
MiniCPM-o & MiniCPM-V
Collection
Multimodal models with leading performance.
•
28 items
•
Updated
•
57
GitHub | CookBook | Technical Report | Demo
MiniCPM-V 4.5 is the latest and most capable model in the MiniCPM-V series. The model is built on Qwen3-8B and SigLIP2-400M with a total of 8B parameters. It exhibits a significant performance improvement over previous MiniCPM-V and MiniCPM-o models, and introduces new useful features. Notable features of MiniCPM-V 4.5 include:
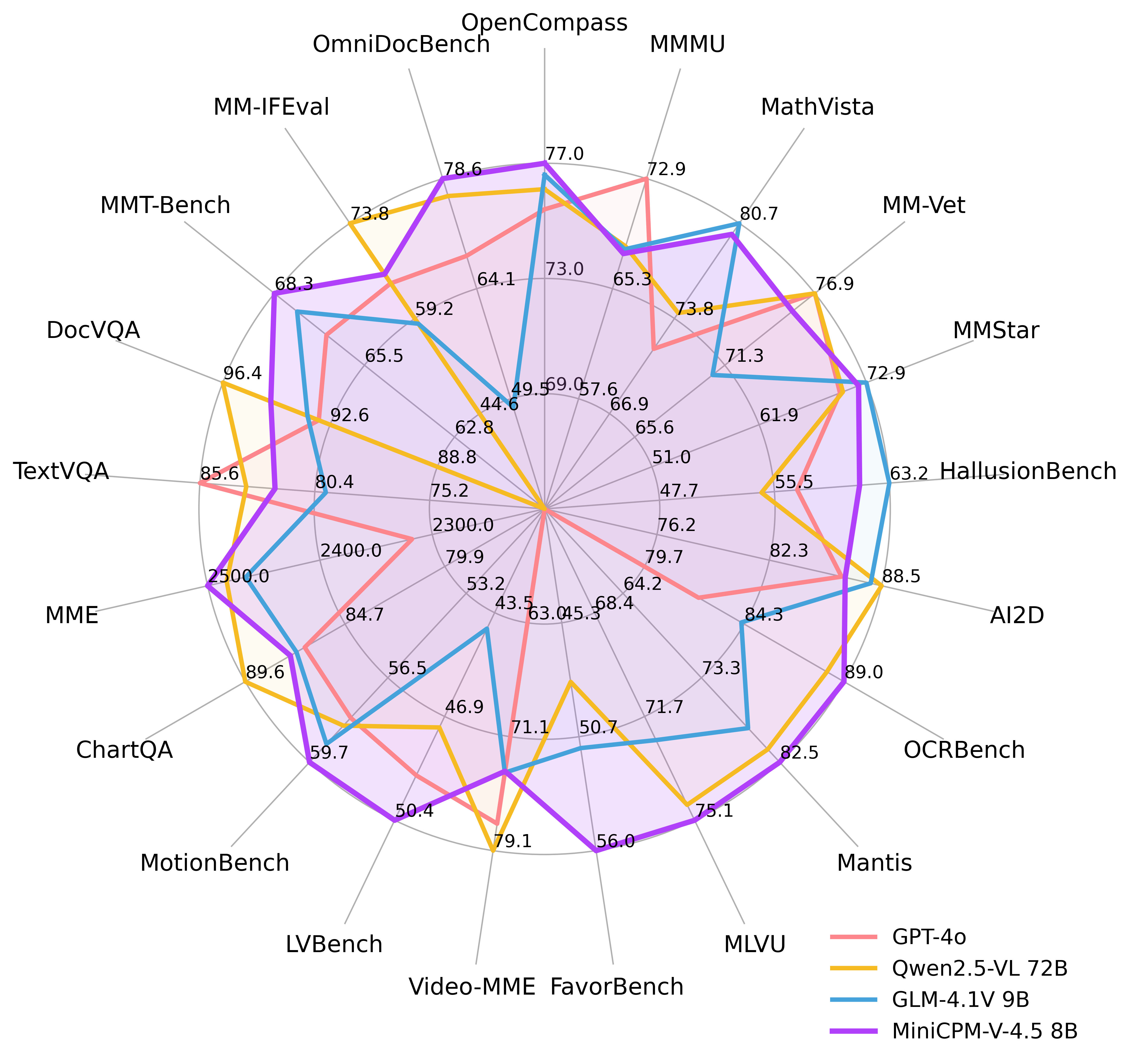
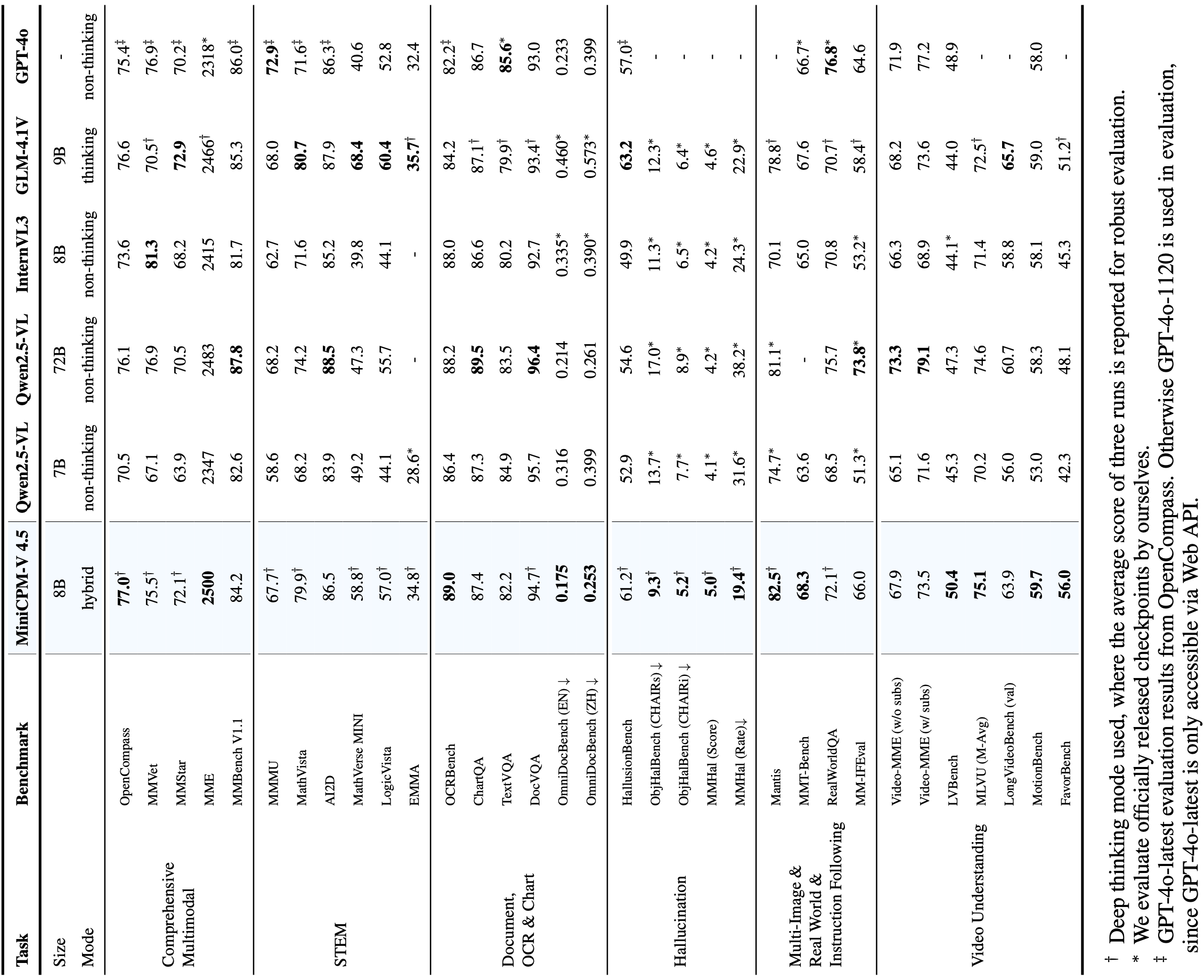
🔥 State-of-the-art Vision-Language Capability. MiniCPM-V 4.5 achieves an average score of 77.0 on OpenCompass, a comprehensive evaluation of 8 popular benchmarks. With only 8B parameters, it surpasses widely used proprietary models like GPT-4o-latest, Gemini-2.0 Pro, and strong open-source models like Qwen2.5-VL 72B for vision-language capabilities, making it the most performant MLLM under 30B parameters.
