
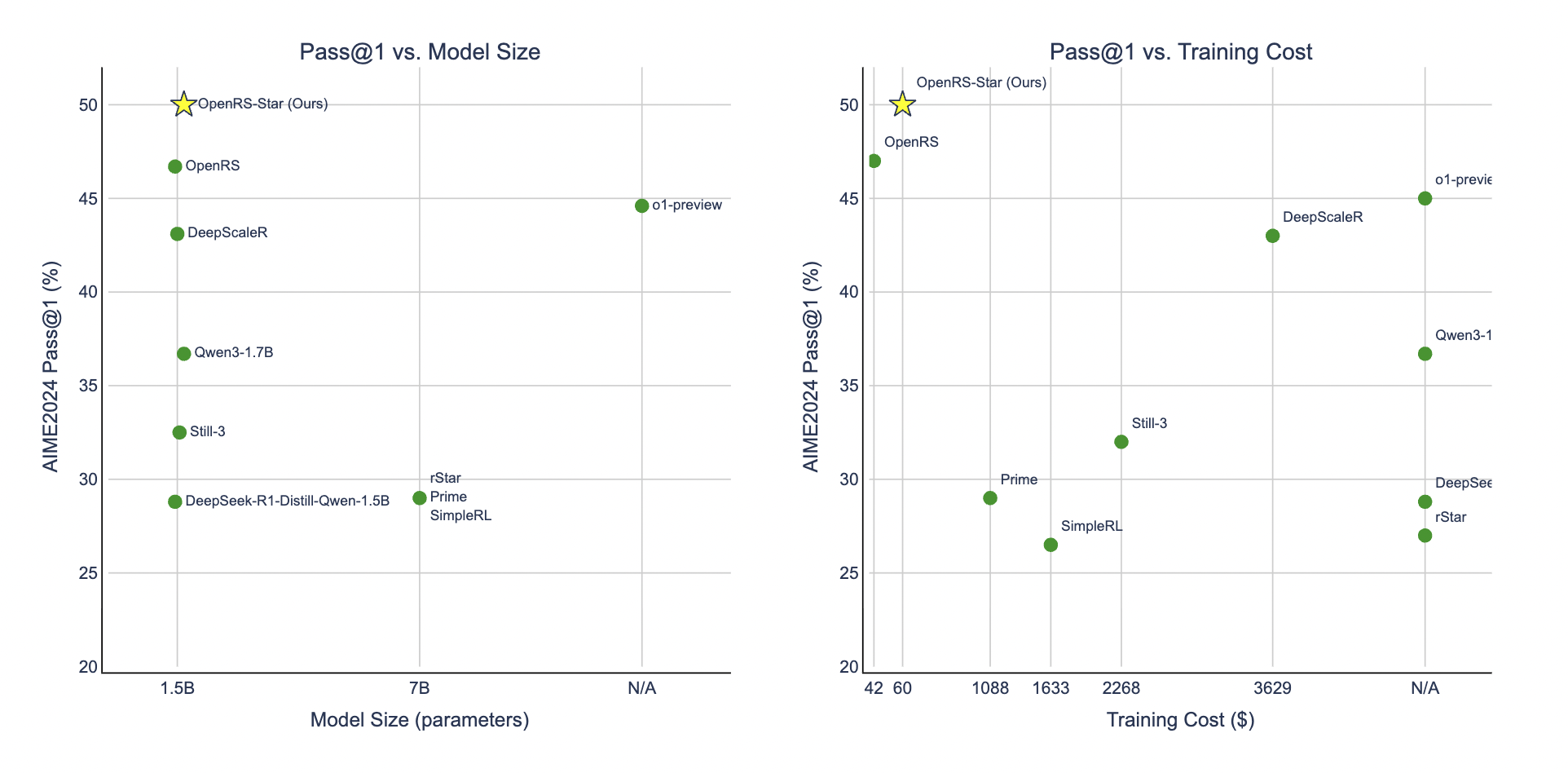
OpenRS-Star
OpenRS-Star extends the OpenRS project and shows that reinforcement learning can further improve reasoning in small LLMs under tight compute constraints.
This model fine-tunes Qwen3-1.7B using a two-stage length training approach and DAPO-style optimizations on a 7,000-sample mathematical reasoning dataset.
Training was completed using 2× A100s and 2× H200s, for a total cost of under $100.
