterID']\r\n classHeader=[]\r\n print 'writing data for ', clf\r\n outfile='..\\Results\\MonthlyIdealPts_'+clf+'.csv'\r\n SaveResults(data,metaHeader,classHeader,outfile=outfile)\r\n SaveWords(words,outfile='..\\Results\\TEST_MonthlyPartisanWords.csv')\r\n return \r\n\r\n\r\n\r\nAggregateEstimate(clfs = ['nb'],samples=[.3],iters=30,outfile='..\\Results\\TEST_AggregatePartisanship.csv')\r\n#MonthlyEstimate(clfs = ['nb'],samples=[.5],iters=30,outfile='..\\Results\\TEST_MonthlyIdeals.csv')\r\n#SaveWords(words,outfile='..\\Results\\TEST_MonthlyPartisanWords.csv')\r\n#f=open('TEST_monthly112Words.pkl','w')\r\n#cPickle.dump(words,f)\r\n#f.close()"
},
{
"alpha_fraction": 0.5581773519515991,
"alphanum_fraction": 0.6139137744903564,
"avg_line_length": 30.3157901763916,
"blob_id": "10d0cf5bbb2827fd9e08fc9d31fc8c3fb54ac256",
"content_id": "0ebe209fb89bcd5139d828c0060c04856cd9d8ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2458,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 76,
"path": "/assets/replication/Scripts/Plot Monthly Partisanship.py",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "\r\n\r\nimport matplotlib.pyplot as plt\r\nimport pandas as pd\r\n\r\n#import monthly data\r\nwith open('..\\Results\\MonthlyIdealPts_nb.csv','r') as f:\r\n df=pd.read_csv(f)\r\n\r\nwith open('..\\Data\\metadata.csv') as f:\r\n meta=pd.read_csv(f) \r\n\r\nmeta.twitter = meta.twitter.replace(np.nan, '', regex=True)\r\nmeta['TwitterID'] = pd.Series([t.lower() for t in meta.twitter])\r\n#dfs=df.join(meta)\r\ndfs = pd.merge(df, meta, how='left', on=['TwitterID'])\r\n\r\n\r\n##plot params\r\n# min is -2.4 and max is 2.3\r\n#need to calculate republican and democrat average each month\r\n#need to set color of line to party of person\r\n#need to label the axes\r\n\r\n#for each person,\r\nx=result.groupby(['party','Time_Label']).mean()\r\nrep_df=x.zLkRatio.R\r\ndem_df=x.zLkRatio.D\r\ndem_series=pd.Series(dem_df.tolist(), index=[dt.datetime.strptime(d,'%b %Y') for d in dem_df.index])\r\nrep_series=pd.Series(rep_df.tolist(), index=[dt.datetime.strptime(d,'%b %Y') for d in rep_df.index])\r\n\r\nrep_col=(231/255.0, 18/255.0, 18/255.0)\r\ndem_col=(18/255.0, 18/255.0, 231/255.0)\r\nrep_col_all=(231/255.0, 18/255.0, 18/255.0,.4)\r\ndem_col_all=(18/255.0, 18/255.0, 231/255.0,.4)\r\n\r\n\r\ngrouped = df.groupby('TwitterID')\r\ni=0\r\nfor name, group in grouped:\r\n# i+=1\r\n print(name)\r\n# if i>10:\r\n# break\r\n ts = pd.Series(group.zLkRatio.tolist(), index=[dt.datetime.strptime(d,'%b %Y') for d in group.Time_Label])\r\n party=list(result[result.TwitterID==name].party)[0]\r\n if party =='D':\r\n col=dem_col\r\n elif party =='R':\r\n col=rep_col\r\n else:\r\n col=(128/255.0,128/255.0,128/255.0)\r\n fig=pd.DataFrame(dict(Republicans = rep_series, Democrats = dem_series, Candidate = ts)).plot(color=[col, dem_col_all,rep_col_all])\r\n #fig=ts.plot()\r\n #fig=dem_series.plot()\r\n #fig=rep_series.plot()\r\n fig.set_ylim(-2,2)\r\n fig.text(-.07, .95, 'Conservative',\r\n horizontalalignment='right',\r\n verticalalignment='bottom',\r\n fontsize=14, color='red',\r\n transform=fig.transAxes)\r\n \r\n fig.text(-.07, .05, 'Liberal',\r\n horizontalalignment='right',\r\n verticalalignment='bottom',\r\n fontsize=14, color='blue',\r\n transform=fig.transAxes)\r\n \r\n \r\n \r\n output = fig.get_figure()\r\n output.savefig('..\\Images2\\\\'+name+'.jpg')#,figsize=(8, 6), dpi=80,) #fig size sets image size in inches - 8in x 6in\r\n fig.clear()\r\n \r\n #create monthly plot\r\n\r\n #save plot as 200x200px jpg with ST-01-d.jpg name"
},
{
"alpha_fraction": 0.508274257183075,
"alphanum_fraction": 0.517809271812439,
"avg_line_length": 36.69512176513672,
"blob_id": "5fc0e75c353f13b034ed5c8969881fd64a0e8603",
"content_id": "d210e7d1182562b1de21b6b30127a54e073e1052",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 12690,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 328,
"path": "/assets/datajs/members.js",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "var divs=[];\r\nvar cardrows=[];\r\n//generates a list of members - [\"John Kennedy\", \"John McCain\"]\r\nfunction getMembers(){\r\n window.data=[];\r\n window.words=[];\r\n var members=[];\r\n d3.csv(\"../assets/replication/Data/metadata.csv\", function(data) {\r\n members.push(data.name);\r\n window.data.push(data);\r\n });\r\n window.words=[];\r\n d3.csv(\"../assets/replication/Results/PartisanWordsPerMember.csv\", function(data) {\r\n window.words.push(data);\r\n });\r\n return members\r\n}\r\n\r\nfunction refreshMemberPage(){\r\n //identify who they're looking for\r\n var newdata=[];\r\n var member_input=$(\".member_select\").val();\r\n if (member_input=='' || member_input=='Select a Member'){\r\n member_input=$(\".member_select\").val(\"Select a Member\");\r\n } \r\n //clean out existing page\r\n $('#main_container').text('');\r\n //insert searched for member\r\n fetchMemberData();\r\n //find and insert competitors\r\n fetchCompetition(); \r\n //find and insert related members\r\n fetchRelatedMemberData();\r\n}\r\n\r\nfunction fetchMemberData(){\r\n var newdata=[];\r\n var member_input=$(\".member_select\").val();\r\n if (member_input=='' || member_input=='Select a Member'){\r\n member_input=$(\".member_select\").val(\"Select a Member\");\r\n }else{\r\n console.log('got here1')\r\n fetchRaceByName(member_input);\r\n //if (location.hostname === \"localhost\" || location.hostname === \"127.0.0.1\"|| location.hostname === \"\"){\r\n // $('#official_name').text('successful name change');\r\n // $('#affiliation').text('succesful party change');\r\n //}else{\r\n // console.log('got here1')\r\n // \r\n // fetchRaceByName(member_input);\r\n //}\r\n //NEED CONDITION IF THEY ENTER AN INVALID NAME \r\n }\r\n $(\".member_select\").val('')\r\n}\r\n\r\nfunction fetchRaceByName(name){\r\n var title=''; //[Chamber] [Full Name]\r\n var affiliation = ''; //[party] from [State]\r\n var party ='';\r\n var state= '';\r\n var district='';\r\n var divs=[];\r\n for (var i = 0; i < window.data.length; i++){\r\n //d3.csv(\"../assets/replication/Data/metadata.csv\", function(data) {\r\n //console.log(data)\r\n //console.log(data.name)\r\n if (window.data[i].name==name){\r\n state=window.data[i].state;\r\n district=window.data[i].district;\r\n console.log('got here 2')\r\n console.log('state'+state);\r\n console.log('district '+district);\r\n console.log(data);\r\n //fetchRaceData(state, district, function(data) {\r\n // showRaceData(data);\r\n //})\r\n fetchRaceData(state,district);\r\n //console.log('got here 5');\r\n //console.log(JSON.stringify(divs))\r\n //cardrows=showRaceData(divs);\r\n }\r\n }\r\n //});\r\n \r\n}\r\n//\r\n//function showRaceData(divs){\r\n// console.log('got here 4')\r\n// //Hide the carousel - NOT NECESSARY if we move to races.html\r\n// $('#slider1-1').hide()\r\n// \r\n// //now that we have all the cards\r\n// //clear the existing container\r\n// $(\"#member_container\").empty()\r\n// $(\"#member_container_example\").hide()\r\n// $(\"#project_summary\").hide();\r\n// \r\n// //var cardrows=[];\r\n// //var card=$(\"<div class='col-\"+ratio.toString()+\" col-sm-\"+ratio.toString()+\"'>\")\r\n// //card.append(div)\r\n// for (r=0; r<=Math.floor(divs.length/3); r++ ){\r\n// var div =[];\r\n// if (divs.length>3){\r\n// div=divs.splice(0,3); //get three per row\r\n// }else{\r\n// div=divs.splice(0,divs.length); //otherwise get all of them\r\n// }\r\n// var cards=[];\r\n// \r\n// var bigrow=$(\"<div class=row></div>\");\r\n// for (var k=0; k<=div.length; k++){\r\n// console.log(JSON.stringify(div[k]))\r\n// if (div.length<3){\r\n// var card=$(\"<div class='col-6 col-sm-6'>\");\r\n// }else{\r\n// var card=$(\"<div class='col-4 col-sm-4'>\");\r\n// }\r\n// card.append(div[k]);\r\n// bigrow.push(card);\r\n// }\r\n// cardrows.push(bigrow)\r\n// console.log('got here final')\r\n// console.log(cardrows)\r\n// return cardrows\r\n// //$(\"#member_container\").append(cardrows); \r\n// } \r\n//}\r\n\r\nfunction fetchRaceData(state,district){\r\n console.log('got here 3')\r\n console.log('state'+state);\r\n console.log('district '+district);\r\n //idea here is person enters a zipcode and we lookup their district.\r\n var title=''; //[Chamber] [Full Name]\r\n var affiliation = ''; //[party] from [State]\r\n var party ='';\r\n cards=[];\r\n divs=[];\r\n for (var i = 0; i < window.data.length; i++){\r\n //d3.csv(\"../assets/replication/Data/metadata.csv\", function(data) {\r\n var count=0;\r\n //console.log(data.state+' '+state+' '+data.district+' '+district)\r\n //console.log('got here 2')\r\n if (window.data[i].state==state & window.data[i].district==district){\r\n count++;\r\n console.log('getting data for ' + window.data[i].name )\r\n var headshot_district_slug='';\r\n if (window.data[i].district=='Senate'){\r\n title='Senator ';\r\n headshot_district_slug='Sen';\r\n } else {\r\n title=\"Representative \";\r\n if (window.data[i].district==0){\r\n headshot_district_slug='';\r\n }else if(window.data[i].district<10 && window.data[i].district>0){\r\n headshot_district_slug=0+window.data[i].district;\r\n }else{\r\n headshot_district_slug=window.data[i].district;\r\n }\r\n }\r\n \r\n if (window.data[i].party=='D'){\r\n party='<span style=\"color: #0000a0\">Democratic</span> Candidate';\r\n }else if (window.data[i].party=='R'){\r\n party='<span style=\"color: #ff0000\">Republican</span> Candidate';\r\n }else{\r\n party='Candidate for ';\r\n }\r\n \r\n var headshot_slug=window.data[i].state+headshot_district_slug+'_'+window.data[i].party;\r\n \r\n\r\n var headshot_url='../assets/images/headshots/'+headshot_slug+'.jpg';\r\n \r\n //headshot_url='../assets/images/headshots/sinclair.jpg';\r\n \r\n //create title\r\n var h=$(\"<h5 style='text-align: center'></h5>\");\r\n var n=$(\"<div id='official_name\"+i.toString()+\"'>\").text(window.data[i].name); //.text(title.concat(window.data[i].name));\r\n h.append(n);\r\n \r\n //create and append first row of profile picture and member info\r\n var row1=$(\"<div class=row></div>\")\r\n var col1=$(\"<div class='col-6 col-sm-6'>\")\r\n var img1=$('<img src='+headshot_url+' style=\"width: 100%;\" id=\"picture_'+count.toString()+'\" title=\"\">');\r\n col1.append(img1)\r\n var col2=$(\"<div class='col-6 col-sm-6'>\")\r\n var af=$('<div id=\"affiliation_'+count.toString()+'\"></div>').html(party);\r\n col2.append(af)\r\n row1.append(col1,col2)\r\n \r\n //create and append second row of history of partisanship\r\n var row2=$(\"<div class=row style='padding-top: 15px'></div>\")\r\n var col3=$(\"<div class='col' style='text-align: center'>\")\r\n if (window.data[i].twitter!=''){\r\n var history_url='/assets/replication/Images/'+window.data[i].twitter.toLowerCase()+'.jpg';\r\n //history_url='/assets/replication/Images/sinclair.jpg';\r\n var photo=$('<img src='+history_url+' style=\"width: 75%;\" data-toggle=\"tooltip\" id=\"history_'+count.toString()+'\" title=\"Estimated partisanship over time\">');\r\n //var words=getWords(data.twitter);\r\n }else{\r\n var photo=$(\"<h5>No Twitter Account Found</h5>\");\r\n photo=$(\"\"); //don't need to say \"no twitter account twice\" as it is pulled in for wordtable too.\r\n //var history_url='/assets/replication/Images/no_data.jpg'; //need to create this image\r\n //history_url='/assets/replication/Images/sinclair.jpg';\r\n }\r\n \r\n col3.append(photo)\r\n row2.append(col3)\r\n \r\n //create and append table of top partisan words\r\n var row3=$(\"<div class=row></div>\")\r\n \r\n //FORMAT TOPWORDS TABLE\r\n if (window.data[i].twitter==''){\r\n var wordtable=$(\"<h5>No Twitter Account Found</h5>\");\r\n }else{\r\n var wordtable=getWordTable(window.data[i].twitter)\r\n }\r\n row3.append('top words table!')\r\n var div=$(\"<div></div>\");\r\n div.append(h,row1,row2,wordtable)\r\n divs.push(div)\r\n \r\n }\r\n }\r\n console.log('number of cards')\r\n console.log(divs.length)\r\n //Hide the carousel\r\n $('#slider1-1').hide()\r\n \r\n //now that we have all the cards\r\n //clear the existing container\r\n $(\"#member_container\").empty()\r\n $(\"#member_container_example\").hide()\r\n $(\"#project_summary\").hide();\r\n //Center heading for results\r\n var main= $(\"<h2 style='text-align:center'>Candidates for \"+ state+ \" \"+district +\" </h5>\");\r\n var cardrows=[];\r\n var cards=[];\r\n console.log('checking multirow results')\r\n for (r=0; r<=Math.floor(divs.length/3); r++ ){\r\n \r\n console.log('r='+r)\r\n //var div=$(\"<div class=row id=testdiv></div>\");\r\n if (divs.length>3){\r\n row=divs.splice(0,3); //get three per row\r\n }else{\r\n row=divs.splice(0,divs.length); //otherwise get all of them\r\n }\r\n var bigrow=$(\"<div class=row ></div>\");\r\n for (var k=0; k<row.length; k++){\r\n console.log('k='+k)\r\n if (row.length>=3){\r\n var card=$(\"<div class='col-lg-4 col-md-6 col-sm-12' style='padding-bottom: 20px'>\");\r\n }else{\r\n var card=$(\"<div class='col-lg-6 col-md-6 col-sm-12' style='padding-bottom: 20px'>\");\r\n }\r\n card.append(row[k]);\r\n cards.push(card);\r\n console.log(cards.length)\r\n \r\n }\r\n bigrow.append(cards);\r\n cardrows.push(bigrow);\r\n }\r\n console.log(JSON.stringify(cardrows))\r\n $(\"#member_container\").append(main,cardrows);\r\n \r\n \r\n //});\r\n //};\r\n //console.log(JSON.stringify(divs))\r\n //return divs\r\n //for (d in div)\r\n //return output\r\n}\r\n\r\nfunction getWordTable(twitter){\r\n //function takes an array of words and returns an html table\r\n console.log('getting words for ' + twitter)\r\n var phrases=[];\r\n for (var i = 0; i < window.words.length; i++){\r\n //console.log(window.words[i].TwitterID+\" \"+twitter)\r\n if (window.words[i].TwitterID==twitter.toLowerCase()){\r\n var raw=window.words[i].words;\r\n raw=raw.replace(new RegExp('mnton_', 'g'), '@');\r\n raw=raw.replace(new RegExp('hshtg_', 'g'), '#');\r\n //raw=raw.split('mnton_').join('@');\r\n phrases=raw.split(',')\r\n console.log(twitter+ ' '+ phrases)\r\n \r\n }\r\n }\r\n var numwordsperrow=3;\r\n var numcols=Math.floor(phrases.length/numwordsperrow);\r\n var rows=[];\r\n for (r=0; r<numcols; r++ ){\r\n console.log(numcols)\r\n var Row=$(\"<tr></tr>\");\r\n cells=[]\r\n if (phrases.length>numwordsperrow){\r\n var tablerow=phrases.splice(0,numwordsperrow); //get three per row\r\n }else{\r\n var tablerow=phrases.splice(0,phrases.length); //otherwise get all of them\r\n }\r\n for (k=0; k<tablerow.length; k++){\r\n var Cell=$(\"<td style='padding:5px'></td>\");\r\n Cell.text(tablerow[k])\r\n cells.push(Cell)\r\n //var cell=words[i]\r\n }\r\n Row.append(cells)\r\n rows.push(Row)\r\n \r\n }\r\n var h=$(\"<h5 style='text-align: center'>Most Partisan Phrases this Year</h5>\");\r\n var table=$(\"<table class=words style='border: 1px solid black; margin: 0 auto' data-toggle='tooltip' title='These are the words used by this candidate that our algorithm predicts are also associated with their party'></table>\");\r\n table.append(rows)\r\n var div=$(\"<div class=row style='padding-top: 15px'></div>\");\r\n var col=$(\"<div class=col style='text-align: center'></div>\");\r\n col.append(h,table)\r\n div.append(col)\r\n return div\r\n}\r\nfunction unitTest(){\r\n \r\n}"
},
{
"alpha_fraction": 0.5997523665428162,
"alphanum_fraction": 0.6139558553695679,
"avg_line_length": 38.73887252807617,
"blob_id": "66763d370f973eee1e4a112c3104522201eca8d8",
"content_id": "88ec5406cd71fd3fb74c376b67c0b025fb6a2238",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13729,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 337,
"path": "/assets/replication/Scripts/PartisanTopicModel.py",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "\r\nimport re, os, csv\r\nimport nltk\r\nimport random as rn\r\n#import hashlib\r\nimport numpy as np\r\nfrom gensim import corpora\r\n#from itertools import groupby\r\n#import cPickle\r\n#import scipy\r\nimport TopicModels\r\nreload(TopicModels)\r\n\r\ndef simple_clean(text,stopwords='nltk'):\r\n if stopwords=='nltk':\r\n stopwords=nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n #print stopwords\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www','co',\r\n 'hlink','mnton','hshtg','mt','rt','amp','htt','rtwt']\r\n text = text.lower()\r\n text = re.findall(r\"[\\w'#@]+\",text)\r\n res = []\r\n for w in text:\r\n if w not in stopwords and len(w)>2:\r\n res.append(w)\r\n return res\r\n \r\ndef Clean_Tweets(text,stopwords='nltk',onlyHashtags=False):\r\n '''this function tokenizes `tweets` using simple rules:\r\n tokens are defined as maximal strings of letters, digits\r\n and apostrophies.\r\n The optional argument `stopwords` is a list of words to\r\n exclude from the tokenzation. This code eliminates hypertext and markup features to\r\n focus on the substance of tweets'''\r\n if stopwords=='nltk':\r\n stopwords=nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n #print stopwords\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www']\r\n retweet=False\r\n if 'RT @' in text:\r\n retweet=True\r\n # make lowercase\r\n text = text.lower()\r\n #ELEMINATE HYPERLINKS\r\n ntext=[]\r\n text=text.split(' ')\r\n for t in text:\r\n if t.startswith('http'):\r\n #ntext.append('hlink')\r\n continue\r\n else:\r\n ntext.append(t)\r\n text=' '.join(ntext)\r\n # grab just the words we're interested in\r\n text = re.findall(r\"[\\d\\w'#@]+\",text)\r\n # remove stopwords\r\n if onlyHashtags==True:\r\n htags=[]\r\n for w in text:\r\n if w.startswith('#'):\r\n htags.append(w)\r\n return htags\r\n res = []\r\n for w in text:\r\n if w=='hlink':\r\n res.append('HLINK')\r\n continue\r\n if w.startswith('@') and w!='@':\r\n res.append('MNTON'+'_'+w[1:])\r\n continue\r\n if w.startswith('#'):\r\n res.append('HSHTG'+'_'+w[1:])\r\n continue\r\n if w not in stopwords:\r\n res.append(w)\r\n if retweet:\r\n res.append('RTWT')\r\n return res\r\n\r\n\r\n\r\ndef ImportTweets(decile=10.0,typ='nonpartisan'):\r\n '''\r\n This function imports tweets from partisanscores.csv, filters out those that are more\r\n partisan than cut, and returns a list with the tweets and ids.\r\n \r\n Input:\r\n cut - max partisanship rating (scale of 0-inf, mean is .69)\r\n \r\n Output\r\n tweets- dictionary of tweet id and pre-cleaned tweet (e.g. {123456789: \"This tweet HLINK})\r\n ids - dictionary of tweet id and twitter id (e.g. {123456789: 'barackobama'})\r\n \r\n '''\r\n \r\n print 'importing tweets' \r\n name='G:\\Homestyle\\Data\\\\partisanscores.csv'\r\n data=[]\r\n directory='G:/Congress/Twitter Ideology/Partisan Scores/'\r\n for fn in os.listdir(directory):\r\n with open(directory+'\\\\'+fn,'r') as f:\r\n twitterid=fn.split('.')[0]\r\n for i,line in enumerate(f.readlines()):\r\n if i==1:\r\n newline=[line.split(\",\")[0],float(line.split(\",\")[1]),','.join(line.split(\",\")[2:])]\r\n \r\n if i>0:\r\n try: \r\n float(line.split(\",\")[0])\r\n data.append([twitterid]+newline)\r\n newline=[line.split(\",\")[0],float(line.split(\",\")[1]),','.join(line.split(\",\")[2:])]\r\n \r\n except:\r\n newline[2]+line\r\n #data.append([twitterid]+newline)\r\n \r\n texts={}\r\n ids={}\r\n # data=[]\r\n # with open(name,'rb') as f:\r\n # dta=csv.reader(f)\r\n # for i,line in enumerate(dta):\r\n # if i >0:\r\n # data.append(line)\r\n if typ=='nonpartisan':\r\n cut=sorted([abs(float(d[2])) for d in data])[int(len(data)/decile)]\r\n for line in data:\r\n if float(line[2])<=cut:\r\n text=line[3].strip('\\n')\r\n text=' '.join(simple_clean(text,stopwords='nltk'))\r\n texts[line[1]]=text\r\n ids[line[1]]=line[0]\r\n if typ=='partisan':\r\n cut=sorted([abs(float(d[2])) for d in data],reverse=True)[int(len(data)/decile)]\r\n for line in data:\r\n if float(line[2])>=cut:\r\n text=line[3].strip('\\n')\r\n text=' '.join(simple_clean(text,stopwords='nltk'))\r\n texts[line[1]]=text\r\n ids[line[1]]=line[0]\r\n return texts,ids\r\n\r\ndef sample(texts,pct):\r\n train={}\r\n test={}\r\n heldout={}\r\n for idx, tweet in texts.iteritems():\r\n ran=rn.random()\r\n if ran<pct:\r\n train[idx]=tweet\r\n elif ran<pct+pct and ran>=pct:\r\n test[idx]=tweet\r\n else:\r\n heldout[idx]=tweet\r\n return train,test,heldout\r\n\r\ndef gensimGenerator(texts,dictionary):\r\n for text in TopicModels.Tokenize(texts):\r\n yield dictionary.doc2bow(text)\r\n\r\n\r\ndef getTopicsGenerator(model,texts,dictionary):\r\n for text in texts:\r\n bow = dictionary.doc2bow(TopicModels.Tokenize(text))\r\n topic_in_doc=dict(model.get_document_topics(corpus))\r\n yield topic_in_doc\r\n\r\n\r\ndef RawTopicScore(texts,numtopics=200,iterations=500,passes=10,name='Twitter_Raw',**exargs):\r\n '''\r\n This code runs a topic model on the texts and returns a vector of texts and proportions of topics in texts\r\n Input:\r\n texts = {id1: \"text1\",id2:'text2',...}\r\n \r\n '''\r\n from gensim import corpora\r\n print 'doing topic modelling on ', len(texts), ' texts and ', numtopics, ' topics'\r\n #runfile('C:\\Users\\Boss\\Documents\\Python Scripts\\onlineldavb.py')\r\n print 'tokenizing ', name\r\n #texts=RemoveStops(texts)\r\n toktexts=TopicModels.Tokenize(texts)\r\n dictionary=TopicModels.vocabulary(toktexts)\r\n print 'original vocabulary size is ', len(dictionary)\r\n dictionary.filter_extremes(**exargs)#)\r\n print 'reduced vocabulary size is ',len(dictionary)\r\n dictionary.compactify()\r\n print 'reduced vocabulary size is ',len(dictionary)\r\n #corpus = [dictionary.doc2bow(text) for text in TopicModels.Tokenize(texts)]\r\n corpusgenerator=gensimGenerator(texts,dictionary)\r\n corpora.MmCorpus.serialize('Data/'+name+'_Corpus.mm', corpusgenerator) \r\n #print 'vectorizing ', name\r\n #tfidf_corpus,tfidf,corpus=TopicModels.vectorize(toktexts,dictionary)\r\n print 'Doing lda ', name\r\n mm = corpora.MmCorpus('Data/'+name+'_Corpus.mm',)\r\n model,topic_in_document=TopicModels.topics(mm,dictionary,strategy='lda', num_topics=numtopics,passes=passes,iterations=iterations) #passes=4\r\n \r\n print 're-formatting data' \r\n topic_in_documents=[dict(res) for res in topic_in_document] #Returns list of lists =[[(top2, prob), (top8, prob8)],[top1,prob]]\r\n Data=[]\r\n for doc, resdict in enumerate(topic_in_documents):\r\n line=[texts.keys()[doc]] #This should line up. If it doesn't the model results will be random noise\r\n for i in xrange(numtopics):\r\n if i in resdict.keys():\r\n line.append(resdict[i])\r\n else:\r\n line.append(0.0)\r\n Data.append(line)\r\n print \"writing Document by Topic scores for \", name\r\n with open('Results/'+name+'_Topic_Scores_'+str(numtopics)+'.csv','wb') as f:\r\n writer=csv.writer(f,delimiter=',')\r\n writer.writerow(['id']+[\"Topic_\"+str(n) for n in xrange(numtopics)])\r\n for info in Data:\r\n writer.writerow([str(i) for i in info])\r\n \r\n print 'writing topic words to Results Folder for ', name\r\n words=TopicModels.wordsInTopics(model, numWords = 25)\r\n with open('Results/'+name+'_TopicsByWords_'+str(numtopics)+'.csv','wb') as f:\r\n writer=csv.writer(f,delimiter=',')\r\n for topic,wordlis in words.iteritems():\r\n writer.writerow([topic]+[\" \".join(wordlis)])\r\n model.save('Results/'+name+'_model.model')\r\n #save(fname, ignore=('state', 'dispatcher'), separately=None, *args, **kwargs)\r\n #NOTE: LOAD MODEEL WITH model = models.LdaModel.load('lda.model')\r\n return model,dictionary\r\n\r\ndef PrepTopicModelTexts(texts,name,**exargs):\r\n \r\n print 'tokenizing ', name\r\n #texts=RemoveStops(texts)\r\n toktexts=TopicModels.Tokenize(texts)\r\n dictionary=TopicModels.vocabulary(toktexts)\r\n print 'original vocabulary size is ', len(dictionary)\r\n dictionary.filter_extremes(**exargs)#)\r\n print 'reduced vocabulary size is ',len(dictionary)\r\n dictionary.compactify()\r\n print 'reduced vocabulary size is ',len(dictionary)\r\n corpus = [dictionary.doc2bow(text) for text in TopicModels.Tokenize(texts)]\r\n corpusgenerator=gensimGenerator(texts,dictionary)\r\n corpora.MmCorpus.serialize('Data/'+name+'_Corpus.mm', corpusgenerator) \r\n mm=corpora.MmCorpus('Data/'+name+'_Corpus.mm',)\r\n return toktexts,dictionary, corpus,mm\r\n\r\ndef GridSearch(test,train,dictionary,numtopics,iterations=10,passes=3,**exargs):\r\n #load corpus\r\n out=[]\r\n train=corpora.MmCorpus('Data/train_Corpus.mm')\r\n test=corpora.MmCorpus('Data/test_Corpus.mm',)\r\n for num in numtopics:\r\n print 'Doing lda ', num\r\n train=corpora.MmCorpus('Data/Train_Corpus.mm')\r\n model,topic_in_document=TopicModels.topics(train,dictionary,strategy='lda', num_topics=num,passes=passes,iterations=iterations) #passes=4\r\n print 'fit model', num\r\n \r\n p=model.bound(test)\r\n print'perplexity: ', num, p\r\n out.append([num,p])\r\n \r\n return out\r\n \r\ndef FitTopicModel(dictionary,numtopics=10,passes=10,iterations=50):#strategy='lda', num_topics=numtopics,passes=passes,iterations=iterations\r\n print 'Doing lda ', name\r\n mm = corpora.MmCorpus('Data/'+name+'_Corpus.mm',)\r\n model,topic_in_document=TopicModels.topics(mm,dictionary,strategy='lda', num_topics=numtopics,passes=passes,iterations=iterations) #passes=4\r\n return\r\n \r\ndef SaveWordsInTopics(model,filename,numWords=25):\r\n print 'writing topic words to Results Folder for ', name\r\n words=TopicModels.wordsInTopics(model)\r\n #with open('Results/'+name+'_TopicsByWords_'+str(numtopics)+'.csv','wb') as f:\r\n with open(filename,'wb') as f:\r\n writer=csv.writer(f,delimiter=',')\r\n for topic,wordlis in words.iteritems():\r\n writer.writerow([topic]+wordlis)\r\n return\r\n \r\ndef SaveTopicsInDocuments(topic_in_documents,filename):\r\n print 're-formatting data' \r\n topic_in_documents=[dict(res) for res in topic_in_document] #Returns list of lists =[[(top2, prob), (top8, prob8)],[top1,prob]]\r\n Data=[]\r\n for doc, resdict in enumerate(topic_in_documents):\r\n line=[texts.keys()[doc]] #This should line up. If it doesn't the model results will be random noise\r\n for i in xrange(numtopics):\r\n if i in resdict.keys():\r\n line.append(resdict[i])\r\n else:\r\n line.append(0.0)\r\n Data.append(line) \r\n print \"writing Topic by Document scores\"\r\n #with open('Results/'+name+'_Topic_Scores.csv','wb') as f: \r\n with open(filename,'wb') as f:\r\n writer=csv.writer(f,delimiter=',')\r\n writer.writerow(['id']+[\"Topic_\"+str(n) for n in xrange(len(Data[0]))])\r\n for info in Data:\r\n writer.writerow([str(i) for i in info])\r\n return\r\n \r\n \r\ndef TopicPipeline(name):\r\n alltexts,ids=ImportTweets(indir='')\r\n train,test,heldout=sample(alltexts,.20) #used to reduce the number of tweets pulled in for code-building and testing purposes.\r\n trainToktexts,trainDictionary, train_bow,serialTrain=PrepTopicModelTexts(train,name)\r\n testToktexts,testDictionary, test_bow, serialTest=PrepTopicModelTexts(test,name='gridtest')\r\n model=FitTopicModel(filename,dictionary)\r\n return out\r\n\r\ndef GridSearchPipeline():\r\n print 'importing tweets'\r\n alltexts,ids=ImportTweets(decile=.6)\r\n print 'creating samples'\r\n train,test,heldout=sample(alltexts,.25) #used to reduce the number of tweets pulled in for code-building and testing purposes.\r\n print 'vectorizing texts of length', len(train)\r\n exargs={'no_below':5,'no_above':.90,'keep_n':10000}\r\n toktexts,dictionary, corpus, serialTrain=PrepTopicModelTexts(train,name='train',**exargs) \r\n toktexts,dictionary, corpus, serialTest=PrepTopicModelTexts(test,name='test',**exargs) \r\n print 'launching grid search'\r\n out = GridSearch(serialTrain,serialTest,dictionary,numtopics=[5,10,20,30,50,70,100],iterations=2,passes=1,**exargs)\r\n return out\r\n#\r\nprint 'importing tweets'\r\nalltexts,ids=ImportTweets(decile=10,typ='nonpartisan')\r\nexargs={'no_below':20,'no_above':.90,'keep_n':10000}\r\nmodel,dictionary=RawTopicScore(alltexts,numtopics=10,iterations=100,passes=10,name='nonpartisan',**exargs)\r\n\r\nprint 'importing tweets'\r\nalltexts,ids=ImportTweets(decile=10,typ='nonpartisan')\r\nexargs={'no_below':20,'no_above':.90,'keep_n':10000}\r\nmodel,dictionary=RawTopicScore(alltexts,numtopics=31,iterations=100,passes=10,name='nonpartisan',**exargs)\r\n\r\nalltexts,ids=ImportTweets(decile=10,typ='partisan')\r\nexargs={'no_below':20,'no_above':.90,'keep_n':10000}\r\nmodel,dictionary=RawTopicScore(alltexts,numtopics=30,iterations=100,passes=10,name='partisan',**exargs)\r\n\r\n\r\n#out=GridSearch(dictionary,[10,20,30,50,70,100],iterations=10,passes=3,**exargs)"
},
{
"alpha_fraction": 0.5384193062782288,
"alphanum_fraction": 0.5638309717178345,
"avg_line_length": 35.56700897216797,
"blob_id": "d994500b06916adb63bae40ee956c9da6525dac4",
"content_id": "75f553066cbff3dff857fc7087f448d3bb73b56e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18220,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 485,
"path": "/assets/replication/Scripts/Tweet_Partisanship.py",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "'''\r\nThis code estimates the ideal point for each tweet based on the twitter\r\nideal points estimated for each member of congress.\r\n'''\r\n\r\nimport cPickle\r\nimport os\r\nimport numpy as np\r\nimport csv\r\nimport datetime as dt\r\nfrom nltk import corpus \r\nimport re\r\nimport random as rn\r\n\r\nfrom sklearn.feature_extraction.text import TfidfVectorizer as tfidf\r\n\r\n\r\ndef simple_tokenizer(text,stopwords='nltk'):\r\n '''\r\n function to tokenize tweets\r\n '''\r\n if stopwords=='nltk':\r\n stopwords=corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n #print stopwords\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www','co',\r\n 'hlink','mnton','hshtg','mt','rt','amp','htt','rtwt']\r\n text = text.lower()\r\n text = re.findall(r\"[\\w'#@]+\",text)\r\n res = []\r\n for w in text:\r\n if w not in stopwords and len(w)>2:\r\n res.append(w)\r\n return res\r\n\r\ndef getStopWords():\r\n stopwords=corpus.stopwords.words('english')\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www','co',\r\n 'hlink','mnton','hshtg','mt','rt','amp','htt','rtwt','https']\r\n return stopwords\r\n\r\ndef importMetaData():\r\n '''\r\n Import the ideal point data \r\n '''\r\n \r\n print 'importing meta data'\r\n data={}\r\n scores={}\r\n fname='..\\Results\\Aggregate_Metadata_nb.csv'\r\n fname='../Results/MonthlyIdealPts_nb.csv'\r\n with open(fname) as f:\r\n dta=csv.reader(f)\r\n for i,line in enumerate(dta):\r\n if i>0:\r\n tid=line[2]\r\n #tid=line[0]\r\n row=line[0:9]\r\n ideal_point = line[len(line)-1]\r\n data[tid]=row+[ideal_point]\r\n scores[tid]=ideal_point \r\n return data, scores\r\n\r\n\r\ndef MakeDateEssays(dates,metaData, indir=''):\r\n '''This function turns a directory (indir) composed of every individual's tweets each contained in a csv file (e.g. barackobama.csv)\r\n into a dictionary of {twitterID: 'parsed tweet1 parsed tweet2'}\r\n \r\n As a part of this data formating process, this code also produces counts of the total number of tweets and characters for each person\r\n returned as 'numTxt' and 'numWds' respectively.\r\n '''\r\n print 'importing tweets' \r\n if indir=='':\r\n indir='G:\\Congress\\Twitter\\Data'\r\n if dates==[]:\r\n dates=['1/01/2018','11/08/2018']\r\n begin=dt.datetime.strptime(dates[0],'%m/%d/%Y')\r\n end=dt.datetime.strptime(dates[1],'%m/%d/%Y')\r\n text={}\r\n for fn in os.listdir(indir):\r\n if fn.endswith('json'):\r\n continue\r\n tid=fn.split(\".\")[0].lower()\r\n if tid in metaData.keys():\r\n texts={}\r\n count=0\r\n with open(indir+'\\\\'+fn,'rb') as f:\r\n data=csv.reader(f)\r\n for i,line in enumerate(data):\r\n if i>0:\r\n time=line[3]\r\n time=time.split(' ')[0]\r\n time=dt.datetime.strptime(time,'%m/%d/%Y')# %a %b %d %H:%M:%S +0000 %Y').strftime('%m/%d/%Y %H:%M:%S')\r\n if time>=begin and time<=end:\r\n texts[line[6]]=line[0]\r\n lastTime=time\r\n text[tid]=texts\r\n return text\r\n\r\n\r\ndef splitDevSample(text,scores, p=''):\r\n '''\r\n This code creates a subsample of tweets from each state to build the state classifier.\r\n Each state must have at least 5 members with at least 30 tweets (in total) or else it is excluded from classification\r\n The subsampling will draw half of the tweets from each of the members from the state, reserving the other half for\r\n estimation.\r\n '''\r\n \r\n Out={}\r\n In={}\r\n if p=='':\r\n p=.50\r\n \r\n Dev={}\r\n Out={}\r\n for handle,tweets in text.iteritems():\r\n Dev[handle]={}\r\n Out[handle]={}\r\n for tid, tweet in tweets.iteritems():\r\n if rn.random()<p:\r\n Dev[handle][tid]={scores[handle]:tweet}\r\n else:\r\n Out[handle][tid]={scores[handle]:tweet}\r\n \r\n \r\n with open('Partisan_Dev.pkl','wb') as fl:\r\n cPickle.dump(Dev,fl)\r\n with open('Partisan_holdout.pkl','wb') as fl:\r\n cPickle.dump(Out,fl)\r\n\r\n return Dev, Out\r\n \r\n\r\ndef Vectorize(texts, vectorizer=''):\r\n Tweets=[]\r\n labels=[]\r\n ids=[]\r\n for handle, scored_tweets in texts.iteritems():\r\n for tid,scores in scored_tweets.iteritems():\r\n for score,tweet in scores.iteritems():\r\n labels.append(score)\r\n Tweets.append(tweet)\r\n ids.append(tid)\r\n if vectorizer=='':\r\n vectorizer= tfidf(Tweets,ngram_range=(1,2),stop_words=getStopWords(),min_df=2,binary=True) #the only real question I have with this is whether it ejects twitter-specific text (ie. @ or #)\r\n vectorizer=vectorizer.fit(Tweets)\r\n return vectorizer\r\n else:\r\n vec= vectorizer.transform(Tweets)\r\n labels=np.asarray(labels) \r\n return vec,labels,vectorizer,ids\r\n\r\ndef FitRF(vec,labels,ids,n_estimators='',clf=''):\r\n print 'fitting the linear model'\r\n from sklearn.ensemble import RandomForestRegressor as rf \r\n from sklearn.metrics import mean_squared_error as mserr\r\n if clf=='':\r\n clf=rf(n_estimators=n_estimators)\r\n clf.fit(vec,labels)\r\n return clf\r\n res={}\r\n prediction=clf.predict(vec)\r\n #report=Evaluate(labels,prediction,clf)\r\n mse=mserr(map(float,labels), prediction)\r\n print \"MSE:\", mse\r\n for idx in set(ids):\r\n res[idx]=[]\r\n for i,row in enumerate(prediction):\r\n res[ids[i]]=row\r\n return res,clf,mse\r\n\r\n\r\ndef makeDevSample(dates=[], p=.15):\r\n '''Function to import tweets and create the Dev and Holdout data '''\r\n if dates==[]: #default behavior is all tweets for 112.\r\n dates=['1/01/2018','11/08/2018']\r\n indir='G:\\Congress\\Twitter\\Data'\r\n metaData,scores=importMetaData()\r\n texts=MakeDateEssays(dates,metaData, indir) \r\n Dev,Out=splitDevSample(texts,scores,p)\r\n return\r\n\r\ndef TrainTestSplit(texts,sampler=.25):\r\n train_tweets=[]\r\n train_labels=[]\r\n train_ids=[]\r\n test_tweets,test_labels,test_ids=[],[],[]\r\n for handle, scored_tweets in texts.iteritems():\r\n for tweetid,scores in scored_tweets.iteritems():\r\n for score,tweet in scores.iteritems():\r\n if rn.random()<sampler:\r\n train_labels.append(score)\r\n train_tweets.append(tweet)\r\n train_ids.append(tweetid)\r\n else:\r\n test_labels.append(score)\r\n test_tweets.append(tweet)\r\n test_ids.append(tweetid)\r\n train_labels=np.asarray(train_labels)\r\n test_labels=np.asarray(test_labels)\r\n return train_tweets,train_labels,train_ids,test_tweets,test_labels,test_ids\r\n \r\ndef Report(res, texts):\r\n data={}\r\n for handle, scored_tweets in texts.iteritems():\r\n data[handle]=[]\r\n for tid,scores in scored_tweets.iteritems():\r\n for score,tweet in scores.iteritems():\r\n if tid in res:\r\n data[handle].append([tid, res[tid], tweet])\r\n \r\n outdir='G:/Congress/Twitter Ideology/Website/Partisan Scores/'\r\n out=[]\r\n for name,lines in data.iteritems():\r\n with open(outdir+name+'.txt','w') as fn:\r\n fn.write('tweetID,partisan_score,tweet \\n')\r\n for line in lines:\r\n fn.write(','.join(map(str,line))+'\\n')\r\n \r\n if len(lines)<10:\r\n out.append([name,'','',''])\r\n else:\r\n m=np.mean([line[1] for line in lines])\r\n var=np.std([line[1] for line in lines])\r\n out.append([name, m, var])\r\n \r\n with open('../Results/Tweet_Partisanship.csv','wb') as fl:\r\n writeit=csv.writer(fl)\r\n writeit.writerow(['TwitterID','tweetMean','tweetSd'])#,'tweetGini'])\r\n for line in out:\r\n writeit.writerow(line)\r\n \r\n return\r\n \r\ndef Train(train_tweets,train_labels,train_ids, n_estimators=''):\r\n print 'vectorizing texts'\r\n vectorizer= tfidf(train_tweets,ngram_range=(1,2),stop_words=getStopWords(),min_df=2,binary=True) #the only real question I have with this is whether it ejects twitter-specific text (ie. @ or #)\r\n vectorizer=vectorizer.fit(train_tweets)\r\n vec= vectorizer.transform(train_tweets) \r\n #clf= FitLM(vec,train_labels,train_ids,C,clf='') #probably need to as.array(labels)\r\n clf= FitRF(vec,train_labels,train_ids,n_estimators,clf='')\r\n return vectorizer, vec, clf\r\n \r\n\r\ndef Test(vectorizer,clf, test_tweets,test_labels,test_ids):\r\n vec= vectorizer.transform(test_tweets) \r\n #res,clf,report= FitLM(vec,test_labels,test_ids,C='',clf=clf) #probably need to as.array(labels)\r\n res,clf,mse= FitRF(vec,test_labels,test_ids,'',clf)\r\n return res,clf,mse\r\n \r\ndef Run(develop=False,DevProb=.15,TrainProb=.3,dates=[]):\r\n '''\r\n function to use when creating the final, publishable data.\r\n Final MSE was .8229\r\n '''\r\n n=''\r\n if develop:\r\n makeDevSample(dates=[],p=DevProb) #create development set\r\n best=SelectModel() #find parameters for linear classifier\r\n n=best['rf']['n_estimators']\r\n with open('Partisan_holdout.pkl','rb') as fl:\r\n Out=cPickle.load(fl)\r\n print 'imported data'\r\n train_tweets,train_labels,train_ids,test_tweets,test_labels,test_ids=TrainTestSplit(Out,sampler=TrainProb)\r\n if n=='':\r\n n=70\r\n vectorizer, vectors, clf=Train(train_tweets,train_labels,train_ids,n_estimators=n)\r\n res,clf,mse=Test(vectorizer,clf, test_tweets,test_labels,test_ids)\r\n #topwords=TopWords(vectorizer,clf,n=30)\r\n Report(res,Out)\r\n #SaveWords(topwords)\r\n \r\n return\r\n\r\ndef SelectModel():\r\n '''\r\n \r\n IN THE ORIGINAL STUDY:\r\n ElasticNetCV shows alpha 2.2x10-5 and l1 of .5 are best. Minimium MSE found is .77\r\n LassoCV shows alpha 2.5x10-5 as best. Minimum MSE is .79\r\n Random forest shows more estimators is better (obviously), best score was .71 but that's not MSE, so can't benchmark\r\n SVM best score was .69 for c=10000, took 3 weeks to run in the dev sample. \r\n \r\n '''\r\n out={}\r\n from sklearn.linear_model import ElasticNetCV\r\n from sklearn.linear_model import LassoCV\r\n from sklearn.ensemble import RandomForestRegressor as rf\r\n from sklearn.svm import SVR\r\n from sklearn.model_selection import GridSearchCV as gridcv\r\n \r\n vec,labels,ids=importDevelopmentSample()\r\n clf=ElasticNetCV()\r\n clf.fit(vec,labels)\r\n #alpha of 2.2x10-5, l1_ratio_ of .5\r\n print 'For ElasticNet'\r\n print '\\t Chosen Alpha: ',clf.alpha_\r\n print '\\t Chosen L1 Ratio: ', clf.l1_ratio_\r\n print '\\t Minimum MSE was ', min([min(x) for x in clf.mse_path_])\r\n #print clf.score(vec,labels)\r\n out['elastic']={'alpha':clf.alpha_, 'l1_ratio':clf.l1_ratio_}\r\n \r\n #CV shows alpha of .00022 is best, but anything in the 5x10-4 or 1x10-5 range is pretty good\r\n #CV shows alpha of .000026\r\n clf=LassoCV()\r\n clf.fit(vec,labels)\r\n print '\\t Chosen Alpha: ',clf.alpha_\r\n print '\\t Minimum MSE was ', min([min(x) for x in clf.mse_path_])\r\n #print clf.score(vec,labels)\r\n out['lasso']={'alpha':clf.alpha_}\r\n \r\n\r\n parameters={'n_estimators':[5,10,20,40,70]}\r\n\r\n rf_clf=gridcv(rf(),parameters)\r\n rf_clf.fit(vec,labels)\r\n out['rf']=rf_clf.best_params_\r\n #Not running the more complex models that take forever for now. Just want to get some code running from start to finish.\r\n #tests=[\r\n # ['gb',SVR(),{'C':np.logspace(-2, 10, 7)} [\"huber\",\"squared_loss\",\"epsilon_insensitive\"]}],\r\n # ['rf',rf(),{'n_estimators':[5,10,20,40,70]}],\r\n #]\r\n #for test in tests:\r\n # name=test[0]\r\n # model=test[1]\r\n # parameters=test[2]\r\n # clf,scores,params=GridSearch(vec,labels,model,parameters)\r\n # print clf.grid_scores_\r\n # print clf.best_params_\r\n # out[name]=[clf,scores,params]\r\n # out[name]=test[4]\r\n return out\r\n\r\n\r\ndef FindNonLinearModels():\r\n '''Unit Function to run all the potential models to find the ideal parameters\r\n \r\n NOTE: This should break now that I've changed the structure of In and Out\r\n\r\n results:\r\n svm - C\r\n 1-5 - mean: 0.09147, std: 0.00041,\r\n 1-4 - mean: 0.09147, std: 0.00041,\r\n 1-3 - mean: 0.09766, std: 0.00090,\r\n .01 - mean: 0.12351, std: 0.00430,\r\n .3 - mean: 0.17737, std: 0.00857,\r\n 3.6 - mean: 0.16453, std: 0.01467,\r\n 46 - mean: 0.15741, std: 0.01202,\r\n 600 - mean: 0.15741, std: 0.01136,\r\n 7000- mean: 0.15385, std: 0.01188, \r\n\r\n rf - n_estimators\r\n 40: mean: 0.19208, std: 0.00948,\r\n 5: mean: 0.17381, std: 0.01136,\r\n 10: mean: 0.17907, std: 0.00672,\r\n 20: mean: 0.18650, std: 0.00730,\r\n 70: mean: 0.18960, std: 0.00545,\r\n gb -\r\n hinge - mean .18, sd = .012 ()\r\n log - mean: 0.15447, std: 0.00327, params: {'estimator__loss': 'log'}\r\n modified_huber - mean: 0.15106, std: 0.00740, params: {'estimator__loss': 'modified_huber'}\r\n '''\r\n from sklearn.ensemble import RandomForestRegressor as rf\r\n from sklearn.linear_model import SGDRegressor as sgd\r\n out={}\r\n \r\n print 'importing Sample'\r\n vec,labels,ids=importDevelopmentSample()\r\n \r\n out={}\r\n tests=[\r\n ['svm',svm.LinearSVC(multi_class='ovr'),{'estimator__C':np.logspace(-5, 5, 10)}],\r\n ['gb',sgd(),{'estimator__loss':[\"modified_huber\",\"squared_loss\"],'alpha':np.logspace(-5, 5, 10)}],\r\n ['rf',rf(),{'estimator__n_estimators':[5,10,20,40]}]\r\n ]\r\n \r\n for test in tests:\r\n print 'running ', test[0]\r\n name=test[0]\r\n model=test[1]\r\n parameters=test[2]\r\n clf,scores,params=GridSearch(vec,labels,model,parameters)\r\n out[name]=[clf,scores,params]\r\n return\r\n\r\ndef importDevelopmentSample():\r\n with open('Partisan_Dev.pkl','rb') as fl:\r\n Dev=cPickle.load(fl)\r\n print \"Number of Tweets: \", len(Dev)\r\n vectorizer=Vectorize(Dev,'') #I use the same names so as not to save these vec/labels data\r\n vec,labels,vectorizer,ids=Vectorize(Dev, vectorizer=vectorizer)\r\n return vec, labels,ids\r\n\r\n\r\ndef NBTopWords(vec,clf,n=20):\r\n topWords={}\r\n feature_names =vec.get_feature_names()\r\n coefs_with_fns = sorted(zip(clf.coef_[0], feature_names))\r\n top = coefs_with_fns[:-(n + 1):-1]\r\n for w in top:\r\n word=w[1]\r\n for j, f in enumerate(vec.get_feature_names()):\r\n if f==word:\r\n dem=np.exp(clf.feature_log_prob_[0][j])\r\n rep=np.exp(clf.feature_log_prob_[1][j])\r\n gen=1*(rep>dem)\r\n topWords[word]=[gen,rep,dem]\r\n return topWords\r\n\r\ndef getTwitterNames():\r\n names=[]\r\n for fn in os.listdir('C:\\Users\\Admin\\Dropbox\\Twitter_NaiveBayes\\Data\\Raw3'):\r\n names.append(fn.split('.')[0])\r\n return names\r\n\r\ndef getIndividualTweets(name,dates,typ='essay', indir=''):\r\n if indir=='':\r\n indir='Data\\Raw3'\r\n begin=dt.datetime.strptime(dates[0],'%m/%d/%Y')\r\n end=dt.datetime.strptime(dates[1],'%m/%d/%Y')\r\n text={}\r\n broken=[]\r\n count=0\r\n times={}\r\n #for name in twitterIDs:\r\n for fn in os.listdir(indir):\r\n tid=fn.split(\".\")[0].lower()\r\n if tid == name:\r\n count+=1\r\n f=open(indir+'\\\\'+fn,'rb')\r\n data=csv.reader(f)\r\n if typ=='tweets':\r\n Texts={}\r\n for i,line in enumerate(data):\r\n if i>0:\r\n count+=1\r\n time=line[3]\r\n time=time.split(' ')[0]\r\n time=dt.datetime.strptime(time,'%m/%d/%Y')# %a %b %d %H:%M:%S +0000 %Y').strftime('%m/%d/%Y %H:%M:%S')\r\n if time>=begin and time<=end:\r\n Texts[line[6]]=' '.join(Twitter_Tokenize(line[0],stopwords='nltk'))\r\n times[line[6]]=time\r\n elif typ=='essay':\r\n texts=[]\r\n for i,line in enumerate(data):\r\n if i>0:\r\n count+=1\r\n time=line[3]\r\n time=time.split(' ')[0]\r\n time=dt.datetime.strptime(time,'%m/%d/%Y')# %a %b %d %H:%M:%S +0000 %Y').strftime('%m/%d/%Y %H:%M:%S')\r\n if time>=begin and time<=end:\r\n texts.append(line[0])\r\n Texts=' '.join(Twitter_Tokenize(' '.join(texts),stopwords='nltk'))\r\n \r\n \r\n #if typ=='essay':\r\n # Texts=' '.join(Twitter_Tokenize(' '.join(texts),stopwords='nltk'))#generate feature space of tweet by eliminating stops and adding metatext features\r\n #elif typ=='tweets':\r\n # for i,txt in enumerte(texts):\r\n # text[tid]=Twitter_Tokenize(' '.join(txt),stopwords='nltk'))\r\n #else:\r\n # Texts=' '.join(Twitter_Tokenize(' '.join(texts),stopwords='nltk'))#generate feature space of tweet by eliminating stops and adding metatext features\r\n #text[tid]=Texts\r\n #f.close()\r\n \r\n if count<1: #if the person is not in the Raw dataset from 113th congress\r\n return None,None\r\n return Texts, times\r\n \r\n\r\ndef writePerson(name,scoredict,times,tweets):\r\n out='G:/Research Data/2017-01-12 Backup/CongressTweets/PartisanScores2'\r\n with open(out+name+'.txt','w') as fn:\r\n fn.write('tweetID,mean,std,time,tweet \\n')\r\n for tid,score in scoredict.iteritems():\r\n fn.write(', '.join([tid]+map(str,score)+[times[tid]]+[tweets[tid]])+'\\n')\r\n return\r\n\r\ndef writeResults(Results):\r\n with open('PartisanTweets2.txt','w') as fn:\r\n fn.write('TwitterID,ProportionTweetsPartisan\\n')\r\n for name, res in Results.iteritems():\r\n fn.write(name+', '+str(res)+'\\n')\r\n return\r\n"
},
{
"alpha_fraction": 0.84375,
"alphanum_fraction": 0.84375,
"avg_line_length": 31,
"blob_id": "305e815af6196f0c376769477c5821e0acfccf9d",
"content_id": "640a3bb56e00636c2527701292a8462a07d6fbee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "# partisanshipproject.github.io\n"
},
{
"alpha_fraction": 0.5655857920646667,
"alphanum_fraction": 0.592475414276123,
"avg_line_length": 38.323463439941406,
"blob_id": "19992c316d64a0e38b30ca3361a6f5051f79bf0f",
"content_id": "cc11dd5b4b5170fa75e5e5c8416e3c8a2b27ae88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17702,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 439,
"path": "/assets/replication/Scripts/TimeCorrectClassifier.py",
"repo_name": "Partisanship-Project/Partisanship-Project.github.io",
"src_encoding": "UTF-8",
"text": "\r\n'''Notes: a few congress people are excluded in this analysis.\r\n\r\nFirst, there were three duplicate IDs that weren't cleaned out from earlier\r\nruns (this needs to be verified to ensure other previous scrapes are not still around - check pkl cache of tweet IDs. If ID is in\r\ndirectory, but not pkl files, then it is old duplicate and should be discarded). They are:\r\n['chuckschumer', '09/19/2013 14:40:11', 51],\r\n['dannykdavis', '07/05/2009 17:27:21', 3],\r\n\r\nSecond, There were two incorrect IDs which has been corrected:\r\n['repdanburton', 0, 1],\r\n['jeanneshaheen', '03/11/2008 17:49:44', 174],\r\n\r\nThird, others simply have >3200 tweets maxing out twitter's\r\nindividual dump parameters. They are by name, earliest tweet, and total number:\r\n\r\n'auctnr1', '01/18/2013 17:19:43', 3193], ['chakafattah', '05/10/2013 00:08:07', 3194], \r\n['danarohrabacher', '02/07/2013 05:44:12', 3228], ['darrellissa', '02/09/2013 14:49:06', 3235],\r\n ['johncornyn', '05/15/2013 11:39:01', 3204], \r\n['repkevinbrady', '04/06/2013 15:39:40', 3238], ['roslehtinen', '07/17/2013 19:40:56', 3196], \r\n['sensanders', '01/31/2013 18:20:21', 3240], ['speakerboehner', '01/24/2013 19:37:19', 3222]\r\n\r\nFinally, others simply did not have tweets in the date range:\r\n['repguthrie', '09/26/2013 16:25:17', 78], \r\n['repinsleenews', '04/23/2009 19:38:47', 59],\r\n['repjohnduncanjr', '09/20/2013 17:49:40', 83],\r\n['senatorisakson', '05/02/2013 15:34:39', 296],\r\n'''\r\n\r\n\r\n\r\nimport datetime as dt\r\nimport re\r\nimport os\r\nimport csv\r\nimport nltk\r\nfrom sklearn import svm\r\nfrom sklearn.naive_bayes import MultinomialNB as mnb\r\nfrom sklearn import neighbors\r\nimport random as rn\r\nimport numpy as np\r\nfrom sklearn.metrics import classification_report\r\n#from sklearn.metrics import accuracy\r\nfrom sklearn.feature_extraction.text import TfidfVectorizer as tfidf\r\nimport cPickle\r\n\r\n\r\ndef Clean_Tweets(text,stopwords='nltk',onlyHashtags=False):\r\n '''this function tokenizes `tweets` using simple rules:\r\n tokens are defined as maximal strings of letters, digits\r\n and apostrophies.\r\n The optional argument `stopwords` is a list of words to\r\n exclude from the tokenzation. This code eliminates hypertext and markup features to\r\n focus on the substance of tweets'''\r\n if stopwords=='nltk':\r\n stopwords=nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n #print stopwords\r\n stopwords+=['bit','fb','ow','twitpic','ly','com','rt','http','tinyurl','nyti','www']\r\n retweet=False\r\n if 'RT @' in text:\r\n retweet=True\r\n # make lowercase\r\n text = text.lower()\r\n #ELEMINATE HYPERLINKS\r\n ntext=[]\r\n text=text.split(' ')\r\n for t in text:\r\n if t.startswith('http'):\r\n #ntext.append('hlink')\r\n continue\r\n else:\r\n ntext.append(t)\r\n text=' '.join(ntext)\r\n # grab just the words we're interested in\r\n text = re.findall(r\"[\\d\\w'#@]+\",text)\r\n # remove stopwords\r\n if onlyHashtags==True:\r\n htags=[]\r\n for w in text:\r\n if w.startswith('#'):\r\n htags.append(w)\r\n return htags\r\n res = []\r\n for w in text:\r\n if w=='hlink':\r\n res.append('HLINK')\r\n continue\r\n if w.startswith('@') and w!='@':\r\n res.append('MNTON'+'_'+w[1:])\r\n continue\r\n if w.startswith('#'):\r\n res.append('HSHTG'+'_'+w[1:])\r\n continue\r\n if w not in stopwords:\r\n res.append(w)\r\n if retweet:\r\n res.append('RTWT')\r\n return res\r\n\r\n\r\ndef Twitter_Tokenize(text,stopwords='nltk'):\r\n '''this function tokenizes `text` using simple rules:\r\n tokens are defined as maximal strings of letters, digits\r\n and apostrophies.\r\n The optional argument `stopwords` is a list of words to\r\n exclude from the tokenzation'''\r\n if stopwords=='nltk':\r\n nltk.corpus.stopwords.words('english')\r\n else:\r\n stopwords=[]\r\n retweet=False\r\n if 'RT @' in text:\r\n retweet=True\r\n # make lowercase\r\n text = text.lower()\r\n # grab just the words we're interested in\r\n text = re.findall(r\"[\\d\\w'#@]+\",text)\r\n # remove stopwords\r\n res = []\r\n for w in text:\r\n if w=='http':\r\n res.append('HLINK')\r\n continue\r\n if w.startswith('@') and w!='@':\r\n res.append('MNTON')\r\n if w.startswith('#'):\r\n res.append('HSHTG')\r\n if w not in stopwords:\r\n res.append(w)\r\n if retweet:\r\n res.append('RTWT')\r\n return(res)\r\n\r\n\r\ndef makeMetaData():\r\n '''metadata header is DWNominate score, name, party, ICPSR, state code, State-District,\r\n data is a dictionary of data[twitterID]=[]'''\r\n print 'importing metadata'\r\n data={}\r\n polKey={}\r\n missing=[]\r\n f=open('Data\\IdealPts_112_House-Twitter.csv')\r\n dta=csv.reader(f)\r\n for i,line in enumerate(dta):\r\n if i>0:\r\n if line[8]!='':\r\n if line[5]=='100': #recode to 1,0 fits with previous code and keeps direction of analysis the sm\r\n party=1\r\n elif line[5]=='200':\r\n party=0\r\n else:\r\n continue\r\n party=''\r\n tid=line[8].lower()\r\n \r\n data[tid]=[line[7],line[6].lower(),party,0,line[1],line[2],line[4]+'-'+line[3]]#,numTxt[tid],numWds[tid]]\r\n polKey[tid]=party\r\n #else:\r\n # missing.append([tid,'House member has Twitter but not in scraped data'])\r\n f.close()\r\n f=open('Data\\IdealPts_112_Senate-Twitter.csv')\r\n dta=csv.reader(f)\r\n for i,line in enumerate(dta):\r\n if i>0:\r\n if line[8]!='':\r\n if line[5]=='100':\r\n party=1\r\n elif line[5]=='200':\r\n party=0\r\n else:\r\n continue\r\n party=''\r\n tid=line[8].lower()\r\n #if tid in numTxt.keys():\r\n data[tid]=[line[7],line[6].lower(),party,1,line[1],line[2],line[4]]#,numTxt[tid],numWds[tid]]\r\n polKey[tid]=party\r\n #else:\r\n # missing.append([tid,'Senator has Twitter but not in scraped data'])\r\n f.close()\r\n \r\n #f=open('Metadata\\112Tweets3.txt','r')\r\n #for n in f.readlines():\r\n # print n\r\n # d=n.split(',')\r\n # data[d[0].lower()]+=[d[1],d[2].strip()]\r\n #f.close()\r\n header=['TwitterID','dw1', 'name', 'party','senate', 'ICPSR', 'stateCode', 'district','Num112Twts','Num112Words','TotalTwts']\r\n \r\n return data, header, polKey, missing\r\n\r\n\r\ndef MakeDateEssays(dates,metaData, indir=''):\r\n '''This function turns a directory (indir) composed of every individual's tweets each contained in a csv file (e.g. barackobama.csv)\r\n into a directory (outdir) of .txt files (e.g. barackobama.txt) of person-level aggregates of those tweets within the date window given in 'dates'\r\n dates=[beginningDate,endDate] formatted as ['1/1/1900','12/30/1900'] \r\n \r\n For example, the .csv file AlFranken.csv in Raw2 contains each tweet collected with the parameters: \r\n text\\tfavorited\\treplyToSN\\tcreated\\ttruncated\\treplyToSID\\tid\\treplyToUID\\tstatusSource\\tscreenName\r\n With this code, that file is turned into a .txt file called AlFranken.txt containing of all tweets under the \"text\" field\r\n separated by \\t\r\n \r\n As a part of this data formating process, this code also produces counts of the total number of tweets and characters for each person\r\n returned as 'numTxt' and 'numWds' respectively.\r\n '''\r\n print 'importing tweets' \r\n if indir=='':\r\n indir='Data\\Raw3'\r\n begin=dt.datetime.strptime(dates[0],'%m/%d/%Y')\r\n end=dt.datetime.strptime(dates[1],'%m/%d/%Y')\r\n text={}\r\n broken=[]\r\n for fn in os.listdir(indir):\r\n tid=fn.split(\".\")[0].lower()\r\n if tid in metaData.keys():\r\n texts=[]\r\n count=0\r\n f=open(indir+'\\\\'+fn,'rb')\r\n data=csv.reader(f)\r\n for i,line in enumerate(data):\r\n if i>0:\r\n count+=1\r\n time=line[3]\r\n time=time.split(' ')[0]\r\n time=dt.datetime.strptime(time,'%m/%d/%Y')# %a %b %d %H:%M:%S +0000 %Y').strftime('%m/%d/%Y %H:%M:%S')\r\n if time>=begin and time<=end:\r\n texts.append(line[0])\r\n lastTime=time\r\n if count>3000 and lastTime>begin:\r\n broken.append([tid,'hit twitter limit in time period - '+str(count)])\r\n #continue\r\n #if len(texts)<2:\r\n #broken.append([tid,'not enough data in time period (min of 2)'])\r\n #continue\r\n numTxt=len(texts)\r\n texts=' '.join(Clean_Tweets(' '.join(texts),stopwords='nltk'))#generate feature space of tweet by eliminating stops and adding metatext features\r\n text[tid]=texts\r\n numWds=len(texts)\r\n metaData[tid]+=[numTxt,numWds,count]\r\n f.close()\r\n \r\n return text, broken, metaData\r\n\r\n\r\ndef Vectorize(texts,polKey):\r\n vectorizer= tfidf(texts.values(),ngram_range=(1,2),stop_words='english',min_df=2) #the only real question I have with this is whether it ejects twitter-specific text (ie. @ or #)\r\n vec=vectorizer.fit_transform(texts.values()) \r\n labels=[]\r\n for k in texts.keys():\r\n labels.append(polKey[k])\r\n labels=np.asarray(labels) \r\n return vec,labels,vectorizer\r\n\r\ndef Sample(vec,labels,texts,clf='knn',pct=.2):\r\n '''This code creates the randomized test/train samples and the trains and tests the classifier\r\n and returns the vectors of test and train texts and labels as well as keys for linking results to TwitterIDs'''\r\n trainIds=rn.sample(xrange(np.shape(labels)[0]),int(round(np.shape(labels)[0]*pct)))\r\n testIds=[]\r\n trainKey={}\r\n testKey={}\r\n ts=0\r\n tr=0\r\n for t in xrange(np.shape(labels)[0]): \r\n if t not in trainIds:\r\n testIds.append(t)\r\n testKey[ts]=texts.keys()[t]\r\n ts+=1\r\n else:\r\n trainKey[tr]=texts.keys()[t]\r\n tr+=1\r\n trainTexts=vec[trainIds]\r\n trainLabels=labels[trainIds]\r\n testTexts=vec[testIds]\r\n testLabels=labels[testIds]\r\n \r\n return trainTexts, trainLabels, testTexts,testLabels,trainKey,testKey\r\n\r\n\r\ndef Classify(trainT,trainL,testT,testL,clf='knn'):\r\n '''Code to train and test classifiers. type can be 'knn' 'nb' or 'svm'\r\n returns the fit matrix #a dictionary of {twitterID: likelihood ratio}'''\r\n if clf=='knn':\r\n cl = neighbors.KNeighborsClassifier()\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n if clf=='svm':\r\n cl=svm.SVC(C=100,gamma=.1,probability=True)\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n if clf=='nb':\r\n cl=mnb()\r\n cl.fit(trainT,trainL)\r\n fit=cl.predict_proba(testT)\r\n #print(cl.score(testT,testL))\r\n return fit, cl\r\n\r\n\r\ndef TopWords(vec,clf,n=20):\r\n topWords={}\r\n feature_names =vec.get_feature_names()\r\n coefs_with_fns = sorted(zip(clf.coef_[0], feature_names))\r\n top = coefs_with_fns[:-(n + 1):-1]\r\n for w in top:\r\n word=w[1]\r\n for j, f in enumerate(vec.get_feature_names()):\r\n if f==word:\r\n demscore=np.exp(clf.feature_log_prob_[0][j])\r\n repscore=np.exp(clf.feature_log_prob_[1][j])\r\n repflag=1*(repscore>demscore)\r\n topWords[word]=[repflag,repscore,demscore]\r\n return topWords\r\n\r\ndef CleanResults(fit,testKeys):\r\n '''This code takes the results of classifier.predict_proba() and cleans out extreme scores and produces z-scored likelihood ratios.\r\n It replaces any probabilites of 1 or 0 (which produce inf likelihoods) with the nearest max and min probabilites given.\r\n It then computes the likelihood ratio and z-scores them, returning res as a dictionary of {twitterID: z-scored likelihood ratio}'''\r\n #identify any possible infinite values and recode using the next maximum probability\r\n if 0 in fit:\r\n lis=sorted(fit[:,0],reverse=True)\r\n lis+=sorted(fit[:,1],reverse=True)\r\n for l in sorted(lis,reverse=True):\r\n if l!=1.0:\r\n fit[fit==1.0]=l\r\n break\r\n for l in sorted(lis):\r\n if l!=0.0:\r\n fit[fit==0.0]=l\r\n break\r\n\r\n res=dict(zip(testKeys.values(),[0 for i in xrange(len(testKeys.keys()))]))\r\n for i,line in enumerate(fit):\r\n res[testKeys[i]]=[line[0],line[1],np.log(line[0]/line[1])]\r\n vals=[i[2] for i in res.values()]\r\n m=np.mean(vals)\r\n sd=np.std(vals)\r\n for k,v in res.iteritems():\r\n res[k]=[v[0],v[1],(v[2]-m)/sd]\r\n \r\n adjust=[m,sd]\r\n return res,adjust\r\n \r\n\r\ndef ClassificationReport(testLabels, testTexts,classifier):\r\n \r\n y_pred=classifier.predict(testTexts)\r\n print(classification_report(testLabels, y_pred))\r\n #print(accuracy(testLabels, y_pred))\r\n report=classification_report(testLabels, y_pred)\r\n \r\n return report\r\n\r\n\r\ndef SaveResults(data,metaHeader,classHeader,outfile=''):\r\n #check code for writing correctness then validate format and add headers for initial data creation\r\n '''This function joins the classifier results with the classifier metadata and the person metadata to\r\n the existing data of the same structure:\r\n PersonData, classifier data, classificaiton results\r\n res is the z-scored likelihood ratio data {twitterid: scored ratio}\r\n metadata is the dictionary {twitterID: list of person data}\r\n classMeta is a list of classifier features including sample pct, type of classifier, and iteration\r\n fname is the name of the data file being dumped to.'''\r\n \r\n print 'saving data'\r\n header=metaHeader+classHeader+['RepProb','DemProb','zLkRatio']\r\n f=open(outfile,'wb')\r\n writeit=csv.writer(f)\r\n writeit.writerow(header)\r\n for line in data:\r\n writeit.writerow(line)\r\n f.close()\r\n return\r\n\r\n\r\ndef GridSearch(clfs = ['nb','knn','svm'],samples=[.5],iters=200,outfile=''):\r\n ''' This code runs the classifiers across iterations and sample sizes producing the core data used in the final\r\n analysis. test data for the classifier in 'clf' for 'iters' number of iterations.\r\n It pulls in the metadata, keys, and essays, and then iterates by random sampling, classification,\r\n and data cleaning producing lists of dictionaries of {TwitterID: z-scored likelihood ratios} for each iteration'''\r\n data=[]\r\n dates=['1/03/2011','1/03/2013']\r\n indir='Data\\Raw3'\r\n adjust={}\r\n words={}\r\n metaData, metaHeader, polKey, missing=makeMetaData()\r\n #print len(missing), \" Number of missing congress members. Here's who and why: \"\r\n #print missing\r\n texts, broken, metaData=MakeDateEssays(dates,metaData, indir) #get polkey from makeMetaData and go from there\r\n #print len(broken), \" Number of excluded congress members. Here's who and why: \"\r\n #print broken\r\n vec,labels,vectorizer=Vectorize(texts,polKey)\r\n f='G:/Research Data/2017-01-12 Backup/CongressTweets/Classifiers/Vectorizer.pkl'\r\n with open(f,'wb') as fl:\r\n cPickle.dump(vectorizer,fl)\r\n for clf in clfs:\r\n for samp in samples:\r\n #accs=[]\r\n for it in xrange(iters):\r\n print \"Doing: \", clf, ' ', samp, ' ', it\r\n classMeta=[clf,samp,it]\r\n classHeader=['Classifier','SamplePct','Iteration']\r\n trainTexts, trainLabels, testTexts,testLabels,trainKey,testKey =Sample(vec,labels,texts,pct=samp)\r\n fit,classifier=Classify(trainTexts, trainLabels, testTexts,testLabels,clf=clf)\r\n report=ClassificationReport(testLabels, testTexts,classifier)\r\n print(report)\r\n #accs.append([classifier.score(testTexts,testLabels),np.mean([int(l) for l in testLabels])])\r\n res,adj=CleanResults(fit, testKey)\r\n if clf=='nb':\r\n words[it]=TopWords(vectorizer,classifier,n=200)\r\n print adj\r\n adjust[clf+'-'+str(it)]=adj\r\n for k,r in res.iteritems():\r\n data.append([k]+metaData[k]+classMeta+r)\r\n f='G:/Research Data/2017-01-12 Backup/CongressTweets/Classifiers/'+clf+str(it)+'clf.pkl'\r\n with open(f,'wb') as fl:\r\n cPickle.dump(classifier,fl)\r\n \r\n #print \"Accuracy of \", clf, \" classifer on \",samp,\" samples is \",np.mean([a[0] for a in accs]),' from ', np.mean([a[1] for a in accs])/2.0 , ' probability'\r\n \r\n print 'writing data'\r\n SaveResults(data,metaHeader,classHeader,outfile=outfile)\r\n with open('Essay_StandardizeValues.txt','w') as f:\r\n f.write('Classifier,Iteration,Mean,Std\\n')\r\n for fn,val in adjust.iteritems():\r\n f.write(fn.replace('-',',')+','+','.join(map(str,val))+'\\n')\r\n \r\n \r\n\r\n return data,adjust,words\r\n\r\n#os.chdir('C:\\Users\\Admin\\Dropbox\\Twitter_NaiveBayes')\r\ndata,adjust,words=GridSearch(clfs = ['nb','svm'],samples=[.5],iters=200,outfile='Results\\\\112Results2.csv')\r\nf=open('Results\\FinalPartisanWords.txt','w')\r\nf.write('Iteration,Word,IsRepub,RepScore,DemScore\\n')\r\nfor it, ws in words.iteritems():\r\n for w,scores in ws.iteritems():\r\n f.write(str(it)+\",\"+w+','.join(map(str,scores))+'\\n')\r\nf.close()"