🎬 Efficient High-FPS and Long Video Understanding. Powered by a new unified 3D-Resampler over images and videos, MiniCPM-V 4.5 can now achieve 96x compression rate for video tokens, where 6 448x448 video frames can be jointly compressed into 64 video tokens (normally 1,536 tokens for most MLLMs). This means that the model can perceive significantly more video frames without increasing the LLM inference cost. This brings state-of-the-art high-FPS (up to 10FPS) video understanding and long video understanding capabilities on Video-MME, LVBench, MLVU, MotionBench, FavorBench, etc., efficiently.
⚙️ Controllable Hybrid Fast/Deep Thinking. MiniCPM-V 4.5 supports both fast thinking for efficient frequent usage with competitive performance, and deep thinking for more complex problem solving. To cover efficiency and performance trade-offs in different user scenarios, this fast/deep thinking mode can be switched in a highly controlled fashion.
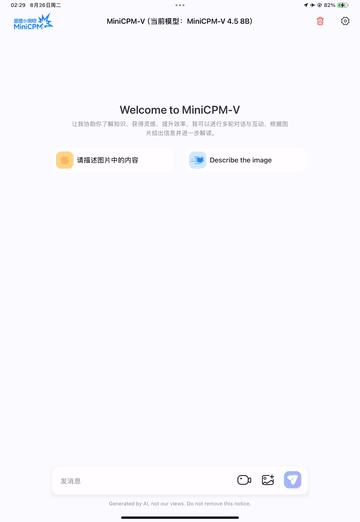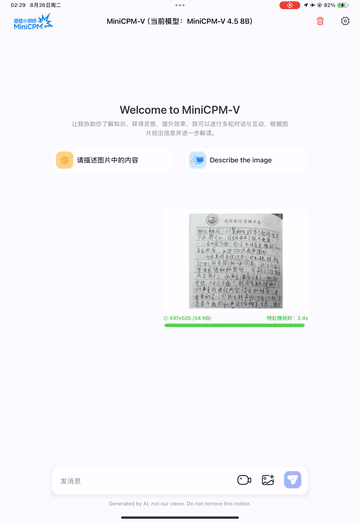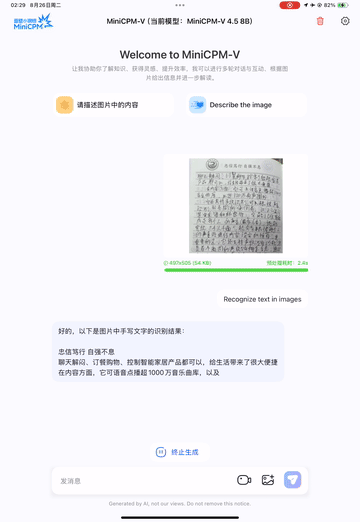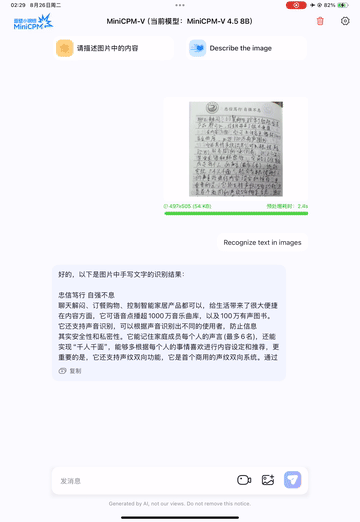
💪 Strong OCR, Document Parsing and Others. Based on LLaVA-UHD architecture, MiniCPM-V 4.5 can process high-resolution images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344), using 4x less visual tokens than most MLLMs. The model achieves leading performance on OCRBench, surpassing proprietary models such as GPT-4o-latest and Gemini 2.5. It also achieves state-of-the-art performance for PDF document parsing capability on OmniDocBench among general MLLMs. Based on the latest RLAIF-V and VisCPM techniques, it features trustworthy behaviors, outperforming GPT-4o-latest on MMHal-Bench, and supports multilingual capabilities in more than 30 languages.
