
prompt
stringlengths 501
4.98M
| target
stringclasses 1
value | chunk_prompt
bool 1
class | kind
stringclasses 2
values | prob
float64 0.2
0.97
⌀ | path
stringlengths 10
394
⌀ | quality_prob
float64 0.4
0.99
⌀ | learning_prob
float64 0.15
1
⌀ | filename
stringlengths 4
221
⌀ |
|---|---|---|---|---|---|---|---|---|
<h1><center>Introductory Data Analysis Workflow</center></h1>

https://xkcd.com/2054
# An example machine learning notebook
* Original Notebook by [Randal S. Olson](http://www.randalolson.com/)
* Supported by [Jason H. Moore](http://www.epistasis.org/)
* [University of Pennsylvania Institute for Bioinformatics](http://upibi.org/)
* Adapted for LU Py-Sem 2018 by [Valdis Saulespurens]([email protected])
**You can also [execute the code in this notebook on Binder](https://mybinder.org/v2/gh/ValRCS/RigaComm_DataAnalysis/master) - no local installation required.**
```
# text 17.04.2019
import datetime
print(datetime.datetime.now())
print('hello')
```
## Table of contents
1. [Introduction](#Introduction)
2. [License](#License)
3. [Required libraries](#Required-libraries)
4. [The problem domain](#The-problem-domain)
5. [Step 1: Answering the question](#Step-1:-Answering-the-question)
6. [Step 2: Checking the data](#Step-2:-Checking-the-data)
7. [Step 3: Tidying the data](#Step-3:-Tidying-the-data)
- [Bonus: Testing our data](#Bonus:-Testing-our-data)
8. [Step 4: Exploratory analysis](#Step-4:-Exploratory-analysis)
9. [Step 5: Classification](#Step-5:-Classification)
- [Cross-validation](#Cross-validation)
- [Parameter tuning](#Parameter-tuning)
10. [Step 6: Reproducibility](#Step-6:-Reproducibility)
11. [Conclusions](#Conclusions)
12. [Further reading](#Further-reading)
13. [Acknowledgements](#Acknowledgements)
## Introduction
[[ go back to the top ]](#Table-of-contents)
In the time it took you to read this sentence, terabytes of data have been collectively generated across the world — more data than any of us could ever hope to process, much less make sense of, on the machines we're using to read this notebook.
In response to this massive influx of data, the field of Data Science has come to the forefront in the past decade. Cobbled together by people from a diverse array of fields — statistics, physics, computer science, design, and many more — the field of Data Science represents our collective desire to understand and harness the abundance of data around us to build a better world.
In this notebook, I'm going to go over a basic Python data analysis pipeline from start to finish to show you what a typical data science workflow looks like.
In addition to providing code examples, I also hope to imbue in you a sense of good practices so you can be a more effective — and more collaborative — data scientist.
I will be following along with the data analysis checklist from [The Elements of Data Analytic Style](https://leanpub.com/datastyle), which I strongly recommend reading as a free and quick guidebook to performing outstanding data analysis.
**This notebook is intended to be a public resource. As such, if you see any glaring inaccuracies or if a critical topic is missing, please feel free to point it out or (preferably) submit a pull request to improve the notebook.**
## License
[[ go back to the top ]](#Table-of-contents)
Please see the [repository README file](https://github.com/rhiever/Data-Analysis-and-Machine-Learning-Projects#license) for the licenses and usage terms for the instructional material and code in this notebook. In general, I have licensed this material so that it is as widely usable and shareable as possible.
## Required libraries
[[ go back to the top ]](#Table-of-contents)
If you don't have Python on your computer, you can use the [Anaconda Python distribution](http://continuum.io/downloads) to install most of the Python packages you need. Anaconda provides a simple double-click installer for your convenience.
This notebook uses several Python packages that come standard with the Anaconda Python distribution. The primary libraries that we'll be using are:
* **NumPy**: Provides a fast numerical array structure and helper functions.
* **pandas**: Provides a DataFrame structure to store data in memory and work with it easily and efficiently.
* **scikit-learn**: The essential Machine Learning package in Python.
* **matplotlib**: Basic plotting library in Python; most other Python plotting libraries are built on top of it.
* **Seaborn**: Advanced statistical plotting library.
* **watermark**: A Jupyter Notebook extension for printing timestamps, version numbers, and hardware information.
**Note:** I will not be providing support for people trying to run this notebook outside of the Anaconda Python distribution.
## The problem domain
[[ go back to the top ]](#Table-of-contents)
For the purposes of this exercise, let's pretend we're working for a startup that just got funded to create a smartphone app that automatically identifies species of flowers from pictures taken on the smartphone. We're working with a moderately-sized team of data scientists and will be building part of the data analysis pipeline for this app.
We've been tasked by our company's Head of Data Science to create a demo machine learning model that takes four measurements from the flowers (sepal length, sepal width, petal length, and petal width) and identifies the species based on those measurements alone.
<img src="img/petal_sepal.jpg" />
We've been given a [data set](https://github.com/ValRCS/RCS_Data_Analysis_Python/blob/master/data/iris-data.csv) from our field researchers to develop the demo, which only includes measurements for three types of *Iris* flowers:
### *Iris setosa*
<img src="img/iris_setosa.jpg" />
### *Iris versicolor*
<img src="img/iris_versicolor.jpg" />
### *Iris virginica*
<img src="img/iris_virginica.jpg" />
The four measurements we're using currently come from hand-measurements by the field researchers, but they will be automatically measured by an image processing model in the future.
**Note:** The data set we're working with is the famous [*Iris* data set](https://archive.ics.uci.edu/ml/datasets/Iris) — included with this notebook — which I have modified slightly for demonstration purposes.
## Step 1: Answering the question
[[ go back to the top ]](#Table-of-contents)
The first step to any data analysis project is to define the question or problem we're looking to solve, and to define a measure (or set of measures) for our success at solving that task. The data analysis checklist has us answer a handful of questions to accomplish that, so let's work through those questions.
>Did you specify the type of data analytic question (e.g. exploration, association causality) before touching the data?
We're trying to classify the species (i.e., class) of the flower based on four measurements that we're provided: sepal length, sepal width, petal length, and petal width.
Petal - ziedlapiņa, sepal - arī ziedlapiņa

>Did you define the metric for success before beginning?
Let's do that now. Since we're performing classification, we can use [accuracy](https://en.wikipedia.org/wiki/Accuracy_and_precision) — the fraction of correctly classified flowers — to quantify how well our model is performing. Our company's Head of Data has told us that we should achieve at least 90% accuracy.
>Did you understand the context for the question and the scientific or business application?
We're building part of a data analysis pipeline for a smartphone app that will be able to classify the species of flowers from pictures taken on the smartphone. In the future, this pipeline will be connected to another pipeline that automatically measures from pictures the traits we're using to perform this classification.
>Did you record the experimental design?
Our company's Head of Data has told us that the field researchers are hand-measuring 50 randomly-sampled flowers of each species using a standardized methodology. The field researchers take pictures of each flower they sample from pre-defined angles so the measurements and species can be confirmed by the other field researchers at a later point. At the end of each day, the data is compiled and stored on a private company GitHub repository.
>Did you consider whether the question could be answered with the available data?
The data set we currently have is only for three types of *Iris* flowers. The model built off of this data set will only work for those *Iris* flowers, so we will need more data to create a general flower classifier.
<hr />
Notice that we've spent a fair amount of time working on the problem without writing a line of code or even looking at the data.
**Thinking about and documenting the problem we're working on is an important step to performing effective data analysis that often goes overlooked.** Don't skip it.
## Step 2: Checking the data
[[ go back to the top ]](#Table-of-contents)
The next step is to look at the data we're working with. Even curated data sets from the government can have errors in them, and it's vital that we spot these errors before investing too much time in our analysis.
Generally, we're looking to answer the following questions:
* Is there anything wrong with the data?
* Are there any quirks with the data?
* Do I need to fix or remove any of the data?
Let's start by reading the data into a pandas DataFrame.
```
import pandas as pd
iris_data = pd.read_csv('../data/iris-data.csv')
# Resources for loading data from nonlocal sources
# Pandas Can generally handle most common formats
# https://pandas.pydata.org/pandas-docs/stable/io.html
# SQL https://stackoverflow.com/questions/39149243/how-do-i-connect-to-a-sql-server-database-with-python
# NoSQL MongoDB https://realpython.com/introduction-to-mongodb-and-python/
# Apache Hadoop: https://dzone.com/articles/how-to-get-hadoop-data-into-a-python-model
# Apache Spark: https://www.datacamp.com/community/tutorials/apache-spark-python
# Data Scraping / Crawling libraries : https://elitedatascience.com/python-web-scraping-libraries Big Topic in itself
# Most data resources have some form of Python API / Library
iris_data.head()
```
We're in luck! The data seems to be in a usable format.
The first row in the data file defines the column headers, and the headers are descriptive enough for us to understand what each column represents. The headers even give us the units that the measurements were recorded in, just in case we needed to know at a later point in the project.
Each row following the first row represents an entry for a flower: four measurements and one class, which tells us the species of the flower.
**One of the first things we should look for is missing data.** Thankfully, the field researchers already told us that they put a 'NA' into the spreadsheet when they were missing a measurement.
We can tell pandas to automatically identify missing values if it knows our missing value marker.
```
iris_data.shape
iris_data.info()
iris_data.describe()
iris_data = pd.read_csv('../data/iris-data.csv', na_values=['NA', 'N/A'])
```
Voilà! Now pandas knows to treat rows with 'NA' as missing values.
Next, it's always a good idea to look at the distribution of our data — especially the outliers.
Let's start by printing out some summary statistics about the data set.
```
iris_data.describe()
```
We can see several useful values from this table. For example, we see that five `petal_width_cm` entries are missing.
If you ask me, though, tables like this are rarely useful unless we know that our data should fall in a particular range. It's usually better to visualize the data in some way. Visualization makes outliers and errors immediately stand out, whereas they might go unnoticed in a large table of numbers.
Since we know we're going to be plotting in this section, let's set up the notebook so we can plot inside of it.
```
# This line tells the notebook to show plots inside of the notebook
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sb
```
Next, let's create a **scatterplot matrix**. Scatterplot matrices plot the distribution of each column along the diagonal, and then plot a scatterplot matrix for the combination of each variable. They make for an efficient tool to look for errors in our data.
We can even have the plotting package color each entry by its class to look for trends within the classes.
```
# We have to temporarily drop the rows with 'NA' values
# because the Seaborn plotting function does not know
# what to do with them
sb.pairplot(iris_data.dropna(), hue='class')
```
From the scatterplot matrix, we can already see some issues with the data set:
1. There are five classes when there should only be three, meaning there were some coding errors.
2. There are some clear outliers in the measurements that may be erroneous: one `sepal_width_cm` entry for `Iris-setosa` falls well outside its normal range, and several `sepal_length_cm` entries for `Iris-versicolor` are near-zero for some reason.
3. We had to drop those rows with missing values.
In all of these cases, we need to figure out what to do with the erroneous data. Which takes us to the next step...
## Step 3: Tidying the data
### GIGO principle
[[ go back to the top ]](#Table-of-contents)
Now that we've identified several errors in the data set, we need to fix them before we proceed with the analysis.
Let's walk through the issues one-by-one.
>There are five classes when there should only be three, meaning there were some coding errors.
After talking with the field researchers, it sounds like one of them forgot to add `Iris-` before their `Iris-versicolor` entries. The other extraneous class, `Iris-setossa`, was simply a typo that they forgot to fix.
Let's use the DataFrame to fix these errors.
```
iris_data['class'].unique()
# Copy and Replace
iris_data.loc[iris_data['class'] == 'versicolor', 'class'] = 'Iris-versicolor'
iris_data['class'].unique()
# So we take a row where a specific column('class' here) matches our bad values
# and change them to good values
iris_data.loc[iris_data['class'] == 'Iris-setossa', 'class'] = 'Iris-setosa'
iris_data['class'].unique()
iris_data.tail()
iris_data[98:103]
```
Much better! Now we only have three class types. Imagine how embarrassing it would've been to create a model that used the wrong classes.
>There are some clear outliers in the measurements that may be erroneous: one `sepal_width_cm` entry for `Iris-setosa` falls well outside its normal range, and several `sepal_length_cm` entries for `Iris-versicolor` are near-zero for some reason.
Fixing outliers can be tricky business. It's rarely clear whether the outlier was caused by measurement error, recording the data in improper units, or if the outlier is a real anomaly. For that reason, we should be judicious when working with outliers: if we decide to exclude any data, we need to make sure to document what data we excluded and provide solid reasoning for excluding that data. (i.e., "This data didn't fit my hypothesis" will not stand peer review.)
In the case of the one anomalous entry for `Iris-setosa`, let's say our field researchers know that it's impossible for `Iris-setosa` to have a sepal width below 2.5 cm. Clearly this entry was made in error, and we're better off just scrapping the entry than spending hours finding out what happened.
```
smallpetals = iris_data.loc[(iris_data['sepal_width_cm'] < 2.5) & (iris_data['class'] == 'Iris-setosa')]
smallpetals
iris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
# This line drops any 'Iris-setosa' rows with a separal width less than 2.5 cm
# Let's go over this command in class
iris_data = iris_data.loc[(iris_data['class'] != 'Iris-setosa') | (iris_data['sepal_width_cm'] >= 2.5)]
iris_data.loc[iris_data['class'] == 'Iris-setosa', 'sepal_width_cm'].hist()
```
Excellent! Now all of our `Iris-setosa` rows have a sepal width greater than 2.5.
The next data issue to address is the several near-zero sepal lengths for the `Iris-versicolor` rows. Let's take a look at those rows.
```
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &
(iris_data['sepal_length_cm'] < 1.0)]
```
How about that? All of these near-zero `sepal_length_cm` entries seem to be off by two orders of magnitude, as if they had been recorded in meters instead of centimeters.
After some brief correspondence with the field researchers, we find that one of them forgot to convert those measurements to centimeters. Let's do that for them.
```
iris_data.loc[iris_data['class'] == 'Iris-versicolor', 'sepal_length_cm'].hist()
iris_data['sepal_length_cm'].hist()
# Here we fix the wrong units
iris_data.loc[(iris_data['class'] == 'Iris-versicolor') &
(iris_data['sepal_length_cm'] < 1.0),
'sepal_length_cm'] *= 100.0
iris_data.loc[iris_data['class'] == 'Iris-versicolor', 'sepal_length_cm'].hist()
;
iris_data['sepal_length_cm'].hist()
```
Phew! Good thing we fixed those outliers. They could've really thrown our analysis off.
>We had to drop those rows with missing values.
Let's take a look at the rows with missing values:
```
iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |
(iris_data['sepal_width_cm'].isnull()) |
(iris_data['petal_length_cm'].isnull()) |
(iris_data['petal_width_cm'].isnull())]
```
It's not ideal that we had to drop those rows, especially considering they're all `Iris-setosa` entries. Since it seems like the missing data is systematic — all of the missing values are in the same column for the same *Iris* type — this error could potentially bias our analysis.
One way to deal with missing data is **mean imputation**: If we know that the values for a measurement fall in a certain range, we can fill in empty values with the average of that measurement.
Let's see if we can do that here.
```
iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].hist()
```
Most of the petal widths for `Iris-setosa` fall within the 0.2-0.3 range, so let's fill in these entries with the average measured petal width.
```
iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].mean()
average_petal_width = iris_data.loc[iris_data['class'] == 'Iris-setosa', 'petal_width_cm'].mean()
print(average_petal_width)
iris_data.loc[(iris_data['class'] == 'Iris-setosa') &
(iris_data['petal_width_cm'].isnull()),
'petal_width_cm'] = average_petal_width
iris_data.loc[(iris_data['class'] == 'Iris-setosa') &
(iris_data['petal_width_cm'] == average_petal_width)]
iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |
(iris_data['sepal_width_cm'].isnull()) |
(iris_data['petal_length_cm'].isnull()) |
(iris_data['petal_width_cm'].isnull())]
```
Great! Now we've recovered those rows and no longer have missing data in our data set.
**Note:** If you don't feel comfortable imputing your data, you can drop all rows with missing data with the `dropna()` call:
iris_data.dropna(inplace=True)
After all this hard work, we don't want to repeat this process every time we work with the data set. Let's save the tidied data file *as a separate file* and work directly with that data file from now on.
```
iris_data.to_json('../data/iris-clean.json')
iris_data.to_csv('../data/iris-data-clean.csv', index=False)
cleanedframe = iris_data.dropna()
iris_data_clean = pd.read_csv('../data/iris-data-clean.csv')
```
Now, let's take a look at the scatterplot matrix now that we've tidied the data.
```
myplot = sb.pairplot(iris_data_clean, hue='class')
myplot.savefig('irises.png')
import scipy.stats as stats
iris_data = pd.read_csv('../data/iris-data.csv')
iris_data.columns.unique()
stats.entropy(iris_data_clean['sepal_length_cm'])
iris_data.columns[:-1]
# we go through list of column names except last one and get entropy
# for data (without missing values) in each column
for col in iris_data.columns[:-1]:
print("Entropy for: ", col, stats.entropy(iris_data[col].dropna()))
```
Of course, I purposely inserted numerous errors into this data set to demonstrate some of the many possible scenarios you may face while tidying your data.
The general takeaways here should be:
* Make sure your data is encoded properly
* Make sure your data falls within the expected range, and use domain knowledge whenever possible to define that expected range
* Deal with missing data in one way or another: replace it if you can or drop it
* Never tidy your data manually because that is not easily reproducible
* Use code as a record of how you tidied your data
* Plot everything you can about the data at this stage of the analysis so you can *visually* confirm everything looks correct
## Bonus: Testing our data
[[ go back to the top ]](#Table-of-contents)
At SciPy 2015, I was exposed to a great idea: We should test our data. Just how we use unit tests to verify our expectations from code, we can similarly set up unit tests to verify our expectations about a data set.
We can quickly test our data using `assert` statements: We assert that something must be true, and if it is, then nothing happens and the notebook continues running. However, if our assertion is wrong, then the notebook stops running and brings it to our attention. For example,
```Python
assert 1 == 2
```
will raise an `AssertionError` and stop execution of the notebook because the assertion failed.
Let's test a few things that we know about our data set now.
```
# We know that we should only have three classes
assert len(iris_data_clean['class'].unique()) == 3
# We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm
assert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5
# We know that our data set should have no missing measurements
assert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |
(iris_data_clean['sepal_width_cm'].isnull()) |
(iris_data_clean['petal_length_cm'].isnull()) |
(iris_data_clean['petal_width_cm'].isnull())]) == 0
# We know that our data set should have no missing measurements
assert len(iris_data.loc[(iris_data['sepal_length_cm'].isnull()) |
(iris_data['sepal_width_cm'].isnull()) |
(iris_data['petal_length_cm'].isnull()) |
(iris_data['petal_width_cm'].isnull())]) == 0
```
And so on. If any of these expectations are violated, then our analysis immediately stops and we have to return to the tidying stage.
### Data Cleanup & Wrangling > 80% time spent in Data Science
## Step 4: Exploratory analysis
[[ go back to the top ]](#Table-of-contents)
Now after spending entirely too much time tidying our data, we can start analyzing it!
Exploratory analysis is the step where we start delving deeper into the data set beyond the outliers and errors. We'll be looking to answer questions such as:
* How is my data distributed?
* Are there any correlations in my data?
* Are there any confounding factors that explain these correlations?
This is the stage where we plot all the data in as many ways as possible. Create many charts, but don't bother making them pretty — these charts are for internal use.
Let's return to that scatterplot matrix that we used earlier.
```
sb.pairplot(iris_data_clean)
;
```
Our data is normally distributed for the most part, which is great news if we plan on using any modeling methods that assume the data is normally distributed.
There's something strange going on with the petal measurements. Maybe it's something to do with the different `Iris` types. Let's color code the data by the class again to see if that clears things up.
```
sb.pairplot(iris_data_clean, hue='class')
;
```
Sure enough, the strange distribution of the petal measurements exist because of the different species. This is actually great news for our classification task since it means that the petal measurements will make it easy to distinguish between `Iris-setosa` and the other `Iris` types.
Distinguishing `Iris-versicolor` and `Iris-virginica` will prove more difficult given how much their measurements overlap.
There are also correlations between petal length and petal width, as well as sepal length and sepal width. The field biologists assure us that this is to be expected: Longer flower petals also tend to be wider, and the same applies for sepals.
We can also make [**violin plots**](https://en.wikipedia.org/wiki/Violin_plot) of the data to compare the measurement distributions of the classes. Violin plots contain the same information as [box plots](https://en.wikipedia.org/wiki/Box_plot), but also scales the box according to the density of the data.
```
plt.figure(figsize=(10, 10))
for column_index, column in enumerate(iris_data_clean.columns):
if column == 'class':
continue
plt.subplot(2, 2, column_index + 1)
sb.violinplot(x='class', y=column, data=iris_data_clean)
```
Enough flirting with the data. Let's get to modeling.
## Step 5: Classification
[[ go back to the top ]](#Table-of-contents)
Wow, all this work and we *still* haven't modeled the data!
As tiresome as it can be, tidying and exploring our data is a vital component to any data analysis. If we had jumped straight to the modeling step, we would have created a faulty classification model.
Remember: **Bad data leads to bad models.** Always check your data first.
<hr />
Assured that our data is now as clean as we can make it — and armed with some cursory knowledge of the distributions and relationships in our data set — it's time to make the next big step in our analysis: Splitting the data into training and testing sets.
A **training set** is a random subset of the data that we use to train our models.
A **testing set** is a random subset of the data (mutually exclusive from the training set) that we use to validate our models on unforseen data.
Especially in sparse data sets like ours, it's easy for models to **overfit** the data: The model will learn the training set so well that it won't be able to handle most of the cases it's never seen before. This is why it's important for us to build the model with the training set, but score it with the testing set.
Note that once we split the data into a training and testing set, we should treat the testing set like it no longer exists: We cannot use any information from the testing set to build our model or else we're cheating.
Let's set up our data first.
```
iris_data_clean = pd.read_csv('../data/iris-data-clean.csv')
# We're using all four measurements as inputs
# Note that scikit-learn expects each entry to be a list of values, e.g.,
# [ [val1, val2, val3],
# [val1, val2, val3],
# ... ]
# such that our input data set is represented as a list of lists
# We can extract the data in this format from pandas like this:
all_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
# Similarly, we can extract the class labels
all_labels = iris_data_clean['class'].values
# Make sure that you don't mix up the order of the entries
# all_inputs[5] inputs should correspond to the class in all_labels[5]
# Here's what a subset of our inputs looks like:
all_inputs[:5]
all_labels[:5]
type(all_inputs)
all_labels[:5]
type(all_labels)
```
Now our data is ready to be split.
```
from sklearn.model_selection import train_test_split
all_inputs[:3]
iris_data_clean.head(3)
all_labels[:3]
# Here we split our data into training and testing data
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25, random_state=1)
training_inputs[:5]
testing_inputs[:5]
testing_classes[:5]
training_classes[:5]
```
With our data split, we can start fitting models to our data. Our company's Head of Data is all about decision tree classifiers, so let's start with one of those.
Decision tree classifiers are incredibly simple in theory. In their simplest form, decision tree classifiers ask a series of Yes/No questions about the data — each time getting closer to finding out the class of each entry — until they either classify the data set perfectly or simply can't differentiate a set of entries. Think of it like a game of [Twenty Questions](https://en.wikipedia.org/wiki/Twenty_Questions), except the computer is *much*, *much* better at it.
Here's an example decision tree classifier:
<img src="img/iris_dtc.png" />
Notice how the classifier asks Yes/No questions about the data — whether a certain feature is <= 1.75, for example — so it can differentiate the records. This is the essence of every decision tree.
The nice part about decision tree classifiers is that they are **scale-invariant**, i.e., the scale of the features does not affect their performance, unlike many Machine Learning models. In other words, it doesn't matter if our features range from 0 to 1 or 0 to 1,000; decision tree classifiers will work with them just the same.
There are several [parameters](http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html) that we can tune for decision tree classifiers, but for now let's use a basic decision tree classifier.
```
from sklearn.tree import DecisionTreeClassifier
# Create the classifier
decision_tree_classifier = DecisionTreeClassifier()
# Train the classifier on the training set
decision_tree_classifier.fit(training_inputs, training_classes)
# Validate the classifier on the testing set using classification accuracy
decision_tree_classifier.score(testing_inputs, testing_classes)
150*0.25
len(testing_inputs)
37/38
from sklearn import svm
svm_classifier = svm.SVC(gamma = 'scale')
svm_classifier.fit(training_inputs, training_classes)
svm_classifier.score(testing_inputs, testing_classes)
svm_classifier = svm.SVC(gamma = 'scale')
svm_classifier.fit(training_inputs, training_classes)
svm_classifier.score(testing_inputs, testing_classes)
```
Heck yeah! Our model achieves 97% classification accuracy without much effort.
However, there's a catch: Depending on how our training and testing set was sampled, our model can achieve anywhere from 80% to 100% accuracy:
```
import matplotlib.pyplot as plt
# here we randomly split data 1000 times in differrent training and test sets
model_accuracies = []
for repetition in range(1000):
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)
decision_tree_classifier = DecisionTreeClassifier()
decision_tree_classifier.fit(training_inputs, training_classes)
classifier_accuracy = decision_tree_classifier.score(testing_inputs, testing_classes)
model_accuracies.append(classifier_accuracy)
plt.hist(model_accuracies)
;
100/38
```
It's obviously a problem that our model performs quite differently depending on the subset of the data it's trained on. This phenomenon is known as **overfitting**: The model is learning to classify the training set so well that it doesn't generalize and perform well on data it hasn't seen before.
### Cross-validation
[[ go back to the top ]](#Table-of-contents)
This problem is the main reason that most data scientists perform ***k*-fold cross-validation** on their models: Split the original data set into *k* subsets, use one of the subsets as the testing set, and the rest of the subsets are used as the training set. This process is then repeated *k* times such that each subset is used as the testing set exactly once.
10-fold cross-validation is the most common choice, so let's use that here. Performing 10-fold cross-validation on our data set looks something like this:
(each square is an entry in our data set)
```
# new text
import numpy as np
from sklearn.model_selection import StratifiedKFold
def plot_cv(cv, features, labels):
masks = []
for train, test in cv.split(features, labels):
mask = np.zeros(len(labels), dtype=bool)
mask[test] = 1
masks.append(mask)
plt.figure(figsize=(15, 15))
plt.imshow(masks, interpolation='none', cmap='gray_r')
plt.ylabel('Fold')
plt.xlabel('Row #')
plot_cv(StratifiedKFold(n_splits=10), all_inputs, all_labels)
```
You'll notice that we used **Stratified *k*-fold cross-validation** in the code above. Stratified *k*-fold keeps the class proportions the same across all of the folds, which is vital for maintaining a representative subset of our data set. (e.g., so we don't have 100% `Iris setosa` entries in one of the folds.)
We can perform 10-fold cross-validation on our model with the following code:
```
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_score
decision_tree_classifier = DecisionTreeClassifier()
# cross_val_score returns a list of the scores, which we can visualize
# to get a reasonable estimate of our classifier's performance
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)
plt.hist(cv_scores)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
;
len(all_inputs.T[1])
print("Entropy for: ", stats.entropy(all_inputs.T[1]))
# we go through list of column names except last one and get entropy
# for data (without missing values) in each column
def printEntropy(npdata):
for i, col in enumerate(npdata.T):
print("Entropy for column:", i, stats.entropy(col))
printEntropy(all_inputs)
```
Now we have a much more consistent rating of our classifier's general classification accuracy.
### Parameter tuning
[[ go back to the top ]](#Table-of-contents)
Every Machine Learning model comes with a variety of parameters to tune, and these parameters can be vitally important to the performance of our classifier. For example, if we severely limit the depth of our decision tree classifier:
```
decision_tree_classifier = DecisionTreeClassifier(max_depth=1)
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)
plt.hist(cv_scores)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
;
```
the classification accuracy falls tremendously.
Therefore, we need to find a systematic method to discover the best parameters for our model and data set.
The most common method for model parameter tuning is **Grid Search**. The idea behind Grid Search is simple: explore a range of parameters and find the best-performing parameter combination. Focus your search on the best range of parameters, then repeat this process several times until the best parameters are discovered.
Let's tune our decision tree classifier. We'll stick to only two parameters for now, but it's possible to simultaneously explore dozens of parameters if we want.
```
from sklearn.model_selection import GridSearchCV
decision_tree_classifier = DecisionTreeClassifier()
parameter_grid = {'max_depth': [1, 2, 3, 4, 5],
'max_features': [1, 2, 3, 4]}
cross_validation = StratifiedKFold(n_splits=10)
grid_search = GridSearchCV(decision_tree_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_labels)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
```
Now let's visualize the grid search to see how the parameters interact.
```
grid_search.cv_results_['mean_test_score']
grid_visualization = grid_search.cv_results_['mean_test_score']
grid_visualization.shape = (5, 4)
sb.heatmap(grid_visualization, cmap='Reds', annot=True)
plt.xticks(np.arange(4) + 0.5, grid_search.param_grid['max_features'])
plt.yticks(np.arange(5) + 0.5, grid_search.param_grid['max_depth'])
plt.xlabel('max_features')
plt.ylabel('max_depth')
;
```
Now we have a better sense of the parameter space: We know that we need a `max_depth` of at least 2 to allow the decision tree to make more than a one-off decision.
`max_features` doesn't really seem to make a big difference here as long as we have 2 of them, which makes sense since our data set has only 4 features and is relatively easy to classify. (Remember, one of our data set's classes was easily separable from the rest based on a single feature.)
Let's go ahead and use a broad grid search to find the best settings for a handful of parameters.
```
decision_tree_classifier = DecisionTreeClassifier()
parameter_grid = {'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'max_depth': [1, 2, 3, 4, 5],
'max_features': [1, 2, 3, 4]}
cross_validation = StratifiedKFold(n_splits=10)
grid_search = GridSearchCV(decision_tree_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_labels)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
```
Now we can take the best classifier from the Grid Search and use that:
```
decision_tree_classifier = grid_search.best_estimator_
decision_tree_classifier
```
We can even visualize the decision tree with [GraphViz](http://www.graphviz.org/) to see how it's making the classifications:
```
import sklearn.tree as tree
from sklearn.externals.six import StringIO
with open('iris_dtc.dot', 'w') as out_file:
out_file = tree.export_graphviz(decision_tree_classifier, out_file=out_file)
```
<img src="img/iris_dtc.png" />
(This classifier may look familiar from earlier in the notebook.)
Alright! We finally have our demo classifier. Let's create some visuals of its performance so we have something to show our company's Head of Data.
```
dt_scores = cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10)
sb.boxplot(dt_scores)
sb.stripplot(dt_scores, jitter=True, color='black')
;
```
Hmmm... that's a little boring by itself though. How about we compare another classifier to see how they perform?
We already know from previous projects that Random Forest classifiers usually work better than individual decision trees. A common problem that decision trees face is that they're prone to overfitting: They complexify to the point that they classify the training set near-perfectly, but fail to generalize to data they have not seen before.
**Random Forest classifiers** work around that limitation by creating a whole bunch of decision trees (hence "forest") — each trained on random subsets of training samples (drawn with replacement) and features (drawn without replacement) — and have the decision trees work together to make a more accurate classification.
Let that be a lesson for us: **Even in Machine Learning, we get better results when we work together!**
Let's see if a Random Forest classifier works better here.
The great part about scikit-learn is that the training, testing, parameter tuning, etc. process is the same for all models, so we only need to plug in the new classifier.
```
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
random_forest_classifier = RandomForestClassifier()
parameter_grid = {'n_estimators': [10, 25, 50, 100],
'criterion': ['gini', 'entropy'],
'max_features': [1, 2, 3, 4]}
cross_validation = StratifiedKFold(n_splits=10)
grid_search = GridSearchCV(random_forest_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_labels)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
grid_search.best_estimator_
```
Now we can compare their performance:
```
random_forest_classifier = grid_search.best_estimator_
rf_df = pd.DataFrame({'accuracy': cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10),
'classifier': ['Random Forest'] * 10})
dt_df = pd.DataFrame({'accuracy': cross_val_score(decision_tree_classifier, all_inputs, all_labels, cv=10),
'classifier': ['Decision Tree'] * 10})
both_df = rf_df.append(dt_df)
sb.boxplot(x='classifier', y='accuracy', data=both_df)
sb.stripplot(x='classifier', y='accuracy', data=both_df, jitter=True, color='black')
;
```
How about that? They both seem to perform about the same on this data set. This is probably because of the limitations of our data set: We have only 4 features to make the classification, and Random Forest classifiers excel when there's hundreds of possible features to look at. In other words, there wasn't much room for improvement with this data set.
## Step 6: Reproducibility
[[ go back to the top ]](#Table-of-contents)
Ensuring that our work is reproducible is the last and — arguably — most important step in any analysis. **As a rule, we shouldn't place much weight on a discovery that can't be reproduced**. As such, if our analysis isn't reproducible, we might as well not have done it.
Notebooks like this one go a long way toward making our work reproducible. Since we documented every step as we moved along, we have a written record of what we did and why we did it — both in text and code.
Beyond recording what we did, we should also document what software and hardware we used to perform our analysis. This typically goes at the top of our notebooks so our readers know what tools to use.
[Sebastian Raschka](http://sebastianraschka.com/) created a handy [notebook tool](https://github.com/rasbt/watermark) for this:
```
!pip install watermark
%load_ext watermark
pd.show_versions()
%watermark -a 'RCS_April_2019' -nmv --packages numpy,pandas,sklearn,matplotlib,seaborn
```
Finally, let's extract the core of our work from Steps 1-5 and turn it into a single pipeline.
```
%matplotlib inline
import pandas as pd
import seaborn as sb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
# We can jump directly to working with the clean data because we saved our cleaned data set
iris_data_clean = pd.read_csv('../data/iris-data-clean.csv')
# Testing our data: Our analysis will stop here if any of these assertions are wrong
# We know that we should only have three classes
assert len(iris_data_clean['class'].unique()) == 3
# We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm
assert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5
# We know that our data set should have no missing measurements
assert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |
(iris_data_clean['sepal_width_cm'].isnull()) |
(iris_data_clean['petal_length_cm'].isnull()) |
(iris_data_clean['petal_width_cm'].isnull())]) == 0
all_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
all_labels = iris_data_clean['class'].values
# This is the classifier that came out of Grid Search
random_forest_classifier = RandomForestClassifier(criterion='gini', max_features=3, n_estimators=50)
# All that's left to do now is plot the cross-validation scores
rf_classifier_scores = cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10)
sb.boxplot(rf_classifier_scores)
sb.stripplot(rf_classifier_scores, jitter=True, color='black')
# ...and show some of the predictions from the classifier
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)
random_forest_classifier.fit(training_inputs, training_classes)
for input_features, prediction, actual in zip(testing_inputs[:10],
random_forest_classifier.predict(testing_inputs[:10]),
testing_classes[:10]):
print('{}\t-->\t{}\t(Actual: {})'.format(input_features, prediction, actual))
%matplotlib inline
import pandas as pd
import seaborn as sb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
def processData(filename):
# We can jump directly to working with the clean data because we saved our cleaned data set
iris_data_clean = pd.read_csv(filename)
# Testing our data: Our analysis will stop here if any of these assertions are wrong
# We know that we should only have three classes
assert len(iris_data_clean['class'].unique()) == 3
# We know that sepal lengths for 'Iris-versicolor' should never be below 2.5 cm
assert iris_data_clean.loc[iris_data_clean['class'] == 'Iris-versicolor', 'sepal_length_cm'].min() >= 2.5
# We know that our data set should have no missing measurements
assert len(iris_data_clean.loc[(iris_data_clean['sepal_length_cm'].isnull()) |
(iris_data_clean['sepal_width_cm'].isnull()) |
(iris_data_clean['petal_length_cm'].isnull()) |
(iris_data_clean['petal_width_cm'].isnull())]) == 0
all_inputs = iris_data_clean[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
all_labels = iris_data_clean['class'].values
# This is the classifier that came out of Grid Search
random_forest_classifier = RandomForestClassifier(criterion='gini', max_features=3, n_estimators=50)
# All that's left to do now is plot the cross-validation scores
rf_classifier_scores = cross_val_score(random_forest_classifier, all_inputs, all_labels, cv=10)
sb.boxplot(rf_classifier_scores)
sb.stripplot(rf_classifier_scores, jitter=True, color='black')
# ...and show some of the predictions from the classifier
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_labels, test_size=0.25)
random_forest_classifier.fit(training_inputs, training_classes)
for input_features, prediction, actual in zip(testing_inputs[:10],
random_forest_classifier.predict(testing_inputs[:10]),
testing_classes[:10]):
print('{}\t-->\t{}\t(Actual: {})'.format(input_features, prediction, actual))
return rf_classifier_scores
myscores = processData('../data/iris-data-clean.csv')
myscores
```
There we have it: We have a complete and reproducible Machine Learning pipeline to demo to our company's Head of Data. We've met the success criteria that we set from the beginning (>90% accuracy), and our pipeline is flexible enough to handle new inputs or flowers when that data set is ready. Not bad for our first week on the job!
## Conclusions
[[ go back to the top ]](#Table-of-contents)
I hope you found this example notebook useful for your own work and learned at least one new trick by reading through it.
* [Submit an issue](https://github.com/ValRCS/LU-pysem/issues) on GitHub
* Fork the [notebook repository](https://github.com/ValRCS/LU-pysem), make the fix/addition yourself, then send over a pull request
## Further reading
[[ go back to the top ]](#Table-of-contents)
This notebook covers a broad variety of topics but skips over many of the specifics. If you're looking to dive deeper into a particular topic, here's some recommended reading.
**Data Science**: William Chen compiled a [list of free books](http://www.wzchen.com/data-science-books/) for newcomers to Data Science, ranging from the basics of R & Python to Machine Learning to interviews and advice from prominent data scientists.
**Machine Learning**: /r/MachineLearning has a useful [Wiki page](https://www.reddit.com/r/MachineLearning/wiki/index) containing links to online courses, books, data sets, etc. for Machine Learning. There's also a [curated list](https://github.com/josephmisiti/awesome-machine-learning) of Machine Learning frameworks, libraries, and software sorted by language.
**Unit testing**: Dive Into Python 3 has a [great walkthrough](http://www.diveintopython3.net/unit-testing.html) of unit testing in Python, how it works, and how it should be used
**pandas** has [several tutorials](http://pandas.pydata.org/pandas-docs/stable/tutorials.html) covering its myriad features.
**scikit-learn** has a [bunch of tutorials](http://scikit-learn.org/stable/tutorial/index.html) for those looking to learn Machine Learning in Python. Andreas Mueller's [scikit-learn workshop materials](https://github.com/amueller/scipy_2015_sklearn_tutorial) are top-notch and freely available.
**matplotlib** has many [books, videos, and tutorials](http://matplotlib.org/resources/index.html) to teach plotting in Python.
**Seaborn** has a [basic tutorial](http://stanford.edu/~mwaskom/software/seaborn/tutorial.html) covering most of the statistical plotting features.
## Acknowledgements
[[ go back to the top ]](#Table-of-contents)
Many thanks to [Andreas Mueller](http://amueller.github.io/) for some of his [examples](https://github.com/amueller/scipy_2015_sklearn_tutorial) in the Machine Learning section. I drew inspiration from several of his excellent examples.
The photo of a flower with annotations of the petal and sepal was taken by [Eric Guinther](https://commons.wikimedia.org/wiki/File:Petal-sepal.jpg).
The photos of the various *Iris* flower types were taken by [Ken Walker](http://www.signa.org/index.pl?Display+Iris-setosa+2) and [Barry Glick](http://www.signa.org/index.pl?Display+Iris-virginica+3).
## Further questions?
Feel free to contact [Valdis Saulespurens]
(email:[email protected])
| true |
code
| 0.521898 | null | null | null | null |
|
```
# "PGA Tour Wins Classification"
```
Can We Predict If a PGA Tour Player Won a Tournament in a Given Year?
Golf is picking up popularity, so I thought it would be interesting to focus my project here. I set out to find what sets apart the best golfers from the rest.
I decided to explore their statistics and to see if I could predict which golfers would win in a given year. My original dataset was found on Kaggle, and the data was scraped from the PGA Tour website.
From this data, I performed an exploratory data analysis to explore the distribution of players on numerous aspects of the game, discover outliers, and further explore how the game has changed from 2010 to 2018. I also utilized numerous supervised machine learning models to predict a golfer's earnings and wins.
To predict the golfer's win, I used classification methods such as logisitic regression and Random Forest Classification. The best performance came from the Random Forest Classification method.
1. The Data
pgaTourData.csv contains 1674 rows and 18 columns. Each row indicates a golfer's performance for that year.
```
# Player Name: Name of the golfer
# Rounds: The number of games that a player played
# Fairway Percentage: The percentage of time a tee shot lands on the fairway
# Year: The year in which the statistic was collected
# Avg Distance: The average distance of the tee-shot
# gir: (Green in Regulation) is met if any part of the ball is touching the putting surface while the number of strokes taken is at least two fewer than par
# Average Putts: The average number of strokes taken on the green
# Average Scrambling: Scrambling is when a player misses the green in regulation, but still makes par or better on a hole
# Average Score: Average Score is the average of all the scores a player has played in that year
# Points: The number of FedExCup points a player earned in that year
# Wins: The number of competition a player has won in that year
# Top 10: The number of competitions where a player has placed in the Top 10
# Average SG Putts: Strokes gained: putting measures how many strokes a player gains (or loses) on the greens
# Average SG Total: The Off-the-tee + approach-the-green + around-the-green + putting statistics combined
# SG:OTT: Strokes gained: off-the-tee measures player performance off the tee on all par-4s and par-5s
# SG:APR: Strokes gained: approach-the-green measures player performance on approach shots
# SG:ARG: Strokes gained: around-the-green measures player performance on any shot within 30 yards of the edge of the green
# Money: The amount of prize money a player has earned from tournaments
#collapse
# importing packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Importing the data
df = pd.read_csv('pgaTourData.csv')
# Examining the first 5 data
df.head()
#collapse
df.info()
#collapse
df.shape
```
2. Data Cleaning
After looking at the dataframe, the data needs to be cleaned:
-For the columns Top 10 and Wins, convert the NaNs to 0s
-Change Top 10 and Wins into an int
-Drop NaN values for players who do not have the full statistics
-Change the columns Rounds into int
-Change points to int
-Remove the dollar sign ($) and commas in the column Money
```
# Replace NaN with 0 in Top 10
df['Top 10'].fillna(0, inplace=True)
df['Top 10'] = df['Top 10'].astype(int)
# Replace NaN with 0 in # of wins
df['Wins'].fillna(0, inplace=True)
df['Wins'] = df['Wins'].astype(int)
# Drop NaN values
df.dropna(axis = 0, inplace=True)
# Change Rounds to int
df['Rounds'] = df['Rounds'].astype(int)
# Change Points to int
df['Points'] = df['Points'].apply(lambda x: x.replace(',',''))
df['Points'] = df['Points'].astype(int)
# Remove the $ and commas in money
df['Money'] = df['Money'].apply(lambda x: x.replace('$',''))
df['Money'] = df['Money'].apply(lambda x: x.replace(',',''))
df['Money'] = df['Money'].astype(float)
#collapse
df.info()
#collapse
df.describe()
```
3. Exploratory Data Analysis
```
#collapse_output
# Looking at the distribution of data
f, ax = plt.subplots(nrows = 6, ncols = 3, figsize=(20,20))
distribution = df.loc[:,df.columns!='Player Name'].columns
rows = 0
cols = 0
for i, column in enumerate(distribution):
p = sns.distplot(df[column], ax=ax[rows][cols])
cols += 1
if cols == 3:
cols = 0
rows += 1
```
From the distributions plotted, most of the graphs are normally distributed. However, we can observe that Money, Points, Wins, and Top 10s are all skewed to the right. This could be explained by the separation of the best players and the average PGA Tour player. The best players have multiple placings in the Top 10 with wins that allows them to earn more from tournaments, while the average player will have no wins and only a few Top 10 placings that prevent them from earning as much.
```
#collapse_output
# Looking at the number of players with Wins for each year
win = df.groupby('Year')['Wins'].value_counts()
win = win.unstack()
win.fillna(0, inplace=True)
# Converting win into ints
win = win.astype(int)
print(win)
```
From this table, we can see that most players end the year without a win. It's pretty rare to find a player that has won more than once!
```
# Looking at the percentage of players without a win in that year
players = win.apply(lambda x: np.sum(x), axis=1)
percent_no_win = win[0]/players
percent_no_win = percent_no_win*100
print(percent_no_win)
#collapse_output
# Plotting percentage of players without a win each year
fig, ax = plt.subplots()
bar_width = 0.8
opacity = 0.7
index = np.arange(2010, 2019)
plt.bar(index, percent_no_win, bar_width, alpha = opacity)
plt.xticks(index)
plt.xlabel('Year')
plt.ylabel('%')
plt.title('Percentage of Players without a Win')
```
From the box plot above, we can observe that the percentages of players without a win are around 80%. There was very little variation in the percentage of players without a win in the past 8 years.
```
#collapse_output
# Plotting the number of wins on a bar chart
fig, ax = plt.subplots()
index = np.arange(2010, 2019)
bar_width = 0.2
opacity = 0.7
def plot_bar(index, win, labels):
plt.bar(index, win, bar_width, alpha=opacity, label=labels)
# Plotting the bars
rects = plot_bar(index, win[0], labels = '0 Wins')
rects1 = plot_bar(index + bar_width, win[1], labels = '1 Wins')
rects2 = plot_bar(index + bar_width*2, win[2], labels = '2 Wins')
rects3 = plot_bar(index + bar_width*3, win[3], labels = '3 Wins')
rects4 = plot_bar(index + bar_width*4, win[4], labels = '4 Wins')
rects5 = plot_bar(index + bar_width*5, win[5], labels = '5 Wins')
plt.xticks(index + bar_width, index)
plt.xlabel('Year')
plt.ylabel('Number of Players')
plt.title('Distribution of Wins each Year')
plt.legend()
```
By looking at the distribution of Wins each year, we can see that it is rare for most players to even win a tournament in the PGA Tour. Majority of players do not win, and a very few number of players win more than once a year.
```
# Percentage of people who did not place in the top 10 each year
top10 = df.groupby('Year')['Top 10'].value_counts()
top10 = top10.unstack()
top10.fillna(0, inplace=True)
players = top10.apply(lambda x: np.sum(x), axis=1)
no_top10 = top10[0]/players * 100
print(no_top10)
```
By looking at the percentage of players that did not place in the top 10 by year, We can observe that only approximately 20% of players did not place in the Top 10. In addition, the range for these player that did not place in the Top 10 is only 9.47%. This tells us that this statistic does not vary much on a yearly basis.
```
# Who are some of the longest hitters
distance = df[['Year','Player Name','Avg Distance']].copy()
distance.sort_values(by='Avg Distance', inplace=True, ascending=False)
print(distance.head())
```
Rory McIlroy is one of the longest hitters in the game, setting the average driver distance to be 319.7 yards in 2018. He was also the longest hitter in 2017 with an average of 316.7 yards.
```
# Who made the most money
money_ranking = df[['Year','Player Name','Money']].copy()
money_ranking.sort_values(by='Money', inplace=True, ascending=False)
print(money_ranking.head())
```
We can see that Jordan Spieth has made the most amount of money in a year, earning a total of 12 million dollars in 2015.
```
#collapse_output
# Who made the most money each year
money_rank = money_ranking.groupby('Year')['Money'].max()
money_rank = pd.DataFrame(money_rank)
indexs = np.arange(2010, 2019)
names = []
for i in range(money_rank.shape[0]):
temp = df.loc[df['Money'] == money_rank.iloc[i,0],'Player Name']
names.append(str(temp.values[0]))
money_rank['Player Name'] = names
print(money_rank)
```
With this table, we can examine the earnings of each player by year. Some of the most notable were Jordan Speith's earning of 12 million dollars and Justin Thomas earning the most money in both 2017 and 2018.
```
#collapse_output
# Plot the correlation matrix between variables
corr = df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values,
cmap='coolwarm')
df.corr()['Wins']
```
From the correlation matrix, we can observe that Money is highly correlated to wins along with the FedExCup Points. We can also observe that the fairway percentage, year, and rounds are not correlated to Wins.
4. Machine Learning Model (Classification)
To predict winners, I used multiple machine learning models to explore which models could accurately classify if a player is going to win in that year.
To measure the models, I used Receiver Operating Characterisitc Area Under the Curve. (ROC AUC) The ROC AUC tells us how capable the model is at distinguishing players with a win. In addition, as the data is skewed with 83% of players having no wins in that year, ROC AUC is a much better metric than the accuracy of the model.
```
#collapse
# Importing the Machine Learning modules
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import confusion_matrix
from sklearn.feature_selection import RFE
from sklearn.metrics import classification_report
from sklearn.preprocessing import PolynomialFeatures
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import MinMaxScaler
```
Preparing the Data for Classification
We know from the calculation above that the data for wins is skewed. Even without machine learning we know that approximately 83% of the players does not lead to a win. Therefore, we will be utilizing ROC AUC as the metric of these models
```
# Adding the Winner column to determine if the player won that year or not
df['Winner'] = df['Wins'].apply(lambda x: 1 if x>0 else 0)
# New DataFrame
ml_df = df.copy()
# Y value for machine learning is the Winner column
target = df['Winner']
# Removing the columns Player Name, Wins, and Winner from the dataframe to avoid leakage
ml_df.drop(['Player Name','Wins','Winner'], axis=1, inplace=True)
print(ml_df.head())
## Logistic Regression Baseline
per_no_win = target.value_counts()[0] / (target.value_counts()[0] + target.value_counts()[1])
per_no_win = per_no_win.round(4)*100
print(str(per_no_win)+str('%'))
#collapse_show
# Function for the logisitic regression
def log_reg(X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y,
random_state = 10)
clf = LogisticRegression().fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy of Logistic regression classifier on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of Logistic regression classifier on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
cf_mat = confusion_matrix(y_test, y_pred)
confusion = pd.DataFrame(data = cf_mat)
print(confusion)
print(classification_report(y_test, y_pred))
# Returning the 5 important features
#rfe = RFE(clf, 5)
# rfe = rfe.fit(X, y)
# print('Feature Importance')
# print(X.columns[rfe.ranking_ == 1].values)
print('ROC AUC Score: {:.2f}'.format(roc_auc_score(y_test, y_pred)))
#collapse_show
log_reg(ml_df, target)
```
From the logisitic regression, we got an accuracy of 0.9 on the training set and an accuracy of 0.91 on the test set. This was surprisingly accurate for a first run. However, the ROC AUC Score of 0.78 could be improved. Therefore, I decided to add more features as a way of possibly improving the model.
```
## Feature Engineering
# Adding Domain Features
ml_d = ml_df.copy()
# Top 10 / Money might give us a better understanding on how well they placed in the top 10
ml_d['Top10perMoney'] = ml_d['Top 10'] / ml_d['Money']
# Avg Distance / Fairway Percentage to give us a ratio that determines how accurate and far a player hits
ml_d['DistanceperFairway'] = ml_d['Avg Distance'] / ml_d['Fairway Percentage']
# Money / Rounds to see on average how much money they would make playing a round of golf
ml_d['MoneyperRound'] = ml_d['Money'] / ml_d['Rounds']
#collapse_show
log_reg(ml_d, target)
#collapse_show
# Adding Polynomial Features to the ml_df
mldf2 = ml_df.copy()
poly = PolynomialFeatures(2)
poly = poly.fit(mldf2)
poly_feature = poly.transform(mldf2)
print(poly_feature.shape)
# Creating a DataFrame with the polynomial features
poly_feature = pd.DataFrame(poly_feature, columns = poly.get_feature_names(ml_df.columns))
print(poly_feature.head())
#collapse_show
log_reg(poly_feature, target)
```
From feature engineering, there were no improvements in the ROC AUC Score. In fact as I added more features, the accuracy and the ROC AUC Score decreased. This could signal to us that another machine learning algorithm could better predict winners.
```
#collapse_show
## Randon Forest Model
def random_forest(X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y,
random_state = 10)
clf = RandomForestClassifier(n_estimators=200).fit(X_train, y_train)
y_pred = clf.predict(X_test)
print('Accuracy of Random Forest classifier on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of Random Forest classifier on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
cf_mat = confusion_matrix(y_test, y_pred)
confusion = pd.DataFrame(data = cf_mat)
print(confusion)
print(classification_report(y_test, y_pred))
# Returning the 5 important features
rfe = RFE(clf, 5)
rfe = rfe.fit(X, y)
print('Feature Importance')
print(X.columns[rfe.ranking_ == 1].values)
print('ROC AUC Score: {:.2f}'.format(roc_auc_score(y_test, y_pred)))
#collapse_show
random_forest(ml_df, target)
#collapse_show
random_forest(ml_d, target)
#collapse_show
random_forest(poly_feature, target)
```
The Random Forest Model scored highly on the ROC AUC Score, obtaining a value of 0.89. With this, we observed that the Random Forest Model could accurately classify players with and without a win.
6. Conclusion
It's been interesting to learn about numerous aspects of the game that differentiate the winner and the average PGA Tour player. For example, we can see that the fairway percentage and greens in regulations do not seem to contribute as much to a player's win. However, all the strokes gained statistics contribute pretty highly to wins for these players. It was interesting to see which aspects of the game that the professionals should put their time into. This also gave me the idea of track my personal golf statistics, so that I could compare it to the pros and find areas of my game that need the most improvement.
Machine Learning Model
I've been able to examine the data of PGA Tour players and classify if a player will win that year or not. With the random forest classification model, I was able to achieve an ROC AUC of 0.89 and an accuracy of 0.95 on the test set. This was a significant improvement from the ROC AUC of 0.78 and accuracy of 0.91. Because the data is skewed with approximately 80% of players not earning a win, the primary measure of the model was the ROC AUC. I was able to improve my model from ROC AUC score of 0.78 to a score of 0.89 by simply trying 3 different models, adding domain features, and polynomial features.
The End!!
| true |
code
| 0.614047 | null | null | null | null |
|
# Minimum spanning trees
*Selected Topics in Mathematical Optimization*
**Michiel Stock** ([email]([email protected]))

```
import matplotlib.pyplot as plt
%matplotlib inline
from minimumspanningtrees import red, green, blue, orange, yellow
```
## Graphs in python
Consider the following example graph:

This graph can be represented using an *adjacency list*. We do this using a `dict`. Every vertex is a key with the adjacent vertices given as a `set` containing tuples `(weight, neighbor)`. The weight is first because this makes it easy to compare the weights of two edges. Note that for every ingoing edges, there is also an outgoing edge, this is an undirected graph.
```
graph = {
'A' : set([(2, 'B'), (3, 'D')]),
'B' : set([(2, 'A'), (1, 'C'), (2, 'E')]),
'C' : set([(1, 'B'), (2, 'D'), (1, 'E')]),
'D' : set([(2, 'C'), (3, 'A'), (3, 'E')]),
'E' : set([(2, 'B'), (1, 'C'), (3, 'D')])
}
```
Sometimes we will use an *edge list*, i.e. a list of (weighted) edges. This is often a more compact way of storing a graph. The edge list is given below. Note that again every edge is double: an in- and outgoing edge is included.
```
edges = [
(2, 'B', 'A'),
(3, 'D', 'A'),
(2, 'C', 'D'),
(3, 'A', 'D'),
(3, 'E', 'D'),
(2, 'B', 'E'),
(3, 'D', 'E'),
(1, 'C', 'E'),
(2, 'E', 'B'),
(2, 'A', 'B'),
(1, 'C', 'B'),
(1, 'E', 'C'),
(1, 'B', 'C'),
(2, 'D', 'C')]
```
We can easily turn one representation in the other (with a time complexity proportional to the number of edges) using the provided functions `edges_to_adj_list` and `adj_list_to_edges`.
```
from minimumspanningtrees import edges_to_adj_list, adj_list_to_edges
adj_list_to_edges(graph)
edges_to_adj_list(edges)
```
## Disjoint-set data structure
Implementing an algorithm for finding the minimum spanning tree is fairly straightforward. The only bottleneck is that the algorithm requires the a disjoint-set data structure to keep track of a set partitioned in a number of disjoined subsets.
For example, consider the following inital set of eight elements.

We decide to group elements A, B and C together in a subset and F and G in another subset.

The disjoint-set data structure support the following operations:
- **Find**: check which subset an element is in. Is typically used to check whether two objects are in the same subset;
- **Union** merges two subsets into a single subset.
A python implementation of a disjoint-set is available using an union-set forest. A simple example will make everything clear!
```
from union_set_forest import USF
animals = ['mouse', 'bat', 'robin', 'trout', 'seagull', 'hummingbird',
'salmon', 'goldfish', 'hippopotamus', 'whale', 'sparrow']
union_set_forest = USF(animals)
# group mammals together
union_set_forest.union('mouse', 'bat')
union_set_forest.union('mouse', 'hippopotamus')
union_set_forest.union('whale', 'bat')
# group birds together
union_set_forest.union('robin', 'seagull')
union_set_forest.union('seagull', 'sparrow')
union_set_forest.union('seagull', 'hummingbird')
union_set_forest.union('robin', 'hummingbird')
# group fishes together
union_set_forest.union('goldfish', 'salmon')
union_set_forest.union('trout', 'salmon')
# mouse and whale in same subset?
print(union_set_forest.find('mouse') == union_set_forest.find('whale'))
# robin and salmon in the same subset?
print(union_set_forest.find('robin') == union_set_forest.find('salmon'))
```
## Heap queue
Can be used to find the minimum of a changing list without having to sort the list every update.
```
from heapq import heapify, heappop, heappush
heap = [(5, 'A'), (3, 'B'), (2, 'C'), (7, 'D')]
heapify(heap) # turn in a heap
print(heap)
# return item lowest value while retaining heap property
print(heappop(heap))
print(heap)
# add new item and retain heap prop
heappush(heap, (4, 'E'))
print(heap)
```
## Prim's algorithm
Prim's algorithm starts with a single vertex and add $|V|-1$ edges to it, always taking the next edge with minimal weight that connects a vertex on the MST to a vertex not yet in the MST.
```
def prim(vertices, edges, start):
"""
Prim's algorithm for finding a minimum spanning tree.
Inputs :
- vertices : a set of the vertices of the Graph
- edges : a list of weighted edges (e.g. (0.7, 'A', 'B') for an
edge from node A to node B with weigth 0.7)
- start : a vertex to start with
Output:
- edges : a minumum spanning tree represented as a list of edges
- total_cost : total cost of the tree
"""
adj_list = edges_to_adj_list(edges) # easier using an adjacency list
... # to complete
return mst_edges, total_cost
```
## Kruskal's algorithm
Kruskal's algorithm is a very simple algorithm to find the minimum spanning tree. The main idea is to start with an intial 'forest' of the individual nodes of the graph. In each step of the algorithm we add an edge with the smallest possible value that connects two disjoint trees in the forest. This process is continued until we have a single tree, which is a minimum spanning tree, or until all edges are considered. In the latter case, the algoritm returns a minimum spanning forest.
```
from minimumspanningtrees import kruskal
def kruskal(vertices, edges):
"""
Kruskal's algorithm for finding a minimum spanning tree.
Inputs :
- vertices : a set of the vertices of the Graph
- edges : a list of weighted edges (e.g. (0.7, 'A', 'B') for an
edge from node A to node B with weigth 0.7)
Output:
- edges : a minumum spanning tree represented as a list of edges
- total_cost : total cost of the tree
"""
... # to complete
return mst_edges, total_cost
```
```
print(vertices)
print(edges[:5])
# compute the minimum spanning tree of the ticket to ride data set
...
```
## Clustering
Minimum spanning trees on a distance graph can be used to cluster a data set.
```
# import features and distance
from clustering import X, D
fig, ax = plt.subplots()
ax.scatter(X[:,0], X[:,1], color=green)
# cluster the data based on the distance
```
| true |
code
| 0.651355 | null | null | null | null |
|
**INITIALIZATION:**
- I use these three lines of code on top of my each notebooks because it will help to prevent any problems while reloading the same project. And the third line of code helps to make visualization within the notebook.
```
#@ INITIALIZATION:
%reload_ext autoreload
%autoreload 2
%matplotlib inline
```
**LIBRARIES AND DEPENDENCIES:**
- I have downloaded all the libraries and dependencies required for the project in one particular cell.
```
#@ IMPORTING NECESSARY LIBRARIES AND DEPENDENCIES:
from keras.models import Sequential
from keras.layers import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense, Dropout
from keras import backend as K
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
from keras.callbacks import LearningRateScheduler
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import numpy as np
```
**VGG ARCHITECTURE:**
- I will define the build method of Mini VGGNet architecture below. It requires four parameters: width of input image, height of input image, depth of image, number of class labels in the classification task. The Sequential class, the building block of sequential networks sequentially stack one layer on top of the other layer initialized below. Batch Normalization operates over the channels, so in order to apply BN, we need to know which axis to normalize over.
```
#@ DEFINING VGGNET ARCHITECTURE:
class MiniVGGNet: # Defining VGG Network.
@staticmethod
def build(width, height, depth, classes): # Defining Build Method.
model = Sequential() # Initializing Sequential Model.
inputShape = (width, height, depth) # Initializing Input Shape.
chanDim = -1 # Index of Channel Dimension.
if K.image_data_format() == "channels_first":
inputShape = (depth, width, height) # Initializing Input Shape.
chanDim = 1 # Index of Channel Dimension.
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=inputShape)) # Adding Convolutional Layer.
model.add(Activation("relu")) # Adding RELU Activation Function.
model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer.
model.add(Conv2D(32, (3, 3), padding='same')) # Adding Convolutional Layer.
model.add(Activation("relu")) # Adding RELU Activation Function.
model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer.
model.add(MaxPooling2D(pool_size=(2, 2))) # Adding Max Pooling Layer.
model.add(Dropout(0.25)) # Adding Dropout Layer.
model.add(Conv2D(64, (3, 3), padding="same")) # Adding Convolutional Layer.
model.add(Activation("relu")) # Adding RELU Activation Function.
model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer.
model.add(Conv2D(64, (3, 3), padding='same')) # Adding Convolutional Layer.
model.add(Activation("relu")) # Adding RELU Activation Function.
model.add(BatchNormalization(axis=chanDim)) # Adding Batch Normalization Layer.
model.add(MaxPooling2D(pool_size=(2, 2))) # Adding Max Pooling Layer.
model.add(Dropout(0.25)) # Adding Dropout Layer.
model.add(Flatten()) # Adding Flatten Layer.
model.add(Dense(512)) # Adding FC Dense Layer.
model.add(Activation("relu")) # Adding Activation Layer.
model.add(BatchNormalization()) # Adding Batch Normalization Layer.
model.add(Dropout(0.5)) # Adding Dropout Layer.
model.add(Dense(classes)) # Adding Dense Output Layer.
model.add(Activation("softmax")) # Adding Softmax Layer.
return model
#@ CUSTOM LEARNING RATE SCHEDULER:
def step_decay(epoch): # Definig step decay function.
initAlpha = 0.01 # Initializing initial LR.
factor = 0.25 # Initializing drop factor.
dropEvery = 5 # Initializing epochs to drop.
alpha = initAlpha*(factor ** np.floor((1 + epoch) / dropEvery))
return float(alpha)
```
**VGGNET ON CIFAR10**
```
#@ GETTING THE DATASET:
((trainX, trainY), (testX, testY)) = cifar10.load_data() # Loading Dataset.
trainX = trainX.astype("float") / 255.0 # Normalizing Dataset.
testX = testX.astype("float") / 255.0 # Normalizing Dataset.
#@ PREPARING THE DATASET:
lb = LabelBinarizer() # Initializing LabelBinarizer.
trainY = lb.fit_transform(trainY) # Converting Labels to Vectors.
testY = lb.transform(testY) # Converting Labels to Vectors.
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"] # Initializing LabelNames.
#@ INITIALIZING OPTIMIZER AND MODEL:
callbacks = [LearningRateScheduler(step_decay)] # Initializing Callbacks.
opt = SGD(0.01, nesterov=True, momentum=0.9) # Initializing SGD Optimizer.
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10) # Initializing VGGNet Architecture.
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"]) # Compiling VGGNet Model.
H = model.fit(trainX, trainY,
validation_data=(testX, testY), batch_size=64,
epochs=40, verbose=1, callbacks=callbacks) # Training VGGNet Model.
```
**MODEL EVALUATION:**
```
#@ INITIALIZING MODEL EVALUATION:
predictions = model.predict(testX, batch_size=64) # Getting Model Predictions.
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=labelNames)) # Inspecting Classification Report.
#@ INSPECTING TRAINING LOSS AND ACCURACY:
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show();
```
**Note:**
- Batch Normalization can lead to a faster, more stable convergence with higher accuracy.
- Batch Normalization will require more wall time to train the network even though the network will obtain higher accuracy in less epochs.
| true |
code
| 0.769622 | null | null | null | null |
|
<h1>Notebook Content</h1>
1. [Import Packages](#1)
1. [Helper Functions](#2)
1. [Input](#3)
1. [Model](#4)
1. [Prediction](#5)
1. [Complete Figure](#6)
<h1 id="1">1. Import Packages</h1>
Importing all necessary and useful packages in single cell.
```
import numpy as np
import keras
import tensorflow as tf
from numpy import array
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import TimeDistributed
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras_tqdm import TQDMNotebookCallback
from sklearn.preprocessing import MinMaxScaler
from tqdm import tqdm_notebook
import matplotlib.pyplot as plt
import pandas as pd
import random
from random import randint
```
<h1 id="2">2. Helper Functions</h1>
Defining Some helper functions which we will need later in code
```
# split a univariate sequence into samples
def split_sequence(sequence, n_steps, look_ahead=0):
X, y = list(), list()
for i in range(len(sequence)-look_ahead):
# find the end of this pattern
end_ix = i + n_steps
# check if we are beyond the sequence
if end_ix > len(sequence)-1-look_ahead:
break
# gather input and output parts of the pattern
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix+look_ahead]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
def plot_multi_graph(xAxis,yAxes,title='',xAxisLabel='number',yAxisLabel='Y'):
linestyles = ['-', '--', '-.', ':']
plt.figure()
plt.title(title)
plt.xlabel(xAxisLabel)
plt.ylabel(yAxisLabel)
for key, value in yAxes.items():
plt.plot(xAxis, np.array(value), label=key, linestyle=linestyles[randint(0,3)])
plt.legend()
def normalize(values):
values = array(values, dtype="float64").reshape((len(values), 1))
# train the normalization
scaler = MinMaxScaler(feature_range=(0, 1))
scaler = scaler.fit(values)
#print('Min: %f, Max: %f' % (scaler.data_min_, scaler.data_max_))
# normalize the dataset and print the first 5 rows
normalized = scaler.transform(values)
return normalized,scaler
```
<h1 id="3">3. Input</h1>
<h3 id="3-1">3-1. Sequence PreProcessing</h3>
Splitting and Reshaping
```
n_features = 1
n_seq = 20
n_steps = 1
def sequence_preprocessed(values, sliding_window, look_ahead=0):
# Normalization
normalized,scaler = normalize(values)
# Try the following if randomizing the sequence:
# random.seed('sam') # set the seed
# raw_seq = random.sample(raw_seq, 100)
# split into samples
X, y = split_sequence(normalized, sliding_window, look_ahead)
# reshape from [samples, timesteps] into [samples, subsequences, timesteps, features]
X = X.reshape((X.shape[0], n_seq, n_steps, n_features))
return X,y,scaler
```
<h3 id="3-2">3-2. Providing Sequence</h3>
Defining a raw sequence, sliding window of data to consider and look ahead future timesteps
```
# define input sequence
sequence_val = [i for i in range(5000,7000)]
sequence_train = [i for i in range(1000,2000)]
sequence_test = [i for i in range(10000,14000)]
# choose a number of time steps for sliding window
sliding_window = 20
# choose a number of further time steps after end of sliding_window till target start (gap between data and target)
look_ahead = 20
X_train, y_train, scaler_train = sequence_preprocessed(sequence_train, sliding_window, look_ahead)
X_val, y_val ,scaler_val = sequence_preprocessed(sequence_val, sliding_window, look_ahead)
X_test,y_test,scaler_test = sequence_preprocessed(sequence_test, sliding_window, look_ahead)
```
<h1 id="4">4. Model</h1>
<h3 id="4-1">4-1. Defining Layers</h3>
Adding 1D Convolution, Max Pooling, LSTM and finally Dense (MLP) layer
```
# define model
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation='relu'),
input_shape=(None, n_steps, n_features)
))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(50, activation='relu', stateful=False))
model.add(Dense(1))
```
<h3 id="4-2">4-2. Training Model</h3>
Defined early stop, can be used in callbacks param of model fit, not using for now since it's not recommended at first few iterations of experimentation with new data
```
# Defining multiple metrics, leaving it to a choice, some may be useful and few may even surprise on some problems
metrics = ['mean_squared_error',
'mean_absolute_error',
'mean_absolute_percentage_error',
'mean_squared_logarithmic_error',
'logcosh']
# Compiling Model
model.compile(optimizer='adam', loss='mape', metrics=metrics)
# Defining early stop, call it in model fit callback
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
# Fit model
history = model.fit(X_train, y_train, epochs=100, verbose=3, validation_data=(X_val,y_val))
```
<h3 id="4-3">4-3. Evaluating Model</h3>
Plotting Training and Validation mean square error
```
# Plot Errors
for metric in metrics:
xAxis = history.epoch
yAxes = {}
yAxes["Training"]=history.history[metric]
yAxes["Validation"]=history.history['val_'+metric]
plot_multi_graph(xAxis,yAxes, title=metric,xAxisLabel='Epochs')
```
<h1 id="5">5. Prediction</h1>
<h3 id="5-1">5-1. Single Value Prediction</h3>
Predicting a single value slided 20 (our provided figure for look_ahead above) values ahead
```
# demonstrate prediction
x_input = array([i for i in range(100,120)])
print(x_input)
x_input = x_input.reshape((1, n_seq, n_steps, n_features))
yhat = model.predict(x_input)
print(yhat)
```
<h3 id="5-2">5-2. Sequence Prediction</h3>
Predicting complete sequence (determining closeness to target) based on data <br />
<i>change variable for any other sequence though</i>
```
# Prediction from Training Set
predict_train = model.predict(X_train)
# Prediction from Test Set
predict_test = model.predict(X_test)
"""
df = pd.DataFrame(({"normalized y_train":y_train.flatten(),
"normalized predict_train":predict_train.flatten(),
"actual y_train":scaler_train.inverse_transform(y_train).flatten(),
"actual predict_train":scaler_train.inverse_transform(predict_train).flatten(),
}))
"""
df = pd.DataFrame(({
"normalized y_test":y_test.flatten(),
"normalized predict_test":predict_test.flatten(),
"actual y_test":scaler_test.inverse_transform(y_test).flatten(),
"actual predict_test":scaler_test.inverse_transform(predict_test).flatten()
}))
df
```
<h1 id="6">6. Complete Figure</h1>
Data, Target, Prediction - all in one single graph
```
xAxis = [i for i in range(len(y_train))]
yAxes = {}
yAxes["Data"]=sequence_train[sliding_window:len(sequence_train)-look_ahead]
yAxes["Target"]=scaler_train.inverse_transform(y_train)
yAxes["Prediction"]=scaler_train.inverse_transform(predict_train)
plot_multi_graph(xAxis,yAxes,title='')
xAxis = [i for i in range(len(y_test))]
yAxes = {}
yAxes["Data"]=sequence_test[sliding_window:len(sequence_test)-look_ahead]
yAxes["Target"]=scaler_test.inverse_transform(y_test)
yAxes["Prediction"]=scaler_test.inverse_transform(predict_test)
plot_multi_graph(xAxis,yAxes,title='')
print(metrics)
print(model.evaluate(X_test,y_test))
```
| true |
code
| 0.68178 | null | null | null | null |
|
## 8. Classification
[Data Science Playlist on YouTube](https://www.youtube.com/watch?v=VLKEj9EN2ew&list=PLLBUgWXdTBDg1Qgmwt4jKtVn9BWh5-zgy)
[](https://www.youtube.com/watch?v=VLKEj9EN2ew&list=PLLBUgWXdTBDg1Qgmwt4jKtVn9BWh5-zgy "Python Data Science")
**Classification** predicts *discrete labels (outcomes)* such as `yes`/`no`, `True`/`False`, or any number of discrete levels such as a letter from text recognition, or a word from speech recognition. There are two main methods for training classifiers: unsupervised and supervised learning. The difference between the two is that unsupervised learning does not use labels while supervised learning uses labels to build the classifier. The goal of unsupervised learning is to cluster input features but without labels to guide the grouping.

### Supervised Learning to Classify Numbers
A dataset that is included with sklearn is a set of 1797 images of numbers that are 64 pixels (8x8) each. There are labels with each to indicate the correct answer. A Support Vector Classifier is trained on the first half of the images.
```
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# train classifier
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
svc = svm.SVC(gamma=0.001)
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
svc.fit(X_train, y_train)
print('SVC Trained')
```

### Test Number Classifier
The image classification is trained on 10 randomly selected images from the other half of the data set to evaluate the training. Run the classifier test until you observe a misclassified number.
```
plt.figure(figsize=(10,4))
for i in range(10):
n = np.random.randint(int(n_samples/2),n_samples)
predict = svc.predict(digits.data[n:n+1])[0]
plt.subplot(2,5,i+1)
plt.imshow(digits.images[n], cmap=plt.cm.gray_r, interpolation='nearest')
plt.text(0,7,'Actual: ' + str(digits.target[n]),color='r')
plt.text(0,1,'Predict: ' + str(predict),color='b')
if predict==digits.target[n]:
plt.text(0,4,'Correct',color='g')
else:
plt.text(0,4,'Incorrect',color='orange')
plt.show()
```

### Classification with Supervised Learning
Select data set option with `moons`, `cirlces`, or `blobs`. Run the following cell to generate the data that will be used to test the classifiers.
```
option = 'moons' # moons, circles, or blobs
n = 2000 # number of data points
X = np.random.random((n,2))
mixing = 0.0 # add random mixing element to data
xplot = np.linspace(0,1,100)
if option=='moons':
X, y = datasets.make_moons(n_samples=n,noise=0.1)
yplot = xplot*0.0
elif option=='circles':
X, y = datasets.make_circles(n_samples=n,noise=0.1,factor=0.5)
yplot = xplot*0.0
elif option=='blobs':
X, y = datasets.make_blobs(n_samples=n,centers=[[-5,3],[5,-3]],cluster_std=2.0)
yplot = xplot*0.0
# Split into train and test subsets (50% each)
XA, XB, yA, yB = train_test_split(X, y, test_size=0.5, shuffle=False)
# Plot regression results
def assess(P):
plt.figure()
plt.scatter(XB[P==1,0],XB[P==1,1],marker='^',color='blue',label='True')
plt.scatter(XB[P==0,0],XB[P==0,1],marker='x',color='red',label='False')
plt.scatter(XB[P!=yB,0],XB[P!=yB,1],marker='s',color='orange',\
alpha=0.5,label='Incorrect')
plt.legend()
```

### S.1 Logistic Regression
**Definition:** Logistic regression is a machine learning algorithm for classification. In this algorithm, the probabilities describing the possible outcomes of a single trial are modelled using a logistic function.
**Advantages:** Logistic regression is designed for this purpose (classification), and is most useful for understanding the influence of several independent variables on a single outcome variable.
**Disadvantages:** Works only when the predicted variable is binary, assumes all predictors are independent of each other, and assumes data is free of missing values.
```
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='lbfgs')
lr.fit(XA,yA)
yP = lr.predict(XB)
assess(yP)
```

### S.2 Naïve Bayes
**Definition:** Naive Bayes algorithm based on Bayes’ theorem with the assumption of independence between every pair of features. Naive Bayes classifiers work well in many real-world situations such as document classification and spam filtering.
**Advantages:** This algorithm requires a small amount of training data to estimate the necessary parameters. Naive Bayes classifiers are extremely fast compared to more sophisticated methods.
**Disadvantages:** Naive Bayes is known to be a bad estimator.
```
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(XA,yA)
yP = nb.predict(XB)
assess(yP)
```

### S.3 Stochastic Gradient Descent
**Definition:** Stochastic gradient descent is a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification.
**Advantages:** Efficiency and ease of implementation.
**Disadvantages:** Requires a number of hyper-parameters and it is sensitive to feature scaling.
```
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier(loss='modified_huber', shuffle=True,random_state=101)
sgd.fit(XA,yA)
yP = sgd.predict(XB)
assess(yP)
```

### S.4 K-Nearest Neighbours
**Definition:** Neighbours based classification is a type of lazy learning as it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the k nearest neighbours of each point.
**Advantages:** This algorithm is simple to implement, robust to noisy training data, and effective if training data is large.
**Disadvantages:** Need to determine the value of `K` and the computation cost is high as it needs to computer the distance of each instance to all the training samples. One possible solution to determine `K` is to add a feedback loop to determine the number of neighbors.
```
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(XA,yA)
yP = knn.predict(XB)
assess(yP)
```

### S.5 Decision Tree
**Definition:** Given a data of attributes together with its classes, a decision tree produces a sequence of rules that can be used to classify the data.
**Advantages:** Decision Tree is simple to understand and visualise, requires little data preparation, and can handle both numerical and categorical data.
**Disadvantages:** Decision tree can create complex trees that do not generalise well, and decision trees can be unstable because small variations in the data might result in a completely different tree being generated.
```
from sklearn.tree import DecisionTreeClassifier
dtree = DecisionTreeClassifier(max_depth=10,random_state=101,\
max_features=None,min_samples_leaf=5)
dtree.fit(XA,yA)
yP = dtree.predict(XB)
assess(yP)
```

### S.6 Random Forest
**Definition:** Random forest classifier is a meta-estimator that fits a number of decision trees on various sub-samples of datasets and uses average to improve the predictive accuracy of the model and controls over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement.
**Advantages:** Reduction in over-fitting and random forest classifier is more accurate than decision trees in most cases.
**Disadvantages:** Slow real time prediction, difficult to implement, and complex algorithm.
```
from sklearn.ensemble import RandomForestClassifier
rfm = RandomForestClassifier(n_estimators=70,oob_score=True,\
n_jobs=1,random_state=101,max_features=None,\
min_samples_leaf=3) #change min_samples_leaf from 30 to 3
rfm.fit(XA,yA)
yP = rfm.predict(XB)
assess(yP)
```

### S.7 Support Vector Classifier
**Definition:** Support vector machine is a representation of the training data as points in space separated into categories by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
**Advantages:** Effective in high dimensional spaces and uses a subset of training points in the decision function so it is also memory efficient.
**Disadvantages:** The algorithm does not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation.
```
from sklearn.svm import SVC
svm = SVC(gamma='scale', C=1.0, random_state=101)
svm.fit(XA,yA)
yP = svm.predict(XB)
assess(yP)
```

### S.8 Neural Network
The `MLPClassifier` implements a multi-layer perceptron (MLP) algorithm that trains using Backpropagation.
**Definition:** A neural network is a set of neurons (activation functions) in layers that are processed sequentially to relate an input to an output.
**Advantages:** Effective in nonlinear spaces where the structure of the relationship is not linear. No prior knowledge or specialized equation structure is defined although there are different network architectures that may lead to a better result.
**Disadvantages:** Neural networks do not extrapolate well outside of the training domain. They may also require longer to train by adjusting the parameter weights to minimize a loss (objective) function. It is also more challenging to explain the outcome of the training and changes in initialization or number of epochs (iterations) may lead to different results. Too many epochs may lead to overfitting, especially if there are excess parameters beyond the minimum needed to capture the input to output relationship.

MLP trains on two arrays: array X of size (n_samples, n_features), which holds the training samples represented as floating point feature vectors; and array y of size (n_samples,), which holds the target values (class labels) for the training samples.
MLP can fit a non-linear model to the training data. clf.coefs_ contains the weight matrices that constitute the model parameters. Currently, MLPClassifier supports only the Cross-Entropy loss function, which allows probability estimates by running the predict_proba method. MLP trains using Backpropagation. More precisely, it trains using some form of gradient descent and the gradients are calculated using Backpropagation. For classification, it minimizes the Cross-Entropy loss function, giving a vector of probability estimates. MLPClassifier supports multi-class classification by applying Softmax as the output function. Further, the model supports multi-label classification in which a sample can belong to more than one class. For each class, the raw output passes through the logistic function. Values larger or equal to 0.5 are rounded to 1, otherwise to 0. For a predicted output of a sample, the indices where the value is 1 represents the assigned classes of that sample.
```
from sklearn.neural_network import MLPClassifier
clf = MLPClassifier(solver='lbfgs',alpha=1e-5,max_iter=200,activation='relu',\
hidden_layer_sizes=(10,30,10), random_state=1, shuffle=True)
clf.fit(XA,yA)
yP = clf.predict(XB)
assess(yP)
```

### Unsupervised Classification
Additional examples show the potential for unsupervised learning to classify the groups. Unsupervised learning does not use the labels (`True`/`False`) so the results may need to be switched to align with the test set with `if len(XB[yP!=yB]) > n/4: yP = 1 - yP
`

### U.1 K-Means Clustering
**Definition:** Specify how many possible clusters (or K) there are in the dataset. The algorithm then iteratively moves the K-centers and selects the datapoints that are closest to that centroid in the cluster.
**Advantages:** The most common and simplest clustering algorithm.
**Disadvantages:** Must specify the number of clusters although this can typically be determined by increasing the number of clusters until the objective function does not change significantly.
```
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2)
km.fit(XA)
yP = km.predict(XB)
if len(XB[yP!=yB]) > n/4: yP = 1 - yP
assess(yP)
```

### U.2 Gaussian Mixture Model
**Definition:** Data points that exist at the boundary of clusters may simply have similar probabilities of being on either clusters. A mixture model predicts a probability instead of a hard classification such as K-Means clustering.
**Advantages:** Incorporates uncertainty into the solution.
**Disadvantages:** Uncertainty may not be desirable for some applications. This method is not as common as the K-Means method for clustering.
```
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=2)
gmm.fit(XA)
yP = gmm.predict_proba(XB) # produces probabilities
if len(XB[np.round(yP[:,0])!=yB]) > n/4: yP = 1 - yP
assess(np.round(yP[:,0]))
```

### U.3 Spectral Clustering
**Definition:** Spectral clustering is known as segmentation-based object categorization. It is a technique with roots in graph theory, where identify communities of nodes in a graph are based on the edges connecting them. The method is flexible and allows clustering of non graph data as well.
It uses information from the eigenvalues of special matrices built from the graph or the data set.
**Advantages:** Flexible approach for finding clusters when data doesn’t meet the requirements of other common algorithms.
**Disadvantages:** For large-sized graphs, the second eigenvalue of the (normalized) graph Laplacian matrix is often ill-conditioned, leading to slow convergence of iterative eigenvalue solvers. Spectral clustering is computationally expensive unless the graph is sparse and the similarity matrix can be efficiently constructed.
```
from sklearn.cluster import SpectralClustering
sc = SpectralClustering(n_clusters=2,eigen_solver='arpack',\
affinity='nearest_neighbors')
yP = sc.fit_predict(XB) # No separation between fit and predict calls
# need to fit and predict on same dataset
if len(XB[yP!=yB]) > n/4: yP = 1 - yP
assess(yP)
```

### TCLab Activity
Train a classifier to predict if the heater is on (100%) or off (0%). Generate data with 10 minutes of 1 second data. If you do not have a TCLab, use one of the sample data sets.
- [Sample Data Set 1 (10 min)](http://apmonitor.com/do/uploads/Main/tclab_data5.txt): http://apmonitor.com/do/uploads/Main/tclab_data5.txt
- [Sample Data Set 2 (60 min)](http://apmonitor.com/do/uploads/Main/tclab_data6.txt): http://apmonitor.com/do/uploads/Main/tclab_data6.txt
```
# 10 minute data collection
import tclab, time
import numpy as np
import pandas as pd
with tclab.TCLab() as lab:
n = 600; on=100; t = np.linspace(0,n-1,n)
Q1 = np.zeros(n); T1 = np.zeros(n)
Q2 = np.zeros(n); T2 = np.zeros(n)
Q1[20:41]=on; Q1[60:91]=on; Q1[150:181]=on
Q1[190:206]=on; Q1[220:251]=on; Q1[260:291]=on
Q1[300:316]=on; Q1[340:351]=on; Q1[400:431]=on
Q1[500:521]=on; Q1[540:571]=on; Q1[20:41]=on
Q1[60:91]=on; Q1[150:181]=on; Q1[190:206]=on
Q1[220:251]=on; Q1[260:291]=on
print('Time Q1 Q2 T1 T2')
for i in range(n):
T1[i] = lab.T1; T2[i] = lab.T2
lab.Q1(Q1[i])
if i%5==0:
print(int(t[i]),Q1[i],Q2[i],T1[i],T2[i])
time.sleep(1)
data = np.column_stack((t,Q1,Q2,T1,T2))
data8 = pd.DataFrame(data,columns=['Time','Q1','Q2','T1','T2'])
data8.to_csv('08-tclab.csv',index=False)
```
Use the data file `08-tclab.csv` to train and test the classifier. Select and scale (0-1) the features of the data including `T1`, `T2`, and the 1st and 2nd derivatives of `T1`. Use the measured temperatures, derivatives, and heater value label to create a classifier that predicts when the heater is on or off. Validate the classifier with new data that was not used for training. Starting code is provided below but does not include `T2` as a feature input. **Add `T2` as an input feature to the classifer. Does it improve the classifier performance?**
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import gridspec
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
try:
data = pd.read_csv('08-tclab.csv')
except:
print('Warning: Unable to load 08-tclab.csv, using online data')
url = 'http://apmonitor.com/do/uploads/Main/tclab_data5.txt'
data = pd.read_csv(url)
# Input Features: Temperature and 1st / 2nd Derivatives
# Cubic polynomial fit of temperature using 10 data points
data['dT1'] = np.zeros(len(data))
data['d2T1'] = np.zeros(len(data))
for i in range(len(data)):
if i<len(data)-10:
x = data['Time'][i:i+10]-data['Time'][i]
y = data['T1'][i:i+10]
p = np.polyfit(x,y,3)
# evaluate derivatives at mid-point (5 sec)
t = 5.0
data['dT1'][i] = 3.0*p[0]*t**2 + 2.0*p[1]*t+p[2]
data['d2T1'][i] = 6.0*p[0]*t + 2.0*p[1]
else:
data['dT1'][i] = np.nan
data['d2T1'][i] = np.nan
# Remove last 10 values
X = np.array(data[['T1','dT1','d2T1']][0:-10])
y = np.array(data[['Q1']][0:-10])
# Scale data
# Input features (Temperature and 2nd derivative at 5 sec)
s1 = MinMaxScaler(feature_range=(0,1))
Xs = s1.fit_transform(X)
# Output labels (heater On / Off)
ys = [True if y[i]>50.0 else False for i in range(len(y))]
# Split into train and test subsets (50% each)
XA, XB, yA, yB = train_test_split(Xs, ys, \
test_size=0.5, shuffle=False)
# Supervised Classification
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import SGDClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
# Create supervised classification models
lr = LogisticRegression(solver='lbfgs') # Logistic Regression
nb = GaussianNB() # Naïve Bayes
sgd = SGDClassifier(loss='modified_huber', shuffle=True,\
random_state=101) # Stochastic Gradient Descent
knn = KNeighborsClassifier(n_neighbors=5) # K-Nearest Neighbors
dtree = DecisionTreeClassifier(max_depth=10,random_state=101,\
max_features=None,min_samples_leaf=5) # Decision Tree
rfm = RandomForestClassifier(n_estimators=70,oob_score=True,n_jobs=1,\
random_state=101,max_features=None,min_samples_leaf=3) # Random Forest
svm = SVC(gamma='scale', C=1.0, random_state=101) # Support Vector Classifier
clf = MLPClassifier(solver='lbfgs',alpha=1e-5,max_iter=200,\
activation='relu',hidden_layer_sizes=(10,30,10),\
random_state=1, shuffle=True) # Neural Network
models = [lr,nb,sgd,knn,dtree,rfm,svm,clf]
# Supervised learning
yP = [None]*(len(models)+3) # 3 for unsupervised learning
for i,m in enumerate(models):
m.fit(XA,yA)
yP[i] = m.predict(XB)
# Unsupervised learning modules
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.cluster import SpectralClustering
km = KMeans(n_clusters=2)
gmm = GaussianMixture(n_components=2)
sc = SpectralClustering(n_clusters=2,eigen_solver='arpack',\
affinity='nearest_neighbors')
km.fit(XA)
yP[8] = km.predict(XB)
gmm.fit(XA)
yP[9] = gmm.predict_proba(XB)[:,0]
yP[10] = sc.fit_predict(XB)
plt.figure(figsize=(10,7))
gs = gridspec.GridSpec(3, 1, height_ratios=[1,1,5])
plt.subplot(gs[0])
plt.plot(data['Time']/60,data['T1'],'r-',\
label='Temperature (°C)')
plt.ylabel('T (°C)')
plt.legend()
plt.subplot(gs[1])
plt.plot(data['Time']/60,data['dT1'],'b:',\
label='dT/dt (°C/sec)')
plt.plot(data['Time']/60,data['d2T1'],'k--',\
label=r'$d^2T/dt^2$ ($°C^2/sec^2$)')
plt.ylabel('Derivatives')
plt.legend()
plt.subplot(gs[2])
plt.plot(data['Time']/60,data['Q1']/100,'k-',\
label='Heater (On=1/Off=0)')
t2 = data['Time'][len(yA):-10].values
desc = ['Logistic Regression','Naïve Bayes','Stochastic Gradient Descent',\
'K-Nearest Neighbors','Decision Tree','Random Forest',\
'Support Vector Classifier','Neural Network',\
'K-Means Clustering','Gaussian Mixture Model','Spectral Clustering']
for i in range(11):
plt.plot(t2/60,yP[i]-i-1,label=desc[i])
plt.ylabel('Heater')
plt.legend()
plt.xlabel(r'Time (min)')
plt.legend()
plt.show()
```
| true |
code
| 0.438905 | null | null | null | null |
|
# 3D Map
While representing the configuration space in 3 dimensions isn't entirely practical it's fun (and useful) to visualize things in 3D.
In this exercise you'll finish the implementation of `create_grid` such that a 3D grid is returned where cells containing a voxel are set to `True`. We'll then plot the result!
```
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
plt.rcParams['figure.figsize'] = 16, 16
# This is the same obstacle data from the previous lesson.
filename = 'colliders.csv'
data = np.loadtxt(filename, delimiter=',', dtype='Float64', skiprows=2)
print(data)
def create_voxmap(data, voxel_size=5):
"""
Returns a grid representation of a 3D configuration space
based on given obstacle data.
The `voxel_size` argument sets the resolution of the voxel map.
"""
# minimum and maximum north coordinates
north_min = np.floor(np.amin(data[:, 0] - data[:, 3]))
north_max = np.ceil(np.amax(data[:, 0] + data[:, 3]))
# minimum and maximum east coordinates
east_min = np.floor(np.amin(data[:, 1] - data[:, 4]))
east_max = np.ceil(np.amax(data[:, 1] + data[:, 4]))
alt_max = np.ceil(np.amax(data[:, 2] + data[:, 5]))
# given the minimum and maximum coordinates we can
# calculate the size of the grid.
north_size = int(np.ceil((north_max - north_min))) // voxel_size
east_size = int(np.ceil((east_max - east_min))) // voxel_size
alt_size = int(alt_max) // voxel_size
voxmap = np.zeros((north_size, east_size, alt_size), dtype=np.bool)
for datum in data:
x, y, z, dx, dy, dz = datum.astype(np.int32)
obstacle = np.array(((x-dx, x+dx),
(y-dy, y+dy),
(z-dz, z+dz)))
obstacle[0] = (obstacle[0] - north_min) // voxel_size
obstacle[1] = (obstacle[1] - east_min) // voxel_size
obstacle[2] = obstacle[2] // voxel_size
voxmap[obstacle[0][0]:obstacle[0][1], obstacle[1][0]:obstacle[1][1], obstacle[2][0]:obstacle[2][1]] = True
return voxmap
```
Create 3D grid.
```
voxel_size = 10
voxmap = create_voxmap(data, voxel_size)
print(voxmap.shape)
```
Plot the 3D grid.
```
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.voxels(voxmap, edgecolor='k')
ax.set_xlim(voxmap.shape[0], 0)
ax.set_ylim(0, voxmap.shape[1])
# add 100 to the height so the buildings aren't so tall
ax.set_zlim(0, voxmap.shape[2]+100//voxel_size)
plt.xlabel('North')
plt.ylabel('East')
plt.show()
```
Isn't the city pretty?
| true |
code
| 0.779175 | null | null | null | null |
|
# Bar charts
This is 'abusing' the scatter object to create a 3d bar chart
```
import ipyvolume as ipv
import numpy as np
# set up data similar to animation notebook
u_scale = 10
Nx, Ny = 30, 15
u = np.linspace(-u_scale, u_scale, Nx)
v = np.linspace(-u_scale, u_scale, Ny)
x, y = np.meshgrid(u, v, indexing='ij')
r = np.sqrt(x**2+y**2)
x = x.flatten()
y = y.flatten()
r = r.flatten()
time = np.linspace(0, np.pi*2, 15)
z = np.array([(np.cos(r + t) * np.exp(-r/5)) for t in time])
zz = z
fig = ipv.figure()
s = ipv.scatter(x, 0, y, aux=zz, marker="sphere")
dx = u[1] - u[0]
dy = v[1] - v[0]
# make the x and z lim half a 'box' larger
ipv.xlim(-u_scale-dx/2, u_scale+dx/2)
ipv.zlim(-u_scale-dx/2, u_scale+dx/2)
ipv.ylim(-1.2, 1.2)
ipv.show()
```
We now make boxes, that fit exactly in the volume, by giving them a size of 1, in domain coordinates (so 1 unit as read of by the x-axis etc)
```
# make the size 1, in domain coordinates (so 1 unit as read of by the x-axis etc)
s.geo = 'box'
s.size = 1
s.size_x_scale = fig.scales['x']
s.size_y_scale = fig.scales['y']
s.size_z_scale = fig.scales['z']
s.shader_snippets = {'size':
'size_vector.y = SCALE_SIZE_Y(aux_current); '
}
```
Using a shader snippet (that runs on the GPU), we set the y size equal to the aux value. However, since the box has size 1 around the origin of (0,0,0), we need to translate it up in the y direction by 0.5.
```
s.shader_snippets = {'size':
'size_vector.y = SCALE_SIZE_Y(aux_current) - SCALE_SIZE_Y(0.0) ; '
}
s.geo_matrix = [dx, 0, 0, 0, 0, 1, 0, 0, 0, 0, dy, 0, 0.0, 0.5, 0, 1]
```
Since we see the boxes with negative sizes inside out, we made the material double sided
```
# since we see the boxes with negative sizes inside out, we made the material double sided
s.material.side = "DoubleSide"
# Now also include, color, which containts rgb values
color = np.array([[np.cos(r + t), 1-np.abs(z[i]), 0.1+z[i]*0] for i, t in enumerate(time)])
color = np.transpose(color, (0, 2, 1)) # flip the last axes
s.color = color
ipv.animation_control(s, interval=200)
```
# Spherical bar charts
```
# Create spherical coordinates
u = np.linspace(0, 1, Nx)
v = np.linspace(0, 1, Ny)
u, v = np.meshgrid(u, v, indexing='ij')
phi = u * 2 * np.pi
theta = v * np.pi
radius = 1
xs = radius * np.cos(phi) * np.sin(theta)
ys = radius * np.sin(phi) * np.sin(theta)
zs = radius * np.cos(theta)
xs = xs.flatten()
ys = ys.flatten()
zs = zs.flatten()
fig = ipv.figure()
# we use the coordinates as the normals, and thus direction
s = ipv.scatter(xs, ys, zs, vx=xs, vy=ys, vz=zs, aux=zz, color=color, marker="cylinder_hr")
ipv.xyzlim(2)
ipv.show()
ipv.animation_control(s, interval=200)
import bqplot
# the aux range is from -1 to 1, but if we put 0 as min, negative values will go inside
# the max determines the 'height' of the bars
aux_scale = bqplot.LinearScale(min=0, max=5)
s.aux_scale = aux_scale
s.shader_snippets = {'size':
'''float sc = (SCALE_AUX(aux_current) - SCALE_AUX(0.0)); size_vector.y = sc;
'''}
s.material.side = "DoubleSide"
s.size = 2
s.geo_matrix = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0.0, 0.5, 0, 1]
ipv.style.box_off()
ipv.style.axes_off()
```
[screenshot](screenshot/bars.gif)
| true |
code
| 0.600716 | null | null | null | null |
|
# Lab 04 : Train vanilla neural network -- solution
# Training a one-layer net on FASHION-MNIST
```
# For Google Colaboratory
import sys, os
if 'google.colab' in sys.modules:
from google.colab import drive
drive.mount('/content/gdrive')
file_name = 'train_vanilla_nn_solution.ipynb'
import subprocess
path_to_file = subprocess.check_output('find . -type f -name ' + str(file_name), shell=True).decode("utf-8")
print(path_to_file)
path_to_file = path_to_file.replace(file_name,"").replace('\n',"")
os.chdir(path_to_file)
!pwd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from random import randint
import utils
```
### Download the TRAINING SET (data+labels)
```
from utils import check_fashion_mnist_dataset_exists
data_path=check_fashion_mnist_dataset_exists()
train_data=torch.load(data_path+'fashion-mnist/train_data.pt')
train_label=torch.load(data_path+'fashion-mnist/train_label.pt')
print(train_data.size())
print(train_label.size())
```
### Download the TEST SET (data only)
```
test_data=torch.load(data_path+'fashion-mnist/test_data.pt')
print(test_data.size())
```
### Make a one layer net class
```
class one_layer_net(nn.Module):
def __init__(self, input_size, output_size):
super(one_layer_net , self).__init__()
self.linear_layer = nn.Linear( input_size, output_size , bias=False)
def forward(self, x):
y = self.linear_layer(x)
prob = F.softmax(y, dim=1)
return prob
```
### Build the net
```
net=one_layer_net(784,10)
print(net)
```
### Take the 4th image of the test set:
```
im=test_data[4]
utils.show(im)
```
### And feed it to the UNTRAINED network:
```
p = net( im.view(1,784))
print(p)
```
### Display visually the confidence scores
```
utils.show_prob_fashion_mnist(p)
```
### Train the network (only 5000 iterations) on the train set
```
criterion = nn.NLLLoss()
optimizer=torch.optim.SGD(net.parameters() , lr=0.01 )
for iter in range(1,5000):
# choose a random integer between 0 and 59,999
# extract the corresponding picture and label
# and reshape them to fit the network
idx=randint(0, 60000-1)
input=train_data[idx].view(1,784)
label=train_label[idx].view(1)
# feed the input to the net
input.requires_grad_()
prob=net(input)
# update the weights (all the magic happens here -- we will discuss it later)
log_prob=torch.log(prob)
loss = criterion(log_prob, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
```
### Take the 34th image of the test set:
```
im=test_data[34]
utils.show(im)
```
### Feed it to the TRAINED net:
```
p = net( im.view(1,784))
print(p)
```
### Display visually the confidence scores
```
utils.show_prob_fashion_mnist(prob)
```
### Choose image at random from the test set and see how good/bad are the predictions
```
# choose a picture at random
idx=randint(0, 10000-1)
im=test_data[idx]
# diplay the picture
utils.show(im)
# feed it to the net and display the confidence scores
prob = net( im.view(1,784))
utils.show_prob_fashion_mnist(prob)
```
| true |
code
| 0.604165 | null | null | null | null |
|
# Segmentation
This notebook shows how to use Stardist (Object Detection with Star-convex Shapes) as a part of a segmentation-classification-tracking analysis pipeline.
The sections of this notebook are as follows:
1. Load images
2. Load model of choice and segment an initial image to test Stardist parameters
3. Batch segment a sequence of images
The data used in this notebook is timelapse microscopy data with h2b-gfp/rfp markers that show the spatial extent of the nucleus and it's mitotic state.
This notebook uses the dask octopuslite image loader from the CellX/Lowe lab project.
```
import matplotlib.pyplot as plt
import numpy as np
import os
from octopuslite import DaskOctopusLiteLoader
from stardist.models import StarDist2D
from stardist.plot import render_label
from csbdeep.utils import normalize
from tqdm.auto import tqdm
from skimage.io import imsave
import json
from scipy import ndimage as nd
%matplotlib inline
plt.rcParams['figure.figsize'] = [18,8]
```
## 1. Load images
```
# define experiment ID and select a position
expt = 'ND0011'
pos = 'Pos6'
# point to where the data is
root_dir = '/home/nathan/data'
image_path = f'{root_dir}/{expt}/{pos}/{pos}_images'
# lazily load imagesdd
images = DaskOctopusLiteLoader(image_path,
remove_background = True)
images.channels
```
Set segmentation channel and load test image
```
# segmentation channel
segmentation_channel = images.channels[3]
# set test image index
frame = 1000
# load test image
irfp = images[segmentation_channel.name][frame].compute()
# create 1-channel XYC image
img = np.expand_dims(irfp, axis = -1)
img.shape
```
## 2. Load model and test segment single image
```
model = StarDist2D.from_pretrained('2D_versatile_fluo')
model
```
### 2.1 Test run and display initial results
```
# initialise test segmentation
labels, details = model.predict_instances(normalize(img))
# plot input image and prediction
plt.clf()
plt.subplot(1,2,1)
plt.imshow(normalize(img[:,:,0]), cmap="PiYG")
plt.axis("off")
plt.title("input image")
plt.subplot(1,2,2)
plt.imshow(render_label(labels, img = img))
plt.axis("off")
plt.title("prediction + input overlay")
plt.show()
```
## 3. Batch segment a whole stack of images
When you segment a whole data set you do not want to apply any image transformation. This is so that when you load images and masks later on you can apply the same transformation. You can apply a crop but note that you need to be consistent with your use of the crop from this point on, otherwise you'll get a shift.
```
for expt in tqdm(['ND0009', 'ND0010', 'ND0011']):
for pos in tqdm(['Pos0', 'Pos1', 'Pos2', 'Pos3', 'Pos4']):
print('Starting experiment position:', expt, pos)
# load images
image_path = f'{root_dir}/{expt}/{pos}/{pos}_images'
images = DaskOctopusLiteLoader(image_path,
remove_background = True)
# iterate over images filenames
for fn in tqdm(images.files(segmentation_channel.name)):
# compile 1-channel into XYC array
img = np.expand_dims(imread(fn), axis = -1)
# predict labels
labels, details = model.predict_instances(normalize(img))
# set filename as mask format (channel099)
fn = fn.replace(f'channel00{segmentation_channel.value}', 'channel099')
# save out labelled image
imsave(fn, labels.astype(np.uint16), check_contrast=False)
```
| true |
code
| 0.609553 | null | null | null | null |
|
# Introduction to Language Processing Concepts
### Original tutorial by Brain Lehman, with updates by Fiona Pigott
The goal of this tutorial is to introduce a few basical vocabularies, ideas, and Python libraries for thinking about topic modeling, in order to make sure that we have a good set of vocabulary to talk more in-depth about processing languge with Python later. We'll spend some time on defining vocabulary for topic modeling and using basic topic modeling tools.
A big thank-you to the good people at the Stanford NLP group, for their informative and helpful online book: https://nlp.stanford.edu/IR-book/.
### Definitions.
1. **Document**: a body of text (eg. tweet)
2. **Tokenization**: dividing a document into pieces (and maybe throwing away some characters), in English this often (but not necessarily) means words separated by spaces and puctuation.
3. **Text corpus**: the set of documents that contains the text for the analysis (eg. many tweets)
4. **Stop words**: words that occur so frequently, or have so little topical meaning, that they are excluded (e.g., "and")
5. **Vectorize**: Turn some documents into vectors
6. **Vector corpus**: the set of documents transformed such that each token is a tuple (token_id , doc_freq)
```
# first, get some text:
import fileinput
try:
import ujson as json
except ImportError:
import json
documents = []
for line in fileinput.FileInput("example_tweets.json"):
documents.append(json.loads(line)["text"])
```
### 1) Document
In the case of the text that we just imported, each entry in the list is a "document"--a single body of text, hopefully with some coherent meaning.
```
print("One document: \"{}\"".format(documents[0]))
```
### 2) Tokenization
We split each document into smaller pieces ("tokens") in a process called tokenization. Tokens can be counted, and most importantly, compared between documents. There are potentially many different ways to tokenize text--splitting on spaces, removing punctionation, diving the document into n-character pieces--anything that gives us tokens that we can, hopefully, effectively compare across documents and derive meaning from.
Related to tokenization are processes called *stemming* and *lemmatiztion* which can help when using tokens to model topics based on the meaning of a word. In the phrases "they run" and "he runs" (space separated tokens: ["they", "run"] and ["he", "runs"]) the words "run" and "run*s*" mean basically the same thing, but are two different tokens. Stemming and/or lemmatization help us compare tokens with the same meaning but different spelling/suffixes.
#### Lemmatization:
Uses a dictionary of words and their possible morphologies to map many different forms of a base word ("lemma") to a single lemma, comparable across documents. E.g.: "run", "ran", "runs", and "running" might all map to the lemma "run"
#### Stemming:
Uses a set of heuristic rules to try to approximate lemmatization, without knowing the words in advance. For the English language, a simple and effective stemming algorithm might simply be to remove an "s" from the ends of words, or an "ing" from the end of words. E.g.: "run", "runs", and "running" all map to "run," but "ran" (an irregularrly conjugated verb) would not.
Stemming is particularly interesting and applicable in social data, because while some words are decidely *not* standard English, conventinoal rules of grammar still apply. A fan of the popular singer Justin Bieber might call herself a "belieber," while a group of fans call themselves "beliebers." You won't find "belieber" in any English lemmatization dictionary, but a good stemming algorithm will still map "belieber" and "beliebers" to the same token ("belieber", or even "belieb", if we remover the common suffix "er").
```
from nltk.stem import porter
from nltk.tokenize import TweetTokenizer
# tokenize the documents
# find good information on tokenization:
# https://nlp.stanford.edu/IR-book/html/htmledition/tokenization-1.html
# find documentation on pre-made tokenizers and options here:
# http://www.nltk.org/api/nltk.tokenize.html
tknzr = TweetTokenizer(reduce_len = True)
# stem the documents
# find good information on stemming and lemmatization:
# https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
# find documentation on available pre-implemented stemmers here:
# http://www.nltk.org/api/nltk.stem.html
stemmer = porter.PorterStemmer()
for doc in documents[0:10]:
tokenized = tknzr.tokenize(doc)
stemmed = [stemmer.stem(x) for x in tokenized]
print("Original document:\n{}\nTokenized result:\n{}\nStemmed result:\n{}\n".format(
doc, tokenized, stemmed))
```
### 3) Text corpus
The text corpus is a collection of all of the documents (Tweets) that we're interested in modeling. Topic modeling and/or clustering on a corpus tends to work best if that corpus has some similar themes--this will mean that some tokens overlap, and we can get signal out of when documents share (or do not share) tokens.
Modeling text tends to get much harder the more different, uncommon and unrelated tokens appear in a text, especially when we are working with social data, where tokens don't necessarily appear in a dictionary. This difficultly (of having many, many unrelated tokens as dimension in our model) is one example of the [curse of dimensionality](https://en.wikipedia.org/wiki/Curse_of_dimensionality).
```
# number of documents in the corpus
print("There are {} documents in the corpus.".format(len(documents)))
```
### 4) Stop words:
Stop words are simply tokens that we've chosen to remove from the corpus, for any reason. In English, removing words like "and", "the", "a", "at", and "it" are common choices for stop words. Stop words can also be edited per project requirement, in case some words are too common in a particular dataset to be meaningful (another way to do stop word removal is to simply remove any word that appears in more than some fixed percentage of documents).
```
from nltk.corpus import stopwords
stopset = set(stopwords.words('english'))
print("The English stop words list provided by NLTK: ")
print(stopset)
stopset.update(["twitter"]) # add token
stopset.remove("i") # remove token
print("\nAdd or remove stop words form the set: ")
print(stopset)
```
### 5) Vectorize:
Transform each document into a vector. There are several good choices that you can make about how to do this transformation, and I'll talk about each of them in a second.
In order to vectorize documents in a corpus (without any dimensional reduction around the vocabulary), think of each document as a row in a matrix, and each column as a word in the vocabulary of the entire corpus. In order to vectorize a corpus, we must read the entire corpus, assign one word to each column, and then turn each document into a row.
**Example**:
**Documents**: "I love cake", "I hate chocolate", "I love chocolate cake", "I love cake, but I hate chocolate cake"
**Stopwords**: Say, because the word "but" is a conjunction, we want to make it a stop word (not include it in our document vectors)
**Vocabulary**: "I" (column 1), "love" (column 2), "cake" (column 3), "hate" (column 4), "chocolate" (column 5)
\begin{equation*}
\begin{matrix}
\text{"I love cake" } & =\\
\text{"I hate chocolate" } & =\\
\text{"I love chocolate cake" } & = \\
\text{"I love cake, but I hate chocolate cake"} & =
\end{matrix}
\qquad
\begin{bmatrix}
1 & 1 & 1 & 0 & 0\\
1 & 0 & 0 & 1 & 1\\
1 & 1 & 1 & 0 & 1\\
2 & 1 & 2 & 1 & 1
\end{bmatrix}
\end{equation*}
Vectorization like this don't take into account word order (we call this property "bag of words"), and in the above example I am simply counting the frequency of each term in each document.
```
# we're going to use the vectorizer functions that scikit learn provides
# define the tokenizer that we want to use
# must be a callable function that takes a document and returns a list of tokens
tknzr = TweetTokenizer(reduce_len = True)
stemmer = porter.PorterStemmer()
def myTokenizer(doc):
return [stemmer.stem(x) for x in tknzr.tokenize(doc)]
# choose the stopword set that we want to use
stopset = set(stopwords.words('english'))
stopset.update(["http","https","twitter","amp"])
# vectorize
# we're using the scikit learn CountVectorizer function, which is very handy
# documentation here:
# http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
vectorizer = CountVectorizer(tokenizer = myTokenizer, stop_words = stopset)
vectorized_documents = vectorizer.fit_transform(documents)
vectorized_documents
import matplotlib.pyplot as plt
%matplotlib inline
_ = plt.hist(vectorized_documents.todense().sum(axis = 1))
_ = plt.title("Number of tokens per document")
_ = plt.xlabel("Number of tokens")
_ = plt.ylabel("Number of documents with x tokens")
from numpy import logspace, ceil, histogram, array
# get the token frequency
token_freq = sorted(vectorized_documents.todense().astype(bool).sum(axis = 0).tolist()[0], reverse = False)
# make a histogram with log scales
bins = array([ceil(x) for x in logspace(0, 3, 5)])
widths = (bins[1:] - bins[:-1])
hist = histogram(token_freq, bins=bins)
hist_norm = hist[0]/widths
# plot (notice that most tokens only appear in one document)
plt.bar(bins[:-1], hist_norm, widths)
plt.xscale('log')
plt.yscale('log')
_ = plt.title("Number of documents in which each token appears")
_ = plt.xlabel("Number of documents")
_ = plt.ylabel("Number of tokens")
```
#### Bag of words
Taking all the words from a document, and sticking them in a bag. Order does not matter, which could cause a problem. "Alice loves cake" might have a different meaning than "Cake loves Alice."
#### Frequency
Counting the number of times a word appears in a document.
#### Tf-Idf (term frequency inverse document frequency):
A statistic that is intended to reflect how important a word is to a document in a collection or corpus. The Tf-Idf value increases proportionally to the number of times a word appears in the document and is inversely proportional to the frequency of the word in the corpus--this helps control words that are generally more common than others.
There are several different possibilities for computing the tf-idf statistic--choosing whether to normalize the vectors, choosing whether to use counts or the logarithm of counts, etc. I'm going to show how scikit-learn computed the tf-idf statistic by default, with more information available in the documentation of the sckit-learn [TfidfVectorizer](http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfTransformer.html).
$tf(t)$ : Term Frequency, count of the number of times each term appears in the document.
$idf(d,t)$ : Inverse document frequency.
$df(d,t)$ : Document frequency, the count of the number of documents in which the term appears.
$$
tfidf(t) = tf(t) * \log\big(\frac{1 + n}{1 + df(d, t)}\big) + 1
$$
We also then take the Euclidean ($l2$) norm of each document vector, so that long documents (documents with many non-stopword tokens) have the same norm as shorter documents.
```
# documentation on this sckit-learn function here:
# http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfTransformer.html
tfidf_vectorizer = TfidfVectorizer(tokenizer = myTokenizer, stop_words = stopset)
tfidf_vectorized_documents = tfidf_vectorizer.fit_transform(documents)
tfidf_vectorized_documents
# you can look at two vectors for the same document, from 2 different vectorizers:
tfidf_vectorized_documents[0].todense().tolist()[0]
vectorized_documents[0].todense().tolist()[0]
```
## That's all for now!
| true |
code
| 0.457318 | null | null | null | null |
|
# Categorical encoders
Examples of how to use the different categorical encoders using the Titanic dataset.
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from feature_engine import categorical_encoders as ce
from feature_engine.missing_data_imputers import CategoricalVariableImputer
pd.set_option('display.max_columns', None)
# Load titanic dataset from OpenML
def load_titanic():
data = pd.read_csv('https://www.openml.org/data/get_csv/16826755/phpMYEkMl')
data = data.replace('?', np.nan)
data['cabin'] = data['cabin'].astype(str).str[0]
data['pclass'] = data['pclass'].astype('O')
data['age'] = data['age'].astype('float')
data['fare'] = data['fare'].astype('float')
data['embarked'].fillna('C', inplace=True)
data.drop(labels=['boat', 'body', 'home.dest'], axis=1, inplace=True)
return data
# load data
data = load_titanic()
data.head()
data.isnull().sum()
# we will encode the below variables, they have no missing values
data[['cabin', 'pclass', 'embarked']].isnull().sum()
data[['cabin', 'pclass', 'embarked']].dtypes
data[['cabin', 'pclass', 'embarked']].dtypes
# let's separate into training and testing set
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['survived', 'name', 'ticket'], axis=1), data['survived'], test_size=0.3, random_state=0)
X_train.shape, X_test.shape
```
## CountFrequencyCategoricalEncoder
The CountFrequencyCategoricalEncoder, replaces the categories by the count or frequency of the observations in the train set for that category.
If we select "count" in the encoding_method, then for the variable colour, if there are 10 observations in the train set that show colour blue, blue will be replaced by 10. Alternatively, if we select "frequency" in the encoding_method, if 10% of the observations in the train set show blue colour, then blue will be replaced by 0.1.
### Frequency
Labels are replaced by the percentage of the observations that show that label in the train set.
```
count_enc = ce.CountFrequencyCategoricalEncoder(
encoding_method='frequency', variables=['cabin', 'pclass', 'embarked'])
count_enc.fit(X_train)
# we can explore the encoder_dict_ to find out the category replacements.
count_enc.encoder_dict_
# transform the data: see the change in the head view
train_t = count_enc.transform(X_train)
test_t = count_enc.transform(X_test)
test_t.head()
test_t['pclass'].value_counts().plot.bar()
```
### Count
Labels are replaced by the number of the observations that show that label in the train set.
```
# this time we encode only 1 variable
count_enc = ce.CountFrequencyCategoricalEncoder(encoding_method='count',
variables='cabin')
count_enc.fit(X_train)
# we can find the mappings in the encoder_dict_ attribute.
count_enc.encoder_dict_
# transform the data: see the change in the head view for Cabin
train_t = count_enc.transform(X_train)
test_t = count_enc.transform(X_test)
test_t.head()
test_t['pclass'].value_counts().plot.bar()
```
### Select categorical variables automatically
If we don't indicate which variables we want to encode, the encoder will find all categorical variables
```
# this time we ommit the argument for variable
count_enc = ce.CountFrequencyCategoricalEncoder(encoding_method = 'count')
count_enc.fit(X_train)
# we can see that the encoder selected automatically all the categorical variables
count_enc.variables
# transform the data: see the change in the head view
train_t = count_enc.transform(X_train)
test_t = count_enc.transform(X_test)
test_t.head()
```
Note that if there are labels in the test set that were not present in the train set, the transformer will introduce NaN, and raise a warning.
## MeanCategoricalEncoder
The MeanCategoricalEncoder replaces the labels of the variables by the mean value of the target for that label. For example, in the variable colour, if the mean value of the binary target is 0.5 for the label blue, then blue is replaced by 0.5
```
# we will transform 3 variables
mean_enc = ce.MeanCategoricalEncoder(variables=['cabin', 'pclass', 'embarked'])
# Note: the MeanCategoricalEncoder needs the target to fit
mean_enc.fit(X_train, y_train)
# see the dictionary with the mappings per variable
mean_enc.encoder_dict_
mean_enc.variables
# we can see the transformed variables in the head view
train_t = count_enc.transform(X_train)
test_t = count_enc.transform(X_test)
test_t.head()
```
### Automatically select the variables
This encoder will select all categorical variables to encode, when no variables are specified when calling the encoder
```
mean_enc = ce.MeanCategoricalEncoder()
mean_enc.fit(X_train, y_train)
mean_enc.variables
# we can see the transformed variables in the head view
train_t = count_enc.transform(X_train)
test_t = count_enc.transform(X_test)
test_t.head()
```
## WoERatioCategoricalEncoder
This encoder replaces the labels by the weight of evidence or the ratio of probabilities. It only works for binary classification.
The weight of evidence is given by: np.log( p(1) / p(0) )
The target probability ratio is given by: p(1) / p(0)
### Weight of evidence
```
## Rare value encoder first to reduce the cardinality
# see below for more details on this encoder
rare_encoder = ce.RareLabelCategoricalEncoder(
tol=0.03, n_categories=2, variables=['cabin', 'pclass', 'embarked'])
rare_encoder.fit(X_train)
# transform
train_t = rare_encoder.transform(X_train)
test_t = rare_encoder.transform(X_test)
woe_enc = ce.WoERatioCategoricalEncoder(
encoding_method='woe', variables=['cabin', 'pclass', 'embarked'])
# to fit you need to pass the target y
woe_enc.fit(train_t, y_train)
woe_enc.encoder_dict_
# transform and visualise the data
train_t = woe_enc.transform(train_t)
test_t = woe_enc.transform(test_t)
test_t.head()
```
### Ratio
Similarly, it is recommended to remove rare labels and high cardinality before using this encoder.
```
# rare label encoder first: transform
train_t = rare_encoder.transform(X_train)
test_t = rare_encoder.transform(X_test)
ratio_enc = ce.WoERatioCategoricalEncoder(
encoding_method='ratio', variables=['cabin', 'pclass', 'embarked'])
# to fit we need to pass the target y
ratio_enc.fit(train_t, y_train)
ratio_enc.encoder_dict_
# transform and visualise the data
train_t = woe_enc.transform(train_t)
test_t = woe_enc.transform(test_t)
test_t.head()
```
## OrdinalCategoricalEncoder
The OrdinalCategoricalEncoder will replace the variable labels by digits, from 1 to the number of different labels. If we select "arbitrary", then the encoder will assign numbers as the labels appear in the variable (first come first served). If we select "ordered", the encoder will assign numbers following the mean of the target value for that label. So labels for which the mean of the target is higher will get the number 1, and those where the mean of the target is smallest will get the number n.
### Ordered
```
# we will encode 3 variables:
ordinal_enc = ce.OrdinalCategoricalEncoder(
encoding_method='ordered', variables=['pclass', 'cabin', 'embarked'])
# for this encoder, we need to pass the target as argument
# if encoding_method='ordered'
ordinal_enc.fit(X_train, y_train)
# here we can see the mappings
ordinal_enc.encoder_dict_
# transform and visualise the data
train_t = ordinal_enc.transform(X_train)
test_t = ordinal_enc.transform(X_test)
test_t.head()
```
### Arbitrary
```
ordinal_enc = ce.OrdinalCategoricalEncoder(encoding_method='arbitrary',
variables='cabin')
# for this encoder we don't need to add the target. You can leave it or remove it.
ordinal_enc.fit(X_train, y_train)
ordinal_enc.encoder_dict_
```
Note that the ordering of the different labels is not the same when we select "arbitrary" or "ordered"
```
# transform: see the numerical values in the former categorical variables
train_t = ordinal_enc.transform(X_train)
test_t = ordinal_enc.transform(X_test)
test_t.head()
```
### Automatically select categorical variables
These encoder as well selects all the categorical variables, if None is passed to the variable argument when calling the enconder.
```
ordinal_enc = ce.OrdinalCategoricalEncoder(encoding_method = 'arbitrary')
# for this encoder we don't need to add the target. You can leave it or remove it.
ordinal_enc.fit(X_train)
ordinal_enc.variables
# transform: see the numerical values in the former categorical variables
train_t = ordinal_enc.transform(X_train)
test_t = ordinal_enc.transform(X_test)
test_t.head()
```
## OneHotCategoricalEncoder
Performs One Hot Encoding. The encoder can select how many different labels per variable to encode into binaries. When top_categories is set to None, all the categories will be transformed in binary variables. However, when top_categories is set to an integer, for example 10, then only the 10 most popular categories will be transformed into binary, and the rest will be discarded.
The encoder has also the possibility to create binary variables from all categories (drop_last = False), or remove the binary for the last category (drop_last = True), for use in linear models.
### All binary, no top_categories
```
ohe_enc = ce.OneHotCategoricalEncoder(
top_categories=None,
variables=['pclass', 'cabin', 'embarked'],
drop_last=False)
ohe_enc.fit(X_train)
ohe_enc.drop_last
ohe_enc.encoder_dict_
train_t = ohe_enc.transform(X_train)
test_t = ohe_enc.transform(X_train)
test_t.head()
```
### Dropping the last category for linear models
```
ohe_enc = ce.OneHotCategoricalEncoder(
top_categories=None,
variables=['pclass', 'cabin', 'embarked'],
drop_last=True)
ohe_enc.fit(X_train)
ohe_enc.encoder_dict_
train_t = ohe_enc.transform(X_train)
test_t = ohe_enc.transform(X_train)
test_t.head()
```
### Selecting top_categories to encode
```
ohe_enc = ce.OneHotCategoricalEncoder(
top_categories=2,
variables=['pclass', 'cabin', 'embarked'],
drop_last=False)
ohe_enc.fit(X_train)
ohe_enc.encoder_dict_
train_t = ohe_enc.transform(X_train)
test_t = ohe_enc.transform(X_train)
test_t.head()
```
## RareLabelCategoricalEncoder
The RareLabelCategoricalEncoder groups labels that show a small number of observations in the dataset into a new category called 'Rare'. This helps to avoid overfitting.
The argument tol indicates the percentage of observations that the label needs to have in order not to be re-grouped into the "Rare" label. The argument n_categories indicates the minimum number of distinct categories that a variable needs to have for any of the labels to be re-grouped into rare. If the number of labels is smaller than n_categories, then the encoder will not group the labels for that variable.
```
## Rare value encoder
rare_encoder = ce.RareLabelCategoricalEncoder(
tol=0.03, n_categories=5, variables=['cabin', 'pclass', 'embarked'])
rare_encoder.fit(X_train)
# the encoder_dict_ contains a dictionary of the {variable: frequent labels} pair
rare_encoder.encoder_dict_
train_t = rare_encoder.transform(X_train)
test_t = rare_encoder.transform(X_train)
test_t.head()
```
### Automatically select all categorical variables
If no variable list is passed as argument, it selects all the categorical variables.
```
## Rare value encoder
rare_encoder = ce.RareLabelCategoricalEncoder(tol = 0.03, n_categories=5)
rare_encoder.fit(X_train)
rare_encoder.encoder_dict_
train_t = rare_encoder.transform(X_train)
test_t = rare_encoder.transform(X_train)
test_t.head()
```
| true |
code
| 0.597725 | null | null | null | null |
|
# Working with 3D city models in Python
**Balázs Dukai** [*@BalazsDukai*](https://twitter.com/balazsdukai), **FOSS4G 2019**
Tweet <span style="color:blue">#CityJSON</span>
[3D geoinformation research group, TU Delft, Netherlands](https://3d.bk.tudelft.nl/)

Repo of this talk: [https://github.com/balazsdukai/foss4g2019](https://github.com/balazsdukai/foss4g2019)
# 3D + city + model ?

