
A Closer Look at Spatiotemporal Convolutions for Action Recognition
Paper
•
1711.11248
•
Published
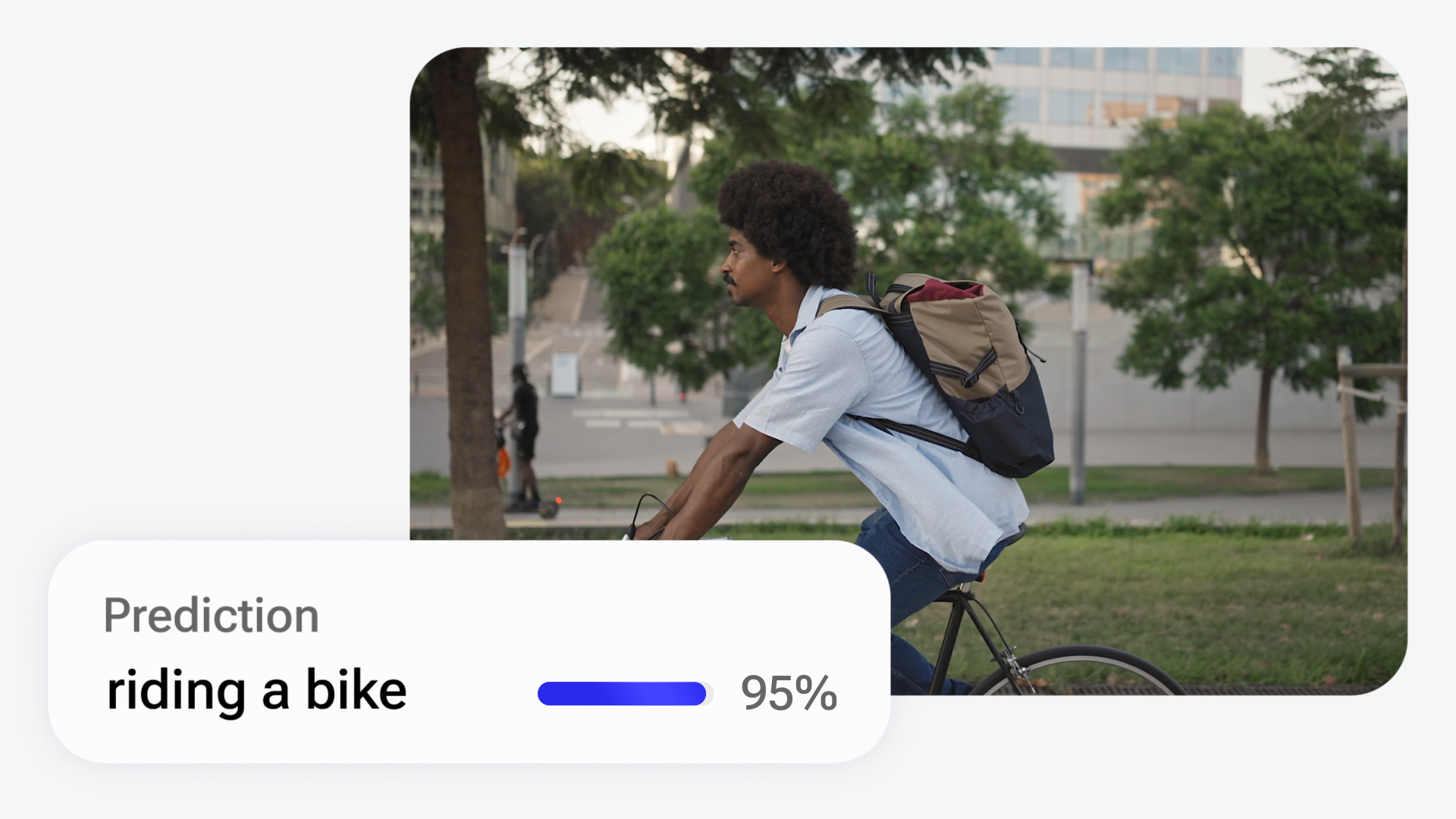
ResNet (2+1)D Convolutions is a network which explicitly factorizes 3D convolution into two separate and successive operations, a 2D spatial convolution and a 1D temporal convolution. It used for video understanding applications.
This model is an implementation of ResNet-2Plus1D found here.
