Transformers documentation
GLM-4.5, GLM-4.6, GLM-4.7
This model was published in HF papers on 2025-08-08 and contributed to Hugging Face Transformers on 2025-07-21.
GLM-4.5, GLM-4.6, GLM-4.7
Overview
GLM-4.7, GLM-4.6 and GLM-4.5 language model use this class. The implementation in transformers does not include an MTP layer.
GLM-4.7
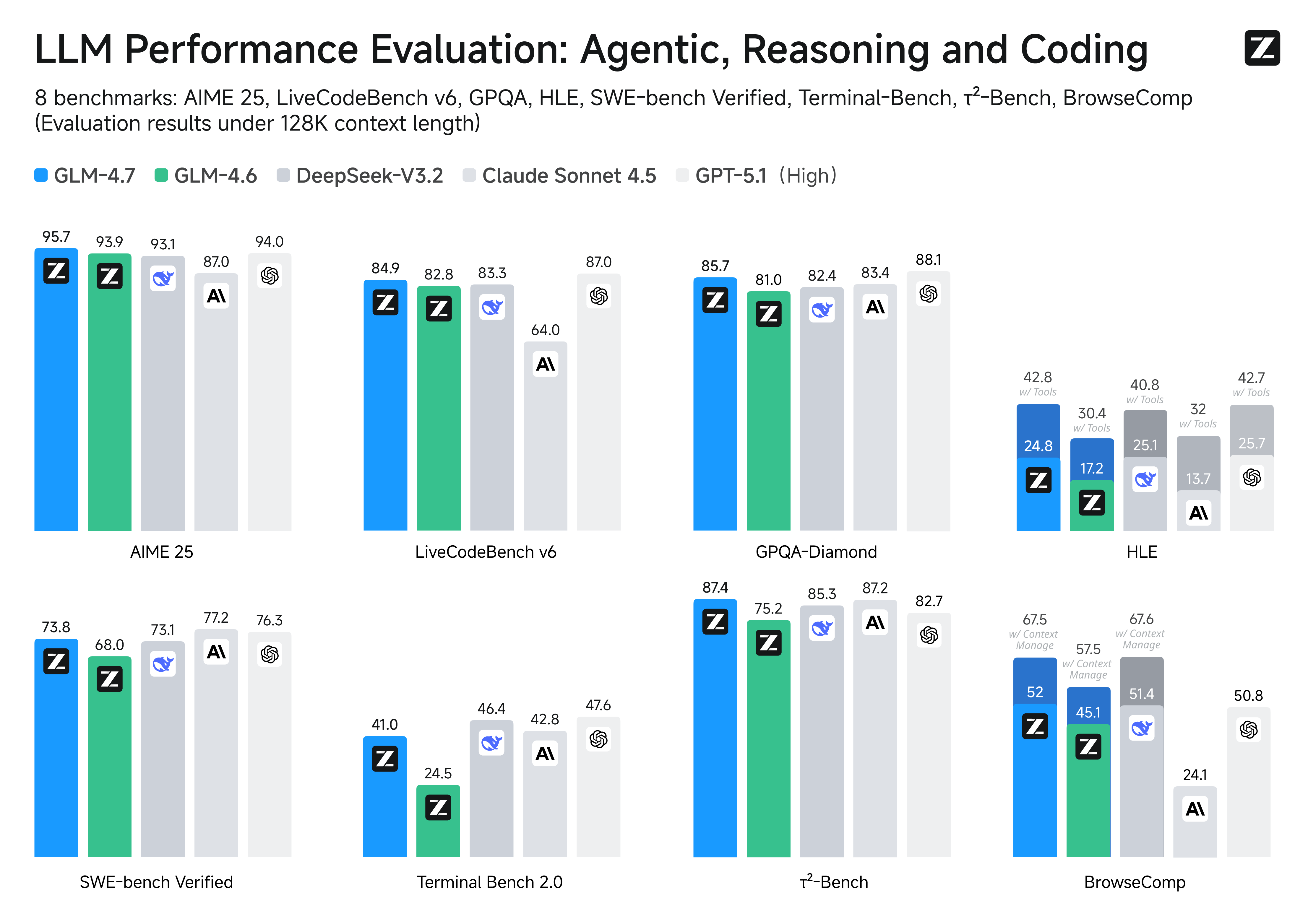
GLM-4.7, your new coding partner, is coming with the following features:
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- Vibe Coding: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
