
VLM-R1-models
Collection
A collection of VLM-R1 Models
•
7 items
•
Updated
•
9
A OVD enhanced Qwen 2.5VL 3B with VLM-R1 reinforcement learning.
Cite: arxiv.org/abs/2504.07615
Project page: https://github.com/om-ai-lab/VLM-R1
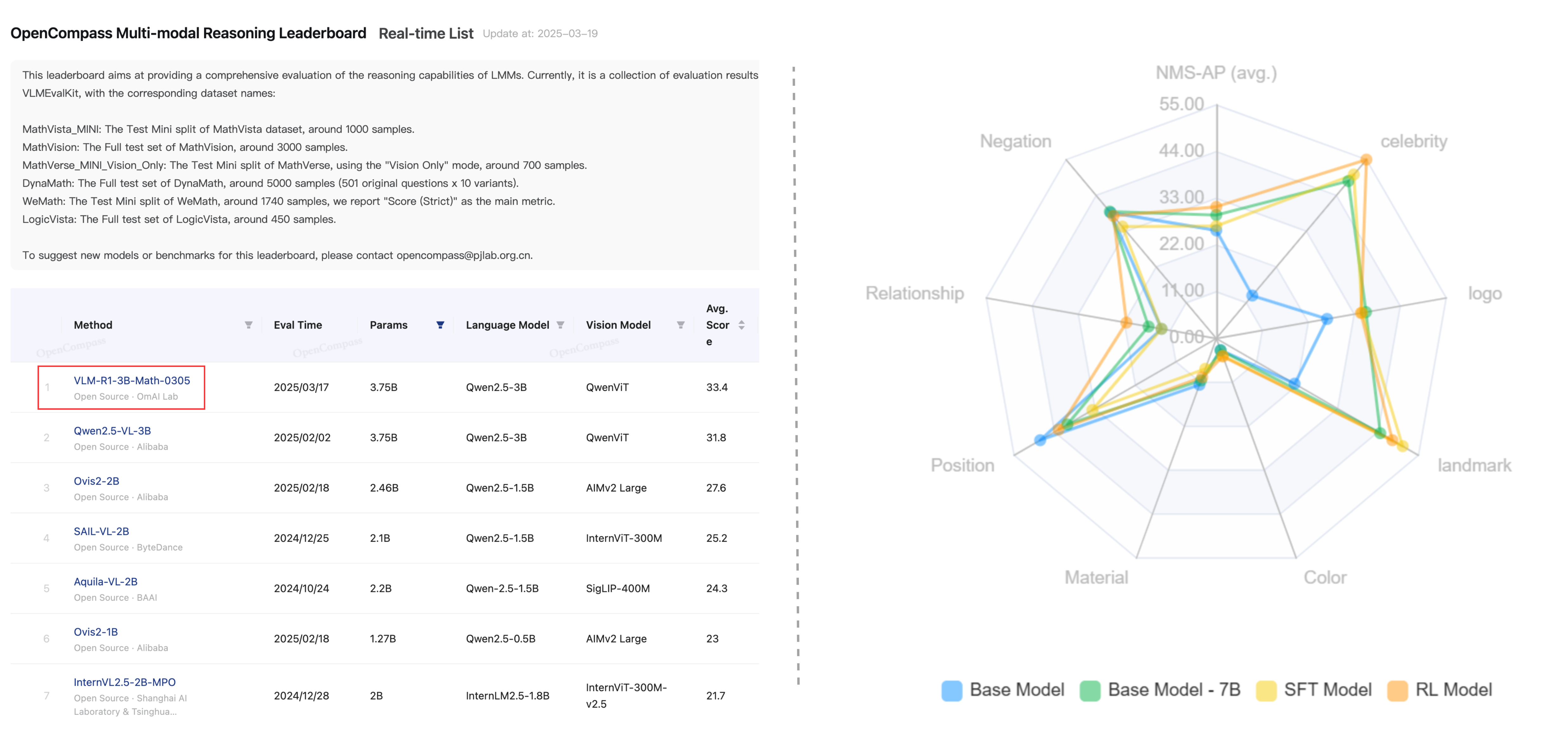
🎉 Our VLM-R1 Math model reaches the top of the Open-Compass Math Leaderboard (under 4B parameters) and OVD model achieves the state-of-the-art performance on OVDEval.
