
File size: 18,763 Bytes
42159d0 711f8e1 42159d0 6ccf596 42159d0 bf7d587 42159d0 bf7d587 42159d0 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 |
---
license: apache-2.0
language:
- th
- en
base_model: iapp/chinda-qwen3-4b
pipeline_tag: text-generation
tags:
- thai
---
# 🇹🇭 Chinda Opensource Thai LLM 4B (GGUF Q4_K_M)
**Latest Model, Think in Thai, Answer in Thai, Built by Thai Startup**
Chinda Opensource Thai LLM 4B is iApp Technology's cutting-edge Thai language model that brings advanced thinking capabilities to the Thai AI ecosystem. Built on the latest Qwen3-4B architecture, Chinda represents our commitment to developing sovereign AI solutions for Thailand.
## 🚀 Quick Links
- **🌐 Demo:** [https://chindax.iapp.co.th](https://chindax.iapp.co.th) (Choose ChindaLLM 4b)
- **📦 Model Download:** [https://huggingface.co/iapp/chinda-qwen3-4b](https://huggingface.co/iapp/chinda-qwen3-4b)
- **🐋 Ollama:** [https://ollama.com/iapp/chinda-qwen3-4b](https://ollama.com/iapp/chinda-qwen3-4b)
- **🏠 Homepage:** [https://iapp.co.th/products/chinda-opensource-llm](https://iapp.co.th/products/chinda-opensource-llm)
- **📄 License:** Apache 2.0
## ✨ Key Features
### 🆓 **0. Free and Opensource for Everyone**
Chinda LLM 4B is completely free and open-source, enabling developers, researchers, and businesses to build Thai AI applications without restrictions.
### 🧠 **1. Advanced Thinking Model**
- **Highest score among Thai LLMs in 4B category**
- Seamless switching between thinking and non-thinking modes
- Superior reasoning capabilities for complex problems
- Can be turned off for efficient general-purpose dialogue
### 🇹🇭 **2. Exceptional Thai Language Accuracy**
- **98.4% accuracy** in outputting Thai language
- Prevents unwanted Chinese and foreign language outputs
- Specifically fine-tuned for Thai linguistic patterns
### 🆕 **3. Latest Architecture**
- Based on the cutting-edge **Qwen3-4B** model
- Incorporates the latest advancements in language modeling
- Optimized for both performance and efficiency
### 📜 **4. Apache 2.0 License**
- Commercial use permitted
- Modification and distribution allowed
- No restrictions on private use
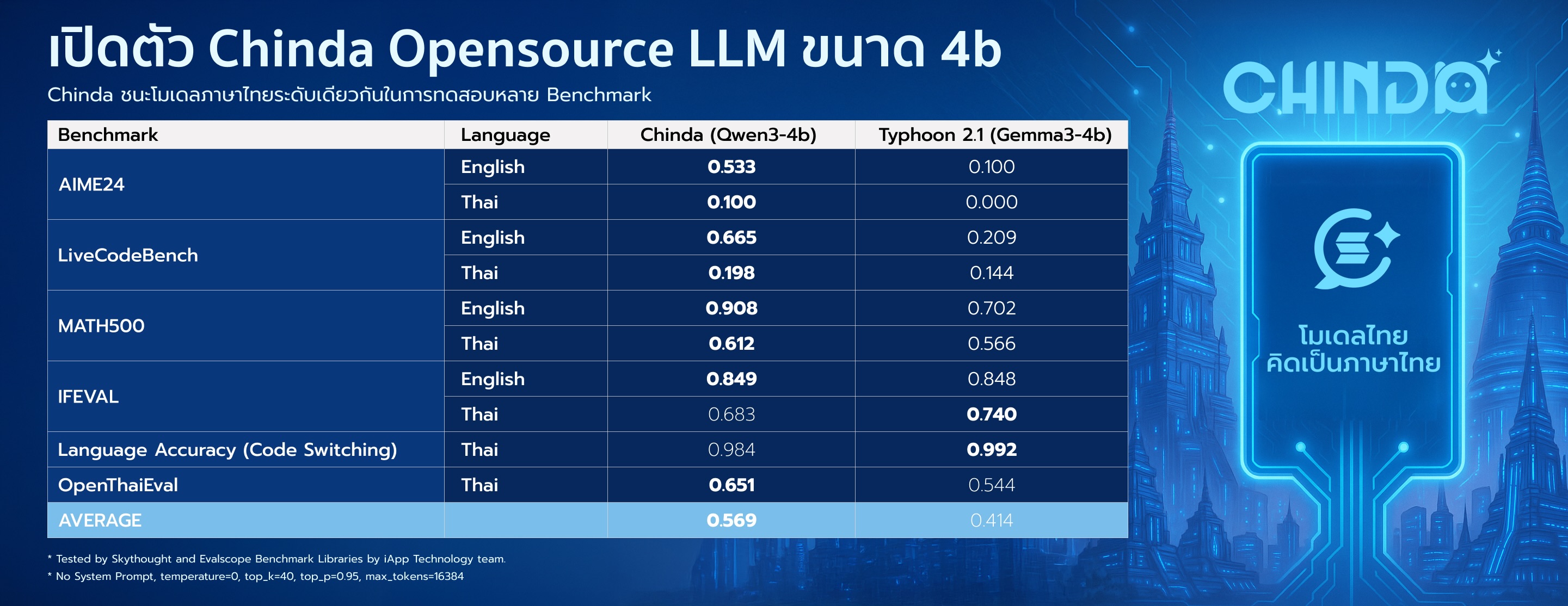
## 📊 Benchmark Results
Chinda LLM 4B demonstrates superior performance compared to other Thai language models in its category:
| Benchmark | Language | Chinda LLM 4B | Alternative* |
|-----------|----------|---------------|-------------|
| **AIME24** | English | **0.533** | 0.100 |
| | Thai | **0.100** | 0.000 |
| **LiveCodeBench** | English | **0.665** | 0.209 |
| | Thai | **0.198** | 0.144 |
| **MATH500** | English | **0.908** | 0.702 |
| | Thai | **0.612** | 0.566 |
| **IFEVAL** | English | **0.849** | 0.848 |
| | Thai | 0.683 | **0.740** |
| **Language Accuracy** | Thai | 0.984 | **0.992** |
| **OpenThaiEval** | Thai | **0.651** | 0.544 |
| **AVERAGE** | | **0.569** | 0.414 |
* Alternative: scb10x_typhoon2.1-gemma3-4b
* Tested by Skythought and Evalscope Benchmark Libraries by iApp Technology team. Results show Chinda LLM 4B achieving **37% better overall performance** than the nearest alternative.
## ✅ Suitable For
### 🔍 **1. RAG Applications (Sovereign AI)**
Perfect for building Retrieval-Augmented Generation systems that keep data processing within Thai sovereignty.
### 📱 **2. Mobile and Laptop Applications**
Reliable Small Language Model optimized for edge computing and personal devices.
### 🧮 **3. Math Calculation**
Excellent performance in mathematical reasoning and problem-solving.
### 💻 **4. Code Assistant**
Strong capabilities in code generation and programming assistance.
### ⚡ **5. Resource Efficiency**
Very fast inference with minimal GPU memory consumption, ideal for production deployments.
