
Improve model card: update pipeline tag, add library name, and enhance content
#1
by
nielsr
HF Staff
- opened
README.md
CHANGED
|
@@ -1,103 +1,178 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
-
|
| 6 |
-
|
| 7 |
-
-
|
| 8 |
-
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
base_model_relation: quantized
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
##
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
4.
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model:
|
| 3 |
+
- ZhipuAI/GLM-4.1V-9B-Thinking
|
| 4 |
+
license: mit
|
| 5 |
+
pipeline_tag: image-text-to-text
|
| 6 |
+
tags:
|
| 7 |
+
- glm4v
|
| 8 |
+
- GPTQ
|
| 9 |
+
- Int4-Int8Mix
|
| 10 |
+
- vLLM
|
| 11 |
+
base_model_relation: quantized
|
| 12 |
+
library_name: transformers
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
This is the quantized version of the **GLM-4.1V-9B-Thinking** model.
|
| 16 |
+
|
| 17 |
+
**Paper**: [GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning](https://arxiv.org/abs/2507.01006)
|
| 18 |
+
**Code**: [https://github.com/THUDM/GLM-4.1V-Thinking](https://github.com/THUDM/GLM-4.1V-Thinking)
|
| 19 |
+
**Hugging Face Demo**: [https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-API-Demo](https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-API-Demo)
|
| 20 |
+
**ModelScope Demo**: [https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo](https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo)
|
| 21 |
+
**API Service**: [https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking](https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking)
|
| 22 |
+
|
| 23 |
+
# GLM-4.1V-9B-Thinking-GPTQ-Int4-Int8Mix
|
| 24 |
+
|
| 25 |
+
<div align="center">
|
| 26 |
+
<img src=https://raw.githubusercontent.com/THUDM/GLM-4.1V-Thinking/99c5eb6563236f0ff43605d91d107544da9863b2/resources/logo.svg width="40%"/>
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
## Model Introduction
|
| 30 |
+
|
| 31 |
+
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs must evolve beyond basic multimodal perception to enhance their reasoning capabilities in complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as complex problem solving, long-context understanding, and multimodal agents.
|
| 32 |
+
|
| 33 |
+
Based on the [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) foundation model, we present the new open-source VLM model **GLM-4.1V-9B-Thinking**, designed to explore the upper limits of reasoning in vision-language models. By introducing a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to support further research into the boundaries of VLM capabilities.
|
| 34 |
+
|
| 35 |
+
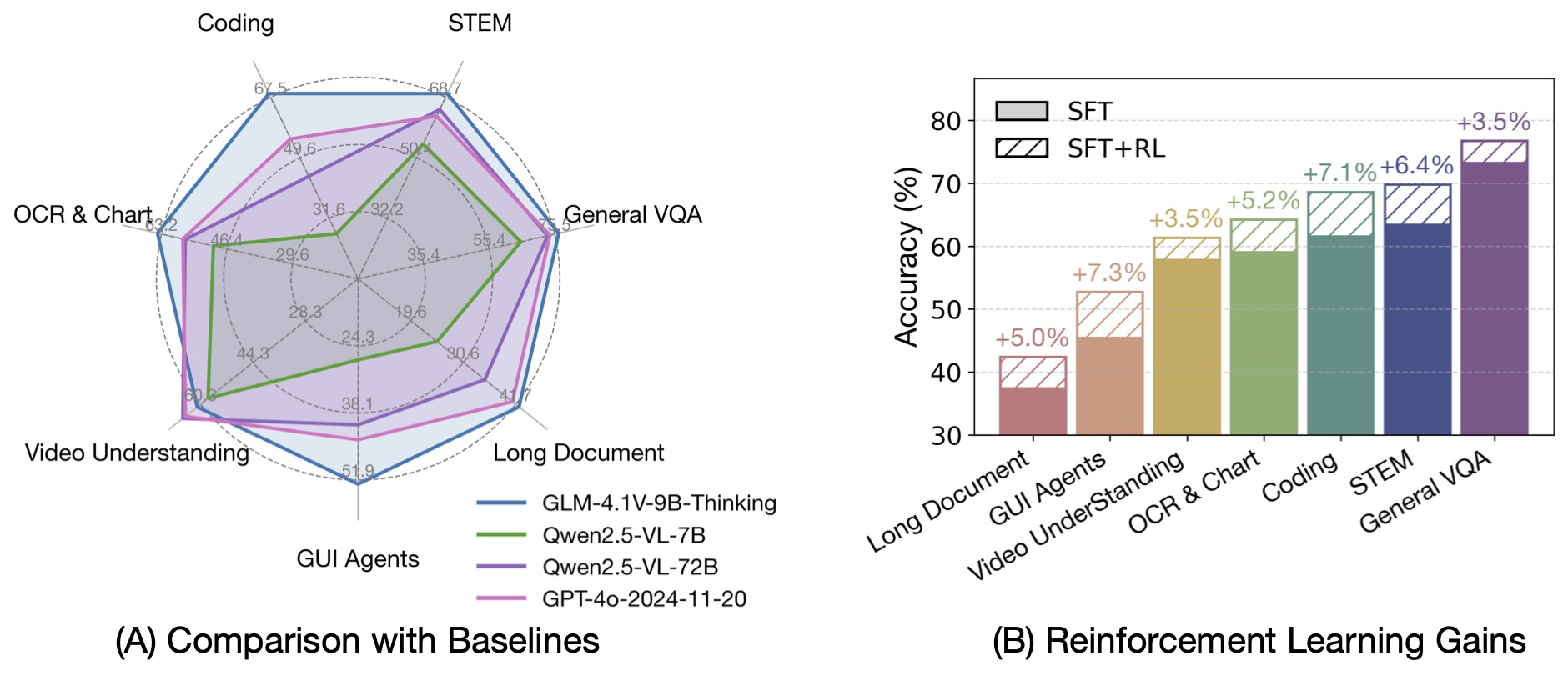
|
| 36 |
+
|
| 37 |
+
Compared to the previous generation models CogVLM2 and the GLM-4V series, **GLM-4.1V-Thinking** offers the following improvements:
|
| 38 |
+
|
| 39 |
+
1. The first reasoning-focused model in the series, achieving world-leading performance not only in mathematics but also across various sub-domains.
