
BLEUBERI
Collection
This collection contains datasets and models related to "BLEUBERI: BLEU is a surprisingly effective reward for instruction following".
•
12 items
•
Updated
[Paper] [HF Collection] [Code]
Authors: Yapei Chang, Yekyung Kim, Michael Krumdick, Amir Zadeh, Chuan Li, Chris Tanner, Mohit Iyyer
Contact: [email protected]
TLDR > We extend RLVR beyond easily verifiable domains like math and code to the more open-ended setting of general instruction following. Surprisingly, we find that BLEU—a simple n-gram matching metric—when paired with high-quality references from strong LLMs, achieves human agreement comparable to 8B and 27B reward models on Chatbot Arena outputs. Based on this insight, we introduce BLEUBERI, which uses BLEU directly as a reward in GRPO training. BLEUBERI matches the performance of RM-guided GRPO across four instruction-following benchmarks and produces more factually grounded outputs, with human raters rating them on par with those from reward model-trained systems.
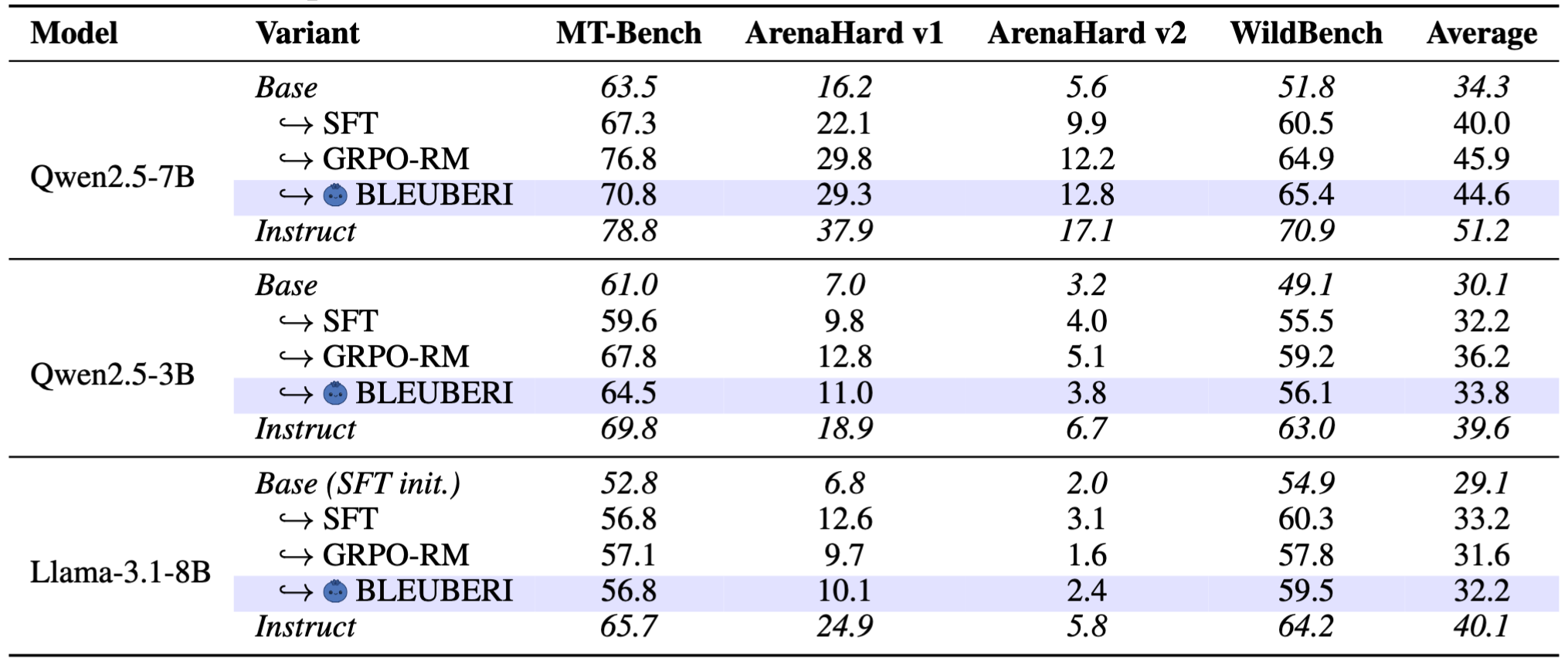
Model performance across four general instruction-following benchmarks.
This model corresponds to the Llama-3.1-8B, Base (SFT Init.) row in the table.
@misc{chang2025bleuberibleusurprisinglyeffective,
title={BLEUBERI: BLEU is a surprisingly effective reward for instruction following},
author={Yapei Chang and Yekyung Kim and Michael Krumdick and Amir Zadeh and Chuan Li and Chris Tanner and Mohit Iyyer},
year={2025},
eprint={2505.11080},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.11080},
}