Probably the most well known 3d city model is what we see in Google Earth. And it is a very nice model to look at and it is improving continuously. However, certain applications require more information than what is stored in such a mesh model. They need to know what does an object in the model represent in the real world.
# Semantic models

That is why we have semantic models, where for each object in the model we store a label of is meaning.
Once we have labels on the object and on their parts, data preparation becomes more simple. An important property for analytical applications, such as wind flow simulations.
# Useful for urban analysis

García-Sánchez, C., van Beeck, J., Gorlé, C., Predictive Large Eddy Simulations for Urban Flows: Challenges and Opportunities, Building and Environment, 139, 146-156, 2018.
But we can do much more with 3d city models. We can use them to better estimate the energy consumption in buildings, simulate noise in cities or analyse views and shadows. In the Netherlands sunshine is precious commodity, so we like to get as much as we can.
# And many more...

There are many open 3d city models available. They come in different formats and quality. However, at our group we are still waiting for the "year of the 3d city model" to come. We don't really see mainstream use, apart of visualisation. Which is nice, I belive they can provide much more value than having a nice thing to simply look at.
# ...mostly just production of the models
many available, but who **uses** them? **For more than visualisation?**

# In truth, 3D CMs are a bit difficult to work with
### Our built environment is complex, and the objects are complex too

### Software are lagging behind
+ not many software supports 3D city models
+ if they do, mostly propietary data model and format
+ large, *"eterprise"*-type applications (think Esri, FME, Bentley ... )
+ few tools accessible for the individual developer / hobbyist
2. GML doesn't help ( *[GML madness](http://erouault.blogspot.com/2014/04/gml-madness.html) by Even Rouault* )
That is why we are developing CityJSON, which is a data format for 3d city models. Essentially, it aims to increase the value of 3d city models by making it more simple to work with them and lower the entry for a wider audience than cadastral organisations.

## Key concepts of CityJSON
+ *simple*, as in easy to implement
+ designed with programmers in mind
+ fully developed in the open
+ flattened hierarchy of objects
+ <span style="color:red">implementation first</span>

CityJSON implements the data model of CityGML. CityGML is an international standard for 3d city models and it is coupled with its GML-based encoding.
We don't really like GML, because it's verbose, files are deeply nested and large (often several GB). And there are many different ways to do one thing.
Also, I'm not a web-developer, but I would be surprised if anyone prefers GML over JSON for sending stuff around the web.
# JSON-based encoding of the CityGML data model

<blockquote class="twitter-tweet"><p lang="en" dir="ltr">I just got sent a CityGML file. <a href="https://t.co/jnTVoRnVLS">pic.twitter.com/jnTVoRnVLS</a></p>— James Fee (@jamesmfee) <a href="https://twitter.com/jamesmfee/status/748270105319006208?ref_src=twsrc%5Etfw">June 29, 2016</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
+ files are deeply nested, and large
+ many "points of entry"
+ many diff ways to do one thing (GML doesn't help, *[GML madness](http://erouault.blogspot.com/2014/04/gml-madness.html) by Even Rouault* )
## The CityGML data model

## Compression ~6x over CityGML

## Compression
| file | CityGML size (original) | CityGML size (w/o spaces) | textures | CityJSON | compression |
| -------- | ----------------------- | ----------------------------- |--------- | ------------ | --------------- |
| [CityGML demo "GeoRes"](https://www.citygml.org/samplefiles/) | 4.3MB | 4.1MB | yes | 524KB | 8.0 |
| [CityGML v2 demo "Railway"](https://www.citygml.org/samplefiles/) | 45MB | 34MB | yes | 4.3MB | 8.1 |
| [Den Haag "tile 01"](https://data.overheid.nl/data/dataset/ngr-3d-model-den-haag) | 23MB | 18MB | no, material | 2.9MB | 6.2 |
| [Montréal VM05](http://donnees.ville.montreal.qc.ca/dataset/maquette-numerique-batiments-citygml-lod2-avec-textures/resource/36047113-aa19-4462-854a-cdcd6281a5af) | 56MB | 42MB | yes | 5.4MB | 7.8 |
| [New York LoD2 (DA13)](https://www1.nyc.gov/site/doitt/initiatives/3d-building.page) | 590MB | 574MB | no | 105MB | 5.5 |
| [Rotterdam Delfshaven](http://rotterdamopendata.nl/dataset/rotterdam-3d-bestanden/resource/edacea54-76ce-41c7-a0cc-2ebe5750ac18) | 16MB | 15MB | yes | 2.6MB | 5.8 |
| [Vienna (the demo file)](https://www.data.gv.at/katalog/dataset/86d88cae-ad97-4476-bae5-73488a12776d) | 37MB | 36MB | no | 5.3MB | 6.8 |
| [Zürich LoD2](https://www.data.gv.at/katalog/dataset/86d88cae-ad97-4476-bae5-73488a12776d) | 3.03GB | 2.07GB | no | 292MB | 7.1 |
If you are interested in a more detailed comparison between CityGML and CityJSON you can read our article, its open access.

And yes, we are guilty of charge.

[https://xkcd.com/927/](https://xkcd.com/927/)
# Let's have a look-see, shall we?

Now let's take a peek under the hood, what's going on in a CityJSON file.
## An empty CityJSON file

In a city model we represent the real-world objects such as buildings, bridges, trees as different types of CityObjects. Each CityObject has its
+ unique ID,
+ attributes,
+ geometry,
+ and it can have children objects or it can be part of a parent object.
Note however, that CityObject are not nested. Each of them is stored at root and the hierachy represented by linking to object IDs.
## A CityObject

Each CityObject has a geometry representation. This geometry is composed of *boundaries* and *semantics*.
## Geometry
+ **boundaries** definition uses vertex indices (inspired by Wavefront OBJ)
+ We have a vertex list at the root of the document
+ Vertices are not repeated (unlike Simple Features)
+ **semantics** are linked to the boundary surfaces

This `MulitSurface` has
5 surfaces
```json
[[0, 3, 2, 1]], [[4, 5, 6, 7]], [[0, 1, 5, 4]], [[0, 2, 3, 8]], [[10, 12, 23, 48]]
```
each surface has only an exterior ring (the first array)
```json
[ [0, 3, 2, 1] ]
```
The semantic surfaces in the `semantics` json-object are linked to the boundary surfaces. The integers in the `values` property of `surfaces` are the 0-based indices of the surfaces of the boundary.
```
import json
import os
path = os.path.join('data', 'rotterdam_subset.json')
with open(path) as fin:
cm = json.loads(fin.read())
print(f"There are {len(cm['CityObjects'])} CityObjects")
# list all IDs
for id in cm['CityObjects']:
print(id, "\t")
```
+ Working with a CityJSON file is straightforward. One can open it with the standard library and get going.
+ But you need to know the schema well.
+ And you need to write everything from scratch.
That is why we are developing **cjio**.
**cjio** is how *we eat what we cook*
Aims to help to actually work with and analyse 3D city models, and extract more value from them. Instead of letting them gather dust in some governmental repository.

## `cjio` has a (quite) stable CLI
```bash
$ cjio city_model.json reproject 2056 export --format glb /out/model.glb
```
## and an experimental API
```python
from cjio import cityjson
cm = cityjson.load('city_model.json')
cm.get_cityobjects(type='building')
```
**`pip install cjio`**
This notebook is based on the develop branch.
**`pip install git+https://github.com/tudelft3d/cjio@develop`**
# `cjio`'s CLI
```
! cjio --help
! cjio data/rotterdam_subset.json info
! cjio data/rotterdam_subset.json validate
! cjio data/rotterdam_subset.json \
subset --exclude --id "{CD98680D-A8DD-4106-A18E-15EE2A908D75}" \
merge data/rotterdam_one.json \
reproject 2056 \
save data/test_rotterdam.json
```
+ The CLI was first, no plans for API
+ **Works with whole city model only**
+ Functions for the CLI work with the JSON directly, passing it along
+ Simple and effective architecture
# `cjio`'s API
Allow *read* --> *explore* --> *modify* --> *write* iteration
Work with CityObjects and their parts
Functions for common operations
Inspired by the *tidyverse* from the R ecosystem
```
import os
from copy import deepcopy
from cjio import cityjson
from shapely.geometry import Polygon
import matplotlib.pyplot as plt
plt.close('all')
from sklearn.preprocessing import FunctionTransformer
from sklearn import cluster
import numpy as np
```
In the following we work with a subset of the 3D city model of Rotterdam

## Load a CityJSON
The `load()` method loads a CityJSON file into a CityJSON object.
```
path = os.path.join('data', 'rotterdam_subset.json')
cm = cityjson.load(path)
print(type(cm))
```
## Using the CLI commands in the API
You can use any of the CLI commands on a CityJSON object
*However,* not all CLI commands are mapped 1-to-1 to `CityJSON` methods
And we haven't harmonized the CLI and the API yet.
```
cm.validate()
```
## Explore the city model
Print the basic information about the city model. Note that `print()` returns the same information as the `info` command in the CLI.
```
print(cm)
```
## Getting objects from the model
Get CityObjects by their *type*, or a list of types. Also by their IDs.
Note that `get_cityobjects()` == `cm.cityobjects`
```
buildings = cm.get_cityobjects(type='building')
# both Building and BuildingPart objects
buildings_parts = cm.get_cityobjects(type=['building', 'buildingpart'])
r_ids = ['{C9D4A5CF-094A-47DA-97E4-4A3BFD75D3AE}',
'{6271F75F-E8D8-4EE4-AC46-9DB02771A031}']
buildings_ids = cm.get_cityobjects(id=r_ids)
```
## Properties and geometry of objects
```
b01 = buildings_ids['{C9D4A5CF-094A-47DA-97E4-4A3BFD75D3AE}']
print(b01)
b01.attributes
```
CityObjects can have *children* and *parents*
```
b01.children is None and b01.parents is None
```
CityObject geometry is a list of `Geometry` objects. That is because a CityObject can have multiple geometry representations in different levels of detail, eg. a geometry in LoD1 and a second geometry in LoD2.
```
b01.geometry
geom = b01.geometry[0]
print("{}, lod {}".format(geom.type, geom.lod))
```
### Geometry boundaries and Semantic Surfaces
On the contrary to a CityJSON file, the geometry boundaries are dereferenced when working with the API. This means that the vertex coordinates are included in the boundary definition, not only the vertex indices.
`cjio` doesn't provide specific geometry classes (yet), eg. MultiSurface or Solid class. If you are working with the geometry boundaries, you need to the geometric operations yourself, or cast the boundary to a geometry-class of some other library. For example `shapely` if 2D is enough.
Vertex coordinates are kept 'as is' on loading the geometry. CityJSON files are often compressed and coordinates are shifted and transformed into integers so probably you'll want to transform them back. Otherwise geometry operations won't make sense.
```
transformation_object = cm.transform
geom_transformed = geom.transform(transformation_object)
geom_transformed.boundaries[0][0]
```
But it might be easier to transform (decompress) the whole model on load.
```
cm_transformed = cityjson.load(path, transform=True)
print(cm_transformed)
```
Semantic Surfaces are stored in a similar fashion as in a CityJSON file, in the `surfaces` attribute of a Geometry object.
```
geom.surfaces
```
`surfaces` does not store geometry boundaries, just references (`surface_idx`). Use the `get_surface_boundaries()` method to obtain the boundary-parts connected to the semantic surface.
```
roofs = geom.get_surfaces(type='roofsurface')
roofs
roof_boundaries = []
for r in roofs.values():
roof_boundaries.append(geom.get_surface_boundaries(r))
roof_boundaries
```
### Assigning attributes to Semantic Surfaces
1. extract the surfaces,
2. make the changes on the surface,
3. overwrite the CityObjects with the changes.
```
cm_copy = deepcopy(cm)
new_cos = {}
for co_id, co in cm.cityobjects.items():
new_geoms = []
for geom in co.geometry:
# Only LoD >= 2 models have semantic surfaces
if geom.lod >= 2.0:
# Extract the surfaces
roofsurfaces = geom.get_surfaces('roofsurface')
for i, rsrf in roofsurfaces.items():
# Change the attributes
if 'attributes' in rsrf.keys():
rsrf['attributes']['cladding'] = 'tiles'
else:
rsrf['attributes'] = {}
rsrf['attributes']['cladding'] = 'tiles'
geom.surfaces[i] = rsrf
new_geoms.append(geom)
else:
# Use the unchanged geometry
new_geoms.append(geom)
co.geometry = new_geoms
new_cos[co_id] = co
cm_copy.cityobjects = new_cos
print(cm_copy.cityobjects['{C9D4A5CF-094A-47DA-97E4-4A3BFD75D3AE}'])
```
### Create new Semantic Surfaces
The process is similar as previously. However, in this example we create new SemanticSurfaces that hold the values which we compute from the geometry. The input city model has a single semantic "WallSurface", without attributes, for all the walls of a building. The snippet below illustrates how to separate surfaces and assign the semantics to them.
```
new_cos = {}
for co_id, co in cm_copy.cityobjects.items():
new_geoms = []
for geom in co.geometry:
if geom.lod >= 2.0:
max_id = max(geom.surfaces.keys())
old_ids = []
for w_i, wsrf in geom.get_surfaces('wallsurface').items():
old_ids.append(w_i)
del geom.surfaces[w_i]
boundaries = geom.get_surface_boundaries(wsrf)
for j, boundary_geometry in enumerate(boundaries):
# The original geometry has the same Semantic for all wall,
# but we want to divide the wall surfaces by their orientation,
# thus we need to have the correct surface index
surface_index = wsrf['surface_idx'][j]
new_srf = {
'type': wsrf['type'],
'surface_idx': surface_index
}
for multisurface in boundary_geometry:
# Do any operation here
x, y, z = multisurface[0]
if j % 2 > 0:
orientation = 'north'
else:
orientation = 'south'
# Add the new attribute to the surface
if 'attributes' in wsrf.keys():
wsrf['attributes']['orientation'] = orientation
else:
wsrf['attributes'] = {}
wsrf['attributes']['orientation'] = orientation
new_srf['attributes'] = wsrf['attributes']
# if w_i in geom.surfaces.keys():
# del geom.surfaces[w_i]
max_id = max_id + 1
geom.surfaces[max_id] = new_srf
new_geoms.append(geom)
else:
# If LoD1, just add the geometry unchanged
new_geoms.append(geom)
co.geometry = new_geoms
new_cos[co_id] = co
cm_copy.cityobjects = new_cos
```
# Analysing CityModels

In the following I show how to compute some attributes from CityObject geometry and use these attributes as input for machine learning. For this we use the LoD2 model of Zürich.
Download the Zürich data set from https://3d.bk.tudelft.nl/opendata/cityjson/1.0/Zurich_Building_LoD2_V10.json
```
path = os.path.join('data', 'zurich.json')
zurich = cityjson.load(path, transform=True)
```
## A simple geometry function
Here is a simple geometry function that computes the area of the groundsurface (footprint) of buildings in the model. It also show how to cast surfaces, in this case the ground surface, to Shapely Polygons.
```
def compute_footprint_area(co):
"""Compute the area of the footprint"""
footprint_area = 0
for geom in co.geometry:
# only LoD2 (or higher) objects have semantic surfaces
if geom.lod >= 2.0:
footprints = geom.get_surfaces(type='groundsurface')
# there can be many surfaces with label 'groundsurface'
for i,f in footprints.items():
for multisurface in geom.get_surface_boundaries(f):
for surface in multisurface:
# cast to Shapely polygon
shapely_poly = Polygon(surface)
footprint_area += shapely_poly.area
return footprint_area
```
## Compute new attributes
Then we need to loop through the CityObjects and update add the new attributes. Note that the `attributes` CityObject attribute is just a dictionary.
Thus we compute the number of vertices of the CityObject and the area of is footprint. Then we going to cluster these two variables. This is completely arbitrary excercise which is simply meant to illustrate how to transform a city model into machine-learnable features.
```
for co_id, co in zurich.cityobjects.items():
co.attributes['nr_vertices'] = len(co.get_vertices())
co.attributes['fp_area'] = compute_footprint_area(co)
zurich.cityobjects[co_id] = co
```
It is possible to export the city model into a pandas DataFrame. Note that only the CityObject attributes are exported into the dataframe, with CityObject IDs as the index of the dataframe. Thus if you want to export the attributes of SemanticSurfaces for example, then you need to add them as CityObject attributes.
The function below illustrates this operation.
```
def assign_cityobject_attribute(cm):
"""Copy the semantic surface attributes to CityObject attributes.
Returns a copy of the citymodel.
"""
new_cos = {}
cm_copy = deepcopy(cm)
for co_id, co in cm.cityobjects.items():
for geom in co.geometry:
for srf in geom.surfaces.values():
if 'attributes' in srf:
for attr,a_v in srf['attributes'].items():
if (attr not in co.attributes) or (co.attributes[attr] is None):
co.attributes[attr] = [a_v]
else:
co.attributes[attr].append(a_v)
new_cos[co_id] = co
cm_copy.cityobjects = new_cos
return cm_copy
df = zurich.to_dataframe()
df.head()
```
In order to have a nicer distribution of the data, we remove the missing values and apply a log-transform on the two variables. Note that the `FuntionTransformer.transform` transforms a DataFrame to a numpy array that is ready to be used in `scikit-learn`. The details of a machine learning workflow is beyond the scope of this tutorial however.
```
df_subset = df[df['Geomtype'].notnull() & df['fp_area'] > 0.0].loc[:, ['nr_vertices', 'fp_area']]
transformer = FunctionTransformer(np.log, validate=True)
df_logtransform = transformer.transform(df_subset)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df_logtransform[:,0], df_logtransform[:,1], alpha=0.3, s=1.0)
plt.show()
def plot_model_results(model, data):
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
colormap = np.array(['lightblue', 'red', 'lime', 'blue','black'])
ax.scatter(data[:,0], data[:,1], c=colormap[model.labels_], s=10, alpha=0.5)
ax.set_xlabel('Number of vertices [log]')
ax.set_ylabel('Footprint area [log]')
plt.title(f"DBSCAN clustering with estimated {len(set(model.labels_))} clusters")
plt.show()
```
Since we transformed our DataFrame, we can fit any model in `scikit-learn`. I use DBSCAN because I wanted to find the data points on the fringes of the central cluster.
```
%matplotlib notebook
model = cluster.DBSCAN(eps=0.2).fit(df_logtransform)
plot_model_results(model, df_logtransform)
# merge the cluster labels back to the data frame
df_subset['dbscan'] = model.labels_
```
## Save the results back to CityJSON
And merge the DataFrame with cluster labels back to the city model.
```
for co_id, co in zurich.cityobjects.items():
if co_id in df_subset.index:
ml_results = dict(df_subset.loc[co_id])
else:
ml_results = {'nr_vertices': 'nan', 'fp_area': 'nan', 'dbscan': 'nan'}
new_attrs = {**co.attributes, **ml_results}
co.attributes = new_attrs
zurich.cityobjects[co_id] = co
```
At the end, the `save()` method saves the edited city model into a CityJSON file.
```
path_out = os.path.join('data', 'zurich_output.json')
cityjson.save(zurich, path_out)
```
## And view the results in QGIS again

However, you'll need to set up the styling based on the cluster labels by hand.
# Other software
## Online CityJSON viewer

## QGIS plugin

## Azul

# Full conversion CityGML <--> CityJSON

# Thank you!
Balázs Dukai
[email protected]
@BalazsDukai
## A few links
Repo of this talk: [https://github.com/balazsdukai/foss4g2019](https://github.com/balazsdukai/foss4g2019)
[cityjson.org](cityjson.org)
[viewer.cityjson.org](viewer.cityjson.org)
QGIS plugin: [github.com/tudelft3d/cityjson-qgis-plugin](github.com/tudelft3d/cityjson-qgis-plugin)
Azul – CityJSON viewer on Mac – check the [AppStore](https://apps.apple.com/nl/app/azul/id1173239678?mt=12)
cjio: [github.com/tudelft3d/cjio](github.com/tudelft3d/cjio) & [tudelft3d.github.io/cjio/](tudelft3d.github.io/cjio/)
| true |
code
| 0.267623 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/rjrahul24/ai-with-python-series/blob/main/01.%20Getting%20Started%20with%20Python/Python_Revision_and_Statistical_Methods.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
**Inheritence in Python**
Object Oriented Programming is a coding paradigm that revolves around creating modular code and stopping mulitple uses of the same structure. It is aimed at increasing stability and usability of code. It consists of some well-known concepts stated below:
1. Classes: These often show a collection of functions and attributes that are fastened to a precise name and represent an abstract container.
2. Attributes: Generally, the data that is associated with each class. Examples are variables declared during creation of the class.
3. Objects: An instance generated from the class. There can be multiple objects of a class and every individual object takes on the properties of the class.
```
# Implementation of Classes in Python
# Creating a Class Math with 2 functions
class Math:
def subtract (self, i, j):
return i-j
def add (self, x, y):
return x+y
# Creating an object of the class Math
math_child = Math()
test_int_A = 10
test_int_B = 20
print(math_child.subtract(test_int_B, test_int_A))
# Creating a Class Person with an attribute and an initialization function
class Person:
name = 'George'
def __init__ (self):
self.age = 34
# Creating an object of the class and printing its attributes
p1 = Person()
print (p1.name)
print (p1.age)
```
**Constructors and Inheritance**
The constructor is an initialization function that is always called when a class’s instance is created. The constructor is named __init__() in Python and defines the specifics of instantiating a class and its attributes.
Class inheritance is a concept of taking values of a class from its origin and giving the same properties to a child class. It creates relationship models like “Class A is a Class B”, like a triangle (child class) is a shape (parent class). All the functions and attributes of a superclass are inherited by the subclass.
1. Overriding: During the inheritance, the behavior of the child class or the subclass can be modified. Doing this modification on functions is class “overriding” and is achieved by declaring functions in the subclass with the same name. Functions created in the subclass will take precedence over those in the parent class.
2. Composition: Classes can also be built from other smaller classes that support relationship models like “Class A has a Class B”, like a Department has Students.
3. Polymorphism: The functionality of similar looking functions can be changed in run-time, during their implementation. This is achieved using Polymorphism, that includes two objects of different parent class but having the same set of functions. The outward look of these functions is the same, but implementations differ.
```
# Creating a class and instantiating variables
class Animal_Dog:
species = "Canis"
def __init__(self, name, age):
self.name = name
self.age = age
# Instance method
def description(self):
return f"{self.name} is {self.age} years old"
# Another instance method
def animal_sound(self, sound):
return f"{self.name} says {sound}"
# Check the object’s type
Animal_Dog("Bunny", 7)
# Even though a and b are both instances of the Dog class, they represent two distinct objects in memory.
a = Animal_Dog("Fog", 6)
b = Animal_Dog("Bunny", 7)
a == b
# Instantiating objects with the class’s constructor arguments
fog = Animal_Dog("Fog", 6)
bunny = Animal_Dog("Bunny", 7)
print (bunny.name)
print (bunny.age)
# Accessing attributes directly
print (bunny.species)
# Creating a new Object to access through instance functions
fog = Animal_Dog("Fog", 6)
fog.description()
fog.animal_sound("Whoof Whoof")
fog.animal_sound("Bhoof Whoof")
# Inheriting the Class
class GoldRet(Animal_Dog):
def speak(self, sound="Warf"):
return f"{self.name} says {sound}"
bunny = GoldRet("Bunny", 5)
bunny.speak()
bunny.speak("Grrr Grrr")
# Code Snippet 3: Variables and data types
int_var = 100 # Integer variable
float_var = 1000.0 # Float value
string_var = "John" # String variable
print (int_var)
print (float_var)
print (string_var)
```
Variables and Data Types in Python
Variables are reserved locations in the computer’s memory that store values defined within them. Whenever a variable is created, a piece of the computer’s memory is allocated to it. Based on the data type of this declared variable, the interpreter allocates varied chunks of memory. Therefore, basis the assignment of variables as integer, float, strings, etc. different sizes of memory allocations are invoked.
• Declaration: Variables in Python do not need explicit declaration to reserve memory space. This happens automatically when a value is assigned. The (=) sign is used to assign values to variables.
• Multiple Assignment: Python allows for multiple variables to hold a single value and this declaration can be done together for all variables.
• Deleting References: Memory reference once created can also be deleted. The 'del' statement is used to delete the reference to a number object. Multiple object deletion is also supported by the 'del' statement.
• Strings: Strings are a set of characters, that Python allows representation through single or double quotes. String subsets can be formed using the slice operator ([ ] and [:] ) where indexing starts from 0 on the left and -1 on the right. The (+) sign is the string concatenation operator and the (*) sign is the repetition operator.
Datatype Conversion
Function Description
int(x [,base]) Converts given input to integer. Base is used for string conversions.
long(x [,base] ) Converts given input to a long integer
float(x) Follows conversion to floating-point number.
complex(real [,imag]) Used for creating a complex number.
str(x) Converts any given object to a string
eval(str) Evaluates given string and returns an object.
tuple(s) Conversion to tuple
list(s) List conversion of given input
set(s) Converts the given value to a set
unichr(x) Conversion from an integer to Unicode character.
Looking at Variables and Datatypes
Data stored as Python’s variables is abstracted as objects. Data is represented by objects or through relations between individual objects. Therefore, every variable and its corresponding values are an object of a class, depending on the stored data.
```
# Multiple Assignment: All are assigned to the same memory location
a = b = c = 1
# Assigning multiple variables with multiple values
a,b,c = 1,2,"jacob"
# Assigning and deleting variable references
var1 = 1
var2 = 10
del var1 # Removes the reference of var1
del var2
# Basic String Operations in Python
str = 'Hello World!'
print (str)
# Print the first character of string variable
print (str[0])
# Prints characters from 3rd to 5th positions
print (str[2:5])
# Print the string twice
print (str * 2)
# Concatenate the string and print
print (str + "TEST")
```
| true |
code
| 0.538134 | null | null | null | null |
|
# Continuous Control
---
In this notebook, you will learn how to use the Unity ML-Agents environment for the second project of the [Deep Reinforcement Learning Nanodegree](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) program.
### 1. Start the Environment
We begin by importing the necessary packages. If the code cell below returns an error, please revisit the project instructions to double-check that you have installed [Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md) and [NumPy](http://www.numpy.org/).
```
import numpy as np
import torch
import matplotlib.pyplot as plt
import time
from unityagents import UnityEnvironment
from collections import deque
from itertools import count
import datetime
from ddpg import DDPG, ReplayBuffer
%matplotlib inline
```
Next, we will start the environment! **_Before running the code cell below_**, change the `file_name` parameter to match the location of the Unity environment that you downloaded.
- **Mac**: `"path/to/Reacher.app"`
- **Windows** (x86): `"path/to/Reacher_Windows_x86/Reacher.exe"`
- **Windows** (x86_64): `"path/to/Reacher_Windows_x86_64/Reacher.exe"`
- **Linux** (x86): `"path/to/Reacher_Linux/Reacher.x86"`
- **Linux** (x86_64): `"path/to/Reacher_Linux/Reacher.x86_64"`
- **Linux** (x86, headless): `"path/to/Reacher_Linux_NoVis/Reacher.x86"`
- **Linux** (x86_64, headless): `"path/to/Reacher_Linux_NoVis/Reacher.x86_64"`
For instance, if you are using a Mac, then you downloaded `Reacher.app`. If this file is in the same folder as the notebook, then the line below should appear as follows:
```
env = UnityEnvironment(file_name="Reacher.app")
```
```
#env = UnityEnvironment(file_name='envs/Reacher_Linux_NoVis_20/Reacher.x86_64') # Headless
env = UnityEnvironment(file_name='envs/Reacher_Linux_20/Reacher.x86_64') # Visual
```
Environments contain **_brains_** which are responsible for deciding the actions of their associated agents. Here we check for the first brain available, and set it as the default brain we will be controlling from Python.
```
# get the default brain
brain_name = env.brain_names[0]
brain = env.brains[brain_name]
```
### 2. Examine the State and Action Spaces
In this environment, a double-jointed arm can move to target locations. A reward of `+0.1` is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of `33` variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector must be a number between `-1` and `1`.
Run the code cell below to print some information about the environment.
```
# reset the environment
env_info = env.reset(train_mode=True)[brain_name]
# number of agents
num_agents = len(env_info.agents)
print('Number of agents:', num_agents)
# size of each action
action_size = brain.vector_action_space_size
print('Size of each action:', action_size)
# examine the state space
states = env_info.vector_observations
state_size = states.shape[1]
print('There are {} agents. Each observes a state with length: {}'.format(states.shape[0], state_size))
print('The state for the first agent looks like:', states[0])
```
### 3. Take Random Actions in the Environment
In the next code cell, you will learn how to use the Python API to control the agent and receive feedback from the environment.
Once this cell is executed, you will watch the agent's performance, if it selects an action at random with each time step. A window should pop up that allows you to observe the agent, as it moves through the environment.
Of course, as part of the project, you'll have to change the code so that the agent is able to use its experience to gradually choose better actions when interacting with the environment!
```
env_info = env.reset(train_mode=False)[brain_name] # reset the environment
states = env_info.vector_observations # get the current state (for each agent)
scores = np.zeros(num_agents) # initialize the score (for each agent)
while True:
actions = np.random.randn(num_agents, action_size) # select an action (for each agent)
actions = np.clip(actions, -1, 1) # all actions between -1 and 1
env_info = env.step(actions)[brain_name] # send all actions to tne environment
next_states = env_info.vector_observations # get next state (for each agent)
rewards = env_info.rewards # get reward (for each agent)
dones = env_info.local_done # see if episode finished
scores += env_info.rewards # update the score (for each agent)
states = next_states # roll over states to next time step
if np.any(dones): # exit loop if episode finished
break
break
print('Total score (averaged over agents) this episode: {}'.format(np.mean(scores)))
```
When finished, you can close the environment.
### 4. It's Your Turn!
Now it's your turn to train your own agent to solve the environment! When training the environment, set `train_mode=True`, so that the line for resetting the environment looks like the following:
```python
env_info = env.reset(train_mode=True)[brain_name]
```
```
BUFFER_SIZE = int(5e5) # replay buffer size
CACHE_SIZE = int(6e4)
BATCH_SIZE = 256 # minibatch size
GAMMA = 0.99 # discount factor
TAU = 1e-3 # for soft update of target parameters
LR_ACTOR = 1e-3 # learning rate of the actor
LR_CRITIC = 1e-3 # learning rate of the critic
WEIGHT_DECAY = 0 # L2 weight decay
UPDATE_EVERY = 20 # timesteps between updates
NUM_UPDATES = 15 # num of update passes when updating
EPSILON = 1.0 # epsilon for the noise process added to the actions
EPSILON_DECAY = 1e-6 # decay for epsilon above
NOISE_SIGMA = 0.05
# 96 Neurons solves the environment consistently and usually fastest
fc1_units=96
fc2_units=96
random_seed=23
def store(buffers, states, actions, rewards, next_states, dones, timestep):
memory, cache = buffers
for state, action, reward, next_state, done in zip(states, actions, rewards, next_states, dones):
memory.add(state, action, reward, next_state, done)
cache.add(state, action, reward, next_state, done)
store
def learn(agent, buffers, timestep):
memory, cache = buffers
if len(memory) > BATCH_SIZE and timestep % UPDATE_EVERY == 0:
for _ in range(NUM_UPDATES):
experiences = memory.sample()
agent.learn(experiences, GAMMA)
for _ in range(3):
experiences = cache.sample()
agent.learn(experiences, GAMMA)
learn
avg_over = 100
print_every = 10
def ddpg(agent, buffers, n_episodes=200, stopOnSolved=True):
print('Start: ',datetime.datetime.now())
scores_deque = deque(maxlen=avg_over)
scores_global = []
average_global = []
min_global = []
max_global = []
best_avg = -np.inf
tic = time.time()
print('\rEpis,EpAvg,GlAvg, Max, Min, Time')
for i_episode in range(1, n_episodes+1):
env_info = env.reset(train_mode=True)[brain_name] # reset the environment
states = env_info.vector_observations # get the current state (for each agent)
scores = np.zeros(num_agents) # initialize the score (for each agent)
agent.reset()
score_average = 0
timestep = time.time()
for t in count():
actions = agent.act(states, add_noise=True)
env_info = env.step(actions)[brain_name] # send all actions to tne environment
next_states = env_info.vector_observations # get next state (for each agent)
rewards = env_info.rewards # get reward (for each agent)
dones = env_info.local_done # see if episode finished
store(buffers, states, actions, rewards, next_states, dones, t)
learn(agent, buffers, t)
states = next_states # roll over states to next time step
scores += rewards # update the score (for each agent)
if np.any(dones): # exit loop if episode finished
break
score = np.mean(scores)
scores_deque.append(score)
score_average = np.mean(scores_deque)
scores_global.append(score)
average_global.append(score_average)
min_global.append(np.min(scores))
max_global.append(np.max(scores))
print('\r {}, {:.2f}, {:.2f}, {:.2f}, {:.2f}, {:.2f}'\
.format(str(i_episode).zfill(3), score, score_average, np.max(scores),
np.min(scores), time.time() - timestep), end="\n")
if i_episode % print_every == 0:
agent.save('./')
if stopOnSolved and score_average >= 30.0:
toc = time.time()
print('\nSolved in {:d} episodes!\tAvg Score: {:.2f}, time: {}'.format(i_episode, score_average, toc-tic))
agent.save('./'+str(i_episode)+'_')
break
print('End: ',datetime.datetime.now())
return scores_global, average_global, max_global, min_global
ddpg
# Create new empty buffers to start training from scratch
buffers = [ReplayBuffer(action_size, BUFFER_SIZE, BATCH_SIZE, random_seed),
ReplayBuffer(action_size, CACHE_SIZE, BATCH_SIZE, random_seed)]
agent = DDPG(state_size=state_size, action_size=action_size, random_seed=23,
fc1_units=96, fc2_units=96)
scores, averages, maxima, minima = ddpg(agent, buffers, n_episodes=130)
plt.plot(np.arange(1, len(scores)+1), scores)
plt.plot(np.arange(1, len(averages)+1), averages)
plt.plot(np.arange(1, len(maxima)+1), maxima)
plt.plot(np.arange(1, len(minima)+1), minima)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.legend(['EpAvg', 'GlAvg', 'Max', 'Min'], loc='upper left')
plt.show()
# Smaller agent learning this task from larger agent experiences
agent = DDPG(state_size=state_size, action_size=action_size, random_seed=23,
fc1_units=48, fc2_units=48)
scores, averages, maxima, minima = ddpg(agent, buffers, n_episodes=200)
plt.plot(np.arange(1, len(scores)+1), scores)
plt.plot(np.arange(1, len(averages)+1), averages)
plt.plot(np.arange(1, len(maxima)+1), maxima)
plt.plot(np.arange(1, len(minima)+1), minima)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.legend(['EpAvg', 'GlAvg', 'Max', 'Min'], loc='lower center')
plt.show()
```
Saves experiences for training future agents. Warning file is quite large.
```
memory, cache = buffers
memory.save('experiences.pkl')
#env.close()
```
### 5. See the pre-trained agent in action
```
agent = DDPG(state_size=state_size, action_size=action_size, random_seed=23,
fc1_units=96, fc2_units=96)
agent.load('./saves/96_96_108_actor.pth', './saves/96_96_108_critic.pth')
def play(agent, episodes=3):
for i_episode in range(episodes):
env_info = env.reset(train_mode=False)[brain_name] # reset the environment
states = env_info.vector_observations # get the current state (for each agent)
scores = np.zeros(num_agents) # initialize the score (for each agent)
while True:
actions = np.random.randn(num_agents, action_size) # select an action (for each agent)
actions = agent.act(states, add_noise=False) # all actions between -1 and 1
env_info = env.step(actions)[brain_name] # send all actions to tne environment
next_states = env_info.vector_observations # get next state (for each agent)
rewards = env_info.rewards # get reward (for each agent)
dones = env_info.local_done # see if episode finished
scores += env_info.rewards # update the score (for each agent)
states = next_states # roll over states to next time step
if np.any(dones): # exit loop if episode finished
break
#break
print('Ep No: {} Total score (averaged over agents): {}'.format(i_episode, np.mean(scores)))
play(agent, 10)
```
### 6. Experiences
Experiences from the Replay Buffer could be saved and loaded for training different agents.
As an example I've provided `experiences.pkl.7z` which you should unpack with your favorite archiver.
Create new ReplayBuffer and load saved experiences
```
savedBuffer = ReplayBuffer(action_size, BUFFER_SIZE, BATCH_SIZE, random_seed)
savedBuffer.load('experiences.pkl')
```
Afterward you can use it to train your agent
```
savedBuffer.sample()
```
| true |
code
| 0.491151 | null | null | null | null |
|
# ML Project 6033657523 - Feedforward neural network
## Importing the libraries
```
from sklearn.metrics import mean_absolute_error
from sklearn.svm import SVR
from sklearn.model_selection import KFold, train_test_split
from math import sqrt
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
```
## Importing the cleaned dataset
```
dataset = pd.read_csv('cleanData_Final.csv')
X = dataset[['PrevAVGCost', 'PrevAssignedCost', 'AVGCost', 'LatestDateCost', 'A', 'B', 'C', 'D', 'E', 'F', 'G']]
y = dataset['GenPrice']
X
```
## Splitting the dataset into the Training set and Test set
```
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
```
## Feedforward neural network
### Fitting Feedforward neural network to the Training Set
```
from sklearn.neural_network import MLPRegressor
regressor = MLPRegressor(hidden_layer_sizes = (200, 200, 200, 200, 200), activation = 'relu', solver = 'adam', max_iter = 500, learning_rate = 'adaptive')
regressor.fit(X_train, y_train)
trainSet = pd.concat([X_train, y_train], axis = 1)
trainSet.head()
```
## Evaluate model accuracy
```
y_pred = regressor.predict(X_test)
y_pred
testSet = pd.concat([X_test, y_test], axis = 1)
testSet.head()
```
Compare GenPrice with PredictedGenPrice
```
datasetPredict = pd.concat([testSet.reset_index(), pd.Series(y_pred, name = 'PredictedGenPrice')], axis = 1).round(2)
datasetPredict.head(10)
datasetPredict.corr()
print("Training set accuracy = " + str(regressor.score(X_train, y_train)))
print("Test set accuracy = " + str(regressor.score(X_test, y_test)))
```
Training set accuracy = 0.9885445650077587<br>
Test set accuracy = 0.9829187423043221
### MSE
```
from sklearn import metrics
print('MSE:', metrics.mean_squared_error(y_test, y_pred))
```
MSE v1: 177.15763887557458<br>
MSE v2: 165.73161615532584<br>
MSE v3: 172.98494783761967
### MAPE
```
def mean_absolute_percentage_error(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(np.abs((y_test - y_pred)/y_test)) * 100
print('MAPE:', mean_absolute_percentage_error(y_test, y_pred))
```
MAPE v1: 6.706572320387714<br>
MAPE v2: 6.926678067146115<br>
MAPE v3: 7.34081953098462
### Visualize
```
import matplotlib.pyplot as plt
plt.plot([i for i in range(len(y_pred))], y_pred, color = 'r')
plt.scatter([i for i in range(len(y_pred))], y_test, color = 'b')
plt.ylabel('Price')
plt.xlabel('Index')
plt.legend(['Predict', 'True'], loc = 'best')
plt.show()
```
| true |
code
| 0.612368 | null | null | null | null |
|
# PyFunc Model + Transformer Example
This notebook demonstrates how to deploy a Python function based model and a custom transformer. This type of model is useful as user would be able to define their own logic inside the model as long as it satisfy contract given in `merlin.PyFuncModel`. If the pre/post-processing steps could be implemented in Python, it's encouraged to write them in the PyFunc model code instead of separating them into another transformer.
The model we are going to develop and deploy is a cifar10 model accepts a tensor input. The transformer has preprocessing step that allows the user to send a raw image data and convert it to a tensor input.
## Requirements
- Authenticated to gcloud (```gcloud auth application-default login```)
```
!pip install --upgrade -r requirements.txt > /dev/null
import warnings
warnings.filterwarnings('ignore')
```
## 1. Initialize Merlin
### 1.1 Set Merlin Server
```
import merlin
MERLIN_URL = "<MERLIN_HOST>/api/merlin"
merlin.set_url(MERLIN_URL)
```
### 1.2 Set Active Project
`project` represent a project in real life. You may have multiple model within a project.
`merlin.set_project(<project-name>)` will set the active project into the name matched by argument. You can only set it to an existing project. If you would like to create a new project, please do so from the MLP UI.
```
PROJECT_NAME = "sample"
merlin.set_project(PROJECT_NAME)
```
### 1.3 Set Active Model
`model` represents an abstract ML model. Conceptually, `model` in Merlin is similar to a class in programming language. To instantiate a `model` you'll have to create a `model_version`.
Each `model` has a type, currently model type supported by Merlin are: sklearn, xgboost, tensorflow, pytorch, and user defined model (i.e. pyfunc model).
`model_version` represents a snapshot of particular `model` iteration. You'll be able to attach information such as metrics and tag to a given `model_version` as well as deploy it as a model service.
`merlin.set_model(<model_name>, <model_type>)` will set the active model to the name given by parameter, if the model with given name is not found, a new model will be created.
```
from merlin.model import ModelType
MODEL_NAME = "transformer-pyfunc"
merlin.set_model(MODEL_NAME, ModelType.PYFUNC)
```
## 2. Train Model
In this step, we are going to train a cifar10 model using PyToch and create PyFunc model class that does the prediction using trained PyTorch model.
### 2.1 Prepare Training Data
```
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
```
### 2.2 Create PyTorch Model
```
import torch.nn as nn
import torch.nn.functional as F
class PyTorchModel(nn.Module):
def __init__(self):
super(PyTorchModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
```
### 2.3 Train Model
```
import torch.optim as optim
net = PyTorchModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
```
### 2.4 Check Prediction
```
dataiter = iter(trainloader)
inputs, labels = dataiter.next()
predict_out = net(inputs[0:1])
predict_out
```
### 2.5 Serialize Model
```
import os
model_dir = "pytorch-model"
model_path = os.path.join(model_dir, "model.pt")
model_class_path = os.path.join(model_dir, "model.py")
torch.save(net.state_dict(), model_path)
```
### 2.6 Save PyTorchModel Class
We also need to save the PyTorchModel class and upload it to Merlin alongside the serialized trained model. The next cell will write the PyTorchModel we defined above to `pytorch-model/model.py` file.
```
%%file pytorch-model/model.py
import torch.nn as nn
import torch.nn.functional as F
class PyTorchModel(nn.Module):
def __init__(self):
super(PyTorchModel, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
```
## 3. Create PyFunc Model
To create a PyFunc model you'll have to extend `merlin.PyFuncModel` class and implement its `initialize` and `infer` method.
`initialize` will be called once during model initialization. The argument to `initialize` is a dictionary containing a key value pair of artifact name and its URL. The artifact's keys are the same value as received by `log_pyfunc_model`.
`infer` method is the prediction method that is need to be implemented. It accept a dictionary type argument which represent incoming request body. `infer` should return a dictionary object which correspond to response body of prediction result.
In following example we are creating PyFunc model called `CifarModel`. In its `initialize` method we expect 2 artifacts called `model_path` and `model_class_path`, those 2 artifacts would point to the serialized model and the PyTorch model class file. The `infer` method will simply does prediction for the model and return the result.
```
import importlib
import sys
from merlin.model import PyFuncModel
MODEL_CLASS_NAME="PyTorchModel"
class CifarModel(PyFuncModel):
def initialize(self, artifacts):
model_path = artifacts["model_path"]
model_class_path = artifacts["model_class_path"]
# Load the python class into memory
sys.path.append(os.path.dirname(model_class_path))
modulename = os.path.basename(model_class_path).split('.')[0].replace('-', '_')
model_class = getattr(importlib.import_module(modulename), MODEL_CLASS_NAME)
# Make sure the model weight is transform with the right device in this machine
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self._pytorch = model_class().to(device)
self._pytorch.load_state_dict(torch.load(model_path, map_location=device))
self._pytorch.eval()
def infer(self, request, **kwargs):
inputs = torch.tensor(request["instances"])
result = self._pytorch(inputs)
return {"predictions": result.tolist()}
```
Now, let's test it locally.
```
import json
with open(os.path.join("input-tensor.json"), "r") as f:
tensor_req = json.load(f)
m = CifarModel()
m.initialize({"model_path": model_path, "model_class_path": model_class_path})
m.infer(tensor_req)
```
## 4. Deploy Model
To deploy the model, we will have to create an iteration of the model (by create a `model_version`), upload the serialized model to MLP, and then deploy.
### 4.1 Create Model Version and Upload
`merlin.new_model_version()` is a convenient method to create a model version and start its development process. It is equal to following codes:
```
v = model.new_model_version()
v.start()
v.log_pyfunc_model(model_instance=EnsembleModel(),
conda_env="env.yaml",
artifacts={"xgb_model": model_1_path, "sklearn_model": model_2_path})
v.finish()
```
To upload PyFunc model you have to provide following arguments:
1. `model_instance` is the instance of PyFunc model, the model has to extend `merlin.PyFuncModel`
2. `conda_env` is path to conda environment yaml file. The environment yaml file must contain all dependency required by the PyFunc model.
3. (Optional) `artifacts` is additional artifact that you want to include in the model
4. (Optional) `code_path` is a list of directory containing python code that will be loaded during model initialization, this is required when `model_instance` depend on local python package
```
with merlin.new_model_version() as v:
merlin.log_pyfunc_model(model_instance=CifarModel(),
conda_env="env.yaml",
artifacts={"model_path": model_path, "model_class_path": model_class_path})
```
### 4.2 Deploy Model and Transformer
To deploy a model and its transformer, you must pass a `transformer` object to `deploy()` function. Each of deployed model version will have its own generated url.
```
from merlin.resource_request import ResourceRequest
from merlin.transformer import Transformer
# Create a transformer object and its resources requests
resource_request = ResourceRequest(min_replica=1, max_replica=1,
cpu_request="100m", memory_request="200Mi")
transformer = Transformer("gcr.io/kubeflow-ci/kfserving/image-transformer:latest",
resource_request=resource_request)
endpoint = merlin.deploy(v, transformer=transformer)
```
### 4.3 Send Test Request
```
import json
import requests
with open(os.path.join("input-raw-image.json"), "r") as f:
req = json.load(f)
resp = requests.post(endpoint.url, json=req)
resp.text
```
## 4. Clean Up
## 4.1 Delete Deployment
```
merlin.undeploy(v)
```
| true |
code
| 0.742306 | null | null | null | null |
|
# PROYECTO CIFAR-10
## CARLOS CABAÑÓ
## 1. Librerias
Descargamos la librería para los arrays en preprocesamiento de Keras
```
from tensorflow import keras as ks
from matplotlib import pyplot as plt
import numpy as np
import time
import datetime
import random
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.preprocessing.image import ImageDataGenerator
```
## 2. Arquitectura de red del modelo
Adoptamos la arquitectura del modelo 11 con los ajustes en Batch Normalization, Kernel Regularizer y Kernel Initializer. Añadimos Batch normalization a las capas de convolución.
```
model = ks.Sequential()
model.add(ks.layers.Conv2D(64, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same', input_shape=(32,32,3)))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(64, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.MaxPooling2D((2, 2)))
model.add(ks.layers.Dropout(0.2))
model.add(ks.layers.Conv2D(128, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(128, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(ks.layers.Dropout(0.2))
model.add(ks.layers.Conv2D(256, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(256, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(256, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(ks.layers.Dropout(0.2))
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Conv2D(512, (3, 3), strides=1, activation='relu', kernel_regularizer=l2(0.0005), kernel_initializer="he_uniform", padding='same'))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Dropout(0.3))
model.add(ks.layers.Flatten())
model.add(ks.layers.Dense(512, activation='relu', kernel_regularizer=l2(0.001), kernel_initializer="he_uniform"))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Dropout(0.4))
model.add(ks.layers.Dense(512, activation='relu', kernel_regularizer=l2(0.001), kernel_initializer="he_uniform"))
model.add(ks.layers.BatchNormalization())
model.add(ks.layers.Dropout(0.5))
model.add(ks.layers.Dense(10, activation='softmax'))
model.summary()
```
## 3. Optimizador, función error
Añadimos el learning rate al optimizador
```
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.001, momentum=0.9),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
```
## 4. Preparamos los datos
```
cifar10 = ks.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
cifar10_labels = [
'airplane', # id 0
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck',
]
print('Number of labels: %s' % len(cifar10_labels))
```
Pintemos una muestra de las imagenes del dataset CIFAR10:
```
# Pintemos una muestra de las las imagenes del dataset MNIST
print('Train: X=%s, y=%s' % (x_train.shape, y_train.shape))
print('Test: X=%s, y=%s' % (x_test.shape, y_test.shape))
for i in range(9):
plt.subplot(330 + 1 + i)
plt.imshow(x_train[i], cmap=plt.get_cmap('gray'))
plt.title(cifar10_labels[y_train[i,0]])
plt.subplots_adjust(hspace = 1)
plt.show()
```
Hacemos la validación al mismo tiempo que el entrenamiento:
```
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
```
Hacemos el OHE para la clasificación
```
le = LabelEncoder()
le.fit(y_train.ravel())
y_train_encoded = le.transform(y_train.ravel())
y_val_encoded = le.transform(y_val.ravel())
y_test_encoded = le.transform(y_test.ravel())
```
## 5. Ajustes: Early Stopping
Definimos un early stopping con base en el loss de validación y con el parámetro de "patience" a 10, para tener algo de margen. Con el Early Stopping lograremos parar el entrenamiento en el momento óptimo para evitar que siga entrenando a partir del overfitting.
```
callback_val_loss = EarlyStopping(monitor="val_loss", patience=5)
callback_val_accuracy = EarlyStopping(monitor="val_accuracy", patience=10)
```
## 6. Transformador de imágenes
### 6.1 Imágenes de entrenamiento
```
train_datagen = ImageDataGenerator(
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
)
train_generator = train_datagen.flow(
x_train,
y_train_encoded,
batch_size=64
)
```
### 6.2 Imágenes de validación y testeo
```
validation_datagen = ImageDataGenerator(
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
)
validation_generator = validation_datagen.flow(
x_val,
y_val_encoded,
batch_size=64
)
test_datagen = ImageDataGenerator(
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
)
test_generator = test_datagen.flow(
x_test,
y_test_encoded,
batch_size=64
)
```
### 6.3 Generador de datos
```
sample = random.choice(range(0,1457))
image = x_train[sample]
plt.imshow(image, cmap=plt.cm.binary)
sample = random.choice(range(0,1457))
example_generator = train_datagen.flow(
x_train[sample:sample+1],
y_train_encoded[sample:sample+1],
batch_size=64
)
plt.figure(figsize=(12, 12))
for i in range(0, 15):
plt.subplot(5, 3, i+1)
for X, Y in example_generator:
image = X[0]
plt.imshow(image)
break
plt.tight_layout()
plt.show()
```
## 7. Entrenamiento
```
t = time.perf_counter()
steps=int(x_train.shape[0]/64)
history = model.fit(train_generator, epochs=100, use_multiprocessing=False, batch_size= 64, validation_data=validation_generator, steps_per_epoch=steps, callbacks=[callback_val_loss, callback_val_accuracy])
elapsed_time = datetime.timedelta(seconds=(time.perf_counter() - t))
print('Tiempo de entrenamiento:', elapsed_time)
```
## 8. Evaluamos los resultados
```
_, acc = model.evaluate(x_test, y_test_encoded, verbose=0)
print('> %.3f' % (acc * 100.0))
plt.title('Cross Entropy Loss')
plt.plot(history.history['loss'], color='blue', label='train')
plt.plot(history.history['val_loss'], color='orange', label='test')
plt.show()
plt.title('Classification Accuracy')
plt.plot(history.history['accuracy'], color='blue', label='train')
plt.plot(history.history['val_accuracy'], color='orange', label='test')
plt.show()
predictions = model.predict(x_test)
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(predicted_label,
100*np.max(predictions_array),
true_label[0]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label[0]].set_color('blue')
```
Dibujamos las primeras imágenes:
```
i = 0
for l in cifar10_labels:
print(i, l)
i += 1
num_rows = 5
num_cols = 4
start = 650
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i+start, predictions[i+start], y_test, x_test)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i+start, predictions[i+start], y_test)
plt.tight_layout()
plt.show()
```
| true |
code
| 0.904144 | null | null | null | null |
|
Deep Learning
=============
Assignment 4
------------
Previously in `2_fullyconnected.ipynb` and `3_regularization.ipynb`, we trained fully connected networks to classify [notMNIST](http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html) characters.
The goal of this assignment is make the neural network convolutional.
```
# These are all the modules we'll be using later. Make sure you can import them
# before proceeding further.
from __future__ import print_function
import time
import numpy as np
import tensorflow as tf
from six.moves import cPickle as pickle
from six.moves import range
pickle_file = 'notMNIST.pickle'
with open(pickle_file, 'rb') as f:
save = pickle.load(f)
train_dataset = save['train_dataset']
train_labels = save['train_labels']
valid_dataset = save['valid_dataset']
valid_labels = save['valid_labels']
test_dataset = save['test_dataset']
test_labels = save['test_labels']
del save # hint to help gc free up memory
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
```
Reformat into a TensorFlow-friendly shape:
- convolutions need the image data formatted as a cube (width by height by #channels)
- labels as float 1-hot encodings.
```
image_size = 28
num_labels = 10
num_channels = 1 # grayscale
import numpy as np
def reformat(dataset, labels):
dataset = dataset.reshape(
(-1, image_size, image_size, num_channels)).astype(np.float32)
labels = (np.arange(num_labels) == labels[:,None]).astype(np.float32)
return dataset, labels
train_dataset, train_labels = reformat(train_dataset, train_labels)
valid_dataset, valid_labels = reformat(valid_dataset, valid_labels)
test_dataset, test_labels = reformat(test_dataset, test_labels)
print('Training set', train_dataset.shape, train_labels.shape)
print('Validation set', valid_dataset.shape, valid_labels.shape)
print('Test set', test_dataset.shape, test_labels.shape)
def accuracy(predictions, labels):
return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1))
/ predictions.shape[0])
```
Let's build a small network with two convolutional layers, followed by one fully connected layer. Convolutional networks are more expensive computationally, so we'll limit its depth and number of fully connected nodes.
```
batch_size = 16
patch_size = 5
depth = 16
num_hidden = 64
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layer1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layer1_biases = tf.Variable(tf.zeros([depth]))
layer2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth], stddev=0.1))
layer2_biases = tf.Variable(tf.constant(1.0, shape=[depth]))
layer3_weights = tf.Variable(tf.truncated_normal(
[image_size // 4 * image_size // 4 * depth, num_hidden], stddev=0.1))
layer3_biases = tf.Variable(tf.constant(1.0, shape=[num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_labels], stddev=0.1))
layer4_biases = tf.Variable(tf.constant(1.0, shape=[num_labels]))
# Model.
def model(data):
conv = tf.nn.conv2d(data, layer1_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer1_biases)
conv = tf.nn.conv2d(hidden, layer2_weights, [1, 2, 2, 1], padding='SAME')
hidden = tf.nn.relu(conv + layer2_biases)
shape = hidden.get_shape().as_list()
reshape = tf.reshape(hidden, [shape[0], shape[1] * shape[2] * shape[3]])
hidden = tf.nn.relu(tf.matmul(reshape, layer3_weights) + layer3_biases)
return tf.matmul(hidden, layer4_weights) + layer4_biases
# Training computation.
logits = model(tf_train_dataset)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(model(tf_valid_dataset))
test_prediction = tf.nn.softmax(model(tf_test_dataset))
num_steps = 1001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print('Initialized')
for step in range(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 50 == 0):
print('Minibatch loss at step %d: %f' % (step, l))
print('Minibatch accuracy: %.1f%%' % accuracy(predictions, batch_labels))
print('Validation accuracy: %.1f%%' % accuracy(
valid_prediction.eval(), valid_labels))
print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
```
---
Problem 1
---------
The convolutional model above uses convolutions with stride 2 to reduce the dimensionality. Replace the strides by a max pooling operation (`nn.max_pool()`) of stride 2 and kernel size 2.
---
```
# TODO
```
---
Problem 2
---------
Try to get the best performance you can using a convolutional net. Look for example at the classic [LeNet5](http://yann.lecun.com/exdb/lenet/) architecture, adding Dropout, and/or adding learning rate decay.
---
```
batch_size = 16
patch_size = 3
depth = 16
num_hidden = 705
num_hidden_last = 205
graph = tf.Graph()
with graph.as_default():
# Input data.
tf_train_dataset = tf.placeholder(
tf.float32, shape=(batch_size, image_size, image_size, num_channels))
tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels))
tf_valid_dataset = tf.constant(valid_dataset)
tf_test_dataset = tf.constant(test_dataset)
# Variables.
layerconv1_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, num_channels, depth], stddev=0.1))
layerconv1_biases = tf.Variable(tf.zeros([depth]))
layerconv2_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth, depth * 2], stddev=0.1))
layerconv2_biases = tf.Variable(tf.zeros([depth * 2]))
layerconv3_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth * 2, depth * 4], stddev=0.03))
layerconv3_biases = tf.Variable(tf.zeros([depth * 4]))
layerconv4_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth * 4, depth * 4], stddev=0.03))
layerconv4_biases = tf.Variable(tf.zeros([depth * 4]))
layerconv5_weights = tf.Variable(tf.truncated_normal(
[patch_size, patch_size, depth * 4, depth * 16], stddev=0.03))
layerconv5_biases = tf.Variable(tf.zeros([depth * 16]))
layer3_weights = tf.Variable(tf.truncated_normal(
[image_size / 7 * image_size / 7 * (depth * 4), num_hidden], stddev=0.03))
layer3_biases = tf.Variable(tf.zeros([num_hidden]))
layer4_weights = tf.Variable(tf.truncated_normal(
[num_hidden, num_hidden_last], stddev=0.0532))
layer4_biases = tf.Variable(tf.zeros([num_hidden_last]))
layer5_weights = tf.Variable(tf.truncated_normal(
[num_hidden_last, num_labels], stddev=0.1))
layer5_biases = tf.Variable(tf.zeros([num_labels]))
# Model.
def model(data, use_dropout=False):
conv = tf.nn.conv2d(data, layerconv1_weights, [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.elu(conv + layerconv1_biases)
pool = tf.nn.max_pool(hidden, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
conv = tf.nn.conv2d(pool, layerconv2_weights, [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.elu(conv + layerconv2_biases)
#pool = tf.nn.max_pool(hidden, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
conv = tf.nn.conv2d(hidden, layerconv3_weights, [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.elu(conv + layerconv3_biases)
pool = tf.nn.max_pool(hidden, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
# norm1
# norm1 = tf.nn.lrn(pool, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
conv = tf.nn.conv2d(pool, layerconv4_weights, [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.elu(conv + layerconv4_biases)
pool = tf.nn.max_pool(hidden, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
# norm1 = tf.nn.lrn(pool, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
conv = tf.nn.conv2d(pool, layerconv5_weights, [1, 1, 1, 1], padding='SAME')
hidden = tf.nn.elu(conv + layerconv5_biases)
pool = tf.nn.max_pool(hidden, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
# norm1 = tf.nn.lrn(pool, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
shape = pool.get_shape().as_list()
#print(shape)
reshape = tf.reshape(pool, [shape[0], shape[1] * shape[2] * shape[3]])
hidden = tf.nn.elu(tf.matmul(reshape, layer3_weights) + layer3_biases)
if use_dropout:
hidden = tf.nn.dropout(hidden, 0.75)
nn_hidden_layer = tf.matmul(hidden, layer4_weights) + layer4_biases
hidden = tf.nn.elu(nn_hidden_layer)
if use_dropout:
hidden = tf.nn.dropout(hidden, 0.75)
return tf.matmul(hidden, layer5_weights) + layer5_biases
# Training computation.
logits = model(tf_train_dataset, True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits, tf_train_labels))
global_step = tf.Variable(0) # count the number of steps taken.
learning_rate = tf.train.exponential_decay(0.1, global_step, 3000, 0.86, staircase=True)
# Optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
valid_prediction = tf.nn.softmax(model(tf_valid_dataset))
test_prediction = tf.nn.softmax(model(tf_test_dataset))
num_steps = 45001
with tf.Session(graph=graph) as session:
tf.initialize_all_variables().run()
print("Initialized")
for step in xrange(num_steps):
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run(
[optimizer, loss, train_prediction], feed_dict=feed_dict)
if (step % 500 == 0):
print("Minibatch loss at step", step, ":", l)
print("Minibatch accuracy: %.1f%%" % accuracy(predictions, batch_labels))
print("Validation accuracy: %.1f%%" % accuracy(
valid_prediction.eval(), valid_labels))
print(time.ctime())
print("Test accuracy: %.1f%%" % accuracy(test_prediction.eval(), test_labels))
```
| true |
code
| 0.645288 | null | null | null | null |
|
# 转置卷积
:label:`sec_transposed_conv`
到目前为止,我们所见到的卷积神经网络层,例如卷积层( :numref:`sec_conv_layer`)和汇聚层( :numref:`sec_pooling`),通常会减少下采样输入图像的空间维度(高和宽)。
然而如果输入和输出图像的空间维度相同,在以像素级分类的语义分割中将会很方便。
例如,输出像素所处的通道维可以保有输入像素在同一位置上的分类结果。
为了实现这一点,尤其是在空间维度被卷积神经网络层缩小后,我们可以使用另一种类型的卷积神经网络层,它可以增加上采样中间层特征图的空间维度。
在本节中,我们将介绍
*转置卷积*(transposed convolution) :cite:`Dumoulin.Visin.2016`,
用于逆转下采样导致的空间尺寸减小。
```
from mxnet import init, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
```
## 基本操作
让我们暂时忽略通道,从基本的转置卷积开始,设步幅为1且没有填充。
假设我们有一个$n_h \times n_w$的输入张量和一个$k_h \times k_w$的卷积核。
以步幅为1滑动卷积核窗口,每行$n_w$次,每列$n_h$次,共产生$n_h n_w$个中间结果。
每个中间结果都是一个$(n_h + k_h - 1) \times (n_w + k_w - 1)$的张量,初始化为0。
为了计算每个中间张量,输入张量中的每个元素都要乘以卷积核,从而使所得的$k_h \times k_w$张量替换中间张量的一部分。
请注意,每个中间张量被替换部分的位置与输入张量中元素的位置相对应。
最后,所有中间结果相加以获得最终结果。
例如, :numref:`fig_trans_conv`解释了如何为$2\times 2$的输入张量计算卷积核为$2\times 2$的转置卷积。

:label:`fig_trans_conv`
我们可以对输入矩阵`X`和卷积核矩阵`K`(**实现基本的转置卷积运算**)`trans_conv`。
```
def trans_conv(X, K):
h, w = K.shape
Y = np.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
```
与通过卷积核“减少”输入元素的常规卷积(在 :numref:`sec_conv_layer`中)相比,转置卷积通过卷积核“广播”输入元素,从而产生大于输入的输出。
我们可以通过 :numref:`fig_trans_conv`来构建输入张量`X`和卷积核张量`K`从而[**验证上述实现输出**]。
此实现是基本的二维转置卷积运算。
```
X = np.array([[0.0, 1.0], [2.0, 3.0]])
K = np.array([[0.0, 1.0], [2.0, 3.0]])
trans_conv(X, K)
```
或者,当输入`X`和卷积核`K`都是四维张量时,我们可以[**使用高级API获得相同的结果**]。
```
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = nn.Conv2DTranspose(1, kernel_size=2)
tconv.initialize(init.Constant(K))
tconv(X)
```
## [**填充、步幅和多通道**]
与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。
例如,当将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。
```
tconv = nn.Conv2DTranspose(1, kernel_size=2, padding=1)
tconv.initialize(init.Constant(K))
tconv(X)
```
在转置卷积中,步幅被指定为中间结果(输出),而不是输入。
使用 :numref:`fig_trans_conv`中相同输入和卷积核张量,将步幅从1更改为2会增加中间张量的高和权重,因此输出张量在 :numref:`fig_trans_conv_stride2`中。

:label:`fig_trans_conv_stride2`
以下代码可以验证 :numref:`fig_trans_conv_stride2`中步幅为2的转置卷积的输出。
```
tconv = nn.Conv2DTranspose(1, kernel_size=2, strides=2)
tconv.initialize(init.Constant(K))
tconv(X)
```
对于多个输入和输出通道,转置卷积与常规卷积以相同方式运作。
假设输入有$c_i$个通道,且转置卷积为每个输入通道分配了一个$k_h\times k_w$的卷积核张量。
当指定多个输出通道时,每个输出通道将有一个$c_i\times k_h\times k_w$的卷积核。
同样,如果我们将$\mathsf{X}$代入卷积层$f$来输出$\mathsf{Y}=f(\mathsf{X})$,并创建一个与$f$具有相同的超参数、但输出通道数量是$\mathsf{X}$中通道数的转置卷积层$g$,那么$g(Y)$的形状将与$\mathsf{X}$相同。
下面的示例可以解释这一点。
```
X = np.random.uniform(size=(1, 10, 16, 16))
conv = nn.Conv2D(20, kernel_size=5, padding=2, strides=3)
tconv = nn.Conv2DTranspose(10, kernel_size=5, padding=2, strides=3)
conv.initialize()
tconv.initialize()
tconv(conv(X)).shape == X.shape
```
## [**与矩阵变换的联系**]
:label:`subsec-connection-to-mat-transposition`
转置卷积为何以矩阵变换命名呢?
让我们首先看看如何使用矩阵乘法来实现卷积。
在下面的示例中,我们定义了一个$3\times 3$的输入`X`和$2\times 2$卷积核`K`,然后使用`corr2d`函数计算卷积输出`Y`。
```
X = np.arange(9.0).reshape(3, 3)
K = np.array([[1.0, 2.0], [3.0, 4.0]])
Y = d2l.corr2d(X, K)
Y
```
接下来,我们将卷积核`K`重写为包含大量0的稀疏权重矩阵`W`。
权重矩阵的形状是($4$,$9$),其中非0元素来自卷积核`K`。
```
def kernel2matrix(K):
k, W = np.zeros(5), np.zeros((4, 9))
k[:2], k[3:5] = K[0, :], K[1, :]
W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k
return W
W = kernel2matrix(K)
W
```
逐行连结输入`X`,获得了一个长度为9的矢量。
然后,`W`的矩阵乘法和向量化的`X`给出了一个长度为4的向量。
重塑它之后,可以获得与上面的原始卷积操作所得相同的结果`Y`:我们刚刚使用矩阵乘法实现了卷积。
```
Y == np.dot(W, X.reshape(-1)).reshape(2, 2)
```
同样,我们可以使用矩阵乘法来实现转置卷积。
在下面的示例中,我们将上面的常规卷积$2 \times 2$的输出`Y`作为转置卷积的输入。
想要通过矩阵相乘来实现它,我们只需要将权重矩阵`W`的形状转置为$(9, 4)$。
```
Z = trans_conv(Y, K)
Z == np.dot(W.T, Y.reshape(-1)).reshape(3, 3)
```
抽象来看,给定输入向量$\mathbf{x}$和权重矩阵$\mathbf{W}$,卷积的前向传播函数可以通过将其输入与权重矩阵相乘并输出向量$\mathbf{y}=\mathbf{W}\mathbf{x}$来实现。
由于反向传播遵循链式法则和$\nabla_{\mathbf{x}}\mathbf{y}=\mathbf{W}^\top$,卷积的反向传播函数可以通过将其输入与转置的权重矩阵$\mathbf{W}^\top$相乘来实现。
因此,转置卷积层能够交换卷积层的正向传播函数和反向传播函数:它的正向传播和反向传播函数将输入向量分别与$\mathbf{W}^\top$和$\mathbf{W}$相乘。
## 小结
* 与通过卷积核减少输入元素的常规卷积相反,转置卷积通过卷积核广播输入元素,从而产生形状大于输入的输出。
* 如果我们将$\mathsf{X}$输入卷积层$f$来获得输出$\mathsf{Y}=f(\mathsf{X})$并创造一个与$f$有相同的超参数、但输出通道数是$\mathsf{X}$中通道数的转置卷积层$g$,那么$g(Y)$的形状将与$\mathsf{X}$相同。
* 我们可以使用矩阵乘法来实现卷积。转置卷积层能够交换卷积层的正向传播函数和反向传播函数。
## 练习
1. 在 :numref:`subsec-connection-to-mat-transposition`中,卷积输入`X`和转置的卷积输出`Z`具有相同的形状。他们的数值也相同吗?为什么?
1. 使用矩阵乘法来实现卷积是否有效率?为什么?
[Discussions](https://discuss.d2l.ai/t/3301)
| true |
code
| 0.760011 | null | null | null | null |
|
# The YUSAG Football Model
by Matt Robinson, [email protected], Yale Undergraduate Sports Analytics Group
This notebook introduces the model we at the Yale Undergraduate Sports Analytics Group (YUSAG) use for our college football rankings. This specific notebook details our FBS rankings at the beginning of the 2017 season.
```
import numpy as np
import pandas as pd
import math
```
Let's start by reading in the NCAA FBS football data from 2013-2016:
```
df_1 = pd.read_csv('NCAA_FBS_Results_2013_.csv')
df_2 = pd.read_csv('NCAA_FBS_Results_2014_.csv')
df_3 = pd.read_csv('NCAA_FBS_Results_2015_.csv')
df_4 = pd.read_csv('NCAA_FBS_Results_2016_.csv')
df = pd.concat([df_1,df_2,df_3,df_4],ignore_index=True)
df.head()
```
As you can see, the `OT` column has some `NaN` values that we will replace with 0.
```
# fill missing data with 0
df = df.fillna(0)
df.head()
```
I'm also going to make some weights for when we run our linear regression. I have found that using the factorial of the difference between the year and 2012 seems to work decently well. Clearly, the most recent seasons are weighted quite heavily in this scheme.
```
# update the weights based on a factorial scheme
df['weights'] = (df['year']-2012)
df['weights'] = df['weights'].apply(lambda x: math.factorial(x))
```
And now, we also are going to make a `scorediff` column that we can use in our linear regression.
```
df['scorediff'] = (df['teamscore']-df['oppscore'])
df.head()
```
Since we need numerical values for the linear regression algorithm, I am going to replace the locations with what seem like reasonable numbers:
* Visiting = -1
* Neutral = 0
* Home = 1
The reason we picked these exact numbers will become clearer in a little bit.
```
df['location'] = df['location'].replace('V',-1)
df['location'] = df['location'].replace('N',0)
df['location'] = df['location'].replace('H',1)
df.head()
```
The way our linear regression model works is a little tricky to code up in scikit-learn. It's much easier to do in R, but then you don't have a full understanding of what's happening when we make the model.
In simplest terms, our model predicts the score differential (`scorediff`) of each game based on three things: the strength of the `team`, the strength of the `opponent`, and the `location`.
You'll notice that the `team` and `opponent` features are categorical, and thus are not curretnly ripe for use with linear regression. However, we can use what is called 'one hot encoding' in order to transform these features into a usable form. One hot encoding works by taking the `team` feature, for example, and transforming it into many features such as `team_Yale` and `team_Harvard`. This `team_Yale` feature will usally equal zero, except when the team is actually Yale, then `team_Yale` will equal 1. In this way, it's a binary encoding (which is actually very useful for us as we'll see later).
One can use `sklearn.preprocessing.OneHotEncoder` for this task, but I am going to use Pandas instead:
```
# create dummy variables, need to do this in python b/c does not handle automatically like R
team_dummies = pd.get_dummies(df.team, prefix='team')
opponent_dummies = pd.get_dummies(df.opponent, prefix='opponent')
df = pd.concat([df, team_dummies, opponent_dummies], axis=1)
df.head()
```
Now let's make our training data, so that we can construct the model. At this point, I am going to use all the avaiable data to train the model, using our predetermined hyperparameters. This way, the model is ready to make predictions for the 2017 season.
```
# make the training data
X = df.drop(['year','month','day','team','opponent','teamscore','oppscore','D1','OT','weights','scorediff'], axis=1)
y = df['scorediff']
weights = df['weights']
X.head()
y.head()
weights.head()
```
Now let's train the linear regression model. You'll notice that I'm actually using ridge regression (adds an l2 penalty with alpha = 1.0) because that prevents the model from overfitting and also limits the values of the coefficients to be more interpretable. If I did not add this penalty, the coefficients would be huge.
```
from sklearn.linear_model import Ridge
ridge_reg = Ridge()
ridge_reg.fit(X, y, sample_weight=weights)
# get the R^2 value
r_squared = ridge_reg.score(X, y, sample_weight=weights)
print('R^2 on the training data:')
print(r_squared)
```
Now that the model is trained, we can use it to provide our rankings. Note that in this model, a team's ranking is simply defined as its linear regression coefficient, which we call the YUSAG coefficient.
When predicting a game's score differential on a neutral field, the predicted score differential (`scorediff`) is just the difference in YUSAG coefficients. The reason this works is the binary encoding we did earlier.
#### More details below on how it actually works
Ok, so you may have noticed that every game in our dataframe is actually duplicated, just with the `team` and `opponent` variables switched. This may have seemed like a mistake but it is actually useful for making the model more interpretable.
When we run the model, we get a coefficient for the `team_Yale` variable, which we call the YUSAG coefficient, and a coefficient for the `opponent_Yale` variable. Since we allow every game to be repeated, these variables end up just being negatives of each other.
So let's think about what we are doing when we predict the score differential for the Harvard-Penn game with `team` = Harvard and `opponent` = Penn.
In our model, the coefficients are as follows:
- team_Harvard_coef = 7.78
- opponent_Harvard_coef = -7.78
- team_Penn_coef = 6.68
- opponent_Penn_coef = -6.68
when we go to use the model for this game, it looks like this:
`scorediff` = (location_coef $*$ `location`) + (team_Harvard_coef $*$ `team_Harvard`) + (opponent_Harvard_coef $*$ `opponent_Harvard`) + (team_Penn_coef $*$ `team_Penn`) + (opponent_Penn_coef $*$ `opponent_Penn`) + (team_Yale_coef $*$ `team_Yale`) + (opponent_Yale_coef $*$ `opponent_Yale`) + $\cdots$
where the $\cdots$ represent data for many other teams, which will all just equal $0$.
To put numbers in for the variables, the model looks like this:
`scorediff` = (location_coef $*$ $0$) + (team_Harvard_coef $*$ $1$) + (opponent_Harvard_coef $*$ $0$) + (team_Penn_coef $*$ $0$) + (opponent_Penn_coef $*$ $1$) + (team_Yale_coef $*$ $0$) + (opponent_Yale_coef $*$ $0$) + $\cdots$
Which is just:
`scorediff` = (location_coef $*$ $0$) + (7.78 $*$ $1$) + (-6.68 $*$ $1$) = $7.78 - 6.68$ = Harvard_YUSAG_coef - Penn_YUSAG_coef
Thus showing how the difference in YUSAG coefficients is the same as the predicted score differential. Furthermore, the higher YUSAG coefficient a team has, the better they are.
Lastly, if the Harvard-Penn game was to be home at Harvard, we would just add the location_coef:
`scorediff` = (location_coef $*$ $1$) + (team_Harvard_coef $*$ $1$) + (opponent_Penn_coef $*$ $1$) = $1.77 + 7.78 - 6.68$ = Location_coef + Harvard_YUSAG_coef - Penn_YUSAG_coef
```
# get the coefficients for each feature
coef_data = list(zip(X.columns,ridge_reg.coef_))
coef_df = pd.DataFrame(coef_data,columns=['feature','feature_coef'])
coef_df.head()
```
Let's get only the team variables, so that it is a proper ranking
```
# first get rid of opponent_ variables
team_df = coef_df[~coef_df['feature'].str.contains("opponent")]
# get rid of the location variable
team_df = team_df.iloc[1:]
team_df.head()
# rank them by coef, not alphabetical order
ranked_team_df = team_df.sort_values(['feature_coef'],ascending=False)
# reset the indices at 0
ranked_team_df = ranked_team_df.reset_index(drop=True);
ranked_team_df.head()
```
I'm goint to change the name of the columns and remove the 'team_' part of every string:
```
ranked_team_df.rename(columns={'feature':'team', 'feature_coef':'YUSAG_coef'}, inplace=True)
ranked_team_df['team'] = ranked_team_df['team'].str.replace('team_', '')
ranked_team_df.head()
```
Lastly, I'm just going to shift the index to start at 1, so that it corresponds to the ranking.
```
ranked_team_df.index = ranked_team_df.index + 1
ranked_team_df.to_csv("FBS_power_rankings.csv")
```
## Additional stuff: Testing the model
This section is mostly about how own could test the performance of the model or how one could choose appropriate hyperparamters.
#### Creating a new dataframe
First let's take the original dataframe and sort it by date, so that the order of games in the dataframe matches the order the games were played.
```
# sort by date and reset the indices to 0
df_dated = df.sort_values(['year', 'month','day'], ascending=[True, True, True])
df_dated = df_dated.reset_index(drop=True)
df_dated.head()
```
Let's first make a dataframe with training data (the first three years of results)
```
thirteen_df = df_dated.loc[df_dated['year']==2013]
fourteen_df = df_dated.loc[df_dated['year']==2014]
fifteen_df = df_dated.loc[df_dated['year']==2015]
train_df = pd.concat([thirteen_df,fourteen_df,fifteen_df], ignore_index=True)
```
Now let's make an initial testing dataframe with the data from this past year.
```
sixteen_df = df_dated.loc[df_dated['year']==2016]
seventeen_df = df_dated.loc[df_dated['year']==2017]
test_df = pd.concat([sixteen_df,seventeen_df], ignore_index=True)
```
I am now going to set up a testing/validation scheme for the model. It works like this:
First I start off where my training data is all games from 2012-2015. Using the model trained on this data, I then predict games from the first week of the 2016 season and look at the results.
Next, I add that first week's worth of games to the training data, and now I train on all 2012-2015 results plus the first week from 2016. After training the model on this data, I then test on the second week of games. I then add that week's games to the training data and repeat the same procedure week after week.
In this way, I am never testing on a result that I have trained on. Though, it should be noted that I have also used this as a validation scheme, so I have technically done some sloppy 'data snooping' and this is not a great predictor of my generalization error.
```
def train_test_model(train_df, test_df):
# make the training data
X_train = train_df.drop(['year','month','day','team','opponent','teamscore','oppscore','D1','OT','weights','scorediff'], axis=1)
y_train = train_df['scorediff']
weights_train = train_df['weights']
# train the model
ridge_reg = Ridge()
ridge_reg.fit(X_train, y_train, weights_train)
fit = ridge_reg.score(X_train,y_train,sample_weight=weights_train)
print('R^2 on the training data:')
print(fit)
# get the test data
X_test = test_df.drop(['year','month','day','team','opponent','teamscore','oppscore','D1','OT','weights','scorediff'], axis=1)
y_test = test_df['scorediff']
# get the metrics
compare_data = list(zip(ridge_reg.predict(X_test),y_test))
right_count = 0
for tpl in compare_data:
if tpl[0] >= 0 and tpl[1] >=0:
right_count = right_count + 1
elif tpl[0] <= 0 and tpl[1] <=0:
right_count = right_count + 1
accuracy = right_count/len(compare_data)
print('accuracy on this weeks games')
print(right_count/len(compare_data))
total_squared_error = 0.0
for tpl in compare_data:
total_squared_error = total_squared_error + (tpl[0]-tpl[1])**2
RMSE = (total_squared_error / float(len(compare_data)))**(0.5)
print('RMSE on this weeks games:')
print(RMSE)
return fit, accuracy, RMSE, right_count, total_squared_error
#Now the code for running the week by week testing.
base_df = train_df
new_indices = []
# this is the hash for the first date
last_date_hash = 2018
fit_list = []
accuracy_list = []
RMSE_list = []
total_squared_error = 0
total_right_count = 0
for index, row in test_df.iterrows():
year = row['year']
month = row['month']
day = row['day']
date_hash = year+month+day
if date_hash != last_date_hash:
last_date_hash = date_hash
test_week = test_df.iloc[new_indices]
fit, accuracy, RMSE, correct_calls, squared_error = train_test_model(base_df,test_week)
fit_list.append(fit)
accuracy_list.append(accuracy)
RMSE_list.append(RMSE)
total_squared_error = total_squared_error + squared_error
total_right_count = total_right_count + correct_calls
base_df = pd.concat([base_df,test_week],ignore_index=True)
new_indices = [index]
else:
new_indices.append(index)
# get the number of games it called correctly in 2016
total_accuracy = total_right_count/test_df.shape[0]
total_accuracy
# get the Root Mean Squared Error
overall_RMSE = (total_squared_error/test_df.shape[0])**(0.5)
overall_RMSE
```
| true |
code
| 0.336638 | null | null | null | null |
|
# Time series analysis on AWS
*Chapter 1 - Time series analysis overview*
## Initializations
---
```
!pip install --quiet tqdm kaggle tsia ruptures
```
### Imports
```
import matplotlib.colors as mpl_colors
import matplotlib.dates as mdates
import matplotlib.ticker as ticker
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import ruptures as rpt
import sys
import tsia
import warnings
import zipfile
from matplotlib import gridspec
from sklearn.preprocessing import normalize
from tqdm import tqdm
from urllib.request import urlretrieve
```
### Parameters
```
RAW_DATA = os.path.join('..', 'Data', 'raw')
DATA = os.path.join('..', 'Data')
warnings.filterwarnings("ignore")
os.makedirs(RAW_DATA, exist_ok=True)
%matplotlib inline
# plt.style.use('Solarize_Light2')
plt.style.use('fivethirtyeight')
prop_cycle = plt.rcParams['axes.prop_cycle']
colors = prop_cycle.by_key()['color']
plt.rcParams['figure.dpi'] = 300
plt.rcParams['lines.linewidth'] = 0.3
plt.rcParams['axes.titlesize'] = 6
plt.rcParams['axes.labelsize'] = 6
plt.rcParams['xtick.labelsize'] = 4.5
plt.rcParams['ytick.labelsize'] = 4.5
plt.rcParams['grid.linewidth'] = 0.2
plt.rcParams['legend.fontsize'] = 5
```
### Helper functions
```
def progress_report_hook(count, block_size, total_size):
mb = int(count * block_size // 1048576)
if count % 500 == 0:
sys.stdout.write("\r{} MB downloaded".format(mb))
sys.stdout.flush()
```
### Downloading datasets
#### **Dataset 1:** Household energy consumption
```
ORIGINAL_DATA = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00321/LD2011_2014.txt.zip'
ARCHIVE_PATH = os.path.join(RAW_DATA, 'energy-consumption.zip')
FILE_NAME = 'energy-consumption.csv'
FILE_PATH = os.path.join(DATA, 'energy', FILE_NAME)
FILE_DIR = os.path.dirname(FILE_PATH)
if not os.path.isfile(FILE_PATH):
print("Downloading dataset (258MB), can take a few minutes depending on your connection")
urlretrieve(ORIGINAL_DATA, ARCHIVE_PATH, reporthook=progress_report_hook)
os.makedirs(os.path.join(DATA, 'energy'), exist_ok=True)
print("\nExtracting data archive")
zip_ref = zipfile.ZipFile(ARCHIVE_PATH, 'r')
zip_ref.extractall(FILE_DIR + '/')
zip_ref.close()
!rm -Rf $FILE_DIR/__MACOSX
!mv $FILE_DIR/LD2011_2014.txt $FILE_PATH
else:
print("File found, skipping download")
```
#### **Dataset 2:** Nasa Turbofan remaining useful lifetime
```
ok = True
ok = ok and os.path.exists(os.path.join(DATA, 'turbofan', 'train_FD001.txt'))
ok = ok and os.path.exists(os.path.join(DATA, 'turbofan', 'test_FD001.txt'))
ok = ok and os.path.exists(os.path.join(DATA, 'turbofan', 'RUL_FD001.txt'))
if (ok):
print("File found, skipping download")
else:
print('Some datasets are missing, create working directories and download original dataset from the NASA repository.')
# Making sure the directory already exists:
os.makedirs(os.path.join(DATA, 'turbofan'), exist_ok=True)
# Download the dataset from the NASA repository, unzip it and set
# aside the first training file to work on:
!wget https://ti.arc.nasa.gov/c/6/ --output-document=$RAW_DATA/CMAPSSData.zip
!unzip $RAW_DATA/CMAPSSData.zip -d $RAW_DATA
!cp $RAW_DATA/train_FD001.txt $DATA/turbofan/train_FD001.txt
!cp $RAW_DATA/test_FD001.txt $DATA/turbofan/test_FD001.txt
!cp $RAW_DATA/RUL_FD001.txt $DATA/turbofan/RUL_FD001.txt
```
#### **Dataset 3:** Human heartbeat
```
ECG_DATA_SOURCE = 'http://www.timeseriesclassification.com/Downloads/ECG200.zip'
ARCHIVE_PATH = os.path.join(RAW_DATA, 'ECG200.zip')
FILE_NAME = 'ecg.csv'
FILE_PATH = os.path.join(DATA, 'ecg', FILE_NAME)
FILE_DIR = os.path.dirname(FILE_PATH)
if not os.path.isfile(FILE_PATH):
urlretrieve(ECG_DATA_SOURCE, ARCHIVE_PATH)
os.makedirs(os.path.join(DATA, 'ecg'), exist_ok=True)
print("\nExtracting data archive")
zip_ref = zipfile.ZipFile(ARCHIVE_PATH, 'r')
zip_ref.extractall(FILE_DIR + '/')
zip_ref.close()
!mv $DATA/ecg/ECG200_TRAIN.txt $FILE_PATH
else:
print("File found, skipping download")
```
#### **Dataset 4:** Industrial pump data
To download this dataset from Kaggle, you will need to have an account and create a token that you install on your machine. You can follow [**this link**](https://www.kaggle.com/docs/api) to get started with the Kaggle API. Once generated, make sure your Kaggle token is stored in the `~/.kaggle/kaggle.json` file, or the next cells will issue an error. In some cases, you may still have an error while using this location. Try moving your token in this location instead: `~/kaggle/kaggle.json` (not the absence of the `.` in the folder name).
To get a Kaggle token, go to kaggle.com and create an account. Then navigate to **My account** and scroll down to the API section. There, click the **Create new API token** button:
<img src="../Assets/kaggle_api.png" />
```
FILE_NAME = 'pump-sensor-data.zip'
ARCHIVE_PATH = os.path.join(RAW_DATA, FILE_NAME)
FILE_PATH = os.path.join(DATA, 'pump', 'sensor.csv')
FILE_DIR = os.path.dirname(FILE_PATH)
if not os.path.isfile(FILE_PATH):
if not os.path.exists('/home/ec2-user/.kaggle/kaggle.json'):
os.makedirs('/home/ec2-user/.kaggle/', exist_ok=True)
raise Exception('The kaggle.json token was not found.\nCreating the /home/ec2-user/.kaggle/ directory: put your kaggle.json file there once you have generated it from the Kaggle website')
else:
print('The kaggle.json token file was found: making sure it is not readable by other users on this system.')
!chmod 600 /home/ec2-user/.kaggle/kaggle.json
os.makedirs(os.path.join(DATA, 'pump'), exist_ok=True)
!kaggle datasets download -d nphantawee/pump-sensor-data -p $RAW_DATA
print("\nExtracting data archive")
zip_ref = zipfile.ZipFile(ARCHIVE_PATH, 'r')
zip_ref.extractall(FILE_DIR + '/')
zip_ref.close()
else:
print("File found, skipping download")
```
#### **Dataset 5:** London household energy consumption with weather data
```
FILE_NAME = 'smart-meters-in-london.zip'
ARCHIVE_PATH = os.path.join(RAW_DATA, FILE_NAME)
FILE_PATH = os.path.join(DATA, 'energy-london', 'smart-meters-in-london.zip')
FILE_DIR = os.path.dirname(FILE_PATH)
# Checks if the data were already downloaded:
if os.path.exists(os.path.join(DATA, 'energy-london', 'acorn_details.csv')):
print("File found, skipping download")
else:
# Downloading and unzipping datasets from Kaggle:
print("Downloading dataset (2.26G), can take a few minutes depending on your connection")
os.makedirs(os.path.join(DATA, 'energy-london'), exist_ok=True)
!kaggle datasets download -d jeanmidev/smart-meters-in-london -p $RAW_DATA
print('Unzipping files...')
zip_ref = zipfile.ZipFile(ARCHIVE_PATH, 'r')
zip_ref.extractall(FILE_DIR + '/')
zip_ref.close()
!rm $DATA/energy-london/*zip
!rm $DATA/energy-london/*gz
!mv $DATA/energy-london/halfhourly_dataset/halfhourly_dataset/* $DATA/energy-london/halfhourly_dataset
!rm -Rf $DATA/energy-london/halfhourly_dataset/halfhourly_dataset
!mv $DATA/energy-london/daily_dataset/daily_dataset/* $DATA/energy-london/daily_dataset
!rm -Rf $DATA/energy-london/daily_dataset/daily_dataset
```
## Dataset visualization
---
### **1.** Household energy consumption
```
%%time
FILE_PATH = os.path.join(DATA, 'energy', 'energy-consumption.csv')
energy_df = pd.read_csv(FILE_PATH, sep=';', decimal=',')
energy_df = energy_df.rename(columns={'Unnamed: 0': 'Timestamp'})
energy_df['Timestamp'] = pd.to_datetime(energy_df['Timestamp'])
energy_df = energy_df.set_index('Timestamp')
energy_df.iloc[100000:, 1:5].head()
fig = plt.figure(figsize=(5, 1.876))
plt.plot(energy_df['MT_002'])
plt.title('Energy consumption for household MT_002')
plt.show()
```
### **2.** NASA Turbofan data
```
FILE_PATH = os.path.join(DATA, 'turbofan', 'train_FD001.txt')
turbofan_df = pd.read_csv(FILE_PATH, header=None, sep=' ')
turbofan_df.dropna(axis='columns', how='all', inplace=True)
print('Shape:', turbofan_df.shape)
turbofan_df.head(5)
columns = [
'unit_number',
'cycle',
'setting_1',
'setting_2',
'setting_3',
] + ['sensor_{}'.format(s) for s in range(1,22)]
turbofan_df.columns = columns
turbofan_df.head()
# Add a RUL column and group the data by unit_number:
turbofan_df['rul'] = 0
grouped_data = turbofan_df.groupby(by='unit_number')
# Loops through each unit number to get the lifecycle counts:
for unit, rul in enumerate(grouped_data.count()['cycle']):
current_df = turbofan_df[turbofan_df['unit_number'] == (unit+1)].copy()
current_df['rul'] = rul - current_df['cycle']
turbofan_df[turbofan_df['unit_number'] == (unit+1)] = current_df
df = turbofan_df.iloc[:, [0,1,2,3,4,5,6,25,26]].copy()
df = df[df['unit_number'] == 1]
def highlight_cols(s):
return f'background-color: rgba(0, 143, 213, 0.3)'
df.head(10).style.applymap(highlight_cols, subset=['rul'])
```
### **3.** ECG Data
```
FILE_PATH = os.path.join(DATA, 'ecg', 'ecg.csv')
ecg_df = pd.read_csv(FILE_PATH, header=None, sep=' ')
print('Shape:', ecg_df.shape)
ecg_df.head()
plt.rcParams['lines.linewidth'] = 0.7
fig = plt.figure(figsize=(5,2))
label_normal = False
label_ischemia = False
for i in range(0,100):
label = ecg_df.iloc[i, 0]
if (label == -1):
color = colors[1]
if label_ischemia:
plt.plot(ecg_df.iloc[i,1:96], color=color, alpha=0.5, linestyle='--', linewidth=0.5)
else:
plt.plot(ecg_df.iloc[i,1:96], color=color, alpha=0.5, label='Ischemia', linestyle='--')
label_ischemia = True
else:
color = colors[0]
if label_normal:
plt.plot(ecg_df.iloc[i,1:96], color=color, alpha=0.5)
else:
plt.plot(ecg_df.iloc[i,1:96], color=color, alpha=0.5, label='Normal')
label_normal = True
plt.title('Human heartbeat activity')
plt.legend(loc='upper right', ncol=2)
plt.show()
```
### **4.** Industrial pump data
```
FILE_PATH = os.path.join(DATA, 'pump', 'sensor.csv')
pump_df = pd.read_csv(FILE_PATH, sep=',')
pump_df.drop(columns={'Unnamed: 0'}, inplace=True)
pump_df['timestamp'] = pd.to_datetime(pump_df['timestamp'], format='%Y-%m-%d %H:%M:%S')
pump_df = pump_df.set_index('timestamp')
pump_df['machine_status'].replace(to_replace='NORMAL', value=np.nan, inplace=True)
pump_df['machine_status'].replace(to_replace='BROKEN', value=1, inplace=True)
pump_df['machine_status'].replace(to_replace='RECOVERING', value=1, inplace=True)
print('Shape:', pump_df.shape)
pump_df.head()
file_structure_df = pump_df.iloc[:, 0:10].resample('5D').mean()
plt.rcParams['hatch.linewidth'] = 0.5
plt.rcParams['lines.linewidth'] = 0.5
fig = plt.figure(figsize=(5,1))
ax1 = fig.add_subplot(1,1,1)
plot1 = ax1.plot(pump_df['sensor_00'], label='Healthy pump')
ax2 = ax1.twinx()
plot2 = ax2.fill_between(
x=pump_df.index,
y1=0.0,
y2=pump_df['machine_status'],
color=colors[1],
linewidth=0.0,
edgecolor='#000000',
alpha=0.5,
hatch="//////",
label='Broken pump'
)
ax2.grid(False)
ax2.set_yticks([])
labels = [plot1[0].get_label(), plot2.get_label()]
plt.legend(handles=[plot1[0], plot2], labels=labels, loc='lower center', ncol=2, bbox_to_anchor=(0.5, -.4))
plt.title('Industrial pump sensor data')
plt.show()
```
### **5.** London household energy consumption with weather data
We want to filter out households that are are subject to the dToU tariff and keep only the ones with a known ACORN (i.e. not in the ACORN-U group): this will allow us to better model future analysis by adding the Acorn detail informations (which by definitions, won't be available for the ACORN-U group).
```
household_filename = os.path.join(DATA, 'energy-london', 'informations_households.csv')
household_df = pd.read_csv(household_filename)
household_df = household_df[(household_df['stdorToU'] == 'Std') & (household_df['Acorn'] == 'ACORN-E')]
print(household_df.shape)
household_df.head()
```
#### Associating households with they energy consumption data
Each household (with an ID starting by `MACxxxxx` in the table above) has its consumption data stored in a block file name `block_xx`. This file is also available from the `informations_household.csv` file extracted above. We have the association between `household_id` and `block_file`: we can open each of them and keep the consumption for the households of interest. All these data will be concatenated into an `energy_df` dataframe:
```
%%time
household_ids = household_df['LCLid'].tolist()
consumption_file = os.path.join(DATA, 'energy-london', 'hourly_consumption.csv')
min_data_points = ((pd.to_datetime('2020-12-31') - pd.to_datetime('2020-01-01')).days + 1)*24*2
if os.path.exists(consumption_file):
print('Half-hourly consumption file already exists, loading from disk...')
energy_df = pd.read_csv(consumption_file)
energy_df['timestamp'] = pd.to_datetime(energy_df['timestamp'], format='%Y-%m-%d %H:%M:%S.%f')
print('Done.')
else:
print('Half-hourly consumption file not found. We need to generate it.')
# We know have the block number we can use to open the right file:
energy_df = pd.DataFrame()
target_block_files = household_df['file'].unique().tolist()
print('- {} block files to process: '.format(len(target_block_files)), end='')
df_list = []
for block_file in tqdm(target_block_files):
# Reads the current block file:
current_filename = os.path.join(DATA, 'energy-london', 'halfhourly_dataset', '{}.csv'.format(block_file))
df = pd.read_csv(current_filename)
# Set readable column names and adjust data types:
df.columns = ['household_id', 'timestamp', 'energy']
df = df.replace(to_replace='Null', value=0.0)
df['energy'] = df['energy'].astype(np.float64)
df['timestamp'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d %H:%M:%S.%f')
# We filter on the households sampled earlier:
df_list.append(df[df['household_id'].isin(household_ids)].reset_index(drop=True))
# Concatenate with the main dataframe:
energy_df = pd.concat(df_list, axis='index', ignore_index=True)
datapoints = energy_df.groupby(by='household_id').count()
datapoints = datapoints[datapoints['timestamp'] < min_data_points]
hhid_to_remove = datapoints.index.tolist()
energy_df = energy_df[~energy_df['household_id'].isin(hhid_to_remove)]
# Let's save this dataset to disk, we will use it from now on:
print('Saving file to disk... ', end='')
energy_df.to_csv(consumption_file, index=False)
print('Done.')
start = np.min(energy_df['timestamp'])
end = np.max(energy_df['timestamp'])
weather_filename = os.path.join(DATA, 'energy-london', 'weather_hourly_darksky.csv')
weather_df = pd.read_csv(weather_filename)
weather_df['time'] = pd.to_datetime(weather_df['time'], format='%Y-%m-%d %H:%M:%S')
weather_df = weather_df.drop(columns=['precipType', 'icon', 'summary'])
weather_df = weather_df.sort_values(by='time')
weather_df = weather_df.set_index('time')
weather_df = weather_df[start:end]
# Let's make sure we have one datapoint per hour to match
# the frequency used for the household energy consumption data:
weather_df = weather_df.resample(rule='1H').mean() # This will generate NaN values timestamp missing data
weather_df = weather_df.interpolate(method='linear') # This will fill the missing values with the average
print(weather_df.shape)
weather_df
energy_df = energy_df.set_index(['household_id', 'timestamp'])
energy_df
hhid = household_ids[2]
hh_energy = energy_df.loc[hhid, :]
start = '2012-07-01'
end = '2012-07-15'
fig = plt.figure(figsize=(5,1))
ax1 = fig.add_subplot(1,1,1)
plot2 = ax1.fill_between(
x=weather_df.loc[start:end, 'temperature'].index,
y1=0.0,
y2=weather_df.loc[start:end, 'temperature'],
color=colors[1],
linewidth=0.0,
edgecolor='#000000',
alpha=0.25,
hatch="//////",
label='Temperature'
)
ax1.set_ylim((0,40))
ax1.grid(False)
ax2 = ax1.twinx()
ax2.plot(hh_energy[start:end], label='Energy consumption', linewidth=2, color='#FFFFFF', alpha=0.5)
plot1 = ax2.plot(hh_energy[start:end], label='Energy consumption', linewidth=0.7)
ax2.set_title(f'Energy consumption for household {hhid}')
labels = [plot1[0].get_label(), plot2.get_label()]
plt.legend(handles=[plot1[0], plot2], labels=labels, loc='upper left', fontsize=3, ncol=2)
plt.show()
acorn_filename = os.path.join(DATA, 'energy-london', 'acorn_details.csv')
acorn_df = pd.read_csv(acorn_filename, encoding='ISO-8859-1')
acorn_df = acorn_df.sample(10).loc[:, ['MAIN CATEGORIES', 'CATEGORIES', 'REFERENCE', 'ACORN-A', 'ACORN-B', 'ACORN-E']]
acorn_df
```
## File structure exploration
---
```
from IPython.display import display_html
def display_multiple_dataframe(*args, max_rows=None, max_cols=None):
html_str = ''
for df in args:
html_str += df.to_html(max_cols=max_cols, max_rows=max_rows)
display_html(html_str.replace('table','table style="display:inline"'), raw=True)
display_multiple_dataframe(
file_structure_df[['sensor_00']],
file_structure_df[['sensor_01']],
file_structure_df[['sensor_03']],
max_rows=10, max_cols=None
)
display_multiple_dataframe(
file_structure_df.loc['2018-04', :].head(6),
file_structure_df.loc['2018-05', :].head(6),
file_structure_df.loc['2018-06', :].head(6),
max_rows=None, max_cols=2
)
display_multiple_dataframe(
file_structure_df.loc['2018-04', ['sensor_00']].head(6),
file_structure_df.loc['2018-05', ['sensor_00']].head(6),
file_structure_df.loc['2018-06', ['sensor_00']].head(6),
max_rows=10, max_cols=None
)
display_multiple_dataframe(
file_structure_df.loc['2018-04', ['sensor_01']].head(6),
file_structure_df.loc['2018-05', ['sensor_01']].head(6),
file_structure_df.loc['2018-06', ['sensor_01']].head(6),
max_rows=10, max_cols=None
)
print('.\n.\n.')
display_multiple_dataframe(
file_structure_df.loc['2018-04', ['sensor_09']].head(6),
file_structure_df.loc['2018-05', ['sensor_09']].head(6),
file_structure_df.loc['2018-06', ['sensor_09']].head(6),
max_rows=10, max_cols=None
)
df1 = pump_df.iloc[:, [0]].resample('5D').mean()
df2 = pump_df.iloc[:, [1]].resample('2D').mean()
df3 = pump_df.iloc[:, [2]].resample('7D').mean()
display_multiple_dataframe(
df1.head(10), df2.head(10), df3.head(10),
pd.merge(pd.merge(df1, df2, left_index=True, right_index=True, how='outer'), df3, left_index=True, right_index=True, how='outer').head(10),
max_rows=None, max_cols=None
)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', 10)
pd.merge(pd.merge(df1, df2, left_index=True, right_index=True, how='outer'), df3, left_index=True, right_index=True, how='outer').head(10)
plt.figure(figsize=(5,1))
for i in range(len(colors)):
plt.plot(file_structure_df[f'sensor_0{i}'], linewidth=2, alpha=0.5, label=colors[i])
plt.legend()
plt.show()
```
## Visualization
---
```
fig = plt.figure(figsize=(5,1))
ax1 = fig.add_subplot(1,1,1)
ax2 = ax1.twinx()
plot_sensor_0 = ax1.plot(pump_df['sensor_00'], label='Sensor 0', color=colors[0], linewidth=1, alpha=0.8)
plot_sensor_1 = ax2.plot(pump_df['sensor_01'], label='Sensor 1', color=colors[1], linewidth=1, alpha=0.8)
ax2.grid(False)
plt.title('Pump sensor values (2 sensors)')
plt.legend(handles=[plot_sensor_0[0], plot_sensor_1[0]], ncol=2, loc='lower right')
plt.show()
reduced_pump_df = pump_df.loc[:, 'sensor_00':'sensor_14']
reduced_pump_df = reduced_pump_df.replace([np.inf, -np.inf], np.nan)
reduced_pump_df = reduced_pump_df.fillna(0.0)
reduced_pump_df = reduced_pump_df.astype(np.float32)
scaled_pump_df = pd.DataFrame(normalize(reduced_pump_df), index=reduced_pump_df.index, columns=reduced_pump_df.columns)
scaled_pump_df
fig = plt.figure(figsize=(5,1))
for i in range(0,15):
plt.plot(scaled_pump_df.iloc[:, i], alpha=0.6)
plt.title('Pump sensor values (15 sensors)')
plt.show()
pump_df2 = pump_df.copy()
pump_df2 = pump_df2.replace([np.inf, -np.inf], np.nan)
pump_df2 = pump_df2.fillna(0.0)
pump_df2 = pump_df2.astype(np.float32)
pump_description = pump_df2.describe().T
constant_signals = pump_description[pump_description['min'] == pump_description['max']].index.tolist()
pump_df2 = pump_df2.drop(columns=constant_signals)
features = pump_df2.columns.tolist()
def hex_to_rgb(hex_color):
"""
Converts a color string in hexadecimal format to RGB format.
PARAMS
======
hex_color: string
A string describing the color to convert from hexadecimal. It can
include the leading # character or not
RETURNS
=======
rgb_color: tuple
Each color component of the returned tuple will be a float value
between 0.0 and 1.0
"""
hex_color = hex_color.lstrip('#')
rgb_color = tuple(int(hex_color[i:i+2], base=16) / 255.0 for i in [0, 2, 4])
return rgb_color
def plot_timeseries_strip_chart(binned_timeseries, signal_list, fig_width=12, signal_height=0.15, dates=None, day_interval=7):
# Build a suitable colormap:
colors_list = [
hex_to_rgb('#DC322F'),
hex_to_rgb('#B58900'),
hex_to_rgb('#2AA198')
]
cm = mpl_colors.LinearSegmentedColormap.from_list('RdAmGr', colors_list, N=len(colors_list))
fig = plt.figure(figsize=(fig_width, signal_height * binned_timeseries.shape[0]))
ax = fig.add_subplot(1,1,1)
# Devising the extent of the actual plot:
if dates is not None:
dnum = mdates.date2num(dates)
start = dnum[0] - (dnum[1]-dnum[0])/2.
stop = dnum[-1] + (dnum[1]-dnum[0])/2.
extent = [start, stop, 0, signal_height * (binned_timeseries.shape[0])]
else:
extent = None
# Plot the matrix:
im = ax.imshow(binned_timeseries,
extent=extent,
aspect="auto",
cmap=cm,
origin='lower')
# Adjusting the x-axis if we provide dates:
if dates is not None:
ax.xaxis.set_major_locator(mdates.MonthLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
for tick in ax.xaxis.get_major_ticks():
tick.label.set_fontsize(4)
tick.label.set_rotation(60)
tick.label.set_fontweight('bold')
ax.tick_params(axis='x', which='major', pad=7, labelcolor='#000000')
plt.xticks(ha='right')
# Adjusting the y-axis:
ax.yaxis.set_major_locator(ticker.MultipleLocator(signal_height))
ax.set_yticklabels(signal_list, verticalalignment='bottom', fontsize=4)
ax.set_yticks(np.arange(len(signal_list)) * signal_height)
plt.grid()
return ax
from IPython.display import display, Markdown, Latex
# Build a list of dataframes, one per sensor:
df_list = []
for f in features[:1]:
df_list.append(pump_df2[[f]])
# Discretize each signal in 3 bins:
array = tsia.markov.discretize_multivariate(df_list)
fig = plt.figure(figsize=(5.5, 0.6))
plt.plot(pump_df2['sensor_00'], linewidth=0.7, alpha=0.6)
plt.title('Line plot of the pump sensor 0')
plt.show()
display(Markdown('<img src="arrow.png" align="left" style="padding-left: 730px"/>'))
# Plot the strip chart:
ax = plot_timeseries_strip_chart(
array,
signal_list=features[:1],
fig_width=5.21,
signal_height=0.2,
dates=df_list[0].index.to_pydatetime(),
day_interval=2
)
ax.set_title('Strip chart of the pump sensor 0');
# Build a list of dataframes, one per sensor:
df_list = []
for f in features:
df_list.append(pump_df2[[f]])
# Discretize each signal in 3 bins:
array = tsia.markov.discretize_multivariate(df_list)
# Plot the strip chart:
fig = plot_timeseries_strip_chart(
array,
signal_list=features,
fig_width=5.5,
signal_height=0.1,
dates=df_list[0].index.to_pydatetime(),
day_interval=2
)
```
### Recurrence plot
```
from pyts.image import RecurrencePlot
from pyts.image import GramianAngularField
from pyts.image import MarkovTransitionField
hhid = household_ids[2]
hh_energy = energy_df.loc[hhid, :]
pump_extract_df = pump_df.iloc[:800, 0].copy()
rp = RecurrencePlot(threshold='point', percentage=30)
weather_rp = rp.fit_transform(weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.reshape(1, -1))
energy_rp = rp.fit_transform(hh_energy['2012-07-01':'2012-07-15'].values.reshape(1, -1))
pump_rp = rp.fit_transform(pump_extract_df.values.reshape(1, -1))
fig = plt.figure(figsize=(5.5, 2.4))
gs = gridspec.GridSpec(nrows=3, ncols=2, width_ratios=[3,1], hspace=0.8, wspace=0.0)
# Pump sensor 0:
ax = fig.add_subplot(gs[0])
ax.plot(pump_extract_df, label='Pump sensor 0')
ax.set_title(f'Pump sensor 0')
ax = fig.add_subplot(gs[1])
ax.imshow(pump_rp[0], cmap='binary', origin='lower')
ax.axis('off')
# Energy consumption line plot and recurrence plot:
ax = fig.add_subplot(gs[2])
plot1 = ax.plot(hh_energy['2012-07-01':'2012-07-15'], color=colors[1])
ax.set_title(f'Energy consumption for household {hhid}')
ax = fig.add_subplot(gs[3])
ax.imshow(energy_rp[0], cmap='binary', origin='lower')
ax.axis('off')
# Daily temperature line plot and recurrence plot:
ax = fig.add_subplot(gs[4])
start = '2012-07-01'
end = '2012-07-15'
ax.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2])
ax.set_title(f'Daily temperature')
ax = fig.add_subplot(gs[5])
ax.imshow(weather_rp[0], cmap='binary', origin='lower')
ax.axis('off')
plt.show()
hhid = household_ids[2]
hh_energy = energy_df.loc[hhid, :]
pump_extract_df = pump_df.iloc[:800, 0].copy()
gaf = GramianAngularField(image_size=48, method='summation')
weather_gasf = gaf.fit_transform(weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.reshape(1, -1))
energy_gasf = gaf.fit_transform(hh_energy['2012-07-01':'2012-07-15'].values.reshape(1, -1))
pump_gasf = gaf.fit_transform(pump_extract_df.values.reshape(1, -1))
fig = plt.figure(figsize=(5.5, 2.4))
gs = gridspec.GridSpec(nrows=3, ncols=2, width_ratios=[3,1], hspace=0.8, wspace=0.0)
# Pump sensor 0:
ax = fig.add_subplot(gs[0])
ax.plot(pump_extract_df, label='Pump sensor 0')
ax.set_title(f'Pump sensor 0')
ax = fig.add_subplot(gs[1])
ax.imshow(pump_gasf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
# Energy consumption line plot and recurrence plot:
ax = fig.add_subplot(gs[2])
plot1 = ax.plot(hh_energy['2012-07-01':'2012-07-15'], color=colors[1])
ax.set_title(f'Energy consumption for household {hhid}')
ax = fig.add_subplot(gs[3])
ax.imshow(energy_gasf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
# Daily temperature line plot and recurrence plot:
ax = fig.add_subplot(gs[4])
start = '2012-07-01'
end = '2012-07-15'
ax.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2])
ax.set_title(f'Daily temperature')
ax = fig.add_subplot(gs[5])
ax.imshow(weather_gasf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
plt.show()
mtf = MarkovTransitionField(image_size=48)
weather_mtf = mtf.fit_transform(weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.reshape(1, -1))
energy_mtf = mtf.fit_transform(hh_energy['2012-07-01':'2012-07-15'].values.reshape(1, -1))
pump_mtf = mtf.fit_transform(pump_extract_df.values.reshape(1, -1))
fig = plt.figure(figsize=(5.5, 2.4))
gs = gridspec.GridSpec(nrows=3, ncols=2, width_ratios=[3,1], hspace=0.8, wspace=0.0)
# Pump sensor 0:
ax = fig.add_subplot(gs[0])
ax.plot(pump_extract_df, label='Pump sensor 0')
ax.set_title(f'Pump sensor 0')
ax = fig.add_subplot(gs[1])
ax.imshow(pump_mtf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
# Energy consumption line plot and recurrence plot:
ax = fig.add_subplot(gs[2])
plot1 = ax.plot(hh_energy['2012-07-01':'2012-07-15'], color=colors[1])
ax.set_title(f'Energy consumption for household {hhid}')
ax = fig.add_subplot(gs[3])
ax.imshow(energy_mtf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
# Daily temperature line plot and recurrence plot:
ax = fig.add_subplot(gs[4])
start = '2012-07-01'
end = '2012-07-15'
ax.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2])
ax.set_title(f'Daily temperature')
ax = fig.add_subplot(gs[5])
ax.imshow(weather_mtf[0], cmap='RdBu_r', origin='lower')
ax.axis('off')
plt.show()
import matplotlib
import matplotlib.cm as cm
import networkx as nx
import community
def compute_network_graph(markov_field):
G = nx.from_numpy_matrix(markov_field[0])
# Uncover the communities in the current graph:
communities = community.best_partition(G)
nb_communities = len(pd.Series(communities).unique())
cmap = 'autumn'
# Compute node colors and edges colors for the modularity encoding:
edge_colors = [matplotlib.colors.to_hex(cm.get_cmap(cmap)(communities.get(v)/(nb_communities - 1))) for u,v in G.edges()]
node_colors = [communities.get(node) for node in G.nodes()]
node_size = [nx.average_clustering(G, [node])*90 for node in G.nodes()]
# Builds the options set to draw the network graph in the "modularity" configuration:
options = {
'node_size': 10,
'edge_color': edge_colors,
'node_color': node_colors,
'linewidths': 0,
'width': 0.1,
'alpha': 0.6,
'with_labels': False,
'cmap': cmap
}
return G, options
fig = plt.figure(figsize=(5.5, 2.4))
gs = gridspec.GridSpec(nrows=3, ncols=2, width_ratios=[3,1], hspace=0.8, wspace=0.0)
# Pump sensor 0:
ax = fig.add_subplot(gs[0])
ax.plot(pump_extract_df, label='Pump sensor 0')
ax.set_title(f'Pump sensor 0')
ax = fig.add_subplot(gs[1])
G, options = compute_network_graph(weather_mtf)
nx.draw_networkx(G, **options, pos=nx.spring_layout(G), ax=ax)
ax.axis('off')
# Energy consumption line plot and recurrence plot:
ax = fig.add_subplot(gs[2])
plot1 = ax.plot(hh_energy['2012-07-01':'2012-07-15'], color=colors[1])
ax.set_title(f'Energy consumption for household {hhid}')
ax = fig.add_subplot(gs[3])
G, options = compute_network_graph(energy_mtf)
nx.draw_networkx(G, **options, pos=nx.spring_layout(G), ax=ax)
ax.axis('off')
# Daily temperature line plot and recurrence plot:
ax = fig.add_subplot(gs[4])
start = '2012-07-01'
end = '2012-07-15'
ax.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2])
ax.set_title(f'Daily temperature')
ax = fig.add_subplot(gs[5])
G, options = compute_network_graph(weather_mtf)
nx.draw_networkx(G, **options, pos=nx.spring_layout(G), ax=ax)
ax.axis('off')
plt.show()
```
## Symbolic representation
---
```
from pyts.bag_of_words import BagOfWords
window_size, word_size = 30, 5
bow = BagOfWords(window_size=window_size, word_size=word_size, window_step=window_size, numerosity_reduction=False)
X = weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.reshape(1, -1)
X_bow = bow.transform(X)
time_index = weather_df.loc['2013-01-01':'2013-01-31']['temperature'].index
len(X_bow[0].replace(' ', ''))
# Plot the considered subseries
plt.figure(figsize=(5, 2))
splits_series = np.linspace(0, X.shape[1], 1 + X.shape[1] // window_size, dtype='int64')
for start, end in zip(splits_series[:-1], np.clip(splits_series[1:] + 1, 0, X.shape[1])):
plt.plot(np.arange(start, end), X[0, start:end], 'o-', linewidth=0.5, ms=0.1)
# Plot the corresponding letters
splits_letters = np.linspace(0, X.shape[1], 1 + word_size * X.shape[1] // window_size)
splits_letters = ((splits_letters[:-1] + splits_letters[1:]) / 2)
splits_letters = splits_letters.astype('int64')
for i, (x, text) in enumerate(zip(splits_letters, X_bow[0].replace(' ', ''))):
t = plt.text(x, X[0, x], text, color="C{}".format(i // 5), fontsize=3.5)
t.set_bbox(dict(facecolor='#FFFFFF', alpha=0.5, edgecolor="C{}".format(i // 5), boxstyle='round4'))
plt.title('Bag-of-words representation for weather temperature')
plt.tight_layout()
plt.show()
from pyts.transformation import WEASEL
from sklearn.preprocessing import LabelEncoder
X_train = ecg_df.iloc[:, 1:].values
y_train = ecg_df.iloc[:, 0]
y_train = LabelEncoder().fit_transform(y_train)
weasel = WEASEL(word_size=3, n_bins=3, window_sizes=[10, 25], sparse=False)
X_weasel = weasel.fit_transform(X_train, y_train)
vocabulary_length = len(weasel.vocabulary_)
plt.figure(figsize=(5,1.5))
width = 0.4
x = np.arange(vocabulary_length) - width / 2
for i in range(len(X_weasel[y_train == 0])):
if i == 0:
plt.bar(x, X_weasel[y_train == 0][i], width=width, alpha=0.25, color=colors[1], label='Time series for Ischemia')
else:
plt.bar(x, X_weasel[y_train == 0][i], width=width, alpha=0.25, color=colors[1])
for i in range(len(X_weasel[y_train == 1])):
if i == 0:
plt.bar(x+width, X_weasel[y_train == 1][i], width=width, alpha=0.25, color=colors[0], label='Time series for Normal heartbeat')
else:
plt.bar(x+width, X_weasel[y_train == 1][i], width=width, alpha=0.25, color=colors[0])
plt.xticks(
np.arange(vocabulary_length),
np.vectorize(weasel.vocabulary_.get)(np.arange(X_weasel[0].size)),
fontsize=2,
rotation=60
)
plt.legend(loc='upper right')
plt.show()
```
## Statistics
---
```
plt.rcParams['xtick.labelsize'] = 3
import statsmodels.api as sm
fig = plt.figure(figsize=(5.5, 3))
gs = gridspec.GridSpec(nrows=3, ncols=2, width_ratios=[1,1], hspace=0.8)
# Pump
ax = fig.add_subplot(gs[0])
ax.plot(pump_extract_df, label='Pump sensor 0')
ax.set_title(f'Pump sensor 0')
ax.tick_params(axis='x', which='both', labelbottom=False)
ax = fig.add_subplot(gs[1])
sm.graphics.tsa.plot_acf(pump_extract_df.values.squeeze(), ax=ax, markersize=1, title='')
ax.set_ylim(-1.2, 1.2)
ax.tick_params(axis='x', which='major', labelsize=4)
# Energy consumption
ax = fig.add_subplot(gs[2])
ax.plot(hh_energy['2012-07-01':'2012-07-15'], color=colors[1])
ax.set_title(f'Energy consumption for household {hhid}')
ax.tick_params(axis='x', which='both', labelbottom=False)
ax = fig.add_subplot(gs[3])
sm.graphics.tsa.plot_acf(hh_energy['2012-07-01':'2012-07-15'].values.squeeze(), ax=ax, markersize=1, title='')
ax.set_ylim(-0.3, 0.3)
ax.tick_params(axis='x', which='major', labelsize=4)
# Daily temperature:
ax = fig.add_subplot(gs[4])
start = '2012-07-01'
end = '2012-07-15'
ax.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2])
ax.set_title(f'Daily temperature')
ax.tick_params(axis='x', which='both', labelbottom=False)
ax = fig.add_subplot(gs[5])
sm.graphics.tsa.plot_acf(weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.squeeze(), ax=ax, markersize=1, title='')
ax.set_ylim(-1.2, 1.2)
ax.tick_params(axis='x', which='major', labelsize=4)
plt.show()
from statsmodels.tsa.seasonal import STL
endog = endog.resample('30T').mean()
plt.rcParams['lines.markersize'] = 1
title = f'Energy consumption for household {hhid}'
endog = hh_energy['2012-07-01':'2012-07-15']
endog.columns = [title]
endog = endog[title]
stl = STL(endog, period=48)
res = stl.fit()
fig = res.plot()
fig = plt.gcf()
fig.set_size_inches(5.5, 4)
plt.show()
```
## Binary segmentation
---
```
signal = weather_df.loc['2013-01-01':'2013-01-31']['temperature'].values.squeeze()
algo = rpt.Binseg(model='l2').fit(signal)
my_bkps = algo.predict(n_bkps=3)
my_bkps = [0] + my_bkps
my_bkps
fig = plt.figure(figsize=(5.5,1))
start = '2012-07-01'
end = '2012-07-15'
plt.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color='#FFFFFF', linewidth=1.2, alpha=0.8)
plt.plot(weather_df.loc['2013-01-01':'2013-01-31']['temperature'], color=colors[2], linewidth=0.7)
plt.title(f'Daily temperature')
plt.xticks(rotation=60, fontsize=4)
weather_index = weather_df.loc['2013-01-01':'2013-01-31']['temperature'].index
for index, bkps in enumerate(my_bkps[:-1]):
x1 = weather_index[my_bkps[index]]
x2 = weather_index[np.clip(my_bkps[index+1], 0, len(weather_index)-1)]
plt.axvspan(x1, x2, color=colors[index % 5], alpha=0.2)
plt.title('Daily temperature segmentation')
plt.show()
```
| true |
code
| 0.224608 | null | null | null | null |
|
## ML Lab 3
### Neural Networks
In the following exercise class we explore how to design and train neural networks in various ways.
#### Prerequisites:
In order to follow the exercises you need to:
1. Activate your conda environment from last week via: `source activate <env-name>`
2. Install tensorflow (https://www.tensorflow.org) via: `pip install tensorflow` (CPU-only)
3. Install keras (provides high level wrapper for tensorflow) (https://keras.io) via: `pip install keras`
## Exercise 1: Create a 2 layer network that acts as an XOR gate using numpy.
XOR is a fundamental logic gate that outputs a one whenever there is an odd parity of ones in its input and zero otherwise. For two inputs this can be thought of as an exclusive or operation and the associated boolean function is fully characterized by the following truth table.
| X | Y | XOR(X,Y) |
|---|---|----------|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
The function of an XOR gate can also be understood as a classification problem on $v \in \{0,1\}^2$ and we can think about designing a classifier acting as an XOR gate. It turns out that this problem is not solvable by any single layer perceptron (https://en.wikipedia.org/wiki/Perceptron) because the set of points $\{(0,0), (0,1), (1,0), (1,1)\}$ is not linearly seperable.
**Design a two layer perceptron using basic numpy matrix operations that implements an XOR Gate on two inputs. Think about the flow of information and accordingly set the weight values by hand.**
### Data
```
import numpy as np
def generate_xor_data():
X = [(i,j) for i in [0,1] for j in [0,1]]
y = [int(np.logical_xor(x[0], x[1])) for x in X]
return X, y
print(generate_xor_data())
```
### Hints
A single layer in a multilayer perceptron can be described by the equation $y = f(\vec{b} + W\vec{x})$ with $f$ the logistic function, a smooth and differentiable version of the step function, and defined as $f(z) = \frac{1}{1+e^{-z}}$. $\vec{b}$ is the so called bias, a constant offset vector and $W$ is the weight matrix. However, since we set the weights by hand feel free to use hard thresholding instead of using the logistic function. Write down the equation for a two layer MLP and implement it with numpy. For documentation see https://docs.scipy.org/doc/numpy-1.13.0/reference/
```
"""
Implement your solution here.
"""
```
### Solution
| X | Y | AND(NOT X, Y) | AND(X,NOT Y) | OR[AND(NOT X, Y), AND(X, NOT Y)]| XOR(X,Y) |
|---|---|---------------|--------------|---------------------------------|----------|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 |
Implement XOR as a combination of 2 AND Gates and 1 OR gate where each neuron in the network acts as one of these gates.
```
"""
Definitions:
Input = np.array([X,Y])
0 if value < 0.5
1 if value >= 0.5
"""
def threshold(vector):
return (vector>=0.5).astype(float)
def mlp(x, W0, W1, b0, b1, f):
x0 = f(np.dot(W0, x) + b0)
x1 = f(np.dot(W1, x0) + b1)
return x1
# AND(NOT X, Y)
w_andnotxy = np.array([-1.0, 1.0])
# AND(X, NOT Y)
w_andxnoty = np.array([1.0, -1.0])
# W0 weight matrix:
W0 = np.vstack([w_andnotxy, w_andxnoty])
# OR(X,Y)
w_or = np.array([1., 1.])
W1 = w_or
# No biases needed
b0 = np.array([0.0,0.0])
b1 = 0.0
print("Input", "Output", "XOR")
xx,yy = generate_xor_data()
for x,y in zip(xx, yy):
print(x, int(mlp(x, W0, W1, b0, b1, threshold))," ", y)
```
## Exercise 2: Use Keras to design, train and evaluate a neural network that can classify points on a 2D plane.
### Data generator
```
import numpy as np
import matplotlib.pyplot as plt
def generate_spiral_data(n_points, noise=1.0):
n = np.sqrt(np.random.rand(n_points,1)) * 780 * (2*np.pi)/360
d1x = -np.cos(n)*n + np.random.rand(n_points,1) * noise
d1y = np.sin(n)*n + np.random.rand(n_points,1) * noise
return (np.vstack((np.hstack((d1x,d1y)),np.hstack((-d1x,-d1y)))),
np.hstack((np.zeros(n_points),np.ones(n_points))))
```
### Training data
```
X_train, y_train = generate_spiral_data(1000)
plt.title('Training set')
plt.plot(X_train[y_train==0,0], X_train[y_train==0,1], '.', label='Class 1')
plt.plot(X_train[y_train==1,0], X_train[y_train==1,1], '.', label='Class 2')
plt.legend()
plt.show()
```
### Test data
```
X_test, y_test = generate_spiral_data(1000)
plt.title('Test set')
plt.plot(X_test[y_test==0,0], X_test[y_test==0,1], '.', label='Class 1')
plt.plot(X_test[y_test==1,0], X_test[y_test==1,1], '.', label='Class 2')
plt.legend()
plt.show()
```
### 2.1. Design and train your model
The current model performs badly, try to find a more advanced architecture that is able to solve the classification problem. Read the following code snippet and understand the involved functions. Vary width and depth of the network and play around with activation functions, loss functions and optimizers to achieve a better result. Read up on parameters and functions for sequential models at https://keras.io/getting-started/sequential-model-guide/.
```
from keras.models import Sequential
from keras.layers import Dense
"""
Replace the following model with yours and try to achieve better classification performance
"""
bad_model = Sequential()
bad_model.add(Dense(12, input_dim=2, activation='tanh'))
bad_model.add(Dense(1, activation='sigmoid'))
bad_model.compile(loss='mean_squared_error',
optimizer='SGD', # SGD = Stochastic Gradient Descent
metrics=['accuracy'])
# Train the model
bad_model.fit(X_train, y_train, epochs=150, batch_size=10, verbose=0)
```
### Predict
```
bad_prediction = np.round(bad_model.predict(X_test).T[0])
```
### Visualize
```
plt.subplot(1,2,1)
plt.title('Test set')
plt.plot(X_test[y_test==0,0], X_test[y_test==0,1], '.')
plt.plot(X_test[y_test==1,0], X_test[y_test==1,1], '.')
plt.subplot(1,2,2)
plt.title('Bad model classification')
plt.plot(X_test[bad_prediction==0,0], X_test[bad_prediction==0,1], '.')
plt.plot(X_test[bad_prediction==1,0], X_test[bad_prediction==1,1], '.')
plt.show()
```
### 2.2. Visualize the decision boundary of your model.
```
"""
Implement your solution here.
"""
```
## Solution
### Model design and training
```
from keras.layers import Dense, Dropout
good_model = Sequential()
good_model.add(Dense(64, input_dim=2, activation='relu'))
good_model.add(Dense(64, activation='relu'))
good_model.add(Dense(64, activation='relu'))
good_model.add(Dense(1, activation='sigmoid'))
good_model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
good_model.fit(X_train, y_train, epochs=150, batch_size=10, verbose=0)
```
### Prediction
```
good_prediction = np.round(good_model.predict(X_test).T[0])
```
### Visualization
#### Performance
```
plt.subplot(1,2,1)
plt.title('Test set')
plt.plot(X_test[y_test==0,0], X_test[y_test==0,1], '.')
plt.plot(X_test[y_test==1,0], X_test[y_test==1,1], '.')
plt.subplot(1,2,2)
plt.title('Good model classification')
plt.plot(X_test[good_prediction==0,0], X_test[good_prediction==0,1], '.')
plt.plot(X_test[good_prediction==1,0], X_test[good_prediction==1,1], '.')
plt.show()
```
#### Decision boundary
```
# Generate grid:
line = np.linspace(-15,15)
xx, yy = np.meshgrid(line,line)
grid = np.stack((xx,yy))
# Reshape to fit model input size:
grid = grid.T.reshape(-1,2)
# Predict:
good_prediction = good_model.predict(grid)
bad_prediction = bad_model.predict(grid)
# Reshape to grid for visualization:
plt.title("Good Decision Boundary")
good_prediction = good_prediction.T[0].reshape(len(line),len(line))
plt.contourf(xx,yy,good_prediction)
plt.show()
plt.title("Bad Decision Boundary")
bad_prediction = bad_prediction.T[0].reshape(len(line),len(line))
plt.contourf(xx,yy,bad_prediction)
plt.show()
```
## Design, train and test a neural network that is able to classify MNIST digits using Keras.
### Data
```
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
"""
Returns:
2 tuples:
x_train, x_test: uint8 array of grayscale image data with shape (num_samples, 28, 28).
y_train, y_test: uint8 array of digit labels (integers in range 0-9) with shape (num_samples,).
"""
# Show example data
plt.subplot(1,4,1)
plt.imshow(x_train[0], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,2)
plt.imshow(x_train[1], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,3)
plt.imshow(x_train[2], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,4)
plt.imshow(x_train[3], cmap=plt.get_cmap('gray'))
plt.show()
"""
Implement your solution here.
"""
```
### Solution
```
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout, Conv2D, MaxPooling2D
"""
We need to add a channel dimension
to the image input.
"""
x_train = x_train.reshape(x_train.shape[0],
x_train.shape[1],
x_train.shape[2],
1)
x_test = x_test.reshape(x_test.shape[0],
x_test.shape[1],
x_test.shape[2],
1)
"""
Train the image using 32-bit floats normalized
between 0 and 1 for numerical stability.
"""
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
input_shape = (x_train.shape[1], x_train.shape[2], 1)
"""
Output should be a 10 dimensional 1-hot vector,
not just an integer denoting the digit.
This is due to our use of softmax to "squish" network
output for classification.
"""
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
"""
We construct a CNN with 2 convolution layers
and use max-pooling between each convolution layer;
we finish with two dense layers for classification.
"""
cnn_model = Sequential()
cnn_model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=input_shape))
cnn_model.add(MaxPooling2D(pool_size=(2, 2)))
cnn_model.add(Conv2D(filters=32,
kernel_size=(3, 3),
activation='relu'))
cnn_model.add(MaxPooling2D(pool_size=(2, 2)))
cnn_model.add(Flatten())
cnn_model.add(Dense(64, activation='relu'))
cnn_model.add(Dense(10, activation='softmax')) # softmax for classification
cnn_model.compile(loss='categorical_crossentropy',
optimizer='adagrad', # adaptive optimizer (still similar to SGD)
metrics=['accuracy'])
"""Train the CNN model and evaluate test accuracy."""
cnn_model.fit(x_train,
y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test)) # never actually validate using test data!
score = cnn_model.evaluate(x_test, y_test, verbose=0)
print('MNIST test set accuracy:', score[1])
"""Visualize some test data and network output."""
y_predict = cnn_model.predict(x_test, verbose=0)
y_predict_digits = [np.argmax(y_predict[i]) for i in range(y_predict.shape[0])]
plt.subplot(1,4,1)
plt.imshow(x_test[0,:,:,0], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,2)
plt.imshow(x_test[1,:,:,0], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,3)
plt.imshow(x_test[2,:,:,0], cmap=plt.get_cmap('gray'))
plt.subplot(1,4,4)
plt.imshow(x_test[3,:,:,0], cmap=plt.get_cmap('gray'))
plt.show()
print("CNN predictions: {0}, {1}, {2}, {3}".format(y_predict_digits[0],
y_predict_digits[1],
y_predict_digits[2],
y_predict_digits[3]))
```
| true |
code
| 0.667581 | null | null | null | null |
|
# Initial Modelling notebook
```
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
import bay12_solution_eposts as solution
```
## Load data
```
post, thread = solution.prepare.load_dfs('train')
post.head(2)
thread.head(2)
```
I will set the thread number to be the index, to simplify matching in the future:
```
thread = thread.set_index('thread_num')
thread.head(2)
```
We'll load the label map as well, which tells us which index goes to which label
```
label_map = solution.prepare.load_label_map()
label_map
```
## Create features from thread dataframe
We will fit a CountVectorizer, which is a simple transformation that counts the number of times the word was found.
The parameter `min_df` sets the minimum number of occurances in our set that will allow a word to join our vocabulary.
```
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(ngram_range=(1, 1), min_df=3)
word_vectors_raw = cv.fit_transform(thread['thread_name'])
```
To save space, this outputs a sparse matrix:
```
word_vectors_raw
```
However, since we'll be using it with a DataFrame, we need to convert it into a Pandas DataFrame:
```
word_df = pd.DataFrame(word_vectors_raw.toarray(), columns=cv.get_feature_names(), index=thread.index)
word_df.head()
```
The only other feature we have from our thread data is the number of replies. Let's add one to get the number of replies. Also, let's use the logarithm of post count as well, just for fun.
We'll concatenate those into our X dataframe (Note that I'm renaming the columns, to keep track more easily):
```
X = pd.concat([
(thread['thread_replies'] + 1).rename('posts'),
np.log(thread['thread_replies'] + 1).rename('log_posts'),
word_df,
], axis='columns')
X.head()
```
Our target is the category number. Remember that this isn't a regression task - there is no actual order between these categories! Also, our Y is one-dimensional, so we'll keep it as a Series (even though it prints less prettily).
```
y = thread['thread_label_id']
y.head()
```
## Split dataset into "training" and "validation"
In order to check the quality of our model in a more realistic setting, we will split all our input (training) data into a "training set" (which our model will see and learn from) and a "validation set" (where we see how well our model generalized). [Relevant link](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html).
```
from sklearn.model_selection import train_test_split
# NOTE: setting the `random_state` lets you get the same results with the pseudo-random generator
validation_pct = 0.25
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=validation_pct, random_state=99)
X_train.shape, y_train.shape
X_val.shape, y_val.shape
```
## Fit a model
Since we are fitting a multiclass model, [this scikit-learn link](https://scikit-learn.org/stable/modules/multiclass.html) is very relevant. To simplify things, we will be using an algorithm that is inherently multi-class.
```
from sklearn.tree import DecisionTreeClassifier
# Just using default parameters... what can do wrong?
cls = DecisionTreeClassifier(random_state=1337)
# Fit
cls.fit(X_train, y_train)
# In-sample and out-of-sample predictions
# NOTE: we
y_train_pred = pd.Series(
cls.predict(X_train),
index=X_train.index,
)
y_val_pred = pd.Series(
cls.predict(X_val),
index=X_val.index,
)
y_val_pred.head()
```
## Score the model
To find out how well the model did, we'll use the [model evaluation functionality of sklearn](https://scikit-learn.org/stable/modules/model_evaluation.html); specifically, the [multiclass classification metrics](https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics).
```
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
```
The [confusion matrix](https://en.wikipedia.org/wiki/Confusion_matrix) shows how our predictions differ from the actual values.
It's important to note how strongly our in-sample (training) and out-of-sample (validation/test) metrics differ.
```
def confusion_df(y_actual, y_pred):
res = pd.DataFrame(
confusion_matrix(y_actual, y_pred, labels=label_map.values),
index=label_map.index.rename('predicted'),
columns=label_map.index.rename('actual'),
)
return res
confusion_df(y_train, y_train_pred).style.highlight_max()
confusion_df(y_val, y_val_pred).style.highlight_max()
```
Oh boy. That's pretty bad - we didn't predict anything for several columns!
Let's look at the metrics to confirm that it is indeed bad.
```
print("Test accuracy:", accuracy_score(y_train, y_train_pred))
print("Validation accuracy:", accuracy_score(y_val, y_val_pred))
report = classification_report(y_val, y_val_pred, labels=label_map.values, target_names=label_map.index)
print(report)
```
Well, that's pretty bad. We seriously overfit our training set... which is sort-of what I expected. Oh well.
By the way, the warnings at the bottom say that we have no real Precision or F-score to use, with no predictions for some classes.
# Predict with the model
Here, we will predict on the test set (predicitions to send in), then save the results and the model.
**IMPORTANT NOTE**: In reality, you need to re-train your same model on the entire set to predict! However, I'm just using the same model as before, as it will bad anyways. ;)
```
post_test, thread_test = solution.prepare.load_dfs('test')
thread_test = thread_test.set_index('thread_num')
thread_test.head(2)
```
We need to attach a `thread_label_id` column, as given in the training set:
```
thread.head(2)
```
Use the fitted CountVectorizer and other features to make our X dataframe:
```
word_vectors_raw_test = cv.transform(thread_test['thread_name'])
word_df_test = pd.DataFrame(word_vectors_raw_test.toarray(), columns=cv.get_feature_names(), index=thread_test.index)
word_df_test.head()
X_test = pd.concat([
(thread_test['thread_replies'] + 1).rename('posts'),
np.log(thread_test['thread_replies'] + 1).rename('log_posts'),
word_df_test,
], axis='columns')
X_test.head()
```
Now we predict with our model, then paste it to a copy of `thread_test` as column `thread_label_id`.
```
y_test_pred = pd.Series(
cls.predict(X_test),
index=X_test.index,
)
y_test_pred.head()
result = thread_test.copy()
result['thread_label_id'] = y_test_pred
result.head()
```
We need to reshape to conform to the submission format specified [here](https://www.kaggle.com/c/ni-mafia-gametype#evaluation).
```
result = result.reset_index()[['thread_num', 'thread_label_id']]
result.head()
```
# Export predictions, model
Our model consists of the text vectorizer `cv` and classifier `cls`. We already formatted our results, we just need to make sure not to write an extra index column.
```
# NOTE: Exporting next to the notebooks - the files are small, but usually you don't want to do this.
out_dir = os.path.abspath('1_output')
os.makedirs(out_dir, exist_ok=True)
result.to_csv(
os.path.join(out_dir, 'baseline_predict.csv'),
index=False, header=True, encoding='utf-8',
)
import joblib
joblib.dump(cv, os.path.join(out_dir, 'cv.joblib'))
joblib.dump(cls, os.path.join(out_dir, 'cls.joblib'))
print("Done. :)")
```
# Final Remarks
I'd like to mention that the above notebook is here JUST TO GET YOU STARTED. Feel free to change anything or everything above.
It may be a good idea to keep a piece of paper with you, and draw out your entire pipeline there, to keep organized.
This model is severely overfit because of a huge number of features from the names. Some ways to combat this are PCA and lowering dimensionality, increasing regularization, using a more feature-limited classifier, etc. You can also split this into two sub-problems: a classifier to tell whether it is a game or `"other"`, then classify game type if it's a game.
| true |
code
| 0.408277 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/keivanipchihagh/Intro_To_MachineLearning/blob/master/Models/Newswires_Classification_with_Reuters.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Newswires Classification with Reuters
##### Imports
```
import numpy as np # Numpy
from matplotlib import pyplot as plt # Matplotlib
import keras # Keras
import pandas as pd # Pandas
from keras.datasets import reuters # Reuters Dataset
from keras.utils.np_utils import to_categorical # Categirical Classifier
import random # Random
```
##### Load dataset
```
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words = 10000)
print('Size:', len(train_data))
print('Training Data:', train_data[0])
```
##### Get the feel of data
```
def decode(index): # Decoding the sequential integers into the corresponding words
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in test_data[0]])
return decoded_newswire
print("Decoded test data sample [0]: ", decode(0))
```
##### Data Prep (One-Hot Encoding)
```
def vectorize_sequences(sequences, dimension = 10000): # Encoding the integer sequences into a binary matrix
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
train_data = vectorize_sequences(train_data)
test_data = vectorize_sequences(test_data)
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
```
##### Building the model
```
model = keras.models.Sequential()
model.add(keras.layers.Dense(units = 64, activation = 'relu', input_shape = (10000,)))
model.add(keras.layers.Dense(units = 64, activation = 'relu'))
model.add(keras.layers.Dense(units = 46, activation = 'softmax'))
model.compile( optimizer = 'rmsprop', loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.summary()
```
##### Training the model
```
x_val = train_data[:1000]
train_data = train_data[1000:]
y_val = train_labels[:1000]
train_labels = train_labels[1000:]
history = model.fit(train_data, train_labels, batch_size = 512, epochs = 10, validation_data = (x_val, y_val), verbose = False)
```
##### Evaluating the model
```
result = model.evaluate(train_data, train_labels)
print('Loss:', result[0])
print('Accuracy:', result[1] * 100)
```
##### Statistics
```
epochs = range(1, len(history.history['loss']) + 1)
plt.plot(epochs, history.history['loss'], 'b', label = 'Training Loss')
plt.plot(epochs, history.history['val_loss'], 'r', label = 'Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf()
plt.plot(epochs, history.history['accuracy'], 'b', label = 'Training Accuracy')
plt.plot(epochs, history.history['val_accuracy'], 'r', label = 'Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
```
##### Making predictions
```
prediction_index = random.randint(0, len(test_data))
prediction_data = test_data[prediction_index]
decoded_prediction_data = decode(prediction_index)
# Info
print('Random prediction index:', prediction_index)
print('Original prediction Data:', prediction_data)
print('Decoded prediction Data:', decoded_prediction_data)
print('Expected prediction label:', np.argmax(test_labels[prediction_index]))
# Prediction
predictions = model.predict(test_data)
print('Prediction index: ', np.argmax(predictions[prediction_index]))
```
| true |
code
| 0.726256 | null | null | null | null |
|
# Baye's Theorem
### Introduction
Befor starting with *Bayes Theorem* we can have a look at some definitions.
**Conditional Probability :**
Conditional Probability is the Probability of one event occuring with some Relationship to one or more events.
Let A and B be the two interdependent event,where A has already occured then the probabilty of B will be
$$ P(B|A) = P(A \cap B)|P(A) $$
**Joint Probability :**
Joint Probability is a Statistical measure that Calculates the Likehood of two events occuring together and at the same point in time.
$$ P(A \cap B) = P(A|B) * P(B) $$
### Bayes Theorem
Bayes Theorem was named after **Thomas Bayes**,who discovered it in **1763** and worked in the field of Decision Theory.
Bayes Theorem is a mathematical formula used to determine the **Conditional Probability** of events without the **Joint Probability**.
**Statement**
If B$_{1}$, B$_{2}$, B$_{3}$,.....,B$_{n}$ are Mutually exclusive event with P(B$_{i}$) $\not=$ 0 ,( i=1,2,3,...,n) of Random Experiment then for any Arbitrary event A of the Sample Space of the above Experiment with P(A)>0,we have
$$ P(B_{i}|A) = P(B_{i})P(A|B_{i})/ \sum\limits_{i=1}^{n} P(B_{i})P(A|B_{i}) $$
**Proof**
Let S be the Sample Space of the Random Experiment.The Event B$_{1}$, B$_{2}$, B$_{3}$,.....,B$_{n}$ being Exhaustive
$$ S = (B_{1} \cup B_{2} \cup ...\cup B_{n}) \hspace{1cm} \hspace{0.1cm} [\therefore A \subset S] $$
$$ A = A \cap S = A \cap ( B_{1} \cup B_{2} \cup B_{3},.....,\cup B_{n}) $$
$$ = (A \cap B_{1}) \cup (A \cap B_{2}) \cup ... \cup (A \cap B_{n}) $$
$$ P(A) = P(A \cap B_{1}) + P (A \cap B_{2}) + ...+ P(A \cap B_{n}) $$
$$ \hspace{3cm} \hspace{0.1cm} = P(B_{1})P(A|B_{1}) + P(B_{2})P(A|B_{2}) + ... +P(B_{n})P(A|B_{n}) $$
$$ = \sum\limits_{i=1}^{n} P(B_{i})P(A|B_{i}) $$
Now,
$$ P(A \cap B_{i}) = P(A)P(B_{i}|A) $$
$$ P(B_{i}|A) = P(A \cap B_{i})/P(A) = P(B_{i})P(A|B_{i})/\sum\limits_{i=1}^{n} P(B_{i})P(A|B_{i}) $$
**P(B)** is the Probability of occurence **B**.If we know that the event **A** has already occured.On knowing about the event **A**,**P(B)** is changed to **P(B|A)**.With the help of **Bayes Theorem we can Calculate P(B|A)**.
**Naming Conventions :**
<br>
P(A/B) : Posterior Probability
<br>
P(A) : Prior Probability
<br>
P(B/A) : Likelihood
<br>
P(B) : Evidence
<br>
So, Bayes Theorem can be Restated as :
$$ Posterior = Likelihood * Prior / Evidence $$
Now we will be looking at some problem examples on Bayes Theorem.
**Example 1** :Suppose that the reliability of a Covid-19 test is specified as follows:
<br>
Of Population having Covid-19 , 90% of the test detect the desire but 10% go undetected.Of Population free of Covid-19 , 99% of the test are judged Covid-19 -tive but 1% are diagnosed showing Covid-19 +tive.From a large population of which only 0.1% have Covid-19,one person is selected at Random,given the Covid-19 test,and the pathologist Report him/her as Covid-19 positive.What is the Probability that the person actually have Covid-19?
**Solution**<br>
Let, <br>
B$_{1}$ = The Person Selected is Actually having Covid-19.<br>
B$_{2}$ = The Person Selected is not having Covid-19.<br>
A = The Person Covid-19 Test is Diagnosed as Positive.<br>
P(B$_{1}$) = 0.1% = 0.1/100 = 0.001<br>
P(B$_{2}$) = 1-P(B$_{1}$) = 1-0.001 = 0.999<br>
P(A|B$_{1}$) = Probability that the person tested Covid-19 +tive given that he / she is actually having Covid-19.= 90/100 = 0.9 <br>
P(A|B$_{2}$) = Probability that the person tested Covid-19 +tive given that he / she is actually not having Covid-19.= 1/100 = 0.01 <br>
Required Probability = P(B$_{1}$|A) = P(B$_{1}$) * P(A|B$_{1}$)/ (((P(B$_{1}$) * P(A|B$_{1}$))+((P(B$_{2}$) * P(A|B$_{2}$)))<br>
= (0.001 * 0.9)/(0.001 * 0.9+0.999 * 0.01) = 90/1089 =0.08264
We will Now use Python to calculate the same.
```
#calculate P(B1|A) given P(B1),P(A|B1),P(A|B2),P(B2)
def bayes_theorem(p_b1,p_a_given_b1,p_a_given_b2,p_b2):
p_b1_given_a=(p_b1*p_a_given_b1)/((p_b1*p_a_given_b1)+(p_b2*p_a_given_b2))
return p_b1_given_a
#P(B1)
p_b1=0.001
#P(B2)
p_b2=0.999
#P(A|B1)
p_a_given_b1=0.9
#P(A|B2)
p_a_given_b2=0.01
result=bayes_theorem(p_b1,p_a_given_b1,p_a_given_b2,p_b2)
print('P(B1|A)=% .3f %%'%(result*100))
```
**Example 2 :** In a Quiz,a contestant either guesses or cheat or knows the answer to a multiple choice question with four choices.The Probability that he/she makes a guess is 1/3 and the Probability that he /she cheats the answer is 1/6.The Probability that his answer is correct,given that he cheated it,is 1/8.Find the Probability that he knows the answer to the question,given that he/she correctly answered it.
**Solution**<br>
Let, <br>
B$_{1}$ = Contestant guesses the answer.<br>
B$_{2}$ = Contestant cheated the answer.<br>
B$_{3}$ = Contestant knows the answer.<br>
A = Contestant answer correctly.<br>
clearly,<br>
P(B$_{1}$) = 1/3 , P(B$_{2}$) =1/6<br>
Since B$_{1}$ ,B$_{2}$, B$_{3}$ are mutually exclusive and exhaustive event.
P(B$_{1}$) + P(B$_{2}$) + P(B$_{3}$) = 1 => P(B$_{3}$) = 1 - (P(B$_{1}$) + P(B$_{2}$))
=1-1/3-1/6=1/2
If B$_{1}$ has already occured,the contestant guesses,the there are four choices out of which only one is correct.<br>
$\therefore$ the Probability that he answers correctly given that he/she has made a guess is 1/4 i.e. **P(A|B$-{1}$) = 1/4**<br>
It is given that he knew the answer = 1<br>
By Bayes Theorem,<br>
Required Probability = P(B$_{3}$|A)<br>
= P(B$_{3}$)P(A|B$_{3}$)/(P(B$_{1}$)P(A|B$_{1}$)+P(B$_{2}$)P(A|B$_{2}$)+P(B$_{3}$)P(A|B$_{3}$))
= (1/2 * 1) / ((1/3 * 1/4) + (1/6 * 1/8) + (1/2 * 1))=24/29
```
#calculate P(B1|A) given P(B1),P(A|B1),P(A|B2),P(B2),P(B3),P(A|B3)
def bayes_theorem(p_b1,p_a_given_b1,p_a_given_b2,p_b2,p_b3,p_a_given_b3):
p_b3_given_a=(p_b3*p_a_given_b3)/((p_b1*p_a_given_b1)+(p_b2*p_a_given_b2)+(p_b3*p_a_given_b3))
return p_b3_given_a
#P(B1)
p_b1=1/3
#P(B2)
p_b2=1/6
#P(B3)
p_b3=1/2
#P(A|B1)
p_a_given_b1=1/4
#P(A|B2)
p_a_given_b2=1/8
#P(A|B3)
p_a_given_b3=1
result=bayes_theorem(p_b1,p_a_given_b1,p_a_given_b2,p_b2,p_b3,p_a_given_b3)
print('P(B3|A)=% .3f %%'%(result*100))
```
| true |
code
| 0.284303 | null | null | null | null |
|
# Redis列表实现一次pop 弹出多条数据

```
# 连接 Redis
import redis
client = redis.Redis(host='122.51.39.219', port=6379, password='leftright123')
# 注意:
# 这个 Redis 环境仅作为练习之用,每小时会清空一次,请勿存放重要数据。
# 准备数据
client.lpush('test_batch_pop', *list(range(10000)))
# 一条一条读取,非常耗时
import time
start = time.time()
while True:
data = client.lpop('test_batch_pop')
if not data:
break
end = time.time()
delta = end - start
print(f'循环读取10000条数据,使用 lpop 耗时:{delta}')
```
## 为什么使用`lpop`读取10000条数据这么慢?
因为`lpop`每次只弹出1条数据,每次弹出数据都要连接 Redis 。大量时间浪费在了网络传输上面。
## 如何实现批量弹出多条数据,并在同一次网络请求中返回?
先使用 `lrange` 获取数据,再使用`ltrim`删除被获取的数据。
```
# 复习一下 lrange 的用法
datas = client.lrange('test_batch_pop', 0, 9) # 读取前10条数据
datas
# 学习一下 ltrim 的用法
client.ltrim('test_batch_pop', 10, -1) # 删除前10条数据
# 验证一下数据是否被成功删除
length = client.llen('test_batch_pop')
print(f'现在列表里面还剩{length}条数据')
datas = client.lrange('test_batch_pop', 0, 9) # 读取前10条数据
datas
# 一种看起来正确的做法
def batch_pop_fake(key, n):
datas = client.lrange(key, 0, n - 1)
client.ltrim(key, n, -1)
return datas
batch_pop_fake('test_batch_pop', 10)
client.lrange('test_batch_pop', 0, 9)
```
## 这种写法用什么问题
在多个进程同时使用 batch_pop_fake 函数的时候,由于执行 lrange 与 ltrim 是在两条语句中,因此实际上会分成2个网络请求。那么当 A 进程
刚刚执行完lrange,还没有来得及执行 ltrim 时,B 进程刚好过来执行 lrange,那么 AB 两个进程就会获得相同的数据。
等 B 进程获取完成数据以后,A 进程的 ltrim 刚刚抵达,此时Redis 会删除前 n 条数据,然后 B 进程的 ltrim 也到了,再删除前 n 条数据。那么最终导致的结果就是,AB 两个进程同时拿到前 n 条数据,但是却有2n 条数据被删除。
## 使用 pipeline 打包多个命令到一个请求中
pipeline 的使用方法如下:
```python
import redis
client = redis.Redis()
pipe = client.pipeline()
pipe.lrange('key', 0, n - 1)
pipe.ltrim('key', n, -1)
result = pipe.execute()
```
pipe.execute()返回一个列表,这个列表每一项按顺序对应每一个命令的执行结果。在上面的例子中,result 是一个有两项的列表,第一项对应 lrange 的返回结果,第二项为 True,表示 ltrim 执行成功。
```
# 真正可用的批量弹出数据函数
def batch_pop_real(key, n):
pipe = client.pipeline()
pipe.lrange(key, 0, n - 1)
pipe.ltrim(key, n, -1)
result = pipe.execute()
return result[0]
# 清空列表并重新添加10000条数据
client.delete('test_batch_pop')
client.lpush('test_batch_pop', *list(range(10000)))
start = time.time()
while True:
datas = batch_pop_real('test_batch_pop', 1000)
if not datas:
break
for data in datas:
pass
end = time.time()
print(f'批量弹出10000条数据,耗时:{end - start}')
client.llen('test_batch_pop')
```



