

Update README.md
Browse files
README.md
CHANGED
|
@@ -14,10 +14,10 @@ A OVD enhanced Qwen 2.5VL 3B with VLM-R1 reinforcement learning.
|
|
| 14 |
|
| 15 |
Cite: arxiv.org/abs/2504.07615
|
| 16 |
|
| 17 |
-
Project page: https://om-ai-lab.github.io/
|
| 18 |
|
| 19 |
<div align="center">
|
| 20 |
-
<img src="./assets/performance4.png" width="900"/>
|
| 21 |
<div>
|
| 22 |
<font size=4>
|
| 23 |
<p>🎉 <b>Our VLM-R1 Math model reaches the top of the Open-Compass Math Leaderboard (under 4B parameters) and OVD model achieves the state-of-the-art performance on OVDEval.</b></p>
|
|
@@ -29,39 +29,41 @@ Since the introduction of [Deepseek-R1](https://github.com/deepseek-ai/DeepSeek-
|
|
| 29 |
|
| 30 |
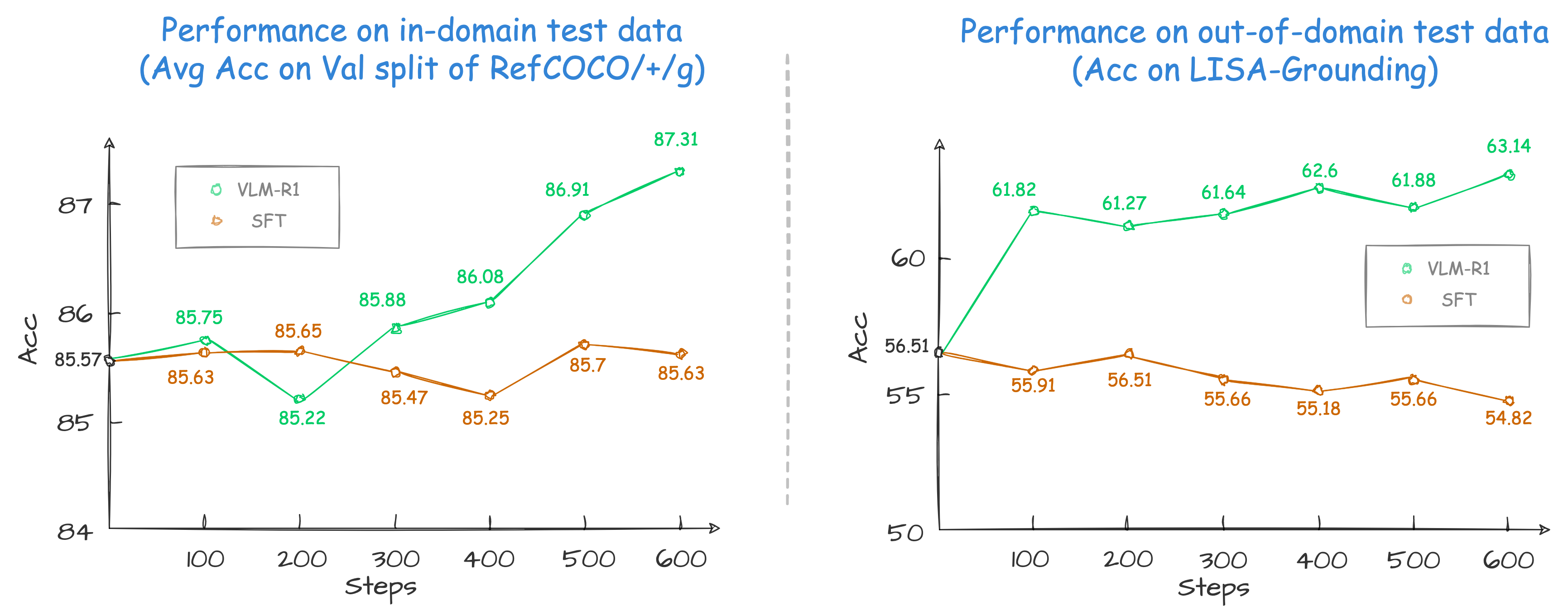
Specifically, for the task of Referring Expression Comprehension (REC), we trained [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL) using both R1 and SFT approaches. The results reveal that, on the in-domain test data, the performance of the SFT model shows little change compared to that of the R1 model base model when the number of training steps is relatively small (100–600 steps), while the R1 model shows a steady improvement (as shown at the left of the figure below). More importantly, on the out-of-domain test data, the SFT model’s performance deteriorates slightly as the number of steps increases. Nevertheless, the RL model generalizes its reasoning ability to the out-of-domain data (as shown at the right of the figure below).
