
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
🤗 Hugging Face | 📖 Github | 📑 Technical report
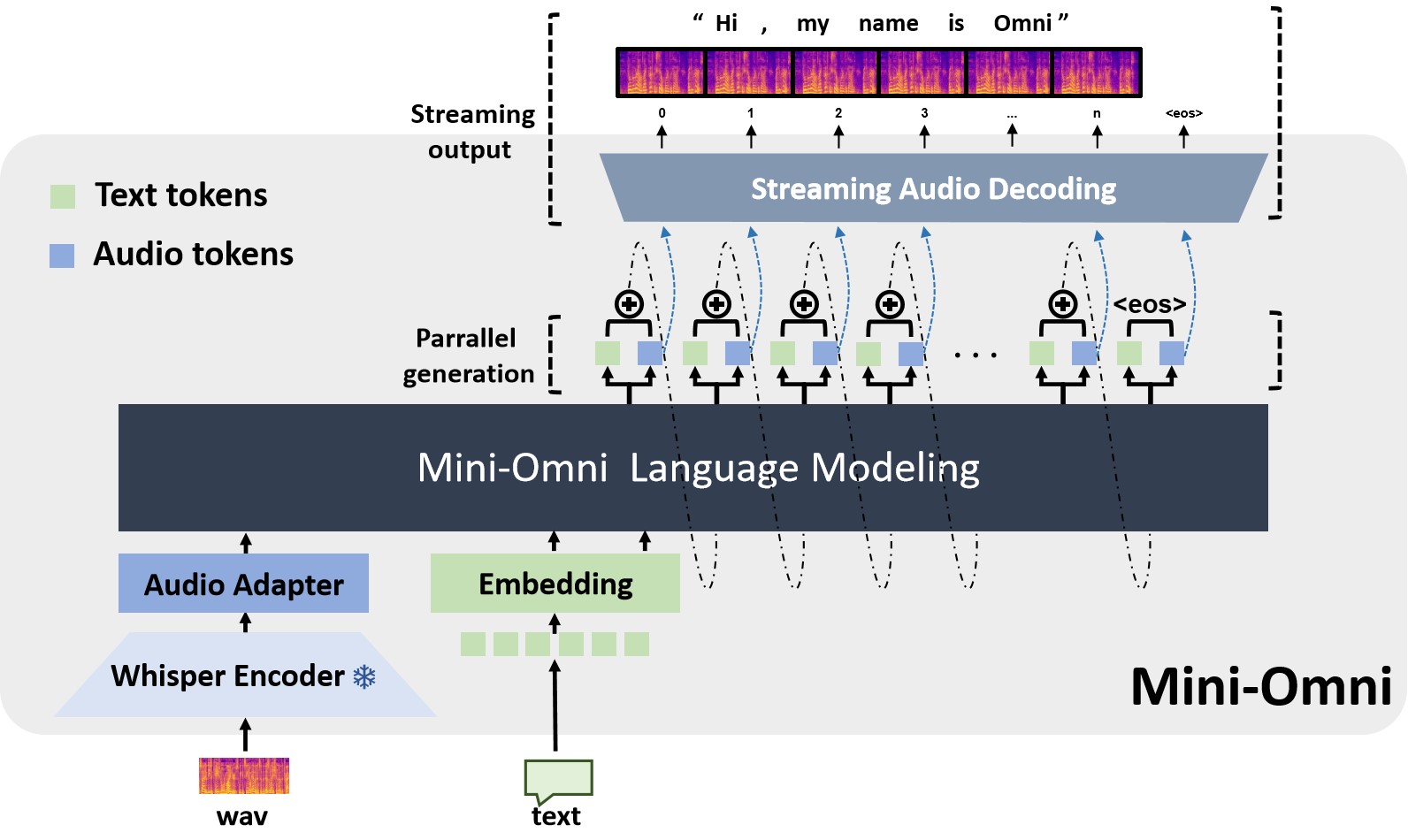
Mini-Omni is an open-source multimodel large language model that can hear, talk while thinking. Featuring real-time end-to-end speech input and streaming audio output conversational capabilities.
Features
✅ Real-time speech-to-speech conversational capabilities. No extra ASR or TTS models required.
✅ Talking while thinking, with the ability to generate text and audio at the same time.
✅ Streaming audio outupt capabilities.
✅ With "Audio-to-Text" and "Audio-to-Audio" batch inference to further boost the performance.
NOTE: please refer to the code repository for more details.
Install
Create a new conda environment and install the required packages:
conda create -n omni python=3.10
conda activate omni
git clone https://github.com/gpt-omni/mini-omni.git
cd mini-omni
pip install -r requirements.txt
Quick start
Interactive demo
- start server
conda activate omni
cd mini-omni
python3 server.py --ip '0.0.0.0' --port 60808
- run streamlit demo
NOTE: you need to run streamlit locally with PyAudio installed.
pip install PyAudio==0.2.14
API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
- run gradio demo
API_URL=http://0.0.0.0:60808/chat python3 webui/omni_gradio.py
example:
NOTE: need to unmute first. Gradio seems can not play audio stream instantly, so the latency feels a bit longer.
https://github.com/user-attachments/assets/29187680-4c42-47ff-b352-f0ea333496d9
Local test
conda activate omni
cd mini-omni
# test run the preset audio samples and questions
python inference.py