| true |
code
| 0.382747 | null | null | null | null |
|
# Word Embeddings in MySQL
This example uses the official MySQL Connector within Python3 to store and retrieve various amounts of Word Embeddings.
We will use a local MySQL database running as a Docker Container for testing purposes. To start the database run:
```
docker run -ti --rm --name ohmysql -e MYSQL_ROOT_PASSWORD=mikolov -e MYSQL_DATABASE=embeddings -p 3306:3306 mysql:5.7
```
```
import mysql.connector
import io
import time
import numpy
import plotly
from tqdm import tqdm_notebook as tqdm
```
# Dummy Embeddings
For testing purposes we will use randomly generated numpy arrays as dummy embbeddings.
```
def embeddings(n=1000, dim=300):
"""
Yield n tuples of random numpy arrays of *dim* length indexed by *n*
"""
idx = 0
while idx < n:
yield (str(idx), numpy.random.rand(dim))
idx += 1
```
# Conversion Functions
Since we can't just save a NumPy array into the database, we will convert it into a BLOB.
```
def adapt_array(array):
"""
Using the numpy.save function to save a binary version of the array,
and BytesIO to catch the stream of data and convert it into a BLOB.
"""
out = io.BytesIO()
numpy.save(out, array)
out.seek(0)
return out.read()
def convert_array(blob):
"""
Using BytesIO to convert the binary version of the array back into a numpy array.
"""
out = io.BytesIO(blob)
out.seek(0)
return numpy.load(out)
connection = mysql.connector.connect(user='root', password='mikolov',
host='127.0.0.1',
database='embeddings')
cursor = connection.cursor()
cursor.execute('CREATE TABLE IF NOT EXISTS `embeddings` (`key` TEXT, `embedding` BLOB);')
connection.commit()
%%time
for key, emb in embeddings():
arr = adapt_array(emb)
cursor.execute('INSERT INTO `embeddings` (`key`, `embedding`) VALUES (%s, %s);', (key, arr))
connection.commit()
%%time
for key, _ in embeddings():
cursor.execute('SELECT embedding FROM `embeddings` WHERE `key`=%s;', (key,))
data = cursor.fetchone()
arr = convert_array(data[0])
```
# Sample some data
To test the I/O we will write and read some data from the database. This may take a while.
```
write_times = []
read_times = []
counts = [500, 1000, 2000, 3000, 4000, 5000]
for c in counts:
print(c)
cursor.execute('DROP TABLE IF EXISTS `embeddings`;')
cursor.execute('CREATE TABLE IF NOT EXISTS `embeddings` (`key` TEXT, `embedding` BLOB);')
connection.commit()
start_time_write = time.time()
for key, emb in tqdm(embeddings(c), total=c):
arr = adapt_array(emb)
cursor.execute('INSERT INTO `embeddings` (`key`, `embedding`) VALUES (%s, %s);', (key, arr))
connection.commit()
write_times.append(time.time() - start_time_write)
start_time_read = time.time()
for key, emb in embeddings(c):
cursor.execute('SELECT embedding FROM `embeddings` WHERE `key`=%s;', (key,))
data = cursor.fetchone()
arr = convert_array(data[0])
read_times.append(time.time() - start_time_read)
print('DONE')
```
# Results
```
plotly.offline.init_notebook_mode(connected=True)
trace = plotly.graph_objs.Scatter(
y = write_times,
x = counts,
mode = 'lines+markers'
)
layout = plotly.graph_objs.Layout(title="MySQL Write Times",
yaxis=dict(title='Time in Seconds'),
xaxis=dict(title='Embedding Count'))
data = [trace]
fig = plotly.graph_objs.Figure(data=data, layout=layout)
plotly.offline.iplot(fig, filename='jupyter-scatter-write')
plotly.offline.init_notebook_mode(connected=True)
trace = plotly.graph_objs.Scatter(
y = read_times,
x = counts,
mode = 'lines+markers'
)
layout = plotly.graph_objs.Layout(title="MySQL Read Times",
yaxis=dict(title='Time in Seconds'),
xaxis=dict(title='Embedding Count'))
data = [trace]
fig = plotly.graph_objs.Figure(data=data, layout=layout)
plotly.offline.iplot(fig, filename='jupyter-scatter-read')
```
| true |
code
| 0.689789 | null | null | null | null |
|
# Migrating scripts from Framework Mode to Script Mode
This notebook focus on how to migrate scripts using Framework Mode to Script Mode. The original notebook using Framework Mode can be find here https://github.com/awslabs/amazon-sagemaker-examples/blob/4c2a93114104e0b9555d7c10aaab018cac3d7c04/sagemaker-python-sdk/tensorflow_distributed_mnist/tensorflow_local_mode_mnist.ipynb
### Set up the environment
```
import os
import subprocess
import sagemaker
from sagemaker import get_execution_role
sagemaker_session = sagemaker.Session()
role = get_execution_role()
```
### Download the MNIST dataset
```
import utils
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
data_sets = input_data.read_data_sets('data', dtype=tf.uint8, reshape=False, validation_size=5000)
utils.convert_to(data_sets.train, 'train', 'data')
utils.convert_to(data_sets.validation, 'validation', 'data')
utils.convert_to(data_sets.test, 'test', 'data')
```
### Upload the data
We use the ```sagemaker.Session.upload_data``` function to upload our datasets to an S3 location. The return value inputs identifies the location -- we will use this later when we start the training job.
```
inputs = sagemaker_session.upload_data(path='data', key_prefix='data/mnist')
```
# Construct an entry point script for training
On this example, we assume that you aready have a Framework Mode training script named `mnist.py`:
```
!pygmentize 'mnist.py'
```
The training script `mnist.py` include the Framework Mode functions ```model_fn```, ```train_input_fn```, ```eval_input_fn```, and ```serving_input_fn```. We need to create a entrypoint script that uses the functions above to create a ```tf.estimator```:
```
%%writefile train.py
import argparse
# import original framework mode script
import mnist
import tensorflow as tf
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# read hyperparameters as script arguments
parser.add_argument('--training_steps', type=int)
parser.add_argument('--evaluation_steps', type=int)
args, _ = parser.parse_known_args()
# creates a tf.Estimator using `model_fn` that saves models to /opt/ml/model
estimator = tf.estimator.Estimator(model_fn=mnist.model_fn, model_dir='/opt/ml/model')
# creates parameterless input_fn function required by the estimator
def input_fn():
return mnist.train_input_fn(training_dir='/opt/ml/input/data/training', params=None)
train_spec = tf.estimator.TrainSpec(input_fn, max_steps=args.training_steps)
# creates parameterless serving_input_receiver_fn function required by the exporter
def serving_input_receiver_fn():
return mnist.serving_input_fn(params=None)
exporter = tf.estimator.LatestExporter('Servo',
serving_input_receiver_fn=serving_input_receiver_fn)
# creates parameterless input_fn function required by the evaluation
def input_fn():
return mnist.eval_input_fn(training_dir='/opt/ml/input/data/training', params=None)
eval_spec = tf.estimator.EvalSpec(input_fn, steps=args.evaluation_steps, exporters=exporter)
# start training and evaluation
tf.estimator.train_and_evaluate(estimator=estimator, train_spec=train_spec, eval_spec=eval_spec)
```
## Changes in the SageMaker TensorFlow estimator
We need to create a TensorFlow estimator pointing to ```train.py``` as the entrypoint:
```
from sagemaker.tensorflow import TensorFlow
mnist_estimator = TensorFlow(entry_point='train.py',
dependencies=['mnist.py'],
role='SageMakerRole',
framework_version='1.13',
hyperparameters={'training_steps':10, 'evaluation_steps':10},
py_version='py3',
train_instance_count=1,
train_instance_type='local')
mnist_estimator.fit(inputs)
```
# Deploy the trained model to prepare for predictions
The deploy() method creates an endpoint (in this case locally) which serves prediction requests in real-time.
```
mnist_predictor = mnist_estimator.deploy(initial_instance_count=1, instance_type='local')
```
# Invoking the endpoint
```
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
for i in range(10):
data = mnist.test.images[i].tolist()
predict_response = mnist_predictor.predict(data)
print("========================================")
label = np.argmax(mnist.test.labels[i])
print("label is {}".format(label))
print("prediction is {}".format(predict_response))
```
# Clean-up
Deleting the local endpoint when you're finished is important since you can only run one local endpoint at a time.
```
mnist_estimator.delete_endpoint()
```
| true |
code
| 0.468183 | null | null | null | null |
|
# HistGradientBoostingClassifier with MaxAbsScaler
This code template is for classification analysis using a HistGradientBoostingClassifier and the feature rescaling technique called MaxAbsScaler
### Required Packages
```
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as se
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.metrics import classification_report,plot_confusion_matrix
from sklearn.preprocessing import MaxAbsScaler
warnings.filterwarnings('ignore')
```
### Initialization
Filepath of CSV file
```
#filepath
file_path=""
```
List of features which are required for model training .
```
#x_values
features = []
```
Target feature for prediction.
```
#y_value
target=''
```
### Data Fetching
Pandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.
We will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry.
```
df=pd.read_csv(file_path)
df.head()
```
### Feature Selections
It is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.
We will assign all the required input features to X and target/outcome to Y.
```
X = df[features]
Y = df[target]
```
### Data Preprocessing
Since the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes.
```
def NullClearner(df):
if(isinstance(df, pd.Series) and (df.dtype in ["float64","int64"])):
df.fillna(df.mean(),inplace=True)
return df
elif(isinstance(df, pd.Series)):
df.fillna(df.mode()[0],inplace=True)
return df
else:return df
def EncodeX(df):
return pd.get_dummies(df)
def EncodeY(df):
if len(df.unique())<=2:
return df
else:
un_EncodedT=np.sort(pd.unique(df), axis=-1, kind='mergesort')
df=LabelEncoder().fit_transform(df)
EncodedT=[xi for xi in range(len(un_EncodedT))]
print("Encoded Target: {} to {}".format(un_EncodedT,EncodedT))
return df
x=X.columns.to_list()
for i in x:
X[i]=NullClearner(X[i])
X=EncodeX(X)
Y=EncodeY(NullClearner(Y))
X.head()
```
#### Correlation Map
In order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns.
```
f,ax = plt.subplots(figsize=(18, 18))
matrix = np.triu(X.corr())
se.heatmap(X.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax, mask=matrix)
plt.show()
```
#### Distribution Of Target Variable
```
plt.figure(figsize = (10,6))
se.countplot(Y)
```
### Data Splitting
The train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data.
```
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123)
```
### Data Rescaling
sklearn.preprocessing.MaxAbsScaler is used
Scale each feature by its maximum absolute value.
Read more at [scikit-learn.org](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MaxAbsScaler.html)
```
Scaler=MaxAbsScaler()
x_train=Scaler.fit_transform(x_train)
x_test=Scaler.transform(x_test)
```
### Model
Histogram-based Gradient Boosting Classification Tree.This estimator is much faster than GradientBoostingClassifier for big datasets (n_samples >= 10 000).This estimator has native support for missing values (NaNs).
[Reference](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingClassifier.html#sklearn.ensemble.HistGradientBoostingClassifier)
> **loss**: The loss function to use in the boosting process. ‘binary_crossentropy’ (also known as logistic loss) is used for binary classification and generalizes to ‘categorical_crossentropy’ for multiclass classification. ‘auto’ will automatically choose either loss depending on the nature of the problem.
> **learning_rate**: The learning rate, also known as shrinkage. This is used as a multiplicative factor for the leaves values. Use 1 for no shrinkage.
> **max_iter**: The maximum number of iterations of the boosting process, i.e. the maximum number of trees.
> **max_depth**: The maximum depth of each tree. The depth of a tree is the number of edges to go from the root to the deepest leaf. Depth isn’t constrained by default.
> **l2_regularization**: The L2 regularization parameter. Use 0 for no regularization (default).
> **early_stopping**: If ‘auto’, early stopping is enabled if the sample size is larger than 10000. If True, early stopping is enabled, otherwise early stopping is disabled.
> **n_iter_no_change**: Used to determine when to “early stop”. The fitting process is stopped when none of the last n_iter_no_change scores are better than the n_iter_no_change - 1 -th-to-last one, up to some tolerance. Only used if early stopping is performed.
> **tol**: The absolute tolerance to use when comparing scores during early stopping. The higher the tolerance, the more likely we are to early stop: higher tolerance means that it will be harder for subsequent iterations to be considered an improvement upon the reference score.
> **scoring**: Scoring parameter to use for early stopping.
```
model = HistGradientBoostingClassifier(random_state = 123)
model.fit(x_train, y_train)
```
#### Model Accuracy
score() method return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
```
print("Accuracy score {:.2f} %\n".format(model.score(x_test,y_test)*100))
```
#### Confusion Matrix
A confusion matrix is utilized to understand the performance of the classification model or algorithm in machine learning for a given test set where results are known.
```
plot_confusion_matrix(model,x_test,y_test,cmap=plt.cm.Blues)
```
#### Classification Report
A Classification report is used to measure the quality of predictions from a classification algorithm. How many predictions are True, how many are False.
* **where**:
- Precision:- Accuracy of positive predictions.
- Recall:- Fraction of positives that were correctly identified.
- f1-score:- percent of positive predictions were correct
- support:- Support is the number of actual occurrences of the class in the specified dataset.
```
print(classification_report(y_test,model.predict(x_test)))
```
#### Creator: Snehaan Bhawal , Github: [Profile](https://github.com/Sbhawal)
| true |
code
| 0.222067 | null | null | null | null |
|
# Microstructure classification using Neural Networks
In this example, we will generate microstructures of 4 different types with different grain sizes.
Then we will split the dataset into training and testing set.
Finally we will trian the neural network using CrysX-NN to make predictions.
## Run the following cell for Google colab
then restart runtime
```
! pip install --upgrade --no-cache-dir https://github.com/manassharma07/crysx_nn/tarball/main
! pip install pymks
! pip install IPython==7.7.0
! pip install fsspec>=0.3.3
```
## Import necessary libraries
We will use PyMKS for generation artificial microstructures.
```
from pymks import (
generate_multiphase,
plot_microstructures,
# PrimitiveTransformer,
# TwoPointCorrelation,
# FlattenTransformer,
# GenericTransformer
)
import numpy as np
import matplotlib.pyplot as plt
# For GPU
import cupy as cp
```
## Define some parameters
like number of samples per type, the width and height of a microstructure image in pixels.
[For Google Colab, generating 10,000 samples of each type results in out of memory error. 8000 seems to work fine.]
```
nSamples_per_type = 10000
width = 100
height = 100
```
## Generate microstructures
The following code will generate microstructures of 4 different types.
The first type has 6 times more grain boundaries along the x-axis than the y-axis.
The second type has 4 times more grain boundaries along the y-axis than the x-axis.
The third type has same number of grain boundaries along the x-axis as well as the y-axis.
The fourth type has 6 times more grain boundaries along the y-axis than the x-axis.
```
grain_sizes = [(30, 5), (10, 40), (15, 15), (5, 30)]
seeds = [10, 99, 4, 36]
data_synth = np.concatenate([
generate_multiphase(shape=(nSamples_per_type, width, height), grain_size=grain_size,
volume_fraction=(0.5, 0.5),
percent_variance=0.2,
seed=seed
)
for grain_size, seed in zip(grain_sizes, seeds)
])
```
## Plot a microstructure of each type
```
plot_microstructures(*data_synth[::nSamples_per_type+0], colorbar=True)
# plot_microstructures(*data_synth[::nSamples_per_type+1], colorbar=True)
# plot_microstructures(*data_synth[::nSamples_per_type+2], colorbar=True)
# plot_microstructures(*data_synth[::nSamples_per_type+3], colorbar=True)
#plt.savefig("Microstructures.png",dpi=600,transparent=True)
plt.show()
```
## Check the shape of the data generated
The first dimension corresponds to the total number of samples, the second and third axes are for width and height.
```
# Print shape of the array
print(data_synth.shape)
print(type(data_synth))
```
## Rename the generated data --> `X_data` as it is the input data
```
X_data = np.array(data_synth)
print(X_data.shape)
```
## Create the target/true labels for the data
The microstructure data we have generated is such that the samples of different types are grouped together. Furthermore, their order is the same as the one we provided when generating the data.
Therefore, we can generate the true labels quite easily by making a numpy array whose first `nSamples_per_type` elements correspond to type 0, and so on upto type 3.
```
Y_data = np.concatenate([np.ones(nSamples_per_type)*0,np.ones(nSamples_per_type)*1,np.ones(nSamples_per_type)*2,np.ones(nSamples_per_type)*3])
print(Y_data)
print(Y_data.shape)
```
## Plot some samples taken from the data randomly as well as their labels that we created for confirmation
```
rng = np.random.default_rng()
### Plot examples
fig, axes = plt.subplots(nrows=2, ncols=6, figsize=(15., 6.))
for axes_row in axes:
for ax in axes_row:
test_index = rng.integers(0, len(Y_data))
image = X_data[test_index]
orig_label = Y_data[test_index]
ax.set_axis_off()
ax.imshow(image)
ax.set_title('True: %i' % orig_label)
```
## Use sklearn to split the data into train and test set
```
from sklearn.model_selection import train_test_split
# Split into train and test
X_train_orig, X_test_orig, Y_train_orig, Y_test_orig = train_test_split(X_data, Y_data, test_size=0.20, random_state=1)
```
## Some statistics of the training data
```
print('Training data MIN',X_train_orig.min())
print('Training data MAX',X_train_orig.max())
print('Training data MEAN',X_train_orig.mean())
print('Training data STD',X_train_orig.std())
```
## Check some shapes
```
print(X_train_orig.shape)
print(Y_train_orig.shape)
print(X_test_orig.shape)
print(Y_test_orig.shape)
```
## Flatten the input pixel data for each sample by reshaping the 2d array of size `100,100`, for each sample to a 1d array of size `100*100`
```
X_train = X_train_orig.reshape(X_train_orig.shape[0], width*height)
X_test = X_test_orig.reshape(X_test_orig.shape[0], width*height)
```
## Check the shapes
```
print(X_train.shape)
print(X_test.shape)
```
## Use a utility from CrysX-NN to one-hot encode the target/true labels
This means that a sample with type 3 will be represented as an array [0,0,0,1]
```
from crysx_nn import mnist_utils as mu
Y_train = mu.one_hot_encode(Y_train_orig, 4)
Y_test = mu.one_hot_encode(Y_test_orig, 4)
print(Y_train.shape)
print(Y_test.shape)
```
## Standardize the training and testing input data using the mean and standard deviation of the training data
```
X_train = (X_train - np.mean(X_train_orig)) / np.std(X_train_orig)
X_test = (X_test - np.mean(X_train_orig)) / np.std(X_train_orig)
# Some statistics after standardization
print('Training data MIN',X_train.min())
print('Training data MAX',X_train.max())
print('Training data MEAN',X_train.mean())
print('Training data STD',X_train.std())
print('Testing data MIN',X_test.min())
print('Testing data MAX',X_test.max())
print('Testing data MEAN',X_test.mean())
print('Testing data STD',X_test.std())
```
## Finally we will begin creating a neural network
Set some important parameters for the Neural Network.
**Note**: In some cases I got NAN values while training. The issue could be circumvented by choosing a different batch size.
```
nInputs = width*height # No. of nodes in the input layer
neurons_per_layer = [500, 4] # Neurons per layer (excluding the input layer)
activation_func_names = ['ReLU', 'Softmax']
nLayers = len(neurons_per_layer)
nEpochs = 4
batchSize = 32 # No. of input samples to process at a time for optimization
```
## Create the neural network model
Use the parameters define above to create the model
```
from crysx_nn import network
model = network.nn_model(nInputs=nInputs, neurons_per_layer=neurons_per_layer, activation_func_names=activation_func_names, batch_size=batchSize, device='GPU', init_method='Xavier')
model.lr = 0.02
```
## Check the details of the Neural Network
```
model.details()
```
## Visualize the neural network
```
model.visualize()
```
## Begin optimization/training
We will use `float32` precision, so convert the input and output arrays.
We will use Categorical Cross Entropy for the loss function.
```
inputs = cp.array(X_train.astype(np.float32))
outputs = cp.array(Y_train.astype(np.float32))
# Run optimization
# model.optimize(inputs, outputs, lr=0.02,nEpochs=nEpochs,loss_func_name='CCE', miniterEpoch=1, batchProgressBar=True, miniterBatch=100)
# To get accuracies at each epoch
model.optimize(inputs, outputs, lr=0.02,nEpochs=nEpochs,loss_func_name='CCE', miniterEpoch=1, batchProgressBar=True, miniterBatch=100, get_accuracy=True)
```
## Error at each epoch
```
print(model.errors)
```
## Accuracy at each epoch
```
print(model.accuracy)
```
## Save model weights and biases
```
# Save weights
model.save_model_weights('NN_crysx_microstructure_96_weights_cupy')
# Save biases
model.save_model_biases('NN_crysx_microstructure_96_biases_cupy')
```
## Load model weights and biases from files
```
model.load_model_weights('NN_crysx_microstructure_96_weights_cupy')
model.load_model_biases('NN_crysx_microstructure_96_biases_cupy')
```
## Performance on Test data
```
## Convert to float32 arrays
inputs = cp.array(X_test.astype(np.float32))
outputs = cp.array(Y_test.astype(np.float32))
# predictions, error = model.predict(inputs, outputs, loss_func_name='BCE')
# print('Error:',error)
# print(predictions)
predictions, error, accuracy = model.predict(inputs, outputs, loss_func_name='CCE', get_accuracy=True)
print('Error:',error)
print('Accuracy %:',accuracy*100)
```
## Confusion matrix
```
from crysx_nn import utils
# Convert predictions to numpy array for using the utility function
predictions = cp.asnumpy(predictions)
# Get the indices of the maximum probabilities for each sample in the predictions array
pred_type = np.argmax(predictions, axis=1)
# Get the digit index from the one-hot encoded array
true_type = np.argmax(Y_test, axis=1)
# Calculation confusion matrix
cm = utils.compute_confusion_matrix(pred_type, true_type)
print('Confusion matrix:\n',cm)
# Plot the confusion matrix
utils.plot_confusion_matrix(cm)
```
## Draw some random images from the test dataset and compare the true labels to the network outputs
```
### Draw some random images from the test dataset and compare the true labels to the network outputs
fig, axes = plt.subplots(nrows=2, ncols=6, figsize=(15., 6.))
### Loop over subplots
for axes_row in axes:
for ax in axes_row:
### Draw the images
test_index = rng.integers(0, len(Y_test_orig))
image = X_test[test_index].reshape(width, height) # Use X_test instead of X_test_orig as X_test_orig is not standardized
orig_label = Y_test_orig[test_index]
### Compute the predictions
input_array = cp.array(image.reshape([1,width*height]))
output = model.predict(input_array)
# Get the maximum probability
certainty = np.max(output)
# Get the index of the maximum probability
output = np.argmax(output)
### Show image
ax.set_axis_off()
ax.imshow(image)
ax.set_title('True: %i, predicted: %i\nat %f ' % (orig_label, output, certainty*100))
```
| true |
code
| 0.756135 | null | null | null | null |
|
# Matplotlib
Matplotlib is a powerful tool for generating scientific charts of various sorts.
This presentation only touches on some features of matplotlib. Please see
<a href="https://jakevdp.github.io/PythonDataScienceHandbook/index.html">
https://jakevdp.github.io/PythonDataScienceHandbook/index.html</a> or many other
resources for a more
detailed discussion,
The following notebook shows how to use matplotlib to examine a simple univariate function.
Please refer to the quick reference notebook for introductions to some of the methods used.
Note there are some FILL_IN_THE_BLANK placeholders where you are expected
to change the notebook to make it work. There may also be bugs purposefully
introduced in the code
samples which you will need fix.
Consider the function
$$
f(x) = 0.1 * x ^ 2 + \sin(x+1) - 0.5
$$
What does it look like between -2 and 2?
```
# Import numpy and matplotlib modules
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
# Get x values between -2 and 2
xs = np.linspace(-2, 2, 21)
xs
# Compute array of f values for x values
fs = 0.2 * xs * xs + np.sin(xs + 1) - 0.5
fs
# Make a figure and plot x values against f values
fig = plt.figure()
ax = plt.axes()
ax.plot(xs, fs);
```
# Solving an equation
At what value of $x$ in $[-2, 2]$ does $f(x) = 0$?
Let's look at different plots for $f$ using functions to automate things.
```
def f(x):
return 0.2 * x ** 2 + np.sin(x + 1) - 0.5
def plot_f(low_x=-2, high_x=2, number_of_samples=30):
# Get an array of x values between low_x and high_x of length number_of_samples
xs = FILL_IN_THE_BLANK
fs = f(xs)
fig = plt.figure()
ax = plt.axes()
ax.plot(xs, fs);
plot_f()
plot_f(-1.5, 0.5)
```
# Interactive plots
We can make an interactive figure where we can try to locate the crossing point visually
```
from ipywidgets import interact
interact(plot_f, low_x=(-2.,2), high_x=(-2.,2))
# But we really should do it using an algorithm like binary search:
def find_x_at_zero(some_function, x_below_zero, x_above_zero, iteration_limit=10):
"""
Given f(x_below_zero)<=0 and f(x_above_zero) >= 0 iteratively use the
midpoint between the current boundary points to approximate f(x) == 0.
"""
for count in range(iteration_limit):
# check arguments
y_below_zero = some_function(x_below_zero)
assert y_below_zero < 0, "y_below_zero should stay at or below zero"
y_above_zero = some_function(x_above_zero)
assert y_above_zero < 0, "y_above_zero should stay at or above zero"
# get x in the middle of x_below and x_above
x_middle = 0.5 * (x_below_zero + x_above_zero)
f_middle = some_function(x_middle)
print(" at ", count, "looking at x=", x_middle, "with f(x)", f_middle)
if f_middle < 0:
FILL_IN_THE_BLANK
else:
FILL_IN_THE_BLANK
print ("final estimate after", iteration_limit, "iterations:")
print ("x at zero is between", x_below_zero, x_above_zero)
print ("with current f(x) at", f_middle)
find_x_at_zero(f, -2, 2)
# Exercise: For the following function:
def g(x):
return np.sqrt(x) + np.cos(x + 1) - 1
# Part1: Make a figure and plot x values against g(x) values
# Part 2: find an approximate value of x where g(x) is near 0.
# Part 3: Use LaTeX math notation to display the function g nicely formatted in a Markdown cell.
```
| true |
code
| 0.646349 | null | null | null | null |
|
```
library(repr) ; options(repr.plot.res = 100, repr.plot.width=5, repr.plot.height= 5) # Change plot sizes (in cm) - this bit of code is only relevant if you are using a jupyter notebook - ignore otherwise
```
<!--NAVIGATION-->
< [Multiple Explanatory Variables](16-MulExpl.ipynb) | [Main Contents](Index.ipynb) | [Model Simplification](18-ModelSimp.ipynb)>
# Linear Models: Multiple variables with interactions <span class="tocSkip">
<h1>Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Introduction" data-toc-modified-id="Introduction-1"><span class="toc-item-num">1 </span>Introduction</a></span><ul class="toc-item"><li><span><a href="#Chapter-aims" data-toc-modified-id="Chapter-aims-1.1"><span class="toc-item-num">1.1 </span>Chapter aims</a></span></li><li><span><a href="#Formulae-with-interactions-in-R" data-toc-modified-id="Formulae-with-interactions-in-R-1.2"><span class="toc-item-num">1.2 </span>Formulae with interactions in R</a></span></li></ul></li><li><span><a href="#Model-1:-Mammalian-genome-size" data-toc-modified-id="Model-1:-Mammalian-genome-size-2"><span class="toc-item-num">2 </span>Model 1: Mammalian genome size</a></span></li><li><span><a href="#Model-2-(ANCOVA):-Body-Weight-in-Odonata" data-toc-modified-id="Model-2-(ANCOVA):-Body-Weight-in-Odonata-3"><span class="toc-item-num">3 </span>Model 2 (ANCOVA): Body Weight in Odonata</a></span></li></ul></div>
# Introduction
Here you will build on your skills in fitting linear models with multiple explanatory variables to data. You will learn about another commonly used Linear Model fitting technique: ANCOVA.
We will build two models in this chapter:
* **Model 1**: Is mammalian genome size predicted by interactions between trophic level and whether species are ground dwelling?
* **ANCOVA**: Is body size in Odonata predicted by interactions between genome size and taxonomic suborder?
So far, we have only looked at the independent effects of variables. For example, in the trophic level and ground dwelling model from [the first multiple explanatory variables chapter](16-MulExpl.ipynb), we only looked for specific differences for being a omnivore *or* being ground dwelling, not for being
specifically a *ground dwelling omnivore*. These independent effects of a variable are known as *main effects* and the effects of combinations of variables acting together are known as *interactions* — they describe how the variables *interact*.
## Chapter aims
The aims of this chapter are[$^{[1]}$](#fn1):
* Creating more complex Linear Models with multiple explanatory variables
* Including the effects of interactions between multiple variables in a linear model
* Plotting predictions from more complex (multiple explanatory variables) linear models
## Formulae with interactions in R
We've already seen a number of different model formulae in R. They all use this syntax:
`response variable ~ explanatory variable(s)`
But we are now going to see two extra pieces of syntax:
* `y ~ a + b + a:b`: The `a:b` means the interaction between `a` and `b` — do combinations of these variables lead to different outcomes?
* `y ~ a * b`: This a shorthand for the model above. The means fit `a` and `b` as main effects and their interaction `a:b`.
# Model 1: Mammalian genome size
$\star$ Make sure you have changed the working directory to `Code` in your stats coursework directory.
$\star$ Create a new blank script called 'Interactions.R' and add some introductory comments.
$\star$ Load the data:
```
load('../data/mammals.Rdata')
```
If `mammals.Rdata` is missing, just import the data again using `read.csv`. You will then have to add the log C Value column to the imported data frame again.
Let's refit the model from [the first multiple explanatory variables chapter](16-MulExpl.ipynb), but including the interaction between trophic level and ground dwelling. We'll immediately check the model is appropriate:
```
model <- lm(logCvalue ~ TrophicLevel * GroundDwelling, data= mammals)
par(mfrow=c(2,2), mar=c(3,3,1,1), mgp=c(2, 0.8,0))
plot(model)
```
Now, examine the `anova` and `summary` outputs for the model:
```
anova(model)
```
Compared to the model from [the first multiple explanatory variables chapter](16-MulExpl.ipynb), there is an extra line at the bottom. The top two are the same and show that trophic level and ground dwelling both have independent main effects. The extra line
shows that there is also an interaction between the two. It doesn't explain a huge amount of variation, about half as much as trophic level, but it is significant.
Again, we can calculate the $r^2$ for the model: $\frac{0.81 + 2.75 + 0.43}{0.81+2.75+0.43+12.77} = 0.238$
The model from [the first multiple explanatory variables chapter](16-MulExpl.ipynb) without the interaction had an $r^2 = 0.212$ — our new
model explains 2.6% more of the variation in the data.
The summary table is as follows:
```
summary(model)
```
The lines in this output are:
1. The reference level (intercept) for non ground dwelling carnivores. (The reference level is decided just by the alphabetic order of the levels)
2. Two differences for being in different trophic levels.
3. One difference for being ground dwelling
4. Two new differences that give specific differences for ground dwelling herbivores and omnivores.
The first four lines, as in the model from the [ANOVA chapter](15-anova.ipynb), which would allow us to find the predicted values for each group *if the size of the differences did not vary between levels because of the interactions*. That is, this part of the model only includes a single difference ground and non-ground species, which has to be the same for each trophic group because it ignores interactions between trophic level and ground / non-ground identity of each species. The last two lines then give the estimated coefficients associated with the interaction terms, and allow cause the size of differences to vary
between levels because of the further effects of interactions.
The table below show how these combine to give the predictions for each group combination, with those two new lines show in red:
$\begin{array}{|r|r|r|}
\hline
& \textrm{Not ground} & \textrm{Ground} \\
\hline
\textrm{Carnivore} & 0.96 = 0.96 & 0.96+0.25=1.21 \\
\textrm{Herbivore} & 0.96 + 0.05 = 1.01 & 0.96+0.05+0.25{\color{red}+0.03}=1.29\\
\textrm{Omnivore} & 0.96 + 0.23 = 1.19 & 0.96+0.23+0.25{\color{red}-0.15}=1.29\\
\hline
\end{array}$
So why are there two new coefficients? For interactions between two factors, there are always $(n-1)\times(m-1)$ new coefficients, where $n$ and $m$ are the number of levels in the two factors (Ground dwelling or not: 2 levels and trophic level: 3 levels, in our current example). So in this model, $(3-1) \times (2-1) =2$. It is easier to understand why
graphically: the prediction for the white boxes below can be found by adding the main effects together but for the grey boxes we need to find specific differences and so there are $(n-1)\times(m-1)$ interaction coefficients to add.
<a id="fig:interactionsdiag"></a>
<figure>
<img src="./graphics/interactionsdiag.png" alt="interactionsdiag" style="width:50%">
<small>
<center>
<figcaption>
Figure 2
</figcaption>
</center>
</small>
</figure>
If we put this together, what is the model telling us?
* Herbivores have the same genome sizes as carnivores, but omnivores have larger genomes.
* Ground dwelling mammals have larger genomes.
These two findings suggest that ground dwelling omnivores should have extra big genomes. However, the interaction shows they are smaller than expected and are, in fact, similar to ground dwelling herbivores.
Note that although the interaction term in the `anova` output is significant, neither of the two coefficients in the `summary` has a $p<0.05$. There are two weak differences (one
very weak, one nearly significant) that together explain significant
variance in the data.
$\star$ Copy the code above into your script and run the model.
Make sure you understand the output!
Just to make sure the sums above are correct, we'll use the same code as
in [the first multiple explanatory variables chapter](16-MulExpl.ipynb) to get R to calculate predictions for us, similar to the way we did [before](16-MulExpl.ipynb):
```
# a data frame of combinations of variables
gd <- rep(levels(mammals$GroundDwelling), times = 3)
print(gd)
tl <- rep(levels(mammals$TrophicLevel), each = 2)
print(tl)
# New data frame
predVals <- data.frame(GroundDwelling = gd, TrophicLevel = tl)
# predict using the new data frame
predVals$predict <- predict(model, newdata = predVals)
print(predVals)
```
$\star$ Include and run the code for gererating these predictions in your script.
If we plot these data points onto the barplot from [the first multiple explanatory variables chapter](16-MulExpl.ipynb), they now lie exactly on the mean values, because we've allowed for interactions. The triangle on this plot shows the predictions for ground dwelling omnivores from the main effects ($0.96 + 0.23 + 0.25 = 1.44$), the interaction of $-0.15$ pushes the prediction back down.
<a id="fig:predPlot"></a>
<figure>
<img src="./graphics/predPlot.svg" alt="predPlot" style="width:70%">
</figure>
# Model 2 (ANCOVA): Body Weight in Odonata
We'll go all the way back to the regression analyses from the [Regression chapter](14-regress.ipynb). Remember that we fitted two separate regression lines to the data for damselflies and dragonflies. We'll now use an interaction to fit these in a single model. This kind of linear model — with a mixture of continuous variables and factors — is often called an *analysis of covariance*, or ANCOVA. That is, ANCOVA is a type of linear model that blends ANOVA and regression. ANCOVA evaluates whether population means of a dependent variable are equal across levels of a categorical independent variable, while statistically controlling for the effects of other continuous variables that are not of primary interest, known as covariates.
*Thus, ANCOVA is a linear model with one categorical and one or more continuous predictors*.
We will use the odonates data that we have worked with [before](12-ExpDesign.ipynb).
$\star$ First load the data:
```
odonata <- read.csv('../data/GenomeSize.csv')
```
$\star$ Now create two new variables in the `odonata` data set called `logGS` and `logBW` containing log genome size and log body weight:
```
odonata$logGS <- log(odonata$GenomeSize)
odonata$logBW <- log(odonata$BodyWeight)
```
The models we fitted [before](12-ExpDesign.ipynb) looked like this:
<a id="fig:dragonData"></a>
<figure>
<img src="./graphics/dragonData.svg" alt="dragonData" style="width:60%">
<small>
<center>
<figcaption>
</figcaption>
</center>
</small>
</figure>
We can now fit the model of body weight as a function of both genome size and suborder:
```
odonModel <- lm(logBW ~ logGS * Suborder, data = odonata)
```
Again, we'll look at the <span>anova</span> table first:
```
anova(odonModel)
```
Interpreting this:
* There is no significant main effect of log genome size. The *main* effect is the important thing here — genome size is hugely important but does very different things for the two different suborders. If we ignored `Suborder`, there isn't an overall relationship: the average of those two lines is pretty much flat.
* There is a very strong main effect of Suborder: the mean body weight in the two groups are very different.
* There is a strong interaction between suborder and genome size. This is an interaction between a factor and a continuous variable and shows that the *slopes* are different for the different factor levels.
Now for the summary table:
```
summary(odonModel)
```
* The first thing to note is that the $r^2$ value is really high. The model explains three quarters (0.752) of the variation in the data.
* Next, there are four coefficients:
* The intercept is for the first level of `Suborder`, which is Anisoptera (dragonflies).
* The next line, for `log genome size`, is the slope for Anisoptera.
* We then have a coefficient for the second level of `Suborder`, which is Zygoptera (damselflies). As with the first model, this difference in factor levels is a difference in mean values and shows the difference in the intercept for Zygoptera.
* The last line is the interaction between `Suborder` and `logGS`. This shows how the slope for Zygoptera differs from the slope for Anisoptera.
How do these hang together to give the two lines shown in the model? We can calculate these by hand:
$\begin{aligned}
\textrm{Body Weight} &= -2.40 + 1.01 \times \textrm{logGS} & \textrm{[Anisoptera]}\\
\textrm{Body Weight} &= (-2.40 -2.25) + (1.01 - 2.15) \times \textrm{logGS} & \textrm{[Zygoptera]}\\
&= -4.65 - 1.14 \times \textrm{logGS} \\\end{aligned}$
$\star$ Add the above code into your script and check that you understand the outputs.
We'll use the `predict` function again to get the predicted values from the model and add lines to the plot above.
First, we'll create a set of numbers spanning the range of genome size:
```
#get the range of the data:
rng <- range(odonata$logGS)
#get a sequence from the min to the max with 100 equally spaced values:
LogGSForFitting <- seq(rng[1], rng[2], length = 100)
```
Have a look at these numbers:
```
print(LogGSForFitting)
```
We can now use the model to predict the values of body weight at each of those points for each of the two suborders:
```
#get a data frame of new data for the order
ZygoVals <- data.frame(logGS = LogGSForFitting, Suborder = "Zygoptera")
#get the predictions and standard error
ZygoPred <- predict(odonModel, newdata = ZygoVals, se.fit = TRUE)
#repeat for anisoptera
AnisoVals <- data.frame(logGS = LogGSForFitting, Suborder = "Anisoptera")
AnisoPred <- predict(odonModel, newdata = AnisoVals, se.fit = TRUE)
```
We've added `se.fit=TRUE` to the function to get the standard error around the regression lines. Both `AnisoPred` and `ZygoPred` contain predicted values (called `fit`) and standard error values (called `se.fit`) for each of the values in our generated values in `LogGSForFitting` for each of the two suborders.
We can add the predictions onto a plot like this:
```
# plot the scatterplot of the data
plot(logBW ~ logGS, data = odonata, col = Suborder)
# add the predicted lines
lines(AnisoPred$fit ~ LogGSForFitting, col = "black")
lines(AnisoPred$fit + AnisoPred$se.fit ~ LogGSForFitting, col = "black", lty = 2)
lines(AnisoPred$fit - AnisoPred$se.fit ~ LogGSForFitting, col = "black", lty = 2)
```
$\star$ Copy the prediction code into your script and run the plot above.
Copy and modify the last three lines to add the lines for the Zygoptera. Your final plot should look like this.
<a id="fig:odonPlot"></a>
<figure>
<img src="./graphics/odonPlot.svg" alt="odonPlot" style="width:70%">
<small>
<center>
<figcaption>
Figure 4
</figcaption>
</center>
</small>
</figure>
---
<a id="fn1"></a>
[1]: Here you work with the script file `MulExplInter.R`
| true |
code
| 0.730428 | null | null | null | null |
|
## Plotting very large datasets meaningfully, using `datashader`
There are a variety of approaches for plotting large datasets, but most of them are very unsatisfactory. Here we first show some of the issues, then demonstrate how the `datashader` library helps make large datasets truly practical.
We'll use part of the well-studied [NYC Taxi trip database](http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml), with the locations of all NYC taxi pickups and dropoffs from the month of January 2015. Although we know what the data is, let's approach it as if we are doing data mining, and see what it takes to understand the dataset from scratch.
### Load NYC Taxi data
(takes 10-20 seconds, since it's in the inefficient but widely supported CSV file format...)
```
import pandas as pd
%time df = pd.read_csv('../data/nyc_taxi.csv',usecols= \
['pickup_x', 'pickup_y', 'dropoff_x','dropoff_y', 'passenger_count','tpep_pickup_datetime'])
df.tail()
```
As you can see, this file contains about 12 million pickup and dropoff locations (in Web Mercator coordinates), with passenger counts.
### Define a simple plot
```
from bokeh.models import BoxZoomTool
from bokeh.plotting import figure, output_notebook, show
output_notebook()
NYC = x_range, y_range = ((-8242000,-8210000), (4965000,4990000))
plot_width = int(750)
plot_height = int(plot_width//1.2)
def base_plot(tools='pan,wheel_zoom,reset',plot_width=plot_width, plot_height=plot_height, **plot_args):
p = figure(tools=tools, plot_width=plot_width, plot_height=plot_height,
x_range=x_range, y_range=y_range, outline_line_color=None,
min_border=0, min_border_left=0, min_border_right=0,
min_border_top=0, min_border_bottom=0, **plot_args)
p.axis.visible = False
p.xgrid.grid_line_color = None
p.ygrid.grid_line_color = None
p.add_tools(BoxZoomTool(match_aspect=True))
return p
options = dict(line_color=None, fill_color='blue', size=5)
```
### 1000-point scatterplot: undersampling
Any plotting program should be able to handle a plot of 1000 datapoints. Here the points are initially overplotting each other, but if you hit the Reset button (top right of plot) to zoom in a bit, nearly all of them should be clearly visible in the following Bokeh plot of a random 1000-point sample. If you know what to look for, you can even see the outline of Manhattan Island and Central Park from the pattern of dots. We've included geographic map data here to help get you situated, though for a genuine data mining task in an abstract data space you might not have any such landmarks. In any case, because this plot is discarding 99.99% of the data, it reveals very little of what might be contained in the dataset, a problem called *undersampling*.
```
%%time
from bokeh.tile_providers import STAMEN_TERRAIN
samples = df.sample(n=1000)
p = base_plot()
p.add_tile(STAMEN_TERRAIN)
p.circle(x=samples['dropoff_x'], y=samples['dropoff_y'], **options)
show(p)
```
### 10,000-point scatterplot: overplotting
We can of course plot more points to reduce the amount of undersampling. However, even if we only try to plot 0.1% of the data, ignoring the other 99.9%, we will find major problems with *overplotting*, such that the true density of dropoffs in central Manhattan is impossible to see due to occlusion:
```
%%time
samples = df.sample(n=10000)
p = base_plot()
p.circle(x=samples['dropoff_x'], y=samples['dropoff_y'], **options)
show(p)
```
Overplotting is reduced if you zoom in on a particular region (may need to click to enable the wheel-zoom tool in the upper right of the plot first, then use the scroll wheel). However, then the problem switches to back to serious undersampling, as the too-sparsely sampled datapoints get revealed for zoomed-in regions, even though much more data is available.
### 100,000-point scatterplot: saturation
If you make the dot size smaller, you can reduce the overplotting that occurs when you try to combat undersampling. Even so, with enough opaque data points, overplotting will be unavoidable in popular dropoff locations. So you can then adjust the alpha (opacity) parameter of most plotting programs, so that multiple points need to overlap before full color saturation is achieved. With enough data, such a plot can approximate the probability density function for dropoffs, showing where dropoffs were most common:
```python
%%time
options = dict(line_color=None, fill_color='blue', size=1, alpha=0.1)
samples = df.sample(n=100000)
p = base_plot(webgl=True)
p.circle(x=samples['dropoff_x'], y=samples['dropoff_y'], **options)
show(p)
```
<img src="../assets/images/nyc_taxi_100k.png">
[*Here we've shown static output as a PNG rather than a live Bokeh plot, to reduce the file size for distributing full notebooks and because some browsers will have trouble with plots this large. The above cell can be converted into code and executed to get the full interactive plot.*]
However, it's very tricky to set the size and alpha parameters. How do we know if certain regions are saturating, unable to show peaks in dropoff density? Here we've manually set the alpha to show a clear structure of streets and blocks, as one would intuitively expect to see, but the density of dropoffs still seems approximately the same on nearly all Manhattan streets (just wider in some locations), which is unlikely to be true. We can of course reduce the alpha value to reduce saturation further, but there's no way to tell when it's been set correctly, and it's already low enough that nothing other than Manhattan and La Guardia is showing up at all. Plus, this alpha value will only work even reasonably well at the one zoom level shown. Try zooming in (may need to enable the wheel zoom tool in the upper right) to see that at higher zooms, there is less overlap between dropoff locations, so that the points *all* start to become transparent due to lack of overlap. Yet without setting the size and alpha to a low value in the first place, the stucture is invisible when zoomed out, due to overplotting. Thus even though Bokeh provides rich support for interactively revealing structure by zooming, it is of limited utility for large data; either the data is invisible when zoomed in, or there's no large-scale structure when zoomed out, which is necessary to indicate where zooming would be informative.
Moreover, we're still ignoring 99% of the data. Many plotting programs will have trouble with plots even this large, but Bokeh can handle 100-200,000 points in most browsers. Here we've enabled Bokeh's WebGL support, which gives smoother zooming behavior, but the non-WebGL mode also works well. Still, for such large sizes the plots become slow due to the large HTML file sizes involved, because each of the data points are encoded as text in the web page, and for even larger samples the browser will fail to render the page at all.
### 10-million-point datashaded plots: auto-ranging, but limited dynamic range
To let us work with truly large datasets without discarding most of the data, we can take an entirely different approach. Instead of using a Bokeh scatterplot, which encodes every point into JSON and stores it in the HTML file read by the browser, we can use the [datashader](https://github.com/bokeh/datashader) library to render the entire dataset into a pixel buffer in a separate Python process, and then provide a fixed-size image to the browser containing only the data currently visible. This approach decouples the data processing from the visualization. The data processing is then limited only by the computational power available, while the visualization has much more stringent constraints determined by your display device (a web browser and your particular monitor, in this case). This approach works particularly well when your data is in a far-off server, but it is also useful whenever your dataset is larger than your display device can render easily.
Because the number of points involved is no longer a limiting factor, you can now use the entire dataset (including the full 150 million trips that have been made public, if you download that data separately). Most importantly, because datashader allows computation on the intermediate stages of plotting, you can easily define operations like auto-ranging (which is on by default), so that we can be sure there is no overplotting or saturation and no need to set parameters like alpha.
The steps involved in datashading are (1) create a Canvas object with the shape of the eventual plot (i.e. having one storage bin for collecting points, per final pixel), (2) aggregating all points into that set of bins, incrementally counting them, and (3) mapping the resulting counts into a visible color from a specified range to make an image:
```
import datashader as ds
from datashader import transfer_functions as tf
from datashader.colors import Greys9
Greys9_r = list(reversed(Greys9))[:-2]
%%time
cvs = ds.Canvas(plot_width=plot_width, plot_height=plot_height, x_range=x_range, y_range=y_range)
agg = cvs.points(df, 'dropoff_x', 'dropoff_y', ds.count('passenger_count'))
img = tf.shade(agg, cmap=["white", 'darkblue'], how='linear')
```
The resulting image is similar to the 100,000-point Bokeh plot above, but (a) makes use of all 12 million datapoints, (b) is computed in only a tiny fraction of the time, (c) does not require any magic-number parameters like size and alpha, and (d) automatically ensures that there is no saturation or overplotting:
```
img
```
This plot renders the count at every pixel as a color from the specified range (here from white to dark blue), mapped linearly. If your display device were linear, and the data were distributed evenly across this color range, then the result of such linear, auto-ranged processing would be an effective, parameter-free way to visualize your dataset.
However, real display devices are not typically linear, and more importantly, real data is rarely distributed evenly. Here, it is clear that there are "hotspots" in dropoffs, with a very high count for areas around Penn Station and Madison Square Garden, relatively low counts for the rest of Manhattan's streets, and apparently no dropoffs anywhere else but La Guardia airport. NYC taxis definitely cover a larger geographic range than this, so what is the problem? To see, let's look at the histogram of counts for the above image:
```
import numpy as np
def histogram(x,colors=None):
hist,edges = np.histogram(x, bins=100)
p = figure(y_axis_label="Pixels",
tools='', height=130, outline_line_color=None,
min_border=0, min_border_left=0, min_border_right=0,
min_border_top=0, min_border_bottom=0)
p.quad(top=hist[1:], bottom=0, left=edges[1:-1], right=edges[2:])
print("min: {}, max: {}".format(np.min(x),np.max(x)))
show(p)
histogram(agg.values)
```
Clearly, most of the pixels have very low counts (under 3000), while a very few pixels have much larger counts (up to 22000, in this case). When these values are mapped into colors for display, nearly all of the pixels will end up being colored with the lowest colors in the range, i.e. white or nearly white, while the other colors in the available range will be used for only a few dozen pixels at most. Thus most of the pixels in this plot convey very little information about the data, wasting nearly all of dynamic range available on your display device. It's thus very likely that we are missing a lot of the structure in this data that we could be seeing.
### 10-million-point datashaded plots: high dynamic range
For the typical case of data that is distributed nonlinearly over the available range, we can use nonlinear scaling to map the data range into the visible color range. E.g. first transforming the values via a log function will help flatten out this histogram and reveal much more of the structure of this data:
```
histogram(np.log1p(agg.values))
tf.shade(agg, cmap=Greys9_r, how='log')
```
We can now see that there is rich structure throughout this dataset -- geographic features like streets and buildings are clearly modulating the values in both the high-dropoff regions in Manhattan and the relatively low-dropoff regions in the surrounding areas. Still, this choice is arbitrary -- why the log function in particular? It clearly flattened the histogram somewhat, but it was just a guess. We can instead explicitly equalize the histogram of the data before building the image, making structure visible at every data level (and thus at all the geographic locations covered) in a general way:
```
histogram(tf.eq_hist(agg.values))
tf.shade(agg, cmap=Greys9_r, how='eq_hist')
```
The histogram is now fully flat (apart from the spacing of bins caused by the discrete nature of integer counting). Effectively, the visualization now shows a rank-order or percentile distribution of the data. I.e., pixels are now colored according to where their corresponding counts fall in the distribution of all counts, with one end of the color range for the lowest counts, one end for the highest ones, and every colormap step in between having similar numbers of counts. Such a visualization preserves the ordering between count values, faithfully displaying local differences in these counts, but discards absolute magnitudes (as the top 1% of the color range will be used for the top 1% of the data values, whatever those may be).
Now that the data is visible at every level, we can immediately see that there are some clear problems with the quality of the data -- there is a surprising number of trips that claim to drop off in the water or in the roadless areas of Central park, as well as in the middle of most of the tallest buildings in central Manhattan. These locations are likely to be GPS errors being made visible, perhaps partly because of poor GPS performance in between the tallest buildings.
Histogram equalization does not require any magic parameters, and in theory it should convey the maximum information available about the relative values between pixels, by mapping each of the observed ranges of values into visibly discriminable colors. And it's clearly a good start in practice, because it shows both low values (avoiding undersaturation) and relatively high values clearly, without arbitrary settings.
Even so, the results will depend on the nonlinearities of your visual system, your specific display device, and any automatic compensation or calibration being applied to your display device. Thus in practice, the resulting range of colors may not map directly into a linearly perceivable range for your particular setup, and so you may want to further adjust the values to more accurately reflect the underlying structure, by adding additional calibration or compensation steps.
Moreover, at this point you can now bring in your human-centered goals for the visualization -- once the overall structure has been clearly revealed, you can select specific aspects of the data to highlight or bring out, based on your own questions about the data. These questions can be expressed at whatever level of the pipeline is most appropriate, as shown in the examples below. For instance, histogram equalization was done on the counts in the aggregate array, because if we waited until the image had been created, we would have been working with data truncated to the 256 color levels available per channel in most display devices, greatly reducing precision. Or you may want to focus specifically on the highest peaks (as shown below), which again should be done at the aggregate level so that you can use the full color range of your display device to represent the narrow range of data that you are interested in. Throughout, the goal is to map from the data of interest into the visible, clearly perceptible range available on your display device.
### 10-million-point datashaded plots: interactive
Although the above plots reveal the entire dataset at once, the full power of datashading requires an interactive plot, because a big dataset will usually have structure at very many different levels (such as different geographic regions). Datashading allows auto-ranging and other automatic operations to be recomputed dynamically for the specific selected viewport, automatically revealing local structure that may not be visible from a global view. Here we'll embed the generated images into a Bokeh plot to support fully interactive zooming. For the highest detail on large monitors, you should increase the plot width and height above.
```
import datashader as ds
from datashader.bokeh_ext import InteractiveImage
from functools import partial
from datashader.utils import export_image
from datashader.colors import colormap_select, Greys9, Hot, inferno
background = "black"
export = partial(export_image, export_path="export", background=background)
cm = partial(colormap_select, reverse=(background=="black"))
def create_image(x_range, y_range, w=plot_width, h=plot_height):
cvs = ds.Canvas(plot_width=w, plot_height=h, x_range=x_range, y_range=y_range)
agg = cvs.points(df, 'dropoff_x', 'dropoff_y', ds.count('passenger_count'))
img = tf.shade(agg, cmap=Hot, how='eq_hist')
return tf.dynspread(img, threshold=0.5, max_px=4)
p = base_plot(background_fill_color=background)
export(create_image(*NYC),"NYCT_hot")
InteractiveImage(p, create_image)
```
You can now zoom in interactively to this plot, seeing all the points available in that viewport, without ever needing to change the plot parameters for that specific zoom level. Each time you zoom or pan, a new image is rendered (which takes a few seconds for large datasets), and displayed overlaid any other plot elements, providing full access to all of your data. Here we've used the optional `tf.dynspread` function to automatically enlarge the size of each datapoint once you've zoomed in so far that datapoints no longer have nearby neighbors.
### Customizing datashader
One of the most important features of datashading is that each of the stages of the datashader pipeline can be modified or replaced, either for personal preferences or to highlight specific aspects of the data. Here we'll use a high-level `Pipeline` object that encapsulates the typical series of steps in the above `create_image` function, and then we'll customize it. The default values of this pipeline are the same as the plot above, but here we'll add a special colormap to make the values stand out against an underlying map, and only plot hotspots (defined here as pixels (aggregation bins) that are in the 90th percentile by count):
```
import numpy as np
from functools import partial
def create_image90(x_range, y_range, w=plot_width, h=plot_height):
cvs = ds.Canvas(plot_width=w, plot_height=h, x_range=x_range, y_range=y_range)
agg = cvs.points(df, 'dropoff_x', 'dropoff_y', ds.count('passenger_count'))
img = tf.shade(agg.where(agg>np.percentile(agg,90)), cmap=inferno, how='eq_hist')
return tf.dynspread(img, threshold=0.3, max_px=4)
p = base_plot()
p.add_tile(STAMEN_TERRAIN)
export(create_image(*NYC),"NYCT_90th")
InteractiveImage(p, create_image90)
```
If you zoom in to the plot above, you can see that the 90th-percentile criterion at first highlights the most active areas in the entire dataset, and then highlights the most active areas in each subsequent viewport. Here yellow has been chosen to highlight the strongest peaks, and if you zoom in on one of those peaks you can see the most active areas in that particular geographic region, according to this dynamically evaluated definition of "most active".
The above plots each followed a roughly standard series of steps useful for many datasets, but you can instead fully customize the computations involved. This capability lets you do novel operations on the data once it has been aggregated into pixel-shaped bins. For instance, you might want to plot all the pixels where there were more dropoffs than pickups in blue, and all those where there were more pickups than dropoffs in red. To do this, just write your own function that will create an image, when given x and y ranges, a resolution (w x h), and any optional arguments needed. You can then either call the function yourself, or pass it to `InteractiveImage` to make an interactive Bokeh plot:
```
def merged_images(x_range, y_range, w=plot_width, h=plot_height, how='log'):
cvs = ds.Canvas(plot_width=w, plot_height=h, x_range=x_range, y_range=y_range)
picks = cvs.points(df, 'pickup_x', 'pickup_y', ds.count('passenger_count'))
drops = cvs.points(df, 'dropoff_x', 'dropoff_y', ds.count('passenger_count'))
drops = drops.rename({'dropoff_x': 'x', 'dropoff_y': 'y'})
picks = picks.rename({'pickup_x': 'x', 'pickup_y': 'y'})
more_drops = tf.shade(drops.where(drops > picks), cmap=["darkblue", 'cornflowerblue'], how=how)
more_picks = tf.shade(picks.where(picks > drops), cmap=["darkred", 'orangered'], how=how)
img = tf.stack(more_picks, more_drops)
return tf.dynspread(img, threshold=0.3, max_px=4)
p = base_plot(background_fill_color=background)
export(merged_images(*NYC),"NYCT_pickups_vs_dropoffs")
InteractiveImage(p, merged_images)
```
Now you can see that pickups are more common on major roads, as you'd expect, and dropoffs are more common on side streets. In Manhattan, roads running along the island are more common for pickups. If you zoom in to any location, the data will be re-aggregated to the new resolution automatically, again calculating for each newly defined pixel whether pickups or dropoffs were more likely in that pixel. The interactive features of Bokeh are now fully usable with this large dataset, allowing you to uncover new structure at every level.
We can also use other columns in the dataset as additional dimensions in the plot. For instance, if we want to see if certain areas are more likely to have pickups at certain hours (e.g. areas with bars and restaurants might have pickups in the evening, while apartment buildings may have pickups in the morning). One way to do this is to use the hour of the day as a category, and then colorize each hour:
```
df['hour'] = pd.to_datetime(df['tpep_pickup_datetime']).dt.hour.astype('category')
colors = ["#FF0000","#FF3F00","#FF7F00","#FFBF00","#FFFF00","#BFFF00","#7FFF00","#3FFF00",
"#00FF00","#00FF3F","#00FF7F","#00FFBF","#00FFFF","#00BFFF","#007FFF","#003FFF",
"#0000FF","#3F00FF","#7F00FF","#BF00FF","#FF00FF","#FF00BF","#FF007F","#FF003F",]
def colorized_images(x_range, y_range, w=plot_width, h=plot_height, dataset="pickup"):
cvs = ds.Canvas(plot_width=w, plot_height=h, x_range=x_range, y_range=y_range)
agg = cvs.points(df, dataset+'_x', dataset+'_y', ds.count_cat('hour'))
img = tf.shade(agg, color_key=colors)
return tf.dynspread(img, threshold=0.3, max_px=4)
p = base_plot(background_fill_color=background)
#p.add_tile(STAMEN_TERRAIN)
export(colorized_images(*NYC, dataset="pickup"),"NYCT_pickup_times")
InteractiveImage(p, colorized_images, dataset="pickup")
export(colorized_images(*NYC, dataset="dropoff"),"NYCT_dropoff_times")
p = base_plot(background_fill_color=background)
InteractiveImage(p, colorized_images, dataset="dropoff")
```
Here the order of colors is roughly red (midnight), yellow (4am), green (8am), cyan (noon), blue (4pm), purple (8pm), and back to red (since hours and colors are both cyclic). There are clearly hotspots by hour that can now be investigated, and perhaps compared with the underlying map data. And you can try first filtering the dataframe to only have weekdays or weekends, or only during certain public events, etc., or filtering the resulting pixels to have only those in a certain range of interest. The system is very flexible, and it should be straightforward to express a very large range of possible queries and visualizations with very little code.
The above examples each used pre-existing components provided for the datashader pipeline, but you can implement any components you like and substitute them, allowing you to easily explore and highlight specific aspects of your data. Have fun datashading!
| true |
code
| 0.416915 | null | null | null | null |
|
```
from IPython import display
from utils import Logger
import torch
from torch import nn
from torch.optim import Adam
from torch.autograd import Variable
from torchvision import transforms, datasets
DATA_FOLDER = './torch_data/VGAN/MNIST'
```
## Load Data
```
def mnist_data():
compose = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
out_dir = '{}/dataset'.format(DATA_FOLDER)
return datasets.MNIST(root=out_dir, train=True, transform=compose, download=True)
data = mnist_data()
batch_size = 100
data_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True)
num_batches = len(data_loader)
```
## Networks
```
class DiscriminativeNet(torch.nn.Module):
"""
A two hidden-layer discriminative neural network
"""
def __init__(self):
super(DiscriminativeNet, self).__init__()
n_features = 784
n_out = 1
self.hidden0 = nn.Sequential(
nn.Linear(n_features, 1024),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.hidden1 = nn.Sequential(
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.hidden2 = nn.Sequential(
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.out = nn.Sequential(
torch.nn.Linear(256, n_out),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.hidden0(x)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.out(x)
return x
def images_to_vectors(images):
return images.view(images.size(0), 784)
def vectors_to_images(vectors):
return vectors.view(vectors.size(0), 1, 28, 28)
class GenerativeNet(torch.nn.Module):
"""
A three hidden-layer generative neural network
"""
def __init__(self):
super(GenerativeNet, self).__init__()
n_features = 100
n_out = 784
self.hidden0 = nn.Sequential(
nn.Linear(n_features, 256),
nn.LeakyReLU(0.2)
)
self.hidden1 = nn.Sequential(
nn.Linear(256, 512),
nn.LeakyReLU(0.2)
)
self.hidden2 = nn.Sequential(
nn.Linear(512, 1024),
nn.LeakyReLU(0.2)
)
self.out = nn.Sequential(
nn.Linear(1024, n_out),
nn.Tanh()
)
def forward(self, x):
x = self.hidden0(x)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.out(x)
return x
# Noise
def noise(size):
n = Variable(torch.randn(size, 100))
if torch.cuda.is_available(): return n.cuda
return n
discriminator = DiscriminativeNet()
generator = GenerativeNet()
if torch.cuda.is_available():
discriminator.cuda()
generator.cuda()
```
## Optimization
```
# Optimizers
d_optimizer = Adam(discriminator.parameters(), lr=0.0002)
g_optimizer = Adam(generator.parameters(), lr=0.0002)
# Loss function
loss = nn.BCELoss()
# Number of steps to apply to the discriminator
d_steps = 1 # In Goodfellow et. al 2014 this variable is assigned to 1
# Number of epochs
num_epochs = 200
```
## Training
```
def real_data_target(size):
'''
Tensor containing ones, with shape = size
'''
data = Variable(torch.ones(size, 1))
if torch.cuda.is_available(): return data.cuda()
return data
def fake_data_target(size):
'''
Tensor containing zeros, with shape = size
'''
data = Variable(torch.zeros(size, 1))
if torch.cuda.is_available(): return data.cuda()
return data
def train_discriminator(optimizer, real_data, fake_data):
# Reset gradients
optimizer.zero_grad()
# 1.1 Train on Real Data
prediction_real = discriminator(real_data)
# Calculate error and backpropagate
error_real = loss(prediction_real, real_data_target(real_data.size(0)))
error_real.backward()
# 1.2 Train on Fake Data
prediction_fake = discriminator(fake_data)
# Calculate error and backpropagate
error_fake = loss(prediction_fake, fake_data_target(real_data.size(0)))
error_fake.backward()
# 1.3 Update weights with gradients
optimizer.step()
# Return error
return error_real + error_fake, prediction_real, prediction_fake
def train_generator(optimizer, fake_data):
# 2. Train Generator
# Reset gradients
optimizer.zero_grad()
# Sample noise and generate fake data
prediction = discriminator(fake_data)
# Calculate error and backpropagate
error = loss(prediction, real_data_target(prediction.size(0)))
error.backward()
# Update weights with gradients
optimizer.step()
# Return error
return error
```
### Generate Samples for Testing
```
num_test_samples = 16
test_noise = noise(num_test_samples)
```
### Start training
```
logger = Logger(model_name='VGAN', data_name='MNIST')
for epoch in range(num_epochs):
for n_batch, (real_batch,_) in enumerate(data_loader):
# 1. Train Discriminator
real_data = Variable(images_to_vectors(real_batch))
if torch.cuda.is_available(): real_data = real_data.cuda()
# Generate fake data
fake_data = generator(noise(real_data.size(0))).detach()
# Train D
d_error, d_pred_real, d_pred_fake = train_discriminator(d_optimizer,
real_data, fake_data)
# 2. Train Generator
# Generate fake data
fake_data = generator(noise(real_batch.size(0)))
# Train G
g_error = train_generator(g_optimizer, fake_data)
# Log error
logger.log(d_error, g_error, epoch, n_batch, num_batches)
# Display Progress
if (n_batch) % 100 == 0:
display.clear_output(True)
# Display Images
test_images = vectors_to_images(generator(test_noise)).data.cpu()
logger.log_images(test_images, num_test_samples, epoch, n_batch, num_batches);
# Display status Logs
logger.display_status(
epoch, num_epochs, n_batch, num_batches,
d_error, g_error, d_pred_real, d_pred_fake
)
# Model Checkpoints
logger.save_models(generator, discriminator, epoch)
```
| true |
code
| 0.928733 | null | null | null | null |
|
```
from simforest import SimilarityForestClassifier, SimilarityForestRegressor
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.datasets import load_svmlight_file
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score
from scipy.stats import pearsonr
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from bias import create_numerical_feature_classification, create_categorical_feature_classification
from bias import create_numerical_feature_regression, create_categorical_feature_regression
from bias import get_permutation_importances, bias_experiment, plot_bias
sns.set_style('whitegrid')
SEED = 42
import warnings
warnings.filterwarnings('ignore')
```
# Read the data
```
X, y = load_svmlight_file('data/heart')
X = X.toarray().astype(np.float32)
y[y==-1] = 0
features = [f'f{i+1}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=features)
df.head()
```
# Add new numerical feature
Create synthetic column, strongly correlated with target.
Each value is calculated according to the formula:
v = y * a + random(-b, b)
So its scaled target value with some noise.
Then a fraction of values is permuted, to reduce the correlation.
In this case, a=10, b=5, fraction=0.05
```
if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_numerical_feature_classification(y, fraction=0.05, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic numerical feature');
```
# Random Forest feature importance
Random Forest offers a simple way to measure feature importance. A certain feature is considered to be important if it reduced node impurity often, during fitting the trees.
We can see that adding a feature strongly correlated with target improved the model's performance, compared to results we obtained without this feature. What is more, this new feature was really important for the predictions. The plot shows that it is far more important than the original features.
```
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestClassifier(random_state=SEED)
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
print(f'Random Forest f1 score: {round(f1_score(y_test, rf_pred), 3)}')
df_rf_importances = pd.DataFrame(rf.feature_importances_, index=df.columns.values, columns=['importance'])
df_rf_importances = df_rf_importances.sort_values(by='importance', ascending=False)
df_rf_importances.plot()
plt.title('Biased Random Forest feature importance');
```
# Permutation feature importance
The impurity-based feature importance of Random Forests suffers from being computed on statistics derived from the training dataset: the importances can be high even for features that are not predictive of the target variable, as long as the model has the capacity to use them to overfit.
Futhermore, Random Forest feature importance is biased towards high-cardinality numerical feautures.
In this experiment, we will use permutation feature importance to asses how Random Forest and Similarity Forest
depend on syntetic feauture. This method is more reliable, and enables to measure feature importance for Similarity Forest, that doesn't enable us to measure impurity-based feature importance.
Source: https://scikit-learn.org/stable/auto_examples/inspection/plot_permutation_importance.html
```
sf = SimilarityForestClassifier(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
fraction_range = [0.0, 0.02, 0.05, 0.08, 0.1, 0.15, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 1.0]
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'classification', 'numerical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'heart')
```
# New categorical feature
```
if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_categorical_feature_classification(y, fraction=0.05, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
df_category = pd.concat([pd.Series(new_feature, name='new_feature'), pd.Series(y, name='y')], axis=1)
fig = plt.figure(figsize=(8, 6))
sns.countplot(data=df_category, x='new_feature', hue='y')
plt.xlabel('Feature value, grouped by class')
plt.ylabel('Count')
plt.title('Synthetic categorical feature', fontsize=16);
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestClassifier(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestClassifier(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'classification', 'categorical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'heart')
```
# Regression, numerical feature
```
X, y = load_svmlight_file('data/mpg')
X = X.toarray().astype(np.float32)
features = [f'f{i+1}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=features)
df.head()
if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_numerical_feature_regression(y, fraction=0.2, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic numerical feature');
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestRegressor(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestRegressor(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'regression', 'numerical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'mpg')
```
# Regression, categorical feature
```
if 'new_feature' in df.columns:
df.pop('new_feature')
new_feature, corr = create_categorical_feature_regression(y, fraction=0.15, seed=SEED, verbose=True)
df = pd.concat([pd.Series(new_feature, name='new_feature'), df], axis=1)
plt.scatter(new_feature, y, alpha=0.3)
plt.xlabel('Feature value')
plt.ylabel('Target')
plt.title('Synthetic categorical feature');
X_train, X_test, y_train, y_test = train_test_split(
df, y, test_size=0.3, random_state=SEED)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
rf = RandomForestRegressor(random_state=SEED).fit(X_train, y_train)
sf = SimilarityForestRegressor(n_estimators=100, random_state=SEED).fit(X_train, y_train)
perm_importance_results = get_permutation_importances(rf, sf,
X_train, y_train, X_test, y_test,
corr, df.columns.values, plot=True)
correlations, rf_scores, sf_scores, permutation_importances = bias_experiment(df, y,
'regression', 'categorical',
fraction_range, SEED)
plot_bias(fraction_range, correlations,
rf_scores, sf_scores,
permutation_importances, 'mpg')
```
| true |
code
| 0.765771 | null | null | null | null |
|
# Pi Estimation Using Monte Carlo
In this exercise, we will use MapReduce and a Monte-Carlo-Simulation to estimate $\Pi$.
If we are looking at this image from this [blog](https://towardsdatascience.com/how-to-make-pi-part-1-d0b41a03111f), we see a unit circle in a unit square:
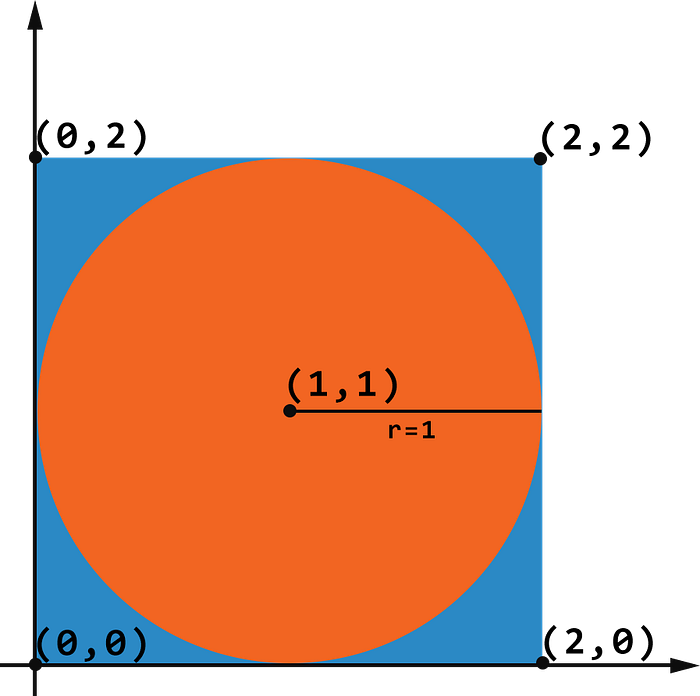
The area:
- for the circle is $A_{circle} = \Pi*r^2 = \Pi * 1*1 = \Pi$
- for the square is $A_{square} = d^2 = (2*r)^2 = 4$
The ratio of the two areas are therefore $\frac{A_{circle}}{A_{square}} = \frac{\Pi}{4}$
The Monte-Carlo-Simulation draws multiple points on the square, uniformly at random. For every point, we count if it lies within the circle or not.
And so we get the approximation:
$\frac{\Pi}{4} \approx \frac{\text{points_in_circle}}{\text{total_points}}$
or
$\Pi \approx 4* \frac{\text{points_in_circle}}{\text{total_points}}$
If we have a point $x_1,y_1$ and we want to figure out if it lies in a circle with radius $1$ we can use the following formula:
$\text{is_in_circle}(x_1,y_1) =
\begin{cases}
1,& \text{if } (x_1)^2 + (y_1)^2 \leq 1\\
0, & \text{otherwise}
\end{cases}$
## Implementation
Write a MapReduce algorithm for estimating $\Pi$
```
%%writefile pi.py
#!/usr/bin/python3
from mrjob.job import MRJob
from random import uniform
class MyJob(MRJob):
def mapper(self, _, line):
for x in range(100):
x = uniform(-1,1)
y = uniform(-1,1)
in_circle = x*x + y*y <=1
yield None, in_circle
def reducer(self, key, values):
values = list(values)
yield "Pi", 4 * sum(values) / len(values)
yield "number of values", len(values)
# for v in values:
# yield key, v
if __name__ == '__main__':
MyJob.run()
```
## Another Approach
Computing the mean in the mapper
```
%%writefile pi.py
#!/usr/bin/python3
from mrjob.job import MRJob
from random import uniform
class MyJob(MRJob):
def mapper(self, _, line):
num_samples = 100
in_circles_list = []
for x in range(num_samples):
x = uniform(-1,1)
y = uniform(-1,1)
in_circle = x*x + y*y <=1
in_circles_list.append(in_circle)
yield None, [num_samples, sum(in_circles_list)/num_samples]
def reducer(self, key, numSamples_sum_pairs):
total_samples = 0
weighted_numerator_sum = 0
for (num_samples, current_sum) in numSamples_sum_pairs:
total_samples += num_samples
weighted_numerator_sum += num_samples*current_sum
yield "Pi", 4 * weighted_numerator_sum / total_samples
yield "weighted_numerator_sum", weighted_numerator_sum
yield "total_samples", total_samples
if __name__ == '__main__':
MyJob.run()
```
### Running the Job
Unfortunately, the library does not work without an input file. I guess this comes from the fact that the hadoop streaming library also does not support this feature, see [stack overflow](https://stackoverflow.com/questions/22821005/hadoop-streaming-job-with-no-input-file).
We fake the number of mappers with different input files. Not the most elegant solution :/
```
!python pi.py /data/dataset/text/small.txt
!python pi.py /data/dataset/text/holmes.txt
```
| true |
code
| 0.326419 | null | null | null | null |
|
# 2019 Formula One World Championship
<div style="text-align: justify">
A Formula One season consists of a series of races, known as Grands Prix (French for ''grand prizes' or 'great prizes''), which take place worldwide on purpose-built circuits and on public roads. The results of each race are evaluated using a points system to determine two annual World Championships: one for drivers, the other for constructors. Drivers must hold valid Super Licences, the highest class of racing licence issued by the FIA. The races must run on tracks graded "1" (formerly "A"), the highest grade-rating issued by the FIA.Most events occur in rural locations on purpose-built tracks, but several events take place on city streets.
There are a number of F1 races coming up:
Singapore GP: Date: Sun, Sep 22, 8:10 AM
Russian GP: Date: Sun, Sep 29, 7:10 AM
Japanese GP: Date: Sun, Oct 13, 1:10 AM
Mexican GP Date: Sun, Oct 13, 1:10 AM
The Singaporean Grand Prix this weekend and the Russian Grand Prix the weekend after, as you can see here.
The 2019 driver standings are given here. Given these standings:
</div>
# Lets Answer few fun questions?
```
#A Probability Distribution; an {outcome: probability} mapping.
# Make probabilities sum to 1.0; assert no negative probabilities
class ProbDist(dict):
"""A Probability Distribution; an {outcome: probability} mapping."""
def __init__(self, mapping=(), **kwargs):
self.update(mapping, **kwargs)
total = sum(self.values())
for outcome in self:
self[outcome] = self[outcome] / total
assert self[outcome] >= 0
def p(event, space):
"""The probability of an event, given a sample space of outcomes.
event: a collection of outcomes, or a predicate that is true of outcomes in the event.
space: a set of outcomes or a probability distribution of {outcome: frequency} pairs."""
# if event is a predicate it, "unroll" it as a collection
if is_predicate(event):
event = such_that(event, space)
# if space is not an equiprobably collection (a simple set),
# but a probability distribution instead (a dictionary set),
# then add (union) the probabilities for all favorable outcomes
if isinstance(space, ProbDist):
return sum(space[o] for o in space if o in event)
# simplest case: what we played with in our previous lesson
else:
return Fraction(len(event & space), len(space))
is_predicate = callable
# Here we either return a simple collection in the case of equiprobable outcomes, or a dictionary collection in the
# case of non-equiprobably outcomes
def such_that(predicate, space):
"""The outcomes in the sample pace for which the predicate is true.
If space is a set, return a subset {outcome,...} with outcomes where predicate(element) is true;
if space is a ProbDist, return a ProbDist {outcome: frequency,...} with outcomes where predicate(element) is true."""
if isinstance(space, ProbDist):
return ProbDist({o:space[o] for o in space if predicate(o)})
else:
return {o for o in space if predicate(o)}
```
# Question Set 1
what is the Probability Distribution for each F1 driver to win the Singaporean Grand Prix?
What is the Probability Distribution for each F1 driver to win both the Singaporean and Russian Grand Prix?
What is the probability for Mercedes to win both races?
What is the probability for Mercedes to win at least one race?
Note that Mercedes, and each other racing team, has two drivers per race.
# Solution
1. what is the Probability Distribution for each F1 driver to win the Singaporean Grand Prix?
```
SGP = ProbDist(LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,RG=8,AG=3,RK=1,
GR=0)
print ("The probability of each driver winnning Singaporean Grand Prix ")
SGP #Driver standing divided by / total of all driver standings, SGP returns total probability as 1
```
2. What is the Probability Distribution for each F1 driver to win both the Singaporean and Russian Grand Prix?
```
SGP = ProbDist(
LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=3,RK=1,GR=0) # data taken on saturday before race starts for Singapore
RGP = ProbDist(
LH=296,VB=231,CL=200,MV=200,SV=194,PG=69,CS=58,AA=42,DR=34,DK=33,NH=33,LN=31,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=4,RK=1,GR=0) # data taken on saturday before race starts for Russia
#perfoms joint probabilities on SGP and RGP probability distributions
def joint(A, B, sep=''):
"""The joint distribution of two independent probability distributions.
Result is all entries of the form {a+sep+b: P(a)*P(b)}"""
return ProbDist({a + sep + b: A[a] * B[b]
for a in A
for b in B})
bothSGPRGP= joint(SGP, RGP, ' ')
print ("The probability of each driver winnning Singaporean Grand Prix and Russian Grand Prix")
bothSGPRGP
```
3. What is the probability for Mercedes to win both races?
```
def mercedes_T(outcome): return outcome == "VB" or outcome == "LH"
mercedesWinningSGPRace = p(mercedes_T, SGP)
#calculate probability of mercedes winning Singapore Frand Pix
def mercedes_T(outcome): return outcome == "VB" or outcome == "LH"
mercedesWinningRGPRace = p(mercedes_T, RGP)
#calculate probability of mercedes winning Russia Grand Pix
print ("The probability of mercedes winnning both the races ")
mercedesWinningBothRaces = mercedesWinningRGPRace * mercedesWinningSGPRace
mercedesWinningBothRaces
#probability of two events occurring together as independent events (P1 * P2)= P
```
4. What is the probability for Mercedes to win at least one race?
```
def p(event, space):
"""The probability of an event, given a sample space of outcomes.
event: a collection of outcomes, or a predicate that is true of outcomes in the event.
space: a set of outcomes or a probability distribution of {outcome: frequency} pairs."""
# if event is a predicate it, "unroll" it as a collection
if is_predicate(event):
event = such_that(event, space)
# if space is not an equiprobably collection (a simple set),
# but a probability distribution instead (a dictionary set),
# then add (union) the probabilities for all favorable outcomes
if isinstance(space, ProbDist):
return sum(space[o] for o in space if o in event)
# simplest case: what we played with in our previous lesson
else:
return Fraction(len(event & space), len(space))
is_predicate = callable
# Here we either return a simple collection in the case of equiprobable outcomes, or a dictionary collection in the
# case of non-equiprobably outcomes
def such_that(predicate, space):
"""The outcomes in the sample pace for which the predicate is true.
If space is a set, return a subset {outcome,...} with outcomes where predicate(element) is true;
if space is a ProbDist, return a ProbDist {outcome: frequency,...} with outcomes where predicate(element) is true."""
if isinstance(space, ProbDist):
return ProbDist({o:space[o] for o in space if predicate(o)})
else:
return {o for o in space if predicate(o)}
mercedesWinningAtleastOneRace = mercedesWinningBothRaces + (mercedesWinningRGPRace * (1 - mercedesWinningSGPRace))+mercedesWinningSGPRace * (1 - mercedesWinningRGPRace)
print ("The probability of mercedes winnning at least one of the races ")
mercedesWinningAtleastOneRace
#probability of an event occurring at least once, it will be the complement of the probability of the event never occurring.
```
# Question Set 2
If Mercedes wins the first race, what is the probability that Mercedes wins the next one?
If Mercedes wins at least one of these two races, what is the probability Mercedes wins both races?
How about Ferrari, Red Bull, and Renault?
# Solution
If Mercedes wins the first race, what is the probability that Mercedes wins the next one? If Mercedes wins at least one of these two races, what is the probability Mercedes wins both races? How about Ferrari, Red Bull, and Renault?
```
SGP = ProbDist(
LH=284,VB=221,CL=182,MV=185,SV=169,PG=65,CS=58,AA=34,DR=34,DK=33,NH=31,LN=25,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=3,RK=1,GR=0)
RGP = ProbDist(
LH=296,VB=231,CL=200,MV=200,SV=194,PG=69,CS=58,AA=42,DR=34,DK=33,NH=33,LN=31,KR=31,SP=27,LS=19,KM=18,
RG=8,AG=4,RK=1,GR=0)
Weather = ProbDist(RA=1, SU=1, SN=1, CL=1, FO=1)
def Mercedes_Win_First(outcome): return outcome.startswith('LH') or outcome.startswith('VB') #choose prob of first set
def Mercedes_Win_Second(outcome): return outcome.endswith('LH') or outcome.endswith('VB')
p(Mercedes_Win_Second, such_that(Mercedes_Win_First,bothSGPRGP)) #given first race is won, the second will be won
def Mercedes_WinBoth(outcome): return 'LH LH' in outcome or 'LH VB' in outcome or 'VB LH' in outcome or 'VB VB' in outcome
def Mercedes_Win(outcome): return 'LH' in outcome or 'VB' in outcome
p(Mercedes_WinBoth, such_that(Mercedes_Win,bothSGPRGP)) # (LH,LH VB,VB LH,VB VB,LH) 4 groups to pickup provided first race is won for the both event
```
If Ferrari wins the first race, what is the probability that Ferrari wins the next one?
```
def Ferrari_WinBoth(outcome): return 'CL CL' in outcome or 'CL SV' in outcome or 'SV SV' in outcome or 'SV CL' in outcome
def Ferrari_Win(outcome): return 'CL' in outcome or 'SV' in outcome
p(Ferrari_WinBoth, such_that(Ferrari_Win,bothSGPRGP))
```
If RedBull wins the first race, what is the probability that RedBull wins the next one
```
def RedBull_WinBoth(outcome): return 'MV MV' in outcome or 'MV AA' in outcome or 'AA AA' in outcome or 'AA MV' in outcome
def RedBull_Win(outcome): return 'MV' in outcome or 'AA' in outcome
p(RedBull_WinBoth, such_that(RedBull_Win,bothSGPRGP))
```
If Renault wins the first race, what is the probability that Renault wins the next one?
```
def Renault_WinBoth(outcome): return 'DR DR' in outcome or 'DR NH' in outcome or 'NH NH' in outcome or 'NH DR' in outcome
def Renault_Win(outcome): return 'DR' in outcome or 'NH' in outcome
p(Renault_WinBoth, such_that(Renault_Win,bothSGPRGP))
```
# Question Set 3
Mercedes wins one of these two races on a rainy day.
What is the probability Mercedes wins both races, assuming races can be held on either rainy, sunny, cloudy, snowy or foggy days?
Assume that rain, sun, clouds, snow, and fog are the only possible weather conditions on race tracks.
# Solution
Mercedes wins one of these two races on a rainy day. What is the probability Mercedes wins both races, assuming races can be held on either rainy, sunny, cloudy, snowy or foggy days? Assume that rain, sun, clouds, snow, and fog are the only possible weather conditions on race tracks.
```
#create Probability Distribution for given Weather Condtions wher p(weather) will be 0.20
GivenFiveWeatherConditons = ProbDist(
RainyDay=1,
SunnyDay=1,
CloudyDay=1,
SnowyDay=1,
FoggyDay=1
)
GivenFiveWeatherConditons
#perfoms joint probabilities on SGP & weather and RGP & weather probability distributions Respectively
def joint(A, B, A1, B1, sep=''):
"""The joint distribution of two independent probability distributions.
Result is all entries of the form {a+sep+b: P(a)*P(b)}"""
return ProbDist({a + sep + a1 + sep + b + sep + b1: A[a] * B[b] *A1[a1] * B1[b1]
for a in A
for b in B
for a1 in A1
for b1 in B1})
bothSGPRGPWeather= joint(SGP, RGP, GivenFiveWeatherConditons,GivenFiveWeatherConditons, ' ')
bothSGPRGPWeather
def Mercedes_Wins_Race_On_Any_Rainy(outcome): return ('LH R' in outcome or 'VB R' in outcome)
such_that(Mercedes_Wins_Race_On_Any_Rainy, bothSGPRGPWeather)
def Mercedes_Wins_Race_On_Both_Rain(outcome): return ('LH' in outcome and 'VB' in outcome) or (outcome.count('LH')==2 ) or (outcome.count('VB')==2 )
p(Mercedes_Wins_Race_On_Both_Rain, such_that(Mercedes_Wins_Race_On_Any_Rainy, bothSGPRGPWeather))
```
End!
| true |
code
| 0.720725 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/JSJeong-me/KOSA-Big-Data_Vision/blob/main/Model/99_kaggle_credit_card_analysis_and_prediction.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Importing Packages
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import os
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from imblearn.over_sampling import SMOTE
from sklearn.metrics import confusion_matrix,ConfusionMatrixDisplay,classification_report,plot_roc_curve,accuracy_score
pd.set_option('display.max_columns',25)
warnings.filterwarnings('ignore')
# Importing Dataset
data = pd.read_csv(r'./credit_cards_dataset.csv')
data.head(10)
data.info()
#info shows that there is no null values and all the features are numeric
data.describe(include='all') # Descriptive analysis
data.rename(columns={'PAY_0':'PAY_1','default.payment.next.month':'def_pay'},inplace=True)
#rename few columns
```
# Exploratory Data Analysis
```
plt.figure(figsize=(10,6))
data.groupby('def_pay')['AGE'].hist(legend=True)
plt.show()
#here we can see that, between age 20 to 45 most of the people will fall into..
sns.distplot(data['AGE'])
plt.title('Age Distribution')
sns.boxplot('def_pay','LIMIT_BAL',data=data)
data[data['LIMIT_BAL']>700000].sort_values(ascending=False,by='LIMIT_BAL')
data[data['LIMIT_BAL']>700000].value_counts().sum()
plt.figure(figsize=(16,5))
plt.subplot(121)
sns.boxplot(x='SEX', y= 'AGE',data = data)
sns.stripplot(x='SEX', y= 'AGE',data = data,linewidth = 0.9)
plt.title ('Sex vs AGE')
plt.subplot(122)
ax = sns.countplot(x='EDUCATION',data = data, order= data['EDUCATION'].value_counts().index)
plt.title ('EDUCATION')
labels = data['EDUCATION'].value_counts()
for i, v in enumerate(labels):
ax.text(i,v+100,v, horizontalalignment='center')
plt.show()
plt.figure(figsize=(20,5))
plt.subplot(121)
sns.boxplot(x='def_pay', y= 'AGE',data = data)
sns.stripplot(x='def_pay', y= 'AGE',data = data,linewidth = 0.9)
plt.title ('Age vs def_pay')
ax2=plt.subplot(1,2,2)
pay_edu = data.groupby('EDUCATION')['def_pay'].value_counts(normalize=True).unstack()
pay_edu = pay_edu.sort_values(ascending=False,by=1)
pay_edu.plot(kind='bar',stacked= True,color=["#3f3e6fd1", "#85c6a9"], ax = ax2)
plt.legend(loc=(1.04,0))
plt.title('Education vs def_pay')
plt.show()
# function for Multivariate analysis
# This method is used to show point estimates and confidence intervals using scatter plot graphs
def plotfig(df1,col11,col22,deft1):
plt.figure(figsize=(16,6))
plt.subplot(121)
sns.pointplot(df1[col11], df1[deft1],hue = df1[col22])
plt.subplot(122)
sns.countplot(df1[col11], hue = df1[col22])
plt.show()
def varplot(df2, col1, col2, deft, bin=3, unique=10):
df=df2.copy()
if len(df[col1].unique())>unique:
df[col1+'cut']= pd.qcut(df[col1],bin)
if len(df[col2].unique())>unique:
df[col2+'cut']= pd.qcut(df[col2],bin)
return plotfig(df,col1+'cut',col2+'cut',deft)
else:
df[col2+'cut']= df[col2]
return plotfig(df,col1+'cut',col2+'cut',deft)
else:
return plotfig(df,col1,col2,deft)
varplot(data,'AGE','SEX','def_pay',3)
varplot(data,'LIMIT_BAL','AGE','def_pay',3)
# Univariate Analysis
df = data.drop('ID',1)
nuniq = df.nunique()
df = data[[col for col in df if nuniq[col]>1 and nuniq[col]<50]]
row, cols = df.shape
colnames = list(df)
graph_perrow = 5
graph_row = (cols+graph_perrow-1)/ graph_perrow
max_graph = 20
plt.figure(figsize=(graph_perrow*12,graph_row*8))
for i in range(min(cols,max_graph)):
plt.subplot(graph_row,graph_perrow,i+1)
coldf = df.iloc[:,i]
if (not np.issubdtype(type(coldf),np.number)):
sns.countplot(colnames[i],data= df, order= df[colnames[i]].value_counts().index)
else:
coldf.hist()
plt.title(colnames[i])
plt.show()
cont_var = df.select_dtypes(exclude='object').columns
nrow = (len(cont_var)+5-1)/5
plt.figure(figsize=(12*5,6*2))
for i,j in enumerate(cont_var):
plt.subplot(nrow,5,i+1)
sns.distplot(data[j])
plt.show()
# from the above,we can see that we have maximum clients from 20-30 age group followed by 31-40.
# Hence with increasing age group the number of clients that will default the payment next month is decreasing.
# Hence we can see that Age is important feature to predict the default payment for next month.
plt.subplots(figsize=(26,20))
corr = data.corr()
sns.heatmap(corr,annot=True)
plt.show()
from statsmodels.stats.outliers_influence import variance_inflation_factor
df= data.drop(['def_pay','ID'],1)
vif = pd.DataFrame()
vif['Features']= df.columns
vif['vif']= [variance_inflation_factor(df.values,i) for i in range(df.shape[1])]
vif
# From this heatmap and VIF we can see that there are some multicolinearity(values >10) in the data which we can handle
# simply doing feature engineering of some columns
bill_tot = pd.DataFrame(data['BILL_AMT1']+data['BILL_AMT2']+data['BILL_AMT3']+data['BILL_AMT4']+data['BILL_AMT5']+data['BILL_AMT6'],columns=['bill_tot'])
pay_tot =pd.DataFrame(data['PAY_1']+data['PAY_2']+data['PAY_3']+data['PAY_4']+data['PAY_5']+data['PAY_6'],columns=['pay_tot'])
pay_amt_tot = pd.DataFrame(data['PAY_AMT1']+data['PAY_AMT2']+data['PAY_AMT3']+data['PAY_AMT4']+data['PAY_AMT5']+data['PAY_AMT6'],columns=['pay_amt_tot'])
frames=[bill_tot,pay_tot,pay_amt_tot,data['def_pay']]
tot = pd.concat(frames,axis=1)
plt.figure(figsize=(20,4))
plt.subplot(131)
sns.boxplot(x='def_pay',y='pay_tot',data = tot)
sns.stripplot(x='def_pay',y='pay_tot',data = tot,linewidth=1)
plt.subplot(132)
sns.boxplot(x='def_pay', y='bill_tot',data=tot)
sns.stripplot(x='def_pay', y='bill_tot',data=tot,linewidth=1)
plt.subplot(133)
sns.boxplot(x='def_pay', y='pay_amt_tot',data=tot)
sns.stripplot(x='def_pay', y='pay_amt_tot',data=tot,linewidth=1)
plt.show()
sns.pairplot(tot[['bill_tot','pay_amt_tot','pay_tot','def_pay']],hue='def_pay')
plt.show()
sns.violinplot(x=tot['def_pay'], y= tot['bill_tot'])
tot.drop('def_pay',1,inplace=True)
data1 = pd.concat([data,tot],1)
data1.groupby('def_pay')['EDUCATION'].hist(legend=True)
plt.show()
data1.groupby('def_pay')['AGE'].hist()
plt.figure(figsize=(12,6))
# we know that the Bill_AMT is the most correlated column so using that we create a data
df= pd.concat([bill_tot,df],1)
df1 = df.drop(['BILL_AMT1','BILL_AMT2','BILL_AMT3','BILL_AMT4','BILL_AMT5','BILL_AMT6'],1)
vif = pd.DataFrame()
vif['Features']= df1.columns
vif['vif']= [variance_inflation_factor(df1.values,i) for i in range(df1.shape[1])]
vif
# above we can see that now our data doesnt have multicollinearty(no values >10)
data2 = df1.copy()
# using the above plot we can create age bins
age = [20,27,32,37,42,48,58,64,80]
lab = [8,7,6,5,4,3,2,1]
data2['AGE'] = pd.cut(data2['AGE'],bins= age,labels=lab)
data2 = pd.concat([data2,data['def_pay']],1)
data2
data2.groupby('def_pay')['AGE'].hist()
plt.figure(figsize=(12,6))
sns.countplot(data2['AGE'])
data2.groupby('def_pay')['LIMIT_BAL'].hist(legend=True)
plt.show()
data2.columns
```
# Model Creation
#### We know that we have a dataset where we have imbalance in the target variable
#### you get a pretty high accuracy just by predicting the majority class, but you fail to capture the minority class
#### which is most often the point of creating the model in the first place.
#### Hence we try to create more model to get the best results
```
x= data2.drop(['def_pay'],1)
y = data2['def_pay']
x_train,x_test, y_train, y_test = train_test_split(x,y,test_size=0.30, random_state=1)
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
# Accuracy is not the best metric to use when evaluating imbalanced datasets as it can be misleading.
# hence we are using Classification Report and Confusion Matrix
# function for accuracy and confusion matrix
def res(y_test_valid,y_train_valid):
cm_log = confusion_matrix(y_test,y_test_valid)
ConfusionMatrixDisplay(cm_log).plot()
print(classification_report(y_test,y_test_valid))
print('train_accuracy:',accuracy_score(y_train,y_train_valid))
print('test_accuracy:',accuracy_score(y_test,y_test_valid))
```
# Logistic model
```
log_model= LogisticRegression()
log_model.fit(x_train,y_train)
y_pred_log = log_model.predict(x_test)
y_pred_train = log_model.predict(x_train)
res(y_pred_log,y_pred_train)
plot_roc_curve(log_model,x_test,y_test)
plt.show()
# log model using Threshold
threshold = 0.36
y_log_prob = log_model.predict_proba(x_test)
y_train_log_prob = log_model.predict_proba(x_train)
y_log_prob=y_log_prob[:,1]
y_train_log_prob= y_train_log_prob[:,1]
y_pred_log_prob = np.where(y_log_prob>threshold,1,0)
y_pred_log_prob_train = np.where(y_train_log_prob>threshold,1,0)
res(y_pred_log_prob,y_pred_log_prob_train)
```
# using Decision Tree model
```
dec_model = DecisionTreeClassifier()
dec_model.fit(x_train,y_train)
y_pred_dec = dec_model.predict(x_test)
y_pred_dec_train = dec_model.predict(x_train)
res(y_pred_dec,y_pred_dec_train)
```
### Hyper parameter tuning for DecisionTree
```
parameters = {'max_depth':[1,2,3,4,5,6],'min_samples_split':[3,4,5,6,7],'min_samples_leaf':[1,2,3,4,5,6]}
tree = GridSearchCV(dec_model, parameters,cv=10)
tree.fit(x_train,y_train)
tree.best_params_
# We know that Decision tree will have high variance due to which the model overfit hence we can reduce this by "Pruning"
# By using the best parameter from GridSearchCV best parameters
dec_model1 = DecisionTreeClassifier(max_depth=4,min_samples_split=10,min_samples_leaf=1)
dec_model1.fit(x_train,y_train)
y_pred_dec1 = dec_model1.predict(x_test)
y_pred_dec_train1 = dec_model1.predict(x_train)
res(y_pred_dec1,y_pred_dec_train1)
```
# Random Forest Model
```
rf_model = RandomForestClassifier(n_estimators=200, criterion='entropy', max_features='log2', max_depth=15, random_state=42)
rf_model.fit(x_train,y_train)
y_pred_rf = rf_model.predict(x_test)
y_pred_rf_train = rf_model.predict(x_train)
#res(y_pred_rf,y_pred_rf_train)
from sklearn.metrics import confusion_matrix
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
cnf_matrix = confusion_matrix(y_test, y_pred_rf)
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=['Non_Default','Default'], normalize=False,
title='Non Normalized confusion matrix')
from sklearn.metrics import recall_score
print("Recall score:"+ str(recall_score(y_test, y_pred_rf)))
```
### Again hyper parameter tuning for Random Forest
```
parameters = {'n_estimators':[60,70,80],'max_depth':[1,2,3,4,5,6],'min_samples_split':[3,4,5,6,7],
'min_samples_leaf':[1,2,3,4,5,6]}
clf = GridSearchCV(rf_model, parameters,cv=10)
clf.fit(x_train,y_train)
clf.best_params_
# {'max_depth': 5,
# 'min_samples_leaf': 4,
# 'min_samples_split': 3,
# 'n_estimators': 70}
# Decision trees frequently perform well on imbalanced data. so using RandomForest uses bagging of n_trees will be a better idea.
rf_model = RandomForestClassifier(n_estimators=80, max_depth=6, min_samples_leaf=2, min_samples_split=5)
rf_model.fit(x_train,y_train)
y_pred_rf = rf_model.predict(x_test)
y_pred_rf_train = rf_model.predict(x_train)
#res(y_pred_rf,y_pred_rf_train)
cnf_matrix = confusion_matrix(y_test, y_pred_rf)
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=['Non_Default','Default'], normalize=False,
title='Non Normalized confusion matrix')
print("Recall score:"+ str(recall_score(y_test, y_pred_rf)))
```
# KNN model
```
# finding the K value
error = []
for i in range(1,21,2):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)
preds = knn.predict(x_test)
error.append(np.mean(preds!=y_test))
plt.plot(range(1,21,2), error, linestyle = 'dashed', marker ='o', mfc= 'red')
# By using the elbow graph we can see that the k=5 will perform better in the first place so impute k = 5
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit(x_train,y_train)
y_pred_knn = knn_model.predict(x_test)
y_pred_knn_train = knn_model.predict(x_train)
res(y_pred_knn,y_pred_knn_train)
```
# SVM Model
```
# use penalized learning algorithms that increase the cost of classification mistakes on the minority class.
svm_model = SVC(class_weight='balanced', probability=True)
svm_model.fit(x_train,y_train)
y_pred_svm = svm_model.predict(x_test)
y_pred_svm_train = svm_model.predict(x_train)
res(y_pred_svm,y_pred_svm_train)
# we can see in SVM that our recall of target variable is 0.56 which is the best we ever predicted.
```
# Naive Bayes
```
nb_model = GaussianNB()
nb_model.fit(x_train,y_train)
y_pred_nb = nb_model.predict(x_test)
y_pred_nb_train = nb_model.predict(x_train)
res(y_pred_nb,y_pred_nb_train)
# But here Naive bayes out performs every other model though over accuracy is acceptable, checkout the recall
```
# Boosting model XGB Classifier
```
from xgboost import XGBClassifier
xgb_model = XGBClassifier()
xgb_model.fit(x_train, y_train)
xgb_y_predict = xgb_model.predict(x_test)
xgb_y_predict_train = xgb_model.predict(x_train)
res(xgb_y_predict,xgb_y_predict_train)
# Even Boosting technique gives low recall for our target variable
# So from the above model we can conclude that the data imbalance is playing a major part
# Hence we try to fix that by doing ReSample techniques
```
# Random under-sampling
### Let’s apply some of these resampling techniques, using the Python library imbalanced-learn.
```
from collections import Counter
from imblearn.under_sampling import RandomUnderSampler
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import TomekLinks
x= data2.drop(['def_pay'],1)
y = data2['def_pay']
rus = RandomUnderSampler(random_state=1)
x_rus, y_rus = rus.fit_resample(x,y)
print('original dataset shape:', Counter(y))
print('Resample dataset shape', Counter(y_rus))
x_train,x_test, y_train, y_test = train_test_split(x_rus,y_rus,test_size=0.20, random_state=1)
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
# again we try to predict using Random Forest
rf_model_rus = RandomForestClassifier(n_estimators=70, max_depth=5, min_samples_leaf=4, min_samples_split=3,random_state=1)
rf_model_rus.fit(x_train,y_train)
y_pred_rf_rus = rf_model_rus.predict(x_test)
y_pred_rf_rus_train = rf_model_rus.predict(x_train)
res(y_pred_rf_rus,y_pred_rf_rus_train)
```
# Random over-sampling
```
x= data2.drop(['def_pay'],1)
y = data2['def_pay']
ros = RandomOverSampler(random_state=42)
x_ros, y_ros = ros.fit_resample(x, y)
print('Original dataset shape', Counter(y))
print('Resample dataset shape', Counter(y_ros))
x_train,x_test, y_train, y_test = train_test_split(x_ros,y_ros,test_size=0.20, random_state=1)
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
rf_model_ros = RandomForestClassifier(n_estimators=70, max_depth=5, min_samples_leaf=4, min_samples_split=3,random_state=1)
rf_model_ros.fit(x_train,y_train)
y_pred_rf_ros = rf_model_ros.predict(x_test)
y_pred_rf_ros_train = rf_model_ros.predict(x_train)
res(y_pred_rf_ros,y_pred_rf_ros_train)
```
# Under-sampling: Tomek links
```
x= data2.drop(['def_pay'],1)
y = data2['def_pay']
tl = TomekLinks(sampling_strategy='majority')
x_tl, y_tl = tl.fit_resample(x,y)
print('Original dataset shape', Counter(y))
print('Resample dataset shape', Counter(y_tl))
x_train,x_test, y_train, y_test = train_test_split(x_tl,y_tl,test_size=0.20, random_state=1)
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
rf_model_tl = RandomForestClassifier(n_estimators=70, max_depth=5, min_samples_leaf=4, min_samples_split=3,random_state=1)
rf_model_tl.fit(x_train,y_train)
y_pred_rf_tl = rf_model_tl.predict(x_test)
y_pred_rf_tl_train = rf_model_tl.predict(x_train)
res(y_pred_rf_tl,y_pred_rf_tl_train)
```
# Synthetic Minority Oversampling Technique (SMOTE)
```
from imblearn.over_sampling import SMOTE
smote = SMOTE()
x_smote, y_smote = smote.fit_resample(x, y)
print('Original dataset shape', Counter(y))
print('Resample dataset shape', Counter(y_smote))
x_train,x_test, y_train, y_test = train_test_split(x_smote,y_smote,test_size=0.20, random_state=1)
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
x_train = pd.DataFrame(x_train).fillna(0)
x_test = pd.DataFrame(x_test).fillna(0)
rf_model_smote = RandomForestClassifier(n_estimators=70, max_depth=5, min_samples_leaf=4, min_samples_split=3,random_state=1)
rf_model_smote.fit(x_train,y_train)
y_pred_rf_smote = rf_model_smote.predict(x_test)
y_pred_rf_smote_train = rf_model_smote.predict(x_train)
res(y_pred_rf_smote,y_pred_rf_smote_train)
```
### Finally using SMOTE we can see our accuracy as well as recall and precision ratio are give equal ratio
### Though all the above models performs well, based on the accuracy but in a imbalance dataset like this,
#### we actually prefer to change the performance metrics
### We can get better result when we do SVM and Naive bayes with our original data
### Even we dont have any variance in the model nor to much of bias
### But when we do over or Under sample the date the other metrics like sensity and specificity was better
### Hence we can conclue that if we use resample technique we will get better result
| true |
code
| 0.504455 | null | null | null | null |
|
# Sequence to Sequence Learning
:label:`sec_seq2seq`
As we have seen in :numref:`sec_machine_translation`,
in machine translation
both the input and output are a variable-length sequence.
To address this type of problem,
we have designed a general encoder-decoder architecture
in :numref:`sec_encoder-decoder`.
In this section,
we will
use two RNNs to design
the encoder and the decoder of
this architecture
and apply it to *sequence to sequence* learning
for machine translation
:cite:`Sutskever.Vinyals.Le.2014,Cho.Van-Merrienboer.Gulcehre.ea.2014`.
Following the design principle
of the encoder-decoder architecture,
the RNN encoder can
take a variable-length sequence as the input and transforms it into a fixed-shape hidden state.
In other words,
information of the input (source) sequence
is *encoded* in the hidden state of the RNN encoder.
To generate the output sequence token by token,
a separate RNN decoder
can predict the next token based on
what tokens have been seen (such as in language modeling) or generated,
together with the encoded information of the input sequence.
:numref:`fig_seq2seq` illustrates
how to use two RNNs
for sequence to sequence learning
in machine translation.

:label:`fig_seq2seq`
In :numref:`fig_seq2seq`,
the special "<eos>" token
marks the end of the sequence.
The model can stop making predictions
once this token is generated.
At the initial time step of the RNN decoder,
there are two special design decisions.
First, the special beginning-of-sequence "<bos>" token is an input.
Second,
the final hidden state of the RNN encoder is used
to initiate the hidden state of the decoder.
In designs such as :cite:`Sutskever.Vinyals.Le.2014`,
this is exactly
how the encoded input sequence information
is fed into the decoder for generating the output (target) sequence.
In some other designs such as :cite:`Cho.Van-Merrienboer.Gulcehre.ea.2014`,
the final hidden state of the encoder
is also fed into the decoder as
part of the inputs
at every time step as shown in :numref:`fig_seq2seq`.
Similar to the training of language models in
:numref:`sec_language_model`,
we can allow the labels to be the original output sequence,
shifted by one token:
"<bos>", "Ils", "regardent", "." $\rightarrow$
"Ils", "regardent", ".", "<eos>".
In the following,
we will explain the design of :numref:`fig_seq2seq`
in greater detail.
We will train this model for machine translation
on the English-French dataset as introduced in
:numref:`sec_machine_translation`.
```
import collections
import math
from mxnet import autograd, gluon, init, np, npx
from mxnet.gluon import nn, rnn
from d2l import mxnet as d2l
npx.set_np()
```
## Encoder
Technically speaking,
the encoder transforms an input sequence of variable length into a fixed-shape *context variable* $\mathbf{c}$, and encodes the input sequence information in this context variable.
As depicted in :numref:`fig_seq2seq`,
we can use an RNN to design the encoder.
Let us consider a sequence example (batch size: 1).
Suppose that
the input sequence is $x_1, \ldots, x_T$, such that $x_t$ is the $t^{\mathrm{th}}$ token in the input text sequence.
At time step $t$, the RNN transforms
the input feature vector $\mathbf{x}_t$ for $x_t$
and the hidden state $\mathbf{h} _{t-1}$ from the previous time step
into the current hidden state $\mathbf{h}_t$.
We can use a function $f$ to express the transformation of the RNN's recurrent layer:
$$\mathbf{h}_t = f(\mathbf{x}_t, \mathbf{h}_{t-1}). $$
In general,
the encoder transforms the hidden states at
all the time steps
into the context variable through a customized function $q$:
$$\mathbf{c} = q(\mathbf{h}_1, \ldots, \mathbf{h}_T).$$
For example, when choosing $q(\mathbf{h}_1, \ldots, \mathbf{h}_T) = \mathbf{h}_T$ such as in :numref:`fig_seq2seq`,
the context variable is just the hidden state $\mathbf{h}_T$
of the input sequence at the final time step.
So far we have used a unidirectional RNN
to design the encoder,
where
a hidden state only depends on
the input subsequence at and before the time step of the hidden state.
We can also construct encoders using bidirectional RNNs. In this case, a hidden state depends on
the subsequence before and after the time step (including the input at the current time step), which encodes the information of the entire sequence.
Now let us [**implement the RNN encoder**].
Note that we use an *embedding layer*
to obtain the feature vector for each token in the input sequence.
The weight
of an embedding layer
is a matrix
whose number of rows equals to the size of the input vocabulary (`vocab_size`)
and number of columns equals to the feature vector's dimension (`embed_size`).
For any input token index $i$,
the embedding layer
fetches the $i^{\mathrm{th}}$ row (starting from 0) of the weight matrix
to return its feature vector.
Besides,
here we choose a multilayer GRU to
implement the encoder.
```
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""The RNN encoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# Embedding layer
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# The output `X` shape: (`batch_size`, `num_steps`, `embed_size`)
X = self.embedding(X)
# In RNN models, the first axis corresponds to time steps
X = X.swapaxes(0, 1)
state = self.rnn.begin_state(batch_size=X.shape[1], ctx=X.ctx)
output, state = self.rnn(X, state)
# `output` shape: (`num_steps`, `batch_size`, `num_hiddens`)
# `state[0]` shape: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
```
The returned variables of recurrent layers
have been explained in :numref:`sec_rnn-concise`.
Let us still use a concrete example
to [**illustrate the above encoder implementation.**]
Below
we instantiate a two-layer GRU encoder
whose number of hidden units is 16.
Given
a minibatch of sequence inputs `X`
(batch size: 4, number of time steps: 7),
the hidden states of the last layer
at all the time steps
(`output` return by the encoder's recurrent layers)
are a tensor
of shape
(number of time steps, batch size, number of hidden units).
```
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.initialize()
X = np.zeros((4, 7))
output, state = encoder(X)
output.shape
```
Since a GRU is employed here,
the shape of the multilayer hidden states
at the final time step
is
(number of hidden layers, batch size, number of hidden units).
If an LSTM is used,
memory cell information will also be contained in `state`.
```
len(state), state[0].shape
```
## [**Decoder**]
:label:`sec_seq2seq_decoder`
As we just mentioned,
the context variable $\mathbf{c}$ of the encoder's output encodes the entire input sequence $x_1, \ldots, x_T$. Given the output sequence $y_1, y_2, \ldots, y_{T'}$ from the training dataset,
for each time step $t'$
(the symbol differs from the time step $t$ of input sequences or encoders),
the probability of the decoder output $y_{t'}$
is conditional
on the previous output subsequence
$y_1, \ldots, y_{t'-1}$ and
the context variable $\mathbf{c}$, i.e., $P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c})$.
To model this conditional probability on sequences,
we can use another RNN as the decoder.
At any time step $t^\prime$ on the output sequence,
the RNN takes the output $y_{t^\prime-1}$ from the previous time step
and the context variable $\mathbf{c}$ as its input,
then transforms
them and
the previous hidden state $\mathbf{s}_{t^\prime-1}$
into the
hidden state $\mathbf{s}_{t^\prime}$ at the current time step.
As a result, we can use a function $g$ to express the transformation of the decoder's hidden layer:
$$\mathbf{s}_{t^\prime} = g(y_{t^\prime-1}, \mathbf{c}, \mathbf{s}_{t^\prime-1}).$$
:eqlabel:`eq_seq2seq_s_t`
After obtaining the hidden state of the decoder,
we can use an output layer and the softmax operation to compute the conditional probability distribution
$P(y_{t^\prime} \mid y_1, \ldots, y_{t^\prime-1}, \mathbf{c})$ for the output at time step $t^\prime$.
Following :numref:`fig_seq2seq`,
when implementing the decoder as follows,
we directly use the hidden state at the final time step
of the encoder
to initialize the hidden state of the decoder.
This requires that the RNN encoder and the RNN decoder have the same number of layers and hidden units.
To further incorporate the encoded input sequence information,
the context variable is concatenated
with the decoder input at all the time steps.
To predict the probability distribution of the output token,
a fully-connected layer is used to transform
the hidden state at the final layer of the RNN decoder.
```
class Seq2SeqDecoder(d2l.Decoder):
"""The RNN decoder for sequence to sequence learning."""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Dense(vocab_size, flatten=False)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# The output `X` shape: (`num_steps`, `batch_size`, `embed_size`)
X = self.embedding(X).swapaxes(0, 1)
# `context` shape: (`batch_size`, `num_hiddens`)
context = state[0][-1]
# Broadcast `context` so it has the same `num_steps` as `X`
context = np.broadcast_to(context, (
X.shape[0], context.shape[0], context.shape[1]))
X_and_context = np.concatenate((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).swapaxes(0, 1)
# `output` shape: (`batch_size`, `num_steps`, `vocab_size`)
# `state[0]` shape: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
```
To [**illustrate the implemented decoder**],
below we instantiate it with the same hyperparameters from the aforementioned encoder.
As we can see, the output shape of the decoder becomes (batch size, number of time steps, vocabulary size),
where the last dimension of the tensor stores the predicted token distribution.
```
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.initialize()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, len(state), state[0].shape
```
To summarize,
the layers in the above RNN encoder-decoder model are illustrated in :numref:`fig_seq2seq_details`.

:label:`fig_seq2seq_details`
## Loss Function
At each time step, the decoder
predicts a probability distribution for the output tokens.
Similar to language modeling,
we can apply softmax to obtain the distribution
and calculate the cross-entropy loss for optimization.
Recall :numref:`sec_machine_translation`
that the special padding tokens
are appended to the end of sequences
so sequences of varying lengths
can be efficiently loaded
in minibatches of the same shape.
However,
prediction of padding tokens
should be excluded from loss calculations.
To this end,
we can use the following
`sequence_mask` function
to [**mask irrelevant entries with zero values**]
so later
multiplication of any irrelevant prediction
with zero equals to zero.
For example,
if the valid length of two sequences
excluding padding tokens
are one and two, respectively,
the remaining entries after
the first one
and the first two entries are cleared to zeros.
```
X = np.array([[1, 2, 3], [4, 5, 6]])
npx.sequence_mask(X, np.array([1, 2]), True, axis=1)
```
(**We can also mask all the entries across the last
few axes.**)
If you like, you may even specify
to replace such entries with a non-zero value.
```
X = np.ones((2, 3, 4))
npx.sequence_mask(X, np.array([1, 2]), True, value=-1, axis=1)
```
Now we can [**extend the softmax cross-entropy loss
to allow the masking of irrelevant predictions.**]
Initially,
masks for all the predicted tokens are set to one.
Once the valid length is given,
the mask corresponding to any padding token
will be cleared to zero.
In the end,
the loss for all the tokens
will be multipled by the mask to filter out
irrelevant predictions of padding tokens in the loss.
```
#@save
class MaskedSoftmaxCELoss(gluon.loss.SoftmaxCELoss):
"""The softmax cross-entropy loss with masks."""
# `pred` shape: (`batch_size`, `num_steps`, `vocab_size`)
# `label` shape: (`batch_size`, `num_steps`)
# `valid_len` shape: (`batch_size`,)
def forward(self, pred, label, valid_len):
# `weights` shape: (`batch_size`, `num_steps`, 1)
weights = np.expand_dims(np.ones_like(label), axis=-1)
weights = npx.sequence_mask(weights, valid_len, True, axis=1)
return super(MaskedSoftmaxCELoss, self).forward(pred, label, weights)
```
For [**a sanity check**], we can create three identical sequences.
Then we can
specify that the valid lengths of these sequences
are 4, 2, and 0, respectively.
As a result,
the loss of the first sequence
should be twice as large as that of the second sequence,
while the third sequence should have a zero loss.
```
loss = MaskedSoftmaxCELoss()
loss(np.ones((3, 4, 10)), np.ones((3, 4)), np.array([4, 2, 0]))
```
## [**Training**]
:label:`sec_seq2seq_training`
In the following training loop,
we concatenate the special beginning-of-sequence token
and the original output sequence excluding the final token as
the input to the decoder, as shown in :numref:`fig_seq2seq`.
This is called *teacher forcing* because
the original output sequence (token labels) is fed into the decoder.
Alternatively,
we could also feed the *predicted* token
from the previous time step
as the current input to the decoder.
```
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""Train a model for sequence to sequence."""
net.initialize(init.Xavier(), force_reinit=True, ctx=device)
trainer = gluon.Trainer(net.collect_params(), 'adam',
{'learning_rate': lr})
loss = MaskedSoftmaxCELoss()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # Sum of training loss, no. of tokens
for batch in data_iter:
X, X_valid_len, Y, Y_valid_len = [
x.as_in_ctx(device) for x in batch]
bos = np.array(
[tgt_vocab['<bos>']] * Y.shape[0], ctx=device).reshape(-1, 1)
dec_input = np.concatenate([bos, Y[:, :-1]], 1) # Teacher forcing
with autograd.record():
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.backward()
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
trainer.step(num_tokens)
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
```
Now we can [**create and train an RNN encoder-decoder model**]
for sequence to sequence learning on the machine translation dataset.
```
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
```
## [**Prediction**]
To predict the output sequence
token by token,
at each decoder time step
the predicted token from the previous
time step is fed into the decoder as an input.
Similar to training,
at the initial time step
the beginning-of-sequence ("<bos>") token
is fed into the decoder.
This prediction process
is illustrated in :numref:`fig_seq2seq_predict`.
When the end-of-sequence ("<eos>") token is predicted,
the prediction of the output sequence is complete.

:label:`fig_seq2seq_predict`
We will introduce different
strategies for sequence generation in
:numref:`sec_beam-search`.
```
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""Predict for sequence to sequence."""
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = np.array([len(src_tokens)], ctx=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# Add the batch axis
enc_X = np.expand_dims(np.array(src_tokens, ctx=device), axis=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# Add the batch axis
dec_X = np.expand_dims(np.array([tgt_vocab['<bos>']], ctx=device), axis=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# We use the token with the highest prediction likelihood as the input
# of the decoder at the next time step
dec_X = Y.argmax(axis=2)
pred = dec_X.squeeze(axis=0).astype('int32').item()
# Save attention weights (to be covered later)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the end-of-sequence token is predicted, the generation of the
# output sequence is complete
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
```
## Evaluation of Predicted Sequences
We can evaluate a predicted sequence
by comparing it with the
label sequence (the ground-truth).
BLEU (Bilingual Evaluation Understudy),
though originally proposed for evaluating
machine translation results :cite:`Papineni.Roukos.Ward.ea.2002`,
has been extensively used in measuring
the quality of output sequences for different applications.
In principle, for any $n$-grams in the predicted sequence,
BLEU evaluates whether this $n$-grams appears
in the label sequence.
Denote by $p_n$
the precision of $n$-grams,
which is
the ratio of
the number of matched $n$-grams in
the predicted and label sequences
to
the number of $n$-grams in the predicted sequence.
To explain,
given a label sequence $A$, $B$, $C$, $D$, $E$, $F$,
and a predicted sequence $A$, $B$, $B$, $C$, $D$,
we have $p_1 = 4/5$, $p_2 = 3/4$, $p_3 = 1/3$, and $p_4 = 0$.
Besides,
let $\mathrm{len}_{\text{label}}$ and $\mathrm{len}_{\text{pred}}$
be
the numbers of tokens in the label sequence and the predicted sequence, respectively.
Then, BLEU is defined as
$$ \exp\left(\min\left(0, 1 - \frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right) \prod_{n=1}^k p_n^{1/2^n},$$
:eqlabel:`eq_bleu`
where $k$ is the longest $n$-grams for matching.
Based on the definition of BLEU in :eqref:`eq_bleu`,
whenever the predicted sequence is the same as the label sequence, BLEU is 1.
Moreover,
since matching longer $n$-grams is more difficult,
BLEU assigns a greater weight
to a longer $n$-gram precision.
Specifically, when $p_n$ is fixed,
$p_n^{1/2^n}$ increases as $n$ grows (the original paper uses $p_n^{1/n}$).
Furthermore,
since
predicting shorter sequences
tends to obtain a higher $p_n$ value,
the coefficient before the multiplication term in :eqref:`eq_bleu`
penalizes shorter predicted sequences.
For example, when $k=2$,
given the label sequence $A$, $B$, $C$, $D$, $E$, $F$ and the predicted sequence $A$, $B$,
although $p_1 = p_2 = 1$, the penalty factor $\exp(1-6/2) \approx 0.14$ lowers the BLEU.
We [**implement the BLEU measure**] as follows.
```
def bleu(pred_seq, label_seq, k): #@save
"""Compute the BLEU."""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
```
In the end,
we use the trained RNN encoder-decoder
to [**translate a few English sentences into French**]
and compute the BLEU of the results.
```
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
```
## Summary
* Following the design of the encoder-decoder architecture, we can use two RNNs to design a model for sequence to sequence learning.
* When implementing the encoder and the decoder, we can use multilayer RNNs.
* We can use masks to filter out irrelevant computations, such as when calculating the loss.
* In encoder-decoder training, the teacher forcing approach feeds original output sequences (in contrast to predictions) into the decoder.
* BLEU is a popular measure for evaluating output sequences by matching $n$-grams between the predicted sequence and the label sequence.
## Exercises
1. Can you adjust the hyperparameters to improve the translation results?
1. Rerun the experiment without using masks in the loss calculation. What results do you observe? Why?
1. If the encoder and the decoder differ in the number of layers or the number of hidden units, how can we initialize the hidden state of the decoder?
1. In training, replace teacher forcing with feeding the prediction at the previous time step into the decoder. How does this influence the performance?
1. Rerun the experiment by replacing GRU with LSTM.
1. Are there any other ways to design the output layer of the decoder?
[Discussions](https://discuss.d2l.ai/t/345)
| true |
code
| 0.80651 | null | null | null | null |
|
If you're opening this Notebook on colab, you will probably need to install 🤗 Transformers and 🤗 Datasets. Right now this requires the current master branch of both. Uncomment the following cell and run it.
```
#! pip install git+https://github.com/huggingface/transformers.git
#! pip install git+https://github.com/huggingface/datasets.git
```
If you're opening this notebook locally, make sure your environment has an install from the last version of those libraries.
To be able to share your model with the community, there are a few more steps to follow.
First you have to store your authentication token from the Hugging Face website (sign up [here](https://huggingface.co/join) if you haven't already!) then uncomment the following cell and input your username and password (this only works on Colab, in a regular notebook, you need to do this in a terminal):
```
from huggingface_hub import notebook_login
notebook_login()
```
Then you need to install Git-LFS and setup Git if you haven't already. Uncomment the following instructions and adapt with your name and email:
```
# !apt install git-lfs
# !git config --global user.email "[email protected]"
# !git config --global user.name "Your Name"
```
Make sure your version of Transformers is at least 4.8.1 since the functionality was introduced in that version:
```
import transformers
print(transformers.__version__)
```
If you're opening this Notebook on colab, you will probably need to install 🤗 Transformers and 🤗 Datasets. Uncomment the following cell and run it.
# Fine-tuning a model on a multiple choice task
In this notebook, we will see how to fine-tune one of the [🤗 Transformers](https://github.com/huggingface/transformers) model to a multiple choice task, which is the task of selecting the most plausible inputs in a given selection. The dataset used here is [SWAG](https://www.aclweb.org/anthology/D18-1009/) but you can adapt the pre-processing to any other multiple choice dataset you like, or your own data. SWAG is a dataset about commonsense reasoning, where each example describes a situation then proposes four options that could go after it.
This notebook is built to run with any model checkpoint from the [Model Hub](https://huggingface.co/models) as long as that model has a version with a mutiple choice head. Depending on you model and the GPU you are using, you might need to adjust the batch size to avoid out-of-memory errors. Set those two parameters, then the rest of the notebook should run smoothly:
```
model_checkpoint = "bert-base-uncased"
batch_size = 16
```
## Loading the dataset
We will use the [🤗 Datasets](https://github.com/huggingface/datasets) library to download the data. This can be easily done with the functions `load_dataset`.
```
from datasets import load_dataset, load_metric
```
`load_dataset` will cache the dataset to avoid downloading it again the next time you run this cell.
```
datasets = load_dataset("swag", "regular")
```
The `dataset` object itself is [`DatasetDict`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasetdict), which contains one key for the training, validation and test set (with more keys for the mismatched validation and test set in the special case of `mnli`).
```
datasets
```
To access an actual element, you need to select a split first, then give an index:
```
datasets["train"][0]
```
To get a sense of what the data looks like, the following function will show some examples picked randomly in the dataset.
```
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(
dataset
), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset) - 1)
while pick in picks:
pick = random.randint(0, len(dataset) - 1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
```
Each example in the dataset has a context composed of a first sentence (in the field `sent1`) and an introduction to the second sentence (in the field `sent2`). Then four possible endings are given (in the fields `ending0`, `ending1`, `ending2` and `ending3`) and the model must pick the right one (indicated in the field `label`). The following function lets us visualize a give example a bit better:
```
def show_one(example):
print(f"Context: {example['sent1']}")
print(f" A - {example['sent2']} {example['ending0']}")
print(f" B - {example['sent2']} {example['ending1']}")
print(f" C - {example['sent2']} {example['ending2']}")
print(f" D - {example['sent2']} {example['ending3']}")
print(f"\nGround truth: option {['A', 'B', 'C', 'D'][example['label']]}")
show_one(datasets["train"][0])
show_one(datasets["train"][15])
```
## Preprocessing the data
Before we can feed those texts to our model, we need to preprocess them. This is done by a 🤗 Transformers `Tokenizer` which will (as the name indicates) tokenize the inputs (including converting the tokens to their corresponding IDs in the pretrained vocabulary) and put it in a format the model expects, as well as generate the other inputs that model requires.
To do all of this, we instantiate our tokenizer with the `AutoTokenizer.from_pretrained` method, which will ensure:
- we get a tokenizer that corresponds to the model architecture we want to use,
- we download the vocabulary used when pretraining this specific checkpoint.
That vocabulary will be cached, so it's not downloaded again the next time we run the cell.
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
You can directly call this tokenizer on one sentence or a pair of sentences:
```
tokenizer("Hello, this one sentence!", "And this sentence goes with it.")
```
Depending on the model you selected, you will see different keys in the dictionary returned by the cell above. They don't matter much for what we're doing here (just know they are required by the model we will instantiate later), you can learn more about them in [this tutorial](https://huggingface.co/transformers/preprocessing.html) if you're interested.
To preprocess our dataset, we will thus need the names of the columns containing the sentence(s). The following dictionary keeps track of the correspondence task to column names:
We can them write the function that will preprocess our samples. The tricky part is to put all the possible pairs of sentences in two big lists before passing them to the tokenizer, then un-flatten the result so that each example has four input ids, attentions masks, etc.
When calling the `tokenizer`, we use the argument `truncation=True`. This will ensure that an input longer that what the model selected can handle will be truncated to the maximum length accepted by the model.
```
ending_names = ["ending0", "ending1", "ending2", "ending3"]
def preprocess_function(examples):
# Repeat each first sentence four times to go with the four possibilities of second sentences.
first_sentences = [[context] * 4 for context in examples["sent1"]]
# Grab all second sentences possible for each context.
question_headers = examples["sent2"]
second_sentences = [
[f"{header} {examples[end][i]}" for end in ending_names]
for i, header in enumerate(question_headers)
]
# Flatten everything
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
# Tokenize
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
# Un-flatten
return {
k: [v[i : i + 4] for i in range(0, len(v), 4)]
for k, v in tokenized_examples.items()
}
```
This function works with one or several examples. In the case of several examples, the tokenizer will return a list of lists of lists for each key: a list of all examples (here 5), then a list of all choices (4) and a list of input IDs (length varying here since we did not apply any padding):
```
examples = datasets["train"][:5]
features = preprocess_function(examples)
print(
len(features["input_ids"]),
len(features["input_ids"][0]),
[len(x) for x in features["input_ids"][0]],
)
```
To check we didn't do anything group when grouping all possibilites then unflattening, let's have a look at the decoded inputs for a given example:
```
idx = 3
[tokenizer.decode(features["input_ids"][idx][i]) for i in range(4)]
```
We can compare it to the ground truth:
```
show_one(datasets["train"][3])
```
This seems alright, so we can apply this function on all the examples in our dataset, we just use the `map` method of our `dataset` object we created earlier. This will apply the function on all the elements of all the splits in `dataset`, so our training, validation and testing data will be preprocessed in one single command.
```
encoded_datasets = datasets.map(preprocess_function, batched=True)
```
Even better, the results are automatically cached by the 🤗 Datasets library to avoid spending time on this step the next time you run your notebook. The 🤗 Datasets library is normally smart enough to detect when the function you pass to map has changed (and thus requires to not use the cache data). For instance, it will properly detect if you change the task in the first cell and rerun the notebook. 🤗 Datasets warns you when it uses cached files, you can pass `load_from_cache_file=False` in the call to `map` to not use the cached files and force the preprocessing to be applied again.
Note that we passed `batched=True` to encode the texts by batches together. This is to leverage the full benefit of the fast tokenizer we loaded earlier, which will use multi-threading to treat the texts in a batch concurrently.
## Fine-tuning the model
Now that our data is ready, we can download the pretrained model and fine-tune it. Since all our task is about mutliple choice, we use the `AutoModelForMultipleChoice` class. Like with the tokenizer, the `from_pretrained` method will download and cache the model for us.
```
from transformers import TFAutoModelForMultipleChoice
model = TFAutoModelForMultipleChoice.from_pretrained(model_checkpoint)
```
The warning is telling us we are throwing away some weights (the `vocab_transform` and `vocab_layer_norm` layers) and randomly initializing some other (the `pre_classifier` and `classifier` layers). This is absolutely normal in this case, because we are removing the head used to pretrain the model on a masked language modeling objective and replacing it with a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
Next, we set some names and hyperparameters for the model. The first two variables are used so we can push the model to the [Hub](https://huggingface.co/models) at the end of training. Remove the two of them if you didn't follow the installation steps at the top of the notebook, otherwise you can change the value of `push_to_hub_model_id` to something you would prefer.
```
model_name = model_checkpoint.split("/")[-1]
push_to_hub_model_id = f"{model_name}-finetuned-swag"
learning_rate = 5e-5
batch_size = batch_size
num_train_epochs = 2
weight_decay = 0.01
```
Next we need to tell our `Dataset` how to form batches from the pre-processed inputs. We haven't done any padding yet because we will pad each batch to the maximum length inside the batch (instead of doing so with the maximum length of the whole dataset). This will be the job of the *data collator*. A data collator takes a list of examples and converts them to a batch (by, in our case, applying padding). Since there is no data collator in the library that works on our specific problem, we will write one, adapted from the `DataCollatorWithPadding`:
```
from dataclasses import dataclass
from transformers.tokenization_utils_base import (
PreTrainedTokenizerBase,
PaddingStrategy,
)
from typing import Optional, Union
import tensorflow as tf
@dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)]
for feature in features
]
flattened_features = sum(flattened_features, [])
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="tf",
)
# Un-flatten
batch = {
k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()
}
# Add back labels
batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
return batch
```
When called on a list of examples, it will flatten all the inputs/attentions masks etc. in big lists that it will pass to the `tokenizer.pad` method. This will return a dictionary with big tensors (of shape `(batch_size * 4) x seq_length`) that we then unflatten.
We can check this data collator works on a list of features, we just have to make sure to remove all features that are not inputs accepted by our model (something the `Trainer` will do automatically for us after):
```
accepted_keys = ["input_ids", "attention_mask", "label"]
features = [
{k: v for k, v in encoded_datasets["train"][i].items() if k in accepted_keys}
for i in range(10)
]
batch = DataCollatorForMultipleChoice(tokenizer)(features)
encoded_datasets["train"].features["attention_mask"].feature.feature
```
Again, all those flatten/un-flatten are sources of potential errors so let's make another sanity check on our inputs:
```
[tokenizer.decode(batch["input_ids"][8][i].numpy().tolist()) for i in range(4)]
show_one(datasets["train"][8])
```
All good! Now we can use this collator as a collation function for our dataset. The best way to do this is with the `to_tf_dataset()` method. This converts our dataset to a `tf.data.Dataset` that Keras can take as input. It also applies our collation function to each batch.
```
data_collator = DataCollatorForMultipleChoice(tokenizer)
train_set = encoded_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels"],
shuffle=True,
batch_size=batch_size,
collate_fn=data_collator,
)
validation_set = encoded_datasets["validation"].to_tf_dataset(
columns=["attention_mask", "input_ids", "labels"],
shuffle=False,
batch_size=batch_size,
collate_fn=data_collator,
)
```
Now we can create our model. First, we specify an optimizer. Using the `create_optimizer` function we can get a nice `AdamW` optimizer with weight decay and a learning rate decay schedule set up for free - but to compute that schedule, it needs to know how long training will take.
```
from transformers import create_optimizer
total_train_steps = (len(encoded_datasets["train"]) // batch_size) * num_train_epochs
optimizer, schedule = create_optimizer(
init_lr=learning_rate, num_warmup_steps=0, num_train_steps=total_train_steps
)
```
All Transformers models have a `loss` output head, so we can simply leave the loss argument to `compile()` blank to train on it.
```
import tensorflow as tf
model.compile(optimizer=optimizer)
```
Now we can train our model. We can also add a callback to sync up our model with the Hub - this allows us to resume training from other machines and even test the model's inference quality midway through training! Make sure to change the `username` if you do. If you don't want to do this, simply remove the callbacks argument in the call to `fit()`.
```
from transformers.keras_callbacks import PushToHubCallback
username = "Rocketknight1"
callback = PushToHubCallback(
output_dir="./mc_model_save",
tokenizer=tokenizer,
hub_model_id=f"{username}/{push_to_hub_model_id}",
)
model.fit(
train_set,
validation_data=validation_set,
epochs=num_train_epochs,
callbacks=[callback],
)
```
One downside of using the internal loss, however, is that we can't use Keras metrics with it. So let's compute accuracy after the fact, to see how our model is performing. First, we need to get our model's predicted answers on the validation set.
```
predictions = model.predict(validation_set)["logits"]
labels = encoded_datasets["validation"]["label"]
```
And now we can compute our accuracy with Numpy.
```
import numpy as np
preds = np.argmax(predictions, axis=1)
print({"accuracy": (preds == labels).astype(np.float32).mean().item()})
```
If you used the callback above, you can now share this model with all your friends, family, favorite pets: they can all load it with the identifier `"your-username/the-name-you-picked"` so for instance:
```python
from transformers import AutoModelForMultipleChoice
model = AutoModelForMultipleChoice.from_pretrained("your-username/my-awesome-model")
```
| true |
code
| 0.732149 | null | null | null | null |
|
# Data Distribution vs. Sampling Distribution: What You Need to Know
This notebook is accompanying the article [Data Distribution vs. Sampling Distribution: What You Need to Know](https://www.ealizadeh.com/blog/statistics-data-vs-sampling-distribution/).
Subscribe to **[my mailing list](https://www.ealizadeh.com/subscribe/)** to receive my posts on statistics, machine learning, and interesting Python libraries and tips & tricks.
You can also follow me on **[Medium](https://medium.com/@ealizadeh)**, **[LinkedIn](https://www.linkedin.com/in/alizadehesmaeil/)**, and **[Twitter]( https://twitter.com/es_alizadeh)**.
Copyright © 2021 [Esmaeil Alizadeh](https://ealizadeh.com)
```
from IPython.display import Image
Image("https://www.ealizadeh.com/wp-content/uploads/2021/01/data_dist_sampling_dist_featured_image.png", width=1200)
```
---
It is important to distinguish between the data distribution (aka population distribution) and the sampling distribution. The distinction is critical when working with the central limit theorem or other concepts like the standard deviation and standard error.
In this post we will go over the above concepts and as well as bootstrapping to estimate the sampling distribution. In particular, we will cover the following:
- Data distribution (aka population distribution)
- Sampling distribution
- Central limit theorem (CLT)
- Standard error and its relation with the standard deviation
- Bootstrapping
---
## Data Distribution
Much of the statistics deals with inferring from samples drawn from a larger population. Hence, we need to distinguish between the analysis done the original data as opposed to analyzing its samples. First, let's go over the definition of the data distribution:
💡 **Data distribution:** *The frequency distribution of individual data points in the original dataset.*
### Generate Data
Let's first generate random skewed data that will result in a non-normal (non-Gaussian) data distribution. The reason behind generating non-normal data is to better illustrate the relation between data distribution and the sampling distribution.
So, let's import the Python plotting packages and generate right-skewed data.
```
# Plotting packages and initial setup
import seaborn as sns
sns.set_theme(palette="pastel")
sns.set_style("white")
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["figure.dpi"] = 150
savefig_options = dict(format="png", dpi=150, bbox_inches="tight")
from scipy.stats import skewnorm
from sklearn.preprocessing import MinMaxScaler
num_data_points = 10000
max_value = 100
skewness = 15 # Positive values are right-skewed
skewed_random_data = skewnorm.rvs(a=skewness, loc=max_value, size=num_data_points, random_state=1)
skewed_data_scaled = MinMaxScaler().fit_transform(skewed_random_data.reshape(-1, 1))
```
Plotting the data distribution
```
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_title("Data Distribution", fontsize=24, fontweight="bold")
sns.histplot(skewed_data_scaled, bins=30, stat="density", kde=True, legend=False, ax=ax)
# fig.savefig("original_skewed_data_distribution.png", **savefig_options)
```
## Sampling Distribution
In the sampling distribution, you draw samples from the dataset and compute a statistic like the mean. It's very important to differentiate between the data distribution and the sampling distribution as most confusion comes from the operation done on either the original dataset or its (re)samples.
💡 **Sampling distribution:** *The frequency distribution of a sample statistic (aka metric) over many samples drawn from the dataset[katex]^{[1]}[/katex]. Or to put it simply, the distribution of sample statistics is called the sampling distribution.*
The algorithm to obtain the sampling distribution is as follows:
1. Draw a sample from the dataset.
2. Compute a statistic/metric of the drawn sample in Step 1 and save it.
3. Repeat Steps 1 and 2 many times.
4. Plot the distribution (histogram) of the computed statistic.
```
import numpy as np
import random
sample_size = 50
sample_means = []
random.seed(1) # Setting the seed for reproducibility of the result
for _ in range(2000):
sample = random.sample(skewed_data_scaled.tolist(), sample_size)
sample_means.append(np.mean(sample))
print(
f"Mean: {np.mean(sample_means).round(5)}"
)
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_title("Sampling Distribution", fontsize=24, fontweight="bold")
sns.histplot(sample_means, bins=30, stat="density", kde=True, legend=False)
# fig.savefig("sampling_distribution.png", **savefig_options)
```
Above sampling distribution is basically the histogram of the mean of each drawn sample (in above, we draw samples of 50 elements over 2000 iterations). The mean of the above sampling distribution is around 0.23, as can be noted from computing the mean of all samples means.
⚠️ *Do not confuse the sampling distribution with the sample distribution. The sampling distribution considers the distribution of sample statistics (e.g. mean), whereas the sample distribution is basically the distribution of the sample taken from the population.*
## Central Limit Theorem (CLT)
💡 **Central Limit Theorem:** *As the sample size gets larger, the sampling distribution tends to be more like a normal distribution (bell-curve shape).*
*In CLT, we analyze the sampling distribution and not a data distribution, an important distinction to be made.* CLT is popular in hypothesis testing and confidence interval analysis, and it's important to be aware of this concept, even though with the use of bootstrap in data science, this theorem is less talked about or considered in the practice of data science$^{[1]}$. More on bootstrapping is provided later in the post.
## Standard Error (SE)
The [standard error](https://en.wikipedia.org/wiki/Standard_error) is a metric to describe *the variability of a statistic in the sampling distribution*. We can compute the standard error as follows:
$$ \text{Standard Error} = SE = \frac{s}{\sqrt{n}} $$
where $s$ denotes the standard deviation of the sample values and $n$ denotes the sample size. It can be seen from the formula that *as the sample size increases, the SE decreases*.
We can estimate the standard error using the following approach$^{[1]}$:
1. Draw a new sample from a dataset.
2. Compute a statistic/metric (e.g., mean) of the drawn sample in Step 1 and save it.
3. Repeat Steps 1 and 2 several times.
4. An estimate of the standard error is obtained by computing the standard deviation of the previous steps' statistics.
While the above approach can be used to estimate the standard error, we can use bootstrapping instead, which is preferable. I will go over that in the next section.
⚠️ *Do not confuse the standard error with the standard deviation. The standard deviation captures the variability of the individual data points (how spread the data is), unlike the standard error that captures a sample statistic's variability.*
## Bootstrapping
Bootstrapping is an easy way of estimating the sampling distribution by randomly drawing samples from the population (with replacement) and computing each resample's statistic. Bootstrapping does not depend on the CLT or other assumptions on the distribution, and it is the standard way of estimating SE$^{[1]}$.
Luckily, we can use [`bootstrap()`](https://rasbt.github.io/mlxtend/user_guide/evaluate/bootstrap/) functionality from the [MLxtend library](https://rasbt.github.io/mlxtend/) (You can read [my post](https://www.ealizadeh.com/blog/mlxtend-library-for-data-science/) on MLxtend library covering other interesting functionalities). This function also provides the flexibility to pass a custom sample statistic.
```
from mlxtend.evaluate import bootstrap
avg, std_err, ci_bounds = bootstrap(
skewed_data_scaled,
num_rounds=1000,
func=np.mean, # A function to compute a sample statistic can be passed here
ci=0.95,
seed=123 # Setting the seed for reproducibility of the result
)
print(
f"Mean: {avg.round(5)} \n"
f"Standard Error: +/- {std_err.round(5)} \n"
f"CI95: [{ci_bounds[0].round(5)}, {ci_bounds[1].round(5)}]"
)
```
## Conclusion
The main takeaway is to differentiate between whatever computation you do on the original dataset or the sampling of the dataset. Plotting a histogram of the data will result in data distribution, whereas plotting a sample statistic computed over samples of data will result in a sampling distribution. On a similar note, the standard deviation tells us how the data is spread, whereas the standard error tells us how a sample statistic is spread out.
Another takeaway is that even if the original data distribution is non-normal, the sampling distribution is normal (central limit theorem).
Thanks for reading!
___If you liked this post, you can [join my mailing list here](https://www.ealizadeh.com/subscribe/) to receive more posts about Data Science, Machine Learning, Statistics, and interesting Python libraries and tips & tricks. You can also follow me on my [website](https://ealizadeh.com/), [Medium](https://medium.com/@ealizadeh), [LinkedIn](https://www.linkedin.com/in/alizadehesmaeil/), or [Twitter](https://twitter.com/es_alizadeh).___
# References
[1] P. Bruce & A. Bruce (2017), Practical Statistics for Data Scientists, First Edition, O’Reilly
# Useful Links
[MLxtend: A Python Library with Interesting Tools for Data Science Tasks](https://www.ealizadeh.com/blog/mlxtend-library-for-data-science/)
| true |
code
| 0.698471 | null | null | null | null |
|
# Time Series analysis of O'hare taxi rides data
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import TimeSeriesSplit, cross_validate, GridSearchCV
pd.set_option('display.max_rows', 6)
plt.style.use('ggplot')
plt.rcParams.update({'font.size': 16,
'axes.labelweight': 'bold',
'figure.figsize': (8,6)})
from mealprep.mealprep import find_missing_ingredients
# pd.set_option('display.max_colwidth', None)
pd.set_option('display.max_rows', None)
import pickle
ORD_df = pd.read_csv('../data/ORD_train.csv').drop(columns=['Unnamed: 0', 'Unnamed: 0.1'])
ORD_df
```
## Tom's functions
```
# Custom functions
def lag_df(df, lag, cols):
return df.assign(**{f"{col}-{n}": df[col].shift(n) for n in range(1, lag + 1) for col in cols})
def ts_predict(input_data, model, n=20, responses=1):
predictions = []
n_features = input_data.size
for _ in range(n):
predictions = np.append(predictions,
model.predict(input_data.reshape(1, -1))) # make prediction
input_data = np.append(predictions[-responses:],
input_data[:n_features-responses]) # new input data
return predictions.reshape((-1, responses))
def plot_ts(ax, df_train, df_test, predictions, xlim, response_cols):
col_cycle = plt.rcParams['axes.prop_cycle'].by_key()['color']
for i, col in enumerate(response_cols):
ax.plot(df_train[col], '-', c=col_cycle[i], label = f'Train {col}')
ax.plot(df_test[col], '--', c=col_cycle[i], label = f'Validation {col}')
ax.plot(np.arange(df_train.index[-1] + 1,
df_train.index[-1] + 1 + len(predictions)),
predictions[:,i], c=col_cycle[-i-2], label = f'Prediction {col}')
ax.set_xlim(0, xlim+1)
ax.set_title(f"Train Shape = {len(df_train)}, Validation Shape = {len(df_test)}",
fontsize=16)
ax.set_ylabel(df_train.columns[0])
def plot_forecast(ax, df_train, predictions, xlim, response_cols):
col_cycle = plt.rcParams['axes.prop_cycle'].by_key()['color']
for i, col in enumerate(response_cols):
ax.plot(df_train[col], '-', c=col_cycle[i], label = f'Train {col}')
ax.plot(np.arange(df_train.index[-1] + 1,
df_train.index[-1] + 1 + len(predictions)),
predictions[:,i], '-', c=col_cycle[-i-2], label = f'Prediction {col}')
ax.set_xlim(0, xlim+len(predictions))
ax.set_title(f"{len(predictions)}-step forecast",
fontsize=16)
ax.set_ylabel(response_cols)
def create_rolling_features(df, columns, windows=[6, 12]):
for window in windows:
df["rolling_mean_" + str(window)] = df[columns].rolling(window=window).mean()
df["rolling_std_" + str(window)] = df[columns].rolling(window=window).std()
df["rolling_var_" + str(window)] = df[columns].rolling(window=window).var()
df["rolling_min_" + str(window)] = df[columns].rolling(window=window).min()
df["rolling_max_" + str(window)] = df[columns].rolling(window=window).max()
df["rolling_min_max_ratio_" + str(window)] = df["rolling_min_" + str(window)] / df["rolling_max_" + str(window)]
df["rolling_min_max_diff_" + str(window)] = df["rolling_max_" + str(window)] - df["rolling_min_" + str(window)]
df = df.replace([np.inf, -np.inf], np.nan)
df.fillna(0, inplace=True)
return df
lag = 3
ORD_train_lag = lag_df(ORD_df, lag=lag, cols=['seats']).dropna()
ORD_train_lag
find_missing_ingredients(ORD_train_lag)
lag = 3 # you can vary the number of lagged features in the model
n_splits = 5 # you can vary the number of train/validation splits
response_col = ['rides']
# df_lag = lag_df(df, lag, response_col).dropna()
tscv = TimeSeriesSplit(n_splits=n_splits) # define the splitter
model = RandomForestRegressor() # define the model
cv = cross_validate(model,
X = ORD_train_lag.drop(columns=response_col),
y = ORD_train_lag[response_col[0]],
scoring =('r2', 'neg_mean_squared_error'),
cv=tscv,
return_train_score=True)
# pd.DataFrame({'split': range(n_splits),
# 'train_r2': cv['train_score'],
# 'train_negrmse': cv['train_']
# 'validation_r2': cv['test_score']}).set_index('split')
pd.DataFrame(cv)
fig, ax = plt.subplots(n_splits, 1, figsize=(8,4*n_splits))
for i, (train_index, test_index) in enumerate(tscv.split(ORD_train_lag)):
df_train, df_test = ORD_train_lag.iloc[train_index], ORD_train_lag.iloc[test_index]
model = RandomForestRegressor().fit(df_train.drop(columns=response_col),
df_train[response_col[0]]) # train model
# Prediction loop
predictions = model.predict(df_test.drop(columns=response_col))[:,None]
# Plot
plot_ts(ax[i], df_train, df_test, predictions, xlim=ORD_train_lag.index[-1], response_cols=response_col)
ax[0].legend(facecolor='w')
ax[i].set_xlabel('time')
fig.tight_layout()
lag = 3 # you can vary the number of lagged features in the model
n_splits = 3 # you can vary the number of train/validation splits
response_col = ['rides']
# df_lag = lag_df(df, lag, response_col).dropna()
tscv = TimeSeriesSplit(n_splits=n_splits) # define the splitter
model = RandomForestRegressor() # define the model
param_grid = {'n_estimators': [50, 100, 150, 200],
'max_depth': [10,25,50,100, None]}
X = ORD_train_lag.drop(columns=response_col)
y = ORD_train_lag[response_col[0]]
gcv = GridSearchCV(model,
param_grid = param_grid,
# X = ORD_train_lag.drop(columns=response_col),
# y = ORD_train_lag[response_col[0]],
scoring ='neg_mean_squared_error',
cv=tscv,
return_train_score=True)
gcv.fit(X,y)
# pd.DataFrame({'split': range(n_splits),
# 'train_r2': cv['train_score'],
# 'train_negrmse': cv['train_']
# 'validation_r2': cv['test_score']}).set_index('split')
gcv.score(X,y)
filename = 'grid_search_model_1.sav'
pickle.dump(gcv, open(filename, 'wb'))
A = list(ORD_train_lag.columns)
A.remove('rides')
pd.DataFrame({'columns' : A, 'importance' : gcv.best_estimator_.feature_importances_}).sort_values('importance', ascending=False)
gcv.best_params_
pd.DataFrame(gcv.cv_results_)
gcv.estimator.best_
```
| true |
code
| 0.569912 | null | null | null | null |
|
# Document embeddings in BigQuery
This notebook shows how to do use a pre-trained embedding as a vector representation of a natural language text column.
Given this embedding, we can use it in machine learning models.
## Embedding model for documents
We're going to use a model that has been pretrained on Google News. Here's an example of how it works in Python. We will use it directly in BigQuery, however.
```
import tensorflow as tf
import tensorflow_hub as tfhub
model = tf.keras.Sequential()
model.add(tfhub.KerasLayer("https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1",
output_shape=[20], input_shape=[], dtype=tf.string))
model.summary()
model.predict(["""
Long years ago, we made a tryst with destiny; and now the time comes when we shall redeem our pledge, not wholly or in full measure, but very substantially. At the stroke of the midnight hour, when the world sleeps, India will awake to life and freedom.
A moment comes, which comes but rarely in history, when we step out from the old to the new -- when an age ends, and when the soul of a nation, long suppressed, finds utterance.
"""])
```
## Loading model into BigQuery
The Swivel model above is already available in SavedModel format. But we need it on Google Cloud Storage before we can load it into BigQuery.
```
%%bash
BUCKET=ai-analytics-solutions-kfpdemo # CHANGE AS NEEDED
rm -rf tmp
mkdir tmp
FILE=swivel.tar.gz
wget --quiet -O tmp/swivel.tar.gz https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1?tf-hub-format=compressed
cd tmp
tar xvfz swivel.tar.gz
cd ..
mv tmp swivel
gsutil -m cp -R swivel gs://${BUCKET}/swivel
rm -rf swivel
echo "Model artifacts are now at gs://${BUCKET}/swivel/*"
```
Let's load the model into a BigQuery dataset named advdata (create it if necessary)
```
%%bigquery
CREATE OR REPLACE MODEL advdata.swivel_text_embed
OPTIONS(model_type='tensorflow', model_path='gs://ai-analytics-solutions-kfpdemo/swivel/*')
```
From the BigQuery web console, click on "schema" tab for the newly loaded model. We see that the input is called sentences and the output is called output_0:
<img src="swivel_schema.png" />
```
%%bigquery
SELECT output_0 FROM
ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT "Long years ago, we made a tryst with destiny; and now the time comes when we shall redeem our pledge, not wholly or in full measure, but very substantially." AS sentences))
```
## Create lookup table
Let's create a lookup table of embeddings. We'll use the comments field of a storm reports table from NOAA.
This is an example of the Feature Store design pattern.
```
%%bigquery
CREATE OR REPLACE TABLE advdata.comments_embedding AS
SELECT
output_0 as comments_embedding,
comments
FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(
SELECT comments, LOWER(comments) AS sentences
FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`
))
```
For an example of using these embeddings in text similarity or document clustering, please see the following Medium blog post: https://medium.com/@lakshmanok/how-to-do-text-similarity-search-and-document-clustering-in-bigquery-75eb8f45ab65
Copyright 2020 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License
| true |
code
| 0.633949 | null | null | null | null |
|
# DLISIO in a Nutshell
## Importing
```
%matplotlib inline
import os
import pandas as pd
import dlisio
import matplotlib.pyplot as plt
import numpy as np
import numpy.lib.recfunctions as rfn
import hvplot.pandas
import holoviews as hv
from holoviews import opts, streams
from holoviews.plotting.links import DataLink
hv.extension('bokeh', logo=None)
```
### You can work with a single file using the cell below - or by adding an additional for loop to the code below, you can work through a list of files. Another option is to use os.walk to get all .dlis files in a parent folder. Example:
for (root, dirs, files) in os.walk(folderpath):
for f in files:
filepath = os.path.join(root, f)
if filepath.endswith('.' + 'dlis'):
print(filepath)
### But for this example, we will work with a single .dlis file specified in the cell below. Note that there are some .dlis file formats that are not supported by DLISIO yet - good to catch them in a try except loop if you are reading files enmasse.
### We will load a dlis file from the open source Volve dataset available here: https://data.equinor.com/dataset/Volve
```
filepath = r""
```
## Query for specific curve
### Very quickly you can use regex to find certain curves in a file (helpful if you are scanning a lot of files for certain curves)
```
with dlisio.dlis.load(filepath) as file:
for d in file:
depth_channels = d.find('CHANNEL','DEPT')
for channel in depth_channels:
print(channel.name)
print(channel.curves())
```
## Examining internal files and frames
### Keep in mind that dlis files can contain multiple files and multiple frames. You can quickly get a numpy array of the curves in each frame below.
```
with dlisio.dlis.load(filepath) as file:
print(file.describe())
with dlisio.dlis.load(filepath) as file:
for d in file:
for fram in d.frames:
print(d.channels)
print(fram.curves())
```
## Metadata including Origin information (well name and header)
```
with dlisio.dlis.load(filepath) as file:
for d in file:
print(d.describe())
for fram in d.frames:
print(fram.describe())
for channel in d.channels:
print(channel.describe())
with dlisio.dlis.load(filepath) as file:
for d in file:
for origin in d.origins:
print(origin.describe())
```
## Reading a full dlis file
### But most likely we want a single data frame of every curve, no matter which frame it came from. So we write a bit more code to look through each frame, then look at each channel and get the curve name and unit information along with it. We will also save the information about which internal file and which frame each curve resides in.
```
curves_L = []
curves_name = []
longs = []
unit = []
files_L = []
files_num = []
frames = []
frames_num = []
with dlisio.dlis.load(filepath) as file:
for d in file:
files_L.append(d)
frame_count = 0
for fram in d.frames:
if frame_count == 0:
frames.append(fram)
frame_count = frame_count + 1
for channel in d.channels:
curves_name.append(channel.name)
longs.append(channel.long_name)
unit.append(channel.units)
files_num.append(len(files_L))
frames_num.append(len(frames))
curves = channel.curves()
curves_L.append(curves)
curve_index = pd.DataFrame(
{'Curve': curves_name,
'Long': longs,
'Unit': unit,
'Internal_File': files_num,
'Frame_Number': frames_num
})
curve_index
```
## Creating a Pandas dataframe for the entire .dlis file
### We have to be careful creating a dataframe for the whole .dlis file as often there are some curves that represent mulitple values (numpy array of list values). So, you can use something like:
df = pd.DataFrame(data=curves_L, index=curves_name).T
### to view the full dlis file with lists as some of the curve values.
### Or we will use the code below to process each curve's 2D numpy array, stacking it if the curve contains multiple values per sample. Then we convert each curve into its own dataframe (uniquifying the column names by adding a .1, .2, .3...etc). Then, to preserve the order with the curve index above, append each data frame together in order to build the final dlis full dataframe.
```
def df_column_uniquify(df):
df_columns = df.columns
new_columns = []
for item in df_columns:
counter = 0
newitem = item
while newitem in new_columns:
counter += 1
newitem = "{}_{}".format(item, counter)
new_columns.append(newitem)
df.columns = new_columns
return df
curve_df = pd.DataFrame()
name_index = 0
for c in curves_L:
name = curves_name[name_index]
np.vstack(c)
try:
num_col = c.shape[1]
col_name = [name] * num_col
df = pd.DataFrame(data=c, columns=col_name)
name_index = name_index + 1
df = df_column_uniquify(df)
curve_df = pd.concat([curve_df, df], axis=1)
except:
num_col = 0
df = pd.DataFrame(data=c, columns=[name])
name_index = name_index + 1
curve_df = pd.concat([curve_df, df], axis=1)
continue
curve_df.head()
## If we have a simpler dlis file with a single logical file and single frame and with single data values in each channel.
with dlisio.dlis.load(filepath) as file:
logical_count = 0
for d in file:
frame_count = 0
for fram in d.frames:
if frame_count == 0 & logical_count == 0:
curves = fram.curves()
curve_df = pd.DataFrame(curves, index=curves[fram.index])
curve_df.head()
```
### Then we can set the index and start making some plots.
```
curve_df = df_column_uniquify(curve_df)
curve_df['DEPTH_Calc_ft'] = curve_df.loc[:,'TDEP'] * 0.0083333 #0.1 inch/12 inches per foot
curve_df['DEPTH_ft'] = curve_df['DEPTH_Calc_ft']
curve_df = curve_df.set_index("DEPTH_Calc_ft")
curve_df.index.names = [None]
curve_df = curve_df.replace(-999.25,np.nan)
min_val = curve_df['DEPTH_ft'].min()
max_val = curve_df['DEPTH_ft'].max()
curve_list = list(curve_df.columns)
curve_list.remove('DEPTH_ft')
curve_df.head()
def curve_plot(log, df, depthname):
aplot = df.hvplot(x=depthname, y=log, invert=True, flip_yaxis=True, shared_axes=True,
height=600, width=300).opts(fontsize={'labels': 16,'xticks': 14, 'yticks': 14})
return aplot;
plotlist = [curve_plot(x, df=curve_df, depthname='DEPTH_ft') for x in curve_list]
well_section = hv.Layout(plotlist).cols(len(curve_list))
well_section
```
# Hopefully that is enough code to get you started working with DLISIO. There is much more functionality which can be accessed with help(dlisio) or at the read the docs.
| true |
code
| 0.278711 | null | null | null | null |
|
# Example 5: Quantum-to-quantum transfer learning.
This is an example of a continuous variable (CV) quantum network for state classification, developed according to the *quantum-to-quantum transfer learning* scheme presented in [1].
## Introduction
In this proof-of-principle demonstration we consider two distinct toy datasets of Gaussian and non-Gaussian states. Such datasets can be generated according to the following simple prescriptions:
**Dataset A**:
- Class 0 (Gaussian): random Gaussian layer applied to the vacuum.
- Class 1 (non-Gaussian): random non-Gaussian Layer applied to the vacuum.
**Dataset B**:
- Class 0 (Gaussian): random Gaussian layer applied to a coherent state with amplitude $\alpha=1$.
- Class 1 (non-Gaussian): random Gaussian layer applied to a single photon Fock state $|1\rangle$.
**Variational Circuit A**:
Our starting point is a single-mode variational circuit [2] (a non-Gaussian layer), pre-trained on _Dataset A_. We assume that after the circuit is applied, the output mode is measured with an _on/off_ detector. By averaging over many shots, one can estimate the vacuum probability:
$$
p_0 = | \langle \psi_{\rm out} |0 \rangle|^2.
$$
We use _Dataset A_ and train the circuit to rotate Gaussian states towards the vacuum while non-Gaussian states far away from the vacuum. For the final classification we use the simple decision rule:
$$
p_0 \ge 0 \longrightarrow {\rm Class=0.} \\
p_0 < 0 \longrightarrow {\rm Class=1.}
$$
**Variational Circuit B**:
Once _Circuit A_ has been optimized, we can use is as a pre-trained block
applicable also to the different _Dataset B_. In other words, we implement a _quantum-to-quantum_ transfer learning model:
_Circuit B_ = _Circuit A_ (pre-trained) followed by a sequence of _variational layers_ (to be trained).
Also in this case, after the application of _Circuit B_, we assume to measure the single mode with an _on/off_ detector, and we apply a similar classification rule:
$$
p_0 \ge 0 \longrightarrow {\rm Class=1.} \\
p_0 < 0 \longrightarrow {\rm Class=0.}
$$
The motivation for this transfer learning approach is that, even if _Circuit A_ is optimized on a different dataset, it can still act as a good pre-processing block also for _Dataset B_. Ineeed, as we are going to show, the application of _Circuit A_ can significantly improve the training efficiency of _Circuit B_.
## General setup
The main imported modules are: the `tensorflow` machine learning framework, the quantum CV
software `strawberryfields` [3] and the python plotting library `matplotlib`. All modules should be correctly installed in the system before running this notebook.
```
# Plotting
%matplotlib inline
import matplotlib.pyplot as plt
# TensorFlow
import tensorflow as tf
# Strawberryfields (simulation of CV quantum circuits)
import strawberryfields as sf
from strawberryfields.ops import Dgate, Kgate, Sgate, Rgate, Vgate, Fock, Ket
# Other modules
import numpy as np
import time
# System variables
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # avoid warning messages
os.environ['OMP_NUM_THREADS'] = '1' # set number of threads.
os.environ['CUDA_VISIBLE_DEVICES'] = '1' # select the GPU unit.
# Path with pre-trained parameters
weights_path = 'results/weights/'
```
Setting of the main parameters of the network model and of the training process.<br>
```
# Hilbert space cutoff
cutoff = 15
# Normalization cutoff (must be equal or smaller than cutoff dimension)
target_cutoff = 15
# Normalization weight
norm_weight = 0
# Batch size
batch_size = 8
# Number of batches (i.e. number training iterations)
num_batches = 500
# Number of state generation layers
g_depth = 1
# Number of pre-trained layers (for transfer learning)
pre_depth = 1
# Number of state classification layers
q_depth = 3
# Standard deviation of random state generation parameters
rot_sd = np.math.pi * 2
dis_sd = 0
sq_sd = 0.5
non_lin_sd = 0.5 # this is used as fixed non-linear constant.
# Standard deviation of initial trainable weights
active_sd = 0.001
passive_sd = 0.001
# Magnitude limit for trainable active parameters
clip = 1
# Learning rate
lr = 0.01
# Random seeds
tf.set_random_seed(0)
rng_data = np.random.RandomState(1)
# Reset TF graph
tf.reset_default_graph()
```
## Variational circuits for state generation and classificaiton
### Input states: _Dataset B_
The dataset is introduced by defining the corresponding random variational circuit that generates input Gaussian and non-Gaussian states.
```
# Placeholders for class labels
batch_labels = tf.placeholder(dtype=tf.int64, shape = [batch_size])
batch_labels_fl = tf.to_float(batch_labels)
# State generation parameters
# Squeezing gate
sq_gen = tf.placeholder(dtype = tf.float32, shape = [batch_size,g_depth])
# Rotation gates
r1_gen = tf.placeholder(dtype = tf.float32, shape = [batch_size,g_depth])
r2_gen = tf.placeholder(dtype = tf.float32, shape = [batch_size,g_depth])
r3_gen = tf.placeholder(dtype = tf.float32, shape = [batch_size,g_depth])
# Explicit definitions of the ket tensors of |0> and |1>
np_ket0, np_ket1 = np.zeros((2, batch_size, cutoff))
np_ket0[:,0] = 1.0
np_ket1[:,1] = 1.0
ket0 = tf.constant(np_ket0, dtype = tf.float32, shape = [batch_size, cutoff])
ket1 = tf.constant(np_ket1, dtype = tf.float32, shape = [batch_size, cutoff])
# Ket of the quantum states associated to the label: i.e. |batch_labels>
ket_init = ket0 * (1.0 - tf.expand_dims(batch_labels_fl, 1)) + ket1 * tf.expand_dims(batch_labels_fl, 1)
# State generation layer
def layer_gen(i, qmode):
# If label is 0 (Gaussian) prepare a coherent state with alpha=1 otherwise prepare fock |1>
Ket(ket_init) | qmode
Dgate((1.0 - batch_labels_fl) * 1.0, 0) | qmode
# Random Gaussian operation (without displacement)
Rgate(r1_gen[:, i]) | qmode
Sgate(sq_gen[:, i], 0) | qmode
Rgate(r2_gen[:, i]) | qmode
return qmode
```
### Loading of pre-trained block (_Circuit A_)
We assume that _Circuit A_ has been already pre-trained (e.g. by running a dedicated Python script) and that the associated optimal weights have been saved to a NumPy file. Here we first load the such parameters and then we define _Circuit A_ as a constant pre-processing block.
```
# Loading of pre-trained weights
trained_params_npy = np.load('pre_trained/circuit_A.npy')
if trained_params_npy.shape[1] < pre_depth:
print("Error: circuit q_depth > trained q_depth.")
raise SystemExit(0)
# Convert numpy arrays to TF tensors
trained_params = tf.constant(trained_params_npy)
sq_pre = trained_params[0]
d_pre = trained_params[1]
r1_pre = trained_params[2]
r2_pre = trained_params[3]
r3_pre = trained_params[4]
kappa_pre = trained_params[5]
# Definition of the pre-trained Circuit A (single layer)
def layer_pre(i, qmode):
# Rotation gate
Rgate(r1_pre[i]) | qmode
# Squeezing gate
Sgate(tf.clip_by_value(sq_pre[i], -clip, clip), 0)
# Rotation gate
Rgate(r2_pre[i]) | qmode
# Displacement gate
Dgate(tf.clip_by_value(d_pre[i], -clip, clip) , 0) | qmode
# Rotation gate
Rgate(r3_pre[i]) | qmode
# Cubic gate
Vgate(tf.clip_by_value(kappa_pre[i], -clip, clip) ) | qmode
return qmode
```
### Addition of trainable layers (_Circuit B_)
As discussed in the introduction, _Circuit B_ can is obtained by adding some additional layers that we are going to train on _Dataset B_.
```
# Trainable variables
with tf.name_scope('variables'):
# Squeeze gate
sq_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=active_sd))
# Displacement gate
d_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=active_sd))
# Rotation gates
r1_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=passive_sd))
r2_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=passive_sd))
r3_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=passive_sd))
# Kerr gate
kappa_var = tf.Variable(tf.random_normal(shape=[q_depth], stddev=active_sd))
# 0-depth parameter (just to generate a gradient)
x_var = tf.Variable(0.0)
parameters = [sq_var, d_var, r1_var, r2_var, r3_var, kappa_var]
# Definition of a single trainable variational layer
def layer_var(i, qmode):
Rgate(r1_var[i]) | qmode
Sgate(tf.clip_by_value(sq_var[i], -clip, clip), 0) | qmode
Rgate(r2_var[i]) | qmode
Dgate(tf.clip_by_value(d_var[i], -clip, clip) , 0) | qmode
Rgate(r3_var[i]) | qmode
Vgate(tf.clip_by_value(kappa_var[i], -clip, clip) ) | qmode
return qmode
```
## Symbolic evaluation of the full network
We first instantiate a _StrawberryFields_ quantum simulator, taylored for simulating a single-mode quantum optical system. Then we synbolically evaluate a batch of output states.
```
prog = sf.Program(1)
eng = sf.Engine('tf', backend_options={'cutoff_dim': cutoff, 'batch_size': batch_size})
# Circuit B
with prog.context as q:
# State generation network
for k in range(g_depth):
layer_gen(k, q[0])
# Pre-trained network (Circuit A)
for k in range(pre_depth):
layer_pre(k, q[0])
# State classification network
for k in range(q_depth):
layer_var(k, q[0])
# Special case q_depth==0
if q_depth == 0:
Dgate(0.001, x_var ) | q[0] # almost identity operation just to generate a gradient.
# Symbolic computation of the output state
results = eng.run(prog, run_options={"eval": False})
out_state = results.state
# Batch state norms
out_norm = tf.to_float(out_state.trace())
# Batch mean energies
mean_n = out_state.mean_photon(0)
```
## Loss function, accuracy and optimizer.
As usual in machine learning, we need to define a loss function that we are going to minimize during the training phase.
As discussed in the introduction, we assume that only the vacuum state probability `p_0` is measured. Ideally, `p_0` should be large for non-Gaussian states (_label 1_), while should be small for Gaussian states (_label 0_). The circuit can be trained to this task by minimizing the _cross entropy_ loss function defined in the next cell.
Moreover, if `norm_weight` is different from zero, also a regularization term is added to the full cost function in order to reduce quantum amplitudes beyond the target Hilbert space dimension `target_cutoff`.
```
# Batch vacuum probabilities
p0 = out_state.fock_prob([0])
# Complementary probabilities
q0 = 1.0 - p0
# Cross entropy loss function
eps = 0.0000001
main_loss = tf.reduce_mean(-batch_labels_fl * tf.log(p0 + eps) - (1.0 - batch_labels_fl) * tf.log(q0 + eps))
# Decision function
predictions = tf.sign(p0 - 0.5) * 0.5 + 0.5
# Accuracy between predictions and labels
accuracy = tf.reduce_mean((predictions + batch_labels_fl - 1.0) ** 2)
# Norm loss. This is monitored but not minimized.
norm_loss = tf.reduce_mean((out_norm - 1.0) ** 2)
# Cutoff loss regularization. This is monitored and minimized if norm_weight is nonzero.
c_in = out_state.all_fock_probs()
cut_probs = c_in[:, :target_cutoff]
cut_norms = tf.reduce_sum(cut_probs, axis=1)
cutoff_loss = tf.reduce_mean((cut_norms - 1.0) ** 2 )
# Full regularized loss function
full_loss = main_loss + norm_weight * cutoff_loss
# Optimization algorithm
optim = tf.train.AdamOptimizer(learning_rate=lr)
training = optim.minimize(full_loss)
```
## Training and testing
Up to now we just defined the analytic graph of the quantum network without numerically evaluating it. Now, after initializing a _TensorFlow_ session, we can finally run the actual training and testing phases.
```
# Function generating a dictionary of random parameters for a batch of states.
def random_dict():
param_dict = { # Labels (0 = Gaussian, 1 = non-Gaussian)
batch_labels: rng_data.randint(2, size=batch_size),
# Squeezing and rotation parameters
sq_gen: rng_data.uniform(low=-sq_sd, high=sq_sd, size=[batch_size, g_depth]),
r1_gen: rng_data.uniform(low=-rot_sd, high=rot_sd, size=[batch_size, g_depth]),
r2_gen: rng_data.uniform(low=-rot_sd, high=rot_sd, size=[batch_size, g_depth]),
r3_gen: rng_data.uniform(low=-rot_sd, high=rot_sd, size=[batch_size, g_depth]),
}
return param_dict
# TensorFlow session
with tf.Session() as session:
session.run(tf.global_variables_initializer())
train_loss = 0.0
train_loss_sum = 0.0
train_acc = 0.0
train_acc_sum = 0.0
test_loss = 0.0
test_loss_sum = 0.0
test_acc = 0.0
test_acc_sum = 0.0
# =========================================================
# Training Phase
# =========================================================
if q_depth > 0:
for k in range(num_batches):
rep_time = time.time()
# Training step
[_training,
_full_loss,
_accuracy,
_norm_loss] = session.run([ training,
full_loss,
accuracy,
norm_loss], feed_dict=random_dict())
train_loss_sum += _full_loss
train_acc_sum += _accuracy
train_loss = train_loss_sum / (k + 1)
train_acc = train_acc_sum / (k + 1)
# Training log
if ((k + 1) % 100) == 0:
print('Train batch: {:d}, Running loss: {:.4f}, Running acc {:.4f}, Norm loss {:.4f}, Batch time {:.4f}'
.format(k + 1, train_loss, train_acc, _norm_loss, time.time() - rep_time))
# =========================================================
# Testing Phase
# =========================================================
num_test_batches = min(num_batches, 1000)
for i in range(num_test_batches):
rep_time = time.time()
# Evaluation step
[_full_loss,
_accuracy,
_norm_loss,
_cutoff_loss,
_mean_n,
_parameters] = session.run([full_loss,
accuracy,
norm_loss,
cutoff_loss,
mean_n,
parameters], feed_dict=random_dict())
test_loss_sum += _full_loss
test_acc_sum += _accuracy
test_loss = test_loss_sum / (i + 1)
test_acc = test_acc_sum / (i + 1)
# Testing log
if ((i + 1) % 100) == 0:
print('Test batch: {:d}, Running loss: {:.4f}, Running acc {:.4f}, Norm loss {:.4f}, Batch time {:.4f}'
.format(i + 1, test_loss, test_acc, _norm_loss, time.time() - rep_time))
# Compute mean photon number of the last batch of states
mean_fock = np.mean(_mean_n)
print('Training and testing phases completed.')
print('RESULTS:')
print('{:>11s}{:>11s}{:>11s}{:>11s}{:>11s}{:>11s}'.format('train_loss', 'train_acc', 'test_loss', 'test_acc', 'norm_loss', 'mean_n'))
print('{:11f}{:11f}{:11f}{:11f}{:11f}{:11f}'.format(train_loss, train_acc, test_loss, test_acc, _norm_loss, mean_fock))
```
## References
[1] Andrea Mari, Thomas R. Bromley, Josh Izaac, Maria Schuld, and Nathan Killoran. _Transfer learning in hybrid classical-quantum neural networks_. [arXiv:1912.08278](https://arxiv.org/abs/1912.08278), (2019).
[2] Nathan Killoran, Thomas R. Bromley, Juan Miguel Arrazola, Maria Schuld, Nicolás Quesada, and Seth Lloyd. _Continuous-variable quantum neural networks_. [arXiv:1806.06871](https://arxiv.org/abs/1806.06871), (2018).
[3] Nathan Killoran, Josh Izaac, Nicolás Quesada, Ville Bergholm, Matthew Amy, and Christian Weedbrook. _Strawberry Fields: A Software Platform for Photonic Quantum Computing_. [Quantum, 3, 129 (2019)](https://doi.org/10.22331/q-2019-03-11-129).
| true |
code
| 0.651327 | null | null | null | null |
|
## Borehole lithology logs viewer
Interactive view of borehole data used for [exploratory lithology analysis](https://github.com/csiro-hydrogeology/pyela)
Powered by [Voila](https://github.com/QuantStack/voila), [ipysheet](https://github.com/QuantStack/ipysheet) and [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet)
### Data
The sample borehole data around Canberra, Australia is derived from the Australian Bureau of Meteorology [National Groundwater Information System](http://www.bom.gov.au/water/groundwater/ngis/index.shtml). You can check the licensing for these data; the short version is that use for demo and learning purposes is fine.
```
import os
import sys
import pandas as pd
import numpy as np
# from bqplot import Axis, Figure, Lines, LinearScale
# from bqplot.interacts import IndexSelector
# from ipyleaflet import basemaps, FullScreenControl, LayerGroup, Map, MeasureControl, Polyline, Marker, MarkerCluster, CircleMarker, WidgetControl
# from ipywidgets import Button, HTML, HBox, VBox, Checkbox, FileUpload, Label, Output, IntSlider, Layout, Image, link
from ipywidgets import Output, HTML
from ipyleaflet import Map, Marker, MarkerCluster, basemaps
import ipywidgets as widgets
import ipysheet
example_folder = "./examples"
# classified_logs_filename = os.path.join(cbr_datadir_out,'classified_logs.pkl')
# with open(classified_logs_filename, 'rb') as handle:
# df = pickle.load(handle)
# geoloc_filename = os.path.join(cbr_datadir_out,'geoloc.pkl')
# with open(geoloc_filename, 'rb') as handle:
# geoloc = pickle.load(handle)
df = pd.read_csv(os.path.join(example_folder,'classified_logs.csv'))
geoloc = pd.read_csv(os.path.join(example_folder,'geoloc.csv'))
DEPTH_FROM_COL = 'FromDepth'
DEPTH_TO_COL = 'ToDepth'
TOP_ELEV_COL = 'TopElev'
BOTTOM_ELEV_COL = 'BottomElev'
LITHO_DESC_COL = 'Description'
HYDRO_CODE_COL = 'HydroCode'
HYDRO_ID_COL = 'HydroID'
BORE_ID_COL = 'BoreID'
# if we want to keep vboreholes that have more than one row
x = df[HYDRO_ID_COL].values
unique, counts = np.unique(x, return_counts=True)
multiple_counts = unique[counts > 1]
# len(multiple_counts), len(unique)
keep = set(df[HYDRO_ID_COL].values)
keep = set(multiple_counts)
s = geoloc[HYDRO_ID_COL]
geoloc = geoloc[s.isin(keep)]
class GlobalThing:
def __init__(self, bore_data, displayed_colnames = None):
self.marker_info = dict()
self.bore_data = bore_data
if displayed_colnames is None:
displayed_colnames = [BORE_ID_COL, DEPTH_FROM_COL, DEPTH_TO_COL, LITHO_DESC_COL] # 'Lithology_1', 'MajorLithCode']]
self.displayed_colnames = displayed_colnames
def add_marker_info(self, lat, lon, code):
self.marker_info[(lat, lon)] = code
def get_code(self, lat, lon):
return self.marker_info[(lat, lon)]
def data_for_hydroid(self, ident):
df_sub = self.bore_data.loc[df[HYDRO_ID_COL] == ident]
return df_sub[self.displayed_colnames]
def register_geolocations(self, geoloc):
for index, row in geoloc.iterrows():
self.add_marker_info(row.Latitude, row.Longitude, row.HydroID)
globalthing = GlobalThing(df, displayed_colnames = [BORE_ID_COL, DEPTH_FROM_COL, DEPTH_TO_COL, LITHO_DESC_COL, 'Lithology_1'])
globalthing.register_geolocations(geoloc)
def plot_map(geoloc, click_handler):
"""
Plot the markers for each borehole, and register a custom click_handler
"""
mean_lat = geoloc.Latitude.mean()
mean_lng = geoloc.Longitude.mean()
# create the map
m = Map(center=(mean_lat, mean_lng), zoom=12, basemap=basemaps.Stamen.Terrain)
m.layout.height = '600px'
# show trace
markers = []
for index, row in geoloc.iterrows():
message = HTML()
message.value = str(row.HydroID)
message.placeholder = ""
message.description = "HydroID"
marker = Marker(location=(row.Latitude, row.Longitude))
marker.on_click(click_handler)
marker.popup = message
markers.append(marker)
marker_cluster = MarkerCluster(
markers=markers
)
# not sure whether we could register once instead of each marker:
# marker_cluster.on_click(click_handler)
m.add_layer(marker_cluster);
# m.add_control(FullScreenControl())
return m
# If printing a data frame straight to an output widget
def raw_print(out, ident):
bore_data = globalthing.data_for_hydroid(ident)
out.clear_output()
with out:
print(ident)
print(bore_data)
def click_handler_rawprint(**kwargs):
blah = dict(**kwargs)
xy = blah['coordinates']
ident = globalthing.get_code(xy[0], xy[1])
raw_print(out, ident)
# to display using an ipysheet
def mk_sheet(d):
return ipysheet.pandas_loader.from_dataframe(d)
def upate_display_df(ident):
bore_data = globalthing.data_for_hydroid(ident)
out.clear_output()
with out:
display(mk_sheet(bore_data))
def click_handler_ipysheet(**kwargs):
blah = dict(**kwargs)
xy = blah['coordinates']
ident = globalthing.get_code(xy[0], xy[1])
upate_display_df(ident)
out = widgets.Output(layout={'border': '1px solid black'})
```
Note: it may take a minute or two for the display to first appear....
Select a marker:
```
plot_map(geoloc, click_handler_ipysheet)
# plot_map(geoloc, click_handler_rawprint)
```
Descriptive lithology:
```
out
## Appendix A : qgrid, but at best ended up with "Model not available". May not work yet with Jupyter lab 1.0.x
# import qgrid
# d = data_for_hydroid(10062775)
# d
# import ipywidgets as widgets
# def build_qgrid():
# qgrid.set_grid_option('maxVisibleRows', 10)
# col_opts = {
# 'editable': False,
# }
# qgrid_widget = qgrid.show_grid(d, show_toolbar=False, column_options=col_opts)
# qgrid_widget.layout = widgets.Layout(width='920px')
# return qgrid_widget, qgrid
# qgrid_widget, qgrid = build_qgrid()
# display(qgrid_widget)
# pitch_app = widgets.VBox(qgrid_widget)
# display(pitch_app)
# def click_handler(**kwargs):
# blah = dict(**kwargs)
# xy = blah['coordinates']
# ident = globalthing.get_code(xy[0], xy[1])
# bore_data = data_for_hydroid(ident)
# grid.df = bore_data
## Appendix B: using striplog
# from striplog import Striplog, Interval, Component, Legend, Decor
# import matplotlib as mpl
# lithologies = ['shale', 'clay','granite','soil','sand', 'porphyry','siltstone','gravel', '']
# lithology_color_names = ['lightslategrey', 'olive', 'dimgray', 'chocolate', 'gold', 'tomato', 'teal', 'lavender', 'black']
# lithology_colors = [mpl.colors.cnames[clr] for clr in lithology_color_names]
# clrs = dict(zip(lithologies, lithology_colors))
# def mk_decor(lithology, component):
# dcor = {'color': clrs[lithology],
# 'component': component,
# 'width': 2}
# return Decor(dcor)
# def create_striplog_itvs(d):
# itvs = []
# dcrs = []
# for index, row in d.iterrows():
# litho = row.Lithology_1
# c = Component({'description':row.Description,'lithology': litho})
# decor = mk_decor(litho, c)
# itvs.append(Interval(row.FromDepth, row.ToDepth, components=[c]) )
# dcrs.append(decor)
# return itvs, dcrs
# def click_handler(**kwargs):
# blah = dict(**kwargs)
# xy = blah['coordinates']
# ident = globalthing.get_code(xy[0], xy[1])
# bore_data = data_for_hydroid(ident)
# itvs, dcrs = create_striplog_itvs(bore_data)
# s = Striplog(itvs)
# with out:
# print(ident)
# print(s.plot(legend = Legend(dcrs)))
# def plot_striplog(bore_data, ax=None):
# itvs, dcrs = create_striplog_itvs(bore_data)
# s = Striplog(itvs)
# s.plot(legend = Legend(dcrs), ax=ax)
# def plot_evaluation_metrics(bore_data):
# fig, ax = plt.subplots(figsize=(12, 3))
# # actual plotting
# plot_striplog(bore_data, ax=ax)
# # finalize
# fig.suptitle("Evaluation metrics with cutoff\n", va='bottom')
# plt.show()
# plt.close(fig)
# %matplotlib inline
# from ipywidgets import interactive
# import matplotlib.pyplot as plt
# import numpy as np
# def f(m, b):
# plt.figure(2)
# x = np.linspace(-10, 10, num=1000)
# plt.plot(x, m * x + b)
# plt.ylim(-5, 5)
# plt.show()
# interactive_plot = interactive(f, m=(-2.0, 2.0), b=(-3, 3, 0.5))
# output = interactive_plot.children[-1]
# output.layout.height = '350px'
# interactive_plot
# def update_sheet(s, d):
# print("before: %s"%(s.rows))
# s.rows = len(d)
# for i in range(len(d.columns)):
# s.cells[i].value = d[d.columns[i]].values
```
| true |
code
| 0.432483 | null | null | null | null |
|
# Classification
This notebook aims at giving an overview of the classification metrics that
can be used to evaluate the predictive model generalization performance. We can
recall that in a classification setting, the vector `target` is categorical
rather than continuous.
We will load the blood transfusion dataset.
```
import pandas as pd
blood_transfusion = pd.read_csv("../datasets/blood_transfusion.csv")
data = blood_transfusion.drop(columns="Class")
target = blood_transfusion["Class"]
```
<div class="admonition note alert alert-info">
<p class="first admonition-title" style="font-weight: bold;">Note</p>
<p class="last">If you want a deeper overview regarding this dataset, you can refer to the
Appendix - Datasets description section at the end of this MOOC.</p>
</div>
Let's start by checking the classes present in the target vector `target`.
```
import matplotlib.pyplot as plt
target.value_counts().plot.barh()
plt.xlabel("Number of samples")
_ = plt.title("Number of samples per classes present\n in the target")
```
We can see that the vector `target` contains two classes corresponding to
whether a subject gave blood. We will use a logistic regression classifier to
predict this outcome.
To focus on the metrics presentation, we will only use a single split instead
of cross-validation.
```
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(
data, target, shuffle=True, random_state=0, test_size=0.5)
```
We will use a logistic regression classifier as a base model. We will train
the model on the train set, and later use the test set to compute the
different classification metric.
```
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(data_train, target_train)
```
## Classifier predictions
Before we go into details regarding the metrics, we will recall what type
of predictions a classifier can provide.
For this reason, we will create a synthetic sample for a new potential donor:
he/she donated blood twice in the past (1000 c.c. each time). The last time
was 6 months ago, and the first time goes back to 20 months ago.
```
new_donor = [[6, 2, 1000, 20]]
```
We can get the class predicted by the classifier by calling the method
`predict`.
```
classifier.predict(new_donor)
```
With this information, our classifier predicts that this synthetic subject
is more likely to not donate blood again.
However, we cannot check whether the prediction is correct (we do not know
the true target value). That's the purpose of the testing set. First, we
predict whether a subject will give blood with the help of the trained
classifier.
```
target_predicted = classifier.predict(data_test)
target_predicted[:5]
```
## Accuracy as a baseline
Now that we have these predictions, we can compare them with the true
predictions (sometimes called ground-truth) which we did not use until now.
```
target_test == target_predicted
```
In the comparison above, a `True` value means that the value predicted by our
classifier is identical to the real value, while a `False` means that our
classifier made a mistake. One way of getting an overall rate representing
the generalization performance of our classifier would be to compute how many
times our classifier was right and divide it by the number of samples in our
set.
```
import numpy as np
np.mean(target_test == target_predicted)
```
This measure is called the accuracy. Here, our classifier is 78%
accurate at classifying if a subject will give blood. `scikit-learn` provides
a function that computes this metric in the module `sklearn.metrics`.
```
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(target_test, target_predicted)
print(f"Accuracy: {accuracy:.3f}")
```
`LogisticRegression` also has a method named `score` (part of the standard
scikit-learn API), which computes the accuracy score.
```
classifier.score(data_test, target_test)
```
## Confusion matrix and derived metrics
The comparison that we did above and the accuracy that we calculated did not
take into account the type of error our classifier was making. Accuracy
is an aggregate of the errors made by the classifier. We may be interested
in finer granularity - to know independently what the error is for each of
the two following cases:
- we predicted that a person will give blood but she/he did not;
- we predicted that a person will not give blood but she/he did.
```
from sklearn.metrics import ConfusionMatrixDisplay
_ = ConfusionMatrixDisplay.from_estimator(classifier, data_test, target_test)
```
The in-diagonal numbers are related to predictions that were correct
while off-diagonal numbers are related to incorrect predictions
(misclassifications). We now know the four types of correct and erroneous
predictions:
* the top left corner are true positives (TP) and corresponds to people
who gave blood and were predicted as such by the classifier;
* the bottom right corner are true negatives (TN) and correspond to
people who did not give blood and were predicted as such by the
classifier;
* the top right corner are false negatives (FN) and correspond to
people who gave blood but were predicted to not have given blood;
* the bottom left corner are false positives (FP) and correspond to
people who did not give blood but were predicted to have given blood.
Once we have split this information, we can compute metrics to highlight the
generalization performance of our classifier in a particular setting. For
instance, we could be interested in the fraction of people who really gave
blood when the classifier predicted so or the fraction of people predicted to
have given blood out of the total population that actually did so.
The former metric, known as the precision, is defined as TP / (TP + FP)
and represents how likely the person actually gave blood when the classifier
predicted that they did.
The latter, known as the recall, defined as TP / (TP + FN) and
assesses how well the classifier is able to correctly identify people who
did give blood.
We could, similarly to accuracy, manually compute these values,
however scikit-learn provides functions to compute these statistics.
```
from sklearn.metrics import precision_score, recall_score
precision = precision_score(target_test, target_predicted, pos_label="donated")
recall = recall_score(target_test, target_predicted, pos_label="donated")
print(f"Precision score: {precision:.3f}")
print(f"Recall score: {recall:.3f}")
```
These results are in line with what was seen in the confusion matrix. Looking
at the left column, more than half of the "donated" predictions were correct,
leading to a precision above 0.5. However, our classifier mislabeled a lot of
people who gave blood as "not donated", leading to a very low recall of
around 0.1.
## The issue of class imbalance
At this stage, we could ask ourself a reasonable question. While the accuracy
did not look bad (i.e. 77%), the recall score is relatively low (i.e. 12%).
As we mentioned, precision and recall only focuses on samples predicted to be
positive, while accuracy takes both into account. In addition, we did not
look at the ratio of classes (labels). We could check this ratio in the
training set.
```
target_train.value_counts(normalize=True).plot.barh()
plt.xlabel("Class frequency")
_ = plt.title("Class frequency in the training set")
```
We observe that the positive class, `'donated'`, comprises only 24% of the
samples. The good accuracy of our classifier is then linked to its ability to
correctly predict the negative class `'not donated'` which may or may not be
relevant, depending on the application. We can illustrate the issue using a
dummy classifier as a baseline.
```
from sklearn.dummy import DummyClassifier
dummy_classifier = DummyClassifier(strategy="most_frequent")
dummy_classifier.fit(data_train, target_train)
print(f"Accuracy of the dummy classifier: "
f"{dummy_classifier.score(data_test, target_test):.3f}")
```
With the dummy classifier, which always predicts the negative class `'not
donated'`, we obtain an accuracy score of 76%. Therefore, it means that this
classifier, without learning anything from the data `data`, is capable of
predicting as accurately as our logistic regression model.
The problem illustrated above is also known as the class imbalance problem.
When the classes are imbalanced, accuracy should not be used. In this case,
one should either use the precision and recall as presented above or the
balanced accuracy score instead of accuracy.
```
from sklearn.metrics import balanced_accuracy_score
balanced_accuracy = balanced_accuracy_score(target_test, target_predicted)
print(f"Balanced accuracy: {balanced_accuracy:.3f}")
```
The balanced accuracy is equivalent to accuracy in the context of balanced
classes. It is defined as the average recall obtained on each class.
## Evaluation and different probability thresholds
All statistics that we presented up to now rely on `classifier.predict` which
outputs the most likely label. We haven't made use of the probability
associated with this prediction, which gives the confidence of the
classifier in this prediction. By default, the prediction of a classifier
corresponds to a threshold of 0.5 probability in a binary classification
problem. We can quickly check this relationship with the classifier that
we trained.
```
target_proba_predicted = pd.DataFrame(classifier.predict_proba(data_test),
columns=classifier.classes_)
target_proba_predicted[:5]
target_predicted = classifier.predict(data_test)
target_predicted[:5]
```
Since probabilities sum to 1 we can get the class with the highest
probability without using the threshold 0.5.
```
equivalence_pred_proba = (
target_proba_predicted.idxmax(axis=1).to_numpy() == target_predicted)
np.all(equivalence_pred_proba)
```
The default decision threshold (0.5) might not be the best threshold that
leads to optimal generalization performance of our classifier. In this case, one
can vary the decision threshold, and therefore the underlying prediction, and
compute the same statistics presented earlier. Usually, the two metrics
recall and precision are computed and plotted on a graph. Each metric plotted
on a graph axis and each point on the graph corresponds to a specific
decision threshold. Let's start by computing the precision-recall curve.
```
from sklearn.metrics import PrecisionRecallDisplay
disp = PrecisionRecallDisplay.from_estimator(
classifier, data_test, target_test, pos_label='donated',
marker="+"
)
_ = disp.ax_.set_title("Precision-recall curve")
```
<div class="admonition tip alert alert-warning">
<p class="first admonition-title" style="font-weight: bold;">Tip</p>
<p class="last">Scikit-learn will return a display containing all plotting element. Notably,
displays will expose a matplotlib axis, named <tt class="docutils literal">ax_</tt>, that can be used to add
new element on the axis.
You can refer to the documentation to have more information regarding the
<a class="reference external" href="https://scikit-learn.org/stable/visualizations.html#visualizations">visualizations in scikit-learn</a></p>
</div>
On this curve, each blue cross corresponds to a level of probability which we
used as a decision threshold. We can see that, by varying this decision
threshold, we get different precision vs. recall values.
A perfect classifier would have a precision of 1 for all recall values. A
metric characterizing the curve is linked to the area under the curve (AUC)
and is named average precision (AP). With an ideal classifier, the average
precision would be 1.
The precision and recall metric focuses on the positive class, however, one
might be interested in the compromise between accurately discriminating the
positive class and accurately discriminating the negative classes. The
statistics used for this are sensitivity and specificity. Sensitivity is just
another name for recall. However, specificity measures the proportion of
correctly classified samples in the negative class defined as: TN / (TN +
FP). Similar to the precision-recall curve, sensitivity and specificity are
generally plotted as a curve called the receiver operating characteristic
(ROC) curve. Below is such a curve:
```
from sklearn.metrics import RocCurveDisplay
disp = RocCurveDisplay.from_estimator(
classifier, data_test, target_test, pos_label='donated',
marker="+")
disp = RocCurveDisplay.from_estimator(
dummy_classifier, data_test, target_test, pos_label='donated',
color="tab:orange", linestyle="--", ax=disp.ax_)
_ = disp.ax_.set_title("ROC AUC curve")
```
This curve was built using the same principle as the precision-recall curve:
we vary the probability threshold for determining "hard" prediction and
compute the metrics. As with the precision-recall curve, we can compute the
area under the ROC (ROC-AUC) to characterize the generalization performance of
our classifier. However, it is important to observe that the lower bound of
the ROC-AUC is 0.5. Indeed, we show the generalization performance of a dummy
classifier (the orange dashed line) to show that even the worst generalization
performance obtained will be above this line.
| true |
code
| 0.633694 | null | null | null | null |
|
Para entrar no modo apresentação, execute a seguinte célula e pressione `-`
```
%reload_ext slide
```
<span class="notebook-slide-start"/>
# Proxy
Este notebook apresenta os seguintes tópicos:
- [Introdução](#Introdu%C3%A7%C3%A3o)
- [Servidor de proxy](#Servidor-de-proxy)
## Introdução
Existe muita informação disponível em repositórios software.
A seguir temos uma *screenshot* do repositório `gems-uff/sapos`.
<img src="images/githubexample.png" alt="Página Inicial de Repositório no GitHub" width="auto"/>
Nessa imagem, vemos a organização e nome do repositório
<img src="images/githubexample1.png" alt="Página Inicial de Repositório no GitHub com nome do repositório selecionado" width="auto"/>
Estrelas, forks, watchers
<img src="images/githubexample2.png" alt="Página Inicial de Repositório no GitHub com watchers, star e fork selecionados" width="auto"/>
Número de issues e pull requests
<img src="images/githubexample3.png" alt="Página Inicial de Repositório no GitHub com numero de issues e pull requests selecionados" width="auto"/>
Número de commits, branches, releases, contribuidores e licensa <span class="notebook-slide-extra" data-count="1"/>
<img src="images/githubexample4.png" alt="Página Inicial de Repositório no GitHub com número de commits, branches, releases, contribuidores e licensa selecionados" width="auto"/>
Arquivos
<img src="images/githubexample5.png" alt="Página Inicial de Repositório no GitHub com arquivos selecionados" width="auto"/>
Mensagem e data dos commits que alteraram esses arquivos por último
<img src="images/githubexample6.png" alt="Página Inicial de Repositório no GitHub com arquivos selecionados" width="auto"/>
Podemos extrair informações de repositórios de software de 3 formas:
- Crawling do site do repositório
- APIs que fornecem dados
- Diretamente do sistema de controle de versões
Neste minicurso abordaremos as 3 maneiras, porém daremos mais atenção a APIs do GitHub e extração direta do Git.
## Servidor de proxy
Servidores de repositório costumam limitar a quantidade de requisições que podemos fazer.
Em geral, essa limitação não afeta muito o uso esporádico dos serviços para mineração. Porém, quando estamos desenvolvendo algo, pode ser que passemos do limite com requisições repetidas.
Para evitar esse problema, vamos configurar um servidor de proxy simples em flask.
Quando estamos usando um servidor de proxy, ao invés de fazermos requisições diretamente ao site de destino, fazemos requisições ao servidor de proxy, que, em seguida, redireciona as requisições para o site de destino.
Ao receber o resultado da requisição, o proxy faz um cache do resultado e nos retorna o resultado.
Se uma requisição já tiver sido feita pelo servidor de proxy, ele apenas nos retorna o resultado do cache.
### Implementação do Proxy
A implementação do servidor de proxy está no arquivo `proxy.py`. Como queremos executar o proxy em paralelo ao notebook, o servidor precisa ser executado externamente.
Entretanto, o código do proxy será explicado aqui.
Começamos o arquivo com os imports necessários.
```python
import hashlib
import requests
import simplejson
import os
import sys
from flask import Flask, request, Response
```
A biblioteca `hashlib` é usada para fazer hash das requisições. A biblioteca `requests` é usada para fazer requisições ao GitHub. A biblioteca `simplejson` é usada para transformar requisiçoes e respostas em JSON. A biblioteca `os` é usada para manipular caminhos de diretórios e verificar a existência de arquivos. A biblioteca `sys` é usada para pegar os argumentos da execução. Por fim, `flask` é usada como servidor.
Em seguida, definimos o site para qual faremos proxy, os headers excluídos da resposta recebida, e criamos um `app` pro `Flask`. Note que `SITE` está sendo definido como o primeiro argumendo da execução do programa ou como https://github.com/, caso não haja argumento.
```python
if len(sys.argv) > 1:
SITE = sys.argv[1]
else:
SITE = "https://github.com/"
EXCLUDED_HEADERS = ['content-encoding', 'content-length', 'transfer-encoding', 'connection']
app = Flask(__name__)
```
Depois, definimos uma função para tratar todas rotas e métodos possíveis que o servidor pode receber.
```python
METHODS = ['GET', 'POST', 'PATCH', 'PUT', 'DELETE']
@app.route('/', defaults={'path': ''}, methods=METHODS)
@app.route('/<path:path>', methods=METHODS)
def catch_all(path):
```
Dentro desta função, definimos um dicionário de requisição com base na requisição que foi recebida pelo `flask`.
```python
request_dict = {
"method": request.method,
"url": request.url.replace(request.host_url, SITE),
"headers": {key: value for (key, value) in request.headers if key != 'Host'},
"data": request.get_data(),
"cookies": request.cookies,
"allow_redirects": False
}
```
Nesta requsição, substituímos o host pelo site de destino.
Em seguida, convertemos o dicionário para JSON e calculamos o hash SHA1 do resultado.
```python
request_json = simplejson.dumps(request_dict, sort_keys=True)
sha1 = hashlib.sha1(request_json.encode("utf-8")).hexdigest()
path_req = os.path.join("cache", sha1 + ".req")
path_resp = os.path.join("cache", sha1 + ".resp")
```
No diretório `cache` armazenamos arquivos `{sha1}.req` e `{sha1}.resp` com a requisição e resposta dos resultados em cache.
Com isso, ao receber uma requisição, podemos ver se `{sha1}.req` existe. Se existir, podemos comparar com a nossa requisição (para evitar conflitos). Por fim, se forem iguais, podemos retornar a resposta que está em cache.
```python
if os.path.exists(path_req):
with open(path_req, "r") as req:
req_read = req.read()
if req_read == request_json:
with open(path_resp, "r") as dump:
response = simplejson.load(dump)
return Response(
response["content"],
response["status_code"],
response["headers"]
)
```
Se a requisição não estiver em cache, transformamos o dicionário da requisição em uma requisição do `requests` para o GitHub, excluimos os headers populados pelo `flask` e criamos um JSON para a resposta.
```python
resp = requests.request(**request_dict)
headers = [(name, value) for (name, value) in resp.raw.headers.items()
if name.lower() not in EXCLUDED_HEADERS]
response = {
"content": resp.content,
"status_code": resp.status_code,
"headers": headers
}
response_json = simplejson.dumps(response, sort_keys=True)
```
Depois disso, salvamos a resposta no cache e retornamos ela para o cliente original.
```python
with open(path_resp, "w") as dump:
dump.write(response_json)
with open(path_req, "w") as req:
req.write(request_json)
return Response(
response["content"],
response["status_code"],
response["headers"]
)
```
No fim do script, iniciamos o servidor.
```python
if __name__ == '__main__':
app.run(debug=True)
```
### Uso do Proxy
Execute a seguinte linha em um terminal:
```bash
python proxy.py
```
Agora, toda requisição que faríamos a github.com, passaremos a fazer a localhost:5000. Por exemplo, ao invés de acessar https://github.com/gems-uff/sapos, acessaremos http://localhost:5000/gems-uff/sapos
### Requisição com requests
A seguir fazemos uma requisição com requests para o proxy. <span class="notebook-slide-extra" data-count="2"/>
```
SITE = "http://localhost:5000/" # Se não usar o proxy, alterar para https://github.com/
import requests
response = requests.get(SITE + "gems-uff/sapos")
response.headers['server'], response.status_code
```
<span class="notebook-slide-scroll" data-position="-1"/>
Podemos que o resultado foi obtido do GitHub e que a requisição funcionou, dado que o resultado foi 200.
Continua: [5.Crawling.ipynb](5.Crawling.ipynb)
| true |
code
| 0.237576 | null | null | null | null |
|
# Deep Reinforcement Learning in Action
### by Alex Zai and Brandon Brown
#### Chapter 3
##### Listing 3.1
```
from Gridworld import Gridworld
game = Gridworld(size=4, mode='static')
import sys
game.display()
game.makeMove('d')
game.makeMove('d')
game.makeMove('d')
game.display()
game.reward()
game.board.render_np()
game.board.render_np().shape
```
##### Listing 3.2
```
import numpy as np
import torch
from Gridworld import Gridworld
import random
from matplotlib import pylab as plt
l1 = 64
l2 = 150
l3 = 100
l4 = 4
model = torch.nn.Sequential(
torch.nn.Linear(l1, l2),
torch.nn.ReLU(),
torch.nn.Linear(l2, l3),
torch.nn.ReLU(),
torch.nn.Linear(l3,l4)
)
loss_fn = torch.nn.MSELoss()
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
gamma = 0.9
epsilon = 1.0
action_set = {
0: 'u',
1: 'd',
2: 'l',
3: 'r',
}
```
##### Listing 3.3
```
epochs = 1000
losses = []
for i in range(epochs):
game = Gridworld(size=4, mode='static')
state_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state1 = torch.from_numpy(state_).float()
status = 1
while(status == 1):
qval = model(state1)
qval_ = qval.data.numpy()
if (random.random() < epsilon):
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_]
game.makeMove(action)
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state2 = torch.from_numpy(state2_).float()
reward = game.reward() #-1 for lose, +1 for win, 0 otherwise
with torch.no_grad():
newQ = model(state2.reshape(1,64))
maxQ = torch.max(newQ)
if reward == -1: # if game still in play
Y = reward + (gamma * maxQ)
else:
Y = reward
Y = torch.Tensor([Y]).detach().squeeze()
X = qval.squeeze()[action_]
loss = loss_fn(X, Y)
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
state1 = state2
if reward != -1: #game lost
status = 0
if epsilon > 0.1:
epsilon -= (1/epochs)
plt.plot(losses)
m = torch.Tensor([2.0])
m.requires_grad=True
b = torch.Tensor([1.0])
b.requires_grad=True
def linear_model(x,m,b):
y = m @ x + b
return y
y = linear_model(torch.Tensor([4.]), m,b)
y
y.grad_fn
with torch.no_grad():
y = linear_model(torch.Tensor([4]),m,b)
y
y.grad_fn
y = linear_model(torch.Tensor([4.]), m,b)
y.backward()
m.grad
b.grad
```
##### Listing 3.4
```
def test_model(model, mode='static', display=True):
i = 0
test_game = Gridworld(mode=mode)
state_ = test_game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state = torch.from_numpy(state_).float()
if display:
print("Initial State:")
print(test_game.display())
status = 1
while(status == 1):
qval = model(state)
qval_ = qval.data.numpy()
action_ = np.argmax(qval_)
action = action_set[action_]
if display:
print('Move #: %s; Taking action: %s' % (i, action))
test_game.makeMove(action)
state_ = test_game.board.render_np().reshape(1,64) + np.random.rand(1,64)/10.0
state = torch.from_numpy(state_).float()
if display:
print(test_game.display())
reward = test_game.reward()
if reward != -1: #if game is over
if reward > 0: #if game won
status = 2
if display:
print("Game won! Reward: %s" % (reward,))
else: #game is lost
status = 0
if display:
print("Game LOST. Reward: %s" % (reward,))
i += 1
if (i > 15):
if display:
print("Game lost; too many moves.")
break
win = True if status == 2 else False
return win
test_model(model, 'static')
```
##### Listing 3.5
```
from collections import deque
epochs = 5000
losses = []
mem_size = 1000
batch_size = 200
replay = deque(maxlen=mem_size)
max_moves = 50
h = 0
for i in range(epochs):
game = Gridworld(size=4, mode='random')
state1_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state1 = torch.from_numpy(state1_).float()
status = 1
mov = 0
while(status == 1):
mov += 1
qval = model(state1)
qval_ = qval.data.numpy()
if (random.random() < epsilon):
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_]
game.makeMove(action)
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state2 = torch.from_numpy(state2_).float()
reward = game.reward()
done = True if reward > 0 else False
exp = (state1, action_, reward, state2, done)
replay.append(exp)
state1 = state2
if len(replay) > batch_size:
minibatch = random.sample(replay, batch_size)
state1_batch = torch.cat([s1 for (s1,a,r,s2,d) in minibatch])
action_batch = torch.Tensor([a for (s1,a,r,s2,d) in minibatch])
reward_batch = torch.Tensor([r for (s1,a,r,s2,d) in minibatch])
state2_batch = torch.cat([s2 for (s1,a,r,s2,d) in minibatch])
done_batch = torch.Tensor([d for (s1,a,r,s2,d) in minibatch])
Q1 = model(state1_batch)
with torch.no_grad():
Q2 = model(state2_batch)
Y = reward_batch + gamma * ((1 - done_batch) * torch.max(Q2,dim=1)[0])
X = \
Q1.gather(dim=1,index=action_batch.long().unsqueeze(dim=1)).squeeze()
loss = loss_fn(X, Y.detach())
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
if reward != -1 or mov > max_moves:
status = 0
mov = 0
losses = np.array(losses)
plt.plot(losses)
test_model(model,mode='random')
```
##### Listing 3.6
```
max_games = 1000
wins = 0
for i in range(max_games):
win = test_model(model, mode='random', display=False)
if win:
wins += 1
win_perc = float(wins) / float(max_games)
print("Games played: {0}, # of wins: {1}".format(max_games,wins))
print("Win percentage: {}".format(100.0*win_perc))
```
##### Listing 3.7
```
import copy
model = torch.nn.Sequential(
torch.nn.Linear(l1, l2),
torch.nn.ReLU(),
torch.nn.Linear(l2, l3),
torch.nn.ReLU(),
torch.nn.Linear(l3,l4)
)
model2 = model2 = copy.deepcopy(model)
model2.load_state_dict(model.state_dict())
sync_freq = 50
loss_fn = torch.nn.MSELoss()
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
```
##### Listing 3.8
```
from IPython.display import clear_output
from collections import deque
epochs = 5000
losses = []
mem_size = 1000
batch_size = 200
replay = deque(maxlen=mem_size)
max_moves = 50
h = 0
sync_freq = 500
j=0
for i in range(epochs):
game = Gridworld(size=4, mode='random')
state1_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state1 = torch.from_numpy(state1_).float()
status = 1
mov = 0
while(status == 1):
j+=1
mov += 1
qval = model(state1)
qval_ = qval.data.numpy()
if (random.random() < epsilon):
action_ = np.random.randint(0,4)
else:
action_ = np.argmax(qval_)
action = action_set[action_]
game.makeMove(action)
state2_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0
state2 = torch.from_numpy(state2_).float()
reward = game.reward()
done = True if reward > 0 else False
exp = (state1, action_, reward, state2, done)
replay.append(exp)
state1 = state2
if len(replay) > batch_size:
minibatch = random.sample(replay, batch_size)
state1_batch = torch.cat([s1 for (s1,a,r,s2,d) in minibatch])
action_batch = torch.Tensor([a for (s1,a,r,s2,d) in minibatch])
reward_batch = torch.Tensor([r for (s1,a,r,s2,d) in minibatch])
state2_batch = torch.cat([s2 for (s1,a,r,s2,d) in minibatch])
done_batch = torch.Tensor([d for (s1,a,r,s2,d) in minibatch])
Q1 = model(state1_batch)
with torch.no_grad():
Q2 = model2(state2_batch)
Y = reward_batch + gamma * ((1-done_batch) * \
torch.max(Q2,dim=1)[0])
X = Q1.gather(dim=1,index=action_batch.long() \
.unsqueeze(dim=1)).squeeze()
loss = loss_fn(X, Y.detach())
print(i, loss.item())
clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
losses.append(loss.item())
optimizer.step()
if j % sync_freq == 0:
model2.load_state_dict(model.state_dict())
if reward != -1 or mov > max_moves:
status = 0
mov = 0
losses = np.array(losses)
plt.plot(losses)
test_model(model,mode='random')
```
| true |
code
| 0.550124 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/reallygooday/60daysofudacity/blob/master/Basic_Image_Classifier.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
hand-written digits dataset from UCI: http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
```
# Importing load_digits() from the sklearn.datasets package
from sklearn.datasets import load_digits
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
digits_data = load_digits()
digits_data.keys()
labels = pd.Series(digits_data['target'])
data = pd.DataFrame(digits_data['data'])
data.head(1)
first_image = data.iloc[0]
np_image = first_image.values
np_image = np_image.reshape(8,8)
plt.imshow(np_image, cmap='gray_r')
f, axarr = plt.subplots(2, 4)
axarr[0, 0].imshow(data.iloc[0].values.reshape(8,8), cmap='gray_r')
axarr[0, 1].imshow(data.iloc[99].values.reshape(8,8), cmap='gray_r')
axarr[0, 2].imshow(data.iloc[199].values.reshape(8,8), cmap='gray_r')
axarr[0, 3].imshow(data.iloc[299].values.reshape(8,8), cmap='gray_r')
axarr[1, 0].imshow(data.iloc[999].values.reshape(8,8), cmap='gray_r')
axarr[1, 1].imshow(data.iloc[1099].values.reshape(8,8), cmap='gray_r')
axarr[1, 2].imshow(data.iloc[1199].values.reshape(8,8), cmap='gray_r')
axarr[1, 3].imshow(data.iloc[1299].values.reshape(8,8), cmap='gray_r')
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
# 50% Train / test validation
def train_knn(nneighbors, train_features, train_labels):
knn = KNeighborsClassifier(n_neighbors = nneighbors)
knn.fit(train_features, train_labels)
return knn
def test(model, test_features, test_labels):
predictions = model.predict(test_features)
train_test_df = pd.DataFrame()
train_test_df['correct_label'] = test_labels
train_test_df['predicted_label'] = predictions
overall_accuracy = sum(train_test_df["predicted_label"] == train_test_df["correct_label"])/len(train_test_df)
return overall_accuracy
def cross_validate(k):
fold_accuracies = []
kf = KFold(n_splits = 4, random_state=2)
for train_index, test_index in kf.split(data):
train_features, test_features = data.loc[train_index], data.loc[test_index]
train_labels, test_labels = labels.loc[train_index], labels.loc[test_index]
model = train_knn(k, train_features, train_labels)
overall_accuracy = test(model, test_features, test_labels)
fold_accuracies.append(overall_accuracy)
return fold_accuracies
knn_one_accuracies = cross_validate(1)
np.mean(knn_one_accuracies)
k_values = list(range(1,10))
k_overall_accuracies = []
for k in k_values:
k_accuracies = cross_validate(k)
k_mean_accuracy = np.mean(k_accuracies)
k_overall_accuracies.append(k_mean_accuracy)
plt.figure(figsize=(8,4))
plt.title("Mean Accuracy vs. k")
plt.plot(k_values, k_overall_accuracies)
#Neural Network With One Hidden Layer
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
# 50% Train / test validation
def train_nn(neuron_arch, train_features, train_labels):
mlp = MLPClassifier(hidden_layer_sizes=neuron_arch)
mlp.fit(train_features, train_labels)
return mlp
def test(model, test_features, test_labels):
predictions = model.predict(test_features)
train_test_df = pd.DataFrame()
train_test_df['correct_label'] = test_labels
train_test_df['predicted_label'] = predictions
overall_accuracy = sum(train_test_df["predicted_label"] == train_test_df["correct_label"])/len(train_test_df)
return overall_accuracy
def cross_validate(neuron_arch):
fold_accuracies = []
kf = KFold(n_splits = 4, random_state=2)
for train_index, test_index in kf.split(data):
train_features, test_features = data.loc[train_index], data.loc[test_index]
train_labels, test_labels = labels.loc[train_index], labels.loc[test_index]
model = train_nn(neuron_arch, train_features, train_labels)
overall_accuracy = test(model, test_features, test_labels)
fold_accuracies.append(overall_accuracy)
return fold_accuracies
from sklearn.neural_network import MLPClassifier
nn_one_neurons = [
(8,),
(16,),
(32,),
(64,),
(128,),
(256,)
]
nn_one_accuracies = []
for n in nn_one_neurons:
nn_accuracies = cross_validate(n)
nn_mean_accuracy = np.mean(nn_accuracies)
nn_one_accuracies.append(nn_mean_accuracy)
plt.figure(figsize=(8,4))
plt.title("Mean Accuracy vs. Neurons In Single Hidden Layer")
x = [i[0] for i in nn_one_neurons]
plt.plot(x, nn_one_accuracies)
# Neural Network With Two Hidden Layers
nn_two_neurons = [
(64,64),
(128, 128),
(256, 256)
]
nn_two_accuracies = []
for n in nn_two_neurons:
nn_accuracies = cross_validate(n)
nn_mean_accuracy = np.mean(nn_accuracies)
nn_two_accuracies.append(nn_mean_accuracy)
plt.figure(figsize=(8,4))
plt.title("Mean Accuracy vs. Neurons In Two Hidden Layers")
x = [i[0] for i in nn_two_neurons]
plt.plot(x, nn_two_accuracies)
nn_two_accuracies
#Neural Network With Three Hidden Layers
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
# 50% Train / test validation
def train_nn(neuron_arch, train_features, train_labels):
mlp = MLPClassifier(hidden_layer_sizes=neuron_arch)
mlp.fit(train_features, train_labels)
return mlp
def test(model, test_features, test_labels):
predictions = model.predict(test_features)
train_test_df = pd.DataFrame()
train_test_df['correct_label'] = test_labels
train_test_df['predicted_label'] = predictions
overall_accuracy = sum(train_test_df["predicted_label"] == train_test_df["correct_label"])/len(train_test_df)
return overall_accuracy
def cross_validate_six(neuron_arch):
fold_accuracies = []
kf = KFold(n_splits = 6, random_state=2)
for train_index, test_index in kf.split(data):
train_features, test_features = data.loc[train_index], data.loc[test_index]
train_labels, test_labels = labels.loc[train_index], labels.loc[test_index]
model = train_nn(neuron_arch, train_features, train_labels)
overall_accuracy = test(model, test_features, test_labels)
fold_accuracies.append(overall_accuracy)
return fold_accuracies
nn_three_neurons = [
(10, 10, 10),
(64, 64, 64),
(128, 128, 128)
]
nn_three_accuracies = []
for n in nn_three_neurons:
nn_accuracies = cross_validate_six(n)
nn_mean_accuracy = np.mean(nn_accuracies)
nn_three_accuracies.append(nn_mean_accuracy)
plt.figure(figsize=(8,4))
plt.title("Mean Accuracy vs. Neurons In Three Hidden Layers")
x = [i[0] for i in nn_three_neurons]
plt.plot(x, nn_three_accuracies)
nn_three_accuracies
```
#Image Classification with PyTorch
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import torchvision
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor()
])),
batch_size=32, shuffle=False)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False,
transform=transforms.Compose([
transforms.ToTensor()
])),
batch_size=32, shuffle=False)
class BasicNN(nn.Module):
def __init__(self):
super(BasicNN, self).__init__()
self.net = nn.Linear(28 * 28, 10)
def forward(self, x):
batch_size = x.size(0)
x = x.view(batch_size, -1)
output = self.net(x)
return F.softmax(output)
model = BasicNN()
optimizer = optim.SGD(model.parameters(), lr=0.001)
def test():
total_loss = 0
correct = 0
for image, label in test_loader:
image, label = Variable(image), Variable(label)
output = model(image)
total_loss += F.cross_entropy(output, label)
correct += (torch.max(output, 1)[1].view(label.size()).data == label.data).sum()
total_loss = total_loss.data[0]/ len(test_loader)
accuracy = correct / len(test_loader.dataset)
return total_loss, accuracy
def train():
model.train()
for image, label in train_loader:
image, label = Variable(image), Variable(label)
optimizer.zero_grad()
output = model(image)
loss = F.cross_entropy(output, label)
loss.backward()
optimizer.step()
best_test_loss = None
for e in range(1, 150):
train()
test_loss, test_accuracy = test()
print("\n[Epoch: %d] Test Loss:%5.5f Test Accuracy:%5.5f" % (e, test_loss, test_accuracy))
# Save the model if the test_loss is the lowest
if not best_test_loss or test_loss < best_test_loss:
best_test_loss = test_loss
else:
break
print("\nFinal Results\n-------------\n""Loss:", best_test_loss, "Test Accuracy: ", test_accuracy)
```
| true |
code
| 0.688364 | null | null | null | null |
|
# A Chaos Game with Triangles
John D. Cook [proposed](https://www.johndcook.com/blog/2017/07/08/the-chaos-game-and-the-sierpinski-triangle/) an interesting "game" from the book *[Chaos and Fractals](https://smile.amazon.com/Chaos-Fractals-New-Frontiers-Science/dp/0387202293)*: start at a vertex of an equilateral triangle. Then move to a new point halfway between the current point and one of the three vertexes of the triangle, chosen at random. Repeat to create *N* points, and plot them. What do you get?
I'll refactor Cook's code a bit and then we'll see:
```
import matplotlib.pyplot as plt
import random
def random_walk(vertexes, N):
"Walk halfway from current point towards a random vertex; repeat for N points."
points = [random.choice(vertexes)]
for _ in range(N-1):
points.append(midpoint(points[-1], random.choice(vertexes)))
return points
def show_walk(vertexes, N=5000):
"Walk halfway towards a random vertex for N points; show reults."
Xs, Ys = transpose(random_walk(vertexes, N))
Xv, Yv = transpose(vertexes)
plt.plot(Xs, Ys, 'r.')
plt.plot(Xv, Yv, 'bs')
plt.gca().set_aspect('equal')
plt.gcf().set_size_inches(9, 9)
plt.axis('off')
plt.show()
def midpoint(p, q): return ((p[0] + q[0])/2, (p[1] + q[1])/2)
def transpose(matrix): return zip(*matrix)
triangle = ((0, 0), (0.5, (3**0.5)/2), (1, 0))
show_walk(triangle, 20)
```
OK, the first 20 points don't tell me much. What if I try 20,000 points?
```
show_walk(triangle, 20000)
```
Wow! The [Sierpinski Triangle](https://en.wikipedia.org/wiki/Sierpinski_triangle)!
What happens if we start with a different set of vertexes, like a square?
```
square = ((0, 0), (0, 1), (1, 0), (1, 1))
show_walk(square)
```
There doesn't seem to be any structure there. Let's try again to make sure:
```
show_walk(square, 20000)
```
I'm still not seeing anything but random points. How about a right triangle?
```
right_triangle = ((0, 0), (0, 1), (1, 0))
show_walk(right_triangle, 20000)
```
We get a squished Serpinski triangle. How about a pentagon? (I'm lazy so I had Wolfram Alpha [compute the vertexes](https://www.wolframalpha.com/input/?i=vertexes+of+regular+pentagon).)
```
pentagon = ((0.5, -0.688), (0.809, 0.262), (0., 0.850), (-0.809, 0.262), (-0.5, -0.688))
show_walk(pentagon)
```
To clarify, let's try again with different numbers of points:
```
show_walk(pentagon, 10000)
show_walk(pentagon, 20000)
```
I definitely see a central hole, and five secondary holes surrounding that, and then, maybe 15 holes surrounding those? Or maybe not 15; hard to tell. Is a "Sierpinski Pentagon" a thing? I hadn't heard of it but a [quick search](https://www.google.com/search?q=sierpinski+pentagon) reveals that yes indeed, it is [a thing](http://ecademy.agnesscott.edu/~lriddle/ifs/pentagon/sierngon.htm), and it does have 15 holes surrounding the 5 holes. Let's try the hexagon:
```
hexagon = ((0.5, -0.866), (1, 0), (0.5, 0.866), (-0.5, 0.866), (-1, 0), (-0.5, -0.866))
show_walk(hexagon)
show_walk(hexagon, 20000)
```
You can see a little of the six-fold symmetry, but it is not as clear as the triangle and pentagon.
| true |
code
| 0.44565 | null | null | null | null |
|
# Part 2: Intro to Private Training with Remote Execution
In the last section, we learned about PointerTensors, which create the underlying infrastructure we need for privacy preserving Deep Learning. In this section, we're going to see how to use these basic tools to train our first deep learning model using remote execution.
Authors:
- Yann Dupis - Twitter: [@YannDupis](https://twitter.com/YannDupis)
- Andrew Trask - Twitter: [@iamtrask](https://twitter.com/iamtrask)
### Why use remote execution?
Let's say you are an AI startup who wants to build a deep learning model to detect [diabetic retinopathy (DR)](https://ai.googleblog.com/2016/11/deep-learning-for-detection-of-diabetic.html), which is the fastest growing cause of blindness. Before training your model, the first step would be to acquire a dataset of retinopathy images with signs of DR. One approach could be to work with a hospital and ask them to send you a copy of this dataset. However because of the sensitivity of the patients' data, the hospital might be exposed to liability risks.
That's where remote execution comes into the picture. Instead of bringing training data to the model (a central server), you bring the model to the training data (wherever it may live). In this case, it would be the hospital.
The idea is that this allows whoever is creating the data to own the only permanent copy, and thus maintain control over who ever has access to it. Pretty cool, eh?
# Section 2.1 - Private Training on MNIST
For this tutorial, we will train a model on the [MNIST dataset](http://yann.lecun.com/exdb/mnist/) to classify digits based on images.
We can assume that we have a remote worker named Bob who owns the data.
```
import tensorflow as tf
import syft as sy
hook = sy.TensorFlowHook(tf)
bob = sy.VirtualWorker(hook, id="bob")
```
Let's download the MNIST data from `tf.keras.datasets`. Note that we are converting the data from numpy to `tf.Tensor` in order to have the PySyft functionalities.
```
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train, y_train = tf.convert_to_tensor(x_train), tf.convert_to_tensor(y_train)
x_test, y_test = tf.convert_to_tensor(x_test), tf.convert_to_tensor(y_test)
```
As decribed in Part 1, we can send this data to Bob with the `send` method on the `tf.Tensor`.
```
x_train_ptr = x_train.send(bob)
y_train_ptr = y_train.send(bob)
```
Excellent! We have everything to start experimenting. To train our model on Bob's machine, we just have to perform the following steps:
- Define a model, including optimizer and loss
- Send the model to Bob
- Start the training process
- Get the trained model back
Let's do it!
```
# Define the model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compile with optimizer, loss and metrics
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
```
Once you have defined your model, you can simply send it to Bob calling the `send` method. It's the exact same process as sending a tensor.
```
model_ptr = model.send(bob)
model_ptr
```
Now, we have a pointer pointing to the model on Bob's machine. We can validate that's the case by inspecting the attribute `_objects` on the virtual worker.
```
bob._objects[model_ptr.id_at_location]
```
Everything is ready to start training our model on this remote dataset. You can call `fit` and pass `x_train_ptr` `y_train_ptr` which are pointing to Bob's data. Note that's the exact same interface as normal `tf.keras`.
```
model_ptr.fit(x_train_ptr, y_train_ptr, epochs=2, validation_split=0.2)
```
Fantastic! you have trained your model acheiving an accuracy greater than 95%.
You can get your trained model back by just calling `get` on it.
```
model_gotten = model_ptr.get()
model_gotten
```
It's good practice to see if your model can generalize by assessing its accuracy on an holdout dataset. You can simply call `evaluate`.
```
model_gotten.evaluate(x_test, y_test, verbose=2)
```
Boom! The model remotely trained on Bob's data is more than 95% accurate on this holdout dataset.
If your model doesn't fit into the Sequential paradigm, you can use Keras's functional API, or even subclass [tf.keras.Model](https://www.tensorflow.org/guide/keras/custom_layers_and_models#building_models) to create custom models.
```
class CustomModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(CustomModel, self).__init__(name='custom_model')
self.num_classes = num_classes
self.flatten = tf.keras.layers.Flatten(input_shape=(28, 28))
self.dense_1 = tf.keras.layers.Dense(128, activation='relu')
self.dropout = tf.keras.layers.Dropout(0.2)
self.dense_2 = tf.keras.layers.Dense(num_classes, activation='softmax')
def call(self, inputs, training=False):
x = self.flatten(inputs)
x = self.dense_1(x)
x = self.dropout(x, training=training)
return self.dense_2(x)
model = CustomModel(10)
# need to call the model on dummy data before sending it
# in order to set the input shape (required when saving to SavedModel)
model.predict(tf.ones([1, 28, 28]))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model_ptr = model.send(bob)
model_ptr.fit(x_train_ptr, y_train_ptr, epochs=2, validation_split=0.2)
```
## Well Done!
And voilà! We have trained a Deep Learning model on Bob's data by sending the model to him. Never in this process do we ever see or request access to the underlying training data! We preserve the privacy of Bob!!!
# Congratulations!!! - Time to Join the Community!
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the movement toward privacy preserving, decentralized ownership of AI and the AI supply chain (data), you can do so in the following ways!
### Star PySyft on GitHub
The easiest way to help our community is just by starring the Repos! This helps raise awareness of the cool tools we're building.
- Star PySyft on GitHub! - [https://github.com/OpenMined/PySyft](https://github.com/OpenMined/PySyft)
- Star PySyft-TensorFlow on GitHub! - [https://github.com/OpenMined/PySyft-TensorFlow]
### Join our Slack!
The best way to keep up to date on the latest advancements is to join our community! You can do so by filling out the form at [http://slack.openmined.org](http://slack.openmined.org)
### Join a Code Project!
The best way to contribute to our community is to become a code contributor! At any time you can go to PySyft GitHub Issues page and filter for "Projects". This will show you all the top level Tickets giving an overview of what projects you can join! If you don't want to join a project, but you would like to do a bit of coding, you can also look for more "one off" mini-projects by searching for GitHub issues marked "good first issue".
- [PySyft Projects](https://github.com/OpenMined/PySyft/issues?q=is%3Aopen+is%3Aissue+label%3AProject)
- [Good First Issue Tickets](https://github.com/OpenMined/PySyft/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)
### Donate
If you don't have time to contribute to our codebase, but would still like to lend support, you can also become a Backer on our Open Collective. All donations go toward our web hosting and other community expenses such as hackathons and meetups!
[OpenMined's Open Collective Page](https://opencollective.com/openmined)
| true |
code
| 0.846578 | null | null | null | null |
|
```
import sys, os
if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/spring20/setup_colab.sh -O- | bash
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week1_intro/submit.py
!touch .setup_complete
# This code creates a virtual display to draw game images on.
# It will have no effect if your machine has a monitor.
if type(os.environ.get("DISPLAY")) is not str or len(os.environ.get("DISPLAY")) == 0:
!bash ../xvfb start
os.environ['DISPLAY'] = ':1'
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
```
### OpenAI Gym
We're gonna spend several next weeks learning algorithms that solve decision processes. We are then in need of some interesting decision problems to test our algorithms.
That's where OpenAI gym comes into play. It's a python library that wraps many classical decision problems including robot control, videogames and board games.
So here's how it works:
```
import gym
env = gym.make("MountainCar-v0")
env.reset()
plt.imshow(env.render('rgb_array'))
print("Observation space:", env.observation_space)
print("Action space:", env.action_space)
```
Note: if you're running this on your local machine, you'll see a window pop up with the image above. Don't close it, just alt-tab away.
### Gym interface
The three main methods of an environment are
* __reset()__ - reset environment to initial state, _return first observation_
* __render()__ - show current environment state (a more colorful version :) )
* __step(a)__ - commit action __a__ and return (new observation, reward, is done, info)
* _new observation_ - an observation right after commiting the action __a__
* _reward_ - a number representing your reward for commiting action __a__
* _is done_ - True if the MDP has just finished, False if still in progress
* _info_ - some auxilary stuff about what just happened. Ignore it ~~for now~~.
```
obs0 = env.reset()
print("initial observation code:", obs0)
# Note: in MountainCar, observation is just two numbers: car position and velocity
print("taking action 2 (right)")
new_obs, reward, is_done, _ = env.step(2)
print("new observation code:", new_obs)
print("reward:", reward)
print("is game over?:", is_done)
# Note: as you can see, the car has moved to the right slightly (around 0.0005)
```
### Play with it
Below is the code that drives the car to the right. However, if you simply use the default policy, the car will not reach the flag at the far right due to gravity.
__Your task__ is to fix it. Find a strategy that reaches the flag.
You are not required to build any sophisticated algorithms for now, feel free to hard-code :)
```
from IPython import display
# Create env manually to set time limit. Please don't change this.
TIME_LIMIT = 250
env = gym.wrappers.TimeLimit(
gym.envs.classic_control.MountainCarEnv(),
max_episode_steps=TIME_LIMIT + 1,
)
actions = {'left': 0, 'stop': 1, 'right': 2}
def policy(obs, t):
# Write the code for your policy here. You can use the observation
# (a tuple of position and velocity), the current time step, or both,
# if you want.
position, velocity = obs
if velocity > 0:
a = actions['right']
else:
a = actions['left']
# This is an example policy. You can try running it, but it will not work.
# Your goal is to fix that.
return a
plt.figure(figsize=(4, 3))
display.clear_output(wait=True)
obs = env.reset()
for t in range(TIME_LIMIT):
plt.gca().clear()
action = policy(obs, t) # Call your policy
obs, reward, done, _ = env.step(action) # Pass the action chosen by the policy to the environment
# We don't do anything with reward here because MountainCar is a very simple environment,
# and reward is a constant -1. Therefore, your goal is to end the episode as quickly as possible.
# Draw game image on display.
plt.imshow(env.render('rgb_array'))
display.clear_output(wait=True)
display.display(plt.gcf())
print(obs)
if done:
print("Well done!")
break
else:
print("Time limit exceeded. Try again.")
display.clear_output(wait=True)
from submit import submit_interface
submit_interface(policy, <EMAIL>, <TOKEN>)
```
| true |
code
| 0.450601 | null | null | null | null |
|
<font size="+1">This notebook will illustrate how to access DeepLabCut(DLC) results for IBL sessions and how to create short videos with DLC labels printed onto, as well as wheel angle, starting by downloading data from the IBL flatiron server. It requires ibllib, a ONE account and the following script: https://github.com/int-brain-lab/iblapps/blob/master/DLC_labeled_video.py</font>
```
run '/home/mic/Dropbox/scripts/IBL/DLC_labeled_video.py'
one = ONE()
```
Let's first find IBL ephys sessions with DLC results:
```
eids= one.search(task_protocol='ephysChoiceworld', dataset_types=['camera.dlc'], details=False)
len(eids)
```
For a particular session, we can create a short labeled video by calling the function Viewer, specifying the eid of the desired session, the video type (there's 'left', 'right' and 'body' videos), and a range of trials for which the video should be created. Most sesions have around 700 trials. In the following, this is illustrated with session '3663d82b-f197-4e8b-b299-7b803a155b84', video type 'left', trials range [10,13] and without a zoom for the eye, such that nose, paw and tongue tracking is visible. The eye-zoom option shows only the four points delineating the pupil edges, which are too small to be visible in the normal view. Note that this automatically starts the download of the video from flatiron (in case it is not locally stored already), which may take a while since these videos are about 8 GB large.
```
eid = eids[6]
Viewer(eid, 'left', [10,13], save_video=True, eye_zoom=False)
```
As usual when downloading IBL data from flatiron, the dimensions are listed. Below is one frame of the video for illustration. One can see one point for each paw, two points for the edges of the tongue, one point for the nose and there are 4 points close together around the pupil edges. All points for which the DLC network had a confidence probability of below 0.9 are hidden. For instance when the mouse is not licking, there is no tongue and so the network cannot detect it, and no points are shown.
The script will display and save the short video in your local folder.

Sections of the script <code>DLC_labeled_video.py</code> can be recycled to analyse DLC traces. For example let's plot the x coordinate for the right paw in a <code>'left'</code> cam video for a given trial.
```
one = ONE()
dataset_types = ['camera.times','trials.intervals','camera.dlc']
video_type = 'left'
# get paths to load in data
D = one.load('3663d82b-f197-4e8b-b299-7b803a155b84',dataset_types=dataset_types, dclass_output=True)
alf_path = Path(D.local_path[0]).parent.parent / 'alf'
video_data = alf_path.parent / 'raw_video_data'
# get trials start and end times, camera time stamps (one for each frame, synced with DLC trace)
trials = alf.io.load_object(alf_path, '_ibl_trials')
cam0 = alf.io.load_object(alf_path, '_ibl_%sCamera' % video_type)
cam1 = alf.io.load_object(video_data, '_ibl_%sCamera' % video_type)
cam = {**cam0,**cam1}
# for each tracked point there's x,y in [px] in the frame and a likelihood that indicates the network's confidence
cam.keys()
```
There is also <code>'times'</code> in this dictionary, the time stamps for each frame that we'll use to sync it with other events in the experiment. Let's get rid of it briefly to have only DLC points and set coordinates to nan when the likelihood is below 0.9.
```
Times = cam['times']
del cam['times']
points = np.unique(['_'.join(x.split('_')[:-1]) for x in cam.keys()])
cam['times'] = Times
# A helper function to find closest time stamps
def find_nearest(array, value):
array = np.asarray(array)
idx = (np.abs(array - value)).argmin()
return idx
```
Let's pick say the 5th trial and find all DLC traces for it.
```
frame_start = find_nearest(cam['times'], trials['intervals'][4][0])
frame_stop = find_nearest(cam['times'], trials['intervals'][4][1])
XYs = {}
for point in points:
x = np.ma.masked_where(
cam[point + '_likelihood'] < 0.9, cam[point + '_x'])
x = x.filled(np.nan)
y = np.ma.masked_where(
cam[point + '_likelihood'] < 0.9, cam[point + '_y'])
y = y.filled(np.nan)
XYs[point] = np.array(
[x[frame_start:frame_stop], y[frame_start:frame_stop]])
import matplotlib.pyplot as plt
plt.plot(cam['times'][frame_start:frame_stop],XYs['paw_r'][0])
plt.xlabel('time [sec]')
plt.ylabel('x location of right paw [px]')
```
| true |
code
| 0.436622 | null | null | null | null |
|
# piston example with explicit Euler scheme
```
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.animation as anim
import numpy as np
import sys
sys.path.insert(0, './code')
import ideal_gas
```
### physical parameters
```
# length of cylinder
l = 0.1
# radius of cylinder
r = 0.05
# thickness of wall
w = 0.006
# derived geometrical data
r2 = 2 * r # diameter of cylinder
w2 = w / 2 # halved thickness of wall
l2 = l - w2
A = r**2 * np.pi # cross-sectional area
def get_v_1(q):
"""first volume"""
return A * (q - w2)
def get_v_2(q):
"""second volume"""
return A * (l2 - q)
# density of aluminium
m_Al = 2700.0
m_Cu = 8960.0
# mass of piston
m = m_Cu * A * w
# thermal conductivity of aluminium
κ_Al = 237.0
κ_Cu = 401.0
# thermal conduction coefficient
α = κ_Cu * A / w
m_inv = 1 / m
```
### initial conditions
determine $n_1$, $n_2$, $s_1$, $s_2$
```
# wanted conditions
v_1 = v_2 = get_v_1(l/2)
θ_1 = 273.15 + 25.0
π_1 = 1.5 * 1e5
θ_2 = 273.15 + 20.0
π_2 = 1.0 * 1e5
from scipy.optimize import fsolve
n_1 = fsolve(lambda n : ideal_gas.S_π(ideal_gas.U2(θ_1, n), v_1, n) - π_1, x0=2e22)[0]
s_1 = ideal_gas.S(ideal_gas.U2(θ_1, n_1), v_1, n_1)
# check temperature
ideal_gas.U_θ(s_1, v_1, n_1) - 273.15
# check pressure
ideal_gas.U_π(s_1, v_1, n_1) * 1e-5
n_2 = fsolve(lambda n : ideal_gas.S_π(ideal_gas.U2(θ_2, n), v_2, n) - π_2, x0=2e22)[0]
s_2 = ideal_gas.S(ideal_gas.U2(θ_2, n_2), v_2, n_2)
# check temperature
ideal_gas.U_θ(s_2, v_2, n_2) - 273.15
# check pressure
ideal_gas.U_π(s_2, v_2, n_2) * 1e-5
x_0 = l/2, 0, s_1, s_2
```
### simulation
```
def set_state(data, i, x):
q, p, s_1, s_2 = x
data[i, 0] = q
data[i, 1] = p
data[i, 2] = v = m_inv * p
data[i, 3] = v_1 = get_v_1(q)
data[i, 4] = π_1 = ideal_gas.U_π(s_1, v_1, n_1)
data[i, 5] = s_1
data[i, 6] = θ_1 = ideal_gas.U_θ(s_1, v_1, n_1)
data[i, 7] = v_2 = get_v_2(q)
data[i, 8] = π_2 = ideal_gas.U_π(s_2, v_2, n_2)
data[i, 9] = s_2
data[i, 10] = θ_2 = ideal_gas.U_θ(s_2, v_2, n_2)
data[i, 11] = E_kin = 0.5 * m_inv * p**2
data[i, 12] = u_1 = ideal_gas.U(s_1, v_1, n_1)
data[i, 13] = u_2 = ideal_gas.U(s_2, v_2, n_2)
data[i, 14] = E = E_kin + u_1 + u_2
data[i, 15] = S = s_1 + s_2
def get_state(data, i):
return data[i, (0, 1, 5, 9)]
def rhs(x):
"""right hand side of the explicit system
of differential equations
"""
q, p, s_1, s_2 = x
v_1 = get_v_1(q)
v_2 = get_v_2(q)
π_1 = ideal_gas.U_π(s_1, v_1, n_1)
π_2 = ideal_gas.U_π(s_2, v_2, n_2)
θ_1 = ideal_gas.U_θ(s_1, v_1, n_1)
θ_2 = ideal_gas.U_θ(s_2, v_2, n_2)
return np.array((m_inv*p, A*(π_1-π_2), α*(θ_2-θ_1)/θ_1, α*(θ_1-θ_2)/θ_2))
t_f = 1.0
dt = 1e-4
steps = int(t_f // dt)
print(f'steps={steps}')
t = np.linspace(0, t_f, num=steps)
dt = t[1] - t[0]
data = np.empty((steps, 16), dtype=float)
set_state(data, 0, x_0)
x_old = get_state(data, 0)
for i in range(1, steps):
x_new = x_old + dt * rhs(x_old)
set_state(data, i, x_new)
x_old = x_new
θ_min = np.min(data[:, (6,10)])
θ_max = np.max(data[:, (6,10)])
# plot transient
fig, ax = plt.subplots(dpi=200)
ax.set_title("piston position q")
ax.plot(t, data[:, 0]);
fig, ax = plt.subplots(dpi=200)
ax.set_title("total entropy S")
ax.plot(t, data[:, 15]);
fig, ax = plt.subplots(dpi=200)
ax.set_title("total energy E")
ax.plot(t, data[:, 14]);
```
the total energy is not conserved well
| true |
code
| 0.666361 | null | null | null | null |
|
# Exercise 6-3
## LSTM
The following two cells will create a LSTM cell with one neuron.
We scale the output of the LSTM linear and add a bias.
Then the output will be wrapped by a sigmoid activation.
The goal is to predict a time series where every $n^{th}$ ($5^{th}$ in the current example) element is 1 and all others are 0.
a) Please read and understand the source code below.
b) Consult the output of the predictions. What do you observe? How does the LSTM manage to predict the next element in the sequence?
```
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
tf.reset_default_graph()
tf.set_random_seed(12314)
epochs=50
zero_steps = 5
learning_rate = 0.01
lstm_neurons = 1
out_dim = 1
num_features = 1
batch_size = zero_steps
window_size = zero_steps*2
time_steps = 5
x = tf.placeholder(tf.float32, [None, window_size, num_features], 'x')
y = tf.placeholder(tf.float32, [None, out_dim], 'y')
lstm = tf.nn.rnn_cell.LSTMCell(lstm_neurons)
state = lstm.zero_state(batch_size, dtype=tf.float32)
regression_w = tf.Variable(tf.random_normal([lstm_neurons]))
regression_b = tf.Variable(tf.random_normal([out_dim]))
outputs, state = tf.contrib.rnn.static_rnn(lstm, tf.unstack(x, window_size, 1), state)
output = outputs[-1]
predicted = tf.nn.sigmoid(output * regression_w + regression_b)
cost = tf.reduce_mean(tf.losses.mean_squared_error(y, predicted))
optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate).minimize(cost)
forget_gate = output.op.inputs[1].op.inputs[0].op.inputs[0].op.inputs[0]
input_gate = output.op.inputs[1].op.inputs[0].op.inputs[1].op.inputs[0]
cell_candidates = output.op.inputs[1].op.inputs[0].op.inputs[1].op.inputs[1]
output_gate_sig = output.op.inputs[0]
output_gate_tanh = output.op.inputs[1]
X = [
[[ (shift-n) % zero_steps == 0 ] for n in range(window_size)
] for shift in range(batch_size)
]
Y = [[ shift % zero_steps == 0 ] for shift in range(batch_size) ]
with tf.Session() as sess:
sess.run(tf.initializers.global_variables())
loss = 1
epoch = 0
while loss >= 1e-5:
epoch += 1
_, loss = sess.run([optimizer, cost], {x:X, y:Y})
if epoch % (epochs//10) == 0:
print("loss %.5f" % (loss), end='\t\t\r')
print()
outs, stat, pred, fg, inpg, cell_cands, outg_sig, outg_tanh = sess.run([outputs, state, predicted, forget_gate, input_gate, cell_candidates, output_gate_sig, output_gate_tanh], {x:X, y:Y})
outs = np.asarray(outs)
for batch in reversed(range(batch_size)):
print("input:")
print(np.asarray(X)[batch].astype(int).reshape(-1))
print("forget\t\t%.4f\ninput gate\t%.4f\ncell cands\t%.4f\nout gate sig\t%.4f\nout gate tanh\t%.4f\nhidden state\t%.4f\ncell state\t%.4f\npred\t\t%.4f\n\n" % (
fg[batch,0],
inpg[batch,0],
cell_cands[batch,0],
outg_sig[batch,0],
outg_tanh[batch,0],
stat.h[batch,0],
stat.c[batch,0],
pred[batch,0]))
```
LSTM gates:

(image source: https://www.stratio.com/wp-content/uploads/2017/10/6-1.jpg)
### Answers
* When the current element is 1, then the forget-gate tells "forget" (value is close to 0) $\Rightarrow$ Reset cell state
* The cell state (long term memory) decreases until it reached some certain point. Then the hidden state is activated and thus the prediction is close to 1.
* The sigomoid output cell ($o_t$) is always close to 1 $\Rightarrow$ the hidden layer directly dependent on the cell state (no short term memory is used).
* The input gate ($i_t$) is always close to 1 thus the cell candidates ($c_t$) will always be accepted
* The cell candidates ($c_t$) are mainly dependent on $x_t$. It is close to 1 when $x_t$ is one (resetting the counter) and negative if $x_t$ is 0 (decreasing the counter).
Note that with other initial values (different seed) it may result in a different local minimum (the counter could increase, $h_t$ could be negative and be scaled negative, ...)
| true |
code
| 0.683116 | null | null | null | null |
|
# Pytorch Basic
```
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from IPython.display import clear_output
torch.cuda.is_available()
```
## Device
```
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
```
## Hyper Parameter
```
input_size = 784
hidden_size = 500
num_class = 10
epochs = 5
batch_size = 100
lr = 0.001
```
## Load MNIST Dataset
```
train_dataset = torchvision.datasets.MNIST(root='../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../data',
train=False,
transform=transforms.ToTensor())
print('train dataset shape : ',train_dataset.data.shape)
print('test dataset shape : ',test_dataset.data.shape)
plt.imshow(train_dataset.data[0])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
```
## Simple Model
```
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_class):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_class)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size,hidden_size,num_class).to(device)
```
## Loss and Optimizer
```
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
```
## Train
```
total_step = len(train_loader)
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1,28*28).to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
clear_output()
print('EPOCH [{}/{}] STEP [{}/{}] Loss {: .4f})'
.format(epoch+1, epochs, i+1, total_step, loss.item()))
```
## Test
```
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
```
## save
```
torch.save(model.state_dict(), 'model.ckpt')
```
---
| true |
code
| 0.849628 | null | null | null | null |
|
# From Variables to Classes
## A short Introduction
Python - as any programming language - has many extensions and libraries at its disposal. Basically, there are libraries for everything.
<center>But what are **libraries**? </center>
Basically, **libraries** are a collection of methods (_small pieces of code where you put sth in and get sth else out_) which you can use to analyse your data, visualise your data, run models ... do anything you like.
As said, methods usually take _something_ as input. That _something_ is usually a **variable**.
In the following, we will work our way from **variables** to **libraries**.
## Variables
Variables are one of the simplest types of objects in a programming language. An [object](https://en.wikipedia.org/wiki/Object_(computer_science) is a value stored in the memory of your computer, marked by a specific identifyer. Variables can have different types, such as [strings, numbers, and booleans](https://www.learnpython.org/en/Variables_and_Types). Differently to other programming languages, you do not need to declare the type of a variable, as variables are handled as objects in Python.
```python
x = 4.2 # floating point number
y = 'Hello World!' # string
z = True # boolean
```
```
x = 4.2
print(type(x))
y = 'Hello World!'
print(type(y))
z = True
print(type(z))
```
We can use operations (normal arithmetic operations) to use variables for getting results we want. With numbers, you can add, substract, multiply, divide, basically taking the values from the memory assigned to the variable name and performing calculations.
Let's have a look at operations with numbers and strings. We leave booleans to the side for the moment. We will simply add the variables below.
```python
n1 = 7
n2 = 42
s1 = 'Looking good, '
s2 = 'you are.'
```
```
n1 = 7
n2 = 42
s1 = 'Looking good, '
s2 = 'you are.'
first_sum = n1 + n2
print(first_sum)
first_conc = s1 + s2
print(first_conc)
```
Variables can be more than just a number. If you think of an Excel-Spreadsheet, a variable can be the content of a single cell, or multiple cells can be combined in one variable (e.g. one column of an Excel table).
So let's create a list -_a collection of variables_ - from `x`, `n1`, and `n2`. Lists in python are created using [ ].
Now, if you want to calculate the sum of this list, it is really exhausting to sum up every item of this list manually.
```python
first_list = [x, n1, n2]
# a sum of a list could look like
second_sum = some_list[0] + some_list[1] + ... + some_list[n] # where n is the last item of the list, e.g. 2 for first_list.
```
Actually, writing the second sum like this is the same as before. It would be great, if this step of calculating the sum could be used many times without writing it out. And this is, what functions are for. For example, there already exists a sum function:
```python
sum(first_list)```
```
first_list = [x, n1, n2]
second_sum = first_list[0] + first_list[1] + first_list[2]
print('manual sum {}'.format(second_sum))
# This can also be done with a function
print('sum function {}'.format(sum(first_list)))
```
## Functions
The `sum()` method we used above is a **function**.
Functions (later we will call them methods) are pieces of code, which take an input, perform some kind of operation, and (_optionally_) return an output.
In Python, functions are written like:
```python
def func(input):
"""
Description of the functions content # called the function header
"""
some kind of operation on input # called the function body
return output
```
As an example, we write a `sumup` function which sums up a list.
```
def sumup(inp):
"""
input: inp - list/array with floating point or integer numbers
return: sumd - scalar value of the summed up list
"""
val = 0
for i in inp:
val = val + i
return val
# let's compare the implemented standard sum function with the new sumup function
sum1 = sum(first_list)
sum2 = sumup(first_list)
print("The python sum function yields {}, \nand our sumup function yields {}.".format(*(sum1,sum2)))
# summing up the numbers from 1 to 100
import numpy as np
ar_2_sum = np.linspace(1,100,100, dtype='i')
print("the sum of the array is: {}".format(sumup(ar_2_sum)))
```
As we see above, functions are quite practical and save a lot of time. Further, they help structuring your code. Some functions are directly available in python without any libraries or other external software. In the example above however, you might have noticed, that we `import`ed a library called `numpy`.
In those libraries, functions are merged to one package, having the advantage that you don't need to import each single function at a time.
Imagine you move and have to pack all your belongings. You can think of libraries as packing things with similar purpose in the same box (= library).
## Functions to Methods as part of classes
When we talk about functions in the environment of classes, we usually call them methods. But what are **classes**?
[Classes](https://docs.python.org/3/tutorial/classes.html) are ways to bundle functionality together. Logically, functionality with similar purpose (or different kind of similarity).
One example could be: think of **apples**.
Apples are now a class. You can apply methods to this class, such as `eat()` or `cut()`. Or more sophisticated methods including various recipes using apples comprised in a cookbook.
The `eat()` method is straight forward. But the `cut()` method may be more interesting, since there are various ways to cut an apple.
Let's assume there are two apples to be cut differently. In python, once you have assigned a class to a variable, you have created an **instance** of that class. Then, methods of are applied to that instance by using a . notation.
```python
Golden_Delicious = apple()
Yoya = apple()
Golden_Delicious.cut(4)
Yoya.cut(8)
```
The two apples Golden Delicious and Yoya are _instances_ of the class apple. Real _incarnations_ of the abstract concept _apple_. The Golden Delicious is cut into 4 pieces, while the Yoya is cut into 8 pieces.
This is similar to more complex libraries, such as the `scikit-learn`. In one exercise, you used the command:
```python
from sklearn.cluster import KMeans
```
which simply imports the **class** `KMeans` from the library part `sklearn.cluster`. `KMeans` comprises several methods for clustering, which you can use by calling them similar to the apple example before.
For this, you need to create an _instance_ of the `KMeans` class.
```python
...
kmeans_inst = KMeans(n_clusters=n_clusters) # first we create the instance of the KMeans class called kmeans_inst
kmeans_inst.fit(data) # then we apply a method to the instance kmeans_inst
...
```
An example:
```
# here we just create the data for clustering
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
%matplotlib inline
X, y = make_blobs(n_samples=100, centers=3, cluster_std= 0.5,
random_state=0)
plt.scatter(X[:,0], X[:,1], s=70)
# now we create an instance of the KMeans class
from sklearn.cluster import KMeans
nr_of_clusters = 3 # because we see 3 clusters in the plot above
kmeans_inst = KMeans(n_clusters= nr_of_clusters) # create the instance kmeans_inst
kmeans_inst.fit(X) # apply a method to the instance
y_predict = kmeans_inst.predict(X) # apply another method to the instance and save it in another variable
# lets plot the predicted cluster centers colored in the cluster color
plt.scatter(X[:, 0], X[:, 1], c=y_predict, s=50, cmap='Accent')
centers = kmeans_inst.cluster_centers_ # apply the method to find the new centers of the determined clusters
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.6); # plot the cluster centers
```
## Summary
This short presentation is meant to make you familiar with the concept of variables, functions, methods and classes. All of which are objects!
* Variables are normally declared by the user and link a value stored in the memory of your pc to a variable name. They are usually the input of functions
* Functions are pieces of code taking an input and performing some operation on said input. Optionally, they return directly an output value
* To facilitate the use of functions, they are sometimes bundled as methods within classes. Classes in turn can build up whole libraries in python.
* Similar to real book libraries, python libraries contain a collection of _recipes_ which can be applied to your data.
* In terms of apples: You own different kinds of apples. A book about apple dishes (_class_) from the library contains different recipes (_methods_) which can be used for your different apples (_instances of the class_).
## Further links
* [Data Science Handbook](https://jakevdp.github.io/PythonDataScienceHandbook/)
* [Python for Geosciences](https://github.com/koldunovn/python_for_geosciences)
* [Introduction to Python for Geoscientists](http://ggorman.github.io/Introduction-to-programming-for-geoscientists/)
* [Full Video course on Object Oriented Programming](https://www.youtube.com/watch?v=ZDa-Z5JzLYM&list=PL-osiE80TeTsqhIuOqKhwlXsIBIdSeYtc)
| true |
code
| 0.589066 | null | null | null | null |
|
```
import numpy as np
from keras.models import Model
from keras.layers import Input
from keras.layers.pooling import AveragePooling3D
from keras import backend as K
import json
from collections import OrderedDict
def format_decimal(arr, places=6):
return [round(x * 10**places) / 10**places for x in arr]
DATA = OrderedDict()
```
### AveragePooling3D
**[pooling.AveragePooling3D.0] input 4x4x4x2, pool_size=(2, 2, 2), strides=None, padding='valid', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(290)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.0'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.1] input 4x4x4x2, pool_size=(2, 2, 2), strides=(1, 1, 1), padding='valid', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=(1, 1, 1), padding='valid', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(291)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.1'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.2] input 4x5x2x3, pool_size=(2, 2, 2), strides=(2, 1, 1), padding='valid', data_format='channels_last'**
```
data_in_shape = (4, 5, 2, 3)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=(2, 1, 1), padding='valid', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(282)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.2'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.3] input 4x4x4x2, pool_size=(3, 3, 3), strides=None, padding='valid', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=None, padding='valid', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(283)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.3'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.4] input 4x4x4x2, pool_size=(3, 3, 3), strides=(3, 3, 3), padding='valid', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=(3, 3, 3), padding='valid', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(284)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.4'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.5] input 4x4x4x2, pool_size=(2, 2, 2), strides=None, padding='same', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=None, padding='same', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(285)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.5'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.6] input 4x4x4x2, pool_size=(2, 2, 2), strides=(1, 1, 1), padding='same', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=(1, 1, 1), padding='same', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(286)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.6'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.7] input 4x5x4x2, pool_size=(2, 2, 2), strides=(1, 2, 1), padding='same', data_format='channels_last'**
```
data_in_shape = (4, 5, 4, 2)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=(1, 2, 1), padding='same', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(287)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.7'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.8] input 4x4x4x2, pool_size=(3, 3, 3), strides=None, padding='same', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=None, padding='same', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(288)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.8'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.9] input 4x4x4x2, pool_size=(3, 3, 3), strides=(3, 3, 3), padding='same', data_format='channels_last'**
```
data_in_shape = (4, 4, 4, 2)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=(3, 3, 3), padding='same', data_format='channels_last')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(289)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.9'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.10] input 2x3x3x4, pool_size=(3, 3, 3), strides=(2, 2, 2), padding='valid', data_format='channels_first'**
```
data_in_shape = (2, 3, 3, 4)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=(2, 2, 2), padding='valid', data_format='channels_first')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(290)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.10'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.11] input 2x3x3x4, pool_size=(3, 3, 3), strides=(1, 1, 1), padding='same', data_format='channels_first'**
```
data_in_shape = (2, 3, 3, 4)
L = AveragePooling3D(pool_size=(3, 3, 3), strides=(1, 1, 1), padding='same', data_format='channels_first')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(291)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.11'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
**[pooling.AveragePooling3D.12] input 3x4x4x3, pool_size=(2, 2, 2), strides=None, padding='valid', data_format='channels_first'**
```
data_in_shape = (3, 4, 4, 3)
L = AveragePooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format='channels_first')
layer_0 = Input(shape=data_in_shape)
layer_1 = L(layer_0)
model = Model(inputs=layer_0, outputs=layer_1)
# set weights to random (use seed for reproducibility)
np.random.seed(292)
data_in = 2 * np.random.random(data_in_shape) - 1
result = model.predict(np.array([data_in]))
data_out_shape = result[0].shape
data_in_formatted = format_decimal(data_in.ravel().tolist())
data_out_formatted = format_decimal(result[0].ravel().tolist())
print('')
print('in shape:', data_in_shape)
print('in:', data_in_formatted)
print('out shape:', data_out_shape)
print('out:', data_out_formatted)
DATA['pooling.AveragePooling3D.12'] = {
'input': {'data': data_in_formatted, 'shape': data_in_shape},
'expected': {'data': data_out_formatted, 'shape': data_out_shape}
}
```
### export for Keras.js tests
```
print(json.dumps(DATA))
```
| true |
code
| 0.511656 | null | null | null | null |
|
<h1 style="text-align:center;text-decoration: underline">Stream Analytics Tutorial</h1>
<h1>Overview</h1>
<p>Welcome to the stream analytics tutorial for EpiData. In this tutorial we will perform near real-time stream analytics on sample weather data acquired from a simulated wireless sensor network.</p>
<h2>Package and Module Imports</h2>
<p>As a first step, we will import packages and modules required for this tutorial. Since <i>EpiData Context (ec)</i> is required to use the application, it is implicitly imported. Sample functions for near real-time analytics are avaialable in <i>EpiData Analytics</i> package. Other packages and modules, such as <i>datetime</i>, <i>pandas</i> and <i>matplotlib</i>, can also be imported at this time.</p>
```
#from epidata.context import ec
from epidata.analytics import *
%matplotlib inline
from datetime import datetime, timedelta
import pandas as pd
import time
import pylab as pl
from IPython import display
import json
```
<h2>Stream Analysis</h2>
<h3>Function Definition</h3>
<p>EpiData supports development and deployment of custom algorithms via Jupyter Notebook. Below, we define python functions for substituting extreme outliers and aggregating temperature measurements. These functions can be operated on near real-time and historic data. In this tutorial, we will apply the functions on near real-time data available from Kafka 'measurements' and 'measurements_cleansed' topics</p>
```
import pandas as pd
import math, numbers
def substitute_demo(df, meas_names, method="rolling", size=3):
"""
Substitute missing measurement values within a data frame, using the specified method.
"""
df["meas_value"].replace(250, np.nan, inplace=True)
for meas_name in meas_names:
if (method == "rolling"):
if ((size % 2 == 0) and (size != 0)): size += 1
if df.loc[df["meas_name"]==meas_name].size > 0:
indices = df.loc[df["meas_name"] == meas_name].index[df.loc[df["meas_name"] == meas_name]["meas_value"].apply(
lambda x: not isinstance(x, basestring) and (x == None or np.isnan(x)))]
substitutes = df.loc[df["meas_name"]==meas_name]["meas_value"].rolling( window=size, min_periods=1, center=True).mean()
df["meas_value"].fillna(substitutes, inplace=True)
df.loc[indices, "meas_flag"] = "substituted"
df.loc[indices, "meas_method"] = "rolling average"
else:
raise ValueError("Unsupported substitution method: ", repr(method))
return df
import pandas as pd
import numpy as np
import json
def subgroup_statistics(row):
row['start_time'] = np.min(row["ts"])
row["stop_time"] = np.max(row["ts"])
row["meas_summary_name"] = "statistics"
row["meas_summary_value"] = json.dumps({'count': row["meas_value"].count(), 'mean': row["meas_value"].mean(),
'std': row["meas_value"].std(), 'min': row["meas_value"].min(),
'max': row["meas_value"].max()})
row["meas_summary_description"] = "descriptive statistics"
return row
def meas_statistics_demo(df, meas_names, method="standard"):
"""
Compute statistics on measurement values within a data frame, using the specified method.
"""
if (method == "standard"):
df_grouped = df.loc[df["meas_name"].isin(meas_names)].groupby(["company", "site", "station", "sensor"],
as_index=False)
df_summary = df_grouped.apply(subgroup_statistics).loc[:, ["company", "site", "station", "sensor",
"start_time", "stop_time", "event", "meas_name", "meas_summary_name", "meas_summary_value",
"meas_summary_description"]].drop_duplicates()
else:
raise ValueError("Unsupported summary method: ", repr(method))
return df_summary
```
<h3>Transformations and Streams</h3>
<p>The analytics algorithms are executed on near real-time data through transformations. A transformation specifies the function, its parameters and destination. The destination can be one of the database tables, namely <i>'measurements_cleansed'</i> or <i>'measurements_summary'</i>, or another Kafka topic.</p>
<p>Once the transformations are defined, they are initiated via <i>ec.create_stream(transformations, data_source, batch_duration)</i> function call.</p>
```
#Stop current near real-time processing
ec.stop_streaming()
# Define tranformations and steam operations
op1 = ec.create_transformation(substitute_demo, [["Temperature", "Wind_Speed"], "rolling", 3], "measurements_substituted")
ec.create_stream([op1], "measurements")
op2 = ec.create_transformation(identity, [], "measurements_cleansed")
op3 = ec.create_transformation(meas_statistics, [["Temperature", "Wind_Speed"], "standard"], "measurements_summary")
ec.create_stream([op2, op3],"measurements_substituted")
# Start near real-time processing
ec.start_streaming()
```
<h3>Data Ingestion</h3>
<p>We can now start data ingestion from simulated wireless sensor network. To do so, you can download and run the <i>sensor_data_with_outliers.py</i> example shown in the image below.</p>
<img src="./static/jupyter_tree.png">
<h3>Data Query and Visualization</h3>
<p>We query the original and processed data from Kafka queue using Kafka Consumer. The data obtained from the quey is visualized using Bokeh charts.</p>
```
from bokeh.io import push_notebook, show, output_notebook
from bokeh.layouts import row, column
from bokeh.plotting import figure
from bokeh.models import ColumnDataSource
from kafka import KafkaConsumer
import json
from pandas.io.json import json_normalize
output_notebook()
plot1 = figure(plot_width=750, plot_height=200, x_axis_type='datetime', y_range=(30, 300))
plot2 = figure(plot_width=750, plot_height=200, x_axis_type='datetime', y_range=(30, 300))
df_kafka_init = pd.DataFrame(columns = ["ts", "meas_value"])
test_data_1 = ColumnDataSource(data=df_kafka_init.to_dict(orient='list'))
test_data_2 = ColumnDataSource(data=df_kafka_init.to_dict(orient='list'))
meas_name = "Temperature"
plot1.circle("ts", "meas_value", source=test_data_1, legend=meas_name, line_color='orangered', line_width=1.5)
line1 = plot1.line("ts", "meas_value", source=test_data_1, legend=meas_name, line_color='orangered', line_width=1.5)
plot1.legend.location = "top_right"
plot2.circle("ts", "meas_value", source=test_data_2, legend=meas_name, line_color='blue', line_width=1.5)
line2 = plot2.line("ts", "meas_value", source=test_data_2, legend=meas_name, line_color='blue', line_width=1.5)
plot2.legend.location = "top_right"
consumer = KafkaConsumer()
consumer.subscribe(['measurements', 'measurements_substituted'])
delay = .1
handle = show(column(plot1, plot2), notebook_handle=True)
for message in consumer:
topic = message.topic
measurements = json.loads(message.value)
df_kafka = json_normalize(measurements)
df_kafka["meas_value"] = np.nan if "meas_value" not in measurements else measurements["meas_value"]
df_kafka = df_kafka.loc[df_kafka["meas_name"]==meas_name]
df_kafka = df_kafka[["ts", "meas_value"]]
df_kafka["ts"] = df_kafka["ts"].apply(lambda x: pd.to_datetime(x, unit='ms').tz_localize('UTC').tz_convert('US/Pacific'))
if (not df_kafka.empty):
if (topic == 'measurements'):
test_data_1.stream(df_kafka.to_dict(orient='list'))
if (topic == 'measurements_substituted'):
test_data_2.stream(df_kafka.to_dict(orient='list'))
push_notebook(handle=handle)
time.sleep(delay)
```
<p>Another way to query and visualize processed data is using <i>ec.query_measurements_cleansed(..) and ec.query_measurements_summary(..)</i> functions. For our example, we specify paramaters that match sample data set, and query the aggregated values using <i>ec.query_measurements_summary(..)</i> function call.</p>
```
# QUERY MEASUREMENTS_CLEANSED TABLE
primary_key={"company": "EpiData", "site": "San_Jose", "station":"WSN-1",
"sensor": ["Temperature_Probe", "RH_Probe", "Anemometer"]}
start_time = datetime.strptime('8/19/2017 00:00:00', '%m/%d/%Y %H:%M:%S')
stop_time = datetime.strptime('8/20/2017 00:00:00', '%m/%d/%Y %H:%M:%S')
df_cleansed = ec.query_measurements_cleansed(primary_key, start_time, stop_time)
print "Number of records:", df_cleansed.count()
df_cleansed_local = df_cleansed.toPandas()
df_cleansed_local[df_cleansed_local["meas_name"]=="Temperature"].tail(10).sort_values(by="ts",ascending=False)
# QUERY MEASUREMNTS_SUMMARY TABLE
primary_key={"company": "EpiData", "site": "San_Jose", "station":"WSN-1", "sensor": ["Temperature_Probe"]}
start_time = datetime.strptime('8/19/2017 00:00:00', '%m/%d/%Y %H:%M:%S')
stop_time = datetime.strptime('8/20/2017 00:00:00', '%m/%d/%Y %H:%M:%S')
last_index = -1
summary_result = pd.DataFrame()
df_summary = ec.query_measurements_summary(primary_key, start_time, stop_time)
df_summary_local = df_summary.toPandas()
summary_keys = df_summary_local[["company", "site", "station", "sensor", "start_time", "stop_time", "meas_name", "meas_summary_name"]]
summary_result = df_summary_local["meas_summary_value"].apply(json.loads).apply(pd.Series)
summary_combined = pd.concat([summary_keys, summary_result], axis=1)
summary_combined.tail(5)
```
<h3>Stop Stream Analytics</h3>
<p>The transformations can be stopped at any time via <i>ec.stop_streaming()</i> function call<p>
```
#Stop current near real-time processing
ec.stop_streaming()
```
<h2>Next Steps</h2>
<p>Congratulations, you have successfully perfomed near real-time analytics on sample data aquired by a simulated wireless sensor network. The next step is to explore various capabilities of EpiData by creating your own custom analytics application!</p>
| true |
code
| 0.431704 | null | null | null | null |
|
**Chapter 16 – Reinforcement Learning**
This notebook contains all the sample code and solutions to the exercices in chapter 16.
# Setup
First, let's make sure this notebook works well in both python 2 and 3, import a few common modules, ensure MatplotLib plots figures inline and prepare a function to save the figures:
```
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import numpy.random as rnd
import os
import sys
# to make this notebook's output stable across runs
rnd.seed(42)
# To plot pretty figures and animations
%matplotlib nbagg
import matplotlib
import matplotlib.animation as animation
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "rl"
def save_fig(fig_id, tight_layout=True):
path = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)
```
# Introduction to OpenAI gym
In this notebook we will be using [OpenAI gym](https://gym.openai.com/), a great toolkit for developing and comparing Reinforcement Learning algorithms. It provides many environments for your learning *agents* to interact with. Let's start by importing `gym`:
```
import gym
```
Next we will load the MsPacman environment, version 0.
```
env = gym.make('MsPacman-v0')
```
Let's initialize the environment by calling is `reset()` method. This returns an observation:
```
obs = env.reset()
```
Observations vary depending on the environment. In this case it is an RGB image represented as a 3D NumPy array of shape [width, height, channels] (with 3 channels: Red, Green and Blue). In other environments it may return different objects, as we will see later.
```
obs.shape
```
An environment can be visualized by calling its `render()` method, and you can pick the rendering mode (the rendering options depend on the environment). In this example we will set `mode="rgb_array"` to get an image of the environment as a NumPy array:
```
img = env.render(mode="rgb_array")
```
Let's plot this image:
```
plt.figure(figsize=(5,4))
plt.imshow(img)
plt.axis("off")
save_fig("MsPacman")
plt.show()
```
Welcome back to the 1980s! :)
In this environment, the rendered image is simply equal to the observation (but in many environments this is not the case):
```
(img == obs).all()
```
Let's create a little helper function to plot an environment:
```
def plot_environment(env, figsize=(5,4)):
plt.close() # or else nbagg sometimes plots in the previous cell
plt.figure(figsize=figsize)
img = env.render(mode="rgb_array")
plt.imshow(img)
plt.axis("off")
plt.show()
```
Let's see how to interact with an environment. Your agent will need to select an action from an "action space" (the set of possible actions). Let's see what this environment's action space looks like:
```
env.action_space
```
`Discrete(9)` means that the possible actions are integers 0 through 8, which represents the 9 possible positions of the joystick (0=center, 1=up, 2=right, 3=left, 4=down, 5=upper-right, 6=upper-left, 7=lower-right, 8=lower-left).
Next we need to tell the environment which action to play, and it will compute the next step of the game. Let's go left for 110 steps, then lower left for 40 steps:
```
env.reset()
for step in range(110):
env.step(3) #left
for step in range(40):
env.step(8) #lower-left
```
Where are we now?
```
plot_environment(env)
```
The `step()` function actually returns several important objects:
```
obs, reward, done, info = env.step(0)
```
The observation tells the agent what the environment looks like, as discussed earlier. This is a 210x160 RGB image:
```
obs.shape
```
The environment also tells the agent how much reward it got during the last step:
```
reward
```
When the game is over, the environment returns `done=True`:
```
done
```
Finally, `info` is an environment-specific dictionary that can provide some extra information about the internal state of the environment. This is useful for debugging, but your agent should not use this information for learning (it would be cheating).
```
info
```
Let's play one full game (with 3 lives), by moving in random directions for 10 steps at a time, recording each frame:
```
frames = []
n_max_steps = 1000
n_change_steps = 10
obs = env.reset()
for step in range(n_max_steps):
img = env.render(mode="rgb_array")
frames.append(img)
if step % n_change_steps == 0:
action = env.action_space.sample() # play randomly
obs, reward, done, info = env.step(action)
if done:
break
```
Now show the animation (it's a bit jittery within Jupyter):
```
def update_scene(num, frames, patch):
patch.set_data(frames[num])
return patch,
def plot_animation(frames, repeat=False, interval=40):
plt.close() # or else nbagg sometimes plots in the previous cell
fig = plt.figure()
patch = plt.imshow(frames[0])
plt.axis('off')
return animation.FuncAnimation(fig, update_scene, fargs=(frames, patch), frames=len(frames), repeat=repeat, interval=interval)
video = plot_animation(frames)
plt.show()
```
Once you have finished playing with an environment, you should close it to free up resources:
```
env.close()
```
To code our first learning agent, we will be using a simpler environment: the Cart-Pole.
# A simple environment: the Cart-Pole
The Cart-Pole is a very simple environment composed of a cart that can move left or right, and pole placed vertically on top of it. The agent must move the cart left or right to keep the pole upright.
```
env = gym.make("CartPole-v0")
obs = env.reset()
obs
```
The observation is a 1D NumPy array composed of 4 floats: they represent the cart's horizontal position, its velocity, the angle of the pole (0 = vertical), and the angular velocity. Let's render the environment... unfortunately we need to fix an annoying rendering issue first.
## Fixing the rendering issue
Some environments (including the Cart-Pole) require access to your display, which opens up a separate window, even if you specify the `rgb_array` mode. In general you can safely ignore that window. However, if Jupyter is running on a headless server (ie. without a screen) it will raise an exception. One way to avoid this is to install a fake X server like Xvfb. You can start Jupyter using the `xvfb-run` command:
$ xvfb-run -s "-screen 0 1400x900x24" jupyter notebook
If Jupyter is running on a headless server but you don't want to worry about Xvfb, then you can just use the following rendering function for the Cart-Pole:
```
from PIL import Image, ImageDraw
try:
from pyglet.gl import gl_info
openai_cart_pole_rendering = True # no problem, let's use OpenAI gym's rendering function
except Exception:
openai_cart_pole_rendering = False # probably no X server available, let's use our own rendering function
def render_cart_pole(env, obs):
if openai_cart_pole_rendering:
# use OpenAI gym's rendering function
return env.render(mode="rgb_array")
else:
# rendering for the cart pole environment (in case OpenAI gym can't do it)
img_w = 600
img_h = 400
cart_w = img_w // 12
cart_h = img_h // 15
pole_len = img_h // 3.5
pole_w = img_w // 80 + 1
x_width = 2
max_ang = 0.2
bg_col = (255, 255, 255)
cart_col = 0x000000 # Blue Green Red
pole_col = 0x669acc # Blue Green Red
pos, vel, ang, ang_vel = obs
img = Image.new('RGB', (img_w, img_h), bg_col)
draw = ImageDraw.Draw(img)
cart_x = pos * img_w // x_width + img_w // x_width
cart_y = img_h * 95 // 100
top_pole_x = cart_x + pole_len * np.sin(ang)
top_pole_y = cart_y - cart_h // 2 - pole_len * np.cos(ang)
draw.line((0, cart_y, img_w, cart_y), fill=0)
draw.rectangle((cart_x - cart_w // 2, cart_y - cart_h // 2, cart_x + cart_w // 2, cart_y + cart_h // 2), fill=cart_col) # draw cart
draw.line((cart_x, cart_y - cart_h // 2, top_pole_x, top_pole_y), fill=pole_col, width=pole_w) # draw pole
return np.array(img)
def plot_cart_pole(env, obs):
plt.close() # or else nbagg sometimes plots in the previous cell
img = render_cart_pole(env, obs)
plt.imshow(img)
plt.axis("off")
plt.show()
plot_cart_pole(env, obs)
```
Now let's look at the action space:
```
env.action_space
```
Yep, just two possible actions: accelerate towards the left or towards the right. Let's push the cart left until the pole falls:
```
obs = env.reset()
while True:
obs, reward, done, info = env.step(0)
if done:
break
plt.close() # or else nbagg sometimes plots in the previous cell
img = render_cart_pole(env, obs)
plt.imshow(img)
plt.axis("off")
save_fig("cart_pole_plot")
```
Notice that the game is over when the pole tilts too much, not when it actually falls. Now let's reset the environment and push the cart to right instead:
```
obs = env.reset()
while True:
obs, reward, done, info = env.step(1)
if done:
break
plot_cart_pole(env, obs)
```
Looks like it's doing what we're telling it to do. Now how can we make the poll remain upright? We will need to define a _policy_ for that. This is the strategy that the agent will use to select an action at each step. It can use all the past actions and observations to decide what to do.
# A simple hard-coded policy
Let's hard code a simple strategy: if the pole is tilting to the left, then push the cart to the left, and _vice versa_. Let's see if that works:
```
frames = []
n_max_steps = 1000
n_change_steps = 10
obs = env.reset()
for step in range(n_max_steps):
img = render_cart_pole(env, obs)
frames.append(img)
# hard-coded policy
position, velocity, angle, angular_velocity = obs
if angle < 0:
action = 0
else:
action = 1
obs, reward, done, info = env.step(action)
if done:
break
video = plot_animation(frames)
plt.show()
```
Nope, the system is unstable and after just a few wobbles, the pole ends up too tilted: game over. We will need to be smarter than that!
# Neural Network Policies
Let's create a neural network that will take observations as inputs, and output the action to take for each observation. To choose an action, the network will first estimate a probability for each action, then select an action randomly according to the estimated probabilities. In the case of the Cart-Pole environment, there are just two possible actions (left or right), so we only need one output neuron: it will output the probability `p` of the action 0 (left), and of course the probability of action 1 (right) will be `1 - p`.
```
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
# 1. Specify the network architecture
n_inputs = 4 # == env.observation_space.shape[0]
n_hidden = 4 # it's a simple task, we don't need more than this
n_outputs = 1 # only outputs the probability of accelerating left
initializer = tf.contrib.layers.variance_scaling_initializer()
# 2. Build the neural network
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
hidden = fully_connected(X, n_hidden, activation_fn=tf.nn.elu,
weights_initializer=initializer)
outputs = fully_connected(hidden, n_outputs, activation_fn=tf.nn.sigmoid,
weights_initializer=initializer)
# 3. Select a random action based on the estimated probabilities
p_left_and_right = tf.concat(axis=1, values=[outputs, 1 - outputs])
action = tf.multinomial(tf.log(p_left_and_right), num_samples=1)
init = tf.global_variables_initializer()
```
In this particular environment, the past actions and observations can safely be ignored, since each observation contains the environment's full state. If there were some hidden state then you may need to consider past actions and observations in order to try to infer the hidden state of the environment. For example, if the environment only revealed the position of the cart but not its velocity, you would have to consider not only the current observation but also the previous observation in order to estimate the current velocity. Another example is if the observations are noisy: you may want to use the past few observations to estimate the most likely current state. Our problem is thus as simple as can be: the current observation is noise-free and contains the environment's full state.
You may wonder why we are picking a random action based on the probability given by the policy network, rather than just picking the action with the highest probability. This approach lets the agent find the right balance between _exploring_ new actions and _exploiting_ the actions that are known to work well. Here's an analogy: suppose you go to a restaurant for the first time, and all the dishes look equally appealing so you randomly pick one. If it turns out to be good, you can increase the probability to order it next time, but you shouldn't increase that probability to 100%, or else you will never try out the other dishes, some of which may be even better than the one you tried.
Let's randomly initialize this policy neural network and use it to play one game:
```
n_max_steps = 1000
frames = []
with tf.Session() as sess:
init.run()
obs = env.reset()
for step in range(n_max_steps):
img = render_cart_pole(env, obs)
frames.append(img)
action_val = action.eval(feed_dict={X: obs.reshape(1, n_inputs)})
obs, reward, done, info = env.step(action_val[0][0])
if done:
break
env.close()
```
Now let's look at how well this randomly initialized policy network performed:
```
video = plot_animation(frames)
plt.show()
```
Yeah... pretty bad. The neural network will have to learn to do better. First let's see if it is capable of learning the basic policy we used earlier: go left if the pole is tilting left, and go right if it is tilting right. The following code defines the same neural network but we add the target probabilities `y`, and the training operations (`cross_entropy`, `optimizer` and `training_op`):
```
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
tf.reset_default_graph()
n_inputs = 4
n_hidden = 4
n_outputs = 1
learning_rate = 0.01
initializer = tf.contrib.layers.variance_scaling_initializer()
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
y = tf.placeholder(tf.float32, shape=[None, n_outputs])
hidden = fully_connected(X, n_hidden, activation_fn=tf.nn.elu, weights_initializer=initializer)
logits = fully_connected(hidden, n_outputs, activation_fn=None)
outputs = tf.nn.sigmoid(logits) # probability of action 0 (left)
p_left_and_right = tf.concat(axis=1, values=[outputs, 1 - outputs])
action = tf.multinomial(tf.log(p_left_and_right), num_samples=1)
cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(cross_entropy)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
We can make the same net play in 10 different environments in parallel, and train for 1000 iterations. We also reset environments when they are done.
```
n_environments = 10
n_iterations = 1000
envs = [gym.make("CartPole-v0") for _ in range(n_environments)]
observations = [env.reset() for env in envs]
with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
target_probas = np.array([([1.] if obs[2] < 0 else [0.]) for obs in observations]) # if angle<0 we want proba(left)=1., or else proba(left)=0.
action_val, _ = sess.run([action, training_op], feed_dict={X: np.array(observations), y: target_probas})
for env_index, env in enumerate(envs):
obs, reward, done, info = env.step(action_val[env_index][0])
observations[env_index] = obs if not done else env.reset()
saver.save(sess, "./my_policy_net_basic.ckpt")
for env in envs:
env.close()
def render_policy_net(model_path, action, X, n_max_steps = 1000):
frames = []
env = gym.make("CartPole-v0")
obs = env.reset()
with tf.Session() as sess:
saver.restore(sess, model_path)
for step in range(n_max_steps):
img = render_cart_pole(env, obs)
frames.append(img)
action_val = action.eval(feed_dict={X: obs.reshape(1, n_inputs)})
obs, reward, done, info = env.step(action_val[0][0])
if done:
break
env.close()
return frames
frames = render_policy_net("./my_policy_net_basic.ckpt", action, X)
video = plot_animation(frames)
plt.show()
```
Looks like it learned the policy correctly. Now let's see if it can learn a better policy on its own.
# Policy Gradients
To train this neural network we will need to define the target probabilities `y`. If an action is good we should increase its probability, and conversely if it is bad we should reduce it. But how do we know whether an action is good or bad? The problem is that most actions have delayed effects, so when you win or lose points in a game, it is not clear which actions contributed to this result: was it just the last action? Or the last 10? Or just one action 50 steps earlier? This is called the _credit assignment problem_.
The _Policy Gradients_ algorithm tackles this problem by first playing multiple games, then making the actions in good games slightly more likely, while actions in bad games are made slightly less likely. First we play, then we go back and think about what we did.
```
import tensorflow as tf
from tensorflow.contrib.layers import fully_connected
tf.reset_default_graph()
n_inputs = 4
n_hidden = 4
n_outputs = 1
learning_rate = 0.01
initializer = tf.contrib.layers.variance_scaling_initializer()
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
hidden = fully_connected(X, n_hidden, activation_fn=tf.nn.elu, weights_initializer=initializer)
logits = fully_connected(hidden, n_outputs, activation_fn=None)
outputs = tf.nn.sigmoid(logits) # probability of action 0 (left)
p_left_and_right = tf.concat(axis=1, values=[outputs, 1 - outputs])
action = tf.multinomial(tf.log(p_left_and_right), num_samples=1)
y = 1. - tf.to_float(action)
cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits)
optimizer = tf.train.AdamOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(cross_entropy)
gradients = [grad for grad, variable in grads_and_vars]
gradient_placeholders = []
grads_and_vars_feed = []
for grad, variable in grads_and_vars:
gradient_placeholder = tf.placeholder(tf.float32, shape=grad.get_shape())
gradient_placeholders.append(gradient_placeholder)
grads_and_vars_feed.append((gradient_placeholder, variable))
training_op = optimizer.apply_gradients(grads_and_vars_feed)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
def discount_rewards(rewards, discount_rate):
discounted_rewards = np.zeros(len(rewards))
cumulative_rewards = 0
for step in reversed(range(len(rewards))):
cumulative_rewards = rewards[step] + cumulative_rewards * discount_rate
discounted_rewards[step] = cumulative_rewards
return discounted_rewards
def discount_and_normalize_rewards(all_rewards, discount_rate):
all_discounted_rewards = [discount_rewards(rewards, discount_rate) for rewards in all_rewards]
flat_rewards = np.concatenate(all_discounted_rewards)
reward_mean = flat_rewards.mean()
reward_std = flat_rewards.std()
return [(discounted_rewards - reward_mean)/reward_std for discounted_rewards in all_discounted_rewards]
discount_rewards([10, 0, -50], discount_rate=0.8)
discount_and_normalize_rewards([[10, 0, -50], [10, 20]], discount_rate=0.8)
env = gym.make("CartPole-v0")
n_games_per_update = 10
n_max_steps = 1000
n_iterations = 250
save_iterations = 10
discount_rate = 0.95
with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
print("\rIteration: {}".format(iteration), end="")
all_rewards = []
all_gradients = []
for game in range(n_games_per_update):
current_rewards = []
current_gradients = []
obs = env.reset()
for step in range(n_max_steps):
action_val, gradients_val = sess.run([action, gradients], feed_dict={X: obs.reshape(1, n_inputs)})
obs, reward, done, info = env.step(action_val[0][0])
current_rewards.append(reward)
current_gradients.append(gradients_val)
if done:
break
all_rewards.append(current_rewards)
all_gradients.append(current_gradients)
all_rewards = discount_and_normalize_rewards(all_rewards, discount_rate=discount_rate)
feed_dict = {}
for var_index, gradient_placeholder in enumerate(gradient_placeholders):
mean_gradients = np.mean([reward * all_gradients[game_index][step][var_index]
for game_index, rewards in enumerate(all_rewards)
for step, reward in enumerate(rewards)], axis=0)
feed_dict[gradient_placeholder] = mean_gradients
sess.run(training_op, feed_dict=feed_dict)
if iteration % save_iterations == 0:
saver.save(sess, "./my_policy_net_pg.ckpt")
env.close()
frames = render_policy_net("./my_policy_net_pg.ckpt", action, X, n_max_steps=1000)
video = plot_animation(frames)
plt.show()
```
# Markov Chains
```
transition_probabilities = [
[0.7, 0.2, 0.0, 0.1], # from s0 to s0, s1, s2, s3
[0.0, 0.0, 0.9, 0.1], # from s1 to ...
[0.0, 1.0, 0.0, 0.0], # from s2 to ...
[0.0, 0.0, 0.0, 1.0], # from s3 to ...
]
n_max_steps = 50
def print_sequence(start_state=0):
current_state = start_state
print("States:", end=" ")
for step in range(n_max_steps):
print(current_state, end=" ")
if current_state == 3:
break
current_state = rnd.choice(range(4), p=transition_probabilities[current_state])
else:
print("...", end="")
print()
for _ in range(10):
print_sequence()
```
# Markov Decision Process
```
transition_probabilities = [
[[0.7, 0.3, 0.0], [1.0, 0.0, 0.0], [0.8, 0.2, 0.0]], # in s0, if action a0 then proba 0.7 to state s0 and 0.3 to state s1, etc.
[[0.0, 1.0, 0.0], None, [0.0, 0.0, 1.0]],
[None, [0.8, 0.1, 0.1], None],
]
rewards = [
[[+10, 0, 0], [0, 0, 0], [0, 0, 0]],
[[0, 0, 0], [0, 0, 0], [0, 0, -50]],
[[0, 0, 0], [+40, 0, 0], [0, 0, 0]],
]
possible_actions = [[0, 1, 2], [0, 2], [1]]
def policy_fire(state):
return [0, 2, 1][state]
def policy_random(state):
return rnd.choice(possible_actions[state])
def policy_safe(state):
return [0, 0, 1][state]
class MDPEnvironment(object):
def __init__(self, start_state=0):
self.start_state=start_state
self.reset()
def reset(self):
self.total_rewards = 0
self.state = self.start_state
def step(self, action):
next_state = rnd.choice(range(3), p=transition_probabilities[self.state][action])
reward = rewards[self.state][action][next_state]
self.state = next_state
self.total_rewards += reward
return self.state, reward
def run_episode(policy, n_steps, start_state=0, display=True):
env = MDPEnvironment()
if display:
print("States (+rewards):", end=" ")
for step in range(n_steps):
if display:
if step == 10:
print("...", end=" ")
elif step < 10:
print(env.state, end=" ")
action = policy(env.state)
state, reward = env.step(action)
if display and step < 10:
if reward:
print("({})".format(reward), end=" ")
if display:
print("Total rewards =", env.total_rewards)
return env.total_rewards
for policy in (policy_fire, policy_random, policy_safe):
all_totals = []
print(policy.__name__)
for episode in range(1000):
all_totals.append(run_episode(policy, n_steps=100, display=(episode<5)))
print("Summary: mean={:.1f}, std={:1f}, min={}, max={}".format(np.mean(all_totals), np.std(all_totals), np.min(all_totals), np.max(all_totals)))
print()
```
# Q-Learning
Q-Learning will learn the optimal policy by watching the random policy play.
```
n_states = 3
n_actions = 3
n_steps = 20000
alpha = 0.01
gamma = 0.99
exploration_policy = policy_random
q_values = np.full((n_states, n_actions), -np.inf)
for state, actions in enumerate(possible_actions):
q_values[state][actions]=0
env = MDPEnvironment()
for step in range(n_steps):
action = exploration_policy(env.state)
state = env.state
next_state, reward = env.step(action)
next_value = np.max(q_values[next_state]) # greedy policy
q_values[state, action] = (1-alpha)*q_values[state, action] + alpha*(reward + gamma * next_value)
def optimal_policy(state):
return np.argmax(q_values[state])
q_values
all_totals = []
for episode in range(1000):
all_totals.append(run_episode(optimal_policy, n_steps=100, display=(episode<5)))
print("Summary: mean={:.1f}, std={:1f}, min={}, max={}".format(np.mean(all_totals), np.std(all_totals), np.min(all_totals), np.max(all_totals)))
print()
```
# Learning to play MsPacman using Deep Q-Learning
```
env = gym.make("MsPacman-v0")
obs = env.reset()
obs.shape
env.action_space
```
## Preprocessing
Preprocessing the images is optional but greatly speeds up training.
```
mspacman_color = np.array([210, 164, 74]).mean()
def preprocess_observation(obs):
img = obs[1:176:2, ::2] # crop and downsize
img = img.mean(axis=2) # to greyscale
img[img==mspacman_color] = 0 # Improve contrast
img = (img - 128) / 128 - 1 # normalize from -1. to 1.
return img.reshape(88, 80, 1)
img = preprocess_observation(obs)
plt.figure(figsize=(11, 7))
plt.subplot(121)
plt.title("Original observation (160×210 RGB)")
plt.imshow(obs)
plt.axis("off")
plt.subplot(122)
plt.title("Preprocessed observation (88×80 greyscale)")
plt.imshow(img.reshape(88, 80), interpolation="nearest", cmap="gray")
plt.axis("off")
save_fig("preprocessing_plot")
plt.show()
```
## Build DQN
```
tf.reset_default_graph()
from tensorflow.contrib.layers import convolution2d, fully_connected
input_height = 88
input_width = 80
input_channels = 1
conv_n_maps = [32, 64, 64]
conv_kernel_sizes = [(8,8), (4,4), (3,3)]
conv_strides = [4, 2, 1]
conv_paddings = ["SAME"]*3
conv_activation = [tf.nn.relu]*3
n_hidden_inputs = 64 * 11 * 10 # conv3 has 64 maps of 11x10 each
n_hidden = 512
hidden_activation = tf.nn.relu
n_outputs = env.action_space.n
initializer = tf.contrib.layers.variance_scaling_initializer()
learning_rate = 0.01
def q_network(X_state, scope):
prev_layer = X_state
conv_layers = []
with tf.variable_scope(scope) as scope:
for n_maps, kernel_size, stride, padding, activation in zip(conv_n_maps, conv_kernel_sizes, conv_strides, conv_paddings, conv_activation):
prev_layer = convolution2d(prev_layer, num_outputs=n_maps, kernel_size=kernel_size, stride=stride, padding=padding, activation_fn=activation, weights_initializer=initializer)
conv_layers.append(prev_layer)
last_conv_layer_flat = tf.reshape(prev_layer, shape=[-1, n_hidden_inputs])
hidden = fully_connected(last_conv_layer_flat, n_hidden, activation_fn=hidden_activation, weights_initializer=initializer)
outputs = fully_connected(hidden, n_outputs, activation_fn=None)
trainable_vars = {var.name[len(scope.name):]: var for var in tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope.name)}
return outputs, trainable_vars
X_state = tf.placeholder(tf.float32, shape=[None, input_height, input_width, input_channels])
actor_q_values, actor_vars = q_network(X_state, scope="q_networks/actor") # acts
critic_q_values, critic_vars = q_network(X_state, scope="q_networks/critic") # learns
copy_ops = [actor_var.assign(critic_vars[var_name])
for var_name, actor_var in actor_vars.items()]
copy_critic_to_actor = tf.group(*copy_ops)
with tf.variable_scope("train"):
X_action = tf.placeholder(tf.int32, shape=[None])
y = tf.placeholder(tf.float32, shape=[None, 1])
q_value = tf.reduce_sum(critic_q_values * tf.one_hot(X_action, n_outputs),
axis=1, keep_dims=True)
cost = tf.reduce_mean(tf.square(y - q_value))
global_step = tf.Variable(0, trainable=False, name='global_step')
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(cost, global_step=global_step)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
actor_vars
from collections import deque
replay_memory_size = 10000
replay_memory = deque([], maxlen=replay_memory_size)
def sample_memories(batch_size):
indices = rnd.permutation(len(replay_memory))[:batch_size]
cols = [[], [], [], [], []] # state, action, reward, next_state, continue
for idx in indices:
memory = replay_memory[idx]
for col, value in zip(cols, memory):
col.append(value)
cols = [np.array(col) for col in cols]
return cols[0], cols[1], cols[2].reshape(-1, 1), cols[3], cols[4].reshape(-1, 1)
eps_min = 0.05
eps_max = 1.0
eps_decay_steps = 50000
import sys
def epsilon_greedy(q_values, step):
epsilon = max(eps_min, eps_max - (eps_max-eps_min) * step/eps_decay_steps)
if rnd.rand() < epsilon:
return rnd.randint(n_outputs) # random action
else:
return np.argmax(q_values) # optimal action
n_steps = 100000 # total number of training steps
training_start = 1000 # start training after 1,000 game iterations
training_interval = 3 # run a training step every 3 game iterations
save_steps = 50 # save the model every 50 training steps
copy_steps = 25 # copy the critic to the actor every 25 training steps
discount_rate = 0.95
skip_start = 90 # Skip the start of every game (it's just waiting time).
batch_size = 50
iteration = 0 # game iterations
checkpoint_path = "./my_dqn.ckpt"
done = True # env needs to be reset
with tf.Session() as sess:
if os.path.isfile(checkpoint_path):
saver.restore(sess, checkpoint_path)
else:
init.run()
while True:
step = global_step.eval()
if step >= n_steps:
break
iteration += 1
print("\rIteration {}\tTraining step {}/{} ({:.1f}%)".format(iteration, step, n_steps, step * 100 / n_steps), end="")
if done: # game over, start again
obs = env.reset()
for skip in range(skip_start): # skip boring game iterations at the start of each game
obs, reward, done, info = env.step(0)
state = preprocess_observation(obs)
# Actor evaluates what to do
q_values = actor_q_values.eval(feed_dict={X_state: [state]})
action = epsilon_greedy(q_values, step)
# Actor plays
obs, reward, done, info = env.step(action)
next_state = preprocess_observation(obs)
# Let's memorize what happened
replay_memory.append((state, action, reward, next_state, 1.0 - done))
state = next_state
if iteration < training_start or iteration % training_interval != 0:
continue
# Critic learns
X_state_val, X_action_val, rewards, X_next_state_val, continues = sample_memories(batch_size)
next_q_values = actor_q_values.eval(feed_dict={X_state: X_next_state_val})
y_val = rewards + continues * discount_rate * np.max(next_q_values, axis=1, keepdims=True)
training_op.run(feed_dict={X_state: X_state_val, X_action: X_action_val, y: y_val})
# Regularly copy critic to actor
if step % copy_steps == 0:
copy_critic_to_actor.run()
# And save regularly
if step % save_steps == 0:
saver.save(sess, checkpoint_path)
```
# Exercise solutions
Coming soon...
| true |
code
| 0.701547 | null | null | null | null |
|
[](http://rpi.analyticsdojo.com)
<center><h1>Basic Text Feature Creation in Python</h1></center>
<center><h3><a href = 'http://rpi.analyticsdojo.com'>rpi.analyticsdojo.com</a></h3></center>
# Basic Text Feature Creation in Python
```
!wget https://raw.githubusercontent.com/rpi-techfundamentals/spring2019-materials/master/input/train.csv
!wget https://raw.githubusercontent.com/rpi-techfundamentals/spring2019-materials/master/input/test.csv
import numpy as np
import pandas as pd
import pandas as pd
train= pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
#Print to standard output, and see the results in the "log" section below after running your script
train.head()
#Print to standard output, and see the results in the "log" section below after running your script
train.describe()
train.dtypes
#Let's look at the age field. We can see "NaN" (which indicates missing values).s
train["Age"]
#Now let's recode.
medianAge=train["Age"].median()
print ("The Median age is:", medianAge, " years old.")
train["Age"] = train["Age"].fillna(medianAge)
#Option 2 all in one shot!
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Age"]
#For Recoding Data, we can use what we know of selecting rows and columns
train["Embarked"] = train["Embarked"].fillna("S")
train.loc[train["Embarked"] == "S", "EmbarkedRecode"] = 0
train.loc[train["Embarked"] == "C", "EmbarkedRecode"] = 1
train.loc[train["Embarked"] == "Q", "EmbarkedRecode"] = 2
# We can also use something called a lambda function
# You can read more about the lambda function here.
#http://www.python-course.eu/lambda.php
gender_fn = lambda x: 0 if x == 'male' else 1
train['Gender'] = train['Sex'].map(gender_fn)
#or we can do in one shot
train['NameLength'] = train['Name'].map(lambda x: len(x))
train['Age2'] = train['Age'].map(lambda x: x*x)
train
#We can start to create little small functions that will find a string.
def has_title(name):
for s in ['Mr.', 'Mrs.', 'Miss.', 'Dr.', 'Sir.']:
if name.find(s) >= 0:
return True
return False
#Now we are using that separate function in another function.
title_fn = lambda x: 1 if has_title(x) else 0
#Finally, we call the function for name
train['Title'] = train['Name'].map(title_fn)
test['Title']= train['Name'].map(title_fn)
test
#Writing to File
submission=pd.DataFrame(test.loc[:,['PassengerId','Survived']])
#Any files you save will be available in the output tab below
submission.to_csv('submission.csv', index=False)
```
| true |
code
| 0.38122 | null | null | null | null |
|
# Quick Start
**A tutorial on Renormalized Mutual Information**
We describe in detail the implementation of RMI estimation in the very simple case of a Gaussian distribution.
Of course, in this case the optimal feature is given by the Principal Component Analysis
```
import numpy as np
# parameters of the Gaussian distribution
mu = [0,0]
sigma = [[1, 0.5],[0.5,2]]
# extract the samples
N_samples = 100000
samples = np.random.multivariate_normal(mu, sigma, N_samples )
```
Visualize the distribution with a 2D histogram
```
import matplotlib.pyplot as plt
plt.figure()
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
plt.gca().set_aspect("equal")
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.title("$P_x(x)$")
plt.show()
```
## Estimate Renormalized Mutual Information of a feature
Now we would like to find a one-dimensional function $f(x_1,x_2)$ to describe this 2d distribution.
### Simplest feature
For example, we could consider ignoring one of the variables:
```
def f(x):
# feature
# shape [N_samples, N_features=1]
return x[:,0][...,None]
def grad_f(x):
# gradient
# shape [N_samples, N_features=1, N_x=2]
grad_f = np.zeros([len(x),1,2])
grad_f[...,0] = 1
return grad_f
def feat_and_grad(x):
return f(x), grad_f(x)
```
Let's plot it on top of the distribution
```
# Range of the plot
xmin = -4
xmax = 4
# Number of points in the grid
N = 100
# We evaluate the feature on a grid
x_linspace = np.linspace(xmin, xmax, N)
x1_grid, x2_grid = np.meshgrid(x_linspace, x_linspace, indexing='ij')
x_points = np.array([x1_grid.flatten(), x2_grid.flatten()]).T
feature = f(x_points)
gradient = grad_f(x_points)
plt.figure()
plt.title("Feature contours")
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.gca().set_aspect('equal')
# Draw the input distribution on the background
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
# Draw the contour lines of the extracted feature
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.contour(x1_grid, x2_grid, feature.reshape([N,N]),15,
linewidths=4, cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
```
$f(x)=x_1$ is clearly a linear function that ignores $x_2$ and increases in the $x_1$ direction
**How much information does it give us on $x$?**
If we used common mutual information, it would be $\infty$, because $f$ is a deterministic function, and $H(y|x) = -\log \delta(0)$.
Let's estimate the renormalized mutual information
```
import rmi.estimation as inf
samples = np.random.multivariate_normal(mu, sigma, N_samples )
feature = f(samples)
gradient = grad_f(samples)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
```
Please note that we perform the plot by calculating the feature on a uniform grid. But, to estimate RMI, the feature should be calculated on x **sampled** from the $x$ distribution.
In particular, we have
```
p_y, delta_y = inf.produce_P(feature)
entropy = inf.Entropy(p_y, delta_y)
fterm = inf.RegTerm(gradient)
print("Entropy\t %2.2f" % entropy)
print("Fterm\t %2.2f" % fterm)
print("Renormalized Mutual Information (x,f(x)): %2.2f" %
(entropy + fterm))
```
Renormalized Mutual Information is the sum of the two terms
- Entropy
- RegTerm
### Reparametrization invariance
Do we gain information if we increase the variance of the feature?
For example, let's rescale our feature. Clearly the information on $x$ should remain the same
```
scale_factor = 4
feature *= scale_factor
gradient *= scale_factor
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
p_y, delta_y = inf.produce_P(feature)
entropy = inf.Entropy(p_y, delta_y)
fterm = inf.RegTerm(gradient)
print("Entropy\t %2.2f" % entropy)
print("Fterm\t %2.2f" % fterm)
```
Let's try even a non-linear transformation. As long as it is invertible, we will get the same RMI
```
# For example
y_lin = np.linspace(-4,4,100)
f_lin = y_lin**3 + 5*y_lin
plt.figure()
plt.title("Reparametrization function")
plt.plot(y_lin, f_lin)
plt.show()
feature_new = feature**3 + 5*feature
gradient_new = 3*feature[...,None]**2*gradient +5*gradient# chain rule...
RMI = inf.RenormalizedMutualInformation(feature_new, gradient_new, 2000)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
p_y, delta_y = inf.produce_P(feature_new)
entropy = inf.Entropy(p_y, delta_y)
fterm = inf.RegTerm(gradient_new)
print("Entropy\t %2.2f" % entropy)
print("Fterm\t %2.2f" % fterm)
```
In this case, we have to increase the number of bins
to calculate the Entropy with reasonable accuracy.
The reason is that the feature now spans a quite larger range but changes very rapidly in the few bins around zero (but we use a uniform binning when estimating the entropy).
```
plt.hist(feature_new,1000)
plt.show()
```
And if we instead appliead a **non-invertible** transformation? The consequence is clear: we will **lose information**.
Consider for example:
```
feature_new = feature**2
gradient_new = 2*feature[...,None]*gradient # chain rule...
RMI_2 = inf.RenormalizedMutualInformation(feature_new, gradient_new, 2000)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI_2)
p_y, delta_y = inf.produce_P(feature_new)
entropy = inf.Entropy(p_y, delta_y)
fterm = inf.RegTerm(gradient_new)
print("Entropy\t %2.2f" % entropy)
print("Fterm\t %2.2f" % fterm)
plt.hist(feature_new,1000)
plt.show()
```
The careful observer will be able to guess how much information we have lost in this case:
our feature is centered in zero and we squared it. We lose the sign, and on average the half of the samples have one sign and the half the other sign. One bit of information is lost. The difference is $\log 2$!
```
deltaRMI = RMI - RMI_2
print("delta RMI %2.3f" %deltaRMI)
print("log 2 = %2.3f" % np.log(2))
```
### Another feature
Let's take another linear feature, for example, this time in the other direction
```
def f(x):
# feature
# shape [N_samples, N_features=1]
return x[:,1][...,None]
def grad_f(x):
# gradient
# shape [N_samples, N_features=1, N_x=2]
grad_f = np.zeros([len(x),1,2])
grad_f[...,1] = 1
return grad_f
def feat_and_grad(x):
return f(x), grad_f(x)
feature = f(x_points)
gradient = grad_f(x_points)
plt.figure()
plt.title("Feature contours")
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.gca().set_aspect('equal')
# Draw the input distribution on the background
samples = np.random.multivariate_normal(mu, sigma, N_samples )
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
# Draw the contour lines of the extracted feature
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.contour(x1_grid, x2_grid, feature.reshape([N,N]),15,
linewidths=4, cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
feature = f(samples)
gradient = grad_f(samples)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
```
This feature seems to better describe our input. This is reasonable: it lies closer to the direction of larger fluctuation of the distribution.
What is the best linear feature that we can take?
```
# Let's define a linear feature
def linear(x, th):
""" linear increasing in the direction given by angle th.
Args:
x (array_like): [N_samples, 2] array of samples
th (float): direction of the feature in which it increases
Returns:
feature (array_like): [N_samples, 1] feature
grad_feature (array_like): [N_samples, 1, N_x] gradient of the feature
"""
Feature = x[:, 0]*np.cos(th) + x[:, 1]*np.sin(th)
Grad1 = np.full(np.shape(x)[0], np.cos(th))
Grad2 = np.full(np.shape(x)[0], np.sin(th))
return Feature, np.array([Grad1, Grad2]).T
samples = np.random.multivariate_normal(mu, sigma, N_samples )
th_lin = np.linspace(0,np.pi, 30)
rmis = []
for th in th_lin:
feature, grad = linear(samples, th)
rmi = inf.RenormalizedMutualInformation(feature,grad)
rmis.append([th,rmi])
rmis = np.array(rmis)
plt.figure()
plt.title("Best linear feature")
plt.xlabel("$\theta$")
plt.ylabel(r"$RMI(x,f_\theta(x))$")
plt.plot(rmis[:,0], rmis[:,1])
plt.show()
best_theta = th_lin[np.argmax(rmis[:,1])]
```
Let's plot the feature with the parameter that gives the largest Renormalized Mutual Information
```
feature, gradient = linear(x_points,best_theta)
plt.figure()
plt.title("Feature contours")
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.gca().set_aspect('equal')
# Draw the input distribution on the background
samples = np.random.multivariate_normal(mu, sigma, N_samples )
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
# Draw the contour lines of the extracted feature
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.contour(x1_grid, x2_grid, feature.reshape([N,N]),15,
linewidths=4, cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
feature, gradient = linear(samples,best_theta)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
```
This is the same feature that we would get if we considered the first Principal Component of PCA. This is the only case in which this is possible: PCA can only extract linear features, and in particular, since it only takes into account the covariance matrix of the distribution, it can provide the best feature only for a Gaussian (which is identified by its mean and covariance matrix)
```
import rmi.pca
samples = np.random.multivariate_normal(mu, sigma, N_samples )
g_pca = rmi.pca.pca(samples,1)
eigenv = g_pca.w[0]
angle_pca = np.arctan(eigenv[1]/eigenv[0])
feature, gradient = linear(samples,angle_pca)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
print("best found angle %2.2f" %best_theta)
print("pca direction %2.2f" %angle_pca)
```
We recall that in this very special case, and as long as the proposed feature is only rotated (without changing the scale), the simple maximization of the Feature Entropy would have given the same result.
Again, this only holds for linear features, and in particular for those whose gradient vector is not affected by a change of parameters).
As soon as we use a non-linear feature, just looking at the entropy of the feature is not enough anymore - entropy is not reparametrization invariant.
Also, given an arbitrary deterministic feature function, RMI is the only quantity that allows to estimate it's dependence with its arguments
## Feature Optimization
Let's try now to optimize a neural network to extract a feature. In this case, as we already discussed, we will still get a linear feature
```
import rmi.neuralnets as nn
# Define the layout of the neural network
# The cost function is implicit when choosing the model RMIOptimizer
rmi_optimizer = nn.RMIOptimizer(
layers=[
nn.K.layers.Dense(30, activation="relu",input_shape=(2,)),
nn.K.layers.Dense(1)
])
# Compile the network === choose the optimizer to use during the training
rmi_optimizer.compile(optimizer=nn.tf.optimizers.Adam(1e-3))
# Print the table with the structure of the network
rmi_optimizer.summary()
# Define an objects that handles the training
rmi_net = nn.Net(rmi_optimizer)
# Perform the training of the neural network
batchsize = 1000
N_train = 5000
def get_batch():
return np.random.multivariate_normal(mu, sigma, batchsize)
rmi_net.fit_generator(get_batch, N_train)
# Plot the training history (value of RMI)
# The large fluctuations can be reduced by increasing the batchsize
rmi_net.plot_history()
```
Calculate the feature on the input points: just apply the object `rmi_net`!
```
feature = rmi_net(x_points)
plt.figure()
plt.title("Feature contours")
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.gca().set_aspect('equal')
# Draw the input distribution on the background
samples = np.random.multivariate_normal(mu, sigma, N_samples )
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
# Draw the contour lines of the extracted feature
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.contour(x1_grid, x2_grid, feature.reshape([N,N]),15,
linewidths=4, cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
```
To calculate also the gradient of the feature, one can use the function `get_feature_and_grad`
```
feature, gradient = rmi_net.get_feature_and_grad(samples)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
```
## Tradeoff between simplicity and compression
When optimizing renormalized mutual information to obtain a **meaningful feature** (in the sense of representation learning), one should avoid to employ too powerful networks.
A good feature should set a convenient tradeoff between its **"simplicity"** (i.e. number of parameters, or how "smooth" the feature is) and its **information content** (i.e. how much the input space is compressed in a smaller dimension).
In other words, useful representations should be "well-behaved", even at the price of reducing their renormalized mutual information. We can show this idea in a straight forward example
```
# Let's define a linear feature
def cheating_feature(x):
Feature = x[:, 0]*np.cos(best_theta) + x[:, 1]*np.sin(best_theta)
step_size = 3
step_width = 1/12
step_argument = x[:, 0]*np.cos(best_theta+np.pi/2) + x[:, 1]*np.sin(best_theta+np.pi/2)
Feature +=step_size*np.tanh(step_argument/step_width)
Grad1 = np.full(x.shape[0], np.cos(best_theta))
Grad2 = np.full(x.shape[0], np.sin(best_theta))
Grad1 += step_size/step_width*np.cos(best_theta+np.pi/2)/np.cosh(step_argument/step_width)**2
Grad2 += step_size/step_width*np.sin(best_theta+np.pi/2)/np.cosh(step_argument/step_width)**2
return Feature, np.array([Grad1, Grad2]).T
samples = np.random.multivariate_normal(mu, sigma, N_samples )
feature, gradient = cheating_feature(x_points)
plt.figure()
plt.title("Feature contours")
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.gca().set_aspect('equal')
# Draw the input distribution on the background
samples = np.random.multivariate_normal(mu, sigma, N_samples )
plt.hist2d(*samples.T, bins=100, cmap=plt.cm.binary)
# Draw the contour lines of the extracted feature
plt.xlim([-4,4])
plt.ylim([-4,4])
plt.contour(x1_grid, x2_grid, feature.reshape([N,N]),15,
linewidths=4, cmap=plt.cm.Blues)
plt.colorbar()
plt.show()
feature, gradient = cheating_feature(samples)
RMI = inf.RenormalizedMutualInformation(feature, gradient)
print("Renormalized Mutual Information (x,f(x)): %2.2f" % RMI)
p_y, delta_y = inf.produce_P(feature)
entropy = inf.Entropy(p_y, delta_y)
fterm = inf.RegTerm(gradient)
print("Entropy\t %2.2f" % entropy)
print("Fterm\t %2.2f" % fterm)
```
This feature has a larger mutual information than the linear one. It is still increasing in the direction of largest variance of $x$.
However, it contains a _jump_ in the orthogonal direction. This jump allows to encode a "bit" of additional information (about the orthogonal coordinate), allowing to unambiguously distinguish whether $x$ was extracted on the left or right side of the Gaussian.
In principle, one can add an arbitrary number of jumps until the missing coordinate can be identified with arbitrary precision. This feature would have an arbitrary high renormalized mutual information (as it should be, since it contains more information on $x$). However, such a non-smooth feature is definitely not useful for feature extraction!
One can avoid these extremely compressed representations by encouraging simpler features (like smooth, or a neural network with a limited number of layers for example).
```
# Histogram of the feature
# The continuous value of x encodes one coordinate,
# the two peaks of the distribution provide additional information
# on the second coordinate!
plt.hist(feature,1000)
plt.show()
```
## Conclusions
This technique can be applied to
- estimate the information that a deterministic feature $f(x)$ carries about a (higher-dimensional) $x$
- in other words, to estimate how useful is a given "macroscopic" quantity to describe a system?
- extract non-linear representations in an unsupervised way, by optimizinng Renormalized Mutual Information.
For more examples:
- see the notebooks with the spiral-shaped distribution for an example with a non-Gaussian input distribution
- see the Wave Packet and Liquid Drop notebooks for proof-of-concept applications in physics (or in general for higher-dimensional input spaces and extraction of a two-dimensional feature)
At the moment, only one-dimensional or two-dimensional features can be extracted with the neural network class. This is due to the implementation of the Entropy estimation, which currently is based on a histogram - which is not efficient in larger dimensions. An alternative (differentiable) way to estimate the Entropy will allow to extend this technique to also extract features with more than 2 dimensions.
| true |
code
| 0.73811 | null | null | null | null |
|
# Boltzmann Machines
Notebook ini berdasarkan kursus __Deep Learning A-Z™: Hands-On Artificial Neural Networks__ di Udemy. [Lihat Kursus](https://www.udemy.com/deeplearning/).
## Informasi Notebook
- __notebook name__: `taruma_udemy_boltzmann`
- __notebook version/date__: `1.0.0`/`20190730`
- __notebook server__: Google Colab
- __python version__: `3.6`
- __pytorch version__: `1.1.0`
```
#### NOTEBOOK DESCRIPTION
from datetime import datetime
NOTEBOOK_TITLE = 'taruma_udemy_boltzmann'
NOTEBOOK_VERSION = '1.0.0'
NOTEBOOK_DATE = 1 # Set 1, if you want add date classifier
NOTEBOOK_NAME = "{}_{}".format(
NOTEBOOK_TITLE,
NOTEBOOK_VERSION.replace('.','_')
)
PROJECT_NAME = "{}_{}{}".format(
NOTEBOOK_TITLE,
NOTEBOOK_VERSION.replace('.','_'),
"_" + datetime.utcnow().strftime("%Y%m%d_%H%M") if NOTEBOOK_DATE else ""
)
print(f"Nama Notebook: {NOTEBOOK_NAME}")
print(f"Nama Proyek: {PROJECT_NAME}")
#### System Version
import sys, torch
print("versi python: {}".format(sys.version))
print("versi pytorch: {}".format(torch.__version__))
#### Load Notebook Extensions
%load_ext google.colab.data_table
#### Download dataset
# ref: https://grouplens.org/datasets/movielens/
!wget -O boltzmann.zip "https://sds-platform-private.s3-us-east-2.amazonaws.com/uploads/P16-Boltzmann-Machines.zip"
!unzip boltzmann.zip
#### Atur dataset path
DATASET_DIRECTORY = 'Boltzmann_Machines/'
def showdata(dataframe):
print('Dataframe Size: {}'.format(dataframe.shape))
return dataframe
```
# STEP 1-5 DATA PREPROCESSING
```
# Importing the libraries
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
movies = pd.read_csv(DATASET_DIRECTORY + 'ml-1m/movies.dat', sep='::', header=None, engine='python', encoding='latin-1')
showdata(movies).head(10)
users = pd.read_csv(DATASET_DIRECTORY + 'ml-1m/users.dat', sep='::', header=None, engine='python', encoding='latin-1')
showdata(users).head(10)
ratings = pd.read_csv(DATASET_DIRECTORY + 'ml-1m/ratings.dat', sep='::', header=None, engine='python', encoding='latin-1')
showdata(ratings).head(10)
# Preparing the training set and the test set
training_set = pd.read_csv(DATASET_DIRECTORY + 'ml-100k/u1.base', delimiter='\t')
training_set = np.array(training_set, dtype='int')
test_set = pd.read_csv(DATASET_DIRECTORY + 'ml-100k/u1.test', delimiter='\t')
test_set = np.array(test_set, dtype='int')
# Getting the number of users and movies
nb_users = int(max(max(training_set[:, 0]), max(test_set[:, 0])))
nb_movies = int(max(max(training_set[:, 1]), max(test_set[:, 1])))
# Converting the data into an array with users in lines and movies in columns
def convert(data):
new_data = []
for id_users in range(1, nb_users+1):
id_movies = data[:, 1][data[:, 0] == id_users]
id_ratings = data[:, 2][data[:, 0] == id_users]
ratings = np.zeros(nb_movies)
ratings[id_movies - 1] = id_ratings
new_data.append(list(ratings))
return new_data
training_set = convert(training_set)
test_set = convert(test_set)
# Converting the data into Torch tensors
training_set = torch.FloatTensor(training_set)
test_set = torch.FloatTensor(test_set)
training_set.
```
# STEP 6
```
# Converting the ratings into binary ratings 1 (Liked) or 0 (Not Liked)
training_set[training_set == 0] = -1
training_set[training_set == 1] = 0
training_set[training_set == 2] = 0
training_set[training_set >= 3] = 1
test_set[test_set == 0] = -1
test_set[test_set == 1] = 0
test_set[test_set == 2] = 0
test_set[test_set >= 3] = 1
training_set
```
# STEP 7 - 10 Building RBM Object
```
# Creating the architecture of the Neural Network
# nv = number visible nodes, nh = number hidden nodes
class RBM():
def __init__(self, nv, nh):
self.W = torch.randn(nh, nv)
self.a = torch.randn(1, nh)
self.b = torch.randn(1, nv)
def sample_h(self, x):
wx = torch.mm(x, self.W.t())
activation = wx + self.a.expand_as(wx)
p_h_given_v = torch.sigmoid(activation)
return p_h_given_v, torch.bernoulli(p_h_given_v)
def sample_v(self, y):
wy = torch.mm(y, self.W)
activation = wy + self.b.expand_as(wy)
p_v_given_h = torch.sigmoid(activation)
return p_v_given_h, torch.bernoulli(p_v_given_h)
def train(self, v0, vk, ph0, phk):
self.W += (torch.mm(v0.t(), ph0) - torch.mm(vk.t(), phk)).t()
self.b += torch.sum((v0 - vk), 0)
self.a += torch.sum((ph0 - phk), 0)
```
# STEP 11
```
nv = len(training_set[0])
nh = 100
batch_size = 100
rbm = RBM(nv, nh)
```
# STEP 12-13
```
# Training the RBM
nb_epochs = 10
for epoch in range(1, nb_epochs + 1):
train_loss = 0
s = 0.
for id_user in range(0, nb_users - batch_size, batch_size):
vk = training_set[id_user:id_user+batch_size]
v0 = training_set[id_user:id_user+batch_size]
ph0,_ = rbm.sample_h(v0)
for k in range(10):
_,hk = rbm.sample_h(vk)
_,vk = rbm.sample_v(hk)
vk[v0<0] = v0[v0<0]
phk,_ = rbm.sample_h(vk)
rbm.train(v0, vk, ph0, phk)
train_loss += torch.mean(torch.abs(v0[v0>=0] - vk[v0>=0]))
s += 1.
print('epoch: '+str(epoch)+' loss: '+str(train_loss/s))
```
# STEP 14
```
# Testing the RBM
test_loss = 0
s = 0.
for id_user in range(nb_users):
v = training_set[id_user:id_user+1]
vt = test_set[id_user:id_user+1]
if len(vt[vt>=0]) > 0:
_,h = rbm.sample_h(v)
_,v = rbm.sample_v(h)
test_loss += torch.mean(torch.abs(vt[vt>=0] - v[vt>=0]))
s += 1.
print('test loss: '+str(test_loss/s))
```
| true |
code
| 0.540985 | null | null | null | null |
|
As a demonstration, create an ARMA22 model drawing innovations from there different distributions, a bernoulli, normal and inverse normal. Then build a keras/tensorflow model for the 1-d scattering transform to create "features", use these features to classify which model for the innovations was used.
```
from blusky.blusky_models import build_model_1d
import matplotlib.pylab as plt
import numpy as np
from scipy.stats import bernoulli, norm, norminvgauss
def arma22(N, alpha, beta, rnd, eps=0.5):
inov = rnd.rvs(2*N)
x = np.zeros(2*N)
# arma22 mode
for i in range(2,N*2):
x[i] = (alpha[0] * x[i-1] + alpha[1]*x[i-2] +
beta[0] * inov[i-1] + beta[1] * inov[i-2] + eps * inov[i])
return x[N:]
N = 512
k = 10
alpha = [0.99, -0.1]
beta = [0.2, 0.0]
eps = 1
series = np.zeros((24*k, N))
y = np.zeros(24*k)
for i in range(8*k):
series[i, :] = arma22(N, alpha, beta, norm(1.0), eps=eps)
y[i] = 0
for i in range(8*k, 16*k):
series[i, :] = arma22(N, alpha, beta, norminvgauss(1,0.5), eps=eps)
y[i] = 1
for i in range(16*k, 24*k):
series[i, :] = arma22(N, alpha, beta, bernoulli(0.5), eps=eps)*2
y[i] = 2
plt.plot(series[3*k,:200], '-r')
plt.plot(series[8*k,:200])
plt.plot(series[-3*k,:200])
plt.legend(['normal', 'inverse normal', 'bernoulli'])
#Hold out data:
k = 8
hodl_series = np.zeros((24*k, N))
hodl_y = np.zeros(24*k)
for i in range(8*k):
hodl_series[i, :] = arma22(N, alpha, beta, norm(1.0), eps=eps)
hodl_y[i] = 0
for i in range(8*k, 16*k):
hodl_series[i, :] = arma22(N, alpha, beta, norminvgauss(1,0.5), eps=eps)
hodl_y[i] = 1
for i in range(16*k, 24*k):
hodl_series[i, :] = arma22(N, alpha, beta, bernoulli(0.5), eps=eps)*2
hodl_y[i] = 2
# hold out data
plt.plot(hodl_series[0,:200], '-r')
plt.plot(hodl_series[8*k,:200])
plt.plot(hodl_series[16*k,:200])
plt.legend(['normal', 'inverse normal', 'bernoulli'])
```
The scattering transform reduces the timeseries to a set of features, which we use for classification. The seperation between the series is more obvious looking at the log- of the features (see below). A support vector machine has an easy time classifying these processes.
```
base_model = build_model_1d(N, 7,6, concatenate=True)
result = base_model.predict(hodl_series)
plt.semilogy(np.mean(result[:,0,:], axis=0), '-r')
plt.semilogy(np.mean(result[8*k:16*k,0,:], axis=0), '-b')
plt.semilogy(np.mean(result[16*k:,0,:], axis=0), '-g')
from sklearn.svm import SVC
from sklearn.metrics import classification_report
model = build_model_1d(N, 7, 6, concatenate=True)
result = np.log(model.predict(series))
X = result[:,0,:]
rdf = SVC()
rdf.fit(X,y)
hodl_result = np.log(model.predict(hodl_series))
hodl_X = hodl_result[:,0,:]
y_pred = rdf.predict(hodl_X)
cls1 = classification_report(hodl_y, y_pred)
print(cls1)
```
Blusky build_model_1d creates a regular old keras model, which you can use like another, think VGG16 etc. The order (order < J) defines the depth of the network. If you want a deeper network, increase this parameter. Here we attach a set of fully connected layers to classify like we did previously with the SVM.
Dropping in a batch normalization here, seeems to be important for regularizong the problem.
```
from tensorflow.keras import Input, Model
import tensorflow.keras.backend as K
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.layers import BatchNormalization, Dense, Flatten, Lambda
from tensorflow.keras.utils import to_categorical
early_stopping = EarlyStopping(monitor="val_loss", patience=50, verbose=True,
restore_best_weights=True)
J = 7
order = 6
base_model = build_model_1d(N, J, order, concatenate=True)
dnn = Flatten()(base_model.output)
# let's add the "log" here like we did above
dnn = Lambda(lambda x : K.log(x))(dnn)
dnn = BatchNormalization()(dnn)
dnn = Dense(32, activation='linear', name='dnn1')(dnn)
dnn = Dense(3, activation='softmax', name='softmax')(dnn)
deep_model_1 = Model(inputs=base_model.input, outputs=dnn)
deep_model_1.compile(optimizer='rmsprop', loss='categorical_crossentropy')
history_1 = deep_model_1.fit(series, to_categorical(y),
validation_data=(hodl_series, to_categorical(hodl_y)),
callbacks=[early_stopping],
epochs=200)
y_pred = deep_model_1.predict(hodl_series)
cls_2 = classification_report(hodl_y, np.argmax(y_pred, axis=1))
base_model.output
plt.plot(history_1.history['loss'][-100:])
plt.plot(history_1.history['val_loss'][-100:])
print(cls_2)
```
| true |
code
| 0.705493 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/DingLi23/s2search/blob/pipelining/pipelining/pdp-exp1/pdp-exp1_cslg-rand-5000_plotting.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
### Experiment Description
Produce PDP for a randomly picked data from cslg.
> This notebook is for experiment \<pdp-exp1\> and data sample \<cslg-rand-5000\>.
### Initialization
```
%load_ext autoreload
%autoreload 2
import numpy as np, sys, os
in_colab = 'google.colab' in sys.modules
# fetching code and data(if you are using colab
if in_colab:
!rm -rf s2search
!git clone --branch pipelining https://github.com/youyinnn/s2search.git
sys.path.insert(1, './s2search')
%cd s2search/pipelining/pdp-exp1/
pic_dir = os.path.join('.', 'plot')
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
```
### Loading data
```
sys.path.insert(1, '../../')
import numpy as np, sys, os, pandas as pd
from s2search_score_pdp import pdp_based_importance, apply_order
sample_name = 'cslg-rand-5000'
f_list = ['title', 'abstract', 'venue', 'authors', 'year', 'n_citations']
pdp_xy = {}
pdp_metric = pd.DataFrame(columns=['feature_name', 'pdp_range', 'pdp_importance'])
for f in f_list:
file = os.path.join('.', 'scores', f'{sample_name}_pdp_{f}.npz')
if os.path.exists(file):
data = np.load(file)
sorted_pdp_data = apply_order(data)
feature_pdp_data = [np.mean(pdps) for pdps in sorted_pdp_data]
pdp_xy[f] = {
'y': feature_pdp_data,
'numerical': True
}
if f == 'year' or f == 'n_citations':
pdp_xy[f]['x'] = np.sort(data['arr_1'])
else:
pdp_xy[f]['y'] = feature_pdp_data
pdp_xy[f]['x'] = list(range(len(feature_pdp_data)))
pdp_xy[f]['numerical'] = False
pdp_metric.loc[len(pdp_metric.index)] = [f, np.max(feature_pdp_data) - np.min(feature_pdp_data), pdp_based_importance(feature_pdp_data, f)]
pdp_xy[f]['weird'] = feature_pdp_data[len(feature_pdp_data) - 1] > 30
print(pdp_metric.sort_values(by=['pdp_importance'], ascending=False))
```
### PDP
```
import matplotlib.pyplot as plt
categorical_plot_conf = [
{
'xlabel': 'Title',
'ylabel': 'Scores',
'pdp_xy': pdp_xy['title']
},
{
'xlabel': 'Abstract',
'pdp_xy': pdp_xy['abstract']
},
{
'xlabel': 'Authors',
'pdp_xy': pdp_xy['authors']
},
{
'xlabel': 'Venue',
'pdp_xy': pdp_xy['venue'],
'zoom': {
'inset_axes': [0.15, 0.45, 0.47, 0.47],
'x_limit': [4900, 5050],
'y_limit': [-9, 7],
'connects': [True, True, False, False]
}
},
]
numerical_plot_conf = [
{
'xlabel': 'Year',
'ylabel': 'Scores',
'pdp_xy': pdp_xy['year']
},
{
'xlabel': 'Citation Count',
'pdp_xy': pdp_xy['n_citations'],
'zoom': {
'inset_axes': [0.4, 0.2, 0.47, 0.47],
'x_limit': [-100, 500],
'y_limit': [-7.5, -6.2],
'connects': [True, False, False, True]
}
}
]
def pdp_plot(confs, title):
fig, axes = plt.subplots(nrows=1, ncols=len(confs), figsize=(20, 5), dpi=100)
subplot_idx = 0
# plt.suptitle(title, fontsize=20, fontweight='bold')
# plt.autoscale(False)
for conf in confs:
axess = axes if len(confs) == 1 else axes[subplot_idx]
axess.plot(conf['pdp_xy']['x'], conf['pdp_xy']['y'])
axess.grid(alpha = 0.4)
if ('ylabel' in conf):
axess.set_ylabel(conf.get('ylabel'), fontsize=20, labelpad=10)
axess.set_xlabel(conf['xlabel'], fontsize=16, labelpad=10)
if not (conf['pdp_xy']['weird']):
if (conf['pdp_xy']['numerical']):
axess.set_ylim([-9, -6])
pass
else:
axess.set_ylim([-15, 10])
pass
if 'zoom' in conf:
axins = axess.inset_axes(conf['zoom']['inset_axes'])
axins.plot(conf['pdp_xy']['x'], conf['pdp_xy']['y'])
axins.set_xlim(conf['zoom']['x_limit'])
axins.set_ylim(conf['zoom']['y_limit'])
axins.grid(alpha=0.3)
rectpatch, connects = axess.indicate_inset_zoom(axins)
connects[0].set_visible(conf['zoom']['connects'][0])
connects[1].set_visible(conf['zoom']['connects'][1])
connects[2].set_visible(conf['zoom']['connects'][2])
connects[3].set_visible(conf['zoom']['connects'][3])
subplot_idx += 1
pdp_plot(categorical_plot_conf, "PDPs for four categorical features")
plt.savefig(os.path.join('.', 'plot', f'{sample_name}-categorical.png'), facecolor='white', transparent=False, bbox_inches='tight')
# second fig
pdp_plot(numerical_plot_conf, "PDPs for two numerical features")
plt.savefig(os.path.join('.', 'plot', f'{sample_name}-numerical.png'), facecolor='white', transparent=False, bbox_inches='tight')
```
| true |
code
| 0.487307 | null | null | null | null |
|
# Alzhippo Pr0gress
##### Possible Tasks
- **Visualizing fibers** passing through ERC and hippo, for both ipsi and contra cxns (4-figs) (GK)
- **Dilate hippocampal parcellations**, to cover entire hippocampus by nearest neighbour (JV)
- **Voxelwise ERC-to-hippocampal** projections + clustering (Both)
## Visulaizating fibers
1. Plot group average connectome
2. Find representative subject X (i.e. passes visual inspection match to the group)
3. Visualize fibers with parcellation
4. Repeat 3. on dilated parcellation
5. If connections appear more symmetric in 4., regenerate graphs with dilated parcellation
### 1. Plot group average connectome
```
import numpy as np
import networkx as nx
import nibabel as nib
import scipy.stats as stats
import matplotlib.pyplot as plt
from nilearn import plotting
import os
import seaborn as sns
import pandas
%matplotlib notebook
def matrixplotter(data, log=True, title="Connectivity between ERC and Hippocampus"):
plotdat = np.log(data + 1) if log else data
plt.imshow(plotdat)
labs = ['ERC-L', 'Hippo-L-noise', 'Hippo-L-tau',
'ERC-R', 'Hippo-R-noise', 'Hippo-R-tau']
plt.xticks(np.arange(0, 6), labs, rotation=40)
plt.yticks(np.arange(0, 6), labs)
plt.title(title)
plt.colorbar()
plt.show()
avg = np.load('../data/connection_matrix.npy')
matrixplotter(np.mean(avg, axis=2))
```
### 2. Find representative subject
```
tmp = np.reshape(avg.T, (355, 36))
tmp[0]
corrs = np.corrcoef(tmp)[-1]
corrs[corrs == 1] = 0
bestfit = int(np.where(corrs == np.max(corrs))[0])
print("Most similar graph: {}".format(bestfit))
dsets = ['../data/graphs/BNU1/combined_erc_hippo_labels/',
'../data/graphs/BNU3/',
'../data/graphs/HNU1/']
files = [os.path.join(d,f) for d in dsets for f in os.listdir(d)]
graph_fname = files[bestfit]
gx = nx.read_weighted_edgelist(graph_fname)
adjx = np.asarray(nx.adjacency_matrix(gx).todense())
matrixplotter(adjx)
print(graph_fname)
```
**N.B.**: The fibers from the subject/session shown above were SCP'd from the following location on Compute Canada's Cedar machine by @gkiar. They are too large for a git repository, but they were downloaded to the `data/fibers/` directory from the root of this project. Please @gkiar him if you'd like access to this file, in lieu of better public storage:
> /project/6008063/gkiar/ndmg/connectomics/ndmg-d/HNU1/fibers/sub-0025444_ses-2_dwi_fibers.npz
### 3. Visualize fibers with parcellation
Because I don't have VTK/Dipy locally, this was done in Docker with the script in `./code/npz2trackviz.py` and submitted to the scheduler with `./code/npzdriver.sh`.
The command to run this in Docker, from the base directory of this project was:
docker run -ti \
-v /Users/greg/code/gkiar/alzhippo/data/:/data \
-v /Users/greg/code/gkiar/alzhippo/code/:/proj \
--entrypoint python2.7 \
bids/ndmg:v0.1.0 \
/proj/npz2trackviz.py /data/fibers/sub-0025444_ses-2_dwi_fibers.npz /data/combined_erc_hippo_labels.nii.gz
The resulting `.trk` files were viewed locally with [TrackVis](http://www.trackvis.org/) to make the screenshot below.
| true |
code
| 0.524273 | null | null | null | null |
|
<h1><center>How to export 🤗 Transformers Models to ONNX ?<h1><center>
[ONNX](http://onnx.ai/) is open format for machine learning models. It allows to save your neural network's computation graph in a framework agnostic way, which might be particulary helpful when deploying deep learning models.
Indeed, businesses might have other requirements _(languages, hardware, ...)_ for which the training framework might not be the best suited in inference scenarios. In that context, having a representation of the actual computation graph that can be shared accross various business units and logics across an organization might be a desirable component.
Along with the serialization format, ONNX also provides a runtime library which allows efficient and hardware specific execution of the ONNX graph. This is done through the [onnxruntime](https://microsoft.github.io/onnxruntime/) project and already includes collaborations with many hardware vendors to seamlessly deploy models on various platforms.
Through this notebook we'll walk you through the process to convert a PyTorch or TensorFlow transformers model to the [ONNX](http://onnx.ai/) and leverage [onnxruntime](https://microsoft.github.io/onnxruntime/) to run inference tasks on models from 🤗 __transformers__
## Exporting 🤗 transformers model to ONNX
---
Exporting models _(either PyTorch or TensorFlow)_ is easily achieved through the conversion tool provided as part of 🤗 __transformers__ repository.
Under the hood the process is sensibly the following:
1. Allocate the model from transformers (**PyTorch or TensorFlow**)
2. Forward dummy inputs through the model this way **ONNX** can record the set of operations executed
3. Optionally define dynamic axes on input and output tensors
4. Save the graph along with the network parameters
```
import sys
!{sys.executable} -m pip install --upgrade git+https://github.com/huggingface/transformers
!{sys.executable} -m pip install --upgrade torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
!{sys.executable} -m pip install --upgrade onnxruntime==1.4.0
!{sys.executable} -m pip install -i https://test.pypi.org/simple/ ort-nightly
!{sys.executable} -m pip install --upgrade onnxruntime-tools
!rm -rf onnx/
from pathlib import Path
from transformers.convert_graph_to_onnx import convert
# Handles all the above steps for you
convert(framework="pt", model="bert-base-cased", output=Path("onnx/bert-base-cased.onnx"), opset=11)
# Tensorflow
# convert(framework="tf", model="bert-base-cased", output="onnx/bert-base-cased.onnx", opset=11)
```
## How to leverage runtime for inference over an ONNX graph
---
As mentionned in the introduction, **ONNX** is a serialization format and many side projects can load the saved graph and run the actual computations from it. Here, we'll focus on the official [onnxruntime](https://microsoft.github.io/onnxruntime/). The runtime is implemented in C++ for performance reasons and provides API/Bindings for C++, C, C#, Java and Python.
In the case of this notebook, we will use the Python API to highlight how to load a serialized **ONNX** graph and run inference workload on various backends through **onnxruntime**.
**onnxruntime** is available on pypi:
- onnxruntime: ONNX + MLAS (Microsoft Linear Algebra Subprograms)
- onnxruntime-gpu: ONNX + MLAS + CUDA
```
!pip install transformers onnxruntime-gpu onnx psutil matplotlib
```
## Preparing for an Inference Session
---
Inference is done using a specific backend definition which turns on hardware specific optimizations of the graph.
Optimizations are basically of three kinds:
- **Constant Folding**: Convert static variables to constants in the graph
- **Deadcode Elimination**: Remove nodes never accessed in the graph
- **Operator Fusing**: Merge multiple instruction into one (Linear -> ReLU can be fused to be LinearReLU)
ONNX Runtime automatically applies most optimizations by setting specific `SessionOptions`.
Note:Some of the latest optimizations that are not yet integrated into ONNX Runtime are available in [optimization script](https://github.com/microsoft/onnxruntime/tree/master/onnxruntime/python/tools/transformers) that tunes models for the best performance.
```
# # An optional step unless
# # you want to get a model with mixed precision for perf accelartion on newer GPU
# # or you are working with Tensorflow(tf.keras) models or pytorch models other than bert
# !pip install onnxruntime-tools
# from onnxruntime_tools import optimizer
# # Mixed precision conversion for bert-base-cased model converted from Pytorch
# optimized_model = optimizer.optimize_model("bert-base-cased.onnx", model_type='bert', num_heads=12, hidden_size=768)
# optimized_model.convert_model_float32_to_float16()
# optimized_model.save_model_to_file("bert-base-cased.onnx")
# # optimizations for bert-base-cased model converted from Tensorflow(tf.keras)
# optimized_model = optimizer.optimize_model("bert-base-cased.onnx", model_type='bert_keras', num_heads=12, hidden_size=768)
# optimized_model.save_model_to_file("bert-base-cased.onnx")
# optimize transformer-based models with onnxruntime-tools
from onnxruntime_tools import optimizer
from onnxruntime_tools.transformers.onnx_model_bert import BertOptimizationOptions
# disable embedding layer norm optimization for better model size reduction
opt_options = BertOptimizationOptions('bert')
opt_options.enable_embed_layer_norm = False
opt_model = optimizer.optimize_model(
'onnx/bert-base-cased.onnx',
'bert',
num_heads=12,
hidden_size=768,
optimization_options=opt_options)
opt_model.save_model_to_file('bert.opt.onnx')
from os import environ
from psutil import cpu_count
# Constants from the performance optimization available in onnxruntime
# It needs to be done before importing onnxruntime
environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))
environ["OMP_WAIT_POLICY"] = 'ACTIVE'
from onnxruntime import GraphOptimizationLevel, InferenceSession, SessionOptions, get_all_providers
from contextlib import contextmanager
from dataclasses import dataclass
from time import time
from tqdm import trange
def create_model_for_provider(model_path: str, provider: str) -> InferenceSession:
assert provider in get_all_providers(), f"provider {provider} not found, {get_all_providers()}"
# Few properties that might have an impact on performances (provided by MS)
options = SessionOptions()
options.intra_op_num_threads = 1
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
# Load the model as a graph and prepare the CPU backend
session = InferenceSession(model_path, options, providers=[provider])
session.disable_fallback()
return session
@contextmanager
def track_infer_time(buffer: [int]):
start = time()
yield
end = time()
buffer.append(end - start)
@dataclass
class OnnxInferenceResult:
model_inference_time: [int]
optimized_model_path: str
```
## Forwarding through our optimized ONNX model running on CPU
---
When the model is loaded for inference over a specific provider, for instance **CPUExecutionProvider** as above, an optimized graph can be saved. This graph will might include various optimizations, and you might be able to see some **higher-level** operations in the graph _(through [Netron](https://github.com/lutzroeder/Netron) for instance)_ such as:
- **EmbedLayerNormalization**
- **Attention**
- **FastGeLU**
These operations are an example of the kind of optimization **onnxruntime** is doing, for instance here gathering multiple operations into bigger one _(Operator Fusing)_.
```
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("bert-base-cased")
cpu_model = create_model_for_provider("onnx/bert-base-cased.onnx", "CPUExecutionProvider")
# Inputs are provided through numpy array
model_inputs = tokenizer("My name is Bert", return_tensors="pt")
inputs_onnx = {k: v.cpu().detach().numpy() for k, v in model_inputs.items()}
# Run the model (None = get all the outputs)
sequence, pooled = cpu_model.run(None, inputs_onnx)
# Print information about outputs
print(f"Sequence output: {sequence.shape}, Pooled output: {pooled.shape}")
```
# Benchmarking PyTorch model
_Note: PyTorch model benchmark is run on CPU_
```
from transformers import BertModel
PROVIDERS = {
("cpu", "PyTorch CPU"),
# Uncomment this line to enable GPU benchmarking
# ("cuda:0", "PyTorch GPU")
}
results = {}
for device, label in PROVIDERS:
# Move inputs to the correct device
model_inputs_on_device = {
arg_name: tensor.to(device)
for arg_name, tensor in model_inputs.items()
}
# Add PyTorch to the providers
model_pt = BertModel.from_pretrained("bert-base-cased").to(device)
for _ in trange(10, desc="Warming up"):
model_pt(**model_inputs_on_device)
# Compute
time_buffer = []
for _ in trange(100, desc=f"Tracking inference time on PyTorch"):
with track_infer_time(time_buffer):
model_pt(**model_inputs_on_device)
# Store the result
results[label] = OnnxInferenceResult(
time_buffer,
None
)
```
## Benchmarking PyTorch & ONNX on CPU
_**Disclamer: results may vary from the actual hardware used to run the model**_
```
PROVIDERS = {
("CPUExecutionProvider", "ONNX CPU"),
# Uncomment this line to enable GPU benchmarking
# ("CUDAExecutionProvider", "ONNX GPU")
}
for provider, label in PROVIDERS:
# Create the model with the specified provider
model = create_model_for_provider("onnx/bert-base-cased.onnx", provider)
# Keep track of the inference time
time_buffer = []
# Warm up the model
model.run(None, inputs_onnx)
# Compute
for _ in trange(100, desc=f"Tracking inference time on {provider}"):
with track_infer_time(time_buffer):
model.run(None, inputs_onnx)
# Store the result
results[label] = OnnxInferenceResult(
time_buffer,
model.get_session_options().optimized_model_filepath
)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import os
# Compute average inference time + std
time_results = {k: np.mean(v.model_inference_time) * 1e3 for k, v in results.items()}
time_results_std = np.std([v.model_inference_time for v in results.values()]) * 1000
plt.rcdefaults()
fig, ax = plt.subplots(figsize=(16, 12))
ax.set_ylabel("Avg Inference time (ms)")
ax.set_title("Average inference time (ms) for each provider")
ax.bar(time_results.keys(), time_results.values(), yerr=time_results_std)
plt.show()
```
# Quantization support from transformers
Quantization enables the use of integers (_instead of floatting point_) arithmetic to run neural networks models faster. From a high-level point of view, quantization works as mapping the float32 ranges of values as int8 with the less loss in the performances of the model.
Hugging Face provides a conversion tool as part of the transformers repository to easily export quantized models to ONNX Runtime. For more information, please refer to the following:
- [Hugging Face Documentation on ONNX Runtime quantization supports](https://huggingface.co/transformers/master/serialization.html#quantization)
- [Intel's Explanation of Quantization](https://nervanasystems.github.io/distiller/quantization.html)
With this method, the accuracy of the model remains at the same level than the full-precision model. If you want to see benchmarks on model performances, we recommand reading the [ONNX Runtime notebook](https://github.com/microsoft/onnxruntime/blob/master/onnxruntime/python/tools/quantization/notebooks/Bert-GLUE_OnnxRuntime_quantization.ipynb) on the subject.
# Benchmarking PyTorch quantized model
```
import torch
# Quantize
model_pt_quantized = torch.quantization.quantize_dynamic(
model_pt.to("cpu"), {torch.nn.Linear}, dtype=torch.qint8
)
# Warm up
model_pt_quantized(**model_inputs)
# Benchmark PyTorch quantized model
time_buffer = []
for _ in trange(100):
with track_infer_time(time_buffer):
model_pt_quantized(**model_inputs)
results["PyTorch CPU Quantized"] = OnnxInferenceResult(
time_buffer,
None
)
```
# Benchmarking ONNX quantized model
```
from transformers.convert_graph_to_onnx import quantize
# Transformers allow you to easily convert float32 model to quantized int8 with ONNX Runtime
quantized_model_path = quantize(Path("bert.opt.onnx"))
# Then you just have to load through ONNX runtime as you would normally do
quantized_model = create_model_for_provider(quantized_model_path.as_posix(), "CPUExecutionProvider")
# Warm up the overall model to have a fair comparaison
outputs = quantized_model.run(None, inputs_onnx)
# Evaluate performances
time_buffer = []
for _ in trange(100, desc=f"Tracking inference time on CPUExecutionProvider with quantized model"):
with track_infer_time(time_buffer):
outputs = quantized_model.run(None, inputs_onnx)
# Store the result
results["ONNX CPU Quantized"] = OnnxInferenceResult(
time_buffer,
quantized_model_path
)
```
## Show the inference performance of each providers
```
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import os
# Compute average inference time + std
time_results = {k: np.mean(v.model_inference_time) * 1e3 for k, v in results.items()}
time_results_std = np.std([v.model_inference_time for v in results.values()]) * 1000
plt.rcdefaults()
fig, ax = plt.subplots(figsize=(16, 12))
ax.set_ylabel("Avg Inference time (ms)")
ax.set_title("Average inference time (ms) for each provider")
ax.bar(time_results.keys(), time_results.values(), yerr=time_results_std)
plt.show()
```
| true |
code
| 0.651604 | null | null | null | null |
|
# Example 1: Detecting an obvious outlier
```
import numpy as np
from isotree import IsolationForest
### Random data from a standard normal distribution
np.random.seed(1)
n = 100
m = 2
X = np.random.normal(size = (n, m))
### Will now add obvious outlier point (3, 3) to the data
X = np.r_[X, np.array([3, 3]).reshape((1, m))]
### Fit a small isolation forest model
iso = IsolationForest(ntrees = 10, ndim = 2, nthreads = 1)
iso.fit(X)
### Check which row has the highest outlier score
pred = iso.predict(X)
print("Point with highest outlier score: ",
X[np.argsort(-pred)[0], ])
```
# Example 2: Plotting outlier and density regions
```
import numpy as np, pandas as pd
from isotree import IsolationForest
import matplotlib.pyplot as plt
from pylab import rcParams
%matplotlib inline
rcParams['figure.figsize'] = 10, 8
np.random.seed(1)
group1 = pd.DataFrame({
"x" : np.random.normal(loc=-1, scale=.4, size = 1000),
"y" : np.random.normal(loc=-1, scale=.2, size = 1000),
})
group2 = pd.DataFrame({
"x" : np.random.normal(loc=+1, scale=.2, size = 1000),
"y" : np.random.normal(loc=+1, scale=.4, size = 1000),
})
X = pd.concat([group1, group2], ignore_index=True)
### Now add an obvious outlier which is within the 1d ranges
### (As an interesting test, remove it and see what happens,
### or check how its score changes when using sub-sampling)
X = X.append(pd.DataFrame({"x" : [-1], "y" : [1]}), ignore_index = True)
### Single-variable Isolatio Forest
iso_simple = IsolationForest(ndim=1, ntrees=100,
penalize_range=False,
prob_pick_pooled_gain=0)
iso_simple.fit(X)
### Extended Isolation Forest
iso_ext = IsolationForest(ndim=2, ntrees=100,
penalize_range=False,
prob_pick_pooled_gain=0)
iso_ext.fit(X)
### SCiForest
iso_sci = IsolationForest(ndim=2, ntrees=100, ntry=10,
penalize_range=True,
prob_pick_avg_gain=1,
prob_pick_pooled_gain=0)
iso_sci.fit(X)
### Fair-Cut Forest
iso_fcf = IsolationForest(ndim=2, ntrees=100,
penalize_range=False,
prob_pick_avg_gain=0,
prob_pick_pooled_gain=1)
iso_fcf.fit(X)
### Plot as a heatmap
pts = np.linspace(-3, 3, 250)
space = np.array( np.meshgrid(pts, pts) ).reshape((2, -1)).T
Z_sim = iso_simple.predict(space)
Z_ext = iso_ext.predict(space)
Z_sci = iso_sci.predict(space)
Z_fcf = iso_fcf.predict(space)
space_index = pd.MultiIndex.from_arrays([space[:, 0], space[:, 1]])
def plot_space(Z, space_index, X):
df = pd.DataFrame({"z" : Z}, index = space_index)
df = df.unstack()
df = df[df.columns.values[::-1]]
plt.imshow(df, extent = [-3, 3, -3, 3], cmap = 'hot_r')
plt.scatter(x = X['x'], y = X['y'], alpha = .15, c = 'navy')
plt.suptitle("Outlier and Density Regions", fontsize = 20)
plt.subplot(2, 2, 1)
plot_space(Z_sim, space_index, X)
plt.title("Isolation Forest", fontsize=15)
plt.subplot(2, 2, 2)
plot_space(Z_ext, space_index, X)
plt.title("Extended Isolation Forest", fontsize=15)
plt.subplot(2, 2, 3)
plot_space(Z_sci, space_index, X)
plt.title("SCiForest", fontsize=15)
plt.subplot(2, 2, 4)
plot_space(Z_fcf, space_index, X)
plt.title("Fair-Cut Forest", fontsize=15)
plt.show()
print("(Note that the upper-left corner has an outlier point,\n\
and that there is a slight slide in the axes of the heat colors and the points)")
```
# Example 3: calculating pairwise distances
```
import numpy as np, pandas as pd
from isotree import IsolationForest
from scipy.spatial.distance import cdist
### Generate random multivariate-normal data
np.random.seed(1)
n = 1000
m = 10
### This is a random PSD matrix to use as covariance
S = np.random.normal(size = (m, m))
S = S.T.dot(S)
mu = np.random.normal(size = m, scale = 2)
X = np.random.multivariate_normal(mu, S, n)
### Fitting the model
iso = IsolationForest(prob_pick_avg_gain=0, prob_pick_pooled_gain=0)
iso.fit(X)
### Calculate approximate distance
D_sep = iso.predict_distance(X, square_mat = True)
### Compare against other distances
D_euc = cdist(X, X, metric = "euclidean")
D_cos = cdist(X, X, metric = "cosine")
D_mah = cdist(X, X, metric = "mahalanobis")
### Correlations
print("Correlations between different distance metrics")
pd.DataFrame(
np.corrcoef([D_sep.reshape(-1), D_euc.reshape(-1), D_cos.reshape(-1), D_mah.reshape(-1)]),
columns = ['SeparaionDepth', 'Euclidean', 'Cosine', 'Mahalanobis'],
index = ['SeparaionDepth', 'Euclidean', 'Cosine', 'Mahalanobis']
)
```
# Example 4: imputing missing values
```
import numpy as np
from isotree import IsolationForest
### Generate random multivariate-normal data
np.random.seed(1)
n = 1000
m = 5
### This is a random PSD matrix to use as covariance
S = np.random.normal(size = (m, m))
S = S.T.dot(S)
mu = np.random.normal(size = m)
X = np.random.multivariate_normal(mu, S, n)
### Set some values randomly as missing
values_NA = (np.random.random(size = n * m) <= .15).reshape((n, m))
X_na = X.copy()
X_na[values_NA] = np.nan
### Fitting the model
iso = IsolationForest(build_imputer=True, prob_pick_pooled_gain=1, ntry=10)
iso.fit(X_na)
### Impute missing values
X_imputed = iso.transform(X_na)
print("MSE for imputed values w/model: %f\n" % np.mean((X[values_NA] - X_imputed[values_NA])**2))
### Comparison against simple mean imputation
X_means = np.nanmean(X_na, axis = 0)
X_imp_mean = X_na.copy()
for cl in range(m):
X_imp_mean[np.isnan(X_imp_mean[:,cl]), cl] = X_means[cl]
print("MSE for imputed values w/means: %f\n" % np.mean((X[values_NA] - X_imp_mean[values_NA])**2))
```
| true |
code
| 0.593845 | null | null | null | null |
|
# 决策树
-----
```
# 准备工作
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# Where to save the figures
PROJECT_ROOT_DIR = ".."
CHAPTER_ID = "decision_trees"
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
def save_fig(fig_id, tight_layout=True):
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(image_path(fig_id) + ".png", format='png', dpi=300)
```
# 训练与可视化
```
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X, y)
from sklearn.tree import export_graphviz
export_graphviz(tree_clf, out_file=image_path("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names = iris.target_names,
rounded=True,
filled=True,
)
```
根据上面得到的dot文件,可以使用`$ dot -Tpng iris_tree.dot -o iris_tree.png
`命令转换为图片,如下:

上图可以看到树是的预测过程。假设想分类鸢尾花, 可以从根节点开始。
首先看花瓣宽度, 如果小于2.45cm, 分入左边节点(深度1,左)。这种情况下,叶子节点不同继续询问,可以直接预测为Setosa鸢尾花。 如果宽度大于2.45cm, 移到右边子节点继续判断。由于不是叶子节点,因此继续判断, 花萼宽度如果小于1.75cm,则很大可能是Versicolor花(深度2, 左)。否则,可能是Virginica花(深度2, 右)。
其中参数含义如下:sample表示训练实例的个数。比如右节点中有100个实例, 花瓣宽度大于2.45cm。(深度1)
其中54个花萼宽度小于1.75cm。value表示实例中每个类别的分分类个数。
gini系数表示实例的杂乱程度。如果等于0, 表示所有训练实例都属于同一个类别。如上setosa花分类。
公式可以计算第i个节点的gini分数。$G_i = 1 - \sum_{k=1}^{n} p_{i,k}^{2}$
P(i,k)表示k实例在i节点中的分布比例。
比如2层左节点的gini等于:$1-(0/50)^{2}-(49/50)^{2}-(5/50)^{2} = 0.168$。
注意:sklearn中使用CART,生成二叉树。但是像ID3可以生成多个孩子的决策树。
```
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap, linewidth=10)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
if plot_training:
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
if legend:
plt.legend(loc="lower right", fontsize=14)
plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf, X, y)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
plt.text(1.40, 1.0, "Depth=0", fontsize=15)
plt.text(3.2, 1.80, "Depth=1", fontsize=13)
plt.text(4.05, 0.5, "(Depth=2)", fontsize=11)
save_fig("decision_tree_decision_boundaries_plot")
plt.show()
```
上图显示了该决策树的决策边界。垂直线表示决策树的根节点(深度0), 花瓣长度等于2.45cm。
由于左边gini为0,只有一种分类,不再进一步分类判断。但是右边不是很纯,因此深度1的右边节点根据花萼宽度1.75cm进一步判断。
由于最大深度为2,决策树停止后面的判断。但是可以设置max_depth为3, 然后,两个深度2节点将各自添加另一个决策边界(由虚线表示)。
补充:可以看到决策树的过程容易理解,称之为白盒模型。与之不同的是,随机森林和神经网络一般称为黑盒模型。
它们预测效果很好,可以很容易地检查其计算结果, 来做出这些预测。但却难以解释为什么这样预测。
决策树提供了很好的和简单的分类规则,甚至可以在需要时手动分类。
# 进行预测和计算可能性
```
tree_clf.predict_proba([[5, 1.5]])
tree_clf.predict([[5, 1.5]])
```
### CART:分类回归树
sklearn使用CART算法对训练决策树(增长树)。思想很简单:首先将训练集分为两个子集,根据特征k和阈值$t_k$(比如花瓣长度小于2.45cm)。重要的是怎么选出这个特征。
通过对每一组最纯的子集(k, $t_k$),根据大小的权重进行搜索。最小化如下损失函数:
#### CART分类的损失函数
$J(k, t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right} $

