
English | 简体中文
#DeepDoc
1. Introduction
With a bunch of documents from various domains with various formats and along with diverse retrieval requirements, an accurate analysis becomes a very challenge task. DeepDoc is born for that purpose. There 2 parts in DeepDoc so far: vision and parser.
2. Vision
We use vision information to resolve problems as human being.
OCR. Since a lot of documents presented as images or at least be able to transform to image, OCR is a very essential and fundamental or even universal solution for text extraction.
Layout recognition. Documents from different domain may have various layouts, like, newspaper, magazine, book and résumé are distinct in terms of layout. Only when machine have an accurate layout analysis, it can decide if these text parts are successive or not, or this part needs Table Structure Recognition(TSR) to process, or this part is a figure and described with this caption. We have 10 basic layout components which covers most cases:
- Text
- Title
- Figure
- Figure caption
- Table
- Table caption
- Header
- Footer
- Reference
- Equation

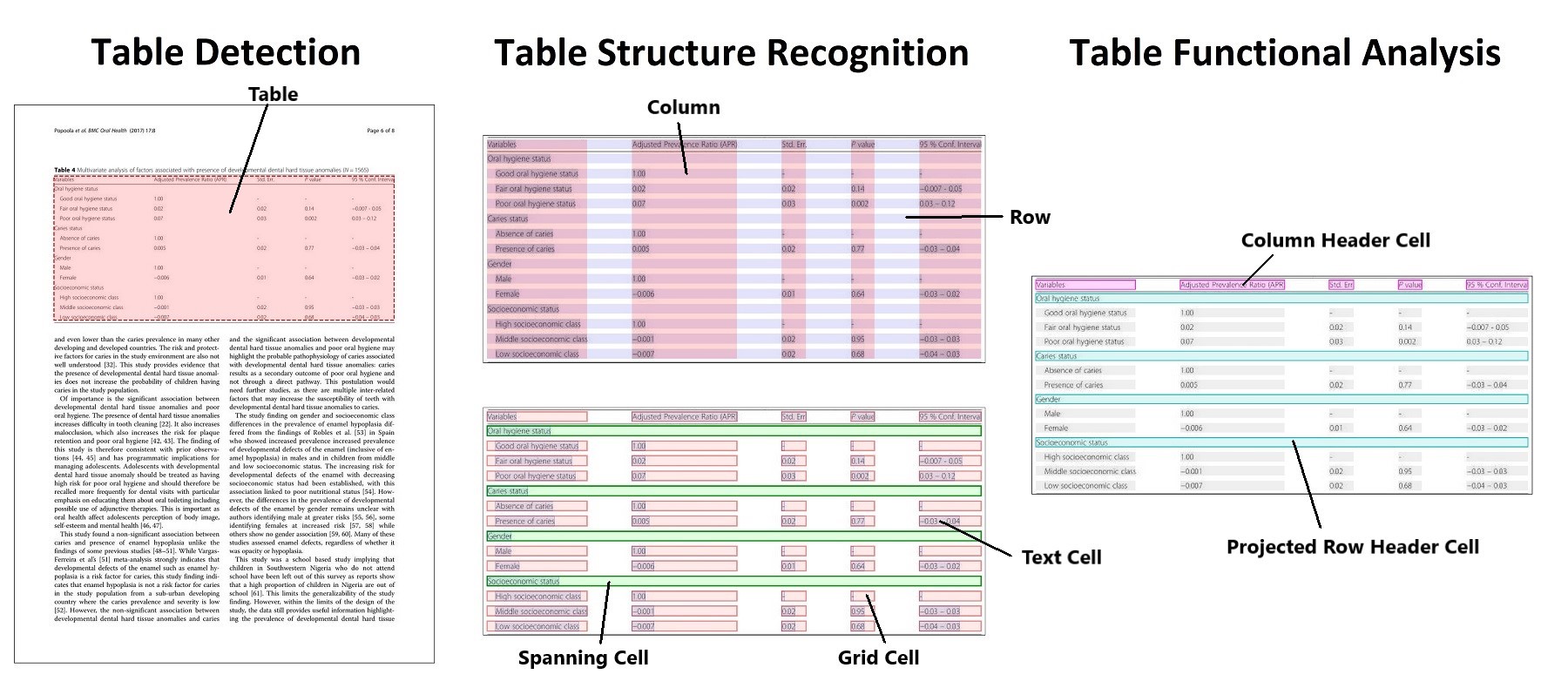
Table Structure Recognition(TSR). Data table is a frequently used structure present data including numbers or text. And the structure of a table might be very complex, like hierarchy headers, spanning cells and projected row headers. Along with TSR, we also reassemble the content into sentences which could be well comprehended by LLM. We have five labels for TSR task:
- Column
- Row
- Column header
- Projected row header
- Spanning cell

3. Parser
Four kinds of document formats as PDF, DOCX, EXCEL and PPT have their corresponding parser. The most complex one is PDF parser since PDF's flexibility. The output of PDF parser includes:
- Text chunks with their own positions in PDF(page number and rectangular positions).
- Tables with cropped image from the PDF, and contents which has already translated into natural language sentences.
- Figures with caption and text in the figures.
###Résumé
The résumé is a very complicated kind of document. A résumé which is composed of unstructured text with various layouts could be resolved into structured data composed of nearly a hundred of fields. We haven't opened the parser yet, as we open the processing method after parsing procedure.