|
| 31 |
|
| 32 |
-
|
|
|
|
|
|
|
| 33 |
\* *We found previous REC SFT exps used a mismatch pixel config. Therefore, we re-run the study with the correct config on a more complex out-of-domain data. See our [findings](https://om-ai-lab.github.io/2025_03_24.html) for details.*
|
| 34 |
|
| 35 |
## 🚀 Features
|
| 36 |
|
| 37 |
This repository supports:
|
| 38 |
|
| 39 |
-
- **`Full Fine-tuning for GRPO`**: see [run_grpo_rec.sh](src/open-r1-multimodal/run_scripts/run_grpo_rec.sh)
|
| 40 |
- **`Freeze Vision Modules`**: set `freeze_vision_modules` as `true` in the script.
|
| 41 |
-
- **`LoRA Fine-tuning for GRPO`**: see [run_grpo_rec_lora.sh](src/open-r1-multimodal/run_scripts/run_grpo_rec_lora.sh)
|
| 42 |
-
- **`Multi-node Training`**: see [multinode_training_demo.sh](src/open-r1-multimodal/run_scripts/
|
| 43 |
-
- **`Multi-image Input Training`**: see [run_grpo_gui.sh](src/open-r1-multimodal/run_scripts/run_grpo_gui.sh)
|
| 44 |
-
- **`For your own data`**: see [here](#for-your-own-data)
|
| 45 |
-
- **`Support various VLMs`**: see [How to add a new model](assets/add_new_model.md), now we support QwenVL and InternVL
|
| 46 |
|
| 47 |
## 🗞️ Update
|
| 48 |
|
| 49 |
- **`2025-04-11`**: 🔥🔥🔥 We release the [technical report](https://arxiv.org/abs/2504.07615) of VLM-R1, summarizing our main results and insights.
|
| 50 |
-
- **`2025-04-03`**: We add the `odLength`, `weighted_sum`, and `cosine` reward used in OVD task, please refer our [blog post](https://om-ai-lab.github.io/2025_03_20.html) and [findings](https://om-ai-lab.github.io/2025_03_24.html) to the details of the reward usage and see [grpo_jsonl.py](src/open-r1-multimodal/src/open_r1/grpo_jsonl.py) for code implementation.
|
| 51 |
- **`2025-03-24`**: 🔥 We release the [findings](https://om-ai-lab.github.io/2025_03_24.html) of VLM-R1-OVD.
|
| 52 |
- **`2025-03-23`**: 🔥 We release the VLM-R1-OVD [model weights](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-OVD-0321) and [demo](https://huggingface.co/spaces/omlab/VLM-R1-OVD), which shows the state-of-the-art performance on OVDEval. Welcome to use it.
|
| 53 |
- **`2025-03-20`**: 🔥 We achieved SOTA results on [OVDEval](https://github.com/om-ai-lab/OVDEval) with our RL-based model, outperforming SFT baselines and specialized object detection models. Read our [blog post](https://om-ai-lab.github.io/2025_03_20.html) for details on how reinforcement learning enhances object detection performance.
|
| 54 |
- **`2025-03-17`**: Our VLM-R1 Math model reaches the top of the [Open-Compass Math Leaderboard](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning/?m=REALTIME) (under 4B parameters). We have released the [checkpoint](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-Math-0305).
|
| 55 |
-
- **`2025-03-15`**: We support multi-image input data. Check the format of multi-image input [here](#for-your-own-data). We also provide an example of multi-image script [run_grpo_gui.sh](src/open-r1-multimodal/run_scripts/run_grpo_gui.sh), see [here](#for-your-own-data) for details.