}
] | 7 |
schubart/tecs | https://github.com/schubart/tecs | 48a3d3116d52d2e11a43f20b155adbc088ac8983 | 69c608ee92b06e9d612e5c83539f3550b2b5d1a9 | 457b684e053a018597093bff452f46a24ab2c6ef | refs/heads/master | "2021-01-02T22:45:33.480472" | "2011-01-08T14:07:56" | "2011-01-08T14:07:56" | 1,181,933 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.36383068561553955,
"alphanum_fraction": 0.43565624952316284,
"avg_line_length": 29.575162887573242,
"blob_id": "63144527dd89ac43c4e16dafb9e58882af4181aa",
"content_id": "cd2d1f85d930c4dfb32cf3f6900e42b90da2fc1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4678,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 153,
"path": "/06/Assembler.py",
"repo_name": "schubart/tecs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport fileinput\nimport re\n\n##############################################################################\n# Static translation tables.\n##############################################################################\n\n# \"comp\" part of C-instruction.\ncomp = {\"0\": \"0101010\",\n \"1\": \"0111111\",\n \"-1\": \"0111010\",\n \"D\": \"0001100\",\n \"A\": \"0110000\", \"M\": \"1110000\",\n \"!D\": \"0001101\",\n \"!A\": \"0110001\", \"!M\": \"1110001\",\n \"-D\": \"0001111\",\n \"-A\": \"0110011\", \"-M\": \"1110011\",\n \"D+1\": \"0011111\",\n \"A+1\": \"0110111\", \"M+1\": \"1110111\",\n \"D-1\": \"0001110\",\n \"A-1\": \"0110010\", \"M-1\": \"1110010\",\n \"D+A\": \"0000010\", \"D+M\": \"1000010\",\n \"D-A\": \"0010011\", \"D-M\": \"1010011\",\n \"A-D\": \"0000111\", \"M-D\": \"1000111\",\n \"D&A\": \"0000000\", \"D&M\": \"1000000\",\n \"D|A\": \"0010101\", \"D|M\": \"1010101\"}\n\n# \"dest\" part of C-instruction.\ndest = {None: \"000\",\n \"M\": \"001\",\n \"D\": \"010\",\n \"MD\": \"011\",\n \"A\": \"100\",\n \"AM\": \"101\",\n \"AD\": \"110\",\n \"AMD\": \"111\"}\n\n# \"jump\" part of C-instruction.\njump = {None: \"000\",\n \"JGT\": \"001\",\n \"JEQ\": \"010\",\n \"JGE\": \"011\",\n \"JLT\": \"100\",\n \"JNE\": \"101\",\n \"JLE\": \"110\",\n \"JMP\": \"111\"}\n\n# Regexp for symbols.\nsymbol_re = \"[a-zA-Z_.$:][a-zA-Z0-9_.$:]*\"\n\n##############################################################################\n# First pass: Count instructions and use labels to populate symbol table.\n##############################################################################\n\n# The symbol table. Key: Symbol. Value: Address (int). Start with\n# the predefined symbols.\nsymbols = {\"SP\": 0,\n \"LCL\": 1,\n \"ARG\": 2,\n \"THIS\": 3,\n \"THAT\": 4,\n \"R0\": 0, \"R1\": 1, \"R2\": 2, \"R3\": 3,\n \"R4\": 4, \"R5\": 5, \"R6\": 6, \"R7\": 7,\n \"R8\": 8, \"R9\": 9, \"R10\": 10, \"R11\": 11,\n \"R12\": 12, \"R13\": 13, \"R14\": 14, \"R15\": 15,\n \"SCREEN\": 16384,\n \"LBD\": 24576}\n\n# The program counter.\npc = 0\n\n# A- and C-instructions.\ninstructions = []\n\nfor line in fileinput.input():\n # Ignore everything from // to end of line.\n line = re.sub(\"//.*\", \"\", line)\n\n # Ignore all whitespace.\n line = re.sub(\"\\s+\", \"\", line)\n\n # Ignore empty lines.\n if line == \"\": continue\n\n # Is it a label?\n m = re.match(\"\\((\" + symbol_re + \")\\)\", line)\n if m:\n label = m.group(1)\n\n # Label has to be new.\n if label in symbols:\n raise Exception(\"'\" + label + \"' is already defined.\")\n\n # Bind label to current program counter.\n symbols[label] = pc\n\n else:\n # It's not a label, so it has to be an A- or C-instruction.\n # Store for translation in seond pass and increase program\n # counter.\n instructions.append(line)\n pc += 1\n\n##############################################################################\n# Second pass: Resolve symbols and translate instructions to binary\n##############################################################################\n\n# Address of the next variable.\nvariable = 16\n\nfor instruction in instructions:\n # Is it an A-instruction with symbolic address?\n m = re.match(\"@(\" + symbol_re + \")\", instruction)\n if m:\n symbol = m.group(1)\n\n # If symbol not defined yet, it has to be a variable.\n if not symbol in symbols:\n # Allocate new variable.\n symbols[symbol] = variable\n variable += 1\n\n # Now the symbol is defined.\n address = symbols[symbol]\n\n # Print as binary.\n print bin(address)[2:].zfill(16)\n continue\n\n # Is it an A-instruction with constant address?\n m = re.match(\"@([0-9]+)\", instruction)\n if m:\n address = int(m.group(1))\n\n # Print as binary. No symbol resolution required.\n print bin(address)[2:].zfill(16)\n continue\n\n # Is it a C-instruction? It has the form \"dest=comp;jump\"\n # with \"dest=\" and \";jump\" being optional.\n m = re.match(\"((.+)=)?([^;]+)(;(.+))?\", instruction)\n if m:\n # Construct binary representation from the three parts.\n # Lookup will fail with \"KeyError\" if a part is invalid. \n print \"111%s%s%s\" % (comp[m.group(3)],\n dest[m.group(2)],\n jump[m.group(5)])\n continue\n\n # Not A- or C-instruction? Must be something invalid.\n raise Exception(\"Syntax error: \" + instruction)\n"
},
{
"alpha_fraction": 0.65625,
"alphanum_fraction": 0.65625,
"avg_line_length": 26.428571701049805,
"blob_id": "6cb6f34c0055de96e123135d8b2f615fc949e450",
"content_id": "9b522ed7bdfafda419b71d892daed9f5b9e71311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 7,
"path": "/06/test.sh",
"repo_name": "schubart/tecs",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nfor program in add/Add max/Max rect/Rect pong/Pong; do\n echo ${program}\n ./Assembler.py ${program}.asm > ${program}.hack.out\n diff ${program}.hack ${program}.hack.out\ndone\n"
}
] | 2 |
ckjoon/teambuilding | https://github.com/ckjoon/teambuilding | 711791952828529ac4c5a44d23a883ae66680836 | ee49e95e1cd56f4e7d8efbb46ab1c38b200c08a6 | 710c6104124e57f778701291d573e746bbc559f3 | refs/heads/master | "2020-04-09T13:33:33.205704" | "2016-12-04T20:20:25" | "2016-12-04T20:20:25" | 68,007,148 | 2 | 0 | null | "2016-09-12T12:31:40" | "2016-09-12T12:41:25" | "2016-12-04T20:20:25" | HTML | [
{
"alpha_fraction": 0.843137264251709,
"alphanum_fraction": 0.843137264251709,
"avg_line_length": 25,
"blob_id": "5b7c9998f9ec3b195e89190396bbdd3564f3264f",
"content_id": "c6e317e0bb290772037b1ee787c546744b349e2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 2,
"path": "/runserver.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "from teambuildingapp import app\napp.run(debug=True)"
},
{
"alpha_fraction": 0.5877411365509033,
"alphanum_fraction": 0.5905413627624512,
"avg_line_length": 35.811763763427734,
"blob_id": "ba83bf6785a19aa938ce1ae3966b7a84bab9b70e",
"content_id": "e6c7b08f67eb5d5f214d67e6bac812c1c56f1088",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9642,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 255,
"path": "/teambuildingapp/views.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "from teambuildingapp import app\r\nfrom flask import render_template, request, url_for, redirect, session, make_response\r\nfrom flask_cas import login_required\r\nimport os\r\n#from roster_processor import process_roster\r\n\r\nfrom teambuildingapp.db_util import *\r\n\r\n\r\[email protected](\"/\")\r\ndef main():\r\n return render_template('signin.html')\r\n\r\[email protected](\"/logout\")\r\ndef logout():\r\n session.clear()\r\n return redirect(\"/\")\r\n\r\n# Route that will process the file upload\r\[email protected]('/upload', methods=['POST'])\r\ndef upload():\r\n if request.method == 'POST':\r\n class_name = request.form.get('coursename')\r\n semester = request.form.get('semester')\r\n teamsize = request.form.get('teamsize') \r\n print(class_name)\r\n print(semester)\r\n print(teamsize)\r\n create_class(class_name, semester, session['username'], teamsize)\r\n return redirect(url_for('prof_home'))\r\n\r\[email protected](\"/prof_home\")\r\n# Uncomment this to require CAS to access this page\r\n# @login_required\r\ndef prof_home():\r\n username = session['username']\r\n #profile, classes = db_util.get_user_info()\r\n # return render_template('prof_home.html', classes)\r\n #if 'last_class' not in session:\r\n classes = get_professor_classes(username)\r\n if len(classes) > 0:\r\n session['last_class'] = (classes[0][0], '{0} ({1})'.format(classes[0][1], classes[0][2]))\r\n session['max_team_size'] = classes[0][3]\r\n session['class_names'] = ['{0} ({1})'.format(x[1], x[2]) for x in classes]\r\n session['teams'] = get_all_teams_in_class(session['last_class'][0])\r\n else:\r\n session['last_class'] = None\r\n session['max_team_size'] = None\r\n session['class_names'] = []\r\n session['teams'] = []\r\n return make_response(render_template('prof_home.html', last_class=session['last_class'], max_team_size=session['max_team_size'], classes=classes, teams=session['teams']))\r\n\r\[email protected](\"/student_home\")\r\n# Uncomment this to require CAS to access this page\r\n# @login_required\r\ndef student_home():\r\n #firsttime = request.cookies.get('firsttime')\r\n #username = request.cookies.get('username')\r\n username = session['username']\r\n #print(username)\r\n if 'class_id' not in session:\r\n student_class_ids = get_student_enrolled_class_id(username)\r\n if len(student_class_ids) > 0:\r\n session['class_id'] = student_class_ids[0]\r\n #student_enrolled_classes = get_student_enrolled_classnames(username)\r\n teamsize = get_class_max_team_size(session['class_id'])\r\n all_teams = get_all_teams_in_class(session['class_id'])\r\n else:\r\n session['class_id'] = None\r\n else:\r\n teamsize = get_class_max_team_size(session['class_id'])\r\n all_teams = get_all_teams_in_class(session['class_id'])\r\n \r\n #print(all_teams)\r\n student_comment = get_user_comment(username)\r\n student_enrolled_classes = get_student_enrolled_classes(username)\r\n cur_classname = None\r\n if student_enrolled_classes is not None:\r\n for cla in student_enrolled_classes:\r\n if str(cla[1]) == str(session['class_id']):\r\n cur_classname = cla[0]\r\n\r\n if cur_classname is None:\r\n cur_classname = \"No Class Selected!\"\r\n #print(student_comment)\r\n #print(student_enrolled_classes)\r\n #print(all_teams)\r\n in_team = False\r\n for team in all_teams:\r\n if team[1] == username:\r\n in_team = True\r\n\r\n\r\n resp = make_response(render_template('student_home.html',\r\n comment = student_comment, max_team_size = teamsize, \r\n classes = student_enrolled_classes, teams = all_teams, in_team=in_team, cur_classname = cur_classname))\r\n #resp.set_cookie('firsttime', '', expires=0)\r\n return resp\r\n\r\[email protected](\"/signin_error\")\r\ndef signin_error():\r\n return render_template('signin_error.html')\r\n\r\[email protected](\"/uploadFile\")\r\ndef uploadFile():\r\n if request.method == 'POST':\r\n file = request.files['file']\r\n if file and allowed_file(file.filename):\r\n file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))\r\n process_roster(filename)\r\n return redirect(url_for('prof_home'))\r\n\r\[email protected](\"/team_manager_panel\")\r\ndef team_manager_panel():\r\n team_id = session['team_id']\r\n class_id = session['class_id']\r\n team_name = get_team_name(class_id, team_id)\r\n team_captain = get_team_captain(class_id, team_id)\r\n team_captain_name = get_student_name(team_captain)\r\n user_captain = False\r\n students = get_all_students_in_team(class_id, team_id)\r\n requests = get_all_students_request(class_id, team_id)\r\n\r\n if session['username'] == team_captain:\r\n user_captain = True \r\n \r\n resp = make_response( \r\n render_template('team_manager_panel.html', \r\n team_name = team_name, team_captain_name = team_captain_name, \r\n user_captain = user_captain, students_in_team = students,\r\n current_user = session['username'], requests = requests ))\r\n return resp\r\n\r\[email protected](\"/api/login\", methods=['POST'])\r\ndef login():\r\n #handle login stuff.\r\n if request.method == 'POST':\r\n gtusername = request.form.get('gtusername')\r\n # password = request.form.get('password')\r\n all_students = get_all_student_usernames()\r\n all_professors = get_all_professor_usernames()\r\n\r\n #print(student_class_ids)\r\n #print(all_professors)\r\n #print(gtusername)\r\n #print(all_students)\r\n #for s in all_students:\r\n #print(s)\r\n is_student = True\r\n if gtusername in all_students:\r\n student_class_ids = get_student_enrolled_class_id(gtusername)\r\n session['username'] = gtusername\r\n #session['firsttime'] = True\r\n if len(student_class_ids) > 0:\r\n session['class_id'] = student_class_ids[0]\r\n team_id = get_student_enrolled_team_id(session['username'], session['class_id'])\r\n session['team_id'] = team_id\r\n if session['team_id'] != None:\r\n resp = make_response(redirect(url_for('team_manager_panel')))\r\n else:\r\n resp = make_response(redirect(url_for('student_home')))\r\n else:\r\n session['class_id'] = None\r\n session['team_id'] = None\r\n \r\n elif gtusername in all_professors:\r\n #prof_class_ids = get_professor_classes(gtusername)\r\n is_student = False\r\n session['username'] = gtusername\r\n #session['firsttime'] = True\r\n\r\n resp = make_response(redirect(url_for('prof_home')))\r\n else:\r\n return redirect(url_for('signin_error'))\r\n return resp\r\n \r\n\r\[email protected](\"/updateIntroduction\", methods=['POST'])\r\ndef updateIntroduction():\r\n if request.method == 'POST':\r\n text = request.form.get('introtext')\r\n update_user_comment(session['username'], text)\r\n return redirect(url_for('student_home'))\r\n\r\[email protected](\"/createTeam\", methods=['POST'])\r\ndef createTeam():\r\n if request.method == 'POST':\r\n text = request.form.get('team_name')\r\n print(text)\r\n create_team(session['class_id'],session['username'], text)\r\n return redirect(url_for('student_home'))\r\n\r\[email protected](\"/acceptdecline\", methods=['POST'])\r\ndef accept_decline():\r\n if request.method == 'POST':\r\n text = request.form.get('gt_username')\r\n print(text)\r\n if (request.form['submit']=='Accept'):\r\n add_to_team(session['class_id'], session['team_id'], text)\r\n\r\n if (request.form['submit']=='Decline'):\r\n remove_from_requests(session['class_id'], session['team_id'], text)\r\n\r\n remove_from_requests(session['class_id'], session['team_id'], text)\r\n return redirect(url_for('team_manager_panel'))\r\n\r\ndef allowed_file(filename):\r\n return '.' in filename and \\\r\n filename.rsplit('.', 1)[1] in app.config['ALLOWED_EXTENSIONS']\r\n\r\[email protected](\"/requestTeam\", methods=['POST'])\r\ndef requestTeam():\r\n if request.method == 'POST':\r\n team_id = request.form.get('team_id')\r\n add_team_request(session['class_id'], team_id, session['username'])\r\n\r\n return redirect(url_for('student_home'))\r\n\r\[email protected](\"/leaveTeam\", methods=['POST'])\r\ndef leaveTeam():\r\n if request.method == 'POST':\r\n remove_from_team(session['team_id'], session['username'])\r\n\r\n return redirect(url_for('student_home'))\r\n\r\[email protected](\"/ar\", methods=['POST'])\r\ndef ar():\r\n if request.method == 'POST':\r\n print(\"here\")\r\n stu = request.form.get('student')\r\n print(\"here1\")\r\n if request.form['submit'] == 'Appoint':\r\n print(\"app\")\r\n assign_team_captain(session['team_id'], stu)\r\n elif request.form['submit'] == 'Remove':\r\n print(\"rem\")\r\n remove_from_team(session['team_id'], stu)\r\n\r\n return redirect(url_for('team_manager_panel'))\r\n\r\[email protected](\"/chooseClass\", methods=['POST'])\r\ndef choose_classs():\r\n if request.method == 'POST':\r\n class_id = request.form.get('class')\r\n print(class_id)\r\n session['class_id'] = class_id\r\n return redirect(url_for('student_home'))\r\n\r\[email protected](\"/chooseClassProf\", methods=['POST'])\r\ndef choose_prof_class():\r\n if request.method == 'POST':\r\n class_id = request.form.get('class')\r\n print(class_id)\r\n session['last_class'] = class_id\r\n return redirect(url_for('prof_home'))\r\n"
},
{
"alpha_fraction": 0.5020576119422913,
"alphanum_fraction": 0.7037037014961243,
"avg_line_length": 15.199999809265137,
"blob_id": "2466bf690f73f8760579c871343613f5cf82f916",
"content_id": "0de81d103c4b42504825a296ed9f8fdcc5fe18dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 15,
"path": "/requirements.txt",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "click==6.6\net-xmlfile==1.0.1\nFlask==0.11.1\nFlask-CAS==1.0.0\nFlask-SQLAlchemy==2.1\nitsdangerous==0.24\njdcal==1.3\nJinja2==2.8\nMarkupSafe==0.23\npsycopg2==2.6.2\nSQLAlchemy==1.0.15\nvirtualenv==15.0.3\nWerkzeug==0.11.11\nxlrd==1.0.0\nxmltodict==0.10.2\n"
},
{
"alpha_fraction": 0.588858425617218,
"alphanum_fraction": 0.5933032035827637,
"avg_line_length": 24.013486862182617,
"blob_id": "501f8403df6dbba2deca82b83d9a684229e293c7",
"content_id": "8fe84af718a34cd2b76d37bef92f59d79f838f7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13499,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 519,
"path": "/teambuildingapp/db_util.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "import psycopg2\r\nfrom teambuildingapp.config import *\r\n\r\ndef get_user_info(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT is_instructor, email, first_name, last_name, comment FROM users WHERE gt_username = \\'%s\\';'\r\n data = (username)\r\n\r\n cur.execute(cmd, data)\r\n\r\n profile = list(cur.fetchone())\r\n\r\n if profile[0]:\r\n cmd = 'SELECT * FROM classes WHERE instructor_gt_username = %s;'\r\n data = (username)\r\n cur.execute(cmd, data)\r\n classes = cur.fetchall()\r\n else:\r\n cmd = 'SELECT * FROM classes WHERE class_id in (SELECT class_id FROM roster WHERE gt_username = %s);'\r\n data = (username)\r\n cur.execute(cmd, data)\r\n classes = cur.fetchall()\r\n\r\n cur.close()\r\n conn.close()\r\n return profile, [list(x) for x in classes]\r\n\r\n\r\ndef create_class(class_name, semester, instructor_username, max_team_size=5):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'INSERT INTO classes (class_name, class_semester, instructor_gt_username, max_team_size) VALUES (%s, %s, %s, %s);'\r\n data = (class_name, semester, instructor_username, max_team_size)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef get_all_teams_in_class(class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n \r\n cmd = ('SELECT team_name, username, emails, countUsers, teamid '\r\n 'FROM ((SELECT team_name, team_id as teamid, COUNT(gt_username) '\r\n 'as countUsers FROM teams where class_id = %s GROUP BY team_id, team_name ) t1 '\r\n ' INNER JOIN '\r\n '(SELECT team_id, gt_username as username FROM teams WHERE is_captain = True GROUP BY team_id, gt_username) t2 '\r\n 'on teamid = t2.team_id) query1 inner join (select gt_username, email as emails from users) query2 on username = query2.gt_username;')\r\n data = (class_id,)\r\n print(cmd)\r\n print(cur.mogrify(cmd, data))\r\n\r\n cur.execute(cmd,data)\r\n \r\n all_teams = cur.fetchall()\r\n \r\n cur.close()\r\n conn.close()\r\n \r\n return all_teams\r\n \r\ndef create_team(class_id, gt_username, team_name):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'INSERT INTO teams (class_id, gt_username, team_name, is_captain) VALUES (%s, %s, %s, %s);'\r\n data = (class_id, gt_username, team_name, True)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef add_to_team(class_id, team_id, gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n \r\n cmd = 'SELECT max_team_size FROM classes WHERE class_id = %s;'\r\n data = (class_id,)\r\n cur.execute(cmd, data)\r\n max_size = int(cur.fetchone()[0])\r\n\r\n cmd = 'SELECT gt_username FROM teams WHERE class_id = %s AND team_id = %s;'\r\n data = (class_id, team_id)\r\n cur.execute(cmd, data)\r\n cur_size = len(cur.fetchall()) \r\n\r\n team_name = get_team_name(class_id, team_id)\r\n\r\n if cur_size == max_size:\r\n raise Exception('Cannot add more team members because the limit is reached')\r\n\r\n cmd = 'INSERT INTO teams (team_id, class_id, gt_username, team_name, is_captain) VALUES (%s, %s, %s, %s, %s);'\r\n data = (team_id, class_id, gt_username, team_name, False)\r\n print(cur.mogrify(cmd, data))\r\n\r\n remove_from_requests(class_id, team_id, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef add_team_request(class_id, team_id, gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'INSERT INTO requests (class_id, team_id, gt_username) VALUES (%s, %s, %s)'\r\n data = (class_id, team_id, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n cur.close()\r\n conn.close()\r\n\r\ndef remove_from_requests(class_id, team_id, gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'DELETE FROM requests WHERE class_id = %s AND team_id = %s AND gt_username = %s;'\r\n data = (class_id, team_id, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef remove_from_team(team_id, gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'DELETE FROM teams WHERE team_id = %s AND gt_username = %s;'\r\n data = (team_id, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef assign_team_captain(team_id, gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'UPDATE teams SET is_captain = %s WHERE team_id = %s;'\r\n data = (False, team_id)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cmd = 'UPDATE teams SET is_captain = %s WHERE gt_username = %s;'\r\n data = (True, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef update_user_comment(username, comment):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'UPDATE users SET comment = %s WHERE gt_username = %s;'\r\n data = (comment, username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n \r\ndef get_user_comment(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT comment from users WHERE gt_username = %s;'\r\n data = (username,)\r\n #print(cur.mogrify(cmd, data))\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n comment = cur.fetchone()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return comment[0]\r\n \r\ndef get_team_captain(class_id, team_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT gt_username from teams WHERE class_id = %s AND team_id = %s AND is_captain = TRUE;'\r\n data = (class_id, team_id)\r\n \r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n team_captain = str(cur.fetchone()[0])\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return team_captain\r\n \r\ndef get_student_name(gt_username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT first_name, last_name from users WHERE gt_username = %s;'\r\n data = (gt_username,)\r\n print(cur.mogrify(cmd, data))\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n name = cur.fetchone()\r\n print(name)\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return name\r\n\r\n\r\ndef get_student_info(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT first from teams WHERE class_id = %s AND team_id = %s AND is_captain = TRUE;'\r\n data = (username,)\r\n #print(cur.mogrify(cmd, data))\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n team_captain = cur.fetchone()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return team_captain[0]\r\n\r\ndef enroll_student(username, class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'INSERT INTO rosters (class_id, gt_username) VALUES (%s, %s);'\r\n data = (class_id, username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n \r\ndef unenroll_student(username, class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'DELETE FROM rosters WHERE class_id = %s AND gt_username = %s);'\r\n data = (class_id, username)\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef get_professor_class_ids(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT class_id FROM classes WHERE instructor_gt_username = %s;'\r\n data = (username,)\r\n \r\n cur.execute(cmd, data)\r\n\r\n classes = [x[0] for x in cur.fetchall()]\r\n\r\n cur.close()\r\n conn.close()\r\n \r\n return classes\r\n\r\ndef get_professor_classes(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT class_id, class_name, class_semester, max_team_size FROM classes WHERE instructor_gt_username = %s;'\r\n data = (username,)\r\n \r\n cur.execute(cmd, data)\r\n\r\n classes = cur.fetchall()\r\n\r\n cur.close()\r\n conn.close()\r\n \r\n return classes\r\n\r\ndef get_all_students_in_team(class_id, team_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT gt_username, first_name, last_name, email FROM users WHERE gt_username in (SELECT gt_username from teams where class_id = %s AND team_id = %s);'\r\n data = (class_id, team_id)\r\n print(cur.mogrify(cmd, data))\r\n\r\n cur.execute(cmd, data)\r\n\r\n students_in_team = cur.fetchall()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return students_in_team\r\n\r\ndef get_all_students_request(class_id, team_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT gt_username, first_name, last_name, email FROM users WHERE gt_username in (SELECT gt_username from requests where class_id = %s AND team_id = %s);'\r\n data = (class_id, team_id)\r\n print(cur.mogrify(cmd, data))\r\n\r\n cur.execute(cmd, data)\r\n\r\n requests = cur.fetchall()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return requests\r\n\r\n\r\ndef get_all_student_usernames():\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT gt_username FROM users WHERE is_instructor = FALSE;'\r\n \r\n cur.execute(cmd)\r\n\r\n student_usernames = [x[0] for x in cur.fetchall()]\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return student_usernames\r\n\r\ndef get_team_name(class_id, team_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT team_name FROM teams WHERE class_id = %s AND team_id = %s;'\r\n data = (class_id, team_id)\r\n cur.execute(cmd, data)\r\n\r\n team_name = cur.fetchone()[0]\r\n\r\n cur.close()\r\n conn.close()\r\n\r\n return team_name\r\n\r\ndef get_all_professor_usernames():\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT gt_username FROM users WHERE is_instructor = TRUE;'\r\n \r\n cur.execute(cmd)\r\n\r\n professor_usernames = [x[0] for x in cur.fetchall()]\r\n \r\n cur.close()\r\n conn.close()\r\n \r\n return professor_usernames\r\n\r\ndef register_user(username, is_instructor, email, first_name, last_name):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'INSERT INTO users (gt_username, is_instructor, email, first_name, last_name, comment) VALUES (%s, %s, %s, %s, %s, %s);'\r\n data = (username, is_instructor, email, first_name, last_name, '')\r\n\r\n cur.execute(cmd, data)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef mass_register_users(userlist):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n print(userlist)\r\n cmd = 'INSERT INTO users (gt_username, is_instructor, email, first_name, last_name, comment) VALUES ' + '(%s, %s, %s, %s, %s, %s), '*(len(userlist)//6-1) + '(%s, %s, %s, %s, %s, %s);'\r\n cur.execute(cmd, userlist)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()\r\n\r\ndef get_student_enrolled_classnames(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT class_name from classes where class_id in (SELECT class_id from rosters WHERE gt_username = %s);'\r\n data = (username,)\r\n\r\n cur.execute(cmd, data)\r\n\r\n class_names = [x[0] for x in cur.fetchall()]\r\n\r\n cur.close()\r\n conn.close()\r\n \r\n return class_names\r\n\r\ndef get_student_enrolled_classes(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT class_name, class_id from classes where class_id in (SELECT class_id from rosters WHERE gt_username = %s);'\r\n data = (username,)\r\n\r\n cur.execute(cmd, data)\r\n\r\n class_names = cur.fetchall()\r\n\r\n cur.close()\r\n conn.close()\r\n \r\n return class_names\r\n\r\n\r\n\r\ndef get_student_enrolled_class_id(username):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT class_id from classes where class_id in (SELECT class_id from rosters WHERE gt_username = %s);'\r\n data = (username,)\r\n\r\n cur.execute(cmd, data)\r\n\r\n class_names = [x[0] for x in cur.fetchall()]\r\n\r\n cur.close()\r\n conn.close()\r\n \r\n return class_names\r\n\r\ndef get_student_enrolled_team_id(gt_username, class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT team_id from teams where class_id = %s AND gt_username = %s;'\r\n data = (class_id, gt_username)\r\n\r\n cur.execute(cmd, data)\r\n\r\n team_id = cur.fetchone()\r\n \r\n cur.close()\r\n conn.close()\r\n \r\n return team_id\r\n\r\ndef get_class_max_team_size(class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n cmd = 'SELECT max_team_size from classes where class_id = %s;'\r\n data = (class_id,)\r\n\r\n cur.execute(cmd, data)\r\n\r\n class_max = cur.fetchone()[0]\r\n print('debug'+str(class_max))\r\n cur.close()\r\n conn.close()\r\n \r\n return class_max\r\n\r\n\r\n\r\ndef enroll_from_roster(students, class_id):\r\n conn = psycopg2.connect(**db)\r\n cur = conn.cursor()\r\n\r\n registered_students = get_all_student_usernames()\r\n print (registered_students)\r\n roster_vals = ()\r\n registration_vals = ()\r\n for s in students:\r\n roster_vals += (class_id, s[0])\r\n if s[0] not in registered_students:\r\n registration_vals += (s[0], False, s[1], s[2], s[3], '')\r\n\r\n mass_register_users(registration_vals)\r\n\r\n cmd = 'INSERT INTO rosters (class_id, gt_username) VALUES ' + '(%s, %s), '*(len(students)-1) + '(%s, %s);'\r\n cur.execute(cmd, roster_vals)\r\n conn.commit()\r\n\r\n cur.close()\r\n conn.close()"
},
{
"alpha_fraction": 0.5710029602050781,
"alphanum_fraction": 0.5819265246391296,
"avg_line_length": 29.484848022460938,
"blob_id": "cbd5eec1b2214bf8456c5f354ccbbeb28559bcf5",
"content_id": "d369338ea732ef946317a21348f88bc4635c72ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1007,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 33,
"path": "/teambuildingapp/roster_processor.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "import xlrd\nimport db_util\n\nclass RosterProcessor:\n def __init__(self, file, class_id=None):\n self.file = file\n self.students = []\n self.class_id = class_id\n\n def process(self):\n wb = xlrd.open_workbook(file_contents=self.file)\n ws = wb.sheet_by_index(0)\n\n for i in range(0, ws.nrows):\n r = ws.row_values(i, start_colx=0, end_colx=ws.ncols)\n if r[-1] == 'Student':\n name = r[0].split(', ')\n self.students.append( (r[1], r[2], name[1], name[0]) )\n #print(self.students)\n\n def export_to_db(self):\n db_util.enroll_from_roster(self.students, self.class_id)\n\nf = open('./../rosters/csxxxx_roster.xls', 'rb+') \ninstance = RosterProcessor(f.read(), 1) #replace 1 with class ID used in the DB\ninstance.process()\ninstance.export_to_db()\n\ndef process_roster(fname):\n with open(fname, 'rb+'):\n instance = RosterProcessor(f.read())\n instance.process()\n instance.export_to_db() \n"
},
{
"alpha_fraction": 0.5280346870422363,
"alphanum_fraction": 0.5289017558097839,
"avg_line_length": 25.919355392456055,
"blob_id": "8b8227453f9111c7f029c3cba13cb24c112b0f94",
"content_id": "6d8bd2567fabb124d2879361a54ea0317fc74a64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3460,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 124,
"path": "/teambuildingapp/db_setup.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "import psycopg2\r\nfrom config import *\r\n\r\ndef setup_tables():\r\n tables = get_tables()\r\n print('Found tables:{}'.format(tables))\r\n if 'users' not in tables:\r\n print('Users table not found, creating one...')\r\n setup_users_table()\r\n\r\n if 'classes' not in tables:\r\n print('Classes table not found, creating one...')\r\n setup_classes_table()\r\n\r\n if 'rosters' not in tables:\r\n print('Rosters table not found, creating one...')\r\n setup_rosters_table()\r\n\r\n if 'teams' not in tables:\r\n print('Teams table not found, creating one...')\r\n setup_teams_table()\r\n \r\n if 'requests' not in tables:\r\n print('Requests table not found, creating one...')\r\n setup_requests_table()\r\n\r\ndef get_tables():\r\n cur = conn.cursor()\r\n cur.execute(\"SELECT table_name FROM information_schema.tables WHERE table_schema = 'public'\")\r\n tables = cur.fetchall()\r\n cur.close()\r\n return [x[0] for x in tables]\r\n\r\ndef setup_users_table():\r\n cur = conn.cursor()\r\n\r\n cmd = \"\"\"CREATE TABLE USERS(\r\n GT_USERNAME TEXT PRIMARY KEY NOT NULL,\r\n IS_INSTRUCTOR BOOL NOT NULL,\r\n EMAIL TEXT NOT NULL,\r\n FIRST_NAME TEXT NOT NULL,\r\n LAST_NAME TEXT NOT NULL,\r\n COMMENT TEXT\r\n);\"\"\"\r\n\r\n cur.execute(cmd)\r\n conn.commit()\r\n\r\n cur.close()\r\n\r\n\r\ndef setup_teams_table():\r\n cur = conn.cursor()\r\n\r\n cmd = \"\"\"CREATE TABLE TEAMS(\r\n TEAM_ID SERIAL NOT NULL,\r\n CLASS_ID INTEGER NOT NULL REFERENCES CLASSES (CLASS_ID),\r\n GT_USERNAME TEXT NOT NULL REFERENCES USERS(GT_USERNAME),\r\n TEAM_NAME TEXT NOT NULL,\r\n IS_CAPTAIN BOOL NOT NULL,\r\n COMMENT TEXT,\r\n PRIMARY KEY(CLASS_ID, TEAM_ID, GT_USERNAME)\r\n);\"\"\"\r\n\r\n cur.execute(cmd)\r\n conn.commit()\r\n\r\n cur.close()\r\n\r\ndef setup_classes_table():\r\n cur = conn.cursor()\r\n\r\n cmd = \"\"\"CREATE TABLE CLASSES(\r\n CLASS_ID SERIAL NOT NULL PRIMARY KEY,\r\n INSTRUCTOR_GT_USERNAME TEXT REFERENCES USERS (GT_USERNAME),\r\n CLASS_NAME TEXT NOT NULL,\r\n CLASS_SEMESTER TEXT NOT NULL,\r\n MAX_TEAM_SIZE INTEGER NOT NULL,\r\n PRIMARY KEY(CLASS_ID, CLASS_NAME, CLASS_SEMESTER)\r\n);\"\"\"\r\n\r\n cur.execute(cmd)\r\n conn.commit()\r\n\r\n cur.close()\r\n\r\ndef setup_rosters_table():\r\n cur = conn.cursor()\r\n\r\n cmd = \"\"\"CREATE TABLE ROSTERS(\r\n CLASS_ID INTEGER NOT NULL REFERENCES CLASSES (CLASS_ID),\r\n GT_USERNAME TEXT NOT NULL REFERENCES USERS (GT_USERNAME),\r\n PRIMARY KEY(CLASS_ID, GT_USERNAME)\r\n);\"\"\"\r\n\r\n cur.execute(cmd)\r\n conn.commit()\r\n\r\n cur.close()\r\n\r\ndef setup_requests_table():\r\n cur = conn.cursor()\r\n\r\n cmd = \"\"\"CREATE TABLE REQUESTS(\r\n CLASS_ID INTEGER NOT NULL REFERENCES CLASSES (CLASS_ID),\r\n TEAM_ID INTEGER NOT NULL,\r\n GT_USERNAME TEXT NOT NULL REFERENCES USERS (GT_USERNAME),\r\n PRIMARY KEY(CLASS_ID, TEAM_ID, GT_USERNAME)\r\n);\"\"\"\r\n\r\n cur.execute(cmd)\r\n conn.commit()\r\n\r\n cur.close()\r\n\r\ndef main():\r\n global conn\r\n conn = psycopg2.connect(**db)\r\n setup_tables()\r\n\r\n\r\n conn.close()\r\n\r\nmain()"
},
{
"alpha_fraction": 0.7200000286102295,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 25.733333587646484,
"blob_id": "43788249c11fe7e7a4e063a925dbabda2dd5dd19",
"content_id": "53338970349caa0f8bb3d2b3d2fe6d64ebec7804",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 15,
"path": "/teambuildingapp/__init__.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom flask_cas import CAS\nfrom flask_sqlalchemy import SQLAlchemy\nfrom teambuildingapp import config\nimport os\napp = Flask(__name__)\nCAS(app, '/cas') # this adds the prefix '/api/cas/' to the /login and /logout\n # routes that CAS provides\n#db = SQLAlchemy(app)\n\napp.config.from_pyfile('config.py')\n\napp.secret_key = os.urandom(24)\n\nimport teambuildingapp.views"
},
{
"alpha_fraction": 0.7467144727706909,
"alphanum_fraction": 0.7482078671455383,
"avg_line_length": 54.79999923706055,
"blob_id": "09a2e697dfc9d6aa8574df1ba5bfec15a9599985",
"content_id": "111ecfe4aa3f458f91cc5836b5ebdda12dbe8051",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3348,
"license_type": "no_license",
"max_line_length": 303,
"num_lines": 60,
"path": "/README.md",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "# Team 17: Team Building Application\nTeam Building Application for Junior Design\n\n## Release Notes\nFeatures:\n* Professors are able to:\n * create classes \n * import roster files from T-Square in .XLS format (see the UI issue workaround in the \"Known Issues\" section).\n * edit imported rosters (add/remove students)\n * switch between different classes they are teaching\n * see teams, their captains, who is in teams, etc.\n* Students are able to:\n * leave relevant information in the comment section of their profile, such as previous experience, programming languages, what kind of team they iare looking for, etc.\n * switch between classes they are in that utilize our service\n * create teams (adding/removing students up to the limi)\n * send requests to join existing teams\n * in cases when a student sends requests to join multiple teams, as soon as one of the requests gets accepted, the rest of the requests will be deleted from the database\n * leave teams\n * if team captain:\n * approve and deny requests to join your team\n * transfer the team captain role to another team member\n \n \nKnown Issues:\n* CAS login. \n * Currently, users can log in using their username only (which is why this should not be used in production until CAS login is integrated). We wrote code that deals with all of that using CAS documentation for their API, but since we haven't received the permit from CAS yet, the code doesn't work. \n* Uploading rosters doesn't work properly through the UI.\n * We created a temporary workaround. You need to create a folder in the root called `rosters/`, put your .XLS roster files imported from T-Square in it, edit filename parameters in `roster_processor.py`, and then it as a python script.\n* Generating final rosters (i.e., auto-matching) is not implemented.\n* Input validation.\n * Weak, which leaves the service in its current somewhat vulnerable.\n\n## Installation Guide\nEnsure that you are using python 3 as well as pip3 and have virtualenv configured\nto work with these versions.\n\nCD into the repository and create a virtual environment using `virtualenv env`.\nThen run the command `source env/bin/activate` (the two commands above are dependent on your OS and terminal application) to move into your virtual environment.\nInstall all the dependencies using `pip install -r requirements.txt`.\nUse `deactivate` to exit the virtual environment when exiting the project directory.\n\nDownload and install [PostgreSQL](https://www.postgresql.org/download/), either locally or on a remote machine or host it using something like AWS or Azure.\n\nOnce you have installed PostgreSQL, create a file in `teambuilding/` called `config.py` and populate using the following parameters:\n```\ndb = {\n 'database': 'your_db_name',\n 'user': 'your_db_username',\n 'password': 'your_db_password',\n 'host': 'your_db_host_address',\n 'port': 'your_db_port'\n}\nUPLOAD_FOLDER = 'uploads/'#path for uploaded files\nALLOWED_EXTENSIONS = set(['csv'])#do not change this\n```\n\n\nWe have also created a script that will set up the appropriate tables that the project utilizes. The script can be found in `teambuildingapp/db_setup.py` and ran using python3 (note that `config.py` setup is a must before running the script).\n\nStart the server by running `runserver.py` as a python file.\n"
},
{
"alpha_fraction": 0.642175555229187,
"alphanum_fraction": 0.6498091816902161,
"avg_line_length": 29.852941513061523,
"blob_id": "534af741d06d81de59ab328e3c813e5c05439c08",
"content_id": "f5cc67b243d548cfc1e5126400731ec6c4f40b3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 34,
"path": "/teambuildingapp/models.py",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "from teambuildingapp import app\nfrom flask_sqlalchemy import Model, Column, Integer, String\n\n# Represents a user. User is related to a team by it's team ID'\nclass User(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n username = db.Column(db.String(80), unique=True)\n email = db.Column(db.String(120), unique=True)\n team_id = db.Column(db.Integer)\n\n def __init__(self, username, email):\n self.username = username\n self.email = email\n\n def __repr__(self):\n return '<User %r>' % self.username\n\n# Represents a Team\nclass Team(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n team_name = db.Column(db.String(120), unique=True)\n team_leader = db.Column(db.Integer, unique=True)\n\n def __init__(self, team_name, team_leader):\n self.team_name = team_name\n self.team_leader = team_leader\n\n def __repr__(self):\n return '<User %r>' % self.team_name\n\n\n# class Roster(db.Model):\n# id = db.Column(db.Integer, primary_key=True)\n # put some stuff about rosters here"
},
{
"alpha_fraction": 0.39105984568595886,
"alphanum_fraction": 0.399423211812973,
"avg_line_length": 39.29166793823242,
"blob_id": "80301ded431d1e851ce73710ae84e1a527154e27",
"content_id": "ffd05b99bf87b61f1cc161961b47e6631ce8d028",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 6935,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 168,
"path": "/teambuildingapp/templates/team_manager_panel.html",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\r\n<html lang=\"en\">\r\n\r\n<head>\r\n <title>My team</title>\r\n\r\n\r\n <link href=\"../static/bootstrap/bootstrap.min.css\" rel=\"stylesheet\">\r\n <script src=\"../static/js/jquery-2.1.4.min.js\"></script>\r\n <script src=\"../static/js/bootstrap.min.js\"></script>\r\n\r\n <link href=\"../static/team_manager_panel.css\" rel=\"stylesheet\">\r\n <style>\r\n .divTable{\r\n\tdisplay: table;\r\n\twidth: 100%;\r\n }\r\n .divTableRow {\r\n display: table-row;\r\n }\r\n .divTableHeading {\r\n background-color: #EEE;\r\n display: table-header-group;\r\n }\r\n .divTableCell, .divTableHead {\r\n border: 1px solid #999999;\r\n display: table-cell;\r\n padding: 3px 10px;\r\n }\r\n .divTableHeading {\r\n background-color: #EEE;\r\n display: table-header-group;\r\n font-weight: bold;\r\n }\r\n .divTableFoot {\r\n background-color: #EEE;\r\n display: table-footer-group;\r\n font-weight: bold;\r\n }\r\n .divTableBody {\r\n display: table-row-group;\r\n }\r\n </style>\r\n</head>\r\n\r\n<body>\r\n\r\n <div class=\"navbar navbar-inverse navbar-fixed-top\">\r\n <div class=\"container\">\r\n <div class=\"navbar-header\">\r\n <button type=\"button\" class=\"navbar-toggle\" data-toggle=\"collapse\" data-target=\".navbar-collapse\">\r\n <span class=\"icon-bar\"></span>\r\n <span class=\"icon-bar\"></span>\r\n <span class=\"icon-bar\"></span>\r\n </button>\r\n <a class=\"navbar-brand\" href=\"/student_home\">GT Team Finder</a>\r\n </div>\r\n <div class=\"collapse navbar-collapse\">\r\n <ul class=\"nav navbar-nav\">\r\n <li><a href=\"/student_home\">Home</a></li>\r\n <li class=\"dropdown\">\r\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">Choose course<span class=\"caret\"></span></a>\r\n <ul class=\"dropdown-menu\">\r\n <li><a href=\"#\">CS 2340 A (Spring 2016)</a></li>\r\n <li><a href=\"#\">CS 4400 B (Spring 2016)</a></li>\r\n </ul>\r\n </li>\r\n <li class=\"active\"><a href=\"#\">My team</a></li>\r\n <li><a href=\"#\">Profile</a></li>\r\n <li><a href=\"/logout\">Sign out</a></li>\r\n </ul>\r\n </div>\r\n <!--/.nav-collapse -->\r\n </div>\r\n </div>\r\n\r\n <div class=\"container\" style=\"margin-top:50px\">\r\n <div class=\"container\">\r\n <div class=\"row col-md-6 col-md-offset-2 table-responsitve\">\r\n <h2><u> {{team_name}}</u></h2>\r\n <h4><br>Team manager: {{team_captain_name[0]}} {{team_captain_name[1]}} \r\n {%if user_captain == True %}\r\n <small>(you)</small></h4>\r\n {% endif %}\r\n <br>\r\n <h3> <u>Current team members</u></h3>\r\n <br>\r\n <table class=\"table table-striped custab\">\r\n <thead>\r\n\r\n <tr>\r\n <th>Name</th>\r\n <th>Email</th>\r\n <th class=\"text-center\">Action</th>\r\n </tr>\r\n </thead>\r\n {% for student in students_in_team%}\r\n <tr>\r\n {% if student[0] == current_user%}\r\n <td>{{student[1]}} {{student[2]}} <small>(you)</small></td>\r\n {%else%}\r\n <td>{{student[1]}} {{student[2]}} </td>\r\n {%endif%}\r\n \r\n <td>{{student[3]}}</td>\r\n {% if current_user == student[0] %}\r\n <form action=\"/leaveTeam\" method=\"POST\">\r\n <td class=\"text-center\"><input type=\"submit\" name=\"leave\" class=\"btn btn-danger btn-xs\" value=\"Leave the team\" /></td>\r\n </form>\r\n {% elif user_captain == True %}\r\n <form action=\"/ar\" method=\"POST\">\r\n <input type=\"hidden\" name=\"student\" value=\"{{student[0]}}\" />\r\n <td class=\"text-center\"><input type=\"submit\" name=\"submit\" class='btn btn-success btn-xs' value=\"Appoint\" /> \r\n <input type=\"submit\" name=\"submit\" class=\"btn btn-danger btn-xs\" value=\"Remove\" /></td>\r\n </form>\r\n {%endif%}\r\n \r\n </tr>\r\n {%endfor%}\r\n <!--\r\n <tr>\r\n <td>James Carter</td>\r\n <td>[email protected]</td>\r\n <td class=\"text-center\"><a class='btn btn-success btn-xs' href=\"#\"> Appoint </a> <a href=\"#\" class=\"btn btn-danger btn-xs\"> Remove</a></td>\r\n </tr>\r\n !-->\r\n {% if user_captain == True %} \r\n </table>\r\n\r\n <h3><br> <u>Pending requests</u></h3>\r\n <br>\r\n\r\n <div class=\"table divTable\">\r\n <div class = \"divTableBody\">\r\n <div class = \"divTableRow\">\r\n\r\n <div class = \"divTableCell\">Name</div>\r\n <div class = \"divTableCell\">Email</div>\r\n <div class = \"divTableCell text-center\">Action</div>\r\n </div>\r\n {% for request in requests%}\r\n\r\n <div class = \"divTableRow\">\r\n <div class = \"divTableCell\">{{request[1]}} {{request[2]}}</div>\r\n <div class = \"divTableCell\">{{request[3]}}</div>\r\n <div class = \"divTableCell text-center\"> \r\n <form action=\"/acceptdecline\" method=\"post\">\r\n <input type=\"hidden\" value=\"{{request[0]}}\" name = \"gt_username\" />\r\n <input type = \"submit\" class=\"btn btn-success btn-xs\" value=\"Accept\" name=\"submit\" />\r\n <input type = \"submit\" class=\"btn btn-danger btn-xs\" value=\"Decline\" name=\"submit\" />\r\n </form>\r\n </div>\r\n </div>\r\n {%endfor%}\r\n\r\n </div>\r\n </div>\r\n {%endif%}\r\n <!--\r\n <a href=\"#\" class=\"btn btn-primary btn-xs pull-right\"><b>+</b> Invite a student</a>\r\n !-->\r\n </div>\r\n </div>\r\n </div>\r\n\r\n</body>\r\n\r\n</html>"
},
{
"alpha_fraction": 0.690559446811676,
"alphanum_fraction": 0.690559446811676,
"avg_line_length": 20.16666603088379,
"blob_id": "0a21acdb80874c3c3d07e86481953b0a1599087a",
"content_id": "a990b269490b95b8dd4b20d5d6b75b1cd0f10a21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 1144,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 54,
"path": "/teambuildingapp/env/lib/python3.4/site-packages/Flask_CAS-1.0.0.dist-info/DESCRIPTION.rst",
"repo_name": "ckjoon/teambuilding",
"src_encoding": "UTF-8",
"text": "Flask-CAS\n=========\n\nFlask-CAS is a Flask extension which makes it easy to\nauthenticate with a CAS.\n\nCAS\n===\n\nThe Central Authentication Service (CAS) is a single sign-on \nprotocol for the web. Its purpose is to permit a user to access \nmultiple applications while providing their credentials (such as \nuserid and password) only once. It also allows web applications \nto authenticate users without gaining access to a user's security \ncredentials, such as a password. The name CAS also refers to a \nsoftware package that implements this protocol. \n\n(Very short) Setup Tutorial\n===========================\n\nFirst create a Flask instance:\n\n.. code:: python\n\n from flask import Flask\n\n app = Flask(__name__)\n\nApply CAS on your Flask instance:\n\n.. code:: python\n\n from flask.ext.cas import CAS\n\n CAS(app)\n\nDo needed configuration:\n\n.. code:: python\n\n app.config['CAS_SERVER'] = 'https://sso.pdx.edu' \n\n app.config['CAS_AFTER_LOGIN'] = 'route_root'\n\nUsing\n=====\n\nAfter you setup you will get two new routes `/login/`\nand `/logout/`.\n\nReference documentation\n=======================\n\nSee https://github.com/cameronbwhite/Flask-CAS\n\n"
}
] | 11 |
raghavendra990/Sentiment-Analysis-of-Tweets | https://github.com/raghavendra990/Sentiment-Analysis-of-Tweets | 20a427961a0d604e11df9ddfaa4e06d6facf408a | 4415c9e524ced97537c41925be46a1e683d21580 | 8701bc9f4386c6c793cc270e449c52473628e236 | refs/heads/master | "2016-08-16T08:24:12.998329" | "2015-06-16T11:50:22" | "2015-06-16T11:50:22" | 33,868,028 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7570332288742065,
"alphanum_fraction": 0.7621483206748962,
"avg_line_length": 51.13333511352539,
"blob_id": "95c4d8350cfeac7b49593c70ea5a4d2457f76f4e",
"content_id": "25b49efb95d128aa97649137a30629f5889256ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 782,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 15,
"path": "/README.md",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "# Sentiment-Analysis-of-Tweets\n\nIt is basically a Flask application. In this we collect real time tweets from twitter about any topic. Than we analyse them, finds there sentiment and present them with the help of google visualization maps.\n\nYou simply have to run app.py file in terminal.\nthen enter the http://localhost:5000/ in browser. \nIt will direct to main.html page , Here you will see the message \"enter the text below\".\nJust enter the word or words for which you have to search tweets. (Eg: you have to find the sentiments of \"Jurassic World\")\nthan it will show you various visualization.\n\n\n<b>NOTE:</b> You have to create mysql data base in your system with database name \"sentiment\" and table name \"data\" with attributes names \"user\", \"time\", \"geo\", \"tweets\".\n\n\nEnjoy :)\n"
},
{
"alpha_fraction": 0.602845311164856,
"alphanum_fraction": 0.6058091521263123,
"avg_line_length": 21.635135650634766,
"blob_id": "2e30bb4e9f9b0f487deac13f02ab5104d6d54d78",
"content_id": "24da60f780274d2a18a629ade6fd256612125c44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 74,
"path": "/route.py",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "from flask import Flask , url_for , request, render_template , jsonify\napp = Flask(__name__)\nimport sys\nfrom tstreaming import *\nfrom hope import *\nimport random\nimport json\n\n# Make the WSGI interface available at the top level so wfastcgi can get it.\nwsgi_app = app.wsgi_app\n\n\n\n\n\n\n#############################################################################################################\n# welcome page main.html\n\n\n\t\n\n\[email protected]('/' , methods=['GET','POST'])\ndef welcome():\n\tif request.method == 'GET':\n\t\treturn render_template(\"main.html\") #render_template(\"main.html\");\n\n\telif request.method == \"POST\" :\n\t\t\n\t\ttitle = request.form['title'].split(\" \");\n\t\ttstream(title)\n\t\t\n\t\t\n\t\treturn render_template(\"donat.html\", variable = json.dumps(donat()))\n\t\t\n\[email protected]('/donat', methods=['GET','POST'])\ndef donat1():\n\t\n\tif request.method == 'GET':\n\t\tvariable = donat()\n\t\treturn render_template('donat.html', variable = json.dumps(variable) )\n\n\n\[email protected]('/scatter', methods=['GET','POST'])\ndef scatter1():\n\t\n\tif request.method == 'GET':\n\t\tvariable = scatter()\n\t\treturn render_template('scatter.html' , variable = json.dumps(variable))\n\n\n\[email protected]('/histogram', methods=['GET','POST'])\ndef histogram1():\n\t\n\tif request.method == 'GET':\n\t\tvariable = histogram()\n\t\treturn render_template('histogram.html' , variable = json.dumps(variable))\n\n\[email protected]('/table', methods=['GET','POST'])\ndef table1():\n\tvariable = table()\n\tif request.method == 'GET':\n\t\treturn render_template('table.html' , variable = json.dumps(variable))\n\n\[email protected]('/map', methods=['GET','POST'])\ndef map1():\n\tif request.method == 'GET':\n\t\treturn render_template('map.html')\n\n\t\t\t\t\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.346422404050827,
"alphanum_fraction": 0.4554758369922638,
"avg_line_length": 29.218734741210938,
"blob_id": "006d2cd997fca14906d019ab9987bcd9da471767",
"content_id": "5ca84c089dc62da1ed8d571a93ebaa9d73667d42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 125168,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 4142,
