
Moodlens
This repository contains Moodlens, a lightweight CNN-based sentiment analysis model trained on Data collected from customer service departments. The model is designed to classify text as either Positive or Negative, making it ideal for applications such as review analysis, social media sentiment tracking, and more.
Key Features:
- Lightweight and Efficient: Moodlens is optimized to run on CPU, making it accessible for environments without GPU resources. It does not require high GPU RAM or specialized hardware.
- Trained on Diverse Data: The model is trained using a blend of open-source, synthetic, and augmented datasets derived from declassified, non-sensitive emails, ensuring strong performance across various text domains.
- Easy to Use: With a simple API, you can quickly integrate Moodlens into your applications for real-time sentiment analysis.
- Customizable: The model architecture and tokenizer are modular, allowing for easy modifications or fine-tuning for specific use cases.
Use Cases:
- Analyzing product reviews or customer feedback.
- Monitoring sentiment on social media platforms.
- Enhancing chatbots with sentiment-aware responses.
- Academic research in natural language processing (NLP).
Performance:
- Moodlens achieves competitive accuracy on sentiment classification tasks while maintaining a small memory footprint. It is designed to deliver fast predictions even on low-resource devices.
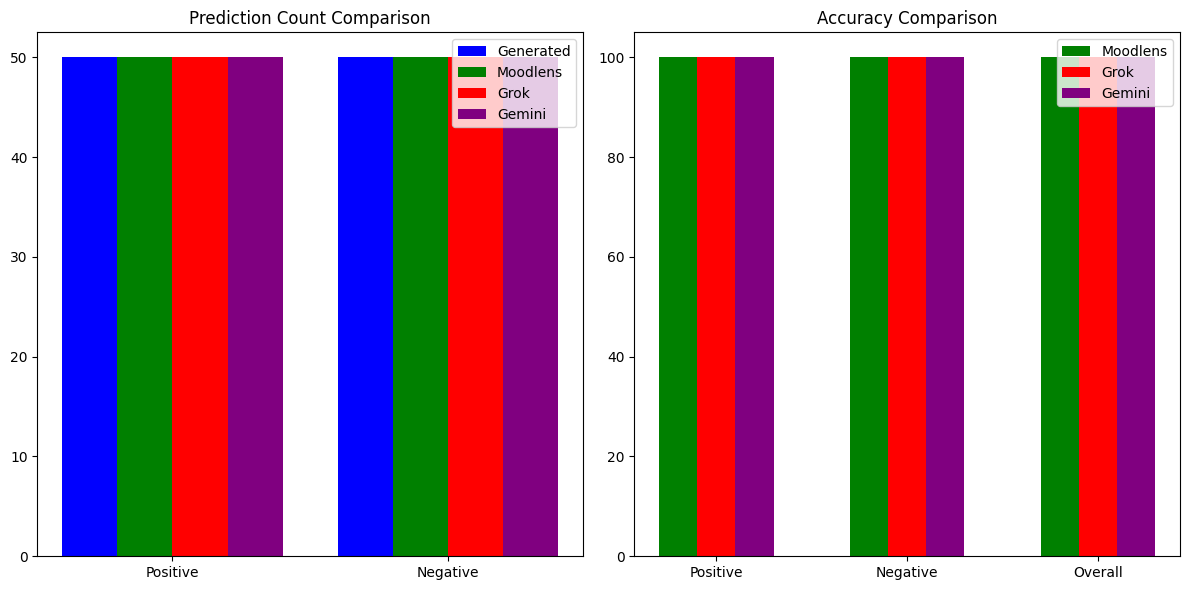
- We compared Moodlens Vs Grok-2 Vs Gemini 1.5 Flash to judge the accuracy of Moodlens.
- MoodLens achieved 100% accuracy for both positive and negative reviews, with an overall accuracy of 100%.
- Grok achieved 100% accuracy for positive reviews, 100% accuracy for negative reviews, and an overall accuracy of 100%.
- Gemini achieved 10% accuracy for positive reviews, 100% accuracy for negative reviews, and an overall accuracy of 100%.
- Various test were run with input tokens ranging 128, 512, 1096 and 2048
Model Details
- Architecture: Convolutional Neural Network (CNN) with multiple filter sizes.
- Parameters: 1 million parameters.
- Output Classes: 2 (Positive, Negative).
Files in the Repository
model_weights.safetensors: The trained model weights insafetensorsformat.vocab_and_hyperparams.json: Contains the vocabulary and hyperparameters used during training.train_bpe_tokenizer.json: Contains the vocabulary and hyperparameters used during training.inference.py: A Python script to load the model and perform inference.README.md: This file, providing instructions for using the model.
Output:
Sentiment: Positive, Probabilities: [[0.1, 0.9]]
Explanation:
- Sentiment: The predicted sentiment (Positive or Negative).
- Probabilities: A 2D array containing the probabilities for each class (Negative, Positive).
Model Performance
The model was trained on a combined dataset of IMDb and Amazon Polarity reviews. It achieves the following performance on the validation set:
- Accuracy: ~90%
- Loss: ~0.25
About
Hi there! I'm Imran Sarwar, a passionate AI enthusiast. Feel free to connect with me on LinkedIn.
Inference Providers
NEW
This model is not currently available via any of the supported third-party Inference Providers, and
the HF Inference API does not support pytorch models with pipeline type text-classification