|
| 40 |
+
2. Supports **64k** context length.
|
| 41 |
+
3. Handles **arbitrary aspect ratios** and up to **4K** image resolution.
|
| 42 |
+
4. Provides an open-source version supporting both **Chinese and English bilingual** usage.
|
| 43 |
+
|
| 44 |
+
## Model Information
|
| 45 |
+
|
| 46 |
+
### Model Download Links
|
| 47 |
+
|
| 48 |
+
| Model | Download Links | Model Type |
|
| 49 |
+
|---|---|---|
|
| 50 |
+
| GLM-4.1V-9B-Thinking | [🤗 Hugging Face](https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Thinking) | Reasoning Model |
|
| 51 |
+
| GLM-4.1V-9B-Base | [🤗 Hugging Face](https://huggingface.co/THUDM/GLM-4.1V-9B-Base)<br> [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Base) | Base Model |
|
| 52 |
+
|
| 53 |
+
The model's algorithm implementation can be found in the official [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v) repository.
|
| 54 |
+
|
| 55 |
+
### Runtime Requirements
|
| 56 |
+
|
| 57 |
+
#### Inference
|
| 58 |
+
|
| 59 |
+
| Device (Single GPU) | Framework | Min Memory | Speed | Precision |
|
| 60 |
+
|---|---|---|---|---|
|
| 61 |
+
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
|
| 62 |
+
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
|
| 63 |
+
|
| 64 |
+
#### Fine-tuning
|
| 65 |
+
|
| 66 |
+
The following results are based on image fine-tuning using the [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) toolkit.
|
| 67 |
+
|
| 68 |
+
| Device (Cluster) | Strategy | Min Memory / # of GPUs | Batch Size (per GPU) | Freezing |
|
| 69 |
+
|---|---|---|---|---|
|
| 70 |
+
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | Freeze VIT |
|
| 71 |
+
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | Freeze VIT |
|
| 72 |
+
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | Freeze VIT |
|
| 73 |
+
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | No Freezing |
|
| 74 |
+
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | No Freezing |
|
| 75 |
+
|
| 76 |
+
> Note: Fine-tuning with Zero2 may result in zero loss; Zero3 is recommended for stable training.
|
| 77 |
+
|
| 78 |
+
## Benchmark Performance
|
| 79 |
+
|
| 80 |
+
Based on the [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) foundation model, we present the new open-source VLM model **GLM-4.1V-9B-Thinking**, which introduces a "thinking" paradigm and leverages Reinforcement Learning with Curriculum Sampling (RLCS) to comprehensively enhance model capabilities. It achieves state-of-the-art performance among vision-language models at the 10B parameter scale, matching or even surpassing the 72B Qwen-2.5-VL on 18 benchmark tasks. We also open-source the base model **GLM-4.1V-9B-Base** to support further research on the frontier of vision-language models.
|
| 81 |
+
|
| 82 |
+

|
| 83 |
+
|
| 84 |
+
## Model Inference
|
| 85 |
+
|
| 86 |
+
### Downloading the Quantized Model via ModelScope
|
| 87 |
+
|
| 88 |
+
```python
|
| 89 |
+
from modelscope import snapshot_download
|
| 90 |
+
snapshot_download('dengcao/GLM-4.1V-9B-Thinking-GPTQ-Int4-Int8Mix', cache_dir="本地路径")
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
### Inference Scripts and Examples
|
| 94 |
+
|
| 95 |
+
All inference scripts are located in the `inference` folder of the [GitHub repository](https://github.com/THUDM/GLM-4.1V-Thinking) and include:
|
| 96 |
+
|
| 97 |
+
+ `trans_infer_cli.py`: A command-line interactive script using the `transformers` library as the backend. It supports multi-turn dialogue.