More general, one would also witness significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
Interleaved Thinking & Preserved Thinking
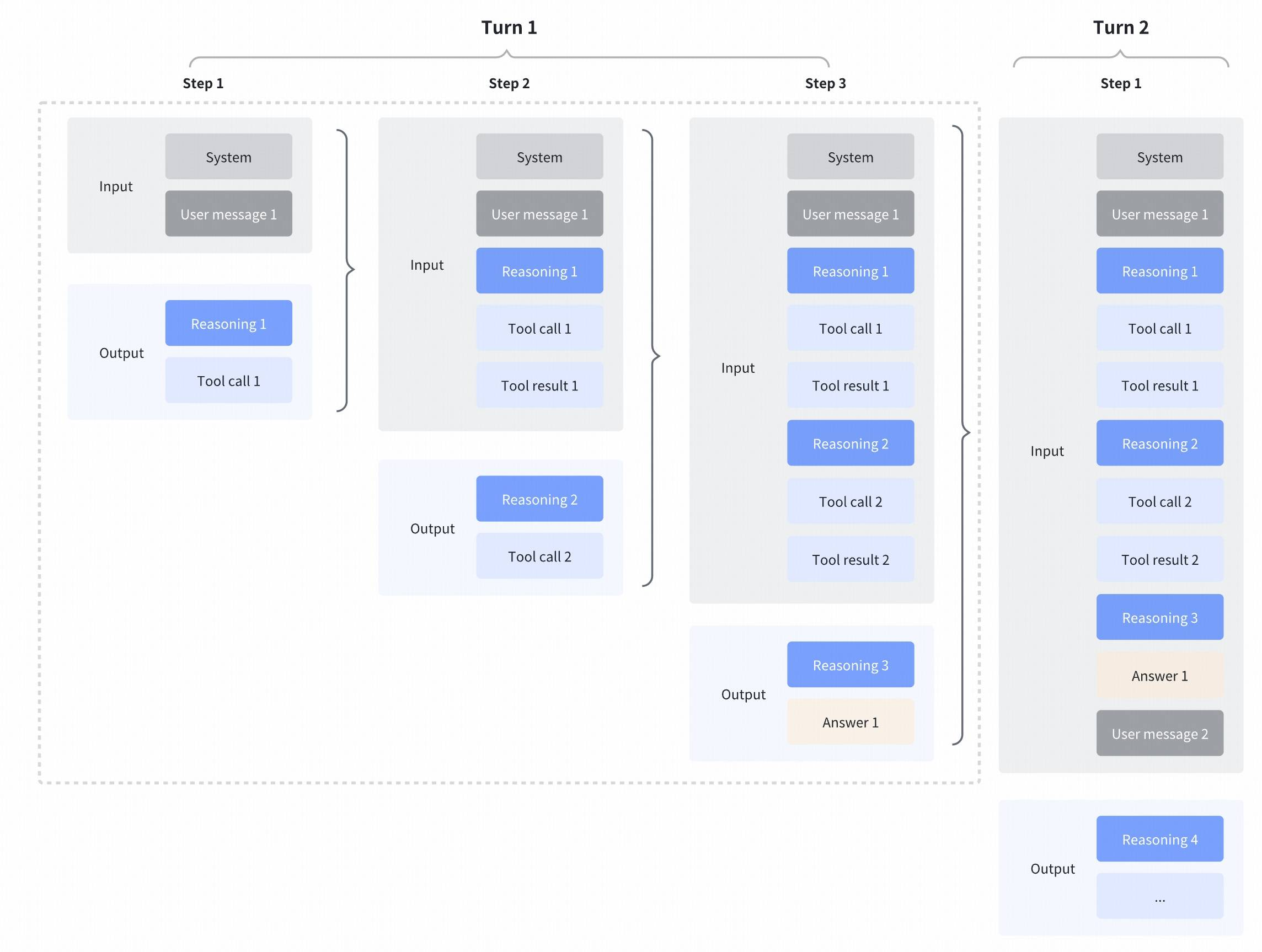
GLM-4.7 further enhances Interleaved Thinking (a feature introduced since GLM-4.5) and introduces Preserved Thinking and Turn-level Thinking. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
- Interleaved Thinking: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
- Preserved Thinking: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks.
