|
|
--- |
|
|
library_name: pytorch |
|
|
license: other |
|
|
tags: |
|
|
- android |
|
|
pipeline_tag: image-classification |
|
|
|
|
|
--- |
|
|
|
|
|
 |
|
|
|
|
|
# EfficientFormer: Optimized for Mobile Deployment |
|
|
## Imagenet classifier and general purpose backbone |
|
|
|
|
|
|
|
|
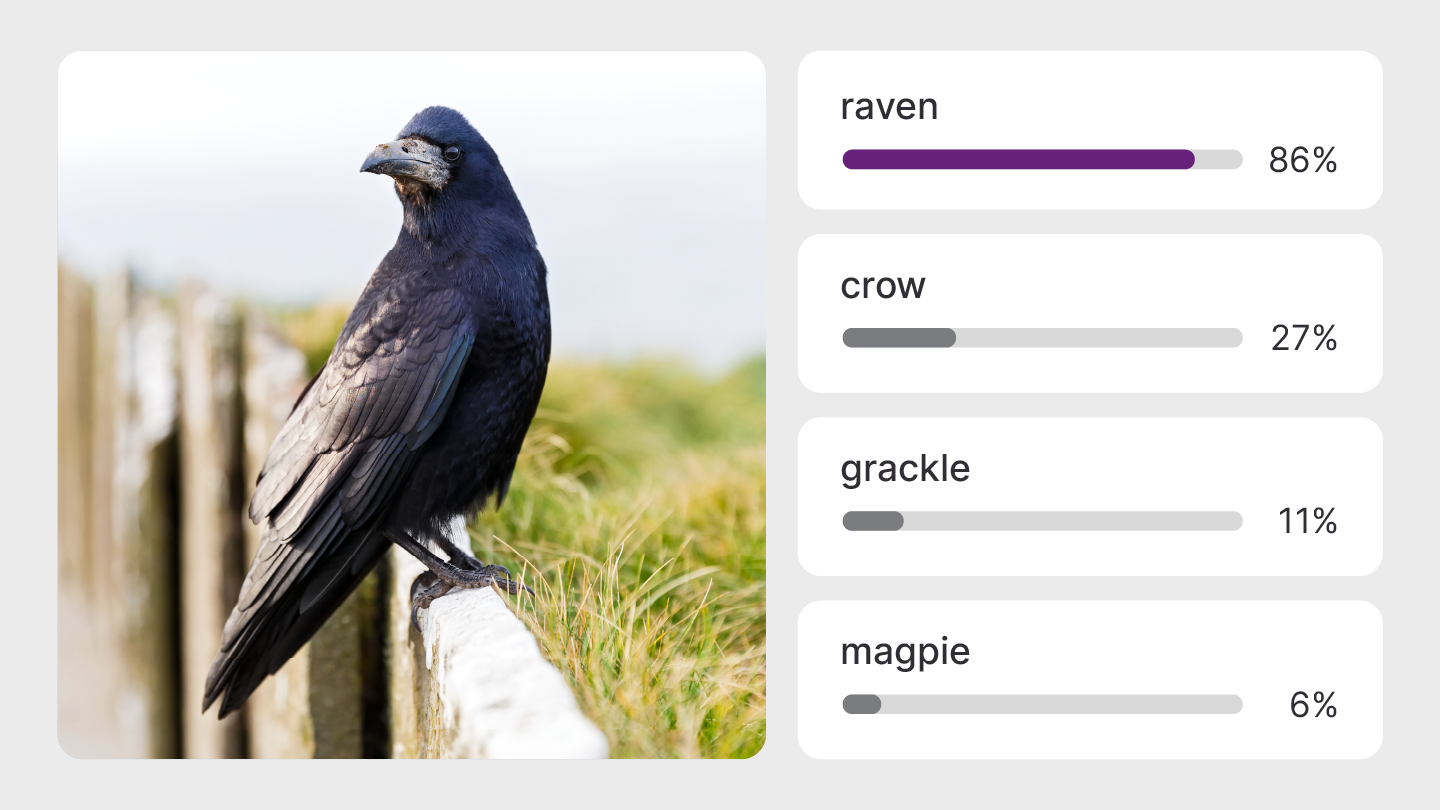
EfficientFormer is a vision transformer model that can classify images from the Imagenet dataset. |
|
|
|
|
|
This model is an implementation of EfficientFormer found [here](https://github.com/snap-research/EfficientFormer). |
|
|
|
|
|
|
|
|
This repository provides scripts to run EfficientFormer on Qualcomm® devices. |
|
|
More details on model performance across various devices, can be found |
|
|
[here](https://aihub.qualcomm.com/models/efficientformer). |
|
|
|
|
|
|
|
|
|
|
|
### Model Details |
|
|
|
|
|
- **Model Type:** Model_use_case.image_classification |
|
|
- **Model Stats:** |
|
|
- Model checkpoint: efficientformer_l1_300d |
|
|
- Input resolution: 224x224 |
|
|
- Number of parameters: 12.3M |
|
|
- Model size (float): 46.9 MB |
|
|
- Model size (w8a16): 12.2 MB |
|
|
|
|
|
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model |
|
|
|---|---|---|---|---|---|---|---|---| |
|
|
| EfficientFormer | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 4.93 ms | 0 - 48 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 4.994 ms | 1 - 34 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 3.825 ms | 0 - 55 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 5.702 ms | 0 - 42 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 1.519 ms | 0 - 157 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 1.617 ms | 1 - 11 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 2.096 ms | 0 - 48 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 2.298 ms | 1 - 34 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 1.523 ms | 0 - 156 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | QNN_DLC | 1.651 ms | 1 - 10 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 5.967 ms | 0 - 39 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.onnx.zip) | |
|
|
| EfficientFormer | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 1.057 ms | 0 - 59 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 1.125 ms | 1 - 44 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 4.096 ms | 0 - 45 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.onnx.zip) | |
|
|
| EfficientFormer | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.941 ms | 0 - 52 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.tflite) | |
|
|
| EfficientFormer | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | QNN_DLC | 0.825 ms | 1 - 38 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 3.739 ms | 1 - 42 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.onnx.zip) | |
|
|