|
| 56 |
-
- **`2025-03-13`**: We support InternVL for GRPO. See [run_grpo_rec_internvl.sh](src/open-r1-multimodal/run_scripts/run_grpo_rec_internvl.sh) for details. The annotation json files used in InternVL are [here](https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/rec_jsons_internvl.zip). If you want to add your new model, please refer to [How to add a new model](assets/add_new_model.md).
|
| 57 |
-
- **`2025-03-02`**: We support LoRA Fine-tuning for GRPO. See [run_grpo_rec_lora.sh](src/open-r1-multimodal/run_scripts/run_grpo_rec_lora.sh) for details.
|
| 58 |
- **`2025-02-27`**: We support the `number of iterations per batch` and `epsilon value for clipping` in the original GRPO algorithm with args: `--num_iterations` and `--epsilon`.
|
| 59 |
-
- **`2025-02-25`**: We support multi-node training for GRPO. See [multinode_training_demo.sh](src/open-r1-multimodal/run_scripts/
|
| 60 |
- **`2025-02-21`**: We release the [checkpoint](https://huggingface.co/omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps) of the VLM-R1 REC model.
|
| 61 |
-
- **`2025-02-20`**: We release the script for [general data loading](#for-your-own-data).
|
| 62 |
-
- **`2025-02-19`**: We incorporate an explanation of the [SFT](#sft) method.
|
| 63 |
- **`2025-02-17`**: We release the VLM-R1 REC [Demo](https://huggingface.co/spaces/omlab/VLM-R1-Referral-Expression) on Hugging Face Spaces.
|
| 64 |
-
- **`2025-02-15`**: We release the VLM-R1 repository and [GRPO](#grpo) training script.
|
| 65 |
|
| 66 |
## 🤖 Models
|
| 67 |
|
|
@@ -75,18 +77,7 @@ This repository supports:
|
|
| 75 |
| VLM-R1-Qwen2.5VL-3B-Math-0305 | Qwen2.5VL-3B | [omlab/VLM-R1-Qwen2.5VL-3B-Math-0305](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-Math-0305) | Multi-Modal Math |
|
| 76 |
| VLM-R1-Qwen2.5VL-3B-REC-500steps | Qwen2.5VL-3B | [omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps](https://huggingface.co/omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps) | REC/Reasoning-Grounding |
|
| 77 |
|
| 78 |
-
## 🎯 ToDo
|
| 79 |
|
| 80 |
-
- [X] Implement multi-node training.
|
| 81 |
-
- [X] Implement LoRA Fine-tuning.
|
| 82 |
-
- [X] Support more Multimodal LLMs.
|
| 83 |
-
- [X] Support multi-image input.
|
| 84 |
-
- [X] Release the VLM-R1 Math model.
|
| 85 |
-
- [X] Release the blog of VLM-R1.
|
| 86 |
-
- [X] Release the VLM-R1-OVD model.
|
| 87 |
-
- [X] Release the technical report of VLM-R1.
|
| 88 |
-
- [ ] Study cross task generalization.
|
| 89 |
-
- [ ] Enhance VLM for other tasks [welcome issue].
|
| 90 |
|
| 91 |
## 🛠️ Setup
|
| 92 |
|
|
@@ -96,149 +87,10 @@ conda activate vlm-r1
|
|
| 96 |
bash setup.sh
|
| 97 |
```
|
| 98 |
|
| 99 |
-
## 💪🏻 Training
|
| 100 |
-
|
| 101 |
-
### Referring Expression Comprehension (REC)
|
| 102 |
-
|
| 103 |
-
#### 📚 GRPO
|
| 104 |
-
|
| 105 |
-
1. Download the [COCO Train2014 image](https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/train2014.zip) and unzip it, and we refer to the image dir as `<your_image_root>`.
|
| 106 |
-
2. Download the [RefCOCO/+/g and LISA-Grounding Annotation files](https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/rec_jsons_processed.zip) and unzip it (LISA-Grounding is used for out-of-domain evaluation).