💫 Easy Usage. MiniCPM-V 4.5 can be easily used in various ways: (1) llama.cpp and ollama support for efficient CPU inference on local devices, (2) int4, GGUF and AWQ format quantized models in 16 sizes, (3) SGLang and vLLM support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks with Transformers and LLaMA-Factory, (5) quick local WebUI demo, (6) optimized local iOS app on iPhone and iPad, and (7) online web demo on server. See our Cookbook for full usages!
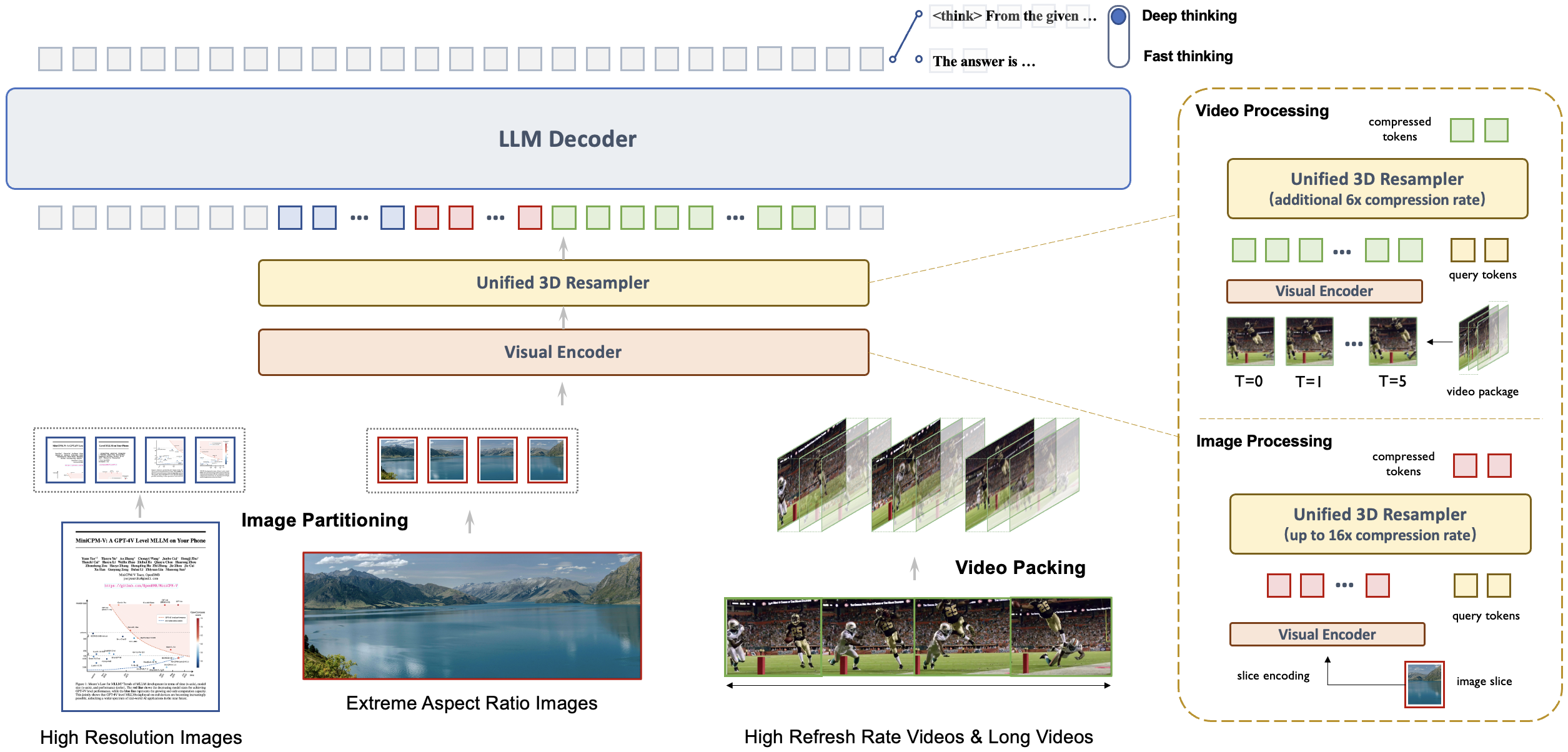
Architechture: Unified 3D-Resampler for High-density Video Compression. MiniCPM-V 4.5 introduces a 3D-Resampler that overcomes the performance-efficiency trade-off in video understanding. By grouping and jointly compressing up to 6 consecutive video frames into just 64 tokens (the same token count used for a single image in MiniCPM-V series), MiniCPM-V 4.5 achieves a 96× compression rate for video tokens. This allows the model to process more video frames without additional LLM computational cost, enabling high-FPS video and long video understanding. The architecture supports unified encoding for images, multi-image inputs, and videos, ensuring seamless capability and knowledge transfer.