"path": "/anew.py",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "word = \"word\"\ndict = \"dict\"\nstem = \"stem\"\navg =\"avg\"\nstd =\"std\"\nfq = \"fg\"\n\n\ndictionary = {\t\t\t\n \"abduction\": {\n dict: \"anew\", word: \"abduction\", stem: \"abduct\",\n avg: [ 5.53, 2.76 ], std: [ 2.43, 2.06 ], fq: 1\n },\n \"abortion\": {\n dict: \"anew\", word: \"abortion\", stem: \"abort\",\n avg: [ 5.39, 3.5 ], std: [ 2.8, 2.3 ], fq: 6\n },\n \"absurd\": {\n dict: \"anew\", word: \"absurd\", stem: \"absurd\",\n avg: [ 4.36, 4.26 ], std: [ 2.2, 1.82 ], fq: 17\n },\n \"abundance\": {\n dict: \"anew\", word: \"abundance\", stem: \"abund\",\n avg: [ 5.51, 6.59 ], std: [ 2.63, 2.01 ], fq: 13\n },\n \"abuse\": {\n dict: \"anew\", word: \"abuse\", stem: \"abus\",\n avg: [ 6.83, 1.8 ], std: [ 2.7, 1.23 ], fq: 18\n },\n \"acceptance\": {\n dict: \"anew\", word: \"acceptance\", stem: \"accept\",\n avg: [ 5.4, 7.98 ], std: [ 2.7, 1.42 ], fq: 49\n },\n \"accident\": {\n dict: \"anew\", word: \"accident\", stem: \"accid\",\n avg: [ 6.26, 2.05 ], std: [ 2.87, 1.19 ], fq: 33\n },\n \"ace\": {\n dict: \"anew\", word: \"ace\", stem: \"ace\",\n avg: [ 5.5, 6.88 ], std: [ 2.66, 1.93 ], fq: 15\n },\n \"ache\": {\n dict: \"anew\", word: \"ache\", stem: \"ach\",\n avg: [ 5, 2.46 ], std: [ 2.45, 1.52 ], fq: 4\n },\n \"achievement\": {\n dict: \"anew\", word: \"achievement\", stem: \"achiev\",\n avg: [ 5.53, 7.89 ], std: [ 2.81, 1.38 ], fq: 65\n },\n \"activate\": {\n dict: \"anew\", word: \"activate\", stem: \"activ\",\n avg: [ 4.86, 5.46 ], std: [ 2.56, 0.98 ], fq: 2\n },\n \"addict\": {\n dict: \"anew\", word: \"addict\", stem: \"addict\",\n avg: [ 5.66, 2.48 ], std: [ 2.26, 2.08 ], fq: 1\n },\n \"addicted\": {\n dict: \"anew\", word: \"addicted\", stem: \"addict\",\n avg: [ 4.81, 2.51 ], std: [ 2.46, 1.42 ], fq: 3\n },\n \"admired\": {\n dict: \"anew\", word: \"admired\", stem: \"admir\",\n avg: [ 6.11, 7.74 ], std: [ 2.36, 1.84 ], fq: 17\n },\n \"adorable\": {\n dict: \"anew\", word: \"adorable\", stem: \"ador\",\n avg: [ 5.12, 7.81 ], std: [ 2.71, 1.24 ], fq: 3\n },\n \"adult\": {\n dict: \"anew\", word: \"adult\", stem: \"adult\",\n avg: [ 4.76, 6.49 ], std: [ 1.95, 1.5 ], fq: 25\n },\n \"advantage\": {\n dict: \"anew\", word: \"advantage\", stem: \"advantag\",\n avg: [ 4.76, 6.95 ], std: [ 2.18, 1.85 ], fq: 73\n },\n \"adventure\": {\n dict: \"anew\", word: \"adventure\", stem: \"adventur\",\n avg: [ 6.98, 7.6 ], std: [ 2.15, 1.5 ], fq: 14\n },\n \"affection\": {\n dict: \"anew\", word: \"affection\", stem: \"affect\",\n avg: [ 6.21, 8.39 ], std: [ 2.75, 0.86 ], fq: 18\n },\n \"afraid\": {\n dict: \"anew\", word: \"afraid\", stem: \"afraid\",\n avg: [ 6.67, 2 ], std: [ 2.54, 1.28 ], fq: 57\n },\n \"aggressive\": {\n dict: \"anew\", word: \"aggressive\", stem: \"aggress\",\n avg: [ 5.83, 5.1 ], std: [ 2.33, 1.68 ], fq: 17\n },\n \"agility\": {\n dict: \"anew\", word: \"agility\", stem: \"agil\",\n avg: [ 4.85, 6.46 ], std: [ 1.8, 1.57 ], fq: 3\n },\n \"agony\": {\n dict: \"anew\", word: \"agony\", stem: \"agoni\",\n avg: [ 6.06, 2.43 ], std: [ 2.67, 2.17 ], fq: 9\n },\n \"agreement\": {\n dict: \"anew\", word: \"agreement\", stem: \"agreement\",\n avg: [ 5.02, 7.08 ], std: [ 2.24, 1.59 ], fq: 106\n },\n \"air\": {\n dict: \"anew\", word: \"air\", stem: \"air\",\n avg: [ 4.12, 6.34 ], std: [ 2.3, 1.56 ], fq: 257\n },\n \"alcoholic\": {\n dict: \"anew\", word: \"alcoholic\", stem: \"alcohol\",\n avg: [ 5.69, 2.84 ], std: [ 2.36, 2.34 ], fq: 3\n },\n \"alert\": {\n dict: \"anew\", word: \"alert\", stem: \"alert\",\n avg: [ 6.85, 6.2 ], std: [ 2.53, 1.76 ], fq: 33\n },\n \"alien\": {\n dict: \"anew\", word: \"alien\", stem: \"alien\",\n avg: [ 5.45, 5.6 ], std: [ 2.15, 1.82 ], fq: 16\n },\n \"alimony\": {\n dict: \"anew\", word: \"alimony\", stem: \"alimoni\",\n avg: [ 4.3, 3.95 ], std: [ 2.29, 2 ], fq: 2\n },\n \"alive\": {\n dict: \"anew\", word: \"alive\", stem: \"aliv\",\n avg: [ 5.5, 7.25 ], std: [ 2.74, 2.22 ], fq: 57\n },\n \"allergy\": {\n dict: \"anew\", word: \"allergy\", stem: \"allergi\",\n avg: [ 4.64, 3.07 ], std: [ 2.34, 1.64 ], fq: 1\n },\n \"alley\": {\n dict: \"anew\", word: \"alley\", stem: \"alley\",\n avg: [ 4.91, 4.48 ], std: [ 2.42, 1.97 ], fq: 8\n },\n \"alone\": {\n dict: \"anew\", word: \"alone\", stem: \"alon\",\n avg: [ 4.83, 2.41 ], std: [ 2.66, 1.77 ], fq: 195\n },\n \"aloof\": {\n dict: \"anew\", word: \"aloof\", stem: \"aloof\",\n avg: [ 4.28, 4.9 ], std: [ 2.1, 1.92 ], fq: 5\n },\n \"ambition\": {\n dict: \"anew\", word: \"ambition\", stem: \"ambit\",\n avg: [ 5.61, 7.04 ], std: [ 2.92, 1.98 ], fq: 19\n },\n \"ambulance\": {\n dict: \"anew\", word: \"ambulance\", stem: \"ambul\",\n avg: [ 7.33, 2.47 ], std: [ 1.96, 1.5 ], fq: 6\n },\n \"angel\": {\n dict: \"anew\", word: \"angel\", stem: \"angel\",\n avg: [ 4.83, 7.53 ], std: [ 2.63, 1.58 ], fq: 18\n },\n \"anger\": {\n dict: \"anew\", word: \"anger\", stem: \"anger\",\n avg: [ 7.63, 2.34 ], std: [ 1.91, 1.32 ], fq: 48\n },\n \"angry\": {\n dict: \"anew\", word: \"angry\", stem: \"angri\",\n avg: [ 7.17, 2.85 ], std: [ 2.07, 1.7 ], fq: 45\n },\n \"anguished\": {\n dict: \"anew\", word: \"anguished\", stem: \"anguish\",\n avg: [ 5.33, 2.12 ], std: [ 2.69, 1.56 ], fq: 2\n },\n \"ankle\": {\n dict: \"anew\", word: \"ankle\", stem: \"ankl\",\n avg: [ 4.16, 5.27 ], std: [ 2.03, 1.54 ], fq: 8\n },\n \"annoy\": {\n dict: \"anew\", word: \"annoy\", stem: \"annoy\",\n avg: [ 6.49, 2.74 ], std: [ 2.17, 1.81 ], fq: 2\n },\n \"answer\": {\n dict: \"anew\", word: \"answer\", stem: \"answer\",\n avg: [ 5.41, 6.63 ], std: [ 2.43, 1.68 ], fq: 152\n },\n \"anxious\": {\n dict: \"anew\", word: \"anxious\", stem: \"anxious\",\n avg: [ 6.92, 4.81 ], std: [ 1.81, 1.98 ], fq: 29\n },\n \"applause\": {\n dict: \"anew\", word: \"applause\", stem: \"applaus\",\n avg: [ 5.8, 7.5 ], std: [ 2.79, 1.5 ], fq: 14\n },\n \"appliance\": {\n dict: \"anew\", word: \"appliance\", stem: \"applianc\",\n avg: [ 4.05, 5.1 ], std: [ 2.06, 1.21 ], fq: 5\n },\n \"arm\": {\n dict: \"anew\", word: \"arm\", stem: \"arm\",\n avg: [ 3.59, 5.34 ], std: [ 2.4, 1.82 ], fq: 94\n },\n \"army\": {\n dict: \"anew\", word: \"army\", stem: \"armi\",\n avg: [ 5.03, 4.72 ], std: [ 2.03, 1.75 ], fq: 132\n },\n \"aroused\": {\n dict: \"anew\", word: \"aroused\", stem: \"arous\",\n avg: [ 6.63, 7.97 ], std: [ 2.7, 1 ], fq: 20\n },\n \"arrogant\": {\n dict: \"anew\", word: \"arrogant\", stem: \"arrog\",\n avg: [ 5.65, 3.69 ], std: [ 2.23, 2.4 ], fq: 2\n },\n \"art\": {\n dict: \"anew\", word: \"art\", stem: \"art\",\n avg: [ 4.86, 6.68 ], std: [ 2.88, 2.1 ], fq: 208\n },\n \"assassin\": {\n dict: \"anew\", word: \"assassin\", stem: \"assassin\",\n avg: [ 6.28, 3.09 ], std: [ 2.53, 2.09 ], fq: 6\n },\n \"assault\": {\n dict: \"anew\", word: \"assault\", stem: \"assault\",\n avg: [ 7.51, 2.03 ], std: [ 2.28, 1.55 ], fq: 15\n },\n \"astonished\": {\n dict: \"anew\", word: \"astonished\", stem: \"astonish\",\n avg: [ 6.58, 6.56 ], std: [ 2.22, 1.61 ], fq: 6\n },\n \"astronaut\": {\n dict: \"anew\", word: \"astronaut\", stem: \"astronaut\",\n avg: [ 5.28, 6.66 ], std: [ 2.11, 1.6 ], fq: 2\n },\n \"athletics\": {\n dict: \"anew\", word: \"athletics\", stem: \"athlet\",\n avg: [ 6.1, 6.61 ], std: [ 2.29, 2.08 ], fq: 9\n },\n \"autumn\": {\n dict: \"anew\", word: \"autumn\", stem: \"autumn\",\n avg: [ 4.51, 6.3 ], std: [ 2.5, 2.14 ], fq: 22\n },\n \"avalanche\": {\n dict: \"anew\", word: \"avalanche\", stem: \"avalanch\",\n avg: [ 5.54, 3.29 ], std: [ 2.37, 1.95 ], fq: 1\n },\n \"avenue\": {\n dict: \"anew\", word: \"avenue\", stem: \"avenu\",\n avg: [ 4.12, 5.5 ], std: [ 2.01, 1.37 ], fq: 46\n },\n \"awed\": {\n dict: \"anew\", word: \"awed\", stem: \"awe\",\n avg: [ 5.74, 6.7 ], std: [ 2.31, 1.38 ], fq: 5\n },\n \"baby\": {\n dict: \"anew\", word: \"baby\", stem: \"babi\",\n avg: [ 5.53, 8.22 ], std: [ 2.8, 1.2 ], fq: 62\n },\n \"bake\": {\n dict: \"anew\", word: \"bake\", stem: \"bake\",\n avg: [ 5.1, 6.17 ], std: [ 2.3, 1.71 ], fq: 12\n },\n \"bandage\": {\n dict: \"anew\", word: \"bandage\", stem: \"bandag\",\n avg: [ 3.9, 4.54 ], std: [ 2.07, 1.75 ], fq: 4\n },\n \"bankrupt\": {\n dict: \"anew\", word: \"bankrupt\", stem: \"bankrupt\",\n avg: [ 6.21, 2 ], std: [ 2.79, 1.31 ], fq: 5\n },\n \"banner\": {\n dict: \"anew\", word: \"banner\", stem: \"banner\",\n avg: [ 3.83, 5.4 ], std: [ 1.95, 0.83 ], fq: 8\n },\n \"bar\": {\n dict: \"anew\", word: \"bar\", stem: \"bar\",\n avg: [ 5, 6.42 ], std: [ 2.83, 2.05 ], fq: 82\n },\n \"barrel\": {\n dict: \"anew\", word: \"barrel\", stem: \"barrel\",\n avg: [ 3.36, 5.05 ], std: [ 2.28, 1.46 ], fq: 24\n },\n \"basket\": {\n dict: \"anew\", word: \"basket\", stem: \"basket\",\n avg: [ 3.63, 5.45 ], std: [ 2.02, 1.15 ], fq: 17\n },\n \"bastard\": {\n dict: \"anew\", word: \"bastard\", stem: \"bastard\",\n avg: [ 6.07, 3.36 ], std: [ 2.15, 2.16 ], fq: 12\n },\n \"bath\": {\n dict: \"anew\", word: \"bath\", stem: \"bath\",\n avg: [ 4.16, 7.33 ], std: [ 2.31, 1.45 ], fq: 26\n },\n \"bathroom\": {\n dict: \"anew\", word: \"bathroom\", stem: \"bathroom\",\n avg: [ 3.88, 5.55 ], std: [ 1.72, 1.36 ], fq: 18\n },\n \"bathtub\": {\n dict: \"anew\", word: \"bathtub\", stem: \"bathtub\",\n avg: [ 4.36, 6.69 ], std: [ 2.59, 1.57 ], fq: 4\n },\n \"beach\": {\n dict: \"anew\", word: \"beach\", stem: \"beach\",\n avg: [ 5.53, 8.03 ], std: [ 3.07, 1.59 ], fq: 61\n },\n \"beast\": {\n dict: \"anew\", word: \"beast\", stem: \"beast\",\n avg: [ 5.57, 4.23 ], std: [ 2.61, 2.41 ], fq: 7\n },\n \"beautiful\": {\n dict: \"anew\", word: \"beautiful\", stem: \"beauti\",\n avg: [ 6.17, 7.6 ], std: [ 2.34, 1.64 ], fq: 127\n },\n \"beauty\": {\n dict: \"anew\", word: \"beauty\", stem: \"beauti\",\n avg: [ 4.95, 7.82 ], std: [ 2.57, 1.16 ], fq: 71\n },\n \"bed\": {\n dict: \"anew\", word: \"bed\", stem: \"bed\",\n avg: [ 3.61, 7.51 ], std: [ 2.56, 1.38 ], fq: 127\n },\n \"bees\": {\n dict: \"anew\", word: \"bees\", stem: \"bee\",\n avg: [ 6.51, 3.2 ], std: [ 2.14, 2.07 ], fq: 15\n },\n \"beggar\": {\n dict: \"anew\", word: \"beggar\", stem: \"beggar\",\n avg: [ 4.91, 3.22 ], std: [ 2.45, 2.02 ], fq: 2\n },\n \"bench\": {\n dict: \"anew\", word: \"bench\", stem: \"bench\",\n avg: [ 3.59, 4.61 ], std: [ 2.07, 1.4 ], fq: 35\n },\n \"bereavement\": {\n dict: \"anew\", word: \"bereavement\", stem: \"bereav\",\n avg: [ 4.2, 4.57 ], std: [ 2.15, 1.7 ], fq: 4\n },\n \"betray\": {\n dict: \"anew\", word: \"betray\", stem: \"betray\",\n avg: [ 7.24, 1.68 ], std: [ 2.06, 1.02 ], fq: 4\n },\n \"beverage\": {\n dict: \"anew\", word: \"beverage\", stem: \"beverag\",\n avg: [ 5.21, 6.83 ], std: [ 2.46, 1.48 ], fq: 5\n },\n \"bird\": {\n dict: \"anew\", word: \"bird\", stem: \"bird\",\n avg: [ 3.17, 7.27 ], std: [ 2.23, 1.36 ], fq: 31\n },\n \"birthday\": {\n dict: \"anew\", word: \"birthday\", stem: \"birthday\",\n avg: [ 6.68, 7.84 ], std: [ 2.11, 1.92 ], fq: 18\n },\n \"black\": {\n dict: \"anew\", word: \"black\", stem: \"black\",\n avg: [ 4.61, 5.39 ], std: [ 2.24, 1.8 ], fq: 203\n },\n \"blackmail\": {\n dict: \"anew\", word: \"blackmail\", stem: \"blackmail\",\n avg: [ 6.03, 2.95 ], std: [ 2.7, 1.95 ], fq: 2\n },\n \"bland\": {\n dict: \"anew\", word: \"bland\", stem: \"bland\",\n avg: [ 3.29, 4.1 ], std: [ 1.89, 1.08 ], fq: 3\n },\n \"blase\": {\n dict: \"anew\", word: \"blase\", stem: \"blase\",\n avg: [ 3.94, 4.89 ], std: [ 1.76, 1.16 ], fq: 7\n },\n \"blasphemy\": {\n dict: \"anew\", word: \"blasphemy\", stem: \"blasphemi\",\n avg: [ 4.93, 3.75 ], std: [ 2.34, 2.26 ], fq: 4\n },\n \"bless\": {\n dict: \"anew\", word: \"bless\", stem: \"bless\",\n avg: [ 4.05, 7.19 ], std: [ 2.59, 1.69 ], fq: 9\n },\n \"blind\": {\n dict: \"anew\", word: \"blind\", stem: \"blind\",\n avg: [ 4.39, 3.05 ], std: [ 2.36, 1.99 ], fq: 47\n },\n \"bliss\": {\n dict: \"anew\", word: \"bliss\", stem: \"bliss\",\n avg: [ 4.41, 6.95 ], std: [ 2.95, 2.24 ], fq: 4\n },\n \"blister\": {\n dict: \"anew\", word: \"blister\", stem: \"blister\",\n avg: [ 4.1, 2.88 ], std: [ 2.34, 1.75 ], fq: 3\n },\n \"blond\": {\n dict: \"anew\", word: \"blond\", stem: \"blond\",\n avg: [ 5.07, 6.43 ], std: [ 2.7, 2.04 ], fq: 11\n },\n \"bloody\": {\n dict: \"anew\", word: \"bloody\", stem: \"bloodi\",\n avg: [ 6.41, 2.9 ], std: [ 2, 1.98 ], fq: 8\n },\n \"blossom\": {\n dict: \"anew\", word: \"blossom\", stem: \"blossom\",\n avg: [ 5.03, 7.26 ], std: [ 2.65, 1.18 ], fq: 7\n },\n \"blubber\": {\n dict: \"anew\", word: \"blubber\", stem: \"blubber\",\n avg: [ 4.57, 3.52 ], std: [ 2.38, 1.99 ], fq: 1\n },\n \"blue\": {\n dict: \"anew\", word: \"blue\", stem: \"blue\",\n avg: [ 4.31, 6.76 ], std: [ 2.2, 1.78 ], fq: 143\n },\n \"board\": {\n dict: \"anew\", word: \"board\", stem: \"board\",\n avg: [ 3.36, 4.82 ], std: [ 2.12, 1.23 ], fq: 239\n },\n \"body\": {\n dict: \"anew\", word: \"body\", stem: \"bodi\",\n avg: [ 5.52, 5.55 ], std: [ 2.63, 2.37 ], fq: 276\n },\n \"bold\": {\n dict: \"anew\", word: \"bold\", stem: \"bold\",\n avg: [ 5.6, 6.8 ], std: [ 2.21, 1.61 ], fq: 21\n },\n \"bomb\": {\n dict: \"anew\", word: \"bomb\", stem: \"bomb\",\n avg: [ 7.15, 2.1 ], std: [ 2.4, 1.19 ], fq: 36\n },\n \"book\": {\n dict: \"anew\", word: \"book\", stem: \"book\",\n avg: [ 4.17, 5.72 ], std: [ 2.49, 1.54 ], fq: 193\n },\n \"bored\": {\n dict: \"anew\", word: \"bored\", stem: \"bore\",\n avg: [ 2.83, 2.95 ], std: [ 2.31, 1.35 ], fq: 14\n },\n \"bottle\": {\n dict: \"anew\", word: \"bottle\", stem: \"bottl\",\n avg: [ 4.79, 6.15 ], std: [ 2.44, 1.49 ], fq: 76\n },\n \"bouquet\": {\n dict: \"anew\", word: \"bouquet\", stem: \"bouquet\",\n avg: [ 5.46, 7.02 ], std: [ 2.47, 1.84 ], fq: 4\n },\n \"bowl\": {\n dict: \"anew\", word: \"bowl\", stem: \"bowl\",\n avg: [ 3.47, 5.33 ], std: [ 2.12, 1.33 ], fq: 23\n },\n \"boxer\": {\n dict: \"anew\", word: \"boxer\", stem: \"boxer\",\n avg: [ 5.12, 5.51 ], std: [ 2.26, 1.8 ], fq: 1\n },\n \"boy\": {\n dict: \"anew\", word: \"boy\", stem: \"boy\",\n avg: [ 4.58, 6.32 ], std: [ 2.37, 1.6 ], fq: 242\n },\n \"brave\": {\n dict: \"anew\", word: \"brave\", stem: \"brave\",\n avg: [ 6.15, 7.15 ], std: [ 2.45, 1.64 ], fq: 24\n },\n \"breast\": {\n dict: \"anew\", word: \"breast\", stem: \"breast\",\n avg: [ 5.37, 6.5 ], std: [ 2.39, 1.78 ], fq: 11\n },\n \"breeze\": {\n dict: \"anew\", word: \"breeze\", stem: \"breez\",\n avg: [ 4.37, 6.85 ], std: [ 2.32, 1.71 ], fq: 14\n },\n \"bride\": {\n dict: \"anew\", word: \"bride\", stem: \"bride\",\n avg: [ 5.55, 7.34 ], std: [ 2.74, 1.71 ], fq: 33\n },\n \"bright\": {\n dict: \"anew\", word: \"bright\", stem: \"bright\",\n avg: [ 5.4, 7.5 ], std: [ 2.33, 1.55 ], fq: 87\n },\n \"broken\": {\n dict: \"anew\", word: \"broken\", stem: \"broken\",\n avg: [ 5.43, 3.05 ], std: [ 2.42, 1.92 ], fq: 63\n },\n \"brother\": {\n dict: \"anew\", word: \"brother\", stem: \"brother\",\n avg: [ 4.71, 7.11 ], std: [ 2.68, 2.17 ], fq: 73\n },\n \"brutal\": {\n dict: \"anew\", word: \"brutal\", stem: \"brutal\",\n avg: [ 6.6, 2.8 ], std: [ 2.36, 1.9 ], fq: 7\n },\n \"building\": {\n dict: \"anew\", word: \"building\", stem: \"build\",\n avg: [ 3.92, 5.29 ], std: [ 1.94, 1.15 ], fq: 160\n },\n \"bullet\": {\n dict: \"anew\", word: \"bullet\", stem: \"bullet\",\n avg: [ 5.33, 3.29 ], std: [ 2.48, 2.06 ], fq: 28\n },\n \"bunny\": {\n dict: \"anew\", word: \"bunny\", stem: \"bunni\",\n avg: [ 4.06, 7.24 ], std: [ 2.61, 1.32 ], fq: 1\n },\n \"burdened\": {\n dict: \"anew\", word: \"burdened\", stem: \"burden\",\n avg: [ 5.63, 2.5 ], std: [ 2.07, 1.32 ], fq: 4\n },\n \"burial\": {\n dict: \"anew\", word: \"burial\", stem: \"burial\",\n avg: [ 5.08, 2.05 ], std: [ 2.4, 1.41 ], fq: 11\n },\n \"burn\": {\n dict: \"anew\", word: \"burn\", stem: \"burn\",\n avg: [ 6.22, 2.73 ], std: [ 1.91, 1.72 ], fq: 15\n },\n \"bus\": {\n dict: \"anew\", word: \"bus\", stem: \"bus\",\n avg: [ 3.55, 4.51 ], std: [ 1.8, 1.57 ], fq: 34\n },\n \"busybody\": {\n dict: \"anew\", word: \"busybody\", stem: \"busybodi\",\n avg: [ 4.84, 5.17 ], std: [ 2.41, 2.02 ], fq: 0\n },\n \"butter\": {\n dict: \"anew\", word: \"butter\", stem: \"butter\",\n avg: [ 3.17, 5.33 ], std: [ 1.84, 1.2 ], fq: 27\n },\n \"butterfly\": {\n dict: \"anew\", word: \"butterfly\", stem: \"butterfli\",\n avg: [ 3.47, 7.17 ], std: [ 2.39, 1.2 ], fq: 2\n },\n \"cabinet\": {\n dict: \"anew\", word: \"cabinet\", stem: \"cabinet\",\n avg: [ 3.43, 5.05 ], std: [ 1.85, 0.31 ], fq: 17\n },\n \"cake\": {\n dict: \"anew\", word: \"cake\", stem: \"cake\",\n avg: [ 5, 7.26 ], std: [ 2.37, 1.27 ], fq: 9\n },\n \"cancer\": {\n dict: \"anew\", word: \"cancer\", stem: \"cancer\",\n avg: [ 6.42, 1.5 ], std: [ 2.83, 0.85 ], fq: 25\n },\n \"candy\": {\n dict: \"anew\", word: \"candy\", stem: \"candi\",\n avg: [ 4.58, 6.54 ], std: [ 2.4, 2.09 ], fq: 16\n },\n \"cane\": {\n dict: \"anew\", word: \"cane\", stem: \"cane\",\n avg: [ 4.2, 4 ], std: [ 1.93, 1.8 ], fq: 12\n },\n \"cannon\": {\n dict: \"anew\", word: \"cannon\", stem: \"cannon\",\n avg: [ 4.71, 4.9 ], std: [ 2.84, 2.2 ], fq: 7\n },\n \"capable\": {\n dict: \"anew\", word: \"capable\", stem: \"capabl\",\n avg: [ 5.08, 7.16 ], std: [ 2.07, 1.39 ], fq: 66\n },\n \"car\": {\n dict: \"anew\", word: \"car\", stem: \"car\",\n avg: [ 6.24, 7.73 ], std: [ 2.04, 1.63 ], fq: 274\n },\n \"carcass\": {\n dict: \"anew\", word: \"carcass\", stem: \"carcass\",\n avg: [ 4.83, 3.34 ], std: [ 2.07, 1.92 ], fq: 7\n },\n \"carefree\": {\n dict: \"anew\", word: \"carefree\", stem: \"carefre\",\n avg: [ 4.17, 7.54 ], std: [ 2.84, 1.38 ], fq: 9\n },\n \"caress\": {\n dict: \"anew\", word: \"caress\", stem: \"caress\",\n avg: [ 5.14, 7.84 ], std: [ 3, 1.16 ], fq: 1\n },\n \"cash\": {\n dict: \"anew\", word: \"cash\", stem: \"cash\",\n avg: [ 7.37, 8.37 ], std: [ 2.21, 1 ], fq: 36\n },\n \"casino\": {\n dict: \"anew\", word: \"casino\", stem: \"casino\",\n avg: [ 6.51, 6.81 ], std: [ 2.12, 1.66 ], fq: 2\n },\n \"cat\": {\n dict: \"anew\", word: \"cat\", stem: \"cat\",\n avg: [ 4.38, 5.72 ], std: [ 2.24, 2.43 ], fq: 0\n },\n \"cell\": {\n dict: \"anew\", word: \"cell\", stem: \"cell\",\n avg: [ 4.08, 3.82 ], std: [ 2.19, 1.7 ], fq: 65\n },\n \"cellar\": {\n dict: \"anew\", word: \"cellar\", stem: \"cellar\",\n avg: [ 4.39, 4.32 ], std: [ 2.33, 1.68 ], fq: 26\n },\n \"cemetery\": {\n dict: \"anew\", word: \"cemetery\", stem: \"cemeteri\",\n avg: [ 4.82, 2.63 ], std: [ 2.66, 1.4 ], fq: 15\n },\n \"chair\": {\n dict: \"anew\", word: \"chair\", stem: \"chair\",\n avg: [ 3.15, 5.08 ], std: [ 1.77, 0.98 ], fq: 66\n },\n \"champ\": {\n dict: \"anew\", word: \"champ\", stem: \"champ\",\n avg: [ 6, 7.18 ], std: [ 2.43, 1.97 ], fq: 1\n },\n \"champion\": {\n dict: \"anew\", word: \"champion\", stem: \"champion\",\n avg: [ 5.85, 8.44 ], std: [ 3.15, 0.9 ], fq: 23\n },\n \"chance\": {\n dict: \"anew\", word: \"chance\", stem: \"chanc\",\n avg: [ 5.38, 6.02 ], std: [ 2.58, 1.77 ], fq: 131\n },\n \"chaos\": {\n dict: \"anew\", word: \"chaos\", stem: \"chao\",\n avg: [ 6.67, 4.17 ], std: [ 2.06, 2.36 ], fq: 17\n },\n \"charm\": {\n dict: \"anew\", word: \"charm\", stem: \"charm\",\n avg: [ 5.16, 6.77 ], std: [ 2.25, 1.58 ], fq: 26\n },\n \"cheer\": {\n dict: \"anew\", word: \"cheer\", stem: \"cheer\",\n avg: [ 6.12, 8.1 ], std: [ 2.45, 1.17 ], fq: 8\n },\n \"child\": {\n dict: \"anew\", word: \"child\", stem: \"child\",\n avg: [ 5.55, 7.08 ], std: [ 2.29, 1.98 ], fq: 213\n },\n \"chin\": {\n dict: \"anew\", word: \"chin\", stem: \"chin\",\n avg: [ 3.31, 5.29 ], std: [ 1.98, 1.27 ], fq: 27\n },\n \"chocolate\": {\n dict: \"anew\", word: \"chocolate\", stem: \"chocol\",\n avg: [ 5.29, 6.88 ], std: [ 2.55, 1.89 ], fq: 9\n },\n \"christmas\": {\n dict: \"anew\", word: \"christmas\", stem: \"christma\",\n avg: [ 6.27, 7.8 ], std: [ 2.56, 1.55 ], fq: 27\n },\n \"church\": {\n dict: \"anew\", word: \"church\", stem: \"church\",\n avg: [ 4.34, 6.28 ], std: [ 2.45, 2.31 ], fq: 348\n },\n \"circle\": {\n dict: \"anew\", word: \"circle\", stem: \"circl\",\n avg: [ 3.86, 5.67 ], std: [ 2.13, 1.26 ], fq: 60\n },\n \"circus\": {\n dict: \"anew\", word: \"circus\", stem: \"circus\",\n avg: [ 5.97, 7.3 ], std: [ 2.59, 1.84 ], fq: 7\n },\n \"city\": {\n dict: \"anew\", word: \"city\", stem: \"citi\",\n avg: [ 5.24, 6.03 ], std: [ 2.53, 1.37 ], fq: 393\n },\n \"cliff\": {\n dict: \"anew\", word: \"cliff\", stem: \"cliff\",\n avg: [ 6.25, 4.67 ], std: [ 2.15, 2.08 ], fq: 11\n },\n \"clock\": {\n dict: \"anew\", word: \"clock\", stem: \"clock\",\n avg: [ 4.02, 5.14 ], std: [ 2.54, 1.54 ], fq: 20\n },\n \"clothing\": {\n dict: \"anew\", word: \"clothing\", stem: \"cloth\",\n avg: [ 4.78, 6.54 ], std: [ 2.88, 1.85 ], fq: 20\n },\n \"clouds\": {\n dict: \"anew\", word: \"clouds\", stem: \"cloud\",\n avg: [ 3.3, 6.18 ], std: [ 2.08, 2.18 ], fq: 38\n },\n \"clumsy\": {\n dict: \"anew\", word: \"clumsy\", stem: \"clumsi\",\n avg: [ 5.18, 4 ], std: [ 2.4, 2.22 ], fq: 6\n },\n \"coarse\": {\n dict: \"anew\", word: \"coarse\", stem: \"coars\",\n avg: [ 4.21, 4.55 ], std: [ 1.84, 1.42 ], fq: 10\n },\n \"coast\": {\n dict: \"anew\", word: \"coast\", stem: \"coast\",\n avg: [ 4.59, 5.98 ], std: [ 2.31, 1.86 ], fq: 61\n },\n \"cockroach\": {\n dict: \"anew\", word: \"cockroach\", stem: \"cockroach\",\n avg: [ 6.11, 2.81 ], std: [ 2.78, 2.11 ], fq: 2\n },\n \"coffin\": {\n dict: \"anew\", word: \"coffin\", stem: \"coffin\",\n avg: [ 5.03, 2.56 ], std: [ 2.79, 1.96 ], fq: 7\n },\n \"coin\": {\n dict: \"anew\", word: \"coin\", stem: \"coin\",\n avg: [ 4.29, 6.02 ], std: [ 2.48, 1.96 ], fq: 10\n },\n \"cold\": {\n dict: \"anew\", word: \"cold\", stem: \"cold\",\n avg: [ 5.19, 4.02 ], std: [ 2.23, 1.99 ], fq: 171\n },\n \"color\": {\n dict: \"anew\", word: \"color\", stem: \"color\",\n avg: [ 4.73, 7.02 ], std: [ 2.64, 1.57 ], fq: 141\n },\n \"column\": {\n dict: \"anew\", word: \"column\", stem: \"column\",\n avg: [ 3.62, 5.17 ], std: [ 1.91, 0.85 ], fq: 71\n },\n \"comedy\": {\n dict: \"anew\", word: \"comedy\", stem: \"comedi\",\n avg: [ 5.85, 8.37 ], std: [ 2.81, 0.94 ], fq: 39\n },\n \"comfort\": {\n dict: \"anew\", word: \"comfort\", stem: \"comfort\",\n avg: [ 3.93, 7.07 ], std: [ 2.85, 2.14 ], fq: 43\n },\n \"computer\": {\n dict: \"anew\", word: \"computer\", stem: \"comput\",\n avg: [ 4.75, 6.24 ], std: [ 1.93, 1.61 ], fq: 13\n },\n \"concentrate\": {\n dict: \"anew\", word: \"concentrate\", stem: \"concentr\",\n avg: [ 4.65, 5.2 ], std: [ 2.13, 1.28 ], fq: 11\n },\n \"confident\": {\n dict: \"anew\", word: \"confident\", stem: \"confid\",\n avg: [ 6.22, 7.98 ], std: [ 2.41, 1.29 ], fq: 16\n },\n \"confused\": {\n dict: \"anew\", word: \"confused\", stem: \"confus\",\n avg: [ 6.03, 3.21 ], std: [ 1.88, 1.51 ], fq: 44\n },\n \"consoled\": {\n dict: \"anew\", word: \"consoled\", stem: \"consol\",\n avg: [ 4.53, 5.78 ], std: [ 2.22, 1.64 ], fq: 2\n },\n \"contempt\": {\n dict: \"anew\", word: \"contempt\", stem: \"contempt\",\n avg: [ 5.28, 3.85 ], std: [ 2.04, 2.13 ], fq: 15\n },\n \"contents\": {\n dict: \"anew\", word: \"contents\", stem: \"content\",\n avg: [ 4.32, 4.89 ], std: [ 2.14, 0.89 ], fq: 16\n },\n \"context\": {\n dict: \"anew\", word: \"context\", stem: \"context\",\n avg: [ 4.22, 5.2 ], std: [ 2.24, 1.38 ], fq: 2\n },\n \"controlling\": {\n dict: \"anew\", word: \"controlling\", stem: \"control\",\n avg: [ 6.1, 3.8 ], std: [ 2.19, 2.25 ], fq: 23\n },\n \"cook\": {\n dict: \"anew\", word: \"cook\", stem: \"cook\",\n avg: [ 4.44, 6.16 ], std: [ 1.96, 1.89 ], fq: 47\n },\n \"cord\": {\n dict: \"anew\", word: \"cord\", stem: \"cord\",\n avg: [ 3.54, 5.1 ], std: [ 2.09, 1.09 ], fq: 6\n },\n \"cork\": {\n dict: \"anew\", word: \"cork\", stem: \"cork\",\n avg: [ 3.8, 5.22 ], std: [ 2.18, 1.13 ], fq: 9\n },\n \"corner\": {\n dict: \"anew\", word: \"corner\", stem: \"corner\",\n avg: [ 3.91, 4.36 ], std: [ 1.92, 1.21 ], fq: 115\n },\n \"corpse\": {\n dict: \"anew\", word: \"corpse\", stem: \"corps\",\n avg: [ 4.74, 2.18 ], std: [ 2.94, 1.48 ], fq: 7\n },\n \"corridor\": {\n dict: \"anew\", word: \"corridor\", stem: \"corridor\",\n avg: [ 3.63, 4.88 ], std: [ 2.41, 1.14 ], fq: 17\n },\n \"corrupt\": {\n dict: \"anew\", word: \"corrupt\", stem: \"corrupt\",\n avg: [ 4.67, 3.32 ], std: [ 2.35, 2.32 ], fq: 8\n },\n \"cottage\": {\n dict: \"anew\", word: \"cottage\", stem: \"cottag\",\n avg: [ 3.39, 6.45 ], std: [ 2.54, 1.52 ], fq: 19\n },\n \"couple\": {\n dict: \"anew\", word: \"couple\", stem: \"coupl\",\n avg: [ 6.39, 7.41 ], std: [ 2.31, 1.97 ], fq: 122\n },\n \"cow\": {\n dict: \"anew\", word: \"cow\", stem: \"cow\",\n avg: [ 3.49, 5.57 ], std: [ 2.13, 1.53 ], fq: 29\n },\n \"coward\": {\n dict: \"anew\", word: \"coward\", stem: \"coward\",\n avg: [ 4.07, 2.74 ], std: [ 2.19, 1.64 ], fq: 8\n },\n \"cozy\": {\n dict: \"anew\", word: \"cozy\", stem: \"cozi\",\n avg: [ 3.32, 7.39 ], std: [ 2.28, 1.53 ], fq: 1\n },\n \"crash\": {\n dict: \"anew\", word: \"crash\", stem: \"crash\",\n avg: [ 6.95, 2.31 ], std: [ 2.44, 1.44 ], fq: 20\n },\n \"crime\": {\n dict: \"anew\", word: \"crime\", stem: \"crime\",\n avg: [ 5.41, 2.89 ], std: [ 2.69, 2.06 ], fq: 34\n },\n \"criminal\": {\n dict: \"anew\", word: \"criminal\", stem: \"crimin\",\n avg: [ 4.79, 2.93 ], std: [ 2.51, 1.66 ], fq: 24\n },\n \"crisis\": {\n dict: \"anew\", word: \"crisis\", stem: \"crisi\",\n avg: [ 5.44, 2.74 ], std: [ 3.07, 2.23 ], fq: 82\n },\n \"crown\": {\n dict: \"anew\", word: \"crown\", stem: \"crown\",\n avg: [ 4.28, 6.58 ], std: [ 2.53, 1.42 ], fq: 19\n },\n \"crucify\": {\n dict: \"anew\", word: \"crucify\", stem: \"crucifi\",\n avg: [ 6.47, 2.23 ], std: [ 2.47, 1.72 ], fq: 2\n },\n \"crude\": {\n dict: \"anew\", word: \"crude\", stem: \"crude\",\n avg: [ 5.07, 3.12 ], std: [ 2.37, 1.65 ], fq: 15\n },\n \"cruel\": {\n dict: \"anew\", word: \"cruel\", stem: \"cruel\",\n avg: [ 5.68, 1.97 ], std: [ 2.65, 1.67 ], fq: 15\n },\n \"crushed\": {\n dict: \"anew\", word: \"crushed\", stem: \"crush\",\n avg: [ 5.52, 2.21 ], std: [ 2.87, 1.74 ], fq: 10\n },\n \"crutch\": {\n dict: \"anew\", word: \"crutch\", stem: \"crutch\",\n avg: [ 4.14, 3.43 ], std: [ 2.05, 1.62 ], fq: 1\n },\n \"cuddle\": {\n dict: \"anew\", word: \"cuddle\", stem: \"cuddl\",\n avg: [ 4.4, 7.72 ], std: [ 2.67, 1.92 ], fq: 0\n },\n \"cuisine\": {\n dict: \"anew\", word: \"cuisine\", stem: \"cuisin\",\n avg: [ 4.39, 6.64 ], std: [ 1.99, 1.48 ], fq: 1\n },\n \"curious\": {\n dict: \"anew\", word: \"curious\", stem: \"curious\",\n avg: [ 5.82, 6.08 ], std: [ 1.64, 1.63 ], fq: 46\n },\n \"curtains\": {\n dict: \"anew\", word: \"curtains\", stem: \"curtain\",\n avg: [ 3.67, 4.83 ], std: [ 1.83, 0.83 ], fq: 8\n },\n \"custom\": {\n dict: \"anew\", word: \"custom\", stem: \"custom\",\n avg: [ 4.66, 5.85 ], std: [ 2.12, 1.53 ], fq: 14\n },\n \"cut\": {\n dict: \"anew\", word: \"cut\", stem: \"cut\",\n avg: [ 5, 3.64 ], std: [ 2.32, 2.08 ], fq: 192\n },\n \"cute\": {\n dict: \"anew\", word: \"cute\", stem: \"cute\",\n avg: [ 5.53, 7.62 ], std: [ 2.71, 1.01 ], fq: 5\n },\n \"cyclone\": {\n dict: \"anew\", word: \"cyclone\", stem: \"cyclon\",\n avg: [ 6.36, 3.6 ], std: [ 2.89, 2.38 ], fq: 0\n },\n \"dagger\": {\n dict: \"anew\", word: \"dagger\", stem: \"dagger\",\n avg: [ 6.14, 3.38 ], std: [ 2.64, 1.77 ], fq: 1\n },\n \"damage\": {\n dict: \"anew\", word: \"damage\", stem: \"damag\",\n avg: [ 5.57, 3.05 ], std: [ 2.26, 1.65 ], fq: 33\n },\n \"dancer\": {\n dict: \"anew\", word: \"dancer\", stem: \"dancer\",\n avg: [ 6, 7.14 ], std: [ 2.2, 1.56 ], fq: 31\n },\n \"danger\": {\n dict: \"anew\", word: \"danger\", stem: \"danger\",\n avg: [ 7.32, 2.95 ], std: [ 2.07, 2.22 ], fq: 70\n },\n \"dark\": {\n dict: \"anew\", word: \"dark\", stem: \"dark\",\n avg: [ 4.28, 4.71 ], std: [ 2.21, 2.36 ], fq: 185\n },\n \"dawn\": {\n dict: \"anew\", word: \"dawn\", stem: \"dawn\",\n avg: [ 4.39, 6.16 ], std: [ 2.81, 2.33 ], fq: 28\n },\n \"daylight\": {\n dict: \"anew\", word: \"daylight\", stem: \"daylight\",\n avg: [ 4.77, 6.8 ], std: [ 2.5, 2.17 ], fq: 15\n },\n \"dazzle\": {\n dict: \"anew\", word: \"dazzle\", stem: \"dazzl\",\n avg: [ 6.33, 7.29 ], std: [ 2.02, 1.09 ], fq: 1\n },\n \"dead\": {\n dict: \"anew\", word: \"dead\", stem: \"dead\",\n avg: [ 5.73, 1.94 ], std: [ 2.73, 1.76 ], fq: 174\n },\n \"death\": {\n dict: \"anew\", word: \"death\", stem: \"death\",\n avg: [ 4.59, 1.61 ], std: [ 3.07, 1.4 ], fq: 277\n },\n \"debt\": {\n dict: \"anew\", word: \"debt\", stem: \"debt\",\n avg: [ 5.68, 2.22 ], std: [ 2.74, 1.17 ], fq: 13\n },\n \"deceit\": {\n dict: \"anew\", word: \"deceit\", stem: \"deceit\",\n avg: [ 5.68, 2.9 ], std: [ 2.46, 1.63 ], fq: 2\n },\n \"decompose\": {\n dict: \"anew\", word: \"decompose\", stem: \"decompos\",\n avg: [ 4.65, 3.2 ], std: [ 2.39, 1.81 ], fq: 1\n },\n \"decorate\": {\n dict: \"anew\", word: \"decorate\", stem: \"decor\",\n avg: [ 5.14, 6.93 ], std: [ 2.39, 1.3 ], fq: 2\n },\n \"defeated\": {\n dict: \"anew\", word: \"defeated\", stem: \"defeat\",\n avg: [ 5.09, 2.34 ], std: [ 3, 1.66 ], fq: 15\n },\n \"defiant\": {\n dict: \"anew\", word: \"defiant\", stem: \"defiant\",\n avg: [ 6.1, 4.26 ], std: [ 2.51, 2.12 ], fq: 3\n },\n \"deformed\": {\n dict: \"anew\", word: \"deformed\", stem: \"deform\",\n avg: [ 4.07, 2.41 ], std: [ 2.34, 1.66 ], fq: 0\n },\n \"delayed\": {\n dict: \"anew\", word: \"delayed\", stem: \"delay\",\n avg: [ 5.62, 3.07 ], std: [ 2.39, 1.74 ], fq: 25\n },\n \"delight\": {\n dict: \"anew\", word: \"delight\", stem: \"delight\",\n avg: [ 5.44, 8.26 ], std: [ 2.88, 1.04 ], fq: 29\n },\n \"demon\": {\n dict: \"anew\", word: \"demon\", stem: \"demon\",\n avg: [ 6.76, 2.11 ], std: [ 2.68, 1.56 ], fq: 9\n },\n \"dentist\": {\n dict: \"anew\", word: \"dentist\", stem: \"dentist\",\n avg: [ 5.73, 4.02 ], std: [ 2.13, 2.23 ], fq: 12\n },\n \"depressed\": {\n dict: \"anew\", word: \"depressed\", stem: \"depress\",\n avg: [ 4.72, 1.83 ], std: [ 2.95, 1.42 ], fq: 11\n },\n \"depression\": {\n dict: \"anew\", word: \"depression\", stem: \"depress\",\n avg: [ 4.54, 1.85 ], std: [ 3.19, 1.67 ], fq: 24\n },\n \"derelict\": {\n dict: \"anew\", word: \"derelict\", stem: \"derelict\",\n avg: [ 4.1, 4.28 ], std: [ 1.94, 1.84 ], fq: 1\n },\n \"deserter\": {\n dict: \"anew\", word: \"deserter\", stem: \"desert\",\n avg: [ 5.5, 2.45 ], std: [ 2.55, 1.8 ], fq: 0\n },\n \"desire\": {\n dict: \"anew\", word: \"desire\", stem: \"desir\",\n avg: [ 7.35, 7.69 ], std: [ 1.76, 1.39 ], fq: 79\n },\n \"despairing\": {\n dict: \"anew\", word: \"despairing\", stem: \"despair\",\n avg: [ 5.68, 2.43 ], std: [ 2.37, 1.47 ], fq: 4\n },\n \"despise\": {\n dict: \"anew\", word: \"despise\", stem: \"despis\",\n avg: [ 6.28, 2.03 ], std: [ 2.43, 1.38 ], fq: 7\n },\n \"destroy\": {\n dict: \"anew\", word: \"destroy\", stem: \"destroi\",\n avg: [ 6.83, 2.64 ], std: [ 2.38, 2.03 ], fq: 48\n },\n \"destruction\": {\n dict: \"anew\", word: \"destruction\", stem: \"destruct\",\n avg: [ 5.82, 3.16 ], std: [ 2.71, 2.44 ], fq: 38\n },\n \"detached\": {\n dict: \"anew\", word: \"detached\", stem: \"detach\",\n avg: [ 4.26, 3.86 ], std: [ 2.57, 1.88 ], fq: 12\n },\n \"detail\": {\n dict: \"anew\", word: \"detail\", stem: \"detail\",\n avg: [ 4.1, 5.55 ], std: [ 2.24, 1.58 ], fq: 72\n },\n \"detest\": {\n dict: \"anew\", word: \"detest\", stem: \"detest\",\n avg: [ 6.06, 2.17 ], std: [ 2.39, 1.3 ], fq: 1\n },\n \"devil\": {\n dict: \"anew\", word: \"devil\", stem: \"devil\",\n avg: [ 6.07, 2.21 ], std: [ 2.61, 1.99 ], fq: 25\n },\n \"devoted\": {\n dict: \"anew\", word: \"devoted\", stem: \"devot\",\n avg: [ 5.23, 7.41 ], std: [ 2.21, 1.37 ], fq: 51\n },\n \"diamond\": {\n dict: \"anew\", word: \"diamond\", stem: \"diamond\",\n avg: [ 5.53, 7.92 ], std: [ 2.96, 1.2 ], fq: 8\n },\n \"dignified\": {\n dict: \"anew\", word: \"dignified\", stem: \"dignifi\",\n avg: [ 4.12, 7.1 ], std: [ 2.29, 1.26 ], fq: 7\n },\n \"dinner\": {\n dict: \"anew\", word: \"dinner\", stem: \"dinner\",\n avg: [ 5.43, 7.16 ], std: [ 2.14, 1.5 ], fq: 91\n },\n \"diploma\": {\n dict: \"anew\", word: \"diploma\", stem: \"diploma\",\n avg: [ 5.67, 8 ], std: [ 2.8, 1.39 ], fq: 0\n },\n \"dirt\": {\n dict: \"anew\", word: \"dirt\", stem: \"dirt\",\n avg: [ 3.76, 4.17 ], std: [ 2.26, 1.77 ], fq: 43\n },\n \"dirty\": {\n dict: \"anew\", word: \"dirty\", stem: \"dirti\",\n avg: [ 4.88, 3.08 ], std: [ 2.29, 2.05 ], fq: 36\n },\n \"disappoint\": {\n dict: \"anew\", word: \"disappoint\", stem: \"disappoint\",\n avg: [ 4.92, 2.39 ], std: [ 2.64, 1.44 ], fq: 0\n },\n \"disaster\": {\n dict: \"anew\", word: \"disaster\", stem: \"disast\",\n avg: [ 6.33, 1.73 ], std: [ 2.7, 1.13 ], fq: 26\n },\n \"discomfort\": {\n dict: \"anew\", word: \"discomfort\", stem: \"discomfort\",\n avg: [ 4.17, 2.19 ], std: [ 2.44, 1.23 ], fq: 7\n },\n \"discouraged\": {\n dict: \"anew\", word: \"discouraged\", stem: \"discourag\",\n avg: [ 4.53, 3 ], std: [ 2.11, 2.16 ], fq: 15\n },\n \"disdainful\": {\n dict: \"anew\", word: \"disdainful\", stem: \"disdain\",\n avg: [ 5.04, 3.68 ], std: [ 2.14, 1.9 ], fq: 2\n },\n \"disgusted\": {\n dict: \"anew\", word: \"disgusted\", stem: \"disgust\",\n avg: [ 5.42, 2.45 ], std: [ 2.59, 1.41 ], fq: 6\n },\n \"disloyal\": {\n dict: \"anew\", word: \"disloyal\", stem: \"disloy\",\n avg: [ 6.56, 1.93 ], std: [ 2.21, 1.61 ], fq: 2\n },\n \"displeased\": {\n dict: \"anew\", word: \"displeased\", stem: \"displeas\",\n avg: [ 5.64, 2.79 ], std: [ 2.48, 2.23 ], fq: 7\n },\n \"distressed\": {\n dict: \"anew\", word: \"distressed\", stem: \"distress\",\n avg: [ 6.4, 1.94 ], std: [ 2.38, 1.1 ], fq: 4\n },\n \"disturb\": {\n dict: \"anew\", word: \"disturb\", stem: \"disturb\",\n avg: [ 5.8, 3.66 ], std: [ 2.39, 2 ], fq: 10\n },\n \"diver\": {\n dict: \"anew\", word: \"diver\", stem: \"diver\",\n avg: [ 5.04, 6.45 ], std: [ 2.1, 1.55 ], fq: 1\n },\n \"divorce\": {\n dict: \"anew\", word: \"divorce\", stem: \"divorc\",\n avg: [ 6.33, 2.22 ], std: [ 2.71, 1.88 ], fq: 29\n },\n \"doctor\": {\n dict: \"anew\", word: \"doctor\", stem: \"doctor\",\n avg: [ 5.86, 5.2 ], std: [ 2.7, 2.54 ], fq: 100\n },\n \"dog\": {\n dict: \"anew\", word: \"dog\", stem: \"dog\",\n avg: [ 5.76, 7.57 ], std: [ 2.5, 1.66 ], fq: 75\n },\n \"doll\": {\n dict: \"anew\", word: \"doll\", stem: \"doll\",\n avg: [ 4.24, 6.09 ], std: [ 2.43, 1.96 ], fq: 10\n },\n \"dollar\": {\n dict: \"anew\", word: \"dollar\", stem: \"dollar\",\n avg: [ 6.07, 7.47 ], std: [ 2.67, 1.72 ], fq: 46\n },\n \"door\": {\n dict: \"anew\", word: \"door\", stem: \"door\",\n avg: [ 3.8, 5.13 ], std: [ 2.29, 1.44 ], fq: 312\n },\n \"dove\": {\n dict: \"anew\", word: \"dove\", stem: \"dove\",\n avg: [ 3.79, 6.9 ], std: [ 2.28, 1.54 ], fq: 4\n },\n \"dreadful\": {\n dict: \"anew\", word: \"dreadful\", stem: \"dread\",\n avg: [ 5.84, 2.26 ], std: [ 2.62, 1.91 ], fq: 10\n },\n \"dream\": {\n dict: \"anew\", word: \"dream\", stem: \"dream\",\n avg: [ 4.53, 6.73 ], std: [ 2.72, 1.75 ], fq: 64\n },\n \"dreary\": {\n dict: \"anew\", word: \"dreary\", stem: \"dreari\",\n avg: [ 2.98, 3.05 ], std: [ 2.18, 1.58 ], fq: 6\n },\n \"dress\": {\n dict: \"anew\", word: \"dress\", stem: \"dress\",\n avg: [ 4.05, 6.41 ], std: [ 1.89, 1.34 ], fq: 67\n },\n \"drown\": {\n dict: \"anew\", word: \"drown\", stem: \"drown\",\n avg: [ 6.57, 1.92 ], std: [ 2.33, 1.48 ], fq: 3\n },\n \"dummy\": {\n dict: \"anew\", word: \"dummy\", stem: \"dummi\",\n avg: [ 4.35, 3.38 ], std: [ 2.25, 1.7 ], fq: 3\n },\n \"dump\": {\n dict: \"anew\", word: \"dump\", stem: \"dump\",\n avg: [ 4.12, 3.21 ], std: [ 2.36, 1.87 ], fq: 4\n },\n \"dustpan\": {\n dict: \"anew\", word: \"dustpan\", stem: \"dustpan\",\n avg: [ 3.43, 3.98 ], std: [ 2, 1.68 ], fq: 0\n },\n \"earth\": {\n dict: \"anew\", word: \"earth\", stem: \"earth\",\n avg: [ 4.24, 7.15 ], std: [ 2.49, 1.67 ], fq: 150\n },\n \"easy\": {\n dict: \"anew\", word: \"easy\", stem: \"easi\",\n avg: [ 4.48, 7.1 ], std: [ 2.82, 1.91 ], fq: 125\n },\n \"easygoing\": {\n dict: \"anew\", word: \"easygoing\", stem: \"easygo\",\n avg: [ 4.3, 7.2 ], std: [ 2.52, 1.5 ], fq: 1\n },\n \"eat\": {\n dict: \"anew\", word: \"eat\", stem: \"eat\",\n avg: [ 5.69, 7.47 ], std: [ 2.51, 1.73 ], fq: 61\n },\n \"ecstasy\": {\n dict: \"anew\", word: \"ecstasy\", stem: \"ecstasi\",\n avg: [ 7.38, 7.98 ], std: [ 1.92, 1.52 ], fq: 6\n },\n \"education\": {\n dict: \"anew\", word: \"education\", stem: \"educ\",\n avg: [ 5.74, 6.69 ], std: [ 2.46, 1.77 ], fq: 214\n },\n \"egg\": {\n dict: \"anew\", word: \"egg\", stem: \"egg\",\n avg: [ 3.76, 5.29 ], std: [ 2.39, 1.82 ], fq: 12\n },\n \"elated\": {\n dict: \"anew\", word: \"elated\", stem: \"elat\",\n avg: [ 6.21, 7.45 ], std: [ 2.3, 1.77 ], fq: 3\n },\n \"elbow\": {\n dict: \"anew\", word: \"elbow\", stem: \"elbow\",\n avg: [ 3.81, 5.12 ], std: [ 2.14, 0.92 ], fq: 10\n },\n \"elegant\": {\n dict: \"anew\", word: \"elegant\", stem: \"eleg\",\n avg: [ 4.53, 7.43 ], std: [ 2.65, 1.26 ], fq: 14\n },\n \"elevator\": {\n dict: \"anew\", word: \"elevator\", stem: \"elev\",\n avg: [ 4.16, 5.44 ], std: [ 1.99, 1.18 ], fq: 12\n },\n \"embarrassed\": {\n dict: \"anew\", word: \"embarrassed\", stem: \"embarrass\",\n avg: [ 5.87, 3.03 ], std: [ 2.55, 1.85 ], fq: 8\n },\n \"embattled\": {\n dict: \"anew\", word: \"embattled\", stem: \"embattl\",\n avg: [ 5.36, 4.39 ], std: [ 2.37, 1.63 ], fq: 1\n },\n \"employment\": {\n dict: \"anew\", word: \"employment\", stem: \"employ\",\n avg: [ 5.28, 6.47 ], std: [ 2.12, 1.81 ], fq: 47\n },\n \"engaged\": {\n dict: \"anew\", word: \"engaged\", stem: \"engag\",\n avg: [ 6.77, 8 ], std: [ 2.07, 1.38 ], fq: 47\n },\n \"engine\": {\n dict: \"anew\", word: \"engine\", stem: \"engin\",\n avg: [ 3.98, 5.2 ], std: [ 2.33, 1.18 ], fq: 50\n },\n \"enjoyment\": {\n dict: \"anew\", word: \"enjoyment\", stem: \"enjoy\",\n avg: [ 5.2, 7.8 ], std: [ 2.72, 1.2 ], fq: 21\n },\n \"ennui\": {\n dict: \"anew\", word: \"ennui\", stem: \"ennui\",\n avg: [ 4.4, 5.09 ], std: [ 2.33, 1.76 ], fq: 0\n },\n \"enraged\": {\n dict: \"anew\", word: \"enraged\", stem: \"enrag\",\n avg: [ 7.97, 2.46 ], std: [ 2.17, 1.65 ], fq: 1\n },\n \"erotic\": {\n dict: \"anew\", word: \"erotic\", stem: \"erot\",\n avg: [ 7.24, 7.43 ], std: [ 1.97, 1.53 ], fq: 8\n },\n \"errand\": {\n dict: \"anew\", word: \"errand\", stem: \"errand\",\n avg: [ 3.85, 4.58 ], std: [ 1.92, 1.74 ], fq: 7\n },\n \"event\": {\n dict: \"anew\", word: \"event\", stem: \"event\",\n avg: [ 5.1, 6.21 ], std: [ 2.4, 1.63 ], fq: 81\n },\n \"evil\": {\n dict: \"anew\", word: \"evil\", stem: \"evil\",\n avg: [ 6.39, 3.23 ], std: [ 2.44, 2.64 ], fq: 72\n },\n \"excellence\": {\n dict: \"anew\", word: \"excellence\", stem: \"excel\",\n avg: [ 5.54, 8.38 ], std: [ 2.67, 0.96 ], fq: 15\n },\n \"excitement\": {\n dict: \"anew\", word: \"excitement\", stem: \"excit\",\n avg: [ 7.67, 7.5 ], std: [ 1.91, 2.2 ], fq: 32\n },\n \"excuse\": {\n dict: \"anew\", word: \"excuse\", stem: \"excus\",\n avg: [ 4.48, 4.05 ], std: [ 2.29, 1.41 ], fq: 27\n },\n \"execution\": {\n dict: \"anew\", word: \"execution\", stem: \"execut\",\n avg: [ 5.71, 2.37 ], std: [ 2.74, 2.06 ], fq: 15\n },\n \"exercise\": {\n dict: \"anew\", word: \"exercise\", stem: \"exercis\",\n avg: [ 6.84, 7.13 ], std: [ 2.06, 1.58 ], fq: 58\n },\n \"fabric\": {\n dict: \"anew\", word: \"fabric\", stem: \"fabric\",\n avg: [ 4.14, 5.3 ], std: [ 1.98, 1.2 ], fq: 15\n },\n \"face\": {\n dict: \"anew\", word: \"face\", stem: \"face\",\n avg: [ 5.04, 6.39 ], std: [ 2.18, 1.6 ], fq: 371\n },\n \"failure\": {\n dict: \"anew\", word: \"failure\", stem: \"failur\",\n avg: [ 4.95, 1.7 ], std: [ 2.81, 1.07 ], fq: 89\n },\n \"fall\": {\n dict: \"anew\", word: \"fall\", stem: \"fall\",\n avg: [ 4.7, 4.09 ], std: [ 2.48, 2.21 ], fq: 147\n },\n \"FALSE\": {\n dict: \"anew\", word: \"FALSE\", stem: \"fals\",\n avg: [ 3.43, 3.27 ], std: [ 2.09, 1.4 ], fq: 29\n },\n \"fame\": {\n dict: \"anew\", word: \"fame\", stem: \"fame\",\n avg: [ 6.55, 7.93 ], std: [ 2.46, 1.29 ], fq: 18\n },\n \"family\": {\n dict: \"anew\", word: \"family\", stem: \"famili\",\n avg: [ 4.8, 7.65 ], std: [ 2.71, 1.55 ], fq: 331\n },\n \"famous\": {\n dict: \"anew\", word: \"famous\", stem: \"famous\",\n avg: [ 5.73, 6.98 ], std: [ 2.68, 2.07 ], fq: 89\n },\n \"fantasy\": {\n dict: \"anew\", word: \"fantasy\", stem: \"fantasi\",\n avg: [ 5.14, 7.41 ], std: [ 2.82, 1.9 ], fq: 14\n },\n \"farm\": {\n dict: \"anew\", word: \"farm\", stem: \"farm\",\n avg: [ 3.9, 5.53 ], std: [ 1.95, 1.85 ], fq: 125\n },\n \"fascinate\": {\n dict: \"anew\", word: \"fascinate\", stem: \"fascin\",\n avg: [ 5.83, 7.34 ], std: [ 2.73, 1.68 ], fq: 3\n },\n \"fat\": {\n dict: \"anew\", word: \"fat\", stem: \"fat\",\n avg: [ 4.81, 2.28 ], std: [ 2.8, 1.92 ], fq: 60\n },\n \"father\": {\n dict: \"anew\", word: \"father\", stem: \"father\",\n avg: [ 5.92, 7.08 ], std: [ 2.6, 2.2 ], fq: 383\n },\n \"fatigued\": {\n dict: \"anew\", word: \"fatigued\", stem: \"fatigu\",\n avg: [ 2.64, 3.28 ], std: [ 2.19, 1.43 ], fq: 3\n },\n \"fault\": {\n dict: \"anew\", word: \"fault\", stem: \"fault\",\n avg: [ 4.07, 3.43 ], std: [ 1.69, 1.38 ], fq: 22\n },\n \"favor\": {\n dict: \"anew\", word: \"favor\", stem: \"favor\",\n avg: [ 4.54, 6.46 ], std: [ 1.86, 1.52 ], fq: 78\n },\n \"fear\": {\n dict: \"anew\", word: \"fear\", stem: \"fear\",\n avg: [ 6.96, 2.76 ], std: [ 2.17, 2.12 ], fq: 127\n },\n \"fearful\": {\n dict: \"anew\", word: \"fearful\", stem: \"fear\",\n avg: [ 6.33, 2.25 ], std: [ 2.28, 1.18 ], fq: 13\n },\n \"feeble\": {\n dict: \"anew\", word: \"feeble\", stem: \"feebl\",\n avg: [ 4.1, 3.26 ], std: [ 2.07, 1.47 ], fq: 8\n },\n \"festive\": {\n dict: \"anew\", word: \"festive\", stem: \"festiv\",\n avg: [ 6.58, 7.3 ], std: [ 2.29, 2.26 ], fq: 2\n },\n \"fever\": {\n dict: \"anew\", word: \"fever\", stem: \"fever\",\n avg: [ 4.29, 2.76 ], std: [ 2.31, 1.64 ], fq: 19\n },\n \"field\": {\n dict: \"anew\", word: \"field\", stem: \"field\",\n avg: [ 4.08, 6.2 ], std: [ 2.41, 1.37 ], fq: 274\n },\n \"fight\": {\n dict: \"anew\", word: \"fight\", stem: \"fight\",\n avg: [ 7.15, 3.76 ], std: [ 2.19, 2.63 ], fq: 98\n },\n \"filth\": {\n dict: \"anew\", word: \"filth\", stem: \"filth\",\n avg: [ 5.12, 2.47 ], std: [ 2.32, 1.68 ], fq: 2\n },\n \"finger\": {\n dict: \"anew\", word: \"finger\", stem: \"finger\",\n avg: [ 3.78, 5.29 ], std: [ 2.42, 1.42 ], fq: 40\n },\n \"fire\": {\n dict: \"anew\", word: \"fire\", stem: \"fire\",\n avg: [ 7.17, 3.22 ], std: [ 2.06, 2.06 ], fq: 187\n },\n \"fireworks\": {\n dict: \"anew\", word: \"fireworks\", stem: \"firework\",\n avg: [ 6.67, 7.55 ], std: [ 2.12, 1.5 ], fq: 5\n },\n \"fish\": {\n dict: \"anew\", word: \"fish\", stem: \"fish\",\n avg: [ 4, 6.04 ], std: [ 2.19, 1.94 ], fq: 35\n },\n \"flabby\": {\n dict: \"anew\", word: \"flabby\", stem: \"flabbi\",\n avg: [ 4.82, 2.66 ], std: [ 2.81, 1.87 ], fq: 0\n },\n \"flag\": {\n dict: \"anew\", word: \"flag\", stem: \"flag\",\n avg: [ 4.6, 6.02 ], std: [ 2.35, 1.66 ], fq: 16\n },\n \"flirt\": {\n dict: \"anew\", word: \"flirt\", stem: \"flirt\",\n avg: [ 6.91, 7.52 ], std: [ 1.69, 1.19 ], fq: 1\n },\n \"flood\": {\n dict: \"anew\", word: \"flood\", stem: \"flood\",\n avg: [ 6, 3.19 ], std: [ 2.02, 1.66 ], fq: 19\n },\n \"flower\": {\n dict: \"anew\", word: \"flower\", stem: \"flower\",\n avg: [ 4, 6.64 ], std: [ 2.44, 1.78 ], fq: 23\n },\n \"foam\": {\n dict: \"anew\", word: \"foam\", stem: \"foam\",\n avg: [ 5.26, 6.07 ], std: [ 2.54, 2.03 ], fq: 37\n },\n \"food\": {\n dict: \"anew\", word: \"food\", stem: \"food\",\n avg: [ 5.92, 7.65 ], std: [ 2.11, 1.37 ], fq: 147\n },\n \"foot\": {\n dict: \"anew\", word: \"foot\", stem: \"foot\",\n avg: [ 3.27, 5.02 ], std: [ 1.98, 0.93 ], fq: 70\n },\n \"fork\": {\n dict: \"anew\", word: \"fork\", stem: \"fork\",\n avg: [ 3.96, 5.29 ], std: [ 1.94, 0.97 ], fq: 14\n },\n \"foul\": {\n dict: \"anew\", word: \"foul\", stem: \"foul\",\n avg: [ 4.93, 2.81 ], std: [ 2.23, 1.52 ], fq: 4\n },\n \"fragrance\": {\n dict: \"anew\", word: \"fragrance\", stem: \"fragranc\",\n avg: [ 4.79, 6.07 ], std: [ 2.54, 1.97 ], fq: 6\n },\n \"fraud\": {\n dict: \"anew\", word: \"fraud\", stem: \"fraud\",\n avg: [ 5.75, 2.67 ], std: [ 2.45, 1.66 ], fq: 8\n },\n \"free\": {\n dict: \"anew\", word: \"free\", stem: \"free\",\n avg: [ 5.15, 8.26 ], std: [ 3.04, 1.31 ], fq: 260\n },\n \"freedom\": {\n dict: \"anew\", word: \"freedom\", stem: \"freedom\",\n avg: [ 5.52, 7.58 ], std: [ 2.72, 2.04 ], fq: 128\n },\n \"friend\": {\n dict: \"anew\", word: \"friend\", stem: \"friend\",\n avg: [ 5.74, 7.74 ], std: [ 2.57, 1.24 ], fq: 133\n },\n \"friendly\": {\n dict: \"anew\", word: \"friendly\", stem: \"friend\",\n avg: [ 5.11, 8.43 ], std: [ 2.96, 1.08 ], fq: 61\n },\n \"frigid\": {\n dict: \"anew\", word: \"frigid\", stem: \"frigid\",\n avg: [ 4.75, 3.5 ], std: [ 2.56, 1.85 ], fq: 5\n },\n \"frog\": {\n dict: \"anew\", word: \"frog\", stem: \"frog\",\n avg: [ 4.54, 5.71 ], std: [ 2.03, 1.74 ], fq: 1\n },\n \"frustrated\": {\n dict: \"anew\", word: \"frustrated\", stem: \"frustrat\",\n avg: [ 5.61, 2.48 ], std: [ 2.76, 1.64 ], fq: 10\n },\n \"fun\": {\n dict: \"anew\", word: \"fun\", stem: \"fun\",\n avg: [ 7.22, 8.37 ], std: [ 2.01, 1.11 ], fq: 44\n },\n \"funeral\": {\n dict: \"anew\", word: \"funeral\", stem: \"funer\",\n avg: [ 4.94, 1.39 ], std: [ 3.21, 0.87 ], fq: 33\n },\n \"fungus\": {\n dict: \"anew\", word: \"fungus\", stem: \"fungus\",\n avg: [ 4.68, 3.06 ], std: [ 2.33, 1.75 ], fq: 2\n },\n \"fur\": {\n dict: \"anew\", word: \"fur\", stem: \"fur\",\n avg: [ 4.18, 4.51 ], std: [ 2.44, 1.88 ], fq: 13\n },\n \"game\": {\n dict: \"anew\", word: \"game\", stem: \"game\",\n avg: [ 5.89, 6.98 ], std: [ 2.37, 1.97 ], fq: 123\n },\n \"gangrene\": {\n dict: \"anew\", word: \"gangrene\", stem: \"gangren\",\n avg: [ 5.7, 2.28 ], std: [ 2.96, 1.91 ], fq: 0\n },\n \"garbage\": {\n dict: \"anew\", word: \"garbage\", stem: \"garbag\",\n avg: [ 5.04, 2.98 ], std: [ 2.5, 1.96 ], fq: 7\n },\n \"garden\": {\n dict: \"anew\", word: \"garden\", stem: \"garden\",\n avg: [ 4.39, 6.71 ], std: [ 2.35, 1.74 ], fq: 60\n },\n \"garment\": {\n dict: \"anew\", word: \"garment\", stem: \"garment\",\n avg: [ 4.49, 6.07 ], std: [ 2.5, 1.61 ], fq: 6\n },\n \"garter\": {\n dict: \"anew\", word: \"garter\", stem: \"garter\",\n avg: [ 5.47, 6.22 ], std: [ 2.15, 1.59 ], fq: 2\n },\n \"gender\": {\n dict: \"anew\", word: \"gender\", stem: \"gender\",\n avg: [ 4.38, 5.73 ], std: [ 2.13, 1.55 ], fq: 2\n },\n \"gentle\": {\n dict: \"anew\", word: \"gentle\", stem: \"gentl\",\n avg: [ 3.21, 7.31 ], std: [ 2.57, 1.3 ], fq: 27\n },\n \"germs\": {\n dict: \"anew\", word: \"germs\", stem: \"germ\",\n avg: [ 4.49, 2.86 ], std: [ 2.24, 1.39 ], fq: 1\n },\n \"gift\": {\n dict: \"anew\", word: \"gift\", stem: \"gift\",\n avg: [ 6.14, 7.77 ], std: [ 2.76, 2.24 ], fq: 33\n },\n \"girl\": {\n dict: \"anew\", word: \"girl\", stem: \"girl\",\n avg: [ 4.29, 6.87 ], std: [ 2.69, 1.64 ], fq: 220\n },\n \"glacier\": {\n dict: \"anew\", word: \"glacier\", stem: \"glacier\",\n avg: [ 4.24, 5.5 ], std: [ 2.29, 1.25 ], fq: 1\n },\n \"glamour\": {\n dict: \"anew\", word: \"glamour\", stem: \"glamour\",\n avg: [ 4.68, 6.76 ], std: [ 2.23, 1.6 ], fq: 5\n },\n \"glass\": {\n dict: \"anew\", word: \"glass\", stem: \"glass\",\n avg: [ 4.27, 4.75 ], std: [ 2.07, 1.38 ], fq: 99\n },\n \"gloom\": {\n dict: \"anew\", word: \"gloom\", stem: \"gloom\",\n avg: [ 3.83, 1.88 ], std: [ 2.33, 1.23 ], fq: 14\n },\n \"glory\": {\n dict: \"anew\", word: \"glory\", stem: \"glori\",\n avg: [ 6.02, 7.55 ], std: [ 2.71, 1.68 ], fq: 21\n },\n \"god\": {\n dict: \"anew\", word: \"god\", stem: \"god\",\n avg: [ 5.95, 8.15 ], std: [ 2.84, 1.27 ], fq: 318\n },\n \"gold\": {\n dict: \"anew\", word: \"gold\", stem: \"gold\",\n avg: [ 5.76, 7.54 ], std: [ 2.79, 1.63 ], fq: 52\n },\n \"golfer\": {\n dict: \"anew\", word: \"golfer\", stem: \"golfer\",\n avg: [ 3.73, 5.61 ], std: [ 2.26, 1.93 ], fq: 3\n },\n \"good\": {\n dict: \"anew\", word: \"good\", stem: \"good\",\n avg: [ 5.43, 7.47 ], std: [ 2.85, 1.45 ], fq: 807\n },\n \"gossip\": {\n dict: \"anew\", word: \"gossip\", stem: \"gossip\",\n avg: [ 5.74, 3.48 ], std: [ 2.38, 2.33 ], fq: 13\n },\n \"graduate\": {\n dict: \"anew\", word: \"graduate\", stem: \"graduat\",\n avg: [ 7.25, 8.19 ], std: [ 2.25, 1.13 ], fq: 30\n },\n \"grass\": {\n dict: \"anew\", word: \"grass\", stem: \"grass\",\n avg: [ 4.14, 6.12 ], std: [ 2.11, 1.44 ], fq: 53\n },\n \"grateful\": {\n dict: \"anew\", word: \"grateful\", stem: \"grate\",\n avg: [ 4.58, 7.37 ], std: [ 2.14, 0.97 ], fq: 25\n },\n \"greed\": {\n dict: \"anew\", word: \"greed\", stem: \"greed\",\n avg: [ 4.71, 3.51 ], std: [ 2.26, 1.93 ], fq: 3\n },\n \"green\": {\n dict: \"anew\", word: \"green\", stem: \"green\",\n avg: [ 4.28, 6.18 ], std: [ 2.46, 2.05 ], fq: 116\n },\n \"greet\": {\n dict: \"anew\", word: \"greet\", stem: \"greet\",\n avg: [ 5.27, 7 ], std: [ 2.31, 1.52 ], fq: 7\n },\n \"grenade\": {\n dict: \"anew\", word: \"grenade\", stem: \"grenad\",\n avg: [ 5.7, 3.6 ], std: [ 2.52, 1.88 ], fq: 3\n },\n \"grief\": {\n dict: \"anew\", word: \"grief\", stem: \"grief\",\n avg: [ 4.78, 1.69 ], std: [ 2.84, 1.04 ], fq: 10\n },\n \"grime\": {\n dict: \"anew\", word: \"grime\", stem: \"grime\",\n avg: [ 3.98, 3.37 ], std: [ 2.29, 1.34 ], fq: 0\n },\n \"gripe\": {\n dict: \"anew\", word: \"gripe\", stem: \"gripe\",\n avg: [ 5, 3.14 ], std: [ 2.19, 1.56 ], fq: 0\n },\n \"guillotine\": {\n dict: \"anew\", word: \"guillotine\", stem: \"guillotin\",\n avg: [ 6.56, 2.48 ], std: [ 2.54, 2.11 ], fq: 0\n },\n \"guilty\": {\n dict: \"anew\", word: \"guilty\", stem: \"guilti\",\n avg: [ 6.04, 2.63 ], std: [ 2.76, 1.98 ], fq: 29\n },\n \"gun\": {\n dict: \"anew\", word: \"gun\", stem: \"gun\",\n avg: [ 7.02, 3.47 ], std: [ 1.84, 2.48 ], fq: 118\n },\n \"gymnast\": {\n dict: \"anew\", word: \"gymnast\", stem: \"gymnast\",\n avg: [ 5.02, 6.35 ], std: [ 2.2, 1.79 ], fq: 1\n },\n \"habit\": {\n dict: \"anew\", word: \"habit\", stem: \"habit\",\n avg: [ 3.95, 4.11 ], std: [ 2.11, 1.77 ], fq: 23\n },\n \"hairdryer\": {\n dict: \"anew\", word: \"hairdryer\", stem: \"hairdryer\",\n avg: [ 3.71, 4.84 ], std: [ 1.75, 0.84 ], fq: 0\n },\n \"hairpin\": {\n dict: \"anew\", word: \"hairpin\", stem: \"hairpin\",\n avg: [ 3.27, 5.26 ], std: [ 2.41, 1.45 ], fq: 1\n },\n \"hamburger\": {\n dict: \"anew\", word: \"hamburger\", stem: \"hamburg\",\n avg: [ 4.55, 6.27 ], std: [ 2.14, 1.5 ], fq: 6\n },\n \"hammer\": {\n dict: \"anew\", word: \"hammer\", stem: \"hammer\",\n avg: [ 4.58, 4.88 ], std: [ 2.02, 1.16 ], fq: 9\n },\n \"hand\": {\n dict: \"anew\", word: \"hand\", stem: \"hand\",\n avg: [ 4.4, 5.95 ], std: [ 2.07, 1.38 ], fq: 431\n },\n \"handicap\": {\n dict: \"anew\", word: \"handicap\", stem: \"handicap\",\n avg: [ 3.81, 3.29 ], std: [ 2.27, 1.69 ], fq: 6\n },\n \"handsome\": {\n dict: \"anew\", word: \"handsome\", stem: \"handsom\",\n avg: [ 5.95, 7.93 ], std: [ 2.73, 1.47 ], fq: 40\n },\n \"haphazard\": {\n dict: \"anew\", word: \"haphazard\", stem: \"haphazard\",\n avg: [ 4.07, 4.02 ], std: [ 2.18, 1.41 ], fq: 2\n },\n \"happy\": {\n dict: \"anew\", word: \"happy\", stem: \"happi\",\n avg: [ 6.49, 8.21 ], std: [ 2.77, 1.82 ], fq: 98\n },\n \"hard\": {\n dict: \"anew\", word: \"hard\", stem: \"hard\",\n avg: [ 5.12, 5.22 ], std: [ 2.19, 1.82 ], fq: 202\n },\n \"hardship\": {\n dict: \"anew\", word: \"hardship\", stem: \"hardship\",\n avg: [ 4.76, 2.45 ], std: [ 2.55, 1.61 ], fq: 9\n },\n \"hat\": {\n dict: \"anew\", word: \"hat\", stem: \"hat\",\n avg: [ 4.1, 5.46 ], std: [ 2, 1.36 ], fq: 56\n },\n \"hate\": {\n dict: \"anew\", word: \"hate\", stem: \"hate\",\n avg: [ 6.95, 2.12 ], std: [ 2.56, 1.72 ], fq: 42\n },\n \"hatred\": {\n dict: \"anew\", word: \"hatred\", stem: \"hatr\",\n avg: [ 6.66, 1.98 ], std: [ 2.56, 1.92 ], fq: 20\n },\n \"hawk\": {\n dict: \"anew\", word: \"hawk\", stem: \"hawk\",\n avg: [ 4.39, 5.88 ], std: [ 2.29, 1.62 ], fq: 14\n },\n \"hay\": {\n dict: \"anew\", word: \"hay\", stem: \"hay\",\n avg: [ 3.95, 5.24 ], std: [ 2.58, 1.24 ], fq: 19\n },\n \"headache\": {\n dict: \"anew\", word: \"headache\", stem: \"headach\",\n avg: [ 5.07, 2.02 ], std: [ 2.74, 1.06 ], fq: 5\n },\n \"headlight\": {\n dict: \"anew\", word: \"headlight\", stem: \"headlight\",\n avg: [ 3.81, 5.24 ], std: [ 2.22, 1.51 ], fq: 0\n },\n \"heal\": {\n dict: \"anew\", word: \"heal\", stem: \"heal\",\n avg: [ 4.77, 7.09 ], std: [ 2.23, 1.46 ], fq: 2\n },\n \"health\": {\n dict: \"anew\", word: \"health\", stem: \"health\",\n avg: [ 5.13, 6.81 ], std: [ 2.35, 1.88 ], fq: 105\n },\n \"heart\": {\n dict: \"anew\", word: \"heart\", stem: \"heart\",\n avg: [ 6.34, 7.39 ], std: [ 2.25, 1.53 ], fq: 173\n },\n \"heaven\": {\n dict: \"anew\", word: \"heaven\", stem: \"heaven\",\n avg: [ 5.61, 7.3 ], std: [ 3.2, 2.39 ], fq: 43\n },\n \"hell\": {\n dict: \"anew\", word: \"hell\", stem: \"hell\",\n avg: [ 5.38, 2.24 ], std: [ 2.62, 1.62 ], fq: 95\n },\n \"helpless\": {\n dict: \"anew\", word: \"helpless\", stem: \"helpless\",\n avg: [ 5.34, 2.2 ], std: [ 2.52, 1.42 ], fq: 21\n },\n \"heroin\": {\n dict: \"anew\", word: \"heroin\", stem: \"heroin\",\n avg: [ 5.11, 4.36 ], std: [ 2.72, 2.73 ], fq: 2\n },\n \"hide\": {\n dict: \"anew\", word: \"hide\", stem: \"hide\",\n avg: [ 5.28, 4.32 ], std: [ 2.51, 1.91 ], fq: 22\n },\n \"highway\": {\n dict: \"anew\", word: \"highway\", stem: \"highway\",\n avg: [ 5.16, 5.92 ], std: [ 2.44, 1.72 ], fq: 40\n },\n \"hinder\": {\n dict: \"anew\", word: \"hinder\", stem: \"hinder\",\n avg: [ 4.12, 3.81 ], std: [ 2.01, 1.42 ], fq: 0\n },\n \"history\": {\n dict: \"anew\", word: \"history\", stem: \"histori\",\n avg: [ 3.93, 5.24 ], std: [ 2.29, 2.01 ], fq: 286\n },\n \"hit\": {\n dict: \"anew\", word: \"hit\", stem: \"hit\",\n avg: [ 5.73, 4.33 ], std: [ 2.09, 2.35 ], fq: 115\n },\n \"holiday\": {\n dict: \"anew\", word: \"holiday\", stem: \"holiday\",\n avg: [ 6.59, 7.55 ], std: [ 2.73, 2.14 ], fq: 17\n },\n \"home\": {\n dict: \"anew\", word: \"home\", stem: \"home\",\n avg: [ 4.21, 7.91 ], std: [ 2.94, 1.63 ], fq: 547\n },\n \"honest\": {\n dict: \"anew\", word: \"honest\", stem: \"honest\",\n avg: [ 5.32, 7.7 ], std: [ 1.92, 1.43 ], fq: 47\n },\n \"honey\": {\n dict: \"anew\", word: \"honey\", stem: \"honey\",\n avg: [ 4.51, 6.73 ], std: [ 2.25, 1.7 ], fq: 25\n },\n \"honor\": {\n dict: \"anew\", word: \"honor\", stem: \"honor\",\n avg: [ 5.9, 7.66 ], std: [ 1.83, 1.24 ], fq: 66\n },\n \"hooker\": {\n dict: \"anew\", word: \"hooker\", stem: \"hooker\",\n avg: [ 4.93, 3.34 ], std: [ 2.82, 2.31 ], fq: 0\n },\n \"hope\": {\n dict: \"anew\", word: \"hope\", stem: \"hope\",\n avg: [ 5.44, 7.05 ], std: [ 2.47, 1.96 ], fq: 178\n },\n \"hopeful\": {\n dict: \"anew\", word: \"hopeful\", stem: \"hope\",\n avg: [ 5.78, 7.1 ], std: [ 2.09, 1.46 ], fq: 12\n },\n \"horror\": {\n dict: \"anew\", word: \"horror\", stem: \"horror\",\n avg: [ 7.21, 2.76 ], std: [ 2.14, 2.25 ], fq: 17\n },\n \"horse\": {\n dict: \"anew\", word: \"horse\", stem: \"hors\",\n avg: [ 3.89, 5.89 ], std: [ 2.17, 1.55 ], fq: 117\n },\n \"hospital\": {\n dict: \"anew\", word: \"hospital\", stem: \"hospit\",\n avg: [ 5.98, 5.04 ], std: [ 2.54, 2.45 ], fq: 110\n },\n \"hostage\": {\n dict: \"anew\", word: \"hostage\", stem: \"hostag\",\n avg: [ 6.76, 2.2 ], std: [ 2.63, 1.8 ], fq: 2\n },\n \"hostile\": {\n dict: \"anew\", word: \"hostile\", stem: \"hostil\",\n avg: [ 6.44, 2.73 ], std: [ 2.28, 1.5 ], fq: 19\n },\n \"hotel\": {\n dict: \"anew\", word: \"hotel\", stem: \"hotel\",\n avg: [ 4.8, 6 ], std: [ 2.53, 1.77 ], fq: 126\n },\n \"house\": {\n dict: \"anew\", word: \"house\", stem: \"hous\",\n avg: [ 4.56, 7.26 ], std: [ 2.41, 1.72 ], fq: 591\n },\n \"hug\": {\n dict: \"anew\", word: \"hug\", stem: \"hug\",\n avg: [ 5.35, 8 ], std: [ 2.76, 1.55 ], fq: 3\n },\n \"humane\": {\n dict: \"anew\", word: \"humane\", stem: \"human\",\n avg: [ 4.5, 6.89 ], std: [ 1.91, 1.7 ], fq: 5\n },\n \"humble\": {\n dict: \"anew\", word: \"humble\", stem: \"humbl\",\n avg: [ 3.74, 5.86 ], std: [ 2.33, 1.42 ], fq: 18\n },\n \"humiliate\": {\n dict: \"anew\", word: \"humiliate\", stem: \"humili\",\n avg: [ 6.14, 2.24 ], std: [ 2.42, 1.34 ], fq: 0\n },\n \"humor\": {\n dict: \"anew\", word: \"humor\", stem: \"humor\",\n avg: [ 5.5, 8.56 ], std: [ 2.91, 0.81 ], fq: 47\n },\n \"hungry\": {\n dict: \"anew\", word: \"hungry\", stem: \"hungri\",\n avg: [ 5.13, 3.58 ], std: [ 2.44, 2.01 ], fq: 23\n },\n \"hurricane\": {\n dict: \"anew\", word: \"hurricane\", stem: \"hurrican\",\n avg: [ 6.83, 3.34 ], std: [ 2.06, 2.12 ], fq: 8\n },\n \"hurt\": {\n dict: \"anew\", word: \"hurt\", stem: \"hurt\",\n avg: [ 5.85, 1.9 ], std: [ 2.49, 1.26 ], fq: 37\n },\n \"hydrant\": {\n dict: \"anew\", word: \"hydrant\", stem: \"hydrant\",\n avg: [ 3.71, 5.02 ], std: [ 1.75, 0.93 ], fq: 0\n },\n \"icebox\": {\n dict: \"anew\", word: \"icebox\", stem: \"icebox\",\n avg: [ 4.17, 4.95 ], std: [ 2.11, 1 ], fq: 3\n },\n \"idea\": {\n dict: \"anew\", word: \"idea\", stem: \"idea\",\n avg: [ 5.86, 7 ], std: [ 1.81, 1.34 ], fq: 195\n },\n \"identity\": {\n dict: \"anew\", word: \"identity\", stem: \"ident\",\n avg: [ 4.95, 6.57 ], std: [ 2.24, 1.99 ], fq: 55\n },\n \"idiot\": {\n dict: \"anew\", word: \"idiot\", stem: \"idiot\",\n avg: [ 4.21, 3.16 ], std: [ 2.47, 1.91 ], fq: 2\n },\n \"idol\": {\n dict: \"anew\", word: \"idol\", stem: \"idol\",\n avg: [ 4.95, 6.12 ], std: [ 2.14, 1.86 ], fq: 7\n },\n \"ignorance\": {\n dict: \"anew\", word: \"ignorance\", stem: \"ignor\",\n avg: [ 4.39, 3.07 ], std: [ 2.49, 2.25 ], fq: 16\n },\n \"illness\": {\n dict: \"anew\", word: \"illness\", stem: \"ill\",\n avg: [ 4.71, 2.48 ], std: [ 2.24, 1.4 ], fq: 20\n },\n \"imagine\": {\n dict: \"anew\", word: \"imagine\", stem: \"imagin\",\n avg: [ 5.98, 7.32 ], std: [ 2.14, 1.52 ], fq: 61\n },\n \"immature\": {\n dict: \"anew\", word: \"immature\", stem: \"immatur\",\n avg: [ 4.15, 3.39 ], std: [ 1.96, 1.7 ], fq: 7\n },\n \"immoral\": {\n dict: \"anew\", word: \"immoral\", stem: \"immor\",\n avg: [ 4.98, 3.5 ], std: [ 2.48, 2.16 ], fq: 5\n },\n \"impair\": {\n dict: \"anew\", word: \"impair\", stem: \"impair\",\n avg: [ 4.04, 3.18 ], std: [ 2.14, 1.86 ], fq: 4\n },\n \"impotent\": {\n dict: \"anew\", word: \"impotent\", stem: \"impot\",\n avg: [ 4.57, 2.81 ], std: [ 2.59, 1.92 ], fq: 2\n },\n \"impressed\": {\n dict: \"anew\", word: \"impressed\", stem: \"impress\",\n avg: [ 5.42, 7.33 ], std: [ 2.65, 1.84 ], fq: 30\n },\n \"improve\": {\n dict: \"anew\", word: \"improve\", stem: \"improv\",\n avg: [ 5.69, 7.65 ], std: [ 2.15, 1.16 ], fq: 39\n },\n \"incentive\": {\n dict: \"anew\", word: \"incentive\", stem: \"incent\",\n avg: [ 5.69, 7 ], std: [ 2.45, 1.72 ], fq: 12\n },\n \"indifferent\": {\n dict: \"anew\", word: \"indifferent\", stem: \"indiffer\",\n avg: [ 3.18, 4.61 ], std: [ 1.85, 1.28 ], fq: 11\n },\n \"industry\": {\n dict: \"anew\", word: \"industry\", stem: \"industri\",\n avg: [ 4.47, 5.3 ], std: [ 2.43, 1.61 ], fq: 171\n },\n \"infant\": {\n dict: \"anew\", word: \"infant\", stem: \"infant\",\n avg: [ 5.05, 6.95 ], std: [ 2.66, 2.08 ], fq: 11\n },\n \"infatuation\": {\n dict: \"anew\", word: \"infatuation\", stem: \"infatu\",\n avg: [ 7.02, 6.73 ], std: [ 1.87, 2.08 ], fq: 4\n },\n \"infection\": {\n dict: \"anew\", word: \"infection\", stem: \"infect\",\n avg: [ 5.03, 1.66 ], std: [ 2.77, 1.34 ], fq: 8\n },\n \"inferior\": {\n dict: \"anew\", word: \"inferior\", stem: \"inferior\",\n avg: [ 3.83, 3.07 ], std: [ 2.05, 1.57 ], fq: 7\n },\n \"inhabitant\": {\n dict: \"anew\", word: \"inhabitant\", stem: \"inhabit\",\n avg: [ 3.95, 5.05 ], std: [ 1.97, 1.34 ], fq: 0\n },\n \"injury\": {\n dict: \"anew\", word: \"injury\", stem: \"injuri\",\n avg: [ 5.69, 2.49 ], std: [ 2.06, 1.76 ], fq: 27\n },\n \"ink\": {\n dict: \"anew\", word: \"ink\", stem: \"ink\",\n avg: [ 3.84, 5.05 ], std: [ 1.88, 0.81 ], fq: 7\n },\n \"innocent\": {\n dict: \"anew\", word: \"innocent\", stem: \"innoc\",\n avg: [ 4.21, 6.51 ], std: [ 1.99, 1.34 ], fq: 37\n },\n \"insane\": {\n dict: \"anew\", word: \"insane\", stem: \"insan\",\n avg: [ 5.83, 2.85 ], std: [ 2.45, 1.94 ], fq: 13\n },\n \"insect\": {\n dict: \"anew\", word: \"insect\", stem: \"insect\",\n avg: [ 4.07, 4.07 ], std: [ 2.46, 2.16 ], fq: 14\n },\n \"insecure\": {\n dict: \"anew\", word: \"insecure\", stem: \"insecur\",\n avg: [ 5.56, 2.36 ], std: [ 2.34, 1.33 ], fq: 3\n },\n \"insolent\": {\n dict: \"anew\", word: \"insolent\", stem: \"insol\",\n avg: [ 5.38, 4.35 ], std: [ 2.37, 1.76 ], fq: 2\n },\n \"inspire\": {\n dict: \"anew\", word: \"inspire\", stem: \"inspir\",\n avg: [ 5, 6.97 ], std: [ 2.53, 1.91 ], fq: 3\n },\n \"inspired\": {\n dict: \"anew\", word: \"inspired\", stem: \"inspir\",\n avg: [ 6.02, 7.15 ], std: [ 2.67, 1.85 ], fq: 25\n },\n \"insult\": {\n dict: \"anew\", word: \"insult\", stem: \"insult\",\n avg: [ 6, 2.29 ], std: [ 2.46, 1.33 ], fq: 7\n },\n \"intellect\": {\n dict: \"anew\", word: \"intellect\", stem: \"intellect\",\n avg: [ 4.75, 6.82 ], std: [ 2.5, 1.96 ], fq: 5\n },\n \"intercourse\": {\n dict: \"anew\", word: \"intercourse\", stem: \"intercours\",\n avg: [ 7, 7.36 ], std: [ 2.07, 1.57 ], fq: 9\n },\n \"interest\": {\n dict: \"anew\", word: \"interest\", stem: \"interest\",\n avg: [ 5.66, 6.97 ], std: [ 2.26, 1.53 ], fq: 330\n },\n \"intimate\": {\n dict: \"anew\", word: \"intimate\", stem: \"intim\",\n avg: [ 6.98, 7.61 ], std: [ 2.21, 1.51 ], fq: 21\n },\n \"intruder\": {\n dict: \"anew\", word: \"intruder\", stem: \"intrud\",\n avg: [ 6.86, 2.77 ], std: [ 2.41, 2.32 ], fq: 1\n },\n \"invader\": {\n dict: \"anew\", word: \"invader\", stem: \"invad\",\n avg: [ 5.5, 3.05 ], std: [ 2.4, 2.01 ], fq: 1\n },\n \"invest\": {\n dict: \"anew\", word: \"invest\", stem: \"invest\",\n avg: [ 5.12, 5.93 ], std: [ 2.42, 2.1 ], fq: 3\n },\n \"iron\": {\n dict: \"anew\", word: \"iron\", stem: \"iron\",\n avg: [ 3.76, 4.9 ], std: [ 2.06, 1.02 ], fq: 43\n },\n \"irritate\": {\n dict: \"anew\", word: \"irritate\", stem: \"irrit\",\n avg: [ 5.76, 3.11 ], std: [ 2.15, 1.67 ], fq: 0\n },\n \"item\": {\n dict: \"anew\", word: \"item\", stem: \"item\",\n avg: [ 3.24, 5.26 ], std: [ 2.08, 0.86 ], fq: 54\n },\n \"jail\": {\n dict: \"anew\", word: \"jail\", stem: \"jail\",\n avg: [ 5.49, 1.95 ], std: [ 2.67, 1.27 ], fq: 21\n },\n \"jealousy\": {\n dict: \"anew\", word: \"jealousy\", stem: \"jealousi\",\n avg: [ 6.36, 2.51 ], std: [ 2.66, 1.83 ], fq: 4\n },\n \"jelly\": {\n dict: \"anew\", word: \"jelly\", stem: \"jelli\",\n avg: [ 3.7, 5.66 ], std: [ 2.29, 1.44 ], fq: 3\n },\n \"jewel\": {\n dict: \"anew\", word: \"jewel\", stem: \"jewel\",\n avg: [ 5.38, 7 ], std: [ 2.54, 1.72 ], fq: 1\n },\n \"joke\": {\n dict: \"anew\", word: \"joke\", stem: \"joke\",\n avg: [ 6.74, 8.1 ], std: [ 1.84, 1.36 ], fq: 22\n },\n \"jolly\": {\n dict: \"anew\", word: \"jolly\", stem: \"jolli\",\n avg: [ 5.57, 7.41 ], std: [ 2.8, 1.92 ], fq: 4\n },\n \"journal\": {\n dict: \"anew\", word: \"journal\", stem: \"journal\",\n avg: [ 4.05, 5.14 ], std: [ 1.96, 1.49 ], fq: 42\n },\n \"joy\": {\n dict: \"anew\", word: \"joy\", stem: \"joy\",\n avg: [ 7.22, 8.6 ], std: [ 2.13, 0.71 ], fq: 40\n },\n \"joyful\": {\n dict: \"anew\", word: \"joyful\", stem: \"joy\",\n avg: [ 5.98, 8.22 ], std: [ 2.54, 1.22 ], fq: 1\n },\n \"jug\": {\n dict: \"anew\", word: \"jug\", stem: \"jug\",\n avg: [ 3.88, 5.24 ], std: [ 2.15, 1.65 ], fq: 6\n },\n \"justice\": {\n dict: \"anew\", word: \"justice\", stem: \"justic\",\n avg: [ 5.47, 7.78 ], std: [ 2.54, 1.35 ], fq: 114\n },\n \"kerchief\": {\n dict: \"anew\", word: \"kerchief\", stem: \"kerchief\",\n avg: [ 3.43, 5.11 ], std: [ 2.08, 1.33 ], fq: 1\n },\n \"kerosene\": {\n dict: \"anew\", word: \"kerosene\", stem: \"kerosen\",\n avg: [ 4.34, 4.8 ], std: [ 2.51, 1.59 ], fq: 6\n },\n \"ketchup\": {\n dict: \"anew\", word: \"ketchup\", stem: \"ketchup\",\n avg: [ 4.09, 5.6 ], std: [ 2.08, 1.35 ], fq: 1\n },\n \"kettle\": {\n dict: \"anew\", word: \"kettle\", stem: \"kettl\",\n avg: [ 3.22, 5.22 ], std: [ 2.23, 0.91 ], fq: 3\n },\n \"key\": {\n dict: \"anew\", word: \"key\", stem: \"key\",\n avg: [ 3.7, 5.68 ], std: [ 2.18, 1.62 ], fq: 88\n },\n \"kick\": {\n dict: \"anew\", word: \"kick\", stem: \"kick\",\n avg: [ 4.9, 4.31 ], std: [ 2.35, 2.18 ], fq: 16\n },\n \"kids\": {\n dict: \"anew\", word: \"kids\", stem: \"kid\",\n avg: [ 5.27, 6.91 ], std: [ 2.36, 1.99 ], fq: 32\n },\n \"killer\": {\n dict: \"anew\", word: \"killer\", stem: \"killer\",\n avg: [ 7.86, 1.89 ], std: [ 1.89, 1.39 ], fq: 21\n },\n \"kind\": {\n dict: \"anew\", word: \"kind\", stem: \"kind\",\n avg: [ 4.46, 7.59 ], std: [ 2.55, 1.67 ], fq: 313\n },\n \"kindness\": {\n dict: \"anew\", word: \"kindness\", stem: \"kind\",\n avg: [ 4.3, 7.82 ], std: [ 2.62, 1.39 ], fq: 5\n },\n \"king\": {\n dict: \"anew\", word: \"king\", stem: \"king\",\n avg: [ 5.51, 7.26 ], std: [ 2.77, 1.67 ], fq: 88\n },\n \"kiss\": {\n dict: \"anew\", word: \"kiss\", stem: \"kiss\",\n avg: [ 7.32, 8.26 ], std: [ 2.03, 1.54 ], fq: 17\n },\n \"kitten\": {\n dict: \"anew\", word: \"kitten\", stem: \"kitten\",\n avg: [ 5.08, 6.86 ], std: [ 2.45, 2.13 ], fq: 5\n },\n \"knife\": {\n dict: \"anew\", word: \"knife\", stem: \"knife\",\n avg: [ 5.8, 3.62 ], std: [ 2, 2.18 ], fq: 76\n },\n \"knot\": {\n dict: \"anew\", word: \"knot\", stem: \"knot\",\n avg: [ 4.07, 4.64 ], std: [ 2.15, 1.36 ], fq: 8\n },\n \"knowledge\": {\n dict: \"anew\", word: \"knowledge\", stem: \"knowledg\",\n avg: [ 5.92, 7.58 ], std: [ 2.32, 1.32 ], fq: 145\n },\n \"lake\": {\n dict: \"anew\", word: \"lake\", stem: \"lake\",\n avg: [ 3.95, 6.82 ], std: [ 2.44, 1.54 ], fq: 54\n },\n \"lamb\": {\n dict: \"anew\", word: \"lamb\", stem: \"lamb\",\n avg: [ 3.36, 5.89 ], std: [ 2.18, 1.73 ], fq: 7\n },\n \"lamp\": {\n dict: \"anew\", word: \"lamp\", stem: \"lamp\",\n avg: [ 3.8, 5.41 ], std: [ 2.12, 1 ], fq: 18\n },\n \"lantern\": {\n dict: \"anew\", word: \"lantern\", stem: \"lantern\",\n avg: [ 4.05, 5.57 ], std: [ 2.28, 1.19 ], fq: 13\n },\n \"laughter\": {\n dict: \"anew\", word: \"laughter\", stem: \"laughter\",\n avg: [ 6.75, 8.45 ], std: [ 2.5, 1.08 ], fq: 22\n },\n \"lavish\": {\n dict: \"anew\", word: \"lavish\", stem: \"lavish\",\n avg: [ 4.93, 6.21 ], std: [ 2.4, 2.03 ], fq: 3\n },\n \"lawn\": {\n dict: \"anew\", word: \"lawn\", stem: \"lawn\",\n avg: [ 4, 5.24 ], std: [ 1.79, 0.86 ], fq: 15\n },\n \"lawsuit\": {\n dict: \"anew\", word: \"lawsuit\", stem: \"lawsuit\",\n avg: [ 4.93, 3.37 ], std: [ 2.44, 2 ], fq: 1\n },\n \"lazy\": {\n dict: \"anew\", word: \"lazy\", stem: \"lazi\",\n avg: [ 2.65, 4.38 ], std: [ 2.06, 2.02 ], fq: 9\n },\n \"leader\": {\n dict: \"anew\", word: \"leader\", stem: \"leader\",\n avg: [ 6.27, 7.63 ], std: [ 2.18, 1.59 ], fq: 74\n },\n \"learn\": {\n dict: \"anew\", word: \"learn\", stem: \"learn\",\n avg: [ 5.39, 7.15 ], std: [ 2.22, 1.49 ], fq: 84\n },\n \"legend\": {\n dict: \"anew\", word: \"legend\", stem: \"legend\",\n avg: [ 4.88, 6.39 ], std: [ 1.76, 1.34 ], fq: 26\n },\n \"leisurely\": {\n dict: \"anew\", word: \"leisurely\", stem: \"leisur\",\n avg: [ 3.8, 6.88 ], std: [ 2.38, 1.81 ], fq: 5\n },\n \"leprosy\": {\n dict: \"anew\", word: \"leprosy\", stem: \"leprosi\",\n avg: [ 6.29, 2.09 ], std: [ 2.23, 1.4 ], fq: 1\n },\n \"lesbian\": {\n dict: \"anew\", word: \"lesbian\", stem: \"lesbian\",\n avg: [ 5.12, 4.67 ], std: [ 2.27, 2.45 ], fq: 0\n },\n \"letter\": {\n dict: \"anew\", word: \"letter\", stem: \"letter\",\n avg: [ 4.9, 6.61 ], std: [ 2.37, 1.59 ], fq: 145\n },\n \"liberty\": {\n dict: \"anew\", word: \"liberty\", stem: \"liberti\",\n avg: [ 5.6, 7.98 ], std: [ 2.65, 1.22 ], fq: 46\n },\n \"lice\": {\n dict: \"anew\", word: \"lice\", stem: \"lice\",\n avg: [ 5, 2.31 ], std: [ 2.26, 1.78 ], fq: 2\n },\n \"lie\": {\n dict: \"anew\", word: \"lie\", stem: \"lie\",\n avg: [ 5.96, 2.79 ], std: [ 2.63, 1.92 ], fq: 59\n },\n \"life\": {\n dict: \"anew\", word: \"life\", stem: \"life\",\n avg: [ 6.02, 7.27 ], std: [ 2.62, 1.88 ], fq: 715\n },\n \"lightbulb\": {\n dict: \"anew\", word: \"lightbulb\", stem: \"lightbulb\",\n avg: [ 4.1, 5.61 ], std: [ 2.02, 1.28 ], fq: 0\n },\n \"lighthouse\": {\n dict: \"anew\", word: \"lighthouse\", stem: \"lighthous\",\n avg: [ 4.41, 5.89 ], std: [ 2.44, 2.08 ], fq: 0\n },\n \"lightning\": {\n dict: \"anew\", word: \"lightning\", stem: \"lightn\",\n avg: [ 6.61, 4.57 ], std: [ 1.77, 2.66 ], fq: 14\n },\n \"limber\": {\n dict: \"anew\", word: \"limber\", stem: \"limber\",\n avg: [ 4.57, 5.68 ], std: [ 2.26, 1.49 ], fq: 2\n },\n \"lion\": {\n dict: \"anew\", word: \"lion\", stem: \"lion\",\n avg: [ 6.2, 5.57 ], std: [ 2.16, 1.99 ], fq: 17\n },\n \"listless\": {\n dict: \"anew\", word: \"listless\", stem: \"listless\",\n avg: [ 4.1, 4.12 ], std: [ 2.31, 1.73 ], fq: 1\n },\n \"lively\": {\n dict: \"anew\", word: \"lively\", stem: \"live\",\n avg: [ 5.53, 7.2 ], std: [ 2.9, 1.97 ], fq: 26\n },\n \"locker\": {\n dict: \"anew\", word: \"locker\", stem: \"locker\",\n avg: [ 3.38, 5.19 ], std: [ 2.13, 1.31 ], fq: 9\n },\n \"loneliness\": {\n dict: \"anew\", word: \"loneliness\", stem: \"loneli\",\n avg: [ 4.56, 1.61 ], std: [ 2.97, 1.02 ], fq: 9\n },\n \"lonely\": {\n dict: \"anew\", word: \"lonely\", stem: \"lone\",\n avg: [ 4.51, 2.17 ], std: [ 2.68, 1.76 ], fq: 25\n },\n \"loser\": {\n dict: \"anew\", word: \"loser\", stem: \"loser\",\n avg: [ 4.95, 2.25 ], std: [ 2.57, 1.48 ], fq: 1\n },\n \"lost\": {\n dict: \"anew\", word: \"lost\", stem: \"lost\",\n avg: [ 5.82, 2.82 ], std: [ 2.62, 1.83 ], fq: 173\n },\n \"lottery\": {\n dict: \"anew\", word: \"lottery\", stem: \"lotteri\",\n avg: [ 5.36, 6.57 ], std: [ 2.45, 2.04 ], fq: 1\n },\n \"louse\": {\n dict: \"anew\", word: \"louse\", stem: \"lous\",\n avg: [ 4.98, 2.81 ], std: [ 2.03, 1.92 ], fq: 3\n },\n \"love\": {\n dict: \"anew\", word: \"love\", stem: \"love\",\n avg: [ 6.44, 8.72 ], std: [ 3.35, 0.7 ], fq: 232\n },\n \"loved\": {\n dict: \"anew\", word: \"loved\", stem: \"love\",\n avg: [ 6.38, 8.64 ], std: [ 2.68, 0.71 ], fq: 56\n },\n \"loyal\": {\n dict: \"anew\", word: \"loyal\", stem: \"loyal\",\n avg: [ 5.16, 7.55 ], std: [ 2.42, 1.9 ], fq: 18\n },\n \"lucky\": {\n dict: \"anew\", word: \"lucky\", stem: \"lucki\",\n avg: [ 6.53, 8.17 ], std: [ 2.34, 1.06 ], fq: 21\n },\n \"lump\": {\n dict: \"anew\", word: \"lump\", stem: \"lump\",\n avg: [ 4.8, 4.16 ], std: [ 2.82, 2.34 ], fq: 7\n },\n \"luscious\": {\n dict: \"anew\", word: \"luscious\", stem: \"luscious\",\n avg: [ 5.34, 7.5 ], std: [ 2.51, 1.08 ], fq: 2\n },\n \"lust\": {\n dict: \"anew\", word: \"lust\", stem: \"lust\",\n avg: [ 6.88, 7.12 ], std: [ 1.85, 1.62 ], fq: 5\n },\n \"luxury\": {\n dict: \"anew\", word: \"luxury\", stem: \"luxuri\",\n avg: [ 4.75, 7.88 ], std: [ 2.91, 1.49 ], fq: 21\n },\n \"machine\": {\n dict: \"anew\", word: \"machine\", stem: \"machin\",\n avg: [ 3.82, 5.09 ], std: [ 2.4, 1.67 ], fq: 103\n },\n \"mad\": {\n dict: \"anew\", word: \"mad\", stem: \"mad\",\n avg: [ 6.76, 2.44 ], std: [ 2.26, 1.72 ], fq: 39\n },\n \"madman\": {\n dict: \"anew\", word: \"madman\", stem: \"madman\",\n avg: [ 5.56, 3.91 ], std: [ 2.78, 2.49 ], fq: 2\n },\n \"maggot\": {\n dict: \"anew\", word: \"maggot\", stem: \"maggot\",\n avg: [ 5.28, 2.06 ], std: [ 2.96, 1.47 ], fq: 2\n },\n \"magical\": {\n dict: \"anew\", word: \"magical\", stem: \"magic\",\n avg: [ 5.95, 7.46 ], std: [ 2.36, 1.64 ], fq: 12\n },\n \"mail\": {\n dict: \"anew\", word: \"mail\", stem: \"mail\",\n avg: [ 5.63, 6.88 ], std: [ 2.36, 1.74 ], fq: 47\n },\n \"malaria\": {\n dict: \"anew\", word: \"malaria\", stem: \"malaria\",\n avg: [ 4.4, 2.4 ], std: [ 2.54, 1.38 ], fq: 3\n },\n \"malice\": {\n dict: \"anew\", word: \"malice\", stem: \"malic\",\n avg: [ 5.86, 2.69 ], std: [ 2.75, 1.84 ], fq: 2\n },\n \"man\": {\n dict: \"anew\", word: \"man\", stem: \"man\",\n avg: [ 5.24, 6.73 ], std: [ 2.31, 1.7 ], fq: 1207\n },\n \"mangle\": {\n dict: \"anew\", word: \"mangle\", stem: \"mangl\",\n avg: [ 5.44, 3.9 ], std: [ 2.1, 2.01 ], fq: 0\n },\n \"maniac\": {\n dict: \"anew\", word: \"maniac\", stem: \"maniac\",\n avg: [ 5.39, 3.76 ], std: [ 2.46, 2 ], fq: 4\n },\n \"manner\": {\n dict: \"anew\", word: \"manner\", stem: \"manner\",\n avg: [ 4.56, 5.64 ], std: [ 1.78, 1.34 ], fq: 124\n },\n \"mantel\": {\n dict: \"anew\", word: \"mantel\", stem: \"mantel\",\n avg: [ 3.27, 4.93 ], std: [ 2.23, 1.4 ], fq: 3\n },\n \"manure\": {\n dict: \"anew\", word: \"manure\", stem: \"manur\",\n avg: [ 4.17, 3.1 ], std: [ 2.09, 1.74 ], fq: 6\n },\n \"market\": {\n dict: \"anew\", word: \"market\", stem: \"market\",\n avg: [ 4.12, 5.66 ], std: [ 1.83, 1.02 ], fq: 155\n },\n \"massacre\": {\n dict: \"anew\", word: \"massacre\", stem: \"massacr\",\n avg: [ 5.33, 2.28 ], std: [ 2.63, 1.74 ], fq: 1\n },\n \"masterful\": {\n dict: \"anew\", word: \"masterful\", stem: \"master\",\n avg: [ 5.2, 7.09 ], std: [ 2.85, 1.78 ], fq: 2\n },\n \"masturbate\": {\n dict: \"anew\", word: \"masturbate\", stem: \"masturb\",\n avg: [ 5.67, 5.45 ], std: [ 2.18, 2.02 ], fq: 0\n },\n \"material\": {\n dict: \"anew\", word: \"material\", stem: \"materi\",\n avg: [ 4.05, 5.26 ], std: [ 2.34, 1.29 ], fq: 174\n },\n \"measles\": {\n dict: \"anew\", word: \"measles\", stem: \"measl\",\n avg: [ 5.06, 2.74 ], std: [ 2.44, 1.97 ], fq: 2\n },\n \"medicine\": {\n dict: \"anew\", word: \"medicine\", stem: \"medicin\",\n avg: [ 4.4, 5.67 ], std: [ 2.36, 2.06 ], fq: 30\n },\n \"meek\": {\n dict: \"anew\", word: \"meek\", stem: \"meek\",\n avg: [ 3.8, 3.87 ], std: [ 2.13, 1.69 ], fq: 10\n },\n \"melody\": {\n dict: \"anew\", word: \"melody\", stem: \"melodi\",\n avg: [ 4.98, 7.07 ], std: [ 2.52, 1.79 ], fq: 21\n },\n \"memories\": {\n dict: \"anew\", word: \"memories\", stem: \"memori\",\n avg: [ 6.1, 7.48 ], std: [ 2.1, 1.61 ], fq: 15\n },\n \"memory\": {\n dict: \"anew\", word: \"memory\", stem: \"memori\",\n avg: [ 5.42, 6.62 ], std: [ 2.25, 1.5 ], fq: 76\n },\n \"menace\": {\n dict: \"anew\", word: \"menace\", stem: \"menac\",\n avg: [ 5.52, 2.88 ], std: [ 2.45, 1.64 ], fq: 9\n },\n \"merry\": {\n dict: \"anew\", word: \"merry\", stem: \"merri\",\n avg: [ 5.9, 7.9 ], std: [ 2.42, 1.49 ], fq: 8\n },\n \"messy\": {\n dict: \"anew\", word: \"messy\", stem: \"messi\",\n avg: [ 3.34, 3.15 ], std: [ 2.37, 1.73 ], fq: 3\n },\n \"metal\": {\n dict: \"anew\", word: \"metal\", stem: \"metal\",\n avg: [ 3.79, 4.95 ], std: [ 1.96, 1.17 ], fq: 61\n },\n \"method\": {\n dict: \"anew\", word: \"method\", stem: \"method\",\n avg: [ 3.85, 5.56 ], std: [ 2.58, 1.76 ], fq: 142\n },\n \"mighty\": {\n dict: \"anew\", word: \"mighty\", stem: \"mighti\",\n avg: [ 5.61, 6.54 ], std: [ 2.38, 2.19 ], fq: 29\n },\n \"mildew\": {\n dict: \"anew\", word: \"mildew\", stem: \"mildew\",\n avg: [ 4.08, 3.17 ], std: [ 1.79, 1.36 ], fq: 1\n },\n \"milk\": {\n dict: \"anew\", word: \"milk\", stem: \"milk\",\n avg: [ 3.68, 5.95 ], std: [ 2.57, 2.16 ], fq: 49\n },\n \"millionaire\": {\n dict: \"anew\", word: \"millionaire\", stem: \"millionair\",\n avg: [ 6.14, 8.03 ], std: [ 2.7, 1.42 ], fq: 2\n },\n \"mind\": {\n dict: \"anew\", word: \"mind\", stem: \"mind\",\n avg: [ 5, 6.68 ], std: [ 2.68, 1.84 ], fq: 325\n },\n \"miracle\": {\n dict: \"anew\", word: \"miracle\", stem: \"miracl\",\n avg: [ 7.65, 8.6 ], std: [ 1.67, 0.71 ], fq: 16\n },\n \"mischief\": {\n dict: \"anew\", word: \"mischief\", stem: \"mischief\",\n avg: [ 5.76, 5.57 ], std: [ 1.95, 2.05 ], fq: 5\n },\n \"misery\": {\n dict: \"anew\", word: \"misery\", stem: \"miseri\",\n avg: [ 5.17, 1.93 ], std: [ 2.69, 1.6 ], fq: 15\n },\n \"mistake\": {\n dict: \"anew\", word: \"mistake\", stem: \"mistak\",\n avg: [ 5.18, 2.86 ], std: [ 2.42, 1.79 ], fq: 34\n },\n \"mobility\": {\n dict: \"anew\", word: \"mobility\", stem: \"mobil\",\n avg: [ 5, 6.83 ], std: [ 2.18, 1.79 ], fq: 8\n },\n \"modest\": {\n dict: \"anew\", word: \"modest\", stem: \"modest\",\n avg: [ 3.98, 5.76 ], std: [ 2.24, 1.28 ], fq: 29\n },\n \"mold\": {\n dict: \"anew\", word: \"mold\", stem: \"mold\",\n avg: [ 4.07, 3.55 ], std: [ 1.98, 1.7 ], fq: 45\n },\n \"moment\": {\n dict: \"anew\", word: \"moment\", stem: \"moment\",\n avg: [ 3.83, 5.76 ], std: [ 2.29, 1.65 ], fq: 246\n },\n \"money\": {\n dict: \"anew\", word: \"money\", stem: \"money\",\n avg: [ 5.7, 7.59 ], std: [ 2.66, 1.4 ], fq: 265\n },\n \"month\": {\n dict: \"anew\", word: \"month\", stem: \"month\",\n avg: [ 4.03, 5.15 ], std: [ 1.77, 1.09 ], fq: 130\n },\n \"moody\": {\n dict: \"anew\", word: \"moody\", stem: \"moodi\",\n avg: [ 4.18, 3.2 ], std: [ 2.38, 1.58 ], fq: 5\n },\n \"moral\": {\n dict: \"anew\", word: \"moral\", stem: \"moral\",\n avg: [ 4.49, 6.2 ], std: [ 2.28, 1.85 ], fq: 142\n },\n \"morbid\": {\n dict: \"anew\", word: \"morbid\", stem: \"morbid\",\n avg: [ 5.06, 2.87 ], std: [ 2.68, 2.14 ], fq: 1\n },\n \"morgue\": {\n dict: \"anew\", word: \"morgue\", stem: \"morgu\",\n avg: [ 4.84, 1.92 ], std: [ 2.96, 1.32 ], fq: 1\n },\n \"mosquito\": {\n dict: \"anew\", word: \"mosquito\", stem: \"mosquito\",\n avg: [ 4.78, 2.8 ], std: [ 2.72, 1.91 ], fq: 1\n },\n \"mother\": {\n dict: \"anew\", word: \"mother\", stem: \"mother\",\n avg: [ 6.13, 8.39 ], std: [ 2.71, 1.15 ], fq: 216\n },\n \"mountain\": {\n dict: \"anew\", word: \"mountain\", stem: \"mountain\",\n avg: [ 5.49, 6.59 ], std: [ 2.43, 1.66 ], fq: 33\n },\n \"movie\": {\n dict: \"anew\", word: \"movie\", stem: \"movi\",\n avg: [ 4.93, 6.86 ], std: [ 2.54, 1.81 ], fq: 29\n },\n \"mucus\": {\n dict: \"anew\", word: \"mucus\", stem: \"mucus\",\n avg: [ 3.41, 3.34 ], std: [ 2.17, 2.29 ], fq: 2\n },\n \"muddy\": {\n dict: \"anew\", word: \"muddy\", stem: \"muddi\",\n avg: [ 4.13, 4.44 ], std: [ 2.13, 2.07 ], fq: 10\n },\n \"muffin\": {\n dict: \"anew\", word: \"muffin\", stem: \"muffin\",\n avg: [ 4.76, 6.57 ], std: [ 2.42, 2.04 ], fq: 0\n },\n \"murderer\": {\n dict: \"anew\", word: \"murderer\", stem: \"murder\",\n avg: [ 7.47, 1.53 ], std: [ 2.18, 0.96 ], fq: 19\n },\n \"muscular\": {\n dict: \"anew\", word: \"muscular\", stem: \"muscular\",\n avg: [ 5.47, 6.82 ], std: [ 2.2, 1.63 ], fq: 16\n },\n \"museum\": {\n dict: \"anew\", word: \"museum\", stem: \"museum\",\n avg: [ 3.6, 5.54 ], std: [ 2.13, 1.86 ], fq: 32\n },\n \"mushroom\": {\n dict: \"anew\", word: \"mushroom\", stem: \"mushroom\",\n avg: [ 4.72, 5.78 ], std: [ 2.33, 2.22 ], fq: 2\n },\n \"music\": {\n dict: \"anew\", word: \"music\", stem: \"music\",\n avg: [ 5.32, 8.13 ], std: [ 3.19, 1.09 ], fq: 216\n },\n \"mutation\": {\n dict: \"anew\", word: \"mutation\", stem: \"mutat\",\n avg: [ 4.84, 3.91 ], std: [ 2.52, 2.44 ], fq: 0\n },\n \"mutilate\": {\n dict: \"anew\", word: \"mutilate\", stem: \"mutil\",\n avg: [ 6.41, 1.82 ], std: [ 2.94, 1.45 ], fq: 3\n },\n \"mystic\": {\n dict: \"anew\", word: \"mystic\", stem: \"mystic\",\n avg: [ 4.84, 6 ], std: [ 2.57, 2.21 ], fq: 3\n },\n \"naked\": {\n dict: \"anew\", word: \"naked\", stem: \"nake\",\n avg: [ 5.8, 6.34 ], std: [ 2.8, 2.42 ], fq: 32\n },\n \"name\": {\n dict: \"anew\", word: \"name\", stem: \"name\",\n avg: [ 4.25, 5.55 ], std: [ 2.47, 2.24 ], fq: 294\n },\n \"narcotic\": {\n dict: \"anew\", word: \"narcotic\", stem: \"narcot\",\n avg: [ 4.93, 4.29 ], std: [ 2.57, 2.3 ], fq: 2\n },\n \"nasty\": {\n dict: \"anew\", word: \"nasty\", stem: \"nasti\",\n avg: [ 4.89, 3.58 ], std: [ 2.5, 2.38 ], fq: 5\n },\n \"natural\": {\n dict: \"anew\", word: \"natural\", stem: \"natur\",\n avg: [ 4.09, 6.59 ], std: [ 2.37, 1.57 ], fq: 156\n },\n \"nature\": {\n dict: \"anew\", word: \"nature\", stem: \"natur\",\n avg: [ 4.37, 7.65 ], std: [ 2.51, 1.37 ], fq: 191\n },\n \"nectar\": {\n dict: \"anew\", word: \"nectar\", stem: \"nectar\",\n avg: [ 3.89, 6.9 ], std: [ 2.48, 1.53 ], fq: 3\n },\n \"needle\": {\n dict: \"anew\", word: \"needle\", stem: \"needl\",\n avg: [ 5.36, 3.82 ], std: [ 2.89, 1.73 ], fq: 15\n },\n \"neglect\": {\n dict: \"anew\", word: \"neglect\", stem: \"neglect\",\n avg: [ 4.83, 2.63 ], std: [ 2.31, 1.64 ], fq: 12\n },\n \"nervous\": {\n dict: \"anew\", word: \"nervous\", stem: \"nervous\",\n avg: [ 6.59, 3.29 ], std: [ 2.07, 1.47 ], fq: 24\n },\n \"neurotic\": {\n dict: \"anew\", word: \"neurotic\", stem: \"neurot\",\n avg: [ 5.13, 4.45 ], std: [ 2.76, 2.23 ], fq: 10\n },\n \"news\": {\n dict: \"anew\", word: \"news\", stem: \"news\",\n avg: [ 5.17, 5.3 ], std: [ 2.11, 1.67 ], fq: 102\n },\n \"nice\": {\n dict: \"anew\", word: \"nice\", stem: \"nice\",\n avg: [ 4.38, 6.55 ], std: [ 2.69, 2.44 ], fq: 75\n },\n \"nightmare\": {\n dict: \"anew\", word: \"nightmare\", stem: \"nightmar\",\n avg: [ 7.59, 1.91 ], std: [ 2.23, 1.54 ], fq: 9\n },\n \"nipple\": {\n dict: \"anew\", word: \"nipple\", stem: \"nippl\",\n avg: [ 5.56, 6.27 ], std: [ 2.55, 1.81 ], fq: 0\n },\n \"noisy\": {\n dict: \"anew\", word: \"noisy\", stem: \"noisi\",\n avg: [ 6.38, 5.02 ], std: [ 1.78, 2.02 ], fq: 6\n },\n \"nonchalant\": {\n dict: \"anew\", word: \"nonchalant\", stem: \"nonchal\",\n avg: [ 3.12, 4.74 ], std: [ 1.93, 1.11 ], fq: 1\n },\n \"nonsense\": {\n dict: \"anew\", word: \"nonsense\", stem: \"nonsens\",\n avg: [ 4.17, 4.61 ], std: [ 2.02, 1.63 ], fq: 13\n },\n \"noose\": {\n dict: \"anew\", word: \"noose\", stem: \"noos\",\n avg: [ 4.39, 3.76 ], std: [ 2.08, 1.64 ], fq: 3\n },\n \"nourish\": {\n dict: \"anew\", word: \"nourish\", stem: \"nourish\",\n avg: [ 4.29, 6.46 ], std: [ 2.51, 1.69 ], fq: 0\n },\n \"nude\": {\n dict: \"anew\", word: \"nude\", stem: \"nude\",\n avg: [ 6.41, 6.82 ], std: [ 2.09, 1.63 ], fq: 20\n },\n \"nuisance\": {\n dict: \"anew\", word: \"nuisance\", stem: \"nuisanc\",\n avg: [ 4.49, 3.27 ], std: [ 2.69, 1.86 ], fq: 5\n },\n \"nun\": {\n dict: \"anew\", word: \"nun\", stem: \"nun\",\n avg: [ 2.93, 4.93 ], std: [ 1.8, 1.89 ], fq: 2\n },\n \"nurse\": {\n dict: \"anew\", word: \"nurse\", stem: \"nurs\",\n avg: [ 4.84, 6.08 ], std: [ 2.04, 2.08 ], fq: 17\n },\n \"nursery\": {\n dict: \"anew\", word: \"nursery\", stem: \"nurseri\",\n avg: [ 4.04, 5.73 ], std: [ 2.74, 2.3 ], fq: 13\n },\n \"obesity\": {\n dict: \"anew\", word: \"obesity\", stem: \"obes\",\n avg: [ 3.87, 2.73 ], std: [ 2.82, 1.85 ], fq: 5\n },\n \"obey\": {\n dict: \"anew\", word: \"obey\", stem: \"obey\",\n avg: [ 4.23, 4.52 ], std: [ 1.72, 1.88 ], fq: 8\n },\n \"obnoxious\": {\n dict: \"anew\", word: \"obnoxious\", stem: \"obnoxi\",\n avg: [ 4.74, 3.5 ], std: [ 2.42, 2.18 ], fq: 5\n },\n \"obscene\": {\n dict: \"anew\", word: \"obscene\", stem: \"obscen\",\n avg: [ 5.04, 4.23 ], std: [ 2.3, 2.3 ], fq: 2\n },\n \"obsession\": {\n dict: \"anew\", word: \"obsession\", stem: \"obsess\",\n avg: [ 6.41, 4.52 ], std: [ 2.13, 2.13 ], fq: 5\n },\n \"ocean\": {\n dict: \"anew\", word: \"ocean\", stem: \"ocean\",\n avg: [ 4.95, 7.12 ], std: [ 2.79, 1.72 ], fq: 34\n },\n \"odd\": {\n dict: \"anew\", word: \"odd\", stem: \"odd\",\n avg: [ 4.27, 4.82 ], std: [ 2.46, 2.04 ], fq: 44\n },\n \"offend\": {\n dict: \"anew\", word: \"offend\", stem: \"offend\",\n avg: [ 5.56, 2.76 ], std: [ 2.06, 1.5 ], fq: 4\n },\n \"office\": {\n dict: \"anew\", word: \"office\", stem: \"offic\",\n avg: [ 4.08, 5.24 ], std: [ 1.92, 1.59 ], fq: 255\n },\n \"opinion\": {\n dict: \"anew\", word: \"opinion\", stem: \"opinion\",\n avg: [ 4.89, 6.28 ], std: [ 2.46, 1.45 ], fq: 96\n },\n \"optimism\": {\n dict: \"anew\", word: \"optimism\", stem: \"optim\",\n avg: [ 5.34, 6.95 ], std: [ 2.58, 2.24 ], fq: 15\n },\n \"option\": {\n dict: \"anew\", word: \"option\", stem: \"option\",\n avg: [ 4.74, 6.49 ], std: [ 2.23, 1.31 ], fq: 5\n },\n \"orchestra\": {\n dict: \"anew\", word: \"orchestra\", stem: \"orchestra\",\n avg: [ 3.52, 6.02 ], std: [ 2.29, 1.89 ], fq: 60\n },\n \"orgasm\": {\n dict: \"anew\", word: \"orgasm\", stem: \"orgasm\",\n avg: [ 8.1, 8.32 ], std: [ 1.45, 1.31 ], fq: 7\n },\n \"outdoors\": {\n dict: \"anew\", word: \"outdoors\", stem: \"outdoor\",\n avg: [ 5.92, 7.47 ], std: [ 2.55, 1.8 ], fq: 6\n },\n \"outrage\": {\n dict: \"anew\", word: \"outrage\", stem: \"outrag\",\n avg: [ 6.83, 3.52 ], std: [ 2.26, 2.12 ], fq: 4\n },\n \"outstanding\": {\n dict: \"anew\", word: \"outstanding\", stem: \"outstand\",\n avg: [ 6.24, 7.75 ], std: [ 2.59, 1.75 ], fq: 37\n },\n \"overcast\": {\n dict: \"anew\", word: \"overcast\", stem: \"overcast\",\n avg: [ 3.46, 3.65 ], std: [ 1.92, 1.61 ], fq: 9\n },\n \"overwhelmed\": {\n dict: \"anew\", word: \"overwhelmed\", stem: \"overwhelm\",\n avg: [ 7, 4.19 ], std: [ 2.37, 2.61 ], fq: 4\n },\n \"owl\": {\n dict: \"anew\", word: \"owl\", stem: \"owl\",\n avg: [ 3.98, 5.8 ], std: [ 1.87, 1.31 ], fq: 2\n },\n \"pain\": {\n dict: \"anew\", word: \"pain\", stem: \"pain\",\n avg: [ 6.5, 2.13 ], std: [ 2.49, 1.81 ], fq: 88\n },\n \"paint\": {\n dict: \"anew\", word: \"paint\", stem: \"paint\",\n avg: [ 4.1, 5.62 ], std: [ 2.36, 1.72 ], fq: 37\n },\n \"palace\": {\n dict: \"anew\", word: \"palace\", stem: \"palac\",\n avg: [ 5.1, 7.19 ], std: [ 2.75, 1.78 ], fq: 38\n },\n \"pamphlet\": {\n dict: \"anew\", word: \"pamphlet\", stem: \"pamphlet\",\n avg: [ 3.62, 4.79 ], std: [ 2.02, 1.05 ], fq: 3\n },\n \"pancakes\": {\n dict: \"anew\", word: \"pancakes\", stem: \"pancak\",\n avg: [ 4.06, 6.08 ], std: [ 2.13, 1.83 ], fq: 0\n },\n \"panic\": {\n dict: \"anew\", word: \"panic\", stem: \"panic\",\n avg: [ 7.02, 3.12 ], std: [ 2.02, 1.84 ], fq: 22\n },\n \"paper\": {\n dict: \"anew\", word: \"paper\", stem: \"paper\",\n avg: [ 2.5, 5.2 ], std: [ 1.85, 1.21 ], fq: 157\n },\n \"paradise\": {\n dict: \"anew\", word: \"paradise\", stem: \"paradis\",\n avg: [ 5.12, 8.72 ], std: [ 3.38, 0.6 ], fq: 12\n },\n \"paralysis\": {\n dict: \"anew\", word: \"paralysis\", stem: \"paralysi\",\n avg: [ 4.73, 1.98 ], std: [ 2.83, 1.44 ], fq: 6\n },\n \"part\": {\n dict: \"anew\", word: \"part\", stem: \"part\",\n avg: [ 3.82, 5.11 ], std: [ 2.24, 1.78 ], fq: 500\n },\n \"party\": {\n dict: \"anew\", word: \"party\", stem: \"parti\",\n avg: [ 6.69, 7.86 ], std: [ 2.84, 1.83 ], fq: 216\n },\n \"passage\": {\n dict: \"anew\", word: \"passage\", stem: \"passag\",\n avg: [ 4.36, 5.28 ], std: [ 2.13, 1.44 ], fq: 49\n },\n \"passion\": {\n dict: \"anew\", word: \"passion\", stem: \"passion\",\n avg: [ 7.26, 8.03 ], std: [ 2.57, 1.27 ], fq: 28\n },\n \"pasta\": {\n dict: \"anew\", word: \"pasta\", stem: \"pasta\",\n avg: [ 4.94, 6.69 ], std: [ 2.04, 1.64 ], fq: 0\n },\n \"patent\": {\n dict: \"anew\", word: \"patent\", stem: \"patent\",\n avg: [ 3.5, 5.29 ], std: [ 1.84, 1.08 ], fq: 35\n },\n \"patient\": {\n dict: \"anew\", word: \"patient\", stem: \"patient\",\n avg: [ 4.21, 5.29 ], std: [ 2.37, 1.89 ], fq: 86\n },\n \"patriot\": {\n dict: \"anew\", word: \"patriot\", stem: \"patriot\",\n avg: [ 5.17, 6.71 ], std: [ 2.53, 1.69 ], fq: 10\n },\n \"peace\": {\n dict: \"anew\", word: \"peace\", stem: \"peac\",\n avg: [ 2.95, 7.72 ], std: [ 2.55, 1.75 ], fq: 198\n },\n \"penalty\": {\n dict: \"anew\", word: \"penalty\", stem: \"penalti\",\n avg: [ 5.1, 2.83 ], std: [ 2.31, 1.56 ], fq: 14\n },\n \"pencil\": {\n dict: \"anew\", word: \"pencil\", stem: \"pencil\",\n avg: [ 3.14, 5.22 ], std: [ 1.9, 0.68 ], fq: 34\n },\n \"penis\": {\n dict: \"anew\", word: \"penis\", stem: \"peni\",\n avg: [ 5.54, 5.9 ], std: [ 2.63, 1.72 ], fq: 0\n },\n \"penthouse\": {\n dict: \"anew\", word: \"penthouse\", stem: \"penthous\",\n avg: [ 5.52, 6.81 ], std: [ 2.49, 1.64 ], fq: 1\n },\n \"people\": {\n dict: \"anew\", word: \"people\", stem: \"peopl\",\n avg: [ 5.94, 7.33 ], std: [ 2.09, 1.7 ], fq: 847\n },\n \"perfection\": {\n dict: \"anew\", word: \"perfection\", stem: \"perfect\",\n avg: [ 5.95, 7.25 ], std: [ 2.73, 2.05 ], fq: 11\n },\n \"perfume\": {\n dict: \"anew\", word: \"perfume\", stem: \"perfum\",\n avg: [ 5.05, 6.76 ], std: [ 2.36, 1.48 ], fq: 10\n },\n \"person\": {\n dict: \"anew\", word: \"person\", stem: \"person\",\n avg: [ 4.19, 6.32 ], std: [ 2.45, 1.74 ], fq: 175\n },\n \"pervert\": {\n dict: \"anew\", word: \"pervert\", stem: \"pervert\",\n avg: [ 6.26, 2.79 ], std: [ 2.61, 2.12 ], fq: 1\n },\n \"pest\": {\n dict: \"anew\", word: \"pest\", stem: \"pest\",\n avg: [ 5.62, 3.13 ], std: [ 2.15, 1.82 ], fq: 4\n },\n \"pet\": {\n dict: \"anew\", word: \"pet\", stem: \"pet\",\n avg: [ 5.1, 6.79 ], std: [ 2.59, 2.32 ], fq: 8\n },\n \"phase\": {\n dict: \"anew\", word: \"phase\", stem: \"phase\",\n avg: [ 3.98, 5.17 ], std: [ 1.82, 0.79 ], fq: 72\n },\n \"pie\": {\n dict: \"anew\", word: \"pie\", stem: \"pie\",\n avg: [ 4.2, 6.41 ], std: [ 2.4, 1.89 ], fq: 14\n },\n \"pig\": {\n dict: \"anew\", word: \"pig\", stem: \"pig\",\n avg: [ 4.2, 5.07 ], std: [ 2.42, 1.97 ], fq: 8\n },\n \"pillow\": {\n dict: \"anew\", word: \"pillow\", stem: \"pillow\",\n avg: [ 2.97, 7.92 ], std: [ 2.52, 1.4 ], fq: 8\n },\n \"pinch\": {\n dict: \"anew\", word: \"pinch\", stem: \"pinch\",\n avg: [ 4.59, 3.83 ], std: [ 2.1, 1.7 ], fq: 6\n },\n \"pistol\": {\n dict: \"anew\", word: \"pistol\", stem: \"pistol\",\n avg: [ 6.15, 4.2 ], std: [ 2.19, 2.58 ], fq: 27\n },\n \"pity\": {\n dict: \"anew\", word: \"pity\", stem: \"piti\",\n avg: [ 3.72, 3.37 ], std: [ 2.02, 1.57 ], fq: 14\n },\n \"pizza\": {\n dict: \"anew\", word: \"pizza\", stem: \"pizza\",\n avg: [ 5.24, 6.65 ], std: [ 2.09, 2.23 ], fq: 3\n },\n \"plain\": {\n dict: \"anew\", word: \"plain\", stem: \"plain\",\n avg: [ 3.52, 4.39 ], std: [ 2.05, 1.46 ], fq: 48\n },\n \"plane\": {\n dict: \"anew\", word: \"plane\", stem: \"plane\",\n avg: [ 6.14, 6.43 ], std: [ 2.39, 1.98 ], fq: 114\n },\n \"plant\": {\n dict: \"anew\", word: \"plant\", stem: \"plant\",\n avg: [ 3.62, 5.98 ], std: [ 2.25, 1.83 ], fq: 125\n },\n \"pleasure\": {\n dict: \"anew\", word: \"pleasure\", stem: \"pleasur\",\n avg: [ 5.74, 8.28 ], std: [ 2.81, 0.92 ], fq: 62\n },\n \"poetry\": {\n dict: \"anew\", word: \"poetry\", stem: \"poetri\",\n avg: [ 4, 5.86 ], std: [ 2.85, 1.91 ], fq: 88\n },\n \"poison\": {\n dict: \"anew\", word: \"poison\", stem: \"poison\",\n avg: [ 6.05, 1.98 ], std: [ 2.82, 1.44 ], fq: 10\n },\n \"politeness\": {\n dict: \"anew\", word: \"politeness\", stem: \"polit\",\n avg: [ 3.74, 7.18 ], std: [ 2.37, 1.5 ], fq: 5\n },\n \"pollute\": {\n dict: \"anew\", word: \"pollute\", stem: \"pollut\",\n avg: [ 6.08, 1.85 ], std: [ 2.42, 1.11 ], fq: 1\n },\n \"poster\": {\n dict: \"anew\", word: \"poster\", stem: \"poster\",\n avg: [ 3.93, 5.34 ], std: [ 2.56, 1.75 ], fq: 4\n },\n \"poverty\": {\n dict: \"anew\", word: \"poverty\", stem: \"poverti\",\n avg: [ 4.87, 1.67 ], std: [ 2.66, 0.9 ], fq: 20\n },\n \"power\": {\n dict: \"anew\", word: \"power\", stem: \"power\",\n avg: [ 6.67, 6.54 ], std: [ 1.87, 2.21 ], fq: 342\n },\n \"powerful\": {\n dict: \"anew\", word: \"powerful\", stem: \"power\",\n avg: [ 5.83, 6.84 ], std: [ 2.69, 1.8 ], fq: 63\n },\n \"prairie\": {\n dict: \"anew\", word: \"prairie\", stem: \"prairi\",\n avg: [ 3.41, 5.75 ], std: [ 2.17, 1.43 ], fq: 21\n },\n \"present\": {\n dict: \"anew\", word: \"present\", stem: \"present\",\n avg: [ 5.12, 6.95 ], std: [ 2.39, 1.85 ], fq: 377\n },\n \"pressure\": {\n dict: \"anew\", word: \"pressure\", stem: \"pressur\",\n avg: [ 6.07, 3.38 ], std: [ 2.26, 1.61 ], fq: 185\n },\n \"prestige\": {\n dict: \"anew\", word: \"prestige\", stem: \"prestig\",\n avg: [ 5.86, 7.26 ], std: [ 2.08, 1.9 ], fq: 29\n },\n \"pretty\": {\n dict: \"anew\", word: \"pretty\", stem: \"pretti\",\n avg: [ 6.03, 7.75 ], std: [ 2.22, 1.26 ], fq: 107\n },\n \"prick\": {\n dict: \"anew\", word: \"prick\", stem: \"prick\",\n avg: [ 4.7, 3.98 ], std: [ 2.59, 1.73 ], fq: 2\n },\n \"pride\": {\n dict: \"anew\", word: \"pride\", stem: \"pride\",\n avg: [ 5.83, 7 ], std: [ 2.48, 2.11 ], fq: 42\n },\n \"priest\": {\n dict: \"anew\", word: \"priest\", stem: \"priest\",\n avg: [ 4.41, 6.42 ], std: [ 2.71, 2 ], fq: 16\n },\n \"prison\": {\n dict: \"anew\", word: \"prison\", stem: \"prison\",\n avg: [ 5.7, 2.05 ], std: [ 2.56, 1.34 ], fq: 42\n },\n \"privacy\": {\n dict: \"anew\", word: \"privacy\", stem: \"privaci\",\n avg: [ 4.12, 5.88 ], std: [ 1.83, 1.5 ], fq: 12\n },\n \"profit\": {\n dict: \"anew\", word: \"profit\", stem: \"profit\",\n avg: [ 6.68, 7.63 ], std: [ 1.78, 1.3 ], fq: 28\n },\n \"progress\": {\n dict: \"anew\", word: \"progress\", stem: \"progress\",\n avg: [ 6.02, 7.73 ], std: [ 2.58, 1.34 ], fq: 120\n },\n \"promotion\": {\n dict: \"anew\", word: \"promotion\", stem: \"promot\",\n avg: [ 6.44, 8.2 ], std: [ 2.58, 1.15 ], fq: 26\n },\n \"protected\": {\n dict: \"anew\", word: \"protected\", stem: \"protect\",\n avg: [ 4.09, 7.29 ], std: [ 2.77, 1.79 ], fq: 31\n },\n \"proud\": {\n dict: \"anew\", word: \"proud\", stem: \"proud\",\n avg: [ 5.56, 8.03 ], std: [ 3.01, 1.56 ], fq: 50\n },\n \"pungent\": {\n dict: \"anew\", word: \"pungent\", stem: \"pungent\",\n avg: [ 4.24, 3.95 ], std: [ 2.17, 2.09 ], fq: 4\n },\n \"punishment\": {\n dict: \"anew\", word: \"punishment\", stem: \"punish\",\n avg: [ 5.93, 2.22 ], std: [ 2.4, 1.41 ], fq: 21\n },\n \"puppy\": {\n dict: \"anew\", word: \"puppy\", stem: \"puppi\",\n avg: [ 5.85, 7.56 ], std: [ 2.78, 1.9 ], fq: 2\n },\n \"pus\": {\n dict: \"anew\", word: \"pus\", stem: \"pus\",\n avg: [ 4.82, 2.86 ], std: [ 2.06, 1.91 ], fq: 0\n },\n \"putrid\": {\n dict: \"anew\", word: \"putrid\", stem: \"putrid\",\n avg: [ 5.74, 2.38 ], std: [ 2.26, 1.71 ], fq: 0\n },\n \"python\": {\n dict: \"anew\", word: \"python\", stem: \"python\",\n avg: [ 6.18, 4.05 ], std: [ 2.25, 2.48 ], fq: 14\n },\n \"quality\": {\n dict: \"anew\", word: \"quality\", stem: \"qualiti\",\n avg: [ 4.48, 6.25 ], std: [ 2.12, 1.59 ], fq: 114\n },\n \"quarrel\": {\n dict: \"anew\", word: \"quarrel\", stem: \"quarrel\",\n avg: [ 6.29, 2.93 ], std: [ 2.56, 2.06 ], fq: 20\n },\n \"quart\": {\n dict: \"anew\", word: \"quart\", stem: \"quart\",\n avg: [ 3.59, 5.39 ], std: [ 2.51, 2.01 ], fq: 3\n },\n \"queen\": {\n dict: \"anew\", word: \"queen\", stem: \"queen\",\n avg: [ 4.76, 6.44 ], std: [ 2.18, 1.43 ], fq: 41\n },\n \"quick\": {\n dict: \"anew\", word: \"quick\", stem: \"quick\",\n avg: [ 6.57, 6.64 ], std: [ 1.78, 1.61 ], fq: 68\n },\n \"quiet\": {\n dict: \"anew\", word: \"quiet\", stem: \"quiet\",\n avg: [ 2.82, 5.58 ], std: [ 2.13, 1.83 ], fq: 76\n },\n \"rabbit\": {\n dict: \"anew\", word: \"rabbit\", stem: \"rabbit\",\n avg: [ 4.02, 6.57 ], std: [ 2.19, 1.92 ], fq: 11\n },\n \"rabies\": {\n dict: \"anew\", word: \"rabies\", stem: \"rabi\",\n avg: [ 6.1, 1.77 ], std: [ 2.62, 0.97 ], fq: 1\n },\n \"radiant\": {\n dict: \"anew\", word: \"radiant\", stem: \"radiant\",\n avg: [ 5.39, 6.73 ], std: [ 2.82, 2.17 ], fq: 8\n },\n \"radiator\": {\n dict: \"anew\", word: \"radiator\", stem: \"radiat\",\n avg: [ 4.02, 4.67 ], std: [ 1.94, 1.05 ], fq: 4\n },\n \"radio\": {\n dict: \"anew\", word: \"radio\", stem: \"radio\",\n avg: [ 4.78, 6.73 ], std: [ 2.82, 1.47 ], fq: 120\n },\n \"rage\": {\n dict: \"anew\", word: \"rage\", stem: \"rage\",\n avg: [ 8.17, 2.41 ], std: [ 1.4, 1.86 ], fq: 16\n },\n \"rain\": {\n dict: \"anew\", word: \"rain\", stem: \"rain\",\n avg: [ 3.65, 5.08 ], std: [ 2.35, 2.51 ], fq: 70\n },\n \"rainbow\": {\n dict: \"anew\", word: \"rainbow\", stem: \"rainbow\",\n avg: [ 4.64, 8.14 ], std: [ 2.88, 1.23 ], fq: 4\n },\n \"rancid\": {\n dict: \"anew\", word: \"rancid\", stem: \"rancid\",\n avg: [ 5.04, 4.34 ], std: [ 2.27, 2.28 ], fq: 0\n },\n \"rape\": {\n dict: \"anew\", word: \"rape\", stem: \"rape\",\n avg: [ 6.81, 1.25 ], std: [ 3.17, 0.91 ], fq: 5\n },\n \"rat\": {\n dict: \"anew\", word: \"rat\", stem: \"rat\",\n avg: [ 4.95, 3.02 ], std: [ 2.36, 1.66 ], fq: 6\n },\n \"rattle\": {\n dict: \"anew\", word: \"rattle\", stem: \"rattl\",\n avg: [ 4.36, 5.03 ], std: [ 2.18, 1.23 ], fq: 5\n },\n \"razor\": {\n dict: \"anew\", word: \"razor\", stem: \"razor\",\n avg: [ 5.36, 4.81 ], std: [ 2.44, 2.16 ], fq: 15\n },\n \"red\": {\n dict: \"anew\", word: \"red\", stem: \"red\",\n avg: [ 5.29, 6.41 ], std: [ 2.04, 1.61 ], fq: 197\n },\n \"refreshment\": {\n dict: \"anew\", word: \"refreshment\", stem: \"refresh\",\n avg: [ 4.45, 7.44 ], std: [ 2.7, 1.29 ], fq: 2\n },\n \"regretful\": {\n dict: \"anew\", word: \"regretful\", stem: \"regret\",\n avg: [ 5.74, 2.28 ], std: [ 2.32, 1.42 ], fq: 1\n },\n \"rejected\": {\n dict: \"anew\", word: \"rejected\", stem: \"reject\",\n avg: [ 6.37, 1.5 ], std: [ 2.56, 1.09 ], fq: 33\n },\n \"relaxed\": {\n dict: \"anew\", word: \"relaxed\", stem: \"relax\",\n avg: [ 2.39, 7 ], std: [ 2.13, 1.77 ], fq: 14\n },\n \"repentant\": {\n dict: \"anew\", word: \"repentant\", stem: \"repent\",\n avg: [ 4.69, 5.53 ], std: [ 1.98, 1.86 ], fq: 1\n },\n \"reptile\": {\n dict: \"anew\", word: \"reptile\", stem: \"reptil\",\n avg: [ 5.18, 4.77 ], std: [ 2.19, 2 ], fq: 0\n },\n \"rescue\": {\n dict: \"anew\", word: \"rescue\", stem: \"rescu\",\n avg: [ 6.53, 7.7 ], std: [ 2.56, 1.24 ], fq: 15\n },\n \"resent\": {\n dict: \"anew\", word: \"resent\", stem: \"resent\",\n avg: [ 4.47, 3.76 ], std: [ 2.12, 1.9 ], fq: 8\n },\n \"reserved\": {\n dict: \"anew\", word: \"reserved\", stem: \"reserv\",\n avg: [ 3.27, 4.88 ], std: [ 2.05, 1.83 ], fq: 27\n },\n \"respect\": {\n dict: \"anew\", word: \"respect\", stem: \"respect\",\n avg: [ 5.19, 7.64 ], std: [ 2.39, 1.29 ], fq: 125\n },\n \"respectful\": {\n dict: \"anew\", word: \"respectful\", stem: \"respect\",\n avg: [ 4.6, 7.22 ], std: [ 2.67, 1.27 ], fq: 4\n },\n \"restaurant\": {\n dict: \"anew\", word: \"restaurant\", stem: \"restaur\",\n avg: [ 5.41, 6.76 ], std: [ 2.55, 1.85 ], fq: 41\n },\n \"reunion\": {\n dict: \"anew\", word: \"reunion\", stem: \"reunion\",\n avg: [ 6.34, 6.48 ], std: [ 2.35, 2.45 ], fq: 11\n },\n \"reverent\": {\n dict: \"anew\", word: \"reverent\", stem: \"rever\",\n avg: [ 4, 5.35 ], std: [ 1.6, 1.21 ], fq: 3\n },\n \"revolt\": {\n dict: \"anew\", word: \"revolt\", stem: \"revolt\",\n avg: [ 6.56, 4.13 ], std: [ 2.34, 1.78 ], fq: 8\n },\n \"revolver\": {\n dict: \"anew\", word: \"revolver\", stem: \"revolv\",\n avg: [ 5.55, 4.02 ], std: [ 2.39, 2.44 ], fq: 14\n },\n \"reward\": {\n dict: \"anew\", word: \"reward\", stem: \"reward\",\n avg: [ 4.95, 7.53 ], std: [ 2.62, 1.67 ], fq: 15\n },\n \"riches\": {\n dict: \"anew\", word: \"riches\", stem: \"rich\",\n avg: [ 6.17, 7.7 ], std: [ 2.7, 1.95 ], fq: 2\n },\n \"ridicule\": {\n dict: \"anew\", word: \"ridicule\", stem: \"ridicul\",\n avg: [ 5.83, 3.13 ], std: [ 2.73, 2.24 ], fq: 5\n },\n \"rifle\": {\n dict: \"anew\", word: \"rifle\", stem: \"rifl\",\n avg: [ 6.35, 4.02 ], std: [ 2.04, 2.76 ], fq: 63\n },\n \"rigid\": {\n dict: \"anew\", word: \"rigid\", stem: \"rigid\",\n avg: [ 4.66, 3.66 ], std: [ 2.47, 2.12 ], fq: 24\n },\n \"riot\": {\n dict: \"anew\", word: \"riot\", stem: \"riot\",\n avg: [ 6.39, 2.96 ], std: [ 2.63, 1.93 ], fq: 7\n },\n \"river\": {\n dict: \"anew\", word: \"river\", stem: \"river\",\n avg: [ 4.51, 6.85 ], std: [ 2.42, 1.69 ], fq: 165\n },\n \"roach\": {\n dict: \"anew\", word: \"roach\", stem: \"roach\",\n avg: [ 6.64, 2.35 ], std: [ 2.64, 1.7 ], fq: 2\n },\n \"robber\": {\n dict: \"anew\", word: \"robber\", stem: \"robber\",\n avg: [ 5.62, 2.61 ], std: [ 2.72, 1.69 ], fq: 2\n },\n \"rock\": {\n dict: \"anew\", word: \"rock\", stem: \"rock\",\n avg: [ 4.52, 5.56 ], std: [ 2.37, 1.38 ], fq: 75\n },\n \"rollercoaster\": {\n dict: \"anew\", word: \"rollercoaster\", stem: \"rollercoast\",\n avg: [ 8.06, 8.02 ], std: [ 1.71, 1.63 ], fq: 0\n },\n \"romantic\": {\n dict: \"anew\", word: \"romantic\", stem: \"romant\",\n avg: [ 7.59, 8.32 ], std: [ 2.07, 1 ], fq: 32\n },\n \"rotten\": {\n dict: \"anew\", word: \"rotten\", stem: \"rotten\",\n avg: [ 4.53, 2.26 ], std: [ 2.38, 1.37 ], fq: 2\n },\n \"rough\": {\n dict: \"anew\", word: \"rough\", stem: \"rough\",\n avg: [ 5.33, 4.74 ], std: [ 2.04, 2 ], fq: 41\n },\n \"rude\": {\n dict: \"anew\", word: \"rude\", stem: \"rude\",\n avg: [ 6.31, 2.5 ], std: [ 2.47, 2.11 ], fq: 6\n },\n \"runner\": {\n dict: \"anew\", word: \"runner\", stem: \"runner\",\n avg: [ 4.76, 5.67 ], std: [ 2.4, 1.91 ], fq: 1\n },\n \"rusty\": {\n dict: \"anew\", word: \"rusty\", stem: \"rusti\",\n avg: [ 3.77, 3.86 ], std: [ 2.16, 1.47 ], fq: 8\n },\n \"sad\": {\n dict: \"anew\", word: \"sad\", stem: \"sad\",\n avg: [ 4.13, 1.61 ], std: [ 2.38, 0.95 ], fq: 35\n },\n \"safe\": {\n dict: \"anew\", word: \"safe\", stem: \"safe\",\n avg: [ 3.86, 7.07 ], std: [ 2.72, 1.9 ], fq: 58\n },\n \"sailboat\": {\n dict: \"anew\", word: \"sailboat\", stem: \"sailboat\",\n avg: [ 4.88, 7.25 ], std: [ 2.73, 1.71 ], fq: 1\n },\n \"saint\": {\n dict: \"anew\", word: \"saint\", stem: \"saint\",\n avg: [ 4.49, 6.49 ], std: [ 1.9, 1.7 ], fq: 16\n },\n \"salad\": {\n dict: \"anew\", word: \"salad\", stem: \"salad\",\n avg: [ 3.81, 5.74 ], std: [ 2.29, 1.62 ], fq: 9\n },\n \"salute\": {\n dict: \"anew\", word: \"salute\", stem: \"salut\",\n avg: [ 5.31, 5.92 ], std: [ 2.23, 1.57 ], fq: 3\n },\n \"sapphire\": {\n dict: \"anew\", word: \"sapphire\", stem: \"sapphir\",\n avg: [ 5, 7 ], std: [ 2.72, 1.88 ], fq: 0\n },\n \"satisfied\": {\n dict: \"anew\", word: \"satisfied\", stem: \"satisfi\",\n avg: [ 4.94, 7.94 ], std: [ 2.63, 1.19 ], fq: 36\n },\n \"save\": {\n dict: \"anew\", word: \"save\", stem: \"save\",\n avg: [ 4.95, 6.45 ], std: [ 2.19, 1.93 ], fq: 62\n },\n \"savior\": {\n dict: \"anew\", word: \"savior\", stem: \"savior\",\n avg: [ 5.8, 7.73 ], std: [ 3.01, 1.56 ], fq: 6\n },\n \"scalding\": {\n dict: \"anew\", word: \"scalding\", stem: \"scald\",\n avg: [ 5.95, 2.82 ], std: [ 2.55, 2.12 ], fq: 1\n },\n \"scandal\": {\n dict: \"anew\", word: \"scandal\", stem: \"scandal\",\n avg: [ 5.12, 3.32 ], std: [ 2.22, 1.81 ], fq: 8\n },\n \"scapegoat\": {\n dict: \"anew\", word: \"scapegoat\", stem: \"scapegoat\",\n avg: [ 4.53, 3.67 ], std: [ 2.13, 1.65 ], fq: 1\n },\n \"scar\": {\n dict: \"anew\", word: \"scar\", stem: \"scar\",\n avg: [ 4.79, 3.38 ], std: [ 2.11, 1.7 ], fq: 10\n },\n \"scared\": {\n dict: \"anew\", word: \"scared\", stem: \"scare\",\n avg: [ 6.82, 2.78 ], std: [ 2.03, 1.99 ], fq: 21\n },\n \"scholar\": {\n dict: \"anew\", word: \"scholar\", stem: \"scholar\",\n avg: [ 5.12, 7.26 ], std: [ 2.46, 1.42 ], fq: 15\n },\n \"scissors\": {\n dict: \"anew\", word: \"scissors\", stem: \"scissor\",\n avg: [ 4.47, 5.05 ], std: [ 1.76, 0.96 ], fq: 1\n },\n \"scorching\": {\n dict: \"anew\", word: \"scorching\", stem: \"scorch\",\n avg: [ 5, 3.76 ], std: [ 2.74, 1.83 ], fq: 0\n },\n \"scorn\": {\n dict: \"anew\", word: \"scorn\", stem: \"scorn\",\n avg: [ 5.48, 2.84 ], std: [ 2.52, 2.07 ], fq: 4\n },\n \"scornful\": {\n dict: \"anew\", word: \"scornful\", stem: \"scorn\",\n avg: [ 5.04, 3.02 ], std: [ 2.56, 2.03 ], fq: 5\n },\n \"scorpion\": {\n dict: \"anew\", word: \"scorpion\", stem: \"scorpion\",\n avg: [ 5.38, 3.69 ], std: [ 3.08, 2.63 ], fq: 0\n },\n \"scream\": {\n dict: \"anew\", word: \"scream\", stem: \"scream\",\n avg: [ 7.04, 3.88 ], std: [ 1.96, 2.07 ], fq: 13\n },\n \"scum\": {\n dict: \"anew\", word: \"scum\", stem: \"scum\",\n avg: [ 4.88, 2.43 ], std: [ 2.36, 1.56 ], fq: 0\n },\n \"scurvy\": {\n dict: \"anew\", word: \"scurvy\", stem: \"scurvi\",\n avg: [ 4.71, 3.19 ], std: [ 2.72, 2 ], fq: 1\n },\n \"seasick\": {\n dict: \"anew\", word: \"seasick\", stem: \"seasick\",\n avg: [ 5.8, 2.05 ], std: [ 2.88, 1.2 ], fq: 0\n },\n \"seat\": {\n dict: \"anew\", word: \"seat\", stem: \"seat\",\n avg: [ 2.95, 4.95 ], std: [ 1.72, 0.98 ], fq: 54\n },\n \"secure\": {\n dict: \"anew\", word: \"secure\", stem: \"secur\",\n avg: [ 3.14, 7.57 ], std: [ 2.47, 1.76 ], fq: 30\n },\n \"selfish\": {\n dict: \"anew\", word: \"selfish\", stem: \"selfish\",\n avg: [ 5.5, 2.42 ], std: [ 2.62, 1.62 ], fq: 8\n },\n \"sentiment\": {\n dict: \"anew\", word: \"sentiment\", stem: \"sentiment\",\n avg: [ 4.41, 5.98 ], std: [ 2.3, 1.71 ], fq: 23\n },\n \"serious\": {\n dict: \"anew\", word: \"serious\", stem: \"serious\",\n avg: [ 4, 5.08 ], std: [ 1.87, 1.59 ], fq: 116\n },\n \"severe\": {\n dict: \"anew\", word: \"severe\", stem: \"sever\",\n avg: [ 5.26, 3.2 ], std: [ 2.36, 1.74 ], fq: 39\n },\n \"sex\": {\n dict: \"anew\", word: \"sex\", stem: \"sex\",\n avg: [ 7.36, 8.05 ], std: [ 1.91, 1.53 ], fq: 84\n },\n \"sexy\": {\n dict: \"anew\", word: \"sexy\", stem: \"sexi\",\n avg: [ 7.36, 8.02 ], std: [ 1.91, 1.12 ], fq: 2\n },\n \"shadow\": {\n dict: \"anew\", word: \"shadow\", stem: \"shadow\",\n avg: [ 4.3, 4.35 ], std: [ 2.26, 1.23 ], fq: 36\n },\n \"shamed\": {\n dict: \"anew\", word: \"shamed\", stem: \"shame\",\n avg: [ 4.88, 2.5 ], std: [ 2.27, 1.34 ], fq: 1\n },\n \"shark\": {\n dict: \"anew\", word: \"shark\", stem: \"shark\",\n avg: [ 7.16, 3.65 ], std: [ 1.96, 2.47 ], fq: 0\n },\n \"sheltered\": {\n dict: \"anew\", word: \"sheltered\", stem: \"shelter\",\n avg: [ 4.28, 5.75 ], std: [ 1.77, 1.92 ], fq: 4\n },\n \"ship\": {\n dict: \"anew\", word: \"ship\", stem: \"ship\",\n avg: [ 4.38, 5.55 ], std: [ 2.29, 1.4 ], fq: 83\n },\n \"shotgun\": {\n dict: \"anew\", word: \"shotgun\", stem: \"shotgun\",\n avg: [ 6.27, 4.37 ], std: [ 1.94, 2.75 ], fq: 8\n },\n \"shriek\": {\n dict: \"anew\", word: \"shriek\", stem: \"shriek\",\n avg: [ 5.36, 3.93 ], std: [ 2.91, 2.22 ], fq: 5\n },\n \"shy\": {\n dict: \"anew\", word: \"shy\", stem: \"shi\",\n avg: [ 3.77, 4.64 ], std: [ 2.29, 1.83 ], fq: 13\n },\n \"sick\": {\n dict: \"anew\", word: \"sick\", stem: \"sick\",\n avg: [ 4.29, 1.9 ], std: [ 2.45, 1.14 ], fq: 51\n },\n \"sickness\": {\n dict: \"anew\", word: \"sickness\", stem: \"sick\",\n avg: [ 5.61, 2.25 ], std: [ 2.67, 1.71 ], fq: 6\n },\n \"silk\": {\n dict: \"anew\", word: \"silk\", stem: \"silk\",\n avg: [ 3.71, 6.9 ], std: [ 2.51, 1.27 ], fq: 12\n },\n \"silly\": {\n dict: \"anew\", word: \"silly\", stem: \"silli\",\n avg: [ 5.88, 7.41 ], std: [ 2.38, 1.8 ], fq: 15\n },\n \"sin\": {\n dict: \"anew\", word: \"sin\", stem: \"sin\",\n avg: [ 5.78, 2.8 ], std: [ 2.21, 1.67 ], fq: 53\n },\n \"sinful\": {\n dict: \"anew\", word: \"sinful\", stem: \"sin\",\n avg: [ 6.29, 2.93 ], std: [ 2.43, 2.15 ], fq: 3\n },\n \"sissy\": {\n dict: \"anew\", word: \"sissy\", stem: \"sissi\",\n avg: [ 5.17, 3.14 ], std: [ 2.57, 1.96 ], fq: 0\n },\n \"skeptical\": {\n dict: \"anew\", word: \"skeptical\", stem: \"skeptic\",\n avg: [ 4.91, 4.52 ], std: [ 1.92, 1.63 ], fq: 7\n },\n \"skijump\": {\n dict: \"anew\", word: \"skijump\", stem: \"skijump\",\n avg: [ 7.06, 7.06 ], std: [ 2.1, 1.73 ], fq: 0\n },\n \"skull\": {\n dict: \"anew\", word: \"skull\", stem: \"skull\",\n avg: [ 4.75, 4.27 ], std: [ 1.85, 1.83 ], fq: 3\n },\n \"sky\": {\n dict: \"anew\", word: \"sky\", stem: \"sky\",\n avg: [ 4.27, 7.37 ], std: [ 2.17, 1.4 ], fq: 58\n },\n \"skyscraper\": {\n dict: \"anew\", word: \"skyscraper\", stem: \"skyscrap\",\n avg: [ 5.71, 5.88 ], std: [ 2.17, 1.87 ], fq: 2\n },\n \"slap\": {\n dict: \"anew\", word: \"slap\", stem: \"slap\",\n avg: [ 6.46, 2.95 ], std: [ 2.58, 1.79 ], fq: 2\n },\n \"slaughter\": {\n dict: \"anew\", word: \"slaughter\", stem: \"slaughter\",\n avg: [ 6.77, 1.64 ], std: [ 2.42, 1.18 ], fq: 10\n },\n \"slave\": {\n dict: \"anew\", word: \"slave\", stem: \"slave\",\n avg: [ 6.21, 1.84 ], std: [ 2.93, 1.13 ], fq: 30\n },\n \"sleep\": {\n dict: \"anew\", word: \"sleep\", stem: \"sleep\",\n avg: [ 2.8, 7.2 ], std: [ 2.66, 1.77 ], fq: 65\n },\n \"slime\": {\n dict: \"anew\", word: \"slime\", stem: \"slime\",\n avg: [ 5.36, 2.68 ], std: [ 2.63, 1.66 ], fq: 1\n },\n \"slow\": {\n dict: \"anew\", word: \"slow\", stem: \"slow\",\n avg: [ 3.39, 3.93 ], std: [ 2.22, 1.6 ], fq: 60\n },\n \"slum\": {\n dict: \"anew\", word: \"slum\", stem: \"slum\",\n avg: [ 4.78, 2.39 ], std: [ 2.52, 1.25 ], fq: 8\n },\n \"slush\": {\n dict: \"anew\", word: \"slush\", stem: \"slush\",\n avg: [ 3.73, 4.66 ], std: [ 2.23, 1.88 ], fq: 0\n },\n \"smallpox\": {\n dict: \"anew\", word: \"smallpox\", stem: \"smallpox\",\n avg: [ 5.58, 2.52 ], std: [ 2.13, 2.08 ], fq: 2\n },\n \"smooth\": {\n dict: \"anew\", word: \"smooth\", stem: \"smooth\",\n avg: [ 4.91, 6.58 ], std: [ 2.57, 1.78 ], fq: 42\n },\n \"snake\": {\n dict: \"anew\", word: \"snake\", stem: \"snake\",\n avg: [ 6.82, 3.31 ], std: [ 2.1, 2.2 ], fq: 44\n },\n \"snob\": {\n dict: \"anew\", word: \"snob\", stem: \"snob\",\n avg: [ 5.65, 3.36 ], std: [ 2.36, 1.81 ], fq: 1\n },\n \"snow\": {\n dict: \"anew\", word: \"snow\", stem: \"snow\",\n avg: [ 5.75, 7.08 ], std: [ 2.47, 1.83 ], fq: 59\n },\n \"snuggle\": {\n dict: \"anew\", word: \"snuggle\", stem: \"snuggl\",\n avg: [ 4.16, 7.92 ], std: [ 2.8, 1.24 ], fq: 4\n },\n \"social\": {\n dict: \"anew\", word: \"social\", stem: \"social\",\n avg: [ 4.98, 6.88 ], std: [ 2.59, 1.82 ], fq: 380\n },\n \"soft\": {\n dict: \"anew\", word: \"soft\", stem: \"soft\",\n avg: [ 4.63, 7.12 ], std: [ 2.61, 1.34 ], fq: 61\n },\n \"solemn\": {\n dict: \"anew\", word: \"solemn\", stem: \"solemn\",\n avg: [ 3.56, 4.32 ], std: [ 1.95, 1.51 ], fq: 12\n },\n \"song\": {\n dict: \"anew\", word: \"song\", stem: \"song\",\n avg: [ 6.07, 7.1 ], std: [ 2.42, 1.97 ], fq: 70\n },\n \"soothe\": {\n dict: \"anew\", word: \"soothe\", stem: \"sooth\",\n avg: [ 4.4, 7.3 ], std: [ 3.08, 1.85 ], fq: 2\n },\n \"sour\": {\n dict: \"anew\", word: \"sour\", stem: \"sour\",\n avg: [ 5.1, 3.93 ], std: [ 1.95, 1.98 ], fq: 3\n },\n \"space\": {\n dict: \"anew\", word: \"space\", stem: \"space\",\n avg: [ 5.14, 6.78 ], std: [ 2.54, 1.66 ], fq: 184\n },\n \"spanking\": {\n dict: \"anew\", word: \"spanking\", stem: \"spank\",\n avg: [ 5.41, 3.55 ], std: [ 2.73, 2.54 ], fq: 0\n },\n \"sphere\": {\n dict: \"anew\", word: \"sphere\", stem: \"sphere\",\n avg: [ 3.88, 5.33 ], std: [ 1.99, 0.87 ], fq: 22\n },\n \"spider\": {\n dict: \"anew\", word: \"spider\", stem: \"spider\",\n avg: [ 5.71, 3.33 ], std: [ 2.21, 1.72 ], fq: 2\n },\n \"spirit\": {\n dict: \"anew\", word: \"spirit\", stem: \"spirit\",\n avg: [ 5.56, 7 ], std: [ 2.62, 1.32 ], fq: 182\n },\n \"spouse\": {\n dict: \"anew\", word: \"spouse\", stem: \"spous\",\n avg: [ 5.21, 7.58 ], std: [ 2.75, 1.48 ], fq: 3\n },\n \"spray\": {\n dict: \"anew\", word: \"spray\", stem: \"spray\",\n avg: [ 4.14, 5.45 ], std: [ 2.28, 1.63 ], fq: 16\n },\n \"spring\": {\n dict: \"anew\", word: \"spring\", stem: \"spring\",\n avg: [ 5.67, 7.76 ], std: [ 2.51, 1.51 ], fq: 127\n },\n \"square\": {\n dict: \"anew\", word: \"square\", stem: \"squar\",\n avg: [ 3.18, 4.74 ], std: [ 1.76, 1.02 ], fq: 143\n },\n \"stagnant\": {\n dict: \"anew\", word: \"stagnant\", stem: \"stagnant\",\n avg: [ 3.93, 4.15 ], std: [ 1.94, 1.57 ], fq: 5\n },\n \"star\": {\n dict: \"anew\", word: \"star\", stem: \"star\",\n avg: [ 5.83, 7.27 ], std: [ 2.44, 1.66 ], fq: 25\n },\n \"startled\": {\n dict: \"anew\", word: \"startled\", stem: \"startl\",\n avg: [ 6.93, 4.5 ], std: [ 2.24, 1.67 ], fq: 21\n },\n \"starving\": {\n dict: \"anew\", word: \"starving\", stem: \"starv\",\n avg: [ 5.61, 2.39 ], std: [ 2.53, 1.82 ], fq: 6\n },\n \"statue\": {\n dict: \"anew\", word: \"statue\", stem: \"statu\",\n avg: [ 3.46, 5.17 ], std: [ 1.72, 0.7 ], fq: 17\n },\n \"stench\": {\n dict: \"anew\", word: \"stench\", stem: \"stench\",\n avg: [ 4.36, 2.19 ], std: [ 2.46, 1.37 ], fq: 1\n },\n \"stiff\": {\n dict: \"anew\", word: \"stiff\", stem: \"stiff\",\n avg: [ 4.02, 4.68 ], std: [ 2.41, 1.97 ], fq: 21\n },\n \"stink\": {\n dict: \"anew\", word: \"stink\", stem: \"stink\",\n avg: [ 4.26, 3 ], std: [ 2.1, 1.79 ], fq: 3\n },\n \"stomach\": {\n dict: \"anew\", word: \"stomach\", stem: \"stomach\",\n avg: [ 3.93, 4.82 ], std: [ 2.49, 2.06 ], fq: 37\n },\n \"stool\": {\n dict: \"anew\", word: \"stool\", stem: \"stool\",\n avg: [ 4, 4.56 ], std: [ 2.14, 1.72 ], fq: 8\n },\n \"storm\": {\n dict: \"anew\", word: \"storm\", stem: \"storm\",\n avg: [ 5.71, 4.95 ], std: [ 2.34, 2.22 ], fq: 26\n },\n \"stove\": {\n dict: \"anew\", word: \"stove\", stem: \"stove\",\n avg: [ 4.51, 4.98 ], std: [ 2.14, 1.69 ], fq: 15\n },\n \"street\": {\n dict: \"anew\", word: \"street\", stem: \"street\",\n avg: [ 3.39, 5.22 ], std: [ 1.87, 0.72 ], fq: 244\n },\n \"stress\": {\n dict: \"anew\", word: \"stress\", stem: \"stress\",\n avg: [ 7.45, 2.09 ], std: [ 2.38, 1.41 ], fq: 107\n },\n \"strong\": {\n dict: \"anew\", word: \"strong\", stem: \"strong\",\n avg: [ 5.92, 7.11 ], std: [ 2.28, 1.48 ], fq: 202\n },\n \"stupid\": {\n dict: \"anew\", word: \"stupid\", stem: \"stupid\",\n avg: [ 4.72, 2.31 ], std: [ 2.71, 1.37 ], fq: 24\n },\n \"subdued\": {\n dict: \"anew\", word: \"subdued\", stem: \"subdu\",\n avg: [ 2.9, 4.67 ], std: [ 1.81, 1.31 ], fq: 8\n },\n \"success\": {\n dict: \"anew\", word: \"success\", stem: \"success\",\n avg: [ 6.11, 8.29 ], std: [ 2.65, 0.93 ], fq: 93\n },\n \"suffocate\": {\n dict: \"anew\", word: \"suffocate\", stem: \"suffoc\",\n avg: [ 6.03, 1.56 ], std: [ 3.19, 0.96 ], fq: 1\n },\n \"sugar\": {\n dict: \"anew\", word: \"sugar\", stem: \"sugar\",\n avg: [ 5.64, 6.74 ], std: [ 2.18, 1.73 ], fq: 34\n },\n \"suicide\": {\n dict: \"anew\", word: \"suicide\", stem: \"suicid\",\n avg: [ 5.73, 1.25 ], std: [ 3.14, 0.69 ], fq: 17\n },\n \"sun\": {\n dict: \"anew\", word: \"sun\", stem: \"sun\",\n avg: [ 5.04, 7.55 ], std: [ 2.66, 1.85 ], fq: 112\n },\n \"sunlight\": {\n dict: \"anew\", word: \"sunlight\", stem: \"sunlight\",\n avg: [ 6.1, 7.76 ], std: [ 2.3, 1.43 ], fq: 17\n },\n \"sunrise\": {\n dict: \"anew\", word: \"sunrise\", stem: \"sunris\",\n avg: [ 5.06, 7.86 ], std: [ 3.05, 1.35 ], fq: 10\n },\n \"sunset\": {\n dict: \"anew\", word: \"sunset\", stem: \"sunset\",\n avg: [ 4.2, 7.68 ], std: [ 2.99, 1.72 ], fq: 14\n },\n \"surgery\": {\n dict: \"anew\", word: \"surgery\", stem: \"surgeri\",\n avg: [ 6.35, 2.86 ], std: [ 2.32, 2.19 ], fq: 6\n },\n \"surprised\": {\n dict: \"anew\", word: \"surprised\", stem: \"surpris\",\n avg: [ 7.47, 7.47 ], std: [ 2.09, 1.56 ], fq: 58\n },\n \"suspicious\": {\n dict: \"anew\", word: \"suspicious\", stem: \"suspici\",\n avg: [ 6.25, 3.76 ], std: [ 1.59, 1.42 ], fq: 13\n },\n \"swamp\": {\n dict: \"anew\", word: \"swamp\", stem: \"swamp\",\n avg: [ 4.86, 5.14 ], std: [ 2.36, 2.24 ], fq: 5\n },\n \"sweetheart\": {\n dict: \"anew\", word: \"sweetheart\", stem: \"sweetheart\",\n avg: [ 5.5, 8.42 ], std: [ 2.73, 0.83 ], fq: 9\n },\n \"swift\": {\n dict: \"anew\", word: \"swift\", stem: \"swift\",\n avg: [ 5.39, 6.46 ], std: [ 2.53, 1.76 ], fq: 32\n },\n \"swimmer\": {\n dict: \"anew\", word: \"swimmer\", stem: \"swimmer\",\n avg: [ 4.82, 6.54 ], std: [ 2.49, 1.64 ], fq: 0\n },\n \"syphilis\": {\n dict: \"anew\", word: \"syphilis\", stem: \"syphili\",\n avg: [ 5.69, 1.68 ], std: [ 3.25, 1.23 ], fq: 0\n },\n \"table\": {\n dict: \"anew\", word: \"table\", stem: \"tabl\",\n avg: [ 2.92, 5.22 ], std: [ 2.16, 0.72 ], fq: 198\n },\n \"talent\": {\n dict: \"anew\", word: \"talent\", stem: \"talent\",\n avg: [ 6.27, 7.56 ], std: [ 1.8, 1.25 ], fq: 40\n },\n \"tamper\": {\n dict: \"anew\", word: \"tamper\", stem: \"tamper\",\n avg: [ 4.95, 4.1 ], std: [ 2.01, 1.88 ], fq: 1\n },\n \"tank\": {\n dict: \"anew\", word: \"tank\", stem: \"tank\",\n avg: [ 4.88, 5.16 ], std: [ 1.86, 1.87 ], fq: 12\n },\n \"taste\": {\n dict: \"anew\", word: \"taste\", stem: \"tast\",\n avg: [ 5.22, 6.66 ], std: [ 2.38, 1.57 ], fq: 59\n },\n \"taxi\": {\n dict: \"anew\", word: \"taxi\", stem: \"taxi\",\n avg: [ 3.41, 5 ], std: [ 2.14, 1.96 ], fq: 16\n },\n \"teacher\": {\n dict: \"anew\", word: \"teacher\", stem: \"teacher\",\n avg: [ 4.05, 5.68 ], std: [ 2.61, 2.12 ], fq: 80\n },\n \"tease\": {\n dict: \"anew\", word: \"tease\", stem: \"teas\",\n avg: [ 5.87, 4.84 ], std: [ 2.56, 2.51 ], fq: 6\n },\n \"tender\": {\n dict: \"anew\", word: \"tender\", stem: \"tender\",\n avg: [ 4.88, 6.93 ], std: [ 2.3, 1.28 ], fq: 11\n },\n \"tennis\": {\n dict: \"anew\", word: \"tennis\", stem: \"tenni\",\n avg: [ 4.61, 6.02 ], std: [ 2.6, 1.97 ], fq: 15\n },\n \"tense\": {\n dict: \"anew\", word: \"tense\", stem: \"tens\",\n avg: [ 6.53, 3.56 ], std: [ 2.1, 1.36 ], fq: 15\n },\n \"termite\": {\n dict: \"anew\", word: \"termite\", stem: \"termit\",\n avg: [ 5.39, 3.58 ], std: [ 2.43, 2.08 ], fq: 0\n },\n \"terrible\": {\n dict: \"anew\", word: \"terrible\", stem: \"terribl\",\n avg: [ 6.27, 1.93 ], std: [ 2.44, 1.44 ], fq: 45\n },\n \"terrific\": {\n dict: \"anew\", word: \"terrific\", stem: \"terrif\",\n avg: [ 6.23, 8.16 ], std: [ 2.73, 1.12 ], fq: 5\n },\n \"terrified\": {\n dict: \"anew\", word: \"terrified\", stem: \"terrifi\",\n avg: [ 7.86, 1.72 ], std: [ 2.27, 1.14 ], fq: 7\n },\n \"terrorist\": {\n dict: \"anew\", word: \"terrorist\", stem: \"terrorist\",\n avg: [ 7.27, 1.69 ], std: [ 2.38, 1.42 ], fq: 0\n },\n \"thankful\": {\n dict: \"anew\", word: \"thankful\", stem: \"thank\",\n avg: [ 4.34, 6.89 ], std: [ 2.31, 2.29 ], fq: 6\n },\n \"theory\": {\n dict: \"anew\", word: \"theory\", stem: \"theori\",\n avg: [ 4.62, 5.3 ], std: [ 1.94, 1.49 ], fq: 129\n },\n \"thermometer\": {\n dict: \"anew\", word: \"thermometer\", stem: \"thermomet\",\n avg: [ 3.79, 4.73 ], std: [ 2.02, 1.05 ], fq: 0\n },\n \"thief\": {\n dict: \"anew\", word: \"thief\", stem: \"thief\",\n avg: [ 6.89, 2.13 ], std: [ 2.13, 1.69 ], fq: 8\n },\n \"thorn\": {\n dict: \"anew\", word: \"thorn\", stem: \"thorn\",\n avg: [ 5.14, 3.64 ], std: [ 2.14, 1.76 ], fq: 3\n },\n \"thought\": {\n dict: \"anew\", word: \"thought\", stem: \"thought\",\n avg: [ 4.83, 6.39 ], std: [ 2.46, 1.58 ], fq: 515\n },\n \"thoughtful\": {\n dict: \"anew\", word: \"thoughtful\", stem: \"thought\",\n avg: [ 5.72, 7.65 ], std: [ 2.3, 1.03 ], fq: 11\n },\n \"thrill\": {\n dict: \"anew\", word: \"thrill\", stem: \"thrill\",\n avg: [ 8.02, 8.05 ], std: [ 1.65, 1.48 ], fq: 5\n },\n \"tidy\": {\n dict: \"anew\", word: \"tidy\", stem: \"tidi\",\n avg: [ 3.98, 6.3 ], std: [ 2.22, 1.56 ], fq: 1\n },\n \"time\": {\n dict: \"anew\", word: \"time\", stem: \"time\",\n avg: [ 4.64, 5.31 ], std: [ 2.75, 2.02 ], fq: 1599\n },\n \"timid\": {\n dict: \"anew\", word: \"timid\", stem: \"timid\",\n avg: [ 4.11, 3.86 ], std: [ 2.09, 1.55 ], fq: 5\n },\n \"tobacco\": {\n dict: \"anew\", word: \"tobacco\", stem: \"tobacco\",\n avg: [ 4.83, 3.28 ], std: [ 2.9, 2.16 ], fq: 19\n },\n \"tomb\": {\n dict: \"anew\", word: \"tomb\", stem: \"tomb\",\n avg: [ 4.73, 2.94 ], std: [ 2.72, 1.88 ], fq: 11\n },\n \"tool\": {\n dict: \"anew\", word: \"tool\", stem: \"tool\",\n avg: [ 4.33, 5.19 ], std: [ 1.78, 1.27 ], fq: 40\n },\n \"toothache\": {\n dict: \"anew\", word: \"toothache\", stem: \"toothach\",\n avg: [ 5.55, 1.98 ], std: [ 2.51, 1.15 ], fq: 0\n },\n \"tornado\": {\n dict: \"anew\", word: \"tornado\", stem: \"tornado\",\n avg: [ 6.83, 2.55 ], std: [ 2.49, 1.78 ], fq: 1\n },\n \"torture\": {\n dict: \"anew\", word: \"torture\", stem: \"tortur\",\n avg: [ 6.1, 1.56 ], std: [ 2.77, 0.79 ], fq: 3\n },\n \"tower\": {\n dict: \"anew\", word: \"tower\", stem: \"tower\",\n avg: [ 3.95, 5.46 ], std: [ 2.28, 1.75 ], fq: 13\n },\n \"toxic\": {\n dict: \"anew\", word: \"toxic\", stem: \"toxic\",\n avg: [ 6.4, 2.1 ], std: [ 2.41, 1.48 ], fq: 3\n },\n \"toy\": {\n dict: \"anew\", word: \"toy\", stem: \"toy\",\n avg: [ 5.11, 7 ], std: [ 2.84, 2.01 ], fq: 4\n },\n \"tragedy\": {\n dict: \"anew\", word: \"tragedy\", stem: \"tragedi\",\n avg: [ 6.24, 1.78 ], std: [ 2.64, 1.31 ], fq: 49\n },\n \"traitor\": {\n dict: \"anew\", word: \"traitor\", stem: \"traitor\",\n avg: [ 5.78, 2.22 ], std: [ 2.47, 1.69 ], fq: 2\n },\n \"trash\": {\n dict: \"anew\", word: \"trash\", stem: \"trash\",\n avg: [ 4.16, 2.67 ], std: [ 2.16, 1.45 ], fq: 2\n },\n \"trauma\": {\n dict: \"anew\", word: \"trauma\", stem: \"trauma\",\n avg: [ 6.33, 2.1 ], std: [ 2.45, 1.49 ], fq: 1\n },\n \"travel\": {\n dict: \"anew\", word: \"travel\", stem: \"travel\",\n avg: [ 6.21, 7.1 ], std: [ 2.51, 2 ], fq: 61\n },\n \"treasure\": {\n dict: \"anew\", word: \"treasure\", stem: \"treasur\",\n avg: [ 6.75, 8.27 ], std: [ 2.3, 0.9 ], fq: 4\n },\n \"treat\": {\n dict: \"anew\", word: \"treat\", stem: \"treat\",\n avg: [ 5.62, 7.36 ], std: [ 2.25, 1.38 ], fq: 26\n },\n \"tree\": {\n dict: \"anew\", word: \"tree\", stem: \"tree\",\n avg: [ 3.42, 6.32 ], std: [ 2.21, 1.56 ], fq: 59\n },\n \"triumph\": {\n dict: \"anew\", word: \"triumph\", stem: \"triumph\",\n avg: [ 5.78, 7.8 ], std: [ 2.6, 1.83 ], fq: 22\n },\n \"triumphant\": {\n dict: \"anew\", word: \"triumphant\", stem: \"triumphant\",\n avg: [ 6.78, 8.82 ], std: [ 2.58, 0.73 ], fq: 5\n },\n \"trophy\": {\n dict: \"anew\", word: \"trophy\", stem: \"trophi\",\n avg: [ 5.39, 7.78 ], std: [ 2.44, 1.22 ], fq: 8\n },\n \"trouble\": {\n dict: \"anew\", word: \"trouble\", stem: \"troubl\",\n avg: [ 6.85, 3.03 ], std: [ 2.03, 2.09 ], fq: 134\n },\n \"troubled\": {\n dict: \"anew\", word: \"troubled\", stem: \"troubl\",\n avg: [ 5.94, 2.17 ], std: [ 2.36, 1.21 ], fq: 31\n },\n \"truck\": {\n dict: \"anew\", word: \"truck\", stem: \"truck\",\n avg: [ 4.84, 5.47 ], std: [ 2.17, 1.88 ], fq: 57\n },\n \"trumpet\": {\n dict: \"anew\", word: \"trumpet\", stem: \"trumpet\",\n avg: [ 4.97, 5.75 ], std: [ 2.13, 1.38 ], fq: 7\n },\n \"trunk\": {\n dict: \"anew\", word: \"trunk\", stem: \"trunk\",\n avg: [ 4.18, 5.09 ], std: [ 2.19, 1.57 ], fq: 8\n },\n \"trust\": {\n dict: \"anew\", word: \"trust\", stem: \"trust\",\n avg: [ 5.3, 6.68 ], std: [ 2.66, 2.71 ], fq: 52\n },\n \"truth\": {\n dict: \"anew\", word: \"truth\", stem: \"truth\",\n avg: [ 5, 7.8 ], std: [ 2.77, 1.29 ], fq: 126\n },\n \"tumor\": {\n dict: \"anew\", word: \"tumor\", stem: \"tumor\",\n avg: [ 6.51, 2.36 ], std: [ 2.85, 2.04 ], fq: 17\n },\n \"tune\": {\n dict: \"anew\", word: \"tune\", stem: \"tune\",\n avg: [ 4.71, 6.93 ], std: [ 2.09, 1.47 ], fq: 10\n },\n \"twilight\": {\n dict: \"anew\", word: \"twilight\", stem: \"twilight\",\n avg: [ 4.7, 7.23 ], std: [ 2.41, 1.8 ], fq: 4\n },\n \"ugly\": {\n dict: \"anew\", word: \"ugly\", stem: \"ugli\",\n avg: [ 5.38, 2.43 ], std: [ 2.23, 1.27 ], fq: 21\n },\n \"ulcer\": {\n dict: \"anew\", word: \"ulcer\", stem: \"ulcer\",\n avg: [ 6.12, 1.78 ], std: [ 2.68, 1.17 ], fq: 5\n },\n \"umbrella\": {\n dict: \"anew\", word: \"umbrella\", stem: \"umbrella\",\n avg: [ 3.68, 5.16 ], std: [ 1.99, 1.57 ], fq: 8\n },\n \"unfaithful\": {\n dict: \"anew\", word: \"unfaithful\", stem: \"unfaith\",\n avg: [ 6.2, 2.05 ], std: [ 2.7, 1.55 ], fq: 1\n },\n \"unhappy\": {\n dict: \"anew\", word: \"unhappy\", stem: \"unhappi\",\n avg: [ 4.18, 1.57 ], std: [ 2.5, 0.96 ], fq: 26\n },\n \"unit\": {\n dict: \"anew\", word: \"unit\", stem: \"unit\",\n avg: [ 3.75, 5.59 ], std: [ 2.49, 1.87 ], fq: 103\n },\n \"untroubled\": {\n dict: \"anew\", word: \"untroubled\", stem: \"untroubl\",\n avg: [ 3.89, 7.62 ], std: [ 2.54, 1.41 ], fq: 0\n },\n \"upset\": {\n dict: \"anew\", word: \"upset\", stem: \"upset\",\n avg: [ 5.86, 2 ], std: [ 2.4, 1.18 ], fq: 14\n },\n \"urine\": {\n dict: \"anew\", word: \"urine\", stem: \"urin\",\n avg: [ 4.2, 3.25 ], std: [ 2.18, 1.71 ], fq: 1\n },\n \"useful\": {\n dict: \"anew\", word: \"useful\", stem: \"use\",\n avg: [ 4.26, 7.14 ], std: [ 2.47, 1.6 ], fq: 58\n },\n \"useless\": {\n dict: \"anew\", word: \"useless\", stem: \"useless\",\n avg: [ 4.87, 2.13 ], std: [ 2.58, 1.42 ], fq: 17\n },\n \"utensil\": {\n dict: \"anew\", word: \"utensil\", stem: \"utensil\",\n avg: [ 3.57, 5.14 ], std: [ 1.98, 1.39 ], fq: 0\n },\n \"vacation\": {\n dict: \"anew\", word: \"vacation\", stem: \"vacat\",\n avg: [ 5.64, 8.16 ], std: [ 2.99, 1.36 ], fq: 47\n },\n \"vagina\": {\n dict: \"anew\", word: \"vagina\", stem: \"vagina\",\n avg: [ 5.55, 6.14 ], std: [ 2.55, 1.77 ], fq: 10\n },\n \"valentine\": {\n dict: \"anew\", word: \"valentine\", stem: \"valentin\",\n avg: [ 6.06, 8.11 ], std: [ 2.91, 1.35 ], fq: 2\n },\n \"vampire\": {\n dict: \"anew\", word: \"vampire\", stem: \"vampir\",\n avg: [ 6.37, 4.26 ], std: [ 2.35, 1.86 ], fq: 1\n },\n \"vandal\": {\n dict: \"anew\", word: \"vandal\", stem: \"vandal\",\n avg: [ 6.4, 2.71 ], std: [ 1.88, 1.91 ], fq: 1\n },\n \"vanity\": {\n dict: \"anew\", word: \"vanity\", stem: \"vaniti\",\n avg: [ 4.98, 4.3 ], std: [ 2.31, 1.91 ], fq: 7\n },\n \"vehicle\": {\n dict: \"anew\", word: \"vehicle\", stem: \"vehicl\",\n avg: [ 4.63, 6.27 ], std: [ 2.81, 2.34 ], fq: 35\n },\n \"venom\": {\n dict: \"anew\", word: \"venom\", stem: \"venom\",\n avg: [ 6.08, 2.68 ], std: [ 2.44, 1.81 ], fq: 2\n },\n \"vest\": {\n dict: \"anew\", word: \"vest\", stem: \"vest\",\n avg: [ 3.95, 5.25 ], std: [ 2.09, 1.33 ], fq: 4\n },\n \"victim\": {\n dict: \"anew\", word: \"victim\", stem: \"victim\",\n avg: [ 6.06, 2.18 ], std: [ 2.32, 1.48 ], fq: 27\n },\n \"victory\": {\n dict: \"anew\", word: \"victory\", stem: \"victori\",\n avg: [ 6.63, 8.32 ], std: [ 2.84, 1.16 ], fq: 61\n },\n \"vigorous\": {\n dict: \"anew\", word: \"vigorous\", stem: \"vigor\",\n avg: [ 5.9, 6.79 ], std: [ 2.66, 1.54 ], fq: 29\n },\n \"village\": {\n dict: \"anew\", word: \"village\", stem: \"villag\",\n avg: [ 4.08, 5.92 ], std: [ 1.87, 1.34 ], fq: 72\n },\n \"violent\": {\n dict: \"anew\", word: \"violent\", stem: \"violent\",\n avg: [ 6.89, 2.29 ], std: [ 2.47, 1.78 ], fq: 33\n },\n \"violin\": {\n dict: \"anew\", word: \"violin\", stem: \"violin\",\n avg: [ 3.49, 5.43 ], std: [ 2.26, 1.98 ], fq: 11\n },\n \"virgin\": {\n dict: \"anew\", word: \"virgin\", stem: \"virgin\",\n avg: [ 5.51, 6.45 ], std: [ 2.06, 1.76 ], fq: 35\n },\n \"virtue\": {\n dict: \"anew\", word: \"virtue\", stem: \"virtu\",\n avg: [ 4.52, 6.22 ], std: [ 2.52, 2.06 ], fq: 30\n },\n \"vision\": {\n dict: \"anew\", word: \"vision\", stem: \"vision\",\n avg: [ 4.66, 6.62 ], std: [ 2.43, 1.84 ], fq: 56\n },\n \"volcano\": {\n dict: \"anew\", word: \"volcano\", stem: \"volcano\",\n avg: [ 6.33, 4.84 ], std: [ 2.21, 2.14 ], fq: 2\n },\n \"vomit\": {\n dict: \"anew\", word: \"vomit\", stem: \"vomit\",\n avg: [ 5.75, 2.06 ], std: [ 2.84, 1.57 ], fq: 3\n },\n \"voyage\": {\n dict: \"anew\", word: \"voyage\", stem: \"voyag\",\n avg: [ 5.55, 6.25 ], std: [ 2.23, 1.91 ], fq: 17\n },\n \"wagon\": {\n dict: \"anew\", word: \"wagon\", stem: \"wagon\",\n avg: [ 3.98, 5.37 ], std: [ 2.04, 0.97 ], fq: 55\n },\n \"war\": {\n dict: \"anew\", word: \"war\", stem: \"war\",\n avg: [ 7.49, 2.08 ], std: [ 2.16, 1.91 ], fq: 464\n },\n \"warmth\": {\n dict: \"anew\", word: \"warmth\", stem: \"warmth\",\n avg: [ 3.73, 7.41 ], std: [ 2.4, 1.81 ], fq: 28\n },\n \"wasp\": {\n dict: \"anew\", word: \"wasp\", stem: \"wasp\",\n avg: [ 5.5, 3.37 ], std: [ 2.17, 1.63 ], fq: 2\n },\n \"waste\": {\n dict: \"anew\", word: \"waste\", stem: \"wast\",\n avg: [ 4.14, 2.93 ], std: [ 2.3, 1.76 ], fq: 35\n },\n \"watch\": {\n dict: \"anew\", word: \"watch\", stem: \"watch\",\n avg: [ 4.1, 5.78 ], std: [ 2.12, 1.51 ], fq: 81\n },\n \"water\": {\n dict: \"anew\", word: \"water\", stem: \"water\",\n avg: [ 4.97, 6.61 ], std: [ 2.49, 1.78 ], fq: 442\n },\n \"waterfall\": {\n dict: \"anew\", word: \"waterfall\", stem: \"waterfal\",\n avg: [ 5.37, 7.88 ], std: [ 2.84, 1.03 ], fq: 2\n },\n \"wealthy\": {\n dict: \"anew\", word: \"wealthy\", stem: \"wealthi\",\n avg: [ 5.8, 7.7 ], std: [ 2.73, 1.34 ], fq: 12\n },\n \"weapon\": {\n dict: \"anew\", word: \"weapon\", stem: \"weapon\",\n avg: [ 6.03, 3.97 ], std: [ 1.89, 1.92 ], fq: 42\n },\n \"weary\": {\n dict: \"anew\", word: \"weary\", stem: \"weari\",\n avg: [ 3.81, 3.79 ], std: [ 2.29, 2.12 ], fq: 17\n },\n \"wedding\": {\n dict: \"anew\", word: \"wedding\", stem: \"wed\",\n avg: [ 5.97, 7.82 ], std: [ 2.85, 1.56 ], fq: 32\n },\n \"whistle\": {\n dict: \"anew\", word: \"whistle\", stem: \"whistl\",\n avg: [ 4.69, 5.81 ], std: [ 1.99, 1.21 ], fq: 4\n },\n \"white\": {\n dict: \"anew\", word: \"white\", stem: \"white\",\n avg: [ 4.37, 6.47 ], std: [ 2.14, 1.59 ], fq: 365\n },\n \"whore\": {\n dict: \"anew\", word: \"whore\", stem: \"whore\",\n avg: [ 5.85, 2.3 ], std: [ 2.93, 2.11 ], fq: 2\n },\n \"wicked\": {\n dict: \"anew\", word: \"wicked\", stem: \"wick\",\n avg: [ 6.09, 2.96 ], std: [ 2.44, 2.37 ], fq: 9\n },\n \"wife\": {\n dict: \"anew\", word: \"wife\", stem: \"wife\",\n avg: [ 4.93, 6.33 ], std: [ 2.22, 1.97 ], fq: 228\n },\n \"win\": {\n dict: \"anew\", word: \"win\", stem: \"win\",\n avg: [ 7.72, 8.38 ], std: [ 2.16, 0.92 ], fq: 55\n },\n \"windmill\": {\n dict: \"anew\", word: \"windmill\", stem: \"windmil\",\n avg: [ 3.74, 5.6 ], std: [ 2.13, 1.65 ], fq: 1\n },\n \"window\": {\n dict: \"anew\", word: \"window\", stem: \"window\",\n avg: [ 3.97, 5.91 ], std: [ 2.01, 1.38 ], fq: 119\n },\n \"wine\": {\n dict: \"anew\", word: \"wine\", stem: \"wine\",\n avg: [ 4.78, 5.95 ], std: [ 2.34, 2.19 ], fq: 72\n },\n \"wink\": {\n dict: \"anew\", word: \"wink\", stem: \"wink\",\n avg: [ 5.44, 6.93 ], std: [ 2.68, 1.83 ], fq: 7\n },\n \"wise\": {\n dict: \"anew\", word: \"wise\", stem: \"wise\",\n avg: [ 3.91, 7.52 ], std: [ 2.64, 1.23 ], fq: 36\n },\n \"wish\": {\n dict: \"anew\", word: \"wish\", stem: \"wish\",\n avg: [ 5.16, 7.09 ], std: [ 2.62, 2 ], fq: 110\n },\n \"wit\": {\n dict: \"anew\", word: \"wit\", stem: \"wit\",\n avg: [ 5.42, 7.32 ], std: [ 2.44, 1.9 ], fq: 20\n },\n \"woman\": {\n dict: \"anew\", word: \"woman\", stem: \"woman\",\n avg: [ 5.32, 6.64 ], std: [ 2.59, 1.76 ], fq: 224\n },\n \"wonder\": {\n dict: \"anew\", word: \"wonder\", stem: \"wonder\",\n avg: [ 5, 6.03 ], std: [ 2.23, 1.58 ], fq: 67\n },\n \"world\": {\n dict: \"anew\", word: \"world\", stem: \"world\",\n avg: [ 5.32, 6.5 ], std: [ 2.39, 2.03 ], fq: 787\n },\n \"wounds\": {\n dict: \"anew\", word: \"wounds\", stem: \"wound\",\n avg: [ 5.82, 2.51 ], std: [ 2.01, 1.58 ], fq: 8\n },\n \"writer\": {\n dict: \"anew\", word: \"writer\", stem: \"writer\",\n avg: [ 4.33, 5.52 ], std: [ 2.45, 1.9 ], fq: 73\n },\n \"yacht\": {\n dict: \"anew\", word: \"yacht\", stem: \"yacht\",\n avg: [ 5.61, 6.95 ], std: [ 2.72, 1.79 ], fq: 4\n },\n \"yellow\": {\n dict: \"anew\", word: \"yellow\", stem: \"yellow\",\n avg: [ 4.43, 5.61 ], std: [ 2.05, 1.94 ], fq: 55\n },\n \"young\": {\n dict: \"anew\", word: \"young\", stem: \"young\",\n avg: [ 5.64, 6.89 ], std: [ 2.51, 2.12 ], fq: 385\n },\n \"youth\": {\n dict: \"anew\", word: \"youth\", stem: \"youth\",\n avg: [ 5.67, 6.75 ], std: [ 2.52, 2.29 ], fq: 82\n },\n \"zest\": {\n dict: \"anew\", word: \"zest\", stem: \"zest\",\n avg: [ 5.59, 6.79 ], std: [ 2.66, 2.04 ], fq: 5\n }\n}\n\n\n"