|
| 98 |
+
+ `trans_infer_gradio.py`: A Gradio-based web UI script using the `transformers` backend. It supports multimodal inputs such as images, videos, PDFs, and PPTs.
|
| 99 |
+
+ OpenAI-compatible API service with `vllm`, along with a simple request example provided in `vllm_api_request.py`.
|
| 100 |
+
|
| 101 |
+
```shell
|
| 102 |
+
vllm serve THUDM/GLM-4.1V-9B-Thinking --limit-mm-per-prompt '{"image":32}' --allowed-local-media-path /
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
+ If `--limit-mm-per-prompt` is not specified, only 1 image is supported. The model supports a maximum of 1 video or 300 images per input — it does **not** support simultaneous image and video inputs.
|
| 106 |
+
+ `--allowed-local-media-path` must be set to permit access to local multimodal inputs.
|
| 107 |
+
|
| 108 |
+
+ `trans_infer_bench`: Academic benchmarking script for inference with `GLM-4.1V-9B-Thinking`. Key features:
|
| 109 |
+
+ Automatically interrupts thinking if it exceeds 8192 tokens and appends `</think><answer>` to prompt the model to generate a final answer.
|
| 110 |
+
+ Demonstrates video-based input; for other modalities, modifications are required.
|
| 111 |
+
+ Only a `transformers` version is provided. For `vLLM`, a custom implementation is needed to support this logic.
|
| 112 |
+
|
| 113 |
+
+ `vllm_request_gui_agent.py`: This script demonstrates how to handle model responses and construct prompts for GUI Agent use cases. It covers strategies for mobile, desktop, and web environments, and can be integrated into your application framework. For detailed documentation about GUI Agent, please refer to [this file](https://github.com/THUDM/GLM-4.1V-Thinking/blob/main/resources/agent.md).
|
| 114 |
+
|
| 115 |
+
+ For Ascend NPU Inference, Check [here](https://gitee.com/ascend/MindSpeed-MM/tree/master/examples/glm4.1v/README.md).
|
| 116 |
+
|
| 117 |
+
## Model Fine-tuning
|
| 118 |
+
|
| 119 |
+
[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) now supports fine-tuning of this model. Below is an example dataset using two images. Prepare your dataset in a `finetune.json` file like the following:
|
| 120 |
+
|
| 121 |
+
```json
|
| 122 |
+
[
|
| 123 |
+
{
|
| 124 |
+
"messages": [
|
| 125 |
+
{
|
| 126 |
+
"content": "<image>Who are they?",
|
| 127 |
+
"role": "user"
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"content": "<think>
|
| 131 |
+
User ask me to observe the image and get the answer. I Know they are Kane and Gretzka from Bayern Munich.</think>
|
| 132 |
+
<answer>They're Kane and Gretzka from Bayern Munich.</answer>",
|
| 133 |
+
"role": "assistant"
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"content": "<image>What are they doing?",
|
| 137 |
+
"role": "user"
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"content": "<think>
|
| 141 |
+
I need to observe what this people are doing. Oh, They are celebrating on the soccer field.</think>
|
| 142 |
+
<answer>They are celebrating on the soccer field.</answer>",
|
| 143 |
+
"role": "assistant"
|
| 144 |
+
}
|
| 145 |
+
],
|
| 146 |
+
"images": [
|
| 147 |
+
"mllm_demo_data/1.jpg",
|
| 148 |
+
"mllm_demo_data/2.jpg"
|
| 149 |
+
]
|
| 150 |
+
}
|
| 151 |
+
]
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
1. Content inside `<think> ... </think>` will **not** be stored in the conversation history or used during fine-tuning.
|
| 155 |
+
2. The `<image>` tag will be replaced with actual image data during preprocessing.
|
| 156 |
+
|
| 157 |
+
After preparing the dataset, you can proceed with fine-tuning using the standard LLaMA-Factory pipeline.
|
| 158 |
+
|
| 159 |
+
## Model License
|
| 160 |
+
|
| 161 |
+
+ The code in this repository is released under the [Apache License 2.0](https://github.com/THUDM/GLM-4.1V-Thinking/blob/main/LICENSE).
|
| 162 |
+
+ The models **GLM-4.1V-9B-Thinking** and **GLM-4.1V-9B-Base** are both licensed under the **MIT License**.
|
| 163 |
+
|
| 164 |
+
## Citation
|
| 165 |
+
|
| 166 |
+
If you find our work helpful, please consider citing the following paper.
|
| 167 |
+
|
| 168 |
+
```bibtex
|
| 169 |
+
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
|
| 170 |
+
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
|
| 171 |
+
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
|
| 172 |
+
year={2025},
|
| 173 |
+
eprint={2507.01006},
|
| 174 |
+
archivePrefix={arXiv},
|
| 175 |
+
primaryClass={cs.CV},
|
| 176 |
+
url={https://arxiv.org/abs/2507.01006},
|
| 177 |
+
}
|
| 178 |
+
```
|