Pre-training: Unified Learning for OCR and Knowledge from Documents. Existing MLLMs learn OCR capability and knowledge from documents in isolated training approaches. We observe that the essential difference between these two training approaches is the visibility of the text in images. By dynamically corrupting text regions in documents with varying noise levels and asking the model to reconstruct the text, the model learns to adaptively and properly switch between accurate text recognition (when text is visible) and multimodal context-based knowledge reasoning (when text is heavily obscured). This eliminates reliance on error-prone document parsers in knowledge learning from documents, and prevents hallucinations from over-augmented OCR data, resulting in top-tier OCR and multimodal knowledge performance with minimal engineering overhead.
Post-training: Hybrid Fast/Deep Thinking with Multimodal RL. MiniCPM-V 4.5 offers a balanced reasoning experience through two switchable modes: fast thinking for efficient daily use and deep thinking for complex tasks. Using a new hybrid reinforcement learning method, the model jointly optimizes both modes, significantly enhancing fast-mode performance without compromising deep-mode capability. Incorporated with RLPR and RLAIF-V, it generalizes robust reasoning skills from broad multimodal data while effectively reducing hallucinations.
OpenCompass
| Model | Size | Avg Score ↑ | Total Inference Time ↓ |
|---|---|---|---|
| GLM-4.1V-9B-Thinking | 10.3B | 76.6 | 17.5h |
| MiMo-VL-7B-RL | 8.3B | 76.4 | 11h |
| MiniCPM-V 4.5 | 8.7B | 77.0 | 7.5h |
Video-MME
| Model | Size | Avg Score ↑ | Total Inference Time ↓ | GPU Mem ↓ |
|---|---|---|---|---|
| Qwen2.5-VL-7B-Instruct | 8.3B | 71.6 | 3h | 60G |
| GLM-4.1V-9B-Thinking | 10.3B | 73.6 | 2.63h | 32G |
| MiniCPM-V 4.5 | 8.7B | 73.5 | 0.26h | 28G |
Both Video-MME and OpenCompass were evaluated using 8×A100 GPUs for inference. The reported inference time of Video-MME includes full model-side computation, and excludes the external cost of video frame extraction (dependent on specific frame extraction tools) for fair comparison.



We deploy MiniCPM-V 4.5 on iPad M4 with iOS demo. The demo video is the raw screen recording without editing.
| Category | Framework | Cookbook Link | Upstream PR | Supported since(branch) | Supported since(release) |
|---|---|---|---|---|---|
| Edge(On-device) | Llama.cpp | Llama.cpp Doc | #15575(2025-08-26) | master(2025-08-26) | b6282 |
| Ollama | Ollama Doc | #12078(2025-08-26) | Merging | Waiting for official release | |
| Serving(Cloud) | vLLM | vLLM Doc | #23586(2025-08-26) | main(2025-08-27) | v0.10.2 |
| SGLang | SGLang Doc | #9610(2025-08-26) | Merging | Waiting for official release | |
| Finetuning | LLaMA-Factory | LLaMA-Factory Doc | #9022(2025-08-26) | main(2025-08-26) | Waiting for official release |
| Quantization | GGUF | GGUF Doc | — | — | — |
| BNB | BNB Doc | — | — | — | |
| AWQ | AWQ Doc | — | — | — | |
| Demos | Gradio Demo | Gradio Demo Doc | — | — | — |
Note: If you'd like us to prioritize support for another open-source framework, please let us know via this short form.