},
{
"alpha_fraction": 0.6152737736701965,
"alphanum_fraction": 0.6268011331558228,
"avg_line_length": 23.535715103149414,
"blob_id": "e0d34980865eef4ff19ead9a92c61470bd49a894",
"content_id": "42f5bc2968aca72f6002e34dbc0831e8df13fb60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 28,
"path": "/prac.py",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "from flask import Flask , url_for , request, render_template\napp = Flask(__name__)\n\n# Make the WSGI interface available at the top level so wfastcgi can get it.\nwsgi_app = app.wsgi_app\n\n#code start from here\n\[email protected]('/', methods =['GET','POST'])\ndef main():\n\tif request.method == 'GET':\n\t\treturn render_template(\"main.html\")\n\n\telif request.method == 'POST':\n\t\ttitle = request.form['title'];\n\t\treturn render_template(\"donat.html\")\n\n'''\nif __name__ == '__main__':\n import os\n HOST = os.environ.get('SERVER_HOST', 'localhost')\n try:\n PORT = int(os.environ.get('SERVER_PORT', '5555'))\n except ValueError:\n PORT = 5555\n app.run(HOST, PORT, debug = True)\n\n'''\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5015576481819153,
"alphanum_fraction": 0.704049825668335,
"avg_line_length": 15.894737243652344,
"blob_id": "fc3a325f726898ff49875c612ce81ef7f2e967bd",
"content_id": "f407317eb88f9699a894e2631b8eaa3f354298d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 19,
"path": "/requirements.txt",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\ngunicorn==19.3.0\nitsdangerous==0.24\nJinja2==2.7.3\nMarkupSafe==0.23\nMySQL-python==1.2.5\nnumpy==1.9.2\noauthlib==0.7.2\npandas==0.16.2\npython-dateutil==2.4.2\npytz==2015.4\nrequests==2.7.0\nrequests-oauthlib==0.5.0\nsimplejson==3.7.3\nsix==1.9.0\nSQLAlchemy==1.0.5\nTwitterSearch==1.0.1\nWerkzeug==0.10.4\nwheel==0.24.0\n"
},
{
"alpha_fraction": 0.4837189316749573,
"alphanum_fraction": 0.5111396908760071,
"avg_line_length": 18.683544158935547,
"blob_id": "b9afa0e69ce40178b92c4a7f25a99cba7accbf1e",
"content_id": "80378861f182102d42ce039d3d68f42801702a2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4668,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 237,
"path": "/hope.py",
"repo_name": "raghavendra990/Sentiment-Analysis-of-Tweets",
"src_encoding": "UTF-8",
"text": "\nfrom sqlalchemy import create_engine\nimport pandas as pd\nimport sys\nfrom anew import *\nfrom flask import jsonify\n\n\n\n\n # so u can use it for search result\n\n\n\n\nengine = create_engine('mysql://root:74332626@localhost')\nengine.execute(\"use sentiment;\")\n#engine.execute(\"\") \n #change\n\ndf = pd.read_sql_query('SELECT * FROM data', engine)\n\n###############################################################################################\n# sentiment of each tweet\n\n\ndef scatter():\n\t\n\ttweets = [['tweets','positions']]\t\n\tscatter = [['Dull-Active', 'Unpleasant-Pleasant']]\n\n\tfor i in range(0, len(df.ix[:,3])):\n\t\t\n\t\ts = df.ix[i,3].split(\" \") \n\t\tfor j in s :\n\t\t\tif j in dictionary.keys():\n\t\t\t\ttweets.append([df.ix[i,3],i])\n\n\n\tfor i in range(1, len(tweets)):\n\t\t\n\t\ts = tweets[i][0].split(\" \")\n\t\tcount= 0 #tweets for calcultion of valance arousal\n\t\ta = 0 # arousal\n\t\tv = 0 # valance\n\t\t\n\n\t\tfor j in s:\n\n\t\t\tif j in dictionary.keys():\n\t\t\t\tcount = count + 1\n\t\t\t\t\n\t\t\t\ta = a + dictionary[j][avg][0] # sum of valance \n\t\t\t\tv = v + dictionary[j][avg][1] # sum os arousal\n\t\t\n\t\ta = a/count\n\t\tv = v/count\n\t\tscatter.append([v,a])\n\treturn scatter\n\n\n############################################################################################\n# Histogram analysis\n\ndef histogram():\n\t\n\ttweets = [['tweets','positions']]\n\tscatter = [['Dull-Active', 'Unpleasant-Pleasant']]\n\n\tfor i in range(0, len(df.ix[:,3])):\n\t\t\n\t\ts = df.ix[i,3].split(\" \") \n\t\tfor j in s :\n\t\t\tif j in dictionary.keys():\n\t\t\t\ttweets.append([df.ix[i,3],i])\n\n\n\tfor i in range(1, len(tweets)):\n\t\t\n\t\ts = tweets[i][0].split(\" \")\n\t\tcount= 0 #tweets for calcultion of valance arousal\n\t\ta = 0 # arousal\n\t\tv = 0 # valance\n\t\t\n\n\t\tfor j in s:\n\n\t\t\tif j in dictionary.keys():\n\t\t\t\tcount = count + 1\n\t\t\t\t\n\t\t\t\ta = a + dictionary[j][avg][0] # sum of valance \n\t\t\t\tv = v + dictionary[j][avg][1] # sum os arousal\n\t\t\n\t\ta = a/count\n\t\tv = v/count\n\t\tscatter.append([v,a])\n\t\n\n\n\n\n\thist = scatter\n\t\n\t\n\ttime = []\n\n\tfor i in range(1,len(tweets)-1):\n\t\tp = tweets[i][1]\n\n\t\tb = df.ix[p,2].split(\" \")[3].split(\":\")\n\t\t\n\t\tfor j in range(0,3):\n\t\t\tb[j] = int(b[j])\n\n\t\ttime.append([b,hist[i+1][0]])\n\treturn time\n\n#############################################################################################\n# Donat chart analysis\ndef donat():\n\t\n\ttweets = [['tweets','positions']]\n\tscatter = [['Dull-Active', 'Unpleasant-Pleasant']]\n\n\tfor i in range(0, len(df.ix[:,3])):\n\t\t\n\t\ts = df.ix[i,3].split(\" \") \n\t\tfor j in s :\n\t\t\tif j in dictionary.keys():\n\t\t\t\ttweets.append([df.ix[i,3],i])\n\n\n\tfor i in range(1, len(tweets)):\n\t\t\n\t\ts = tweets[i][0].split(\" \")\n\t\tcount= 0 #tweets for calcultion of valance arousal\n\t\ta = 0 # arousal\n\t\tv = 0 # valance\n\t\t\n\n\t\tfor j in s:\n\n\t\t\tif j in dictionary.keys():\n\t\t\t\tcount = count + 1\n\t\t\t\t\n\t\t\t\ta = a + dictionary[j][avg][0] # sum of valance \n\t\t\t\tv = v + dictionary[j][avg][1] # sum os arousal\n\t\t\n\t\ta = a/count\n\t\tv = v/count\n\t\tscatter.append([v,a])\n\n\n\n\n\t\n\tdon = scatter\n\tcount1 = count2 = count3 = count4 = count5 = 0 \n\tfor i in range(1,len(don)):\n\n\n\t\tif don[i][0]>= 7:\n\t\t\tcount1= count1 + 1\n\n\t\tif don[i][0]< 7 and don[i][0]>5.5:\n\t\t\tcount2= count2 + 1\n\t\t\n\t\tif don[i][0]<=5.5 and don[i][0]>4.5:\n\t\t\tcount3= count3 + 1\n\t\t\n\t\tif don[i][0]<=4.5 and don[i][0]>2.5:\n\t\t\tcount4= count4 + 1\n\t\t\n\t\tif don[i][0]<=2.5:\n\t\t\tcount5= count5 + 1\n\n\tdonat = [['Opinion', 'Number of people'],['Pleasant',count1],['Happy',count2],['Relax',count3],['Sad',count4],['Unpleasant',count5]]\n\treturn donat\n\n\n################################################################################################################################\n# Table visualization\n\n'''\ndef table():\n\ttable = []\n\ttab = scatter()\n\t\n\tfor i in range(1,len(tweets)):\n\t\tp = tweets[i][1]\n\n\t\ttable.append([df.ix[i,2],df.ix[p,3],tab[i][0],tab[i][1],tweets[i][0]])\n\treturn table\n\n'''\ndef table():\n\t\n\ttweets = [['tweets','positions']]\t\n\tscatter = [['Dull-Active', 'Unpleasant-Pleasant']]\n\n\tfor i in range(0, len(df.ix[:,3])):\n\t\t\n\t\ts = df.ix[i,3].split(\" \") \n\t\tfor j in s :\n\t\t\tif j in dictionary.keys():\n\t\t\t\ttweets.append([df.ix[i,3],i])\n\n\n\tfor i in range(1, len(tweets)):\n\t\t\n\t\ts = tweets[i][0].split(\" \")\n\t\tcount= 0 #tweets for calcultion of valance arousal\n\t\ta = 0 # arousal\n\t\tv = 0 # valance\n\t\t\n\n\t\tfor j in s:\n\n\t\t\tif j in dictionary.keys():\n\t\t\t\tcount = count + 1\n\t\t\t\t\n\t\t\t\ta = a + dictionary[j][avg][0] # sum of valance \n\t\t\t\tv = v + dictionary[j][avg][1] # sum os arousal\n\t\t\n\t\ta = a/count\n\t\tv = v/count\n\t\tscatter.append([v,a])\n\n\n\n\n\ttable = []\n\ttab = scatter\n\t\n\tfor i in range(1, len(tweets)):\n\t\tp = tweets[i][1]\n\t\ttable.append([df.ix[p,2],df.ix[p,1],str(tab[i][0]),str(tab[i][1]),tweets[i][0]])\n\treturn table\n\n\n"
}
] | 6 |
SVBhuvanChandra/SW-APP-DEV | https://github.com/SVBhuvanChandra/SW-APP-DEV | 292069570a6bde6fbbd095282af22e4ded9d783f | 0e97c33ece61e44d62ffdbc6e3c42dbbf530a4e9 | 68c401ef51bed0f00e7198e90c5496199cd2176b | refs/heads/master | "2021-05-24T10:18:32.529483" | "2020-05-16T07:49:36" | "2020-05-16T07:49:36" | 253,515,077 | 0 | 0 | null | "2020-04-06T14:03:07" | "2020-04-22T08:02:52" | "2020-05-16T07:49:36" | HTML | [
{
"alpha_fraction": 0.6763623952865601,
"alphanum_fraction": 0.67669677734375,
"avg_line_length": 32.9886360168457,
"blob_id": "e238b543186a88ffb176fc2b6caf7047fa811d6e",
"content_id": "5d3151775f25238c5b32442b36071e573e044f1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2991,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 88,
"path": "/project1/application.py",
"repo_name": "SVBhuvanChandra/SW-APP-DEV",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import Flask, session\nfrom flask_session import Session\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.orm import scoped_session, sessionmaker\nfrom flask import render_template, request, session\nfrom data import *\nfrom datetime import datetime\n\napp = Flask(__name__)\n\n# Check for environment variable\n# if not os.getenv(\"DATABASE_URL\"):\n# raise RuntimeError(\"DATABASE_URL is not set\")\n\n# Configure session to use filesystem\napp.config[\"SESSION_PERMANENT\"] = False\napp.config[\"SESSION_TYPE\"] = \"filesystem\"\nSession(app)\n\napp.config[\"SQLALCHEMY_DATABASE_URI\"] = os.getenv(\"DATABASE_URL\")\napp.config[\"SQLALCHEMY_TRACK_MODIFICATIONS\"] = False\napp.app_context().push()\n\ndb.init_app(app)\napp.secret_key = \"temp\"\n\ndb.create_all()\n\n# Set up database\n# engine = create_engine(os.getenv(\"DATABASE_URL\"))\n# db = scoped_session(sessionmaker(bind=engine))\n\n#Below implementation to redirect to route.\[email protected](\"/\")\ndef index():\n if 'username' in session:\n username = session['username']\n return render_template(\"login.html\", name=username)\n else:\n return render_template(\"registration.html\")\n\[email protected](\"/admin\")\ndef admin():\n users = User.query.order_by(\"timestamp\").all()\n # users = User.query.order_by(User.user_created_on.desc())\n return render_template(\"admin.html\", users = users)\n\n# Below implementation is to redirect to Registration page\[email protected](\"/registration\", methods = ['GET', 'POST'])\ndef register():\n if request.method==\"POST\":\n name = request.form.get(\"name\")\n print(name)\n password = request.form.get(\"Password\")\n print(password)\n regist = User(username = name, password = password)\n if User.query.get(name):\n return render_template(\"registration.html\", name1 = name)\n db.session.add(regist)\n db.session.commit()\n return render_template(\"registration.html\", name = name)\n return render_template(\"registration.html\")\n\n# Below implementation is to redirect to Login page\[email protected](\"/auth\", methods = ['GET', 'POST'])\ndef auth():\n if(request.method==\"POST\"):\n name = request.form.get(\"name\")\n print(name)\n password = request.form.get(\"Password\")\n print(password)\n obj = User.query.get(name)\n if obj is None:\n return render_template(\"registration.html\", message = \"Invalid Credentials\")\n if (obj.username == name and obj.password == password):\n session['username'] = request.form.get(\"name\")\n return render_template(\"login.html\", name=name)\n if (obj.username != name or obj.password != password):\n return render_template(\"registration.html\", message = \"Invalid Credentials\")\n return render_template(\"registration.html\", message = \"Invalid Credentials\")\n\n# Below implementation is to redirects back after Logout.\[email protected](\"/logout\")\ndef logout():\n session.pop('username')\n return render_template(\"registration.html\")\n"
},
{
"alpha_fraction": 0.6437908411026001,
"alphanum_fraction": 0.6437908411026001,
"avg_line_length": 30.586206436157227,
"blob_id": "8d2f9cf1afa40965f0caee95209470430d68d7bc",
"content_id": "f51b6fafc7e91c1274e77c9bb14edd4a36597e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 918,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 29,
"path": "/project1/data.py",
"repo_name": "SVBhuvanChandra/SW-APP-DEV",
"src_encoding": "UTF-8",
"text": "from flask_sqlalchemy import SQLAlchemy\nfrom datetime import datetime\n\ndb = SQLAlchemy()\n\n# A class created to make SQL database.\nclass User(db.Model):\n __tablename__ = \"userdata\"\n username = db.Column(db.String, primary_key = True)\n password = db.Column(db.String, nullable = False)\n timestamp = db.Column(db.DateTime, nullable = False)\n\n def __init__(self, username, password):\n self.username = username\n self.password = password\n self.timestamp = datetime.now()\n\nclass Book(db.Model):\n __tablename__ = \"book\"\n isbn = db.Column(db.String, primary_key = True)\n title = db.Column(db.String, nullable = False)\n author = db.Column(db.String, nullable = False)\n year = db.Column(db.String, nullable = False)\n\n def __init__(self, isbn, title, author, year):\n self.isbn = isbn\n self.title = title\n self.author = author\n self.year = year\n\n\n"
},
{
"alpha_fraction": 0.7023809552192688,
"alphanum_fraction": 0.726190447807312,
"avg_line_length": 40,
"blob_id": "bb8a819cbaf6028140f96690600d0bf4b125178c",
"content_id": "5f9c0a2ff7bff57d35a8709444bf7ee9e1f67683",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 2,
"path": "/Sample code/test.py",
"repo_name": "SVBhuvanChandra/SW-APP-DEV",
"src_encoding": "UTF-8",
"text": "\nprint(\"Hello I am sample\")\nprint(\"Changes done as per the Module 2.2 Assignment\")\n\n"
},
{
"alpha_fraction": 0.7034482955932617,
"alphanum_fraction": 0.7113300561904907,
"avg_line_length": 25.6842098236084,
"blob_id": "cf0a903052a434a586e7f86aa5a4f68e46d7610a",
"content_id": "41c206d385dc58408e65c2d95e30454dcde0e2f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1015,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 38,
"path": "/project1/import.py",
"repo_name": "SVBhuvanChandra/SW-APP-DEV",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import Flask, session\nfrom flask_session import Session\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.orm import scoped_session, sessionmaker\nfrom flask import render_template, request, session\nfrom data import *\nimport csv\n\napp1 = Flask(__name__)\n\n# Check for environment variable\n# if not os.getenv(\"DATABASE_URL\"):\n# raise RuntimeError(\"DATABASE_URL is not set\")\n\n# Configure session to use filesystem\napp1.config[\"SESSION_PERMANENT\"] = False\napp1.config[\"SESSION_TYPE\"] = \"filesystem\"\nSession(app1)\n\napp1.config[\"SQLALCHEMY_DATABASE_URI\"] = os.getenv(\"DATABASE_URL\")\napp1.config[\"SQLALCHEMY_TRACK_MODIFICATIONS\"] = False\napp1.app_context().push()\n\ndb.init_app(app1)\ndb.create_all()\n\ndef uploadcsv():\n csvfile = open(\"books.csv\")\n reader = csv.reader(csvfile)\n for isbn,title, author,year in reader:\n b = Book(isbn = isbn, title = title, author = author, year = year)\n db.session.add(b)\n db.session.commit()\n\nif __name__ == \"__main__\":\n uploadcsv()\n\n"
},
{
"alpha_fraction": 0.5928879976272583,
"alphanum_fraction": 0.6168162226676941,
"avg_line_length": 24.866071701049805,
"blob_id": "cff2cc2e701dd8dc5e2f950df7ed48fe3c575e83",
"content_id": "b0ceb766fa2fbe58a6d468cc1261d57257a8838f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 3009,
"license_type": "no_license",
"max_line_length": 270,
"num_lines": 112,
"path": "/Sample code/bhuvanmsit.html",
"repo_name": "SVBhuvanChandra/SW-APP-DEV",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\r\n<html>\r\n<head>\r\n\t<title>MSIT Journey</title>\r\n\t<style>\r\n\t\th1 {\r\n\t\t\tcolor: teal;\r\n\t\t\ttext-align: center;\r\n\t\t\tfont-weight: bold;\r\n\t\t\tfont-family: sans-serif;\r\n\t\t\tfont-size: 30;\r\n\t\t}\r\n\t\th2 {\r\n\t\t\tcolor : brown;\r\n\t\t\tfont-weight: bold;\r\n\t\t}\r\n\t\tdiv {\r\n\t\t\tborder: 2px solid green;\r\n\t\t\tmargin: 20px;\r\n\t\t\tpadding: 20px;\r\n\t\t}\r\n\t\ttable {\r\n\t\t\tborder: 2px solid black;\r\n\t\t\tborder-collapse: collapse;\r\n\t\t\twidth: 25%;\r\n\t\t}\r\n\t\tth {\r\n\t\t\tborder: 1px solid black;\r\n\t\t\tbackground-color: lightgrey;\r\n\t\t\tpadding: 5px\r\n\t\t}\r\n\t\ttd {\r\n\t\t\tborder: 1px solid black;\r\n\t\t\tpadding: 5px\r\n\t\t}\r\n\t\timg {\r\n\t\t\tmargin: 20px;\r\n\t\t}\r\n\t\tinput {\r\n\t\t\twidth: 50%;\r\n\t\t\theight: 60px;\r\n\t\t\tborder: 2px solid lightgrey;\r\n\t\t}\r\n\t</style>\r\n</head>\r\n<body style=\"background-color: #faf9cd\">\r\n\t<h1>Bhuvan's MSIT Journey</h1>\r\n\t<div>Welcome to MSIT my frinds, please go through below information to know about my MSIT journey. I have mentioned few key insights such as course durations and important points.</div>\r\n\t<img src=\"MSITlogo.jfif\" width=\"10%\">\r\n\t<img src=\"journey.gif\" width=\"225px\" height = \"150px\">\r\n\t<img src=\"FBpic.jpg\" width=\"10%\">\r\n\t<p style=\"color: darkmagenta; font-size: 18; font-family: cursive;\">Hello everyone! I am very much happy to share my views about the MSIT program which is a Post graduation program in International Institute of Information Technology, Hyderabad (IIITH).</p>\r\n\t<p style=\"color: darkmagenta; font-size: 18; font-family: cursive;\">I have learnt a lot of technical and softskills in this programm and I reached to a level from writing a simple a+b program to designing a sample webpage on my first day of Web programming classes.</p>\r\n\t<h2>How I started my journey?</h2>\r\n\t<ol>\r\n\t\t<li>Resigned my job</li>\r\n\t\t<li>Prepared for GAT exam</li>\r\n\t\t<li>Attended councelling</li>\t\r\n\t</ol>\r\n\t<h2>Key aspects I experienced</h2>\r\n\t<ul>\r\n\t\t<li>Learning by doing</li>\r\n\t\t<li>Softskills</li>\r\n\t\t<li>Coding contests</li>\r\n\t\t<li>Being industry ready</li>\r\n\t</ul>\r\n\t<h2>Mandatory Courses and their duration</h2>\r\n\t<table>\r\n\t\t<tr>\r\n\t\t\t<th>S.No</th>\r\n\t\t\t<th>Course</th>\r\n\t\t\t<th>Duration(weeks)</th>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>1</td>\r\n\t\t\t<td>Computational thinking</td>\r\n\t\t\t<td>2</td>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>2</td>\r\n\t\t\t<td>CSPP1</td>\r\n\t\t\t<td>4</td>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>3</td>\r\n\t\t\t<td>Introduction to Data Science</td>\r\n\t\t\t<td>2</td>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>4</td>\r\n\t\t\t<td>OOP(java)</td>\r\n\t\t\t<td>4</td>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>5</td>\r\n\t\t\t<td>ADS 1</td>\r\n\t\t\t<td>4</td>\r\n\t\t</tr>\r\n\t\t<tr>\r\n\t\t\t<td>6</td>\r\n\t\t\t<td>Database</td>\r\n\t\t\t<td>2</td>\r\n\t\t</tr>\r\n\t</table>\r\n\t<h3 style=\"color:green; font-size: 17; font-family: cursive;\">Please give me your feedback on the content.</h3>\r\n\t<form>\r\n\t\t<input type=\"text\" placeholder = \"Give your comments...\" name=\"Feedback\">\r\n\t\t<button style=\"background-color: lightgrey; font-weight: bold; width: 85px; height: 40px;\">Submit</button>\r\n\t</form>\r\n\t<h5 style=\"color: brown; text-align: center; font-size: 18; font-family: serif;\">Thank you for visiting my webpage</h5>\r\n</body>\r\n</html>\r\n"
}
] | 5 |
walhog/raspberry_pi3_arcade | https://github.com/walhog/raspberry_pi3_arcade | b932f10ddab8bdc6b51b39fe1ca38aa56f3f68e3 | 191757dddb6be13ede76a7cf4e6d8a1f150a4965 | bdb80f5db14bb87b10b797365dc2aaecdbab59a5 | refs/heads/master | "2020-03-20T20:25:50.525748" | "2018-06-17T20:14:19" | "2018-06-17T20:14:19" | 137,687,294 | 0 | 0 | null | "2018-06-17T21:10:05" | "2018-06-17T20:14:26" | "2018-06-17T20:14:25" | null | [
{
"alpha_fraction": 0.509746253490448,
"alphanum_fraction": 0.5535123348236084,
"avg_line_length": 19.291044235229492,
"blob_id": "80f56f27d7c06a37fb505090d6f3f91fcf194ab4",
"content_id": "d110e85602726de2abf847ef3fc7b8e4e82710e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2719,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 134,
"path": "/python/gpio.py",
"repo_name": "walhog/raspberry_pi3_arcade",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nimport sys\nfrom time import sleep\n\nclass GPIOhelper:\n\n def blink(self,pin):\n\t\ttime = 0.5\n\t\tmessage = pin + \":on\"\n\t\t\n\t\tpin = int(pin)\n\t\tif pin == 1:\n\t\t\tpin = 21\n\t\tif pin == 2:\n\t\t\tpin = 21\n\t\tif pin == 3:\n\t\t\tpin = 21\n\t\tif pin == 4:\n\t\t\tpin = 21\n\n\t\tif pin in [21,11111,1112,1113]:\n\t\t\tGPIO.setwarnings(False)\n\t\t\tGPIO.setmode(GPIO.BCM)\n\t\t\tGPIO.setup(int(pin), GPIO.OUT, initial=GPIO.HIGH)\n\t\t\tsleep(float(time));\n\t\t\tGPIO.output(int(pin), 0)\n\t\telse:\n message = \"pin not found\"\n\n\t\tGPIO.cleanup()\n\t\treturn message\n\n def animation1(self):\n\t\ttime = 0.5\n\t\tmessage = \"\"\n pins = [\"21\"]\n pinsReverse = [\"21\"]\n GPIO.setwarnings(False)\n GPIO.setmode(GPIO.BCM)\n\n #refactor when the pinnrs are know.\n for x in pins:\n GPIO.setup(int(x), GPIO.OUT, initial=GPIO.HIGH)\n sleep(float(time));\n GPIO.output(int(x), 0)\n\n for x in pinsReverse:\n GPIO.setup(int(x), GPIO.OUT, initial=GPIO.HIGH)\n sleep(float(time));\n GPIO.output(int(x), 0)\n\n\t\tGPIO.cleanup()\n\t\treturn message\n\n def animation2(self):\n\t\ttime = 0.5\n\t\tmessage = \"\"\n GPIO.setwarnings(False)\n GPIO.setmode(GPIO.BCM)\n\n for x in range(2):\n GPIO.setup(21, GPIO.OUT, initial=GPIO.HIGH)\n GPIO.setup(21, GPIO.OUT, initial=GPIO.HIGH)\n GPIO.setup(21, GPIO.OUT, initial=GPIO.HIGH)\n GPIO.setup(21, GPIO.OUT, initial=GPIO.HIGH)\n sleep(float(time));\n\n GPIO.output(21, 0)\n GPIO.output(21, 0)\n GPIO.output(21, 0)\n GPIO.output(21, 0)\n sleep(float(time));\n\n\t\tGPIO.cleanup()\n\t\treturn message\n\n def switchOn(self,pin):\n\t\tpin = int(pin)\n\t\tmessage = \"\"\n\n\t\tif pin == 1:\n\t\t\tpin = 21\n\t\tif pin == 2:\n\t\t\tpin = 21\n\t\tif pin == 3:\n\t\t\tpin = 21\n\t\tif pin == 4:\n\t\t\tpin = 21\n\n\t\tif pin in [21,11111,1112,1113]:\n\t\t\tGPIO.setwarnings(False)\n\t\t\tGPIO.setmode(GPIO.BCM)\n\t\t\tGPIO.setup(int(pin), GPIO.OUT, initial=GPIO.HIGH)\n\t\telse:\n\t\t message = \"pin not found\"\n\n\t\tGPIO.cleanup()\n\t\treturn message\n\n def switchOff(self,pin):\n\t\tpin = int(pin)\n\t\tmessage = \"\"\n\n\t\tif pin == 1:\n\t\t\tpin = 21\n\t\tif pin == 2:\n\t\t\tpin = 21\n\t\tif pin == 3:\n\t\t\tpin = 21\n\t\tif pin == 4:\n\t\t\tpin = 21\n\n\t\tif pin in [21,11111,1112,1113]:\n\t\t\tGPIO.setwarnings(False)\n\t\t\tGPIO.setmode(GPIO.BCM)\n\t\t\tGPIO.setup(int(pin), GPIO.OUT, initial=GPIO.LOW)\n\t\telse:\n\t\t message = \"pin not found\"\n\n\t\tGPIO.cleanup()\n\t\treturn message\n\n def reset(self):\n message = \"\"\n pins = [\"21\"]\n\n GPIO.setwarnings(False)\n GPIO.setmode(GPIO.BCM)\n\n for x in pins:\n GPIO.setup(int(x), GPIO.OUT, initial=GPIO.LOW)\n\n GPIO.cleanup()\n return message\n"
},
{
"alpha_fraction": 0.6532663106918335,
"alphanum_fraction": 0.6954773664474487,
"avg_line_length": 31.112903594970703,
"blob_id": "0cfdb9a0b5404ab71c575f9438f1fa33b7a4e800",
"content_id": "16e932846d04059278fe59734d4a439d4c900e34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1990,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 62,
"path": "/README.md",
"repo_name": "walhog/raspberry_pi3_arcade",
"src_encoding": "UTF-8",
"text": "# Raspberry PI3\n\n1. download and install SD cardFormatter for Mac (or windows) https://www.sdcard.org/downloads/formatter_4/index.html\n2. download NOOffBS https://www.raspberrypi.org/downloads/noobs/\n3. Format the SDcard\n4. Extract the NOOBS zipfile and copy the contents to the SDcard (1.83GB)\n5. Eject the SDcard\n6. Put in the raspberry pi connect keyboard monitor, mouse and power\n7. On the installation menu choose Raspbian (debian)\n8. Launch the terminal on the raspberry and:\n 1. sudo apt-get install apache2\n 2. sudo pip install flask\n 3. sudo apt-get install git-core\n\n 5. cd /home/Pi\n 6. git clone git://git.drogon.net/wiringPi\n 7. cd wiringPi\n 8. ./build\n 10. cd /var\n 11. sudo chown pi:pi www\n 12. cd /var/www\n 13. git clone https://github.com/PH-F/raspberry_pi3_arcade.git\n\n```update to run with apache```\n\n 16. sudo nano /etc/apache2/sites-available/000-default.conf\n 1. replace /var/www/html -> /var/www/app/public\n 2. add <Directory /var/www/app>AllowOverride All</Directory> above the </VirtualHost>\n 3. sudo /etc/init.d/apache2 restart\n 17. sudo usermod -a -G gpio www-data\n 18. sudo /etc/init.d/apache2 restart\n 19. sudo chmod 777 /sys/class/gpio/gpio18/\n 20. sudo apt-get install python-dev python-pip gcc\n 21. sudo pip install evdev\n 22. sudo modprobe uinput\n9. Start the pythonscript at boot\n\t1. sudo chmod 755 /var/www/app/boot.sh\n\t2. sudo mkdir var/log/cron\n\t3. sudo chmod 777 var/log/cron/\n\t4. sudo crontab -e \n\t\tAdd: @reboot sh /var/www/app/boot.sh > /var/log/cron/cronlog 2>&1\n10. Start the browser at boot\n\t1. in the terminal edit ~/.bashrc\n\t2. Add at the bottom: chromium-browser --kiosk localhost\n\t3. save and reboot\n\t4. Note: crtl W will close the browser!\n\n\n# Run (in the background)\nsudo python python/emulateKeyBoard.py\n\n# Build with Python\n\n\n## GamePlay\n- key 1 = game\n- key 2 = movie\n- key 3 = quiz\n- key q = option 1\n- key w = option 2\n- key e = option 3\n- key r = option 4"
},
{
"alpha_fraction": 0.6129893064498901,
"alphanum_fraction": 0.6610320210456848,
"avg_line_length": 27.769229888916016,
"blob_id": "56c801de4a999c5b95933a802ff41055c219da2f",
"content_id": "a8733a1a0b627c8bdd1cd247b1db7d098621eed4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1124,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 39,
"path": "/python/emulateKeyBoard.py",
"repo_name": "walhog/raspberry_pi3_arcade",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nimport time\nfrom evdev import UInput, ecodes as e\n\nGPIO.setmode(GPIO.BCM)\nGPIO.setup(18, GPIO.IN, pull_up_down = GPIO.PUD_UP)\nGPIO.setup(17, GPIO.IN, pull_up_down = GPIO.PUD_UP)\nGPIO.setup(22, GPIO.IN, pull_up_down = GPIO.PUD_UP)\nGPIO.setup(13, GPIO.IN, pull_up_down = GPIO.PUD_UP)\n\nui = UInput()\n\ndef button18(channel):\n ui.write(e.EV_KEY, e.KEY_LEFT ,1)\n ui.write(e.EV_KEY, e.KEY_LEFT ,0)\n ui.syn()\n\ndef button17(channel):\n ui.write(e.EV_KEY, e.KEY_DOWN ,1)\n ui.write(e.EV_KEY, e.KEY_DOWN ,0)\n ui.syn()\n\ndef button22(channel):\n ui.write(e.EV_KEY, e.KEY_UP ,1)\n ui.write(e.EV_KEY, e.KEY_UP ,0)\n ui.syn()\n\ndef button13(channel):\n ui.write(e.EV_KEY, e.KEY_P ,1)\n ui.write(e.EV_KEY, e.KEY_P ,0)\n ui.syn()\n\nGPIO.add_event_detect(18, GPIO.FALLING, callback = button18, bouncetime = 500) \nGPIO.add_event_detect(17, GPIO.FALLING, callback = button17, bouncetime = 500) \nGPIO.add_event_detect(22, GPIO.FALLING, callback = button22, bouncetime = 500) \nGPIO.add_event_detect(13, GPIO.FALLING, callback = button13, bouncetime = 500) \n\nwhile 1: \n time.sleep(1) \n"
}
] | 3 |
b2aff6009/crawler | https://github.com/b2aff6009/crawler | aa4b6f238cb7de6695057444946be352c46a128c | a13807f9fcaf3acea12f070e7c95ae0f59218e8b | facdecf8345e22b7c50423df22d0884647e908b3 | refs/heads/master | "2021-05-16T23:39:45.052651" | "2020-12-27T15:50:15" | "2020-12-27T15:50:15" | 250,519,758 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7688266038894653,
"alphanum_fraction": 0.7688266038894653,
"avg_line_length": 24.909090042114258,
"blob_id": "3e7cb8fd44980f77fa8856e0e2e180f3b108c48e",
"content_id": "da7e55546423436dca7e24bcebe949025576c3b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 571,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 22,
"path": "/TODO.md",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "# TODO\n\n## Settings\n- document all settings\n- create a default setting file\n\n## Google Crawler\n- write test for \"login\"\n- ctor should take credentials as part of settings, path or object\n- write test for generator\n- implement return generator\n- write test for return list\n- implement returning a list of sheets\n- write test for using callback function\n\n## Git Cralwer\n- write test for using a git account\n- write test for generator\n- implement return generator\n- write test for return list\n- implement returning a list of sheets\n- write test for using callback function\n "
},
{
"alpha_fraction": 0.5715222954750061,
"alphanum_fraction": 0.5820209980010986,
"avg_line_length": 36.60493850708008,
"blob_id": "2441a9b232753645daddfbc9967b2732c4bbb7a7",
"content_id": "f4a3ab65a08117780330d7b7c4c2a49170f228bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3048,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 81,
"path": "/tests/testutils.py",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport inspect\ncurrent_dir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))\nparent_dir = os.path.dirname(current_dir)\nsys.path.insert(0, parent_dir)\nimport crawler as crawler\n\ndef find_gen(baseSettings, tests):\n for i, test in enumerate(tests):\n settings = baseSettings\n for key,val in test[0].items():\n settings[key] = val\n myCrawler = crawler.createCrawler(settings)\n myCrawler.memo = []\n gen = myCrawler.generator()\n cnt = 0\n results = []\n try:\n while True:\n name = next(gen)\n results.append(name)\n assert name in test[2], \"Unexpected file ({}) appeared in found files. During Test: {}\".format(name, i)\n cnt += 1\n except StopIteration:\n assert cnt == test[1], \"Found {} instead of {} {} files\".format(cnt, test[1], test[0])\n\ndef find_list(baseSettings, tests):\n for i,test in enumerate(tests):\n settings = baseSettings\n for key,val in test[0].items():\n settings[key] = val\n myCrawler = crawler.createCrawler(settings)\n myCrawler.memo = []\n try:\n results = myCrawler.getList()\n assert len(results) == test[1], \"Found {} instead of {} files\".format(len(results), test[1])\n if len(test[2]) > 0:\n for name in results:\n assert name in test[2], \"Unexpected file ({}) in Test {} appeared in found files. Expected {}\".format(name, i, test[2])\n except ValueError as VE:\n assert settings[\"onlyOnce\"] == False, \"Unexpected exeption raises\"\n\nsingleReturnCnt = 0\ndef callback_singleReturn(baseSettings, tests):\n global singleReturnCnt\n settings = baseSettings\n settings[\"onlyOnce\"] = False\n \n for test in tests:\n for key,val in test[0].items():\n settings[key] = val\n singleReturnCnt = 0 \n def callback (file):\n global singleReturnCnt\n if len(test[2]) > 0:\n assert file in test[2], \"Couldn't find file ({}) in {}\".format(file, test[2])\n singleReturnCnt +=1\n\n myCrawler = crawler.createCrawler(settings, callback)\n myCrawler.process()\n assert singleReturnCnt == test[1], \"Found {} instead of {} files\".format(singleReturnCnt, test[1])\n\n\ndef callback_listReturn(baseSettings, tests):\n settings = baseSettings\n settings[\"singleReturn\"] = False\n \n for test in tests:\n for key,val in test[0].items():\n settings[key] = val\n settings[\"onlyOnce\"] = True\n def callback (files):\n if len(test[2]) > 0:\n for file in files:\n assert file in test[2], \"Couldn't find file ({}) in {}\".format(file, test[2])\n assert len(files) == test[1], \"Found {} instead of {} files\".format(len(files), test[1]) \n\n myCrawler = crawler.createCrawler(settings, callback)\n myCrawler.memo = []\n myCrawler.process()\n\n\n"
},
{
"alpha_fraction": 0.6421267986297607,
"alphanum_fraction": 0.647580087184906,
"avg_line_length": 31.61111068725586,
"blob_id": "3224f65768fbf742fd29ad2536c18a7378489380",
"content_id": "7184db5da2a02183f6f3a871006dc2dd30ca150c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2934,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 90,
"path": "/tests/test_crawler.py",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "import pytest\n\nimport os\nimport sys\nimport inspect\nimport json\nimport datetime \ncurrent_dir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))\nparent_dir = os.path.dirname(current_dir)\nsys.path.insert(0, parent_dir)\nimport crawler as crawler\n\nbaseSettings = {\n \"type\": \"local\",\n \"memo\" : \"./tests/testdata/memo.json\",\n \"onlyOnce\" : True,\n #LocalCrawler Settings\n \"path\" : \"./tests/testdata/\",\n \"extension\" : \"\",\n #GoogleCrawler Settings\n \"credentialPath\" : \"./dummy-credentials.json\",\n }\n\ndef test_createCrawlerFactory():\n settings = baseSettings\n \n tests = [\n [\"local\", crawler.localCrawler],\n [\"google\", crawler.googleCrawler],\n [\"git\", crawler.gitCrawler]\n ]\n for test in tests:\n settings[\"type\"] = test[0]\n myCrawler = crawler.createCrawler(settings)\n testCrawler = test[1](settings)\n assert type(myCrawler) == type(testCrawler),\"Wrong crawler type was created. Created crawler was: {}\".format(type(myCrawler))\n\ndef test_save():\n dummyName = \"dummyMemo\"\n mCrawler = crawler.createCrawler(baseSettings)\n mCrawler.memo.append(dummyName)\n mCrawler.save()\n with open(baseSettings[\"memo\"], 'rb') as f:\n data = json.load(f)\n assert dummyName in data, \"Didn't found {} in {}\".format(dummyName, baseSettings[\"memo\"]) \n\ndef test_load():\n dummyName = \"dummyLoad\"\n data = [dummyName]\n with open(baseSettings['memo'], 'w') as f:\n json.dump(data, f, indent=4)\n mCrawler = crawler.createCrawler(baseSettings)\n assert len(mCrawler.memo) == 1, \"Crawler memo contains not exactly one item\"\n assert mCrawler.memo[0] == dummyName, \"Crawlers memo contains {} instead of {}\".format(mCrawler.memo[0], dummyName) \n\ncnt = 0\ndef test_service():\n global cnt\n settings = baseSettings\n settings[\"service\"] = True\n settings[\"sleep\"] = 1\n settings[\"onlyOnce\"] = True\n cnt = 0\n mId = 3\n cycles = 10\n\n def callback(file, id, processingCrawler):\n global cnt\n cnt = cnt + 1\n assert id == mId, \"Argurments doesn't match the expected. Got {} instead of {}\".format(id, mId)\n if cnt >= cycles: \n processingCrawler.settings[\"service\"] = False\n\n mCrawler = crawler.createCrawler(settings, callback)\n startTime = datetime.datetime.now()\n mCrawler.process(mId, mCrawler)\n endTime = datetime.datetime.now()\n diffTime = endTime - startTime\n def checkTime(seconds):\n if seconds > (cycles-1)*settings[\"sleep\"] and seconds < (cycles+1)*settings[\"sleep\"]:\n return True\n return False\n\n assert checkTime(diffTime.seconds), \"Test took {}s, expceted time would be {}s\".format(diffTime.seconds, cycles*settings[\"sleep\"])\n assert cnt == cycles, \"Wrong number of cycles. Got {} instead of {}\".format(cnt, cycles)\n\n \nif __name__ == \"__main__\":\n #test_createCrawlerFactory()\n test_service()"
},
{
"alpha_fraction": 0.7474916577339172,
"alphanum_fraction": 0.7516722679138184,
"avg_line_length": 58.849998474121094,
"blob_id": "135d6b87ba2a55ca1fff71eac43217ba706551de",
"content_id": "3839639bd2a98e17f983ae83d673f26a6fae61ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1196,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 20,
"path": "/README.md",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "# crawler\n\n\n## Settings\n\n### Global\n- type : \"google\"/\"local\" #Defines which crawler type will be created.\n- onlyOnce: true/false #Stores all pares file names/pathes in a memo file and will not return a file if it is already in the memo file.\n- memo : \"\" #Defines the path to a memo file, which will contain all found files/sheets. \n\n### Local Crawler\n- extension: \"\" #Applies a filter for the given extension, returns all if extensions is set to \"\".\n- path: \"\" #Defines a folder which will be the strating point for searching\n\n### Google Crawler\n- credentials : \"\" #Path to a file which contains the googleApi credentials.\n- spreadsheets : \"\" #Only spreadsheets which contains this string will be returned (\"\" will return all spreadsheets)\n- worksheets : \"\" #Only worksheets (tables) which contains this string will be returned (\"\" will return all worksheets) \n- enableWorksheets : true/false #Defines if crawler will return spreadsheets or worksheets\n- returnType : \"path\"/\"data\" #Defines if the crawler will return a string (path to spreadsheet/worksheet) or a object which poitns to a spreadsheet/worksheet"
},
{
"alpha_fraction": 0.5275450348854065,
"alphanum_fraction": 0.5309324264526367,
"avg_line_length": 37.95138931274414,
"blob_id": "eb2608da795fe42dc28d217c49a9786ca72d5120",
"content_id": "39b4c01819dc176dc6fc8ff5274359c5faab694f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5609,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 144,
"path": "/crawler.py",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport time\nimport sys\n\n\ndef createCrawler(settings, callback = None):\n selector = {\n \"local\" : localCrawler,\n \"google\" : googleCrawler,\n \"git\" : gitCrawler\n }\n return selector[settings.get(\"type\", \"local\")](settings, callback)\n\nclass Crawler:\n def __init__(self, settings, callback = None):\n self.settings = settings\n self.debug = settings.get(\"debug\",0)\n self.loadMemo()\n self.callback = callback\n if self.debug > 0:\n print(\"Crawler: initilised.\")\n\n def generator(self):\n if self.debug > 2:\n print(\"Crawler: Generator\") \n pass\n\n def getList(self):\n if(self.settings[\"onlyOnce\"] == True):\n return list(self.generator())\n raise ValueError(\"onlyOnce option is disabled, this would lead to an infinity list\")\n\n def loadMemo(self):\n if self.settings[\"onlyOnce\"] == True:\n if self.debug > 2:\n print(\"Crawler: read Memo.\")\n if os.path.isfile(self.settings[\"memo\"]) == False:\n self.memo = []\n with open(self.settings[\"memo\"], 'w+') as f:\n json.dump(self.memo, f, indent = 4)\n\n with open(self.settings[\"memo\"], 'rb') as f:\n self.memo = json.load(f) \n else:\n self.memo = []\n\n def save(self):\n with open(self.settings[\"memo\"], 'w') as f:\n json.dump(self.memo, f, indent = 4)\n\n def process(self, *args):\n if self.callback == None:\n raise ValueError(\"Callback function is not defined, which is needed to the process call. You might want to use generator() instead.\")\n firstRun = True\n if self.debug > 0:\n print(\"Crawler: process\")\n while self.settings.get(\"service\", False) or firstRun:\n firstRun = False\n try:\n if self.settings.get(\"singleReturn\",False) == True:\n for myfile in self.generator():\n if self.debug > 3:\n print(\"Crawler: fire callback with file: {}\".format(myfile))\n self.callback(myfile, *args)\n else:\n files = self.getList()\n if self.debug > 3:\n print(\"Crawler: fire callback with files: {}\".format(\", \".join(files)))\n self.callback(files, *args)\n time.sleep(self.settings.get(\"sleep\", 1))\n except:\n print(\"Oops!\", sys.exc_info()[0], \"occured.\")\n time.sleep(self.settings.get(\"sleep\", 1)*10)\n\nclass localCrawler(Crawler):\n def __init__(self, settings, callback = None):\n super().__init__(settings, callback)\n\n def generator(self):\n super().generator()\n if self.debug > 3:\n print(\"Crawler: local crawls thru {}\".format(self.settings[\"path\"])) \n for subdir, dirs, files in os.walk(self.settings[\"path\"]):\n for filename in files:\n if self.debug > 5:\n print(\"Crawler: Test file {}\".format(filename))\n if (filename.lower().endswith(self.settings[\"extension\"].lower())):\n filepath = os.path.join(subdir, filename)\n if self.debug > 4:\n print(\"Crawler: found file {}\".format(filepath))\n if (self.settings[\"onlyOnce\"] == False or filepath not in self.memo):\n self.memo.append(filepath)\n self.save()\n if self.debug > 4:\n print(\"Crawler: yield file {}\".format(filepath))\n yield filepath\n\n\nimport gspread \nfrom oauth2client.service_account import ServiceAccountCredentials\nclass googleCrawler(Crawler):\n def __init__(self, settings, callback = None):\n super().__init__(settings, callback)\n self.scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']\n self.creds = ServiceAccountCredentials.from_json_keyfile_name(settings[\"credentialPath\"], self.scope)\n self.client = gspread.authorize(self.creds)\n\n def generator(self):\n sheets = self.client.openall()\n for sheet in sheets:\n if (self.settings[\"spreadsheets\"] not in sheet.title):\n continue\n\n if (self.settings[\"enableWorksheets\"] == False):\n if (self.settings[\"returnType\"] == \"path\"):\n yield sheet.title\n else:\n yield sheet\n else:\n for worksheet in sheet.worksheets():\n if (self.settings[\"worksheets\"] not in worksheet.title):\n continue\n if (self.settings[\"returnType\"] == \"path\"):\n yield sheet.title + \"/\" + worksheet.title\n else:\n yield worksheet\n\n def search(self):\n sheets = self.client.openall()\n self.reader.setFile(self.settings.get(\"path\"))\n self.sheets = self.reader.getSheets()\n result = []\n for sheet in self.sheets:\n if sheet not in self.settings[\"skip\"]:\n if self.settings[\"onlyOnce\"] == False or sheet not in self.memo.get(\"files\"):\n self.memo.get(\"files\").append(sheet)\n result.append(sheet)\n self.dumpMemo()\n return result\n\nclass gitCrawler(Crawler):\n def __init__(self, settings, callback = None):\n super().__init__(settings)\n"
},
{
"alpha_fraction": 0.6284900307655334,
"alphanum_fraction": 0.6501424312591553,
"avg_line_length": 31.518518447875977,
"blob_id": "175b612f3014e41868a68d10d7e61ae1bb5f4f73",
"content_id": "6217645572e2f63da57429b175a00a549c35f0a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1755,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 54,
"path": "/tests/test_googlecrawler.py",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "import pytest\n\nimport os\nimport sys\nimport inspect\ncurrent_dir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))\nparent_dir = os.path.dirname(current_dir)\nsys.path.insert(0, parent_dir)\nimport crawler as crawler\n\nimport testutils as tu\n\nbaseSettings = {\n \"type\": \"google\",\n \"memo\" : \"./tests/testdata/memo.json\",\n \"onlyOnce\" : True,\n \"service\" : False,\n \"sleep\" : 1,\n \"singleReturn\" : True,\n #google specific settings\n \"credentialPath\" : \"./dummy-credentials.json\",\n \"spreadsheets\" : \"\",\n \"worksheets\": \"\",\n \"enableWorksheets\": False,\n \"returnType\" : \"path\" \n}\n\ntests = [\n [{\"enableWorksheets\": False, \"spreadsheets\": \"\", \"worksheets\": \"\"}, 2, [\"Dummy1\", \"Dummy2\"]],\n [{\"enableWorksheets\": False, \"spreadsheets\": \"1\", \"worksheets\": \"\"}, 1, [\"Dummy1\"]],\n [{\"enableWorksheets\": True, \"spreadsheets\": \"\", \"worksheets\": \"\"}, 5, [\"Dummy1/Test1\", \"Dummy1/Test2\",\"Dummy1/Test3\", \"Dummy2/Sheet1\",\"Dummy2/Sheet2\" ]],\n [{\"enableWorksheets\": True, \"spreadsheets\": \"1\", \"worksheets\": \"\"}, 3, [\"Dummy1/Test1\", \"Dummy1/Test2\",\"Dummy1/Test3\"]],\n [{\"enableWorksheets\": True, \"spreadsheets\": \"\", \"worksheets\": \"1\"}, 2, [\"Dummy1/Test1\", \"Dummy2/Sheet1\"]],\n [{\"enableWorksheets\": True, \"spreadsheets\": \"1\", \"worksheets\": \"1\"}, 1, [\"Dummy1/Test1\"]],\n]\n\ndef test_create_google_crawler():\n settings = baseSettings\n crawler.createCrawler(settings)\n\ndef test_find_gen():\n tu.find_gen(baseSettings, tests)\n\ndef test_find_list():\n tu.find_list(baseSettings, tests)\n\ndef test_callback_singleReturn():\n tu.callback_singleReturn(baseSettings, tests)\n\ndef test_callback_listReturn():\n tu.callback_listReturn(baseSettings, tests)\n\nif __name__ == '__main__':\n test_callback_listReturn()"
},
{
"alpha_fraction": 0.485097199678421,
"alphanum_fraction": 0.49719223380088806,
"avg_line_length": 33.04411697387695,
"blob_id": "2e5c7d1249ae88bdaef2025901ffc71e700ca3d1",
"content_id": "c09bed25b5b1ed1848a6d883c05e7bfb743451c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2315,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 68,
"path": "/tests/test_localcrawler.py",
"repo_name": "b2aff6009/crawler",
"src_encoding": "UTF-8",
"text": "import pytest\n\nimport os\nimport sys\nimport inspect\ncurrent_dir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))\nparent_dir = os.path.dirname(current_dir)\nsys.path.insert(0, parent_dir)\nimport crawler as crawler\n\nimport testutils as tu\n\nbaseSettings = {\n \"type\": \"local\",\n \"memo\" : \"./tests/testdata/memo.json\",\n \"onlyOnce\" : True,\n \"path\" : \"./tests/testdata/\",\n \"extension\" : \"\",\n \"service\" : False,\n \"sleep\" : 1,\n \"singleReturn\" : True \n}\n\ntests = [\n [{\"extension\": \".csv\"}, 5, [\"./tests/testdata/test1.csv\",\n \"./tests/testdata/test2.csv\", \n \"./tests/testdata/test3.csv\", \n \"./tests/testdata/test4.csv\", \n \"./tests/testdata/test5.csv\"]],\n\n [{\"extension\": \".xml\"}, 2, [\"./tests/testdata/test1.xml\", \n \"./tests/testdata/test2.xml\"]],\n\n [{\"extension\": \".json\"}, 1, [\"./tests/testdata/memo.json\"]],\n\n [{\"extension\": \"\"}, 8, [\"./tests/testdata/test1.csv\",\n \"./tests/testdata/test2.csv\",\n \"./tests/testdata/test3.csv\",\n \"./tests/testdata/test4.csv\", \n \"./tests/testdata/test5.csv\",\n \"./tests/testdata/test1.xml\",\n \"./tests/testdata/test2.xml\",\n \"./tests/testdata/memo.json\"]],\n [{\"onlyOnce\" : False,\"extension\": \"\"}, 8, [\"./tests/testdata/test1.csv\",\n \"./tests/testdata/test2.csv\",\n \"./tests/testdata/test3.csv\",\n \"./tests/testdata/test4.csv\", \n \"./tests/testdata/test5.csv\",\n \"./tests/testdata/test1.xml\",\n \"./tests/testdata/test2.xml\",\n \"./tests/testdata/memo.json\"]]\n]\n\ndef test_find_list():\n tu.find_list(baseSettings, tests)\n\ndef test_find_gen():\n tu.find_gen(baseSettings, tests)\n\n\ndef test_callback_singleReturn():\n tu.callback_singleReturn(baseSettings, tests)\n\ndef test_callback_listReturn():\n tu.callback_listReturn(baseSettings, tests)\n\nif __name__ == '__main__':\n test_callback_singleReturn()\n"
}
] | 7 |
dominguezjavier/CIS104_Roll_The_Dice_Game | https://github.com/dominguezjavier/CIS104_Roll_The_Dice_Game | 376ee3e224aa915477310e688a4691b3c6892f92 | fb54c4a9ccf1885c6e34f8b14f03afb0e7f13d92 | 61c2bdc9b9aef51f33d2ce958e52830dbf8f1480 | refs/heads/master | "2020-05-17T05:10:35.672038" | "2019-04-26T00:15:49" | "2019-04-26T00:15:49" | 183,527,168 | 1 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6359687447547913,
"alphanum_fraction": 0.6498696804046631,
"avg_line_length": 28.342105865478516,
"blob_id": "efb45fd47d4f56d95bafdb8b2959839c0a0fdc95",
"content_id": "e0ab093cfe46b51970d1560a72795b9041b6ae16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 38,
"path": "/Lab_8_Roll_The_Dice.py",
"repo_name": "dominguezjavier/CIS104_Roll_The_Dice_Game",
"src_encoding": "UTF-8",
"text": "import random\r\n\r\n# get random number step 1\r\ndef getRandomNumber ():\r\n return random.randint (1,101) #random.randit gives you an integer.\r\n\r\ndef compareNumbers (randNumber, userNumber):\r\n return userNumber - randNumber\r\n\r\nrandNumber = getRandomNumber ()\r\n\r\nkeepGoing = True\r\n\r\nwhile(keepGoing):\r\n\r\n# step 2 ask user for a number\r\n userNumber = input(\"Please choose a number between 1 and 100: \")\r\n try:\r\n intuserNumber = int(userNumber) # step 2.5 convert the user number to an integer\r\n except:\r\n print(\"Please try again with a number. \")\r\n continue # a continue option will let you stay in the loop and try again.\r\n # a break will terminate the program completely.\r\n# step 3 compare numbers\r\n difference = compareNumbers (randNumber, intuserNumber)\r\n\r\n#print (str(randNumber) + \" \" + str(userNumber))\r\n\r\n# step 4 give user feedback\r\n if(difference < 0):\r\n print(\"Your choice is too low. \")\r\n elif(difference > 0):\r\n print(\"Your choice is too high. \")\r\n else:\r\n print(\"Your choice is correct. \")\r\n keepGoing = False\r\n\r\nprint (\" Game Over! Congratulations. \")"
},
{
"alpha_fraction": 0.6134868264198303,
"alphanum_fraction": 0.6184210777282715,
"avg_line_length": 21.230770111083984,
"blob_id": "0060b9d8e7adb9d1a6819267de83b64776a65f0c",
"content_id": "97d817cee8c97aca13b85e6c19896bbaf70d211c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 26,
"path": "/Lab_8_Roll_The_Dice_1.py",
"repo_name": "dominguezjavier/CIS104_Roll_The_Dice_Game",
"src_encoding": "UTF-8",
"text": "import random\r\n\r\n\r\n# get random number rolled from the dice step 1\r\ndef rollRandomNumber ():\r\n return random.randint (1, 7) #random.randit gives you an integer.\r\n\r\n\r\nkeepRolling = True\r\n\r\n\r\nwhile(keepRolling):\r\n\r\n \r\n print(\" This is the number you rolled \" + str(rollRandomNumber()) + \" .Would you like to roll again? \")\r\n\r\n playersChoice = input(\"If you would like to roll again press y to continue or n to stop. \")\r\n\r\n \r\n \r\n if playersChoice == 'y':\r\n rollRandomNumber()\r\n\r\n else:\r\n print (\" Thank you for playing. Keep it rolling. \")\r\n keepRolling = False\r\n\r\n\r\n"
}
] | 2 |
HansKallekleiv/rtools | https://github.com/HansKallekleiv/rtools | 968b698aea2db73b38b299b8b79dd998e8a3256c | eb6fc83793d3e5f7f27e74f11c703c0e2631945a | 4d3b1ea542adb64a82e57b4399fca4f00336f4b9 | refs/heads/master | "2019-01-07T01:13:49.343278" | "2016-11-28T18:37:37" | "2016-11-28T18:37:37" | 75,002,802 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6598639488220215,
"alphanum_fraction": 0.668367326259613,
"avg_line_length": 30,
"blob_id": "c5490b3a5e51fa2f05c5ee875873e9c1bdae3772",
"content_id": "66456b18a4612e5a6e2fd1914bdac16c5d7cf242",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 19,
"path": "/statistics/facies.py",
"repo_name": "HansKallekleiv/rtools",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport bokeh\nfrom bokeh.charts import defaults,show,output_file\ndf = pd.read_excel(\"statistics_report_1.xls\",skiprows=3)\ndf = df.fillna(method='ffill')\n\ndf = df[df['Zone'] != \"Selection\"]\ndf = df[df['Zone'] != \"Limits\"]\ndf = df[df['Zone'] != \"Min\"]\ndf = df[df['Zone'] != \"Max\"]\ndf['Percent'] = pd.to_numeric(df['Percent'])\nprint df.dtypes\nprint df\n\nd = bokeh.charts.Donut(df,label=['Zone','Facies'], values='Sum')\n#hist = bokeh.charts.Histogram(df, values='Sum', color = 'Zone', legend='top_right', bins=20)\noutput_file(\"histogram.html\")\nshow(d)\ndf.to_csv(\"test2.csv\")"
}
] | 1 |
kunalwade/Binary-search | https://github.com/kunalwade/Binary-search | fef4c409e423ef76a87d5674ec3ade7b52f53aee | 33a3e7c5751028c2ce66535964ef09c2e0d25794 | 64827de49ae7769d1b7840cb545daa8c87647774 | refs/heads/main | "2023-04-21T23:55:42.886051" | "2021-05-22T04:32:07" | "2021-05-22T04:32:07" | 369,714,384 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 56.5,
"blob_id": "8cbbfad60fe4dec40c6f1ca07ae4dc3bcd6bdebb",
"content_id": "86008e0f55a8431fabf68bd33c6eb810b3886f01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 2,
"path": "/README.md",
"repo_name": "kunalwade/Binary-search",
"src_encoding": "UTF-8",
"text": "# Binary-search: implementation of binary search algorithm\n#proving that binary search is faster than naive search\n"
},
{
"alpha_fraction": 0.5720496773719788,
"alphanum_fraction": 0.5919254422187805,
"avg_line_length": 24.847457885742188,
"blob_id": "1757e39154930580ae5daa25341206c38d242dea",
"content_id": "ee4ec73ef3ecabf2e57495ab6a26ab4502ee8dc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1610,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 59,
"path": "/binary_search.py",
"repo_name": "kunalwade/Binary-search",
"src_encoding": "UTF-8",
"text": "\r\n#implementation of binary search algorithm\r\n#proving that binary search is faster than naive search\r\n#naive search : scan entire list and ask if its equal to target\r\n#if yyes return index\r\n#if no then return -1\r\n\r\nimport random\r\nimport time\r\n\r\ndef naive_search(l, target):\r\n #example l =[1,3,10,12]\r\n for i in range(len(l)):\r\n if l[i] == target:\r\n return i\r\n return -1\r\n\r\ndef binary_search(l, target, low= None, high=None):\r\n if low is None:\r\n low=0\r\n if high is None:\r\n high= len(l) -1\r\n\r\n if high < low:\r\n return -1\r\n \r\n midpoint = (low + high) //2\r\n\r\n if l[midpoint] == target:\r\n return midpoint\r\n elif target < l[midpoint]:\r\n return binary_search(l, target, low , midpoint-1)\r\n\r\n else:\r\n #target > l(midpont)\r\n return binary_search(l, target, midpoint+1, high)\r\n\r\nif __name__ == '__main__':\r\n # l= [3,5,4,8,9]\r\n # target=8\r\n # print(naive_search(l, target))\r\n #print(binary_search(l,target))\r\n length=10000\r\n#build a sorted list of length 10000\r\nsorted_list= set()\r\nwhile len(sorted_list) < length:\r\n sorted_list.add(random.randint(-3*length, 3*length))\r\nsorted_list = sorted(list(sorted_list))\r\n\r\nstart = time.time()\r\nfor target in sorted_list:\r\n naive_search(sorted_list,target)\r\nend = time.time()\r\nprint(\"Naive search time: \", (end - start)/length, \"seconds\")\r\n\r\nstart = time.time()\r\nfor target in sorted_list:\r\n binary_search(sorted_list,target)\r\nend = time.time()\r\nprint(\"Binary search time: \", (end - start)/length, \"seconds\")\r\n \r\n \r\n \r\n \r\n"
}
] | 2 |
Ashima161991/deep-neurals-networks | https://github.com/Ashima161991/deep-neurals-networks | 43761d317fb862f9b64736d4d2c6ee84bcb3abb7 | 1ec5bc9880fb5537f5c5a7ec6240e8e51e68334d | d9b4d5c0d15e817b7494e7cb999ef952d6f4b720 | refs/heads/master | "2020-04-18T15:36:34.582452" | "2019-01-25T21:43:37" | "2019-01-25T21:43:37" | 167,615,506 | 2 | 0 | null | "2019-01-25T21:20:59" | "2019-01-25T21:21:02" | "2019-01-25T21:39:08" | null | [
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 23,
"blob_id": "0eaf00c7e6336fa1b3342a91d9563193bb6a2302",
"content_id": "4656b27b476bb74aa040b6adc79ae944be9c08b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Ashima161991/deep-neurals-networks",
"src_encoding": "UTF-8",
"text": "# deep-neurals-networks"
},
{
"alpha_fraction": 0.6360396146774292,
"alphanum_fraction": 0.6669306755065918,
"avg_line_length": 23.495145797729492,
"blob_id": "f047eeba2711f2b262a073a976adfac3b998accc",
"content_id": "7a7bb2cea3bdf0f79ef01fc8c08e22af713ac17c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2527,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 103,
"path": "/IMDB.py",
"repo_name": "Ashima161991/deep-neurals-networks",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[1]:\n\n\n##import the libraries \n\nfrom keras.datasets import imdb\nfrom keras import models\nfrom keras import layers\nfrom keras import optimizers\nimport matplotlib.pyplot as plt\nimport numpy as np\n\n\n# In[2]:\n\n\n# Load the IMDB data\n(train_data, train_labels), (test_data, test_labels) = imdb.load_data(\n num_words=10000)#argument num_words=10000 means you’ll only keep the top 10,000 most frequently occurring words\n#train_data[0]\n#train_labels[0]\n\n## One hot encode the input\ndef vectorize_sequences(sequences, dimension=10000):\n results = np.zeros((len(sequences), dimension)) \n for i, sequence in enumerate(sequences):\n results[i, sequence] = 1. \n return results\n\nx_train = vectorize_sequences(train_data) \nx_test = vectorize_sequences(test_data) \n\ny_train = np.asarray(train_labels).astype('float32')\ny_test = np.asarray(test_labels).astype('float32')\n\n\n###########validation set by setting apart 10,000 samples from the original training data\nx_val = x_train[:10000]\npartial_x_train = x_train[10000:]\ny_val = y_train[:10000]\npartial_y_train = y_train[10000:]\n\n\n# In[4]:\n\n\n## Keras Sequential Model\n\nmodel = models.Sequential()\nmodel.add(layers.Dense(16, activation='relu', input_shape=(10000,)))\nmodel.add(layers.Dense(16, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))\nmodel.compile(optimizer=optimizers.RMSprop(lr=0.001),\n loss='binary_crossentropy',\n metrics=['accuracy'])\nhistory = model.fit(partial_x_train,\n partial_y_train,\n epochs=20,\n batch_size=512,\n validation_data=(x_val, y_val))\n\nresults = model.evaluate(x_test, y_test)\nresults\n\n\n# In[7]:\n\n\nhistory_dict = history.history\nhistory_dict.keys()\n\n\nhistory_dict = history.history\nloss_values = history_dict['loss']\nval_loss_values = history_dict['val_loss']\nacc=history_dict['acc']\n\n\nepochs = range(1, len(acc) + 1)\n\nplt.plot(epochs, loss_values, 'bo', label='Training loss') \nplt.plot(epochs, val_loss_values, 'b', label='Validation loss') \nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\n\nplt.show()\n\nacc_values = history_dict['acc']\n\nval_acc= history_dict['val_acc']\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\n\nplt.show()\n\n"
}
] | 2 |
hmarcuzzo/FA-inverseWord | https://github.com/hmarcuzzo/FA-inverseWord | 4102d905d088b45a001ceea45b361fccc800636a | bcdec5e602332d25a4bfbe5ef280049bd750dcf6 | 5e22b02c983b7101e4c190f4cf47cf7aa155cc7f | refs/heads/master | "2020-08-09T01:49:46.634690" | "2019-10-15T02:46:12" | "2019-10-15T02:46:12" | 213,970,138 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5568602085113525,
"alphanum_fraction": 0.5742552876472473,
"avg_line_length": 31.624113082885742,
"blob_id": "bcfca571add801008a83d2f85eb78bf8d71b8753",
"content_id": "0b2e11ecb2c843e5a6b9c2781cd7df3527eda81b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4618,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 141,
"path": "/inverse.py",
"repo_name": "hmarcuzzo/FA-inverseWord",
"src_encoding": "UTF-8",
"text": "import sys\nimport subprocess\n\n\"\"\" Classe com todas as linhas de um automato finito. \"\"\"\nclass FiniteAutomaton(object):\n def __init__(self):\n self.machine = []\n self.input_alphabet = []\n self.lambda_ = []\n self.states = []\n self.initial_state = []\n self.final_states = []\n self.transitions = []\n\n\n\n\"\"\" Todas as linhas do automato finito são pegas pelos variaveis da Classe \"\"\"\nfa = []\nfa.append(FiniteAutomaton())\nfp = open(sys.argv[1], \"r\")\nlines_cmd = fp.readlines()\nfp.close()\nlines = []\nfor line in lines_cmd:\n lines.append(line.rstrip())\nfa[0].machine = lines[0].split()\nfa[0].input_alphabet = lines[1].split()\nfa[0].lambda_ = lines[2]\nfa[0].states = lines[3].split()\nfa[0].initial_state = lines[4].split()\nfa[0].final_states = lines[5].split()\nfor j in range(6, len(lines)):\n fa[0].transitions.append(lines[j].split())\n\n\ndef printfaData(fa_aux, i):\n print()\n print(f'Tipo da máquina {i+1} : {fa_aux.machine}')\n print(f'Alfabeto da máquina {i+1} : {fa_aux.input_alphabet}')\n print(f'Branco da máquina {i+1} : {fa_aux.lambda_}')\n print(f'Estados da máquina {i+1} : {fa_aux.states}')\n print(f'Estado incial da máquina {i+1} : {fa_aux.initial_state}')\n print(f'Estado final da máquina {i+1} : {fa_aux.final_states}')\n print(f'Transições da máquina {i+1} : ')\n for j in fa_aux.transitions:\n print(j)\n print()\n\n\nfa.append(FiniteAutomaton())\n\n\"\"\" Copiando o estado da máquina \"\"\"\nfor i in range(len(fa[0].machine)):\n fa[1].machine.append(fa[0].machine[i])\n\n\"\"\" Capituramos para o Automato Finito inverso todos os alfabetos de entrada do automato finito principal\"\"\"\nfor j in range(len(fa[0].input_alphabet)):\n fa[1].input_alphabet.append(fa[0].input_alphabet[j])\n\n#######################################################\n\n\"\"\" Copia o lambda de um automato para outro \"\"\"\nfa[1].lambda_.append(fa[0].lambda_)\n\n# #######################################################\n\n\"\"\" Copiamos os estados existens no Automato finito \"\"\"\n\nfor i in range(len(fa[0].states)):\n fa[1].states.append(fa[0].states[i])\nfa[1].states.append(\"q\" + str(len(fa[0].states)))\n\n#######################################################\n\n\"\"\" Define como estado inicial do automato inverso, o estado criado para ser o inicializador \"\"\"\nfa[1].initial_state.append( \"q\" + str(len(fa[0].states)))\n\n#######################################################\n\n\"\"\" Define como estado final da automato inverso, o estado inical do automato principal \"\"\"\nfor i in range(len(fa[0].initial_state)):\n fa[1].final_states.append(fa[0].initial_state[i])\n\n#######################################################\n\n\"\"\" São copiadas as transições para depois fazerem as devidas trocas \"\"\"\nfor i in range(len(fa[0].final_states)):\n fa[1].transitions.append( \n (str(fa[1].initial_state[0]) + \" \" + str(fa[1].lambda_[0]) + \" \" + str(fa[0].final_states[i])).split() )\n\n######################################################\n\n\"\"\" É feita a inversão das transições \"\"\"\naux = []\nfor i in range(len(fa[0].transitions)):\n aux = fa[0].transitions[i][0]\n (fa[0].transitions[i])[0] = str(fa[0].transitions[i][2])\n\n (fa[0].transitions[i])[2] = str(aux)\n\n fa[1].transitions.append(fa[0].transitions[i])\n\n\n#######################################################\n\nprintfaData(fa[1], 1)\nprint(\"\\n\\n\")\n\n\"\"\" Aberto o arquivo vindo por comando, na pasta .\"/fla/dfa.txt\" e escreve a união das duas fa \"\"\"\ninverse = open(sys.argv[2], 'w')\nfor i in range(len(fa[1].machine)):\n inverse.write(fa[1].machine[i] + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].input_alphabet)):\n inverse.write(fa[1].input_alphabet[i] + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].lambda_)):\n inverse.write(fa[1].lambda_[i] + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].states)):\n inverse.write(str(fa[1].states[i]) + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].initial_state)):\n inverse.write(str(fa[1].initial_state[i]) + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].final_states)):\n inverse.write(str(fa[1].final_states[i]) + \" \")\ninverse.write(\"\\n\")\nfor i in range(len(fa[1].transitions)):\n for j in range(len(fa[1].transitions[i])):\n inverse.write(str(fa[1].transitions[i][j]) + \" \")\n inverse.write(\"\\n\")\n\ninverse.close()\n#######################################################\n\n\"\"\" Verifica se o automato aceita \"\"\"\ninputTest = \"\"\nfor i in range(len(sys.argv[3:])):\n inputTest = inputTest + sys.argv[3:][i]\nreturn_code = subprocess.call('python3 ./fla/main.py ' + sys.argv[2] + \" \" + inputTest, shell=True)"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.7439613342285156,