## ❌ Not Suitable For
### 📚 **Factual Questions Without Context**
As a 4B parameter model, it may hallucinate when asked for specific facts without provided context. Always use with RAG or provide relevant context for factual queries.
## 🛠️ Quick Start
### Installation
```bash
pip install transformers torch
```
### Basic Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "iapp/chinda-qwen3-4b"
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Prepare the model input
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable thinking mode for better reasoning
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
top_k=20,
do_sample=True
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Parse thinking content (if enabled)
try:
# Find </think> token (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 Thinking:", thinking_content)
print("💬 Response:", content)
```
### Switching Between Thinking and Non-Thinking Mode
#### Enable Thinking Mode (Default)
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable detailed reasoning
)
```
#### Disable Thinking Mode (For Efficiency)
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Fast response mode
)
```
### API Deployment
#### Using vLLM
```bash
pip install vllm>=0.8.5
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
```
#### Using SGLang
```bash
pip install sglang>=0.4.6.post1
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
```
#### Using Ollama (Easy Local Setup)
**Installation:**
```bash
# Install Ollama (if not already installed)
curl -fsSL https://ollama.com/install.sh | sh
# Pull Chinda LLM 4B model
ollama pull iapp/chinda-qwen3-4b
```
**Basic Usage:**
```bash
# Start chatting with Chinda LLM
ollama run iapp/chinda-qwen3-4b
# Example conversation
ollama run iapp/chinda-qwen3-4b "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
```
**API Server:**
```bash
# Start Ollama API server
ollama serve
# Use with curl
curl http://localhost:11434/api/generate -d '{
"model": "iapp/chinda-qwen3-4b",
"prompt": "สวัสดีครับ",
"stream": false
}'
```
**Model Specifications:**<br>
- **Size:** 2.5GB (quantized)<br>
- **Context Window:** 40K tokens<br>
- **Architecture:** Optimized for local deployment<br>
- **Performance:** Fast inference on consumer hardware<br>
## 🔧 Advanced Configuration
### Processing Long Texts
Chinda LLM 4B natively supports up to 32,768 tokens. For longer contexts, enable YaRN scaling:
```json
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
### Recommended Parameters
**For Thinking Mode:**
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
- Min-P: 0
**For Non-Thinking Mode:**
- Temperature: 0.7
- Top-P: 0.8
- Top-K: 20
- Min-P: 0
## 📝 Context Length & Template Format
### Context Length Support
- **Native Context Length:** 32,768 tokens
- **Extended Context Length:** Up to 131,072 tokens (with YaRN scaling)
- **Input + Output:** Total conversation length supported
- **Recommended Usage:** Keep conversations under 32K tokens for optimal performance
### Chat Template Format
Chinda LLM 4B uses a standardized chat template format for consistent interactions:
```python
# Basic template structure
messages = [
{"role": "system", "content": "You are a helpful Thai AI assistant."},
{"role": "user", "content": "สวัสดีครับ"},
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
]
# Apply template with thinking mode
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
```
### Template Structure
The template follows the standard conversational format:
```
<|im_start|>system
You are a helpful Thai AI assistant.<|im_end|>
<|im_start|>user
สวัสดีครับ<|im_end|>
<|im_start|>assistant
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
<|im_start|>user
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
<|im_start|>assistant
```
### Advanced Template Usage
```python