- Turn-level Thinking: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability.
More details: https://docs.z.ai/guides/capabilities/thinking-mode
For more eval results, show cases, and technical details, please visit GLM-4.7 technical blog.
GLM-4.6
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
For more eval results, show cases, and technical details, please visit GLM-4.6 technical blog.
GLM-4.5
The GLM-4.5 series models are foundation models designed for intelligent agents, MoE variants are documented here as Glm4Moe.
GLM-4.5 has 355 billion total parameters with 32 billion active parameters, while GLM-4.5-Air adopts a more compact design with 106 billion total parameters and 12 billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of 63.2, in the 3rd place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at 59.8 while maintaining superior efficiency.
For more eval results, show cases, and technical details, please visit our technical report or technical blog.
The model code, tool parser and reasoning parser can be found in the implementation of transformers, vLLM and SGLang.
Glm4MoeConfig
class transformers.Glm4MoeConfig
< source >( transformers_version: str | None = None architectures: list[str] | None = None output_hidden_states: bool | None = False return_dict: bool | None = True dtype: typing.Union[str, ForwardRef('torch.dtype'), NoneType] = None chunk_size_feed_forward: int = 0 is_encoder_decoder: bool = False id2label: dict[int, str] | dict[str, str] | None = None label2id: dict[str, int] | dict[str, str] | None = None problem_type: typing.Optional[typing.Literal['regression', 'single_label_classification', 'multi_label_classification']] = None vocab_size: int = 151552 hidden_size: int = 4096 intermediate_size: int = 10944 num_hidden_layers: int = 46 num_attention_heads: int = 96 num_key_value_heads: int = 8 hidden_act: str = 'silu' max_position_embeddings: int = 131072 initializer_range: float = 0.02 rms_norm_eps: float = 1e-05 use_cache: bool = True tie_word_embeddings: bool = False rope_parameters: transformers.modeling_rope_utils.RopeParameters | dict | None = None attention_bias: bool = False attention_dropout: float | int = 0.0 moe_intermediate_size: int = 1408 num_experts_per_tok: int = 8 n_shared_experts: int = 1 n_routed_experts: int = 128 routed_scaling_factor: float = 1.0 n_group: int = 1 topk_group: int = 1 first_k_dense_replace: int = 1 norm_topk_prob: bool = True use_qk_norm: bool = False bos_token_id: int | None = None eos_token_id: int | list[int] | None = None pad_token_id: int | None = None )
Parameters
- vocab_size (
int, optional, defaults to151552) — Vocabulary size of the model. Defines the number of different tokens that can be represented by theinput_ids. - hidden_size (
int, optional, defaults to4096) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to10944) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to46) — Number of hidden layers in the Transformer decoder. - num_attention_heads (
int, optional, defaults to96) — Number of attention heads for each attention layer in the Transformer decoder. - num_key_value_heads (
int, optional, defaults to8) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details, check out this paper. If it is not specified, will default tonum_attention_heads. - hidden_act (
str, optional, defaults tosilu) — The non-linear activation function (function or string) in the decoder. For example,"gelu","relu","silu", etc. - max_position_embeddings (
int, optional, defaults to131072) — The maximum sequence length that this model might ever be used with. - initializer_range (
float, optional, defaults to0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - rms_norm_eps (
float, optional, defaults to1e-05) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=Trueor when the model is a decoder-only generative model. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether to tie weight embeddings according to model’stied_weights_keysmapping. - rope_parameters (
Union[~modeling_rope_utils.RopeParameters, dict], optional) — Dictionary containing the configuration parameters for the RoPE embeddings. The dictionary should contain a value forrope_thetaand optionally parameters used for scaling in case you want to use RoPE with longermax_position_embeddings. - attention_bias (
bool, optional, defaults toFalse) — Whether to use a bias in the query, key, value and output projection layers during self-attention. - attention_dropout (