|
| 107 |
-
3. Write the path of the annotation files in the `src/open-r1-multimodal/data_config/rec.yaml` file.
|
| 108 |
-
|
| 109 |
-
```bash
|
| 110 |
-
datasets:
|
| 111 |
-
- json_path: /path/to/refcoco_train.json
|
| 112 |
-
- json_path: /path/to/refcocop_train.json
|
| 113 |
-
- json_path: /path/to/refcocog_train.json
|
| 114 |
-
```
|
| 115 |
-
|
| 116 |
-
4. ``bash src/open-r1-multimodal/run_scripts/run_grpo_rec.sh``
|
| 117 |
-
|
| 118 |
-
> [!NOTE]
|
| 119 |
-
> If you encounter 'CUDA out of memory' error, you can try to (1) set `gradient_checkpointing` as `true`, (2) reduce the `per_device_train_batch_size`, or (3) use lora.
|
| 120 |
-
|
| 121 |
-
```bash
|
| 122 |
-
cd src/open-r1-multimodal
|
| 123 |
-
|
| 124 |
-
torchrun --nproc_per_node="8" \
|
| 125 |
-
--nnodes="1" \
|
| 126 |
-
--node_rank="0" \
|
| 127 |
-
--master_addr="127.0.0.1" \
|
| 128 |
-
--master_port="12346" \
|
| 129 |
-
src/open_r1/grpo_rec.py \
|
| 130 |
-
--deepspeed local_scripts/zero3.json \
|
| 131 |
-
--output_dir output/$RUN_NAME \
|
| 132 |
-
--model_name_or_path Qwen/Qwen2.5-VL-3B-Instruct \
|
| 133 |
-
--dataset_name data_config/rec.yaml \
|
| 134 |
-
--image_root <your_image_root> \
|
| 135 |
-
--max_prompt_length 1024 \
|
| 136 |
-
--num_generations 8 \
|
| 137 |
-
--per_device_train_batch_size 8 \
|
| 138 |
-
--gradient_accumulation_steps 2 \
|
| 139 |
-
--logging_steps 1 \
|
| 140 |
-
--bf16 \
|
| 141 |
-
--torch_dtype bfloat16 \
|
| 142 |
-
--data_seed 42 \
|
| 143 |
-
--report_to wandb \
|
| 144 |
-
--gradient_checkpointing false \
|
| 145 |
-
--attn_implementation flash_attention_2 \
|
| 146 |
-
--num_train_epochs 2 \
|
| 147 |
-
--run_name $RUN_NAME \
|
| 148 |
-
--save_steps 100 \
|
| 149 |
-
--save_only_model true \
|
| 150 |
-
--freeze_vision_modules false # If you want to only finetune the language model, set this to true.
|
| 151 |
-
```
|
| 152 |
-
|
| 153 |
-
<div align="center">
|
| 154 |
-
<img src="./assets/iou.jpg" width="750"/>
|
| 155 |
-
</div>
|
| 156 |
-
<!--  -->
|
| 157 |
-
|
| 158 |
-
#### 📚 Multi-Node GRPO
|
| 159 |
-
|
| 160 |
-
For multi-node training, please refers to [multinode_training_demo.sh](src/open-r1-multimodal/multinode_training_demo.sh).
|
| 161 |
-
|
| 162 |
-
#### 📚 SFT
|
| 163 |
-
|
| 164 |
-
We use [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) to train the SFT model.
|
| 165 |
-
|
| 166 |
-
1. Clone the [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) repository and install the dependencies.
|
| 167 |
-
|
| 168 |
-
```bash
|
| 169 |
-
git clone https://github.com/hiyouga/LLaMA-Factory.git
|
| 170 |
-
cd LLaMA-Factory
|
| 171 |
-
pip install -e ".[torch,metrics]"
|
| 172 |
-
```
|
| 173 |
-
|
| 174 |
-
2. Download the dataset_info.json, mllm_rec_json.json, and qwen2_5_vl_full_sft.yaml we provided [here](https://huggingface.co/datasets/omlab/VLM-R1/tree/main/sft_related). Put the json files in the `LLaMA-Factory/data` directory and the yaml file in the `LLaMA-Factory/examples/train_full` directory.