# Multi-turn conversation with thinking control
def create_conversation(messages, enable_thinking=True):
# Add system message if not present
if not messages or messages[0]["role"] != "system":
system_msg = {
"role": "system",
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
}
messages = [system_msg] + messages
# Apply chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
return text
# Example usage
conversation = [
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
]
prompt = create_conversation(conversation, enable_thinking=True)
```
### Dynamic Mode Switching
You can control thinking mode within conversations using special commands:
```python
# Enable thinking for complex problems
messages = [
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
]
# Disable thinking for quick responses
messages = [
{"role": "user", "content": "/no_think สวัสดี"}
]
```
### Context Management Best Practices
1. **Monitor Token Count:** Keep track of total tokens (input + output)
2. **Truncate Old Messages:** Remove oldest messages when approaching limits
3. **Use YaRN for Long Contexts:** Enable rope scaling for documents > 32K tokens
4. **Batch Processing:** For very long texts, consider chunking and processing in batches
```python
def manage_context(messages, max_tokens=30000):
"""Simple context management function"""
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
while total_tokens > max_tokens and len(messages) > 2:
# Keep system message and remove oldest user/assistant pair
if messages[1]["role"] == "user":
messages.pop(1) # Remove user message
if len(messages) > 1 and messages[1]["role"] == "assistant":
messages.pop(1) # Remove corresponding assistant message
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
return messages
```
## 🏢 Enterprise Support
For enterprise deployments, custom training, or commercial support, contact us at:
- **Email:** [email protected]
- **Website:** [iapp.co.th](https://iapp.co.th)
## ❓ Frequently Asked Questions
<details>
<summary><strong>🏷️ Why is it named "Chinda"?</strong></summary>
The name "Chinda" (จินดา) comes from "จินดามณี" (Chindamani), which is considered the first book of Thailand written by Phra Horathibodi (Sri Dharmasokaraja) in the Sukhothai period. Just as จินดามณี was a foundational text for Thai literature and learning, Chinda LLM represents our foundation for Thai sovereign AI - a model that truly understands and thinks in Thai, preserving and advancing Thai language capabilities in the digital age.
</details>
<details>
<summary><strong>⚖️ Can I use Chinda LLM 4B for commercial purposes?</strong></summary>
Yes! Chinda LLM 4B is released under the **Apache 2.0 License**, which allows:
- ✅ **Commercial use** - Use in commercial products and services
- ✅ **Research use** - Academic and research applications
- ✅ **Modification** - Adapt and modify the model
- ✅ **Distribution** - Share and redistribute the model
- ✅ **Private use** - Use for internal company projects
No restrictions on commercial applications - build and deploy freely!
</details>
<details>
<summary><strong>🧠 What's the difference between thinking and non-thinking mode?</strong></summary>
**Thinking Mode (`enable_thinking=True`):**
- Model shows its reasoning process in `<think>...</think>` blocks
- Better for complex problems, math, coding, logical reasoning
- Slower but more accurate responses
- Recommended for tasks requiring deep analysis
**Non-Thinking Mode (`enable_thinking=False`):**
- Direct answers without showing reasoning
- Faster responses for general conversations
- Better for simple queries and chat applications
- More efficient resource usage
You can switch between modes or let users control it dynamically using `/think` and `/no_think` commands.