This repository provides scripts to run ResNet-2Plus1D on Qualcomm® devices. More details on model performance across various devices, can be found here.
| Model | Precision | Device | Chipset | Target Runtime | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit | Target Model |
|---|---|---|---|---|---|---|---|---|
| ResNet-2Plus1D | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 696.429 ms | 0 - 64 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 82.047 ms | 0 - 76 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 418.762 ms | 0 - 85 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 27.563 ms | 2 - 84 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 375.747 ms | 0 - 28 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 12.771 ms | 2 - 31 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | ONNX | 11.932 ms | 0 - 140 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 370.736 ms | 0 - 63 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 98.955 ms | 0 - 78 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 696.429 ms | 0 - 64 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 82.047 ms | 0 - 76 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 378.692 ms | 0 - 27 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 12.777 ms | 2 - 31 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 446.725 ms | 0 - 57 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 22.956 ms | 0 - 57 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 378.118 ms | 0 - 27 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 12.816 ms | 2 - 25 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 370.736 ms | 0 - 63 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 98.955 ms | 0 - 78 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 279.963 ms | 0 - 91 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 9.201 ms | 2 - 94 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 8.73 ms | 2 - 93 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | float | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | TFLITE | 276.089 ms | 0 - 65 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | QNN_DLC | 7.331 ms | 0 - 79 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | ONNX | 7.171 ms | 0 - 57 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | float | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | TFLITE | 275.699 ms | 0 - 67 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | float | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | QNN_DLC | 5.386 ms | 2 - 75 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | ONNX | 5.426 ms | 2 - 65 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | float | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 13.192 ms | 828 - 828 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | float | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 12.271 ms | 60 - 60 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | Dragonwing RB3 Gen 2 Vision Kit | Qualcomm® QCS6490 | TFLITE | 1794.855 ms | 268 - 429 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | Dragonwing RB3 Gen 2 Vision Kit | Qualcomm® QCS6490 | QNN_DLC | 17.296 ms | 0 - 117 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Dragonwing RB3 Gen 2 Vision Kit | Qualcomm® QCS6490 | ONNX | 318.104 ms | 96 - 127 MB | CPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | TFLITE | 1098.746 ms | 0 - 66 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | QCS8275 (Proxy) | Qualcomm® QCS8275 (Proxy) | QNN_DLC | 13.04 ms | 1 - 56 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | TFLITE | 560.225 ms | 0 - 97 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | QCS8450 (Proxy) | Qualcomm® QCS8450 (Proxy) | QNN_DLC | 7.432 ms | 1 - 72 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | TFLITE | 556.108 ms | 0 - 35 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | QNN_DLC | 4.421 ms | 1 - 17 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | QCS8550 (Proxy) | Qualcomm® QCS8550 (Proxy) | ONNX | 4.383 ms | 0 - 82 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | TFLITE | 571.558 ms | 35 - 101 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | QCS9075 (Proxy) | Qualcomm® QCS9075 (Proxy) | QNN_DLC | 4.611 ms | 1 - 55 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | TFLITE | 1412.677 ms | 406 - 439 MB | CPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | RB5 (Proxy) | Qualcomm® QCS8250 (Proxy) | ONNX | 252.112 ms | 59 - 107 MB | CPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | SA7255P ADP | Qualcomm® SA7255P | TFLITE | 1098.746 ms | 0 - 66 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | SA7255P ADP | Qualcomm® SA7255P | QNN_DLC | 13.04 ms | 1 - 56 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | TFLITE | 550.773 ms | 0 - 34 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | SA8255 (Proxy) | Qualcomm® SA8255P (Proxy) | QNN_DLC | 4.437 ms | 0 - 19 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | SA8295P ADP | Qualcomm® SA8295P | TFLITE | 634.736 ms | 0 - 68 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | SA8295P ADP | Qualcomm® SA8295P | QNN_DLC | 7.595 ms | 1 - 58 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | TFLITE | 557.798 ms | 0 - 35 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | SA8650 (Proxy) | Qualcomm® SA8650P (Proxy) | QNN_DLC | 4.424 ms | 0 - 19 