Since the introduction of Deepseek-R1, numerous works have emerged focusing on reproducing and improving upon it. In this project, we propose VLM-R1, a stable and generalizable R1-style Large Vision-Language Model.
Specifically, for the task of Referring Expression Comprehension (REC), we trained Qwen2.5-VL using both R1 and SFT approaches. The results reveal that, on the in-domain test data, the performance of the SFT model shows little change compared to that of the R1 model base model when the number of training steps is relatively small (100–600 steps), while the R1 model shows a steady improvement (as shown at the left of the figure below). More importantly, on the out-of-domain test data, the SFT model’s performance deteriorates slightly as the number of steps increases. Nevertheless, the RL model generalizes its reasoning ability to the out-of-domain data (as shown at the right of the figure below).
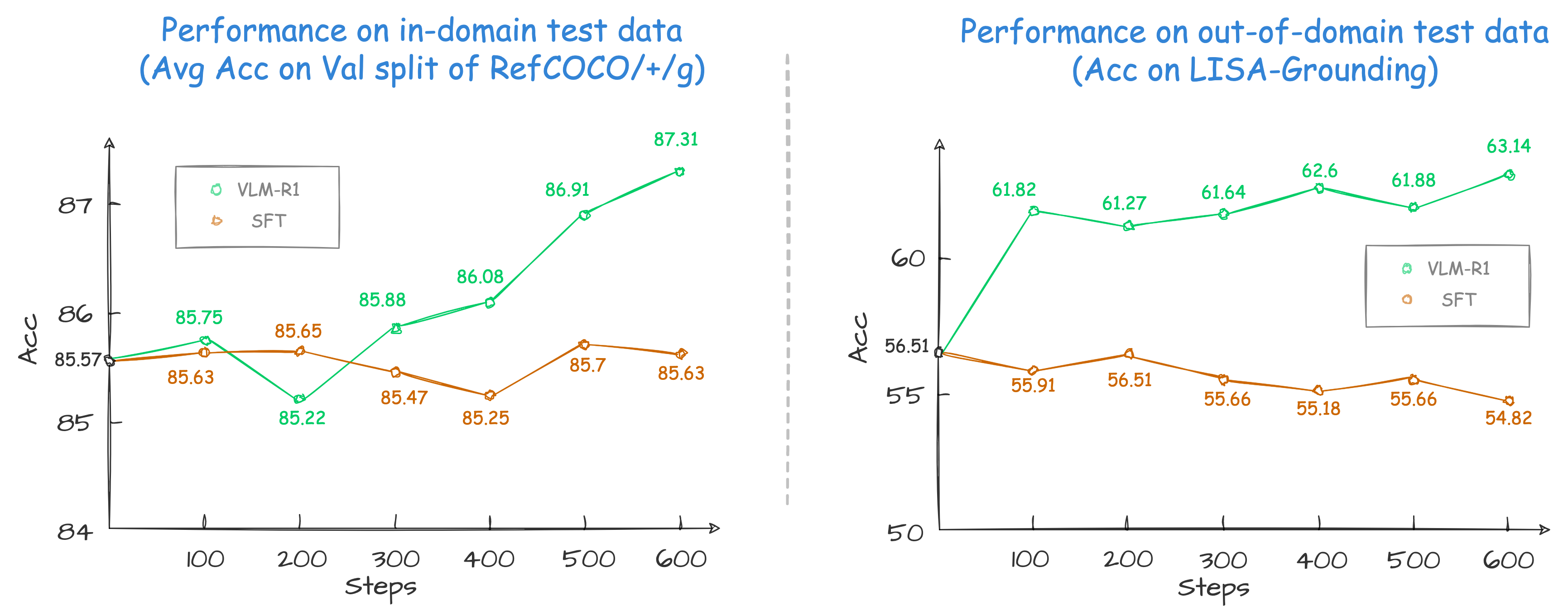
* We found previous REC SFT exps used a mismatch pixel config. Therefore, we re-run the study with the correct config on a more complex out-of-domain data. See our findings for details.