"avg_line_length": 22.11111068725586,
"blob_id": "49ff582458824be800f2d6540fa4f71cc11a036e",
"content_id": "8097c66fd6fd7f90c408f14b72345f44584ac352",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 9,
"path": "/README.md",
"repo_name": "hmarcuzzo/FA-inverseWord",
"src_encoding": "UTF-8",
"text": "# FA-inverseWorld\nO automato inverso funciona se o arquivo txt que contém o automato a ser invertido \nnão tiver quebra de linha em seu meio.\n\n## Run\n```\npython3 inverse.py dfa.txt inverse.txt \"entrada\"\n\n```"
}
] | 2 |
karolpociask/Lab | https://github.com/karolpociask/Lab | c5d990a2918f6327ae6976604b22740b688b8bb7 | 9bd2f7fc5761f5ca64aea8b6dfc73ecb78d8919b | 5dde122aeb95904f24619c7651e049a298264db7 | refs/heads/main | "2023-03-30T20:55:24.346312" | "2021-04-08T12:37:46" | "2021-04-08T12:37:46" | 355,864,380 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.35699981451034546,
"alphanum_fraction": 0.4074276387691498,
"avg_line_length": 22.783550262451172,
"blob_id": "7f21f691b10fdd9de3c35d17dab58a817a0dfa2b",
"content_id": "2610a00ac9d78d97c7208293c8e16f3fb2ddda34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5493,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 231,
"path": "/main.py",
"repo_name": "karolpociask/Lab",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n'''\n# --------------------------------------- array ---------------------------\narr = np.array([1, 2, 3, 4, 5])\nprint(arr)\n\nA = np.array([[1, 2, 3], [7, 8, 9]])\nprint(A)\nA = np.array([[1, 2, 3],\n [7, 8, 9]])\nA = np.array([[1, 2, \\\n 3],\n [7, 8, 9]])\nprint(A)\n# --------------------------------------- arrange ---------------------------\nv = np.arange(1, 7)\nprint(v, \"\\n\")\nv = np.arange(-2, 7)\nprint(v, \"\\n\")\nv = np.arange(1, 10, 3)\nprint(v, \"\\n\")\nv = np.arange(1, 10.1, 3)\nprint(v, \"\\n\")\nv = np.arange(1, 11, 3)\nprint(v, \"\\n\")\nv = np.arange(1, 2, 0.1)\nprint(v, \"\\n\")\n# --------------------------------------- linspace ---------------------------\nv = np.linspace(1, 3, 4)\nprint(v)\nv = np.linspace(1, 10, 4)\nprint(v)\n\n# --------------------------------------- funkcje pomocnicze ---------------------------\nX = np.ones((2, 3))\nY = np.zeros((2, 3, 4))\nZ = np.eye(2)\nQ = np.random.rand(2, 5)\nprint(X, \"\\n\\n\", Y, \"\\n\\n\", Z, \"\\n\\n\", Q)\n# --------------------------------------- mieszane ---------------------------\nV = np.block([[\nnp.block([\nnp.block([[np.linspace(1, 3, 3)],\n[np.zeros((2, 3))]]),\nnp.ones((3, 1))])\n],\n[np.array([100, 3, 1/2, 0.333])]])\nprint(V)\n# --------------------------------------- elementy tablicy ---------------------------\nprint(V[0, 2])\nprint(V[3, 0])\nprint(V[3, 3])\nprint(V[-1, -1])\nprint(V[-4, -3])\nprint(V[3, :])\nprint(V[:, 2])\nprint(V[3, 0:3])\nprint(V[np.ix_([0, 2, 3], [0, -1])])\nprint(V[3])\n# --------------------------------------- usuwanie fragmentow ---------------------------\nQ = np.delete(V, 2, 0)\nprint(Q)\nQ = np.delete(V, 2, 1)\nprint(Q)\nv = np.arange(1, 7)\nprint(np.delete(v, 3, 0))\n# --------------------------------------- sprawdzanie rozmiarow ---------------------------\nnp.size(v)\nnp.shape(v)\nnp.size(V)\nnp.shape(V)\n# --------------------------------------- operacje na macierzach ---------------------------\nA = np.array([[1, 0, 0],\n[2, 3, -1],\n[0, 7, 2]])\nB = np.array([[1, 2, 3],\n[-1, 5, 2],\n[2, 2, 2]])\nprint(A+B)\nprint(A-B)\nprint(A+2)\nprint(2*A)\n# --------------------------------------- mnozenie macierzowe ---------------------------\nMM1 = A@B\nprint(MM1)\nMM2 = B@A\nprint(MM2)\n# --------------------------------------- mnozenie tablicowe ---------------------------\nMT1 = A*B\nprint(MT1)\nMT2 = B*A\nprint(MT2)\n# --------------------------------------- dzielenie tablicowe ---------------------------\nDT1 = A/B\nprint(DT1)\n# --------------------------------------- dzielenie macierzowe URL ---------------------------\nC = np.linalg.solve(A, MM1)\nprint(C)\nx = np.ones((3, 1))\nb = A@x\ny = np.linalg.solve(A, b)\nprint(y)\n# --------------------------------------- potegowanie ---------------------------\nPM = np.linalg.matrix_power(A, 2)\nPT = A**2\n# --------------------------------------- transpozycja ---------------------------\nA.T\nA.transpose()\nA.conj().T\nA.conj().transpose()\n\n# --------------------------------------- logika ---------------------------\nA == B\nA != B\n2 < A\nA > B\nA < B\nA >= B\nA <= B\nnp.logical_not(A)\nnp.logical_and(A, B)\nnp.logical_or(A, B)\nnp.logical_xor(A, B)\nprint(np.all(A))\nprint(np.any(A))\nprint(v > 4)\nprint(np.logical_or(v > 4, v < 2))\nprint(np.nonzero(v > 4))\nprint(v[np.nonzero(v > 4)])\nprint(np.max(A))\nprint(np.min(A))\nprint(np.max(A, 0))\nprint(np.max(A, 1))\nprint(A.flatten())\nprint(A.flatten('F'))\n# --------------------------------------- wykres ---------------------------\nx = [1,2,3]\ny = [4,6,5]\nplt.plot(x,y)\nplt.show()\n# --------------------------------------- sinus ---------------------------\nx = np.arange(0.0, 2.0, 0.01)\ny = np.sin(2.0*np.pi*x)\nplt.plot(x,y)\nplt.show()\n# --------------------------------------- ulepszone ---------------------------\nx = np.arange(0.0, 2.0, 0.01)\ny = np.sin(2.0*np.pi*x)\nplt.plot(x, y,'r:',linewidth=6)\nplt.xlabel('Czas')\nplt.ylabel('Pozycja')\nplt.title('Nasz pierwszy wykres')\nplt.grid(True)\nplt.show()\n# --------------------------------------- kilka wykresow ---------------------------\nx = np.arange(0.0, 2.0, 0.01)\ny1 = np.sin(2.0*np.pi*x)\ny2 = np.cos(2.0*np.pi*x)\nplt.plot(x, y1, 'r:', x, y2, 'g')\nplt.legend(('dane y1', 'dane y2'))\nplt.xlabel('Czas')\nplt.ylabel('Pozycja')\nplt.title('Wykres ')\nplt.grid(True)\nplt.show()\n# --------------------------------------- druga wersja ---------------------------\nx = np.arange(0.0, 2.0, 0.01)\nx = np.arange(0.0, 2.0, 0.01)\ny1 = np.sin(2.0*np.pi*x)\ny2 = np.cos(2.0*np.pi*x)\ny = y1*y2\nl1, = plt.plot(x, y, 'b')\nl2,l3 = plt.plot(x, y1, 'r:', x, y2, 'g')\nplt.legend((l2, l3, l1), ('dane y1', 'dane y2', 'y1*y2'))\nplt.xlabel('Czas')\nplt.ylabel('Pozycja')\nplt.title('Wykres ')\nplt.grid(True)\nplt.show()\n'''\n# zadanie 3\nA_1 = np.array([np.linspace(1, 5, 5), np.linspace(5, 1, 5)])\nA_2 = np.zeros((3, 2))\nA_3 = np.ones((2, 3))*2\nA_4 = np.linspace(-90, -70, 3)\nA_5 = np.ones((5, 1))*10\n\nA = np.block([[A_3], [A_4]])\nA = np.block([A_2, A])\nA = np.block([[A_1], [A]])\nA = np.block([A, A_5])\n\n\n# zadanie 4\n\nB = A[1] + A[3]\n\n# zadanie 5\n\nC = np.array([max(A[:, 0]), max(A[:, 1]), max(A[:, 2]), max(A[:, 3]), max(A[:, 4]), max(A[:, 5])])\n\n\n# zadanie 6\n\nD = np.delete(B, 0)\nD = np.delete(D, len(D)-1)\n\n# zadanie 7\n\nfor x in range(4):\n if(D[x]==4):\n D[x]=0\n\n# zadanie 8\nmax = C[0]\nmax_ID = 0\nmin = C[0]\nmin_ID = 0\nfor x in range(len(C)):\n if(C[x] > max):\n max = C[x]\n max_ID = x\nE = np.delete(C, max_ID)\nfor x in range(len(E)):\n if(E[x] < min):\n min = C[x]\n min_ID = x\nE = np.delete(E, min_ID)\nprint(C)\nprint(E)"
}
] | 1 |
nongdaxiaofeng/RFAthM6A | https://github.com/nongdaxiaofeng/RFAthM6A | 161a2b80fc3580d9dd34358be22f34d3adfd4d7b | 7cf8ee3ecca9189ca5f8ea8c38fe16e49aba3644 | 170fe13ef94cee16565805052c2d23b2c50e5fb7 | refs/heads/master | "2021-09-05T10:05:44.142450" | "2018-01-26T08:44:03" | "2018-01-26T08:44:03" | 103,135,701 | 3 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.4150664806365967,
"alphanum_fraction": 0.4815361797809601,
"avg_line_length": 21.566667556762695,
"blob_id": "7b08fac3dbd1a718150e7f1fbcff574717b9466a",
"content_id": "80fa0242a72958b64e0a8f9d50dc31655b7fbc31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 30,
"path": "/dataset/encode_chen.py",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "#from __future__ import division\nimport sys\nfrom functools import reduce\nf=open(sys.argv[1])\nfw=open(sys.argv[2],'w')\n#w=int(sys.argv[3])\nw=50\n\ndict1={'A':[1,1,1],'T':[0,1,0],'C':[0,0,1],'G':[1,0,0],'N':[0,0,0]}\n \nfor line in f:\n col=line.split(',')\n if col[2]=='1':\n fw.write('+1 ')\n else:\n fw.write('-1 ')\n seq=col[3].rstrip()\n v=[]\n p=0\n dict2={'A':0,'T':0,'C':0,'G':0,'N':0}\n for n in seq[50-w:50+w+1]:\n p=p+1\n dict2[n]+=1\n v.extend(dict1[n]+[dict2[n]/p])\n \n out=reduce(lambda x,y:x+' '+y,map(lambda x,y:str(x)+\":\"+str(y),range(1,len(v)+1),v))\n fw.write(out+'\\n')\n\nfw.close()\nf.close()\n"
},
{
"alpha_fraction": 0.6545454263687134,
"alphanum_fraction": 0.7292929291725159,
"avg_line_length": 39.08333206176758,
"blob_id": "e9998cdbe10d2d41a7985a2df95d34ec4c15dcce",
"content_id": "1126cd37ca82c5e870ae2ca17fc5e5f5ae9ff6bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 12,
"path": "/dataset/predict_test_ksnpf.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\ntestresponse=as.factor(c(rep(1,418),rep(0,418)))\r\nd1<-read.csv('coding_train_ksnpf',header=F,stringsAsFactors=F)\r\nd1=d1[4:ncol(d1)]\r\ntestd1<-read.csv('coding_test_ksnpf',header=F,stringsAsFactors=F)\r\ntestd1=testd1[4:ncol(testd1)]\r\nscore=rep(0,nrow(testd1))\r\nmodel=randomForest(x=d1,y=response,ntree=1000,norm.votes=F)\r\npred=predict(model,testd1,type='prob')\r\nscore=pred[,2]\r\nwrite(score,file='ksnpf_test_score',sep='\\n')\r\n\r\n"
},
{
"alpha_fraction": 0.3787696063518524,
"alphanum_fraction": 0.41013267636299133,
"avg_line_length": 24.74193572998047,
"blob_id": "30ca68cc769558ff2aba6e8278a93456aa4da58e",
"content_id": "53b540e259b58586ae343f0566da597783442711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 31,
"path": "/ks.py",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "import sys\r\n\r\nf=open(sys.argv[1])\r\nfw=open(sys.argv[2],'w')\r\nkn=5\r\nfor line in f:\r\n freq=[]\r\n for i in range(kn):\r\n freq.append({})\r\n for n1 in ['A','C','T','G']:\r\n freq[i][n1]={}\r\n for n2 in ['A','C','T','G']:\r\n freq[i][n1][n2]=0\r\n col=line.split(',')\r\n seq=col[2].rstrip()\r\n seq=seq.strip('N')\r\n seq_len=len(seq)\r\n for k in range(kn):\r\n for i in range(seq_len-k-1):\r\n n1=seq[i]\r\n n2=seq[i+k+1]\r\n if n1 in 'ATCG' and n2 in 'ATCG':\r\n freq[k][n1][n2]+=1\r\n fw.write(col[0]+','+col[1])\r\n for i in range(kn):\r\n for n1 in ['A','C','T','G']:\r\n for n2 in ['A','C','T','G']:\r\n fw.write(','+ str(freq[i][n1][n2]/(seq_len-i-1)))\r\n fw.write('\\n')\r\nfw.close()\r\nf.close()\r\n"
},
{
"alpha_fraction": 0.6974359154701233,
"alphanum_fraction": 0.7384615540504456,
"avg_line_length": 31.5,
"blob_id": "56eadd12aab46fb779e7bacf95f24687fccef356",
"content_id": "b1df50b031c864fad941835782fea96790af8615",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 6,
"path": "/dataset/combine_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(pROC)\nksscore=scan('ksnpf_cv_score')\ndpscore=scan('psdsp_cv_score')\nkmscore=scan('knf_cv_score')\nscore=0.2*ksscore+0.35*dpscore+0.45*kmscore\nwrite(score,file='combine_cv_score',sep='\\n')\n"
},
{
"alpha_fraction": 0.3499067723751068,
"alphanum_fraction": 0.4313237965106964,
"avg_line_length": 24.71666717529297,
"blob_id": "52be7d3258367c450187bb07924d9f8b8e02117e",
"content_id": "4a3a09004692d8199e34cd82645c0922fe5f230a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1609,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 60,
"path": "/dataset/encode_sun.py",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom functools import reduce\r\nf=open(sys.argv[1])\r\nfw=open(sys.argv[2],'w')\r\n\r\ndict1={'A':[0,0,0,1],'T':[0,0,1,0],'C':[0,1,0,0],'G':[1,0,0,0],'N':[0,0,0,0]}\r\nmer2={}\r\nmer3={}\r\nmer4={}\r\nfor n1 in 'ATCG':\r\n for n2 in 'ATCG':\r\n mer2[n1 + n2]=0\r\n for n3 in 'ATCG':\r\n mer3[n1+n2+n3]=0\r\n for n4 in 'ATCG':\r\n mer4[n1+n2+n3+n4]=0\r\n \r\nfor line in f:\r\n mer2={}\r\n mer3={}\r\n mer4={}\r\n for n1 in 'ATCG':\r\n for n2 in 'ATCG':\r\n mer2[n1 + n2]=0\r\n for n3 in 'ATCG':\r\n mer3[n1+n2+n3]=0\r\n for n4 in 'ATCG':\r\n mer4[n1+n2+n3+n4]=0\r\n col=line.split(',')\r\n if col[2]=='1':\r\n fw.write('+1 ')\r\n else:\r\n fw.write('-1 ')\r\n seq=col[3].rstrip()\r\n v1=reduce(lambda x,y:x+y,map(lambda x:dict1[x],seq[30:71]))\r\n seq=seq.replace('N','')\r\n seq_len=len(seq)\r\n for p in range(seq_len-3):\r\n mer2[seq[p:p+2]]+=1\r\n mer3[seq[p:p+3]]+=1\r\n mer4[seq[p:p+4]]+=1\r\n mer2[seq[p+1:p+3]]+=1\r\n mer2[seq[p+2:p+4]]+=1\r\n mer3[seq[p+1:p+4]]+=1\r\n v2=[]\r\n v3=[]\r\n v4=[]\r\n for n1 in 'ATCG':\r\n for n2 in 'ATCG': \r\n v2.append(mer2[n1+n2]/(seq_len-1))\r\n for n3 in 'ATCG':\r\n v3.append(mer3[n1+n2+n3]/(seq_len-2))\r\n for n4 in 'ATCG':\r\n v4.append(mer4[n1+n2+n3+n4]/(seq_len-3))\r\n v=v1+v2+v3+v4\r\n out=reduce(lambda x,y:x+' '+y,map(lambda x,y:str(x)+\":\"+str(y),range(1,len(v)+1),v))\r\n fw.write(out+'\\n')\r\n\r\nfw.close()\r\nf.close()\r\n \r\n"
},
{
"alpha_fraction": 0.4779411852359772,
"alphanum_fraction": 0.5597426295280457,
"avg_line_length": 22.177778244018555,
"blob_id": "6e755e073f4f9c8d9ed121570d762c89fa43f610",
"content_id": "57e23eba491331cce1ef79eabad42b89e0329208",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 45,
"path": "/dataset/psnsp_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\nd=read.csv('trainset',header=F,stringsAsFactors=F)\r\ngroup=scan('fold')\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\nscore=numeric(nrow(d))\r\nfor(i in 1:5){\r\n\tm1=matrix(0,4,99)\r\n\trownames(m1)=c('A','T','C','G')\r\n\tm2=matrix(0,4,99)\r\n\trownames(m2)=c('A','T','C','G')\r\n\td1=d[group!=i,]\r\n\tfor(r in 1:nrow(d1)){\r\n\t\tm=matrix(0,4,99)\r\n\t\trownames(m)=c('A','T','C','G')\r\n\t\texon=unlist(strsplit(d1[r,4],''))\r\n\t\texon=exon[-(51:52)]\r\n\t\tfor(p in 1:length(exon)){\r\n\t\t\tif(exon[p]!='N'){\r\n\t\t\t\tm[exon[p],p]=1\r\n\t\t\t}\r\n\t\t}\r\n\t\tif(d1[r,3]==1){\r\n\t\t\tm1=m1+m\r\n\t\t}else{\r\n\t\t\tm2=m2+m\r\n\t\t}\r\n\t}\r\n\tm1=sweep(m1,2,apply(m1,2,sum),'/')\r\n\tm2=sweep(m2,2,apply(m2,2,sum),'/')\r\n\tm=m1-m2\r\n\tcoding=matrix(0,nr=4200,nc=99)\r\n\tfor(r in 1:nrow(d)){\r\n\t\ts=substring(d[r,4],c(1:50,53:101),c(1:50,53:101))\r\n\t\tfor(p in 1:length(s)){\r\n\t\t\tif(s[p]!='N'){\r\n\t\t\t\tcoding[r,p]=m[s[p],p]\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n\tmodel=randomForest(x=coding[group!=i,],y=response[group!=i],ntree=1000,norm.votes=F)\r\n\tpred=predict(model,coding[group==i,],type='prob')\r\n\tscore[group==i]=pred[,2]\r\n\t\r\n}\r\nwrite(score,file='psnsp_cv_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.7864865064620972,
"alphanum_fraction": 0.7934362888336182,
"avg_line_length": 56.53333282470703,
"blob_id": "a8367d60101a8f84dbdf190d8b7b5a682bdeb5df",
"content_id": "a8d936853e5066c32fcfa6c74ccb820ea8bb39ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2590,
"license_type": "no_license",
"max_line_length": 513,
"num_lines": 45,
"path": "/README.md",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "# RFAthM6A\nRFAthM6A is a tool for predicting m6A sites in Arabidopsis thaliana.\n\n1. Prerequisites to use RFAthM6A\n\nPython3 is installed in the computer. R software is installed in the computer. The R package randomForest is installed. \n\nIf randomForest is not installed, you can run this command in R:\n>install.packages('randomForest')\n\n2. Use well-trained models to predict m6A sites in Arabidopsis thaliana.\n\nFirst, enter into the directory where the scripts are placed and prepare the exon sequence file in fasta format and the exon sequence should only contain letters \"A\", \"T\", \"C\" and \"G\". We used the file 'test.fasta' as an example to illustrate the prediction process. Run the following command to find the \"RRACH\" motif, which are saved to the file \"test_site\".\n\n>python find_site.py test.fasta test_site\n\nRun the following command to predict m6A sites by RFPSNSP model and the prediction scores are saved to the file \"psnsp_score\".\n\n>Rscript predict_by_psnsp.R test_site psnsp_score\n\nRun the following command to predict m6A sites by RFPSDSP model and the prediction scores are saved to the file \"psdsp_score\".\n\n>Rscript predict_by_psdsp.R test_site psdsp_score\n\nUse the following commands to do the KSNPF encoding and RFKSNPF predicting.\n\n>python ks.py test_site test_ks\n\n>Rscript predict_by_ksnpf.R test_ks ksnpf_score\n\nUse the following commands to do the KNF encoding and RFKNF predicting.\n\n>python knf.py test_site test_knf\n\n>Rscript predict_by_knf.R test_knf knf_score\n\nUse the following commands to combine the prediction scores of RFPSDSP, RFKSNPF and RFKNF and save the results to the file \"combine_score\".\n\n>Rscript RFCombine.R psdsp_score ksnpf_score knf_score score\n\nAll the score files contain 3 columns. The first column is the name of the test sequence. The second column is the position of the \"RRACH\" motif in the sequence. The second column is the prediction score. The prediction score is between 0 and 1, and can be considered as the predictive probability to be m6A.\n\n3.Repeating the work of the paper and building your own prediction models\n\nThe \"dataset\" directory includes the datasets and sourcecodes metioned in the paper \"RFAthM6A: a new tool for predicting m6A sites in Arabidopsis thaliana\" (unpublished). Making use of the files in the directory and according to the introduction of the Readme file in the directory, one can repeat the main work in the paper, including feature encoding, 5-fold cross validation and independent test for different methods. This directory also includes the files of rules we extracted from the random forest models. \n"
},
{
"alpha_fraction": 0.6492805480957031,
"alphanum_fraction": 0.6906474828720093,
"avg_line_length": 37.71428680419922,
"blob_id": "35fa8a77189653c46c20cfa4c81b4cfcae9f1e83",
"content_id": "e9ce805ce6fdbf39021905c912f1c2940e4b6091",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 14,
"path": "/dataset/sun_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "fold=scan('fold')\r\nlines=readLines('coding_train_sun')\r\nresponse=c(rep(1,2100),rep(0,2100))\r\ng=2^-8\r\nc=2^5\r\npred_value=numeric(length(lines))\r\nfor(label in 1:5){\r\n\twriteLines(lines[fold!=label],'train_temp1')\r\n\twriteLines(lines[fold==label],'test_temp1')\r\n\tsystem(paste('~/libsvm/svm-train -g',g,'-c',c,'train_temp1 model_temp1'))\r\n\tv=system(paste('~/libsvm/svm-predict test_temp1 model_temp1 output_temp1|grep -v ^Accuracy'),intern=TRUE)\r\n\tpred_value[fold==label]=as.numeric(v)\r\n}\r\nwrite(paste(response,pred_value,sep='\\t'),file='sun_cv_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.5144981145858765,
"alphanum_fraction": 0.5925650596618652,
"avg_line_length": 23.37735939025879,
"blob_id": "3d35857107d7469fb428a8614902fc77fdc97f70",
"content_id": "572e5f1cf5fa5571e70d70ca3f459ceb82a6db74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1345,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 53,
"path": "/dataset/predict_test_psdsp.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\nd=read.csv('trainset',header=F,stringsAsFactors=F)\r\nd1=read.csv('testset',header=F,stringsAsFactors=F)\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\ntestresponse=as.factor(c(rep(1,418),rep(0,418)))\r\ndn=as.vector(outer(c('A','T','C','G'),c('A','T','C','G'),'paste',sep=''))\r\nm1=matrix(0,16,100)\r\nrownames(m1)=dn\r\nm2=matrix(0,16,100)\r\nrownames(m2)=dn\r\nfor(r in 1:nrow(d)){\r\n\tm=matrix(0,16,100)\r\n\trownames(m)=dn\r\n\texon=d[r,4]\r\n\tfor(p in 1:(nchar(exon)-1)){\r\n\t\tif(substr(exon,p,p)!='N' && substr(exon,p+1,p+1)!='N'){\r\n\t\t\tm[substr(exon,p,p+1),p]=1\r\n\t\t}\r\n\t}\r\n\tif(d[r,3]==1){\r\n\t\tm1=m1+m\r\n\t}else{\r\n\t\tm2=m2+m\r\n\t}\r\n}\r\nm1=sweep(m1,2,apply(m1,2,sum),'/')\r\nm2=sweep(m2,2,apply(m2,2,sum),'/')\r\nm=m1-m2\r\ncoding=matrix(0,nr=4200,nc=100)\r\nfor(r in 1:nrow(d)){\r\n\ts=d[r,4]\r\n\tfor(p in 1:(nchar(s)-1)){\r\n\t\tif(substr(s,p,p)!='N' && substr(s,p+1,p+1)!='N'){\r\n\t\t\tcoding[r,p]=m[substr(s,p,p+1),p]\r\n\t\t}\r\n\t}\r\n}\r\ncoding=coding[,-51]\r\nmodel=randomForest(x=coding,y=response,ntree=1000,norm.votes=F)\r\ntestcoding=matrix(0,nr=nrow(d1),nc=100)\r\nfor(r in 1:nrow(d1)){\r\n\ts=d1[r,4]\r\n\tfor(p in 1:(nchar(s)-1)){\r\n\t\tif(substr(s,p,p)!='N' && substr(s,p+1,p+1)!='N'){\r\n\t\t\ttestcoding[r,p]=m[substr(s,p,p+1),p]\r\n\t\t}\r\n\t}\r\n}\r\ntestcoding=testcoding[,-51]\r\npred=predict(model,testcoding,type='prob')\r\nscore=pred[,2]\r\n\r\nwrite(score,file='psdsp_test_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.6828479170799255,
"alphanum_fraction": 0.7281553149223328,
"avg_line_length": 43.14285659790039,
"blob_id": "000c8f883c827dbe2bc4cc9159220535130115d7",
"content_id": "8307bf9bb5f60c3ec8108468aa92b9fad3803137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 7,
"path": "/predict_by_ksnpf.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "arg=commandArgs(TRUE)\nlibrary(randomForest)\nload('ksnpf.RData')\ntestd1<-read.csv(arg[1],header=F,stringsAsFactors=F)\ncolnames(testd1)=paste('V',2:83,sep='')\npred=predict(ksmodel,testd1[3:ncol(testd1)],type='prob')\nwrite.table(cbind(testd1[,1:2],pred[,2]),file=arg[2],row.names=F,col.names=F,quote=F,sep='\\t')\n"
},
{
"alpha_fraction": 0.49310624599456787,
"alphanum_fraction": 0.587996780872345,
"avg_line_length": 22.65999984741211,
"blob_id": "5a14764c989c6605fc45286c86da0deeff1b09b3",
"content_id": "c9ce648eb01ccbf4508d019f790fdbd0a046e0ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1233,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 50,
"path": "/dataset/predict_test_psnsp.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\nd=read.csv('trainset',header=F,stringsAsFactors=F)\r\nd1=read.csv('testset',header=F,stringsAsFactors=F)\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\ntestresponse=as.factor(c(rep(1,418),rep(0,418)))\r\nm1=matrix(0,4,99)\r\nrownames(m1)=c('A','T','C','G')\r\nm2=matrix(0,4,99)\r\nrownames(m2)=c('A','T','C','G')\r\nfor(r in 1:nrow(d)){\r\n\tm=matrix(0,4,99)\r\n\trownames(m)=c('A','T','C','G')\r\n\texon=unlist(strsplit(d[r,4],''))\r\n\texon=exon[-(51:52)]\r\n\tfor(p in 1:length(exon)){\r\n\t\tif(exon[p]!='N'){\r\n\t\t\tm[exon[p],p]=1\r\n\t\t}\r\n\t}\r\n\tif(d[r,3]==1){\r\n\t\tm1=m1+m\r\n\t}else{\r\n\t\tm2=m2+m\r\n\t}\r\n}\r\nm1=sweep(m1,2,apply(m1,2,sum),'/')\r\nm2=sweep(m2,2,apply(m2,2,sum),'/')\r\nm=m1-m2\r\ncoding=matrix(0,nr=4200,nc=99)\r\nfor(r in 1:nrow(d)){\r\n\ts=substring(d[r,4],c(1:50,53:101),c(1:50,53:101))\r\n\tfor(p in 1:length(s)){\r\n\t\tif(s[p]!='N'){\r\n\t\t\tcoding[r,p]=m[s[p],p]\r\n\t\t}\r\n\t}\r\n}\r\nmodel=randomForest(x=coding,y=response,ntree=1000,norm.votes=F)\r\ntestcoding=matrix(0,nr=nrow(d1),nc=99)\r\nfor(r in 1:nrow(d1)){\r\n\ts=substring(d1[r,4],c(1:50,53:101),c(1:50,53:101))\r\n\tfor(p in 1:length(s)){\r\n\t\tif(s[p]!='N'){\r\n\t\t\ttestcoding[r,p]=m[s[p],p]\r\n\t\t}\r\n\t}\r\n}\r\npred=predict(model,testcoding,type='prob')\r\nscore=pred[,2]\r\nwrite(score,file='psnsp_test_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.641686201095581,
"alphanum_fraction": 0.6861826777458191,
"avg_line_length": 33.58333206176758,
"blob_id": "2a45df1125182204eaa6db623e41d68043ffd0a9",
"content_id": "da912f859a33800e44bf87a466ef5fc540cfdc7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 12,
"path": "/dataset/knf_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(pROC)\r\nlibrary(randomForest)\r\ngroup=scan('fold')\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\nd<-read.csv('coding_train_knf',header=F,stringsAsFactors=F)\r\nscore=numeric(nrow(d))\r\nfor(i in 1:5){\r\n\tmodel=randomForest(x=d[group!=i,4:ncol(d)],y=response[group!=i],ntree=1000,norm.votes=F)\r\n\tpred=predict(model,d[group==i,4:ncol(d)],type='prob')\r\n\tscore[group==i]=pred[,2]\r\n}\r\nwrite(score,file='knf_cv_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.6889952421188354,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32.83333206176758,
"blob_id": "6bdf7b3844b34a68582933b48bf9e3c8c07a8027",
"content_id": "8d94fe2857eadc44ab819fce696a0ae678611d15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 6,
"path": "/dataset/predict_test_combine.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(pROC)\r\nksscore=scan('ksnpf_test_score')\r\ndpscore=scan('psdsp_test_score')\r\nkmscore=scan('knf_test_score')\r\nscore=0.2*ksscore+0.35*dpscore+0.45*kmscore\r\nwrite(score,file='combine_test_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.5878136157989502,
"alphanum_fraction": 0.6290322542190552,
"avg_line_length": 30.823530197143555,
"blob_id": "786bffbd06a861611f6bb3d702f35be92ce6d6bb",
"content_id": "35980c6873381537880e3f90a7ecf29e84d6e26e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 17,
"path": "/predict_by_psdsp.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "arg=commandArgs(TRUE)\r\nlibrary(randomForest)\r\nd1=read.csv(arg[1],header=F,stringsAsFactors=F)\r\nload('psdsp.RData')\r\nm=psdsp\r\ntestcoding=matrix(0,nr=nrow(d1),nc=100)\r\nfor(r in 1:nrow(d1)){\r\n\ts=d1[r,3]\r\n\tfor(p in 1:(nchar(s)-1)){\r\n\t\tif(is.element(substr(s,p,p),c('A','T','C','G')) && is.element(substr(s,p+1,p+1),c('A','T','C','G'))){\r\n\t\t\ttestcoding[r,p]=m[substr(s,p,p+1),p]\r\n\t\t}\r\n\t}\r\n}\r\ntestcoding=testcoding[,-51]\r\npred=predict(psdsp_model,testcoding,type='prob')\r\nwrite.table(cbind(d1[,1:2],pred[,2]),file=arg[2],sep='\\t',row.names=F,col.names=F,quote=F)\r\n"
},
{
"alpha_fraction": 0.6297117471694946,
"alphanum_fraction": 0.6873614192008972,
"avg_line_length": 35.58333206176758,
"blob_id": "580af41c9a3295e35eac0ab9fa0cc6b4393e2919",
"content_id": "0f13afa6c62a97194d683e952d25bca8ddf545ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 12,
"path": "/dataset/ksnpf_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\ngroup=scan('fold')\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\nd1<-read.csv('coding_train_ksnpf',header=F,stringsAsFactors=F)\r\nd1=d1[4:ncol(d1)]\r\nscore=rep(0,nrow(d1))\r\nfor(i in 1:5){\r\n\tmodel=randomForest(x=d1[group!=i,],y=response[group!=i],ntree=1000,norm.votes=F)\r\n\tpred=predict(model,d1[group==i,],type='prob')\r\n\tscore[group==i]=pred[,2]\r\n}\r\nwrite(score,file='ksnpf_cv_score',sep='\\n',quote=F,row.names=F,col.names=F)\r\n"
},
{
"alpha_fraction": 0.6763636469841003,
"alphanum_fraction": 0.7381818294525146,
"avg_line_length": 54,
"blob_id": "1038e951a3bbf2494a128f4497257a7a1a60b3b2",
"content_id": "d4c4ecda91fdc5a652c96bea038245093b519fbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 5,
"path": "/RFCombine.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "arg=commandArgs(TRUE)\npsdsp=read.table(arg[1],stringsAsFactors=F)\nksnpf=read.table(arg[2],stringsAsFactors=F)\nknf=read.table(arg[3],stringsAsFactors=F)\nwrite.table(cbind(psdsp[1:2],0.35*psdsp[3]+0.2*ksnpf[3]+0.45*knf[3]),file=arg[4],sep='\\t',quote=F,col.names=F,row.names=F)\n"
},
{
"alpha_fraction": 0.6927223801612854,
"alphanum_fraction": 0.7358490824699402,
"avg_line_length": 45.375,
"blob_id": "4dec564b27a6ecc736bc2b28bf4b81196a5d56dc",
"content_id": "07ff6c19db98063f4d22364ced3b0cef5d0d129f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 371,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 8,
"path": "/predict_by_knf.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "arg=commandArgs(TRUE)\nlibrary(randomForest)\nload('knf.RData')\n#system('~/python/bin/python3 ks.py pattern patternkscoding')\ntestd1<-read.csv(arg[1],header=F,stringsAsFactors=F)\ncolnames(testd1)=paste('V',2:339,sep='')\npred=predict(knfmodel,testd1[3:ncol(testd1)],type='prob')\nwrite.table(cbind(testd1[,1:2],pred[,2]),file=arg[2],row.names=F,col.names=F,quote=F,sep='\\t')\n"
},
{
"alpha_fraction": 0.4919724762439728,
"alphanum_fraction": 0.5229358077049255,
"avg_line_length": 22.567567825317383,
"blob_id": "fe0b554c0ea6a8bb31d6e91a409d456e7b28f826",
"content_id": "2da2f953f34cb72c5b82419fb20186ca47d5efcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 872,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 37,
"path": "/find_site.py",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "import re\nimport sys\n\np=re.compile('[AG][AG]AC[ACT]')\np1=re.compile('chr\\w:(\\d+)-(\\d+) (\\w+) LENGTH=(\\d+)')\np2=re.compile('(\\d+)-(\\d+)')\n\nlocus=[]\nexon=[]\nf=open(sys.argv[1])\ni=-1\nfor line in f:\n if line[0]=='>':\n i=i+1\n locus.append(line[1:].strip())\n exon.append('')\n else:\n exon[i]+=line.strip()\nf.close()\n\nfw=open(sys.argv[2],'w')\nfor k in range(len(locus)):\n exon_seq=exon[k]\n position=1\n i=p.search(exon_seq,position-1)\n while i:\n position=i.start()+2\n fw.write(locus[k] + ',' + str(position+1) + \",\")\n if position < 50:\n fw.write('N'*(50-position) + exon_seq[0:position+51])\n else:\n fw.write(exon_seq[position-50:position+51])\n ne=len(exon_seq)-1-position\n fw.write('N' * (50-ne))\n fw.write('\\n')\n i=p.search(exon_seq,position-1)\nfw.close()\n"
},
{
"alpha_fraction": 0.6567567586898804,
"alphanum_fraction": 0.6972972750663757,
"avg_line_length": 44.5,
"blob_id": "95ce4b6804e4e3dba5999c6583ef0b9b2c24ae15",
"content_id": "cd7232552e41d11d336c639dd9479c432f6213df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 8,
"path": "/dataset/predict_test_sun.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "test_response=c(rep(1,418),rep(0,418))\r\ng=2^-8\r\nc=2^5\r\npred_value=numeric(836)\r\nsystem(paste('~/libsvm/svm-train -g',g,'-c',c,'coding_train_sun sun_model'))\r\nv=system(paste('~/libsvm/svm-predict coding_test_sun sun_model sun_output|grep -v ^Accuracy'),intern=TRUE)\r\npred_value=as.numeric(v)\r\nwrite(paste(test_response,pred_value,sep='\\t'),file='sun_test_score',sep='\\n')"
},
{
"alpha_fraction": 0.36853933334350586,
"alphanum_fraction": 0.43295881152153015,
"avg_line_length": 25.244897842407227,
"blob_id": "2af36923508b1c5aaa2c3d31097314b37b45c919",
"content_id": "4fc6ad70b80208a7fd5c97935e79be5e12cca136",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 49,
"path": "/knf.py",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom functools import reduce\r\nf=open(sys.argv[1])\r\nfw=open(sys.argv[2],'w')\r\n\r\nnset=set('ATCG')\r\nfor line in f:\r\n mer2={}\r\n mer3={}\r\n mer4={}\r\n for n1 in 'ATCG':\r\n for n2 in 'ATCG':\r\n mer2[n1 + n2]=0\r\n for n3 in 'ATCG':\r\n mer3[n1+n2+n3]=0\r\n for n4 in 'ATCG':\r\n mer4[n1+n2+n3+n4]=0\r\n col=line.split(',')\r\n seq=col[2].rstrip()\r\n seq=seq.strip('N')\r\n seq_len=len(seq)\r\n for p in range(seq_len-3):\r\n if set(seq[p:p+2]) <= nset:\r\n mer2[seq[p:p+2]]+=1\r\n if set(seq[p:p+3])<=nset:\r\n mer3[seq[p:p+3]]+=1\r\n if set(seq[p:p+4])<=nset:\r\n mer4[seq[p:p+4]]+=1\r\n if set(seq[p+1:p+3])<=nset:\r\n mer2[seq[p+1:p+3]]+=1\r\n if set(seq[p+2:p+4]) <= nset:\r\n mer2[seq[p+2:p+4]]+=1\r\n if set(seq[p+1:p+4]) <= nset:\r\n mer3[seq[p+1:p+4]]+=1\r\n v2=[]\r\n v3=[]\r\n v4=[]\r\n for n1 in 'ATCG':\r\n for n2 in 'ATCG': \r\n v2.append(mer2[n1+n2]/(seq_len-1))\r\n for n3 in 'ATCG':\r\n v3.append(mer3[n1+n2+n3]/(seq_len-2))\r\n for n4 in 'ATCG':\r\n v4.append(mer4[n1+n2+n3+n4]/(seq_len-3))\r\n out=','.join(col[0:2]+[str(i) for i in (v2+v3+v4)])\r\n fw.write(out+'\\n')\r\n\r\nfw.close()\r\nf.close()\r\n"
},
{
"alpha_fraction": 0.6552631855010986,
"alphanum_fraction": 0.6947368383407593,
"avg_line_length": 45.25,
"blob_id": "ea67c9a12b26dfce27e0ab7f007ccd487303cb1e",
"content_id": "b9004326f6601c3b4ea87fb3665417010397b4e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 8,
"path": "/dataset/predict_test_chen.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "test_response=c(rep(1,418),rep(0,418))\r\ng=2^-5\r\nc=2^1\r\npred_value=numeric(836)\r\nsystem(paste('~/libsvm/svm-train -g',g,'-c',c,'coding_train_chen chen_model'))\r\nv=system(paste('~/libsvm/svm-predict coding_test_chen chen_model chen_output|grep -v ^Accuracy'),intern=TRUE)\r\npred_value=as.numeric(v)\r\nwrite(paste(test_response,pred_value,sep='\\t'),file='chen_test_score',sep='\\n')\r\n\r\n"
},
{
"alpha_fraction": 0.7534691691398621,
"alphanum_fraction": 0.763212263584137,
"avg_line_length": 68.52083587646484,
"blob_id": "628ec3ee581d40b35993f572d82ebb1ec4c63886",
"content_id": "49261883ffd1f53e4e8ffda9d1704abfb5e9e89b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 3387,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 48,
"path": "/dataset/Readme.txt",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "All the commands listed in this file are run in the \"dataset\" directory.\r\n1.AthMethPre\r\n1)encode the trainset and the testset and save the coding to the file \"coding_train_sun\" and \"coding_test_sun\".\r\n>python encode_sun.py trainset coding_train_sun\r\n>python encode_sun.py testset coding_test_sun\r\n2)do the 5-fold cross validation and the prediction scores are saved to the file \"sun_cv_score\"(the path of the \"LIBSVM\" software should be set in the file \"sun_cv.R\").\r\n>Rscript sun_cv.R\r\n3)do the independent test and the prediction scores are saved to the file \"sun_test_score\" (the path of the \"LIBSVM\" software should be set in the file \"predict_test_sun.R\").\r\n>Rscript predict_test_sun.R\r\n2.M6ATH\r\n1)encode the trainset and testset and save the coding to the file \"coding_train_chen\" and \"coding_test_chen\".\r\n>python encode_chen.py trainset coding_train_chen\r\n>python encode_chen.py testset coding_test_chen\r\n2)do the 5-fold cross validation and the prediction scores are saved to the file \"chen_cv_score\"(the path of the \"LIBSVM\" software should be set in the file \"chen_cv.R\").\r\n>Rscript chen_cv.R\r\n3)do the independent test and the prediction scores are saved to the file \"chen_test_score\" (the path of the \"LIBSVM\" software should be set in the file \"predict_test_chen.R\").\r\n>Rscript predict_test_chen.R\r\n3.RFPSNSP\r\n1)encode the feature and do the 5-fold cross validation. The prediction scores are saved to the file \"psnsp_cv_score\"(the path of the \"LIBSVM\" software should be set in the file \"psnsp_cv.R\").\r\n>Rscript psnsp_cv.R\r\n2)do the independent test and the prediction scores are saved to the file \"psnsp_test_score\" (the path of the \"LIBSVM\" software should be set in the file \"predict_test_psnsp.R\").\r\n>Rscript predict_test_psnsp.R\r\n4.RFPSDSP\r\n1)encode the feature and do the 5-fold cross validation. The prediction scores are saved to the file \"psdsp_cv_score\"(the path of the \"LIBSVM\" software should be set in the file \"psdsp_cv.R\").\r\n>Rscript psdsp_cv.R\r\n2)do the independent test and the prediction scores are saved to the file \"psdsp_test_score\" (the path of the \"LIBSVM\" software should be set in the file \"predict_test_psdsp.R\").\r\n>Rscript predict_test_psdsp.R\r\n5.RFKSNPF\r\n1)encode the trainset and the testset and save the coding to the file \"coding_train_ksnpf\" and \"coding_test_ksnpf\".\r\n>python encode_ksnpf.py trainset coding_train_ksnpf\r\n>python encode_ksnpf.py testset coding_test_ksnpf\r\n2)do the 5-fold cross validation and the prediction scores are saved to the file \"ksnpf_cv_score\".\r\n>Rscript ksnpf_cv.R\r\n3)do the independent test and the prediction scores are saved to the file \"ksnpf_test_score\".\r\n>Rscript predict_test_ksnpf.R\r\n6.RFKNF\r\n1)encode the trainset and the testset and save the coding to the file \"coding_train_knf\" and \"coding_test_knf\".\r\n>python encode_knf.py trainset coding_train_knf\r\n>python encode_knf.py testset coding_test_knf\r\n2)do the 5-fold cross validation and the prediction scores are saved to the file \"knf_cv_score\".\r\n>Rscript knf_cv.R\r\n3)do the independent test and the prediction scores are saved to the file \"knf_test_score\".\r\n>Rscript predict_test_knf.R\r\n7.RFCombine\r\n1)do the 5-fold cross validation and the prediction scores are saved to the file \"combine_cv_score\".\r\n>Rscript knf_cv.R\r\n2)do the independent test and the prediction scores are saved to the file \"combine_test_score\".\r\n>Rscript predict_test_combine.R\r\n\r\n"
},
{
"alpha_fraction": 0.49352890253067017,
"alphanum_fraction": 0.566868007183075,
"avg_line_length": 23.19565200805664,
"blob_id": "ade8a591122d93f26f0be9b622c538a31111933d",
"content_id": "d1fac4d39bfc1eb1a09895fd44ff60d00ff32c5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 46,
"path": "/dataset/psdsp_cv.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "library(randomForest)\r\nd=read.csv('trainset',header=F,stringsAsFactors=F)\r\ngroup=scan('fold')\r\nresponse=as.factor(c(rep(1,2100),rep(0,2100)))\r\nscore=numeric(nrow(d))\r\ndn=as.vector(outer(c('A','T','C','G'),c('A','T','C','G'),'paste',sep=''))\r\nfor(i in 1:5){\r\n\tm1=matrix(0,16,100)\r\n\trownames(m1)=dn\r\n\tm2=matrix(0,16,100)\r\n\trownames(m2)=dn\r\n\td1=d[group!=i,]\r\n\tfor(r in 1:nrow(d1)){\r\n\t\tm=matrix(0,16,100)\r\n\t\trownames(m)=dn\r\n\t\texon=d[r,4]\r\n\t\tfor(p in 1:(nchar(exon)-1)){\r\n\t\t\tif(substr(exon,p,p)!='N' && substr(exon,p+1,p+1)!='N'){\r\n\t\t\t\tm[substr(exon,p,p+1),p]=1\r\n\t\t\t}\r\n\t\t}\r\n\t\tif(d1[r,3]==1){\r\n\t\t\tm1=m1+m\r\n\t\t}else{\r\n\t\t\tm2=m2+m\r\n\t\t}\r\n\t}\r\n\tm1=sweep(m1,2,apply(m1,2,sum),'/')\r\n\tm2=sweep(m2,2,apply(m2,2,sum),'/')\r\n\tm=m1-m2\r\n\tcoding=matrix(0,nr=4200,nc=100)\r\n\tfor(r in 1:nrow(d)){\r\n\t\ts=d[r,4]\r\n\t\tfor(p in 1:(nchar(s)-1)){\r\n\t\t\tif(substr(s,p,p)!='N' && substr(s,p+1,p+1)!='N'){\r\n\t\t\t\tcoding[r,p]=m[substr(s,p,p+1),p]\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n\tcoding=coding[,-51]\r\n\tmodel=randomForest(x=coding[group!=i,],y=response[group!=i],ntree=1000,norm.votes=F)\r\n\tpred=predict(model,coding[group==i,],type='prob')\r\n\tscore[group==i]=pred[,2]\r\n\t\r\n}\r\nwrite(score,file='psdsp_cv_score',sep='\\n')\r\n"
},
{
"alpha_fraction": 0.5692007541656494,
"alphanum_fraction": 0.6335282921791077,
"avg_line_length": 26.5,
"blob_id": "d72411a4f6900f804b2854ce10a7a44ae454d388",
"content_id": "2ab119356e61d848f208de7f6315f988a661aec1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 18,
"path": "/predict_by_psnsp.R",
"repo_name": "nongdaxiaofeng/RFAthM6A",
"src_encoding": "UTF-8",
"text": "arg=commandArgs(TRUE)\r\nlibrary(randomForest)\r\nd1=read.csv(arg[1],header=F,stringsAsFactors=F)\r\nload('psnsp.RData')\r\nm=psnsp\r\ntestcoding=matrix(0,nr=nrow(d1),nc=99)\r\nfor(r in 1:nrow(d1)){\r\n\ts=substring(d1[r,3],c(1:50,53:101),c(1:50,53:101))\r\n\tfor(p in 1:length(s)){\r\n\t\tif(is.element(s[p],c('A','T','C','G'))){\r\n\t\t\ttestcoding[r,p]=m[s[p],p]\r\n\t\t}\r\n\t}\r\n}\r\npred=predict(psnsp_model,testcoding,type='prob')\r\nscore=pred[,2]\r\n\t\r\nwrite.table(cbind(d1[,1:2],pred[,2]),file=arg[2],sep='\\t',row.names=F,col.names=F,quote=F)\r\n"
}
] | 24 |
aDwCarrazzone/PythonUsingRegex | https://github.com/aDwCarrazzone/PythonUsingRegex | f2441103a62702263f5e9c8995bc8c2faff20018 | f2fcf0fbeaa1f0a4c410de4e30c2d3c9f0ddd388 | 19e8dc5ff593c5e1a97112a36bf0e47c26be8af3 | refs/heads/master | "2020-03-28T15:03:41.427413" | "2018-09-13T01:01:07" | "2018-09-13T01:01:07" | 148,551,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.613095223903656,
"alphanum_fraction": 0.6547619104385376,
"avg_line_length": 27.16666603088379,
"blob_id": "fd956fa0149f967a084505dd80d35b30c4038df3",
"content_id": "5607ca601aa38c22b94670d5e8b9e59dcee26272",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 6,
"path": "/test.py",
"repo_name": "aDwCarrazzone/PythonUsingRegex",
"src_encoding": "UTF-8",
"text": "import re\nFile1 = open('test', 'r')\nregex = re.compile(r'\\b(?:22822)#[^#]+#')\nstring = File1.read()\nitemdesc = regex.findall(string)\n\tfor word in itemdesc: print (word)"
},
{
"alpha_fraction": 0.5373134613037109,
"alphanum_fraction": 0.5746268630027771,
"avg_line_length": 16.933332443237305,
"blob_id": "b176e758296407cc927a3defd5bc12d1bf8ea151",
"content_id": "4f239581bb5054caa1357ce628fd610892ed881d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 15,
"path": "/test2.py",
"repo_name": "aDwCarrazzone/PythonUsingRegex",
"src_encoding": "UTF-8",
"text": "import re\ni = 1\nmax = 10000\nFile1 = open('text.txt', 'r')\nregex = re.compile(r'\\b(?:{})#[^#]+#'.format (i))\nstring = File1.read()\nitemdesc = regex.findall(string)\nwhile i < max:\n\tif i < max:\n\t\tprint (i)\n\t\tfor word in itemdesc:\n\t\t\tprint (word)\n\t\t\ti += 1\n\telse:\n\t\ti += 1"
}
] | 2 |
Bharadwaj-G/pubsub | https://github.com/Bharadwaj-G/pubsub | 8e9321e753eecd0fdf51c0c50ed6c5a174507e7f | d6d562b9f708c00c72cacc244cac06de2c5172cf | 54d85d5e96e46aa4ee5fb19c6d584c8fb59eaf91 | refs/heads/main | "2023-06-12T00:48:13.011464" | "2021-07-02T06:47:16" | "2021-07-02T06:47:16" | 382,252,335 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6899717450141907,
"alphanum_fraction": 0.6991525292396545,
"avg_line_length": 34,
"blob_id": "48ded720c8ddc3b45e88c29d1ba46bba6f02a8b7",
"content_id": "6512a12d6744d4414caf27f697478acbdbbc26c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1416,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 39,
"path": "/sub.py",
"repo_name": "Bharadwaj-G/pubsub",
"src_encoding": "UTF-8",
"text": "\r\nimport os\r\nfrom concurrent.futures import TimeoutError\r\nfrom google.cloud import pubsub_v1\r\n\r\nos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'sa_credentials.json'\r\nsubscription_id = \"gcp-training-topic-sub\"\r\nproject_id = \"trainingproject-317506\"\r\ntimeout = 100.0\r\nf = open(\"output.txt\", \"w\")\r\nsubscriber = pubsub_v1.SubscriberClient()\r\n# The `subscription_path` method creates a fully qualified identifier\r\n# in the form `projects/{project_id}/subscriptions/{subscription_id}`\r\nsubscription_path = subscriber.subscription_path(project_id, subscription_id)\r\n\r\nprint(\"Received msgs\")\r\ndef callback(message):\r\n print(f\"Received {message}.\")\r\n print(f\"{message.data}.\")\r\n data = (message.data).decode(\"utf-8\")\r\n if data.strip():\r\n f.write(data)\r\n message.ack()\r\n\r\nstreaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)\r\nprint(f\"Listening for messages on {subscription_path}..\\n\")\r\n\r\n# Wrap subscriber in a 'with' block to automatically call close() when done.\r\nwith subscriber:\r\n try:\r\n # When `timeout` is not set, result() will block indefinitely,\r\n # unless an exception is encountered first.\r\n streaming_pull_future.result(timeout=timeout)\r\n except TimeoutError:\r\n streaming_pull_future.cancel() # Trigger the shutdown.\r\n streaming_pull_future.result() # Block until the shutdown is complete.\r\n\r\n\r\n\r\nf.close()\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5872483253479004,
"alphanum_fraction": 0.6023489832878113,
"avg_line_length": 32.90196228027344,
"blob_id": "c755ddd6394020f27a1b1f9108c1b0c13f80900b",
"content_id": "9838fa0f149f436a0ad8144ef3dc42a62f999d51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1788,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 51,
"path": "/pub.py",
"repo_name": "Bharadwaj-G/pubsub",
"src_encoding": "UTF-8",
"text": "import uuid\r\nimport random\r\nimport string\r\nimport os\r\nimport time \r\nfrom google.cloud import pubsub_v1\r\n\r\n\r\nos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'sa_credentials.json'\r\n\r\nif __name__ == \"__main__\":\r\n characters = string.digits + string.ascii_uppercase\r\n f = open(\"input.txt\", \"w\")\r\n f.write(\"Student_name, Roll_number(10 digit number), registration_number (UUID in caps without hyphens), Branch, Address1, Address2\\n\")\r\n\r\n for i in range(10):\r\n n = random.randint(5,15)\r\n name = ''.join(random.choice(string.ascii_letters) for i in range(n))\r\n roll_no = ''.join(random.choice(string.digits) for i in range(10))\r\n reg_no = uuid.uuid4().hex.upper()\r\n branch = ''.join(random.choice(string.ascii_letters) for i in range(n))\r\n address1 = ''.join(random.choice(characters) for i in range(n))\r\n address2 = ''.join(random.choice(string.ascii_letters) for i in range(n))\r\n\r\n data = name+','+roll_no+','+reg_no+','+branch+','+address1+','+address2\r\n\r\n #print(data)\r\n f.write(data)\r\n f.write('\\n')\r\n\r\n f.close()\r\n \r\n # Replace with your pubsub topic\r\n pubsub_topic = 'projects/trainingproject-317506/topics/gcp-training-topic'\r\n\r\n # Replace with your input file path\r\n input_file = 'input.txt'\r\n\r\n # create publisher\r\n publisher = pubsub_v1.PublisherClient()\r\n\r\n with open(input_file, 'rb') as ifp:\r\n # skip header\r\n header = ifp.readline() \r\n \r\n # loop over each record\r\n for line in ifp:\r\n event_data = line # entire line of input CSV is the message\r\n print('Publishing {0} to {1}'.format(event_data, pubsub_topic))\r\n publisher.publish(pubsub_topic, event_data)\r\n time.sleep(1) \r\n\r\n\r\n"
}
] | 2 |
IlyasYOY/wmd-relax | https://github.com/IlyasYOY/wmd-relax | 96e7fefbff2d432c20a2fad1926c38421c8330b5 | 9b7eb561314bc4b01e2071f8ae324e7691832368 | 299df36cd6c48adc87df34c7661959c839a3f57b | refs/heads/master | "2020-04-03T12:02:56.974503" | "2018-10-29T16:02:27" | "2018-10-29T16:07:09" | 155,239,987 | 1 | 0 | NOASSERTION | "2018-10-29T15:57:05" | "2018-10-26T21:35:05" | "2018-10-26T21:35:03" | null | [
{
"alpha_fraction": 0.5601209402084351,
"alphanum_fraction": 0.6092138290405273,
"avg_line_length": 36.731544494628906,
"blob_id": "8d6b3d4dab77fb9a41445b0771491cfe28696619",
"content_id": "e6dae6fbde7f265289ad39df963023f2fd5bdd47",
"detected_licenses": [
"LicenseRef-scancode-dco-1.1",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5622,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 149,
"path": "/test.py",
"repo_name": "IlyasYOY/wmd-relax",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy\nimport scipy.spatial.distance\nimport libwmdrelax\nimport wmd\nfrom numbers import Number\n\n\nclass Base(unittest.TestCase):\n def setUp(self):\n numpy.random.seed(777)\n\n def _get_w1_w2_dist_0(self):\n vecs = numpy.random.rand(4, 4)\n dist = scipy.spatial.distance.squareform(\n scipy.spatial.distance.pdist(vecs)).astype(numpy.float32)\n w1 = numpy.ones(4, dtype=numpy.float32) / 4\n w2 = numpy.ones(4, dtype=numpy.float32) / 4\n return w1, w2, dist\n\n def _get_w1_w2_dist(self):\n vecs = numpy.random.rand(4, 4)\n dist = scipy.spatial.distance.squareform(\n scipy.spatial.distance.pdist(vecs)).astype(numpy.float32)\n w1 = numpy.ones(4, dtype=numpy.float32) / 2\n w1[0] = w1[1] = 0\n w2 = numpy.ones(4, dtype=numpy.float32) / 2\n w2[2] = w2[3] = 0\n return w1, w2, dist\n\n\nclass RelaxedTests(Base):\n def test_no_cache_0(self):\n w1, w2, dist = self._get_w1_w2_dist_0()\n r = libwmdrelax.emd_relaxed(w1, w2, dist)\n self.assertAlmostEqual(r, 0)\n\n def test_no_cache(self):\n w1, w2, dist = self._get_w1_w2_dist()\n r = libwmdrelax.emd_relaxed(w1, w2, dist)\n self.assertAlmostEqual(r, 0.6125112)\n\n def test_with_cache(self):\n cache = libwmdrelax.emd_relaxed_cache_init(4)\n w1, w2, dist = self._get_w1_w2_dist()\n r = libwmdrelax.emd_relaxed(w1, w2, dist, cache)\n self.assertAlmostEqual(r, 0.6125112)\n r = libwmdrelax.emd_relaxed(w1, w2, dist, cache=cache)\n self.assertAlmostEqual(r, 0.6125112)\n libwmdrelax.emd_relaxed_cache_fini(cache)\n\n\nclass ExactTests(Base):\n def test_no_cache_0(self):\n w1, w2, dist = self._get_w1_w2_dist_0()\n r = libwmdrelax.emd(w1, w2, dist)\n self.assertAlmostEqual(r, 0)\n\n def test_no_cache(self):\n w1, w2, dist = self._get_w1_w2_dist()\n r = libwmdrelax.emd(w1, w2, dist)\n self.assertAlmostEqual(r, 0.6125115)\n\n def test_with_cache(self):\n cache = libwmdrelax.emd_cache_init(4)\n w1, w2, dist = self._get_w1_w2_dist()\n r = libwmdrelax.emd(w1, w2, dist, cache)\n self.assertAlmostEqual(r, 0.6125115)\n r = libwmdrelax.emd(w1, w2, dist, cache=cache)\n self.assertAlmostEqual(r, 0.6125115)\n libwmdrelax.emd_cache_fini(cache)\n\n\nclass TailVocabularyOptimizerTests(Base):\n def ndarray_almost_equals(self, a, b, msg=None):\n \"\"\"Compares two 1D numpy arrays approximately.\"\"\"\n if len(a) != len(b):\n if msg is None:\n msg = (\"Length of arrays are not equal: {} and {}\"\n .format(len(a), len(b)))\n raise self.failureException(msg)\n for i, (x, y) in enumerate(zip(a, b)):\n try:\n self.assertAlmostEqual(x, y)\n except AssertionError as err:\n if msg is None:\n msg = (\"Arrays differ at index {}: {}\" .format(i, err))\n raise self.failureException(msg)\n\n def setUp(self):\n self.tvo = wmd.TailVocabularyOptimizer()\n self.addTypeEqualityFunc(numpy.ndarray, self.ndarray_almost_equals)\n\n def test_trigger_ratio_getter_type(self):\n trigger_ratio = self.tvo.trigger_ratio\n self.assertIsInstance(trigger_ratio, Number)\n\n def test_trigger_ratio_constructor(self):\n tvo = wmd.TailVocabularyOptimizer(0.123)\n self.assertAlmostEqual(tvo.trigger_ratio, 0.123)\n\n def test_trigger_ratio_setter(self):\n self.tvo.trigger_ratio = 0.456\n self.assertAlmostEqual(self.tvo.trigger_ratio, 0.456)\n\n def test_trigger_ratio_too_low(self):\n with self.assertRaises(Exception):\n self.tvo.trigger_ratio = -0.5\n\n def test_trigger_ratio_too_high(self):\n with self.assertRaises(Exception):\n self.tvo.trigger_ratio = 1.5\n\n def test_call_below_trigger(self):\n tvo = wmd.TailVocabularyOptimizer(0.5)\n words = numpy.array([1, 2, 3], dtype=int)\n weights = numpy.array([0.5, 0.2, 0.3], dtype=numpy.float32)\n vocabulary_max = 10\n ret_words, ret_weights = tvo(words, weights, vocabulary_max)\n self.assertEqual(words, ret_words)\n self.assertEqual(weights, ret_weights)\n\n def test_call_too_many_words(self):\n tvo = wmd.TailVocabularyOptimizer(0.5)\n words = numpy.array([11, 22, 33, 44, 55, 66, 77], dtype=int)\n weights = numpy.array([0.5, 0.1, 0.4, 0.8, 0.6, 0.2, 0.7], dtype=numpy.float32)\n vocabulary_max = 2\n ret_words, ret_weights = tvo(words, weights, vocabulary_max)\n self.assertEqual(len(ret_words), vocabulary_max)\n self.assertEqual(len(ret_weights), vocabulary_max)\n sorter = numpy.argsort(ret_words)\n self.assertEqual(ret_words[sorter], numpy.array([44, 77]))\n self.assertEqual(ret_weights[sorter], numpy.array([0.8, 0.7]))\n\n def test_call(self):\n tvo = wmd.TailVocabularyOptimizer(0.5)\n words = numpy.array([11, 22, 33, 44, 55, 66, 77], dtype=int)\n weights = numpy.array([0.5, 0.1, 0.4, 0.8, 0.6, 0.2, 0.7], dtype=numpy.float32)\n vocabulary_max = 6\n ret_words, ret_weights = tvo(words, weights, vocabulary_max)\n self.assertEqual(len(ret_words), len(ret_weights))\n self.assertLessEqual(len(ret_words), vocabulary_max)\n sorter = numpy.argsort(ret_words)\n self.assertEqual(ret_words[sorter], numpy.array([11, 33, 44, 55, 77]))\n self.assertEqual(ret_weights[sorter], numpy.array([0.5, 0.4, 0.8, 0.6, 0.7]))\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.722129762172699,
"alphanum_fraction": 0.7332224249839783,
"avg_line_length": 43,
"blob_id": "c15a1f3797b829f7d7b9b6a7c4a67cc3abd140b9",
"content_id": "ac82f259ee64f58e4bd05832cd4201848c8b08cd",
"detected_licenses": [
"LicenseRef-scancode-dco-1.1",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 1803,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 41,
"path": "/CMakeLists.txt",
"repo_name": "IlyasYOY/wmd-relax",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.2)\nproject(wmdrelax)\nset(CMAKE_MODULE_PATH ${CMAKE_HOME_DIRECTORY}/cmake)\nfind_package(OpenMP REQUIRED)\nif (NOT DISABLE_PYTHON)\n if (APPLE)\n # workaround\n # https://github.com/Homebrew/legacy-homebrew/issues/25118\n # https://cmake.org/Bug/view.php?id=14809\n find_program(PYTHON_CONFIG_EXECUTABLE python3-config)\n message(\"-- Found python3-config: ${PYTHON_CONFIG_EXECUTABLE}\")\n execute_process(COMMAND ${PYTHON_CONFIG_EXECUTABLE} --prefix OUTPUT_VARIABLE PYTHON_PREFIX OUTPUT_STRIP_TRAILING_WHITESPACE)\n message(\"-- Discovered Python 3.x prefix: ${PYTHON_PREFIX}\")\n set(PYTHON_EXECUTABLE \"${PYTHON_PREFIX}/bin/python3\")\n endif()\n find_package(PythonInterp 3 REQUIRED)\n find_package(PythonLibs 3 REQUIRED)\n if (NOT NUMPY_INCLUDES)\n execute_process(COMMAND ${PYTHON_EXECUTABLE} -c \"import numpy; print(numpy.get_include())\" OUTPUT_VARIABLE NUMPY_INCLUDES)\n endif()\nendif()\n#set(CMAKE_VERBOSE_MAKEFILE on)\nset(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} -march=native -Wall -Wno-sign-compare -Werror -std=c++11 ${OpenMP_CXX_FLAGS}\")\nif (NOT CMAKE_BUILD_TYPE STREQUAL \"Debug\")\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} -flto\")\nendif()\ninclude_directories(or-tools/src)\nset(SOURCE_FILES or-tools/src/graph/min_cost_flow.cc or-tools/src/graph/max_flow.cc\n or-tools/src/base/stringprintf.cc or-tools/src/base/logging.cc\n or-tools/src/base/sysinfo.cc or-tools/src/util/stats.cc)\nif (PYTHONLIBS_FOUND)\n list(APPEND SOURCE_FILES python.cc)\nendif()\nadd_library(wmdrelax SHARED ${SOURCE_FILES})\nif (PYTHONLIBS_FOUND)\n include_directories(${PYTHON_INCLUDE_DIRS} ${NUMPY_INCLUDES})\n target_link_libraries(wmdrelax ${PYTHON_LIBRARIES})\nendif()\nif (SUFFIX)\n set_target_properties(wmdrelax PROPERTIES SUFFIX ${SUFFIX})\nendif()"
},
{
"alpha_fraction": 0.6615384817123413,
"alphanum_fraction": 0.6662207245826721,
"avg_line_length": 32.22222137451172,
"blob_id": "f901ef11f6fd6a5cd51becdb39ebc7bde6823e0f",
"content_id": "882510ea7ef5a00c3ecc942a65790aae4876f894",
"detected_licenses": [
"LicenseRef-scancode-dco-1.1",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1495,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 45,
"path": "/spacy_example.py",
"repo_name": "IlyasYOY/wmd-relax",
"src_encoding": "UTF-8",
"text": "# sys.argv[1:] defines Wikipedia page titles\n# This example measures WMDs from the first page to all the rest\n\nfrom collections import Counter\nimport sys\n\nimport numpy\nimport spacy\nimport requests\nfrom wmd import WMD\n\n# Load English tokenizer, tagger, parser, NER and word vectors\nprint(\"loading spaCy\")\nnlp = spacy.load(\"en\")\n\n# List of page names we will fetch from Wikipedia and query for similarity\ntitles = sys.argv[1:] or [\"Germany\", \"Spain\", \"Google\"]\n\ndocuments = {}\nfor title in titles:\n print(\"fetching\", title)\n pages = requests.get(\n \"https://en.wikipedia.org/w/api.php?action=query&format=json&titles=%s\"\n \"&prop=extracts&explaintext\" % title).json()[\"query\"][\"pages\"]\n print(\"parsing\", title)\n text = nlp(next(iter(pages.values()))[\"extract\"])\n tokens = [t for t in text if t.is_alpha and not t.is_stop]\n words = Counter(t.text for t in tokens)\n orths = {t.text: t.orth for t in tokens}\n sorted_words = sorted(words)\n documents[title] = (title, [orths[t] for t in sorted_words],\n numpy.array([words[t] for t in sorted_words],\n dtype=numpy.float32))\n\n\n# Hook in WMD\nclass SpacyEmbeddings(object):\n def __getitem__(self, item):\n return nlp.vocab[item].vector\n\ncalc = WMD(SpacyEmbeddings(), documents)\nprint(\"calculating\")\n# Germany shall be closer to Spain than to Google\nfor title, relevance in calc.nearest_neighbors(titles[0]):\n print(\"%24s\\t%s\" % (title, relevance))\n"
},
{
"alpha_fraction": 0.7313167452812195,
"alphanum_fraction": 0.7313167452812195,
"avg_line_length": 16.030303955078125,
"blob_id": "d4e90bf52cc748153782f374fc1955d651980270",
"content_id": "5bafd4d27c47827c647e86b0f376d0f48a09dabb",
"detected_licenses": [
"LicenseRef-scancode-dco-1.1",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 562,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 33,
"path": "/doc/README.md",
"repo_name": "IlyasYOY/wmd-relax",
"src_encoding": "UTF-8",
"text": "For installing Sphinx:\n\n```bash\npip install Sphinx\n```\n\nYou'll also need the \"doxygen\" command installed. This is usually\ninstalled with:\n\n```bash\n(apt or yum or whatever your distro uses) install doxygen\n```\n\nFor generating/updating the API doc: \n\n```bash\ncd doc\nsphinx-apidoc -o wmd ../wmd/\n```\n\nFor generating Doxygen XML files:\n```bash\ndoxygen # Should use doc/Doxyfile, generates to doc/doxyhtml\n```\n\nFor generating/updating the HTML files:\n\n```\nmake html\n```\n\nThese should include a link to the Doxygen documentation in Sphinx'\ndoc/_build/html/index.html.\n"
},
{
"alpha_fraction": 0.6232798099517822,
"alphanum_fraction": 0.6341742873191833,
"avg_line_length": 20.799999237060547,
"blob_id": "99ffbe9c71365d915f6278ee9d596a1dd1eb1a4e",
"content_id": "30c33fb84ed981ded3a3ff829ad009c71e911728",
"detected_licenses": [
"LicenseRef-scancode-dco-1.1",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1744,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 80,
"path": "/cache.h",
"repo_name": "IlyasYOY/wmd-relax",
"src_encoding": "UTF-8",
"text": "#ifndef WMDRELAX_CACHE_H_\n#define WMDRELAX_CACHE_H_\n\n#include <cstdio>\n#include <mutex>\n\nnamespace wmd {\n\n/// This is supposed to be the base class for all the other caches.\n/// \"Cache\" here means the carrier of reusable buffers which should eliminate\n/// memory allocations. It should be used as follows:\n///\n/// Cache instance;\n/// instance.allocate(100500);\n/// // thread safety\n/// {\n/// // the problem size is 100\n/// std::lock_guard<std::mutex> _(instance.enter(100));\n/// auto whatever = instance.whatever();\n/// // ... use whatever ...\n/// }\nclass Cache {\n public:\n enum AllocationError {\n kAllocationErrorSuccess = 0,\n /// Can't allocate empty cache.\n kAllocationErrorInvalidSize,\n /// You have to deallocate the cache first before allocating again.\n kAllocationErrorDeallocationNeeded\n };\n\n Cache() : size_(0) {}\n virtual ~Cache() {}\n\n AllocationError allocate(size_t size) {\n if (size == 0) {\n return kAllocationErrorInvalidSize;\n }\n if (size_ != 0) {\n return kAllocationErrorDeallocationNeeded;\n }\n size_ = size;\n _allocate();\n return kAllocationErrorSuccess;\n }\n\n void reset() noexcept {\n _reset();\n size_ = 0;\n }\n\n std::mutex& enter(size_t size) const {\n#ifndef NDEBUG\n assert(size_ >= size && \"the cache is too small\");\n#else\n if (size_ < size) {\n fprintf(stderr, \"emd: cache size is too small: %zu < %zu\\n\",\n size_, size);\n throw \"the cache is too small\";\n }\n#endif\n return lock_;\n }\n\n protected:\n virtual void _allocate() = 0;\n virtual void _reset() noexcept = 0;\n\n size_t size_;\n\n private:\n Cache(const Cache&) = delete;\n Cache& operator=(const Cache&) = delete;\n\n mutable std::mutex lock_;\n};\n\n}\n\n#endif // WMDRELAX_CACHE_H_\n"
}
] | 5 |
abasu1007/abasu1007.github.io | https://github.com/abasu1007/abasu1007.github.io | 5d85811e676e232695af8288cd91e65be5455938 | f19d4697d135e9c6112a344870b5b66625fef62d | 6d76175f2704b6a6fbc4d89f085cb0b915e04d5a | refs/heads/master | "2021-01-17T14:25:34.475229" | "2016-10-31T18:57:28" | "2016-10-31T18:57:28" | 55,708,396 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6480331420898438,
"alphanum_fraction": 0.6542443037033081,
"avg_line_length": 23.200000762939453,
"blob_id": "53c53c8105428dc53987b788a2157bb0c4ca7ed1",
"content_id": "1ad973e4dd45ebe3505e6a15ab3ef37a5452cda4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 483,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 20,
"path": "/list_of_lists.py",
"repo_name": "abasu1007/abasu1007.github.io",
"src_encoding": "UTF-8",
"text": "# Enter your code here. Read input from STDIN. Print output to STDOUT\nN = input()\nstudents = []\nscore_list = []\nfor i in range(N):\n name = raw_input()\n score = raw_input()\n students.append([name, float(score)])\n \nsecond_lowest = sorted(list(set([score for name, score in students])),reverse = True)[-2]\n\nname_list = []\nfor student in students:\n if student[1] == second_lowest:\n name_list.append(student[0])\n\nname_list.sort()\n\nfor name in name_list:\n print name"
}
] | 1 |
lidandan0814/douban | https://github.com/lidandan0814/douban | 271dd4523dae45a2ea7359721c54c501fa4d1090 | ed8a14b0d1f51c08e0e25e60c76e9b65a2130891 | f3913859f6d556de2b9aca7d2d28537e2bd0295b | refs/heads/master | "2020-06-15T15:56:05.598263" | "2019-07-05T03:57:42" | "2019-07-05T03:57:42" | 195,335,843 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5660660862922668,
"avg_line_length": 31.225807189941406,