最小化如上函数,一旦成功分为两个子集, 就可以使用相同逻辑递归进行切分。当到达给定的最大深度时(max_depth)停止,或者不能再继续切分(数据集很纯,无法减少杂质)。
如下超参数控制其他的停止条件(min_samples_split, min_sample_leaf, min_weight_fraction_leaf, max_leaf_nodes).
### 计算复杂度
默认的,经常使用gini impurity测量标准,但是也可以使用entropy impuirty来测量。

```
not_widest_versicolor = (X[:, 1] != 1.8) | (y==2)
X_tweaked = X[not_widest_versicolor]
y_tweaked = y[not_widest_versicolor]
tree_clf_tweaked = DecisionTreeClassifier(max_depth=2, random_state=40)
tree_clf_tweaked.fit(X_tweaked, y_tweaked)
plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf_tweaked, X_tweaked, y_tweaked, legend=False)
plt.plot([0, 7.5], [0.8, 0.8], "k-", linewidth=2)
plt.plot([0, 7.5], [1.75, 1.75], "k-", linewidth=2)
plt.text(1.0, 0.9, "Depth=0", fontsize=15)
plt.text(1.0, 1.80, "Depth=0", fontsize=13)
save_fig("decision_tree_instability_plot")
plt.show()
```
### 限制超参数
如下情况所示,防止过拟合数据,需要限制决策树的自由度,这个过程也叫正则(限制)。
决策树的max_depth超参数来控制拟合程度,默认不限制。可以减少max_depth来限制模型,减少过拟合的风险。
```
from sklearn.datasets import make_moons
Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53)
deep_tree_clf1 = DecisionTreeClassifier(random_state=42)
deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
deep_tree_clf1.fit(Xm, ym)
deep_tree_clf2.fit(Xm, ym)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(deep_tree_clf1, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("No restrictions", fontsize=16)
plt.subplot(122)
plot_decision_boundary(deep_tree_clf2, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14)
save_fig("min_samples_leaf_plot")
plt.show()
```
DecisionTreeClassifier有如下超参数:min_samples_split表示切分数据时包含的最小实例, min_samples_leaf表示一个叶子节点必须拥有的最小样本数目, min_weight_fraction_leaf(与min_samples_leaf相同,但表示为加权实例总数的一小部分), max_leaf_nodes(最大叶节点数)和max_features(在每个节点上分配的最大特性数), 增加min_*超参数或减少max_*超参数将使模型规范化。
其他算法开始时对决策树进行无约束训练,之后删除没必要的特征,称为减枝。
如果一个节点的所有子节点所提供的纯度改善没有统计学意义,则认为其和其子节点是不必要的。
```
angle = np.pi / 180 * 20
rotation_maxtrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xr = X.dot(rotation_maxtrix)
tree_clf_r = DecisionTreeClassifier(random_state=42)
tree_clf_r.fit(Xr, y)
plt.figure(figsize=(8, 3))
plot_decision_boundary(tree_clf_r, Xr, y, axes=[0.5, 7.5, -1.0, 1], iris=False)
plt.show()
```
# 不稳定性
目前为止,决策树有很多好处:它们易于理解和解释,易于使用,用途广泛,而且功能强大。
但是也有一些限制。首先, 决策树喜欢正交决策边界(所有的分割都垂直于一个轴),这使得它们对训练集的旋转很敏感。如下右图所示,旋转45度之后,尽管分类的很好,但是不会得到更大推广。其中的一种解决办法是PCA(后面介绍)。
更普遍的,决策树对训练集中的微小变化很敏感。比如上图中移除一个实例的分类结果又很大的不同。
随机森林可以通过对许多树进行平均预测来限制这种不稳定, 对异常值,微小变化更加适用。
```
np.random.seed(6)
Xs = np.random.rand(100, 2) - 0.5
ys = (Xs[:, 0] > 0).astype(np.float32) * 2
angle = np.pi / 4
rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix)
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs, ys)
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr, ys)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(tree_clf_s, Xs, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.subplot(122)
plot_decision_boundary(tree_clf_sr, Xsr, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
save_fig("sensitivity_to_rotation_plot")
plt.show()
```
### 回归树
```
import numpy as np
# 带噪声的2阶训练集
np.random.seed(42)
m = 200
X = np.random.rand(m ,1)
y = 4 * (X - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg.fit(X, y)
```
该回归决策树最大深度为2, dot后如下:

与分类树非常类似。 主要的不同在于,分类树根据每个节点预测每个分类。
比如当x1 = 0.6时进行预测。从根开始遍历树,最终到达叶节点,该节点预测值=0.1106。
这个预测仅仅是与此叶节点相关的110个训练实例的平均目标值。这个预测的结果是一个平均平方误差(MSE),在这110个实例中等于0.0151。
请注意,每个区域的预测值始终是该区域实例的平均目标值。该算法以一种使大多数训练实例尽可能接近预测值的方式来分割每个区域。
```
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
def plot_regression_predictions(tree_reg, X, y, axes=[0, 1, -0.2, 1], ylabel="$y$"):
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
y_pred = tree_reg.predict(x1)
plt.axis(axes)
if ylabel:
plt.ylabel(ylabel, fontsize=18, rotation=0)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_regression_predictions(tree_reg1, X, y)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
plt.text(0.21, 0.65, "Depth=0", fontsize=15)
plt.text(0.01, 0.2, "Depth=1", fontsize=13)
plt.text(0.65, 0.8, "Depth=1", fontsize=13)
plt.legend(loc="upper center", fontsize=18)
plt.title("max_depth=2", fontsize=14)
plt.subplot(122)
plot_regression_predictions(tree_reg2, X, y, ylabel=None)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2)
for split in (0.0458, 0.1298, 0.2873, 0.9040):
plt.plot([split, split], [-0.2, 1], "k:", linewidth=1)
plt.text(0.3, 0.5, "Depth=2", fontsize=13)
plt.title("max_depth=3", fontsize=14)
save_fig("tree_regression_plot")
plt.show()
# 画出分类图
export_graphviz(
tree_reg1,
out_file=image_path("regression_tree.dot"),
feature_names=["x1"],
rounded=True,
filled=True
)
tree_reg1 = DecisionTreeRegressor(random_state=42)
tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10)
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred1, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
plt.subplot(122)
plt.plot(X, y, "b.")
plt.plot(x1, y_pred2, "r.-", linewidth=2, label=r"$\hat{y}$")
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14)
save_fig("tree_regression_regularization_plot")
```