</details>
<details>
<summary><strong>📊 How does Chinda LLM 4B compare to other Thai language models?</strong></summary>
Chinda LLM 4B achieves **37% better overall performance** compared to the nearest alternative:
- **Overall Average:** 0.569 vs 0.414 (alternative)
- **Math (MATH500):** 0.908 vs 0.702 (English), 0.612 vs 0.566 (Thai)
- **Code (LiveCodeBench):** 0.665 vs 0.209 (English), 0.198 vs 0.144 (Thai)
- **Thai Language Accuracy:** 98.4% (prevents Chinese/foreign text output)
- **OpenThaiEval:** 0.651 vs 0.544
It's currently the **highest-scoring Thai LLM in the 4B parameter category**.
</details>
<details>
<summary><strong>💻 What are the system requirements to run Chinda LLM 4B?</strong></summary>
**Minimum Requirements:**
- **GPU:** 8GB VRAM (RTX 3070/4060 Ti or better)
- **RAM:** 16GB system memory
- **Storage:** 8GB free space for model download
- **Python:** 3.8+ with PyTorch
**Recommended for Production:**
- **GPU:** 16GB+ VRAM (RTX 4080/A4000 or better)
- **RAM:** 32GB+ system memory
- **Storage:** SSD for faster loading
**CPU-Only Mode:** Possible but significantly slower (not recommended for production)
</details>
<details>
<summary><strong>🔧 Can I fine-tune Chinda LLM 4B for my specific use case?</strong></summary>
Yes! As an open-source model under Apache 2.0 license, you can:
- **Fine-tune** on your domain-specific data
- **Customize** for specific tasks or industries
- **Modify** the architecture if needed
- **Create derivatives** for specialized applications
Popular fine-tuning frameworks that work with Chinda:
- **Unsloth** - Fast and memory-efficient
- **LoRA/QLoRA** - Parameter-efficient fine-tuning
- **Hugging Face Transformers** - Full fine-tuning
- **Axolotl** - Advanced training configurations
Need help with fine-tuning? Contact our team at [email protected]
</details>
<details>
<summary><strong>🌍 What languages does Chinda LLM 4B support?</strong></summary>
**Primary Languages:**
- **Thai** - Native-level understanding and generation (98.4% accuracy)
- **English** - Strong performance across all benchmarks
**Additional Languages:**
- 100+ languages supported (inherited from Qwen3-4B base)
- Focus optimized for Thai-English bilingual tasks
- Code generation in multiple programming languages
**Special Features:**
- **Code-switching** between Thai and English
- **Translation** between Thai and other languages
- **Multilingual reasoning** capabilities
</details>
<details>
<summary><strong>🔍 Is the training data publicly available?</strong></summary>
The model weights are open-source, but the specific training datasets are not publicly released. However:
- **Base Model:** Built on Qwen3-4B (Alibaba's open foundation)
- **Thai Optimization:** Custom dataset curation for Thai language tasks
- **Quality Focus:** Carefully selected high-quality Thai content
- **Privacy Compliant:** No personal or sensitive data included
For research collaborations or dataset inquiries, contact our research team.
</details>
<details>
<summary><strong>🆘 How do I get support or report issues?</strong></summary>
**For Technical Issues:**
- **GitHub Issues:** Report bugs and technical problems
- **Hugging Face:** Model-specific questions and discussions
- **Documentation:** Check our comprehensive guides
**For Commercial Support:**
- **Email:** [email protected]
- **Enterprise Support:** Custom training, deployment assistance
- **Consulting:** Integration and optimization services
**Community Support:**
- **Thai AI Community:** Join discussions about Thai AI development
- **Developer Forums:** Connect with other Chinda users
</details>
<details>
<summary><strong>📥 How large is the model download and what format is it in?</strong></summary>
**Model Specifications:**
- **Parameters:** 4.02 billion (4B)
- **Download Size:** ~8GB (compressed)
- **Format:** Safetensors (recommended) and PyTorch
- **Precision:** BF16 (Brain Float 16)
**Download Options:**
- **Hugging Face Hub:** `huggingface.co/iapp/chinda-qwen3-4b`
- **Git LFS:** For version control integration
- **Direct Download:** Individual model files
- **Quantized Versions:** Available for reduced memory usage (GGUF, AWQ)
**Quantization Options:**
- **4-bit (GGUF):** ~2.5GB, runs on 4GB VRAM
- **8-bit:** ~4GB, balanced performance/memory
- **16-bit (Original):** ~8GB, full performance
</details>
## 📚 Citation
If you use Chinda LLM 4B in your research or projects, please cite:
```bibtex
@misc{chinda-llm-4b,
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
author={iApp Technology},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/iapp/chinda-qwen3-4b}
}
```
---
*Built with 🇹🇭 by iApp Technology - Empowering Thai Businesses with Sovereign AI Excellence*

**Powered by iApp Technology**
<i>Disclaimer: Provided responses are not guaranteed.</i> |