"blob_id": "78e53c057fe250e55f9d874aabd4d9f716a0ee8c",
"content_id": "18e7666ae8f4904b728aa5b28fef411a5262937b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2172,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 62,
"path": "/douban/doubanbook.py",
"repo_name": "lidandan0814/douban",
"src_encoding": "UTF-8",
"text": "import requests\nfrom pyquery import PyQuery as pq\nimport json\nimport time\nfrom openpyxl import Workbook\nlines = []\n\ndef get_html(url):\n headers = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'\n }\n response = requests.get(url, headers=headers)\n if response.status_code == 200:\n return response.text\n return None\n\n\ndef parse_html(html):\n doc = pq(html)\n items = doc.find('.subject-list li').items()\n for item in items:\n book = {}\n book['书名'] = item.find('.info h2 a').text()\n book['价格'] = item.find('.info .pub').text().split('/')[-1]\n book['出版日期'] = item.find('.info .pub').text().split('/')[-2]\n book['出版社'] = item.find('.info .pub').text().split('/')[-3]\n book['作者'] = item.find('.info .pub').text().split('/')[0]\n book['评分'] = item.find('.info .star .rating_nums').text()\n book['评价人数'] = item.find('.info .star .pl').text()\n book['评论摘要'] = item.find('.info p').text()\n #print(book)\n booklist = [book['书名'], book['价格'], book['出版日期'], book['出版社'],\n book['作者'], book['评分'], book['评价人数'], book['评论摘要']]\n lines.append(booklist)\n return lines\n\n\ndef write_to_file(result):\n #保存到Excel\n workbook = Workbook()\n worksheet = workbook.active\n worksheet.append(['书名','价格', '出版日期', '出版社', '作者','评分', '评价人数', '评论摘要'])\n for line in lines:\n worksheet.append(line)\n workbook.save('豆瓣编程书籍清单.xlsx')\n #保存为txt格式\n# with open('result.txt', 'a', encoding='utf-8') as f:\n# f.write(json.dumps(result, ensure_ascii=False) + '\\n')\n\n\ndef main(offset):\n print('第', i + 1 , '页')\n url = 'https://book.douban.com/tag/%E7%BC%96%E7%A8%8B?start=' + str(offset) + '&type=T'\n html = get_html(url)\n for lines in parse_html(html):\n write_to_file(lines)\n\n\nif __name__ == '__main__':\n for i in range(15):\n main(offset=i * 20)\n time.sleep(10)\n"
}
] | 1 |
UBC-MDS/PrepPy | https://github.com/UBC-MDS/PrepPy | 59298473c6e74fbb416c772d7ea3a733a1e2c31e | de1dc48f6517277a4aade32b446c8c9b63e613f0 | cb78606091413e1e4f746aabc2fa1fb4d3f1030f | refs/heads/master | "2021-01-15T03:29:58.442862" | "2020-03-27T01:10:51" | "2020-03-27T01:10:51" | 242,864,114 | 3 | 0 | MIT | "2020-02-24T23:13:41" | "2020-03-25T20:24:49" | "2020-03-27T00:54:02" | Python | [
{
"alpha_fraction": 0.44859811663627625,
"alphanum_fraction": 0.44859811663627625,
"avg_line_length": 10.88888931274414,
"blob_id": "89ce085276ef9a105c2f9cb6242168c81f86688c",
"content_id": "ace3150a3eb6acd06d1c9ada78a0ae28651422b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 9,
"path": "/CONTRIBUTORS.md",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "## Contributors\n\n* Chimaobi Amadi <[email protected]>\n\n* Jasmine Qin <[email protected]>\n \n* George Thio <[email protected]>\n\n* Matthew Connell <[email protected]>\n"
},
{
"alpha_fraction": 0.47690901160240173,
"alphanum_fraction": 0.5050297379493713,
"avg_line_length": 33.171875,
"blob_id": "a040ae283df68da7ba98dba6c97344deb6deb1e2",
"content_id": "be81111f122fa0a43badd238cf42da330773e699",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4374,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 128,
"path": "/preppy524/train_valid_test_split.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\n\n\ndef train_valid_test_split(X,\n y,\n valid_size=0.25,\n test_size=None,\n stratify=None,\n random_state=None,\n shuffle=True):\n \"\"\"\n Splits dataframes into random train, validation and test subsets\n The proprotion of the train set relative to the input data will be\n valid_size * (1 - test)\n ....\n Parameters\n ----------\n X, y: Sequence of indexables of the same length / shape[0]\n Allowable inputs are lists, numpy arrays, scipy-sparse matrices or\n pandas dataframes\n test_size: float or None, optional (default=None)\n float, a value between 0.0 and 1.0 to represent the proportion of the\n input dataset toccomprise the size of the test subset\n If None, the value is set to 0.25\n valid_size: float or None, (default=0.25)\n float, a value between 0.0 and 1.0 to represent the proportion of the\n input dataset toccomprise the size of the validation subset\n Default value is set to 0.25\n stratify: array-like or None (default=None)\n If not None, splits categorical data in a stratified fashion preserving\n the same proportion of classes in the train, valid and test sets,\n using this input as the class labels\n random_state: integer, optional (default=None)\n A value for the seed to be used by the random number generator\n If None, the value will be set to 1\n shuffle: logical, optional (default=TRUE)\n Indicate whether data is to be shuffled prior to splitting\n Returns\n -------\n splits: list, length = 3 * len(arrays)\n List containing train, validation and test splits of the input data\n Examples\n --------\n >>> from PrepPy import PrepPy as pp\n >>> X, y = np.arange(16).reshape((8, 2)), list(range(8))\n >>> X\n array([[0, 1],\n [2, 3],\n [4, 5],\n [6, 7],\n [8, 9],\n [10, 11],\n [12, 13],\n [14, 15]])\n >>> list(y)\n [0, 1, 2, 3, 4, 5, 6, 7]\n >>> X_train, X_valid, X_test, y_train, y_valid, y_test =\n pp.train_valid_test_split(X,\n y,\n test_size=0.25,\n valid_size=0.25,\n random_state=777)\n >>> X_train\n array([[4, 5],\n [0, 1],\n [6, 7],\n [12, 13]])\n >>> y_train\n [3, 0, 2, 5]\n >>> X_valid\n array([[2, 3],\n [10, 11]])\n >>> y_valid\n [1, 4]\n >>> X_test\n array([[8, 9],\n [14, 15]])\n >>> y_test\n [7, 6]\n >>> pp.train_valid_test_split(X, test_size=2, shuffle=False)\n >>> X_train\n array([[2, 3],\n [14, 15],\n [6, 7],\n [12, 13],\n [4, 5],\n [10, 11]])\n >>> X_test\n array([[8, 9],\n [0, 1]])\n \"\"\"\n\n if not isinstance(X, (np.ndarray, pd.DataFrame)):\n raise Exception(\"Please provide a valid Pandas DataFrame object for X\")\n\n if not isinstance(y, (np.ndarray, pd.DataFrame, list)):\n raise Exception(\"Please provide a valid Pandas DataFrame object for\")\n\n assert len(X) != 0, \"Your input is empty\"\n assert len(y) != 0, \"Your input is empty\"\n\n # Split into `test` set and `resplit` set to be resplit into `train`\n # and `valid` sets\n X_resplit, X_test, y_resplit, y_test =\\\n train_test_split(X,\n y,\n test_size=test_size,\n stratify=stratify,\n random_state=random_state,\n shuffle=shuffle)\n X_train, X_valid, y_train, y_valid =\\\n train_test_split(X_resplit,\n y_resplit,\n test_size=valid_size,\n stratify=stratify,\n random_state=random_state,\n shuffle=shuffle)\n\n splits = (pd.DataFrame(X_train),\n pd.DataFrame(X_valid),\n pd.DataFrame(X_test),\n pd.DataFrame(y_train),\n pd.DataFrame(y_valid),\n pd.DataFrame(y_test))\n\n return splits\n"
},
{
"alpha_fraction": 0.5104719996452332,
"alphanum_fraction": 0.5329790711402893,
"avg_line_length": 40.54545593261719,
"blob_id": "2689d45f06709795d79ab48c2c4dd2ee4fbf42bb",
"content_id": "1468fa1e82ee3addd9cf23a5bcc883d806ce2b8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3199,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 77,
"path": "/tests/test_scaler.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "from preppy524 import scaler\n\nimport numpy as np\n\nimport pandas as pd\n\nimport pytest\n\nfrom pytest import raises\n\n\[email protected]\ndef input_data():\n dataset = {}\n x_train = pd.DataFrame(np.array([['Blue', 56, 4], ['Red', 35, 6],\n ['Green', 18, 9]]),\n columns=['color', 'count', 'usage'])\n dataset['x_train'] = x_train\n x_test = pd.DataFrame(np.array([['Blue', 66, 6], ['Red', 42, 8],\n ['Green', 96, 0]]),\n columns=['color', 'count', 'usage'])\n dataset['x_test'] = x_test\n x_validation = pd.DataFrame(np.array([['Blue', 30, 18], ['Red', 47, 2],\n ['Green', 100, 4]]),\n columns=['color', 'count', 'usage'])\n dataset['x_validation'] = x_validation\n colnames = ['count', 'usage']\n dataset['colnames'] = colnames\n df_empty = pd.DataFrame() # empty dataframe\n dataset['df_empty'] = df_empty\n wrong_type = np.zeros(6)\n dataset['wrong_type'] = wrong_type\n return dataset\n\n\ndef test_output(input_data):\n # Test data\n x_train = input_data['x_train']\n x_test = input_data['x_test']\n x_validation = input_data['x_validation']\n colnames = input_data['colnames']\n df_empty = input_data['df_empty']\n wrong_type = input_data['wrong_type']\n assert np.equal(round(scaler.scaler(x_train,\n x_validation,\n x_test,\n colnames)\n ['x_train']['usage'][0], 5),\n round(-1.135549947915338, 5))\n assert np.equal(round(scaler.scaler(x_train,\n x_validation,\n x_test,\n colnames)\n ['x_test']['usage'][2], 4),\n round(-1.3728129459672882, 4))\n\n assert np.equal(scaler.scaler(x_train, x_validation, x_test, colnames)[\n 'x_train'].shape, x_train.shape).all()\n assert np.equal(scaler.scaler(x_train, x_validation, x_test, colnames)[\n 'x_test'].shape, x_test.shape).all()\n assert np.equal(scaler.scaler(x_train, x_validation, x_test, colnames)[\n 'x_validation'].shape, x_validation.shape).all()\n assert x_train.equals(scaler.scaler(\n x_train, x_validation, x_test, colnames)['x_train']) is False\n assert x_validation.equals(scaler.scaler(\n x_train, x_validation, x_test, colnames)['x_validation']) is False\n assert x_test.equals(scaler.scaler(\n x_train, x_validation, x_test, colnames)['x_test']) is False\n # assert Exception\n with raises(ValueError, match=\"Input data cannot be empty\"):\n scaler.scaler(df_empty, x_validation, x_test, colnames)\n with raises(TypeError, match=\"A wrong data type has been passed. Please \" +\n \"pass a dataframe\"):\n scaler.scaler(wrong_type, x_validation, x_test, colnames)\n with raises(TypeError, match=\"Numeric column names is not in a list \" +\n \"format\"):\n scaler.scaler(x_train, x_validation, x_test, x_train)\n"
},
{
"alpha_fraction": 0.528132975101471,
"alphanum_fraction": 0.5664961934089661,
"avg_line_length": 16,
"blob_id": "4f81b48f8751da0020ac5fdce6f3a63b4b6fbda2",
"content_id": "f44c3b7cca3f4d8d902811fd0f1e7b960c48ecab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 782,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 46,
"path": "/docs/source/preppy524.rst",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "preppy524 package\n=================\n\nSubmodules\n----------\n\npreppy524.datatype module\n-------------------------\n\n.. automodule:: preppy524.datatype\n :members:\n :undoc-members:\n :show-inheritance:\n\npreppy524.onehot module\n-----------------------\n\n.. automodule:: preppy524.onehot\n :members:\n :undoc-members:\n :show-inheritance:\n\npreppy524.scaler module\n-----------------------\n\n.. automodule:: preppy524.scaler\n :members:\n :undoc-members:\n :show-inheritance:\n\npreppy524.train\\_valid\\_test\\_split module\n------------------------------------------\n\n.. automodule:: preppy524.train_valid_test_split\n :members:\n :undoc-members:\n :show-inheritance:\n\n\nModule contents\n---------------\n\n.. automodule:: preppy524\n :members:\n :undoc-members:\n :show-inheritance:\n"
},
{
"alpha_fraction": 0.6538923978805542,
"alphanum_fraction": 0.6727960109710693,
"avg_line_length": 33.22941207885742,
"blob_id": "f77e31585681d16ec1e69159dc488267657af291",
"content_id": "ce75147144dfbc15b364ff3f300e95df80d49e31",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5819,
"license_type": "permissive",
"max_line_length": 313,
"num_lines": 170,
"path": "/README.md",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "## PrepPy\n\n [](https://codecov.io/gh/UBC-MDS/PrepPy) \n\n[](https://preppy524.readthedocs.io/en/latest/?badge=latest)\n\n### Package Summary\n\n`PrepPy` is a package for Python to help preprocessing in machine learning tasks.\nThere are certain repetitive tasks that come up often when doing a machine learning project and this package aims to alleviate those chores.\nSome of the issues that come up regularly are: finding the types of each column in a dataframe, splitting the data (whether into train/test sets or train/test/validation sets, one-hot encoding, and scaling features.\nThis package will help with all of those tasks.\n\n### Installation:\n\n```\npip install -i https://test.pypi.org/simple/ preppy524\n```\n\n### Features\n\nThis package has the following features:\n\n- `train_valid_test_split`: This function splits the data set into train, validation, and test sets.\n\n- `data_type`: This function identifies data types for each column/feature. It returns one dataframe for each type of data.\n\n- `one-hot`: This function performs one-hot encoding on the categorical features and returns a dataframe for the train, test, validation sets with sensible column names.\n\n- `scaler`: This function performs standard scaling on the numerical features. \n\n\n\n### Dependencies\n\n- import pandas as pd\n\n- import numpy as np\n\n- from sklearn.preprocessing import OneHotEncoder\n\n- from sklearn.preprocessing import StandardScaler, MinMaxScaler\n\n- from sklearn.model_selection import train_test_split\n\n\n### Usage\n\n#### preppy524.datatype module\nThe `data_type()` function identifies features of different data types: numeric or categorical. \n\n__Input:__ Pandas DataFrame \n__Output:__ A tuple (Pandas DataFrame of numeric features, Pandas DataFrame of categorical features)\n\n```\nfrom preppy524 import datatype \ndatatype.data_type(my_data)\n```\n\n**Example:** \n\n```\nmy_data = pd.DataFrame({'fruits': ['apple', 'banana', 'pear'],\n 'count': [3, 5, 8],\n 'price': [1.0, 6.5, 9.23]})\n```\n\n`datatype.data_type(my_data)[0]`\n\n| |count| price |\n|---|----|----|\n| 0 | 3 | 1.0 |\n| 1 | 5 | 6.5 |\n| 2 | 8 | 9.23 |\n\n`datatype.data_type(my_data)[1]`\n\n| | fruits |\n|---|--------|\n| 0 | apple |\n| 1 | banana |\n| 2 | pear |\n\n#### preppy524.train_valid_test_split module\nThe `train_valid_test_split()` splits dataframes into random train, validation and test subsets.\n\n__Input:__ Sequence of Pandas DataFrame of the same length / shape[0] \n__Output:__ List containing train, validation and test splits of the input data\n\n```\nfrom preppy524 import train_valid_test_split \ntrain_valid_test_split.train_valid_test_split(X, y)\n```\n\n**Example:** \n\n```\nX, y = np.arange(16).reshape((8, 2)), list(range(8))\n\nX_train, X_valid, X_test, y_train, y_valid, y_test =\n train_valid_test_split.train_valid_test_split(X,\n y,\n test_size=0.25,\n valid_size=0.25,\n random_state=777)\n \ny_train\n```\n\n[3, 0, 2, 5]\n\n#### preppy524.onehot module\nThe `onehot()` function encodes features of categorical type.\n\n__Input:__ List of categorical features, Train set, Validation set, Test set (Pandas DataFrames) \n__Output:__ Encoded Pandas DataFrame\n\n```\nfrom preppy524 import onehot\nonehot.onehot(cols=['catgorical_columns'], train=my_data)\n```\n\n**Example:** \n\n`onehot.onehot(['fruits'], my_data)['train']`\n\n| | apple | banana | pear |\n|---|-------|--------|------|\n| 0 | 1 | 0 | 0 |\n| 1 | 0 | 1 | 0 |\n| 2 | 0 | 0 | 1 |\n\n#### preppy524.scaler module\nThe `scaler()` performs standard scaling of numeric features.\n\n__Input:__ Train set, Validation set, Test set (Pandas DataFrames), List of numeric features \n__Output:__ Dictionary of transformed sets (Pandas DataFrames)\n\n```\nfrom preppy524 import scaler\nscaler.scaler(x_train, x_validation, x_test, colnames)\n```\n\n**Example:** \n\n`scaler.scaler(my_data, my_data, my_data, ['count'])['x_validation']`\n\n| | count |\n|---|-------|\n| 0 | -0.927 |\n| 1 | -0.132 |\n| 2 | 1.059 |\n\n\n### Our package in the Python ecosystem\n\nMany of the functions in this package can also be done using the various functions of `sklearn`.\nHowever, some of the functions in `sklearn` take multiple steps to complete what our package can do in one line.\nFor example, if one wants to split a dataset into train, test, and validation sets, they would need to use `sklearn`'s `train_test_split` twice.\nThis package's `train_test_val_split` allows users to do this more efficiently.\nFurther, the one-hot encoder in `sklearn` does not make sensible column names unless the user does some wrangling.\nThe `one-hot` function in this package will implement `sklearn`'s one-hot encoder, but will wrangle the columns and name them automatically.\nOverall, this package fits in well with the Python ecosystem and can help make machine learning a little easier. \n\n\n### Documentation\nThe official documentation is hosted on Read the Docs: <https://preppy524.readthedocs.io/en/latest/>\n\n### Credits\nThis package was created with Cookiecutter and the UBC-MDS/cookiecutter-ubc-mds project template, modified from the [pyOpenSci/cookiecutter-pyopensci](https://github.com/pyOpenSci/cookiecutter-pyopensci) project template and the [audreyr/cookiecutter-pypackage](https://github.com/audreyr/cookiecutter-pypackage).\n"
},
{
"alpha_fraction": 0.5603799223899841,
"alphanum_fraction": 0.5603799223899841,
"avg_line_length": 15.02173900604248,
"blob_id": "4aac0d9653d5b9fc788b2b6dd0fd2da8ade36803",
"content_id": "4c213408ed5afd8e5729d856e308313416013bed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 737,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 46,
"path": "/docs/source/PrepPy.rst",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "PrepPy package\n==============\n\nSubmodules\n----------\n\nPrepPy.datatype module\n----------------------\n\n.. automodule:: PrepPy.datatype\n :members:\n :undoc-members:\n :show-inheritance:\n\nPrepPy.onehot module\n--------------------\n\n.. automodule:: PrepPy.onehot\n :members:\n :undoc-members:\n :show-inheritance:\n\nPrepPy.scaler module\n--------------------\n\n.. automodule:: PrepPy.scaler\n :members:\n :undoc-members:\n :show-inheritance:\n\nPrepPy.train\\_valid\\_test\\_split module\n---------------------------------------\n\n.. automodule:: PrepPy.train_valid_test_split\n :members:\n :undoc-members:\n :show-inheritance:\n\n\nModule contents\n---------------\n\n.. automodule:: PrepPy\n :members:\n :undoc-members:\n :show-inheritance:\n"
},
{
"alpha_fraction": 0.5499351620674133,
"alphanum_fraction": 0.5546908974647522,
"avg_line_length": 29.4342098236084,
"blob_id": "e6778923943a8ba16c7c3dcbaeb02e2d9eddf2cc",
"content_id": "2985fc887408ee62810d218cbc2f167a49ab84e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2313,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 76,
"path": "/preppy524/onehot.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "from sklearn.preprocessing import OneHotEncoder\nimport numpy as np\nimport pandas as pd\n\n\ndef onehot(cols, train, valid=None, test=None):\n \"\"\"\n One-hot encodes features of categorical type\n\n Arguments:\n ---------\n cols : list\n list of column names\n\n train : pandas.DataFrame\n The train set from which the columns come\n\n valid : pandas.DataFrame\n The validation set from which the columns come\n\n test : pandas.DataFrame\n The test set from which the columns come\n\n Returns\n train_encoded, valid_encoded, test_encoded : pandas.DataFrames\n The encoded DataFrames\n\n Examples\n --------\n >>> from PrepPy import onehot\n >>> my_data = pd.DataFrame(np.array([['monkey'], ['dog'], ['cat']]),\n columns=['animals'])\n >>> onehot.onehot(['animals'], my_data)['train']\n animals_monkey animals_dog animals_cat\n 1 0 0\n 0 1 0\n 0 0 1\n \"\"\"\n ohe = OneHotEncoder(sparse=False)\n\n names = []\n\n for i in train[cols].columns:\n for j in np.sort(train[i].unique()):\n names.append(i + '_' + str(j))\n\n train_encoded, valid_encoded, test_encoded = (None, None, None)\n\n train_encoded = pd.DataFrame(ohe.fit_transform(train[cols]),\n columns=names)\n\n if valid is not None:\n\n # Try-except for data_type\n if not isinstance(valid, pd.DataFrame):\n raise Exception(\"Please provide a valid Pandas DataFrame object\")\n elif len(valid) == 0:\n raise Exception(\"Your 'valid' DataFrame is empty\")\n\n valid_encoded = pd.DataFrame(ohe.transform(valid[cols]),\n columns=names)\n\n if test is not None:\n\n # Try-except for data_type\n if not isinstance(test, pd.DataFrame):\n raise Exception(\"Please provide a valid Pandas DataFrame object\")\n elif len(test) == 0:\n raise Exception(\"Your 'test' DataFrame is empty\")\n\n test_encoded = pd.DataFrame(ohe.transform(test[cols]),\n columns=names)\n\n return {\"train\": train_encoded,\n \"valid\": valid_encoded,\n \"test\": test_encoded}\n"
},
{
"alpha_fraction": 0.5324675440788269,
"alphanum_fraction": 0.5627705454826355,
"avg_line_length": 31.23255729675293,
"blob_id": "d8dd166bdacb4bb50cb0dc2c54fcdff39cc7df15",
"content_id": "9068460e51b57347d3dbc7bb10eda1158a322d95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1386,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 43,
"path": "/tests/test_datatype.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "from preppy524 import datatype\nimport pandas as pd\nimport pytest\n\n\ntest_dict = {'cat1': ['apple', None, 'pear', 'banana', 'blueberry', 'lemon'],\n 'num1': [0, 1, 2, 3, 4, 5],\n 'cat2': [True, False, False, True, False, None],\n 'num2': [0, 16, 7, None, 10, 14],\n 'num3': [0.5, 3, 3.9, 5.5, 100.2, 33]}\n\ntest_data = pd.DataFrame(test_dict)\n\n\ndef test_datatype_num():\n # test if numeric data is correctly separated from original data\n assert datatype.data_type(test_data)[0].equals(test_data[['num1',\n 'num2',\n 'num3']])\n\n\ndef test_datatype_cat():\n # test if categorical data is correctly separated from original data\n assert datatype.data_type(test_data)[1].equals(test_data[['cat1',\n 'cat2']])\n\n\ndef check_exception_wrong_input():\n # test if an invalid input will be handled by function correctly\n with pytest.raises(Exception):\n datatype.data_type(\"df\")\n\n\ndef check_exception_empty_df():\n # test if an empty input will be handled by function correctly\n with pytest.raises(Exception):\n datatype.data_type(pd.DataFrame())\n\n\ntest_datatype_num()\ntest_datatype_cat()\ncheck_exception_wrong_input()\ncheck_exception_empty_df()\n"
},
{
"alpha_fraction": 0.5464052557945251,
"alphanum_fraction": 0.5620915293693542,
"avg_line_length": 29.197368621826172,
"blob_id": "1114ad3dc6b4d5b3ec5eaced4e49525e3e1a9c02",
"content_id": "282c126d0f7a52f10c11bbc500a9b6686295aa3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2295,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 76,
"path": "/tests/test_onehot.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "from preppy524 import onehot\nimport pandas as pd\nimport numpy as np\nimport pytest\n\nhelperdata1 = pd.DataFrame(np.array([['monkey'],\n ['dog'],\n ['cat']]),\n columns=['animals'])\n\n\ndef onehot_test1():\n # test if train set has been encoded correctly\n output = onehot.onehot(cols=['animals'],\n train=helperdata1)\n assert(output['train'].shape == (3, 3))\n\n\ndef onehot_test2():\n # test if validation set has been encoded correctly\n output = onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=helperdata1)\n assert(output['valid'].shape == (3, 3))\n\n\ndef onehot_test3():\n # test if output is correct when three sets are passed to the function\n output = onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=helperdata1,\n test=helperdata1)\n assert(len(output) == 3)\n\n\ndef check_exception1():\n # check exception handling when validation set input is of wrong data type\n with pytest.raises(Exception):\n onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=\"helperdata1\")\n\n\ndef check_exception2():\n # check exception handling when test set input is of wrong data type\n with pytest.raises(Exception):\n onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=helperdata1,\n test=\"helper\")\n\n\ndef check_exception3():\n # check exception handling when validation set input is an empty data frame\n with pytest.raises(Exception):\n onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=pd.DataFrame())\n\n\ndef check_exception4():\n # check exception handling when test set input is an empty data frame\n with pytest.raises(Exception):\n onehot.onehot(cols=['animals'],\n train=helperdata1,\n valid=helperdata1,\n test=pd.DataFrame())\n\n\nonehot_test1()\nonehot_test2()\nonehot_test3()\ncheck_exception1()\ncheck_exception2()\ncheck_exception3()\ncheck_exception4()\n"
},
{
"alpha_fraction": 0.6642857193946838,
"alphanum_fraction": 0.6765305995941162,
"avg_line_length": 24.789474487304688,
"blob_id": "99df0b890e8934ab4560a903bbed8e1dcc10fa55",
"content_id": "c2464886eeb74509060cb50adacbd6e018a67b93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 980,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 38,
"path": "/tests/test_train_valid_test_split.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "from preppy524 import train_valid_test_split\nimport numpy as np\n\nimport pytest\n\n\n# Check data input types and parameters\n\nX, y = np.arange(16).reshape((8, 2)), list(range(8))\n\n\ndef test_train_test_valid_split():\n \"\"\"\n This script will test the output of the train_valid_test_split function\n which splits dataframes into random train, validation and test subsets.\n The proportion of the train set relative to the input data will be\n equal to valid_size * (1 - test_size).\n \"\"\"\n\n X_train, X_valid, X_test, y_train, y_valid, y_test =\\\n train_valid_test_split.train_valid_test_split(X, y)\n\n assert(len(X_train) == 4)\n assert(len(X_valid) == 2)\n assert(len(X_test) == 2)\n\n\ndef check_exception():\n\n with pytest.raises(Exception):\n train_valid_test_split.train_valid_test_split(\"test\", y)\n\n with pytest.raises(Exception):\n train_valid_test_split.train_valid_test_split(X, \"test\")\n\n\ntest_train_test_valid_split()\ncheck_exception()\n"
},
{
"alpha_fraction": 0.5188087821006775,
"alphanum_fraction": 0.5415360331535339,
"avg_line_length": 26.148935317993164,
"blob_id": "6364a9f2b89d55632bf1545168eee4826a80cf91",
"content_id": "9f9aa1902fb6d782dc0ffacb86abf0c1bf18d5a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1276,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 47,
"path": "/preppy524/datatype.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\n\ndef data_type(df):\n \"\"\"\n Identify features of different data types.\n\n Parameters\n ----------\n df : pandas.core.frame.DataFrame\n Original feature dataframe containing one column for each feature.\n\n Returns\n -------\n tuple\n Stores the categorical and numerical columns separately\n as two dataframes.\n\n Examples\n --------\n >>> from PrepPy import datatype\n >>> my_data = pd.DataFrame({'fruits': ['apple', 'banana', 'pear'],\n 'count': [3, 5, 8],\n 'price': [1.0, 6.5, 9.23]})\n >>> datatype.data_type(my_data)[0]\n count price\n 0 3 1.0\n 1 5 6.5\n 2 8 9.23\n >>> datatype.data_type(my_data)[1]\n fruits\n 0 apple\n 1 banana\n 2 pear\n \"\"\"\n\n # Try-except for data_type\n if not isinstance(df, pd.DataFrame):\n raise Exception(\"Please provide a valid Pandas DataFrame object\")\n elif len(df) == 0:\n raise Exception(\"Your DataFrame is empty\")\n\n cols = df.columns\n numeric_vars = df._get_numeric_data().columns\n categorical_vars = [c for c in cols if c not in numeric_vars]\n\n return (df[numeric_vars], df[categorical_vars])\n"
},
{
"alpha_fraction": 0.545342743396759,
"alphanum_fraction": 0.6012911200523376,
"avg_line_length": 39.160491943359375,
"blob_id": "6b620fa97aebd4be355c24622e8da05d4b7057ca",
"content_id": "3983e5a3c645988d1039281361122f7dc02666ec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3253,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 81,
"path": "/preppy524/scaler.py",
"repo_name": "UBC-MDS/PrepPy",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\nfrom sklearn.preprocessing import StandardScaler\n\n\ndef scaler(x_train, x_validation, x_test, colnames):\n \"\"\"\n Perform standard scaler on numerical features.\n Parameters\n ----------\n x_train : pandas.core.frame.DataFrame, numpy array or list\n Dataframe of train set containing columns to be scaled.\n x_validation : pandas.core.frame.DataFrame, numpy array or list\n Dataframe of validation set containing columns to be scaled.\n x_test : pandas.core.frame.DataFrame, numpy array or list\n Dataframe of test set containing columns to be scaled.\n num_columns : list\n A list of numeric column names\n Returns\n -------\n dict\n Stores the scaled and transformed x_train and x_test sets separately as\n two dataframes.\n Examples\n --------\n >>> from PrepPy import prepPy as pp\n >>> x_train = pd.DataFrame(np.array([['Blue', 56, 4], ['Red', 35, 6],\n ['Green', 18, 9]]),\n columns=['color', 'count', 'usage'])\n >>> x_test = pd.DataFrame(np.array([['Blue', 66, 6], ['Red', 42, 8],\n ['Green', 96, 0]]),\n columns=['color', 'count', 'usage'])\n >>> x_validation = pd.DataFrame(np.array([['Blue', 30, 18], ['Red', 47, 2],\n ['Green', 100, 4]]),\n columns=['color', 'count', 'usage'])\n >>> colnames = ['count', 'usage']\n >>> x_train = pp.scaler(x_train, x_validation, x_test, colnames)['x_train']\n >>> x_train\n color count usage\n 0 Blue 1.26538 -1.13555\n 1 Red -0.0857887 -0.162221\n 2 Green -1.17959 1.29777\n\n >>> x_validation = pp.scaler(x_train, x_validation,\n x_test, colnames)['x_validation']\n >>> x_validation\n color count usage\n 0 Blue 1.80879917 -0.16222142\n 1 Red 0.16460209 1.81110711\n 2 Green 2.43904552 -4.082207\n >>> x_test = pp.scaler(x_train, x_validation, x_test, colnames)['x_test']\n >>> x_test\n color count usage\n 0 Blue 1.90879917 -0.16222142\n 1 Red 0.36460209 0.81110711\n 2 Green 3.83904552 -3.082207\n \"\"\"\n # Type error exceptions\n if not isinstance(x_train, pd.DataFrame) or \\\n not isinstance(x_test, pd.DataFrame) \\\n or not isinstance(x_validation, pd.DataFrame):\n raise TypeError('A wrong data type has been passed. Please pass a ' +\n 'dataframe')\n if not isinstance(colnames, list):\n raise TypeError('Numeric column names is not in a list format')\n if ((x_train.empty is True) or (x_test.empty is True) or\n (x_validation.empty is True) or\n (len(colnames) == 0)):\n raise ValueError('Input data cannot be empty')\n scaled_data = {}\n sc = StandardScaler()\n x_train_scaled = x_train.copy()\n x_train_scaled[colnames] = sc.fit_transform(x_train[colnames])\n scaled_data['x_train'] = x_train_scaled\n x_validation_scaled = x_validation.copy()\n x_validation_scaled[colnames] = sc.fit_transform(x_validation[colnames])\n scaled_data['x_validation'] = x_validation_scaled\n x_test_scaled = x_test.copy()\n x_test_scaled[colnames] = sc.fit_transform(x_test[colnames])\n scaled_data['x_test'] = x_test_scaled\n return scaled_data\n"
}
] | 12 |
andreiluca96/gecco19-thief | https://github.com/andreiluca96/gecco19-thief | ed04e665bcbb067a8640ed693d925831833bbaeb | bb716e4302bc340b1344e24a827c0894c86f4f81 | 8957b4678397d6424e79b7c90f319c58d29084e4 | refs/heads/master | "2020-04-27T21:17:32.863332" | "2019-04-14T10:42:33" | "2019-04-14T10:42:33" | 174,690,896 | 0 | 0 | null | "2019-03-09T12:21:24" | "2019-02-19T06:32:31" | "2019-01-21T15:58:42" | null | [
{
"alpha_fraction": 0.6499525308609009,
"alphanum_fraction": 0.668376088142395,
"avg_line_length": 30.704818725585938,
"blob_id": "b5a2cdab174bc89c5bfa4651f99d5ea276e17f4c",
"content_id": "f0c751992f0108319944d389c6b9ddda2a11d650",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5265,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 166,
"path": "/alternative/main.py",
"repo_name": "andreiluca96/gecco19-thief",
"src_encoding": "UTF-8",
"text": "import math\n\nimport numpy as np\nfrom deap import base, creator\n\nfrom data.repository import read_problem\n\ncreator.create(\"FitnessMinMax\", base.Fitness, weights=(-1.0, 1.0))\ncreator.create(\"Individual\", dict, fitness=creator.FitnessMinMax)\n\nimport random\nfrom deap import tools\n\nproblem = read_problem(\"test-example-n4\")\n\nprint(\"### Problem instance ###\")\nprint(problem.items)\nprint(problem.cities)\nprint(\"###\")\n\n\ndef initIndividual(container, city_func, item_func):\n return container(zip(['cities', 'items'], [city_func(), item_func()]))\n\n\ndef initPermutation():\n return random.sample(range(problem.no_cities - 1), problem.no_cities - 1)\n\n\ndef initZeroOne():\n return 1 if random.random() > 0.9 else 0\n\n\ndef euclidean_distance(a, b):\n return math.sqrt(\n math.pow(problem.cities[a][0] - problem.cities[b][0], 2) + math.pow(problem.cities[a][1] - problem.cities[b][1],\n 2))\n\n\ndef evaluate(individual):\n pi = individual['cities']\n z = individual['items']\n\n # print(full_pi, z)\n\n profit = 0\n time = 0\n weight = 0\n\n full_pi = [x + 1 for x in pi]\n\n for index, city in enumerate([0] + full_pi):\n possible_items_for_current_city = problem.items.get(city, [])\n items_collected_for_current_city = filter(lambda x: z[x[0] - 1] == 1, possible_items_for_current_city)\n\n for item in items_collected_for_current_city:\n profit += item[1]\n weight += item[2]\n\n speed = problem.max_speed - (weight / problem.knapsack_capacity) * (problem.max_speed - problem.min_speed)\n next = full_pi[(index + 1) % (problem.no_cities - 1)]\n\n # print(\"Cities: \", city, next)\n\n distance = math.ceil(euclidean_distance(city, next))\n\n # print(distance)\n\n # print(distance, speed)\n\n time += distance / speed\n\n if weight > problem.knapsack_capacity:\n time = np.inf\n profit = - np.inf\n break\n\n return time, profit\n\n\ndef crossover(ind1, ind2, city_crossover, item_crossover, indpb1, indpb2):\n pi1 = ind1['cities']\n z1 = ind1['items']\n\n pi2 = ind2['cities']\n z2 = ind2['items']\n\n city_crossover_result1, city_crossover_result2 = city_crossover(pi1, pi2)\n item_crossover_result1, item_crossover_result2 = item_crossover(z1, z2)\n\n return initIndividual(creator.Individual, lambda: city_crossover_result1, lambda: item_crossover_result1), \\\n initIndividual(creator.Individual, lambda: city_crossover_result2, lambda: item_crossover_result2)\n\n\ndef mutation(ind, city_mutation, item_mutation, indpb1, indpb2):\n pi = ind['cities']\n z = ind['items']\n\n return initIndividual(creator.Individual, lambda: city_mutation(pi, indpb1), lambda: item_mutation(z, indpb2))\n\n\ntoolbox = base.Toolbox()\n\ntoolbox.register(\"city_attribute\", initPermutation)\ntoolbox.register(\"items_attribute\", tools.initRepeat, list, initZeroOne, problem.no_items)\ntoolbox.register(\"individual\", initIndividual, creator.Individual, toolbox.city_attribute, toolbox.items_attribute)\ntoolbox.register(\"population\", tools.initRepeat, list, toolbox.individual)\n\ntoolbox.register(\"evaluate\", evaluate)\ntoolbox.register(\"mate\", crossover, city_crossover=tools.cxPartialyMatched, item_crossover=tools.cxOnePoint, indpb1=None, indpb2=None)\ntoolbox.register(\"mutate\", mutation, city_mutation=tools.mutShuffleIndexes, item_mutation=tools.mutFlipBit, indpb1=0.05, indpb2=0.05)\ntoolbox.register(\"select\", tools.selNSGA2)\n\nstats = tools.Statistics(key=lambda ind: ind.fitness.values)\nstats.register(\"avg\", np.mean, axis=0)\nstats.register(\"std\", np.std, axis=0)\nstats.register(\"min\", np.min, axis=0)\nstats.register(\"max\", np.max, axis=0)\n\n# stats.register(\"profit-avg\", np.mean, axis=1)\n# stats.register(\"profit-std\", np.std, axis=1)\n# stats.register(\"profit-min\", np.min, axis=1)\n# stats.register(\"profit-max\", np.max, axis=1)\n\n\npop = toolbox.population(n=10)\nCXPB, MUTPB, NGEN = 0.3, 0.1, 50\n\n# Evaluate the entire population\nfitnesses = map(toolbox.evaluate, pop)\nfor ind, fit in zip(pop, fitnesses):\n ind.fitness.values = fit\n\nfor g in range(NGEN):\n # Logging current population fitnesses\n record = stats.compile(pop)\n print(record)\n\n # Select the next generation individuals\n offspring = toolbox.select(pop, 10)\n # Clone the selected individuals\n offspring = list(map(toolbox.clone, offspring))\n\n # Apply crossover and mutation on the offspring\n for child1, child2 in zip(offspring[::2], offspring[1::2]):\n if random.random() < CXPB:\n toolbox.mate(child1, child2)\n del child1.fitness.values\n del child2.fitness.values\n\n for mutant in offspring:\n if random.random() < MUTPB:\n toolbox.mutate(mutant)\n del mutant.fitness.values\n\n # Evaluate the individuals with an invalid fitness\n invalid_ind = [ind for ind in offspring if not ind.fitness.valid]\n fitnesses = map(toolbox.evaluate, invalid_ind)\n for ind, fit in zip(invalid_ind, fitnesses):\n ind.fitness.values = fit\n\n # The population is entirely replaced by the offspring\n pop[:] = offspring\n\nfor ind in pop:\n print([1] + [x + 2 for x in ind['cities']], ind['items'], evaluate(ind))\n\n\n"
},
{
"alpha_fraction": 0.43795621395111084,
"alphanum_fraction": 0.4562043845653534,
"avg_line_length": 18.571428298950195,
"blob_id": "2ef21facd1a0b355940560f8f8ad6dc6864e4120",
"content_id": "558471dd18d6068c83db87ccffce35ecc044deb3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 14,
"path": "/alternative/data/problem.py",
"repo_name": "andreiluca96/gecco19-thief",
"src_encoding": "UTF-8",
"text": "class Problem:\n\n def __init__(self):\n self.no_cities = 0\n self.no_items = 0\n self.knapsack_capacity = 0\n self.min_speed = 0\n self.max_speed = 0\n\n self.cities = []\n self.items = []\n\n self.pi = []\n self.z = []\n"
},
{
"alpha_fraction": 0.4706616699695587,
"alphanum_fraction": 0.4810653328895569,
"avg_line_length": 28.280487060546875,
"blob_id": "75808063551c319e54bd6faa3eba6f813369827f",
"content_id": "ab492a6517649a08189414b5e98f4ed6a846f50b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2403,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 82,
"path": "/alternative/data/repository.py",
"repo_name": "andreiluca96/gecco19-thief",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom data.problem import Problem\n\nINPUT_DIRECTORY = \"input\"\n\n\ndef read_problem(problem_name):\n\n cities = []\n items = {}\n with open(os.path.join(INPUT_DIRECTORY, problem_name + \".txt\")) as f:\n lines = f.readlines()\n\n line_no = 0\n while line_no < len(lines):\n line = lines[line_no]\n\n if 'DIMENSION' in line:\n no_cities = int(line.split(\":\")[1].strip())\n elif 'NUMBER OF ITEMS' in line:\n no_items = int(line.split(\":\")[1].strip())\n elif 'CAPACITY OF KNAPSACK' in line:\n knapsack_capacity = int(line.split(\":\")[1].strip())\n elif 'MIN SPEED' in line:\n min_speed = float(line.split(\":\")[1].strip())\n elif 'MAX SPEED' in line:\n max_speed = float(line.split(\":\")[1].strip())\n elif 'NODE_COORD_SECTION' in line:\n\n line_no += 1\n line = lines[line_no]\n for node_no in range(no_cities):\n coords = line.split()\n cities.append((float(coords[1].strip()), float(coords[2].strip())))\n\n line_no += 1\n line = lines[line_no]\n\n line_no -= 1\n\n elif 'ITEMS SECTION' in line:\n\n line_no += 1\n line = lines[line_no]\n for node_no in range(no_items):\n item = line.split()\n\n city = int(item[3].strip()) - 1\n if city not in items:\n items[city] = []\n\n items[city].append([int(item[0].strip()), float(item[1].strip()), float(item[2].strip())])\n\n line_no += 1\n if line_no == len(lines):\n break\n line = lines[line_no]\n\n line_no += 1\n\n problem = Problem()\n\n problem.no_cities = no_cities\n problem.no_items = no_items\n problem.knapsack_capacity = knapsack_capacity\n problem.min_speed = min_speed\n problem.max_speed = max_speed\n\n problem.cities = cities\n problem.items = items\n\n return problem\n\n\nif __name__ == \"__main__\":\n problem = read_problem(\"a280-n279\")\n\n print(problem.items)\n\n assert problem.no_cities >= len(problem.items.keys())\n assert problem.no_cities == len(problem.cities)\n\n\n"
},
{
"alpha_fraction": 0.6596820950508118,
"alphanum_fraction": 0.6690751314163208,
"avg_line_length": 35.90666580200195,
"blob_id": "0e71e852360184f020b76121541f855236402e09",
"content_id": "082479c56da6ed3202b2f1b97028c24c44bc7e71",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2768,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 75,
"path": "/src/main/java/algorithms/JeneticAlgorithm.java",
"repo_name": "andreiluca96/gecco19-thief",
"src_encoding": "UTF-8",
"text": "package algorithms;\n\nimport io.jenetics.*;\nimport io.jenetics.engine.Engine;\nimport io.jenetics.ext.moea.MOEA;\nimport io.jenetics.ext.moea.UFTournamentSelector;\nimport io.jenetics.ext.moea.Vec;\nimport io.jenetics.util.ISeq;\nimport io.jenetics.util.IntRange;\nimport model.NonDominatedSet;\nimport model.Solution;\nimport model.TravelingThiefProblem;\n\nimport java.util.List;\nimport java.util.stream.Collectors;\n\n@SuppressWarnings(\"unchecked\")\npublic class JeneticAlgorithm implements Algorithm {\n\n private TravelingThiefProblem problem;\n\n private Vec<double[]> fitness(final Genotype gt) {\n Solution solution = getSolutionFromGenotype(gt);\n\n return Vec.of(solution.profit, -solution.time);\n }\n\n @Override\n public List<Solution> solve(TravelingThiefProblem problem) {\n this.problem = problem;\n\n Genotype encoding = Genotype.of(\n PermutationChromosome.ofInteger(problem.numOfCities - 1),\n (Chromosome) BitChromosome.of(problem.numOfItems, 0.05)\n );\n\n final Engine engine = Engine\n .builder(this::fitness, encoding)\n .optimize(Optimize.MAXIMUM)\n .maximalPhenotypeAge(5)\n .alterers(new Mutator(0.01), new UniformCrossover(0.03))\n .populationSize(700)\n .offspringSelector(new TournamentSelector<>(4))\n .survivorsSelector(UFTournamentSelector.ofVec())\n .build();\n\n final ISeq<Phenotype> genotypes = (ISeq<Phenotype>) engine.stream()\n .limit(300)\n .collect(MOEA.toParetoSet(IntRange.of(200)));\n\n List<Solution> solutions = genotypes.stream()\n .map(Phenotype::getGenotype)\n .map(this::getSolutionFromGenotype)\n .peek(solution -> solution.source = \"JENETIC\")\n .collect(Collectors.toList());\n NonDominatedSet nonDominatedSet = new NonDominatedSet();\n solutions.forEach(nonDominatedSet::add);\n\n return nonDominatedSet.entries;\n }\n\n private Solution getSolutionFromGenotype(Genotype genotype) {\n final PermutationChromosome dc = (PermutationChromosome) genotype.getChromosome(0);\n final BitChromosome bc = (BitChromosome) genotype.getChromosome(1);\n\n List<Integer> permutationGenes = (List<Integer>) dc.stream().map(gene -> ((EnumGene) gene).getAlleleIndex()).collect(Collectors.toList());\n List<Boolean> booleanGenes = bc.stream().map(BitGene::booleanValue).collect(Collectors.toList());\n\n permutationGenes = permutationGenes.stream().map(integer -> integer + 1).collect(Collectors.toList());\n permutationGenes.add(0, 0);\n\n return problem.evaluate(permutationGenes, booleanGenes, true);\n }\n\n}\n"
},
{
"alpha_fraction": 0.5760869383811951,
"alphanum_fraction": 0.595652163028717,
"avg_line_length": 16.037036895751953,
"blob_id": "95a825c57f71995aa7eb4631dc22300614bf3501",
"content_id": "9d85a5c2598678e4dd66fd00a445566d77bfbe07",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 27,
"path": "/visualization/pareto_front_visualization.py",
"repo_name": "andreiluca96/gecco19-thief",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\nfile_name = \"TEAM_JENETICS_a280-n279.f\"\nfile = open(\"data/input/%s\" % file_name, \"r\")\n\nlines = file.readlines()\n\ncost = []\ntime = []\n\nfor line in lines:\n splits = line.split(\" \")\n\n if len(splits) == 2:\n c = float(splits[0])\n t = float(splits[1])\n\n cost.append(c)\n time.append(t)\n\n\nplt.plot(cost, time, 'ro')\nplt.xlabel('cost')\nplt.ylabel('time')\n\nplt.savefig('data/output/fig.jpg')\nplt.show()\n"
}
] | 5 |
bjoshi123/python-scripts | https://github.com/bjoshi123/python-scripts | 5d0912c69bfeb1e20af77a127e7e67a0b97a56d1 | f918537fdef0cedba5e80ad64bd556964016ba7e | e705f4ce852dd99f728e9ca8288470c8c529c4c2 | refs/heads/master | "2020-07-05T20:00:33.553916" | "2019-09-03T11:53:05" | "2019-09-03T11:53:05" | 202,757,909 | 0 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.6184210777282715,
"alphanum_fraction": 0.6285424828529358,
"avg_line_length": 23.700000762939453,
"blob_id": "df44f9ccbb6d998aa33deaaf7d8d3a0133f57b4c",
"content_id": "db4c738598a87bab5a8aef6dae83bbb0b30a92ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 988,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 40,
"path": "/SlackConnection.py",
"repo_name": "bjoshi123/python-scripts",
"src_encoding": "UTF-8",
"text": "from slackclient import SlackClient\nfrom flask import request, Flask\n\napp = Flask(__name__)\nslack_token = \"Bot token\" #replace this with bot token\nsc = SlackClient(slack_token)\n\[email protected]('/endpoint', methods=[\"POST\"])\ndef requestcontroller():\n slack_message = request.get_json()\n\n if 'challenge' in slack_message:\n return slack_message['challenge']\n\n if 'user' in slack_message['event']:\n channelid = slack_message['event']['channel']\n usermessage = slack_message['event']['text']\n\n reponse = getUserTextResponse(usermessage)\n\n sc.api_call(\n \"chat.postMessage\",\n channel=channelid,\n text=reponse\n )\n return '200'\n else:\n return '200'\n\n\ndef getUserTextResponse(usertext):\n '''\n Implement this message according to your usecase\n :param usertext: User message\n :return: Response for user message\n '''\n pass\n\nif __name__ == '__main__':\n app.run(debug=True, port=8080)\n"
},
{
"alpha_fraction": 0.6224866509437561,
"alphanum_fraction": 0.6319245100021362,
"avg_line_length": 28.265060424804688,
"blob_id": "85860a4c966d74f11d5200d365ef40d9f37275b8",
"content_id": "e45bb55ba8081d572c6d9eeeb22884d67a81a743",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2437,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 83,
"path": "/SpeechToText.py",
"repo_name": "bjoshi123/python-scripts",
"src_encoding": "UTF-8",
"text": "import speech_recognition as sr\nimport pyaudio\nimport wave\nimport requests\n\n\ndef record_audio(chunk, a_format, channels, frame_rate, record_seconds=5, file_name='output.wav'):\n '''\n API to record audio in wav format\n '''\n p = pyaudio.PyAudio()\n stream = p.open(format=a_format,\n channels=channels,\n rate=frame_rate,\n input=True,\n frames_per_buffer=chunk) # buffer\n\n print(\"***recording started***\")\n frames = []\n\n for i in range(0, int(frame_rate / chunk * record_seconds)):\n data = stream.read(chunk)\n frames.append(data)\n\n print(\"***recording stopped***\")\n\n stream.stop_stream()\n stream.close()\n p.terminate()\n\n wf = wave.open(file_name, 'wb')\n wf.setnchannels(channels)\n wf.setsampwidth(p.get_sample_size(a_format))\n wf.setframerate(frame_rate)\n wf.writeframes(b''.join(frames))\n wf.close()\n\ndef google_speech_to_text(file_name):\n '''\n API to convert speech to text using google speech recognition\n '''\n r = sr.Recognizer()\n with sr.AudioFile(file_name) as source:\n audio = r.record(source)\n try:\n s = r.recognize_google(audio)\n print(\"Google Text: \" + s)\n except Exception as e:\n print(\"Sorry I don't understand\")\n\ndef nuance_speech_to_text(file_name):\n '''\n API to convert speech to text using nuance speech to text api\n make a account in nuance.developer.com, create app or from sandbox credential you will get app-id, app key\n id is device id\n '''\n url = 'https://dictation.nuancemobility.net/NMDPAsrCmdServlet/dictation?appId=[app-id]&appKey=[app-key]&id=[device-id]'\n headers = {}\n headers['Content-Type'] = 'audio/x-wav;codec=pcm;bit=16;rate=8000'\n headers['Accept-Language'] = 'eng-IND'\n headers['Accept'] = 'application/xml'\n headers['Accept-Topic'] = 'Dictation'\n data = open(file_name, 'rb')\n print(\"request started\")\n r = requests.post(url, headers=headers, data=data)\n\n if r.status_code == 200:\n print(\"Nuance API: \", r.text)\n else:\n print(\"Sorry I don't understand\")\n #print(r.content)\n\n\nchunk = 1024\na_format = pyaudio.paInt16\nchannels = 1\nframe_rate = 8000\nrecord_seconds = 2\nfile_name = \"output.wav\"\n\nrecord_audio(chunk, a_format, channels, frame_rate, record_seconds, file_name)\ngoogle_speech_to_text(file_name)\nnuance_speech_to_text(file_name)\n\n\n\n\n\n\n\n\n"
}
] | 2 |
laleye/decoder-sp-data | https://github.com/laleye/decoder-sp-data | 3aa2d5b26a94b105f539512985003841335a7426 | 0228c6dfa79546d16b89f612dc8e9d79af3eb6bd | 9935459f0a5d56cb6bf8481e70b557690dad1c3c | refs/heads/master | "2022-06-20T21:27:41.108589" | "2020-05-04T01:24:49" | "2020-05-04T01:24:49" | 260,994,034 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5584396719932556,
"alphanum_fraction": 0.5768260359764099,
"avg_line_length": 34.62982177734375,
"blob_id": "269eddbfa5558753a110786ea590ee9536262b8e",
"content_id": "b4b8adcb4ddb7de01827d8de3f5e7e9daa6c65b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13869,
"license_type": "no_license",
"max_line_length": 224,
"num_lines": 389,
"path": "/raw_data/get_stackoverflow_data.py",
"repo_name": "laleye/decoder-sp-data",
"src_encoding": "UTF-8",
"text": "import requests, re, sys, json\nfrom datetime import datetime\nfrom bs4 import BeautifulSoup as bs # Scraping webpages\nimport pandas as pd\nfrom stackapi import StackAPI\nfrom parser_java import normalize_code, parse_annotated_code\nfrom tqdm import tqdm\nimport argparse\n\n\n#print(SITE.max_pages, SITE.page_size)\n#sys.exit(0)\n## Using requests module for downloading webpage content\n#response = requests.get('https://stackoverflow.com/tags')\n\n## Parsing html data using BeautifulSoup\n#soup = bs(response.content, 'html.parser')\n\n## body \n#body = soup.find('body')\n\np_href = re.compile('/questions/\\d+/')\n_answers = list()\n\ndef get_code_span(html, match):\n start, end = match.span()\n code = match.group(1)\n start += html[start:end].find(code)\n end = start + len(code)\n return (start, end)\n\n\ndef merge_spans(html, code_spans, sel_spans):\n masks = np.zeros(len(html))\n for start, end in code_spans:\n masks[start:end] += 1.\n for start, end in sel_spans:\n masks[start:end] += 1.\n masks = masks == 2\n for i in range(1, len(html)):\n if html[i].isspace() and masks[i - 1]:\n masks[i] = True\n for i in reversed(range(len(html) - 2)):\n if html[i].isspace() and masks[i + 1]:\n masks[i] = True\n for start, end in code_spans:\n code = [c for c, m in zip(html[start:end], masks[start:end]) if m]\n if len(code) > 0:\n yield ''.join(code)\n \n#parse selection ranges to (html_text, start_offset, end_offset)\ndef parse_range(post_id, selected_range, is_code):\n source, source_id = selected_range['source'].split('-')\n source_id = int(source_id)\n if source == 'title':\n text = titles[source_id]\n else:\n text = posts[source_id]\n start, end = selected_range['start'], selected_range['end']\n return text, start, end\n\ndef parse_selection(post_id, selection, is_code):\n ref_text = selection['html']\n sel_spans = []\n source_text = None\n for selected_range in selection['pos']:\n text, start, end = parse_range(post_id, selected_range, is_code)\n if source_text is None:\n source_text = text\n else:\n assert source_text == text\n sel_spans.append((start, end))\n sel_text = '\\n'.join(merge_spans(source_text, get_code_spans(source_text, is_code), sel_spans))\n return source_text, sel_text, re.sub('<[^<]+?>', '', ref_text.strip())\n\n\n\ndef get_code_spans(html, is_code):\n if not is_code:\n return [(0, len(html))]\n matches = re.finditer(r\"<pre[^>]*>[^<]*<code[^>]*>((?:\\s|[^<]|<span[^>]*>[^<]+</span>)*)</code></pre>\", html)\n return [get_code_span(html, m) for m in matches]\n\n\n\ndef parse_title(title):\n if title.lower().startswith('how ') or title.lower().startswith('what '):\n return title\n if title.strip().endswith('?'):\n return title\n return None\n \n\ndef get_body(question_id, answer_id):\n try:\n top_answer = SITE.fetch('questions/' + str(question_id) + '/answers', min=10, sort='votes', filter='withbody')\n for item in top_answer['items']:\n if item['answer_id'] == answer_id and 'body' in item:\n return item['body']\n return None\n except:\n return None\n \ndef get_all_answers(filename):\n with open('scrap0/stackoverflow_answers_dump_{}.json'.format(filename)) as f:\n answers = json.load(f)\n #answers = list(answers[0])\n \n #print(type(answers))\n #sys.exit(0)\n lst_answers = dict()\n for answer in answers:\n for item in answer['items']:\n lst_answers[item['answer_id']] = item['body'] \n \n #print(lst_answers)\n return lst_answers\n \n\ndef get_code_from_answer(question_id, answer_id, answers):\n\n if answer_id in answers:\n body = answers[answer_id]\n else:\n body = None\n \n if body is None:\n return []\n \n\n codes = get_code_spans(body, is_code=True)\n \n if len(codes) == 0:\n return []\n index_lines = codes[0] # to get the first code lines in the answer\n \n return [body[index_lines[0]:index_lines[1]]]\n \n \n \ndef annotation(qid, question, code):\n return {\n 'question_id': qid,\n 'intent': question.strip(),\n 'snippet': code,\n }\n \ndef extractQuestions_using_api(page):\n questions = SITE.fetch('questions', fromdate=datetime(2010,10,1), todate=datetime(2020,4,29), sort='votes', page=page, tagged='java')\n \n data = questions['items']\n ids = list()\n for item in tqdm(data, desc='Question Ids extraction', file=sys.stdout, total=len(data)):\n ids.append(item['question_id'])\n \n dt = datetime.now().strftime(\"%d_%m_%Y_%H_%M_%S\")\n \n #dt = str(datetime(2020,5,1)).replace(' ', '_')\n with open('scrap1/stackoverflow_questions_dump_{}.json'.format(dt), 'w', encoding='utf8') as f:\n json.dump(questions, f, ensure_ascii=False, indent=4)\n \n \n for id in tqdm(ids, desc='Answer extraction', file=sys.stdout, total=len(ids)):\n top_answers = SITE.fetch('questions/{}/answers'.format(id), min=10, sort='votes', filter='withbody')\n _answers.append(top_answers)\n \n with open('scrap1/stackoverflow_answers_dump_{}.json'.format(dt), 'w', encoding='utf8') as f:\n json.dump(_answers, f, ensure_ascii=False, indent=4)\n \n return questions['page']\n \n \ndef processed_data(files):\n \n examples = list()\n is_question = 0\n code_in_answer = 0\n is_java_code = 0\n tag_java_with_answer = 0\n all_data = 0\n #for filename in tqdm(files, desc='Process raw data', file=sys.stdout, total=len(files)):\n for filename in files:\n print('Processing of scrap0/stackoverflow_questions_dump_{}.json'.format(filename))\n with open('scrap0/stackoverflow_questions_dump_{}.json'.format(filename)) as f:\n questions = json.load(f)\n \n answers = get_all_answers(filename)\n data = questions['items']\n all_data += len(questions['items'])\n #print(len(data))\n #for item in tqdm(data, desc='Post', file=sys.stdout, total=len(data)):\n for item in data:\n question_id = item['question_id']\n if question_id in [6549821]:\n continue\n example = dict()\n val = 0\n title = parse_title(item['title'])\n #print(title)\n if title is None:\n continue\n is_question += 1\n #if item['tags'][0] == 'java': # take into account if java is the first tag\n if 'java' in item['tags']: # take into account if java is in the tag list\n val += 1\n if item['is_answered']:\n val += 1\n if 'accepted_answer_id' in item and isinstance(item['accepted_answer_id'], int):\n val += 1\n answer_id = item['accepted_answer_id']\n \n if val == 3:\n tag_java_with_answer += 1\n code = get_code_from_answer(question_id, answer_id, answers)\n\n if len(title) > 0 and len(code) > 0:\n code_in_answer += 1\n code = code[0]\n code = re.sub('<[^<]+?>', '', code.strip())\n with open('log_normalization', 'a') as f:\n code = normalize_code(code, f)\n #print('code {}'.format(code))\n if code is not None:\n is_java_code += 1\n #if is_java_code == 4:\n #break\n examples.append(annotation(question_id, title, code))\n \n print('Number of posts is {}\\n'.format(all_data))\n print('Number of questions is {}\\n'.format(is_question))\n print('Number of questions which have accepted answer and java as a first tag is {}'.format(tag_java_with_answer))\n print('Number of questions which have code in their accepted answers is {}'.format(code_in_answer))\n print('Number of questions whose the code is a java code is {}\\n'.format(is_java_code))\n print('Number of annotated examples is {}'.format(len(examples)))\n \n with open('stackoverflow-java_scrap0_java_in_tags.json', 'w', encoding='utf8') as f:\n json.dump(examples, f, ensure_ascii=False, indent=4)\n \n \n \n \n \ndef get_answer(url):\n # Using requests module for downloading webpage content\n response = requests.get(url)\n\n # Parsing html data using BeautifulSoup\n soup = bs(response.content, 'html.parser')\n body= soup.find('body')\n \n print(body)\n \n\n # Extracting Top Questions\n question_links = body.select(\"h3 a.question-hyperlink\")\n #question_ids = get_questions_id(question_links)\n #error_checking(question_links, question_count) # Error Checking\n questions = [i.text for i in question_links]\n print(questions)\n\ndef getTags():\n lang_tags = body.find_all('a', class_='post-tag')\n languages = [i.text for i in lang_tags]\n return languages\n\ndef error_checking(list_name, length):\n if (len(list_name) != length):\n print(\"Error in {} parsing, length not equal to {}!!!\".format(list_name, length))\n return -1\n else:\n pass\n\ndef get_questions_id(questions):\n qids = dict()\n for i, q in enumerate(questions):\n q = str(q)\n r = re.findall(r'/questions/\\d+/', q)\n qid = re.findall(r'\\d+', str(r))\n qids[i] = qid[0]\n return qids\n\ndef get_top_questions(url, question_count):\n # WARNING: Only enter one of these 3 values [15, 30, 50].\n # Since, stackoverflow, doesn't display any other size questions list\n #url = url + \"?sort=votes&pagesize={}\".format(question_count)\n url = \"https://api.stackexchange.com/docs/questions#fromdate=2020-04-02&todate=2020-05-01&order=desc&sort=activity&filter=default&site=stackoverflow\"\n \n # Using requests module for downloading webpage content\n response = requests.get(url)\n\n # Parsing html data using BeautifulSoup\n soup = bs(response.content, 'html.parser')\n body1 = soup.find('body')\n \n\n # Extracting Top Questions\n question_links = body1.select(\"h3 a.question-hyperlink\")\n question_ids = get_questions_id(question_links)\n #print(question_links[0])\n error_checking(question_links, question_count) # Error Checking\n questions = [i.text for i in question_links] # questions list\n \n # Extracting Summary\n summary_divs = body1.select(\"div.excerpt\")\n error_checking(summary_divs, question_count) # Error Checking\n summaries = [i.text.strip() for i in summary_divs] # summaries list\n \n # Extracting Tags\n tags_divs = body1.select(\"div.summary > div:nth-of-type(2)\")\n \n error_checking(tags_divs, question_count) # Error Checking\n a_tags_list = [i.select('a') for i in tags_divs] # tag links\n \n tags = []\n\n for a_group in a_tags_list:\n tags.append([a.text for a in a_group]) # tags list\n \n # Extracting Number of votes\n vote_spans = body1.select(\"span.vote-count-post strong\")\n error_checking(vote_spans, question_count) # Error Checking\n no_of_votes = [int(i.text) for i in vote_spans] # votes list\n \n # Extracting Number of answers\n answer_divs = body1.select(\"div.status strong\")\n #print(answer_divs)\n error_checking(answer_divs, question_count) # Error Checking\n no_of_answers = [int(i.text) for i in answer_divs] # answers list\n \n # Extracting Number of views\n div_views = body1.select(\"div.supernova\")\n \n error_checking(div_views, question_count) # Error Checking\n no_of_views = [i['title'] for i in div_views]\n no_of_views = [i[:-6].replace(',', '') for i in no_of_views]\n no_of_views = [int(i) for i in no_of_views] # views list\n #print(body1)\n \n # Putting all of them together\n df = pd.DataFrame({'question': questions, \n 'summary': summaries, \n 'tags': tags,\n 'no_of_votes': no_of_votes,\n 'no_of_answers': no_of_answers,\n 'no_of_views': no_of_views})\n\n return df\n\ndef post_extraction():\n \n ## question extraction\n page = 51\n while True:\n try:\n page = extractQuestions_using_api(page)\n page = page + 1\n except Exception as e:\n print('Last page: {}'.format(page))\n print(e)\n with open('scrap1/stackoverflow_answers_dump_tmp.json', 'w', encoding='utf8') as f:\n json.dump(_answers, f, ensure_ascii=False, indent=4)\n break\n \n\ndef process_data():\n ## processed data\n lst_files0 = ['01_05_2020_02_13_11', '01_05_2020_02_41_19', '01_05_2020_03_32_53', '01_05_2020_03_44_52', '01_05_2020_03_57_02', '01_05_2020_04_08_09', '02_05_2020_17_23_18', '03_05_2020_01_57_49', '03_05_2020_01_58_24']\n processed_data(lst_files0)\n\n\nif __name__ == '__main__':\n \n parser = argparse.ArgumentParser()\n parser.add_argument('--online', action='store_true', help='extract post from stack overflow')\n parser.add_argument('--offline', action='store_true', help='extract title and snippet from dumped data')\n\n args = parser.parse_args()\n \n if args.online:\n stack_key = \"z*Iyq7es6KYXld3DtM3qSw((\"\n stack_access_token = \"3rI*g4ZjjUUtyZIdMCJzrQ((\"\n\n SITE = StackAPI('stackoverflow', key=stack_key, client_secret=stack_access_token)\n SITE.max_pages = 100\n post_extraction()\n elif args.offline:\n process_data()\n else:\n print('unknow arguments')\n \n"