Key Contributions
Improved Performance
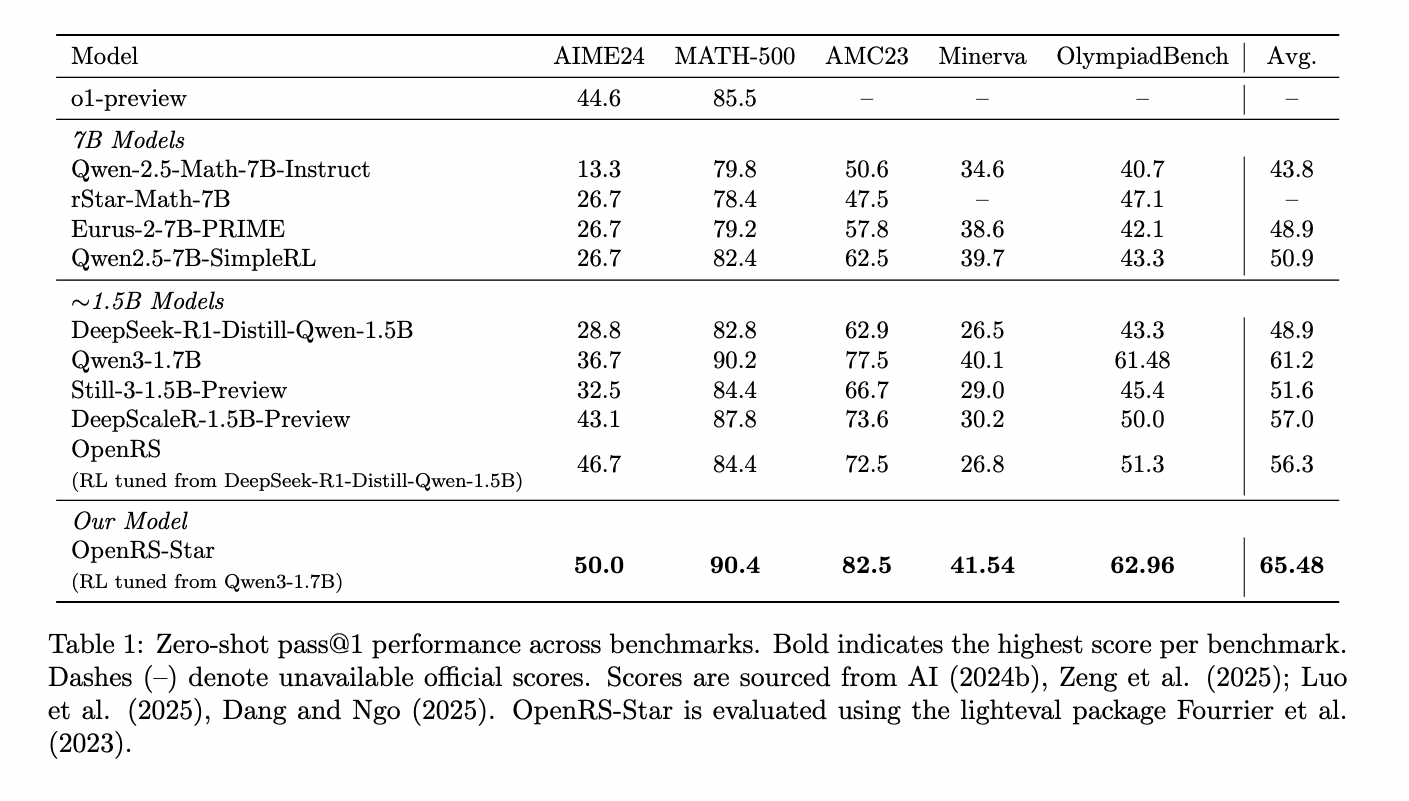
- AIME24: 50.0% (+13.3% over base model)
- AMC23: 82.5% (+5% over base model)
- Consistent or slightly improved results on MATH-500, OlympiadBench, and Minerva.
Multi-Stage Fine-Tuning
- Stage 1: 4k-token completions (50 PPO steps)
- Stage 2: 8k-token completions (38 PPO steps)
Optimizations
Applied GRPO + DAPO-style tricks for stability and learning signal quality:
- Clip-Higher
- Pure Accuracy Reward
- Reward masking for truncated answers
- Token-average loss
- Dynamic sampling filter
Efficient Training
- Total compute cost: under $100
- Training completed in fewer than 100 PPO steps total
For full details, see the GitHub repository.
- Downloads last month
- 7
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support