如上图所示, 回归树根据最小化mse来切分数据集。
决策树在处理回归任务时倾向于过度拟合。
如上左图,超参数默认,不加约束时容易过拟合。通过设置min_samples_leaf 将模型更合理的约束。
# 课后习题
#### 1. 无约束情况下,一百万个实例的训练集训练得到的决策树的大约深度是多少?
#### 2. 节点的gini impurity一般是小于还是大于其父节点?一般情况下这样,还是一直都这样?
#### 3. 如果决策树过拟合, 减少max_depth是一个好方法吗?
#### 4. 如果决策树欠拟合,缩放输入的特征是一个好方法吗?
#### 5. 如果在一个包含100万个实例的训练集上训练决策树需要一个小时,那么在包含1000万个实例的训练集上训练另一个决策树需要花费多少时间呢?
#### 6. 如果您的训练集包含100,000个实例,将设置presort=True 可以加快训练吗?
#### 7. 训练并调节决策树模型,使用moons数据集。
a. 使用 make_moons(n_samples=10000, noise=0.4)生成数据集。
b. 使用train_test_split(). 切分数据集。
c. 使用网格搜索并进行交叉验证,去找到最合适的超参数。尝试max_leaf_nodes参数。
d. 使用全部数据进行训练,并在测试集上估计性能。应该在85到87之间。
#### 8. 生成森林。
a. 继续上一题, 生成训练集的1000个子集所谓验证集。随机选择100实例。
b. 每一个子集训练一棵树,使用上述得到的最合适超参数。在测试集上评估这1000棵树。
由于它们是在较小的集合上进行训练的,所以这些决策树可能比第一个决策树更糟糕,只实现了大约80%的精度。
c. 对于每个测试集实例,生成1,000个决策树的预测,并且只保留最频繁的预测(您可以使用SciPy的mode()函数来实现这一点)。这给了对测试集的多数投票预测.
d. 评估测试集的这些预测:您应该获得比第一个模型稍高的精度(大约高0.5到1.5%)。恭喜你,你训练了一个随机森林分类器!
| true |
code
| 0.619586 | null | null | null | null |
|
```
%matplotlib inline
```
Creating Extensions Using numpy and scipy
=========================================
**Author**: `Adam Paszke <https://github.com/apaszke>`_
**Updated by**: `Adam Dziedzic <https://github.com/adam-dziedzic>`_
In this tutorial, we shall go through two tasks:
1. Create a neural network layer with no parameters.
- This calls into **numpy** as part of its implementation
2. Create a neural network layer that has learnable weights
- This calls into **SciPy** as part of its implementation
```
import torch
from torch.autograd import Function
```
Parameter-less example
----------------------
This layer doesn’t particularly do anything useful or mathematically
correct.
It is aptly named BadFFTFunction
**Layer Implementation**
```
from numpy.fft import rfft2, irfft2
class BadFFTFunction(Function):
@staticmethod
def forward(ctx, input):
numpy_input = input.detach().numpy()
result = abs(rfft2(numpy_input))
return input.new(result)
@staticmethod
def backward(ctx, grad_output):
numpy_go = grad_output.numpy()
result = irfft2(numpy_go)
return grad_output.new(result)
# since this layer does not have any parameters, we can
# simply declare this as a function, rather than as an nn.Module class
def incorrect_fft(input):
return BadFFTFunction.apply(input)
```
**Example usage of the created layer:**
```
input = torch.randn(8, 8, requires_grad=True)
result = incorrect_fft(input)
print(result)
result.backward(torch.randn(result.size()))
print(input)
```
Parametrized example
--------------------
In deep learning literature, this layer is confusingly referred
to as convolution while the actual operation is cross-correlation
(the only difference is that filter is flipped for convolution,
which is not the case for cross-correlation).
Implementation of a layer with learnable weights, where cross-correlation
has a filter (kernel) that represents weights.
The backward pass computes the gradient wrt the input and the gradient wrt the filter.
```
from numpy import flip
import numpy as np
from scipy.signal import convolve2d, correlate2d
from torch.nn.modules.module import Module
from torch.nn.parameter import Parameter
class ScipyConv2dFunction(Function):
@staticmethod
def forward(ctx, input, filter, bias):
# detach so we can cast to NumPy
input, filter, bias = input.detach(), filter.detach(), bias.detach()
result = correlate2d(input.numpy(), filter.numpy(), mode='valid')
result += bias.numpy()
ctx.save_for_backward(input, filter, bias)
return torch.as_tensor(result, dtype=input.dtype)
@staticmethod
def backward(ctx, grad_output):
grad_output = grad_output.detach()
input, filter, bias = ctx.saved_tensors
grad_output = grad_output.numpy()
grad_bias = np.sum(grad_output, keepdims=True)
grad_input = convolve2d(grad_output, filter.numpy(), mode='full')
# the previous line can be expressed equivalently as:
# grad_input = correlate2d(grad_output, flip(flip(filter.numpy(), axis=0), axis=1), mode='full')
grad_filter = correlate2d(input.numpy(), grad_output, mode='valid')
return torch.from_numpy(grad_input), torch.from_numpy(grad_filter).to(torch.float), torch.from_numpy(grad_bias).to(torch.float)
class ScipyConv2d(Module):
def __init__(self, filter_width, filter_height):
super(ScipyConv2d, self).__init__()
self.filter = Parameter(torch.randn(filter_width, filter_height))
self.bias = Parameter(torch.randn(1, 1))
def forward(self, input):
return ScipyConv2dFunction.apply(input, self.filter, self.bias)
```
**Example usage:**
```
module = ScipyConv2d(3, 3)
print("Filter and bias: ", list(module.parameters()))
input = torch.randn(10, 10, requires_grad=True)
output = module(input)
print("Output from the convolution: ", output)
output.backward(torch.randn(8, 8))
print("Gradient for the input map: ", input.grad)
```
**Check the gradients:**
```
from torch.autograd.gradcheck import gradcheck
moduleConv = ScipyConv2d(3, 3)
input = [torch.randn(20, 20, dtype=torch.double, requires_grad=True)]
test = gradcheck(moduleConv, input, eps=1e-6, atol=1e-4)
print("Are the gradients correct: ", test)
```
| true |
code
| 0.833697 | null | null | null | null |
|
# Dask Overview
Dask is a flexible library for parallel computing in Python that makes scaling out your workflow smooth and simple. On the CPU, Dask uses Pandas (NumPy) to execute operations in parallel on DataFrame (array) partitions.
Dask-cuDF extends Dask where necessary to allow its DataFrame partitions to be processed by cuDF GPU DataFrames as opposed to Pandas DataFrames. For instance, when you call dask_cudf.read_csv(…), your cluster’s GPUs do the work of parsing the CSV file(s) with underlying cudf.read_csv(). Dask also supports array based workflows using CuPy.
## When to use Dask
If your workflow is fast enough on a single GPU or your data comfortably fits in memory on a single GPU, you would want to use cuDF or CuPy. If you want to distribute your workflow across multiple GPUs, have more data than you can fit in memory on a single GPU, or want to analyze data spread across many files at once, you would want to use Dask.
One additional benefit Dask provides is that it lets us easily spill data between device and host memory. This can be very useful when we need to do work that would otherwise cause out of memory errors.
In this brief notebook, you'll walk through an example of using Dask on a single GPU. Because we're using Dask, the same code in this notebook would work on two, eight, 16, or 100s of GPUs.
# Creating a Local Cluster
The easiest way to scale workflows on a single node is to use the `LocalCUDACluster` API. This lets us create a GPU cluster, using one worker per GPU by default.
In this case, we'll pass the following arguments.
- `CUDA_VISIBLE_DEVICES`, to limit our cluster to a single GPU (for demonstration purposes).
- `device_memory_limit`, to illustrate how we can spill data between GPU and CPU memory. Artificial memory limits like this reduce our performance if we don't actually need them, but can let us accomplish much larger tasks when we do.
- `rmm_pool_size`, to use the RAPIDS Memory Manager to allocate one big chunk of memory upfront rather than having our operations call `cudaMalloc` all the time under the hood. This improves performance, and is generally a best practice.
```
from dask.distributed import Client, fire_and_forget, wait
from dask_cuda import LocalCUDACluster
from dask.utils import parse_bytes
import dask
cluster = LocalCUDACluster(
CUDA_VISIBLE_DEVICES="0,1",
device_memory_limit=parse_bytes("3GB"),
rmm_pool_size=parse_bytes("16GB"),
)
client = Client(cluster)
client
```
Click the **Dashboard** link above to view your Dask dashboard.
## cuDF DataFrames to Dask DataFrames
Dask lets scale our cuDF workflows. We'll walk through a couple of examples below, and then also highlight how Dask lets us spill data from GPU to CPU memory.
First, we'll create a dataframe with CPU Dask and then send it to the GPU
```
import cudf
import dask_cudf
ddf = dask_cudf.from_dask_dataframe(dask.datasets.timeseries())
ddf.head()
```
### Example One: Groupby-Aggregations
```
ddf.groupby(["id", "name"]).agg({"x":['sum', 'mean']}).head()
```
Run the code above again.
If you look at the task stream in the dashboard, you'll notice that we're creating the data every time. That's because Dask is lazy. We need to `persist` the data if we want to cache it in memory.
```
ddf = ddf.persist()
wait(ddf);
ddf.groupby(["id", "name"]).agg({"x":['sum', 'mean']}).head()
```
This is the same API as cuDF, except it works across many GPUs.
### Example Two: Rolling Windows
We can also do things like rolling window calculations with Dask and GPUs.
```
ddf.head()
rolling = ddf[['x','y']].rolling(window=3)
type(rolling)
rolling.mean().head()
```
## Larger than GPU Memory Workflows
What if we needed to scale up even more, but didn't have enough GPU memory? Dask handles spilling for us, so we don't need to worry about it. The `device_memory_limit` parameter we used while creating the LocalCluster determines when we should start spilling. In this case, we'll start spilling when we've used about 4GB of GPU memory.
Let's create a larger dataframe to use as an example.
```
ddf = dask_cudf.from_dask_dataframe(dask.datasets.timeseries(start="2000-01-01", end="2003-12-31", partition_freq='60d'))
ddf = ddf.persist()
len(ddf)
print(f"{ddf.memory_usage(deep=True).sum().compute() / 1e9} GB of data")
ddf.head()
```
Let's imagine we have some downstream operations that require all the data from a given unique identifier in the same partition. We can repartition our data based on the `name` column using the `shuffle` API.
Repartitioning our large dataframe will spike GPU memory higher than 4GB, so we'll need to spill to CPU memory.
```
ddf = ddf.shuffle(on="id")
ddf = ddf.persist()
len(ddf)
```
Watch the Dask Dashboard while this runs. You should see a lot of tasks in the stream like `disk-read` and `disk-write`. Setting a `device_memory_limit` tells dask to spill to CPU memory and potentially disk (if we overwhelm CPU memory). This lets us do these large computations even when we're almost out of memory (though in this case, we faked it).
# Dask Custom Functions
Dask DataFrames also provide a `map_partitions` API, which is very useful for parallelizing custom logic that doesn't quite fit perfectly or doesn't need to be used with the Dask dataframe API. Dask will `map` the function to every partition of the distributed dataframe.
Now that we have all the rows of each `id` collected in the same partitions, what if we just wanted to sort **within each partition**. Avoiding global sorts is usually a good idea if possible, since they're very expensive operations.
```
sorted_ddf = ddf.map_partitions(lambda x: x.sort_values("id"))
len(sorted_ddf)
```
We could also do something more complicated and wrap it into a function. Let's do a rolling window on the two value columns after sorting by the id column.
```
def sort_and_rolling_mean(df):
df = df.sort_values("id")
df = df.rolling(3)[["x", "y"]].mean()
return df
result = ddf.map_partitions(sort_and_rolling_mean)
result = result.persist()
wait(result);
# let's look at a random partition
result.partitions[12].head()
```
Pretty cool. When we're using `map_partitions`, the function is executing on the individual cuDF DataFrames that make up our Dask DataFrame. This means we can do any cuDF operation, run CuPy array manipulations, or anything else we want.
# Dask Delayed
Dask also provides a `delayed` API, which is useful for parallelizing custom logic that doesn't quite fit into the DataFrame API.
Let's imagine we wanted to run thousands of regressions models on different combinations of two features. We can do this experiment super easily with dask.delayed.
```
from cuml.linear_model import LinearRegression
from dask import delayed
import dask
import numpy as np
from itertools import combinations
# Setup data
np.random.seed(12)
nrows = 1000000
ncols = 50
df = cudf.DataFrame({f"x{i}": np.random.randn(nrows) for i in range(ncols)})
df['y'] = np.random.randn(nrows)
feature_combinations = list(combinations(df.columns.drop("y"), 2))
feature_combinations[:10]
len(feature_combinations)
# Many calls to linear regression, parallelized with Dask
@delayed
def fit_ols(df, feature_cols, target_col="y"):
clf = LinearRegression()
clf.fit(df[list(feature_cols)], df[target_col])
return feature_cols, clf.coef_, clf.intercept_
# scatter the data to the workers beforehand
data_future = client.scatter(df, broadcast=True)
results = []
for features in feature_combinations:
# note how i'm passing the scattered data future
res = fit_ols(data_future, features)
results.append(res)
res = dask.compute(results)
res = res[0]
print("Features\t\tCoefficients\t\t\tIntercept")
for i in range(5):
print(res[i][0], res[i][1].values, res[i][2], sep="\t")
```
# Handling Parquet Files
Dask and cuDF provide accelerated Parquet readers and writers, and it's useful to take advantage of these tools.
To start, let's write out our DataFrame `ddf` to Parquet files using the `to_parquet` API and delete it from memory.
```
print(ddf.npartitions)
ddf.to_parquet("ddf.parquet")
del ddf
```
Let's take a look at what happened.
```
!ls ddf.parquet | head
```
We end up with many parquet files, and one metadata file. Dask will write one file per partition.
Let's read the data back in with `dask_cudf.read_parquet`.
```
ddf = dask_cudf.read_parquet("ddf.parquet/")
ddf
```
Why do we have more partitions than files? It turns out, Dask's readers do things like chunk our data by default. Additionally, the `_metadata` file helps provide guidelines for reading the data. But, we can still read them on a per-file basis if want by using a `*` wildcard in the filepath and ignoring the metadata.
```
ddf = dask_cudf.read_parquet("ddf.parquet/*.parquet")
ddf
```
Let's now write one big parquet file and then read it back in. We can `repartition` our dataset down to a single partition.
```
ddf.repartition(npartitions=1).to_parquet("big_ddf.parquet")
dask_cudf.read_parquet("big_ddf.parquet/")
```
We still get lots of partitions? We can control the splitting behavior using the `split_row_groups` parameter.
```
dask_cudf.read_parquet("big_ddf.parquet/", split_row_groups=False)
```
In general, we want to avoid massive partitions. The sweet spot is probably around 2-3 GB of data per partition for a 32GB V100.
# Understanding Persist and Compute
Before we close, it's worth coming back to the concepts of `persist` and `compute`. We've seen them several times, but haven't gone into depth.
Most Dask operations are lazy. This is a common pattern in distributed computing, but is likely unfamiliar to those who primarily use single-machine libraries like pandas and cuDF. As a result, you'll usually need to call an **eager** operation like `len` or `persist` to actually trigger work.
In general, you should avoid calling `compute` except when collecting small datasets or scalars. When we spin up a cluster, we're interacting with our cluster in what we call the `Client` Python process. When we created a `Client` object above, this is what we did. Calling `compute` brings all of the results back to a single GPU cuDF DataFrame in the client process, not in any of the worker processes. This means we're not using the same memory pool, so we could go out of memory if we're not careful.
For those of you with Spark experience, you can think of `persist` as triggering work and caching the dataframe in distributed memory and `compute` as collecting the data or results into a single GPU dataframe (cuDF) on the driver.
### Should I Persist My Data?
Persisting is generally a good idea if the data needs to be accessed multiple times, to avoid repeated computation. However, if the size of your data would lead to memory pressure, this could cause spilling, which hurts performance. As a best practice, we recommend persisting only when necessary or when you're using an eager operation in the middle of your workflow (to avoid repeating computation).
Note that calling `df.head` is an eager operation, which will trigger some computation. If you're going to be doing exploratory data analysis or visually inspecting the data, you would want to persist beforehand.
# Summary
RAPIDS lets us scale up and take advantage of GPU acceleration. Dask lets us scale out to multiple machines. Dask supports both cuDF DataFrames and CuPy arrays, with generally the same APIs as the single-machine libraries.
We encourage you to read the Dask [documentation](https://docs.dask.org/en/latest/) to learn more, and also look at our [10 Minute Guide to cuDF and Dask cuDF](https://docs.rapids.ai/api/cudf/nightly/10min.html)
| true |
code
| 0.462776 | null | null | null | null |
|
# Hypothesis: Are digitised practices causing more failures?
## Hypothesis
We believe that practices undergoing Lloyd Gerge digitisation have an increased failure rate.
We will know this to be true when we look at their data for the last three months, and see that either their failures have increased, or that in general their failures are higher than average.
## Context
From the months of May-Aug 2021, we see a steady increase of TPP-->EMIS Large message general failures. A general hypothesis is that this is due to record sizes increasing, which could be due to Lloyd George digitisation. This has prompted a more general hypothesis to identify whether digitisation is impacting failure rates.
## Scope
- Generate a transfer outcomes table for each of the below CCGs split down for May, June, July:
- Sunderland
- Fylde and Wyre
- Chorley and South Ribble
- Blackpool
- Birmingham and Solihull
- Show technical failure rate for each month, for each practice in the CCG
- Separate out outcomes for transfers in, and transfers out
- Do this for practices as a sender and as a requester
```
import pandas as pd
import numpy as np
import paths
from data.practice_metadata import read_asid_metadata
asid_lookup=read_asid_metadata("prm-gp2gp-ods-metadata-preprod", "v2/2021/8/organisationMetadata.json")
transfer_file_location = "s3://prm-gp2gp-transfer-data-preprod/v4/"
transfer_files = [
"2021/5/transfers.parquet",
"2021/6/transfers.parquet",
"2021/7/transfers.parquet"
]
transfer_input_files = [transfer_file_location + f for f in transfer_files]
transfers_raw = pd.concat((
pd.read_parquet(f)
for f in transfer_input_files
))
transfers = transfers_raw\
.join(asid_lookup.add_prefix("requesting_"), on="requesting_practice_asid", how="left")\
.join(asid_lookup.add_prefix("sending_"), on="sending_practice_asid", how="left")\
transfers['month']=transfers['date_requested'].dt.to_period('M')
def generate_monthly_outcome_breakdown(transfers, columns):
total_transfers = (
transfers
.groupby(columns)
.size()
.to_frame("Total Transfers")
)
transfer_outcomes=pd.pivot_table(
transfers,
index=columns,
columns=["status"],
aggfunc='size'
)
transfer_outcomes_pc = (
transfer_outcomes
.div(total_transfers["Total Transfers"],axis=0)
.multiply(100)
.round(2)
.add_suffix(" %")
)
failed_transfers = (
transfers
.assign(failed_transfer=transfers["status"] != "INTEGRATED_ON_TIME")
.groupby(columns)
.agg({'failed_transfer': 'sum'})
.rename(columns={'failed_transfer': 'ALL_FAILURE'})
)
failed_transfers_pc = (
failed_transfers
.div(total_transfers["Total Transfers"],axis=0)
.multiply(100)
.round(2)
.add_suffix(" %")
)
return pd.concat([
total_transfers,
transfer_outcomes,
failed_transfers,
transfer_outcomes_pc,
failed_transfers_pc,
],axis=1).fillna(0)
```
## Generate national transfer outcomes
```
national_metrics_monthly=generate_monthly_outcome_breakdown(transfers, ["month"])
national_metrics_monthly
```
## Generate digitised CCG transfer outcomes
```
ccgs_to_investigate = [
"NHS SUNDERLAND CCG",
'NHS FYLDE AND WYRE CCG',
'NHS CHORLEY AND SOUTH RIBBLE CCG',
'NHS BLACKPOOL CCG',
'NHS BIRMINGHAM AND SOLIHULL CCG'
]
is_requesting_ccg_of_interest = transfers.requesting_ccg_name.isin(ccgs_to_investigate)
is_sending_ccg_of_interest = transfers.sending_ccg_name.isin(ccgs_to_investigate)
requesting_transfers_of_interest = transfers[is_requesting_ccg_of_interest]
sending_transfers_of_interest = transfers[is_sending_ccg_of_interest]
```
### Requesting CCGs (Digitised)
```
requesting_ccgs_monthly=generate_monthly_outcome_breakdown(
transfers=requesting_transfers_of_interest,
columns=["requesting_ccg_name", "month"]
)
requesting_ccgs_monthly
```
### Sending CCGs (Digitised)
```
sending_ccgs_monthly=generate_monthly_outcome_breakdown(
transfers=sending_transfers_of_interest,
columns=["sending_ccg_name", "month"]
)
sending_ccgs_monthly
```
### Requesting practices (digitised)
```
requesting_practices_monthly=generate_monthly_outcome_breakdown(
transfers=requesting_transfers_of_interest,
columns=["requesting_ccg_name", "requesting_practice_name", "requesting_practice_ods_code", "requesting_supplier", "month"]
)
requesting_practices_monthly
```
### Sending practices (digitised)
```
sending_practices_monthly=generate_monthly_outcome_breakdown(
transfers=sending_transfers_of_interest,
columns=["sending_ccg_name", "sending_practice_name", "sending_practice_ods_code", "sending_supplier", "month"]
)
sending_practices_monthly
```
## Looking at failure rate trends by CCG when requesting a record
```
barplot_config = {
'color': ['lightsteelblue', 'cornflowerblue', 'royalblue'],
'edgecolor':'black',
'kind':'bar',
'figsize': (15,6),
'rot': 30
}
def requesting_ccg_barplot(column_name, title):
(
pd
.concat({'All CCGs': national_metrics_monthly}, names=['requesting_ccg_name'])
.append(requesting_ccgs_monthly)
.unstack()
.plot(
y=column_name,
title=title,
**barplot_config
)
)
requesting_ccg_barplot('ALL_FAILURE %', 'Total Failure Percentage (Digitised CCGs - Requesting)')
requesting_ccg_barplot('TECHNICAL_FAILURE %', 'Technical Failure Percentage (Digitised CCGs - Requesting)')
requesting_ccg_barplot('PROCESS_FAILURE %', 'Process Failure Percentage (Digitised CCGs - Requesting)')
requesting_ccg_barplot('UNCLASSIFIED_FAILURE %', 'Unlassified Failure Percentage (Digitised CCGs - Requesting)')
```
## Looking at failure rate trends by CCG when sending a record
```
def sending_ccg_barplot(column_name, title):
(
pd
.concat({'All CCGs': national_metrics_monthly}, names=['sending_ccg_name'])
.append(sending_ccgs_monthly)
.unstack()
.plot(
y=column_name,
title=title,
**barplot_config
)
)
sending_ccg_barplot('ALL_FAILURE %', 'Total Failure Percentage (Digitised CCGs - Sending)')
sending_ccg_barplot('TECHNICAL_FAILURE %', 'Technical Failure Percentage (Digitised CCGs - Sending)')
sending_ccg_barplot('PROCESS_FAILURE %', 'Process Failure Percentage (Digitised CCGs - Sending)')
sending_ccg_barplot('UNCLASSIFIED_FAILURE %', 'Unlassified Failure Percentage (Digitised CCGs - Sending)')
```
## Write CCG transfer outcomes by sending and requesting practice to Excel
```
with pd.ExcelWriter('PRMT-2332-Digitisation-Failure-Rates-May-July-2021.xlsx') as writer:
national_metrics_monthly.to_excel(writer, sheet_name="National Baseline")
requesting_ccgs_monthly.to_excel(writer, sheet_name="Digitised CCGs (Req)")
sending_ccgs_monthly.to_excel(writer, sheet_name="Digitised CCGs (Send)")
requesting_practices_monthly.to_excel(writer, sheet_name="Digitised Practices (Req)")
sending_practices_monthly.to_excel(writer, sheet_name="Digitised Practices (Send)")
```
| true |
code
| 0.373504 | null | null | null | null |
|
# Data Collection Using Web Scraping
## To solve this problem we will need the following data :
● List of neighborhoods in Pune.
● Latitude and Longitudinal coordinates of those neighborhoods.
● Venue data for each neighborhood.
## Sources
● For the list of neighborhoods, I used
(https://en.wikipedia.org/wiki/Category:Neighbourhoods_in_Pune)
● For Latitude and Longitudinal coordinates: Python Geocoder Package
(https://geocoder.readthedocs.io/)
● For Venue data: Foursquare API (https://foursquare.com/)
## Methods to extract data from Sources
To extract the data we will use python packages like requests, beautifulsoup and geocoder.
We will use Requests and beautifulsoup packages for web
scraping(https://en.wikipedia.org/wiki/Category:Neighbourhoods_in_Pune ) to get the list of
neighborhoods in Pune and geocoder package to get the latitude and longitude coordinates of
each neighborhood.
Then we will use Folium to plot these neighborhoods on the map.
After that, we will use the foursquare API to get the venue data of those neighborhoods. Foursquare API will provide many categories of the venue data but we are particularly interested in the supermarket category in order to help us to solve the business problem.
## Imports
```
import numpy as np # library to handle data in a vectorized manner
import pandas as pd # library for data analsysis
pd.set_option("display.max_columns", None)
pd.set_option("display.max_rows", None)
import json # library to handle JSON files
from geopy.geocoders import Nominatim # convert an address into latitude and longitude values
!pip install geocoder
import geocoder # to get coordinates
!pip install requests
import requests # library to handle requests
from bs4 import BeautifulSoup # library to parse HTML and XML documents
from pandas.io.json import json_normalize # tranform JSON file into a pandas dataframe
print("Libraries imported.")
```
## Collecting the nebourhood data using Requests, BeautifulSoup, and Geocoder labries
```
data = requests.get("https://en.wikipedia.org/wiki/Category:Neighbourhoods_in_Pune").text
# parse data from the html into a beautifulsoup object
soup = BeautifulSoup(data, 'html.parser')
# create a list to store neighborhood data
neighborhood_List = []
# append the data into the list
for row in soup.find_all("div", class_="mw-category")[0].findAll("li"):
neighborhood_List.append(row.text)
# create a new DataFrame from the list
Pune_df = pd.DataFrame({"Neighborhood": neighborhood_List})
Pune_df.tail()
# define a function to get coordinates
def get_cord(neighborhood):
coords = None
# loop until you get the coordinates
while(coords is None):
g = geocoder.arcgis('{}, Pune, Maharashtra'.format(neighborhood))
coords = g.latlng
return coords
# create a list and store the coordinates
coords = [ get_cord(neighborhood) for neighborhood in Pune_df["Neighborhood"].tolist() ]
coords[:10]
df_coords = pd.DataFrame(coords, columns=['Latitude', 'Longitude'])
# merge the coordinates into the original dataframe
Pune_df['Latitude'] = df_coords['Latitude']
Pune_df['Longitude'] = df_coords['Longitude']
# check the neighborhoods and the coordinates
print(Pune_df.shape)
Pune_df.head(10)
# save the DataFrame as CSV file
Pune_df.to_csv("Pune_df.csv", index=False)
```
## Collecting the nebourhood venue data using Foursquare API
```
# define Foursquare Credentials and Version
CLIENT_ID = '5HUDVH14DMECWUAFI2MICONBTTDPW1CCL1C4TFGE3FEHEUHJ' # your Foursquare ID
CLIENT_SECRET = 'R0WIH5UIW2SADKBUW4B4WMY2QWBBT0Q02IURAXQXVJZMTDIV' # your Foursquare Secret
VERSION = '20180605' # Foursquare API version
print('Your credentails:')
print('CLIENT_ID: ' + CLIENT_ID)
print('CLIENT_SECRET:' + CLIENT_SECRET)
radius = 3000
LIMIT = 150
venues = []
for lat, long, neighborhood in zip(Pune_df['Latitude'], Pune_df['Longitude'], Pune_df['Neighborhood']):
# create the API request URL
url = "https://api.foursquare.com/v2/venues/explore?client_id={}&client_secret={}&v={}&ll={},{}&radius={}&limit={}".format(
CLIENT_ID,
CLIENT_SECRET,
VERSION,
lat,
long,
radius,
LIMIT)
# make the GET request
results = requests.get(url).json()["response"]['groups'][0]['items']
# return only relevant information for each nearby venue
for venue in results:
venues.append((
neighborhood,
lat,
long,
venue['venue']['name'],
venue['venue']['location']['lat'],
venue['venue']['location']['lng'],
venue['venue']['categories'][0]['name']))
# convert the venues list into a new DataFrame
venues_df = pd.DataFrame(venues)
# define the column names
venues_df.columns = ['Neighborhood', 'Latitude', 'Longitude', 'VenueName', 'VenueLatitude', 'VenueLongitude', 'VenueCategory']
print(venues_df.shape)
venues_df.head()
print('There are {} uniques categories.'.format(len(venues_df['VenueCategory'].unique())))
# print out the list of categories
venues_df['VenueCategory'].unique()
venues_df.to_csv("venues_df.csv")
```
| true |
code
| 0.39908 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/PacktPublishing/Hands-On-Computer-Vision-with-PyTorch/blob/master/Chapter15/Handwriting_transcription.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!wget https://www.dropbox.com/s/l2ul3upj7dkv4ou/synthetic-data.zip
!unzip -qq synthetic-data.zip
!pip install torch_snippets torch_summary editdistance
from torch_snippets import *
from torchsummary import summary
import editdistance
device = 'cuda' if torch.cuda.is_available() else 'cpu'
fname2label = lambda fname: stem(fname).split('@')[0]
images = Glob('synthetic-data')
vocab = 'QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm'
B,T,V = 64, 32, len(vocab)
H,W = 32, 128
class OCRDataset(Dataset):
def __init__(self, items, vocab=vocab, preprocess_shape=(H,W), timesteps=T):
super().__init__()
self.items = items
self.charList = {ix+1:ch for ix,ch in enumerate(vocab)}
self.charList.update({0: '`'})
self.invCharList = {v:k for k,v in self.charList.items()}
self.ts = timesteps
def __len__(self):
return len(self.items)
def sample(self):
return self[randint(len(self))]
def __getitem__(self, ix):
item = self.items[ix]
image = cv2.imread(item, 0)
label = fname2label(item)
return image, label
def collate_fn(self, batch):
images, labels, label_lengths, label_vectors, input_lengths = [], [], [], [], []
for image, label in batch:
images.append(torch.Tensor(self.preprocess(image))[None,None])
label_lengths.append(len(label))
labels.append(label)
label_vectors.append(self.str2vec(label))
input_lengths.append(self.ts)
images = torch.cat(images).float().to(device)
label_lengths = torch.Tensor(label_lengths).long().to(device)
label_vectors = torch.Tensor(label_vectors).long().to(device)
input_lengths = torch.Tensor(input_lengths).long().to(device)
return images, label_vectors, label_lengths, input_lengths, labels
def str2vec(self, string, pad=True):
string = ''.join([s for s in string if s in self.invCharList])
val = list(map(lambda x: self.invCharList[x], string))
if pad:
while len(val) < self.ts:
val.append(0)
return val
def preprocess(self, img, shape=(32,128)):
target = np.ones(shape)*255
try:
H, W = shape
h, w = img.shape
fx = H/h
fy = W/w
f = min(fx, fy)
_h = int(h*f)
_w = int(w*f)
_img = cv2.resize(img, (_w,_h))
target[:_h,:_w] = _img
except:
...
return (255-target)/255
def decoder_chars(self, pred):
decoded = ""
last = ""
pred = pred.cpu().detach().numpy()
for i in range(len(pred)):
k = np.argmax(pred[i])
if k > 0 and self.charList[k] != last:
last = self.charList[k]
decoded = decoded + last
elif k > 0 and self.charList[k] == last:
continue
else:
last = ""
return decoded.replace(" "," ")
def wer(self, preds, labels):
c = 0
for p, l in zip(preds, labels):
c += p.lower().strip() != l.lower().strip()
return round(c/len(preds), 4)
def cer(self, preds, labels):
c, d = [], []
for p, l in zip(preds, labels):
c.append(editdistance.eval(p, l) / len(l))
return round(np.mean(c), 4)
def evaluate(self, model, ims, labels, lower=False):
model.eval()
preds = model(ims).permute(1,0,2) # B, T, V+1
preds = [self.decoder_chars(pred) for pred in preds]
return {'char-error-rate': self.cer(preds, labels),
'word-error-rate': self.wer(preds, labels),
'char-accuracy' : 1 - self.cer(preds, labels),
'word-accuracy' : 1 - self.wer(preds, labels)}
from sklearn.model_selection import train_test_split
trn_items, val_items = train_test_split(Glob('synthetic-data'), test_size=0.2, random_state=22)
trn_ds = OCRDataset(trn_items)
val_ds = OCRDataset(val_items)
trn_dl = DataLoader(trn_ds, batch_size=B, collate_fn=trn_ds.collate_fn, drop_last=True, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=B, collate_fn=val_ds.collate_fn, drop_last=True)
from torch_snippets import Reshape, Permute
class BasicBlock(nn.Module):
def __init__(self, ni, no, ks=3, st=1, padding=1, pool=2, drop=0.2):
super().__init__()
self.ks = ks
self.block = nn.Sequential(
nn.Conv2d(ni, no, kernel_size=ks, stride=st, padding=padding),
nn.BatchNorm2d(no, momentum=0.3),
nn.ReLU(inplace=True),
nn.MaxPool2d(pool),
nn.Dropout2d(drop)
)
def forward(self, x):
return self.block(x)
class Ocr(nn.Module):
def __init__(self, vocab):
super().__init__()
self.model = nn.Sequential(
BasicBlock( 1, 128),
BasicBlock(128, 128),
BasicBlock(128, 256, pool=(4,2)),
Reshape(-1, 256, 32),
Permute(2, 0, 1) # T, B, D
)
self.rnn = nn.Sequential(
nn.LSTM(256, 256, num_layers=2, dropout=0.2, bidirectional=True),
)
self.classification = nn.Sequential(
nn.Linear(512, vocab+1),
nn.LogSoftmax(-1),
)
def forward(self, x):
x = self.model(x)
x, lstm_states = self.rnn(x)
y = self.classification(x)
return y
def ctc(log_probs, target, input_lengths, target_lengths, blank=0):
loss = nn.CTCLoss(blank=blank, zero_infinity=True)
ctc_loss = loss(log_probs, target, input_lengths, target_lengths)
return ctc_loss
model = Ocr(len(vocab)).to(device)
!pip install torch_summary
from torchsummary import summary
summary(model, torch.zeros((1,1,32,128)).to(device))
def train_batch(data, model, optimizer, criterion):
model.train()
imgs, targets, label_lens, input_lens, labels = data
optimizer.zero_grad()
preds = model(imgs)
loss = criterion(preds, targets, input_lens, label_lens)
loss.backward()
optimizer.step()
results = trn_ds.evaluate(model, imgs.to(device), labels)
return loss, results
@torch.no_grad()
def validate_batch(data, model):
model.eval()
imgs, targets, label_lens, input_lens, labels = data
preds = model(imgs)
loss = criterion(preds, targets, input_lens, label_lens)
return loss, val_ds.evaluate(model, imgs.to(device), labels)
model = Ocr(len(vocab)).to(device)
criterion = ctc
optimizer = optim.AdamW(model.parameters(), lr=3e-3)
n_epochs = 50
log = Report(n_epochs)
for ep in range( n_epochs):
# if ep in lr_schedule: optimizer = AdamW(ocr.parameters(), lr=lr_schedule[ep])
N = len(trn_dl)
for ix, data in enumerate(trn_dl):
pos = ep + (ix+1)/N
loss, results = train_batch(data, model, optimizer, criterion)
# scheduler.step()
ca, wa = results['char-accuracy'], results['word-accuracy']
log.record(pos=pos, trn_loss=loss, trn_char_acc=ca, trn_word_acc=wa, end='\r')
val_results = []
N = len(val_dl)
for ix, data in enumerate(val_dl):
pos = ep + (ix+1)/N
loss, results = validate_batch(data, model)
ca, wa = results['char-accuracy'], results['word-accuracy']
log.record(pos=pos, val_loss=loss, val_char_acc=ca, val_word_acc=wa, end='\r')
log.report_avgs(ep+1)
print()
for jx in range(5):
img, label = val_ds.sample()
_img = torch.Tensor(val_ds.preprocess(img)[None,None]).to(device)
pred = model(_img)[:,0,:]
pred = trn_ds.decoder_chars(pred)
print(f'Pred: `{pred}` :: Truth: `{label}`')
print()
log.plot_epochs(['trn_word_acc','val_word_acc'], title='Training and validation word accuracy')
```
| true |
code
| 0.767569 | null | null | null | null |
|
# Stochastic Variational GP Regression
## Overview
In this notebook, we'll give an overview of how to use SVGP stochastic variational regression ((https://arxiv.org/pdf/1411.2005.pdf)) to rapidly train using minibatches on the `3droad` UCI dataset with hundreds of thousands of training examples. This is one of the more common use-cases of variational inference for GPs.
If you are unfamiliar with variational inference, we recommend the following resources:
- [Variational Inference: A Review for Statisticians](https://arxiv.org/abs/1601.00670) by David M. Blei, Alp Kucukelbir, Jon D. McAuliffe.
- [Scalable Variational Gaussian Process Classification](https://arxiv.org/abs/1411.2005) by James Hensman, Alex Matthews, Zoubin Ghahramani.
```
import tqdm
import math
import torch
import gpytorch
from matplotlib import pyplot as plt
# Make plots inline
%matplotlib inline
```
For this example notebook, we'll be using the `song` UCI dataset used in the paper. Running the next cell downloads a copy of the dataset that has already been scaled and normalized appropriately. For this notebook, we'll simply be splitting the data using the first 80% of the data as training and the last 20% as testing.
**Note**: Running the next cell will attempt to download a **~136 MB** file to the current directory.
```
import urllib.request
import os
from scipy.io import loadmat
from math import floor
# this is for running the notebook in our testing framework
smoke_test = ('CI' in os.environ)
if not smoke_test and not os.path.isfile('../elevators.mat'):
print('Downloading \'elevators\' UCI dataset...')
urllib.request.urlretrieve('https://drive.google.com/uc?export=download&id=1jhWL3YUHvXIaftia4qeAyDwVxo6j1alk', '../elevators.mat')
if smoke_test: # this is for running the notebook in our testing framework
X, y = torch.randn(1000, 3), torch.randn(1000)
else:
data = torch.Tensor(loadmat('../elevators.mat')['data'])
X = data[:, :-1]
X = X - X.min(0)[0]
X = 2 * (X / X.max(0)[0]) - 1
y = data[:, -1]
train_n = int(floor(0.8 * len(X)))
train_x = X[:train_n, :].contiguous()
train_y = y[:train_n].contiguous()
test_x = X[train_n:, :].contiguous()
test_y = y[train_n:].contiguous()
if torch.cuda.is_available():
train_x, train_y, test_x, test_y = train_x.cuda(), train_y.cuda(), test_x.cuda(), test_y.cuda()
```
## Creating a DataLoader
The next step is to create a torch `DataLoader` that will handle getting us random minibatches of data. This involves using the standard `TensorDataset` and `DataLoader` modules provided by PyTorch.
In this notebook we'll be using a fairly large batch size of 1024 just to make optimization run faster, but you could of course change this as you so choose.
```
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(train_x, train_y)
train_loader = DataLoader(train_dataset, batch_size=1024, shuffle=True)
test_dataset = TensorDataset(test_x, test_y)
test_loader = DataLoader(test_dataset, batch_size=1024, shuffle=False)
```
## Creating a SVGP Model
For most variational/approximate GP models, you will need to construct the following GPyTorch objects:
1. A **GP Model** (`gpytorch.models.ApproximateGP`) - This handles basic variational inference.
1. A **Variational distribution** (`gpytorch.variational._VariationalDistribution`) - This tells us what form the variational distribution q(u) should take.
1. A **Variational strategy** (`gpytorch.variational._VariationalStrategy`) - This tells us how to transform a distribution q(u) over the inducing point values to a distribution q(f) over the latent function values for some input x.
Here, we use a `VariationalStrategy` with `learn_inducing_points=True`, and a `CholeskyVariationalDistribution`. These are the most straightforward and common options.
#### The GP Model
The `ApproximateGP` model is GPyTorch's simplest approximate inference model. It approximates the true posterior with a distribution specified by a `VariationalDistribution`, which is most commonly some form of MultivariateNormal distribution. The model defines all the variational parameters that are needed, and keeps all of this information under the hood.
The components of a user built `ApproximateGP` model in GPyTorch are:
1. An `__init__` method that constructs a mean module, a kernel module, a variational distribution object and a variational strategy object. This method should also be responsible for construting whatever other modules might be necessary.
2. A `forward` method that takes in some $n \times d$ data `x` and returns a MultivariateNormal with the *prior* mean and covariance evaluated at `x`. In other words, we return the vector $\mu(x)$ and the $n \times n$ matrix $K_{xx}$ representing the prior mean and covariance matrix of the GP.
```
from gpytorch.models import ApproximateGP
from gpytorch.variational import CholeskyVariationalDistribution
from gpytorch.variational import VariationalStrategy
class GPModel(ApproximateGP):
def __init__(self, inducing_points):
variational_distribution = CholeskyVariationalDistribution(inducing_points.size(0))
variational_strategy = VariationalStrategy(self, inducing_points, variational_distribution, learn_inducing_locations=True)
super(GPModel, self).__init__(variational_strategy)
self.mean_module = gpytorch.means.ConstantMean()
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
inducing_points = train_x[:500, :]
model = GPModel(inducing_points=inducing_points)
likelihood = gpytorch.likelihoods.GaussianLikelihood()
if torch.cuda.is_available():
model = model.cuda()
likelihood = likelihood.cuda()
```
### Training the Model
The cell below trains the model above, learning both the hyperparameters of the Gaussian process **and** the parameters of the neural network in an end-to-end fashion using Type-II MLE.
Unlike when using the exact GP marginal log likelihood, performing variational inference allows us to make use of stochastic optimization techniques. For this example, we'll do one epoch of training. Given the small size of the neural network relative to the size of the dataset, this should be sufficient to achieve comparable accuracy to what was observed in the DKL paper.
The optimization loop differs from the one seen in our more simple tutorials in that it involves looping over both a number of training iterations (epochs) *and* minibatches of the data. However, the basic process is the same: for each minibatch, we forward through the model, compute the loss (the `VariationalELBO` or ELBO), call backwards, and do a step of optimization.
```
num_epochs = 1 if smoke_test else 4
model.train()
likelihood.train()
optimizer = torch.optim.Adam([
{'params': model.parameters()},
{'params': likelihood.parameters()},
], lr=0.01)
# Our loss object. We're using the VariationalELBO
mll = gpytorch.mlls.VariationalELBO(likelihood, model, num_data=train_y.size(0))
epochs_iter = tqdm.notebook.tqdm(range(num_epochs), desc="Epoch")
for i in epochs_iter:
# Within each iteration, we will go over each minibatch of data
minibatch_iter = tqdm.notebook.tqdm(train_loader, desc="Minibatch", leave=False)
for x_batch, y_batch in minibatch_iter:
optimizer.zero_grad()
output = model(x_batch)
loss = -mll(output, y_batch)
minibatch_iter.set_postfix(loss=loss.item())
loss.backward()
optimizer.step()
```
### Making Predictions
The next cell gets the predictive covariance for the test set (and also technically gets the predictive mean, stored in `preds.mean()`). Because the test set is substantially smaller than the training set, we don't need to make predictions in mini batches here, although this can be done by passing in minibatches of `test_x` rather than the full tensor.
```
model.eval()
likelihood.eval()
means = torch.tensor([0.])
with torch.no_grad():
for x_batch, y_batch in test_loader:
preds = model(x_batch)
means = torch.cat([means, preds.mean.cpu()])
means = means[1:]
print('Test MAE: {}'.format(torch.mean(torch.abs(means - test_y.cpu()))))
```
| true |
code
| 0.650217 | null | null | null | null |
|
# MRCA estimation
-------
You can access your data via the dataset number. For example, ``handle = open(get(42), 'r')``.
To save data, write your data to a file, and then call ``put('filename.txt')``. The dataset will then be available in your galaxy history.
Notebooks can be saved to Galaxy by clicking the large green button at the top right of the IPython interface.<br>
More help and informations can be found on the project [website](https://github.com/bgruening/galaxy-ipython).
## Inputs
------
This notebook expects two inputs from Galaxy history:
1. a comma separated list of accession numbers and corresponding collection dates
2. a phylogenetic tree (in newick format) in which OTU labels correspond to accession numbers from input 1
Here is an example of input 1:
```
Accession,Collection_Date
MT049951,2020-01-17
MT019531,2019-12-30
MT019529,2019-12-23
MN975262,2020-01-11
MN996528,2019-12-30
MT019532,2019-12-30
MT019530,2019-12-30
MN994468,2020-01-22
```
```
# Set history items for datasets containing accession/dates and a maximum likelihood tree:
# These numbers correspond to numbers of Galaxy datasets
acc_date = 1
tree = 116
!pip install --upgrade pip==20.0.2
!pip install --upgrade statsmodels==0.11.0
!pip install --upgrade pandas==0.24.2
from Bio import Phylo as phylo
from matplotlib import pyplot as plt
import pandas as pd
import datetime
import statsmodels.api as sm
import statsmodels.formula.api as smf
%matplotlib inline
# Get accessions and dates
acc_path = get(acc_date)
# Get ML tree
tree_path = get(tree)
!mv {acc_path} acc_date.csv
!mv {tree_path} tree.nwk
col_dates = pd.read_csv('acc_date.csv')
col_dates
tree = next( phylo.parse( 'tree.nwk', "newick" ) )
plt.rcParams['figure.figsize'] = [15, 50]
phylo.draw( tree )
def root_to_tip( tree, date_df ):
accum = []
def tree_walker( clade, total_branch_length ):
for child in clade.clades:
if child.is_terminal:
if child.name is not None:
date = date_df[date_df['Accession']==child.name]['Collection_Date'].to_string(index=False)
accum.append( ( child.name, date, total_branch_length + child.branch_length ) )
tree_walker( child, total_branch_length + child.branch_length )
tree_walker( tree.clade, 0 )
return pd.DataFrame( accum, columns=["name","date","distance_to_root"] )
for clade in list( tree.find_clades() ):
tree.root_with_outgroup( clade )
df = root_to_tip( tree, col_dates )
df['date'] = pd.to_datetime(df['date'])
df['date_as_numeric'] = [d.year + (d.dayofyear-1)/365 for d in df['date']]
plt.rcParams['figure.figsize'] = [15, 10]
df.plot( x="date", y="distance_to_root" )
df['date_as_numeric'] = [d.year + (d.dayofyear-1)/365 for d in df['date']]
```
## MRCA timing is ...
```
import datetime
def decimal_to_calendar (decimal):
years = int (decimal)
d = datetime.datetime (years, 1,1) + datetime.timedelta (days = int ((decimal-years)*365))
return d
model = smf.ols(formula='distance_to_root ~ date_as_numeric ', data=df)
results = model.fit()
print( results.summary() )
print ("Root predicted at {}".format(decimal_to_calendar(-results.params.Intercept/results.params.date_as_numeric)))
```
| true |
code
| 0.576721 | null | null | null | null |
|
# Bias Removal
Climate models can have biases relative to different verification datasets. Commonly, biases are removed by postprocessing before verification of forecasting skill. `climpred` provides convenience functions to do so.
```
import climpred
import xarray as xr
import matplotlib.pyplot as plt
from climpred import HindcastEnsemble
hind = climpred.tutorial.load_dataset('CESM-DP-SST') # CESM-DPLE hindcast ensemble output.
obs = climpred.tutorial.load_dataset('ERSST') # observations
hind["lead"].attrs["units"] = "years"
```
We begin by removing a mean climatology for the observations, since `CESM-DPLE` generates its anomalies over this same time period.
```
obs = obs - obs.sel(time=slice('1964', '2014')).mean('time')
hindcast = HindcastEnsemble(hind)
hindcast = hindcast.add_observations(obs)
hindcast.plot()
```
The warming of the `observations` is similar to `initialized`.
## Mean bias removal
Typically, bias depends on lead-time and therefore should therefore also be removed depending on lead-time.
```
bias = hindcast.verify(metric='bias', comparison='e2o', dim=[], alignment='same_verifs')
bias.SST.plot()
```
Against `observations`, there is small cold bias in 1980 and 1990 initialization years and warm bias before and after.
```
# lead-time dependant mean bias over all initializations is quite small but negative
mean_bias = bias.mean('init')
mean_bias.SST.plot()
```
### Cross Validatation
To remove the mean bias quickly, the mean bias over all initializations is subtracted. For formally correct bias removal with cross validation, the given initialization is left out when subtracting the mean bias.
`climpred` wraps these functions in `HindcastEnsemble.remove_bias(how='mean', cross_validate={bool})`.
```
hindcast.remove_bias(how='mean', cross_validate=True, alignment='same_verifs').plot()
plt.title('hindcast lead timeseries removed for unconditional mean bias')
plt.show()
```
## Skill
Distance-based accuracy metrics like (`mse`,`rmse`,`nrmse`,...) are sensitive to mean bias removal. Correlations like (`pearson_r`, `spearman_r`) are insensitive to bias correction.
```
metric='rmse'
hindcast.verify(metric=metric,
comparison='e2o',
dim='init',
alignment='same_verifs')['SST'].plot(label='no bias correction')
hindcast.remove_bias(cross_validate=False,
alignment='same_verifs') \
.verify(metric=metric,
comparison='e2o',
dim='init',
alignment='same_verifs').SST.plot(label='bias correction without cross validation')
hindcast.remove_bias(cross_validate=True,
alignment='same_verifs') \
.verify(metric=metric,
comparison='e2o',
dim='init',
alignment='same_verifs').SST.plot(label='formally correct bias correction with cross validation')
plt.legend()
plt.title(f"{metric.upper()} SST evaluated against observations")
plt.show()
```
| true |
code
| 0.718798 | null | null | null | null |
|
# Least-squares technique
## References
- Statistics in geography: https://archive.org/details/statisticsingeog0000ebdo/
## Imports
```
from functools import partial
import numpy as np
from scipy.stats import multivariate_normal, t
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from ipywidgets import interact, IntSlider
inv = np.linalg.inv
df = pd.read_csv('regression_data.csv')
df.head(3)
```
## Population
0.5 and 0.2 are NOT the population parameters. Although we used them to generate the population, the population parameters can be different from them.
```
def get_y(x):
ys = x * 0.5 + 0.2
noises = 1 * np.random.normal(size=len(ys))
return ys + noises
np.random.seed(52)
xs = np.linspace(0, 10, 10000)
ys = get_y(xs)
np.random.seed(32)
np.random.shuffle(xs)
np.random.seed(32)
np.random.shuffle(ys)
plt.scatter(xs, ys, s=5)
plt.show()
```
## Design matrices
```
PHI = xs.reshape(-1, 1)
PHI = np.hstack([
PHI,
np.ones(PHI.shape)
])
T = ys.reshape(-1, 1)
```
## Normal equation with regularization
```
def regularized_least_squares(PHI, T, regularizer=0):
assert PHI.shape[0] == T.shape[0]
pseudo_inv = inv(PHI.T @ PHI + np.eye(PHI.shape[1]) * regularizer)
assert pseudo_inv.shape[0] == pseudo_inv.shape[1]
W = pseudo_inv @ PHI.T @ T
return {'slope' : float(W[0]), 'intercept' : float(W[1])}
```
## Sampling distributions
### Population parameters
```
pop_params = regularized_least_squares(PHI, T)
pop_slope, pop_intercept = pop_params['slope'], pop_params['intercept']
```
### Sample statistics
Verify that the sampling distribution for both regression coefficients are normal.
```
n = 10 # sample size
num_samps = 1000
def sample(PHI, T, n):
idxs = np.random.randint(PHI.shape[0], size=n)
return PHI[idxs], T[idxs]
samp_slopes, samp_intercepts = [], []
for i in range(num_samps):
PHI_samp, T_samp = sample(PHI, T, n)
learned_param = regularized_least_squares(PHI_samp, T_samp)
samp_slopes.append(learned_param['slope']); samp_intercepts.append(learned_param['intercept'])
np.std(samp_slopes), np.std(samp_intercepts)
fig = plt.figure(figsize=(12, 4))
fig.add_subplot(121)
sns.kdeplot(samp_slopes)
plt.title('Sample distribution of sample slopes')
fig.add_subplot(122)
sns.kdeplot(samp_intercepts)
plt.title('Sample distribution of sample intercepts')
plt.show()
```
Note that the two normal distributions above are correlated. This means that we need to be careful when plotting the 95% CI for the regression line, because we can't just plot the regression line with the highest slope and the highest intercept and the regression line with the lowest slope and the lowest intercept.
```
sns.jointplot(samp_slopes, samp_intercepts, s=5)
plt.show()
```
## Confidence interval
**Caution.** The following computation of confidence intervals does not apply to regularized least squares.
### Sample one sample
```
n = 500
PHI_samp, T_samp = sample(PHI, T, n)
```
### Compute sample statistics
```
learned_param = regularized_least_squares(PHI_samp, T_samp)
samp_slope, samp_intercept = learned_param['slope'], learned_param['intercept']
samp_slope, samp_intercept
```
### Compute standard errors of sample statistics
Standard error is the estimate of the standard deviation of the sampling distribution.
$$\hat\sigma = \sqrt{\frac{\text{Sum of all squared residuals}}{\text{Degrees of freedom}}}$$
Standard error for slope:
$$\text{SE}(\hat\beta_1)=\hat\sigma \sqrt{\frac{1}{(n-1)s_X^2}}$$
Standard error for intercept:
$$\text{SE}(\hat\beta_0)=\hat\sigma \sqrt{\frac{1}{n} + \frac{\bar X^2}{(n-1)s_X^2}}$$
where $\bar X$ is the sample mean of the $X$'s and $s_X^2$ is the sample variance of the $X$'s.
```
preds = samp_slope * PHI_samp[:,0] + samp_intercept
sum_of_squared_residuals = np.sum((T_samp.reshape(-1) - preds) ** 2)
samp_sigma_y_give_x = np.sqrt(sum_of_squared_residuals / (n - 2))
samp_sigma_y_give_x
samp_mean = np.mean(PHI_samp[:,0])
samp_var = np.var(PHI_samp[:,0])
SE_slope = samp_sigma_y_give_x * np.sqrt(1 / ((n - 1) * samp_var))
SE_intercept = samp_sigma_y_give_x * np.sqrt(1 / n + samp_mean ** 2 / ((n - 1) * samp_var))
SE_slope, SE_intercept
```
### Compute confidence intervals for sample statistics
```
slope_lower, slope_upper = samp_slope - 1.96 * SE_slope, samp_slope + 1.96 * SE_slope
slope_lower, slope_upper
intercept_lower, intercept_upper = samp_intercept - 1.96 * SE_intercept, samp_intercept + 1.96 * SE_intercept
intercept_lower, intercept_upper
```
### Compute confidence interval for regression line
#### Boostrapped solution
Use a 2-d Guassian to model the joint distribution between boostrapped sample slopes and boostrapped sample intercepts.
**Fixed.** `samp_slopes` and `samp_intercepts` used in the cell below are not boostrapped; they are directly sampled from the population. Next time, add the boostrapped version. Using `samp_slopes` and `samp_intercepts` still has its value, though; it shows the population regression line lie right in the middle of all sample regression lines. Remember that, when ever you use bootstrapping to estimate the variance / covariance of the sample distribution of some statistic, there might be an equation that you can use from statistical theory.
```
num_resamples = 10000
resample_slopes, resample_intercepts = [], []
for i in range(num_resamples):
PHI_resample, T_resample = sample(PHI_samp, T_samp, n=len(PHI_samp))
learned_params = regularized_least_squares(PHI_resample, T_resample)
resample_slopes.append(learned_params['slope']); resample_intercepts.append(learned_params['intercept'])
```
**Fixed.** The following steps might improve the results, but I don't think they are part of the standard practice.
```
# means = [np.mean(resample_slopes), np.mean(resample_intercepts)]
# cov = np.cov(resample_slopes, resample_intercepts)
# model = multivariate_normal(mean=means, cov=cov)
```
Sample 5000 (slope, intercept) pairs from the Gaussian.
```
# num_pairs_sampled = 10000
# pairs = model.rvs(num_pairs_sampled)
```
Scatter samples, plot regression lines and CI.
```
plt.figure(figsize=(20, 10))
plt.scatter(PHI_samp[:,0], T_samp.reshape(-1), s=20) # sample
granularity = 1000
xs = np.linspace(0, 10, granularity)
plt.plot(xs, samp_slope * xs + samp_intercept, label='Sample') # sample regression line
plt.plot(xs, pop_slope * xs + pop_intercept, '--', color='black', label='Population') # population regression line
lines = np.zeros((num_resamples, granularity))
for i, (slope, intercept) in enumerate(zip(resample_slopes, resample_intercepts)):
lines[i] = slope * xs + intercept
confidence_level = 95
uppers_95 = np.percentile(lines, confidence_level + (100 - confidence_level) / 2, axis=0)
lowers_95 = np.percentile(lines, (100 - confidence_level) / 2, axis=0)
confidence_level = 99
uppers_99 = np.percentile(lines, confidence_level + (100 - confidence_level) / 2, axis=0)
lowers_99 = np.percentile(lines, (100 - confidence_level) / 2, axis=0)
plt.fill_between(xs, lowers_95, uppers_95, color='grey', alpha=0.7, label='95% CI')
plt.plot(xs, uppers_99, color='grey', label='99% CI')
plt.plot(xs, lowers_99, color='grey')
plt.legend()
plt.show()
```
#### Analytic solution
**Reference.** Page 97, Statistics of Geograph: A Practical Approach, David Ebdon, 1987.
For a particular value $x_0$ of the independent variable $x$, its confidence interval is given by:
$$\sqrt{\frac{\sum e^{2}}{n-2}\left[\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{\sum x^{2}-n \bar{x}^{2}}\right]}$$
where
- $\sum e^2$ is the sum of squares of residuals from regression,
- $x$ is the independent variables,
- $\bar{x}$ is the sample mean of the independent variables.
```
sum_of_squared_xs = np.sum(PHI_samp[:,0] ** 2)
SEs = np.sqrt(
(sum_of_squared_residuals / (n - 2)) *
(1 / n + (xs - samp_mean) ** 2 / (sum_of_squared_xs - n * samp_mean ** 2))
)
t_97dot5 = t.ppf(0.975, df=n-2)
t_99dot5 = t.ppf(0.995, df=n-2)
yhats = samp_slope * xs + samp_intercept
uppers_95 = yhats + t_97dot5 * SEs
lowers_95 = yhats - t_97dot5 * SEs
uppers_99 = yhats + t_99dot5 * SEs
lowers_99 = yhats - t_99dot5 * SEs
plt.figure(figsize=(20, 10))
plt.scatter(PHI_samp[:,0], T_samp.reshape(-1), s=20) # sample
granularity = 1000
xs = np.linspace(0, 10, granularity)
plt.plot(xs, samp_slope * xs + samp_intercept, label='Sample') # sample regression line
plt.plot(xs, pop_slope * xs + pop_intercept, '--', color='black', label='Population') # population regression line
plt.fill_between(xs, lowers_95, uppers_95, color='grey', alpha=0.7, label='95% CI')
plt.plot(xs, uppers_99, color='grey', label='99% CI')
plt.plot(xs, lowers_99, color='grey')
plt.legend()
plt.show()
```
## Regularized least squares
```
def plot_regression_line(PHI, T, regularizer):
plt.scatter(PHI[:,0], T, s=5)
params = regularized_least_squares(PHI, T, regularizer)
x_min, x_max = PHI[:,0].min(), PHI[:,0].max()
xs = np.linspace(x_min, x_max, 2)
ys = params['slope'] * xs + params['intercept']
plt.plot(xs, ys, color='orange')
plt.ylim(-3, 10)
plt.show()
plot_regression_line(PHI, T, regularizer=20)
def plot_regression_line_wrapper(regularizer, num_points):
plot_regression_line(PHI[:num_points], T[:num_points], regularizer)
```
Yes! The effect of regularization does change with the size of the dataset.
```
_ = interact(
plot_regression_line_wrapper,
regularizer=IntSlider(min=0, max=10000, value=5000, continuous_update=False),
num_points=IntSlider(min=2, max=1000, value=1000, continuous_update=False)
)
```
| true |
code
| 0.648745 | null | null | null | null |
|
```
from IPython.display import display, HTML
from pyspark.sql import SparkSession
from pyspark import StorageLevel
import pandas as pd
from pyspark.sql.types import StructType, StructField,StringType, LongType, IntegerType, DoubleType, ArrayType
from pyspark.sql.functions import regexp_replace
from sedona.register import SedonaRegistrator
from sedona.utils import SedonaKryoRegistrator, KryoSerializer
from pyspark.sql.functions import col, split, expr
from pyspark.sql.functions import udf, lit
from sedona.utils import SedonaKryoRegistrator, KryoSerializer
from pyspark.sql.functions import col, split, expr
from pyspark.sql.functions import udf, lit
```
# Create Spark Session for application
```
spark = SparkSession.\
builder.\
master("local[*]").\
appName("Demo-app").\
config("spark.serializer", KryoSerializer.getName).\
config("spark.kryo.registrator", SedonaKryoRegistrator.getName) .\
config("spark.jars.packages", "org.apache.sedona:sedona-python-adapter-3.0_2.12:1.1.0-incubating,org.datasyslab:geotools-wrapper:1.1.0-25.2") .\
getOrCreate()
SedonaRegistrator.registerAll(spark)
sc = spark.sparkContext
```
# Geotiff Loader
1. Loader takes as input a path to directory which contains geotiff files or a parth to particular geotiff file
2. Loader will read geotiff image in a struct named image which contains multiple fields as shown in the schema below which can be extracted using spark SQL
```
# Path to directory of geotiff images
DATA_DIR = "./data/raster/"
df = spark.read.format("geotiff").option("dropInvalid",True).load(DATA_DIR)
df.printSchema()
df = df.selectExpr("image.origin as origin","ST_GeomFromWkt(image.wkt) as Geom", "image.height as height", "image.width as width", "image.data as data", "image.nBands as bands")
df.show(5)
```
# Extract a particular band from geotiff dataframe using RS_GetBand()
```
''' RS_GetBand() will fetch a particular band from given data array which is the concatination of all the bands'''
df = df.selectExpr("Geom","RS_GetBand(data, 1,bands) as Band1","RS_GetBand(data, 2,bands) as Band2","RS_GetBand(data, 3,bands) as Band3", "RS_GetBand(data, 4,bands) as Band4")
df.createOrReplaceTempView("allbands")
df.show(5)
```
# Map Algebra operations on band values
```
''' RS_NormalizedDifference can be used to calculate NDVI for a particular geotiff image since it uses same computational formula as ndvi'''
NomalizedDifference = df.selectExpr("RS_NormalizedDifference(Band1, Band2) as normDiff")
NomalizedDifference.show(5)
''' RS_Mean() can used to calculate mean of piel values in a particular spatial band '''
meanDF = df.selectExpr("RS_Mean(Band1) as mean")
meanDF.show(5)
""" RS_Mode() is used to calculate mode in an array of pixels and returns a array of double with size 1 in case of unique mode"""
modeDF = df.selectExpr("RS_Mode(Band1) as mode")
modeDF.show(5)
''' RS_GreaterThan() is used to mask all the values with 1 which are greater than a particular threshold'''
greaterthanDF = spark.sql("Select RS_GreaterThan(Band1,1000.0) as greaterthan from allbands")
greaterthanDF.show()
''' RS_GreaterThanEqual() is used to mask all the values with 1 which are greater than a particular threshold'''
greaterthanEqualDF = spark.sql("Select RS_GreaterThanEqual(Band1,360.0) as greaterthanEqual from allbands")
greaterthanEqualDF.show()
''' RS_LessThan() is used to mask all the values with 1 which are less than a particular threshold'''
lessthanDF = spark.sql("Select RS_LessThan(Band1,1000.0) as lessthan from allbands")
lessthanDF.show()
''' RS_LessThanEqual() is used to mask all the values with 1 which are less than equal to a particular threshold'''
lessthanEqualDF = spark.sql("Select RS_LessThanEqual(Band1,2890.0) as lessthanequal from allbands")
lessthanEqualDF.show()
''' RS_AddBands() can add two spatial bands together'''
sumDF = df.selectExpr("RS_AddBands(Band1, Band2) as sumOfBand")
sumDF.show(5)
''' RS_SubtractBands() can subtract two spatial bands together'''
subtractDF = df.selectExpr("RS_SubtractBands(Band1, Band2) as diffOfBand")
subtractDF.show(5)
''' RS_MultiplyBands() can multiple two bands together'''
multiplyDF = df.selectExpr("RS_MultiplyBands(Band1, Band2) as productOfBand")
multiplyDF.show(5)
''' RS_DivideBands() can divide two bands together'''
divideDF = df.selectExpr("RS_DivideBands(Band1, Band2) as divisionOfBand")
divideDF.show(5)
''' RS_MultiplyFactor() will multiply a factor to a spatial band'''
mulfacDF = df.selectExpr("RS_MultiplyFactor(Band2, 2) as target")
mulfacDF.show(5)
''' RS_BitwiseAND() will return AND between two values of Bands'''
bitwiseAND = df.selectExpr("RS_BitwiseAND(Band1, Band2) as AND")
bitwiseAND.show(5)
''' RS_BitwiseOR() will return OR between two values of Bands'''
bitwiseOR = df.selectExpr("RS_BitwiseOR(Band1, Band2) as OR")
bitwiseOR.show(5)
''' RS_Count() will calculate the total number of occurence of a target value'''
countDF = df.selectExpr("RS_Count(RS_GreaterThan(Band1,1000.0), 1.0) as count")
countDF.show(5)
''' RS_Modulo() will calculate the modulus of band value with respect to a given number'''
moduloDF = df.selectExpr("RS_Modulo(Band1, 21.0) as modulo ")
moduloDF.show(5)
''' RS_SquareRoot() will calculate calculate square root of all the band values upto two decimal places'''
rootDF = df.selectExpr("RS_SquareRoot(Band1) as root")
rootDF.show(5)
''' RS_LogicalDifference() will return value from band1 if value at that particular location is not equal tp band1 else it will return 0'''
logDiff = df.selectExpr("RS_LogicalDifference(Band1, Band2) as loggDifference")
logDiff.show(5)
''' RS_LogicalOver() will iterate over two bands and return value of first band if it is not equal to 0 else it will return value from later band'''
logOver = df.selectExpr("RS_LogicalOver(Band3, Band2) as logicalOver")
logOver.show(5)
```
# Visualising Geotiff Images
1. Normalize the bands in range [0-255] if values are greater than 255
2. Process image using RS_Base64() which converts in into a base64 string
3. Embedd results of RS_Base64() in RS_HTML() to embedd into IPython notebook
4. Process results of RS_HTML() as below:
```
''' Plotting images as a dataframe using geotiff Dataframe.'''
df = spark.read.format("geotiff").option("dropInvalid",True).load(DATA_DIR)
df = df.selectExpr("image.origin as origin","ST_GeomFromWkt(image.wkt) as Geom", "image.height as height", "image.width as width", "image.data as data", "image.nBands as bands")
df = df.selectExpr("RS_GetBand(data,1,bands) as targetband", "height", "width", "bands", "Geom")
df_base64 = df.selectExpr("Geom", "RS_Base64(height,width,RS_Normalize(targetBand), RS_Array(height*width,0.0), RS_Array(height*width, 0.0)) as red","RS_Base64(height,width,RS_Array(height*width, 0.0), RS_Normalize(targetBand), RS_Array(height*width, 0.0)) as green", "RS_Base64(height,width,RS_Array(height*width, 0.0), RS_Array(height*width, 0.0), RS_Normalize(targetBand)) as blue","RS_Base64(height,width,RS_Normalize(targetBand), RS_Normalize(targetBand),RS_Normalize(targetBand)) as RGB" )
df_HTML = df_base64.selectExpr("Geom","RS_HTML(red) as RedBand","RS_HTML(blue) as BlueBand","RS_HTML(green) as GreenBand", "RS_HTML(RGB) as CombinedBand")
df_HTML.show(5)
display(HTML(df_HTML.limit(2).toPandas().to_html(escape=False)))
```
# User can also create some UDF manually to manipulate Geotiff dataframes
```
''' Sample UDF calculates sum of all the values in a band which are greater than 1000.0 '''
def SumOfValues(band):
total = 0.0
for num in band:
if num>1000.0:
total+=1
return total
calculateSum = udf(SumOfValues, DoubleType())
spark.udf.register("RS_Sum", calculateSum)
sumDF = df.selectExpr("RS_Sum(targetband) as sum")
sumDF.show()
''' Sample UDF to visualize a particular region of a GeoTiff image'''
def generatemask(band, width,height):
for (i,val) in enumerate(band):
if (i%width>=12 and i%width<26) and (i%height>=12 and i%height<26):
band[i] = 255.0
else:
band[i] = 0.0
return band
maskValues = udf(generatemask, ArrayType(DoubleType()))
spark.udf.register("RS_MaskValues", maskValues)
df_base64 = df.selectExpr("Geom", "RS_Base64(height,width,RS_Normalize(targetband), RS_Array(height*width,0.0), RS_Array(height*width, 0.0), RS_MaskValues(targetband,width,height)) as region" )
df_HTML = df_base64.selectExpr("Geom","RS_HTML(region) as selectedregion")
display(HTML(df_HTML.limit(2).toPandas().to_html(escape=False)))
```
| true |
code
| 0.639201 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/mees/calvin/blob/main/RL_with_CALVIN.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
<h1>Reinforcement Learning with CALVIN</h1>
The **CALVIN** simulated benchmark is perfectly suited for training agents with reinforcement learning, in this notebook we will demonstrate how to integrate your agents to these environments.
## Installation
The first step is to install the CALVIN github repository such that we have access to the packages
```
# Download repo
%mkdir /content/calvin
%cd /content/calvin
!git clone https://github.com/mees/calvin_env.git
%cd /content/calvin/calvin_env
!git clone https://github.com/lukashermann/tacto.git
# Install packages
%cd /content/calvin/calvin_env/tacto/
!pip3 install -e .
%cd /content/calvin/calvin_env
!pip3 install -e .
!pip3 install -U numpy
# Run this to check if the installation was succesful
from calvin_env.envs.play_table_env import PlayTableSimEnv
```
## Loading the environment
After the installation has finished successfully, we can start using the environment for reinforcement Learning.
To be able to use the environment we need to have the appropriate configuration that define the desired features, for this example, we will load the static and gripper camera.
```
%cd /content/calvin
from hydra import initialize, compose
with initialize(config_path="./calvin_env/conf/"):
cfg = compose(config_name="config_data_collection.yaml", overrides=["cameras=static_and_gripper"])
cfg.env["use_egl"] = False
cfg.env["show_gui"] = False
cfg.env["use_vr"] = False
cfg.env["use_scene_info"] = True
print(cfg.env)
```
The environment has similar structure to traditional OpenAI Gym environments.
* We can restart the simulation with the *reset* function.
* We can perform an action in the environment with the *step* function.
* We can visualize images taken from the cameras in the environment by using the *render* function.
```
import time
import hydra
import numpy as np
from google.colab.patches import cv2_imshow
env = hydra.utils.instantiate(cfg.env)
observation = env.reset()
#The observation is given as a dictionary with different values
print(observation.keys())
for i in range(5):
# The action consists in a pose displacement (position and orientation)
action_displacement = np.random.uniform(low=-1, high=1, size=6)
# And a binary gripper action, -1 for closing and 1 for oppening
action_gripper = np.random.choice([-1, 1], size=1)
action = np.concatenate((action_displacement, action_gripper), axis=-1)
observation, reward, done, info = env.step(action)
rgb = env.render(mode="rgb_array")[:,:,::-1]
cv2_imshow(rgb)
```
## Custom environment for Reinforcement Learning
There are some aspects that needs to be defined to be able to use it for reinforcement learning, including:
1. Observation space
2. Action space
3. Reward function
We are going to create a Custom environment that extends the **PlaytableSimEnv** to add these requirements. <br/>
The specific task that will be solved is called "move_slider_left", here you can find a [list of possible tasks](https://github.com/mees/calvin_env/blob/main/conf/tasks/new_playtable_tasks.yaml) that can be evaluated using CALVIN.
```
from gym import spaces
from calvin_env.envs.play_table_env import PlayTableSimEnv
class SlideEnv(PlayTableSimEnv):
def __init__(self,
tasks: dict = {},
**kwargs):
super(SlideEnv, self).__init__(**kwargs)
# For this example we will modify the observation to
# only retrieve the end effector pose
self.action_space = spaces.Box(low=-1, high=1, shape=(7,))
self.observation_space = spaces.Box(low=-1, high=1, shape=(7,))
# We can use the task utility to know if the task was executed correctly
self.tasks = hydra.utils.instantiate(tasks)
def reset(self):
obs = super().reset()
self.start_info = self.get_info()
return obs
def get_obs(self):
"""Overwrite robot obs to only retrieve end effector position"""
robot_obs, robot_info = self.robot.get_observation()
return robot_obs[:7]
def _success(self):
""" Returns a boolean indicating if the task was performed correctly """
current_info = self.get_info()
task_filter = ["move_slider_left"]
task_info = self.tasks.get_task_info_for_set(self.start_info, current_info, task_filter)
return 'move_slider_left' in task_info
def _reward(self):
""" Returns the reward function that will be used
for the RL algorithm """
reward = int(self._success()) * 10
r_info = {'reward': reward}
return reward, r_info
def _termination(self):
""" Indicates if the robot has reached a terminal state """
success = self._success()
done = success
d_info = {'success': success}
return done, d_info
def step(self, action):
""" Performing a relative action in the environment
input:
action: 7 tuple containing
Position x, y, z.
Angle in rad x, y, z.
Gripper action
each value in range (-1, 1)
output:
observation, reward, done info
"""
# Transform gripper action to discrete space
env_action = action.copy()
env_action[-1] = (int(action[-1] >= 0) * 2) - 1
self.robot.apply_action(env_action)
for i in range(self.action_repeat):
self.p.stepSimulation(physicsClientId=self.cid)
obs = self.get_obs()
info = self.get_info()
reward, r_info = self._reward()
done, d_info = self._termination()
info.update(r_info)
info.update(d_info)
return obs, reward, done, info
```
# Training an RL agent
After generating the wrapper training a reinforcement learning agent is straightforward, for this example we will use stable baselines 3 agents
```
!pip3 install stable_baselines3
```
To train the agent we create an instance of our new environment and send it to the stable baselines agent to learn a policy.
> Note: the example uses Soft Actor Critic (SAC) which is one of the state of the art algorithm for off-policy RL.
```
import gym
import numpy as np
from stable_baselines3 import SAC
new_env_cfg = {**cfg.env}
new_env_cfg["tasks"] = cfg.tasks
new_env_cfg.pop('_target_', None)
new_env_cfg.pop('_recursive_', None)
env = SlideEnv(**new_env_cfg)
model = SAC("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000, log_interval=4)
```
| true |
code
| 0.672359 | null | null | null | null |
|
# Polish phonetic comparison
> "Transcript matching for E2E ASR with phonetic post-processing"
- toc: false
- branch: master
- hidden: true
- categories: [asr, polish, phonetic, todo]
```
from difflib import SequenceMatcher
import icu
plipa = icu.Transliterator.createInstance('pl-pl_FONIPA')
```
The errors in E2E models are quite often phonetic confusions, so we do the opposite of traditional ASR and generate the phonetic representation from the output as a basis for comparison.
```
def phonetic_check(word1, word2, ignore_spaces=False):
"""Uses ICU's IPA transliteration to check if words are the same"""
tl1 = plipa.transliterate(word1) if not ignore_spaces else plipa.transliterate(word1.replace(' ', ''))
tl2 = plipa.transliterate(word2) if not ignore_spaces else plipa.transliterate(word2.replace(' ', ''))
return tl1 == tl2
phonetic_check("jórz", "jusz", False)
```
The Polish `y` is phonetically a raised schwa; like the schwa in English, it's often deleted in fast speech. This function returns true if the only differences between the first word and the second is are deletions of `y`, except at the end of the word (which is typically the plural ending).
```
def no_igrek(word1, word2):
"""Checks if a word-internal y has been deleted"""
sm = SequenceMatcher(None, word1, word2)
for oc in sm.get_opcodes():
if oc[0] == 'equal':
continue
elif oc[0] == 'delete' and word1[oc[1]:oc[2]] != 'y':
return False
elif oc[0] == 'delete' and word1[oc[1]:oc[2]] == 'y' and oc[2] == len(word1):
return False
elif oc[0] == 'insert' or oc[0] == 'replace':
return False
return True
no_igrek('uniwersytet', 'uniwerstet')
no_igrek('uniwerstety', 'uniwerstet')
phonetic_alternatives = [ ['u', 'ó'], ['rz', 'ż'] ]
def reverse_alts(phonlist):
return [ [i[1], i[0]] for i in phonlist ]
sm = SequenceMatcher(None, "już", "jurz")
for oc in sm.get_opcodes():
print(oc)
```
Reads a `CTM`-like file, returning a list of lists containing the filename, start time, end time, and word.
```
def read_ctmish(filename):
output = []
with open(filename, 'r') as f:
for line in f.readlines():
pieces = line.strip().split(' ')
if len(pieces) <= 4:
continue
for piece in pieces[4:]:
output.append([pieces[0], pieces[2], pieces[3], piece])
return output
```
Returns the contents of a plain text file as a list of lists containing the line number and the word, for use in locating mismatches
```
def read_text(filename):
output = []
counter = 0
with open(filename, 'r') as f:
for line in f.readlines():
counter += 1
for word in line.strip().split(' ')
output.append([counter, word])
return output
ctmish = read_ctmish("/mnt/c/Users/Jim O\'Regan/git/notes/PlgU9JyTLPE.ctm")
rec_words = [i[3] for i in ctmish]
```
| true |
code
| 0.310773 | null | null | null | null |
|
This notebook compares the email activities and draft activites of an IETF working group.
Import the BigBang modules as needed. These should be in your Python environment if you've installed BigBang correctly.
```
import bigbang.mailman as mailman
from bigbang.parse import get_date
#from bigbang.functions import *
from bigbang.archive import Archive
from ietfdata.datatracker import *
```
Also, let's import a number of other dependencies we'll use later.
```
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import numpy as np
import math
import pytz
import pickle
import os
```
## Load the HRPC Mailing List
Now let's load the email data for analysis.
```
wg = "httpbisa"
urls = [wg]
archives = [Archive(url,mbox=True) for url in urls]
activities = [arx.get_activity(resolved=False) for arx in archives]
activity = activities[0]
```
## Load IETF Draft Data
Next, we will use the `ietfdata` tracker to look at the frequency of drafts for this working group.
```
import glob
path = '../../archives/datatracker/httpbis/draft_metadata.csv' # use your path
draft_df = pd.read_csv(path, index_col=None, header=0, parse_dates=['date'])
```
We will want to use the data of the drafts. Time resolution is too small.
```
draft_df['date'] = draft_df['date'].dt.date
```
## Gender score and tendency measures
This notebook uses the (notably imperfect) method of using first names to guess the gender of each draft author.
```
from gender_detector import gender_detector as gd
detector = gd.GenderDetector('us')
def gender_score(name):
"""
Takes a full name and returns a score for the guessed
gender.
1 - male
0 - female
.5 - unknown
"""
try:
first_name = name.split(" ")[0]
guess = detector.guess(first_name)
score = 0
if guess == "male":
return 1.0
elif guess == "female":
return 0.0
else:
# name does not have confidence to guesss
return 0.5
except:
# Some error, "unknown"
return .5
```
## Gender guesses on mailing list activity
Now to use the gender guesser to track the contributions by differently gendered participants over time.
```
from bigbang.parse import clean_name
gender_activity = activity.groupby(
by=lambda x: gender_score(clean_name(x)),
axis=1).sum().rename({0.0 : "women", 0.5 : "unknown", 1.0 : "men"},
axis="columns")
```
Note that our gender scoring method currently is unable to get a clear guess for a large percentage of the emails!
```
print("%f.2 percent of emails are from an unknown gender." \
% (gender_activity["unknown"].sum() / gender_activity.sum().sum()))
plt.bar(["women","unknown","men"],gender_activity.sum())
plt.title("Total emails sent by guessed gender")
```
## Plotting
Some preprocessing is necessary to get the drafts data ready for plotting.
```
from matplotlib import cm
viridis = cm.get_cmap('viridis')
drafts_per_day = draft_df.groupby('date').count()['title']
dpd_log = drafts_per_day.apply(lambda x: np.log1p(x))
```
For each of the mailing lists we are looking at, plot the rolling average (over `window`) of number of emails sent per day.
Then plot a vertical line with the height of the drafts count and colored by the gender tendency.
```
window = 100
plt.figure(figsize=(12, 6))
for i, gender in enumerate(gender_activity.columns):
colors = [viridis(0), viridis(.5), viridis(.99)]
ta = gender_activity[gender]
rmta = ta.rolling(window).mean()
rmtadna = rmta.dropna()
plt.plot_date(np.array(rmtadna.index),
np.array(rmtadna.values),
color = colors[i],
linestyle = '-', marker = None,
label='%s email activity - %s' % (wg, gender),
xdate=True)
vax = plt.vlines(drafts_per_day.index,
0,
drafts_per_day,
colors = 'r', # draft_gt_per_day,
cmap = 'viridis',
label=f'{wg} drafts ({drafts_per_day.sum()} total)'
)
plt.legend()
plt.title("%s working group emails and drafts" % (wg))
#plt.colorbar(vax, label = "more womanly <-- Gender Tendency --> more manly")
#plt.savefig("activites-marked.png")
#plt.show()
```
### Is gender diversity correlated with draft output?
```
from scipy.stats import pearsonr
import pandas as pd
def calculate_pvalues(df):
df = df.dropna()._get_numeric_data()
dfcols = pd.DataFrame(columns=df.columns)
pvalues = dfcols.transpose().join(dfcols, how='outer')
for r in df.columns:
for c in df.columns:
pvalues[r][c] = round(pearsonr(df[r], df[c])[1], 4)
return pvalues
drafts_per_ordinal_day = pd.Series({x[0].toordinal(): x[1] for x in drafts_per_day.items()})
drafts_per_ordinal_day
ta.rolling(window).mean()
garm = np.log1p(gender_activity.rolling(window).mean())
garm['diversity'] = (garm['unknown'] + garm['women']) / garm['men']
garm['drafts'] = drafts_per_ordinal_day
garm['drafts'] = garm['drafts'].fillna(0)
garm.corr(method='pearson')
calculate_pvalues(garm)
```
Some variations...
```
garm_dna = garm.dropna(subset=['drafts'])
```
| true |
code
| 0.399841 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/totti0223/deep_learning_for_biologists_with_keras/blob/master/notebooks/PlantDisease_tutorial.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Training a Plant Disease Diagnosis Model with PlantVillage Dataset
```
import numpy as np
import os
import matplotlib.pyplot as plt
from skimage.io import imread
from sklearn.metrics import classification_report, confusion_matrix
from sklearn .model_selection import train_test_split
import keras
import keras.backend as K
from keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator
from keras.utils.np_utils import to_categorical
from keras import layers
from keras.models import Sequential, Model
from keras.callbacks import EarlyStopping, ModelCheckpoint
```
# Preparation
## Data Preparation
```
!apt-get install subversion > /dev/null
#Retreive specifc diseases of tomato for training
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___Bacterial_spot image/Tomato___Bacterial_spot > /dev/null
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___Early_blight image/Tomato___Early_blight > /dev/null
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___Late_blight image/Tomato___Late_blight > /dev/null
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___Septoria_leaf_spot image/Tomato___Septoria_leaf_spot > /dev/null
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___Target_Spot image/Tomato___Target_Spot > /dev/null
!svn export https://github.com/spMohanty/PlantVillage-Dataset/trunk/raw/color/Tomato___healthy image/Tomato___healthy > /dev/null
#folder structure
!ls image
plt.figure(figsize=(15,10))
#visualize several images
parent_directory = "image"
for i, folder in enumerate(os.listdir(parent_directory)):
print(folder)
folder_directory = os.path.join(parent_directory,folder)
files = os.listdir(folder_directory)
#will inspect only 1 image per folder
file = files[0]
file_path = os.path.join(folder_directory,file)
image = imread(file_path)
plt.subplot(1,6,i+1)
plt.imshow(image)
plt.axis("off")
name = folder.split("___")[1][:-1]
plt.title(name)
#plt.show()
#load everything into memory
x = []
y = []
class_names = []
parent_directory = "image"
for i,folder in enumerate(os.listdir(parent_directory)):
print(i,folder)
class_names.append(folder)
folder_directory = os.path.join(parent_directory,folder)
files = os.listdir(folder_directory)
#will inspect only 1 image per folder
for file in files:
file_path = os.path.join(folder_directory,file)
image = load_img(file_path,target_size=(64,64))
image = img_to_array(image)/255.
x.append(image)
y.append(i)
x = np.array(x)
y = to_categorical(y)
#check the data shape
print(x.shape)
print(y.shape)
print(y[0])
x_train, _x, y_train, _y = train_test_split(x,y,test_size=0.2, stratify = y, random_state = 1)
x_valid,x_test, y_valid, y_test = train_test_split(_x,_y,test_size=0.4, stratify = _y, random_state = 1)
print("train data:",x_train.shape,y_train.shape)
print("validation data:",x_valid.shape,y_valid.shape)
print("test data:",x_test.shape,y_test.shape)
```
## Model Preparation
```
K.clear_session()
nfilter = 32
#VGG16 like model
model = Sequential([
#block1
layers.Conv2D(nfilter,(3,3),padding="same",name="block1_conv1",input_shape=(64,64,3)),
layers.Activation("relu"),
layers.BatchNormalization(),
#layers.Dropout(rate=0.2),
layers.Conv2D(nfilter,(3,3),padding="same",name="block1_conv2"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.MaxPooling2D((2,2),strides=(2,2),name="block1_pool"),
#block2
layers.Conv2D(nfilter*2,(3,3),padding="same",name="block2_conv1"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.Conv2D(nfilter*2,(3,3),padding="same",name="block2_conv2"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.MaxPooling2D((2,2),strides=(2,2),name="block2_pool"),
#block3
layers.Conv2D(nfilter*2,(3,3),padding="same",name="block3_conv1"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.Conv2D(nfilter*4,(3,3),padding="same",name="block3_conv2"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.Conv2D(nfilter*4,(3,3),padding="same",name="block3_conv3"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.MaxPooling2D((2,2),strides=(2,2),name="block3_pool"),
#layers.Flatten(),
layers.GlobalAveragePooling2D(),
#inference layer
layers.Dense(128,name="fc1"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.Dense(128,name="fc2"),
layers.BatchNormalization(),
layers.Activation("relu"),
#layers.Dropout(rate=0.2),
layers.Dense(6,name="prepredictions"),
layers.Activation("softmax",name="predictions")
])
model.compile(optimizer = "adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.summary()
```
## Training
```
#utilize early stopping function to stop at the lowest validation loss
es = EarlyStopping(monitor='val_loss', patience=10, verbose=1, mode='auto')
#utilize save best weight model during training
ckpt = ModelCheckpoint("PlantDiseaseCNNmodel.hdf5", monitor='val_loss', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
#we will define a generator class for training data and validation data seperately, as no augmentation is not required for validation data
t_gen = ImageDataGenerator(rotation_range=90,horizontal_flip=True)
v_gen = ImageDataGenerator()
train_gen = t_gen.flow(x_train,y_train,batch_size=98)
valid_gen = v_gen.flow(x_valid,y_valid,batch_size=98)
history = model.fit_generator(
train_gen,
steps_per_epoch = train_gen.n // 98,
callbacks = [es,ckpt],
validation_data = valid_gen,
validation_steps = valid_gen.n // 98,
epochs=50)
```
## Evaluation
```
#load the model weight file with lowest validation loss
model.load_weights("PlantDiseaseCNNmodel.hdf5")
#or can obtain the pretrained model from the github repo.
#check the model metrics
print(model.metrics_names)
#evaluate training data
print(model.evaluate(x= x_train, y = y_train))
#evaluate validation data
print(model.evaluate(x= x_valid, y = y_valid))
#evaluate test data
print(model.evaluate(x= x_test, y = y_test))
#draw a confusion matrix
#true label
y_true = np.argmax(y_test,axis=1)
#prediction label
Y_pred = model.predict(x_test)
y_pred = np.argmax(Y_pred, axis=1)
print(y_true)
print(y_pred)
#https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html#sphx-glr-auto-examples-model-selection-plot-confusion-matrix-py
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
def plot_confusion_matrix(y_true, y_pred, classes,
normalize=False,
title=None,
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if not title:
if normalize:
title = 'Normalized confusion matrix'
else:
title = 'Confusion matrix, without normalization'
# Compute confusion matrix
cm = confusion_matrix(y_true, y_pred)
# Only use the labels that appear in the data
#classes = classes[unique_labels(y_true, y_pred)]
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
fig, ax = plt.subplots(figsize=(5,5))
im = ax.imshow(cm, interpolation='nearest', cmap=cmap)
#ax.figure.colorbar(im, ax=ax)
# We want to show all ticks...
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
# ... and label them with the respective list entries
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
# Loop over data dimensions and create text annotations.
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
return ax
np.set_printoptions(precision=2)
plot_confusion_matrix(y_true, y_pred, classes=class_names, normalize=True,
title='Normalized confusion matrix')
```
## Predicting Indivisual Images
```
n = 15 #do not exceed (number of test image - 1)
plt.imshow(x_test[n])
plt.show()
true_label = np.argmax(y_test,axis=1)[n]
print("true_label is:",true_label,":",class_names[true_label])
prediction = model.predict(x_test[n][np.newaxis,...])[0]
print("predicted_value is:",prediction)
predicted_label = np.argmax(prediction)
print("predicted_label is:",predicted_label,":",class_names[predicted_label])
if true_label == predicted_label:
print("correct prediction")
else:
print("wrong prediction")
```
| true |
code
| 0.555254 | null | null | null | null |
|
# Chapter 3: Inferential statistics
[Link to outline](https://docs.google.com/document/d/1fwep23-95U-w1QMPU31nOvUnUXE2X3s_Dbk5JuLlKAY/edit#heading=h.uutryzqeo2av)
Concept map:

#### Notebook setup
```
# loading Python modules
import math
import random
import numpy as np
import pandas as pd
import seaborn as sns
from scipy.stats.distributions import norm
# set random seed for repeatability
np.random.seed(42)
# notebooks figs setup
%matplotlib inline
import matplotlib.pyplot as plt
sns.set(rc={'figure.figsize':(8,5)})
blue, orange = sns.color_palette()[0], sns.color_palette()[1]
# silence annoying warnings
import warnings; warnings.filterwarnings('ignore')
```
## Overview
- Main idea = learn about a population based on a sample
- Recall Amy's two research questions about the employee lifetime value (ELV) data:
- Question 1 = Is there a difference between ELV of the two groups? → **hypothesis testing**
- Question 2 = How much difference in ELV does stats training provide? → **estimation**
- Inferential statistics provides us with tools to answer both of these questions
## Estimators
We'll begin our study of inferential statistics by introducing **estimators**,
which are used for both **hypothesis testing** and **estimation**.

$\def\stderr#1{\mathbf{se}_{#1}}$
$\def\stderrhat#1{\hat{\mathbf{se}}_{#1}}$
### Definitions
- We use the term "estimator" to describe a function $f$ that takes samples as inputs,
which is written mathematically as:
$$
f \ \colon \underbrace{\mathcal{X}\times \mathcal{X}\times \cdots \times \mathcal{X}}_{n \textrm{ copies}}
\quad \to \quad \mathbb{R},
$$
where $n$ is the samples size and $\mathcal{X}$ denotes the possible values of the random variable $X$.
- We give different names to estimators, depending on the use case:
- **statistic** = a function computed from samples (descriptive statistics)
- **parameter estimators** = statistics that estimates population parameters
- **test statistic** = an estimator used as part of hypothesis testing procedure
- The **value** of the estimator $f(\mathbf{x})$ is computer from a particular sample $\mathbf{x}$.
- The **sampling distribution** of an estimator is when $f$ is the distribution of $f(\mathbf{X})$,
where $\mathbf{X}$ is a random sample.
- Example of estimators we discussed in descriptive statistics:
- Sample mean
- estimator: $\overline{x} = g(\mathbf{x}) = \frac{1}{n}\sum_{i=1}^n x_i$
- gives an estimate for the population mean $\mu$
- sampling distribution: $\overline{X} = g(\mathbf{X}) = \frac{1}{n}\sum_{i=1}^n X_i$
- Sample variance
- estimator: $s^2 = h(\mathbf{x}) = \frac{1}{n-1}\sum_{i=1}^n (x_i-\overline{x})^2$
- gives an estimate for the population variance $\sigma^2$
- sampling distribution: $S^2 = h(\mathbf{X}) = \frac{1}{n-1}\sum_{i=1}^n (X_i-\overline{X})^2$
- In this notebook we focus on one estimator: **difference between group means**
- estimator: $d = \texttt{mean}(\mathbf{x}_A) - \texttt{mean}(\mathbf{x}_{B}) = \overline{x}_{A} - \overline{x}_{B}$
- gives an estimate for the difference between population means: $\Delta = \mu_A - \mu_{B}$
- sampling distribution: $D = \overline{X}_A - \overline{X}_{B}$, which is a random variable
### Difference between group means
Consider two random variables $X_A$ and $X_B$:
$$ \large
X_A \sim \mathcal{N}\!\left(\mu_A, \sigma^2_A \right)
\qquad
\textrm{and}
\qquad
X_B \sim \mathcal{N}\!\left(\mu_B, \sigma^2_B \right)
$$
that describe the probability distribution for groups A and B, respectively.
- A sample of size $n_A$ from $X_A$ is denoted $\mathbf{x}_A = x_1x_2\cdots x_{n_A}$=`xA`, and let $\mathbf{x}_B = x_1x_2\cdots x_{n_B}$=`xB` be a random sample of size $n_B$ from $X_B$.
- We compute the mean in each group: $\overline{x}_{A} = \texttt{mean}(\mathbf{x}_A)$
and $\overline{x}_{B} = \texttt{mean}(\mathbf{x}_B)$
- The value of the estimator is $d = \overline{x}_{A} - \overline{x}_{B}$
```
def dmeans(xA, xB):
"""
Estimator for the difference between group means.
"""
d = np.mean(xA) - np.mean(xB)
return d
```
Note the difference between group means is precisely the estimator Amy need for her analysis (**Group S** and **Group NS**). We intentionally use the labels **A** and **B** to illustrate the general case.
```
# example parameters for each group
muA, sigmaA = 300, 10
muB, sigmaB = 200, 20
# size of samples for each group
nA = 5
nB = 4
```
#### Particular value of the estimator `dmeans`
```
xA = norm(muA, sigmaA).rvs(nA) # random sample from Group A
xB = norm(muB, sigmaB).rvs(nB) # random sample from Group B
d = dmeans(xA, xB)
d
```
The value of $d$ computed from the samples is an estimate for the difference between means of two groups: $\Delta = \mu_A - \mu_{B}$ (which we know is $100$ in this example).
#### Sampling distribution of the estimator `dmeans`
How well does the estimate $d$ approximate the true value $\Delta$?
**What is the accuracy and variability of the estimates we can expect?**
To answer these questions, consider the random samples
$\mathbf{X}_A = X_1X_2\cdots X_{n_A}$
and $\mathbf{X}_B = X_1X_2\cdots X_{n_B}$,
then compute the **sampling distribution**: $D = \overline{X}_A - \overline{X}_{B}$.
By definition, the sampling distribution of the estimator is obtained by repeatedly generating samples `xA` and `xB` from the two distributions and computing `dmeans` on the random samples. For example, we can obtain the sampling distribution by generating $N=1000$ samples.
```
def get_sampling_dist(statfunc, meanA, stdA, nA, meanB, stdB, nB, N=1000):
"""
Obtain the sampling distribution of the statistic `statfunc`
from `N` random samples drawn from groups A and B with parmeters:
- Group A: `nA` values taken from `norm(meanA, stdA)`
- Group B: `nB` values taken from `norm(meanB, stdB)`
Returns a list of samples from the sampling distribution of `statfunc`.
"""
sampling_dist = []
for i in range(0, N):
xA = norm(meanA, stdA).rvs(nA) # random sample from Group A
xB = norm(meanB, stdB).rvs(nB) # random sample from Group B
stat = statfunc(xA, xB) # evaluate `statfunc`
sampling_dist.append(stat) # record the value of statfunc
return sampling_dist
# Generate the sampling distirbution for dmeans
dmeans_sdist = get_sampling_dist(statfunc=dmeans,
meanA=muA, stdA=sigmaA, nA=nA,
meanB=muB, stdB=sigmaB, nB=nB)
print("Generated", len(dmeans_sdist), "values from `dmeans(XA, XB)`")
# first 3 values
dmeans_sdist[0:3]
```
#### Plot the sampling distribution of `dmeans`
```
fig3, ax3 = plt.subplots()
title3 = "Samping distribution of D = mean($\mathbf{X}_A$) - mean($\mathbf{X}_B$) " + \
"for samples of size $n_A$ = " + str(nA) + \
" from $\mathcal{N}$(" + str(muA) + "," + str(sigmaA) + ")" + \
" and $n_B$ = " + str(nB) + \
" from $\mathcal{N}$(" + str(muB) + "," + str(sigmaB) + ")"
sns.distplot(dmeans_sdist, kde=False, norm_hist=True, ax=ax3)
_ = ax3.set_title(title3)
```
#### Theoretical model for the sampling distribution of `dmeans`
Let's use probability theory to build a theoretical model for the sampling distribution of the difference-between-means estimator `dmeans`.
- The central limit theorem
the rules of to obtain a model for the random variable $D = \overline{X}_A - \overline{X}_{B}$,
which describes the sampling distribution of `dmeans`.
- The central limit theorem tells us the sample mean within the two group are
$$ \large
\overline{X}_A \sim \mathcal{N}\!\left(\mu_A, \tfrac{\sigma^2_A}{n_A} \right)
\qquad \textrm{and} \qquad
\overline{X}_B \sim \mathcal{N}\!\left(\mu_B, \tfrac{\sigma^2_B}{n_B} \right)
$$
- The rules of probability theory tells us that the [difference of two normal random variables](https://en.wikipedia.org/wiki/Sum_of_normally_distributed_random_variables#Independent_random_variables) requires subtracting their means and adding their variance, so we get:
$$ \large
D \sim \mathcal{N}\!\left(\mu_A - \mu_B, \ \tfrac{\sigma^2_A}{n_A} + \tfrac{\sigma^2_B}{n_B} \right)
$$
In other words, the sampling distribution for the difference of means estimator has mean and standard deviation given by:
$$ \large
\mu_D = \mu_A - \mu_B
\qquad \textrm{and} \qquad
\sigma_D = \sqrt{ \tfrac{\sigma^2_A}{n_A} + \tfrac{\sigma^2_B}{n_B} }
$$
Let's plot the theoretical prediction on top of the simulated data to see if they are a good fit.
```
Dmean = muA - muB
Dstd = np.sqrt(sigmaA**2/nA + sigmaB**2/nB)
print("Probability theory predicts the sampling distribution had"
"mean", round(Dmean, 3),
"and standard deviation", round(Dstd, 3))
x = np.linspace(min(dmeans_sdist), max(dmeans_sdist), 10000)
D = norm(Dmean, Dstd).pdf(x)
label = 'Theory prediction'
ax3 = sns.lineplot(x, D, ax=ax3, label=label, color=blue)
fig3
```
### Regroup and reality check
How are you doing, dear readers?
I know this was a lot of math and a lot of code, but the good news is we're done now!
The key things to remember is that we have two ways to compute sampling distribution for any estimator:
- Repeatedly generate random samples from model and compute the estimator values (histogram)
- Use probability theory to obtain a analytical formula
#### Why are we doing all this modelling?
The estimator `dmeans` we defined above measures the quantity we're interested in:
the difference between the means of two groups (**Group S** and **Group NS** in Amy's statistical analysis of ELV data).
Using the functions we developed above, we now have the ability to simulate the data from any two groups by simply choosing the appropriate parameters. In particular if we choose `stdS=266`, `nS=30`; and `stdNS=233`, `nNS=31`,
we can generate random data that has similar variability to Amy ELV measurements.
Okay, dear reader, we're about to jump into the deep end of the statistics pool: **hypothesis testing**,
which is one of the two major ideas in the STATS 101 curriculum.
Heads up this will get complicated, but we have to go into it because it is an essential procedure
that is used widely in science, engineering, business, and other types of research.
You need to trust me this one: it's worth knowing this stuff, even if it is boring.
Don't worry about it though, since you have all the prerequisites needed to get through this!
____
Recall Amy's research Question 1:
Is there a difference between ELV of the employees in **Group S** and the employees in **Group NS**?
## Hypothesis testing
- An approach to formulating research questions as **yes-no decisions** and a **procedure for making these decisions**
- Hypothesis testing is a standardized procedure for doing statistical analysis
(also, using stats jargon makes everything look more convincing ;)
- We formulate research question as two **competing hypotheses**:
- **Null hypothesis $H_0$** = no effect
in our example: "no difference between means," which is written as $\color{red}{\mu_S = \mu_{NS} = \mu_0}$.
In other words, the probability models for the two groups are:
$$ \large
H_0: \qquad X_S = \mathcal{N}(\color{red}{\mu_0}, \sigma_S)
\quad \textrm{and} \quad
X_{NS} = \mathcal{N}(\color{red}{\mu_0}, \sigma_{NS}) \quad
$$
- **Alternative hypothesis $H_A$** = an effect exists
in our example: "means for Group S different from mean for Group NS", $\color{blue}{\mu_S} \neq \color{orange}{\mu_{NS}}$.
The probability models for the two groups are:
$$
H_A: \qquad X_S = \mathcal{N}(\color{blue}{\mu_S}, \sigma_S)
\quad \textrm{and} \quad
X_{NS} = \mathcal{N}(\color{orange}{\mu_{NS}}, \sigma_{NS})
$$
- The purpose of hypothesis testing is to perform a basic sanity-check to show the difference between the group means
we observed ($d = \overline{x}_{S} - \overline{x}_{NS} = 130$) is **unlikely to have occurred by chance**
- NEW CONCEPT: $p$-value is the probability of observing $d$ or more extreme under the null hypothesis.
### Overview of the hypothesis testing procedure
Here is the high-level overview of the hypothesis testing procedure:
- **inputs**: sample statistics computed from the observed data
(in our case the signal $\overline{x}_S$, $\overline{x}_{NS}$,
and our estimates of the noise $s^2_S$, and $s^2_{NS}$)
- **outputs**: a decision that is one of: "reject the null hypothesis" or "fail to reject the null hypothesis"

We'll now look at two different approaches for computing the sampling distribution of
the difference between group means statistic, $D = \overline{X}_S - \overline{X}_{NS}$:
permutation tests and analytical approximations.
### Interpreting the results of hypothesis testing (optional)
- The implication of rejecting the null hypothesis (no difference) is that there must is a difference between the group means.
In other words, the ELV data for employees who took the statistics training (**Group S**) is different form
the average ELV for employees who didn't take the statistics training (**Group NS**),
which is what Amy is trying to show.
- Note that rejecting null hypothesis (H0) is not the same as "proving" the alternative hypothesis (HA),
we have just shown that the data is unlikely under the null hypothesis and we must be *some* difference between the groups,
so is worth looking for *some* alternative hypothesis.
- The alternative hypothesis we picked above, $\mu_S \neq \mu_{NS}$, is just a placeholder,
that includes desirable effect: $\mu_S > \mu_{NS}$ (stats training improves ELV),
but also includes the opposite effect: $\mu_S < \mu_{NS}$ (stats training decreases ELV).
- Using statistics jargon, when we reject the hypothesis H0 we say we've observed a "statistically significant" result,
which sounds a lot more impressive statement than it actually is.
Recall hypothesis test is just used to rule out "occurred by chance," which is a very basic sanity check.
- The implication of failing to reject the null hypothesis is that the observed difference
between means is "not significant," meaning it could have occurred by chance,
so there is no need to search for an alternative hypothesis.
- Note that "failing to reject" is not the same as "proving" the null hypothesis
- Note also "failing to reject H0" doesn't mean we reject HA.
In fact, the alternative hypothesis didn't play any role in the calculations whatsoever.
I know all this sounds super complicated and roundabout (an it is!),
but you will get a hang of it in no time with some practice.
Trust me, you need to know this shit.
### Start by load data again...
First things first, let's reload the data which we prepared back in the DATA where we left off back in the [01_DATA.ipynb](./01_DATA.ipynb) notebook.
```
df = pd.read_csv('data/employee_lifetime_values.csv')
df
# remember the descriptive statistics
df.groupby("group").describe()
def dmeans(sample):
"""
Compute the difference between groups means.
"""
xS = sample[sample["group"]=="S"]["ELV"]
xNS = sample[sample["group"]=="NS"]["ELV"]
d = np.mean(xS) - np.mean(xNS)
return d
# the observed value in Amy's data
dmeans(df)
```
Our goal is to determine how likely or unlikely this observed value is under the null hypothesis $H_0$.
In the next two sections, we'll look at two different approaches for obtaining the sampling distribution of $D$ under $H_0$.
## Approach 1: Permutation test for hypothesis testing
- The permutation test allow us to reject $H_0$ using existing sample $\mathbf{x}$ that we have,
treating the sample as if it were a population.
- Relevant probability distributions:
- Sampling distribution = obtained from repeated samples from a hypothetical population under $H_0$.
- Approximate sampling distribution: obtained by **resampling data from the single sample we have**.
- Recall Goal 1: make sure data cannot be explained by $H_0$ (observed difference due to natural variability)
- We want to obtain an approximation of the sampling distribution under $H_0$
- The $H_0$ probability model describes a hypothetical scenario with **no difference between groups**,
which means data from **Group S** and **Group NS** comes the same distribution.
- To generate a new random sample $\mathbf{x}^p$ from $H_0$ model we can reuse the sample we have obtained $\mathbf{x}$, but randomly mix-up the group labels. Since under the $H_0$ model, the **S** and **NS** populations are identical, mixing up the labels should have no effect.
- The math term for "mixing up" is **permutation**, meaning
each value is input is randomly reassigned to a new random place in the output.
```
def resample_under_H0(sample, groupcol="group"):
"""
Return a copy of the dataframe `sample` with the labels in the column `groupcol`
modified based on a random permutation of the values in the original sample.
"""
resample = sample.copy()
labels = sample[groupcol].values
newlabels = np.random.permutation(labels)
resample[groupcol] = newlabels
return resample
resample_under_H0(df)
# resample
resample = resample_under_H0(df)
# compute the difference in means for the new labels
dmeans(resample)
```
The steps in the above code cell give us a simple way to generate samples from the null hypothesis and compute the value of `dmeans` statistic for these samples. We used the assumption of "no difference" under the null hypothesis, and translated this to the "forget the labels" interpretation.
#### Running a permutation test
We can repeat the resampling procedure `10000` times to get the sampling distribution of $D$ under $H_0$,
as illustrated in the code procedure below.
```
def permutation_test(sample, statfunc, groupcol="group", permutations=10000):
"""
Compute the p-value of the observed `statfunc(sample)` under the null hypothesis
where the labels in the `groupcol` are randomized.
"""
# 1. compute the observed value of the statistic for the sample
obsstat = statfunc(sample)
# 2. generate the sampling distr. using random permutations of the group labels
resampled_stats = []
for i in range(0, permutations):
resample = resample_under_H0(sample, groupcol=groupcol)
restat = statfunc(resample)
resampled_stats.append(restat)
# 3. compute p-value: how many `restat`s are equal-or-more-extreme than `obsstat`
tailstats = [restat for restat in resampled_stats \
if restat <= -abs(obsstat) or restat >= abs(obsstat)]
pvalue = len(tailstats) / len(resampled_stats)
return resampled_stats, pvalue
sampling_dist, pvalue = permutation_test(df, statfunc=dmeans)
# plot the sampling distribution in blue
sns.displot(sampling_dist, bins=200)
# plot red line for the observed statistic
obsstat = dmeans(df)
plt.axvline(obsstat, color='r')
# plot the values that are equal or more extreme in red
tailstats = [rs for rs in sampling_dist if rs <= -obsstat or rs >= obsstat]
_ = sns.histplot(tailstats, bins=200, color="red")
```
- Once we have the sampling distribution of `D` under $H_0$,
we can see where the observed value $d=130$
falls within this distribution.
- p-value: the probability of observing value $d$ or more extreme under the null hypothesis
```
pvalue
```
We can now make the decision based on the $p$-value and a pre-determined threshold:
- If the observed value $d$ is unlikely under $H_0$ ($p$-value less than 5% chance of occurring),
then our decision will be to "reject the null hypothesis."
- Otherwise, if the observed value $d$ is not that unusual ($p$-value greater than 5%),
we conclude that we have "failed to reject the null hypothesis."
```
if pvalue < 0.05:
print("DECISION: Reject H0", "( p-value =", pvalue, ")")
print(" There is a statistically significant difference between xS and xNS means")
else:
print("DECISION: Fail to reject H0")
print(" The difference between groups means could have occurred by chance")
```
#### Permutations test using SciPy
The above code was given only for illustrative purposes.
In practice, you can use the SciPy implementation of permutation test,
by calling `ttest_ind(..., permutations=10000)` to perform a permutation test, then obtain the $p$-value.
```
from scipy.stats import ttest_ind
xS = df[df["group"]=="S"]["ELV"]
xNS = df[df["group"]=="NS"]["ELV"]
ttest_ind(xS, xNS, permutations=10000).pvalue
```
#### Discussion
- The procedure we used is called a **permutations test** for comparison of group means.
- The permutation test takes it's name from the action of mixing up the group-membership labels
and computing a statistic which is a way to generate samples from the null hypothesis
in situations where we're comparing two groups.
- Permutation tests are very versatile since we can use them for any estimator $h(\mathbf{x})$.
For example, we could have used difference in medians by specifying the `median` as the input `statfunc`.
## Approach 2: Analytical approximations for hypothesis testing
We'll now look at another approach for answering Question 1:
using and analytical approximation,
which is the way normally taught in STATS 101 courses.
How likely or unlikely is the observed difference $d=130$ under the null hypothesis?
- Analytical approximations are math models for describing the sampling distribution under $H_0$
- Sampling distributions = obtained by repeated sampling from $H_0$
- Analytical approximation = probability distribution model based on estimated parameters
- Assumption: population is normally distributed
- Based on this assumption we can use the theoretical model we developed above for difference between group means
to obtain a **closed form expression** for the sampling distribution of $D$
- In particular, the probability model for the two groups under $H_0$ are:
$$ \large
H_0: \qquad X_S = \mathcal{N}(\color{red}{\mu_0}, \sigma_S)
\quad \textrm{and} \quad
X_{NS} = \mathcal{N}(\color{red}{\mu_0}, \sigma_{NS}), \quad
$$
from which we can derive the model for $D = \overline{X}_S - \overline{X}_{NS}$:
$$ \large
D \sim \mathcal{N}\!\left( \color{red}{0}, \ \tfrac{\sigma^2_S}{n_S} + \tfrac{\sigma^2_{NS}}{n_{NS}} \right)
$$
In words, the sampling distribution of the difference between group means is
normally distributed with mean $\mu_D = 0$ and variance $\sigma^2_D$ dependent
on the variance of the two groups $\sigma^2_S$ and $\sigma^2_{NS}$.
Recall we obtained this expression earlier when we discussed difference of means between groups A and B.
- However, the population variances are unknown $\sigma^2_S$ and $\sigma^2_{NS}$,
and we only have the estimated variances $s_S^2$ and $s_{NS}^2$ calculated from the sample.
- That's OK though, since sample variances are good approximation to the population variances.
There are two common ways to obtain an approximation for $\sigma^2_D$:
- Pooled variance: $\sigma^2_D \approx s^2_p = \frac{(n_S-1)s_S^2 \; + \; (n_{NS}-1)s_{NS}^2}{n_S + n_{NS} - 2}$
(takes advantage of assumption that both samples come from the same population under $H_0$)
- Unpooled variance: $\sigma^2_D \approx s^2_u = \tfrac{s^2_S}{n_S} + \tfrac{s^2_{NS}}{n_{NS}}$
(follows from general rule of prob theory)
- NEW CONCEPT: **Student's $t$-distribution** is a model for $D$ which takes into account
we are using $s_S^2$ and $s_{NS}^2$ instead of $\sigma_S^2$ and $\sigma_{NS}^2$.
- NEW CONCEPT: **degrees of freedom**, denoted `dof` in code or $\nu$ (Greek letter *nu*) in equations,
is the parameter Student's $t$ distribution related to the sample size used to estimate quantities.
### Student's t-test (pooled variance)
[Student's t-test for comparison of difference between groups means](https://statkat.com/stattest.php?&t=9),
is a procedure that makes use of the pooled variance $s^2_p$.
#### Black-box approach
The `scipy.stats` function `ttest_ind` will perform all the steps of the $t$-test procedure,
without the need for us to understand the details.
```
from scipy.stats import ttest_ind
# extract data for two groups
xS = df[df["group"]=="S"]['ELV']
xNS = df[df["group"]=="NS"]['ELV']
# run the complete t-test procedure for ind-ependent samples:
result = ttest_ind(xS, xNS)
result.pvalue
```
The $p$-value is less than 0.05 so our decision is to **reject the null hypothesis**.
#### Student's t-test under the hood
The computations hidden behind the function `ttest_ind` involve a six step procedure that makes use of the pooled variance $s^2_p$.
```
from statistics import stdev
from scipy.stats.distributions import t
# 1. calculate the mean in each group
meanS, meanNS = np.mean(xS), np.mean(xNS)
# 2. calculate d, the observed difference between means
d = meanS - meanNS
# 3. calculate the standard deviations in each group
stdS, stdNS = stdev(xS), stdev(xNS)
nS, nNS = len(xS), len(xNS)
# 4. compute the pooled variance and standard error
var_pooled = ((nS-1)*stdS**2 + (nNS-1)*stdNS**2)/(nS + nNS - 2)
std_pooled = np.sqrt(var_pooled)
std_err = np.sqrt(std_pooled**2/nS + std_pooled**2/nNS)
# 5. compute the value of the t-statistic
tstat = d / std_err
# 6. obtain the p-value for the t-statistic from a
# t-distribution with 31+30-2 = 59 degrees of freedom
dof = nS + nNS - 2
pvalue = 2 * t(dof).cdf(-abs(tstat)) # 2* because two-sided
pvalue
```
#### Welch's t-test (unpooled variances)
An [alternative t-test procedure](https://statkat.com/stattest.php?&t=9) that doesn't assume the variances in groups are equal.
```
result2 = ttest_ind(xS, xNS, equal_var=False)
result2.pvalue
```
Welch's $t$-test differs only in steps 4 through 6 as shown below:
```
# 4'. compute the unpooled standard deviation of D
stdD = np.sqrt(stdS**2/nS + stdNS**2/nNS)
# 5'. compute the value of the t-statistic
tstat = d / stdD
# 6'. obtain the p-value from a t-distribution with
# (insert crazy formula here) degrees of freedom
dof = (stdS**2/nS + stdNS**2/nNS)**2 / \
((stdS**2/nS)**2/(nS-1) + (stdNS**2/nNS)**2/(nNS-1) )
pvalue = 2 * t(dof).cdf(-abs(tstat)) # 2* because two-sided
pvalue
```
### Summary of Question 1
We saw two ways to answer Question 1 (is there a difference between group means) and obtain the p-value.
We interpreted the small p-values as evidence that the observed difference, $d=130$, is unlikely to be due to chance,
i.e. we rejected the null hypothesis.
Note this whole procedure is just a sanity check—we haven't touched the alternative hypothesis at all yet,
and for all we know the stats training could have the effect of decreasing ELV!
____
It's time to study Question 2, which is to estimate the magnitude of the change in ELV obtained from completing the stats training, which is called *effect size* in statistics.
## Estimating the effect size
- Question 2 of statistical analysis is to estimate the difference in ELV gained by stats training.
- NEW CONCEPT: **effect size** is a measure of difference between intervention and control groups.
- We assume the data of **Group S** and **Group NS** come from different populations with means $\mu_S$ and $\mu_{NS}$
- We're interested in the difference between population means, denoted $\Delta = \mu_S - \mu_{NS}$.
- By analyzing the sample, we have obtained an estimate $d=130$ for the unknown $\Delta$,
but we know our data contains lots of variability, so we know our estimate might be off.
- We want an answer to Question 2 (What is the estimated difference between group means?)
that takes into account the variability of the data.
- NEW CONCEPT: **confidence interval** is a way to describe a range of values for an estimate
- We want to provide an answer to Question 2 in the form of a confidence interval that tells
us a range of values where we believe the true value of $\Delta$ falls.
- Similar to how we showed to approaches for hypothesis testing,
we'll work on effect size estimation using two approaches: resampling methods and analytical approximations.
### Approach 1: estimate the effect size using bootstrap method
- We want to estimate the distribution of ELV values for the two groups,
and compute the difference between the means of these distributions.
- Distributions:
- Sampling distributions = obtained by repeated sampling from the populations
- Bootstrap sampling distributions = resampling data from the samples we have (with replacement)
- Intuition: treat the samples as if they were the population
- We'll compute $B=5000$ bootstrap samples from the two groups and compute the difference,
then look at the distribution of the bootstrap sample difference to obtain $CI_{\Delta}$,
the confidence interval for the difference between population means.
```
from statistics import mean
def bootstrap_stat(sample, statfunc=mean, B=5000):
"""
Compute the bootstrap estimate of the function `statfunc` from the sample.
Returns a list of statistic values from bootstrap samples.
"""
n = len(sample)
bstats = []
for i in range(0, B):
bsample = np.random.choice(sample, n, replace=True)
bstat = statfunc(bsample)
bstats.append(bstat)
return bstats
# load data for two groups
df = pd.read_csv('data/employee_lifetime_values.csv')
xS = df[df["group"]=="S"]['ELV']
xNS = df[df["group"]=="NS"]['ELV']
# compute bootstrap estimates for mean in each group
meanS_bstats = bootstrap_stat(xS, statfunc=mean)
meanNS_bstats = bootstrap_stat(xNS, statfunc=mean)
# compute the difference between means from bootstrap samples
dmeans_bstats = []
for bmeanS, bmeanNS in zip(meanS_bstats, meanNS_bstats):
d = bmeanS - bmeanNS
dmeans_bstats.append(d)
sns.displot(dmeans_bstats)
# 90% confidence interval for the difference in means
CI_boot = [np.percentile(dmeans_bstats, 5), np.percentile(dmeans_bstats, 95)]
CI_boot
```
#### SciPy bootstrap method
```
from scipy.stats import bootstrap
def dmeans2(sample1, sample2):
return np.mean(sample1) - np.mean(sample2)
res = bootstrap((xS, xNS), statistic=dmeans2, vectorized=False,
confidence_level=0.9, n_resamples=5000, method='percentile')
CI_boot2 = [res.confidence_interval.low, res.confidence_interval.high]
CI_boot2
```
### Approach 2: Estimates using analytical approximation method
- Assumption 1: populations for **Group S** and **Group NS** are normally distributed
- Assumption 2: the variance of the two populations is the same (or approximately equal)
- Using the theoretical model for the populations,
we can obtain a formula for CI of effect size $\Delta$:
$$
\textrm{CI}_{(1-\alpha)}
= \left[ d - t^*\!\cdot\!\sigma_D, \,
d + t^*\!\cdot\!\sigma_D
\right].
$$
The confidence interval is centred at $d$,
with width proportional to the standard deviation $\sigma_D$.
The constant $t^*$ denotes the value of the inverse CDF of Student's $t$-distribution
with appropriate number of degrees of freedom `dof` evaluated at $1-\frac{\alpha}{2}$.
For a 90% confidence interval, we choose $\alpha=0.10$,
which gives $(1-\frac{\alpha}{2}) = 0.95$, $t^* = F_{T_{\textrm{dof}}}^{-1}\left(0.95\right)$.
- We can use the two different analytical approximations to obtain a formula for $\sigma_D$
just as we did in the hypothesis testing:
- Pooled variance: $\sigma^2_p = \frac{(n_S-1)s_S^2 + (n_{NS}-1)s_{NS}^2}{n_S + n_{NS} - 2}$,
and `dof` = $n_S + n_{NS} -2$
- Unpooled variance: $\sigma^2_u = \tfrac{s^2_A}{n_A} + \tfrac{s^2_B}{n_B}$, and `dof` = [...](https://en.wikipedia.org/wiki/Student%27s_t-test#Equal_or_unequal_sample_sizes,_unequal_variances_(sX1_%3E_2sX2_or_sX2_%3E_2sX1))
#### Using pooled variance
The calculations are similar to Student's t-test for hypothesis testing.
```
from scipy.stats.distributions import t
d = np.mean(xS) - np.mean(xNS)
nS, nNS = len(xS), len(xNS)
stdS, stdNS = stdev(xS), stdev(xNS)
var_pooled = ((nS-1)*stdS**2 + (nNS-1)*stdNS**2)/(nS + nNS - 2)
std_pooled = np.sqrt(var_pooled)
std_err = std_pooled * np.sqrt(1/nS + 1/nNS)
dof = nS + nNS - 2
# for 90% confidence interval, need 10% in tails
alpha = 0.10
# now use inverse-CDF of Students t-distribution
tstar = abs(t(dof).ppf(alpha/2))
CI_tpooled = [d - tstar*std_err, d + tstar*std_err]
CI_tpooled
```
#### Using unpooled variance
The calculations are similar to the Welch's t-test for hypothesis testing.
```
d = np.mean(xS) - np.mean(xNS)
nS, nNS = len(xS), len(xNS)
stdS, stdNS = stdev(xS), stdev(xNS)
stdD = np.sqrt(stdS**2/nS + stdNS**2/nNS)
dof = (stdS**2/nS + stdNS**2/nNS)**2 / \
((stdS**2/nS)**2/(nS-1) + (stdNS**2/nNS)**2/(nNS-1) )
# for 90% confidence interval, need 10% in tails
alpha = 0.10
# now use inverse-CDF of Students t-distribution
tstar = abs(t(dof).ppf(alpha/2))
CI_tunpooled = [d - tstar*stdD, d + tstar*stdD]
CI_tunpooled
```
#### Summary of Question 2 results
We now have all the information we need to give a precise and nuanced answer to Question 2: "How big is the increase in ELV produced by stats training?".
The basic estimate of the difference is $130$ can be reported, and additionally can can report the 90% confidence interval for the difference between group means, that takes into account the variability in the data we have observed.
Note the CIs obtained using different approaches are all similar (+/- 5 ELV points), so it doesn't matter much which approach we use:
```
CI_boot, CI_boot2, CI_tpooled, CI_tunpooled
```
### Standardized effect size (optional)
It is sometimes useful to report the effect size using a "standardized" measure for effect sizes.
*Cohen's $d$* one such measure, and it is defined as the difference between two means divided by the pooled standard deviation.
```
def cohend(sample1, sample2):
"""
Compute Cohen's d measure of effect size for two independent samples.
"""
n1, n2 = len(sample1), len(sample2)
mean1, mean2 = np.mean(sample1), np.mean(sample2)
var1, var2 = np.var(sample1, ddof=1), np.var(sample2, ddof=1)
# calculate the pooled variance and standard deviaiton
var_pooled = ((n1-1)*var1 + (n2-1)*var2) / (n1 + n2 - 2)
std_pooled = np.sqrt(var_pooled)
# compute Cohen's d
cohend = (mean1 - mean2) / std_pooled
return cohend
cohend(xS, xNS)
```
We can interpret the value of Cohen's d obtained using the [reference table](https://en.wikipedia.org/wiki/Effect_size#Cohen's_d) of values:
| Cohen's d | Effect size |
| ----------- | ----------- |
| 0.01 | very small |
| 0.20 | small |
| 0.50 | medium |
| 0.80 | large |
We can therefore say the effect size of offering statistics training for employees has an **medium** effect size.
## Conclusion of Amy's statistical analysis
Recall the two research questions that Amy set out to answer in the beginning of this video series:
- Question 1: Is there a difference between the means in the two groups?
- Question 2: How much does statistics training improve the ELV of employees?
The statistical analysis we did allows us to answer these two questions as follows:
- Answer 1: There is a statistically significant difference between Group S and Group NS, p = 0.048.
- Answer 2: The estimated improvement in ELV is 130 points, which is corresponds to Cohen's d value of 0.52 (medium effect size). A 90% confidence interval for the true effect size is [25.9, 234.2].
Note: we used the numerical results obtained from resampling methods (Approach 1), but conclusions would be qualitatively the same if we reported results obtained from analytical approximations (Approach 2).
### Using statistics for convincing others
You may be wondering if all this probabilistic modelling and complicated statistical analysis was worth it to reach a conclusion that seems obvious in retrospect. Was all this work worth it? The purpose of all this work is to obtains something close to an objective conclusion. Without statistics it is very easy to fool ourselves and interpret patterns in data the way we want to, or alternatively, not see patterns that are present. By following the standard statistical procedures, we're less likely to fool ourselves, and more likely to be able to convince others.
It can very useful to imagine Amy explaining the results to a skeptical colleague. Suppose the colleague is very much against the idea of statistical training, and sees it as a distraction, saying things like "We hire employees to do a job, not to play with Python." and "I don't know any statistics and I'm doing my job just fine!" You get the picture.
Imagine Amy presenting her findings about how 100 hours of statistical training improves employee lifetime value (ELV) results after one year, and suggesting the statistical training be implemented for all new hires from now on. The skeptical colleague immediately rejects the idea and questions Amy's recommendation using emotional arguments like about necessity, time wasting, and how statistics is a specialty topic that is not required for all employees. Instead of arguing based on opinions and emotions with her colleague, Amy explains her recommendation is based on a statistical experiment she conducted, and shows the results.
- When the colleague asks if the observed difference could be due to chance, Amy says that this is unlikely, and quotes the p-value of 0.048 (less than 0.05), and interprets the result as saying the probability of observed difference between **Group S** and **Group NS** to be due to chance is less than 5%.
- The skeptical colleague is forced to concede that statistical training does improve ELV, but then asks about the effect size of the improvement: "How much more ELV can we expect if we provide statistics training?" Amy is ready to answer quoting the observed difference of $130$ ELV points, and further specifies the 90% confidence interval of [25.9, 234.2] for the improvement, meaning in the worst case there is 25 ELV points improvement.
The skeptic is forced to back down from their objections, and the "stats training for all" program is adopted in the company. Not only was Amy able to win the argument using statistics, but she was also able to set appropriate expectations for the results. In other words, she hasn't promised a guaranteed +130 ELV improvement, but a realistic range of values that can be expected.
## Comparison of resampling methods and analytical approximations
In this notebook we saw two different approaches for doing statistical analysis: resampling methods and analytical approximations. This is a general pattern in statistics where there is not only one correct answer: multiple approaches to data analysis are valid, and you need to think about the specifics of each data analysis situation. You'll learn about both approaches in the book.
Analytical approximations currently taught in most stats courses (STAT 101). Historically, analytical approximations have been used more widely because they require only simple arithmetic calculations: statistic practitioners (scientists, engineers, etc.) simply need to compute sample statistics, plug them into a formula, and obtain a $p$-value. This convenience is at the cost of numerous assumptions about the data distribution, which often don't hold in practice (e.g. assuming population is normal, when it is isn't).
In recent years, resampling methods like the permutation test and bootstrap estimation are becoming more popular and widely in industry, and increasingly also taught at to university students (*modern statistics*). **The main advantage so resampling methods is that they require less modelling assumptions.** Procedures like the permutation test can be applied broadly to any scenarios where two groups are compared, and don't require developing specific formulas for different cases. Resampling methods are easier to understand since the statistical procedure they require are directly related to the sampling distribution, and there are no formulas to memorize.
Understanding resampling methods requires some basic familiarity with programming, but the skills required are not advanced: knowledge of variables, expressions, and basic `for` loop is sufficient. If you were able to follow the code examples described above (see `resample_under_H0`, `permutation_test`, and `bootstrap_stat`), then you've already **seen all the code you will need for the entire book!**
## Other statistics topics in the book
The goal of this notebook was to focus on the two main ideas of inferential statistics ([Chapter 3](https://docs.google.com/document/d/1fwep23-95U-w1QMPU31nOvUnUXE2X3s_Dbk5JuLlKAY/edit#heading=h.uutryzqeo2av)): hypothesis testing and estimation. We didn't have time to cover many of the other important topics in statistics, which will be covered in the book (and in future notebooks). Here is a list of some of these topics:
- Null Hypothesis Significance Testing (NHST) procedure in full details (Type I and Type II error, power, sample size calculations)
- Statistical assumptions behind analytical approximations
- Cookbook of statistical analysis recipes (analytical approximations for different scenarios)
- Experimental design (how to plan and conduct statistical experiments)
- Misuses of statistics (caveats to watch out for and mistakes to avoid)
- Bayesian statistics (very deep topic; we'll cover only main ideas)
- Practice problems and exercises (real knowledge is when you can do the calculations yourself)
___
So far our statistical analysis was limited to comparing two groups, which is referred to as **categorical predictor variable** using stats jargon. In the next notebook we'll learn about statistical analysis with **continuous predictor variables**: instead of comparing stats vs. no-stats, we analyze what happens when variable amount of stats training is provided (a continuous predictor variable).
Open the notebook [04_LINEAR_MODELS.ipynb](./04_LINEAR_MODELS.ipynb) when you're ready to continue.
```
code = list(["um"])
```
| true |
code
| 0.756684 | null | null | null | null |
|
## This Notebook - Goals - FOR EDINA
**What?:**
- Standard classification method example/tutorial
**Who?:**
- Researchers in ML
- Students in computer science
- Teachers in ML/STEM
**Why?:**
- Demonstrate capability/simplicity of core scipy stack.
- Demonstrate common ML concept known to learners and used by researchers.
**Noteable features to exploit:**
- use of pre-installed libraries: <code>numpy</code>, <code>scikit-learn</code>, <code>matplotlib</code>
**How?:**
- clear to understand - minimise assumed knowledge
- clear visualisations - concise explanations
- recognisable/familiar - use standard methods
- Effective use of core libraries
<hr>
# Classification - K nearest neighbours
K nearest neighbours is a simple and effective way to deal with classification problems. This method classifies each sample based on the class of the points that are closest to it.
This is a supervised learning method, meaning that data used contains information on some feature that the model should predict.
This notebook shows the process of classifying handwritten digits.
<hr>
### Import libraries
On Noteable, all the libaries required for this notebook are pre-installed, so they simply need to be imported:
```
import numpy as np
import sklearn.datasets as ds
import sklearn.model_selection as ms
from sklearn import decomposition
from sklearn import neighbors
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib inline
```
<hr>
# Data - Handwritten Digits
In terms of data, [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html) has a loading function for some data regarding hand written digits.
```
# get the digits data from scikit into the notebook
digits = ds.load_digits()
```
The cell above loads the data as a [bunch object](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html), meaning that the data (in this case images of handwritten digits) and the target (the number that is written) can be split by accessing the attributes of the bunch object:
```
# store data and targets seperately
X = digits.data
y = digits.target
print("The data is of the shape", X.shape)
print("The target data is of the shape", y.shape)
```
The individual samples in the <code>X</code> array each represent an image. In this representation, 64 numbers are used to represent a greyscale value on an 8\*8 square. The images can be examined by using pyplot's [matshow](https://matplotlib.org/3.3.0/api/_as_gen/matplotlib.pyplot.matshow.html) function.
The next cell displays the 17th sample in the dataset as an 8\*8 image.
```
# create figure to display the 17th sample
fig = plt.matshow(digits.images[17], cmap=plt.cm.gray)
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
```
Suppose instead of viewing the 17th sample, we want to see the average of samples corresponding to a certain value.
This can be done as follows (using 0 as an example):
- All samples where the target value is 0 are located
- The mean of these samples is taken
- The resulting 64 long array is reshaped to be 8\*8 (for display)
- The image is displayed
```
# take samples with target=0
izeros = np.where(y == 0)
# take average across samples, reshape to visualise
zeros = np.mean(X[izeros], axis=0).reshape(8,8)
# display
fig = plt.matshow(zeros, cmap=plt.cm.gray)
fig.axes.get_xaxis().set_visible(False)
fig.axes.get_yaxis().set_visible(False)
```
<hr>
# Fit and test the model
## Split the data
Now that you have an understanding of the data, the model can be fitted.
Fitting the model involves setting some of the data aside for testing, and allowing the model to "see" the target values corresponding to the training samples.
Once the model has been fitted to the training data, the model will be tested on some data it has not seen before.
The next cell uses [train_test_split](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html) to shuffle all data, then set some data aside for testing later.
For this example, $\frac{1}{4}$ of the data will be set aside for testing, and the model will be trained on the remaining training set.
As before, <code>X</code> corresponds to data samples, and <code>y</code> corresponds to labels.
```
# split data to train and test sets
X_train, X_test, y_train, y_test = \
ms.train_test_split(X, y, test_size=0.25, shuffle=True,
random_state=22)
```
The data can be examined - here you can see that 1347 samples have been put into the training set, and 450 have been set aside for testing.
```
# print shape of data
print("training samples:", X_train.shape)
print("testing samples :", X_test.shape)
print("training targets:", y_train.shape)
print("testing targets :", y_test.shape)
```
## Using PCA to visualise data
Before diving into classifying, it is useful to visualise the data.
Since each sample has 64 dimensions, some dimensionality reduction is needed in order to visualise the samples as points on a 2D map.
One of the easiest ways of visualising high dimensional data is by principal component analysis (PCA). This maps the 64 dimensional image data onto a lower dimension map (here we will map to 2D) so it can be easily viewed on a screen.
In this case, the 2 most important "components" are maintained.
```
# create PCA model with 2 components
pca = decomposition.PCA(n_components=2)
```
The next step is to perform the PCA on the samples, and store the results.
```
# transform training data to 2 principal components
X_pca = pca.fit_transform(X_train)
# transform test data to 2 principal components
T_pca = pca.transform(X_test)
# check shape of result
print(X_pca.shape)
print(T_pca.shape)
```
As you can see from the above cell, the <code>X_pca</code> and <code>T_pca</code> data is now represented by only 2 elements per sample. The number of samples has remained the same.
Now that there is a 2D representation of the data, it can be plotted on a regular scatter graph. Since the labels corresponding to each point are stored in the <code>y_train</code> variable, the plot can be colour coded by target value!
Different coloured dots have different target values.
```
# choose the colours for each digit
cmap_digits = plt.cm.tab10
# plot training data with labels
plt.figure(figsize = (9,6))
plt.scatter(X_pca[:,0], X_pca[:,1], s=7, c=y_train,
cmap=cmap_digits, alpha=0.7)
plt.title("Training data coloured by target value")
plt.colorbar();
```
## Create and fit the model
The scikit-learn library allows fitting of a k-NN model just as with PCA above.
First, create the classifier:
```
# create model
knn = neighbors.KNeighborsClassifier()
```
The next step fits the k-NN model using the training data.
```
# fit model to training data
knn.fit(X_train,y_train);
```
## Test model
Now use the data that was set aside earlier - this stage involves getting the model to "guess" the samples (this time without seeing their target values).
Once the model has predicted the sample's class, a score can be calculated by checking how many samples the model guessed correctly.
```
# predict test data
preds = knn.predict(X_test)
# test model on test data
score = round(knn.score(X_test,y_test)*100, 2)
print("Score on test data: " + str(score) + "%")
```
98.44% is a really high score, one that would not likely be seen on real life applications of the method.
It can often be useful to visualise the results of your example. Below are plots showing:
- The labels that the model predicted for the test data
- The actual labels for the test data
- The data points that were incorrectly labelled
In this case, the predicted and actual plots are very similar, so these plots are not very informative. In other cases, this kind of visualisation may reveal patterns for you to explore further.
```
# plot 3 axes
fig, axes = plt.subplots(2,2,figsize=(12,12))
# top left axis for predictions
axes[0,0].scatter(T_pca[:,0], T_pca[:,1], s=5,
c=preds, cmap=cmap_digits)
axes[0,0].set_title("Predicted labels")
# top right axis for actual targets
axes[0,1].scatter(T_pca[:,0], T_pca[:,1], s=5,
c=y_test, cmap=cmap_digits)
axes[0,1].set_title("Actual labels")
# bottom left axis coloured to show correct and incorrect
axes[1,0].scatter(T_pca[:,0], T_pca[:,1], s=5,
c=(preds==y_test))
axes[1,0].set_title("Incorrect labels")
# bottom right axis not used
axes[1,1].set_axis_off()
```
So which samples did the model get wrong?
There were 7 samples that were misclassified. These can be displayed alongside their actual and predicted labels using the cell below:
```
# find the misclassified samples
misclass = np.where(preds!=y_test)[0]
# display misclassified samples
r, c = 1, len(misclass)
fig, axes = plt.subplots(r,c,figsize=(10,5))
for i in range(c):
ax = axes[i]
ax.matshow(X_test[misclass[i]].reshape(8,8),cmap=plt.cm.gray)
ax.set_axis_off()
act = y_test[misclass[i]]
pre = preds[misclass[i]]
strng = "actual: {a:.0f} \npredicted: {p:.0f}".format(a=act, p=pre)
ax.set_title(strng)
```
Additionally, a confusion matrix can be used to identify which samples are misclassified by the model. This can help you identify if their are samples that are commonly misidentified - for example you may identify that 8's are often mistook for 1's.
```
# confusion matrix
conf = metrics.confusion_matrix(y_test,preds)
# figure
f, ax = plt.subplots(figsize=(9,5))
im = ax.imshow(conf, cmap=plt.cm.RdBu)
# set labels as ticks on axes
ax.set_xticks(np.arange(10))
ax.set_yticks(np.arange(10))
ax.set_xticklabels(list(range(0,10)))
ax.set_yticklabels(list(range(0,10)))
ax.set_ylim(9.5,-0.5)
# axes labels
ax.set_ylabel("actual value")
ax.set_xlabel("predicted value")
ax.set_title("Digit classification confusion matrix")
# display
plt.colorbar(im).set_label(label="number of classifications")
```
| true |
code
| 0.642769 | null | null | null | null |
|
# Programación lineal
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://upload.wikimedia.org/wikipedia/commons/thumb/0/0c/Linear_Programming_Feasible_Region.svg/2000px-Linear_Programming_Feasible_Region.svg.png" width="400px" height="125px" />
> La programación lineal es el campo de la optimización matemática dedicado a maximizar o minimizar (optimizar) funciones lineales, denominada función objetivo, de tal forma que las variables de dicha función estén sujetas a una serie de restricciones expresadas mediante un sistema de ecuaciones o inecuaciones también lineales.
**Referencias:**
- https://es.wikipedia.org/wiki/Programaci%C3%B3n_lineal
- https://docs.scipy.org/doc/scipy-0.18.1/reference/optimize.html
## 1. Apuntes históricos
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://upload.wikimedia.org/wikipedia/commons/5/5e/JohnvonNeumann-LosAlamos.gif" width="400px" height="125px" />
- 1826: Joseph Fourier anticipa la programación lineal. Carl Friedrich Gauss resuelve ecuaciones lineales por eliminación "gaussiana".
- 1902: Gyula Farkas concibe un método para resolver sistemas de inecuaciones.
- Es hasta la Segunda Guerra Mundial que se plantea la programación lineal como un modelo matemático para planificar gastos y retornos, de modo que se reduzcan costos de guerra y aumentar pérdidas del enemigo. Secreto hasta 1947 (posguerra).
- 1947: George Dantzig publica el algoritmo simplex y John von Neumann desarrolló la teoría de la dualidad. Se sabe que Leonid Kantoróvich también formuló la teoría en forma independiente.
- Fue usado por muchas industrias en la planificación diaria.
**Hasta acá, tiempos exponenciales de solución. Lo siguiente, tiempo polinomial.**
- 1979: Leonid Khachiyan, diseñó el llamado Algoritmo del elipsoide, a través del cual demostró que el problema de la programación lineal es resoluble de manera eficiente, es decir, en tiempo polinomial.
- 1984: Narendra Karmarkar introduce el método del punto interior para resolver problemas de programación lineal.
**Mencionar complejidad computacional.**
## 2. Motivación
Ya la clase pasada habíamos mencionado que cuando se quería optimizar una función de varias variables con restricciones, se podía aplicar siempre el método de Multiplicadores de Lagrange. Sin embargo, este método es computacionalmente muy complejo conforme crece el número de variables.
Por tanto, cuando la función a optimizar y las restricciones son de caracter lineal, los métodos de solución que se pueden desarrollar son computacionalmente eficientes, por lo que es útil realizar la distinción.
## 3. Problemas de programación lineal
### 3.1. Ejemplo básico
Una compañía produce dos productos ($X_1$ y $X_2$) usando dos máquinas ($A$ y $B$). Cada unidad de $X_1$ que se produce requiere 50 minutos en la máquina $A$ y 30 minutos en la máquina $B$. Cada unidad de $X_2$ que se produce requiere 24 minutos en la máquina $A$ y 33 minutos en la máquina $B$.
Al comienzo de la semana hay 30 unidades de $X_1$ y 90 unidades de $X_2$ en inventario. El tiempo de uso disponible de la máquina $A$ es de 40 horas y el de la máquina $B$ es de 35 horas.
La demanda para $X_1$ en la semana actual es de 75 unidades y de $X_2$ es de 95 unidades. La política de la compañía es maximizar la suma combinada de unidades de $X_1$ e $X_2$ en inventario al finalizar la semana.
Formular el problema de decidir cuánto hacer de cada producto en la semana como un problema de programación lineal.
#### Solución
Sean:
- $x_1$ la cantidad de unidades de $X_1$ a ser producidas en la semana, y
- $x_2$ la cantidad de unidades de $X_2$ a ser producidas en la semana.
Notar que lo que se quiere es maximizar $x_1+x_2$.
Restricciones:
1. El tiempo de uso disponible de la máquina $A$ es de 40 horas: $50x_1+24x_2\leq 40(60)\Rightarrow 50x_1+24x_2\leq 2400$.
2. El tiempo de uso disponible de la máquina $B$ es de 35 horas: $30x_1+33x_2\leq 35(60)\Rightarrow 30x_1+33x_2\leq 2100$.
3. La demanda para $X_1$ en la semana actual es de 75 unidades: $x_1+30\geq 75\Rightarrow x_1\geq 45\Rightarrow -x_1\leq -45$.
4. La demanda para $X_2$ en la semana actual es de 95 unidades: $x_2+90\geq 95\Rightarrow x_2\geq 5\Rightarrow -x_2\leq -5$.
Finalmente, el problema puede ser expresado en la forma explicada como:
\begin{equation}
\begin{array}{ll}
\min_{x_1,x_2} & -x_1-x_2 \\
\text{s. a. } & 50x_1+24x_2\leq 2400 \\
& 30x_1+33x_2\leq 2100 \\
& -x_1\leq -45 \\
& -x_2\leq -5,
\end{array}
\end{equation}
o, eqivalentemente
\begin{equation}
\begin{array}{ll}
\min_{\boldsymbol{x}} & \boldsymbol{c}^T\boldsymbol{x} \\
\text{s. a. } & \boldsymbol{A}_{eq}\boldsymbol{x}=\boldsymbol{b}_{eq} \\
& \boldsymbol{A}\boldsymbol{x}\leq\boldsymbol{b},
\end{array}
\end{equation}
con
- $\boldsymbol{c}=\left[-1 \quad -1\right]^T$,
- $\boldsymbol{A}=\left[\begin{array}{cc}50 & 24 \\ 30 & 33\\ -1 & 0\\ 0 & -1\end{array}\right]$, y
- $\boldsymbol{b}=\left[2400\quad 2100\quad -45\quad -5\right]^T$.
Preferiremos, en adelante, la notación vectorial/matricial.
### 3.2. En general
De acuerdo a lo descrito anteriormente, un problema de programación lineal puede escribirse en la siguiente forma:
\begin{equation}
\begin{array}{ll}
\min_{x_1,\dots,x_n} & c_1x_1+\dots+c_nx_n \\
\text{s. a. } & a^{eq}_{j,1}x_1+\dots+a^{eq}_{j,n}x_n=b^{eq}_j \text{ para } 1\leq j\leq m_1 \\
& a_{k,1}x_1+\dots+a_{k,n}x_n\leq b_k \text{ para } 1\leq k\leq m_2,
\end{array}
\end{equation}
donde:
- $x_i$ para $i=1,\dots,n$ son las incógnitas o variables de decisión,
- $c_i$ para $i=1,\dots,n$ son los coeficientes de la función a optimizar,
- $a^{eq}_{j,i}$ para $j=1,\dots,m_1$ e $i=1,\dots,n$, son los coeficientes de la restricción de igualdad,
- $a_{k,i}$ para $k=1,\dots,m_2$ e $i=1,\dots,n$, son los coeficientes de la restricción de desigualdad,
- $b^{eq}_j$ para $j=1,\dots,m_1$ son valores conocidos que deben ser respetados estrictamente, y
- $b_k$ para $k=1,\dots,m_2$ son valores conocidos que no deben ser superados.
Equivalentemente, el problema puede escribirse como
\begin{equation}
\begin{array}{ll}
\min_{\boldsymbol{x}} & \boldsymbol{c}^T\boldsymbol{x} \\
\text{s. a. } & \boldsymbol{A}_{eq}\boldsymbol{x}=\boldsymbol{b}_{eq} \\
& \boldsymbol{A}\boldsymbol{x}\leq\boldsymbol{b},
\end{array}
\end{equation}
donde:
- $\boldsymbol{x}=\left[x_1\quad\dots\quad x_n\right]^T$,
- $\boldsymbol{c}=\left[c_1\quad\dots\quad c_n\right]^T$,
- $\boldsymbol{A}_{eq}=\left[\begin{array}{ccc}a^{eq}_{1,1} & \dots & a^{eq}_{1,n}\\ \vdots & \ddots & \vdots\\ a^{eq}_{m_1,1} & \dots & a^{eq}_{m_1,n}\end{array}\right]$,
- $\boldsymbol{A}=\left[\begin{array}{ccc}a_{1,1} & \dots & a_{1,n}\\ \vdots & \ddots & \vdots\\ a_{m_2,1} & \dots & a_{m_2,n}\end{array}\right]$,
- $\boldsymbol{b}_{eq}=\left[b^{eq}_1\quad\dots\quad b^{eq}_{m_1}\right]^T$, y
- $\boldsymbol{b}=\left[b_1\quad\dots\quad b_{m_2}\right]^T$.
**Nota:** el problema $\max_{\boldsymbol{x}}\boldsymbol{g}(\boldsymbol{x})$ es equivalente a $\min_{\boldsymbol{x}}-\boldsymbol{g}(\boldsymbol{x})$.
#### Bueno, y una vez planteado, ¿cómo se resuelve el problema?
Este problema está sencillo pues solo es en dos variables. La solución gráfica es válida.
```
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
def res1(x1):
return (2400-50*x1)/24
def res2(x1):
return (2100-30*x1)/33
x1 = np.linspace(40, 50)
r1 = res1(x1)
r2 = res2(x1)
plt.figure(figsize = (8,6))
plt.plot(x1, res1(x1), 'b--', label = 'res1')
plt.plot(x1, res2(x1), 'r--', label = 'res2')
plt.plot([45, 45], [0, 25], 'k', label = 'res3')
plt.plot([40, 50], [5, 5], 'm', label = 'res4')
plt.fill_between(np.array([45.0, 45.6]), res1(np.array([45.0, 45.6])), 5*np.ones(2))
plt.text(44,4,'$(45,5)$',fontsize=10)
plt.text(45.1,6.35,'$(45,6.25)$',fontsize=10)
plt.text(45.6,4,'$(45.6,5)$',fontsize=10)
plt.legend(loc = 'best')
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.axis([44, 46, 4, 7])
plt.show()
```
**Actividad.** Mónica hace aretes y cadenitas de joyería. Es tan buena, que todo lo que hace lo vende.
Le toma 30 minutos hacer un par de aretes y una hora hacer una cadenita, y como Mónica también es estudihambre, solo dispone de 10 horas a la semana para hacer las joyas. Por otra parte, el material que compra solo le alcanza para hacer 15 unidades (el par de aretes cuenta como unidad) de joyas por semana.
La utilidad que le deja la venta de las joyas es \$15 en cada par de aretes y \$20 en cada cadenita.
¿Cuántos pares de aretes y cuántas cadenitas debería hacer Mónica para maximizar su utilidad?
Formular el problema en la forma explicada y obtener la solución gráfica (puede ser a mano).
**Diez minutos: quien primero lo haga, pasará a explicarlo al tablero y le subiré la nota de alguna tarea a 100. Debe salir a explicar el problema en el pizarrón.**
## 5. ¿Cómo se resuelve en python?
### 5.1 Librería `SciPy`
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://scipy.org/_static/images/scipy_med.png" width="200px" height="75px" />
`SciPy` es un softwar de código abierto basado en `Python` para matemáticas, ciencia e ingeniería.
En particular, los siguientes son algunos de los paquetes básicos:
- `NumPy`
- **Librería `SciPy`**
- `SymPy`
- `matplotlib`
- `pandas`
La **Librería `SciPy`** es uno de los paquetes principales y provee varias rutinas numéricas eficientes. Entre ellas, para integración numérica y optimización.
En esta clase, y en lo que resta del módulo, estaremos utilizando el módulo `optimize` de la librería `SciPy`.
**Importémoslo**
```
# Importar el módulo optimize de la librería scipy
import scipy.optimize as opt
```
El módulo `optimize` que acabamos de importar contiene varias funciones para optimización y búsqueda de raices ($f(x)=0$). Entre ellas se encuentra la función `linprog`
```
# Función linprog del módulo optimize
help(opt.linprog)
```
la cual resuelve problemas como los que aprendimos a plantear.
### 5.2 Solución del ejemplo básico con linprog
Ya hicimos la solución gráfica. Contrastemos con la solución que nos da `linprog`...
```
# Importar numpy para crear las matrices
import numpy as np
# Crear las matrices para resolver el problema
c = np.array([-1, -1])
A = np.array([[50, 24],
[30, 33],
[-1, 0],
[0, -1]])
b = np.array([2400, 2100, -45, -5])
b
# Resolver utilizando linprog
resultado = opt.linprog(c, A_ub=A, b_ub=b)
# Mostrar el resultado
resultado
# Extraer el vector solución
resultado.x
```
**Conclusión**
- Para maximizar el inventario conjunto de cantidad de productos X1 y X2, se deben producir 45 unidades de X1 y 6.25 unidades de X2.
- Con esa producción, el inventario conjunto al finalizar la semana es de 1.25 unidades.
**Otra forma:** poner las cotas de las variables a parte
```
# Escribir matrices y cotas
c = np.array([-1, -1])
A = np.array([[50, 24],
[30, 33]])
b = np.array([2400, 2100])
x1_bound = (45, None)
x2_bound = (5, None)
# Resolver
resultado2 = opt.linprog(c, A_ub=A, b_ub=b, bounds=(x1_bound,x2_bound))
# Mostrar el resultado
resultado2
```
**Actividad.** Resolver el ejemplo de Mónica y sus tiliches con `linprog`
```
# Resolver acá
c = np.array([-15, -20])
A = np.array([[1, 2],
[1, 1]])
b = np.array([20, 15])
resultado_monica = opt.linprog(c, A_ub=A, b_ub=b)
resultado_monica
```
## 6. Problema de transporte 1
- **Referencia**: https://es.wikipedia.org/wiki/Programaci%C3%B3n_lineal
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://upload.wikimedia.org/wikipedia/commons/a/a0/Progr_Lineal.PNG" width="400px" height="125px" />
Este es un caso curioso, con solo 6 variables (un caso real de problema de transporte puede tener fácilmente más de 1.000 variables) en el cual se aprecia la utilidad de este procedimiento de cálculo.
Existen tres minas de carbón cuya producción diaria es:
- la mina "a" produce 40 toneladas de carbón por día;
- la mina "b" produce 40 t/día; y,
- la mina "c" produce 20 t/día.
En la zona hay dos centrales termoeléctricas que consumen:
- la central "d" consume 40 t/día de carbón; y,
- la central "e" consume 60 t/día.
Los costos de mercado, de transporte por tonelada son:
- de "a" a "d" = 2 monedas;
- de "a" a "e" = 11 monedas;
- de "b" a "d" = 12 monedas;
- de "b" a "e" = 24 monedas;
- de "c" a "d" = 13 monedas; y,
- de "c" a "e" = 18 monedas.
Si se preguntase a los pobladores de la zona cómo organizar el transporte, tal vez la mayoría opinaría que debe aprovecharse el precio ofrecido por el transportista que va de "a" a "d", porque es más conveniente que los otros, debido a que es el de más bajo precio.
En este caso, el costo total del transporte es:
- transporte de 40 t de "a" a "d" = 80 monedas;
- transporte de 20 t de "c" a "e" = 360 monedas; y,
- transporte de 40 t de "b" a "e" = 960 monedas,
Para un total 1.400 monedas.
Sin embargo, formulando el problema para ser resuelto por la programación lineal con
- $x_1$ toneladas transportadas de la mina "a" a la central "d"
- $x_2$ toneladas transportadas de la mina "a" a la central "e"
- $x_3$ toneladas transportadas de la mina "b" a la central "d"
- $x_4$ toneladas transportadas de la mina "b" a la central "e"
- $x_5$ toneladas transportadas de la mina "c" a la central "d"
- $x_6$ toneladas transportadas de la mina "c" a la central "e"
se tienen las siguientes ecuaciones:
Restricciones de la producción:
- $x_1 + x_2 \leq 40$
- $x_3 + x_4 \leq 40$
- $x_5 + x_6 \leq 20$
Restricciones del consumo:
- $x_1 + x_3 + x_5 \geq 40$
- $x_2 + x_4 + x_6 \geq 60$
La función objetivo será:
$$\min_{x_1,\dots,x_6}2x_1 + 11x_2 + 12x_3 + 24x_4 + 13x_5 + 18x_6$$
Resolver con `linprog`
```
# Matrices y cotas
c = np.array([2, 11, 12, 24, 13, 18])
A = np.array([[1, 1, 0, 0, 0, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 1],
[-1, 0, -1, 0, -1, 0],
[0, -1, 0, -1, 0, -1]])
b = np.array([40, 40, 20, -40, -60])
# Resolver
resultado_transporte = opt.linprog(c, A_ub=A, b_ub=b)
# Mostrar resultado
resultado_transporte
```
**Conclusión**
- La estrategia de menor costo es llevar 40 toneladas de la mina "a" a la central "e", 40 toneladas de la mina "b" a la central "d" y 20 toneladas de la mina "c" a la central "e". El costo total de esta estrategia de transporte es 1280 monedas.
## 7. Optimización de inversión en bonos
**Referencia:**
```
from IPython.display import YouTubeVideo
YouTubeVideo('gukxBus8lOs')
```
El objetivo de este problema es determinar la mejor estrategia de inversión, dados diferentes tipos de bono, la máxima cantidad que puede ser invertida en cada bono, el porcentaje de retorno y los años de madurez. También hay una cantidad fija de dinero disponible ($\$750,000$). Por lo menos la mitad de este dinero debe ser invertido en bonos con 10 años o más para la madurez. Se puede invertir un máximo del $25\%$ de esta cantidad en cada bono. Finalmente, hay otra restricción que no permite usar más de $35\%$ en bonos de alto riesgo.
Existen seis (6) opciones de inversión con las letras correspondientes $A_i$
1. $A_1$:(Tasa de retorno=$8.65\%$; Años para la madurez=11, Riesgo=Bajo)
1. $A_2$:(Tasa de retorno=$9.50\%$; Años para la madurez=10, Riesgo=Alto)
1. $A_3$:(Tasa de retorno=$10.00\%$; Años para la madurez=6, Riesgo=Alto)
1. $A_4$:(Tasa de retorno=$8.75\%$; Años para la madurez=10, Riesgo=Bajo)
1. $A_5$:(Tasa de retorno=$9.25\%$; Años para la madurez=7, Riesgo=Alto)
1. $A_6$:(Tasa de retorno=$9.00\%$; Años para la madurez=13, Riesgo=Bajo)
Lo que se quiere entonces es maximizar el retorno que deja la inversión.
Este problema puede ser resuelto con programación lineal. Formalmente, puede ser descrito como:
$$\max_{A_1,A_2,...,A_6}\sum^{6}_{i=1} A_iR_i,$$
donde $A_i$ representa la cantidad invertida en la opción, y $R_i$ representa la tasa de retorno respectiva.
Plantear restricciones...
```
# Matrices y cotas
# Resolver
# Mostrar resultado
```
Recordar que en el problema minimizamos $-\sum^{6}_{i=1} A_iR_i$. El rendimiento obtenido es entonces:
**Conclusión**
-
## 8. Tarea
### 1. Diseño de la Dieta Óptima
Se quiere producir comida para gatos de la manera más barata, no obstante se debe también asegurar que se cumplan los datos requeridos de analisis nutricional. Por lo que se quiere variar la cantidad de cada ingrediente para cumplir con los estandares nutricionales. Los requisitos que se tienen es que en 100 gramos, se deben tener por lo menos 8 gramos de proteína y 6 gramos de grasa. Así mismo, no se debe tener más de 2 gramos de fibra y 0.4 gramos de sal.
Los datos nutricionales se pueden obtener de la siguiente tabla:
Ingrediente|Proteína|Grasa|Fibra|Sal
:----|----
Pollo| 10.0%|08.0%|00.1%|00.2%
Carne| 20.0%|10.0%|00.5%|00.5%
Cordero|15.0%|11.0%|00.5%|00.7%
Arroz| 00.0%|01.0%|10.0%|00.2%
Trigo| 04.0%|01.0%|15.0%|00.8%
Gel| 00.0%|00.0%|00.0%|00.0%
Los costos de cada producto son:
Ingrediente|Costo por gramo
:----|----
Pollo|$\$$0.013
Carne|$\$$0.008
Cordero|$\$$0.010
Arroz|$\$$0.002
Trigo|$\$$0.005
Gel|$\$$0.001
Lo que se busca optimizar en este caso es la cantidad de productos que se debe utilizar en la comida de gato, para simplificar la notación se van a nombrar las siguientes variables:
$x_1:$ Gramos de pollo
$x_2:$ Gramos de carne
$x_3:$ Gramos de cordero
$x_4:$ Gramos de arroz
$x_5:$ Gramos de trigo
$x_6:$ Gramos de gel
Con los datos, se puede plantear la función objetivo, está dada por la siguiente expresión:
$$\min 0.013 x_1 + 0.008 x_2 + 0.010 x_3 + 0.002 x_4 + 0.005 x_5 + 0.001 x_6$$
Las restricciones estarían dadas por el siguiente conjunto de ecuaciones:
$x_1+x_2+x_3+x_4+x_5+x_6=100$
$(10.0 x_1+ 20.0 x_2+ 15.0 x_3+ 00.0 x_4+ 04.0 x_5+ 00.0 x_6)/100 \geq 8.0$
$(08.0 x_1+ 10.0 x_2+ 11.0 x_3+ 01.0 x_4+ 01.0 x_5+ 00.0 x_6)/100 \geq 6.0$
$(00.1 x_1+ 00.5 x_2+ 00.5 x_3+ 10.0 x_4+ 15.0 x_5+ 00.0 x_6)/100 \leq 2.0$
$(00.2 x_1+ 00.5 x_2+ 00.7 x_3+ 00.2 x_4+ 00.8 x_5+ 00.0 x_6)/100 \leq 0.4$
La primer condición asegura que la cantidad de productos que se usará cumple con los 100 gramos. Las siguientes sólo siguen los lineamientos planteados para cumplir con los requisitos nutrimentales.
### 2. Otro problema de transporte
Referencia: https://relopezbriega.github.io/blog/2017/01/18/problemas-de-optimizacion-con-python/
Supongamos que tenemos que enviar cajas de cervezas de 2 cervecerías (Modelo y Cuauhtémoc Moctezuma) a 5 bares de acuerdo al siguiente gráfico:
<img style="float: center; margin: 0px 0px 15px 15px;" src="https://relopezbriega.github.io/images/Trans_problem.png" width="500px" height="150px" />
Asimismo, supongamos que nuestro gerente financiero nos informa que el costo de transporte por caja de cada ruta se conforma de acuerdo a la siguiente tabla:
```
import pandas as pd
info = pd.DataFrame({'Bar1': [2, 3], 'Bar2': [4, 1], 'Bar3': [5, 3], 'Bar4': [2, 2], 'Bar5': [1, 3]}, index = ['CerveceriaA', 'CerveceriaB'])
info
```
Y por último, las restricciones del problema, van a estar dadas por las capacidades de oferta y demanda de cada cervecería (en cajas de cerveza) y cada bar, las cuales se detallan en el gráfico de más arriba.
Sean:
- $x_i$ cajas transportadas de la cervecería A al Bar $i$,
- $x_{i+5}$ cajas transportadas de la cervecería B al Bar $i$.
La tarea consiste en plantear el problema de minimizar el costo de transporte de la forma vista y resolverlo con `linprog`.
Deben crear un notebook de jupyter (archivo .ipynb) y llamarlo Tarea4_ApellidoNombre, y subirlo a moodle.
**Definir fecha**
<script>
$(document).ready(function(){
$('div.prompt').hide();
$('div.back-to-top').hide();
$('nav#menubar').hide();
$('.breadcrumb').hide();
$('.hidden-print').hide();
});
</script>
<footer id="attribution" style="float:right; color:#808080; background:#fff;">
Created with Jupyter by Esteban Jiménez Rodríguez.
</footer>
| true |
code
| 0.363209 | null | null | null | null |
|
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = "retina"
# print(plt.style.available)
plt.style.use("ggplot")
# plt.style.use("fivethirtyeight")
plt.style.use("seaborn-talk")
from tqdm import tnrange, tqdm_notebook
def uniform_linear_array(n_mics, spacing):
return spacing*np.arange(-(n_mics-1)/2, (n_mics-1)/2+1).reshape(1, n_mics)
def compute_MVDR_weight(source_steering_vector, signals):
snapshot = signals.shape[1]
sample_covariance_matrix = signals.dot(signals.transpose().conjugate()) / snapshot
inverse_sample_covariance_matrix = np.linalg.inv(sample_covariance_matrix)
normalization_factor = (source_steering_vector.transpose().conjugate().dot(inverse_sample_covariance_matrix).dot(source_steering_vector))
weight = inverse_sample_covariance_matrix.dot(source_steering_vector) / normalization_factor
return weight
def compute_steering_vector_ULA(u, microphone_array):
return np.exp(1j*2*np.pi*microphone_array.geometry*u).reshape((microphone_array.n_mics, 1))
def generate_gaussian_samples(power, shape):
return np.sqrt(power/2)*np.random.randn(shape[0], shape[1]) + 1j*np.sqrt(power/2)*np.random.randn(shape[0], shape[1]); # signal samples
class MicrophoneArray():
def __init__(self, array_geometry):
self.dim = array_geometry.shape[0]
self.n_mics = array_geometry.shape[1]
self.geometry = array_geometry
class BaseDLBeamformer(object):
def __init__(self, vs, bf_type="MVDR"):
"""
Parameters
----------
vs: Source manifold array vector
bf_type: Type of beamformer
"""
self.vs = vs
self.bf_type = bf_type
self.weights_ = None
def _compute_weights(self, training_data):
n_training_samples = len(training_data)
n_mics, snapshot = training_data[0].shape
D = np.zeros((n_mics, n_training_samples), dtype=complex)
for i_training_sample in range(n_training_samples):
nv = training_data[i_training_sample]
if self.bf_type == "MVDR":
w = compute_MVDR_weight(vs, nv)
D[:, i_training_sample] = w.reshape(n_mics,)
return D
def _initialize(self, X):
pass
def _choose_weights(self, x):
n_dictionary_atoms = self.weights_.shape[1]
R = x.dot(x.transpose().conjugate())
proxy = np.diagonal(self.weights_.transpose().conjugate().dot(R).dot(self.weights_))
optimal_weight_index = np.argmin(proxy)
return self.weights_[:, optimal_weight_index]
def fit(self, training_data):
"""
Parameters
----------
X: shape = [n_samples, n_features]
"""
D = self._compute_weights(training_data)
self.weights_ = D
return self
def choose_weights(self, x):
return self._choose_weights(x)
```
#### Setup
```
array_geometry = uniform_linear_array(n_mics=10, spacing=0.5)
microphone_array = MicrophoneArray(array_geometry)
us = 0
vs = compute_steering_vector_ULA(us, microphone_array)
SNRs = np.arange(0, 31, 10)
n_SNRs = len(SNRs)
sigma_n = 1
```
#### Training data
```
n_training_samples = 5000
training_snapshots = [10, 50, 1000]
interference_powers = [10, 20, 30]
n_interference_list = [1, 2, 3]
# interference_powers = [20]
# n_interference_list = [1]
# sigma = 10**(20/10)
training_noise_interference_data_various_snapshots = []
for training_snapshot in training_snapshots:
training_noise_interference_data = []
for i_training_sample in range(n_training_samples):
n_interferences = np.random.choice(n_interference_list)
nv = np.zeros((microphone_array.n_mics, training_snapshot), dtype=complex)
for _ in range(n_interferences):
u = np.random.uniform(0, 1)
vi = compute_steering_vector_ULA(u, microphone_array)
sigma = 10**(np.random.choice(interference_powers)/10)
ii = generate_gaussian_samples(power=sigma, shape=(1, training_snapshot))
nv += vi.dot(ii)
noise = generate_gaussian_samples(power=sigma_n, shape=(microphone_array.n_mics, training_snapshot))
nv += noise
training_noise_interference_data.append(nv)
training_noise_interference_data_various_snapshots.append(training_noise_interference_data)
```
#### Train baseline dictionary
```
dictionaries = []
for i_training_snapshot in range(len(training_snapshots)):
training_noise_interference_data = training_noise_interference_data_various_snapshots[i_training_snapshot]
dictionary = BaseDLBeamformer(vs)
dictionary.fit(training_noise_interference_data);
dictionaries.append(dictionary)
```
#### Testing
```
n_trials = 200
snapshots = np.array([10, 20, 30, 40, 60, 100, 200, 500, 1000])
n_snapshots = len(snapshots)
ui1 = np.random.uniform(0, 1)
ui2 = np.random.uniform(0, 1)
sigma_1 = 10**(20/10)
sigma_2 = 0*10**(20/10)
vi1 = compute_steering_vector_ULA(ui1, microphone_array)
vi2 = compute_steering_vector_ULA(ui2, microphone_array)
n_interferences = np.random.choice(n_interference_list)
interference_steering_vectors = []
for _ in range(n_interferences):
u = np.random.uniform(0, 1)
vi = compute_steering_vector_ULA(u, microphone_array)
interference_steering_vectors.append(vi)
sinr_snr_mvdr = np.zeros((n_SNRs, n_snapshots))
sinr_snr_mpdr = np.zeros((n_SNRs, n_snapshots))
sinr_snr_baseline_mpdr = np.zeros((len(training_snapshots), n_SNRs, n_snapshots))
for i_SNR in tqdm_notebook(range(n_SNRs), desc="SNRs"):
sigma_s = 10**(SNRs[i_SNR] / 10)
Rs = sigma_s * vs.dot(vs.transpose().conjugate())
for i_snapshot in tqdm_notebook(range(n_snapshots), desc="Snapshots", leave=False):
snapshot = snapshots[i_snapshot]
sinr_mvdr = np.zeros(n_trials)
sinr_mpdr = np.zeros(n_trials)
sinr_baseline_mpdr = np.zeros((len(training_snapshots), n_trials))
for i_trial in range(n_trials):
ss = generate_gaussian_samples(power=sigma_s, shape=(1, snapshot)) # signal samples
nn = generate_gaussian_samples(power=sigma_n, shape=(microphone_array.n_mics, snapshot)) # Gaussian noise samples
# ii1 = generate_gaussian_samples(power=sigma_1, shape=(1, snapshot)) # first interference samples
# ii2 = generate_gaussian_samples(power=sigma_2, shape=(1, snapshot)) # second interference samples
nv = np.zeros((microphone_array.n_mics, snapshot), dtype=complex)
Rn = np.zeros((microphone_array.n_mics, microphone_array.n_mics), dtype=complex)
for i_interference in range(n_interferences):
sigma = 10**(np.random.choice(interference_powers)/10)
ii = generate_gaussian_samples(power=sigma, shape=(1, snapshot))
nv += interference_steering_vectors[i_interference].dot(ii)
Rn += sigma*interference_steering_vectors[i_interference].dot(interference_steering_vectors[i_interference].transpose().conjugate())
Rn += sigma_n*np.identity(microphone_array.n_mics)
Rninv = np.linalg.inv(Rn)
Wo = Rninv.dot(vs) / (vs.transpose().conjugate().dot(Rninv).dot(vs))
SINRopt = ( np.real(Wo.transpose().conjugate().dot(Rs).dot(Wo)) / np.real(Wo.transpose().conjugate().dot(Rn).dot(Wo)) )[0][0]
nv += nn
sv = vs.dot(ss)
xx = sv + nv
wv = compute_MVDR_weight(vs, nv)
wp = compute_MVDR_weight(vs, xx)
for i_dictionary in range(len(dictionaries)):
dictionary = dictionaries[i_dictionary]
w_baseline_p = dictionary.choose_weights(xx)
sinr_baseline_mpdr[i_dictionary, i_trial] = np.real(w_baseline_p.transpose().conjugate().dot(Rs).dot(w_baseline_p)) / np.real(w_baseline_p.transpose().conjugate().dot(Rn).dot(w_baseline_p))
sinr_mvdr[i_trial] = np.real(wv.transpose().conjugate().dot(Rs).dot(wv)) / np.real(wv.transpose().conjugate().dot(Rn).dot(wv))
sinr_mpdr[i_trial] = np.real(wp.transpose().conjugate().dot(Rs).dot(wp)) / np.real(wp.transpose().conjugate().dot(Rn).dot(wp))
sinr_snr_mvdr[i_SNR, i_snapshot] = np.sum(sinr_mvdr) / n_trials
sinr_snr_mpdr[i_SNR, i_snapshot] = np.sum(sinr_mpdr) / n_trials
for i_dictionary in range(len(dictionaries)):
sinr_snr_baseline_mpdr[i_dictionary, i_SNR, i_snapshot] = np.sum(sinr_baseline_mpdr[i_dictionary, :]) / n_trials
```
#### Visualize results
```
fig = plt.figure(figsize=(9, 6*n_SNRs));
for i_SNR in range(n_SNRs):
sigma_s = 10**(SNRs[i_SNR] / 10)
Rs = sigma_s * vs.dot(vs.transpose().conjugate())
SINRopt = ( np.real(Wo.transpose().conjugate().dot(Rs).dot(Wo)) / np.real(Wo.transpose().conjugate().dot(Rn).dot(Wo)) )[0][0]
ax = fig.add_subplot(n_SNRs, 1, i_SNR+1)
ax.semilogx(snapshots, 10*np.log10(sinr_snr_mvdr[i_SNR, :]), marker="o", label="MVDR")
ax.semilogx(snapshots, 10*np.log10(sinr_snr_mpdr[i_SNR, :]), marker="*", label="MPDR")
for i_training_snapshot in range(len(training_snapshots)):
ax.semilogx(snapshots, 10*np.log10(sinr_snr_baseline_mpdr[i_training_snapshot, i_SNR, :]),
label="Baseline - {} training snapshots".format(training_snapshots[i_training_snapshot]))
ax.set_xlim(10, 1000); ax.set_ylim(-10, 45)
ax.legend(loc="lower right")
ax.set_xlabel("Number of snapshots")
ax.set_ylabel(r"$SINR_0$ [dB]")
ax.set_title("Testing performance, {} training samples".format(n_training_samples))
plt.tight_layout()
fig.savefig("baseline_dl_mvdr_various_interferences.jpg", dpi=600)
```
| true |
code
| 0.64791 | null | null | null | null |
|
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Automated Machine Learning
_**Orange Juice Sales Forecasting**_
## Contents
1. [Introduction](#Introduction)
1. [Setup](#Setup)
1. [Compute](#Compute)
1. [Data](#Data)
1. [Train](#Train)
1. [Predict](#Predict)
1. [Operationalize](#Operationalize)
## Introduction
In this example, we use AutoML to train, select, and operationalize a time-series forecasting model for multiple time-series.
Make sure you have executed the [configuration notebook](../../../configuration.ipynb) before running this notebook.
The examples in the follow code samples use the University of Chicago's Dominick's Finer Foods dataset to forecast orange juice sales. Dominick's was a grocery chain in the Chicago metropolitan area.
## Setup
```
import azureml.core
import pandas as pd
import numpy as np
import logging
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
from azureml.automl.core.featurization import FeaturizationConfig
```
This sample notebook may use features that are not available in previous versions of the Azure ML SDK.
```
print("This notebook was created using version 1.19.0 of the Azure ML SDK")
print("You are currently using version", azureml.core.VERSION, "of the Azure ML SDK")
```
As part of the setup you have already created a <b>Workspace</b>. To run AutoML, you also need to create an <b>Experiment</b>. An Experiment corresponds to a prediction problem you are trying to solve, while a Run corresponds to a specific approach to the problem.
```
ws = Workspace.from_config()
# choose a name for the run history container in the workspace
experiment_name = 'automl-ojforecasting'
experiment = Experiment(ws, experiment_name)
output = {}
output['Subscription ID'] = ws.subscription_id
output['Workspace'] = ws.name
output['SKU'] = ws.sku
output['Resource Group'] = ws.resource_group
output['Location'] = ws.location
output['Run History Name'] = experiment_name
pd.set_option('display.max_colwidth', -1)
outputDf = pd.DataFrame(data = output, index = [''])
outputDf.T
```
## Compute
You will need to create a [compute target](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-set-up-training-targets#amlcompute) for your AutoML run. In this tutorial, you create AmlCompute as your training compute resource.
#### Creation of AmlCompute takes approximately 5 minutes.
If the AmlCompute with that name is already in your workspace this code will skip the creation process.
As with other Azure services, there are limits on certain resources (e.g. AmlCompute) associated with the Azure Machine Learning service. Please read this article on the default limits and how to request more quota.
```
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
amlcompute_cluster_name = "oj-cluster"
# Verify that cluster does not exist already
try:
compute_target = ComputeTarget(workspace=ws, name=amlcompute_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
max_nodes=6)
compute_target = ComputeTarget.create(ws, amlcompute_cluster_name, compute_config)
compute_target.wait_for_completion(show_output=True)
```
## Data
You are now ready to load the historical orange juice sales data. We will load the CSV file into a plain pandas DataFrame; the time column in the CSV is called _WeekStarting_, so it will be specially parsed into the datetime type.
```
time_column_name = 'WeekStarting'
data = pd.read_csv("dominicks_OJ.csv", parse_dates=[time_column_name])
data.head()
```
Each row in the DataFrame holds a quantity of weekly sales for an OJ brand at a single store. The data also includes the sales price, a flag indicating if the OJ brand was advertised in the store that week, and some customer demographic information based on the store location. For historical reasons, the data also include the logarithm of the sales quantity. The Dominick's grocery data is commonly used to illustrate econometric modeling techniques where logarithms of quantities are generally preferred.
The task is now to build a time-series model for the _Quantity_ column. It is important to note that this dataset is comprised of many individual time-series - one for each unique combination of _Store_ and _Brand_. To distinguish the individual time-series, we define the **time_series_id_column_names** - the columns whose values determine the boundaries between time-series:
```
time_series_id_column_names = ['Store', 'Brand']
nseries = data.groupby(time_series_id_column_names).ngroups
print('Data contains {0} individual time-series.'.format(nseries))
```
For demonstration purposes, we extract sales time-series for just a few of the stores:
```
use_stores = [2, 5, 8]
data_subset = data[data.Store.isin(use_stores)]
nseries = data_subset.groupby(time_series_id_column_names).ngroups
print('Data subset contains {0} individual time-series.'.format(nseries))
```
### Data Splitting
We now split the data into a training and a testing set for later forecast evaluation. The test set will contain the final 20 weeks of observed sales for each time-series. The splits should be stratified by series, so we use a group-by statement on the time series identifier columns.
```
n_test_periods = 20
def split_last_n_by_series_id(df, n):
"""Group df by series identifiers and split on last n rows for each group."""
df_grouped = (df.sort_values(time_column_name) # Sort by ascending time
.groupby(time_series_id_column_names, group_keys=False))
df_head = df_grouped.apply(lambda dfg: dfg.iloc[:-n])
df_tail = df_grouped.apply(lambda dfg: dfg.iloc[-n:])
return df_head, df_tail
train, test = split_last_n_by_series_id(data_subset, n_test_periods)
```
### Upload data to datastore
The [Machine Learning service workspace](https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-workspace), is paired with the storage account, which contains the default data store. We will use it to upload the train and test data and create [tabular datasets](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.tabulardataset?view=azure-ml-py) for training and testing. A tabular dataset defines a series of lazily-evaluated, immutable operations to load data from the data source into tabular representation.
```
train.to_csv (r'./dominicks_OJ_train.csv', index = None, header=True)
test.to_csv (r'./dominicks_OJ_test.csv', index = None, header=True)
datastore = ws.get_default_datastore()
datastore.upload_files(files = ['./dominicks_OJ_train.csv', './dominicks_OJ_test.csv'], target_path = 'dataset/', overwrite = True,show_progress = True)
```
### Create dataset for training
```
from azureml.core.dataset import Dataset
train_dataset = Dataset.Tabular.from_delimited_files(path=datastore.path('dataset/dominicks_OJ_train.csv'))
train_dataset.to_pandas_dataframe().tail()
```
## Modeling
For forecasting tasks, AutoML uses pre-processing and estimation steps that are specific to time-series. AutoML will undertake the following pre-processing steps:
* Detect time-series sample frequency (e.g. hourly, daily, weekly) and create new records for absent time points to make the series regular. A regular time series has a well-defined frequency and has a value at every sample point in a contiguous time span
* Impute missing values in the target (via forward-fill) and feature columns (using median column values)
* Create features based on time series identifiers to enable fixed effects across different series
* Create time-based features to assist in learning seasonal patterns
* Encode categorical variables to numeric quantities
In this notebook, AutoML will train a single, regression-type model across **all** time-series in a given training set. This allows the model to generalize across related series. If you're looking for training multiple models for different time-series, please see the many-models notebook.
You are almost ready to start an AutoML training job. First, we need to separate the target column from the rest of the DataFrame:
```
target_column_name = 'Quantity'
```
## Customization
The featurization customization in forecasting is an advanced feature in AutoML which allows our customers to change the default forecasting featurization behaviors and column types through `FeaturizationConfig`. The supported scenarios include:
1. Column purposes update: Override feature type for the specified column. Currently supports DateTime, Categorical and Numeric. This customization can be used in the scenario that the type of the column cannot correctly reflect its purpose. Some numerical columns, for instance, can be treated as Categorical columns which need to be converted to categorical while some can be treated as epoch timestamp which need to be converted to datetime. To tell our SDK to correctly preprocess these columns, a configuration need to be add with the columns and their desired types.
2. Transformer parameters update: Currently supports parameter change for Imputer only. User can customize imputation methods. The supported imputing methods for target column are constant and ffill (forward fill). The supported imputing methods for feature columns are mean, median, most frequent, constant and ffill (forward fill). This customization can be used for the scenario that our customers know which imputation methods fit best to the input data. For instance, some datasets use NaN to represent 0 which the correct behavior should impute all the missing value with 0. To achieve this behavior, these columns need to be configured as constant imputation with `fill_value` 0.
3. Drop columns: Columns to drop from being featurized. These usually are the columns which are leaky or the columns contain no useful data.
```
featurization_config = FeaturizationConfig()
featurization_config.drop_columns = ['logQuantity'] # 'logQuantity' is a leaky feature, so we remove it.
# Force the CPWVOL5 feature to be numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeros.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill missing values in the INCOME column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
# Fill missing values in the Price column with forward fill (last value carried forward).
featurization_config.add_transformer_params('Imputer', ['Price'], {"strategy": "ffill"})
```
## Forecasting Parameters
To define forecasting parameters for your experiment training, you can leverage the ForecastingParameters class. The table below details the forecasting parameter we will be passing into our experiment.
|Property|Description|
|-|-|
|**time_column_name**|The name of your time column.|
|**forecast_horizon**|The forecast horizon is how many periods forward you would like to forecast. This integer horizon is in units of the timeseries frequency (e.g. daily, weekly).|
|**time_series_id_column_names**|The column names used to uniquely identify the time series in data that has multiple rows with the same timestamp. If the time series identifiers are not defined, the data set is assumed to be one time series.|
## Train
The [AutoMLConfig](https://docs.microsoft.com/en-us/python/api/azureml-train-automl-client/azureml.train.automl.automlconfig.automlconfig?view=azure-ml-py) object defines the settings and data for an AutoML training job. Here, we set necessary inputs like the task type, the number of AutoML iterations to try, the training data, and cross-validation parameters.
For forecasting tasks, there are some additional parameters that can be set in the `ForecastingParameters` class: the name of the column holding the date/time, the timeseries id column names, and the maximum forecast horizon. A time column is required for forecasting, while the time_series_id is optional. If time_series_id columns are not given, AutoML assumes that the whole dataset is a single time-series. We also pass a list of columns to drop prior to modeling. The _logQuantity_ column is completely correlated with the target quantity, so it must be removed to prevent a target leak.
The forecast horizon is given in units of the time-series frequency; for instance, the OJ series frequency is weekly, so a horizon of 20 means that a trained model will estimate sales up to 20 weeks beyond the latest date in the training data for each series. In this example, we set the forecast horizon to the number of samples per series in the test set (n_test_periods). Generally, the value of this parameter will be dictated by business needs. For example, a demand planning application that estimates the next month of sales should set the horizon according to suitable planning time-scales. Please see the [energy_demand notebook](https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/automated-machine-learning/forecasting-energy-demand) for more discussion of forecast horizon.
We note here that AutoML can sweep over two types of time-series models:
* Models that are trained for each series such as ARIMA and Facebook's Prophet.
* Models trained across multiple time-series using a regression approach.
In the first case, AutoML loops over all time-series in your dataset and trains one model (e.g. AutoArima or Prophet, as the case may be) for each series. This can result in long runtimes to train these models if there are a lot of series in the data. One way to mitigate this problem is to fit models for different series in parallel if you have multiple compute cores available. To enable this behavior, set the `max_cores_per_iteration` parameter in your AutoMLConfig as shown in the example in the next cell.
Finally, a note about the cross-validation (CV) procedure for time-series data. AutoML uses out-of-sample error estimates to select a best pipeline/model, so it is important that the CV fold splitting is done correctly. Time-series can violate the basic statistical assumptions of the canonical K-Fold CV strategy, so AutoML implements a [rolling origin validation](https://robjhyndman.com/hyndsight/tscv/) procedure to create CV folds for time-series data. To use this procedure, you just need to specify the desired number of CV folds in the AutoMLConfig object. It is also possible to bypass CV and use your own validation set by setting the *validation_data* parameter of AutoMLConfig.
Here is a summary of AutoMLConfig parameters used for training the OJ model:
|Property|Description|
|-|-|
|**task**|forecasting|
|**primary_metric**|This is the metric that you want to optimize.<br> Forecasting supports the following primary metrics <br><i>spearman_correlation</i><br><i>normalized_root_mean_squared_error</i><br><i>r2_score</i><br><i>normalized_mean_absolute_error</i>
|**experiment_timeout_hours**|Experimentation timeout in hours.|
|**enable_early_stopping**|If early stopping is on, training will stop when the primary metric is no longer improving.|
|**training_data**|Input dataset, containing both features and label column.|
|**label_column_name**|The name of the label column.|
|**compute_target**|The remote compute for training.|
|**n_cross_validations**|Number of cross-validation folds to use for model/pipeline selection|
|**enable_voting_ensemble**|Allow AutoML to create a Voting ensemble of the best performing models|
|**enable_stack_ensemble**|Allow AutoML to create a Stack ensemble of the best performing models|
|**debug_log**|Log file path for writing debugging information|
|**featurization**| 'auto' / 'off' / FeaturizationConfig Indicator for whether featurization step should be done automatically or not, or whether customized featurization should be used. Setting this enables AutoML to perform featurization on the input to handle *missing data*, and to perform some common *feature extraction*.|
|**max_cores_per_iteration**|Maximum number of cores to utilize per iteration. A value of -1 indicates all available cores should be used
```
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(
time_column_name=time_column_name,
forecast_horizon=n_test_periods,
time_series_id_column_names=time_series_id_column_names
)
automl_config = AutoMLConfig(task='forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_mean_absolute_error',
experiment_timeout_hours=0.25,
training_data=train_dataset,
label_column_name=target_column_name,
compute_target=compute_target,
enable_early_stopping=True,
featurization=featurization_config,
n_cross_validations=3,
verbosity=logging.INFO,
max_cores_per_iteration=-1,
forecasting_parameters=forecasting_parameters)
```
You can now submit a new training run. Depending on the data and number of iterations this operation may take several minutes.
Information from each iteration will be printed to the console. Validation errors and current status will be shown when setting `show_output=True` and the execution will be synchronous.
```
remote_run = experiment.submit(automl_config, show_output=False)
remote_run
remote_run.wait_for_completion()
```
### Retrieve the Best Model
Each run within an Experiment stores serialized (i.e. pickled) pipelines from the AutoML iterations. We can now retrieve the pipeline with the best performance on the validation dataset:
```
best_run, fitted_model = remote_run.get_output()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
```
## Transparency
View updated featurization summary
```
custom_featurizer = fitted_model.named_steps['timeseriestransformer']
custom_featurizer.get_featurization_summary()
```
# Forecasting
Now that we have retrieved the best pipeline/model, it can be used to make predictions on test data. First, we remove the target values from the test set:
```
X_test = test
y_test = X_test.pop(target_column_name).values
X_test.head()
```
To produce predictions on the test set, we need to know the feature values at all dates in the test set. This requirement is somewhat reasonable for the OJ sales data since the features mainly consist of price, which is usually set in advance, and customer demographics which are approximately constant for each store over the 20 week forecast horizon in the testing data.
```
# forecast returns the predictions and the featurized data, aligned to X_test.
# This contains the assumptions that were made in the forecast
y_predictions, X_trans = fitted_model.forecast(X_test)
```
If you are used to scikit pipelines, perhaps you expected `predict(X_test)`. However, forecasting requires a more general interface that also supplies the past target `y` values. Please use `forecast(X,y)` as `predict(X)` is reserved for internal purposes on forecasting models.
The [forecast function notebook](../forecasting-forecast-function/auto-ml-forecasting-function.ipynb).
# Evaluate
To evaluate the accuracy of the forecast, we'll compare against the actual sales quantities for some select metrics, included the mean absolute percentage error (MAPE).
We'll add predictions and actuals into a single dataframe for convenience in calculating the metrics.
```
assign_dict = {'predicted': y_predictions, target_column_name: y_test}
df_all = X_test.assign(**assign_dict)
from azureml.automl.core.shared import constants
from azureml.automl.runtime.shared.score import scoring
from matplotlib import pyplot as plt
# use automl scoring module
scores = scoring.score_regression(
y_test=df_all[target_column_name],
y_pred=df_all['predicted'],
metrics=list(constants.Metric.SCALAR_REGRESSION_SET))
print("[Test data scores]\n")
for key, value in scores.items():
print('{}: {:.3f}'.format(key, value))
# Plot outputs
%matplotlib inline
test_pred = plt.scatter(df_all[target_column_name], df_all['predicted'], color='b')
test_test = plt.scatter(df_all[target_column_name], df_all[target_column_name], color='g')
plt.legend((test_pred, test_test), ('prediction', 'truth'), loc='upper left', fontsize=8)
plt.show()
```
# Operationalize
_Operationalization_ means getting the model into the cloud so that other can run it after you close the notebook. We will create a docker running on Azure Container Instances with the model.
```
description = 'AutoML OJ forecaster'
tags = None
model = remote_run.register_model(model_name = model_name, description = description, tags = tags)
print(remote_run.model_id)
```
### Develop the scoring script
For the deployment we need a function which will run the forecast on serialized data. It can be obtained from the best_run.
```
script_file_name = 'score_fcast.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', script_file_name)
```
### Deploy the model as a Web Service on Azure Container Instance
```
from azureml.core.model import InferenceConfig
from azureml.core.webservice import AciWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
inference_config = InferenceConfig(environment = best_run.get_environment(),
entry_script = script_file_name)
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 2,
tags = {'type': "automl-forecasting"},
description = "Automl forecasting sample service")
aci_service_name = 'automl-oj-forecast-01'
print(aci_service_name)
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
aci_service.get_logs()
```
### Call the service
```
import json
X_query = X_test.copy()
# We have to convert datetime to string, because Timestamps cannot be serialized to JSON.
X_query[time_column_name] = X_query[time_column_name].astype(str)
# The Service object accept the complex dictionary, which is internally converted to JSON string.
# The section 'data' contains the data frame in the form of dictionary.
test_sample = json.dumps({'data': X_query.to_dict(orient='records')})
response = aci_service.run(input_data = test_sample)
# translate from networkese to datascientese
try:
res_dict = json.loads(response)
y_fcst_all = pd.DataFrame(res_dict['index'])
y_fcst_all[time_column_name] = pd.to_datetime(y_fcst_all[time_column_name], unit = 'ms')
y_fcst_all['forecast'] = res_dict['forecast']
except:
print(res_dict)
y_fcst_all.head()
```
### Delete the web service if desired
```
serv = Webservice(ws, 'automl-oj-forecast-01')
serv.delete() # don't do it accidentally
```
| true |
code
| 0.578686 | null | null | null | null |
|
# IllusTrip: Text to Video 3D
Part of [Aphantasia](https://github.com/eps696/aphantasia) suite, made by Vadim Epstein [[eps696](https://github.com/eps696)]
Based on [CLIP](https://github.com/openai/CLIP) + FFT/pixel ops from [Lucent](https://github.com/greentfrapp/lucent).
3D part by [deKxi](https://twitter.com/deKxi), based on [AdaBins](https://github.com/shariqfarooq123/AdaBins) depth.
thanks to [Ryan Murdock](https://twitter.com/advadnoun), [Jonathan Fly](https://twitter.com/jonathanfly), [@eduwatch2](https://twitter.com/eduwatch2) for ideas.
## Features
* continuously processes **multiple sentences** (e.g. illustrating lyrics or poems)
* makes **videos**, evolving with pan/zoom/rotate motion
* works with [inverse FFT](https://github.com/greentfrapp/lucent/blob/master/lucent/optvis/param/spatial.py) representation of the image or **directly with RGB** pixels (no GANs involved)
* generates massive detailed textures (a la deepdream), **unlimited resolution**
* optional **depth** processing for 3D look
* various CLIP models
* can start/resume from an image
**Run the cell below after each session restart**
Ensure that you're given Tesla T4/P4/P100 GPU, not K80!
```
#@title General setup
!pip install ftfy==5.8 transformers
!pip install gputil ffpb
try:
!pip3 install googletrans==3.1.0a0
from googletrans import Translator, constants
translator = Translator()
except: pass
# !apt-get -qq install ffmpeg
work_dir = '/content/illustrip'
import os
os.makedirs(work_dir, exist_ok=True)
%cd $work_dir
import os
import io
import time
import math
import random
import imageio
import numpy as np
import PIL
from base64 import b64encode
import shutil
from easydict import EasyDict as edict
a = edict()
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms as T
from torch.autograd import Variable
from IPython.display import HTML, Image, display, clear_output
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import ipywidgets as ipy
from google.colab import output, files
import warnings
warnings.filterwarnings("ignore")
!pip install git+https://github.com/openai/CLIP.git --no-deps
import clip
!pip install sentence_transformers
from sentence_transformers import SentenceTransformer
!pip install kornia
import kornia
!pip install lpips
import lpips
!pip install PyWavelets==1.1.1
!pip install git+https://github.com/fbcotter/pytorch_wavelets
%cd /content
!rm -rf aphantasia
!git clone https://github.com/eps696/aphantasia
%cd aphantasia/
from clip_fft import to_valid_rgb, fft_image, rfft2d_freqs, img2fft, pixel_image, un_rgb
from utils import basename, file_list, img_list, img_read, txt_clean, plot_text, old_torch
from utils import slice_imgs, derivat, pad_up_to, slerp, checkout, sim_func, latent_anima
import transforms
import depth
from progress_bar import ProgressIPy as ProgressBar
shutil.copy('mask.jpg', work_dir)
depth_mask_file = os.path.join(work_dir, 'mask.jpg')
clear_output()
def save_img(img, fname=None):
img = np.array(img)[:,:,:]
img = np.transpose(img, (1,2,0))
img = np.clip(img*255, 0, 255).astype(np.uint8)
if fname is not None:
imageio.imsave(fname, np.array(img))
imageio.imsave('result.jpg', np.array(img))
def makevid(seq_dir, size=None):
char_len = len(basename(img_list(seq_dir)[0]))
out_sequence = seq_dir + '/%0{}d.jpg'.format(char_len)
out_video = seq_dir + '.mp4'
print('.. generating video ..')
!ffmpeg -y -v warning -i $out_sequence -crf 18 $out_video
data_url = "data:video/mp4;base64," + b64encode(open(out_video,'rb').read()).decode()
wh = '' if size is None else 'width=%d height=%d' % (size, size)
return """<video %s controls><source src="%s" type="video/mp4"></video>""" % (wh, data_url)
# Hardware check
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
import GPUtil as GPU
gpu = GPU.getGPUs()[0] # XXX: only one GPU on Colab and isn’t guaranteed
!nvidia-smi -L
print("GPU RAM {0:.0f}MB | Free {1:.0f}MB)".format(gpu.memoryTotal, gpu.memoryFree))
#@title Load inputs
#@markdown **Content** (either type a text string, or upload a text file):
content = "" #@param {type:"string"}
upload_texts = False #@param {type:"boolean"}
#@markdown **Style** (either type a text string, or upload a text file):
style = "" #@param {type:"string"}
upload_styles = False #@param {type:"boolean"}
#@markdown For non-English languages use Google translation:
translate = False #@param {type:"boolean"}
#@markdown Resume from the saved `.pt` snapshot, or from an image
#@markdown (resolution settings below will be ignored in this case):
if upload_texts:
print('Upload main text file')
uploaded = files.upload()
text_file = list(uploaded)[0]
texts = list(uploaded.values())[0].decode().split('\n')
texts = [tt.strip() for tt in texts if len(tt.strip())>0 and tt[0] != '#']
print(' main text:', text_file, len(texts), 'lines')
workname = txt_clean(basename(text_file))
else:
texts = [content]
workname = txt_clean(content)[:44]
if upload_styles:
print('Upload styles text file')
uploaded = files.upload()
text_file = list(uploaded)[0]
styles = list(uploaded.values())[0].decode().split('\n')
styles = [tt.strip() for tt in styles if len(tt.strip())>0 and tt[0] != '#']
print(' styles:', text_file, len(styles), 'lines')
else:
styles = [style]
resume = False #@param {type:"boolean"}
if resume:
print('Upload file to resume from')
resumed = files.upload()
resumed_filename = list(resumed)[0]
resumed_bytes = list(resumed.values())[0]
assert len(texts) > 0 and len(texts[0]) > 0, 'No input text[s] found!'
tempdir = os.path.join(work_dir, workname)
os.makedirs(tempdir, exist_ok=True)
print('main dir', tempdir)
```
**`content`** (what to draw) is your primary input; **`style`** (how to draw) is optional, if you want to separate such descriptions.
If you load text file[s], the imagery will interpolate from line to line (ensure equal line counts for content and style lists, for their accordance).
```
#@title Google Drive [optional]
#@markdown Run this cell, if you want to store results on your Google Drive.
using_GDrive = True#@param{type:"boolean"}
if using_GDrive:
import os
from google.colab import drive
if not os.path.isdir('/G/MyDrive'):
drive.mount('/G', force_remount=True)
gdir = '/G/MyDrive'
tempdir = os.path.join(gdir, 'illustrip', workname)
os.makedirs(tempdir, exist_ok=True)
print('main dir', tempdir)
#@title Main settings
sideX = 1280 #@param {type:"integer"}
sideY = 720 #@param {type:"integer"}
steps = 200 #@param {type:"integer"}
frame_step = 100 #@param {type:"integer"}
#@markdown > Config
method = 'RGB' #@param ['FFT', 'RGB']
model = 'ViT-B/32' #@param ['ViT-B/16', 'ViT-B/32', 'RN101', 'RN50x16', 'RN50x4', 'RN50']
# Default settings
if method == 'RGB':
align = 'overscan'
colors = 2
contrast = 1.2
sharpness = -1.
aug_noise = 0.
smooth = False
else:
align = 'uniform'
colors = 1.8
contrast = 1.1
sharpness = 1.
aug_noise = 2.
smooth = True
interpolate_topics = True
style_power = 1.
samples = 200
save_step = 1
learning_rate = 1.
aug_transform = 'custom'
similarity_function = 'cossim'
macro = 0.4
enforce = 0.
expand = 0.
zoom = 0.012
shift = 10
rotate = 0.8
distort = 0.3
animate_them = True
sample_decrease = 1.
DepthStrength = 0.
print(' loading CLIP model..')
model_clip, _ = clip.load(model, jit=old_torch())
modsize = model_clip.visual.input_resolution
xmem = {'ViT-B/16':0.25, 'RN50':0.5, 'RN50x4':0.16, 'RN50x16':0.06, 'RN101':0.33}
if model in xmem.keys():
sample_decrease *= xmem[model]
clear_output()
print(' using CLIP model', model)
```
**`FFT`** method uses inverse FFT representation of the image. It allows flexible motion, but is either blurry (if smoothed) or noisy (if not).
**`RGB`** method directly optimizes image pixels (without FFT parameterization). It's more clean and stable, when zooming in.
There are few choices for CLIP `model` (results do vary!). I prefer ViT-B/32 for consistency, next best bet is ViT-B/16.
**`steps`** defines the length of animation per text line (multiply it to the inputs line count to get total video duration in frames).
`frame_step` sets frequency of the changes in animation (how many frames between motion keypoints).
## Other settings [optional]
```
#@title Run this cell to override settings, if needed
#@markdown [to roll back defaults, run "Main settings" cell again]
style_power = 1. #@param {type:"number"}
overscan = True #@param {type:"boolean"}
align = 'overscan' if overscan else 'uniform'
interpolate_topics = True #@param {type:"boolean"}
#@markdown > Look
colors = 2 #@param {type:"number"}
contrast = 1.2 #@param {type:"number"}
sharpness = 0. #@param {type:"number"}
#@markdown > Training
samples = 200 #@param {type:"integer"}
save_step = 1 #@param {type:"integer"}
learning_rate = 1. #@param {type:"number"}
#@markdown > Tricks
aug_transform = 'custom' #@param ['elastic', 'custom', 'none']
aug_noise = 0. #@param {type:"number"}
macro = 0.4 #@param {type:"number"}
enforce = 0. #@param {type:"number"}
expand = 0. #@param {type:"number"}
similarity_function = 'cossim' #@param ['cossim', 'spherical', 'mixed', 'angular', 'dot']
#@markdown > Motion
zoom = 0.012 #@param {type:"number"}
shift = 10 #@param {type:"number"}
rotate = 0.8 #@param {type:"number"}
distort = 0.3 #@param {type:"number"}
animate_them = True #@param {type:"boolean"}
smooth = True #@param {type:"boolean"}
if method == 'RGB': smooth = False
```
`style_power` controls the strength of the style descriptions, comparing to the main input.
`overscan` provides better frame coverage (needed for RGB method).
`interpolate_topics` changes the subjects smoothly, otherwise they're switched by cut, making sharper transitions.
Decrease **`samples`** if you face OOM (it's the main RAM eater), or just to speed up the process (with the cost of quality).
`save_step` defines, how many optimization steps are taken between saved frames. Set it >1 for stronger image processing.
Experimental tricks:
`aug_transform` applies some augmentations, which quite radically change the output of this method (and slow down the process). Try yourself to see which is good for your case. `aug_noise` augmentation [FFT only!] seems to enhance optimization with transforms.
`macro` boosts bigger forms.
`enforce` adds more details by enforcing similarity between two parallel samples.
`expand` boosts diversity (up to irrelevant) by enforcing difference between prev/next samples.
Motion section:
`shift` is in pixels, `rotate` in degrees. The values will be used as limits, if you mark `animate_them`.
`smooth` reduces blinking, but induces motion blur with subtle screen-fixed patterns (valid only for FFT method, disabled for RGB).
## Add 3D depth [optional]
```
### deKxi:: This whole cell contains most of whats needed,
# with just a few changes to hook it up via frame_transform
# (also glob_step now as global var)
# I highly recommend performing the frame transformations and depth *after* saving,
# (or just the depth warp if you prefer to keep the other affines as they are)
# from my testing it reduces any noticeable stretching and allows the new areas
# revealed from the changed perspective to be filled/detailed
# pretrained models: Nyu is much better but Kitti is an option too
depth_model = 'nyu' # @ param ["nyu","kitti"]
DepthStrength = 0.01 #@param{type:"number"}
MaskBlurAmt = 33 #@param{type:"integer"}
save_depth = False #@param{type:"boolean"}
size = (sideY,sideX)
#@markdown NB: depth computing may take up to ~3x more time. Read the comments inside for more info.
#@markdown Courtesy of [deKxi](https://twitter.com/deKxi)
if DepthStrength > 0:
if not os.path.exists("AdaBins_nyu.pt"):
!gdown https://drive.google.com/uc?id=1lvyZZbC9NLcS8a__YPcUP7rDiIpbRpoF
if not os.path.exists('AdaBins_nyu.pt'):
!wget https://www.dropbox.com/s/tayczpcydoco12s/AdaBins_nyu.pt
# if depth_model=='kitti' and not os.path.exists(os.path.join(workdir_depth, "pretrained/AdaBins_kitti.pt")):
# !gdown https://drive.google.com/uc?id=1HMgff-FV6qw1L0ywQZJ7ECa9VPq1bIoj
if save_depth:
depthdir = os.path.join(tempdir, 'depth')
os.makedirs(depthdir, exist_ok=True)
print('depth dir', depthdir)
else:
depthdir = None
depth_infer, depth_mask = depth.init_adabins(model_path='AdaBins_nyu.pt', mask_path='mask.jpg', size=size)
def depth_transform(img_t, img_np, depth_infer, depth_mask, size, depthX=0, scale=1., shift=[0,0], colors=1, depth_dir=None, save_num=0):
# d X/Y define the origin point of the depth warp, effectively a "3D pan zoom", [-1..1]
# plus = look ahead, minus = look aside
dX = 100. * shift[0] / size[1]
dY = 100. * shift[1] / size[0]
# dZ = movement direction: 1 away (zoom out), 0 towards (zoom in), 0.5 stay
dZ = 0.5 + 23. * (scale[0]-1)
# dZ += 0.5 * float(math.sin(((save_num % 70)/70) * math.pi * 2))
if img_np is None:
img2 = img_t.clone().detach()
par, imag, _ = pixel_image(img2.shape, resume=img2)
img2 = to_valid_rgb(imag, colors=colors)()
img2 = img2.detach().cpu().numpy()[0]
img2 = (np.transpose(img2, (1,2,0))) # [h,w,c]
img2 = np.clip(img2*255, 0, 255).astype(np.uint8)
image_pil = T.ToPILImage()(img2)
del img2
else:
image_pil = T.ToPILImage()(img_np)
size2 = [s//2 for s in size]
img = depth.depthwarp(img_t, image_pil, depth_infer, depth_mask, size2, depthX, [dX,dY], dZ, rescale=0.5, clip_range=2, save_path=depth_dir, save_num=save_num)
return img
```
## Generate
```
#@title Generate
if aug_transform == 'elastic':
trform_f = transforms.transforms_elastic
sample_decrease *= 0.95
elif aug_transform == 'custom':
trform_f = transforms.transforms_custom
sample_decrease *= 0.95
else:
trform_f = transforms.normalize()
if enforce != 0:
sample_decrease *= 0.5
samples = int(samples * sample_decrease)
print(' using %s method, %d samples' % (method, samples))
if translate:
translator = Translator()
def enc_text(txt):
if translate:
txt = translator.translate(txt, dest='en').text
emb = model_clip.encode_text(clip.tokenize(txt).cuda()[:77])
return emb.detach().clone()
# Encode inputs
count = 0 # max count of texts and styles
key_txt_encs = [enc_text(txt) for txt in texts]
count = max(count, len(key_txt_encs))
key_styl_encs = [enc_text(style) for style in styles]
count = max(count, len(key_styl_encs))
assert count > 0, "No inputs found!"
# !rm -rf $tempdir
# os.makedirs(tempdir, exist_ok=True)
# opt_steps = steps * save_step # for optimization
glob_steps = count * steps # saving
if glob_steps == frame_step: frame_step = glob_steps // 2 # otherwise no motion
outpic = ipy.Output()
outpic
if method == 'RGB':
if resume:
img_in = imageio.imread(resumed_bytes) / 255.
params_tmp = torch.Tensor(img_in).permute(2,0,1).unsqueeze(0).float().cuda()
params_tmp = un_rgb(params_tmp, colors=1.)
sideY, sideX = img_in.shape[0], img_in.shape[1]
else:
params_tmp = torch.randn(1, 3, sideY, sideX).cuda() # * 0.01
else: # FFT
if resume:
if os.path.splitext(resumed_filename)[1].lower()[1:] in ['jpg','png','tif','bmp']:
img_in = imageio.imread(resumed_bytes)
params_tmp = img2fft(img_in, 1.5, 1.) * 2.
else:
params_tmp = torch.load(io.BytesIO(resumed_bytes))
if isinstance(params_tmp, list): params_tmp = params_tmp[0]
params_tmp = params_tmp.cuda()
sideY, sideX = params_tmp.shape[2], (params_tmp.shape[3]-1)*2
else:
params_shape = [1, 3, sideY, sideX//2+1, 2]
params_tmp = torch.randn(*params_shape).cuda() * 0.01
params_tmp = params_tmp.detach()
# function() = torch.transformation(linear)
# animation controls
if animate_them:
if method == 'RGB':
m_scale = latent_anima([1], glob_steps, frame_step, uniform=True, cubic=True, start_lat=[-0.3])
m_scale = 1 + (m_scale + 0.3) * zoom # only zoom in
else:
m_scale = latent_anima([1], glob_steps, frame_step, uniform=True, cubic=True, start_lat=[0.6])
m_scale = 1 - (m_scale-0.6) * zoom # ping pong
m_shift = latent_anima([2], glob_steps, frame_step, uniform=True, cubic=True, start_lat=[0.5,0.5])
m_angle = latent_anima([1], glob_steps, frame_step, uniform=True, cubic=True, start_lat=[0.5])
m_shear = latent_anima([1], glob_steps, frame_step, uniform=True, cubic=True, start_lat=[0.5])
m_shift = (m_shift-0.5) * shift * abs(m_scale-1.) / zoom
m_angle = (m_angle-0.5) * rotate * abs(m_scale-1.) / zoom
m_shear = (m_shear-0.5) * distort * abs(m_scale-1.) / zoom
def get_encs(encs, num):
cnt = len(encs)
if cnt == 0: return []
enc_1 = encs[min(num, cnt-1)]
enc_2 = encs[min(num+1, cnt-1)]
return slerp(enc_1, enc_2, steps)
def frame_transform(img, size, angle, shift, scale, shear):
if old_torch(): # 1.7.1
img = T.functional.affine(img, angle, shift, scale, shear, fillcolor=0, resample=PIL.Image.BILINEAR)
img = T.functional.center_crop(img, size)
img = pad_up_to(img, size)
else: # 1.8+
img = T.functional.affine(img, angle, shift, scale, shear, fill=0, interpolation=T.InterpolationMode.BILINEAR)
img = T.functional.center_crop(img, size) # on 1.8+ also pads
return img
global img_np
img_np = None
prev_enc = 0
def process(num):
global params_tmp, img_np, opt_state, params, image_f, optimizer, pbar
if interpolate_topics:
txt_encs = get_encs(key_txt_encs, num)
styl_encs = get_encs(key_styl_encs, num)
else:
txt_encs = [key_txt_encs[min(num, len(key_txt_encs)-1)][0]] * steps if len(key_txt_encs) > 0 else []
styl_encs = [key_styl_encs[min(num, len(key_styl_encs)-1)][0]] * steps if len(key_styl_encs) > 0 else []
if len(texts) > 0: print(' ref text: ', texts[min(num, len(texts)-1)][:80])
if len(styles) > 0: print(' ref style: ', styles[min(num, len(styles)-1)][:80])
for ii in range(steps):
glob_step = num * steps + ii # saving/transforming
### animation: transform frame, reload params
h, w = sideY, sideX
# transform frame for motion
scale = m_scale[glob_step] if animate_them else 1-zoom
trans = tuple(m_shift[glob_step]) if animate_them else [0, shift]
angle = m_angle[glob_step][0] if animate_them else rotate
shear = m_shear[glob_step][0] if animate_them else distort
if method == 'RGB':
if DepthStrength > 0:
params_tmp = depth_transform(params_tmp, img_np, depth_infer, depth_mask, size, DepthStrength, scale, trans, colors, depthdir, glob_step)
params_tmp = frame_transform(params_tmp, (h,w), angle, trans, scale, shear)
params, image_f, _ = pixel_image([1,3,h,w], resume=params_tmp)
img_tmp = None
else: # FFT
if old_torch(): # 1.7.1
img_tmp = torch.irfft(params_tmp, 2, normalized=True, signal_sizes=(h,w))
if DepthStrength > 0:
img_tmp = depth_transform(img_tmp, img_np, depth_infer, depth_mask, size, DepthStrength, scale, trans, colors, depthdir, glob_step)
img_tmp = frame_transform(img_tmp, (h,w), angle, trans, scale, shear)
params_tmp = torch.rfft(img_tmp, 2, normalized=True)
else: # 1.8+
if type(params_tmp) is not torch.complex64:
params_tmp = torch.view_as_complex(params_tmp)
img_tmp = torch.fft.irfftn(params_tmp, s=(h,w), norm='ortho')
if DepthStrength > 0:
img_tmp = depth_transform(img_tmp, img_np, depth_infer, depth_mask, size, DepthStrength, scale, trans, colors, depthdir, glob_step)
img_tmp = frame_transform(img_tmp, (h,w), angle, trans, scale, shear)
params_tmp = torch.fft.rfftn(img_tmp, s=[h,w], dim=[2,3], norm='ortho')
params_tmp = torch.view_as_real(params_tmp)
params, image_f, _ = fft_image([1,3,h,w], resume=params_tmp, sd=1.)
image_f = to_valid_rgb(image_f, colors=colors)
del img_tmp
optimizer = torch.optim.Adam(params, learning_rate)
# optimizer = torch.optim.AdamW(params, learning_rate, weight_decay=0.01, amsgrad=True)
if smooth is True and num + ii > 0:
optimizer.load_state_dict(opt_state)
# get encoded inputs
txt_enc = txt_encs[ii % len(txt_encs)].unsqueeze(0) if len(txt_encs) > 0 else None
styl_enc = styl_encs[ii % len(styl_encs)].unsqueeze(0) if len(styl_encs) > 0 else None
### optimization
for ss in range(save_step):
loss = 0
noise = aug_noise * (torch.rand(1, 1, *params[0].shape[2:4], 1)-0.5).cuda() if aug_noise > 0 else 0.
img_out = image_f(noise)
img_sliced = slice_imgs([img_out], samples, modsize, trform_f, align, macro)[0]
out_enc = model_clip.encode_image(img_sliced)
if method == 'RGB': # empirical hack
loss += 1.5 * abs(img_out.mean((2,3)) - 0.45).mean() # fix brightness
loss += 1.5 * abs(img_out.std((2,3)) - 0.17).sum() # fix contrast
if txt_enc is not None:
loss -= sim_func(txt_enc, out_enc, similarity_function)
if styl_enc is not None:
loss -= style_power * sim_func(styl_enc, out_enc, similarity_function)
if sharpness != 0: # mode = scharr|sobel|naive
loss -= sharpness * derivat(img_out, mode='naive')
# loss -= sharpness * derivat(img_sliced, mode='scharr')
if enforce != 0:
img_sliced = slice_imgs([image_f(noise)], samples, modsize, trform_f, align, macro)[0]
out_enc2 = model_clip.encode_image(img_sliced)
loss -= enforce * sim_func(out_enc, out_enc2, similarity_function)
del out_enc2; torch.cuda.empty_cache()
if expand > 0:
global prev_enc
if ii > 0:
loss += expand * sim_func(prev_enc, out_enc, similarity_function)
prev_enc = out_enc.detach().clone()
del img_out, img_sliced, out_enc; torch.cuda.empty_cache()
optimizer.zero_grad()
loss.backward()
optimizer.step()
### save params & frame
params_tmp = params[0].detach().clone()
if smooth is True:
opt_state = optimizer.state_dict()
with torch.no_grad():
img_t = image_f(contrast=contrast)[0].permute(1,2,0)
img_np = torch.clip(img_t*255, 0, 255).cpu().numpy().astype(np.uint8)
imageio.imsave(os.path.join(tempdir, '%05d.jpg' % glob_step), img_np, quality=95)
shutil.copy(os.path.join(tempdir, '%05d.jpg' % glob_step), 'result.jpg')
outpic.clear_output()
with outpic:
display(Image('result.jpg'))
del img_t
pbar.upd()
params_tmp = params[0].detach().clone()
outpic = ipy.Output()
outpic
pbar = ProgressBar(glob_steps)
for i in range(count):
process(i)
HTML(makevid(tempdir))
files.download(tempdir + '.mp4')
## deKxi: downloading depth video
if save_depth and DepthStrength > 0:
HTML(makevid(depthdir))
files.download(depthdir + '.mp4')
```
If video is not auto-downloaded after generation (for whatever reason), run this cell to do that:
```
files.download(tempdir + '.mp4')
if save_depth and DepthStrength > 0:
files.download(depthdir + '.mp4')
```
| true |
code
| 0.545649 | null | null | null | null |
|
<img src="http://akhavanpour.ir/notebook/images/srttu.gif" alt="SRTTU" style="width: 150px;"/>
[](https://notebooks.azure.com/import/gh/Alireza-Akhavan/class.vision)
# <div style="direction:rtl;text-align:right;font-family:B Lotus, B Nazanin, Tahoma"> تولید متن با شبکه بازگشتی LSTM در Keras</div>
<div style="direction:rtl;text-align:right;font-family:Tahoma">
کدها برگرفته از فصل هشتم کتاب
</div>
[Deep Learning with Python](https://www.manning.com/books/deep-learning-with-python?a_aid=keras&a_bid=76564dff)
<div style="direction:rtl;text-align:right;font-family:Tahoma">
و گیت هاب نویسنده کتاب و توسعه دهنده کراس
</div>
[François Chollet](http://nbviewer.jupyter.org/github/fchollet/deep-learning-with-python-notebooks/blob/master/8.1-text-generation-with-lstm.ipynb)
<div style="direction:rtl;text-align:right;font-family:Tahoma">
است.
</div>
```
import keras
keras.__version__
```
# Text generation with LSTM
## Implementing character-level LSTM text generation
Let's put these ideas in practice in a Keras implementation. The first thing we need is a lot of text data that we can use to learn a
language model. You could use any sufficiently large text file or set of text files -- Wikipedia, the Lord of the Rings, etc. In this
example we will use some of the writings of Nietzsche, the late-19th century German philosopher (translated to English). The language model
we will learn will thus be specifically a model of Nietzsche's writing style and topics of choice, rather than a more generic model of the
English language.
### <div style="direction:rtl;text-align:right;font-family:B Lotus, B Nazanin, Tahoma"> مجموعه داده
</div>
```
import keras
import numpy as np
path = keras.utils.get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open(path).read().lower()
print('Corpus length:', len(text))
```
Next, we will extract partially-overlapping sequences of length `maxlen`, one-hot encode them and pack them in a 3D Numpy array `x` of
shape `(sequences, maxlen, unique_characters)`. Simultaneously, we prepare a array `y` containing the corresponding targets: the one-hot
encoded characters that come right after each extracted sequence.
```
# Length of extracted character sequences
maxlen = 60
# We sample a new sequence every `step` characters
step = 3
# This holds our extracted sequences
sentences = []
# This holds the targets (the follow-up characters)
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('Number of sequences:', len(sentences))
# List of unique characters in the corpus
chars = sorted(list(set(text)))
print('Unique characters:', len(chars))
# Dictionary mapping unique characters to their index in `chars`
char_indices = dict((char, chars.index(char)) for char in chars)
# Next, one-hot encode the characters into binary arrays.
print('Vectorization...')
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
```
## <div style="direction:rtl;text-align:right;font-family:B Lotus, B Nazanin, Tahoma"> ایجاد شبکه (Building the network)</div>
Our network is a single `LSTM` layer followed by a `Dense` classifier and softmax over all possible characters. But let us note that
recurrent neural networks are not the only way to do sequence data generation; 1D convnets also have proven extremely successful at it in
recent times.
```
from keras import layers
model = keras.models.Sequential()
model.add(layers.LSTM(128, input_shape=(maxlen, len(chars))))
model.add(layers.Dense(len(chars), activation='softmax'))
```
Since our targets are one-hot encoded, we will use `categorical_crossentropy` as the loss to train the model:
```
optimizer = keras.optimizers.RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
```
## Training the language model and sampling from it
Given a trained model and a seed text snippet, we generate new text by repeatedly:
* 1) Drawing from the model a probability distribution over the next character given the text available so far
* 2) Reweighting the distribution to a certain "temperature"
* 3) Sampling the next character at random according to the reweighted distribution
* 4) Adding the new character at the end of the available text
This is the code we use to reweight the original probability distribution coming out of the model,
and draw a character index from it (the "sampling function"):
```
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
```
Finally, this is the loop where we repeatedly train and generated text. We start generating text using a range of different temperatures
after every epoch. This allows us to see how the generated text evolves as the model starts converging, as well as the impact of
temperature in the sampling strategy.
```
import random
import sys
for epoch in range(1, 60):
print('epoch', epoch)
# Fit the model for 1 epoch on the available training data
model.fit(x, y,
batch_size=128,
epochs=1)
# Select a text seed at random
start_index = random.randint(0, len(text) - maxlen - 1)
generated_text = text[start_index: start_index + maxlen]
print('--- Generating with seed: "' + generated_text + '"')
for temperature in [0.2, 0.5, 1.0, 1.2]:
print('------ temperature:', temperature)
sys.stdout.write(generated_text)
# We generate 400 characters
for i in range(400):
sampled = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated_text):
sampled[0, t, char_indices[char]] = 1.
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_char = chars[next_index]
generated_text += next_char
generated_text = generated_text[1:]
sys.stdout.write(next_char)
sys.stdout.flush()
print()
```
As you can see, a low temperature results in extremely repetitive and predictable text, but where local structure is highly realistic: in
particular, all words (a word being a local pattern of characters) are real English words. With higher temperatures, the generated text
becomes more interesting, surprising, even creative; it may sometimes invent completely new words that sound somewhat plausible (such as
"eterned" or "troveration"). With a high temperature, the local structure starts breaking down and most words look like semi-random strings
of characters. Without a doubt, here 0.5 is the most interesting temperature for text generation in this specific setup. Always experiment
with multiple sampling strategies! A clever balance between learned structure and randomness is what makes generation interesting.
Note that by training a bigger model, longer, on more data, you can achieve generated samples that will look much more coherent and
realistic than ours. But of course, don't expect to ever generate any meaningful text, other than by random chance: all we are doing is
sampling data from a statistical model of which characters come after which characters. Language is a communication channel, and there is
a distinction between what communications are about, and the statistical structure of the messages in which communications are encoded. To
evidence this distinction, here is a thought experiment: what if human language did a better job at compressing communications, much like
our computers do with most of our digital communications? Then language would be no less meaningful, yet it would lack any intrinsic
statistical structure, thus making it impossible to learn a language model like we just did.
## Take aways
* We can generate discrete sequence data by training a model to predict the next tokens(s) given previous tokens.
* In the case of text, such a model is called a "language model" and could be based on either words or characters.
* Sampling the next token requires balance between adhering to what the model judges likely, and introducing randomness.
* One way to handle this is the notion of _softmax temperature_. Always experiment with different temperatures to find the "right" one.
| true |
code
| 0.607809 | null | null | null | null |
|
# Getting to know LSTMs better
Created: September 13, 2018
Author: Thamme Gowda
Goals:
- To get batches of *unequal length sequences* encoded correctly!
- Know how the hidden states flow between encoders and decoders
- Know how the multiple stacked LSTM layers pass hidden states
Example: a simple bi-directional LSTM which takes 3d input vectors
and produces 2d output vectors.
```
import torch
from torch import nn
lstm = nn.LSTM(3, 2, batch_first=True, bidirectional=True)
# Lets create a batch input.
# 3 sequences in batch (the first dim) , see batch_first=True
# Then the logest sequence is 4 time steps, ==> second dimension
# Each time step has 3d vector which is input ==> last dimension
pad_seq = torch.rand(3, 4, 3)
# That is nice for the theory
# but in practice we are dealing with un equal length sequences
# among those 3 sequences in the batch, lets us say
# first sequence is the longest, with 4 time steps --> no padding needed
# second seq is 3 time steps --> pad the last time step
pad_seq[1, 3, :] = 0.0
# third seq is 2 time steps --> pad the last two steps
pad_seq[2, 2:, :] = 0.0
print("Padded Input:")
print(pad_seq)
# so we got these lengths
lens = [4,3,2]
print("Sequence Lenghts: ", lens)
# lets send padded seq to LSTM
out,(h_t, c_t) = lstm(pad_seq)
print("All Outputs:")
print(out)
```
^^ Output is 2x2d=4d vector since it is bidirectional
forward 2d, backward 2d are concatenated
Total vectors=12: 3 seqs in batch x 4 time steps;; each vector is 4d
> Hmm, what happened to my padding time steps? Will padded zeros mess with the internal weights of LSTM when I do backprop?
---
Lets look at the last Hidden state
```
print(h_t)
```
Last hidden state is a 2d (same as output) vectors,
but 2 for each step because of bidirectional rnn
There are 3 of them since there were three seqs in the batch
each corresponding to the last step
But the definition of *last time step* is bit tricky
For the left-to-right LSTM, it is the last step of input
For the right-to-left LSTM, it is the first step of input
This makes sense now.
---
Lets look at $c_t$:
```
print("Last c_t:")
print(c_t)
```
This should be similar to the last hidden state.
## Question:
> what happened to my padding time steps? Did the last hidden state exclude the padded time steps?
I can see that last hidden state of the forward LSTM didnt distinguish padded zeros.
Lets see output of each time steps and last hidden state of left-to-right LSTM, again.
We know that the lengths (after removing padding) are \[4,3,2]
```
print("All time stamp outputs:")
print(out[:, :, :2])
print("Last hidden state (forward LSTM):")
print(h_t[0])
```
*Okay, Now I get it.*
When building sequence to sequence (for Machine translation) I cant pass last hidden state like this to a decoder.
We have to inform the LSTM about lengths.
How?
Thats why we have `torch.nn.utils.rnn.pack_padded_sequence`
```
print("Padded Seqs:")
print(pad_seq)
print("Lens:", lens)
print("Pack Padded Seqs:")
pac_pad_seq = torch.nn.utils.rnn.pack_padded_sequence(pad_seq, lens, batch_first=True)
print(pac_pad_seq)
```
Okay, this is doing some magic -- getting rid of all padded zeros -- Cool!
`batch_sizes=tensor([3, 3, 2, 1]` seems to be the main ingredient of this magic.
`[3, 3, 2, 1]` I get it!
We have 4 time steps in batch.
- First two step has all 3 seqs in the batch.
- third step is made of first 2 seqs in batch.
- Fourth step is made of first seq in batch
I now understand why the sequences in the batch has to be sorted by descending order of lengths!
Now let us send it to LSTM and see what it produces
```
pac_pad_out, (pac_ht, pac_ct) = lstm(pac_pad_seq)
# Lets first look at output. this is packed output
print(pac_pad_out)
```
Okay this is packed output. Sequences are of unequal lengths.
Now we need to restore the output by padding 0s for shorter sequences.
```
pad_out = nn.utils.rnn.pad_packed_sequence(pac_pad_out, batch_first=True, padding_value=0)
print(pad_out)
```
Output looks good! Now Let us look at the hidden state.
```
print(pac_ht)
```
This is great. As we see the forward (or Left-to-right) LSTM's last hidden state is proper as per the lengths. So should be the c_t.
Let us concatenate forward and reverse LSTM's hidden states
```
torch.cat([pac_ht[0],pac_ht[1]], dim=1)
```
----
# Multi Layer LSTM
Let us redo the above hacking to understand how 2 layer LSTM works
```
n_layers = 2
inp_size = 3
out_size = 2
lstm2 = nn.LSTM(inp_size, out_size, num_layers=n_layers, batch_first=True, bidirectional=True)
pac_out, (h_n, c_n) = lstm2(pac_pad_seq)
print("Packed Output:")
print(pac_out)
pad_out = nn.utils.rnn.pad_packed_sequence(pac_out, batch_first=True, padding_value=0)
print("Pad Output:")
print(pad_out)
print("Last h_n:")
print(h_n)
print("Last c_n:")
print(c_n)
```
The LSTM output looks similar to single layer LSTM.
However the ht and ct states are bigger -- since there are two layers.
Now its time to RTFM.
> h_n of shape `(num_layers * num_directions, batch, hidden_size)`: tensor containing the hidden state for `t = seq_len`.
Like output, the layers can be separated using `h_n.view(num_layers, num_directions, batch, hidden_size)` and similarly for c_n.
```
batch_size = 3
num_dirs = 2
l_n_h_n = h_n.view(n_layers, num_dirs, batch_size, out_size)[-1]
# last layer last time step hidden state
print(l_n_h_n)
last_hid = torch.cat([l_n_h_n[0], l_n_h_n[1]], dim=1)
print("last layer last time stamp hidden state")
print(last_hid)
print("Padded Outputs :")
print(pad_out)
```
| true |
code
| 0.647548 | null | null | null | null |
|
## Differential Privacy - Simple Database Queries
The database is going to be a VERY simple database with only one boolean column. Each row corresponds to a person. Each value corresponds to whether or not that person has a certain private attribute (such as whether they have a certain disease, or whether they are above/below a certain age). We are then going to learn how to know whether a database query over such a small database is differentially private or not - and more importantly - what techniques we can employ to ensure various levels of privacy
#### Create a Simple Database
To do this, initialize a random list of 1s and 0s (which are the entries in our database). Note - the number of entries directly corresponds to the number of people in our database.
```
import torch
# the number of entries in our DB / this of it as number of people in the DB
num_entries = 5000
db = torch.rand(num_entries) > 0.5
db
```
## Generate Parallel Databases
> "When querying a database, if I removed someone from the database, would the output of the query change?".
In order to check for this, we create "parallel databases" which are simply databases with one entry removed.
We'll create a list of every parallel database to the one currently contained in the "db" variable. Then, create a helper function which does the following:
- creates the initial database (db)
- creates all parallel databases
```
def create_parallel_db(db, remove_index):
return torch.cat((db[0:remove_index], db[remove_index+1:]))
def create_parallel_dbs(db):
parallel_dbs = list()
for i in range(len(db)):
pdb = create_parallel_db(db, i)
parallel_dbs.append(pdb)
return parallel_dbs
def create_db_and_parallels(num_entries):
# generate dbs and parallel dbs on the fly
db = torch.rand(num_entries) > 0.5
pdbs = create_parallel_dbs(db)
return db, pdbs
db, pdbs = create_db_and_parallels(10)
pdbs
print("Real database:", db)
print("Size of real DB", db.size())
print("A sample parallel DB", pdbs[0])
print("Size of parallel DB", pdbs[0].size())
```
# Towards Evaluating The Differential Privacy of a Function
Intuitively, we want to be able to query our database and evaluate whether or not the result of the query is leaking "private" information.
> This is about evaluating whether the output of a query changes when we remove someone from the database. Specifically, we want to evaluate the *maximum* amount the query changes when someone is removed (maximum over all possible people who could be removed).
To find how much privacy is leaked, we'll iterate over each person in the database and **measure** the difference in the output of the query relative to when we query the entire database.
Just for the sake of argument, let's make our first "database query" a simple sum. Aka, we're going to count the number of 1s in the database.
```
db, pdbs = create_db_and_parallels(200)
def query(db):
return db.sum()
query(db)
# the output of the parallel dbs is different from the db query
query(pdbs[1])
full_db_result = query(db)
print(full_db_result)
sensitivity = 0
sensitivity_scale = []
for pdb in pdbs:
pdb_result = query(pdb)
db_distance = torch.abs(pdb_result - full_db_result)
if(db_distance > sensitivity):
sensitivity_scale.append(db_distance)
sensitivity = db_distance
sensitivity
```
#### Sensitivity
> The maximum amount the query changes when removing an individual from the DB.
# Evaluating the Privacy of a Function
The difference between each parallel db's query result and the query result for the real database and its max value (which was 1) is called "sensitivity". It corresponds to the function we chose for the query. The "sum" query will always have a sensitivity of exactly 1. We can also calculate sensitivity for other functions as well.
Let's calculate sensitivity for the "mean" function.
```
def sensitivity(query, num_entries=1000):
db, pdbs = create_db_and_parallels(num_entries)
full_db_result = query(db)
max_distance = 0
for pdb in pdbs:
# for each parallel db, execute the query (sum, or mean, ..., etc)
pdb_result = query(pdb)
db_distance = torch.abs(pdb_result - full_db_result)
if (db_distance > max_distance):
max_distance = db_distance
return max_distance
# our query is now the mean
def query(db):
return db.float().mean()
sensitivity(query)
```
Wow! That sensitivity is WAY lower. Note the intuition here.
>"Sensitivity" is measuring how sensitive the output of the query is to a person being removed from the database.
For a simple sum, this is always 1, but for the mean, removing a person is going to change the result of the query by rougly 1 divided by the size of the database. Thus, "mean" is a VASTLY less "sensitive" function (query) than SUM.
# Calculating L1 Sensitivity For Threshold
TO calculate the sensitivty for the "threshold" function:
- First compute the sum over the database (i.e. sum(db)) and return whether that sum is greater than a certain threshold.
- Then, create databases of size 10 and threshold of 5 and calculate the sensitivity of the function.
- Finally, re-initialize the database 10 times and calculate the sensitivity each time.
```
def query(db, threshold=5):
"""
Query that adds a threshold of 5, and returns whether sum is > threshold or not.
"""
return (db.sum() > threshold).float()
for i in range(10):
sens = sensitivity(query, num_entries=10)
print(sens)
```
# A Basic Differencing Attack
Sadly none of the functions we've looked at so far are differentially private (despite them having varying levels of sensitivity). The most basic type of attack can be done as follows.
Let's say we wanted to figure out a specific person's value in the database. All we would have to do is query for the sum of the entire database and then the sum of the entire database without that person!
## Performing a Differencing Attack on Row 10 (How privacy can fail)
We'll construct a database and then demonstrate how one can use two different sum queries to explose the value of the person represented by row 10 in the database (note, you'll need to use a database with at least 10 rows)
```
db, _ = create_db_and_parallels(100)
db
# create a parallel db with that person (index 10) removed
pdb = create_parallel_db(db, remove_index=10)
pdb
# differencing attack using sum query
sum(db) - sum(pdb)
# a differencing attack using mean query
sum(db).float() /len(db) - sum(pdb).float() / len(pdb)
# differencing using a threshold
(sum(db).float() > 50) - (sum(pdb).float() > 50)
```
# Local Differential Privacy
Differential privacy always requires a form of randommess or noise added to the query to protect from things like Differencing Attacks.
To explain this, let's look at Randomized Response.
### Randomized Response (Local Differential Privacy)
Let's say I have a group of people I wish to survey about a very taboo behavior which I think they will lie about (say, I want to know if they have ever committed a certain kind of crime). I'm not a policeman, I'm just trying to collect statistics to understand the higher level trend in society. So, how do we do this? One technique is to add randomness to each person's response by giving each person the following instructions (assuming I'm asking a simple yes/no question):
- Flip a coin 2 times.
- If the first coin flip is heads, answer honestly
- If the first coin flip is tails, answer according to the second coin flip (heads for yes, tails for no)!
Thus, each person is now protected with "plausible deniability". If they answer "Yes" to the question "have you committed X crime?", then it might becasue they actually did, or it might be because they are answering according to a random coin flip. Each person has a high degree of protection. Furthermore, we can recover the underlying statistics with some accuracy, as the "true statistics" are simply averaged with a 50% probability. Thus, if we collect a bunch of samples and it turns out that 60% of people answer yes, then we know that the TRUE distribution is actually centered around 70%, because 70% averaged with a 50% (a coin flip) is 60% which is the result we obtained.
However, it should be noted that, especially when we only have a few samples, this comes at the cost of accuracy. This tradeoff exists across all of Differential Privacy.
> NOTE: **The greater the privacy protection (plausible deniability) the less accurate the results. **
Let's implement this local DP for our database before!
The main goal is to:
* Get the most accurate query with the **greatest** amount of privacy
* Greatest fit with trust models in the actual world, (don't waste trust)
Let's implement local differential privacy:
```
db, pdbs = create_db_and_parallels(100)
db
def query(db):
true_result = torch.mean(db.float())
# local differential privacy is adding noise to data: replacing some
# of the values with random values
first_coin_flip = (torch.rand(len(db)) > 0.5).float()
second_coin_flip = (torch.rand(len(db)) > 0.5).float()
# differentially private DB ...
augmented_db = db.float() * first_coin_flip + (1 - first_coin_flip) * second_coin_flip
# the result is skewed if we do:
# torch.mean(augmented_db.float())
# we remove the skewed average that was the result of the differential privacy
dp_result = torch.mean(augmented_db.float()) * 2 - 0.5
return dp_result, true_result
db, pdbs = create_db_and_parallels(10)
private_result, true_result = query(db)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
# Increasing the size of the dateset
db, pdbs = create_db_and_parallels(100)
private_result, true_result = query(db)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
# Increasing the size of the dateset even further
db, pdbs = create_db_and_parallels(1000)
private_result, true_result = query(db)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
```
As we have seen,
> The more data we have the more the noise will tend to not affect the output of the query
# Varying Amounts of Noise
We are going to augment the randomized response query to allow for varying amounts of randomness to be added. To do this, we bias the coin flip to be higher or lower and then run the same experiment.
We'll need to both adjust the likelihood of the first coin flip AND the de-skewing at the end (where we create the "augmented_result" variable).
```
# Noise < 0.5 sets the likelihood that the coin flip will be heads, and vice-versa.
noise = 0.2
true_result = torch.mean(db.float())
# let's add the noise to data: replacing some of the values with random values
first_coin_flip = (torch.rand(len(db)) > noise).float()
second_coin_flip = (torch.rand(len(db)) > 0.5).float()
# differentially private DB ...
augmented_db = db.float() * first_coin_flip + (1 - first_coin_flip) * second_coin_flip
# since the result will be skewed if we do: torch.mean(augmented_db.float())
# we'll remove the skewed average above by doing below:
dp_result = torch.mean(augmented_db.float()) * 2 - 0.5
sk_result = augmented_db.float().mean()
print('True result:', true_result)
print('Skewed result:', sk_result)
print('De-skewed result:', dp_result)
def query(db, noise=0.2):
"""Default noise(0.2) above sets the likelihood that the coin flip will be heads"""
true_result = torch.mean(db.float())
# local diff privacy is adding noise to data: replacing some
# of the values with random values
first_coin_flip = (torch.rand(len(db)) > noise).float()
second_coin_flip = (torch.rand(len(db)) > 0.5).float()
# differentially private DB ...
augmented_db = db.float() * first_coin_flip + (1 - first_coin_flip) * second_coin_flip
# the result is skewed if we do:
# torch.mean(augmented_db.float())
# we remove the skewed average that was the result of the differential privacy
sk_result = augmented_db.float().mean()
private_result = ((sk_result / noise ) - 0.5) * noise / (1 - noise)
return private_result, true_result
# test varying noise
db, pdbs = create_db_and_parallels(10)
private_result, true_result = query(db, noise=0.2)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
# Increasing the size of the dateset even further
db, pdbs = create_db_and_parallels(100)
private_result, true_result = query(db, noise=0.4)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
# Increasing the size of the dateset even further
db, pdbs = create_db_and_parallels(10000)
private_result, true_result = query(db, noise=0.8)
print(f"Without noise {private_result}")
print(f"With noise: {true_result}")
```
From the analysis above, with more data, its easier to protect privacy with noise. It becomes a lot easier to learn about general characteristics in the DB because the algorithm has more data points to look at and compare with each other.
So differential privacy mechanisms has helped us filter out any information unique to individual data entities and try to let through information that is consistent across multiple different people in the dataset.
> The larger the dataset, the easier it is to protect privacy.
# The Formal Definition of Differential Privacy
The previous method of adding noise was called "Local Differentail Privacy" because we added noise to each datapoint individually. This is necessary for some situations wherein the data is SO sensitive that individuals do not trust noise to be added later. However, it comes at a very high cost in terms of accuracy.
However, alternatively we can add noise AFTER data has been aggregated by a function. This kind of noise can allow for similar levels of protection with a lower affect on accuracy. However, participants must be able to trust that no-one looked at their datapoints _before_ the aggregation took place. In some situations this works out well, in others (such as an individual hand-surveying a group of people), this is less realistic.
Nevertheless, global differential privacy is incredibly important because it allows us to perform differential privacy on smaller groups of individuals with lower amounts of noise. Let's revisit our sum functions.
```
db, pdbs = create_db_and_parallels(100)
def query(db):
return torch.sum(db.float())
def M(db):
query(db) + noise
query(db)
```
So the idea here is that we want to add noise to the output of our function. We actually have two different kinds of noise we can add - Laplacian Noise or Gaussian Noise. However, before we do so at this point we need to dive into the formal definition of Differential Privacy.