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | SA8775P ADP | Qualcomm® SA8775P | TFLITE | 571.558 ms | 35 - 101 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | SA8775P ADP | Qualcomm® SA8775P | QNN_DLC | 4.611 ms | 1 - 55 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | TFLITE | 414.353 ms | 0 - 94 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | QNN_DLC | 3.247 ms | 1 - 75 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S24 | Snapdragon® 8 Gen 3 Mobile | ONNX | 3.26 ms | 0 - 72 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | TFLITE | 349.865 ms | 0 - 71 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | QNN_DLC | 2.42 ms | 1 - 58 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Samsung Galaxy S25 | Snapdragon® 8 Elite For Galaxy Mobile | ONNX | 2.618 ms | 0 - 49 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | Snapdragon 7 Gen 4 QRD | Snapdragon® 7 Gen 4 Mobile | TFLITE | 1264.311 ms | 321 - 345 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | Snapdragon 7 Gen 4 QRD | Snapdragon® 7 Gen 4 Mobile | QNN_DLC | 7.695 ms | 1 - 55 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Snapdragon 7 Gen 4 QRD | Snapdragon® 7 Gen 4 Mobile | ONNX | 284.127 ms | 83 - 98 MB | CPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | TFLITE | 432.6 ms | 0 - 71 MB | NPU | ResNet-2Plus1D.tflite |
| ResNet-2Plus1D | w8a8 | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | QNN_DLC | 1.789 ms | 1 - 61 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Snapdragon 8 Elite Gen 5 QRD | Snapdragon® 8 Elite Gen5 Mobile | ONNX | 1.943 ms | 1 - 50 MB | NPU | ResNet-2Plus1D.onnx.zip |
| ResNet-2Plus1D | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | QNN_DLC | 4.759 ms | 306 - 306 MB | NPU | ResNet-2Plus1D.dlc |
| ResNet-2Plus1D | w8a8 | Snapdragon X Elite CRD | Snapdragon® X Elite | ONNX | 4.475 ms | 31 - 31 MB | NPU | ResNet-2Plus1D.onnx.zip |
Install the package via pip:
# NOTE: 3.10 <= PYTHON_VERSION < 3.14 is supported.
pip install "qai-hub-models[resnet-2plus1d]"
Sign-in to Qualcomm® AI Hub Workbench with your
Qualcomm® ID. Once signed in navigate to Account -> Settings -> API Token.
With this API token, you can configure your client to run models on the cloud hosted devices.
qai-hub configure --api_token API_TOKEN
Navigate to docs for more information.
The package contains a simple end-to-end demo that downloads pre-trained weights and runs this model on a sample input.
python -m qai_hub_models.models.resnet_2plus1d.demo
The above demo runs a reference implementation of pre-processing, model inference, and post processing.
NOTE: If you want running in a Jupyter Notebook or Google Colab like environment, please add the following to your cell (instead of the above).
%run -m qai_hub_models.models.resnet_2plus1d.demo
In addition to the demo, you can also run the model on a cloud-hosted Qualcomm® device. This script does the following:
python -m qai_hub_models.models.resnet_2plus1d.export
This export script leverages Qualcomm® AI Hub to optimize, validate, and deploy this model on-device. Lets go through each step below in detail:
Step 1: Compile model for on-device deployment
To compile a PyTorch model for on-device deployment, we first trace the model
in memory using the jit.trace and then call the submit_compile_job API.
import torch
import qai_hub as hub
from qai_hub_models.models.resnet_2plus1d import Model
# Load the model
torch_model = Model.from_pretrained()
# Device
device = hub.Device("Samsung Galaxy S25")
# Trace model
input_shape = torch_model.get_input_spec()
sample_inputs = torch_model.sample_inputs()
pt_model = torch.jit.trace(torch_model, [torch.tensor(data[0]) for _, data in sample_inputs.items()])
# Compile model on a specific device
compile_job = hub.submit_compile_job(
model=pt_model,
device=device,
input_specs=torch_model.get_input_spec(),
)
# Get target model to run on-device
target_model = compile_job.get_target_model()
Step 2: Performance profiling on cloud-hosted device
After compiling models from step 1. Models can be profiled model on-device using the
target_model. Note that this scripts runs the model on a device automatically
provisioned in the cloud. Once the job is submitted, you can navigate to a
provided job URL to view a variety of on-device performance metrics.
profile_job = hub.submit_profile_job(
model=target_model,
device=device,
)
Step 3: Verify on-device accuracy
To verify the accuracy of the model on-device, you can run on-device inference on sample input data on the same cloud hosted device.
input_data = torch_model.sample_inputs()
inference_job = hub.submit_inference_job(
model=target_model,
device=device,
inputs=input_data,
)
on_device_output = inference_job.download_output_data()
With the output of the model, you can compute like PSNR, relative errors or spot check the output with expected output.
Note: This on-device profiling and inference requires access to Qualcomm® AI Hub Workbench. Sign up for access.
The models can be deployed using multiple runtimes:
TensorFlow Lite (.tflite export): This
tutorial provides a
guide to deploy the .tflite model in an Android application.
QNN (.so export ): This sample
app
provides instructions on how to use the .so shared library in an Android application.
Get more details on ResNet-2Plus1D's performance across various devices here. Explore all available models on Qualcomm® AI Hub