|
| 175 |
-
3. Run the following command to train the SFT model.
|
| 176 |
-
|
| 177 |
-
```bash
|
| 178 |
-
llamafactory-cli train examples/train_full/qwen2_5_vl_full_sft.yaml
|
| 179 |
-
```
|
| 180 |
-
|
| 181 |
-
### For your own data
|
| 182 |
-
|
| 183 |
-
<div style="text-align: justify;">
|
| 184 |
-
|
| 185 |
-
We also support data loading the jsonl data of this format in [`src/open-r1-multimodal/src/open_r1/grpo_jsonl.py`](src/open-r1-multimodal/src/open_r1/grpo_jsonl.py). Please note that you may need to use different reward functions for your specialized tasks. Welcome to PR to add your own reward functions or share any other interesting findings!
|
| 186 |
-
|
| 187 |
-
</div>
|
| 188 |
-
|
| 189 |
-
The jsonl has the format as follows:
|
| 190 |
-
|
| 191 |
-
```json
|
| 192 |
-
{
|
| 193 |
-
"id": 1,
|
| 194 |
-
"image": "Clevr_CoGenT_TrainA_R1/data/images/CLEVR_trainA_000001_16885.png",
|
| 195 |
-
"conversations": [
|
| 196 |
-
{"from": "human", "value": "<image>What number of purple metallic balls are there?"},
|
| 197 |
-
{"from": "gpt", "value": "0"}
|
| 198 |
-
]
|
| 199 |
-
}
|
| 200 |
-
```
|
| 201 |
-
|
| 202 |
-
If you want to use multi-image input, you can use the following format:
|
| 203 |
|
| 204 |
-
|
| 205 |
-
{
|
| 206 |
-
"id": 1,
|
| 207 |
-
"image": ["Clevr_CoGenT_TrainA_R1/data/images/CLEVR_trainA_000001_16885.png", "Clevr_CoGenT_TrainA_R1/data/images/CLEVR_trainA_000001_16886.png"],
|
| 208 |
-
"conversations": [
|
| 209 |
-
{"from": "human", "value": "<image><image>What number of purple metallic balls in total within the two images?"},
|
| 210 |
-
{"from": "gpt", "value": "3"}
|
| 211 |
-
]
|
| 212 |
-
}
|
| 213 |
-
```
|
| 214 |
-
|
| 215 |
-
> [!NOTE]
|
| 216 |
-
> The image path in the jsonl file should be relative to the image folder specified in `--image_folders`. The absolute path of the input image is constructed as `os.path.join(image_folder, data['image'])`. For example:
|
| 217 |
-
|
| 218 |
-
- If your jsonl has `"image": "folder1/image1.jpg"`
|
| 219 |
-
- And you specify `--image_folders "/path/to/images/"`
|
| 220 |
-
- The full image path will be `/path/to/images/folder1/image1.jpg`
|
| 221 |
-
|
| 222 |
-
Multiple data files and image folders can be specified using ":" as a separator:
|
| 223 |
-
|
| 224 |
-
```bash
|
| 225 |
-
--data_file_paths /path/to/data1.jsonl:/path/to/data2.jsonl \
|
| 226 |
-
--image_folders /path/to/images1/:/path/to/images2/
|
| 227 |
-
```
|
| 228 |
-
|
| 229 |
-
The script can be run like this:
|
| 230 |
-
|
| 231 |
-
```bash
|
| 232 |
-
torchrun --nproc_per_node="8" \
|
| 233 |
-
--nnodes="1" \
|
| 234 |
-
--node_rank="0" \
|
| 235 |
-
--master_addr="127.0.0.1" \
|
| 236 |
-
cd src/eval
|
| 237 |
|
| 238 |
-
|
| 239 |
-
torchrun --nproc_per_node="X" test_rec_r1.py # for GRPO. 'X' is the number of GPUs you have.
|
| 240 |
-
torchrun --nproc_per_node="X" test_rec_baseline.py # for SFT.