This repository supports:
Full Fine-tuning for GRPO: see run_grpo_rec.shFreeze Vision Modules: set freeze_vision_modules as true in the script.LoRA Fine-tuning for GRPO: see run_grpo_rec_lora.shMulti-node Training: see multinode_training_demo.shMulti-image Input Training: see run_grpo_gui.shFor your own data: see hereSupport various VLMs: see How to add a new model, now we support QwenVL and InternVL2025-04-11: 🔥🔥🔥 We release the technical report of VLM-R1, summarizing our main results and insights.2025-04-03: We add the odLength, weighted_sum, and cosine reward used in OVD task, please refer our blog post and findings to the details of the reward usage and see grpo_jsonl.py for code implementation.2025-03-24: 🔥 We release the findings of VLM-R1-OVD.2025-03-23: 🔥 We release the VLM-R1-OVD model weights and demo, which shows the state-of-the-art performance on OVDEval. Welcome to use it.2025-03-20: 🔥 We achieved SOTA results on OVDEval with our RL-based model, outperforming SFT baselines and specialized object detection models. Read our blog post for details on how reinforcement learning enhances object detection performance.2025-03-17: Our VLM-R1 Math model reaches the top of the Open-Compass Math Leaderboard (under 4B parameters). We have released the checkpoint.2025-03-15: We support multi-image input data. Check the format of multi-image input here. We also provide an example of multi-image script run_grpo_gui.sh, see here for details.2025-03-13: We support InternVL for GRPO. See run_grpo_rec_internvl.sh for details. The annotation json files used in InternVL are here. If you want to add your new model, please refer to How to add a new model.2025-03-02: We support LoRA Fine-tuning for GRPO. See run_grpo_rec_lora.sh for details.2025-02-27: We support the number of iterations per batch and epsilon value for clipping in the original GRPO algorithm with args: --num_iterations and --epsilon.2025-02-25: We support multi-node training for GRPO. See multinode_training_demo.sh for details.2025-02-21: We release the checkpoint of the VLM-R1 REC model.2025-02-20: We release the script for general data loading.2025-02-19: We incorporate an explanation of the SFT method.2025-02-17: We release the VLM-R1 REC Demo on Hugging Face Spaces.2025-02-15: We release the VLM-R1 repository and GRPO training script.OVD: Trained with VLM-R1, our Open-Vocabulary Detection (OVD) model achieves the state-of-the-art performance on OVDEval.Math: Through VLM-R1 training, our math model focuses on multimodal reasoning tasks and has achieved Top1 on the OpenCompass Multi-modal Reasoning Leaderboard among models < 4B.REC: Trained with VLM-R1, our Referring Expression Comprehension (REC) model showcases the superior performance on out-of-domain data and a series of reasoning-grounding tasks.| Version | Base VLM | Checkpoint | Task Type |
|---|---|---|---|
| VLM-R1-Qwen2.5VL-3B-OVD-0321 | Qwen2.5VL-3B | omlab/VLM-R1-Qwen2.5VL-3B-OVD-0321 | Open-Vocabulary Detection |
| VLM-R1-Qwen2.5VL-3B-Math-0305 | Qwen2.5VL-3B | omlab/VLM-R1-Qwen2.5VL-3B-Math-0305 | Multi-Modal Math |
| VLM-R1-Qwen2.5VL-3B-REC-500steps | Qwen2.5VL-3B | omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps | REC/Reasoning-Grounding |
conda create -n vlm-r1 python=3.10
conda activate vlm-r1
bash setup.sh
For full training instructions—including data preparation, hyperparameter setup, and how to reproduce our results—please refer to the Training Guide in our GitHub repository: VLM-R1
We would like to express our sincere gratitude to DeepSeek, Open-R1, QwenVL, Open-R1-Multimodal, R1-V, RefCOCO, RefGTA, LLaMA-Factory, OVDEval, GUI-Testing-Arena, and LISA for providing open-source resources that contributed to the development of this project.
If you find this project useful, welcome to cite us.
@article{shen2025vlm,
title={Vlm-r1: A stable and generalizable r1-style large vision-language model},
author={Shen, Haozhan and Liu, Peng and Li, Jingcheng and Fang, Chunxin and Ma, Yibo and Liao, Jiajia and Shen, Qiaoli and Zhang, Zilun and Zhao, Kangjia and Zhang, Qianqian and Xu, Ruochen and Zhao, Tiancheng },
journal={arXiv preprint arXiv:2504.07615},
year={2025}
}