},
{
"alpha_fraction": 0.5934426188468933,
"alphanum_fraction": 0.6005464196205139,
"avg_line_length": 28.047618865966797,
"blob_id": "4b81e2726826a05a58e5a18b962d442b6615d6c1",
"content_id": "893f2670bb1cf90df91117aae5269e06f6f98503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1830,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 63,
"path": "/raw_data/parser_java.py",
"repo_name": "laleye/decoder-sp-data",
"src_encoding": "UTF-8",
"text": "import os\nimport re\n\nos.environ['CLASSPATH'] = 'libs/javaparser-core-3.2.10.jar:' \\\n 'libs/java_codemining-1.0-SNAPSHOT.jar'\n\n\nfrom jnius import autoclass\n\nParser = autoclass('edu.cmu.codemining.Parser')\nparser = Parser()\n\ndef normalize_code(code, log_file=None):\n try:\n # normalized_code = parser.parse(code)\n # if normalized_code:\n # normalized_code = normalized_code.strip()\n #\n # return normalized_code\n normalized_code = normalize_code_with_meta(code)\n if normalized_code:\n return normalized_code.value\n\n return None\n except Exception as ex:\n if log_file:\n log_file.write('*' * 30 + '\\n')\n log_file.write('Original:\\n')\n log_file.write(code + '\\n')\n log_file.write('*' * 30 + '\\n')\n log_file.write('Normalized:\\n')\n log_file.write(code + '\\n')\n return None\n \ndef normalize_code_with_meta(code):\n return parser.parseCodeWithMetaInfo(code)\n\nprint_pattern = re.compile('^(if|while|for).*\\n( )+System\\.out\\.println.*;\\n\\}$')\n\ndef parse_annotated_code(code):\n parsed_code = normalize_code_with_meta(code)\n #print('function type {}'.format(parsed_code.type))\n if parsed_code and parsed_code.type == 'function':\n parsed_code.value = get_function_body(parsed_code.value)\n\n if parsed_code:\n m = print_pattern.search(parsed_code.value)\n if m:\n new_code = '\\n'.join(parsed_code.value.split('\\n')[:-2])\n new_code += '}'\n parsed_code = normalize_code_with_meta(new_code)\n\n return parsed_code.value if parsed_code else None\n\n\ndef get_function_body(parsed_code):\n return parser.getFunctionBody(parsed_code)\n\n\n\n#code = \"if (count++ == 1) return 1;\"\n\n#parse_annotated_code(code)\n"
},
{
"alpha_fraction": 0.49736717343330383,
"alphanum_fraction": 0.49928194284439087,
"avg_line_length": 35.6315803527832,
"blob_id": "1bbd07bf1508d5420ad2246345ef0223d451b118",
"content_id": "0fee44a4fec4c1cb839e896bcb63099e45dadc03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2089,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 57,
"path": "/dataset_scripts/java_data_conala.py",
"repo_name": "laleye/decoder-sp-data",
"src_encoding": "UTF-8",
"text": "import json \n\n\nfilename = 'data/java/conala-java.json'\noutput_anno = 'data/java/conala-java.anno'\noutput_code = 'data/java/conala-java.code'\n\ndef get_annotations(elt):\n if 'title' in elt and elt['title'] is not None:\n return elt['annotations']\n return None\n \n\ndef load_conala_data(jsonfile):\n with open(jsonfile) as f:\n data = json.load(f)\n queries = list()\n codes = list()\n #print(data)\n print('len of data in {} is {}'.format(jsonfile, len(data)))\n if len(data) > 0:\n examples = list()\n for elt in data:\n if isinstance(elt, dict):\n annotations = get_annotations(elt)\n title = elt['title']\n if annotations is not None:\n example = dict()\n for i, annotation in enumerate(annotations):\n intent = annotation['intent']\n if len(intent.strip()) > 0:\n queries.append(intent)\n example['intent'] = intent\n else:\n queries.append(title)\n example['intent'] = title\n code = annotation['normalized_code_snippet']\n codes.append(code)\n example['snippet'] = code\n examples.append(example)\n \n #if annotation['normalized_code_snippet'].strip() != annotation['code_snippet'].strip():\n #print('normalization code problem at {} title: {}'.format(i, title))\n\n print('Number of examples: {}'.format(len(examples)))\n with open('data/conala-java-processed.json', 'w', encoding='utf8') as f:\n json.dump(examples, f, ensure_ascii=False, indent=4)\n #print(queries)\n #with open(output_anno, 'w') as f:\n #for nl in queries:\n #f.write(nl+'\\n')\n \n #with open(output_code, 'w') as f:\n #for cd in codes:\n #f.write(cd+'\\n')\n \nload_conala_data(filename)\n\n"
},
{
"alpha_fraction": 0.7230018377304077,
"alphanum_fraction": 0.7559487223625183,
"avg_line_length": 31.780000686645508,
"blob_id": "eaf10ffe0554789a982ef44678f9fc0d9acc3ea0",
"content_id": "4e8b29ef4fc3f064e47b2480fde3c139e8c210cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1678,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 50,
"path": "/raw_data/done.md",
"repo_name": "laleye/decoder-sp-data",
"src_encoding": "UTF-8",
"text": "# Data collection from stackoverflow\n\n**du mardi 28 Avril au jeudi 30 avril**\n\nJ'ai utilisé l'API Stack exchange pour récupérer des posts sur le site.\nLa difficulté est que le nombre de requêtes vers le site est limité par jour.\nL'objectif est de recupérer des données java pour construire le dataset.\n\nLes étapes d'extraction et de traitement des posts est le suivant:\n\n## extraction des posts\n\nJ'ai récupérer les posts ayant plus de votes du 01/10/2010 au 29/04/2020 avec comme *java* comme\ntag. Actuellement, seulement **55 pages** sont extraites. Les données sont enregistrées sous format json.\n\n## traitement des posts\n\nUn post est utilisé si son titre respecte les critères suvants:\n\n> le titre doit commencer par *how* ou *what* ou terminer par *?*\n\n> *java* doit être le premier élément de la liste des tags (ou un élément de la liste des tags, à tester)\n\n> la question posée doit avoir eu des réponses\n\n> une des réponses doit être une réponse acceptée\n\n> la réponse acceptée doit contenir du code source\n\n> le code source doit être du code java (using java parser)\n \n## Données obtenues après traitement\n\n> nombre total de posts parcourus (A): 11396\n\n> nombre total de questions obtenues (B): 5239\n\n> nombre de questions ayant une réponse acceptée et java comme premier tag (C): 4482\n\n> nombre de questions ayant du code source dans la réponse acceptée (D): 2284\n\n> nombre de questions ayant du code source java dans la réponse acceptée (E): 1058\n\n> nombre d'exemples (text/snippet) après traitement dans le dataset (F): **1058**\n\n## Recap\n\nFrom stackoverflow: **1058 text/snippet**\n\nFrom conala dataset: **330 text/snippet**\n"
}
] | 4 |
akashsky7799/uKnightedParking | https://github.com/akashsky7799/uKnightedParking | 6f952154761e5376b55266bda8d20ab0b90708a9 | 11489f2a0f7c8759685ccf8f2c0ad49e1438149d | f2a53d4d67d47282db6cf3e9ad55ee9ba204fad0 | refs/heads/master | "2016-09-14T02:00:54.608003" | "2016-04-20T00:10:03" | "2016-04-20T00:10:03" | 56,273,867 | 0 | 2 | null | "2016-04-14T22:28:02" | "2016-04-14T22:30:38" | "2016-04-18T19:57:46" | Arduino | [
{
"alpha_fraction": 0.5687331557273865,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 24.5,
"blob_id": "445ded526572052b2a6c672cb07b675a3b306072",
"content_id": "b85f1d3e31f43bdf2a8f3b787125fd18498a3351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 42,
"path": "/db_view.php",
"repo_name": "akashsky7799/uKnightedParking",
"src_encoding": "UTF-8",
"text": "<?php\r\n// array for JSON response\r\n$response = array();\r\n\r\n// make sure we have the connect file\r\nrequire_once __DIR__ . '/db_connect.php';\r\n\r\n// make a connection\r\n$db = new DB_CONNECT();\r\n\r\n// get all products from parking table (table name must match table in database)\r\n$result = mysql_query(\"SELECT * FROM parking\") or die(mysql_error());\r\n\r\n// check for empty result\r\nif (mysql_num_rows($result) > 0) {\r\n // looping through all results\r\n $response[\"parking\"] = array();\r\n\r\n while ($row = mysql_fetch_array($result)) {\r\n // temp user array\r\n $Part = array();\r\n $Part[\"id\"] = $row[\"id\"];\r\n $Part[\"name\"] = $row[\"name\"];\r\n $Part[\"openspots\"] = $row[\"openspots\"];\r\n\r\n // push data into final response array\r\n array_push($response[\"parking\"], $Part);\r\n }\r\n // success\r\n $response[\"success\"] = 1;\r\n\r\n // echoing JSON response\r\n echo json_encode($response);\r\n} else {\r\n // no data found\r\n $response[\"success\"] = 0;\r\n $response[\"message\"] = \"No parts inserted\";\r\n\r\n // echo no users JSON\r\n echo json_encode($response);\r\n}\r\n?>\r\n"
},
{
"alpha_fraction": 0.5994659662246704,
"alphanum_fraction": 0.6174899935722351,
"avg_line_length": 37.28205108642578,
"blob_id": "ef07b118324bdb4f979a5089254aa58dc6b9a66b",
"content_id": "308b61ba73e54be04a9da44489661d560a2b15b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1498,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 39,
"path": "/Detection.py",
"repo_name": "akashsky7799/uKnightedParking",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -----------------------\n# Import required Python libraries\n# -----------------------------------\nimport RPi.GPIO as GPIO # import GPIO libararies, Code will not run without actual GPIO\nimport time\nimport os\nimport smtplib\nimport socket\nsensor1 = 14 #GPIO pin for output\nsensor2 = 15 #GPIO pin for input\nimport MySQLdb\n\ndef SendSignal(garage, num):\n db = MySQLdb.connect(host='209.131.253.72', # your host, usually localhost\n user='testUser', # your username\n passwd='12345', # your password\n db='uknightparkingdb') # name of the data base\n\n cur = db.cursor()\n cur.execute(\"Update Parking set openspots = openspots +\" + str(num) + \" where name = '\"+garage+\"';\")\n db.commit()\n db.close()\n\nGPIO.setmode(GPIO.BCM) #initalize all GPIO\nGPIO.setup(sensor1, GPIO.IN, GPIO.PUD_DOWN) # initialize GPIO Pin for input\n\nGPIO.setup(sensor2, GPIO.IN, GPIO.PUD_DOWN) # initialize GPIO pin for output\n\n\n\nwhile True: \n if GPIO.input(sensor1): #if detects digital high from arduino pin 10\n print(\"Car is leaving 1 pin %d\" % (GPIO.input(sensor1))) #print status of car going out\n SendSignal('A', 1) # increment number of spots\n\n if GPIO.input(sensor2): #if detects digital high from arduino pin 11\n print(\"Car is entering %d is\" % (GPIO.input(sensor2))) # print status of car coming in. \n SendSignal('A', -1) # decrement number of spots\n \n"
},
{
"alpha_fraction": 0.6807817816734314,
"alphanum_fraction": 0.6807817816734314,
"avg_line_length": 49.16666793823242,
"blob_id": "34afee3a96ecb2ef7e75650f19ab19b63b188c1b",
"content_id": "05785511c2249b5435a37fa5484f58175b6d5bcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 6,
"path": "/db_config.php",
"repo_name": "akashsky7799/uKnightedParking",
"src_encoding": "UTF-8",
"text": "<?php\t// db_config.php\r\n\tdefine('DB_USER', \"remoteApp\"); // database user (read only permissions to database)\r\n\tdefine('DB_PASSWORD', \"4emj7CqQ6UmtM3yr\"); // database password for user above\r\n\tdefine('DB_DATABASE', \"uknightparkingdb\"); // database name\r\n\tdefine('DB_SERVER', \"localhost\"); // database server\r\n?>\r\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 17,
"blob_id": "d46d67bde3796235a7f4775ce4aac092c0cebd7a",
"content_id": "824aaba4158027182c4edf3f4e7b56f3d34e29b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 2,
"path": "/README.md",
"repo_name": "akashsky7799/uKnightedParking",
"src_encoding": "UTF-8",
"text": "# uKnightedParking\nProject for POOP\n"
}
] | 4 |
pt657407064/shippoTracking | https://github.com/pt657407064/shippoTracking | a9a9168df49fa3e1f32bb25e859a8668bf43f1f9 | 8722d9530551aa93e4da518c816cb52ae3273ee9 | 256473ffab4793ddd3c6e149f07487efb138c953 | refs/heads/master | "2021-01-19T08:48:07.846783" | "2017-10-01T20:24:55" | "2017-10-01T20:24:55" | 87,678,315 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8510638475418091,
"alphanum_fraction": 0.8510638475418091,
"avg_line_length": 46,
"blob_id": "e3d09c86afa55db0cadb03e1e7312072940ea3c0",
"content_id": "ab9115866f609276aec41fcde71978efd3bafb3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 1,
"path": "/README.md",
"repo_name": "pt657407064/shippoTracking",
"src_encoding": "UTF-8",
"text": "Package Tracking API implementation in Python.\n"
},
{
"alpha_fraction": 0.555629551410675,
"alphanum_fraction": 0.564290463924408,
"avg_line_length": 31.619565963745117,
"blob_id": "506009f59a13ce60c6b9bd16ebd232f433e24414",
"content_id": "6f3a2e0c4514e62e665c0bb123b800f2267f2b50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3002,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 92,
"path": "/generator.py",
"repo_name": "pt657407064/shippoTracking",
"src_encoding": "UTF-8",
"text": "import threading\nfrom time import sleep\n\nimport shippo\n\n\nclass generator:\n shippo.api_key = \"shippo_test_a0159d5cfb4013f15b4db6360f5be757edb6a2d4\"\n\n def __init__(self,fromname,fromaddress,fromcity,fromstate,fromcountry,fromzipcode,fromemail,fromphone,\n toname,toaddress,tocity,tostate,tocountry,tozipcode,toemail,tophone,\n width,length,weight,unit,height):\n print(fromname,fromaddress,fromcity,fromstate,fromcountry,fromzipcode,fromemail,fromphone,\n toname,toaddress,tocity,tostate,tocountry,tozipcode,toemail,tophone,\n width,length,weight,unit,height)\n\n self.fromname = fromname\n self.fromaddress = fromaddress\n self.fromcity = fromcity\n self.fromstate = fromstate\n self.fromcountry = fromcountry\n self.fromzipcode = fromzipcode\n self.fromemail = fromemail\n self.fromphone = fromphone\n self.toname = toname\n self.toaddress = toaddress\n self.tocity = tocity\n self.tostate = tostate\n self.tocountry = tocountry\n self.tozipcode = tozipcode\n self.toemail = toemail\n self.tophone = tophone\n self.width = width\n self.length = length\n self.weight = weight\n if unit == \"Inch\":\n self.unit = \"in\"\n else:\n self.unit=\"cm\"\n self.height = height\n\n\n\n def construct(self):\n self.person_from = {\n \"name\": self.fromname,\n \"street1\": self.fromaddress,\n \"city\": self.fromcity,\n \"state\": self.fromstate,\n \"zip\": self.fromzipcode,\n \"country\": self.fromcountry,\n \"phone\": self.fromphone,\n \"email\": self.fromemail\n }\n self.person_to = {\n \"name\": self.toname,\n \"street1\": self.toaddress,\n \"city\": self.tocity,\n \"state\": self.tostate,\n \"zip\": self.tozipcode,\n \"country\": self.tocountry,\n \"phone\": self.tophone,\n \"email\": self.toemail\n }\n self.parcel = {\n \"length\": self.length,\n \"width\": self.width,\n \"height\": self.height,\n \"distance_unit\": self.unit,\n \"weight\": self.weight,\n \"mass_unit\": \"lb\"\n }\n\n def generating(self):\n self.shipment = shippo.Shipment.create(\n address_from=self.person_from,\n address_to=self.person_to,\n parcels = self.parcel,\n async=False\n )\n\n print(self.person_to)\n print(self.person_from)\n print(self.parcel)\n rate = self.shipment.rates[0]\n transaction = shippo.Transaction.create(rate=rate.object_id, async=False)\n\n if transaction.status == \"SUCCESS\":\n print(\"tracking number %s\" % str(transaction.tracking_number) + \"\\n\" +\n \"Label url %s\" % str(transaction.label_url))\n else:\n print(\"fail\")\n\n"
},
{
"alpha_fraction": 0.6678670644760132,
"alphanum_fraction": 0.6913718581199646,
"avg_line_length": 56.88450622558594,
"blob_id": "d72c4cbf5f1521efa5782472a87769eb864d04c6",
"content_id": "6657707fb5d00141f46a753c1c7bbc4f68eed128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20549,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 355,
"path": "/main.py",
"repo_name": "pt657407064/shippoTracking",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file '.\\etherousUI.ui'\n#\n# Created by: PyQt5 UI code generator 5.8.2\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom PyQt5.QtWidgets import QMessageBox\nfrom generator import generator\n\n\nclass Ui_mainFrame(object):\n\n def setupUi(self, mainFrame):\n mainFrame.setObjectName(\"mainFrame\")\n mainFrame.resize(1386, 1457)\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(1)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(mainFrame.sizePolicy().hasHeightForWidth())\n mainFrame.setSizePolicy(sizePolicy)\n mainFrame.setFrameShape(QtWidgets.QFrame.StyledPanel)\n mainFrame.setFrameShadow(QtWidgets.QFrame.Raised)\n self.generateBtn = QtWidgets.QPushButton(mainFrame)\n self.generateBtn.setGeometry(QtCore.QRect(570, 1300, 225, 69))\n self.generateBtn.setObjectName(\"generateBtn\")\n self.generateBtn.clicked.connect(self.buttonClick)\n\n self.line = QtWidgets.QFrame(mainFrame)\n self.line.setGeometry(QtCore.QRect(650, 0, 71, 841))\n self.line.setFrameShape(QtWidgets.QFrame.VLine)\n self.line.setFrameShadow(QtWidgets.QFrame.Sunken)\n self.line.setObjectName(\"line\")\n self.line_2 = QtWidgets.QFrame(mainFrame)\n self.line_2.setGeometry(QtCore.QRect(0, 830, 1381, 20))\n self.line_2.setFrameShape(QtWidgets.QFrame.HLine)\n self.line_2.setFrameShadow(QtWidgets.QFrame.Sunken)\n self.line_2.setObjectName(\"line_2\")\n self.lineEdit_7 = QtWidgets.QLineEdit(mainFrame)\n self.lineEdit_7.setGeometry(QtCore.QRect(1510, 500, 71, 45))\n self.lineEdit_7.setText(\"\")\n self.lineEdit_7.setObjectName(\"lineEdit_7\")\n self.label_16 = QtWidgets.QLabel(mainFrame)\n self.label_16.setGeometry(QtCore.QRect(1420, 500, 138, 39))\n self.label_16.setObjectName(\"label_16\")\n self.line_3 = QtWidgets.QFrame(mainFrame)\n self.line_3.setGeometry(QtCore.QRect(0, 1220, 1381, 20))\n self.line_3.setFrameShape(QtWidgets.QFrame.HLine)\n self.line_3.setFrameShadow(QtWidgets.QFrame.Sunken)\n self.line_3.setObjectName(\"line_3\")\n self.formLayoutWidget = QtWidgets.QWidget(mainFrame)\n self.formLayoutWidget.setGeometry(QtCore.QRect(10, 20, 651, 741))\n self.formLayoutWidget.setObjectName(\"formLayoutWidget\")\n self.fromInfo = QtWidgets.QFormLayout(self.formLayoutWidget)\n self.fromInfo.setContentsMargins(0, 0, 0, 0)\n self.fromInfo.setObjectName(\"fromInfo\")\n self.label_2 = QtWidgets.QLabel(self.formLayoutWidget)\n self.label_2.setObjectName(\"label_2\")\n self.fromInfo.setWidget(0, QtWidgets.QFormLayout.LabelRole, self.label_2)\n self.fromFirstNamelabel = QtWidgets.QLabel(self.formLayoutWidget)\n self.fromFirstNamelabel.setObjectName(\"fromFirstNamelabel\")\n self.fromInfo.setWidget(1, QtWidgets.QFormLayout.LabelRole, self.fromFirstNamelabel)\n self.fromFirstName = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromFirstName.setObjectName(\"fromFirstName\")\n self.fromInfo.setWidget(1, QtWidgets.QFormLayout.FieldRole, self.fromFirstName)\n self.fromLastNamelabel = QtWidgets.QLabel(self.formLayoutWidget)\n self.fromLastNamelabel.setObjectName(\"fromLastNamelabel\")\n self.fromInfo.setWidget(2, QtWidgets.QFormLayout.LabelRole, self.fromLastNamelabel)\n self.fromLastName = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromLastName.setObjectName(\"fromLastName\")\n self.fromInfo.setWidget(2, QtWidgets.QFormLayout.FieldRole, self.fromLastName)\n self.midNameLabel = QtWidgets.QLabel(self.formLayoutWidget)\n self.midNameLabel.setObjectName(\"midNameLabel\")\n self.fromInfo.setWidget(4, QtWidgets.QFormLayout.LabelRole, self.midNameLabel)\n self.fromMidName = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromMidName.setObjectName(\"fromMidName\")\n self.fromInfo.setWidget(4, QtWidgets.QFormLayout.FieldRole, self.fromMidName)\n self.addressLabel = QtWidgets.QLabel(self.formLayoutWidget)\n self.addressLabel.setObjectName(\"addressLabel\")\n self.fromInfo.setWidget(5, QtWidgets.QFormLayout.LabelRole, self.addressLabel)\n self.fromStreet = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromStreet.setObjectName(\"fromStreet\")\n self.fromInfo.setWidget(5, QtWidgets.QFormLayout.FieldRole, self.fromStreet)\n self.label_6 = QtWidgets.QLabel(self.formLayoutWidget)\n self.label_6.setObjectName(\"label_6\")\n self.fromInfo.setWidget(7, QtWidgets.QFormLayout.LabelRole, self.label_6)\n self.fromCity = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromCity.setText(\"\")\n self.fromCity.setObjectName(\"fromCity\")\n self.fromInfo.setWidget(7, QtWidgets.QFormLayout.FieldRole, self.fromCity)\n self.label_7 = QtWidgets.QLabel(self.formLayoutWidget)\n self.label_7.setObjectName(\"label_7\")\n self.fromInfo.setWidget(8, QtWidgets.QFormLayout.LabelRole, self.label_7)\n self.fromState = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromState.setText(\"\")\n self.fromState.setObjectName(\"fromState\")\n self.fromInfo.setWidget(8, QtWidgets.QFormLayout.FieldRole, self.fromState)\n self.label_8 = QtWidgets.QLabel(self.formLayoutWidget)\n self.label_8.setObjectName(\"label_8\")\n self.fromInfo.setWidget(9, QtWidgets.QFormLayout.LabelRole, self.label_8)\n self.fromCountry = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromCountry.setText(\"\")\n self.fromCountry.setObjectName(\"fromCountry\")\n self.fromInfo.setWidget(9, QtWidgets.QFormLayout.FieldRole, self.fromCountry)\n self.label_9 = QtWidgets.QLabel(self.formLayoutWidget)\n self.label_9.setObjectName(\"label_9\")\n self.fromInfo.setWidget(10, QtWidgets.QFormLayout.LabelRole, self.label_9)\n self.fromZipcode = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromZipcode.setText(\"\")\n self.fromZipcode.setObjectName(\"fromZipcode\")\n self.fromInfo.setWidget(10, QtWidgets.QFormLayout.FieldRole, self.fromZipcode)\n self.fromEmailLabel = QtWidgets.QLabel(self.formLayoutWidget)\n self.fromEmailLabel.setObjectName(\"fromEmailLabel\")\n self.fromInfo.setWidget(11, QtWidgets.QFormLayout.LabelRole, self.fromEmailLabel)\n self.fromEmail = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromEmail.setText(\"\")\n self.fromEmail.setObjectName(\"fromEmail\")\n self.fromInfo.setWidget(11, QtWidgets.QFormLayout.FieldRole, self.fromEmail)\n self.fromEmailLabel_2 = QtWidgets.QLabel(self.formLayoutWidget)\n self.fromEmailLabel_2.setObjectName(\"fromEmailLabel_2\")\n self.fromInfo.setWidget(12, QtWidgets.QFormLayout.LabelRole, self.fromEmailLabel_2)\n self.fromPhone = QtWidgets.QLineEdit(self.formLayoutWidget)\n self.fromPhone.setText(\"\")\n self.fromPhone.setObjectName(\"fromPhone\")\n self.fromInfo.setWidget(12, QtWidgets.QFormLayout.FieldRole, self.fromPhone)\n self.formLayoutWidget_2 = QtWidgets.QWidget(mainFrame)\n self.formLayoutWidget_2.setGeometry(QtCore.QRect(690, 20, 661, 741))\n self.formLayoutWidget_2.setObjectName(\"formLayoutWidget_2\")\n self.toInfo = QtWidgets.QFormLayout(self.formLayoutWidget_2)\n self.toInfo.setContentsMargins(0, 0, 0, 0)\n self.toInfo.setObjectName(\"toInfo\")\n self.label_18 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_18.setObjectName(\"label_18\")\n self.toInfo.setWidget(0, QtWidgets.QFormLayout.LabelRole, self.label_18)\n self.label_10 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_10.setObjectName(\"label_10\")\n self.toInfo.setWidget(1, QtWidgets.QFormLayout.LabelRole, self.label_10)\n self.toFirstName = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toFirstName.setObjectName(\"toFirstName\")\n self.toInfo.setWidget(1, QtWidgets.QFormLayout.FieldRole, self.toFirstName)\n self.toLastName = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toLastName.setObjectName(\"toLastName\")\n self.toInfo.setWidget(2, QtWidgets.QFormLayout.FieldRole, self.toLastName)\n self.toMiddleName = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toMiddleName.setObjectName(\"toMiddleName\")\n self.toInfo.setWidget(3, QtWidgets.QFormLayout.FieldRole, self.toMiddleName)\n self.toStreet = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toStreet.setObjectName(\"toStreet\")\n self.toInfo.setWidget(4, QtWidgets.QFormLayout.FieldRole, self.toStreet)\n self.toCity = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toCity.setText(\"\")\n self.toCity.setObjectName(\"toCity\")\n self.toInfo.setWidget(5, QtWidgets.QFormLayout.FieldRole, self.toCity)\n self.toState = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toState.setText(\"\")\n self.toState.setObjectName(\"toState\")\n self.toInfo.setWidget(6, QtWidgets.QFormLayout.FieldRole, self.toState)\n self.toCountry = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toCountry.setText(\"\")\n self.toCountry.setObjectName(\"toCountry\")\n self.toInfo.setWidget(7, QtWidgets.QFormLayout.FieldRole, self.toCountry)\n self.toZipcode = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toZipcode.setText(\"\")\n self.toZipcode.setObjectName(\"toZipcode\")\n self.toInfo.setWidget(8, QtWidgets.QFormLayout.FieldRole, self.toZipcode)\n self.toEmail = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toEmail.setText(\"\")\n self.toEmail.setObjectName(\"toEmail\")\n self.toInfo.setWidget(9, QtWidgets.QFormLayout.FieldRole, self.toEmail)\n self.toPhone = QtWidgets.QLineEdit(self.formLayoutWidget_2)\n self.toPhone.setText(\"\")\n self.toPhone.setObjectName(\"toPhone\")\n self.toInfo.setWidget(10, QtWidgets.QFormLayout.FieldRole, self.toPhone)\n self.label_17 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_17.setObjectName(\"label_17\")\n self.toInfo.setWidget(2, QtWidgets.QFormLayout.LabelRole, self.label_17)\n self.label_13 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_13.setObjectName(\"label_13\")\n self.toInfo.setWidget(3, QtWidgets.QFormLayout.LabelRole, self.label_13)\n self.label_11 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_11.setObjectName(\"label_11\")\n self.toInfo.setWidget(4, QtWidgets.QFormLayout.LabelRole, self.label_11)\n self.label_12 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_12.setObjectName(\"label_12\")\n self.toInfo.setWidget(5, QtWidgets.QFormLayout.LabelRole, self.label_12)\n self.label_19 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_19.setObjectName(\"label_19\")\n self.toInfo.setWidget(6, QtWidgets.QFormLayout.LabelRole, self.label_19)\n self.label_15 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_15.setObjectName(\"label_15\")\n self.toInfo.setWidget(7, QtWidgets.QFormLayout.LabelRole, self.label_15)\n self.label_14 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.label_14.setObjectName(\"label_14\")\n self.toInfo.setWidget(8, QtWidgets.QFormLayout.LabelRole, self.label_14)\n self.toEmailLabel = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.toEmailLabel.setObjectName(\"toEmailLabel\")\n self.toInfo.setWidget(9, QtWidgets.QFormLayout.LabelRole, self.toEmailLabel)\n self.fromEmailLabel_3 = QtWidgets.QLabel(self.formLayoutWidget_2)\n self.fromEmailLabel_3.setObjectName(\"fromEmailLabel_3\")\n self.toInfo.setWidget(10, QtWidgets.QFormLayout.LabelRole, self.fromEmailLabel_3)\n self.label_3 = QtWidgets.QLabel(mainFrame)\n self.label_3.setGeometry(QtCore.QRect(10, 820, 158, 78))\n self.label_3.setObjectName(\"label_3\")\n self.formLayoutWidget_3 = QtWidgets.QWidget(mainFrame)\n self.formLayoutWidget_3.setGeometry(QtCore.QRect(120, 850, 333, 362))\n self.formLayoutWidget_3.setObjectName(\"formLayoutWidget_3\")\n self.formLayout = QtWidgets.QFormLayout(self.formLayoutWidget_3)\n self.formLayout.setContentsMargins(0, 0, 0, 0)\n self.formLayout.setObjectName(\"formLayout\")\n self.label_4 = QtWidgets.QLabel(self.formLayoutWidget_3)\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Preferred, QtWidgets.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_4.sizePolicy().hasHeightForWidth())\n self.label_4.setSizePolicy(sizePolicy)\n self.label_4.setFrameShape(QtWidgets.QFrame.NoFrame)\n self.label_4.setObjectName(\"label_4\")\n self.formLayout.setWidget(0, QtWidgets.QFormLayout.LabelRole, self.label_4)\n self.label_20 = QtWidgets.QLabel(self.formLayoutWidget_3)\n self.label_20.setObjectName(\"label_20\")\n self.formLayout.setWidget(1, QtWidgets.QFormLayout.LabelRole, self.label_20)\n self.label_22 = QtWidgets.QLabel(self.formLayoutWidget_3)\n self.label_22.setObjectName(\"label_22\")\n self.formLayout.setWidget(2, QtWidgets.QFormLayout.LabelRole, self.label_22)\n self.label_21 = QtWidgets.QLabel(self.formLayoutWidget_3)\n self.label_21.setObjectName(\"label_21\")\n self.formLayout.setWidget(3, QtWidgets.QFormLayout.LabelRole, self.label_21)\n self.label_23 = QtWidgets.QLabel(self.formLayoutWidget_3)\n self.label_23.setObjectName(\"label_23\")\n self.formLayout.setWidget(4, QtWidgets.QFormLayout.LabelRole, self.label_23)\n self.label_5 = QtWidgets.QLabel(self.formLayoutWidget_3)\n self.label_5.setObjectName(\"label_5\")\n self.formLayout.setWidget(5, QtWidgets.QFormLayout.LabelRole, self.label_5)\n self.width = QtWidgets.QLineEdit(self.formLayoutWidget_3)\n self.width.setObjectName(\"width\")\n self.formLayout.setWidget(0, QtWidgets.QFormLayout.FieldRole, self.width)\n self.length = QtWidgets.QLineEdit(self.formLayoutWidget_3)\n self.length.setText(\"\")\n self.length.setObjectName(\"length\")\n self.formLayout.setWidget(1, QtWidgets.QFormLayout.FieldRole, self.length)\n self.weight = QtWidgets.QLineEdit(self.formLayoutWidget_3)\n self.weight.setObjectName(\"weight\")\n self.formLayout.setWidget(2, QtWidgets.QFormLayout.FieldRole, self.weight)\n self.distanceUnit = QtWidgets.QComboBox()\n self.distanceUnit.setObjectName(\"unit\")\n self.distanceUnit.addItem(\"Inch\")\n self.distanceUnit.addItem(\"CM\")\n self.formLayout.setWidget(3, QtWidgets.QFormLayout.FieldRole, self.distanceUnit)\n self.height = QtWidgets.QLineEdit(self.formLayoutWidget_3)\n self.height.setObjectName(\"height\")\n self.formLayout.setWidget(5, QtWidgets.QFormLayout.FieldRole, self.height)\n\n self.retranslateui(mainFrame)\n QtCore.QMetaObject.connectSlotsByName(mainFrame)\n\n def retranslateui(self, mainFrame):\n _translate = QtCore.QCoreApplication.translate\n mainFrame.setWindowTitle(_translate(\"mainFrame\", \"Frame\"))\n self.generateBtn.setText(_translate(\"mainFrame\", \"Generate\"))\n self.label_16.setText(_translate(\"mainFrame\", \"State\"))\n self.label_2.setText(_translate(\"mainFrame\", \"From:\"))\n self.fromFirstNamelabel.setText(_translate(\"mainFrame\", \"First Name *\"))\n self.fromLastNamelabel.setText(_translate(\"mainFrame\", \"Last Name *\"))\n self.midNameLabel.setText(_translate(\"mainFrame\", \"Mid \"))\n self.addressLabel.setText(_translate(\"mainFrame\", \"Address *\"))\n self.label_6.setText(_translate(\"mainFrame\", \"City*\"))\n self.label_7.setText(_translate(\"mainFrame\", \"State\"))\n self.label_8.setText(_translate(\"mainFrame\", \"Counrty *\"))\n self.label_9.setText(_translate(\"mainFrame\", \"Zip Code *\"))\n self.fromEmailLabel.setText(_translate(\"mainFrame\", \"Email *\"))\n self.fromEmailLabel_2.setText(_translate(\"mainFrame\", \"Phone *\"))\n self.label_18.setText(_translate(\"mainFrame\", \"To:\"))\n self.label_10.setText(_translate(\"mainFrame\", \"First Name *\"))\n self.label_17.setText(_translate(\"mainFrame\", \"Last Name *\"))\n self.label_13.setText(_translate(\"mainFrame\", \"Mid\"))\n self.label_11.setText(_translate(\"mainFrame\", \"Address*\"))\n self.label_12.setText(_translate(\"mainFrame\", \"City*\"))\n self.label_19.setText(_translate(\"mainFrame\", \"State\"))\n self.label_15.setText(_translate(\"mainFrame\", \"Counrty*\"))\n self.label_14.setText(_translate(\"mainFrame\", \"Zip Code*\"))\n self.toEmailLabel.setText(_translate(\"mainFrame\", \"Email *\"))\n self.fromEmailLabel_3.setText(_translate(\"mainFrame\", \"Phone *\"))\n self.label_3.setText(_translate(\"mainFrame\", \"Parcel\"))\n self.label_4.setText(_translate(\"mainFrame\", \"Width\"))\n self.label_20.setText(_translate(\"mainFrame\", \"Length\"))\n self.label_22.setText(_translate(\"mainFrame\", \"weight\"))\n self.label_21.setText(_translate(\"mainFrame\", \"distanceUnit\"))\n self.label_23.setText(_translate(\"mainFrame\", \"mass(lb)\"))\n self.label_5.setText(_translate(\"mainFrame\", \"Height\"))\n\n def buttonClick(self):\n if self.check() == False:\n msg = QMessageBox()\n msg.setText(\"Some info has not been filled!\")\n msg.exec()\n else:\n self.convert()\n print(\"now generating\")\n w = generator(self.name1, self.street1, self.city1, self.state1, self.country1, self.zipcode1, self.email1,\n self.phone1,self.name2, self.street2, self.city2, self.state2, self.country2, self.zipcode2,\n self.email2,self.phone2,self.parwidth,self.parlength,self.parweight,self.distance_unit,self.parheight)\n w.construct()\n w.generating()\n\n def convert(self):\n self.name1 = str(self.fromFirstName.text() + self.fromLastName.text())\n self.street1 = str(self.fromStreet.text())\n self.city1 = str(self.fromCity.text())\n self.state1 = str(self.fromState.text())\n self.country1 = str(self.fromCountry.text())\n self.zipcode1 = str(self.fromZipcode.text())\n self.email1 = str(self.fromEmail.text())\n self.phone1 = str(self.fromPhone.text())\n\n self.name2 = str(self.toFirstName.text() + self.toLastName.text())\n self.street2 = str(self.toStreet.text())\n self.city2 = str(self.toCity.text())\n self.state2 = str(self.toState.text())\n self.country2 = str(self.toCountry.text())\n self.zipcode2 = str(self.toZipcode.text())\n self.email2 = str(self.toEmail.text())\n self.phone2 = str(self.toPhone.text())\n\n self.parwidth = str(self.width.text())\n self.parlength = str(self.length.text())\n self.parweight = str(self.weight.text())\n self.distance_unit = str(self.distanceUnit.currentText())\n self.parheight = str(self.height.text())\n\n def check(self):\n if self.fromFirstName.text() == \"\" or self.fromLastName.text() == \"\" or self.fromStreet == \"\" \\\n or self.fromCity.text() == \"\" or self.fromState.text() == \"\" or self.fromCountry.text() == \"\" \\\n or self.fromZipcode.text() == \"\" or self.fromEmail.text() == \"\" or self.fromPhone.text() == \"\" \\\n or self.toFirstName.text() == \"\" or self.toLastName.text() == \"\" or self.toStreet == \"\" \\\n or self.toCity.text() == \"\" or self.toState.text() == \"\" or self.toCountry.text() == \"\" \\\n or self.toZipcode.text() == \"\" or self.toEmail.text() == \"\" or self.toPhone.text() == \"\" \\\n or self.width.text() == \"\" or self.length.text() == \"\" or self.weight.text() == \"\" \\\n or self.height.text() == \"\":\n return False\n else:\n print(\"Hello\")\n return True\n\n\nif __name__ == \"__main__\":\n import sys\n\n app = QtWidgets.QApplication(sys.argv)\n mainFrame = QtWidgets.QFrame()\n ui = Ui_mainFrame()\n ui.setupUi(mainFrame)\n mainFrame.show()\n sys.exit(app.exec_())\n"
}
] | 3 |
RainGod6/SDET11-LY | https://github.com/RainGod6/SDET11-LY | 1859458bdf2444ff3c298cab1334f9df67f907c9 | 82ec2d70679ba662064be1a5ddfe4d33a25c63f7 | bee74773254655e881263123d241dab3c8b0abf5 | refs/heads/master | "2020-11-27T17:35:27.174112" | "2020-09-24T08:18:50" | "2020-09-24T08:18:50" | 229,516,671 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6693251729011536,
"alphanum_fraction": 0.6815950870513916,
"avg_line_length": 39.775001525878906,
"blob_id": "c4da958367fc9d9f4a13c2d4d2abf6161227f0fb",
"content_id": "c4ecc0283f47ed0714a65bae1c76d22eb1ba9b72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1634,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 40,
"path": "/test_appium/test_xueqiu.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "# This sample code uses the Appium python client\n# pip install Appium-Python-Client\n# Then you can paste this into a file and simply run with Python\nfrom time import sleep\nfrom appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\nfrom selenium.webdriver.support import expected_conditions\nfrom selenium.webdriver.support.wait import WebDriverWait\n\n\nclass TestXueQiu:\n\n def setup(self):\n caps = {}\n caps[\"platformName\"] = \"android\"\n caps[\"deviceName\"] = \"test1\"\n caps[\"appPackage\"] = \"com.xueqiu.android\"\n caps[\"appActivity\"] = \".view.WelcomeActivityAlias\"\n caps[\"chromedriverExecutable\"] = \"/Users/user/tool/chromedriver/2.20/chromedriver\"\n self.driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n WebDriverWait(self.driver, 10).until(expected_conditions.element_to_be_clickable((MobileBy.ID, 'com.xueqiu.android:id/tv_agree')))\n self.driver.find_element(MobileBy.ID, 'com.xueqiu.android:id/tv_agree').click()\n self.driver.implicitly_wait(10)\n\n def test_webview_context(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='交易' and contains(@resource-id,'tab_name')]\").click()\n # WebDriverWait(self.driver, 15).until(lambda x: len(self.driver.contexts) > 1)\n for i in range(5):\n print(self.driver.contexts)\n sleep(1)\n print(self.driver.page_source)\n self.driver.switch_to.context(self.driver.contexts[-1])\n print(self.driver.contexts)\n print(self.driver.page_source)\n\n\n\n def teardown(self):\n sleep(20)\n self.driver.quit()"
},
{
"alpha_fraction": 0.6443701386451721,
"alphanum_fraction": 0.648829460144043,
"avg_line_length": 36.375,
"blob_id": "7582cafbc9bdb8833ef14fd7b10c4c4b2be1473a",
"content_id": "4b891d2be8dcac3ef9a733c4d6ad733c48506cb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 24,
"path": "/test_appium_page_object/page/main.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from appium.webdriver.common.mobileby import MobileBy\nfrom selenium.webdriver.support import expected_conditions\nfrom selenium.webdriver.support.wait import WebDriverWait\n\nfrom test_appium_page_object.page.apply_etc_card.apply_credit_card import ApplyCreditCard\nfrom test_appium_page_object.page.base_page import BasePage\n\n\nclass Main(BasePage):\n def goto_etc_home(self):\n self.find(MobileBy.XPATH, \"//*[@text='ETC']\").click()\n WebDriverWait(self._driver, 20).until(expected_conditions.element_to_be_clickable((MobileBy.ID,\n \"android:id/button1\")))\n self.find(MobileBy.ID, \"android:id/button1\").click()\n return ApplyCreditCard(self._driver)\n\n def goto_etc_services_more(self):\n pass\n\n def goto_profile(self):\n pass\n\n def goto_message(self):\n pass\n"
},
{
"alpha_fraction": 0.6695278882980347,
"alphanum_fraction": 0.6695278882980347,
"avg_line_length": 22.399999618530273,
"blob_id": "da50d825e89e15733ed8fe7fa8cc44476ddfbbef",
"content_id": "61720368a6efd0a0cef103a9730b062b50d6083d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/test_appium_page_object/testcase/test_apply_credit_card.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from test_appium_page_object.page.app import App\n\n\nclass TestApplyCreditCard:\n\n def setup(self):\n self.main = App().start().main()\n\n def test_apply_credit_card(self):\n self.main.goto_etc_home().apply_credit_card()"
},
{
"alpha_fraction": 0.6672297120094299,
"alphanum_fraction": 0.6672297120094299,
"avg_line_length": 25.909090042114258,
"blob_id": "899a058383294939864d91fadb1d23866ccd7041",
"content_id": "73fa41633c691da761c3fb664a94564884262154",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 22,
"path": "/test_appium_page_object/page/apply_etc_card/apply_credit_card.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from appium.webdriver.common.mobileby import MobileBy\nfrom test_appium_page_object.page.base_page import BasePage\n\n\nclass ApplyCreditCard(BasePage):\n\n _name_apply_card_element = (MobileBy.ID, \"com.wlqq.phantom.plugin.etc:id/tv_online_open_card\")\n _name_nfc_element = (MobileBy.ID, \"com.wlqq:id/btn_back\")\n\n def apply_credit_card(self):\n self.find(self._name_apply_card_element).click()\n self.find(self._name_nfc_element).click()\n return self\n\n def goto_faq(self):\n pass\n\n def goto_bind_card(self):\n pass\n\n def goto_obu(self):\n pass\n"
},
{
"alpha_fraction": 0.5602027773857117,
"alphanum_fraction": 0.5703421831130981,
"avg_line_length": 47.32653045654297,
"blob_id": "9d19c609c6cec9666a78c1336314eaa621e2c2e9",
"content_id": "6a6f4b76ad4c93fcead81fe00ea6f531aa917b79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2405,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 49,
"path": "/test_appium_page_object/page/app.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\nfrom selenium.webdriver.support import expected_conditions\nfrom selenium.webdriver.support.wait import WebDriverWait\nfrom test_appium_page_object.page.base_page import BasePage\nfrom test_appium_page_object.page.main import Main\n\n\nclass App(BasePage):\n _appPackage = \"com.wlqq\"\n _appActivity = \".activity.HomeActivity\"\n\n def start(self):\n\n if self._driver is None:\n caps = {}\n caps['platformName'] = 'android'\n caps['deviceName'] = '28d6f388'\n caps[\"appPackage\"] = self._appPackage\n caps[\"appActivity\"] = self._appActivity\n caps[\"automationname\"] = \"uiautomator2\"\n caps[\"chromedriverExecutable\"] = \"/Users/user/tool/chromedriver/2.35/chromedriver\"\n self._driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n self._driver.implicitly_wait(10)\n self.find(MobileBy.ID, \"com.wlqq:id/dialog_btn_right\").click()\n return self\n else:\n self._driver.start_activity(self._appPackage, self._appActivity)\n\n def restart(self):\n pass\n\n def stop(self):\n pass\n\n # 类型提示 ->\n def main(self) -> Main:\n # todo: wait main page\n WebDriverWait(self._driver, 30).until(expected_conditions.element_to_be_clickable((MobileBy.ID,\n \"android:id/button1\")))\n self.find(MobileBy.ID, \"android:id/button1\").click()\n self.find(MobileBy.XPATH, \"//*[@text='知道了']\").click()\n WebDriverWait(self._driver, 30).until(expected_conditions.element_to_be_clickable((MobileBy.XPATH,\n \"//*[contains(@resource-id,'content')]\\\n //*[@class ='android.widget.FrameLayout']//*[@class='android.widget.ImageView']\")))\n self.find(MobileBy.XPATH, \"//*[contains(@resource-id,'content')]\\\n //*[@class ='android.widget.FrameLayout']//*[@class='android.widget.ImageView']\").click()\n # WebDriverWait(self._driver, 30).until(lambda x: \"ETC\" in self._driver.page_source) # 等待首页元素出现完成加载\n return Main(self._driver)"
},
{
"alpha_fraction": 0.6014735698699951,
"alphanum_fraction": 0.6215673089027405,
"avg_line_length": 32.155555725097656,
"blob_id": "cd2223210a47a42d0b89794b3c471ea7690dd755",
"content_id": "beb7fdb6f78adabc6a62303b387b0e6014b7bccc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1671,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 45,
"path": "/test_appium/hcb_app/test_hcb_home.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from time import sleep\n\nfrom appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\n\n\nclass TestHcb:\n\n def setup(self):\n caps = {}\n caps['platformName'] = 'android'\n caps['deviceName'] = '28d6f388'\n caps['appPackage'] = 'com.wlqq'\n caps['appActivity'] = 'com.wlqq.activity.HomeActivity'\n\n self.driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n self.driver.implicitly_wait(5)\n # 启动APP点击同意\n el1 = self.driver.find_element(MobileBy.ID, 'com.wlqq:id/dialog_btn_right')\n el1.click()\n self.driver.implicitly_wait(15)\n # 点击首页温馨提示\n el2 = self.driver.find_element(MobileBy.ID, 'com.wlqq:id/text_positive')\n el2.click()\n self.driver.implicitly_wait(20) # 隐式等待:在设置超时时间范围内,一直寻找元素,若在时间内找到则立即执行后面操作,若时间内未找到则抛出异常\n # 点击NFC授权\n el3 = self.driver.find_element(MobileBy.ID, 'android:id/button1')\n el3.click()\n\n def test_etc_home(self):\n e2 = self.driver.find_element(MobileBy.XPATH, '//android.widget.ImageView[@text=\"ETC\"]')\n e2.click()\n print(e2.get_attribute('text'))\n\n print(\"点击ETC服务完成,进入ETC插件首页\")\n # print(self.driver.page_source)\n assert 'ETC' == e2.get_attribute('text')\n\n def test_hcb_home(self):\n el1 = self.driver.find_element(MobileBy.XPATH, '//android.view.View[@text=\"ETC服务\"]')\n el1.click()\n\n def teardown(self):\n sleep(20) # 强制等待\n self.driver.quit()\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 11,
"blob_id": "6861e528dd16fe73f3b4a3eb875351a6e72e3ba0",
"content_id": "b54c2b7cde9ca254202f023d9dfacd0a60d62338",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 12,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 1,
"path": "/README.md",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "# SDET11-LY\n"
},
{
"alpha_fraction": 0.5841338038444519,
"alphanum_fraction": 0.5942364931106567,
"avg_line_length": 50.89655303955078,
"blob_id": "3c2c9d57399c4f4aa56ee18c9ed276919c5ca965",
"content_id": "ef5b9b869866554848fc1d282c16df6eaa611ddf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6458,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 116,
"path": "/test_appium/YMM_APP/TestYmmPY.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "# This sample code uses the Appium python client\n# pip install Appium-Python-Client\n# Then you can paste this into a file and simply run with Python\nfrom time import sleep\n\nfrom appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\nfrom appium.webdriver.common.touch_action import TouchAction\nfrom selenium.webdriver.support import expected_conditions\nfrom selenium.webdriver.support.wait import WebDriverWait\n\n\nclass TestYmmAPP:\n\n def setup(self):\n caps = {}\n caps[\"platformName\"] = \"android\"\n caps[\"deviceName\"] = \"xiaomi5\"\n caps[\"appPackage\"] = \"com.xiwei.logistics\"\n caps[\"appActivity\"] = \"com.xiwei.logistics.carrier.ui.CarrierMainActivity\"\n # caps[\"noReset\"] = True\n self.driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n self.driver.implicitly_wait(15) # 全局隐式等待\n # 同意协议\n self.driver.find_element_by_id(\"com.xiwei.logistics:id/dialog_btn_right\").click()\n # 加入显示等待机制,因为此处页面元素呈现较慢,需要等待20s\n WebDriverWait(self.driver, 20).until(expected_conditions.element_to_be_clickable((MobileBy.ID, \"android:id/button1\")))\n # 同意NFC授权\n self.driver.find_element(MobileBy.ID, \"android:id/button1\").click()\n # 点击知道了弹框\n self.driver.find_element(MobileBy.ID, \"com.xiwei.logistics:id/buttons_layout\").click()\n # 关闭广告弹窗x按钮\n WebDriverWait(self.driver, 10).until(\n expected_conditions.element_to_be_clickable((MobileBy.ID, \"com.xiwei.logistics:id/iv_close\")))\n self.driver.find_element(MobileBy.ID, \"com.xiwei.logistics:id/iv_close\").click()\n\n def test_etchome(self):\n # page_source方法返回页面xml结构\n # print(self.driver.page_source)\n tab = \"// *[@text='服务']/../../..\" # 父节点\n tab1 = \"//*[contains(@resource-id,'ll_tab_container')]\" # 模糊匹配:使用contains\n tab2 = \"//*[contains(@resource-id,'tv_tab') and @text='服务']\" # 使用多表达式组合 and\n # 点击服务,进入满帮服务首页\n self.driver.find_element(MobileBy.XPATH, \"//*[contains(@resource-id,'tv_tab') and @text='服务']\").click()\n # 滑动屏幕\n action = TouchAction(self.driver)\n window_rect = self.driver.get_window_rect()\n print(window_rect)\n width = window_rect['width']\n height = window_rect['height']\n for i in range(3):\n action.press(x=width * 1 / 2, y=height * 5 / 6).wait(2000).move_to(x=width * 1 / 2,\n\n y=height * 1 / 6).release().perform()\n # 再滑动回至原位置\n for i in range(3):\n action.press(x=width * 1 / 2, y=height * 1 / 6).wait(2000).move_to(x=width * 1 / 2,\n y=height * 5 / 6).release().perform()\n\n etc_tab = \"//*[@text='ETC']\"\n self.driver.find_element(MobileBy.XPATH, etc_tab).click()\n WebDriverWait(self.driver, 15).until(\n expected_conditions.element_to_be_clickable((MobileBy.ID, \"android:id/button1\")))\n # 点击NFC授权\n self.driver.find_element(MobileBy.ID, \"android:id/button1\").click()\n quick_appaly_image = \"//*[contains(@resource-id,'ll_online_open_card')]\"\n assert not (self.driver.find_element(MobileBy.XPATH, quick_appaly_image).get_attribute(\n \"resourceId\")) != \"com.wlqq.phantom.plugin.etc:id/ll_online_open_card\"\n\n def test_apply_card(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[contains(@resource-id,'tv_tab') and @text='服务']\").click()\n etc_tab = \"//*[@text='ETC']\"\n self.driver.find_element(MobileBy.XPATH, etc_tab).click()\n WebDriverWait(self.driver, 15).until(\n expected_conditions.element_to_be_clickable((MobileBy.ID, \"android:id/button1\")))\n # 点击NFC授权\n self.driver.find_element(MobileBy.ID, \"android:id/button1\").click()\n quick_appaly_image = \"//*[contains(@resource-id,'ll_online_open_card')]\"\n assert (self.driver.find_element(MobileBy.XPATH, quick_appaly_image).get_attribute(\n \"resourceId\")) == \"com.wlqq.phantom.plugin.etc:id/ll_online_open_card\"\n # 点击快速开卡\n WebDriverWait(self.driver, 15).until(\n expected_conditions.element_to_be_clickable((MobileBy.XPATH, \"//*[@text='快速开卡']\")))\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='快速开卡']\").click()\n # 点击返回\n self.driver.find_element(MobileBy.ID, 'com.xiwei.logistics:id/btn_back').click()\n WebDriverWait(self.driver, 30).until(lambda x: len(self.driver.contexts) > 1)\n print(self.driver.contexts)\n\n\n def test_ui_selector(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[contains(@resource-id,'tv_tab') and @text='服务']\").click()\n # 利用ui_selector滑动查找元素进行定位\n self.driver.find_element_by_android_uiautomator('new UiScrollable(new UiSelector().'\n 'scrollable(true).instance(0)).'\n 'scrollIntoView(new UiSelector().textContains(\"去卖车\").'\n 'instance(0));').click()\n\n # 加入显示等待,新调转的页面是webview,后面需要修改断言代码\n WebDriverWait(self.driver, 10).until(expected_conditions.visibility_of_element_located(MobileBy.ID,\n \"com.xiwei.logistics:id/tv_title\"))\n assert self.driver.find_element(MobileBy.XPATH, \"//*[contains(@resource-id,'tv_title')]\").\\\n get_attribute('text') == '我要卖车'\n\n def test_etc_services(self):\n etc_service_more = \"//*[@text='ETC服务']//*[@text='查看更多']\"\n etc_service_apply_credit_card = \"//*[@text='ETC服务']//*[contains(@text,'全国记账卡')]//*[@text='去办卡']\"\n etc_service_apply_stored_card = \"//*[@text='ETC服务']//*[contains(@text,'全国储值卡')]//*[@text='去办卡']\"\n\n def test_etc_apply_card(self):\n quick_apply = \"//*[contains(@resource-id,'pager_banner')][1]\"\n apply_card_tab = \" \"\n\n def teardown(self):\n # self.driver.quit()\n pass\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.4820574223995209,
"alphanum_fraction": 0.5047847032546997,
"avg_line_length": 19.390243530273438,
"blob_id": "31c798a0dff232bf782795a899e60732e86f24f5",
"content_id": "717ce26166c5fad4d729648d7dabe9a82a7ab627",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1045,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 41,
"path": "/leetcode/Solution.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "\"\"\"\n给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。\n\n你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。\n\n示例:\n\n给定 nums = [2, 7, 11, 15], target = 9\n\n因为 nums[0] + nums[1] = 2 + 7 = 9\n所以返回 [0, 1]\n\n来源:力扣(LeetCode)\n链接:https://leetcode-cn.com/problems/two-sum\n\"\"\"\nfrom typing import List\n\n\nclass Solution(object):\n def twoSum(self, nums, target):\n \"\"\"\n :type nums: List[int]\n :type target: int\n :rtype: List[int]\n \"\"\"\n a = []\n for i in range(len(nums)):\n for j in range(1, len(nums)):\n if nums[i] + nums[j] == target:\n if i not in a:\n a.append(i)\n a.append(j)\n return a\n\n\nif __name__ == \"__main__\":\n s = Solution()\n nums = [3,2,4]\n b = 6\n result = s.twoSum(nums, b)\n print(result)\n"
},
{
"alpha_fraction": 0.726190447807312,
"alphanum_fraction": 0.7454212307929993,
"avg_line_length": 31.058822631835938,
"blob_id": "2276848f840ed402c5dfa9683724362965acea56",
"content_id": "7cb2310cf6ba58f711c9ea6aa0a436240211c24c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1154,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 34,
"path": "/test_appium/YMM_APP/TestYmm.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "# This sample code uses the Appium python client\n# pip install Appium-Python-Client\n# Then you can paste this into a file and simply run with Python\n\nfrom appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\n\ncaps = {}\ncaps[\"platformName\"] = \"android\"\ncaps[\"deviceName\"] = \"xiaomi5\"\ncaps[\"appPackage\"] = \"com.xiwei.logistics\"\ncaps[\"appActivity\"] = \"com.xiwei.logistics.carrier.ui.CarrierMainActivity\"\n# caps[\"noReset\"] = True\n\ndriver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n\n# 同意协议\nel1 = driver.find_element_by_id(\"com.xiwei.logistics:id/dialog_btn_right\")\nel1.click()\n\n# 同意NFC授权,需要等待20s\ndriver.implicitly_wait(25)\nel2 = driver.find_element(MobileBy.ID, \"android:id/button1\")\nel2.click()\n\n# 点击知道了弹框\nel3 = driver.find_element(MobileBy.ID, \"com.xiwei.logistics:id/buttons_layout\")\n# el3 = driver.find_element(MobileBy.XPATH, \"//*[@text='知道了' and contains(@resource-id,'com.xiwei.logistics:id/buttons_layout')]\")\nel3.click()\n\n# 关闭广告弹窗x按钮\ndriver.implicitly_wait(15)\nel4 = driver.find_element(MobileBy.ID, \"com.xiwei.logistics:id/iv_close\")\nel4.click()\n\n\n"
},
{
"alpha_fraction": 0.6297258138656616,
"alphanum_fraction": 0.6389610171318054,
"avg_line_length": 53.140625,
"blob_id": "1250240bc2362c19368a9a3c64358766c9446cd6",
"content_id": "df76af41b3074967549d5daf9478708c4495a647",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3591,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 64,
"path": "/test_appium/hcb_app/test_hcb_demo.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from time import sleep\n\nfrom appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.support import expected_conditions\nfrom selenium.webdriver.support.wait import WebDriverWait\n\n\nclass TestHcbDemo:\n\n def setup(self):\n caps = {}\n caps['platformName'] = 'android'\n caps['deviceName'] = '28d6f388'\n caps[\"appPackage\"] = \"com.wlqq\"\n caps[\"appActivity\"] = \".activity.HomeActivity\"\n caps[\"automationname\"] = \"uiautomator2\"\n caps[\"chromedriverExecutable\"] = \"/Users/user/tool/chromedriver/2.35/chromedriver\"\n self.driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n self.driver.implicitly_wait(10)\n self.driver.find_element(MobileBy.ID, \"com.wlqq:id/dialog_btn_right\").click()\n WebDriverWait(self.driver, 30).until(expected_conditions.element_to_be_clickable((MobileBy.ID,\n \"android:id/button1\")))\n self.driver.find_element(MobileBy.ID, \"android:id/button1\").click()\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='知道了']\").click()\n WebDriverWait(self.driver, 30).until(expected_conditions.element_to_be_clickable((MobileBy.XPATH,\n \"//*[contains(@resource-id,'content')]\\\n //*[@class ='android.widget.FrameLayout']//*[@class='android.widget.ImageView']\")))\n self.driver.find_element(MobileBy.XPATH, \"//*[contains(@resource-id,'content')]\\\n //*[@class ='android.widget.FrameLayout']//*[@class='android.widget.ImageView']\").click()\n\n def test_etc_home(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='ETC']\").click()\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='快速办卡']\").click()\n\n def test_webview(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='ETC']\").click()\n WebDriverWait(self.driver, 20).until(expected_conditions.element_to_be_clickable((MobileBy.ID,\n \"android:id/button1\")))\n self.driver.find_element(MobileBy.ID, \"android:id/button1\").click()\n WebDriverWait(self.driver, 15).until(expected_conditions.element_to_be_clickable((MobileBy.ID, 'com.wlqq.phantom.plugin.etc:id/tv_online_open_card')))\n self.driver.find_element(MobileBy.ID, \"com.wlqq.phantom.plugin.etc:id/tv_online_open_card\").click()\n print(self.driver.contexts)\n self.driver.find_element(MobileBy.ID, \"com.wlqq:id/btn_back\").click()\n # 打印当前页面结构page_source,当前xml结构\n # print(self.driver.page_source)\n # 等待上下文出现,webview出现\n WebDriverWait(self.driver, 20).until(lambda x: (len(self.driver.contexts) > 1))\n # 切换至webview容器\n self.driver.switch_to.context(self.driver.contexts[-1])\n # 打印当前页面结构page_source,当前html结构\n print(self.driver.page_source)\n self.driver.find_element(By.CSS_SELECTOR, \".button-container.fixed-button\").click()\n # webview中toast定位获取到div中的id属性\n toast = self.driver.find_element(By.CSS_SELECTOR, \"#goblin-toast\").text\n print(toast)\n assert \"未选择车牌\" in toast\n print(self.driver.contexts)\n # self.driver.switch_to.context(self.driver.contexts['NATIVE_APP'])\n self.driver.find_element(MobileBy.ID, \"com.wlqq:id/back_btn\").click()\n\n def teardown(self):\n pass\n"
},
{
"alpha_fraction": 0.5235602259635925,
"alphanum_fraction": 0.5314136147499084,
"avg_line_length": 21.235294342041016,
"blob_id": "56758f2a541d5b1ca2a73d8305b8d02f94281d22",
"content_id": "f5a74f28bda82c8d84591d1e1adc9327dc96196d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 17,
"path": "/test_yaml/test_yaml.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "import pytest\nimport yaml\n\n\nclass TestYaml:\n\n def test_yaml(self):\n print(yaml.load(\"\"\"\n - Hesperiidae\n - Papilionidae\n - Apatelodidae\n - Epiplemidae\n \"\"\"))\n\n @pytest.mark.parametrize(\"a,b\", yaml.safe_load(open(\"testyaml.yaml\", encoding='utf-8')))\n def test_yaml_read(self, a, b):\n assert a + b == 10\n\n\n\n\n"
},
{
"alpha_fraction": 0.5668485760688782,
"alphanum_fraction": 0.5736698508262634,
"avg_line_length": 44.625,
"blob_id": "eea20cc9ed49f3fd4484f62bdc543e0f4a802e6b",
"content_id": "0bcd84af5dd9731645c46bf05c8806f6015835b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1502,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 32,
"path": "/test_appium/testApiDemo.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "from appium import webdriver\nfrom appium.webdriver.common.mobileby import MobileBy\n\n\nclass TestApiDemo:\n\n def setup(self):\n caps = {}\n caps['platformName'] = \"android\"\n caps['deviceName'] = \"小米5\"\n caps['appPackage'] = \"io.appium.android.apis\"\n caps['appActivity'] = \".ApiDemos\"\n self.driver = webdriver.Remote(\"http://localhost:4723/wd/hub\", caps)\n self.driver.implicitly_wait(10)\n\n def test_toast(self):\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='Views' and contains(@resource-id,'text1')]\").click()\n self.driver.find_element(MobileBy.ANDROID_UIAUTOMATOR, 'new UiScrollable(new UiSelector().'\n 'scrollable(true).instance(0)).'\n 'scrollIntoView(new UiSelector().textContains(\"Popup Menu\").'\n 'instance(0));').click()\n self.driver.find_element(MobileBy.ACCESSIBILITY_ID, 'Make a Popup!').click()\n self.driver.find_element(MobileBy.XPATH, \"//*[@text='Search']\").click()\n # toast定位,由于toast短暂最好用变量存下来\n toast = self.driver.find_element(MobileBy.XPATH, \"//*[@class='android.widget.Toast']\").text\n print(toast)\n assert 'Clicked' in toast\n assert 'popup menu' in toast\n assert 'API Demos:Clicked popup menu item Search' == toast\n\n def teardown(self):\n pass\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.48182180523872375,
"alphanum_fraction": 0.4846184551715851,
"avg_line_length": 35.246376037597656,
"blob_id": "04dba3a1b6c1ac217ae492cf2439afadb16c16f5",
"content_id": "25372f54386cebed03974cd6c565f837073dc331",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2779,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 69,
"path": "/test_appium_page_object/page/base_page.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "import yaml\nfrom appium.webdriver import WebElement\nfrom appium.webdriver.webdriver import WebDriver\nimport logging\n\n\nclass BasePage:\n logging.basicConfig(level=logging.INFO) # 使用logging\n _driver: WebDriver\n _black_list = []\n _error_max = 5\n _error_count = 0\n\n def __init__(self, driver: WebDriver = None):\n self._driver = driver\n\n # todo:当有广告、各种异常弹框出现的时候,要进行异常处理,通常用装饰器进行异常处理\n def find(self, locator, value: str = None):\n logging.info(locator, value)\n try:\n # 寻找控件\n element = self._driver.find_element(*locator) if isinstance(locator, tuple) else self._driver.find_element(\n locator, value)\n # 如果成功,清空错误计数\n self._error_count = 0\n return element\n # todo:self._error_max = 0\n except Exception as e:\n # 如果次数太多,就退出异常处理,直接报错\n if self._error_count > self._error_max:\n raise e\n # 记录一直异常的次数\n self._error_max += 1\n # 对黑名单弹框进行处理\n for element in self._black_list:\n elements = self._driver.find_elements(*element)\n if len(elements) > 0:\n elements[0].click()\n # 继续寻找原来正常的控件,使用递归\n return self.find(locator, value)\n # 如果黑名单也没找到,就报错\n logging.warn(\"black list no found\")\n raise e\n\n def steps(self, path):\n with open(path) as f:\n # 读取步骤定义文件\n steps: list[dict] = yaml.safe_load(f)\n # 保存一个目标对象\n element: WebElement = None\n for step in steps:\n logging.info(step)\n if \"by\" in step.keys():\n element = self.find(step[\"by\"], step[\"locator\"])\n if \"action\" in step.keys():\n action = step[\"action\"]\n if action == \"find\":\n pass\n elif action == \"click\":\n element.click()\n elif action == \"text\":\n element.text()\n elif action == \"attribute\":\n element.get_attribute(step[\"value\"])\n elif action in [\"send\", \"input\"]:\n content: str = step[\"value\"]\n for key in self._params.keys():\n content = content.replace(\"{%s}\" % key, self._params[key])\n element.send_keys(content)\n\n\n"
},
{
"alpha_fraction": 0.5849056839942932,
"alphanum_fraction": 0.6132075190544128,
"avg_line_length": 13.714285850524902,
"blob_id": "b4a2a2c432977a37252ba7ccd3b3945b3a47b818",
"content_id": "4bf9419bc65d2a0ba21f6d01a116d12c8a81396b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 7,
"path": "/unit/test_unit.py",
"repo_name": "RainGod6/SDET11-LY",
"src_encoding": "UTF-8",
"text": "import unittest\n\n\nclass TestSum(unittest.TestCase):\n\n def test_sum(self):\n assert 1 + 2 == 3\n\n\n\n"
}
] | 15 |