|
| 241 |
-
```
|
| 242 |
|
| 243 |
## 🤝 Acknowledgements
|
| 244 |
|
|
|
|
| 14 |
|
| 15 |
Cite: arxiv.org/abs/2504.07615
|
| 16 |
|
| 17 |
+
Project page: https://om-ai-lab.github.io/2025_03_24.html
|
| 18 |
|
| 19 |
<div align="center">
|
| 20 |
+
<!-- <img src="./assets/performance4.png" width="900"/> -->
|
| 21 |
<div>
|
| 22 |
<font size=4>
|
| 23 |
<p>🎉 <b>Our VLM-R1 Math model reaches the top of the Open-Compass Math Leaderboard (under 4B parameters) and OVD model achieves the state-of-the-art performance on OVDEval.</b></p>
|
|
|
|
| 29 |
|
| 30 |
Specifically, for the task of Referring Expression Comprehension (REC), we trained [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL) using both R1 and SFT approaches. The results reveal that, on the in-domain test data, the performance of the SFT model shows little change compared to that of the R1 model base model when the number of training steps is relatively small (100–600 steps), while the R1 model shows a steady improvement (as shown at the left of the figure below). More importantly, on the out-of-domain test data, the SFT model’s performance deteriorates slightly as the number of steps increases. Nevertheless, the RL model generalizes its reasoning ability to the out-of-domain data (as shown at the right of the figure below).
|
| 31 |
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
\* *We found previous REC SFT exps used a mismatch pixel config. Therefore, we re-run the study with the correct config on a more complex out-of-domain data. See our [findings](https://om-ai-lab.github.io/2025_03_24.html) for details.*
|
| 36 |
|
| 37 |
## 🚀 Features
|
| 38 |
|
| 39 |
This repository supports:
|
| 40 |
|
| 41 |
+
- **`Full Fine-tuning for GRPO`**: see [run_grpo_rec.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_rec.sh)
|
| 42 |
- **`Freeze Vision Modules`**: set `freeze_vision_modules` as `true` in the script.
|
| 43 |
+
- **`LoRA Fine-tuning for GRPO`**: see [run_grpo_rec_lora.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_rec_lora.sh)
|
| 44 |
+
- **`Multi-node Training`**: see [multinode_training_demo.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/multinode_training_demo.sh)
|
| 45 |
+
- **`Multi-image Input Training`**: see [run_grpo_gui.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_gui.sh)
|
| 46 |
+
- **`For your own data`**: see [here](https://github.com/om-ai-lab/VLM-R1/blob/main/README.md#for-your-own-data)
|
| 47 |
+
- **`Support various VLMs`**: see [How to add a new model](https://github.com/om-ai-lab/VLM-R1/blob/main/assets/add_new_model.md), now we support QwenVL and InternVL
|
| 48 |
|
| 49 |
## 🗞️ Update
|
| 50 |
|
| 51 |
- **`2025-04-11`**: 🔥🔥🔥 We release the [technical report](https://arxiv.org/abs/2504.07615) of VLM-R1, summarizing our main results and insights.
|
| 52 |
+
- **`2025-04-03`**: We add the `odLength`, `weighted_sum`, and `cosine` reward used in OVD task, please refer our [blog post](https://om-ai-lab.github.io/2025_03_20.html) and [findings](https://om-ai-lab.github.io/2025_03_24.html) to the details of the reward usage and see [grpo_jsonl.py](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/src/open_r1/grpo_jsonl.py) for code implementation.
|
| 53 |
- **`2025-03-24`**: 🔥 We release the [findings](https://om-ai-lab.github.io/2025_03_24.html) of VLM-R1-OVD.
|
| 54 |
- **`2025-03-23`**: 🔥 We release the VLM-R1-OVD [model weights](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-OVD-0321) and [demo](https://huggingface.co/spaces/omlab/VLM-R1-OVD), which shows the state-of-the-art performance on OVDEval. Welcome to use it.