Union[float, int], optional, defaults to0.0) — The dropout ratio for the attention probabilities. - moe_intermediate_size (
int, optional, defaults to1408) — Intermediate size of the routed expert MLPs. - num_experts_per_tok (
int, optional, defaults to8) — Number of experts to route each token to. This is the top-k value for the token-choice routing. - n_shared_experts (
int, optional, defaults to1) — Number of shared experts. - n_routed_experts (
int, optional, defaults to128) — Number of routed experts. - routed_scaling_factor (
float, optional, defaults to1.0) — Scaling factor or routed experts. - n_group (
int, optional, defaults to 1) — Number of groups for routed experts. - topk_group (
int, optional, defaults to1) — Number of selected groups for each token (for each token, ensuring the selected experts is only withintopk_groupgroups). - first_k_dense_replace (
int, optional, defaults to 1) — Number of dense layers in shallow layers(embed->dense->dense->…->dense->moe->moe…->lm_head). --k dense layers—/ - norm_topk_prob (
bool, optional, defaults toTrue) — Whether to normalize the weights of the routed experts. - use_qk_norm (
bool, optional, defaults toFalse) — Whether to use query-key normalization in the attention. - bos_token_id (
int, optional) — Token id used for beginning-of-stream in the vocabulary. - eos_token_id (
Union[int, list[int]], optional) — Token id used for end-of-stream in the vocabulary. - pad_token_id (
int, optional) — Token id used for padding in the vocabulary.
This is the configuration class to store the configuration of a Glm4MoeModel. It is used to instantiate a Glm4 Moe model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the zai-org/GLM-4.5
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
Example:
>>> from transformers import Glm4MoeModel, Glm4MoeConfig
>>> # Initializing a Glm4Moe style configuration
>>> configuration = Glm4MoeConfig()
>>> # Initializing a model from the GLM-4-MOE-100B-A10B style configuration
>>> model = Glm4MoeModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configGlm4MoeModel
class transformers.Glm4MoeModel
< source >( config: Glm4MoeConfig )
Parameters
- config (Glm4MoeConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Glm4 Moe Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: torch.LongTensor | None = None attention_mask: torch.Tensor | None = None position_ids: torch.LongTensor | None = None past_key_values: transformers.cache_utils.Cache | None = None inputs_embeds: torch.FloatTensor | None = None use_cache: bool | None = None **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → BaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values).
Returns
BaseModelOutputWithPast or tuple(torch.FloatTensor)
A BaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Glm4MoeConfig) and inputs.
The Glm4MoeModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output.past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding.hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Glm4MoeForCausalLM
class transformers.Glm4MoeForCausalLM
< source >( config )
Parameters
- config (Glm4MoeForCausalLM) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Glm4 Moe Model for causal language modeling.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: torch.LongTensor | None = None attention_mask: torch.Tensor | None = None position_ids: torch.LongTensor | None = None past_key_values: transformers.cache_utils.Cache | None = None inputs_embeds: torch.FloatTensor | None = None labels: torch.LongTensor | None = None use_cache: bool | None = None logits_to_keep: int | torch.Tensor = 0 **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - logits_to_keep (
Union[int, torch.Tensor], optional, defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
CausalLMOutputWithPast or tuple(torch.FloatTensor)
A CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (Glm4MoeConfig) and inputs.
The Glm4MoeForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction).logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Example:
>>> from transformers import AutoTokenizer, Glm4MoeForCausalLM
>>> model = Glm4MoeForCausalLM.from_pretrained("meta-glm4_moe/Glm4Moe-2-7b-hf")
>>> tokenizer = AutoTokenizer.from_pretrained("meta-glm4_moe/Glm4Moe-2-7b-hf")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."