
System Requirements ? (Crashed on 4x NVIDIA RTX 6000A)
#3
by
danielplominski
- opened

Hello Team,
we try to load it in a Docker instance, but the RAM fills up after a while and the Docker instance terminates with OOM.
- Ubuntu24 VM
- 128 GB RAM
- 4x NVIDIA RTX 6000A (Passthrough)
root@ai-ubuntu24gpu-large:~# cat /opt/NVIDIA/llama-3.3-nemotron-super-49b-v1.sh
#!/bin/sh
export CUDA_VISIBLE_DEVICES="0,1,2,3"
export NGC_API_KEY=XXX
export LOCAL_NIM_CACHE=/opt/NVIDIA/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
docker run \
--gpus='"device=0,1,2,3"' \
--runtime=nvidia \
--shm-size=16GB \
-it \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u 1000 \
-p 8000:8000 \
nvcr.io/nim/nvidia/llama-3.3-nemotron-super-49b-v1:latest
# EOF
root@ai-ubuntu24gpu-large:~#
Error
... 'llama3'}, 'rope_theta': 500000.0, 'tie_word_embeddings': False, 'torch_dtype': 'bfloat16', 'transformers_version': '4.48.3', 'use_cache': True, 'vocab_size': 128256}, max_prompt_embedding_table_size=None, max_encoder_input_len=None)
INFO 2025-03-21 08:06:38.698 build_utils.py:179] Detected model architecture: DeciLMForCausalLM
INFO 2025-03-21 08:08:50.15 build_utils.py:239] Total time of reading and converting rank1 checkpoint: 131.70 s
INFO 2025-03-21 08:08:50.17 build_utils.py:239] Total time of reading and converting rank0 checkpoint: 131.32 s
INFO 2025-03-21 08:08:50.328 build_utils.py:239] Total time of reading and converting rank3 checkpoint: 131.98 s
INFO 2025-03-21 08:08:50.328 build_utils.py:239] Total time of reading and converting rank2 checkpoint: 132.27 s
--------------------------------------------------------------------------
Primary job terminated normally, but 1 process returned
a non-zero exit code. Per user-direction, the job has been aborted.
--------------------------------------------------------------------------
--------------------------------------------------------------------------
mpirun noticed that process rank 1 with PID 0 on node 84b8fb153500 exited on signal 9 (Killed).
--------------------------------------------------------------------------
root@ai-ubuntu24gpu-large:/opt/NVIDIA#

At 49B it's gonna be hard to load that model, even with 128GB of ram.
If you just want to run the model, llama.cpp is your best bet: https://huggingface.co/bartowski/nvidia_Llama-3_3-Nemotron-Super-49B-v1-GGUF
It doesn't matter how much RAM the VM has, even with 256 GB RAM it doesn't load properly.
The GPU VRAM should be used, but this is not the case.
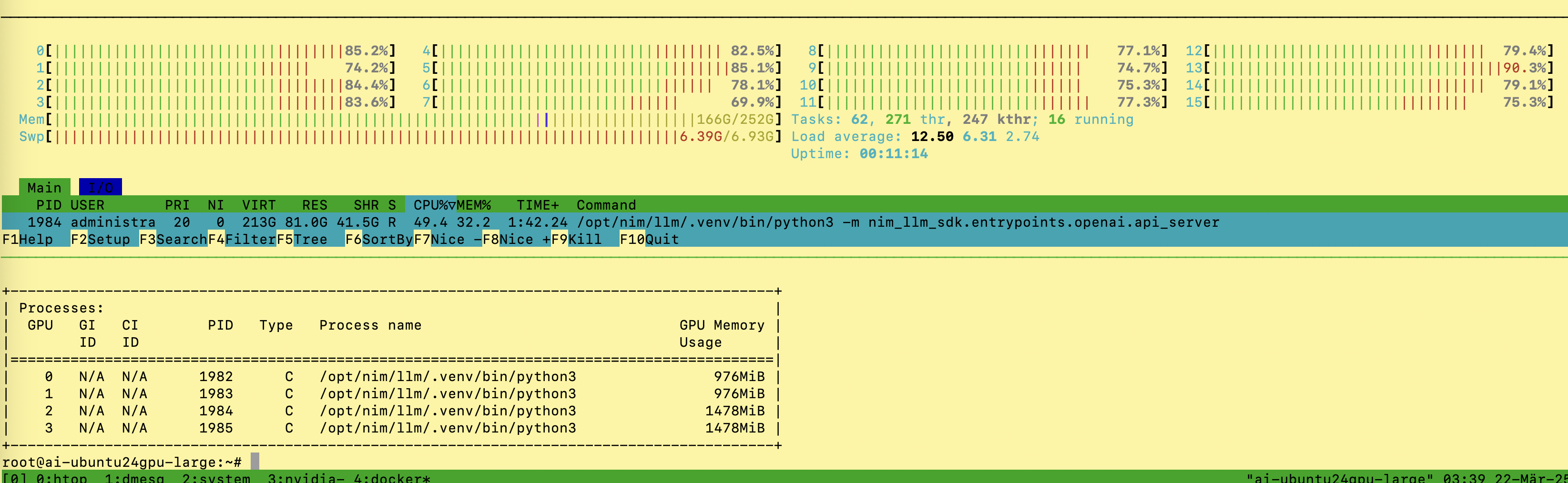
Unexpectedly, it did load after a while.
The GPU VRAM utilization is at the limit, the RAM occupancy at 128 GB, several cores are permanently utilized.
The performance is pretty good with test queries using CURL.