|
| 55 |
- **`2025-03-20`**: 🔥 We achieved SOTA results on [OVDEval](https://github.com/om-ai-lab/OVDEval) with our RL-based model, outperforming SFT baselines and specialized object detection models. Read our [blog post](https://om-ai-lab.github.io/2025_03_20.html) for details on how reinforcement learning enhances object detection performance.
|
| 56 |
- **`2025-03-17`**: Our VLM-R1 Math model reaches the top of the [Open-Compass Math Leaderboard](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning/?m=REALTIME) (under 4B parameters). We have released the [checkpoint](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-Math-0305).
|
| 57 |
+
- **`2025-03-15`**: We support multi-image input data. Check the format of multi-image input [here](https://github.com/om-ai-lab/VLM-R1/blob/main/README.md#for-your-own-data). We also provide an example of multi-image script [run_grpo_gui.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_gui.sh), see [here](https://github.com/om-ai-lab/VLM-R1/blob/main/README.md#for-your-own-data) for details.
|
| 58 |
+
- **`2025-03-13`**: We support InternVL for GRPO. See [run_grpo_rec_internvl.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_rec_internvl.sh) for details. The annotation json files used in InternVL are [here](https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/rec_jsons_internvl.zip). If you want to add your new model, please refer to [How to add a new model](https://github.com/om-ai-lab/VLM-R1/blob/main/assets/add_new_model.md).
|
| 59 |
+
- **`2025-03-02`**: We support LoRA Fine-tuning for GRPO. See [run_grpo_rec_lora.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/run_grpo_rec_lora.sh) for details.
|
| 60 |
- **`2025-02-27`**: We support the `number of iterations per batch` and `epsilon value for clipping` in the original GRPO algorithm with args: `--num_iterations` and `--epsilon`.
|
| 61 |
+
- **`2025-02-25`**: We support multi-node training for GRPO. See [multinode_training_demo.sh](https://github.com/om-ai-lab/VLM-R1/blob/main/src/open-r1-multimodal/run_scripts/multinode_training_demo.sh) for details.
|
| 62 |
- **`2025-02-21`**: We release the [checkpoint](https://huggingface.co/omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps) of the VLM-R1 REC model.
|
| 63 |
+
- **`2025-02-20`**: We release the script for [general data loading](https://github.com/om-ai-lab/VLM-R1/blob/main/README.md#for-your-own-data).
|
| 64 |
+
- **`2025-02-19`**: We incorporate an explanation of the [SFT](https://github.com/om-ai-lab/VLM-R1/tree/main#sft) method.
|
| 65 |
- **`2025-02-17`**: We release the VLM-R1 REC [Demo](https://huggingface.co/spaces/omlab/VLM-R1-Referral-Expression) on Hugging Face Spaces.
|
| 66 |
+
- **`2025-02-15`**: We release the VLM-R1 repository and [GRPO](https://github.com/om-ai-lab/VLM-R1/tree/main#grpo) training script.
|
| 67 |
|
| 68 |
## 🤖 Models
|
| 69 |
|
|
|
|
| 77 |
| VLM-R1-Qwen2.5VL-3B-Math-0305 | Qwen2.5VL-3B | [omlab/VLM-R1-Qwen2.5VL-3B-Math-0305](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-Math-0305) | Multi-Modal Math |
|
| 78 |
| VLM-R1-Qwen2.5VL-3B-REC-500steps | Qwen2.5VL-3B | [omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps](https://huggingface.co/omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps) | REC/Reasoning-Grounding |
|
| 79 |
|
|
|
|
| 80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
|
| 82 |
## 🛠️ Setup
|
| 83 |
|
|
|
|
| 87 |
bash setup.sh
|
| 88 |
```
|
| 89 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 90 |
|
| 91 |
+
## 💪🏻 Training
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 92 |
|
| 93 |
+
For full training instructions—including data preparation, hyperparameter setup, and how to reproduce our results—please refer to the Training Guide in our GitHub repository: [VLM-R1](https://github.com/om-ai-lab/VLM-R1)
|
|
|
|
|
|
|
|
|
|
| 94 |
|
| 95 |
## 🤝 Acknowledgements
|
| 96 |
|