If you wish to enable thinking mode, provide the argument enable_thinking=True to the chat function.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [generated_text]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
You will get the following output:
# round1
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.
This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.
# round2
When traveling to a karst landscape like this, here are some important tips:
1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.
By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
## The 3d-resampler compresses multiple frames into 64 tokens by introducing temporal_ids.
# To achieve this, you need to organize your video data into two corresponding sequences:
# frames: List[Image]
# temporal_ids: List[List[Int]].
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
from scipy.spatial import cKDTree
import numpy as np
import math
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=180 # Indicates the maximum number of frames received after the videos are packed. The actual maximum number of valid frames is MAX_NUM_FRAMES * MAX_NUM_PACKING.
MAX_NUM_PACKING=3 # indicates the maximum packing number of video frames. valid range: 1-6
TIME_SCALE = 0.1
def map_to_nearest_scale(values, scale):
tree = cKDTree(np.asarray(scale)[:, None])
_, indices = tree.query(np.asarray(values)[:, None])
return np.asarray(scale)[indices]
def group_array(arr, size):
return [arr[i:i+size] for i in range(0, len(arr), size)]
def encode_video(video_path, choose_fps=3, force_packing=None):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
fps = vr.get_avg_fps()
video_duration = len(vr) / fps
if choose_fps * int(video_duration) <= MAX_NUM_FRAMES:
packing_nums = 1
choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))
else:
packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)
if packing_nums <= MAX_NUM_PACKING:
choose_frames = round(video_duration * choose_fps)
else:
choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)
packing_nums = MAX_NUM_PACKING
frame_idx = [i for i in range(0, len(vr))]
frame_idx = np.array(uniform_sample(frame_idx, choose_frames))
if force_packing:
packing_nums = min(force_packing, MAX_NUM_PACKING)
print(video_path, ' duration:', video_duration)
print(f'get video frames={len(frame_idx)}, packing_nums={packing_nums}')
frames = vr.get_batch(frame_idx).asnumpy()
frame_idx_ts = frame_idx / fps
scale = np.arange(0, video_duration, TIME_SCALE)
frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALE
frame_ts_id = frame_ts_id.astype(np.int32)
assert len(frames) == len(frame_ts_id)
frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]
frame_ts_id_group = group_array(frame_ts_id, packing_nums)
return frames, frame_ts_id_group
video_path="video_test.mp4"
fps = 5 # fps for video
force_packing = None # You can set force_packing to ensure that 3D packing is forcibly enabled; otherwise, encode_video will dynamically set the packing quantity based on the duration.
frames, frame_ts_id_group = encode_video(video_path, fps, force_packing=force_packing)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
use_image_id=False,
max_slice_nums=1,
temporal_ids=frame_ts_id_group
)
print(answer)
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4_5', trust_remote_code=True)
question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')
msgs = [
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
{'role': 'user', 'content': [image_test, question]}
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
👏 Welcome to explore key techniques of MiniCPM-V 4.5 and other multimodal projects of our team:
VisCPM | RLPR | RLHF-V | LLaVA-UHD | RLAIF-V
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
@misc{yu2025minicpmv45cookingefficient,
title={MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe},
author={Tianyu Yu and Zefan Wang and Chongyi Wang and Fuwei Huang and Wenshuo Ma and Zhihui He and Tianchi Cai and Weize Chen and Yuxiang Huang and Yuanqian Zhao and Bokai Xu and Junbo Cui and Yingjing Xu and Liqing Ruan and Luoyuan Zhang and Hanyu Liu and Jingkun Tang and Hongyuan Liu and Qining Guo and Wenhao Hu and Bingxiang He and Jie Zhou and Jie Cai and Ji Qi and Zonghao Guo and Chi Chen and Guoyang Zeng and Yuxuan Li and Ganqu Cui and Ning Ding and Xu Han and Yuan Yao and Zhiyuan Liu and Maosong Sun},
year={2025},
eprint={2509.18154},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.18154},
}
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}