
Crashes after several responses

For some reason it crashes after one or two responses. For example i ask it to write code, it gives answer, then i ask it to improve the code, and then it crashes. Both in LM Studio and in llama.cpp. Could it be because i'm on AMD + vulkan ? No problems with other models though...
Update: trying 0/49 layers to GPU now, same problem.

Try using --batch-size 365
Recent problem with GLM-32b (have to use -b 8 -ub 8), now this... What's going on...

Recent problem with GLM-32b (have to use -b 8 -ub 8), now this... What's going on...
Did you upload to the latest version? Does it still crash on the smaller non Moe models?
Yes, recent version *UD-Q3_K_XL.gguf. I know there was a problem with template, but this is probably a different bug. Only crash on this model. But @sidran suggestion seems to help, which is --batch-size 365.
@urtuuuu
I was just guessing and wrote this just in case it might help.
https://github.com/ggml-org/llama.cpp/issues/13164
@sidran btw, i wonder how you have only 10.7t/s? I don't even have a graphics card. Mini PC Ryzen 7735hs integrated graphics. It allows me to use my 32gb RAM for VRAM, which i can set to 8GB. I offload all 49/49 layers to GPU in vulkan llama.cpp and the speed is 24t/s in the beginning. Haven't tried how much context is possible, i just set it to 10000.
Oh, actually i'm using Q3_K_XL... yours is probably Q8 or something :)
@urtuuuu
I really dont know mate but I am suspecting you probably made an error since you made a few here as well. First you said that you use "32B-UD-Q3_K_XL.gguf" (no way you are running a dense model this fast), then you said you allocate 8Gb and shove whole 30b? into that much (impossible), then you say 49/49 layers but 30b has only 48. I cannot be sure but I am suspecting that you are mixing something up as my numbers seem quite good for my hardware. I am using Qwen3-30B-A3B-UD-Q4_K_XL.gguf with context 12288 and get slightly over 12 t/s at the very start with a hundred or so tokens. I am running dense models like QWQ 32B at terrible speed of 1.7 t/s which is to be expected and so is the same for Qwen3 32b (dense). All with same 12288 context length.
I dont know what your architecture really is but too much is confusing. I know Macs have unified memory and run LLMs on par with best GPUs but I dont think your Ryzen has such memory.
Maybe I am missing something but I really dont know what.


It shows 49/49 thats why i said 49.
It just runs like this with ~24gb ram left, rest turned into 8gb vram. Because it's MOE model, it runs that fast. But dense models like GLM32 are slow, i can get maximum 3.5t/s and it only slows down after that...(offloaded 62/62 layers to GPU)
No idea how it works, but if i don't offload all layers to GPU, the speed gets much slower
@urtuuuu
Ok, please tag me next time or it doesnt notify me by email. I saw your reply only by chance.
When I say its running just over 12 t/s I mean Llama.cpp server web UI's small counter while its outputing text:
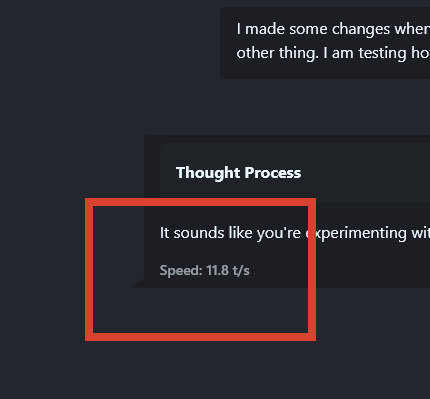
There are places in its server log where I saw much larger x t/s but this counter seems closest to reality.

Can you check what LLama.cpp server web UI's counter report on your machine?

The only explanation I have is that your specific architecture (integrated GPU with inferior but variable memory) creates a favorable mix for this model.
Just now I downloaded CPU only AVX2 Llama.cpp and with CPU and RAM only it runs ~8t/s from the start.
My guess is that architecture (MoE) benefits from being run without partial offloading while it still has GPU acceleration like in your case.
I am suspecting that Vulkan and partial offloading have some serious drawbacks around such massive, multi-expert model. Something is not running as fast as it could.
@urtuuuu
Mystery solved :)
Here is ChatGPTs answer regarding your system's architecture. You are basically rocking something akin to Apple's unified memory which kicks ass for LLMs (on your $400 box lol). I am glad that you benefit from it and I learned something new today. I thought Apple overpriced computers were special regarding this feature.
ChatGPTs answer:
Yes, the AMD Ryzen 7 7735HS with its integrated Radeon 680M GPU does leverage a Unified Memory Architecture (UMA), allowing the GPU to access system RAM directly. This design is akin to Apple's unified memory approach, where the CPU and GPU share the same memory pool, facilitating efficient data access without the need for copying between separate memory spaces.
However, while the architecture supports UMA, the performance benefits for Large Language Model (LLM) inference are nuanced:
Memory Bandwidth: The efficiency of UMA heavily depends on the system's memory bandwidth. The 7735HS supports DDR5 memory, which offers higher bandwidth compared to DDR4. Systems equipped with dual-channel DDR5 configurations will provide better performance for GPU tasks due to increased memory throughput.
GPU Capabilities: The Radeon 680M, based on RDNA 2 architecture, is a competent integrated GPU. Yet, for LLM inference, which is both compute and memory-intensive, its performance might not match that of discrete GPUs or Apple's M-series chips, which have more powerful integrated GPUs and higher memory bandwidth.
Software Support: Effective utilization of UMA for LLM tasks also depends on software support. Tools like llama.cpp can offload computations to the GPU, but the performance gains are contingent on optimized drivers and runtime environments that can fully exploit the shared memory architecture.
In summary, while the Ryzen 7 7735HS's UMA design offers a foundation similar to Apple's unified memory, the actual performance gains for LLM inference will vary based on system configuration and software optimization. For tasks heavily reliant on GPU performance and memory bandwidth, systems with higher-end integrated GPUs or discrete GPUs may offer superior results.