| EfficientFormer | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 1.904 ms | 102 - 102 MB | NPU | [EfficientFormer.dlc](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.dlc) | |
|
|
| EfficientFormer | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 6.192 ms | 24 - 24 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer.onnx.zip) | |
|
|
| EfficientFormer | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 1.695 ms | 0 - 27 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 0.852 ms | 0 - 46 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 0.744 ms | 0 - 59 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 0.997 ms | 0 - 27 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | RB3 Gen 2 (Proxy) | Qualcomm® QCS6490 (Proxy) | TFLITE | 4.185 ms | 0 - 39 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 44.509 ms | 1 - 80 MB | GPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | TFLITE | 0.743 ms | 0 - 59 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | Samsung Galaxy S23 | Snapdragon® 8 Gen 2 Mobile | ONNX | 9.494 ms | 25 - 49 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.onnx.zip) | |
|
|
| EfficientFormer | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 0.53 ms | 0 - 45 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 6.246 ms | 23 - 82 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.onnx.zip) | |
|
|
| EfficientFormer | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | TFLITE | 0.41 ms | 1 - 34 MB | NPU | [EfficientFormer.tflite](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.tflite) | |
|
|
| EfficientFormer | w8a8 | Snapdragon 8 Elite QRD | Snapdragon® 8 Elite Mobile | ONNX | 5.503 ms | 28 - 71 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.onnx.zip) | |
|
|
| EfficientFormer | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 8.31 ms | 25 - 25 MB | NPU | [EfficientFormer.onnx.zip](https://huggingface.co/qualcomm/EfficientFormer/blob/main/EfficientFormer_w8a8.onnx.zip) | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## Installation |
|
|
|
|
|
|
|
|
Install the package via pip: |
|
|
```bash |
|
|
pip install "qai-hub-models[efficientformer]" |
|
|
``` |
|
|
|
|
|
|
|
|
## Configure Qualcomm® AI Hub to run this model on a cloud-hosted device |
|
|
|
|
|
Sign-in to [Qualcomm® AI Hub](https://app.aihub.qualcomm.com/) with your |
|
|
Qualcomm® ID. Once signed in navigate to `Account -> Settings -> API Token`. |
|
|
|
|
|
With this API token, you can configure your client to run models on the cloud |
|
|
hosted devices. |
|
|
```bash |
|
|
qai-hub configure --api_token API_TOKEN |
|
|
``` |
|
|
Navigate to [docs](https://app.aihub.qualcomm.com/docs/) for more information. |
|
|
|
|
|
|
|
|
|
|
|
## Demo off target |
|
|
|
|
|
The package contains a simple end-to-end demo that downloads pre-trained |
|
|
weights and runs this model on a sample input. |
|
|
|
|
|
```bash |
|
|
