
Overview
This is a fine-tuned version of the LLaMA-3.3-70B-Instruct model with a focus on Turkish language processing, leveraging LoRA (Low-Rank Adaptation) for efficient adaptation to specialized tasks. The model is trained to handle causal language modeling tasks, excelling at text generation, comprehension, and structured reasoning in Turkish.
Model Description
- Model Type: LLaMA (Large Language Model Meta AI)
- Version: 3.3-70B-Instruct
- Number of Parameters: 70 Billion
- Pretraining Task: Causal Language Modeling
- Training Objective: To fine-tune the base LLaMA model for improved Turkish language understanding with LoRA.
- Tokenizer: Special tokenizer adapted to Turkish, enabling efficient tokenization of the language.
- Training Data: A specialized Turkish corpus tailored for tasks such as reasoning, comprehension, and structured output generation.
Intended Use
This model is designed for tasks requiring Turkish text generation and comprehension, such as:
- Text Generation: Generating coherent, contextually relevant text in Turkish.
- Question Answering: Answering questions posed in Turkish, leveraging both the fine-tuned model and structural task handling.
- Text Summarization: Summarizing complex Turkish texts into concise outputs.
- Dialogue Systems: Enabling interactive dialogue systems that can converse in Turkish.
Model Parameters
- Max Position Embeddings: 131072
- Number of Attention Heads: 64
- Number of Hidden Layers: 80
- Vocab Size: 128256
- Pretraining TP: 1
- Rope Scaling Factors:
- High Frequency: 4.0
- Low Frequency: 1.0
- Tie Word Embeddings: False
- RMS Norm EPS: 1e-05
- Training Arguments:
- Epochs: 3
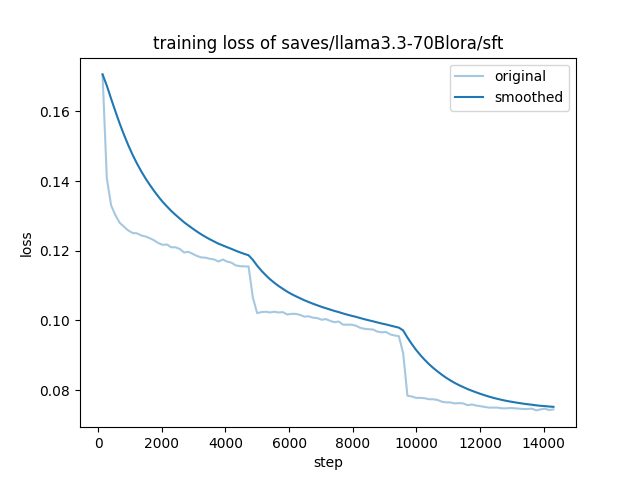
- Training Loss: 0.0995
- Training Samples per Second: 3.417
- Training Steps per Second: 0.027
- Training Runtime: 6 days, 4:59:46.09
Training Results
- Epoch: 3.0
- Total FLOPs: 224.76 TFLOPS (224,757,703 GF)
- Train Loss: 0.0995
- Train Runtime: 6 days, 4:59:46.09
- Train Samples per Second: 3.417
- Train Steps per Second: 0.027
- Training Loss Figure:
Evaluation Results
The model was evaluated on a dataset containing 67,882 examples. The evaluation results are as follows:
- Eval Loss: 0.108
- Eval Runtime: 2:39:22.40
- Eval Samples per Second: 7.099
- Eval Steps per Second: 0.887
Usage Example
To use the model for text generation in Turkish, you can load it with the transformers library like so:
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("newmindai/Llama-3.3-70B-Instruct-Instruct-V3")
tokenizer = LlamaTokenizer.from_pretrained("newmindai/Llama-3.3-70B-Instruct-Instruct-V3")
input_text = "Merhaba, nasılsınız?"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"], max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- Downloads last month
- 8
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support