_Image From: "The Algorithmic Foundations of Differential Privacy" - Cynthia Dwork and Aaron Roth - https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf_
This definition does not _create_ differential privacy, instead it is a measure of how much privacy is afforded by a query M. Specifically, it's a comparison between running the query M on a database (x) and a parallel database (y). As you remember, parallel databases are defined to be the same as a full database (x) with one entry/person removed.
Thus, this definition says that FOR ALL parallel databases, the maximum distance between a query on database (x) and the same query on database (y) will be e^epsilon, but that occasionally this constraint won't hold with probability delta. Thus, this theorem is called "epsilon delta" differential privacy.
# Epsilon
Let's unpack the intuition of this for a moment.
Epsilon Zero: If a query satisfied this inequality where epsilon was set to 0, then that would mean that the query for all parallel databases outputed the exact same value as the full database. As you may remember, when we calculated the "threshold" function, often the Sensitivity was 0. In that case, the epsilon also happened to be zero.
Epsilon One: If a query satisfied this inequality with epsilon 1, then the maximum distance between all queries would be 1 - or more precisely - the maximum distance between the two random distributions M(x) and M(y) is 1 (because all these queries have some amount of randomness in them, just like we observed in the last section).
# Delta
Delta is basically the probability that epsilon breaks. Namely, sometimes the epsilon is different for some queries than it is for others. For example, you may remember when we were calculating the sensitivity of threshold, most of the time sensitivity was 0 but sometimes it was 1. Thus, we could calculate this as "epsilon zero but non-zero delta" which would say that epsilon is perfect except for some probability of the time when it's arbitrarily higher. Note that this expression doesn't represent the full tradeoff between epsilon and delta.
# How To Add Noise for Global Differential Privacy
Global Differential Privacy adds noise to the output of a query.
We'll add noise to the output of our query so that it satisfies a certain epsilon-delta differential privacy threshold.
There are two kinds of noise we can add
- Gaussian Noise
- Laplacian Noise.
Generally speaking Laplacian is better, but both are still valid. Now to the hard question...
### How much noise should we add?
The amount of noise necessary to add to the output of a query is a function of four things:
- the type of noise (Gaussian/Laplacian)
- the sensitivity of the query/function
- the desired epsilon (ε)
- the desired delta (δ)
Thus, for each type of noise we're adding, we have different way of calculating how much to add as a function of sensitivity, epsilon, and delta.
Laplacian noise is increased/decreased according to a "scale" parameter b. We choose "b" based on the following formula.
`b = sensitivity(query) / epsilon`
In other words, if we set b to be this value, then we know that we will have a privacy leakage of <= epsilon. Furthermore, the nice thing about Laplace is that it guarantees this with delta == 0. There are some tunings where we can have very low epsilon where delta is non-zero, but we'll ignore them for now.
### Querying Repeatedly
- if we query the database multiple times - we can simply add the epsilons (Even if we change the amount of noise and their epsilons are not the same).
# Create a Differentially Private Query
Let's create a query function which sums over the database and adds just the right amount of noise such that it satisfies an epsilon constraint. query will be for "sum" and for "mean". We'll use the correct sensitivity measures for both.
```
epsilon = 0.001
import numpy as np
db, pdbs = create_db_and_parallels(100)
db
def sum_query(db):
return db.sum()
def laplacian_mechanism(db, query, sensitivity):
beta = sensitivity / epsilon
noise = torch.tensor(np.random.laplace(0, beta, 1))
return query(db) + noise
laplacian_mechanism(db, sum_query, 0.01)
def mean_query(db):
return torch.mean(db.float())
laplacian_mechanism(db, mean_query, 1)
```
# Differential Privacy for Deep Learning
So what does all of this have to do with Deep Learning? Well, these mechanisms form the core primitives for how Differential Privacy provides guarantees in the context of Deep Learning.
### Perfect Privacy
> "a query to a database returns the same value even if we remove any person from the database".
In the context of Deep Learning, we have a similar standard.
> Training a model on a dataset should return the same model even if we remove any person from the dataset.
Thus, we've replaced "querying a database" with "training a model on a dataset". In essence, the training process is a kind of query. However, one should note that this adds two points of complexity which database queries did not have:
1. do we always know where "people" are referenced in the dataset?
2. neural models rarely never train to the same output model, even on identical data
The answer to (1) is to treat each training example as a single, separate person. Strictly speaking, this is often overly zealous as some training examples have no relevance to people and others may have multiple/partial (consider an image with multiple people contained within it). Thus, localizing exactly where "people" are referenced, and thus how much your model would change if people were removed, is challenging.
The answer to (2) is also an open problem. To solve this, lets look at PATE.
## Scenario: A Health Neural Network
You work for a hospital and you have a large collection of images about your patients. However, you don't know what's in them. You would like to use these images to develop a neural network which can automatically classify them, however since your images aren't labeled, they aren't sufficient to train a classifier.
However, being a cunning strategist, you realize that you can reach out to 10 partner hospitals which have annotated data. It is your hope to train your new classifier on their datasets so that you can automatically label your own. While these hospitals are interested in helping, they have privacy concerns regarding information about their patients. Thus, you will use the following technique to train a classifier which protects the privacy of patients in the other hospitals.
- 1) You'll ask each of the 10 hospitals to train a model on their own datasets (All of which have the same kinds of labels)
- 2) You'll then use each of the 10 partner models to predict on your local dataset, generating 10 labels for each of your datapoints
- 3) Then, for each local data point (now with 10 labels), you will perform a DP query to generate the final true label. This query is a "max" function, where "max" is the most frequent label across the 10 labels. We will need to add laplacian noise to make this Differentially Private to a certain epsilon/delta constraint.
- 4) Finally, we will retrain a new model on our local dataset which now has labels. This will be our final "DP" model.
So, let's walk through these steps. I will assume you're already familiar with how to train/predict a deep neural network, so we'll skip steps 1 and 2 and work with example data. We'll focus instead on step 3, namely how to perform the DP query for each example using toy data.
So, let's say we have 10,000 training examples, and we've got 10 labels for each example (from our 10 "teacher models" which were trained directly on private data). Each label is chosen from a set of 10 possible labels (categories) for each image.
```
import numpy as np
num_teachers = 10 # we're working with 10 partner hospitals
num_examples = 10000 # the size of OUR dataset
num_labels = 10 # number of lablels for our classifier
# fake predictions
fake_preds = (
np.random.rand(
num_teachers, num_examples
) * num_labels).astype(int).transpose(1,0)
fake_preds[:,0]
# Step 3: Perform a DP query to generate the final true label/outputs,
# Use the argmax function to find the most frequent label across all 10 labels,
# Then finally add some noise to make it differentially private.
new_labels = list()
for an_image in fake_preds:
# count the most frequent label the hospitals came up with
label_counts = np.bincount(an_image, minlength=num_labels)
epsilon = 0.1
beta = 1 / epsilon
for i in range(len(label_counts)):
# for each label, add some noise to the counts
label_counts[i] += np.random.laplace(0, beta, 1)
new_label = np.argmax(label_counts)
new_labels.append(new_label)
# new_labels
new_labels[:10]
```
# PATE Analysis
```
# lets say the hospitals came up with these outputs... 9, 9, 3, 6 ..., 2
labels = np.array([9, 9, 3, 6, 9, 9, 9, 9, 8, 2])
counts = np.bincount(labels, minlength=10)
print(counts)
query_result = np.argmax(counts)
query_result
```
If every hospital says the result is 9, then we have very low sensitivity.
We could remove a person, from the dataset, and the query results still is 9,
then we have not leaked any information.
Core assumption: The same patient was not present at any of this two hospitals.
Removing any one of this hospitals, acts as a proxy to removing one person, which means that if we do remove one hospital, the query result should not be different.
```
from syft.frameworks.torch.differential_privacy import pate
num_teachers, num_examples, num_labels = (100, 100, 10)
# generate fake predictions/labels
preds = (np.random.rand(num_teachers, num_examples) * num_labels).astype(int)
indices = (np.random.rand(num_examples) * num_labels).astype(int) # true answers
preds[:,0:10] *= 0
# perform PATE to find the data depended epsilon and data independent epsilon
data_dep_eps, data_ind_eps = pate.perform_analysis(
teacher_preds=preds,
indices=indices,
noise_eps=0.1,
delta=1e-5
)
print('Data Independent Epsilon', data_ind_eps)
print('Data Dependent Epsilon', data_dep_eps)
assert data_dep_eps < data_ind_eps
data_dep_eps, data_ind_eps = pate.perform_analysis(teacher_preds=preds, indices=indices, noise_eps=0.1, delta=1e-5)
print("Data Independent Epsilon:", data_ind_eps)
print("Data Dependent Epsilon:", data_dep_eps)
preds[:,0:50] *= 0
data_dep_eps, data_ind_eps = pate.perform_analysis(teacher_preds=preds, indices=indices, noise_eps=0.1, delta=1e-5, moments=20)
print("Data Independent Epsilon:", data_ind_eps)
print("Data Dependent Epsilon:", data_dep_eps)
```
# Where to Go From Here
Read:
- Algorithmic Foundations of Differential Privacy: https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
- Deep Learning with Differential Privacy: https://arxiv.org/pdf/1607.00133.pdf
- The Ethical Algorithm: https://www.amazon.com/Ethical-Algorithm-Science-Socially-Design/dp/0190948205
Topics:
- The Exponential Mechanism
- The Moment's Accountant
- Differentially Private Stochastic Gradient Descent
Advice:
- For deployments - stick with public frameworks!
- Join the Differential Privacy Community
- Don't get ahead of yourself - DP is still in the early days
# Application of DP in Private Federated Learning
DP works by adding statistical noise either at the input level or output level of the model so that you can mask out individual user contribution, but at the same time gain insight into th overall population without sacrificing privacy.
> Case: Figure out average money one has in their pockets.
We could go and ask someone how much they have in their wallet. They pick a random number between -100 and 100. Add that to the real value, say $20 and a picked number of 100. resulting in 120. That way, we have no way to know what the actual amount of money in their wallet is.
When sufficiently large numbers of people submit these results, if we take the average, the noise will cancel out and we'll start seeing the true average.
Apart from statistical use cases, we can apply DP in Private Federated learning.
Suppose you want to train a model using distributed learning across a number of user devices. One way to do that is to get all the private data from the devices, but that's not very privacy friendly.
Instead, we send the model from the server back to the devices. The devices will then train the model
using their user data, and only send the privatized model updates back to the server.
Server will then aggregate the updates and make an informed decision of the overall model on the server.
As you do more and more rounds, slowly the model converges to the true population without
private user data having to leave the devices.
If you increase the level of privacy, the model converges a bit slower and vice versa.
# Project:
For the final project for this section, you're going to train a DP model using this PATE method on the MNIST dataset, provided below.
```
import torchvision.datasets as datasets
mnist_trainset = datasets.MNIST(root='./data', train=True, download=True, transform=None)
train_data = mnist_trainset.train_data
train_targets = mnist_trainset.train_labels
test_data = mnist_trainset.test_data
test_targets = mnist_trainset.test_labels
```
| true |
code
| 0.513363 | null | null | null | null |
|
# Lesson 9 Practice: Supervised Machine Learning
Use this notebook to follow along with the lesson in the corresponding lesson notebook: [L09-Supervised_Machine_Learning-Lesson.ipynb](./L09-Supervised_Machine_Learning-Lesson.ipynb).
## Instructions
Follow along with the teaching material in the lesson. Throughout the tutorial sections labeled as "Tasks" are interspersed and indicated with the icon: . You should follow the instructions provided in these sections by performing them in the practice notebook. When the tutorial is completed you can turn in the final practice notebook. For each task, use the cell below it to write and test your code. You may add additional cells for any task as needed or desired.
## Task 1a: Setup
Import the following package sets:
+ packages for data management
+ pacakges for visualization
+ packages for machine learning
Remember to activate the `%matplotlib inline` magic.
```
%matplotlib inline
# Data Management
import numpy as np
import pandas as pd
# Visualization
import seaborn as sns
import matplotlib.pyplot as plt
# Machine learning
from sklearn import model_selection
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
```
## Task 2a: Data Exploration
After reviewing the data in sections 2.1, 2.2, 2.3 and 2.4 do you see any problems with this iris dataset? If so, please describe them in the practice notebook. If not, simply indicate that there are no issues.
## Task 2b: Make Assumptions
After reviewing the data in sections 2.1, 2.2, 2.3 and 2.4 are there any columns that would make poor predictors of species?
**Hint**: columns that are poor predictors are:
+ those with too many missing values
+ those with no difference in variation when grouped by the outcome class
+ variables with high levels of collinearity
## Task 3a: Practice with the random forest classifier
Now that you have learned how to perform supervised machine learning using a variety of algorithms, lets practice using a new algorithm we haven't looked at yet: the Random Forest Classifier. The random forest classifier builds multiple decision trees and merges them together. Review the sklearn [online documentation for the RandomForestClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html). For this task:
1. Perform a 10-fold cross-validation strategy to see how well the random forest classifier performs with the iris data
2. Use a boxplot to show the distribution of accuracy
3. Use the `fit` and `predict` functions to see how well it performs with the testing data.
4. Plot the confusion matrix
5. Print the classification report.
```
iris = sns.load_dataset('iris')
X = iris.loc[:,'sepal_length':'petal_width'].values
Y = iris['species'].values
X = preprocessing.robust_scale(X)
Xt, Xv, Yt, Yv = model_selection.train_test_split(X, Y, test_size=0.2, random_state=10)
kfold = model_selection.KFold(n_splits=10, random_state=10)
results = {
'LogisticRegression' : np.zeros(10),
'LinearDiscriminantAnalysis' : np.zeros(10),
'KNeighborsClassifier' : np.zeros(10),
'DecisionTreeClassifier' : np.zeros(10),
'GaussianNB' : np.zeros(10),
'SVC' : np.zeros(10),
'RandomForestClassifier': np.zeros(10)
}
results
# Create the LogisticRegression object prepared for a multinomial outcome validation set.
alg = RandomForestClassifier()
# Execute the cross-validation strategy
results['RandomForestClassifier'] = model_selection.cross_val_score(alg, Xt, Yt, cv=kfold,
scoring="accuracy", error_score=np.nan)
# Take a look at the scores for each of the 10-fold runs.
results['RandomForestClassifier']
pd.DataFrame(results).plot(kind="box", rot=90);
# Create the LinearDiscriminantAnalysis object with defaults.
alg = RandomForestClassifier()
# Create a new model using all of the training data.
alg.fit(Xt, Yt)
# Using the testing data, predict the iris species.
predictions = alg.predict(Xv)
# Let's see the predictions
predictions
accuracy_score(Yv, predictions)
labels = ['versicolor', 'virginica', 'setosa']
cm = confusion_matrix(Yv, predictions, labels=labels)
print(cm)
```
| true |
code
| 0.622 | null | null | null | null |
|
### Hyper Parameter Tuning
One of the primary objective and challenge in machine learning process is improving the performance score, based on data patterns and observed evidence. To achieve this objective, almost all machine learning algorithms have specific set of parameters that needs to estimate from dataset which will maximize the performance score. The best way to choose good hyperparameters is through trial and error of all possible combination of parameter values. Scikit-learn provide GridSearch and RandomSearch functions to facilitate automatic and reproducible approach for hyperparameter tuning.
```
from IPython.display import Image
Image(filename='../Chapter 4 Figures/Hyper_Parameter_Tuning.png', width=1000)
```
### GridSearch
```
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
from sklearn import cross_validation
from sklearn import metrics
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
seed = 2017
# read the data in
df = pd.read_csv("Data/Diabetes.csv")
X = df.ix[:,:8].values # independent variables
y = df['class'].values # dependent variables
#Normalize
X = StandardScaler().fit_transform(X)
# evaluate the model by splitting into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=seed)
kfold = cross_validation.StratifiedKFold(y=y_train, n_folds=5, random_state=seed)
num_trees = 100
clf_rf = RandomForestClassifier(random_state=seed).fit(X_train, y_train)
rf_params = {
'n_estimators': [100, 250, 500, 750, 1000],
'criterion': ['gini', 'entropy'],
'max_features': [None, 'auto', 'sqrt', 'log2'],
'max_depth': [1, 3, 5, 7, 9]
}
# setting verbose = 10 will print the progress for every 10 task completion
grid = GridSearchCV(clf_rf, rf_params, scoring='roc_auc', cv=kfold, verbose=10, n_jobs=-1)
grid.fit(X_train, y_train)
print 'Best Parameters: ', grid.best_params_
results = cross_validation.cross_val_score(grid.best_estimator_, X_train,y_train, cv=kfold)
print "Accuracy - Train CV: ", results.mean()
print "Accuracy - Train : ", metrics.accuracy_score(grid.best_estimator_.predict(X_train), y_train)
print "Accuracy - Test : ", metrics.accuracy_score(grid.best_estimator_.predict(X_test), y_test)
```
### RandomSearch
```
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint as sp_randint
# specify parameters and distributions to sample from
param_dist = {'n_estimators':sp_randint(100,1000),
'criterion': ['gini', 'entropy'],
'max_features': [None, 'auto', 'sqrt', 'log2'],
'max_depth': [None, 1, 3, 5, 7, 9]
}
# run randomized search
n_iter_search = 20
random_search = RandomizedSearchCV(clf_rf, param_distributions=param_dist, cv=kfold,
n_iter=n_iter_search, verbose=10, n_jobs=-1, random_state=seed)
random_search.fit(X_train, y_train)
# report(random_search.cv_results_)
print 'Best Parameters: ', random_search.best_params_
results = cross_validation.cross_val_score(random_search.best_estimator_, X_train,y_train, cv=kfold)
print "Accuracy - Train CV: ", results.mean()
print "Accuracy - Train : ", metrics.accuracy_score(random_search.best_estimator_.predict(X_train), y_train)
print "Accuracy - Test : ", metrics.accuracy_score(random_search.best_estimator_.predict(X_test), y_test)
from bayes_opt import BayesianOptimization
from sklearn.cross_validation import cross_val_score
def rfccv(n_estimators, min_samples_split, max_features):
return cross_val_score(RandomForestClassifier(n_estimators=int(n_estimators),
min_samples_split=int(min_samples_split),
max_features=min(max_features, 0.999),
random_state=2017),
X_train, y_train, 'f1', cv=kfold).mean()
gp_params = {"alpha": 1e5}
rfcBO = BayesianOptimization(rfccv, {'n_estimators': (100, 1000),
'min_samples_split': (2, 25),
'max_features': (0.1, 0.999)})
rfcBO.maximize(n_iter=10, **gp_params)
print('RFC: %f' % rfcBO.res['max']['max_val'])
```
| true |
code
| 0.645874 | null | null | null | null |
|
# Example Map Plotting
### At the start of a Jupyter notebook you need to import all modules that you will use
```
import pandas as pd
import xarray as xr
import matplotlib.pyplot as plt
import numpy as np
from scipy.interpolate import griddata
import cartopy
import cartopy.crs as ccrs # For plotting maps
import cartopy.feature as cfeature # For plotting maps
from cartopy.util import add_cyclic_point # For plotting maps
import datetime
```
### Define the directories and file of interest for your results. This can be shortened to less lines as well.
```
#result_dir = "/home/buchholz/Documents/code_database/untracked/my-notebook/Janyl_plotting/"
result_dir = "../../data/"
file = "CAM_chem_merra2_FCSD_1deg_QFED_monthly_2019.nc"
#the netcdf file is now held in an xarray dataset named 'nc' and can be referenced later in the notebook
nc_load = xr.open_dataset(result_dir+file)
#to see what the netCDF file contains, just call the variable you read it into
nc_load
```
### Extract the variable of choice at the time and level of choice
```
#extract grid variables
lat = nc_load['lat']
lon = nc_load['lon']
#extract variable
var_sel = nc_load['PM25']
print(var_sel)
#print(var_sel[0][0][0][0])
#select the surface level at a specific time and convert to ppbv from vmr
#var_srf = var_sel.isel(time=0, lev=55)
#select the surface level for an average over three times and convert to ppbv from vmr
var_srf = var_sel.isel(time=[2,3,4], lev=55) # MAM chosen
var_srf = var_srf.mean('time')
var_srf = var_srf*1e09 # 10-9 to ppb
print(var_srf.shape)
# Add cyclic point to avoid white line over Africa
var_srf_cyc, lon_cyc = add_cyclic_point(var_srf, coord=lon)
```
### Plot the value over a specific region
```
plt.figure(figsize=(20,8))
#Define projection
ax = plt.axes(projection=ccrs.PlateCarree())
#define contour levels
clev = np.arange(0, 100, 1)
#plot the data
plt.contourf(lon_cyc,lat,var_srf_cyc,clev,cmap='Spectral_r',extend='both')
# add coastlines
#ax.coastlines()
ax.add_feature(cfeature.COASTLINE)
#add lat lon grids
ax.gridlines(draw_labels=True, color='grey', alpha=0.5, linestyle='--')
#longitude limits in degrees
ax.set_xlim(20,120)
#latitude limits in degrees
ax.set_ylim(5,60)
# Title
plt.title("CAM-chem 2019 O$_{3}$")
#axes
# y-axis
ax.text(-0.09, 0.55, 'Latitude', va='bottom', ha='center',
rotation='vertical', rotation_mode='anchor',
transform=ax.transAxes)
# x-axis
ax.text(0.5, -0.10, 'Longitude', va='bottom', ha='center',
rotation='horizontal', rotation_mode='anchor',
transform=ax.transAxes)
# legend
ax.text(1.18, 0.5, 'O$_{3}$ (ppb)', va='bottom', ha='center',
rotation='vertical', rotation_mode='anchor',
transform=ax.transAxes)
plt.colorbar()
plt.show()
```
### Add location markers
```
##Now lets look at the sufrace plot again, but this time add markers for observations at several points.
#first we need to define our observational data into an array
#this can also be imported from text files using various routines
# Kyzylorda, Urzhar, Almaty, Balkhash
obs_lat = np.array([44.8488,47.0870,43.2220,46.2161])
obs_lon = np.array([65.4823,81.6315,76.8512,74.3775])
obs_names = ["Kyzylorda", "Urzhar", "Almaty", "Balkhash"]
num_obs = obs_lat.shape[0]
plt.figure(figsize=(20,8))
#Define projection
ax = plt.axes(projection=ccrs.PlateCarree())
#define contour levels
clev = np.arange(0, 100, 1)
#plot the data
plt.contourf(lon_cyc,lat,var_srf_cyc,clev,cmap='Spectral_r')
# add coastlines
ax.add_feature(cfeature.COASTLINE)
ax.add_feature(cfeature.BORDERS)
#add lat lon grids
ax.gridlines(draw_labels=True, color='grey', alpha=0.5, linestyle='--')
#longitude limits in degrees
ax.set_xlim(20,120)
#latitude limits in degrees
ax.set_ylim(5,60)
# Title
plt.title("CAM-chem 2019 O$_{3}$")
#axes
# y-axisCOUNTRY
ax.text(-0.09, 0.55, 'Latitude', va='bottom', ha='center',
rotation='vertical', rotation_mode='anchor',
transform=ax.transAxes)
# x-axis
ax.text(0.5, -0.10, 'Longitude', va='bottom', ha='center',
rotation='horizontal', rotation_mode='anchor',
transform=ax.transAxes)
# legend
ax.text(1.18, 0.5, 'O$_{3}$ (ppb)', va='bottom', ha='center',
rotation='vertical', rotation_mode='anchor',
transform=ax.transAxes)
#convert your observation lat/lon to Lambert-Conformal grid points
#xpt,ypt = m(obs_lon,obs_lat)
#to specify the color of each point it is easiest plot individual points in a loop
for i in range(num_obs):
plt.plot(obs_lon[i], obs_lat[i], linestyle='none', marker="o", markersize=8, alpha=0.8, c="black", markeredgecolor="black", markeredgewidth=1, transform=ccrs.PlateCarree())
plt.text(obs_lon[i] - 0.8, obs_lat[i] - 0.5, obs_names[i], fontsize=20, horizontalalignment='right', transform=ccrs.PlateCarree())
plt.colorbar()
plt.show()
cartopy.config['data_dir']
```
| true |
code
| 0.621311 | null | null | null | null |
|
# DECOMON tutorial #3
## Local Robustness to Adversarial Attacks for classification tasks
## Introduction
After training a model, we want to make sure that the model will give the same output for any images "close" to the initial one, showing some robustness to perturbation.
In this notebook, we start from a classifier built on MNIST dataset that given a hand-written digit as input will predict the digit. This will be the first part of the notebook.
<img src="./data/Plot-of-a-Subset-of-Images-from-the-MNIST-Dataset.png" alt="examples of hand-written digit" width="600"/>
In the second part of the notebook, we will investigate the robustness of this model to unstructured modification of the input space: adversarial attacks. For this kind of attacks, **we vary the magnitude of the perturbation of the initial image** and want to assess that despite this noise, the classifier's prediction remain unchanged.
<img src="./data/illustration_adv_attacks.jpeg" alt="examples of hand-written digit" width="600"/>
What we will show is the use of decomon module to assess the robustness of the prediction towards noise.
## The notebook
### imports
```
import os
import tensorflow.keras as keras
import matplotlib.pyplot as plt
import matplotlib.patches as patches
%matplotlib inline
import numpy as np
import tensorflow.keras.backend as K
from tensorflow.keras.models import Sequential, Model, load_model
from tensorflow.keras.layers import Dense
from tensorflow.keras.datasets import mnist
from ipywidgets import interact, interactive, fixed, interact_manual
from ipykernel.pylab.backend_inline import flush_figures
import ipywidgets as widgets
import time
import sys
sys.path.append('..')
import os.path
import os
import pickle as pkl
from contextlib import closing
import time
import tensorflow as tf
import decomon
from decomon.wrapper import refine_boxes
x_min = np.ones((3, 4, 5))
x_max = 2*x_min
refine_boxes(x_min, x_max, 10)
```
### load images
We load MNIST data from keras datasets.
```
ara
img_rows, img_cols = 28, 28
(x_train, y_train_), (x_test, y_test_) = mnist.load_data()
x_train = x_train.reshape((-1, 784))
x_test = x_test.reshape((-1, 784))
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train_)
y_test = keras.utils.to_categorical(y_test_)
```
### learn the model (classifier for MNIST images)
For the model, we use a small fully connected network. It is made of 6 layers with 100 units each and ReLU activation functions. **Decomon** is compatible with a large set of Keras layers, so do not hesitate to modify the architecture.
```
model = Sequential()
model.add(Dense(100, activation='relu', input_dim=784))
model.add(Dense(100, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile('adam', 'categorical_crossentropy', metrics='acc')
model.fit(x_train, y_train, batch_size=32, shuffle=True, validation_split=0.2, epochs=5)
model.evaluate(x_test, y_test, batch_size=32)
```
After training, we see that the assessment of performance of the model on data that was not seen during training shows pretty good results: around 0.97 (maximum value is 1). It means that out of 100 images, the model was able to guess the correct digit for 97 images. But how can we guarantee that we will get this performance for images different from the ones in the test dataset?
- If we perturbate a "little" an image that was well predicted, will the model stay correct?
- Up to which perturbation?
- Can we guarantee that the model will output the same digit for a given perturbation?
This is where decomon comes in.
<img src="./data/decomon.jpg" alt="Decomon!" width="400"/>
### Applying Decomon for Local Robustness to misclassification
In this section, we detail how to prove local robustness to misclassification. Misclassification can be studied with the global optimisation of a function f:
$$ f(x; \Omega) = \max_{z\in \Omega} \text{NN}_{j\not= i}(z) - \text{NN}_i(z)\;\; \text{s.t}\;\; i = argmax\;\text{NN}(x)$$
If the maximum of f is **negative**, this means that whathever the input sample from the domain, the value outputs by the neural network NN for class i will always be greater than the value output for another class. Hence, there will be no misclassification possible. This is **adversarial robustness**.
<img src="./data/tuto_3_formal_robustness.png" alt="Decomon!" width="400"/>
In that order, we will use the [decomon](https://gheprivate.intra.corp/CRT-DataScience/decomon/tree/master/decomon) library. Decomon combines several optimization trick, including linear relaxation
to get state-of-the-art outer approximation.
To use **decomon** for **adversarial robustness** we first need the following imports:
+ *from decomon.models import convert*: to convert our current Keras model into another neural network nn_model. nn_model will output the same prediction that our model and adds extra information that will be used to derive our formal bounds. For a sake of clarity, how to get such bounds is hidden to the user
+ *from decomon import get_adv_box*: a genereric method to get an upper bound of the funtion f described previously. If the returned value is negative, then we formally assess the robustness to misclassification.
+ *from decomon import check_adv_box*: a generic method that computes the maximum of a lower bound of f. Eventually if this value is positive, it demonstrates that the function f takes positive value. It results that a positive value formally proves the existence of misclassification.
```
import decomon
from decomon.models import convert
from decomon import get_adv_box, get_upper_box, get_lower_box, check_adv_box, get_upper_box
```
For computational efficiency, we convert the model into its decomon version once and for all.
Note that the decomon method will work on the non-converted model. To obtain more refined guarantees, we activate an option denoted **forward**. You can speed up the method by removing this option in the convert method.
```
decomon_model = convert(model)
from decomon import build_formal_adv_model
adv_model = build_formal_adv_model(decomon_model)
x_=x_train[:1]
eps=1e-2
z = np.concatenate([x_[:, None]-eps, x_[:, None]+eps], 1)
get_adv_box(decomon_model, x_,x_, source_labels=y_train[0].argmax())
adv_model.predict([x_, z, y_train[:1]])
# compute gradient
import tensorflow as tf
x_tensor = tf.convert_to_tensor(x_, dtype=tf.float32)
from tensorflow.keras.layers import Concatenate
with tf.GradientTape() as t:
t.watch(x_tensor)
z_tensor = Concatenate(1)([x_tensor[:,None]-eps,\
x_tensor[:, None]+eps])
output = adv_model([x_, z_tensor, y_train[:1]])
result = output
gradients = t.gradient(output, x_tensor)
mask = gradients.numpy()
# scale between 0 and 1.
mask = (mask-mask.min())
plt.imshow(gradients.numpy().reshape((28,28)))
img_mask = np.zeros((784,))
img_mask[np.argsort(mask[0])[::-1][:100]]=1
plt.imshow(img_mask.reshape((28,28)))
plt.imshow(mask.reshape((28,28)))
plt.imshow(x_.reshape((28,28)))
```
We offer an interactive visualisation of the basic adversarial robustness method from decomon **get_adv_upper**. We randomly choose 10 test images use **get_adv_upper** to assess their robustness to misclassification pixel perturbations. The magnitude of the noise on each pixel is independent and bounded by the value of the variable epsilon. The user can reset the examples and vary the noise amplitude.
Note one of the main advantage of decomon: **we can assess robustness on batches of data!**
Circled in <span style="color:green">green</span> are examples that are formally assessed to be robust, <span style="color:orange">orange</span> examples that could be robust and <span style="color:red">red</span> examples that are formally non robust
```
def frame(epsilon, reset=0, filename='./data/.hidden_index.pkl'):
n_cols = 5
n_rows = 2
n_samples = n_cols*n_rows
if reset:
index = np.random.permutation(len(x_test))[:n_samples]
with closing(open(filename, 'wb')) as f:
pkl.dump(index, f)
# save data
else:
# check that file exists
if os.path.isfile(filename):
with closing(open(filename, 'rb')) as f:
index = pkl.load(f)
else:
index = np.arange(n_samples)
with closing(open(filename, 'wb')) as f:
pkl.dump(index, f)
#x = np.concatenate([x_test[0:1]]*10, 0)
x = x_test[index]
x_min = np.maximum(x - epsilon, 0)
x_max = np.minimum(x + epsilon, 1)
n_cols = 5
n_rows = 2
fig, axs = plt.subplots(n_rows, n_cols)
fig.set_figheight(n_rows*fig.get_figheight())
fig.set_figwidth(n_cols*fig.get_figwidth())
plt.subplots_adjust(hspace=0.2) # increase vertical separation
axs_seq = axs.ravel()
source_label = np.argmax(model.predict(x), 1)
start_time = time.process_time()
upper = get_adv_box(decomon_model, x_min, x_max, source_labels=source_label)
lower = check_adv_box(decomon_model, x_min, x_max, source_labels=source_label)
end_time = time.process_time()
count = 0
time.sleep(1)
r_time = "{:.2f}".format(end_time - start_time)
fig.suptitle('Formal Robustness to Adversarial Examples with eps={} running in {} seconds'.format(epsilon, r_time), fontsize=16)
for i in range(n_cols):
for j in range(n_rows):
ax= axs[j, i]
ax.imshow(x[count].reshape((28,28)), cmap='Greys')
robust='ROBUST'
if lower[count]>=0:
color='red'
robust='NON ROBUST'
elif upper[count]<0:
color='green'
else:
color='orange'
robust='MAYBE ROBUST'
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Create a Rectangle patch
rect = patches.Rectangle((0,0),27,27,linewidth=3,edgecolor=color,facecolor='none')
ax.add_patch(rect)
ax.set_title(robust)
count+=1
interact(frame, epsilon = widgets.FloatSlider(value=0.,
min=0.,
max=5./255.,
step=0.0001, continuous_update=False, readout_format='.4f',),
reset = widgets.IntSlider(value=0.,
min=0,
max=1,
step=1, continuous_update=False),
fast = widgets.IntSlider(value=1.,
min=0,
max=1,
step=1, continuous_update=False)
)
```
As explained previously, the method **get_adv_upper** output a constant upper bound that is valid on the whole domain.
Sometimes, this bound can be too lose and needs to be refined by splitting the input domain into sub domains.
Several heuristics are possible and you are free to develop your own or take an existing one of the shelf.
| true |
code
| 0.698638 | null | null | null | null |
|
# Capsule Networks (CapsNets)
Based on the paper: [Dynamic Routing Between Capsules](https://arxiv.org/abs/1710.09829), by Sara Sabour, Nicholas Frosst and Geoffrey E. Hinton (NIPS 2017).
Inspired in part from Huadong Liao's implementation: [CapsNet-TensorFlow](https://github.com/naturomics/CapsNet-Tensorflow).
# Introduction
Watch [this video](https://www.youtube.com/embed/pPN8d0E3900) to understand the key ideas behind Capsule Networks:
```
from IPython.display import HTML
# Display the video in an iframe:
HTML("""<iframe width="560" height="315"
src="https://www.youtube.com/embed/pPN8d0E3900"
frameborder="0"
allowfullscreen></iframe>""")
```
# Imports
To support both Python 2 and Python 3:
```
from __future__ import division, print_function, unicode_literals
```
To plot pretty figures:
```
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
```
We will need NumPy and TensorFlow:
```
import numpy as np
import tensorflow as tf
```
# Reproducibility
Let's reset the default graph, in case you re-run this notebook without restarting the kernel:
```
tf.reset_default_graph()
```
Let's set the random seeds so that this notebook always produces the same output:
```
np.random.seed(42)
tf.set_random_seed(42)
```
# Load MNIST
Yes, I know, it's MNIST again. But hopefully this powerful idea will work as well on larger datasets, time will tell.
```
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/")
```
Let's look at what these hand-written digit images look like:
```
n_samples = 5
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
sample_image = mnist.train.images[index].reshape(28, 28)
plt.imshow(sample_image, cmap="binary")
plt.axis("off")
plt.show()
```
And these are the corresponding labels:
```
mnist.train.labels[:n_samples]
```
Now let's build a Capsule Network to classify these images. Here's the overall architecture, enjoy the ASCII art! ;-)
Note: for readability, I left out two arrows: Labels → Mask, and Input Images → Reconstruction Loss.
```
Loss
↑
┌─────────┴─────────┐
Labels → Margin Loss Reconstruction Loss
↑ ↑
Length Decoder
↑ ↑
Digit Capsules ────Mask────┘
↖↑↗ ↖↑↗ ↖↑↗
Primary Capsules
↑
Input Images
```
We are going to build the graph starting from the bottom layer, and gradually move up, left side first. Let's go!
# Input Images
Let's start by creating a placeholder for the input images (28×28 pixels, 1 color channel = grayscale).
```
X = tf.placeholder(shape=[None, 28, 28, 1], dtype=tf.float32, name="X")
```
# Primary Capsules
The first layer will be composed of 32 maps of 6×6 capsules each, where each capsule will output an 8D activation vector:
```
caps1_n_maps = 32
caps1_n_caps = caps1_n_maps * 6 * 6 # 1152 primary capsules
caps1_n_dims = 8
```
To compute their outputs, we first apply two regular convolutional layers:
```
conv1_params = {
"filters": 256,
"kernel_size": 9,
"strides": 1,
"padding": "valid",
"activation": tf.nn.relu,
}
conv2_params = {
"filters": caps1_n_maps * caps1_n_dims, # 256 convolutional filters
"kernel_size": 9,
"strides": 2,
"padding": "valid",
"activation": tf.nn.relu
}
conv1 = tf.layers.conv2d(X, name="conv1", **conv1_params)
conv2 = tf.layers.conv2d(conv1, name="conv2", **conv2_params)
```
Note: since we used a kernel size of 9 and no padding (for some reason, that's what `"valid"` means), the image shrunk by 9-1=8 pixels after each convolutional layer (28×28 to 20×20, then 20×20 to 12×12), and since we used a stride of 2 in the second convolutional layer, the image size was divided by 2. This is how we end up with 6×6 feature maps.
Next, we reshape the output to get a bunch of 8D vectors representing the outputs of the primary capsules. The output of `conv2` is an array containing 32×8=256 feature maps for each instance, where each feature map is 6×6. So the shape of this output is (_batch size_, 6, 6, 256). We want to chop the 256 into 32 vectors of 8 dimensions each. We could do this by reshaping to (_batch size_, 6, 6, 32, 8). However, since this first capsule layer will be fully connected to the next capsule layer, we can simply flatten the 6×6 grids. This means we just need to reshape to (_batch size_, 6×6×32, 8).
```
caps1_raw = tf.reshape(conv2, [-1, caps1_n_caps, caps1_n_dims],
name="caps1_raw")
```
Now we need to squash these vectors. Let's define the `squash()` function, based on equation (1) from the paper:
$\operatorname{squash}(\mathbf{s}) = \dfrac{\|\mathbf{s}\|^2}{1 + \|\mathbf{s}\|^2} \dfrac{\mathbf{s}}{\|\mathbf{s}\|}$
The `squash()` function will squash all vectors in the given array, along the given axis (by default, the last axis).
**Caution**, a nasty bug is waiting to bite you: the derivative of $\|\mathbf{s}\|$ is undefined when $\|\mathbf{s}\|=0$, so we can't just use `tf.norm()`, or else it will blow up during training: if a vector is zero, the gradients will be `nan`, so when the optimizer updates the variables, they will also become `nan`, and from then on you will be stuck in `nan` land. The solution is to implement the norm manually by computing the square root of the sum of squares plus a tiny epsilon value: $\|\mathbf{s}\| \approx \sqrt{\sum\limits_i{{s_i}^2}\,\,+ \epsilon}$.
```
def squash(s, axis=-1, epsilon=1e-7, name=None):
with tf.name_scope(name, default_name="squash"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis,
keep_dims=True)
safe_norm = tf.sqrt(squared_norm + epsilon)
squash_factor = squared_norm / (1. + squared_norm)
unit_vector = s / safe_norm
return squash_factor * unit_vector
```
Now let's apply this function to get the output $\mathbf{u}_i$ of each primary capsules $i$ :
```
caps1_output = squash(caps1_raw, name="caps1_output")
```
Great! We have the output of the first capsule layer. It wasn't too hard, was it? However, computing the next layer is where the fun really begins.
# Digit Capsules
To compute the output of the digit capsules, we must first compute the predicted output vectors (one for each primary / digit capsule pair). Then we can run the routing by agreement algorithm.
## Compute the Predicted Output Vectors
The digit capsule layer contains 10 capsules (one for each digit) of 16 dimensions each:
```
caps2_n_caps = 10
caps2_n_dims = 16
```
For each capsule $i$ in the first layer, we want to predict the output of every capsule $j$ in the second layer. For this, we will need a transformation matrix $\mathbf{W}_{i,j}$ (one for each pair of capsules ($i$, $j$)), then we can compute the predicted output $\hat{\mathbf{u}}_{j|i} = \mathbf{W}_{i,j} \, \mathbf{u}_i$ (equation (2)-right in the paper). Since we want to transform an 8D vector into a 16D vector, each transformation matrix $\mathbf{W}_{i,j}$ must have a shape of (16, 8).
To compute $\hat{\mathbf{u}}_{j|i}$ for every pair of capsules ($i$, $j$), we will use a nice feature of the `tf.matmul()` function: you probably know that it lets you multiply two matrices, but you may not know that it also lets you multiply higher dimensional arrays. It treats the arrays as arrays of matrices, and it performs itemwise matrix multiplication. For example, suppose you have two 4D arrays, each containing a 2×3 grid of matrices. The first contains matrices $\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{D}, \mathbf{E}, \mathbf{F}$ and the second contains matrices $\mathbf{G}, \mathbf{H}, \mathbf{I}, \mathbf{J}, \mathbf{K}, \mathbf{L}$. If you multiply these two 4D arrays using the `tf.matmul()` function, this is what you get:
$
\pmatrix{
\mathbf{A} & \mathbf{B} & \mathbf{C} \\
\mathbf{D} & \mathbf{E} & \mathbf{F}
} \times
\pmatrix{
\mathbf{G} & \mathbf{H} & \mathbf{I} \\
\mathbf{J} & \mathbf{K} & \mathbf{L}
} = \pmatrix{
\mathbf{AG} & \mathbf{BH} & \mathbf{CI} \\
\mathbf{DJ} & \mathbf{EK} & \mathbf{FL}
}
$
We can apply this function to compute $\hat{\mathbf{u}}_{j|i}$ for every pair of capsules ($i$, $j$) like this (recall that there are 6×6×32=1152 capsules in the first layer, and 10 in the second layer):
$
\pmatrix{
\mathbf{W}_{1,1} & \mathbf{W}_{1,2} & \cdots & \mathbf{W}_{1,10} \\
\mathbf{W}_{2,1} & \mathbf{W}_{2,2} & \cdots & \mathbf{W}_{2,10} \\
\vdots & \vdots & \ddots & \vdots \\
\mathbf{W}_{1152,1} & \mathbf{W}_{1152,2} & \cdots & \mathbf{W}_{1152,10}
} \times
\pmatrix{
\mathbf{u}_1 & \mathbf{u}_1 & \cdots & \mathbf{u}_1 \\
\mathbf{u}_2 & \mathbf{u}_2 & \cdots & \mathbf{u}_2 \\
\vdots & \vdots & \ddots & \vdots \\
\mathbf{u}_{1152} & \mathbf{u}_{1152} & \cdots & \mathbf{u}_{1152}
}
=
\pmatrix{
\hat{\mathbf{u}}_{1|1} & \hat{\mathbf{u}}_{2|1} & \cdots & \hat{\mathbf{u}}_{10|1} \\
\hat{\mathbf{u}}_{1|2} & \hat{\mathbf{u}}_{2|2} & \cdots & \hat{\mathbf{u}}_{10|2} \\
\vdots & \vdots & \ddots & \vdots \\
\hat{\mathbf{u}}_{1|1152} & \hat{\mathbf{u}}_{2|1152} & \cdots & \hat{\mathbf{u}}_{10|1152}
}
$
The shape of the first array is (1152, 10, 16, 8), and the shape of the second array is (1152, 10, 8, 1). Note that the second array must contain 10 identical copies of the vectors $\mathbf{u}_1$ to $\mathbf{u}_{1152}$. To create this array, we will use the handy `tf.tile()` function, which lets you create an array containing many copies of a base array, tiled in any way you want.
Oh, wait a second! We forgot one dimension: _batch size_. Say we feed 50 images to the capsule network, it will make predictions for these 50 images simultaneously. So the shape of the first array must be (50, 1152, 10, 16, 8), and the shape of the second array must be (50, 1152, 10, 8, 1). The first layer capsules actually already output predictions for all 50 images, so the second array will be fine, but for the first array, we will need to use `tf.tile()` to have 50 copies of the transformation matrices.
Okay, let's start by creating a trainable variable of shape (1, 1152, 10, 16, 8) that will hold all the transformation matrices. The first dimension of size 1 will make this array easy to tile. We initialize this variable randomly using a normal distribution with a standard deviation to 0.01.
```
init_sigma = 0.01
W_init = tf.random_normal(
shape=(1, caps1_n_caps, caps2_n_caps, caps2_n_dims, caps1_n_dims),
stddev=init_sigma, dtype=tf.float32, name="W_init")
W = tf.Variable(W_init, name="W")
```
Now we can create the first array by repeating `W` once per instance:
```
batch_size = tf.shape(X)[0]
W_tiled = tf.tile(W, [batch_size, 1, 1, 1, 1], name="W_tiled")
```
That's it! On to the second array, now. As discussed earlier, we need to create an array of shape (_batch size_, 1152, 10, 8, 1), containing the output of the first layer capsules, repeated 10 times (once per digit, along the third dimension, which is axis=2). The `caps1_output` array has a shape of (_batch size_, 1152, 8), so we first need to expand it twice, to get an array of shape (_batch size_, 1152, 1, 8, 1), then we can repeat it 10 times along the third dimension:
```
caps1_output_expanded = tf.expand_dims(caps1_output, -1,
name="caps1_output_expanded")
caps1_output_tile = tf.expand_dims(caps1_output_expanded, 2,
name="caps1_output_tile")
caps1_output_tiled = tf.tile(caps1_output_tile, [1, 1, caps2_n_caps, 1, 1],
name="caps1_output_tiled")
```
Let's check the shape of the first array:
```
W_tiled
```
Good, and now the second:
```
caps1_output_tiled
```
Yes! Now, to get all the predicted output vectors $\hat{\mathbf{u}}_{j|i}$, we just need to multiply these two arrays using `tf.matmul()`, as explained earlier:
```
caps2_predicted = tf.matmul(W_tiled, caps1_output_tiled,
name="caps2_predicted")
```
Let's check the shape:
```
caps2_predicted
```
Perfect, for each instance in the batch (we don't know the batch size yet, hence the "?") and for each pair of first and second layer capsules (1152×10) we have a 16D predicted output column vector (16×1). We're ready to apply the routing by agreement algorithm!
## Routing by agreement
First let's initialize the raw routing weights $b_{i,j}$ to zero:
```
raw_weights = tf.zeros([batch_size, caps1_n_caps, caps2_n_caps, 1, 1],
dtype=np.float32, name="raw_weights")
```
We will see why we need the last two dimensions of size 1 in a minute.
### Round 1
First, let's apply the softmax function to compute the routing weights, $\mathbf{c}_{i} = \operatorname{softmax}(\mathbf{b}_i)$ (equation (3) in the paper):
```
routing_weights = tf.nn.softmax(raw_weights, dim=2, name="routing_weights")
```
Now let's compute the weighted sum of all the predicted output vectors for each second-layer capsule, $\mathbf{s}_j = \sum\limits_{i}{c_{i,j}\hat{\mathbf{u}}_{j|i}}$ (equation (2)-left in the paper):
```
weighted_predictions = tf.multiply(routing_weights, caps2_predicted,
name="weighted_predictions")
weighted_sum = tf.reduce_sum(weighted_predictions, axis=1, keep_dims=True,
name="weighted_sum")
```
There are a couple important details to note here:
* To perform elementwise matrix multiplication (also called the Hadamard product, noted $\circ$), we use the `tf.multiply()` function. It requires `routing_weights` and `caps2_predicted` to have the same rank, which is why we added two extra dimensions of size 1 to `routing_weights`, earlier.
* The shape of `routing_weights` is (_batch size_, 1152, 10, 1, 1) while the shape of `caps2_predicted` is (_batch size_, 1152, 10, 16, 1). Since they don't match on the fourth dimension (1 _vs_ 16), `tf.multiply()` automatically _broadcasts_ the `routing_weights` 16 times along that dimension. If you are not familiar with broadcasting, a simple example might help:
$ \pmatrix{1 & 2 & 3 \\ 4 & 5 & 6} \circ \pmatrix{10 & 100 & 1000} = \pmatrix{1 & 2 & 3 \\ 4 & 5 & 6} \circ \pmatrix{10 & 100 & 1000 \\ 10 & 100 & 1000} = \pmatrix{10 & 200 & 3000 \\ 40 & 500 & 6000} $
And finally, let's apply the squash function to get the outputs of the second layer capsules at the end of the first iteration of the routing by agreement algorithm, $\mathbf{v}_j = \operatorname{squash}(\mathbf{s}_j)$ :
```
caps2_output_round_1 = squash(weighted_sum, axis=-2,
name="caps2_output_round_1")
caps2_output_round_1
```
Good! We have ten 16D output vectors for each instance, as expected.
### Round 2
First, let's measure how close each predicted vector $\hat{\mathbf{u}}_{j|i}$ is to the actual output vector $\mathbf{v}_j$ by computing their scalar product $\hat{\mathbf{u}}_{j|i} \cdot \mathbf{v}_j$.
* Quick math reminder: if $\vec{a}$ and $\vec{b}$ are two vectors of equal length, and $\mathbf{a}$ and $\mathbf{b}$ are their corresponding column vectors (i.e., matrices with a single column), then $\mathbf{a}^T \mathbf{b}$ (i.e., the matrix multiplication of the transpose of $\mathbf{a}$, and $\mathbf{b}$) is a 1×1 matrix containing the scalar product of the two vectors $\vec{a}\cdot\vec{b}$. In Machine Learning, we generally represent vectors as column vectors, so when we talk about computing the scalar product $\hat{\mathbf{u}}_{j|i} \cdot \mathbf{v}_j$, this actually means computing ${\hat{\mathbf{u}}_{j|i}}^T \mathbf{v}_j$.
Since we need to compute the scalar product $\hat{\mathbf{u}}_{j|i} \cdot \mathbf{v}_j$ for each instance, and for each pair of first and second level capsules $(i, j)$, we will once again take advantage of the fact that `tf.matmul()` can multiply many matrices simultaneously. This will require playing around with `tf.tile()` to get all dimensions to match (except for the last 2), just like we did earlier. So let's look at the shape of `caps2_predicted`, which holds all the predicted output vectors $\hat{\mathbf{u}}_{j|i}$ for each instance and each pair of capsules:
```
caps2_predicted
```
And now let's look at the shape of `caps2_output_round_1`, which holds 10 outputs vectors of 16D each, for each instance:
```
caps2_output_round_1
```
To get these shapes to match, we just need to tile the `caps2_output_round_1` array 1152 times (once per primary capsule) along the second dimension:
```
caps2_output_round_1_tiled = tf.tile(
caps2_output_round_1, [1, caps1_n_caps, 1, 1, 1],
name="caps2_output_round_1_tiled")
```
And now we are ready to call `tf.matmul()` (note that we must tell it to transpose the matrices in the first array, to get ${\hat{\mathbf{u}}_{j|i}}^T$ instead of $\hat{\mathbf{u}}_{j|i}$):
```
agreement = tf.matmul(caps2_predicted, caps2_output_round_1_tiled,
transpose_a=True, name="agreement")
```
We can now update the raw routing weights $b_{i,j}$ by simply adding the scalar product $\hat{\mathbf{u}}_{j|i} \cdot \mathbf{v}_j$ we just computed: $b_{i,j} \gets b_{i,j} + \hat{\mathbf{u}}_{j|i} \cdot \mathbf{v}_j$ (see Procedure 1, step 7, in the paper).
```
raw_weights_round_2 = tf.add(raw_weights, agreement,
name="raw_weights_round_2")
```
The rest of round 2 is the same as in round 1:
```
routing_weights_round_2 = tf.nn.softmax(raw_weights_round_2,
dim=2,
name="routing_weights_round_2")
weighted_predictions_round_2 = tf.multiply(routing_weights_round_2,
caps2_predicted,
name="weighted_predictions_round_2")
weighted_sum_round_2 = tf.reduce_sum(weighted_predictions_round_2,
axis=1, keep_dims=True,
name="weighted_sum_round_2")
caps2_output_round_2 = squash(weighted_sum_round_2,
axis=-2,
name="caps2_output_round_2")
```
We could go on for a few more rounds, by repeating exactly the same steps as in round 2, but to keep things short, we will stop here:
```
caps2_output = caps2_output_round_2
```
### Static or Dynamic Loop?
In the code above, we created different operations in the TensorFlow graph for each round of the routing by agreement algorithm. In other words, it's a static loop.
Sure, instead of copy/pasting the code several times, we could have written a `for` loop in Python, but this would not change the fact that the graph would end up containing different operations for each routing iteration. It's actually okay since we generally want less than 5 routing iterations, so the graph won't grow too big.
However, you may prefer to implement the routing loop within the TensorFlow graph itself rather than using a Python `for` loop. To do this, you would need to use TensorFlow's `tf.while_loop()` function. This way, all routing iterations would reuse the same operations in the graph, it would be a dynamic loop.
For example, here is how to build a small loop that computes the sum of squares from 1 to 100:
```
def condition(input, counter):
return tf.less(counter, 100)
def loop_body(input, counter):
output = tf.add(input, tf.square(counter))
return output, tf.add(counter, 1)
with tf.name_scope("compute_sum_of_squares"):
counter = tf.constant(1)
sum_of_squares = tf.constant(0)
result = tf.while_loop(condition, loop_body, [sum_of_squares, counter])
with tf.Session() as sess:
print(sess.run(result))
```
As you can see, the `tf.while_loop()` function expects the loop condition and body to be provided _via_ two functions. These functions will be called only once by TensorFlow, during the graph construction phase, _not_ while executing the graph. The `tf.while_loop()` function stitches together the graph fragments created by `condition()` and `loop_body()` with some additional operations to create the loop.
Also note that during training, TensorFlow will automagically handle backpropogation through the loop, so you don't need to worry about that.
Of course, we could have used this one-liner instead! ;-)
```
sum([i**2 for i in range(1, 100 + 1)])
```
Joke aside, apart from reducing the graph size, using a dynamic loop instead of a static loop can help reduce how much GPU RAM you use (if you are using a GPU). Indeed, if you set `swap_memory=True` when calling the `tf.while_loop()` function, TensorFlow will automatically check GPU RAM usage at each loop iteration, and it will take care of swapping memory between the GPU and the CPU when needed. Since CPU memory is much cheaper and abundant than GPU RAM, this can really make a big difference.
# Estimated Class Probabilities (Length)
The lengths of the output vectors represent the class probabilities, so we could just use `tf.norm()` to compute them, but as we saw when discussing the squash function, it would be risky, so instead let's create our own `safe_norm()` function:
```
def safe_norm(s, axis=-1, epsilon=1e-7, keep_dims=False, name=None):
with tf.name_scope(name, default_name="safe_norm"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis,
keep_dims=keep_dims)
return tf.sqrt(squared_norm + epsilon)
y_proba = safe_norm(caps2_output, axis=-2, name="y_proba")
```
To predict the class of each instance, we can just select the one with the highest estimated probability. To do this, let's start by finding its index using `tf.argmax()`:
```
y_proba_argmax = tf.argmax(y_proba, axis=2, name="y_proba")
```
Let's look at the shape of `y_proba_argmax`:
```
y_proba_argmax
```
That's what we wanted: for each instance, we now have the index of the longest output vector. Let's get rid of the last two dimensions by using `tf.squeeze()` which removes dimensions of size 1. This gives us the capsule network's predicted class for each instance:
```
y_pred = tf.squeeze(y_proba_argmax, axis=[1,2], name="y_pred")
y_pred
```
Okay, we are now ready to define the training operations, starting with the losses.
# Labels
First, we will need a placeholder for the labels:
```
y = tf.placeholder(shape=[None], dtype=tf.int64, name="y")
```
# Margin loss
The paper uses a special margin loss to make it possible to detect two or more different digits in each image:
$ L_k = T_k \max(0, m^{+} - \|\mathbf{v}_k\|)^2 - \lambda (1 - T_k) \max(0, \|\mathbf{v}_k\| - m^{-})^2$
* $T_k$ is equal to 1 if the digit of class $k$ is present, or 0 otherwise.
* In the paper, $m^{+} = 0.9$, $m^{-} = 0.1$ and $\lambda = 0.5$.
* Note that there was an error in the video (at 15:47): the max operations are squared, not the norms. Sorry about that.
```
m_plus = 0.9
m_minus = 0.1
lambda_ = 0.5
```
Since `y` will contain the digit classes, from 0 to 9, to get $T_k$ for every instance and every class, we can just use the `tf.one_hot()` function:
```
T = tf.one_hot(y, depth=caps2_n_caps, name="T")
```
A small example should make it clear what this does:
```
with tf.Session():
print(T.eval(feed_dict={y: np.array([0, 1, 2, 3, 9])}))
```
Now let's compute the norm of the output vector for each output capsule and each instance. First, let's verify the shape of `caps2_output`:
```
caps2_output
```
The 16D output vectors are in the second to last dimension, so let's use the `safe_norm()` function with `axis=-2`:
```
caps2_output_norm = safe_norm(caps2_output, axis=-2, keep_dims=True,
name="caps2_output_norm")
```
Now let's compute $\max(0, m^{+} - \|\mathbf{v}_k\|)^2$, and reshape the result to get a simple matrix of shape (_batch size_, 10):
```
present_error_raw = tf.square(tf.maximum(0., m_plus - caps2_output_norm),
name="present_error_raw")
present_error = tf.reshape(present_error_raw, shape=(-1, 10),
name="present_error")
```
Next let's compute $\max(0, \|\mathbf{v}_k\| - m^{-})^2$ and reshape it:
```
absent_error_raw = tf.square(tf.maximum(0., caps2_output_norm - m_minus),
name="absent_error_raw")
absent_error = tf.reshape(absent_error_raw, shape=(-1, 10),
name="absent_error")
```
We are ready to compute the loss for each instance and each digit:
```
L = tf.add(T * present_error, lambda_ * (1.0 - T) * absent_error,
name="L")
```
Now we can sum the digit losses for each instance ($L_0 + L_1 + \cdots + L_9$), and compute the mean over all instances. This gives us the final margin loss:
```
margin_loss = tf.reduce_mean(tf.reduce_sum(L, axis=1), name="margin_loss")
```
# Reconstruction
Now let's add a decoder network on top of the capsule network. It is a regular 3-layer fully connected neural network which will learn to reconstruct the input images based on the output of the capsule network. This will force the capsule network to preserve all the information required to reconstruct the digits, across the whole network. This constraint regularizes the model: it reduces the risk of overfitting the training set, and it helps generalize to new digits.
## Mask
The paper mentions that during training, instead of sending all the outputs of the capsule network to the decoder network, we must send only the output vector of the capsule that corresponds to the target digit. All the other output vectors must be masked out. At inference time, we must mask all output vectors except for the longest one, i.e., the one that corresponds to the predicted digit. You can see this in the paper's figure 2 (at 18:15 in the video): all output vectors are masked out, except for the reconstruction target's output vector.
We need a placeholder to tell TensorFlow whether we want to mask the output vectors based on the labels (`True`) or on the predictions (`False`, the default):
```
mask_with_labels = tf.placeholder_with_default(False, shape=(),
name="mask_with_labels")
```
Now let's use `tf.cond()` to define the reconstruction targets as the labels `y` if `mask_with_labels` is `True`, or `y_pred` otherwise.
```
reconstruction_targets = tf.cond(mask_with_labels, # condition
lambda: y, # if True
lambda: y_pred, # if False
name="reconstruction_targets")
```
Note that the `tf.cond()` function expects the if-True and if-False tensors to be passed _via_ functions: these functions will be called just once during the graph construction phase (not during the execution phase), similar to `tf.while_loop()`. This allows TensorFlow to add the necessary operations to handle the conditional evaluation of the if-True or if-False tensors. However, in our case, the tensors `y` and `y_pred` are already created by the time we call `tf.cond()`, so unfortunately TensorFlow will consider both `y` and `y_pred` to be dependencies of the `reconstruction_targets` tensor. The `reconstruction_targets` tensor will end up with the correct value, but:
1. whenever we evaluate a tensor that depends on `reconstruction_targets`, the `y_pred` tensor will be evaluated (even if `mask_with_layers` is `True`). This is not a big deal because computing `y_pred` adds no computing overhead during training, since we need it anyway to compute the margin loss. And during testing, if we are doing classification, we won't need reconstructions, so `reconstruction_targets` won't be evaluated at all.
2. we will always need to feed a value for the `y` placeholder (even if `mask_with_layers` is `False`). This is a bit annoying, but we can pass an empty array, because TensorFlow won't use it anyway (it just does not know it yet when it checks for dependencies).
Now that we have the reconstruction targets, let's create the reconstruction mask. It should be equal to 1.0 for the target class, and 0.0 for the other classes, for each instance. For this we can just use the `tf.one_hot()` function:
```
reconstruction_mask = tf.one_hot(reconstruction_targets,
depth=caps2_n_caps,
name="reconstruction_mask")
```
Let's check the shape of `reconstruction_mask`:
```
reconstruction_mask
```
Let's compare this to the shape of `caps2_output`:
```
caps2_output
```
Mmh, its shape is (_batch size_, 1, 10, 16, 1). We want to multiply it by the `reconstruction_mask`, but the shape of the `reconstruction_mask` is (_batch size_, 10). We must reshape it to (_batch size_, 1, 10, 1, 1) to make multiplication possible:
```
reconstruction_mask_reshaped = tf.reshape(
reconstruction_mask, [-1, 1, caps2_n_caps, 1, 1],
name="reconstruction_mask_reshaped")
```
At last! We can apply the mask:
```
caps2_output_masked = tf.multiply(
caps2_output, reconstruction_mask_reshaped,
name="caps2_output_masked")
caps2_output_masked
```
One last reshape operation to flatten the decoder's inputs:
```
decoder_input = tf.reshape(caps2_output_masked,
[-1, caps2_n_caps * caps2_n_dims],
name="decoder_input")
```
This gives us an array of shape (_batch size_, 160):
```
decoder_input
```
## Decoder
Now let's build the decoder. It's quite simple: two dense (fully connected) ReLU layers followed by a dense output sigmoid layer:
```
n_hidden1 = 512
n_hidden2 = 1024
n_output = 28 * 28
with tf.name_scope("decoder"):
hidden1 = tf.layers.dense(decoder_input, n_hidden1,
activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2,
activation=tf.nn.relu,
name="hidden2")
decoder_output = tf.layers.dense(hidden2, n_output,
activation=tf.nn.sigmoid,
name="decoder_output")
```
## Reconstruction Loss
Now let's compute the reconstruction loss. It is just the squared difference between the input image and the reconstructed image:
```
X_flat = tf.reshape(X, [-1, n_output], name="X_flat")
squared_difference = tf.square(X_flat - decoder_output,
name="squared_difference")
reconstruction_loss = tf.reduce_sum(squared_difference,
name="reconstruction_loss")
```
## Final Loss
The final loss is the sum of the margin loss and the reconstruction loss (scaled down by a factor of 0.0005 to ensure the margin loss dominates training):
```
alpha = 0.0005
loss = tf.add(margin_loss, alpha * reconstruction_loss, name="loss")
```
# Final Touches
## Accuracy
To measure our model's accuracy, we need to count the number of instances that are properly classified. For this, we can simply compare `y` and `y_pred`, convert the boolean value to a float32 (0.0 for False, 1.0 for True), and compute the mean over all the instances:
```
correct = tf.equal(y, y_pred, name="correct")
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
```
## Training Operations
The paper mentions that the authors used the Adam optimizer with TensorFlow's default parameters:
```
optimizer = tf.train.AdamOptimizer()
training_op = optimizer.minimize(loss, name="training_op")
```
## Init and Saver
And let's add the usual variable initializer, as well as a `Saver`:
```
init = tf.global_variables_initializer()
saver = tf.train.Saver()
```
And... we're done with the construction phase! Please take a moment to celebrate. :)
# Training
Training our capsule network is pretty standard. For simplicity, we won't do any fancy hyperparameter tuning, dropout or anything, we will just run the training operation over and over again, displaying the loss, and at the end of each epoch, measure the accuracy on the validation set, display it, and save the model if the validation loss is the lowest seen found so far (this is a basic way to implement early stopping, without actually stopping). Hopefully the code should be self-explanatory, but here are a few details to note:
* if a checkpoint file exists, it will be restored (this makes it possible to interrupt training, then restart it later from the last checkpoint),
* we must not forget to feed `mask_with_labels=True` during training,
* during testing, we let `mask_with_labels` default to `False` (but we still feed the labels since they are required to compute the accuracy),
* the images loaded _via_ `mnist.train.next_batch()` are represented as `float32` arrays of shape \[784\], but the input placeholder `X` expects a `float32` array of shape \[28, 28, 1\], so we must reshape the images before we feed them to our model,
* we evaluate the model's loss and accuracy on the full validation set (5,000 instances). To view progress and support systems that don't have a lot of RAM, the code evaluates the loss and accuracy on one batch at a time, and computes the mean loss and mean accuracy at the end.
*Warning*: if you don't have a GPU, training will take a very long time (at least a few hours). With a GPU, it should take just a few minutes per epoch (e.g., 6 minutes on an NVidia GeForce GTX 1080Ti).
```
n_epochs = 10
batch_size = 50
restore_checkpoint = True
n_iterations_per_epoch = mnist.train.num_examples // batch_size
n_iterations_validation = mnist.validation.num_examples // batch_size
best_loss_val = np.infty
checkpoint_path = "./my_capsule_network"
with tf.Session() as sess:
if restore_checkpoint and tf.train.checkpoint_exists(checkpoint_path):
saver.restore(sess, checkpoint_path)
else:
init.run()
for epoch in range(n_epochs):
for iteration in range(1, n_iterations_per_epoch + 1):
X_batch, y_batch = mnist.train.next_batch(batch_size)
# Run the training operation and measure the loss:
_, loss_train = sess.run(
[training_op, loss],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch,
mask_with_labels: True})
print("\rIteration: {}/{} ({:.1f}%) Loss: {:.5f}".format(
iteration, n_iterations_per_epoch,
iteration * 100 / n_iterations_per_epoch,
loss_train),
end="")
# At the end of each epoch,
# measure the validation loss and accuracy:
loss_vals = []
acc_vals = []
for iteration in range(1, n_iterations_validation + 1):
X_batch, y_batch = mnist.validation.next_batch(batch_size)
loss_val, acc_val = sess.run(
[loss, accuracy],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch})
loss_vals.append(loss_val)
acc_vals.append(acc_val)
print("\rEvaluating the model: {}/{} ({:.1f}%)".format(
iteration, n_iterations_validation,
iteration * 100 / n_iterations_validation),
end=" " * 10)
loss_val = np.mean(loss_vals)
acc_val = np.mean(acc_vals)
print("\rEpoch: {} Val accuracy: {:.4f}% Loss: {:.6f}{}".format(
epoch + 1, acc_val * 100, loss_val,
" (improved)" if loss_val < best_loss_val else ""))
# And save the model if it improved:
if loss_val < best_loss_val:
save_path = saver.save(sess, checkpoint_path)
best_loss_val = loss_val
```
Training is finished, we reached over 99.3% accuracy on the validation set after just 5 epochs, things are looking good. Now let's evaluate the model on the test set.
# Evaluation
```
n_iterations_test = mnist.test.num_examples // batch_size
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
loss_tests = []
acc_tests = []
for iteration in range(1, n_iterations_test + 1):
X_batch, y_batch = mnist.test.next_batch(batch_size)
loss_test, acc_test = sess.run(
[loss, accuracy],
feed_dict={X: X_batch.reshape([-1, 28, 28, 1]),
y: y_batch})
loss_tests.append(loss_test)
acc_tests.append(acc_test)
print("\rEvaluating the model: {}/{} ({:.1f}%)".format(
iteration, n_iterations_test,
iteration * 100 / n_iterations_test),
end=" " * 10)
loss_test = np.mean(loss_tests)
acc_test = np.mean(acc_tests)
print("\rFinal test accuracy: {:.4f}% Loss: {:.6f}".format(
acc_test * 100, loss_test))
```
We reach 99.43% accuracy on the test set. Pretty nice. :)
# Predictions
Now let's make some predictions! We first fix a few images from the test set, then we start a session, restore the trained model, evaluate `caps2_output` to get the capsule network's output vectors, `decoder_output` to get the reconstructions, and `y_pred` to get the class predictions:
```
n_samples = 5
sample_images = mnist.test.images[:n_samples].reshape([-1, 28, 28, 1])
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
caps2_output_value, decoder_output_value, y_pred_value = sess.run(
[caps2_output, decoder_output, y_pred],
feed_dict={X: sample_images,
y: np.array([], dtype=np.int64)})
```
Note: we feed `y` with an empty array, but TensorFlow will not use it, as explained earlier.
And now let's plot the images and their labels, followed by the corresponding reconstructions and predictions:
```
sample_images = sample_images.reshape(-1, 28, 28)
reconstructions = decoder_output_value.reshape([-1, 28, 28])
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
plt.imshow(sample_images[index], cmap="binary")
plt.title("Label:" + str(mnist.test.labels[index]))
plt.axis("off")
plt.show()
plt.figure(figsize=(n_samples * 2, 3))
for index in range(n_samples):
plt.subplot(1, n_samples, index + 1)
plt.title("Predicted:" + str(y_pred_value[index]))
plt.imshow(reconstructions[index], cmap="binary")
plt.axis("off")
plt.show()
```
The predictions are all correct, and the reconstructions look great. Hurray!
# Interpreting the Output Vectors
Let's tweak the output vectors to see what their pose parameters represent.
First, let's check the shape of the `cap2_output_value` NumPy array:
```
caps2_output_value.shape
```
Let's create a function that will tweak each of the 16 pose parameters (dimensions) in all output vectors. Each tweaked output vector will be identical to the original output vector, except that one of its pose parameters will be incremented by a value varying from -0.5 to 0.5. By default there will be 11 steps (-0.5, -0.4, ..., +0.4, +0.5). This function will return an array of shape (_tweaked pose parameters_=16, _steps_=11, _batch size_=5, 1, 10, 16, 1):
```
def tweak_pose_parameters(output_vectors, min=-0.5, max=0.5, n_steps=11):
steps = np.linspace(min, max, n_steps) # -0.25, -0.15, ..., +0.25
pose_parameters = np.arange(caps2_n_dims) # 0, 1, ..., 15
tweaks = np.zeros([caps2_n_dims, n_steps, 1, 1, 1, caps2_n_dims, 1])
tweaks[pose_parameters, :, 0, 0, 0, pose_parameters, 0] = steps
output_vectors_expanded = output_vectors[np.newaxis, np.newaxis]
return tweaks + output_vectors_expanded
```
Let's compute all the tweaked output vectors and reshape the result to (_parameters_×_steps_×_instances_, 1, 10, 16, 1) so we can feed the array to the decoder:
```
n_steps = 11
tweaked_vectors = tweak_pose_parameters(caps2_output_value, n_steps=n_steps)
tweaked_vectors_reshaped = tweaked_vectors.reshape(
[-1, 1, caps2_n_caps, caps2_n_dims, 1])
```
Now let's feed these tweaked output vectors to the decoder and get the reconstructions it produces:
```
tweak_labels = np.tile(mnist.test.labels[:n_samples], caps2_n_dims * n_steps)
with tf.Session() as sess:
saver.restore(sess, checkpoint_path)
decoder_output_value = sess.run(
decoder_output,
feed_dict={caps2_output: tweaked_vectors_reshaped,
mask_with_labels: True,
y: tweak_labels})
```
Let's reshape the decoder's output so we can easily iterate on the output dimension, the tweak steps, and the instances:
```
tweak_reconstructions = decoder_output_value.reshape(
[caps2_n_dims, n_steps, n_samples, 28, 28])
```
Lastly, let's plot all the reconstructions, for the first 3 output dimensions, for each tweaking step (column) and each digit (row):
```
for dim in range(3):
print("Tweaking output dimension #{}".format(dim))
plt.figure(figsize=(n_steps / 1.2, n_samples / 1.5))
for row in range(n_samples):
for col in range(n_steps):
plt.subplot(n_samples, n_steps, row * n_steps + col + 1)
plt.imshow(tweak_reconstructions[dim, col, row], cmap="binary")
plt.axis("off")
plt.show()
```
# Conclusion
I tried to make the code in this notebook as flat and linear as possible, to make it easier to follow, but of course in practice you would want to wrap the code in nice reusable functions and classes. For example, you could try implementing your own `PrimaryCapsuleLayer`, and `DenseRoutingCapsuleLayer` classes, with parameters for the number of capsules, the number of routing iterations, whether to use a dynamic loop or a static loop, and so on. For an example a modular implementation of Capsule Networks based on TensorFlow, take a look at the [CapsNet-TensorFlow](https://github.com/naturomics/CapsNet-Tensorflow) project.
That's all for today, I hope you enjoyed this notebook!
| true |
code
| 0.760017 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/Anmol42/IDP-sem4/blob/main/notebooks/Sig-mu_vae.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
import torch
import torchvision
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torchvision.transforms as transforms
import numpy as np
from torch.utils.data.dataloader import DataLoader
from google.colab import drive
drive.mount('/content/drive')
!unzip -q /content/drive/MyDrive/Datasets/faces.zip ## Silenced the unzip action
from skimage.io import imread_collection
path = "/content/faces/*.jpg"
train_ds = imread_collection(path)
from skimage.io import imread_collection
from skimage.color import rgb2lab,lab2rgb
from skimage.transform import resize
def get_img_data(path):
train_ds = imread_collection(path)
images = torch.zeros(len(train_ds),3,128,128)
for i,im in enumerate(train_ds):
im = resize(im, (128,128,3),
anti_aliasing=True)
image = rgb2lab(im)
image = torch.Tensor(image)
image = image.permute(2,0,1)
images[i]=image
return images
def normalize_data(data):
data[:,0] = data[:,0]/100
data[:,1:] = data[:,1:]/128
return data
images = get_img_data(path)
images = normalize_data(images)
batch_size = 100
class component(nn.Module):
def __init__(self):
super(component,self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(1,8,kernel_size=3,padding=1,stride=2),
nn.BatchNorm2d(8),
nn.LeakyReLU())
self.conv2 = nn.Sequential(nn.Conv2d(8,16,kernel_size=5,padding=2,stride=2),
nn.BatchNorm2d(16),
nn.LeakyReLU())
self.conv3 = nn.Sequential(nn.Conv2d(16,32,kernel_size=3,padding=1,stride=2),
nn.BatchNorm2d(32),
nn.LeakyReLU())
self.conv4 = nn.Sequential(nn.Conv2d(32,64,kernel_size=5,padding=2,stride=2), #size is 8x8 at this point
nn.LeakyReLU())
# BottleNeck
self.bottleneck = nn.Sequential(nn.Conv2d(64,128,kernel_size=3,stride=2,padding=1),
nn.LeakyReLU()) # size 4x4
self.linear = nn.Linear(128*4*4,256)
def forward(self,xb,z):
out1 = self.conv1(xb)
out2 = self.conv2(out1)
out3 = self.conv3(out2)
out4 = self.conv4(out3)
out5 = self.bottleneck(out4)
out5 = out5.view(z.shape[0],-1)
out6 = self.linear(out5)
return out6
## generator model
class generator(nn.Module):
def __init__(self,component): # z is input noise
super(generator,self).__init__()
self.sigma = component()
self.mu = component()
self.deconv7 = nn.Sequential(nn.ConvTranspose2d(256,128,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv6 = nn.Sequential(nn.ConvTranspose2d(128,64,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv5 = nn.Sequential(nn.ConvTranspose2d(64,64,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv4 = nn.Sequential(nn.ConvTranspose2d(64,32,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv3 = nn.Sequential(nn.ConvTranspose2d(32,16,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv2 = nn.Sequential(nn.ConvTranspose2d(16,8,kernel_size=4,stride=2,padding=1),
nn.ReLU())
self.deconv1 = nn.Sequential(nn.ConvTranspose2d(8,2,kernel_size=4,stride=2,padding=1),
nn.Tanh())
self.linear = nn.Linear(128*4*4,512)
def forward(self,xb,z):
sig = self.sigma(xb,z)
mm = self.mu(xb,z)
noise = z*sig + mm
out5 = self.deconv7(noise.unsqueeze(2).unsqueeze(2))
out5 = self.deconv6(out5)
out5 = self.deconv5(out5)
out5 = self.deconv4(out5)
out5 = self.deconv3(out5)
out5 = self.deconv2(out5)
out5 = self.deconv1(out5)
return torch.cat((xb,out5),1)
## discriminator
class discriminator(nn.Module):
def __init__(self):
super(discriminator,self).__init__()
self.network = nn.Sequential(
nn.Conv2d(3,8,kernel_size=3,stride=1),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Conv2d(8,16,kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Conv2d(16,32,kernel_size=3),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Conv2d(32,64,kernel_size=3),
nn.MaxPool2d(kernel_size=2),
nn.ReLU(),
nn.Flatten()
)
self.linear1 = nn.Linear(64*25,128)
self.linear2 = nn.Linear(128,1)
def forward(self,x):
out = self.network(x)
out = self.linear1(out)
out = self.linear2(out)
out = torch.sigmoid(out)
return out
gen_model = generator(component)
dis_model = discriminator()
train_dl = DataLoader(images[:10000],batch_size,shuffle=True,pin_memory=True,num_workers=2)
val_dl = DataLoader(images[10000:11000],batch_size, num_workers=2,pin_memory=True)
test_dl = DataLoader(images[11000:],batch_size,num_workers=2)
bceloss = nn.BCEWithLogitsLoss()
#minimise this # t is whether the image is fake or real; x is prob vect of patches being real/fake.
def loss_inf(x,t): # probability vector from discriminator as input
return int(t)*(bceloss(x,torch.ones_like(x))) + (1-int(t))*bceloss(x,torch.zeros_like(x))
l1loss = nn.L1Loss()
def gen_loss(x,y):
return l1loss(x,y)
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
train_dl = DeviceDataLoader(train_dl,'cuda')
val_dl = DeviceDataLoader(val_dl,'cuda')
test_dl = DeviceDataLoader(test_dl,'cuda')
gen_model.to('cuda')
dis_model.to('cuda')
def fit(epochs,lr_g,lr_d,generator,discriminator,batch_size,opt_func=torch.optim.Adam):
gen_optimize = opt_func(generator.parameters(),lr_g)
dis_optimize = opt_func(discriminator.parameters(),lr_d)
train_g_history,train_d_history = [],[]
val_g_history, val_d_history = [],[]
for epoch in range(epochs):
epoch_loss_g = torch.zeros(1).to('cuda')
epoch_loss_d = torch.zeros(1).to('cuda')
noise = torch.randn(batch_size,256).to('cuda')
for batch in train_dl:
for i in range(5):
out = generator(batch[:,0].unsqueeze(1),noise) # gives a,b channel for LAB color scheme
real_score = discriminator(batch) # how real is the og input image
fake_score = discriminator(out) # how real is the generated image
loss_d = loss_inf(real_score,1) + loss_inf(fake_score,0)# discriminator
#print(loss_d.item())
loss_d.backward()
dis_optimize.zero_grad()
dis_optimize.step()
out = generator(batch[:,0].unsqueeze(1),noise) # gives a,b channel for LAB color scheme
real_score = discriminator(batch) # how real is the og input image
fake_score = discriminator(out) # how real is the generated image
loss_g = 4*gen_loss(out,batch) + loss_inf(fake_score,1)
loss_g.backward()
gen_optimize.step()
gen_optimize.zero_grad()
with torch.no_grad():
epoch_loss_g += loss_g
epoch_loss_d += loss_d
train_d_history.append(epoch_loss_d)
train_g_history.append(epoch_loss_g)
epoch_loss_g = 0
epoch_loss_d = 0
for batch in val_dl:
with torch.no_grad():
out = generator(batch[:,0].unsqueeze(1),noise) # gives a,b channel for LAB color scheme
real_score = discriminator(batch) # how real is the og input image
fake_score = discriminator(out) # how real is the generated image
loss_d = loss_inf(real_score,1) + loss_inf(fake_score,0)# discriminator
loss_g = 4*gen_loss(out,batch) + loss_inf(fake_score,1)
epoch_loss_g += loss_g
epoch_loss_d += loss_d
val_g_history.append(epoch_loss_g.item())
val_d_history.append(epoch_loss_d.item())
if epoch % 3 == 0:
print("Gen Epoch Loss",epoch_loss_g)
print("Discriminator Epoch loss",epoch_loss_d)
return train_d_history,train_g_history,val_d_history,val_g_history
loss_h = fit(6,0.001,0.001,gen_model,dis_model,batch_size,opt_func=torch.optim.Adam)
import matplotlib.pyplot as plt
plt.plot(loss_h[1])
from skimage.color import rgb2lab,lab2rgb,rgb2gray
def tensor_to_pic(tensor : torch.Tensor) -> np.ndarray:
tensor[0] *= 100
tensor[1:]*= 128
image = tensor.permute(1,2,0).detach().cpu().numpy()
image = lab2rgb(image)
return image
def show_images(n,dataset = images,gen=gen_model,dis=dis_model) -> None:
gen_model.eval()
dis_model.eval()
z = torch.randn(1,256).to('cuda')
#z = torch.ones_like(z)
image_tensor = dataset[n].to('cuda')
gen_tensor = gen(image_tensor[0].unsqueeze(0).unsqueeze(0),z)[0]
image = tensor_to_pic(image_tensor)
#print(torch.sum(gen_tensor))
gray = np.zeros_like(image)
bw = rgb2gray(image)
gray[:,:,0],gray[:,:,1],gray[:,:,2] = bw,bw,bw
gen_image = tensor_to_pic(gen_tensor)
to_be_shown = np.concatenate((gray,gen_image,image),axis=1)
plt.figure(figsize=(15,15))
plt.imshow(to_be_shown)
plt.show()
i = np.random.randint(3500,20000)
print(i)
show_images(i) ## Shows generated and coloured images side by side
```
| true |
code
| 0.881997 | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.