python -m qai_hub_models.models.efficientformer.demo |
|
|
``` |
|
|
|
|
|
The above demo runs a reference implementation of pre-processing, model |
|
|
inference, and post processing. |
|
|
|
|
|
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like |
|
|
environment, please add the following to your cell (instead of the above). |
|
|
``` |
|
|
%run -m qai_hub_models.models.efficientformer.demo |
|
|
``` |
|
|
|
|
|
|
|
|
### Run model on a cloud-hosted device |
|
|
|
|
|
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm® |
|
|
device. This script does the following: |
|
|
* Performance check on-device on a cloud-hosted device |
|
|
* Downloads compiled assets that can be deployed on-device for Android. |
|
|
* Accuracy check between PyTorch and on-device outputs. |
|
|
|
|
|
```bash |
|
|
python -m qai_hub_models.models.efficientformer.export |
|
|
``` |
|
|
|
|
|
|
|
|
|
|
|
## How does this work? |
|
|
|
|
|
This [export script](https://aihub.qualcomm.com/models/efficientformer/qai_hub_models/models/EfficientFormer/export.py) |
|
|
leverages [Qualcomm® AI Hub](https://aihub.qualcomm.com/) to optimize, validate, and deploy this model |
|
|
on-device. Lets go through each step below in detail: |
|
|
|
|
|
Step 1: **Compile model for on-device deployment** |
|
|
|
|
|
To compile a PyTorch model for on-device deployment, we first trace the model |
|
|
in memory using the `jit.trace` and then call the `submit_compile_job` API. |
|
|
|
|
|
```python |
|
|
import torch |
|
|
|
|
|
import qai_hub as hub |
|
|
from qai_hub_models.models.efficientformer import Model |
|
|
|
|
|
# Load the model |
|
|
torch_model = Model.from_pretrained() |
|
|
|
|
|
# Device |
|
|
device = hub.Device("Samsung Galaxy S24") |
|
|
|
|
|
# Trace model |
|
|
input_shape = torch_model.get_input_spec() |
|
|
sample_inputs = torch_model.sample_inputs() |
|
|
|
|
|
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()]) |
|
|
|
|
|
# Compile model on a specific device |
|
|
compile_job = hub.submit_compile_job( |
|
|
model=pt_model, |
|
|
device=device, |
|
|
input_specs=torch_model.get_input_spec(), |
|
|
) |
|
|
|
|
|
# Get target model to run on-device |
|
|
target_model = compile_job.get_target_model() |
|
|
|
|
|
``` |
|
|
|
|
|
|
|
|
Step 2: **Performance profiling on cloud-hosted device** |
|
|
|
|
|
After compiling models from step 1. Models can be profiled model on-device using the |
|
|
`target_model`. Note that this scripts runs the model on a device automatically |
|
|
provisioned in the cloud. Once the job is submitted, you can navigate to a |
|
|
provided job URL to view a variety of on-device performance metrics. |
|
|
```python |
|
|
profile_job = hub.submit_profile_job( |
|
|
model=target_model, |
|
|
device=device, |
|
|
) |
|
|
|
|
|
``` |
|
|
|
|
|
Step 3: **Verify on-device accuracy** |
|
|
|
|
|
To verify the accuracy of the model on-device, you can run on-device inference |
