Datasets:

annotations_creators:
- expert-generated
language:
- en
size_categories:
- 1K<n<10K
source_datasets:
- MS COCO-2017
task_categories:
- image-text-to-text
pretty_name: SPHERE
tags:
- image
- text
- vlm
- spatial-perception
- spatial-reasoning
configs:
- config_name: counting_only-paired-distance_and_counting
data_files: single_skill/counting_only-paired-distance_and_counting.parquet
- config_name: counting_only-paired-position_and_counting
data_files: single_skill/counting_only-paired-position_and_counting.parquet
- config_name: distance_only
data_files: single_skill/distance_only.parquet
- config_name: position_only
data_files: single_skill/position_only.parquet
- config_name: size_only
data_files: single_skill/size_only.parquet
- config_name: distance_and_counting
data_files: combine_2_skill/distance_and_counting.parquet
- config_name: distance_and_size
data_files: combine_2_skill/distance_and_size.parquet
- config_name: position_and_counting
data_files: combine_2_skill/position_and_counting.parquet
- config_name: object_manipulation
data_files: reasoning/object_manipulation.parquet
- config_name: object_manipulation_w_intermediate
data_files: reasoning/object_manipulation_w_intermediate.parquet
- config_name: object_occlusion
data_files: reasoning/object_occlusion.parquet
- config_name: object_occlusion_w_intermediate
data_files: reasoning/object_occlusion_w_intermediate.parquet
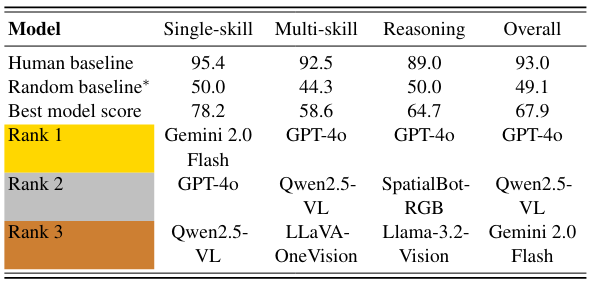
SPHERE (Spatial Perception and Hierarchical Evaluation of REasoning) is a benchmark for assessing spatial reasoning in vision-language models. It introduces a hierarchical evaluation framework with a human-annotated dataset, testing models on tasks ranging from basic spatial understanding to complex multi-skill reasoning. SPHERE poses significant challenges for both state-of-the-art open-source and proprietary models, revealing critical gaps in spatial cognition.
Project page: https://sphere-vlm.github.io/

Dataset Usage
To use this dataset, run the following:
from datasets import load_dataset
dataset = load_dataset("wei2912/SPHERE-VLM", "counting_only-paired-distance_and_counting")
where the second argument to load_dataset is the subset of your choice (see Dataset Structure).
Dataset Structure
The dataset is split into the following subsets:
Single-skill
- Position (
position_only) - 357 samples- Egocentric: 172, Allocentric: 185
- Counting (
counting_only-paired-distance_and_counting+counting_only-paired-position_and_counting) - 201 samples- The
counting_only-paired-distance_and_countingsubset comprises questions corresponding to those indistance_and_counting, and similarly forcounting_only-paired-position_and_countingwithposition-and_counting. - For instance, every question in
distance_and_counting(e.g. "How many crows are on the railing farther from the viewer?") has a corresponding question incounting_only-paired-distance_and_countingto count all such instances (e.g. "How many crows are in the photo?")
- The
- Distance (
distance_only) - 202 samples - Size (
size_only) - 198 samples
Multi-skill
- Position + Counting (
position_and_counting) - 169 samples- Egocentric: 64, Allocentric: 105
- Distance + Counting (
distance_and_counting) - 158 samples - Distance + Size (
distance_and_size) - 199 samples
Reasoning
- Object occlusion (
object_occlusion) - 402 samples- Intermediate: 202, Final: 200
- The
object_occlusion_w_intermediatesubset contains final questions with intermediate answers prefixed in the following format:"Given that for the question: <intermediate step question> The answer is: <intermediate step answer>. <final step question> Answer the question directly."
- For instance, given the two questions "Which object is thicker?" (intermediate) and "Where can a child be hiding?" (final) in
object_occlusion, the corresponding question inobject_occlusion_w_intermediateis:"Given that for the question: Which object is thicker? Fire hydrant or tree trunk? The answer is: Tree trunk. Where can a child be hiding? Behind the fire hydrant or behind the tree? Answer the question directly."
- Object manipulation (
object_manipulation) - 399- Intermediate: 199, Final: 200
Data Fields
The data fields are as follows:
question_id: A unique ID for the question.question: Question to be passed to the VLM.option: A list of options that the VLM can select from. For counting tasks, this field is left as null.answer: The expected answer, which must be either one of the strings inoption(for non-counting tasks) or a number (for counting tasks).metadata:viewpoint: Either "allo" (allocentric) or "ego" (egocentric).format: Expected format of the answer, e.g. "bool" (boolean), "name", "num" (numeric), "pos" (position).source_dataset: Currently, this is "coco_test2017" (MS COCO-2017) for our entire set of annotations.source_img_id: Source image ID in MS COCO-2017.skill: For reasoning tasks, a list of skills tested by the question, e.g. "count", "dist" (distance), "pos" (position), "shape", "size", "vis" (visual).
Dataset Preparation
This version of the dataset was prepared by combining the JSON annotations with the corresponding images from MS COCO-2017.
The script used can be found at prepare_parquet.py, to be executed in the root of our GitHub repository.
Licensing Information
Please note that the images are subject to the Terms of Use of MS COCO-2017:
Images
The COCO Consortium does not own the copyright of the images. Use of the images must abide by the Flickr Terms of Use. The users of the images accept full responsibility for the use of the dataset, including but not limited to the use of any copies of copyrighted images that they may create from the dataset.
BibTeX
@article{zhang2025sphere,
title={SPHERE: Unveiling Spatial Blind Spots in Vision-Language Models Through Hierarchical Evaluation},
author={Zhang, Wenyu and Ng, Wei En and Ma, Lixin and Wang, Yuwen and Zhao, Jungqi and Koenecke, Allison and Li, Boyang and Wang, Lu},
journal={arXiv},
year={2025}
}