|
|
on sample input data on the same cloud hosted device. |
|
|
```python |
|
|
input_data = torch_model.sample_inputs() |
|
|
inference_job = hub.submit_inference_job( |
|
|
model=target_model, |
|
|
device=device, |
|
|
inputs=input_data, |
|
|
) |
|
|
on_device_output = inference_job.download_output_data() |
|
|
|
|
|
``` |
|
|
With the output of the model, you can compute like PSNR, relative errors or |
|
|
spot check the output with expected output. |
|
|
|
|
|
**Note**: This on-device profiling and inference requires access to Qualcomm® |
|
|
AI Hub. [Sign up for access](https://myaccount.qualcomm.com/signup). |
|
|
|
|
|
|
|
|
|
|
|
## Run demo on a cloud-hosted device |
|
|
|
|
|
You can also run the demo on-device. |
|
|
|
|
|
```bash |
|
|
python -m qai_hub_models.models.efficientformer.demo --eval-mode on-device |
|
|
``` |
|
|
|
|
|
**NOTE**: If you want running in a Jupyter Notebook or Google Colab like |
|
|
environment, please add the following to your cell (instead of the above). |
|
|
``` |
|
|
%run -m qai_hub_models.models.efficientformer.demo -- --eval-mode on-device |
|
|
``` |
|
|
|
|
|
|
|
|
## Deploying compiled model to Android |
|
|
|
|
|
|
|
|
The models can be deployed using multiple runtimes: |
|
|
- TensorFlow Lite (`.tflite` export): [This |
|
|
tutorial](https://www.tensorflow.org/lite/android/quickstart) provides a |
|
|
guide to deploy the .tflite model in an Android application. |
|
|
|
|
|
|
|
|
- QNN (`.so` export ): This [sample |
|
|
app](https://docs.qualcomm.com/bundle/publicresource/topics/80-63442-50/sample_app.html) |
|
|
provides instructions on how to use the `.so` shared library in an Android application. |
|
|
|
|
|
|
|
|
## View on Qualcomm® AI Hub |
|
|
Get more details on EfficientFormer's performance across various devices [here](https://aihub.qualcomm.com/models/efficientformer). |
|
|
Explore all available models on [Qualcomm® AI Hub](https://aihub.qualcomm.com/) |
|
|
|
|
|
|
|
|
## License |
|
|
* The license for the original implementation of EfficientFormer can be found |
|
|
[here](https://github.com/snap-research/EfficientFormer?tab=License-1-ov-file#readme). |
|
|
* The license for the compiled assets for on-device deployment can be found [here](https://qaihub-public-assets.s3.us-west-2.amazonaws.com/qai-hub-models/Qualcomm+AI+Hub+Proprietary+License.pdf) |
|
|
|
|
|
|
|
|
|
|
|
## References |
|
|
* [Rethinking Vision Transformers for MobileNet Size and Speed](https://arxiv.org/abs/2212.08059) |
|
|
* [Source Model Implementation](https://github.com/snap-research/EfficientFormer) |
|
|
|
|
|
|
|
|
|
|
|
## Community |
|
|
* Join [our AI Hub Slack community](https://aihub.qualcomm.com/community/slack) to collaborate, post questions and learn more about on-device AI. |
|
|
* For questions or feedback please [reach out to us](mailto:[email protected]). |
|
|
|
|
|
|
|
|
|

